爬取wwdc全部视频链接(基本完成)
假期跟进了一下iOS开发的新进展, 主要是swift和spritekit.
当前5.1版本的swift据说可以保证ABI的稳定性, API/语法稳定性依旧不保证, 就是说以前的代码肯定跑不起来, 现在的代码, 以后也不保证能用.
这是一开始没想明白还是故意整大家, 我不清楚, 很佩服苹果的勇气.
反正Java1.1的代码在java12上兼容, 98年的JS代码依旧可用, Python鼓捣3的时候也没有扔掉2...
从wwdc的视频着手, 挂网盘上都下载下来.
具体就是从All -> 具体页面 -> 每个视频的链接
步骤如下:
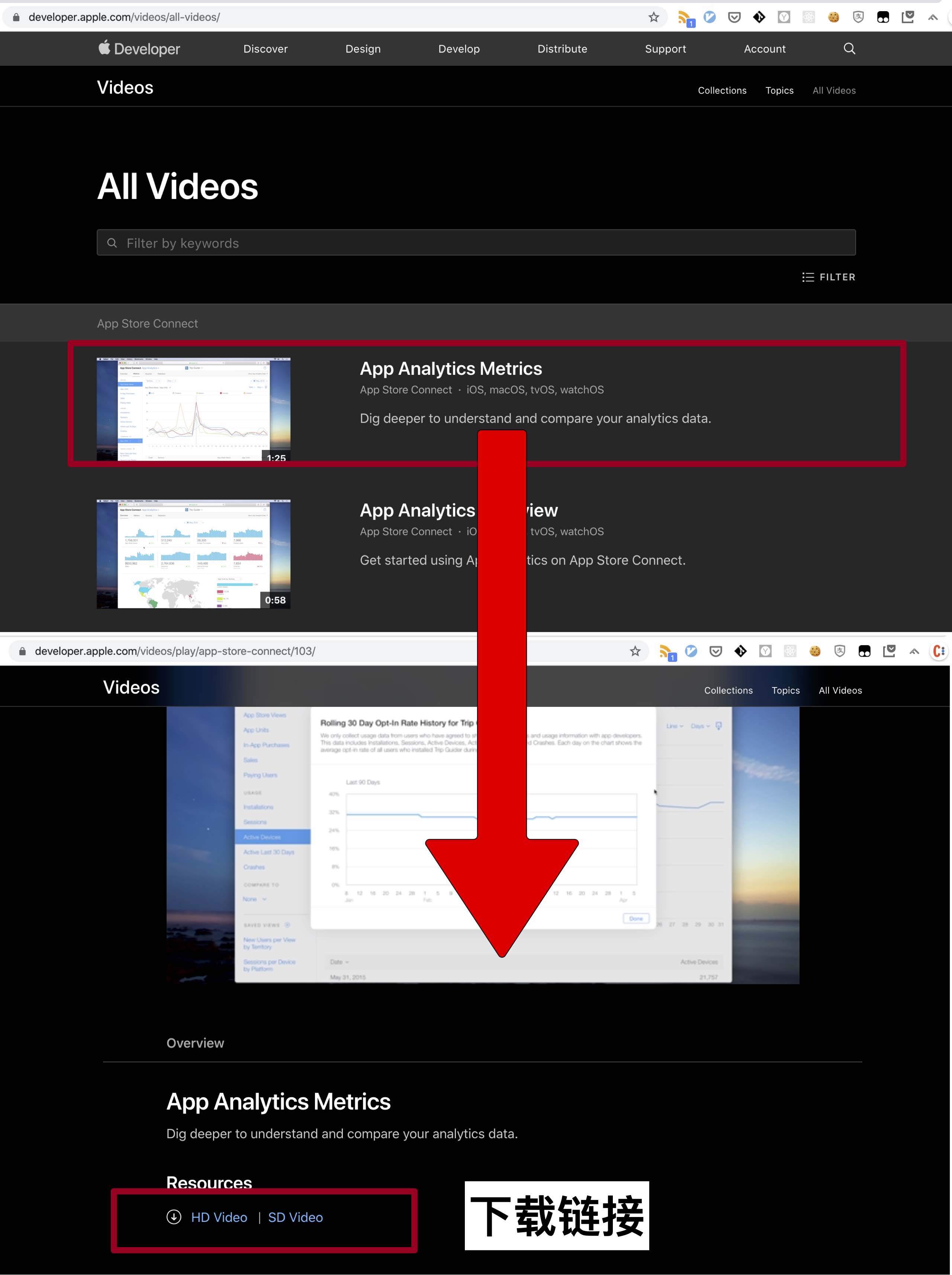
准备工作
本篇文章的代码只有在解决以下两个问题的情况下才可执行, sorry guys.
跨域问题
跨越需要在服务器端增加http reponse的header, 但爬取网页的时候, 对方服务器不受我们控制, 只能从本地解决. 我发现比较简单的方式是安装个chrome插件, 本地禁用CORS限制 允许跨域的插件
打开这个插件, 跨域就OK了.
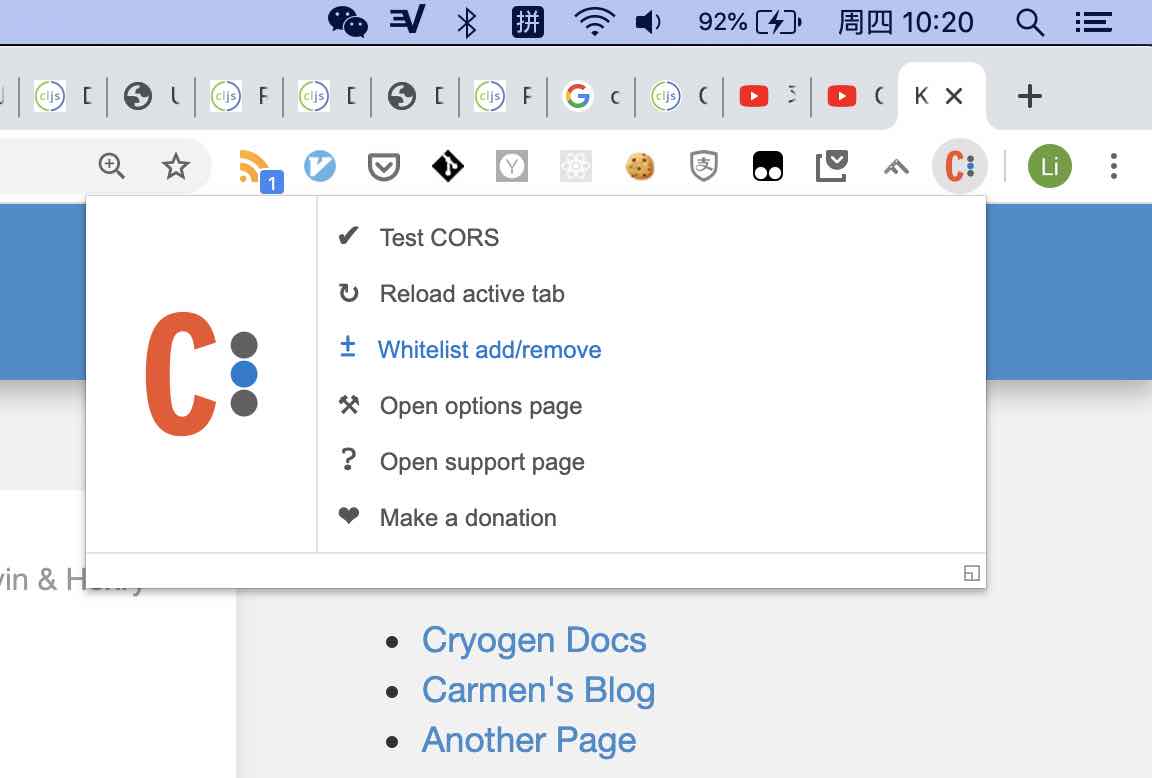
raw.github.com 被墙
axja是从github raw模式下载编译的, 当前国内防火墙已经阻断了raw.github.com的访问, 要运行下面的代码需要翻墙, 要不然会报错.
问题分析
分为五步, 和下面的代码对应. 最终拿到的输出可以直接下载.
step1 step2 step3 step4
+---------------+ +--------------------+ +---------------------+ +---------------------+
| | 1 item | | 1k | | 1k | |
| main-page/GET|---chan---->|main-page-html-parse|--chan-->| video-page/GET +--chan->|video-page-html-parse|
| | string | | string | | string | |
+---------------+ html +--------------------+ url +---------------------+ html +---------------------+
| list of links
chan
step 5 |
+----------+----------+
| |
| print |
| |
+---------------------+
(ns show.core.async
(:require-macros [cljs.core.async.macros :refer [go go-loop]])
(:require [cljs.core.async :as async
:refer [>! <! put! chan alts! take! pipeline]]
[ajax.core :as ajax]))
cljs方案
爬取全部网页的内容在190m左右, 异步比同步速度快30倍左右, 可以自己尝试.
cljs和clojure的代码基本兼容, 除了ajax部分, 可以简单替换个函数在clojure端执行, 我是最初先在clojure上实现, 后改的cljs.
core.async异步爬取
(defn parse-urls
"step2: 从首页找到视频网页的链接"
[html-str]
(->> html-str
(re-seq #"/videos/play/.*[0-9]{3}")
(map #(str "https://developer.apple.com" %))
(take 10) ;; 注意此处我加了数量限制, 只拿部分链接, 因为一共有1300多个
sort
distinct))
(defn links->chan
"step1~step2: 下载首页, 解析视频网页的链接, 所有的链接逐个都丢到channel上"
[]
(let [c (chan) ]
(ajax/GET "https://developer.apple.com/videos/all-videos/"
{:handler (fn [body]
(doseq [url (parse-urls body)]
(put! c url)))})
c))
(defn parse-video-links
"step4: 从视频html中找到视频链接"
[html]
(re-seq #"https.*(?:mov|mp4)\?dl=1" html))
(defn videos->chan
"step3~step4: 下载并且解析video"
[link c]
(ajax/GET link
{:handler #(put! c (parse-video-links %))}))
(defn links-html []
(let [links-c (links->chan) ;; step1:首页下载, 返回放了所有链接的channel
download-c (chan)] ;; 在download-c执行下载操作
(go-loop [] ;; step 2~4
(videos->chan (<! links-c) download-c)
(recur))
(go-loop [] ;; step 5
(doseq [video (<! download-c)]
(prn video))
(recur))))
(links-html)
core.async同步爬取
其实就是在第三步阻塞一下 增加一个专门店额channel来做阻塞
你会发现同爬取的时候链接是逐步出现的, 而且顺序是确定的, 速度肯定不如同步获得要快.
(def b-c (chan))
(put! b-c "unlock");; 保证channel里有一个元素
(defn videos->chan
"step3~step4: 下载并且解析video"
[link c]
(go
(<! b-c) ;; parking 在此处
(ajax/GET link
{:handler (fn [html]
(put! b-c "unlock") ;; unpark 在此处
(put! c (parse-video-links html)))})))
(links-html)
js实现(by 丁凡)
Promise版本
const time1 = Date.now()
fetch('https://developer.apple.com/videos/all-videos/')
.then(resp => resp.text())
.then((text) => {
const myRe = /\/videos\/play\/.*[0-9]{3}/g;
return text.match(myRe).map(m => "https://developer.apple.com" + m).slice(1, 10)
})
.then ((links) => {
let forks = links.map(m => fetch(m).then(resp => resp.text()));
let joined = Promise.all(forks);
return joined
})
.then(htmls => {
const re = /https.*(?:mov|mp4)\?dl=1/g;
return htmls.map(html => html.match(re))
})
.then ((files) => {
console.log(files.flat())
const time2 = Date.now()
console.log('all done in Promise', time2 - time1);
})
async/await 版本
const getHtmlFromUrl = async (url) => {
const resp = await fetch(url)
return resp.text()
}
async function job() {
// const resp = await fetch('https://developer.apple.com/videos/all-videos/')
// const html = await resp.text()
const html = await getHtmlFromUrl('https://developer.apple.com/videos/all-videos/')
const pageLinkRegex = /\/videos\/play\/.*[0-9]{3}/g
const links = html.match(pageLinkRegex).map(rel => `https://developer.apple.com/${rel}`).slice(1, 10)
const forks = links.map(getHtmlFromUrl)
const pages = await Promise.all(forks)
const videos = pages.map(text => text.match(/https.*(?:mov|mp4)\?dl=1/g)).flat()
console.log(videos)
}
const time3 = Date.now()
job().then(() => {
const time4 = Date.now()
console.log('all done in async', time4 - time3)
})
结论
core.async, promise, async/await都解决了问题, 但是明显js的代码要简洁优美, cljs以core.async为核心的解决方案暴露了太多底层细节.