clj代码规范和最佳实践2021-03-27(不断更新)
(require '[reagent.core :as r])
clojure
变量,函数, 命名空间命名规则遵循clojure风格指南的约定.
一般地, api接口文件和函数命令规范:
同一业务多个文件放在相同目录, 比如order下有, routes.clj,spec.clj,service.clj,db.clj等文件
service, db,spec等类似
每个db的namespace里尽可能使用一个sql文件, 但是可视情况多个.
(ns demo.modules.user.user-db
(:require [conman.core :as conman]
[demo.db.core :refer [*db*]]))
(conman/bind-connection *db*
"sql/user.sql") ;此处推荐一个sql文件, 可以多个
函数和函数内部局部变量命令, 单词之间使用中线, 比如
(defn get-order-detail-by-order-no
"通过订单编号获取订单详情"
[order_id]
(prn "test"))
接口的request和response单词之间使用下划线链接, 也就是spec定义里的单词之间使用下划线, sql里使用下划线, 如:
-- :name find-user-menus :? :*
-- :获取用户菜单
SELECT m.* from t_sys_user u, t_sys_user_role ur, t_sys_role r, t_sys_role_menu rm, t_sys_menu m
WHERE u.delete_flag = 0 and r.delete_flag = 0 AND m.delete_flag = 0 and
u.id = ur.user_id and ur.role_id = r.id and r.id = rm.role_id and rm.menu_id = m.id and u.id = :user-id GROUP BY m.id
浮点数精准计算使用ratio
clojure中提供了分数最为基础数据类型, 避免了不精确的浮点数计算.
推荐的数值计算: 所有步骤使用分数来计算. 避免分数(float, double, 甚至是BigDecimal).
在Java中, 别无选择, 只有使用bigdec, 但是BigDecimal长度也有限, 最大36位, 而且也有不少边缘情况.
最著名的0.3问题:
;; 0.3 != 0.1 + 0.2????
(= 0.3 (+ 0.1 0.2))
;; 注意下面的值
(+ 0.1 0.2)
使用bigdec, 或者clojure的字面bigdec定义
;; bigdec
(== (bigdec 0.3) (+ (bigdec 0.2) (bigdec 0.1)))
;; literal bigdec
(== 0.3M (+ 0.2M 0.1M))
使用分数
clojure提供的ratio这个数据类型, 可以从根本上解决有理数精度计算的问题.
(type 1/3)
;; => clojure.lang.Ratio
根据我们的小学数学知识:
- 有理数 = 整数 + 分数(小数).
- 分数 = 循环小数和不循环小数
各种数学进制都会产生无限循环小数, 比如0.3在二进制中就只能表示为循环小数.
虽然数学上, 分数和小数是等价的, 但在计算机中, 小数受限于二进制存储的位数, 无法完全表示, 而分数不存在这方面的问题.
Java没有把分数作为一个基本类型, 但是Java语言也有不少分数类型的第三方实现, 比如普林斯顿大学的一个Java类. Clojure中, ratio是一个基础数据类型
有理数可以通过rational?函数来判断, 注意只有bigdeclimal, ratio被认为是有理数.
;; Both True
(ratio? 22/7)
;; => true
(rational? 22/7)
;; => true
;; Different
(ratio? 22)
;; => false
(rational? 22)
;; => true
;; Both False
(ratio? 0.5)
;; => false
(rational? 0.5)
;; => false
(rational? 0.1)
;; => false
(rational? 0.1M)
;; => true
小数可以通过rationalize转化为分数.
;; ratio
(== (rationalize 0.3) (+ (rationalize 0.2) (rationalize 0.1)))
;; => true
浮点数有精度损失:
(let [approx-interval (/ 209715 2097152) actual-interval (/ 1 10)
hours (* 3600 100 10)
actual-total (double (* hours actual-interval))
approx-total (double (* hours approx-interval))]
(- actual-total approx-total))
;;=> 0.34332275390625
使用ratio可以避免计算中的精度损失:
(let [approx-interval 209715/2097152
actual-interval 1/10
hours (* 3600 100 10)
actual-total (* hours actual-interval)
approx-total (* hours approx-interval)]
(- actual-total approx-total))
;; => 0
时间处理
使用库java-time, 这个是基于Java8的java.time的一个库, 渐趋主流.
java.util.Date和java-time的转化
todo:时间格式化示例代码
和周, 日, 年的对应
时间段
input/output
stream/writer/reader/file/connection 资源务必要执行close, disconnect操作
(let [file (-> url (clojure.string/split #"/") last)
con (-> url java.net.URL. .openConnection)
fields (reduce (fn [h v]
(assoc h (.getKey v) (into [] (.getValue v))))
{} (.getHeaderFields con))
size (first (fields "Content-Length"))
in (java.io.BufferedInputStream. (.getInputStream con))
out (java.io.BufferedOutputStream.
(java.io.FileOutputStream. file))
buffer (make-array Byte/TYPE 10e6)]
(loop [g (.read in buffer)
r 0]
(if-not (= g -1)
(do
(println (str "file:" file "" r "/" size))
(.write out buffer 0 g)
(recur (.read in buffer) (+ r g)))))
(.close in)
(.close out)
(.disconnect con))
使用with-open 更佳, 异常情况也会一并处理, 保证资源正常释放.
资源文件
资源文件在lein工程中, 放到resurces目录下, 打包成jar后不可以以文件形式直接访问. 如果需要以文件形式访问: 以如下形式拿到out.file文件.
(with-open
[r (-> "clojure/core.clj"
clojure.java.io/resource
clojure.java.io/reader)
f (clojure.java.io/writer "out.file")]
(clojure.java.io/copy r f))
异常处理
clojure提供了几个工具函数, 帮我们更好的处理异常. 异常处理的指导原则: 拿到尽可能完整的信息, 包括异常消息, 异常原因, 以及完整的异常stack-trace.
ex-info&ex-data抛出信息丰富的ex-info, 然后用ex-data来解析这些信息.(try (throw (ex-info "Clojure异常" {:error-code 123})) (catch Throwable e (ex-data e))) ;; 返回 {:error-code 123} ;; 对于 Java 异常 (try (throw (Exception. "Java异常")) (catch Throwable e (ex-data e))) ;; 返回 nilex-cause适用于所有继承自Throwable的异常, 包括Java标准异常和Clojure的异常.提取异常的原因, 即调用 Java 异常的 getCause 方法. 对于 Clojure 通过 ex-info 抛出的异常, 如果指定了 :cause, 也能正确提取.
(try (throw (Exception. "外层异常" (Exception. "内层原因"))) (catch Throwable e (ex-message (ex-cause e)))) ;; 返回 "内层原因"ex-message适用于所有继承自 Throwable 的异常, 包括 Java 标准异常和 Clojure 的异常(如通过 ex-info 创建的异常).
提取异常的消息, 等同于调用 Java 异常的 getMessage 方法.
(try (throw (Exception. "这是一个Java异常")) (catch Throwable e (ex-message e))) ;; 返回 "这是一个Java异常"stack-trace
(with-out-str (clojure.stacktrace/print-stack-trace e)) ;; 返回完整的堆栈跟踪字符串通常日志库使用timbre,需要完整的异常信息时不要执行
getMessage,直接打印e,如下:(try ;;删除模板记录 (db-utils/update! {:table-name (:table-name report-forms-template) :updates {:delete_flag 1} :id-name (:table-primary-key report-forms-template) :id id}) (catch Exception e (error "删除报表模板报错:" e)))如果区分想dev模式和生产模式分别打印不同粒度的日志,如下例子:
(defn exception-handler
"自定义异常处理
默认返回500错误码及简洁错误信息,开发环境下返回详细信息"
[status error e request]
(let [env (get-env) ;; 假设有一个函数获取当前环境
base-body {:code error
:msg (str "发生系统内部异常: " (ex-message e))}
detailed-body (cond-> base-body
(ex-cause e) (assoc :cause (ex-message (ex-cause e)))
(ex-data e) (assoc :data (ex-data e))
(= env :development) (assoc :ex-trace (with-out-str (clojure.stacktrace/print-stack-trace e))))]
{:status status
:body (if (= env :production)
base-body
detailed-body)}))
不推荐:
(require '[clojure.stacktrace :as stacktrace])
(try
;;删除模板记录
(db-utils/update!
{:table-name (:table-name report-forms-template)
:updates {:delete_flag 1}
:id-name (:table-primary-key report-forms-template)
:id id})
(catch Exception e
(log :error "删除报表模板报错:"
(with-out-str
(stacktrace/print-stack-trace e)))))
数据库操作
数据库迁移 (migration)
数据库的历史版本我们维护在migration文件中, 有以下注意事项.
- 数据库迁移文件的每个语句需要使用
--;;来做分隔符. 不可漏掉和多加.
create table ...
--;; 分隔符漏掉会导致执行错误
insert into ...
--;;
delete from ...
--;;
insert into tbl vals
('a', 'b'), --;; 多加分隔符也会切断语句, 导致执行错误
('c', 'd');
- 使用PostgreSQL的时候, 注意search_path的设定, 因为一开始的
schema_migrations表在public schema下, 如果对search_path有修改, 一定要改回为public
...
...
...
--;;
set search_path = public;
- 每次更新migration文件以后, 务必在repl中重置一次db, 验证sql没有问题.
(restart)
(reset-db)
避免循环操作数据库, 更新使用batch操作
- 批量查询: 使用
where id in (....)的语法, 避免循环用=多次查询. - 批量插入: 利用
INSERT...VALUES (...),(...),(...)的语法, 可以插入多个tuple, 大小有限制, 由参数max_allowed_packet决定.
我本地的可以一次插入6m的数据, 怎么也够用了.
show variables like 'max_allowed_packet'
| Variable_name | Value |
|--------------------+----------|
| max_allowed_packet | 67108864 |
;;bad
(defn save-size-pattern [size_id pattern_ids company_id]
(conman/with-transaction [*db*]
(size-db/delete-pattern-size-by-sizeid {:size_id size_id})
(doseq [patten_id pattern_ids]
(size-db/save-pattern-size {...}))))
;;good
(defn save-size-pattern [size_id pattern_ids company_id]
(size-db/batch-update ...))
spec
接口的request和response都要定义spec, spec相关函数和route在两个namespace里编码. spec定义时需要的库和用法示例参考.
(require '[clojure.spec.alpha :as s])
(require '[spec-tools.core :as st])
(require '[spec-tools.data-spec :as ds])
(s/def ::id
(st/spec
{:spec string?
:swagger/default "1001"
:description "系统用户ID"}))
(s/def ::username
(st/spec
{:spec string?
:swagger/default "Bob"
:description "用户名"}))
(s/def ::nickname
(st/spec
{:spec string?
:swagger/default "风清扬"
:description "昵称"}))
(s/def ::phone
(st/spec
{:spec int?
:swagger/default 15011001100
:description "手机号"})))
;;user search spec
(s/def :this-ns/user-list
(s/keys :req-un [::base/page ::base/size]
:opt-un [::username ::nickname]))
;;user list response
(s/def :this-ns/user-list
(s/coll-of (s/keys :req-un [::id ::username ::nickname]
:opt-un [::phone])))
hugsql
hugsql是咱们和数据库打交道的好伙伴.
hugsql使用注释和sql结合, 生成我们可以直接调用的函数.
注释决定了sql的执行方式和结果的返回方式.
sql的执行方式:
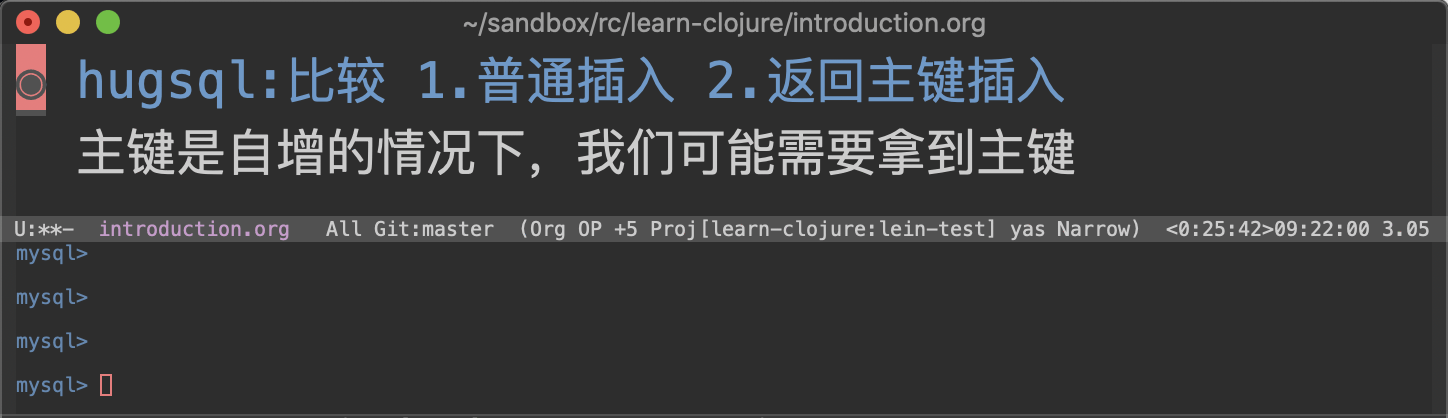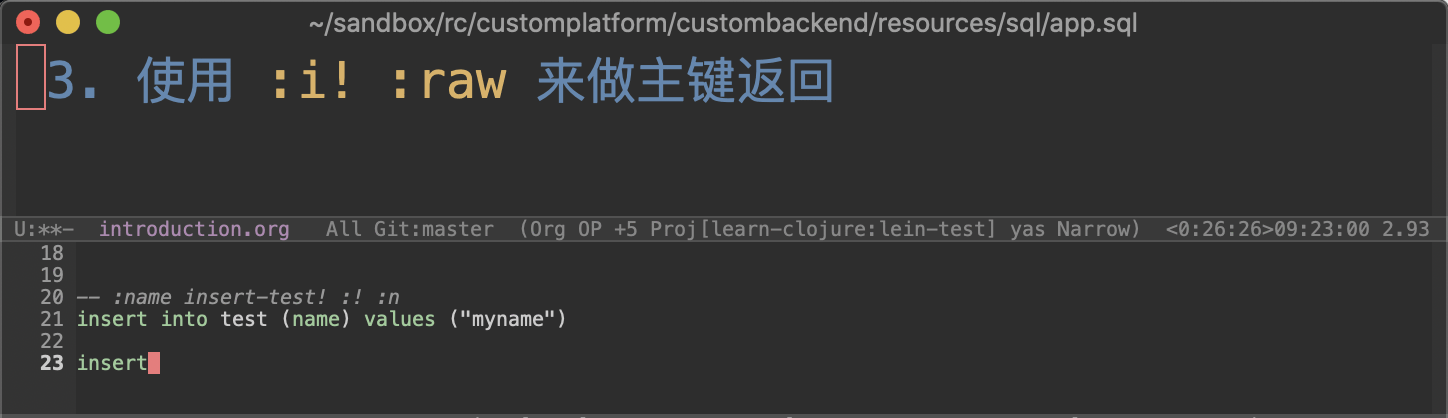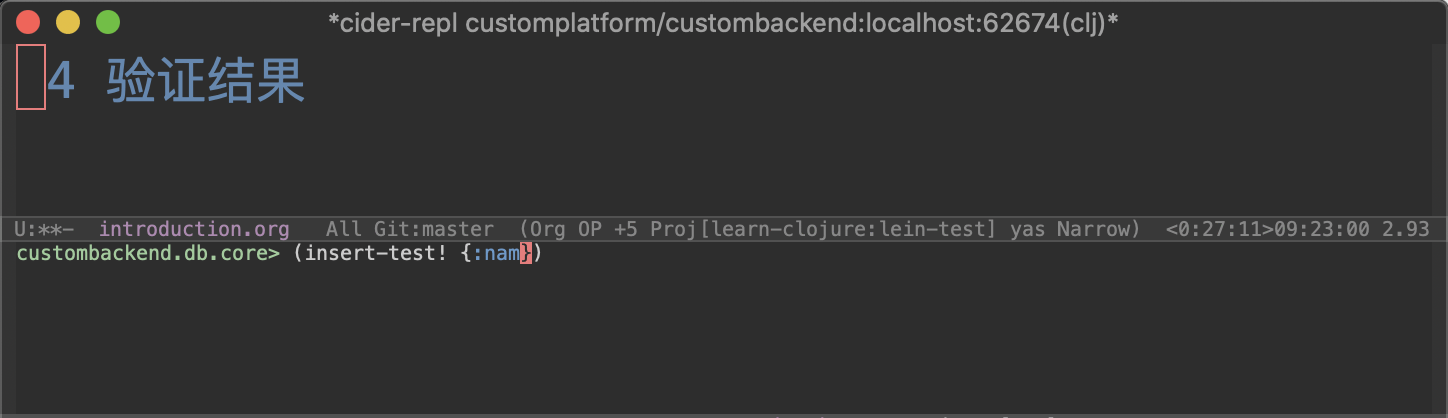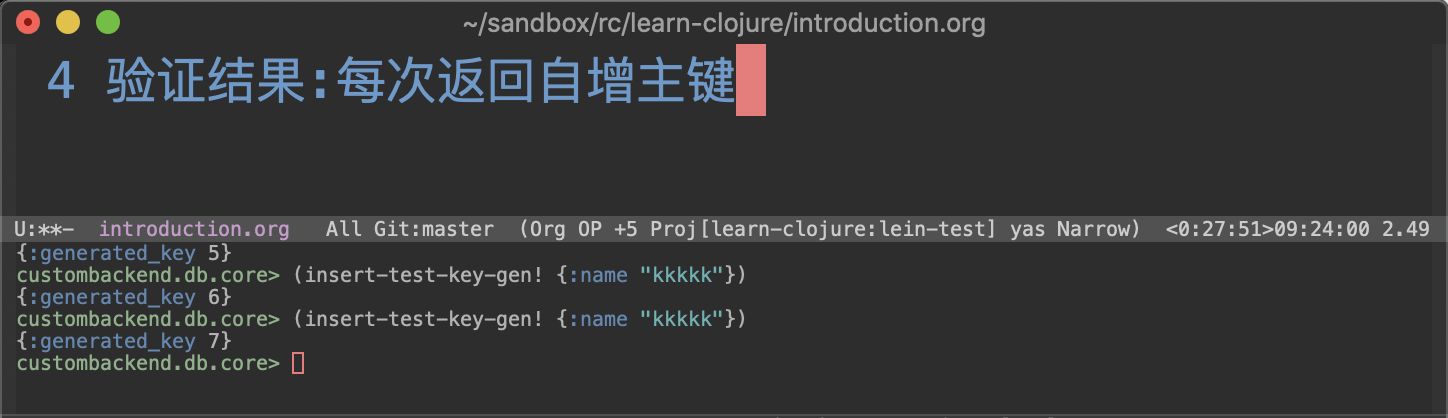
:?= 执行查询 (default):!= insert/delete/update:<!= 支持 INSERT ... RETURNING, 返回插入的结果集, mysql 不支持, 忽略:i!= 支持 insert 和 jdbc .getGeneratedKeys, 用于获得自增的主键的插入值. 参见下面的例子.
:? 和 :! 的区别反映在 clojure.java.jdbc的 fetch和execute函数上. 这个出错的可能性不大, 混用会报异常.
sql的执行结果映射:
:1= 返回一个hashmap:*= 返回一个hashmap的vector:n= 收到影响的行数 (inserted/updated/deleted):raw= 返回一个list (default)
规则
- select 返回多行用
:* - select 确认返回唯一结果, 比如用uniq id查询的情况, 使用
:1 - insert/update/delete 使用
:n,需要返回结果使用:result
比如Insert!函数:
-- :name insert! :<! :1
/* :doc 新增插入一条记录
`:table-name`: 指定插入的表名。
`:inserter`: 要插入数据库的对象
`:returns`: 插入数据库后要返回的内容
*/
/* :require [clojure.string :as cstring] */
INSERT INTO :i:table-name
--~(str "(" (cstring/join "," (map name (keys (:inserter params)))) ")")
VALUES
/*~(str "("
(cstring/join ","
(for [[field _] (:inserter params)]
(str " :v:inserter." (name field))))
")")~*/
--~(when (seq (:returns params)) (str "RETURNING " :i*:returns))
;
调用方法:
(:id (db-utils/insert!
{:table-name (:table-name computer)
:inserter (-> (dissoc params :computer_start_runs)
(assoc :start_project_path (get-open-project-path)))
:returns ["id"]}))
参考HugSql Insert ,比如sqlite3和mysql也可以使用:LAST_INSERT_ID(),但是就要先插入再获取一次,比较麻烦。而PostgreSQL可以使用RETURNING字句。我们规定按上面使用。
工具和过程
git
使用rebase, 避免merge
使用rebase
- rebase提供了一个机会来整理自己的commit, 使用interactive rebase, 集中提交
- rebase处理之后历史记录单线, 简洁清晰
使用.gitignore文件
忽略IDE, 项目编译, 缓存, 本地特殊配置等临时文件, 需要加入到我们维护的项目模版.
/target
/lib
/classes
/checkouts
pom.xml
*.jar
*.class
/.lein-*
profiles.clj
/.env
.nrepl-port
/node_modules
/log
/.idea/*
.DS_Store
*.iml
../.idea/*
.idea/*
dev-config.edn
test-config.edn
[#]*[#]
emacs
鉴于emacs是我们的主要编辑器, 下面这些配置加入工程模版.
proejctile
projectile是cider的作者提供的一个emacs工程插件. 提供全工程的检索, 查找等功能. 为了排除临时文件, 在工程根目录下做如下配置.proejctile.
-/log
-/tmp
-/node_modules
-/target
-/.shadow-cljs
解决依赖的jar包冲突
- lein可以用
lein deps :tree来发现库的冲突 - 在依赖中使用
exclustions来排除重复的不同版本的引入 - 原则上使用低版本的库, 保证兼容性
工具也会给出这个建议, 比如下面
[ch.qos.logback/logback-classic "1.2.3"] -> [org.slf4j/slf4j-api "1.7.25"]
overrides
[com.aliyun/aliyun-java-sdk-core "4.4.0"] -> [org.slf4j/slf4j-api "1.7.26"]
Consider using these exclusions:
[com.aliyun/aliyun-java-sdk-core "4.4.0" :exclusions [org.slf4j/slf4j-api]]
单元测试
发布管理
根据profile执行
比如要进行测试
lein with-profiles +test run
打包时排除源代码
使用 leiningen 进行项目打包时, 不能将源代码打到发布包中. 源代码分为两部分, 一部分是自己写的源代码文件, 一部分为第三方依赖库的文件, 在 project.clj 文件中添加如下配置即可.
{:profiles {
:uberjar {
;; 解决自己写的源代码文件打包
:omit-source true
:aot :all
:source-paths ["env/prod/clj" "src/clj"]
;; 解决第三方依赖库文件的打包
:uberjar-exclusions [#"\.(clj|java)"]
}
}}