Clojure的性能度量

因为日常我们的领域是写出正确的程序, 性能一般都是挂在嘴上, 而没有实际深入考虑的内容, 在这个领域, 永远是度量优先.
抛弃直觉, 用数据说话, 需要有方法和工具来侦测应用的行为, 度量CPU, 内存的消耗. 本文介绍了Clojure上的性能套件.
运行时间衡量
性能最直观的印象就是执行的时间消耗, 时间消耗越少, 性能越高.
对于时间比较长的操作, 比如请求baidu.com的首页, 是有参考意义的:
(time (slurp "http://baidu.com "))
;; => ;; "Elapsed time: 557.892959 msecs"
告诉我们打开这个网页至少需要0.5秒.
但是对于耗时很短的操作:
(time (reduce + (map #(/ % 100.0) (range 100))))
;; => "Elapsed time: 0.410583 msecs"
计算100个百分数需要0.5 毫秒就有点离谱了. time宏包括了编译clj代码到字节码, 字节码载入等很多的额外负担.
直接返回nil都要耗时0.1毫秒
(time nil)
;; => "Elapsed time: 0.148167 msecs"
此外, 字节码的执行方式有两种, 即解释执行和JIT执行的, 多次执行的字节码会以JIT的方式, 进一步编译为原生代码的方式加速执行, 代价是第一次会慢. 解释执行对于反复执行的代码不是典型情况, 而仅仅执行一次的字节码JVM也不会去做JIT.
我们只有多次执行同一段代码, 才能得到一个比较准确的结果, 执行计算一百万次, 得到平均执行时间为0.002毫秒(2微秒):
(time (dotimes [_ 1e6] (reduce + (map #(/ % 100.0) (range 100)))))
;; => "Elapsed time: 2076.518667 msecs"
运行时间的度量criterium 来精确度量
cri·te·ri·um | ˌkrīˈtirēəm |, 自行车绕圈赛
项目依赖中引入[criterium "0.4.6"]:
(require '[criterium.core :refer [bench quick-bench]])
(quick-bench (reduce + (map #(/ % 100.0) (range 100))))
criterium执行了333708次, 得到以下结果:
Evaluation count : 333708 in 6 samples of 55618 calls.
Execution time mean : 1.798531 µs
Execution time std-deviation : 5.765753 ns
Execution time lower quantile : 1.790717 µs ( 2.5%)
Execution time upper quantile : 1.805064 µs (97.5%)
Overhead used : 2.685768 ns
criterium有两个主要的函数bench和quick-bench, 大多数情况下quick-bench就够了, bench虽然结果更加准确一些, 代价是更长的测试时间.
运行空间的衡量
需要引入clj-memory-meter引入
[com.clojure-goes-fast/clj-memory-meter "0.2.2"]
可以看到不同类型的容器的大小差异
(require '[clj-memory-meter.core :as mm])
(import '[java.util.stream Collectors])
(import '[java.util ArrayList Arrays])
(defn int-array->arrayList [a]
(-> (Arrays/stream a)
(.boxed)
(.collect (Collectors/toList))))
;; 内存使用
(def size (int 1e6))
(mm/measure (int-array size))
;; => "3.8 MiB"
(mm/measure (int-array->arrayList (int-array size)))
;; => "4.6 MiB"
(mm/measure (vec (int-array size)))
;; => "5.2 MiB"
(mm/measure (apply list (int-array size)))
;; => "38.1 MiB"
(mm/measure (apply list (int-array size)) :shallow true)
;; => "40 B"
此外, 以上是内存的物理大小, 生成的对象的个数是另一个衡量纬度.
int-array的数量是1, ArrayList的数量是 1 + 1e6, vector和list的数量是 1 + 1e6 + 5e5.
对于JVM垃圾回收器(GC)的负担是完全不一样的.
使用profiler来度量cpu和内存
火焰图可以说说是性能衡量的最直观工具
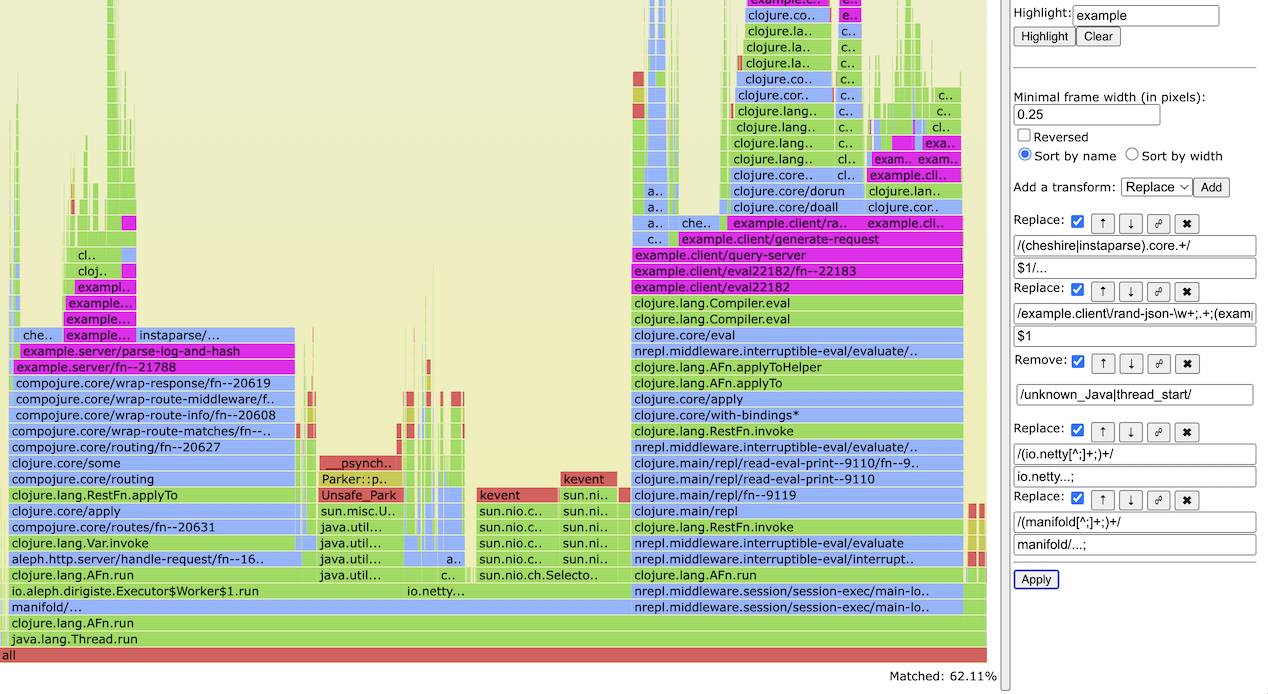
clj-async-profiler可以帮我启动一个web界面的profiler.
引入依赖
[com.clojure-goes-fast/clj-async-profiler "1.0.3"]
在linux系统上, 性能收集需要设置如下系统变量
sudo sysctl -w kernel.perf_event_paranoid=1
sudo sysctl -w kernel.kptr_restrict=0
(require '[clj-async-profiler.core :as prof])
;; 在8089端口上提供记录的火焰图web服务, 可以直接在浏览器查看
(prof/serve-ui 8089)
(prof/start)
;; 留一段时间30s以上, 给profiler收集性能参数用
(prof/stop)
与其他分析工具相比,clj-async-profiler有几个明显的优势, 是一件性能分析的利器.
- 低开销, 凭借其个位数百分比开销,clj-async-profiler适合在生产服务器上使用,以获取实际生产场景中的性能配置文件。
- 可嵌入, profiler仅需要引入单个依赖项, 无论是在开发还是在生产中,这都很方便。
- 可编程控制, 在生产场景中, 能够从应用程序代码中驱动分析器可以实现多种有趣的使用模式,例如按计划启动分析器,或作为对某些事件的反应.
- 方便的演示, 火焰图作为轮廓表示非常具有描述性和示范性, 底层原始数据是纯文本的,这使得它可以延展到额外的处理和转换.
- 不仅仅是CPU分析, clj-async-profiling还支持配置分析(显示代码的哪些部分分配了最多的对象/内存)、锁、上下文切换和操作系统支持的其他事件.
结论
Clojure语言在性能度量和优化方面, 秉持着一贯的优雅和实用, 让JVM平台更好的为我们服务.
在Java中,必须在启动时预加载profiler,并将测量代码放入测试文件中。在Clojure中,可以按需加载它,并随时在REPL中已有的对象上执行,而无需设置执行环境。