clojure参考手册
Table of Contents
- 1. 第一部分: 简介
- 2. 第二部分. 基础知识
- 2.1. 2 创建和操纵函数
- 2.2. 3 基本构件
- 2.3. 4 创建和检视宏
- 2.4. 5 数值运算
- 2.4.1. 5.1 概述
- 2.4.2. 5.2 任意精度
- 2.4.3. 5.3 回滚精度
- 2.4.4. 5.4 非转换, 回滚精度
- 2.4.5. 5.5 +, -, * 和 /
- 2.4.6. 5.6 inc 和 dec
- 2.4.7. 5.7 quot, rem 和 mod
- 2.4.8. 5.8 max 和 min
- 2.4.9. 5.9 max-key 和 min-key
- 2.4.10. 5.10 rand 和 rand-int
- 2.4.11. 5.11 with-precision
- 2.4.12. 5.12 +', -', *', inc' 和 dec'
- 2.4.13. 5.13 unchecked-add 和其他 unchecked 运算符
- 2.4.14. 5.14 unchecked-add-int 和其他 unckecked-int 运算符
- 2.4.15. 5.15 pos?, zero? 和 neg?
- 2.4.16. 5.16 总结
- 2.5. 6 比较与相等性
- 2.6. 7 Reducer 和 Transducer
- 3. 第三部分. 数据结构
- 3.1. 8 集合
- 3.2. 9 序列
- 3.3. 10 顺序处理
- 3.3.1. 10.1 rest, next, fnext, nnext, ffirst, nfirst 和 butlast
- 3.3.2. 10.2 drop, drop-while, drop-last, take, take-while, take-last, nthrest, nthnext
- 3.3.3. 10.3 keep 和 keep-indexed
- 3.3.4. 10.4 mapcat
- 3.3.5. 10.5 interpose 和 interleave
- 3.3.6. 10.6 partition, partition-all 和 partition-by
- 3.3.7. 10.7 flatten
- 3.3.8. 10.8 distinct, dedupe 和 distinct?
- 3.3.9. 10.9 take-nth
- 3.3.10. 10.10 split-at 和 split-with
- 3.3.11. 10.11 when-first
- 3.3.12. 10.12 chunk-cons, chunk-first, chunk-rest, chunk-next, chunk-buffer, chunk-append 和 chunk
- 3.3.13. 10.13 总结
- 3.4. 11 映射
- 3.5. 12 向量
- 3.6. 13 集合
- 4. 第四部分. 解决特定问题
- 4.1. 14 并发
- 4.2. 15 类型, 类, 层次结构和多态
- 4.2.1. 15.1 symbol 和 keyword
- 4.2.2. 15.2 类型检查和强制转换
- 4.2.3. 15.3 gen-class 和 gen-interface
- 4.2.4. 15.4 deftype 和 definterface
- 4.2.5. 15.5 proxy
- 4.2.6. 15.6 reify
- 4.2.7. 15.7 defrecord
- 4.2.8. 15.8 defprotocol
- 4.2.9. 15.9 extend, extend-type 和 extend-protocol
- 4.2.10. 15.10 derive 和 make-hierarchy
- 4.2.11. 15.11 defmulti 和 defmethod
- 4.2.12. 15.12 总结
- 4.3. 16 Var 和命名空间
- 4.3.1. 16.1 def, declare, intern 和 defonce
- 4.3.2. 16.2 var, find-var 和 resolve
- 4.3.3. 16.3 alter-var-root 和 with-redefs
- 4.3.4. 16.4 binding
- 4.3.5. 16.5 with-local-vars, var-get 和 var-set
- 4.3.6. 16.6 ns, in-ns, create-ns 和 remove-ns
- 4.3.7. 16.7 alias, ns-aliases 和 ns-unalias
- 4.3.8. 16.8 ns-map 和 ns-unmap
- 4.3.9. 16.9 ns-publics, ns-interns, ns-imports
- 4.3.10. 16.10 refer, refer-clojure, require, loaded-libs, use, import
- 4.3.11. 16.11 find-ns 和 all-ns
- 4.3.12. 16.12 the-ns, ns-name 和 namespace
- 4.3.13. 16.13 meta, with-meta, vary-meta, alter-meta! 和 reset-meta!
- 4.3.14. 16.14 总结
- 4.4. 17 评估
- 4.4.1. 17.1 read 和 read-string
- 4.4.2. 17.2 eval
- 4.4.3. 17.3 load, load-file, load-reader 和 load-string
- 4.4.4. 17.4 compile
- 4.4.5. 17.5 test 和 assert
- 4.4.6. 17.6 clojure.edn/read 和 clojure.edn/read-string
- 4.4.7. 17.7 tagged-literal 和 tagged-literal?
- 4.4.8. 17.8 default-data-readers
- 4.4.9. 17.9 reader-conditional 和 reader-conditional?
- 4.4.10. 17.10 总结
- 4.5. 18 格式化和打印
- 4.6. 19 字符串和正则表达式
- 4.6.1. 19.1 str
- 4.6.2. 19.2 join
- 4.6.3. 19.3 replace, replace-first, re-quote-replacement
- 4.6.4. 19.4 subs, split 和 split-lines
- 4.6.5. 19.5 trim, triml, trimr, trim-newline
- 4.6.6. 19.6 escape, char-name-string, char-escape-string
- 4.6.7. 19.7 lower-case, upper-case, capitalize
- 4.6.8. 19.8 index-of, last-index-of
- 4.6.9. 19.9 blank?, ends-with?, starts-with?, includes?
- 4.6.10. 19.10 re-pattern, re-matcher, re-groups, re-seq, re-matches, re-find
- 4.6.11. 19.11 总结
- 4.7. 20 变异和副作用
- 4.8. 21 Java 互操作
- 4.9. 22 工具箱
- 4.10. 23 标准库中的动态变量
- 4.10.1. 23.1 *1, *2, *3 和 *e
- 4.10.2. 23.2 in, out 和 err
- 4.10.3. 23.3 agent
- 4.10.4. 23.4 assert
- 4.10.5. 23.5 clojure-version 和 command-line-args
- 4.10.6. 23.6 compile-files
- 4.10.7. 23.7 compile-path
- 4.10.8. 23.8 compiler-options
- 4.10.9. 23.9 file 和 source-path
- 4.10.10. 23.10 use-context-classloader
- 4.10.11. 23.11 allow-unresolved-vars
- 4.10.12. 23.12 read-eval 和 suppress-read
- 4.10.13. 23.13 data-readers 和 default-data-reader-fn
- 4.10.14. 23.14 load-tests 和 stack-trace-depth
- 4.10.15. 23.15 feeling-lucky, local-javadocs 和 core-java-api
- 4.10.16. 23.16 flush-on-newline
- 4.10.17. 23.17 ns 和 loading-verbosely
- 4.10.18. 23.18 math-context
- 4.10.19. 23.19 warn-on-reflection 和 unchecked-math
- 4.10.20. 23.20 漂亮打印变量
- 4.10.21. 23.21 其他动态变量
- 4.10.22. 23.22 总结
- 5. 附录 A:
- 6. 附录 B:
- 7. 附录 C:
1. 第一部分: 简介
1.1. 1 了解你的工具
本章涵盖
- 作为你工具箱中基础部分的标准库
- 将" 枯燥的规范" 转变为有趣且有教育意义的体验
- Clojure 标准库的高层结构
- 库在实际应用中的一些示例
软件开发尽管主要是一项智力活动, 但常被比作一门手艺. 虽然软件开发本质上是抽象的, 但它有许多面向手艺的方面:
- 键盘需要时间和专注才能正确操作. 关于程序员最佳键盘布局的讨论无休无止, 例如为了提高打字速度 1.
- 开发环境是程序员生产力的一个关键方面, 也是另一个争论的来源 (几乎达到了宗教般的内涵). 精通一个开发环境通常意味着学习有用的组合键和自定义最常用操作的方法.
- 围绕语言的库, 工具和习惯用法. 几乎所有纯粹语法规则之上的东西.
掌握多种编程语言在就业市场上绝对是一个加分项, 实现这一点的途径是通过定期实践, 包括熟悉该语言提供的 API 和库.
根据应用领域的不同, 许多其他方面也需要特定的技能: 教学, 演讲或领导力.
对掌握编程技能的关注如此重要, 以至于它成为了软件工艺运动 2 的核心目标之一. 软件工艺倡导通过实践学习, 并提倡一种与其他职业类似的学徒制过程.
标准库无疑是掌握一门语言最重要的工具之一. 标准库的一个特点是, 当你初次体验一门语言时, 它已经与语言打包在一起. 有趣的是, 对于这样一个触手可及的工具, 它并没有得到你所期望的关注度. 本书将向你展示 Clojure 标准库中隐藏了多少智慧和潜力.
1.1.1. 1.1 为什么我应该关心标准库?
一门语言的表达能力通常被描述为将想法转化为可用软件的速度. 部分表达能力来自于语言本身的语法, 但另一个基本部分来自于通常开箱即用的标准库.
一个好的标准库将程序员从最繁琐的任务中解放出来, 如连接数据源, 解析 XML, 处理数字等等. 当标准库做得很好时, 开发者可以自由地专注于应用程序的核心业务方面, 从而提高生产力和投资回报.
还应考虑到, 对标准库的深入了解通常是区分普通开发者和专家的标志. 专家能比初学者更优雅, 更快速地解决问题, 因为除了之前解决过同样的问题外, 他们还能通过从标准库中提取小块来组合成复 杂的解决方案.
最后, 标准库包含了对常见编程问题的解决方案, 这些方案已经在几代先前的应用程序中经过了实战检验. Clojure 的情况当然也是如此. 通过这种压力测试所带来的健壮性和可靠性是难以通过其他方 式实现的. 可能只有少数情况下, 标准库中的某些东西不符合你的需求, 需要重新实现.
1.1.2. 1.2 规范不就是很无聊吗?
简短的回答是: 它们不必如此. 还要考虑到, 语言规范并不总是强制规定附加的语言实用工具和工具的内容. 因此, 标准库可以以一种不那么正式的方式来描述和记录.
Clojure 没有正式的语言规范, 更不用说标准库规范了. Clojure 的非正式 (且务实) 的方法在文档方面也是其主要弱点: 语言和标准库以一种非常简洁的风格进行描述, 这通常被认为对初学者不友好 3.
近来, 人们为改进 Clojure 文档付出了很多努力, 尽管在撰写本文时, 标准库仍然缺乏一个全面和集中的参考资料.
本书花费了大量精力以一种可读和愉快的方式阐释函数, 使用了大量现实生活中的例子和视觉结构来吸引读者对核心部分的注意.
尽管本书不是设计为从头到尾阅读的书籍, 但每个函数本身都是一篇愉快而有趣的读物, 同时也提供了对函数式 (以及通用) 编程的洞见.
以下是 fnil 函数的简化版本, 与其在书中的呈现方式非常相似. 它已被注释以显示每个部分的用途:

Figure 1: 本书中函数说明的模板, 用椭圆形解释了每个部分的内容.
1.1.3. 1.3 Clojure 的不同版本
Clojure 有许多针对不同" 运行时" 的活跃维护实现. " 运行时" 是一个依赖于平台的可执行文件, 允许 Clojure 应用程序在不同的操作系统和硬件架构上运行.
事实上的参考实现运行在 Java 虚拟机上, 但值得注意的是还有另外两个活跃维护的 Clojure 版本: ClojureCLR (github.com/clojure/clojure-clr) 和 ClojureScript (clojurescript.org).
Clojure 的发明者 Rich Hickey 在很长一段时间内同时维护了 Clojure 的 Java 虚拟机 (JVM) 和通用语言运行时 (CLR) 版本 4. Rich 后来因为维护两者所需的大量工作而放弃了 CLR 版本.
幸运的是, 对于 Clojure 社区来说, David Miller 在 2009 年决定将 Clojure JVM 移植到 CLR, 这就是现在所谓的" ClojureCLR" 5.
与 ClojureCLR 类似, 一个能够转换为 JavaScript (然后在浏览器中运行) 的 Clojure 版本在 Clojure 项目历史的早期就被讨论过, 并产生了一个概念验证 6. Rich Hickey 最终在 2011 年的纽约市用户组会议上宣布了 ClojureScript 7.
ClojureCLR 和 ClojureScript 与 Clojure JVM 版本非常密切相关, 但它们从未被设计为直接替代品. 这意味着虽然 Clojure (JVM) 中可用的许多函数在其他平台上确实也可用 , 但它们的工作方式可能存在重大差异. 因此, 一个为 JVM 版本编写的 Clojure 应用程序可能 (而且很可能) 需要修改才能在 ClojureCLR 或 ClojureScript 上运行.
尽管本书专门针对 Clojure 的 JVM 版本, 但这里描述的许多函数和宏在其他 Clojure 运行时上的工作方式几乎完全相同. 但是, 如果你需要关于某个函数或宏在其他运行时上如何工作的具体信息, 请参考它们各自网站上提供的文档. 从现在开始, 请将本书中的任何主题都视为与 Clojure 标准库的 JVM 版本相关.
1.1.4. 1.4 Clojure 标准库
Clojure 标准库相当全面, 大致可以分为 3 个部分:
- 单个命名空间
clojure.core的内容 (通常被称为" core" ). Core 包含了那些已经演变为该语言主要公共 API 的函数, 包括基本的数学运算符, 创建和操作其他函数的函数, 条件语句. Core 目前包含约 700 个函数和宏的定义. core 中的函数在任何命名空间中都始终可用, 无需任何显式引用. - 除" core" 以外的命名空间 (仍作为 Clojure 的一部分提供). 这些通常以
clojure开头, 后面跟着一个描述性名称, 如clojure.test,clojure.zippers或clojure.string. 这些命名空间中的函数有时只需加上它们的命名空间前缀即可使用 (如clojure.string/upper-case), 但在其他情况下, 它们需要使用require8 导入到当前命名空间. - Java SDK 的内容, 通过 Clojure 的 Java 互操作性功能可以轻松获得. 本书展示了许多从 Clojure 使用 Java 标准库的例子, 但不会详细描述 Java 的例子.
在本书中, 我们将把 Clojure 标准库称为上述的前两个部分, 基本上就是你只需下载 Clojure 包而无需下载其他库就能获得的所有内容.
通常, 标准库中的项被标记为 public, 尽管一些函数在 Clojure 文档字符串中被标记为 "alpha" 并可能发生变化. 本书会提醒读者注意那些可以使用但不能保证会留在库中的函数.
标准库的内容可以根据 Clojure 引入的主要特性以及最常见的编程任务进行大致分类. 例如, 有大量函数专门用于软件事务内存 (Software Transactional Memory) 9, 并发和持久化集合.
当然, Clojure 也为常见任务如 IO, 序列处理, 数学运算, XML, 字符串等提供了所有必要的支持. Clojure 标准库中显然缺少的是 Java SDK 已经提供的解决方案, 例如加密, 底层网络, HTTP, 2D 图形等.
对于所有实际目的而言, 这些功能并不是缺失, 而是可以直接从 Java 中使用, 无需在 Clojure 中重新实现. Java 互操作性是 Clojure 的一大优势, 它使得从 Clojure 程序中轻松使用 Java SDK (Standard Development Kit) 成为可能.
本书将涵盖 clojure.core (标准库中的绝大多数函数) 以及下图中所描述并按应用领域大致分组的附加命名空间.

Figure 2: 所有其他非核心命名空间.
- Core 支持命名空间在已有的核心功能之上集成了额外的功能.
clojure.string可能是最好的例子. Core 已经包含了str, 但任何其他有用的字符串功能都已移出到clojure.string命名空间.clojure.template包含一些用于创建宏的辅助函数.clojure.set关乎 "set" 数据结构.clojure.pprint包含几乎所有 Clojure 数据类型的格式化器, 以便它们可以以美观, 人类可读的形式打印. 最后,clojure.stacktrace包含用于操作异常及其格式化的函数. - REPL 命名空间包含了专用于 REPL (Clojure 提供的读-求值-打印循环) 的功能.
clojure.main包括处理 Clojure 可执行文件主入口点的功能, 以及后来被拆分到clojure.repl的部分 REPL 功能. 最新的增加,clojure.core.server实现了服务器套接字功能. - 通用支持是指核心之外的附加 API. 这里的命名空间为 Clojure 增添了新功能. 例如,
clojure.walk和clojure.zip是两种遍历和操作树状数据结构的方法.clojure.xml提供了 XML 解析能力.clojure.test是 Clojure 附带的单元测试框架.clojure.sh包含向操作系统" shell-out" 命令的函数.clojure.core.reducers提供了一种并行计算模型. - Java 是专用于 Java 互操作的命名空间, 超出了核心已有的功能.
clojure.java.browser和clojure.java.javadoc分别提供了打开原生浏览器显示通用网页或 javadoc 文档的可能性.clojure.reflect封装了 Java 反射 API, 在其之上提供了一个符合 Clojure 习惯的层.clojure.java.io为java.io提供了一种合理的方法, 消除了所有使 Java IO 如此混乱的特质, 比如要知道将流转换为读取器以及反向转换的正确构造函数组合. 最后,clojure.inspector提供了一个用于导航数据结构的简单 UI. - 数据序列化涉及 Clojure 数据可以编码为字符串作为交换格式的方式.
clojure.edn是进入 EDN 10 格式序列化的主要入口点.clojure.data仅包含一个用户专用的函数clojure.data/diff, 用于计算数据结构之间的差异.clojure.instant定义了时间相关类型的编码.
尽管上述分类很好地概述了核心函数之外还有哪些可用功能, 但本书的结构使得 clojure.core 函数和非核心函数在必要时被重新分组, 以反映它们的应用领域. 几个显著的例子是:
clojure.reflect/reflect出现在 "Java 互操作" 章节, 与proxy,gen-class或doto等核心函数一起.clojure.walk/stringify-keys与其他核心哈希映射函数一起出现.
本书假设读者相对关心一个函数具体存在于何处 (如果仅仅是为了在命名空间顶部 require 它以便使用), 但他们更关心在有特定问题需要解决时知道这个函数的存在.
尽管标准库中的绝大多数项目是函数或宏, 但本书也描述了一些动态变量. 动态变量是一种特殊类型的引用, 可以在线程本地的基础上重新绑定 (有关动态变量的详细解释, 请参阅 "Joy of Clojure" 中的精彩描述 11). 本书也描述动态变量的原因是, 它们通常是配置标准库中其他函数的方式.
1.1.5. 1.5 让你的开发生活更轻松
标准库不仅是为了解决常见的重复编程问题, 也是为了给新的开发挑战提供优雅的解决方案. "优雅"在这里意味着易于阅读和维护的可组合解决方案. 让我们看下面的例子.
假设要创建一个报告, 以人类可读的形式在屏幕上显示信息. 信息来自一个外部系统, 并且已经有一个库在处理那部分通信.
只知道输入是以以下 XML 结构到达的 (这里保存为一个本地的 balance var 定义):
(def balance "<balance> <accountId>3764882</accountId> <lastAccess>20120121</lastAccess> <currentBalance>80.12389</currentBalance> </balance>")
余额需要以用户友好的方式显示:
- 移除除字母外的任何不需要的符号.
- 分隔像
lastAccess或currentBalance这样的词 (使用大写字母作为分隔符). - 将余额格式化为带两位小数的货币.
可能会倾向于像这样解决问题:
(require '[clojure.java.io :as io]) (require '[clojure.xml :as xml]) (defn- to-double [k m] (update-in m [k] #(Double/valueOf %))) (defn parse [xml] ; ❶ (let [xml-in (java.io.ByteArrayInputStream. (.getBytes xml)) results (to-double :currentBalance (apply merge (map #(hash-map (:tag %) (first (:content %))) (:content (xml/parse xml-in)))))] (.close xml-in) results)) (defn clean-key [k] ; ❷ (let [kstr (str k)] (if (= \: (first kstr)) (apply str (rest kstr)) kstr))) (defn- up-first [[head & others]] (apply str (conj others (.toUpperCase (str head))))) (defn separate-words [k] ; ❸ (let [letters (map str k)] (up-first (reduce #(str %1 (if (= %2 (.toLowerCase %2)) %2 (str " " %2))) "" letters)))) (defn format-decimals [v] ; ❹ (if (float? v) (let [[_ nat dec] (re-find #"(\d+)\.(\d+)" (str v))] (cond (= (count dec) 1) (str v "0") (> (count dec) 2) (apply str nat "." (take 2 dec)) :default (str v))) v)) (defn print-balance [xml] ; ❺ (let [balance (parse xml)] (letfn [(transform [acc item] (assoc acc (separate-words (clean-key item)) (format-decimals (item balance))))] (reduce transform {} (keys balance))))) (print-balance balance) ;; {"Account Id" 3764882, "Last Access" "20120121", "Current Balance" "80.12"}
❶ parse 接收 XML 输入字符串并将其解析为一个只包含必要键的 map. parse 还将 :currentBalance 转换为 double.
❷ clean-key 解决了移除每个属性名开头 ":" 的问题. 它在移除可能不需要的字符之前检查属性的开头.
❸ separate-words 负责搜索大写字母并在其前添加一个空格. 这里使用 reduce 来存储到目前为止的更改累积, 同时我们将原始字符串作为输入来读取.
up-first 被提取为一个方便的支持函数, 用于将第一个字母大写.
❹ format-decimals 处理浮点数的格式. 它使用 re-find 搜索数字, 然后要么追加 (填充零) 要么截断小数位.
❺ 最后, print-balance 将所有转换组合在一起. 同样, reduce 被用来创建一个带有转换的新 map, 同时我们读取原始的 map. 这个 reducing 函数足够大, 建议在 letfn 形式中使用一个匿名函数.
该函数的核心是将新的格式化属性与格式化后的值在要显示的新 map 中进行 assoc.
尽管相对容易阅读 (3 个格式化规则在某种程度上被分成了函数), 但这个例子只展示了标准库所提供功能的极少一部分.
它包含了 map, reduce, apply 和一些其他的函数, 包括 XML 解析, 这些当然是重要的函数 (并且通常是初学者首先学习的). 但标准库中肯定还有其他函数可以让同样的代码更简洁, 更可读.
让我们再看看需求, 看是否能做得更好. 上面代码的复杂性根源可以追溯到以下几点:
- 字符串处理: 字符串需要被分析和分解.
clojure.string命名空间浮现在脑海. - Map 相关的计算: 键和值都需要特定的处理. 这里使用了
reduce, 因为我们想同时逐步改变键和值. 但zipmap听起来是一个值得探索的可行替代方案. - 最终输出的格式化规则: 比如数字的字符串填充或小数的四舍五入. 有一个有趣的
clojure.pprint/cl-format函数可能会派上用场. - 其他细节, 如嵌套形式和 IO 副作用. 在第一种情况下, 可以使用线程宏来提高可读性. 最后, 像
with-open这样的宏消除了开发者需要记住初始化正确的 Java IO 类型并在结束时关闭它的需要.
通过思考我们需要解决的问题的各个方面, 我们列出了一些可能有帮助的函数或宏. 下一步是验证我们的假设并重写示例:
(require '[clojure.java.io :as io]) (require '[clojure.xml :as xml]) (require '[clojure.string :refer [split capitalize join]]) (require '[clojure.pprint :refer [cl-format]]) (defn- to-double [k m] (update-in m [k] #(Double/valueOf %))) (defn parse [xml] ; ❶ (with-open [xml-in (io/input-stream (.getBytes xml))] (->> (xml/parse xml-in) :content (map #(hash-map (:tag %) (first (:content %)))) (into {}) (to-double :currentBalance)))) (defn separate-words [s] (->> (split s #"(?=[A-Z])") ; ❷ (map capitalize) ; ❸ (join " "))) (defn format-decimals [v] (if (float? v) (cl-format nil "~$" v) ; ❹ v)) (defn print-balance [xml] (let [balance (parse xml) ks (map (comp separate-words name) (keys balance)) vs (map format-decimals (vals balance))] (zipmap ks vs))) ; ❺ (print-balance balance) ;; {"Account Id" 3764882, "Last Access" "20120121", "Current Balance" "80.12"}
❶ parse 现在避免了 let 块, 包括不再需要关闭输入流. 这是通过 with-open 实现的. 使用了 ->> 线程宏来为之前嵌套的 XML 处理提供更线性的流程.
❷ separate-words 现在使用了几个来自 clojure.string 的函数. split 接受一个正则表达式, 我们可以用它来按大写字母分割字符串.
将这个版本与之前使用 reduce 的版本进行比较: 这个更容易阅读和理解.
❸ 我们现在将每个单词首字母大写, 最后将所有内容连接成一个新的字符串.
❹ format-decimals 几乎完全委托给 clojure.pprint/cl-format, 它完成了所有格式化小数的工作.
❺ zipmap 在我们处理 map 的方式上带来了另一个戏剧性的变化. 我们可以将对键的更改 (组合单词分隔和移除不需要的 ":") 和对值的更改隔离到两个独立的 map 操作中. zipmap 方便地将它们重新组合成一个新的 map, 而不需要 reduce 或 assoc.
第二个例子展示了关于"了解你的工具" (在这里是 Clojure 标准库) 的一个重要事实: 使用一组不同的函数不仅将行数从 45 行减少到 30 行, 而且还为设计开辟了完全不同的决策.
除了我们将整个子任务委托给其他函数 (如 cl-format 用于格式化小数或 name 用于清理键) 的情况外, 主要的算法逻辑采用了不使用 reduce 或 assoc 的不同方法.
一个更短, 更具表达力的解决方案显然更容易演进和维护.
1.1.6. 1.6 信息碎片化的问题
自 2010 年以来, Chas Emerick 一直在以年度调查的形式向 Clojure 社区提出一些问题, 以收集关于 Clojure 在行业中采用情况的反馈.
Cognitect, 这家积极赞助 Clojure 开发的公司, 正在延续这一传统, 最新可用的 2019 年结果已发布在其网站上 12. 自调查开始以来, 人们报告的主要担忧之一就是关于 Clojure 文档的数量和质量.
Clojure 社区 (主要在 Alex Miller 和其他核心团队成员的指导下) 在增强 Clojure 指南和教程方面取得了巨大进展, 最终开源发布了 Clojure 文档网站, 使任何人都能轻松贡献 13.
而 Clojure 本身附带的文档则简洁明了. 这对于快速记住某样东西应该如何工作是好的, 但不一定详尽. 例如, 如果你在 REPL 中输入 (doc interleave), 你会看到:
user=> (doc interleave) ------------------------- clojure.core/interleave ([] [c1] [c1 c2] [c1 c2 & colls]) Returns a lazy seq of the first item in each coll, then the second etc. nil
"Returns a lazy seq of the first item in each coll, then the second etc." (返回每个 coll 中第一个元素的惰性序列, 然后是第二个, 依此类推. ) 是精确和基本的.
它假设你理解什么是"惰性序列", 并且省略了像处理大小不均的集合时会发生什么这样的细节.
可以在 REPL 中输入示例来进一步探索 interleave, 或者, 如果没有输入什么的想法, 可以在互联网上搜索代码片段. 一些背景概念记录在 Clojure 网站的"参考"部分 (clojure.org/reference).
参考文档从一开始就存在, 并且遵循与 REPL 中的 doc 相同的基本风格. 如果你是一位有一定函数式经验的资深程序员, 你肯定会对此感到舒适, 但对于 Clojure 的初学者来说并非总是如此.
最近推出的"Clojure 文档" 网站 clojure-doc.org 是社区贡献努力的开端, 更倾向于"入门".
尽管 clojure-doc.org 现在已经存在, 但多年来已经启动了多项努力来填补原始文档留下的空白. 以下是撰写本文时可用的其他资源的摘要:
- clojuredocs.org 是一个社区驱动的文档引擎. 它基本上在标准库文档之上提供了示例和注释, 包括交叉链接. 一个函数的文档质量从无到有许多示例和评论不等.
- groups.google.com/forum/#!forum/clojure 是主要的 Clojure 邮件列表. 那里记录了绝对精彩的帖子, 包括由 Rich Hickey 本人和其他核心团队成员讨论 Clojure 整体愿景和设计的主题.
- web.archive.org/web/http://clojure-log.n01se.net IRC Clojure 频道的日志. 与邮件列表相同, 有一些重要的讨论塑造了未来 Clojure 版本的设计.
- 书籍. 到目前为止编写的 Clojure 书籍数量令人印象深刻. 人们真的很喜欢写关于 Clojure 的书, 本书也不例外!
- stackoverflow.com/search?q=clojure Clojure 相关问题是巨大信息的惊人来源. 几乎所有可以想象到的问题, 无论是哲学上的还是实践上的, 都在那里得到了回答.
- 博客: 有太多好的博客无法在此一一列举. planet.clojure.in/ 在持续聚合博客文章, 文章和不断出现在网络上的其他 Clojure 资源方面做得很好.
正如你所看到的, 文档以多种形式存在, 并且总体上非常有价值, 但它是碎片化的: 在所有不同来源之间跳转非常耗时, 包括搜索正确的地方并不总是显而易见. 本书的主要目标之一就是为你做这项工作: 将所有有价值的信息来源汇集到一个单一, 易于访问的地方.
1.1.7. 1.7 Clojure 忍者的秘诀
学习标准库中的函数通常是一个从一开始就启动的过程. 它发生在你初次接触某些教程或书籍时, 例如当作者展示一个漂亮的一行代码解决一个看似大问题的时候.
通常开发者不会特别注意标准库中的函数, 认为知识会在学习语言特性时有所增加. 这种方法在一定程度上可以奏效, 但不太可能扩展.
如果你认真学习这门语言, 考虑分配专门的时间来理解类似函数的不同细微差别或某些晦涩命名空间的内容.
证明这是值得花时间的事情, 可以通过阅读他人的经验找到: 网络上有很多文章描述了学习 Clojure 的过程或记录了发现 (可能是最好的例子是 Jay Field 的博客 14).
以下是一个能让你成为真正的 Clojure 大师的绝妙技巧. 除了学习教程, 书籍或像 Clojure Koans 15 这样的练习之外, 考虑加入以下内容:
- 每天从本书的目录中选择一个函数. 例如, 可以是午餐或通勤时间. 另一个选择是把这本书放在你的桌子上, 偶尔随机翻开一页.
- 研究你面前的函数的细节. 首先查看官方文档, 在 REPL 中尝试示例, 在网络上或 www.github.com 上搜索使用它的 Clojure 项目.
- 尝试找出函数在什么情况下会出错或其他特殊的边界情况. 传递
nil或意外的类型作为参数, 看看会发生什么. - 第二天或定期重复.
不要忘记打开函数的源代码, 特别是如果它属于 "core" Clojure 命名空间. 通过查看 Clojure 源代码, 你有独特的机会从 Rich Hickey 和核心团队的工作中学习. 你会惊讶地发现标准库中的一个函数背后有多少设计和思考.
你甚至可能发现一个函数的历史很有趣, 特别是如果它追溯到 Lisp 的起源: 例如, "apply" 直接与 1958 年 Lisp 诞生的麻省理工学院人工智能实验室相关联! 16
只有通过扩展你对标准库内容的知识, 你才能完全欣赏 Clojure 的力量.
1.1.8. 1.8 完美的伴侣书籍
我们认为这本书非常适合希望理解一个函数 (并最终理解 Clojure) 如何工作的中级或资深 Clojure 程序员.
如果你刚开始学习 Clojure, 这本书涵盖了一些理论和背景知识, 让你能够舒适地理解一个函数的主要目标, 但它不应该是你唯一的教材.
如果你已经拥有或计划购买一本更具入门性的书籍, 我们认为这本书是一个完美的补充选择: 随时深入本书, 寻找关于一个函数或宏的更详尽信息.
如果你是中级或经验丰富的 Clojure 程序员, 我们认为你会发现本书中的资源很有价值. 我们投入了大量精力收集真实世界的例子和分析 Clojure 的内部机制.
参考文献, 指针和书目也通过引导好奇的读者获取额外的学习材料, 增加了整体体验.
作者们希望这本书能成为标准库事实上的参考, 我们当然也希望为读者提供关于 Clojure 最全面的信息来源之一.
1.1.9. 1.9 总结
- 标准库是通过安装 Clojure 开箱即用的函数和宏的集合.
- Clojure 标准库丰富而健壮, 允许开发者专注于应用程序的核心业务方面.
- 关于标准库的信息往往是零散的, 但本书将所有内容收集在一个单一, 易于访问的地方.
- 对标准库内容的深入了解能以指数级提高代码的表达能力.
- 虽然许多人认为标准库是在有特定需求时才访问的被动资源, 但本书建议采用更有趣的方法, 以更系统的方式学习它.
- 本书投入了大量精力, 使第二部分的内容成为一种有趣且丰富的体验, 而不仅仅是一份枯燥的规范列表.
2. 第二部分. 基础知识
本书的这一部分描述了 Clojure 标准库中一些最基本的函数. 这种分类 (如同本书中所有其他分类一样) 只是一个指导工具, 书中各章节之间当然没有" 明确的界限".
该部分按应用领域划分为章节, 每个章节又进一步划分为相关函数的子组. 章节的结构应该能逐渐引导用户找到解决问题的最佳方法, 并让他们了解标准库中可能有所帮助的其他相关函数.
书末还提供了其他分类, 以进一步帮助寻找最佳解决方案.
2.1. 2 创建和操纵函数
毫不奇怪, 函数式语言特别擅长为开发者提供用于创建和组合函数的工具和语法支持. 本章汇集了 Clojure 标准库中专门用于操纵或生成其他函数的函数. 本章将它们分为 4 大类:
- 函数定义. 函数是 Clojure 中组合的基本单位. 本节包含了专门用于声明新函数的主要宏.
- 高阶函数. 本节描述了其主要目标是根据用户定义的计算或其他现有定义来产生新函数的函数和宏.
- 线程宏. 这组重要的宏为 Clojure 提供了一种视觉上吸引人的语法来描述处理管道.
- 函数执行. 最后, 另一组专门用于管理其他函数执行的函数.
还有其他函数和宏可以用相同的标准进行分类, 但在这个初始的" 基础" 章节中, 我们专注于最重要的那些, 而其他的则在本书的其他部分进行描述.
2.1.1. 2.1 函数定义
Clojure 是专门围绕" 函数" 这个概念设计的. 函数, 毫不奇怪, 是函数式语言中主要的组合机制: 一旦一组计算步骤被捕获为一个函数, 它就可以被调用或与其他函数组合以提升更高的抽象层次.
标准库中定义函数最重要的入口是 defn. 此外, Clojure 提供了其他方式来帮助模块化应用程序: 例如, definline 在 Java 互操作的情况下可以提高性能, 而 fn 则可以嵌入到其他函数中.
后面将描述的宏与之有重叠, 但考虑到它们引入了一种自己的小语言, 它们被专门安排了一个章节.
- 2.1.1 defn 和 defn-
自 1.0 起为宏
(defn [name & fdecl])
defn(及其私有版本defn-) 是 Clojure 中函数创建的基本构件和主要入口点之一. 它支持丰富的功能集, 如解构, 多重元数, 类型提示,:pre和:post条件等 (通过与其密切相关的fn实现). 其调用约定本身就像一门小语言, 而defn就是专门用来解析这个小语法的.defn最常用的形式可能是简单的单参数情况:(defn hello [person] ; ❶ (str "hello " person))
❶ 一个简单的函数定义. 函数
hello接收一个字符串并返回一个字符串.defn与def(用于在当前命名空间中绑定其名称) 和fn(用于前置/后置条件和解构) 协同工作. 由于defn是一个宏, 我们可以对其调用macroexpand来理解其工作原理:(macroexpand ; ❶ '(defn hello [person] (str "hello " person))) ;; (def hello ;; (clojure.core/fn ; ❷ ;; ([person] (str "hello " person)))) (hello "people") ; ❸ ;; "hello people"
❶ 我们可以对之前的函数定义调用
macroexpand, 看看 Clojure 如何将匿名函数的创建与当前命名空间中的 var 定义组合在一起.❷ 通过
fn创建的 lambda 被赋给一个新的 Var 对象 "hello".❸ "hello" 符号在当前命名空间中可用于执行, 使用环绕的括号.
- 约定
defn的约定相当复杂, 本着保持本书实用性的精神, 我们不打算使用严格的语法来描述这个或书中的其他函数. 我们将使用一种非正式的语法 , 希望它比相应的函数文档更具表达力, 但并不旨在涵盖所有可能情况的全部范围 (也不是 100% 一致). 读者应使用该语法来大致了解函数的作用, 然后参考下面的示例来涵盖其余情况.以下是本书中使用的语法词汇表 (同样的词汇表也已添加到附录中):
"<term>": 尖括号中的术语是终结符, 不会产生任何进一步的展开."[]": 方括号中的术语是函数定义中的实际向量."()": 圆括号中的术语是函数定义中的实际列表."OR": 表示在可能的选项中进行选择.":=>": 显示一个可以进一步展开为其他术语的术语."..": 意思是" …的多次重复" ."?": 在一个术语之后表示该术语是可选的.
有了这个小语法, 我们可以这样表达
defn的用法:(defn ^<metamap>? <name> fdecl) fdecl :=> <docstring>? <metamap>? arities <metamap>? arities :=> ^<metamap>? [arity] body OR (^<metamap>? [arity1] body) (^<metamap>? [arity2] body) .. (^<metamap>? [arityN] body) arity :=> <ret-typehint>? [<arg1-typehint>? <arg1> .. <argN-typehint>? <argN>] body :=> <metamap> <forms>
"<metamap>"是一个可选的键值对 map (例如^{:a true}) ."<metamap>"也接受一种简洁的语法, 只使用键^:tagname1 ^:tagname2, 其中值隐式为 true. 请注意, 这种替代语法仅在允许"<metamap>"的某些位置可用. 标签与函数定义创建的 var 一起存储. 此外, 根据位置,<metamap>可能需要^前缀出现在左花括号之前."<name>"是强制性的, 必须是有效的符号 17."<docstring>"是一个可选的字符串, 用于描述函数. 文档字符串也存储在函数定义产生的 var 对象中. 你可以使用doc函数查看文档字符串.([arity1]) ([arity2]) .. ([arityN])是不同长度的参数向量. 在只有一个[arity]的情况下, 外围的括号是可选的."<ret-typehint>"是一个可选的类型提示, 适用于该元数的返回值."<ret-typehint>"也可以出现在该元数的"<metamap>"中, 形式为{:tag <typehint>}, 行为等效."<arg-typehint>"是参数向量中一个参数的可选类型提示. 这也可以表示为"<metamap>"."body"包含调用函数时求值的表达式. 它被隐式地包裹在一个do块中. 当没有 body 时, 假定为nil. 在 body 中的其他表达式之前, 允许有一个额外的"<metamap>"(没有前缀^). 当参数向量和 body 都包含"<metamap>"时, 如果键发生冲突, body 中的那个优先. 注意, 前置和后置条件 (见下文) 只允许在参数向量之后的"<metamap>"中使用.
defn返回一个引用刚创建的函数对象的clojure.lang.Var. 函数名在当前命名空间中无需任何额外前缀即可使用. 值得注意的是, 元数据 map 可以出现在多个位置. - 示例
defn的用法当然是广泛的. 以下示例说明了一些最重要的方面.- 元数据放置
从约定中我们可以看到,
defn接受元数据定义, 在多个位置具有略微不同的语法和含义. 一些元数据作为生成的 var 定义的一部分可用, 其他的则在表达式解析期间通知编译器 , 还有一些在函数求值期间的运行时使用. 我们可以在以下 (公认是人为构造的) 示例中一次性看到它们:(defn ^{:t1 1} foo ; ❶ "docstring" {:t2 2} (^{:t3 3} [a b] {:t4 4} (+ a b)) ; ❷ {:t5 5}) ; ❸ (meta #'foo) ; ❹ ;; {:ns #object[clojure.lang.Namespace 0x33f17f86 "user"], ;; :name foo, ;; :t2 2, ;; :file ;; "/private/var/form-init5372276344059831979.clj", ;; :column 1, ;; :line 1, ;; :arglists ([a b]), ;; :doc "docstring", ;; :t1 1, ;; :t5 5} (meta (first (:arglists (meta #'foo)))) ; ❺ ;; {:t3 3, :t4 4}
❶ 元数据的第一个位置是在
defn声明之后. 在这个位置, 它需要前缀^.❷ 元数据 map 在这一行中出现了 3 次: 在第一个元数声明之前, 在第一个元数声明内部, 以及在函数体之前.
❸ 最后的元数据 map 在所有定义之后可用.
❹ 我们可以看到
:t1,:t2,:t5出现在 var 元数据中. 其他上下文相关的信息 (如命名空间对象或列/行信息) 在从另一个 REPL 打印时可能会有所不同.❺ 元数定义内的两个元数据 map 已合并为一个附加到
":arglists"值的元数据 map.值得注意的是, 函数末尾的元数据只有在元数 (参数向量后跟函数体) 被括号包裹时才可用. 当函数只有一个元数时, 记住这一点很重要, 因为这通常是在没有外围括号的情况下编写的.
例如, 上面的例子之所以有效, 是因为
([a b] (+ a b))被括号包裹着.除了像
:doc,:tag,:pre或:post这样的保留键之外, 我们可以使用元数据来用任何类型的上下文信息注释函数. 注释可以稍后被库或工具分析和处理.例如, 元数据在
core.test命名空间中被广泛使用, 以将函数标记为" test" 并相应地运行它. 元数据中的键值对可以是任何类型, 例如字符串, 数字或其他结构化数据.然而, 布尔值非常频繁, 以至于它们通常被称为" 标签" . 标签提供了一个额外的前缀语法, 使用脱字符号
"^:".以下示例展示了一个性能分析功能, 它扫描一个命名空间以查找标记为
^:bench的函数. 当存在这样的标签时, 相应的函数将被重新定义以检查执行时间:(ns profilable) (defn ^:bench profile-me [ms] ; ❶ (println "Crunching bits for" ms "ms") (Thread/sleep ms)) (defn dont-profile-me [ms] (println "not expecting profiling")) (ns user) (defn- wrap [f] (fn [& args] (time (apply f args)))) (defn- make-profilable [v] (alter-var-root v (constantly (wrap @v)))) (defn- tagged-by [tag nsname] (->> (ns-publics nsname) vals (filter #(get (meta %) tag)))) (defn prepare-bench [nsname] ; ❷ (->> (tagged-by :bench nsname) (map make-profilable) dorun)) (profilable/profile-me 500) ; ❸ ;; Crunching bits for 500 ms (prepare-bench 'profilable) (profilable/profile-me 500) ; ❹ ;; Crunching bits for 500 ms ;; "Elapsed time: 502.422309 msecs" (profilable/dont-profile-me 0) ; ❺ ;; not expecting profiling
❶ "profilable" 命名空间中的函数
profile-me有一个:bench注释, 它会进入元数据 map.❷
prepare-bench在给定的命名空间中搜索所有标记为:bench的函数, 并将它们包装到一个新的函数中, 该函数进行性能分析.❸ 在调用
prepare-bench之前,profile-me打印预期的消息.❹ 但在调用
prepare-bench之后,profile-me还会打印经过的时间以及消息.❺ 其他未标记的函数不受影响.
- 文档化
为一个函数附加一个简短的文档字符串来描述其用途是一种很好的做法. Clojure 为文档字符串提供了一个特定的位置, 以便编译器可以适当地存储此信息. 然后, 您可以使用
clojure.repl/doc函数来打印有关该函数的有用信息, 包括文档字符串:(defn hello "A function to say hello" ; ❶ [person] (str "Hello " person)) (clojure.repl/doc hello) ; ❷ ;; ------------------------- ;; user/hello ;; ([person]) ;; A function to say hello ;; ([person]) ;; A function to say hello ; ❸ ;; nil (:doc (meta #'hello)) ; ❹ ;; "A function to say hello"
❶ 文档字符串出现在函数名之后.
❷ 我们使用函数
doc并将 var "hello" 作为参数传递.❸ 文档字符串与函数签名一起打印在屏幕上.
❹ 或者, 我们可以从元数据中提取键
:doc. - 前置/后置条件
下一个例子展示了如何使用前置和后置条件. 条件是函数, 可以访问参数和返回值 (仅限后置条件). Clojure 会检查参数向量后的元数据 map 中是否存在
:pre或:post键.当存在
:pre或:post键时, 它们的值必须是谓词的集合. 谓词分别在函数执行之前或之后被调用.下面的
save!函数, 将一个项目保存到某个存储. 在将其推送到存储之前, 它使用前置条件检查有关输入的一些事实. 保存到存储后, 它用后置条件验证该项目是否具有正确的":id":(require '[clojure.test :refer [are]]) (defn save! [item] {:pre [(are [x] x ; ❶ (map? item) ; ❷ (integer? (:mult item)) ; ❸ (#{:double :triple} (:width item)))] ; ❹ :post [(clojure.test/is (= 10 (:id %)))]} ; ❺ (assoc item :id (* (:mult item) 2))) (save! {:mult "4" :width :single}) ;; FAIL in () (form-init828.clj:2) ; ❻ ;; expected: (integer? (:mult item)) ;; actual: (not (integer? "4")) ;; ;; FAIL in () (form-init828.clj:2) ;; expected: (#{:double :triple} (:width item)) ;; actual: nil ;; ;; AssertionError Assert failed: ;; (clojure.test/are [x] x (map? item) (integer? (:mult item)) ;; (#{:double :triple} (:width item))) user/save! (save! {:mult 4 :width :double}) ; ❼ ;; FAIL in () (form-init8288562343337105678.clj:6) ;; expected: (= 10 (:id %)) ;; actual: (not (= 10 8)) ;; ;; AssertionError Assert failed: ;; (clojure.test/is (= 10 (:id %))) (save! {:mult 5 :width :double}) ; ❽ ;; {:mult 5, :width :double, :id 10}
❶
"clojure.test/are"将多个断言组合在一起. 本例中的断言如果失败, 都预期返回逻辑假 (包括nil).❷ 这个谓词检查
item是否为 map 类型. 注意参数"item"在前置和后置条件中都可用.❸ 类似地, 这个谓词检查键
:mult的值是否为整数类型.❹ 使用集合包含来验证
:width键的值是否属于一小组允许的值.❺ 后置条件的工作方式类似, 增加了占位符
%百分号来访问函数的返回值. 在这种情况下, 我们检查返回的 map 是否包含一个等于 10 的 id.❻ 由于
clojure.test函数, 失败的断言被很好地打印出来.clojure.test是标准库的一部分.❼ 在下一次尝试中, 我们修复了前置条件, 但后置条件有问题.
❽ 我们终于看到了对
save!的成功调用.注意
该示例演示了一个有用的技巧, 即用
clojure.test/is或clojure.test/are宏包装前置和后置条件. 条件仍然会因java.lang.AssertionError而失败, 但clojure.test包装器会显示一个更 友好的消息. - 类型提示
类型提示是连接 Clojure 动态类型世界 (几乎所有东西都被视为通用的
java.lang.Object) 和 Java 静态类型世界的桥梁. 在大多数情况下, Clojure 中的类型提示是可选的, 但当速度很重要时, 它们是必需的 (其他常见的技巧包括禁用检查数学, 使用原始未装箱类型, 使用瞬态等, 具体取决于具体情况).当 Clojure 函数调用 Java 方法时, 通常需要类型提示. Clojure 编译器使用类型信息来避免在生成的 Java 字节码中进行反射. 反射是一个非常有用 (但很慢) 的 Java API, 用于发现和调用 Clojure 运行时所需的 Java 方法.
为了说明这一点, 以下示例是关于使用密钥对请求进行签名. Java 标准库包含了我们完成此任务所需的一切, 因此不需要外部库. 对请求进行签名的想法如下:
- 有一些我们想要签名的事件的唯一字符串表示. 在本例中, 我们将使用一个 URL.
- 两方想要交换信息, 但他们想确保信息在中间没有被篡改. 因此, 他们生成并存储一个用于签署消息的密钥, 别人无法访问.
- 当 "A" 想向 "B" 发送消息时, 它通过附加一个签名来签署消息. "B" 接收到消息, 应用相同的过程, 并验证生成的签名与接收到的签名相同.
这里是一些实现该协议的代码:
(ns crypto (:import java.io.ByteArrayOutputStream javax.crypto.spec.SecretKeySpec javax.crypto.Mac java.util.Base64 java.net.URLEncoder java.nio.charset.StandardCharsets)) (set! *warn-on-reflection* true) ; ❶ (defn get-bytes [s] (.getBytes s (StandardCharsets/UTF_8))) (defn create-spec [secret] (SecretKeySpec. (get-bytes secret) "HmacSHA256")) (defn init-mac [spec] (doto (Mac/getInstance "HmacSHA256") (.init spec))) (defn compute-hmac [mac canonical] (.doFinal mac (get-bytes canonical))) (defn encode [hmac] (URLEncoder/encode (.encodeToString (Base64/getEncoder) hmac))) (defn sign [canonical secret] ; ❷ (-> secret create-spec init-mac (compute-hmac canonical) encode)) (defn sign-request [url] ; ❸ (let [signature (sign url "secret-password")] (format "%s?signature=%s" url signature))) (sign-request "http://example.com/tx/1") ;; "http://example.com/tx/1?signature=EtUPpQpumBqQ5c6aCclS8xDIItfP6cINNkKJXtlP1pc%3D"
❶ Clojure 提供了
*warn-on-reflection*动态 var, 以显示编译器无法推断类型的位置.❷
sign函数显示了签名所需的步骤. 我们不需要深入了解算法的细节, 但创建一个 sha256 hmac 是很常见的程序 18.❸
sign-request接受一个代表交易的 url. 该函数返回相同的 URL, 并将签名作为请求参数之一附加, 准备通过网络发送.当我们在编译期间查看输出时, Clojure 会打印类似以下内容:
Reflection warning, crypto.clj:12:3 - call to method getBytes can't be resolved (target class is unknown). Reflection warning, crypto.clj:21:3 - call to method doFinal can't be resolved (target class is unknown).
源代码行/列引用可能不同, 但消息表明至少有两个地方编译器无法推断类型并正在使用反射. 如果在我们的示例中, 我们假设每秒有 100k 笔交易的峰值, 我们可能需要审查
sign-request的性能. 像 Criterium 这样的高级工具是基准测试的最佳选择, 但在这个具体案例中, 我们可以仅通过使用time清楚地看到发生了什么:(time (dotimes [i 100000] ; ❶ (sign-request (str "http://example.com/tx/" i)))) ;; "Elapsed time: 1054.507977 msecs"
❶
time是一个小宏, 它用时间测量来包装一个表达式.注意
此处 (以及本书其他部分) 显示的经过时间取决于执行基准测试的硬件, 因此在其他机器上可能会显示不同的数字. 重要的是基准测试实例之间的相对差异, 这应该与硬件无关.
现在让我们为编译器警告突出显示的函数定义添加类型提示:
(defn get-bytes [^String s] ; ❶ (.getBytes s (StandardCharsets/UTF_8))) (defn compute-hmac [^Mac mac canonical] ; ❷ (.doFinal mac (get-bytes canonical))) (time (dotimes [i 100000] (sign-request (str "http://example.com/tx/" i)))) ;; "Elapsed time: 449.417098 msecs" ; ❸
❶ 参数 "s" 被标记为
^String, 因此接下来的.getBytes是完全限定的.❷ 参数 "mac" 被标记为类型
^Mac. 编译器的其他警告也消失了, 因为.doFinal也通过推断变得完全限定.❸ 添加了两个类型提示后, 我们能够将处理时间减少 50%.
正如新的测量时间所示, 当移除反射调用后, 我们可以获得更好的性能.
- 不超过 20 个!
Clojure 中的函数定义限制为最多 20 个非可变参数:
(defn a [a1 a2 a3 a4 a5 a6 a7 a8 a9 a10 a11 a12 a13 a14 a15 a16 a17 a18 a19 a20 a21]) ;; CompilerException java.lang.RuntimeException: Can't specify more than 20 params [...]
以上代码会导致编译时异常. 这个限制可能看起来是任意的或限制性的, 但选择背后的理由很简单: Clojure 非常注重速度, 并且有一些编译器优化, 这些优化从为每个参数数量都有一个特定的 Java 方法中获益匪浅. 在 Clojure 代码库中有几个地方可以看到这一点 19, 当然, 这并不容易阅读, 维护或演进.
除了编译器实现细节外, 任何超过三或四个参数的函数都应该看起来可疑. 参数太多应该引发一个问题, 即是否缺少一个将它们组合在一起的抽象.
- 元数据放置
- 另请参阅
fn在defn的底层被用来生成函数体并实现解构. 与defn不同,fn不会创建 var 对象, 也不会作为副作用改变当前命名空间. 因此,fn是在不需要外部名称的情况下在本地使用函数的更好选择.fn经常与序列操作如reduce一起使用, 以创建一个两个参数的匿名函数.definline创建一个defn定义, 但也包含一个内联版本的函数体以提高 Java 互操作性. 如果函数体除了包装一个 Java 方法调用外没有做太多其他事情, 考虑为性能敏感的函数使用definline.letfn是与let绑定关联的匿名函数定义的语法糖. 优先使用letfn来创建一个或多个命名的本地函数. - 性能考虑和实现细节
defn是一个宏, 主要影响 Clojure 的编译时间.defn的常见用法在程序运行时不应产生顾虑.defn的定义在标准库引导的早期发生, 当时大多数常见的 Clojure 设施尚未定义. 这一方面, 加上与内联和类型提示相关的复杂性, 使得defn的源码不易理解.
- 约定
- 2.1.2 fn
自 1.0 版本以来的宏
(fn [params] exprs)
fn创建一个新函数, 并支持重要功能, 如解构, 类型提示, 前置和后置条件 (在defn中已说明) 以及基于参数数量 (或 Clojure 文档中常说的" 元数" ) 的多个签名.fn函数是 Clojure 中的一等公民: 你可以将它们作为参数传递或在本地绑定.函数对象 (也称为 lambdas) 在函数式编程中非常普遍, 以至于 Clojure 为它们提供了一种特殊的读取器语法 (读取器宏
#()). 以下示例展示了用fn和更短的读取器语法创建的相同函数:((fn [x] (* (Math/random) x)) ; ❶ (System/currentTimeMillis)) ; ❷ ;; 1.314465483718698E12 (#(* (Math/random) %) ; ❸ (System/currentTimeMillis)) ;; 1.2215726280027874E12
❶
fn用于声明一个单参数的匿名函数.❷ 创建的函数立即可供调用, 并需要一个参数. 在这种情况下, 我们传递当前的毫秒时间, 该时间乘以 0 到 1 之间的一个随机数. 结果, 它返回过去的一个随机瞬间 (但在 1970 年 1 月 1 日之后, 即纪元时间的开始 20).
❸ 相同的函数使用
#()函数字面量语法表示. 函数内部的百分号 (%) 是所需参数的占位符 (替换了前一个示例中的 "x"). 如果函数字面量接受多个参数, 也可以使用带编号的参数:%1,%2等. 还有一个可变参数的 catch-all 版本%&, 意思是" 在此处使用函数字面量的所有参数" .- 约定
与标准库中的其他一些函数和宏一样,
fn有一个相当复杂的签名, 类似于一个小型语法. 以下非正式约定展示了fn的最重要特性 (请检查下面的示例以明确它们的工作方式).(fn <name>? arities) arities :=> ^<metamap>? [arity] body OR (^<metamap>? [arity1] body) (^<metamap>? [arity2] body) .. (^<metamap>? [arityN] body) arity :=> [<arg1-typehint>? <arg1> .. <argN-typehint>? <argN>] body :=> <metamap>? <forms>
"<name>?"是一个可选的符号, 它将生成的函数绑定到函数本身的局部作用域. 该名称允许函数是递归的 (参见下面的示例)."arities"是一个或多个元数声明的列表 (例如, 函数(fn ([] "a") ([x] "x"))包含两个元数, 分别是零个和一个参数). 每个元数允许一个可选的以"^"为前缀的元数据 map, 后面跟着一个强制性的参数向量和一个可选的函数体. 在单参数的情况下, 外围的括号可以省略. 每个向量的内容可以是纯符号或更复杂的解构表达式."^<metamap>"是一个可选的关键字-值对的 map. 它可能包含类型提示或自定义元数据. 当它出现在参数向量之前时, 该 map 需要使用前缀"^". 当"<metamap>"出现在参数向量之后时, 它不需要前缀."arity"是参数向量的内容. 除了名称, 每个参数都可以单独进行类型提示.<body>, 当存在时, 包含实际的函数表达式. 它被隐式地包裹在一个do块中. 当没有函数体时, 假定为nil. 当函数体包含一个顶层 map 并且后面跟着一个表达式时, 那么该 map 将被用作元数据. 当"<metamap>"同时出现在参数向量之前和之后时, 如果键发生冲突, 后面的那个优先.- 返回: 刚创建的函数对象.
- 示例
fn是所有声明函数和宏的最小公分母. 例如, 在用defn声明的函数中为参数给出的类型提示是由fn在底层处理的. 尽管在fn中实现, 类型提示或前置和后置条件通常出现在defn声明中. 对于本节中未出现的内容, 邀请读者也查看defn的示例.- 命名递归
第一个例子演示了可选名称的一种可能用法, 它使函数在最内层作用域内被绑定. 例如, 它可以用于基本斐波那契数列 21 的递归定义中:
((fn fibo [n] ; ❶ (if (< n 2) n (+ (fibo (- n 1)) (fibo (- n 2))))) 10) ;; 55
❶ 一个查找第 n 个斐波那契数的函数实现.
通过增加一个带有 3 个参数的元数, 我们现在可以提供一个尾调用优化的斐波那契函数, 而无需改变之前的定义:
((fn fibo ; ❶ ([n] (fibo 1 0 n)) ([a b cnt] (if (zero? cnt) b (recur (+ a b) a (dec cnt))))) 10) ;; 55
❶ 一个包含两个" 元数" 的
fn命名 lambda 声明的示例. fn和解构
函数字面量语法
#()在 Clojure 中非常惯用, 但在某些情况下, 它提供的功能不足: 例如, 函数字面量语法不支持解构. 以下示例展示了一个 map 通过应用键和值的混合更改来转换为另一个 map. 我们没有使用简洁但功能有限的#()读取器字面量, 而是用fn显式地定义了 lambda 并引入了解构:(def sample-person {:person_id 1234567 :person_name "John Doe" :image {:url "http://focus.on/me.jpg" :preview "http://corporate.com/me.png"} :person_short_name "John"}) (def cleanup ; ❶ {:person_id [:id str] :person_name [:name (memfn toLowerCase)] :image [:avatar :url]}) (defn transform [orig mapping] (apply merge (map (fn [[k [k' f]]] {k' (f (k orig))}) ; ❷ mapping))) (transform sample-person cleanup) ;; {:id "1234567", :name "john doe", :avatar "http://focus.on/me.jpg"}
❶
cleanup是输入键名和向量对之间的映射. 该对包含输出 map 中键的新名称和用于转换值的函数. 例如, 第一个键表示:person_id应重命名为:id, 并且应将str函数应用于该值.❷
transform函数接受一个输入 maporig和映射规则作为参数 (sample-person和cleanup是示例中使用的实例). 这里使用map函数来应用所有的转换规则. 通过使用fn, 我们可以解构cleanup的内容, 如果我们使用特殊的读取器形式#(), 这将是不可能的.如果不使用解构,
fnlambda 会被first或second的调用污染, 以访问向量元素, 如下面的transform函数重写所示:(defn transform [orig mapping] ; ❶ (apply merge ;; prefer destructuring instead of this (map (fn [rules] (let [k (first rules) k' (first (second rules)) f (second (second rules))] {k' (f (k orig))})) mapping)))
❶ 重写
transform函数, 以说明在不使用解构时需要多少次first和second的重复.fn是 Clojure 的函数式 lambda
函数式语言通常具有两个主要特点:
- 它们支持高阶函数
- 它们倾向于引用透明 22
高阶函数是可以接受其他函数作为参数或向其调用者返回函数的函数. 一种语言需要支持函数作为语言中的一等公民对象, 这样它们就可以作为" 数据" 传递给其他函数. 创建函数对象的方式因语言而异, 但历史上它们一直被称为 lambdas (源自 Lambda 演算, 这是 Alonzo Church 在 1930 年左右引入的第一个广泛采用的数学函数形式化表示法 23). 一些语言甚至使用
lambda作为关键字来强调这种联系. Clojure 没有lambda关键字, 但fn无疑是 Clojure 的 lambda 实现.引用透明保证了函数的返回值仅依赖于其参数, 而不依赖于其他任何东西. 强制执行引用透明的函数式语言, 通常会因此获得许多其他特性: 惰性, 不可变值, 无限序列等等. Clojure 无疑是支持以上所有功能的主流函数式语言之一.
- 命名递归
- 另请参阅
fn*是fn的一个轻微变体, 它在首次调用后还执行" 局部变量清理" . 有关更多信息, 请参阅fn*的文档.defn显然与fn相关. 主要区别在于,defn旨在通过 var 对象将函数对象" 绑定" 到封闭的命名空间. 每当有被其他函数重用的机会时, 你可能应该考虑将fn定义重构为defn.identity是一个返回一个参数的匿名函数的示例函数. - 性能考虑和实现细节
与
defn类似,fn的处理主要在编译时发生, 因此在运行时性能方面通常不是一个问题. 与defn不同,fn不会产生副作用, 即不会创建一个 var 定义, 然后将其添加到当前命名空间的映射中.
- 约定
- 2.1.3 fn*
(感谢 Nicola Mometto 贡献本节)
自 1.0 版本以来的特殊形式
(fn* [& fdecl]) ; ❶
❶ 在声明新函数时, 请参考
defn以获取支持功能的扩展版本.fn*是fn宏底层的特殊形式. 它支持的功能较少, 例如缺少对前置和后置条件 (或解构) 的支持.fn*的主要目标是内存优化.fn*独家支持创建具有仅运行一次保证的闭包对象.由
fn创建的普通 lambda 可以在多个地方引用 (这在大型应用程序中通常是这种情况) 并根据需要重用. Clojure 编译器无法跟踪对 lambda 的所有引用, 因此在一次执行后, lambda (及其在相关生成的 Java 类中的内部状态) 需要为潜在的新执行保留下来. 但是有一类 lambda, 我们事先知道它们只会运行一次: 例如,delay或future宏, 它们在外部线程中运行.这些线程通常保留在线程池中, 与它们一起的还有它们运行的函数对象. 函数对象反过来可能持有一个对任意大数据的引用, 即使函数已经返回了它的结果.
fn*确保函数持有的引用在结果返回后被设置为nil. 当编写委托给包装函数的宏时, 这也是一个重要的特性, 这是一种相当常见的惯用模式, 以避免内存保留时间超过实际需要.- 约定
参考
fn的约定, 请记住仅有的两个区别:- 它不支持
fn接受的各种元数据 map. - 它将为
fn*符号具有^:once元数据的形式赋予特殊的编译时含义, (而fn不支持此功能).
- 它不支持
- 示例
我们将只展示
fn*独有的" 仅一次" 功能, 对于所有其他示例和用法, 请参考fn并避免直接使用fn*.通过将未求值的函数体包装在匿名函数中, 将宏的实现委托给它们的函数版本, 是一种常见的模式, 也是一种良好的实践 24. 这有几个优点:
- 它使得理解宏的实现更容易
- 通过提供函数版本, 它提高了其可组合性和功能, 因为它使得该功能不仅可用于编译时特性, 也可用于运行时使用.
这个确切的模式在
clojure.core本身中出现过几次:future是一个宏, 它使用刚才描述的相同技术委托给future-call函数:(defmacro future [& body] ; ❶ `(future-call (^{:once true} fn* [] ~@body))) ; ❷
❶
future宏的定义, 如clojure.core命名空间中所示.❷ 注意在调用
fn*之前使用了:once true元数据键.future将在稍后的某个时间点在单独的线程中执行函数体. 关于future设计的另一个重要方面是, 函数体旨在仅执行一次 (也就是说, 该线程应该运行一次并且永不重新调度). 因此, 作为像future这样的宏的作者, 我们已经知道函数使用的资源, 一旦执行, 就可以被 JVM 回收. 我们基本上有能力告诉 Clojure 编译器, 一旦函数体执行完毕, 编译代码中对 lambda 的每个引用都可以设置为 null, 从而允许 JVM 尽快回收资源. 这是 Clojure 编译器完成的一项重要的内存优化, 称为" 局部变量清理" 25.通过简单地将
fn替换为^:once fn*(从而向编译器承诺函数体将永远不会被执行超过一次), 编译器现在能够执行局部变量清理优化, 并避免潜在的内存泄漏 26.邀请读者回顾
future-call, 书中探讨了一个显示局部变量清理效果的示例. - 另请参阅
fn是应该总是优先于fn*使用的宏, 除非你需要^:once特性.future将一个表达式包装在一个无参数的fn*函数中, 具有仅一次的语义. - 性能考虑和实现细节
与
defn或fn类似,fn*在运行时影响很小, 因为函数的实际生成发生在编译时. 因此, 当寻找性能改进时, 用户不应关心fn*.fn*是一种特殊形式, 这意味着它的实现是编译器执行时的" 既定事实" . 特别对于 Clojure 而言, 这意味着fn*的实现仅以 Java 代码存在.
- 约定
2.1.2. 2.2 高阶函数
- 2.2.1 fnil
自 1.2 版本以来的函数
(fnil ([f default1]) ([f default1 default2]) ([f default1 default2 default3]))
fnil从另一个输入函数 "f" 开始生成一个新函数.fnil的主要用例是装饰 "f", 以便在输入为nil的情况下它可以默认为可选值.fnil按位置操作: "default1" 将用于作为第一个参数传递的nil, "default2" 用于作为第二个参数传递的nil, "default3" 用于作为第三个参数传递的nil.fnil不支持超过 3 个默认值, 因此(fnil + 1 2 3 4)会导致抛出异常.- 约定
- "f" 可以是任意数量参数的函数, 返回任意类型.
- "default1,default2,default3" 是当生成的函数分别接收到
nil作为其第一, 第二或第三个参数时应使用的默认值.
- 示例
fnil的主要用例是包装一个现有的函数, 该函数不按我们期望的方式处理nil参数 (例如, 它甚至可能抛出异常).fnil将nil输入替换为给定的默认值, 并且该默认值又被传递给原始函数.在存在
nil的情况下,inc(递增数字的简单函数) 是一个异常行为的例子. 如果我们出于任何原因给inc输入nil, 我们可以使用fnil来定义一个替代行为. 在下面的例子中, 我们想用update27 来更新 map 中的数值:(update {:a 1 :b 2} :c inc) ; ❶ ;; NullPointerException (update {:a 1 :b 2} :c (fnil inc 0)) ; ❷ ;; {:a 1 :b 2 :c 1}
❶ 我们尝试更新 map 中的
":c"键, 但事先不知道内容是什么, 我们不知道 map 是否包含该键. 如果输入是nil,inc会严重失败, 这就是这种情况.❷ 我们可以使用
fnil来包装inc的nil参数情况. 如果inc得到一个nil,fnil会将nil替换为 0, 然后将 0 传递给inc.一个典型的不可预测值 (特别是对于 web 应用程序) 是来自输入表单的字符串. 在这种情况下,
fnil会很方便. 在这个例子中, 一个输入表单被转换为request-paramsmap:(require '[clojure.string :refer [split]]) (def request-params ; ❶ {:name "Jack" :selection nil}) (defn as-nums [selection] ; ❷ (let [nums (split selection #",")] (map #(Integer/valueOf %) nums))) (as-nums (:selection request-params)) ; ❸ ;; NullPointerException
❶
request-params模拟了一个已经转换为 Clojure 数据结构的 web 表单的内容. 一些参数是结构化的, 比如":selection", 它是一个逗号分隔的字符串.❷
as-nums被设计为接收":selection"参数, 将其分割成一个字符串列表, 并将这些字符串转换为数字.❸ 不幸的是, 网页上的用户没有按预期填写
":selection"(或者发生了其他错误), 导致了一个nil的选择.:selection键通常是一个逗号分隔的数字列表, 但如果用户没有填写相关的输入字段, 它可能会导致一个nil. 在nil选择的情况下,as-nums会抛出异常, 因为它在null字符串上调用了split. 我们可以用fnil包装as-nums来解决这个问题:(def as-nums+ (fnil as-nums "0,1,2")) ; ❶ (as-nums+ (:selection request-params)) ; ❷ ;; (0 1 2)
❶
fnil现在包装了as-nums. 默认的":selection"是 0,1,2.❷ 现在使用
as-nums+而不是旧的函数, 正确地处理了nil的":selection"键.新函数
as-nums+通过将nil(从参数中检索:selection键的结果) 替换为字符串"0,1,2"来处理这种情况 (对于这个特定的例子, 我们假设"0,1,2"等同于" 无选择" ). 一旦定义, 新的as-nums+可以安全地替换任何旧的, 会抛出异常的普通as-nums的用法.fnil也可以类似地对第 2 和第 3 个参数进行操作, 例如:(require '[clojure.string :as string]) (def greetings (fnil string/replace "Nothing to replace" "Morning" "Evening")) (greetings "Good Morning!" "Morning" "Evening") ; ❶ ;; "Good Evening!" (greetings nil "Morning" "Evening") ;; "Nothing to replace" (greetings "Good Morning!" nil "Evening") ;; "Good Evening!" (greetings "Good Morning!" "Morning" nil) ;; "Good Evening!"
❶ 该示例展示了
fnil处理replace的nil参数和 3 个可能抛出异常的nil调用.- 超越第 3 个参数: 一个扩展的 fnil
fnil最多可以处理给定输入函数的 3 个位置默认值. 将fnil扩展到可以处理任意数量的默认选项相对容易:(defn fnil+ [f & defaults] (fn [& args] ; ❶ (apply f (map (fn [value default] ; ❷ (if (nil? value) default value)) args (concat defaults (repeat nil)))))) (+ 1 2 nil 4 5 nil) ; ❸ ;; NullPointerException (def zero-defaulting-sum ; ❹ (apply fnil+ + (repeat 0))) (zero-defaulting-sum 1 2 nil 4 5 nil) ;; 12
❶
fnil+返回一个接受任意数量参数的函数.❷
map可以接受 2 个或更多个序列参数. 我们利用这个特性来组合实际参数和可能的默认值.❸ 如果我们尝试将
nil作为 5 个数字之和的一部分传递, 它会抛出错误.❹ 假设当一个数字为
nil时 "0" 是一个好的默认值, 我们可以使用apply和repeat来增强+以接受任意位置的nil参数.新函数
fnil+接受任意位置的nil默认值.map可以遍历任意数量的序列集合, 这在许多情况下非常方便. 第一个序列"args"是函数的实际参数列表. 传递给map的第二个序列是传递给fnil的给定"defaults"和任意数量的额外nil参数的串联, 以便遍历"args".我们还利用
map的惰性来覆盖潜在的无限数量的默认参数, 如zero-defaulting-sum所示. 由(repeat 0)创建的无限零序列覆盖了+的所有 (潜在无限) 参数的nil值.对于这种
map的用法, 需要考虑的另一个重要方面是, 当到达最短序列的末尾时, 它会自动停止映射. 这仅仅用 3 行代码就展示了 Clojure 中可用的大部分功能的一个很好的例子. 28
- 超越第 3 个参数: 一个扩展的 fnil
- 另请参阅
some->可以用来达到与fnil类似的效果. 例如, 考虑(some-> nil clojure.string/upper-case): 这个形式正确地返回了nil而没有抛出异常. 如果你需要阻止一个单参数的函数抛出异常,some->可能是一个更好的选择. 然而,some->的默认值是固定的, 不能更改 (它总是返回nil). - 性能考虑和实现细节
→ O(1) 函数生成
→ O(1) 生成的函数
fnil的使用没有相关的性能影响. 输出函数是在常数时间内产生的. 调用生成的函数也是常数时间, 考虑到它受限于它可以处理的参数数量 (仅 3 个).
- 约定
- 2.2.2 comp
(comp ([]) ([f]) ([f g]) ([f g & fs]))
comp接受零个或多个函数并返回另一个函数. 这个新函数是输入的组合. 例如, 给定函数f1,f2,f3,comp创建一个新函数, 使得:((comp f1 f2 f3) x)等同于(f1 (f2 (f3 x))). 这种等价性是comp看起来是反向读取的原因, 例如:((comp inc +) 2 2) ; ❶ ;; 5
❶
+和inc之间函数组合的一个简单例子.在上面的例子中,
+出现在参数列表的最后, 但却是第一个应用的.注意
当没有参数调用时,
comp返回恒等函数. 这在要组合的函数列表是在运行时动态生成且可能为空的情况下很有帮助.comp会欣然接受一个空的参数列表, 而不是处理错误情况.- 约定
- 示例
函数串联是
comp的主要用例. 考虑以下例子, 我们要计算需要购买多少邮票来寄送不同目的地的信件:(require '[clojure.string :refer [split-lines]]) (def mailing ; ❶ [{:name "Mark", :label "12 High St\nAnchorage\n99501"} {:name "John", :label "1 Low ln\nWales\n99783"} {:name "Jack", :label "4 The Plaza\nAntioch\n43793"} {:name "Mike", :label "30 Garden pl\nDallas\n75395"} {:name "Anna", :label "1 Blind Alley\nDallas\n75395"}]) (defn postcodes [mailing] ; ❷ (map #(last (split-lines (:label %))) mailing)) (postcodes mailing) ;; ("99501" "99783" "43793" "75395" "75395") (frequencies (postcodes mailing)) ; ❸ ;; {"99501" 1, "99783" 1, "43793" 1, "75395" 2}
❶ 输入是 map 组成的向量形式, 这是一种传输结构相似但值不同的数据的常用格式.
❷ 函数
postcodes在解析:label值的内容后, 返回一个 (可能重复的) 邮政编码列表. 请注意, 函数体包含 4 个对其他函数的嵌套调用 (map,last,split-lines和用作函数的键":label").❸ 我们可以使用
frequencies来计算每个邮政编码的出现次数.函数
postcodes包含一个映射函数, 该函数对每个邮件项应用 3 个转换. 我们可以使用comp通过组合来构建相同的表达式 29:(defn postcodes [mailing] ; ❶ (map (comp last split-lines :label) mailing)) (frequencies (postcodes mailing)) ; ❷ ;; {"99501" 1, "99783" 1, "43793" 1, "75395" 2}
❶ 我们用
comp重写了postcodes.❷ 更改后, 我们确保结果与之前相同.
通过使用
comp, 我们增加了对转换序列的强调. 这是移除括号的效果, 这反过来又允许自然的垂直对齐. 请注意, 在这种情况下使用comp是可能的, 因为所有函数都接受 1 个参数.comp也是组合变换器的主要结构. 这里是之前看到的同样用变换器编写的postcodes:(defn postcodes [mailing] ; ❶ (sequence (comp ; ❷ (map :label) (map split-lines) (map last)) mailing)) (frequencies (postcodes mailing)) ; ❸ ;; {"99501" 1, "99783" 1, "43793" 1, "75395" 2}
❶ 我们重写了
postcodes以使用变换器.❷
map现在用于生成变换器, 我们需要使用sequence来应用它们.❸ 结果仍然与前一个例子相同.
请注意, 与之前使用
map而不是sequence的postcodes版本相比, 变换函数的顺序是相反的. 这是变换器实现方式的影响, 但结果是相同的.在下面的例子中, 我们在转换中增加了一个步骤, 以从邮政编码列表中移除阿拉斯加, 并在最终输出中防止重复. 请注意, 由于组合, 我们可以使用更吸引人的垂直对齐方式来添加转换:
(require '[clojure.string :refer [starts-with? split-lines]]) (defn alaska? [postcode] (starts-with? postcode "99")) (defn unique-postcodes [mailing] (sequence (comp (map :label) (map split-lines) (map last) (remove alaska?) ; ❶ (distinct)) mailing)) (unique-postcodes mailing) ;; ("43793" "75395")
❶ 新的
unique-postcodes函数从列表中移除了阿拉斯加并移除了重复项. - 另请参阅
juxt是另一个函数生成器. 它不像comp那样组合函数, 而是独立地执行它们并收集结果. 当输入函数在输入上独立操作时, 使用juxt.sequence接受变换器的组合, 如示例所示.transduce是另一个经常与comp一起出现的变换函数. - 性能考虑和实现细节
→ O(1) 函数生成
调用
comp在常数时间内生成一个新函数, 对性能分析几乎没有兴趣.
- 约定
- 2.2.3 complement
自 1.0 版本以来的函数
(complement [f])
complement是一个简单的函数包装器. 它接受一个输入函数f并输出另一个函数. 新创建的函数接受任意数量的参数, 并调用包装的函数f, 用not对其输出取反:((complement true?) (integer? 1)) ; ❶ ;; false
❶ 使用
complement来反转检查一个值是否为整数的含义的一个简单例子.- 约定
- 示例
complement利用了 Clojure 中所有东西都有扩展布尔含义的特点, 并且总是返回true或false:((complement {:a 1 :b 2}) :c) ; ❶ ;; true ((complement {:a 1 :b nil}) :b) ; ❷ ;; true
❶ 这个例子展示了如何反转验证 map 中是否存在某个键的含义. 如果
:c不在 map 中, 它返回true.❷ 然而, 在存在
nil值的情况下, 我们应该小心使用complement. 在第二种情况下,:b在 map 中, 但它的值为nil.如上例所示, 在存在
nil的情况下应谨慎使用complement. 然而, 如果nil的存在是可控的, 我们可以以一种非常简洁的方式检查一个项是否不属于一个集合:(filter (complement #{:a :b :c}) [:d 2 :a 4 5 :c]) ; ❶ ;; (:d 2 4 5) (filter (complement #{nil :a 2}) [:a 2 nil nil]) ; ❷ ;; (nil nil)
❶ 一种过滤所有不匹配一组值的所有项的简洁方法.
❷ 这种方法假设被补充的集合不包含
nil作为要移除的值之一. 在这种情况下, 它将无法从输入中移除nil.complement提供了从否定函数中提取函数的能力. 我们无法用not做同样的事情, 因为它是一个布尔运算符. 例如, 这里有一种用彼此来表达典型对立面如" 左" 和" 右" 的方法:(defn turning-left? [wheel] (= :left (:turn wheel))) (def turning-right? (complement turning-left?)) ; ❶ (defn turn-left [wheel] (if (turning-left? wheel) (println "already turning left") (println "turning left"))) (defn turn-right [wheel] (if (turning-right? wheel) ; ❷ (println "already turning right") (println "turning right")))
❶ 我们使用
complement来定义turning-right?. 注意我们不能用not来否定一个函数, 因为not只接受布尔输入.❷ 我们也可以写成:
(if-not (turning-left? wheel)), 代价是在语句中有一个否定.调用
(turning-right? wheel)和(not (turning-left? wheel))的结果是相同的, 但not的存在产生了一种稍微不那么可读的形式. 当用已有的名称建模相反的概念时 (例如左和右, 上和下, 北和南等等), 这一点尤其明显. Clojure 本身就包含这样一个例子. 这里是remove的定义:(defn remove [pred coll] ; ❶ (filter (complement pred) coll))
❶ 从标准库中出现的
remove的实现中移除了一些实现细节. - 另请参阅
not不产生函数, 只是反转其参数的布尔含义. - 性能考虑和实现细节
→ O(1) 函数生成
complement在性能分析中不是特别有趣: 它在常数时间内生成所请求的函数. 生成的函数在被调用时, 使用apply应用其参数 (最多 20 个).
- 约定
- 2.2.4 constantly
自 1.0 版本以来的函数
(constantly [x])
constantly生成一个函数, 该函数无论以何种数量和类型的参数调用, 都始终返回相同的结果. 输出函数总是返回初始参数作为唯一答案.- 约定
- 示例
constantly可以用于所有需要更新函数的情况, 但新值不依赖于旧值. 例如,update接受一个 map, 一个键和一个函数. 该函数接收该键的旧值, 并期望使用该值来计算新值.以下示例实现了一个
quantize-volume函数, 用于计算一组音符的平均音量. 声音的表现力由:volume和:expr键共同表示:(def notes [{:name "f" :volume 60 :duration 118 :expr ">"} {:name "f" :volume 63 :duration 120 :expr "<"} {:name "a" :volume 64 :duration 123 :expr "-"}]) (defn- expressiveness [average exp] (case exp ">" (+ average 5) "<" (- average 5) average)) (defn- process-note [note fns] ; ❶ (letfn [(update-note [note [k f]] (update note k f))] ; ❷ (reduce update-note note fns))) ; ❸ (defn quantize-volume [notes] ; ❹ (let [avg (quot (reduce + (map :volume notes)) (count notes)) fns {:volume (constantly avg) ; ❺ :expr (partial expressiveness avg)}] ; ❻ (map #(process-note % fns) notes))) (quantize-volume notes) ; ❼ ;; ({:name "f", :volume 62, :duration 118, :expr 67} ;; {:name "f", :volume 62, :duration 120, :expr 57} ;; {:name "a", :volume 62, :duration 123, :expr 62})
❶
process-note接受一个音符和一个函数 map. Clojure map 支持顺序访问, 可以用作reduce的输入.❷
update-note用letfn在本地绑定. 它定义了下一行中reduce使用的 reducing 函数. 除了解构第二个参数外, 它还用给定的键和函数对音符应用update.❸
process-note多次应用update(每次都用一个作为参数传入的更新函数, 位于 "fns" map 中). 由于 Clojure hash-map 是持久化数据结构, 我们需要确保每个函数产生的更新后的音符是下一个更新函数的输入.reduce实现了我们正在寻找的更新语义, 确保每个中间步骤都作为输入传递给下一个步骤. 我们对reduce的" 初始值" 变成了" 音符" , 我们从那里开始更新链.❹
quantize-volume的主要目标是为update准备输入函数, 并将它们应用于所有音符.❺ 每个音符都有一个
:volume键, 我们希望所有音量都是平均值.constantly在这里是一个很好的选择: 我们需要所有音符都使用相同的" 平均" 值, 以及一个返回该值的函数包装器.❻
:expr键需要旧值来确定新值, 所以我们传入一个从旧表现力到新表现力的函数.❼ 当我们最终处理音符时, 我们可以看到 map 按预期更新,
:volume更新为平均值,:expr更新为相对于音量高于或低于平均值的关系.constantly的另一个用途是在测试中" 打桩" 函数调用. 一个好的测试设置会将待测函数与不太可预测的行为 (如网络请求) 隔离开来, 提供打桩的响应. 打桩的响应也用于控制待测函数的特定方面, 以便可以验证其行为.with-redefs经常与constantly结合使用:(ns book.unit (:require [clojure.test :refer [deftest testing is]])) (defn- third-party-service [url p1 p2] ; ❶ "Simulation of expensive call" (Thread/sleep 1000) {:a "a" :b "b"}) (defn fn-depending-on-service [s] ; ❷ (let [result (third-party-service "url" "p1" "p2")] (if (= "b" (:b result)) (str s "1") (str s "2")))) (deftest test-logic (with-redefs [third-party-service (constantly {:b "x"})] ; ❸ (testing "should concatenate 2" (is (= "s2" (fn-depending-on-service "s"))))))
❶
third-party-service是一个模拟对我们无法控制的服务进行昂贵调用的函数. 它需要 3 个参数.❷
fn-depending-on-service是一个依赖于第三方服务调用的函数.❸ 单元测试用
with-redefs创建了一个本地的重定义绑定, 将第三方调用替换为一个打桩的版本. 由于我们对传递给函数的参数不感兴趣, 我们可以使用constantly来打桩返回值.开启直接链接后,
with-redefs将停止工作.with-redefs依赖于 var 的间接性来临时交换函数实现. 当 Clojure 编译时开启直接链接, var 的内容会被直接内联, 无法更改. - 另请参阅
identity也返回作为参数传入的参数. 但identity不返回函数, 仅返回其自身的值.identity经常用于与constantly类似的目标, 唯一的限制是identity只接受一个参数而不是多个.with-redefs在测试时经常与constantly结合使用以生成打桩的响应. - 性能考虑和实现细节
→ O(1) 函数生成
→ O(1) 生成的函数
constantly只是在每次调用时返回相同的结果. 函数生成和使用生成的函数都是常数时间操作.
- 约定
- 2.2.5 identity
自 1.0 版本以来的函数
(identity [x])
identity是标准库中的一个小函数. 它只是将其单个参数作为输出返回:(identity 1) ;; 1
尽管看起来很简单, 但在许多情况下
identity都能派上用场 (参见示例部分).identity的名字来源于等价的数学概念 (也称为恒等变换或关系 30).(identity x)
- 示例
第一个例子说明了一种将 map 转换为键值对的扁平序列的惯用方法. 它是一行代码和一个函数调用. 所有其他选项都将包含第二个函数调用:
(mapcat identity {:a 1 :b 2 :c 3}) ; ❶ ;; (:a 1 :b 2 :c 3)
❶ 一种惯用的用法, 使用
mapcat和identity将 map 转换为序列.mapcat同时进行迭代和连接. 由于迭代一个 hash-map 会产生一个包含键值对的向量序列, 我们只需要在将所有向量连接在一起之前进行identity变换.identity也可以用作" noop" (无操作的缩写), 在需要函数但又不应产生任何效果时提供一个函数. 一个有用的情况是, 当我们需要从序列中过滤掉所有逻辑假元素时 (任何为nil或false的元素):(defn custom-filter [x] ; ❶ (if (or (nil? x) (false? x)) false true)) (filter custom-filter [0 1 2 false 3 4 nil 5]) ; ❷ ;; (0 1 2 3 4 5) (filter identity [0 1 2 false 3 4 nil 5]) ; ❸ ;; (0 1 2 3 4 5)
❶
custom-filter以一种非常冗长的方式实现了我们想要达到的目标: 我们没有考虑到 Clojure 接受任何值为逻辑真/假的事实, 所以这被认为是不惯用的.❷ 显示
custom-filter按预期工作, 从序列中过滤掉所有不需要的nil和false.❸ 使用
identity可以在没有自定义函数的情况下达到相同的结果. 其工作原理是像false或nil这样的值是 Clojure 逻辑假定义的一部分.filter使用nil或false作为标记, 决定哪些项应该或不应该出现在最终结果中.identity按原样传递值, 所以filter可以直接使用它们.以下示例展示了如何使用
identity和some从集合中检索下一个逻辑真元素. 超市中的收银员列表通过在其对应索引的向量中添加一个数字来标记为可用. 一旦客户选择了一个通道, 收银员就会变忙, 我们需要更新该索引处的值, 以便没有其他客户可以选择同一个通道. 为避免对收银员队列进行并发读/写, 我们使用ref, 这是 Clojure 中的一种并发原语. 通过使用ref, 我们可以在单个事务中检查可用性并预订通道:(def cashiers (ref [1 2 3 4 5])) ; ❶ (defn next-available [] ; ❷ (some identity @cashiers)) (defn make-available! [n] ; ❸ (alter cashiers assoc (dec n) n) n) (defn make-unavailable! [n] (alter cashiers assoc (dec n) false) n) (defn book-lane [] ; ❹ (dosync (if-let [lane (next-available)] (make-unavailable! lane) (throw (Exception. "All cashiers busy!"))))) (book-lane) ; ❺ ;; 1 (book-lane) ;; 2 (dosync (make-available! 2)) ;; 2 @cashiers ;; [false 2 3 4 5]
❶
cashiers包含一个用数字初始化的向量 (代表空闲的收银通道). 该向量被ref包装.❷
next-available在收银员向量上使用identity和some. 它返回第一个真结果, 或者在到达向量末尾后返回nil. 注意,next-available是对ref的只读操作, 不需要显式的事务上下文.❸
make-available!和make-unavailable!接受一个数字作为参数, 并在该索引处添加或删除元素. 这有效地将收银员标记为可用或不可用, 因为标记为" 不可用" 会在向量的该索引处添加一个false, 导致next-available继续搜索.❹
book-lane协调查找下一个可用收银员和预订通道.dosync需要包装读/写操作才能生效, 因为其他客户可能同时试图使用同一个通道. 如果再没有可用通道,book-lane会抛出异常.❺ 我们可以通过预订和释放几个通道来快速模拟该系统.
当我们需要对序列中的连续元素进行分组时, 可以使用
identity和partition-by. 以下示例展示了如何搜索单词中的强调部分, 假设重复的字母表示强调:(def they-say ; ❶ [{:user "mark" :sentence "hmmm this cake looks delicious"} {:user "john" :sentence "Sunday was warm outside."} {:user "steve" :sentence "The movie was sooo cool!"} {:user "ella" :sentence "Candies are bad for your health"}]) (defn- enthusiast? [s] (> (->> (:sentence s) (partition-by identity) ; ❷ (map count) (apply max)) 2)) (defn enthusiatic-people [sentences] (->> sentences (filter enthusiast?) (map :user))) (enthusiatic-people they-say) ; ❸ ;; ("mark" "steve")
❶
they-say包含句子及其作者的样本.❷ 我们使用
partition-by和identity作为判别函数, 因此字母只有在序列中相同时才会一起出现. 创建组后, 我们可以对它们进行计数, 并查看是否有大于 2 个字母的组.❸ 我们可以看到样本中谁在使用" 丰富多彩" 的语言.
- 另请参阅
nil?是一个更好的选项, 可用作filter的谓词, 用于处理序列中的nil元素. 正如我们在示例中所见,identity与filter一起使用时也会移除false元素, 而nil?不会:(remove nil? [0 1 2 false 3 4 nil 5]) ;; (0 1 2 false 3 4 5)
constantly返回一个接受任意数量参数但总是返回相同给定结果的函数. 如果你需要可变数量的参数并返回相同的结果, 请使用constantly而不是identity. - 性能考虑和实现细节
=> O(1) 函数生成
identity, 标准库中最简单的函数之一, 在性能分析中不是特别有趣.
自 1.1 版本以来的函数
(juxt ([f]) ([f g]) ([f g h]) ([f g h & fs]))
juxt 接受一个函数列表作为参数, 并返回一个新的" 并列" 函数, 该函数将每个原始函数应用于相同的参数集. 所有结果随后被收集到一个向量中. juxt 可以被描述为" 函数多路复用器" , 因为它调用多个函数以返回多个结果. 这里是如何使用 juxt 来查看在列表上调用 first, second 和 last 的不同效果:
((juxt first second last) (range 10)) ; ❶ ;; [0 1 9]
❶ 一个简单的 juxt 示例.
我们可以用下图" 直观地" 描述上述示例:
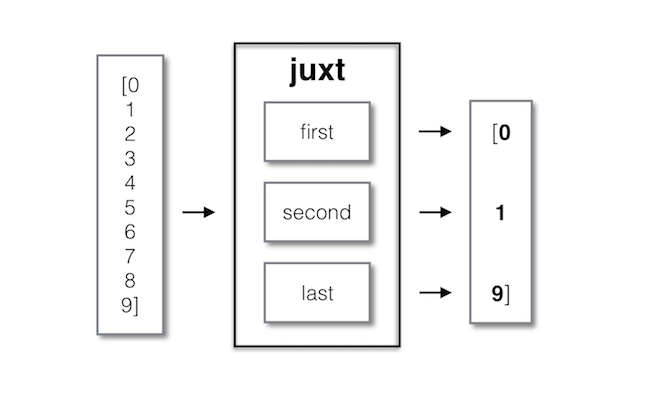
Figure 3: 在一个集合上调用带有 3 个简单函数的 juxt 的效果.
- 约定
- 输入
juxt需要至少一个参数, 最多可接受无限数量的参数.- "f", "g" 和 "h" 是函数. 它们需要接受与输出函数将被调用的参数数量相同的参数. 例如, 如果生成的函数被调用时带有 2 个参数, 那么 "f", "g" 和 "h" 也将被调用时带有这 2 个参数.
- "fs" 是在 "f", "g" 和 "h" 之后的任何附加函数.
- 值得注意的异常
当
juxt在没有参数的情况下被调用, 或者当生成的函数被调用时带有错误数量的参数时, 抛出clojure.lang.ArityException. - 输出
juxt返回一个接受任意数量参数并返回一个向量的函数. 结果向量的大小等于初始函数的数量.
- 输入
- 示例
juxt对于将多个动作组合在一起非常有用. 一个简单的例子是在一个由二维坐标标识的单元格网格中搜索邻居. 邻居是位于另一个单元格上方, 下方, 左侧和右侧的 4 个单元格. 给定一对坐标[x, y], 我们需要应用 4 个变换来找到相邻的单元格. 下图显示了单元格[2 1]及其邻居:不过, 我们需要小心, 因为网格的尺寸是有限的, 我们不希望返回不存在的邻居:
(def dim #{0 1 2 3 4}) ; ❶ (defn up [[x y]] [x (dec y)]) ; ❷ (defn down [[x y]] [x (inc y)]) (defn left [[x y]] [(dec x) y]) (defn right [[x y]] [(inc x) y]) (defn valid? [[x y]] ; ❸ (and (dim x) (dim y))) (defn neighbors [cell] (filter valid? ((juxt up down left right) cell))) ; ❹ (neighbors [2 1]) ; ❺ ;; ([2 0] [2 2] [1 1] [3 1]) (neighbors [0 0]) ; ❻ ;; ([0 1] [1 0])
❶
dim使用从 0 开始的索引定义了网格坐标的可能值.❷
up,down,left,right是接受坐标对[x y]并分别计算上方, 下方, 左侧或右侧单元格坐标的函数.❸
valid?是一个函数, 如果给定的[x,y]单元格包含在给定的网格尺寸内, 则返回 true.❹
juxt将我们需要计算邻居的函数组合在一起, 形成一次调用.❺ 我们可以看到这些是有效的坐标, 看看上面的图表.
❻ 这是一个在网格边缘的单元格的例子, 它只返回两个可用的邻居.
juxt的另一个惯用法是用于在转换过程中保留某个值的未更改版本. 例如, 如果我们有一个单词向量, 并且我们想显示它们的长度, 我们可以使用juxt和identity:(def words ["book" "this" "an" "awesome" "is"]) (map (juxt count identity) words) ; ❶ ;; ([4 "book"] [4 "this"] [2 "an"] [7 "awesome"] [2 "is"])
❶ 使用
juxt为句子中的每个单词装饰其长度的示例.通过使用
juxt, 我们能够映射单词序列, 保持单词副本不变, 并用其长度来装饰单词. 我们可以使用匿名函数达到类似的结果, 但我们将不得不显式地处理参数, 并将结果包装在一个向量中:(map #(vector (count %) %) words) ; ❶ ;; ([4 "book"] [4 "this"] [2 "an"] [7 "awesome"] [2 "is"])
❶ 一个使用匿名函数而不是
juxt来并列函数的替代版本, 导致形式更难阅读.juxt的另一个相当常见的用途是作为从 map 中提取值的辅助函数. 以下示例展示了我们如何通过将相关的键连接在一起来创建一条消息:(require '[clojure.string :refer [join]]) (def post {:formatted-tag "Fireworks 2016" :destinations ["north" "south"] :count 200 :css-align "ending" :normal-title "people expected tonight" :headline "Admiral Derek on the ship to Nebraska"}) (->> post ((juxt :count :normal-title)) ; ❶ (join " ")) ; ❷ ;; "200 people expected tonight"
❶
post是一个示例数据 map, 我们通过一组变换将其传递给->>. 第一个变换用juxt创建一个函数, 该函数应用于postmap. 输出显示了与:count和:normal-title键对应的值.❷
join通过在输入序列之间插入空格来生成一个字符串.在有一系列 map 的情况下, 我们可以使用
juxt和sort-by(或group-by) 以嵌套的方式按多个属性对一系列 map 进行排序:(sort-by (juxt count str) ["wd5" "aba" "yp" "csu" "nwd7"]) ; ❶
❶ 这个对
sort-by的调用首先按计数排序, 然后在具有相同大小的字符串之间按字母顺序排序.在处理表格数据时, 嵌套分组很常见, 例如数据库结果集. 下面的
person-table定义显示了一些原始数据一旦加载到内存中可能会出现的样子. 我们可以使用sort-by,group-by和juxt的组合来查询该表:(def person-table ; ❶ [{:id 1234567 :name "Annette Kann" :age 31 :nick "Ann" :sex :f} {:id 1000101 :name "Emma May" :age 33 :nick "Emma" :sex :f} {:id 1020010 :name "Johanna Reeves" :age 31 :nick "Jackie" :sex :f} {:id 4209100 :name "Stephen Grossmann" :age 33 :nick "Steve" :sex :m}]) (def sort-criteria (juxt :age :nick)) ; ❷ (def group-criteria (juxt :age :sex)) (defn sort-by-age [t] ; ❸ (->> t (sort-by sort-criteria) (map sort-criteria))) (sort-by-age person-table) ;; ([31 "Ann"] [31 "Jackie"] [33 "Emma"] [33 "Steve"]) (defn group-by-age-sex [t] ; ❹ (->> t (group-by group-criteria) (map (fn [[k v]] {k (map sort-criteria v)})))) (group-by-age-sex person-table) ;; ({[31 :f] ([31 "Ann"] [31 "Jackie"])} ;; {[33 :f] ([33 "Emma"])} ;; {[33 :m] ([33 "Steve"])})
❶ 一个人表在这里表示为 map 的序列. 这通常是从 SQL 数据库查询表的结果. 每条记录包含一个人的属性, 我们有兴趣以某种有用的方式呈现它们.
❷
sort-criteria和group-criteria是由juxt返回的两个函数的定义. 我们将它们提取到它们自己的 var 定义中, 这样我们就可以在其他地方重用这些标准.❸
sort-by-age使用juxt创建的排序标准来对表进行排序, 然后再映射它 (再次使用juxt) 以仅显示相关属性. 请注意, 当与sort-by或group-by结合使用时,juxt的含义是" 首先按第一个参数排序" , 并且当已经处于这种排序条件下时, 还" 按第二个参数排序" .juxt实际上是在嵌套排序和分组操作.❹
group-by-age-sex与sort-by-age类似, 只是应用了略有不同的标准. 和以前一样, 我们既使用juxt创建的标准进行分组, 也用于在 map 操作中仅过滤有趣的键. - 另请参阅
comp与juxt有一些相似之处, 因为它们都将多个函数组合成一个, 但它们在函数组合以获得最终结果的方式上有所不同, 例如:((comp f g h) x)等价于(f (g (h x))), 而((juxt f g h) x)等价于[(f x) (g x) (h x)]. 当目标是每个函数的输出成为下一个函数的输入时, 使用comp而不是juxt. 当函数应在同一输入上并行操作时, 使用juxt.select-keys应该优先用于从 map 中过滤键和值. 我们在示例中看到,juxt可以有效地用作" 仅选择值" .zipmap可以用于从一个序列创建键值对, 类似于(map (juxt :somekey identity) maps), 但语法略有不同:(zipmap (map :somekey maps) maps). 虽然zipmap产生一个无序的 map, 但带有juxt的map会创建一个保持顺序的键值对向量. - 性能考虑和实现细节
→ O(1) 函数生成
→ O(n) 生成的函数 (n 是参数的数量)
juxt不太可能与性能瓶颈有关, 因为通常组合在一起的输入函数的数量相当少. 在宏扩展为调用带有许多输入函数 (> 1000 作为起点) 的juxt的情况下, 你应该考虑调用生成函数所必需的线性配置文件. 这个考虑不包括输入函数的性能配置文件, 后者应该分开考虑.juxt对少于 3 个参数的实现只是在一个向量中调用每个函数以返回结果. 可变参数的情况由apply或reduce处理.
自 1.0 版本以来的宏
(memfn [name & args])
memfn 允许将 Java 实例方法作为参数传递给 Clojure 函数. 以下示例展示了 java.lang.String 类的 Java 方法 toUpperCase 使用和不使用 memfn 传递给 map 函数:
(map (memfn toUpperCase) ["keep" "calm" "and" "drink" "tea"]) ; ❶ ;; ("KEEP" "CALM" "AND" "DRINK" "TEA") (map toUpperCase ["keep" "calm" "and" "drink" "tea"]) ; ❷ ;; RuntimeException: Unable to resolve symbol: toUpperCase
❶ 正确的方法使用 memfn 来确保 toUpperCase 在向量中的每个字符串上被调用.
❷ 错误的方法显示 Clojure 正在尝试将 toUpperCase 解析为一个符号.
memfn 产生的效果类似于匿名函数: 它包装了一些可以稍后发送给其他函数的计算. 与 fn 或相应的 #() 读取器字面量不同, memfn 仅用于包装 Java 互操作调用.
(memfn [<tags> name & <args>])
- 输入
"tags"是一个可选的元标记列表 (形式为^:tagname1 ^:tagname2, 用空格分隔)."tags"会传播到接收方法调用的目标对象. 标记的主要用途是类型提示."name"必须是表示 Java 类上可调用方法的符号."args"是一个可选的符号枚举. 可选的"args"被委托给 Java 方法.
- 值得注意的异常
在需要向
memfn传递超过 20 个参数的极少数情况下, 会抛出RuntimeException. - 输出
memfn返回一个至少有一个参数的新函数. 第一个参数是函数将接收的 Java 对象实例. 第一个参数之后的任何其他参数都按原样传递给方法调用.
memfn 提供的价值主要与 Java 互操作性场景有关, 特别是当高阶函数在 Java 对象上执行时. 下面的例子展示了如何处理一个 java.time.Instant 序列, 以找出它们从一个初始瞬间 t0 开始的持续时间. 或者, 调用时的时间被作为起点:
(import '[java.time Instant Duration]) (def instants (repeatedly (fn [] ; ❶ (Thread/sleep (rand-int 100)) (Instant/now)))) (defn durations [instants & [t0]] (let [start (or t0 (Instant/now))] (->> instants (map #(Duration/between % start)) ; ❷ (map (memfn toMillis))))) ; ❸ (let [two (doall (take 2 instants))] (durations two)) ; ❹ ;; (67 0) (let [t1 (Instant/now) ; ❺ times (doall (take 2 instants))] (Thread/sleep 200) (first (durations times t1))) ;; 21144
❶ repeatedly 接受一个无参数的函数, 并返回该函数调用结果的无限序列. instants 使用 repeatedly 来休眠一些 rand-int 时间量, 然后将当前时间添加到序列中. 结果是一个惰性的无限瞬间序列.
❷ Duration/between 是对静态 Java 方法的调用. 与实例方法相比, 静态方法不需要使用 memfn.
❸ memfn 包装了实例方法符号 toMillis. 这然后被用作 map 的高阶函数.
❹ 我们为我们的实验获取并实现了几个瞬间. 没有 doall, (Instant/now) 会在稍后的某个时间被调用, 从而混淆结果.
❺ 第二次调用显示我们可以传递我们自己的起点来测量持续时间.
memfn 扩展为一个匿名函数定义, 如果我们对形式进行宏展开, 就可以看到:
(macroexpand '(memfn toMillis)) ;; (fn* ([target24222] (. target24222 (toMillis)))) ; ❶
❶ macroexpand 显示 memfn 实际上是创建了一个函数. 函数体使用 Java 互操作语法 (单点) 来在给定的参数上调用一个实例方法.
使用 memfn 时需要记住的一个方面与多个参数有关. 如果实例方法需要一个或多个参数, memfn 可以被指示通过添加像本例中的 "ch" 这样的参数来传递它们:
(map (memfn indexOf ch) ["abba" "trailer" "dakar"] ["a" "a" "a"]) ;; (0 2 1)
两个序列的 map 需要一个两个参数的函数, 一个用于第一个序列的项, 一个用于第二个序列的项. 第一个参数是隐式的 (因为 memfn 生成一个至少有一个参数的函数以传递给实例方法), 而第二个参数必须是显式的, 如上例所示 (由符号 "ch" 表示). 但你需要小心. 传递给 memfn 的额外参数不应与部分应用混淆: 例如, 以下试图在字符串中查找字母索引的尝试不会编译:
(map (memfn indexOf "a") ["abba" "trailer" "dakar"]) ;; CompilerException java.lang.Exception: Unsupported binding form: a
如果我们对形式进行宏展开, 问题的根源就会变得清晰:
(macroexpand '(memfn indexOf "a")) ;; (fn* ([target12358 p__12359] ;; (clojure.core/let ["a" p__12359] ;; (. target12358 (indexOf "a"))))) ; ❶
❶ 宏展开显示字符串 "a" 被用作 let 形式中的局部绑定. 这就是为什么第一个参数之后的所有参数都需要是有效的符号 (在编译时) 和有效的方法签名 (在运行时).
fn 和相关的函数字面量 #(), 可以在所有使用 memfn 的地方使用. 然而, memfn 是调用 Java 实例方法作为高阶函数的更好选择.
doto 有助于处理有副作用的 Java 方法调用, 允许多个调用链接在一起. 如果你需要调用的实例方法有副作用 (比如 setter 方法), 优先使用 doto.
→ O(1) 常数时间宏展开和运行时调用
memfn 的实现相对简单. 该宏展开为一个 let 形式, 后跟一个使用 fn 的基本函数定义. 在运行时, 该函数调用 Java 互操作调用:
(defmacro memfn [name & args] (let [t (with-meta (gensym "target") (meta name))] ; ❶ `(fn [~t ~@args] (. ~t (~name ~@args))))) ; ❷
❶ 请注意, 与第一个参数相关联的任何元数据都会传播到目标对象实例.
❷ 可选的 args 在方法名后被" 非引用拼接" .
影响 memfn 的一个重要性能方面与 Java 互操作期间的反射调用有关. 以下示例展示了在没有类型提示的情况下使用 memfn 会发生什么:
(set! *warn-on-reflection* true) (time (dotimes [n 100000] ; ❶ (map (memfn toLowerCase) ["A" "B"]))) ;; Reflection warning, form-init41.clj:1:6 call to toLowerCase can't be resolved ;; "Elapsed time: 11.294886 msecs" ;; nil
❶ 我们使用 dotimes 和 time (一种初步但足够的基准测试方法) 来显示映射 toLowerCase 100000 次所消耗的时间的粗略估计.
memfn 在第一个参数上存在时接受并传播元数据. 我们可以利用这个方面来对 Java 调用进行类型提示以消除反射:
(time (dotimes [n 100000] (map (memfn ^String toLowerCase) ["A" "B"]))) ; ❶ ;; "Elapsed time: 5.701509 msecs" ;; nil
❶ 类型提示似乎影响了 toLowerCase, 但 memfn 在宏展开后将其传播到正确的位置.
有了类型提示, 消耗的时间大约减少了一半. 可以安全地建议, memfn 的存在 (特别是在集合上用作高阶函数时) 应该触发对昂贵反射调用存在的检查.
自 1.0 版本以来的函数
(partial ([f]) ([f arg1]) ([f arg1 arg2]) ([f arg1 arg2 arg3]) ([f arg1 arg2 arg3 & more]))
当一个函数需要一个或多个参数, 但在调用时并非所有参数都可用时 (例如, 因为函数被传递给另一个函数), 使用 partial:
(def incrementer (partial + 1)) ; ❶ (incrementer 1 1) ; ❷ ;; 3
❶ partial 将参数 "1" " 注入" 到函数 + 中, 创建另一个 incrementer 函数作为输出. incrementer 函数不会立即求值, 而是等待其他参数在稍后的某个时间点可用.
❷ incrementer 用 2 个额外的参数求值, 使传递的总参数达到 3 个.
partial 产生的效果类似于通过在该点注入可用参数来暂停函数的执行, 然后等待所有其他参数可用.
- 约定
"f"是一个至少有一个参数的函数.partial会接受一个零参数的函数, 但在那时partial会不必要地包装目标函数而没有增加价值."arg1, arg2, arg3"是任何类型的可选参数"more"仅表示其余的潜在参数作为可变参数- 返回: 一个新生成的函数, 接受可变数量的参数, 该函数会将任何额外的参数附加到目标函数之前调用它.
生成的函数的行为将取决于初始的目标函数: 用超过总允许参数的数量调用生成的函数将导致错误:
(def finder (partial clojure.string/index-of "tons-and-tons-of-text")) ; ❶ (finder "tons") ; ❷ ;; 0 (finder "tons" (count "tons")) ; ❸ ;; 9 (finder "tons" 5 "unsupported") ; ❹ ;; ArityException Wrong number of args (4) passed to: string/index-of
❶
finder持有一个在clojure.string/index-of之上创建的partial的引用, 该函数最多接受 3 个参数. 我们传入要搜索的目标文本.❷ 按预期, 单词 "tons" 的首次出现被发现在索引零处.
❸ 要搜索其他出现, 我们需要搜索过第一个. 因此, 我们使用第三个参数来告诉我们这次要从哪里开始搜索.
❹
partial并没有阻止我们超出目标函数的最大参数数量, 尽管生成的finder接受任意数量的参数.也许更有趣的是,
partial是位置性的, 并且可以严格地从左边开始捕获参数. 假设从前面的例子中, 我们只想" 固定" 要搜索的单词总是 "tons", 但将目标文本作为自由变量.partial不会允许我们这样做. - 示例
partial实现了与fn(或字面量语法#()) 类似的效果, 但灵活性降低了. 虽然fn支持在任何位置 (并可能有间隙) 缺少参数, 但partial只允许在函数签名的末尾缺少参数:(let [f (partial str "thank you ")] (f "all!")) ; ❶ ;; "thank you all!" (let [f #(str %1 "thank you " %2)] (f "A big " "all!")) ; ❷ ;; "A big thank you all!"
❶ 使用
partial的 "all!" 只能结束句子. 例如, 我们不能在 "thank you" 之前添加任何东西.❷ 使用函数字面量
#()(它是匿名函数fn的语法糖), 我们可以灵活地接受额外的参数, 将它们放在其他参数之前.与
fn相比,partial在移除一些多余的括号方面仍有优势. 当部分参数是某个其他参数的" 配置" 时,partial尤其有效, 例如, 命名可重用的计算片段, 稍后可以组合:(defn as [x] (partial = x)) ; ❶ (defn same? [item coll] (apply (as item) (seq coll))) ; ❷ (def all-a? (partial same? \a)) ; ❸ (def all-red? (partial same? :red)) ; ❹ (all-a? "aaaaa") ; ❺ ;; true (all-red? [:red :red :red]) ; ❻ ;; true
❶
partial用于在第一个参数后暂停相等性 "=". 我们希望某个东西等于 "x", 但我们还不知道那将是什么.❷
same?包含了对(as item)的调用, 传递与作为参数传入的集合中一样多的参数. 这将始终对可以接受任意数量参数的相等性起作用.❸ 我们再次使用
partial来暂停same?的第二个参数, 以创建 "=" 的另一个特化版本, 仅用于检查序列中的单个字符\a.❹ 类似地, 我们可以对其他类型的项 (例如关键字) 做同样的事情, 并重用我们目前所写的一切.
❺ 如预期, 它对字符串 (字符序列) 有效.
❻ 由于
partial的另一个特化, 我们可以对关键字集合使用all-red?.虽然它总是可以重写为一个自定义函数, 但当一个已有的函数在编写时没有接收到所有必要的参数时, 应优先使用
partial以强调这一点.partial的这一方面在与序列处理函数 (map, filter 等) 结合使用时尤其有效, 如下面这个关于验证 map 的简短示例所示:(defn- validate [whitelist req] ; ❶ (and (every? not-empty (vals req)) (every? whitelist (keys req)))) (def valid-req {:id "1322" :cache "rb001" :product "cigars"}) (def invalid-req {:id "1323" :cache "rb004" :spoof ""}) (map (partial validate #{:id :cache :product}) ; ❷ [valid-req invalid-req]) ;; (true false)
❶
validate对 map 的键和值应用一些简单的规则, 用every将它们组合成一个最终的真/假答案. 它还需要一个" 白名单" 键列表用于其中一个验证检查.❷
map操作发生在一个待验证的 map 集合上. 此时我们知道每个 map 中允许哪些键, 而实际的 map 来自内部迭代.partial给了我们所需要的高阶函数的所有方面: 它接受我们已经知道的参数, 并创建我们map所需的单参数函数. 在这里使用匿名函数的替代方案仍然是可能的, 但更冗长.- 柯里化
Clojure 中的部分应用经常被比作" 柯里化" . 根据形式化程度的不同, 这两个概念经常被混淆, 但通常存在一个与宿主编程语言对柯里化的支持程度有关的区别. 柯里化是一个受数学启发的概念, 关系到多参数函数可以表示为单参数函数的串联. 以下示例说明了这一思想:
(defn f1 [a b c d] (+ a b c d)) (defn f2 [a b c] (fn [d] (+ a b c d))) (defn f3 [a b] (fn [c] (fn [d] (+ a b c d)))) (defn f4 [a] (fn [b] (fn [c] (fn [d] (+ a b c d))))) (f1 1 2 3 4) ((f2 1 2 3) 4) (((f3 1 2) 3) 4) ((((f4 1) 2) 3) 4)
f1,f2,f3和f4都产生相同的结果, 但它们在需要调用的参数数量和返回函数的嵌套级别上有所不同, 迫使我们逐一" 展开" 参数. 如果我们受到语言的限制, 只能有单参数的函数, 那么我们就必须像f4那样模拟多参数的函数. 幸运的是, Clojure (或任何其他主流语言) 中不存在这样的限制, 但正如我们在本章中partial的示例中所看到的, 有时将函数的一部分暂停直到有更多参数可用是很有用的. 因此, 在 Clojure 中, 我们不会显式地定义f2,f3或f4, 而是优先使用partial:((partial f1 1 2 3) 4) ((partial f1 1 2) 3 4) ((partial f1 1) 2 3 4)
Clojure 在这里采取的方法是只使用高阶函数来移除所有否则将是必要的嵌套. 其他语言超越了部分应用, 在编译器级别支持柯里化. 例如, 在 Haskell 中, 所有用少于声明参数数量的参数调用的函数都会自动转换为它们的柯里化形式:
f = (+ 1) ❶ -- is equivalent to: f x = x + 1
❶
f是一个将其输入加 1 的单参数函数. 我们没有创建自己的实现, 而是使用了已有的函数+并" 柯里化" 了第一个参数, 使其始终为 1.在上面的 Haskell 示例中, 编译器接受用少于允许参数数量的参数调用 plus, 以产生一个接受剩余一个参数的函数
f. 不需要像 Clojure 版本那样调用显式的partial函数, 也不需要在 Haskell 中有显式的多重元数.
- 柯里化
- 另请参阅
当我们要暂停的参数不是参数列表中的最后一个时, 可以使用
fn(或等效的读取器宏#()) 代替partial.fn实际上是一个通用的partial, 让我们能够按需包装目标函数. 对于所有其他情况,partial可能更清晰地传达了函数正在等待更多参数的想法. 总的来说, 这两种形式是品味问题. - 性能考虑和实现细节
=> O(1) 函数生成
与本章中的其他函数一样,
partial通常不是性能分析或优化的目标, 因为函数本身的生成是常数时间.在生成的函数上调用的参数数量对性能有微小但可见的影响.
partial为生成的函数提供了一些特殊的元数来处理 1, 2 或 3 个参数的调用. 超过 3 个参数,partial实现了一个 catch-all 可变参数调用, 这会导致轻微的速度下降:(require '[criterium.core :refer [bench]]) (let [myvec (partial vector :start)] (bench (myvec 1 2 3))) ; ❶ ;; Execution time mean : 9.466062 ns (let [myvec (partial vector :start)] (bench (myvec 1 2 3 4))) ; ❷ ;; Execution time mean : 214.156293 ns (let [myvec (fn [a b c d] (vector :start a b c d))] (bench (myvec 1 2 3 4))) ; ❸ ;; Execution time mean : 8.156293 ns
❶
myvec是一个总是在向量开头插入":start"的小函数. 我们首先用 3 个参数调用myvec.vector也有几个优化的元数, 我们试图利用这一事实. ❷ 第二个基准测试在调用myvec时增加了一个额外的参数, 尽管vector有一个针对 5 个参数调用的特定元数, 但这导致了可见的性能影响 (vector切换到 catch-all 可变参数的阈值是 6 个参数). ❸ 作为比较, 让我们看一下使用显式 lambda 函数的类似解决方案.读者应记住, 在现实场景中, 像我们正在执行的这样的微基准测试会受到许多其他因素的影响, 所述的速度影响在绝对值上是微小的. 但是, 如果你恰好在一个紧凑的循环中使用超过 4 个参数的
partial, 你可能应该考虑使用fn.
自 1.3 版本以来的函数
(every-pred ([p]) ([p1 p2]) ([p1 p2 p3]) ([p1 p2 p3 & ps])) (some-fn ([p]) ([p1 p2]) ([p1 p2 p3]) ([p1 p2 p3 & ps]))
every-pred 和 some-fn 接受一个或多个谓词并产生一个新函数. 返回的函数接受零个或多个参数, 并对所有参数调用所有谓词, 分别用等效的 and 或 or 操作组合结果.
every-pred 和 some-fn 都对谓词的组合应用短路行为, 在第一个返回以下结果的谓词处停止求值:
- 对于
every-pred, 要么是nil要么是false. - 对于
some-fn, 是一个真值.
- 约定
- 输入
- "p", "p1", "p2" 和 "p3" 必须是支持单参数调用并返回任意类型的函数. 即使谓词返回的结果不是布尔类型, 返回的值也会按照 Clojure 的约定被求值为真或假.
- "ps" 是第三个之后所有剩余谓词的列表.
- 值得注意的异常
当
every-pred或some-fn在没有参数的情况下被调用, 或者当任何谓词需要超过 1 个参数时, 抛出ArityException. - 输出
every-pred: 返回一个接受任意数量的任意类型参数的函数, 该函数返回true或false.some-fn: 返回一个接受任意数量的任意类型参数的函数, 该函数返回任意类型. 返回值通常使用扩展布尔逻辑进行解释.
- 输入
- 示例
当需要对一个或多个值应用足够大的谓词组合时, 经常会发现
every-pred和some-fn. 例如, 很自然地会认为以下是可能的并且可以正常工作:(remove (and number? pos? odd?) (range 10)) ; ❶ ;; (0 2 4 6 8)
❶ 一个棘手的表达式, 看起来工作正常, 实际上并非如此.
我们想要实现的是用
and组合一组谓词, 这样输入集合中的每个元素都会被remove接受或不接受. 但是and是一个宏, 它的求值发生在形式编译时, 导致以下内容被求值:(remove odd? (range 10)) ; ❶
❶ 前一个示例中的形式在经过 Clojure 编译器编译后的样子.
and表达式返回最后一个不为假或nil的值, 在本例中是函数odd?. 我们真正想要的是将谓词组合起来, 以便它们在每个项上求值, 所以我们可以这样做:(remove #(and (number? %) (pos? %) (odd? %)) (range 10)) ; ❶ ;; (0 2 4 6 8)
❶ 组合多个谓词的正确方法需要添加一个包装的匿名函数, 并为每个谓词重复该参数.
在添加了包装的匿名函数并为每个谓词重复了参数后, 组合多个谓词的正确方法读起来不如以前好. 需要组合的谓词越多, 情况就越糟. 例如, 这里是如何在项目集合中找到回文 (正反读都一样的单词):
(defn symmetric? [xs] ; ❶ (= (seq xs) (reverse xs))) (defn palindromes [coll] ; ❷ (filter (fn [word] (and (some? word) (string? word) (not-empty word) (symmetric? word))) coll)) (palindromes ["a" nil :abba 1 "" "racecar" "abba" \a]) ;; ("a" "racecar" "abba")
❶
symmetric?验证序列集合"xs"是否等于其反转. 这是一个好的 (尽管效率不高) 回文序列的定义.❷
palindromes应用一系列步骤来确定集合中的一个单词是否是回文: 首先它不应为nil, 其次它应为字符串, 第三它不应为空, 最后, 它应等于其反转.用于过滤回文的函数, 包含一个谓词串联, 参数
"word"重复了 4 次. 通过使用every-pred, 我们可以移除匿名函数, 不再需要传递"word"参数, 也不再需要使用and:(defn symmetric? [xs] (= (seq xs) (reverse xs))) (defn palindromes [coll] ; ❶ (filter (every-pred some? string? not-empty symmetric?) coll)) (palindromes ["a" nil :abba 1 "" "racecar" "abba" \a]) ;; ("a" "racecar" "abba")
❶ 引入
every-pred后,palindromes明显更容易阅读.该示例显示了
every-pred的就地使用, 没有给生成的函数命名. 我们也可以给every-pred赋一个名称, 并在不同的地方重用相同的谓词组合. 以下示例将回文检查提取到一个新的palindrome?函数中:(defn symmetric? [xs] (= (seq xs) (reverse xs))) (def palindrome? ; ❶ (every-pred some? string? not-empty symmetric?)) (defn palindromes [coll] ; ❷ (filter palindrome? coll)) (palindromes ["a" nil :abba 1 "" "racecar" "abba" \a]) ;; ("a" "racecar" "abba")
❶ 用于检查回文单词的谓词组合现在可用于代码的其他部分重用.
❷
palindromes函数现在只是在集合上调用filter.现在让我们来看看
some-fn. 在下面的例子中, 我们将对一个值进行多次检查, 以确定一封电子邮件是否为垃圾邮件:(defn any-unwanted-word? [words] ; ❶ (some #{"free" "sexy" "click"} words)) (defn any-link? [words] ; ❷ (some #(re-find #"http[s]?://.*\." %) words)) (defn any-blacklisted-sender? [words] ; ❸ (some #{"spamz@email.com" "phish@now.co.uk"} words)) (def spam? ; ❹ (some-fn any-unwanted-word? any-link? any-blacklisted-sender?)) (defn words [email] ; ❺ (clojure.string/split email #"\s+")) (spam? (words "from: alex@tiv.com just wanted to say hi.")) ; ❻ ;; nil (spam? (words "from: nobody@all.tw, click here for a free gift.")) ; ❼ ;; "click"
❶
any-unwanted-word?包含一个不希望出现的单词的集合, 我们想知道其中任何一个是否出现在消息中. 我们使用some应用于单词序列, 并使用集合本身作为函数. 如果单词在集合中, 则返回单词本身.some返回集合中单词的首次出现, 否则返回nil.❷ 第二个函数应用一个正则表达式来验证单词中是否有任何一个是网页上外部内容的链接. 在这个简化的例子中, 我们认为任何带有链接的电子邮件都是可疑的.
❸
any-blacklisted-sender?根据我们认为是垃圾邮件的电子邮件地址集合来检查电子邮件的内容.any-blacklisted-sender?的工作方式与any-unwanted-word?完全相同.❹ 我们使用
some-fn将所有函数组合成一个新函数, 该函数返回第一个正向检查 (逻辑真). 我们还选择将生成的函数定义为spam?以促进进一步的重用.❺
words使用"clojure.string/split"分割一个字符串.❻ 我们可以看到一个没有匹配单词的" 干净" 电子邮件的例子.
some-fn在调用谓词函数链后最终返回nil.❼ 最后一次调用发现了一个黑名单单词.
some-fn可以用于从匹配的谓词中检索结果 (如上例所示) 或在条件语句中, 我们有选项完全忽略返回的精确值. 参考前面的例子, 我们可以使用when-let来组合条件逻辑和值匹配:(when-let [match (spam? (words "from: nobody@all.tw, click here for a free gift."))] ; ❶ (throw (Exception. (str "Spam found: " match)))) ;; Exception Spam found: click
❶ 我们可以在条件逻辑中以及检索特定值时使用
some-fn. 在这种情况下,when-let既将匹配的值赋给局部绑定"match", 又进入条件并抛出异常.- some-fn 和 every-pred: 名称是怎么回事?
网景公司曾有人说过:" 计算机科学中只有两件难事: 缓存失效和命名" 31. 和许多其他语言一样, Lisp 派生的语言也必须非常注意把名字起对, 考虑到类型的缺失减少了周围的上下文, 并提供了关于函数作用的更少提示. 总的来说, 用一两个词传达一个函数的完整语义是一个复杂的问题.
你通常会在标准库中注意到有意义的名称, 但有些情况会在公共论坛上引发反复的辩论.
some-fn和every-pred就是其中之一. 你可能会问为什么some-fn不叫some-pred? 或者类似地: 为什么every-pred不叫every-fn?让我们考虑一下" 谓词" 的定义: 严格来说, 谓词是返回布尔类型的函数.
some-fn, 正如我们在示例中看到的, 返回第一个匹配的值. 而every-pred生成的函数则返回严格的true或false值, 因此名称中带有" pred" 后缀.还有一个额外的考虑因素, 证明了对潜在的
every-fn函数缺乏兴趣. 让我们尝试模拟我们自己的every-fn来理解为什么.every-fn的目标是像every-pred一样, 但返回匹配项而不是true/false:(defn every-fn [& ps] ; ❶ (fn [& xs] (partition (count ps) (for [x xs p ps] (p x))))) (def contains-two? #(re-find #"two" %)) ; ❷ (def is-7-long? #(= 7 (count %))) ((every-fn contains-two? is-7-long?) "guestimate" "artwork" "threefold") ; ❸ ;; ((nil false) ("two" true) (nil false)) ((every-pred contains-two? is-7-long?) "guestimate" "artwork" "threefold") ; ❹ ;; false
❶
every-fn的接口与every-pred相同: 接受一个函数列表 (据推测是谓词), 并返回另一个函数, 该函数对输入中的每个项调用 "ps" 中的所有谓词. 我们的实现为 "ps" 中的所有谓词对每个输入生成排列, 并用partition将它们组合在一起.❷ 该示例提供了两个简单的谓词 (一个扩展的定义, 包括逻辑真和逻辑假).
❸ 我们现在可以用一个样本输入调用
every-fn. 结果显示了谓词的返回值, 按每个输入分组.❹ 相比之下,
every-pred会查看每个值, 并在第一次出现nil或false时停止, 返回false.every-fn被设计为返回将每个谓词应用于每个输入的明确结果. 如果不进行进一步处理, 我们看不到every-pred返回的同样有用的信息, 例如是否存在至少一个不满足所有谓词的输入. 我们仍然可以以其他方式使用结果, 但在那时我们可以解决同样的问题而无需创建自定义函数:(map (juxt contains-two? is-7-long?) (vector "guestimate" "artwork" "threefold")) ; ❶ ;; ([nil false] ["two" true] [nil false])
❶
every-fn的效果是在不使用自定义函数的情况下产生的.juxt将多个函数应用于同一输入, 在这种情况下它看起来是一个不错的选择.
- some-fn 和 every-pred: 名称是怎么回事?
- 另请参阅
every?被every-pred实现所使用. 如果你只有一个谓词要应用于多个参数, 优先使用"every?"而不是every-pred.some-fn与every-pred非常相似, 只不过它不是验证所有谓词都为真, 而是验证至少有一个为真 (等同于布尔的 "or" 运算符).some应用了与some-fn类似的逻辑. 但它不是将多个谓词组合在一起, 而是对序列的每个元素使用一个谓词. 如果你只对一个谓词应用于多个值感兴趣, 请使用some而不是some-fn. - 性能考虑和实现细节
→ O(1) 函数生成
→ O(n) 生成的函数 (n 个参数, 最坏情况)
本节中的性能考虑对
every-pred和some-fn同样有效, 除非另有说明.every-pred和some-fn在常数时间内生成函数, 对于 4 个或更多参数有轻微的性能损失. 如果every-pred或some-fn作为处理大型集合或快速循环的一部分出现, 读者应考虑这些方面. 以下基准测试说明了这一点:(require '[criterium.core :refer [quick-bench]]) (quick-bench (every-pred 1)) ; ❶ (quick-bench (every-pred 1 2)) (quick-bench (every-pred 1 2 3)) (quick-bench (every-pred 1 2 3 4)) (quick-bench (every-pred 1 2 3 4 5)) ;; Execution time mean : 4.072343 ns ;; Execution time mean : 4.276523 ns ;; Execution time mean : 4.333870 ns ;; Execution time mean : 18.539700 ns ;; Execution time mean : 22.359127 ns
❶ 我们比较了用
every-pred从 1 个参数到 5 个参数创建函数.请注意, 3 个和 4 个参数之间的差异很小, 可能还有其他类型的占主导地位的计算需要考虑. 从计算中消除生成时间的一个直接解决方案是将生成的函数命名为
let绑定或命名空间中的 var. 如果我们看一下生成函数的性能, 我们可以看到类似的行为:(require '[criterium.core :refer [quick-bench]]) (defn p [x] true) ; ❶ (let [e1 (every-pred p) ; ❷ e2 (every-pred p p) e3 (every-pred p p p) e4 (every-pred p p p p) e5 (every-pred p p p p p)] (quick-bench (e1 1)) (quick-bench (e2 1)) (quick-bench (e3 1)) (quick-bench (e4 1)) (quick-bench (e5 1))) ;; Execution time mean : 4.403670 ns ;; Execution time mean : 4.577825 ns ;; Execution time mean : 3.701983 ns ;; Execution time mean : 112.987134 ns ;; Execution time mean : 133.402111 ns
❶ 一个总是返回
true的伪谓词p. 这是every-pred的最坏情况, 因为它没有办法短路计算.❷ 我们用
every-pred生成了一些函数, 传递了不同数量的谓词.3 个和 4 个参数之间的差异取决于生成的函数也被优化为最多 3 个参数. 总的来说, 谓词求值为真的参数越多, 计算所需的时间就越高, 因为生成的函数需要找到一个假值才能立即返回. 因此, 在最坏的情况下呈线性行为.
2.1.3. 2.3 线程宏
- 2.3.1 ->
自 1.0 版本以来的宏
(-> [x & forms])
->(也称为线程优先宏或画眉鸟运算符) 可用于组合或分组一系列操作.->宏的参数包括一个表达式 (强制) 和一系列形式 (可选).其思想是将表达式定位为后续形式的第一个参数. 例如, 以下是求值
(-> {:a 2} :a inc)时发生的情况的逐步解释. 虽然这并非严格意义上宏的实现方式, 但它是一个很好的思维模型:- 关键字
:a是初始表达式{:a 2}后的第一个可选形式. 在内部, 该形式被添加到一个列表中 (除非它已经是). 由于:a还不是一个列表, 它被转换为(:a). - 表达式
{:a 2}被放置为先前创建列表中的第二项, 结果为(:a {:a 2}). 生成的形式被求值并传递下去. 在这种情况下,(:a { :a 2})等于 2, 2 被传递给下一个形式. inc是形式列表中的下一项. 和以前一样, 它不是一个列表, 所以需要被转换为(inc).- 先前的结果, 2, 然后被放置为前一个列表中的第二项:
(inc 2). - 我们终于到达了结尾. 最终的形式被求值并返回.
在宏展开期间, Clojure 编译器将
(-> {:a 2} :a inc)转换为(inc (:a {:a 2})). 在求值期间, 该形式求值为数字 3.macroexpand证实了我们的理论:(macroexpand '(-> {:a 2} :a inc)) ;; (inc (:a {:a 2}))
->倾向于提高某类序列操作的可读性, 否则这些操作会反向阅读 (或从内到外). 转换管道 (其中第一个操作的结果需要传递给下一个操作) 通常是使用->进行" 线程化" 的良好候选者.- 约定
- 输入
"x"可以是任何有效的 Clojure 表达式. 将"x"记为 "eXpression" 中的 "x" 会很有用, 这就是 → 线程穿过后续 "forms" 的内容."forms"是一个可选的参数列表. 如果任何可选的形式还不是一个列表, 它将通过在其上调用list来使其成为列表. 每个形式的第一个元素必须是一个可调用的函数 (使得(ifn? (first form))求值为 true).
- 值得注意的异常
- 如果在没有参数的情况下调用, 会抛出
ArityException. - 如果任何形式不可调用, 则会抛出
ClassCastException, 例如(→ 1 2 []).
- 如果在没有参数的情况下调用, 会抛出
- 输出
->产生最后一个形式的求值结果, 使用先前求值形式的结果, 遵循上面揭示的线程优先规则. 如果没有提供形式, 它返回第一个参数 "x" 的求值结果.
- 输入
- 示例
->对于处理管道特别有用, 其中初始输入在每个步骤中都被转换. 对于 map 处理的常见情况也是如此. 以下示例展示了一种将 HTTP 请求解析为哈希映射的方法:(def req {:host "http://mysite.com" ; ❶ :path "/a/123" :x "15.1" :y "84.2" :trace [:received] :x-forward-to "AFG45HD32BCC"}) (defn prepare [req] ; ❷ (update (dissoc (assoc req :url (str (:host req) (:path req)) :coord [(Double/valueOf (:x req)) (Double/valueOf (:y req))]) :x-forward-to :x :y) :trace conj :prepared)) (pprint (prepare req)) ; ❸ ;; {:host "http://mysite.com", ;; :path "/a/123", ;; :trace [:received :prepared] ;; :url "http://mysite.com/a/123", ;; :coord [15.1 84.2]}
❶
req是一个示例请求. 某个 web 框架负责将请求转换为 map.❷
prepare接收请求并assoc几个额外的键. 然后它移除不再需要的键, 最后更新:trace.❸ 我们可以使用
clojure.pprint/pprint来更好地格式化输出.pprint在 REPL 中直接可用, 但在其他情况下需要显式require.为了准备上述请求, 我们需要进行几次转换: 将主机和路径连接在一起形成
:url, 从坐标中创建一个向量, 移除坐标和转发头, 最后更新跟踪以包括已完成的准备步骤. 在实际应用中, 请求处理可能是任意长和复杂的. 我们可以利用->来增加转换的可读性:(defn prepare [req] ; ❶ (-> req (assoc :url (str (:host req) (:path req)) :coord [(Double/valueOf (:x req)) (Double/valueOf (:y req))]) (dissoc :x-forward-to :x :y) (update :trace conj :prepared)))
❶
prepare函数已被重构以利用->.在
prepare函数中引入->创建了一个从上到下的视觉流程, 更易于阅读:req输入被" 向下传递" 到第一个assoc操作, 然后是dissoc, 最后是update.->的另一个有趣用法是与匿名 lambda 形式#()结合使用. 当应用于单个参数时,->的行为类似于identity函数, 因此(-> 1)等价于(identity 1). 为了理解这如何有用, 让我们看一下以下失败的示例:(def items [:a :a :b :c :d :d :e]) (map #({:count 1 :item %}) items) ; ❶ ;; ArityException Wrong number of args (0) passed to: PersistentArrayMap
❶ 我们希望从
items中的每个元素创建一个 map, 但这不是正确的方式.我们在上述示例中希望实现的是, 从
items向量中的每个元素创建一个 map, 该 map 包含一个键:count(其值始终为 1) 和一个键:item(其值为原始元素). 上述代码的问题在于, 匿名函数#({:count 1 :item %})试图在没有参数的情况下调用该 map. 我们需要对该形式进行宏展开才能看到发生了什么:(macroexpand '#({:count 1 :item %})) ; ❶ ;; (fn* [p1] ({:count 1, :item p1}))
❶
macroexpand是一个有用的调试工具, 用于可视化宏转换.macroexpand显示了尝试在没有参数的情况下将数组映射作为函数调用 (这会失败). 现在有几种方法可以解决这个问题. 以下形式都产生预期的结果:(map #(hash-map :count 1 :item %) items) ; ❶ (map #(identity {:count 1 :item %}) items) ; ❷ (map #(do {:count 1 :item %}) items) ; ❸ (map #(-> {:count 1 :item %}) items) ; ❹
❶ 一组 4 种形式, 在相同的项目向量上都产生相同的结果. 第一种使用
hash-map, 这是一种惯用的选择.❷ 我们可以使用
identity并继续使用带有花括号{}的 map 字面量语法, 但对identity的需求很难理解.❸
identity的一个更短的替代方案是do. 然而,do的存在通常与副作用相关联, 而这种形式中没有任何副作用. 总的来说, 这个选项和第二个选项一样令人困惑.❹ 最终的形式使用
->, 简短而切中要点.使用
->的最后一个选项有效地传达了操作的信息: 它简短易读, 没有引入identity或do的语义混乱. 使用hash-map和->的选项都是惯用的, 但它们产生的结果略有不同:(map type (map #(hash-map :count 1 :item %) [1])) ; ❶ ;; (clojure.lang.PersistentHashMap) (map type (map #(-> {:count 1 :item %}) [1])) ; ❷ ;; (clojure.lang.PersistentArrayMap)
❶ 使用
hash-map创建 map 会产生clojure.lang.PersistentHashMap类型. ❷ 使用带有最少键集的 map 字面量语法{}会产生一个clojue.lang.PersistentArrayMap类型.请参考
array-map和hash-map来理解这种类型差异. 大多数时候, Clojure 会透明地处理从一种 map 类型到另一种 map 类型的转换, 用户无需知道.- 线程宏和 T-组合子
组合逻辑是一种表示法 (如 lambda 演算), 它消除了数学逻辑中对自由变量的需求 32. 它在编程中引起了关注, 因为组合子在函数组合中可以用来增强表达能力. 特别是 T-组合子, 允许函数应用" 反向" 发生. Clojure 线程运算符产生的效果与 T-组合子类似, 但作为一个宏, 它的应用受到限制:
(/ (Math/abs (- (* (inc 1) 5) 1)) 3) ; ❶ (-> 1 ; ❷ inc (* 5) (- 1) (Math/abs) (/ 3))
❶ 一个写成嵌套函数应用的简单数学表达式
❷ 使用
->宏垂直书写的相同表达式上面示例中的两个表达式返回相同的结果, 但第二个表达式更清楚地揭示了流程. 然而,
->作为 T-组合子受到限制, 因为它不支持带参数的嵌套函数, 例如:(-> 1 (fn [x] (inc x))) ;; IllegalArgumentException Parameter declaration 1 should be a vector
以上结果会导致编译错误. 宏展开清楚地显示了问题所在:
(macroexpand-1 '(-> 1 (fn [x] (inc x)))) ;; (fn 1 [x] (inc x))
这就是为什么有时 Clojure 中的线程运算符被比作一个受限的 T-组合子 33.
- 线程宏和 T-组合子
- 另请参阅
->只是 Clojure 提供的几种线程宏之一. 最初只有->, 随后在 1.1 中有了->>, 并在 Clojure 1.5 版本中有了更大的扩展, 增加了as->,some->,some->>,cond->和cond->>. 其他相关的线程宏是:->>被称为" 线程末尾" 宏, 与->非常相似, 但它将元素放在下一个形式的末尾, 而不是作为第二个元素. 它对于序列处理特别有用, 其中输入序列通常出现在参数列表的最后."as->"启用占位符的选择, 明确元素在下一个形式中的位置. 当需要精细控制元素在下一个形式中的位置时, 使用as->. 这个线程宏的缺点是更冗长, 因为占位符在每个形式中都重复.some->负责处理任何初始或中间的nil值, 立即停止而不是将其传递给下一个形式. 当一个形式求值为nil导致异常时,some->很有用.cond->启用一个自定义条件来决定处理是否应该继续. 这是唯一允许完全跳过一个步骤的线程宏.get-in获取任意嵌套的关联数据结构 (如 Clojure map) 的值. 例如:(-> {:a 1 :b {:c "c"}} :b :c)等价于(get-in {:a 1 :b {:c "c"}} [:b :c]). 如果你需要访问深度嵌套 map 中的值, 考虑使用get-in而不是->.
- 性能考虑和实现细节
→ O(n) n 个形式的数量 (展开时间)
->宏展开与运行时性能分析无关, 因为表达式的成本仅适用于编译. 在编译时, 反转函数参数的应用顺序与形式的数量成线性关系.
- 关键字
- 2.3.2 ->>
自 1.1 版本以来的宏
(->> [x & forms])
->>(也称为线程末尾宏) 可用于组合或分组一系列操作, 方法是将第一个表达式定位为后续形式的最后一个参数 (类似于"->", 它将其放在第一个位置).->>倾向于提高某类序列操作的可读性, 否则这些操作会反向阅读 (或从内到外). 转换管道 (其中第一个操作的结果需要传递给下一个操作) 通常是使用->>进行" 线程化" 的良好候选者.->>宏的参数包括一个表达式 (强制) 和一系列形式 (可选). 其思想是第一个表达式被" 管道化" 通过其他形式, 这些形式有机会在返回最终输出之前在每个步骤中处理该表达式.- 约定
- 输入
"x"是一个强制性表达式. 该表达式被求值并放置在后续形式的最后 (如果有)."forms"是一个可选的形式列表. 如果任何形式还不是一个列表, 它将被一个列表包装. 每个形式的第一个元素必须是一个可调用对象 (使得(ifn? (first form))为真). 每个求值的形式被放置在后续形式的最后, 然后求值, 直到没有更多的形式.
- 值得注意的异常
- 如果在没有参数的情况下调用, 会抛出
ArityException. - 如果任何形式不可调用, 则会抛出
ClassCastException. 例如, 在(->> "a" "b" [])中, 字符串 "a" 被视为一个函数.
- 如果在没有参数的情况下调用, 会抛出
- 返回
- 返回: 最后一个形式 (如果有) 的求值结果, 通过将先前求值的形式作为下一个形式的最后一个参数. 如果没有提供形式, 它返回表达式 "x" 的求值结果.
- 输入
- 示例
->>非常适合于序列处理管道, 其中初始输入通过每个步骤转换为最终输出. 以下示例展示了我们如何使用->>重写几个filter操作的嵌套. 我们想要过滤所有由相同重复数字组成, 能被 3 整除的偶数正数:(filter pos? ; ❶ (filter #(apply = (str %)) (filter #(zero? (mod % 3)) (filter even? (range 1000))))) ;; (6 66 222 444 666 888) (->> (range 1000) ; ❷ (filter even?) (filter #(zero? (mod % 3))) (filter #(apply = (str %))) (filter pos?)) ;; (6 66 222 444 666 888)
❶ 这组嵌套的过滤器相当容易理解, 但我们仍然需要费力地寻找最内层的形式并向外移动来理解它.
❷
->>反转了之前的流程, 首先是输入序列, 然后是按实际应用顺序排列的操作集.以下示例说明了
->>是多么灵活, 例如, 当涉及不同的序列操作时, 就像解析 web 请求的查询字符串一样. 这里是第一个选项, 它嵌套了每个处理步骤, 而没有使用线程末尾宏:(require '[clojure.string :refer [split]]) (def sample-query "guidx=123&flip=true") (defn params [query] ; ❶ (apply merge ; ❷ (map #(apply hash-map %) ; ❸ (map #(split % #"=") ; ❹ (split query #"&"))))) ; ❺ (params sample-query) ;; {"guidx" "123", "flip" "true"}
❶
params是一个对字符串输入应用一系列转换的函数.❷ 这个
merge操作是最后执行的, 但它出现在最前面.❸ 在这一步, 我们取每一对分割后的字符串, 并用它们构建一个 map.
❹ 这一步在 "=" 符号出现的地方分割每个字符串.
❺ 初始的字符串输入按 "&" 符号分割.
处理参数的函数不易理解, 因为它是反向阅读的. 这里是利用
->>的新版params:(defn params [query] ; ❶ (->> (split query #"&") (map #(split % #"=")) (map #(apply hash-map %)) (apply merge)))
❶ 重写
params函数以利用线程末尾宏.新的
params函数包含与之前完全相同数量的步骤, 只是排列顺序不同. 值得注意的是, 这次相同的操作如何自然地按顺序流动, 所以我们可以从顶部开始阅读第一个操作, 并沿着垂直流程到底部. - 另请参阅
->>是最常用和最通用的线程末尾宏之一. 还有其他线程末尾的变体, 它们与处理管道的交互更具体:some->>是一个 nil 感知的线程末尾宏, 它在求值链中第一次出现 nil 时停止处理.cond->>允许在每个步骤中都有一个条件来决定是否继续. 这个版本的线程末尾宏允许完全跳过一个或多个步骤.
- 性能考虑和实现细节
→ O(n) n 个形式的数量 (宏展开)
在使用
->>宏之前, 没有特别的性能考虑. 反转函数参数的应用顺序与函数的数量成线性关系, 但这发生在宏展开时, 通常列表不会超过几个项目. 总的来说, 所有线程宏在性能分析中都不被认为特别重要.
- 约定
- 2.3.3 cond-> 和 cond->>
自 1.5 版本以来的宏
(cond-> [expr & clauses]) (cond->> [expr & clauses])
cond->和cond->>分别是基本线程宏->和->>的专门版本.cond->接受一个表达式, 并在一个子句为真时将该表达式" 线程优先" 地传入后续形式中 (作为形成函数的第一参数). 类似地, 当条件为true时,cond->>将表达式" 线程末尾" 地传入. 每个形式都由一个子句前导, 该子句用于决定先前的求值是否应该通过该形式.关于条件线程宏的一个重要事实是它们不是短路的. 如果子句为假, 相关的形式只是被跳过, 计算从下一个继续. 另外值得注意的是, 子句不能访问其他形式的求值结果, 只能访问周围的局部绑定, 就像代码中任何其他非宏求值部分一样. 具体来说, 子句不能引用前一个形式的结果 (即" 被线程穿过" 的内容). 这种行为可以用来重复检查一个初始表达式 (或某些其他给定的选项), 而与之前发生的转换无关.
这里有一个逐步解释来阐明
(cond->)的逻辑:(let [x \c] ; ❶ (cond-> x ; ❷ (char? x) int ; ❸ (char? x) inc ; ❹ (string? x) reverse ; ❺ (= \c x) (/ 2))) ; ❻ ;; 50
❶ 一个局部绑定 "x" 被建立为字符
\c.❷ "x" 被线程穿过
cond->.❸ 子句
(char? x)被求值. 由于 "x" 是一个字符类型, 相关的形式被求值. 由于int函数不是一个序列, 它在宏展开时被转换为一个列表(list int). 然后 "x" 被用作(int x)的第二个参数, 求值为数字 99 (\c的 ascii 等价物).❹ 子句
(char? x)再次被求值, 它仍然是 "true", 因为它被绑定到没有改变的 "x". 但这一次, 前一个形式的结果被用作inc的参数, 结果为数字 100.❺ 子句
(string? x)被求值. x 不是一个字符串 (它是一个字符), 所以reverse不会发生.❻
(= \c x)为真, 所以下面的形式被求值. 前一个求值形式的结果 (100) 被用作形式的第二个参数, 如(/ 100 2), 结果为数字 50.类似地, 这里有一个关于
cond->>如何对其参数进行操作的逐步示例:(let [x [\a 1 2 3 nil 5]] ; ❶ (cond->> x ; ❷ (char? (first x)) rest ; ❸ true (remove nil?) ; ❹ (> (count x) 5) (reduce +))) ; ❺ ;; 11
❶ 一个局部绑定 "x" 为向量
[\a 1 2 3 nil 5]建立.❷ "x" 被线程穿过
cond->>宏.❸ 子句
(char? (first x))被求值. 由于\a是一个字符类型, 该形式被求值. 由于rest函数不是一个序列, 它在内部被转换为一个列表(list rest). x 被用作(rest x)的第二个参数, 求值为列表(1 2 3 nil 5).❹ 当
true用作子句时, 形式总是被求值. 先前的求值被添加为(remove nil?)的最后一个参数, 结果为(remove nil? (1 2 3 nil 5)), 求值为新列表(1 2 3 5).❺ 最后一个子句
(> (count x) 5)对 "x" 中的元素进行计数 (这是原始表达式, 而不是先前求值的列表). 由于有超过 5 个项, 先前求值的列表被用作当前形式的最后一个参数:(reduce + (1 2 3 5)). 最终结果是 11.- 约定
- 示例
cond->的一个惯用法是在条件形式中, "true" 分支应该转换输入, 而 "false" 分支则保持不变. 例如, 以下形式是等效的:(let [x "123"] (if (string? x) (Integer. x) x)) ; ❶ (let [x "123"] (cond-> x (string? x) Integer.)) ; ❷
❶ 变量 "x" 可以是字符串或数字. 如果它是字符串, 我们想将它转换为数字, 否则我们什么都不做. 条件形式需要在最后重复 "x" 一次, 只是为了保持原样.
❷ 在
cond->版本中, 我们避免了第三次重复 "x", 因为它仅在条件为真时才通过Integer构造函数进行线程化.cond->可以用于处理异构数据, 使它们最终以相同的" 形状" 出现. 这种情况可能发生, 例如, 当一个应用程序接收到同一实体的 XML 或 JSON, 但在结构或值上存在细微差异时 (树状数据结构可以直接在 Clojure 中表示和处理为哈希映射). 下面的shape-up函数检查传入的哈希映射是否符合一组规则, 并相应地进行更改:(defn same-initial? [m] (apply = (map (comp first name) (keys m)))) (defn shape-up [m] (cond-> m :always (assoc-in [:k3 :j1] "default") ; ❶ (same-initial? m) (assoc :same true) ; ❷ (map? (:k2 m)) (assoc :k2 (apply str (vals (:k2 m)))))) ; ❸ (map shape-up [{:k1 "k1" :k2 {:h1 "h1" :h2 "h2"} :k3 {:j2 "j2"}} {:k1 "k1" :k2 "k2"} {:k1 "k1" :k2 {:h1 "h1" :h3 "h3"} :k3 {:j1 "j1"}}]) ;; ({:k1 "k1", :k2 "h1h2", :k3 {:j2 "j2", :j1 "default"}, :same true} ;; {:k1 "k1", :k2 "k2", :k3 {:j1 "default"}, :same true} ;; {:k1 "k1", :k2 "h1h3", :k3 {:j1 "default"}, :same true})
❶ 第一个形式强制要求存在一个
:k3键, 指向 map{:j1 "default"}(如果该键已存在, 它将被替换). 在这第一步之后, 我们确信:k3 :j1键组合存在, 可能带有一个 "default" 值. 为了强制该条件始终被应用, 使用了":always"作为子句.":always"是逻辑真, 因此相关的表达式总是被求值.❷ 第二个子句检查所有键是否以相同的字母开头. 如果是这种情况, 我们添加一个键
:same true.❸ 在最后一步, 如果键
:k2的值是另一个哈希映射, 那么我们取该内部哈希映射的所有值, 并将它们连接成一个字符串. 我们最终用新字符串替换相同的:k2键.一个有趣的
cond->>用法类似于非条件的->>线程末尾宏, 但带有可选的步骤. 序列非常适合类似管道的处理, 因为它们在末尾接收输入数据.cond->>增加了条件以增强灵活性. 例如, 这里是一个用于假设的音频信号处理应用的函数:(def signals [111 214 311 413 107 221 316 421 112 222 317 471 115 223 308 482]) (defn process [signals opts] (let [{:keys [boost? bypass? interpolate? noise? cutoff?]} opts] ; ❶ (cond->> signals (< (count signals) 10) (map inc) ; ❷ interpolate? (mapcat range) ; ❸ bypass? (filter bypass?) ; ❹ noise? (random-sample noise?) ; ❺ cutoff? (take-while #(< % cutoff?))))) ; ❻ (process signals {:bypass? even? :interpolate? true :noise? 0.5 :cutoff? 200}) ;; (0 4 12 14 16 ...
❶ 使用解构, 我们可以从输入 map 中提取相关的键.
❷ 信号处理首先检查我们收到了多少采样事件. 如果少于某个数量, 每个信号都会递增. 在我们的例子中, 这个操作没有被求值.
❸ 为了模拟新数据的引入 (插值), 对序列中的每个信号调用
range, 生成一个不同大小的嵌套序列列表.mapcat负责将所有内容重新连接在一起. 在我们的例子中, map 中设置了该选项, 插值发生在原始信号列表上, 因为上一步没有执行.❹ 这一步根据
bypass?键过滤信号. 如果bypass?是nil, 那么就没有过滤. 当bypass?包含除nil以外的内容时, 它假设bypass?是filter的谓词. 在我们的例子中, 使用even?作为谓词进行过滤操作.❺ 这一步通过使用
random-sample对列表进行随机采样, 可选地向信号添加噪声. 由于设置了noise?键, 这一步也使用 50% (0.5) 的概率进行.❻ 最后, 截止步骤移除所有超过某个阈值的信号. 该步骤以 200 的阈值执行.
- 可视化垂直流
Clojure 的函数和宏在功能上可以非常丰富. 它们越富有表达力和功能, 就需要越多的文档来理解它们.
cond->和cond->>这样的线程宏就是这种情况. 幸运的是, 它们的自然垂直流有助于更好地理解它们.在
cond->>的情况下, 借助一些格式化, 更容易看到在执行过程中垂直流动的两列: 一列是条件 (左侧), 另一列是形式 (右侧). 这是引言中使用的相同示例:(let [x [\a 1 2 3 nil 5]] (cond->> x (char? (first x)) rest true (remove nil?) (> (count x) 5) (reduce +)))
条件列可以访问局部和全局绑定 (就像代码的任何其他部分一样), 但它对右侧列一无所知. 类似地, 右侧的处理列对左侧的条件没有任何影响 (假设没有副作用).
请记住, 上述缩进风格在此处用于强调
cond->>的垂直流, 通常不使用. 应将通过缩进 (或列) 进行强调视为一种 sparingly 使用的特殊文档情况. 当对如何为函数或宏使用正确的缩进风格有疑问时, 用户贡献的 Clojure 风格指南是权威参考 34.
- 可视化垂直流
- 另请参阅
"->"是" 线程优先" 宏. 与cond->不同, 它不为下一个形式的执行应用任何子句.->>是" 线程末尾" 宏. 与cond->>不同, 它不为下一个形式的执行检查条件."some->"大致可以与cond->进行比较, 其中所有条件都只检查nil. 然而,"some->"在nil的情况下会短路并立即返回.some->>大致与cond->>比较, 其中所有条件都检查nil. 然而, 如果某些形式求值为nil,some->>会短路并立即返回.
- 性能考虑和实现细节
→ O(n) n 个形式的数量 (编译时间)
cond->和cond->>通常与运行时性能分析无关, 因为处理形式的成本在编译时应用. 在编译时, 反转函数参数的应用顺序与形式的数量成线性关系.
- 约定
- 2.3.4 some-> 和 some->>
自 1.5 版本以来的宏
(some-> [expr & forms]) (some->> [expr & forms])
some->和some->>是线程优先宏->和线程末尾宏"->>"的变体, 如果任何形式求值为nil, 它们会立即返回. 这对于那些在存在nil的情况下会抛出NullPointerException的函数特别有用 (这是 Java 互操作中的常见情况, 但不仅限于此):(-> {:a 1 :b 2} :c inc) ; ❶ ;; NullPointerException (some-> {:a 1 :b 2} :c inc) ; ❷ ;; nil
❶ 尝试递增 map 中键
:c的值. 该键不存在, 返回nil. 在nil的情况下,inc会抛出异常.❷ 同样的例子使用
some->返回nil.- 约定
- 示例
some->的一个惯用法是在使用 Java 互操作时, 例如将字符串转换为数字. 这在从环境变量中读取时经常发生, 这在系统启动时很常见:(defn system-port [] (or (some-> (System/getenv "PORT") Integer.) ; ❶ 4444)) (system-port) ; ❷ ;; 4444
❶
some->在这里防止了当"PORT"变量不存在时出现NumberFormatException.❷ 调用
(system-port)不论是否存在"PORT"环境变量都能正常工作. 当"PORT"存在时, 它会覆盖默认值, 当"PORT"不存在时则使用默认值.re-seq是与some->>进行条件处理的一个很好的候选者:re-seq接收目标字符串作为最后一个参数, 并且它不容忍nil参数. 这里有一个函数, 用于从某个 HTML 文档中提取<title></title>标签之间的内容:(defn titles [doc] ; ❶ (some->> doc ; ❷ (re-seq #"<title>(.+?)</title>") ; ❸ (map peek))) ; ❹ (titles nil) ;; nil (titles "<html><head>Document without a title</head></html>") ;; nil (titles "<html><head> <title>Once upon a time</title> <title>Kingston upon Thames</title> </head></html>") ;; ("Once upon a time" "Kingston upon Thames")
❶
match-title是一个简单的函数, 它在 HTML 文档中搜索一对<title></title>标签, 然后验证标题是否包含给定的正则表达式.❷
some->>省去了对可能为nil值的保护.❸ 如果整个文档为
nil, 我们不希望re-seq生成NullPointerException.❹
re-seq以向量对的形式返回匹配结果.peek是访问向量中最后一项的最佳方式.使用正则表达式来匹配大型 HTML 文档是可能的, 但效率不高. 对于密集的 HTML 处理, 最好使用许多可用的 HTML 解析库之一 (例如 Enlive 35).
- 宏家族的故事
你可能会认为 Clojure 已经用现有的线程宏覆盖了管道处理的所有细微差别. 但线程宏非常有用, 以至于有几个库扩展了它们. 两个值得注意的例子是: LonoCloud Synthread 36 和 Pallet Ops thread-expr 37.
这里有几个来自这些库的线程宏的例子:
(->/as {:a 2 :b 2} {:keys [b]} (assoc :large-b (> b 10))) ;; {:a 2 :b 2 :large-b false}
Synthread 包含一个支持普通 Clojure 解构的增强版
as->宏. 键:b从 map 中提取并分配为后续形式的局部绑定.(-> 1 (for-> [x [1 2 3]] (+ x))) ;; 7
来自 Pallet Ops 的
thread-expr for->允许在一个已有的->线程优先宏中重复形式. 这里显示的例子展开为:(-> 1 (+ 1) (+ 2) (+ 3)).(def ^:dynamic *a* 0) (-> 1 (binding-> [*a* 1] (+ *a*))) ;; 2
binding->(同样来自 Pallet Ops) 允许在线程化的形式中直接进行绑定. 正如你在这里看到的,*a*的值在每个线程的基础上变为 1.(-> {:a 1 :b {:c 2}} (->/update :a inc -) (->/in [:b :c])) ;; 2
这些是来自 Synthread 库的两个例子.
->/update和->/in是两个专门用于 map 的线程宏, 类似于update和get-in, 但支持在一次调用中线程化多个更新, 如(->/update :a inc -)所示, 它递增并改变键:a指向的值的符号.
- 宏家族的故事
- 另请参阅
fnil是一个通过包装另一个函数来工作的函数生成器. 当围绕nil值的检查与参数相关时,fnil是首选. - 性能考虑和实现细节
→ O(n) n 个形式的数量 (编译时间)
在使用
some->宏之前, 没有特别的性能考虑. 它基本上委托给->, 它在编译时处理形式 (通常没有太大的性能影响, 考虑到通常在线程宏中使用的形式数量很少).
- 约定
- 2.3.5 as->
自 1.5 版本以来的宏
(as-> [expr name & forms])
as->通过添加一个新参数来专门化两个基本的线程宏->和->>, 该参数用作占位符, 将前一个形式的求值结果定位到下一个形式中. 使用->和->>, 顶部的表达式求值结果分别被放置在下一个形式的第二个位置或末尾. 链中的所有形式都需要遵循相同的定位.as->可以精确地放置下一个形式的求值结果:(as-> {:a 1 :b 2 :c 3} x ; ❶ (assoc x :d 4) ; ❷ (vals x) ; ❸ (filter even? x) ; ❹ (apply + x)) ;; 6
❶
as->链以 2 个元素开始, 即要传入的表达式和局部绑定 "x".❷ "x" 在下一个形式中用作占位符来驱动其定位, 在这种情况下, 紧跟在
<assoc,assoc>>之后.❸ 请注意, 即使没有歧义, "x" 也需要在形式中明确.
❹ 这是一个作为最后一个参数放置的例子, 等同于
->>的定位.对形式进行宏展开显示了这是如何轻松完成的:
(macroexpand-1 ; ❶ '(as-> {:a 1 :b 2 :c 3} x (assoc x :d 4) (vals x) (filter even? x) (apply + x))) (let [x {:a 1, :b 2, :c 3} x (assoc x :d 4) x (vals x) x (filter even? x) x (apply + x)] x)
❶ 使用
macroexpand-1可以防止展开超出as→本身.由于
as->基于let, 它也支持解构 (尽管这仅从 Clojure 1.8 开始启用).- 约定
- 示例
as->在线程化值在每个形式中位置不同的情况下很有用. 这里有一个例子, 序列处理 (通常是线程末尾操作) 与 map 处理 (线程优先操作) 混合在一起. 该示例模拟从某个 URL 端点获取数据, 该端点包含 id, name, count 三元组:(defn fetch-data [url] ; ❶ [{:id "aa1" :name "reg-a" :count 2} {:id "aa2" :name "reg-b" :count 6} {:id "aa7" :name "reg-d" :count 1} {:id "aa7" :name nil :count 1}]) (defn url-from [path] ; ❷ (str "http://localhost" "/" path)) (defn process [path] ; ❸ (as-> path <$> (url-from <$>) (fetch-data <$>) (remove #(nil? (:name %)) <$>) (reduce + (map :count <$>)))) (process "home/index.html") ; 9
❶
fetch-data模拟从远程服务获取数据后的响应. 本例中未使用 url 参数.❷
url-from从简单路径创建有效 URL.❸ 我们可以看到
as->在起作用. 前 3 个形式要求线程化值出现在最后, 而最后一个形式则将占位符置于嵌套位置.在上面的例子中,
process使用了as->线程宏. 为了对相关项的:count键求和, 所需的操作链需要混合函数调用和序列操作, 因此前一个形式的求值需要在不同的位置. 占位符符号<$>的选择是任意的, 但这个符号在形式中更显眼.以下示例说明了与
as->一起使用解构. 要理解的一个重要方面是, 尽管只在顶部出现一次, 但在每次求值期间都会应用相同的解构. 这允许每个形式根据先前的求值看到局部绑定的新更新:(let [point {:x "15.1" :y "84.2"}] (as-> point {:keys [x y] :as <$>} ; ❶ (update <$> :x #(Double/valueOf %)) (update <$> :y #(Double/valueOf %)) (assoc <$> :sum (+ x y)) ; ❷ (assoc <$> :keys (keys <$>)))) ; ❸ ;; {:x 15.1, :y 84.2, :sum 99.3, :keys (:x :y :sum)}
❶ 一个 map 包含点的坐标 x,y 作为字符串. 我们在声明
as->的占位符时解构了该 map.❷ 在计算的这一步, x 和 y 的值是对前一个形式应用解构的结果, 在 x 和 y 都从字符串转换为双精度浮点数之后.
❸ 注意, 占位符
<$>可以在表达式的任何位置使用, 不仅仅是在开头. - 另请参阅
基本的线程宏
->和->>可以被视为as->的专门形式, 其中结果在下一个形式中的位置是固定的 (要么是下一个形式中的第一个参数, 要么是最后一个). - 性能考虑和实现细节
→ O(n) n 个形式的数量 (编译时间)
as->通常与运行时性能分析无关, 因为处理形式的成本在编译时应用. 在编译时, 反转函数参数的应用顺序与形式的数量成线性关系.
- 约定
2.1.4. 2.4 函数执行
- 2.4.1 apply
自 1.0 版本以来的函数
(apply ([f args]) ([f x args]) ([f x y args]) ([f x y z args]) ([f a b c d & args]))
apply, 在最常用的形式中, 接受一个函数和一个参数集合, 并返回对列表中的参数调用函数的结果.apply在函数参数是动态生成且在编写表达式时尚未知的情况下很有用.apply可以想象为从列表中" 展开" 或" 铺开" 参数来调用一个函数.- 约定
- 示例
apply的一个常见用例是字符串连接, 当要连接的字符串集合是作为某些运行时计算的结果而知晓时. 例如, 这里是一个生成长度为 "n" 的随机二进制字符串的函数:(defn rand-b [n] (->> #(rand-int 2) ; ❶ (repeatedly n) ; ❷ (apply str))) ; ❸ (rand-b 10) ; "1000000011"
❶ 第一步创建一个无参数的函数, 以等概率生成随机的 0 或 1. 这个函数是下面
repeatedly所需的.❷ 随机生成器被传递给
repeatedly, 它创建一个随机 "n" 位的惰性序列.❸ 我们使用
apply和str进行最终的字符串连接.该示例展示了如何生成一个随机的位列表, 然后将其转换为单个字符串.
apply的另一个常见用法是使用列表作为输入来创建 map:(defn event-stream [] ; ❶ (interleave (repeatedly (fn [] (System/nanoTime))) (range))) (apply hash-map (take 4 (event-stream))) ; ❷ ; {52284399855900 1, 52284399847705 0}
❶
event-stream模拟了来自某个外部源的事件流, 形式为一个时间戳后跟一个值的简单序列.❷
hash-map需要键值对作为参数. 我们可以使用apply将事件集合转换为参数列表.以下示例说明了
apply与map结合使用.map接受任意数量的集合作为输入, 因此apply可以用于向map" 铺开" 参数, 例如处理一个二维向量表:(def header [:sold :sigma :end]) ; ❶ (def table [[120 3 399] [100 2 242] [130 6 3002]]) (defn totals [table] (->> table (apply map +) ; ❷ (interleave header))) ; ❸ (println "totals" (totals table)) ;; totals (:sold 350 :sigma 11 :end 3643)
❶
header和table代表了将二维表解构为 Clojure 数据结构的典型方式.table包含按 3 个项目分组的实际行, 而header是每列的标题.❷ 对于这个例子,
(apply map + table)等价于(map + [120 3 399] [100 2 242] [130 6 3002]).+可以接受任意数量的参数 (在本例中为 3 个), 为每列创建一个总和.❸ 最后, 我们为每个总和添加标题.
- Apply: 一段 Lisp 历史
Clojure 是 Lisp 的一种方言, 而 Lisp 是一种古老的语言 (最初的论文" Recursive Functions of Symbolic Expressions and Their Computation by Machine" 日期为 1960 年, 但朝着一种新的符号表达式语言的研究始于 1957 年左右). 最初, Lisp 采用了一种基于 M 表达式 (或元语言表达式) 的语法, 这种语法不是基于列表 (像现在这样), 看起来有点像:
λ[[y;z];cons[car[y];cdr[z]]]
以上是一个接受两个列表参数
y,z的函数, 它产生一个新的列表作为输出, 合并(first y)和(last z), 相当于 Clojure 中的(fn [y z] (cons (first y) (last z))).在 1958 年到 1959 年之间的某个时候, McCarthy 想证明 Lisp 在表达可计算性方面比图灵机的形式主义更好. 该挑战的一部分也是定义一个" 通用 Lisp 函数" , 一个能够解析和执行用相同语法编写的自己的另一个副本的函数 (就像通用图灵机能够接受自身的定义一样).
McCarthy 必须找到一种方法来以 Lisp 自身可以消化的形式表达 Lisp 函数, 并决定将它们编码在列表中, 使用列表的第一个元素是函数名, 列表的其余部分是参数的约定. McCarthy 称这种新表示法为 S 表达式 (其中 S 代表 Symbolic). 上述" cons" M 表达式作为 S 表达式将如下所示 (这在现代 Lisp 中是完全有效的):
(LAMBDA (Y Z) (CONS (CAR Y) (CDR Z)))
能够解析 S 表达式并将其应用于参数的通用函数确实被称为
apply. McCarthy 设想apply纯粹用于研究, 没有实际范围, 直到 Steve Russel (他的毕业生之一) 决定用机器语言实现apply, 从而有效地创建了第一个 Lisp REPL.
- Apply: 一段 Lisp 历史
- 另请参阅
into可以用来创建 map (以及其他集合类型), 类似于我们在示例中看到的. 一个区别是输入序列需要已经是向量对的集合形式.当你有两个集合, 一个包含键, 另一个包含值时,
zipmap是创建 hash-map 的完美选择. 将键和值组合在一起并传递给apply会更冗长.reduce可以用来连接字符串, 类似于apply, 限制是reduce只接受两个参数的函数. 例如:(apply str ["h" "e" "l" "l" "o"])产生与(reduce str ["h" "e" "l" "l" "o"])相同的结果.eval将表达式作为列表求值.注意
reduce在字符串连接方面的性能比apply差.str利用java.lang.StringBuilder, 一个可变的 Java 对象来增量构建字符串, 但只有当参数同时传递时才有效. 而reduce则反复调用str, 每次只用 2 个参数, 从而创建了许多中间的字符串构建器. 根据经验法则, 当函数专门为长输入序列进行优化时, 使用apply. - 性能考虑和实现细节
→ O(1) 常数时间 (最多 5 个参数)
→ O(n) 线性时间 (超过 5 个参数)
apply是常数时间操作, 最多到第 5 个参数, 不包括最后的集合. 显式传递超过 5 个参数后, 它变为线性.(require '[criterium.core :refer [quick-bench]]) (defn noop [& args]) (quick-bench (apply noop 1 2 [])) ; ❶ (quick-bench (apply noop 1 2 3 4 [])) (quick-bench (apply noop 1 2 3 4 5 6 [])) (quick-bench (apply noop 1 2 3 4 5 6 7 8 [])) (quick-bench (apply noop 1 2 3 4 5 6 7 8 9 10 [])) Execution time mean : 61.081153 ns Execution time mean : 63.026292 ns Execution time mean : 126.053233 ns Execution time mean : 202.979379 ns Execution time mean : 306.982878 ns
❶ 基准测试在增加显式参数数量的同时测量
apply.超过第 5 个显式参数,
apply使用递归创建一个嵌套的cons列表. 超过 5 个参数的情况不常见, 因此在正常情况下,apply不应被视为有问题的性能热点.
- 约定
- 2.4.2 memoize
自 1.0 版本以来的函数
(memoize [f])
memoize生成一个函数, 该函数使用参数值作为键来存储现有函数的结果. 当包装的函数用相同的参数列表调用时, 结果会立即从缓存中返回, 而无需任何额外的计算. 如果我们从包装的函数中打印一些消息,memoize的效果会立即可见. 我们期望每个键的消息只出现一次:(defn- f* [a b] ; ❶ (println (format "Cache miss for [%s %s]" a b)) (+ a b)) (def f (memoize f*)) ; ❷ (f 1 2) ;; Cache miss for [1 2] ;; 3 (f 1 2) ;; 3 (f 1 3) ;; Cache miss for [1 3] ;; 4
❶
f*是我们打算放入缓存的函数.❷
memoize接受目标函数作为参数, 其他什么都不需要. 它产生一个新函数, 我们可以将其定义在当前命名空间中.第一次调用会生成消息, 而后续对相同键组合的调用则不会, 这证实了包装的函数
f*没有被再次调用.没有通用的命名约定, 但考虑到目标函数和
memoize生成的函数之间的联系, 这两个名称应该有一定的相关性. 在我们的示例中, 函数的公共接口保持不变, 而记忆化版本是私有的, 并在末尾添加了一个星号 "*".- 约定
- 示例
memoize对于那些接受和返回内存占用较小的值的非平凡计算效果很好. 以下示例说明了这一点. Levenshtein 距离 38 是一个简单的度量标准, 用于测量两个字符串之间的差异. 例如, 该距离可用于为常见的拼写错误建议更正. 该距离实现起来很简单, 但对于较长的字符串 (10 个字符或更多), 计算量会变得很大. 我们可以使用memoize来避免一遍又一遍地计算相同字符串对的距离. 输入 (字符串参数) 和输出 (一个小的整数) 的大小相对较小, 因此我们可以缓存大量它们而不会耗尽内存 (假设调用该函数的单词列表是我们可以估计的某个有限数量).为了提供我们的示例, 我们将使用一个纯文本格式的单词词典 (在 Unix 系统上, 这样的文件位于 "/usr/share/dict/words"). 如果我们被要求实现一个自动更正服务, 它的工作方式如下:
- 用户输入一个拼写错误的单词.
- 系统检查该单词与词典中单词的距离.
- 结果按距离从小到大的顺序列出.
我们还将预先计算几个以单词首字母开头的小词典, 这是一种进一步加快距离计算的技术:
(defn levenshtein* [[c1 & rest1 :as str1] ; ❶ [c2 & rest2 :as str2]] (let [len1 (count str1) len2 (count str2)] (cond (zero? len1) len2 (zero? len2) len1 :else (min (inc (levenshtein* rest1 str2)) (inc (levenshtein* str1 rest2)) (+ (if (= c1 c2) 0 1) (levenshtein* rest1 rest2)))))) (def levenshtein (memoize levenshtein*)) ; ❷ (defn to-words [txt init] ; ❸ (->> txt slurp clojure.string/split-lines (filter #(.startsWith % init)) (remove #(> (count %) 8)) doall)) (defn best [misp dict] ; ❹ (->> dict (map #(-> [% (levenshtein misp %)])) (sort-by last) (take 3))) (defn dict [init] (to-words "/usr/share/dict/words" init)) (def dict-ac (dict "ac")) ; ❺ (time (best "achive" dict-ac)) ;; "Elapsed time: 4671.226198 msecs" ; ❻ ;; (["achieve" 1] ["achime" 1] ["active" 1]) (time (best "achive" dict-ac)) ;; "Elapsed time: 0.854094 msecs" ; ❼ ;; (["achieve" 1] ["achime" 1] ["active" 1])
❶ 这里介绍的 Levenshtein 算法是网上许多类似算法的一种变体. 需要记住的重要方面是, 它的增长大致为 O(n*m), 其中 m 和 n 是字符串的长度, 换句话说, 在最坏的情况下为 O(n2).
❷ 这个
def实际上通过memoize构建了包装函数, 方便地称为levenshtein, 没有最后的 *, 后者是为非记忆化版本保留的.❸
to-words是一个辅助函数, 用于准备按初始字符串过滤的词典.to-words是算法的" 静态" 或" 学习" 阶段的一部分, 因为我们可以离线按首字母准备单词, 并存储它们以备后用.❹
best函数负责将levenshtein记忆化函数应用于词典中的单词. 然后它用sort-by对结果进行排序, 并返回最小的距离.❺
def调用定义了一个以 "ac" 开头的过滤词典, 因此它不需要被计算多次. 这也防止了time函数报告读取和处理文件所需的时间.❻ 第一次调用搜索拼写错误单词的最佳匹配项返回了近 5 秒.
❼ 第二次调用返回得快得多.
函数的记忆化版本将每个新的字符串对作为键, 返回的距离作为值存储在一个内部 map 中. 每次用相同的参数调用该函数时, 返回值都从 map 中获取.
该示例还展示了一种在实际使用前" 训练" 记忆化距离的方法. 一个真实的应用程序可以根据首字母预先计算一组词典, 类似于数据库内部发生的索引. 这种技术有助于我们实现中看到的速度提升, 但对于严肃的应用程序, 有性能优于 Levenshtein 的算法 39.
- 另请参阅
lazy-seq创建一个" thunk" (围绕一个值的包装函数), 在第一次访问时求值其内容, 并在后续调用时返回缓存的版本. 当 thunk 连接在一起形成一个序列时, 它形成一个惰性序列. 惰性序列可以与缓存相比较, 其中键的顺序和值是预先确定的. 在集合上实现" 求值一次" 的语义可以通过lazy-seq实现. 由于所有 Clojure 序列都是惰性的, 你可能已经在不知不觉中使用了" 缓存的数据结构" .atom创建一个 Clojure Atom, 这是 Clojure 可能的引用类型之一.memoize使用一个 atom 来存储结果. 当memoize的实现对于特定类型的缓存过于限制时, 使用自定义的 atom. 例如, 你可以考虑使用 Clojure hash-map 以外的东西来在 map 中存储项, 比如带有软引用的可变 Java map 40. 请记住, 如果你正在寻找这个, 已经有像 core.cache (github.com/clojure/core.cache) 这样的库来提供常见的缓存策略. - 性能考虑和实现细节
=> O(1) 步骤 (函数生成)
=> O(n log n) 步骤 (生成的函数), n 个唯一键的数量
=> O(n) 空间 (生成的函数), n 个唯一键的数量
关于
memoize, 需要考虑的主要方面是它会无限期地存储缓存的项. 新缓存值的不断累积最终会耗尽内存.memoize的使用者在设计他们的解决方案时应注意这些事实, 特别是关于缓存中键的预期分布. 在长时间运行的服务中, 当参数排列的数量可能是无限的或不易预测时, 不应使用memoize.我们可以通过对原始
memoize函数进行一些更改来收集有关键分布的一些统计信息. 以下memoize2包含额外的 atom, 用于在运行时收集数据缓存命中, 未命中和总调用次数.(defn memoize2 [f] (let [mem (atom {}) ; ❶ hits (atom 0) miss (atom 0) calls (atom 0)] (fn [& args] (if (identical? :done (first args)) ; ❷ (let [count-chars (reduce + (map count (flatten (keys @mem))))] {:calls @calls :hits @hits :misses @miss :count-chars count-chars :bytes (* (int (/ (+ (* count-chars 2) 45) 8)) 8)}) ; ❸ (do (swap! calls inc) ; ❹ (if-let [e (find @mem args)] (do (swap! hits inc) (val e)) (let [ret (apply f args) _ (swap! miss inc)] (swap! mem assoc args ret) ret)))))))
❶ 除了实际的缓存外, 初始的
let块中还添加了额外的计数器.❷
:done是一个哨兵值, 可用于在运行时提取统计信息.❸ 这是根据字符数估算存储键所需内存量的估计值 41.
❹ 为了更新计数器, 执行了额外的
swap!操作.通过在运行时访问额外的统计信息, 我们可以估算键空间的大小或内存占用. 如果我们运行相同的 Levenshtein 示例, 将
memoize替换为memoize2, 我们可以提取以下结果:(def levenshtein (memoize2 levenshtein*)) (best "achive" dict-ac) ;; (["achieve" 1] ["achime" 1] ["active" 1]) (levenshtein :done) ;; {:calls 400, :hits 0, :misses 400 :count-chars 5168 :bytes 10376} (best "achive" dict-ac) ;; (["achieve" 1] ["achime" 1] ["active" 1]) (levenshtein :done) ;; {:calls 800, :hits 400, :misses 400 :count-chars 5168 :bytes 10376}
如你所见, 第一次调用
best函数时, 它产生了 400 次未命中, 而第二次调用则全部命中. 我们还可以估算存储在内存中的字符串所占用的内存, 大约是 10Kb.使用
memoize时需要考虑的第二个方面是, 为每个呈现为输入的新的键组合都增加了额外的 hash-mapassoc操作和 atomswap!. hash-map 增加 O(n log n) 步来添加一个新键, 而 atom 在高线程竞争下可能会性能不佳. 根据应用程序的要求,memoize可以建立在瞬态数据结构之上, 以避免填充缓存的性能损失. 另一种可以考虑的选择是, 在可能的情况下, " 预热缓存" : 当应用程序还未提供实时流量时, 缓存可以用最常见的键进行人工填充.
- 约定
- 2.4.3 trampoline
自 1.0 版本以来的函数
(trampoline ([f]) ([f & args]))
trampoline是一个函数调用辅助工具, 通常与相互递归结合使用 (有关更多详细信息, 请参见下面的标注). 它调用给定的函数并检查结果: 如果调用返回另一个函数,trampoline会再次调用它, 直到结果不再是函数为止.trampoline本身是一个递归函数 (基于loop-recur), 它使用输入的类型作为退出条件.- 约定
- 输入
"f"是一个接受任意数量参数的函数, 它可以返回一个可调用对象 (使得(fn? object)产生 true)."f"将需要至少一次返回一个对象, 使得(fn? object)为 false, 以防止trampoline进入无限递归."args"是传递给"f"的可选参数.
- 输出
调用
"f"在可选的"args"上的结果, 直到返回类型不是函数.trampoline退出条件用fn?检查返回的类型. 向量, 集合, 关键字和符号也是可调用对象, 但trampoline不认为它们是可调用的.如果输入函数
"f"已经返回一个函数作为最终结果, 那么该函数需要被包装在一个集合中 (或其他对象, 以便(fn? object)为 false), 以确保trampoline有一个适当的退出条件.
- 输入
- 示例
trampoline可用于将消耗堆栈的相互递归函数转换为尾递归迭代. 相互递归在日常编程中不经常出现, 但它有几个有趣的应用. 例如, 状态机是相互递归优雅解决问题的一个著名例子. 以下示例显示了如何将交通灯 (基于美国交通法规) 实现为状态机, 以及如何在非常长的状态转换序列的情况下使用trampoline来防止堆栈溢出:(defn- invoke ; ❶ [f-key & args] (apply (resolve (symbol (name f-key))) args)) (defn green [[light & lights]] ; ❷ #(case light :red false nil true (invoke light lights))) (defn red [[light & lights]] #(case light :amber false nil true (invoke light lights))) (defn amber [[light & lights]] #(case light :green false nil true (invoke light lights))) (defn flashing-red [[light & lights]] ; ❸ #(if (nil? light) true (invoke light lights))) (defn flashing-amber [[light & lights]] #(if (nil? light) true (invoke light lights))) (defn traffic-light [lights] ; ❹ (trampoline flashing-amber lights)) (traffic-light [:red :amber :red]) ;; false (traffic-light [:red :green :amber :red]) ;; true (time (traffic-light (take 10000000 (cycle [:amber :red :green])))) ;; "Elapsed time: 5919.991775 msecs" ;;true
❶
invoke接受一个关键字形式的函数 (例如:+)和相关的参数 (1 2), 并调用(+ 1 2), 前提是:+可以在当前命名空间中找到. 该示例使用invoke来调用交通灯可能的状态之一, 并将剩余的所需转换作为参数传递.❷
green状态函数处理当绿灯已经亮起时的交通灯. 该函数将根据下一个所需的状态转换来确定应该发生什么. 其他颜色的其他函数工作方式相同.case开关被指示在转换不可能时返回false, 这种情况会强制trampoline中断链条.nil需要单独处理, 因为这是转换列表的终止标记. 终止标记表示所有转换都成功.case语句末尾的 catch-all 分支处理任何额外的有效转换. 一旦颜色关键字 (任何:green,:amber或:red) 被转换为相应的函数,invoke就会调用下一个转换.❸
flashing-red和flashing-amber少处理一种情况, 因为从闪烁灯光条件下允许所有状态. 与之前的状态相比,case语句已被if替换.❹
traffic-light是入口点. 它通过trampoline启动调用链. 一旦交通灯首次打开, 第一个状态是flashing-amber.示例中的最后一个对
traffic-light的调用显示了当我们调用一个生命周期长的交通灯状态列表时会发生什么 (每个循环总时间为 2 分钟, 1000 万个周期相当于大约 39 年的连续交通灯活动). 列表中的每个项都可能创建一个新的堆栈帧, 但由于trampoline, 相互递归在堆上执行. - 另请参阅
iterate具有与递归类似的效果, 但它创建一系列中间结果, 而不是返回最终结果.iterate不是trampoline的替代品, 因为它们解决不同的问题.loop-recur是trampoline实现的核心, 消除了消耗整个堆栈空间的问题. - 性能考虑和实现细节
=> O(n) 其中 n 取决于输入函数
=> O(1) 空间
正如本章所讨论的,
trampoline是相互递归函数的重要工具. 考虑到额外的包装函数成本可以忽略不计, 总是使用它可能是个好主意.trampoline完成计算所需的步骤数完全由输入函数决定.trampoline很好地利用了loop-recur来防止消耗堆栈, 并且不使用任何其他内存空间.
- 约定
2.1.5. 2.5 总结
在本章中, 我们学习了如何定义和使用函数. 标准库中的许多函数和宏会生成具有特定属性的其他函数, 例如 fnil 或 juxt, 这些新函数可以用来组合新的行为.
特别是线程宏非常有趣, 因为它们改变了正常的求值流程以产生不同的语法.
2.2. 3 基本构件
本章汇集了 Clojure (以及类似的其他编程语言) 中一些最重要的构件: 条件分支, 迭代和局部作用域定义. 还有其他方面可以添加到此类别, 如命名空间, 变量或函数, 但由于它们的复杂性, 它们被分开处理.
你可能会惊讶地发现像条件语句, switch 语句或循环这样的东西是标准库的一部分. 但 Clojure (像之前的许多 Lisp 一样) 是从一组称为特殊形式的小型原语构建起来的, 许多在其他语言中被认为是" 保留字" 的构件反而在标准库中定义. 这就是为什么 Clojure 标准库也可以被认为是语言规范的原因.
本书对特殊形式, 宏和函数一视同仁, 前提是它们在 Clojure 引导后可供公开使用. 然而, 其中一些是为 Clojure 内部使用而设计的, 仅作简要提及.
2.2.1. 3.1 词法绑定
词法绑定是一种为值创建可访问性边界的机制. 该机制通过将值赋给由周围括号定义的作用域中的符号来工作 (因此被称为" 词法" ). 例如, 下图显示了 let 宏创建的边界:

Figure 4: 局部绑定符号 "b" 的词法作用域.
由 let 宏定义的符号 "b" 只有在考虑周围的括号时才是可见的. 当调用 add-one 时, 我们不能再使用 "b", 因为它在新建的作用域中无法解析. 函数声明创建的作用域和 let 类形式创建的作用域之间确实存在密切关系. 实际上, let 可以被认为是 lambda 函数调用的语法糖, 如以下示例所示:
((fn [a b] (* (+ a b) b)) 1 2) ; ❶ (let [a 1 b 2] (* (+ a b) b)) ; ❷
❶ 用 fn 创建的匿名函数立即对一对参数调用. 该函数声明了两个参数 "a" 和 "b", 它们在求值期间被局部绑定到值 "1" 和 "2". 一旦进入函数体, 这些参数就可以被多次使用而无需进一步求值. "a" 和 "b" 的作用域由定义匿名函数的括号词法绑定.
❷ 这个 let 声明达到了与前一个匿名函数相同的效果, 但读起来好得多: 符号和值现在紧密相连, 后面跟着主代码块.
let 和匿名函数之间有明显的等价性, 这使得局部绑定与通常的过程式变量赋值有所不同: 这完全是不可变的参数传递. 尽管如此, 即使是纯函数式的词法绑定, 由于其惊人的相似性, 也通常被称为" 赋值" . 像命令式赋值变量一样, let 绑定的符号在整个词法作用域中都可用, 无需进一步求值它们所引用的表达式. 尽管通常将符号称为" 赋值变量" , 但与命令式世界的相似之处仅此而已:
- 没有值存储位置的概念.
- 一旦绑定, 就无法改变符号以产生不同的值.
- 同一个符号可以通过使用另一个绑定形式来重新绑定, 从而遮蔽前一个 (完全不改变的) 符号.
本组中的宏和特殊形式提供了创建词法绑定的不同可能性. 最通用的 let 之后是几个可以有条件地定义符号或函数的变体. 例如, if-let 和 letfn 在创建局部符号时有助于减少一些输入开销. 所有 let 类形式 (除了 letfn, 它有略微不同的语法) 都接受一个键值对的向量, 这些键值对用于创建绑定, 以及一个在这些绑定下执行的主体. 词法绑定形式还额外提供了像解构这样的便利功能, 这是一种允许 Clojure 集合的部分直接赋给符号的简洁语法 (有关解构如何工作及其语法的详细信息, 请参见 destructure).
- 3.1.1 let 和 let*
宏 (
let) 特殊形式 (let*) 自 1.0 版本起(let [bindings & body])
let是一个非常常用的 Clojure 宏.let的主要用途之一是创建一个局部名称, 代表一个表达式的求值结果, 这样该表达式就不需要在每次使用时重新求值. 例如:(let [x (rand-int 10)] ; ❶ (if (>= x 5) (str x " is above the average") (str x " is below the average")))
❶ "x" 有 50% 的概率低于或高于 5.
rand-int的求值只发生一次.一旦局部绑定 "x" 建立, 该符号就可以在不重新求值
rand-int的情况下使用 (否则会产生问题, 因为每次调用都会返回不同的值).当在函数参数中应用等效的解构不可能或不切实际时,
let的另一个常见用例是解构.let*是let内部用于解析和验证绑定的特殊形式. 从用户的角度来看, 没有直接使用let*的特定理由, 所以本章主要关注let.(let [bindings & <body>]) bindings :=> [<bind1> <expr1>, <bind2> <expr2> .. <bind-N> <expr-N>]
- 输入
"bindings"是一个 (可能为空) 的向量, 包含偶数个元素."bind1","bind2", .. ,"bind-N"是根据解构语义的有效绑定表达式. 它们必须出现在绑定向量的偶数索引位置 (位置 0, 2, 4 等)."expr1","expr2", .. ,"expr-N"是有效的 Clojure 表达式, 必须出现在绑定向量的奇数索引位置 (位置 1, 3, 5 等)."<body>"是一组可选的表达式 (它们不需要显式地包装在列表或其他数据结构中)."body"会自动包装在一个do块中.
- 值得注意的异常
当用原始类型对局部绑定进行类型提示时, 抛出
UnsupportedOperationException. 例如, 以下表达式是无效的:(let [^long i 0]).let自动识别原始局部变量 (如 longs, doubles 等) 的类型, 在这种情况下不接受类型提示. - 输出
let返回"body"中最后一个表达式的求值结果 (如果存在多个), 允许表达式引用由绑定对设置的绑定名称. 如果"body"为空, 则返回nil.
- 输入
- 示例
以下代码实现了在多玩家游戏中常见的交互循环. 如果我们假设一个人与电脑对战, 通常会有一个" 输入" 阶段, 接着是电脑采取的行动, 包括在屏幕上打印当前移动或决定谁是赢家. 让我们以控制台版的石头剪刀布 42 为例:
(defn rule [moves] (let [[p1 p2] moves] ; ❶ (cond (= p1 p2) "tie game" (every? #{"rock" "paper"} moves) "paper wins over rock" (every? #{"scissor" "rock"} moves) "rock wins over scissor" (every? #{"paper" "scissor"} moves) "scissor wins over paper" :else "computer can't win that!"))) (defn game-loop [] ; ❷ (println "Rock, paper or scissors?") (let [human (read-line) ; ❸ ai (rand-nth ["rock" "paper" "scissor"]) res (rule [human ai])] (if (= "exit" human) "Game over" (do (println (format "Computer played %s: %s" ai res)) (recur))))) ; ❹ (game-loop) ;; Rock, paper or scissors? ;; Bang ;; Computer played scissor: computer can't win that! ;; Rock, paper or scissors? ;; paper ;; Computer played rock: paper wins over rock ;; Rock, paper or scissors? ;; exit ;; "Game over"
❶
rule包含石头剪刀布的规则, 这很容易实现. 我们需要检查两个选择是否包含在其中一个可能的集合中 (与顺序无关), 并返回相应的消息. 例如, 这是使用集合作为函数谓词和every?来验证每个选择的惯用用法. 这里let仅用于解构:p1和p2现在可以在没有任何first或last的帮助下被引用, 以从moves参数中提取它们.❷
game-loop是一个递归函数, 它重复多次游戏, 直到人类玩家在控制台输入 "exit".read-line用于从标准输入读取.❸
let声明了三个局部绑定, 这些绑定将在其包含的块中被 (可能多次) 使用. 你可以看到ai也直接在以下绑定中用于检索规则结果.❹ 我们最后在函数上
recur(没有loop语句).石头剪刀布的例子展示了关于
let的两个事实 (这也适用于其他变体letfn和if-let): 局部绑定的符号 (在本例中是ai) 立即对其他绑定定义可用. 这隐式地定义了右侧表达式的求值顺序, 因此它们可以相互引用定义的符号.该示例的第二个有趣之处在于
let已在rule函数中用于将单个序列 (向量) 参数解构为其第一个和最后一个组件. 解构消除了在if语句的条件中使用(= (first moves) (last moves))的需要, 节省了相当多的击键次数. 由于let与函数参数的概念如此紧密相关, 解构对defn的可用方式完全相同. 在defn或内部let中使用它, 本质上是一个机会和品味的问题.- 不同 Lisp 的不同 let
来自 Common Lisp 的人可能会对
let*(" let star" ) 感到困惑, 这是一个 Clojure 特殊形式, 不支持解构, 也不供公众使用. 原因是 Common Lisp 有两种let的风格:- Common Lisp
let独立地创建绑定 (并且可能并行, 尽管这是一个编译器实现细节), 因此每个单独的对都看不到由另一个对定义的局部符号. 然后, 所有的局部符号将在主let块中同时可用. - Common Lisp
let*则与 Clojurelet相同, 允许求值中的表达式立即建立一个绑定, 以看到先前声明的符号.
Common Lisp 提供这两种形式, 并将较不强大的
let作为默认选择的原因, 经常成为辩论的主题 43. Clojure 的作者决定将只有let*的风格一次性地并入 Clojure (简单地重命名为let), 从而防止了任何进一步的辩论. - Common Lisp
- 不同 Lisp 的不同 let
- 另请参阅
letfn从一个符号直接创建一个到函数定义的局部绑定. 它取代了稍微更冗长的(let [f (fn [x])])来声明一个局部函数.if-let和when-let是专门的let版本, 在let定义之上包装一个条件. 当let主体以if或when开始时使用它们. 在这种情况下, 如果对中的表达式求值为nil,let绑定可以被完全跳过.for可以被认为是一个序列let, 并且它也支持解构. 当符号应该绑定到序列的下一个元素, 每次求值主体时, 考虑使用for. - 性能考虑和实现细节
=> O(n) 与绑定对的数量成线性关系
let的性能影响对于所有实际目的都是微不足道的或不重要的. 一个原因是, 作为一个宏,let仅在编译时有影响. 第二个原因是, 它的正常使用并不意味着有大量的绑定.一旦同意
let的性能配置文件没有正常的实际影响, 以下机器自动生成的let生成器在此处为好奇的读者展示. 我们可以使用一个宏来生成一个巨大的let定义:(defn- generate-symbol [n] (symbol (str "a" n))) (defn- generate [n] (->> (range n) (map (juxt generate-symbol identity)) flatten vec)) (defmacro large-let [n] (let [bindings (generate n)] `(let ~bindings (reduce + [~@(map generate-symbol (range n))])))) (macroexpand '(large-let 2)) ; ❶ ;; (let* [a0 0 a1 1] (reduce + [a0 a1])) (large-let 5000) ; ❷ ;; CompilerException java.lang.RuntimeException: Method code too large!
❶
macroexpand显示了宏在做什么, 它只是按顺序声明了几个符号a0,a1, .. 并在主体中对它们的值进行reduce.❷
large-let然后被用来伪造一个异常大的let.如你所见,
large-let生成了一个大的let定义, 这反过来又生成了足够的字节码, 超出了 JVM 对单个方法长度的限制. 让我们使用一个像 no.disassemble 44 这样的反汇编工具来看看底层发生了什么:(require '[no.disassemble :refer [disassemble]]) (println (disassemble (fn [] (large-let 2)))) public final class LetPerf extends clojure.lang.AFunction { // Omitted some static class attributes declaration. // Method descriptor #11 ()Ljava/lang/Object; // Stack: 6, Locals: 5 public java.lang.Object invoke() { ❶ // 0 lconst_0 // 1 lstore_1 [a0] // 2 lconst_1 // 3 lstore_3 [a1] // Omitted bytecode related to loading reduce // 28 lload_1 [a0] // 29 invokestatic clojure.lang.Numbers.num(long) : java.lang.Number [34] // 32 lload_3 [a1] // 33 invokestatic clojure.lang.Numbers.num(long) : java.lang.Number [34] // 36 invokeinterface clojure.lang.IFn.invoke(Object, Object) : Object [37] // 41 invokeinterface clojure.lang.IFn.invoke(Object, Object) : Object [37] // 46 areturn } // Omitted static block initializer }
❶
no.disassemble的输出被稍微清理了一下, 以显示最重要的特性. 基本上, 为允许fn创建的函数被调用而生成的invoke()方法, 为绑定中的每一对在堆栈上分配一个长常量, 这解释了为什么大量的它们可以超出允许的方法长度.生成的字节码也解释了性能配置文件的线性方面, 因为
let*Java 代码需要遍历每个传递的绑定以创建必要的字节码调用.
宏
自 1.0 (if-let, when-let) 起
自 1.6 (if-some, when-some) 起
(defmacro if-let ([bindings then]) ([bindings then else)) (defmacro when-let [bindings & body]) (defmacro if-some ([bindings then]) ([bindings then else)) (defmacro when-some [bindings & body])
if-let, when-let, if-some 和 when-some 是创建词法绑定名称的 let 的专门版本. 它们在绑定向量中支持单个符号-表达式对. 主体中的形式根据表达式为逻辑真/假 (if-let 和 when-let) 或 nil (if-some 和 when-some) 进行有条件地求值 (符号包含在局部作用域中).
if-let 和 if-some 允许根据条件选择执行两个可能的形式中的一个, 而 when-let 和 when-some 要么执行这些形式 (使用隐式的 do), 要么返回 nil (分别等同于 if 和 when 的语义). 以下是一些简单的例子来演示它们的用法:
(if-let [n "then"] n "else") ;; "then" (if-let [n false] n "else") ;; "else" (when-let [n "then"] n) ;; "then" (when-let [n false] n) ;; nil
if-some 和 when-some 基于表达式被求值为" 非 nil" . 将它们心理上翻译为" if-not-nil?" 和" when-not-nil?" 会更容易理解:
(if-some [n "then"] n "else") ;; "then" (if-some [n nil] n "else") ;; "else" (when-some [n "then"] n) ;; "then" (when-some [n nil] n) ;; nil
唯一需要小心的情况是" 逻辑真" 和" 非 nil" 的概念重叠和不同的地方, 比如测试 false:
(if-let [n false] n "else") ; ❶ ;; "else" (if-some [n false] n "else") ; ❷ ;; false
❶ if-let 测试逻辑真/假. 表达式为假, 因此返回备选主体 "else".
❷ if-some 测试非 nil. 由于 false 不同于 nil, 表达式 (not (nil? false)) 为真, 并且返回第一个主体, 返回绑定变量的内容以进行求值.
(if-let [bind expr] <then-form> <else-form>) (if-some [bind expr] <then-form> <else-form>) (when-let [bind expr] <then-form>) (when-some [bind expr] <then-form>)
- 输入
"bind"必须是根据解构的有效绑定表达式."expr"是任何可求值的形式. 其求值结果被绑定 (并可能解构) 到"bind"."then-form"是任何可求值的形式. 对于if-let/if-some,"then-form"必须作为单个顶层表达式存在. 对于when-let/when-some,"then-form"被隐式的do块包装, 允许在同一级别有多个形式 (或根本没有形式)."else-form"是可选的.
- 输出
if-let如果"expr"是逻辑真, 则返回"then-form"的求值结果, 如果"expr"是逻辑假, 则返回"else-form"的求值结果. 如果"expr"是逻辑假并且没有提供"else-form"表达式, 则返回nil.if-some如果"expr"不是nil, 则返回"then-form"的求值结果, 否则返回"else-form"的求值结果. 如果"expr"是逻辑假并且没有提供"else-form"表达式, 则返回nil.when-let如果"expr"是真, 则返回"then-form"的求值结果, 否则返回nil.when-some如果"expr"不是nil, 则返回"then-form"的求值结果. 否则返回nil.
条件 let 表达式最常见的用法是在 let 形式之后紧跟一个 if 或 when 条件, 该条件测试局部绑定符号的内容. 例如, 以下函数计算 classpath (Java 实现的虚拟文件系统, 聚合了所有已知的代码源) 中文件的代码行数 (LOC):
(require '[clojure.java.io :as io]) (require '[clojure.string :as s]) (defn loc [resource] (let [f (io/resource resource)] ; ❶ (when f (count (s/split-lines (slurp f)))))) ; ❷ (defn total-loc [& files] ; ❸ (reduce + (keep loc files))) (total-loc "non-existent" "clojure/core.clj" "clojure/pprint.clj") ;; 7570
❶ clojure.java.io/resource 是一个从 classpath 中的文件创建 java.net.URL 对象的函数. 如果找不到文件, 它返回 nil.
❷ 我们不希望在可能为 nil 的资源上执行 slurp, 因为这会迫使我们处理一个异常. 所以我们用 when 来防止这种情况.
❸ total-loc 接受可变数量的文件. 总数是用 reduce 计算的, 在对每个文件调用 loc 并使用 keep 移除任何可能的不存在文件的 nil 之后.
loc 函数可以通过将资源的创建和检查与 when-let 结合起来进行改进:
(defn loc [resource] (when-let [f (io/resource resource)] ; ❶ (count (s/split-lines (slurp f))))) (total-loc "non-existent" "clojure/core.clj" "clojure/pprint.clj") ;; 7570
❶ when 简单地消失了, 在这个过程中移除了一组括号.
请注意, 在这种情况下使用 when-some 可能会允许 "f" 为假, 从而迫使 slurp 生成异常. 我们知道 io/resource 的契约不允许假, 但总的来说, 我们可能不知道我们正在调用的函数的确切细节.
if-let 扩展了 when-let 的可能性, 提供了一个在局部绑定为 nil 或假的情况下执行的附加主体. 例如, 我们可以处理文件未找到的情况, 返回一个计数 0 而不是 nil:
(defn loc [resource] (if-let [f (io/resource resource)] ; ❶ (count (s/split-lines (slurp f))) 0)) ; ❷ (defn total-loc [& files] (reduce + (map loc files))) ; ❸ (total-loc "non-existent" "clojure/core.clj" "clojure/pprint.clj") ;; 7570
❶ if-let 现在替换了 when-let. 由于 "else" 主体是可选的, 这将像以前一样工作, 没有其他更改. 但在这种情况下, 我们希望返回一个除 nil 之外的特定值.
❷ "else" 主体只是 "0". 这有效地阻止了函数返回 nil.
❸ 引入 if-let 和 0 默认值的一个积极影响向下传播到 reduce: 我们不再需要考虑 nil 的潜在存在.
尽管名称中缺少" let" , if-some 和 when-some 的工作方式与 if-let 和 when-let 相同, 但经过修改以适应 nil 与 false 具有不同含义的场景. 这种行为的一个例子发生在处理 core.async 通道时 45.
core.async 将计算建模为通过通道从生产者流向消费者的项目流. 通道被设计为" 开放式的" , 生产者和消费者之间约定来标记计算的结束. 通过在通道上调用 close!, 生产者发送一个常规的 nil 元素, 以向消费者发出不再有项目的信号. 这就是为什么除了关闭通信之外, nil 不能因其他原因通过通道发送.
以下示例显示了使用 core.async 的典型主从模型. 工作者需要循环处理可用项目直到达到 nil 信号, 逐一处理它们. 这是 if-some 的一个很好的用例:
(require '[clojure.core.async :refer [go go-loop chan >! <! <!! close!]]) (defn- master [items in] ; ❶ (go (doseq [item items] (>! in item)) (close! in))) (defn- worker [out] ;❷ (let [in (chan)] (go-loop [] (if-some [item (<! in)] ; ❸ (do (>! out (str "*" item "*")) ; ❹ (recur)) (close! out))) ; ❺ in)) (defn process [items] ; ❻ (let [out (chan)] (master items (worker out)) ; ❼ (loop [res []] (if-some [item (<!! out)] ; ❽ (recur (conj res item)) res))))
❷ 工作者接收结果应发送到的通道, 并创建将由主函数用于发送项目通过的输入通道.
❸ if-some 将下一个元素赋给后续词法作用域中的符号 item. 如果该项不为 nil (因此包括潜在的布尔值 true 或 false), 则处理该项并递归循环.
❹ 处理通过用 "*" 装饰每个项目来模拟.
❺ 如果通道返回 nil, 则输出将被关闭.
❻ process 协调工作者和主函数. 它还在计算完成后迭代输出通道的结果, 将结果转换回序列.
❼ 这行代码有效地开始了计算. 工作者调用首先被求值. 由于 go 块, 输入通道上的等待不会阻塞 (只是暂停), 返回主函数所需的输入通道.
❽ 另一个出于与之前相同原因使用 if-some 的示例.
- 条件 let 扩展
有点像线程宏, 与词法作用域相关的函数经常会受到扩展和改进. Clojure 已经用
let,if-let,when-let和letfn很好地覆盖了常见的用例, 因此不需要依赖外部库. 对于那些需要更多灵活性的特殊情况, 这里有一些来自其他语言和库的想法. 以下是来自 Clojure 之外的几个例子:letrec和aif.- Scheme letrec
Scheme 中的
letrec扩展了可见性的概念, 使得符号即使在定义该符号之前的表达式中也可用.letrec可用于创建相互引用的let绑定, 例如 (这里翻译成它在 Clojure 中会是什么样子):(letrec [is-even? #(or (zero? %) (is-odd? (dec %))) is-odd? #(and (not (zero? %)) (is-even? (dec %)))] (is-odd? 11))
相互递归函数的具体问题, 可以在 Clojure 中用
letfn解决. Clojure 中一个潜在的letrec宏需要一些技巧. 主要的复杂性在于" 暂停" 在第一次调用时尚未定义的符号, 并在第一次使用时传递正确的表达式. Michal Marczyk 不久前对此做了一次尝试, 可作为一个 gist 46 获取. - Arc 照应宏
Arc 编程语言 47 包含一组基本的 Lisp 宏, 它们的名字相同, 但带有 "a" 前缀 (aif, acond, awhen 等). "a" 代表" 照应的" : 它们的灵感来自自然语言代词 (照应). 就像在自然语言中我们使用" 它" 来指代句子中刚刚提到的同一个主语一样, 照应宏" 捕获" 符号
"it"以便在宏内部使用:(defmacro aif [expr then & [else]] `(let [~'it ~expr] (if ~'it ~then ~else))) (aif true (println "it is" it) (println "no 'it' here")) (aif false (println it) (println "no 'it' here"))
aif类似于一个简化的if-let宏, 不需要绑定向量. 它被注入的事实带来了两个后果:aif不能 (轻易地) 嵌套, 因为it绑定会相互包装和隐藏, 产生歧义.- 像任何捕获的绑定一样, 用户可能会在外部作用域中合法地使用它, 并认为它在
aif内部也能正确解析:
(let [it 3] (aif true (println "it is" it)))
it已被宏捕获, 其值在println期间不能为 3.
- Scheme letrec
let是if-let的通用版本, 无条件地分配局部绑定.if和when是if-let和when-let所基于的基本条件. 如果不需要局部绑定变量, 你可以直接使用它们.
宏 (letfn) 特殊形式 (letfn*) 自 1.0 版本起
(letfn [fnspecs & body])
letfn 类似于 let 和 fn 的组合. 除了只能声明局部作用域的函数外, letfn 与 let 的不同之处在于, 函数名立即对所有函数同时可见, 从而实现了相互递归调用. 每当函数中的一个非平凡部分足够自包含以值得拥有自己的名称, 但又不够通用以至于需要被提取到命名空间中时, 也应考虑使用 letfn. 一个 letfn 的简单例子是从 map 操作中提取一个平方函数:
(letfn [(square [x] (* x x))] (map square (range 10))) ;; (0 1 4 9 16 25 36 49 64 81)
letfn* 则是负责在更被文档化和广泛使用的 letfn 中实现大部分功能的特殊形式, 直接使用它没有特别的价值.
(letfn [fnspec+ & <body>]) fnspec ==> (<fname> [<params>*] <exprs>?)
- 输入
"fnspec"是一个参数列表, 包含一个强制的函数名, 一个强制的参数向量 (可能为空) 和一个可选的函数体."fname"是任何有效的 Clojure 符号"params"是一个可选的空向量, 包含函数的参数. 像往常一样,letfn函数也支持解构."exprs"是函数的可选主体, 当函数被调用时将被执行. 当没有提供主体时, 它被认为是一个隐式的nil."body"是将在由letfn生成的局部绑定上下文中求值的可选形式.
- 输出
letfn返回在由"fnspec"创建的局部绑定上下文中求值的"body"的结果, 如果没有提供"body", 则返回nil.
letfn 与其他词法绑定函数的一个略有不同的方面是, 绑定在符号赋值链中向前和向后都是可见的. 这允许相互递归函数 (有关相互递归的详细解释, 请参见 trampoline). 这使我们能够在 Clojure 中定义类似 letrec 的行为 (letrec 是其他类型 Lisp 中的常见形式, 请参见 let 中的标注部分):
(letfn [(is-even? [n] (or (zero? n) #(is-odd? (dec n)))) ; ❶ (is-odd? [n] (and (not (zero? n)) #(is-even? (dec n))))] (trampoline is-odd? 120)) ; ❷ ;; false
❶ is-odd? 尚未定义, 但 is-even? 仍然能够调用它.
❷ 在涉及相互递归时, trampoline 总是一个避免堆栈溢出的好主意. trampoline 将必要的 recur 调用添加到调用链中, 以避免消耗堆栈.
涉及 letfn 的其他用例与自包含的计算片段有关, 这些片段对于函数是私有的, 如果留在中间, 会破坏可读性. 例如, 请看以下 locs-xform 变换器. top-locs 使用该变换器返回匹配命名空间中前 10 个最长的函数:
(require '[clojure.string :as s] '[clojure.repl :refer [source-fn]]) (defn locs-xform [match] (comp (filter (fn [ns] ; ❶ (re-find (re-pattern match) (str (ns-name ns))))) (map ns-interns) (mapcat vals) (map meta) (map (fn [{:keys [ns name]}] ; ❷ (symbol (str ns) (str name)))) (map (juxt identity (fn [sym] (count (s/split-lines ; ❸ (or (source-fn sym) "")))))))) (defn top-locs ([match] (top-locs match 10)) ([match n] (->> (all-ns) (sequence (locs-xform match)) ; ❹ (sort-by last >) (take n)))) (top-locs "clojure.core" 1) ;; ['clojure.core/generate-class 382]
❶ 变换器链从过滤掉一组命名空间中所有不匹配给定名称的命名空间开始. 为此, 它使用了 re-find.
❷ 在变换器链的某个点, 我们需要将一个 Var 对象转换为一个完全限定的符号 (例如, 从 #'clojure.core/+ 到 'clojure.core/+).
❸ 代码行数的计算是通过请求 clojure.repl/source-fn 来检索函数的原始文本, 将其分割成行并计数来完成的. 这是一个非常简单的方法, 没有考虑空行或注释.
❹ 变换器被转换为一个序列, 然后按计数排序, 并返回最后 n 个元素. 请注意: 你在这里看到的结果在不同的机器上执行时可能会不同, 这取决于你本地 classpath 的内容.
locs-xform 返回的变换器的自上而下的流程在每次需要使用非平凡函数时都会被水平缩进打断. 还要考虑, 匿名函数不一定能传达它产生的内容. 通过将匿名函数移入 letfn 形式, 我们可以更好地理解正在发生的事情.
(defn locs-xform [match] (letfn [(matching? [ns] ; ❶ (re-find (re-pattern match) (str (ns-name ns)))) (var->sym [{:keys [ns name]}] (symbol (str ns) (str name))) (count-lines [fsym] (count (clojure.string/split-lines (or (clojure.repl/source-fn fsym) ""))))] (comp ; ❷ (filter matching?) (map ns-interns) (mapcat vals) (map meta) (map var->sym) (map (juxt identity count-lines)))))
❶ 这 3 个函数现在在 letfn 中都有了名字.
❷ 我们可以再次从上到下阅读变换器, 没有太多混乱.
正如你在这个第二个版本中看到的, comp 内部的变换器链几乎可以像纯英文一样阅读:
- 过滤匹配的命名空间
- 用
ns-interns提取所有 interned 符号 - 只取结果 map 的
vals - 从相关 var 中提取元数据
- 将 var 名称转换为符号名称
- 组装名称和它们的 LOC 对
- Lisp labels 和 flet
letfn直接受到 Common Lisplabels的启发:(labels ((even? (n) (if (= n 0) t (odd? (- n 1)))) (odd? (n) (if (= n 0) nil (even? (- n 1))))) (even? 11))
Common Lisp 还包括一个稍微不同的宏
flet, 它没有 Clojure 的等价物, 但它与 Clojure 的let后跟fn声明相同:(let [a (fn [])]). 为什么会使用flet而不是labels的原因并不直接, 它涉及到用同名函数进行遮蔽. 使用 Clojure 的let + fn来模拟flet语法:(let [a (fn [n] (* 2 n))] (let [a (fn [n] (+ 3 (a n)))] (a 2))) ;; 7
你可以注意到内部的
let声明了一个函数a, 该函数既在外部的let中定义, 也在内部的let中重新定义. 第二个函数a对(a n)进行调用, 这不会导致堆栈溢出, 因为它不是递归的. 使用letfn的相同尝试会消耗堆栈, 因为来自内部letfn的对a的调用将是递归的:(letfn [(a [n] (* 2 n))] (letfn [(a [n] (+ 3 (a n)))] (a 2))) ;; StackOverflowError
let 比 letfn 更通用. 用 let 你可以给任何表达式分配局部绑定, 而不仅仅是函数定义. 同时, let 无法预见其他符号定义, 从而阻止了相互引用的表达式 (就像我们在第一个例子中看到的那样). 当局部绑定的唯一原因是函数声明, 或者存在相互引用的表达式时, 优先使用 letfn.
当调用由 letfn 提供的相互引用的局部定义函数时, 应该使用 trampoline.
=> O(n) 线性 (绑定数量)
letfn 的性能影响与所有其他词法绑定宏一样, 可以忽略不计或不重要.
2.2.2. 3.2 布尔和位运算符
布尔运算符 (在 Clojure 中和其他语言一样) 以某种有意义的方式组合布尔值. 严格来说, 布尔表达式是返回 true 或 false 的表达式. Clojure 只包含基本的短路 and 运算符 (与 Java 相比, Java 还包括非短路的 & 和 | 变体). not 运算符只是反转其单个参数的布尔含义. 本章中的每个函数都提供了一个真值表 48.
根据定义, 其他运算符也可能包含在布尔运算符组中, 如 =, >, < 等. 但由于" 比较" 在 Clojure 中有更深的含义, 有一整章专门详细讨论比较和同一性.
在讨论布尔运算符时, 一个重要的区别是逻辑真和逻辑假的含义. 布尔类型只有 true 和 false 两个可能的值, Clojure 将它们扩展到所有其他类型. 因此, 例如, 整数值 1 也被认为是 true, 并且允许在期望布尔类型的地方使用. 下表显示了其他 Clojure 值的一些显著的布尔转换示例:
| 描述 | 示例 | 布尔值 |
|---|---|---|
| 数字零 | 0 |
true |
| 空字符串 | "" |
true |
| 空列表 | () |
true |
| nil 的列表 | (nil) |
true |
| Nil | nil |
false |
Clojure 在被认为是假的东西上与 Common Lisp 不同: 例如, 在 Lisp 中, 空列表 () 是假, 而在 Clojure 中它是真. 在 Clojure 中, 除了 false 本身之外, 唯一求值为假的只有 nil.
Clojure 还包含一组丰富的位运算符 (这些只是函数, 但由于它们经常被直接在硬件中实现, 我们倾向于像其他属于 CPU 指令集的运算符一样称它们为" 运算符" ). 位运算符对于计算机科学中经常出现的某类操作更有效率. 我们还应该记住, 数学算术总是被简化为 CPU 寄存器内部的位操作 (即使正常的编程发生在更高的抽象层次). 我们将在以下部分看到如何使用它们.
- 3.2.1 not
自 1.0 版本以来的函数
(not [x])
not是一个极其简单的函数, (字面上) 实现为(if x false true). 它只是反转其单个参数的布尔含义, 可以简单地使用如下:(not true) ;; false
像
complement一样,not接受任何类型的输入 (不一定是布尔值), 将其映射为true或false. 尽管简单,not在提高代码的可读性和表达力方面扮演着重要角色, 并且在标准库本身中被广泛使用. 许多函数和宏如some?,complement,if-not都是直接在not的基础上实现的.以下是
not的真值表:Table 2: not 真值表 x (not x) truefalsefalsetrue- 约定
- 示例
通常需要测试字符串是否为空 (零字符长度), 但有时这个定义需要扩展到仅包含空格的字符串.
clojure.string命名空间已经包含blank?来测试这种情况, 但缺少一个补集版本. 例如, 在下面的pluralize函数中, 我们使用not来防止向空字符串追加 "s":(defn pluralize [s] ; ❶ (if (not (clojure.string/blank? s)) (str s "s") s)) (pluralize "flower") ;; flowers (pluralize "") ;; "" (pluralize " ") ;; " "
❶
pluralize是一个简单的函数, 它通过追加 "s" 来返回一个单词的复数形式.当布尔测试的否定有一个强烈的约定名称时, 将该形式提取出来并明确该名称可能是个好主意, 就像下面的
weekday?函数一样:(defn weekend? [day] (contains? #{"saturday" "sunday"} day)) (defn weekday? [day] (not (weekend? day))) ; ❶ (weekday? "monday") ;; true (weekend? "sunday") ;; true (weekend? "monday") ;; false
❶ 一个工作日明确地是周末之外的任何一天. 与其在整个代码中使用
(not (weekend? day)), 不如直接命名一个工作日, 避免解析否定形式所涉及的思维努力. - 另请参阅
标准库中相关的
not函数和宏通常处理" 否定" 的特定情况. 总的来说, 优先使用特定替代方案 (如果可用) 的更惯用的用法, 而不是在not之上构建相同的逻辑.complement使用not来否定作为参数传递的函数的输出. 对于否定函数输出的特定情况, 使用complement, 而不是更长的(not (f)).boolean可以被认为是not的反面,因为它将输入转换为布尔值而不否定它.not通过返回其输入的逻辑反面来达到相同的结果.bit-not是二进制数的否定. 它通过考虑其二进制表示并将每个 1 转换为 0, 反之亦然来否定一个数字操作数.
- 性能考虑和实现细节
=> O(1) 常数时间
not以最小的开销对单个参数进行操作. 本节没有有趣的性能分析.
- 约定
- 3.2.2 and, or
自 1.0 版本以来的宏
(and ([]) ([x]) ([x & next])) (or ([]) ([x]) ([x & next]))
and和or是广泛使用的宏. 它们分别实现逻辑合取和析取. 说明逻辑运算符行为的最佳方法之一是通过真值表, 其中描述了true和false的所有组合 49:Table 3: and 和 or 真值表 p q (and p q) (or p q) truetruetruetruetruefalsefalsetruefalsetruefalsetruefalsefalsefalsefalse从表中你可以看到,
or对false的存在更宽容, 而and只有在所有操作数都为true时才返回true. 虽然该表只显示了p和q, 但 Clojure 允许 "and" 和 "or" 都接收两个以上的参数 (参见约定部分). 例如, 这是and在条件分支中的典型用法:(let [probe {:temp 150 :rpm "max"}] (when (and (> (:temp probe) 120) ; ❶ (= (:rpm probe) "max")) (println "Too hot, going protection mode."))) ;; Too hot, going protection mode.
❶
and和or经常出现在if和when语句的条件中.你也可以在条件之外使用
and和or, 例如用于nil检查. 我们将在下面的示例部分看到这个和其他惯用用法.- 约定
"and" 和 "or" 都接受 0 个或多个表达式, 并从左到右求值它们.
and返回:- 在没有参数的情况下返回
true. - 在只有一个参数的情况下返回该参数 (行为类似于
identity). - 如果任何表达式求值为
false, 则返回false. - 如果任何表达式求值为
nil, 则返回nil. - 在任何其他情况下返回最后一个表达式的求值结果.
or返回:- 在没有参数的情况下返回
nil. - 在只有一个参数的情况下返回该参数 (行为类似于
identity). - 第一个不为
nil或false的表达式的求值结果. - 在任何其他情况下返回最后一个表达式的求值结果.
- 在没有参数的情况下返回
- 示例
正如你从约定中看到的,
and和or都包含一个规则, 当达到特定条件时停止对其他操作数的进一步求值 (这种逻辑也称为" 短路" ). 因此,and和or都可以" 遍历" 一个表达式链:- 在
and的情况下, 在第一个false或nil出现时停止. - 在
or的情况下, 在第一个逻辑真项处停止.
我们不再专注于在条件分支中" 正常" 使用
and和or, 而是看看它们还能用来做什么.and的行为可以被利用来" 保护" 后续表达式免于处理nil, 例如在使用 Java 互操作时. 以下示例展示了一种从绝对文件名中提取" 路径" 部分的方法 (不包含文件名本身的部分):(defn path [s] (let [s (and s (.trim s))] ; ❶ (and (seq s) ; ❷ (subs s 0 (.lastIndexOf s "/"))))) (path "/tmp/exp/lol.txt") ;; "/tmp/exp" (path " ") ;; nil (path "") ;; nil (path nil) ;; nil
❶ 第一个
and保护使得 "s" 可以安全地被修剪, 可能会产生一个nil或一个空字符串. 这个第二个 "s" 局部绑定将隐藏来自函数参数的那个.❷ 第二个
and保护阻止了subs在空字符串上执行.(seq coll)是在 Clojure 中验证集合是否为空的惯用方法.or可用于在nil表达式的情况下提供一个默认值, 例如解析可选的命令行选项:(defn start-server [opts] (let [port (or (:port opts) 8080)] (str "starting server on localhost:" port))) (start-server {:port 9001}) ;; "starting server on localhost:9001" (start-server {}) ;; "starting server on localhost:8080"
本节中说明的两个示例都非常惯用, 并在 Clojure 项目中非常常用.
- 在
- 另请参阅
and和or宏展开为嵌套的if语句. 请参阅本章后面的实现细节.every?可以用来检查一个表达式集合是否都求值为真, 使用(every? identity [e1 e2 e3])而不是不适用的(apply and [e1 e2 e3]).some->或some->>是在存在nil时退出处理链的另一个选项. - 性能考虑和实现细节
=> O(n) 最坏情况, 与 n (表达式数量) 成线性关系
and和or宏在编译时与参数数量成线性关系. 它们的运行时形式是一个嵌套的if表达式链, 在性能分析中通常不是一个问题. 例如, 在and上调用macroexpand-all, 会揭示其工作原理:(clojure.walk/macroexpand-all '(and false true true)) (let* [and__4467__auto__ false] ; ❶ (if and__4467__auto__ (let* [and__4467__auto__ true] (if and__4467__auto__ ; ❷ true and__4467__auto__)) and__4467__auto__))
❶
and在编译时展开, 以调用自身在其余的表达式上, 直到达到最后一个.❷ 在运行时, 嵌套的
if语句被执行, 可能会在第一个逻辑假值处提前停止, 而不触及链的底部.正如你从第一个
let*表达式中看到的, 短路逻辑在运行时应用. 因此, 如果一些机器生成的代码产生带有大量表达式的and形式, 它们可能会遇到StackOverflow异常, 即使第一个条件是假:(clojure.walk/macroexpand-all ; ❶ `(and false ~@(take 1000 (repeat true)))) CompilerException java.lang.StackOverflowError
❶ 我们故意通过生成一个带有 1000 个参数的编译时表达式来给
and制造麻烦.上述情况不太可能发生, 在正常应用中不应引起任何关注.
- 约定
- 3.2.3 bit-and 和 bit-or
自 1.0 版本以来的函数
注意
本节还简要介绍了其他相关函数, 如:
bit-xor,bit-not,bit-flip,bit-set,bit-shift-right,bit-shift-left,bit-and-not,bit-clear,bit-test和unsigned-bit-shift-right.(bit-not [x]) (bit-and [x y & more]) (bit-or [x y & more]) (bit-xor [x y & more]) (bit-and-not [x y & more]) (bit-clear [x n]) (bit-set [x n]) (bit-flip [x n]) (bit-test [x n]) (bit-shift-left [x n]) (bit-shift-right [x n]) (unsigned-bit-shift-right [x n])
Clojure 提供了一组丰富的位运算符. Clojure 中没有" 位集" 类型, 但我们可以使用字节, 短整型, 整型或长整型作为位容器:
(Long/toBinaryString 201) ; ❶ ;; "11001001" (Long/toBinaryString 198) ;; "11000110" (bit-and 201 198) ; ❷ ;; 192 (Long/toBinaryString ; ❸ (bit-and 2r11001001 2r11000110)) ;; "11000000"
❶ 使用
Long/toBinaryString我们可以看到一个数字的二进制表示.❷
bit-and使用来自第一个和第二个数字相同位置的位执行布尔与操作.❸ 我们可以在二进制表示中执行相同的操作. 位字符串 "11000000" 是数字 192 的二进制表示. 我们可以通过在数字前加上 "Xr" 来使用 Clojure 的二进制数字字面量语法, 其中 "X" 是基数.
位运算符对位模式进行操作, 为执行某些类别的算术函数提供了快速的方法. 速度的提升也是位自然映射到 CPU 内部寄存器的结果: 现代硬件通常提供 Clojure 通过 JVM 利用的本地位运算符. 使用位运算符的一个负面是它们是低级的, 并且与特定的位大小和表示紧密相连.
- 约定
- 输入
位运算符可以根据它们的输入分为几组. 除非另有说明, 参数必须是
byte,short,int或long类型, 并且不能是nil:bit-not接受一个参数.bit-and,bit-or,bit-xor和bit-and-not需要至少 2 个参数, 最多可接受任意数量的参数.bit-clear,bit-set,bit-flip,bit-test,bit-shift-left,bit-shift-right和unsigned-bit-shift-right都接受 2 个参数. 第一个是数值位集表示, 第二个是集中位的索引 (从最低有效位开始).
- 值得注意的异常
- 如果参数类型不同, 则抛出
IllegalArgumentException. - 如果任何参数为
nil, 则会抛出NullPointerException.
- 如果参数类型不同, 则抛出
- 输出
除了
bit-test之外, 所有位运算符都返回一个java.lang.Long, 该java.lang.Long解释为二进制时是相关位运算的结果. 如果索引 "n" 处的位是 "1", 则bit-test返回布尔值true, 否则返回false.
- 输入
- 示例
位运算通常被引入以使用最少的 CPU 周期来加速重复的算术运算 50.
bit-and,bit-or,bit-xor,bit-shift-left,bit-shift-right和unsigned-bit-shift-right是其他运算构建在其上的基本操作. 我们将首先看一下它们, 并在可用时引入更短的形式.bit-and接受 2 个或更多个参数, 并对每对 (三元组, 四元组等) 相应位执行and操作:(require '[clojure.pprint :refer [cl-format]]) (defn bin [n] ; ❶ (cl-format nil "~2,8,'0r" n)) (bin (bit-and 2r11001001 2r11000110 2r01011110)) ; ❷ ;; "01000000"
❶
bin使用cl-format将二进制数正确格式化为固定的 8 位大小. 它在这里和本节的其余部分都用于提高可读性.❷ 在这个例子中,
bit-and接受超过 2 个参数. 垂直对齐有助于可视化操作中涉及的位三元组.我们称一个特意构建以" 屏蔽" 某些位的位集为" 位掩码" . 给定一个目标位 "x", 与 "1" (真) 进行
and操作的结果可以回答 "x" 是否为真或假的问题:(def fourth-bit-set-mask 2r00001000) ; ❶ (bin (bit-and 2r11001001 fourth-bit-set-mask)) ; ❷ ;; "00001000"
❶ 这个二进制数的第 4 位是 "1". 当与
bit-and一起使用时, 它代表一个掩码, 用于回答" 另一个参数中的第 4 位是否被设置?" 的问题. 我们为这个二进制数定义了一个名称, 以便在后续的位运算中明确其含义.❷ 通过
bit-and, 我们可以执行" 掩码" 操作来检查一个或多个位是否被设置为 "1". 在这个例子中, 答案是第 4 位确实被设置为 "1".bit-test将掩码的创建和位的检查合并为单个操作 (bit-and对于一次性在多个位上执行相同操作很有用):(bit-test 2r11001001 3) ; ❶ ;; true
❶ 如果索引 3 (从 0 开始) 处的位被设置为 "1",
bit-test返回true.bit-test在将问题委托给 Java 的按位与操作之前, 内部创建了必要的掩码.通过翻转掩码位集中的位, 我们可以达到将相应的位设置为零的效果:
(def turn-4th-bit-to-zero-mask 2r11110111) (bin (bit-and 2r11001001 turn-4th-bit-to-zero-mask)) ; ❶ ;; "11000001"
❶ 注意, 掩码中与 "0" 配对的位在结果中被设置为 "0". 其他与 "1" 配对的位保持不变. 我们可以推断出, true (或 "1") 是
and的" 单位" 值.bit-clear达到了将一个位设置为 "0" 的相同效果, 而无需提供一个掩码位集:(bin (bit-clear 2r11001001 3)) ; ❶ ;; "11000001"
❶ 使用
bit-clear将索引 "3" (从零开始) 的位设置为 "0" (或假).bit-or的工作方式与bit-and类似, 通过对位对应用布尔操作or, 但bit-or的掩码与bit-and相反.更有趣的是
bit-xor的情况. " xor" (代表" 异或" ) 是or的一个变体, 如果两个位都为真, 则结果为假, 而不是真. 以下示例通过比较bit-or和bit-xor来说明这种效果:(map bin ((juxt bit-or bit-xor) 2r1 2r1)) ; ❶ ;; ("00000001" "00000000")
❶ 我们分别将 "1" 和 "1" 作为操作数传递给
bit-or和bit-xor(使用juxt). 这是这两个位运算符不同的唯一情况.bit-xor对于比较相似的位集特别有用. 例如, 如果结果只包含 "0", 我们可以判断两个位集是相同的. 结果中每个不同的位都包含 "1":(bin (bit-xor 2r11001001 2r11001000)) ; ❶ ;; "00000001"
❶ 如果对应的位对相同, 位集包含 "0", 如果它们不同, 则包含 "1". 在这个例子中, 我们可以看到这两个位集只有一个地方不同.
bit-xor在掩码方面也很有用. 一个包含 "1" 的掩码可以达到" 翻转" 该位置位的效果:(bin (bit-xor 2r11001001 2r00010001)) ; ❶ ;; "11011000"
❶
bit-xor与一个掩码, 其中最低有效位置 (从右边索引 0) 和第 4 位的位已被反转.另一大类位运算是移位. 移位包括将所有位向右或向左推, 分别丢弃最低或最高有效位. 在 Java 中, 所有数值类型都是有符号的, 因此最高有效位代表符号. 然而, 在右移期间, 符号位被保留, 并引入 "1" 作为填充. 通过保留符号位, 正数保持为正数, 负数保持为负数 (这也称为" 算术移位" ).
让我们从一个简单的负数右移开始. 如你所见, Clojure 继承了 Java 的位运算语义, 包括用于表示负数的二进制补码格式 51:
(Integer/toBinaryString -147) ; ❶ ;; "11111111111111111111111101101101" (Integer/toBinaryString (bit-shift-right -147 1)) ; ❷ ;; "11111111111111111111111110110110" (Integer/toBinaryString (bit-shift-right -147 2)) ; ❸ ;; "11111111111111111111111111011011"
❶ 我们可以使用
Integer/toBinaryString打印二进制数. 这类似于我们在本节开头使用cl-format, 但cl-format会保留左侧的零 (如果有的话). 注意, 该数字是使用二进制补码格式表示的, 即翻转所有位并加 1.❷
bit-shift-right将 -147 右移 1 位. 最高有效位 (最左边) 是符号位, 保持不变. 右侧的最低有效位已被丢弃.❸ 这次
bit-shift-right将 2 位向右推. 左侧添加了两个 "1", 右侧的 "01" 被丢弃.每向右移一位, 相当于将数字除以 2. 更一般地, 数字被除以 2
n, 其中 "n" 是移位的次数:
(bit-shift-right -144 1) ; ❶ ;; -72 (bit-shift-right -144 2) ; ❷ ;; -36
❶ 右移一位相当于整数除以 2.
❷ 每向右移一位, 数字就会进一步被除.
bit-shift-left对bit-shift-right具有对称效果, 这应该不令人意外. 一个有趣的特性是, 每向左移一位, 相当于将数字乘以 2n, 其中 "n" 对应于左移的次数:
(dotimes [i 5] ; ❶ (println [(int (* -92337811 (Math/pow 2 i))) (Integer/toBinaryString (bit-shift-left -92337811 i))])) ;; [-92337811 11111010011111110000100101101101] ; ❷ ;; [-184675622 11110100111111100001001011011010] ;; [-369351244 11101001111111000010010110110100] ;; [-738702488 11010011111110000100101101101000] ;; [-1477404976 10100111111100001001011011010000]
❶
bit-shift-left对 -92337811 最多移位 4 位的效果. 该表达式同时打印十进制数和对应的二进制数.❷ 打印的第一行对应于零位移, 这等同于位集本身. 随着移位的进行, 我们可以看到 "0" 从右侧被推入, 而符号位被保留.
对于那些我们可以忽略符号位的情况 (因为它实际上不代表符号), 我们可以使用
unsigned-bit-shift-right:(require '[clojure.pprint :refer [cl-format]]) (defn right-pad [n] ; ❶ (cl-format nil "~64,'0d" n)) (dotimes [i 5] ; ❷ (->> i (unsigned-bit-shift-right -22) Long/toBinaryString right-pad println)) ;; 1111111111111111111111111111111111111111111111111111111111101001 ; ❸ ;; 0111111111111111111111111111111111111111111111111111111111110100 ;; 0011111111111111111111111111111111111111111111111111111111111010 ;; 0001111111111111111111111111111111111111111111111111111111111101 ;; 0000111111111111111111111111111111111111111111111111111111111110
❶
right-pad负责处理较大的 64 位集, 从右侧用 "0" 填充.❷ 我们可以看到将数字 -22 右移 4 位的效果 (第一行是未移位的位集).
❸ 零开始从左侧出现, 将一推向右侧. 通过使用负数, 我们确保可以清楚地看到这种效果, 对比左侧的零和一.
无符号右移 (也称为" 逻辑移位" ) 总是从左侧用零填充, 不管是否存在符号位. 由于 Clojure 总是返回 64 位
long类型的数字, 我们现在可以看到位运算符的完整解析度. 对负数进行逻辑移位总是返回一个正数, 因为填充后最高有效位将出现一个" 0" .注意
没有
unsigned-bit-shift-left, 因为效果与bit-shift-left完全相同. - 另请参阅
and-or是常见的布尔运算符. 除非你对一次性处理多个操作感兴趣, 否则你应该使用and-or而不是位运算符. - 性能考虑和实现细节
=> O(1) 常数时间
对于所有实际目的, 位运算都是常数时间. 对位数目的潜在依赖大多不相关且与硬件相关. 根据具体的硬件实现, 位运算在单个或几个时钟周期内执行.
有几个已知的算法已被翻译成使用位运算符. 其中之一是检索一个集合的所有子集的算法, 也称为" 幂集" . 我们在讨论
hash-set时看到了一个幂集函数的实现, 以下是基于bit-test的不同公式. 其思想是使用一个整数索引直到可能的子集数量, 并使用位的排列来选择子集的元素. 例如, 以下位集显示了 3 位的所有可能排列:(dotimes [i 8] ; ❶ (println (Integer/toBinaryString i))) ;; 0 ;; 1 ;; 10 ;; 11 ;; 100 ;; 101 ;; 110 ;; 111
❶ 这个表达式表明, 增加的二进制数构成了位集中不同位置的所有可能位组合.
利用这一事实, 我们可以制定一个新的
bit-powerset函数, 该函数使用一个for循环来迭代位集, 并使用一个内部循环来从输入集合中获取相应的索引:(defn bit-powerset [coll] (let [cnt (count coll) bits (Math/pow 2 cnt)] ; ❶ (for [i (range bits)] (for [j (range cnt) :when (bit-test i j)] ; ❷ (nth coll j))))) (bit-powerset [1 2 3]) ; ❸ ;; (() (1) (2) (1 2) (3) (1 3) (2 3) (1 2 3))
❶ 我们需要 2 n 个位集, 对应于 "coll" 中项的可能组合数量.
❷
for中的:when约束控制了输入集合中的哪些元素应该最终出现在子集中.❸
bit-powerset返回输入的所有组合, 包括空集合和输入本身.hash-set和bit-powerset中提出的实现使用了完全不同的方法.bit-powerset的优点是组合仅仅通过递增整数来生成, 并且不涉及等式来检查位是否被设置:(require '[criterium.core :refer [quick-bench]]) (require '[clojure.set :refer [union]]) (defn powerset [items] ; ❶ (reduce (fn [s x] (union s (map #(conj % x) s))) (hash-set #{}) items)) (let [s (vec (range 10))] (quick-bench (powerset s))) ; ❷ ;; Execution time mean : 765.768984 µs (let [s (vec (range 10))] (quick-bench (doall (bit-powerset s)))) ;; Execution time mean : 48.088184 µs
❶ 这是在
hash-set中提出的相当优雅的解决方案, 用于生成幂集.❷ 基准测试证实, 基于位集的解决方案快了 10 倍以上.
- 约定
2.2.3. 3.3 条件分支
分支是编程语言中最常用的特性之一, 也是最有用的特性之一. 分支指令的存在假设程序遵循某种自然的流程. 对于命令式语言, 流程通常是自上而下的垂直布局 (偶尔会跳转到其他地方编写的过程), 而对于像 Clojure 这样的函数式语言, 它更倾向于从左到右的函数串联.
Clojure 中条件形式的一个共同特点是它们不遵循参数的通用求值规则. 通常参数是从左到右求值的, 并且在它们被传入的函数之前. 条件形式可能会改变正常的顺序或根本不求值参数. 这绝对是它们选择性求值特性的结果.
分支通常对代码的可读性有负面影响, 因为某些代码部分的执行现在受制于可能远离当前可见内容的条件. 为了控制分支, Clojure 提供了一些构件和辅助函数, 这些是以下各节的主题. 更一般地说, 函数式编程通过移除或最小化互斥分支之间的副作用 (命令式风格的状态改变语言的常见问题) 来帮助降低软件复杂性. 纯粹性的一个明显结果是条件形式总是返回一个值.
- 3.3.1 if, if-not, when 和 when-not
特殊形式 (
if) 宏 (if-not,when,when-not) 自 1.0 版本起(if ([test then]) ([test then else])) (if-not ([test then]) ([test then else])) (when [test & then]) (when-not [test & then])
if,if-not,when和when-not是 Clojure 中条件分支的核心. 它们 (像在许多其他语言中一样) 用于启用或阻止代码某些部分的求值. 求值的条件是任何有效的 Clojure 表达式, 该表达式被用作逻辑真或假.if和if-not可用于选择两个分支之一, 而when和when-not支持对单个分支进行决策. 任何形式中的-not后缀只是反转条件的含义, 在" 否定" 应被赋予更多突出地位时增强了表达力.if可以简单地使用如下:(if true :a :b) ;; :a
- 约定
- 输入
"test"是一个强制性的 Clojure 表达式. 求值后, 该表达式产生一个逻辑布尔值, 用于求值另一个参数."then"是第一个可求值的参数. 与普通函数不同, 此参数可能实际上不会求值. 对于if和if-not是强制性的, 对于when和when-not是可选的.when和when-not会自动将"then"视为包装在一个do块中."else"对于if和if-not有意义 (when和when-not只会将其视为隐式do块中的附加"then"形式). 当存在时, 当"test"为假 (对于if) 或当测试为真 (对于if-not) 时求值. 当不存在时, 其行为就像传递了一个nil:(if false :a)等价于(if false :a nil).
- 输出
返回: 根据条件求值表达式的结果.
if求值:- 如果
"test"是逻辑真, 则为"then". - 如果
"test"是逻辑假, 则为"else". - 如果
"test"是逻辑假且未给出"else", 则为nil.
if-not求值:- 如果
"test"是逻辑假, 则为"then". - 如果
"test"是逻辑真, 则为"else". - 如果
"test"是逻辑真且未给出"else", 则为nil.
when求值:- 如果
"test"是逻辑真, 则为"then". - 否则为
nil.
when-not求值:- 如果
"test"是逻辑假, 则为"then". - 否则为
nil.
- 如果
- 输入
- 示例
抛硬币是典型的二选一问题, 返回两种可能性之一. 下面展示了一个简单的
if, 其中两个分支的求值概率相等:(defn toss [] (if (> 0.5 (rand)) ; ❶ "head" "tail")) (take 5 (repeatedly toss)) ; ❷ ;; ("head" "head" "head" "head" "tail")
❶
rand返回 0 到 1 之间的一个浮点数. 询问返回的值是否高于或低于 0.5 的中点, 等同于 50% 的机会.❷
repeatedly是一个很好的函数, 可以连续调用另一个函数. 然后我们可以轻松地模拟多次抛硬币, 并取任意数量.条件的另一个常见用法是在递归算法中, 用于确定何时停止递归. 虽然这不是一个通用的规则, 但在本例中, 我们希望设计递归函数, 以便条件的第一个分支退出循环. 其效果是退出分支将立即在函数顶部可见. 如果条件不满足, 最后一个分支应继续递归.
一个简单的递归问题是遍历一棵树以返回其有多少个子级 (也称为树的深度). 递归是通过检查当前元素的类型来完成的, 如果它是一个我们可以进一步" 导航" 的类型 (例如向量), 那么我们再次递归. 如果我们按原样使用
vector?函数, 我们将不得不在if的第一个分支上递归. 我们可以简单地使用if-not来保持退出条件在顶部而无需使用not:(def tree [:a 1 :b :c [:d [1 2 3 :a [1 2 [1 2 [3 [4 [0]]]]] ; ❶ [:z [1 2 [1]]] 8]] nil]) (defn walk [depth tree] (if-not (vector? tree) ; ❷ depth (map (partial walk (inc depth)) tree))) (defn depth [tree] (apply max (flatten (walk 0 tree)))) ; ❸ (depth tree) ;; 8
❶ 我们通过任意嵌套向量来模拟一棵树. 缩进最深的项有 8 层深.
❷ 我们利用
if-not来强调这样一个事实: 第一个分支, 当被选择时, 意味着几个重要的事实: 我们到达了一个叶子, 我们返回一个结果, 并且我们不再进行进一步的递归.❸ 映射到一个序列上, 并使用函数本身作为映射函数, 产生一个类似嵌套的序列, 其中元素已被一个计数 (在这种情况下) 替换. 因此, 我们需要展平并取最大值.
尽管不是一个普适的规则, 但
when和when-not的存在可能表示当返回的nil被丢弃时的副作用. 例如,when在组件系统的拆卸阶段关闭连接时非常常见:(defn start [] ; ❶ (try (java.net.ServerSocket. 9393 0 (java.net.InetAddress/getByName "localhost")) (catch Exception e (println "error starting the socket")))) (defn stop [s] (when s ; ❷ (try (.close s) (catch Exception e (println "error closing socket"))))) (def socket (start)) (.isClosed socket) ;; false (stop socket) ; ❸ ;; nil (.isClosed socket) ;; true
❶ 用 Java 互操作启动一个套接字非常简单.
start返回新创建的处于打开状态的套接字.❷
when在这里用作对可能为nil的套接字的保护, 该套接字在初始化期间可能没有正确设置. 如果套接字存在, 我们真正关心的是关闭套接字, 否则什么都不做.❸ 有副作用的
when的客户端不关心知道操作的结果. - 另请参阅
not是反转if或when含义的显式方式. 你不太可能需要使用它来代替if-not或when-not.cond本质上是可读形式的嵌套if-else语句. 当需要多个嵌套条件时使用它们.- 当条件分支跟随一个
let绑定, 并且条件发生在刚刚绑定的符号上时, 可以使用if-let和when-let.
- 性能考虑和实现细节
=> O(1) 编译时间
条件分支不是特别昂贵. 分支形式是宏和特殊形式, 即使在编译时也几乎没有影响.
if作为特殊形式很有趣. 这仅仅意味着没有需要为if的执行而调用的 Clojure 端定义的函数或宏.if的实现位于编译器的IfExpr内部类中.Parser部分与标准库中的其他宏非常相似 (但在这种情况下是用 Java 编写的). 字节码的生成相对简单 (与其他特殊形式相比), 主要的复杂性与在if表达式周围的类型提示可用时发出未装箱的表达式求值有关.
- 约定
- 3.3.2 cond
自 1.0 版本以来的宏
(cond [& clauses])
cond迭代一个条件-表达式对的参数列表, 求值 (并立即返回) 与第一个逻辑真条件相对应的表达式:(let [a false b true] (cond a :a b :b ; ❶ :else :c)) ; ❷ ;; :b
❶
b在let绑定中声明为 true.cond将返回相应的表达式, 在本例中是关键字:b.❷ 请注意最后的
:else :c条件-表达式对, 如果没有其他条件匹配, 它将被用作默认值.:else是一个完全任意的" 真" 值 (任何其他关键字或字符串都可以使用, 除了nil和false).cond的行为等同于嵌套的if结构. 前面的例子可以表示为:(let [a false b true] (if a :a (if b :b (if :else :c)))) ;; :b
cond比相应的嵌套if更易于阅读, 因为条件和表达式是垂直对齐的, 可以快速显示哪个分支属于哪个测试表达式. 例如, 最后的catch-all :else :c对比相应的嵌套if更容易看到, 在嵌套if中它最终成为最内层的形式. 值得注意的是,:else按惯例用作最后一个条件, 但任何逻辑真值都可以使用 (在 Clojure 中, 除了nil和false之外的任何东西).(cond [clauses]) clause :=> <condition> <expression>
- 输入
"clauses"可以是零个或多个, 将按顺序求值."clause"是由"condition"和"expression"组成的对."condition"是任何有效的 Clojure 形式."expression"可以是任何有效的 Clojure 形式.
- 值得注意的异常
当传递的参数数量为奇数时, 抛出
IllegalArgumentException, 这意味着至少有一个不完整的对, 例如(cond (= 1 1))会抛出异常, 因为没有形式可作为真表达式的结果来求值. - 输出
cond返回:- 当没有子句调用时返回
nil. - 第一个条件求值为逻辑真的表达式的求值结果.
- 当所有条件都为逻辑假时返回
nil.
- 当没有子句调用时返回
- 输入
- 示例
cond是处理除了if已经涵盖的简单二分支情况之外的互斥条件分支的重要工具. 例如, 我们可以使用cond来为 web 请求设置正确的 HTTP 响应代码:(defn response-code [data] (cond ; ❶ (:error data) 500 (not= :failure (:status data)) 200 :else 400)) (def good-data {:id 8498 :status :success :payload "<tx>489ajfk</tx>"}) (def bad-data {:id 8490 :error "database error" :status nil :payload nil}) (response-code good-data) ;; 200 (response-code bad-data) ;; 500
❶
response-code包含一个有 3 个选项的cond形式.data参数被检查是否有错误或失败. 如果没有其他匹配项, 则返回默认的 400 选项.根据经验法则, 对于需要 3 个或更多分支的任何条件, 都应使用
cond, 而对于常见的 2 分支情况, 与if相比, 它会显得多余.- 其他语言中的 if-else
虽然在其他语言中, 有特殊的语法或关键字来表示
if语句的else分支包含另一个if语句, 但 Clojure 利用其 Lisp 的传统, 用宏来解决这个问题. 例如, Ruby 有关键字elsif:if a > b print "X" elsif a == b print "Y" else print "Z" end
Python 有一个类似的
elif关键字:var = 100 if var == 200: print "1 - Got a true expression value" elif var == 150: print "2 - Got a true expression value" elif var == 100: print "3 - Got a true expression value" else: print "4 - Got a false expression value"
Ruby 的
elsif和 Python 的elif是编译器原生理解的保留字. 通过定义一个像cond这样的宏, Clojure 解决了有额外条件分支的问题, 而没有给编译器增加任何额外的复杂性.
- 其他语言中的 if-else
- 另请参阅
if对于短的 "if-else" 组合仍然是一个可能的解决方案, 但cond通常读起来更好. 优先使用cond而不是 2 个或更多的嵌套if语句.defmulti与defmethod一起在 Clojure 中定义多方法. 如果cond中的条件质量和数量倾向于频繁扩展以处理以前未知的情况, 考虑使用多方法.defmulti提供了一个灵活的多态分派, 包括从不同命名空间扩展多方法的可能性 (而所有cond表达式都需要在一个形式内定义).cond->将多个条件求值与通过表达式线程化一个值的选项结合起来. 当你基于条件也想逐步构建结果时, 使用when.如果条件只是在不同值上重复,
condp可以避免一些输入, 例如(cond (= x 1) "a" (= x 2) "b"). - 性能考虑和实现细节
=> O(n) 与子句数量成线性关系
cond宏有一个相当简单的实现, 它在进入一个消耗堆栈的递归之前求值第一个条件. 在本节的示例上执行的clojure.walk/macroexpand-all显示了预期的嵌套if:(clojure.walk/macroexpand-all '(cond (:error data) 500 (not= :failure (:status data)) 200 :else 400)) ;; (if (:error data) ;; 500 ;; (if (not= :failure (:status data)) ;; 200 ;; (if :else ;; 400 ;; nil)))
在性能分析中, 正常使用只有几个子句的
cond不应特别相关. 在某些情况下, 当cond是紧密循环的一部分时, 可能有用case替换它的选项. 然而, 这并非总是可能的. 请访问case中的性能部分以了解更多信息.
自 1.0 版本以来的宏
(condp [pred expr & clauses])
condp 是与 cond 和 case 一起用于条件分支的另一个有用的工具. condp 对不同的值使用相同的谓词函数 (名称中的" p" ) 来决定执行哪个分支. 使用相等性作为谓词是一个非常常见的情况, 例如:
(defn op [sel] ; ❶ (condp = sel "plus" + "minus" - "mult" * "div" /)) ((op "mult") 3 3) ;; 9
❶ 一个从文本解析操作的简单计算器.
谓词 ("=" 在示例中) 被应用于 "plus", "minus", 最终是 "mult", 这是第一个求值为逻辑真的表达式, 因此 * 被选为返回值.
(condp <pred> <expr> [clauses] [<default>]) clause :=> pair || triplet pair :=> <selector> <choice> triplet :=> <selector> :>> <f>
- 输入
"pred"是一个接受 2 个参数 ("selector"和"expr") 的强制性函数. 返回值被解释为逻辑布尔值."expr"是强制性的, 可以是任何有效的 Clojure 表达式."clauses"可以是零个或多个, 并按顺序求值."clause"可以包含 2 个 ("pair") 或 3 个 ("triplet") 项."pair"是一个"selector"后跟一个"choice". 两者都是任何类型的有效 Clojure 表达式."triplet"是一个"selector"后跟符号:>>和一个函数"f".selector是任何有效的 Clojure 表达式, 而"f"必须接受一个任意类型的单个参数, 并可以返回任意类型."default"是任何有效的 Clojure 表达式.
- 值得注意的异常
当找不到匹配的子句 (与
cond会返回nil不同) 且没有提供默认值时,condp会抛出IllegalArgumentException. - 输出
- 当没有匹配的子句时为
"default". - 第一个对子句的
"choice"的求值结果, 其中(pred selector expr)是逻辑真. - 第一个三元子句的
(f (pred selector expr))的求值结果, 其中(pred selector expr)是逻辑真.
- 当没有匹配的子句时为
mime-type 函数负责通过查看给定 URL 的扩展名来设置正确的 mime-type (媒体类型, 也称为 mime-type, 浏览器用它来解释 web 服务器返回的响应, 该响应最终只是一个字节流). 我们可以使用 condp 来决定分配哪个 mime-type:
(defn extension [url] ; ❶ (last (clojure.string/split url #"\."))) (defn mime-type [url] (let [ext (extension url)] (condp = ext ; ❷ "jpg" "image/jpeg" "png" "image/png" "bmp" "image/bmp" "application/octet-stream"))) (mime-type "http://example.com/image.jpg") ; ❸ ;; "image/jpeg" (mime-type "http://example.com/binary.bin") ;; "application/octet-stream"
❶ extension 是一个辅助函数, 用于提取 url 中最后一个 "." 之后的部分.
❷ mime-type 将扩展名传递给 condp 来决定它对应的 mime-type. 请注意, 默认的 "octect-stream" 标识了一个我们无法识别的通用二进制类型.
❸ 返回的字符串是可以在响应中使用的 mime-type.
我们可以使用 condp 来实现" FizzBuzz" 52:
(defn fizz-buzz [n] (condp #(zero? (mod %2 %1)) n ; ❶ 15 "fizzbuzz" ; ❷ 3 "fizz" 5 "buzz" n)) (map fizz-buzz (range 1 20)) ; ❸ ;; (1 2 "fizz" 4 "buzz" "fizz" 7 8 "fizz" ;; "buzz" 11 "fizz" 13 14 "fizzbuzz" 16 17 "fizz" 19)
❶ 为了解决 FizzBuzz 问题, 我们使用了一个两个参数的谓词. 如果数字是彼此的倍数, 谓词返回 true.
❷ 字符串 "fizzbuzz" 需要出现在最前面, 以避免返回可被 3 或 5 整除的结果 (这两者都是 15 的除数).
❸ 这个 FizzBuzz 的实现适用于正自然数以检索结果. 我们可以使用 nth 来从结果中隔离单个项.
最后一个例子展示了我们如何使用 :>> (一个在 condp 中的特殊关键字) 来将动作附加到选择上. 它的工作方式与基本的 condp 相同, 但是当 :>> 关键字出现在子句中时, 三元组的最后一个元素被认为是一个函数, 并用谓词的结果来调用它. 在下面的 (简化的) 扑克游戏实现中, condp 是游戏决策步骤的核心 53.
第一组函数是稍后用来识别相关牌组合的辅助函数:
(def card-rank first) ; ❶ (def card-suit second) (defn freq-by-rank [hand] ; ❷ (->> hand (map card-rank) frequencies)) (defn sort-by-rank [hand] (->> hand (map card-rank) sort)) (defn max-rank [hand] (->> hand freq-by-rank (sort-by card-suit) card-suit card-rank)) (defn- n-of-a-kind [hand n] (when (->> hand freq-by-rank vals (some #{n})) hand))
❶ card-rank 和 card-suit 分别是 first 和 second 的别名. 在这种情况下使用别名有助于提高可读性, 通过为一个原本非常通用的标准库函数赋予一个精确的含义 (感谢 Ted Schrader 建议这个以及本节中的其他更改).
❷ 示例的第一个函数是辅助函数, 按花色 (4 种类型之一) 或按点数 (在我们的示例中, Jack, Queen, King 和 Ace 分别被编号为 11, 12, 13 和 14) 排列牌.
下一组函数建立在前一组函数之上, 以识别扑克游戏中的获胜组合. 还有更多, 但在这个例子中, 我们只实现了几个以使例子更短:
(defn three-of-a-kind [hand] ; ❶ (n-of-a-kind hand 3)) (defn four-of-a-kind [hand] (n-of-a-kind hand 4)) (defn straight-flush [hand] ; ❷ (let [sorted (sort-by-rank hand) lower (card-rank sorted) expected (range lower (+ 5 lower))] (when (and (= sorted expected) (apply = (map card-suit hand))) hand))) (defn n-of-a-kind-highest [hands] ; ❸ (->> hands (sort-by max-rank) last)) (defn straight-flush-highest [hands] (->> hands (filter straight-flush) (sort-by (comp card-rank sort-by-rank)) card-suit))
❶ 使用 n-of-a-kind, 我们可以创建函数来识别一手牌中是否包含 3 张或 4 张相同种类的牌.
❷ 同花顺需要额外的逻辑来对牌进行排序.
❸ 识别获胜组合的函数使用线程末尾操作符 →> 来以有意义的方式组合辅助函数.
最后, condp 是游戏的核心, 用于在给定一组坐在桌旁的玩家的情况下确定谁是赢家. 这是通过基于不同类型的获胜组合过滤玩家, 然后在平局的情况下选择最高的来实现的:
(defn game [players] (sort (condp (comp seq filter) players ; ❶ straight-flush :>> straight-flush-highest four-of-a-kind :>> n-of-a-kind-highest three-of-a-kind :>> n-of-a-kind-highest (n-of-a-kind-highest players))))
❶ condp 通过 comp 将一个 filter 操作与 seq 组合在一起, 这样如果 filter 返回一个空列表, 那么它就会产生一个 nil.
这里描述的简化版扑克游戏只检查了真实游戏中 7 种潜在获胜条件中的 3 种, 没有考虑 full-house 或顺子. condp 围绕以下设计聚合了决策逻辑:
- 排名较高的组合应该首先被检查, 因为一旦我们有了一个匹配项 (例如四条), 我们就不再对其他排名较低的组合感兴趣.
- 谓词给了我们按牌组合过滤玩家的可能性, 并将它们传递给相关的子句.
- 在玩家拥有同等排名组合的情况下, 我们将匹配的玩家传递给子句函数 (通过
:>>), 该函数根据更具体的排名对组合进行排序. - 我们最终对结果的牌组进行排序, 这样它们总是以相同的顺序出现.
以下游戏验证了扑克游戏是否已正确实现. 每张牌都编码为一对点数-花色, 其中梅花 (♣) 是 :c, 方块 (♦) 是 :d, 红心 (♥) 是 :h, 黑桃 (♠) 是 :s:
(game [#{[2 :h] [2 :s] [2 :c] [2 :d] [8 :h]} ; ❶ #{[8 :h] [1 :h] [1 :s] [1 :c] [1 :d]} #{[2 :h] [2 :s] [2 :d] [12 :s] [12 :h]} #{[5 :d] [4 :s] [7 :d] [14 :s] [14 :h]} #{[8 :s] [4 :c] [3 :d] [10 :s] [10 :h]}]) ;; ([2 :h] [2 :s] [2 :c] [2 :d] [8 :h]) ; ❷ (game [#{[1 :h] [1 :s] [1 :c] [1 :d] [8 :h]} #{[4 :d] [5 :d] [6 :d] [7 :d] [8 :d]} #{[3 :h] [5 :h] [4 :h] [7 :h] [6 :h]}]) ;; ([4 :d] [5 :d] [6 :d] [7 :d] [8 :d]) ; ❸
❶ 游戏被实现为集合的集合. 每个集合代表一个玩家. 我们用点数和花色对来编码牌.
❷ 这个游戏模拟有 4 个玩家. 有一手四条的玩家获胜.
❸ 这个游戏包含两个同花顺. 点数最高的那个获胜.
- condp 和 fcase
有时, 了解标准库中的函数是如何演变成现在这样是有用或有趣的.
condp有一些记录在案的历史, 因为它是在 Clojure 社区的帮助下提出和扩展的.condp被包含在 core Clojure 中的讨论很久以前就在邮件列表中进行了 54. 最初, 它是由 Stuart Sierra 在" contrib" 中编写的, 这是所有用户贡献的旧外部存储库. 在" contrib" 中, 它被称为fcase, 除了缺少:>>功能外, 它与condp相同."needle"
:>>符号 (最初是:>) 在几个月后的另一个帖子中被讨论 55.:>>的灵感来自于 Schemecond中的相同功能 56.
cond 支持与 condp 类似的功能. 当你需要每个子句都有不同的谓词时, 使用 cond. 如果你有相同的谓词, 或者你对匹配后触发一个函数的 :>> 形式感兴趣, 使用 condp.
cond-> 有类似的目的, 即选择一个或多个分支 (尽管它不是短路的, 所以它可能会执行多个真分支). 当你不需要执行相同的谓词, 并且你对执行多个分支感兴趣时, 使用 cond->.
=> O(n) 与子句数量成线性关系
condp 宏的实现基于 cond, 因此同样的性能考虑也适用, 并且像 cond 一样, 在正在运行的应用程序中, 它通常不是热点的来源. 有关任何其他信息, 请参考 cond.
自 1.2 版本以来的宏
(case [expression & clauses])
case 是一个条件语句, 它接受一个测试条件列表来决定执行哪个分支. 从表面上看, case 与 cond 或 condp 没有太大区别, 并且可以被认为是同一宏家族的一部分:
(let [n 1] ; ❶ (case n 0 "O" 1 "l" 4 "A")) ;; "l"
❶ 一个简单的 case 表达式的例子.
在底层, case 与 cond 的不同之处在于它对测试表达式的处理, 这些表达式在宏展开时不会被求值. 这意味着像 (inc 0) 这样的表达式不会被替换为 "1" 作为测试表达式. 在 case 的上下文中, (inc 0) 等价于包含符号 inc 和数字 0 的集合:
(let [n 1] (case n (inc 0) "inc" ; ❶ (dec 1) "dec" ; ❷ :none)) ;; "dec"
❶ case 语句的这个分支验证数字 "1" (符号 "n" 的当前局部绑定) 是否存在于由 "inc" 和 "0" 组成的集合中. 答案是假, 控制权向前移动.
❷ 下一个分支包含数字 "1", "dec" 被选为答案.
与其他条件形式相比, case 是专门为性能而设计的. case 的实现会编译成优化的 "tableswitch" JVM 字节码指令 57, 该指令提供常数时间查找 (而不是像 cond 那样是线性的). case 的常数查找时间是以对测试表达式的一些限制为代价的, 我们将在本章中对此进行研究.
(case <expr> [clauses] [<default>]) clause :=> <test> <then>
- 输入
"expr"是强制性的, 可以是任何有效的 Clojure 表达式."clauses"分组为一个或多个对. 如果没有子句, 至少应该有一个"default"出口."test"是一个编译时字面量, 在宏展开时不会被求值. 有效的字面量例子有::a(关键字),'a(符号), 1, 1.0, 1M, 1N (数字), {} #{} () [] (集合字面量), "a" (字符串), \a (字符), 1/2 (比率), #"regex" (正则表达式)."then"是任何有效的 Clojure 形式. 当相应的"test"常量匹配时, 该形式被求值."default"是任何有效的 Clojure 形式或表达式.
请注意, 测试表达式中的列表字面量
()是按包含比较, 而不是按等价比较. 有关更多信息, 请参见下面的示例. - 异常
当出现以下情况时, 抛出
java.lang.IllegalArgumetnException:- 对于给定的表达式, 没有匹配的
"test", 并且没有给出"default". - 有一个重复的
"test"常量.
- 对于给定的表达式, 没有匹配的
- 输出
- 如果存在一个或多个子句但没有一个匹配,
case返回"default". case返回第一个对子句的"then"的求值结果, 其中(identical? test expr)为真.
- 如果存在一个或多个子句但没有一个匹配,
让我们首先澄清一下约定的一些方面. case 测试是编译时常量, 这意味着像下面这样尝试使用符号 'alpha, 'beta 和 'pi 进行分支会有一些影响:
(case 'pi ; ❶ 'alpha \α 'beta \β 'pi \π) ;; IllegalArgumentException: Duplicate case test constant: quote (macroexpand ''alpha) ; ❷ ;; (quote alpha) (case 'pi ; ❸ (quote alpha) \α (quote beta) \β (quote pi) \π) ;; IllegalArgumentException: Duplicate case test constant: quote (case 'pi ; ❹ alpha \α beta \β pi \π) ;; \π
❶ 像 'alpha 这样的符号在 REPL 中会被求值为符号本身, 但在这里它们不被求值. 这个 case 表达式失败了, 声称有一个我们没有立即看到的 "quote" 符号.
❷ case 在宏展开时看到了 'alpha 的引用版本, 这等同于在 REPL 中" 双引用" 该符号, 如此处所示.
❸ 如果我们用完整的调用 (quote) 来替换单引号字符 ', 我们可以看到问题所在. 符号 "quote" 出现在左手边的所有测试表达式中, 导致了不明确的多个匹配分支.
还要注意, 列表 (quote alpha) 是测试 "'pi" 是否存在于由 "quote" 和 "alpha" 组成的集合中, 它不是一个真正的 clojure.lang.PersistentList 实例.
❹ 匹配符号的正确方法是完全移除测试常量中的单引号.
在使用除数字, 字符串和关键字之外的测试表达式时, 你应该特别注意 case. 需要记住的特殊情况是:
- 包含读取器宏的表达式在它们的展开之前进行比较. 我们看到了单引号符号的例子, 但其他常见的情况是 var 字面量
#'或解引用字面量@. - 列表字面量是按包含比较而不是等价比较 (参见下面的例子).
- 其他集合字面量, 如向量, 集合和 map, 使用正常的相等性进行比较.
case 通过检查列表字面量是否包含测试表达式来比较它们. 我们可以利用列表字面量在以下中缀计算器中枚举匹配的运算符:
(defn error [& args] (println "Unrecognized operator for" args)) (defn operator [op] ; ❶ (case op ("+" "plus" "sum") + ("-" "minus" "subtract") - ("*" "x" "times") * ("/" "÷" "divide") / error)) (defn execute [arg1 op arg2] ; ❷ ((operator op) (Integer/valueOf arg1) (Integer/valueOf arg2))) (defn calculator [s] ; ❸ (let [[arg1 op arg2] (clojure.string/split s #"\s+")] (execute arg1 op arg2))) (calculator "10 ÷ 5") ; ❹ ;; 2
❶ operator 将一个字符串形式的运算符转换为相应的 Clojure 函数. 我们可以使用 case 来在操作之间进行选择, 或者使用一个错误函数来处理无法识别的运算符. 注意我们如何可以使用列表字面量为四种基本操作添加多个同义词.
❷ execute 接受运算符和操作数, 并在运算符被 case 语句转换后求值相应的操作.
❸ calculator 接受原始的未求值的字符串, 并将其转换为准备求值的" 标记" .
❹ 调用计算器产生预期的结果.
考虑到列表对 case 有特殊含义, 如果我们想将列表作为实际集合进行比较, 显然会遇到麻烦. Clojure 的相等性不区分列表和向量作为容器类型, 只比较它们的内容, 从而允许我们匹配列表. 我们将在下面的例子中看到如何做到这一点, 该例子旨在为 Vim 用户在键盘上的效率打分 58.
Vim 是一款流行的编辑器, 它利用简短的助记符键序列来执行任意复杂的任务. 我们可以根据实现某个编辑任务的最佳键组合来给用户打分 (通常是击键次数最少的获胜). 为简单起见, 我们将考虑一个非常简单的任务: 将光标从 5x5 网格终端的左下角移动到右上角, 如下图所示:
Figure 5: 以可视化方式表示 Vim 击键移动, 从一个角移动到另一个角.
字母 "k" 将光标向上移动, 而字母 "l" 将其向右移动. 一个糟糕的解决方案是连续按 "k" 四次, 然后再按 "l" 四次 (左图): 在这种情况下, 我们会承认成就, 但给出 "5" 的低分. 一个更好的解决方案是按 "4" 后跟移动字母, 与前一种方案相比, 击键次数减半 (右图). 对这种结果进行评分的代码可以实现为以下 case 语句:
(defn score [ks] (case ks ; ❶ [\k \k \k \k \l \l \l \l] 5 [\4 \k \4 \l] 10 0)) (defn check [s] (score (seq s))) ; ❷ (check "kl") ;; 0 (check "kkkkllll") ;; 5 (check "4k4l") ;; 10
❶ 我们将移动常量分组在一个向量中, 每个向量代表 case 语句中的一个测试表达式. 请注意, case 不认为在多个向量中存在字母 "k" 或 "l" 是重复的 (如果我们使用列表字面量, 这将是一个异常).
❷ 由于输入是一个字符串, 我们只需要在其上调用 seq 即可将其转换为一个字符序列.
关于前面的例子, 有几点需要注意:
- 存在由向量顺序决定的隐式击键顺序. 当顺序不重要时, Clojure Set 可以用作测试表达式.
score是通过传递一个序列作为参数来调用的.case使用 Clojure 的等价性比较它们的内容.
- "case" 和表分支
case的实现方式与在switch语句 (也称为 "case" 或 "select" 语句) 中使用的著名编译器优化类似.其思想如下: 将测试常量转换为适合哈希的键, 并使用哈希表查找来检查是否有匹配项. 问题就转化为将常量转换为整数. 还有一个重要的方面需要考虑: 如果键是连续的 (即, 连续整数之间没有间隙), 那么可以通过一个简单的条件来进入开关, 以检查表达式是否在允许的范围内. Clojure 的优势在于 JVM 已经提供了一些抽象来用
tableswitch操作码构建查找表, 这需要以下条件:- 测试值必须是
int或等效的 int (char, bytes, shorts). - 测试值必须是连续的 (可能需要多次添加默认情况标签以填补间隙).
- 开关表的总大小不应超过 8192 字节.
对 Clojure 的实际影响是, 必须有一种方法将编译时常量或它们的组合转换为整数, 并移位/掩码这些整数以获得键之间尽可能小的间隙. 另一个潜在的问题发生在哈希冲突时, 以及通常在将复合体转换为整数时. 因此, 尽管思想简单, Clojure 必须做相当多的非平凡处理才能正确实现它 59. "core.clj" 中有几个相当复杂的函数 (
prep-hashes,merge-hash-collisions,fits-table?等) 专门用于将case常量转换为一个无间隙的非冲突整数列表. - 测试值必须是
cond 与 case 具有类似的语义. 最显著的区别是在编译时求值测试表达式的可能性.
condp 允许输入用于匹配的谓词, 并添加了额外的 :>> 语义.
distinct?: Clojure 在实现 case 时内部使用 distinct? 来寻找合适的哈希组合. distinct? 中的示例展示了这是如何工作的.
cond 和 condp 通常更灵活. 根据经验, 在有字面量或性能特别重要的情况下优先使用 case.
=> O(n) 宏展开时间
=> O(1) 运行时
case 的主要卖点是常数时间访问查找, 与语句中存在的测试-然后对的数量无关. 我们可以使用 Criterium 快速验证这一说法:
(require '[criterium.core :refer :all]) (defn c1 [n] (cond (= n 0) "0" (= n 1) "1" (= n 2) "2" (= n 3) "3" (= n 4) "4" (= n 5) "5" (= n 6) "6" (= n 7) "7" (= n 8) "8" (= n 9) "9" :default :none)) (bench (c1 9)) ;; Execution time mean : 10.825367 ns (defn c2 [n] (case n 0 "0" 1 "1" 2 "2" 3 "3" 4 "4" 5 "5" 6 "6" 7 "7" 8 "8" 9 "9" :default)) (bench (c2 9)) ;; Execution time mean : 6.716657 ns
如你所见, 平均执行时间从使用 cond 的版本的 10.825367 ns 降到使用 case 的版本的 6.716657 ns, 大约快了 40%. 这种加速也得益于 cond 使用了 "=" 相等运算符, 而 case 基于常量字面量, 隐式地使用了引用相等性. 一个更" 公平" 的基准测试可能会使用 identical?, 但这会限制 cond 的正常操作范围, 可能会产生令人惊讶的结果:
(defn c1 [n] (case n 127 "127" 128 "128" :none)) (c1 127) ;; "127" (c1 128) ; ❶ ;; "128" (defn c2 [n] (cond (identical? n 127) "127" (identical? n 128) "128" :else :none)) (c2 127) ;; "127" (c2 128) ; ❷ ;; :none
❶ case 正确地报告 "128" 为正确答案.
❷ 带有 identical? 的 cond 没有进入预期的分支, 因为内部 JVM 对装箱整数的缓存只对 127 以下的整数可用 60.
请注意, cond 的实现没有任何问题, 但这更多地与使用 identical? 作为相等运算符的含义有关. case 简单地避免了理解使用 identical? 的含义所需的额外认知时间.
如果我们对一个简单的例子进行宏展开, 我们可以看到 case 如何委托给 case* (一个特殊形式), 传递创建必要字节码所需的参数:
(macroexpand '(case a 0 "0" 1 "1" :default)) ;; (let* ;; [G__759 a] ;; (case* G__759 ;; 0 0 :default ;; {0 [0 "0"], 1 [1 "1"]} ;; :compact :int))
再往下看产生的 JVM 字节码, case* 特殊形式会产生以下内容 (只显示主要的 tableswitch 和相关细节):
(require '[no.disassemble :refer [disassemble]]) ; ❶ (println (disassemble ; ❷ #(let [a 8] (case a 0 "0" 1 "1" :default)))) ;; [...] ; ❸ 0 ldc2_w <Long 8> [12] 3 lstore_1 [a] 4 lload_1 [a] 5 lstore_3 [G__22423] 6 lload_3 [G__22423] 7 l2i 8 tableswitch default: 54 case 0: 32 case 1: 43 ;; [...]
❶ disassemble 是本例中用于反编译求值 Clojure 形式所产生的对象的库.
❷ 我们在一个包装在 let 块中的 case 表达式上调用 disassemble.
❸ 反汇编的对象很长, 包含许多此处未显示的其他部分. 我们只对显示表达式中 case 语句转换为字节码的特定部分感兴趣. 如你所见, case 被转换为一个 tableswitch 字节码指令.
作为 case 关于编译时常量的限制的结果, 产生的 tableswitch 指令已经包含了执行所需的所有必要信息, 无需进一步的求值.
2.2.4. 3.4 迭代和循环
本节探讨了 Clojure 中专用于迭代和循环的一些操作. 迭代是一种语言特性, 允许以受控的方式重复相同的代码部分. 函数式语言与其他语言的一个区别在于状态的缺失 (或非常有限的作用域), 这一事实在迭代过程中有所体现: Clojure 提倡无副作用的循环, 其中输入值从一次迭代传递到下一次迭代, 无需可变变量. 让我们比较一下 Java 中典型的 for 语句和 Clojure 中的 loop 结构. 以下是打印 0 到 9 之间数字的平方:
Stack s = new Stack(); for (int i = 0; i < 10; i++) { s.push(* i i); // i = 9; ❶ } System.out.println(s); // [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
❶ 这行被注释掉的代码会缩短循环. 可能, 但也可能很危险. 如果我们赋 i = 8 呢?
在 Java 版本中, 可变变量 "i" 在循环开始时创建, 并在每次迭代时改变. "i" 控制着循环, 我们可以通过在循环内部改变它来干预, 这在 Clojure 中是很难且需要明确实现的. 在 Clojure 中, 我们会将连续的值作为" 参数" (更确切地说是局部绑定) 传递给下一次迭代:
(loop [i 0 s []] (if (< i 10) (recur (inc i) (conj s (* i i))) s)) ;; [0 1 4 9 16 25 36 49 64 81]
在 Clojure 中, 无法在循环体内改变 "i", 因为 "i" 是不可变的. 其次, Java 的 "for" 语句只允许通过改变状态来与外部世界交互 (在本例中是外部作用域的 java.util.Stack 对象), 而 Clojure 则在退出循环前返回最后一个表达式. 公平地说, 两种语言都允许非惯用的替代方法:
public static Stack square(int i, Stack s) { if (i < 10) { s.push(i * i); square(++i, s); ❶ } return s; } System.out.println(square(0, new Stack())); // [0 1 4 9 16 25 36 49 64 81]
❶ 递归的 square 调用发生在互斥分支的最后一条指令 (要么 "i" 小于 10, 要么不是). 这个递归计算可以被转换为迭代 61.
由于编译器缺乏自动尾调用优化能力, Java 并不大力推崇递归 (有关详细解释, 请参见 loop 中的尾递归部分). 在 Java 中, 任何足够大的递归迭代最终都会消耗整个堆栈, 即使递归发生在最后一条指令 (如我们的示例中). 类似地, Clojure 允许以下可变循环:
(let [i (atom 0) s (atom [])] ; ❶ (while (< @i 10) (swap! s #(conj % (* @i @i))) (swap! i inc)) @s) ;; [0 1 4 9 16 25 36 49 64 81]
❶ Clojure 只允许通过原子 (或像引用这样的其他并发感知原语) 进行受控的改变.
与非惯用的 Java 递归一样, 上述使用 while 和可变原子的用法显著增加了代码的复杂性, 并且是强烈不鼓励的 (并且非常不符合 Clojure 的惯用风格).
递归非常普遍, 以至于它有特定的词汇:
loop和fn函数声明家族被认为是递归" 目标" , 即在recur后执行跳转的指令.- " 退出条件" 是一个条件形式 (通常是
if或cond), 它决定何时退出循环. 一个条件总是存在的 (如果我们排除了退化的单次迭代和无限迭代的情况). - 当递归调用作为当前作用域的最后一条指令发生时, 该递归被称为" 尾递归" .
- 3.4.1 loop, recur 和 loop*
自 1.0 版本以来的宏和特殊形式
(loop [bindings & body]) (recur & args) (loop* [bindings & body])
loop-recur是 Clojure 中最基本的递归结构.loop是恢复执行的可能目标之一, 而recur执行受控的" 跳转" , 将控制权转移到最内层的loop或fn形式 (包括defn,defn-,fn*和匿名函数字面量#()). 总的来说, Clojure 允许 3 种方式进行递归:从函数内部调用函数本身. 在这种情况下不使用
loop或recur. 递归调用可以出现在任何地方, 不仅仅是作为最后一条指令, 就像这个返回斐波那契数列中第 n 个元素的例子一样 62:(defn fib [n] (if (<= 0 n 1) n (+ (fib (- n 1)) (fib (- n 2))))) ; ❶ (map fib (range 10)) ;; (0 1 1 2 3 5 8 13 21 34)
❶ 请注意, 尽管这行是互斥
if分支中的最后一行, 但第一个fib调用不在尾部位置, 因为后面还有一个(- n 2)的求值.在没有
loop目标的情况下调用的recur特殊形式将使用最内层的包含函数定义. 这里是重写以避免两次递归的相同示例:(defn fib [a b cnt] (if (zero? cnt) b (recur (+ a b) a (dec cnt)))) ; ❶ (map (partial fib 1 0) (range 10)) ;; (0 1 1 2 3 5 8 13 21 34)
❶ 这里的
recur目标是顶层函数定义fib, 因为没有其他更内层的定义, 也没有loop指令.用
loop目标调用的recur特殊形式将从最内层的loop形式重新开始计算. 以下可能是迄今为止介绍的 3 个fib版本中最有效的.loop的存在处理了一些不需要在函数外部进行的初始化, 同时我们也没有进行两次递归:(defn fib [n] (loop [a 1 b 0 cnt n] ; ❶ (if (zero? cnt) b (recur (+ a b) a (dec cnt))))) (map fib (range 10)) ;; (0 1 1 2 3 5 8 13 21 34)
❶ 请注意, 调用函数时必须发送 0 和 1 的初始化参数. 它们现在由
loop处理, 而不被导出到函数参数中.
这些是递归调用函数和使用
recur变体之间的主要区别:- 编译器确保如果存在
recur, 它必须在尾部位置. 如果recur不在尾部位置, 编译器会抛出异常. - 编译器在使用
recur时会启用一种特殊的优化, 不会消耗堆栈 (有关详细解释, 请参见下面的尾递归部分). loop提供了对局部绑定的额外控制, 而不干扰函数参数, 例如初始化值或向递归添加额外的参数.- 当速度很重要时,
loop也是迭代的主要选择.loop负责传播类型信息以避免不必要的装箱/拆箱步骤, 这通常是快速代码执行的重要因素 63. 我们将在本节后面进一步说明关于loop-recur速度的更多方面.
(target [binding-parameters] (<body> (recur <params>?))) target :=> <loop> | <defn> | <defn-> | <fn> | <fn*> | <#()> binding-parameters :=> params | bindings params :=> <sym1>, <sym2> .. <sym> bindings :=> <bind1> <expr1>, <bind2> <expr2> .. <bind> <expr>
- 输入
"target"可以是loop,defn,defn-,fn*或匿名函数字面量#()中的任何一个.recur必须始终有一个目标, 尽管简短的(recur)是有效的 Clojure, 会导致无限循环."binding-parameters"是一个包含符号及其初始值绑定的向量."params"与recur一起使用.recur调用必须具有与"target"声明的参数数量相同的参数 (包括没有参数的情况)."bindings"在以loop为目标的递归情况下使用. 绑定是一个 (可能为空) 的向量, 包含偶数个元素.recur调用必须具有相同数量的局部绑定, 这等于绑定的数量.loop中的"bindings"本质上等同于let中的"bindings"."body"包含与计算有关的所有内容, 包括recur作为最后一条指令. 它需要至少包含一个条件指令来选择何时递归以及何时返回结果.
- 值得注意的异常
java.lang.UnsupportedOperationException: Can only recur from tail position. 异常的消息解释了recur被使用, 但在递归返回后还需要求值另一个形式. 在这种情况下, 不能使用loop-recur. 如果算法不能用尾递归重新表述, 那么唯一可用的选项是使用显式递归. - 输出
主体中最后一个非递归指令的求值.
- 示例
我们简要地描述了
recur使用任何专用于创建函数的宏的可能性. 以下是使用fn和函数字面量()重写的斐波那契示例. 除了需要以不同的方式调用外, 它们等价于本章开头看到的带有defn的recur, 但它们肯定可读性较差. 虽然第一个使用fn作为目标的示例对于非常小的函数是可以容忍的, 但第二个使用函数字面量()的示例很少使用:(map (partial (fn [a b cnt] ; ❶ (if (zero? cnt) b (recur (+ a b) a (dec cnt)))) 1 0) (range 10)) ;; (0 1 1 2 3 5 8 13 21 34) (map (partial #(if (zero? %3) ; ❷ %2 (recur (+ %1 %2) %1 (dec %3))) 1 0) (range 10)) ;; (0 1 1 2 3 5 8 13 21 34)
❶ 在这个例子中,
fn是recur的目标.❷ 函数字面量
#()被展开为一个带有三个参数的匿名函数声明, 等同于我们目前看到的其他函数声明形式. 现在参数a,b和cnt分别被替换为%1,%2和%3, 生成的形式不太可读.loop-recur也可以用在迭代不一定是集合遍历的情况下 (在这种情况下, 像map这样的序列操作会是显而易见的选择). 本书包含了在集合遍历之外的上下文中使用的loop的有趣示例. 邀请读者看一下以下内容:let展示了一个无限 (且有副作用的) 循环, 用于为互动游戏收集用户输入.if-let展示了一个主-从计算模式, 其中工作者在一个无限的loop-recur中等待工作.clojure.zip/zipper展示了如何用 zipper 遍历一棵树, 这是recur的另一个典型用法.
以下示例探讨了使用显式递归的另一个好理由: 速度. 让我们看看当执行速度至关重要时,
loop-recur如何替代集合遍历的示例. 牛顿法计算数字的平方根描述了一种算法, 其中初始猜测收敛到一个近似解 64. 假设我们不知道Math/sqrt的存在, 让我们用序列来实现一个解决方案. 以下方法包括从一个逐渐改善的近似值的无限流中提取, 然后当解足够精确时停止:(set! *warn-on-reflection* true) (defn lazy-root [^double x] ; ❶ (->> 1. ; ❷ (iterate #(/ (+ (/ x %) %) 2)) ; ❸ (filter #(< (Math/abs (- (* % %) x)) 1e-8)) ; ❹ first)) (defn sq-root [x] ; ❺ (cond (or (zero? x) (= 1 x)) x (neg? x) (Double/NaN) :else (lazy-root x))) (sq-root 2) ;; 1.4142135623746899
❶ 通过将参数类型提示为
double, 我们确保 Clojure 在无需反射的情况下正确调用(Math/abs), 正如*warn-on-reflection*正确指出的那样. 仅此一项就会使lazy-root慢一个数量级.❷ 尽管有更复杂的方法来选择初始猜测值, 但在这里 1 是足够合理的 65.
❸ 传递给
iterate的匿名函数接受当前的猜测值%, 并通过将%与(/ x %%)平均来产生一个更好的猜测值. 我们使用iterate来计算一步, 并将新改进的猜测值的结果输入到下一次迭代中, 从而有效地产生一个无限的惰性猜测序列, 我们可以从中提取尽可能多改进的猜测值.❹ 我们现在可以从越来越好的猜测值中过滤出最好的猜测值, 并取第一项. 谓词函数使用猜测值的平方
(* % %%)来验证我们离完美解有多远. 我们使用一个非常小的数字, 如 1e-8. 通过使这个数字更小, 我们可以获得更高的精度, 但代价是需要计算更多的猜测值.❺ 包装函数
sq-root只是确保特殊情况被考虑在内. 例如, 我们不希望允许负数的平方根.lazy-root足够可读, 惯用且速度合理. 请注意lazy-root如何通过为处理猜测采用类似流的模型来隐式地收集所有结果: 我们可以简单地移除对last的调用来查看所有结果. 这个额外的功能可能有用也可能没用, 具体取决于上下文, 但它隐含在按需处理猜测流的方式中. 现在让我们专注于性能, 并检查我们与 Java 的Math/sqrt(这可能是一个更快的对手) 相比做得如何:(require '[criterium.core :refer [bench]]) (bench (lazy-root 2.)) ;; Execution time mean : 590.703818 ns ;; [extended output omitted] (bench (Math/sqrt 2.)) ;; Execution time mean : 6.250582 ns ;; [extended output omitted]
基准测试显示,
lazy-root比 JDK 的Math/sqrt函数慢大约 100 倍. 除了教我们在可能的情况下使用 JDK 的数学函数外, 该基准测试还显示了生成和消费惰性序列会带来相关的成本, 这取决于用例, 可能被视为问题, 也可能不是. 例如:- 我们需要将函数传递给
iterate和take-while, 这增加了一些调用间接性. 其次, 这迫使 Clojure 为通用类型进行编译, 因为在没有类型提示的情况下, 编译器无法在编译时知道x是一个double. Clojure 从高阶函数中获益匪浅, 但在追求纯速度时,loop递归消除了这两个问题. - 每个序列处理步骤都在生成中间数据结构.
take-while维护一个与iterate不同的项集合.lazy-root函数包含一个小的处理管道, 但对于更长的操作链, 问题变得更大. - 遍历一个序列 (如在
last的情况下) 比仅仅保留最后一个更昂贵.
事实证明, 计算平方根的牛顿法可以很容易地重新表述为递归. 实际上, 递归版本经常出现在函数式编程书籍中:
(defn recursive-root [x] (loop [guess 1.] (if (> (Math/abs (- (* guess guess) x)) 1e-8) (recur (/ (+ (/ x guess) guess) 2.)) guess))) (bench (recursive-root 2.)) ;; Execution time mean : 14.237573 ns ;; [other output omitted]
recursive-root版本读起来肯定很好, 性能也好得多: 尽管仍然慢两倍, 但现在可以与 Java 版本相媲美. 请注意:- 匿名函数是不必要的.
guess局部绑定的double类型现在在迭代之间被强制执行, 不需要类型提示. - 没有猜测或结果的集合, 也没有任何中间集合. 只有最后一个猜测在调用之间传递.
- 在这种情况下, 递归模型足够容易理解, 但总的来说, 与其他类型的计算相比, 为递归创建心智模型需要一些练习.
本章中的例子并不是建议放弃像惰性序列这样强大的工具, 而是当速度是一个重要因素时, 寻找一个等效的显式
loop-recur.- 尾递归优化和尾递归语言
尾递归是递归代码的一个有趣特性. 在讨论相关的优化之前, 我们需要回顾一下关于子程序和调用栈的足够信息. 过程的概念 (也称为例程, 函数或方法, 取决于语言) 是许多编程范式的核心. 没有命名代码特定部分的可能性, 很难想象今天的编程. 命名是实现重用的基本工具, 在主流编程语言中是理所当然的.
伴随子程序而来的是与传递参数和返回值的复杂性. 语言运行时可能需要记住" 跳转" 之前创建的任何局部作用域, 以便当过程返回一个值时, 该值可以在调用之前的上下文中使用. 持有整个上下文的数据结构称为" 执行栈" (或简称调用栈), 栈中的一个项称为" 帧" . 在程序执行的某个时刻, 每个栈帧对应一个尚未返回结果的过程, 以及关于调用站点的任何附加上下文信息.
从概念上讲, 递归调用与异构调用没有区别: 每次调用都会创建一个新的栈帧, 而与调用者是调用自身还是其他东西无关. 但是, 虽然正常的调用链是由代码如何手动布局驱动的, 但递归调用是由数据驱动的: 它们通常围绕某个数据结构映射, 在每个元素上执行操作直到耗尽, 或者像平方根的情况一样, 直到达到某个想要的精度. 可用于创建帧的空间受可用内存量的限制, 递归可以轻易地消耗所有可用的空间 (可怕的
StackOverflow异常).尾递归很重要, 因为当一个递归调用是一组重复指令的最后一条指令时, 无需在该时间点记住函数的状态: 在这种情况下, 无需创建帧, 因为没有其他指令会从记住该时间点的执行状态中获益. 高级编译器 (Scheme 是一个显著的例子) 能够自动识别尾部位置的递归调用, 并防止基于栈的传播. 编译器然后可以将重复指令的序列视为在过程的最后一次调用中有一个" 跳转" 或" goto" 指令, 没有任何栈创建, 只有当前值作为参数.
Clojure 不提供自动的尾递归优化, 但可以用
loop-recur结构优化尾递归. 自动检测尾调用可优化代码会相对简单, 但 Clojure 倾向于依赖 Java 的方法调用语义, 而 Java 不实现尾调用优化 66.
- 另请参阅
trampoline处理相互递归的情况, 这是loop-recur没有设计的. 有趣的是, 它以一种基于loop-recur的直接方式实现相互递归.while执行基于副作用的迭代代码. 它专门用于处理那些 (主要是 Java 互操作) 需要副作用来控制退出条件的情况. 它应该谨慎使用.for是 Clojure 的列表推导式形式.for对于生成可能复杂的序列以驱动进一步的处理非常有用. 如果我们将递归视为由参数传递和参数处理组成的算法配方,for代表了随时间传递的参数序列, 而其他序列函数执行实际的计算. 两种模型在不同情况下都有优势,loop-recur通常更低级, 性能更好. - 性能考虑和实现细节
=> O(n) 与迭代次数成线性关系
使用
loop-recur进行显式递归的性能影响是本章的重点. 就loop-recur结构本身而言, 它在编译时具有常数时间成本 (生成相关字节码的实际工作量), 并且与它需要执行的迭代次数成线性关系.正如我们在示例中所看到的,
loop足够聪明, 能够识别并维护在loop绑定中声明的原始类型. 让我们反汇编一小段代码来看看发生了什么:(require '[no.disassemble :refer [disassemble]]) ; ❶ (println (disassemble (fn [n] (loop [i 0] (< i n) (inc i))))) ; ❷ ;; Compiled from form-init72854.clj (version 1.5 : 49.0, super bit) ;; some details removed for clarity public final class user$eval444$fn__445 extends clojure.lang.AFunction { public java.lang.Object invoke(java.lang.Object n); 0 lconst_0 1 lstore_2 [i] 2 lload_2 [i] 3 aload_1 [n] 4 invokestatic clojure.lang.Numbers.lt(long, java.lang.Object) ; ❸ 7 pop 8 lload_2 [i] 9 invokestatic clojure.lang.Numbers.inc(long) : long [21] ; ❹ 15 areturn }
❶
disassemble库可以在这里找到: github.com/gtrack/no.disassemble❷ 这里展示的函数只是为了说明类型. 它实际上没有意义, 也不需要.
❸ Clojure 知道
i的类型, 这要归功于loop绑定. 它不知道n的类型, 所以它需要调用通用的Numbers.lt, 这反过来又需要将其转换为数字.❹ 由于
loop结构, 将i递增为long没有问题.但是, 如果不向编译器自动无法识别的绑定添加类型,
loop的类型识别将无法充分发挥其潜力. 我们只需要添加必要的提示:(println (disassemble (fn [^long n] (loop [i 0] (< i n) (inc i))))) ;; Compiled from form-init789662854.clj (version 1.5 : 49.0, super bit) ;; some details removed for clarity public final class user$eval448$fn__449 extends clojure.lang.AFunction { public final java.lang.Object invokePrim(long n); 0 lconst_0 1 lstore_3 [i] 2 lload_3 [i] 3 lload_1 [n] 4 invokestatic clojure.lang.Numbers.lt(long, long) : boolean [19] ; ❶ 7 pop 8 lload_3 [i] 9 invokestatic clojure.lang.Numbers.inc(long) : long [23] 15 areturn }
❶ Clojure 现在正在生成带有原始类型的完美调用, 这不会产生任何转换或装箱的惩罚.
如果你还记得我们示例中的
lazy-root函数, 我们没有在函数参数中为x添加类型提示. 原因在于, 尽管类型提示会产生性能更好的字节码, 但循环中执行的操作类型超过了优化. 唯一知道这一点的方法是, 在做出任何决定之前, 始终用像 Criterium 这样的工具进行一致的测量.
自 1.0 版本以来的函数
(defn range ([]) ([end]) ([start end]) ([start end step]))
range 是一个具有许多实际应用的通用数字生成器. 最常用的元数之一是带有一个参数的, 它产生一个整数序列:
(range 10) ;; (0 1 2 3 4 5 6 7 8 9)
range 的主要用例是提供一个数字序列, 其他序列处理操作可以使用该序列来创建更复杂的行为.
- 约定
- 输入
"end"是一个数字, 用于界定生成的序列应该在哪里停止 (它在"end"减 1 处停止).(number? end)必须返回true. 当不给出"end"(没有参数) 时, 它默认为正无穷, 创建一个无限范围."start"是生成的序列应该开始的数字.(number? start)必须返回true. 当不给出"start"(只存在"end") 时,"start"默认为 0."step"是序列中每个元素之间的增量.(number? step)必须返回true. 当只给出"start"和"end"时,"step"默认为 1.
- 值得注意的异常
当存在超过 3 个参数时, 会抛出
clojure.lang.ArityException. - 输出
range返回:- 无参数时: 一个从 0 开始的单调递增的无限数字序列.
- 带有单个正
"end"参数时: 一个从 0 开始并在(- end 1)处结束的单调递增序列. 当"end"为 0 或负数时, 返回空列表. - 带有
"start"和"end"参数, 且"start"小于"end"时: 一个从"start"开始并在(- end 1)处结束的单调递增序列. 当(>= start end)时, 返回空列表. - 带有
"start","end"和"step"参数时: 一个按"step"单调递增/递减的数字序列. 当:(>= start end)且"step"为正, 或(<= start end)且"step"为负时, 返回空列表.
range返回一个遵循任意精度运算符规则的" 数字" 列表, 包括在超过长整型边界时自动将长整型提升为大整数:(range (dec Long/MAX_VALUE) (+' Long/MAX_VALUE 3)) ;; (9223372036854775806 ;; 9223372036854775807 ;; 9223372036854775808N ; ❶ ;; 9223372036854775809N)
❶ 结果序列中的项会自动从长整型提升为大整数.
- 输入
- 示例
让我们从一些有趣的
range用法开始, 然后再进入更复杂的问题. 通过使用 "step" 参数可以轻松获得偶数列表:(range 0 20 2) ; ❶ ;; (0 2 4 6 8 10 12 14 16 18)
❶ 从 0 开始, 步长为 2, 产生偶数.
可以使用负步长和负数作为极值来产生负数范围:
(range -1 -20 -2) ; ❶ ;; (-1 -3 -5 -7 -9 -11 -13 -15 -17 -19)
❶ 使用负 "end" 和负 "step" 从较大的 "start" 递减的负奇数序列.
值得记住的是,
range适用于任何类型的数字. 要与其他数值类型一起工作, 可能需要记住加法的类型转换规则. 通常, 将 "step" 或 "end" 设置为特定类型会触发输出序列具有该类型:(range 0.5 5 0.5) ; ❶ ;; (0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5) (range 1 0 -1/10) ; ❷ ;; (1 9/10 4/5 7/10 3/5 1/2 2/5 3/10 1/5 1/10)
❶ 小数步长在范围内产生 0.5 的增量.
❷ 另一个使用比率类型的序列的例子.
通过组合
range和map, 我们可以获得一些有趣的行为, 例如一个其他序列的序列, 其大小逐渐增加:(map range (range 10)) ; ❶ ;; (() ;; (0) ;; (0 1) ;; (0 1 2) ;; (0 1 2 3) ;; (0 1 2 3 4) ;; (0 1 2 3 4 5) ;; (0 1 2 3 4 5 6) ;; (0 1 2 3 4 5 6 7) ;; (0 1 2 3 4 5 6 7 8))
❶
map的每个应用都产生一个具有不同 "end" 位置的范围.同样的概念可以扩展到创建连续的序列, 其中" 两端" 被移除:
(->> (reverse (range 10)) ; ❶ (map range (range 10)) ; ❷ (remove empty?)) ; ❸ ;; ((0 1 2 3 4 5 6 7 8) ; ❹ ;; (1 2 3 4 5 6 7) ;; (2 3 4 5 6) ;; (3 4 5) ;; (4))
❶ 起点是一个反转的正数范围.
❷ 第一步是将相同的范围和它的反转组合到一个
map操作中.map函数又是range, 它将接收两个输入参数, 每个参数都来自另一个range. 来自正向range的第一个数字将是 "start", 而来自反向range的第二个数字将是 "end".❸ 当范围的 "end" 大于 "start" 时, 我们需要修剪掉一些最后的元素, 这些元素会变成空列表.
❹ 为了清晰起见, 输出被缩进, 但通常会显示为单行.
现在让我们看看如何在实践中使用
range. 许多算法都是基于对集合的某种非平凡迭代. 例如, 比较列表的边缘是搜索回文的基础 67. 回文是向前和向后读都相同的字母序列: " Was it a car or a cat I saw" 是一个典型的例子. 找出字符串是否是回文的一种方法是检查中间的字母是否相同, 然后向外进行以验证其他的, 直到我们到达序列的末尾:|<-------------------------------( n )------------------------------->| w a s i t a c a r o r a c a t i s a w |<------------(quot n 2)----------->| |<-- (- idx) -->|<-- (+ idx) -->|
以下实现了上述算法:
(require '[clojure.string :as s]) (defn palindrome? [xs cnt] ; ❶ (let [idx (range (quot cnt 2) -1 -1)] ; ❷ (every? #(= (nth xs %) (nth xs (- cnt % 1))) idx))) ; ❸ (defn string-palindrome? [s] ; ❹ (let [chars (some->> s s/lower-case (remove (comp s/blank? str)))] (palindrome? chars (count chars)))) (string-palindrome? "Was it a car or a cat I saw") ;; true
❶
palindrome?是一个接受序列xs和序列中元素计数的函数.❷
idx包含以反向从计数的一半开始到 0 的索引来访问序列. 我们使用quot来避免通过除法操作/发生的转换为比率类型.❸ 我们用
nth按索引访问序列. 注意, 如果xs是一个惰性序列, 第一个nth调用会实现大约一半的序列 (如果集合支持分块求值, 求值可能会停止在半点之后直到当前块的末尾). 在用=比较了所有的对称对之后, 我们用every?验证是否有任何一个是假的.❹
string-palindrome?进行一些初始准备, 比如将字母小写和移除空格.some->>防止可能的nil输入.这里介绍的回文示例是检查一个序列是否为回文的多种方法之一. 根据问题的要求 (如内存分配, 序列长度或回文的概率), 基于向量的其他解决方案可能会表现得更好 (例如, 看看如何使用
rseq和向量来检查回文). 性能部分包含了一些关于range效率和惰性权衡的更多考虑. - 另请参阅
for可以被认为是range的大哥. 它在选择序列应如何生成方面提供了更多的灵活性. 如果你需要一个简单的数字序列, 使用range; 如果你需要以更复杂的方式过滤序列的元素, 或者你需要跨越多个生成方法或不同的项类型, 使用for.iterate接受一个函数, 该函数被调用时带有前一次计算的结果以生成下一个项. 例如,(take 10 (iterate inc 0))等价于(range 10), 但增加了将inc更改为另一个函数的灵活性. - 性能考虑和实现细节
=> O(n) 线性 (最坏情况, 完全消耗)
=> O(n) 内存 (最坏情况, 保留头部)
range创建一个惰性序列 (更具体地说, 是一个实现clojure.lang.ISeq接口的 Java 对象). 惰性是对计算的承诺: 需要一个消费者来请求元素以开始计算. 这就是为什么(def a (range 1e20))在 REPL 中求值时会立即返回: 1e20 次迭代中没有一次已经执行. 出于同样的原因, 可以有一个无限的范围(range), 前提是它永远不会被完全消耗.range通过生成与请求的项目数量成线性关系的行为来计算序列. 内存消耗也呈线性增长, 假设我们持有序列的头部 (最坏情况, 否则为常数空间):(let [r (range 1e7)] (first r) (last r)) ; ❶ ;; 9999999 (let [r (range 1e7)] (last r) (first r)) ; ❷ ;; OutOfMemoryError GC overhead limit exceeded
❶ 该示例显示了对用
range创建的大序列的最后一个元素的访问. 由于last也是求值整个形式的最终结果, 序列的其余部分可以在序列被处理时安全地进行垃圾回收.❷
last操作出现在访问大序列的另一个操作之前. 结果, 由range产生的序列需要完全保留在内存中, 从而可能产生OutOfMemoryError(也取决于允许的堆大小).range(像iterate,repeat和cycle) 是作为一个 Java 类实现的, 并为reduce和包括变换器在内的相关函数提供了一种专门的算法. 要激活快速路径, 你需要注意不要将range包装在一个序列生成函数中:(require '[criterium.core :refer [quick-bench]]) (let [xs (range 1000000)] (quick-bench (reduce + (map inc xs)))) ; ❶ ;; Execution time mean : 42.022867 ms (let [xs (range 1000000)] (quick-bench (transduce (map inc) + xs))) ; ❷ ;; Execution time mean : 16.044716 ms
❶
reduce无法激活range的快速路径, 因为该范围被包装在一个map函数中. 因此选择了reduce的默认序列路径.❷ 转换现在是变换器的一部分,
range类型对于可以激活快速路径的transduce来说是可见的.transduce内部使用reduce.类似的考虑也适用于
apply, 它不遵循快速的reduce路径. 以下函数kth计算 (x - 1)n 的第 k 个系数 (这是根据 AKS 素性测试 68 测试一个数是否为素数所需计算的一部分). 该函数使用
range来创建可能长的序列, 并为了比较, 已用apply和range实现:(defn kth [n k] ; ❶ (/ (apply *' (range n (- n k) -1)) (apply *' (range k 0 -1)) (if (and (even? k) (< k n)) -1 1))) (quick-bench (kth 820 6)) ;; Execution time mean : 924.071439 ns (defn kth [n k] ; ❷ (/ (reduce *' (range n (- n k) -1)) (reduce *' (range k 0 -1)) (if (and (even? k) (< k n)) -1 1))) (quick-bench (kth 820 6)) ;; Execution time mean : 401.906780 ns
❶ 该函数使用
apply两次来创建必要的系数.❷
apply已被reduce替换. 基准测试证实了速度的提升.
自 1.0 版本以来的宏
(for [seq-exprs body-expr])
for 是一个强大的 Clojure 宏. 它通常被描述为" 列表推导" , 与具有类似结构的其他语言进行类比 (有关其他背景信息, 请参见 while 内部的标注). " 推导" 既意味着" 理解" 又意味着" 包含" , 正确地暗示了使用 for 来聚合, 过滤或以其他方式操纵多个集合以形成最终输出. for 有助于消除嵌套的 map - filter 组合 (这可能更难理解), 并生成非平凡的序列. for 不应与在其他语言中找到的命令式迭代结构混淆, 因为在 Clojure 中它不基于任何变异机制.
以下示例说明了 for 的一些特性, 这些特性将在本章中进一步解释:
(for [i (range 10) ; ❶ [k v] {:a "!" :b "?" :c "$"} ; ❷ :let [s (str i k v)] ; ❸ :while (not= :b k) ; ❹ :when (odd? i)] ; ❺ s) ;; ("1:a!" "3:a!" "5:a!" "7:a!" "9:a!")
❶ "i" 被声明为一个局部绑定, 并将在绑定和 for 宏的主体中进一步向下可见.
❷ "k" 和 "v" 也是局部变量, 表明在 map 上可以使用解构. 当 "i" 的第一个值被赋给时, "k" 和 "v" 将作为键值对 ":a !", ":b ?", 等等, 假设 map 中的所有值, 直到 "i" 和 "k v" 的所有排列都已形成.
❸ ":let" 表达式创建了一个额外的局部绑定, 它不是基于像 "i" 或 "k v" 那样的序列迭代.
❹ ":while" 表达式接受一个谓词, 该谓词对每个排列求值. 一旦谓词为假, :while 的存在就会停止当前的迭代 (在我们的例子中是 "k v" 迭代局部绑定对 map). 在这种情况下, 迭代将在 "k" 等于关键字 ":b" 时停止, 从而阻止该排列以及 map 中任何其他后续的排列进入最终结果.
❺ ":when" 过滤器的工作方式类似于 ":while" 过滤器, 通过阻止某些排列进入最终的结果序列. 与 ":while" 不同, 它不会影响在使谓词为假的那个之后的迭代中的其他元素.
(for [bindings] <body>) binding :=> bind-expr OR let-expr OR while-expr OR when-expr bind-expr :=> [<name> <range>] let-expr :=> [:let [<local> <name>]] when-expr :=> [:when <predicate>] while-expr :=> [:while <predicate>]
至少需要一个绑定对和一个非空的 "body".
- 在绑定表达式中的
"name"是任何可以表示局部变量的有效 Clojure 符号. 绑定的变量在其他绑定对和主体中可见, 加上任何后续的:let,:when,:while表达式. "range"是任何可以转换为序列的 Clojure 表达式, 使得(instance? clojure.lang.Seqable range)为真."let-expr","when-expr"和"while-expr"是可选的, 但可以出现多次. 它们不允许出现在绑定的开头, 至少必须先出现一个bind-expr.
for 返回: 一个 clojure.lang.LazySeq 实例, 这是通过应用以下规则收集的元素的惰性序列:
- 由包含序列的所有绑定表达式的排列给出的生成规则.
- 由可选的
:when和:while绑定表达式给出的过滤规则. - 由
"body"决定的组装规则.
- 示例
下表收集了一些
for的显著示例, 重点关注一些非平凡的方面. 每一行包含一个示例和描述.Table 4: "for" 宏的一些有趣方面. 描述 示例 :when 或 :while 依赖于多个局部绑定. 相当于基于局部绑定的函数 f(x1,x2,..xn) 的约束. 这是为了指出约束是灵活的, 可以一次依赖于多个局部绑定. (for [x (range 100) y (range 10) :when (= x (* y y))] [y x]);;([0 0] [1 1] [2 4] [3 9] [4 16] [5 25] [6 36] [7 49] [8 64] [9 81])使用无限惰性序列作为输入. for惰性地消耗输入序列, 因此我们可以使用无限序列作为输入, 可能会产生另一个无限序列作为输出.(take 6 (for [i (range) j (range) :while (< j 3)] (str i j)));; ("00" "01" "02" "10" "11" "12")无限惰性序列上的冲突约束. 当使用无限惰性序列时, 你需要小心不要创建导致永不结束迭代的冲突约束. 这里我们请求 3 个 "i" 等于 1 的元素, 但因为另一个绑定是在一个只有 2 个字母的序列上, "i" 将在我们能够收集到所请求的第三个元素之前切换到 2. for没有意识到无限的(range)将永远不会再包含值 1!;;; 警告: 永不结束. (take 3 (for [i (range) j ["a" "b"] :when (= i 1)] (str i j)))使用多个 :while 表达式. 可以用独立的 :while 绑定来约束输入序列. 每个 :while 都通过在谓词变为假时停止当前迭代来影响紧接其前的绑定表达式. (for [x (range) :while (< x 4) y (range) :while (<= y x)] (+ x y));; (0 1 2 2 3 4 3 4 5 6)以下是一个充分利用
for宏的完整示例. 康威的生命游戏是细胞自动机的一个经典例子 69. 细胞自动机是数学模型, 展示了由非常简单的规则反过来产生的高度复杂性 70. 它们通常被可视化为二维网格, 网格中的元素是细胞, 并应用规则来定义它们之间的相互作用, 如下图所示.
Figure 6: 一个 5x5 的生命游戏网格, 在初始状态和一次迭代后呈现一个" 闪烁体" . 方括号中的数字 [x y] 是细胞 [1 2] 邻居的坐标.
时间的流逝可以实现为一个离散的" 滴答" , 在此期间应用规则, 将细胞从死 (未着色的白色方块) 转换为活 (黑色方块), 反之亦然. 控制生命游戏的 4 条规则与某些生物体社会 (因此得名) 有某种类比:
- 健康: 任何有两个或三个活邻居的活细胞都会活到下一代.
- 繁殖: 任何有恰好三个活邻居的死细胞都会变成活细胞.
- 人口不足: 任何少于两个活邻居的活细胞都会死亡.
- 人口过剩: 任何多于三个活邻居的活细胞都会死亡.
以下示例展示了如何在 Clojure 中实现生命游戏. 由于
for可以轻松创建非平凡的序列, 我们可以用它来" 导航" 网格并定义邻居的含义:(defn count-neighbors [h w x y cells] (->> (for [dx [-1 0 1] ; ❶ dy [-1 0 1] :let [x' (+ x dx) ; ❷ y' (+ y dy)] :when (and (not (= dx dy 0)) ; ❸ (<= 0 x' (dec w)) (<= 0 y' (dec h)))] [x' y']) (filter cells) count)) (defn under? [n alive?] (and (< n 2) alive?)) (defn healthy? [n alive?] (or (and alive? (= n 2)) (= n 3))) (defn over? [n alive?] (and (> n 3) alive?)) (defn reproduce? [n alive?] (and (= n 3) (not alive?))) (defn apply-rules [h w x y cells] (let [n (count-neighbors h w x y cells) alive (contains? cells [x y]) should-live (or (healthy? n alive) (reproduce? n alive)) should-die (or (under? n alive) (over? n alive))] (and should-live (not should-die)))) ; ❹ (defn next-gen [h w cells] (into #{} (for [x (range 0 w) ; ❺ y (range 0 h) :when (apply-rules h w x y cells)] [x y]))) ;; testing a blinker: (next-gen 5 5 #{[2 1] [2 2] [2 3]}) ;; #{[1 2] [2 2] [3 2]} (next-gen 5 5 (next-gen 5 5 #{[2 1] [2 2] [2 3]})) ;; #{[2 1] [2 2] [2 3]}
❶
for的第一个应用是用来计算一个[x y]单元格的邻居. 在一个二维系统中, 单元格由 x 和 y 坐标标识 (像我们的情况一样), 寻找邻居的问题就是将坐标上下左右和对角线移动 (通过轮流递增和递减). 两个增量dx和dy是我们需要的排列范围.❷
for宏内部的:let表达式帮助我们定义在循环内可用的临时局部变量, 而它们不必是值推导的一部分 (就像dx和dy那样). 在:let中, 我们定义了通过递增或递减给定单元格[x y]找到的单元格.❸
:when为推导定义了一个过滤器. 在我们的情况下, 我们不想要[x y]单元格本身, 也不想要网格之外的单元格.❹ 所有规则的组合应用发生在
apply-rules函数内部, 该函数基本上是基于布尔逻辑进行操作. 这个结果稍后将在最后一个for宏中使用, 以保留或移除我们不希望在最终计算中出现的单元格.❺ 最后一个
for生成了一个大小为w,h的网格的所有可能的单元格坐标. 假设单元格坐标对的存在表示该单元格是活的, 我们的工作就是移除所有不会活到下一代的单元格. 同时, 我们希望其他单元格根据游戏规则变为活的. 这个过滤是通过另一个:when表达式实现的, 该表达式只是委托给apply-rules. - 另请参阅
while. 如果for是在没有可变变量的情况下进行迭代的函数式方式, 那么while是为那些需要副作用来控制循环的情况而提供的. 在 Java 互操作中使用while, 特别是当 Java 代码在某个你无法控制的外部库中, 需要显式地使用副作用来控制循环时.如果推导应该产生一个单调递增的整数序列,
range就足够了.map,filter和take-while在for内部的:let,:when和:while表达式中有些可比性. 当输入来自多个集合并应导致来自两者的元素排列时, 优先使用for, 避免嵌套的map表达式. 如果我们想为常见的扑克牌生成字符串编码, 那么以下内容:(for [i (range 1 14) a ["D" "C" "H" "S"] :let [card (str i "-" a)]] card)
应该优先于等效但更不易阅读的嵌套 map 版本:
(mapcat (fn [i] (map (fn [a] (str i "-" a)) ["D" "C" "H" "S"])) (range 1 14))
- 性能考虑和实现细节
=> O(n) 线性编译时间, n 为绑定数量
=> O(n
c) 多项式运行时, c 个绑定, 每个绑定有 n 个元素
for的计算复杂性主要是运行时方面. 在大多数情况下, 性能影响无需担心. 处理for宏的输出的性能配置文件与使用任何其他惰性序列 (有关使用惰性序列的性能影响的深入分析, 请参见lazy-seq) 的性能配置文件相同, 并且与产生的项目数量呈指数关系. 因此, 例如, 以下for宏有 5 个绑定表达式, 每个都包含一个 10 个元素的范围:(for [a1 (range 10) a2 (range 10) a3 (range 10) a4 (range 10) a5 (range 10)] (+ a1 a2 a3 a4 a5))
如果完全展开 (例如用
count), 生成的惰性序列将导致 "n" (每个范围中的元素数量) 的 "c" (绑定数量) 次方迭代步骤.for的惰性和丰富的功能可能不是性能重要的紧密循环的最佳解决方案. 在这种情况下, 使用自定义loop(甚至瞬态) 可能是更好的选择.实现细节主要与惰性序列的创建机制有关, 正如在对一个简单形式进行宏展开时可以看到的 (代码已经格式化和清理):
(macroexpand '(for [i (range 3)] i)) (let* [main-fn (fn recur-fn [xs] (lazy-seq (loop [xs xs] (when-let [xs (seq xs)] ; ❶ (if (chunked-seq? xs) (let [fchunk (chunk-first xs) chunk-size (int (count fchunk)) chunk-buff (chunk-buffer chunk-size)] (if (loop [i (int 0)] (if (< i chunk-size) (let [i (.nth fchunk i)] (do (chunk-append chunk-buff i) (recur (unchecked-inc i)))) true)) (chunk-cons (chunk chunk-buff) (recur-fn (chunk-rest xs))) ; ❷ (chunk-cons (chunk chunk-buff) nil))) (let [i (first xs)] (cons i (recur-fn (rest xs)))))))))] (main-fn (range 3)))
❶ 输入序列是根据它本身是否是惰性序列来进行迭代的.
❷ 输入序列的块使用
<lazy-seq>附加到输出惰性序列中.尽管不是最容易理解的代码, 但
for的主要目标是创建一个" 分块的" 惰性序列 (Clojure 惰性序列的默认实现). 该代码片段之所以复杂, 是因为输入序列需要根据它是否已经是惰性的来区别对待, 以便可以相应地迭代内部块: 从这个角度来看,for可以被认为是惰性序列构建的复杂机器.
自 1.0 版本以来的宏
(while [test & body])
while 迭代宏可能是最接近其他命令式语言中找到的循环结构的. while 接受一个测试表达式和一个主体, 并重复执行主体, 直到表达式求值为假. 因此, 除了主体返回的结果之外, 需要一些副作用来将测试表达式从真变为假. 例如, 以下代码片段在测试表达式中使用 rand 来退出 while 循环:
(while (> 0.5 (rand)) (println "loop")) ;; loop ;; loop ;; nil
rand 是一个不纯的函数, 因为最终的返回值取决于应用程序控制之外的东西 (通常是一些操作系统原语). while 的使用应限制在少数特殊情况下, 例如 Java 互操作, 因为 Clojure 中存在更多不需要副作用的惯用迭代形式 (例如, for 构建一个初始范围, 然后是 map 或 filter 函数). 尽管如此, 仍然有一些使用 while 的合法情况, 这将在示例中说明.
- 约定
- 示例
Java 中的
"while true"表达式在创建守护线程以与主应用程序并行运行任务时非常常见. 我们可以使用while来启动一个永不结束的循环, 例如, 在控制台输出上打印健康检查消息, 以监控应用程序的良好健康状况:(defn forever [] (while true ; ❶ (Thread/sleep 5000) ; ❷ (println "App running. Waiting for input..."))) (defn status-thread [] (let [t (Thread. forever)] ; ❸ (.start t) t)) (def t (status-thread)) ;; App running. Waiting for input... ;; App running. Waiting for input... ;; App running. Waiting for input... (.stop t) ; ❹ ;; nil
❶ 我们可以通过使用一个只能为真的表达式来创建一个无限的
while循环.❷ 我们让当前线程休眠 5 秒, 以防止输出消息泛滥.
❸ 线程通过简单地使用构造函数并传递它们需要执行的函数来创建. 然后线程立即启动.
❹ 在
while宏中使用的始终为真的表达式只能从循环体外部受到影响. 在这种情况下, 其结果是我们需要停止整个线程来停止循环.while通常与 Java IO 一起使用. Java IO 经常需要测试流的状态以了解何时到达末尾. 从流中读取字节的主要操作还有一个副作用, 即前进一个持有当前读取位置的" 光标" , 这正是我们希望在测试表达式中读取的. 以下 Clojure 代码计算了一个文件的 SHA-256 哈希值 71.注意
对于 Java 9 及以上版本,
javax.xml.bind包是与主 JDK 分开的, 需要添加到 classpath 的依赖项中. 有关更多信息, 请参阅以下 StackOverflow 问题 tinyurl.com/yd89g4qn.(import 'java.io.File 'javax.xml.bind.DatatypeConverter 'java.security.MessageDigest 'java.security.DigestInputStream) (require '[clojure.java.io :as io]) (defn sha [file] (let [sha (MessageDigest/getInstance "SHA-256")] ; ❶ (with-open [dis (DigestInputStream. (io/input-stream file) sha)] ; ❷ (while (> (.read dis) -1))) ; ❸ (DatatypeConverter/printHexBinary (.digest sha)))) ; ❹ (sha (File. "/etc/hosts")) ;; "04F186E74288A10E09DFBF8A88D64A1F33C0E698AAA6B75CDB0AC3ABA87D5644"
❶ 我们需要为我们需要的哈希类型获取一个
MessageDigest实例. 这里创建的sha实例持有 SHA-256 计算的当前状态, 并且可以在从输入流读取文件的每次读取时更新.❷
DigestInputStream实例是在sha实例之上创建的. 请注意,with-open用于在我们完成从下面一行读取流后自动关闭流.❸ 这里使用
while来持续从DigestInputStream读取, 直到它返回 "-1", 这是 Java 中常用的模式. 这个while形式在两个方面有副作用: 当文件中光标的状态超出文件末尾时, 表达式变为假, 并且最后因为它没有主体:sha实例仅通过从输入流读取来更新.❹ 计算出的
sha最终被转换为可读的形式.- 迭代和列表推导
命令式语言通常通过变异来实现迭代. 例如, 这是典型的 Java
do while循环:int count = 1; do { System.out.println("Count is: " + count); count++; } while (count < 4);
count可变变量需要在循环体中被改变, 以便循环在某个点退出 (这里使用++运算符进行改变). 函数式语言不支持 (或强烈不鼓励) 使用这种风格进行迭代, 而是偏好递归或列表推导.递归是通过一个调用自身的函数 (或多个相互递归的函数, 参见
trampoline) 来实现的, 将改变的变量作为下一次调用的参数传递. 下面的例子是将do whileJava 代码重构为 Clojure:(loop [count 1] (when (< count 4) (println "Count is:" count) (recur (inc count)))) ;; Count is: 1 ;; Count is: 2 ;; Count is: 3 ;; nil
如你所见, 改变的元素成为
recur函数的参数, 并且在每次迭代时递增. 与 Java 代码相比, 以前在while中的测试表达式在 Clojure 代码中被转换为一个when调用: 在loop-recur内部总是需要一个条件来退出循环, 这在递归代码中是典型的.列表推导则是从一个初始的值列表开始, 将许多处理步骤串联起来. 推导也可以用来模拟迭代, 但它超越了这一点, 形成了一种新的编程风格. 不是通过改变或递归地改变值来检查测试表达式, 而是首先组装所有值的序列, 然后从这些值开始构建计算. 如果我们看前面的例子, 我们可以像这样收集每次迭代中
count变量的不同值:(loop [count 1 res []] (if (< count 4) (recur (inc count) (conj res count)) res)) ;; [1 2 3]
一旦决定了迭代应该执行的值, 我们就可以使用序列操作函数来构建计算. 在这种情况下, 我们不需要
loop-recur只是为了构建从 1 到 4 的自然正数, 我们可以使用map或for:(dorun (map #(println "Count is:" %) (range 1 4))) (dorun (for [i (range 1 4)] (println "Count is:" i))) ;; Count is: 1 ;; Count is: 2 ;; Count is: 3 ;; nil
两种形式都通过向
println提供一个初始的值列表来产生与初始示例相同的输出. 我们可以在初始值生成之上添加更多的处理步骤, 模拟命令式语言中多个孤立循环的等价物. 得益于 Clojure 的map,for,filter,reduce(以及许多其他函数), 通过列表推导进行编程产生的代码比其命令式对应物更简洁, 更具表达力.
- 迭代和列表推导
- 另请参阅
for是在像 Clojure 这样的函数式语言中通过变异进行迭代的惯用替代方案. 它提供了一种强大的语法来生成驱动值, 以便用像map或filter这样的序列操作函数进行处理. 除非变异是迭代的重要组成部分, 否则优先使用for而不是while.loop是 Clojure 中许多类似迭代形式的共同底层, 也在while的实现中使用.loop提供了对迭代的更大控制, 包括局部绑定的定义. 当其他参数 (很可能没有副作用) 控制循环并应作为局部绑定变量出现时, 使用loop和recur. - 性能考虑和实现细节
=> O(1) 宏展开
=> O(n) 与循环次数成线性关系
while的性能考虑与dotimes非常相似, 与应用程序热点的相关性通常很小或不存在 (这当然不考虑while仅作为参数接收的表达式或主体的内存).就实现细节而言,
while是一个非常简单的宏. 例如, 请看本章开头介绍的rand示例的宏展开:(macroexpand '(while (> 0.5 (rand)) (println "loop"))) ;; (loop* [] ;; (when (> 0.5 (rand)) ;; (println "loop") ;; (recur)))
展开揭示了
loop-recur递归模式的基本用法, 并用一个when来验证表达式.
自 1.0 版本以来的宏
(dotimes [bindings & body])
dotimes 用于重复执行某部分代码多次. 要重复的形式作为宏的最后一个参数出现, 而第一个参数是一个绑定向量, 包含一个局部绑定和所需的重复次数, 例如:
(dotimes [i 3] (println i)) ;; 0 ;; 1 ;; 2 ;; nil
dotimes 是 Clojure 迭代器家族的一部分, 旨在处理有副作用的操作 (或实现惰性序列), 该家族还包括 doseq, doall, dorun 和 run!.
(dotimes <bindings> body) bindings :=> [local n]
"bindings"必须是一个只包含两个元素的向量."body"是任何数量的表达式, 将被求值零次或多次."local"是一个局部绑定变量的名称, 可以在"body"中使用."local"将在每次迭代时递增一 (除非"n"小于或等于零)."n"通常是一个正数, 因为负数和零会阻止"body"的求值.- 返回:
nil.
- 示例
dotimes的主要用例是处理副作用, 如返回的nil结果所证明的那样.dotimes可以在 REPL 中用于测量 Clojure 代码的性能, 例如:(time (dotimes [_ 1000000] ; ❶ (apply max (range 100)))) ;; "Elapsed time: 1305.668357 msecs" ;; nil
❶ 一种典型的
dotimes用法, 用于重复执行一些代码并计算总经过时间.为了测量上面
max的性能, 该形式被求值了大量的次数, 并用time测量了总的经过时间. 通过使用dotimes, 可以在使用更严谨的方法 (例如 Hugo Duncan 的 Criterium) 之前快速验证关于性能的假设.在 REPL 用法之外,
dotimes经常与副作用的执行相关联.dotimes提供的局部绑定变量非常适合数组访问操作. 以下示例展示了condp章节中介绍的fizz-buzz游戏的一个更快版本:(require '[criterium.core :refer [quick-bench]]) (defn fizz-buzz-for [n] ; ❶ (condp #(zero? (mod %2 %1)) n 15 "fizzbuzz" 3 "fizz" 5 "buzz" n)) (defn fizz-buzz-slow [n] ; ❷ (doall (map fizz-buzz-for (range n)))) (defn fizz-buzz [n] (let [res (transient [])] ; ❸ (dotimes [i n] (assoc! res i (fizz-buzz-for i))) ; ❹ (persistent! res))) ; ❺ (quick-bench (fizz-buzz-slow 1000)) ;; Execution time mean : 34.320885 µs (quick-bench (fizz-buzz 1000)) ;; Execution time mean : 28.308923 µs
❶
fizz-buzz-for是包含条件的函数, 该条件决定是否需要根据除数将数字替换为相应的字符串.❷
fizz-buzz-slow与之前完全相同, 只是添加了一个doall来完全实现惰性序列. 尽管声称这个版本较慢,fizz-buzz-slow仍然是解决该问题的一种非常惯用和自然的方式, 除非原始性能是重要因素, 否则应将其视为最佳解决方案.❸ 新的
fizz-buzz函数首先创建一个空的瞬态向量, 并使用dotimes在索引上执行副作用.❹ 这里使用
assoc!来在dotimes迭代的当前索引"n"处永久地改变瞬态向量.❺ 瞬态向量最终作为正常的持久化集合返回以供结果.
正如你从基准测试中看到的, 使用瞬态 72 会有明显的速度提升.
dotimes是执行向向量中添加元素的副作用的完美选择, 包括必要的递增索引.- 保留序列的头部
Clojure API 文档 (以及一般的 Clojure 文献) 经常警告不要" 持有头部" 或" 保留头部" 一个惰性序列. 惰性序列 (Clojure 中几种数据结构的默认设置) 的优点是它们不需要完全加载到内存中, 除了应用程序当前正在处理的部分. 惰性序列的行为当然对于" 大数据" 应用很重要, 因为输入可能比可用内存大得多.
在处理可能大的惰性序列时, Clojure 开发者需要特别注意不要保留头部 (或任何其他初始部分). 有时头部保留的问题很难发现 73, 但一个更明显的例子是使用像
doall这样的迭代器时, 它属于dotimes所属的同一家族.当
doall迭代一个惰性序列时, 它会强制项被实现. 由于doall返回已实现的集合, 集合中的所有项在某个时刻被强制加载到内存中, 阻止了垃圾回收. 虽然doall的行为有时是可取的, 但doseq,dorun和dotimes都设计为返回nil, 以避免在迭代产生集合时发生任何内存溢出.
- 保留序列的头部
- 另请参阅
doseq与dotimes非常相似, 但它支持扩展绑定, 包括多个局部变量和解构. 当dotimes提供的单个递增整数不足时, 优先使用doseq.doall接受一个序列作为输入, 并迭代该序列, 实现其项. 当迭代的唯一目标是实现一个惰性序列时, 使用doall.dorun与doall类似, 但返回nil而不持有序列的头部. 当输入是一个一旦实现就包含副作用项的序列时, 优先使用dorun. - 性能考虑和实现细节
=> O(1) 宏展开
=> O(n) 运行时执行
dotimes宏展开为一个loop-recur形式, 该形式执行 "body" 参数给定的次数. 宏在常数时间内展开, 循环几乎不增加执行主体的开销, 后者通常是算法的主要部分. 因此,dotimes的使用很少与性能热点有关. 例如, 这里是一个展开的形式 (为清晰起见略作清理):(macroexpand '(dotimes [i 3] (println i))) ;; (let* [n (long 3)] ;; (loop [i 0] ;; (when (< i n) ;; (println i) ;; (recur (unchecked-inc i)))))
值得注意的是, 为了使
loop-recur循环尽可能快, 数字绑定 (迭代执行的次数) 被转换为long并用unchecked-inc递增.
2.2.5. 3.5 集合处理一瞥
Clojure 标准库包含大量专门用于集合处理的函数和宏. 对于函数式语言来说, 这并非巧合, 因为算法往往是建立在一小组核心数据结构之上的 (而在其他范式中, 例如面向对象编程, 自定义对象及其关系也扮演着重要角色).
集合处理是如此重要, 以至于像 map 或 first 这样的函数在总体上是最常用的. 如果我们用本书索引中的函数和宏的名称 (大约 700 个) 来查询 GitHub (最大的 Clojure 项目公共存储库), 我们可以很容易地看到这一点:
| 名称 | 频率 |
|---|---|
ns |
394490 |
defn |
293918 |
require |
279210 |
let |
237654 |
def |
172983 |
refer |
163654 |
map |
159781 |
fn |
154482 |
str |
145899 |
nil? |
125109 |
use |
119952 |
test |
115419 |
first |
98908 |
get |
93911 |
true? |
91826 |
when |
91463 |
name |
90469 |
string? |
86492 |
if |
85942 |
keys |
85435 |
即使本节对集合 (更具体地说是" 序列" 类型) 所能做的事情只提供了一个小小的概述, 以下子集也足够强大, 足以让你入门:
first是方便的辅助函数, 用于获取集合的头部, 第二个元素或尾部.map是对元素应用转换的主要方式.filter根据谓词函数从集合中产生特定的元素.reduce可用于将集合收敛到最终结果, 该结果是通过以某种有意义的方式组合一组项获得的.
其他集合/序列函数将在它们的专门章节中进一步讨论 74.
- 3.5.1 first, second 和 last
自 1.0 版本以来的函数
(first [xs]) (second [xs]) (last [xs])
first,second和last是接受一个可序列化集合 (任何可以使用序列接口迭代的 Clojure 集合) 并提取其名称所描述位置的元素的函数. 它们可以像这样简单地使用:(def numbers '(1 2 3 4)) (first numbers) ;; 1 (second numbers) ;; 2 (last numbers) ;; 4
first,second和last是访问序列集合特定部分的更大函数组的一部分.最终是具体的集合类型来决定如何实现序列访问操作. 例如, 像集合和映射这样的无序集合也实现了
clojure.lang.Seqable:hash-maps: 当顺序迭代时, 一个 map 变成一个键值对的列表. 但是当获取元素时, 它们不一定遵循插入顺序:
(def a-map (hash-map :a 1 :b 2 :c 3 :d 4 :e 5 :f 6 :g 7 :h 8 :i 9)) (first a-map) ;; [:e 5] (second a-map) ;; [:g 7] (last a-map) ;; [:a 1]
sets: 与 hash-maps 类似, 它们没有排序的概念 (有关此目的, 请参见
sorted-set), 因此适用相同的不确定性因素:(def a-set #{1 2 3 4 5 6 7 8 9}) (first a-set) ;; 7 (second a-set) ;; 1 (last a-set) ;; 8
- 约定
- 示例
- first
一个常见的用例是将
first作为参数传递给高阶函数. 以下示例展示了如何使用first和map从一个小序列中仅提取第一个元素. 提取字符串的一部分 (在本例中是电话号码) 是一种常见情况:(def phone-numbers ["221 610-5007" "221 433-4185" "661 471-3948" "661 653-4480" "661 773-8656" "555 515-0158"]) (defn unique-area-codes [numbers] (->> numbers (map #(clojure.string/split % #" ")) (map first) ; ❶ distinct)) ; ❷ (unique-area-codes phone-numbers) ;; ("221" "661" "555")
❶ 此时, 包含整个电话号码的字符串已根据空格字符的位置被分割成两部分. 我们只需要区号, 所以我们请求第一个.
❷
distinct可用于去除序列中的重复项. 我们在这里用它来删除重复的区号.first的另一个用法涉及递归, 其中可能需要在继续处理其余部分之前对第一个元素进行操作. 例如, 这里有一个all-positives?函数, 检查所有给定的数字是否为正:(defn all-positives? [coll] (cond (empty? coll) true ; ❶ (pos? (first coll)) (recur (rest coll)) ; ❷ :else false)) ; ❸ (all-positives? (list 1 2 3)) ;; true (all-positives? (list -1 0 1)) ;; false
❶ 如果集合为空, 我们假设结果为真.
❷ 如果第一个元素不是正数, 我们就完成了,
cond返回假. 如果第一个元素是正数, 我们需要通过递归序列的其余部分来检查其他元素.❸ 在任何其他情况下, 我们返回假.
- second
从序列中提取第二个元素足够频繁, 以至于有一个专门的函数. 其中一个原因是, 数据处理中的许多中间步骤都涉及小列表, 与等效的
(first (rest xs))相比,second可以节省一些击键. 以下示例显示了一个来自不同地点的温度样本序列, 报告了当天记录的最高和最低温度. 最高温度出现在第一个元素之后. 我们可以像这样使用sort-by按第二个元素来提取最高温度:(def temp '((60661 95.2 72.9) (38104 84.5 50.0) (80793 70.2 43.8))) (defn max-recorded [temp] (->> temp (sort-by second >) ; ❶ first)) ; ❷ (max-recorded temp) ;; (60661 95.2 72.9)
❶
sort-by接受一个函数和可选的比较器来决定如何对序列进行排序. 这里我们使用second来定义三元组中的哪个元素应该用于排序. 第二个参数是比较器 > "大于", 用于按降序排序.❷ 排序序列后, 我们可以只丢弃所有内容, 除了现在位于顶部的最高记录温度.
- last
与
first和second类似,last可用于获取序列中的最后一个元素. 以下示例展示了last与re-seq和正则表达式的结合使用. 给定一个长的命令字符串, 我们想知道在发送消息之前最后设置的用户是谁, 假设用户是用消息中的语法user:username设置的:(def message "user:root echo[b] user:ubuntu mount /dev/so user:root chmod 755 /usr/bin/pwd") (last (re-seq #"user\:\S+" message)) ; ❶ ;; "user:root"
❶
re-seq返回一个匹配模式的列表, 在本例中是任何形式为 "user:colon-name" 的内容. - car, cadr 和 cdr
first和second与 Lisp 中与" cons 单元" 概念相关的类似函数car和cadr有某种关系. 而cdr则是rest的等价物, 与car一起是访问列表所有部分的基本要素: 例如,cadr只是(car (cdr x))的缩写, 使得可以访问列表中的第二个元素.尽管表面上相似, 这些函数的原始 Lisp 实现与当时硬件的限制有关. 在 Lisp 发明的 IBM 704 上, "car" 和 "cdr" 是寄存器 (部分) 名称: 分别是" 内容地址寄存器" 和" 内容递减寄存器" .
最初的 Lisp 实现使用内存" 字" 来分配列表, 将每个字分成两部分: 地址部分包含
(car x)的结果, 递减部分包含(cdr x)的结果. 这里有一个来自第一版 Lisp 程序员手册的图表, 展示了简单列表(A, (B,C), D)的内存结构:
Figure 7: 一个基于 cons 单元的简单列表的结构.
随后出现的许多 Lisp 实现都延续了将访问列表第一个和最后一个元素的函数命名为
car和cdr的传统, 即使硬件不再有这样的寄存器. 如今, Common Lisp, Scheme, Arc (以及许多其他) 仍然使用car和cdr及其所有组合, 而 Clojure 决定将它们命名不同, 以摆脱 Lisp 遗产的这一古老部分:Table 6: Lisp VS Clojure 列表访问函数的命名. Lisp Clojure carfirstcdrrest或nextcaarffirstcadrsecond或fnextcdarnfirstcddrnnextClojure 的名称可能稍微长一些, 但它们更好地传达了函数的语义.
- first
- 另请参阅
first,second和last只是访问序列部分的众多方法中的几种. 这些函数将在它们自己的部分中进行详细解释, 但以下是可用功能的一个有用摘要:next和rest返回丢弃序列第一个元素后剩余的部分. 它们在处理空集合的方式上有所不同.drop接受要从序列头部移除的元素数量, 不仅仅是第一个.drop-last和butlast丢弃最后一个元素并保留其余部分.take和drop-last从序列末尾移除元素并保留剩下的部分. 区别在于对 "n" 的解释:take将返回一个包含 "n" 个元素的集合,drop-last将确保最后的 "n" 个元素被移除.ffirst,nfirst,nnext和fnext是涉及包含其他序列的序列的常见操作的快捷方式. 第一个字母 "f" 或 "n" 表示第一个操作, 要么是first要么是next, 名称的其余部分表示第二个操作. 因此, 例如ffirst等价于(first (first xs)),fnext等价于(first (next xs))等等.nth是通过索引访问集合中元素的通用方法.rand-nth从序列中提取一个随机元素.nthrest和nthnext返回第 n 个元素之后的所有内容.
还有其他类似于上述的函数, 它们针对特定的集合类型进行了优化:
peek获取列表和队列的第一个元素. 向量的最后一个元素.pop返回除队列, 向量和列表的最后一个元素之外的所有内容.pop!返回瞬态向量的最后一个元素.get主要用于哈希映射, 但也适用于向量和字符串以获取特定索引处的元素. 它在集合上用于检查元素的包含情况.subvec专用于在某个索引 n 处分割向量.
- 性能考虑和实现细节
=> O(1) first 和 second
=> O(n) last
first和second是常数时间操作, 而last通常需要" 展开" 整个序列才能访问最后一个元素, 因此在 "n" 个输入元素的情况下呈线性性能. 关键在于first,second和last被设计为在序列或可以顺序迭代的集合上工作. 尽管其他集合类型也被接受为输入, 但它们需要被转换为序列, 这可能会产生次优的性能. 例如, 在向量上应避免使用last, 因为有性能更好的函数 (例如peek).下表显示了最常用的集合类型, 并在存在时建议了一个比
first或last更快的替代方案.注意
请注意, 在这里和书中的其他几个地方, O(1) 被用作 O(log32N) 的近似值. 对于大多数实际目的, O(log32N) 非常接近 O(1). 当差异重要时, 会适当地明确说明.
Table 7: 访问有序集合类型的头部或尾部的替代方法. 类型 示例 头部 尾部 PersistentList '(1 2 3)first, O(1)last, O(n)PersistentVector [1 2 3]nth/get, O(1)peek, O(1)PersistentQueue (import 'clojure.lang.PersistentQueue)(PersistentQueue/EMPTY)peek, O(1)last, O(n)PersistentTreeSet (sorted-set 1 2 3)first, O(1)(first (rseq s)), O(log n)PersistentTreeMap (sorted-map :a 1 :b 2)first, O(1)(first (rseq s)), O(1)PersistentArrayMap (array-map :a 1 :b 2)first, O(1)last, O(n)LongRange (range 10)first, O(1)last, O(n)LazySeq (for [i [1 2]] i)first, O(1)last, O(n)String "abcd"(.charAt "abcd" 0), O(1)(.length "abcd"), O(1)
- 3.5.2 map 和 map-indexed
自 1.0 版本以来的函数
(map ([f]) ([f c1]) ([f c1 c2]) ([f c1 c2 c3]) ([f c1 c2 c3 & colls])) (map-indexed ([f]) ([f coll]))
map是几乎所有函数式语言中的一个基本工具. 基本形式接受一个函数和一个集合, 并返回将函数应用于集合中每个元素的结果序列. 例如, 下面的代码反转了列表中每个数字的符号:(map - (range 10)) ;; (0 -1 -2 -3 -4 -5 -6 -7 -8 -9)
map-indexed的行为与map类似, 但为函数f增加了一个额外的参数, 即输入集合中当前项的索引. 例如, 我们可以使用map-indexed来构建一个带有整数键的 map, 给定一个项的集合:(into {} (map-indexed vector [:a :b :c])) ;; {0 :a, 1 :b, 2 :c}
- 约定
map的约定根据传递给输入的映射函数之后的集合数量而有所不同. "f" 最好是无副作用的, 因为map和map-indexed操作于惰性序列, 无法保证对 "f" 有特定的" 仅一次" 调用语义.让我们根据这些情况来划分约定.
(map f): 无输入集合
当仅用 "f" 调用
map时, 它返回一个变换器, 在变换器被调用之前, 不会执行 "f" 的实际调用.(map f coll): 单个集合作为输入
"f"被调用时带有 1 个参数, 并且可以返回任何类型."f"需要至少支持元数-1, 但也可以有其他的, 例如:(map - (range 10))."coll"是一个可以顺序迭代的集合, 因此(instance? clojure.lang.Seqable coll)返回真.- 返回: 一个惰性序列, 包含将
f应用于输入集合中所有元素的结果.
(map f c1 c2 & colls): 任意数量 "n" 的集合
"f"需要支持 n-参数调用, 其中 n 是集合参数的数量."f"可以返回任何类型."c1","c2", .. , &"colls"是" 可序列化" 的集合, 因此(instance? clojure.lang.Seqable c)为真.- 返回: 一个惰性序列, 包含将
f应用于所有第一个元素, 然后是第二个元素, 依此类推, 在最短的集合处停止."f"被多次调用, 首先是每个集合的所有第一项, 然后是第二项, 依此类推. 迭代在到达最短集合的末尾时停止的事实可以通过以下示例来说明:
(map str (range 10) ["a" "b" "c"] "hijklm") ;; ("0ah" "1bi" "2cj")
如你所见, 包含 3 个字母
["a" "b" "c"]的" 中间" 向量决定了map操作何时结束.str在每次调用时接收 3 个参数: "0 a h", "1 b i" 和 "2 c j".map-indexed的约定更具限制性:- 当仅用
"f"调用map时, 它返回一个变换器, 该变换器可以稍后被组合或应用. "f"必须是至少 2 个参数的函数, 返回任何类型.- 返回: 一个惰性序列, 包含将
f(idx,item)应用于集合中每个项的结果.
- 示例
map通常出现在数据转换中 (与filter一起), 为进一步处理准备数据. 在下面的例子中, 一系列信贷产品包含了一些基本数据, 如年利率和最低允许信贷额. 给定一个贷款金额和期望的年限, 我们希望输出我们将需要偿还的总额以及信贷成本. 最终结果为我们提供了一种比较我们希望借入的金额的最便宜信贷的方式:(def products ; ❶ [{:id 1 :min-loan 6000 :rate 2.6} {:id 2 :min-loan 3500 :rate 3.3} {:id 3 :min-loan 500 :rate 7.0} {:id 4 :min-loan 5000 :rate 4.8} {:id 5 :min-loan 1000 :rate 4.3}]) (defn compound-interest [product loan-amount period] ; ❷ (let [rate (inc (/ (:rate product) 100. 12))] (* loan-amount (Math/pow rate (* 12 period))))) (defn add-costs [loan-amount period] ; ❸ (fn [product] (let [total-cost (compound-interest product loan-amount period) credit-cost (- total-cost loan-amount)] (-> product (assoc :total-cost total-cost) (assoc :credit-cost credit-cost))))) (defn min-amount [loan-amount] ; ❹ (fn [product] (> loan-amount (:min-loan product)))) (defn round-decimals [product] ; ❺ (letfn [(round-2 [x] (/ (Math/ceil (* 100 x)) 100))] (-> product (update-in [:total-cost] round-2) (update-in [:credit-cost] round-2)))) (defn cost-of-credit [loan-amount period] ; ❻ (->> products (filter (min-amount loan-amount)) (map (add-costs loan-amount period)) (map round-decimals) (sort-by :credit-cost))) (cost-of-credit 2000 5) ;; ({:id 5 :min-loan 1000 :rate 4.3 :total-cost 2478.78 :credit-cost 478.78} ;; {:id 3 :min-loan 500 :rate 7.0 :total-cost 2835.26 :credit-cost 835.26})
❶ 在这个例子中, 产品列表很短并且在内存中. 它可能来自一个单独的来源, 并包含更详细的数据.
❷ 复利公式是维基百科版本 75 的直接翻译.
❸
add-cost是将两个新键注入输入产品的函数. 总付款和信贷成本是带有许多数字的双精度数.❹
min-amount返回一个依赖于请求贷款金额的谓词函数. 它将在下面的主计算中被filter使用.❺
round-decimals是我们与map一起使用的第二个函数. 在这种情况下, 给定一个产品, 我们希望将两个成本四舍五入到小数点后两位.update-in对于这个目标相对直接.❻ 最后, 我们用
->>将所有东西链接在一起. 过滤操作首先出现, 这样计算的下游部分接收的工作量就更少.从例子中我们可以看到, 对于我们借款 2000 并在 5 年内偿还的请求, 产品 id "5" 是最佳选择, 尽管其他产品如 id "1" 具有非常有竞争力的利率, 但它们不允许借款 2000.
现在是一个与
map-indexed相关的例子, 当我们想给集合中的元素关联一个序数 (通常是自然数) 时, 它会很方便, 这样就可以将它们与其位置关联起来.map-indexed为我们省去了显式传递一个范围的麻烦. 显示彩票的中奖票据可以是这样一个例子:(def tickets ["QA123A3" "ZR2345Z" "GT4535A" "PP12839" "AZ9403E" "FG52490"]) (defn draw [n tickets] ; ❶ (take n (random-sample 0.5 tickets))) (defn display [winners] ; ❷ (map-indexed (fn [idx ticket] (format "winner %s: %s" (inc idx) ticket)) winners)) (display (draw 3 tickets)) ;; ("winner 1: QA123A3" "winner 2: GT4535A" "winner 3: PP12839")
❶
draw接收彩票并执行 n 个中奖者的random-sample. 0.5 是集合中该元素成为最终序列一部分的概率. 请注意, 根据实际采样的彩票数量, 函数有可能返回少于 3 张彩票.❷
display使用map-indexed来将抽取的顺序 (从而获得更高的奖金) 与抽取的彩票交错, 并以良好的格式打印它们.- map 和 lambda 表示法
map是另一个早期的 Lisp 函数 (例如, 与eval或apply一起), 最初被称为maplist. Herbert Stoyan 在他的<早期 LISP 历史>论文中指出,maplist的要求可能导致了 lambda 表示法被引入 Lisp. 例如, 以下是一个很早期的微分函数diff的设计, 它利用maplist来返回另一个函数的导数:diff = (ctr(J) = 1 -> 0, ; ❶ car(J) = "x" -> 1, car(J) = "plus" -> consel("plus", maplist(cdr(J), K, diff(K))), ; ❷ car(J) = "times" -> consel("plus", maplist(cdr(J), K, consel( "times" -> consel( "plus", maplist(cdr(J), K, consel( "times", maplist(cdr(J), L, (L = K -> copy (L))))))))))
❶ 注意使用了 M-Expressions, 这是 Lisp 最初被设计来书写的方式.
❷
maplist的首次使用出现在这一行. 另请注意, 为了清晰起见, 添加了换行符, 但最初的 Lisp 应该写成单行连续的.我们不需要深入了解
diff应该如何工作的细节, 但我们可以看看maplist在这个片段中是如何使用的:maplist(cdr(J), K, diff(K))
在这个早期设计中 (1958 年初),
maplist接受 3 个参数: 一个项目列表 (例如(cdr(J))), 一个用于收集结果的目标列表 (K L) 和一个函数的实际调用 (diff). McCarthy 在发现按设计实现maplist不切实际后, 引入了 lambda 表示法. 以下是稍后某个时间重写的diff函数:diff(L,V) = (car(L)=const->copy(CO), car(L)= var -> (car (cdr(L)) = V -> copy(C1, 1->copy(C0)), car(L)= plus -> consel(plus, maplist(CDR(L), λ(J diff(car(J), V)))), car(L)= times-> consel(plus, maplist(cdr(L), λ(J, consel(times, maplist(cdr(L), λ(K, (J != K -> copy(car(K)), l->diff(car(K), V))))))))))
对
maplist的调用现在使用了 2 个参数, 如下片段所示:maplist(CDR(L), λ(J diff(car(J), V)))
第一个参数现在是要映射的列表 (例如 CDR(L)), 以及一个 lambda λ(J, f) 函数 J, 后跟函数体, 从而移除了传递一个列表 K 来保存结果的需要.
maplist最终出现在著名的 1960 年原始 Lisp 论文中, 定义如下:maplist[x; f] = [null[x] -> NIL; T -> cons[f[x]; maplist[cdr[x]; f]]]
maplist的定义可以解释为:maplist[x; f]是一个列表x和一个函数f的函数.- 当
null[x]时, 只返回NIL. - 在任何其他情况下, 返回
f应用于x与在集合x的其余部分和函数f上再次递归的maplist的cons.
在 Clojure 中, 这与当前的
map实现非常相似 (尽管在 Clojure 中, 这因将结果序列构建为惰性序列而变得复杂).
- map 和 lambda 表示法
- 另请参阅
mapcat在将f应用于一个项的结果又是一个序列时很有用, 总体结果是产生一个序列的序列.mapcat对结果列表应用最终的concat操作, 将结果展平.amap在 Java 数组上以与map相同的语义操作.mapv是map的一个专门版本, 它产生一个向量而不是惰性序列作为输出. 它内部使用一个瞬态, 因此比等效的(into [] (map f coll))更快.pmap在一个单独的线程中执行map操作, 从而创建一个并行的 map. 当处理函数f的总成本小于将f处理到单独线程的成本时, 用pmap替换map是有意义的. 长或其他消耗处理器的操作通常从使用pmap中受益.clojure.core.reducers/map是在 reducers 上下文中使用的map版本. 它具有与map相同的语义, 并且应该在 reducers 链的上下文中类似地使用.
- 性能考虑和实现细节
=> O(n) 与输入集合中项目数量 "n" 成线性关系
map需要的计算时间随着输入集合的增大而线性增加. 在分配的内存空间方面,map" 惰性地" 将f应用于输入集合中的项目, 这意味着f函数的实际求值只在某个上游需要更多元素时发生. 因此, 除非用户显式地持有输出序列的头部,map不会一次性加载所有处理过的项目. 例如, 请看以下内容:(let [res (map inc (range 1e7))] (first res) (last res)) ; ❶ (let [res (map inc (range 1e7))] (last res) (first res)) ; ❷
❶
last强制map对所有元素执行计算以返回序列中的最后一个元素. 由于在关闭作用域后没有其他东西需要局部绑定res, 除了最后一个之外的每个项目都可以安全地进行垃圾回收.❷ 这里首先请求了
(last res), 强制map遍历所有 10M 元素并递增它们. 与之前不同的是, 我们之后仍然需要res, 因为局部绑定的作用域中还有另一个指令. 这个第二个版本很可能会耗尽内存 (取决于硬件和 JDK 设置), 因为在first被求值之前, 输出集合的任何元素都不能被垃圾回收.尽管在约定部分我们笼统地谈论" 集合" 作为输入, 但通过查看实现, 我们现在可以更精确.
map在输入集合上调用seq, 这意味着输入集合必须实现clojure.lang.Seqable接口. 由于 Clojure 中几乎所有" 可迭代" 的东西都实现了Seqable, 我们可以谈论一个" 输入集合" , 但map技术上是一个序列输入序列输出的操作. 你可能对这个细节感兴趣的唯一原因是, 如果你想创建自己的序列, 并希望它与 Clojure 生态系统的其余部分很好地集成.
- 约定
- 3.5.3 filter 和 remove
自 1.0 版本以来的函数
(filter ([pred]) ([pred coll])) (remove ([pred]) ([pred coll]))
filter和remove是序列上非常常见的操作. 它们基于一个谓词 (一个返回逻辑真或假的函数) 来执行从序列中移除/保留一个项的相同操作:filter在谓词为真时允许该项通过.remove在谓词为真时阻止该项出现在结果序列中.
filter本质上是remove的补操作 (反之亦然):(filter odd? [1 2 3 4 5]) ;; (1 3 5) (remove even? [1 2 3 4 5]) ;; (1 3 5)
- 约定
"pred"是强制性参数. 它必须是一个接受 1 个参数并返回任意类型的函数 (该类型将被解释为逻辑真或假)."pred"最好没有副作用, 因为filter和remove操作在惰性序列上, 无法保证对"pred"有特定的" 仅一次" 调用语义."coll"可以是任何序列集合 (使得(instance? clojure.lang.Seqable coll)为真).- 返回: 一个 (可能为空的) 惰性序列, 其大小与输入序列相同或更小. 当
(true? (pred item))时,filter保留项, 而remove在相同的谓词结果下移除它们.
- 示例
filter和remove通常出现在处理管道中. 一些数据从一端进入管道, 并经过一系列变换以产生结果. 在进行任何其他昂贵计算之前, 移除不需要的元素通常是一个好主意. 因此, 像filter或remove这样的操作很可能出现在链的顶部. 本书中有一些值得回顾的filter示例:- 在情感分析示例中过滤出有趣的句子.
- 在 Levenshtein 距离示例中, 为词典按首字母准备索引.
filter在变换器链中也很常见, 如下面的示例, 用于在命名空间中查找最长的函数.
在本节中, 我们将展示一个
remove与some-fn结合的常见用法, 以移除计算过程中累积的某些类型的值. 在下面的例子中, 一个连接到气象站的传感器网络会产生定期的读数, 这些读数被编码为一系列 map. 每个 map 包含一些识别数据, 一个时间戳和一个包含所有可用传感器数据的有效负载. 一个潜在的问题是, 任何传感器都可能发生故障, 导致该特定键缺失或报告:error值. 我们希望能够处理此类事件并处理可能的错误:(def events [{:device "AX31F" :owner "heathrow" :date "2016-11-19T14:14:35.360Z" :payload {:temperature 62 :wind-speed 22 :solar-radiation 470.2 :humidity 38 :rain-accumulation 2}} {:device "AX31F" :owner "heathrow" :date "2016-11-19T14:15:38.360Z" :payload {:wind-speed 17 ; ❶ :solar-radiation 200.2 :humidity 46 :rain-accumulation 12}} {:device "AX31F" :owner "heathrow" :date "2016-11-19T14:16:35.362Z" :payload {:temperature :error ; ❷ :wind-speed 18 :humidity 38 :rain-accumulation 2}} {:device "AX31F" :owner "heathrow" :date "2016-11-19T14:16:35.364Z" :payload {:temperature 60 :wind-speed 18 :humidity 38 ; ❸ :rain-accumulation 2}}]) (def event-stream ; ❹ (cycle events)) (defn average [k n] (let [sum (->> event-stream (map (comp k :payload)) ; ❺ (remove (some-fn nil? keyword?)) ; ❻ (take n) (reduce + 0))] (/ sum n))) (average :temperature 60) ; ❼ ;; 61 (average :solar-radiation 60) ;; 335.200000004
❶ 此事件没有温度读数.
❷
:error的温度读数表示传感器无法测量温度.❸ 此其他事件没有太阳辐射读数.
❹ 为了模拟大量此类事件, 我们对它们进行迭代以创建一个无限序列.
❺ 注意我们如何使用
comp来访问一个深度嵌套的 map. 键必须以相反的访问顺序列出.❻ 类似地, 我们可以使用
some-fn和remove来防止reduce接收除数字以外的值. 如果我们不移除nil或:error元素,reduce会失败. 另请注意remove如何方便地出现在take之前, 这样我们就可以在计算平均值之前确保我们有请求的元素数量.❼ 考虑到每秒一个事件, 这 60 个事件的温度平均值将是最后一分钟的平均值.
注意
我们将在讨论
completing时, 用变换器来看到处理事件并计算其平均值的相同示例.- 将 filter 扩展到支持多个集合
map的一个很好的特性是能够传递多个集合作为输入参数. 通过传递一个可以接受多个参数 (每个集合一个) 的谓词函数pred, 我们可以以类似的方式扩展filter. 我们将这个新函数称为filter+:(defn walk-all "Returns a lazy-seq of all first elements in coll, then all second elements and so on." [colls] (lazy-seq (let [ss (map seq colls)] ; ❶ (when (every? identity ss) ; ❷ (cons (map first ss) (walk-all (map rest ss))))))) ; ❸ (defn filter+ ([pred coll] ; ❹ (filter pred coll)) ([pred c1 c2 & colls] ; ❺ (filter+ #(apply pred %) (walk-all (conj colls c2 c1)))))
❶ 我们使用
walk-all辅助函数来创建一个惰性序列, 该序列包含输入集合列表中的所有第一个元素, 然后是第二个元素, 依此类推, 当我们到达第一个集合的末尾时停止. 在此之前, 我们用seq确保所有集合都不为空.❷ 我们还需要确保没有到达任何一个集合的末尾. 我们可以通过检查
identity是否对序列中的每个元素都返回true来确保没有nil.❸ 我们通过用
cons将所有到目前为止的第一个元素和在walk-all对所有剩余元素的再次递归中来构建惰性序列.❹
filter+的基本元数只是调用filter.❺
filter+的扩展元数接受walk-all函数的结果, 并将谓词应用于所有第一个元素, 然后是第二个元素, 依此类推.与
map相比, 如何使用我们的新扩展filter+并不立即明显. 一个想法是将谓词视为一个接受多个参数的函数, 返回一个将被解释为逻辑真或假的结果. 例如, 我们可以只过滤那些包含至少一个与其在输入集合中出现索引实例的数字 (作为字符串):(filter+ re-seq ; ❶ (map re-pattern (map str (range))) ; ❷ ["234983" "5671" "84987"]) ;; ((#"1" "5671")) ; ❸
❶
re-seq是一个两个参数的函数, 正好是我们这个例子中两个集合输入所需要的.❷ 第一个集合从一个无限范围构建成一个正则表达式列表:
#"1",#"2"等等. 它使用一个字符串作为re-pattern的输入.❸ "5671" 出现在输入向量的索引 "1" 处, 并且包含数字 "1", 所以它出现在最终结果中.
- 另请参阅
keep是map和remove的交叉: 像map一样, 它将一个函数应用于一个序列, 像remove与nil?一样, 它从输出中移除nil. 当使用identity作为函数时, 它可以与(remove nil?)产生类似的效果:(keep identity coll).filterv是为向量优化的等效操作. 你应该在可以假定输入类型为向量时使用mapv, 因为在这种情况下操作要快得多. - 性能考虑和实现细节
=> O(n) 与输入元素数量 n 成线性关系
不出所料,
filter和remove需要遍历输入集合的所有元素才能返回结果, 从而产生线性的计算成本. 像map一样,filter惰性地操作, 因此同样的考虑也适用: 只有当请求整个输出时才会发生全部计算成本. 可以通过小心并且不" 持有序列的头部" 来避免全部内存分配成本 (再次, 请查看map性能部分以获取示例).从实现的角度来看,
filter与其他序列输入-序列输出的函数类似. 由于处理惰性和块的复杂性, 实现变得复杂, 以便可以正确处理不同的序列实现.
- 3.5.4 reduce 和 reductions
自 1.0 版本以来的函数
(reduce ([f coll]) ([f val coll])) (reductions ([f coll]) ([f val coll]))
reduce接受一个两个参数的函数. 在对第一个项 (或 "val", 如果提供) 调用该函数后, 它会继续用前一个结果对序列中的下一个项调用相同的函数. 在遍历输入序列的每一步中, 该函数都有机会用" 到目前为止的结果" 和下一个元素做一些事情.与本章中介绍的其他函数类似,
reduce是一个著名的函数式工具. 在描述序列 (或 Clojure 集合) 上的操作时,reduce经常与map和filter一起被提及, 因为它经常作为处理管道的最后一步出现. 以下示例显示了一个初始的数字列表, 该列表被转换为平方, 并且它们的总和用于计算平均值:(defn sum-of-squares [n] (->> (range n) ; ❶ (map #(* % %)) ; ❷ (reduce +))) ; ❸ (defn average-of-squares [n] (/ (sum-of-squares n) (double n))) (average-of-squares 10) ;; 28.5
❶
range产生初始数据集.❷
map将每个数字转换为该数字的平方.❸
reduce迭代到目前为止的结果, 将数字相加.reductions有助于可视化reduce的过程. 它具有与reduce相同的接口, 但它还输出所有中间结果:(reductions + (map #(* % %) (range 5))) ;; (0 1 5 14 30)
上面
reductions的输出是以下步骤的结果:(+ 0 0)是第一步. " 到目前为止的总和" 仍然是 0, 第一个元素也是 0.(+ 0 1)然后将" 到目前为止的总和" 加到序列中的第二个元素: 1.(+ 1 4)" 到目前为止的总和" 变为 1, 并将其加到范围中第二个数字的平方.(+ 5 9)倒数第二步继续相同的想法.(+ 14 16)序列最后一个元素的平方 16 被加到" 到目前为止的总和" . 没有更多的输入, 最后的求值是 "30".
由于
reduce和reductions之间的关系, 可以说, 给定一个集合 "coll" 和一个函数 "f":(= (reduce f coll) (last (reductions f coll))).reduce实现了典型的递归迭代过程 (其中增量结果出现在参数列表中), 并包含一个标准的词汇表:- " 累加器" 是赋予" 到目前为止的结果" 的名称. 在源代码中有时缩写为 "acc".
- " reducing 函数" 是两个参数的函数 "f". 请注意, " reducing" 不一定意味着输出是标量值或" 单个对象" . 你实际上可以将
reduce与哈希映射一起使用, 用新键来丰富它们 (参见约定后的示例部分). - " 折叠" 是
reduce所属的操作类别, 更具体地说是" 左折叠" . 这是因为输入集合的元素从左边逐渐被消耗, 就像我们在" 折叠" 序列一样.
- 约定
- 输入
"f"应提供 0 和 2 个参数的元数 (可用 0 或 2 个参数调用), 并且是必需参数. 0 参数版本仅在没有 "val" 初始值且集合为空或nil时调用:(reduce + nil) ; ❶ ;; 0 (reduce / []) ; ❷ ;; ArityException
❶ 集合为
nil, 因此(+)在没有参数的情况下被调用, 返回加法的单位元. ❷ 在空集合上抛出异常, 因为除法没有 0 元数调用."coll"也是必需的, 可以是nil或空. 如果"coll"不为nil,"coll"需要实现Seqable接口, 使得(instance? clojure.lang.Seqable coll)返回true(唯一不支持的类型是瞬态)."val", 当存在时, 用作计算的起始值, 而不是集合中的第一个项. 因此,(reduce + 1 [1 2 3])和(reduce + [1 1 2 3])是等价的. 当"coll"为nil或空时, 总是返回"val".
- 值得注意的异常
- 当
"coll"不是序列集合时 (瞬态和标量), 抛出IllegalArgumentException. - 当函数
"f"不支持零参数的元数且集合为nil或空时, 抛出ArityException.
- 当
- 输出
- 在 "coll" 包含至少一个项的最常见情况下,
reduce返回将 "f" 应用于 "val" (或缺少该项的第一个项) 和 "coll" 中的下一个项的结果. 然后将 "f" 应用于前一个结果和下一个项, 依此类推, 直到最后一个项. - 当 "coll" 只包含一个项时: 如果没有初始的 "val", 则返回该项. 如果提供了 "val", 则用 "val" 和该项调用一次 "f".
- 当 "coll" 为空或
nil时: 如果没有初始的 "val", 则在没有参数的情况下调用 "f". 如果提供了 "val", 则返回 "val".
reductions返回一个序列, 其中包含调用函数 "f" 的所有中间结果, 遵循相同的reduce规则. - 在 "coll" 包含至少一个项的最常见情况下,
- 输入
- 示例
reduce有广泛的应用 (通常与map和filter或其他基于序列的函数结合使用) 来准备输入.reduce也与大数据应用相关 76. 称为" map-reduce" 的计算模型通过将计算限制为map和reduce操作的混合来解决问题. 我们可以在计算文本中单词数量时看到 map-reduce 的主要思想:(defn count-occurrences [coll] (->> coll (map #(vector % 1)) ; ❶ (reduce (fn [m [k cnt]] ; ❷ (assoc m k (+ cnt (get m k 0)))) {}))) ; ❸ (defn word-count [s] (count-occurrences (.split #"\s+" s))) (word-count "To all things, all men, all of the women and children") ;;{"To" 1 ;; "all" 3 ;; "and" 1 ;; "children" 1 ;; "men," 1 ;; "of" 1 ;; "the" 1 ;; "things," 1 ;; "women" 1}
❶ 第一个操作是为列表中的每个项关联数字 "1".
❷ 接下来是
reduce, 用来" 减少" 同一键出现的多个 "1". 我们在这里将输入中的每个向量项解构为键 "k" 和值 "cnt" 的绑定.❸
reduce的起点是一个空 map. 我们assoc键 "k" 处的元素, 知道它可能找不到. 通过使用get来获取当前计数器, 我们可以为总和传递一个默认的初始化器 0.方便的是, 示例中的
count-occurrences函数可以处理任何项类型, 不仅仅是" 单词" (前提是项包含某种可以用来将它们存储在 hash-map 中的相等性定义). 更方便的是, Clojure 在标准库中已经包含了这样一个函数, 它叫做frequencies:(defn word-count [s] (frequencies (.split #"\s+" s))) ; ❶ (word-count "To all things, all men, all of the women and children") ;;{"To" 1 ;; "all" 3 ;; "and" 1 ;; "children" 1 ;; "men," 1 ;; "of" 1 ;; "the" 1 ;; "things," 1 ;; "women" 1}
❶ 自定义的
count-occurrences已被标准库中的等价物frequencies替换.标准库中的
frequencies实现与我们的count-occurrences非常相似 (增加了使用瞬态来提高性能). 虽然单词计数可以轻松地用frequencies解决, 但示例中说明的通用机制可以在其他更具体的场景中使用.现在让我们看一个涉及
reductions的例子.reductions被设计为跟踪 reducing 函数随时间的每次求值. 这个特性可能在显示时间序列时很有用, 比如" 移动平均线" . 这个技术在金融领域是众所周知的, 它被用来消除局部异常值并突出趋势 77. 下面的例子计算了股票价格的每个传入值的平均值 (但还有其他可能性, 比如将一天中的所有值批处理, 我们在这里为了移除一些复杂性而不考虑):(defn next-average [[cnt sum avg] x] ; ❶ (let [new-cnt (inc cnt) new-sum (+ sum x) new-avg (/ new-sum (double new-cnt))] [new-cnt new-sum new-avg])) (defn stock-prices [values] (reductions next-average [0 0 0] values)) ; ❷ (stock-prices [5.4 3.4 7 8.2 11]) ; ❸ ;; ([0 0 0] ;; [1 5.4 5.4] ;; [2 8.8 4.4] ;; [3 15.8 5.266666666666667] ;; [4 24.0 6.0] ;; [5 35.0 7.0])
❶
next-average是我们的 reducing 函数. 它将到目前为止的结果解构为一个计数器, 总和和最后计算的平均值. 然后它继续生成一个新的平均值, 该平均值存储在一个新的三元组中, 准备好为下一次迭代返回.❷
reductions用 reducing 函数, 一个全零的初始化三元组和一个值的集合来调用.❸ 调用
stock-prices的结果显示了所有生成的三元组. 如果我们只对平均值感兴趣, 我们可以对结果(map last), 忽略其余的.- 你需要右折叠还是左折叠?
早期的 Lisp 没有
reduce. "fold" (像reduce这样的运算符更通用的分类) 的概念最早在 1952 年 Stephen C. Kleene 的书<Introduction to Mathematics>中被提及, 并于 1962 年由 APL 引入主流编程 [fn:APL 是启发了许多其他语言特性的应用语言的一个例子. 更多信息请参阅 en.wikipedia.org/wiki/APL(programminglanguage). ]. 折叠可以看作是处理递归列表 (像 Lisp 中的 cons 单元那样的列表) 的一种机制, 这样列表就可以被归约为某个初始值. 我们可以像这样对一个数字列表求和:(def numbers (cons 1 (cons 2 (cons 3 (cons 4 (list)))))) ; ❶ (defn foldl [f init xs] (if (empty? xs) init (foldl f (f init (first xs)) (rest xs)))) ; ❷ (foldl + 0 numbers) ;; 10
❶
number被用典型的" cons-cell" 设计来定义, 以显示由foldl操作的列表折叠中的从左到右的移动.❷ 递归在每次迭代中" 展开" 列表, 将 "f" 应用于第一个元素和到目前为止的结果 (存储在 "init" 中).
以上是
reduce在 Clojure 中对列表如何实现的概念性说明 78. 该示例显示了在输入列表迭代的每个步骤中发生的情况. 第一次递归,"init"是(+ 0 1), 然后是(+ 1 2), 然后是(+ 3 3), 最后是(+ 6 4). 从视觉上看, 计算从左边开始应用 "f", 这就是为什么 Clojurereduce也被称为左折叠的原因. 另请注意foldl是如何进行尾递归的, 因为新的foldl调用是循环中的最后一个操作.还有另一种方法可以编写相同的操作, 即暂停 "f" 的应用, 直到我们到达列表的末尾:
(defn foldr [f init xs] (if-let [x (first xs)] (f x (foldr f init (rest xs))) ; ❶ init)) (foldr + 0 numbers) ;; 10
❶ 最后一个操作现在是在参数上调用 "f", 其中集合由对
foldr的递归调用表示.上面的实现也称为右折叠, 因为 "f" 的第一次调用是使用集合的尾部 (数字 4) 并且向后移动, 直到它到达头部以执行最后一个操作. 为了获得这种效果, 递归的
foldr调用发生在最后一行 "f" 的内部, 迫使计算暂停直到帧返回. 请注意foldr现在不是尾递归的, 并且可能会受到堆栈溢出的影响 (像 Haskell 这样的激进惰性语言反而有选择地在不耗尽堆栈的情况下很好地使用foldr).foldr和foldl之间的一个实际区别在于非关联操作, 其中消耗列表的顺序很重要. 例如, 像除法/这样的操作, 在foldl或foldr中的行为是不同的:foldl用/的展开将导致(/ (/ (/ (/ 1. 1.) 2.) 3.) 4.), 而foldr将产生等价于(/ 1 (/ 2 (/ 3 (/ 4 1.))))的结果, 从而产生不同的输出:(foldl / 1. numbers) ;; 0.041666666666666664 (foldr / 1. numbers) ;; 0.375
foldr不是 Clojure 标准库的一部分, 部分原因是尾递归问题, 部分原因是它可以用reverse轻松实现 (尽管性能成本更高):(defn foldr [f init xs] (reduce (fn [x y] (f y x)) init (reverse xs))) ; ❶ (foldr / 1. numbers) ;; 0.375
❶ 用
reduce和reverse实现的foldr. 注意, reducing 函数 "f" 需要交换其参数.
- 你需要右折叠还是左折叠?
- 另请参阅
reduce-kv是reduce对关联数据结构的类似物.reduce-kv接受 3 个参数: 一个 map 累加器和一个键值对, 而不是一个 2 个参数的函数. 在对 hash-map 进行 reduce 时, 优先使用reduce-kv.loop是几乎所有序列处理函数的共同底层. 总有一种方法可以将reduce转换为loop-recur, 在其中你可以自定义归约的所有方面, 包括在必要时传播类型.frequencies在示例中被提及为reduce的完美应用, 其中最终的数据结构通过遍历一个序列输入来增量创建.reduced是一组函数, 你可以用它来微调reduce或reductions的行为. 当序列中的一个元素是reduced?时,reduce停止计算并立即返回结果. 这种行为需要一个知道如何处理特殊元素的 reducing 函数:(reductions (fn [acc itm] (if (> itm 5) (reduced (+ itm acc)) ; ❶ (+ itm acc))) (range 10)) ;; (0 1 3 6 10 15 21)
❶ 如果一个元素被
reduced包装,reduce和reductions停止循环. - 性能考虑和实现细节
=> O(n) 与输入集合中项目数量 "n" 成线性关系
reduce的实现因输入类型而异, 协议如CollReduce和InternalReduce(在clojure.core.protocols命名空间中) 可用于新的集合实现以提供自定义的reduce. 以下图表显示了在几种集合类型和大小上调用的标准reduce: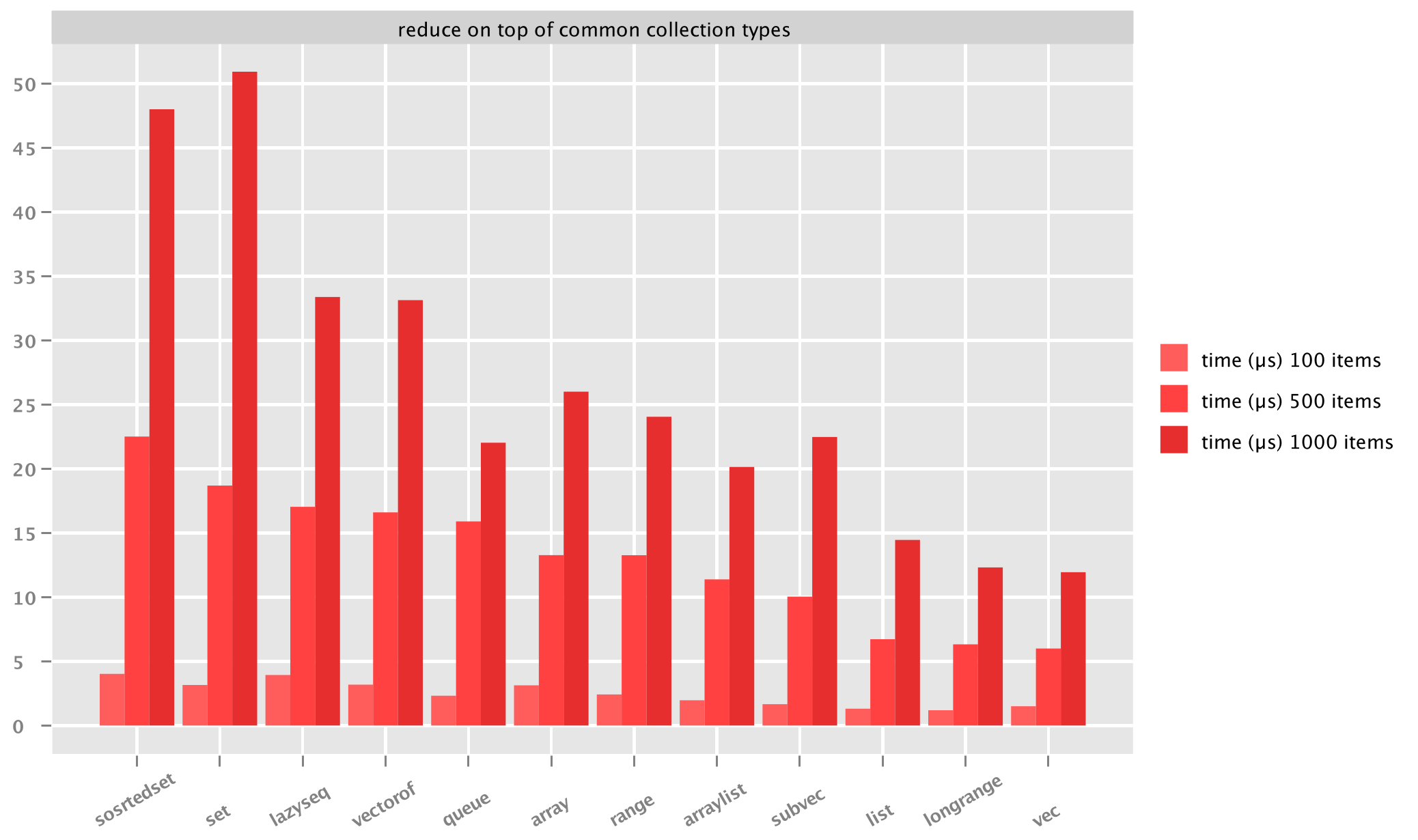
Figure 8: 在不同集合类型和大小上调用的 reduce. 数字越低表示执行越快.
该图表显示了
reduce在集合大小从 100 增加到 500 再到 1000 项时的线性行为. 它还显示了在集合上 (有序或无序) 的reduce大约比向量慢 5 倍, 向量是基准测试中最快的. 在绝对值上,reduce(尤其是在向量或列表上) 很难被超越, 即使是用loop-recur.reduce按设计遍历整个序列, 因此它不是惰性的 (尽管有办法使用reduced进行短路). 内存占用很大程度上取决于 reducing 函数. 假设 "f" 不会在内存中累积整个输入, 即使是大序列也可以在线性时间内被 reduce, 而无需担心内存不足:(let [xs (range 1e8)] (reduce + xs)) ; ❶ ;; 4999999950000000 (take 10 (reduce merge '() (range 1e8))) ; ❷ ;; java.lang.OutOfMemoryError: GC overhead limit exceeded
❶
+使用这些项来完成求和, 但在那之后它们可以被安全地进行垃圾回收, 导致在任何给定时间只有大集合的一部分在内存中.❷ 在这个第二个例子中, reducing 函数是
merge. 结果是一个与输入大小相同的集合, 迫使所有元素都进入内存. 可能的结果 (取决于 JVM 设置) 是一个内存不足错误.其他耗尽内存的情况不太容易找到:
(let [xs (range 1e8)] (last xs) (reduce + xs)) ; ❶ ;; OutOfMemory
❶ 对
last的调用发生在reduce之前. 由于它们出现在同一个形式中,xs的内容在reduce也有机会扫描序列之前不能被垃圾回收.last和reduce函数调用在孤立的情况下通常不会产生内存不足. 问题在于它们出现在同一个表达式中, 所以通常在last扫描序列时会启动的垃圾回收器无法运行, 因为reduce持有序列的头部, 阻止了垃圾回收.最后说一下本节也包含的
reductions. 尽管表现出相同的行为,reduce和reductions在性能上有很大的不同.reductions不是reduce的直接替代品, 因为它总是按顺序遍历输入集合, 而不管潜在的自定义reduce实现如何:(require '[criterium.core :refer [quick-bench]]) (let [xs (range 1000)] (quick-bench (last (reductions unchecked-add-int xs)))) ;; Execution time mean : 56.880736 µs (let [xs (range 1000)] (quick-bench (reduce unchecked-add-int xs))) ;; Execution time mean : 4.692101 µs ; ❶
❶ 值得注意的是,
reductions的性能与reduce不同, 两者不应互换使用.
2.2.6. 3.6 总结
本章包含了一系列强大的 Clojure 函数和宏. 选择它们是因为它们涵盖了编程的一些最重要方面, 例如条件分支, 迭代和集合处理的基础知识. 与其它语言相比, Clojure 广泛使用序列和集合, 但专门用于它们的函数列表很长, 因此它们被安排在各自的章节中.
但在我们讨论数据结构 (本书第三部分) 之前, 我们需要看到更多 Clojure 的基础知识, 例如宏 (第 4 章), 算术运算 (第 5 章), 相等性 (第 6 章) 和变换器 (第 7 章).
2.3. 4 创建和检视宏
感谢 Clojure 核心提交者 Nicola Mometto 贡献本章 (除了 definline).
可以说, 任何 LISP 最强大的方面之一就是它们能够定义自定义且任意复杂的宏, 而 Clojure 也不例外.
尽管许多语言都有宏的概念, 但 LISP 的宏完全是另一回事, 实际上为语言的用户提供了在其他语言中只有编译器作者才能拥有的表达能力.
鉴于其强大功能, 人们可能会期望宏是一个复杂且高级的功能, 但事实并非如此: 由于 Clojure 的同像性 79, 定义一个宏就像定义函数和操作数据一样简单:
宏实际上只是编译器在编译时调用的常规函数, 将它们的参数作为输入传递, 就像包装在一个隐式的 quote 调用中一样, 并返回一个在运行时求值的有效 Clojure 表达式.
宏可以用于各种原因, 从简单地减少重复代码量, 到允许代码以更简洁的方式表达, 再到编写复杂的 DSL 或嵌入小型编译器 80.
本章专门介绍标准库 (和语言) 中用于创建, 检视和帮助使用宏的设施. 这里是一个简要的总结:
defmacro是语言中创建宏的主要入口点. 宏的主体被赋给当前命名空间中新创建的 var, 并准备好被引用. 尽管一些 Clojure 设施也可以在宏之外使用, 但许多几乎只在创建它们时才出现 (例如syntax-quote). 我们将在说明defmacro时看到其中的一些.macroexpand是调试工具, 用于显示宏将如何处理一些输入而无需实际执行. " 展开" 的宏只是被打印出来以供检视.quote是一个函数, 它阻止对作为参数传入的内容进行求值. 它很简单, 但对于宏编程至关重要.gensym是一个辅助函数, 用于生成唯一的符号名称. 它是宏卫生 81 的一部分.definline接受一个主体, 并定义一个函数和一个该函数的" 内联" 版本. 内联版本与宏非常相似, 并共享相同的语法.destructure被标准库中的许多宏用来实现解构, 这是 Clojure 的一个关键特性.apply-template和do-template专用于在宏展开期间替换表达式中的符号.
2.3.1. 4.1 defmacro
自 1.0 版本以来的宏
(defmacro [name & fdecl])
defmacro 对宏的作用, 就如同 defn 对函数的作用一样, 但函数在编译后求值, 而宏则在其主体编译时求值.
这给了宏一个机会来改变编译器的输出, 包括在参数被求值之前拦截它们 (这在普通的 Clojure 函数中是正常情况). 作为一个宏本身, defmacro 的行为可以通过 macroexpand 来揭示:
(macroexpand '(defmacro simple [a] (str a))) ; ❶ ;; (do ;; (clojure.core/defn simple ([&form &env a] (str a))) ; ❷ ;; (. (var simple) (setMacro)) ; ❸ ;; (var simple)) ; ❹
❶ 被定义的宏只是返回其唯一参数的字符串转换.
❷ defmacro 产生一个以调用 defn 开始的 do 块, 定义了一个最初只是函数的东西. 如你所见, 生成的函数自动添加了两个参数, &form 和 &env, 其含义将在本章后面解释.
❸ 一旦函数被定义, 它就被转换为一个宏, 直接访问前一行刚刚在当前命名空间中 intern 的 clojure.lang.Var 对象.
❹ 最后一个形式返回刚刚创建并被设置为宏的 var 对象.
因为 defmacro 是建立在 defn 之上的, 它支持其所有特性, 包括多重元数, 解构, :pre 和 :post 条件等等. 请检查 defn 的约定和示例以了解这些特性.
Clojure 标准库提供的所有宏都是用 defmacro 本身定义的 (除了需要先定义的 defn). 例如, 这是 when 的定义方式:
(defmacro when "Evaluates test. If logical true, evaluates body in an implicit do." ; ❶ {:added "1.0"} ; ❷ [test & body] (list 'if test (cons 'do body))) ; ❸
❶ 文档化宏的字符串需要在宏的名称和参数声明之间. ❷ 这里有一个额外的元数据 map. ❸ 宏主体返回一个列表. 由于宏在编译时执行, 该列表被求值 (基本上是移除 "list" 并用适当的展开替换 "test" 和 "body") 并在调用站点" 内联" .
我们可以用 macroexpand-1 来验证预期的行为, 为清晰起见, 它不会进一步展开超过第一层:
(macroexpand-1 '(when (= 1 2) (println "foo"))) ;; (if (= 1 2) ; ❶ ;; (do (println "foo"))) (when (= 1 2) ; ❷ (println "foo")) ;; nil
❶ 传递给宏的参数不像普通函数调用那样被求值, 而是作为它们的引用值传递给宏, 并返回一个有效的 Clojure 表达式.
❷ 因为 when 是作为一个宏实现的, 所以只有当测试表达式返回真时, 主体表达式才会被求值. 这用普通函数是无法实现的. b .约定
- 输入
defmacro使用与defn相同的语法. 邀请读者回顾defn以获取完整的选项集."name"必须是有效的 Clojure 符号."name"用作宏的名称, 是必需的."fdecl"通常作为参数向量和主体给出. 参数向量总是添加 2 个隐式参数,&form和&env.
- 输出
defmacro返回一个引用刚创建的宏的clojure.lang.Var对象. 宏"name"作为副作用在当前命名空间中变得可用.注意
defmacro对固定参数数量的硬性限制不是 20 而是 18, 因为有 2 个隐式参数.
最常见的用法之一是 with- 风格的宏, 这是一类宏, 它们在定义的上下文中执行其主体, 自动执行一些日志记录或清理逻辑.
这里有一个这样的宏的用法示例, 应用于联系某个涉及网络调用的第三方服务的问题. 当涉及网络时, 应用程序需要始终为最坏的情况做准备, 例如间歇性连接, 无法访问的主机等等. 因此, 一个常见的模式是跟踪网络错误, 并在完全放弃并引发适当的错误之前, 重试联系第三方服务一定次数:
(defn backoff! [attempt timeout] ; ❶ (-> attempt (inc) (rand-int) (* timeout) (Thread/sleep))) (defn frequently-failing! [] ; ❷ (when-not (-> (range 30) (rand-nth) (zero?)) (throw (Exception. "Fake IO Exception")))) (defmacro with-backoff! ; ❸ [{:keys [timeout max-attempts warning-after] :or {timeout 100}} & body] `(letfn [(warn# [level# n#] ; ❹ (binding [*out* *err*] (println (format "%s: expression %s failed %s times" (name level#) '(do ~@body) ; ❺ n#))))] (loop [attempt# 1] ; ❻ (when (not= :success (try ~@body :success (catch Exception e#))) (when (= ~warning-after attempt#) (warn# :WARN attempt#)) (if (not= ~max-attempts attempt#) (do (backoff! attempt# ~timeout) (recur (inc attempt#))) (warn# :ERR attempt#)))))) (with-backoff! ; ❼ {:timeout 10 :max-attempts 50 :warning-after 15} (frequently-failing!)) ;; WARN : expression (do (frequently-failing!)) failed 15 times ;; nil
❶ backoff! 函数实现了一个简单的退避算法: 接受尝试次数和一个超时作为输入, 然后选择一个 0 到尝试次数之间的随机数 n, 并休眠 n*timeout 毫秒.
❷ frequently-failing! 函数模拟了一个经常失败的函数, 只有 1/30 的几率成功.
❸ with-backoff! 宏接受一个定义所需退避行为的 map 和一个在该退避上下文中执行的主体.
❹ 我们立即在宏的返回表达式上使用语法引用, 确保我们返回一个表示程序的数据结构, 而不是执行那个程序. 我们立即利用了语法引用相对于普通引用的额外特性, 对我们定义的局部函数及其参数都使用了 gensym 特性. 特别是, 我们定义的 warn 函数将处理向 *err* 打印警告或错误消息, 报告重试次数和正在重试的表达式.
❺ 这里我们使用了语法引用的非引用拼接特性, 将表达式列表拼接到一个 do 主体中. 请注意, 例如, 如果我们将 with-backoff! 定义为一个接受匿名函数的函数, 这种级别的报告将是不可能的, 因为函数无法访问它们被传递的参数的实际表示.
❻ 宏然后发出一个循环, 在其中求值主体. 如果其求值导致异常, 异常被捕获, 我们继续进行潜在的退避和重试, 否则循环简单地返回.
❼ 这里我们演示了 with-backoff! 的用法, 使用之前定义的 frequently-failing! 函数作为其主体, 退避超时为 10 毫秒, 最大尝试次数为 50 次, 并告诉宏在 15 次执行其主体失败后打印一个警告.
- 语法引用
尽管语法引用 (由反引号标识) 的使用不一定与编写宏相关, 但它是其最常见的用例. 语法引用是引用的表亲, 它提供了四个重要特性, 使其成为编写宏的完美工具: 符号的自动限定, gensym (
#), 非引用 (~) 和非引用拼接 (@).符号的自动限定是语法引用的一个特性, 它使得在语法引用表达式中使用的每个符号字面量都会自动用该符号解析到的命名空间进行限定, 或者如果无法解析, 则用当前命名空间进行限定. 举个例子:
(require '[clojure.string :as s :refer [lower-case]]) `s/upper-case ;; clojure.string/upper-case `lower-case ;; clojure.string/lower-case `foo ;; user/foo
自动 gensym 是在语法引用表达式中产生非限定符号的两种方法之一: 如果一个符号以
#结尾, 语法引用会自动在该符号的末尾附加一个唯一的标识符, 就像通过gensym一样:`(let [x# 1] x#) ;; (clojure.core/let [x__37__auto__ 1] x__37__auto__)
在语法引用表达式中产生非限定符号的唯一其他方法是使用 ~' (波浪线-单引号) " 模式" : 通过对一个引用的符号进行非引用, 语法引用将不会尝试限定或 gensym 该符号, 而是会嵌入非引用的符号:
`[foo foo# ~'foo] ;; [user/foo foo__45__auto__ foo]
强烈不鼓励使用波浪线-单引号" 模式" : 自动限定和 gensym 特性的原因是为了避免 LISP 宏的古老问题, 即意外的符号捕获, 而无需实现纯粹的卫生宏系统 82, 而这个" 模式" 绕过了这些安全措施. 确实有合法的情况需要这种行为 (一些实例出现在 clojure.core 代码库本身中), 但它们极为罕见, 通常只在非常复杂的上下文中才需要.
非引用是将语法引用转变为 Clojure 表达式的完整模板引擎的转义机制. 通过在从语法引用上下文中使用的表达式前加上非引用符号 ~, 该表达式将被正常求值, 而不是被引用, 并且其求值结果将嵌入到语法引用表达式中:
`[1 2 (+ 1 2) ~(+ 1 2)] ;; [1 2 (clojure.core/+ 1 2) 3] ; ❶
❶ 方括号内的所有内容都应被引用且不求值, 但非引用 (波浪线) 会为其前面的形式 (包括其所有内部形式) 暂时开启正常的求值引擎.
非引用拼接是语法引用的最后一个强大功能: 它不仅像非引用 (波浪线) 一样起作用, 而且假设返回的值是一个集合, 它将该集合的每个元素拼接到外部表达式中, 该表达式本身也必须是一个集合:
`[1 2 ~[3 4] ~@[3 (+ 1 2)]] ;; [1 2 [3 4] 3 3] ; ❶
❶ 非引用拼接 (波浪线-@) 会开启求值并将后续形式视为一个集合.
如果出现以下情况, 非引用拼接将导致抛出异常:
- 首先, 它不是在语法引用内部使用的.
- 要拼接的值不是一个集合 (或
nil). - 它不是在集合内部使用的.
例如:
[~@[1 2]] ;; java.lang.IllegalStateException: Attempting to call unbound fn: #'clojure.core/unquote-splicing `[~@:foo] ;; IllegalArgumentException Don't know how to create ISeq from: clojure.lang.Keyword `~@[1] ;; IllegalStateException splice not in list clojure.lang.LispReader$SyntaxQuoteReader.syntaxQuote
- &form 和 &env 隐式参数
前面提到过, 宏有两个隐式参数:
&form和&env, 虽然很少使用, 但在编写复杂的宏时它们会很有用. 让我们来看看它们是关于什么的:- &form
这个几乎是不言自明的:
&form将解析为当前宏被调用的原始形式 (作为数据). 一个例子胜过千言万语:(defmacro just-print-me [& args] ; ❶ (println &form)) (just-print-me foo :bar 123) ; ❷ ;; (just-print-me foo :bar 123) ;; nil
❶ 我们定义了
just-print-me宏, 它完全如其名所示: 它打印正在被调用的形式并返回nil.❷ 对这个宏的快速调用显示它的行为符合预期, 精确地打印了正在被调用的形式.
有些人可能会观察到, 前面的宏可以在不需要
&form的情况下重写, 就像这样:(defmacro just-print-me [& args] (println (apply list 'just-print-me args)))
那么
&form的意义何在呢? 答案有两个方面:&form对可能的重命名具有弹性. 如果我们重命名了之前的宏, 我们也必须重命名它的主体以反映这一变化.&form让我们能够访问原始形式的元数据. 这也许是它存在的最重要的原因, 允许宏作者将宏的用户附加的元数据传播到生成的形式. 这对于保留附加到宏调用上的类型提示特别有用.
- &env
这个隐式参数将持有一个在宏展开时可用的局部绑定的 map. 键将是局部符号, 值将持有这些局部绑定的未文档化的内部编译器表示.
只有少数宏会需要使用
&env, 而需要访问这个 map 的值部分的宏则更少 83.这里有一个宏的例子, 它通过自动将所有可用的词法绑定转换为它们的
toString表示来使用&env:(defmacro with-locals-to-string [& body] (let [locals (vec (keys &env))] ; ❶ `(let [~locals (mapv str ~locals)] ; ❷ ~@body))) (let [a 1 b [:foo :bar]] (with-locals-to-string [a b])) ; ❸ ;; ["1" "[:foo :bar]"]
❶
with-locals-to-string宏使用(keys &env)检索在宏展开时可用的局部符号, 并将它们放入一个向量中, 以便可以在解构let中使用该向量.❷ 然后它发出一个包装主体的解构
let语句, 其中每个局部变量将被重新绑定到对其自身调用str的结果.❸ 这里有一个如何使用
with-locals-to-string的例子. 不幸的是, 无法在保留词法上下文的情况下使用macroexpand-1来检查使用&env的宏, 但这就是该表达式将宏展开成的样子:(let [a 1 b [:foo :bar]] (let [[a b] (mapv str [a b])] [a b]))
- &form
- LISP 宏简史
尽管宏如今是所有 LISP 的一个基本和标志性特性, 但宏并不存在于 McCarthy 最初的 LISP 论文中, 事实上, 它们在第一个 LISP 实现后的半个多世纪才开始出现在 LISP 实现中 84.
在宏被提出之前的几年里, 一些 LISP 实现有一些类似的东西:
fexpr, 像宏一样接受未求值的参数, 但不求值返回值的函数.fexpr中唯一发生的求值是其主体的求值; 用 Clojure 的话说, 一个伪fexpr可以实现为一个返回包装在额外quote中的值的宏:(defmacro deffexpr [name args & body] `(defmacro ~name ~args (list 'quote (do ~@body)))) (deffexpr if-pos [test then else] (if (pos? (eval test)) (eval then) (eval else))) (if-pos 1 (println "pos") (println "neg")) ;; pos ;; nil
宏后来被提出, 并迅速取代了
fexpr, 因为它们对人类来说更容易理解, 并且允许编译器在优化表达式方面做得更好 85. 时至今日, 仍有少数次要的 LISP 使用fexpr而不是宏, 例如 newLISP 86 和 PicoLisp 87.LISP 宏的演变并没有随着它们的提出而停止, 不同的 LISP 有不同的实现, 因此提供了不同的行为: 例如, MIT PDP-6 LISP 在函数调用时动态展开宏, 而不是在函数定义时. 这有一个优点, 即允许宏重新定义而不需要重新定义使用这些宏的函数, 但要求解释器每次都展开相同的宏调用, 从而降低了执行速度.
LISP 宏演化时间线上的一个巨大飞跃发生在 70 年代中期, ZetaLisp 中引入了语法引用模板系统. 这使得宏可以用明显更简洁的风格编写, 也让普通人能够编写宏 (当时编写复杂的宏被认为是只有真正的专家才能做的事情).
在 80 年代, 宏卫生的问题出现了, 并导致 Scheme 与当时另一个主要的 LISP, Common Lisp, 显著分化. Common Lisp 试图通过指示程序员使用
gensym来回避这个问题 (Clojure 使用与 Common Lisp 相同的宏风格, 但不是依赖用户使用gensym, 而是通过在语法引用表达式中自动限定符号来强制他们这样做), 而 Scheme 则认为defmacro风格的宏太难写, 既允许在宏主体中进行任意计算, 又迫使用户处理宏卫生和手动解析等问题.为了解决这些问题, Scheme 放弃了
defmacro风格的宏定义, 转而支持define-syntax,syntax-rules以及后来的syntax-case. 这些原语允许用户通过简单地用 BNF 88 风格定义输入语言并声明一个转换来创建宏作为语法转换器, 这里有一个when宏在 Scheme 中如何定义的例子 (注意没有显式的引用/非引用):(define-syntax when (syntax-rules () ((when pred body ..) (if pred (begin body ..)))))
在 Clojure 中有几个库实现了类似的功能, 并且 Clojure 本身可能会在未来的版本中包含类似的东西 89.
eval 是一个提供与宏相反功能的函数, 它接受一个引用的表达式并求值它.
当调试或试图理解一个宏时, macroexpand 是非常有价值的函数, 它允许在绕过求值器的情况下检查宏调用的结果.
quote 是一个特殊形式, 用于阻止编译器求值一个表达式. 从概念上讲, 一个宏可以通过适当地组合 eval 和 quote 来模拟.
definline 模糊了 defn 和 defmacro 之间的区别, 定义了一个在非高阶上下文中也可以作为宏的函数.
=> O(1) 常数时间宏生成
defmacro 在编译时求值, 与应用程序在运行时的性能分析不是特别相关. 尽管对参数进行了迭代, 但考虑到 18 个的硬性限制, defmacro 在所有实际用途中都是常数时间.
编译器在分析一个设置了宏标志的函数时实现了不同的行为. 当这样的标志为真时, 编译器会继续分析主体 (以及主体内部的任何进一步的宏调用), 直到无法再进行扩展, 即当最内层的 var 不再被标记为宏时. 递归分析步骤的存在是区分宏与普通函数的地方, 普通函数会直接调用生成的 Java 类. macroexpand 允许用户调用递归分析过程, 并在求值步骤之前停止.
2.3.2. 4.2 macroexpand, macroexpand-1 和 macroexpand-all
自 1.0 版本以来的函数
(macroexpand form) (macroexpand-1 form) (clojure.walk/macroexpand-all form)
编写宏有时可能是一种令人困扰的经历, 调试一个行为不当的宏可能是一场真正的噩梦. 当一个人发现自己处于这两种情况之一时, macroexpand, macroexpand-1 和 clojure.walk/macroexpand-all 这组宏展开函数就是求助的工具. 这组宏展开函数几乎只在 REPL 中使用, 要么是为了理解一个宏如何工作, 要么是作为编写或调试宏时的辅助工具. 它们都在输入形式上执行宏展开步骤, 而不求值结果, 而是返回它:
(macroexpand-1 '(when false (println "this will never be printed!"))) ; ❶ ;; (if false (do (println "this will never be printed!")))
❶ 宏展开一个简单的 when 形式的结果. 请注意, 需要使用语法引用 (') 以便 Clojure 运行时不会立即求值该形式.
macroexpand-1, macroexpand 和 clojure.walk/macroexpand-all 之间的区别在于它们在返回之前将宏展开多深:
macroexpand-1只对最外层的形式执行一次宏展开, 并立即返回 (因此有 -1 后缀).macroexpand反复宏展开所有最外层的表达式, 直到它们不再返回一个宏, 但不进入潜在的内层形式.macroexpand是最常用的宏展开.
-clojure.walk/macroexpand-all 的行为类似于 macroexpand, 但在必要时会宏展开第一个形式内部的其他形式.
- 约定
- 示例
这里有一个在同一形式上使用所有三种
macroexpand*变体的例子, 展示了它们工作方式的差异:(macroexpand-1 '(when-first [a [1 2 3]] (println a))) ; ❶ ;; (clojure.core/when-let [xs__5218__auto__ (clojure.core/seq [1 2 3])] ;; (clojure.core/let [a (clojure.core/first xs__5218__auto__)] ;; (println a))) (macroexpand '(when-first [a [1 2 3]] (println a))) ; ❷ ;; (let* [temp__4670__auto__ (clojure.core/seq [1 2 3])] ;; (clojure.core/when temp__4670__auto__ ;; (clojure.core/let [xs__5218__auto__ temp__4670__auto__] ;; (clojure.core/let [a (clojure.core/first xs__5218__auto__)] ;; (println a))))) (clojure.walk/macroexpand-all '(when-first [a [1 2 3]] (println a))) ; ❸ ;; (let* [temp__4670__auto__ (clojure.core/seq [1 2 3])] ;; (if temp__4670__auto__ ;; (do ;; (let* [xs__5218__auto__ temp__4670__auto__] ;; (let* [a (clojure.core/first xs__5218__auto__)] ;; (println a))))))
❶
macroexpand-1在输入形式上只运行一次宏展开器, 正如我们所见,when-first宏展开为when-let,seq和let的组合.❷
macroexpand在形式上循环macroexpand-1, 直到第一个元素不再解析为宏为止, 在这种情况下, 它将运行 3 次:when-first宏展开为when-let表达式,when-let宏展开为let表达式,let宏展开为let*表达式.❸
clojure.walk/macroexpand-all遍历表达式, 对每个子形式运行宏展开, 使用广度优先遍历. 返回形式中的所有宏调用都已完全宏展开.虽然
macroexpand*函数几乎只在 REPL 中用于交互式探索和调试, 但它们在代码中也可用于实现真正复杂的宏或工具实用程序. 在下面的示例中, 我们使用macroexpand-all和clojure.walk/walk来近似地找到另一个函数调用的所有函数:(require '[clojure.walk :as w]) (defn find-invoked-functions [expression] ; ❶ (let [!fns (atom #{}) ; ❷ walkfn! (fn walkfn! [expr] (if (and (seq? expr) (symbol? (first expr))) ; ❸ (let [head (first expr)] (when-not (= 'quote head) ; ❹ (some->> head resolve (swap! !fns conj)) (w/walk walkfn! identity expr))) (when (coll? expr) ; ❺ (w/walk walkfn! identity expr))))] (walkfn! (w/macroexpand-all expression)) ; ❻ @!fns)) (find-invoked-functions '(when-first [a (vector 1 2 3)] ; ❼ (inc a))) ;;#{#'clojure.core/vector #'clojure.core/seq #'clojure.core/first #'clojure.core/inc}
❶
find-invoke-functions是一个接受引用表达式并返回一个近似于该表达式引用的实际函数集的 var 集合的函数.❷
!fns是一个原子, 我们将用它来在遍历表达式时收集引用的 var.❸
walkfn!是一个递归函数, 在可能包含函数调用的每个子形式上调用, 并收集调用的函数. 它首先检查子表达式是否是第一个元素是符号的序列, 这是 Clojure 中函数调用的语法.❹ 如果子表达式是函数调用, 我们尝试使用
resolve将函数位置的符号解析为一个 var, 如果返回一个 var, 我们将其与!fns连接, 然后使用clojure.walk/walk在子表达式上递归调用walkfn!. 如果函数调用中的符号是quote, 我们跳过递归遍历, 因为quote主体中的任何内容都不会被求值, 因此不可能引用函数.❺ 如果子表达式是集合, 那么我们对其内容递归调用
walkfn!, 否则我们什么也不做.❻ 这里我们在给定的表达式上调用
walkfn!, 首先在其上调用clojure.walk/macroexpand-all, 以确保我们找到表达式主体引用的所有函数.❼ 最后, 我们在一个简单的表达式上调用
find-invoke-functions, 结果显示一个clojure.corevar 的集合. 正如我们所看到的, 结果集合包含seq和first, 它们都没有显式出现在我们的表达式中, 但被when-first的展开所使用; 如果我们没有使用clojure.walk/macroexpand-all, 我们就无法知道它们被引用了.刚刚展示的函数并不完美 (例如, 它不会找到用作值的函数), 但它是一个很好的例子, 说明了我们如何在不使用复杂分析工具的情况下实现一个简单的调用解析算法.
- 另请参阅
eval是一个接受 Clojure 表达式并将其作为代码求值的函数; 宏展开是 Clojure 编译器管道中形式求值的一部分.read-string是一个接受 Clojure 表达式作为字符串并返回其作为 Clojure 数据结构表示的函数; 读取在 Clojure 编译器管道中先于宏展开.quote是一个特殊形式, 用于阻止编译器求值一个表达式, Clojure 形式可以通过使用quote或read-string传递给macroexpand*.
2.3.3. 4.3 quote
自 1.0 版本以来的特殊形式
(quote [expr])
quote 是一个特殊形式, 它简单地返回其输入表达式而不求值:
(quote (+ 1 2)) ; ❶ ;; (+ 1 2) '(+ 1 2) ; ❷ ;; (+ 1 2)
❶ 我们可以通过对其调用 quote 来引用一个表达式.
❷ 或者, Clojure 还提供了一个等效的读取器宏 ' (单引号).
与影响 Clojure 形式如何求值的所有实用程序一样, quote 主要在元编程上下文中很有用. 由于 quote 对语言来说是多么原始, Clojure 提供了一个简短的语法, 通过读取器宏 $$'££ 来引用表达式. 换句话说, (quote foo) 可以方便地重写为更简洁和等效的语法 'foo.
- 约定
- 示例
由于 Clojure 的求值规则, 如果一个符号指向一个 var, 那么该 var 的值就会在原地被解引用. 使用
quote是在代码中嵌入列表和符号字面量的唯一方法. 字面量符号在 Clojure 中用于各种目的, 最常见的是作为提供运行时自省功能的函数的输入, 例如resolve:(resolve '+) ;; #'clojure.core/+
如果没有
quote特殊形式, 人们将被迫这样写那个调用:(resolve (read-string "+")) ;; #'clojure.core/+
这不仅写起来更麻烦, 而且性能也更差: 与其在编译时嵌入一个常量, 这将迫使 Clojure 在每次求值该表达式时都解析字符串并创建一个新符号.
除了在代码中嵌入符号字面量的更常见用法外,
quote有时在宏中用于复杂的syntax-quote表达式中, 作为其自动命名空间限定功能的逃生口, 通过" 非引用-引用" 模式'. 为了展示这个模式, 我们定义了一个名为defrecord*的宏, 它通过使其实现clojure.lang.IFn接口来增强defrecord, 这样用defrecord*创建的记录就像 map 一样是可调用的:(defmacro defrecord* [name fields & impl] `(defrecord ~name ~fields ; ❶ ~@impl clojure.lang.IFn (~'invoke [this# key#] ; ❷ (get this# key#)) (~'invoke [this# key# not-found#] (get this# key# not-found#)) (~'applyTo [this# args#] ; ❸ (case (count args#) (1 2) (this# (first args#) (second args#)) (throw (AbstractMethodError.)))))) (defrecord* Foo [a]) ; ❹ ((Foo. 1) :a) ;; 1 ((Foo. 1) :b 2) ;; 2
❶ 我们定义了
defrecord*宏, 接受记录名称, 字段和默认实现作为输入, 并将这些参数插入到一个defrecord表达式中.❷ 在提供的记录实现之后, 我们实现了
clojure.lang.IFn及其invoke方法的两个元数, 这两个元数只是委托给get. 这里我们使用了非引用-引用模式, 这样方法名将是invoke而不是user/invoke.❸ 类似地, 我们实现了
applyTo方法, 这样我们也可以在我们的记录上使用apply.❹ 我们可以通过实例化一个示例记录并将其作为函数调用来验证我们的宏是否做了它应该做的事情.
- 另请参阅
eval是一个函数, 它接受一个引用的表达式作为输入, 并返回其求值后的值.syntax-quote是一个读取器宏, 可以被认为是quote的增强版, 也是编写宏的首选工具. - 性能考虑和实现细节
=> O(1) 常数时间
quote基本上是一个无操作, 因为它所做的只是返回一个常量值, 它没有任何性能影响.
2.3.4. 4.4 gensym
自 1.0 版本以来的函数
(gensym ([]) ([prefix-string]))
gensym 是一个简单的函数, 其唯一目的是在每次调用时返回一个唯一的符号. 它主要在编写宏的上下文中使用, 以避免在 syntax-quote 的自动符号生成功能不足时出现意外的符号捕获问题, 但也可以在任何需要随机符号的情况下使用, 例如生成唯一的标签.
(gensym) ; ❶ ;; G__14 (gensym "my-prefix") ; ❷ ;; my-prefix17
❶ 没有参数的 gensym 返回一个以 "G__" 为前缀的符号.
❷ 如果我们提供一个前缀, 生成的符号会以给定的前缀开始.
- 约定
- 示例
这里有一个在为一个小型逻辑语言操作符号表达式时展示
gensym的示例. 一阶逻辑 90 允许用像" 任意" (存在至少一个项使得表达式为真) 和" 所有" (表达式对所有项都应为真) 这样的量词来对逻辑变量进行量化. 用一阶逻辑编写的表达式适合于保持公式之间逻辑等价性的转换. 其中之一允许将量化的表达式" 上拉" :(OR (EXIST x (Q x)) (P y)) ; ❶
❶ 量词" EXIST" 仅适用于" OR" 中的一个表达式.
上面的逻辑公式读作: 要么存在至少一个 "x", 使得 "Q" of "x" 为真, 要么 "P" of "y" 为真. "Q" 和 "P" 代表逻辑谓词. 逻辑谓词类似于函数: 它们接受一个逻辑变量 (例如 "x" 或 "y"), 并在一个逻辑表达式中求值为真或假. 我们可以用 "<=>" 符号 (意思是" 当且仅当" ) 来声称这个表达式与另一个逻辑等价:
(OR (EXIST x (Q x)) (P y)) <=> (EXIST x (OR (Q x) (P y))) ; ❶
❶ 两个逻辑表达式在给定相同的 "x", "y" 输入时求值相同, 则它们是逻辑等价的.
我们的目标是编写一个 Clojure 函数, 在一个逻辑公式中" 上拉" 一个嵌套的量词, 这样量词就会出现在表达式的外部, 如上述逻辑等价性所示. 与此转换相关的一个问题是潜在的意外捕获逻辑变量. 观察以下内容:
(OR (EXIST x (Q x)) (P x)) <!=> (EXIST x (OR (P x) (Q x))) ; ❶
❶ 意外捕获 "x" 并不保证这些表达式之间的等价性. 在一个案例中, "x" 被量化, 但该量化不应任意扩展到其他谓词.
在最后一个例子中, 谓词
(P x)突然成为变量 "x" 量化的一部分, 而之前并非如此, 从而打破了表达式之间的逻辑等价性. 我们需要确保在转换表达式时, 我们改变了量化的变量以避免意外捕获. 我们可以通过使用gensym来实现这一点, 如下所示:(defn- quantifier? [[quant & args]] ; ❶ (#{'EXIST 'ALL} quant)) (defn- emit-quantifier [op expr1 expr2] ; ❷ (let [new-local (gensym "local") ; ❸ [quant local [pred _]] expr1] `(~quant ~new-local (~op ~expr2 (~pred ~new-local))))) ; ❹ (defn pull-quantifier [[op expr1 expr2 :as form]] ; ❺ (cond (quantifier? expr1) (emit-quantifier op expr1 expr2) (quantifier? expr2) (emit-quantifier op expr2 expr1) :else form)) (pull-quantifier '(OR (EXIST x (Q x)) (P x))) ;; (EXIST local2747 (OR (P x) (Q local2747))) (pull-quantifier '(OR (P x) (EXIST x (Q x)))) ;; (EXIST local2750 (OR (P x) (Q local2750)))
❶
quantifier?函数如果参数是以 "EXIST" 或 "ALL" 开头的序列, 则返回真.❷
emit-quantifier根据一个量词和原始表达式来组装一个新的量化表达式.❸ 为了组装新的表达式,
emit-quantifier确保量化的变量是全新的, 这样它就不会与任一表达式中已有的变量冲突.❹ 同时, 我们需要确保最初是量化表达式一部分的谓词也接收到新创建的变量名. 注意最终的表达式是如何用
syntax-quote轻松组装的.❺ 调用者使用
pull-quantifier函数执行转换. 这个函数理解哪个表达式包含量词, 并相应地调用emit-quantifier.用一个示例表达式调用
pull-quantifier验证了转换按预期执行了替换. 生成的符号有 "local" 前缀和一个数字. 请注意, 根据你的 REPL 的年龄, 这个数字可能会任意大 (但总是单调递增). - 另请参阅
defmacro是一个宏,gensym主要在其中使用, 用于在宏展开时生成唯一的符号, 宏将在其展开中使用这些符号.symbol是一个函数, 用于在运行时从给定的名称创建一个符号. - 性能考虑和实现细节
=> O(1) 常数时间
在内部,
gensym使用一个java.util.concurrent.atomic.AtomicInteger实例来在正在运行的应用程序实例中生成唯一的数字. 因此, 每当它被调用时, 都会导致 JVM 使用一个内存屏障. 然而, 在现代 JVM 实现中, 原子操作是在硬件中实现的, 它们在性能分析中不应成为任何问题.
2.3.5. 4.5 definline
实验性宏, 自 1.0 版本起
(definline [name & decl])
definline 是一个宏, 它接受一个函数体并将其展开为一个标准的 defn 声明, 该声明还包含相同函数体的" 内联" 版本 91. definline 等价于声明一个函数, 该函数还包含一个相同函数体的 :inline 元数据关键字. 在这个意义上, definline 的行为类似于 defmacro, 提供了函数的编译时版本以及标准的运行时版本.
definline 的典型且有效的用法是桥接 Clojure 和 Java, 在某些互操作调用之上提供一个 Clojure 入口点. definline 允许客户端正确地传播类型信息 (通常是为了提高性能), 并消除了通过 :inline 元数据关键字添加第二个函数实现的需要.
截至 Clojure 1.10, 它是 clojure.core 命名空间中唯一剩下的" 实验性" 声明. 实验性应被解读为" 风险自负" . 在 Clojure 1.6.0 之前的版本中, definline 至少有一个与 AOT 编译相关的严重问题 92, 并可能在未来的 Clojure 版本中被不同的解决方案所取代. 例如, 正在考虑类似 Lisp 的 [compiler-macros] 93. 尽管存在这些问题, definline 和 :inline 关键字在大小项目中被广泛使用 94.
宏展开将阐明 definline 的工作原理. 这里有一个 timespi 函数, 用于将一个数字乘以 Pi, 以及它的宏展开形式:
(definline timespi [x] ; ❶ `(* ~x 3.14)) (timespi 3) ; ❷ ;; 9.42 (macroexpand-1 '(definline timespi [x] `(* ~x 3.14))) ; ❸ ;; after removing core namespaces (do (defn timespi [x] ; ❹ (* x 3.14)) (alter-meta! (var timespi) ; ❺ assoc :inline (fn timespi [x] (seq (concat (list (quote *)) (list x) (list 3.14))))) (var timespi))
❶ timespi 函数是用 definline 宏定义的.
❷ 要使用 timespi 函数, 我们只需像往常一样调用它.
❸ 打印相同 timespi 函数的宏展开.
❹ definline 展开为预期的 timespi 函数定义, 完全就像我们通常定义它一样.
❺ 但 definline 也改变了 var 的元数据定义, 以添加 :inline 键. 这里可以看到的 (fn timespi [x]...) 函数定义只是 (* x 3.14) 的一个非常复杂的等价物.
当函数的内联版本与主体相同时 (至少对于部分元数而言), 使用 :inline 元数据关键字会产生重复, definline 可以处理这个问题. 与元数据关键字一样, definline 允许编译器根据其调用方式不同地处理函数. 内联函数的直接调用将类似于宏进行扩展, 而在函数作为参数传递的高阶用法中, 将像任何其他函数定义一样处理.
函数内联的主要用例与 Java 互操作 (通常称为" interop" ) 期间的性能优化有关. 有了函数的内联版本, 编译器就有机会使用类型提示的存在来调用正确的 Java 方法 (当存在许多重载时). 没有内联版本, Clojure 将不得不将原始 Java 类型参数包装到一个 java.lang.Object 中.
- 约定
- 输入
"name"是definline将作为宏展开的一部分生成的函数的名称. 该名称应是根据 Clojure Reader 规则的有效符号 95."&decl"尽管有"&","decl"实际上并不是可选的. 因为definline必须展开为一个defn声明,"decl"必须至少包含一个向量 (表示函数的参数列表). 因此:(definline f [])是完全有效的, 但(definline f)是不允许的.
- 输出
definline返回一个指向刚刚声明的函数的clojure.lang.Var对象. 该函数在当前命名空间中创建, 因此通常无需持有返回的 var 来调用该函数.注意
与普通的宏和函数不同,
definline不支持多重元数.
- 输入
- 示例
以下示例将探讨一个假设的整数数学 Java 库, 我们希望从 Clojure 中使用. 为简单起见, 该库接受不同的数字类型, 但只输出整数. 该数学库包含一个为装箱数字 (例如
java.lang.Integer) 和原始类型 (int) 重载的plus方法. 它还包含一个 catch-all 的plus方法, 接受通用的java.lang.Object, 作为可以转换为java.lang.Number的其他类型的最后手段:public class IntegerMath { ; ❶ public static int plus(Object op1, Object op2) { System.out.println("int plus(Object Object)"); return ((Number) op1).intValue() + ((Number) op2).intValue(); } public static int plus(Integer op1, Integer op2) { System.out.println("int plus(Integer Integer)"); return op1 + op2; } public static int plus(int op1, int op2) { System.out.println("int plus(int int)"); return op1 + op2; } //[...] other types }
❶
IntegerMathJava 类模拟了一个我们希望从 Clojure 程序中使用的快速数学库.我们的目标, 作为在
IntegerMath类之上构建 Clojure 层的开发者, 是能够根据推断的或显式的类型调用正确的plus方法. 这也包括客户端在需要时调用原生未装箱的int选项的可能性. 最后, 我们希望向 Clojure 应用程序的开发者隐藏 Java 互操作的所有复杂性. 为了实现这种隔离, 我们设计了以下中间层:(ns math-lib ; ❶ (:import IntegerMath)) (defn plus [x y] ; ❷ (IntegerMath/plus x y))
❶ 一个 Clojure 命名空间, 隐藏了与在 Java 类上调用方法相关的复杂性.
❷ 希望使用
IntegerMath类的 Clojure 客户端只看到一个接受 2 个参数的plus函数.math-lib命名空间被设计为希望使用IntegerMath类的客户端的公共接口. 以下示例说明了如何使用该命名空间将一个数字与一个其他数字列表相加:(ns math-lib-client (:require [math-lib :as m])) (defn vsum [x xs] (map #(m/plus x %) xs)) ; ❶ (vsum 3 [1 2 3]) ;; int plus(Object Object) ; ❷ ;; int plus(Object Object) ;; int plus(Object Object) ;; (4 5 6)
❶ 客户端代码需要该库, 并在没有任何 Java 互操作知识的情况下执行一些数字的求和.
❷ 打印输出显示, 我们最终调用了通用的对象
plus, 而不是更专门的整数版本.Clojure 对
vsum在编译完成后执行何种类型的求和一无所知: 它可能是求和装箱或未装箱的数字, 浮点数或整数. 此信息缺失的原因是plus被编译为一个 Java 类, 其invoke方法接受并返回Object. 尝试强制转换类型也行不通, 因为math-lib库已经编译, 如下例所示:(ns math-lib-client (:require [math-lib :as m])) (defn vsum [x xs] (map #(m/plus (int x) (int %)) xs)) ; ❶ (vsum 3 [1 2 3]) ;; int plus(Object Object) ; ❷ ;; int plus(Object Object) ;; int plus(Object Object) ;; (4 5 6)
❶ 唯一的改变是将
x和向量中的项转换为整数, 但编译器仍然不会利用这一点.❷ 尽管有到
int的类型转换, 我们仍然调用了 Java 方法的通用plus版本.definline允许在编译时进行类型发现, 为客户端提供了一种向编译器传递类型信息的方式. 我们可以用definline重新表述plus函数:(ns math-lib (:import IntegerMath)) (definline plus [x y] ; ❶ `(IntegerMath/plus ~x ~y))
❶ 用
definline重写math-lib中的plus函数. 注意与编写宏的相似性.现在
plus在调用处展开, 其中有关类型的信息仍然可用:(ns math-lib-client (:require [math-lib :as m])) (defn vsum [x xs] (map #(m/plus (int x) (int %)) xs)) (vsum 3 [1 2 3]) ; ❶ ;; int plus(int int) ;; int plus(int int) ;; int plus(int int) ;; (4 5 6)
❶ 新的打印输出证实,
plus现在被路由到更具体的 Java 方法, 用于未装箱的整数.- Definline 和代码重载
definline, 像任何其他基于宏的展开一样, 在代码重载时可能会导致意外. 代码重载经常在 REPL 中进行开发, 或者在生产环境中用于特定情况. 为了说明这一点, 让我们用一个简单的函数来对一个数字进行平方, 然后改变它:(definline sq [x] ; ❶ `(let [x# ~x] (* x# x#))) (defn direct-use [x] ; ❷ (sq x)) (defn higher-order-use [xs] ; ❸ (map sq xs)) (direct-use 2.0) ;; 4.0 (first (higher-order-use [2.0])) ;; 4.0
❶
sq只是将其参数乘以自身.let形式和符号 "x" 的表面重定义是为了防止双重求值 (通用宏编程的常见做法, 因为 "x" 可能是一个包含副作用的完整形式). 宏中的"#"磅符号后缀是gensym的语法糖.❷
direct-use是一个直接调用sq的函数.❸
higher-order-use是一个将sq传递给另一个函数的函数, 在本例中是map.如预期, 直接使用和高阶使用返回相同的结果. Clojure 使用内联形式编译函数的直接使用, 有效地用其宏展开形式替换对
sq的直接调用. 上面的direct-use函数实际上被替换为:(defn direct-use [x] (let [x__1 x] (* x__1 x__1)))
这就是为什么
definline需要使用宏语法, 因为它在编译时会被类似地处理为宏展开, 以替换所有对函数的直接使用. 现在让我们假设一种情况, 我们在 REPL 中解决一个问题. 我们决定平方函数必须返回整数, 并用int对结果进行转换. 在 REPL 中, 一个非常常见的做法是返回到本地历史记录中函数的定义, 更改我们想要更改的内容, 然后重新求值函数, 这正是我们下面要做的, 而不重新定义direct-use:(definline sq [x] ; ❶ `(let [x# ~x] (int (* x# x#)))) (direct-use 2.0) ;; 4.0 (first (higher-order-use [2.0])) ;; 4
❶ 请注意,
sq的新定义与之前相同, 只是增加了对int的转换.如你所见,
direct-use没有将返回值截断为整数, 而高阶版本按预期返回 "4". 如果更改一个宏而忘记重新求值使用它的函数, 也会发生同样的情况, 这是一个常见的" 重载" 问题. 在像这样的简单示例中, 很容易看出为什么会发生这种情况, 但在更大的命名空间中, 其依赖图在 REPL 中被求值, 这种行为可能会让你措手不及.
- Definline 和代码重载
- 另请参阅
当为高阶函数包装对 Java 对象实例方法的调用时,
memfn是一个不错的选择.definline有类似的效果, 以编写一个额外的函数为代价, 更好地控制类型传递. 例如, 以下对 Java 对象上的toString方法的调用是等效的. 在这种情况下, 优先使用memfn解决方案:(map (memfn toString) [(Object.) (Object.)]) ;; ("java.lang.Object@65b38578" "java.lang.Object@88df565") (definline to-string [o] `(.toString ~o)) (map to-string [(Object.) (Object.)]) ;; ("java.lang.Object@4ea61560" "java.lang.Object@4ea61560")
如果函数的逻辑主要与编译时方面有关 (作为宏), 并且高阶函数从不使用, 考虑使用
defmacro来明确该函数的唯一预期用途是作为宏.
2.3.6. 4.6 destructure
自 1.0 版本以来的函数
(destructure [bindings])
destructure 是 Clojure 标准库中一个未文档化的函数, 它被像 fn 和 let 这样的宏用来增强它们的特殊形式原语 fn* 和 let* 以支持解构. 它可以被认为是一个源到源的编译器, 接受一个解构表达式作为输入, 并发出用于产生这些绑定的普通 Clojure let 对作为输出. 这里有一个例子:
(destructure '[[x y] [1 2]]) ; ❶ ; [vec__14 [1 2] ; x (nth vec__14 0 nil) ; y (nth vec__14 1 nil)]
❶ defstructure 返回一个形式, 该形式在求值时产生一个集合类型 (在本例中是向量) 的解构.
我们可以通过在 let 绑定中使用 destructure 的输出来证明它的工作符合预期:
(eval `(let ~(destructure '[[x y] [1 2]]) ; ❶ (+ ~'x ~'y))) ;; 3
❶ 我们可以使用 syntax-quote 组合一个 let 表达式, 并以编程方式决定使用哪种解构.
- 约定
解构表达式可以变得非常复杂, 语法支持许多不同的选项, 并且可以任意嵌套; 这里是我们尝试的一个伪形式化规范:
(destructure [bindings]) bindings :-> [bind1 expr1 .. bindN exprN] bind :-> sym OR vec-bind OR map-bind vec-bind :-> [bind1 .. <& bindN> <:as sym>] map-bind :-> {<:keys [qbind1 .. qbindN]> <:strs [sym1 .. symN]> <:syms [qbind1 .. qbindN]> <:or {sym1 expr1 .. symN exprN}> <:as sym> <bind1 expr1 .. bindN exprN>}
"sym"是任何非命名空间限定的 Clojure 符号."qbind"是任何符号或关键字."expr"是任何 Clojure 表达式."vec-bind"代表序列解构表达式, 每个绑定的"expr"将绑定到匹配表达式的第 n 个元素, 它支持通过&符号进行" 尾部解构" (其中第一个之后的所有项被组合在一起) 和通过:as关键字进行集合别名."map-bind"代表关联解构表达式, 它支持多种不同的选项::strs,:keys和:syms可用于分别解构 map 中的字符串键, 关键字键或符号键,:or可用于在要解构的 map 不包含特定键的情况下提供默认值,:as可用于为原始集合起别名, 普通符号可用于解构 map 中的特定键.
虽然上述规范描述了解构表达式的语法约定, 但它们的语义含义将在示例中逐案解释 96.
- 示例
- 序列解构
序列解构适用于任何实现了序列顺序概念的集合类型, 这包括 Clojure 序列和向量, 字符串, Java 数组和列表. 它用于高效简洁地为集合的第 n 个或第 n 个之后的元素起别名, 而无需显式地访问每个索引处的元素. 例如:
(let [my-vec [1 2 3 4] [a b] my-vec ; ❶ [_ _ & r] my-vec ; ❷ [_ _ c d e :as v] my-vec] ; ❸ [a b c d e r v]) ;;[1 2 3 4 nil (3 4) [1 2 3 4]]
❶ 这是序列解构的最简单用法: 解构表达式
[a b]应用于向量[1 2 3 4], 导致a和b分别绑定到 1 和 2, 向量的其余部分被忽略.❷ 这个解构表达式使用了序列解构的" 尾部解构" 功能, 通过
&符号: 在忽略向量的前两个元素后,r被绑定到集合的其余部分, 根据nthnext(这意味着如果序列结束,r将被绑定到nil而不是一个空序列). 请注意,_在解构中不是一个特殊的符号, 它只是一个惯用的局部绑定名称, 用于我们不感兴趣的值.❸ 最后, 这个解构表达式使用了通过
:as关键字的" 集合别名" 功能:v将被绑定到正在被解构的原始集合, 保留其原始类型和元数据 (如果适用). 这个解构表达式还展示了如何解构比被解构集合中更多的元素: 在这种情况下,e将被绑定到nil.序列解构在惯用的 Clojure 程序中有很多用法, 一种常见的模式是在使用递归遍历序列时使用它, 这里是一个
dedupe-string函数的定义示例, 该函数移除字符串中连续的重复字符:(defn dedupe-string [s] (loop [[el & more] s ; ❶ [cur ret :as state] [nil ""]] ; ❷ (cond (not el) ; ❸ (str ret cur) (= el cur) ; ❹ (recur more state) :else ; ❺ (recur more [el (str ret cur)])))) (dedupe-string "") ;; "" (dedupe-string "foobar") ;; "fobar" (dedupe-string "fubar") ;; "fubar"
❶ 该函数实现为对字符串的循环, 在循环的每一步中, 我们都想考虑剩余字符串的第一个字符, 所以我们使用解构来将第一个字符 (绑定到
el) 从字符串的其余部分 (绑定到more) 中分离出来.❷ 循环还需要保留一些内部状态, 表示我们当前正在去重的字符和到目前为止构建的去重后的字符串. 我们使用解构来将当前字符绑定到
cur(初始化为nil), 将去重后的字符串绑定到ret(初始化为空字符串), 并将整个状态向量别名为state.❸ 我们现在在循环的主体中, 如果
el是nil, 这意味着字符串已被完全消耗, 所以我们通过将当前去重后的字符串与最后一个正在去重的字符连接起来退出循环.❹ 如果有一个要考虑的字符, 并且它与正在去重的字符相同, 我们简单地在字符串的其余部分上递归, 并保持状态不变, 丢弃当前字符.
❺ 如果要考虑的当前字符与正在去重的字符不同, 我们在字符串的其余部分上递归, 并将
cur更新为当前字符, 将ret更新为ret和cur的连接. - 关联解构
关联解构适用于任何实现了键值对概念的集合, 这包括 Clojure map, set, vector, record 和 string. 它用于高效简洁地从关联集合中提取和别名值:
(let [my-map {:x 1 :y 2 :z nil} {x :x y :y :as m} my-map ; ❶ {:keys [x y]} my-map ; ❷ {:keys [z t] :or {z 3 t 4}} my-map] ; ❸ [x y z t m]) ;; [1 2 nil 4 {:x 1, :y 2, :z nil}]
❶ 这是关联解构的最简单示例: 解构表达式
{x :x y :y :as m}应用于 map{:x 1 :y 2 :z nil}, 导致x和y分别绑定到 1 和 2. map 中的其他值被忽略.:as关键字导致m绑定到原始集合, 就像在序列解构中一样.❷ 因为我们通常希望将 map 的键的值绑定到一个同名的符号, 为了避免重复, 我们可以使用
:keys(当键是关键字时, 当键是字符串或符号时, 我们可以分别使用:strs或:syms). 解构表达式{:keys [x y]}等价于{x :x y :y}.❸ 当解构不存在于被解构集合中的键时, 可以使用
:or来提供默认值, 根据contains?. 在这种情况下,t将被绑定到 4, 而z将被绑定到nil.由于在 map 中越来越多地使用命名空间关键字, 自 Clojure 1.6.0 起,
:keys和:syms已得到改进, 以支持命名空间关键字和符号的解构:(let [{:keys [::x foo/bar]} {::x 1 :foo/bar 2}] ; ❶ [x bar]) ;; [1 2]
❶ 双冒号 "::" 表示法表示用当前命名空间限定的关键字. 因此, 如果此表达式在
user命名空间中的 repl 中求值,::x将等价于:user/x.因为 Clojure 鼓励使用 map 作为函数的命名或可选参数 (而不是更典型的 LISP 关键字参数), map 解构在函数定义的参数中非常常见.
- 嵌套和组合解构
序列和关联解构表达式都可以被组合和任意嵌套. 深度嵌套的解构表达式很快会变得难以阅读, 因此惯用的 Clojure 通常不会嵌套超过 2 个解构表达式. 例如, 这里有一个解构的
extract-info函数, 它接受像:address或:contacts这样的 map 中的键, 并额外地解构它们:(defn extract-info [{:keys [name surname] ; ❶ {:keys [street city]} :address ; ❷ [primary-contact secondary-contact] :contacts}] ; ❸ (println name surname "lives at" street "in" city) (println "His primary contact is:" primary-contact) (when secondary-contact (println "His secondary contact is:" secondary-contact))) (extract-info {:name "Foo" :surname "Bar" :address {:street "Road Fu 123" :city "Baz"} :contacts ["123-456-789", "987-654-321"]}) ;; Foo Bar lives at: Road Fu 123 Baz ;; His primary contact is: 123-456-789 ;; His secondary contact is: 987-654-321
❶ 首先, 我们使用
:keys解构从输入 map 中提取 "name" 和 "surname".❷ 在不关闭第一个解构的情况下, 我们进一步将
":address"解构为 "street" 和 "city".❸ 最后,
":contacts"受到进一步的序列解构.解构的参数向量在函数的签名中也很有用, 因为它们将被包含在
doc的输出中, 用于描述输入数据结构的形状.
- 序列解构
- 另请参阅
let可以说是最常使用解构的宏, 因为解构减少了从嵌套集合中提取值的思维开销.fn也在其参数向量中支持解构, 内部依赖于destructure. 关键字参数支持可以通过组合可变参数和关联解构来实现, 因为使用关联解构来解构一个序列只是将该序列转换为一个 map, 遵循(apply hash-map the-sequence)的规则.loop,doseq,for以及所有其他支持argvecs或绑定向量的宏都支持解构, 因为它们通常建立在let或fn之上. - 性能考虑和实现细节
destructure经过优化, 其性能与显式编写的相同数据查找相似:- 序列解构具有与在输入集合上重复使用
nth(以及用于尾部解构的nthnext) 相同的性能特征. - 关联解构具有与在输入集合上重复使用
get相同的性能特征.
- 序列解构具有与在输入集合上重复使用
2.3.7. 4.7 clojure.template/apply-template
自 1.0 版本以来的函数
(apply-template [argv expr values])
clojure.template/apply-template 是一个在 Clojure 表达式中执行符号替换的函数:
(require '[clojure.template :refer [apply-template]]) (apply-template '[x y] '(+ x y x) [1 2]) ; ❶ ; (+ 1 2 1)
❶ 一个在从 clojure.template 命名空间中 require 该函数后的简单 apply-template 示例.
apply-template 在宏编程和一般的符号操作中有一些特定的用例.
- 约定
- 示例
虽然其文档字符串明确指出其主要用法应在宏中, 但实际上在这种场景下使用
apply-template并不是一个好主意, 除非完全理解其作用机制, 因为它可能导致一些意想不到的结果.apply-template在没有特定形式语义知识的情况下进行词法展开. 例如:(require '[clojure.template :refer [apply-template]]) (apply-template '[x] '(let [x x] x) [1]) ; ❶ ; (let [1 1] 1)
❶ 一个小小的
apply-template展开示例显示, 在两个参数中都使用相同的符号 "x" 会生成不正确的 Clojure 代码.即使这个小例子足够简单, 足以理解发生了什么以及应该如何修复 ("expr" 不应使用出现在 "argv" 中的绑定符号), 但如果 "expr" 是由使用此函数的宏的用户提供的, 则可能会发生类似的问题.
出于这个以及其他原因,
apply-template的原作者在多个场合表示, 将其包含在 Clojure 标准库中可能是一个坏主意 97.对于其他情况,
apply-template可能是一个用于应用简单替换的有用工具. 例如, 这里是如何在一个任意嵌套的表达式中将变量 "x" 替换为 "y":(apply-template '[x] '(P(x) ∧ (∃ x Q(x))) '[y]) ; ❶ ;; (P (y) ∧ (∃ y Q (y)))
❶ 我们使用
apply-template将逻辑表达式中所有出现的符号 "x" 替换为 "y". - 另请参阅
clojure.template/do-template是一个宏, 它使用clojure.template/apply-template来多次展开同一个模板 "expr", 每次使用不同的值集作为 "argv" 中符号的替代.postwalk-replace是一个函数, 它深度遍历 Clojure 表达式, 并在途中替换匹配的表达式. 它是clojure.template/apply-template的一个更通用的版本. - 性能考虑和实现细节
=> O(n) 线性时间
像所有代码遍历函数一样,
clojure.template/apply-template在 "expr" 中的值的数量上是线性的."argv"中的符号数量或"values"中的值的数量不影响其性能.
2.3.8. 4.8 clojure.template/do-template
自 1.0 版本以来的宏
(do-template [argv expr & values])
clojure.template/do-template 是一个宏, 它重复执行一个模板表达式, 每次都用提供的替换值替换模板符号:
(require '[clojure.template :refer [do-template]]) (do-template [x] (println x) 1 2 3) ;; 1 ;; 2 ;; 3 ;; nil
do-template 等价于用不同的替换多次求值 apply-template. 如你从示例中所见, do-template 总是返回 nil, 这暗示需要副作用 (例如打印到标准输出).
- 约定
- 示例
以下是一个打印带有不同替换的相同表达式的简单示例:
(require '[clojure.template :refer [do-template]]) (do-template [x] (println '(P(x) ∧ (∃ x Q(x)))) y z) ; ❶ ;; (P (y) ∧ (∃ y Q (y))) ;; (P (z) ∧ (∃ z Q (z)))
❶ 我们需要一个像
println这样的副作用函数才能看到do-template的效果. 另请注意, 结果中的一些空格在原始形式中不存在.do-template具有与clojure.template/apply-template相同的缺点和问题, 因此, 除非完全理解其限制和问题, 否则不鼓励在宏替换中使用do-template. 如果需要类似的功能, 更好的解决方案是求助于像 contrib 库core.unify98 这样的东西, 这是一个提供具有明确扩展点的模板函数的适当统一库. - 另请参阅
clojure.template/apply-template是clojure.template/do-template用于执行模板展开的函数.clojure.test/are是一个clojure.test宏, 它使用clojure.template/do-template来重复测试一个使用不同值的表达式. - 性能考虑和实现细节
=> O(n) 在宏展开时 ("n" 是值的数量)
=> O(n) 在运行时
do-template在编译时和运行时都与替换值的数量呈线性关系.
2.3.9. 4.9 总结
在本章中, 我们了解了如何创建宏, 这是一种与 Clojure 编译过程交互的优雅工具. 宏功能强大, 但由于其特殊的语法, 初学者可能难以理解. defmacro 总结了宏的所有基本部分, 而 macroexpand 是我们进行宏调试的首选工具. quote (产生未求值的形式), apply-template, do-template 和 gensym 也是宏开发的基本工具. definline 的用途有限, 仅限于 Java 互操作的性能改进. 我们还了解了 destructure, 它是支持像 fn 或 let 这样的形式的解构引擎.
2.4. 5 数值运算
2.4.1. 5.1 概述
算术运算是语言的基本特性. 本章收集了 Clojure 提供的主要是算术运算. 列表可能看起来相当小, 原因是 Clojure 既没有重新实现也没有包装 Java 提供的众多数学函数. 例如, 如果你正在寻找一个截断小数或求平方根的函数, 它们可以很容易地通过 Java 互操作来利用.
Clojure 仍然在标准库中提供了最常见的数学运算的显式版本. 这主要是为了在不需要显式类型提示的情况下提供最佳性能. Clojure 提供的运算是本章的一部分, 并由下表总结:
+ |
是 4 种基本算术运算. 与 Java 不同, 它们在溢出时会抛出异常. |
|---|---|
inc |
是常用的将数字加一或减一的快捷方式. |
quot |
Clojure 提供了一个函数来检索一个数的商和两种类型的余数运算. |
max |
计算一组数中的最大值和最小值. |
max-key |
在应用转换函数后计算最大值或最小值. |
rand |
生成随机数. |
with-precision |
用于设置小数运算的舍入策略的实用程序. |
+' |
具有自动提升能力的核心算术运算集 (注意名称后附加的单引号). |
unchecked-add 和其他 unchecked-* 函数 |
Java 风格的长整型算术. 在溢出时会发生截断. 这是 Clojure 调用相应的 Java 基本数学运算符的方式. |
unchecked-add-int 和其他 unchecked-*-int 函数 |
Java 风格的整型算术. 在溢出时也可能发生截断. |
pos? |
用于确定一个数是正数, 零还是负数的谓词. |
对于许多应用来说, 整数类型的默认精度已经足够. 但有些类型的应用需要表示大于 2
63 (64 位有符号位能表示的最大长整数) 的数字. 如果是这种情况, 与 Java 相比, " 单引号" 运算符会使你的生活轻松得多. Java 的大整数算术是基于类和对象的, 没有重载的数学运算符, 这意味着除了创建它们各自的实例并调用它们的方法外, 没有简单的方法来对两个 BigInteger 求和. Clojure 只需使用 +' 就会自动使用正确的精度.
注意
你可能已经注意到, Clojure 的任意精度运算符缺少一个
/'(除法-引号) 的等价物. 你应该考虑到/已经很特殊了,因为它可能会产生分数, 这些分数已经保留了所有可能的精度 (例如(/ 10 3)返回符号表示 10/3, 而没有实际计算任何小数). 其次, 如果两个参数都是长整型,/不会产生长整型溢出 (排除了" 零" 的特殊情况).
2.4.2. 5.2 任意精度
基本数学运算 +, -, *, inc 和 dec 都是简单精度运算符的例子. 当它们的 short, int 或 long 类型操作数超出 Long/MIN_VALUE 和 Long/MAX_VALUE 的边界时, 这些运算符会抛出异常. Clojure 还提供了另一种选择: 任意精度运算符 +' (注意名称末尾附加的单引号) 会自动将其返回值提升为 BigInt 类型, 该类型可以容纳任意大小的数字 (受内存可用性限制).
2.4.3. 5.3 回滚精度
回滚精度定义了 Clojure 标准库中的一组函数, 当达到该类型的分配存储空间时, 它们不会导致异常 (或类型提升). long 类型的回滚行为指的是:
- 到达
Long/MAX_VALUE后, 将数字加一会导致LONG/MIN_VALUE. - 到达
Long/MIN_VALUE后, 将数字减一会导致Long/MAX_VALUE.
2.4.4. 5.4 非转换, 回滚精度
另一组数学运算符以模式" unchecked-*-int" 命名 (用操作的名称替换 *): unchecked-add-int, unchecked-subtract-int, unchecked-multiply-int, unchecked-divide-int, unchecked-inc-int, unchecked-dec-int, unchecked-negate-int, unchecked-remainder-int. 这 8 个函数非常相似, 它们仅在 int 类型上操作, 我们将在 unchecked-add-int 函数下将它们作为一个单独的组来描述.
2.4.5. 5.5 +, -, * 和 /
自 1.0 版本以来的函数
(+ ([]) ([x]) ([x y]) ([x y & more])) (- ([x]) ([x y]) ([x y & more])) (* ([]) ([x]) ([x y]) ([x y & more])) (/ ([x]) ([x y]) ([x y & more]))
基本算术运算有许多共同的特性. 除非另有说明, 否则以下描述适用于 +, -, *, /. Clojure 中主要数学运算的一个主要方面是它们利用多个" 元数" 在不同上下文中以极大的灵活性和性能工作.
注意
在 Clojure 1.2 之前, 基本数学运算符的工作方式与当前的自动提升版本 (以单引号结尾的函数) 等效. 在 Clojure 1.2 之后, 它们的行为被转换为当前的 (通过抛出异常而不是自动提升) 以避免相关的性能损失.
- 约定
-和/不支持无参数元数.- 当没有参数调用时,
(+)和*分别返回它们的单位元, 即 0 和 1. - 当用一个参数调用时,
(- x)反转参数 "x" 的符号. - 当用一个参数调用时,
(/ x)返回 "x" 的倒数, 通常表示为(1/x). - 当用单个参数调用时,
+和*都只返回该参数. - 所有参数都必须是
java.lang.Number类型或其子类 ((number? x) 对所有参数都必须返回真). 当一个参数不是Number类型时, 会抛出ClassCastException.
返回类型根据输入参数而变化. 下表总结了各种可能性 (暂时排除了紧随其后列出的少数异常情况). 表中的每个框显示了每种数学运算的返回类型, 考虑了 x-y 轴上的操作数类型. 如果一种运算有多种返回类型 (例如
(/) ratio long), 这意味着返回类型还取决于操作数类型之外的其他方面:short/int/long float/double BigInt BigDecimal Ratio short/int/long (+)long (-)long (*)long (/)ratio long (+)double (-)double (*)double (/)double (+)bigint (-)bigint (*)bigint (/)bigint (+)bigdec (-)bigdec (*)bigdec (/)bigdec (+)ratio bigdec (-)ratio bigdec (*)ratio bigdec (/)ratio bigdec float/double (+)double (-)double (*)double (/)double (+)double (-)double (*)double (/)double (+)double (-)double (*)double (/)double (+)double (-)double (*)double (/)double (+)double (-)double (*)double (/)double BigInt (+)bigint (-)bigint (*)bigint (/)ratio bigint (+)double (-)double (*)double (/)double (+)bigint (-)bigint (*)bigint (/)ratio bigint (+)bigdec (-)bigdec (*)bigdec (/)bigdec[!] (+)ratio (-)ratio (*)ratio (/)ratio bigint BigDecimal (+)bigdec (-)bigdec (*)bigdec (/)bigdec[!] (+)double (-)double (*)double (/)double (+)bigdec (-)bigdec (*)bigdec (/)bigdec[!] (+)bigdec (-)bigdec (*)bigdec (/)bigdec[!] (+)bigdec (-)bigdec (*)bigdec (/)bigdec[!] Ratio (+)ratio (-)ratio (*)ratio (/)ratio bigint (+)double (-)double (*)double (/)double (+)ratio (-)ratio (*)ratio bigint (/)ratio (+)bigdec (-)bigdec (*)bigdec (/)bigdec[!] (+)ratio bigint (-)ratio bigint (*)ratio bigint (/)ratio bigint 标有 [!] 的操作数类型可能会导致
ArithmeticException"Non-terminating decimal expansion". 请参阅with-precision. - 示例
- 0-元数和 1-元数
让我们先看看 0 元数和 1 元数.
+和*支持无参数调用, 这在避免对空序列进行多余检查时很有用. 例如, 这里是 0 元数在空集合上使用apply的例子:(def empty-coll []) ; ❶ (apply + empty-coll) ; ❷ 0 (apply * empty-coll) ; ❸ 1
❶ 一个简单的
empty-collvar 模拟了某些计算的结果, 我们事先不知道其基数, 结果是一个空集合.❷ 由于
+配备了一个零元数变体, 它在空序列上工作得很好, 无需显式检查.❸
*的工作方式相同, 只是返回 1 而不是 0.更一般地,
+和*分别实现了加法和乘法的单位元 99./的单操作数版本可用于表示一系列数的倒数. 例如, 黎曼 zeta 函数在 2 处的值是自然数平方的倒数之和 100. 其他黎曼 zeta 函数在统计学和物理学中很重要. 我们可以通过从该系列中取一些元素来近似 zeta 在 2 处的值 (可以证明该系列收敛到 PI2/6, 这是欧拉在 1734 年解决的巴塞尔问题):(defn x-power-of-y [x y] (reduce * (repeat y x))) ; ❶ (def square #(x-power-of-y % 2)) ; ❷ (def cube #(x-power-of-y % 3)) (defn reciprocal-of [f] ; ❸ (->> (range) (map f) rest (map /))) (defn riemann-zeta [f n] ; ❹ (->> f reciprocal-of (take n) (reduce +) float)) (riemann-zeta square 1000) ; ❺ ;; 1.6439346 (/ (* Math/PI Math/PI) 6) ; ❻ ;; 1.6449340668482264 (riemann-zeta cube 100) ; ❼ ;; 1.2020074
❶
x-power-of-y是一个通用的辅助函数, 用于将 x 提升到 y 次幂.❷
square是x-power-of-y的一个特定实例, 用于对一个数求平方.cube类似.❸
reciprocal-of包含(map /)映射, 用于创建倒数. 我们传入f, 决定我们想要什么的倒数 (例如平方或立方).❹
riemann-zeta接受f作为要计算的黎曼 zeta 函数的种类. 黎曼 zeta 在 2 处表示平方的倒数, 在 3 处表示立方的倒数, 依此类推.❺ 我们调用
riemann-zeta进行平方, 并指示我们想在系列的第 1000 个元素处停止. 在 10000 时, 在普通笔记本电脑上已经超过一分钟, 所以要小心.❻ 该系列应该收敛到的实际数字在 1000 的精度时非常接近.
❼ 黎曼 zeta 在 3 处也收敛, 该数字称为 Apéry 常数.
- 2-元数
下一个例子展示了可能是基本数学运算符最常用的参数数量: 两个操作数. 例如, 年利率公式是确定初始资本随时间增长多少的一种方法. 我们将看到, 通过使用部分应用, 数学公式可以很容易地转换为 Clojure:
ca 1, ca 2, ca 3, ca 4, ...
其中:
- c = 初始投资
- r = 利率
- a = 1 + r
系列中的每一项代表每年的总金额. 因此, 如果我们假设初始投资为 c = $1000, 并且我们想知道在 3 年后以 20% 的利率银行里会有多少钱, 我们将需要查看列表中的第 3 个元素: 1000 * (1 + 0.2)3 = 1728. 我们可以用 Clojure 推广该公式, 创建一个无限序列, 从中我们可以获取任意多年的年度预测:
(defn powers-of [n] ; ❶ (iterate (partial * n) 1)) (defn interest-at [rate initial year] ; ❷ (->> (powers-of (inc rate)) (map (partial * initial)) (take year) last)) (interest-at 0.2 1000 4) ;; 1728.0
❶
powers-of创建数字 n 的幂的无限序列. 我们使用partial和*来让iterate传递前一次乘法的结果.❷
interest-at将公式的其余部分组合在一起. 同样, 使用partial准备前一系列幂中的一个元素, 以便与初始投资相乘. - 精度
常见的 (和默认的) 数学运算符可能会抛出异常 (在这方面 Clojure 与 Java 不同). Clojure 的数字字面量默认被处理为
long, 对应于 Java 的java.lang.Long类. 因此, 例如, 快速增长的序列 n = (n - 1)n-1 很快就会抛出
ArithmeticException:(take 7 (iterate #(* % %) 2)) ; ❶ ;; ArithmeticException integer overflow (take 7 (iterate #(*' % %) 2)) ;; (2 4 16 256 65536 4294967296 18446744073709551616N) ; ❷
❶ 该系列的第 7 个元素是: 4294967296
4294967296, 它超出了
Long/MAX_VALUE. 由于 Clojure 的基本数学运算符不会自动提升, 它在超过该限制时会抛出异常. ❷ 为了接受比那些更大的结果, 我们可以使用*'. 我们现在可以看到, 序列中的最后一个元素包含 "N" 后缀, 表明它是一个BigInt类型.注意
请注意, 尽管 Clojure 默认将数字视为
Long, 但错误消息总是引用" 整数" 溢出. 它应该更广泛地被理解为" 自然数" 溢出, 这些可以是整数或长整数.在 Java 中,
+运算符会愉快地执行溢出操作并返回一个负数! 这就是为什么在 Java 中检查上溢/下溢或使用BigInteger类 101 是常见的习惯用法. Clojure 采取了更保守的方法, 即操作永远不应导致任何隐式截断或符号更改. 如果需要, 开发者仍然可以通过使用相同运算符的" 未检查" 版本来访问该行为. - 你永远不会忘记的事: 你的第一个 (+ 1 1)
这绝对不是一个规则, 但加法通常是开始学习 Clojure 的人执行的第一个函数. 一个典型的 Clojure 第一课是打开一个 REPL 并玩一些 Clojure. 新手首先要学习的一件事是使用括号来执行函数 (当然, 除非他们来自其他 Lisp 语言). 通过执行一个简单的
(+ 1 1), 新手可以很好地了解用括号和前缀运算符调用函数. 这就是为什么+可能是学习 Clojure 的人执行的第一个函数.
- 0-元数和 1-元数
- 另请参阅
操作符号后附加的单引号
'定义了该操作的自动提升版本. 它不是在达到 Java 长整型的限制时抛出异常, 而是将长整型提升为可以处理任意精度的BigInt实例. 例如, 当精度对你的应用很重要时, 使用*'. 请注意, 精度是有代价的.unchecked-add是数学运算符的未检查版本 (包括本章中描述的基本运算符), 移除了上/下溢出检查. 这是标准的 Java 行为. 如果你愿意以性能换取在溢出时发生符号更改的可能性, 请使用未检查版本. 如果你的应用永远不会看到大数, 并且你需要性能提升, 你可以放心地使用未检查版本.unchecked-add-int甚至更快. 所有其他运算符都会将int操作数提升为long并返回long. 当主要处理整数时, 使用unchecked-int版本以避免不必要的转换为long. 除非你在做快速的整数数学, 否则你不太可能需要未检查的整数运算. - 性能考虑和实现细节
=> O(n) 与参数数量成线性关系
如相关函数中所示, 基本数学运算符在检查溢出/下溢条件并将所有数字视为长整型方面相当复杂. 你的主要性能关注点将是移除这些检查和转换. 但即使考虑到这些性能方面, 替换
+为unchecked-add或unchecked-add-int等操作, 只有在处理应用的特定数值方面以寻求原始速度时才应进行. 另一个要考虑的方面是要相加的整数数量.+将对超过 2 的元数使用reduce, 而reduce与参数数量成线性关系. 总而言之: 在开发通用应用时, 除非应用的某些部分专门处理大量整数, 否则+不应是寻求速度的主要关注点.
2.4.6. 5.6 inc 和 dec
自 1.2 版本以来的函数
(inc [x]) (dec [x])
inc 和 dec 函数基本上是 #(+' % 1) 和 #(-' % 1) 的快捷方式. 递增和递减是日常编程中的常见操作, 因此 inc 和 dec 在典型的 Clojure 开发生活中负责节省大量的击键. 使用 inc 或 dec 非常简单:
(inc 1) ;; 2 (dec 1) ;; 0
- 约定
"x"是单个强制的数值类型参数 (即(number? x)必须为真)- 返回: 通过将 x 递增或递减 1 获得的值. 在
(Long/MAX_VALUE)或(Long/MIN_VALUE)溢出时抛出ArithmeticException.
- 示例
Maps, atoms 或任何其他提供" 更新" 函数的数据结构都是存储计数器的良好候选者, 并且可以与
inc或dec结合使用. 以下示例展示了一个instrument函数, 该函数接受另一个函数作为参数, 并用一个计数器" 注入" 它, 以存储它接收到的调用次数. 该数字稍后可以使用一个特殊的关键字来读取:(defn instrument [f] (let [calls (atom 0)] ; ❶ (fn [& args] (if (= "s3cr3tC0d3" (first args)) ; ❷ @calls (do (swap! calls inc) ; ❸ (apply f args)))))) (def say-hello ; ❹ (instrument #(println "hello" %))) (say-hello "john") ;; hello john ;; nil (say-hello "laura") ;; hello laura ;; nil (say-hello "s3cr3tC0d3") ; ❺ ;; 2
❶ 每次调用
instrument时都会创建一个初始化为零的原子实例. 比较和交换语义 (CAS) 即使在高度并发的环境中调用此函数, 也能有效地防止丢失 (或重复) 计数.❷ 我们拦截参数, 当第一个参数是一个特殊的" 秘密" 代码时, 函数返回到目前为止的计数, 而不是委托给包装的函数.
❸ 在所有其他情况下, 我们递增计数器. 对于原子, 只需将递增函数传递给
swap!进行更新即可. 我们需要一个接受一个参数并递增它的函数:inc的完美位置.❹
say-hello展示了如何使用instrument来包装另一个函数.❺ 在多次使用
say-hello后, 我们可以看到当我们使用显示内部println被调用次数的秘密代码时会发生什么.- 其他语言中的递增和递减
可能每一种发明的语言 (除了纯研究性的语言) 都有一个加法运算符
"+"或等效的函数. 但并非所有语言都有一个特殊的递增/递减运算符. 它之所以特殊, 是因为它隐式地认为 "1" 是加/减的第二个操作数, 从而节省了一些击键. 这里有三个来自 Haskell, Ruby 和 Java 的代表性例子:- Haskell
Haskell 有
"pred"和"succ"函数, 它们的工作方式与 Clojure 类似:> succ 1 2 > pred 0 -1
Haskell 还可以以非常紧凑的形式定义柯里化函数, 因此尽管我们使用常见的
+和-运算符, 我们可以像这样轻松地表达递增和递减:> (+1) 1 2 > ((-) 1) 1 0
虽然对于减法, 由于
-1作为负数文字产生的歧义, 它工作得不那么好. - Ruby
在这种情况下, Ruby 的主要灵感是面向对象. 数字是对象, 可以接收" 消息" . 我们可以像这样向一个数字发送消息
succ或pred:irb(main):001:0> 1.succ => 2 irb(main):002:0> 1.succ.pred => 1
- Java
与 Ruby 不同, Java 的数字字面量不能直接接收方法调用. 虽然数字可以首先被包装在一个新的
Integer()对象中, 但没有方法可以获取一个数字的下一个. 唯一的方法是通过变异. Java 从 C 继承了递增和递减运算符. Java 的++递增运算符和 Haskell 的succ之间有一个很大的区别: Java 的++在使其变大的同时也会改变一个变量:class Test { public static void main (String[] args) { int i = 0; System.out.println("incrementing " + ++i); System.out.println("and i is? " + i); } } >> incrementing 1 >> and i is? 1
- Haskell
- 其他语言中的递增和递减
- 另请参阅
inc'和dec': 类似于+'和-', 单引号'标识了inc和dec的自动提升版本. 如果数字是Long/MAX_VALUE或Long/MIN_VALUE, 它在尝试递增或递减时会抛出异常. 单引号版本会通过将long提升为BigInt来避免该问题.unchecked-inc和unchecked-dec: 这个版本的运算符既不自动提升也不抛出异常. 在达到上/下限时, 结果会简单地反转符号并从另一端开始:(unchecked-inc Long/MAX_VALUE) ;; -9223372036854775808
unchecked-inc-int和unchecked-dec-int: 与其他未检查的int函数版本一样, 它不会尝试对所有数字进行隐式转换为Long. 这意味着参数和结果类型都将被视为java.lang.Integer. 因此, 在递增或递减之前, 符号会更改的操作数上限是Integer/MAX_VALUE,Integer/MIN_VALUE.
- 性能考虑和实现细节
=> O(1) 常数时间
递增或递减运算符不太可能是性能瓶颈的来源, 除非你的核心业务专门是整数数学, 否则你不应该担心. 对于那些重要的情况, Clojure 提供了替代方案, 比如上面" 另请参阅" 部分中描述的那些. 重要的是要理解, 尽管有更快的方法来递增或递减, 但任何为寻求原始性能而进行的更改都应该被准确地分析. 话虽如此, 以下示例显示了从普通
inc到未检查的int的微小改进:(require '[criterium.core :refer [bench]]) (defn slower [n] (loop [n (int n) i 0] (if (< i n) (recur n (inc i)) ; ❶ i))) (defn faster [n] (loop [n (int n) ; ❷ i 0] (if (< i n) (recur n (unchecked-inc i)) ; ❸ i))) (bench (slower 10000)) ;; Execution time mean : 13.381100 µs (bench (faster 10000)) ;; Execution time mean : 2.595440 µs
❶
slower函数使用普通的inc来递增一个数字.❷ 请注意我们在两个函数中初始化循环时使用的技巧. 我们将
"n"转换为int类型, 以防止"<"比较需要从对象到数字的转换. 如果我们不优化这方面, 对象转换会主导inc的执行.❸
faster与slower的唯一区别是它使用unchecked-inc而不是简单的inc.注意
该示例通过移除整数溢出检查显示了明显的改进. 但该示例也显示了, 可能有其他操作主导了性能配置文件, 而不是我们试图优化的那个. 在我们的情况下, 比较
(< i n)(其中 n 没有转换为 int) 主导了unchecked-inc, 使情况更糟. 在对目标热点进行任何不会产生明显效果的更改之前, 总是使用分析器来验证假设.
2.4.7. 5.7 quot, rem 和 mod
自 1.0 版本以来的函数
(quot [num div]) (rem [num div]) (mod [num div])
在欧几里得除法 (两个整数的除法过程 102) 中, " 商" 是除法的结果, 而" 余数" 是当两个数不是彼此的倍数时剩下的任何东西. 在 Clojure 中, quot 返回除法的结果, 而 rem 返回整数除法的余数, 如果有的话. 商也可以定义为除数除以 "num" 的次数, 不包括任何小数部分, 这反过来又相当于取除法的结果并截断小数. 最后, " 模" 运算 mod 与 rem 非常相似, 但在处理负数时返回结果的规则略有不同 103. 因此, 例如:
(quot 38 4) ;; 9 (rem 38 4) ;; 2
以上意味着数字 "4" (除数) 在大于被除数 "38" 之前累加 9 次. 该操作的余数将是 2. 这个描述不是很严谨, 因为当涉及到负数时, 事情会变得棘手. 这就是 mod 和 rem 的不同之处:
(rem -38 4) ;; -2 (mod -38 4) ;; 2
我们不会深入探讨 rem 和 mod 对负数的具体细节, 因为实际应用中最常见的用法是围绕正数量.
- 约定
- 示例
quot和rem经常出现在一些物品应被分配到容器中的问题中. 如果我们无法将物品物理地切成一半或其他分数,quot在发现我们可以均匀地分配多少物品到容器中时很有用. 假设我们需要用一些货物装载一辆卡车, 而这辆卡车只接受 22 个容器. 给定 900 件物品要运输, 我们想知道我们应该在每个容器中放多少物品:(defn optimal-size [n m] (let [size (quot n m) ; ❶ left? (zero? (rem n m))] ; ❷ (if left? size (inc size)))) (optimal-size 900 22) ; ❸ ;; 41 (partition-all (optimal-size 900 22) (range 900)) ; ❹ ;; ((0 1 2 3 ... 38 39 40) ;; (41 42 43 ... 79 80 81) ;; ... ;; (82 83 84 ...
❶
optimal-size将返回给定 n 个物品和 m 个容器的最佳容器大小. 它很好地利用了quot来找出所有容器中可以容纳多少物品.❷
rem然后被用来查看会剩下多少物品. 如果有物品剩下, 最佳大小增加一.❸ 当我们用示例参数调用
optimal-size时, 我们可以看到每个容器的最佳物品数量是 41.❹ 我们也可以使用
partition-all来查看物品应该如何分配在每个容器中. 输出相当大, 所以从示例中省略了.尽管上面的例子在
rem和mod之间是可以互换的, 但有一种情况与mod的关联性比rem更强 (虽然即使在这种情况下, 由于所有量都是正的, 它仍然没有区别): 在有限集上定义基本运算符. 以字母表为例: 我们想实现一个递增运算符, 以便它返回下一个字母. 在将字母表创建为数组后, 我们可以很好地利用索引.(def alpha ["a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s" "t" "u" "v" "w" "x" "y" "z"]) (defn ++ [c] ; ❶ (-> (.indexOf alpha c) inc (mod 26) alpha)) (++ "a") ;; "b" (++ "z") ;; "a"
❶ 这个单行代码中有几个有趣的事情正在发生: 首先, 我们使用 Java 互操作
indexOf(向量类型支持) 从数组中提取字母的位置. 递增它之后, 我们需要确保我们不在边界处, 如果我们在, 我们希望优雅地溢出并从头开始. 关键的推动者是(mod x 26), 它将任何数字 x 重新计算到域 0-25 中, 包括任何从头开始的余数的可能回滚. 一旦我们有了新的索引, 我们就再次访问数组. 注意alpha被用作一个函数, 传递索引以检索该索引处的元素.那么, 是
rem还是mod? 一些混淆源于这样一个事实: 在 "C" 语言中, 有一个 % 运算符, 通常被称为 "mod", 但实际上它实现了余数操作. 因此, 一些典型的余数用法示例在那些语言中被称为使用mod.- 为什么不直接调用 Java 的商和余数运算符?
Clojure 的主要卖点之一是 Java 互操作性. 尽管它工作得很好, 但没有办法直接调用 Java 的运算符, 如
+,-,/,%. 甚至在 Java 中也没有, 在 Java 中, 反射机制在任何可以从对象实例或类调用的东西上都停止了. 所以 Clojure 为它们中的每一个都提供了一个包装器, 有时是简短的形式 (比如单字符符号), 有时是稍长的形式 (比如本章中介绍的quot或rem). 关于 Clojure 提供的更长形式的一个积极事实是, 记住运算符是什么更容易. 例如, 考虑一下 Clojure 的unsigned-bit-shift-right与 Java 的>>>: 它可能更冗长, 但至少记住它做什么要容易得多!
- 为什么不直接调用 Java 的商和余数运算符?
- 另请参阅
/是常见的除法运算符. 它会返回分数, 而不是像quot那样移除小数. 只有当你需要专门处理整数数量时才使用quot.unchecked-remainder-int可用于在数量在Integer/MIN_VALUE和Integer/MAX_VALUE之间时提高性能. 这个版本的余数操作不会自动提升或转换为长整型. 有关更多详细信息, 请参阅性能考虑部分. - 性能考虑和实现细节
=> O(1) 函数生成
对于所有实际用途,
quot,rem和mod都是常数时间操作. 现代硬件知道如何优化实际上是除法的操作, 所以在性能优化期间它不应该是意外的来源. 当需要BigInt提升时, 紧凑循环中存在一些差异.对于某类应用 (比如哈希, 优雅的溢出被认为是一个特性), Clojure 还提供了
unchecked-reminder-int, 一个不检查整数溢出的rem版本. 以下基准测试比较了两者:(require '[criterium.core :refer [quick-bench]]) (let [num 100 div 10] (quick-bench (rem num div))) ; ❶ ;; Execution time mean : 15.733921 ns (let [num (int 100) div (int 10)] (quick-bench (unchecked-remainder-int num div))) ; ❷ ;; Execution time mean : 8.169385 ns
❶
let的存在将"num"和"div"的类型传递给编译器, 所以当表达式作为 Java 字节码生成时,"num"和"div"以原始long类型出现. 这对于避免在大写Long类类型和原始类型之间的转换 (也称为" 装箱/拆箱" ) 很重要.❷ 我们肯定可以观察到速度的提升.
我们可以观察到 50% 的改进, 这是实质性的, 但在绝对值上很小 (时间单位是纳秒). 只有当你能够证明没有其他因素主导表达式的执行时, 才使用
unchecked-remainder-int.
2.4.8. 5.8 max 和 min
自 1.0 版本以来的函数
(max ([x]) ([x y]) ([x y & more])) (min ([x]) ([x y]) ([x y & more]))
max 和 min 是标准库中两个有用的数学相关函数. 给定一个数字参数列表, 它们分别返回列表中的最大值和最小值. 所以:
(max 5 7 3 7) ;; 7 (min -18 4 -12) ;; -18
max 和 min 函数意味着某种排序概念, 这对于数字来说几乎总是得到保证的. 棘手的排序数字的显著例子是" 无穷大" 和" NaN" . 虽然对于无穷大, 我们按惯例有负无穷和正无穷 (所以总是可以确定哪个更大), 但涉及 NaN (非数字 104) 的 max 或 min 操作总是返回 NaN.
- 约定
- 输入
"x","y"和"more"是数字 (使得(number? x)为真).
- 已知异常
如果任何参数不是数字, 则会抛出
ClassCastException. - 输出
max和min分别返回它们各自参数中的最大值或最小值. 如果负无穷是参数之一,min将总是返回负无穷. 如果正无穷是参数之一,max将总是返回正无穷. 当其中一个参数是 NaN 时, 它们都返回 NaN:(max Long/MAX_VALUE 5 (/ 1.0 0)) ; ❶ ;; Infinity (min 1 Long/MIN_VALUE (/ -1.0 0)) ;; -Infinity (max (/ 1.0 0) (/ 0.0 0)) ;; NaN
❶
max和min在处理特殊数字时的最重要边界情况.
- 输入
- 示例
max和min显然与统计学有关. 第一个应用可以是找到给定集合的极值, 这可以用一个简单的一行代码来解决:(apply (juxt min max) (range 20)) ; ❶ ;; [0 19]
❶ 由于
max和min不直接接受集合, 我们使用apply来展开集合. 为了在一次调用中组合max和min, 我们使用了juxt.为了将示例扩展到搜索局部最大值的方向, 我们可以实现一个" 最佳圈速" 函数, 用于显示比赛中当前的最佳圈速:
(defn tracker [] (let [times (atom [])] (fn [t] ; ❶ (swap! times conj t) ; ❷ (apply min @times)))) ; ❸ (def timer (tracker)) (timer 37.21) ;; 37.21 (timer 38.34) ;; 37.21 (timer 36.44) ;; 36.44 (timer 37.21) ;; 36.44
❶
tracker函数每次调用时都会初始化一个新的状态原子. 然后它" 闭包" 了初始化的状态, 返回一个接受单个" 时间" 参数的新函数. 该高阶函数被返回给调用者, 准备使用.❷ 每次我们收到一个新的时间测量值时, 我们都将其添加到存储在原子中的时间事件集合中.
❸ 返回到目前为止收集到的最佳时间. 我们使用
min和apply来找出集合中的最小数字.- NaN 的确切含义是什么?
在计算中, NaN 是一种将未定义或无法表示的值存储为位的约定. 它是由 1985 年的 IEEE 754 浮点标准引入的. NaN, 字面上是" 非数字" , 可能是几种数学" 奇点" 的结果:
(def ∞ (/ 1. 0)) (/ 0. 0) (/ ∞ ∞) (* 0 ∞) (- ∞ ∞) (Math/pow 1 ∞) (Math/sqrt -1) ;; all producing: ;; NaN
Clojure 主要遵循 Java 对 NaN 的规则, 并方便地作为
java.lang.Double的静态属性提供. 尽管名字声称它不是, NaN 是一个数字, 并且可以在算术运算中使用:(number? Double/NaN) ; ❶ ;; true (inc Double/NaN) ; ❷ ;; NaN (instance? Double Double/NaN) ; ❸ ;; true
❶ " 非数字" 是一个数字!
❷ 因此, 我们可以在算术运算或数字比较中使用 NaN.
❸ 更具体地说, NaN 是一个双精度数.
NaN 的令人惊讶的行为不止于此. NaN 的一个有趣特性是它是唯一一个不等于自身的数字:
(== Double/NaN Double/NaN) ; ❶ ;; false
❶ NaN 不等于它自己.
- NaN 的确切含义是什么?
- 另请参阅
max-key的工作方式与min和max非常相似, 只不过它们可以接受任何类型的参数, 限制是必须有一种方法将它们转换为数值. 作为第一个参数传递的函数将用于确定参数应如何转换为数字. - 性能考虑和实现细节
=> O(n) 线性时间
=> O(1) 空间分配
找到最小值或最大值的算法必须将当前候选值与集合中的所有其他数字进行比较, 即使集合是已排序的 (如向量或
sorted-set). 这种线性关系可以在没有任何特定性能工具的情况下得到验证 (所以不要太注意实际数字, 只需注意数量级):(let [s (apply sorted-set (range 100000))] (time (apply min s))) ;; "Elapsed time: 25.701355 msecs" (let [s (apply sorted-set (range 10000000))] (time (apply min s))) ;; "Elapsed time: 1292.216983 msecs"
因此, 如果速度是一个限制, 并且算法可以被设计为随时间累积结果的集合, 理想的解决方案是在结果准备好时将元素推入一个
sorted-set中, 然后取first或last, 而不是调用min或max.
2.4.9. 5.9 max-key 和 min-key
自 1.0 版本以来的函数
(max-key ([k x]) ([k x y]) ([k x y & more])) (min-key ([k x]) ([k x y]) ([k x y & more]))
max-key 和 min-key 在概念上建立在 max 和 min 函数之上. 虽然 max 只对数字进行操作, max-key 和 min-key 也可以接受其他类型和一个附加的函数 (键), 以帮助将这些参数转换或提取为数字, 并最终确定最大或最小值. max-key 和 min-key 不仅仅返回最小或最大的数字, 而是返回一个与参数类型相同的值:
(min-key last [:a 1000] [:b 500]) ;; [:b 500] (max-key :age {:name "anna" :age 31} {:name "jack" :age 21}) ;; {:name "anna", :age 31}
- 约定
- 输入
"k"是一个单参数函数, 返回一个数值类型."k"在参数上被调用:(k x),(k y)等等."x","y"(以及任何附加参数) 可以是任何类型.
- 值得注意的异常
当
"k"返回一个非数字的结果时, 会抛出ClassCastException. - 输出
max-key和min-key分别返回调用"k"后返回最大或最小结果的参数.与
max不同,min-key和max-key不处理 NaN (而它们处理正无穷和负无穷则没有问题). 因此, 在使用min-key和max-key以及可能在任何参数中生成 NaN 的数字处理时需要注意.以下示例显示了由于存在 NaN 而产生的错误结果. 这个计算声速的函数包含了一个稍微错误的公式:
(def air-temp [[:cellar 4] [:loft 25] [:kitchen 16] [:shed -4] [:porch 0]]) (defn speed-of-sound [temp] ; ❶ (* 331.3 (Math/sqrt temp))) ;; ouch (apply max-key #(speed-of-sound (last %)) air-temp) ; ❷ ;; [:porch 0]
❶ 空气中的声速大致随温度的平方根增加而增加. 这个公式的问题在于, 我们应该讨论的是绝对温度:
(inc (/ temp 273.15)). 但我们忘了做转换.❷ 在寻找房子里声音传播最快的部分时, 我们得到了一个错误的结果, 却没有引发异常. 问题在于对负数求平方根会产生 NaN, 迫使
max-key总是返回集合的最后一个参数, 尽管其他参数更大.防止上述问题的正确公式如下:
(defn speed-of-sound [temp] ; ❶ (* 331.3 (Math/sqrt (inc (/ temp 273.15))))) (apply max-key #(speed-of-sound (last %)) air-temp) ; ❷ ;; [:loft 25]
❶ 我们更改公式, 使其将温度转换为绝对开尔文 (假设输入正确, 绝对开尔文永远不会是负数).
❷ 我们可以看到, 声音在阁楼中传播得很快, 因为那里的温度更高.
- 输入
- 示例
在讨论
min时, 我们使用了一个tracker函数, 当它按顺序被调用时, 总是响应当前的最小值. 我们现在想扩展这个例子, 以便它还可以记录额外的信息, 比如运动员的名字, 这样我们就可以用它来显示比赛的获胜者, 而不仅仅是最佳时间.min-key很快解决了这个问题:(defn update-stats [event stats] ; ❶ (let [events (conj (:events stats) event) newmin (apply min-key :time events) ; ❷ newmax (apply max-key :time events)] (assoc stats :events events :min newmin :max newmax))) (defn new-competition [] ; ❸ (let [stats (atom {:min {} :max {} :events []})] (fn ([] (str "The winner is: " (:min @stats))) ; ❹ ([t] (swap! stats (partial update-stats t)))))) ; ❺ (def race1 (new-competition)) ; ❻ (:min (race1 {:athlete "Souza J." :time 38.34})) ; ❼ ;; {:athlete "Souza J.", :time 38.34} (:min (race1 {:athlete "Kinley F." :time 37.21})) ;; {:athlete "Kinley F.", :time 37.21} (:max (race1 {:athlete "Won T." :time 36.44})) ;; {:athlete "Souza J.", :time 38.34} (race1) ; ❽ ;; "The winner is: {:athlete \"Won T.\", :time 36.44}"
❶
update-stats是一个接受新事件和当前统计数据并计算新统计数据的函数.❷ 使用
min-key和max-key, 我们可以计算最佳和最差时间, 同时保留所有其他相关信息.❸
new-competition包装了初始状态的设置. 初始状态存储在一个原子中, 由几个由相关键标识的嵌套数据结构组成. 局部状态是返回给调用者的函数绑定的一部分.❹ 无参数元数在比赛结束时调用, 以显示获胜者.
❺ 第二个元数接受新事件作为输入, 并继续用
swap!更新状态, 将更新状态函数传递给旧状态. 新事件也通过partial传递给update-state.❻ 通过调用不带参数的主
new-competition函数来创建新的比赛.❼ 示例显示, 在向比赛发送新事件后, 返回的值可以查询统计信息, 如最佳时间或最差时间.
❽ 不带参数调用的
race1函数打印最终结果.另一种看待涉及最小和最大值的问题的方法是, 当试图最小化或最大化一个函数时, 例如最近邻搜索. Donald Knuth 非正式地将这类搜索称为" 邮局问题" 105.
让我们字面上接受挑战, 尝试解决以下问题: 给定一个邮局的地理坐标列表, 我们想知道将哪个邮局分配给该地区的新房子. 我们可以通过搜索最小化欧几里得距离 (为球面近似) 的值来解决这个问题. 这更严格地由 Haversine 公式 106 表达:
(defn sq [x] (* x x)) ; ❶ (defn rad [x] (Math/toRadians x)) (defn cos [x] (Math/cos (rad x))) (defn sq-diff [x y] (sq (Math/sin (/ (rad (- x y)) 2)))) (defn haversine [[lon1 lat1] [lon2 lat2]] ; ❷ (let [earth-radius-km 6372.8 dlat (sq-diff lat2 lat1) dlon (sq-diff lon2 lon1) a (+ dlat (* dlon (cos lat1) (cos lat1)))] (* earth-radius-km 2 (Math/asin (Math/sqrt a))))) (defn closest [geos geo] ; ❸ (->> geos (map (juxt (partial haversine geo) identity)) (apply min-key first))) (def post-offices [[51.74836 -0.32237] [51.75958 -0.22920] [51.72064 -0.33353] [51.77781 -0.37057] [51.77133 -0.29398] [51.81622 -0.35177] [51.83104 -0.19737] [51.79669 -0.18569] [51.80334 -0.20863] [51.74472 -0.19791]]) (def residence [51.75049331 -0.34248299]) (closest post-offices residence) ; ❹ ;; [2.2496423923820656 [51.74836 -0.32237]]
❶
sq,rad,cos和sq-diff都是转换和其他几何相关变换所需的辅助函数.❷
haversine计算球面距离, 这在地球上会被近似, 因为半径并不总是相同的. 对于这个练习来说, 它绝对是一个足够好的近似值.❸
closest是决定邮局的哪个位置与目标住宅坐标的距离最小的函数. 我们首先获取邮局位置的向量, 用map操作和到目标住宅的距离来装饰它, 然后用min-key来查看哪个是最近的.❹ 调用
closest函数返回一个包含最短距离 (以千米为单位) 的对. - 另请参阅
max和min有类似的目标, 但它们只接受数值参数, 没有选项传递一个" 键" 函数来决定如何处理其他类型的参数. 当你只对从一组数字中检索实际的最小值或最大值, 而不关心任何其他相关数据时, 优先使用max.reduce是min-key和max-key所采用过程的推广.reduce可以迭代一个序列, 同时为下一步的执行存储一些信息. 这正是在为当前比较选举一个局部最小值或最大值, 然后用下一个重复该过程时发生的情况. 如果你需要不同类型的聚合统计数据, 例如中位数, 考虑使用reduce. - 性能考虑和实现细节
=> O(n) 线性时间
=> O(1) 空间分配
性能考虑与
max或min函数类似, 加上 "key" 函数产生的开销. 总而言之: 如果参数数量很大, 但可以逐步将它们累积到一个有序集合中 (例如, 在一个sorted-set中), 那么尝试通过从有序结果中取第一个或最后一个来避免使用min-key或max-key.
2.4.10. 5.10 rand 和 rand-int
自 1.0 版本以来的函数
(rand ([]) ([n])) (rand-int [n])
生成随机数是许多语言中的一个常见特性. 在 Clojure 中, 它们分别使用 Java 的伪随机生成能力来生成 double 或 int 类型的随机数. 对于许多实际应用来说, 这种随机数已经足够好. 它们不被认为适合于像蒙特卡洛生成 107 这样的更强随机性要求. 默认情况下, rand 产生一个范围在 0 ⇐ x < 1 的 double 数, 而 rand-int 生成一个从 0 到指定边界的随机整数:
(rand) ;; 0.6591252808399537 (rand-int -10) ;; -5
- 约定
- 示例
随机性在许多领域都有应用. 一个简单的用例是 A/B 测试, 当我们希望一部分用户选择新功能时. 假设我们想增加回答调查的人数, 并且我们认为显示还剩多少问题是一个好主意. 同时, 我们不想冒着对所有参与调查的客户群体做出潜在错误决定的风险, 所以我们决定只向 50% 的总请求推出. 我们可以通过使用
rand来实现这一点:(def questions [["What is your current Clojure flavor?" ["Clojure" "ClojureScript" "CLR"]] ["What language were you using before?" ["Java" "C#" "Ruby"]] ["What is your company size?" ["1-10" "11-100" "100+"]]]) (defn format-options [options] (apply str (map-indexed #(format "[%s] %s " (inc %1) %2) options))) (defn render [[question options] prefix] (str "Q" prefix question " " (format-options options))) (defn A-B [prob A B] ; ❶ (if (< prob (rand)) A B)) (defn progress-handler [total] ; ❷ (A-B 0.5 (fn [progress] (format "(%s/%s): " total progress)) (constantly ": "))) (defn ask [questions] (let [progress (progress-handler (count questions))] ; ❸ (loop [[q & others] questions a []] (if q (do (println (render q (progress (inc (count a))))) ; ❹ (recur others (conj a (read)))) a)))) (ask questions) ;; Q(3/1): What is your current Clojure flavor? [1] Clojure [2] ClojureScript [3] CLR ;; 2 ;; Q(3/2): What language were you using before? [1] Java [2] C# [3] Ruby ;; 1 ;; Q(3/3): What is your company size? [1] 1-10 [2] 11-100 [3] 100+ ;; 3 ;; [2 1 3]
❶
A-B是一个与if非常相似的分支函数, 但它还接受一个 0 到 1 之间的数字来确定条件的一个分支与另一个分支相比的使用概率. 通过将输入概率与调用rand的结果进行比较, 可以非常简单地实现这一点, 这实际上将其转换为在if语句中选择选项 A 或选项 B 的概率.❷
progress-handler, 在我们的调查管理器提供的所有功能中, 是受 A/B 测试影响的功能. 因此, 它只是使用A-B来实施一个 90% 的概率, 即新功能 "A" 将被呈现给用户, 而不是旧功能 "B". 我们使用 50% (这里转换为 0.5), 因此用户将被呈现一个" 进度指示器" , 而不是在 100 次中有 50 次仅是一个冒号 ":" 符号.❸ 当需要提问时, 我们通过循环遍历问题来开始调查. 因为我们希望所有问题要么显示进度, 要么不显示, A-B 条件分支需要在循环之前发生.
❹ 由于我们缺少正在被问问题的当前索引, 我们需要等到该数据在循环内可用. 这就是为什么
progress-handler返回一个到目前为止的进度函数, 该函数需要在实际调用时作为参数传递. 在这次println期间, 我们有可用的信息, 所以我们调用在progress-handler中创建的高阶函数.- 随机性不是一件容易的事!
在编程语言的背景下, 我们通常谈论的是" 伪随机" 数生成, 而不是" 精确的" . 原因是, 有效地随机并不是一件容易的事, 而且通常需要在速度和易用性之间进行权衡. 有许多与随机数生成相关的算法, 该领域的研究也在不断进行中. Java (因此 Clojure) 使用的是一种线性同余生成器 (LCG), 它基本上使用一些初始种子 (通常与硬件纪元时间相关), 然后使用特定的乘法和模运算公式来生成一组有限的不同数字, 直到序列重复 (这被称为生成器的周期).
如开头所述, 这类随机生成器对于大多数应用来说已经足够好, 但它们无法满足许多需要强随机性的科学模拟. Java LCG 的周期 (2
- 不是唯一的问题, 因为 LCG 还存在一定程度的:
- " 平面掉落"
- 随机性在位之间分布不均.
第一个问题与随机数的分布有关, 如果我们将随机点绘制在 3D 空间中, 就可以可视化, 因此得名 (这篇 1968 年的论文 www.pnas.org/content/61/1/25.full.pdf 可能是第一个这样称呼这个问题的). 一个比其他算法更容易出现这个问题的 LCG 算法是 RANDU 108, 尽管它已经被更好的算法所取代, 但它有助于理解这个问题. 如下图所示, 绘制的点并不像人们期望的那样均匀分布, 而是形成了二维平面的可预测模式.

Figure 9: RANDU 生成的 3D 点: 模式以 2D 平面的形式可见.
第二个问题与数字的生成方式有关, 它基本上是在每个新数字上重复的位操作. 当我们以位的形式看待生成的数字时, 我们可以看到一个模式的出现. 这一次我们可以直接在
java.util.Random上验证我们的假设, 并用以下示例可视化这个问题:(import 'java.awt.image.BufferedImage 'java.util.Random 'javax.imageio.ImageIO 'java.io.File) (def ^:const width 256) (def ^:const height 256) (def ^:const black 0xffffff) (def ^:const white 0x000000) (defn coords [x y] (for [m (range x) n (range y)] [m n])) (defn save! [img] (ImageIO/write img "PNG" (File. "/tmp/rand-noise.png"))) (defn rand-pixel [r] (if (== 0 (bit-and (.nextInt r) 1)) white black)) (defn a [] (let [r (Random.) img (BufferedImage. width height BufferedImage/TYPE_BYTE_BINARY)] (doseq [[x y] (coords width height)] (.setRGB img x y (rand-pixel r))) (save! img)))

Figure 10: java.util.Random::nextInt() 的位被可视化为黑白点.
示例中的代码创建了一个 256x256 像素的二进制图像对象, 并将每个像素随机地涂成黑色或白色. 正如你在生成的图像中看到的, 点在某些地方水平对齐, 而不是均匀分布, 这证明了 LCG 的另一个局限性.
- 随机性不是一件容易的事!
- 另请参阅
rand-nth接受一个序列并返回该序列中的一个随机元素. 当你对一个随机整数感兴趣, 以便用它来访问一个集合, 而不是对随机整数本身感兴趣时, 使用它.shuffle接受一个集合作为输入, 并返回一个新集合, 其中包含元素的随机排列. 当你只对随机交换集合中的元素感兴趣时, 使用shuffle.random-sample接受一个集合作为输入和一个概率因子 "p". 它将返回一个新序列, 该序列有 "p" 的概率包含原始元素. 概率越小, 返回的元素就越少. - 性能考虑和实现细节
=> O(1) 常数时间, 内存和计算
在计算
rand或rand-int的复杂性时没有涉及变量, 在任何给定时间, 只有 32 位的当前生成的随机数保存在内存中. Clojure 的实现只是委托给 Java 的Math.random(), 后者又使用了一个 LCG (线性同余生成器) 算法. LCG 可能不是所有可能问题的最佳随机生成器, 但它在简单性, 速度和准确性之间是一个很好的权衡.
2.4.11. 5.11 with-precision
自 1.0 版本以来的宏
(with-precision [precision & exprs])
with-precision 创建一个上下文, 在该上下文中, BigDecimal 操作以给定的精度和舍入模式执行. 当包装的表达式是或可以产生 BigDecimal 数字时, with-precision 很有用, 例如那些包含 "big M" 字面量 (例如 2M 是表示 2 为 BigDecimal 数字的字面量) 的表达式. 如果不指定精度, BigDecimal 上的操作可能会在小数位数" 非终止" 时导致 ArithmeticException. 这里有一个例子, 显示了 22/7 的前 3 位小数. 如果不指定精度, 同样的操作会产生异常:
(/ 22. 7) ; ❶ ;; 3.142857142857143 (/ 22M 7) ; ❷ ;; ArithmeticException Non-terminating decimal expansion; [...] (with-precision 4 (/ 22M 7)) ; ❸ ;; 3.143M
❶ 第一个小数展开足够精确, 但并不完美. 假设不需要额外的精度, 它是允许的.
❷ 如果我们试图获得最大精度, 我们需要面对一个永不终止的小数列表的问题, 这需要无限的内存. 这显然是不允许的, 会产生一个异常.
❸ 使用 with-precision, 我们可以指定我们想要分配多少内存来存储小数. 我们要求在第四个有效小数位 (不包括) 处停止.
(with-precision <precision> [<rounding>] [<exprs>]) ; ❶ precision :=> ; ❷ 0 <= X <= Integer/MAX_VALUE rounding :=> ; ❸ :rounding [CEILING|FLOOR|HALF_UP|HALF_DOWN|HALF_EVEN|UP|DOWN|UNNECESSARY] exprs :=> ; ❹ form1,form2,..,formN
❶ with-precision 接受一个强制的精度参数, 一个可选的舍入类型和零个或多个要求值的形式.
❷ 强制的精度是一个从零 (含) 到 Integer/MAX_VALUE 的正整数.
❸ 可选的舍入类型是关键字 :rounding, 后跟方括号中的任何一个值. 如果没有指定舍入类型, 则默认假定为 :rounding HALF_UP.
❹ exprs 是可选的 Clojure 形式. 如果没有形式作为输入传递, with-precision 返回 nil.
- 示例
with-precision在任何处理java.math.BigDecimal对象实例的数值计算中都有应用. 这可能是因为直接使用了BigDecimalClojure 字面量, 或者因为一个函数接收它们作为参数.BigDecimal类型被称为" 传染性的" , 因为一旦一个表达式在代码的某个地方引入了它, 其余的部分都会受到影响. 一种基于BigDecimal设计应用程序内部的策略是, 假设在函数外部, 参数是double类型, 它们的精度已经处理好了. 在函数内部, 我们提升为BigDecimal, 执行计算, 最后根据关于所需精度的约定再次返回double类型.例如, 以下显示了如何计算一个账户在以当前市场价格购买一定数量的股票后的价值:
(defn share-qty [account price] ; ❶ (let [accountM (bigdec account) priceM (bigdec price)] (if (zero? priceM) 0 (long (with-precision 5 :rounding DOWN (/ accountM priceM)))))) ; ❷ (defn increment [current price qty] (let [currentM (bigdec current) priceM (bigdec price)] (double (with-precision 5 (+ currentM (* priceM qty)))))) ; ❸ (share-qty 800 1.03) ;; 776 (increment 210 0.38 20) ;; 217.6
❶ 输入参数用
bigdec提升为BigDecimal. 它们现在已准备好进行任何后续计算, 不用担心会造成精度损失.❷
with-precision用于防止在当前账户总额与股票期权市场价格的比率有无限小数位时出现不必要的ArithmeticException. 在这种情况下, 我们还希望始终为账户中的股票数量返回整数数量, 所以我们接受始终将它们向下舍入.❸
qty参数没有被转换, 假设股票的数量总是一个整数.- 为什么我们需要 BigDecimal?
BigDecimal最被讨论的用法之一是用于货币计算. 问题源于这样一个事实, 即用于存储双精度浮点数的二进制浮点格式无法正确表示某些 10 的幂, 包括货币的常见分数, 如分:(- 1.03 0.42) ;; 0.6100000000000001 ; ❶
❶ 为什么会有那么多零?
尽管误差很小, 但当扩展到数百万次操作时, 它会累积成更令人担忧的数额. 因此, 所有主流语言都有一些方法来处理这种潜在的精度损失. Java 有用于浮点数的
BigDecimal和用于无限大小整数的BigInteger. Clojure 在这些基础之上构建, 使得在提升, 构造或操作它们时代码变得极其不那么冗长.
- 为什么我们需要 BigDecimal?
- 另请参阅
bigdec用于将其他类型转换为BigDecimal, 而with-precision处理应用于后续操作的参数.*math-context*是with-precision用选定的精度和舍入模式设置的动态变量. 如果你需要更精确地控制BigDecimal周围的MathContext, 你可以直接包装你的代码, 绕过with-precision:(binding [*math-context* (java.math.MathContext. 10 java.math.RoundingMode/UP)] (/ 10M 3)) ;; 3.333333334M
- 性能考虑和实现细节
=> O(1) 常数时间
with-precision准备块中传递的所有表达式, 以遵循一个特定的MathContext, 在其中执行BigDecimal操作. 开销是微不足道的, 并且与参数的数量或类型无关. 因此,with-precision在性能分析中不应成为一个问题.
2.4.12. 5.12 +', -', *', inc' 和 dec'
自 1.0 版本以来的函数
(+' ([]) ([x]) ([x y]) ([x y & more])) (*' ([]) ([x]) ([x y]) ([x y & more])) (-' ([x]) ([x y]) ([x y & more])) (inc' [x]) (dec' [x])
如预期的那样, +' -' *' inc' 和 dec' 与它们" 未引用" 的对应物非常相似. 它们遵循与 + - * inc' 和 dec' 类似的基本操作规则, 仅在结果超出 Long/MIN_VALUE 和 Long/MAX_VALUE 时改变行为. 本章将主要关注这些差异.
- 约定
对于一般的约定, 请参考
+和inc. 唯一的区别是, 当操作结果 "x" 超出x < Long/MIN_VALUE OR x > Long/MAX_VALUE(分别是长整型精度的下限和上限) 时, 结果会自动转换为clojure.lang.BigInt.请注意, 自提升是在假设参数是整数类型 (可能是
clojure.lang.BigInt实例) 的情况下进行的. 如果我们想将任意精度运算符与浮点数一起使用, 我们需要先将参数转换为java.math.BigDecimal:(+' Double/MAX_VALUE Double/MAX_VALUE) ; ❶ ;; Infinity (+' (bigdec Double/MAX_VALUE) (bigdec Double/MAX_VALUE)) ; ❷ ;; 3.5953862697246314E+308M (+ (bigdec Double/MAX_VALUE) (bigdec Double/MAX_VALUE)) ; ❸ ;; 3.5953862697246314E+308M
❶ 带有
+'的任意精度加法是在假设参数是整数类型的情况下进行的. 如果我们尝试使用非常大的浮点值, 结果是Infinity.❷ 如果我们希望运算符在浮点数上工作, 我们需要用
bigdec显式地转换它们.❸ 这也适用于普通加法.
- 示例
Diffie-Hellman 密钥交换算法是第一个公开的算法, 它允许两个对等方交换一个私钥来开始一个加密的对话 109.
在 Diffie-Hellman 之前, 双方必须使用一些物理媒介 (如纸张) 来交换密钥, 就像在二战期间设置恩尼格玛机一样. 一旦密钥被共享, 两个对等方就可以使用一个对称密钥密码开始加密对话. 该算法的一个重要部分是模数 "p" 和初始密钥 "a" 和 "b" 足够大以防止暴力攻击. 因此, 它们被选择得远远超出了 2
64 位空间的
long限制. 相关的数学运算将需要在大整数上操作, 因此任意精度运算符非常适合.以下是一个简化的示例, 它没有使用现代协议 (如 SKIP, 简单密钥管理互联网协议) 后来包含的更复杂的参数约定, 但它仍然是功能性的和可用的:
(defn genbig [n] ; ❶ (->> #(rand-int 10) (repeatedly n) (apply str) (BigInteger.) bigint)) (defn I [n] (.toBigInteger n)) ; ❷ (defn prime? [n accuracy] (.isProbablePrime (.toBigInteger (bigint n)) accuracy)) (defn next-prime [n] ; ❸ (loop [candidate n] (if (prime? candidate 10) candidate (recur (if (neg? candidate) (dec' candidate) (inc' candidate)))))) (defn- mod-pow [b e m] ; ❹ (bigint (.modPow (I b) (I e) (I (next-prime m))))) (defn public-share [base secret modulo] ; ❺ (mod-pow base secret modulo)) (defn shared-secret [public secret modulo] ; ❻ (mod-pow public secret modulo)) (def modulo-pub (genbig 30)) ; ❼ (def base-pub (genbig 30)) (def a-pub (public-share base-pub 123456789N modulo-pub)) ; ❽ (def b-pub (public-share base-pub 987654321N modulo-pub)) (def a-common-secret (shared-secret b-pub 123456789N modulo-pub)) ; ❾ a-common-secret ;; 395976829969556119817932826983N (def b-common-secret (shared-secret a-pub 987654321N modulo-pub)) ; ❿ b-common-secret ;; 395976829969556119817932826983N (= a-common-secret b-common-secret) ; ⓫ ;; true
❶
genbig是一个辅助函数, 用于生成交换期间强保护所需的极大数字. 最终产品是 Clojurebigint类型.❷
I函数有一个非常规的名称. 然而, 它是将 Clojureint类型 (小写" i" ) 转换为 JavaBigInteger(大写" I" ) 的一个引人注目的助记符.❸
next-prime是找到给定数字的最近素数所必需的. 我们需要这个函数来确保模数是一个素数. 由于我们随机生成数字, 我们使用next-prime来获取最近的素数. 这是我们很好地利用inc'和dec'的地方, 因为如果我们传入的数字n不需要bigint范围, 我们就不需要自提升.❹
mod-pow包装了 JavaBigInteger类提供的相同函数. Clojure 中没有处理大整数的" pow" 操作, 所以我们使用 Java 提供的那个.❺
public-share根据 diffie-hellman 规范对基数, 密钥和模数应用mod-pow操作.❻
shared-secret是完全相同的操作, 已被定义为一个不同的函数, 这样参数的名称可以清楚地突出这两个函数应该被使用的两个不同上下文.❼ 这一步是我们的示例用法开始的地方. 我们首先决定一个模数和一个基数. 所有由以 -pub 结尾的函数产生的值都可以在公共场合共享. 因此, 两方 A 和 B 可以通过电子邮件等方式就基数和模数达成一致, 无需任何加密.
❽ A 现在可以生成一个公共" 掩码" , 覆盖可以明文发送的私钥 "123456789N". 尽管这个公共部分是明文发送的, 但要找到哪个密钥生成了公共掩码的可能性太多了. B 用 "987654321N" 作为密钥做同样的事情. 请注意, 这些私钥永远不需要离开本地计算机.
❾
a-common-secret的生成方式与public-share类似, 使用 B 共享的公共部分和 A 的私钥. 这个数字是 A 可以用来加密所有后续消息的东西.❿ B 执行相同的操作, 获得
b-common-secret, 这将用于解密和加密发送给 A 的消息.⓫ 如你所见,
a-common-secret和b-common-secret实际上是相同的数字.上面的例子凸显了在使用
bigint时的一个潜在问题: 尽管比 Java 的等效语法简洁得多, 但一旦需要使用仅在 Java 端实现的功能, 就需要一些与 JavaBigInteger之间的来回转换.- clojure.lang.BigInt 和 java.math.BigInteger
你可能已经注意到, Clojure 和 Java 之间似乎存在重复. 为什么一个
bigdec映射到一个java.lang.BigDecimal, 而一个 Clojurebigint映射到一个自定义的 Clojure Java 类:(type 2M) ;; java.math.BigDecimal (type 2N) ;; clojure.lang.BigInt
当我们在 REPL 中输入一个
bigint字面量时,clojure.lang.BigInt类似乎替换了相应的java.math.BigDecimal. Clojure 实现这个类的原因是因为Long.hashCode()和BigInteger.hashCode()返回的值不同. 对于 Clojure 来说, 两个哈希码相同是很重要的, 因为如果不是,1N和1可能会在同一个 map 或 Set 中.BigInt也被优化为, 如果它们表示的数字在long的精度限制内, 就使用数字原语.
- clojure.lang.BigInt 和 java.math.BigInteger
- 另请参阅
bigint从所有数字类型创建一个clojure.lang.BigInt, 包括java.math.BigInteger甚至字符串:(bigint "1")给出1N.如果你确定应用程序永远不需要升级到
BigInt, 你可以使用普通运算符,+.unchecked-add是相关的unchecked-*版本, 直接映射到 Java 的基本操作. 未检查的版本不会自动提升, 并且在超过long边界时不会抛出异常, 而是简单地从另一端的相反符号开始. 如果精度很重要, 不应使用未检查的数学版本. - 性能考虑和实现细节
=> O(n) 与参数数量成线性关系
+',-',*'与参数数量成线性关系.inc'和dec'等价于将一个数加一, 因此它们是常数时间. 实现自提升所需的额外开销与在使大整数运算易于编写方面所获得的回报相比可以忽略不计. 如果你需要特定的优化, 这就是预期的性能损失:(require '[criterium.core :refer [quick-bench]]) (quick-bench (loop [i 0] (if (< i 10000) (recur (inc i)) i))) ;; Execution time mean : 14.304079 µs (quick-bench (loop [i 0] (if (< i 10000) (recur (inc' i)) i))) ;; Execution time mean : 53.189780 µs
如你所见, 除非应用程序专门处理大量大整数数学, 否则这些操作不应成为性能分析中的主要关注点. 然而, 如果你可以将应用程序的性能敏感部分限制为只使用
long(甚至更好的是int), 那么可能值得转向未检查的运算符 (你可以在关于inc的性能部分看到一个例子).
2.4.13. 5.13 unchecked-add 和其他 unchecked 运算符
注意
本节还包括
unchecked-subtract,unchecked-multiply,unchecked-inc,unchecked-dec和unchecked-negate.
自 1.0 版本以来的函数
(unchecked-add [x y]) (unchecked-subtract [x y]) (unchecked-multiply [x y]) (unchecked-inc [x]) (unchecked-dec [x]) (unchecked-negate [x])
" unchecked-*" 运算符家族是 Clojure 标准库中的一组函数, 它们复制了基本数学运算符的行为, 除了不处理超过两个参数和移除整数溢出检查. 它们可以像这样随时使用:
(unchecked-add 1 2) ;; 3 (unchecked-subtract 2 38) ;; -36 (unchecked-multiply 10 3) ;; 30 (unchecked-inc 100) ;; 101 (unchecked-dec 12) ;; 11 (unchecked-negate 1) ;; -1
- 约定
- 输入
与其他数学运算符不同,
unchecked-add,unchecked-subtract,unchecked-multiply,unchecked-inc,unchecked-dec和unchecked-negate的参数数量有限:unchecked-add,unchecked-subtract和unchecked-multiply只接受 2 个数字参数.unchecked-inc,unchecked-dec和unchecked-negate接受一个数字参数.
- 输出
它们都返回相应操作的结果. 最终的类型取决于参数的类型, 遵循最" 具传染性" 类型的规则. 有关类型提升的优先规则, 请参阅本章中的标注.
- 输入
- 示例
Clojure 中的
long类型数字使用 Java 中的等效有符号long类型, 该类型有 64 位. 一位用于符号, 因此long类型的可用范围是从 -263 到 2
63 (含):
[(long (- (Math/pow 2 63))) (long (Math/pow 2 63))] ; ❶ ;; [-9223372036854775808 9223372036854775807]
❶ 可用长整型表示的数字范围. 请注意, 我们需要强制转换为长整型, 因为
Math/pow返回一个科学记数法表示的双精度浮点数.如果我们使用
unchecked-inc递增最大的长整型数, 结果会从另一端重新开始, 并改变符号. 类似地, 如果我们递减最小的数:(unchecked-inc (long (Math/pow 2 63))) ; ❶ ;; -9223372036854775808 (unchecked-dec (long (- (Math/pow 2 63)))) ; ❷ ;; 9223372036854775807
❶ 在 63 位上可表示的最大长整型数上使用
unchecked-inc的效果.❷ 类似地, 对最小 (负数) 长整型数使用
unchecked-dec会达到从最大数重新开始的效果.正如文献中经常提到的, 整数溢出操作在哈希中很有用. 为了理解为什么是这种情况, 让我们实现一个类似于 Java 本身使用的字符串哈希函数 (
.hashCode "string"), 但返回长整型而不是整型. 这个版本的哈希函数不是产生 232 (约 43 亿) 个键, 而是提供 2
64 (约 180 亿亿) 个潜在的不同键. 如果我们需要哈希数百万个字符串并降低冲突的风险, 这么多的可能性可能是合理的.
(defn scramble [^long x ^long y] ; ❶ (unchecked-add (unchecked-multiply 31 x) y)) ; ❷ (defn hash-str [s] ; ❸ (let [large-prime 1125899906842597] ; ❹ (reduce scramble large-prime (map int s)))) ; ❺ (hash-str "couple words") ; ❻ ;; 1664082230529263278 (hash-str "even longer sentences") ;; -7674745620208396614
❶
scramble是一个接受两个长整型数 "x" 和 "y" 的函数, 并应用一些简单的算术. 我们需要将参数" 类型提示" 为长整型, 因为该函数稍后会传递给reduce. 我们需要这样做的原因是, 编译器在运行时无法看到类型, 并将它们视为装箱对象. 不幸的是, 如果任何一个操作数是装箱的 Java 对象, 未检查的运算符将使用普通数学, 这个问题正在讨论中, 可能会在后续的 Clojure 版本中修复 110.❷ 这是我们需要使用可以处理可能很大的数字, 超出长整型值的东西的地方. 由于我们对精度不感兴趣, 只关心位的关系, 我们可以接受操作溢出. 溢出仍然会产生一个有效的长整型, 这正是我们想要的. 数字 "31" 是一个素数. 素数具有在操作中较少引入位偏差的特性.
❸
hash-str是一个接受我们想要哈希的任意长字符串的函数.❹ 我们需要一个大数来开始求和. 主要原因是为了避免对于较短的字符串, 高位总是被设置为零. 这个大数也是一个素数, 同样是为了避免引入不希望的位偏差.
❺ 我们需要将字符串中的每个字符转换为一个数字. 为此, 我们可以使用 ASCII 表. 下一步是应用
scramble并对结果求和.❻ 当调用时,
hash-str返回一个数字, 该数字转换为二进制时是预期的 64 位长.- 传染性类型
编程语言通常支持具有不同行为的一系列数值类型. 数值类型可以根据支持的精度进行分类, 描述了每种类型可以处理的下限/上限. 标准库中的函数受语言中存在的类型的影响, 它们应该描述当对不同的数值类型应用操作时会发生什么.
直观地讲, 如果一个具有更高精度的运算符与一个精度较低的运算符一起使用, 那么返回的类型应该至少具有最精确操作数的精度. Clojure 大致应用了图中显示的优先列表来确定操作结果应该如何提升:
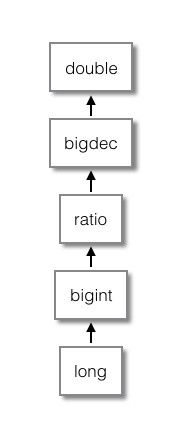
Figure 11: 传染规则: 运算符的结果将大致返回操作数类型中最精确的那个.
Clojure" 大致" 应用了图中描述的传染规则, 因为正如我们在本章开头的返回类型关系表中看到的, 该规则有几个例外. 还要考虑到,
double, 最具传染性的类型, 也有一个非常特殊的精度定义:(double (- 10 1/3)) ; ❶ ;; 9.666666666666668
❶ 一个显示周期性小数最后一位自动舍入的通用操作.
上面的代码片段只是显示了现代计算机浮点算术中一个众所周知的事实, 因为 CPU 寄存器只有有限的精度, 并且对于像周期性浮点数这样的东西需要进行一些舍入. 因此, 如果精度很重要, 你应该设计能够显式处理精度的代码, 而不是让语言使用传染规则来决定.
- 传染性类型
- 另请参阅
unchecked-*-int函数家族与本章中描述的unchecked-*密切相关. 它们主要在两个方面有所不同: 参数将被转换为int(因此值高于或低于(Integer/MAX_VALUE)和(Integer/MIN_VALUE)分别会产生错误), 并且溢出是在整数而不是长整数上操作的. 除此之外, 参数和操作语义是相同的.hash是 Clojure 提供的为所有标准库中的类型创建哈希 (int) 数的函数. 有时它委托给 Java, 有时它实现了更好的选项 (比如对集合使用 Murmur3 111). 你不太可能需要实现自己的哈希函数, 在这样做之前, 请检查hash是否已经足够好.*unchecked-math*是一个动态变量, 即使在使用标准算术运算符时也启用未检查的数学. 有一些条件需要满足: 它只在原始类型上工作, 因此类型提示信息是必不可少的. - 性能考虑和实现细节
=> O(1) 常数时间
鉴于参数数量的限制,
unchecked-add,unchecked-subtract,unchecked-multiply,unchecked-inc,unchecked-dec和unchecked-negate都是常数时间. 由于缺少溢出检查或自提升功能,unchecked-*函数在长整型上的性能也优于任何其他数学运算符. 有关更多信息和基准测试, 请检查inc.
2.4.14. 5.14 unchecked-add-int 和其他 unckecked-int 运算符
注意
本节还包括:
unchecked-add-int,unchecked-subtract-int,unchecked-multiply-int,unchecked-divide-int,unchecked-inc-int,unchecked-dec-int,unchecked-negate-int和unchecked-remainder-int.
自 1.0 版本以来的函数
(unchecked-add-int [x y]) (unchecked-subtract-int [x y]) (unchecked-multiply-int [x y]) (unchecked-divide-int [x y]) (unchecked-inc-int [x]) (unchecked-dec-int [x]) (unchecked-negate-int [x]) (unchecked-remainder-int [x y])
unchecked-add-int, unchecked-subtract-int, unchecked-multiply-int, unchecked-divide-int, unchecked-inc-int, unchecked-dec-int, unchecked-negate-int, unchecked-remainder-int 是一个由 8 个函数组成的家族, 它们具有与本章中我们迄今为止看到的基本数学运算符相似的特性.
与 6 个" 未检查" 运算符 (那些名称末尾没有 "int" 后缀的) 不同, 它们将其参数转换为原始 int 类型. 另一个显著的区别是它们也返回一个 int, 而其他" 未检查" 运算符则会提升返回类型以适应精度更高的参数, 例如:
(unchecked-add 2.0 1) ; ❶ ;; 3.0 (unchecked-add-int 2.0 1) ; ❷ ;; 3 (type (unchecked-add-int 2.0 1)) ;; java.lang.Integer
❶ unchecked-add 将第二个参数提升为双精度类型以返回一个双精度数.
❷ unchecked-add-int 返回一个原始的 int 类型.
unchecked-*-int 家族对于实现哈希算法和一般的整数数学特别有用, 当 Clojure 使用 long 类型的默认行为没有用或不可取时.
- 约定
- 输入
unchecked-add-int,unchecked-subtract-int,unchecked-multiply-int,unchecked-divide-int和unchecked-remainder-int都接受 2 个参数. 这些参数必须是数字, 并且在整数精度范围内:(Integer/MAX_VALUE)和(Integer/MIN_VALUE).unchecked-inc-int,unchecked-dec-int,unchecked-negate-int接受一个数字int参数.
- 输出
它们都返回操作结果的原始
int类型, 在达到int精度 (32 位有符号位) 的限制时会溢出.
- 输入
- 示例
仅整数的算法在计算机科学中非常普遍. 哈希是通常限制为
int(和相关的装箱java.lang.Integer) 类型的领域, 我们已经说明了如何在为" unchecked-*" 运算符提供的示例中将哈希扩展到long.在下一个例子中, 我们将使用一个多维 Java 数组来处理简单的图像 (其中像素可以是 0 或 1). 这种表示法对于坐标 (图像中的像素只能有整数坐标, 因为 Java 数组的最大大小是
Integer/MAX_VALUE) 和数据都是基于整数的. 为了使事情更简单, 颜色深度将只有 2 种: 黑色 (1) 或白色 (0). 由于我们知道域将仅为整数, 我们可以利用本章中描述的" unchecked-*-int" 函数.我们希望能够在数字画布上绘制点和线. 斜线在用离散像素绘制时特别棘手, 迫使我们" 插值" 点, 使它们大致对齐. 布雷森汉姆直线算法 112 可以帮助我们找出在这种条件下构成直线的点. 由于有许多部分需要解释, 让我们从几个辅助函数开始:
(defn- steep? [x1 x2 y1 y2] ; ❶ (> (Math/abs (unchecked-subtract-int y1 y2)) (Math/abs (unchecked-subtract-int x1 x2)))) (defn- adjust-slope [x1 x2 y1 y2] ; ❷ (if (steep? x1 x2 y1 y2) [y1 x1 y2 x2] [x1 x2 y1 y2])) (defn- adjust-direction [x1 x2 y1 y2] ; ❸ (if (> (int x1) (int x2)) [x2 y2 x1 y1] [x1 y1 x2 y2])) (defn- adjust [x1 x2 y1 y2] ; ❹ (->> [x1 x2 y1 y2] (apply adjust-slope) (apply adjust-direction))) (defn- swap [steep?] ; ❺ (fn [[x y]] (if steep? [y x] [x y])))
❶ 这条线由四个坐标
x1,y1和x2,y2表示, 它们是线的两个端点.steep?帮助我们找出斜率的方向, 是向上还是向下.❷
adjust-slope如果线向上指, 则交换端点的坐标. 我们需要这个以及其他转换来在搜索线点之前" 标准化" 线信息.❸
adjust-direction考虑 "x" 坐标来交换线的端点.❹
adjust将转换组合在一起, 调整斜率的倾斜度和线的方向.❺
swap创建一个函数, 该函数根据斜率的倾斜度来交换 x,y 点的坐标.以下
to-points函数接受一条线的两个端点 (x1, x2, y1, y2), 并应用布雷森汉姆直线插值算法来返回构成该线的点的集合. 如你所见, 我们在整个过程中都进行了转换或使用了未检查的整数运算符:(defn to-points [x1 y1 x2 y2] (let [[^int x1 ^int y1 ^int x2 ^int y2] (adjust x1 x2 y1 y2) ; ❶ dx (unchecked-subtract-int x2 x1) dy (Math/abs (unchecked-subtract-int y1 y2))] (map (swap (steep? x1 x2 y1 y2)) (loop [x x1 ; ❷ y y1 error (unchecked-divide-int dx 2) points []] (if (> x x2) points (if (< error dy) (recur (unchecked-inc-int x) ; ❸ (if (< y1 y2) (unchecked-inc-int y) (unchecked-dec-int y)) (unchecked-add-int error (unchecked-subtract-int dx dy)) (conj points [x y])) (recur (unchecked-inc-int x) y (unchecked-subtract-int error dy) (conj points [x y]))))))))
❶ 带类型提示的
let是一个常见的惯用语, 用于强制 Clojure 编译器在编译时理解类型. 如果未设置类型提示, Clojure 会使用通用的<运算符来处理对象, 而不是基本整数. 通过设置(set! unchecked-math :warn-on-boxed)可以在装箱数学上看到警告.❷ 计算的主循环在下一个点坐标 (x,y) 上递归, 这些坐标是通过对先前找到的点应用增量/减量来找到的.
❸ 我们根据在一条线中放置当前点所产生的近似误差, 以两种不同的方式进行递归. 新的 x,y 坐标是使用
unchecked-inc-int或unchecked-dec-int找到的.最后, 在提取构成直线的点之后, 我们需要将它们绘制出来. 下一个函数
paint!接受一个画布 (一个二维的零数组) 并通过绘制给定的点来修改它:(defn paint! [^"[[I" img points] ; ❶ (let [pset (into #{} points)] (dotimes [i (alength img)] (dotimes [j (alength (aget img 0))] (if (pset [i j]) (aset-int img i j 1))))) ; ❷ img) (defn zeros [n] (take n (repeat 0))) (defn new-image [n] (into-array (map int-array (take n (repeat (zeros n)))))) (mapv vec (paint! (new-image 12) (to-points 2 3 10 10))) ; ❸ ;; after adding line breaks for clarity: ;; [ ;; [0 0 0 0 0 0 0 0 0 0 0 0] ;; [0 0 0 0 0 0 0 0 0 0 0 0] ;; [0 0 0 1 0 0 0 0 0 0 0 0] ;; [0 0 0 0 1 0 0 0 0 0 0 0] ;; [0 0 0 0 0 1 0 0 0 0 0 0] ;; [0 0 0 0 0 0 1 0 0 0 0 0] ;; [0 0 0 0 0 0 1 0 0 0 0 0] ;; [0 0 0 0 0 0 0 1 0 0 0 0] ;; [0 0 0 0 0 0 0 0 1 0 0 0] ;; [0 0 0 0 0 0 0 0 0 1 0 0] ;; [0 0 0 0 0 0 0 0 0 0 1 0] ;; [0 0 0 0 0 0 0 0 0 0 0 0] ;; ]
❶ 通过将图像类型提示为整数数组的数组 (你实际上可以用一个包含 Java 渲染的二维整数数组 "]]I" 的字符串来类型提示一个局部变量), Clojure 可以使用正确的整数多态调用, 避免任何反射调用.
❷
aset用于在给定位置用 "1" 改变数组, 如果这是一个线的点.❸ 对于我们的例子, 我们需要一些更多的辅助函数来设置一个空画布. 但一旦一切准备就绪, 我们可以调用
to-points来产生 (2,3) 和 (10,10) 之间的线近似 (例如), 并将这些点传递给paint!函数进行最后的绘制. 我们需要将数组转换为一个向量才能在屏幕上实际打印它.如你所见, " 1 的线" 近似于一条有时会将几个" 1" 彼此叠加的线, 这是由于线的倾斜度. 当在更大的画布上看到时, 这实际上会显示为一条直线.
在这种情况下使用未检查的整数运算符的主要原因是 一致性和性能. 由于 Java 数组是整数索引的, 甚至数组的内容也是整数, 因此避免任何转换 (即使是隐式的) 以进一步强调所有计算都在整数范围内是有意义的. 其次, 未检查的整数运算符消除了不必要的装箱和反射调用, 从而总体上提高了性能.
- 影响循环中原始整数的 bug
本章中介绍的布雷森汉姆算法的实现 (即
to-points函数的内容), 尽管在形式上是正确的, 但它受到一个影响所有 Clojure 版本直到 1.8 的 bug 的影响, 该 bug 阻止了原始整数 (以及浮点数) 在循环中使用而不会被编译器自动加宽为长整数 (或双精度浮点数) 113.根据循环的内容, 由于
unchecked-inc-int会将参数转换为int并产生int, 与类似使用unchecked-inc的情况相比, 它实际上可能会因为从long到int的持续 (不可避免的) 转换而使情况变得更糟.由于其他操作可能主导由于转换而导致的性能损失, 因此在得出任何结论之前, 总是测量是很好的. 事实上, 我们的布雷森汉姆算法就是这种情况:
;; New version of to-points that is using long throughout. (defn to-points-long [x1 y1 x2 y2] (let [[^long x1 ^long y1 ^long x2 ^long y2] (adjust x1 x2 y1 y2) dx (unchecked-subtract x2 x1) dy (Math/abs (unchecked-subtract y1 y2))] (map (swap (steep? x1 x2 y1 y2)) (loop [x x1 y y1 error (long (mod dx 2)) points []] (if (> x x2) points (if (< error dy) (recur (unchecked-inc x) (if (< y1 y2) (unchecked-inc y) (unchecked-dec y)) (unchecked-add error (unchecked-subtract dx dy)) (conj points [x y])) (recur (unchecked-inc x) y (unchecked-subtract error dy) (conj points [x y])))))))) (bench (to-points 3 0 214 197)) ; ❶ ;; Execution time mean : 10.191922 µs (bench (to-points-long 3 0 214 197)) ; ❷ ;; Execution time mean : 9.765748 µs
❶ 仅
int版本的基准测量❷ 使用
long的版本的基准测量如你所见, 这两个版本之间的差异很小, 表明计算的其他部分主导了从
int~到~long~的转换. 由于在下一个 Clojure 版本中 (其中包含对不希望的加宽为 ~long的修复), 结果可能会有所不同, 我们建议无论如何都使用未检查的int数学运算符. 有关更多信息, 请参见性能考虑部分.
- 影响循环中原始整数的 bug
- 另请参阅
按限制行为的顺序:
- 如果你不在一个仅整数的域中, 你可以使用简单的未检查运算符:
unchecked-add. - 如果你不需要溢出行为, 但需要精度, 自提升运算符就是你所需要的:
+'. hash是 Clojure 提供的为所有 Clojure 常见对象创建整数哈希的函数.
- 如果你不在一个仅整数的域中, 你可以使用简单的未检查运算符:
- 性能考虑和实现细节
=> O(1) 常数时间
unchecked-*-int家族是寻求数学相关问题原始速度的终极工具. 当一个问题可以被限制在 32 位整数的域内, 相关的运算符和没有溢出检查时, 我们可以获得与 JVM 为快速循环生成的完全相同的字节码. 不幸的是, 标注中描述的影响循环的 bug 会在某些条件下阻止获得全部的速度增益. 我们可以用一个简单的循环来显示这个问题, 并测量差异:(require '[criterium.core :refer :all]) (bench (loop [i (int 0)] (if (= i 1000000) i (recur (unchecked-inc-int i))))) Evaluation count : 79680 in 60 samples of 1328 calls. ; ❶ Execution time mean : 770.432197 µs Execution time std-deviation : 41.971531 µs Execution time lower quantile : 737.707313 µs ( 2.5%) Execution time upper quantile : 894.806741 µs (97.5%) Overhead used : 1.717123 ns Evaluation count : 206280 in 60 samples of 3438 calls. ; ❷ Execution time mean : 291.866997 µs Execution time std-deviation : 7.085264 µs Execution time lower quantile : 282.293988 µs ( 2.5%) Execution time upper quantile : 307.504766 µs (97.5%) Overhead used : 1.747339 ns
❶ 第一个测试使用的是当前的 Clojure 主分支, 没有任何额外的更改. 平均执行时间约为 770 微秒.
❷ 第二个测试是针对一个本地修补的 Clojure 进行的, 显示了超过 50% 的性能提升 (约为 291 微秒).
建议无论如何都使用未检查的
int运算符, 因为这个问题是已知的, 并且很可能会在下一个 Clojure 版本中修复.
2.4.15. 5.15 pos?, zero? 和 neg?
自 1.0 版本以来的函数
(pos? [x]) (zero? [x]) (neg? [x])
这些谓词是非常简单的函数, 分别用于验证一个数是正数, 零还是负数. 读者可能会想知道为什么 Clojure 费心创建如此简单的函数, 而不是将数 "x" 与零进行比较, 原因在于它们非常常用. 除了立即可读之外, 这些谓词与创建自定义函数相比, 可以节省一些击键, 如下例所示:
(filter #(> % 0) [4 -3 2 -6 10 9 0 -22]) ; ❶ ;; (4 2 10 9) (filter pos? [4 -3 2 -6 10 9 0 -22]) ; ❷ ;; (4 2 10 9)
❶ 使用比较器移除负数 (也包括零).
❷ 只需使用 pos?, 就可以用明显更少的击键次数达到同样的效果.
在非数字 (包括 nil) 上使用 pos?, zero? 或 neg? 会产生异常.
像往常一样, 在存在 NaN 的情况下, 处理双精度数时要小心, 因为 (pos? Double/NaN), (neg? Double/NaN) 和 (zero? Double/NaN) 都是假的.
2.4.16. 5.16 总结
在本章中, 我们看到了 Clojure 在保持简洁语法的同时, 对高性能和高精度的数学函数投入了多少心血. 与 Java 相比, 在 Clojure 中处理大数 (包括) 要容易和愉快得多. 当需要时, Clojure 提供了几乎与 Java 一样快的方法, 这一特性从早期就受到赞赏. 本章不包括相等性和比较运算符, 它们需要特殊处理. 我们将在下一章看到它们.
2.5. 6 比较与相等性
Clojure 中的相等性在比较" 对象" 时会考虑几个方面 (" 对象" 在这里是广义的, 与面向对象编程无关):
- 它们的值. 对象的" 值" 是 Clojure 相等性的主要成分. 一个结果是, 集合不一定需要具有相同的类型才能相等. 值满足了
(1 2)和[1 2]相等的常识, 尽管clojure.lang.PersistentList和clojure.lang.PersistentVector不是同一类型. 相等运算符=主要基于这个原则. - 它们的类型. 类型绝对是比较的一个相关方面. 例如, 类型用于在有序集合的情况下为相等性添加语义.
- 它们的身份. 最后, Clojure 还提供了一种用
identical?检查两个对象是否是同一个实例的方法 (这大多数时候都解析为检查它们在内存中是否有相同的地址).
Clojure 的相等性被设计为在大多数时候都是直观的 (不需要对类型有特定的了解), 但有几个边界情况, 将在本章中进行说明. 与面向对象编程相比, 函数式编程不那么强调容器对象及其对自定义相等性实现的需求 (因此也就不那么强调哈希). 另一方面, Clojure 提供了类似的自定义数据结构, 称为记录 (用 defrecord 创建), 它们带有基于属性的内置相等性.
在本章中, 我们将看到处理 Clojure 中比较的所有函数, 从基本构建块开始, 到 diff 结束:
=>主要用作条件中的运算符. 它们知道如何处理 Clojure 数据结构, 并直观地比较它们中的大多数.==>>是一个专门用于数字的相等运算符. 对于不同类型的数字有特定的比较规则.<是标准的比较运算符, 要求参数在处理结果时实现一个排序的概念.compare提供有关参数相对顺序的完整信息. 在没有提供其他比较器时, 它也用于标准排序.identical?允许 Clojure 通过引用访问 Java 的相等性.hash是 Clojure 中的主要哈希函数. 与基本的 Java 哈希相比, Clojure 的哈希需要一个特定的优化来处理在哈希映射中作为键的集合.clojure-data-diff建立在相等性的基础上, 提供了一种检索深度嵌套数据结构中差异的方法.
在编程语言中正确地处理相等性是一项非常困难的任务, Clojure 还必须处理与 Java 语义集成的问题. 总的结果是最好的权衡. 如果一方面你仍然需要注意一些粗糙的边缘, 另一方面 Clojure 在 JVM, 纯函数式数据结构和可用的相等性之间达到了完美的平衡.
2.5.1. 6.1 = (等于) 和 not= (不等于)
自 1.0 版本以来的函数
(= ([x]) ([x y]) ([x y & more])) (not= ([x]) ([x y]) ([x y & more]))
= (" 等于" ) 是 Clojure 中非常常用的函数之一. not= (" 不等于" ) 只是 = 的反面, 可以缩短更冗长的 (not (= a b)). 它们都接受一个或多个参数进行比较, 当它们" 相同" 时返回 true (或对于 not= 返回 false). 尽管解释很简单, " 相同" 的含义取决于被比较的东西的种类, 这不一定是其他编程语言中的定义. 基本用法非常简单:
(= "a" "a" "a") ;; true (not= 1 2) ;; true
用 = 实现的等价性考虑了值及其表示, 这意味着例如对于集合, 比较是针对内容而不是容器的类型. 本章的约定部分更具体地说明了规则和例外.
- 约定
- 输入
"x","y"和"more"可以是任何类型的 Clojure 表达式, 字面量或nil. 至少需要一个参数.
- 输出
=根据类型和内容返回true或false. 如果我们称"x"的类型为T1,"y"的类型为T2, 我们可以用兼容性组的概念来大致划分类型:- 类似列表的组 (有序比较): 列表, 向量, 子向量, 持久队列, 范围, 惰性序列.
- 类似 map 的组 (无序比较): 哈希映射, 排序映射, 数组映射.
- 类似 set 的组 (无序比较): 集合和排序集合 (排序映射和排序集合在顺序访问时是排序的, 但在比较时忽略排序).
- 整数组: 字节, 短整型, 整型, 长整型, 大整数, 比率.
- 浮点数组: 浮点数, 双精度数.
上面未提及的任何其他类型只能与相同类型的对象进行比较: 大十进制数, 字符串, 符号, 关键字,
deftypes,defrecords, 普通 Java 类型 (遵循普通的 Java 语义). 给定上述兼容性组, " Object1" 和 " Object2" 之间的相等性大致描述如下:- 如果 Object1 Object2 是兼容且有序的容器,
=如果内容相同且顺序相同, 则返回true. - 如果 Object1 Object2 是兼容且无序的容器,
=如果内容相同但顺序任意, 则返回true. - 如果 Object1 Object2 兼容但不是容器,
=如果对象具有相同的值, 则返回true. - 在任何其他情况下返回
false.
以下部分包含许多示例, 深入探讨了每种比较.
- 输入
- 示例
=的约定很难用一种形式化的方式来表达, 以包含所有可能的对象类型排列. 理解等价性的最佳方式是通过示例:(= 1N (byte 1))为真, 因为操作数属于兼容的数值整数类 (字节和大整数). 它们兼容的主要原因是它们的值在潜在的类型转换中不会损失精度.(= 1M 1.)为假, 因为大十进制数和浮点数不在同一兼容性组中. 有一个专门的==运算符用于数字等价性, 在这种情况下返回真.(= '(1 2 3) [1 2 3])为真, 因为两个集合都属于兼容的类列表有序组, 并且它们的内容相同且顺序相同.(= [0 1 2] [2 1 0])为假, 因为向量属于兼容的类列表有序组, 即使内容和类型相同, 顺序也不同.(= #{1 2 3} #{3 2 1})为真, 因为集合属于同一兼容的类集合无序组.(= (sorted-set 2 1) (sorted-set 1 2))为真, 尽管有" 排序的" 指定. 集合总是进行比较而不考虑排序, 但它们可以为顺序访问而排序.(= {:a "a" :b "b"} {:b "b" :a "a"})类似于集合比较, 为真, 因为 map 是无序的, 并且在比较时不考虑排序.(= (sorted-map :a "a" :b "b") (sorted-map :b "b" :a "a"))为真, 因为排序映射的排序仅应用于顺序访问. 在比较时不考虑排序.(defrecord SomeRecord [x y]), (= (SomeRecord. 1 2) (SomeRecord. 1 2))为真, 因为两个记录中的两个字段 x 和 y 是相同的.(deftype SomeType [x y]), (= (SomeType. 1 2) (SomeType. 1 2))为假, 因为除了从 JavaObject继承的之外, 没有处理相等性的方法 (默认情况下使用identical?).(= [1 2 3] #{1 2 3})为假, 因为类型组不兼容.(= "hi" [\h \i])为假, 因为类型组不兼容.(= (Object.) (Object.))为假, 因为 Clojure 将对象的相等性委托给 Java 语义 (.equalsTo(Object o)方法调用).
相等性接受任意数量的参数, 不仅仅是两个. 我们可以在以下模拟中使用可变数量的参数. 在经典的老虎机赌博游戏中, 三个 (或更多) 卷轴在旋转一段时间后会停止. 如果卷轴对齐显示相同的符号, 用户就赢了. 这里是一个模拟老虎机在 Clojure 中如何实现的:
(defn generate [& [{:keys [cheat reels] :or {cheat 0 reels 3}}]] ; ❶ (->> (repeatedly rand) ; ❷ (map #(int (* % 100))) ; ❸ (filter pos?) ; ❹ (map #(mod (- 100 cheat) %)) ; ❺ (take reels))) ; ❻ (defn play [& [opts]] (let [res (generate opts)] {:win (apply = res) ; ❼ :result res})) (play) ;; {:win false, :result (12 9 19)} (play {:cheat 100}) ;; {:win true, :result (0 0 0)} (play {:reels 10}) ;; {:win false, :result (38 29 31 2 16 7 14 4 46 40)}
❶
generate函数负责生成数字 (而不是真实老虎机中的符号或图案). 它接受两个可选参数, 分别用于要使用的卷轴数量和从 0 (不作弊) 到 100 (100% 作弊) 的作弊因子, 以便我们可以操纵结果. 这个功能在真实系统中显然应该被很好地隐藏起来!❷ 我们从一个 0 到 1 之间的无限随机数流开始生成.
❸ 下一步将浮点数转换为 0 到 100 之间的整数.
❹ 我们需要过滤掉零, 因为我们不希望下一步使用
mod时出现除以零的错误.❺
mod用于强制生成多次返回相同的数字. 作弊因子越高, 数字相同的概率就越接近.❻ 最后, 我们只提取我们需要生成的数字的数量.
❼ 为了检查生成的数字是否是获胜位置, 我们使用
apply和=来查看它们是否都相同.- 关于相等性, 究竟有什么难的?
虽然在口语中称两件事物" 相同" 通常是直观的, 但在编程中找到一个正式的定义却更困难. 人类通常根据上下文或对话的其他方面来推断相等性的含义, 并因此调整精度. 在计算中, 相等性涉及一个 (可能很昂贵的) 逐位比较. 然而, 在大多数现代语言中, 有一组约定好的类型可以跳过完整的字节比较.
对于 Clojure 来说, 相等性因与 Java 语义的差异而变得更加复杂. Java 区分" 原始" 类型和" 对象" 类型. 当在类中声明变量为原始类型 (如 int, short, long 等) 时, 我们告知 Java 编译器两个事实: 变量的值具有一个众所周知的特定大小 (例如, int 为 4 字节), 并且当编译器看到一个整数文字 (如 1, 2, 3 等) 时, 没有必要一遍又一遍地存储相同的位模式 (实际上, 一些 Java 整数和字符串被缓存在常量池中).
Java 的
==对原始类型工作得很好. 但是 Java 不支持在集合中使用原始类型, 并会自动执行" 装箱" 操作, 将原始类型转换为相关的" 装箱" 类型 (通常是相同的名称, 首字母大写). 不同类型的装箱数字即使它们的内容相同, 也完全不同:// primitive types comparison behave intuitively: System.out.println(1 == 1L) ; // true System.out.println(1 == (short)1) ; // true System.out.println(1 == 1.) ; // true // reference types can't compare even when they represent the same number: System.out.println(new Integer(1).equals(new Long(1))) ; // false System.out.println(new Integer(1).equals(new Short((short)1))); // false System.out.println(new Integer(1).equals(new Double(1))) ; // false
Clojure 的
==定义移除了原始类型 VS 引用类型二元性的任何痕迹:(== 1 1N (Integer. 1) 1. 1M)会如预期那样返回真. 尽管有了巨大的改进,==仍然受到影响以二进制表示的浮点数的臭名昭著的问题:(== 0.1 (float 0.1)) ;; false (== 1. (float 1.)) ;; true
公平地说, Clojure 在这里能做的并不多, 因为 0.1 的表示在 Java 使用的浮点数标准中并不精确 114.
当我们考虑哈希时, 情况甚至更糟, 哈希操作将用于决定一个键是否已经存在于哈希映射或哈希集合中. 浮点数值的近似程度甚至受到不同 JVM 实现的影响! Clojure 需要付出巨大的努力来补偿这种差异, 并保证一个在哈希映射中使用浮点数键的程序在不同架构上都能同样工作. 这就是为什么
=(单等号) 的方法是创建可比较类型的人工类别, 并保证一些直观的行为发生, 而不允许非常微妙的错误出现.使用
=进行相等性检查可以在以下关键方面实现正确的哈希行为:- 集合的
=允许具有相同内容的不同类型容器被表示为哈希映射中的单个键. - 数字的
=确保具有不同精度特性的数字之间总是存在区别, 因此如果它们比较为假且它们不是浮点数, 我们就可以肯定地知道它们是不同的 (对于浮点数, 你应该始终考虑潜在的精度问题).
我们应该从
=和==的实现中得到的教训是, 你几乎可以在哈希映射中自由地使用任何你想要的东西作为键, 但如果你使用浮点数作为键, 可能会发生非常微妙的错误. 其次, 如果你知道你正在比较的只是数字, 你应该使用==来移除=引入的人工类别. Clojure 中的相等性设计可能是 Java 约束, 直观行为和 Clojure 启用的更自由的集合使用之间的完美妥协. - 集合的
- 另请参阅
==是在最一般的情况下比较数字时应该使用的.==遵循 Java 对原始数字比较的语义, 但防止了 Javaequals()对原始数字进行装箱的要求.<=和>=也专用于数字, 并且还检查参数之间的相对顺序.identical?通过检查两个对象是否位于内存中的同一地址来验证它们是否相同 (遵循 Java 语义). 因此,(identical? 1. 1.)为假, 因为创建了两个java.lang.Double对象, 它们位于内存中的两个不同地址. 由于 -128 到 127 之间的整数被编译器缓存,(identical? 127 127)为真, 但(identical? 128 128)为假.如果你正在寻找集合中的所有唯一元素,
distinct可能是一个有趣的选择. 这等同于从集合中移除相同的元素. - 性能考虑和实现细节
=> O(n) 最坏情况, 与参数数量成线性关系
=> O(1) 常数空间
=通常对大多数常见情况都进行了很好的优化, 除非分析工具另有显示, 否则=不应成为性能瓶颈. 不出所料,=与参数数量成线性关系:(require '[criterium.core :refer :all]) (def k (take 1000 (repeat 0))) (def m (take 1000000 (repeat 0))) (def half (seq (into [] (concat (take 500000 (repeat 0)) (take 1 (repeat 1)) (take 500000 (repeat 0)))))) (bench (apply = k)) ; ❶ ;; Execution time mean : 63.865057 µs (bench (apply = m)) ; ❷ ;; Execution time mean : 62885.110 µs (bench (apply = half)) ; ❸ ;; Execution time mean : 18051.236 µs
❶
=被应用于一个相对较短的包含 1000 个零的序列.❷
=然后被应用于一个 1000 倍大的零序列, 如线性关系所预期的那样, 速度减慢了大约 1000 倍.❸
=最后被应用于一个类似的大序列, 我们在中间放置了一个 "1". 我们期望=在第一次出现假时短路, 正如基准测试报告的时间介于前两个测量值之间所证实的那样.在追求紧密循环中的原始速度时, 考虑使用 Java 的
.equals()方法可能值得, 该方法移除了 Clojure=的一些开销, 但代价是暴露于 Java 的相等性语义. 例如, 以下是比较长整型时发生的情况:(require '[criterium.core :refer [bench]]) (set! *warn-on-reflection* true) ; ❶ (defn plain= [m n] (= m n)) (bench (let [m 1 n 2] (plain= m n))) ;; Execution time mean : 6.963935 ns (defn raw= [^Long m ^Long n] (.equals m n)) (bench (let [m 1 n 2] (raw= m n))) ;; Execution time mean : 5.215350 ns ; ❷
❶ 将
*warn-on-reflection*动态变量设置为true, 会显示任何强制编译器使用反射的.equals用法. 我们只是想确保正确的类型提示到位, 以避免不公平的基准测试.❷ 请注意, 时间与测试运行的具体硬件有关, 所以如果你自己尝试这些例子, 这些数字可能会有所不同 (尽管你应该会看到使用
.equals会有速度提升).如你所见, 使用
.equals有大约 25% 的速度提升, 尽管有一些权衡需要考虑.- 我们被迫处理显式的类型提示, 以避免产生反射惩罚.
- 我们现在被迫使用装箱的数字 (大写的
java.lang.Long而不是简单的long). - 在装箱的数字上的 Java 相等性会导致像
(.equals (Integer. 1) (Short. (short 1)))为假这样的意外, 我们需要意识到这一点.
2.5.2. 6.2 == (双等号)
自 1.0 版本以来的函数
(== ([x]) ([x y]) ([x y & more]))
== 是一个专门用于数字的相等运算符. 虽然 = (单等号) 更严格, 仅当数字属于同一数值类别时才进行比较 (有关它们的定义, 请参见 =), 但 == 也可以跨类别进行比较:
(== 1M 1.) ; ❶ ;; true (= 1M 1.) ; ❷ ;; false
❶ 一个大十进制数 "1M" 和一个双精度浮点数 "1." 对于 == 是相等的.
❷ = "单等号" 将数字视为属于特定类别. 大十进制数和双精度浮点数不属于同一类别, 因此返回假.
- 约定
- 输入
==至少需要一个参数. 用单个参数 (数字或非数字) 调用==默认总是返回true."x","y"和任何其他参数必须是数字, 使得(number? x)为真.
- 值得注意的异常
如果存在多个参数且任何参数不是数值类型, 则会抛出
ClassCastException. - 输出
==返回:- 如果所有数字都相同或具有不同的类型, 并且存在从精度较低的类型到精度较高的类型的转换, 则返回
true. 可用的转换由 Java 语言规范的二进制提升 115 或最终委托给第一个操作数的java.lang.Object::equalsTo()实现来规定. - 在所有其他情况下返回
false.
- 如果所有数字都相同或具有不同的类型, 并且存在从精度较低的类型到精度较高的类型的转换, 则返回
- 输入
- 示例
Clojure 包含
=和==运算符的主要原因之一是它们被专门用于特定任务, 而非互斥.==最适合用于数字, 因为它尊重数字等价性独立于类型或二进制表示的一般概念.在下一个例子中, 我们想实现一个交换服务, 以便买家和卖家之间能够进行交易. 交易在不同的市场上进行, 每个市场提供略有不同的 API 来列出当前的买/卖请求. 我们可以通过它们的股票符号来匹配请求, 并为每个兼容的对创建一个交易. 如果它们的买入价与一个等价的卖出价相匹配, 则请求是兼容的. 以下是请求进入系统时的样子:
(def tokyo ; ❶ [{:market :TYO :symbol "AAPL" :type :buy :bid 22.1M} {:market :TYO :symbol "CSCO" :type :buy :bid 12.4M} {:market :TYO :symbol "EBAY" :type :sell :bid 22.1M}]) (def london ; ❷ [{:market :LDN :symbol "AAPL" :type :sell :bid 23} {:market :LDN :symbol "AAPL" :type :sell :bid 22} {:market :LDN :symbol "INTC" :type :sell :bid 14} {:market :LDN :symbol "EBAY" :type :buy :bid 76}]) (def nyc ; ❸ [{:market :NYC :symbol "YHOO" :type :sell :bid 28.1} {:market :NYC :symbol "AAPL" :type :buy :bid 22.0} {:market :NYC :symbol "INTC" :type :buy :bid 31.9} {:market :NYC :symbol "PYPL" :type :sell :bid 44.1}])
❶ 东京市场的 API 返回大十进制数的出价.
❷ 伦敦将金额四舍五入到最近的整数.
❸ 纽约市市场使用双精度浮点数.
价格最终是整数, 双精度浮点数和大十进制数的混合, 取决于它们来自哪个市场. 该服务需要使用混合类型算术来比较数字, 这是
==最适合的:(defn group-orders [& markets] ; ❶ (group-by :symbol (apply concat markets))) (defn- compatible? [{t1 :type b1 :bid} {t2 :type b2 :bid}] ; ❷ (and (not= t1 t2) (== b1 b2))) (defn- matching [orders] ; ❸ (for [order1 orders order2 orders :when (compatible? order1 order2)] #{order1 order2})) (defn exchange [listing] ; ❹ (->> listing (map last) ; ❺ (mapcat matching) ; ❻ distinct)) ; ❼ (exchange (group-orders tokyo london nyc)) ; ❽ ;; (#{{:bid 22 :market :LDN :symbol "AAPL" :type :sell} ;; {:bid 22.0 :market :NYC :symbol "AAPL" :type :buy}})
❶
group-orders是一个辅助函数, 用于聚合来自不同市场的列表, 并按股票符号对它们进行分组. 结果 map 包含符号作为键, 请求列表作为值.❷
compatible?告诉我们两个请求是否匹配. 规则是: 它们需要是一个买/卖对, 并且金额相同. 这里使用not=来确保请求不是买/买或卖/卖对.==用于验证出价对于两个请求是否相同, 而与类型无关. 请注意, 两个请求都以 map 的形式传入, 并在函数定义中被解构.❸
matching为同一股票符号的请求列表创建所有可能的排列.for非常适合创建排列, 包括通过直接使用:when指令应用兼容性规则来过滤, 以移除不需要的对.❹
exchange是计算的主要入口函数. 它接受按符号分组的不同市场的请求, 并尝试匹配它们.❺ 我们需要访问每个输入对的最后一个. 第一个是每个列表分组的符号. 最后一个元素是我们想要匹配的请求列表.
❻ 我们需要对来自
matching的每个结果进行mapcat, 因为它们都返回在它们自己的序列中 (也可能是空的). 通过连接, 我们确保它们都被展平成同一个序列, 没有" 间隙" .❼
distinct是必要的, 因为matching在两个方向上都返回匹配的对: 如果它们兼容, 结果中会同时返回#{order1 order2}和#{order2 order1}.distinct摆脱了这种重复 (这要归功于知道如何处理无序集合的=运算符).❽ 我们终于可以看到匹配一个价值 22 美元的苹果股票的示例请求, 该请求可以进行交易.
- 浮点类型的比较
编程语言中的浮点算术是最具争议的主题之一, 每种语言都为精确表示它们的问题提供了权衡和解决方案.
这一切都源于二进制表示浮点数所施加的精度限制 (默认情况下, 这是范围和精度之间的权衡 116). 这个数字不需要很大或很复杂就能揭示问题:
0.1 ; ❶ ;; 0.1 (BigDecimal. 0.1) ; ❷ ;; 0.1000000000000000055511151231257827021181583404541015625M
❶ 在 REPL 中输入 "0.1" 会产生一个双精度类型.
❷ 用于初始化
BigDecimal实例的相同数字会产生更多的小数位数, 揭示了关于" 精度" 概念的有趣事实.例如, 数字 0.1 以其字面形式打印, 因为舍入操作正确地显示了它. 一旦我们通过创建一个
java.lang.BigDecimal来开启全精度, 我们就可以看到 64 位中究竟存储了什么. 即使不使用大十进制数, 我们也可以通过一个简单的操作看到舍入问题的传播:(== 0.3 (+ 0.1 0.1 0.1)) ; ❶ ;; false
❶ 由于浮点数表示精度不足而产生的意外结果的典型案例.
这种基本的非精确性是货币不应被表示为 "float" 或 "double" 的原因. 例如, 可以用像 big-decimal 这样的包装器来实现更精确的表示, 它最终将精度委托给
BigDecimal实例内部的 Java 数组 (大小为Integer/MAX_VALUE).
- 浮点类型的比较
- 另请参阅
=是一个更通用的相等运算符 (因为它在除数字之外的其他类型上操作), 但同时更适合于 Clojure 数据结构 (尤其是在 map 和 set 中使用集合作为键). 你应该在混合上下文 (数字和其他类型) 或任何其他非数值情况下使用=单等号运算符.identical?通过检查两个对象是否位于内存中的同一地址来验证它们是否相同 (遵循 Java 语义). 你应该主要在需要引用相等性的 Java 互操作场景中使用identical?. - 性能考虑和实现细节
=> O(n) 最坏情况, 与参数数量成线性关系
=> O(1) 常数空间
==与=具有类似的性能配置文件, 与参数数量成线性关系, 并且能够在第一次出现假的情况下短路, 而不扫描整个参数列表.在比较超过 2 个参数时, 两种相等性之间存在微小 (且可能可以忽略不计) 的速度差异, 例如:
(require '[criterium.core :refer [quick-bench]]) (quick-bench (= 1 1 1 1 1)) ; ❶ Execution time mean : 86.508844 ns (quick-bench (== 1 1 1 1 1)) ; ❷ Execution time mean : 63.125153 ns
❶
=和==都有一个 catch-all 可变参数来处理超过 2 个参数的情况.❷
==只是比=快一点.正如对
=所建议的, 通过直接在数字上使用 Java 互操作和.equals是有可能获得一些速度提升的 (但有一些权衡需要考虑, 请检查=以了解更多).
2.5.3. 6.3 < , > , <= , >=
自 1.0 版本以来的函数
(< ([x]) ([x y]) ([x y & more])) (> ([x]) ([x y]) ([x y & more])) (<= ([x]) ([x y]) ([x y & more])) (>= ([x]) ([x y]) ([x y & more]))
< (" 小于" 或" lt" ), > (" 大于" 或" gt" ), <= (" 小于或等于" 或" lte" ) 和 >= (" 大于或等于" 或" gte" ) 是许多语言中的常见运算符. 它们通过假设给定参数之间存在顺序关系来工作, 如果该关系对所有参数都成立, 则返回 true 或 false. 排序谓词的用法无处不在. 在 Clojure 中, 它们只接受一个或多个数字参数:
(< 0 (byte 1) 2 2.1 3N 4M 21/2) ; ❶ ;; true (< 0 (byte 1) 2 2.1 3N 2M 21/2) ; ❷ ;; false
❶ 一个展示比较运算符支持的所有可能数字参数的示例.
❷ 请注意, 由于 (== 2 2M), 所以 < 并不对所有参数都满足. 而 <= 在这种情况下会返回 true.
- 约定
- 输入
- 当只有一个参数 "x" 存在时, "x" 可以是任何类型 (它不局限于数字). 例如, ~ (< "a")~ 是一个有效的表达式, 返回
true, 而(< "a" "b")是不允许的, 会抛出异常. - 当有 2 个或更多个参数存在时: 在这种情况下, 参数必须是数字, 即
(number? x)对所有参数都必须为true. 整数, 小数, 比率, 大整数和大小数都接受, 其他 Java 数字类型 (如AtomicLong) 也接受.
- 当只有一个参数 "x" 存在时, "x" 可以是任何类型 (它不局限于数字). 例如, ~ (< "a")~ 是一个有效的表达式, 返回
- 值得注意的异常
- 调用时没有参数会抛出
clojure.lang.ArityException. - 如果存在多个参数, 且其中任何一个不是数字 (即
(number? x)返回false), 则会抛出java.lang.ClassCastException.
- 调用时没有参数会抛出
- 输出
- 当只有一个参数 (任何类型) 时为
true. - 当有 2 个或更多个参数, 且所有参数的排序关系都成立时为
true(见下文). - 在任何其他情况下为
false.
<,>,<=和>=设计用于验证的顺序关系定义如下:- 严格单调递增
<: 当从左到右取参数时, 它们总是在从小到大的关系中 (但永远不相等). - 单调递增
<=: 与上面相同, 但也允许参数相等 (使用与==相同的语义进行数字相等性比较). - 严格单调递减
>: 当从左到右取参数时, 它们总是在从大到小的关系中 (但永远不相等). - 单调递减
>=: 与上面相同, 但允许参数相等 (使用与==相同的语义进行数字相等性比较).
- 当只有一个参数 (任何类型) 时为
- 输入
- 示例
<,>,<=和>=接受两个以上参数的事实, 在检查某个数量是否属于某个范围时非常方便. 我们已经在本书的其他章节中看到过这一点:- 在讨论
for时, 在生命游戏示例中, 我们看到了如何使用(<= 0 x' (dec w))来约束邻居单元格的排列. 在这个表达式中, 要检查的数量x'位于 0 和(dec w)之间. 该表达式只允许大于或等于零且同时小于或等于(dec w)的x'. 这与输入:(and (>= x' 0) (<= x' (dec w)))是相同的. - 在递归中, 通常会存在一个比较谓词, 特别是在
loop-recur中. 这是由于存在退出循环的条件. 你可以在fn中包含的斐波那契数列实现中看到一个例子.
总的来说,
<,>,<=和>=可以用来验证一个数字集合是否是有序的:(apply < [2.1 4 5.2 8 124 9012 1e4]) ; ❶ ;; true
❶ 一种验证输入集合是否有序的方法.
<,>,<=和>=的其他值得注意的用法是与像sort或sort-by这样的排序操作结合使用. 假设输入包含数字, 我们可以例如通过使用一个排序谓词来反向排序:(sort > (range 10)) ; ❶ ;; (9 8 7 6 5 4 3 2 1 0)
❶ 反向排序一个序列.
在下面的例子中, 我们想从一个序列中消耗元素, 直到它们达到某个阈值, 这个操作可以很容易地用
drop-while和一个比较谓词来完成:(drop-while (partial > 90) ; ❶ (shuffle (range 100))) ; ❷ ;; (96 23 46 18 61 84 60 83 56 32 38 54 87...) ; ❸
❶ 用
partial我们可以固定返回元素的阈值.❷ 我们用
shuffle模拟随机数.❸ 这个序列中的第一个元素总是一个大于 90 的数.
- 在讨论
- 另请参阅
compare返回 -1, 0, 1 来表示参数之间的关系. 当你需要根据操作数的顺序采取不同的行动时使用.compare也适用于其他类型, 如字符串, 前提是它们是" 可比较的" .reverse可以用来反转一个集合的顺序. - 性能考虑和实现细节
=> O(n) 最坏情况, 与参数数量成线性关系
=> O(1) 常数空间
简而言之: 性能通常不是比较谓词的问题. 它们是" 类型启用的" , 一旦类型提示到位, 它们就会正确地传播到字节码生成. 观察以下示例以及在生成的字节码中的相关调用:
(require '[no.disassemble :refer [disassemble]]) (defn boxed< [x y] (< x y)) ; ❶ (println (disassemble boxed<)) ;; ... omitted output ;; invokestatic clojure.lang.Numbers.lt(java.lang.Object, java.lang.Object) (defn unboxed< [^long x ^long y] (< x y)) ; ❷ (println (disassemble unboxed<)) ;; ... omitted output ;; invokestatic clojure.lang.Numbers.lt(long, long)
❶ 第一个例子不包含类型提示. 编译器不知道运行时会发生什么, 被迫采取保守的方法, 将参数视为
Object类型. 相关的字节码显示在下面.❷ 第二个例子包含类型提示, 因此编译器可以推断出
long类型. 生成的字节码显示, 生成的方法调用现在可以更具体地说明类型 (从而导致速度提升).与单等号或双等号运算符类似,
<,>,<=和>=消耗的处理时间与参数 "n" 的数量成线性关系. 任何确定为假谓词的输入对会立即终止求值, 避免遍历整个序列.Clojure Jira 板上提出了一个简单的改进 (可见于 clojure.atlassian.net/browse/CLJ-1912), 以加快超过 2 个参数的谓词.
<的实现相当容易理解, 所以让我们先看看当前版本, 再看看提议的改进:(defn < {:inline (fn [x y] `(. clojure.lang.Numbers (lt ~x ~y))) :inline-arities #{2} :added "1.0"} ([x] true) ([x y] (. clojure.lang.Numbers (lt x y))) ; ❶ ([x y & more] (if (< x y) (if (next more) ; ❷ (recur y (first more) (next more)) ; ❸ (< y (first more))) false)))
❶ 比较谓词将实际的比较委托给
clojure.lang.Numbers, 后者分派给相关的 Java 运算符或特定类型的比较 (例如, 对于BigDecimal的java.math.BigDecimal::compareTo()). 该操作对第二个元数进行了内联, 这使得在编译时能够将类型传播到 JVM 字节码 (参见definline).❷ 当操作数超过两个时, 会发生递归以展开输入序列. 每次迭代我们都会检查谓词与序列中的前两个参数. 如果需要, 代码会在这里短路为
false.❸ 如果迭代需要向前移动, 我们用下一个要检查的对和序列的其余部分进行递归. 请注意
(next more)是如何被求值两次的.改进消除了在有超过 2 个参数且迭代需要向序列末尾移动时发生的
(next more)的双重求值. 通过引入一个let可以轻松修复:(defn new< {:inline (fn [x y] `(. clojure.lang.Numbers (lt ~x ~y))) :inline-arities #{2} :added "1.0"} ([x] true) ([x y] (. clojure.lang.Numbers (lt x y))) ([x y & more] (if (< x y) (let [nmore (next more)] ; ❶ (if nmore (recur y (first more) nmore) (< y (first more)))) false)))
❶
let语句现在阻止了(next more)的双重求值.我们可以使用 Criterium 来基准测试新函数以看到好处:
(require '[criterium.core :refer [bench]]) (bench (< 0 1 2 3 4 5 6 7 8 9 10 11 12)) ;; Execution time mean : 258.386277 ns (bench (new< 0 1 2 3 4 5 6 7 8 9 10 11 12)) ;; Execution time mean : 228.939113 ns
尽管在绝对尺度上不是巨大的改进, 但像上面这样的简单改进可以在非常紧凑的循环中产生明显的差异. 同样的变化将应用于所有其他谓词, 也包括
==和=.
2.5.4. 6.4 compare
自 1.0 版本以来的函数
(compare [x y])
compare 是 Clojure 提供的比较值的选项之一. 与像 =, ==, <, >, <=, >= 这样的比较谓词的主要区别是, compare 返回一个 java.lang.Integer (1, 0 或 -1, 或更一般地, 一个负数, 零或正数) 来分别表示 "x" 小于, 等于或大于 "y". 因此, 一个条件表达式的详尽 compare 将需要 3 个分支:
(let [c (compare 1 2)] (cond (neg? c) "less than" ; ❶ (zero? c) "equal" (pos? c) "greater than")) ;; "less than"
❶ 一个示例, 显示了覆盖 compare 所有可能结果所需的 3 个分支.
一个给定两个参数并返回一个整数以指示相对顺序的函数也被称为" 比较器" . compare 是 Clojure 中的默认比较器 (如果没有给出其他比较器), 用于像 sort 或 sort-by 这样的函数. compare 也适用于不一定是数字甚至自定义的类型, 前提是它们实现了 java.lang.Comparable 接口 117. 许多 Java 类已经实现了 Comparable, 因此 compare 可以用于例如 java.lang.String, java.util.Calendar 和许多其他类:
(import 'java.util.GregorianCalendar) (def t1 (GregorianCalendar/getInstance)) ; ❶ (def t2 (GregorianCalendar/getInstance)) ; ❷ (compare t1 t2) ;; -1
❶ 瞬间 t1 是用第一个调用记录的.
❷ 瞬间 t2 必然在瞬间 t1 之后.
类似地, Clojure 为几种 Clojure 内部类型实现了 Comparable 接口:
- 用
vector或[]字面量语法创建的向量 (clojure.lang.Vector). - 关键字 (
clojure.lang.Keyword). - 比率 (
clojure.lang.Ratio) 像字面量2/3. - 用
ref创建的引用 (clojure.lang.Ref). - 符号 (
clojure.lang.Symbol).
每种 Clojure 类型都为 compare 提供了特定的解释, 其中一些并不明显. 例如, ref 是根据它们的创建顺序来比较的 (这主要应被视为实现细节):
(compare (ref :a) (ref :a)) ; ❶ ;; -1
❶ ref 是根据创建顺序进行比较的, 而与它们的内容无关. 这是一个实现细节, 用于在事务中建立 ref 更新的优先顺序.
我们将在下面的扩展示例中看到一些 compare 如何在内部 Clojure 类型和其他 Java 类型上工作的例子.
- 约定
- 输入
"x"和"y"是强制性的. 当出现以下情况时,"x"可以与"y"进行比较:nil作为其中一个参数或两个参数出现.(instance? java.lang.Number x)和(instance? java.lang.Number y)都为真.(instance? java.util.Comparable x)为真 (当(identical? x y)为真时, 对此情况有一个概括, 在那时"x"可以是任何类型)."x"(如果有) 提供的compareTo()实现允许与"y"类型的实例进行比较.compareTo()是java.util.Comparable接口所需的方法.
- 异常
clojure.lang.ArityException:compare恰好需要 2 个参数.java.lang.ClassCastException: 当"x"不实现java.lang.Comparable接口时 (但当(identical? x y)为真时除外)."x"提供的compareTo()实现的任何其他特定异常条件.
- 输出
根据
"x"和"y"的比较方式, 返回一个负数, 零或正数的java.lang.Integer. 如果"x"小于"y", 则为负数, 如果"x"等于"y", 则为 0, 否则为正数.(compare nil (/ -1. 0)) ; ❶
❶ 一个
compare提供的异常结果的极端例子. 数字(/ -1. 0)是负无穷,compare报告nil更小. 这更应该被视为当任一操作数为nil时的未定结果的例子.
- 输入
- 示例
让我们从一些简单的例子开始, 更好地解释约定部分中描述的一些
compare的特性.nil被接受为可能的参数, 并且总是被认为是" 最小的" 值, 甚至比负无穷还要小:(def -∞ (/ -0 0.)) (map compare [nil nil "a"] [-∞ nil nil]) ; ❶ ;; (-1 0 1)
❶ 一个
compare提供的异常结果的极端例子. 这更应该被视为当任一操作数为nil时的未定结果的例子.NaN 总是与任何其他数字或其本身相同:
(def nan Double/NaN) (map compare [nan nan 1] [1 nan nan]) ; ❶ ;; (0 0 0)
❶ NaN 是在比较中存在时的另一个未定结果的特殊情况.
当两个参数相同时 (如
identical?, 这意味着它们是同一个 Java 对象),compare返回 0. 在这个例子中, 我们表面上在比较范围, 但compare返回零, 因为它们是同一个对象实例:(instance? java.lang.Comparable (range 10)) ; ❶ ;; false (compare (range 10) (range 10)) ; ❷ ;; ClassCastException (let [x (range 10) y x] (compare x y)) ; ❸ ;; 0
❶
clojure.lang.LongRange对象不是Comparable.❷ 如果我们尝试比较范围, 我们会得到预期的异常.
❸ 然而, 当我们只是面对相等对象在它们是同一个实例时的明显结果时, 我们显然可以比较相同的范围.
关于如何比较参数的最终决定被委托给第一个参数的类型中定义的
compareTo()的具体实现 (如果可用). 例如, 向量首先按大小比较, 然后通过并列每一对项进行比较:(compare [1 1 1 1] [2 2 2]) ; ❶ ;; 1 (compare [1 2 4] [1 2 3]) ; ❷ ;; 1
❶ 第一个向量包含 4 个元素, 而第二个只包含 3 个. 这等价于比较
(compare 4 3), 完全忽略了内容.❷ 如果大小相同, 则比较第一对. 如果它们相等, 则比较第二对, 依此类推, 直到第一对不相等或到达向量末尾. 最后一对
[4 3]是产生结果的对.Clojure 字符串是
java.lang.String实例, 因此提供了为 Java 字符串定义的相同的可比较行为.compare s1, s2返回:- 第一个不同字符之间的 ASCII 距离, 如果有的话.
- 当
s1是s2的子字符串时,s1和s2之间的长度差异. - 当字符串相同时为 0.
(compare "a" "z") ; ❶ ;; -25 (compare "abcz" "abc") ; ❷ ;; 1
❶ "a" 和 "z" 在 ASCII 表中按升序排列, "a" 排在前面, 决定了负结果. 它们之间有 25 个字母.
❷ 这两个字符串大小不同, "abc" 是 "abcz" 的子字符串. 它们的长度被比较.
Clojure 关键字和符号的行为类似于字符串, 另外, 如果它们是命名空间限定的, 那么命名空间字符串的比较优先:
(map compare [:a :my/a :a :my/a :abc123/a] ; ❶ [:z :my/z :my/a :a :abc/a ]) ;; (-25 -25 -1 1 3) (map compare ['a 'my/a 'a 'my/a 'abc123/a] ; ❷ ['z 'my/z 'my/a 'a 'abc/a ]) ;; (-25 -25 -1 1 3)
❶ 当两个关键字都是命名空间限定时, 命名空间的比较优先, 遵循与字符串相同的规则, 并且只忽略关键字的名称. 当两个关键字都不是命名空间限定时, 字符串比较只在关键字名称上进行. 如果第一个关键字不是限定的, 但第二个是, 结果总是 -1. 如果第二个关键字是命名空间限定的, 但第一个不是, 那么结果总是正 1.
❷ 完全相同的规则也适用于符号, 符号内部被存储为关键字.
在下一个例子中, 我们将为 Clojure 提供一种使用我们的
compare定义来排序自定义类型的方法. 我们想知道, 给定我们汽车当前所在的起始位置, 哪个加油站是最近的. 加油站和位置的概念都通过defrecord声明来建模, 并用我们自己的compareTo版本来增强, 使它们可比较. 为简单起见, 我们假设位置在一个二维平面上 118:(defn- sq [x] (* x x)) (defn- distance [x1 y1 x2 y2] ; ❶ (Math/sqrt (+ (sq (- x1 x2)) (sq (- y1 y2))))) (defrecord Point [x y distance-origin] ; ❷ Comparable (compareTo [this other] (compare (distance-origin (:x this) (:y this)) ; ❸ (distance-origin (:x other) (:y other))))) (defn relative-point [x1 y1 x2 y2] ; ❹ (->Point x1 y1 (partial distance x2 y2))) (defrecord GasStation [brand location] ; ❺ Comparable (compareTo [this other] (compare (:location this) (:location other)))) ; ❻
❶
distance使用经典公式计算两点之间的欧几里得距离.❷ 我们将一个
Point定义为一个记录, 包含预期的坐标 (x,y) 加上一个额外的函数.distance-origin用于计算此位置与" 原点" 的距离, 原点是任意选择的点, 所有其他距离都从此点计算.❸ 我们的
compareTo实现使用了compare, 参数是distance-origin返回的结果, 这是一个数字. 任何其他遵循返回整数 (负数, 零或正数) 约定的实现都可以.❹
relative-point包含了构建新点的逻辑. 我们的点都需要一个函数来计算给定坐标的距离.relative-point创建了一个新位置, 该位置也嵌入了有关" 原点" 的信息, 这是一个特殊的位置, 用于描述正在进行搜索的用户所在的位置.❺ 第二个
defrecord定义用于描述一个GasStation, 它包含一个品牌 (或销售汽油的公司的名称) 及其位置.❻ 加油站也可以比较. 一个加油站比另一个加油站" 小" , 当它离原点更近时, 反之亦然.
compareTo是通过调用compare, 传递两个加油站的位置来实现的. 一个位置被表示为一个Point对象, 因此Point对象的compareTo实现将被调用来比较加油站.通过为
GasStation和Point对象提供一个compareTo逻辑, 我们现在能够根据我们所在的位置来对加油站进行排序:(def gas-stations (let [x 3 y 5] ; ❶ [(->GasStation "Shell" (relative-point 3.4 5.1 x y)) (->GasStation "Gulf" (relative-point 1 1 x y)) (->GasStation "Exxon" (relative-point -5 8 x y)) (->GasStation "Speedway" (relative-point 10 -1 x y)) (->GasStation "Mobil" (relative-point 2 2.7 x y)) (->GasStation "Texaco" (relative-point -4.4 11 x y)) (->GasStation "76" (relative-point 3 -3 x y)) (->GasStation "Chevron" (relative-point -2 5.3 x y)) (->GasStation "Amoco" (relative-point 8 -1 x y))])) (map :brand (sort gas-stations)) ; ❷ ;; ("Shell" "Mobil" "Gulf" "Chevron" ;; "Amoco" "76" "Exxon" "Speedway" "Texaco")
❶ 我们的坐标被用来创建加油站对象.
relative-point构造函数负责创建一个与原点相关的Point.❷
sort在不需要特定比较器的情况下工作.compare将被默认使用, 并在运行时分派给提供的compareTo实现.- 当心 NaN
当涉及到 NaN 时, 事情很快就会变得特殊, 这应该不足为奇. 我们在谈论
max时已经看到了 NaN 的效果,compare也不例外:(compare Double/NaN 1) ;; 0 (compare 1 Double/NaN) ;; 0 (compare Double/NaN Double/NaN) ;; 0
当存在
Double/NaN时,compare总是返回 0, 其结果是NaN与任何其他数字相同. 相当令人困惑, 特别是当我们记得(== Double/NaN Double/NaN)反而是假的时候. 为了增加混淆, 请考虑以下内容:(sort [3 2 Double/NaN 0]) ;; (0 2 3 NaN) (sort [2 3 Double/NaN 0]) ;; (2 3 NaN 0)
sort默认使用compare作为比较器, 由于compare对 NaN 总是返回 0, 根据向量中 NaN 之前出现的元素的相对顺序会产生不同的结果. 如果我们想使用数字集合作为哈希映射 (或集合) 中的键, 这种行为可能会特别成问题, 在排序后会导致意外的唯一键. 在这种情况下, 我们学到的教训是不要使用数字作为键, 首先是因为潜在的舍入问题, 其次如果它们是 NaN.
- 另请参阅
comparator, 给定一个两个参数的函数, 返回一个将函数结果转换为 -1, 0 或 1 的包装器. 当你需要一个类似比较器的函数, 并且已经有一个谓词类函数, 其结果可以被转换为整数时使用.identical?通过检查两个对象是否位于内存中的同一地址来验证它们是否相同 (遵循 Java 语义). 你应该主要在需要引用相等性的 Java 互操作场景中使用identical?.- 如果你只对知道两个参数是否相同感兴趣, 而不关心它们的相对顺序关系, 则应使用
=或==.
- 性能考虑和实现细节
=> O(1) 某些标准库类型的最佳情况
=> O(n) 其他标准库类型的最坏情况
compare本质上是一个在运行时分派比较逻辑的多态函数. 没有单一的性能配置文件, 而是有很多, 这取决于比较应用的类型. 下表是比较最常见的 Clojure 和 Java 类型时期望值的快速摘要:Table 8: 基于参数类型的各种 compare 性能配置文件. 类型 最佳情况 最坏情况 所有类型 O(1) 一个参数是 nil与最佳情况相同. O(1) 参数是 identical?向量 O(1) 不同长度 O(n) 相同长度和相同内容 O(1) 相同长度但第一个元素不同 数字 O(1) O(1) 字符串 O(1) 第一个字符不同 O(n) 相同长度和相同内容 关键字和符号 O(1) 一个不是命名空间限定的 O(n) 没有命名空间, 相同名称长度和相同名称内容 O(1) 命名空间中第一个字符不同 O(m*n) 相同命名空间, 相同名称 O(1) 名称中第一个字符不同 总的来说, 你需要注意非常大的向量或字符串的潜在线性扫描.
2.5.5. 6.5 identical?
自 1.0 版本以来的函数
(identical? [x y])
identical? 可能是 Clojure 中最强的比较函数. identical? 的主要目的是确定给定的两个参数是否完全" 相同" . 这里的" 相同" 意味着验证参数是否存储在同一个内存位置. 当 identical? 返回 true 时, 这意味着内存中只有一个对象被分配, 并且被两个 (可能不同的) 绑定引用, 例如:
(let [x #{1 2 3} ; ❶ y x] ; ❷ (identical? x y)) ;; true
❶ "x" 是一个与哈希集合关联的局部绑定.
❷ "y" 是另一个与 "x" 关联的局部绑定. 因此, "x" 和 "y" 是指向同一个实体的两个引用.
identical? 有一些与对象身份相关的特定用例, 不应被用作通用的相等性机制. identical? 的结果有时会令人惊讶, 因为一些基本类型 (包括 Java 和 Clojure) 实现了" interning" , 这是一种自动缓存机制以提高性能. 请检查" 使用 identical? 时的意外" 部分以了解一些有趣的情况.
- 约定
- 示例
当我们需要跟踪某个特定值的身份时, 会使用
identical?, 这个值可能会与逻辑上相同但实例不同的其他实例混淆. 这种情况发生, 例如, 在检查" 哨兵" 值时. 哨兵是在数据驱动算法中通常使用的特殊值 119.哨兵值可以与正常的业务数据自由混合, 因为生产者和消费者之间对特殊值的含义有共同的协议. 哨兵对于守护进程类的进程特别有用: 当缺乏新数据不足以表示输入结束时, 可以使用哨兵来强制一个结果.
以下示例显示了一个消费者-生产者对, 它们约定一个哨兵对象来停止计算. 守护进程线程打印客户端发送的对象的哈希值. 服务器在一个无限循环中执行, 等待客户端发送的任意数量的事件. 由于任何对象都可以被哈希编码, 我们需要一种方法让他们相互约定一个退出循环的信号:
(import 'java.util.concurrent.LinkedBlockingQueue) (def channel (LinkedBlockingQueue. 1)) ; ❶ (def SENTINEL (Object.)) ; ❷ (defn encode [] ; ❸ (let [e (.take channel)] (if (identical? SENTINEL e) (println "done") (do (println (hash e)) (recur))))) (defn start [] ; ❹ (let [out *out*] (.start (Thread. #(binding [*out* out] (encode)))))) (do (start) (.offer channel :a) (.offer channel (Object.)) ; ❺ (.offer channel SENTINEL) (.offer channel :a)) ; ❻ ;; -2123407586 ;; 1430420663 ;; done
❶ 我们使用一个阻塞队列来协调生产者线程 (在本例中是 REPL 线程) 和消费者之间的通信. 然后服务器线程可以在一个无限循环中运行, 等待输入. 对队列的
take操作是阻塞的, 因此服务器在每个循环中等待至少有一个元素存在.❷ 哨兵是在当前命名空间中定义的通用
java.lang.Object实例.❸
encode包含一个循环, 用于检查阻塞队列提供的下一个事件. 一旦识别到哨兵, 循环就会停止. 由于生产者可以发送任何对象, 我们不想使用=单个等号来消除将另一个对象实例与我们的哨兵混淆的风险.❹
start专用于为正确的通信准备两个线程, 例如确保它们都使用相同的标准输出.❺ 我们可以向通道发送任何类型的事件 (甚至另一个对象实例), 因为我们确信除了哨兵对象本身, 没有任何东西在与
identical?比较时会返回true.❻ 但是当我们实际发送
SENTINEL对象时, 循环会像 "done" 消息显示的那样退出. 对通道的额外提供将不再打印哈希码.- 使用 identical? 时的意外
内部化是编译器用来减少分配对象数量的一种缓存形式. Java 对字符串字面量 (代码中出现的双引号字符串) 使用它们, Clojure 对 -127 到 128 的
java.lang.Long实例继承了相同的机制. Clojure 还额外引入了关键字的内部化. 内部化的含义是identical?在比较某些类型的字面量时可能返回true或false, 从而暴露它们的实现细节:(map identical? ["A" 1 \a :a] ["A" 1 \a :a]) ; ❶ ;; (true true true true)
❶ 一些数据字面量自动内部化的演示.
另一方面, 其他数据字面量不受内部化影响, 或者是真正的全局常量:
(identical? '() '()) ; ❶ ;; true (identical? 2/1 2/1) ; ❷ ;; true
❶ 空列表字面量是正在运行的 JVM 中空列表的唯一实例.
❷
clojure.lang.Ratio实例2/1内部保存为long类型:(class 2/1)是java.long.Long. 比率通常不被内部化.内部化并不适用于所有可能的
long和char类型字面量, 仅适用于最常用的 -127 到 128 (对于 longs) 和 0-127 ASCII 转换 (对于 chars). 另一方面, 内部化适用于所有字符串字面量. 完全的字符串内部化是基于这样一个假设: 一个平均的程序在源代码中只会包含有限数量的字符串. 当然, 在应用程序的生命周期中会创建更大的字符串实例, 这些实例是不会被内部化的.以下示例显示了一组不相同的字面量集合, 要么是因为它们超出了其内部化能力的范围, 要么是因为它们根本不支持内部化:
(map identical? [128 \λ 1N 1M 1/2 1. #"1" [1] '(1) 'a] ; ❶ [128 \λ 1N 1M 1/2 1. #"1" [1] '(1) 'a]) ;; (false false false false false false false false false false)
❶ 一组未被内部化的数据值. 例如, 注意符号未被内部化.
最后, 请注意, 一旦使用原生类型来创建相应引用类型的新实例, 内部化就不再可能, 因为 Java 没有机会查找缓存以返回内部化的实例:
(identical? (Long. 100) 100) ; ❶ ;; false
❶ 通过用相应的数字初始化器包装数字 100, 我们明确要求 JVM 创建一个新的数字实例, 忽略任何内部化选项.
要给 Java 机会查找数字的内部化缓存, 我们需要使用
Long/valueOf而不是构造函数. 这正是 Java 用来将原生参数转换为引用的机制, 例如, 将参数传递给方法:(identical? (Long/valueOf "100") (Long/valueOf "100")) ; ❶ ;; true
❶
Long/valueOf是知晓内部化的.这里讨论的
identical?的最后一个有趣行为与" 装箱" 有关. 装箱是将原生数据类型包装到相应的完整类中的行为的非正式名称. 让我们比较以下identical?的应用, 其中参数分别被绑定为 var 和 let:(def a 1000) (def b a) (identical? a b) ; ❶ ;; true (let [x 1000 y x] (identical? x y)) ; ❷ ;; false
❶ 在创建 var "a" 时, 原始的 1000 已被传递给
clojure.lang.Var的构造函数, 作为(Long/valueOf 1000), 因为 var 是从一个通用的java.lang.Object创建的. 请注意, 1000 不属于内部化的整数常量池. Clojure 从现在起自动解引用任何对 "a" 的使用, 包括第二个 var "b" 的定义, 将包含在 "a" 中的相同长整型实例传递给 "b". 请注意, 1000 之前已经被转换为引用类型, 不需要再转换一次. 如预期, 用identical?比较 var "a" 和 "b" 会报告我们正在谈论同一个长整型实例.❷ 同一个数字 1000 现在在没有 var 间接的
let块中使用. "y" 再次被赋给 "x", 但作为原生原始值. 我们期望与之前有相同的等价性, 但这并没有发生, 表明已经构建了两个独立的 1000 实例.在第二种情况下, "x" 是一个没有 var 包装的原生类型. 在生成的代码中, 原始的
long1000 作为参数传递给clojure.lang.Util/identical?(Object x, Object y), 迫使 Java 将该原语两次装箱为引用java.lang.Long, 一次为 "x", 一次为 "y". 这等价于以下重写:(let [x 1000 y x] (identical? (Long/valueOf x) (Long/valueOf y))) ; ❶ ;; false
❶ 这是对前一个代码片段的重写, 显示了是什么样的行为导致了
identical?的意外结果.如示例所示,
identical?受到许多你需要注意的异常行为的影响. 在可能的情况下, Clojure 的相等性=应该是等价性测试的首选选项.
- 使用 identical? 时的意外
- 另请参阅
当你有兴趣比较数量 (而非引用) 并尊重操作数的相对顺序时, 使用
compare.=是最通用和最灵活的比较运算符. 它不是混合数字比较的最佳选择, 但它适用于集合和其他 Clojure 数据类型.==是专用于数值等价性的运算符. 当你对比较数值数量而不是引用感兴趣时, 使用它. - 性能考虑和实现细节
=> O(1) 函数生成
identical?是一个常数时间操作. 考虑到它缺乏分派逻辑和只关注引用相等性, 它也相当快.identical?的实现委托给了 Java 端的clojure.lang.Util类, 后者又只调用了 Java 的==双等号运算符. 与其他 Clojure 包装方法不同,clojure.lang.Util/identical(Object k1, Object k2)的签名只接受对象. 这阻止了从 Clojure 分派原始类型, 迫使了我们在前面示例中看到的自动装箱.
2.5.6. 6.6 hash
注意
本节还提到了其他相关函数, 如:
mix-collection-hash,hash-ordered-coll和hash-unordered-coll.
自 1.0 (hash) 版本以来的函数
(hash [x]) (hash-ordered-coll [coll]) (hash-unordered-coll [coll]) (mix-collection-hash [hash-basis count])
hash 是 Clojure 中的默认哈希函数实现. hash-ordered-coll, hash-unordered-coll 和 mix-collection-hash 是帮助对象和集合与 Clojure 哈希实现集成的函数. hash 接受任何类型的对象, 并将其转换为一个 32 位 (有符号) 整数:
(hash "hello") ; ❶ ;; 1715862179 (type (hash "hello")) ; ❷ ;; java.lang.Integer
❶ hash 实现了默认的 Clojure 哈希算法.
❷ hash 返回一个 java.lang.Integer.
注意
Java 带有自己的哈希算法, 可通过每个对象实例上的
hashCode()方法访问. Clojure 通过在其自己的集合上实现hashCode()来支持 Java 的哈希要求. 然而, Java 的哈希在某些惯用的 Clojure 场景中表现不佳, 例如在关联数据结构中使用集合作为键. 这是 Clojure 提供自己的哈希函数的主要原因之一.
- 约定
- 输入
hash:"x"是唯一必需的参数. 它可以是任何类型, 包括nil.hash-ordered-coll和hash-unordered-coll:"coll"是唯一强制性参数. 它必须实现java.lang.Iterable接口.mix-collection-hash:"hash-basis"和"count"都是必需的long类型参数.
- 值得注意的异常
- 当向
hash-ordered-coll或hash-unordered-coll传递nil时, 抛出NullPointerException. - 如果
hash-ordered-coll或hash-unordered-coll的参数不实现java.lang.Iterable接口, 则会抛出ClassCastException.
- 当向
- 输出
hash返回一个介于 -231 和 2
31-1 之间的
java.lang.Integer数. 当"x"是数字, 字符串或实现了clojure.lang.IHashEq时, 输出与 Clojure 的哈希实现一致. 对于所有其他类型,hash委托给java.lang.Object的.hashCode().hash-ordered-coll和hash-unordered-coll返回一个介于 -231 和 2
31-1 之间的
java.lang.Long数.mix-collection-hash:"hash-basis"和"count"都是必需的long类型参数.
- 输入
- 示例
对
hash函数的最后一次更改 (包括引入hash-ordered-coll,hash-unordered-coll和mix-collection-hash) 是相对较新的. 在 Clojure 1.6 之前, 通过在 map 中使用复合键可能会产生效率低下的程序. 效率低下是由于在这种情况下频繁发生冲突的结果 120. 要理解为什么 Clojure 需要自己的哈希, 请看以下示例:(def long-keys [-3 -2 -1 0 1 2]) (def composite-keys [#{[8 5] [3 6]} #{[3 5] [8 6]}]) (map (memfn hashCode) long-keys) ; ❶ ;; (2 1 0 0 1 2) (map (memfn hashCode) composite-keys) ; ❷ ;; (2274 2274)
❶ 我们可以看到 Java
hashCode()对long类型数字的影响. Java 只是将 64 位长整数的高位和低位组合在一起, 以将它们缩小到所需的 32 位大小. 但这样做, 它在负数和正数之间造成了一些明显的冲突.❷
hashCode()的另一个问题在具有重复项模式的小集合 (Clojure 的常见情况) 上表现出来. 这里介绍的集合如果使用hashCode()会发生冲突.Java 的
hashCode()会产生相对容易的冲突, 例如, 在需要哈希的算法或数据结构中, 在long, 向量或集合上.hash通过考虑这些因素来改进 Java:(map hash long-keys) ; ❶ ;; (-1797448787 -1438076027 1651860712 0 1392991556 -971005196) (map hash composite-keys) ; ❷ ;; (2055406432 -916052234)
❶
hash通过移除简单的 64 到 32 位压缩效果来改进long的哈希.❷ 类似地,
hash已扩展到 Clojure 集合, 产生均匀分布的哈希数.Clojure 集合内部使用与
hash提供的相同的哈希函数, 因此我们可以自由地使用数字或小集合作为键, 而不用担心会产生频繁的冲突. 然而, 当涉及到 Java 互操作性场景时, 我们需要小心:(import 'java.util.ArrayList) (def k1 (ArrayList. [1 2 3])) ; ❶ (def k2 [1 2 3]) (def arraymap {k1 :v1 k2 :v2}) ; ❷ ;; IllegalArgumentException: Duplicate key [1, 2, 3] (= k1 k2) ;; true (def hashmap (hash-map k1 :v1 k2 :v2)) ; ❸ (= (hash k1) (hash k2)) ;; false ;; #'user/hashmap
❶ 在这个与 Java 的互操作场景中, 我们有两个内容相同但类型不同的集合. 一个是向量, 另一个是
java.util.ArrayList.❷ 我们无法创建一个数组映射, 因为它不使用哈希来检查键的存在. 它使用 Clojure 的相等性, 正确地声称这两个集合是相同的.
❸ 我们能够创建一个哈希映射, 因为这两个集合使用不同的哈希算法, 它们显示为不同的键.
array-map和hash-map之间的不同行为与其设计目标一致, 并且ArrayList使用与 Clojure 集合不同的哈希算法. 对于其他未实现clojure.lang.IHashEq接口的自定义类型 (不一定是集合), 应该预期有类似的行为.如果我们想在集合上一致地使用 Clojure 哈希, 而与它们的内容 (但不依赖于它们的类型) 无关, 我们可以使用
hash-ordered-coll或hash-unordered-coll. 使用" 无序" 版本时, 输出哈希在内容顺序改变时不会改变. 这在将不同的集合类型混合作为 Clojure 哈希映射中的键, 同时保证哈希一致性时可能很有用:(import 'java.util.ArrayList) (import 'java.util.HashSet) (defn hash-update [m k f] ; ❶ (update m (hash-unordered-coll k) f)) (def k1 (ArrayList. [1 2 3])) (def k2 (HashSet. #{1 2 3})) (def m (hash-map)) (-> m ; ❷ (hash-update [1 2 3] (fnil inc 0)) (hash-update k1 (fnil inc 0)) (hash-update k2 inc)) ;; {439094965 3}
❶
hash-update是 map 的普通update的一个小包装函数.hash-update不是直接使用给定的键, 而是首先调用hash-unordered-coll.❷
hash-map"m"使用hash-update重复更新. 尽管用作键的集合非常不同, 它们都更新相同的值 (而不是创建新键).上面的例子意味着
hash-unordered-coll会为内容相同但顺序任意的不同集合类型生成相同的键:(= (hash-unordered-coll [1 2 3]) ; ❶ (hash-unordered-coll [3 2 1]) (hash-unordered-coll #{1 2 3})) ;; true (= (hash-ordered-coll [1 2 3]) ; ❷ (hash-ordered-coll [3 2 1]) (hash-ordered-coll #{1 2 3})) ;; false
❶ 我们可以验证
hash-unordered-coll为不同顺序的集合生成相同的哈希数.❷ 如果我们需要排序来确定不同的哈希数, 我们可以使用
hash-ordered-coll.hash-ordered-coll和hash-unordered-coll适用于实现了java.lang.Iterable接口的集合.Iterable接口在 Clojure 和 Java 中都占了很大一部分. 不幸的是, 如果一个集合是不可迭代的, 我们就不能使用我们目前看到的集合哈希函数.java.util.HashMap是一个不可迭代集合的常见例子:(import 'java.util.HashMap) (hash-unordered-coll (HashMap. {:a 1 :b 2})) ; ❶ ;; ClassCastException java.util.HashMap cannot be cast to java.lang.Iterable
❶ 我们不能直接在
java.util.HashMap类型上使用hash-unordered-coll.在下一个例子中, 我们将设计一个与 Clojure 兼容的哈希函数, 该函数可以在
java.util.HashMap上工作, 从而使我们能够在 Clojure 和 Java map 的混合上比较哈希. 我们可以通过迭代 hash-map 并对每个键值对求哈希和来实现这一点. 然而, 我们还需要处理一个最后的问题, 这是 Clojure 用hash-unordered-coll为我们实现的, 我们需要复制它.哈希算法通常会遇到一个与输入改变时哈希中多少位会改变相关的问题. 一个好的哈希算法在输入中的每次改变都导致输出中至少一半的位改变时, 会产生一个" 雪崩效应" (可能全部, 尽管这并非总是可能). 雪崩效应最好通过最后一步" 混合" 位来最大化变化来实现. 由于我们将实现我们自己的哈希算法, 我们还需要在最后一步显式地调用
mix-collection-hash:(defn hash-java-map [^java.util.Map m] (let [iter (.. m entrySet iterator)] ; ❶ (loop [ret 0 cnt 0] (if (.hasNext iter) (let [^java.util.Map$Entry item (.next iter) ; ❷ kv [(.getKey item) (.getValue item)]] (recur (unchecked-add ret ^int (hash kv)) ; ❸ (unchecked-inc cnt))) (.intValue ^Long (mix-collection-hash ret cnt)))))) ; ❹ (= (hash (HashMap. {1 2 3 4})) ; ❺ (hash {1 2 3 4})) ;; false (= (hash-java-map (HashMap. {1 2 3 4})) ; ❻ (hash {1 2 3 4})) ;; true
❶ 要迭代
java.util.HashMap, 我们需要先通过它的EntrySet, 这是一个可迭代的对象.❷ 一个
Iterator对象是有状态的, 每次我们在它上面调用.next时都会前进.❸ 注意, 要哈希一个
java.util.HashMap$Entry, 我们需要它的键和值组件来形成一个向量.❹ 在对所有哈希过的 map 对求和后, 我们调用
mix-collection-hash以确保良好的雪崩效应.❺ 在
java.util.HashMap上调用hash会产生与在clojure.lang.PersistentArrayMap上调用相同函数不同的数字.❻ 但如果我们使用
hash-java-map, 我们就在 Java map 对象上启用了 Clojure 风格的哈希. - 性能考虑和实现细节
=> O(n) 与要哈希的项数成线性关系
集合对象上的
hash函数与要哈希的项数成线性关系. 具有自定义hashCode()实现的集合或标量类型可能会受到不同的复杂性成本的影响, 因为hash会在它们存在时委托给它们. 在性能分析方面,hash使用 Murmur3 算法, 该算法通常非常高效.
2.5.7. 6.7 clojure.data/diff
自 1.3 版本以来的函数
(diff [a b])
diff 建立在 Clojure 相等性运算符之上, 以检索任意嵌套数据结构之间的差异. 虽然 = 在参数不同时只会返回 false, 但 diff 还会描述它们的不同之处:
(require '[clojure.data :refer [diff]]) ; ❶ (diff {:a "1" :b "2"} {:b "2" :c "4"}) ; ❷ ;; ({:a "1"} ; ❸ ;; {:c "4"} ; ❹ ;; {:b "2"}) ; ❺
❶ 注意, diff 不属于 clojure.core 命名空间, 因此默认不可用.
❷ diff 接受两个参数, 并返回一个包含 3 个元素的序列.
❸ 结果中的第一项是仅存在于第一个参数中而不在第二个参数中的内容.
❹ 同样, 结果中的第二项是仅存在于第二个参数中而不在第一个参数中的内容.
❺ 结果中的最后一个, 也是最终的项是参数之间共有的内容, 如果有的话.
diff 适用于所有 Clojure 数据结构和标量类型, 但有一些限制, 本章将对此进行说明.
- 约定
- 输入
"a"和"b"是两个强制性参数. 它们可以是任何类型, 包括nil.
- 值得注意的异常
clojure.lang.ArityException: 当不完全是 2 个参数时.
- 输出
一个包含 3 个元素的序列集合 (列表或向量), 分别位于索引 0, 1 或 2. 结果的三元组包含:
- 当
"a"和"b"没有任何共同之处或当"a"和"b"的类型不兼容时 (见下文), 为[a b nil]. - 当
"a"和"b"有共同之处且它们具有兼容的类型时, 为[only-in-a only-in-b common-items].
对于集合, 假设
"a"是类型 A,"b"是类型 B, 则当出现以下情况时, A 和 B 是兼容的:- 它们都是 Java 数组 (使得
(.isArray (class a))和(.isArray (class b))都为真). - 它们都是
java.util.Set(使得(instance? java.util.Set a)和(instance? java.util.Set b)都为真). - 它们都是
java.util.List(使得(instance? java.util.List a)和(instance? java.util.List b)都为真). 这就是使列表和向量兼容的原因. - 它们都是
java.util.Map(使得(instance? java.util.Map a)和(instance? java.util.Map b)都为真).
对于标量 (任何不是容器的其他类型),
diff遵循=单等号兼容性规则.一旦确定
"a"和"b"对于diff是兼容的, 那么结果包含:- 在索引 0 处: 一个类型为 A 的元素, 它包含所有仅存在于
"a"中而不在"b"中的项 (和子项). 当"a"和"b"没有任何共同之处时, 索引-0 的元素包含"a"本身. - 在索引 1 处: 一个类型为 B 的元素, 它包含所有仅存在于
"b"中而不在"a"中的项 (和子项). 当"a"和"b"没有任何共同之处时, 索引-1 的元素包含"b"本身. - 在索引 2 处:
"a"和"b"共有的元素, 以列表或向量的形式, 或者在它们没有任何共同之处的情况下为单个nil.
示例部分包含最有趣的
diff应用的示例.结果三元组中任何交错的
nil出现都应被忽略, 因为它可能是diff内部处理的结果, 而不是输入参数中nil的实际出现. 因此,diff不适合处理带有显式nil或空集合的输入, 因为在结果三元组中将它们与缺失的元素区分开来会很成问题. - 当
- 输入
- 示例
让我们从一系列小例子开始, 展示
diff在与约定部分中说明的类型类别相关的行为. 如果你想像下面的例子一样使用diff, 记得要require clojure.data:(diff 1.0 1) ; ❶ ;; [1.0 1 nil] (diff [1 "x" 3 4] ; ❷ '(1 "y" 3 5)) ;; [[nil "x" nil 4] ;; [nil "y" nil 5] ;; [1 nil 3]] (diff {:a "a" :b {:c "c"}} ; ❸ {:a 1 :b {:c 2}}) ;; ({:a "a" :b {:c "c"}} ;; {:a 1 :b {:c 2}} ;; nil) (diff [1 {:a [1 2] :b {:c "c"}}] ; ❹ [1 {:a [1 3] :b {:c "c" :d "d"}}]) ;; [[nil {:a [nil 2]}] ;; [nil {:a [nil 3] :b {:d "d"}}] ;; [1 {:a [1] :b {:c "c"}}]] (diff (int-array [1 2 3]) ; ❺ (int-array [1 4 3])) ;; [[nil 2] [nil 4] [1 nil 3]] (diff #{:a :c :b} #{:c :b :a}) ; ❻ ;; [nil nil #{:a :b :c}] (diff {"x" 42} (sorted-map :x 42)) ; ❼ ;; java.lang.ClassCastException
❶ 遵循
(= 1.0 1)的假语义.❷
nil出现在集合中, 作为diff内部处理的一部分. 重要的是, "x" 和 4 只在第一个参数中, "y" 和 5 只在第二个参数中, 1-3 是共有的. 注意向量和列表是兼容的参数.❸ 两个 map 没有任何共同之处.
❹ 如果 map 键的值是另一个集合,
diff会显示哪些元素是共有的, 并进入嵌套级别.❺
diff与 Java 数组一起工作.❻ 集合按预期工作.
❼ 一个已知的 bug 影响了在排序 map 上的
diff121.diff是一个比较嵌套数据结构并获得关于它们如何不同的即时反馈的强大工具. 例如, 用 Clojure 编写的服务通常会产生具有任意嵌套数据结构的 JSON 或 EDN 输出. 如果我们想对服务进行更改, 并且想确保不引入任何回归, 我们可以将新服务的输出与旧的进行比较, 并检查差异. 其中一些可能是预期的, 其他的则不是.在下面的例子中, 一个服务返回关于 Clojure 库及其依赖项的元数据. 这是来自实时服务的项目 "prj1" 的一个示例响应:
(def orig {:defproject :prj1 :description "the prj" :url "https://theurl" :license {:name "EPL" :url "http://epl-v10.html"} :dependencies {:dep1 "1.6.0" :dep2 "1.0.13" :dep6 "1.7.5"} :profiles {:uberjar {:main 'some.core :aot "all"} :dev {:dependencies {:dep8 "1.6.3"} :plugins {:dep9 "3.1.1" :dep11 {:id 13}}}}})
我们现在向新服务发出相同的请求, 新服务只是使用相同的数据库/基础设施的不同代码:
(def new-service {:defproject :prj1 :description "the prj" :url "https://theurl" :license {:name "EPL" :url "http://epl-v10.html"} :dependencies {:dep1 "1.6.0" :dep2 "1.0.13" :dep6 "1.7.5"} :profiles {:uberjar {:main 'some.core :aot :all} :dev {:dependencies {:dep8 "1.6.1"} :plugins {:dep9 "3.1.1" :dep11 {:id 13}}}}})
它们看起来显然是相同的, 但我们如何能确定呢? 为了让我们的生活更轻松, 我们希望使用一些自动化来提取两个数据结构不同的所有路径, 而没有任何嵌套或实际值.
diff可以完成繁重的工作, 我们只需要在其之上进行构建:(require '[clojure.data :refer [diff]]) (defn walk-diff [d path] ; ❶ (if (map? d) (map #(walk-diff (% d) (conj path %)) (keys d)) ; ❷ path)) (defn flatten-paths [paths] ; ❸ (->> paths (tree-seq seq? identity) ; ❹ (filter vector?))) (defn diff-to-path [orig other] ; ❺ (let [d (diff orig other)] (flatten-paths (walk-diff (first d) []))))
❶
walk-diff是一个知道如何解析diff返回的结果的函数. 我们有兴趣为diff发现的每个差异创建一个向量形式的哈希映射键的路径, 比如[:a :b :c]. 为此, 我们需要递归地遍历diff的结果, 并在每次发现一个新的哈希映射时深入.❷ 如果作为参数
d呈现的是一个哈希映射, 我们知道存在差异, 我们会跟踪每个键以找出它们的深度. 我们递归地调用walk-diff, 将到目前为止找到的路径作为第二个参数传递.❸
flatten-paths帮助我们清理最终的输出, 移除任何包含单个向量路径的不必要的嵌套列表. 这是必要的, 因为walk-diff递归地为每个 map 调用生成嵌套列表.❹
tree-seq是 Clojure 标准库中的另一个巨大资源.tree-seq将任意嵌套的序列转换为一个树, 并返回其深度优先遍历. 我们可以在这里用它来产生一个树, 其中节点是我们要过滤掉的向量路径.❺
diff-to-path是我们的入口点. 它接受一个orig和其他参数与diff进行比较. 我们取diff三元组中的第一个结果 (取第二个结果也一样), 并将其通过walk-diff. 如前所述,walk-diff的输出需要从围绕路径的杂乱嵌套列表中清理出来.现在让我们看看一切是如何协同工作的:
(first (diff orig new-service)) ; ❶ ;; {:profiles ;; {:dev ;; {:dependencies ;; {:dep8 "1.6.3"}} ;; :uberjar {:aot "all"}}} (diff-to-path orig new-service) ; ❷ ;; ([:profiles :dev :dependencies :dep8] ;; [:profiles :uberjar :aot]) (get-in orig [:profiles :dev :dependencies :dep8]) ; ❸ ;; "1.6.3"
❶ 从
diff的输出中我们可以看到确实存在差异. 然而, 找出原始输出中的不同之处可能需要一些时间, 特别是如果差异更多的话.❷
diff-to-path产生了另一种差异视图. 我们可以很快地看到有两个差异, 以及它们在输入中的位置.❸ 这是我们如何通过其中一个路径来查看不同值的方法.
- 另请参阅
diff是本章中包含的所有函数中最复杂的选项. 但如果你需要一个简单的运算符或相等谓词, 它可能就 overkill 了. 以下所有替代方案都是较低的抽象级别和更专业的:=是diff的基础. 用=来测试简单的条件, 并且当深度嵌套的相等性不是重点时.compare提供了一种一次性验证多个可比较条件的方法.==是数字的相等性, 它应该在所有主要涉及数字的情况下使用.
如果
diff不能满足你的需求, 标准库中的其他函数可以用来" 导航" 数据结构:clojure.walk/walk可以迭代树状数据结构. 当找到一个节点时要执行的行为可以轻松定制.tree-seq在本章中已经看到了. 它不提供在找到节点时执行行为的方法, 但它会产生一个深度优先的遍历, 之后可以进行处理.
- 性能考虑和实现细节
=> O(n) 最坏情况下, "n" 是元素的总数
在最坏的情况下,
diff对输入进行完整的遍历, 至少访问数据结构的每个节点一次, 并可能导致最坏情况 O(n) (其中 "n" 是任意深度级别的元素总数). 因此, 比较平均只有少量共同节点的大型数据结构可能会遇到性能损失. 如果" 差异比较" 是系统的核心部分, 并且你还需要速度, 你可能需要更专业化你的算法. 对于所有其他一般情况 (如测试或偶尔搜索差异),diff完全符合目的.diff使用堆栈来执行遍历. 在平均情况下, 即输入是良好平衡的 (输入呈现的平均深度分布在所有分支中), 消耗的空间大约是 log(n). 我们可以通过以下方法验证输入数据结构需要有多深才能完全消耗堆栈 (根据硬件和 JVM 设置, 测试可能会返回不同的结果):(require 'clojure.data) (defn generate [n] ; ❶ (reduce (fn [m e] (assoc-in m (range e) {e e})) {} (range 1 n))) (defn blow [depth] ; ❷ (doseq [n (range depth 100 -50)] (let [a (generate n) b (generate (inc n))] (try (clojure.data/diff a b) (catch StackOverflowError soe (println "StackOverflow at" n "deep.")))))) (blow 700) ;; StackOverflow at 700 deep. ;; StackOverflow at 650 deep. ;; StackOverflow at 600 deep. ;; StackOverflow at 550 deep. ;; StackOverflow at 500 deep. ;; ... from here diff starts working ; ❸ ;; correctly from the bottom of the stack
❶
generate生成一个嵌套的 n 层深的 map. 例如,(generate 3)生成哈希映射{0 {1 {2 2}}}.❷
blow反复调用diff, 每次使用逐渐变浅的 map (每次减少 50 层), 等待一个StackOverflowError停止出现的点. 生成的 mapa和b在它们最深的嵌套 map 中有一个差异, 迫使diff遍历整个结构以找出它.❸ 由于
diff首先只使用=单等号来遍历结构以找到 a 分支与 b 分支不同的第一个地方, 堆栈是第一个被消耗的东西, 它会立即抛出异常. 一旦数据结构小到足以容纳在堆栈中, 实际的diff计算开始, 并且可能需要几分钟才能结束.如你所见, 你需要非常深的数据结构才能开始遇到堆栈大小问题 (大约在 450 到 500 层深), 并且在到达堆栈末尾之前, 你的堆空间很可能会用完. 幸运的是, 现实生活中的数据结构不太可能有那么深, 如果有, 你可能首先需要解决设计问题.
2.5.8. 6.8 总结
本章关于比较和相等性, 这是编程语言设计中的两个重要方面. =>> 是最灵活和最常用的函数, 但也有专门用于数字的 ==>> 版本和用于排序和 Java 互操作的 compare. 哈希与在哈希表中比较键时的相等性有关. Clojure 有一个自定义的哈希实现, 它针对在数据结构中大量使用集合作为键进行了优化.
在下一章中, 我们将从描述语言的基础转向看一些 Clojure 特有的东西: reducer 和 transducer.
2.6. 7 Reducer 和 Transducer
Reducer 和 Transducer 是同一函数式抽象的连续改进. 它们都基于 reduce 来提供改进的集合处理. 在 reducer 的情况下, 重点是并行性, 而 transducer 主要关注重用. 它们还带来了其他改进, 如更好的可组合性和更高的性能. Transducer 在函数式抽象方面比 reducer 有所改进, 但 reducer 提供了扩展的并行性. 以下是它们主要特性的总结:
- Transducer 可以在现有的库函数 (如
map或filter) 上进行组合. Reducer 需要相同函数的替代实现. - Transducer 和 reducer 都与
comp组合. - Reducer 可以使用
fold并行运行 (尽管这仅适用于向量, map 和r/foldcat对象). Transducer 仍然可以在 reducer 之上并行运行, 但对可用的 transducer 有限制 (只有无状态的 transducer 才能可靠地并行工作). - Transducer 和 reducer 都在对输入集合的" 单次遍历" 中应用多个组合的 reducing 函数. 这与标准的集合处理不同, 在标准的集合处理中, 每个操作 (如
clojure.core/map或clojure.core/filter) 都会产生中间结果. - Transducer 和 reducer 都可以扩展: 特定的集合类型可以定义自己的折叠或转换行为.
- Transducer 可以惰性使用, 而 reducer 总是急切地消耗其输入.
本章将涉及这些方面, 并说明所涉及的不同函数. 附注部分包含了一些展示 reducer 和 transducer 可扩展性的示例. 这些是:
- 创建自己的可折叠集合 (在
fold中). - 设计一个并行 reducer (在
reducer中). - 创建一个自定义 transducer (在
transduce中).
2.6.1. 7.1 Reducers
Reducer 在 Clojure 1.5 中被引入. Reducer 的实现在 clojure.core.reducers 命名空间中可以找到 (在使用前需要 require). Reducer 在 Java fork-join 框架 (Java 1.7 中引入的一种并行模型) 之上包含一个包装层. Reducer 还包含一组与核心中同名的集合处理函数: map, filter, reduce 等等. 与 clojure.core 中的那些相比, 它们创建了一个延迟的" 处理配方" , 在调用 reduce 时执行:
(require '[clojure.core.reducers :as r]) ; ❶ (def map-inc (r/map inc)) ; ❷ (def filter-odd (r/filter odd?)) ; ❸ (def compose-all (comp map-inc filter-odd)) ; ❹ (def apply-to-input (compose-all (range 10))) ; ❺ (reduce + apply-to-input) ; ❻ ;; 30
❶ 在使用 reducer 之前, 我们需要 require 相关的命名空间.
❷ r/map 可以在不指定输入集合的情况下使用. 它返回一个可以与其他 reducer 进一步组合的" reducer" 函数.
❸ r/filter 和命名空间中可用的其他类序列操作也是如此.
❹ 这里使用 comp 来组合这两个操作.
❺ 如果我们现在在一个输入集合上调用 reducer, 我们会得到一个可归约的集合. 计算尚未执行. 可归约集合提供了 reduce 使用的 clojure.core.reducers/CollFold 协议的实现.
❻ 我们最终可以将计算提交给 reduce. inc 和 odd? 的组合在迭代集合时一次性应用.
Reducer 还引入了一些读者应该了解的新词汇:
- " 可归约" 集合是为
reduce提供自定义实现的集合. 如果集合实现了clojure.core.reducers/CollFold协议,reduce会将迭代委托给集合本身, 而不是使用通用机制. 例如,(range 10)是一个可归约的 (序列) 集合.(r/map inc (range 10))也是一个可归约的集合, 尽管它不表现出集合的其他典型属性. - " reducing 函数" 是可用于
reduce操作的两个参数的函数 (例如,+). - " reducer" 是一个函数, 当在可归约集合上调用时, 返回一个" 可归约的转换集合" . 例如,
(r/map inc (range 10))是一个可归约的转换集合, 因为对这个集合的reduce操作也会产生一个转换 (inc).
reducers 命名空间引入了以下 reducer 函数:
map, reduce, take, mapcat, cat, take-while, remove, drop, flatten, filter
它们的语义与 clojure.core 中的相关函数相同, 因此本章的其余部分主要专门讨论 reducer 特有的那些函数: fold, reducer, monoid, folder, foldcat, cat 和 append!. 为了避免与 clojure.core 中的同名函数混淆, 这些函数通常以 r/ 为前缀 (这是 clojure.core.reducers 的常规别名).
- 7.1.1 fold
自 1.5 版本以来的函数
(fold ([reducef coll]) ([combinef reducef coll] ) ([n combinef reducef coll]))
在其最简单的形式中,
fold接受一个 reducing 函数 (一个至少支持 2 个参数的函数) 和一个集合. 如果输入集合支持并行折叠 (目前是向量, map 和foldcat对象), 它会将输入集合分割成大小大致相同的块, 并行地在每个分区上执行 reducing 函数 (并且在可能的情况下在多个 CPU 核上执行). 然后它将结果组合回单个输出:(require '[clojure.core.reducers :as r]) ; ❶ (r/fold + (into [] (range 1000000))) ; ❷ ;; 499999500000
❶ Reducer 与 Clojure 捆绑在一起, 但在使用前需要被
require.❷
fold将 100 万个元素的向量分割成大小约为 512 的块 (默认值). 然后将块发送到 fork-join 线程池进行并行执行, 在那里它们被+归约. 随后, 这些块再次用+组合起来.fold提供了基于" 分而治之" 的并行性: 创建工作块, 并行进行计算, 同时, 完成的任务被组合回最终结果. 下图说明了一个集合经过fold操作的过程:
Figure 12: fork-join 模型如何并行地进行 reduce-combine.
fold实现的一个重要机制 (该图在不混淆的情况下无法清楚地显示) 是工作窃取. 在fold将一个块发送到 Java fork-join 框架后, 每个工作线程可以进一步将工作分割成更小的部分, 从而产生大小不一的块. 当空闲时, 一个工作线程可以从另一个工作线程那里" 窃取" 工作 122. 工作窃取优于基本的线程池, 特别是对于不太可预测的工作, 这种工作会意外地让一个或多个线程保持忙碌.- 约定
- 输入
根据可选的
"combinef"函数是否存在以及输入集合是否为 map, 约定有所不同:"reducef"是强制性参数. 它必须是至少支持 2 个参数 (并且在未提供"combinef"时支持 0 个参数调用) 的函数. 2 个参数调用实现了接收累加器和当前元素的规范reduce约定. 0 个参数调用用于建立结果的种子, 类似于reduce中的"init"参数. 当未提供"combinef"时, 对每个块调用一次 0 元数以建立归约的种子. 当未提供组合函数时,"reducef"也用于代替"combinef". 在这种情况下,"reducef"必须是关联的, 因为块可以按任何顺序重新组合."combinef"是可选的, 当存在时, 它必须允许 0 或 2 个参数."combinef"需要是关联的, 以允许块按任何顺序组合. 2 个参数调用用于将块连接回最终结果. 当存在"combinef"时, 永远不会调用"reducef"的 0 元数, 而是调用"combinef"."n"是最小计算块的大致大小. 默认值为 512."coll"可以是任何序列类型, 空或nil. 如果"coll"不是向量, hash-map 或clojure.core.reducers.Cat对象 (有关更多信息, 请参见r/foldcat),fold会回退到顺序reduce而不是并行. 当"coll"是 hash-map 时,"reducef"和"combinef"都用 3 个参数而不是 2 个来调用, 根据reduce-kv约定.
- 值得注意的异常
对于少数不支持的集合类型, 会引发
IllegalArgumentException. 例如, 当"coll"是瞬态或像java.util.HashMap这样的 Java 集合时, 可能会发生这种情况. 排除不安全的线程可变集合是有充分理由的, 否则它们会受到并发的影响. 其他线程安全的 Java 集合 (如java.util.concurrent.ConcurrentHashMap) 可以被制成" 可折叠的" , 我们将在扩展示例中探讨这一点. - 输出
- 当
"coll"为nil或只包含一个元素时, 返回调用(reducef)或(combinef)且没有参数的结果. - 返回将
"reducef"应用于集合中下一个项的结果. 然后再将"reducef"应用于前一个结果和下一个项, 依此类推, 直到集合中的最后一个项. 如果存在"combinef", 那么部分累积会用"combinef"合并回来. 返回应用"reducef"(或"combinef") 的最后一个结果.
- 当
- 输入
- 示例
fold在reduce-combine模型之上启用了并行性. 许多类型的计算都受益于 (或者可以适应于) 类似fold的操作. 基于reduce的数据管道是一个很好的候选者, 就像我们在reduce部分看到的单词计数示例一样. 在那个示例中, 我们使用了一个顺序的count-occurrences函数来计算大文本中单词的频率. 我们可以像这样重写该示例以使用fold:(require '[clojure.core.reducers :as r]) (defn count-occurrences [coll] (r/fold (r/monoid #(merge-with + %1 %2) (constantly {})) ; ❶ (fn [m [k cnt]] (assoc m k (+ cnt (get m k 0)))) ; ❷ (r/map #(vector % 1) (into [] coll)))) ; ❸ (defn word-count [s] (count-occurrences (.split #"\s+" s))) (def war-and-peace "https://tinyurl.com/wandpeace") (def book (slurp war-and-peace)) (def freqs (word-count book)) (freqs "Andrew") ;; 700
❶
r/monoid是一个用于创建适合"combinef"的函数的辅助函数.r/monoid的第一个参数是当两部分组合在一起时要使用的合并函数. 我们想要对同一个单词的计数求和, 我们可以用merge-with来做到这一点.❷
"reducef"需要将每个单词关联到结果 map"m". 有两种可能的情况: 单词已经存在, 计数递增, 或者单词不存在, 0 被用作初始计数.❸
"coll"需要是一个向量, 所以我们确保输入用into转换. 每行的转换包括创建一个包含单词和数字 1 的元组 (2 个项的向量). 我们为此使用 reducers 库中的r/map, 以便转换被延迟到并行执行.fold也原生支持 map. 我们可以用之前产生的freqs作为另一个fold操作的新输入. 例如, 我们可以看到一个单词的首字母与其在书中的频率之间的关系.以下示例按首字母对单词进行分组, 然后计算它们的平均频率. 此操作是并行
fold的一个很好的候选者, 因为输入包含数千个键 (输入文本中找到的每个单词一个):(defn group-by-initial [freqs] ; ❶ (r/fold (r/monoid #(merge-with into %1 %2) (constantly {})) ; ❷ (fn [m k v] ; ❸ (let [c (Character/toLowerCase (first k))] (assoc m c (conj (get m c []) v)))) freqs)) (defn update-vals [m f] ; ❹ (reduce-kv (fn [m k v] (assoc m k (f v))) {} m)) (defn avg-by-initial [by-initial] ; ❺ (update-vals by-initial #(/ (reduce + 0. %) (count %)))) (defn most-frequent-by-initial [freqs] ; ❻ (->> freqs group-by-initial avg-by-initial (sort-by second >) (take 5))) (most-frequent-by-initial freqs) ; ❼ ;; ([\t 41.06891634980989] ;; [\o 33.68537074148296] ;; [\h 28.92705882352941] ;; [\w 26.61111111111111] ;; [\a 26.54355400696864])
❶
group-by-initial使用fold, 期望一个从字符串到数字的哈希映射. 输出是一个小得多的从字母到向量的 map. 这个 map 中的键的数量等于字母表中的字母数量 (假设文本足够大, 并且我们过滤掉了数字和符号). 这个 map 中的字母 "a" 包含像[700, 389, 23, 33, 44]这样的东西, 它们是书中每个以字母 "a" 开头的单词的出现次数.❷ 组合函数是用
r/monoid组装的. 每个 reducing 操作的初始值是空 map{}. 部分结果通过按键合并它们的向量值到一个单独的向量中来组合在一起.❸ reducing 函数接受三个参数: 一个部分结果的 map
"m", 当前的键"k"和当前的值"v". 类似地, 为了计算单词频率, 我们获取一个可能存在的键 (使用一个空向量作为默认值), 并将其conj到值"v"的向量中. 键是输入 map 中找到的每个单词的首字母.❹
update-vals接受一个 map 和一个单参数的函数"f". 然后它使用reduce-kv将"f"应用于 map 中的每个值.❺
avg-by-initial将 map 中的每个向量值替换为其中数字的平均值.❻
most-frequent-by-initial协调到目前为止看到的函数, 以按首字母提取最频繁的单词.❼
freqs是示例中之前单词计数的结果.在运行
most-frequent-by-initial后, 我们可以看到字母 "t" 平均是单词开头最常用的, 紧随其后的是 "o", "h", "w" 和 "a". 这表明以字母 "t" 开头的单词在整本书中平均重复次数最多 (而其他一些不以 "t" 开头的单词可能在绝对数量上是最频繁的).- 创建自己的 fold
fold是一个基于协议的可扩展机制. 大多数 Clojure 集合都提供了一个基于reduce的基本顺序折叠机制, 除了向量, map 和foldcat对象, 它们配备了并行的 reduce-and-combine 算法. 像java.util.HashMap这样的类没有适当的fold, 这与将可变数据结构暴露给潜在并行线程的危险有关, 这是有充分理由的. 其他线程安全的类, 如java.util.concurrent.ConcurrentHashMap, 可以是可折叠的, 这正是本节的主题. 我们将对java.util.concurrent.ConcurrentHashMap看到的, 可以很容易地扩展到其他集合 (前提是它们支持并发访问).为了驱动我们的例子, 让我们使用一个大的
ConcurrentHashMap, 其中键是整数, 值也是整数, 以及一个昂贵的函数来应用于所有的键. 像inc或str这样的值上的简单转换对于fold并行性来说可能是 overkill, 所以我们将使用莱布尼茨公式来近似 "Pi" (我们在讨论filterv时已经遇到过这个公式). 我们希望并行地对每个键执行转换.并行执行的设计如下: 我们将分割键, 而不是分割值. 与每个分区对应的值由单独的线程并行转换. 通常不会发生冲突 (因为键是唯一的), 但 fork-join 是一种工作窃取算法, 因此一个分区可能会被路由到一个已经分配了另一个分区的线程, 从而产生重叠. 这就是为什么我们需要
java.util.concurrent.ConcurrentHashMap而不是普通的java.util.HashMap.(import 'java.util.concurrent.ConcurrentHashMap) (require '[clojure.core.reducers :as r]) (defn pi [n] ; ❶ "Pi Leibniz formula approx." (->> (range) (filter odd?) (take n) (map / (cycle [1 -1])) (reduce +) (* 4.0))) (defn large-map [i j] ; ❷ (into {} (map vector (range i) (repeat j)))) (defn combinef [init] ; ❸ (fn ([] init) ([m _] m))) (defn reducef [^java.util.Map m k] ; ❹ (doto m (.put k (pi (.get m k))))) (def a-large-map (ConcurrentHashMap. (large-map 100000 100))) (dorun ; ❺ (r/fold (combinef a-large-map) reducef a-large-map)) ;; IllegalArgumentException No implementation of method: :kv-reduce
❶
pi计算 π 值的近似值. 数字 "n" 越大, 近似值越好. 数量级在数百的相对较小的数字会产生昂贵的计算.❷
large-map用于创建一个大的ConcurrentHashMap, 以在我们的示例中使用. map 的键是递增的整数, 而值总是相同的.❸ 没有参数的
combinef返回基础 map, 所有线程都应该并发更新这个 map. 不需要连接, 因为更新发生在同一个可变的ConcurrentHashMap实例上. 因此, 带有两个参数的combinef只返回两者之一 (它们是同一个对象).combinef可以有效地被(constantly m)替换.❹
reducef将一个现有的键替换为计算出的 "pi". 注意使用doto, 这样像.put这样的 Java 操作, 否则会返回nil, 会返回 map 本身.❺
fold不成功, 因为它搜索一个合适的reduce-kv实现, 但没有找到.我们面临着第一个问题:
fold失败, 因为缺少两个多态分派:fold没有针对java.util.concurrent.ConcurrentHashMap的特定并行版本, 因此它将调用路由到reduce-kv.reduce-kv也失败了, 因为有针对 Clojure hash-map 的实现, 但没有针对 JavaConcurrentHashMap的实现. 作为第一步, 我们可以提供一个reduce-kv版本来移除错误, 但这个解决方案不足以并行运行转换:(extend-protocol ; ❶ clojure.core.protocols/IKVReduce java.util.concurrent.ConcurrentHashMap (kv-reduce [m f _] (reduce (fn [amap [k v]] (f amap k)) m m))) (time ; ❷ (dorun (r/fold (combinef a-large-map) reducef a-large-map))) ;; "Elapsed time: 41113.49182 msecs" (.get a-large-map 8190) ; ❸ ;; 3.131592903558553
❶ 我们可以通过使用
extend-protocol来向一个协议添加一个类型. 我们的reduce-kv不需要值, 因为我们正在就地改变 JavaConcurrentHashMap.❷
fold现在可以正常运行了. 我们需要dorun来防止 map 被打印在屏幕上. 我们还打印了一个相当不错的操作完成所用时间的估计, 超过了 40 秒.❸ 为了确保
a-large-map已经被有效地更新, 我们检查了随机键 "8190". 它包含了一个 "pi" 的近似值, 如预期.尽管我们提供了一个合适的
reduce-kv实现,java.util.concurrent.ConcurrentHashMap仍然没有一个适当的并行fold. 与reduce-kv类似, 我们需要通过扩展正确的协议来提供一个fold实现. 其思想是分割键集而不是 map, 并让每个线程并行地处理给定的子集:(defn foldmap [m n combinef reducef] ; ❶ (#'r/foldvec (into [] (keys m)) n combinef reducef)) (extend-protocol r/CollFold ; ❷ java.util.concurrent.ConcurrentHashMap (coll-fold [m n combinef reducef] (foldmap m n combinef reducef))) (def a-large-map (ConcurrentHashMap. (large-map 100000 100))) (time ; ❸ (dorun (into {} (r/fold (combinef a-large-map) reducef a-large-map)))) "Elapsed time: 430.96208 msecs"
❶
foldmap实现了java.util.concurrent.ConcurrentHashMap的并行策略. 它委托给 reducers 命名空间中的foldvec, 并使用来自 map 的键, 从而有效地重用向量的并行性.❷ 我们指示
CollFold协议在fold遇到java.util.concurrent.HashMap实例时使用foldmap.❸ 在重新创建大型 map (记住每次执行后它是如何被改变的) 之后, 我们再次尝试
fold, 结果是预期的性能提升 (从顺序情况下的 40 多秒降到 430 毫秒). 我们还负责将fold返回的ConcurrentHashMap转换回一个持久化数据结构以供后用.在扩展了
clojure.core.reducers命名空间中的CollFold协议后, 我们可以看到fold有效地并行运行了 map 的更新, 从而显著地减少了执行时间. 作为比较, 这是在默认并行的持久化哈希映射上执行的相同操作:(def a-large-map (large-map 100000 100)) (time (dorun (r/fold (r/monoid merge (constantly {})) (fn [m k v] (assoc m k (pi v))) a-large-map))) ;; "Elapsed time: 17977.183154 msecs" ; ❶
❶ 我们可以看到, 尽管 Clojure 的哈希映射是并行启用的, 但它是持久化数据结构的事实在快速并发更新方面对其不利. 这不是 Clojure 数据结构的弱点, 因为它们的设计目标完全不同.
- 创建自己的 fold
- 另请参阅
pmap也并行地将一个转换函数应用于一个输入序列.fold和pmap有共同之处, 但它们在计算模型上有所不同.pmap支持惰性, 并且有可变数量的工作线程 (取决于集合的块大小加上可用核心数加 2). 然而, 在移动到序列中的下一个块之前,pmap必须等待当前块中的所有工作线程完成. 不太可预测的操作 (那些让一个工作线程比通常更忙的操作) 实际上会阻止pmap的完全并发. 另一方面,fold允许一个空闲的工作线程帮助一个忙碌的工作线程处理一个比预期更长的请求. 根据经验, 优先使用pmap在可预测的任务上启用惰性处理, 但在不太可预测的场景中使用fold, 在这些场景中惰性不那么重要. - 性能考虑和实现细节
=> O(n) 线性
fold被实现为递归地将一个集合分割成块, 并将它们发送到 fork-join 框架, 从而有效地在 O(log n) 次传递中构建一棵树. 然而, 每个块都受到一个线性的reduce的影响, 该reduce主导了对数遍历: 初始集合越大, 对 reducing 函数的调用就越多, 从而使其成为一个整体的线性行为.并行线程的编排是有代价的, 在并行执行操作时应该考虑到这一点: 像
pmap一样,fold在对可能大的数据集进行非平凡的转换时表现最佳. 例如, 以下简单的操作在并行执行时会导致性能下降:(require '[criterium.core :refer [quick-bench]]) (require '[clojure.core.reducers :as r]) (let [not-so-big-data (into [] (range 1000))] (quick-bench (reduce + not-so-big-data))) ;; Execution time mean : 11.481952 µs (let [not-so-big-data (into [] (range 1000))] (quick-bench (r/fold + not-so-big-data))) ;; Execution time mean : 32.683242 µs
随着集合变得更大, 计算变得更复杂, 可用的核心数量增加,
fold开始优于类似的顺序操作. 潜在的性能提升仍然不足以保证需要fold, 因为还有其他变量需要考虑, 比如内存需求.fold被设计为一个急切的操作, 因为输入块被每个工作线程进一步分割以允许有效的工作窃取算法. 像本章中的示例那样的fold操作需要在执行开始前 (或作为执行的一部分) 将整个数据集加载到内存中. 当fold产生的结果比输入小得多时, 有办法防止整个数据集加载到内存中, 例如, 通过在磁盘 (或数据库) 上对其进行索引, 并在 reducing 函数中包含必要的 IO 以加载数据. 这种方法在 Iota 库 123 中被使用, 该库扫描大文件以索引它们的行, 并将其用作fold的输入集合.
- 约定
- 7.1.2 reducer 和 folder
自 1.5 版本以来的函数
(reducer [coll xf]) (folder [coll xf])
reducer和folder都接受一个集合和一个单参数的函数. 它们用由"xf"参数指定的自定义reduce实现 (以及在folder的情况下还包括fold) 来增强它们的输入集合. 这里有一个由reducer增强的集合和一个由folder增强的集合的例子:(require '[clojure.core.reducers :as r]) ; ❶ (defn divisible-by-10 [current-reducing-fn] ; ❷ (fn [acc el] (if (zero? (mod el 10)) (current-reducing-fn acc el) acc))) (into [] ; ❸ (r/reducer (range 100) divisible-by-10)) ;; [0 10 20 30 40 50 60 70 80 90] (r/fold ; ❹ (r/monoid merge (constantly {})) (fn [m k v] (assoc m k (+ 3 v))) (r/folder (zipmap (range 100) (range 100)) (fn [rf] (fn [m k v] (if (zero? (mod k 10)) (rf m k v) m))))) ;; {0 3, 70 73, 20 23, 60 63, 50 53, 40 43, 90 93, 30 33, 10 13, 80 83}
❶
reducer和folder都位于reducers命名空间中. 在使用前你需要require该命名空间.❷
divisible-by-10是对 reducing 函数进行转换的一个例子.reducer使用divisible-by-10作为新的 reducing 行为来转换输入集合.divisible-by-10验证当前元素是否能被 10 整除, 并且仅在这种情况下才应用当前的 reducing 函数.❸ 这里使用
into来显示集合现在是如何被转换的.into是在reduce之上实现的, 因此转换会发生.divisible-by-10的效果与过滤输入集合相同.❹
folder的工作方式与fold类似. 这是通过使用一个哈希映射作为输入来演示的.folder对 reducing 函数进行检测, 只有当键是 10 的倍数时才会通过. 另一个 reducing 函数存在, 用于将每个值加 3. 这两个最终会连接在一起.输入函数
"xf"在reducer和folder中都有机会拦截对原始 reducing 函数的当前调用, 并可能改变结果.reducer和folder在定义自定义 reducer 时很有用 (它们在 reducer 本身的实现中被广泛使用). 下表是可用 reducer 及其可折叠行为的摘要:Table 9: reducers 命名空间中可用的 reducer 名称 描述 可折叠? r/map对 coll 中的所有元素应用 f. 是. r/mapcat对所有元素应用 f 并连接结果. 是. r/filter从 coll 中返回谓词为真的元素. 是. r/remove从 coll 中移除谓词为真的元素. 是. r/flatten消除集合嵌套. 是. r/cat技术上不是一个 reducer, 而是一个组合函数. 它产生一个可折叠的. 是. r/take-while当谓词为真时停止归约. 否. r/take在消耗 n 个值后停止归约. 否. r/drop从 coll 中移除前 n 个元素. 否. 该表告诉我们, 除了
r/take-while,r/take和r/drop之外, 所有其他标准 reducer 都是可折叠的. 实际效果是, 如果你使用任何一个不可折叠的 reducer, 你可能会在fold期间阻止并行性. 有关如何在并行上下文中也启用不可折叠的 reducer 的信息, 请参阅示例后的标注部分.- 约定
- 输入
"coll"是seq支持的任何集合, 不包括瞬态和已弃用的结构体."xf"是一个接受 1 个参数并返回一个接受 2 个参数的函数的函数. "x" 代表" 转换" , 而 "r" 代表" 归约" .reducer在reduce调用的上下文中调用"xf", 传递原始的 reducing 函数."xf"返回一个根据reduce约定接受 2 个参数的函数.reducer将原始的 reducing 函数替换为"xf"返回的新 reducing 函数.
- 输出
reducer返回增强了由"xf"参数指定的额外行为的"coll", 这些行为将在reduce调用的上下文中应用.folder应用与reducer相同的更改, 但也包括在fold操作的上下文中增强输入集合.folder只拦截"reducef"的行为, 不拦截"combinef"(请参见fold约定).
- 输入
- 示例
dedupe是标准库中的一个函数, 用于移除集合中连续出现的相同项. 我们想创建一个reducer-dedupe版本, 它能与clojure.core.reducers命名空间中的其他转换函数很好地协同工作. 为此, 我们将使用reducer来包装给定的集合, 并为其添加一些额外的行为:(require '[clojure.core.reducers :as r]) (defn reducer-dedupe [coll] (r/reducer coll ; ❶ (fn [rf] (let [prev (volatile! ::none)] ; ❷ (fn [acc el] (let [v @prev] (vreset! prev el) (if (= v el) ; ❸ acc (rf acc el)))))))) (->> (range 10) ; ❹ (r/map range) (r/mapcat conj) (r/filter odd?) reducer-dedupe (into [])) ;; [1 3 1 3 1 3 5 1 3 5 1 3 5 7 1 3 5 7]
❶
reducer包装了传入的集合, 并通过传递一个单参数函数"rf"(原始的 reducing 函数, 例如into使用的conj) 来指示应如何改变归约过程.❷ 我们的
reducer-dedupe需要在每次调用 reducing 函数时记住前一个元素. 我们需要存储状态, 并且由于状态是包装归约的函数的局部变量, 我们可以使用volatile!(一个 atom 也可以, 但在并发上下文中会引入额外的线程隔离复杂性).❸ 链中的每个 reducer, 包括
reducer-dedupe, 都会决定如何处理接下来的转换. 在reducer-dedupe的情况下, 只有当当前元素不是重复的时, 才会发生下一个转换.❹ 我们现在可以像使用其他 reducer 函数一样使用
reducer-dedupe.在前面的例子中,
reducer被用来增强输入集合.reducer不提供fold实现, 因此当向量或 map 作为fold操作的输入时, 我们的reducer-dedupe会阻止并行性 (没有任何警告):(->> (range 1500) (into []) (r/map #(do (println ; ❶ (str (Thread/currentThread))) %)) (r/map range) (r/mapcat conj) (r/filter odd?) reducer-dedupe (r/fold +)) ;; Thread[main,5,main] ; ❷ ;; Thread[main,5,main] ;; .... ;; 280338192
❶
r/map函数为集合中的每个元素打印线程签名, 从而显示归约发生在哪个线程上.❷ 屏幕上的打印来自主线程, 证实了
reducer-dedupe正在阻止并行折叠.在尝试实现一个并行的
reducer-dedupe之前, 读者必须意识到, 并非所有的 reducer 都适合直接的并行化. 在设计并行 reducer (或 transducer, 因为它们基于相同的设计) 时, 有几个原因需要考虑:- 关联性. reducer 的顺序语义在并行上下文中可能不直接适用. 例如, 从一个集合中删除 10 个项与从集合头部删除 5 个元素和从尾部删除 5 个元素是不同的. 可以定义替代的语义, 例如决定从每个块中删除 "n" 个元素, 但这导致与顺序执行的相同操作的结果截然不同. 类似的考虑也适用于
r/take或r/take-while. - 线程安全的状态化 reducer. 当并行运行时, reducer 内部的状态需要是线程感知的. 当 reducer 作为并行
fold指令的一部分运行时, 状态会受到多个 fork-join 线程的并发访问.
我们的
reducer-dedupereducer 在没有专门为并发访问设计的情况下不适合并行化. 尽管没有警告,fold会拒绝启用并行性, 除非所有涉及的 reducer 都是并行启用的. 相同的行为不会在 transducer 中重复 (它们基于不同的实现技术, 不涉及类型扩展), 因此r/fold会允许有状态的 transducer 并行折叠, 可能会产生不一致的结果. 有关更多信息, 请参阅下面的扩展示例.注意
像我们示例中实现的
reducer-dedupe这样的 Reducer 也被称为" 有状态的" , 因为它们需要在 reducing 函数的调用之间传播信息 (reducers 命名空间已经包含了r/take和r/drop有状态的 reducer). 有状态的 reducer 通常定义一个volatile!类型或一个 atom 的局部变量.- 设计一个并行 reducer
这是一个关于 reducer 和并行性的扩展示例部分. 我们的目标是实现一个
r/drop版本, 当在fold中使用时, 它会传播并行性. 新的pdropreducer (用于 parallel-drop) 被设计为并行地从每个块中移除相同数量的项. 这种行为与标准库中的drop的定义截然不同: 结果根据块大小而不同, 而不仅仅是输入集合 (块越多, 相同数量的 "n" 元素被移除的次数就越多). 在决定这是一个理想的行为之后, 下图显示了并行drop将如何工作:
Figure 13: 从每个块中并行删除元素.
图中的深色方块是要从每个分区集合的头部移除的目标. 我们可以用以下代码顺序实现相同的行为:
(->> (vec (range 1600)) ; ❶ (partition 200) (mapcat #(drop 10 %)) (reduce +)) ;; 1222840
❶ 一个包含 1600 个数字的集合被分割成 8 个分区, 每个分区包含 200 个项. 标准
drop用于移除每个分区的前 10 个项. 这些数字最终被加在一起.我们的第一次尝试很自然地遵循了使用
folder而不是reducer来包装drop操作的想法. 这立即启用了并行性, 但却带来了令人惊讶的结果:(require '[clojure.core.reducers :as r]) (import 'java.util.concurrent.atomic.AtomicInteger) (set! *warn-on-reflection* true) (defn pdrop ; ❶ [n coll] (r/folder coll (fn [rf] (let [nv (volatile! n)] (fn ([result input] (let [n @nv] (vswap! nv dec) (if (pos? n) result (rf result input))))))))) (distinct ; ❷ (for [i (range 1000)] (->> (vec (range 1600)) (pdrop 10) (r/fold 200 + +)))) ;; (1279155 1271155 1277571 ...)
❶
pdrop是一个使用r/folder来定义特定可折叠行为的自定义 reducer. 当执行时,pdrop不会为前 "n" 个元素传播归约, 从而在最终结果中有效地忽略它们.❷ 我们现在尝试在一个定义了 200 个块大小的 1600 个数字上进行折叠. 为了显示不一致性, 一个
for循环重复了相同的操作 1000 次. 正如我们所看到的, 结果不仅与预期的 1222840 不同, 而且是随机变化的.启用了并行的
pdrop返回了不一致的结果. 其原因在于volatile!如何在 reducing 函数上闭包. 每个 fork-join 任务都是围绕标准的reduce创建的, 后者又使用了我们增强的 reducing 函数. 问题在于每个reduce任务都看到了相同的volatile"nv", 并且每个任务都可能在单独的线程上运行. 根据哪个线程何时读取 "nv", 我们会删除比预期更少或更多的项. 即使假设我们可以在每个线程上使用隔离的计数器, 工作窃取也可能将一个块迁移到另一个具有不同计数器条件的线程.一个解决方案是在每次
reduce调用时初始化状态, 而不是在 reducer 创建时. 为此, 我们需要创建我们自己的折叠算法 (一个与标准库中找到的非常相似的版本) 和一个修订版的pdrop, 它将状态的创建延迟到 fork-join 任务内部的执行点. 当前r/foldvecreduce-combine 算法唯一需要做的更改是在使用之前" 解包" 围绕"reducef"创建的附加函数:(defn stateful-foldvec [v n combinef reducef] (cond (empty? v) (combinef) (<= (count v) n) (reduce (reducef) (combinef) v) ; ❶ :else (let [split (quot (count v) 2) v1 (subvec v 0 split) v2 (subvec v split (count v)) fc (fn [child] #(stateful-foldvec child n combinef reducef))] (#'r/fjinvoke #(let [f1 (fc v1) t2 (#'r/fjtask (fc v2))] (#'r/fjfork t2) (combinef (f1) (#'r/fjjoin t2))))))) (defn pdrop [dropn coll] (reify ; ❷ r/CollFold (coll-fold [this n combinef reducef] (stateful-foldvec coll n combinef (fn [] ; ❸ (let [nv (volatile! dropn)] (fn [result input] (let [n @nv] (vswap! nv dec) (if (pos? n) result (reducef result input)))))))))) (distinct ; ❹ (for [i (range 1000)] (->> (vec (range 1600)) (pdrop 10) (r/fold 200 + +)))) ;; (1222840)
❶
stateful-foldvec是从 reducers 命名空间内的私有函数foldvec复制而来的. 只有一个小小的变化, 即在对一个块调用reduce时,"reducef"被圆括号包装以初始化 reducing 函数并移除附加的包装函数.❷
pdrop实现了自己的reify用于CollFold协议.prdop指示fold调用新的stateful-foldvec. reducing 函数的转换发生在将最后一个参数传递给stateful-foldvec时.❸ reducing 函数被包装在一个" thunk" 中 (一个没有参数的 lambda, 唯一的目标是延迟求值). thunk 在执行时被
stateful-foldvec解包.❹ 我们现在可以看到预期的单个结果.
上面揭示的有状态 reducer 并行化的思想, 可以通过以类似的方式包装状态初始化来扩展到 transducer. 从 reducers 中也需要改变标准的
r/foldvec函数, 但我们不需要在新的 transducer 实现中包含它:(defn drop-xform [n] (fn [rf] (fn [] ; ❶ (let [nv (volatile! n)] (fn ([] (rf)) ([result] (rf result)) ([result input] (let [n @nv] (vswap! nv dec) (if (pos? n) result (rf result input))))))))) (defn stateful-folder [coll] ; ❷ (reify r/CollFold (coll-fold [this n combinef reducef] (stateful-foldvec coll n combinef reducef)))) (distinct ; ❸ (for [i (range 1000)] (r/fold 200 + ((drop 10) +) (vec (range 1600))))) ;; (1279155 1271155 1267155 1275155 1275145 ... ) (distinct ; ❹ (for [i (range 1000)] (r/fold 200 + ((drop-xform 10) +) (stateful-folder (vec (range 1600)))))) ;; (1222840)
❶ 新版本的
drop变换器与标准库中的版本相同, 只是在状态初始化之前引入了一层间接性. 这只是一个没有参数的 lambda 函数, 它阻止了volatile!实例的求值.❷ 为了防止
r/fold使用标准向量的并行化, 我们用一个reify调用来包装向量实例, 该调用将基础实现替换为我们新的stateful-foldvec.❸ 我们想比较在没有任何修改的情况下使用
drop变换器和我们版本之间的差异. 如你所见, 在并行上下文中使用的drop变换器显示了多个不一致的结果.❹ 相比之下, 启用了并行的
drop-xform一致地显示了预期的结果.
- 关联性. reducer 的顺序语义在并行上下文中可能不直接适用. 例如, 从一个集合中删除 10 个项与从集合头部删除 5 个元素和从尾部删除 5 个元素是不同的. 可以定义替代的语义, 例如决定从每个块中删除 "n" 个元素, 但这导致与顺序执行的相同操作的结果截然不同. 类似的考虑也适用于
- 另请参阅
reify是reducer和folder使用的主要机制. 如果你需要对clojure.core.protocols/CollReduce或clojure.core.reducers/CollFold协议的实现进行额外的控制, 请在目标集合上使用reify. - 性能考虑和实现细节
=> O(1) 常数时间
reducer和folder是在reify的基础上实现的. 这是对输入集合的一次性转换, 它不随输入大小而改变, 因此是常数时间.正如本章所讨论的,
reducer和folder产生类似的结果, 另外folder还提供了对fold操作的增强.r/take-while,r/take和r/drop不使用folder, 因此在某些条件下会阻止并行性, 例如:(time (->> (range 50000) (into []) (r/map range) (r/mapcat conj) (r/drop 0) ; ❶ (r/filter odd?) (r/fold +))) ;; "Elapsed time: 45516.963356 msecs" ;; 10416041675000 (time (->> (range 50000) (into []) (r/map range) (r/mapcat conj) (r/filter odd?) (r/fold +))) ;; "Elapsed time: 9190.562896 msecs" ; ❷ ;; 10416041675000
❶ 在这个 reducer 链中使用了
r/drop, 实际上没有删除任何元素, 只是为了显示对计算的影响. 经过的时间约为 45 秒.❷ 相同的操作 (除了
r/drop) 现在并行执行, 大大减少了执行时间, 不到 10 秒.使用
r/take-while,r/take,r/drop或任何使用reducer来reify输入集合的自定义 reducer 的fold操作, 看起来会正常工作, 但读者应该意识到在这种情况下没有并行性.
- 约定
- 7.1.3 monoid
自 1.5 版本以来的函数
(monoid [op ctor])
monoid是clojure.core.reducers命名空间中的一个高阶函数. 它包装一个两个参数的函数, 以便它在没有参数调用时也能提供一个结果. 这种情况在fold上下文中是 reducing 函数的初始值的典型情况:(require '[clojure.core.reducers :as r]) ; ❶ (r/fold (r/monoid str (constantly "Concatenate ")) ; ❷ ["th" "is " "str" "ing"]) ;; "Concatenate this string"
❶ 我们需要
requirereducers 命名空间.❷ 这里使用
monoid作为r/fold的 reducing 函数. 与普通的reduce不同, 如果没有提供初始值,r/fold会调用 reducing 函数的零参数元数.普通的
reduce有一个额外的参数来传递归约的初始值. 另一方面,fold不提供这个选项 (已经有很多参数了). 如果fold的 reducing 函数不提供零参数调用,monoid提供了一个快速修复问题的方法, 无需使用匿名函数.- 约定
- 输入
"op"必须是接受两个参数的函数, 并且是必需参数."ctor"必须是接受零参数调用的函数, 并且是必需参数.
- 值得注意的异常
当
"ctor"作为值 (例如, 数字或空向量) 而不是无参数函数给出时, 通常会看到ArityException或ClassCastException:(r/fold (r/monoid + 0) (range 10)) ;; ClassCastException java.lang.Long cannot be cast to clojure.lang.IFn
为了防止这种情况发生, 记住要用像
constantly这样的东西来包装常量值. - 输出
返回一个接受零个或两个参数的函数, 该函数有两个元数. 当没有参数调用时, 它返回调用
(ctor)的结果. 当存在两个参数时, 它们按顺序传递给"op". 这等价于(op a b), 如果 "a" 和 "b" 是参数.
- 输入
- 示例
monoid主要用于构建fold的"reducef"或"combinef"参数. 例如, 在处理哈希映射时,fold经常需要一个空的哈希映射作为起点:(r/fold (r/monoid merge (constantly {})) ; ❶ (fn [m k v] (assoc m k (str v))) (zipmap (range 10) (range 10))) ;; {0 "0", 7 "7", 1 "1", 4 "4", 6 "6", 3 "3", 2 "2", 9 "9", 5 "5", 8 "8"}
❶ 这里使用
monoid来创建一个用merge组合部分结果的函数.fold在每个块上执行的每个 reduce 操作都将使用monoid提供的零参数元数 (空 map).还请查看
fold以获取另一个使用monoid计算某些长文本的单词频率的示例.- Monoid: 名字是怎么回事?
Monoid 是代数中一个众所周知的概念 124. 它们描述了一个集合在存在一个二元关联操作和一个单位元的情况下的属性. 自然数与
"+"和作为单位元的"0"是一个 monoid. 为了证明这一点, 我们应该证明 monoid 的规则成立:- 单位元: 集合中存在一个唯一的元素, 当它用于二元运算符时, 它返回另一个参数不变.
- 关联性: 二元运算应用于不同子集时与顺序无关.
让我们验证一下自然数与
"+"(二元运算符) 和"0"(单位元) 确实是一个 monoid:(+ 99 0) ; ❶ ;; 99 (= (+ (+ 1 2) 3) ; ❷ (+ 1 (+ 2 3))) ;; true
❶ 当使用单位元 "0" 时, 另一个参数返回时没有变化. 这是用一个随机数测试的, 但根据零加法的定义, 它对所有其他自然数都成立.
❷ 这里我们有一个由 "1,2,3" 组成的自然数的子集. 将 "+" 应用于 "1,2" 和 "3" 与先应用于 "2,3" 再应用于 "1" 是相同的.
r/monoid的命名考虑了其应用上下文.fold中 reducing 函数的零参数元数提供了一种用初始元素引导reduce的方法. 初始值可以选择性地作为 reducing 函数的单位元 (如"+"的 "0"), 从而为第一个元素提供一个恒等变换.r/monoid的名称提醒标准库的用户,fold中的二元操作应该是关联的 (特别是当 reducing 函数也用作连接时), 因为它可能是并行的, 并以任何顺序执行.
- Monoid: 名字是怎么回事?
- 另请参阅
completing与monoid有类似的目标.completing与自定义变换器一起使用, 以向 reducing 函数提供额外的元数. 变换器中的单个元数调用用于表示归约的结束.completing提供了一种在主 reducing 函数周围创建所有必需元数的快速方法.fold, 正如本章所解释的, 是monoid创建组合函数的主要用例. - 性能考虑和实现细节
=> O(1) 常数时间
monoid的实现非常简单, 它只是在一个新函数中调用其参数. 没有特别的性能考虑.
- 约定
- 7.1.4 foldcat, cat 和 append!
自 1.5 版本以来的函数
(foldcat [coll]) (cat ([]) ([ctor]) ([left right])) (append! [acc el])
r/foldcat,r/cat和r/append!是clojure.core.reducers命名空间中的相关函数 (请注意, 这里的cat与clojure.core/cat(变换器) 不同, 因此它以 reducers 命名空间的缩写为前缀). 它们可以独立使用, 但它们的设计考虑了一个特定的优化: 避免频繁更新临时的持久化数据结构.不可变的持久化向量或 map 通常由像
conj或assoc这样的函数创建.fold操作期间的每个块都可能产生一个这样的持久化数据结构. 一旦产生, 相同的数据结构会被组合, 再次产生在fold操作返回后永远不会被消费的临时对象 (有关更多信息, 请参见fold中 combine-reduce 模型的图表).为了解决这个问题,
r/append!允许增量构建可变数据结构, 而r/cat将它们附加到树上. 这两种效果的协调是通过r/foldcat实现的, 它只是使用r/cat作为"combinef"和r/append!作为"reducef":(require '[clojure.core.reducers :as r]) (def input (r/map inc (into [] (range 1000)))) (take 5 (r/fold r/cat r/append! input)) ; ❶ ;; (1 2 3 4 5) (take 5 (r/foldcat input)) ; ❷ ;; (1 2 3 4 5)
❶ 这个例子显示了如何用
fold显式地使用r/cat和r/append!.❷ 第二个例子与第一个等效, 显示了使用
r/foldcat来达到相同的结果.r/foldcat返回由fold产生的块的根, 作为一个由Cat对象 (注意大写的 "c" 表示类名而不是函数) 组成的网络.Cat节点是" 计数的" (它们支持clojure.lang.Counted接口, 并且可以在常数时间内计数), 可归约的和可折叠的, 因此它们可以有效地用作reduce或fold的进一步输入.- 约定
- 输入
- r/foldcat
"coll"遵循fold的约定.
- r/cat
- 无参数时, 它产生一个空的
java.util.ArrayList实例. 当r/cat用作fold操作的"combinef"参数时, 空的ArrayList用作"reducef"reducing 函数的初始元素. "ctor"覆盖了空参数调用的选择."ctor"必须是无参数的函数."left"和"right"可以是支持count的任何类型, 包括nil. 当r/cat用作fold中的"combinef"时, 它们可以是 reducing 函数的结果 (叶子), 或者是另一个r/cat操作的结果 (节点).
- 无参数时, 它产生一个空的
- r/append!
"acc"可以是java.util.Collection的任何子类型. Java 方法.add在内部被r/append!使用. 当用作 reducing 函数时,"acc"代表累加器."el"可以是任何类型.r/append!调用.add, 使用"el"作为要添加到累加器的元素.
- r/foldcat
- 输出
r/foldcat的行为与fold类似, 但结果的类型要么是java.util.ArrayList(当输入的大小小于请求的块大小时, 默认为 512), 要么是clojure.core.reducers.Cat对象 (对于更大的集合).Cat类型表示一个具有左右子节点的二叉树的节点.fold处理的块越多, 树就越深.- 无参数的
r/cat返回一个空的ArrayList. 带一个参数时返回一个新函数, 该函数通过调用"ctor"无参数来覆盖无参数行为. 带两个非空参数时, 它返回一个新的clojure.core.reducers.Cat对象, 其count等于"left"和"right"对象计数的总和. r/append!返回在"acc"上调用java.util.Collection/add方法并使用"el"作为参数的结果.
- 输入
- 示例
r/foldcat内部使用r/cat和r/append!来生成结果. 以下示例显示了我们如何使用 reducer 和r/foldcat处理大文本中的单词:(require '[clojure.core.reducers :as r]) (require '[clojure.string :as s]) (def text ; ❶ (-> "https://tinyurl.com/wandpeace" slurp s/split-lines)) (def r-word ; ❷ (comp (r/map #(vector % (count %))) (r/map s/lower-case) (r/remove s/blank?) (r/map #(re-find #"\w+" %)) (r/mapcat #(s/split % #"\s+")))) (def words (r/foldcat (r-word text))) ; ❸ (take 5 words) ;; (["the" 3] ["project" 7] ["gutenberg" 9] ["ebook" 5] ["of" 2])
❶ 我们从古腾堡计划 (一个文学经典的集合) 获取了一本大书" 战争与和平" . 我们需要将文件分割成行来创建
r/foldcat的初始向量.❷
r-word是专用于文本处理和清理的 reducer 的组合. 它们自下而上应用: 行被分割成单词, 非字母字符和空字符串被移除, 单词被转换为小写, 最后为每个单词及其长度形成一个对.❸
r/foldcat接受包装在 reducer 调用中的行集合.如果我们检查前面的结果, 我们可以看到 "words" 不是一个普通的集合 (如果文件少于 512 个单词, 它将是一个 ArrayList):
(type words) ; ❶ ;; clojure.core.reducers.Cat (.count words) ; ❷ ;; 565985 (.left words) ; ❸ ;; #object[clojure.core.reducers.Cat 0x28e8dde3 "clojure.core.reducers.Cat@28e8dde3"] (.right words) ; ❹ ;; #object[clojure.core.reducers.Cat 0x1f6c9cd8 "clojure.core.reducers.Cat@1f6c9cd8"]
❶
r/foldcat返回了一个clojure.core.reducers.Cat的实例, 这是reducers命名空间中的一个deftype定义. 这代表了一个二叉树的根.❷
clojure.core.reducers.Cat对象有 3 个字段:"count","left"和"right"."count"是处理后的单词数量.❸ 当我们调用 Java 方法
"left"时, 我们可以看到左分支下的一个类似对象. 请注意,"left"不是一个 Clojure 函数,Cat对象的内部实现可能会在 Clojure 的未来版本中更改. 不要在生产代码中使用!❹ 类似地, 当我们调用
"right"时, 我们可以遍历根节点的右分支.如果我们一直走到树的叶子, 我们可以找到一个通过在每个块上调用
r/append!创建的java.util.ArrayList实例:(loop [root words cnt 0] (if (< (count root) 512) ; ❶ (str (type root) " " (count root) " elems, depth: " cnt) (recur (.left root) (inc cnt)))) ;; "class java.util.ArrayList 321 elems, depth:8" ; ❷
❶ 512 是
fold操作中一个计算块的默认大小. 当块大小低于该阈值时, 我们知道我们正面对着树中的一个叶子.❷ 在这种情况下, 我们还知道在该叶子上找到的
ArrayList包含 321 个单词.通过了解二叉树的深度, 我们还知道创建的节点的大致数量, 这对应于处理初始行向量所需的工件块数. 二叉树最底层节点的数量是 2
k, 其中 k 是树的最后一层 (从 0 开始计数). 在我们的例子中, 大约创建了 2
8 = 256 个分割.
在查看结果中的单词后, 很容易发现有很多重复项:
(count (distinct (seq words))) ; ❶ ;; 17200
❶ 请注意, 在
r/foldcat返回的Cat树实例上使用了seq.Cat对象支持count, 但不支持nth(以及许多其他序列操作).在 565985 个单词中有 17200 个不同的单词, 这表明返回的大部分单词都是重复的. 我们可以利用
java.util.HashSet的特性来去除重复项.r/cat有一个单参数调用, 允许交换可变数据结构的内部实现, 只要它暴露一个.add方法:(import '[java.util HashSet]) (def words (r/fold (r/cat #(HashSet.)) ; ❶ r/append! (r-word text))) (count words) ; ❷ ;; 185561
❶
r/cat接受一个无参数的函数. 该函数将用于初始化在每个并行块上开始归约时使用的数据结构. 我们可以在这里传递HashSet构造函数.❷ 我们对结果进行计数, 以查看单词现在是否是唯一的.
在尝试计算结果时, 我们看到了一个令人惊讶的数字. 这个数字低于单词的总数, 但远未达到 17200. 原因是, 尽管在连接之前集合包含唯一的元素, 但它们是作为序列连接的, 可能会引入重复项. 为了解决这个问题, 我们可以遍历树, 将各个
HashSet合并回一个集合中, 从而去除重复项:(defn distinct-words [words] (letfn [(walk [root res] ; ❶ (cond (instance? clojure.core.reducers.Cat root) (do (walk (.left root) res) (walk (.right root) res)) (instance? java.util.HashSet root) (doto res (.addAll root)) :else res))] (into #{} (walk words (HashSet.))))) ; ❷ (count (distinct-words words)) ; ❸ ;; 17200
❶
walk是一个递归函数, 它将每个叶子的内容合并到一个新的HashSet实例中. 它为每个左分支和右分支开始新的递归 (当我们在一个Cat节点上时).❷ 该函数封装了合并的可变部分, 仅在最后一步返回一个持久化数据结构.
❸ 不同的单词数量现在与我们使用顺序
distinct找到的数量相同.通过迭代
r/cat产生的树结构, 我们可以继续使用一个可变的数据结构来增量构建结果. 或者,r/cat也是可归约和可折叠的, 这意味着我们可以进一步在结果上使用reduce甚至r/fold, 从而产生另一个并行计算:(reduce + (r/map last words)) ; ❶ ;; 1105590 (defn letter-frequency [words] (let [res (r/fold (r/cat #(StringBuilder.)) ; ❷ #(doto %1 (.append %2)) (r/map first words))] (frequencies res))) ; ❸ (take 5 (sort-by last > (letter-frequency words))) ;; ([\e 144858] [\n 82295] [\i 80318] [\s 78874] [\a 78159])
❶
reduce可以很好地用在r/foldcat的结果或带有r/cat作为组合函数的r/fold的结果上. 这里我们正在对集合中所有单词的长度求和.❷ 在这个
r/fold调用中, 我们正在使用一个自定义的r/cat构造函数和一个自定义的 reducing 函数 (而不是标准的r/append!). 每个块都并行处理以创建一个StringBuilder实例, 这是一种快速连接大量字符串的方法.❸ 结果是使用
clojure.core.reducers.Cat提供的顺序接口来迭代, 以创建一个频率 map. 这个操作和后续的sort-by是在fold操作之外执行的, 因此是顺序的.关于并行块处理在可变数据结构中累积结果的选择应由性能测量来指导. 有许多参数会影响速度, 例如块的大小, 请求的处理量以及产生的输出的最终用途. 这些问题在本章末尾的性能部分得到了更好的解决.
- 另请参阅
fold是r/foldcat,r/cat和r/append!运行的核心引擎.fold中涵盖的细节对于理解本章所涵盖的内容至关重要. 与r/foldcat相比, 使用普通的fold在选择组合和 reducing 函数方面提供了额外的灵活性. 当提供的ArrayList构建块足以覆盖给定的用例时, 使用r/foldcat. 使用带有特定r/cat初始化器的r/fold以对可变数据结构有额外的控制.cat是一个基于reduce的连接变换器.cat的用途比r/cat更通用, 后者与 reducer 和折叠相关联. 如果你的目标是展平嵌套集合, 请使用cat.concat用于顺序地连接r/fold产生的树.concat比单独的r/cat更通用, 可以用来将集合合并在一起. - 性能考虑和实现细节
=> O(n) (foldcat)
有关
r/foldcat性能特征的一般讨论, 请阅读fold性能部分.r/foldcat是r/fold的一个应用, 它不改变其性能配置文件.r/cat或r/append!在隔离中的使用是常数时间.在性能方面,
r/foldcat与普通r/fold相比, 最有趣的方面是与使用可变数据结构相关的速度提升:(require '[criterium.core :refer [quick-bench]]) (quick-bench (doall (r/foldcat (r-word text)))) ; ❶ ;; Execution time mean : 166.526116 ms (quick-bench (doall (r/fold concat conj (r-word text)))) ; ❷ ;; Execution time mean : 659.501099 ms
❶ 有关
r-wordreducer 和text初始行集合的定义, 请参阅本章开头.❷ 基于标准
conj的类似计算显示了计算时间的显著增加.如果你正在解决的问题包括一个大的输入数据集, 非平凡的处理步骤并且仍然产生一个集合, 那么
r/foldcat很可能会优于普通的r/fold. 此外, 如果r/foldcat的输出需要额外的处理, 它可以再次使用额外的fold操作并行处理.
- 约定
2.6.2. 7.2 Transducers
Transducer 是最近引入的 Clojure 特性, 它对许多标准库函数产生了影响, 包括引入了像 transduce, eduction, completing 或 cat 这样的新的专用函数. Transducer 对现有函数的影响通常包括增加一个新的元数, 该元数返回一个特定的 transducer 类型. 以下是标准库中目前可用的所有启用 transducer 的函数的摘要以及它们在这种上下文中的用途的简要描述. 它们将在本章后面更详细地说明:
transduce: 将一个 reducing 函数和相关的 transducer 链应用于一个集合.completing: 用所需的调用来完成一个二元函数, 以便它可以作为一个 transducer 被调用.eduction: 将一个 transducer 链应用于一个集合, 产生一个转换后元素的惰性序列.sequence: 类似于eduction, 但如果序列被多次迭代, 则有额外的缓存.into: 将元素从一个集合类型复制到另一个, 可选地用一个 transducer 链来转换它们.cat: 是标准库中的一个 transducer. 它将每个 (集合) 项输入连接到一个集合输出中.
所有以下集合处理函数, 当没有它们的集合参数调用时, 都返回一个 transducer:
map: 返回一个对每个元素应用转换的 transducer.map-indexed: 像map一样, 但产生的 transducer 还包括每个项的索引.mapcat: 返回一个将每个项的转换连接到最终结果的 transducer.filter: 返回一个根据谓词来决定是否应用 reducing 函数的 transducer.remove: 类似于filter, 但反转谓词的含义.take: 产生一个在给定数量的元素后终止归约的 transducer.take-while: 产生一个当谓词返回true时终止归约的 transducer.take-nth: 产生一个收集集合中每个" 第 n 个" 元素的 transducer.drop: 产生一个不对前 "n" 个元素调用归约的 transducer.drop-while: 产生一个直到谓词返回true才调用归约的 transducer.replace: 产生一个根据给定的替换 map 替换输入集合中每个元素的 transducer.partition-by: 产生一个每次给定函数应用于每个元素时返回不同值时就分割输入集合的 transducer.partition-all: 像partition-by一样, 但允许分区在末尾有少于请求的元素数量.keep: 产生一个转换每个元素并保留那些在转换后不为nil的元素的 transducer.keep-indexed: 像keep一样, 但产生的 transducer 还包括每个项的索引.distinct: 产生一个从前一个 transducer 的输出中移除所有重复项的 transducer.interpose: 产生一个将输入项与给定的分隔符交替的 transducer.dedupe: 像distinct一样, 但产生的 transducer 只移除连续的重复项, 如果有东西将它们分开, 则允许重复.random-sample: 产生一个根据给定的概率值让每个项通过的 transducer.
- 7.2.1 transduce
自 1.7 版本以来的函数
(transduce ([xform f coll]) ([xform f init coll]))
transduce是进入 transducer 抽象的主要入口点之一. 它的工作方式类似于reduce, 但它还接受一个转换 reducing 函数 (所谓的 transducer) 的组合作为参数"xform". 以下示例显示了用reduce和transduce执行的相同操作, 以查看它们的比较:(reduce + (map inc (filter odd? (range 10)))) ; ❶ ;; 30 (transduce (comp (filter odd?) (map inc)) + (range 10)) ; ❷ ;; 30
❶
reduce用于在递增并只保留奇数后对 10 个数字求和.❷ 相同的操作现在用
transduce执行.与
reduce的相似性是显而易见的和故意的, 因为这两个操作是相同迭代形式的表达. 主要区别在于transduce在参数列表中隔离了转换操作 (如map或filter) 以及其他参数. 这种设计有很多有趣的后果, 例如能够在其他上下文中重用相同的转换链 (例如 core.async 库).- 约定
- 输入
"xform"是一个遵循 transducer 语义的函数, 是一个强制性参数."xform"用 reducing 函数"f"调用, 并应返回另一个支持至少两个元数的函数: 一个单参数调用, 在归约结束时调用, 以及一个用于实际归约的双元数调用. 一个可选的零参数调用目前不被transduce使用, 但将来可能会."f"是一个两个参数的 reducing 函数, 接收到目前为止的结果和"coll"中的下一个项. 它是一个强制性参数."init"是可选的. 当存在时, 它被用作归约过程中的第一个累加器值, 类似于reduce."coll"是reduce支持的任何集合. 不支持瞬态和标量 (如数字, 关键字等). 其他所有都支持, 包括nil, Java Iterable 和数组.
- 值得注意的异常
- 当
"xform"或"f"为nil时, 抛出NullPointerException. - 如果给定的
"xform"不支持某些必需的元数, 可能会发生ArityException. 除非你使用自定义 transducer, 否则你不应该担心这个. 如果你正在使用自定义 transducer, 请检查completing.
- 当
- 输出
返回: 将 reducing 函数以及任何其他转换 reducing 函数应用于
"coll"的结果. 当"coll"为nil时, 返回"init"或调用(f)且没有参数的结果. 在这两种情况下, 结果还取决于链中任何 transducer 的单参数元数. 一个 transducer 实际上可以改变归约的最终结果 (例如, 像partition-all那样, 如果需要, 刷新最后一个部分分区).
- 输入
- 示例
大多数时候
transduce可以替换reduce, 前提是可以将输入的转换 (如果有的话) 重新排列为带有comp的 transducer 链. 以下示例通过展示如何实现埃及乘法算法 125 来说明这一点. 古埃及人不用乘法表来乘数, 而是通过将数按 2 的幂分解来计算乘法:(defn egypt-mult [x y] (->> (map vector ; ❶ (iterate #(quot % 2) x) (iterate #(* % 2) y)) (take-while #(pos? (first %))) (filter #(odd? (first %))) (map second) (reduce +))) ; ❷ (egypt-mult 640 10) ;; 6400
❶ 计算从生成数字对开始, 其中第一个数越来越减半, 而第二个数越来越加倍.
❷ 在第一个零出现时停止后, 我们过滤奇数. 最后一步是使用
reduce来对对中的第二个元素求和.egypt-mult函数是transduce的一个潜在候选者: 它包含一个作为最后一次调用的reduce调用和一些初始输入的处理. 尽管操作的形状很有希望,transduce不支持多个输入集合, 所以在第一次尝试中, 我们需要将初始的对的构建留在transduce之外:(defn egypt-mult [x y] (transduce ; ❶ (comp ; ❷ (take-while #(pos? (first %))) (filter #(odd? (first %))) (map second)) + (map vector ; ❸ (iterate #(quot % 2) x) (iterate #(* % 2) y)))) (egypt-mult 640 10) ;; 6400
❶ 线程宏和最终的
reduce操作已被一个tranduce调用替换.❷
comp将所有预处理步骤组合在一起, 除了初始的对的创建.❸ 数字对序列的创建通过
map进行, 并且不是 transducer 组合的一部分.egypt-mult现在使用一个 transducer 链, 但这是在形成数字对之后发生的. 最好能将所有处理都包含在transduce中, 因为这会创建一个我们希望避免的中间序列. 我们唯一的希望是有一种方法可以用另一种设计来表达对的形成, 以便它可以包含在transduce中. 虽然不能保证存在这样的替代设计, 但在这种情况下, 我们可以用interleave和partition-all来表达对的形成.下一个标注部分显示了如何做到这一点, 包括如果标准库没有提供, 如何创建自定义 transducer.
- 创建一个自定义 transducer
在上一节中, 我们看到了一个涉及埃及乘法法的
transduce示例. 在将该方法转换为使用transduce的版本时, 我们提到该示例仅部分可适应, 因为transduce不允许多个集合作为输入. 然而, 有一种不同的方式来表达相同的算法, 如果我们使用interleave和partition-all, 则完全可以进行 transducer 化:(defn egypt-mult [x y] (->> (interleave ; ❶ (iterate #(quot % 2) x) (iterate #(* % 2) y)) (partition-all 2) (take-while #(pos? (first %))) (filter #(odd? (first %))) (map second) (reduce +))) (egypt-mult 640 10) ;; 6400
❶ 对
egypt-mult的唯一更改是将(map vector)表达式替换为interleave后跟partition-all.新算法与原始算法非常相似, 只是将交错与对创建分离开来. 这使我们能够在一个序列上设计归约, 而另一个是 transducer 链创建的一部分. 不过, 有一个问题: 标准库中没有
interleavetransducer. 我们可以创建我们自己的interleave-xformtransducer, 如下所示:(defn interleave-xform ; ❶ [coll] (fn [rf] (let [fillers (volatile! (seq coll))] ; ❷ (fn ([] (rf)) ([result] (rf result)) ([result input] (if-let [[filler] @fillers] ; ❸ (let [step (rf result input)] (if (reduced? step) ; ❹ step (do (vswap! fillers next) ; ❺ (rf step filler)))) (reduced result))))))) ; ❻
❶
interleave-xform是根据标准库中interleave函数的相同语义建模的: 它将元素交错, 直到最短序列的末尾.interleave-xform包含所有必需的元数: 无参数, 单参数和双参数.❷
interleave-xform假设交错来自创建 transducer 时传递的集合. 另一个是 transducing 集合. 我们需要跟踪序列中剩余的项, 因为我们消耗它们, 所以其余的项存储在一个volatile!实例中.❸ 在归约步骤中, 我们验证至少还有一个元素要交错, 然后才允许归约. 请注意在
volatile实例内容的第一个元素上使用if-let和解构.❹ 像任何好的 transducer " 公民" 一样, 我们需要检查链中的另一个 transducer 是否已请求归约的结束. 在这种情况下, 我们遵守, 而不传播任何进一步的归约步骤.
❺ 相反, 如果我们还没有到归约的末尾, 并且我们有更多要交错的元素, 我们可以继续更新我们的
volatile状态, 并使用来自内部状态的 "filler" 元素调用下一个 transducer. 请注意, 此时, 这是我们第二次调用 "rf": 第一次是正常的归约步骤, 第二次是用于交错的额外归约步骤.❻ 如果我们没有更多要交错的项, 我们用
reduced结束归约. 这防止了nil元素出现在最终输出中, 与正常的interleave完全相同.有了
interleave-xform, 我们可以将埃及乘法表示如下:(defn egypt-mult [x y] (transduce (comp (interleave-xform (iterate #(* % 2) y)) ; ❶ (partition-all 2) (take-while #(pos? (first %))) (filter #(odd? (first %))) (map second)) + (iterate #(quot % 2) x))) ; ❷ (egypt-mult 4 5) ;; 20
❶ 以前在
(map vector)形式中作为第二个迭代出现的递增加倍数字, 现在被视为我们创建 transducer 时传递的交错序列.❷ 另一个递减减半数字的迭代现在是
transduce的正常输入. 这两个序列被交错在一起, 并在 transducing 步骤中被分区为向量.
- 创建一个自定义 transducer
- 另请参阅
reduce是transduce语义的核心抽象.reduce对于所有无法用transduce重构算法的情况仍然是必需的. 还有一些与惰性相关的原因, 阻止了某些算法用transduce实现 (有关这方面与 transducer 的关系, 请参见sequence).fold是 Clojure 中可用的另一个类似reduce的操作, 它启用了并行性 (尽管有一些限制).completing是一个经常与transduce结合使用的实用函数. 它完成了 (正如名称所示) 如果你已经有一个两个参数的转换 reducing 函数, 则完成两个缺失的元数. 这在创建自己的 transducer 时更常见, 因为标准库中的 transducer 已经提供了所有相关的元数. - 性能考虑和实现细节
=> O(n) 与输入集合中项目数量 "n" 成线性关系
transduce是在reduce之上实现的, 因此同样的性能方面也适用.transduce是基于输入长度的线性步骤数, 并且不是惰性的. 内存分配和其他性能方面很大程度上取决于 reducing 函数和 transducer 链, 但它们不依赖于transduce本身.transducer 在性能方面的一个创新特性是, 它们在处理输入之前避免了中间序列的生成. 因此, 在
reduce之前需要额外处理的归约更有可能获得性能提升. 以下基准测试在一个简单的操作上证明了这一点:(require '[criterium.core :refer [quick-bench]]) (let [coll (into [] (range 1000))] ; ❶ (quick-bench (reduce + (filter odd? (map inc coll))))) ;; Execution time mean : 39.507721 µs (let [coll (into [] (range 1000))] ; ❷ (quick-bench (transduce (comp (map inc) (filter odd?)) + coll))) ;; Execution time mean : 16.090126 µs
❶
reduce用于对已递增和过滤的数字集合求和.❷ 相同的操作用
transduce执行, 它允许在迭代集合进行归约的同时进行处理.如果你的算法可以很容易地用 transducer 的组合来重写, 你就不应该犹豫使用
transduce. 本章中的埃及乘法例子应该被认为是临界情况: 它需要一个新的设计和一个自定义的 transducer, 这增加了复杂性, 需要用它带来的性能改进来证明.
- 约定
- 7.2.2 eduction
自 1.7 版本以来的函数
(eduction [& xforms])
eduction接受任意数量的 transducer (有或没有显式的comp组合) 和一个集合, 并将 transducer 链应用于集合中的每个元素:(take 2 (eduction (filter odd?) (map inc) (range))) ; ❶ ;; (2 4)
❶ 请注意, 尽管使用了无限序列,
eduction仍惰性工作并返回所请求的元素.与其他的 transducer 感知函数 (
sequence,transduce或into) 相比,eduction是唯一一个支持多个 transducer 而无需显式comp的函数. 然而, 与sequence不同,eduction为每个顺序操作开始一个全新的循环, 包括再次运行 transducer.eduction是惰性的, 但不严格, 因为它会生成足够多的序列以满足 32 项一组的块中的请求 126.- 约定
- 输入
- 0 个参数: 总是返回空列表.
- 1 个参数: 当只有一个参数时, 这被假定为一个序列集合 (所有
sequence支持的). 在这种情况下, 集合被转换为一个序列并进行迭代, 而不进行转换. 它接受nil作为单个参数. - 2 个或更多个参数: 除了最后一个参数外的所有参数都被认为是 transducer 形式, 而最后一个参数是一个集合.
- 值得注意的异常
- 如果任何
xformtransducer 为nil, 则抛出NullPointerException. - 如果
xform位置的参数不是 transducer, 则抛出IllegalArgumentException.
- 如果任何
- 输出
输出根据
nil的存在和参数数量而变化:- 如果没有参数, 或者传递
nil作为参数, 返回()(空列表). - 如果只有一个参数并且
seq支持该参数, 返回"coll"的序列版本. - 在任何其他情况下, 返回
"coll"的转换后迭代, 如 transducer 组合所指示.
- 如果没有参数, 或者传递
- 输入
- 示例
eduction的结果是一个罕见的惰性序列类集合的例子, 它不缓存其结果. 当 transducer 的组合为输入中的每个项返回一个值时, 不会创建 cons 单元链来包含结果值. 标准的惰性序列会缓存它们的结果, 这样就可以在不重复计算的情况下重复访问同一个项 (从而消除了潜在副作用的重复).当最终目标是归约输出时,
eduction比sequence更快, 归约操作不需要缓存任何结果. 以下示例说明了缓存的效果:(let [input (sequence (map #(do (print ".") %)) (range 10)) ; ❶ odds (filter odd? input) evens (filter even? input)] (if (> (first odds) (first evens)) (println "ok") (println "ko"))) ;; ..........ok ; ❷
❶ 我们使用一个有副作用的
println来观察缓存效果.❷ 请注意输出中打印了 10 个点.
该示例显示, 即使同一个序列需要多次遍历 (在这种情况下, 先过滤奇数, 然后再过滤偶数), 它也只执行一次初始计算 (每个项只打印一次点). 为了达到这个结果,
sequence产生了一个可供后续访问的缓存值链. 现在, 在用eduction替换sequence后, 观察相同的示例:(let [input (eduction (map #(do (print ".") %)) (range 10)) ; ❶ odds (filter odd? input) evens (filter even? input)] (if (> (first odds) (first evens)) (println "ok") (println "ko"))) ;; ....................ok ; ❷
❶ 与前一个示例相比, 我们只将
sequence更改为eduction.❷ 你现在可以数出输出中打印了 20 个点.
上一个例子中
eduction输出了 20 个点, 这表明源序列在每次我们对其调用filter时都需要一次新的计算.这里有一个更有趣的例子. 我们将设计一个
best-product函数, 它对一个大的金融产品集合 (为了本例的目的保持较小) 应用转换. 该函数接受影响 transducer 组合的参数. 但首先, 让我们看一下输入数据:(def data [{:fee-attributes [49 8 13 38 100] :product {:visible true :online true :name "Switcher AA126" :company-id 183 :part-repayment true :min-loan-amount 5000 :max-loan-amount 1175000 :fixed true} :created-at 1504556932728} {:fee-attributes [11 90 79 7992] :product {:visible true :online true :name "Green Professional" :company-id 44 :part-repayment true :min-loan-amount 25000 :max-loan-amount 3000000 :floating true} :created-at 15045569334789} {:fee-attributes [21 12 20 15 92] :product {:visible true :online true :name "Fixed intrinsic" :company-id 44 :part-repayment true :min-loan-amount 50000 :max-loan-amount 1000000 :floating true} :created-at 15045569369839}])
接下来, 我们定义两组 transducer. 第一组
prepare-data以与原始输入略有不同的形式塑造数据, 而filter-data则根据用户参数对其进行过滤. 还存在几个辅助函数以提高可读性:(import 'java.util.Date) (defn- merge-into [k ks] ; ❶ (map (fn [m] (merge (m k) (select-keys m ks))))) (defn- update-at [k f] (map (fn [m] (update m k f)))) (defn- if-key [k] (filter (fn [m] (if k (m k) true)))) (defn if-equal [k v] (filter (fn [m] (if v (= (m k) v) true)))) (defn if-range [k-min k-max v] (filter (fn [m] (if v (<= (m k-min) v (m k-max)) true)))) (def prepare-data ; ❷ (comp (merge-into :product [:fee-attributes :created-at]) (update-at :created-at #(Date. %)))) (defn filter-data [params] ; ❸ (comp (if-key :visible) (if-key (params :rate)) (if-equal :company-id (params :company-id)) (if-key (params :repayment-method)) (if-range :min-loan-amount :max-loan-amount (params :loan-amount)))) (defn xform [params] ; ❹ (comp prepare-data (filter-data params)))
❶
merge-into,if-key,update-at,if-equal和if-range是map或filtertransducer 的小包装器. 通过将它们从comp中提取出来并给它们命名, 我们可以保持 transducer 链的紧凑和表达性.❷
prepare-data是 transducer 的第一个组合. 它包含与转换或重塑输入数据相关的所有内容. 例如, 我们在这里展示了如何将纪元时间转换为java.util.Date对象, 并且我们希望所有键都出现在产品哈希映射中.❸
filter-data包含对输入数据的过滤器组合. 它们中的大多数都基于搜索参数, 但其他 (如" 可见性" ) 则不是. 例如, 我们可以只显示那些可以满足给定贷款金额请求的产品.❹ 到目前为止的所有 transducer 都被组装成一个最终的
xform组合.xform是一个包含准备和过滤阶段的 transducer 组合. 为了返回结果列表, 我们将使用eduction而不是sequence. 这是可能的, 因为计算的归约性质, 从大列表到单个或少数产品. 如果我们必须保留所有转换后的产品以便多次访问它们, 那么sequence将是更好的选择. 这里是如何实现best-product函数:(defn- best-fee [p1 p2] ; ❶ (if (< (peek (:fee-attributes p1)) (peek (:fee-attributes p2))) p1 p2)) (defn best-product [params data best-fn] (reduce best-fn (eduction (xform params) data))) ; ❷ (best-product {:repayment-method :part-repayment :loan-amount 500000} data best-fee) ;; {:name "Fixed intrinsic", ;; :fee-attributes [21 12 20 15 92], ;; :company-id 44, ;; :floating true, ;; :part-repayment true, ;; :online true, ;; :max-loan-amount 1000000, ;; :visible true, ;; :min-loan-amount 50000, ;; :created-at #inst "2446-10-10T12:49:29.839-00:00"}
❶ 有点武断地, 我们决定最好的产品是提供最低最后一个费用属性的那个.
❷
eduction也接受一个已经组合好的 transducer 作为参数. 我们使用请求中的参数来准备一个不同的 transducer 配置. 你可以看到eduction的输出是封闭的reduce操作的输入.eduction缺乏缓存通常在归约上下文中提供比sequence更好的性能. 它还提供了保存一个等效于" 延迟的 reduce 配方" 的选项, 该配方可以在稍后的某个时间点使用. 参考前面的例子, 我们可以为最流行的输入参数定义几个eduction:(def best-part-repayment ; ❶ (eduction (xform {:repayment-method :part-repayment}) data)) (def best-fixed ; ❷ (eduction (xform {:rate :fixed}) data)) (:name (reduce best-fee best-part-repayment)) ; ❸ ;; "Fixed intrinsic" (:name (reduce best-fee best-fixed)) ;; "Switcher AA126"
❶
best-part-repayment代表了检索哪个产品具有允许" 部分还款" 作为还款方法的最低费用的计算和必要的数据. 计算被定义, 但尚未运行. 这类似于一个延迟的 reduce 操作.❷ 我们还定义了另一个归约
best-fixed, 它检索最便宜的固定利率产品.❸ 通过使用
reduce, 我们强制执行eduction并检索一个结果.在前面的示例中定义的
eduction是在编译时创建的, 并在应用程序的整个生命周期内重用, 从而进一步提高了性能. - 另请参阅
sequence是eduction的近亲 (在 transducer 的上下文中). 当你计划多次使用产生的输出时, 例如将其赋给一个局部绑定, 使用sequence. 当没有计划对输出集合进行多次扫描时, 使用eduction, 从而节省不必要的缓存. 有关一些附加信息, 也请参见性能部分.transduce允许创建一个转换的 reducing 函数, 使用 transducer 组合来驱动对每个项的计算. 当不需要延迟计算, 或利用某种形式的并行性使用fold时, 优先使用transduce. - 性能考虑和实现细节
=> O(n) 与输入集合中项目数量 "n" 成线性关系
eduction的性能是线性的, 它遍历这些项以执行 transducer 链所指定的转换.eduction是惰性的, 只消耗上游请求的足够多的项.eduction中的惰性是分块的: 新的项以 32 个元素为一组的块来处理. 一旦到达第 32 个元素, 就会处理到第 64 个的所有其他元素, 依此类推.正如本章多次解释的那样,
eduction不缓存结果. 为了理解缓存的含义, 我们可以使用一个特殊的有副作用的计数 transducer, 这样我们就可以看到 transducer 被调用了多少次:(def cnt1 (atom 0)) (let [res (eduction (map #(do (swap! cnt1 inc) %)) (range 10))] (conj (rest res) (first res)) ; ❶ @cnt1) ;; 20 (def cnt2 (atom 0)) (let [res (sequence (map #(do (swap! cnt2 inc) %)) (range 10))] (conj (rest res) (first res)) ; ❷ @cnt2) ;; 10
❶
first和rest的作用是强制eduction重新执行, 至少达到满足请求所需的块大小. 尽管输入集合只包含 10 个元素, 但似乎我们迭代了它们两次, 如 "@cnt1" 计数器所打印的那样.❷ 我们现在对一个序列重复相同的操作, 该序列通过不再次执行计算来显示缓存行为. 计数器 "@cnt2" 正确地只显示了 10 次求值.
eduction的方法在内存分配方面有好处, 但代价是可能重新求值. 由于结果不被缓存, 也没有" 持有头部" 的问题:(defn busy-mem [] (str (/ (- (.. Runtime getRuntime totalMemory) (.. Runtime getRuntime freeMemory)) 1024. 1024.) " Mb")) (System/gc) (busy-mem) ; ❶ ;; 5.574 Mb (def s1 (eduction (map inc) (range 1e7))) (last s1) (System/gc) (busy-mem) ; ❷ ;; 7.615 Mb (def s2 (sequence (map inc) (range 1e7))) (last s2) (System/gc) (busy-mem) ; ❸ ;; 304.5126 Mb
❶ 我们用 -Xmx512M 选项启动一个新的 REPL, 以分配最大 512MB 的堆大小. 刚启动后, 我们请求 JVM 进行垃圾回收, 并测量当前使用的堆大小, 大约是 5Mb.
❷ 我们现在对 1000 万个元素执行一次
eduction遍历, 只取最后一个. 这将处理整个序列, 将迭代器从第一个项移动到最后一个. 我们通过存储序列的头部 "s1" 来保持eduction的活动, 但到我们调用垃圾回收器并再次测量内存时, 我们可以看到堆大小只增加了几兆字节.❸ 如果我们尝试用
sequence代替, 我们可以看到即使在调用垃圾回收器后, 内存仍然被分配.sequence缓存所有元素, 通过持有头部 "s2", 所有项都保留在内存中.eduction的实现方式是在每次调用eduction时构建一个java.lang.Iterable对象. 任何需要访问序列的操作都将收到一个全新的java.lang.Iterator, 支持典型的hasNext()后跟next()语义. 迭代器只能向前移动, 一旦它移过一个项, 该项就有资格进行垃圾回收. 与普通序列不同, 序列的头部不会通过缓存来保持序列的其余部分活动. 在前面的例子中,"s1"指向eduction的第一个块, 而其他所有东西都已经有资格进行垃圾回收了.
- 约定
- 7.2.3 completing
自 1.7 版本以来的函数
(completing ([f]) ([f cf]))
completing提供 (或替换) reducing 函数中的单参数调用. 这在使用transduce时很有用:(transduce (map inc) - 0 (range 10)) ; ❶ ;; 55 (transduce (map inc) (completing -) 0 (range 10)) ; ❷ ;; -55
❶
transduce在归约的最后一步用归约的结果调用减法-. 用单个参数的减法(- -55)对已经为负的输出取负, 结果是明显错误的结果.❷
completing在减法的单参数上包装了identity作为默认值, 这使得结果保持不变.在使用带有
transduce的 reducing 函数时, 可能会出现三个与单参数调用相关的问题:- reducing 函数的单参数版本产生了不希望的更改. 这是我们在前面例子中看到的情况.
- reducing 函数的单参数版本不存在. 在这种情况下, 我们希望提供一个以避免异常.
- 我们想为
transduce提供一个特定的收尾行为, 这样当归约完成时, 我们仍然可以控制最后一步.
根据上述场景列表,
completing是一个方便的函数, 它可以为transduce完成或修复 reducing 函数.- 约定
- 示例
以下示例说明了当用
transduce调用时, 调用如何通过一个 transducer 链流动.identity-xform是一个自定义的 transducer, 它的工作方式类似于identity函数, 并在一个动态变量设置为true时有额外的打印. 通过启用跟踪来执行 transducer, 我们可以跟踪屏幕上的调用:(def ^:dynamic *debug* false) (defn- print-if [s] ; ❶ (when *debug* (print (str s " ")))) (defn- identity-xform ; ❷ ([] (fn [rf] (fn ([] (print-if "#0") (rf)) ([acc] (print-if "#1") (rf acc)) ([acc item] (print-if "#2") (rf acc item))))) ([x] x)) (defn- completing-debug [f] ; ❸ (completing f #(do (print-if "#done!") %))) (binding [*debug* true] ; ❹ (transduce (comp (map inc) (identity-xform)) (completing-debug +) [1 2 3])) ;; #2 #2 #2 #1 #done! 9
❶
print-if根据动态变量*debug*有条件地打印到标准输出.❷
identity-xform自定义 transducer 为每个提供的元数打印不同的消息. 它不会以任何其他方式触及结果. 我们需要这个自定义 transducer 来查看在归约结束时调用单参数调用时会发生什么.❸ 类似地,
completing-debug包装completing以在屏幕上打印消息. 我们想验证由completing生成的函数何时被调用.❹ 我们在调用
transduce时将所有东西组合在一起.*debug*设置为true以便我们可以看到相关的消息在屏幕上. transducing 链对每个项进行递增, 然后将它们传递给identity-xform自定义 transducer.从示例的结果中我们可以看到, 在对输入集合中的每个元素调用了双参数调用之后, 每个 transducer 的单参数元数被调用 (我们只看到来自
identity-xform的消息, 但maptransducer 的单参数元数在那之前被调用). 最后一步由complteing-debug执行, 它在返回结果之前打印 "#done!" 消息.请注意, 0 元数调用目前不被任何 transducing 上下文使用, 但将来可能会. 尽管 transducer 尚未使用它, 其他上下文可能正在使用它, 例如
fold: 可以用fold使用一个无状态的 transducer, 但 reducing 函数在没有参数调用时需要提供一个初始化值. 例如,(map inc)用+生成 0, 从而启用fold的使用:(r/fold ((map inc) +) (range 10)).注意到 reducing 函数的 1 元数版本是最后被调用的, 我们可以创建一个基于
completing来计算数字平均值的函数. 以下是在filter中找到的相同示例, 但重写以利用 transducer:(def events ; ❶ (apply concat (repeat [{:device "AX31F" :owner "heathrow" :date "2016-11-19T14:14:35.360Z" :payload {:temperature 62.0 :wind-speed 22 :solar-radiation 470.2 :humidity 38 :rain-accumulation 2}} {:device "AX31F" :owner "heathrow" :date "2016-11-19T14:15:38.360Z" :payload {:wind-speed 17 :solar-radiation 200.2 :humidity 46 :rain-accumulation 12}} {:device "AX31F" :owner "heathrow" :date "2016-11-19T14:16:35.360Z" :payload {:temperature 63.0 :wind-speed 18 :humidity 38 :rain-accumulation 2}}]))) (defn average [k n] ; ❷ (transduce (comp (map (comp k :payload)) (remove nil?) (take n)) (completing + #(/ % n)) events)) (average :temperature 10) ;; 62.5 (average :solar-radiation 60) ;; 335.2000000000004
❶
events是一个模拟来自连接到中央服务器的气象传感器的无限系列读数的. 我们只是将相同的 3 个事件连接起来以生成一个无限流.❷
average包含一个对transduce的调用, 并处理两个参数以改变返回的数据. 在选择要读取的特定传感器后, 我们移除可能为空的结果, 并取所需的信息量.completing向+添加了最后一步, 计算平均值.- 对 completing 的需求
completing的存在主要是因为一些与标准reduce一起正常工作的函数, 在与transduce一起使用时可能会返回不同的结果. 这种行为的根本原因是有状态的 transducer. 一些有状态的 transducer 会存储部分结果, 然后等待一个信号, 表明归约已经到达终点 (例如, 请参见partition-all).没有东西可以指示集合中的最后一个项何时通过 transducer 链. 除此之外, 任何 transducer 都可以使用
reduced来请求归约的结束. 出于这些原因,transduce被设计为通过使用 transducer 链顶部的函数的单参数调用来表示归约的结束. 以下示例显示了transduce调用内部发生的步骤:(def xform ; ❶ (comp (map inc) (partition-all 3) cat)) (def xform-reductor ; ❷ (xform (completing + #(do (print "#done! ") %)))) (xform-reductor 0 0) ; ❸ ;; 0 (xform-reductor 0 0) ; ❹ ;; 0 (xform-reductor 0) ; ❺ ;; #done! 2
❶ transducer 链像往常一样组装. 请注意,
partition-all是一个内部缓冲区长度为 3 的有状态 transducer. 随后的cattransducer 解包由partition-all创建的任何内部列表.❷ transducer 链用
+调用, 准备执行.❸
xform-reductor的第一次调用模拟了当 0 是输入集合中的第一个元素时发生的情况. 当它到达partition-all时, 它会被递增, 后者将该数字存储在内部缓冲区中, 因为它尚未达到大小 3. 返回 0, 因为+尚未被调用.❹ 在再次用 0 调用
xform-reductor后,partition-all在其内部缓冲区中包含[1,1].❺ 我们现在通过用单个参数调用
xform-reductor来模拟归约的结束.该示例显示了在用包含两个零的集合调用
transduce时transduce内部发生的情况:[0 0]. 首先用+调用 transducer 链, 这会实例化所有的 transducing 函数. 它被命名为xform-reductor,partition-all在此时初始化其内部状态.xform-reductor是一个功能齐全的 reducing 函数, 它递增每个项, 将其临时存储在partition-all中 (最多 3 个), 并将此项与先前结果相加.如果没有最后一步
(xform-reductor 0), 结果将只是 "0". 这是因为patition-all没有机会清空内部缓冲区.transduce为我们方便地调用了最后一步, 确保 transducer 状态的拆除一致地发生.总而言之:
- Transducer 需要信号表示归约已结束.
- reducing 函数 (
+在我们的示例中) 位于 transducer 链的末端, 最后的 transducer (cat在我们的示例中) 不知道接下来会发生什么. - 单参数调用规则确保任何状态在归约结束时都得到正确的清理.
- 链末尾的 reducing 函数受相同的规则影响, 并需要为此做好准备.
completing是一个方便的辅助函数, 用于修复 reducing 函数在这方面的任何可能问题.
- 对 completing 的需求
- 另请参阅
monoid与completing有一些相似之处, 但它们是为不同的目的而制作的, 不能互换使用.monoid弥补了 reducing 函数中缺少零参数调用的问题, 而completing主要专用于单参数调用.transduce是completing的主要用例. - 性能考虑和实现细节
=> O(1) 函数生成
completing在常数时间内生成一个新函数. 在性能或实现细节方面没有特别相关的内容.
- 7.2.4 cat
自 1.7 版本以来的函数
(cat [rf])
cat是标准库中唯一一个纯粹的 transducer (它不与已有的序列函数相关联). 虽然有许多其他可以通过调用一个序列处理函数 (通常没有参数) 来获得的 transducer, 但cat是唯一一个可以直接使用的:(eduction (map range) (partition-all 2) cat cat ; ❶ (range 5)) ;; (0 0 1 0 1 2 0 1 2 3)
❶ 注意使用
cat时没有包装括号. 这只是eduction的一个效果, 它在内部通过comp组合 transducer.cat假设前一个 transducer (或其组合) 正在产生一个序列结果.cat遍历内部的序列步骤以移除一层序列包装.- 约定
- 示例
以下示例说明了
cat与reduce的关系:((cat +) 0 (range 10)) ; ❶ ;; 45 (reduce + 0 (range 10)) ; ❷ ;; 45
❶ 我们可以用一个像
+这样的 reducing 函数来调用cat. 通常这不是cat的使用方式,cat是在 transducer 组合的上下文中使用.❷ 一旦为
cat分配了一个 reducing 函数, 它的工作方式就像调用reduce.前面的例子显示,
cat一旦被像+(加法) 这样的 reducing 函数指示, 就期望输入是序列性的. 与reduce不同,cat是一个真正的 transducer, 可以用来展平上游步骤产生的内部集合:(def team ["jake" "ross" "trevor" "ella"]) (def week ["mon" "tue" "wed" "thu" "fri" "sat" "sun"]) (defn rotate [xs] ; ❶ (sequence cat (repeat xs))) (def rota ; ❷ (sequence (map vector) (rotate team) (rotate week))) (last (take 8 rota)) ;; ["ella" "mon"]
❶
rotate是一个从有限枚举创建重复元素的无限序列的函数. 例如, 我们可以重复一周中的几天或一个团队的成员.repeat创建一个新序列来包围输入的无限重复, 但我们不希望内部的包装层出现.cat用来消除内部集合, 形成一个扁平的序列.❷
rota展示了如何为一周的每一天分配一个团队成员, 即使这两个枚举的长度不同.rota函数可以用来决定每天谁负责项目的特定方面.- cat 和 mapcat
回顾本章中的例子, 你可以看到
cat实际上只是连接逻辑, 而sequence(或其他 transducer 感知的迭代机制) 则处理迭代. 在 Clojure 1.7 中引入cat之前, 解决类似问题的最接近的习惯用法是使用mapcat和identity:(def seasons ["spring" "summer" "autumn" "winter"]) (nth (mapcat identity (repeat seasons)) 10) ; ❶ ;; autumn (nth (eduction cat (repeat seasons)) 10) ; ❷ ;; "autumn"
❶ 在这种情况下, 我们只需要连接, 而不需要转换. 因此,
map的" 映射" 部分被赋予了identity作为转换函数.❷ 只使用
cat可以完全移除identity.cat本质上是mapcat的 "cat" 部分. 由于迭代机制现在由 transducer 实现, 我们不必 обязательно地携带映射部分, 可以在适当时单独使用cat.当展平包括一个转换步骤时,
mapcat(它也是 transducer-ready 的) 仍然有用. 例如:(take 10 (eduction (mapcat range) (range))) ; ❶ ;; (0 0 1 0 1 2 0 1 2 3)
❶ 在另一个
range之上使用range和mapcat会产生一系列越来越大的从零开始的枚举.
- cat 和 mapcat
- 另请参阅
mapcat在连接之前增加了转换步骤. 如果你的算法总是需要一个转换, 优先使用mapcat而不是catovermap. 当 transducer 不是一个选项时,mapcat也是必需的 (这通常与 transducer 提供的与正常序列处理相比不同的惰性保证有关).concat惰性地将集合连接在一起.flatten是一种更强的连接形式, 它还包括移除任何嵌套集合的层, 而不仅仅是第一层.cat和mapcat只会影响第一层嵌套, 而不触及内部集合. 当你想要移除任何级别的嵌套集合时, 使用flatten.r/cat在 reducers 中是一个专门用于高效执行fold的特定连接操作.r/foldcat将r/fold和r/cat组合在一起. 像r/cat一样, 这是一个仅在 reducers 中使用的特定操作.
- 性能考虑和实现细节
=> O(1) 函数生成
=> O(n) 运行时
cat是一个函数生成器. 生成是一个常数时间操作, 对性能优化没有相关影响. 在运行时性能配置文件方面,cat与上游步骤创建的元素数量成线性关系 (与cat实现所基于的reduce相同).
- 约定
2.6.3. 7.3 reduced, reduced?, ensure-reduced, unreduced
函数
自 1.5 (reduced 和 reduced?) 起
自 1.7 (ensure-reduced 和 unreduced) 起
(reduced [x]) (reduced? [x]) (ensure-reduced [x]) (unreduced [x])
本节中的四个函数控制了在其他 Clojure 对象周围包装 clojure.lang.Reduced 标记对象的存在. reduced 信号机制允许 reducing 函数强制提前结束归约:
(reduce (fn [acc el] ; ❶ (if (> el 5) (reduced acc) ; ❷ (+ acc el))) (range 10)) ;; 15
❶ 传递给 reduce 的自定义 reducing 函数包含一个关于传入元素 "el" 的条件. 只有当元素小于 5 时, 它才用 + 进行归约.
❷ 当元素大于 5 时, 返回一个包装了到目前为止结果的 reduced 值.
当 reduce 找到一个包装在 Reduced 实例中的元素时, 它会停止对输入中剩余元素的递归. reducers 和 transducer 都利用该信号机制来表示归约的提前结束 (例如, take-while 立即将到目前为止的结果包装在 reduced 中, 以便后续的 reducer/transducer 有机会避免计算密集型操作).
包装的 reduced 实例支持 IDeref 接口, 允许使用 @ (at) 运算符轻松地进行检查:
(def r (reduced "string")) (reduced? r) ;; true r ;; #object[Reduced 0x3e7d {:status :ready :val "string"}] @r ; ❶ ;; "string"
❶ reduced 对象支持 IDeref 接口, 类似于原子或其他引用对象.
- 约定
- 输入
- 在所有情况下都需要参数
"x". 它可以是一个已经包装在clojure.lang.Reduced实例中的对象, 也可以是任何类型的普通对象.
- 在所有情况下都需要参数
- 值得注意的异常
当忘记先解引用就使用包装的
reduced对象时, 通常会遇到ClassCastException. - 输出
reduced: 返回包装在新clojure.lang.Reduced实例中的输入对象"x".reduced?: 如果"x"是一个reduced对象, 返回true, 否则返回false.ensure-reduced: 类似于reduced, 但当"x"已经是一个reduced对象时, 不会再次包装.unreduced: 当"x"是一个reduced对象时, 检索"x"的解引用版本.
注意
有 3 种方法可以查看
reduced对象的内容: 给定"r"是reduced, 那么:@r,(deref r)和(unreduce r)是等效的.
- 输入
- 示例
通过
reduced, 我们可以提供一种在满足某个条件后从集合中删除元素的替代方法.drop-while实现了类似的概念, 但如果我们对" 之后" 的第一个元素感兴趣, 我们需要一个额外的first调用.reduced选项不仅更短, 而且可能更快; 根据输入集合的类型, 迭代可能已经为reduce进行了优化.让我们在以下示例中比较这两种形式 127:
(def random-vectors ; ❶ (repeatedly #(vec (drop (rand-int 10) (range 10))))) (first ; ❷ (drop-while #(>= 3 (count %)) random-vectors)) ;; [2 3 4 5 6 7 8 9] (reduce ; ❸ #(when (> (count %2) 3) (reduced %2)) random-vectors) ;; [4 5 6 7 8 9]
❶
random-vectors产生一个无限流, 其中包含不同大小的向量, 从 0 到 10 个项.❷ 有几种方法可以解决返回第一个长度大于 3 的向量的问题. 其中一种是使用序列函数, 如
drop-while, 从序列的头部移除项, 直到谓词为真. 在那一点上, 我们需要调用first从列表中剩余的向量中获取第一项.❸ 我们可以使用
reduce和reduced来达到类似的效果, 并在找到第一个满足谓词的项时停止底层的循环.reduced停止计算并在该点退出reduce, 从而消除了从剩余项中取第一个元素的需要." 移动平均线" 是一个随时间变化的平均值的时间序列. 它对于显示随时间变化的快照结果很有用, 而不一定需要等待可能仍在传输中的其他值. 一个完美的例子是股票价格的典型图表, 其中图表上的每个点都是前一个 (每日或其他) 的平均值 128. 其思想是阻塞式地使用
reduce, 在值到达时开始处理它们, 有效地暂停循环. 我们需要一些工具来实现这一点:java.util.concurrent.LinkedBlockingQueue是一种队列, 其中推-弹操作会阻塞, 等待队列中有元素. 我们可以用它作为通道来输入新值.- 我们还需要一个" 信号" 来标记事件流的结束, 以便
reduce操作可以解除阻塞并返回.
为了提供给定的设计, 我们需要在归约过程中创建和检查
reduced元素. 客户端向队列发送一个reduced信号, 以表示该会话的事件结束. 在 reducing 函数中解释reduced信号, 并将其传播到reduce实现以停止循环 (在正常情况下, 信号将是输入序列的结束, 但在这种情况下我们没有).(import 'java.util.concurrent.LinkedBlockingQueue) (def values (LinkedBlockingQueue. 1)) ; ❶ (defn value-seq [] ; ❷ (lazy-seq (cons (.take values) (value-seq)))) (defn moving-average [[cnt sum avg] x] ; ❸ (let [new-cnt (inc cnt) new-sum (+ sum (unreduced x)) new-avg (/ new-sum (double new-cnt)) res [new-cnt new-sum new-avg]] (println res) (if (reduced? x) (reduced res) res))) (defn start [] ; ❹ (let [out *out*] (.start (Thread. #(binding [*out* out] (println "Done:" (reduce moving-average [0 0 0] (value-seq)))))))) (start) (.offer values 10) ;; [1 10 10.0] (.offer values 10) ;; [2 20 10.0] (.offer values 50) ;; [3 70 23.333333333333332] (.offer values (reduced 20)) ;; [4 90 22.5] ;; Done: [4 90 22.5]
❶ 一个大小为一的链接队列表示, 一旦第一个元素被添加, 就不再允许向队列中推入更多元素, 直到该元素被消费. 这导致
reduce阻塞, 等待另一个元素可用.❷
value-seq在队列之上创建一个惰性序列, 这是一个reduce可以理解和使用的序列接口, 而无需了解阻塞队列的内部.❸
moving-average是 reducing 函数. 该函数不知道基于队列的实现, 并且可以在普通的reduce调用中正常工作. 该函数假设, 在任何时候, 参数"x"都可能是reduced. 在这种情况下, 归约结束的信号通过将返回的结果包装在一个reduced调用中发送给reduce实现.❹
start函数在单独的线程中启动归约. 主线程用于客户端向队列发送值, 而后台线程运行 (否则会阻塞的) 归约. 请注意, 我们将新线程的标准输出重定向到当前线程, 以便我们可以在 REPL 中看到消息. 对reduce的调用是阻塞的, 只有当一个reduced元素被发送到队列时才会返回.在示例中, 交互从分叉一个包含后台 (阻塞)
reduce调用的新线程开始. 当前线程持有对队列的引用, 该队列可用于向reduce发送值. 一旦我们提供一个由reduced包装的值, 线程就会停止并退出, 显示最后一个可用的平均值. 该向量包含一个三元组, 其中包含到目前为止看到的元素计数, 它们的总和以及最终的平均值.从示例中, 我们可以看到
reduced,reduced?和unreduced是如何使用的:- 要将普通元素转换为
reduced元素, 使用reduced. - 要验证一个元素是否为
reduced, 使用reduced?. - 要使用一个元素而不管它是否是
reduced, 使用unreduced. 在这种情况下使用@的解引用形式会导致异常, 而不先用reduced?检查.
- Transducers 和 reduced
ensure-reduced是示例中唯一剩下的函数.ensure-reduced特别在多个函数参与归约且每个函数都有同等机会停止循环时使用.在这种情况下, 我们希望能够将某些东西标记为
reduced, 而不必检查它是否已经如此.ensure-reduced是在与 transducer 同一时间引入的, 因为 transducer 链是ensure-reduced的主要客户端之一: 一个 transducer 希望能够表示归约的结束, 而与链中的其他 transducer 无关,ensure-reduced避免了条件形式.可以在
taketransducer 中找到ensure-reduced的一个例子: 在取了给定数量的元素后,take使用ensure-reduced来表示归约的结束.
- 另请参阅
reduce是reduced对象的主要接收者. 如果你需要使用本节中的函数, 值得多了解一些关于reduce的知识. - 性能考虑和实现细节
=> O(1) 函数生成
reduced,reduced?,unreduced和ensure-reduced对计算的影响很小. 在常数时间内创建的reduced对象包含对原始对象的引用, 这几乎不增加内存占用.
2.6.4. 7.4 总结
Reducer 和 transducer 是强大的工具. 它们被逐步添加到标准库中, 以与已有的序列处理原语集成. reducers 通过 fork-join 框架提供并行性, 弥补了 pmap 在处理不太可预测任务时的局限性. transducer 提供了一种组合模型, 对于更大数据转换, 其扩展性优于序列处理.
3. 第三部分. 数据结构
本书的这一部分专门介绍在数据结构上操作的函数, 这通常涉及一个或多个集合作为参数. 数据结构以及在它们上操作的函数是 Clojure (以及其他编程语言) 的一个基本部分. 本书使用术语" 数据结构" 来标识数据的容器, 并将其与" 标量" 或" 单例" 区分开来, 后者是不能进一步分割的原子数据.
Clojure 实现了许多类型的数据结构, 并且与 Java 提供的那些也很好地互操作. Clojure 的数据结构通常是不可变的和持久的 (有一些例外, 由于强烈的约定而被很好地标记). 当一个数据结构在 Clojure 中被" 改变" 时, 它会产生一个看起来是新的东西, 但在内部它们共享了大部分的数据. 对于所有实际目的, 数据结构的客户端不需要知道是否存在结构共享或它是如何工作的, 因为 Clojure 负责所有的实现细节.
在数据结构上操作的函数被大致分类如下:
- 集合 集合是最通用的分类. 术语" 集合" 在本书中被用来描述最通用函数的输入, 这些函数在一系列广泛的数据结构上一致地操作. 集合基本上是 Clojure 中所有内置的数据结构. 该术语也被用来描述 Java 集合, 尽管在这种情况下, " Java" 总是存在以避免混淆.
- 序列 序列是另一个广泛的分类, 它描述了一个特定的抽象数据类型 129. 一个序列最好用其属性来描述, 我们将在专门讨论它们的两个章节中看到. 许多非序列的数据结构 (提供元素的直接查找) 可以被迭代以符合序列接口. 与序列接口相关的函数组是最大的.
- 列表 列表是一个支持序列接口的持久化数据类型. 列表在列表的前面添加新元素, 并需要完全扫描才能访问列表中的最后一个元素. 列表不是出现在它们自己的章节中, 而是作为关于序列的章节的一部分.
- 队列 队列是一种实现先进先出语义的具体数据类型. 队列是序列的, 但它们不是原生的序列.
- 向量 向量是一个提供通过索引直接访问的持久化集合. 向量是" 关联的" , 因为向量中的每个项都隐式地与其整数索引相关联. 新项被添加到向量的末尾. 本章中的函数是特定的向量操作.
- 集合 一个集合代表一个唯一且无序的值的集合. 该章描述了集合上可用的典型数学函数, 如并集或交集, 以及其他相关函数. 集合也有一种变体, 它基于值的比较来保持排序.
映射 一个 map 是另一种关联数据结构, 提供通过键 (不一定是像向量那样的整数) 的直接查找. Map 有不同的风格: 数组映射保持插入顺序, 不需要哈希, 但只适用于小 map. 哈希映射是最通用的, 通过其键的哈希提供直接查找. 排序 map 使用比较器来保持其元素的排序.
不用说, 这种分类既不完美也不确定. 许多在范围和范围上重叠的函数已被包含在它们最常使用的数据结构中.
- 集合初始化器
你可能在学习数据结构及其函数时注意到了一个模式: Clojure 通常提供一个接受任意数量项的构造函数 (如 vector, hash-set 等) 和另一个从现有集合构建的构造函数 (如 vec, set). 下表包含了不同集合类型的最常见构造函数:
| 类型 | 从项初始化 | 从 coll 初始化 | 字面量 |
|---|---|---|---|
| 向量 | vector |
vec |
[] |
| 列表 | list |
list* |
() |
| 集合 | hash-set |
set |
#{} |
| 映射 | hash-map |
zipmap |
{} |
| 排序映射 | sorted-map |
n.a. | n.a. |
| 排序集合 | sorted-set |
n.a. | n.a. |
| 数组映射 | array-map |
zipmap |
{} |
| 子向量 | n.a. | subvec |
n.a. |
| vector-of | vector-of |
n.a. | n.a. |
| 队列 | n.a. | n.a. | n.a. |
我们可以观察到以下几点:
array-map和hash-map共享相同的字面量, 因为两种类型之间的转换是自动的, 并且基于大小. *queue是clojure.lang.PersistentQueue的简称. 构建队列的唯一方法是通过(clojure.lang.PersistentQueue/EMPTY)空实例, 然后使用into添加元素. 另请参阅peek以获取一些相关示例.
3.1. 8 集合
本章汇集了可以在不同数据结构上一致使用的函数. 它们的一致性由以下一个或多个属性的组合来表示:
- 它们的性能在不同集合上是一致的, 几乎没有或没有可察觉的差异.
- 即使存在性能差异, 它们的使用在不同数据结构中也是惯用的.
- 该函数完成工作非常迅速, 以至于在" 错误" 的数据结构上使用它的权衡是可以接受的.
- 该函数被设计为多态的, 并在不同集合上操作.
本章进一步分为附加的子章节. 我们将首先看一下创建, 计数或以最通用的方式访问集合的基本函数. 接下来是设计为多态的函数. 最后, 最后一个子章节专门介绍通用的函数, 如分组, 排序, 分区等, 这些函数在日常使用中非常常见.
3.1.1. 8.1 基础
- 8.1.1 into
自 1.0 版本以来的函数
(into ([]) ([to]) ([to from]) ([to xform from]))
into是 Clojure 标准库中一个经常使用的函数.into将源集合 "from" 的所有项连接到目标集合 "to" 中:(into #{} (range 10)) ;; #{0 7 1 4 6 3 2 9 5 8} ; ❶ (into [:g :x :d] [1 5 9]) ;; [:g :x :d 1 9 5] ; ❷
❶
into将序列的内容连接到一个空的 Set 中.❷
into将向量的内容连接到另一个已经包含一些元素的向量中.输出集合可以 (并且最常见的是) 与源集合 "from" 的类型不同.
into也可以用于在连接数据的同时应用一个 transducer 链 "xform":(into (vector-of :int) (comp (map inc) (filter even?)) (range 10)) ;; [2 4 6 8 10] ; ❶
❶
into在将序列内容连接到基本类型的向量中的同时应用一个 transducer 链.- 约定
- 输入
"from"可以是任何可序列化的集合或nil."to"应该使得(coll? to)为真: 列表, 向量, 集合, 队列或 map 都是允许的目标集合. 以下非持久化数据结构则不受支持: 瞬态, 数组或通用的 Java 容器."to"也可以是nil, 在这种情况下, 默认使用一个列表作为目标集合."xform"是一个 transducer 的组合 (或单个 transducer), 是可选参数.
- 值得注意的异常
当
"to"是 map 类型的集合, 而"from"输入不是conj可以为 map 处理的形式时, 会出现ClassCastException: "X" cannot be cast to java.util.Map$Entry. 在这种情况下,"from"集合应该使用对或其他 map 来结构化, 例如:(into {} [[:a "1"] [:b "2"]]) ; ❶ ;; {:a "1", :b "2"} (into {} [{:a "1"} {:b "2"}]) ; ❷ ;; {:a "1", :b "2"}
❶ 该示例说明了当目标集合是 map 时, 输入集合应呈现的正确格式.
❷ 第二种形式与前一种等效.
- 输出
"to" 集合对象, 带有从输入集合添加的附加元素, 如果有的话. 元素按照
conj的语义添加到 "to" 集合.
- 输入
- 示例
当应用程序需要特定数据结构的特性, 但输入却是以不同的数据结构给出时, 可以使用
into. 例如, 邀请读者查看for章节. 该章中的生命游戏实现使用了一个 Set 作为主要数据结构, 以便轻松检查集合中是否存在单元格. 但由于for返回一个序列, 所以使用into将结果转换回一个 set 以进行进一步的计算. 类似地, 以下maintain函数应用序列处理 (如map或filter), 确保输出与输入集合保持相同的类型:(defn maintain [fx f coll] ; ❶ (into (empty coll) (fx f coll))) (->> #{1 2 3 4 5} ; ❷ (maintain map inc) (maintain filter odd?)) ;; #{3 5} (->> {:a 1 :b 2 :c 5} ; ❸ (maintain filter (comp odd? last))) ;; {:a 1 :c 5}
❶
maintain将集合的处理委托给输入的 "fx" 和 "f" 函数. 然后它使用empty来创建一个与输入集合相同类型的空集合.into最终用于在返回之前复制处理过的内容.❷ 一个 Set 被递增, 偶数被移除. 标准的
map和filter调用会返回一个惰性序列.❸ 另一个使用 map 的例子.
我们可以轻松地扩展
maintain以处理 transducer 链的可选存在. 为了也展示 Clojure 标准库中的其他有趣数据类型, 我们将使用一个队列作为输入集合:(import 'clojure.lang.PersistentQueue) (def xform ; ❶ (comp (map dec) (drop-while neg?) (filter even?))) (defn queue [& items] ; ❷ (reduce conj (PersistentQueue/EMPTY) items)) (defn maintain ; ❸ ([fx f coll] (into (empty coll) (fx f coll))) ([xform coll] (into (empty coll) xform coll))) (def input-queue (queue -10 -9 -8 -5 -2 0 1 3 4 6 8 9)) (def transformed-queue ; ❹ (maintain xform input-queue)) (peek transformed-queue) ; ❺ ;; 0 (into [] transformed-queue) ; ❻ ;; [0 2 8]
❶
xform是一个简单的 transducer 链, 假设输入是数字.❷
queue是一个队列初始化器. 它使用reduce和conj来构建一个PersistentQueue类型.❸
maintain现在允许一个额外的元数, 它只接受一个集合和一个 transducer.❹
maintain和以前一样使用, 这次只是传递了 transducer 链.❺ 输出队列可以按预期使用, 使用
peek.❻ 最后一次使用
into在数据类型之间移动, 并将队列的内容作为向量进行检查.- into 和元数据
Clojure 中的元数据主要专用于需要用额外数据 (字面上是关于数据的数据, 因此称为元数据) 来装饰 Clojure 数据结构的应用程序 (或库) 实现者. 元数据能够在不引入特殊符号的情况下对数据结构进行装饰, 这些符号否则会对所有集合处理操作可见. 例如, 我们可以像这样向一个集合添加一个时间戳值:
(def v (with-meta [1 2 3] {:ts (System/currentTimeMillis)})) ; ❶ (meta v) ; ❷ ;; {:ts 1490773173006}
❶
with-meta将元数据信息附加到数据结构上. 该 map 可以包含任意一组键值对.❷
meta用于读出元数据信息.标准库的函数和宏通常与元数据很好地配合, 按照人们的预期携带它们.
into采取的方法是保留 "to" 集合中已经存在的任何元数据, 而丢弃 "from" 集合中的元数据:(defn sign [c] ; ❶ (with-meta c {:signature (apply str c)})) (meta (into (sign [1 2 3]) (sign (range 10)))) ; ❷ ;; {:signature "123"}
❶ 函数
sign将元数据附加到传入的集合 "c" 上. 元数据值是输入集合中内容的字符串转换.❷ 一个简单的实验表明, 调用
into产生的元数据来自目标集合.
- into 和元数据
- 另请参阅
当目标集合要返回一个原生数组时,
into-array是等效的操作.into不支持数组.当输入不是一个集合而只是一个单项时, 可以类似地使用
conj.into基于conj在类型和行为方面的语义. - 性能考虑和实现细节
=> O(n) 与输入集合中的项目数量 n 成线性关系
into的实现基于reduce, 这是性能配置文件中的主导部分. 如果目标集合实现了clojure.lang.IEditableCollection,into会将元素复制到一个可变的瞬态中, 然后再将其转换回一个持久化集合. 对于大型可编辑集合 (如向量, 集合, 数组映射和映射), 速度提升是显著的.以下代码执行了两系列基准测试, 一个使用向量作为目标, 另一个使用列表 (不支持瞬态). 每个基准测试都使用一个越来越大的集合, 结果使用
clj-xchart库绘制:(require '[criterium.core :refer [quick-benchmark]]) (require '[com.hypirion.clj-xchart :as c]) ; ❶ (defmacro b [expr] ; ❷ `(first (:mean (quick-benchmark ~expr {})))) (defn sample [c] ; ❸ (for [n (range 100000 1e6 100000)] (b (into c (range n))))) (c/view ; ❹ (c/xy-chart {"(list)" [(sample '()) (range 100000 1e6 100000)] "(vector)" [(sample []) (range 100000 1e6 100000)]}))
❶ 要
require clj-xchart, 请确保它在 classpath 中可用.❷ 这个宏从 Criterium 返回的指标 map 中提取相关的平均执行时间.
❸
sample接受目标集合作为输入, 并用越来越大的输入执行 10 个循环.❹
view和xy-chart是clj-xchart所需的唯一原语.
Figure 14: into 与向量相比, into 与列表. x 轴是时间 (以秒为单位).
该图显示了
into的行为近似是线性的 (由于只有 10 个样本, 线不是完全直的). 但在最初的几个样本之后, 带有向量的版本变得更快, 特别是对于更大的集合.以下基准测试比较了
apply merge和into {}将多个 map 合并为一个 map:(require '[criterium.core :refer [quick-bench]]) (let [maps (map #(apply hash-map %) (partition-all 10 (range 100)))] ; ❶ (quick-bench (apply merge maps))) ;; Execution time mean : 6.890232 µs (let [maps (map #(apply hash-map %) (partition-all 10 (range 100)))] ; ❷ (quick-bench (into {} maps))) ;; Execution time mean : 6.126766 µs
❶ 该基准测试创建了一个包含 10 个 map 的序列, 每个 map 有 5 个键. 键是不同的, 所以结果 map 将包含原始的总共 100 个键.
❷ 该基准测试揭示了两者之间没有太大区别.
两种形式都是惯用的 Clojure, 并且它们的性能大致相同, 但
into {}在传达操作的整体含义方面似乎略胜一筹, 并借助了 map 字面量 "{}" 的视觉辅助.
- 约定
- 8.1.2 count
自 1.0 版本以来的函数
(count [coll])
count接受一个集合作为输入, 并返回它包含的元素数量.count是每种编程语言中的一个重要操作, Clojure 特别注意确保它在所有相关数据结构上以最佳方式工作. 使用count很简单:(count [1 2 3]) ;; 3
count最终要求输入集合自己进行计数, 这是一个设计决策, 允许每个数据结构提供最有效的实现. 有关此决策如何影响速度的更多信息, 请参见性能部分.- 约定
- 输入
"coll"可以是任何集合类型, 记录或结构体.(count nil)为 0.
- 值得注意的异常
- 当
"coll"无法被计数时, 抛出UnsupportedOperationException, 例如对于标量如关键字, 符号, 数字等. - 如果集合中的元素数量超过
Integer/MAX_VALUE, 则会抛出ArithmeticException, 例如:(count (range (inc Integer/MAX_VALUE))).
- 当
- 输出
返回: 一个
java.lang.Integer, 表示"coll"中的元素数量. " 元素" 的定义是类型特定的: 它可以是一个元组, 如在 map 的情况下, 也可以是一个记录中的字段数量.
- 输入
- 示例
计数的需在编程和算法中无处不在. 这里是一个涉及以某种形式使用
count的问题的广泛分类:- 确定一组或一组项中的最大/最小值.
- 数学公式, 如平均值, 最小值或最大值.
- 确定由 n 步组成的过程的" 进度" .
- 将项分批/分割成一定大小.
- 确定频率, 重复次数.
- 重试请求一定次数.
count的一个简单用法可以在检查命令行参数的一致性时找到. 以下示例展示了一个copy命令的实现, 该命令至少需要 2 个参数 (以及一个可选的第三个参数) 来知道要复制哪个文件以及复制到哪里:(require '[clojure.java.io :as io]) (defn- print-usage [] ; ❶ (println "Usage: copy 'file-name' 'to-location' ['work-dir']")) (defn- copy ; ❷ ([in out] (copy in out "./")) ([in out dir] (io/copy (io/file (str dir in)) (io/file out)))) (defn -main [& args] ; ❸ (cond (< (count args) 2) (print-usage) (= 2 (count args)) (copy (first args) (second args)) (> (count args) 2) (copy (first args) (second args) (last args)))) (-main "project.clj" "/tmp/copy1.clj") ; ❹ ;; nil (-main "copy1.clj" "/tmp/copy2.clj" "/tmp/") ; ❺ ;; nil
❶ 我们通过这个辅助函数打印命令的预期用法.
❷核心逻辑在
copy函数中实现, 该函数包含 2 个元数. 该函数接受 2 或 3 个参数.❸ Clojure 中的入口点函数, 使用了惯用的 "-" 后缀. Clojure 引导序列可以被指示搜索这个主签名函数. 这里我们使用一个
cond指令来计算参数.❹ 为简单起见, 我们直接调用
-main函数, 否则我们将不得不编译并调用生成的类, 这需要几个其他系统特定的步骤. 这个带有 2 个参数的版本假设当前文件夹是" 源" , 从那里应该加载输入文件. Java 中的当前文件夹通常意味着 JVM 被调用的文件夹.❺ 在第二个版本中, 我们传递了第三个参数. 额外的 "dir" 参数被用作" 源" , 而不是当前文件夹.
- 另请参阅
counted?验证给定的对象是否支持clojure.lang.Counted接口, 对于 Clojure 集合来说, 这意味着常数时间的count. 其他值得注意的 Java 类型, 如字符串和数组, 虽然不是counted, 但仍然是常数时间操作. - 性能考虑和实现细节
=> O(1) 最佳情况
=> O(n) 最坏情况 (惰性序列)
count在可能的情况下将计数逻辑委托给目标集合. 在大多数情况下,count是一个快速的常数时间操作, 因为计数实际上是在集合构建时发生的.下表总结了不同集合类型的
count时间复杂度:Table 11: 按集合类型划分的 count 性能摘要. 类型 计数的? 示例 复杂度 列表 true(count '())O(1) 向量 true(count [])O(1) 队列 true(count (PersistentQueue/EMPTY))O(1) 集合 true(count #{})O(1) 映射 true(count {})O(1) 排序映射 true(count (sorted-map))O(1) 排序集合 true(count (sorted-set))O(1) 数组映射 true(count (array-map))O(1) 数组 false(count (int-array [1]))O(1) 字符串 false(count "abc")O(1) 长范围 true(count (range 10))O(1) 范围 false(count (range 1e3))O(n) 惰性序列 false(count (for [i [1]] i)O(n) 分块的 false(count (seq (for [i [1]] i)))O(n) 序列集 false(count (seq #{1}))O(n) 序列映射 false(count (seq #{1}))O(n) 序列排序集 false(count (seq (sorted-set 1))O(n) 序列排序映射 false(count (seq (sorted-map 1))O(n) 序列向量 true(count (seq [1]))O(1) 序列数组映射 true(count (seq (array-map 1 2))O(1) 该表描述了一个总体上非常好的情况, 大多数集合类型在常数时间内进行计数. 有一些值得注意的线性时间例外:
- 惰性集合和分块序列 130. 请注意,
count在计数时也会实现惰性序列. long-range的行为与其他类型 (例如双精度浮点数) 上创建的range不同. 在long-range上的count是常数时间, 而在其他类型上则不是.- 在集合, 映射, 排序集合和排序映射上调用
seq也是线性时间的 (而在向量或数组映射上则为常数时间).
如果计数是代码的一个必要步骤, 并且代码也应尽可能快, 那么你应该特别注意在使用
seq后作为中间结果构建的惰性序列, 因为它们经常强制进行线性时间计数操作. - 惰性集合和分块序列 130. 请注意,
- 约定
- 8.1.3 nth
自 1.0 版本以来的函数
(nth ([coll index]) ([coll index not-found]))
nth返回在作为参数传递的集合中指定索引处找到的值:(let [coll [0 1 2 3 4]] (nth coll 2)) ;; 2
在索引不存在的情况下,
nth会抛出错误 (而不是像get在顺序访问时那样返回nil). 当提供默认值时,nth不会抛出异常:(nth [] 2) ; ❶ ;; IndexOutOfBoundsException (nth [] 2 0) ; ❷ ;; 0
❶ 当请求的索引不可用时,
nth会抛出异常.❷ 当提供默认值时, 相同的操作会成功返回.
nth专为提供随机访问查找的数据结构而设计, 如向量, 子向量, 原始向量和瞬态向量. 它也同样高效地处理原生数组和 Java 数组.nth可以在序列上进行访问, 尽管在这种情况下效率较低. 它根本不适用于关联数据结构 (例如 map, set 和相关的有序变体), 对于这些数据结构存在一个专用的替代方案 (get).- 约定
- 输入
"coll"可以是任何集合类型, 不包括 map, set (包括有序, 无序或创建为瞬态的)."index"可以是任何类型的正数, 直到Integer/MAX_VALUE. 如果包含小数,"index"会被截断为整数:(nth [1 2 3] 3/4)等价于(nth [1 2 3] 0). 使用Double/NaN作为"index"的nth总是返回第一个元素 (如果存在)."not-found"是可选的, 可以是任何类型. 当请求的索引不存在时, 返回"not-found".nil被接受为一种退化的集合类型. 对nil调用nth除非提供了"not-found", 否则返回nil.
- 值得注意的异常
- 当
"coll"不支持任何类型的索引访问时, 抛出UnsupportedOperationException. - 当请求的索引超出当前请求的索引范围时, 抛出
IndexOutOfBoundsException. - 当给定的
"index"超出整数范围 (>"index" Integer/MAX_VALUE) 时, 抛出IllegalArgumentException.
- 当
- 输出
nth返回:- 在
"index"处找到的值, 如果可用. - 在缺少所请求的
"index"的情况下, 返回"not-found"参数 (如果存在). - 当
"coll"为nil且没有给出默认值时, 返回nil.
- 在
- 输入
- 示例
许多数据结构都可以在数组之上实现. 例如, 哈希表可以在通过哈希计算出的索引处存储一个对象 131. 下一个例子展示了我们如何在一个向量之上实现一个基本的哈希表.
这个数据结构的核心概念是为每个键值对计算哈希数. 我们可以使用
hash函数来给定键检索这样的数字, 并使用该数字将项存储在向量的索引处.这个解决方案的一个问题是需要预先分配可能很大的向量 (即使只为一个元素). 这是因为哈希可能是 -2
31 到 2
31-1 之间的任何数字.
注意
读者应该在任何实际用途中都考虑使用一个合适的哈希映射. 这里给出的实现应该能让你很好地了解创建健壮数据结构的挑战.
为了减少内存消耗, 我们将哈希限制在 2
16 个正整数, 代价是增加了冲突的概率 (这仍然相对较低, 对于这个例子来说是足够的):
(defn to-hash [n] ; ❶ (bit-and (hash n) 0xFFFF)) (defn grow [upto ht] ; ❷ (if (> upto (count ht)) (let [t (transient ht)] (dotimes [i (- upto (count ht))] (conj! t nil)) (persistent! t)) ht)) (defn assign [ht kvs] ; ❸ (let [t (transient ht)] (doseq [[k v] kvs] (assoc! t k v)) (persistent! t))) (defn with-hashed-keys [args] ; ❹ (map (fn [[k v]] (vector (to-hash k) v)) (partition 2 args))) (defn put [ht & args] ; ❺ (cond (odd? (count args)) (throw (IllegalArgumentException.)) (zero? (count args)) ht :else (let [kvs (with-hashed-keys args) ht (grow (apply max (map first kvs)) ht)] (assign ht kvs)))) (defn hashtable [& args] ; ❻ (apply put [] args)) (defn fetch [ht k] ; ❼ (nth ht (to-hash k)))
❶ 哈希函数建立在 Clojure 自己的
hash函数之上. 我们需要限制哈希的域, 使其不超过 216 并且不返回负数 (这对向量索引是无效的). 我们可以使用bit-and来同时应用这两个约束.❷
grow函数通过检查输入键中的最高哈希值来决定我们是否需要在持有哈希表的向量中分配更多空间. 如果其中一个键需要向量中超出其长度的索引, 则该向量将被conj所需的额外次数.transient-persistent惯用法被用来在此过程中获得一些速度.❸
assign函数假设持有哈希表的向量已经具有正确的大小. 它再次使用transient-persistent惯用法来高效地写入多个键值对.❹
with-hashed-keys是一个辅助函数, 用于处理将一个参数列表转换为一个对的列表, 其中第一个元素 (键) 是哈希过的版本.❺
put在初始构建和后续更新中都使用. 它首先检查参数, 然后继续可能地增长哈希表 (如果其中一个参数没有足够的空间), 并分配新元素.❻
hashtable用于构建一个新的哈希表, 它只是用一个空向量调用put.❼
fetch将直接访问哈希表, 以根据哈希过的键检索一个特定的值.请注意使用
nth从向量化的哈希表中高效地获取元素. 哈希表的实现可以如下使用:(def ht (hashtable :a 1 :b 2)) ; ❶ (fetch (put ht :c 3) :b) ; ❷ ;; 2
❶ 创建一个包含几个键的哈希表.
❷ 显示了通过
fetch访问:b键, 以及如何使用put向其添加项. - 另请参阅
get的方法与nth类似, 但特别关注关联数据结构. 尽管get也可以用于向量, 但当输入已知为向量时, 没有特别的需要这样做.向量也可以用作函数, 结果与
nth相同:([1 2 3] 1). 向量作为函数很方便, 性能也相当好, 但它们不支持默认值. - 性能考虑和实现细节
=> O(1) 最佳情况
=> O(n) 最坏情况 (主要是序列)
nth的实现取决于它被应用的类型. Clojure 中的clojure.lang.Indexed接口表示一个特定的集合是否提供了一个常数时间的nth实现. 下表总结了一些重要数据结构的nth时间复杂度:Table 12: 按集合类型划分的 nth 性能摘要. 类型 索引的? 示例 复杂度 向量 true(nth [1 2 3] 0)O(1) 子向量 true(nth (subvec [1 2 3] 0) 0)O(1) vector-of true(nth (vector-of :int 1 2 3) 0)O(1) 瞬态 true(nth (transient [1 2 3]) 0)O(1) 列表 false(nth '(1 2 3) 0)O(n) 队列 false(nth queue 0)O(n) 长范围 false(nth (range 10) 0)O(n) 范围 false(nth (range 1e3) 0)O(n) 数组 false(nth (int-array [1]) 0)O(1) 字符串 false(nth "abc" 0)O(1) ArrayList false(nth (ArrayList. (range 3)) 0)O(1) 该表显示了 3 个主要组:
- 像向量这样支持
clojure.lang.Indexed接口的数据结构. 这个类包括所有类型的向量, 并提供常数访问时间. - 不支持
clojure.lang.Indexed接口的序列和惰性序列 (如列表或范围). 在这种情况下,nth的性能是线性的. - 数组和基于数组的 Java 集合, 它们不是
clojure.lang.Indexed, 但仍然是常数时间访问.
从表中可以清楚地看出,
nth是为索引查找而优化的, 这表明nth几乎只应该用于向量. - 像向量这样支持
- 约定
- 8.1.4 empty
自 1.0 版本以来的函数
(empty [coll])
empty是一个简单的函数, 它创建了一个与输入参数类型相同的空集合:(empty (range 10)) ;; () (empty (frequencies [1 1 2 3])) ;; {}
empty最终委托输入集合来创建空实例. 几乎所有集合 (当(coll? coll)为真时) 都提供此功能. 请检查本节的其余部分, 了解empty不按预期工作 (或抛出异常) 的一些情况.- 约定
- 输入
"coll"应该是一个集合类型 ((coll? coll) 为真), 但也可以是任何其他类型 (包括nil).
- 值得注意的异常
当
"coll"是一个集合但empty不支持时, 会抛出UnsupportedOperationException. 这只发生在记录上:(defrecord Address [number street town]) (def home (Address. 12 "High st" "Alberta")) (coll? home) ;; true (empty home) ;; UnsupportedOperationException Can't create empty: user.Address
- 输出
empty返回的类型和值根据输入集合而变化. 下表显示了在最常见的 Clojure 和 Java 集合上调用empty的结果:Table 13: 在最常见的集合类型上调用 empty 的结果摘要. 类型 coll? 示例 结果 向量 true(empty [1 2 3])[]子向量 true(empty (subvec [1 2 3] 0))[]vector-of true(empty (vector-of :int 1 2 3))[](原始类型)列表 true(empty '(1 2 3))()队列 true(empty queue)(队列实例) 长范围 true(empty (range 10))()瞬态 false(empty (transient [1 2 3]))nil数组 false(empty (int-array [1]))nil字符串 false(empty "abc")nilArrayList false(empty (ArrayList. (range 3)))nil记录 true(defrecord Test []) (empty (Test.))异常 MapEntry true(empty (first {:a 1}))nilnil false(empty nil)nil请注意, 表中的
queue表示(PersistentQueue/EMPTY)构造函数. 从瞬态开始的表下半部分显示了一些有趣的结果:- 瞬态确实有一个空的表示, 但它们按惯例只由
transient函数创建. 这是一种强制在显式上下文中使用瞬态 (它们是可变数据结构) 的方式. 允许其他函数返回瞬态会逃避这种形式的控制. 类似地, 其他可变数据结构如数组和 Java 数组也是如此. - 记录具有一个身份, 其中属性是其不可分割的一部分. 从另一个记录创建一个空记录实际上会创建一个不同的类型. 这破坏了
empty的约定. - 一个
MapEntry是 Clojure map 如何作为序列结构迭代的实现细节. 一个MapEntry仅用于包含一对键值, 有一个空的没有意义. nil(以及其他标量类型) 不会抛出异常, 而是返回nil.
- 瞬态确实有一个空的表示, 但它们按惯例只由
- 输入
- 示例
empty的一个主要目标是避免使用条件来验证集合的类型, 以便可以创建相同类型的另一个. 要看一个这方面的例子, 邀请读者查看into, 其中empty被用来防止输入集合被转换为另一种类型.以下示例显示了在使用
empty时可以替换哪种条件逻辑:(let [coll [1 2 3]] ; ❶ (cond (list? coll) '() (map? coll) {} (vector? coll) [] :else "not found")) ;; [] (empty [1 2 3]) ; ❷ ;; []
❶
cond检查coll的类型以决定返回哪个空集合. 请注意, 这不是一个详尽的列表, 如果使用像(range 10)这样的东西作为输入"coll", 则会失败.empty实际上实现了比这个说明性示例多得多的功能.❷
empty有效地" 隐藏" 了条件, 避免了列出所有集合类型的繁琐任务.在保持原始类型的同时创建新节点是" 遍历" 集合时的典型问题. 遍历是嵌套数据结构的典型特征, 并且通常涉及保持原始结构的更改. 以下示例显示了我们如何遍历任意嵌套的数据结构, 以便可以将函数应用于某些元素. 我们期望输出具有与输入相同的结构, 包括相同类型的节点和集合:
(defn walk [data pred f] ; ❶ (letfn [(walk-c [d] (map ; ❷ (fn [k] (walk k pred f)) d)) (walk-m [d] (reduce-kv ; ❸ (fn [m k v] (assoc m k (walk v pred f))) {} d))] (cond (map? data) (walk-m data) (coll? data) (into (empty data) (walk-c data)) ; ❹ :else (if (pred data) (f data) data)))) (def coll {:a [1 "a" [] {:c "z"} [1 2]] :av 1N}) (walk coll (every-pred number? odd?) inc) ; ❺ ;; {:a [2 "a" [] {:c "z"} [2 2]] :av 2N}
❶ 遍历任意嵌套集合的逻辑由递归函数
walk实现. 函数主体是一个cond指令, 它区分 map, 其他集合类型和非集合. 需要区分 map 和集合的原因是它们需要以略有不同的方式进行迭代和组装.❷
walk-c是专用于迭代集合的局部函数. 该函数在嵌套集合的项上映射, 以再次将walk应用于每个元素.❸ 类似地,
walk-m是专用于迭代和重建哈希映射的函数. 当 Clojure map 像集合一样迭代时, 它们会产生一个包含键值对元组的序列. 因此, 当嵌套集合是 map 类型时,walk-c不能按原样使用.❹ 在处理了前一个
cond分支中的哈希映射后, 我们现在可以很好地利用empty来确保walk-c产生的任何东西 (很可能是一个惰性序列) 总是被转换回原始的集合类型 (例如一个向量).❺ 我们现在调用
walk, 要求在任意深度级别递增所有奇数. - 另请参阅
into经常与empty结合使用以构建特定类型的集合.empty?是检查集合是否包含元素的谓词函数.(empty? (empty coll))按定义为真. - 性能考虑和实现细节
=> O(1) 常数时间
empty是一个非常简单的函数. 该实现是一行代码, 用于将调用分派到所有实现了clojure.lang.IPersistentCollection接口的类上存在的empty方法. 当输入参数不实现集合接口时,empty简单地返回nil. 空集合的生成非常快, 通常在几纳秒的量级. 因此,empty在性能分析中不是特别有趣.
- 约定
- 8.1.5 every?, not-every?, some 和 not-any?
自 1.0 版本以来的函数
(every? [pred coll]) (not-every? [pred coll]) (some [pred coll]) (not-any? [pred coll])
every?,not-every?,some和not-any?是四个相关的函数, 它们接受一个谓词和一个集合作为参数. 它们将谓词应用于集合中的元素, 并使用像AND,OR和NOT这样的布尔逻辑运算符来组合结果.例如,
every?如果谓词对集合中的每个元素都为真, 则返回true(等同于AND连接(and (pred c1) (pred c2) (pred cN)), 其中c1, c2, .. , cN是"coll"中的项):(every? pos? [1 2 3 4]) ; ❶ ;; true
❶ 集合中的所有项都是正数.
not-every?,some和not-any?通过分别用NOT AND,OR和NOT OR组合谓词结果来类似地工作:(not-every? neg? [-1 -2 0 -3]) ; ❶ ;; true (some neg? [-1 -2 0 -3]) ; ❷ ;; true (not-any? neg? [1 2 0 3]) ; ❸ ;; true
❶
not-every?返回true, 因为列表中的并非所有数字都是负数.❷
some返回true, 因为集合中至少有一项是负数.❸
not-any?返回true, 因为至少有一个负数是假的.值得注意的是以下关系:
not-every?等价于对相同形式的every?结果取反.not-any?等价于对相同形式的some结果取反.every?和not-every?回答了与集合中所有项都满足谓词相关的问题.some和not-any?回答了与集合中至少有一项满足谓词相关的问题.
- 约定
- 输入
"pred"是一个接受一个参数并返回任意类型的函数. 即使在谓词返回的结果不是布尔值的情况下, 返回的值也会根据 Clojure 的约定被求值为真或假."coll"必须是支持使用seq函数的集合. 几乎所有的 Clojure 集合都被seq接受 (值得注意的例外是瞬态和现在已弃用的结构体). 其他 Java 类型也是兼容的, 比如数组和java.util.Collection家族中的其他类型.
- 值得注意的异常
当集合不支持
ISeq序列接口时, 会抛出IllegalArgumentException(在标准库中, 唯一的例子是瞬态). - 输出
every?,not-every?和not-any?返回true或false(这一事实也从名称末尾附加的问号中可以明显看出).some返回第一个不为nil的谓词结果.
- 输入
- 示例
像
every?或some(以及它们的补码" not" 变体) 这样的函数在与标准库中的其他函数结合使用时有一些惯用用法. 它们的使用避免了额外的函数调用, 有时允许更具可读性的形式. 例如, 以下按电话号码 (或任何其他唯一属性) 搜索可以写成不带filter或first:(def address-book [{:phone "664 223 8971" :name "Jack"} {:phone "222 231 9008" :name "Sarah"} {:phone "343 928 9911" :name "Oliver"}]) (->> address-book ; ❶ (filter #(= "222 231 9008" (:phone %))) first) ;; {:phone "222 231 9008" :name "Sarah"} (some #(when (= "222 231 9008" (:phone %)) %) address-book) ; ❷ ;; {:phone "222 231 9008" :name "Sarah"}
❶ 线程形式过滤了给定电话号码的地址簿. 它产生一个过滤后的项的序列, 我们知道其中包含一个条目.
❷
some用于过滤掉序列中第一个导致谓词不为nil的项. 我们不需要额外的first调用来解包单个返回的结果.every?在与标准库中的其他函数结合使用时也有一些惯用的用法. 以下示例显示了我们如何验证一个列表中的所有集合是否每个都至少包含一个元素:(every? seq (list [:g] [:a :b] [] [:c])) ; ❶ ;; false
❶ 当参数是空集合时,
seq返回nil.every?返回false, 因为输入中至少有一个元素是nil.在下一个例子中, 我们使用一个集合作为函数来检查一个集合中的所有项是否也包含在一个集合中.
bingo?函数通过使用抽取的集合来检查卡片中的所有数字是否都包含在今天的数字中:(def drawn #{4 38 20 16 87}) (def cards [[37 2 94 4 38] [20 16 87 19 1] [87 20 16 38 4]]) (defn bingo? [card] ; ❶ (every? drawn card)) (map bingo? cards) ; ❷ ;;(false false true)
❶
bingo?包装了对卡片应用every?的用法.❷ 几张卡片包含今天抽取的元素, 但只有一张卡片 (列表中的最后一张) 包含所有抽取的数字.
尽管实现了类似的目标,
some与本节中的其他函数略有不同. 主要区别是:- 它直接返回将谓词应用于一个元素的结果 (没有布尔转换).
- 它永远不会返回
false. 如果"el"是"coll"中的一个元素, 并且(pred el)的结果是false,some不会停止, 而是继续处理下一个项. - 只有当
true是输入集合的元素 (并且谓词返回true) 时, 它才会返回true. - 只有当谓词对所有输入元素求值为
nil或false时, 它才会返回nil.
以下示例显示了我们如何使用
some来实现两个效果: 一是选择一组有效选项中的第一个, 二是使用哈希映射来转换值:(def prizes {"AB334XC" "2 Weeks in Mexico" ; ❶ "QA187ZA" "Vespa Scooter" "EF133KX" "Gold jewelry set" "RE395GG" "65 inches Tv set" "DF784RW" "Bicycle"}) (defn win [tickets] ; ❷ (or (some prizes tickets) "Sorry, try again")) (win ["TA818GS" "RE395GG" "JJ148XN"]) ; ❸ ;; "65 inches Tv set" (win ["MP357SQ" "MB263DK" "HF359PB"]) ;; "Sorry, try again" (win ["MP357SQ" "MB263DK" "QA187ZA"]) ;; "Vespa Scooter"
❶
prizes哈希映射包含了一系列彩票号码及其相关的奖品.❷ 在
win函数中, 我们可以检查一个人拥有的所有彩票. 使用some, 我们可以将一个潜在的双重中奖者 (因为他们有多于一张中奖彩票) 限制为只获得第一张中奖彩票的奖品. 从彩票号码到相关奖品的转换是通过使用哈希映射作为谓词函数来实现的.❸
win接收彩票列表, 以验证是否有中奖者以及他们获得了什么奖品. 如果some返回nil, 这意味着列表中没有中奖彩票. 我们可以用or来检查这种情况. 当没有找到奖品时, 会打印默认消息. - 另请参阅
every-pred与every?非常相似, 但它允许多个谓词, 用一个逻辑" 与" 组合所有排列. 如果你需要多个谓词, 请使用every-pred.some?不应与some(没有问号) 混淆.some?等同于(not (nil? x)), 用于验证某物不是nil. - 性能考虑和实现细节
=> O(n) 最坏情况, n 个集合中的项数
every?,not-every?,some和not-any?具有相似的性能配置文件. 在最坏的情况下, 它们需要对集合中的每个项检查谓词, 从而产生线性依赖. 最佳情况发生在集合为空时.通用实现基于尾递归
recur. 无需持有集合的头部, 因此实现是内存友好的. 以下代码产生十亿次迭代, 需要一些时间来执行 (取决于硬件配置):(every? pos? (range 1 (long 1e9)))
尽管创建了大量的长整型数, 内存配置文件仍然稳定, 垃圾回收工作量最小. 以下图片是在执行上述代码行时拍摄的, 显示了 VisualVM 132 对 JVM 内存的检查:
Figure 15: VisualVM 显示了在运行示例时 JVM 的内存配置文件.
在 "19:39:00", 执行在短暂的预热后开始. 代表已使用堆的蓝线在求值返回约 "19:39:30" 之前增长并释放了几次. 正如读者所见, 已使用的堆与当前分配的 330MB (橙色线可以增长到 512MB 的最大允许大小, 然后才会内存不足) 相比相当小, 并且被垃圾回收器优雅地回收了几次.
- 8.1.6 empty? 和 not-empty
自 1.0 版本以来的函数
(empty? [coll]) (not-empty [coll])
empty?和not-empty是用于验证集合是否为空或相反的简单函数:(empty? []) ;; true (not-empty []) ;; nil (empty? [1 2 3]) ;; false
not-empty并非严格意义上与empty?相反, 因为缺少问号表示not-empty返回nil或"coll"本身以表示逻辑真或假 (而不是布尔类型).- 约定
- 输入
"coll"可以是集合类型,nil, 字符串, 数组或通用的 Java iterable (例如(instance? java.lang.Iterable coll)为真). 不支持瞬态.
- 值得注意的异常
当 Clojure 无法将
"coll"转换为序列时, 会抛出IllegalArgumentException. 除了标量 (它们不是集合, 如数字, 符号, 关键字等) 之外, 对于瞬态和现在已弃用的结构体, 也会抛出异常. - 输出
empty?返回:- 当
"coll"为空, 或"coll"是空字符串, 或为nil时, 为true. - 否则为
false.
not-empty返回:- 当
"coll"为空, 或"coll"是空字符串, 或为nil时, 为nil. - 否则为
"coll".
注意
包含
nil的集合不是空集合! 因此(empty? [nil])为假. - 当
- 输入
- 示例
empty?和not-empty是用于组合一些惯用形式的方便函数. 例如, 以下代码片段从一个集合中移除所有空字符串 (包括nil), 但不移除至少有一个字符或更长的字符串:(remove empty? [nil "a" "" "nil" "" "b"]) ; ❶ ;; ("a" "nil" "b") ; ❷
❶
remove与empty?一起用作谓词.❷ 请注意, 字符串
"nil"不应与nil常量混淆.以下示例可用于将字符串转换为数字. 如果未使用
not-empty, 同样的代码将需要一个带有多个分支的条件或抛出异常. 通过使用not-empty, 我们可以摆脱像nil或空字符串这样的边界情况:(defn digit? [s] (every? #(Character/isDigit %) s)) ; ❶ (defn to-num [s] (and (not-empty s) (digit? s) (Long/valueOf s))) ; ❷ (to-num nil) ; ❸ ;; nil (to-num "") ;; nil (to-num "a") ;; false (when-let [n (to-num "12")] (* 2 n)) ; ❹ ;; 24 (when-let [n (to-num "12A")] (* 2 n)) ;; nil
❶
digit?验证一个字符串是否只包含数字. 注意, 当 "s" 为空时,every?返回空列表, 当 "s" 为nil时, 返回真.❷
and是短路的, 所以一旦其中一个表达式返回nil, 就不会有进一步的求值. 通过在链的顶部使用not-empty, 我们确保后续的求值不会得到nil或空字符串.❸ 一些使用
to-num的例子, 显示了当字符串不是一个合适的数字时会发生什么. 没有抛出异常, 唯一的可能输出是nil或假.❹
to-num的行为可以与when-let结合使用, 这样我们只有在绑定被设置后才能将 "n" 视为一个数字.请注意,
not-empty与when-let的使用在少量代码中实现了相当多的功能:(def coll [1 2 3]) (when-let [c (not-empty coll)] (pop c)) ; ❶ ;; [1 2] (when-let [c (seq coll)] (pop c)) ; ❷ ;; ClassCastException
❶
not-empty确保集合不为空, 而when-let仅根据not-empty的结果来分配局部绑定. 然后, 作为结果, 主体被用原始输入集合进行求值.❷
not-empty和seq之间的比较.seq大致等同于not-empty, 但有一个重要的注意事项:seq将集合转换为一个序列迭代器, 该迭代器与后续的pop调用不兼容. - 另请参阅
clojure.string/blank?是一个专门用于检查空字符串的函数.blank?比not-empty更健壮, 因为它会考虑空白. 例如, 如果一个字符串只包含空格:(clojure.string/blank? " ")返回true, 而(empty? " ")返回false. 如果字符串处理是主要目标,clojure.string中的函数通常更合适.seq在标准库中被广泛用于遍历序列集合.seq也可以用来检查一个集合是否不为空, 使用(seq coll).not-empty和seq在检查空集合时的主要区别是not-empty返回未更改的集合, 而seq返回输入集合的序列迭代器. 这个因素很重要, 如果seq或not-empty稍后在if-let或when-let中使用, 并且集合被进一步处理. - 性能考虑和实现细节
=> O(1) 常数时间
用
empty?检查一个集合是否为空是一个相当快的操作.empty?花费的时间与集合中元素的数量无关. 尽管使用empty?不应产生性能损失, 但如果你需要在紧凑的循环中检查空, 有一些方法可以使其更快, 例如使用count或将检查委托给 Java 的isEmpty()方法. 以下基准测试在向量上比较了这些方法:(require '[criterium.core :refer [quick-bench]]) (let [v (vec (range 1000))] (quick-bench (empty? v))) ; ❶ ;; Execution time mean : 18.222054 ns (let [v (vec (range 1000))] (quick-bench (zero? (count v)))) ; ❷ ;; Execution time mean : 7.026762 ns (let [v (vec (range 1000))] (quick-bench (.isEmpty ^java.util.Collection v))) ; ❸ ;; Execution time mean : 4.663188 ns
❶
empty?在向量 "v" 上使用.❷ 同样的向量使用
count来查看是否等于零. 这大约快了 50%.❸ Java 方法
isEmpty()存在于所有 Clojure 集合上. 为了避免使用反射, 应该使用类型提示. 这最后一种方法比count大约快 50%.empty?和not-empty的实现是基于seq的. 这在过去是许多讨论的主题 133. 如果, 一方面,seq在确定一个集合是否为空方面不如count快, 另一方面, 它允许惰性序列保持 (几乎) 惰性:seq(因此empty?) 只需要实现第一个元素 (或块). 以下示例说明了这一点:(empty? (map #(do (println "realizing" %) %) (range 100))) ; ❶ ;; realizing 0 ;; realizing 1 ;; [..] ;; realizing 31 ;; false (zero? (count (map #(do (println "realizing" %) %) (range 100)))) ; ❷ ;; realizing 0 ;; realizing 1 ;; [..] ;; realizing 99 ;; false
❶
empty?用于检查一个惰性序列是否为空. 该惰性序列包含一个副作用, 即在屏幕上打印一条消息. 我们可以看到在返回结果之前打印了 32 条消息, 这是实现一个惰性 (分块的) 序列的第一个" 块" 的结果.❷ 当在相同的输入上使用
count时, 整个惰性序列被实现.
- 约定
3.1.2. 8.2 多态
本章包含一系列缺乏与特定集合类型强关联的函数. 因此, 它们的行为可能根据输入而发生巨大变化.
没有完美的规则来决定哪个函数应该在本节中. 以下是选择 conj, get 和 contains? 而其他函数在别处描述的一些原因:
- 像
assoc这样的函数具有类似的多态能力:assoc可以在向量和 map 上使用, 语义非常不同. 尽管如此,assoc主要用于 map, 并且与它们有很强的关联. 对于一个专门讨论 map 的章节来说, 不包含assoc是很奇怪的, 因此它没有出现在这里. - 像
nth这样的函数也适用于许多类型 (不包括哈希映射和集合). 但nth在列表, 向量, 惰性序列等上使用时的行为是相同的.nth可以被认为是多态的, 但你需要注意的不是行为上的巨大差异 (除了性能配置文件).
注意
更一般地, 读者应将本书实现的分类视为一种工具, 以更好地可视化标准库的内容, 并通过关联, 命名或含义来帮助记住其内容.
- 8.2.1 conj
自 1.0 版本以来的函数
(conj ([coll x]) ([coll x & xs]))
conj(conjoining 的缩写) 将一个或多个元素插入到现有的集合中. 它将集合作为第一个参数:(conj [1 "a" :c] \x) ; ❶ ;; [1 "a" :c \x] (conj (range 3) 99) ; ❷ ;; (99 0 1 2) (conj {:a 1} [:b 2]) ; ❸ ;; {:a 1 :b 2}
❶ 字母
\x出现在输入向量的末尾.❷ 数字 "99" 出现在序列的开头.
❸ 向量
[:b 2]被conj解释为输入哈希映射的键值对.该示例显示了
conj在以下方面的多态行为: 元素被添加的位置 (在开头或结尾) 或一些特殊的输入格式 (例如 map 需要两个项的向量). 总的来说,conj委托接受的集合来执行最有效的插入.- 约定
- 输入
"coll"可以是任何集合类型, 但不支持数组和 Java 集合 (例如java.util.ArrayList). 当"coll"为nil时, 默认使用空列表()."x & xs"是要添加到"coll"的一个或多个项. 它们可以是nil.
"x & xs"对于列表, 向量, 子向量, 集合和一般序列可以是任何类型. 对于其他类型的"coll"有一些限制:- 如果
"coll"是类型为 "T" 的原始类型向量, 那么"x"需要是与 "T" 兼容的类型. 兼容性可以通过将"x"应用到类型 "T" 的 Clojure 类型转换运算符 (如int,char等) 之一来验证, 例如:(int \a)是一个有效的操作, 所以一个(vector-of :char)可以接受整数 (只在 0 到 65535 之间, 这是java.lang.Character的允许范围, 一个无符号的 16 位值). - 如果
"coll"是 map 类型 (不包括排序的), 那么"x"可以是: - 一个两个元素的向量.
- 一个实现了
java.util.Entry接口的对象 (一个例子是在用(first {:a 1}})进行序列化时获得的clojure.lang.MapEntry对象). - 另一个 map (如
(conj {:a 1} {:b 2 :c 3})). - 一个记录定义 (例如
(defrecord Point [x y])). - 一个空的序列集合, 如
#{},""或(). 注意不支持列表对, 所以(conj {} '(1 2))会抛出异常. - 如果
"coll"是一个排序的集合或排序的 map, 那么"x"需要遵循"coll"中元素类型之间的compare兼容性规则. 对于 map, 该规则仅适用于键.
- 值得注意的异常
当
"coll"是 map 类型且"x"是seq不支持的集合时, 抛出IllegalArgumentException. - 输出
返回: 将
"x"和任何其他参数添加到"coll"的结果. 元素将出现在"coll"的开头 (对于列表和惰性序列), 在"coll"的末尾 (对于向量系列的类型), 或不确定 (对于无序集合如 map 或 set).
- 输入
- 示例
conj最常见的用法是向向量或序列中插入单个项. 但正如约定中所示,conj还有更多用于不同集合类型的方式. 以下示例显示了一些最有趣的情况:(conj () 1 2 3) ; ❶ ;; (3 2 1) (conj {:a 1 :b 2} {:c 3 :d 4}) ; ❷ ;; {:a 1, :b 2, :c 3, :d 4} (defrecord Person [name age]) (defrecord Address [number street zip]) (defrecord Phone [mobile work]) (conj ; ❸ (Person. "Jake" "38") (Address. 18 "High Street" 60160) (Phone. "801-506-213" "299-12-213-22")) ;; #user.Person{:name "Jake", :age "38", :number 18, :street "High Street", :zip 60160, :mobile "801-506-213", :work "299-12-213-22"} (def q (conj (clojure.lang.PersistentQueue/EMPTY) 1 2 3)) ; ❹ (peek q) ;; 1
❶ 可以在一次调用中添加多个元素.
❷ 这种
conj的用法等价于merge. 参数中的第二个 map 被顺序迭代, 每个键值对被添加到第一个 map 参数中.❸ 由于记录实现了 map 语义, 我们可以使用
conj来将多个记录合并在一起.❹
conj当然是将元素推入PersistentQueue的一种惯用方法.在递归期间,
conj可用于增量地构建结果. 以下示例显示了一个将文本片段写入磁盘的函数. 该函数期望一个包含标题和片段作为字符串的向量作为输入. 该函数写入磁盘并输出创建的文件的列表:(require '[clojure.java.io :as io]) (defn- fname [dir path] ; ❶ (str dir "/" path ".clj")) (defn write [examples root] ; ❷ (loop [[title forms :as more] examples files []] (if title (let [dir (str root "/" title) paths (map-indexed #(vector (fname dir %1) %2) forms)] ; ❸ (doseq [[path content] paths] (io/make-parents (io/file path)) ; ❹ (spit path content)) ; ❺ (recur (nnext more) (apply conj files paths))) ; ❻ (map first files)))) (def examples ["add" ["(+ 1 1)" "(+ 1 2 2)" "(apply + (range 10))"] "sub" ["(map - [1 2 3])" "(- 1)"] "mul" ["(*)" "(fn sq [x] (* x x))"] "div" ["(/ 1 2)" "(/ 1 0.)"]]) (write examples "/tmp") ; ❼ ;; ("/tmp/add/0.clj" ;; "/tmp/add/1.clj" ;; "/tmp/add/2.clj" ;; "/tmp/sub/0.clj" ;; "/tmp/sub/1.clj" ;; "/tmp/mul/0.clj" ;; "/tmp/mul/1.clj" ;; "/tmp/div/0.clj" ;; "/tmp/div/1.clj")
❶
fname将一个文件夹路径和一个带有扩展名 "clj" 的文件名连接在一起.❷
write是一个在输入示例列表上递归的函数. 它写入片段到磁盘, 在每次迭代时累积它们的绝对路径. 累积过程是conj的一个很好的候选者.❸
map-indexed创建一个包含数字, 路径和内容元组的列表.doseq在map-indexed的输出上解构, 在下面几行.❹ 第一个副作用是创建一个或多个与文件应写入的路径相对应的文件夹.
❺ 第二个副作用为每个片段创建一个文件, 用一个序列号命名该文件.
❻ 函数递归, 使用
nnext步进到输入的下 2 个元素. 在调用recur时, 结果通过conj推入累积的结果向量中.❼ 我们可以看到在调用
write函数后创建的文件的列表.- conj 和 cons
对于 Clojure 初学者来说, 理解
conj和cons这两个名字非常相似 (目标也非常相似) 的函数存在的原因常常是一个问题.cons是一个具有 Lisp 传统的函数, 与通过创建一个额外的" 单元" 来容纳新项和列表其余部分来将新元素链接到列表的概念相关. Clojure 实现了一个类似的设计, 其中新元素包装了现有的列表, 因此在迭代期间, 最后添加的元素首先出现.cons在 Clojure 中存在, 其具体目标是创建一个新的" cons 单元" , 因此它只对列表或序列有意义.cons也适用于向量, 但向量首先被转换为序列, 完全忽略了向量的特性.为了让 Clojure 支持序列和类似向量的集合 (向量, 映射和集合都基于相同的 数据结构), 设计了一个
conj函数, 将插入逻辑与集合实现解耦.conj委托输入集合以最佳方式添加新元素. 对于序列, 它只是委托回cons逻辑, 但对于向量, 它将新元素添加到向量的末尾, 那里有一个" 尾部缓冲区" 可用 (有关实现细节, 请参见vector). 委托输入参数以找到实现操作的最佳方式是 Clojure 标准库中的一个常见主题.
- conj 和 cons
- 另请参阅
cons适用于序列 (列表, 范围或惰性序列) 和序列对象 (因此包括向量, 集合, 映射等).conj委托给列表和序列的内部cons方法, 因此在一般情况下,conj是最佳选择.cons还有其他应用, 包括构建自定义的惰性序列.conj!是一个专门用于瞬态的conj操作. 瞬态是一个特殊的集合状态, 在该状态下, 通常不可变的数据结构可以变异. 一组专门用于瞬态的函数 (以感叹号结尾).into, 类似于conj, 将一个集合的元素添加到另一个. 对于批量插入许多项, 优先使用into, 因为into针对此类操作进行了优化. 优先使用conj来一次一个地逐步构建一个集合.assoc在某个索引处插入一个新值. 对于映射, 索引是键, 对于向量, 它是项序列中的从零开始的序数位置. 在向量上使用conj将简单地添加到向量的末尾, 用assoc你可以更多地控制新元素将出现的位置 (完全替换旧的). 当目标是在特定位置/键处插入和替换一个元素时, 使用assoc.
- 性能考虑和实现细节
=> O(1) (近) 常数时间 (无序集合)
=> O(log n) 对数时间 (有序集合)
conj委托输入集合来找到添加新元素的最佳方式.conj对 map 和 set (有序或无序) 的实现与对序列集合 (向量, 列表, 范围等) 的实现是非常不同的操作, 后者可以简单地追加元素而无需担心现有内容.下图显示了 map 和 set (有序和无序) 的比较. 在所有情况下,
conj都用于向一个越来越大的数据结构中添加一个不存在的键 (最多 100 万个键). 对于排序的集合, 新键被选择为大致在中间 (使用整数类型) 的现有键.
Figure 16: conj 对 set 和 map 的效率, 有序和无序.
conj对于排序的 map 和排序的 set 是 O(log N). 这对于一个有序集合来说是一个显著的特性. 在无序 map (或 set) 上的conj则是近 O(1) 常数时间 (更准确地说是 O(log 32 N), 这在大多数实际情况下是无关紧要的).下一个图表在一些最常用的序列类型上重复了类似的基准测试. 如预期的那样,
conj在这些类型上的性能更快, 因为不需要检查元素的存在, 或在底层数据结构的特定位置为新的键值对准备空间.
Figure 17: conj 对序列数据结构的效率.
列表和范围上非常快的结果主要是因为
conj只是创建了一个 cons-cell, 一个链接到集合其余部分的小对象. 读者还应记住,conj并非为批量插入许多元素而设计 (对于这种情况, 其他函数如into更适合).
- 约定
- 8.2.2 get
自 1.0 版本以来的函数
(get ([map key]) ([map key not-found]))
在访问集合的函数组中 (
nth和find是其他函数),get专门用于 map (尽管它也适用于其他类型):(get {:a "a" :b "b"} :a) ;; "a"
get的设计是避免抛出异常, 当集合类型不支持时, 优先返回nil:(get (list 1 2 3) 1) ;; nil
get提供了一个第三个参数, 当元素未找到或集合不受支持时返回该参数:(def colls [[1 2 3] {:a 1 :b 2} '(1 2 3)]) (def ks [-1 :z 0]) (def messages ["not found" "not found" "not supported"]) (map get colls ks messages) ; ❶ ;; ("not found" "not found" "not supported")
❶ 我们使用
map的可变参数性来同时用每个集合中的一组项来调用get.这一点, 加上返回
nil而不是异常, 使得get在处理混合类型输入时非常灵活:- 约定
- 输入
第一个名为 "map" 的参数不限于 map 类型. 它也可以是:
- Set (有序但非瞬态).
- 用
defrecord创建的记录. - 实现了
java.util.Map接口的类 (例如java.util.HashMap对象实例).
其他参数是:
"key"可以是任何对象. 当"map"参数是向量时,"key"被限制为直到(Integer/MAX_VALUE)的正整数. 当"key"超出该范围时,get的结果可能难以预测, 因为"key"将被截断为整数, 可能会丢失精度."not-found"是可选的, 可以是任何类型. 当请求的索引不存在时, 返回"not-found".nil被接受为一种退化的集合类型. 对nil调用get总是返回nil, 除非提供了"not-found".
当
"key"是一个数字时,"map"还可以是:- 向量 (包括子向量和原生向量).
- 一个原生 Java 数组 (例如用
make-array或int-array创建的). - 一个字符串.
- 值得注意的异常
当
"coll"是一个sorted-map或sorted-set且"key"与"coll"的内容不兼容时, 会抛出ClassCastException. 要兼容,"key"的类型和"coll"的内容需要是相同的或有一个合适的比较器. 有关更多信息, 请参见示例. - 输出
get返回一个值, 该值的含义取决于"coll"的类型:- 当
coll是哈希映射, 排序映射, 数组映射或它们的瞬态变体时, 返回键 "key" 处的值 (排序映射除外, 它不能是瞬态的). - 当
coll是Set,transient set或sorted-set且"key"是集合中的元素之一时, 返回 "key". - 当
"coll"是向量, 瞬态向量, 子向量或原生向量时, 返回索引 "key" 处的项. "key" 在这种情况下被假定为数值. - 在记录实例中, 返回字段 "key" 处的值, 类似于 map 访问.
- 在缺少所请求的索引, 值或项的情况下, 返回 "not-found" 参数 (如果存在).
- 当
"coll"为nil且没有给出默认值时, 返回nil. - 在所有其他情况下返回
nil.
- 当
- 输入
- 示例
get约定包含一些值得作为示例强调的异常情况. 第一个与排序集合有关. 当元素被添加到排序集合时, 类型受是否存在一个合适的比较器来比较它们的限制. 这种限制的原因来自于 Clojure 中排序集合实现的二叉树搜索算法. 搜索通过与目标对象比较来决定下降左分支还是右分支. 有序树允许 O(logN) 平均搜索时间, 但代价是一些灵活性降低:(get (sorted-map :a 1 :b 2) :c "not-found") ; ❶ ;; "not-found" (get (sorted-map :a 1 :b 2) "c" "not-found") ; ❷ ;; ClassCastException clojure.lang.Keyword cannot be cast to java.lang.String
❶
get正在搜索一个不存在的键. 因此返回默认值.❷ 另一个不存在的键的情况, 但其类型无法与 map 中的关键字进行比较.
get约定的第二个有趣案例与瞬态集合有关.get可以正确访问瞬态 map 或 vector, 但不能对瞬态 set 做同样的事情. 这是一个应该在下一个 Clojure 版本中修复的 bug 134:(get (transient {:a 1 :b 2}) :a) ; ❶ ;; 1 (get (transient [1 2 3]) 0) ; ❷ ;; 1 (get (transient #{0 1 2}) 1) ; ❸ ;; nil
❶
get在一个瞬态 map 上使用.❷
get在一个瞬态 vector 上使用.❸ 在一个瞬态 set 上使用的
get无法找到一个现有的元素.最后一个令人惊讶的行为发生在数值键超过整数允许的最大值时.
get的实现使用了(Number/intValue)进行有损的整数截断, 这可能会返回意想不到的结果. 数值键允许用于向量, 字符串和数组:(+ 2 (* 2 (Integer/MAX_VALUE))) ; ❶ ;; 4294967296 (.intValue 4294967296) ;; 0 (get ["a" "b" "c"] 4294967296) ; ❷ ;; "a" (get "abcd" 4294967296) ;; \a (get (int-array [0 1 2]) 4294967296) ;; 0
❶ 一个足够大的数在被强制转换为整数时可能会错误地返回有效的索引.
❷
get在向量, 字符串和数组上使用一个足够大的数. 预期是get会返回nil.get是专用于集合中元素查找的一组函数中最具弹性的. 它适用于所有类型 (甚至标量), 代价是返回nil而不是抛出异常. 它还接受nil集合作为输入, 这使其在目标集合可能为nil时成为一个很好的候选者:(def mixed-bag [{1 "a"} [0 2 4] nil "abba" 3 '(())]) (map #(get % 1) mixed-bag) ; ❶ ;; ("a" 2 nil \b nil nil)
❶
get在几乎所有情况下都有效.get也接受实现了java.util.Map接口的对象, 这在一些 Java 互操作性场景中很典型. 例如, 像System/getProperties或System/getenv这样的 Java 方法对于收集有关运行环境的信息很有用, 它们返回 Java map. 以下示例展示了我们如何使用get来搜索有趣的环境属性:(defn select-matching [m k] ; ❶ (let [regex (re-pattern (str ".*" k ".*"))] (->> (keys m) (filter #(re-find regex (.toLowerCase %))) ; ❷ (reduce #(assoc %1 (keyword %2) (get m %2)) {})))) ; ❸ (defn search [k] ; ❹ (merge (select-matching (System/getProperties) k) (select-matching (System/getenv) k))) (search "user") ; ❺ ;; {:USER "reborg" ;; :user.country "GB" ;; :user.language "en" ;; :user.name "reborg"}
❶
select-matching在 Java map 中搜索给定的键 (或其一部分).❷ 正则表达式是根据给定的键名构建的, 并用于过滤匹配的键, 不区分大小写.
❸ 后续的
reduce操作会构建一个包含匹配键的新 Clojure map. 使用get对于访问 Java map 的相关值至关重要.❹
search包装了对系统属性和环境的访问, 在实际选择之前将它们合并在一起.❺ 我们可以看到搜索 "user" 的结果, 产生一个包含匹配键的 Clojure map. 在其他系统上, 内容可能会有所不同.
- Clojure 中访问 map 的多种方式
get可能是 Clojure 中访问 map 最正式的方式. 除非你特别关心get对nil的处理或 Java 互操作性, 否则开发者更喜欢其他 (通常更简洁) 的方式. 这些方式如下所示.- map 作为可调用函数
" Map 作为函数" 是 Clojure 区别于其他语言的特性之一. 它的工作原理是将 map 作为列表中的第一项, 这样它就可以被解释为一个函数调用及其参数:
({:a 1 :b 2} :b) ; ❶ ;; 2 ({:a 1 :b 2} :c "Not found") ; ❷ ;; "Not found"
❶ 使用哈希映射
{:a 1 :b 2}作为函数来访问:b键.❷ 可选的第二个参数在找不到键时返回.
哈希映射实现了
clojure.lang.IFn接口, 因此定义了一个invoke方法, 当 map 出现在可调用位置时使用. 它支持第二个参数, 当找不到键时用作默认值, 正如get函数一样.get和" map as a function" 甚至共享相同的实现, 最终都调用了clojure.lang.ILookup接口的valAt()方法. - 关键字作为可调用函数
关键字也像 map 一样是可调用函数. 它们接受一个 map 作为它们的第一个参数 (以及其他类型的关联数据结构, 如向量). 然后关键字将在 map 键中查找其自身的实例:
(:b {:a 1 :b 2}) ; ❶ ;; 2 (:c {:a 1 :b 2} "Not found") ; ❷ ;; "Not found"
❶ 关键字在可调用位置时行为类似于 map. ❷ 像
get一样, 它们也支持一个可选的第二个参数, 在找不到键时返回.关键字也实现了
clojure.lang.IFn接口, 并委托给相同的valAt()方法. - Java 互操作
Clojure map 也是
java.util.Map的实例, 所以你也可以用get(Object key)Java 方法来访问它们:(.get {:a 1 :b 2} :b) ; ❶ ;; 2 (.getOrDefault {:a 1 :b 2} :c "Not found") ; ❷ ;; "Not found"
❶ 注意
".get"前面的 ".". 它是调用 Java 方法 "get" 在对象{"a 1 "b 2}上的语法糖.❷ 与
get, " map 作为函数" 和" 关键字作为函数" 不同,java.util.Map接口没有一个接受可选的第二个参数的get()方法重载. 取而代之的是一个特定的方法getOrDefault(). - Find
find与目前看到的其他方法类似, 但将结果包装在一个java.util.Map.Entry对象中 (Clojure 在其自己的clojure.lang.IMapEntry接口中扩展了该对象). 除了将最终结果包装在一个新创建的 map 条目对象中, 它与get共享相同的实现:(find {:a 1 :b 2} :b) ; ❶ ;; [:b 2] (type (find {:a 1 :b 2} :b)) ; ❷ ;; clojure.lang.MapEntry
❶ 使用
find访问 map 中的键.❷
find不支持用于默认值的可选第二个参数. 我们可以看到返回的类型, 虽然打印起来像一个向量, 但实际上是一个MapEntry对象.在 Map 中选择哪种方式访问键取决于不同应用如何使用 Map. 在这种情况下, 性能不是一个问题, 因为无论使用哪种方法, Map 访问总体上都是一个非常快速的操作.
- map 作为可调用函数
- Clojure 中访问 map 的多种方式
- 另请参阅
find类似于get, 但它返回条目 map 元组 (一个两个元素的向量), 而不仅仅是值. 如果你需要使用值但又想保持它与其键的关系,find是完美的选择.select-keys可以一次性访问多个键, 并返回一个包含这些键值对的 map. 使用select-keys可以一次性选择多个值及其对应的键.nth通过索引访问一个元素.get也适用于向量, 但nth是专门用于该目标的. 当参数是向量时,get实际上使用nth. 除非你对get处理nil的灵活性感兴趣, 否则在向量上优先使用nth.get-in允许从嵌套的 map (或get支持的不同类型的集合) 中获取值, 而无需嵌套get调用:(def m {:a "a" :b [:x :y :z]}) (get (get m :b) 0) ; ❶ ;; :x (get-in m [:b 0]) ; ❷ ;; x
❶
getofget用于访问键":b"处的向量.❷ 可以用
get-in访问向量中的相同元素. - 性能考虑和实现细节
=> O(1) 常数时间 (最佳情况, 无序集合)
=> O(log n) 对数时间 (最坏情况, 有序集合)
get的性能取决于输入集合的类型. 以下基准测试图表显示了在越来越大的集合上使用get对不同类型集合的情况. 该基准测试是通过创建一个随机关键字键的 map (例如::12376,:47882等) 来获得的. 目标键大致位于可用值的中间.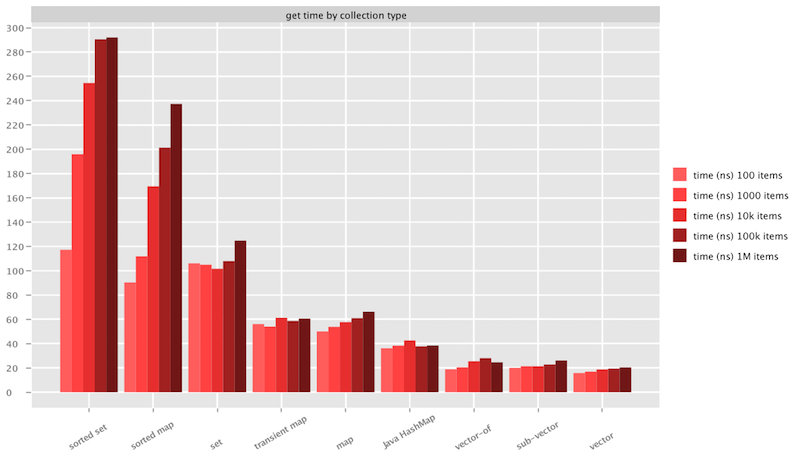
Figure 18: 使用 get 访问几种集合类型.
总的来说,
get是一个快速的操作, 不应引起特别的关注 (时间单位是纳秒, 在最近的笔记本电脑上). 排序集合受到惩罚, 因为访问需要比较一个平衡树 135 的每个分支的键. 另请注意, 对于排序集合,get是 O(log N) 操作, 而对于其他集合, 它大致是常数时间 (它不是完美的常数时间, 因为持久化集合是建立在一个非常浅的树之上的). 在排序集合之后, 集合大约比 map 慢 2 倍. 在此之后, 向量在get访问方面快 2 倍.就
get与其他访问 map 的方式相比 (我们在本章前面说明了访问 map 的不同方式), 请看下图.该图比较了在越来越大的 map 上 (最多 100 万个键) 访问一个键的 6 种不同方式. 请再次注意, 时间单位是纳秒, 总的来说我们谈论的是非常快速的操作. 图中的条形图, 从左到右, 是:
"get"显示了对 map 的get访问. 它的平均访问时间约为 30 纳秒."find"使用了函数find, 尽管创建了 map-entry 对象, 但它的性能大致与get相同. 这可以用find中缺少对nil的检查和默认值来解释."keyword"使用键本身来访问 map. 它比get快 10%.".get clj-map"使用 Java 互操作.getJava 方法来访问 Clojure 中的持久化哈希映射."map"使用 map 本身作为函数来访问键.".get java-map"再次使用 Java 互操作, 但不是访问 Clojure map, 而是显示了当我们访问一个原生的可变java.util.HashMap对象时会发生什么.
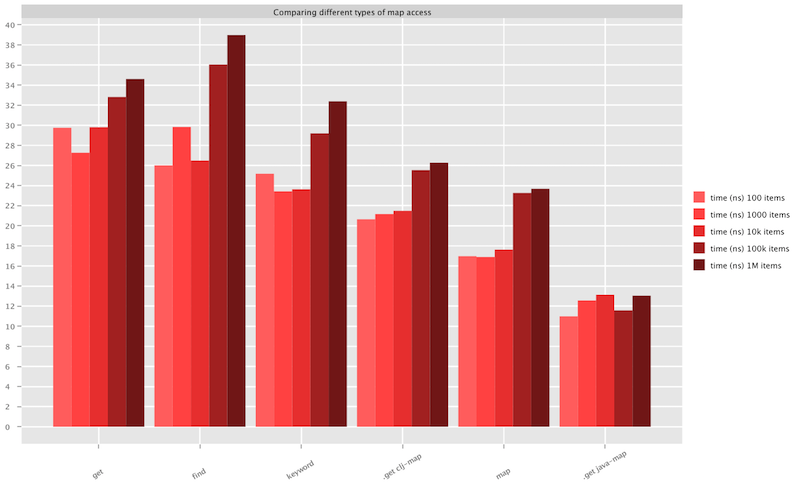
Figure 19: 比较访问 map 的不同方式.
该图基本上显示了 Clojure 在 (读访问) 方面与可变的 Java HashMap 的性能有多好. 它还显示了将 map 对象直接用作键上的函数是可读性和速度的最佳选择之一. 当我们想要处理可能为
nil的 map 而不使用显式条件, 或者我们想要访问 Java HashMap 时,get仍然是一个非常好的选择.
- 约定
- 8.2.3 contains?
自 1.0 版本以来的函数
(contains? [coll key])
contains?验证在支持直接访问查找的集合中是否存在" 键" (元素或索引). 根据查找实现的不同, 如果找到了与键相等的元素, 或者在由键指示的索引处找到了元素, 它会返回true或false. 以下是最常见的用法:(contains? {:a "a" :b "b"} :b) ; ❶ ;; true (contains? #{:x :y :z} :z) ; ❷ ;; true (contains? [:a :b :c] 1) ; ❸ ;; true
❶ 在哈希映射中找到了一个等于
":b"的键.❷ 在集合中找到了一个等于
":z"的元素.❸ 在向量的索引 "1" 处存在一个元素.
支持其他类型, 尽管它们的使用不太常见. 约定部分将更详细地介绍.
- 约定
- 输入
contains?的主要目标是检查" 关联" 数据结构中是否存在元素. 在 Clojure 中, " 关联" 是一个广泛的类别, 包括 map, vector, 以及与 map 相关的 record. set 不实现clojure.lang.Associative接口, 但contains?支持它们. 以下是" coll" 参数所有支持的集合及其相关限制的详尽列表:- map (排序但非瞬态).
- Set (排序但非瞬态).
- vector (包括子向量和原生向量).
- 用
defrecord创建的记录. - 实现了
java.util.Map接口的类 (例如java.util.HashMap对象实例). - 实现了
java.util.Set接口的类 (例如java.util.HashSet对象实例). - 当
"key"是一个数字时,"coll"还可以是一个字符串或一个原生 Java 数组. nil被接受为一种退化的集合类型.
当
"coll"是向量类型时,"key"可以是任何正整数, 直到 2- 当
"key"超出该范围时,contains?的结果取决于将键截断为整数的结果 (这可能是有损的). 例如:
(def power-2-32 (long (Math/pow 2 32))) ; ❶ (contains? [1 2 3] power-2-32) ; ❷ ;; true
❶
power-2-32是 4294967296. 它超出了 Java 的 32 位整数大小.❷
contains?内部通过用(.intValue 4294967296)将"key"截断来确保它是整数, 结果为 0. - 值得注意的异常
- 当在特定集合类型上不支持
contains?时, 抛出IllegalArgumentException. 值得注意的例子包括clojure.lang.PersistentQueue,java.util.ArrayList和一般的瞬态. - 当
"coll"是sorted-map或sorted-set且"key"与"coll"的内容不兼容时, 抛出ClassCastException.
- 当在特定集合类型上不支持
- 输出
contains?的含义取决于"coll"的类型. 当出现以下情况时,contains?返回true:- 当
"coll"是哈希映射, 排序映射, 数组映射或 Java map 类型时, "key" 存在. - 当
"coll"是Set或sorted-set或 Java set 类型时, "key" 在集合中. - 当
"coll"是向量, 子向量, 原生向量或字符串时, 索引 "key" 存在. "key" 在这种情况下必须是数字. - 当
"coll"是原生 Java 数组时, 索引 "key" 存在. - 在记录实例中有字段 "key", 类似于 map 访问.
当
"coll"为nil以及对于所有其他类型时,contains?返回false(或异常). - 当
- 输入
- 示例
contains?区分了哈希映射中存在值为nil的键和不存在键. 其他函数, 如get, 当用作条件时可能会返回意想不到的结果:(def m {:a 1 :b nil :c 3}) ; ❶ (if (get m :b) "Key found" "Key not found") ; ❷ ;; Key not found (if (contains? m :b) "Key found" "Key not found") ; ❸ ;; Key found (if-not (= ::none (get m :b ::none)) "Key found" "Key not found") ; ❹ ;; Key found
❶ map "m" 包含一个值为
nil的键":b".❷ 使用
get检查键的存在会给出错误的结果, 因为这里的nil指的是值nil, 而不是":b"键的缺失.❸
contains?是检查键是否存在的更好选择.❹ 要用
get达到同样的效果, 我们需要一个哨兵值::none作为默认值, 以便与潜在的nil区分开来.为了进一步说明这个问题, 让我们来看一组电子设备的输出. 该设备呈现一个" nil" 来表示传感器在被请求时没有发送响应. 以下示例显示了我们如何使用
contains?来验证 Clojure 哈希集合中是否存在一个nil" 键" :(def sensor-read ; ❶ [{:id "AR2" :location 2 :status "ok"} {:id "EF8" :location 2 :status "ok"} nil {:id "RR2" :location 1 :status "ok"} nil {:id "GT4" :location 1 :status "ok"} {:id "YR3" :location 4 :status "ok"}]) (defn problems? [sensors] (contains? (into #{} sensors) nil)) ; ❷ (defn raise-on-error [sensors] (if (problems? sensors) (throw (RuntimeException. "At least one sensor is malfunctioning")) :ok)) (raise-on-error sensor-read) ; ❸ ;; RuntimeException At least one sensor is malfunctioning
❶
sensor-read是一个包含传感器数据作为 map 的向量的示例. 两个传感器没有返回数据, 结果是nil.❷
contains?被用来构建一个谓词函数problems?, 该函数可用于验证集合中是否存在nil.❸ 在至少一个传感器读取失败的情况下, 它正确地抛出了一个异常.
请注意, 使用集合作为函数并传递
nil作为参数的常见方法在这种情况下将不起作用:((into #{} sensor-read) nil) ; ❶ ;; nil
❶ 在集合中检查
nil的存在, 使用集合作为函数会产生一个模棱两可的结果.在这种情况下返回的
nil是模棱两可的: 它可能指nil是一个匹配的元素, 也可能指nil不在集合中.contains?是解决这个问题的正确函数.- contains? 的多种含义
当人们第一次接触
contains?时, 它经常会产生混淆 136. 这种混淆主要来自于在向量中搜索键的含义 (与在集合或 map 中相比). 下面例子中使用的键 "4" 代表了向量中一个可能的索引. 该向量在索引 0 到 3 处包含元素, 因此在这种情况下contains?返回假:(contains? [1 2 3 4] 4) ; ❶ ;; false (contains? [:a :b :c :d] :a) ; ❷ ;; false
❶ 在向量上使用
contains?需要使用一个整数作为第二个参数.❷ 数组索引应在整数范围内. 当使用除整数以外的类型时, 在向量上使用
contains?总是返回假.在向量上使用
contains?只有在第二个参数是整数时才有效. 其他类型也被接受, 但它们总是返回假, 这增加了某些表达式的混淆, 其中元素明显存在于向量中.Clojure 初学者期望在向量上使用
contains?会对向量中的元素进行线性搜索, 而不是检查元素在索引处的存在, 过去有很多关于更改contains?名称或引入一个不同的函数来扫描集合中元素的讨论.contains?被有意地设计成这样, 以防止在那些可能产生线性搜索的上下文中使用. Clojure 中有其他可用的选项来进行元素的线性扫描, 这些选项更明确 (例如some或.containsJava 互操作). 这防止了对标准库函数和数据结构的滥用, 这会导致性能次优.
- contains? 的多种含义
- 另请参阅
some可用于在向量和其他序列集合上执行线性扫描:(some #{:a} [:a :b :c]). 与contains?相比, 有两个限制:some需要一个谓词, 所以要搜索的元素通常最终会放在一个集合中. 另一个问题是它不能用来搜索nil元素. 这可以通过使用相等性作为谓词来解决: 当val是nil时,(some #(= val %) coll)是有效的..contains不属于标准库, 但它是一个类似的 Java 方法. 许多 Clojure 数据结构都支持java.util.Collection接口, 但 map 除外..contains也适用于字符串, 并允许搜索子字符串:(.contains [:a :b :c :d] :a) ; ❶ ;; true (.contains {:a 1} :a) ; ❷ ;; IllegalArgumentException No matching method found (.contains "somelongstring" "long") ; ❸ ;; true
❶ 与
contains?相比, Java 互操作版本.contains验证了元素在集合中的存在 (而不是索引).❷
.contains在哈希映射上不起作用, 但它在哈希集合 (有序, 无序或瞬态) 上起作用.❸ 在字符串上,
.contains验证子字符串的存在. - 性能考虑和实现细节
=> O(1) 常数时间 (实际)
=> O(log N) 真实
contains?是围绕关联数据结构 (支持按索引直接查找的集合) 设计的. Map, set 和 vector 是作为哈希数组映射树 137 的变体实现的, 具有缓慢增加的 O(log 32 N) 配置文件, 而排序的集合是二叉树, 这同样是对数的, 但具有不同的常数因子 (O log 2 N). 算法家族在所有情况下都是对数的.然而, 我们在实践中将
contains?的性能称为常数时间 (这是对许多其他 Clojure 函数的有效考虑). 我们可以通过下面的图表来验证这个假设, 该图表显示了contains?在不同的常数因子下以对数时间执行 138: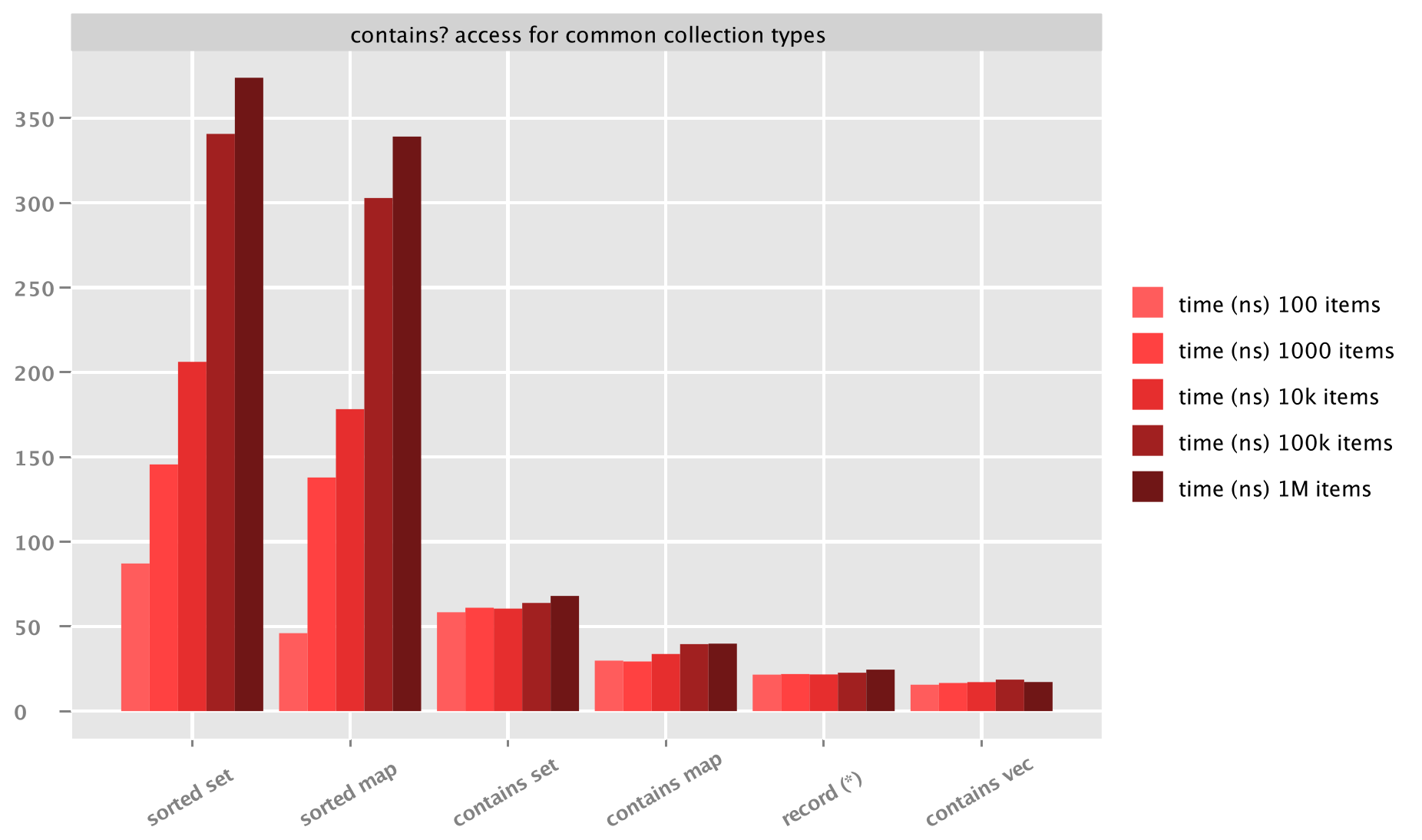
Figure 20: contains? 对于所有实际目的, 性能大致为常数时间.
该图表显示, 随着集合中项目数量的增加, 所有集合类型的平均访问时间都在缓慢增加. 考虑到规模, 对排序集合来说, 这比对向量更容易看到. 在实现方面,
contains?主要是在 Clojure 的 Java 端编写的, 其中一个简单的入口点将调用分派到正确的数据类型. 对于向量, 实现只是检查所请求的索引是否在向量的长度范围内.
- 约定
3.1.3. 8.3 通用
本章包含了一系列可以与不同集合一起使用的通用函数. 尽管它们在某些集合类型上可能有轻微的性能问题, 但它们产生的代码很简洁, 对于大多数情况来说都足够强大. 对每个函数都说明了广泛的示例和惯用法. 对于那些仍然需要理解其权衡的函数, 添加了按集合类型的性能图表.
- 8.3.1 rand-nth
自 1.2 版本以来的函数
(rand-nth [coll])
rand-nth从一个集合中随机选择一个元素 (不包括 map 和 set) 并返回它:(rand-nth (range 10)) ; ❶ ;; 2 (rand-nth "abcdefghijklmnopqrstuvwxyz") ; ❷ ;; \b
❶
rand-nth用于检索一个随机的个位数.❷
rand-nth返回集合中的任何一个元素. 在这种情况下, 它返回了\b, 但在你的电脑上结果可能会有所不同.rand-nth提供的" 随机性" 与rand提供的相同,rand是一个基于标准 Java 库的伪数生成器. 对于许多实际应用,rand-nth已经足够随机, 并且在输入集合的元素之间平均分配选择概率. 有关rand-nth限制的更多信息, 请参阅rand中的标注部分.- 约定
rand-nth(正如其名所示) 是建立在nth之上的, 集合需要被" 计数" 以防止超出最大可用索引 (有关计数集合的更多信息, 请参阅count).nth和count的限制组合适用于rand-nth, 如下所示:- 输入
"coll"可以是任何集合类型, 不包括 map (hash-map, sorted-map, record), set 和瞬态.rand-nth也适用于java.util.ArrayList或原生数组.- 不接受空集合作为输入.
nil被接受为一种退化的集合类型, 并且总是返回nil作为输出.
- 值得注意的异常
IndexOutOfBoundsException: 当输入集合为空时.UnsupportedOperationException: 当"coll"不是一个序列集合时, 例如对于标量值 (长整型, 字符) 或不支持的数据类型, 如 map 和 set.ArithmeticException: 如果集合中的元素数量超过(Integer/MAX_VALUE).
- 输出
- 从输入集合中随机选择的一个元素.
- 当
"coll"为nil或当nil存在于集合中并被选中时, 返回nil.
- 输入
- 示例
rand-nth可用于从典型的枚举中检索随机选择, 例如骰子的面或抛硬币:(defn roll-dice [] ; ❶ (rand-nth [1 2 3 4 5 6])) (defn flip-coin [] ; ❷ (rand-nth ["heads" "tails"]))
❶ 简单的实用函数
roll-dice, 用于返回 1 到 6 之间等概率的数字.❷ 同样简单的辅助函数
flip-coin, 用于以 50% 的概率返回 "heads" 或 "tails".rand-nth经常在游戏中用于避免重复性. 例如, 在let中实现" 石头剪刀布" 游戏时, 它被用来随机化计算机的选择.以下示例展示了如何根据语法生成谚语. 尽管语法规则非常简单, 它仍然可以生成一些真实的结果:
(def article ["A" "The" "A" "All"]) (def adjective ["nearer" "best" "better" "darkest" "good" "bad" "hard" "long" "sharp"]) (def subject ["fool" "wise" "penny" "change" "friend" "family" "proof" "necessity" "experience" "honesty" "no one" "everyone" "every"]) (def action ["is" "is not" "are" "are not" "help" "be" "create"]) (def ending ["dying." "a dangerous thing." "a lot of noise." "no pain." "stronger than words." "those who fall." "nothing."]) (def grammar ; ❶ [article adjective subject action ending]) (defn to-sentence [grammar] ; ❷ (->> grammar (map rand-nth) ; ❸ (interpose " ") (apply str))) (defn generate ; ❹ ([] (generate 1)) ([n] (repeatedly n #(to-sentence grammar)))) (generate 5) ;; ("A bad experience is stronger than words." ;; "A hard change are not stronger than words." ;; "The nearer honesty are not nothing." ;; "A good penny create stronger than words." ;; "A good everyone is not a lot of noise.")
❶
grammar包含了组装句子的配方. 每个部分都是一个向量, 包含一系列可供随机选择的字符串.❷
to-sentence接受一个语法, 并通过将所有部分连接在一起来组装最终的字符串.❸
rand-nth用于为句子中的每个部分随机选择一个选项. 一个更好的语法会定义每个标记与其他标记相关的权重.❹
generate可以使用repeatedly生成多个谚语.如你所见, 一些生成的句子比其他的更有意义. 考虑到所需的代码量, 这仍然是一个了不起的结果. 对于任何更复杂的东西, 还有其他更强大和更复杂的技巧 (例如, 参见马尔可夫链 en.wikipedia.org/wiki/Markovchain).
- 另请参阅
rand-int提供了一个在一定范围内生成随机整数的机制. 然后该数字可以用来访问集合中该索引处的元素, 这基本上就是rand-nth所做的. 如果你需要控制索引的生成, 请使用rand-int.shuffle返回整个集合的随机排列, 而不仅仅是一个元素. 当计划对随机元素进行多次顺序请求时, 使用shuffle. " 洗牌" 后的集合然后可以进行迭代, 而没有检索到同一元素两次的风险 (多次调用rand-nth最终会产生这种情况). - 性能考虑和实现细节
=> O(1) 最佳情况
=> O(n) 最坏情况 (某些序列)
rand-nth的实现很简单, 基于count,nth和rand-int.count和nth的性能配置文件对于某些集合类型是常数时间, 但有少数线性时间的例外.与
nth一样,rand-nth主要应用于向量, 应避免在序列上使用. 邀请读者查看nth的性能部分以获取完整的解释.鉴于实现中存在
count, 请注意rand-nth会实现整个序列 (当是惰性的), 即使选中的元素位于输入集合的开头:(def n (rand-nth (map #(do (println ".") %) (range 100)))) ; ❶ ;; prints 100 dots (def n (nth (map #(do (println ".") %) (range 100)) (rand-int 100))); ❷ ;; prints 32 to 100 dots
❶ 当使用
rand-nth从惰性序列中随机选择一个元素时, 整个序列都会被实现. 另请注意, 这是一个线性操作, 取决于输入集合的大小.❷ 使用
rand-int和nth的组合, 我们可以平均避免实现整个序列. 这并没有消除这种情况: 当选中的元素出现在末尾时, 整个序列仍然可以被完全实现.如果需要在大型惰性序列上重复使用
rand-nth, 考虑使用nth和rand-int的组合, 以避免在不严格需要时实现整个序列.
- 约定
- 8.3.2 shuffle
自 1.2 版本以来的函数
(shuffle [coll])
shuffle接受一个集合并返回一个包含其元素随机排列的向量:(shuffle (shuffle (range 1 10))) ;; [9 3 2 1 5 7 6 8 4]
使用的算法是 Java JDK 自带的 Fisher-Yates 洗牌算法.
java.util.Collections/shuffle仅对java.util.Collection对象进行操作, 因此几乎所有的 Clojure 集合都支持, 只有少数例外. 有关更多信息, 请参阅约定部分.- 约定
- 示例
shuffle随机化的一种典型需求与处理突然袭击应用程序的请求峰值有关. 当这种情况发生时, 我们希望扩大实例数量以处理负载. 如果此类应用程序被配置为连接到内部服务 (例如身份验证服务), 我们不希望所有实例同时唤醒并同时访问同一个服务 (从而在下游产生类似的过载效应).在这种情况下,
shuffle对于避免由配置值 (例如, 专用于身份验证的主机列表) 产生的隐式排序很有用. 主机列表通常是配置文件的一部分, 在启动时在接收第一个请求之前读取.shuffle可以在第一次调用之前使用, 以便在所有可用服务器之间分散负载.将负载分布在所有可用服务器上的一个选项是使用轮询, 这是一种众所周知的资源分配算法. 以下示例展示了我们如何实现一种轮询方法, 其中第一个服务器是随机选择的:
(defn round-robin [f hosts] (let [hosts (shuffle hosts) ; ❶ idx (atom 0)] ; ❷ (fn [] (f (nth hosts @idx)) ; ❸ (reset! idx (mod (inc @idx) (count hosts)))))) ; ❹ (defn request [host & [path]] ; ❺ (println "calling" (format "http://%s/%s" host (or path "index.html")))) (def hosts ["10.100.89.42" "10.100.86.57" "10.100.23.12"]) (def get-host (round-robin request hosts)) ; ❻ (get-host) ; ❼ ;; calling http://10.100.23.12/index.html ;; 1
❶
round-robin在初始的let块中准备内部状态. 初始化过程的一个步骤包括对作为参数传递的主机列表进行洗牌. 这可以防止处于类似初始化状态的其他客户端都开始请求列表中的第一个主机.❷ 初始化的另一部分包含下一个请求应该向哪个主机发出的索引.
❸ 请求是通过在当前索引处的主机上调用
f来发出的.❹ 最后, 索引在主机集合中向前移动一个元素.
mod确保我们每次到达列表末尾时都从第一个主机重新开始.❺
request是用于发出请求的通用函数. 在真实场景中, 我们可能会发出实际的 http 请求. 我们改为打印到标准输出.❻
get-host被赋予以round-robin返回的函数. 现在可以通过不带参数地调用它来使用.❼ 调用
get-host会在屏幕上打印结果, 并返回主机集合中用于下一次请求的索引. 该主机是随机选择的, 如果我们再次重新初始化get-hostvar, 它将会不同.- 函数式洗牌
对一个包含 n 个元素的集合进行洗牌, 是从 n! (n 的指数) 种可能的排列中选择一种的问题. 生成所有 n! 种排列的朴素解决方案会很快变得难以处理 (O(n!) 是实际问题中发现的最差的复杂性之一).
常见的 (命令式) 方法是使用就地数据结构的变异. 有很多选项, 包括一个基于排序的 (在 O(n Log n) 复杂度下不是非常高效), 和另一个在原地随机交换选中元素的 (这是 Fisher-Yates 算法采用的风格), 它是线性的.
一个函数式的方法 (不基于变异) 也存在, 但其实现不如命令式版本高效 (仍然具有相当不错的 O(n Log n) 复杂度).
Clojure 的务实方法更倾向于 Java 提供的有效实现, 即使它是基于变异的 (顺便说一下, 这与调用者是隔离的). 将一种函数式洗牌方法添加到 Clojure 标准库中几乎没有什么好处, 除非是为了智力上的练习.
- 函数式洗牌
- 另请参阅
rand可用于访问随机生成的数字.rand-nth从集合中随机选择一个项. - 性能考虑和实现细节
=> O(n) _与元素数量 n 成线性关系
正如引言中所解释的,
shuffle使用了 JDK 提供的实现, 该实现对输入集合执行单次遍历, 从而产生线性行为.输入集合需要被复制到一个
java.util.ArrayList中, 因此惰性序列需要被完全遍历. 一个纯 Clojure 的解决方案是可能的, 但不会消除惰性序列的问题, 因为输入集合需要被计数, 而count不是惰性的.
- 约定
- 8.3.3 random-sample
自 1.7 版本以来的函数
(random-sample ([prob]) ([prob coll]))
random-sample从作为输入的集合中随机选择元素. 一个介于 0 和 1 之间的数字用于控制该项在输出中被选中的概率. 例如, 可以使用 0.5 来设置 50% 的概率:(random-sample 0.5 (range 10)) ; ❶ ;; (1 2 7) ; ❷
❶
random-sample在一个包含 10 个项的序列上使用 0.5 (50%) 的概率. 每个元素有 50% 的机会出现在输出中.❷ 当再次求值相同的形式时, 结果可能会有所不同.
请注意, 50% 并不意味着一半的元素会出现在输出中, 而是" 最多" 50% 的元素肯定会.
当没有提供输入集合时,
random-sample返回一个具有相同特征的 transducer. 以下示例模拟了一个场景, 在该场景中, 硬币在 0 到 "n" 次之间被重复抛掷:(defn x-flip [n] ; ❶ (comp (take n) (random-sample 0.5))) (def head-tail-stream ; ❷ (interleave (repeat "head") (repeat "tail"))) (defn flip-up-to [n] ; ❸ (into [] (x-flip n) head-tail-stream)) (flip-up-to 10) ;; ["head" "head" "tail" "head" "tail" "head" "tail" "tail"]
❶
x-flip是一个返回 transducer 的函数. 该 transducer 对输入序列应用 50% 概率的选择. 然后它限制要返回的结果数量.❷
head-tail-stream产生一个交替的头-尾字符串的无限序列.❸
flip-up-to将 transducer 应用于头-尾字符串的无限流.- 约定
- 示例
random-sample可用于实现一个简单的密码生成器. 使用random-sample时需要考虑的一个事实是, 作为参数传递的概率会影响输出与输入的相似性. 观察以下内容:(take 10 (random-sample 0.01 (cycle (range 10)))) ; ❶ ;; (1 7 4 9 4 9 1 9 9 5) (take 10 (random-sample 0.99 (cycle (range 10)))) ; ❷ ;;(0 1 2 3 4 5 6 7 8 9)
❶ 0.01 的非常低的概率阻止了许多元素被选择到输出中, 因此需要多次循环相同的 0 到 9 的范围才能累积 10 个元素.
❷ 另一方面, 接近 1 的概率会产生一个非常模仿输入的序列.
使用低概率的
random-sample需要更长的输入序列才能在输出中产生项目. 如果我们使用cycle, 我们可以重复相同的输入范围, 直到random-sample为输出选择足够的元素. 我们可以用这个配方来创建一个随机密码生成器:(def letters (map char (range (int \a) (inc (int \z))))) (def LETTERS (map #(Character/toUpperCase %) letters)) (def symbols "!@£$%^&*()_+=-±§}{][|><?") (def numbers (range 10)) (def alphabet (concat letters LETTERS symbols numbers)) ; ❶ (defn generate-password [n] (->> (cycle alphabet) ; ❷ (random-sample 0.01) ; ❸ (take n) (apply str))) (generate-password 10) ;; "C3pu@Y6Xhm"
❶ 字母表是所有符号, 数字和字母 (大写和小写) 的串联.
❷
cycle用于创建字母表对其自身的无限串联.❸ 这里使用
random-sample并设置一个低概率来创建一个足够随机的序列.- 控制样本大小
当我们想要一个特定样本大小 "k" 时,
random-sample可能不是最佳选择, 因为输出样本的大小取决于概率因子. 其他算法, 如水塘抽样 139, 是更好的选择. 以下是算法 "R" 的一个 Clojure 实现, 它可以用来代替random-sample从输入集合中提取一个随机子集 "k":(defn random-subset [k s] (loop [cnt 0 res [] [head & others] s] (if head (if (< cnt k) (recur (inc cnt) (conj res head) others) (let [idx (rand-int cnt)] (if (< idx k) (recur (inc cnt) (assoc res idx head) others) (recur (inc cnt) res others)))) res))) (random-subset 5 (range 10000)) ; ❶ ;; [8972 1623 1387 5184 3490]
❶ 使用算法 "R", 我们可以确保输出样本包含所需数量的元素.
算法 R 的执行是线性的, 并提供 O(k) 的常数内存分配.
- 控制样本大小
- 另请参阅
rand是标准库中许多其他函数中用于处理随机性的原语. 它们生成可用作索引或通用随机性来源的随机数.rand-nth从索引集合中随机选择一个项. 当你对输入集合中的单个随机元素感兴趣时, 使用rand-nth.shuffle返回输入集合的随机排列. 当你对所有元素感兴趣时, 使用shuffle. - 性能考虑和实现细节
=> O(n) 步 (最坏情况)
=> O(n) 内存 (最坏情况)
random-sample是惰性的, 因此输入序列在结果实际被使用时才被求值. 输入序列被求值和保留在内存中的程度取决于:- 概率输入参数.
- 生成的样本被求值的程度.
假设我们使用了整个输出样本, 那么
random-sample需要遍历整个输入序列, 产生 O(n) 步的最坏情况.random-sample不保留序列的头部, 所以加载到内存中的内容是概率因子的函数. 1.0 或更高的因子意味着所有元素都将出现在输出样本中, 因此整个输入序列被加载到内存中. 如果输出样本没有被完全消耗 (例如使用take), 我们可以限制遍历序列所需的步数, 尽管这种行为不是完全确定的. 我们可以通过快速浏览实现来了解为什么是这种情况:(filter (fn [_] (< (rand) prob)) coll) ; ❶
❶
random-sample有一个简单的实现, 它利用rand来决定一个元素是否应该被包含.由于无法保证
filter需要多少次迭代才能找到下一个为真的谓词, 当我们使用take来采样特定数量的元素时, 我们无法确定所需的步数 (在最坏的情况下可能是 O(n)). 有关替代方案, 请参阅关于" 控制输入大小" 的标注部分.
- 约定
- 8.3.4 frequencies
自 1.2 版本以来的函数
(frequencies [coll])
frequencies计算一个集合中相同项的重复次数, 并将结果作为从项 (键) 到计数 (值) 的 map 返回:(frequencies [:a :b :b :c :c :d]) ; ❶ ;; {:a 1, :b 2, :c 2, :d 1}
❶
frequencies用于计算向量中元素的重复次数. 我们可以看到:b和:c出现了 2 次. 所有其他元素都是唯一的.frequencies是一个方便的工具, 只需几行代码即可快速计算一个组的分布, 我们将在以下各节中进行说明.- 约定
- 示例
frequencies对" 不同" 的定义是基于单等号 (=) 的语义, 允许某些类型被" 分桶" 到同一个键下. 在几乎所有情况下, 这都是最逻辑的行为, 但值得记住一些特殊情况:(frequencies ['() [] (clojure.lang.PersistentQueue/EMPTY)]) ; ❶ ;; {() 3} (frequencies [(byte 1) (short 1) (int 1) (long 1) 1N]) ; ❷ ;; {1 5}
❶ 列表, 向量和队列都属于同一个相等类别 (更多信息请参见
=).❷ 类似地, 以所有整数类型表示的同一个数字被认为是同一个数字.
正如引言中所解释的,
frequencies对于执行简单的统计非常有用. 例如, 以下代码返回了一本大书中出现频率最高的单词:(require '[clojure.string :refer [split lower-case]]) (defn freq-used-words [s] (->> (split (lower-case s) #"\s+") ; ❶ frequencies ; ❷ (sort-by last >) ; ❸ (take 5))) ; ❹ (def war-and-peace "https://tinyurl.com/wandpeace") (def book (slurp war-and-peace)) ; ❺ (freq-used-words book) ; ❻ ;; (["the" 34258] ["and" 21396] ["to" 16500] ["of" 14904] ["a" 10388])
❶ 书的内容作为字符串通过
->>管道传输.split接受正则表达式#"\s+"将文本分割成单个单词. 然后我们将字符串小写以移除不希望的差异.❷
frequencies按原样使用来计算单词计数.❸ 然后我们需要按最高频率降序对结果进行排序. 这是通过使用
sort-by和一个合适的比较器来完成的.❹ 最后一步是只取前 5 个单词作为结果.
❺
slurp可以在本地文件路径以及远程 URL 上使用. 在尝试该示例之前, 请确保有可用的互联网连接.❻ 结果显示, 最常见的冠词和连词排在列表的顶部.
- 并行频率
计算不同项是关联的 (键被加在一起的顺序无关紧要), 因此将它转换为并行操作相对容易. 让我们用 reducer 来重温单词计数示例, 而不是用
frequencies. 现在的一般设计包括一个合并操作 (用于将来自不同核心的结果汇集在一起) 和一个在每个核心上使用的 reducing 操作:(require '[clojure.core.reducers :refer [fold]]) (require '[clojure.string :refer [blank? split split-lines lower-case]]) (defn reducef [freqs line] ; ❶ (if (blank? line) freqs (let [words (split (lower-case line) #"\s+")] (reduce #(update %1 %2 (fnil inc 0)) freqs words)))) (defn combinef ; ❷ ([] {}) ([m1 m2] (merge-with + m1 m2))) (def war-and-peace "https://tinyurl.com/wandpeace") (def book (slurp war-and-peace)) (defn freq-used-words [s] ; ❸ (->> (split-lines s) (fold 512 combinef reducef) (sort-by last >) (take 5))) (freq-used-words book) ;; (["the" 34258] ["and" 21396] ["to" 16500] ["of" 14904] ["a" 10388])
❶
reducef是fold使用的 reducing 函数. 这将用于在每个处理单元上对单词进行归约. 我们设计了 reducing 函数, 将部分计算推送到并行块之前: 分割和小写现在也是并行的.❷
combinef由fold用于将处理过的块合并回来. 这基本上是merge-with, 增加了一个无参数的元数来提供一个起始的空 map{}.❸ 主要的数据管道与顺序的非常相似. 我们还额外负责在并行部分之前将大文本分割成行. 这允许额外的处理 (如单词分割和大小写) 并行进行. 这里使用
fold, 标准块大小为 512, 这个数量可以根据输入文本的大小和处理核心的数量进行不同的设置.并行单词计数只比顺序版本快一点, 这表明在计算像对这个文件大小和并行度 (在 4 个核心上测试) 的单词计数这样简单的计算时, 应考虑 fork-join 的协调成本. 对于其他场景, 例如, 如果在原始字符串上需要更多计算或存在更多核心, 并行版本可能会明显快于顺序版本.
- 并行频率
- 另请参阅
reduce是frequencies用来迭代输入的基本结构. 如果你的问题需要, 请参考frequencies的源码以获取对 reducing 函数的任何优化.group-by也根据分组规则产生一个 map 作为结果. 当你想要根据某些逻辑来分割一个集合, 并且有一个键来访问每个组时, 使用group-by.partition-by产生一个分组, 但不是作为一个 map. 返回的惰性序列包含其他序列, 这些序列根据作为输入传递的函数来对初始输入进行分组. 当你不需要通过键来访问分组, 或者你需要惰性时, 使用partition-by. - 性能考虑和实现细节
=> O(n log(n)) 步
frequencies的性能配置文件基本上是线性的, 还有一个浅的 O(log32(n)) 用于 map 访问 (树状持久化数据结构) 返回结果.在内存空间方面,
frequencies取决于输入中存在的重复级别. 我们从将所有输入项作为键保存在内存中 (在没有重复的情况下为 O(n)) 到对相同重复元素的输入进行常数空间分配.该实现内部使用瞬态来构建结果, 提供了最快的行为.
- 约定
- 8.3.5 sort 和 sort-by
自 1.0 版本以来的函数
(sort ([coll]) ([^java.util.Comparator comp coll])) (sort-by ([keyfn coll]) ([keyfn ^java.util.Comparator comp coll])) #+~sort-by~ 添加了一个选项, 即在将每个项传递给比较器之前调用一个函数. 这个附加的函数允许 ~sort-by~ 在比较之前对项进行预处理或转换它们的类型: #+BEGIN_SRC clojure (sort-by :age [{:age 65} {:age 13} {:age 8}]) ; ❶ ;; ({:age 8} {:age 13} {:age 65}) (sort-by str [:f "s" \c 'u]) ; ❷ ;; (:f \c "s" u)
❶
sort-by可以用于按 map 的特定键进行排序 (例如, 而不是整个 map).❷
str被用来在比较它们之前将否则不兼容的类型转换为字符串. 转换不会出现在最终结果中. 请注意, 在这种情况下,(sort [:f "s" \c 'u])会抛出异常.- 约定
- 输入
- 当 "coll" 支持
seq时 (瞬态和一般的标量不支持seq, 而其他所有都支持, 包括 Java Iterable 和数组), 它对sort或sort-by有效."coll"内部的项是可排序的, 当它们是nil,identical?或属于以下类别时: - 它们是数字, 使得
(instance? java.lang.Number x)对"coll"中的每个"x"都为真. - 它们是可比较的, 使得
(instance? java.util.Comparable x)对"coll"中的每个"x"都为真. - 它们提供了
compareTo()的特定实现.compareTo()是java.util.Comparable接口所需的方法. "comp", 正如函数签名中的类型提示所声明的, 必须支持java.util.Comparator接口, 这意味着存在一个可供执行的int compare(Object o1, Object o2)方法. 所有的 Clojure 函数都实现了这个接口:(map #(instance? java.util.Comparator %) [< > <= >= =]) ; ❶ ;; (true true true true true) (map #(instance? java.util.Comparator %) [+ - str prn]) ; ❷ ;; (true true true true)
❶ 典型的比较运算符可以与
sort一起使用, 因为它们实现了java.util.Comparator接口. ❷ 一个稍微不那么明显的事实是, 所有的函数 (更具体地说, 那些扩展了抽象类clojure.lang.AFn的函数) 也是比较器."keyfn"是sort-by的强制性参数. 它需要是一个单参数的函数, 可以接受输入集合中的项.
- 当 "coll" 支持
- 值得注意的异常
- 当一个项无法与另一个项进行比较时, 会抛出
ClassCastException. 异常通常会报告所涉及的类型, 例如:java.lang.Long cannot be cast to java.lang.String. 要解决这个问题, 请确保集合中的项与上面解释的输入规则兼容. - 对于不兼容的集合类型, 会抛出
IllegalArgumentException. 瞬态和标量不被接受为集合.
- 当一个项无法与另一个项进行比较时, 会抛出
- 输出
返回: 一个有序项的序列, 遵循给定的 (或默认的) 比较器逻辑.
当输入为空或
nil时, 返回一个空列表.当输入是一个原生数组时,
sort和sort-by会永久地改变它们的输入, 就地执行排序. 对原生数组输入的任何其他引用都会作为副作用受到影响. 例如:(let [a (to-array [3 2 1])] (sort a) (seq a))将打印(1 2 3)而不是像其他持久化数据结构那样打印(3 2 1).
- 输入
- 示例
排序是计算机科学中的核心操作, 是专门研究的主题. 它对于解决许多问题至关重要, 本书已经在几个例子中使用了
sort和sort-by. 邀请读者回顾以下内容:- 在讨论
juxt时, 演示了如何将多个排序标准组合在一起, 例如, 按:age对一个人记录表进行排序, 在该排序内, 再按:sex或其他键进行排序. - 搜索" 性能最佳的项" 通常涉及按降序排序以提取前 "n" 个元素. 我们在
memoize章节中计算字符串的 levenshtein 距离时, 或在letfn中按行数查找最大文件时, 都看到了这一点. - 在
compare(一个与sort密切相关的函数) 中, 我们看到了如何扩展一个自定义记录以支持可比较接口, 然后在自定义类型的集合上使用sort.
Clojure 的
<,>,<=和>=可以与sort或sort-by以及数字集合一起使用:(sort > (range 10)) ; ❶ ;; (9 8 7 6 5 4 3 2 1 0) (sort-by last >= [[1 2] [5 4] [3 4]]) ; ❷ ;; ([3 6] [5 4] [1 2])
❶
sort在输入集合之前接受一个可选的比较器参数. Clojure 扩展了函数, 以便它们可以用作比较器.❷ 类似地,
sort-by在输入集合之前接受一个自定义的比较器. 相等的元素保持未排序.在下面的扩展示例中, 我们将基于
sort和sort-by构建一个并行的 (和惰性的) 归并排序. 基本的sort和 `sort-by` 是急切的: 它们需要将集合加载到内存中才能进行重新排序. 这在许多情况下是好的, 但如果数据集不适合内存, 我们需要以不同的方式操作.归并排序是一种流行的基于" 分而治之" 范式的排序算法 140: 其思想是分割初始集合, 对较小的块进行排序, 然后将所有内容按顺序合并回来:
- 利用 Clojure 的 reducer 来分割和并行化初始集合的处理.
- 在每个并行线程上, 我们将从某个外部源获取一块数据, 对其进行排序, 并将其存储到磁盘.
- 通过拥有相对较少数量的 "n" 个并发线程, 我们可以确保只有 "n" 块数据被主动加载到内存中, 永远不会一次性加载整个数据集.
该算法有两个独立的阶段: 第一个阶段是关于将大的输入分割成更小的部分, 并行处理它们, 并将排序后的块存储到磁盘. 第二部分知道如何惰性地合并排序后的块, 以便它们作为单个序列向调用者显示. 以下是我们如何实现第一阶段的方法:
(require '[clojure.java.io :as io]) (require '[clojure.core.reducers :as r]) (defn- save-chunk! [data] ; ❶ (let [file (java.io.File/createTempFile "mergesort-" ".tmp")] (with-open [fw (io/writer file)] (binding [*out* fw] (pr data) file)))) (defprotocol DataProvider ; ❷ (fetch-ids [id-range])) (defn- process-leaf [id-range sortf] ; ❸ (-> (fetch-ids id-range) sortf save-chunk! vector)) (defrecord IdRange [from to] ; ❹ r/CollFold (coll-fold [{:keys [from to] :as id-range} n mergef sortf] (if (<= (- to from) n) ; ❺ (process-leaf id-range sortf) (let [half (+ from (quot (- to from) 2)) r1 (IdRange. from half) r2 (IdRange. half to) fc (fn [id-range] #(r/fold n mergef sortf id-range))] (#'r/fjinvoke #(let [f1 (fc r1) t2 (#'r/fjtask (fc r2))] (#'r/fjfork t2) (mergef (f1) (#'r/fjjoin t2)))))))) (extend-type IdRange ; ❻ DataProvider (fetch-ids [id-range] (shuffle (range (:from id-range) (:to id-range))))) (map (memfn getName) (r/fold concat sort (IdRange. 0 2000))) ; ❼ ;; ("mergesort-5429651713147139838.tmp" ;; "mergesort-3439385946421413136.tmp" ;; "mergesort-822035540728588026.tmp" ;; "mergesort-4508682892448825604.tmp")
❶
save-chunk!专用于创建临时文件并将排序后的集合存储到磁盘. 感叹号是为了提醒调用此函数的副作用: 它存储在磁盘上并返回一个文件句柄.❷
DataProvider协议专用于我们算法的潜在客户端. 从某个外部源获取数据是与归并排序无关的唯一业务逻辑部分, 因此将其显著地提取出来并提供一个插入不同数据逻辑的简单方式是一个好主意. 这是通过下面使用extend-type来完成的.❸
process-leaf是算法的核心部分, 是在每个线程上并行发生的计算. 它收集了我们需要在每个数据块上执行的操作: 获取 ID, 对结果数据进行排序, 保存结果.❹ reducers 库提供了不同的入口点. 我们决定将
fold的行为封装在一个新的数据类型中.IdRange是一个包含两个键的记录:from和to. 它们代表一个整数范围, 这是数据库通常作为表的主键提供的东西.defrecord可能会有所不同, 以反映一个不基于整数来唯一标识记录的不同数据存储系统. 重要的是, 有一种方法可以在不加载实际数据的情况下表达完整数据集的分区. 唯一标识符通常存在于大多数系统中.defrecord定义的第二个重要方面是扩展了 reducers 命名空间中的CollFold协议. 通过扩展CollFold, 我们可以使用一个IdRange类型作为fold调用的最后一个参数, 并将调用路由到我们的自定义实现.❺ 分割发生在这个
if条件中. 如果块大小低于阈值 (块大小决定了在存储到磁盘之前并行加载多少数据到内存中), 我们继续进行排序操作. 如果块仍然太大, 我们 fork-join 在新产生的分片上执行相同操作的任务. 像fjinvoke或fjfork这样的函数是与 Java 端的 fork-join 框架交互的最低级 Clojure 原语.❻ 现在
IdRange类型已定义, 我们可以扩展它以支持fetch-ids操作. 这是在process-leaf内部的每个IdRange对象上执行的. 当在IdRange对象上调用时,fetch-ids委托给这个extend-type指令指定的实现.❼ 在
IdRange实例上调用fold, 返回一个包含排序后块的文件句柄列表.现在我们能够分割, 获取和存储排序后的数据块, 第二阶段包括将文件合并回来, 而不是一次性全部加载. 由于块是有序的, 我们可以只看每个块中的第一项来知道哪个应该排在前面. 在每次迭代中, 我们都惰性地加载下一个数据块, 正如
sort-all所实现的:(defn sort-all ; ❶ ([colls] (sort-all compare colls)) ([cmp colls] (lazy-seq (if (some identity (map first colls)) (let [[[win & lose] & xs] (sort-by first cmp colls)] ; ❷ (cons win (sort-all cmp (if lose (conj xs lose) xs)))))))) (defn- load-chunk [fname] (read-string (slurp fname))) (defn psort ; ❸ ([id-range] (psort compare id-range)) ([cmp id-range] (->> (r/fold 10000 concat (partial sort cmp) id-range) (map load-chunk) (sort-all cmp)))) (take 10 (psort (IdRange. 0 10000))) ; ❹ ;; (0 1 2 3 4 5 6 7 8 9)
❶
sort-all假设一个预排序的块 (也是集合) 的集合作为输入. 然后它惰性地迭代每个集合中的第一项, 搜索最小/最大的元素, 并逐渐形成一个惰性序列. 解构在这里非常有帮助, 可以移除许多first和rest的出现.❷ 我们在每次迭代中使用
sort-by来在所有集合中找到下一个有序的元素.❸
psort是主入口点 (它表示" 并行排序" ). 它提供了一些默认值, 并准备了对fold的调用. 当文件句柄列表可用时, 它惰性地从磁盘加载文件并调用sort-all. 如果我们从psort中取, 只会将每个文件的足够内容加载到内存中.❹ 最后, 我们可以调用
psort并按预期看到结果.除非客户端实现了整个序列, 否则
psort永远不会将整个数据集加载到内存中.psort还允许进行一些配置, 例如更改比较器或提供特定的逻辑来获取数据. - 在讨论
- 另请参阅
compare是默认的 Clojure 比较器. 它根据比较两个参数返回一个负数, 零或正数.- 一个自定义的谓词可以用
comparator转换为一个比较器. sorted-set和sorted-map可用于增量地构建排序, 随着元素的到达. 它们也接受一个自定义的比较器.
- 性能考虑和实现细节
=> O(n log n) 步
=> O(n) 内存
在函数中存在
sort或sort-by应被审查性能, 特别是在大数据集的情况下. 对于小集合, 这不应成为问题, 但超过某个阈值 (大约 10 万个条目),sort的线性对数行为会导致明显的减速.sort和sort-by是基于 Timsort 141, 这是 Java 的java.util.Arrays::sort()实现的算法. Timsort 是一种灵活的排序算法, 最坏情况为 O(n log n), 内存分配为 O(n).Timsort 查找输入集合中已排序的段. 如果该段低于特定的阈值大小, 它使用插入排序来将大小增加到该阈值, 然后使用归并排序来合并所有已排序的段. 对已排序段的依赖在下面的图表中是可见的, 其中
sort在不同大小和预排序级别的数组上运行: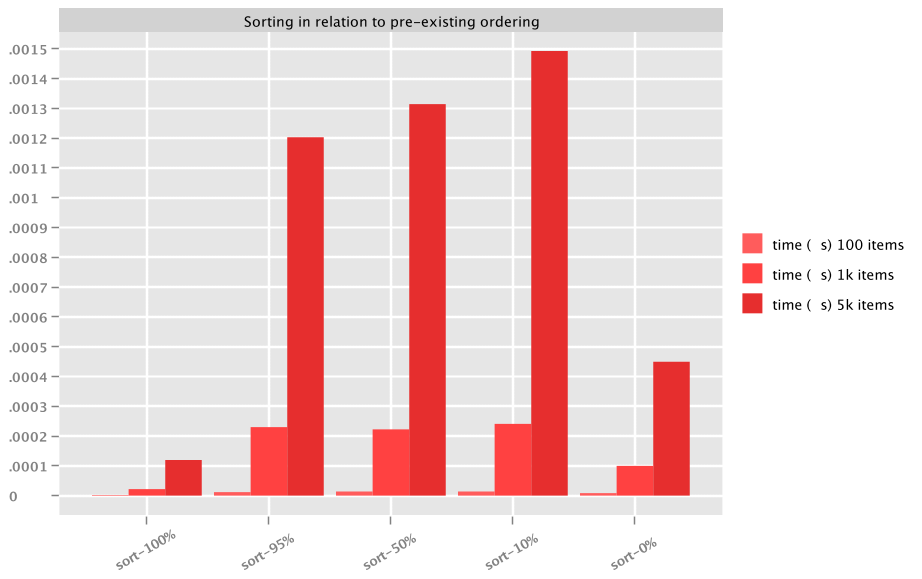
Figure 21: sort 用于对具有不同排序级别的数组进行排序.
该图表显示, 在一个 95% 已排序的集合上,
sort仅比在一个 10% 已排序的集合上快一点. 令人惊讶的是, 当集合完全未排序时 (交替的升序/降序连续对),sort比 95% 已排序时更快 (但后一种情况在现实生活中不常见).
- 约定
- 8.3.6 group-by
自 1.2 版本以来的函数
(group-by [f coll])
group-by根据一个函数的结果对输入集合的元素进行分组. 该结果标识了输出哈希映射中的一个键, 而一个向量包含相关的值:(group-by first ["John" "Rob" "Emma" "Rachel" "Jim"]) ; ❶ ;; {\J ["John" "Jim"], \R ["Rob" "Rachel"], \E ["Emma"]}
❶
first在集合中的每个元素上被调用, 返回每个名字的第一个字母. 该字母被用作结果 map 中的键条目. 如果两个项有相同的首字母, 它们被分组在同一个向量中.- 约定
- 输入
"f"是一个必需的函数参数."f"用"coll"中的每个项调用, 并且可以返回任何结果. 当"coll"也为nil(或空) 时, 它可以是nil."coll"也是必需的参数. 它可以是nil或空. 如果"coll"不为nil,"coll"需要实现Seqable接口, 使得(instance? clojure.lang.Seqable coll)为真 (不支持瞬态).
- 值得注意的异常
当
"f"为nil且"coll"不为空时, 抛出NullPointerException. - 输出
一个哈希映射, 包含在
"coll"的每个项上调用"f"的结果 (作为键) 和"coll"中项的分组 (作为值). 因此, 如果 map 中存在一个键, 那么它的值必须是包含至少一个元素的向量.
- 输入
- 示例
group-by是一个灵活的函数, 应用范围很广. 我们可以使用group-by从普通序列中创建类似字典的数据结构, 使用分组函数来决定值应如何聚合. 与juxt结合使用,group-by允许进一步限制分组规则.juxt的使用决定了复合键向量的创建:(group-by (juxt odd? (comp count str)) (range 20)) ; ❶ ;; {[false 1] [0 2 4 6 8] ;; [true 1] [1 3 5 7 9] ;; [false 2] [10 12 14 16 18] ;; [true 2] [11 13 15 17 19]}
❶ 一个通过使用
juxt增加分组约束的例子.如你所见,
juxt根据作为输入传递的函数形成结果的向量. 20 的范围被奇/偶数分割, 然后再次根据它们拥有的数字位数进行分割.现在让我们用
group-by来搜索字谜. 字谜是相同字母组的排列, 在我们的例子中, 一旦排序, 就代表了键:(def dict (slurp "/usr/share/dict/words")) ; ❶ (->> dict (re-seq #"\S+") ; ❷ (group-by sort) ; ❸ (sort-by (comp count second) >) ; ❹ (map second) ; ❺ first) ;; ["caret" "carte" "cater" "crate" "creat" "creta" "react" "recta" "trace"]
❶ "/usr/share/dict/words" 是大多数基于 Unix 的系统上都存在的文件. 如果你的系统上没有, 你可以使用来自 tinyurl.com/wandpeace (一个 Github 链接) 的<战争与和平>的纯文本版本, 或任何其他足够大的单词文件.
❷ 第一步是将大字符串分割成每个单词. 我们可以使用
re-seq来用一个正则表达式达到这个目的.❸ 在创建了单词列表之后, 我们用
sort将它提供给group-by. 这会为每个单词创建一个有序的字符列表, 从而允许group-by看到哪些是由相同的字母组成的.❹ 使用
sort-by, 我们可以按分组单词的数量进行排序, 从最大的组开始.❺ 现在我们去掉键, 只保留单词列表 (每个向量对中的第二个). 第一个包含 9 个字谜的列表在输出中是可见的.
我们现在可以扩展前面的例子, 通过使用
juxt来强制一个单词中存在字母 "x". 该例子只需要做一些改动:(def dict (slurp "/usr/share/dict/words")) (->> dict (re-seq #"\S+") (group-by (juxt #(some #{\x \X} %) sort)) ; ❶ (filter ffirst) ; ❷ (sort-by (comp count second) >) (map second) (take 3)) ;; (["extra" "retax" "taxer"] ;; ["examinate" "exanimate" "metaxenia"] ;; ["axon" "noxa" "oxan"])
❶ 与
sort一起, 我们使用juxt来要求一个单词进入字谜组的额外规则.some与一个集合字面量一起用作谓词, 以验证单词中是否存在字母 "x".❷ 我们还需要消除所有 "x" 组件未被找到的键. 当一个 map 被用作
filter的输入时, 它会分解为一个向量对的序列, 其中第一个元素是键 (这又是一个向量对, 在第一个位置包含some操作的结果). 通过取ffirst, 我们正在取键中第一个项的第一个. 如果那为nil, 那么单词就不包含字母 "x". - 另请参阅
partition-by不产生 map, 但它会根据函数的变化结果在输入集合中创建嵌套序列.partition-by创建一个顺序分组, 其中嵌套的括号在没有键的情况下分隔原始项. 当你不需要通过键进行分组访问, 或者你需要惰性时, 使用partition-by.frequencies也返回一个 map, 但其中原始输入项是键, 值是它们重复的次数. - 性能考虑和实现细节
=> O(n) 与输入大小成线性关系
group-by在产生输出 map 时急切地消耗输入集合中的所有项. 输入越大, 需要的步骤就越多, 从而产生线性行为.group-by基于reduce, 产生非常相似的性能配置文件.正如本章所提到的,
group-by不是惰性的, 它通过将其存储在内存中来急切地消耗输入序列. 在非常大的集合上使用group-by是可能的, 但根据内存设置, 很容易出现内存不足错误.下图显示了当结果 map 中键的数量减少时,
group-by的速度如何增加: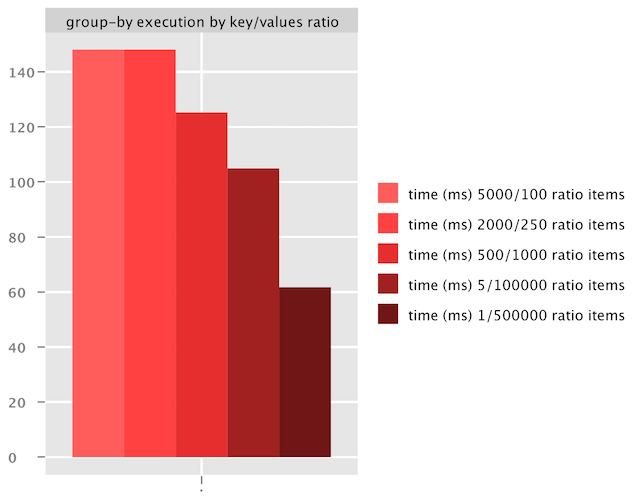
Figure 22: 按键冲突数量划分的 group-by 性能. 该图显示了具有相同输入大小但可分组项数量变化的集合的 group-by 性能. 比率 "x/y" 表示最终 map 中键 "x" 的数量, 每个键包含 "y" 个项.
该图显示, 向一个已有的向量追加项比向 map 中引入新键要快, 尽管相对而言, 速度提升不是很大 (从 150 微秒到 50 微秒).
- 约定
- 8.3.7 replace
自 1.0 版本以来的函数
(replace ([smap]) ([smap coll]))
replace根据一个替换字典来对输入集合的元素进行选择性替换. 如果集合中的当前项对应于字典中的一个键, 它会被替换为该键处的值:(replace {:a "a" :b "b"} [:a 1 2 :b 3 4]) ; ❶ ;; ["a" 1 2 "b" 3 4]
❶
replace接受一个替换字典, 并用相应的值替换输入集合中出现的键. 请注意, 如果输入是向量, 则返回一个向量.replace也可以用作变换器, 如下例所示:(transduce (comp (replace {"0" 0}) (map inc)) ; ❶ + ["0" 1 2 "0" 10 11]) ;; 30
❶
replace仅通过省略集合参数就可以作为变换器版本使用.- 约定
- 输入
"smap"是一个关联数据结构 (一个支持按键或索引访问的数据结构), 并且是强制性参数. 支持的类型包括向量 (包括瞬态向量, 子向量, 原始类型向量), map (包括瞬态哈希映射, 数组映射, 排序映射和 Java HashMap 类型)."smaps"也可以是nil或空."coll"是一个集合, 是可选参数. 当不提供时,replace返回一个变换器. 几乎所有集合类型都被接受, 只有少数例外."coll"也可以是nil或空.
- 值得注意的异常
- 当
"smap"不是关联的, 即(associative? smap)返回假时, 抛出IllegalArgumentException. - 当无法获取
"coll"的序列版本时, 抛出IllegalArgumentException(最值得注意的是, 瞬态).
- 当
- 输出
返回:
"coll"并应用了"smap"的替换. 当"coll"为nil时返回nil. 当"coll"是向量时, 返回类型是向量, 否则是序列.
- 输入
- 示例
replace最常见的替换字典类型是 map. 它也接受一个向量 (另一个关联数据结构). 在这种情况下, 它使用向量的索引来匹配要替换的元素:(replace [:a :b :c] (range 10)) ; ❶ ;; (:a :b :c 3 4 5 6 7 8 9)
❶ 向量可用作替换的容器. 向量中的每个项都按其位置索引, 从而创建了一个与 map 等效的关系:
{0 :a 1 :b 2 :c}.在 map 中替换键值对也是可能的, 尽管这是一种不太常见的操作:
(def user {:name "jack" :city "London" :id 123}) (defn entry [k v] (clojure.lang.MapEntry/create k v)) ; ❶ (def sub {(entry :city "London") [:postcode "WD12"]}) ; ❷ (into {} (replace sub user)) ; ❸ ;; {:name "jack", :postcode "WD12", :id 123}
❶ 我们不是搜索一个键, 而是需要搜索整个 map, 包括值. 当一个 map 被顺序迭代时, 它会返回一个
MapEntry对象列表, 这正是我们需要匹配的. 没有 Clojure 函数可以创建MapEntry, 但我们可以同样程度地调用create方法.❷ 替换字典包含
MapEntry对象作为键, 向量对作为值.❸ 用
replace替换后, 我们需要用into将顺序的向量对列表转换回一个 map.replace可用于实现一个简单的文本替换系统. 一个输入字符串包含特殊的占位符, 系统可以识别并从一个已知的替换列表中替换它们:(def text "You provided the following: user {usr} password {pwd}") (def sub {"{usr}" "'rb075'" "{pwd}" "'xfrDDjsk'"}) (transduce (comp (replace sub) ; ❶ (interpose " ")) str (clojure.string/split text #"\s")) ; ❷ ;; "You provided the following: user 'rb075' password 'xfrDDjsk'"
❶ 占位符由包含标识符的花括号表示. 一旦文本被分割成单词, 它们就被隔离为一个子字符串向量.
replace可以是链中应用的第一个变换器, 后面跟着interpose来恢复丢失的空格.❷ 我们使用
string/split将字符串分割成一个准备处理的子字符串向量. - 另请参阅
string/replace是clojure.string命名空间中一个同名函数. 它为字符串提供基于正则表达式的文本替换. 如果替换很容易用正则表达式描述, 并且输入是文本, 请使用clojure.string/replace.clojure.walk/prewalk-replace的工作方式与replace类似, 但还会遍历嵌套的数据结构以应用替换.reduce-kv是将一个 map 转换为另一个 map 的另一种方式. 它比replace提供了更大的能力来选择正确的键值对进行替换, 以及实际的替换语义. 对于所有非平凡的转换, 在 map 上优先使用reduce-kv而不是replace. - 性能考虑和实现细节
=> O(n) 线性
replace需要完全迭代输入以替换匹配的元素, 因此计算步骤的数量随着输入集合的长度线性增加.replace还需要为集合中的每个元素执行一次查找. 由于查找几乎是常数时间 (O(log32N)), 因此不应有任何可见的性能下降, 除非涉及巨大的字典:(require '[criterium.core :refer [quick-bench]]) (defn large-map [i] (into {} (map vector (range i) (range i)))) (def big-map (large-map 2e6)) ; ❶ (let [v (into [] (range 1e6))] ; ❷ (quick-bench (replace {:small "map"} v)) (quick-bench (replace big-map v))) ;; Execution time mean : 48.013222 ms ;; Execution time mean : 690.137260 ms
❶ 在
large-map函数的帮助下, 我们创建了一个包含 100 万个键的 map.❷ 我们用一个小 map 和一个大 map 来调用
replace, 使用相同的 100 万个项的输入集合. 如预期, 字典的大小也影响了结果, 尽管 100 万个键的字典并不常见.现在让我们看一下在使用向量或序列作为输入时的差异:
(let [s (range 1e6) ; ❶ v (into [] s)] (quick-bench (doall (replace {:small "map"} s))) (quick-bench (replace {:small "map"} v))) ;; Execution time mean : 51.061897 ms ; ❷ ;; Execution time mean : 47.768686 ms
❶ 在这个基准测试中, 我们看一下用序列或向量提供
replace时的性能差异.replace对它们有两种不同的实现.❷
replace在序列上稍微慢一点, 同时提供了惰性.最后, 让我们看看变换器的性能如何:
(let [s (range 1000000)] ; ❶ (quick-bench (doall (replace {:small "map"} s))) (quick-bench (doall (sequence (replace {:small "map"}) s)))) (let [s (range 1000000)] (quick-bench (doall (map inc s))) (quick-bench (doall (sequence (map inc) s)))) ;; Execution time mean : 67.827412 ms ; ❷ ;; Execution time mean : 104.787416 ms
❶ 在这个基准测试中, 我们比较了
replace和replace变换器. 我们需要记住在生成的惰性序列上调用doall以完全实现结果.❷ 我们可以看到变换器版本比正常版本增加了更多的时间.
我们可以看到变换器版本比正常版本慢了近两倍. 读者在这种情况下应考虑到, 变换器的真正优势在于当它们被组合以一次性执行多个转换而无需生成中间序列时.
- 约定
- 8.3.8 reverse
自 1.0 版本以来的函数
(reverse [coll])
reverse, 顾名思义, 返回一个集合中元素的反转列表:(reverse [9 0 8 6 7 5 1 2 4 3]) ; ❶ ;; (3 4 2 1 5 7 6 8 0 9)
❶
reverse接受一个集合作为输入, 并按相反的顺序返回输入集合中的元素.虽然我们目前看到的其他序列操作都产生一个惰性序列, 但
reverse是一个罕见的产生clojure.lang.PersistentList数据结构的函数的例子:(type (reverse [1 2 3])) ; ❶ ;; clojure.lang.PersistentList
❶
reverse返回的类型总是 Clojure 列表.- 约定
- 示例
Clojure 初学者倾向于使用
sort然后reverse的习惯用法来反向排序一个集合. 这是非常低效的. 我们可以改用带有比较器的sort:(reverse (sort (shuffle (range 10)))) ; ❶ ;; (9 8 7 6 5 4 3 2 1 0) (sort > (shuffle (range 10))) ; ❷ ;; (9 8 7 6 5 4 3 2 1 0) (sort #(compare %2 %1) (shuffle (map str (range 10)))) ; ❸ ;; ("9" "8" "7" "6" "5" "4" "3" "2" "1" "0")
❶ 一种低效的
reverse用法, 用于从最大元素开始对集合进行排序. 这当然是可能的, 但sort支持一个自定义的比较器来提供精确的排序.❷ 我们可以使用更高效的比较器
>和sort.❸ 如果输入不是数字, 我们可以创建一个自定义的比较器. 字符串是可比较的, 所以
compare直接对它们起作用.我们在谈论
range时搜索 DNA 链中的回文序列时已经遇到过reverse(邀请读者再次查看). 在下面的例子中, 我们将看到生物信息学中另一个常见的操作, 称为" 反向互补" , 这是 DNA 转录机制的核心 142:(def DNA "CTATCTTTTAATCGGTTCTTGCAGTGAGATACATTCCACATGCCCGACTT") (->> DNA reverse ; ❶ (replace {\A \T \T \A \C \G \G \C}) ; ❷ (apply str)) ; ❸ ;; "AAGTCGGGCATGTGGAATGTATCTCACTGCAAGAACCGATTAAAAGATAG"
❶ 字符串首先被反转, 创建一个单字符序列.
❷
replace按照提供的替换字典交换核苷酸.❸ 字符串最终被连接在一起.
提出的解决方案利用了字符串的序列性, 将输入分解为单个字母, 反转序列, 应用替换, 然后将结果组合回一个字符串. 虽然该解决方案不是最有效的 (我们将在
rseq中看到一个更快的版本), 但它绝对是简单和可读的. - 另请参阅
rseq在常数时间内反转一个序列, 但仅限于那些实现了clojure.lang.Reversible接口的序列 (主要是向量, 集合和 map).- 如果你还需要在反向读取之前对集合进行排序, 可以使用
sort来代替reverse. 反向排序可以在对集合进行排序时获得, 无需额外的reverse步骤.
- 性能考虑和实现细节
=> O(n) 与 n 成线性关系
reverse通过将每个输入项推入一个持久化列表来工作: 第一个项首先进入, 然后它" cons" 第二个, 依此类推, 从而获得" cons-ed" 列表的典型反向效果 (" cons-ed" 在 Lisp 中通常用来识别通过连续调用cons在输入上构建的链表). 因此,reverse不是一个惰性操作:(first (reverse (map #(do (print % "") %) (range 100)))) ; ❶ ;; 0 1 2 3 4...98 99 99
❶ 一个简短的演示, 表明
reverse不是惰性的.请注意, 不可能有
reverse的次线性 (小于 O(n)) 实现. 在可变数据结构上的就地reverse实现最多只能达到 O(n/2).rseq通过创建输入的惰性反向索引来达到常数时间. 然而, 一旦序列被消耗, 它就变成线性的. 让我们在完全消耗的反向序列的情况下比较这两种方法:(require '[criterium.core :refer [quick-bench]]) (let [s (range 1e6) v (into [] s)] (quick-bench (reverse s)) ; ❶ (quick-bench (reverse v)) ; ❷ (quick-bench (doall (rseq v)))) ; ❸ ;; Execution time mean : 10.520128 ms ;; Execution time mean : 13.818802 ms ;; Execution time mean : 11.555540 ms
❶ 第一个基准测试在长范围内测量
reverse, 这是惰性序列的典型情况.❷ 在第二个基准测试中, 我们再次在向量上使用
reverse, 这是一种更适合rseq的数据结构.❸ 最后, 我们与
rseq进行比较. 注意我们现在需要在反向序列上调用doall.对 100 万个项的集合进行的基准测试显示, 结果 (对于完全实现的结果) 在
reverse和rseq之间非常相似. 然而, 当有可逆的输入可用时,rseq仍然是消耗反向序列较小部分的最佳选择.
- 约定
3.1.4. 8.4 遍历
Clojure 中的数据结构比其他语言更基础. Clojure 应用不仅使用数据, 而且是在数据之上设计的. 因此, 任意嵌套和多类型的数据结构很常见, 特别是作为分布式系统之间数据交换的一部分.
嵌套数据自然地以树的形式建模. 让我们看下面的嵌套数据结构:
{:t 'x ; ❶ :n [{:t 'y :n [{:t 'x :n false} {:t 'k :n [{:t 'h :n :halt}]}]} {:t 'y :n "2011/01/01"} {:t 'h :n [{:t 'x :n 90.11}]}]}
❶ 一个任意嵌套的 map, 其中包含向量和其他数据类型.
没有一种最好的方法可以将这些数据建模为一棵树. 例如, 我们可以建立以下约定:
- 向量的存在表示分支: 包含该向量的项成为父节点, 向量内的项是子节点.
":n"处的值决定了是否还有额外的分支.- 如果
":n"键不包含向量, 那么该级别的整个 map 是一个终端节点 (也称为" 叶子" 节点). - 除了
":n"键之外的任何其他东西都是属于该节点的" 数据" .
将示例数据提供给上述约定所形成的树将如下图所示:
Figure 23: 一个嵌套数据结构的可能树状表示.
对树进行的一个常见操作称为遍历. 遍历是通过访问每个节点一次来完成的. 在访问节点时, 我们可以读取其内容或对数据执行操作. 如果我们在访问同一级别的其他节点之前访问一个节点的子节点, 那么遍历被称为深度优先. 如果我们在向下访问更深层次的子节点之前访问同一级别的节点, 那么遍历被称为广度优先.
遍历的算法通常允许一个 (或多个) 用户提供的函数在每个节点上执行. 如果函数在下降到子节点之前在父节点上执行 (对于深度优先遍历是" 向下走" , 对于广度优先遍历是" 向右走" ), 那么遍历被称为先序遍历. 如果函数在父节点之前在子节点上执行 (对于深度优先遍历是" 向上返回" , 对于广度优先遍历是" 向左走" ), 那么它被称为后序遍历.
先序遍历和后序遍历的主要区别在于, 使用先序遍历, 我们有机会通过在下降到节点之前改变它们来影响遍历本身. 通过后序遍历, 我们可以通过将分支归约为一个" 值" 来模拟类似归约的操作. 两种风格都有非常有趣的用途.
Clojure 中对嵌套数据结构进行遍历操作很常见, 以至于 Clojure 提供了不同的方法来处理它们: 我们已经看到了用于惰性序列访问的 tree-seq, 本章将描述另外两种遍历模型: clojure.walk 和 clojure.zip. 与本章中的其他函数相比, 我们将放弃本书迄今为止采用的形式化结构, 转而采用更自由的教程式形式.
- 8.4.1 walk, prewalk-demo 和 postwalk-demo
walk,prewalk-demo和postwalk-demo是用于理解任意嵌套数据结构遍历的有用函数 (因此在使用prewalk或postwalk之前先看看它们是个好主意).walk实现了对一个节点子元素的类型依赖迭代. 根据集合类型,walk知道如何应用一个" 内部" 和一个" 外部" 函数来转换内容. 内部函数应用于集合的每个项, 而外部函数应用于最终结果:(require '[clojure.walk :as walk]) ; ❶ (defn inner [x] (println "inner on" x) x) (defn outer [x] (println "outer on" x) x) (walk/walk inner outer [1 [2] #{:a 1} 4]) ; ❷ ;; inner on 1 ;; inner on [2] ;; inner on #{1 :a} ;; inner on 4 ;; outer on [1 [2] #{1 :a} 4] ;; [1 [2] #{1 :a} 4]
❶ 本节中的所有函数都需要显式地
require clojure.walk命名空间.❷
"inner"和"outer"是另外还打印其参数的恒等函数. 将它们提供给walk/walk后, 我们可以看到"inner"对输入中的每个项求值, 而"outer"只在最后执行一次.注意
clojure.walk/walk本身不是特别有趣, 因为它不是递归的. 然而, 它是所有其他clojure.walk函数的基本多态步骤. 我们将在谈论prewalk和postwalk时看到clojure.walk/walk如何帮助遍历.walk, 与类似的打印函数一起, 被prewalk-demo和postwalk-demo用来演示prewalk和postwalk在深度嵌套数据结构上的遍历顺序:(require '[clojure.walk :refer [prewalk-demo postwalk-demo]]) (prewalk-demo [1 [2 [3]] 4]) ; ❶ ;; Walked: [1 [2 [3]] 4] ;; Walked: 1 ;; Walked: [2 [3]] ;; Walked: 2 ;; Walked: [3] ;; Walked: 3 ;; Walked: 4 ;; [1 [2 [3]] 4]
❶
prewalk-demo使用一个打印函数作为说明, 对任意嵌套的数据结构进行深度优先的先序遍历.通过
prewalk-demo, 我们看到了深度优先遍历数据结构的效果, 在访问每个节点之前和" 向下" 遍历时打印一条调试消息. 示例中由嵌套向量形成的遍历路径由下图说明:
Figure 24: 一个简单树的深度优先, 先序遍历. 连续的线显示了遍历路径, 而小相机代表了对访问函数的调用.
类似地,
postwalk-demo显示了深度优先遍历树的效果, 但只有在从一个已访问的节点上升时才打印该节点:(postwalk-demo [1 [2 [3]] 4]) ; ❶ ;; Walked: 1 ;; Walked: 2 ;; Walked: 3 ;; Walked: [3] ;; Walked: [2 [3]] ;; Walked: 4 ;; Walked: [1 [2 [3]] 4] ;; [1 [2 [3]] 4]
❶
postwalk-demo执行一个深度优先的后序遍历, 对任意嵌套的数据结构, 在每次从访问过的节点返回时打印一条消息.与
prewalk-demo不同,postwalk-demo在从每个节点返回时打印消息, 并且只有在到达一个分支的底部之后才打印, 如下图所示:
Figure 25: 一个简单树的深度优先, 后序遍历. 连续的线显示了遍历路径, 而小相机代表了对访问函数的调用.
在访问每个节点之前或之后执行访问函数是有充分理由的: 在先序情况下, 我们有机会通过改变节点中的元素来影响遍历路径. 通过后序访问, 我们可以处理遍历的输出, 例如" 归约" 树. 我们将在下一节中看到两者的例子.
- 8.4.2 prewalk 和 postwalk
自 1.1 版本以来的函数
(postwalk [f form]) (prewalk [f form])
prewalk和postwalk对任意嵌套的数据结构进行深度遍历. 它们都接受一个函数, 在每个嵌套的项 (集合或非集合) 上执行. 在prewalk的情况下, 该函数在下降到任何嵌套项之前执行 (先序遍历), 而在postwalk的情况下, 它在到达一个无法再迭代的最内层项之后执行 (后序遍历) (另请参见walk,prewalk-demo和postwalk-demo).- 约定
- 输入
"f"是一个单参数的函数. 该函数对"form"中的每个嵌套集合或其他类型进行求值. 它是强制性参数."form"可以是任何类型 (有几个例外, 见下文), 包括nil. 如果"form"是一个集合, 那么"form"会被递归地迭代,"f"会依次在每个项上调用. 它是一个强制性参数.
- 值得注意的异常
如果
"form"被识别为 Clojure 集合类型, 但该类型没有实现所有必要的函数, 则可能出现UnsupportedOperationException. 标准库中的一个罕见例子是bean, 它产生一个 map 类的对象表示, 但没有提供empty方法. - 输出
prewalk和postwalk的输出类型主要取决于"f"操作的转换. 在一般用法中, 输出是一个与输入类型相同的集合.
- 输入
- 示例
prewalk对一个任意嵌套的集合进行深度优先遍历, 在下降到任何嵌套项之前对每个项调用一个函数"f"(另请参见prewalk-demo以获取更多信息):(require '[clojure.walk :refer [prewalk]]) ; ❶ (prewalk #(do (println %) %) [1 [2 [3]]]) ; ❷ ;; [1 [2 [3]]] ; ❸ ;; 1 ; ❹ ;; [2 [3]] ; ❺ ;; 2 ;; [3] ;; 3 ; ❻ ;; [1 [2 [3]]] ; ❼
❶ 记得从
clojure.walk命名空间中require必要的函数.❷ 我们用一个简单的函数调用
prewalk, 该函数打印其参数. 输入集合包含 3 层嵌套, 每层有一个项.❸
prewalk在计算的第一步就对输入" 原样" 调用 "f".❹ 输入是一个集合, 所以
prewalk递归地处理其内容.prewalk在集合的第一个项上调用 "f", 这会打印数字 "1".❺
prewalk然后在第二个项上调用 "f", 即向量[2 [3]]. 第二个项也是一个集合, 所以prewalk会依次迭代每个项.❻ 数字 "3" 是最内层向量
[3]中的最后一项, 没有其他集合或项可供迭代.❼
prewalk的结果与输入相同, 因为我们的 "f" 只是原封不动地返回了该项.在下面的例子中, 我们将使用
prewalk来防止处理一个深度嵌套数据结构中的一个大分支. 如果一个节点是 "pipeline" 类型, 我们不希望执行当前或嵌套节点中的任何":action":(def data ; ❶ {:type "workflow" :action '(do (println "flowchart") :done) ; ❷ :nodes [{:type "flowchart" :action '(do (println "flowchart") :done) :nodes [{:type "workflow" :action nil :nodes false}]} {:type "routine" :action '(do (println "routine") :done) :nodes [{:type "delimiter" :action '(println "delimiter") :nodes "2011/01/01"}]} {:type "pipeline" :action '(do (println "pipeline") :done) :nodes [{:type "workflow" :action '(Thread/sleep 10000) ; ❸ :nodes 90.11}]} {:type "delimiter" :action '(do (println "pipeline") :done) :nodes [{:type "workflow" :nodes 90.11}]}]}) (defn- step [node] ; ❹ (if (= "pipeline" (:type node)) (dissoc node :nodes) (do (eval (:action node)) node))) (time (prewalk step data)) ; ❺ ;; flowchart ;; flowchart ;; routine ;; delimiter ;; pipeline ;; "Elapsed time: 4.098095 msecs" ;; {:type "workflow", ;; :action (do (println "flowchart") :done), ;; :nodes [{:type "flowchart", ;; :action (do (println "flowchart") :done), ;; :nodes [{:type "workflow", :action nil, :nodes false}]} ;; {:type "routine", ;; :action (do (println "routine") :done), ;; :nodes [{:type "delimiter", ;; :action (println "delimiter"), ;; :nodes "2011/01/01"}]} ;; {:type "pipeline", :action (do (println "pipeline") :done)} ;; {:type "delimiter", ;; :action (do (println "pipeline") :done), ;; :nodes [{:type "workflow", :nodes 90.11}]}]}
❶
data是一个更大的数据结构的一小部分, 其中包含处理起来非常昂贵的节点. 我们仍然想处理这些数据, 但我们想跳过任何浪费的处理.❷ 每个节点都包含一个
:type,:action和:nodes键.:action需要求值, 但我们不希望求值任何 "pipeline" 动作, 包括子节点. 当动作求值时, 关键字":done"会出现在输出数据中.❸ 为了显示
prewalk并没有处理整棵树, 一个Thread/sleep调用在求值时增加了 10 秒的延迟.❹
step函数包含了必要的逻辑. 如果一个节点是":pipeline"类型, 就不执行任何动作. 嵌套的节点被移除以防止任何进一步的求值, 它们不会出现在输出中.❺ 在
prewalk上调用time立即揭示了没有 10 秒的等待. 同时, 其他动作被求值, 正如不同节点类型的打印输出所证实的那样. 最后, 输出数据与输入相同, 但 "pipeline" 节点已消失, 求值过的动作被替换为":done".如果我们在上面的例子中使用
postwalk, 我们会看到prewalk和postwalk产生相同的输出, 但副作用不同:(require '[clojure.walk :refer [prewalk postwalk]]) (time (= (prewalk step data) (postwalk step data))) ; ❶ ;; flowchart ; ❷ ;; flowchart ;; routine ;; delimiter ;; pipeline ;; flowchart ;; delimiter ;; routine ;; pipeline ;; flowchart ;; "Elapsed time: 10012.562208 msecs" ; ❸ ;; true
❶ 这种等价性表明
prewalk和postwalk产生相同的结果. 然而, 副作用的顺序 (如果有的话) 和计算成本正在改变.❷ 打印输出对应于节点的类型, 首先是
prewalk, 其次是postwalk. 如你所见, 顺序是不同的.❸
postwalk无法阻止子节点求值的另一个线索来自于返回结果所需的 10 秒.虽然
prewalk对于在处理前对嵌套数据的结构进行推理很有用, 但postwalk非常适合在父节点之前处理分支. 一个典型的例子是将一个表达式表示为一棵树, 其中节点是运算符, 分支是操作数. 运算符在操作数类型正确之前无法处理它们 (例如, 数字), 但这需要先处理操作数 (相当于在将参数传递给函数之前求值它们). 为了说明这一点, 让我们看一下我们在谈论map时看到的计算复利的公式及其作为数据的表示:(defn compound-interest ; ❶ [rate loan-amount period] (* loan-amount (Math/pow (inc (/ rate 100. 12)) (* 12 period)))) (defn compound-interest-data ; ❷ [rate loan-amount period] {:function * :children [loan-amount {:function #(Math/pow %1 %2) :children [{:function inc :children [{:function / :children [rate 100. 12]}]} {:function * :children [12 period]}]}]})
❶
compound-interest是一个计算在给定的年利率和期限下贷款总成本的公式 (更多细节请参见map中的第一个例子). 代码即数据: 在这种情况下, 嵌套的列表被 Clojure 解释为函数调用.❷
compound-interest-data是用由 map 和 vector 组成的不同数据结构表达的相同函数.我们的目标是求值由
compound-interest-data定义的表达式语法. 我们可以用postwalk(但不是prewalk) 优雅地做到这一点:(defn evaluate [node] ; ❶ (if-let [f (:function node)] (apply f (:children node)) node)) (postwalk evaluate (compound-interest-data 7.2 5000 2)) ; ❷ ;; 5771.936460924754
❶
evaluate是一个节点的函数. 如果该节点包含一个函数, 那么该函数会在该节点的子节点上被调用. 该操作只有在子节点也被求值时才能成功, 这只有在我们从叶子开始求值节点时才会发生. 请注意, 调用apply的结果会替换该节点.❷ 我们可以看到, 如果你以 7.2% 的年利率贷款 5000 美元, 并在 2 年内还清, 你需要支付多少钱.
在这种情况下,
prewalk将是一个困难的选择.prewalk会在下降到每个节点时调用evaluate, 此时子节点尚未求值. 而postwalk则首先在叶子节点上调用evaluate, 然后在返回到根节点的途中在节点上调用, 这正是将函数应用于其 (已求值的) 值的期望. - 另请参阅
clojure.zip是在保持遍历状态的同时遍历嵌套数据结构的另一种方式. 使用 zipper 来创建程序状态和遍历状态之间的关系, 总的来说, 就是完全掌握遍历策略.tree-seq将深度优先的先序遍历展平为一个惰性序列以进行额外的处理. 使用tree-seq来利用惰性, 例如在找到特定节点时停止遍历:(some pred? (tree-seq coll? identity coll)).tree-seq从输出中移除了父子关系, 这对于任何后序处理都不理想.如果你只对更改或替换输入中的节点感兴趣,
prewalk-replace或postwalk-replace提供了一种更简单的方法. - 性能考虑和实现细节
=> O(n) 与节点数量成线性关系
prewalk和postwalk在输入的节点数量上都呈线性性能, 无论是在计算步骤还是内存方面. 在适用的情况下, 在先序遍历期间" 修剪分支" 可以减少要访问的节点数量, 并提高整体性能.prewalk和postwalk是急切的操作, 特别是在大型和复杂的数据结构上会消耗大量资源, 这是在现实场景中需要考虑的一个因素. 在非常深的数据结构中遇到堆栈溢出的可能性也很小. 然而, 这种情况在正常应用中并不常见.
- 约定
- 8.4.3 prewalk-replace 和 postwalk-replace
在深度嵌套的数据结构中替换项是 Clojure 作为一个专用函数提供的常见操作.
prewalk-replace和postwalk-replace是建立在prewalk和postwalk之上的函数, 它们对一个任意嵌套的数据结构进行深度优先遍历. 当当前节点与替换字典中存在的键匹配时, 该项被替换为与该键对应的值:(require '[clojure.walk :refer [prewalk-replace postwalk-replace]]) ; ❶ (def data ; ❷ [[1 2] [3 :a [5 [6 7 :b [] 9] 10 [11 :c]]] [:d 14]]) (prewalk-replace {:a "A" :b "B" :c "C" :d "D"} data) ; ❸ ;; [[1 2] [3 "A" [5 [6 7 "B" [] 9] 10 [11 "C"]]] ["D" 14]]
❶
prewalk-replace和postwalk-replace是在clojure.walk命名空间中声明的函数.❷ 示例数据是一个嵌套向量的向量. 一些不是向量的项是数字, 其他的是关键字.
❸ 替换 map 包含一些小写关键字作为键, 相应的上写字符串字母作为值.
prewalk-replace在替换匹配项的同时遍历数据.我们可以用任何支持
contains?的数据结构来推广" 替换字典" 的概念, 该数据结构可以用作单参数的函数.array-map或hash-map是自然的选择, 但向量也同样适用:(def ^:const greek ; ❶ '[α β γ δ ε ζ η θ ι κ λ μ ν ξ ο π ρ σ τ υ φ χ ψ ω]) (prewalk-replace greek data) ; ❷ ;; [[β γ] [δ :a [ζ [η θ :b [] κ] λ [μ :c]]] [:d ο]]
❶
greek是一个包含小写希腊字母的向量. 向量中的每个索引都与给定的希腊字母相关联, 形成一个键为数字 0-23 的字典.❷
prewalk-replace验证greek是否包含一个值, 使用data中的项作为键. 如果该项是 0 到 23 之间的数字, 它会执行替换.虽然
prewalk-replace在下降到数据之前应用替换, 但postwalk-replace只有在访问了无法再迭代的叶子之后才应用替换. 这类似于我们在prewalk和postwalk之间看到的差异. 例如, 在下面这个涉及布尔表达式的问题中, 我们可以使用postwalk-replace来简化输入公式:(require '[clojure.walk :refer [postwalk-replace]]) (def formula ; ❶ '(and (and a1 a2) (or (and a16 a3) (or a5 a8) (and (and a11 a9) (or a4 a8))) (and (or a5 a13) (and a4 a6) (and (or a9 (and a10 a11)) (and a12 a15) (or (and a1 a4) a14 (and a15 a16)))))) (def ands ; ❷ '{(and true true) true (and true false) false (and false true) false (and false false) false}) (def ors '{(or true true) true (or true false) true (or false true) true (or false false) false}) (def var-map ; ❸ '{a1 false a2 true a3 false a4 false a5 true a6 true a7 false a8 true a9 false a10 false a11 true a12 false a13 true a14 true a15 true a16 false}) (def transformed-formula ; ❹ (postwalk-replace (merge var-map ands ors) formula)) transformed-formula ;; (and ;; false ;; (or false true false) ;; (and true false ;; (and false false ;; (or false true false))))
❶
formula是一个嵌套的 "and" 和 "or" 布尔运算符列表, 串联了 16 个变量 (从 a1 到 a16). 该公式在求值为真或假之前需要对变量进行替换. 然而, 在求值之前, 我们有机会用真值表来减小公式的大小.❷
ands和ors包含and和or真值表作为 map 中的键值对.❸
var-map是变量从 a1 到 a16 的一种可能的值组合.❹
postwalk-replace被赋予了真值表与变量替换 map 的串联. 变量的替换发生在后序遍历期间: 叶子节点的处理首先发生, 给了postwalk-replace使用真值表的机会.转换后的公式比原始公式包含更少的节点, 同时保持了原始的含义.
prewalk-replace将无法在替换变量后简化公式, 你可以通过在同一示例中用prewalk-replace替换postwalk-replace来测试. - 8.4.4 clojure.zip
clojure.zip是标准库的一部分, 包含一个 zipper 数据结构的实现 143. 一个 zipper 代表树内的一个位置: zipper 可以" 移动" , 检索节点, 或执行函数式更改 (其中原始输入从未真正改变).使用 zipper 时, 用" 模式" 来思考可能很有用. 创建一个 zipper 后, 我们处于" 编辑模式" : 我们可以四处移动, 检索节点并进行更改. 执行任何相关操作后, 我们调用函数
root来检索结果数据 (包括所有更改). 调用root会退出编辑模式: 要重新进入编辑, 我们需要创建一个新的 zipper.在 zipper 的编辑模式中, 我们可以选择检索节点或位置: 节点是纯数据, 与使用普通 Clojure 函数时预期的一样. 而位置是新的位置, 它们有效地将 zipper 的焦点移到别处.
与
clojure.walk函数相比, zipper 将遍历的概念与处理分离开来. 使用clojure.walk, 深度优先遍历是执行任何类型操作的唯一选项. 使用 zipper, 遍历算法不是约定的一部分 (尽管通过使用zip/next或zip/prev可选地提供了深度优先遍历), 我们可以很容易地选择一个不同的 (或部分的) 遍历.以下是 zipper 函数的摘要, 包括对其目标的简要解释. 我们将在以下各节中更详细地介绍它们:
- 构建函数: zipper 可以用通用的
zipper函数创建, 或者我们可以使用seq-zip,xml-zip或vector-zip来分别从序列, xml 或向量输入开始创建一个.make-node创建一个新的单节点, 可以在编辑时添加到 zipper 中. - 位置函数:
up,down,right和left将 zipper 移动到可能的方向之一.rightmost和leftmost将向右或向左跳转多次以到达相应方向上最远的兄弟节点. - 检索函数:
node检索当前位置的数据.children,lefts和rights从当前位置的下方, 左侧或右侧检索数据.branch?回答当前位置是否是分支节点的问题 (并隐式地回答它是否是叶子). 最后,path返回到达 zipper 当前位置所需的节点列表. - 更新函数:
replace应用当前节点与新节点的替换.edit类似, 但它接受一个从当前节点到新节点的函数.insert-left,insert-right和append-child在相应的方向之一添加一个新节点. - 遍历函数: zipper 带有一个内置的深度优先遍历功能, 可以从任何位置开始.
next检索下一个深度优先的位置.prev检索反向深度优先顺序中的前一个位置. 到达遍历的末尾后,end?在到达遍历的末尾后返回true.
- 构建 Zippers
Clojure 提供了从嵌套向量 (包括子向量和原始向量), 列表 (包括其他原生序列类型) 和 XML (由
clojure.xml/parse返回) 创建 zipper 的选项:(require '[clojure.zip :as zip]) ; ❶ (require '[clojure.xml :as xml]) (require '[clojure.java.io :as io]) (def vzip ; ❷ (zip/vector-zip [(subvec [1 2 2] 0 2) [3 4 [5 10 (vector-of :int 11 12)]] [13 14]])) (def szip ; ❸ (zip/seq-zip (list (range 2) (take 2 (cycle [1 2 3])) '(3 4 (5 10)) (cons 1 '(0 2 3))))) (def xzip ; ❹ (zip/xml-zip (-> "<b> <a>3764882</a> <c>80.12389</c> <f> <f1>77488</f1> <f2>1921.89</f2> </f> </b>" .getBytes io/input-stream xml/parse)))
❶ Clojure zippers 位于
clojure.zip命名空间中, 需要显式引用.❷ 第一个例子展示了如何从一个向量创建一个 zipper, 包括 Clojure 提供的其他类似向量的类型.
❸ 类似地, 我们可以从一些类型序列开始创建一个 zipper (那些实现了
clojure.lang.ISeq的序列, 它们是原生序列list,cons和序列生成器, 如range或cycle).❹
zip/xml-zip从 XML 文档创建 zipper. 该文档需要是clojure.xml/parse输出的格式, 后者又需要一个输入流.vector-zip,seq-zip或xml-zip返回的 zipper 对象是一个元组 (两个项的向量), 它包含当前位置的数据 (最初是整个输入) 和一个描述周围节点的 map (最初为nil):vzip ; ❶ ;; [[[1 2] [3 4 [5 10 [11 12]]] [13 14]] ;; nil]
❶ 探索一个新创建的 zipper 的内容.
描述如何导航特定类型数据结构的配方作为元数据嵌入在 zipper 中:
(pprint (meta vzip)) ; ❶ ;; {:zip/branch? ; ❷ ;; "clojure.core$vector_QMARK___4369@23802cfd"], ;; :zip/children ; ❸ ;; "clojure.core$seq__4357@265a07d7"], ;; :zip/make-node ; ❹ ;; "clojure.zip$vector_zip$fn__7605@4cae7ff1"]}
❶ 告诉 zipper 如何遍历数据结构的配方被嵌入为元数据.
❷
zip/branch?键类似于tree-seq中的 "branch?" 参数, 包含一个函数, 告诉 zipper 如何区分分支和叶子. 如果对输入中的任何项(branch? item)返回true, 那么 zipper 就知道该项可以进一步下降.❸
zip/children键包含一个从分支中检索子元素的函数.❹ 最后,
:zip/make-node包含在需要时用于创建新节点的函数.默认的 zipper 构建器涵盖了一些有趣的情况, 它们是在 XML 是常见数据交换格式的时代创建的. 对于一般用途, 你可能需要最通用的
zipper函数. 但在创建自定义 zipper 之前, 我们需要介绍一些更多的原语来更改和检索位置. - 位置函数
一个 zipper 的" 位置" 是在构造后和调用一个位置函数后立即返回的两个项的向量. 该位置包含原始输入的解构副本, 以表示数据结构中的当前位置. 一个位置函数是一个改变这种解构以表示另一个位置的函数. 让我们看看
zip/down如何改变位置:(pprint vzip) ;; [[[1 2] [3 4 [5 10 [11 12]]] [13 14]] ; ❶ ;; nil] (pprint (zip/down vzip)) ;; [[1 2] ; ❷ ;; {:l [], ;; :pnodes [[[1 2] [3 4 [5 10 [11 12]]] [13 14]]], ;; :ppath nil, ;; :r ([3 4 [5 10 [11 12]]] [13 14])}] (pprint (zip/rightmost (zip/down vzip))) ;; [[13 14] ; ❸ ;; {:l [[1 2] [3 4 [5 10 [11 12]]]], ;; :pnodes [[[1 2] [3 4 [5 10 [11 12]]] [13 14]]], ;; :ppath nil, ;; :r nil}]
❶ 这是由
zip/vector-zip构造函数构建的原始vzip实例. 输入数据作为向量的第一项保持完整.❷ 在调用
zip/down之后, 原始数据的焦点变成了[1 2], 而其余部分则作为元组中第二项 map 的一部分出现. 该 map 包含:l左节点 (在此级别没有左节点),:r右节点 (我们有 2 个节点[3 4 [5 10 [11 12]]]和[13 14]) 以及:pnodes父节点, 从我们来的地方向上看.❸ 对
zip/rightmost的调用现在与位置[1 2]相关. 它将位置一直移动到该遍历点可用的最右边的节点, 即[13 14].如你所见, 每个位置函数都保留了在数据结构中向其他方向移动所需的信息, 而无需任何额外的状态. 在任何方向上到达数据边缘时, 位置函数都返回
nil:(-> vzip zip/down zip/down zip/down) ; ❶ ;; nil
❶ 到达一个叶子节点 (在本例中是数字 1) 时, 下一个向下移动的请求会导致返回一个
nil. 这表示我们到达了数据的边缘, 不能再向该方向移动. 另请注意, 使用->宏来组合位置函数是很惯用的.查看位置内部对于理解 zipper 的工作原理很有用, 但这并不是它们实际的使用方式. 到达所需位置后, 有专门的函数可以访问当前或邻近的节点, 我们将在下一节中看到.
- 检索函数
在将 zipper 移动到特定位置后, 最常用的函数之一是
zip/node, 它以纯数据的形式检索当前位置的节点:(-> xzip zip/down zip/node) ; ❶ ;; {:tag :a, :attrs nil, :content ["3764882"]}
❶
zip/node返回与特定位置对应的数据.我们也可以从一个位置开始" 环顾四周" , 检索位于当前节点右侧, 左侧或下方的节点:
(-> xzip zip/down zip/children) ; ❶ ;; ("3764882") (-> xzip zip/down zip/lefts) ; ❷ ;; nil (-> xzip zip/down zip/rights) ; ❸ ;; ({:tag :c, :attrs nil, :content ["80.12389"]} ;; {:tag :f, ;; :attrs nil, ;; :content ;; [{:tag :f1, :attrs nil, :content ["77488"]} ;; {:tag :f2, :attrs nil, :content ["1921.89"]}]})
❶
zip/children接受一个位置并返回一个子节点列表. 在这种情况下, 唯一的子节点是通过遍历 xml map 结构的:content键来获得的.❷ 在当前位置开始, 没有可用的
zip/lefts节点.zip/lefts返回nil.❸ 在当前位置的右侧有 2 个
zip/rights节点.使用
zip/path函数, 我们可以从当前位置" 向上看" , 并检索到目前为止下降的父节点路径. 例如, 如果我们通过在本节开头创建的序列 zipper 向下移动到 "(5 10)" 节点, 我们可以用zip/path收集到目前为止访问过的父节点:(zip/node szip) ; ❶ ;; ((0 1) (1 2) (3 4 (5 10)) (1 0 2 3)) (-> szip ; ❷ zip/down zip/right zip/right zip/down zip/rightmost zip/down zip/path) ;; [((0 1) (1 2) (3 4 (5 10)) (1 0 2 3)) ; ❸ ;; (3 4 (5 10)) ;; (5 10)]
❶ 打印序列 zipper 的根以跟踪遍历很有用.
❷ 我们通过位置来传递序列 zipper
"szip"以到达"(5 10)"节点. 在链的末尾, 我们调用zip/path来收集到目前为止所有访问过的节点.❸
zip/path的结果只包括zip/down被调用的节点.注意
zip/path不返回所有访问过的节点的遍历. 正如你从上面的例子中看到的, 像"(0 1)"和"(1 2)"这样的节点也是访问的一部分, 但它们没有被zip/path收集. 我们将在下面看到如何用zip/next实现正确的遍历. - 创建自定义 zippers
现在我们已经看到了如何在位置之间移动, 我们可以回到在任何数据结构之上创建 zipper 的问题. 我们已经看到, 内置的向量, 列表和 XML 文件的构造函数很有用, 但仅限于那些特定的用例.
一个更典型的场景是与 JSON 文件之间的数据转换, 这涉及混合向量和具有任意嵌套的 map. 以下是一个更大数据结构中的片段, 是解析 JSON 文档的结果:
(def document ; ❶ {:tag :balance :meta {:class "bold"} :node [{:tag :accountId :meta nil :node [3764882]} {:tag :lastAccess :meta nil :node ["2011/01/01"]} {:tag :currentBalance :meta {:class "red"} :node [{:tag :checking :meta nil :node [90.11]}]}]})
❶ 这里呈现的文档是一个最初作为 JSON 文件传输的更大数据结构的一个片段. 一个节点由一个带有
:tag,:meta和:node键的 map 表示. 如果:node键处的值是一个 map 的集合, 那么这些就代表了该节点的子节点.对于这些类型的数据, 没有内置的 zipper 构造函数, 但我们将从与
xml-zip非常相似的实现中获得灵感来构建我们自己的:(defn custom-zip [root] (zip/zipper ; ❶ #(some-> % :node first map?) ; ❷ (comp seq :node) ; ❸ (fn [node children] ; ❹ (assoc node :node (vec children))) root)) ; ❺ (def czip (custom-zip document)) ; ❻ (-> czip zip/down zip/rightmost zip/down zip/node) ;; {:tag :checking, :meta nil, :node [90.11]}
❶ 我们可以使用
zip/zipper为自定义数据结构创建一个通用构造函数.❷
some->是组合确定传递的参数是否为分支的条件的一个很好的选择. 它需要包含一个:node键, 该节点处的值有一个第一个元素, 并且该元素是map?.❸ 第二个参数是" children" 函数. 该函数嵌入了从节点中提取一个序列的逻辑.
❹ 我们还需要告诉如何根据节点和子元素集合来组装一个新节点, 尽管在这个具体的例子中我们没有使用它.
❺ 最后一个参数是输入数据结构.
❻ 我们像往常一样使用
custom-zipper来创建一个新的 zipper 并导航到最深的节点. - 更新函数
Clojure 提供了几个函数来更改, 插入或删除 zipper 中的节点.
replace会覆盖当前位置的节点, 而不查看其当前内容, 而edit则需要一个从旧节点到新节点的函数.remove只是删除当前节点:(-> vzip zip/down zip/rightmost (zip/replace :replaced) zip/up zip/node) ; ❶ ;; [[1 2] [3 4 [5 10 [11 12]]] :replaced] (-> vzip zip/down zip/rightmost (zip/edit conj 15) zip/up zip/node) ; ❷ ;; [[1 2] [3 4 [5 10 [11 12]]] [13 14 15]] (-> vzip zip/down zip/rightmost zip/remove zip/root) ; ❸ ;; [[1 2] [3 4 [5 10 [11 12]]]]
❶
vzip是在 zipper 部分开头创建的向量 zipper. 在这个第一个例子中, 我们可以看到如何将位置更改为"[13 14]"并用关键字:replaced替换其内容.❷ 如果我们在此位置使用
zip/edit而不是zip/replace,conj会接收"[13 14]"作为第一个参数, 并向其添加 "15".❸ 在最后一个例子中, 节点被完全从输出中移除. 请注意, 我们使用了
zip/root直接解开到根, 而没有使用zip/up.请注意, 对于所有更新函数, 当前位置都保持不变, 除了
zip/remove. 删除一个节点后, 当前位置变成在深度优先遍历顺序中位于被删除节点之前的节点的位置:(-> vzip zip/down zip/rightmost zip/remove zip/node) ; ❶ ;; 12 (zip/node vzip) ;; [[1 2] ;; [3 4 [5 10 [11 12]]] <-- location jump on 12 ;; [13 14]] <-- removes here
❶
zip/remove移除当前节点, 在本例中是"[13 14]", 并跳转到深度遍历顺序中的前一个位置, 在本例中是 "12". 请注意, 该位置可能会跳转到一个完全不同的分支, 就像本例中一样.Zipper 还提供了几个添加节点的选项:
insert-left和insert-right分别在当前位置的左侧或右侧添加一个新节点:(-> vzip zip/down zip/rightmost (zip/insert-left 'INS) zip/up zip/node) ; ❶ ;; [[1 2] [3 4 [5 10 [11 12]]] INS [13 14]] (-> vzip zip/down zip/rightmost (zip/insert-right 'INS) zip/up zip/node) ; ❷ ;; [[1 2] [3 4 [5 10 [11 12]]] [13 14] INS] (-> vzip zip/down zip/rightmost (zip/insert-child 'INS) zip/up zip/node) ; ❸ ;; [[1 2] [3 4 [5 10 [11 12]]] [INS 13 14]] (-> vzip zip/down zip/rightmost zip/down (zip/insert-child 'INS)) ; ❹ ;; Exception called children on a leaf node
❶ 对于所有 3 个示例, 在任何插入操作之前, 位置都会移动到节点
[13 14]. 在第一个案例中, 我们在当前位置的左侧和同一级别添加一个节点 "INS".❷ 使用
zip/insert-right, 新元素被添加到右侧.❸
insert-child将一个新元素添加为现有子元素集合中最左边的项.❹
insert-child不会自动将叶节点提升为分支. 如果该节点是叶子, 它会抛出异常.insert-child和append-child是仅用于分支节点的类似操作.insert-child将一个新的子节点作为最左边的节点添加到当前位置, 而append-node则将新节点附加为最右边的节点:(-> vzip zip/down zip/rightmost (zip/insert-child 'INS) zip/up zip/node) ; ❶ ;; [[1 2] [3 4 [5 10 [11 12]]] [INS 13 14]] (-> vzip zip/down zip/rightmost (zip/append-child 'INS) zip/up zip/node) ; ❷ ;; [[1 2] [3 4 [5 10 [11 12]]] [13 14 INS]] (-> vzip zip/down zip/rightmost zip/down (zip/insert-child 'INS)) ; ❸ ;; Exception called children on a leaf node
❶
insert-child将一个新元素添加为现有子元素集合中最左边的项.❷
append-child反而将新元素添加为最右边的项.❸
insert-child和append-child都不会自动将叶子节点提升为分支. 如果该节点是叶子, 该操作会抛出异常.make-node对于创建可以成为现有 zipper 一部分的新分支节点很有用, 而无需必然知道节点是如何组装在一起的. 例如, 我们可以使用make-node编写一个函数来从节点中移除第一个子节点, 如下所示:(defn remove-child [loc] ; ❶ (zip/replace loc (zip/make-node loc (zip/node loc) (rest (zip/children loc))))) (-> vzip zip/down zip/rightmost remove-child zip/up zip/node) ; ❷ ;; [[1 2] [3 4 [5 10 [11 12]]] [14]] (-> vzip zip/down zip/rightmost remove-child remove-child zip/up zip/node) ; ❸ ;; [[1 2] [3 4 [5 10 [11 12]]] []]
❶
make-node接受一个位置和一个子元素集合. 与 zipper 内部相关的细节作为元数据出现在位置处.❷
remove-child的使用方式与 zipper 接口的其余部分类似. 调用remove-children会移除该位置的第一个子节点.❸ 我们可以重复调用
remove-child, 直到没有更多的子元素可以移除, 使该节点为空. - 遍历函数
zipper命名空间包含一些函数, 它们按照预定的方向移动当前位置, 遵循深度优先的遍历路径.zip/next和zip/prev分别将位置移动到下一个或前一个深度优先的位置:(-> vzip zip/next zip/node) ; ❶ ;; [1 2] (-> vzip zip/next zip/next zip/node) ;; 1 (-> vzip zip/next zip/next zip/next zip/node) ;; 2 (-> vzip zip/next zip/next zip/next zip/next zip/node) ;; [3 4 [5 10 [11 12]]]
❶
vzip是在本章开头定义的向量 zipper. 我们可以跟随重复调用zip/next的结果, 下降到第一个节点"[1 2]", 访问其元素, 最后向上移动到下一个节点.如果我们想对所有可用的节点进行遍历, 我们可以用
iterate重复地调用zip/next在前一次调用的结果上. 注意使用zip/end?来决定何时停止遍历:(->> vzip (iterate zip/next) ; ❶ (take-while (complement zip/end?)) ; ❷ (map zip/node)) ; ❸ ;; ([[1 2] [3 4 [5 [6 7 8 [] 9] 10 [11 12]]] [13 14]] ;; [1 2] ;; 1 2 ;; [3 4 [5 [6 7 8 [] 9] 10 [11 12]]] ;; 3 4 ;; [5 [6 7 8 [] 9] 10 [11 12]] ;; 5 ;; [6 7 8 [] 9] ;; 6 7 8 [] 9 10 ;; [11 12] ;; 11 12 ;; [13 14] ;; 13 14)
❶
iterate重复地在前一次调用期间返回的位置上调用zip/next(最初是向量 zipper "vzip", 这是第一个位置).❷ 有一个特定的
zip/end?谓词, 当位置是遍历中最后一个可用的位置时, 它返回true.❸ 到目前为止收集的所有位置都需要被转换为简单的节点以可视化其内容.
将
clojure.zip与clojure.walk进行比较是很自然的. 关键的区别是:zipper函数, 除了zip/next和zip/prev, 不强制要求特定的遍历算法.clojure.walk仅与深度优先遍历一起工作 (可以选择先序或后序).clojure.walk没有遍历状态. 因此, 我们将需要使用一些可变的状态 (例如一个原子) 来在遍历期间收集节点列表. Zipper 对这两种用例都自然适用: 将节点收集到一个扁平列表中或保留原始的嵌套.
使用
iterate的前一个遍历的结果是一个访问过的节点的惰性列表. 在下一个例子中, 我们用loop-recur急切地处理问题, 在保持原始嵌套结构的同时进行转换:(defn zip-walk [f z] ; ❶ (if (zip/end? z) (zip/root z) (recur f (zip/next (f z))))) (zip-walk ; ❷ #(if (zip/branch? %) % (zip/edit % * 2)) (zip/vector-zip [1 2 [3 4]])) ;; [2 4 [6 8]]
❶
zip-walk类似于clojure.walk/prewalk. 它接受一个位置的函数和一个 zipper, 并遍历 zipper, 将该函数应用于每个节点.❷ 我们传递给
zip-walk的函数接受一个 zipper 位置并返回一个位置. 在这种情况下, 我们只有在节点不是分支时才执行该操作. - 遍历后无法返回
请注意, 一旦 zipper 遍历用
zip/next完成, 就无法返回或移动位置:(def zipper-end ; ❶ (-> (zip/vector-zip [1 2]) zip/next zip/next zip/next)) (zip/end? zipper-end) ; ❷ ;; true (zip/prev zipper-end) ; ❸ ;; nil
❶ 简单的向量
"[1 2]"产生一个同样简单的 zipper.❷ 调用
zip/next3 次后, 我们到达了遍历的末尾.❸ 到达遍历末尾后, 该位置不能用于任何进一步的导航, 包括用
zip/prev返回遍历路径.如果遍历没有到达末尾, 那么
zip/prev或任何其他位置更改都是可能的. 另请注意,zip/prev在到达根节点时没有相同的行为: 在根位置上zip/prev之后zip/next按预期工作.这结束了我们对 zipper 函数和集合章节的描述. 我们将在下一章中看到一个更专门的集合版本, 称为" 序列" .
- 构建函数: zipper 可以用通用的
3.1.5. 8.5 总结
在本章中, 我们说明了专门用于集合处理的函数, 这是一大类函数, 包括计数, 迭代, 访问和遍历等通用设施. 集合是 Clojure 中最通用的容器类型, 在接下来的两章中, 我们将描述一个更专门的数据抽象, 称为" 序列" . 大多数情况下, Clojure 程序员可以忽略它们之间的区别, 因为标准库负责在这两者之间进行优雅的转换. 此外, 大多数集合函数都扩展到 Java 集合和数组, 以实现无缝的互操作性.
3.2. 9 序列
Clojure 序列是一种抽象数据类型. 抽象数据类型 (或 ADT) 描述了数据结构的行为, 而不强制要求特定的实现. 该抽象的主要属性如下:
- 顾名思义, 它是按顺序迭代的: 你不能在没有先访问第 n - 1 个元素的情况下访问第 n 个元素 (并且没有间隙).
- 它的工作方式像一个无状态的光标: 迭代只能向前移动.
- 它是持久且不可变的: 像所有其他核心数据结构一样, 序列一旦创建就不能被改变, 但可以基于前一个序列 (通过结构共享) 进行更改.
可选地, 序列还支持以下特性 (尽管它们不是约定的一部分):
- 它们通常 (但非必须) 是惰性的: 只有当请求了下一个元素时, 才会生成该元素.
- 它们也被缓存: 第一次访问序列元素会产生每个项的缓存版本. 后续访问序列不需要进一步的计算.
- 它们经常应用" 分块" 来提高性能. 分块包括处理比请求的更多的元素, 假设调用者很快就会向前移动并访问序列的其余部分.
Clojure 大量使用序列, 因此有很多专门用于它们的函数. 本书为此主题 посвятила了两章, 一章关于序列的生成方式, 另一章关于它们的处理. 下图显示了标准库中序列的生产者和消费者.
Figure 26: 创建序列的不同内置设施.
下一章是关于序列生产者的. 基本上有 4 种创建它们的方式:
- " Seqable" 集合是支持序列接口的集合. 通过直接在它们上调用
seq, 或者隐式地通过许多处理函数之一 (内部使用seq) 来产生一个序列视图. - 按需生成: 数据在消费序列之前不存在, 但在请求时立即生成. 像
range这样的函数是一个完美的例子: 数字列表在被请求之前不存在.range(和其他类似的函数) 描述了生成数据的配方, 但它不是数据本身. - 自定义生成: 在某些数据源之上构建一个序列 (通常通过使用
lazy-seq), 这些数据源不一定是有结构的或在内存中可用的. - 原生序列: Clojure 提供了两种具体的数据结构, 它们原生实现序列接口: cons 列表和持久化列表.
3.2.1. 9.1 序列集合
seq 从一个启用了的集合类型生成一个序列. 几乎所有 Clojure 集合都实现了 clojure.lang.Seqable 接口, 该接口产生一个符合顺序访问的集合视图. 除了 seq 产生的标准的只向前迭代外, Clojure 还提供了其他风格的顺序访问:
rseq创建一个反向序列, 一个从最后一个元素向后读取的序列.subseq和rsubseq从一个已排序的集合 (如sorted-set或sorted-map) 的部分产生一个序列.seque创建一个阻塞序列, 一个由阻塞队列支持的序列, 如果消费者领先于生产者, 可能会阻塞.pmap在并行应用转换的同时产生一个序列.
我们现在将详细地看一下不同类型的序列生成.
- 9.1.1 seq 和 sequence
自 1.0 版本以来的函数
(seq [coll]) (sequence ([coll]) ([xform coll]) ([xform coll & colls]))
seq和sequence在现有集合之上启用序列行为. 集合最终负责发送数据, 但最终结果必须符合 Clojure 的" 序列" , 一个持久且不可变的数据结构. 根据目标集合, 序列会被额外地缓存或分块 (有关这些特性的简要解释, 请参见本章开头).尽管
seq对于 Clojure 的内部机制非常重要 (所有序列函数都以某种方式调用seq), 但显式地使用seq只有少数惯用法. 例如,seq可以用来检查一个集合是否至少包含一个元素:(def coll []) (if (seq coll) :full :empty) ; ❶ ;; :empty (if (empty? coll) :empty :full) ; ❷ ;; :empty (if (not-empty coll) :full :empty) ; ❸ ;; :empty
❶
seq的一个惯用法是提供一种统一的方式来检查一个集合是否至少包含一个元素. 一个空集合的seq返回nil(而不是空集合), 这使得这个条件能够正常工作.❷ 假设我们乐于反转条件分支的顺序 (首先强调集合是空的这一事实), 我们可以改用
emtpy?.❸ 最后, 如果我们同意否定条件形式, 我们也可以使用
not-empty.sequence有额外的特性. 当与单个集合参数一起使用时, 它的工作方式与seq类似, 唯一的区别在于对空集合的处理:(seq nil) ;; nil (sequence nil) ; ❶ ;; () (seq []) ;; nil (sequence []) ; ❷ ;; ()
❶ 在
nil集合上调用时,seq返回nil.sequence返回一个新空列表.❷
seq在空集合上返回nil, 而sequence返回一个空列表.在向标准库添加 transducer 后,
sequence也提供了应用 transducer 的可能性:(sequence (map str) [1 2 3] [:a :b :c]) ; ❶ ;; ("1:a" "2:b" "3:c")
❶
sequence接受一个 transducer (或其组合) 和可变数量的集合.sequence也是唯一一个支持多个集合输入的 transducer 感知函数:(sequence (map *) (range 10) (range 10)) ; ❶ ;; (0 1 4 9 16 25 36 49 64 81)
❶ 当存在多个集合时, 第一个 transducer 会收到一个带有 2 个 (或更多) 参数的转换调用. 在这种情况下, 映射函数 "*" 接收两个参数来生成一个数的平方.
- 约定
- 输入
"coll & colls"是兼容的集合类型, 包括 Clojure 集合 (不包括瞬态), 其他序列, 字符串, 数组或 Java iterable.seq需要一个可以为空或nil的集合参数.sequence允许可变数量的空或nil集合, 但至少必须存在一个."xform"是一个遵循 transducer 语义的函数.sequence是唯一支持多个集合输入的 transducer 函数. 如果sequence接收两个或更多个"colls"参数, 那么 transducer"xform"也接收两个或更多个参数.
- 值得注意的异常
对于不支持的集合类型, 会抛出
IllegalArgumentException. - 输出
返回: 一个表示输入集合的序列视图的序列. 如果存在一个或多个 transducer,
sequence会将 transducer 链应用于输出序列中返回的每个元素. 当存在多个集合时, 输出在到达最短的输入后停止.
- 输入
- 示例
seq有一些惯用用法. 我们在引言中看到, 它可以用来验证一个集合是否不为空. 这在递归中很有用, 例如, 逐步消耗一个集合. 这里是用于反转一个通用集合输入的一般机制:(defn rev [coll] (loop [xs (seq coll) done ()] ; ❶ (if (seq xs) ; ❷ (recur (rest xs) ; ❸ (cons (first xs) done)) ; ❹ done))) (rev [8 9 10 3 7 2 0 0]) ; ❺ ;; (0 0 2 7 3 10 9 8)
❶ 为了绝对确保我们可以通过序列接口在
"coll"上操作, 我们在首次初始化loop-recur结构时调用seq. 这会在最早的可能点抛出异常. 如果rev函数只在 Clojure 数据结构的上下文中操作, 通常不需要显式的seq.❷
seq用于检查一个集合是否不为空. 我们也可以询问集合是否是empty?并反转if语句, 但根据算法的重点和编程风格, 同时拥有这两个选项总是好的.❸ 我们现在可以肯定地调用
rest, 因为我们在循环的开头强制进行了seq"xs" 转换.❹ 我们在
"done"上使用cons, 这是一个最初绑定到空列表的局部名称. 列表原生支持序列接口, 无需序列适配器.❺ 像向量这样的集合不是原生序列, 但 Clojure 通过遍历它们的内部结构可以轻松地适应它们.
以类似的方式,
seq可以用作谓词来验证一个列表中的所有集合是否每个都包含至少一个项:(every? seq [#{} [:a] "hey" nil {:a 1}]) ; ❶ ;; false
❶
seq可用作涉及集合列表的操作的谓词.在引入 transducer 之后,
sequence现在可用于一系列全新的应用. 与seq类似,sequence在输入集合之上产生一个序列视图. 此外,sequence使用提供的 transducer 链对每个项应用一个转换.在下面的例子中, 我们将解析一些非结构化的输入来提取我们需要的信息. 我们需要连接到一个设备, 该设备返回一个类似于电子表格网格的二维表示的数据. 输出还包含我们不需要的交错行. 这里是我们想要提取的数据的例子, 以及它在连接到设备时出现的样子:
;; == example data pattern == ; ❶ ;; Wireless MXD CXP ; header: kind & codes ;; ClassA 34.97 34.5 ; metric: name & measures ;; ClassT 11.7 11.4 ; metric: name & measures ;; ClassH 0.7 0.4 ; metric: name & measures (def device-output ; ❷ [["Communication services version 2"] ["Radio controlled:" "Enabled"] ["Ack on transmission" "Enabled" ""] ["TypeA"] ["East" "North" "South" "West"] ["10.0" "11.0" "12.0" "13.0"] ["Wireless" "MXD" ""] ["ClassA" "34.97" "" "34.5"] ["ClassB" "11.7" "11.4"] ["Unreadable line"] ["North" "South" "East" "West"] ["10.0" "11.0" "12.0" "13.0"] ["Wired" "QXD"] ["ClassA" "34.97" "33.6" "34.5"] ["ClassC" "11.0" "11.4"]])
❶ 该示例显示了我们正在搜索的数据模式的类型: 它包含一个头, 后面跟着几行数值指标.
❷ 这是我们从设备接收到的输出. 有趣的数据以交错的方式出现在输出中, 夹杂着我们想要移除的额外" 噪音" .
我们遵循的方法是自上而下读取设备输出, 并逐步创建行组. 只有当一个组符合我们感兴趣的数据模式时, 我们才保留它. 我们可以使用以下谓词来检查一组行是否是我们感兴趣的:
(defn measure? [measure] ; ❶ (and measure (re-matches #"[0-9\.]*" measure))) (defn metric? [[name & measures]] ; ❷ (and name (re-matches #"Class\D" name) (every? measure? measures))) (defn header? [[kind & [code]]] ; ❸ (and (#{"Wireless" "Wired"} kind) (#{"MXD" "QXD" "CXP"} code))) (defn pattern? [[header & metrics]] ; ❹ (and (header? header) (every? metric? metrics))) (pattern? [["Wireless" "MXD" ""] ; ❺ ["ClassA" "34.97" "" "34.5"] ["ClassB" "11.7" "11.4"]]) ;; true
❶ 一个
measure?是一个表示十进制数的字符串. 为了这个例子的目的, 正则表达式非常简单.❷ 一个
metric?是一个包含一个名称和任意数量的度量的列表. 名称必须以 "Class" 开头, 后跟一个字母.❸ 一个
header?是一个字符串列表. 它应该以一个" 种类" (要么是 "Wireless" 要么是 "Wired") 开始, 后跟一个" 代码" .❹ 一个
pattern?匹配整个规范. 它检查第一行是否是一个有效的头, 后面跟着的是度量.❺ 我们可以在一个测试规范上尝试这个谓词.
现在我们已经实现了识别我们感兴趣的数据模式的谓词, 是时候处理来自设备的原始数据了. 我们通过迭代一个从 0 到输入行数的范围来进行, 然后使用
nthrest来逐步地从顶部移除它们. 这会生成输入的所有有序子集. 我们知道输入的某些子集可能是我们感兴趣的数据模式.sequence在使用 transducer 处理这个序列时非常方便:(defn all-except-first [lines] ; ❶ #(nthrest lines %)) (def if-header-or-metric ; ❷ #(take-while (some-fn header? metric?) %)) (defn filter-pattern [lines] ; ❸ (sequence (comp (map (all-except-first lines)) (keep if-header-or-metric) (filter pattern?)) (range (count lines)))) (filter-pattern device-output) ;; ((["Wireless" "MXD" ""] ;; ["ClassA" "34.97" "" "34.5"] ;; ["ClassB" "11.7" "11.4"]) ;; (["Wired" "QXD"] ;; ["ClassA" "34.97" "33.6" "34.5"] ;; ["ClassC" "11.0" "11.4"]))
❶ 第一个变换器接收所有行, 但不包括第一个 "n" 行, 其中 "n" 来自一个范围输入的迭代.
❷ 第二个变换器只保留一个子集中的行, 这些行要么是头, 要么是指标, 这正是我们感兴趣的唯一行类型.
❸
filter-pattern将所有变换器组合在一起.当我们最终在来自设备的原始输入上测试
filter-pattern时, 我们可以看到它正确地组装了我们正在搜索的数据模式.- Clojure 中序列的作用是什么?
对于所有实际目的, 序列是一个集合. 与其他集合不同, 序列不为其数据实现容器 (除了缓存值), 而是从某个源接收数据.
seq和sequence从其他集合接收它们的数据, 但还有其他获取数据的方式: 序列的数据可以按需由内置函数 (例如range) 生成, 通过请求一个自定义的生产者 (使用lazy-seq), 或其他对象 (使用resultset-seq,xml-seq,tree-seq等) 来生成.另一个重要的方面是, 序列是惰性构造的. 访问下一个元素的机制 (从序列到隐藏的集合) 实际上只在上游请求元素时才操作. 这对于数据生成器特别有效, 因为数据在请求元素之前根本不在内存中.
一个序列还提供了一个基本的缓存机制. 序列可以被赋给一个
let块并被多次访问, 底层的集合或生成器不会执行任何额外的工作 (只要任何涉及的函数没有副作用, 就会产生一致的结果).
- Clojure 中序列的作用是什么?
- 另请参阅
list创建一个具体的集合, 它也是一个原生的序列.lazy-seq提供了一种为序列创建自定义数据生成器的方法.iterator-seq返回一个在java.util.Iterator实例之上的序列视图. 许多 Clojure 和 Java 集合都可以通过Iterator接口访问.
- 性能考虑和实现细节
=> O(n) 步 (完全求值)
=> O(n) 内存 (最坏情况)
seq和sequence取决于完全消耗的序列集合 (或生成器) 的长度. 值被缓存, 因此当完全消耗时, 序列生成会创建一个输入集合的副本, 在内存空间中产生线性行为.从实现的角度来看,
seq和sequence要求输入类型提供序列接口. 输入有机会为构建其元素的序列提供一个最优的算法.下图显示了在包含相同 10000 个项的最常见序列类型上调用的
(doall (seq coll)).vector-of是性能最差的, 其次是Set和hash-map及其有序变体.#CAPTION: seq 在最常见的序列类型上调用. "hset" 和 "hmap" 分别是
hash-set和hash-map的缩写.
在图表的快速一侧, 我们找到了原生序列集合和生成器, 如范围和长范围. 其他类型的向量也表现良好. 对于图表中基准测试的许多类型, 序列转换的相对重要性不大, 因为它们的主要目标是提供直接的查找访问.
缓存是性能的一个重要因素, 特别是当涉及昂贵的计算时. 如果需要重用, 序列可以被闭包 (例如用一个
let绑定) 并有效地重用. 我们可以进一步扩展之前看到的解析器输出示例, 通过添加一个有副作用的 transducer 来查看相同的消息是否出现不止一次:(defn filter-pattern [lines] ; ❸ (sequence (comp (map (all-except-first lines)) (keep if-header-or-metric) (filter pattern?) (map #(do (println "executing xducers") %))) ; ❶ (range (count lines)))) (let [groups (filter-pattern device-output)] ; ❷ [(dorun (seq groups)) (dorun (first groups)) (dorun (last groups))]) ;; executing xducers ; ❸ ;; executing xducers ;; [nil nil nil]
❶ 有副作用的 transducer 是一个
maptransducer, 它打印到标准输出并返回输入而没有任何修改.❷
groups是sequence调用结果的局部名称. 然后我们在此之上创建另一个序列, 访问第一个和最后一个元素.❸ 我们可以看到两个打印输出, 对应于输入中找到的组. 尽管
first和last都在它们的输入上调用seq(有效地在groups之上创建了一个新的序列), 但没有看到其他打印输出, 这表明 transducer 链再也没有被调用.eduction在期望 transducer 再次执行的情况下会阻止这种行为.惰性和缓存在处理可变集合 (如 Java 集合) 时有影响, 并且在序列视图创建后会发生变异. 这里有一个例子, 显示了变异对序列视图的影响:
(import '[java.util ArrayList]) (let [a (ArrayList. [:o :o :o]) s (seq a)] ; ❶ [(.set a 0 :x) (first s) (.get a 0)]) ; ❷ ;; [:o :x :x] (let [a (ArrayList. [:o :o :o]) s (seq a)] ; ❸ [(first s) (.set a 0 :x) (first s) (.get a 0)]) ;; [:o :o :o :x]
❶ 序列是在这里创建的, 当
seq在一个java.util.ArrayList实例上被调用时.❷
ArrayList被改变为现在在第一个位置包含一个不同的项. 这发生在我们对先前创建的序列 "s" 调用first之前, 所以新值被打印而不是旧值.❸ 我们现在在变异之前访问第一个元素, 所以我们首先得到当前的
":o"内容. 在改变了ArrayList之后, 序列的第一个元素没有改变, 因为该值被缓存了.关于使用
sequence和 transducer 的性能方面的最后一点说明.sequence的 transducer 实现使用了一个缓冲机制来临时停放每个转换后的项, 并在序列被消费时返回它. 对于简单的 transducer 链, 正常的序列生成比 transducer 序列生成更快:(require '[criterium.core :refer [bench quick-bench]]) ; ❶ (let [xs (range 500000)] (bench (last (filter odd? (map inc xs))))) ; ❷ ;; Execution time mean : 26.944707 ms (let [xs (range 500000)] (bench (last (sequence (comp (map inc) (filter odd?)) xs)))) ; ❸ ;; Execution time mean : 37.773642 ms
❶ 我们使用 Criterium 库以最准确的方式测量性能.
❷ 一个包含 500,000 个项的范围通过访问最后一个元素被完全求值. 涉及的处理非常简单.
❸ 我们用
sequence和一个 transducer 链进行类似的操作. 我们可以看到轻微的性能下降.在考虑是使用 transducer 版本的
sequence还是普通的序列生成时, 惰性绝对起着作用. 为了看到一些性能下降, 我们需要完全消耗一个相对较大的范围, 如基准测试所示: 你可以放心地对中等大小的输入或非平凡的 transducer 链使用带有 transducer 的sequence.
- 约定
- 9.1.2 rseq
自 1.0 版本以来的函数
(rseq rev)
rseq在一个集合之上创建一个反向的序列视图. 该集合需要知道如何产生这样的视图才能与rseq一起工作 (它需要实现clojure.lang.Reversible接口).rseq的一个主要用途是为向量, 排序映射和排序集提供一个常数时间的反转版本, 否则它们将被迫进行线性序列扫描.rseq返回输入数据结构的一个" 反向视图" , 因此当元素被迭代时, 它们以反向顺序返回:(rseq [:b :a :c :d]) ; ❶ ;; (:d :c :a :b) (rseq (sorted-map :d 0 :b 3 :a 2)) ; ❷ ;; ([:d 0] [:b 3] [:a 2])
❶ 在一个向量上使用
rseq返回一个反向的序列.❷
rseq返回排序映射中条目的一个反向序列.如我们所见, 结果打印在圆括号内. 这正确地表明返回类型是序列的 (向量, 排序映射和排序集返回一个实现序列接口的特定
rseq包装器):(conj (rseq [1 2 3]) :a) ; ❶ ;; (:a 3 2 1)
❶
conj到反向向量中会插入到" 头部" 而不是尾部位置 (就像向量的情况一样).在向量上使用
rseq会有效地返回一个序列. 因此, 请注意, 即使输入数据结构是向量, 像peek或nth这样的操作也不会对rseq的输出进行优化.rseq与reverse在处理空集合和nil方面有所不同.(reverse nil)和(reverse [])返回nil, 但(rseq nil)会导致抛出NullPointerException.- 约定
- 输入
"rev"是唯一强制性参数."rev"必须是实现了clojure.lang.Reversible接口的集合. 可以使用一个辅助函数来检查这是否对"rev"为真:(reversible? rev)应该返回true. 目前只有用vector,vector-of或subvec创建的向量是可逆的. 此外, 排序映射和排序集合也是可逆的.
- 值得注意的异常
- 当
"reversible"不实现clojure.lang.Reversible时, 会抛出ClassCastException. 向量和排序映射/集合与rseq兼容. - 如果
"reversible"为nil, 则会抛出NullPointerException.
- 当
- 输出
rseq返回:- 当
"reversible"非空时, "rev" 中元素的反向顺序的序列. - 如果
"reversible"是一个非空的排序映射, 那么是 map 中键值对的反向键顺序的序列. - 当
"reversible"是一个空向量, 排序映射或排序集合时为nil.
- 当
- 输入
- 示例
我们已经在讨论
range时看到了回文. 回文有许多应用, 例如, 它们在遗传学中用于在 DNA 链中寻找酶启用的位置 144. DNA 由核苷酸字符串组成. 按照惯例, 核苷酸被称为 A, T, G 和 C. A 和 T 相互补充, C 和 G 也是如此.一个 DNA 核苷酸序列是回文的, 如果它等于其反向互补序列. 让我们看看如何使用
rseq来编写一个程序, 在 DNA 序列中寻找回文:(defn complement-dna [nucl] ; ❶ ({\a \t \t \a \c \g \g \c} nucl)) (defn is-palindrome? [dna] (= (map complement-dna dna) (rseq dna))) ; ❷ (defn find-palindromes [dna] ; ❸ (for [i (range (count dna)) j (range (inc i) (count dna)) :when (is-palindrome? (subvec dna i (inc j)))] [i j])) (mapv complement-dna [\a \c \c \t \a \g \g \t]) ;; => [\t \g \g \a \t \c \c \a] (is-palindrome? [\a]) ;; => false (is-palindrome? [\a \c \c \t \a \g \g \t]) ;; => true (find-palindromes [\a \c \g \t]) ;; => ([0 3] [1 2])
❶ 我们使用一个 map 来寻找每个核苷酸的互补.
❷
is-palindrome?检查一个 DNA 序列是否是回文. 它计算互补并使用rseq反转序列. 结果与输入序列进行比较.❸ 我们使用
for列表推导来迭代 DNA 的所有由两个或更多个核苷酸组成的子向量.find-palindromes返回一个惰性序列, 其中包含指定每个回文的开始和结束的对 (如果有的话).上面的算法是一个优雅的例子, 它展示了
rseq的使用并避免了反转输入. 然而, 它并不是为生产规模设计的, 对于现实生活中的问题, 你应该寻找更复杂的技巧 145. - 另请参阅
seq用于在不反转其内容的情况下返回集合的序列.reverse在所有可序列化的集合上返回一个反向序列, 而不仅仅是向量.
- 性能考虑和实现细节
=> O(1) 时间, 序列创建
=> O(n) 时间, 完全消耗
=> O(n) 空间, 完全消耗
一个简单的
rseq调用在常数时间内执行, 因为它实际上不迭代输入. 如果结果序列被迭代, 那么rseq的性能与集合中元素的数量成线性关系.rseq, 像seq一样, 在内存中缓存值, 在项目数量上呈线性消耗内存.显而易见的比较是与
reverse. 让我们再次访问在range的" 性能考虑" 部分展示的回文示例. 在那个示例中, 我们想知道一个非常长的 DNA 序列是否是回文. 该示例考虑了两种解决方案: 一种是从中间开始比较项, 另一种是使用reverse然后与原始输入进行比较. 这里将基于reverse的解决方案与基于rseq的解决方案进行比较:(require '[criterium.core :refer [quick-bench]]) (defn complement-dna [nucleotide] ; ❶ ({\a \t \t \a \c \g \g \c} nucleotide)) (defn random-dna [n] ; ❷ (repeatedly n #(rand-nth [\a \c \g \t]))) (defn palindrome-reverse? [dna] ; ❸ (= (map complement-dna dna) (reverse dna))) (defn palindrome-rseq? [dna] ; ❹ (= (map complement-dna dna) (rseq dna))) (let [dna (random-dna 1e4)] (quick-bench (palindrome-reverse? dna))) ;; Execution time mean : 834.510161 µs (let [dna (vec (random-dna 1e4))] (quick-bench (palindrome-rseq? dna))) ;; Execution time mean : 2.940745 µs ; ❺ (let [dna (apply concat (repeat 1e4 [\a \c \c \t \a \g \g \t]))] (quick-bench (palindrome-reverse? dna))) ;; Execution time mean : 12.991438 ms (let [dna (vec (apply concat (repeat 1e4 [\a \c \c \t \a \g \g \t])))] (quick-bench (palindrome-rseq? dna))) ;; Execution time mean : 11.238614 ms ; ❻
❶ 这是示例中显示的用于补充核苷酸的相同函数.
❷
random-dna创建长度为 "n" 的随机 DNA 序列.❸
palindrome-reverse?是用于比较 DNA 序列的基于reverse的版本. 请注意, 此版本不需要向量作为输入.❹
palindrome-rseq?使用rseq来检查回文. 请注意, 此版本需要一个可逆的输入 (例如一个向量).❺ 我们可以看到, 一个随机序列 (是回文的概率很低) 用
rseq发现的速度比用reverse快得多 (超过两个数量级).❻ 如果我们改用一个长度相似且是回文的序列 (比较的最坏情况), 我们可以看到几乎没有区别.
基于
rseq的解决方案比基于reverse的类似解决方案快两个数量级以上. 这个结果是在考虑到随机序列是回文的概率非常低, 并且相等性在迭代开始后很快就会返回假, 而无需完全实现反向序列的情况下获得的.
- 约定
- 9.1.3 subseq 和 rsubseq
自 1.0 版本以来的函数
(subseq ([sc test key]) ([sc start-test start-key end-test end-key])) (rsubseq ([sc test key]) ([sc start-test start-key end-test end-key]))
subseq和rsubseq从一个已排序的集合中由一个上/下界包围的元素中创建一个序列:(subseq (apply sorted-set (range 10)) > 2 < 8) ; ❶ ;; (3 4 5 6 7) (rsubseq (apply sorted-map (range 10)) <= 5) ; ❷ ;; ([4 5] [2 3] [0 1])
❶
subseq产生一个所有元素大于 2 且小于 8 的序列.❷
rsubseq产生一个所有键小于或等于 5 的键值对的反向序列.rsubseq与subseq的不同之处在于序列生成的顺序: 从第一个匹配的元素 (subseq) 或从最后一个 (rsubseq).subseq和rsubseq隐式地要求输入集合支持一个排序的概念, 这限制了可能的输入类型为sorted-set和sorted-map.- 约定
- 输入
"sc"是一个实现了clojure.lang.Sorted接口的已排序的集合. 标准库中目前有两个具体的实现:sorted-set和sorted-map."test"可以是四个比较器之一:<,⇐,>或>=."key"类型需要与"sc"的内容可比较. 在大多数实际情况下, 这意味着"key"的类型与"sc"中的键的类型相同."start-test","start-key","end-test"和"end-key"的类型分别与"test"和"key"相同. 不同的名称只是在函数调用中同时出现两个边界时才需要.
- 值得注意的异常
当
"key"与"sc"中的键不可比较时, 或者当"sc"不是一个已排序的集合时, 会抛出ClassCastException. - 输出
subseq: 返回一个前向的元素序列, 该序列包含在下/上界之间的元素 (当两者都存在时). 当上界不存在时, 序列的开始/结束隐式地界定了上/下界.rsubseq: 像subseq一样工作, 但反转了元素在输出序列中返回的顺序.
- 输入
- 示例
subseq和rsubseq可用于执行搜索高于或低于某个键的元素. 例如, 这里是如何回答" 键大于/小于 x 的最小/最大元素是什么" 的问题:(defn smallest> [coll x] (first (subseq coll > x))) ; ❶ (defn smallest>= [coll x] (first (subseq coll >= x))) (defn greatest< [coll x] (first (rsubseq coll < x))) ; ❷ (defn greatest<= [coll x] (first (rsubseq coll <= x))) (def coll (sorted-map "a" 5 "f" 23 "z" 12 "g" 1 "b" 0)) (smallest> coll "f") ;; ["g" 1] (smallest>= coll "f") ;; ["f" 23] (greatest< coll "f") ;; ["b" 0] (greatest<= coll "f") ;; ["f" 23]
❶
smallest>的实现检索了超出给定边界的上层序列. 第一个元素是在目标之后最小的.❷
greatest<使用rsubseq来避免从结果序列中取最后一个. 访问序列的最后一个在性能方面通常不是一个好主意, 我们有一个直接的方法来避免它.以下示例展示了如何实现一个单词的自动补全, 给定前几个字母. 我们可以在应用程序引导时将一个词典加载到一个
sorted-set中, 并用它来快速选择一个单词范围来补全用户输入.(require '[clojure.string :refer [split]]) (def dict (into (sorted-set) ; ❶ (split (slurp "/usr/share/dict/words") #"\s+"))) (defn complete [w dict] ; ❷ (take 4 (subseq dict >= w))) (map #(complete % dict) ["c" "cl" "clo" "clos" "closu"]) ; ❸ ;; (("c" "ca" "caam" "caama") ;; ("clabber" "clabbery" "clachan" "clack") ;; ("cloaca" "cloacal" "cloacaline" "cloacean") ;; ("closable" "close" "closecross" "closed") ;; ("closure" "clot" "clotbur" "clote"))
❶ 我们从一个单词列表 (在本例中是 Unix 标准词典位置) 开始构建一个词典. 该词典被创建为一个
sorted-set.❷
complete接受一个单词, 或更可能是前几个字母, 并从词典中返回该片段之后的头 4 个单词.❸ 这里你可以看到用户输入的一个模拟, 逐步尝试拼写" closure" . 你可以看到该单词在第 5 个字母时首先出现 (如果我们取更长的自动补全列表, 它可能会更早出现).
- 红黑树
Clojure 中理想哈希树的使用在文章和演示文稿中有很好的文档记录 (Phil Bagwell 的 HAMT 树思想已被改编为 Clojure 中持久化数据结构的基础, 你可以在这里阅读原始论文 lampwww.epfl.ch/papers/idealhashtrees.pdf). 但 Clojure 也实际使用了其他有趣的数据结构, 如红黑树, 这是一种自平衡树, 是排序集和排序哈希映射的基础 146.
在红黑树节点中, 有一位专用于标识一种颜色 (按惯例是黑色或红色), 这有助于在插入期间保持树的平衡. Clojure 当前红黑树实现的灵感来自 Okasaki 147, 并在 Clojure 邮件列表上部分描述过 148.
除了直接使用
sorted-set和sorted-map进行基本排序外,subseq和rsubseq是标准库中唯一显式使用clojure.lang.PersistentTreeMap方法的函数. 原因是 O(log n) 的访问保证 (与序列中的线性访问相比), 以达到请求的元素, 从那里开始生成序列. 即使假设一个有序的向量或序列, 用其他数据结构达到请求的元素也需要线性时间.
- 红黑树
- 另请参阅
subs从另一个更大的字符串中检索一个子字符串.subvec根据一个开始和结束索引创建一个子向量.drop和take可以用它们的变体来隔离一个序列的一部分.rseq可以用来从一个集合的元素中反向生成一个序列.sort用于对一个集合的内容进行排序.sorted-set和sorted-map用一个比较器来按顺序存储它们的内容.
- 性能考虑和实现细节
=> O(log n) 步, 平均
=> O(n) 步, 最坏情况
=> O(n) 空间, 平均
subseq和rsubseq利用二叉树搜索来执行高效的搜索. 更具体地说, 它们都提供了在返回第一个匹配谓词的元素方面的 O(log n) 保证. 在找到入口点后, 序列的任何进一步生成都取决于所请求序列的长度 n (尽管这是在生成的输出被完全消耗时的最坏情况).以下示例执行一个搜索, 以找到出现在阈值 "x" 之后的最小项, 显示当集合是一个
sorted-set时 (与在序列中对项进行排序相比),subseq要快得多:(require '[criterium.core :refer [quick-bench]]) (def items (shuffle (range 1e5))) (let [x 5000 xs (sort items)] (quick-bench (first (drop-while #(>= x %) xs)))) ; ❶ ;; Execution time mean : 88.201576 µs (let [x 5000 ss (into (sorted-set) items)] (quick-bench (first (subseq ss > x)))) ; ❷ ;; Execution time mean : 0.767148269 µs
❶ 在我们搜索阈值之前, 我们需要显式地对 "items" 序列进行排序. 然后我们继续
drop-while, 直到我们达到阈值, 然后返回第一个元素. 这是一个对序列的线性扫描.❷ 同样的 "items" 被用来创建一个
sorted-set. 我们使用subseq来访问达到 "x" 之后的最小项.该示例显示了
subseq在这类操作中的明显优势 (从 88 微秒到不到一微秒). 然而, 该示例没有显示的是, 与创建排序序列相比, 创建sorted-set所需的时间. 在围绕subseq设计一个算法时, 需要考虑一个权衡, 即排序集合在应用程序生命周期中创建和演变的方式.subseq和rsubseq的性能对于像从字典中建议单词 (并可选地在初始创建后添加更多单词) 这样的用例来说绝对是好的, 正如本章中所介绍的.
- 约定
- 9.1.4 seque
自 1.0 版本以来的函数
(seque ([s]) ([n-or-q s]))
seque(发音为 "seek") 在一个生产者序列之上创建一个内存中的队列 (这个名字确实是" 序列上的队列" 的助记符).seque通过包装生产者序列来使用:(seque (range 10)) ; ❶ ;; (0 1 2 3 4 5 6 7 8 9)
❶ 在一个范围上使用
seque会产生另一个具有相同内容的惰性序列.在幕后,
seque创建了一个能够进行后台计算的异步缓冲区.seque对于协调运行速度与生产者不同的消费者很有用, 例如处理由物理设备, 分布式服务或某些密集计算提供的序列.- 约定
- 输入
"s"是任何支持序列接口的集合 (seq将在"s"上被调用以产生一个序列视图), 并且是强制性参数. 它可以是空的或nil."n-or-q"是可选的. 当存在时, 它可以是一个正整数 (直到Integer/MAX_VALUE) 或一个支持java.util.concurrent.BlockingQueue接口的对象. 虽然 Java 中有几种BlockingQueue的实现, 但seque与其中一些不兼容 (该BlockingQueue还应该是排序的, 有限的, 并且能够接受nil作为元素). 因此, 建议只使用java.util.concurrent.LinkedBlockingQueue作为队列实现.
- 值得注意的异常
- 如果
"n"为 0 或负数, 则会抛出IllegalArgumentException. - 如果
"n"为nil, 则会抛出NullPointerException.
- 如果
- 输出
seque产生通过迭代 "s" 中的元素获得的序列, 如果生成的序列没有被及时消费, 可能会停放多达 "n" (默认为 100) 个来自 "s" 的项.- 如果 "s" 为空或
nil, 则为空序列.
- 输入
- 示例
为了理解
seque的工作原理, 让我们首先探讨一个没有seque的简单示例. 以下列表显示了一个用range创建的快速生产的输入序列, 以及一个用Thread/sleep模拟的慢速消费者. 当快速生产者被连接到慢速消费者时, 我们会看到以下情况:(defn fast-producer [n] ; ❶ (->> (into () (range n)) (map #(do (println "produce" %) %)))) (defn slow-consumer [xs] ; ❷ (keep #(do (println "consume" %) (Thread/sleep 2000)) xs)) (slow-consumer (fast-producer 5)) ; ❸ ;; produce 4 ;; consume 4 ; ❹ ;; produce 3 ;; consume 3 ;; produce 2 ;; consume 2 ;; produce 1 ;; consume 1 ;; produce 0 ;; consume 0
❶
fast-producer是一个创建列表的函数, 该列表原生支持序列接口 (特别是在本例中, 它没有使用任何会产生令人困惑的输出的优化). 添加了map来打印每个产生的元素.❷
slow-consumer接受一个序列 "xs" 作为输入, 并模拟一些冗长的计算. 这里使用keep来映射每个项, 并抑制nil输出, 否则会在打印输出中产生混淆.❸ 在使用快速生产者输入调用慢速消费者之后, 我们可以看到每个项每 2 秒产生一对" 生产-消费" 的行.
❹ 每个" 消费" 打印输出都在相关的" 生产" 之后 2 秒发生.
我们现在可以在生产者和消费者之间添加
seque.seque创建一个内存缓冲区, 以帮助减少生产者等待消费者的需要:(slow-consumer (seque (fast-producer 5))) ; ❶ ;; produce 4 ;; produce 3 ;; produce 2 ;; produce 1 ;; produce 0 ; ❷ ;; consume 4 ;; consume 3 ;; consume 2 ;; consume 1 ;; consume 0
❶ 与前一个示例相比, 唯一的增加是包装快速生产者的
seque调用.❷
fast-producer现在可以无需等待地向前移动.slow-consumer大约 2 秒后开始追赶, 缓慢地从输入序列中消费项, 但不依赖于快速生产者, 后者现在有机会停放资源或做其他工作.这里有一个类似但角色相反的例子. 一个慢速生产者被连接到一个快速消费者, 并且
seque介于它们之间:(defn slow-producer [n] ; ❶ (->> (into () (range n)) (map #(do (println "produce" %) (Thread/sleep 2000) %)))) (defn fast-consumer [xs] ; ❷ (map #(do (println "consume" %) %) xs)) (first (fast-consumer (seque (slow-producer 5)))) ; ❸ produce 4 ; ❹ produce 3 produce 2 consume 4 4 produce 1 produce 0
❶
slow-producer现在包含了 2 秒的模拟Thread/sleep.❷
fast-consumer现在可以自由地只映射输入序列而无需停止.❸ 我们在慢速生产者和快速消费者之间添加了
seque. 请注意, 我们只取了结果处理管道的第一个元素.❹ 每个 "produce" 都会等待大约 2 秒, 然后再继续下一个.
当
seque存在于慢速生产者和快速消费者之间时, 它允许生产者在后台提前处理 "n" 个项目, 即使我们只请求第一个项目.请注意, 尽管与序列" 分块" (一种允许序列提前计算一定数量项的内部优化) 类似, 但
seque的操作是独立的, 即使在不一定分块的序列上也是如此.像
seque这样的机制可以用来实现一种形式的预读分页. 当消费者忙于处理第一批结果时, 计算可以在后台继续, 准备接下来的 "n" 个结果:(defn by-type [ext] ; ❶ (fn [^String fname] (.endsWith fname ext))) (defn lazy-scan [] ; ❷ (->> (java.io.File. "/") file-seq (map (memfn getPath)) (filter (by-type ".txt")) (seque 50))) (defn go [] (loop [results (partition 5 (lazy-scan))] ; ❸ (println (with-out-str (clojure.pprint/write (first results)))) (println "more?") (when (= "y" (read-line)) (recur (rest results))))) (go) ("/usr/local/Homebrew/docs/robots.txt" ; ❹ "/usr/local/Homebrew/LICENSE.txt" "/usr/local/var/homebrew/linked/z3/todo.txt" "/usr/local/var/homebrew/linked/z3/LICENSE.txt" "/usr/local/var/homebrew/linked/z3/share/z3/examples/c++/CMakeLists.txt") ;; more?
❶
by-type是一个为下面的filter构建谓词的函数. 如果文件名以给定的扩展名结尾, 它返回true.❷
lazy-scan从主文件夹开始创建一个文件序列, 并且只有给定的扩展名.file-seq通过沿着每个可用文件夹向下遍历文件系统来提供初始的惰性序列. 我们请求seque在这个序列上预读 50 个项. 请注意, 即使文件夹包含许多文件或子文件夹, 生产者也只提前生成一定数量的项, 而不触发整个文件系统扫描.❸ 这个循环要求用户输入 "y" 来查看下一页结果, 或任何其他字母来停止. 当显示前 5 个项时,
seque正在后台搜索接下来的 50 个.❹ 结果列表在不同的机器上可能会有所不同.
seque还允许使用自定义队列. 我们可以利用这个特性来在缓冲区满时打印一条消息, 这对于根据消费者的相对速度来理解最佳缓冲区大小很有用. 缓冲区指示器从不同的线程运行, 每秒打印队列中有多少项:(import '[java.util.concurrent LinkedBlockingQueue]) (def q (LinkedBlockingQueue. 2000)) ; ❶ (defn counter [] ; ❷ (let [out *out*] (future (binding [*out* out] (dotimes [n 50] (Thread/sleep 1000) (println "buffer" (.size q))))))) (defn lazy-scan [] ; ❸ (->> (java.io.File. "/") file-seq (map (memfn getPath)) (filter (by-type ".txt")) (seque q))) (counter) ; ❹ ;; #object[clojure.core$future_call$reify__8454 0x4b672daa {:status :pending, :val nil}] ;; buffer 0 ;; buffer 0 ;; buffer 0 (go) ;; ("/usr/local/Homebrew/docs/robots.txt" ; ❺ ;; "/usr/local/Homebrew/LICENSE.txt" ;; "/usr/local/var/homebrew/linked/z3/todo.txt" ;; "/usr/local/var/homebrew/linked/z3/LICENSE.txt" ;; "/usr/local/var/homebrew/linked/z3/share/z3/examples/c++/CMakeLists.txt") ;; more? ;; buffer 544 ; ❻ ;; buffer 745 ;; buffer 745 ;; buffer 749 ;; buffer 749 ;; ... ;; buffer 2000 ;; buffer 2000 ;; ...
❶ 阻塞队列存储在一个 var 中. 为了显示
seque在后台工作, 我们制作了一个更大的 2000 个文件的缓冲区, 这样就有时间打印缓冲区不断增加的大小.❷
counter启动一个 future, 每秒钟唤醒一次以打印缓冲区的大小. 这会发生 50 次, 然后退出, 这足以在 REPL 中键入指令时看到进度.❸
lazy-scan与之前相同, 只是在构建seque时有所不同. 我们不是传递缓冲区大小, 而是直接传递队列实例.❹ 我们首先启动计数器, 我们可以看到它每秒钟打印 "buffer 0".
❺ 一旦我们调用
(go)函数, 我们可以看到第一页的结果 (这在不同的机器上可能会有所不同).❻ 计数器在后台继续, 显示缓冲区从 0 到 2000 个项的填充进度. 如果我们等足够长的时间而不做任何事情, 我们可以看到它持续打印 2000, 表明缓冲区已满, 磁盘上没有更多的 I/O 在继续.
通过调整缓冲区大小, 我们可以向生产序列提供" 背压" 149. 如果生产序列是惰性的 (如我们的情况), 当缓冲区满时, 文件扫描会暂停, 等待分页呈现所有 2000 个结果.
- seque 原始设计的一点历史
像标准库中的其他函数一样,
seque是早期 Clojure 采纳者和 Rich Hickey 合作设计的. 2008 年, Chris Houser 在 Clojure 邮件列表上首次讨论了创建一个序列来处理异步 XML 处理 (groups.google.com/d/msg/clojure/5TeVm7dtuo/lunp2qAyAFkJ). 在 #Clojure IRC 频道上经过一些改进后 (web.archive.org/web/http://clojure-log.n01se.net/date/2008-06-30.html#10:44c),seque诞生了.现在作为标准库一部分的
seque版本与最初围绕 XML 解析的想法的设计有所不同. 例如, 当前的seque无法处理异步回调 (现在用core.async优雅地解决了这类问题).以下是尝试解决从阻塞队列构建序列的原始问题的方法. 该队列可以在回调之间共享和传递:
(import '[java.util.concurrent LinkedBlockingQueue]) (def q (LinkedBlockingQueue. 5)) ; ❶ (def sentinel (Object.)) ; ❷ (defmacro start [& body] ; ❸ `(let [out# *out*] (future (binding [*out* out#] ~@body)))) (defn producer [^LinkedBlockingQueue q items] ; ❹ (start (loop [[x & xs :as items] items] (Thread/sleep 1000) (let [x (or x sentinel)] (println "adding" x) (if (.offer q x) (when-not (identical? x sentinel) (recur xs)) (recur (or items sentinel))))))) (defn seque2 [^LinkedBlockingQueue q] ; ❺ (lazy-seq (let [x (.take q)] (cons (if (identical? x sentinel) nil x) (seque2 q))))) (defn consumer [q] ; ❻ @(start (map #(do (println "consume" %) (Thread/sleep 1000)) (seque2 q))))
❶ 一个
LinkedBlockingQueue的实例通过一个 var 共享. 注意最大队列大小被设置为 5, 这是一个小的数字, 以帮助我们理解这个例子. 在真实场景中, 这个数字需要根据内存容量和消费者/生产者之间的相对速度进行调整.❷
sentinel是一个哨兵对象, 生产者用它来表示没有更多的可用项目. 一个" 哨兵" 是将控制信号与数据混合的有用的模式. 消费者和生产者需要事先就哨兵对象达成一致, 该对象需要与数据的任何实例都不同.❸
start宏包装了future, 以确保创建的线程使用主标准输出. 我们需要一个单独的线程, 以便能够为了演示目的打印到同一个标准输出.❹ 回调由
producer函数模拟. 主要思想是将队列引用传递给任何需要向其放置项目的回调.producer在单独的线程中模拟从一个固定的"items"参数生成项目. 在真实场景中, 新项目作为对带有" 事件" 参数的回调的调用而出现.❺
seque2在阻塞队列之上创建一个惰性序列, 只有在收到哨兵时才停止. 惰性是用标准的lazy-seq和cons模式创建的.❻ 最后, 一个消费者在另一个线程中启动. 消费者使用
seque2在阻塞队列上创建一个序列视图.这个例子中的消费者和生产者被有意地减慢了, 这样我们就可以玩弄它们. 下面是当我们启动生产者时会发生什么:
(producer q (range 8)) ; ❶ ;; adding 0 ;; adding 1 ;; adding 2 ;; adding 3 ;; adding 4 ;; adding 5 ;; adding 5 ;; adding 5 (take 3 (consumer q)) ; ❷ ;; consume 0 ;; adding 5 ;; consume 1 ;; adding 6 ;; consume 2 ;; adding 7 (take 5 (consumer q)) ; ❸ ;; consume 3 ;; consume 4 ;; consume 5 ;; consume 6 ;; consume 7
❶ 生产者以 1 秒的间隔向队列发送 8 个项. 当达到第 5 个数字时, 队列已满, 相同的项被无限期地重试.
❷ 消费者从队列中取出 3 个项. 一旦这发生, 生产者就可以将所有剩余的项发送到队列中. 生产者也向下队列发送哨兵对象.
❸ 我们现在从序列中取出另外 5 个项. 当消费者看到哨兵时, 序列终止, 控制权返回到主线程. 任何从消费者序列中取出项的额外请求现在都将阻塞, 等待更多项可用.
虽然这是解决在阻塞队列上构建序列问题的一种可能想法, 但像
core.async(github.com/clojure/core.async) 这样的库为该问题提供了健壮的解决方案, 在推出像上面介绍的自定义解决方案之前应该进行评估.
- seque 原始设计的一点历史
- 另请参阅
sequence可以按照标准的, 非阻塞的方法在LinkedBlockingQueue上创建序列视图.lazy-seq是seque的基本构建块. 值得重新审视lazy-seq允许创建惰性序列的机制以理解seque. - 性能考虑和实现细节
=> O(n) 最坏情况, 时间和内存
seque遵循通用的序列处理规则: 在输出完全消耗的情况下,seque需要处理输入序列中的所有项, 从而产生典型的线性行为. 当输入没有被完全消耗时, 惰性有助于避免最坏情况.惰性序列会缓存结果. 如果输出的头部被保留并且完全消耗,
seque会产生一个包含输入完整副本的序列 (这当然是最坏的情况). 缓冲区的大小也会对内存占用产生线性影响: 缓冲区越大, 潜在地驻留在内存中的项就越多, 特别是当消费者不够快时.seque的实现是agent的一个早期例子:- 一个
agent在一个循环中迭代输入序列. 它处理足够多的序列以适应LinkedBlockingQueue实例. 序列的其余部分作为agent的新状态存储, 任务退出. - 当
agent填充队列时, 主计算线程正在从队列中构建一个惰性序列. 每次循环能够从队列中取出一个项时, 就会向agent发送另一个" 填充" 请求. 发送给agent的每个任务都从输入序列的剩余部分恢复. - 任何错误都会从前一个状态重试.
- 哨兵对象用于表示输入的结束, 这会传播到最终返回
nil的惰性序列.
- 一个
- 约定
- 9.1.5 pmap, pcalls 和 pvalues
函数:
pmap和pcalls宏:pvalues自 1.0 版本起(pmap ([f coll]) ([f coll & colls])) (pcalls [& fns]) (pvalues [& exprs])
pmap,pcalls和pvalues通过并行处理一组表达式 (使用 future) 来构建一个惰性序列.pcalls和pvalues都建立在pmap之上.pmap的接口与map类似, 但输入转换是并行应用的:(pmap + (range 10) (range 10)) ; ❶ ;; (0 2 4 6 8 10 12 14 16 18)
❶
pmap的接口与map类似, 但输入转换是并行进行的.pcalls建立在pmap之上, 接受任意数量的函数作为输入. 然后它从调用无参数函数的结果中创建一个惰性序列.pcalls是并行处理副作用转换的一个很好的解决方案:(pcalls ; ❶ (constantly "Function") #(System/currentTimeMillis) #(println "side-effect")) ;; side-effect ; ❷ ;; ("Function" 1553770187108 nil)
❶
pcalls期望无参数的函数, 推测是为了副作用.❷ 一个有副作用的函数在屏幕上产生字符串 "side-effect", 而其他的则产生除
nil以外的输出.pvalues是一个同样建立在pmap之上的宏. 它接受任意数量的表达式, 这些表达式被并行求值, 以生成结果的序列:(pvalues ; ❶ (+ 1 1) (Math/sqrt 2) (str "last" " " "item")) ;; (2 1.4142135623730951 "last item") ; ❷
❶
pvalues是一个宏, 允许对输入中的表达式进行延迟和并行求值.❷ 结果是输入中表达式求值的惰性序列.
所有函数,
pmap,pcalls和pvalues, 都产生一个惰性的序列输出, 该输出对应于输入中项的有序求值.- 约定
- 输入
"f"在pmap中是强制性参数."f"必须是一个接受一个或多个参数的函数. 参数数量对应于输入集合的数量."coll"在pmap中是强制性参数."coll"需要提供一个序列视图, 使得(instance? clojure.lang.Seqable coll)为真."colls"在pmap中表示在"coll"之后接受任意数量的附加集合. 集合的数量决定了"f"所需的元数."fns"在pcalls中是零个或多个无参数的函数."exprs"在pvalues中是任何数量的有效 Clojure 表达式, 包括一个空的表达式参数列表.
- 值得注意的异常
当调用
pmap时没有至少一个"coll", 会抛出ArityException. 注意: 没有pmap的变换器版本. - 输出
pmap返回一个惰性序列, 该序列包含将"f"应用于输入集合中所有元素的结果. 有关多个集合存在的一般考虑, 请参见map.pcalls返回一个惰性序列, 该序列包含调用每个输入函数且没有参数的结果.pvalues返回一个惰性序列, 该序列包含所有表达式参数的求值结果.
- 输入
- 示例
pmap用相同的map接口实现了简单和直接的并行性. 然而, 有充分的理由避免用pmap替换map的每一次使用:- 转换函数 (或在
pcalls/pvalues的情况下的参数) 的计算成本应该是可观的. 在这种情况下, 线程编排的成本很可能会超过任何性能上的好处. pmap通过执行有序的并行计算批次来按与输入相同的顺序产生输出. 如果一个输入在批次中产生的工作量明显多于另一个,pmap在移动到下一个批次之前需要等待. 批次中更长的计算会降低并行度 (有关示例, 请参见性能部分).
即使考虑到上述限制, 一个足够大的应用程序通常也包含一些 justify the need for
pmap的代码部分. 其中一种情况是处理大数据集时, 例如查询 ElasticSearch 150 或其他一些服务所产生的文档. 邀请读者回顾本书中已经用pmap说明的一些解决方案:xml-seq包含一个处理大型文档的示例, 该示例使用pmap来加速处理. 每个文档的长度大致相同, 并且转换不是微不足道的.partition也包含一个pmap的有趣示例, 该示例使用聚合将较小的任务分组为较大的任务.
在有意义使用
pmap的情况下, 根据转换 "f" 的类型和输入大小, 我们可以通过使用partution-all来控制线程编排. 通过对项进行分组, 我们创建了顺序处理的分区, 这可能会提高性能:(require '[criterium.core :refer [quick-bench]]) (let [xs (range 10000)] ; ❶ (quick-bench (last (map eval xs)))) ;; Execution time mean : 23.182619 ms (let [xs (range 10000)] ; ❷ (quick-bench (last (pmap eval xs)))) ;; Execution time mean : 19.001539 ms (let [xs (range 10000)] ; ❸ (quick-bench (last (last (pmap #(map eval %) (partition-all 1000 xs)))))) ;; Execution time mean : 3.208768 ms
❶ "xs" 是一个相对较大的序列. 我们使用
eval来模拟一个非平凡的计算. 对一个数字调用eval只会产生相同的数字. 我们可以看到, 平均处理输入序列需要大约 23 毫秒.❷ 我们决定试一下
pmap, 假设eval的开销足以证明线程编排的成本是合理的. 这是真的, 但优势很小, 平均大约需要 19 毫秒.❸ 通过对输入进行分区, 我们牺牲了一些并行性来换取减少的线程开销, 在这种情况下, 这绝对是值得的.
在
pmap的优势与顺序情况相比似乎很小的情况下, 值得测试一下对输入进行分区是否会产生积极的影响. 然而, 读者应始终记住要仔细地对这些假设进行基准测试.- 理解 pmap
关于
pmap的一个常见问题是实际上有多少线程在并行工作. 我们不能直接控制pmap的并行性, 但我们对输入序列的块大小有一些控制 (另一个选项是增加 CPU 核心数). 最容易理解的情况是假设输入序列没有分块:(defn dechunk [xs] ; ❶ (lazy-seq (when-first [x xs] (cons x (dechunk (rest xs)))))) (defn f [x] ; ❷ (Thread/sleep (+ (* 10 x) 500)) (println (str "done-" x)) x) (def s (pmap f (dechunk (range 100)))) ; ❸ ;; done-0 ;; done-1 (first s) ; ❹ 0 ;; done-2 ;; done-3 ;; done-4 ;; done-5 ;; done-6 (take 2 s) ; ❺ (0 1) ;; done-7
❶
dechunk在另一个序列之上创建一个惰性序列, 为上游消费者移除任何分块.❷ 我们用一个跟踪函数调用
pmap, 该函数在每次调用时略微增加的睡眠时间后打印一条消息. 增加的睡眠时间给了println足够的时间将整个字符串刷新到标准输出, 这样我们就可以看到每条消息出现在不同的行上 (否则它们会交错).❸ 有趣的是, 在定义时启动了两个线程, 即使我们不从序列中消费元素. 这是
pmap实现内部解构输入的副产品. 总的来说, 这不应该是一个问题, 除非你正在寻求最大的惰性.❹ 一旦我们取了第一项,
pmap就会继续计算. 该表达式是在一台 4 核机器上求值的.pmap被设计为保持在所请求项之前 (+ 2 N-cores) 的位置. 所请求的项是第一个, 之前已经计算了 2 项, 还有 4 项被求值.❺ 从这一点开始, 后续的请求将计算的头部向前移动一个元素, 每次都启动一个新的 future.
如果输入序列没有分块,
pmap会保持在所请求项之前(+ 2 N-cores)的位置, 为传入的请求提供现成的缓存结果. 如果我们突然请求最后一个元素,pmap保证它永远不会超过(+ 2 N-cores)个并发请求. 对于分块序列, 情况有所不同, 因为对一个项的下一个请求可能会导致整个块被实现:(def s (pmap f (range 1000))) ; ❶ ;; done-0 ;; ... ;; done-31 (first s) ; ❷ 0 (first (drop 26 s)) ; ❸ ;; done-32 ;; ... ;; done-63
❶ 从序列 "s" 的创建中移除了对
dechunk的调用.range产生一个块大小为 32 的分块序列. 一旦表达式被求值, 32 个 future 就会开始对第一个块进行计算.❷ 第一个元素已经计算完毕, 以及接下来的
(+ 2 N-cores), 所以这次什么也不打印.❸ 为了看到下一个 32 个线程的块, 我们需要从序列中至少删除
(- chunk-size 2 N-cores)个 (当核心数为 4 时, 该数字为 26).以下规则可用于理解
pmap一次运行多少个线程 (假设任务的计算成本大致相同). 最小级别对应于消费者比生产者慢的情况, 而最大级别是消费者比生产者快的情况:- 当序列没有分块时 (例如
subvec), 最小并行度为 1, 最大并行度为(+ 2 N-cores). 例如: 有 12 个核心时,(doall (pmap #(Thread/sleep %) (subvec (into [] (range 1000)) 0 999)))会让 12+2 个线程保持忙碌. - 在分块序列的情况下 (绝大多数大小为 32), 最小并行度为
(min chunk-size (+ 2 n-cores)), 而最大数量等于(+ chunk-size 2 N-cores). 例如: 有 12 个核心时,(doall (pmap #(Thread/sleep %) (range 1000)))会让 12+2+32 个线程保持忙碌.
有了这些规则, 通过改变块大小, 我们可以得到任何程度的并行性:
(defn re-chunk [n xs] ; ❶ (lazy-seq (when-let [s (seq (take n xs))] (let [cb (chunk-buffer n)] (doseq [x s] (chunk-append cb x)) (chunk-cons (chunk cb) (re-chunk n (drop n xs))))))) (def s (pmap f (re-chunk 1000 (range 1000)))) ; ❷
❶
re-chunk接受一个 (可能已经分块的) 序列, 并产生另一个具有不同块大小的分块序列.❷ 这个
pmap定义立即启动 1000 个并发线程. 请谨慎使用!具有自定义块大小的序列很少见但可能. 如果你的应用程序实现了这样一个序列, 使用
pmap并且块大小在数千, 那么有可能使无界的 future 线程池饱和并失去对 JVM 的控制. 这一点需要记住. - 当序列没有分块时 (例如
- 转换函数 (或在
- 另请参阅
fold是进入一种称为" fork-join" 的不同并行计算模型的主要入口点.fold被设计为通过一种称为" 工作窃取" 的算法来处理计算复杂性的一些变化.future是pmap用来将计算发送到并行线程的线程原语. - 性能考虑和实现细节
=> O(n) 线性 (输入大小)
pmap的计算成本与输入大小成线性关系. 与其他惰性函数一样, 假设我们完全消耗输入, 内存占用将与输入大小成线性关系. 内存分配变为 O(1) 的唯一情况是我们不持有序列的头部. 有关这方面的更多信息, 请参见map.pmapfuture 编排是有代价的. 当转换 (或表达式) 是微不足道的时候, 编排线程的成本超过了并行计算的性能好处. 以下典型的例子, 展示了滥用pmap对微不足道的计算造成的性能下降:(require '[criterium.core :refer [quick-bench]]) (let [xs (range 100000)] (quick-bench (last (map inc xs)))) ; ❶ ;; Execution time mean : 4.651943 ms (let [xs (range 100000)] (quick-bench (last (pmap inc xs)))) ; ❷ ;; Execution time mean : 325.748151 ms
❶ 这个简单的转换对一个大序列中的每个数进行递增.
❷ 与
pmap的等价版本大约慢 100 倍.即使有聚合, 当计算过于简单时, 情况也不一定有所改善. 然而, 如果我们用聚合重复相同的例子, 我们可以看到
pmap现在只慢了 2 倍:(let [xs (partition-all 1000 (range 100000))] (quick-bench (into [] (comp cat (map inc)) xs))) ; ❶ ;; Execution time mean : 6.553814 ms (let [xs (partition-all 1000 (range 100000))] (quick-bench (into [] cat (pmap #(map inc %) xs)))) ; ❷ ;; Execution time mean : 13.539197 ms
❶
patition-all将输入项分组为每个包含 1000 个项的内部序列. 我们可以使用带有变换器的into来处理内部序列中的每个项, 并用cat移除内部组.❷
pmap现在只慢了 2 倍.另一个需要考虑的方面是计算成本在输入中的均匀性. 以下示例将 10 个长时间的计算分布在一个 320 项的输入序列中. 输入的大小和长任务的分布加剧了
pmap对分块序列的依赖:(def xs (map #(if (zero? (mod % 32)) 1000 1) (range 0 320))) ; ❶ (time (dorun (map #(Thread/sleep %) xs))) ; ❷ ;; "Elapsed time: 10019.599748 msecs" (time (dorun (pmap #(Thread/sleep %) xs))) ; ❸ ;; "Elapsed time: 10024.762327 msecs"
❶ 输入序列
"xs"包含 320 个重复的数字 1, 但每 32 个项中, 1 被替换为 1000. 这意味着"xs"的每个大小为 32 的块中恰好包含 1 个数字 1000.❷ 我们首先用一个函数运行普通的
map, 该函数等待输入项指示的毫秒数. 如预期, 顺序执行大约持续 10 秒.❸ 第二次运行使用
pmap代替map. 尽管有并行性, 但执行仍然持续 10 秒.上面的例子是
pmap的最坏情况, 它与顺序情况完全一样执行. 但是, 如果我们将多个 1000 的出现推入同一个块中 (数字越大, 任务越慢), 我们就给了pmap并行执行它们的机会:(time (dorun (pmap #(Thread/sleep %) (sort xs)))) ; ❶ ;; "Elapsed time: 1028.686387 msecs"
❶ 与前一个例子相比, 唯一的改变是对输入进行排序.
对输入进行排序后, 我们实现了将所有长时间运行的任务压缩到同一个块中的效果, 这表明均匀性是
pmap的关键.
- 约定
3.2.2. 9.2 抽象生成器
本节汇集了生成序列而不受顺序数据源驱动的函数. 它们使用算法配方, 例如调用函数或使用一组固定的项. range (关于生成数字序列) 应该包含在这组中, 但它被广泛使用, 因此在关于基本构件的章节中被给予了 prominence.
这里是一个简要的总结:
repeatedly调用一个无参数的函数来获取序列的下一个元素.iterate调用一个函数, 并用其结果再次调用相同的函数以获取序列的下一个元素.repeat重复相同的输入项以产生一个序列.cycle按顺序重复相同的输入项以产生一个扁平化的序列.
- 实现说明
像
iterate,repeat,cycle和range这样的生成器在 Clojure 内部都有一个专用的 Java 实现 (而repeatedly是唯一一个用纯 Clojure 编写的). 在 Java 中实现它们有很好的性能原因 (特别是在归约和变换时提供快速路径), 但作为函数式设计的练习, 这里是它们在 Clojure 中如何用cons和lazy-seq实现的:(defn repeatedly* [f] ; ❶ (lazy-seq (cons (f) (repeatedly* f)))) (defn iterate* [f x] ; ❷ (lazy-seq (cons x (iterate* f (f x))))) (defn repeat* [x] ; ❸ (lazy-seq (cons x (repeat* x)))) (defn cycle* [coll] ; ❹ ((fn step [[x & xs]] (lazy-seq (if x (cons x (step xs)) (cycle* coll)))) coll)) (defn range* [n] ; ❺ ((fn step [x] (lazy-seq (when (< x n) (cons x (step (inc x)))))) 0))
❶
repeatedly*是这个集合中唯一一个已经在 Clojure 中实现的函数. 实现被复制过来作为其他的模型. 我们可以看到, 为了创建序列, 我们需要在每次迭代中" cons"(f).❷
iterate*以不同的方式对待函数, 因为我们希望每次(f x)的结果成为下一次迭代的输入.(f x)在迭代时被调用, 我们" cons" 在再次迭代之前返回的值.❸
repeat*不使用函数. 我们只是在生成惰性序列时在每次迭代中反复" cons" 输入.❹
cycle*的工作方式与repeat*类似, 但输入集合需要被迭代的事实需要一个由step函数包装的额外内部循环. 外部递归从用 "coll" (初始化参数) 调用step函数开始. 在解构输入后, 我们验证我们是否有更多来自 "coll" 的项, 在这种情况下, 我们将它们中的第一个" cons" 到序列中. 如果我们没有更多的项, 我们用 "coll" 再次开始一个新的外部循环.❺ 这里介绍的
range*是核心中函数的一个简化版本. 与cycle*类似, 我们需要使用一个内部递归来维持一个递增的计数器. 每一步递归, 我们将当前的数字" cons" 到序列中, 并再次调用step递增它. 当计数器等于 "n" 时, 我们就完成了.以下是本节中每个函数的更正式的处理.
自 1.x 版本以来的函数
(repeatedly ([f]) ([n f]))
repeatedly 通过调用同一个没有参数的函数并收集结果来生成一个无限的惰性序列:
(take 3 (repeatedly rand)) ; ❶ ;; (0.2416205627046507 0.8326807316362209 0.9275189497929626)
❶ rand 返回 0 到 1 之间的一个随机双精度数. repeatedly 每次都调用 rand, 产生一个不同的数, 该数被收集为一个惰性序列. 记住要用 take 来避免在屏幕上打印无限的数.
repeatedly 对于从有副作用的函数创建序列很有用. 对于一个纯函数 (一个在给定相同输入时返回相同输出的函数), 它会一遍又一遍地返回相同的项 (并且 repeat 已经存在用于该用例).
repeatedly 还接受一个数字 "n" 作为要执行的重复次数, 在此之后停止:
(repeatedly 3 #(if (> (rand) 0.5) true false)) ; ❶ ;; (true false true)
❶ 一个展示要产生的重复次数 "n" 的示例. 有副作用的函数将随机数转换为真或假的序列.
- 约定
- 示例
repeatedly在本书中被广泛用于随机数据生成. 一个有趣的例子是在讨论rand-nth时生成谚语. 其他例子生成随机数流, 但我们也可以用gensym生成字符串或关键字:(zipmap (map keyword (repeatedly gensym)) (range 5)) ; ❶ ;; {:G__52 0, :G__53 1, :G__54 2, :G__55 3, :G__56 4}
❶ 我们使用
repeatedly和gensym为 map 生成更有趣的键.副作用函数的另一个例子是
future. 一个future接受一个形式主体而不求值它, 并将该形式发送到单独的线程进行求值. 利用这一知识, 我们可以构建一个无限的惰性工作者序列. 当我们需要更多的工作者时, 我们从序列中获取并开始并发计算. 结果序列包含计算的结果:(import '[java.util.concurrent ConcurrentLinkedQueue]) (def q (ConcurrentLinkedQueue. (range 1000))) ; ❶ (def ^:const parallel 5) (defn task [job] ; ❷ (Thread/sleep (rand-int 2000)) (println "Work done on" job) (inc job)) (def workers ; ❸ (repeatedly #(let [out *out*] (future (binding [*out* out] (when-let [item (.poll q)] (task item))))))) (defn run [workers] ; ❹ (println "-> starting" parallel "new workers") (let [done? #(> (reduce + (remove nil? %)) 30) ; ❺ futures (doall (take parallel workers)) ; ❻ results (mapv deref futures)] ; ❼ (cond ; ❽ (done? results) results (.isEmpty q) (println "Empty.") :esle (recur (drop parallel workers))))) (run workers) ; ❾ ;; -> starting 5 new workers ;; Work done on 0 ;; Work done on 1 ;; Work done on 2 ;; Work done on 3 ;; Work done on 4 ;; -> starting 5 new workers ;; Work done on 5 ;; Work done on 6 ;; Work done on 7 ;; Work done on 8 ;; Work done on 9 ;; [6 7 8 9 10]
❶ 我们需要一个并发的数据结构来容纳工作者的输入. 工作者竞争从数据结构中取出一个项来产生一个结果.
java.util.concurrent.ConcurrentLinkedQueue是一个不错的选择, 因为在现实场景中, 我们可以在工作者运行时向这个队列中推入更多的输入. 对于这个例子, 我们向队列中推入整数.❷
task是每个工作者的核心工作. 该例子通过等待几毫秒, 打印一条消息并返回递增的整数来简化任务.❸
workers构建一个准备好处理任务的无限工作者序列. 传递给repeatedly的函数需要建立主线程的标准输出和future中的标准输出之间的绑定. 这里这样做是为了在屏幕上显示消息.future调用的主体从队列中取出一项并产生一个结果.❹
run协调应该投入多少工作者以及我们应该何时停止.❺
done?是一个谓词, 它决定当前的结果集是否满足停止并返回我们找到的结果的全局条件. 在这个例子中, 我们检查结果的总和是否大于 30 来完成计算.❻ 每次迭代, 我们都会获取并实现一些数量的
future(在这个例子中是 5 个, 但在现实场景中并发线程的数量可能会更高).(doall (take parallel workers))实现了由repeatedly返回的无限序列的前 5 个元素, 这意味着 5 个并发线程将投入工作.doall是必需的, 因为如果没有它,take操作将是惰性的.❼
mapv和deref确保future在检查结果之前已经完成 (相当于一个" 连接" 操作来等待所有线程).❽ 如果我们已经完成了结果, 我们就返回它们, 以便可以检查. 如果队列是空的, 我们停止递归并返回没有结果. 如果我们可以继续, 我们在丢弃我们刚刚使用的前 5 个工作者之后递归.
❾ 在运行循环之前我们看不到任何输出消息, 这证实了整个设计是完全惰性的, 在我们开始之前没有任何线程在运行.
调用
run后, 我们可以看到一批 5 个工作者在打印消息. 达到退出条件后,run打印产生正确结果的那一批. - 另请参阅
repeat从一个单一的重复值或表达式开始产生一个序列, 而不是一个无参数的函数.dotimes不产生序列, 而是为副作用执行主体给定的次数. 当计算纯粹是为了副作用并且没有结果要收集时, 使用dotimes.iterate将前一次调用的结果作为下一次调用的输入. 当你每次调用的结果之间存在关系时, 使用iterate.rand,future或atom是repeatedly的典型目标, 通常作为传递给参数的函数的一部分出现.lazy-seq是repeatedly的构建块. 在lazy-seq中讨论的关于惰性的一般考虑也适用于repeatedly. - 性能考虑和实现细节
=> O(n) 线性 (最坏情况, 完全消耗)
=> O(n) 内存 (最坏情况, 保留头部)
repeatedly在常数时间内生成序列, 因为在消费者请求项之前没有实际的迭代. 当请求项时,repeatedly创建一个缓存结果的惰性序列. 因此, 内存占用与请求的项数成线性关系 (假设我们保持对序列头部的引用).关于惰性的其他考虑 (比如持有序列头部的风险或惰性序列的递归嵌套) 与
lazy-seq章节中讨论的类似.repeatedly生成一个可能无限的项序列, 只要我们不持有序列的头部, 就可以消耗和从内存中移除. 这个测试是在 JVM 上施加一个故意小的堆大小来快速证明这一点的:(let [rands (repeatedly 1e7 rand)] (first rands) (last rands)) ; ❶ ;; 0.5900717554100915 (let [rands (repeatedly 1e7 rand)] (last rands) (first rands)) ; ❷ ;; OutOfMemoryError GC overhead limit exceeded
❶ 我们生成一个大的随机数序列. 当我们访问最后一个项时, 在表单的末尾之前没有其他需要消费该序列的东西, 因此序列中的项可以被迭代和丢弃, 从而给垃圾回收器一个从内存中移除它们的机会.
❷ 第二个例子再次请求最后一个项, 但我们还想在表单求值的末尾访问第一个项. 该序列不能被垃圾回收, 需要留在内存中以满足这个最后的要求. 同时, 前一个
last请求完全求值了该序列, 将所有随机数缓存在内存中. 我们可以看到典型的OutOfMemoryError消息, 因为垃圾回收器无法足够快地释放内存以缓存其他项.正如生成器部分开头所提到的,
repeatedly没有像其他生成器那样有快速的归约/变换路径. 有以下后果:- 当调用
reduce或任何变换函数 (如transduce或into) 时, 迭代是通过惰性序列进行的, 没有优化 (而其他生成器有自定义的归约路径). - 在归约期间, 结果被缓存, 因此在同一序列上的多个
reduce调用也被缓存.
关于归约期间缓存的最后一点对于像
repeatedly这样设计为与副作用一起工作的函数很重要: 如果结果没有被缓存, 你可能会在每次调用时看到不同的结果. 与其他纯函数一起工作的生成器可以跳过缓存, 并在reduce或transduce期间获得速度. - 当调用
自 1.0 版本以来的函数
(iterate f x)
iterate 接受一个函数 "f" 和一个初始参数 "x", 并在 "x" 上调用 "f". 调用的结果被用作再次调用 "f" 的新参数, 从而返回下一个结果, 依此类推, 逐渐构建一个结果序列:
(take 10 (iterate inc 0)) ; ❶ ;; (0 1 2 3 4 5 6 7 8 9)
❶ 这里使用 iterate 来模拟 range. 0 是序列的显式起点, 然后 (inc 0) 产生 1, (inc 1) 产生 2, 依此类推, 直到我们取 10 个元素.
iterate 的一个主要用例是生成任意复杂的惰性序列, 用作其他序列处理的输入.
- 约定
- 输入
"f"是一个单参数的函数, 是一个强制性参数. 与repeatedly相比,"f"应该是无副作用的."x"是"f"的参数, 可以是任何类型. 它也是一个必需的参数.
- 值得注意的异常
- 当
"f"为nil时, 抛出NullPointerException. - 当
"f"不是一个函数时 (不实现clojure.lang.IFn), 抛出ClassCastException.
- 当
- 输出
返回:
x的无限惰性序列, 后跟(f x),(f (f x))等等.iterate返回一个clojure.lang.Iterate对象, 它是一种序列 (实现了clojure.lang.ISeq接口).
- 输入
- 示例
iterate的经典例子之一是生成斐波那契数的函数. 该系列以固定的" 0,1" 对开始, 然后后面的数是前两个数的和:(def fibo (iterate ; ❶ (fn [[x y]] [y (+' x y)]) [0 1])) (take 10 (map first fibo)) ; ❷ ;; (0 1 1 2 3 5 8 13 21 34)
❶ 该函数的设计直接源于该系列的定义.
iterate的初始参数是给定的对[0 1]. 迭代通过使用元素的和作为下一个对中的新项来向前移动该对. 注意使用+'来启用自动提升为clojure.lang.BigInt. 这对于斐波那契数很有用, 因为它们增长得相当快.❷ 序列中的向量对携带了下一次迭代所需的所有信息, 但要提取实际结果, 我们只需要取第一个元素.
iterate在前一个元素与下一个元素有关系的系列中表现出色, 比如斐波那契或莱布尼茨近似 Pi 151 的反正切系列. 我们在filterv的序列版本中已经看到了这个公式.iterate有一个自定义的reduce实现, 我们希望通过用transduce重写公式来利用这一点:(defn calculate-pi [precision] ; ❶ (transduce (comp (map #(/ 4 %)) (take-while #(> (Math/abs %) precision))) + (iterate #(* ((if (pos? %) + -) % 2) -1) 1.0))) (calculate-pi 1e-6) ; ❷ ;; 3.141592153589724
❶
calculate-pi是filterv中提出的计算 Pi 近似值的函数的重写. 将公式转换为使用transduce是直接的: 源成为iterate的目标, 处理现在是 transducer 组合的一部分.❷ 我们可以看到如何计算 Pi 的一个近似值. 小数在第 6 位小数处是正确的. 请注意, 要求额外的精度需要指数级更多的时间.
iterate可以推广到任何状态依赖于前一个状态的过程, 不一定只是简单的数字. 我们在讨论for时已经创建了一个生命游戏的实现, 但我们从未用它来进行完整的模拟. 邀请读者回顾该实现, 但为了迭代生命游戏的状态, 我们只对next-gen函数感兴趣.next-gen接受细胞生活的网格的高度和宽度, 以及一个初始的活细胞集合. 它返回下一个状态, 也是一个集合. 我们将迭代一定数量的next-gen状态并打印它们:;; please see "next-gen" from the "for" chapter. (defn grid [h w cells] ; ❶ (letfn [(concats [& strs] (apply str (apply concat strs))) (edge [w] (concats " " (repeat (* 2 w) "-") " \n")) (row [h w cells] (concats "|" (for [x (range w) :let [y h]] (if (cells [x y]) "<>" " ")) "|\n"))] (concats (edge w) (for [y (range h) :let [x w]] (row y x cells)) (edge w)))) (defn life [height width init] ; ❷ (iterate (partial next-gen height width) init)) (def pulsar-init ; ❸ #{[2 4] [2 5] [2 6] [2 10] [2 11] [2 12] [4 2] [4 7] [4 9] [4 14] [5 2] [5 7] [5 9] [5 14] [6 2] [6 7] [6 9] [6 14] [7 4] [7 5] [7 6] [7 10] [7 11] [7 12] [9 4] [9 5] [9 6] [9 10] [9 11] [9 12] [10 2] [10 7] [10 9] [10 14] [11 2] [11 7] [11 9] [11 14] [12 2] [12 7] [12 9] [12 14] [14 4] [14 5] [14 6] [14 10] [14 11] [14 12]}) (defn pulsar [] ; ❹ (let [height 17 width 17 init pulsar-init] (doseq [state (take 3 (life height width init))] (println (grid height width state)))))
❶
grid函数包含了格式化生命游戏网格所需的所有代码. 一个活细胞用 "<>" 打印, 否则留空. 该函数还负责打印水平和垂直的边缘以包围网格.❷
life包含一个对iterate的调用, 以从给定的初始状态创建一个无限的生命游戏状态序列. "height" 和 "width" 对于next-gen计算邻居是必需的.next-gen函数在for章节的示例部分是可见的.❸ 一个 <www.ericweisstein.com/encyclopedias/life/Pulsar.html,Pulsar> 是一个周期为 3 的振荡器, 它会创建一个漂亮的形状. 我们可以将 3 个状态中的任何一个作为初始种群. 初始化是一个活细胞的集合.
❹ 为了打印一个 Pulsar, 我们需要一个足够大的 17x17 单元格的网格. 我们使用
doseq来取 3 个状态 (之后打印会从初始状态重新开始).pulsar产生的输出如下所示:(pulsar) ---------------------------------- | | | <><><> <><><> | | | | <> <> <> <> | | <> <> <> <> | | <> <> <> <> | | <><><> <><><> | | | | <><><> <><><> | | <> <> <> <> | | <> <> <> <> | | <> <> <> <> | | | | <><><> <><><> | | | ---------------------------------- ---------------------------------- | | | <> <> | | <> <> | | <><> <><> | | | | <><><> <><> <><> <><><> <><><> | | <> <> <> <> <> | | <><> <><> | | | | <><> <><> | | <> <> <> <> <> | | <><><> <><> <><> <><><> <><><> | | | | <><> <><> | | <> <> | | <> <> | | | ---------------------------------- ---------------------------------- | | | <><> <><> | | <><> <><> | | <> <> <> <> <> | | <><><> <><> <><> <><><> <><><> | | <> <> <> <> <> | | <><> <><> | | | | <><> <><> | | <> <> <> <> <> | | <><><> <><> <><> <><><> <><><> | | <> <> <> <> <> | | <><> <><> | | <><> <><> | | | ----------------------------------
- 另请参阅
repeat从一个单一的重复值或表达式开始产生一个序列, 而不是一个在前一个参数上调用的函数.repeatedly的具体重点在于有副作用的函数来产生输出序列.dotimes迭代主体并产生nil. 主体仅为副作用而求值.
- 性能考虑和实现细节
=> O(n) 线性 (最坏情况, 完全消耗)
=> O(n) 内存 (最坏情况, 保留头部)
像其他惰性序列生成器一样,
iterate在常数时间内生成惰性序列. 消耗由iterate产生的惰性序列与请求的元素数量成线性关系. 内存也遵循相同的线性行为, 假设最坏的情况下头部不能被垃圾回收, 并且惰性序列被消耗.正如生成器部分开头所简要提醒的,
iterate是用 Java 实现的. Java 实现的优势之一是更好地控制归约上下文.reduce将关于如何归约自身的细节委托给特定的数据结构. 默认的reduce是顺序的: 归约是通过重复的next调用直到序列结束来完成的. 但是iterate的实现提供了一个自定义的reduce实现, 也可以与变换器一起使用. 优势在以下基准测试中是可见的:(require '[criterium.core :refer [quick-bench]]) (defn iterate* [f x] ; ❶ (lazy-seq (cons x (iterate* f (f x))))) (quick-bench (into [] (take 1e6) (iterate* inc 0))) ; ❷ ;; Execution time mean : 97.414648 ms (quick-bench (into [] (take 1e6) (iterate inc 0))) ; ❸ ;; Execution time mean : 44.920465 ms
❶
iterates*是一个使用lazy-seq和cons的直接实现.iterate*显示了一个纯 Clojure 的实现会是什么样子.❷ 第一个基准测试测量了我们基于惰性序列的
iterate*实现.into使用了reduce, 在这种情况下没有优化.❸ 第二个基准测试在标准优化的
iterate上重复了相同的操作.请注意,
iterate的自定义reduce实现缺少典型的序列缓存. 在这方面,iterate类似于eduction:(let [itr (iterate* #(do (println "eval" %) (inc %)) 0) ; ❶ v1 (into [] (take 2) itr) v2 (into [] (comp (drop 2) (take 2)) itr)] (into v1 v2)) ;; eval 0 ;; eval 1 ;; eval 2 ;; eval 3 ;; [0 1 2 3] (let [itr (iterate #(do (println "eval" %) (inc %)) 0) ; ❷ v1 (into [] (take 2) itr) v2 (into [] (comp (drop 2) (take 2)) itr)] (into v1 v2)) ;; eval 0 ;; eval 0 ;; eval 1 ;; eval 2 ;; [0 1 2 3]
❶ 第一个例子显示了
iterate*(一个使用cons和lazy-seq的iterate的实现) 在两次独立的into调用中被使用, 以创建一个向量并应用一个take-drop变换器组合. 用于迭代的函数也打印每个递增的数字.❷ 在第二个例子中, 使用了核心的
iterate来进行完全相同的操作.我们可以看到
iterate*如何缓存项的求值 (并且还提前求值一个额外的项, 以便在创建惰性lazy-seq实例之前检查序列的结束条件). 标准的iterate版本会产生同一项求值的多次打印, 表明没有缓存. 当iterate与有副作用的函数一起使用时, 这一点特别重要, 因为无法保证iterate会调用该函数多少次.
自 1.0 版本以来的函数
(repeat ([x]) ([n x])) (cycle [coll])
repeat 和 cycle 有类似的目标, 即通过执行一些输入的重复来生成一个序列. repeat 接受一个单一的值 "x", 并通过重复它无限次 (或 "n" 次) 来产生一个惰性序列. cycle 则接受一个值的集合, 并通过循环集合的内容来产生一个序列:
(take 5 (repeat (+ 1 1))) ; ❶ ;; (2 2 2 2 2) (take 5 (cycle [1 2 3])) ; ❷ ;; (1 2 3 1 2)
❶ repeat 遵循正常的求值规则, 求值作为参数传递的表达式. 然后该数字被无限期地重复, 创建一个无限序列. 我们从序列中取一些项来显示结果.
❷ cycle 使用给定的集合作为重复的来源, 循环地取集合中的项, 并从中产生一个新的序列.
repeat 还接受一个元素数量来限制序列的长度:
(repeat 5 1) ; ❶ ;; (1 1 1 1 1)
❶ 只重复 "1" 5 次.
- 约定
- 输入
"x"可以是任何表达式或值, 包括nil. 它是一个强制性参数."n"是可选的. 当存在时, 它可以是正数或零. 如果为 0 或负数,repeat产生一个空的clojure.lang.PersistentList. 如果"n"是一个双精度数, 它会被截断为最接近的整数."coll"是一个序列集合 (一个可以根据seq约定产生一个序列的集合) 或nil.
- 值得注意的异常
当
"n"为nil时, 抛出NullPointerException. - 输出
repeat通过重复单个值"x"无限次 (或 "n" 次) 来生成一个序列. 结果的类型是一个与序列兼容的clojure.lang.Repeat对象.cycle通过无限次循环一个值集合来生成一个序列. 结果的类型是一个与序列兼容的clojure.lang.Cycle对象. 当序列为空时, 它产生一个空的clojure.lang.PersistentList.
- 输入
- 示例
repeat和cycle是用于序列处理的灵活工具. 例如,repeat可以用作map的第二个输入来转换一个单词集合:(defn bang [sentence] ; ❶ (map str (.split #"\s+" sentence) (repeat "!"))) (bang "Add exclamation each word") ;; ("Add!" "exclamation!" "each!" "word!")
❶
bang函数将一个字符串分割成单独的单词.repeat用于生成一个无限的感叹号序列, 该序列可以适应单词序列作为map的输入.第二个参数
"n"可用于限制序列的长度, 例如, 用以下方法计算 xy (x 的 y 次幂):
(defn pow [x y] (reduce * (repeat y x))) ; ❶ (pow 2 3) ;; 8
❶ 我们使用
repeat来创建一个乘法因子序列, 我们可以用"*"来归约以获得最终结果.以下示例实现了一个计数标记系统 152:
(defn to-tally [n] ; ❶ (apply str (concat (repeat (quot n 5) "卌") (repeat (mod n 5) "|")))) (defn new-tally [] ; ❷ (let [cnt (atom 0)] (fn [] (to-tally (swap! cnt inc))))) (def t (new-tally)) (t) ; ❸ ;; "|" (t) ;; "||" (t) ;; "|||" (t) ;; "||||" (t) ;; "卌" (repeatedly 5 t) ; ❹ ;; ("卌|" "卌||" "卌|||" "卌||||" "卌卌")
❶ 计数系统的实现是基于其序数对组成字符的串联. 特殊 UTF-8 符号 卌 (U+534C) 用于模拟每 4 条竖线后的水平删除线.
repeat被使用了两次, 一次用于删除线的重复, 另一次用于最后一个删除线后的余数.❷ 通过在一个原子状态上闭包来创建一个新的计数. 这模拟了每次我们调用生成的函数时出现一个新的计数符号.
❸ 每次调用计数函数
t都会返回计数的下一个状态, 直到使用删除线为止.❹ 我们可以选择性地使用
repeatedly在一个序列中生成许多它们.cycle可用于将一个短集合调整以适应一个更大的序列视图. 我们在书中已经看到了一些例子, 邀请读者回顾:cycle在trampoline中被用来为一个交通灯的颜色变化构建一个无限的状态序列. 只有三种颜色, 但它们被cycle调整以模拟无限的交通灯变化.- 我们用
cycle在random-sample中用一个有限的符号字母表生成一个任意长的密码. - 莱布尼茨 Pi 的近似公式在" 创建你自己的折叠" 标注中也使用了
cycle.
对于
cycle的惯用用法, 以下应优先于concat:(take 10 (apply concat (repeat [1 2 3]))) ; ❶ ;; (1 2 3 1 2 3 1 2 3 1) (take 10 (cycle [1 2 3])) ; ❷ ;; (1 2 3 1 2 3 1 2 3 1)
❶
concat与repeat一起在一个元素集合上使用, 产生一个[1 2 3]向量的嵌套序列.❷ 这正是
cycle的用武之地. - 另请参阅
iterate是一个灵活的重复形式, 用于生成一个惰性序列, 其函数根据前一个来决定下一个项. 例如,repeat可以用iterate来写成:(iterate identity x).repeatedly对有副作用的函数产生输出序列有特定的关注.constantly产生一个函数而不是一个序列. 该函数可以传递任意数量的参数, 并且总是返回相同的结果.dotimes迭代主体并产生nil. 主体仅为副作用而求值.
- 性能考虑和实现细节
=> O(n) 线性 (最坏情况, 完全消耗)
=> O(n) 内存 (最坏情况, 保留头部)
两个函数都以常数时间创建惰性序列, 因为没有消耗项. 从
repeat或cycle消耗项与请求的项数成线性关系. 内存消耗也呈线性增长, 只有当头部被保留, 导致最坏情况时才如此.与
range或iterate一样,repeat和cycle有一个快速的归约路径. 当repeat或cycle直接用作归约的源时 (包括变换器), 它们不使用默认的顺序归约. 在用repeat或cycle创建的相对较大的序列上进行归约的应用可以利用变换器, 特别是当涉及转换时:(require '[criterium.core :refer [quick-bench]]) (quick-bench (reduce + (take 1e6 (map * (range) (cycle [1 -1]))))) ; ❶ ;; Execution time mean : 193.403844 ms (quick-bench (transduce (comp (map-indexed *) (take 1e6)) + (cycle [1 -1]))) ; ❷ ;; Execution time mean : 80.234017 ms
❶ 初始的
map操作, 以两个序列作为输入, 产生交替符号的整数序列(0 1 -2 3 -4 5 -6 7 -8 9)等, 并计算前一百万个数的总和.❷ 相同操作的
transduce版本使用map-indexed生成正数, 并将cycle作为唯一的源. 我们可以看到大约 50% 的速度提升.
3.2.3. 9.3 其他生成器
生成器从不一定被设计为包含数据的对象 (与向量, 哈希映射或列表或其他内置集合不同) 开始创建序列. 这个类别包括:
- 短暂的传输对象 (例如一个 Java
BufferedReader). - 迭代抽象 (如迭代器或枚举).
- 任意嵌套的复合对象 (如解析 XML 文档或列出文件系统上文件夹内容的结果).
其中一些机制相当通用 (如 tree-seq), 其他则非常具体 (如从数据库 ResultSet 构建一个序列).
- 9.3.1 lazy-seq
自 1.0 版本以来的宏
(lazy-seq [& body])
lazy-seq是一个宏, 它从一个通用的序列输入返回一个序列:(lazy-seq '(1 2 3)) ; ❶ ; (1 2 3) (type (lazy-seq [1 2 3])) ; ❷ ;; clojure.lang.LazySeq (seq? (lazy-seq [1 2 3])) ; ❸ ;; true (lazy-seq 1 2 [3]) ; ❹ ;; (3)
❶ REPL 自动打印最后一个求值表达式的结果. 当值是序列时, 就像本例中一样, 它会打印为一个列表.
❷ 我们可以尝试另一个序列输入, 例如一个向量. 我们可以看到类型是一个特殊的
clojure.lang.LazySeq对象.❸ 由
lazy-seq返回的对象是一个符合clojure.lang.ISeq接口的序列.❹ 请注意, 你可以传递可变数量的参数. 它们被隐式地在一个
do块中处理.此时, 读者可能会想知道, 将一个序列对象 (可以转换为一个序列的东西) 包装在一个序列中有什么目的. 有两个原因.
lazy-seq作为一个宏的主要目的是延迟输入的求值:(def output (lazy-seq (println "evaluated") '(1 2 3))) ; ❶ ;; #'user/output (first output) ; ❷ ;; evaluated ;; 1
❶ 请注意, 我们在参数中添加了一个有副作用的
println.lazy-seq阻止了输入的求值: 当我们声明输出时, 我们没有看到消息. ❷ 一旦我们访问output, 例如获取第一项, 主体就会求值.lazy-seq的第二个目标是缓存输入求值的结果. 当同一个lazy-seq形式再次求值时, 结果来自内部缓存:(defn trace [x] (println "evaluating" x) x) ; ❶ (def output (lazy-seq (list (trace 1) 2 3))) ; ❷ (first output) ; ❸ ;; evaluating 1 ;; 1 (first output) ; ❹ ;; 1
❶
trace是一个简单的调试函数, 它在返回参数之前打印该参数, 而不作任何更改.❷ 我们使用
list来产生一个包含 3 个数字的列表. 第一个数字被包装在trace函数中. 在创建lazy-seq时, 屏幕上没有任何打印.❸ 求值第一个元素也会产生消息.
❹ 第二次我们访问输出时, 我们只看到数字 1, 而没有 "evaluating" 字符串.
lazy-seq只求值主体一次, 然后缓存了求值表达式的结果.lazy-seq的基本属性在单独使用时不是特别有趣, 但它是与cons配合产生惰性序列的基本构建块. 我们可以将lazy-seq对象链接在一起, 以延迟序列中项的求值 (惰性的基本方面). 有关详细信息, 请参见示例部分.- 约定
- 输入
"& body"是一个可变长度的参数. 这些参数被隐式地包装在一个do块中. 求值do块表达式的结果需要是序列的 (任何实现了clojure.lang.Seqable接口的集合).
- 值得注意的异常
当
"body"不求值为一个序列集合时, 会抛出IllegalArgumentException, 遵循seq的语义. 请注意, 鉴于隐式的do参数, 最后一个表达式需要返回一个序列集合:(lazy-seq 1 2 3) ; ❶ ;; IllegalArgumentException Don't know how to create ISeq
❶
lazy-seq接受任意数量的参数, 这些参数被视为一个隐式的do块.do块求值的结果需要返回一个序列集合. 在这种情况下, "3" 不是序列的. - 输出
返回: 一个表示输入
"body"的序列视图的序列. 如果没有参数, 或者参数是一个空集合, 则返回一个空序列.lazy-seq永远不会返回nil.
- 输入
- 示例
一个序列操作, 如转换序列中的每个项, 可以通过在每个转换步骤中插入一个延迟的
lazy-seq来变得惰性. 在递归函数中使用lazy-seq和cons的模式是 Clojure 中生成惰性序列的规范方式 (并且在整个标准库中被广泛使用). 请比较以下函数, 将输入"coll"转换为一个列表 (一个自定义版本的map):(defn eager-map [f coll] ; ❶ (when-first [x coll] (println "iteration") (cons (f x) (eager-map f (rest coll))))) (def eager-out (eager-map str '(0 1 2))) ; ❷ ;; iteration ;; iteration ;; iteration (defn lazy-map [f coll] ; ❸ (lazy-seq (when-first [x coll] (println "iteration") (cons (f x) (lazy-map f (rest coll)))))) (def lazy-out (lazy-map str '(0 1 2))) ; ❹ (first lazy-out) ; ❺ ;; "iteration" ;; "0"
❶
eager-map是一个创建cons" 对" 列表的递归函数. 每次迭代都通过将当前转换的项与列表其余部分的计算配对来产生一个cons对象.❷ 我们可以看到, 即使不使用
eager-map的输出, 我们也已经完全求值了递归, 包括执行了所有的转换. 新转换的cons序列在求值后立即存在于内存中.❸
lazy-map将外部形式包装在一个lazy-seq调用中. 这是与eager-map相比的唯一变化.cons产生一个序列类型, 该类型被lazy-seq接受 (与持久化列表一起,cons是另一个原生的序列 Clojure 类型).❹ 函数调用被求值, 但不产生任何输出.
❺ 此外, 我们可以看到请求一个元素会产生一个递归循环. 这是因为下一个
lazy-seq包装器不会强制另一个递归, 除非明确请求.下图显示了该模式的一般思想: 基本方面是在函数
myfn的主体之前存在包装的lazy-seq调用, 该函数可以在任何点被递归调用.
Figure 27: 构建惰性序列的通用递归模式.
我们可以应用相同的模式在各种数据生产者之上构建惰性序列抽象 (标准库广泛地这样做了). 数据生产者可以是具体的集合, 服务或抽象的生成器.
下面的埃拉托斯特尼筛法的朴素实现, 使用一个自然数生成器来返回一个无限的素数序列 153:
(defn sieve [n] (letfn [(divisor-of? [m] #(zero? (rem % m))) ; ❶ (step [[x & xs]] ; ❷ (lazy-seq (cons x ; ❸ (step (remove (divisor-of? x) xs)))))] ; ❹ (take n (step (nnext (range)))))) (sieve 10) ;; (2 3 5 7 11 13 17 19 23 29)
❶
divisor-of?谓词接受被除数 "m", 并返回一个可用于查找 "m" 的除数的函数. 例如,((divisor-of? 4) 2)为真.❷
step函数包含递归操作. 每一步对应于递归期间的一次迭代.step在其主体周围包装了lazy-seq, 并包含了计算下一个数字的逻辑. 初始的解构为 "x" 和 "xs" 有助于稍后移除first和rest的出现.❸ 基本的递归步骤包括取列表开头的当前数字 "x", 并将其
cons到计算的其余部分. "x" 已经是一个素数, 因为计算的其余部分从所有自然数的列表中移除了它的所有除数.❹ 递归的开始准备了一个从 2 开始的正整数的无限列表 (使用
nnext等同于调用next两次).使用
lazy-seq的一个有趣效果是将一个消耗堆栈的算法转换为消耗堆的算法. 让我们宏展开前面例子中的lazy-map实现:(macroexpand ; ❶ '(lazy-seq (when coll (cons (f (first coll)) (lazy-map f (next coll)))))) ;; (new clojure.lang.LazySeq ;; (fn* [] ;; (when coll ;; (cons ;; (f (first coll)) ;; (lazy-map f (next coll))))))
❶ 我们在
lazy-map函数的主体定义上调用macroexpand, 如前面例子中所示.展开显示
lazy-seq是一个 Java 对象构造函数, 接受一个函数对象作为参数. 该函数对象没有参数, 当调用时, 它会求值主体的内容. 出现在函数主体内部的对lazy-map的递归调用不在堆栈上, 因为它立即返回下一个clojure.lang.LazyMap对象. 该对象包含在某个稍后时间进行计算的承诺, 并被停放在堆上 (对象分配的默认驻留地).当一个消费者从惰性序列中拉取一个项时, 外部的
LazySeq对象会求值并缓存其值. 同时, 递归会产生下一个计算的承诺. 当消费者请求额外的项时, 递归操作会产生更多的计算承诺. 如果没有东西持有序列的头部, 第一个外部的LazySeq可以被垃圾回收, 整个序列永远不会一次性驻留在内存中.简单的递归与
lazy-seq产生线性的, 消耗堆的惰性序列, 如此图所示:
Figure 28: lazy-seq 的递归使用产生了一个 cons 对象的串联, 最后的 LazySeq 持有无限序列的未实现部分.
当嵌套递归的惰性序列生成器时, 你需要小心. 这种情况在设计典型的序列处理算法时经常发生. 问题在于, 即使你没有预料到, 嵌套也可能最终消耗掉堆栈. 下面的
lazy-bomb函数说明了这个问题:(defn lazy-bomb [[x & xs]] (letfn [(step [[y & ys]] (lazy-seq (when y (cons y (step ys)))))] ; ❶ (lazy-seq (when x (cons x (lazy-bomb (step xs))))))) ; ❷ (last (lazy-bomb (range 10000))) ; ❸ ;; StackOverflowError
❶
lazy-bomb包含一个step函数, 该函数包含另一个使用典型的lazy-seq模式的递归.step除了解构和用中间的递归调用重建输入外, 什么也不做.❷
lazy-bomb的主函数体是一个类似的递归, 它从输入中取每个项, 并将其cons到一个对内部step函数的调用中.❸
lazy-bomb对几千项的中等大小的输入会产生堆栈溢出.lazy-bomb中的step函数遵循标准的lazy-seq模式, 但当我们期望一个堆消耗的递归时, 它会产生一个堆栈溢出错误. 问题在于lazy-bomb的外部递归和step的内部递归的交错. 算法的结构是这样的,lazy-bomb总是返回一个未实现的序列作为第一个cons的目标, 如下图所示.
Figure 29: lazy-seq 的嵌套使用可以产生一个带有中间未实现步骤的序列.
为了满足对更多项的请求, 需要遍历出现在头部的未实现惰性序列才能到达范围生成器. 请求的项越远, 到达生成器的遍历就越长. 遍历是在堆栈上进行的, 因为它是求值" 错位" 的
lazy-seq的一部分.不幸的是, 嵌套的
lazy-seq递归可能隐藏在其他无辜的函数后面, 使得它们难以发现. 如果你仔细观察前面介绍的sieve函数, 它包含了伪装成remove调用的这种意外嵌套. 我们可以重做sieve函数, 将remove调用内联, 并使其显式化:(defn sieve [n] (letfn [(remove-step [x [y & ys]] ; ❶ (lazy-seq (when y (if (zero? (rem y x)) ; ❷ (remove-step x ys) (cons y (remove-step x ys)))))) (sieve-step [[x & xs]] ; ❸ (lazy-seq (cons x (sieve-step (remove-step x xs)))))] (take n (sieve-step (nnext (range)))))) (sieve 10) ; ❹ ;; (2 3 5 7 11 13 17 19 23 29) (sieve 10000) ; ❺ ;; StackOverflowError
❶ 前面的
remove调用已被一个remove-step局部函数替换, 这只是一个带有固定谓词的remove的实现.❷
divisor-of?在这里作为if条件的一部分出现, 这是一般移除项的规则: 如果下一个数是当前素数的除数, 则忽略并迭代下一个.❸ 对
sieve的递归调用也被提取到一个新的sieve-step中. 外部sieve-step和内部remove-step之间的关系现在是显式的.❹ 我们可以看到, 这像以前一样生成了素数.
❺ 对于大数, 这个
sieve的实现会发生堆栈溢出.到目前为止描述的
sieve函数存在lazy-seq嵌套的问题, 对于相对较小的数会产生堆栈溢出. 有几种替代方案可以考虑, 包括将算法重新表述为尾递归. 这样做, 我们有机会查看迄今为止累积的素数列表, 并利用这些知识来减少下一个素数的搜索空间 154:- 我们可以只搜索奇数, 因为没有偶数可能是素数.
- 我们可以只专注于从最后一个找到的素数开始.
- 我们可以检查素数候选数的平方根以下的素数因子.
以下
sieve使用上述建议生成一个向量:(defn sieve [n] ; ❶ (letfn [(odds-from [n] ; ❷ (iterate #(+ 2 %) (if (odd? n) (+ 2 n) (+ 1 n)))) (divisor? [p] ; ❸ #(zero? (rem p %))) (cross-upto [n primes] ; ❹ (take-while #(<= (* % %) n) primes))] (loop [cnt (dec n) primes [2]] ; ❺ (if (pos? cnt) (recur (dec cnt) (conj primes (first (drop-while ; ❻ #(some (divisor? %) (cross-upto % primes)) (odds-from (peek primes)))))) primes)))) (peek (sieve 10000)) ; ❼ ;; 104729
❶
sieve在进入主loop-recur递归之前, 先定义了几个供内部使用的函数.❷
odds-from从 "n" 之后的第一个可用奇数开始一个奇数范围.❸
divisor?返回一个谓词, 用于检查一个数是否是 "p" 的除数.❹
cross-upto接受一个素数列表, 并返回它们, 直到第一个素数的平方超过给定的候选素数 "n". "cross" 唤起了埃拉托斯特尼筛法中的类似操作.❺ 主循环通过设置计数器和初始的素数向量 (总是从 2 开始) 来启动.
❻ 下一个素数是我们在使用谓词函数交叉相关的除数后丢弃候选数后的第一个.
❼ 调用
sieve来查看第 10000 个素数的结果不会导致堆栈溢出.虽然上面描述的算法不消耗堆栈, 但它远非高效. 请求一百万个素数需要相当长的时间, 并且结果不是惰性的, 消耗线性内存. 改进这样的算法是可能的, 但超出了本书的目标.
- 另请参阅
seq从支持序列接口的集合中产生一个惰性序列.concat从 2 个或更多个集合的串联中创建一个惰性序列.
- 性能考虑和实现细节
=> O(1) 宏执行
=> O(1) 内存
lazy-seq宏在常数时间内构建一个 Java 对象和相关的fn闭包.lazy-seq缓存是大多数标准库序列处理函数线性 O(n) 内存占用的原因. 同时, 缓存是惰性序列功能和灵活性的基础.在内部,
lazy-seq非常注意在缓存结果后立即清除求值所需的临时变量 (在用完后将变量赋为null称为" 局部变量清理" , 这在LazySeq对象和生成的fn中都发生, 这是一个有趣的 ^{:once true} 元数据的情况).当在求值期间发生错误时,
lazy-seq的局部变量清理功能可能会偶尔出现NullPointerException(一个已知的 bug, 请参见 clojure.atlassian.net/browse/CLJ-2069):(defn squares [x] ; ❶ (cons (* x x) (lazy-seq (squares (* x x))))) (def sq2 (squares 2)) (take 5 sq2) ; ❷ ;; (4 16 256 65536 4294967296) (take 6 sq2) ; ❸ ;; ArithmeticException integer overflow (take 6 sq2) ; ❹ ;; NullPointerException
❶
squares生成一个前一个数的平方的序列.❷ 从 2 开始的序列增长得相当快, 在第 5 个项之后很快达到
Long/MAX_VALUE.❸ 乘法无法产生比
long容量更大的数, 这是预期的.❹ 但后续的调用会产生一个意想不到的
NullPointerException.上面的例子显示, 在
lazy-seq步骤能够缓存结果之前, 局部变量清理已经移除了对局部绑定的引用. 对同一项的额外请求导致LazySeq对象无法缓存结果, 而不是显示之前的错误.
- 约定
- 9.3.2 tree-seq
自 1.0 版本以来的函数
(tree-seq [branch? children root])
tree-seq是一个通用的机制, 用于遍历一个任意嵌套的数据结构并产生一个被访问节点的惰性序列:(defn pretty-print [x] ; ❶ (println (with-out-str (clojure.pprint/write x)))) (pretty-print ; ❷ (tree-seq vector? identity [[1 2 [3 [[4 5] [] 6]]]])) ;; ([[1 2 [3 [[4 5] [] 6]]]] ;; [1 2 [3 [[4 5] [] 6]]] ;; 1 ;; 2 ;; [3 [[4 5] [] 6]] ;; 3 ;; [[4 5] [] 6] ;; [4 5] ;; 4 ;; 5 ;; [] ;; 6)
❶
pretty-print是一个辅助函数, 用于将tree-seq的结果格式化为多行.❷ 在指示
tree-seq如何识别一个分支后, 它会返回一个按深度优先遍历顺序访问的节点的惰性序列.tree-seq需要以下信息才能正常工作:- 如何区分一个分支节点: 当找到一个分支时,
tree-seq会迭代其内容, 可能会进一步下降到其他分支. - 在分支内容不是序列的情况下如何迭代.
- 在进一步移动之前如何预处理节点.
tree-seq是clojure.walk的惰性等价物. 通过产生一个惰性的深度优先遍历, 它可以处理不适合内存的大型数据结构 (注意不要持有序列的头部).- 约定
- 示例
tree-seq对于遍历深度嵌套的数据结构以处理有趣的节点很有用. 在下面的例子中, 我们可以看到如何从一个嵌套的向量中收集所有正值:(defn collect [pred? branch?] ; ❶ (fn [children] (filter (fn [node] (or (branch? node) (pred? node))) children))) (defn collect-if [pred? root] ; ❷ (let [branch? vector? children (collect pred? branch?)] (->> root (tree-seq branch? children) (remove branch?)))) ; ❸ (collect-if pos? [[1] [-2 4 [-3 [4] 5 8] -6 7]]) ; ❹ ;; (1 4 4 5 8 7)
❶
collect是一个接受 2 个谓词 "pred?" 和 "branch?" 的函数. "pred?" 用于处理不是分支的节点 (在我们的例子中, 是所有不是向量的东西). "branch?" 用于理解哪个节点是分支.collect返回一个子节点集合的函数. 这个函数决定了哪些节点应该属于最终的结果.❷
collect-if准备对tree-seq的调用. 它定义了什么是" 分支?" 以及如何处理" 子节点" .❸ 请注意, 如果我们只关心终端节点, 我们需要从结果中移除分支.
❹ 我们可以看到遍历按深度优先的顺序返回了正节点.
这里有另一个有趣的例子. 下面的
tree-seq遍历从本地文件系统的根 "/" 开始创建一个文件序列. 值得注意的是, 由于惰性, 这个例子运行得很快, 因为不需要执行完整的文件系统扫描 (除非我们消耗整个序列):(import java.io.File) (take 5 (tree-seq (memfn ^File isDirectory) ; ❶ (comp seq (memfn ^File listFiles)) ; ❷ (File. "/"))) ; ❸ ;; (#object[java.io.File 0x527f7b54 "/"] ; ❹ ;; #object[java.io.File 0x27049765 "/home"] ;; #object[java.io.File 0x6e76794f "/usr"] ;; #object[java.io.File 0x5f1781e5 "/usr/bin"] ;; #object[java.io.File 0x769be488 "/usr/bin/uux"])
❶
tree-seq为每个文件调用File/isDirectory方法. 目录的存在会促使tree-seq下降到其内容中.❷
File/listFiles被tree-seq用于每个表示目录的File对象. 当项是目录时,listFiles产生一个文件对象数组 (否则为nil).seq将数组转换为序列内容.❸ 根对象是一个表示迭代开始的文件对象.
❹ 请注意, 这里呈现的输出在其他系统上可能会有所不同.
在下面的例子中, 我们想处理一个包含向量和哈希映射混合的嵌套文档. 这样的数据结构通常是解析 JSON 或类似交换格式的结果:
(def document ; ❶ {:tag :balance :meta {:class "bold"} :node [{:tag :accountId :meta nil :node [3764882]} {:tag :lastAccess :meta nil :node ["2011/01/01"]} {:tag :currentBalance :meta {:class "red"} :node [{:tag :checking :meta nil :node [90.11]}]}]}) (def branch? (every-pred map? :node)) ; ❷ (def document-seq ; ❸ (tree-seq branch? :node document)) (remove branch? document-seq) ; ❹ ;; (3764882 "2011/01/01" 90.11) (keep :meta document-seq) ; ❺ ;; ({:class "bold"} {:class "red"})
❶ 该文档通过 map 和 vector 来实现分支. 如果一个节点是 map 类型并且包含一个
:node键, 那么子节点就作为该键的值可用. 终端节点要么是字符串, 要么是数字. 该文档似乎自上而下遵循这一约定.❷
branch?谓词断言一个节点是分支, 如果它是一个 Clojure map 并且包含:node键.❸
document-seq将文档序列的惰性求值存储在一个 var 中. " children" 只是关键字:node.❹ 如前所述, 我们从最终结果中移除分支节点以专注于简单值.
❺ 其他类型的过滤也是可能的, 例如显示所有的
:meta值.- 一个急切的 tree-seq
标准库中的
tree-seq实现包括一个惰性的递归遍历, 只生成所请求的那么多输出. 对于那些输出被完全消耗的场景, 我们可以通过放弃惰性来获得更好的性能, 如下所示:(defn eager-tree-seq [branch? children root] (letfn [(step [res root] ; ❶ (let [res (conj! res root)] (if (branch? root) (reduce step res (children root)) res)))] (persistent! (step (transient []) root)))) ; ❷
❶
step函数通过对当前节点的子节点进行归约来使用递归. 当我们到达一个分支的底部时, 它返回到目前为止的结果, 而不进行任何进一步的归约.❷ 我们可以引入一个可变的瞬态来更有效地收集结果.
新的
eager-tree-seq函数放弃了惰性以换取一些速度. 请检查性能部分以查看惰性版和急切版tree-seq的完整比较.
- 一个急切的 tree-seq
- 另请参阅
clojure.walk/walk对任意嵌套的数据结构进行深度优先遍历.clojure.walk/walk的" 分支?" 谓词对所有最常见的集合类型都隐式为真.clojure.walk/walk保持输入的原始嵌套, 而不是创建一个扁平的节点序列.zipper是遍历深度嵌套数据结构的另一种选择. zipper 是最灵活的选项, 因为它们将遍历逻辑 (对于tree-seq和clojure.walk/walk都固定为深度优先) 与遍历状态分离开来. - 性能考虑和实现细节
=> O(n) 线性 (最坏情况)
=> O(n) 内存 (最坏情况)
tree-seq在节点数量上是线性的.tree-seq是惰性的, 所以它在节点数量上线性消耗内存, 但只有当输出被完全消耗时才如此.现在让我们比较标准的
tree-seq和前面介绍的急切解决方案. 在下面的例子中, 我们解析一个大的 XML 文档 (大约 450 KB), 但基准测试只适用于其遍历:(require '[clojure.xml :refer [parse]]) (require '[criterium.core :refer [quick-bench]]) (def document (parse "https://nvd.nist.gov/feeds/xml/cve/misc/nvd-rss.xml")) (let [branch? (complement string?) ; ❶ children (comp seq :content)] (quick-bench (dorun (tree-seq branch? children document)))) ;; Execution time mean : 2304.531 µs (let [branch? (complement string?) ; ❷ children (comp seq :content)] (quick-bench (doall (eager-tree-seq branch? children document)))) ;; Execution time mean : 437.484386 µs
❶ 第一个基准测试使用标准的
tree-seq. 我们需要dorun来完全实现该序列.❷ 这是使用之前看到的
eager-tree-seq的相同基准测试. 这个函数产生一个向量而不是一个序列, 并且不需要dorun.急切的版本大约快了 5 倍. 这并不意味着
lazy-seq就一定慢. 在选择一个较慢但惰性的函数和一个更快但内存消耗大的急切版本之间, 有许多因素影响着选择. 如果你计划只访问输出的初始部分, 并可能向后移动, 那么lazy-seq仍然是最佳选择. 如果你的应用程序需要最大的速度, 并且输入树的大小合理, 那么优先选择一个急切的版本. 例如, 一个急切的文件系统扫描应用, 很容易就会消耗掉全部内存.
- 如何区分一个分支节点: 当找到一个分支时,
- 9.3.3 file-seq
自 1.0 版本以来的函数
(file-seq [dir])
file-seq接受一个java.io.File对象, 并返回一个惰性序列, 其中包含所有包含的文件和子文件夹的java.io.File对象:(require '[clojure.java.io :as io]) (count (file-seq (io/file "/usr/share/man"))) ; ❶ ;; 16727 (->> (io/file "/etc") ; ❷ (file-seq) (map (memfn getPath)) (take 6)) ;; ("/etc" ;; "/etc/afpovertcp.cfg" ;; "/etc/aliases" ;; "/etc/aliases.db" ;; "/etc/apache2" ;; "/etc/apache2/extra")
❶ "/usr/share/man" 是命令手册的典型 Unix 位置. 在这个系统上, 有 16727 个文件和文件夹, 因为
file-seq两者都返回.❷ "/etc" 是 Unix 系统上的另一个标准文件夹.
file-seq返回一个java.io.File对象的序列, 我们可以用getPath从中提取完整的路径作为字符串. 这里使用memfn来创建一个 Java 互操作的匿名函数.file-seq执行深度优先的文件遍历: 如果下一个文件是一个文件夹,file-seq会立即下降到该文件夹中, 然后再遍历同一级别的其他文件. 上面的例子显示file-seq在发现 "apache2" 后立即下降到其中 ("apache2/extract" 紧随其后出现).- 约定
- 示例
让我们从说明
file-seq在存在几个特殊的java.io.File对象时的行为开始. 其中一些会产生一个有效的 (抽象的) 路径, 这会导致出现明显为空的文件夹:(def work-dir (file-seq (java.io.File. "."))) (def abstract-path (file-seq (java.io.File. ""))) (def non-existent (file-seq (java.io.File. "NONE"))) (.getAbsolutePath (first work-dir)) ; ❶ ;; "/Users/reborg/book/." (count work-dir) ;; 5110 (.getAbsolutePath (first abstract-path)) ; ❷ ;; "/Users/reborg/book" (count abstract-path) ;; 1 (.getAbsolutePath (first non-existent)) ; ❸ ;; "/Users/reborg/book/NONE" (count abstract-path) ;; 1
❶ "." 是当前文件夹的标准表示, 即 JVM 进程启动的文件夹.
❷ 空字符串被接受为有效路径, 但由于它不是物理路径, 因此被称为" 抽象路径" . 它会带来潜在的不一致性, 应该避免. 我们可以看到它打印了当前文件夹, 但这是当前文件夹的名称加上空的抽象路径文件夹, 这仍然是一个不存在的文件夹.
❸ 一个格式错误的路径 (一个随机字符串 "NONE") 显示了一个附加到工作目录的不存在的文件夹. 它的效果与空的抽象路径相同.
以下示例显示了一个简化的" grep" 实用程序. " grep" 是一个常见的 Unix 命令, 用于验证一个字符串是否存在于一个文件中. 我们的" grep" 提供了从工作文件夹开始搜索特定文件扩展名的可能性:
(require '[clojure.string :as str]) (defn grep-by-type [q ext] ; ❶ (sequence (comp (remove (memfn isDirectory)) ; ❷ (map (memfn getAbsolutePath)) ; ❸ (filter #(= ext (last (str/split % #"\.")))) ; ❹ (filter #(str/includes? (slurp %) q))) ; ❺ (file-seq (java.io.File. ".")))) (grep-by-type "file-seq" "adoc") ;; ("/Users/reborg/book/./manuscript/08-Sequential-Generation.adoc")
❶
grep-by-type将结果处理为变换器转换的管道.❷ 我们不希望文件夹出现在结果中, 所以我们移除了它们.
❸ 一个
java.io.File对象包含许多我们在这个例子中不需要的属性. 我们从每个文件对象中获取绝对文件路径作为字符串.❹ 这一步只保留与给定扩展名匹配的文件. 我们假设扩展名出现在文件路径的最后一个点之后.
❺ 最后, 我们加载文件的内容以搜索给定的查询 "q".
slurp是一个简单的选项, 但其他方法, 如line-seq, 可能更好地只加载文件足够多的内容到内存中以找到第一个匹配项. - 另请参阅
clojure.java.io/file是在 Clojure 中创建文件对象的推荐方法.tree-seq是file-seq用于执行文件夹遍历的通用机制. 如果你需要以特定的方式执行文件遍历, 请查看file-seq是如何实现的. - 性能考虑和实现细节
=> O(n) 线性最坏情况
=> O(n) 内存最坏情况
file-seq实现了一个基于tree-seq的惰性深度优先遍历. 在完全求值输出时,file-seq需要对每个文件执行一次isDirectory检查, 对每个目录执行一次listFiles操作. 同时,file-seq为序列中的每个项创建一个java.io.File对象. 内存占用与文件对象的数量成线性关系, 创建最终序列的步骤数也是如此.惰性允许部分地消耗
file-seq的结果, 而无需执行完整的扫描 (在一个大的文件系统上这可能是一个冗长的操作). 有关额外的性能考虑, 请参阅tree-seq.
- 约定
- 9.3.4 xml-seq
自 1.0 版本以来的函数
(xml-seq [root])
XML 是一种分层的标记语言 [fn:XML 规范的更多细节请访问维基百科页面: en.wikipedia.org/wiki/XML]. XML 节点可以嵌套, 有属性和内容. XML 是文本的, 因此分层属性是通过使用开/闭标签来编码的.
存在许多用于 XML 的解析器, Clojure 通过
clojure.xml/parse函数提供了一个.xml-seq被设计为遍历clojure.xml/parse的输出:(require '[clojure.java.io :as io]) (require '[clojure.xml :as xml]) (def balance "<balance> <accountId>3764882</accountId> <currentBalance>80.12389</currentBalance> <contract> <contractId>77488</contractId> <currentBalance>1921.89</currentBalance> </contract> </balance>") (def xml (-> balance .getBytes io/input-stream xml/parse)) ; ❶ (filter (comp string? first :content) (xml-seq xml)) ; ❷ ;; ({:tag :accountId, :attrs nil, :content ["3764882"]} ;; {:tag :currentBalance, :attrs nil, :content ["80.12389"]} ;; {:tag :contractId, :attrs nil, :content ["77488"]} ;; {:tag :currentBalance, :attrs nil, :content ["1921.89"]})
❶ 为了说明的目的, 我们将使用一个直接编码为字符串的小型 XML 片段.
xml/parse要求我们在解析之前将字符串转换为一个输入流.❷ 由
xml-seq产生的输出序列包含分支节点, 这些节点有一个:content键, 它引用其他节点. 这里我们只对 XML 结构的终端节点感兴趣, 那些:content键包含字符串的节点.xml-seq在一个 XML 是进程间通信的通用语言的时期被添加到标准库中. 如今, 其他格式被普遍使用, 但xml-seq仍然是基本 XML 处理的有效方法.- 约定
- 示例
RSS 订阅是一种特定格式的 XML 文档. 它被用作订阅阅读器的一种标准, 这是一类专门用于聚合和管理来自不同在线来源的信息的应用. RSS 订阅在新闻网站中被广泛使用, 在下一个例子中, 我们想构建一个小应用来搜索一系列订阅.
让我们用
clojure.xml/parse来解析原始的 XML, 以产生订阅内容的分层视图. 然后我们可以用xml-seq来处理所有节点的序列视图, 以提取有趣的信息 (否则这些信息会埋在 xml 树的几层深处). 我们可以编排节点的处理来为每篇文章提取标题, 使用一个变换器链. 以下是从一些流行的 RSS 订阅中检索突发新闻:(require '[clojure.java.io :as io]) (require '[clojure.xml :as xml]) (def feeds [[:guardian "https://git.io/guardian-world-rss-xml"] [:wash-post "https://git.io/washpost-rss-xml"] [:nytimes "https://git.io/nyt-world-rss-xml"] [:wsj "https://git.io/wsj-rss-xml"] [:reuters "https://git.io/reuters-rss-xml"]]) (defn search-news [q [feed url]] (let [content (comp first :content)] [feed (sequence (comp (filter (comp string? content)) ; ❶ (filter (comp #{:title} :tag)) ; ❷ (filter #(re-find q (content %))) ; ❸ (map content)) (xml-seq (xml/parse url)))])) (pmap (partial search-news #"(?i)climate") feeds) ; ❹ ;; ([:guardian ()] ;; [:wash-post ()] ;; [:nytimes ;; ("Economic Giants Are Restarting. ;; Here' s What It Means for Climate Change.")] ;; [:wsj ()] ;; [:reuters ()])
❶ 首先要做的是保留
content属性为字符串类型的节点.❷ 有许多类型的终端节点, 包括那些只有元数据, 链接等的节点. 接下来选择带有标题的节点.
❸ 是时候根据给定的正则表达式进行匹配, 并只保留与查询匹配的那些节点.
❹ 每个订阅都会产生一个可能很昂贵的 http 调用.
pmap是通过并行处理订阅来获得更好性能的简单选择.上一个例子的输出可能会根据订阅中的新闻类型而有所不同. 在将该示例添加到本书时, 它只找到了一条与" 气候" 相关的新闻.
- 另请参阅
clojure.xml/parse是调用xml-seq之前的强制性步骤. 你可以用其他工具来解析 xml, 并且仍然能够调用xml-seq, 只要确保解析器的输出符合所需的格式.tree-seq实现了对嵌套数据结构的通用深度优先遍历.xml-seq和本章中的其他函数一样, 都是基于tree-seq的. - 性能考虑和实现细节
=> O(n) 时间最坏情况
=> O(n) 内存最坏情况
xml-seq是使用tree-seq的另一个树遍历的例子, 因此它具有类似的性能配置文件. 消耗整个输出序列会强制进行完整的遍历以到达所有节点, 从而在输入 XML 中的节点数量上产生线性行为.xml-seq是惰性的, 只遍历足够的输入以产生所请求的输出. 然而, 请注意,clojure.xml/parse会将整个 XML 内容加载到内存中.xml-seq仅在遍历方面是惰性的, 而不是在解析 XML 方面.
- 约定
- 9.3.5 re-seq
自 1.0 版本以来的函数
(re-seq [re s])
re-seq从一个字符串中一个正则表达式的匹配实例创建一个惰性序列:(re-seq #"\d+" "This sentence has 2 numbers and 6 words.") ; ❶ ;; ("2" "6")
❶
re-seq从这个句子中创建一个数字序列. 这些数字仍然是它们原来的字符串格式.- 约定
- 输入
"re"是一个java.util.regex.Pattern类型的对象. Clojure 有一个读取器字面量#"regex"来创建一个Pattern实例, 或者你可以用 Java 互操作来使用扩展形式."s"是一个java.lang.CharSequence. 它通常是一个字符串, 但也可以是实现了相同接口的其他对象. 例如:(def sb (doto (StringBuilder.) (.append "23") (.append "aa 42"))) (re-seq #"\d+" sb) ; ❶ ;; ("23" "42")
❶
re-seq也接受一个java.lang.StringBuilder作为输入, 不仅仅是字符串.
- 值得注意的异常
如果
"re"或"s"为nil, 则会抛出NullPointerException. - 输出
返回: 在字符串 "s" 中 "re" 的匹配实例的序列. 这可能是一个字符串列表或字符串向量, 取决于是否存在匹配组. 当 "s" 是空字符串时, 返回
nil.
- 输入
- 示例
字符串在 Clojure 中本质上是序列的, 产生一个构成该字符串的
java.lang.Character对象的序列.re-seq可以用来产生一个字符串的序列列表, 而不是字符:(seq "hello") ; ❶ ;; (\h \e \l \l \o) (map (memfn toUpperCase) (map str "hello")) ; ❷ ;; ("H" "E" "L" "L" "O") (map (memfn toUpperCase) (re-seq #"\w" "hello")) ; ❸ ;; ("H" "E" "L" "L" "O")
❶ 将一个字符串用
seq转换为一个序列的结果是一个java.lang.Character对象的惰性序列.❷ 注意, 在应用
toUpperCase之前, 我们需要将每个Character转换为一个String.❸
re-seq可用于将字符串分割为单个字母, 这些字母已经转换为java.lang.Character而无需使用str.如果存在匹配组,
re-seq会返回匹配实例及其各自的匹配组. 在下面的例子中, 我们匹配并解构了一系列重复的姓名和电话号码:(def signed-up ; ❶ "Jack 221 610-5007 (call after 9pm), Anna 221 433-4185, Charlie 661 471-3948, Hugo 661 653-4480 (busy on Sun), Jane 661 773-8656, Ron 555 515-0158") (let [people (re-seq #"(\w+) (\d{3}) \d{3}-\d{4}" signed-up)] ; ❷ {:names (map second people) :area (map last people)}) ; ❸ ;; {:names ("Jack" "Anna" "Charlie" "Hugo" "Jane" "Ron") ;; :area ("221" "221" "661" "661" "661" "555")}
❶ 这是一个长长的注册教孩子们编程的人员名单的示例字符串. 文本中包含了姓名, 电话和关于可用性的可选注释.
❷ 我们可以使用正则表达式来解构文本, 因为姓名和电话号码在整个文件中都以相同的模式出现.
re-seq被赋予了要搜索的模式和字符串. 注意模式中的圆括号: 我们希望能够隔离匹配子字符串的特定部分 (这是标准正则表达式格式的一部分).❸
re-seq返回一个包含匹配字符串和任何组的向量. 我们可以用这个向量列表来分组我们需要的信息.在下一个例子中, 我们将利用
re-seq对一些大文本的惰性. 该文本包含一个相当长的 100 万位 Pi 的列表 155:(def pi-digits (slurp "https://tinyurl.com/pi-digits")) ; ❶ (def pi-seq ; ❷ (sequence (comp cat ; ❸ (map int) ; ❹ (map #(mod % 48))) ; ❺ (re-seq #"\d{10}" pi-digits))) (take 20 pi-seq) ;; (1 4 1 5 9 2 6 5 3 5 8 9 7 9 3 2 3 8 4 6)
❶
pi-digits包含" Pi 电子书" 的文本版本, 这是一本包含 Pi 数字直到 100 万位的书. 该文本主要包含数字,但也包括一个引言和一个特定空格分隔的数字格式.❷ 我们可以通过按 10 位一组来匹配 Pi 数字, 来从书中产生 Pi 数字的匹配序列, 这就是它们在书中的格式.
❸
cattransducer 接受每个 10 位的字符串, 将它们分割成单个数字, 并将它们连接起来.❹
java.lang.Character实例被强制转换为int, 会产生它在 ASCII 表中存储的索引.❺ 由于 "0" 在 ASCII 表中是 48, 模运算的效果是将 ASCII 条目索引转换为实际的数字.
由于
re-seq的惰性, 我们不需要匹配整本书来检索前 20 个数字, 这为我们节省了一些计算步骤, 如果我们不想消耗所有数字的话. 然而, 请注意, 我们仍然被迫在开始计算之前将整本书加载到内存中. 在下一个扩展示例中, 我们将看到如何解决这个问题.- 比惰性更惰性
re-seq在从内存中的字符串中构建匹配模式的序列方面是惰性的. 如果字符串足够大, 我们可能无法使用re-seq, 仅仅因为字符串无法加载到内存中.以下
restream-seq函数是re-seq的一个重构, 它使用一个输入流而不是一个字符串. 我们将使用restream-seq来构建 Pi 的数字列表, 就像本章前面讨论的例子一样:(import '[java.io InputStream] '[java.net URL] '[java.util Scanner] '[java.util.regex Pattern]) (defn restream-seq [^Pattern re ^InputStream is] ; ❶ (let [s (Scanner. is "UTF-8")] ((fn step [] (if-let [token (.findInLine s re)] (cons token (lazy-seq (step))) (when (.hasNextLine s) (.nextLine s) (step))))))) (defn pi-seq [is] ; ❷ (sequence (comp cat (map int) (map #(mod % 48))) (restream-seq #"\d{10}" is))) (def pi-digits (URL. "https://tinyurl.com/pi-digits")) (with-open [is (.openStream pi-digits)] ; ❸ (doall (take 20 (pi-seq is)))) ;; (1 4 1 5 9 2 6 5 3 5 8 9 7 9 3 2 3 8 4 6)
❶
restream-seq的实现是基于一个java.util.Scanner, 这是一个可以在流中搜索连续标记 (如正则表达式) 的 Java 类. 扫描器是在java.io.InputStream实例之上构建的. 惰性序列是通过递归地向下移动输入流中的行来构建的. 每个匹配的标记都开始一个新的递归, 该递归构建最终的惰性序列.❷ 我们之前使用的处理管道被调整以接受输入流并使用新的
restream-seq函数.❸ 我们需要将任何 Pi 数字的生成都包装在一个
with-open调用中, 这样我们就可以确保在完成后正确地关闭流.序列生成只下载足够的 HTTP 请求以满足要打印的数字数量, 从而防止整本书一次性驻留在内存中.
- 比惰性更惰性
- 另请参阅
re-find是专用于正则表达式匹配的其他函数, 它们不创建序列. 如果你对字符串中匹配模式的序列视图感兴趣, 请使用re-seq. - 性能考虑和实现细节
=> O(n) 时间最坏情况
=> O(n) 内存最坏情况
re-seq所需的步骤取决于正则表达式. 生成的匹配项越多, 完全消耗时序列就越长. 总的来说,re-seq在输入字符串中匹配的模式数量上是线性的. 像本章中的其他函数一样,re-seq是惰性的, 只构建足够的序列以满足上游的请求.在任何性能敏感的算法中都应仔细考虑正则表达式的存在. 这与
re-seq无关, 也不是正则表达式的实现不好. 问题在于, 正则表达式虽然功能强大且富有表现力, 但被设计为解决广泛类别的问题, 并且相对容易低效地产生它们.对于简单的字符串部分匹配, 如果速度是一个问题, 请考虑以下替代方案:
(.startsWith "Some string" "Some")在字符串 "Some string" 的开头匹配字符串 "Some".(.contains "Some string" "e s")在字符串 "Some string" 的任何部分匹配 "a e".(.endsWith "Some string" "ing")在字符串 "Some string" 的末尾匹配 "ing".
- 约定
- 9.3.6 line-seq
自 1.0 版本以来的函数
(line-seq [rdr])
line-seq从一个字符流中创建一个行的序列. 在输入中每找到一个行终止标记, 序列中就会创建一个新的行项:(require '[clojure.java.io :refer [reader]]); ❶ (with-open [r (reader "https://tinyurl.com/pi-digits")] ; ❷ (count (line-seq r))) ; ❸ ;; 29301
❶ 我们需要创建一个
java.io.Readable的实例才能与line-seq一起工作.clojure.java.io命名空间包含了必要的函数.❷ 我们将在本节中经常使用
with-open宏, 因为我们必须始终确保在处理完输入后正确释放读取器资源.❸
line-seq在这里用于计算一个大文本中的行数.- 约定
- 示例
line-seq对于处理大型文本文件而不将其完全加载到内存中非常有用. 这可以通过两种方式发生:- 惰性序列从未被完全实现, 在处理几个项后就停止处理.
- 惰性序列被完全实现, 但处理只访问该项以保留一些部分信息 (例如计数或其他统计信息). 这样做, 序列的头部不会被保留, 并且每个项都可以在我们处理输入其余部分时被垃圾回收.
在下面的例子中, 我们将访问前 100 万个 Alexa 条目 (Alexa 是一家提供网络分析的公司), 这是一个相对较大的 (15 MB) 存档, 包含按流量排名的最受欢迎的网站. 存档是压缩的, 但我们可以在逐行处理内容的同时解压缩它. 我们想知道排名最高的 ".me" 域名是什么:
(import '[java.net URL]) (import '[java.util.zip ZipInputStream]) (require '[clojure.java.io :as io]) (def alexa "http://s3.amazonaws.com/alexa-static/top-1m.csv.zip") (defn zip-reader [url] ; ❶ (-> (URL. url) .openConnection .getInputStream ZipInputStream. (doto .getNextEntry) io/reader)) (defn domain [^String line] ; ❷ (some-> line (.split "\\.") last)) (defn first-of-domain [ext] ; ❸ (with-open [r (zip-reader alexa)] (some #(when (= ext (domain %)) %) (line-seq r)))) (first-of-domain "me") ; ❹ ;; "246,line.me"
❶
zip-reader从一个 URL 开始创建一个java.io.BufferedReader. 如你所见, Clojure 通过从打开读取器所需的许多对象中创建直接和可读的代码, 做得很好. 一个重要的细节是, 在打开一个 zip 存档时, 你必须用getNextEntry将输入流定位到下一个条目的开头. 在我们的例子中, 这相对容易, 因为存档只包含一个条目.❷
domain接受一行并提取它包含的网站的域名.❸
first-of-domain接受一个扩展名作为参数. 然后它在with-open块的上下文中访问序列.some用于取足够的序列, 直到谓词首次返回一个匹配项, 这是包含该域的相应行.❹ 我们可以看到, 流量最高的 ".me" 网站是 "https://line.me/", 一个用于发送免费短信的网站. 这个结果在其他时间可能会有所不同.
搜索第一个匹配的域名执行得相对较快, 这表明 URL 没有被完全下载. 下一个例子通过按最频繁的域名对列表进行排名来扩展前一个例子:
(defn top-10-domains-by-traffic [archive] (with-open [r (zip-reader archive)] (->> (line-seq r) (map domain) frequencies ; ❶ (sort-by last >) (take 10)))) (top-10-domains-by-traffic alexa) ;; ["com" 487682] ["org" 50189] ["ru" 43619] ;; ["net" 42955] ["de" 36887] ["br" 20192] ;; ["uk" 18828] ["ir" 16915] ["pl" 16730] ["it" 11708]
❶ 我们使用相同的
zip-reader函数在with-open调用的上下文中操作序列. 这确保了在计算结束时任何资源都被正确关闭.line-seq开始生成惰性序列, 我们从中提取域名扩展, 然后将整个序列传递给frequencies.第二个例子使用了
frequencies, 这是一个急切的函数, 它扫描整个输入来填充它的计数器. 这样做, 它不持有序列的头部.line-seq的使用允许在内存中处理非常大的文件, 前提是收集的信息 (在frequencies的情况下是键和数字) 可以存储在内存中. 任何没有保留在最终结果中的东西, 在处理仍在进行时都可以安全地进行垃圾回收. - 另请参阅
slurp将 URL 或本地文件的内容作为一个字符串下载到内存中. 对于配置文件或其他小文件, 这通常是一个直接的选择.split-lines可用于将一个大字符串分割成行, 产生一个向量. 它不是惰性的, 所以当它产生的内存占用是可预测的时才应使用. - 性能考虑和实现细节
=> O(n) 时间最坏情况
=> O(n) 内存最坏情况
与产生序列的其他函数一样,
line-seq在输入中包含的行数上是线性的. 内存也类似: 从输出中消耗的项越多, 在内存中收集的项就越多 (序列是惰性的和缓存的). 通过避免保留序列的头部, 我们可以完全消耗甚至大的序列而不会耗尽全部内存. 当序列没有被完全消耗时, 惰性在性能中扮演着一个角色, 在这种情况下, 性能配置文件在时间和内存上都是次线性的.line-seq的实现相当直接: 在BufferedReader实例上为每个可用的行产生一个惰性序列, 当缓冲区产生一个nil表示流的结束时结束.
- 约定
- 9.3.7 resultset-seq
自 1.0 版本起可用的函数
(defn resultset-seq [rs])
resultset-seq从一个java.sql.ResultSet对象生成一个序列.ResultSet通常是在关系型数据库上调用 SQL 查询的结果, 尽管也存在其他实现 156.ResultSet对数据库中的表进行建模: 一系列行, 其中每个值代表相应的列属性.创建一个合适的
ResultSet需要一个符合 JDBC 规范的数据库驱动程序. 不过, 为了演示目的, 我们将使用一个具体化的ResultSet对象, 它模拟了与数据库驱动程序的交互:(import '[java.sql ResultSet ResultSetMetaData]) (defn db-driver [attrs] ; ❶ (reify ResultSet (getMetaData [_] (reify ResultSetMetaData (getColumnCount [_] (count attrs)) (getColumnLabel [_ idx] (nth attrs (dec idx))))) (next [_] true) (close [_]) (^Object getObject [_ ^int idx] (rand-int 1000)))) (take 3 (resultset-seq (db-driver ["id" "count"]))) ; ❷ ;; ({:id 886, :count 433} ;; {:id 211, :count 431} ;; {:id 51, :count 939})
❶
db-driver使用reify创建了一个ResultSet实现的动态实例. 它包含了resultset-seq使用的函数的实现, 以及一个产生半真实结果的小机制. 请注意,next的实现总是返回true.❷ 在创建了
ResultSet存根的实例之后, 我们可以直接在其上调用resultset-seq. 我们需要始终记住从结果的无限序列中获取有限数量的元素.契约
- 输入
"rs"必须是java.sql.ResultSet的一个实例, 并且是必需的参数. - 主要异常
如果
"rs"是nil, 则抛出NullPointerException.如果
"rs"不是java.sql.ResultSet的实例, 则抛出ClassCastException. - 输出
返回: 一个由 (现已废弃的) Clojure 结构体类型组成的序列. 每个结构体包含数据库中列名的关键字表示, 后面跟着该记录在该键处的值.
虽然结构体现在已被
defrecord废弃, 但你可以像访问普通哈希映射一样访问它们. 它们在resultset-seq中的使用不需要任何其他特定知识.示例
以下示例展示了与数据库的基本 JDBC 交互以及
resultset-seq包装结果的方式. 该示例要求 Java 的 SQLite 驱动程序 (可从 github.com/xerial/sqlite-jdbc 获取) 在运行进程的类路径中. 我们将使用配置为内存数据库的 SQLite:(import '[java.sql DriverManager ResultSet]) (defn create-sample-data [stmt] ; ❶ (.executeUpdate stmt "drop table if exists person") (.executeUpdate stmt "create table person (id integer, name string)") (.executeUpdate stmt "insert into person values(1, 'leo')") (.executeUpdate stmt "insert into person values(2, 'yui')")) (with-open [conn (DriverManager/getConnection "jdbc:sqlite::memory:") ; ❷ stmt (.createStatement conn)] (create-sample-data stmt) (->> (.executeQuery stmt "SELECT * FROM person") ; ❸ resultset-seq doall)) ; ❹ ;; ({:id 1, :name "leo"} ;; {:id 2, :name "yui"})
❶
create-sample-data删除并重新创建一个名为 "person" 的表, 该表包含一个 id 和一个 name.❷ 在使用完结果后, 有必要关闭连接和语句以释放资源. 我们可以使用
with-open来自动关闭它们.❸ 在创建了一个连接对象和一个语句之后, 我们准备好填充数据并执行查询, 这将返回一个
ResultSet实例.❹ 我们需要在离开
with-open上下文之前用doall完全实现惰性的ResultSet. 如果我们不使用doall, 我们将只看到初始结果.当序列创建发生在关闭连接的
try-finally块内时, 请确保所有必要的操作都在该块内发生. 如果未实现的序列部分逸出了该块, 你可能会遇到 "connection already closed" 异常. 解决这个问题的一种方法 (尽管它消除了惰性的好处) 是像示例中那样使用doall. 另一种对惰性友好的选择是将处理函数传递到try-finally块的主体中.resultset-seq在以下情况下能发挥其全部潜力:- 数据库驱动程序从服务器流式传输结果 (而不是将它们批量加载到内存中).
- 结果太大而无法一次性加载到内存中, 但我们能够增量处理它们.
SQLite 驱动程序默认情况下会惰性地流式传输结果 (对于其他流行的驱动程序, 如 MySql, 情况并非如此). 如果你正在处理大量结果并希望惰性地处理它们, 你需要确保驱动程序支持流式处理功能.
另请参阅
可以使用
lazy-seq和cons(Clojure 惰性序列的构建块, 包括resultset-seq) 创建迭代 JDBCResultSet的临时解决方案. 对于任何其他标准迭代, 请考虑使用resultset-seq.性能考虑和实现细节
=> 最坏情况下的时间复杂度为
O(n)=> 最坏情况下的内存复杂度为
O(n)与本章中的其他函数一样,
resultset-seq在ResultSet对象内的行数上是线性的.惰性对于
resultset-seq尤其重要. 数据库旨在存储超出单台机器内存容量的数据量. 借助resultset-seq, 我们能够处理大型数据集 (例如使用reduce), 假设处理函数不需要整个数据集在内存中, 并且不持有序列的头部.
- 输入
- 9.3.8 iterator-seq 和 enumeration-seq
自 1.0 版本起可用的函数
(iterator-seq [iter]) (enumeration-seq [e])
iterator-seq和enumeration-seq是从两个标准的 Java 接口生成序列的函数:java.util.Enumeration是迭代 Java 集合的原始方式, 而java.util.Iterator是后来作为改进引入的. 这两个接口仍在使用中, 所以 Clojure 提供了一种从两者创建序列视图的方法:(import '[java.util Collections]) (def an-iterator (.iterator [1 2 3])) ; ❶ (def an-enumeration (Collections/enumeration [1 2 3])) ; ❷ (iterator-seq an-iterator) ; ❸ ;; (1 2 3) (enumeration-seq an-enumeration) ; ❹ ;; (1 2 3)
❶
java.util.Iterator::iterator方法存在于大多数 Clojure 和 Java 集合中. 我们可以在这里看到如何在一个 ClojurePersistentVector上调用它.❷
Enumeration对象更难找到, 因为该接口已逐渐被迭代器取代. 为了向后兼容, JDK 中仍有大量示例. 方法java.util.Collections::enumeration可用于从任何支持迭代器的集合中提取枚举.❸ 这里使用
iterator-seq从迭代器对象生成一个序列.❹ 你可以看到
enumeration-seq的输出与iterator-seq相同.契约
- 输入
"iter"必须实现java.util.Iterator接口."e"必须实现java.util.Enumeration接口. - 主要异常
当
"iter"或"e"为nil时, 抛出NullPointerException. - 输出
返回: 通过迭代
Iterator或Enumeration对象生成的序列. 对于来自空集合的迭代器或枚举, 它返回nil.示例
绝大多数 Java 和 Clojure 集合都支持
Iterator接口. 集合不直接实现该接口, 而是提供一个iterator()方法, 为每次新的迭代获取一个新的Iterator对象. 虽然seq知道如何使用iterator()方法生成序列, 但iterator-seq仍然适用于那些只有Iterator对象可用的情况 (例如, 作为另一个函数调用的返回类型).Java 8 引入了
java.util.stream.Stream, 这是一个新接口, 用于支持 Java 中更函数式的集合处理风格.Stream支持迭代器接口, 所以我们可以使用iterator-seq来生成一个序列:(->> "Clojure is the best language" (.splitAsStream #"\s+") ; ❶ .iterator ; ❷ iterator-seq) ; ❸ ;; ("Clojure" "is" "the" "best" "language")
❶
splitAsStream在正则表达式模式上可用, 并且可以应用于字符串. 在这种情况下, 正则表达式返回任何由 1 个或多个非空格字符组成的组.❷
stream默认不是序列性的, 并且它不实现Iterable接口. 调用seq会抛出异常. 我们可以改为显式调用iterator来检索此流的迭代器.❸
iterator-seq知道如何将迭代器转换为序列.iterator-seq产生一个缓存的序列. 从迭代器源处理一个项目后, 该项目会被生成的序列缓存, 从而有效地创建了该时间点迭代器的不可变视图. 与 Clojure 的设计原则相反,Iterator接口甚至包括一个remove方法, 允许客户端从迭代器的源对象中移除对象! 这些更改 (如果有的话) 在生成输出序列后对iterator-seq不可见. 读者在包装重用相同迭代器实例的 Java 类时应记住此行为.Java 标准库中仍有一些对象提供
Enumeration视图而不是Iteration视图. 一个例子是java.lang.concurrent.ConcurrentHashMap, 一个广泛使用的并发集合. 以下示例展示了我们如何使用ConcurrentHashMap来实现一个并行版本的distinct. 我们实际需要的数据结构类型是ConcurrentHashSet, 这在 JDK 中并不存在 157:(import '[java.util.concurrent ConcurrentHashMap]) (require '[clojure.core.reducers :refer [fold]]) (defn parallel-distinct [v] (let [m (ConcurrentHashMap.) combinef (fn ([] m) ([_ _])) reducef (fn [^ConcurrentHashMap m k] (.put m k 1) m)] (fold combinef reducef v) ; ❶ (enumeration-seq (.keys m)))) ; ❷ (defn many-repeating-numbers [n] (into [] (take n (apply concat (repeat (range 10)))))) (parallel-distinct (many-repeating-numbers 1e6)) ; ❸ ;; (0 1 2 3 4 5 6 7 8 9)
❶
reducers/fold在一个可变但并发的数据结构上使用. 这就是为什么combinef总是用对映射 "m" 的引用来种子化初始归约. 也没有combinef步骤, 因为没有要连接的块.❷ 最后一步将可变哈希映射 (这是
parallel-distinct工作方式的实现细节) 转换回不可变序列, 方法是在映射的键上使用enumeration-seq.❸ 在生成一个包含大量重复数字的长向量后, 我们可以看到
parallel-distinct返回了它们而不重复.另请参阅
sequence从实现java.util.Iterable接口的对象生成序列. 当该接口不可用但有其他方法可以生成java.util.Iterator对象时, 请改用iterator-seq.lazy-seq是用于从可迭代或可枚举对象创建序列的主要机制.性能考虑和实现细节
=> 最坏情况下时间复杂度为
O(n)=> 最坏情况下内存复杂度为
O(n)当完全消耗时,
iteration-seq和enumeration-seq必须执行迭代直到最后一个元素, 从而在原始集合中的项目数量上产生线性行为.这两个函数都是惰性的, 但
iterator-seq以每个 32 个项目的块来评估输入迭代器, 而enumeration-seq是完全惰性的:(import 'java.util.Collections) (defn dbg-coll [n] ; ❶ (let [xs (into () (range n 0 -1))] (map #(do (print % ", ") %) xs))) (first (iterator-seq (.iterator (dbg-coll 100)))) ; ❷ ;; 1 , 2 , ... , 32 , 33 , 1 (first (enumeration-seq (Collections/enumeration (dbg-coll 100)))) ; ❸ ;; 1 , 1
❶
dbg-coll创建一个给定大小的新列表, 并为每个被评估的元素包装控制台日志.❷ 我们可以用
.iterator从 Clojure 序列中提取一个Iterator, 因为它们都实现了Iterable. 我们可以看到iterator-seq从输入序列中拉出 32+1 个项目: 32 个项目是当我们调用first时被评估的块的大小, 另 1 个项目是从下一个块中评估的, 以检查是否有更多输入.❸
enumeration-seq是完全惰性的, 没有任何分块.iteration-seq提供分块行为的原因是最近与启用带transducer的序列相关工作的副产品, 而这又是受性能驱动的. 总的来说, 序列的分块行为通常是性能和完全惰性之间的权衡.
- 输入
- 9.3.9 concat 和 lazy-cat
自 1.0 版本起可用的函数和宏
(concat ([]) ([x]) ([x y]) ([x y & zs])) (lazy-cat [& colls])
concat和lazy-cat通过将零个或多个序列集合连接在一起来生成一个序列. 第一个集合的项目首先被添加, 其次是第二个集合, 依此类推, 直到所有输入都被消耗:(concat [1 2 3] () {:a 1} "hi" #{5}) ; ❶ ;; (1 2 3 [:a 1] \h \i 5)
❶ 这里使用
concat来连接几种类型的序列集合. 它产生一个lazy-seq.lazy-cat是一个基于concat构建的宏, 它在将输入集合传递给concat之前将其包装在lazy-seq中. 这一额外的保护层使得可以在不评估参数的情况下进行惰性连接. 我们可以通过宏展开一个简单的形式来看lazy-cat与concat的密切关系:(macroexpand '(lazy-cat [1 2 3] (range))) ; ❶ ;; (concat (lazy-seq [1 2 3]) (lazy-seq (range)))
❶
lazy-cat的宏展开显示了将参数包装在lazy-seq中并与concat一起使用.惰性是
concat和lazy-cat最有趣的方面, 我们将在示例部分看到如何使用它.契约
- 输入
- 没有参数时,
concat返回空序列(). "x"单个参数被concat接受. 它需要是序列类型 (使得(instance? java.lang.Seqable x)为真) 或nil. 只有一个参数时,concat的行为类似于lazy-seq, 从"x"生成一个惰性序列."x","y"和"zs"可以是序列集合或nil.
- 没有参数时,
- 主要异常
如果任何输入不是序列性的, 则抛出
IllegalArgumentException, 根据seq契约. - 输出
返回: 通过连接
"x","y"和"zs"(如果有) 的内容生成的惰性序列, 否则返回空序列.示例
concat对于在不同源上创建统一视图非常有用, 每个源都产生一个独立的集合或惰性序列. 例如, 这是一个标识符函数, 它产生一个唯一的对象标识符, 其中包括所有已实现的类和接口:(defn identifier [x] (let [classname #(.getName ^Class %) ; ❶ split #(.split % "\\.") typex (type x)] (apply str (interpose "-" (concat (split (classname typex)) ; ❷ (mapcat (comp split classname) (supers typex))))))) ; ❸ (identifier #"regex") ; ❹ ;; "java-util-regex-Pattern-java-io-Serializable-java-lang-Object"
❶
let块定义了两个辅助函数:classname用于获取类的名称作为字符串,split用于在每个 "." 点位置分割字符串.❷ 名称的一个来源是包和类名.
❸ 另一个名称来源是通过处理同一类的
supers得出的. 我们将它们连接在一起, 然后用破折号 "-" 符号插入它们之间.❹ 你可以用一个对象 (如
java.util.regex.Pattern) 或一个 Clojure 向量 (会产生一个更长的列表) 来尝试identifier.当源集合的列表仅在运行时才为人所知时,
concat可以与apply一起使用来连接所有参数:(def sold-icecreams ; ❶ [[:strawberry :banana :vanilla] '(:vanilla :chocolate) #{:hazelnut :pistachio} [:vanilla :hazelnut] [:peach :strawberry]]) (defn next-day-quantities [sold-icecreams] (->> (apply concat sold-icecreams) ; ❷ frequencies (sort-by second >))) (next-day-quantities sold-icecreams) ; ❸ ;; ([:vanilla 3] [:strawberry 2] [:hazelnut 2] ;; [:banana 1] [:chocolate 1] [:pistachio 1] [:peach 1])
❶ 在这个例子中, 我们收到了今天售出的冰淇淋列表. 列表在长度和结构上都已简化, 仅报告每个冰淇淋包含的口味组合.
❷ 我们希望能够看到所有口味, 这样我们就可以计算第二天需要储备多少原料.
apply concat是一个有用的习惯用法, 可以将所有列表连接在一起.❸ 我们可以看到哪些口味最受欢迎, 并据此进行储备.
也许
concat和lazy-cat中最有趣的方面是惰性. 它们都只连接足够的输入来满足消费者的请求:(defn trace [x] (println "evaluating" x) x) ; ❶ (def l1 (map trace (list 1 2 3))) ; ❷ (def l2 (map trace (list 3 4 5))) (def l1+l2 (concat l1 l2)) ; ❸ (first l1+l2) ; ❹ ;; evaluating 1 ;; 1
❶
trace是一个简单的函数, 它在返回其参数之前打印它.❷
l1和l2是用map构建的惰性序列.❸ 调用
concat时不会打印任何内容.❹ 访问第一个元素只实现足够的连接来返回第一个元素.
此外,
lazy-cat不会评估参数, 这对于连接具有不同创建成本的非惰性集合很有用. 例如, 我们可以构建一个越来越难获取的项目的惰性序列. 如果大多数消费者只消费前几个项目, 他们将立即得到服务, 而其他人 (少数) 可能需要等待更长时间.(time (first (concat (vec (range 10)) (vec (range 1e7))))) ; ❶ ;; "Elapsed time: 1032.928937 msecs" (time (first (lazy-cat (vec (range 10)) (vec (range 1e7))))) ; ❷ ;; "Elapsed time: 0.313782 msecs"
❶
concat在一个小向量和一个大得多的向量上使用. 我们只想要第一个元素, 但我们还是承担了创建大向量的成本.❷
lazy-cat将参数的评估推迟到最后一刻. 由于我们只看第一个元素, 大向量从未被物化.我们可以利用惰性来为字符串生成 "填充": 我们想用空格填充字符串的右侧, 直到它达到给定的宽度. 以下示例展示了我们如何使用
concat在屏幕上绘制一个矩形来包围给定的句子:(require '[clojure.string :as s]) (defn padder [width] ; ❶ #(take width (concat % (repeat " ")))) (defn line [width] ; ❷ (apply str (repeat (+ 2 width) "-"))) (defn quote-sentence [sentence width] (transduce ; ❸ (comp (map (padder width)) (map #(apply str %)) (map #(str "|" % "|\n"))) (completing str #(str % (line width))) (str (line width) "\n") (s/split sentence #"\s+"))) (println (quote-sentence "Clojure is my favorite language" 12)) ; ❹ ;; -------------- ;; |Clojure | ;; |is | ;; |my | ;; |favorite | ;; |language | ;; --------------
❶
padder为给定宽度创建一个填充函数. 创建后, 它可以作为map的转换函数使用. 我们在输入字符串 (它是序列性的) 和空格字符的无限重复上使用lazy-cat. 由于无限序列出现在底部, 我们可以根据需要获取任意多的填充, 而不必担心上限.❷
line是一个创建由破折号组成的行的函数, 准备好进行显示.❸
transduce将构成绘图的各行组合在一起. 水平标题是归约函数的初始参数, 而闭合的页脚是作为归约函数的单参数调用创建的. 我们使用completing来组合最终化函数和归约函数str.❹ 我们可以看到如何使用
quote-sentence在给定句子周围绘制一个矩形. - 增量构建结果时使用
concat
concat可以在递归循环中使用, 当中间步骤是序列时, 用于构建结果. 但与concat调用的嵌套方式相关的潜在问题:(defn get-batch [id] ; ❶ (repeat id id)) (defn step ([n] (step n ())) ([n res] (if (pos? n) (recur (dec n) (concat res (get-batch n))) ; ❷ res))) (step 4) ; ❸ ;; (4 4 4 4 3 3 3 2 2 1) (first (step 10000)) ; ❹ ;; StackOverflowError
❶
get-batch模拟一些计算来检索一个项目列表. 在实际场景中, 这可能是一个数据库查询.❷
concat将最后的结果连接到当前批次的前面. 该操作是递归的, 直到我们达到所需的步骤数量.❸ 用一个小数调用
step会得到一个扁平的序列.❹ 但足够大的步骤会产生一个意想不到的
StackOverflowError.StackOverflowError是令人惊讶的, 因为我们使用的是loop-recur, 这是一个不消耗堆栈的结构. 问题不在于从尾部位置递归, 而在于逐渐在堆栈上累积的嵌套concat调用.每次迭代,
concat都会产生一个包装在lazy-seq对象中的新结果.lazy-seq段的链条增长到遍历需要太多堆栈帧的程度 158. 一个快速的解决方案是通过反转concat参数的顺序来打破lazy-seq的嵌套. 请注意, 这也改变了结果的顺序:(defn step ([n] (step n ())) ([n res] (if (pos? n) (recur (dec n) (concat (get-batch n) res)) ; ❶ res))) (step 4) ; ❷ ;; (1 2 2 3 3 3 4 4 4 4) (last (step 10000)) ;; 10000
❶
res现在在concat调用的底部, 首先是由repeat产生的惰性序列.❷ 我们可以看到结果现在是反转的, 因为递归从最后一个
get-bach调用开始构建, 将之前的批次推到最终序列的头部.新版本的
step函数遍历序列而不是lazy-seq闭包来产生结果, 生成一个消耗堆的算法. 然而, 结果现在有了不同的排序, 这在某些情况下可能不是一个选项.另请参阅
当连接之前有转换时,
mapcat是首选. 例如:(apply concat (map rest [[1 2 3] [4 5 6]])) ; ❶ ;; (2 3 5 6) (mapcat rest [[1 2 3] [4 5 6]]) ; ❷ ;; (2 3 5 6)
❶
map后面跟着concat来消除序列的内部嵌套.❷
mapcat以更简洁的方式产生相同的结果.cat是concat的transducer版本.性能考虑和实现细节
=> 最好情况下是
O(1)常数时间=> 最坏情况下生成的序列是
O(n)concat和lazy-cat以常数时间返回, 因为它们在第一个未评估的lazy-seqthunk 处停止, 等待消费者从序列中拉出额外的元素. 内存消耗可以达到输入中项目的总和, 最坏情况是O(n), 如果输出被完全消耗.concat的实现 (lazy-cat基于此) 是对第一个参数的递归lazy-seq-cons模式, 其次是第二个 (以及可能其他的). 如果序列是分块的, 那么递归会以项目块而不是单个项目进行."示例" 部分已经说明了惰性对于连接的一些优点,
lazy-cat允许对非惰性集合的评估进行额外控制.lazy-cat也支持递归定义. 下面的fibs定义包含一个斐波那契数的惰性序列 (即前两个数之和的数列). 这个定义无疑是优雅的, 但它在设计上持有了序列的头部 (它被分配给了一个 var):(def fibs (lazy-cat [0 1] (map +' fibs (rest fibs)))) ; ❶ (take 10 fibs) ; ❷ ;; (0 1 1 2 3 5 8 13 21 34) (last (take 1e6 fibs)) ; ❸ ;; java.lang.OutOfMemoryError: Java heap space
❶ 注意
fibs即将被定义, 但已在定义本身中使用. 这是可能的, 因为lazy-seq是一个宏, 不会评估其参数. 在这种情况下,concat将无法工作.❷ 我们可以看到, 对于小数,
fibs按预期工作.❸ 如果我们试图访问第 1 百万个斐波那契数, 我们会遇到一个
OutOfMemoryError(也取决于 JVM 设置).将用
lazy-cat创建的惰性序列直接分配给一个 var 是有潜在危险的. 这是因为当我们向序列的更深处迭代时,fibsvar 持有对头部的引用. 然而, 这是一个典型的教科书示例, 用于展示惰性和递归.
- 输入
3.2.4. 9.4 列表
术语 "list" 受到重叠定义的影响. 在 Clojure 中, "list" 是一种具体的数据类型 (clojure.lang.PersistentList), 与向量或映射一样. list 函数也是同一种数据类型的构建器. 列表也是序列, 因为它们直接实现了这个抽象, 但它们在技术上不是序列生成器, 因为它们本身就是序列. 列表是基础的, 从评估一个 Clojure 文件会创建一个列表, 最终提供给编译器这一事实开始.
cons, 与 list 一起, 是另一个直接扩展 clojure.lang.ASeq 的具体数据类型 (其他集合有适配器类). cons 也是一个同名的构建器函数, 类似于 list. 这两种类型, list 和 cons, 关系密切, 一些函数对它们进行互换或透明处理 (得益于支持相同的序列接口). cons 和 list 共享相同的构建链式链接单元以创建序列效果的系统. list 比 cons 支持更多特性, 例如, 列表可以在常数时间内计数或使用优化算法进行归约.
- 9.4.1 list
自 1.0 版本起可用的函数
(list [& args])
list函数从给定的项创建一个新的clojure.lang.PersistentList数据类型:(list 1 2 3 4 5) ; ❶ ;; (1 2 3 4 5)
❶ 用 5 个数字创建一个列表.
list构造函数在语言中是基础的: 以文本形式出现的 Clojure 代码首先被转换为列表和符号, 然后进行宏展开, 最终编译成字节码. 函数参数也作为列表处理.list是标准库中核心命名空间顶部定义的第一个函数, 这并非巧合 159.尽管列表在语言本身中有广泛使用, 但与惰性序列, 向量, 集合或哈希映射相比, 它们在日常 Clojure 编程中灵活性较差. 然而, 我们将在示例部分探讨一些用例.
契约
- 输入
"args"是零个或多个参数, 包括nil. - 输出
返回: 一个包含参数的
clojure.lang.PersistentList对象, 如果没有参数, 则返回空列表.示例
列表是通过将元素相互 "链接" 来创建的. 最后一个进入列表的项被添加到头部 (打印时列表的左侧), 并指向前一个头部, 形成一个链. 下图显示了一个典型列表的构成:

Figure 30: Figure 9.6. 由一系列 PersistentList 对象组成的列表. EmptyList 是 PersistentList 的一个特化版本, 用于处理尾部位置.
conj可用于将元素推入列表. 每个项都被推到列表的头部, 这使得列表在打印时看起来是反向的:(-> () (conj 1)) ; ❶ ;; (1) (-> () (conj 1) (conj 2)) ;; (2 1) (-> () (conj 1) (conj 2) (conj 3)) ; ❷ ;; (3 2 1)
❶ 多功能的
conj知道如何将元素推入列表, 以及如何将元素推入许多其他数据类型.❷ 当我们将列表打印出来时, 推入列表的参数看起来是反向的.
列表将新元素连接到头部的这一事实, 可以与
into(它重复使用conj) 一起使用来反转另一个集合的内容:(defn rev [coll] (into () coll)) ; ❶ (rev (range 10)) ; ❷ ;; (9 8 7 6 5 4 3 2 1 0)
❶ 通过将项推入空列表来创建列表. 现在生成的列表打印出来是反向的, 因为
into使用conj将新元素推到列表的头部.❷ 该表达式使用
rev来反转一个包含 10 个元素的范围的内容.列表是实现栈 (后进先出的队列也称为栈) 的一个好选择, 因为它支持 peek-pop 接口. 在下面的例子中, 我们将使用一个列表来构建一个栈, 以找到最近的较小值的序列 160.
要理解最近的较小值搜索是如何工作的, 让我们先看一个小输入. 给定一个列表
(8 11 4 12 5 6), 最近的较小值的序列是(8 4 4 5):- "8" 没有前一个数, 所以没有东西可以添加到结果中.
- "11" 有一个较小的前一个值, 所以 "8" 被添加到结果中.
- "4" 有两个前一个值, 但没有一个更小.
- "12" 有三个较小的前一个数. "4" 是最近的, 并被添加到输出中.
- "5" 最近的较小值是 "4", 所以输出中又出现了一个 "4".
- "6" 最近且较小的值是 "5".
注意, 一旦发现 "y" 大于 "x" (例如, 在前面的列表中 y="12", x="5"), 我们可以排除 "y" 之前所有大于 "y" 的元素 (例如, 我们不需要将 "5" 与 "11" 比较). 我们将使用一个栈来跟踪访问过的元素, 这隐式地给了我们一个机会在下一次迭代中跳过项:
(defn stack [] ()) ; ❶ (defn push [x stack] (conj stack x)) ; ❷ (defn nearest-smaller [xs] ; ❸ (letfn [(step [xs st] (lazy-seq (when-first [x xs] (loop [st st] ; ❹ (if-let [s (peek st)] (if (< s x) (cons s (step (rest xs) (push x st))) (recur (pop st))) (step (rest xs) (push x st)))))))] ; ❺ (step xs (stack)))) (nearest-smaller [0 8 4 12 2 10 6 14 1 9 5 13 3 11 7 15]) ;; (0 0 4 0 2 2 6 0 1 1 5 1 3 3 7)
❶
stack是创建新列表的 "语法糖". 它实际上将list重命名为stack, 帮助我们正确地处理这个抽象.❷ 类似地, 原始的
conj操作被重命名为push, 以强制正确使用栈.❸
nearest-smaller的总体设置遵循典型的lazy-seq模式:step内部函数在接收到输入序列和一个空栈后生成惰性序列. 一旦when-first返回nil, 生成就结束了.nearest-smaller的特点是存在一个内部的loop-recur结构来迭代栈的内容.❹ 内部 (非惰性) 循环在递归期间的那个点上执行栈内容的迭代. 我们正在栈中搜索第一个比输入当前头部小的数. 如果我们找到了一个, 它会立即进入生成的输出序列. 如果我们找不到, 我们会搜索栈的下一个顶部, 依此类推.
❺ 每当我们到达栈底而没有找到一个更小的项时, 我们就会跳过下一次迭代而不进行
cons. 注意, 生成输出的递归总是将 "x" 推入 "st" (当前的栈视图), 这意味着列表的当前头部被放置在栈的顶部.在
nearest-smaller中, 外部的step递归和内部的loop是嵌套的. 嵌套循环的存在通常表示O(nm)的行为 (其中 m 是嵌套的层级, n 是输入的长度), 但在这种情况下不是. 每个项最多被推入和弹出栈一次, 这有效地将内部循环的操作数量限制在一个常数因子内. - 列表的多种含义
Clojure 中的
list与一般计算机科学中的列表相比, 具有非常特定的含义. Clojure 的list函数是PersistentList类的构造函数, 一个通用的数据结构.而 "列表" 抽象数据类型则定义了一个具有有序访问的可迭代数据结构. 典型的实现是在许多语言中找到的单链表或双向链表. Clojure 的
list是单链表的一个例子. 与数组相比, 列表是动态的, 因为它们可以在运行时增长和缩小.将
cons到一个列表中是可能的, 但会产生另一个类型为clojure.lang.Cons而不是clojure.lang.PersistentList的列表. 从那时起, 列表就形成了两种单元类型的混合体, 任何后续操作 (如into或conj) 都会产生一个clojure.lang.Cons类型, 它既不可归约也不可计数.conj应该始终是向集合添加元素的首选, 特别是对于列表, 因为单元类型很容易在不注意的情况下混合.另请参阅
与
list相比,vector提供了通过索引直接查找元素的功能.conj是在构造后将元素推入列表的主要工具.cons也是一种列表形式 (其构造函数是list*, 注意名称末尾的 "星号").cons链通常不作为数据结构使用, 因为它们提供的灵活性非常有限 (它们既不可计数也不可归约).cons的主要用例是作为惰性序列的构建块.seq生成一个惰性序列, 除了惰性之外, 其行为与list类似.性能考虑和实现细节
=> 与 args 数量呈
O(n)线性关系列表是通过链接
clojure.lang.PersistentList单元对象来创建的. 访问一个元素是线性的, 在获取最后一个元素时最坏情况为O(n). 因此, 当操作发生在头部时, 列表的性能最好. 全扫描搜索或按索引访问会受到线性行为的影响, 应谨慎使用.列表是可计数的和可归约的. 可计数意味着在
conj操作期间, 它们会更新一个内部计数器, 稍后可以在常数时间内检索. 可归约是指提供一个特殊的实现来进行reduce. 我们可以从下面的基准测试中看到这一点的重要性:(require '[criterium.core :refer [quick-bench]]) (defn alist [n] ; ❶ (into (list) (range n))) (defn acons [n] ; ❷ (reduce #(cons %2 %1) () (range n))) (let [l1 (alist 1e5)] (quick-bench (reduce + l1))) ; ❸ ;; 1.5ms (let [l2 (acons 1e5)] (quick-bench (reduce + l2))) ;; 3.1ms (let [l1 (alist 1e5)] (quick-bench (count l1))) ; ❹ ;; 12.5ns (let [l2 (acons 1e5)] (quick-bench (count l2))) ;; 3.6ms
❶
alist使用into创建一个list.❷
acons需要cons到一个初始的空list中来创建一个由cons单元组成的链表. 专用的构造函数list*只接受有限数量的单元.❸ 在列表上进行
reduce的速度是相同操作在cons单元列表上的两倍.❹ 在列表上进行
count的速度比在相同长度的cons-list上快两个数量级. 注意我们从纳秒变成了毫秒. 在cons-list上的count是一个线性操作.列表支持序列接口, 无需适配器. 同时, 这也阻止了列表提供像范围或向量那样的分块行为. 值得记住的是, 列表是序列性的, 但不是惰性的: 它们的创建已经意味着所有元素的评估.
由于列表的实际用例之一是实现栈, 让我们将它们与向量进行比较. 下面的
check函数用于验证括号是否平衡 (该示例在peek中完整呈现). 我们需要做的就是将不同的stack参数传递给函数, 以使用不同类型的栈:(require '[clojure.set :refer [map-invert]]) (def push conj) (def brackets {\[ \] \( \) \{ \}}) (defn check [form stack] ; ❶ (reduce (fn [q x] (cond (brackets x) (push q x) ((map-invert brackets) x) (if (= (brackets (peek q)) x) (pop q) (throw (ex-info (str "Unmatched delimiter " x) {}))) :else q)) stack form)) (check "(let [a (inc 1]) (+ a 2))" ()) ;; ExceptionInfo Unmatched delimiter ] (check "(let [a (inc 1)] (+ a 2))" ()) ;;()
❶ 我们只需将不同的东西作为
stack参数传递给check函数, 就可以更改栈的实现.我们现在要比较
check函数的向量栈和列表栈:(require '[criterium.core :refer [quick-bench]]) (def small (str (seq (take 100 (iterate list ()))))) ; ❶ (def large (str (seq (take 1000 (iterate list ()))))) (quick-bench (check small ())) ;; 3.24 ms (quick-bench (check small [])) ;; 4.80 ms (quick-bench (check large ())) ;; 317 ms (quick-bench (check large [])) ;; 386 ms
❶
small和large包含类似的嵌套括号模式, 例如 "". 该模式在不同的深度重复, 直到由take指导的给定最大值, 迫使更深的栈并对不同的栈实现施加压力.我们可以看到, 列表在实现栈方面优于向量, 尽管优势不大.
- 输入
- 9.4.2 cons 和 list*
自 1.0 版本起可用的函数
(cons [x seq]) (list* ([args]) ([a args]) ([a b args]) ([a b c args]) ([a b c d & more]))
cons通过将给定元素链接到一个序列尾部来创建一个新的clojure.lang.Cons数据结构:(cons :a [1 2 3]) ; ❶ ;; '(:a 1 2 3)
❶
cons接受要添加的元素和另一个序列数据结构, 将它们连接成一个新的序列视图.cons的输出本身是序列性的, 可以用于另一个cons, 逐渐形成更长的cons单元链表:(cons 1 (cons 2 (cons 3 (cons 4 ())))) ; ❶ ;; (1 2 3 4)
❶
cons调用是嵌套的, 以形成一个链表.除了最初的几个项之外,
list*可用于创建更长的cons链并避免重复:(list* 1 2 3 4 5 ()) ; ❶ ;; (1 2 3 4 5)
❶
list*通过在输入中的每个元素上重复应用cons来创建cons单元的链表. 与cons类似, 最后一个元素需要是序列性的.cons单元的列表很少用于创建大型数据结构 (例如, Clojure 内部使用list*将参数组合成单个列表).cons主要用作惰性序列的构建块.尽管名字如此,
list*创建的是一个clojure.lang.Cons, 而不是一个clojure.lang.PersistentList(就像list所做的那样).cons*可能会是一个更好的名字.契约
- 输入
"x"可以是任何类型, 对于cons是必需的."seq"是一个序列集合 (根据seq契约) 或nil."a","b","c"和"d"对于list*可以是任何类型."a"是被添加到结果cons列表的最后一项.list*中的"args"表示最后一个参数与其他参数不同, 并且要求是序列性的或nil.list*中的"more"允许任意数量的参数, 但最后一个需要是序列集合或nil.
- 主要异常
当
"seq"不是序列性时, 会抛出IllegalArgumentException. 这通常是在混淆conj和cons时反转参数的结果. - 输出
cons返回:- 包含
"x"作为第一个元素和"seq"作为其余部分的clojure.lang.Cons实例. - 当
"seq"是nil时, 它返回clojure.lang.PersistentList而不是clojure.lang.Cons.
list*返回:- 一个由
clojure.lang.Cons单元对象组成的链表, 其中"args"作为最后一个元素.
示例
创建比几个项更长的
cons-list是可能的, 但不鼓励, 因为它们作为集合的使用会受到一般性能考虑的惩罚. 如果你正在考虑使用apply来创建更长的链, 请记住最终结果可能不是一个纯粹的cons-list:(def l (apply list* -2 -1 (range 10) ())) ; ❶ ;; (-2 -1 0 1 2 3 4 5 6 7 8 9) (type (next l)) ; ❷ ;; clojure.lang.Cons (type (nnext l)) ; ❸ ;; clojure.lang.LongRange
❶
nil或()都是list*最后一个元素的有效选项.❷ 如果我们开始检查元素的类型, 我们可以看到它们是预期的
clojure.lang.Cons.❸ 但是在范围被连接进来的地方, 是整个一个
clojure.lang.LongRange, 而不是一个cons对象.要创建一个纯粹的基于
cons的列表, 我们可以使用reduce:(def l (reduce #(cons %2 %1) () (range 9 -3 -1))) ; ❶ ;; (-2 -1 0 1 2 3 4 5 6 7 8 9) (type (nthrest l 10)) ; ❷ ;; clojure.lang.Cons
❶ 使用
reduce来重复调用cons.❷ 深入到列表的元素中, 表明它们都是
clojure.lang.Cons对象.如引言中所讨论的,
cons的主要用例之一是构建惰性序列. 让我们回顾一下典型的序列生成场景, 并关注cons的使用:(defn lazy-loop [xs] ; ❶ (lazy-seq (when-first [x xs] (cons x ; ❷ (lazy-loop (rest xs)))))) (last (lazy-loop (range 100000))) ; ❸ ;; 99999
❶
lazy-loop从其输入生成一个惰性序列, 不进行任何转换. 这个看似无用的循环的一个副作用是, 在迭代分块序列时会移除分块.❷ 在检查是否有更多项要处理后, 它用
cons将当前项推入下一次递归.❸ 我们可以访问远离头部的元素而不用消耗堆栈, 即使没有尾递归.
cons被设计用来处理一个序列性的尾部 (不像list那样是另一个clojure.lang.PersistentList). 因此,cons不必评估其内容, 这允许了lazy-seq产生的典型评估暂停. 作为反例, 下面尝试使用PersistentList创建惰性序列是消耗堆栈的:(defn lazy-loop [xs] (lazy-seq (when-first [x xs] (conj ; ❶ (lazy-loop (rest xs)) x)))) (last (lazy-loop (range 100000))) ; ❷ ;; StackOverflowError
❶ 与前面的例子相比, 我们使用的是
conj而不是cons. 注意我们必须反转参数顺序.❷ 这次, 由于
conj一个没有序列尾部选项的PersistentList,lazy-seq无法保持主体未被评估.Clojure 中的 Cons 单元与其他 Lisp 中的 cons 单元不同. 在大多数 Lisp 中, "cons" 持有指向任意对象的指针. 在那些 Lisp 中, 你可以使用 cons 单元来构建树. Clojure 的 cons 接受任意对象作为头部, 但只允许一个
ISeq作为尾部.另请参阅
conj了解所有 Clojure 类型, 包括list, 根据输入集合的类型调用正确的 "追加" 语义. 使用cons创建惰性序列 (或小的一次性列表), 并且在你绝对确定conj在你的情况下不起作用时使用它.lazy-seq理解cons, 它与cons紧密相连, 用于生成惰性序列.性能考虑和实现细节
=>
O(1)常数时间,cons=>
O(n)步数,list*cons在常数时间内创建clojure.lang.Cons的一个实例. 第二个参数可以是任何序列对象, 包括另一个clojure.lang.Cons实例. 尾部仅在必要时才被评估, 所以就第二个参数的评估而言,cons可以被认为是惰性的.在性能方面, 自然的比较是与
list. 这在list章节中已经完成, 因此请读者回顾那部分内容.list*需要遍历参数来构建链表, 所以其行为在输入项的数量上是线性的. - 包含
- 输入
3.2.5. 9.5 总结
本章是关于序列是如何创建的. 最常见的方式是通过顺序迭代一个现有的集合, 但序列也可以从一个计算配方或外部数据生成. 本章还包括两个直接实现序列接口的数据结构: list 和 cons. 在下一章中, 我们将探讨标准库中处理序列的函数.
3.3. 10 顺序处理
本章是关于顺序处理的函数和宏. 这些函数通常将其输入转换为序列 (如果它还不是), 并产生另一个序列. 尽管顺序函数可以与任何提供顺序接口的集合类型一起使用, 但它们在纯顺序输入/输出下表现最佳.
顺序处理可以大致分类如下:
- 分割: 通过索引, 项目数量或使用自定义谓词来隔离序列的连续部分. 像
split这样的函数属于这一组, 还有drop,rest和它们的变化形式. - 选择: 从序列中检索特定项目, 但不一定是连续的选择, 例如
take-nth或filter. - 转换: 对序列中的每个项目应用一个函数以产生另一个序列, 如
map,keep或mapcat. - 组合: 组合多个序列以形成另一个序列, 如
interpose或concat. - 分块: 按多个元素的组而不是一次一个地处理序列. Clojure 提供了一个小的 API 来创建分块序列, 这在
chunk-cons部分有描述.
像 first , map 或 filter 这样的一些函数也属于这里, 但它们在 "基本构造" 章节中有特别的强调.
3.3.1. 10.1 rest, next, fnext, nnext, ffirst, nfirst 和 butlast
自 1.0 版本起可用的函数
(rest [coll]) (next [coll]) (butlast [coll]) (nnext [coll]) (nfirst [coll]) (fnext [coll]) (ffirst [coll])
rest, next, butlast, nnext 和 nfirst 在从输入集合的头部或尾部最多移除 1 个元素后生成一个惰性序列. fnext 和 ffirst 则返回单个元素.
下表总结了本节中的函数及其目标:
| 名称 | 描述 | 输入 | 输出 |
|---|---|---|---|
rest |
除了第一个项目外的 "coll", 或空列表. | '(0 1 2 3) |
(1 2 3) |
next |
除了第一个项目外的 "coll", 或 nil. | '(0 1 2 3) |
(1 2 3) |
butlast |
除了最后一个项目外的 "coll", 或 nil. | '(0 1 2 3) |
(0 1 2) |
nnext |
"coll" 的 next 的 next. | '(0 1 2 3) |
(2 3) |
nfirst |
"coll" 的 first 的 next. | '((0) 1 2) |
(1 2) |
fnext |
"coll" 的 next 的 first. | '(0 1 2 3) |
1 |
ffirst |
"coll" 的 first 的 first. | '((0) 1 2) |
0 |
如你所见, 这些函数在一些方面有所不同, 比如如果没有更多项目时它们返回什么 (空序列或 nil), 它们操作输入的哪一侧 (开始或结束), 或者它们是返回一个序列还是一个单个项目.
rest 和 next (以及 first) 在序列输入的递归算法定义中扮演着重要角色. 它们的组合 (fnext, nnext, ffirst 和 nfirst) 在需要时可以节省一些按键和括号.
契约
- 输入
"coll"可以是任何序列性输入或nil. 当一个集合为seq提供了序列化策略时, 它就是 "seqable" 的. 大多数 Clojure 数据结构都是序列性的, 最重要的 Java 数据结构也是如此. - 主要异常
特别是对于
ffirst和nfirst, 它们假设有嵌套的数据结构, 可能会抛出IllegalArgumentException. - 输出
rest,next,butlast和nfirst返回一个序列. 在没有项目可返回以满足请求操作的情况下,rest返回一个空列表, 而其他的返回nil.ffirst,nnext和fnext返回单个项目或nil, 如果操作导致没有可用的项目.示例
通过使用
juxt, 我们可以快速理解这些函数在nil和空集合上的行为:((juxt rest next butlast nfirst ffirst nnext fnext) nil) ; ❶ ;; [() nil nil nil nil nil nil] ((juxt rest next butlast nfirst ffirst nnext fnext) []) ; ❷ ;; [() nil nil nil nil nil nil]
❶ 所有函数都可以在
nil上调用.rest是唯一返回空列表的函数.❷ 所有函数也接受空集合作为输入, 产生完全相同的结果.
如引言中所述,
rest(或next) 与first一起是序列的基本递归习语的一部分:(defn rest-loop [coll] ; ❶ (loop [xs coll results []] ; ❷ (if-let [xs (seq xs)] ; ❸ (recur (rest xs) ; ❹ (conj results (first xs))) results))) (rest-loop (range 10)) ;; [0 1 2 3 4 5 6 7 8 9]
❶
rest-loop迭代给定集合的元素并将它们放入一个向量中, 不进行任何转换.❷
loop-recur结构定义了默认值. 我们在循环内将"coll"绑定到"xs", 所以我们可以在每次迭代中自由地消耗它."results"持有输出的逐渐累积.❸ 在开始另一次递归之前, 我们需要检查
"xs"中是否有元素. 这里使用seq将一个潜在的空列表 (rest返回的) 转换为nil, 以便可以在if-let条件中使用它.❹ 如果有更多元素要处理, 第一个元素被添加到结果中,
"xs"的其余部分用于下一次递归.现在应该很清楚为什么如果我们想在集合本身上使用条件,
next会很有用. 由于next返回nil来表示输入的结束 (而不是空列表), 我们可以将数据结构本身用作逻辑布尔值 (Clojure 中称为 "nil punning" 的习语). 这样做我们可以移除if-let绑定:(defn next-loop [coll] ; ❶ (loop [xs (seq coll) results []] (if xs ; ❷ (recur (next xs) ; ❸ (conj results (first xs))) results))) (next-loop (range 10)) ;; [0 1 2 3 4 5 6 7 8 9]
❶
next-loop是前一个rest-loop的重写, 以利用next的nil-punning特性.❷
if条件现在直接在"xs"上发生,"xs"是序列的当前视图. 然而请注意, 我们不得不在xs的循环绑定期间添加一个一次性的seq调用来处理空输入的情况:(next-loop [])应该得到[]而不是[nil].❸ 使用
next代替rest.请注意,
rest-loop和next-loop这两个函数被设计为完全消耗其输入, 没有特别关注惰性. 然而, 如果输入是计算成本极高的数据, 那么我们可能会对rest和next在惰性方面的差异感兴趣. 为了说明这一点, 让我们现在使用next创建一个lazy-seq递归循环:(defn lazy-expensive [] ; ❶ (map #(do (println "thinking hard") %) (into () (range 10)))) (defn lazy-loop [xs] ; ❷ (lazy-seq (when xs (cons (first xs) (lazy-loop (next xs)))))) ; ❸ (first (lazy-loop (lazy-expensive))) ; ❹ ;; thinking hard ;; thinking hard ;; 9
❶ 我们的输入是一个昂贵的惰性序列.
lazy-expensive通过在屏幕上打印来产生副作用, 这样我们就可以看到何时有东西被产生.❷
lazy-loop使用递归的lazy-seq习语在输入之上构建一个惰性序列. 作为函数的作者, 我们不知道会传入什么样的输入, 但我们向外界保证我们将惰性地消耗它.❸ 我们决定使用
next循环风格, 在when条件中利用nil punning.❹ 当我们请求第一个元素时, 屏幕上有两次打印.
在现实生活中,
lazy-expensive可能会产生副作用, 比如将大文件读入内存. 惰性给了我们一个机会, 在必要时只消耗足够的昂贵计算, 但为了避免消耗额外的 (不想要的) 项目, 我们必须使用rest:(defn lazy-loop [xs] ; ❶ (lazy-seq (when-first [x xs] (cons x (lazy-loop (rest xs)))))) ; ❷ (first (lazy-loop (lazy-expensive))) ; ❸ ;; thinking hard ;; 9
❶
lazy-loop已被更改以适应rest递归风格. 我们正在使用方便的when-first快捷方式, 它会扩展为一个将(first xs)赋值给局部绑定 "x" 的操作.❷ 我们现在可以使用
rest而不是next.❸ 输出现在是完全惰性的, 不会消耗比实际请求更多的项目.
在下面的例子中, 我们将使用
butlast来实现一个不需要使用comp来组合transducer的into版本 (一个类似的机制在标准库中为eduction实现):(defn into* [to & args] ; ❶ (into to (apply comp (butlast args)) ; ❷ (last args))) (into* [] (range 10)) ; ❸ ;; [0 1 2 3 4 5 6 7 8 9] (into* [] (map inc) (range 10)) ;; [1 2 3 4 5 6 7 8 9 10] (into* [] (map inc) (filter odd?) (range 10)) ;; [1 3 5 7 9]
❶ 我们的
into*在处理参数后内部重用into. 在第一个参数 "to" 之后, 有一个可以包含transducer的 "args" 全捕获.❷ 我们用
butlast在参数中隔离潜在的transducer. 我们知道总是需要一个源集合, 所以我们可以安全地排除最后一个参数. 我们可以依赖into进行参数验证.❸ 一些测试以验证
into*是否按预期工作.ffirst和fnext在嵌套序列中实现一种 "前瞻" 行为可能很有用, 例如, 将传入的项目配对或在到达序列末尾时将项目标记为 "不完整":(def message [["A" 1 28] ["H" 37 82 11] ["N" 127 0]]) ; ❶ (defn process [message] ; ❷ (lazy-seq (when-let [xs (seq message)] (let [e1 (ffirst xs) e2 (fnext xs)] ; ❸ (cons (if (nil? e2) {:item e1 :succ :incomplete} {:item e1 :succ e2}) (process (rest xs))))))) (process message) ; ❹ ;; ({:item "A", :succ ["H" 37 82 11]} ;; {:item "H", :succ ["N" 127 0]} ;; {:item "N", :succ :incomplete})
❶ 这里展示的示例消息是一个短向量, 但
process函数被设计为接受一个 (任意长的) 惰性序列并返回另一个惰性序列.❷
process从输入消息生成一个惰性序列. 我们可以选择自定义递归, 以便我们可以检查序列中的后续元素来决定做什么.❸
ffirst和fnext是访问元素的当前头部和下一个元素的便利函数.❹ 在最终输出中, 我们可以看到每个元素都可能与下一个元素链接, 最后一个元素被标记为 "不完整".
- 为什么有一个
rest和一个next?
next是在重新设计惰性序列时引入的 161.rest过去做的是现在next做的事情: 要么集合包含一个以上的项, 要么为nil. 为了做到这一点, 至少需要评估下一个项目以查看是否还有更多. 虽然这在大多数情况下不是问题, 但当项目仅仅因为它们暂时处于序列的头部而被评估时, 有时会产生意外.为了防止任何形式的急切性,
rest的实现方式是它永远不会评估元素, 除非明确要求 (用seq).next被创建来为那些惰性不是问题的案例保留旧的rest行为.另请参阅
first和last是访问序列特定元素的其他流行函数.second相当于fnext, 用于访问序列中的第二个元素. 没有 "third" 函数或后续的序数词.pop相当于向量上的butlast.butlast为了移除最后一个元素, 需要遍历整个序列, 达到线性行为 (最坏情况). 向量专门为尾部访问进行了优化,pop是摆脱最后一个元素的正确方法.性能考虑和实现细节
=>
O(1)(rest,next,fnext,nnext,ffirst,nfirst)=>
O(n)(butlast)本节中的函数大多是常数时间, 因为它们只操作序列的头部.
butlast是唯一一个线性行为的例子, 因为它需要遍历整个序列来丢弃最后一个元素.rest和next(包括fnext和nnext) 之间的惰性有所不同. 对于自定义惰性序列的生成, 这种差异很重要, 其中选择rest或next决定了是否多评估一个项目. 当我们考虑到惰性序列的步长不一定是 1 时, 不必要的评估就更重要了. 例如, 标准库包含分块序列, 它们以 32 个项目的块进行评估:(defn counter [cnt] ; ❶ (fn [x] (swap! cnt inc) x)) (defn not-chunked [f] ; ❷ (let [cnt (atom 0)] (f (drop 31 (map (counter cnt) (into () (range 100))))) @cnt)) (defn chunked [f] ; ❸ (let [cnt (atom 0)] (f (drop 31 (map (counter cnt) (range 100)))) @cnt)) (not-chunked rest) ; 32 (not-chunked next) ; 33 (chunked rest) ; 32 (chunked next) ; 64
❶
counter创建一个映射函数, 该函数闭包了一个可变的atom. 我们可以使用该状态来计算流经序列的项目数量.❷
not-chunked通过使用持久化列表作为map操作的源来创建一个非分块序列.map将在列表上调用seq, 而列表不使用分块. 请注意, 列表是在分块范围之上创建的这一事实, 一旦我们用它来构建列表, 就会被中和.❸ 另一方面,
chunked通过直接使用范围来创建一个分块序列.not-chunked和chunked在对结果序列应用 "f" 之前都丢弃了 31 个项目.执行
not-chunked和chunked时我们看到的 4 个结果可以解释如下:- 在丢弃 31 个项目后, 我们对一个非分块序列调用
rest. 索引为 31 的项目被评估, 以便rest向前移动. 评估的项目总数为 32 (它们从零开始). - 我们对一个非分块序列调用
next, 同样丢弃前 31 个项目. 索引为 31 的项目被评估以便next通过, 索引为 32 的项目被评估以确定是返回nil还是不返回. 总共评估了 33 个项目. - 在丢弃 31 个项目后, 我们对一个分块序列调用
rest. 索引为 31 的项目需要被评估以进入序列中的下一个块, 该块尚未被评估. 总共评估了 32 个项目, 即从索引 0 到 31 的整个块的内容. - 最后, 我们对分块序列调用
next. 我们丢弃了 31 个项目, 索引为 31 的项目需要评估, 索引为 32 的项目也需要评估以验证序列的结束. 但索引为 32 的项目位于下一个块中, 因此第二个块被评估, 导致总共评估了 64 个项目.
分块评估是一种权衡, 它放弃了一些惰性, 以换取对超出实际请求范围的额外项目进行预先缓存. 鉴于 32 是持久性数据结构的分支因子, 这里显然存在一种关联: 一个块的评估对应于哈希数组映射树 (HAMT) 中一个节点的大规模数组复制 (请参考向量章节的引言以了解更多关于 Clojure 持久性数据结构的实现细节).
- 在丢弃 31 个项目后, 我们对一个非分块序列调用
3.3.2. 10.2 drop, drop-while, drop-last, take, take-while, take-last, nthrest, nthnext
函数
自 1.0 (drop,drop-while,drop-last,take,take-while,nthnext)
自 1.1 (take-last)
自 1.3 (nthrest)
(drop ([n]) ([n coll])) (drop-while ([pred]) ([pred coll])) (drop-last ([coll]) ([n coll])) (take ([n]) ([n coll])) (take-while ([pred]) ([pred coll])) (take-last [n coll]) (nthrest [coll n]) (nthnext [coll n])
本节中的函数从输入集合中生成连续元素的序列. 它们提供不同的参数来控制选择的发生方式:
- 按输入头部或尾部的项目数量 (drop, drop-last, take, take-last, nthrest, nthnext)
- 使用谓词 (drop-while 和 take-while)
- 保留头部, 丢弃尾部 (take, take-while, drop-last)
- 丢弃头部, 保留尾部 (drop, drop-while, take-last, nthrest, nthnext)
下表总结了本节中的函数及其目标:
| 名称 | 描述 | 可 Transduce? | 完全惰性? |
|---|---|---|---|
drop |
丢弃前 n 个元素. | 是 | 是 |
drop-while |
丢弃项目, 直到给定谓词返回 false. | 是 | 是 |
drop-last |
丢弃最后 n 个元素 (默认为 1). | 否 | 是 |
take |
保留前 n 个元素, 丢弃其余. | 是 | 是 |
take-while |
保留元素, 直到给定谓词返回 false. | 是 | 是 |
take-last |
保留最后 n 个元素 (n 没有默认值). | 否 | 否 |
nthrest |
类似 drop, 但参数颠倒. 永不返回 nil. | 否 | 否 |
nthnext |
类似 nthrest, 但如果超出输入长度则返回 nil. | 否 | 否 |
正如读者从表中可以看到的, 一些函数提供了 transducer 版本, 而其他一些 (特别是 take-last, nthrest 和 nthnext) 则部分地评估它们的参数. 更多细节请看下面的 "示例" 部分.
契约
- 输入
"n"可以是任何数字: 正数, 零, 负数, 整数或浮点数. 对于drop-last, 它默认为 1. 对于take-last,drop,take,nthrest和nthnext, 它是必需的参数. 负的"n"等同于传递零."pred"是一个单参数函数, 返回逻辑真或假. 对于drop-while和take-while, 它是必需的参数."coll"可以是任何序列性输入或nil(当一个集合为seq提供了序列化策略或本身就是一个序列时, 它就是 "seqable"). 对于支持 transducer 的函数:drop,drop-while,take和take-while, 它是可选输入. - 主要异常
当
"coll"不是序列性的 (根据seq契约) 时, 抛出IllegalArgumentException. - 输出
本节中的函数从输入集合生成一个序列 (除非返回 transducer 版本, 见下文):
drop返回一个移除了前"n"个项目的序列, 或者如果"n"大于(count coll)则返回一个空序列. 当只有"n"存在时, 它返回一个 transducer, 在 transducer 链中使用时移除前"n"个元素.drop-while从"coll"的头部移除那些(pred item)返回逻辑真的项目. 另一种描述方式是:drop-while从"coll"丢弃元素, 直到(pred item)第一次返回 false 时停止. 当"coll"未提供时, 返回该函数的 transducer 版本. 当没有足够的项目满足请求时, 返回空序列.drop-last从输入的尾部移除"n"个项目. 当"n"是 1 时移除最后一个项目. 当没有足够的项目满足请求时, 返回空序列.take保留前"n"个项目, 丢弃其余. 当"coll"未提供时, 返回一个保留前"n"个元素的 transducer 版本. 当"n"大于(count coll)时返回空序列.take-while保留那些(pred item)为真的项目. 当"coll"未提供时, 返回该函数的 transducer 版本. 当没有足够的项目满足请求时, 返回空序列.take-last保留从"coll"尾部开始的最后"n"个元素. 如果"n"大于(count coll), 则返回空序列.nthrest从"coll"移除前"n"个项目. 当"n"大于(count coll)时, 返回空列表.nthnext类似nthrest, 但当"n"大于(count coll)时返回nil.
当
"coll"不存在时返回 transducer 的函数是:take,take-while,drop和drop-while. 返回的 transducer 遵循 transducer 契约, 并接受一个在 transducing 上下文中使用的归约函数.示例
drop和take通常在要丢弃或获取的项目数量已知时使用. 例如, 如果我们想处理当前年份的剩余天数 (假设今天是 12 月 25 日):(import '[java.util Calendar]) (def day-of-year (.get (Calendar/getInstance) (Calendar/DAY_OF_YEAR))) ; ❶ (drop day-of-year (range 1 366)) ; ❷ ;; (360 361 362 363 364 365)
❶ 一种获取当前年份天数的方法.
❷ 一旦我们有了当前年份的天数, 我们可以从一年中的天数范围中丢弃它.
我们可以以类似的方式使用
take, 例如提取总是出现在集合开头的信息. 在下面的例子中, 一个消息中心包含来自其他应用程序的消息. 消息被编码为一个以错误代码开头的向量. 我们只想处理一些消息, 并根据错误代码和消息生成的月份丢弃其他消息:(def hub-sample ; ❶ [[401 7 :mar "-0800" :GET 1.1 12846] [200 9 :mar "-0800" :GET 1.1 4523] [200 2 :mar "-0800" :GET 1.1 6291] [401 17 :mar "-0800" :GET 1.1 7352] [200 23 :mar "-0800" :GET 1.1 5253] [200 7 :mar "-0800" :GET 1.1 11382] [400 27 :mar "-0800" :GET 1.1 4924] [200 27 :mar "-0800" :GET 1.1 12851]]) (defn error-in-month? [code month] ; ❷ (and (= (>= code 400) (= :mar month)))) (defn process-errors [hub-messages] ; ❸ (filter #(let [[code _ month] (take 3 %)] (error-in-month? code month)) hub-sample)) (process-errors hub-sample) ;; ([401 7 :mar "-0800" :GET 1.1 12846] ;; [401 17 :mar "-0800" :GET 1.1 7352] ;; [400 27 :mar "-0800" :GET 1.1 4924])
❶ 为本例创建了消息中心内容的一个小样本.
❷
error-in-month?函数隔离特定月份的错误代码.❸
process-error包含遍历中心消息的逻辑. 它使用一个filter函数来隔离有趣的消息.filter的谓词只从每条消息中获取前 3 个项目, 其中包括一个错误代码, 一个月份中的某天 (未使用) 和该消息所属的月份名称. 错误代码和月份被发送到error-in-month?以决定是否应保留该消息.当有一个规则驱动应该获取/移除什么时, 我们可以改用谓词函数. 下面的例子展示了我们如何实现一个函数来隔离列表中的连续项目并生成它们的惰性序列:
(defn tokenize [pred xs] (lazy-seq (when-let [ys (seq (drop-while (complement pred) xs))] ; ❶ (cons (take-while pred ys) ; ❷ (tokenize pred (drop-while pred ys)))))) ; ❸ (def digits '(1 4 1 5 9 2 6 4 3 5 8 9 3 2 6)) (tokenize odd? digits) ; ❹ ;; ((1) (1 5 9) (3 5) (9 3))
❶ 第一步涉及使用
drop-while从列表头部移除所有我们不想要的项目. 一旦我们定位到我们感兴趣的东西 (本例中是第一个奇数), 我们就开始收集结果. 注意这里我们需要使用seq, 因为当我们到达输入末尾时drop-while返回一个空列表.❷
take-while收集我们想要分组并从序列头部隔离的项目. 这些项目用cons推入正在构建的惰性序列.❸ 在我们重新开始之前, 我们需要用
drop-while丢弃我们刚刚收集的所有项目, 因为我们不希望在输入的剩余部分再次看到它们.❹ 我们可以使用一个数字列表来测试结果. 结果的惰性序列包含输入中存在的所有连续奇数组.
take,drop和take-while,drop-while也提供了 transducer 版本:(transduce (comp (drop 3) (map inc)) + (range 10)) ; ❶ ;; 49
❶ 我们可以看到
drop的 transducer 版本被用来在用+求和之前移除前 3 个项目.take,drop,take-while和drop-while是有状态的 transducer. 有状态的 transducer 在并发场景中会产生不一致的结果. 你在使用它们与fold或core.async管道结构时应特别注意 (参见 clojuredocs.org/clojure.core.async/pipeline 和 transducer 章节以获取更多信息). - 惰性考虑
在处理无限序列时, 你需要注意本节中的一些函数:
(defn xs [] (map #(do (print ".") %) (iterate inc 0))) ; ❶ (def take-test (take 1e7 (xs))) ; ❷ ;; #'user/take-test (def time-bomb (drop 1e7 (xs))) ; ❸ ;; #'user/time-bomb
❶ 我们设置一个测试用的无限惰性序列, 它会打印评估的项目数量作为副作用. 我们可以用它来验证序列处理函数支持惰性的方式.
❷ 从无限序列中
take不会产生任何评估, 这是预期的, 并且不应该带来意外.❸
drop的行为相同, 在创建时不评估任何项目. 不过你必须小心, 因为对 "time-bomb" 的任何进一步操作都将评估 1e7 (一千万) 个元素.惰性也有不同的程度. 像
take-last这样的函数在创建时会急切地评估其输入, 所以你需要格外小心:(def eager (take-last 1 (take 10 (xs)))) ; ❶ ;; ..........#'user/eager (def lazy-bomb (drop-last (xs))) ; ❷ ;; #'user/lazy-bomb
❶ 如果没有先从无限序列 "xs" 中取出 10 个元素, 这个对
take-last元素的调用将永远挂起. 注意打印了 10 个点, 表明take-last已经评估了结果.❷
drop-last没有同样的问题, 但它可能创建一个 lazy-bomb (像本例中), 因为任何触及序列的操作都会导致无限评估.nthrest和nthnext也急切地评估, 但它们比take-last更惰性:(def lazier (nthrest (xs) 3)) ; ❶ ;; ...#'user/lazier
❶ 我们可以看到打印了 3 个点, 表明
nthrest评估了前 3 个元素 (那些无论如何都将被丢弃的元素).使用
nthrest或nthnext进行急切评估的一个有趣效果是, 即使序列中的剩余元素从未被评估, 也有可能执行副作用. 在下一个例子中, 一个服务产生一个由与每个项目连接的临时文件支持的序列. 一些应用程序逻辑决定在将序列返回给客户端之前从序列中丢弃元素. 在控件从服务返回后, 我们不知道客户端是否会消耗序列的其余部分, 但我们确切地知道我们可以清理与从序列中丢弃的项目相关的文件:(require '[clojure.java.io :as io]) (import '[java.io File]) (defn generate-file [id] ; ❶ (let [file (File/createTempFile (str "temp" id "-") ".tmp")] (with-open [fw (io/writer file)] (binding [*out* fw] (pr id) file)))) (defn fetch-clean [f] ; ❷ (let [content (slurp f)] (println "Deleting file" (.getName f)) (io/delete-file f) content)) (defn service [] ; ❸ (let [data (map #(generate-file %) (list 1 2 3 4 5))] (nthrest (map fetch-clean data) 2))) (def consumer (service)) ; ❹ ;; Deleting file temp1-8176280320841013882.tmp ;; Deleting file temp2-6114428806665839159.tmp
❶
generate-file创建一个内容为数字的临时文件, 用于测试目的.❷
fetch-clean是文件的处理函数. 它加载内容并在完成后删除文件.❸
service包含从序列开头移除元素的应用程序逻辑. 我们将此逻辑简化到最低限度, 只是为了显示nthrest的效果.❹ 服务的消费者可以决定立即消耗数据或等待其他条件发生. 在此期间, 任何从序列中丢弃的东西都已经被清理, 正如我们从关于删除 2 个文件的消息中看到的那样.
通过使用
nthrest而不是drop, 我们确保只有相关的文件仍然可用于未来的计算, 并急切地处理掉其余的, 从而释放资源.另请参阅
rest及其相关函数与本节中的函数类似, 大多数操作中"n"默认为 1.subvec可以用于以类似于drop或take的方式提取向量的部分, 性能更好.在向量上应使用
pop而不是drop-last, 因为drop-last会先将向量转换为序列.性能考虑和实现细节
=> 最好情况下时间和空间复杂度为
O(1)=> 最坏情况下步数和空间复杂度为
O(n)对于本节中的大多数函数, 最坏情况是完全消耗输入序列, 从而决定了线性行为. 以下是强制对长度为 "n" 的输入序列 "xs" 进行完全评估的参数组合:
(drop n xs) ; ❶ (drop-while (constantly false) xs) ; ❷ (drop-last xs) ; ❸ (take n xs) ; ❹ (take-while (constantly true) xs) ; ❺ (take-last 1 xs) ; ❻ (nthrest xs n) ; ❼ (nthnext xs n) ; ❽
❶ 对输入长度进行
drop, 完全评估输入, 但不保留任何元素, 空间复杂度为O(1).❷ 对于带有始终为 false 谓词的
drop-while也是如此.❸
drop-last, 默认"n"为 1, 完全评估其输入并持有头部, 决定了O(n)的空间复杂度.❹ 对序列长度进行
take相当于序列本身, 加上由take刚创建的序列的元素副本. 此操作是O(n)步数和O(n)空间.❺ 对于带有始终为 true 谓词的
take-while也是如此.❻ 对单个元素的
take-last是O(n)步数和O(1)空间.❼ 对输入长度进行
nthrest评估所有内容, 但不持有任何东西, 空间复杂度为O(1).❽
nthnext与nthrest相同.某些函数提供的惰性程度有所不同. 例如,
take-last,nthrest和nthnext在创建时部分评估结果, 如上文 "惰性考虑" 中所述.在非序列性数据上使用序列处理函数通常不是一个好主意, 因为它们需要被转换为序列. 必要时, 存在等效的向量操作, 例如
subvec. 以下是我们如何用subvec来编写drop和take:(defn dropv [n v] (subvec v n (count v))) ; ❶ (dropv 5 (vec (range 10))) ;; [5 6 7 8 9] (defn takev [n v] (subvec v 0 n)) ; ❷ (takev 5 (vec (range 10))) ;; [0 1 2 3 4]
❶ 为向量编写的
drop, 使用subvec.❷ 为向量编写的
take, 使用subvec.
3.3.3. 10.3 keep 和 keep-indexed
自 1.2 版本起可用的函数
(keep ([f]) ([f coll])) (keep-indexed ([f]) ([f coll]))
keep 对输入集合的元素应用一个转换, 并额外移除任何生成的 nil:
(keep first [[1 2] [2] [] nil [0] [2]]) ; ❶ ;; (1 2 0 2)
❶ keep 用于从输入的每个集合中获取第一个元素. 注意, 当 first 作用于空集合 (或 nil) 时, 生成的 nil 不会出现在最终输出中.
keep 与 map 有很多共同之处, 包括一个 keep-indexed 版本, 它还维护当前项目的索引:
(keep-indexed #(nthnext (repeat %2 %1) %1) [1 3 8 3 4 5 6]) ; ❶ ;; ((0) (1 1) (2 2 2 2 2 2))
❶ 与 map-indexed 类似, keep 有一个 keep-indexed 版本. 我们在这里用它来生成正整数的重复序列. 输入集合驱动每个索引的重复次数 (例如, 在向量的索引 2 处我们有数字 8), 转换函数从重复中丢弃 "index" 个元素 (例如, 如果索引是 2, 该索引处的数字是 8, 它会重复数字 2 八次, 然后移除其中的 2 个). 当索引处的数字与索引相同时 (例如, 向量中的数字 4,5,6), 它会产生一个 nil, 该 nil 从最终结果中移除.
与 map 不同, keep 不接受多个集合参数, 但像 map 一样, 它提供了一个 transducer 版本. 例如, 以下是我们如何复制 random-sample 的功能:
(sequence (keep #(when (> 0.5 (rand)) %)) (range 20)) ; ❶ ;; (0 2 3 4 5 10 13 15 16 17 18 19)
❶ keep 用于模拟 random-sample.
契约
- 输入
"f"是一个接受一个 (keep) 或两个 (keep-indexed) 参数的函数. 在 2 个参数的情况下, 第一个是作为第二个参数传递的项目的索引. 它是强制性参数."coll"是任何遵循seq契约的序列感知集合. 当"coll"不存在时, 它返回 transducer 版本. - 主要异常
当
map-indexed被错误地传递一个只接受一个参数的函数时, 抛出ArityException. - 输出
- 当
"coll"存在时: 通过对"coll"中的每个元素应用转换"f"生成的惰性序列. 如果任何"f"的应用返回nil,nil将从最终输出中移除. - 当
"coll"不存在时,keep和keep-indexed返回一个 transducer, 它接受一个归约函数, 如 transducer 契约所要求的那样.
示例
keep在本书中已经使用了几次. 邀请读者回顾这些示例:flatten有一个示例, 保留应用带有re-find的正则表达式结果的最后一项.sequence包含一个keep的 transducer 示例, 用于解析一些结构化输出.seque包含一个keep的示例, 用于从输出中移除不想要的nil.
习惯上,
keep被认为是表达(remove nil? (map f coll))的更简洁方式:(def dict {1 "one" 2 "two" 3 "three"}) ; ❶ (remove nil? (map dict [5 3 2])) ; ❷ ;; ("three" "two") (keep dict [5 3 2]) ; ❸ ;; ("three" "two")
❶
dict是一个字典, 包含整数 id 和字符串之间的关系.❷ 我们可以使用
dict作为函数并把有趣的键放在一个向量中来提取特定的值. 但这会在输出中引入潜在的nil, 对于缺失的键. 所以我们被迫使用remove.❸ 表达相同计算的更好方法是使用
keep.下面的例子展示了如何使用
keep-indexed实现一个first-index-of函数来返回一个元素在序列中的位置:(defn first-index-of [x coll] ; ❶ (first (keep-indexed #(when (= %2 x) %1) coll))) (first-index-of 2 (list 3 9 1 0 2 3 2)) ; ❷ ;; 4 (first-index-of 11 (list 3 9 1 0 2 3 2)) ; ❸ ;; nil
❶
first-index-of的实现利用了keep提供的nil过滤功能.map-indexed会产生一个除了匹配项之外都是nil的序列.❷ 通过使用
keep-indexed, 输出只包含一个元素 (或nil).❸ 注意这不是一个包含
nil元素的集合, 而是表示没有匹配的nil. - 当
- 将
keep扩展到多个集合
与
map不同,keep不允许多个集合作为输入. 我们可以扩展keep以允许可变数量的集合, 并在那些结果不应包含nil的情况下使用它:(defn keep+ [f & colls] ; ❶ (lazy-seq (let [ss (map seq colls)] ; ❷ (when (every? identity ss) ; ❸ (let [x (apply f (map first ss)) ; ❹ rs (map rest ss)] (if (nil? x) ; ❺ (apply keep+ f rs) (cons x (apply keep+ f rs)))))))) (keep+ #(and %1 %2 %3) ; ❻ [1 2 nil 4] [5 nil 7 8] (range)) ;; (0 3) ; ❼
❶ 函数的一般设计遵循
map的实现. 想法是迭代每个集合中的所有第一个元素, 应用给定的函数, 并根据nil的存在来决定何时cons结果.❷
keep+产生一个惰性序列, 并利用rest来防止任何不想要的评估. 然后我们需要通过将任何空列表替换为nil来确保每个集合中至少还有一个元素.❸ 现在
"ss"中只包含列表或nil(但没有空列表), 我们可以使用every?来确保我们可以进行另一次迭代.❹ 这是我们将
"f"应用于每个集合的第一组项的地方.❺
keep的逻辑在这个条件中, 它会根据是否将下一个元素cons到输出序列中而进行递归.❻ 一个使用
keep+的例子, 回答了这个问题: 当应用于所有输入向量时, 哪些索引会产生非nil的值?❼ 答案是 0 (会产生值 1 和 5) 和 3 (会产生值 4 和 8).
另请参阅
map和map-indexed与keep和keep-indexed类似, 但不进行nil过滤.filter可以用于任何序列处理之上, 以移除nil或其他不想要的项.range可以用于生成一个无限的正整数列表, 以用作不涉及keep-indexed的自定义解决方案中的索引.性能考虑和实现细节
=> 最坏情况下
O(n)步数=> 最坏情况下
O(n)空间keep和keep-indexed的性能特征与map和其他处理序列的函数非常相似. 当完全实现时, 转换应用于所有元素, 产生线性行为.与其他序列处理函数一样,
keep期望一个序列性输入并缓存序列性输出, 当结果被完全消耗时, 在空间上产生线性行为.另请参阅
map和lazy-seq的性能部分以获取更多信息.
3.3.4. 10.4 mapcat
自 1.0 版本起可用的函数
(mapcat ([f]) ([f & colls]))
mapcat 的功能由其名称很好地描述, 即 map 操作和由 map 产生的转换的连接的联合. 为了使连接部分正常工作, 假设转换产生一个序列集合:
(map range [1 5 10]) ; ❶ ;; ((0) (0 1 2 3 4) (0 1 2 3 4 5 6 7 8 9)) (mapcat range [1 5 10]) ; ❷ ;; (0 0 1 2 3 4 0 1 2 3 4 5 6 7 8 9)
❶ 我们将一个范围映射到几个数字. 这会产生一个越来越长的内部序列的序列.
❷ mapcat 移除中间的序列.
mapcat 接受可变数量的集合. 以下是与 mapcat 的 transducer 版本一起使用的多个集合的示例:
(sequence (mapcat repeat) [1 2 3] ["!" "?" "$"]) ; ❶ ;; ("!" "?" "?" "$" "$" "$")
❶ mapcat transducer 与两个集合输入一起使用. 函数 repeat 接受两个参数: 第一个是重复次数 (出现在第一个集合中), 第二个是要重复的项目 (出现在第二个集合中).
契约
- 输入
"f"是一个接受一个或多个参数的函数, 返回任何序列类型 (如seq契约所描述) 或nil. 它是强制性参数."f"接受的参数数量对应于作为输入传递的"colls"的数量."colls"是 0 个或多个序列集合 (如seq契约所描述) 的可变数量."colls"是可选的. - 主要异常
如果转换
"f"不产生序列输出, 通常会抛出IllegalArgumentException. - 输出
返回: 通过对
"coll"中的每个元素应用"f"产生的转换的连接的惰性序列. 如果存在多个"colls", 则"f"应用于"colls"中的所有第一个元素, 然后是所有第二个元素, 依此类推, 直到达到最短集合的末尾. 如果没有提供"colls", 它返回mapcat的 transducer 版本.示例
mapcat与多个集合可以用于从一个更大的集合中隔离出不同的范围, 然后将它们合并回来. 例如, 十六进制字符由数字范围 "0123456789" 和六个字母 "ABCDF" 定义. 这两个集合在 ASCII 集合中都可用, 但索引不同. 数字的索引范围是 48-58, 而 "ABCDEF" 的范围是 65-71:(def hex? (set (sequence ; ❶ (comp (mapcat range) ; ❷ (map char)) [48 65] ; ❸ [58 71]))) (every? hex? "CAFEBABE") ; ❹ ;; true
❶
hex?函数利用了 Set 可以用作单参数函数来决定一个元素是否属于该集合的事实. 我们只需将该集合def给变量hex?就可以创建一个正常工作的谓词.❷
mapcat必须是列表中的第一个 transducer, 因为它负责处理来自多个集合的输入. 它后面跟着一个 int 到 char 的转换.❸ 这两个输入向量包含我们感兴趣的字符的索引范围. 所有下界出现在第一个向量中, 所有上界在第二个向量中. 这是为了让
range以正确的顺序接收它们.❹ 我们可以对一个字符串使用带有
every?的谓词.我们可以在下面的拓扑排序中看到
mapcat的作用 162. 在编译器中一个典型的问题是找到加载应用程序模块的正确顺序. 一个模块的依赖项需要在模块本身之前加载. 类似地, 如果该依赖项还有其他依赖项, 它们也需要先加载. 我们可以通过对模块 (节点) 及其依赖项 (顶点) 形成的直接图进行排序来解决这个问题.该示例使用一个映射
libs, 包含库名及其直接依赖项. 我们可以使用mapcat, 将映射作为函数, 来提取下一层传递性依赖. 让我们先单独看看这个模式:(def libs {:async [:analyzer.jvm] ; ❶ :analyzer.jvm [:memoize :analyzer :reader :asm] :memoize [:cache] :cache [:priority-map] :priority-map [] :asm []}) (mapcat libs (:analyzer.jvm libs)) ; ❷ ;; (:cache)
❶
libs是一个从每个库名到其依赖列表的映射.❷ 我们可以使用
libs作为mapcat的函数, 传递库名列表. 每个键拉出一个依赖列表, 这些列表由mapcat连接起来. 在这里我们可以看到在我们加载:analyzer.jvm之前需要满足哪些依赖项.在任何一组键上使用
mapcat, 我们可以看到第一层传递性依赖. 为了确保所有依赖项都得到满足, 我们需要进一步迭代, 直到我们找到一个没有依赖项的库. 然后我们可以反向遍历依赖项列表来读取我们应该满足依赖项的顺序:(defn tp-sort [deps k] ; ❶ (loop [res () ks [k]] (if (empty? ks) ; ❷ (butlast res) (recur (apply conj res ks) ; ❸ (mapcat deps ks))))) (tp-sort libs :async) ; ❹ ;; (:priority-map :cache :asm ;; :reader :analyzer :memoize ;; :analyzer.jvm)
❶
tp-sort实现了一种简化的拓扑排序 (它不检测循环). 它包含一个loop-recur, 在准备初始参数后用于内部递归.❷ 递归的终止条件是一个空的传递性键依赖列表, 这意味着我们已经跟踪了所有依赖项.
❸ 这里使用
mapcat将新发现的传递性依赖层发送到下一次迭代. 同时结果通过conj累积到一个列表中. 带apply的形式允许将 "ks" 列表像独立的参数一样插入到列表中, 从而移除不想要的嵌套. 注意cons不支持可变数量的参数.❹ 我们要求
tp-sort找到要处理的依赖项的顺序, 以便根模块:async得到满足.注意
tp-sort是一个通用函数, 适用于模块, 任务或任何其他形式的直接无环图 (DAG). 然而, 如果图中包含循环,tp-sort可能会无限循环. 循环检测是图论中另一个有趣的问题, 留给读者作为练习.另请参阅
map在mapcat之前用于应用转换.concat将两个或多个序列集合连接在一起.cat是concat的 transducer 版本.r/mapcat是mapcat的 reducer 版本.性能考虑和实现细节
=>
O(1)函数生成=>
O(n)生成的函数mapcat是在concat和map之上实现的, 用于转换, 并被设计为惰性的. 其性能特征与其他序列处理函数类似, 以线性时间消耗其输入 (当完全评估时).mapcat的参数处理基于apply, 用于为concat展开参数. 因此,mapcat不是完全惰性的, 总是消耗前四个参数:(def a (mapcat range (map #(do (print ".") %) (into () (range 10))))) ; ❶ ;; ....
❶ 这里使用
mapcat来连接不同范围的数字. 即使没有生成序列的消费者, 我们也可以看到打印了 4 个点.如果
mapcat的初始急切性是一个问题, 下面的mapcat*替代方案可以消除不想要的评估:(defn mapcat* [f & colls] (letfn [(step [colls] (lazy-seq (when-first [c colls] (concat c (step (rest colls))))))] (step (apply map f colls)))) ; ❶ (def a (mapcat* range (map #(do (print ".") %) (into () (range 10))))) ; ❷
❶ 我们可以惰性地将转换应用于所有集合, 使用
map. 惰性问题影响的是在核心实现中位于此第一个之上的第二个apply调用.❷ 使用相同的例子, 这次没有打印点, 这表明
mapcat*是完全惰性的.mapcat还有一个 transducer 版本, 我们可以比较它用于序列生成或归约. 我们期望mapcattransducer 比普通mapcat有优势, 因为 transducer 版本消除了map内部生成的中间序列的需要. 下面的基准测试测量了用mapcat产生输出的不同方式:(require '[criterium.core :refer [bench]]) ; ❶ (let [xs (range 1000)] (bench (last (mapcat range xs)))) ;; 18ms ; ❷ (let [xs (range 1000)] (bench (last (sequence (mapcat range) xs)))) ;; 48ms ; ❸ (let [xs (range 1000)] (bench (last (eduction (mapcat range) xs)))) ;; 48ms (let [xs (range 1000)] (bench (reduce + (mapcat range xs)))) ;; 8.5ms ; ❹ (let [xs (range 1000)] (bench (transduce (mapcat range) + xs))) ;; 6.9ms
❶ 像往常一样, 我们在整本书中都使用了 Criterium 基准测试库.
❷ 这是基本的
mapcat, 生成一个不使用 transducer 的惰性序列. 我们只从 Criterium 详细的输出中取平均耗时.❸ 接下来对
sequence和eduction进行基准测试. 它们比基本的mapcat慢得多.❹ 最后我们可以看到使用
mapcat的reduce和transduce之间的比较.transduce版本比reduce版本略快, 但sequence或eduction的性能比普通mapcat慢 3 倍. 这可以用sequence实现为了启用 transducer 必须处理的额外复杂性来解释. 这个问题在sequence的性能部分有更详细的讨论. 如果性能很重要, 并且 transducer 链不是特别复杂, 那么对于序列访问, 最好的选择是使用基本的mapcat.或者, 如果惰性不是问题,
mapcattransducer 可以使用into生成一个向量, 性能非常好:(let [xs (range 1000)] (bench (into [] (mapcat range) xs))) ;; 10.4ms ; ❶
❶ 使用
mapcat的 transducer 链创建向量比惰性序列的mapcat更快.
3.3.5. 10.5 interpose 和 interleave
自 1.0 版本起可用的函数
(interpose ([sep]) ([sep coll])) (interleave ([]) ([c1]) ([c1 c2]) ([c1 c2 & colls]))
interpose 和 interleave 通过交替来自不同输入的元素来产生一个序列. interpose 使用第一个参数作为 "coll" 中各项之间的插入元素:
(interpose :orange [:green :red :green :red]) ; ❶ ;; (:green :orange :red :orange :green :orange :red) (sequence (interpose :orange) [:green :red :green :red]); ❷ ;; (:green :orange :red :orange :green :orange :red)
❶ interpose 将关键字 ":orange" 交替插入到一个向量的每个元素之间. 注意输出序列的最后一个元素不是关键字 ":orange".
❷ interpose 也有一个 transducer 版本, 这里展示了它的用法.
interleave 将 interpose 更进一步, 提供了一种定义要交替的元素来源的方法:
(interleave [:green :red :blue] [:yellow :magenta :cyan]) ; ❶ ;; (:green :yellow :red :magenta :blue :cyan)
❶ interleave 接受两个或多个序列输入, 以产生一个由它们交替元素组成的惰性序列.
interleave 在到达最短参数后停止交替元素.
契约
- 输入
"sep"是任何表达式或常量值, 包括nil. 它是interpose的必需参数."c1","c2","coll"或"colls"是支持序列接口 (见sequence契约) 的集合参数或nil. - 输出
- 没有集合时,
interpose返回一个在归约步骤中交替"sep"的 transducer. - 没有参数或任何参数为
nil时,interleave返回空列表. - 只有一个集合时,
interleave将输入转换为惰性序列, 不改变其内容. - 有 2 个或更多
"colls"时,interleave从每个集合中交替项, 形成一个新的输出序列, 直到最短的输入结束.
示例
interpose和interleave是用于通用序列处理的灵活函数. 例如,interpose与字符串连接配合得很好:(def grocery ["apple" "banana" "mango" "other fruits"]) (apply str (interpose ", " grocery)) ; ❶ ;; "apple, banana, mango, other fruits" (transduce (interpose ", ") str grocery) ; ❷ ;; "apple, banana, mango, other fruits"
❶
interpose可以使用分隔符将单词合并在一起. 默认情况下, 输出序列的末尾不会出现分隔符, 这在这种场景下是一个很好的特性 (我们不希望句子末尾出现一个拖尾的 ",").❷ 在 transducer 上下文中执行相同的操作. 关于这两种形式的比较, 请参见性能部分.
本书中有许多例子可以作为起点, 来观察
interpose或interleave在实践中的使用:random-sample特色在于利用interleave的惰性, 为抛硬币模拟交替两个无限的 "头" 和 "尾" 结果序列.rand-nth包含一个interpose的例子, 从一个单词列表生成一个句子.partition包含一个interpose的例子, 用于格式化提交的 SQL 查询.transduce展示了我们如何创建一个interleavetransducer.
下面的例子展示了多次传递
interleave来首先轮换单个团队的成员, 然后再轮换每个团队, 以便为某种活动或比赛轮班:(defn team [& names] ; ❶ (apply interleave (map repeat names))) (defn shifts [& teams] ; ❷ (apply interleave teams)) (def a-team (team :john :rob :jessica)) (def b-team (team :arthur :giles)) (def c-team (team :paul :eva :donald :jake)) (take 10 (shifts a-team b-team)) ; ❸ ;; (:john :arthur :rob :giles :jessica :arthur :john :giles :rob :arthur)
❶ 我们需要一种方法来定义一个接受名字列表的团队. 我们希望列表重复, 这样我们就可以将内容与其他团队交叉. 每个名字首先被无限重复, 然后按它们进入函数的顺序与其他名字交错.
❷ 其次, 我们需要交错每个团队的成员.
interleave会在最短的团队处停止, 但我们确保每个团队都是其成员无限重复的序列.shifts的输出又是一个交错团队成员的无限序列.❸ 在为测试创建了几个团队之后, 我们可以看到生成的序列是所有团队中所有团队成员的平均值. 较小的团队出现得更频繁, 需要做更多的工作.
- 没有集合时,
interleave的逆操作
interleave通过交替它们的元素将两个序列合并成一个新序列. 我们想找出一个函数来反转这个过程并产生相反的效果.不过, 我们至少需要做一个改变:
interleave接受可变数量的集合作为输入, 但在 Clojure 中, 一个函数不能有 "可变数量的输出". 结果是, 我们的函数将返回一个最初交错的序列的序列. 其次, 一旦我们接收到一个交错的输入, 我们就失去了最初交错了多少个输入序列的信息. 我们需要这个数字作为输入的一部分. 以下是我们如何处理这个问题:(defn untangle [n xs] ; ❶ (letfn [(step [xs] ; ❷ (lazy-seq (cons (take-nth n xs) ; ❸ (step (rest xs)))))] ; ❹ (take n (step xs)))) (untangle 2 (interleave (range 3) (repeat 3 "."))) ;; ((0 1 2) ("." "." ".")) ; ❺
❶
untangle接受一个典型的interleave调用的输出 "xs" 和原始输入的数量 "n".❷ 该函数使用一个内部的
step, 它构建一个无限的惰性序列.❸
take-nth是解决这个问题的一个好选择, 因为它从输入序列中选择交替的元素. 我们可以通过选择索引 (0,2,4..) 的第一系列交替项来开始, 将它们cons到结果中. 这就是第一个被交错的序列.❹ 我们现在使用
take-nth再次进行下一次迭代, 向前移动一个位置.❺ 用两个交错的序列调用
untangle, 提取出解开的序列.另一个需要考虑的方面是惰性.
interleave通过接受无限序列作为输入并创建一个完全惰性的输出来处理惰性. 如果输入 "xs" 中的交错序列是无限的, 我们需要小心在返回它们时不要实现它们:(def infinite ; ❶ (interleave (iterate inc 1) (iterate dec 0) (iterate inc 1/2))) (def untangled (untangle 3 infinite)) ; ❷ (take 10 (first untangled)) ; ❸ ;; (1 2 3 4 5 6 7 8 9 10) (take 10 (second untangled)) ;; (0 -1 -2 -3 -4 -5 -6 -7 -8 -9) (take 10 (last untangled)) ;; (1/2 3/2 5/2 7/2 9/2 11/2 13/2 15/2 17/2 19/2)
❶
infinite包含 3 个无限序列的交错.❷
untangled包含解开交错序列的惰性序列.❸ 我们可以在
first,second和last的位置访问原始序列. 它们是无限序列, 所以我们需要小心从每个序列中访问特定数量的元素.另请参阅
concat连接集合, 不交错它们的元素.clojure.string/join使用可选的分隔符执行字符串合并. 如果你不关心惰性, 并且只针对字符串的格式化, 请考虑使用clojure.string/join.性能考虑和实现细节
=> 最坏情况下时间复杂度为
O(n)=> 最坏情况下空间复杂度为
O(n)interpose和interleave产生惰性序列. 假设它们在长度为 "n" 的某个输入上被完全评估, 那么最坏情况是时间和空间上的线性依赖. 小心持有序列的头部:(let [s (interleave (range 1e7) (range 1e7))] (- (first s) (last s))) ; ❶ ;; -9999999 (let [s (interleave (range 1e7) (range 1e7))] (- (last s) (first s))) ; ❷ ;; likely OOM
❶ 访问序列的末尾是最后执行的操作. 到目前为止缓存的所有元素都可以被垃圾回收, 因为没有东西持有对它们的显式引用.
❷ 序列的末尾首先被访问, 但序列的头部需要保留下来, 以便
first在那之后访问第一个元素. 根据 JVM 设置, 这可能导致垃圾回收器的大量工作, 最终导致内存不足错误.interpose也可以作为 transducer 使用. 如果惰性很重要 (没有可预测的计划来消耗整个输出), 并且序列除了插入元素外不需要太多的额外处理, 那么基本的interpose可能是最好的选择:(require '[clojure.string :as st]) (require '[criterium.core :refer [quick-bench]]) (def large-text "https://tinyurl.com/wandpeace") (def lines (st/split-lines (slurp large-text))) ; ❶ (quick-bench (last (eduction (interpose "|") lines))) ; ❷ ;; Execution time mean : 13.429075 ms (quick-bench (last (interpose "|" lines))) ; ❸ ;; Execution time mean : 3.717828 ms
❶ 对于这个基准测试, 我们使用一本大型公共领域书籍, 将其分割成行 (从而消除换行符).
❷
interposetransducer 作为eduction运行, 并产生一个非缓存的序列作为结果.❸ 在这种情况下, 基本的
interpose更快.一旦我们需要额外的处理, transducer 版本就比序列版本表现得更好:
(def xform ; ❶ (comp (mapcat #(st/split % #"\s+")) (map st/upper-case) (remove #(re-find #"\d+" %)) (interpose "|"))) (defn plainform [xs] ; ❷ (->> xs (mapcat #(st/split % #"\s+")) (map st/upper-case) (remove #(re-find #"\d+" %)) (interpose "|"))) (quick-bench (last (eduction xform lines))) ;; Execution time mean : 296.121150 ms (quick-bench (last (plainform lines))) ;; Execution time mean : 326.535851 ms
❶
xform对大型文本的每一行执行额外的处理. 在将行分割成单词后, 单词被转换为大写, 数字被移除, 最后用管道符号分隔它们.❷
plainform是相同 transducer 链的嵌套序列版本.即使在多个处理步骤的情况下, 优势也是微不足道的, 这表明在很少的情况下, 使用
interposetransducer 来产生新的序列输出比基本的interpose更好.如果我们放弃惰性并归约结果, 例如生成单个字符串, 结果就不同了:
(quick-bench (str (reduce ; ❶ #(.append ^StringBuilder %1 %2) (StringBuilder.) (interpose "|" lines)))) ;; Execution time mean : 14.763760 ms (quick-bench (transduce ; ❷ (interpose "|") (completing #(.append ^StringBuilder %1 %2) str) (StringBuilder.) lines)) ;; Execution time mean : 9.631605 ms (quick-bench (st/join "|" lines)) ; ❸ ;; Execution time mean : 9.021710 ms
❶ 我们使用一个可变的
StringBuilder来增量创建字符串, 并避免创建许多中间字符串.interpose是初始序列转换的一部分. 该序列然后被用作reduce的输入. 归约函数将到目前为止累积的字符串 (包括管道分隔符) 附加到一个最初为空的StringBuilder实例. 我们需要记住类型提示, 因为StringBuilder实例作为通用对象传递到归约函数中, 否则类型信息会丢失.❷ 相同的操作被实现为
transduce. 除了使用interposetransducer 和几个小的差异外, 原理是相同的.❸ 与
clojure.string/join的进一步比较显示了类似的性能. 如果处理输入的唯一原因是连接成最终的字符串,clojure.string/join无疑更简单.我们可以看到通过使用
transduce而不是reduce(标准interpose的等效操作) 带来了速度上的提升. 总而言之: 如果使用interpose的主要目标是完全评估序列输出 (放弃惰性), 那么值得研究interpose作为 transducer 提供的选项. 如果惰性仍然很重要, 只有当同一 transducer 链中还有其他序列转换时,interposetransducer 才能提供一些优势.
3.3.6. 10.6 partition, partition-all 和 partition-by
自 1.0-1.2 版本起可用的函数
(partition ([n coll]) ([n step coll]) ([n step pad coll])) (partition-all ([n]) ([n coll]) ([n step coll])) (partition-by ([f]) ([f coll]))
这一段中的三个分区函数从输入集合中创建子序列 (一个包含其他序列的惰性序列). partition 和 partition-all 使用计数器来决定何时分割成下一个子序列:
(partition 3 (range 10)) ; ❶ ;; ((0 1 2) (3 4 5) (6 7 8)) (partition-all 3 (range 10)) ; ❷ ;; ((0 1 2) (3 4 5) (6 7 8) (9))
❶ partition 用于创建每个恰好包含 3 个元素的子序列.
❷ partition-all 更灵活, 允许最后一个子序列包含不同数量的项.
这个简单的例子已经显示了 partition 和 partition-all 之间的主要区别, 前者严格要求产生具有请求数量项的子序列, 后者允许任何 "余数" 最终出现在最后一个 (可能更小) 的子序列中.
与按计数分割输入不同, partition-by 使用一个函数来决定在哪里分割一个新的子序列:
(partition-by count (map str [12 11 8 2 100 102 105 1 3])) ; ❶ ;; (("12" "11") ("8" "2") ("100" "102" "105") ("1" "3"))
❶ 每当数字列表中的数字位数发生变化时, 就会创建一个新的子序列.
这些函数之间有一些差异, 使它们适用于不同的问题. 我们将在契约和示例部分看到它们是什么以及如何使用它们.
契约
- 输入
"coll"是要分区的输入集合. 对于partition,"coll"是强制性的, 但对于partition-by或partition-all不是: 在这种情况下, 它们返回一个 transducer."coll"必须与seq兼容, 以便在"coll"还不是序列的情况下生成一个序列."n"确定每个分区中的最大项目数. 对于基于此的partition或partition-all, 这是强制性的, 但对于partition-by不是, 它改用用户提供的函数来决定分割点. 它可以是负数 (在这种情况下返回一个空列表), 0 (返回一个可能无限的空列表序列) 或正数 (这是最常见的情况)."step"仅由partition使用. 它确定每个子序列应该开始的距离 (以相隔多少个项目为单位). 它的工作方式类似于偏移量, 可能会在多个子序列中重复元素."padding"是partition唯一支持的另一个集合. 当输入集合中有剩余项目无法适应分区时,partition可以使用填充集合来填补空白并返回剩余的项目. 它可以是空的或nil, 并且需要被seq支持."f"是partition-by的强制性参数."f"是一个接受 1 个参数并返回任何类型的函数. 从"f"返回的值被比较, 每次值改变时 (根据相等性契约), 就会创建一个新的子序列.
- 主要异常
虽然不是严格的异常, 但可能会导致无限递归:
(partition 3 0 (range 10)) ; ❶ ;; WARNING infinite sequence of ((0 1 2) (0 1 2)...)
❶ 我们要求
partition返回每个包含 3 个项目的子序列, 偏移量为零, 总是从 "0" 重新开始创建下一个分区. 使用take来限制你所需的结果数量. - 输出
返回: 由给定输入参数决定的输入集合
"coll"的分区的惰性序列, 或者当"coll"为nil时返回nil.示例
让我们从几个例子开始, 说明填充和偏移量:
(partition 3 3 (range 10)) ; ❶ ;; ((0 1 2) (3 4 5) (6 7 8)) (partition 3 2 (range 10)) ; ❷ ;; ((0 1 2) (2 3 4) (4 5 6) (6 7 8))
❶ 默认的
"step"与分区大小"n"相同: 下一个子序列应该从前一个子序列的开头开始 3 个元素之后. 默认步长可以省略而不改变结果.❷ 我们减小了
"step", 我们可以看到每个下一个子序列现在都从前一个子序列的开头开始 2 个元素之后, 即使这意味着在不同的子序列中重复相同的项.(partition 3 3 [:a :b :c] (range 10)) ; ❶ ;; ((0 1 2) (3 4 5) (6 7 8) (9 :a :b))
❶ 最后一个子序列, 也就是包含数字 "9" 的那个, 现在出现了, 这要归功于也提供了填充集合. 填充集合
[:a :b :c]提供了额外的填充元素来补偿最后一个分区中缺失的 2 个元素.(partition-all 3 (range 10)) ; ❶ ;; ((0 1 2) (3 4 5) (6 7 8) (9)) (partition-all 3 2 (range 10)) ; ❷ ;; ((0 1 2) (2 3 4) (4 5 6) (6 7 8) (8 9))
❶ 如果我们不关心不均匀的分区,
partition-all可以实现与partition类似的结果, 而无需填充.❷
partition-all也允许指定一个偏移量, 其工作方式与partition类似, 任何剩余的项都会被添加到最后一个分区中.partition-all经常用于生成批量请求. 批处理是一种技术, 它允许将一组操作视为一个单一的 "执行单元". 如果一个应用程序需要执行大量的请求, 而每个请求都是一个昂贵的操作 (比如数据库调用或 HTTP 请求), 那么可以使用partition-all来分割这些请求, 并对每个组执行操作. 每个组也可以分配给不同的线程进行并行执行, 例如使用pmap:(def records (map #(-> {:id % :data (str %)}) (range 1000))) ; ❶ (defn log [query] (str (.substring query 0 70) "...\n")) ; ❷ (defn insert-query [records] ; ❸ (let [->value (fn [{:keys [id data]}] (format "(%s,%s)" id data)) rows (apply str (interpose "," (map ->value records)))] (log (str "INSERT INTO records (id, data) VALUES " rows " ON DUPLICATE KEY UPDATE")))) (println (pmap insert-query (partition-all 10 records))) ; ❹ ;; (INSERT INTO records (id, data) VALUES (0,0),(1,1),(2,2),(3,3),(4,4),(5... ;; INSERT INTO records (id, data) VALUES (10,10),(11,11),(12,12),(13,13),... ;; ;; [...] ;; INSERT INTO records (id, data) VALUES (990,990),(991,991),(992,992),(9...)
❶ 记录是一个包含 id 和 data 键的映射列表.
❷ 在这个例子中, 我们只是打印查询, 而不是使用 SQL 库来真正执行查询.
❸
insert-query函数的目标是格式化一个批处理风格的 SQL 更新语句. 它接受一个记录列表作为输入, 并创建一个适合在 SQL 数据库上执行的字符串. 记录被格式化成一个逗号分隔的值列表. 我们可以看到查询的一部分, 一旦它被打印到标准输出.❹ 这里
partition-all允许将大型集合分割成更小的批次. 尽管用整个集合调用一次insert-query是可能的, 但即使是单个记录失败, 也会导致整个更新失败.partition-all创建了更易于管理的分区, 可以单独重试. 这是pmap的一个很好的用例, 因为 SQL 更新函数并非微不足道, 我们可以并行处理分区 (假设记录有不同的键).partition-by习惯上与identity一起使用, 将元素本身转换为分区函数. 这具有在输入集合中为每个连续重复的元素分割的效果. 例如, 假设一个传感器网络每分钟读取一次温度. 为了知道温度变化的速度, 我们可以使用partition:(def temps [42 42 42 42 43 43 43 44 44 44 45 45 46 48 45 44 42 42 42 42 41 41]) (map count (partition-by identity temps)) ; ❶ ;; (4 3 3 2 1 1 1 1 4 2) ; ❷
❶ 与
identity一起使用的partition-by在突出显示搅动率方面有一些有趣的应用, 比如每分钟温度变化多少.❷ 我们可以将结果解读为: 4 分钟后温度变化, 然后 3 分钟后再次变化, 然后 3 分钟后等等, 直到我们每分钟都看到不同的读数, 这意味着一个急剧的梯度变化.
partition-by在演示identity函数时也用于一个简单的情感分析. 在那里,partition-by的使用是基于一个假设, 即情感有时在文本中以字母的重复来表达. 邀请读者回顾该示例, 看看partition-by是如何使用的.最后,
partition-all和partition-by都可以与 transducer 一起使用:(eduction ; ❶ (map range) (partition-all 2) (range 6)) ;; ([() (0)] ; ❷ ;; [(0 1) (0 1 2)] ;; [(0 1 2 3) (0 1 2 3 4)])
❶
eduction产生一个无缓存的序列, 并接受任意数量的 transducer 作为输入 (无需使用comp).❷ 注意, 在 transducer 的情况下, 由
partition-all或partition-by产生的分区不是一个惰性序列, 而是一个向量. - 用于其他分区策略的
partition-with
partition和partition-all提供了一种基于每个分区中元素数量的分区策略.partition-by更通用, 但分区受到分区函数 "f" 结果变化的限制. 某些类型的问题会受益于更通用的策略, 该策略考虑前一个和当前元素来决定何时分割. 使分区策略更通用有多困难? 答案是: 不太难. 让我们看看partition-by是如何实现的:(defn partition-by [f coll] ; ❶ (lazy-seq (when-let [s (seq coll)] (let [fst (first s) fv (f fst) run (cons fst (take-while #(= fv (f %)) (next s)))] ; ❷ (cons run (partition-by f (seq (drop (count run) s))))))))
❶
partition-by在 core 中的实现, 但去除了 transducer 的实现.❷ 分区的 "秘诀" 在这里.
"coll"被take-while累积, 直到找到一个(f item)与(f first-item)不同的项. 此时, 我们获取累积, 并用剩余的元素递归调用partition-by.要更改分区策略, 我们可以更改
take-while谓词. 例如, 这是一个接受两个参数的谓词 "f": 当前项和集合中的下一个项. 根据返回真或假, 我们创建一个新的分区:(defn partition-with [f coll] ; ❶ (lazy-seq (when-let [s (seq coll)] (let [prev (first s) run (cons prev (take-while #(f prev %) (next s)))] ; ❷ (cons run (partition-with f (seq (drop (count run) s))))))))
❶ 该函数被重命名为
partition-with.❷ 实现不同策略的更改非常小. 我们需要做的就是将函数 "f" 传递给第一个元素, 并对后续的元素进行分区, 直到 "f" 返回真. 一旦 "f" 返回假, 我们就用剩余的项像以前一样递归.
新的
partition-with可用于时间序列, 其中一个事件列表作为包含时间标记的映射列表传递:(import '[java.time Duration Instant] '[java.time.format DateTimeFormatter] '[java.time.temporal TemporalAccessor]) (def events [{:t "2017-05-04T13:08:57Z" :msg "msg1"} ; ❶ {:t "2017-05-04T13:09:52Z" :msg "msg2"} {:t "2017-05-04T13:11:03Z" :msg "msg3"} {:t "2017-05-04T23:13:10Z" :msg "msg4"} {:t "2017-05-04T23:13:23Z" :msg "msg5"}]) (defn ->inst [{t :t}] ; ❷ (Instant/from (.parse (DateTimeFormatter/ISO_INSTANT) t))) (defn burst? [t1 t2] ; ❸ (let [diff (.getSeconds (Duration/between (->inst t2) (->inst t1)))] (<= (Math/abs diff) 120))) (partition-with burst? events) ; ❹ ;; (({:t "2017-05-04T13:08:57Z", :msg "msg1"} ;; {:t "2017-05-04T13:09:52Z", :msg "msg2"}) ;; ({:t "2017-05-04T13:11:03Z", :msg "msg3"}) ;; ({:t "2017-05-04T23:13:10Z", :msg "msg4"} ;; {:t "2017-05-04T23:13:23Z", :msg "msg5"}))
❶ 事件作为 "流" 进入我们的示例系统, 一个附加到某些 IO 设施的惰性序列. 为了说明目的, 它们只是一个包含几个项目的向量.
❷ 函数名
→inst以箭头→为前缀, 表示从一种格式 (时间戳作为字符串) 到另一种格式 (时间戳作为java.time.Instant对象) 的转换.❸
burst?函数是两个instant的谓词. 如果它们的差异超过 120 秒, 它返回 false, 表明这两个事件相距太远, 不能被视为同一组的一部分.❹ 我们使用前面说明的
partition-with, 使用burst?函数作为谓词.partition-with的结果包含输入事件的分区, 以便两个或多个事件如果它们的时间差低于 2 分钟就在一起. 如果超过 2 分钟, 则该事件被视为下一组的一部分.另请参阅
mapcat和partition经常一起出现在处理管道中, 因为partition引入了一个新的嵌套分区级别, 而mapcat移除该级别, 返回到一个扁平的序列.pmap是一个并行的map实现. 它通常与partition-all关联, 以执行并行批处理.split-at是类似的分区函数, 它只将输入序列分成两部分. 如果你在序列中寻找单个分割点, 请使用split-at或split-with.性能考虑和实现细节
=>
O(n)线性分区函数是基于一个相对简单的递归实现的, 每次创建一个新分区时都会开始. 迭代次数与输入项的数量相关, 产生线性行为.
分区函数是惰性的, 只产生调用者请求的足够多的迭代:
(first (partition 3 (map #(do (println %) %) (range)))) ;; 0 ;; 1 ;; 2 ;; (0 1 2) ; ❶
❶
partition,partition-all和partition-by是惰性函数. 正如预期的那样, 我们可以看到只有形成第一个分区所必需的项目被实现.带 transducer 的惰性工作方式不同, 通常更急切. 即使只请求一个分区, 这个 transducer
partition-all也会实现 n*(32+1) 个项目. 这是因为sequence的工作方式, 总是从 transducer 的结果中请求至少 32 个项目, 这会转化为 32 个 n 个元素的分区, 即使只请求了一个:(first (sequence (comp (map #(do (print % ",") %)) ; ❶ (partition-all 100)) ; ❷ (range))) ;; 0, 1, 2, ....., 3299, ; ❸ ;; [0 1 2 ... 98 99]
❶ 我们使用一个 transducer, 它只是打印一条消息并按原样传回元素.
❷ 这里使用
partition-all作为 transducer.❸ 打印 transducer 显示请求了 3299 个项目, 这对应于输出中第
(* 100 (+ 1 32))3300 个元素.作为另一个例子, 比较下面的普通
partition-by及其 transducer 版本. 我们创建一个只包含数字 "0" 的分区, 和另一个包含所有其他正数的分区. 我们可以从序列的partition-by请求第一个项, 但我们不能对 transducer 版本做同样的事情:(partition-by pos? (range 10)) ; ❶ ;; ((0) (1 2 3 4 5 6 7 8 9)) (first (partition-by pos? (range))) ; ❷ ;; (0) (first (sequence (partition-by pos?) (range))) ; ❸ ;; WARNING: hangs
❶ 这个例子展示了按
pos?对数字进行分区是什么样的: "0" 不是正数, 最终独自在第一个分区, 而其他所有东西都进入正数的分区.❷ 我们现在移除了对数字范围大小的限制, 创建了一个无限序列.
partition-by是严格惰性的, 只评估足够的量来给出结果.❸ transducer 版本在内部是急切的, 并试图实现第二个 (无限) 分区.
正如你从例子中看到的,
partition-all的实现在 transducer 的情况下变得急切.
3.3.7. 10.7 flatten
自 1.2 版本起可用的函数
(flatten [x])
flatten 是一个函数, 它接受一个任意嵌套的数据结构, 并返回通过连接任何嵌套级别的受支持集合中的项形成的序列:
(flatten [[1 2 [2 3] '(:x :y [nil []])]]) ; ❶ ;; (1 2 2 3 :x :y nil)
❶ flatten 的简单用法, 将 "包装" 的元素移除到一个扁平的序列中.
flatten 只对 sequential? 返回 true 的集合操作. 这些主要是列表和向量 (以及契约部分描述的其他类型).
(flatten coll)不是(mapcat identity coll)的替代品. 虽然从函数的描述中这可能看起来很明显, 但在假设 "coll" 只有一层嵌套的情况下自由使用flatten可能是危险的, 因为它也会移除任何其他嵌套. 当目标只是连接第一层嵌套时, 最好用mapcat明确表达意图.
契约
- 输入
"x"是唯一强制性参数. 它可以是任何类型, 包括nil. 如果"x"中的所有嵌套集合都兼容,flatten返回它们内容的线性序列. 支持的类型如下表所示:类型 支持? 示例 c.l.PersistentList 是 (list 1 2)c.l.PersistentVector 是 (vector 1 2)c.l.PersistentVector$TransientVector 否 (transient (vector 1 2))c.l.APersistentVector$SubVector 是 (subvec (apply vector (range 8)) 4)clojure.core.Vec 是 (vector-of :int 1 2)c.l.PersistentHashSet 否 #{1 2}c.l.PersistentArrayMap 否 {1 2 5 6}c.l.PersistentTreeSet 否 (sorted-set 0 4)c.l.PersistentTreeMap 否 (sorted-map 2 1 9 2)c.l.LongRange 是 (range 4)c.l.LazySeq 是 (map inc (range 4))[I 否 (int-array [1 2])c.l.PersistentQueue 是 (conj (c.l.PersistentQueue/EMPTY) 1)java.util.ArrayList 否 (doto (ArrayList.) (.add 1))java.lang.String 否 "string"c.l.Cons 是 (cons 1 ()) - 主要异常
无.
- 输出
返回: 一个惰性序列, 它连接了任何嵌套级别的所有受支持集合.
示例
让我们从展示
flatten在存在不支持的类型时的行为开始:(import 'java.util.ArrayList) (flatten [[{:a 1} #{2 3} (doto (ArrayList.) (.add 1) (.add 2))]]) ; ❶ ;; ({:a 1} #{3 2} [1 2])
❶ 注意映射, 集合或
ArrayList不被支持,flatten不会遍历它们的内容.当集合类型不受支持时,
flatten会跳过它们的遍历, 并按原样传递它们.一个典型的嵌套数据结构是宏展开的结果. 在下一个例子中, 我们将收集在展开一个宏后使用的所有 Clojure (core) 函数. 我们知道核心函数通常以
clojure.core命名空间为前缀. 值得记住的是, Clojure 代码是数据 (Lisp 语言的一个著名特性), 数据类型只是嵌套的列表和符号. 我们可以使用flatten从它们的嵌套位置中浮现出所有符号:(require '[clojure.walk :as w]) (defn core-fns [form] (->> (w/macroexpand-all form) ; ❶ flatten ; ❷ (map str) (map #(re-find #"clojure\.core/(.*)" %)) (keep last) distinct)) ; ❸ (core-fns ; ❹ '(for [[head & others] coll :while #(< i %) :let [a (mod i 2)]] (when (zero? a) (doseq [item others] (print item))))) ;; ("seq" "chunked-seq?" "chunk-first" "int" ;; "count" "chunk-buffer" "<" "first" "next" ;; "chunk-append" "unchecked-inc" "chunk-rest" ;; "chunk-cons" "chunk" "cons" "rest")
❶
macroexpand-all是一个函数, 给定一个形式, 递归地调用宏展开, 直到没有更多的宏可以展开. 然后它返回展开的形式. 这通常比原始形式大得多, 取决于其中宏的使用和复杂性.❷ 在展开的形式上调用
flatten返回所有符号, 在解包所有嵌套级别之后.❸ 在将符号转换为字符串并过滤
clojure.core的符号后, 我们需要移除重复的函数名.❹ 我们使用一个
for循环作为输入.结果显示了一个示例
for循环使用的函数, 尽管特殊形式如let*,if,loop或recur是不可见的, 因为它们没有用clojure.core命名空间限定.另请参阅
mapcat对集合中的每个元素应用一个函数. 假设转换产生一个序列层,mapcat将它们的内容连接成一个线性序列. 当与identity一起使用时,mapcat移除一层嵌套的集合.transducer cat和reducer cat应用一个与mapcat类似的概念, 从它们的输入集合中移除一个单一的嵌套.性能考虑和实现细节
=>
O(n)线性flatten需要遍历每个集合并可能解包它们的内容. 因此, 执行的步数与输入中任何级别的元素数量呈线性关系.从实现的角度来看,
flatten是建立在tree-seq之上的. 然后就是区分受支持的集合类型并只处理它们的内容的问题.flatten是惰性操作的, 只会拉取足够的输入序列来输出请求的结果:(->> (range) ; ❶ (map range) (map-indexed vector) flatten (take 10)) ;; (0 1 0 2 0 1 3 0 1 2)
❶ 这个处理链的输入源是由
range调用产生的无限整数序列. 它可以安全地与flatten一起使用.
3.3.8. 10.8 distinct, dedupe 和 distinct?
函数
自 1.0 (distinct, distinct?)
自 1.7 (dedupe)
(distinct ([]) ([coll])) (dedupe ([]) ([coll])) (distinct? ([x]) ([x y]) ([x y & more]))
distinct 和 dedupe 从输入集合中移除重复项, 而 distinct? 只是报告它们的存在, 返回真或假. distinct 和 distinct? 检测集合 (或参数列表) 中的所有重复项, 而 dedupe 只移除连续的重复项:
(distinct [1 2 1 1 3 2 4 1]) ; ❶ ;; (1 2 3 4) (distinct? 1 2 3 2 4 1) ; ❷ ;; false (dedupe [1 2 1 1 3 2 4 1]) ; ❸ ;; (1 2 1 3 2 4 1)
❶ distinct 移除整个集合中的重复项, 不论它们的相对位置.
❷ distinct? 检测重复的参数, 返回真或假.
❸ dedupe 只移除连续重复的相同项, 保留那些至少相隔一个元素的重复项.
distinct, dedupe 和 distinct? 使用 Clojure 的扩展相等性语义, 接受标量 (数字, 关键字, 符号等) 和集合. Clojure 的相等性使用兼容性组来决定两个项何时相同 (请参考 = 以获得详尽的解释).
distinct, dedupe 和 distinct? 在 Clojure 中相当常用, 反映了计算机科学中处理重复项的许多问题 (例如数据压缩 163).
契约
本节中说明的函数之间存在一些小的契约差异. distinct 不接受集合或映射作为参数 (包括相关的 Java 类型, HashMap 和 HashSet), 而 dedupe 接受它们. 总的来说, 将映射或集合提供给 distinct 或 dedupe 几乎没有意义, 因为它们不能有重复项.
- 输入
distinct和dedupe:"coll"是可选的, 可以是nil. 当"coll"不存在时, 两个函数都返回相关的 transducer. 不接受 transient.distinct不允许集合或映射.dedupe适用于所有集合类型, 不包括 transient.
distinct?:"x","y"和"more"是像distinct?这样的可变参数函数的典型签名."x","y"和"more"可以是任何类型的 Clojure 形式, 字面量或nil. 至少需要一个参数.
- 主要异常
- 当输入是 Set, map,
java.util.HashMap或java.util.HashSet时,distinct抛出UnsupportedOperationException. - 当没有参数调用
distinct?时, 抛出ArityException. 在使用apply时, 有一个不太容易检测的特殊情况:(apply distinct? [])在空集合上产生异常, 需要进行如下检查:(and (seq []) (apply distinct? [])).
- 当输入是 Set, map,
- 输出
distinct和dedupe:"coll"中非重复项的惰性序列.dedupe允许至少相隔一项的重复项.- 当
"coll"是nil时, 返回一个空列表.
distinct?:- 当没有重复项时返回
true, 不论它们在参数列表中的位置. - 当至少有一个重复项时返回
false.
示例
一个投票系统允许对 3 个不同的候选人最多投 5 票. 系统用户可能会对一个候选人重复投票 (无论是故意的还是失误), 我们希望移除来自同一用户的对一个候选人的任何额外投票:
(def votes ; ❶ [{:id 14637 :vote 3 :secs 5} {:id 39212 :vote 4 :secs 9} {:id 39212 :vote 4 :secs 9} {:id 14637 :vote 2 :secs 43} {:id 39212 :vote 4 :secs 121} {:id 39212 :vote 4 :secs 121} {:id 45678 :vote 1 :secs 19}]) (->> votes ; ❷ (group-by :id) (reduce-kv (fn [m user votes] (assoc m user (distinct (map :vote votes)))) {})) ;; {14637 (3 2), 39212 (4), 45678 (1)}
❶ 投票作为比赛结束时所有投票的列表进入系统. 这里我们展示了一个更大列表的一小部分样本. 每个 ":id" 是一个用户, 后面是为一个候选人投票的 ":vote" 作为数字, 最后是比赛开始以来经过的秒数.
❷ 使用
group-by按用户对投票进行分组后, 我们可以看到每个候选人从每个用户那里收到了多少票. 我们可以用reduce-kv处理这个映射, 并确保每个值不包含特定候选人的重复投票, 使用distinct.投票系统由一个软件服务和一个用于表达偏好的硬件按钮组成. 分析数据后, 投票系统暴露出一个奇怪的行为. 发现硬件每次用户按下按钮投票时都会产生 "点击爆发", 而它应该只发送一个选择. 我们希望尽早摆脱不想要的点击, 因为它们对系统的可扩展性构成了问题. 幸运的是, 有问题的点击发生在几毫秒之间, 所以我们可以清楚地判断哪些投票应该被丢弃. 我们可以在
group-by之前用dedupe来做到这一点:(->> votes ; ❶ dedupe (group-by :id) (reduce-kv (fn [m user votes] (assoc m user (distinct (map :vote votes)))) {})) ;; {14637 (3 2), 39212 (4), 45678 (1)} ; ❷
❶ 我们执行与之前相同的操作, 但我们首先用
dedupe摆脱连续的重复项.❷ 结果与之前相同, 正如预期的那样.
distinct?可以用作谓词来查找不同项的集合. 例如, Clojure 内部使用distinct?来在实现case时找到合适的哈希组合.case需要调整测试表达式, 以便它们可以适应相关 JVM 指令的 switch-table, 这需要不同的整数键. 当case测试常量是泛型对象时,case计算每个对象的哈希, 然后尝试多种位/掩码组合来找到一个产生不同键的转换:(def max-mask-bits 13) ; ❶ (defn- shift-mask [shift mask hash] ; ❷ (-> hash (bit-shift-right shift) (bit-and mask))) (defn- maybe-min-hash [hashes] ; ❸ (let [mask-bits (range 1 (inc max-mask-bits)) shift-bits (range 0 31) masks (map #(dec (bit-shift-left 1 %)) mask-bits) shift-masks (for [mask masks shift shift-bits] [shift mask])] (first (filter (fn [[s m]] (apply distinct? ; ❹ (map #(shift-mask s m %) hashes))) shift-masks)))) (maybe-min-hash (map (memfn hashCode) [:a :b :c :d])) ; ❺ ;; [1 3] ;; (case op :a "a" :b "b" :c "c" :d "d") ; ❻ (map #(shift-mask 1 3 %) (map (memfn hashCode) [:a :b :c :d])) ;; (0 2 1 3)
❶ 这个特定的
max-mask-bits是因为 JVMtableswitch指令允许的 32 位大小 164.❷
shift-mask对一个哈希数应用位移和特定的掩码. 这最终是我们想要应用到每个测试用例表达式的转换, 但前提是它不产生重复.❸
maybe-min-hash使用一个for循环生成所有可能的位移和位掩码的排列. 然后将它们应用到给定的哈希值上, 得到一个集合, 我们只想要第一个不产生重复的组合.❹
apply distinct?接受shift-mask转换的结果, 并验证它是否为case语句的每个哈希测试表达式产生不同的结果. 我们不想要不同值的实际集合, 所以我们使用谓词来过滤shift-mask组合.❺ 我们可以看到如何在
[:a :b :c :d]上使用maybe-min-hash. 结果 "[1 3]" 应该被解释为: 每个哈希右移 "1" 位, 然后每个哈希与掩码 "3" 进行位与. 这会生成用于生成的 JVM 指令的不同键.❻ 这显示了本例的
case表达式会是什么样子. 用作文本表达式的 4 个关键字可以用移位掩码转换 "[1 3]" 编码为整数键 "0,2,1,3".作为 transducer,
distinct和dedupe可以通过调用它们的零元版本来使用:(sequence (comp (map range) cat (distinct)) ; ❶ (range 10)) ;; (0 1 2 3 4 5 6 7 8) (sequence (dedupe) ; ❷ [1 1 1 2 1 1 1 3 1 1]) ;; (1 2 1 3 1)
❶ 作为 transducer 的
distinct需要用括号包装, 不像直接在上面的cat.❷
dedupetransducer 像序列版本一样移除连续的重复项. - 重复项, 排序和集合
在搜索重复项, 排序和集合之间存在一种关系. 例如, 你可以通过组合
sort和dedupe来实现distinct:(def duplicates [8 1 2 1 1 7 3 3]) (distinct duplicates) ; ❶ ;; (8 1 2 7 3) (dedupe (sort duplicates)) ; ❷ ;; (1 2 3 7 8)
❶ 在标准库中实现的
distinct, 在移除重复项的同时保持原始集合的顺序.❷
sort的作用是将重复项组合在一起, 以便dedupe可以完全移除它们.distinct和带sort的dedupe都移除所有重复项, 但它们返回相同数字列表的顺序不同. 还有一种具有非常相似属性的数据结构: 哈希集合, 通过设计强制其元素的唯一性, 可以用来移除重复项:(set duplicates) ; ❶ ;; #{7 1 3 2 8}
❶
Set可以直接从另一个集合创建一个 ClojureSet, 不产生重复项.我们在本节中已经看到了许多移除重复项的方法. 使用哪一种取决于几个因素:
- 对输出排序的约束: 如果初始集合的排序很重要, 那么
distinct是首选. - 输入集合上的转换的存在: 那么最好的选择是使用
distinct或dedupe的 transducer 版本. - 在移除重复项的同时需要检查元素是否存在: 将输入转换为哈希集合可以在同时执行查找和重复项移除.
另请参阅
sort被提到了几次.sort不移除重复项, 但将输入集合置于可以管理它们的状态.dedupe可以与sort结合使用, 以获得一种有序的distinct.Set从输入集合中产生一个 Clojure 哈希集合, 在此过程中自动移除重复项.性能考虑和实现细节
=>
distinct:O(n)步数,O(n)内存 (最坏情况)=>
dedupe:O(n)步数,O(1)内存=>
distinct?:O(n)步数,O(n)内存, n 是参数数量distinct,dedupe和distinct?是使用类似模式实现的, 该模式包括将当前看到的项的视图维护为 ClojureSet. 这代表了在扫描所有项相互对比所需的O(n2)步数 (不消耗内存) 和在集合中维护每个项的副本所需的额外内存 (在没有重复项时是最坏情况) 之间的权衡.除了
disctinct?(它被设计用于相对较少数量的参数) 之外,distinct和dedupe都是惰性 (或半惰性) 操作:(first (distinct (map #(do (print % ",") %) (range)))) ; ❶ ;; 0 ,0 (first (dedupe (map #(do (print % ",") %) (range)))) ; ❷ ;; 0 ,1 ,2 ,3 ,..,32,0
❶
distinct是最惰性的, 精确地消耗满足请求所需的项目数量.❷
dedupe是半惰性的, 因为它是建立在其 transducer 版本之上的, 该版本利用了sequence, 而sequence总是消耗前 32+1 个项目.distinct的 transducer 版本在略微降低 (或在transduce的情况下移除) 惰性的代价下, 性能优于标准的序列实现:(require '[criterium.core :refer [quick-bench]]) ; ❶ (defn with-dupes [n] ; ❷ (shuffle (into [] (apply concat (take n (repeat (range n))))))) (let [c (with-dupes 1000)] ; ❸ (quick-bench (doall (distinct c))) (quick-bench (doall (dedupe c))) (quick-bench (doall (sequence (distinct) c))) (quick-bench (doall (sequence (dedupe) c)))) ;; Execution time mean : 271.592546 ms ;; Execution time mean : 102.599305 ms ;; Execution time mean : 93.271275 ms ;; Execution time mean : 105.953654 ms
❶ 我们贯穿全书使用的 Criterium 库可以在 GitHub 上找到.
❷
with-dupes是一个辅助函数, 用于创建一个包含 n*n 个带有重复元素的集合.❸ 该基准测试比较了
distinct和dedupe在其标准版本和 transducer 版本中的表现. 为了清晰起见, 省略了部分 Criterium 输出.简单基准测试的结果显示,
distincttransducer 版本的性能明显优于标准版本, 而dedupe的性能大致相同. 一个更精确的基准测试应该考虑到原始输入中存在的重复项的数量及其顺序, 因为它们都影响最终结果, 特别是在dedupe的情况下. - 对输出排序的约束: 如果初始集合的排序很重要, 那么
3.3.9. 10.9 take-nth
自 1.0 版本起可用的函数
(take-nth ([n]) ([n coll]))
take-nth 从另一个集合中选择一组元素来创建一个惰性序列. 它默认包含第一个元素, 其他元素通过重复丢弃相同数量的项来识别:
(take-nth 3 [0 1 2 3 4 5 6 7 8 9]) ; ❶ ;; (0 3 6 9)
❶ take-nth 选择 "0" 作为第一个元素. 然后它跳过 3 个项以到达数字 "3", 该数字被添加到输出中. 这个过程重复进行, 直到到达输入的末尾.
take-nth 实现了一种通过索引进行过滤的形式, 这在许多情况下都很有用, 通常与其他专门用于顺序处理的函数结合使用. take-nth 也可以作为 (有状态的) transducer 使用:
(into [] (take-nth 2) (range 10)) ; ❶ ;; [0 2 4 6 8]
❶ 不带集合参数的 take-nth 返回一个具有类似功能的 transducer.
契约
- 输入
"n"是在第一个元素之后要丢弃的元素数量, 以便到达要包含在输出中的下一个元素.take-nth要求一个大于零的正数. 小数是可能的, 但会自动四舍五入."coll"可以是任何序列集合, 并且是可选参数. - 主要异常
ArithmeticException除以零错误: 仅在 transducer 版本中, 当 n = 0 且"coll"非空时, 例如(into [] (take-nth 0) [1 2 3]).在 transducer 版本中, 当
"n"为nil且"coll"至少包含一个元素时, 抛出NullPointerException. - 输出
transducer 版本和序列版本在处理某些边界情况上有所不同. 在两种情况下, 当
"n"是正整数时,take-nth返回通过从"coll"中取第一个元素, 丢弃"n"- 1 个元素, 然后取"n"位置的元素, 再丢弃"n"- 1 个接下来的元素, 依此类推生成的序列.take-nth序列版本对于下面列出的情况有以下输出:"n"为nil: 返回空序列."n"为零或负数: 返回一个包含"coll"中第一项的无限列表."n"为小数:"n"会向上舍入到下一个整数 (例如,(take-nth 1.1 [1 2 3])等同于(take-nth 2 [1 2 3]))
take-nthtransducer 版本则有以下行为:"n"为nil且"coll"非空:NullPointerException."n"为零:ArithmeticException. 这已被标记为潜在的 bug."n"为负整数: 与正整数相同."n"为小数:"n"会被加倍 (例如,(into [] (take-nth 2.5) (range 10))等同于(into [] (take-nth 5) (range 10))).
transducer 版本的一些边界情况已被报告为 bug, 链接如下: clojure.atlassian.net/browse/CLJ-1665.
示例
take-nth是生成一个数的倍数的自然解决方案:(defn mult-n [n] ; ❶ (rest (take-nth n (range)))) (take 10 (mult-n 11)) ; ❷ ;; (11 22 33 44 55 66 77 88 99 110) (take 10 (mult-n 42)) ;; (42 84 126 168 210 252 294 336 378 420)
❶
mult-n是一个函数, 给定一个数字, 生成其倍数的无限序列. 我们使用rest来从列表中丢弃初始的零.❷ 我们可以看到如何为数字 "11" 和 "42" 生成倍数.
在处理可变数量的键值对参数时,
take-nth也很有用. 例如, 下面是一个创建稀疏向量的函数, 这是一个在除了参数指定的索引外, 其他所有索引处都为零的向量:(defn sparsev [& kv] (let [idx (take-nth 2 kv) ; ❶ xs (take-nth 2 (next kv)) ; ❷ items (zipmap idx xs)] ; ❸ (reduce #(conj %1 (items %2 0)) ; ❹ [] (range 0 (inc (apply max idx)))))) ; ❺ (sparsev 1 4 3 7 21 8) ;; [0 4 0 7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 8]
❶ 第一次
take-nth调用是为了选择索引.❷ 用
next向前移动一位后, 我们可以选择值.❸
zipmap负责从两个列表中创建一个映射. 这个映射稍后在构建输出向量时使用. 注意, 我们不需要考虑键和值之间可能存在的不同长度: 默认情况下会忽略单个值.❹ 我们可以使用
reduce来增量构建向量. 如果有性能限制, 我们可以使用一个瞬态向量.transduce也是一个可行的选项.❺ 我们创建一个包含所有可能索引的范围, 从 0 到我们需要用非零值填充的最大索引.
- 实现
drop-nth
take-nth很自然地引出了一个具有类似特性但含义相反的drop-nth: 生成一个惰性序列, 该序列是在我们从输入序列中移除每个 "nth" 元素后剩下的项. 一个起点可以是查看take-nth的源代码并更改相关部分:(defn drop-nth [n coll] ; ❶ (lazy-seq (when-let [s (seq coll)] (concat (take (dec n) (rest s)) ; ❷ (drop-nth n (drop n s)))))) ; ❸ (drop-nth 3 (range 10)) ;; (1 2 4 5 7 8)
❶ 除了名称更改外, 函数的总体设计与
take-nth保持相同.❷ 与
cons结果不同, 我们需要concat它们, 因为我们选择的是第 n 个间隙之间的多个元素, 而不是第 n 个元素. 我们需要跳过处于第 n 个位置的第一项, 然后再取最多 n - 1 个项.❸ 下一次迭代使用丢弃了所有直到下一个第 n 个元素为止的序列.
或者, 我们可以使用
rem来查看哪些项对应哪个索引, 并在keep-indexed之上实现drop-nth2:(defn drop-nth2 [n coll] ; ❶ (keep-indexed ; ❷ #(when-not (zero? (rem %1 n)) %2) ; ❸ coll)) (drop-nth2 3 (range 10)) ;; (1 2 4 5 7 8)
❶ 使用不同方法实现的
drop-nth2.❷ 需要
keep-indexed, 因为每次处理索引是 "n" 的倍数的项时, 我们都会产生一个nil.❸ 使用
rem我们可以识别相隔 "n" 个元素的项.第二种使用
keep-indexed的方法还有一个直接的 transducer 版本, 可以通过移除"coll"来获得:(defn xdrop-nth [n] ; ❶ (keep-indexed #(when-not (zero? (rem %1 n)) %2))) (sequence (xdrop-nth 3) (range 10)) ;; (1 2 4 5 7 8)
❶ 对于 transducer 版本, 我们可以使用其 transducer 版本的
keep-indexed.drop-nth2稍微更简洁, 但哪个更快呢? 我们可以用 Criterium 看一下:(require '[criterium.core :refer [quick-bench]]) (let [xs (range 1e5)] (quick-bench (last (drop-nth 3 xs)))) ;; 13.511636 ms (let [xs (range 1e5)] (quick-bench (last (drop-nth2 3 xs)))) ;; 4.586312 ms
drop-nth2既更小又更快.另请参阅
filter使用谓词从序列中移除元素, 而不是使用元素之间的距离.split-at在请求的索引处将序列分成两部分.partition也将序列分割成请求大小的子序列.性能考虑和实现细节
=> 最坏情况下
O(n)步数=> 最坏情况下
O(n)空间take-nth具有典型的顺序处理性能特征.take-nth产生的输出是惰性的, 所以请求的元素数量决定了函数做多少工作, 最多为 "n" 步, 如果 "n" 是输入的长度.完全评估的输出的内存占用在输入序列的长度 "n" 上也是线性的. 如果
take-nth在归约场景中使用 (其中输出大小小于输入), 内存占用可以通过不持有生成的输出的头部来减少 (例如, 参见map性能部分关于持有序列头部的例子).take-nth也可以作为 transducer 使用. transducer 的实现往往更快:(require '[criterium.core :refer [quick-bench]]) (let [xs (range 1000000)] (quick-bench (last (take-nth 2 xs)))) ; ❶ ;; Execution time mean : 75.020203 ms (let [xs (range 1000000)] (quick-bench (last (sequence (take-nth 2) xs)))) ; ❷ ;; Execution time mean : 69.482801 ms
❶
take-nth的基本版本与 transducer 版本在生成另一个序列的相同场景下进行基准测试. 注意使用last来完全评估序列.❷ 我们可以看到 transducer 版本略快. 这部分是由于
take-nth的 transducer 版本使用了不同的实现.我们可以在归约上下文中进行类似的比较:
(let [xs (range 1000000)] (quick-bench (reduce + (take-nth 2 xs)))) ; ❶ ;; Execution time mean : 70.808658 ms (let [xs (range 1000000)] (quick-bench (transduce (take-nth 2) + xs))) ; ❷ ;; Execution time mean : 45.558123 ms
❶ 我们使用
reduce来对最多 1 百万个元素中 2 的倍数求和.❷ transducer 版本比普通的
reduce版本更快.我们可以看到, 归约上下文对 transducer 版本产生了有利的结果.
3.3.10. 10.10 split-at 和 split-with
自 1.0 版本起可用的函数
(split-at [n coll]) (split-with [pred coll])
split-at 和 split-with 按大小或使用谓词分割一个序列性输入:
(split-at 8 (range 10)) ; ❶ ;; [(0 1 2 3 4 5 6 7) (8 9)] (split-with (complement zero?) [1 4 5 0 3 2 0 1 1 0]) ; ❷ ;; [(1 4 5) (0 3 2 0 1 1 0)]
❶ split-at 与一个代表我们希望分割发生的索引的数字一起使用. 在这种情况下, 例如, 我们表示我们希望在到达序列中的第 8 个元素时进行分割.
❷ split-with 的工作方式与 take-while 相同, 使用一个谓词, 一旦谓词在一个项上返回 false, 就分割输入. 我们可以看到分割发生在第一次出现零的时候.
与 partition 或 partition-all 不同, split-at 和 split-with 被设计为只返回两个分区.
契约
- 输入
"n"可以是任何大于或等于零的整数. 负数是可能的, 但其效果与"n"设置为零相同. 小数也是可能的, 并向上舍入到最接近的整数. 如果"n"大于"coll"的大小, 它返回一个包含"coll"和空列表的向量对. 对于split-at, 它是必需的参数."pred"是一个接受一个参数并返回逻辑真或假的函数. 对于split-with, 它是必需的参数."coll"是任何序列集合 (根据seq契约) 或nil. - 主要异常
当
"coll"不是序列性的 (根据seq契约) 时, 抛出IllegalArgumentException. - 输出
split-at返回一个包含两个元素的向量: 第一个是包含"coll"中前"n"个项的惰性序列, 第二个是剩余的(- (count coll) n)个项.split-with返回一个包含两个元素的向量: 第一个是直到"pred"的第一个 false 评估为止的元素的惰性序列, 第二个包含所有剩余的项.示例
split-at和split-with的输出向量通常作为let绑定的一部分进行解构:(let [[head others] (split-at 8 (range 10))] ; ❶ (+ (last head) (last others))) ;; 16
❶
split-at的向量结果可以很容易地被解构, 这样两个部分就可以独立处理.这两个函数都对其输入进行惰性操作:
(take 10 (last (split-at 10 (range)))) ; ❶ ;; (10 11 12 13 14 15 16 17 18 19)
❶
split-at在一个无限范围上被调用. 分割的第二部分仍然是一个无限序列.我们可以使用一个
Set作为split-with的谓词, 以基于一个项的存在来分割一个集合. 由于分割发生在谓词的第一个 false 评估上, 我们需要记住要补充谓词:(split-with (complement #{\a \e \i \o \u}) "hello") ; ❶ ;; [(\h) (\e \l \l \o)]
❶ 我们创建了一个包含元音的集合字面量, 并以补充形式将其用作谓词. 该表达式返回单词在任何元音第一次出现时的分割.
我们也可以分割一个有序集合或有序映射.
split-with也适用于普通集合或映射, 但结果是不确定的:(defn k? [k] (complement #{k})) ; ❶ (defn kv? [k v] (complement #{[k v]})) (split-with (k? 5) (apply sorted-set (range 10))) ; ❷ ;; [(0 1 2 3 4) (5 6 7 8 9)] (split-with (kv? 4 5) (apply sorted-map (range 10))) ; ❸ ;; [([0 1] [2 3]) ([4 5] [6 7] [8 9])] (split-with (k? 5) (set (range 10))) ; ❹ ;; [(0 7 1 4 6 3 2 9) (5 8)] (split-with (kv? 4 5) (apply hash-map (range 10))) ; ❺ ;; [([0 1]) ([4 5] [6 7] [2 3] [8 9])]
❶
k?和kv?是帮助生成适合与split-with一起使用的谓词的函数.❷ 第一个例子显示了
split-with在一个有序集合上的使用. 结果是直观和预期的.❸ 我们也可以在一个有序映射上使用
split-with. 在这种情况下, 结果包含来自输入映射的键值对, 在请求的键处进行分割.❹ 在一个普通集合上进行分割仍然是可能的, 但分割的结果是不确定的.
❺ 在哈希映射上进行分割也会返回一个不确定的键值对分区.
- 使用
split-by进行多次分割
split-with在谓词第一次返回 false 时分割输入集合. 任何产生相同结果的额外项都不会导致序列再次分割. 下面的split-by函数递归地调用split-with, 以在谓词每次从真变为假时进一步分割输入:(defn split-by [pred coll] ; ❶ (lazy-seq (when-let [s (seq coll)] ; ❷ (let [!pred (complement pred) [xs ys] (split-with !pred s)] ; ❸ (if (seq xs) ; ❹ (cons xs (split-by pred ys)) ; ❺ (let [skip (take-while pred s) ; ❻ others (drop-while pred s) [xs ys] (split-with !pred others)] ; ❼ (cons (concat skip xs) (split-by pred ys)))))))) (take 3 (split-by #(zero? (mod % 5)) (range))) ; ❽ ;; ((0 1 2 3 4) (5 6 7 8 9) (10 11 12 13 14))
❶
split-by遵循典型的惰性序列组织模式. 在递归调用split-by之前有两个可能的cons点.❷ 这个条件验证输入的结束并终止递归.
❸ 在每次递归中, 我们在输入序列中向前移动一个虚拟光标, 并可以在该点调用
split-with.❹ 有两种可能的结果: 序列以一个分割点 (或序列中的多个分割点) 开始, 或者分割点在第一个元素之后. 如果分割点是第一个元素,
split-with返回一个空的 "xs" 序列.❺ 如果分割点在第一个元素之后, "xs" 是要
cons到结果中的第一批结果. 我们用其余的 "ys" 进行递归.❻ 如果分割点在第一个元素上, 我们需要进行额外的处理来发现下一个分割点, 而不丢弃元素. 为此, 我们使用
take-while直到谓词变为 false, 这会到达我们的下一个分割点. 我们称这些初始元素为 "skip" 元素. "others" 是新分割点之后的任何东西.❼ 我们现在可以在 "others" 上应用一个新的
split-with并从那里继续. 进入结果的cons是我们必须 "skip" 的项与新组 "xs" 的连接. 然后我们用第二个分割点之后的其余项进行递归.❽ 我们可以使用
split-by将一个整数列表分割成 5 的倍数. 注意partition-by可以做类似的事情, 不同之处在于分割项被隔离在它们自己的分区中.另请参阅
partition是通用的分区函数, 支持多个分割点.drop-while和take-while的工作原理与split-with类似.性能考虑和实现细节
=> 最坏情况下
O(n)步数=> 最坏情况下
O(n)空间split-at和split-by在最坏情况下具有线性行为, 取决于实际消耗的输出量. 尽管返回一个向量,split-at和split-by是惰性函数, 类似于它们所基于的take-while或drop-while. 邀请读者回顾与drop相关的性能部分以获取更多细节.这两种情况下的实现都相当简单, 值得在这里复制以供检查:
(defn split-at [n coll] ; ❶ [(take n coll) (drop n coll)]) (defn split-with [pred coll] ; ❷ [(take-while pred coll) (drop-while pred coll)])
❶
split-at在 core 中的实现方式.❷ 类似地, 对于
split-with, 实现将一个向量包装在drop-while和take-while调用周围.
3.3.11. 10.11 when-first
自 1.0 版本起可用的宏
(when-first [bindings & body])
when-first 是一个相对简单的宏, 用于自动化将局部绑定分配给序列第一个元素的操作:
(when-first [x (range 10)] (str x)) ; ❶ ;; "0" (when-first [x ()] (print "never gets here")) ; ❷ ;; nil
❶ 我们使用 when-first 来访问序列中的第一个元素.
❷ 如果没有第一个元素, when-first 返回 nil, 并且主体不被评估.
(when-first bindings <body>) bindings :=> [<name> <value>]
- 输入
"bindings"是一个恰好包含 2 个元素的向量: 局部绑定的 "name" 和它的 "value"."name"应该是一个有效的 Clojure 符号,"value"是任何序列集合 (如seq所支持)."body"可以是任何 Clojure 形式. 局部绑定"name"将在编译时 (宏展开期间) 可用于body中. - 主要异常
如果
"bindings"不恰好包含 2 个参数或者不是一个向量, 则抛出IllegalArgumentException. - 输出
返回: 当
"value"是一个至少包含一项的集合时, 评估"body"的结果, 否则返回nil."name"在评估"body"期间成为可用符号.示例
when-first的一个好用法是提高习惯用法中的惰性递归循环的可读性. 下面的dechunk函数循环遍历输入以从分块序列 (例如范围或向量) 中移除分块. 序列分块通常是有用的特性, 但在某些情况下, 我们可能希望完全控制评估 (例如处理昂贵或有副作用的输入):(first (map #(do (print ".") %) (range 100))) ; ❶ ;; ................................0 (defn dechunk [xs] ; ❷ (lazy-seq (when-first [x xs] ; ❸ (cons x (dechunk (rest xs)))))) (first (map #(do (print ".") %) (dechunk (range 100)))) ; ❹ ;; .0
❶ 在第一个实验中, 我们使用一个有副作用的
map操作来为每个请求的元素打印一个 "." 点. 我们可以看到, 通过从一个范围请求第一个元素, 会打印 32 个点.❷
dechunk实现了一个简单的惰性循环, 将输入的第一个项cons到输出序列中, 不进行任何额外的转换.❸ 通过使用
when-first, 我们可以避免在 "x" 上使用first, 从而减少一组括号.❹ 我们可以在分块序列前使用
dechunk, 以防止其余的顺序计算以 32 个项的块执行. 单个点的打印证实了分块已被移除. 请注意, 分块是在范围创建的上游被移除的, 但范围本身仍然一次评估 32 个项.when-first还通过重用输入到序列的转换来提取第一项, 从而避免了对输入的双重评估. 有关when-first评估策略的更多细节, 请查看下面的性能部分.另请参阅
first用于访问序列集合的第一项.when-let实现了与when-first类似的机制, 当且仅当一个泛型对象 (集合或非集合) 被评估为真时, 为其创建一个局部绑定.性能考虑和实现细节
=>
O(1)常数时间when-first是一个宏, 其展开与输入的大小无关, 在常数时间内发生. 展开后,when-first产生访问序列中第一个元素的代码, 这也是常数时间:(clojure.pprint/pprint ; ❶ (macroexpand '(when-first [x coll] (println x)))) ;; (let* [temp_123 (seq coll)] ; ❷ ;; (when temp_123 ;; (let [xs_123 temp_123] ;; (let [x (first xs_123)] ; ❸ ;; (println x)))))
❶ 我们使用
pprint将宏展开格式化为多行. 为清晰起见, 已从函数中移除命名空间.❷
seq在"coll"上被调用, 效果是创建一个序列版本 (如果它还不是一个序列). 当"coll"为空时, 它生成nil.❸ 如果
"temp_123"(一个随机生成的符号名) 不是nil, 这意味着我们有一些内容要处理. 这就是我们使用first将输入的第一个元素绑定到"x"的地方.我们可以从宏展开中看到,
"coll"只被评估一次, 作为seq的参数. 这个特性可能很重要, 例如, 如果"coll"不是一个缓存的序列, 而我们想防止多次评估. 下面的take-first函数说明了这个问题. 该函数使用输入集合的第一个元素产生一个惰性序列. 这个初始版本不使用when-first:(defn take-first [coll] ; ❶ (lazy-seq (when (seq coll) ; ❷ (cons (first coll) ())))) (take-first (sequence (map #(do (println "eval" %) %)) '(1))) ; ❸ ;; eval 1 ;; (1) (take-first (eduction (map #(do (println "eval" %) %)) '(1))) ; ❹ ;; eval 1 ;; eval 1 ;; (1)
❶
take-first是一个简单的函数, 用于创建一个只包含输入"coll"第一个元素的惰性序列.❷
sequence作为一个函数可以用来验证一个序列是否为空. 我们不想在生成的输出中推入一个nil, 所以我们首先检查"coll"中是否有任何东西.❸
take-first在一个用sequence产生的输入上被调用. 注意, 我们为每个项目评估打印 "eval". 我们可以看到对数字 1 的一次打印 "eval".❹ 现在
take-first在一个用eduction产生的序列上使用, 这是一个非缓存序列. 我们可以看到对数字 1 的两次评估打印.提供的
take-first的实现评估了输入两次, 一次是检查它是否为空, 第二次是获取第一个元素. 我们之所以没有看到双重评估, 唯一的原因是sequence提供的隐式缓存.eduction使得这个问题变得明显, 因为它不缓存输入的评估. 现在让我们使用when-first:(defn take-first [coll] (lazy-seq (when-first [x coll] ; ❶ (cons x ())))) (take-first (sequence (map #(do (println "eval" %) %)) '(1))) ; ❷ ;; eval 1 ;; (1) (take-first (eduction (map #(do (println "eval" %) %)) '(1))) ; ❸ ;; eval 1 ;; (1)
❶ 第二个版本的
take-first使用when-first, 它只评估"coll"一次. 它还移除了对first的一次函数调用.❷ 新版本的
take-first不仅用缓存序列产生相同的结果, 而且也更高效. 它实际上避免了再次回到缓存中获取第一项.❸ 现在用非缓存序列的测试显示我们没有两次评估输入.
3.3.12. 10.12 chunk-cons, chunk-first, chunk-rest, chunk-next, chunk-buffer, chunk-append 和 chunk
自 1.1 版本起可用的函数
(chunk-cons [chunk rest]) (chunk-first [s]) (chunk-rest [s]) (chunk-next [s]) (chunk-buffer [capacity]) (chunk-append [b x]) (chunk [b]) (chunked-seq? [s])
本节中的函数 (现在简称为 chunk-* ) 是分块序列抽象的一部分. 分块是 Clojure 的一个特性, 它允许数据结构在顺序迭代期间强制执行特定的获取粒度. 没有分块, 惰性序列总是会一次实现一个项, 将相关的迭代器在集合中向前推进一个位置. 有了分块, 要处理的项的数量可以不止一个, 即使它们不是立即被消耗. 分块的项被停放在一个中间迭代器 (缓冲区) 中, 该迭代器提供元素直到块的末尾. 如果上游请求更多的项, 就会创建另一个块并放置在缓冲区中. 这个循环重复进行, 直到输入结束并且所有项都被消耗.
分块主要是一种性能优化, 它利用了一些序列集合的内部数据布局: 向量, vector-of 和范围是那些从分块中获益最多的集合. 本节中的 chunk-* 函数允许其他数据源利用分块来提高它们在顺序处理期间的性能, 并且可以分为两组:
chunk-cons,chunk-first,chunk-rest和chunk-next几乎是惰性序列中cons构造以及first,rest和next的直接替代品.chunk-buffer,chunk-append和chunk的目的是创建中间 (可变) 缓冲区, 并将缓冲区返回给chunk-cons. 缓冲区应该用作处理分块序列的内部构件.
chunked-seq? 验证一个序列是否支持分块抽象.
chunk-*函数作为 Clojure 1.1 的一部分发布, 并被标记为 "实现细节" 165. 发布说明还指出, 它们被公开是为了允许实验. 多年以后, 分块函数在标准库中被广泛使用, 尽管仍然没有文档, 但没有迹象表明它们将被废弃, 更改或移除.
契约
- 输入
"chunk"是clojure.lang.IChunk类型的对象, 它是chunk的返回类型和chunked-cons的输入."rest"是任何序列集合 (根据seq契约), 不一定是分块的."s"表示一个分块序列, 使得(chunk-seq? s)返回 true."capacity"是一个正整数 (必须小于Integer/MAX_VALUE), 代表缓冲区的大小."b"必须是clojure.lang.ChunkBuffer类型的对象, 它本质上是 Java 对象数组的包装器."x"可以是任何对象. - 主要异常
如果
"s"或"capacity"为nil, 则抛出NullPointerException.如果
"capacity"小于 0, 则抛出NegativeArraySizeException.当试图在已满的
chunk-buffer上进行chunk-append时, 抛出ArrayIndexOutOfBoundsException.在非分块序列上尝试
chunk-first,chunk-rest或chunk-next时抛出ClassCastException. 值得注意的是,(chunk-rest ())会产生错误, 因为空列表是序列性的但不是分块的. - 输出
根据具体函数而定:
chunk-cons返回一个clojure.lang.ChunkedCons对象, 类似于cons返回的clojure.lang.Cons对象.chunk-first返回分块序列输入的第一个块.chunk-rest返回移除第一个块后的分块序列集合的其余部分, 否则返回空列表.chunk-next返回移除第一个块后的分块序列集合的其余部分, 否则返回nil.chunk-buffer返回一个给定"capacity"的clojure.lang.ChunkBuffer.chunk-append向一个clojure.lang.ChunkBuffer实例添加一个元素, 直到缓冲区中的可用空间用完.chunk从一个clojure.lang.ChunkBuffer实例返回一个clojure.lang.IChunk类型的对象.
示例
在展示一个完整的例子之前, 单独说明分块的某些方面是有用的. 缓冲区是处理块中数据所必需的, 因为
chunk-first返回一个对集合内部状态的 (不可变) 视图, 不能直接处理. 缓冲区可以如下创建和使用:(def b (chunk-buffer 10)) ; ❶ (chunk-append b 0) ; ❷ (chunk-append b 1) (chunk-append b 2) (def first-chunk (chunk b)) ; ❸ (chunk-cons first-chunk ()) ; ❹ ;; (0 1 2)
❶
chunk-buffer创建一个大小为 10 的可变缓冲区对象.❷ 我们可以向缓冲区追加最多 10 个元素, 之后它会开始抛出
ArrayIndexOutOfBoundsException.❸
chunk将临时缓冲区转换为一个新的块.❹ 从缓冲区创建的块准备好用于生成分块序列.
请注意, 用于创建块的缓冲区将变得不可用:
(def b (chunk-buffer 10)) (chunk-append b 0) (chunk b) (chunk-append b 0) ; ❶ ;; NullPointerException clojure.lang.ChunkBuffer.add
❶ 一旦缓冲区被转换为一个块, 任何后续尝试向该缓冲区进行
chunk-append的操作都会失败并抛出异常. 缓冲区应该只使用一次来创建缓冲区, 然后丢弃.如引言中所述,
chunk-*函数用于处理分块序列. 下面的map-chunked是map的一个分块版本, 用于转换分块序列中的项.map-chunked与map以及其他函数如filter,keep的实现方式非常相似.map-chunked中使用的方法是通用的, 可以用于其他需要分块感知的序列函数中:(defn map-chunked [f coll] (lazy-seq (when-let [s (seq coll)] ; ❶ (let [cf (chunk-first s) ; ❷ b (chunk-buffer (count cf))] ; ❸ (.reduce cf (fn [b x] (chunk-append b (f x)) b) b) ; ❹ (chunk-cons (chunk b) (map-chunked f (chunk-rest s))))))) ; ❺ (take 10 (map-chunked inc (range 10000))) ;; (1 2 3 4 5 6 7 8 9 10)
❶ 此递归的退出条件是
"coll"中至少有一项.❷ 我们可以继续从分块序列中取
chunk-first.❸ 创建一个新的
chunk-buffer并分配给一个局部绑定.❹ 像
range或vector这样的分块对象都配备了一个只能通过 Java 互操作访问的reduce实现.❺ 缓冲区被转换为相应的分块数组实例,
chunk-cons使用它进入递归, 逐渐构建一个惰性分块序列.在下面的例子中, 我们将创建我们自己的分块序列. 物理设备 (如磁盘或网络) 上的数据可能会受到与硬件相关的约束, 如特定的存储块大小或传输包大小. 例如, 在文件系统上, 数据通常以块的形式组织, 以产生统一的分配和可预测的性能. 我们希望能够惰性地从文件中读取字节, 同时能够为设备选择最佳的块大小:
(import '[java.io FileInputStream InputStream]) (defn byte-seq [^InputStream is size] (let [ib (byte-array size)] ((fn step [] ; ❶ (lazy-seq (let [n (.read is ib)] ; ❷ (when (not= -1 n) ; ❸ (let [cb (chunk-buffer size)] ; ❹ (dotimes [i size] (chunk-append cb (aget ib i))) ; ❺ (chunk-cons (chunk cb) (step)))))))))) ; ❻ (with-open [fis (FileInputStream. "/usr/share/dict/words")] ; ❼ (let [bs (byte-seq fis 4096)] (String. (byte-array (take 20 bs))))) ;; "A\na\naa\naal\naalii\naam"
❶
byte-seq遵循典型的惰性序列生成模式, 将step函数的主体封装在lazy-seq调用中."is"和"ib"(分别是输入流和输入缓冲区) 都是可变对象, 不需要作为参数传递给内部的step. 所以step函数被定义并立即调用 (注意额外的括号).❷
"ib"是一个字节数组缓冲区, 它向.read操作指示要获取多少字节 (本例中是从文件系统). 每次迭代都会用新数据覆盖它.❸
.read返回读取的字节数. "-1" 表示输入结束, 所以我们停止递归, 除非有更多的字节要处理.❹ 第二个缓冲区
"cb"被创建来容纳第一个缓冲区的内容. 这是多余的, 但两个缓冲区的类型不兼容, 输入缓冲区不能直接用于创建chunk-cons.❺
dotimes用于将"ib"缓冲区的内容用chunk-append传输到"cb"缓冲区中.❻
chunk-cons在进入step递归之前的最后一步被调用.❼ 当
java.io.InputStream类涉及惰性处理时,.close操作需要在计算结束后发生. 在本例中, 我们使用 4096 的缓冲区大小读取 20 个字节. 我们需要在关闭输入流的with-open块结束前处理这些字节.请注意, 上面的
byte-seq函数对于从输入流中惰性地处理非结构化字节很有用. 还有其他方法可以急切地加载文本文件的内容 (如slurp) 或逐行加载 (line-seq).另请参阅
lazy-seq允许chunk-cons(和cons) 惰性地生成序列.first和rest是不支持分块的序列的chunk-first,chunk-rest的等效物.性能考虑和实现细节
=>
O(1)步数, 块处理=>
O(n)步数, 块缓冲本节中的函数被设计为协同工作. 总的来说, 它们以线性方式处理序列, 线性于项的数量 (或块的数量, 如果输入序列是分块的). 我们可以大致将性能考虑分为两组:
chunk-cons,chunk-first,chunk-rest和chunk-next以常数时间操作来提取和产生一个块.chunk-buffer,chunk-append和chunk管理中间缓冲区. 在这 3 个函数中,chunk在块大小上是线性的, 而chunk-buffer和chunk-append是常数时间操作.
chunk-*函数的目的是按块建模计算, 极大地提高了那些数据形状是重要因素的数据结构的处理性能. 通过选择正确的块大小, 昂贵的获取操作可以被最小化, 而客户端可以继续按项处理.为了了解它们在多大程度上改善了向量的序列化, 我们可以比较不支持分块的子向量上的相同操作 (尽管它们在结构上共享相同的数据):
(require '[criterium.core :refer [quick-bench]]) ; ❶ (let [xs (into [] (range 10000))] ; ❷ (quick-bench (doall (map inc xs)))) ;; Execution time mean : 330.650098 µs (let [xs (subvec (into [] (range 10000)) 0 9999)] ; ❸ (quick-bench (doall (map inc xs)))) ;; Execution time mean : 988.394350 µs
❶ 我们使用 Criterium 库来正确执行基准测试.
❷ 创建一个包含 10k 个整数的向量, 并用
map进行迭代. 一旦map内部调用seq, 向量就会返回一个知道如何从内部数据结构加载项的分块迭代器.doall是必需的, 以便完全评估序列.❸ 相同的操作在一个子向量上执行. 子向量不提供分块迭代器. 我们可以看到
subvec所需的时间大约是vector的 3 倍.
3.3.13. 10.13 总结
标准库中对序列抽象的使用是普遍的. 许多算法都建立在顺序处理之上, 并经常被展示为典型的 Clojure 示例. 这当然是为什么有这么多专门用于顺序处理的函数, 以及为什么 Clojure 开发者应该花必要的时间来理解它们. 在前两章中, 我们看到了专门用于序列创建和处理的重要函数. 在第二部分的剩余部分, 我们将看到所有其他具体的数据结构, 如向量, 集合和映射.
3.4. 11 映射
映射, 连同序列和向量, 可能是最灵活和最常用的 Clojure 数据结构. 它们以几种方式支持 Clojure 应用程序设计:
- 为数据附加 "标签". 映射中的每个键都是一个值的名称. 命名的值在代码中更容易推理, 并得到语言其他特性的支持 (例如解构).
- 以高效的方式支持不变性和持久性 (映射使用与向量相同的 HAMT Hash Array Mapped Trie 数据结构 166).
- 允许按键查找, 包括使用映射本身作为函数.
- 标准库包含许多专门用于映射操作的函数 (例如
assoc,merge,select-keys等). 对这些函数的描述是本章的主题.
Clojure 包含几种类型的映射 (或类映射对象), 它们通过其构造函数名称和实际 Java 类型 (除非另有说明, 类名属于 clojure.lang 包) 的混合来描述. 以下列表中的类型实现了 IPersistentMap, 这是最具体的映射接口 167:
array-map是小映射的默认选择. 类名是PersistentArrayMap.array-map对于大映射的扩展性不好. 因此, Clojure 会在超过特定大小阈值时自动将array-map提升为hash-map. 与结构体一起, 它在迭代期间也保持插入顺序.hash-map是最灵活的实现. 类是PerisestentHashMap. 它在键数量较大时扩展得很好, 同时保持良好的平均性能. 它不保留插入顺序, 所以当请求键或值时, 它们不一定以添加的相同顺序返回.sorted-map借助一个比较器来维护键值对的内部顺序. 类型是PeristentTreeMap. 有序映射在某些用例中很方便, 但性能比hash-map慢.record是动态生成的类, 具有类键的属性. 它们的设计不是为了扩展到几个键之外, 因为它们的主要目标是提供类似对象的特性, 例如行为的继承 (通过协议).struct基于PersistentHashMap, 但它们维护了一个额外的最小键集的概念, 或 "结构", 作为一个新的PersistentStructMap类类型. 它们具有与hash-map类似的特性以及额外的约束. 在引入defrecord之后, 不鼓励使用它们.
其他 Clojure 集合表现出映射的特性, 但它们不是严格意义上的映射. 这是因为有几个接口共同构成了映射的最终行为. 其中之一是 clojure.lang.Associative, 它与向量等其他集合共享. 因此, 向量获得了一部分映射的属性, 例如可以 assoc 或 dissoc 项. 另一个例子是瞬态映射, 它们支持用 get 进行查找, 但暴露了一个完全不同的 assoc! (注意感叹号) 函数.
本章描述的函数适用于关联数据结构 (除非另有说明).
clojure.lang.Associative是一个接口, 目前由以下类型实现:hash-map,sorted-map,array-map,record,struct,vector,sub-vector和native-vector.
本章进一步分为以下几个部分:
- "创建" 包含不同类型映射的映射构造函数. 本节中的函数可用于创建任何映射类型的新实例. 其他函数如
frequencies或group-by也创建映射, 但在处理通用集合的上下文中. - "访问" 是专门用于获取特定键或一组键的函数, 返回它们的值, 带有或不带有其关联的键.
- "处理" 包含用于更改映射内容的函数. 所有映射类型 (除了瞬态映射) 都是不可变的 (你不能就地改变它们) 和持久的 (每次更改都会生成一个新版本, 而旧的更改仍然可以访问).
- "实用函数" 包含其他用于操作映射的有趣函数.
3.4.1. 11.1 创建
- 11.1.1 hash-map
自 1.0 版本起可用的函数
(hash-map ([]) ([& keyvals]))
hash-map是 Clojure 哈希映射的构建函数, 这是一种支持按键直接访问查找 (在其他语言中也称为哈希表) 的不可变数据结构类型:(def phone-book (hash-map "Jack N" "381-883-1312" ; ❶ "Book Shop" "381-144-1256" "Lee J." "411-742-0032" "Jack N" "534-131-9922")) (phone-book "Jack N") ; ❷ ;; "534-131-9922"
❶
hash-map接受任意数量的键值对. 注意 "Jack N" 是重复的条目.❷ 调用
hash-map的结果 (映射本身) 可以用作函数, 按键查找其内容. 与 "Jack N" 条目关联的最后一个值会覆盖任何先前与相同键关联的条目.契约
- 输入
"keyvals"可以是任意数量 (偶数) 的参数, 包括无参数. - 主要异常
当参数数量不是偶数时, 抛出
IllegalArgumentException. - 输出
返回: 一个包含给定键值对的
clojure.lang.PersistentHashMap实例, 或为空. 当同一个键出现多次时, 进入映射的最后一个键值对会覆盖前一个的内容. 注意键上的元数据 (如果有的话) 会从原始键中保留:(def map-with-meta ; ❶ (hash-map (with-meta 'k {:m 1}) 1 (with-meta 'k {:m 2}) 2)) (map-with-meta 'k) ; ❷ ;; 2 (-> map-with-meta ; ❸ (find 'k) (first) (meta)) ;; {:m 1}
❶ 一个带有重复键 "k" 的哈希映射. 注意, 每次我们添加相同的键时, 我们都使用不同的元数据.
❷ 访问该键确认最后一个值被覆盖.
❸ 键上的元数据从原始键传播而来.
示例
hash-map和语法字面量{}有类似的目标. 然而,{}要求在编译时指定键值对, 而hash-map允许在运行时组装参数, 可能来自其他集合:(apply hash-map (mapcat vector (repeatedly #(rand-int 10)) (range 4))) ; ❶ ;; {1 3, 9 2, 8 0} {(rand-int 10) 3 ; ❷ (rand-int 10) 2 (rand-int 10) 0} ;; Syntax error. Duplicate key: (rand-int 10)
❶ 这个哈希映射中的键是随机生成的. 如果生成过程产生冲突 (就像本例中), 映射包含的键会少于预期的 4 个 (由表达式中的
(range 4)决定).❷ 尝试使用语法字面量
{}生成类似的映射失败, 因为在编译时没有对键表达式进行求值:(rand-int 10)作为列表和符号进入映射, 而不是求值为一个随机数.键值对的一个常见情况是 URL 参数. 在下面的例子中, 我们有一个相对较长的 URL, 我们希望从请求中构建一个参数的映射:
(require '[clojure.string :as s]) (def long-url ; ❶ (str "https://notifications.google.com/u/0/_" "/NotificationsOgbUi/data/batchexecute?" "f.sid=4896754370137081598&hl=en&soc-app=208&" "soc-platform=1&soc-device=1&_reqid=53227&rt=")) (defn split-pair [pair] ; ❷ (let [[k v] (s/split pair #"=")] (if v [k v] [k nil]))) (defn params [url] ; ❸ (as-> url x (s/split x #"\?") (last x) (s/split x #"\&") (mapcat split-pair x) (apply hash-map x))) (params long-url) ; ❹ ;; {"soc-device" "1" ;; "_reqid" "53227" ;; "soc-platform" "1" ;; "f.sid" "4896754370137081598" ;; "rt" nil ;; "soc-app" "208" ;; "hl" "en"}
❶ 为了避免一行过长, URL 被人为地分割成多个字符串. 这样也更容易识别键及其值.
❷
split-pair接受一个 "a=b" 形式的字符串对, 并返回一个[a b]的向量. 唯一需要处理的复杂性是值可能不存在, 这种情况下用nil替换.❸
params被组织成垂直流动, 很好地利用了as->. 每一行执行一小段处理, 输出成为下一形式的输入, 使用 "x" 占位符.hash-map是最后应用的部分.❹ 输出显示了 URL 中存在的参数, 并处理了可能缺失的值.
另请参阅
apply可以与hash-map结合使用, 从一个集合中展开参数, 而不是显式地枚举它们.zipmap允许从两个有序集合创建映射, 第一个提供键, 第二个提供值.into提供了另一种构建映射的选项, 从一个键值对列表开始. 与hash-map(需要apply) 不同,into直接接受一个键值对集合.性能考虑和实现细节
=>
O(n)步数, n 为键值对数量=>
O(n)空间hash-map创建一个新的clojure.lang.PersistentHashMap实例, 并在参数数量上呈线性执行. 类似地, 新的哈希映射占用的内存空间在不同键的数量上呈线性关系. 任何后续的assoc操作大致是常数时间 (准确地说是O(log32N)). 对于非常大的映射 (百万个键),assoc的对数性能特征会变得明显 (更多信息请参见assoc的性能特征).以下基准测试比较了
hash-map与其他创建相同大映射 (一百万个键) 的解决方案:(require '[criterium.core :refer [quick-bench]]) (import 'java.util.HashMap) (let [pairs (into [] (range 2e6))] ; ❶ (quick-bench (apply hash-map pairs))) ;; Execution time mean : 595.268066 ms (let [pairs (into [] (map-indexed vector (range 1e6)))] ; ❷ (quick-bench (into {} pairs))) ;; Execution time mean : 716.550233 ms (let [m (HashMap. (apply hash-map (into [] (range 2e6))))] ; ❸ (quick-bench (into {} m))) ;; Execution time mean : 602.384550 ms (let [ks (doall (range 1e6)) vs (doall (range 1e6))] ; ❹ (quick-bench (zipmap ks vs))) ;; Execution time mean : 632.163418 ms
❶ 第一个基准测试在扁平的项目列表上使用
apply,hash-map将其用作键值对.❷ 在第二种方法中, 我们创建了一个适合
into的键值对列表. 生成的映射与第一个例子中的相同.❸ 第三个例子假设我们有一个在别处创建的 Java
java.util.HashMap. 用于基准测试的java.util.HashMap实例是从 Clojure 映射创建的, 但这只是为了基准测试.❹ 最后一个基准测试使用
zipmap.我们可以看到,
hash-map,into或zipmap方法之间没有巨大的差异,hash-map相对于into显示出轻微的优势.如果键和值以向量形式给出, 我们可以使用受
zipmap启发的以下zipmap*. 我们将在内部使用瞬态, 假设放松不变性将提高性能:(defn zipmap* [v1 v2] ; ❶ (let [cnt (count v1)] (loop [m (transient {}) idx 0] (if (< idx cnt) (recur (assoc! m (v1 idx) (v2 idx)) (unchecked-inc idx)) (persistent! m))))) (let [v1 (into [] (range 1e6)) v2 (into [] (range 1e6))] ; ❷ (quick-bench (zipmap* v1 v2))) ;; Execution time mean : 479.392200 ms
❶ 这个版本的
zipmap*假设参数是向量. 有了这个约束, 我们可以直接访问项目并增量构建最终的映射. 注意映射如何作为瞬态进入循环以暂时移除持久性. 它在最后被转换回persistent!.❷ 通过移除对键和值的任何顺序访问, 我们提高了大约 100 毫秒.
- 输入
- 11.1.2 array-map
自 1.0 版本起可用的函数
(array-map ([]) ([& keyvals]))
array-map创建一个新的clojure.lang.PersistentArrayMap, 这是一种类似于哈希映射的关联数据结构:(def m (array-map :a 1 :b 2)) ; ❶ (m :a) ; ❷ ;; 1
❶
array-map的接口与hash-map相同, 接受偶数个参数.❷ 由
array-map创建的映射可以完全像hash-map一样使用.array-map保持与hash-map相同的接口, 但它有一个更简单的线性实现 (与clojure.lang.PersistentHashMap的树状实现相比), 不需要对键进行哈希. 与hash-map或sorted-map相比, 一个独特的方面是array-map在迭代期间保持插入顺序.契约
- 输入
"keyvals"是任意类型的偶数个参数列表, 包括无参数. - 主要异常
当参数数量不是偶数时, 抛出
IllegalArgumentException, 显示哪个键缺少相应的值. - 输出
返回: 一个包含给定
"keyvals"的clojure.lang.PersistentArrayMap, 在迭代时按插入顺序排列. 在有重复键的情况下, 最后一个键的值会覆盖前一个, 而键上的元数据 (如果有的话) 会从原始键中保留 (参见hash-map契约中的元数据保留示例).示例
Clojure 包含一种
array-map自动提升为hash-map的机制. 这可以在使用映射字面量时看到:(type {0 1 2 3 4 5 6 7 8 9}) ;; clojure.lang.PersistentArrayMap ; ❶ (type {0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19}) ;; clojure.lang.PersistentHashMap ; ❷
❶ 一个有 5 个键的映射被创建为
PersistentArrayMap.❷ 一旦映射增长到超过 10 个键, 它就会自动提升为
PersistentHashMap.assoc(以及像zipmap这样基于它的函数) 在必要时也会将array-map提升为hash-map:(def an-array-map (apply array-map (range 200))) (type an-array-map) ;; clojure.lang.PersistentArrayMap ; ❶ (def an-array-map? (assoc an-array-map :a :b)) (type an-array-map?) ;; clojure.lang.PersistentHashMap ; ❷ (def an-array-map! (dissoc an-array-map 0)) (type an-array-map!) ;; clojure.lang.PersistentArrayMap ; ❸
❶ 我们从一个有 100 个键的
array-map开始. 它被正确地报告为PersistentArrayMap实例.❷ 一旦我们对
an-array-map使用assoc, 我们就会得到一个PersistentHashMap实例.❸ 然而请注意,
dissoc不会自动提升.自动提升的原因是
array-map是一个简单的类映射数据结构, 扩展性不超过几百个条目. 即使有这个限制,array-map在其迭代期间的插入顺序保证方面也有一些应用. 例如, 我们可以将表的标题聚合为array-map, 以便将其内容存储为 CSV 文件 (CSV, 或逗号分隔值, 是一种简单而普遍的用于表格数据的纯文本交换格式):- 键是将数据导出到 CSV 文件时使用的列名.
- 值是一个向量对, 包含数据库列中的映射和一个可用于验证相应数据的函数.
- 映射中键的位置是相应列应该出现的位置.
假设我们从数据库中获取数据作为
query-results, 以下是它的工作方式:(def query-results ; ❶ [{:date "01/05/2012 12:51" :surname "Black" :name "Mary" :title "Mrs" :n "20" :address "Hillbank St" :town "Kelso" :postcode "TD5 7JW"} {:date "01/05/2012 17:02" :surname "Bowie" :name "Chris" :title "Miss" :n "44" :address "Hall Rd" :town "Sheffield" :postcode "S5 7PW"} {:date "01/05/2012 17:08" :surname "Burton" :name "John" :title "Mr" :n "41" :address "Warren Rd" :town "Yarmouth" :postcode "NR31 9AB"}]) (defn checkfn [predicate] ; ❷ (fn [val] (let [res (predicate val)] (if (predicate val) val (throw (RuntimeException. (str "Error: '" val "' is not valid"))))))) (def customers-format ; ❸ (array-map 'TITLE [:title (checkfn #{"Mrs" "Miss" "Mr"})] 'FIRST [:name (checkfn (comp some? seq))] 'LAST [:surname (checkfn (comp some? seq))] 'NUMBER [:n (checkfn #(re-find #"^\d+$" %))] 'STREET [:address (checkfn (comp some? seq))] 'CITY [:town (checkfn (comp some? seq))] 'POST [:postcode (checkfn #(re-find #"^\w{2,4} \w{2,4}$" %))] 'JOINED [:date (checkfn #(re-find #"^\d{2}/\d{2}/\d{4} \d{2}:\d{2}$" %))])) (defn csv-str [coll] ; ❹ (str (apply str (interpose "," coll)) "\n")) (defn format-row [format] ; ❺ (fn [row] (let [specs (map second format) data (map (fn [[column checkfn]] (checkfn (row column))) specs)] (csv-str data)))) (defn format-data [data format] ; ❻ (let [headers (csv-str (keys format)) body (map (format-row format) data)] (apply str headers (seq body)))) (println (format-data query-results customers-format)) ; ❼ ;; TITLE,FIRST,LAST,NUMBER,STREET,CITY,POST,JOINED ;; Mrs,Mary,Black,20,Hillbank St,Kelso,TD5 7JW,01/05/2012 12:51 ;; Miss,Chris,Bowie,44,Hall Rd,Sheffield,S5 7PW,01/05/2012 17:02 ;; Mr,John,Burton,41,Warren Rd,Yarmouth,NR31 9AB,01/05/2012 17:08
❶
query-results是一个典型的关于客户的数据库查询的示例输出. 数据按映射组织, 键对应于相应表的列. 这些列不一定符合数据导出所需的格式, 例如 CSV 文件.❷
checkfn创建验证函数. 它接受一个单参数函数, 并创建一个可用于验证的函数. "predicate" 用于确定输入的有效性. 如果输入无效, 它会抛出一个RuntimeException.❸
customer-format是一个array-map, 表示内部数据库格式和外部格式之间的关系. 键有正确的名称和正确的顺序. 值是两个元素的向量: 第一个是数据库中的列名, 第二个是用checkfn创建的验证函数. 注意使用符号而不是关键字作为键: 符号按原样打印, 没有 ":" 前缀, 不需要移除.❹
csv-str接受一个值集合, 并将它们组合成一个以换行符结尾的逗号分隔字符串.❺
format-row函数接受一个 "format" 参数规范, 并用它来创建另一个函数. 输出函数可以与单个 "row" 参数一起使用. 返回的函数接受 1 个数据库行, 并产生一个单行逗号分隔字符串, 包含按正确顺序选择的数据. 该函数还负责调用每个列的验证函数.❻
format-data将每条记录转换为相应的行, 对每个数据库记录调用format-row.❼ 我们可以看到在所有验证都成功时
format-data的输出. - 将信息存储在元数据中
Clojure 包含一个名为 "元数据" 的特性. 元数据允许用通用信息 "标记" 一些 Clojure 类型. 这些信息通常是不可见的, 但可以通过像
meta这样的函数访问, 并在 Clojure 内部广泛用于携带类型和调试描述.例如, 我们可以将数据库列和所需外部名称之间的映射信息附加到哈希映射或数组映射的键上. 如果例如 "JOINED" 是外部格式所需的名称, 但 ":createdat" 是数据库中的名称, 那么将它们链接起来是有意义的. 一种选择当然是示例中提供的那种 (作为映射的值), 但另一种是使用键上的元数据:
(def customers-format ; ❶ (array-map (with-meta 'TITLE {:db :title }) (checkfn #{"Mrs" "Miss" "Mr"}) (with-meta 'FIRST {:db :name }) (checkfn (comp some? seq)) (with-meta 'LAST {:db :surname }) (checkfn (comp some? seq)) (with-meta 'NUMBER {:db :n }) (checkfn #(re-find #"^\d+$" %)) (with-meta 'STREET {:db :address }) (checkfn (comp some? seq)) (with-meta 'CITY {:db :town }) (checkfn (comp some? seq)))) (map (comp :db meta) (keys customers-format)) ; ❷ ;; (:title :name :surname :n :address :town)
❶ 我们可以将元数据附加到符号上 (但不能在关键字上), 并从映射的值中移除数据库列信息.
❷
meta提供对元数据的访问.另请参阅
hash-map是array-map的更健壮和可扩展的版本.array-map在实现细节, 性能特征和插入顺序保证方面与hash-map不同.sorted-map实现并维护项的排序. 当你需要一个按比较器排序 (并保持排序) 的类映射数据结构时, 请使用sorted-map.assoc用于向array-map中增量添加元素. 请记住,array-map在超过 10 个键后可以自动提升为hash-map(确切的数字是实现细节, 而不是可以依赖的特性).性能考虑和实现细节
=> 最好情况下
O(n)步数=> 最坏情况下
O(n^2)步数array-map尽管有类映射的接口, 但它基于数组. 键值对连续存储在一个数组中: 一个项是键, 下一个项是值. 持久性 (不可变数据结构在允许访问先前版本的同时表现出可变性的属性) 是通过在用assoc添加新对之前复制数组来实现的. 按键访问是线性的而不是常数时间, 因为键是通过从数组开头迭代来搜索的.array-map的性能因素导致像assoc这样的函数尽快升级到hash-map.array-map函数本身, 在参数数量上线性地创建一个新的clojure.lang.PersistentArrayMap. 然而, 与hash-map不同,array-map需要额外的工作来处理重复的键. 如果在参数列表中找到一个重复项, 则需要更新前一个键, 这会生成一个线性扫描来搜索它.我们可以通过创建一个有 500 个键的
array-map并将最后一个键额外添加 500 次来看键重复的影响:(require '[criterium.core :refer [quick-bench]]) (let [r1 (doall (concat (range 1000) (repeat 1000 999))) ; ❶ r2 (doall (range 2000))] ; ❷ [(quick-bench (apply array-map r1)) (quick-bench (apply array-map r2))]) ;; Execution time mean : 11.177368 ms ;; Execution time mean : 4.417755 ms
❶
"r1"是一个包含 2000 个元素的范围, 其中最后 1000 个重复相同的数字. 结果的映射将包含 500 个唯一的键.❷
"r2"是一个包含 2000 个不重复项的范围. 结果的映射将包含 1000 个键.重复的可能影响是另一个不鼓励创建大型数组映射的原因, 尽管我们的基准测试模拟了一个不太可能发生的情况.
- 输入
- 11.1.3 sorted-map 和 sorted-map-by
自 1.0 版本起可用的函数
(sorted-map [& keyvals]) (sorted-map-by [comparator & keyvals])
sorted-map是clojure.lang.PersistentTreeMap的构造函数, 这是一种类似于hash-map的数据结构类型, 但它保持键的顺序:(sorted-map :c 3 :b 2 :a 1) ; ❶ ;; {:a 1, :b 2, :c 3}
❶
sorted-map从一个偶数个键值对列表中创建一个映射, 并按顺序打印元素.sorted-map使用默认的比较器来维持顺序.sorted-map-by可以用来传递一个不同的比较器:(sorted-map-by #(< (:age %1) (:age %2)) ; ❶ {:age 35} ["J" "K"] {:age 13} ["Q" "R"] {:age 14} ["T" "V"]) ;; {{:age 13} ["Q" "R"], {:age 14} ["T" "V"], {:age 35} ["J" "K"]}
❶
sorted-map-by接受一个接受两个参数并返回 -1 (第一个参数小于第二个), 0 (参数相等) 或 1 (第一个参数大于第二个) 的函数, 这是比较器的典型接口.排序要求映射中的键是可比较的. 因此, 键对象:
- 需要支持
java.lang.Comparable接口. - 键必须与映射中第一个键的类型相同 (或提供一个接受不同类型的
Comparable接口).
契约
- 输入
"keyvals"是任意类型的参数列表, 包括无参数. 参数需要成对出现, 所以列表计数必须是偶数."comparator"是一个接受 2 个参数的函数. 该函数应返回一个负数, 0 或正数, 以分别表示第一个参数小于, 等于或大于第二个参数. 它是sorted-map-by的强制性参数. - 主要异常
当参数数量不是偶数时, 抛出
IllegalArgumentException, 显示哪个键缺少相应的值.当键不能被转换为
java.lang.Comparable或两个键类型不同且没有兼容的Comparable接口时, 抛出ClassCastException. - 输出
返回: 一个
clojure.lang.PersistentTreeMap, 包含给定的"keyvals", 顺序由默认比较器 (sorted-map) 或给定的比较器 (sorted-map-by) 决定. 在有重复键的情况下, 最后一个键的值会覆盖前一个, 而键上的元数据 (如果有的话) 会从原始键中保留.示例
像其他映射类型 (
hash-map和array-map) 一样, 在有重复键的情况下,sorted-map会保留第一个键的元数据 (如果有的话) 和第二个 (或之后) 键的值:(defn timed [s] ; ❶ (let [t (System/nanoTime)] (println "key" s "created at" t) (with-meta s {:created-at t}))) (def m (sorted-map (timed 'a) 1 (timed 'a) 2)) ; ❷ ;; key a created at 206892376620199 ;; key a created at 206892376884656 (println m) ; ❸ ;; {a 2} (meta (ffirst m)) ; ❹ ;; {:created-at 207021400730108}
❶
timed函数接受一个符号 "s", 并在添加包含创建时间的元数据后返回该符号. 它还在标准输出上打印键的创建时间.❷ 我们使用
timed函数来插入键, 创建一个sorted-map. 第二个键与第一个相同.❸ 我们可以看到 "a" 键的值是添加的第二个值.
❹ 但键上的元数据来自第一个键的创建.
sorted-map的一个有趣用途是实现优先队列 168. 优先队列是计算机科学中重要算法的基础, 例如在图中搜索最优路径. 例如, A* (a-star) 算法可以使用优先队列来实现 169.A* 算法是在 60 年代末设计的, 用于引导机器人在障碍物周围以最优化方式移动, 至今仍在游戏和导航软件中使用. A* 需要一个启发式函数, 即到目的地的近似距离, 用于过滤掉不想要的路径. 以汽车导航系统为例, 启发式函数可以是两个位置之间的直线距离, 这很容易从地理空间数据中获得.
我们可以使用带有复合向量键的
sorted-map-by来实现最优路径的优先队列. 以下是在处理从 "origin" 出发到 "point 1" 和 "point 2" 的两条路径后它的样子:(sorted-map-by compare ; ❶ [4.5 "point 2"] [["origin"] 1.5] ; ❷ [5.5 "point 3"] [["origin"] 2.5]) ; ❸
❶ 我们使用
compare作为比较器, 用sorted-map-by创建一个优先队列.❷ 键是向量, 包含复合距离 (物理路径距离加上启发式距离) 和它所指的位置 ("point 2" 或 "point 3").
❸ 映射中的值也是向量: 第一个元素是到达键所需的位*置*向量 (本例中只有 "origin"), 第二个包含从上一个访问位置到当前位置的距离 (例如从 "origin" 到 "point 2" 的距离是 1.5).
上面例子中的
sorted-map-by展示了如何在有序映射中使用复合键. 向量可以用作键, 但它们本身不实现java.lang.Comparable接口, 需要显式使用compare作为比较器.在我们迭代位置之前, 我们需要一个合适的表示. 位置可以被图形化地表示为一个循环有向图, 如下图所示:
Figure 31: Figure 11.1. 位置和连接它们的路线. 我们希望使用最短路径从 "Orig" 移动到 "Dest".
我们可以用一个包含所有位置作为键的映射来翻译这个图:
(def graph {:orig [{:a 1.5 :d 2} 0] ; ❶ :a [{:orig 1.5 :b 2} 4] :b [{:a 2 :c 3} 2] :c [{:b 3 :dest 4} 4] :dest [{:c 4 :e 2} 0] :e [{:dest 2 :d 3} 2] :d [{:orig 2 :e 3} 4.5]})
❶ 每个位置键的值是一个包含两个项的向量. 第一项是另一个映射, 包含连接的位置和它们与键的距离. 第二个元素是该位置的启发式值.
A* 算法的以下实现接受
graph作为输入, 一个起点和一个终点. 该算法由三个函数实现:a*是主入口点,walk是一个遍历图的尾递归函数,discover帮助在每次迭代中移除已经访问过的节点 (消除潜在的无限循环). 每次walk迭代都会选择使启发式值加上从起点开始的实际距离最小化的节点. 同时, 我们发现新的节点放入优先队列以供下一次迭代:(defn discover [node path visited] (let [walkable (first (graph node)) ; ❶ seen (map last (keys visited))] (reduce dissoc walkable (conj seen (last path))))) ; ❷ (defn walk [visited dest] (loop [visited visited] (let [[[score node :as current] [path total-distance]] (first visited)] ; ❸ (if (= dest node) (conj path dest) (recur (reduce-kv ; ❹ (fn [m neighbour partial-distance] (let [d (+ total-distance partial-distance) score (+ d (last (graph neighbour)))] (assoc m [score neighbour] [(conj path node) d]))) ; ❺ (dissoc visited current) ; ❻ (discover node path visited))))))) (defn a* [graph orig dest] (walk (sorted-map-by compare [0 orig] [[] 0]) dest)) ; ❼ (a* graph :orig :dest) ; ❽ ;; [:orig :d :e :dest] (a* graph :d :c) ;; [:d :e :dest :c]
❶ 为了访问从当前位置可访问的所有节点, 我们需要使用位置 "node" 作为键来访问图.
❷ 重复使用
dissoc移除我们已经见过的节点.❸ 解构在这里非常重要, 有助于减少我们需要编写的代码量. 从
visited中取出的第一个是当前使到目前为止的距离与启发式 (在本例中是到目的地的直线距离) 之和最小化的位置.❹
reduce-kv从访问过的位置的优先映射开始, 遍历可遍历节点的列表. 它还计算聚合指标, 如从起点的总距离.❺ 移动到一个新位置时, 我们还需要构建到达它的路径, 以防这个位置成为解决方案 (当前位置是目的地).
❻ 在再次开始计算之前, 我们需要移除优先列表中的第一个节点, 以避免无限递归.
❼ 在初始化期间, 我们用
sorted-map-by创建一个只包含 "orig" 的有序映射.❽ 我们可以调用
a*来搜索从:orig到:dest或任何其他位置对的最佳路径. - 比较器和元素的唯一性
正如我们将在
sorted-set-by中看到的,sorted-map-by的自定义比较器需要精心设计, 以便能正确地处理各种类型的键. 例如, 当键是集合时, 可能会有一个难以检测的特定问题. 观察下面的例子, 我们试图创建一个有序集合, 其向量键按其大小的倒数排序:(sorted-map-by #(compare (count %2) (count %1)) ; ❶ [:a :b] 1 [:a] 2 [:b] 3) ;; {[:a :b] 1, [:a] 3}
❶ 一个有缺陷的
sorted-map-by自定义比较器.比较器工作不正常的第一个迹象是结果集中缺少了 `[:b]` 键. 第二个提示是后续操作会不可预测地失败:
(def ordered-by-count ; ❶ (sorted-map-by #(compare (count %2) (count %1)) [:a :b] 1 [:a] 2 [:b] 3)) (assoc ordered-by-count [:x] 4) ; ❷ ;; {[:a :b] 1, [:a] 4} (dissoc ordered-by-count [:x]) ; ❸ ;; {[:a :b] 1}
❶
ordered-by-count是一个按其向量键大小的倒数排序的sorted-set-by.❷ 我们尝试将键 `[:x]` 与值 "4" 关联, 但键没有出现在结果集中.
❸ 当我们尝试
dissoc一个不存在的键时, 结果是移除了一个实际存在但不同的键.比较器工作不正常, 因为它既用于检查一个键是否在映射中, 也用于决定它在结果有序映射中的相对顺序. 比较器没有考虑到第一个方面, 即它将被用来检查键是否已经在映射中:
(def flawed-comparator #(compare (count %2) (count %1))) (flawed-comparator [:a] [:x]) ; ❶ ;; 0
❶ 这在概念上是如何使用比较器来验证键 `[:x]` 与有序集合中另一个已存在键 `[:a]` 相同. 这里的 "0" 意味着键是相同的, 但这只意味着 "大小相同" 而不是 "相等".
比较器被调用来比较有序集合中已有的每个键和要插入的新键 `[:x]`. 由于它们的大小相同, 它错误地得出 `[:x]` 已经在集合中的结论, 不应被添加. 缺少的是一个额外的检查, 以确定键是否实际上相同:
(def good-comparator ; ❶ #(compare [(count %2) %1] [(count %1) %2])) (good-comparator [:a] [:x]) ; ❷ ;; -23
❶ 一个好的复合键比较器应该检查特定的自定义排序约束以及完整的键相等性. 通过将这两个方面配对在一个向量中, 我们使用向量相等性来同时验证它们.
❷
good-comparator现在返回 "-23", 这是字母 "a" 和 "x" 在字母表中的距离差异. 但从compare的角度来看, 我们关心的是这个数字是负数, 表明这两个键不相等, 并且它们都应该是sorted-set的一部分.通过正确地制定自定义比较器, 我们可以看到
sorted-set-by的行为符合预期:(def ordered-by-count (sorted-map-by #(compare [(count %2) %1] [(count %1) %2]) [:a :b] 1 [:a] 2 [:b] 3)) (assoc ordered-by-count [:x] 4) ; ❶ ;; {[:a :b] 1, [:a] 2, [:b] 3, [:x] 4} (dissoc ordered-by-count [:x]) ; ❷ ;; {[:a :b] 1, [:a] 2, [:b] 3}
❶ 修复自定义比较器后, 新键的
assoc行为符合预期, 同时也保持了按键大小排序 (大向量在前).❷
dissoc也按预期工作, 不会移除不应该被移除的元素.也请读者查看
sorted-set中的标注部分以获取更多考虑.另请参阅
sorted-set是创建有序集合而不是映射的类似函数.subseq用于从有序映射或集合的元素开始生成序列.hash-map或array-map是 Clojure 中可用的其他类型的持久化类字典数据结构.性能考虑和实现细节
=>
O(N)线性于要插入的键数sorted-map和sorted-map-by是作为持久化红黑树实现的, 这是一种提供O(logN)访问, 插入和删除保证的解决方案 170.O(logN)中的 "N" 指的是在插入新键时有序映射中的键数. 然而, 在从头构建有序映射时, 步数与要插入的键数呈线性关系.在下面的基准测试中, 我们比较了创建具有 1000 个键的有序映射的不同方法, 最后一个例子使用 Java
TreeMap进行比较:(require '[criterium.core :refer [quick-bench]]) (import '[java.util TreeMap]) (let [pairs (into [] (range 2e3))] ; ❶ (quick-bench (apply sorted-map pairs))) ;; Execution time mean : 452.317814 µs (let [pairs (into [] (map-indexed vector (range 1e3)))] ; ❷ (quick-bench (into (sorted-map) pairs))) ;; Execution time mean : 469.676463 µs (let [m (apply hash-map (into [] (range 2e3)))] ; ❸ (quick-bench (TreeMap. m))) ;; Execution time mean : 158.487373 µs
❶ 我们使用
apply将键值对列表展开给sorted-map构造函数.❷ 在这种情况下, 我们使用
into传入相同数量的键.❸ 最后一个案例构建一个类似但可变的 Java 数据结构.
基准测试显示
apply和into之间几乎没有区别. 正如预期的那样, 可变的 Java 版本大约快 3 倍.在讨论 a* 算法时, 我们使用
first来从有序映射中访问最佳位置. 虽然first通常是一个不错的选择, 但它增加了将有序映射转换为序列的开销. 实现有序映射的 Java 类包含两个未在标准库中公开的公共方法min和max. 以下基准测试显示了当我们使用 Java 互操作访问.min时性能有显著提升:(require '[criterium.core :refer [quick-bench]]) (import '[clojure.lang PersistentTreeMap]) (let [m (apply sorted-map (range 10))] ; ❶ (quick-bench (first m))) ; ❷ ;; Execution time mean : 57.393946 ns (let [m (apply sorted-map (range 10))] (quick-bench (.min ^PersistentTreeMap m))) ; ❸ ;; Execution time mean : 6.234699 ns
❶, ❷ 第一个基准测试使用
first访问映射.❸ 在第二种情况下, 我们通过 Java 互操作使用
PersistentTreeMap::min()方法. 我们可以看到一个数量级的速度提升.访问有序映射以检索第一个或最后一个元素是常见情况 (特别是当它们用作优先队列时). 在这种情况下, 我们可以直接使用
min或max方法, 记住要对映射进行类型提示以避免非常昂贵的反射查找.
- 需要支持
- 11.1.4 create-struct, defstruct, struct-map, struct 和 accessor
函数 (除了
defstruct) 自 1.0 版本起可用(create-struct [& keys]) (defstruct [name & keys]) (struct-map [s & inits]) (struct [s & vals]) (accessor [s key])
这组四个函数和一个宏 (
defstruct) 是 Clojure 中struct类型的编程接口.struct是clojure.lang.PersistentStructMap的一个实例, 这是一种类映射类型, 它嵌入了一个结构定义: 与普通映射不同,struct总是保证定义的一组键的存在.struct被设计用来在需要创建许多类映射对象时减少键的重复 (例如, 在将大型结构化数据解析到 Clojure 中后保存它们). 它们后来被defrecord取代,defrecord额外提供了一些形式的继承. 然而,struct并没有被废弃 (函数体中没有官方的 "废弃" 标签), 并且仍在 Clojure 标准库的某些部分中使用 (例如 XML 处理,resultset-seq或cl-format). 与array-map和defrecord一样,struct是唯一其他保持键插入顺序的映射类型.契约
- 输入
"keys"是struct中应存在的最小键集."name"定义了struct的名称, 它被分配给当前命名空间中的一个局部变量 (由defstruct)."s"是用create-struct或defstruct创建的struct定义. 它被struct-map,struct和accessor用来访问先前定义的struct."inits"是可以传递给struct-map以初始化新struct实例的非结构化键值对.vals是传递给struct的值列表. 值应在位置上与struct定义中的键相匹配.key被accessor用来创建一个函数, 以访问给定struct实例中的那个键. - 主要异常
如果传递给
struct的"vals"太多, 鉴于定义中的键少于给定的值, 则抛出IllegalArgumentException.尝试
dissoc一个属于struct定义的键时抛出RuntimeException. - 输出
create-struct创建一个包含给定"keys"的新PersistentStructMap$Def定义对象. 至少需要一个键.defstruct相当于将create-struct创建的定义分配给一个变量.struct-map基于一个struct定义和一个键值对列表"inits"创建一个新的struct实例. 如果"inits"不包含struct中定义的键, 则这些键被分配一个默认的nil值. 除了定义中的键, 其他键值对也被接受.struct接受一个定义和一个值列表.struct会尝试在位置上将值与键定义相关联. 键的缺失值会导致被分配一个默认值nil."vals"的数量可以等于或小于键的数量.accessor返回一个接受一个参数的函数. 该函数接受一个struct实例并检索特定"key"处的值.示例
struct是具有最小必需键集的类映射类型. 当使用struct时, 我们需要区分它们的定义 (调用create-struct的结果) 和它们的实例化 (在定义上调用struct或struct-init的结果). 例如, 相等性对于定义和实例具有不同的含义:(= (create-struct :x :y) ; ❶ (create-struct :x :y)) ;; false (= (struct (create-struct :x :y) 1 2) ; ❷ (struct (create-struct :x :y) 1 2)) ;; true
❶ 在第一个例子中, 我们比较了两个
struct定义. 尽管它们包含相同的键, 但这两个定义是独立的.❷ 第二个例子使用相同的值从定义中实例化一个实际的
struct对象. 具有相同键和值的两个实例是相同的.此外, 具有不同键集的定义可以通过添加缺失的键来生成相等的
struct实例:(defstruct point-2d :x :y) ; ❶ (defstruct point-3d :x :y :z) ; ❷ (= (assoc (struct point-2d 1 2) :z 3) ; ❸ (struct point-3d 1 2 3)) ;; true
❶
point-2d是一个包含两个坐标 ":x" 和 ":y" 的struct定义.❷
point-3d向定义中添加了第三个维度 ":z".❸ 一个只有两个维度的点可以通过添加缺失的坐标来与三维点相同. 注意, 为了使等价性成立, 键需要具有相同的名称, 值和顺序.
struct比更强大的defrecord简单得多. 一个根本的区别是create-struct创建一个匿名的struct定义, 而defrecord则作为副作用创建一个 Java 类.defrecord按设计生成一个类: 这允许强大的特性, 如记录类型的继承. 同时,record在命名空间之间使用更复杂 (因为它们需要一个显式的import语句), 并且当它们的定义改变时重新加载也更棘手. 下面的例子说明了这种差异:(struct (create-struct :a :b :c) 1 2 3) ; ❶ ;; {:a 1, :b 2, :c 3} (type (defrecord abc [a b c])) ; ❷ ;; java.lang.Class (abc. 1 2 3) ; ❸ ;; #user.abc{:a 1, :b 2, :c 3}
❶
struct定义可以在不必分配名称的情况下存在, 所以它们可以被直接创建和实例化.❷ 另一方面,
defrecord需要一个名称并生成一个不能直接使用的java.lang.Class.❸ 由
defrecord生成的类 "abc" 现在在 "user" 命名空间中可用, 并可用于初始化一个新的记录实例.在下面的例子中, 我们将使用内联的
struct定义. 一个 "waypoint" 包含地球上一个兴趣点的坐标. 它包含一个类型, id, 纬度和经度. 这是相关的struct定义:(require '[clojure.string :refer [split-lines split]]) (def waypoints "https://tinyurl.com/station-locs") ; ❶ (def lines (-> waypoints slurp split-lines)) (def waypoints (let [sdef (create-struct :type :lat :lon :id)] ; ❷ (transduce (comp (map #(split % #"\s+")) (map #(apply struct sdef %))) ; ❸ conj lines))) (first waypoints) ; ❹ ;; {:type "VHF", :lat "0.000000", :lon "0.000000", :id "ABI"}
❶ 这个 url 指向一个包含约 50000 个兴趣点的列表 (最初从 ral.ucar.edu/maps/Station.loc 下载). 我们可以加载其内容并使用
clojure.string/split-lines分割行.❷
struct定义是作为解析列表的计算的一部分, 用create-struct创建的. 注意, 如果需要, 定义可以在运行时更改, 例如, 查看航点的 ":type" 来添加特定的键.❸ 每一行被分割成四个值, 这些值被应用到
struct定义中.❹ 我们可以看到一个航点的例子, 它打印出来就像一个普通的映射.
struct-map是实例化struct的另一种方式. 当将一个普通的哈希映射转换为一个具有相应键的struct时, 它很有用:(defstruct waypoint :type :lat :lon :id) ; ❶ (def coordinates [ ; ❷ {:alt 150 :lat "18.3112" :lon "3.1314" :id "XVA"} {:alt 312 :lon "10.04883" :id "FFA" :type "XFV"} {:temp 78.3 :lat "23.7611" :id "XJP"}]) (defn to-waypoints [coords] ; ❸ (map #(apply struct-map waypoint (mapcat identity %)) coords)) (to-waypoints coordinates) ; ❹ ;; ({:type nil, :lat "18.3112", :lon "3.1314", :id "XVA", :alt 150} ;; {:type "XFV", :lat nil, :lon "10.04883", :id "FFA", :alt 312} ;; {:type nil, :lat "23.7611", :lon nil, :id "XJP", :temp 78.3})
❶
waypointstruct现在是使用一个命名空间局部变量定义来定义的. 从这一点开始, 该定义在当前命名空间 (或如果需要, 其他命名空间) 中是可见的.❷ 我们收到一个异构坐标的向量, 有时有我们需要的键, 有时有缺失的数据.
❸
to-waypoints将一个映射列表转换为waypointstruct对象. 我们需要使用mapcat将映射的内容扁平化为一个没有括号的键值对的普通列表. 然后我们可以使用apply将列表馈送到struct-map.❹ 最终结果是一个
struct列表. 与之前不同的是, 保证了来自waypoint定义的最小键集的存在, 尽管相应的值可能是nil.accessor通过跳过典型的基于哈希的访问, 使用更快的数组索引查找来优化对struct字段的频繁访问. 参考前面的例子, 我们可以定义访问器来访问waypoint实例, 如下所示:(def k-type (accessor waypoint :type)) ; ❶ (def k-lat (accessor waypoint :lat)) (def k-lon (accessor waypoint :lon)) (def k-id (accessor waypoint :id)) (def waypoints (to-waypoints coordinates)) (map k-id waypoints) ; ❷ ;; ("XVA" "FFA" "XJP")
❶
accessor在当前命名空间中创建一个接受struct实例的函数. 我们为waypoint中的每个键定义一个访问器.请参阅下面的性能部分, 以了解可能的性能增益.
- Lisp
defstruct
defstruct指定了一组支持的键, 类似于 Java 类声明支持的属性. 同时,struct创建了这样一个规范的实例, 类似于对象表示类的实例. 因此, Clojure 邮件列表上一个常见的问题是如何使用defstruct设计继承, 因为它有类似类的外观. 但defstruct并不提供对象系统提供的任何强大功能, 例如行为继承. 另一个将struct视为类和对象的原因是 Common Lisp 中存在相同的关键字:;; Lisp code (defstruct ; ❶ (person (:constructor create-person (id name age))) id name age) (create-person 1 "reborg" 40) ; ❷ ;; #S(PERSON :ID 1 :NAME "reborg" :AGE 40)
❶
defstruct也存在于 Common Lisp 中, 并且早于 CLOS (Common Lisp Object System) 的集成. 我们在这里声明一个具有 id, name 和 age 的 "person" 记录的构造函数.❷ 生成的构造函数可以通过使用所需参数调用它来使用.
Common Lisp
defstruct被设计为提供面向对象的特性, 如继承:(defstruct (female (:include person)) ; ❶ (gender "female" :type string)) (make-female :name "Debby") ;; #S(FEMALE :ID NIL :NAME "Debby" :AGE NIL :GENDER "female")
❶ 通过包含 "person", 我们继承了所有人都共有的属性, 同时我们也可以定义额外的属性, 如 "GENDER".
Clojure
defstruct和 Common Lisp 之间的相似性可能解释了为什么早期来到 Clojure 的人 (特别是来自 Lisp 背景的人) 试图以不同于其预期用途 (一种优化) 的方式使用struct. 几年后, Clojure 引入的defrecord和defprotocol消除了这种歧义.defrecord也提供了与defstruct相同的功能: 目前, 很少有用例需要使用struct而不是defrecord, 并且本章已经强调了一些差异. 这就是为什么 Clojure 官方文档会引导读者使用defrecord而不是defstruct的原因.另请参阅
defrecord有效地替代了defstruct, 用于定义强类型的类映射结构. 它额外提供了一种形式的继承和对接口声明的支持. 优先使用defrecord来模拟面向对象编程. 除非你需要用于内部计算的轻量级一次性类映射对象, 否则defrecord几乎总是首选.性能考虑和实现细节
=> 只有
accessor是O(1)=> 其他函数和宏是
O(n)创建
struct定义在请求的键数上是线性的, 并受 Java 数组中可寻址的最大元素数量 ((Integer/MAXVALUE) 或 2,147,483,647 个键) 的限制. 给定一个定义, 创建一个struct实例在键数上也是线性的.accessor是唯一一个以常数时间返回的函数.为了实际使用, 让我们验证
struct与defrecord的性能比较. 参考从文件中创建大量航点, 我们可以比较struct,defrecord,array-map和hash-map之间的总体性能和内存开销:(require '[clojure.java.io :refer [reader]]) (require '[clojure.string :refer [split-lines split]]) (require '[criterium.core :refer [quick-bench]]) (def waypoints "https://tinyurl.com/station-locs") (def lines (->> waypoints slurp split-lines (map #(split % #"\s+")))) (last lines) ;; ["ARP" "44.244823" "-84.179802" "Y31"] ; ❶ (defstruct w-struct :type :lat :lon :id) ; ❷ (defrecord w-record [type lat lon id]) (defn w-map [type lat lon id] {:type type :lat lat :lon lon :id id}) (defn w-hmap [type lat lon id] (hash-map :type type :lat lat :lon lon :id id)) (quick-bench (doall (map #(apply struct w-struct %) lines))) ;; Execution time mean : 8.602227 ms (quick-bench (doall (map #(apply ->w-record %) lines))) ;; Execution time mean : 6.172892 ms (quick-bench (doall (map #(apply w-map %) lines))) ;; Execution time mean : 7.157129 ms (quick-bench (doall (map #(apply w-hmap %) lines))) ;; Execution time mean : 20.554723 ms
❶
lines包含一个航点列表, 作为字符串的向量. 通过请求最后一个, 我们已经完全实现了这个序列.❷
w-struct,→w-record,w-map和w-hmap是我们测试所需的 4 个构造函数. 注意,w-map创建的是array-map而不是hash-map.我们可以看到
defrecord是这组中最快的,array-map和struct紧随其后. 创建hash-map的性能最差. 我们现在可以对访问航点进行基准测试. 每种类型都有几种方法来根据键访问值. 对于struct, 我们将创建特定的访问器:(def points-struct (doall (map #(apply struct w-struct %) lines))) (def points-record (doall (map #(apply ->w-record %) lines))) (def points-map (doall (map #(apply w-map %) lines))) (def points-hmap (doall (map #(apply w-hmap %) lines))) (def id (accessor w-struct :id)) (let [w (first points-struct)] (quick-bench (id w))) ; ❶ ;; Execution time mean : 4.318680 ns (let [w (first points-struct)] (quick-bench (:id w))) ;; Execution time mean : 10.249677 ns (let [w (first points-record)] (quick-bench (:id w))) ;; Execution time mean : 4.626574 ns (let [w (first points-map)] (quick-bench (:id w))) ;; Execution time mean : 9.730 ns (let [w (first points-hmap)] (quick-bench (:id w))) ;; Execution time mean : 14.216794 ns (let [^user.w-record w (first points-record)] (quick-bench (.id w))) ; ❷ ;; Execution time mean : 3.612035 ns
❶ 我们可以看到, 当使用更快的访问器时,
defrecord和struct之间存在实质性的等价性.❷
defrecord还生成一个 Java 类型, 接受对其类上的访问器方法的直接访问. 我们需要记住给编译器一个类型提示, 结果会稍微快一些.总的来说, 与
defstruct相比,defrecord在创建和访问数据方面更快, 并提供了额外的 Java 互操作选项以实现进一步的速度提升. 下图显示了到目前为止所检查的 4 种类结构类型的内存分析. 字节数是通过在 VisualVM 中使用内存分析, 在一个空的 JVM 上加载前面介绍的相同航点列表获得的 171:
Figure 32: Figure 11.2. 不同类型的类映射结构的内存分配比较.
我们可以看到大约 42,900 个分配的对象, 对应于文件中的航点数量.
clojure.lang.PersistentStructMap代表defstruct, 分配了 1,716,360 字节.defstruct比下面的user.poi-recorddefrecord(2,069,632 字节) 更便宜. 这组中最便宜的是array-map, 总共分配了 1,373,152 字节. 这组中的最后一项是clojure.lang.PersistentHashMap, 即普通的hash-map. 在这种情况下, 也分配了BitmapIndexedNode实例, 总内存分配增加到 2,746,328 字节.
- 输入
- 11.1.5 zipmap
自 1.0 版本起可用的函数
(zipmap [keys vals])
zipmap从一个键集合和一个值集合创建一个新的array-map(或hash-map, 取决于键的数量). 键值对是通过对两个输入集合进行有序的顺序访问来形成的:(zipmap [:a :b :c] [1 2 3]) ; ❶ ;; {:a 1, :b 2, :c 3} (type (zipmap (range 10) (range 10))) ; ❷ ;; clojure.lang.PersistentHashMap
❶
zipmap接受两个有序集合, 并生成一个新的array-map.❷ 当键的数量足够大时, 输出会自动提升为
hash-map.当键和值来自处理分离的集合时,
zipmap是一个创建映射的有用函数.契约
- 输入
"keys"和"vals"都是遵循seq契约以转换为序列的序列集合 (如有必要). 它们都是必需的参数, 但可以为空或nil. - 主要异常
如果
"keys"或"vals"不是序列性的, 则抛出IllegalArgumentException. - 输出
返回: 由交替从
"keys"和"vals"中取出的键和值形成的映射. 如果"keys"包含重复项, 则最后一个键 (及相应的值) 会覆盖前一个 (遵循assoc语义). 如果键和值的数量不同,zipmap在达到两者中最短的一个后停止. 如果任一参数为nil或空, 它返回一个空映射.请注意,
zipmap返回的实际类型可以是clojure.lang.PersistentArrayMap(对于少于 10 个键的小映射) 或clojure.lang.PersistentHashMap(对于 10 个或更多键). 这与hash-map相关函数 (如assoc) 的自动提升行为一致. 还要注意, 映射的打印 (或迭代) 顺序可能与初始 "keys" 和 "vals" 的顺序不同.示例
首先, 值得记住的是,
zipmap不保证生成的映射遵循输入的顺序:(zipmap (range 10) (range 10)) ; ❶ ;; {0 0, 7 7, 1 1, 4 4, 6 6, 3 3, 2 2, 9 9, 5 5, 8 8}
❶ 该示例显示, 即使键和值是按顺序给出的, 打印时映射的内部排序也是不确定的.
尽管没有排序保证, 以下表达式始终为真:
(let [m {:a 1 :b 2 :c 3 :d 4 :e 5}] (= m (zipmap (keys m) (vals m)))) ; ❶ ;; true
❶ 我们总是可以通过在输入映射 "m" 上调用基于哈希的函数, 并使用
zipmap来构建一个新的映射, 从而构建一个等效的映射. 原始映射 "m" 和新创建的映射是等效的, 尽管排序不确定.zipmap可用于生成一个所有值都相同的映射 (例如, 将它们初始化为 "1"):(zipmap ["red" "blue" "green"] (repeat 1)) ; ❶
❶ 无限序列对于
zipmap不是问题. 在这里我们可以看到每个颜色键都得到一个值为 "1".当键和值不一定在编译时可用时,
zipmap对于构建映射很有用. 一个典型的情况是面向记录的数据, 如数据库结果集或逗号分隔值文件. 在下面的例子中, 我们要处理一个 CSV 文件 (通常包含一个标题和许多行的纯文本文件). 我们希望将每一行值转换为一个 Clojure 映射, 使用标题作为键:(require '[clojure.java.io :as io]) (require '[clojure.string :as s]) (def file-content ; ❶ "TITLE,FIRST,LAST,NUMBER,STREET,CITY,POST,JOINED Mrs,Mary,Black,20,Hillbank St,Kelso,TD5 7JW,01/05/2012 12:51 Miss,Chris,Bowie,44,Hall Rd,Sheffield,S5 7PW,01/05/2012 17:02 Mr,John,Burton,41,Warren Rd,Yarmouth,NR31 9AB,01/05/2012 17:08") (defn split-line [line] ; ❷ (s/split line #",")) (defn transform [data] ; ❸ (let [lines (line-seq data) headers (split-line (first lines))] (eduction (map split-line) (map (partial zipmap headers)) ; ❹ (rest lines)))) (with-open [data (io/reader (char-array file-content))] ; ❺ (doall (transform data))) ;; ({"TITLE" "Mrs", "FIRST" "Mary", "LAST" "Black", "NUMBER" "20", ;; "STREET" "Hillbank St", "CITY" "Kelso", "POST" "TD5 7JW", ;; "JOINED" "01/05/2012 12:51"} ;; {"TITLE" "Miss", "FIRST" "Chris", "LAST" "Bowie", "NUMBER" "44", ;; "STREET" "Hall Rd", "CITY" "Sheffield", "POST" "S5 7PW", ;; "JOINED" "01/05/2012 17:02"} ;; {"TITLE" "Mr", "FIRST" "John", "LAST" "Burton", "NUMBER" "41", ;; "STREET" "Warren Rd", "CITY" "Yarmouth", "POST" "NR31 9AB", ;; "JOINED" "01/05/2012 17:08"})
❶ CSV 文件的一小部分在内存中使用字符串进行模拟.
❷
split-line函数包含将行字符串分割成多个字符串并移除它们之间所有 "," 的逻辑. 结果序列可用作zipmap的值.❸
transform包含将 "data" (假设为java.io.Reader实例) 转换为格式良好的映射的转换逻辑. 关闭读取器的责任委托给调用者.❹ transducer 的组合用
eduction对计算进行建模.zipmap是应用于每个值列表的最后一个 transducer 的一部分. 标题已经分配给一个局部绑定, 并准备好使用.❺ 我们使用
char-array模拟从一个示例字符串加载, 而不是从文件. 要从文件加载数据, 我们需要将绑定 "data" 更改为(io/reader "somefile.csv"), 无需其他更改.另请参阅
hash-map是标准的映射构造函数, 接受任意数量的参数 (作为键值对). 当键值对被显式枚举或当键和值来自单个集合时, 可以使用hash-map.array-map是映射的一个特殊版本, 保持插入顺序. 它对于少数键 (如作为函数参数传递的映射) 很有效, 但它存在低效的线性访问问题.sorted-map提供了一种使用比较器按键创建有序映射的方法.into也可以生成映射, 前提是输入集合具有正确的格式 (一个键值对的集合).性能考虑和实现细节
=>
O(n)线性于键的数量zipmap是作为输入的loop-recur实现的, 需要 n 步才能返回输出, 其中 "n" 是 "keys" 和 "vals" 中较短的一个.zipmap的实现不使用瞬态, 这是一个被into等采用的解决方案. 我们在讨论hash-map性能时已经看到了对zipmap的改进, 假设 "keys" 和 "vals" 是向量. 我们现在可以展示一个适用于所有类型参数的更快的zipmap实现:(require '[criterium.core :refer [quick-bench]]) (defn zipmap* [keys vals] ; ❶ (loop [m (transient {}) ks (seq keys) vs (seq vals)] (if (and ks vs) (recur (assoc! m (first ks) (first vs)) (next ks) (next vs)) (persistent! m)))) (let [s1 (range 1000) s2 (range 1000)] (quick-bench (zipmap s1 s2))) ;; Execution time mean : 150.549758 µs (let [s1 (range 1000) s2 (range 1000)] (quick-bench (zipmap* s1 s2))) ; ❷ ;; Execution time mean : 128.869009 µs
❶ 新的
zipmap*是对现有实现的一个轻微修改, 以便使用一个瞬态映射.❷ 我们可以看到, 在这个 1000 个键的例子中, 使用瞬态可以提高大约 30% 的速度.
这个使用瞬态的
zipmap*的实现曾被考虑用于 Clojure 核心, 但从未进入 Clojure 的发布版本 172.
- 输入
3.4.2. 11.2 访问
- 11.2.1 keys 和 vals
(keys [map]) (vals [map])
keys和vals是两个用于从类映射类型 (hash-map, array-map, sorted-map, struct-map 或其他实现java.util.Map接口的对象) 中检索键或值序列的工具函数:(keys {:a 1 :b 2 :c 3 :d 4 :e 5 :f 6 :h 7 :i 8 :j 9}) ; ❶ ;; (:e :c :j :h :b :d :f :i :a) (vals (array-map :a 1 :b 2 :c 3 :d 4 :e 5 :f 6 :h 7 :i 8 :j 9)) ; ❷ ;; (1 2 3 4 5 6 7 8 9)
❶
keys从给定映射中检索键的序列. 注意, 由于输入是hash-map类型, 返回的键的顺序没有保证.❷
vals检索映射中值的序列. 注意, 由于输入映射是array-map, 序列是有序的.keys和vals不保证输出的顺序, 这取决于输入的类型.契约
- 输入
"map"是唯一的参数, 并且是必需的. 它可以是 Clojure 映射类型之一 (实现clojure.lang.IPersistentMap接口), Java 映射类型 (扩展java.util.Map) 或java.util.Map$Entry(表示键值对的类) 的集合. 空集合或nil也是可能的参数. - 主要异常
当
"map"不是允许的映射类型之一, 或者当集合不包含java.util.Map$Entry实例时, 抛出ClassCastException. - 输出
keys返回"map"中键的序列, 顺序取决于"map"的类型.vals返回"map"中值的序列, 顺序取决于"map"的类型.虽然
keys和vals可能返回顺序不确定的结果 (取决于输入类型), 但在使用相同输入时, 顺序是一致的.示例
契约允许在所有类型的 Clojure 和 Java 映射上调用
keys或vals. 它还包括使用java.util.Map$Entry对象集合的选项.java.util.Map$Entry是将映射作为序列处理的结果, 例如在映射上使用map或filter:(def filter-odd (filter (comp odd? second) {:a 1 :b 2 :c 3 :d 4})) (map type filter-odd) ;; (clojure.lang.MapEntry clojure.lang.MapEntry) (keys filter-odd) ; ❶ ;; (:a :c)
❶ 我们在一个映射上调用
filter. 映射被转换为java.util.Map$Entry的序列. 我们可以使用keys来查看哪个键具有奇数值.keys和vals可用于从配置映射中提取有意义的信息. 通常, 在启动时读取配置映射以确定应用程序的行为. 例如, 我们可以用它来实现一种简单的语言处理形式. 以下配置映射包含有关用于评估句子语气的 n-gram (词的组合) 的数据, 我们将用它来衡量句子中使用的强调程度:(def matchers ; ❶ {"next generation" 10 "incredible" 10 "revolution" 10 "you love" 9 "more robust" 9 "additional benefits" 8 "evolve over time" 8 "brings" 7 "perfect" 5 "better solution" 7 "now with" 6}) (defn avg-xf [rf] ; ❷ (let [cnt (volatile! 0)] (fn ([] (rf)) ([result] (rf (if (zero? @cnt) 0. (float (/ result @cnt))))) ([result input] (vswap! cnt inc) (rf result input))))) (defn score [text] ; ❸ (transduce (comp (map #(re-find (re-pattern %) text)) (keep #(matchers %)) avg-xf) + (keys matchers))) ; ❹ (score "All-new XT600 brings all the features ; ❺ you love about XT300, now with a new design, improved sound and a lower price!") ;; 7.3333335 (score ; ❻ "We think this book is a perfect fit for the intermediate or seasoned Clojure programmer who wants to understand how a function (and ultimately Clojure) works") ;; 5.0
❶
matchers是一个从单词到权重的映射. 权重越高, 该片段在确定句子强调程度方面越重要. 在实际场景中, 该映射将是对一些大型文本应用自然语言处理的结果.❷
avg-xf是一个平均值 transducer."xf"是命名 transducer 的典型后缀. 这个特殊的 transducer 需要是只处理数字的组合链中的最后一个. 在内部,avg-xf维护一个计数器, 记录有多少项被加到最终总和中, 并在退出步骤中产生平均值.❸
score包含计算给定句子总分的逻辑. 文本被搜索片段, 每个片段根据matchers映射的内容有不同的权重.❹
matchers映射的键是transduce的输入. 每个键在正则表达式中使用, 然后再次用于访问权重.❺ 一个典型的广告消息在我们简单的强调度量上得分约为 7.
❻ 一个不那么强调的消息得分 5.0 分.
另请参阅
find在映射中搜索给定的键, 并返回相应的java.util.Map$Entry键值对对象.key和val分别从java.util.Map$Entry实例中提取键或值.select-keys返回一个只包含从另一个输入映射中选择的键的映射.性能考虑和实现细节
=>
O(1)常数时间keys和vals请求在给定映射 (或适用的集合) 的内容之上创建一个迭代器. 在请求之前, 实际上没有项目被迭代, 产生一个与输入大小无关的性能曲线:(def big-map (apply hash-map (range 1e7))) ; ❶ (time (first (keys big-map))) ; ❷ ;; "Elapsed time: 0.055119 msecs" (time (last (keys big-map))) ; ❸ ;; "Elapsed time: 930.845288 msecs"
❶
big-map包含 5 百万个键.❷ 从
keys中检索第一个键是廉价操作.❸ 然后我们强制遍历映射的所有键以访问最后一个元素. 我们可以看到这需要更多的处理时间.
虽然创建是常数时间, 但由
keys或vals返回的序列的迭代在映射中存在的键的数量上是线性的.
- 输入
- 11.2.2 find, key 和 val
自 1.0 版本起可用的函数
(find [map key]) (key [e]) (val [e])
find在一个映射中搜索一个键, 例如由hash-map,array-map,sorted-map,struct或实现java.util.Map的对象 (如defrecord) 创建的映射:(import 'java.util.HashMap) (defrecord R [a b c]) (find (hash-map :a 1 :b 2) :a) (find (array-map :a 1 :b 2) :a) (find (sorted-map :a 1 :b 2) :a) (find (struct (create-struct :a :b) 1 2) :a) (find (HashMap. {:a 1 :b 2}) :a) (find (R. 1 2 3) :a) ;; [:a 1] ; ❶
❶ 示例中所有对
find的调用在搜索键:a时都产生相同的结果[:a 1].find也接受向量, 子向量和原生向量. 在这种情况下,find在给定的索引处查找一个项:(find [:a :b :c] 1) ; ❶ ;; [1 :b] (find (subvec [:x :a :b :c] 1 3) 1) ; ❷ ;; [1 :b] (find (vector-of :int 1 2 3) 1) ; ❸ ;; [1 2]
❶
find在一个普通向量上使用. 如果在索引处找到一个元素, 则返回一个包含两者的Map$Entry.❷
find在一个子向量上的工作方式类似.❸ 最后,
find可以在用vector-of构建的原生向量上使用.到目前为止, 所有
find示例的返回类型都是一个由键和值组成的java.util.Map$Entry实例.key和val是专门用于从Map$Entry中提取键或值的函数, 而无需使用 Java 互操作性:(key (first {:a 1 :b 2})) ; ❶ ;; :a (key (find {:a 1 :b 2} :a)) ; ❷ ;; :a ((juxt key val) (last (System/getenv))) ; ❸ ;; ["JENV_LOADED" "1"]
❶
key可以在由映射产生的序列的元素上使用. 在这里, 我们提取第一个键值对, 然后是键.❷
find类似地产生一个Map$Entry实例, 我们可以然后访问以检索键.❸
System/getenv返回一个包含正在运行的 Java 虚拟机可见的所有环境变量的映射. 我们可以直接使用last访问最后一个键值对, 但在这里我们更喜欢检索一个向量而不是Map$Entry, 所以我们使用juxt与key和val. 请注意, 相同的示例在不同的机器上可能会返回不同的结果.契约
- 输入
find:"map"可以是java.util.Map的实例 (包括 Clojure 映射类型) 或clojure.lang.Associative的实例 (包括向量系列的类型). 它是必需的参数, 但可以是nil或正确类型的空集合."key"可以是任何类型. 在向量的情况下,"key"代表一个可能的索引.
key和val:"e"代表 "entry", 并且必须是java.util.Map$Entry类型.
- 主要异常
如果
key或val用nil参数调用, 则抛出NullPointerException.如果
"map"是一个瞬态 (仅适用于 Clojure 版本 < 1.9), 则抛出ClassCastException. - 输出
find返回一个java.uti.Map$Entry对, 包含"key"和该"key"处的值 (如果找到), 否则返回nil. 如果"map"是一个向量, 那么任何非 0 和 232 之间的正整数的"key"类型都可能产生不可预测的结果 (参见标注部分以获取示例).key和val分别返回在"e"中找到的键和值.自 Clojure 1.9 版本起,
find也接受瞬态映射或向量作为参数, 返回一个具有相同语义的java.util.Map$Entry实例.示例
find的工作方式类似于filter, 返回特定键的java.util.Map$Entry实例. 我们可以用它在一个映射列表上隔离有趣的键值对:(def records ; ❶ [{(with-meta 'id {:tags [:expired]}) "1311" 'b "Mary" 'c "Mrs"} {(with-meta 'id {:tags []}) "4902" 'b "Jane" 'c "Miss"} {(with-meta 'id {:tags []}) "1201" 'b "John" 'c "Mr"}]) (def ids (keep #(find % 'id) records)) ; ❷ (-> ids first key meta :tags) ; ❸ ;; [:expired]
❶
records是一个示例映射列表, 来自某些数据存储. 每个记录的 'id' 键还包含元数据.❷ 我们可以直接使用
(map 'id records), 但那会移除键和可能 有用的元数据. 使用find, 我们可以提取键值对, 并决定以后如果需要的话再使用元数据.❸ 我们可以访问附加到每个键的元数据, 例如第一个, 使用
key然后meta. find和 GIGO
Clojure 初学者有时会对
find与其他语言相比的具体含义感到困惑. 例如, 他们可能会惊讶地发现:(find [:a :b :c :d] :c) ; ❶ ;; nil
❶
"find"的普遍含义与此表达式应该返回nil以外的东西的直觉相悖.当
find在向量上使用时,"key"参数成为可用的索引之一. 因此,"key"应该是一个有意义的正整数. 传递任何其他类型作为索引是可能的, 但可能会导致nil.标准库中有几个案例, 文档没有指定在不是为其设计的类型上使用函数的结果. 这有很好的理由, 比如保持文档的紧凑和精要. 阅读 Clojure 文档的一个经验法则是, 如果函数没有提到一个特定的案例, 那很可能违反了函数契约. 这被称为 "GIGO" (口语上是 "垃圾进, 垃圾出"), 通常会产生不确定的结果.
find的一个明显 GIGO 例子如下:(def power-2-32 (long (Math/pow 2 32))) ; ❶ (find [1 2 3] power-2-32) ; ❷ ;; [4294967296 1]
❶
2^32 - 1对应于 Java 中 32 位整数可以容纳的最大数. 为了表示2^32及以上, 它需要超过 32 位. 整数被截断以访问数组索引, 所以2^32变成 0.❷
find实际上在索引2^32处检索到了东西: 0 是将2^32截断为 Java 整数的结果.Clojure 是一种充满权衡的语言, GIGO 就是其中之一. Clojure 不会主动捕获和警告所有可能的函数误用, 而是委托调用者构建一个由实际用例驱动的更健壮的契约屏障.
另请参阅
contains?的工作方式与find类似, 但它返回true或false以指示元素是否存在. 它也扩展到其他非关联类型, 如集合, 因为它不验证元素在特定索引处的存在 (在集合上这是不可能的, 因为它们是无序的).get与contains和find相比是最灵活和最通用的, 并且适用于更广泛的类型.性能考虑和实现细节
=>
O(log N)步数对于所有实际目的,
find是一个常数时间操作. 然而,find对于所有支持的类型都是O(log 32 N), 除了sorted-map, 它是O(log 2 N). 在所有情况下, 算法族都是对数的, 但sorted-map有一个更高的常数因子. 我们对contains?做了类似的考虑, 邀请读者回顾.find的实现主要委托给 Clojure 的 Java 端.clojure.lang.RT/find包含一个类型分派, 实际的搜索委托给具体的集合实现.
- 输入
- 11.2.3 select-keys 和 get-in
函数自 1.0 (select-keys), 1.2 (get-in)
(select-keys map keyseq) (get-in ([m ks]) ([m ks not-found]))
select-keys和get-in是用于从映射中访问键和值的函数:(select-keys {:a 1 :b 2 :c 3} [:a :c]) ; ❶ ;; {:a 1, :c 3} (get-in {:a 1 :b {:c 3}} [:b :c]) ; ❷ ;; 3
❶
select-keys从一个映射中检索键和相关的值, 返回一个包含所选对的新映射, 如果有的话.❷
get-in只检索值, 但它可以深入任意嵌套的映射多个层次.select-keys和get-in也适用于向量 (尽管它们最常用于映射):(select-keys [:a :b :c :d :e] [1 3]) ; ❶ ;; {1 :b, 3 :d} (get-in [:a :b :c [:d :e]] [3 1]) ; ❷ ;; :e
❶ 在向量上使用
select-keys返回一个映射, 其中包含整数作为键, 值来自输入向量. 键是作为输入传递的索引.❷
get-in接受整数坐标, 并遍历一个嵌套的向量以检索索引处的值.契约
- 输入
select-keys"map"可以是任何类型的映射 (hash-map,array-map,sorted-map,struct-map,defrecord, JavaMap) 或向量 (vector,subvector,vector-of) 或nil. 不支持相关的瞬态版本."keyseq"是任何可seq的集合或nil.
get-in"m"应该是一个关联数据结构 (所有映射和向量, 包括瞬态).get-in也适用于集合 (有序的或瞬态的). 许多其他数据结构也被接受, 包括最常用的 Java 集合, 尽管不是所有都产生有意义的结果."ks"可以是任何类型的序列集合."not-found"在键处找不到值时用作默认值 (否则get-in只会返回nil, 这在键处实际存在nil的情况下可能会有歧义).
- 主要异常
select-keys在不支持的类型上抛出IllegalArgumentException. - 输出
select-keys总是返回一个映射类型 (array-map对于小映射,hash-map当有超过 10 个键时). 结果映射包含来自"keyseq"的匹配键, 如果有的话. 如果"map"或"keyseq"是nil, 则返回一个空映射.get-in返回通过按顺序使用"ks"中的键访问"m"找到的值."ks"中的每个键都从"m"的更深层级中提取一个值, 如果有的话. 如果找不到值, 则返回nil, 如果存在默认值, 则返回"not-found". 像范围或列表这样的序列集合不适用于get-in:(get-in '(0 1 2 3) [0]) ; ❶ ;; nil
❶ 使用
get-in访问列表总是返回nil, 即使相应的nth操作可以正常工作.示例
让我们从注意
select-keys和get-in在使用空向量作为键时的相反行为开始:(select-keys {:a 1 :b 2} []) ; ❶ ;; {} (get-in {:a 1 :b 2} []) ; ❷ ;; {:a 1 :b 2}
❶ 当使用空向量来选择键时,
select-keys返回一个空映射.❷
get-in反而返回输入.select-keys经常用于从一个更大的映射中提取一个受限的键值对集合:(def large-input-map {:a 1 :b 2 :c 3 :d 4 :e 5}) ; ❶ (select-keys large-input-map [:a :c :e]) ; ❷ ;; {:a 1, :c 3, :e 5}
❶ 我们假设
large-input-map定义了一个有数千个键的大映射实例.❷
select-keys提取一个更小, 更易于管理的映射, 只包含我们感兴趣的键.select-keys也保留元数据:(def m ^:original {:a 1 :b 2}) ; ❶ (meta m) ;; {:original true} (meta (select-keys m [:a])) ; ❷ ;; {:original true}
❶
"m"是一个使用字面量表示法"^:"来附加元数据的映射. 该表示法意味着:original键会自动与一个真值关联.❷ 由
select-keys返回的映射保留了给定的元数据.select-keys可以与向量一起使用, 例如, 从一个单词或句子中提取字母:(let [word "hello"] (select-keys (vec word) (filter even? (range (count word))))) ;; {0 \h, 2 \l, 4 \o}
现在让我们看看如何使用
get-in从深度嵌套的数据结构 (通常是映射和向量的混合) 中提取值. 例如, Json 格式的数据用于在数据服务之间编码信息, 并且往往是任意嵌套的. 在下面的例子中, 我们收到了一个按法律费用最低排序的金融产品列表. 该列表已经使用众多可用库之一从 Json (JavaScript 对象表示法) 转换为 Edn (可扩展数据表示法), 并准备好进行处理. 以下是输入数据的样子:(def products ; ❶ [{:product {:legal-fee-added {:rate "2%" :period "monthly"} :company-name "Together" :fee-attributes [["Jan" 8] 99 50 13 38 62] :initial-rate 9.15 :initial-term-label {:bank "provided" :form "Coverage"} :created-at 1504556932727}} {:product {:legal-fee-added {:rate "4.2%" :period "yearly"} :company-name "SGI" :fee-attributes [["Mar" 8] 99 50 13 38 62] :initial-rate 2.15 :initial-term-label {:bank "provided" :form "Coverage"} :created-at 1504556432722}} {:product {:legal-fee-added {:rate "2.6%" :period "monthly"} :company-name "Together" :fee-attributes [["Jan" 8] 99 50 13 38 62] :initial-rate 5.5 :initial-term-label {:bank "Chase" :form "Assisted"} :created-at 1504556332211}}])
❶
products是一个更大数据源的小样本. 它包含一个产品的初始向量, 每个产品都用额外的嵌套向量和映射进行了详细说明.我们可以检查任何产品以获取有趣的指标. 假设我们知道要从顶层向量中访问哪个索引, 我们可以使用
get-in:(defn rate-at [products idx] ; ❶ (get-in products [idx :product :legal-fee-added :rate])) (rate-at products 0) ;; "2%" (rate-at products 1) ;; "4.2%"
❶
rate-at接受产品向量和一个索引.get-in访问索引"idx"处的元素, 然后从内部映射中提取 "rate" 信息.另请参阅
get不提供对嵌套数据结构的访问. 要访问未嵌套的值, 优先使用get而不是get-in.keys从映射实例中检索键的集合.zipmap从一个键集合和一个值集合开始创建一个新的映射.性能考虑和实现细节
=>
O(n)线性select-keys和get-in在选择键的数量上都具有线性行为. 如果你需要从一个更大的映射中选择大量的键, 你可能会考虑使用dissoc掉不想要的键, 而不是选择想要的键.select-keys的实现需要通过逐渐引入键来构建输出. 目前它没有利用瞬态 (这已经被捕获为下一个 Clojure 版本的增强功能 173). 我们可以继续产生这样一个实现, 并将其与当前版本进行比较:(require '[criterium.core :refer [quick-bench]]) (defn select-keys2 [m keyseq] ; ❶ (with-meta (transduce (keep #(find m %)) (completing conj! persistent!) (transient {}) keyseq) (meta m))) (let [m (apply hash-map (range 40))] ; ❷ (quick-bench (select-keys m [0 2 4 6 8 10 12]))) ;; Execution time mean : 773.492163 ns (let [m (apply hash-map (range 40))] ; ❸ (quick-bench (select-keys2 m [0 2 4 6 8 10 12]))) ;; Execution time mean : 545.102979 ns
❶ 这个版本的
select-keys被称为select-keys2, 它基于transduce. 它迭代"keyseq"并使用每个键对输入映射"m"调用find. 每个条目然后使用conj!添加到瞬态结果中. 结果最终使用completing和persistent!转换回持久性数据结构.❷ 该基准测试测试一个平均大小为 20 个键的映射和一个包含 7 个键的选择.
❸ 我们可以看到
select-keys2相对于标准版本有一些优势.select-keys2比普通的select-keys更快, 特别是在处理更大的映射和更大的键集时.
- 输入
3.4.3. 11.3 处理
- 11.3.1 assoc, assoc-in 和 dissoc
自 1.0 版本起可用的函数
(assoc ([map key val]) ([map key val & kvs])) (assoc-in [map ks val]) (dissoc ([map]) ([map key]) ([map key & ks]))
assoc,assoc-in和dissoc是映射的基本操作 (它们也适用于其他关联数据结构, 如向量).assoc替换现有键的值, 或者如果键不存在则插入一个新键:(def m {:a "1" :b "2" :c "3"}) (assoc m :b "changed") ; ❶ ;; {:a "1" :b "changed" :c "3"} m ; ❷ ;; {:a "1" :b "2" :c "3"}
❶ 在存在现有键的情况下,
assoc的效果是替换其值.❷ 与所有其他持久性 Clojure 数据结构一样,
assoc返回一个带有更改的新输入实例, 任何对相同输入数据结构的引用都保持不变.dissoc从输入集合中移除一个或多个键:(def m {:a "1" :b "2" :c "3"}) (dissoc m :a :c) ; ❶ ;; {:b "2"}
❶ 我们对原始变量 "m" 使用
dissoc, 它包含对先前创建的映射的引用.最后,
assoc-in是assoc的一个特殊版本, 它知道如何在不同的嵌套级别上操作:(def m {:a "1" :b "2" :c {:x1 {:x2 "z1"}}}) (assoc-in m [:c :x1 :x2] "z2") ; ❶ ;; {:a "1" :b "2" :c {:x1 {:x2 "z2"}}}
❶ 向量
[:c :x1 :x2]标识了嵌套数据结构 "m" 中的一个下降路径. 在从输入集合中连续提取嵌套映射后, 值 "z2" 与 "z1" 交换.契约
第一个输入参数
"map"对这三个函数是通用的. 它是一个关联数据结构 (使得(associative? map)为真). 当为nil时, 它默认为空映射. 它是必需的参数.- assoc 输入
"key": 对于映射, 它可以是任何对象, 而对于向量, 它必须是一个整数. 为了匹配一个现有的键,"key"使用=相等性语义进行比较. 它是必需的参数."val": 是"key"的值. 它是必需的参数."kvs": 是任何额外的键值对. 它们是可选的, 但如果存在, 它们必须是偶数个项. - assoc-in 输入
"ks"是一个键的序列 (函数上的文档将参数报告为[k & ks]以包含解构). 每个键用于随后查找在上一个键处找到的值. 当为空或nil时, 它等同于[nil](即, 它访问输入"map"第一级的nil键). 在嵌套向量输入的情况下,"ks"应该是一个非空的整数序列."val"是要与"map"关联的值. - dissoc 输入
"key"可以是任何对象. 它用于使用相等性比较来匹配现有的键, 类似于assoc. 它是可选的参数."ks"是要从"map"中移除的任何额外的键. - 主要异常
当
assoc-in中的"kvs"不是一个键的序列时, 抛出UnsupportedOperationException. 要传递单个键, 请将键包装在一个序列集合中.当
"key"或任何"ks"大于 n+1 (其中 "n" 是向量的最大可用索引) 时, 抛出IndexOutOfBoundsException.IllegalArgumentException: 当在向量上尝试assoc时,"key"不能为nil. 类似地, 当在向量上尝试assoc-in时,"ks"不能是空向量.ClassCastException: 当在向量上进行assoc或dissoc时,"key"不是整数. - 输出
assoc返回"map", 其中包含一个或多个新添加的键, 或对已存在键的一个或多个更改.assoc-in使用"ks"中的键来下降一个或多个嵌套级别, 然后插入一个新的键值对或更新一个已存在的键.dissoc从"map"中移除零个或多个键值对. 当没有匹配的键或没有传递"key"时, 不会移除键值对.示例
assoc和dissoc是处理映射的流行函数. 它们经常与其他的映射处理函数一起出现在->线程优先宏中, 形成一个转换管道:(def m {nil 0 :c 2}) (-> m ; ❶ (assoc :a 1) (dissoc nil) (update :c inc) (merge {:b 2})) ;; {:c 3, :a 1, :b 2} ; ❷
❶
"m"是一个部分构建的映射. 我们可以看到每一步都对映射执行一些操作, 垂直排列有助于跟踪流程.❷ 处理后的映射返回, 没有任何特定的键排序.
assoc也可以与reduce一起逐渐构建一个映射. 当值可以从键中派生时, 这可能很有用, 例如, 使用 "id" 来检索数据:(defn lookup [id] ; ❶ {:index "backup" :bucket (rand-int (* 100 id))}) (def request [12 41 11]) ; ❷ (reduce (fn [m item] (assoc m item (lookup item))) {} request) ; ❸ ;; {12 {:index "backup" :bucket 888} ;; 41 {:index "backup" :bucket 4058} ;; 11 {:index "backup" :bucket 355}}
❶
lookup模拟与服务或数据库的交互, 以按 id 检索结构化信息.❷ 同样,
request包含一个随机选择的 id, 在现实生活中的应用程序中, 这些 id 可能来自某些用户交互.❸
reduce接受一个空映射字面量{}来开始创建新结果.reduce迭代request的内容, 以传递到目前为止的映射内容和下一个要assoc的 "item". 键是 item 本身, 而值来自查找服务.assoc-in倾向于与深度嵌套的数据结构一起使用, 特别是那些混合了映射和向量的数据结构,assoc-in可以独立于嵌套类型进行遍历:(def articles ; ❶ [{:title "Another win for India" :date "2017-11-23" :ads [2 5 8] :author "John McKinley"} {:title "Hottest day of the year" :date "2018-08-15" :ads [1 3 5] :author "Emma Cribs"} {:title "Expected a rise in Bitcoin shares" :date "2018-12-11" :ads [2 4 6] :author "Zoe Eastwood"}]) (assoc-in articles [2 :ads 1] 3) ; ❷ ;; [{:title "Another win for India" ;; :date "2017-11-23" ;; :ads [2 5 8] ;; :author "John McKinley"} ;; {:title "Hottest day of the year" ;; :date "2018-08-15" ;; :ads [1 3 5] ;; :author "Emma Cribs"} ;; {:title "Expected a rise in Bitcoin shares" ;; :date "2018-12-11" ;; :ads [2 3 6] ; ❸ ;; :author "Zoe Eastwood"}])
❶
articles是一个更大映射的简化部分, 它包含多种形式的嵌套, 如向量 (用于需要列出的项) 或映射 (用于可以通过键检索的项).:ads键包含文章中广告的位置, 例如在第 2, 5 和 8 段之后.❷ 我们想更改最后一篇文章的广告位置, 将一个广告向上移动一个位置, 放在第 3 段之后而不是第 4 段之后.
❸ 我们可以看到从
[2 4 6]变为[2 3 6].值得记住的是,
assoc也是更新向量和更改其内容的有效选项. 例如, 我们在identity中使用assoc来更改建模为向量的队列中收银员的可用性. 对于那些一个元素可以被替换或添加到向量中的情况,assoc也可以作为conj的替代方案:(def pairs [[:f 1] [:t 0] [:r 2] [:w 0]]) ; ❶ (map (fn [[item index :as v]] ; ❷ (assoc v index item)) pairs) ;; ([:f :f] [:t 0] [:r 2 :r] [:w 0]) ; ❸
❶ 每对的第二个元素是一个数字, 可用作后续
assoc操作的索引.❷ 使用解构, 我们访问第一个 "item", "index" 和整个对 "v". 然后我们可以使用 "index" 作为键, "item" 作为值来
assoc对 "v".❸ 结果显示了所涉及的不同转换: 当索引为 1 时, 对被重复, 当索引为 0 时, 没有任何变化, 当索引为 2 时, 对变成三元组.
dissoc-in
标准库中没有
dissoc-in, 但在这个扩展部分, 我们将创建一个. 与assoc不同, 它对映射和向量都工作得相当自然, 我们需要多做一些工作来dissoc一个向量, 特别是在中间移除一个项. 让我们一步一步来, 先解决映射的dissoc-in:(def m {:a {:b 2 :c {:d 4 :e 5}}}) ; ❶ (defn dissoc-in [m [k & ks]] ; ❷ (if ks (assoc m k (dissoc-in (get m k) ks)) (dissoc m k))) (dissoc-in m [:a :c :d]) ; ❸ ;; {:a {:b 2, :c {:e 5}}}
❶ 输入 "m" 包含几个嵌套的映射, 我们只想
dissoc掉 ":d" 键.❷
dissoc-in与实际的assoc-in实现类似. 策略是递归, 直到我们达到一个只能移除一个键的级别. 这就是我们可以使用dissoc的地方. 修改后的映射需要替换掉旧的映射, 所以我们在返回时使用assoc.❸ 结果证实
dissoc-in按预期工作.一个只适用于映射的不同且优雅的
dissoc-in版本如下:(defn dissoc-in [m ks] ; ❶ (update-in m (butlast ks) dissoc (last ks))) (let [m {:a [0 1 2 {:d 4 :e [0 1 2]}]}] (dissoc-in m [:a 3 :e])) ;; {:a [0 1 2 {:d 4}]} ; ❷
❶ 这个版本的
dissoc-in巧妙地利用了update-in和dissoc.❷ 我们可以看到我们能够从最内层的映射中移除 ":e" 键.
但是, 当最后的
dissoc在一个向量而不是映射上执行时, 这个版本的dissoc-in会失败:(let [m {:a [0 1 2 {:d 4 :e [0 1 2]}]}] ; ❶ (dissoc-in m [:a 3 :e 0])) ;; ClassCastException clojure.lang.PersistentVector ;; cannot be cast to clojure.lang.IPersistentMap
❶ 当要从中移除的最后一个元素是向量时, 这个版本的
dissoc-in会失败.为了像
assoc-in那样处理向量, 我们需要对它们进行不同的处理. 与subvec相关的部分也包含一个名为remove-at的示例函数, 可用于在向量中给定索引处移除一个元素. 我们可以在检查集合类型后, 使用remove-at从向量中dissoc:(def m {:a [0 1 2 {:d 4 :e [0 1 2]}]}) (defn remove-at [v idx] ; ❶ (into (subvec v 0 idx) (subvec v (inc idx) (count v)))) (defn dissoc-in [m [k & ks]] (if ks (assoc m k (dissoc-in (get m k) ks)) (cond (map? m) (dissoc m k) (vector? m) (remove-at m k) :else m))) ; ❷ (dissoc-in m [:a 3 :e 0]) ; ❸ ;; {:a [0 1 2 {:d 4, :e [1 2]}]}
❶
remove-at在讨论subvec时被引入. 邀请读者在必要时回顾subvec, 但机制非常简单: 分割向量, 使不想要的元素被排除在外, 然后将向量合并回来.❷ 对
dissoc-in的唯一更改是引入了一个条件, 以验证我们需要从哪种类型中移除键.❸ 结果证实了当我们嵌套映射和向量在一起时, 函数的总体设计是正确的.
我们可以看到, 最后的解决方案解决了所有嵌套组合.
另请参阅
assoc!是专门为瞬态设计的assoc版本.get-in和update-in是与assoc-in类似的函数, 用于处理嵌套数据结构的读/写. 与assoc-in不同,update-in接受一个旧值的函数来产生新值.性能考虑和实现细节
=>
O(log32N)映射, 数组映射, 结构体, 向量=>
O(log2N)有序映射=>
O(n)defrecord许多 Clojure 持久性集合, 如映射和向量, 都是建立在 HAMT (哈希数组映射树) 上的, 这是一种浅层的位映射树数据结构. HAMT 上的大多数常见操作, 如遍历或更新, 都是
O(log32N), 其中 "N" 是项的数量. 唯一的例外是sorted-map, 它实现为二叉树 (更准确地说, 是一种称为红黑树的自调整变体).sorted-map的assoc仍然是对数的, 但常数因子是 2 而不是 32: 在实践中, 差异很小 (大映射) 或没有 (小映射).assoc-in的性能特征与assoc不同, 因为它还对输入"ks"的长度有线性依赖, 这主导了树的遍历. 在实践中,"ks"通常只包含几个项, 因为它代表了输入的嵌套级别.在下图中, 我们将比较
assoc在一些支持的数据结构上的表现. 该基准测试在不同大小的映射类型上执行assoc: 10 个键, 50 个键和 100 个键. 键被选择为存在于当前结构中, 替换现有的值:
Figure 33: Figure 11.3. 不同映射类型的 assoc 基准测试.
我们可以看到
defrecord比其他类型慢一个数量级. 这可以用以下事实来解释:defrecord将其关联性建立在 Java 类属性之上:assoc是通过在condp条件中匹配所需的键来实现的, 从而导致线性行为. 由于defrecord的正常使用只包括少数几个键, 所以它不应该是性能的担忧.
- assoc 输入
- 11.3.2 update 和 update-in
函数自 1.7 (update), 1.0 (update-in)
(update ; ❶ ([m k f]) ([m k f x]) ([m k f x y]) ([m k f x y z]) ([m k f x y z & more])) (update-in ([m ks f & args]))
❶
update提供的多种元数是针对最频繁调用的性能优化.update和update-in都旨在更改关联数据结构中的值. 与assoc和assoc-in不同, 它们接受一个从旧值到新值的函数:(update {:a 1 :b 2} :b inc) ; ❶ ;; {:a 1, :b 3} (update-in {:a 1 :b {:c 2}} [:b :c] inc) ; ❷ ;; {:a 1, :b {:c 3}}
❶
inc是一个单参数函数.update用":b"键的当前值调用inc, 并用相应的增量值替换它.❷
update-in接受一个键列表[:b :c]作为输入. 每个键依次用于获取嵌套的关联集合.这两个函数都建立在
assoc之上, 因此关于输入类型和性能的类似考虑也适用.契约
"m"是一个关联数据结构. 这意味着(associative? m)为真. 它是强制性参数."k": 当"m"是映射类型 (hash-map,sorted-map,array-map,record,struct或原生 Java 映射) 时,"k"可以是任何对象. 当"m"是向量类型 (vector,sub-vector或原生向量) 时,"k"必须是小于 232 的整数. 为了匹配一个现有的键,"k"使用=相等性语义进行比较."ks"是一个键的序列. 每个键遵循与"k"相同的契约, 适用于在该嵌套级别找到的关联数据结构的类型."f"是一个从泛型对象到另一个泛型对象的函数."f"被调用时, 传入在相关键处找到的值."x","y","z","more"和"args"是函数"f"的额外参数 (除了在键处找到的值, 该值作为第一个参数传递).- 主要异常
如果你在使用
update-in时忘记将"ks"包装在列表或向量中, 会发生UnsupportedOperationException.使用非整数的键访问向量时, 包括在
update-in中嵌套向量时, 抛出IllegalArgumentException. - 输出
update返回输入"m"的一个新版本, 其中由"k"指示的值"v"被调用(f v)的结果替换. 如果"k"不存在且"m"是一个映射, 则创建"k", 并使用(f nil)的结果作为新值. 如果"m"是一个向量, 则"k"必须在 0 和(dec (count m))之间.update-in返回输入"m"的一个新版本, 其中由"ks"指示的值"v"(在任何嵌套级别) 被调用(f v)的结果替换."ks"被解释为第一个键用于在"m"中获取一个值, 第二个键用于在上一个值中获取一个值, 依此类推, 直到最后一个键."ks"受与update相同的考虑.示例
与
assoc不同,update和update-in可以用于 "upsert" 新键 (更新或插入, 而不是替换或插入). 这个模型很适用于计数器, 或者通常任何需要前一个值存在的更新.fnil经常与update一起使用, 为没有键的情况提供一个默认值:(def words {"morning" 2 "bye" 1 "hi" 5 "gday" 2}) ; ❶ (defn insert-word [w words] (update words w (fnil inc 0))) ; ❷ (insert-word "hello" words) ;; {"morning" 2, "bye" 1, "hi" 5, "gday" 2, "hello" 1} ; ❸
❶ 我们有一个单词及其频率的列表.
❷
update用于增加一个已存在单词的计数器或插入一个新单词. 如果单词不在列表中,inc会失败并抛出NullPointerException. 通过用fnil包装inc, 我们可以防止用nil值调用该函数. 我们选择一个默认值 "0", 然后将其传递给inc进行递增.❸ 我们可以看到 "hello" 出现在
words映射中, 频率为 1.向量上的
update遵循类似的模式, 当"k"等于向量的长度时, 允许在尾部添加一个新元素:(update [:a :b :c] 3 (fnil keyword "d")) ; ❶ ;; [:a :b :c :d] (update [:a :b :c] 4 (fnil keyword "d")) ; ❷ ;; IndexOutOfBoundsException
❶ 索引 "3" 对于
update是允许的, 但对于[:a :b :c]来说是越界的, 其中唯一可用的索引是 0 (:a), 1 (:b) 和 2 (:c).❷ 向向量中添加新项只在最后一个项之后才有效. 尝试访问超过向量大小的位置会导致
IndexOutOfBoundsException.在下面的例子中,
"products"是一个映射, 有一个专门用于存储库存数量的键. 当一个产品被售出时, 我们想要减少相应的数量:(def products ; ❶ {"A011" {:in-stock 10 :name "Samsung G5"} "B032" {:in-stock 4 :name "Apple iPhone"} "AE33" {:in-stock 13 :name "Motorola N1"}}) (defn sale [products id] ; ❷ (update-in products [id :in-stock] (fnil dec 2))) (get-in ; ❸ (sale products "B032") ["B032" :in-stock]) ;; 3
❶
"products"是一个来自数据库的更大列表的示例版本. 产品通过键定位, 值包含详细信息, 包括还有多少库存.❷ 我们使用
update-in按键访问一个产品, 然后更新:in-stock键, 将其内容减 1.❸
get-in对于关注新更新的:in-stock键很有用.update(以及assoc及其 *-in 变体) 经常与swap!结合使用, 以在比较和交换 (CAS) 事务期间更改atom174. 参考前面的例子, 我们现在可以允许并发销售:(def products ; ❶ (atom {"A011" {:in-stock 10 :name "Samsung G5"} "B032" {:in-stock 4 :name "Apple iPhone"} "AE33" {:in-stock 13 :name "Motorola N1"}})) (defn total-products [products] ; ❷ (reduce + (map :in-stock (vals products)))) (total-products @products) ; ❸ ;; 27 (defn sale! [products id] ; ❹ (swap! products update-in [id :in-stock] (fnil dec 2)) products) (defn sale-simulation! [ids] ; ❺ (dorun (pmap (partial sale! products) ids))) (sale-simulation! ["B032" "AE33" "A011" "A011" "AE33" "B032"]) ;; nil (total-products @products) ; ❻ ;; 21
❶
products是仓库状态的内存视图. 它将状态包装在atom中以实现并发控制.❷
total-products用于计算总共有多少产品仍在库存中. 它使用reduce对所有:in-stock键进行计数.❸ 我们可以看到在销售发生前, 仓库中有 27 件商品.
❹
sale!与我们之前定义的函数类似, 但它现在对产品状态产生副作用.swap!的参数与update-in类似: 它接受一个从旧值到新值的函数, 以及任何要传递给update-in的额外参数. 效果类似于线程优先宏->:products被置于update-in的第一个参数, 后面跟着键的向量和fnil默认值.❺
sale-simulation!模拟多个客户端并发交互. 我们使用pmap并行启动多个销售. 注意函数名末尾的常规 "!" bang 符号, 表示一个有副作用的函数.❻ 如果我们检查总产品数量, 我们可以看到它始终销售正确数量的产品. 通过使用
swap!, 我们确保操作总是将库存数量减一, 因为如果操作结束时另一个线程能够同时减少数量, 事务会重复.另请参阅
fnil在示例中被提到了几次. 它不是update的替代品, 但它很适合为缺失的键提供默认值.当新值不依赖于旧值时,
assoc产生与update类似的效果.assoc-in与update-in的比较也是如此.get和get-in检索值而不做更改.性能考虑和实现细节
=>
O(log32N)映射, 数组映射, 结构体, 向量=>
O(log2N)有序映射=>
O(n)defrecordupdate和update-in是建立在assoc之上的. 支持的类型相同, 性能特征也相同. 邀请读者访问assoc的性能部分以获取更多细节.与
assoc一样,update和update-in在平均映射操作上表现良好, 还考虑到它们不在序列上操作, 从而防止了不想要的线性行为.
- 主要异常
- 11.3.3 merge 和 merge-with
自 1.0 版本起可用的函数
(merge [& maps]) (merge-with [f & maps])
merge和merge-with专门用于将一个或多个映射连接在一起:(merge {:a 1 :b 2} {:c 3 :d 4}) ; ❶ ;; {:a 1, :b 2, :c 3, :d 4}
❶ 使用
merge连接两个映射 (每个映射两个键) 的简单用法.当
merge在冲突的情况下只是在目标处 "覆盖" 一个现有的键时,merge-with允许指定如果同一个键被找到多次该怎么做:(merge-with + {:a 1} {:b 2 :a 10}) ; ❶ ;; {:a 11, :b 2}
❶
merge-with允许决定如果目标键已存在于目标中该怎么做. 在这种情况下, 键 ":a" 的当前值会与新值相加.契约
- 输入
"maps"是任意数量的映射类型 (hash-map,sorted-map,array-map,record,struct, 但不是原生的java.util.HashMap).maps中的第一个映射是 "目标" 映射, 并决定了返回类型. 也接受序列类型 (如向量或列表), 但它们不能正确合并, 其中一个或多个会形成嵌套级别. 因此, 不支持映射以外的类型."f"是merge-with的强制性参数. 如果一个键已经存在于结果中, 则调用"f", 传入键的当前值和键的新值."f"的结果将替代旧值. - 主要异常
当目标映射不是
clojure.lang.IPersistentCollection时, 抛出ClassCastException.当目标映射后面跟着的元素不是键值对时, 抛出
IllegalArgumentException, 例如(merge {} [1 2 3]). 这是因为merge试图将序列集合传输到目标映射中, 但有一个键 ("3") 缺少值. - 输出
- 没有参数或
nil参数时: 返回nil. - 只有一个非
nil参数时: 返回参数本身. - 在所有其他情况下,
merge尝试将(rest maps)的内容传输到(first maps)中, 复制每个键值对. 在键冲突的情况下, 最后一个进入输出的键对应的值会覆盖前一个值. merge-with的输出与merge相同, 但键冲突的解决由自定义函数"f"处理.
输出类型与目标 (
first maps) 相同, 遵循以下规则:- 当目标是
array-map时, 输出可以根据键的数量自动提升为hash-map(通常超过 10 个). - 当目标是
sorted-map时, 来自(rest maps)的键需要能与(first maps)中的键进行比较.
下面的例子澄清了最后一条规则:
(def sorted-map-of-keywords (sorted-map :z 3 :f 5 :c 4)) (def map-of-ints (hash-map 1 "a" 2 "b" 5 "c")) (merge sorted-map-of-keywords map-of-ints) ; ❶ ;; ClassCastException clojure.lang.Keyword cannot be cast to java.lang.Number (def map-of-keywords (hash-map :a 1 :b 4 :e 4)) (merge sorted-map-of-keywords map-of-keywords) ; ❷ ;; {:a 1, :b 4, :c 4, :e 4, :f 5, :z 3}
❶
sorted-map(merge的第一个参数) 的接口契约优先于其他映射类型. 在本例中, 我们无法合并映射, 因为整数键无法与关键字键进行比较.❷ 我们可以成功地将一个
sorted-map与一个hash-map合并, 前提是键类型兼容 (本例中都是关键字).示例
除了下面介绍的示例, 本书在其他章节中也展示了
merge和merge-with的用法. 邀请读者快速浏览:fn包含一个在任意数量的输入映射上使用merge的示例. 如果输入是映射列表的形式, 可以使用apply与merge.->>包含一个在解析 URL 参数后合并参数的类似示例.merge和merge-with在组合算法中也很典型.fold包含几个基于merge-with并使用reducers/monoid的组合函数示例, 如(r/monoid merge (constantly {})).
如果输入中的值都是向量, 我们可以使用
into来合并属于相同键的向量. 这对于将值分组很有用:(let [m1 {:id [11] :colors ["red" "blue"]} ; ❶ m2 {:id [10] :colors ["yellow"]} m3 {:id [31] :colors ["brown" "red"]}] (merge-with into m1 m2 m3)) ;; {:id [11 10 31], ; ❷ ;; :colors ["red" "blue" "yellow" "brown" "red"]}
❶ 注意, 所有映射
"m1","m2","m3"的":id"和":colors"都需要是向量.❷
(merge-with into)的结果是一个具有相同键的映射, 以及该键所有映射中所有值的并集.下面的
merge-into函数可用于从一个任意嵌套的映射中提取键. 在本例中, 我们收到一些包含多个嵌套映射和向量的产品数据. 我们想选择一些深度嵌套的键并将它们合并到映射的顶层:(defn merge-into [k ks] ; ❶ (fn [m] (merge (get m k {}) (select-keys m ks)))) (def product-merge ; ❷ (merge-into :product [:fee-attribute :created-at])) (def product ; ❸ {:fee-attributes [49 8 13 38 62] :product {:visible false :online true :name "Switcher AA126" :company-id 183 :part-repayment true :min-loan-amount 5000 :max-loan-amount 1175000} :created-at 1504556932728}) (product-merge product) ; ❹ ;; {:visible false, ;; :online true, ;; :name "Switcher AA126", ;; :company-id 183, ;; :part-repayment true, ;; :min-loan-amount 5000, ;; :max-loan-amount 1175000, ;; :created-at 1504556932728}
❶
merge-into生成一个要转换的映射的函数. 该函数将键"ks"的选择合并到映射"m"的顶层键"k"中.❷ 一个由
merge-into生成的函数被分配给一个变量. 我们称这个特化为product-merge.❸ 这是一个产品数据的例子.
:fee-attributes和:created-at键属于:product, 但它们出现在顶层.❹
product-merge将输入转换为一个新的映射, 该映射包含之前在:product下的所有内容, 包括:fee-attributes和:created-at(之前不在).在下一个例子中, 我们将使用
merge-with来实现复数的加法. 复数有一个实部和一个虚部, 我们可以将其实现为记录中的键.defrecord提供了一个语法上吸引人的形式来实现复数, 包括未来扩展可用操作集的选项:(defprotocol IComplex ; ❶ (sum [c1 c2])) (defrecord Complex [re im] IComplex (sum [c1 c2] (merge-with + c1 c2))) ; ❷ (sum (Complex. 2 5) (Complex. 1 3)) ;; #user.Complex{:re 3, :im 8}
❶ 协议
IComplex定义了一个合适的接口来描述复数操作 (后缀 "I" 意为 "接口").❷ 定义为 Clojure
defrecord的复数的和可以使用merge-with来实现. - 没有参数或
- 多类型合并
合并映射时,
merge和merge-with提供了两种处理相同键的不同值的策略:merge简单地用新值替换旧值, 而merge-with接受一个旧值和新值的函数以进行额外的定制. 如果所有映射中的值都是同质的 (例如, 所有值都是向量), 那么我们可以使用merge-with和into将所有值折叠到同一个键中. 我们在上面看到了一个这样的例子.但是如果值不是向量或者它们是不同的类型呢? 我们可以为
merge-with编写一个自定义函数, 用conj将新值存储在一个向量中:(let [m1 {:a 1 :b 2} m2 {:a 'a :b 'b} m3 {:a "a" :b "b"}] (merge-with (fn [v1 v2] (if (vector? v1) ; ❶ (conj v1 v2) [v1 v2])) m1 m2 m3)) ;; {:a [1 a "a"], :b [2 b "b"]} ; ❷
❶ 这是一个条件, 用于判断我们是否可以在旧值上累积 (因为它已经是一个向量?), 还是创建一个新向量开始累积.
这种方法似乎有效, 但如果值已经是向量, 就会失败:
(let [m1 {:a [1 3] :b 2} ; ❶ m2 {:a 'a :b 'b} m3 {:a "a" :b "b"}] (merge-with (fn [v1 v2] (if (vector? v1) (conj v1 v2) [v1 v2])) m1 m2 m3)) ;; {:a [1 3 a "a"], :b [2 b "b"]} ; ❷
❶ 输入映射
"m1"包含一个向量作为键":a"的值.❷ 结果中的键
":a"应该包含原始的[1 3]向量, 但内部嵌套被错误地移除了.为了修复向量值的特殊处理, 我们需要一种方法来区分 "用户值" 和 "特殊值". 我们添加的包装向量具有特殊的含义, 不应与任何类型的用户值混淆. 我们可以使用元数据来将我们的向量与任何其他向量区分开来:
(let [m1 {:a [1 3] :b 2} m2 {:a 'a :b 'b} m3 {:a "a" :b "b"}] (merge-with (fn [v1 v2] (if (:multi (meta v1)) ; ❶ (conj v1 v2) ^:multi [v1 v2])) ; ❷ m1 m2 m3)) ;; {:a [[1 3] a "a"], :b [2 b "b"]} ; ❸
❶ 我们不是检查是否存在
vector?, 而是检查是否存在只有我们的函数才能创建的自定义元数据.❷ 如果元数据不存在, 我们就确定传入的值需要包装在一个新的向量中, 并带有额外的元数据, 以区别于任何其他向量.
❸ 我们可以看到结果现在是预期的了.
另请参阅
group-by可以用来将一个集合列表折叠成一个基于数据某些特征的映射. 虽然group-by更关注按键分组, 但merge更关注值是如何组合的. 与merge-with相比,group-by将整个输入收集为结果映射的值, 这对于大输入可能是不想要的特性. 使用merge-with, 决定输入中哪部分最终进入结果有更大的灵活性.性能考虑和实现细节
=>
O(n)线性于键数 "n"merge和merge-with都需要循环遍历输入的键. 处理步骤的数量随着输入映射中键的数量 (或多个映射输入中的聚合键) 线性增加.在绝对值上,
merge在大输入上可能成本很高. 通过用瞬态实现merge可以获得一些改进:(require '[criterium.core :as c]) (let [m1 (apply hash-map (range 2000)) m2 (apply hash-map (range 1 2001))] (c/quick-bench (merge m1 m2))) ; ❶ ;; Execution time mean : 221.025373 µs (defn merge* [m & maps] (when (some identity maps) (persistent! (reduce conj! (transient (or m {})) maps)))) (let [m1 (apply hash-map (range 2000)) m2 (apply hash-map (range 1 2001))] (c/quick-bench (merge* m1 m2))) ; ❷ ;; Execution time mean : 162.887879 µs
❶ 我们创建一个有 1000 个键的哈希映射, 和另一个同样大小但键不同, 没有重叠的哈希映射.
❷ 我们可以看到通过使用瞬态, 速度有明显的提升.
我们可以对
merge-with使用瞬态, 得到类似的结果:(let [m1 (apply hash-map (range 2000)) m2 (apply hash-map (range 1 2001))] (c/quick-bench (merge-with + m1 m2))) ; ❶ ;; Execution time mean : 304.863164 µs (defn merge-with* [f & maps] ; ❷ (when (some identity maps) (letfn [(merge-entry [m [k v]] (assoc! m k (if-not (= ::none (get m k ::none)) ; ❸ (f (get m k) v) v))) (merge-into [m1 m2] ; ❹ (reduce merge-entry (transient (or m1 {})) (seq m2)))] (persistent! (reduce merge-into maps))))) ; ❺ (let [m1 (apply hash-map (range 2000)) m2 (apply hash-map (range 1 2001))] (c/quick-bench (merge-with* + m1 m2))) ; ❻ ;; Execution time mean : 220.885976 µs
❶ 首先, 让我们用 2 个有 1000 个不重叠键的映射来对普通的
merge-with进行基准测试.❷ 瞬态需要
assoc!而不是普通的assoc.❸ 注意我们不能直接在瞬态上使用
contains?, 因为它不支持. 我们可以改用get, 前提是我们使用一个哨兵值, 比如::none, 来确定键是否存在 (可能的值是nil).❹ 内部函数
merge-into决定何时从普通的哈希映射切换到瞬态映射.❺ 对
persistent!的调用在计算结束时发生.❻ 我们可以看到
merge-with*比标准的merge-with明显更快.
- 输入
- 11.3.4 reduce-kv
自 1.4 版本起可用的函数
(reduce-kv [f init coll])
reduce-kv是reduce的一个特殊版本, 用于关联数据结构 (契约部分对允许哪些类型更精确). 映射和向量的处理涉及键, 不仅仅是值, 所以有一个相应的特殊版本的reduce是有意义的. 以下是两种风格的比较:(reduce ; ❶ (fn [m [k v]] (assoc m k (inc v))) {} {:a 1 :b 2 :c 3}) ;; {:a 2, :b 3, :c 4} (reduce-kv ; ❷ (fn [m k v] (assoc m k (inc v))) {} {:a 1 :b 2 :c 3}) ;; {:a 2, :b 3, :c 4}
❶ 对于像
array-map或hash-map这样的映射类型, 普通的reduce需要一个归约函数, 该函数理解下一个项是一个由键和值组成的条目. 我们使用解构来单独获取它们. 在底层,reduce被迫先将关联数据结构转换为一个序列.❷
reduce-kv专门用于关联数据结构, 所以归约函数接受 3 个参数而不是 2 个: 累加器, 键和值. 然而, 看不见的是,reduce-kv采用了一个更快的路径来迭代输入.reduce-kv允许输入数据结构通过专门的clojure.core.protocols/IKVReduce协议提供一个特定的实现. 兼容的 Clojure 数据结构已经实现了IKVReduce, 其他关联类型可以扩展相同的抽象. 我们将在例子中看到如何将reduce-kv扩展到其他类映射类型.契约
- 输入
"f"需要是一个接受 3 个参数的函数, 预计返回到目前为止的结果的累积. 它是必需的参数."init"是在第一次调用时作为第一个参数传递给"f"的值. 这通常是一个空集合 (不一定是关联的),reduce-kv应该用结果来填充它."coll"可以是支持的类型之一或nil. 支持的类型是那些实现clojure.lang.IKVReduce或clojure.lang.IPersistentMap的类型. 前者接口表示一个通常性能更好的自定义实现. 下表包含了支持且不抛出异常的类型的摘要:类型 函数 接口 实现 PersistentArrayMap array-mapIKVReduce 快速路径 PersistentHashMap hash-mapIKVReduce 快速路径 PersistentTreeMap sorted-mapIKVReduce 快速路径 PersistentVector vectorIKVReduce 快速路径 PersistentStructMap structIPersistentMap 慢速路径 Record defrecordIPersistentMap 慢速路径 nil nilnil 返回 "init" 像
subvector或java.util.Map这样的关联集合不受支持 (而通常本章中的其他函数支持它们). - 主要异常
当没有针对特定类型 (例如
list) 的reduce-kv实现时, 抛出IllegalArgumentException. - 输出
返回: 在
"init"和"coll"中的第一项上应用"f"的结果, 接着在前一个结果和"coll"中的第二项上再次应用"f", 依此类推, 直到没有更多的项.示例
reduce-kv对于处理映射很有用, 例如, 更新所有值, 键或两者. 例如, 我们可以将代表环境变量的键转换为遵循正常 Clojure 命名约定的关键字:(def env ; ❶ {"TERM_PROGRAM" "iTerm.app" "SHELL" "/bin/bash" "COMMAND_MODE" "Unix2003"}) (defn transform [^String s] ; ❷ (some-> s .toLowerCase (.replace "_" "-") keyword)) (reduce-kv ; ❸ (fn [m k v] (assoc m (transform k) v)) {} env) ;; {:term-program "iTerm.app", ; ❹ ;; :shell "/bin/bash", ;; :command-mode "Unix2003"}
❶
env包含一个环境变量列表, 它们通常是大写的并带有下划线.❷ 我们想要应用的转换是
toLowerCase, 将下划线替换为破折号, 并转换为关键字的组合. 使用some->是一个好主意, 以防转换接收到nil, 这会用字符串操作函数产生NullPointerException. 类型提示有助于加强对输入类型的期望, 并提高性能.❸
reduce-kv的调用相对直接. 我们将从输入映射中移动条目到另一个映射, 同时转换键.❹ 我们可以看到转换后的键, 正如我们期望它们在标准 Clojure 代码中格式化的那样.
- 输入
3.4.4. 11.4 实用函数
一些可与映射类型一起使用的函数不包含在核心命名空间中. 这并不意味着不应该使用它们, 只是它们是在解决其他问题时创建的. 以下函数可有效地用于映射, 并已相应地添加到本章中:
keywordize-keys和stringify-keys位于clojure.walk命名空间中. 它们将任意嵌套映射的键分别转换为关键字或字符串.rename-keys来自clojure.set, 允许重命名映射中的键.map-invert同样来自clojure.set命名空间, 交换映射中的键和值.
在本节中, 我们将简要概述它们的功能和相关信息.
- 11.4.1 clojure.walk/keywordize-keys 和 clojure.walk/stringify-keys
keywordize-keys和stringify-keys接受一个映射输入 (所有实现clojure.lang.IPersistentMap的类型, 即hash-map,array-map,sorted-map,record和struct), 并将键的类型分别转换为关键字或字符串:(require '[clojure.walk :refer [keywordize-keys stringify-keys]]) ; ❶ (keywordize-keys {"a" 1 "b" 2}) ; ❷ ;; {:a 1 :b 2} (stringify-keys {:a 1 :b 2}) ; ❸ ;; {"a" 1 "b" 2}
❶
keywordize-keys和stringify-keys需要一个显式的require指令才能在当前命名空间中可用.❷ 输入
array-map的键是字符串, 它们被转换为关键字.❸ 输入
array-map现在有关键字作为键, 它们被转换为字符串.keywordize-keys和stringify-keys仅限于将转换应用于字符串键 (keywordize-keys) 或关键字键 (stringify-keys). 其他键类型不会导致任何更改:(keywordize-keys {1 "a" 2 "b"}) ; ❶ ;; {1 "a", 2 "b"} (stringify-keys {1 "a" 2 "b"}) ; ❷
❶ 输入映射没有变化, 因为键不是字符串类型.
❷ 同样, 如果键类型不是关键字,
stringify-keys也不会转换键.也许
keywordize-keys和stringify-keys最有趣的特性是它们在任何嵌套级别上都有效. 例如, 我们可以使用keywordize-keys来转换深度嵌套数据结构中的键:(require '[clojure.walk :refer [keywordize-keys]]) (def products ; ❶ [{"type" "Fixed" "bookings" [{"upto" 999 "flat" 249.0}] "enabled" false} {"type" "Variable" "bookings" [{"upto" 200 "flat" 20.0}] "enabled" true}]) (keywordize-keys products) ;; [{:type "Fixed" ; ❷ ;; :bookings [{:upto 999 :flat 249.0}] ;; :enabled false} ;; {:type "Variable" ;; :bookings [{:upto 200 :flat 20.0}] ;; :enabled true}]
❶
products包含多个嵌套级别的向量和哈希映射.❷ 我们可以看到
keywordize-keys递归地遍历products, 关键字键也出现在嵌套结构中.两个函数都接受所有映射类型, 但它们总是返回
array-map(或对于更大的输入,hash-map, 遵循array-map的自动提升规则). - 11.4.2 clojure.set/rename-keys
rename-keys的名称非常不言自明. 给定一个输入映射和一个字典映射, 它会根据字典的内容重命名键:(require '[clojure.set :refer [rename-keys]]) ; ❶ (rename-keys {:a 1 :b 2 :c 3} {:a "AA" :b "B1" :c "X"}) ; ❷ ;; {"AA" 1, "B1" 2, "X" 3}
❶
rename-keys是clojure.set命名空间中的一个公共函数, 它是标准库的一部分.❷ 第一个映射中的每个匹配键都被第二个映射中相应的值替换.
rename-keys是一个用于简单重命名键的有用函数, 例如在将一种数据格式转换为另一种时. 重命名仅限于第一层, 不会循环遍历嵌套的映射 (如果有的话).rename-keys有一些依赖于输入映射类型的限制需要考虑.rename-keys总是返回array-map或hash-map, 不论输入类型.(defrecord A [a b c]) (rename-keys (A. 1 2 3) {:a :y :b :z}) ; ❶ ;; {:c 3, :y 1, :z 2} (type *1) ; ❷ ;; clojure.lang.PersistentArrayMap
❶ 在创建了一个包含 3 个字段
:a,:b和:c的简单记录 "A" 之后, 我们要求rename-keys更改一些键.❷ 操作成功, 但结果的类型是
array-map而不是记录.我们可以在
sorted-map上使用rename-keys, 前提是替换的类型与现有键的类型相同:(rename-keys (sorted-map :a 1 :b 2 :c 3) {:a :z}) ; ❶ ;; {:b 2, :c 3, :z 1} (rename-keys (sorted-map :a 1 :b 2 :c 3) {:a 9}) ; ❷ ;; ClassCastException clojure.lang.Keyword cannot be cast to java.lang.Number
❶ 我们使用一个
sorted-map作为rename-keys的输入. 操作成功完成, 返回的类型也是一个sorted-map.❷ 我们需要小心并使用正确的替换类型, 因为新的键类型需要能与旧的进行比较.
最后, 关于
struct的一个说明. 由于rename-keys首先使用dissoc移除目标键,struct会抛出错误, 因为不允许移除属于定义一部分的键:(rename-keys (struct (create-struct :a :b :c) 1 2 3) {:a 9}) ; ❶ ;; RuntimeException Can't remove struct key
❶
rename-keys不适用于struct. - 11.4.3 clojure.set/map-invert
map-invert交换映射中的键和值:(require '[clojure.set :refer [map-invert]]) ; ❶ (map-invert {:a 1 :b 2}) ; ❷ ;; {1 :a, 2 :b}
❶
map-invert位于clojure.set命名空间中.❷ 一个简单的输入映射被反转, 值变成键, 键变成值.
如果输入映射中有相同的值, 则值的最后一个实例获胜. 然而,
hash-map中键的顺序是不确定的, 所以最终出现在结果中的键也是不确定的:(def m (hash-map :y 0 :y 0 :d 0 :k 0 :w 0 :i 0 :f 0 :a 0 :n 0 :v 0 :s 0 :w 0)) ; ❶ (map-invert m) ; ❷ ;; {0 :a}
❶
hash-map"m" 只包含零值.❷ 键
:a在创建映射时不是最后一个, 但它成为作为键 "0" 的值进入映射的最后一个键.让我们来看一些空集合的边界情况:
(map-invert {}) (map-invert []) (map-invert ()) (map-invert "") ;; {} ; ❶
❶ 所有这些例子都返回相同的空映射, 尽管输入类型不一定是映射类型.
总的来说, 所有映射类型都可以被反转. 在下面的例子中, 所有
map-invert都返回一个具有相同键和值的映射, 然而顺序可能不同:(map-invert (hash-map :a 1 :b 2 :c 3)) ; ❶ ;; {3 :c, 2 :b, 1 :a} (map-invert (array-map :a 1 :b 2 :c 3)) ;; {1 :a, 2 :b, 3 :c} (map-invert (sorted-map :a 1 :b 2 :c 3)) ;; {1 :a, 2 :b, 3 :c} (map-invert (struct (create-struct :a :b :c) 1 2 3)) ;; {1 :a, 2 :b, 3 :c} (defrecord A [a b c]) (map-invert (A. 1 2 3)) ;; {1 :a, 2 :b, 3 :c} (import 'java.util.HashMap) (map-invert (HashMap. {:a 1 :b 2 :c 3})) ; ❷ ;; {2 :b, 3 :c, 1 :a}
❶ 输入
hash-map以不确定的顺序返回项, 这在map-invert的结果中是可见的.❷ 另一个不确定键顺序的例子.
map-invert对于启用双向映射查找很有用, 例如实现一个简单的加扰算法来混淆文本:(def scramble-key ; ❶ {\a \t \b \m \c \o \d \l \e \z \f \i \g \b \h \u \i \h \j \n \k \s \l \r \m \a \n \q \o \d \p \e \q \k \r \y \s \f \t \c \u \p \v \w \w \x \x \j \y \g \z \v \space \space}) (defn scramble [text scramble-key] ; ❷ (apply str (map scramble-key text))) (defn unscramble [text scramble-key] ; ❸ (apply str (map (map-invert scramble-key) text))) (scramble "try to read this if you can" scramble-key) ;; "cyg cd yztl cuhf hi gdp otq" (unscramble "cyg cd yztl cuhf hi gdp otq" scramble-key) ; ❹ ;; "try to read this if you can"
❶
scramble-key是一个从字符到字符的映射, 将字母表中的每个字母与另一个随机字母配对.❷
scramble使用scramble-key来混淆一个句子的内容.❸
unscramble可以使用随机化的字母 (在scramble-key中作为值出现) 作为键来反转混淆效果. 我们可以通过使用map-invert快速获得这种效果.❹ 混淆的文本被转换回正确的明文.
这结束了专门用于映射及其处理函数的章节.
3.4.5. 11.5 总结
映射是每个开发者工具箱中的重要资产. Clojure 提供了丰富的函数来处理映射, 包括对归约 (reduce-kv) 或折叠 (reducers/fold) 的特定支持. 本章包含几个关于如何有效使用它们的例子. 下一章专门介绍另一个宝贵的主力: 向量.
3.5. 12 向量
3.5.1. 12.1 感谢 Rachel Bowyer 对本章的贡献.
Clojure 的向量是该语言的突出特性之一: 高性能, 不可变且具有方便的字面量语法. 早在 2009 年 Clojure 1.0 发布时, 没有其他东西能与之媲美; 它使 Clojure 与早期的 LISP 语言区别开来. 从那时起, 其他函数式语言如 Scala 175 和 Haskell 176 也添加了它们自己的不可变向量.
Clojure 的向量按顺序存储元素, 使用从零开始的索引. 它提供了高效的读, 写和追加操作, 可以直接访问元素的索引. 它还支持从向量尾部高效删除 (使用 pop), 但不支持从其他位置删除 (对此最好的解决方法是使用 subvec).
向量的字面量语法仅包括将以空格分隔的元素列表括在一对方括号中:
[:a :b :c] ; ❶ ;; => [:a :b :c]
❶ 通过将元素括在方括号中简单地创建一个新向量.
向量不仅是一个数据结构, 还是一个可以查找值的函数. 它接受一个参数, 即从零开始的索引, 如果超出范围, 则会抛出 IndexOutOfBoundsException:
(ifn? []) ; ❶ ;; true ([:a :b :c] 2) ; ❷ ;; :c ([:a :b :c] 3) ; ❸ ;; IndexOutOfBoundsException
❶ 询问 [] 是否可以作为函数调用返回 true.
❷ 向量的索引从零开始. 这里我们访问向量中的最后一项.
❸ 索引为 3 的元素在向量中不存在.
(get [:a :b :c] 2) ;; :c (nth [:a :b :c] 2) ;; :c (assoc [:a :b :c] 2 :d) ;; [:a :b :d] (conj [:a :b :c] 3.1 :e) ;; [:a :b :c 3.1 :e] (pop [:a :b :c]) ;; [:a :b] (peek [:a :b :c]) ;; :c
要确定一个序列是否是向量, 我们可以使用 vector?. 与其他数据结构相比, contains? 函数的工作方式可能不如预期. 当在向量上使用时, 它按位置工作, 不比较值. contains? 确定向量是否在特定索引处分配了元素. 如果你关心的是值, 一个解决方案是改用底层的 Java .contains 函数.
(contains? [1 2 :a :b] 3) ; ❶ ;; true (contains? [1 2 :a :b] :a) ;; false (.contains [1 2 :a :b] 3) ; ❷ ;; false (.contains [1 2 :a :b] :a) ;; true
❶ 来自标准库的 contains? 函数用于验证索引 3 处是否有元素, 而不是值 "3" 是否存在于向量中.
❷ 注意, 这个 contains 调用前有一个点 ".", 表示对用于实现 Clojure 向量的 Java 类型的实例方法 "contain" 的调用.
向量是 "seq-able" 的 (也就是说, (instance? clojure.lang.Seqable []) 为真), 所以它们可以与任何期望序列的函数一起工作, 尽管它们通常不如直接在向量上操作的函数高效:
(first [:a :b :c]) ; ❶ ;; :a
❶ 向量支持序列接口, 使得序列函数可以无缝使用.
尽管向量可以像序列一样行为, 因此可以用作
seq的参数, 但它们本身不是序列类型:seq?返回 false. 这对向量的影响是, 所有序列操作都可以在向量上工作, 但它们被隐式地转换为序列.
有专门版本的 map 和 filter, 分别称为 mapv 和 filterv. mapv 和 filterv 返回一个向量而不是一个序列. 向量还提供了一种用 rseq 高效反转的方法. 同样, subvec 可以被认为是 rest 的一个特殊版本.
- 持久向量和 RBB 树
Clojure 的向量是基于一个从外部世界无法访问的可变实现. 然而, 从数据结构客户端的角度来看, 向量表现为不可变的. 这是通过在旧版本的向量仍然被运行的应用程序引用时, 将它们保留在内存中来实现的. 这样的数据结构被称为 "持久的".
尽管通过每次修改时复制向量来创建一个持久向量是直接的, 但这在时间和空间上都非常低效. Clojure 采用的解决方案, 受到 Phil Bagwell 的论文 "Ideal Hash Trees" 177 的启发, 是使用一个平衡树, 其叶节点包含向量中的元素. 下图显示了一个包含 "Pride and Prejudice" 文本的持久向量的一部分.
Figure 34: Figure 12.1. 一个包含 "Pride and Prejudice" 文本的持久向量的一部分.
当一个元素被修改时, 叶节点, 根节点以及从叶节点到根的所有路径上的节点都必须被复制, 但关键是其他节点都不需要. 此外, 该树在每个非叶节点 (以及包含最多 32 个值的叶节点) 处使用 32 路分支, 导致树非常浅. 整本 "Pride and Prejudice" 的文本可以放入一个只有 4 层深的树中! 因此, 尽管从技术上讲, 修改一个有 n 个元素的向量中的一个元素在时间上是
O(log n), 但实际上其行为几乎是常数时间. 这是因为树非常浅. 即使是一个包含十亿个元素的向量也只有 6 层深, 因为log32(1 billion) < 6178.2011 年 9 月, Bagwell 和 Rompf 扩展了 Clojure 向量的实现, 创建了松弛基数平衡树 (RRB Trees). 它们在
O(log n)而不是O(n)时间内提供了连接和在指定位置插入的功能. RRB Trees 仍然是一个活跃的持续研究课题 179.clojure.lang.PersistentVector是最常见的. 它由向量字面量语法[], 函数vector或vec创建.clojure.lang.APersistentVector$SubVector是 "subvector" 的类型, 由subvec返回.clojure.core.Vec是通常称为 "gvec" 的类型, 即由vector-of返回的基于原始类型的向量.clojure.lang.MapEntry是元组 (一个包含两个元素的向量), 是将映射作为序列迭代时形成的.不幸的是, 这些名称不是特别具有描述性. 特别是 "gvec" 也是一个持久向量. 然而, Clojure 社区在讨论它们时使用这些名称, 而不是冗长的类类型.
下表是不同类型向量行为的快速摘要. 要了解更多关于它们的特性, 请参阅相关函数的条目.
创建方式: 支持瞬态? 存储 nil? 存储混合数据类型? 空间效率? 高效构造? vector是 是 是 否 是 vector-of否 否 否 是 否 subvec否 取决于底层向量 取决于底层向量 是 是 (first {:a 1})否 是 是 是 是
3.5.2. 12.2 操作向量的函数
有重写的 get, nth, assoc, conj 和 pop 版本可以用于向量. 可以使用 get 或 nth 从向量的任何位置检索元素. 可以使用 assoc 写入元素, 用 conj 追加元素. 向量末尾的元素可以使用 pop 移除, 用 peek 检索. 以下是一些最常用函数的基本用法示例:
3.5.3. 12.3 四种类型的向量
Clojure 不止一种, 而是有四种类型的向量. 语言的最终用户不一定需要了解具体的类型, 但有时它们的差异会发挥作用:
3.5.4. 12.4 vector
自 1.0 版本起可用的函数
(vector ([]) ([a]) ([a b]) ([a b c]) ([a b c d]) ([a b c d e]) ([a b c d e f]) ([a b c d e f & args]))
函数 vector 创建一个向量 (Clojure 的主要数据结构之一), 其元素由其参数组成. 向量中元素的顺序与提供给函数的参数顺序相同:
(vector :a :b :c) ; ❶ ;; [:a :b :c]
❶ vector 函数用给定的项作为内容创建一个新向量.
vector 产生与读宏字面量 [] (一对方括号括住其他形式或常量) 相同的输出:
[:a :b :c] ; ❶ ;; [:a :b :c]
❶ 向量读宏字面量 [] 的工作方式与 vector 函数类似.
如果在编写代码时元素的类型和数量是已知的, 那么通常使用字面量 [] 而不是函数, 因为它更短且更符合习惯 180. 当无法显式写入每个参数时, 仍然会使用该函数, 例如收集函数声明的所有参数:
(defn var-args [a b & all] (apply vector a b all)) ; ❶ (var-args :a :b :c) ;; [:a :b :c]
❶ apply 用于收集参数序列并将其传递给 vector. 注意在这种情况下使用向量字面量语法是不可能的. 这是因为函数 "var-args" 的所有参数都被收集到 "all" 中, 作为一个类型为列表的单个元素.
契约
- 输入
vector接受零个参数, 返回一个空向量."a","b","c","d","e","f"(以及任何附加参数) 可以是任何类型, 包括nil或其他向量.虽然所有提供的元数都将创建相同类型的向量, 但前 7 个 (从 0 到 6 个参数) 会稍快一些 (这是 Clojure 标准库中的一个常见模式). 更多细节请参见下文的标注部分.
- 输出
一个类型为
clojure.lang.PersistentVector的对象, 按顺序包含给定的参数. 如果没有参数, 则返回一个空的持久向量.示例
在引言中, 我们已经看到了使用
vector作为函数与语法字面量[]之间的区别. 另一个需要使用vector而不是方括号的情况是, 当它是函数字面量调用的一部分时. 语法#()会扩展为一个函数调用, 不适合将向量字面量作为第一个形式. 下面的longest-palindrome例子说明了从函数字面量内部使用vector:(def palindromes ["hannah" "kayak" "civic" "deified"]) (defn longest-palindrome [words] (->> words (filter #(= (seq %) (reverse %))) ; ❶ (map #(vector (count %) %)) ; ❷ (sort-by first >) first)) (macroexpand '#([(count %) %])) ; ❸ ;; (fn* [p1] ([(count p1) p1])) (longest-palindrome palindromes) ;; [7 "deified"]
❶ 我们反转单词以与自身进行比较. 这种快速解决寻找回文问题的方法对于这个例子来说足够简单, 但有更有效的替代方案 (见
rseq).❷ 类似但不正确的语法, 使用向量字面量
(map ([(count %) %])), 将在运行时抛出ArityException. 这是因为函数字面量()将其内容扩展为一个函数调用 (见下文).❸ 这个宏展开显示了为什么函数字面量内的向量字面量不起作用. 展开显示生成的
fn将向量用作函数, 调用它时没有必需的参数.下一个例子展示了如何将属于两个房地产系统的数据在比较之前连接起来. 这可能在发布新版本的数据之前发生, 这样新版本就可以对旧版本进行回归测试:
(require '[clojure.data :refer [diff]]) (def old-data [{:summary "Bijou love nest" :status "SSTC"} {:summary "Country pile" :status "available"}]) (def new-data [{:summary "Bijou love nest" :status "SSTC"} {:summary "Country pile" :status "SSTC"}]) (doseq [[old-instruction new-instruction] ; ❶ (map vector old-data new-data)] ; ❷ (let [[only-first only-second common] (diff old-instruction new-instruction)] (when (or only-first only-second) (println "Differences:" old-instruction new-instruction)))) ;; Differences: {:summary Country pile, :status available} ;; {:summary Country pile, :status SSTC} ;; nil
❶ 向量解构用于检索两个房地产指令.
❷ 为了让
doseq一次处理两个元素, 首先使用map vector创建一个键值对序列.使用
map和vector是创建矩阵转置的典型方法 181:(def m [[1 2 3] ; ❶ [4 5 6] [7 8 9]]) (apply map vector m) ; ❷ ;; ([1 4 7] ;; [2 5 8] ;; [3 6 9])
❶ 矩阵是一个具有行和列的二维结构. 我们可以将矩阵编码为一个嵌套向量. 每个内部向量代表矩阵的一行.
❷
map迭代 "m" 中的每一行, 从它们中取相同索引处的项. 在这种情况下,vector接收三个参数来重新创建新的转置行. - Clojure 更快的 "arities"
vector带有许多明显重叠的元数. 所以当你在 REPL 中使用doc时, 你会看到:(doc vector) ; ❶ ;; ([] [a] [a b] [a b c] [a b c d] [a b c d e] [a b c d e f] ;; [a b c d e f & args]) ;; Creates a new vector containing the args.
❶
doc函数在 Clojure REPL 中随时可用. 如果在你的环境中不是这样, 你可以用(require '[clojure.repl :as repl])来require它, 然后是(repl/doc vector).标准库中的许多其他函数都遵循类似的模式. 你可能会想知道为什么签名不简单地是
(defn vector [& args]), 原因在于性能. 有两个与元数和性能相关的方面:- 一般来说, " & args" 元数的存在意味着函数实现中某处包含了对可变数量参数的迭代. 这种迭代比直接访问参数更昂贵.
- 根据函数实现的不同, 不同的元数可能只是共享相同的底层代码, 或者有完全不同的方式来达到最终结果.
vector特别利用了在编译时知道参数数量 (0 到 6) 的优势, 直接创建持久向量的尾部. 而可变元数的情况则使用了一个更灵活的 "创建和扩展" 循环. 这里有一个简单的基准测试, 显示了速度的提升:(require '[criterium.core :refer [quick-bench]]) (quick-bench (vector 1 2 3 4 5 6)) ;; Execution time mean : 8.281921 ns (quick-bench (vector 1 2 3 4 5 6 7)) ; ❶ ;; Execution time mean : 214.268271 ns
❶ 添加到向量中的额外元素使创建速度减慢了约 20 倍.
前 6 个参数的行为涵盖了创建小向量作为中间结果的广泛情况. 它还涵盖了在应用程序中将数据建模为小组的可能需求: 元组, 三元组等等.
总而言之: 如果某个业务问题需要将大量数据处理为各种大小的小向量, 那么如果向量最多包含 6 个项, 处理速度会更快. 如果应用程序需要更大的块, 你可以使用下面的宏来生成额外的向量处理器:
(defmacro defnvector [n] ; ❶ (let [args (map #(symbol (str "x" %)) (range n))] `(defn ~(symbol (str "vector" n)) [~@args] [~@args]))) (macroexpand '(defnvector 7)) ; ❷ ;; (def vector7 (fn ([x0 x1 x2 x3 x4 x5 x6] [x0 x1 x2 x3 x4 x5 x6]))) (defnvector 7) ; ❸ (defnvector 8) (defnvector 9) (defnvector 10) (quick-bench (vector7 1 2 3 4 5 6 7)) ; ❹ ;; Execution time mean : 8.577230 ns
❶
defnvector宏在当前命名空间中用defn生成一个函数定义. 它接受一个参数数量 n, 用于生成参数和构建向量.❷ 我们可以通过用
macroexpand展开宏来看它是如何工作的.❸ 新的向量构建器需要显式声明.
❹ 基准测试显示, 生成的函数的速度与原始
vector实现最多 6 个参数时相当.另请参阅
vec从一个可 seq 的集合创建一个持久向量. 如果新创建的向量的输入内容来自一个已存在的序列, 优先使用vec.vector-of创建一个指定原始 Java 类型的向量. 如果空间效率是最大的考虑, 使用vector-of.make-array创建一个 Java 数组. 如果需要可变数据结构的性能优势, 或者在与 Java 代码接口时, 使用 Java 数组.assoc可用于交换向量中指定索引处的元素. 虽然主要用于映射, 但在向量上使用assoc对于快速更改向量的内容非常宝贵.replace允许使用类字典结构在向量上一次进行多次更改. 相应索引处的所有项都将被相关的更改替换.性能考虑和实现细节
=>
O(n log(n))时间, n 为参数数量=>
O(n)空间vector和vec有相似的性能特征, 所以本节适用于两者, 除非另有说明, "n" 指的是参数数量或当调用(vec coll)时的"coll".如本章引言所述, 持久向量是作为 32 路树实现的. 向量中的最后
(inc (mod (dec n) 32))个元素是分开存储的. 这些元素被称为向量的 "尾部". 分开存储尾部是允许用peek等在常数时间内访问向量中最后一个元素的原因.在 32 项及以上的
vector实现中, 在 Java 端会创建一个空的, 可变的瞬态对象. 然后元素被逐一追加. 在 32 项以下, 尾部有空间, 添加一个新项在常数时间内完成. 但总的来说, 每隔 32 个元素, 尾部就会溢出, 必须添加到树中. 这需要O(log32n)次操作, 导致创建一个持久向量的时间复杂度为O(n log(n)). 然而, 对于所有实际目的, 性能可以被认为是线性的.vec的实现也基于输入集合的类型.vec与vector共享相同的实现, 除了两种情况:- 如果输入集合是 "reducible" (实现
clojure.lang.IReduce接口), 那么vec最终会委托给输入集合的reduce实现. - 如果输入集合是一个包含 32 个或更少元素的 Java 非原始数组, 那么不会创建空向量, 而是创建尾部, 从而创建对 Java 数组的别名.
以下基准测试检查了随着 n 的增加,
vector和vec的速度如何变化:(require '[criterium.core :refer [benchmark]]) (defmacro b [expr] ; ❶ `(first (:mean (benchmark ~expr {})))) (def results ; ❷ (doall (for [i (range 10)] (let [num-elements (* (inc i) 100000) data (range num-elements)] [(b (vec data)) (b (apply vector data))]))))
❶
b宏仅从基准测试中提取平均执行时间, 移除所有与本测试无关的其他统计数据.❷ 该循环在项目数量从 100,000 增加到 1,000,000 (增量为 100,000) 的同时, 为
vector和vec生成基准测试."results" 包含一个对的集合: 第一项是
vec的耗时 (纳秒), 第二项是vector的耗时. 为了便于可视化, 我们可以使用以下代码生成一个图表:(require '[com.hypirion.clj-xchart :as chart]) ; ❶ (let [[vec-results vector-results] (apply map vector results) labels (range 100000 1100000 100000)] ; ❷ (chart/view (chart/xy-chart {"(vec)" [vec-results labels] "(vector)" [vector-results labels]})))
❶ 我们在本书的其他部分使用过
clj-xchart来生成视觉上吸引人的图表.❷ 我们需要隔离每个结果系列来绘制图表的每一条线.
Figure 35: Figure 12.2. vec vs vector 的性能比较
可以清楚地看到函数的线性行为.
vec的运行速度略快于vector, 因为vector使用first/next语义迭代输入, 而reduce更快. 我们可以通过使用一个不实现IReduce的惰性序列来验证这个假设:(require '[criterium.core :refer [quick-bench]]) (let [reducible (doall (range 1000)) lazy (doall (map inc (range 1000)))] (quick-bench (vec lazy)) (quick-bench (apply vector lazy)) (quick-bench (vec reducible)) (quick-bench (apply vector reducible))) ;; Execution time mean : 22.523189 µs ; ❶ ;; Execution time mean : 22.624104 µs ;; Execution time mean : 16.058917 µs ; ❷ ;; Execution time mean : 19.471246 µs
❶ 当输入集合是可
seq但不可归约时,vector和vec的执行时间是相当的.❷ 如果输入提供的
reduce实现性能更好,vec会更快.现在让我们使用 Java Jamm 库 182 来看看内存分配. 下面的代码片段用于说明下面图表中持久向量使用的内存 (要运行该示例, Jamm 需要用 `-javaagent` 设置一个特定的 Java 代理):
(import 'org.github.jamm.MemoryMeter) (defn test-memory-vector-of-jamm [] (let [meter (MemoryMeter.) results (for [elements (range 100000 1100000 100000)] [elements (.measureDeep meter (make-array Object elements)) (.measureDeep meter (vec (repeat elements nil)))])] (doseq [i (range 4)] (doseq [result results] (printf "%11d " (get result i))) (println))))
下一个图表 (使用电子表格图表功能创建) 显示了 Clojure 向量的内存使用情况 (以兆字节为单位), 并证实了随着 "n" 的增加, 行为是线性的.
Figure 36: Figure 12.3. 持久向量消耗的内存
不幸的是, 不变性和动态增长的能力是有代价的. 下图显示了使用 Clojure 向量与 Java 数组相比的开销百分比. 该百分比说明了向量与具有相同内容的
java.util.ArrayList相比消耗了多少额外的空间:
Figure 37: Figure 12.4. 使用持久向量与 Java 数组相比的内存开销
对于小向量, 开销非常高, 但在 1000 个元素之后, 它稳定在 35% 左右. 这是因为每次数组调整大小时, 其长度都会增加 50%. 然而, 如果
ArrayList的大小是预先知道的, 那么数组将被正确地调整大小以适应元素数量, 并产生更小的开销.
3.5.5. 12.5 vec
自 1.0 版本起可用的函数
(vec coll)
vec 从另一个集合作为输入创建一个新向量. vec 适用于几乎所有集合类型:
- 常见的 Clojure 集合, 如列表, 集合, 映射等.
- Java 可迭代对象, 如
clojure.lang.PersistentQueue或java.util.ArrayList - 原生 Java 数组 (如用
make-array创建的那些).
结果向量的顺序与输入中元素的顺序匹配, 除了无序集合 (如集合或映射), 对于这些集合没有特定的顺序. vec 可以像这样使用:
(vec '(:a 1 nil {})) ; ❶ ;; [:a 1 nil {}]
❶ 注意, vec 不会递归地转换其他嵌套的集合.
如果输入集合是一个包含 32 个或更少元素的引用类型的 Java 数组,
vec产生的输出向量将只是原生数组的一个别名. 因此, 在调用vec之后不应修改 Java 数组, 否则不可变的 Clojure 向量可能会改变值! 更多信息请参见示例.
契约
- 输入
"coll"可以是任何可seq的集合, 一个 "可迭代" 的集合 (使得(instance? java.lang.Iterable coll)为真), 或一个 Java 数组 (使得 `(.isArray (class coll))` 为真)."coll"也可以是nil.唯一不适用于
vec的类集合 Clojure 数据结构是瞬态和结构体. - 主要异常
如果
"coll"不能转换为序列, 则抛出RunTimeException. - 输出
vec返回一个包含"coll"中元素的持久向量实例. 对于有序集合, 生成的向量中的顺序是受尊重的.下表显示了使用不同集合类型的
vec的几个例子. 表中给出了简短的注释来解释结果. 注意:clojure.lang缩写为 "c.l":输入类型 示例 注释 c.l.PersistentList (vec (list 1 2 3))输出向量是有序的. c.l.PersistentVector $TransientVector (vec (transient [1 2 3]))抛出 RuntimeException.clojure.core.Vec (vec (vector-of :int 1 2 3))输出向量是有序的. c.l.APersistentVector $SubVector (vec (subvec [1 2 3] 1))输出向量是有序的. c.l.PersistentHashSet (vec #{1 2 3 4 5 6})输出向量是无序的. c.l.PersistentHashMap (vec (apply hash-map (range 10)))元组的向量是无序的. c.l.PersistentTreeSet (vec (sorted-set :a :b :c))输出向量是有序的. c.l.PersistentTreeMap (vec (sorted-map :a 1 :b 2))元组的向量是有序的. c.l.PersistentArrayMap (vec (array-map :c "c" :d "d"))元组的向量是有序的. c.l.LongRange (vec (range 10))输出向量是有序的. c.l.LazySeq (vec (map inc (range 10)))输出向量是有序的. [[Ljava.lang.Long (vec (make-array Long 0))输出向量是别名的. [I (vec (int-array [1 2 3]))输出向量不是别名的. c.l.PersistentQueue (vec (c.l.PersistentQueue/EMPTY))输出向量是有序的. record (defrecord Name [first last]) (vec (Name. "John" "Doe"))工作方式类似于哈希映射. java.lang.Iterable (import java.util.ArrayList) (vec (ArrayList.))输出向量是有序的. 示例
下面的例子显示了在 Java 数组上使用
vec的潜在副作用:(def a (make-array Long 3)) ; ❶ (def v (vec a)) v ;; [nil nil nil] (aset a 1 99) ;; 99 v ;; [nil 99 nil] ; ❷
❶ 注意, 我们使用引用类型
Long而不是原始类型long来创建 Java 数组.❷ 在数组上的
aset操作对由vec创建的向量产生副作用.对于原始类型的数组, 不会发生同样的情况:
(def a (long-array 3)) ; ❶ (def v (vec a)) v ;; [0 0 0] (aset a 1 99) ;; 99 v ;; [0 0 0] ; ❷
❶ 这一次, 数组是原始类型
long.❷ 我们可以看到, 用
vec创建的新向量没有副作用.现在是一个更复杂的例子. Madison 正在 "Rachel's Rags" 网站上寻找一件蓝色连衣裙. 首先, 她在网站上搜索蓝色连衣裙. 在幕后, 网站查询数据库, 将结果转换为向量, 分配一个搜索 id 并缓存结果. 然后网站将结果的第一页作为 JSON 返回给 Madison 的浏览器, 同时还有搜索 id. Madison 的浏览器然后将 JSON 渲染为 HTML.
然后, Madison 不知为何决定查看结果的第 3 页. 作为响应, 她的浏览器向网站发出一个 AJAX 请求, 传递搜索 id 183. 网站然后检索结果的第 3 页并将其作为 JSON 返回给她的浏览器.
将搜索结果缓存为向量效果特别好, 因为 Madison 可以在搜索结果的页面之间随机跳转. 然而, 由于大多数 Clojure 数据库库会将其结果作为序列返回, 所以需要
vec来将结果转换为向量. 服务器代码的简化版本, 数据库被模拟, 可能看起来像这样:(import '(java.util UUID)) (defn search-merchandise [& search-options] ; ❶ '({:description "Pencil Dress" :type :dress :color :blue :price 60} {:description "Asymmetric Lace Dress" :type :dress :color :blue :price 70} {:description "Short Sleeve Wrap Dress" :type :dress :color :blue :price 45})) (def cache (atom {})) ; ❷ (defn cache-user-search-results! [search-id search-results] (swap! cache assoc search-id (vec search-results))) ; ❸ (defn retrieve-user-search-results [search-id page] ; ❹ (get (get @cache search-id) page)) (defn render-to-json [{:keys [description price]}] ; ❺ (format "[{'description':'%s', 'price':'%s'}]" description price)) (def search-id (str (UUID/randomUUID))) ; ❻ (cache-user-search-results! search-id (search-merchandise {:type :dress :color :blue})) (println (-> (retrieve-user-search-results search-id 0) render-to-json)) ;; [{'description':'Pencil Dress', 'price':'60'}] (println ; ❼ (-> (retrieve-user-search-results search-id 2) render-to-json)) ;; [{'description':'Short Sleeve Wrap Dress', 'price':'45'}]
❶
search-merchandise根据传入的 "search-options" 搜索数据库并返回一个列表. 为简单起见, 结果已被模拟.❷ 搜索结果被缓存到一个由
atom持有的映射中. 这是线程安全的, 对于小型系统, 根据内存要求是完全合适的. 更大更复杂的系统可能会受益于使用像core.cache184 这样的库或像 Redis 185 这样的分布式缓存.❸
cache-user-search-results!获取搜索结果, 使用vec将它们转换为向量, 并将它们存储在缓存中.❹ 给定一个搜索 id,
retrieve-user-search-results返回要在给定页面上显示的结果. "page" 是所需结果的页面, 并且是从零开始索引的, 例如, 要检索结果的第二页, "page" 将是 1.retrieve-user-search-results是高效的, 因为结果被存储为向量. 为了保持示例简单, 每页返回一项.❺
render-to-json是一个简单的 json 渲染器. 现实世界的系统会使用像 Cheshire 186 这样的外部库.❻ 这段代码模拟了 Madison 发起搜索时的场景. 使用 Java UUID 生成随机分配一个唯一的搜索 id. 然后对数据库进行 "蓝色连衣裙" 的搜索, 并缓存结果. 最后检索她的结果的第一页并转换为 JSON.
❼ 这段代码模拟了 Madison 查看第三个结果页面时的场景. 使用现有的搜索 id, 从缓存中检索她的结果的第三页并转换为 JSON.
另请参阅
vector-of创建一个原始类型的向量. 如果空间效率是最大的考虑, 使用vector-of.make-array创建一个 Java 数组. 如果需要可变数据结构的性能优势或与 Java 代码接口, 使用 Java 数组.long-array创建一个原始类型long的 Java 数组.into可用于将一个集合的内容 "传输" 到另一个集合, 包括向量. 与vec相比, 有一些小的差异:into不会为数组创建别名, 它支持 transducer, 也可以创建其他集合类型. 如果你只关注向量,vec更能传达转换的含义, 并且节省一些按键.性能考虑和实现细节
=>
O(n log(n))时间, n 为参数数量=>
O(n)空间vec创建新向量的逻辑基于输入集合的类型.vec与vector共享相同的可seq集合的实现, 但在以下情况下采取不同的路径:- 如果输入集合是 "reducible" (实现
clojure.lang.IReduce接口), 那么vec最终会委托给输入集合的reduce实现. - 如果输入集合是一个包含 32 个或更少元素的 Java (非原始) 数组, 那么不会创建空向量, 而是创建尾部, 从而创建对 Java 数组的别名.
- 如果输入集合特别是
java.util.ArrayList, 那么输入会用一个索引进行迭代. - 如果输入集合通常是
java.lang.Iterable(例如java.util.LinkedList), 那么输入会用first/rest类似的语义进行迭代.
区分
vec和vector的一个重要方面是,vec提供了让输入自己构建自己的选项. 如果输入集合支持clojure.lang.IReduce接口, 这是可能的. 在那种情况下, 使用reduce来构建向量. 因此,vec的性能特征取决于输入集合的类型, 正如下面的基准测试所证明的那样:(require '[criterium.core :refer [quick-benchmark]]) (import '[java.util ArrayList LinkedList]) (defmacro b [expr] ; ❶ `(first (:mean (quick-benchmark ~expr {})))) (let [c1 (range 1000) ; ❷ c2 (map inc c1) c3 (ArrayList. c1) c4 (LinkedList. c1)] (for [t [c1 c2 c3 c4]] [(type t) (b (vec t))])) ;; ([clojure.lang.LongRange 1.0874153277485413E-5] ;; [clojure.lang.LazySeq 2.0303272494887527E-5] ;; [java.util.ArrayList 1.0039155519384434E-5] ;; [java.util.LinkedList 1.4243774103139014E-5])
❶
b宏从 Criterium 返回的统计数据中提取平均执行时间 (以秒为单位).❷
vec用于创建一个包含 1000 个元素的向量. 我们测试了四种类型的输入集合. 使用java.util.ArrayList的版本是这组中最快的, 而lazy-seq是最慢的.既然我们之前简单地比较了
into和vec, 这里是它们之间的基准测试:(require '[criterium.core :refer [bench]]) (let [l (range 1000)] (bench (vec l))) ;; Execution time mean : 16.765533 µs (let [l (range 1000)] (bench (into [] l))) ; ❶ ;; Execution time mean : 17.946582 µs
❶
into的性能略逊于vec.into和vec之间的差异非常小, 不足以单独确定一个明确的赢家. 如前所述, 在向量处理的上下文中应优先使用vec, 以更好地传达计算的含义. 在实现方面,into主要是在 Clojure 中实现的, 而vec几乎立即委托给clojure.lang.LazilyPersistentVector, 后者继续在输入序列上调用正确的顺序转换以创建最终的向量. - 如果输入集合是 "reducible" (实现
3.5.6. 12.6 peek 和 pop
自 1.0 版本起可用的函数
(peek [coll]) (pop [coll])
peek 和 pop 从向量, 列表或队列中访问或移除 (在不可变数据结构的意义上) "头部元素". 头部的位置取决于集合类型, 不一定是第一个元素:
(import '[clojure.lang PersistentQueue]) (def q (into (PersistentQueue/EMPTY) [1 2 3])) (def v [1 2 3]) (def l '(1 2 3)) (peek q) ; 1 ; ❶ (peek v) ; 3 ; ❷ (peek l) ; 1 ; ❸
❶ 在 clojure.lang.PersistentQueue 类型上调用 peek 返回添加到队列的第一个元素.
❷ 在向量上调用 peek, 返回添加到向量的最后一个元素 (打印时, 这显示为最右边的元素).
❸ peek 在列表上使用, 返回第一个添加的元素 (打印时它显示为最左边的元素).
这很容易让人困惑, 因为识别集合中一个项的位置有多种含义. 它可以是:
- 最先或最后添加的元素.
- 关于项内部如何存储的实现细节.
- 项打印时的方式.
pop 返回移除集合头部后剩下的部分:
(-> (PersistentQueue/EMPTY) (conj "a" "b" "c") pop vec) ; ❶ ;; ["b" "c"] (pop ["a" "b" "c"]) ; ❷ ;; ["a" "b"] (pop '("a" "b" "c")) ; ❸ ;; ("b" "c")
❶ 当我们在一个队列上调用 pop 时, 会返回不可打印的队列对象. 我们可以使用 vec 来查看队列的内容.
❷ 在向量上调用 pop 会移除尾部元素, 即打印时最右边的项, 也是最后添加的项.
❸ 在列表上使用 pop 会移除头部元素, 即最左边的项, 也是最先添加的项.
下表总结了我们到目前为止所看到的:
| 类型 | peek |
pop |
Pop 空的? |
|---|---|---|---|
| 队列 | 检索第一个添加的 | 移除第一个添加的 | OK |
| 向量 | 检索最后一个添加的 | 移除最后一个添加的 | 抛出异常 |
| 列表 | 检索第一个添加的 | 移除第一个添加的 |
该表还显示, 在空集合上调用 pop 只适用于队列.
契约
- 输入
"coll"是唯一强制性参数. 该集合需要实现IPersistentStack接口, 这可以用(instance? clojure.lang.IPersistentStack coll)来验证. 支持此接口的常用集合类型是: 队列, 列表和向量. - 主要异常
当集合不支持
IPersistentStack接口时, 抛出ClassCastException. 产生此错误的常见示例是:(peek (range 10))或(peek #{1 2 3 4}).尝试在空向量或空列表上调用
pop时抛出IllegalStateException. 在空队列上调用pop是可以的. - 输出
peek: 返回最先添加的元素 (对于队列和列表) 或最后添加的元素 (对于向量). 如果"coll"为空或nil,peek返回nil.pop: 返回移除peek返回的元素后剩下的部分. 对于空向量或列表,pop抛出异常. 当"coll"为nil时返回nil.示例
peek和pop是典型的队列操作. 它们在标准库中的存在有助于传达这一含义. 队列是一种抽象数据类型, 其特点是其插入/提取顺序 187.由于
peek和pop, LIFO 队列 (后进先出的队列也称为栈) 可以在向量之上高效实现 (FIFO 队列直接由queue实现). 在下面的例子中, 我们可以使用基于向量的 LIFO 队列来验证一个 Clojure 形式是否包含平衡的括号:(require '[clojure.set :refer [map-invert]]) (defn queue [] []) ; ❶ (def push conj) ; ❷ (def brackets {\[ \] \( \) \{ \}}) ; ❸ (defn check [form] ; ❹ (reduce (fn [q x] (cond (brackets x) (push q x) ; ❺ ((map-invert brackets) x) ; ❻ (if (= (brackets (peek q)) x) (pop q) (throw (ex-info (str "Unmatched delimiter " x) {}))) :else q)) (queue) form)) ; ❼ (check "(let [a (inc 1]) (+ a 2))") ;; ExceptionInfo Unmatched delimiter ] (check "(let [a (inc 1)] (+ a 2))") ;; []
❶ 为了更好地符合使用队列的想法, 我们添加了这个简单的构造函数, 它包装了一个空向量. 我们可以用一个空列表或其他队列实现来替换它, 前提是它们支持
peek,pop和conj语义.❷ 类似地,
push只是conj的一个别名, 帮助我们从队列的角度思考.❸ 我们需要一个所有允许的括号及其匹配对的列表. 我们可以将此组织为一个字典, 以快速查找给定开括号的闭括号作为键.
❹
check函数执行对输入的扫描. 它被组织为一个围绕一个 (最初为空的) 队列和输入标记列表的reduce操作.❺ 每个字符都经过一个
cond表达式: 如果我们有一个开括号, 我们就把它推入队列, 等待下一次迭代发生什么.❻ 如果我们有一个闭括号, 我们检查相关的开括号是否是我们看到的最后一件事. 这是一个从队列中进行的
peek操作. 如果我们有匹配, 我们就弹出匹配的括号, 并等待下一次迭代. 如果没有匹配, 就抛出异常. 注意使用来自clojure.set命名空间的map-invert来反转映射中的键值.❼ 如果标记不是括号, 我们什么也不做, 返回队列.
peek和pop也可以在基于向量的循环中高效使用, 其中当前项在每次迭代中被提取, 剩余部分通过recur发送到下一次:(defn reverse-mapv [f v] ; ❶ (loop [v v res (transient [])] ; ❷ (if (peek v) ; ❸ (recur ; ❹ (pop v) (conj! res (f (peek v)))) (persistent! res)))) ; ❺ (reverse-mapv str (vec (range 10))) ;; ["9" "8" "7" "6" "5" "4" "3" "2" "1" "0"]
❶
reverse-mapv返回一个向量的反转, 同时可以对每个元素应用一个转换.❷ 循环通过将向量分配给局部绑定
"v"并为结果创建一个空向量来开始. 为了提高效率, 我们可以使用一个瞬态向量, 因为结果的累积是循环的局部.❸ 当没有更多元素时,
peek返回nil, 所以我们可以将其用作停止递归的信号.❹
recur的两个参数是向量其余部分的pop, 以及我们将第一个元素的转换conj进去的新结果向量.❺ 在离开局部上下文之前, 需要用
persistent!将瞬态向量再次变为不可变的.另请参阅
conj用于将元素推入列表, 向量和队列. 标准库中没有 "push" 函数, 但conj可以以相同的方式使用.first和rest虽然在列表上原生工作, 但在向量上使用时需要转换为序列.peek和pop代表了在向量上执行类似操作的高效方式.性能考虑和实现细节
=>
O(1)常数时间peek和pop是快速的常数时间操作. 下图显示了它们在不同大小的支持集合上执行的情况:
Figure 38: Figure 12.5. peek 和 pop 基准测试.
列表在两个基准测试中都倾向于表现得更好, 尽管在绝对值上这些都是非常快的操作. 由于基准测试中的小波动, 直方图不是完全平坦的 (按集合类型). 在这几毫秒的分辨率下, 可能存在一些不精确性.
3.5.7. 12.7 vector-of
自 1.2 版本起可用的函数
(vector-of ([t]) ([t x1]) ([t x1 x2]) ([t x1 x2 x3]) ([t x1 x2 x3 x4]) ([t x1 x2 x3 x4 & xn]))
vector-of 创建一个持久向量, 其元素在内部存储为原始类型. 当需要比 vector 创建的版本更低的内存占用时, 并且原始类型可用于特定问题时, 会使用它. vector-of 的行为与普通向量非常相似: 它可以被随机访问或作为序列处理, 它可以被用作函数以通过索引访问其元素, 并且它是可比较的:
(vector-of :int) ; ❶ ;; [] (vector-of :int 16/5 2.8 1M Double/NaN) ; ❷ ;; [3 2 1 0] ((vector-of :int 1 2 3) 2) ; ❸ ;; 3 (sort [(vector-of :int 7 8 9) ; ❹ (vector-of :int 0 1 2)]) ;; ([0 1 2] [7 8 9])
❶ 一个整数原始类型的空向量.
❷ 最初不是原始类型的数字类型可以添加到向量中, 前提是它们可以被转换为目标原始类型. 例如, 在这个例子中, 参见比率和 bigdec. 注意, Double/NaN 在被强制转换为 int 时等于 0.
❸ 使用一个新创建的向量作为函数. 单个数字参数用于访问该索引处的向量 (从零开始).
❹ 用 vector-of 创建的向量支持通过 compare 语义进行排序.
契约
- 输入
"t"是以下 8 个关键字之一, 代表它们各自的类型::int,:long,:float,:double,:byte,:short,:char或:boolean."x1","x2","x3,"x4和"xn"是可选参数. 元素可以与"t"的类型不同, 但它们必须能够被强制转换为"t". - 主要异常
(vector-of Integer 1 2 3) ; ❶ ;; NullPointerException (vector-of :double \a \b \c) ; ❷ ;; ClassCastException (vector-of :int 1 2 nil 3 4) ; ❸ ;; NullPointerException (vector-of :short (inc Short/MAX_VALUE)) ; ❹ ;; IllegalArgumentException out of range: 32768
❶ 当
"t"不是 8 种可接受的类型之一时, 抛出NullPointerException. 这在 Clojure 1.9 中已修复 188.❷ 如果一个元素不能被强制转换为
"type", 则抛出CastClassException.❸ 如果一个元素是
nil, 则抛出NullPointerException.❹ 如果一个元素发生下溢或上溢, 则抛出
IllegalArgumentException. - 输出
一个持久向量, 按顺序包含给定的元素, 如果有的话. 否则为一个空向量.
用
vector-of创建的向量不能包含nil, 无论是在构造时传递还是通过conj添加. 这是因为vector-of只允许原始类型.示例
vector-of在数值计算中很有用, 其中许多数字必须存储在内存中, 例如在创建分形图像时. 像曼德勃罗特集 189 这样的分形图像已经进入了流行文化, 并展示了数学的美丽和复杂性.
Figure 39: Figure 12.6. 曼德勃罗特集.
为了生成曼德勃罗特集图像, 一个迭代过程被应用于复平面上的数字. 对于每个复数 190, 计算过程趋向无穷大之前的迭代次数. 由实部, 虚部和迭代次数组成的三元组可以有效地存储在一个原始类型的向量中. 然后绘制这些三元组: 实部在 x 轴上, 虚部在 y 轴上, 迭代次数映射到一个颜色梯度上.
以下是生成曼德勃罗特集图像代码的简化版本 191:
(def max-iterations 99) ; ❶ (defn calc-mandelbrot [c-re c-im] ; ❷ (let [sq (fn [x] (* x x)) iter (reduce (fn [[z-re z-im] i] (if (or (= i 99) (> (+ (sq z-re) (sq z-im)) 4)) (reduced i) [(+ c-re (sq z-re) (- (sq z-im))) (+ c-im (* 2 z-re z-im))])) [0 0] (range (inc max-iterations)))] (vector-of :double c-re c-im iter))) ; ❸ (def mandelbrot-set ; ❹ (for [im (range 1 -1 -0.05) re (range -2 0.5 0.0315)] (calc-mandelbrot re im))) (doseq [row (partition 80 mandelbrot-set)] ; ❺ (doseq [point row] (print (if (> max-iterations (get point 2)) "*" " "))) (println)) ;; ************************************************************************** ;; ******************************************************** ***************** ;; ***************************************************** **************** ;; **************************************************** *************** ;; ***************************************************** *************** ;; ************************************************** * ** ************* ;; ******************************************* *** ********** ;; ****************************************** ** **** ;; ******************************************* **** ;; ***************************************** ***** ;; **************************************** **** ;; ************************************** * ;; **************************** ********* ** ;; *********************** * * ***** ** ;; *********************** *** ** ;; ********************* * ** ;; ********************* ** ;; ***************** **** ;; *** ***** ****** ;; ***************** **** ;; ********************* ** ;; ********************* * ** ;; *********************** *** ** ;; *********************** * * ***** ** ;; **************************** ********* ** ;; ************************************** * ;; **************************************** **** ;; ***************************************** ***** ;; ******************************************* **** ;; ****************************************** ** **** ;; ******************************************* *** ********** ;; ************************************************** * ** ************* ;; ***************************************************** *************** ;; **************************************************** *************** ;; ***************************************************** **************** ;; ******************************************************** ***************** ;; **************************************************************************
❶ 索引从零开始.
❷
calc-mandelbrot接受一个复数 c (表示为 c-re 和 c-im, 分别对应实部和虚部). 然后它应用迭代计算 zi = zi-12 + c, z0 = 0, 并计算 zi 开始趋向无穷大之前的迭代次数.❸ 它以一个建模为 3 元素
vector-ofdouble 的三元组返回其结果.❹ 在这个例子中, 只计算了大约一千个曼德勃罗集的元素. 然而, 对于高分辨率图像, 需要计算数百万个数字.
mandelbrot-setvar 定义存储了该集合以供以后使用.❺ 这是一个简单的低分辨率基于 ASCII 的渲染器.
vector-of: Clojure 中的一个理想哈希树实现
vector-of, 在所有常见情况和场景下, 其行为都像一个向量, 产生一个受限于原始类型的持久化数据结构. 但如果我们看它们是如何实现的, 会发现更深层次的差异. 原始 Clojure 1.0 附带的vector实现是 Clojure 的主要卖点之一: 一个线程安全且高效的持久化数据结构. 它是用 Java 编写的, 并且是所有持久化数据类型的基础 (有关其实现方式的概述, 请参阅vector中的标注部分). 而vector-of是用 Clojure 本身编写的, 在一个名为 "gvec.clj" 的文件中 192, 该文件在引导 Clojure 时由 "core" 导入.阅读
vector-of实现的源代码是一个有趣的學習经验, 原因有很多:- 看看如何在 Clojure 中实现一个理想的哈希树.
- 它很好地利用了
definterface和deftype来混合多种接口, 以支持序列行为, 相等性语义, 分块, 打印以及成为一个 "好的 Clojure 公民" 所需的其他一切. - 如果你需要用 Clojure 实现自己的数据结构, 请参考 gvec.clj 来看看需要支持哪些接口 (有很多).
- 它从 Clojure 中使用低级 Java 数组来高效地构建高效持久性所需的 32 路浅层树.
另请参阅
vec从不同类型的集合创建一个向量. 你可能大部分时间都想使用普通向量, 因为它们最灵活. 然而, 如果应用程序在存储许多小向量方面有内存限制, 请考虑使用vector-of原始类型.make-array用于创建一个 Java 数组. 如果除了空间优化外, 还需要可变数据结构的性能优势, 请使用 Java 数组. 如果需要与需要它们的 Java 代码接口, 也请使用 Java 数组.性能考虑和实现细节
=>
O(n log(n))时间, n 为参数数量=>
O(n)空间除了最后一个, 所有元数都是创建新向量的更快选项:
(require '[criterium.core :refer [quick-bench bench]]) (quick-bench (vector-of :int 1 2 3 4)) ; ❶ ;; Execution time mean : 15.340593 ns (quick-bench (vector-of :int 1 2 3 4 5)) ; ❷ ;; Execution time mean : 124.127511 ns
❶ 一个用
vector-of和 4 个初始元素创建的向量.❷ 在创建向量时添加了第五个元素. 额外的元素迫使
vector-of迭代最终的可变参数列表, 导致明显的减速.对于更大的向量, 没有
vec-of函数, 但开销可以通过使用conj略微减轻:(def data (doall (range 100000))) (bench (apply vector-of :int data)) ;; Execution time mean : 6.975521 ms (bench (reduce conj (vector-of :int) data)) ; ❶ ;; Execution time mean: 5.926824 ms
❶ 通过使用
conj, 性能提升了大约 15%.vector-of的调用语义与vector类似. 这两者可以通过以下基准测试进行比较, 该测试显示vector比vector-of快两倍以上:(require '[criterium.core :refer [quick-bench]]) (let [xs (range 100)] (quick-bench (apply vector xs))) ; ❶ ;; Execution time mean : 2.051646 µs (let [xs (range 100)] (quick-bench (apply vector-of :long xs))) ; ❷ ;; Execution time mean : 5.004903 µs
❶
apply用于创建多参数的向量.❷ 类似地, 创建了一个
vector-of:long.vector利用了一种优化, 其中内部使用瞬态来创建一个可变数据结构, 然后返回对最终不可变数据结构的引用. 然而,vector-of没有实现类似的优化 193.正如本章中提醒的那样,
vector-of的最佳应用场景是空间效率. 曼德勃罗特集示例使用了用vector-of而不是vector创建的三元组. 用vector-of创建的三元组的空间节省可以用 JAMM 库来测量 194. 要执行以下示例, REPL 进程需要用 JAMM 提供的 Java Agent 进行插桩:(import '[org.github.jamm MemoryMeter]) (defn memory-vector-of [] (let [items (range 1.0 1e3) ; ❶ meter (MemoryMeter.) bytes-vector (.measureDeep meter (apply vector items)) bytes-vector-of (.measureDeep meter (apply vector-of :double items)) saving (* (double (/ (- bytes-vector bytes-vector-of) bytes-vector)) 100)] (println "Bytes used by vector" bytes-vector) (println "Bytes used by vector of" bytes-vector-of) (println (str "Saving " (format "%3.2f" saving) "%")))) (memory-vector-of) ; ❷ ;; Bytes used by vector 29456 ;; Bytes used by vector of 9472 ;; Saving 67.84%
❶
range生成 1000 个双精度浮点数.❷ 使用
vector-of带来的空间增益是巨大的.vector-of在访问元素方面也不如vector快:(let [v1 (vec (range 10000))] (bench (nth v1 1000))) ; ❶ ;; Execution time mean : 12.264993 ns (let [v1 (apply vector-of :int (range 10000))] (bench (nth v1 1000))) ; ❷ ;; Execution time mean : 19.324863 ns
❶ 在一个用
vec创建的普通向量上使用nth访问索引为 "1000" 的元素.❷ 在一个用
vector-of创建的向量上访问相同的索引为 "1000" 的元素.如示例所示, 减速可能高达 40% (但在绝对尺度上, 我们仍在谈论纳秒级的非常快的访问时间). 其原因是访问器函数
get和nth, 甚至使用向量作为函数, 都返回一个引用类型. 因此, 元素在返回之前必须被装箱. 因此,vector-of的使用者应该注意, 如果向量被频繁访问, 并权衡内存空间的增益与访问速度, 来决定使用哪种实现.
3.5.8. 12.8 mapv
自 1.4 版本起可用的函数
(mapv ([f coll]) ([f c1 c2]) ([f c1 c2 c3]) ([f c1 c2 c3 & colls]))
mapv 是 map 的一个特殊版本, 返回一个持久向量而不是一个序列. 它将作为参数传递的函数应用于集合中的每个元素, 并将结果返回在一个向量中:
(mapv inc [0 1 2 3]) ; ❶ ;; [1 2 3 4]
❶ mapv 的接口与 map 类似, 但返回一个向量.
mapv 也适用于多个集合. 在这种情况下, "f" 同时应用于每个集合中的第一个元素, 然后是第二个, 依此类推, 直到达到最短集合的末尾:
(mapv hash-map [:a :b :c] (range)) ;; [{:a 0} {:b 1} {:c 2}]
mapv 和 map 之间有两个关键区别:
mapv返回一个向量而不是一个惰性序列. 在这样做时, 它也完全消耗任何惰性输入.- 没有用于产生 transducer 的单参数版本的
mapv.
契约
- 输入
"f"是一个返回任何类型的函数, 其元数必须与传递给mapv的集合数量相匹配. 建议"f"是一个纯函数."c1, c2, c3 和 coll"是可seq的集合 (使得(instance? clojure.lang.Seqable coll)为真). 任何nil都会被视为空集合, 导致输出一个空向量."colls"是可选的附加可seq集合. - 主要异常
如果
"f"的元数不正确, 则抛出ArityException.如果
"f"不是一个函数, 则抛出ClassCastException.如果
"colls"中的任何集合不是可seq的, 则抛出IllegalArgumentException. - 输出
一个持久向量, 其第一个元素由对
"coll"中的第一个元素和附加"colls"中的每个第一个元素应用"f"组成, 其第二个元素由对"coll"中的第二个元素和附加"colls"中的每个第二个元素应用"f"组成, 依此类推. - 我的 "removev" 函数在哪里?
由于 Clojure 有
mapv和filterv, 很自然地会问序列函数的其他向量版本在哪里. 答案是只有map和filter有向量版本. 然而, Clojure 1.7 中添加的 transducer 允许轻松创建其他序列函数的高效向量版本. 所以, 与其写:(require '[criterium.core :refer [quick-bench]]) (vec (remove odd? (range 10))) ; ❶ ;; => [0 2 4 6 8] (let [r (range 100)] (quick-bench (vec (remove odd? r)))) ; ❷ ;; Execution time mean : 3.619460 µs
❶
vec从一个基于序列的计算中产生一个向量.❷ 基准测试报告的平均执行时间约为 3.61 微秒.
现在可以写:
(into [] (remove odd?) (range 10)) ; ❶ ;; => [0 2 4 6 8] (let [r (range 100)] (quick-bench (into [] (remove odd?) r))) ; ❷ ;; Execution time mean : 1.605351 µs
❶ 不带最后一个序列参数的
remove会产生一个 transducer.❷ 基准测试报告的平均执行时间约为 1.60.
在本例中, transducer 的运行速度比序列版本快 50% 以上, 从而消除了对 "removev" 的需求.
示例
长度为 "n" 的
double类型持久向量可用于表示\mathbb{R}^n195 中的数学向量. 然后, 使用mapv实现加法, 减法, 标量乘法就很直接了, 如下所示:(defn create-vector-fn [f] ; ❶ (fn [a & b] (apply mapv f a b))) (def add (create-vector-fn +)) ; ❷ (def subtract (create-vector-fn -)) (defn scalar-multiply [c a] (mapv (partial * c) a)) (defn dot-product [a b] ; ❸ (reduce + (map * a b))) (add [1 2] [3 4]) ;; [4 6] (subtract [2 7 3] [5 4 1]) ;; [-3 3 2] (scalar-multiply 3 [1 2 3]) ;; [3 6 9] (dot-product [1 1 0] [0 0 1]) ; ❹ ;; 0
❶ 这个函数中有很多东西. 它是一个高阶函数, 接受一个函数 "f" 作为输入, 并返回另一个函数. 返回的函数接受一个或多个向量作为参数, 并使用
mapv将 "f" 应用于它们的元素. 参数 "b" 可选地包含一个向量列表, 因此需要apply来正确执行mapv.❷ 这里我们利用了高阶函数
create-vector-fn. 我们传入操作符+, 然后返回一个将一个或多个向量相加的函数. 该函数然后被绑定到 "add", 使用def.❸ 这个函数实现了代数点积 196. 该操作在求和之前将向量中的元素相乘. 由于返回的是一个标量, 而不是一个向量, 所以
mapv对我们没有帮助. 相反, 使用了map和reduce.❹ 由于
[1 1 0]和[0 0 1]是垂直的, 所以它们的点积应该是 0, 正如预期的那样.另请参阅
map是标准map操作, 它产生一个 transducer 或一个惰性链表. 当你对结果不是向量感兴趣时, 使用标准map.mapcat在将 f 应用于一个项的结果又是一个序列时很有用, 整体结果是产生一个序列的序列.mapcat对结果列表应用一个最终的concat操作, 将结果展平一层.amap在 Java 数组上以与map相同的语义操作.pmap在一个单独的线程中执行map操作, 从而创建一个并行的map执行池. 当将函数 f 处理到单独线程的总体成本低于 f 本身的执行成本时, 用pmap替换map是有意义的. 长时间或处理器消耗大的操作通常会从使用pmap中受益.clojure.core.reducers/map是在 reducer 上下文中使用的map版本. 它具有与map相同的语义, 并且应该在 reducer 链的上下文中类似地使用.性能考虑和实现细节
=>
O(n)时间和空间, n 为最短输入集合中的元素数量不考虑惰性,
mapv通常优于map的单输入集合版本, 因为mapv将其结果直接写入一个瞬态向量, 而map创建一个惰性序列:(require '[criterium.core :refer [quick-bench]]) (let [r (range 10000)] (quick-bench (into [] (map inc r)))) ; ❶ ;; Execution time mean : 428.559902 µs (let [r (range 10000)] (quick-bench (mapv inc r))) ; ❷ ;; Execution time mean : 257.362476 µs
❶ 我们通过将序列强制转换为向量来放弃惰性, 因为这是当前比较的目标.
❷ 使用
mapv的类似操作快了大约 40%.使用带 transducer 的
map跳过了中间序列的创建, 性能比基本map版本好得多, 但仍然比mapv版本差:(let [r (range 10000)] (quick-bench (into [] (map inc) r))) ; ❶ ;; Execution time mean : 293.384399 µs
❶ 使用
map和into通过 transducer 的解决方案的性能大致介于之前看到的另外两个版本之间.在其他一些情况下, 惰性的好处导致使用双参数版本的
map的代码性能优于mapv. 例如, 如果一个应用程序主要只使用大集合中的少数几个项, 那么使用惰性序列而不是向量是有意义的 (如果可能的话):(let [r (range 10000)] (quick-bench (subvec (mapv inc r) 0 10))) ; ❶ ;; Execution time mean : 263.561818 µs (let [r (range 10000)] (quick-bench (vec (take 10 (map inc r))))) ; ❷ ;; Execution time mean : 1.548534 µs
❶ 在递增向量的元素后, 我们使用
subvec来提取其中的前 10 个.❷ 类似地, 在应用
map后提取前 10 个元素, 最后进行向量转换. 这个操作, 由于它只实现序列中的少数几个元素, 快了 200 倍!mapv接受多个集合的元数并不直接使用瞬态. 尽管输入/输出仍然是向量, 但mapv会执行一个到序列再返回的中间转换, 对性能有明显的影响:(let [r (range 10000)] (quick-bench (into [] (map + r r)))) ; ❶ ;; Execution time mean : 1.139211 ms (let [r (range 10000)] (quick-bench (mapv + r r))) ; ❷ ;; Execution time mean : 1.171993 ms
❶ 现在使用多个集合作为输入.
❷
mapv现在的性能与普通map大致相同 (mapv对于多个集合的实现确实与前一行中显示的相同).如果我们想实现一个使用两个集合作为输入且性能更好的
mapv版本, 下面可能是一个可行的选项:(defn mapv+ [f c1 c2] ; ❶ (let [cnt (dec (min (count c1) (count c2)))] (loop [idx 0 res (transient [])] (if (< cnt idx) (persistent! res) (recur (+ 1 idx) (conj! res (f (nth c1 idx) (nth c2 idx)))))))) (let [r (vec (range 10000))] (quick-bench (mapv+ + r r))) ; ❷ ;; Execution time mean : 427.152060 µs
❶
mapv+的策略是在两个输入向量中较短的一个上使用loop-recur. 然后使用conj!逐渐构建一个瞬态向量. 当达到最大元素数时, 返回一个persistent!向量.❷ 基准测试证实了与普通
mapv相比有大约 50% 的改进.
3.5.9. 12.9 filterv
自 1.4 版本起可用的函数
(filterv pred coll)
filterv 是 filter 的一个特殊版本, 返回一个持久向量而不是一个序列. filterv 接受一个谓词, 并用它来决定哪些项应该被保留 (并隐式地决定哪些应该被移除) 在最终的结果向量中:
(filterv odd? (range 8)) ; ❶ ;; [1 3 5 7]
❶ filterv 的基本应用.
除了返回一个向量, filterv 与 filter 在以下方面有所不同:
filterv不是惰性的, 会急切地将结果向量加载到内存中.filterv缺少用于 transducer 的元数.
契约
- 输入
"pred"是一个谓词函数. 返回值被解释为逻辑布尔值."coll"是任何可seq的集合. 如果"coll"是nil, 则它被视为空集合. - 异常
如果
"pred"的元数不正确, 则抛出ArityException.如果
"pred"不是一个函数, 则抛出ClassCastException.如果
"coll"不是可seq的, 则抛出IllegalArgumentException. - 输出
一个持久向量, 包含
"coll"中所有(pred item)为真值的项. 向量中项的顺序与"coll"中项的顺序匹配.示例
在下面的例子中, 两个任务需要异步处理. 协调异步任务的一个宝贵工具是 "core.async" 197, 这是一个在许多并发 Clojure 应用程序中常见的库 198.
在第一个任务完成后, 可以使用
filterv从所有通道列表中移除已完成的通道 199. 为简单起见, 下面的代码计算数学常数 "e" 和 "π", 而不是调用外部资源. 需要考虑的重要概念是, 任务将根据请求的精度而忙碌相当长的时间:(require '[clojure.core.async :refer [>!! <!! >! <! alts!! chan go]]) (defn calculate-pi [precision] ; ❶ (->> (iterate #(* ((if (pos? %) + -) % 2) -1) 1.0) (map #(/ 4 %)) (take-while #(> (Math/abs %) precision)) (reduce +))) (defn calculate-e [precision] ; ❷ (letfn [(factorial [n] (reduce * (range 1 (inc n))))] (->> (range) (map #(/ (+ (* 2.0 %) 2) (factorial (inc (* 2 %))))) (take-while #(> (Math/abs %) precision)) (reduce +)))) (defn get-results [channels] ; ❸ (let [[result channel] (alts!! channels) new-channels (filterv #(not= channel %) channels)] ; ❹ (if (empty? new-channels) [result] (conj (get-results new-channels) result)))) (let [[pi-in pi-out e-in e-out] (repeatedly 4 chan)] (go (>! pi-out {:type :pi :num (calculate-pi (<! pi-in))})) ; ❺ (go (>! e-out {:type :e :num (calculate-e (<! e-in))})) (>!! pi-in 1e-4) ; ❻ (>!! e-in 1e-5) (get-results [e-out pi-out])) ;; [{:num 3.1415426535898248, :type :pi} {:num 2.718281525573192, :type :e}]
❶ π 是使用莱布尼茨公式计算的 200. 数学家将 π 的计算视为一个无限级数的求和, 像 Clojure 这样的函数式语言的能力可以很容易地反映这一点. "precision" 以一种非正式的方式用于指定精度.
❷ e 是使用 Brothers 公式之一计算的 201. 同样, "precision" 以一种非正式的方式用于指定精度.
❸
get-results是一个递归函数, 它依次等待每个通道完成并返回其结果.❹
filterv用于从所有通道列表中移除已完成的通道. 如果代码使用filter而不是filterv, 它仍然可以正常工作, 但会引入一个微妙的问题. 当调用get-results时,"channels"是一个向量. 但filter返回一个序列, 因此"channels"的数据类型在代码运行时以一种不明显的方式改变了. 这种行为应该避免, 因为它可能导致 bug.❺ 设置了两个
go块, 第一个计算 π, 第二个计算 e.❻ 计算 π 和 e 的请求被放在适当的通道上, 然后代码等待两个结果.
另请参阅
filter是filterv的不那么具体且更常用的姐妹函数.filterv的使用应限于输入/输出预期是 (并保持是) 向量的情况. 当输出的类型不相关或惰性更重要时, 优先使用filter而不是filterv.mapv是另一个面向向量的操作, 用于处理向量的每个元素.性能考虑和实现细节
=>
O(n)时间和空间, 其中 n 是"coll"中项的数量mapv的 "性能考虑和实现细节" 部分中关于 transducer 和惰性的注释也适用于filterv和filter. 总而言之,filterv通常优于filter的双参数版本, 因为filterv将其结果直接写入一个瞬态向量, 而filter首先创建一个惰性序列. 例如:(require '[criterium.core :refer [quick-bench]]) (let [r (range 10000)] (quick-bench (into [] (filter odd? r)))) ; ❶ ;; Execution time mean : 309.609565 µs (let [r (range 10000)] (quick-bench (filterv odd? r))) ; ❷ ;; Execution time mean : 117.814547 µs (let [r (range 10000)] (quick-bench (into [] (filter odd?) r))) ; ❸ ;; Execution time mean : 196.445960 µs
❶ 我们通过将最终结果强制转换为向量来从
filter中移除惰性.❷
filterv快了约 60%.❸
filter的 transducer 版本显示了良好的结果.
3.5.10. 12.10 subvec
自 1.0 版本起可用的函数
(subvec ([v start]) ([v start end]))
subvec 从另一个向量中包含的连续项创建一个 "子向量", 而无需从头开始遍历所有元素. 例如, 我们可以通过指定一个结束和开始来提取输入向量中的特定 "窗口":
(subvec [1 2 3 4] 1 3) ; ❶ ;; [2 3]
❶ 创建一个从索引 "1" 到索引 "3" 的子向量.
可以在其他类型的向量之上创建子向量. 在这种情况下, 结果子向量会继承底层向量的特性:
(def subv (subvec (vector-of :int 1 2 3) 1)) ; ❶ (conj subv \a) ;; [2 3 97] ; ❷ (conj subv nil) ;; java.lang.NullPointerException ; ❸
❶ subvec 在一个原始整数类型的 vector-of 上使用.
❷ 字符 `\a` 作为从 char 到 int 的强制转换结果进入向量.
❸ 在原始向量中不允许有 nil. 这同样会影响结果子向量.
由
subvec返回的向量是输入向量中包含的一系列元素的独立视图. 一旦生成了subvec, 原始向量可以被更改, 而不会对相关的subvec实例产生任何影响. 尽管这两个实例基本上是独立的, 但有一个微妙的副作用: 正如 Fogus M. 和 Houser C. 所警告的 202, 向量不是队列,subvec不应该被用来实现从向量前端的pop. 尽管subvec在常数时间内完成, 但subvec保留了对底层向量的引用, 因此任何被弹出的项都不会被垃圾回收. 更多细节请参见下面的 "性能和实现细节" 部分.
契约
- 输入
"v"参数是一个向量. 因此(vector? v)必须为真."v"可以为空, 但不能为nil."start"和"end"是整数范围内的数字 (从Integer/MIN_VALUE到Integer/MAX_VALUE), 分别表示子向量开始的索引 (包含) 和结束的索引 (不包含). - 主要异常
如果
"v"不是一个向量, 则抛出ClassCastException.如果
"v"是nil, 则抛出NullPointerException.如果
"start"或"end"不能被强制转换为一个数字, 则抛出ClassCastException.如果
"start"或"end"超出整数范围, 则抛出IllegalArgumentException.如果
"start" < 0或"start" >= (count v), 则抛出IndexOutOfBoundsException.如果提供了
"end"并且"end" < "start"或"end" > (count v), 则抛出IndexOutOfBoundsException. - 输出
subvec创建的子向量从零基位置"start"(包含) 开始, 一直到零基位置"end"(不包含). 如果提供了"end", 否则它会一直运行到"v"的末尾.如果省略了
"end", 子向量包含从索引"start"(包含) 处的元素开始到(count v)(不包含) 的范围:(subvec [1 2 3 4] 1) ; ❶ ;; [2 3 4]
❶
"end"参数是可选的. 当没有给出"end"时, 使用(count v)作为默认值.示例
subvec是从向量中 "移除" 元素的一种高效解决方案. 向量是不可变的数据结构, 所以 "移除" 一个元素意味着从两个子向量中创建一个新向量, 其中要移除的元素被排除在外:(defn remove-at [v idx] ; ❶ (into (subvec v 0 idx) (subvec v (inc idx) (count v)))) (remove-at [0 1 2 3 4 5] 3) ; ❷ ;; [0 1 2 4 5]
❶
into可以用于第一个子向量以包含第二个, 从给定的索引idx加 1 开始.❷
remove-at返回一个新的子向量, 该子向量无限期地持有对 "v" 的引用. 如果 "v" 很大, 考虑将结果转换回一个向量. 更多信息请参见性能部分.subvec可用于递归, 类似于first/rest用于推进一个序列. 下面的norm函数计算一个向量的范数 203:(defn norm [v] (loop [v v res 0.] (if (= 0 (count v)) (Math/sqrt res) (recur (subvec v 1) ; ❶ (+ res (Math/pow (nth v 0) 2)))))) ; ❷ (norm [-2 1]) ;; 2.23606797749979
❶ 带有输入向量和 1 作为参数的
subvec类似于序列上rest的效果.❷ 向量的 "头部" 通过
nth访问.subvec是分治算法在向量上的自然选择. 例如,subvec可以用来实现一个递归的纯函数式归并排序 204:(defn- merge-vectors [v1-initial v2-initial cmp] ; ❶ (loop [result [] v1 v1-initial v2 v2-initial] (cond (empty? v1) (into result v2) (empty? v2) (into result v1) :else (let [[v1-head & v1-tail] v1 [v2-head & v2-tail] v2] (if (cmp v1-head v2-head) (recur (conj result v1-head) v1-tail v2) (recur (conj result v2-head) v1 v2-tail)))))) (defn merge-sort ([v] (merge-sort v <=)) ([v cmp] (if (< (count v) 2) v (let [split (quot (count v) 2) v1 (subvec v 0 split) ; ❷ v2 (subvec v split (count v))] (merge-vectors (merge-sort v1 cmp) (merge-sort v2 cmp) cmp))))) (merge-sort [2 1 5 0 3]) ;; [0 1 2 3 5] (merge-sort [[2 :b] [2 :a] [1 :c]] #(<= (first %1) (first %2))) ; ❸ ;; [[1 :c] [2 :b] [2 :a]]
❶
merge-vectors接受两个已排序的向量 ("v1-initial" 和 "v2-initial") 和一个比较函数 "cmp", 并将这两个向量合并成一个已排序的向量. 它比较每个向量的第一个元素, 根据比较函数, 较小的元素被添加到 "result" 向量中. 这个过程递归地重复, 直到所有元素都被合并.❷
subvec用于将向量 "v" 分成两半. 每一半在被合并到最终向量之前都会被排序.❸ 归并排序算法的一个关键特性是它是一种稳定排序, 这意味着如果两个元素有相等的键, 它们的相对顺序不会改变. 在这里, `[2 :b]` 和 `[2 :a]` 的键都是 2, 所以它们的顺序保持不变.
另请参阅
vec和vector也从可seq的集合中产生一个持久向量. 当新向量的创建不涉及从另一个向量中取子集时, 使用vec. 使用vector来指定应该属于该向量的元素.vector-of用于创建一个原始类型的向量. 如果空间效率是最大的考虑, 使用vector-of.into在本章中被用来将子向量重新连接在一起.性能考虑和实现细节
=>
O(1)时间和空间subvec是将一个向量分割成部分的一种非常高效的方法, 与向量的长度无关. 尽管subvec是常数时间, 它仍然有相关的成本. 让我们重新审视norm的例子, 比较基于subvec的解决方案和基于索引的解决方案:(require '[criterium.core :refer [quick-bench]]) (defn norm [v] ; ❶ (loop [v v res 0. idx (dec (count v))] (if (< idx 0) (Math/sqrt res) (recur (subvec v 0 idx) (+ res (Math/pow (peek v) 2)) (dec idx))))) (let [v (vec (range 1000))] (quick-bench (norm v))) ;; Execution time mean : 91.908294 µs ; ❷ (defn norm-idx [v] ; ❸ (loop [idx (dec (count v)) res 0.] (if (< idx 0) (Math/sqrt res) (recur (dec idx) (+ res (Math/pow (nth v idx) 2)))))) (let [v (vec (range 1000))] (quick-bench (norm-idx v))) ;; Execution time mean : 15.174786 µs ; ❹
❶
norm与示例中的版本相比略有修改. 在loop-recur的参数中引入索引idx避免了在每次迭代中都使用count来计算子向量中剩余的元素.❷ 对于一个中等大小的 1000 个元素的向量, 耗时约为 91 微秒 (10-6 秒)..
❸
norm-idx与norm非常相似. 变化是移除了子向量并使用nth来获取索引idx处的元素.❹
norm-idx大约快 6 倍. 考虑到循环是相同的, 但缺少子向量 (nth和peek之间的差异可以忽略不计), 减速是由单独使用subvec决定的.由于不变性, 由
subvec创建的视图与原始向量上发生的额外更改是隔离的. 然而, 隔离并不完美, 在处理大向量时可能导致微妙的副作用. 新创建的子向量本质上是原始向量的一个包装器, 筛选掉不想要的元素, 所以不会发生元素的复制, 因此subvec在常数时间和空间内完成. 然而, 生成的子向量会保留对原始向量的引用, 这可以防止元素被垃圾回收. 下面的例子说明了这个问题: 创建两个子向量, 意图稍后将它们连接起来:(defn bigv [n] (vec (range n))) (let [v1 (subvec (bigv 1e7) 0 5) ; ❶ v2 (subvec (bigv 1e7) 5 10)] (into v1 v2)) ;; OutOfMemoryError GC overhead limit exceeded ; ❷ (let [v1 (into [] (subvec (bigv 1e7) 0 5)) ; ❸ v2 (into [] (subvec (bigv 1e7) 5 10))] (into v1 v2)) ;; [0 1 2 3 4 5 6 7 8 9] ; ❹
❶
subvec用于从一个大得多的向量中切出一小片. 大向量在其他地方没有被引用, 但被subvec实现内部的一个引用保持存活.❷ 根据 JVM 的设置, 你可能需要调整大向量的大小才能看到这里显示的内存不足问题. 在这种情况下, JVM 是用 512Mb 的堆大小启动的.
❸ 每个子向量都被传输到一个新的向量实例中, 这样它们的内部向量引用就可以被垃圾回收.
❹ 通过这个更改, 不会发生内存不足的问题.
3.5.11. 12.11 总结
向量是一种通用的数据结构, 在许多语言中都很常见. Clojure 的向量实现是线程安全的, 不可变的, 并且在大多数情况下表现良好. 在本章中, 我们已经看到了专门用于向量的函数, 但集合和序列函数也适用于向量 (在性能和意图上有所不同).
在向量和序列之间做出选择取决于许多因素: 速度, 内存消耗和惰性影响等等. 一个需要考虑的重要方面 (也是 Clojure初学者经常遇到的问题) 是避免通过将序列强制转换为向量 (或反之) 来混合不同的抽象. 在做出选择之后, 保持一致性很重要. 如果无法实现这一点, 最好通过为每个数据结构提供不同版本的相同函数 (例如参见 mapv 或 filterv) 来将选择权交给用户.
3.6. 13 集合
集合是一种可以存储唯一项而没有特定顺序的数据结构. 集合在计算机科学中被广泛使用, 并与数学集合论有很强的联系. Clojure 提供了两种类型的集合及其相应的初始化函数:
hash-set是最常用的, 提供快速查找, 一个特殊的字面量语法#{}和一个瞬态版本.hash-set是在clojure.lang.PersistentHashSet之上实现的, 而后者又是clojure.lang.PersistentHashMap(与hash-map相同) 的一个薄层.hash-set和hash-map都是哈希数组映射树 (Hash Array Mapped Trie) 205 的实例.hash-set提供近乎常数时间的查找 (O(log32N)), 添加和移除项.sorted-set也保证项的唯一性, 但额外地基于一个比较器来维护顺序. 它们的实现基于红黑树 (参见subseq标注部分), 并提供了一个均衡的对数访问 (O(log2N)).
两种集合类型都可以作为函数使用 (特别是作为谓词) 来验证项的存在, 语法简洁:
((sorted-set 5 3 1) 1) ; ❶ ;; 1 (some #{1 2 3} [0 4 6 8 1]) ; ❷ ;; 1
❶ 使用 sorted-set 作为函数的例子. sorted-set 在集合中查找参数并返回它, 如果存在的话. 否则返回 nil 或一个默认值.
❷ 另一个习惯用法是使用集合与 some 来确定输入向量中是否至少有一项在集合中. 在这种情况下, 数字 "1" 存在并被返回.
clojure.core 命名空间包含一些用于创建集合 (hash-set, Set, sorted-set) 或从集合中移除元素 (disj) 的基本函数. conj 和 into 也适用于集合 (以及许多其他集合类型). 像 union, intersection 或 difference 这样的函数可从 clojure.set 命名空间中获得.
本章最后概述了像 project, select 或 index (同样来自 clojure.set) 这样的函数, 它们专门用于 "关系". 关系是一种使用一组映射来表示数据的方法, 其灵感来自关系数据库.
3.6.1. 13.1 hash-set
自 1.0 版本起可用的函数
(hash-set [& keys])
hash-set 是 Clojure 无序集合的主要初始化函数. 注意任何重复的项都会从结果集合中移除:
(hash-set :yellow :red :green :green) ; ❶ ;; #{:yellow :green :red}
❶ hash-set 接受任意数量的值. 注意 :green 在输入中出现了两次, 但在结果集合中只出现一次.
契约
- 输入
"keys"可以是任意数量的任何类型的项. - 输出
返回: 一个包含给定
"keys"的clojure.lang.PersistentHashSet实例. 当不带参数调用时, 返回一个空集合. 如果存在多个相同项的实例 (根据相等性语义), 则只有一*个*实例被添加到集合中.示例
hash-set(像hash-map一样) 有一个语法字面量#{}以便快速创建集合.(= #{3 2 1} (hash-set 1 2 3)) ; ❶ ;; true
❶ 读宏字面量
#{}扩展为创建相关的hash-set数据结构.然而请注意, 语法字面量
#{}不会自动处理重复项:#{:yellow :red :green :green} ; ❶ ;; IllegalArgumentException Duplicate key: :green
❶ 与
hash-set不同, 集合语法字面量不允许重复的键, 并且不会创建集合, 而是抛出异常.语法字面量使得集合作为谓词的使用变得优雅, 就像下面的例子中使用
some一样:(some #{:x :c} [:a :b :c :d :e]) ; ❶ ;; :c (some #{:x :y} [:a :b :c :d :e]) ; ❷ ;; nil
❶ 用
hash-set或语法字面量#{}创建的集合也是一个函数. 作为一个函数, 集合验证给定的参数是否存在于集合中.some将集合作为谓词应用于输入集合中的所有元素, 在第一个返回非nil的元素处停止.❷ 如果集合中没有任何来自集合的元素,
some返回nil.与语法字面量不同, 当输入项不是编译时常量 (如数字, 字符串, 关键字等) 而是需要求值时,
hash-set很有用:#{(rand) (rand) (rand)} ; ❶ ;; IllegalArgumentException Duplicate key: (rand) (hash-set (rand) (rand) (rand)) ; ❷ ;; #{0.53148213003 0.7171734431 0.5055531620}
❶ 我们试图创建一个包含 3 个随机数的集合. 语法字面量
#{}将输入项视为编译时常量, 并在将其添加到集合后才对表达式(rand)求值. 这会导致一个重复键异常.❷ 使用
hash-set, 我们确保输入元素在进入集合之前被求值, 从而避免了意外的编译时错误.让我们在元数据的上下文中澄清集合中项的唯一性的含义. 如果将多个相同值的实例添加到集合中, 并且它们有不同的元数据,
hash-set会保留第一个项的元数据:(def set-with-meta (hash-set ; ❶ (with-meta 'a {:pos 1}) (with-meta 'a {:pos 2}) (with-meta 'a {:pos 3}))) set-with-meta ; ❷ ;; #{a} (meta (first set-with-meta)) ; ❸ ;; {:pos 1}
❶ 我们像往常一样使用
hash-set. 这些项都是相同的符号a, 但元数据不同.❷ 当我们检查集合的内容时, 我们按预期看到了一个单一的元素.
❸ 元素上的元数据是第一个被插入的元素的元数据. 这个行为与
hash-map对多个相同键实例的处理类似. - 集合的幂集
集合论是数学的一个重要分支, 研究对象的集合及其关系. 它包含丰富的函数集, Clojure 在标准库中提供了一些:
union,difference和intersection可在clojure.set命名空间中找到, 并设计用于集合操作.与集合相关的一个有趣问题是生成一个集合的所有子集的集合, 也称为幂集. 我们将探讨生成幂集的问题, 因为它迫使我们使用与
hash-set相关的几个函数和概念. 问题如下: 给定一组初始项 "s", "powerset-of-s" 包含这些项的所有无序组合:(def s #{:a :b :c}) ; ❶ (def powerset-of-s ; ❷ #{#{} #{:a} #{:b} #{:c} #{:a :b} #{:a :c} #{:b :c} #{:a :b :c}})
❶ 我们的输入是一个包含 3 个元素的集合. 我们想找到这 3 个元素的所有组合, 不论顺序, 包括空集
#{}. 如果我们要考虑顺序, 我们应该更具体地谈论排列而不是组合.❷ 我们在这里可以看到预期的输出. 注意, 我们对外部和内部集合都使用了集合字面量
#{}, 以强制项的唯一性.一个集合的幂集包含
(Math/pow 2 (count s))个项 (上面的例子包含2^3个元素, 包括空集), 其中(count s)是输入的大小. 计算幂集有几种方法. 参考 3 个项:a,:b和:c的幂集, 我们可以从观察以下等价性 (伪代码) 开始:[[] [:a] [:b] [:a :b]] U ; ❶ [[:c] [:a :c] [:b :c] [:a :b :c]] = ; ❷ ____________________________________ [[] [:a] [:b] [:c] [:a :b] [:a :c] [:b :c] [:a :b :c]] ; ❸
❶ U 运算符表示并集. 并集的第一个项是
powerset(:a, :b, :c)在移除所有包含项:c的子集之后. 项:c是随机选择的.❷ 并集的第二个项是所有其他包含先前移除的项
:c的子集. 注意, 这个第二个子集可以通过将:c添加到第一个子集的每个项中来得出.❸ 并集 U 得到完整的
powerset(:a, :b, :c).我们对上面例子中观察到的更正式的定义是:
powerset(:a :b :c)可以由powerset(:a :b)与从powerset(:a :b)中每个元素都添加了:c后得到的集合的并集组装而成. 我们可以利用这个观察来递归地构建一个幂集:(require '[clojure.set :refer [union]]) (defn powerset [s] (when-first [x s] ; ❶ (let [p (or (powerset (disj s x)) (hash-set #{}))] ; ❷ (union p (set (map conj p (repeat x))))))) ; ❸ (powerset #{1 2 3}) ; ❹ ;; #{#{} #{3} #{2} #{1} #{1 3 2} #{1 3} #{1 2} #{3 2}}
❶
when-first从输入集合中取第一个元素, 同时检查它是否为nil. 当输入集合 "s" 为空时, 我们完成了递归.❷ 接下来使用
disj从集合中移除第一个元素. 递归的powerset调用在到达集合的末尾 (when-first的结果) 后可能返回nil, 所以我们使用or为计算提供初始值. 这是包含另一个空集的空哈希集. 我们可以写成{{}}, 但双重嵌套的常量字面量可读性较差.❸ 我们现在有了在 "s" (减去一项) 上调用
powerset的结果, 可用作局部绑定 "p". 我们现在可以应用观察的其余部分:clojure.set/union函数应用于 "p", 以及将移除的元素合并回 "p" 的每个项的结果.❹ 测试证实
powerset函数产生了预期的 8 个输出项.这个
powerset的公式忠实地实现了我们最初对 "幂集" 构成的观察, 但它不是尾递归的. 它采用了一种自顶向下的方法, 通过消耗堆栈并返回时构建实际结果, 从其最终内容定义到空集. 如果我们想将其表示为尾递归, 我们需要一种方法来从下到上累积结果, 从空集开始, 逐渐向每个子集添加元素. 观察是相同的, 但反向读取: 下一个幂集等于前一个的并集加上每个项都添加了一个新元素的集合. 下面的公式采用了这种方法, 得到了性能更好, 代码更简洁的结果:(defn powerset [items] (reduce ; ❶ (fn [s x] (union s (map #(conj % x) s))) ; ❷ (hash-set #{}) items)) (powerset #{1 2 3}) ; ❸ ;; #{#{} #{3} #{2} #{1} #{1 3 2} #{1 3} #{1 2} #{3 2}}
❶ 与自定义递归或
loop-recur不同, 我们现在可以委托递归给reduce, 并从空集开始构建增量结果.❷ 每次
reduce递归, 我们都会得到到目前为止的幂集的部分视图和下一个元素 "x". 我们可以继续应用观察, 使用当前幂集 "s" 与在 "s" 中每个元素添加了新元素 "x" 后的所有元素的并集.❸ 我们确认新的公式返回相同的结果.
另请参阅
Set经过优化, 可以从一个已存在的集合开始创建一个集合. 要从集合创建一个集合, 优先使用Set而不是hash-set和apply.sorted-set通过一个比较器 (默认或自定义) 来维持集合中项的顺序. 当迭代集合时, 项会按照比较器生成的顺序返回. 如果你需要集合中元素的排序, 使用sorted-set而不是hash-set. 注意sorted-set不是基于插入顺序的 (例如像array-map). 如果你需要插入顺序, 最接近的选择是使用一个向量, 并在迭代前用distinct移除重复项.性能考虑和实现细节
=>
O(n)线性, n 为项的数量=>
O(n)空间hash-set的性能特征与hash-map非常相似. 相似之处超出了性能, 因为hash-set的实现是基于PersistentHashMap的, 与hash-map相同. 将一个集合折叠成一个映射的方式是, 集合中的每个项都对应于底层映射中的一个键值对, 其中键与值相同.以下基准测试比较了
hash-set与创建大型集合的其他方法. 我们可以看到它们之间差异很小, 主要是因为它们都使用了一个瞬态版本的集合来移除构造期间的不变性开销:(require '[criterium.core :refer [bench]]) (let [items (into [] (range 100000))] ; ❶ (bench (apply hash-set items))) ;; Execution time mean : 20.470692 ms (let [items (into [] (range 100000))] ; ❷ (bench (into #{} items))) ;; Execution time mean : 18.549452 ms (let [items (into [] (range 100000))] ; ❸ (bench (set items))) ;; Execution time mean : 19.287860 ms
❶ 第一个基准测试使用
hash-set和apply来创建一个大型集合.apply将参数转换为一个序列, 每个元素都被添加到集合中. 在内部, 项被添加到一个瞬态版本的集合中.❷
into支持瞬态. 多个conj操作现在可以在一个可变实例上发生.❸
Set是一个专门用于将其他集合转换为集合的函数. 它也使用瞬态.另请查看
Set的性能部分, 以获取与不同集合类型和输入中不同元素百分比相关的其他基准测试.
3.6.2. 13.2 set
自 1.0 版本起可用的函数
(set [coll])
set 从给定输入集合中的项创建一个新的 clojure.lang.PersistentHashSet (Clojure 集合类型):
(set [1 2 3 4 1 4]) ; ❶ ;; #{1 4 3 2}
❶ set 将输入向量 "转换" 为一个新的集合实例. 注意, 输出集合没有特定的顺序, 也不包含重复项.
与 hash-set 和 into 一起, set 是创建新集合实例的主要方式.
契约
- 输入
"coll"是唯一强制性参数."coll"可以是任何集合, 包括最常见的 Java 可迭代类型, 但不包括瞬态. - 主要异常
当
"coll"不是一个集合时, 抛出IllegalArgumentException. - 输出
返回: 一个包含输入集合中项的新集合实例. 如果
"coll"为空或nil, 它返回一个空集合."coll"中的所有重复项 (如果有的话) 都会在输出集合中被移除. 如果"coll"已经是一个集合, 则输入会不经转换地通过, 但元数据 (如果有的话) 会被移除.示例
set的一个典型用途是转换一个现有的集合, 在此过程中移除任何重复项, 并在未来的操作中防止新的重复项. 注意,set意味着创建一个新的独立集合, 所以如果输入中存在任何元数据, 它会被有意地移除:(def input-set (with-meta #{} {:original true})) ; ❶ (meta input-set) ; ❷ ;; {:original true} (meta (set input-set)) ; ❸ ;; nil
❶ 原始输入集合有一些使用
with-meta附加的元数据.❷ 我们可以随时使用
meta查看元数据.❸ 输入集合被用作
set函数的输入. 我们可以看到元数据被剥离了.还要注意, 如果输入是一个
sorted-set, 它不会被转换为一个无序的hash-set:(type (set (sorted-set 8 7 4 2 1 3))) ; ❶ ;; clojure.lang.PersistentTreeSet (type (into #{} (sorted-set 8 7 4 2 1 3))) ; ❷ ;; clojure.lang.PersistentHashSet
❶ 在
sorted-set上调用set不会将类型更改为clojure.lang.PeristentHashSet.❷
into执行从有序到无序的转换.使用
set进行转换也与contains?结合使用很有用. 在下面的例子中, 我们设置一个简单的 "蜜罐" 机制来防止 Web 表单的欺诈性使用 206. 蜜罐由一个对人类用户不可见但在机器人解析页面时看起来合法的输入 HTML 标签组成.一旦 Web 请求以哈希映射的形式进来, 我们需要验证它是否包含为蜜罐输入编码的特定值. 根据页面的不同, 可能会有一个或多个具有合法名称 (如 "option1" 或 "option2") 的蜜罐字段:
(def honeypot-code "HP1234") (def valid-request {:name "John" :phone "555-1411-112" :option1 "" :option2 ""}) ; ❶ (def fake-request {:name "Sarah" :phone "555-2413-111" :option1 "HP1234" ; ❷ :option2 ""}) (defn honeypot? [req] (contains? (set (vals req)) ; ❸ honeypot-code)) (honeypot? valid-request) ;; false (honeypot? fake-request) ;; true
❶
valid-request包含一些正确为空的蜜罐字段. 合法用户看不到相应的输入, 也无法做出选择.❷ 如果我们改为访问相同网页的原始源代码 (就像自动程序会做的那样), 就没有办法区分蜜罐输入 (至少在这个简单的例子中是这样). 自动程序然后会继续分析页面并用蜜罐代码填充输入 (例如, 因为它是单选按钮的必选项).
❸ 验证一个或多个蜜罐代码存在的一个直接方法是在请求映射的值序列上使用
set.contains?支持集合 (它不适用于序列或向量) 来验证蜜罐代码的存在.另请参阅
hash-set也创建新的集合数据结构, 允许任意数量的项作为参数. 一般来说, 应优先使用(set coll)而不是(apply hash-set coll)来从一个集合创建一个集合.sorted-set是一个有序版本的集合. 排序基于一个比较器. 比较器用于建立集合中项的相对顺序.contains?经常与集合一起使用来验证一个元素的存在.性能考虑和实现细节
=>
O(n)线性于项的数量set的性能特征与hash-set类似, 并且在项的数量上是线性的.set实现一个循环, 使用reduce将项conj到新集合中, 而hash-set在 Java 中执行类似的循环.下图显示了
set应用于相同大小的不同集合类型 (该图还包括一个原生数组). 我们看不到大的差异, 因为reduce对大多数集合类型都进行了优化:
Figure 40: Figure 13.1. 显示针对不同集合类型的基准测试的图表.
在与
hash-set的比较方面, 两个函数都使用瞬态来填充一个新的可变集合, 并在返回之前将其转换为持久的. 在纯粹的速度方面, 差异很小,set有一些优势:(require '[criterium.core :refer [quick-bench]]) (let [coll (range 10000)] (quick-bench (apply hash-set coll))) ;; Execution time mean : 1.282033 ms (let [coll (range 10000)] (quick-bench (set coll))) ;; Execution time mean : 1.132248 ms
现在让我们探讨一下
set与不同元素百分比相关的行为. 下面的图表证实了输入中重复的项越多 (与输出中已存在的项冲突), 创建速度就越快:
Figure 41: Figure 13.2. 显示创建速度如何随着输入中不同项的百分比变化的图表 (100% 表示没有重复项, 0% 表示输入包含相同的重复元素).
3.6.3. 13.3 sorted-set 和 sorted-set-by
函数自 1.0 (sorted-set), 1.1 (sorted-set-by)
(sorted-set [& keys]) (sorted-set-by [comparator & keys])
sorted-set 和 sorted-set-by 是有序集合的初始化器, 这是一种类似于 hash-set 的集合类型, 但它还基于一个比较器来维护顺序. 我们可以通过传递所需的元素作为参数来构建一个新的 sorted-set:
(sorted-set "t" "d" "j" "w" "y") ; ❶ ;; #{"d" "j" "t" "w" "y"}
❶ 字符串是可比较的对象. sorted-set 使用一个默认的比较器来调用 Comparable::compareTo() 方法, 用两个字符串来知道哪个应该排在前面.
我们可以使用 sorted-set-by 来强制使用一个不同于默认的比较器:
(sorted-set-by #(compare %2 %1) "t" "d" "j" "w" "y") ; ❶ ;; #{"y" "w" "t" "j" "d"}
❶ 当默认排序不可取时, 我们可以向 sorted-set-by 传递一个新的比较器. 标准库中的 compare 函数与许多 Clojure 和 Java 类型兼容, 也可以与字符串一起使用. 如果我们想反转顺序, 我们只需要交换参数.
契约
- 输入
"keys"可以是要添加到新创建的有序集合中的任意数量的元素."comparator"可以是任何实现java.util.Comparator接口的对象. Clojure 函数 (除了用作函数的数据结构) 实现了Comparator接口, 这是一个允许 <, >, >=, ⇐ 作为比较器的不错技巧. - 主要异常
当任何一对
"keys"不可比较时, 抛出ClassCastException. 通常, 当键是不同类型时, 它们是不可比较的 (尽管不同的数字类型是可比较的). 关于边界情况的更详细列表, 请参见compare. - 输出
返回: 一个新的
clojure.lang.PersistentTreeSet实例, 这是 Clojure 中实现有序集合的类. 新实例包含作为输入传递的所有不同的"keys". 当迭代时, 有序集合按照"comparator"(或如果没有给出, 则为默认比较器) 决定的顺序返回"keys".请注意, 与普通的
hash-set不同,sorted-set或sorted-map没有瞬态版本.示例
sorted-set和sorted-set-by保证其内容不包含重复项. 像hash-map和hash-set一样,sorted-map在有不同元数据的重复项的情况下, 会保留第一个插入项的元数据:(defn timed [s] ; ❶ (let [t (System/nanoTime)] (println "key" s "created at" t) (if (instance? clojure.lang.IMeta s) (with-meta s {:created-at t}) s))) (def s (sorted-set (timed 'a) (timed 'a))) ; ❷ ;; key a created at 206892376620199 ;; key a created at 206892376884656 (meta (first s)) ; ❸ ;; {:created-at 206892376620199}
❶ 我们使用
timed函数在项上, 将创建日期作为对象元数据的一部分存储.❷
"s"是一个用相同的符号 "a" 创建两次的sorted-set. 符号与大多数集合类型一样支持元数据.❸ 我们可以看到保留的元数据是附加到第一个符号的元数据.
sorted-set对于在集合增量更新时保持顺序很有用, 因为每个新项都会按照比较器插入到正确的位置. 在下一个例子中, 我们让用户用他们自己的自定义单词和拼写来更新一个核心的单词词典. 如果我们将词典存储在一个sorted-set中, 每次更新后就不需要排序了:(require '[clojure.string :refer [split-lines]]) (def dict ; ❶ (atom (->> "/usr/share/dict/words" slurp split-lines (into (sorted-set))))) (defn new-word [w] ; ❷ (println "Could not find the word:" w) (println "Add word to dictionary? [y/n]") (when (= "y" (read-line)) (swap! dict conj w) (take 5 (subseq @dict >= w)))) ; ❸ (defn spell-check [w] (if (contains? @dict w) ; ❹ (println "Word spelled correctly") (new-word w))) (defn ask-word [] (println "Please type word:") (when-let [w (read-line)] (spell-check w))) (ask-word) ; ❺ ;; Please type word: ;; google ;; Could not find the word: google ;; Add word to dictionary? [y/n] ;; y ;; word added (google googly googol googolplex googul) (ask-word) ;; Please type word: ;; google ;; Word spelled correctly
❶
dict是当前命名空间中的一个顶层定义, 它保存了从本地文件初始加载的单词. `/usr/share/dict/words` 是大多数 Unix 文件系统上都存在的文件. 在将文件分割成行之后, 我们将相应的单词存储到一个sorted-set中. 该集合被包装在一个atom中以允许受控的变异.❷ 当我们在词典中找不到一个单词时, 使用
new-word. 该函数询问用户是否要添加该单词, 并继续更新atom.❸
subseq是从有序集合中提取一部分的完美选择, 因为它避免了线性扫描来达到目标单词. 我们可以提供关于单词在词典中位置的快速反馈.❹
sorted-set上的另一个习惯用法是contains?, 我们在这里用它来验证一个单词是否在集合中.❺ 我们可以看到一个用户与示例交互以向词典中添加一个新单词.
- 自定义比较器
由于 Clojure 的扩展相等性, 我们也可以在
sorted-set中使用集合:(sorted-set [1 "b" :x] [1 "a" :y]) ; ❶ ;; #{[1 "a" :y] [1 "b" :x]} (sorted-set-by compare [1 "b" :x] [1 "a" :y]) ; ❷ ;; #{[1 "a" :y] [1 "b" :x]}
❶ 向量的相等性与每个项按位置的相等性相同. 在检查 "1" 相同后, 比较继续到下一个项. 由于 "a" 在 "b" 之前, 整个包含 "a" 的向量被移动到包含 "b" 的整个向量之前.
❷ 这个使用
sorted-set-by和compare的第二种形式与第一种等效. 如果默认行为不是你想要的, 你可以使用sorted-set-by传入一个不同的比较器.如果默认的
compare不够用, 我们可以传递一个自定义的, 例如只按第一个或最后一个元素排序. 在这一点上, 理解比较器如何工作是很有用的. 向sorted-set添加一个新元素涉及两个不同的阶段:- 如果项已经在集合中, 则跳过该项. 为此, 比较器会在每个现有项和新项上调用. 如果任何比较返回 "0" (这意味着它们对于一个可能自定义的相等性定义是相同的), 那么该元素就不会被添加到集合中.
- 如果不在集合中, 则在结构上修改集合以在正确的位置容纳新项. 这个阶段再次使用比较器来决定新项应该被添加到哪里.
一个需要考虑的重要方面是, 相等性和相对排序不一定相同. 在下面的例子中, 我们想创建一个向量的
sorted-set, 以便它们按count排序, 大小在前的优先:(sorted-set-by ; ❶ (fn [a b] (compare (count b) (count a))) [1 :a] [:b] [3 :c] [:v]) ;; #{[1 :a] [:b]}
❶ 一个创建按相对大小排序的向量的
sorted-set的天真尝试.这种方法的问题在于, 输入中的一些项没有出现在输出中, 这从比较器的角度来看是正确的, 因为当项具有相同大小时, 它返回 "0".
为了防止这个问题, 自定义比较器应该区分两个方面: 相等性和相对排序. 下面的例子在两种大小相同的情况下引入了一个条件. 在那种情况下, 我们想验证元素是否也相等:
(sorted-set-by (fn [a b] (let [cmp (compare (count b) (count a))] (if (zero? cmp) ; ❶ (compare a b) cmp))) [1 :a] [:b] [3 :c] [:v]) ;; #{[1 :a] [3 :c] [:b] [:v]}
❶ 仅仅比较大小是不够的, 因为两个项 "a" 和 "b" 可能大小相同但内容不等.
上面的比较器产生了预期的行为. 我们现在可以写一个相同行为的更简洁的版本, 使用包装向量. 这是可能的, 因为向量相等性按索引比较项, 这里我们创建一个包装向量, 先是计数, 然后是实际内容:
(sorted-set-by (fn [a b] ; ❶ (compare [(count b) a] [(count a) b])) [1 :a] [:b] [3 :c] [:v]) ;; #{[1 :a] [3 :c] [:b] [:v]}
❶ 一个更简洁的比较器版本, 它先使用计数, 然后使用实际内容来比较向量.
另请参阅
hash-set和sorted-set服务于不同的目的, 并且有不同的性能特征. 如果你不关心排序但仍然需要唯一性保证, 请使用hash-set.sorted-map与sorted-set和sorted-set-by非常接近. 它们实际上是基于相同的实现. 当有键值对有意义时, 使用sorted-map.compare在本章中被多次提及. 它可能是比较最灵活的工具, 因为它将相等性语义扩展到大多数 Clojure 类型.性能考虑和实现细节
=>
O(N)线性于要插入的项数sorted-set创建一个新的clojure.lang.PeristentTreeSet对象, 它是clojure.lang.PersistentTreeMap的一个薄包装器. 在映射之上实现集合的原理很简单: 集合中的每个项都成为映射中的一个键值对 (其中键与值相同).因此,
sorted-set和sorted-set-by的性能特征与sorted-map和sorted-map-by非常相似: 新元素的插入与要添加的元素数量呈线性关系, 其他操作是O(log32N). 邀请读者回顾sorted-map章节以获取更多性能信息.
3.6.4. 13.4 disj
自 1.0 版本起可用的函数
(disj ([set]) ([set key]) ([set key & ks]))
disj 从一个集合 (有序或无序) 中移除一个或多个元素:
(disj #{1 4 6 8} 4 8) ; ❶ ;; #{1 6} (disj (sorted-set-by > 1 4 6) 4) ; ❷ ;; #{6 1}
❶ disj 用于从输入集合中移除数字 "4" 和 "8".
❷ disj 同样可以在有序集合上使用.
契约
- 输入
"set"是输入集合的参数名. 当这是唯一的参数时, 它可以是任何类型, 包括nil. 当存在附加参数时,"set"应实现clojure.lang.IPersistentSet接口. 有两种 Clojure 内置类型实现了IPersistentSet, 即使用Set和sorted-set创建的类型."key"和"ks"是要移除的任意数量的项. 它们可以是任何类型, 并且是可选参数. - 主要异常
当
"set"未实现clojure.lang.IPersistentSet接口时, 抛出ClassCastException. 要了解"set"参数是否实现了正确的接口, 你可以使用set?函数, 或者, `(instance? clojure.lang.IPersistentSet set)` 应该返回true. - 输出
返回: 移除了元素
"key"或"ks"的相同输入"set". 如果"set"是唯一的参数, 它返回参数本身. 如果"set"是nil, 那么即使"key"或"ks"存在,disj也返回nil.示例
在第一个例子中,
disj用于检测无效值的存在. 我们收到一个包含配置值的向量和一个允许值的列表. 以下是disj如何检测不想要的值:(defn valid? [allowed values] (empty? (apply disj (set values) allowed))) ; ❶ (def allowed [:a :b :c]) (valid? allowed [:c :c 1 :a]) ; ❷ ;; false (valid? allowed [:c :c :a]) ; ❸ ;; true
❶ 在将输入值转换为一个
Set(这也移除了任何重复项) 之后, 我们用disj重复移除所有允许的值. 如果有任何剩余, 它就不属于有效值列表.❷ 当
valid?对一个包含无效数字的集合使用时, 它返回 false.❸ 移除无效数字后,
valid?返回 true.在下一个例子中, 我们将使用一个
Set来维护一个打开连接的列表. 每个连接对应于一个由回显服务器 (一个监听传入连接并通过重复输入来回复的服务器) 服务的本地端口. 我们在一个全局可访问的端口哈希集合中维护一个已用端口列表, 并且只有在端口空闲时才启动一个新的监听器:(require '[clojure.java.io :as io]) (import '[java.net ServerSocket]) (def ports (atom #{})) ; ❶ (defn serve [port] (if (= @ports (swap! ports conj port)) ; ❷ "Port already serving requests." (future ; ❸ (with-open [server (ServerSocket. port) ; ❹ socket (.accept server) writer (io/writer socket)] (.write writer (.readLine (io/reader socket))) (.flush writer)) (swap! ports disj port)))) ; ❺
❶
ports是一个包装了最初为空的端口集合的atom.❷ 在我们创建新的服务器监听器之前, 我们需要验证端口是否已经在集合中, 这意味着它已经被使用. 我们依赖于集合的唯一性属性来验证在调用
conj之后,ports的内容是否已更改.swap!总是返回更改后的atom.❸ 如果
ports确实发生了变化, 这意味着请求的端口没有被使用. 在这种情况下, 我们想用future在一个单独的线程中创建一个 JavaServerSocket对象, 这样当前的调用就不会阻塞主线程.❹ 接下来是创建具有给定端口的新
ServerSocket对象, 从套接字读取并写回套接字然后关闭它所需的 Java 互操作性. 我们需要记住 "flush" 任何进入输出流的东西, 因为任何缓冲写入器 (例如由io/writer返回的) 都有一个内部的字节缓存.❺ 在关闭线程之前, 我们确保从
ports中移除已服务的端口. 这允许后续请求重用相同的端口.请注意, 为了简化前面的示例, 检查空闲端口存在和后续启动新
ServerSocket的条件不在同一个事务中. 对同一端口的许多并发请求实际上可能会导致异常, 因为该端口已被使用.要看到回显服务器的运行情况, 我们需要在 REPL 中混合使用 Clojure 和像 Telnet 207 这样的命令. 在 REPL 中调用
serve后, 我们需要从命令行进行相应的 telnet 来解锁端口:(serve 10001) ; ❶ ;; #object[future_call 0x41da {:status :pending, :val nil}] (serve 10001) ; ❷ ;; "Port already serving requests."
;; telnet localhost 10001 ; ❸ ;; Connected to localhost. ;; Escape character is '^]'. ;; hello ;; hello ;; Connection closed by foreign host.❶ 在一个未使用的端口上调用
serve会创建一个新的future实例, 它以:pending状态返回, 因为从标准输入读取的readLine调用是阻塞的. 该线程准备好从端口 10001 接收请求.❷ 在同一端口上第二次调用
serve, 会返回一个端口已在使用的消息.❸ 我们从命令行使用
telnet. 建立连接后,telnet等待输入. 输入在键盘上按 "return" 后结束. 如果我们输入 "hello" 并按 "return", 我们可以看到下面又重复了一个 "hello".另请参阅
dissoc是hash-map的等效操作.disj!是瞬态集合的等效操作.conj是disj的反操作, 但disj不像conj那样是多态的, 只适用于集合.difference是从集合中移除多个项的另一个选项.difference接受要移除的项分组在一个集合中, 而disj接受它们作为不同的参数.性能考虑和实现细节
=>
O(log32N)单项,hash-set=>
O(log2N)单项,sorted-set=>
O(n)线性于参数数量disj(类似于dissoc) 对要移除的键的数量具有线性依赖性. 在单个键的情况下, 性能特征根据集合的类型而不同: 对于hash-set的disj接近常数时间, 更精确地说是log32N, 其中 "N" 是集合中项的数量. 对于有序集合的disj仍然是对数的, 但具有不同的常数因子 (基数是 2 而不是 32). 总的来说, 从集合中移除单个元素是一个快速的操作, 不应引起任何重大关注.在需要使用
disj移除多个参数的情况下, 有其他选择可以考虑. 在下面的基准测试中, 我们测量了disj和clojure.set/difference:(require '[clojure.set :refer [difference]]) (require '[criterium.core :refer [quick-bench]]) (let [s (set (range 1000)) ; ❶ xs (range 400 600)] (quick-bench (apply disj s xs))) ;; Execution time mean : 40.580589 µs (let [s (set (range 1000)) ; ❷ xs (range 400 600)] (quick-bench (difference s (set xs)))) ;; Execution time mean : 59.548475 µs (let [s (set (range 1000)) ; ❸ xs (set (range 400 600))] (quick-bench (difference s xs))) ;; Execution time mean : 37.345393 µs
❶ 第一个基准测试在一个中等大小的集合上测量
disj移除 200 个参数. 注意, 我们需要使用apply来展开参数集合.❷
clojure.set/difference要求要移除的项在一个集合中. 第二个基准测试假设你还没有一个集合, 所以我们用参数创建一个集合, 同时调用difference.❸ 在最后的基准测试中, 我们假设最优情况, 即参数已经是一个集合.
在这种特定情况下,
disj和clojure.set/difference之间的差异很小, 但如果要移除的项已经在集合中, 你应该使用clojure.set/difference(创建集合会大大减慢基准测试).如果你的应用程序有一个需要从集合中移除项的关键部分, 你应该考虑使用瞬态:
(defn disj* [s & ks] ; ❶ (persistent! (reduce disj! (transient s) ks))) (let [s (set (range 1000)) ; ❷ xs (range 400 600)] (quick-bench (apply disj* s xs))) ;; Execution time mean : 21.942524 µs
❶ 这个版本的
disj称为disj*, 在移除项之前将集合转换为瞬态.❷ 基准测试证实, 在集合处于瞬态状态时移除项对速度有积极影响.
disj*大约比普通disj快 50%, 但请记住, 这仅在要移除的项数量足够大时才成立.
3.6.5. 13.5 union, difference 和 intersection
自 1.0 版本起可用的函数
(union ([]) ([s1]) ([s1 s2]) ([s1 s2 & sets])) (intersection ([s1]) ([s1 s2]) ([s1 s2 & sets])) (difference ([s1]) ([s1 s2]) ([s1 s2 & sets]))
clojure.set/union, clojure.set/difference 和 clojure.set/intersection 是源自集合论的常见集合操作 208. 它们不包含在核心命名空间中, 因此需要一个 require 指令才能使用:
(require '[clojure.set :as s]) (s/union #{1 2 3} #{4 2 6}) ; ❶ ;; #{1 4 6 3 2} (s/difference #{1 2 3} #{4 2 6}) ; ❷ ;; #{1 3} (s/intersection #{1 2 3} #{4 2 6}) ; ❸ ;; #{2}
❶ 两个集合的并集将两个集合中的所有项组合在一起, 并移除重复项.
❷ 两个集合的差集移除第一个集合中也存在于第二个集合中的所有项.
❸ 两个集合的交集将两个集合之间所有共有的项组合在一起.
契约
- 输入
union是唯一接受无参数的函数.intersection和difference至少需要一个集合参数或nil."s1"和"s2"可以是nil,hash-set或sorted-set. 如果它们不是nil, 那么(set? s1)和(set? s2)应返回true, 并且它们都应实现clojure.lang.IPersistentSet接口."sets"是任何遵循与"s1"和"s2"相同规范的附加集合. - 主要异常
大多数异常发生在参数未实现
clojure.lang.IPersistentSet接口时:- 当一个参数不是集合类型且不支持
count时, 抛出UnsupportedOperationException. - 当一个参数不是序列性时, 抛出
IllegalArgumentException.
- 当一个参数不是集合类型且不支持
- 输出
union,intersection和difference返回一个新的集合实例或nil. 新的集合实例的类型与第一个参数的类型相同 (hash-set或sorted-set, 如果是原生集合类型, 或可能是nil). 结果集合的内容取决于操作:"s1","s2"和"sets"的并集是包含来自"s1","s2"和任何附加"sets"的所有唯一元素的集合."s1","s2"和"sets"的交集是包含"s1","s2"或任何附加"sets"中所有公共元素的集合."s1","s2"和"sets"的差集是包含"s1"中所有项, 减去"s2"中的公共项, 再减去任何附加"sets"中的其他公共元素的集合.
在其他类型的集合上使用
union,difference和intersection可能会无声地失败, 产生不可预测的结果. 请尝试确保在使用它们之前, 所有参数都是集合.示例
让我们先说明几个有趣的案例. 如果任何集合为空或分别为
nil,intersection的结果是空集合或nil. 即使存在nil, 如果最后一个参数是空集合, 它也会返回空集合:(require '[clojure.set :as s]) (s/intersection #{1 2 3} #{} #{4 2 6}) ; ❶ ;; #{} (s/intersection #{1 2 3} nil #{4 2 6}) ; ❷ ;; nil (s/intersection #{1 2 3} nil #{}) ; ❸ ;; #{}
❶ 如果任何参数为空,
intersection返回一个空集合.❷ 类似地, 如果任何参数为
nil,intersection返回nil.❸ 但是, 如果最后一个参数是空集合,
intersection在存在nil的情况下返回空集合.nil(或空集合) 的存在效果取决于它在参数列表中的出现位置. 在任何情况下, 如果nil是参数之一, 你不应该依赖空集合等价性来实现条件语句. 最安全的选择是移除nil:(apply s/intersection (remove nil? [#{1 2 3} nil #{4 2 6}])) ; ❶ ;; #{2}
❶ 在使用
intersection之前, 我们使用remove来摆脱潜在的nil参数.基于集合的数学基础, 我们可以创建其他有趣的操作. 例如, 两个集合的 "对称差" 是指在任一集合中但不在它们交集中的项的组. 我们可以使用下图来可视化集合 "S1" 和 "S2" 之间的对称差:
Figure 42: Figure 13.3. 显示 S1 和 S2 之间对称差的图表 (深色).
"s1" 和 "s2" 的对称差等同于移除它们的交集后集合的并集:
(require '[clojure.set :refer [union difference intersection]]) (defn symmetric-difference [s1 s2] ; ❶ (difference (union s1 s2) (intersection s1 s2))) (symmetric-difference (sorted-set 1 2 4) #{1 6 8}) ; ❷ ;; #{2 4 6 8}
❶
symmetric-difference函数几乎字面上实现了对称差的定义, 展示了union,difference和intersection的良好用法.❷ 注意使用
sorted-set作为第一个参数, 这会产生一个有序的集合作为输出.另请参阅
当与多个参数一起使用时,
disj的工作方式与difference类似. 当所有参数都是集合的一部分时, 优先使用difference. 如果要减去的项是另一个集合类型的一部分, 那么使用apply和disj是一个可能的选项. 在disj部分讨论了需要考虑的轻微性能影响.性能考虑和实现细节
=>
O(n)线性union,difference和intersection是线性操作, "n" 取决于函数:union需要遍历所有参数的所有项, 所以 "n" 等于所有参数的计数总和.difference在第一个参数的项计数上是线性的.intersection也在第一个参数的项计数上是线性的.
3.6.6. 13.6 subset? 和 superset?
- 13.6.1 → 命名空间: clojure.set
这个简短的部分描述了用于验证集合之间包含关系的函数. 给定两个集合 "s1" 和 "s2", 如果 "s1" 中的所有项也都存在于 "s2" 中, 则
subset?返回 true, 而当 "s1" 包含 "s2" 中也存在的所有项时,superset?返回 true:(require '[clojure.set :as s]) ; ❶ (s/subset? #{1 2} #{1 2 3}) ; ❷ ;; true (s/superset? #{:a :b :c} #{:a :c}) ; ❸ ;; true
❶
subset?和superset?位于clojure.set命名空间中.❷ 数字 "1" 和 "2" (第一个集合的全部内容) 也存在于第二个集合中.
❸ 第一个集合包含来自第二个集合的
:a和:c关键字.与本章中的其他函数一样,
subset?和superset?不应与除集合或nil之外的集合类型一起使用:(s/superset? nil #{}) ; ❶ ;; true (s/subset? #{0 3} [:a :b :c :d]) ; ❷ ;; true
❶ 你应该避免使用
nil参数, 因为它们可能给出不一致的结果.❷ 类似地, 你应该避免现在不是集合的集合类型. 在这个例子中, 我们正在测试第二个向量参数中索引 "0" 和 "3" 处的项的存在, 而不是实际内容.
3.6.7. 13.7 select, index, rename, join 和 project
- 13.7.1 → 命名空间: clojure.set
这个简短的部分描述了
clojure.set命名空间中的一组专用函数. 这些函数受到关系代数的启发 209:select,index,project,rename和join.关系在 Clojure 中实现为一组映射, 如下所示:
(def users ; ❶ #{{:user-id 1 :name "john" :age 22 :type "personal"} {:user-id 2 :name "jake" :age 28 :type "company"} {:user-id 3 :name "amanda" :age 63 :type "personal"}}) (def accounts ; ❷ #{{:acc-id 1 :user-id 1 :amount 300.45 :type "saving"} {:acc-id 2 :user-id 2 :amount 1200.0 :type "saving"} {:acc-id 3 :user-id 1 :amount 850.1 :type "debit"}})
❶ 像
users这样的关系与关系数据库中的表有很强的相似性.❷
accounts关系包含一个 "user-id" 键. 这个键可以用来在另一个关系中查找相关的记录, 通常被称为 "外键"."users"和"accounts"与现代数据库中表的相似性并非巧合. 我们现在可以使用面向关系的函数来对关系执行有趣的查询:(require '[clojure.set :as s]) (s/select #(> (:age %) 30) users) ; ❶ ;; #{{:user-id 3, :name "amanda", :age 63, :type "personal"}} (s/project ; ❷ (s/join users accounts {:user-id :user-id}) ; ❸ [:user-id :acc-id :name]) ;; #{{:user-id 2, :acc-id 2, :name "jake"} ;; {:user-id 1, :acc-id 1, :name "john"} ;; {:user-id 1, :acc-id 3, :name "john"}} (s/project (s/join users accounts {:user-id :user-id}) [:user-id :acc-id :type]) ; ❹ ;; #{{:user-id 2, :acc-id 2, :type "saving"} ;; {:user-id 1, :acc-id 1, :type "saving"} ;; {:user-id 1, :acc-id 3, :type "debit"}} (s/project (s/join users (s/rename accounts {:type :atype})) ; ❺ [:user-id :acc-id :type :atype]) ;; #{{:user-id 1, :acc-id 1, :type "personal", :atype "saving"} ;; {:user-id 2, :acc-id 2, :type "company", :atype "saving"} ;; {:user-id 1, :acc-id 3, :type "personal", :atype "debit"}} (s/index users [:type]) ; ❻ ;; {{:type "company"} ;; #{{:user-id 2, :name "jake", :age 28, :type "company"}}, ;; {:type "personal"} ;; #{{:user-id 3, :name "amanda", :age 63, :type "personal"} ;; {:user-id 1, :name "john", :age 22, :type "personal"}}}
❶
s/select类似于 SQL 中的 "select" 结构. SQL 是关系数据库中使用的结构化查询语言.s/select基于一个谓词来过滤关系 (这类似于 SQL 中的 "where" 子句).❷
s/project只保留关系中每个映射的给定键, 移除所有其他键. 它类似于将select-keys应用于集合中的所有关系.❸ 我们也可以
s/join两个关系, 这会基于一个或多个键的共同值来创建关系的并集. 在这个特定的例子中, 一个用户映射合并到具有相同:used-id值的帐户映射中.s/join会自动在 user-id 上连接, 即使我们没有像我们做的那样明确地传递映射. 注意我们没有在名称中看到 "Amanda", 因为没有帐户属于她, 并且在accounts中没有匹配的 user-id.❹ 我们在关系之间存在键冲突的问题: 如果我们连接两个具有相同键的映射, 最后一个被合并的键会覆盖任何先前的值. 如果我们想同时看到用户类型和帐户类型怎么办?
❺ 我们可以在
s/join之前使用s/rename给特定的键一个新名称来解决连接中的键冲突问题. 我们可以看到现在我们可以访问两种类型. 这相当于 SQL 中的 "AS" 重命名契约. 注意这次我们没有传递一个显式的键来连接, 因为s/join自动使用存在于两个关系中的 user-id.❻ 最后一个例子显示了我们如何使用
s/index按特定键对关系进行分组 (类似于 SQL 中的 "GROUP BY").关系和操作它们的函数为 Clojure 启用了一个小而全功能的内存数据库. 内存数据库可用于相对较小的数据集, 如配置, 规则或其他仅限于应用程序生命周期的结构化数据.
3.6.8. 13.8 总结
本章阐述了关于集合的函数, 这是计算机科学中另一个重要的数据结构. 基本的集合函数是 clojure.core 命名空间的一部分, 但 Clojure 也在 clojure.set 命名空间中提供了专门用于关系代数 210 的附加函数.
4. 第四部分. 解决特定问题
本书的最后一部分汇集了专门用于解决特定编程问题的函数和宏. 这些广泛类别的例子有并发, 多态类型, 变量定义, 格式化和打印等等.
本书的这一部分使用一种不那么正式的结构来描述函数, 放弃了前几部分采用的固定模板. 这样做, 本书希望更加关注日常编程的实际方面. 因此, 以下部分中的函数更有可能按应用领域分组出现.
最后一章名为 "工具箱", 将这种方法推向极致, 只简要概述了标准库中所有剩余的命名空间. 这一选择也反映了一些函数具有非常狭窄的应用领域的事实.
4.1. 14 并发
与其他主流语言不同, Clojure 的主要并发方法不需要显式锁定 211. 锁定仍然可以作为一种低级选项使用, 但持久性数据结构的默认使用为 Clojure 提供了解决最困难并发问题的替代策略.
本章描述了标准库中哪些函数专用于并发以及如何使用它们. 它们主要有三组:
future,promise和delay以不同方式控制线程. 这些函数不与特定的状态处理方式相关联, 它们本身也不包装任何状态.ref,atom和agent是设计用于处理状态的并发模型, 每个模型在并发访问的情况下提供不同的保证.var和volatile!也属于这一组, 但它们在其他章节中因其在纯并发之外的场景中的作用而被阐述.deref, 验证器和观察者是所有并发模型中实现的共同特性.- 最后,
locking是围绕代码关键部分处理并发的最后手段. 显式锁定的需求通常是例外的, 并且被 releg relegated 到一些低级 Java 互操作的情况下.
4.1.1. 14.1 future
本节还提到了其他相关函数, 如:
future-call,future-done?,future-cancel,future-cancelled?和future?
future 接受一个或多个表达式作为输入, 并在另一个线程中异步评估它们:
(defn timer [seconds] ; ❶ (future (Thread/sleep (* 1000 seconds)) (println "done" seconds "seconds."))) (def t1 (timer 10)) ; ❷ ;; #'user/t1 ;; done 10 seconds.
❶ timer 函数接受一个秒数作为输入, 并创建一个包含对请求时间的 Thread/sleep 调用和在屏幕上打印一条消息的 future. 计算的结果是 nil.
❷ 调用 timer 不会阻塞. 消息在请求的秒数后打印.
future-done?和future?
future和future-call返回一个实现java.util.concurrent.Future接口的对象. Clojure 提供了一些方便的函数来管理future内部的计算, 而不是使用原生的 Java 函数. 例如, 我们可以执行一个检查来验证对象是否是future或者计算是否已完成:(def t2 (timer 10)) ; ❶ (future? t2) ; ❷ ;; true (future-done? t2) ; ❸ ;; false ;; wait 10 seconds. (future-done? t2) ; ❹ ;; true
❶
timer与本节开头定义的函数相同. 我们创建第二个计时器 "t2", 设置为 10 秒. 计时器立即启动.❷
future?确认 "t2" 确实是一个future对象.❸
future-done?期望一个类型为java.util.concurrent.Future的对象, 这是future返回的接口的一部分. 当计时器仍在运行时,future-done?返回 false.❹ 当 "done 10 seconds." 消息打印时, 计时器完成了对形式的评估.
我们不一定需要等待
future完成. 我们可以使用deref(或相应的读宏@) 来访问计算的结果. 请注意, 如果future尚未完成, 对deref的调用将会阻塞:(def sum (future (Thread/sleep 10000) (+ 1 1))) ; ❶ (realized? sum) ; ❷ ;; false (deref sum) ; ❸ ;; 2 (realized? sum) ; ❹ ;; true (deref sum) ; ❺
❶ 表达式
(+ 1 1)在一个future中评估, 前面有一个 10 秒的暂停.❷ 如果我们立即对
future调用realized?, 它会返回 false, 因为它还没有完成.❸ 在
sum上调用deref会阻塞, 直到线程唤醒并且表达式(+ 1 1)被评估. 此时, 它返回结果 "2".❹ 在
future评估后调用realized?返回 true.❺ 注意, 第二次调用
deref不会再次导致 10 秒的暂停, 因为结果现在已被缓存,future永远不会再次评估.future-cancel和future-cancelled?
future-cancel尝试取消一个可能正在运行的future. 如果future已经被取消或由于其他原因 (例如future没有响应 (无论出于何种原因)), 该操作会失败:(def an-hour (timer (* 60 60))) ; ❶ (future-cancelled? an-hour) ; ❷ ;; false (future-cancel an-hour) ; ❸ ;; true (future-cancelled? an-hour) ; ❹ ;; true (future-cancel an-hour) ; ❺ ;; false
❶
an-hour是一个长达一小时的计时器.❷ 创建后立即询问
future是否被取消, 但它没有 (如预期的那样).❸
future-cancel成功地尝试停止正在运行的计时器.❹ 我们可以看到
future已被取消.❺ 任何其他尝试
future-cancel已经取消的future的操作都会返回 false.future-call
future-call是future宏用来创建future的低级函数. 很少有理由直接使用future-call. 一个原因是如果你需要将它用作高阶函数:(mapv future [:f1 :f2]) ; ❶ ;; CompilerException java.lang.RuntimeException (pprint (mapv future-call [(^:once fn* [] :f1) (^:once fn* [] :f2)])) ; ❷ ;; [#<Future@3ef6c6cd: :f1> #<Future@1d90b8d2: :f2>]
❶ 你不能将宏传递给函数.
❷
mapv使用future-call为向量中的每个项创建一个future. 注意,future-call需要一个函数, 而不是一个表达式.你可能在上面的例子中注意到一个罕见的
fn*与 "once" 元数据的使用, 它创建了一个支持局部变量清除的函数闭包. 以下是为什么这在future中是一个好主意.- Future 的局部变量清除
与
future-call相比,future宏对包装用户表达式的函数应用了一个可能很重要的优化:(defmacro future [& body] ; ❶ `(future-call (^{:once true} fn* [] ~@body))) ; ❷
❶
future宏是future-call的一个包装器.❷
fn*被赋予了:once元数据, 这会影响编译器如何生成相关的类.当使用带有
^{:once true}元数据的fn*创建函数时, Clojure 编译器会生成一个强制清除所有类属性的方法. 清除是通过尽快将参数设置为 "null" 来实现的. 这可以防止同一个函数对象再次被调用:(let [s "yes" f1 (^:once fn* [] (str "local-var: " (or s "no"))) f2 (^{:once false} fn* [] (str "local-var: " (or s "no")))] [(f1) (f1) (f2) (f2)]) ;; ["local-var: yes" ;; "local-var: no" ; ❶ ;; "local-var: yes" ;; "local-var: yes"] ; ❷
❶ 注意, 第二次调用 "f1" 时, 局部值 "s" 已被清除. 注意
^{:once true}和^:true是等效的表示法.❷ 当禁用一次性语义时, 局部变量永远不会被清除.
future从一次性语义中受益的原因是, 在运行主体表达式后,future对象可能会停留任意长的时间 (即使已终止). 一次性语义给了垃圾回收器一个机会, 即使当future仍然被线程池引用时 (一种常见情况), 也可以移除可能很大的局部变量. 如果你决定直接使用future-call, 建议你使用一次性语义来避免潜在的内存不足问题.future的一个用途是将当前线程与一个或多个昂贵的计算解耦. 在下一个例子中, 几个future包装了可能很长的 http 请求, 每个调用需要大致相同的时间. 通过使用future, 所有请求都并行开始 (当最慢的请求完成时, 结果可用):(require '[clojure.xml :as xml]) (defn fetch-async [url] ; ❶ (future (doall (xml-seq (xml/parse url))))) (let [guardian (fetch-async "https://git.io/guardian-world-rss-xml") ; ❷ nytimes (fetch-async "https://git.io/nyt-world-rss-xml") reuters (fetch-async "https://git.io/reuters-rss-xml") washpost (fetch-async "https://git.io/washpost-rss-xml") wsj (fetch-async "https://git.io/wsj-rss-xml")] (count (concat ; ❸ (take 10 @guardian) (take 5 (drop 15 @nytimes)) (take 5 (drop 20 @wsj)) (take 2 (drop 5 @washpost)) (take 10 @reuters)))) ;; 32
❶
fetch-async接受一个 URL, 并作为xml/parse的一部分发出一个 HTTP 请求. 结果的 XML 被转换为 Clojure 数据结构, 并被完全实现.❷
let块中的每个绑定都使用fetch-async来下载不同的源.future解耦了调用并立即返回, 而不是为每个 http 请求阻塞.❸ 在连接文章的时候, 一些请求可能已经完成, 但其他请求仍在下载. 返回结果的最后一个对
deref(@) 的调用是耗时最长的调用. 但到那时, 所有的源都已下载完毕.虽然
future有效地建模了独立的线程, 但当与像promise或delay这样的其他并发函数一起使用时, 它变得更加强大. 我们将在接下来的部分看到相关的例子.
4.1.2. 14.2 promise 和 deliver
promise 在一个最初为空的内存位置周围创建一个 "门". 该门保护内容免受试图访问它的线程的侵害. 函数 deliver 原子地将一个值写入该位置并打开门. 一旦值被传递, 所有阻塞的线程都能立即看到并使用该值:
(def p (promise)) ; ❶ (future (println "Thread 1 got access to" @p)) ; ❷ (future (println "Thread 2 got access to" @p)) (future (println "Thread 3 got access to" @p)) (deliver p :location) ; ❸ ;; #object[clojure.core$promise$reify__7005 0x16fb93fb {:status :ready, :val :location}] ;; Thread 3 got access to Thread 2 got access to Thread 1 ;; got access to :location:location:location
❶ promise 创建一个受保护的位置 "p". 该位置最初是空的, 任何尝试 deref "p" 的操作都会导致阻塞调用 (除非使用带超时的 deref).
❷ 我们用 future 创建三个独立的线程. 表达式包含一个访问受保护位置 "p" 的请求, 并立即阻塞. 在 REPL 中评估这些形式的线程永远不会阻塞.
❸ deliver 执行以下原子操作: 它将值 :location 存储在 promise "p" 中, 并打开门以允许访问. 我们看到的是之前创建的线程的并发打印.
正如你从上面的例子中看到的, 一旦一个值被传递到承诺的位置, 所有阻塞的线程都会同时获得对该位置的访问权限. promise 创建一个可调用对象 (由 deliver 使用):
(def p (promise)) (future (println "Delivered" @p)) (p :value) ; ❶ ;; Delivered :value (realized? p) ; ❷ ;; true (p :value) ; ❸ ;; nil
❶ 一个 promise 对象也是一个接受一个参数的函数. 我们可以用一个值调用该函数以获得与 deliver 相同的效果.
❷ realized? 返回 promise 的当前状态, 它可以是已实现的或未实现的.
❸ 对 promise 的任何进一步传递都不会产生任何操作.
promise 和 future 对于线程协调很有用. 下一个例子受到了 Suhas Patil 在 1971 年描述的香烟吸烟者问题的启发 212. 该问题模拟了以下情况:
- 一支香烟需要烟草, 纸和火柴才能准备和吸食.
- 3 个吸烟者坐在桌旁, 分别拥有无限供应的烟草, 纸或火柴, 但缺少另外两种成分.
- 一个不在桌旁的人随机挑选两种成分并放在桌子上.
- 每一轮, 应该只有一个人能够点燃一支香烟.
这个问题提出了一些有趣的挑战, 如线程竞争和同步. 我们可以使用 promise 来为每种成分建模, 使用 future 来为每个玩家建模:
(def msgs (atom [])) ; ❶ (defn smoke [smoker ingr1 ingr2] ; ❷ (swap! msgs conj (str smoker " attempts")) (deref ingr1) (deref ingr2) (swap! msgs conj (str smoker " successful!"))) (defn pick-two [tobacco paper matches] ; ❸ (rest (shuffle [#(deliver tobacco :tobacco) #(deliver paper :paper) #(deliver matches :matches)]))) (defn run [] ; ❹ (dotimes [i 5] (swap! msgs conj (str "Round " i)) (let [tobacco (promise) paper (promise) matches (promise)] (future (smoke "tobacco holder" paper matches)) (future (smoke "paper holder" tobacco matches)) (future (smoke "matches holder" tobacco paper)) (doseq [add (pick-two tobacco paper matches)] (add)) (Thread/sleep 10))) @msgs)
❶ 由于多个线程试图写入同一个流, 向标准输出打印会产生不可读的消息. 一个可能的选择是将消息序列化到一个 atom 内的向量中.
❷ smoke 接受一个吸烟者的名字和他们正在等待的两种缺失的成分. 然后它对两种成分进行 deref, 以试图完成并点燃一支香烟.
❸ pick-two 随机选择两种成分. 它使用 shuffle 来随机化对成分的访问. 注意, 我们需要将 deliver 请求包装在一个函数中以避免立即执行.
❹ run 协调模拟. 每个 promise 代表一个成分的位置, future 包装了每个吸烟者尝试吸烟的行为. doseq 只评估两种成分的传递, 而三个吸烟者在争夺它们. run 返回到目前为止收集到的消息.
如果例如, 持有烟草的吸烟者拿走了纸, 而另一个吸烟者拿走了桌上的火柴, 也可能发生死锁. 模拟避免了这种死锁, 因为 promise 在内部缓存了它的值. 不幸的是, 我们需要修复另一个问题. 让我们检查一下模拟的输出:
(pprint (partition 5 (run))) ; ❶ ;; ("Round 0" ; ❷ ;; "tobacco holder attempts" ;; "paper holder attempts" ;; "matches holder attempts" ;; "matches holder successful!") ;; ("Round 1" ;; "tobacco holder attempts" ;; "paper holder attempts" ;; "tobacco holder successful!" ;; "matches holder attempts") ;; ("Round 2" ;; "tobacco holder attempts" ;; "paper holder attempts" ;; "matches holder attempts" ;; "tobacco holder successful!") ;; ("Round 3" ;; "tobacco holder attempts" ;; "paper holder attempts" ;; "matches holder attempts" ;; "matches holder successful!") ;; ("Round 4" ;; "tobacco holder attempts" ;; "paper holder attempts" ;; "paper holder successful!" ;; "matches holder attempts"))
❶ run 返回模拟期间检索到的消息集合. 我们使用 partition 按迭代对消息进行分组.
❷ 每一轮只有一个成功的吸烟者, 正如预期的那样.
桌上的每一轮分发都会导致一个吸烟者成功点燃一支香烟. 但另外两个吸烟者的命运如何? 只有一个吸烟者收到了正确的成分, 而另外两个正在等待一个永远不会被传递的成分. future 线程永远挂起, 等待 deref promise. 按照设计, 模拟每个周期都会泄漏线程, 在几千个线程后可能会使 Java 虚拟机崩溃. 我们可以通过在 deref 调用上使用超时参数来阻止泄漏, 这是 Clojure 提供的用于管理并发的一个重要特性:
(defn smoke [smoker ingr1 ingr2] ; ❶ (let [i1 (deref ingr1 100 "fail!") i2 (deref ingr2 100 "fail!")] (swap! msgs conj (str smoker " " i1 " " i2)))) (run) (print @msgs) ;; ["Round 0" ; ❷ ;; "tobacco holder :paper :matches" ;; "Round 1" ;; "matches holder :tobacco :paper" ;; "Round 2" ;; "matches holder :tobacco :paper" ;; "Round 3" ;; "tobacco holder :paper :matches" ;; "Round 4" ;; "tobacco holder :paper :matches" ;; "matches holder fail! :paper" ;; "paper holder fail! :matches" ;; "tobacco holder :paper fail!" ;; "paper holder :tobacco fail!" ;; "paper holder :tobacco fail!" ;; "tobacco holder :paper fail!" ;; "matches holder fail! :paper" ;; "paper holder fail! :matches" ;; "matches holder fail! :paper" ;; "paper holder fail! :matches"]
❶ 新版本的 smoke 函数在 deref 调用上添加了 100 毫秒的超时. 它还添加了一个在达到超时时返回的默认消息.
❷ 消息现在在超时到期后显示失败消息.
使用超时的 deref 的修改版本可以防止线程在成分未传递到 promise 时无限期挂起. 我们不能像以前那样对结果进行分区, 因为现在其他吸烟者可能会有任意数量的尝试来点燃香烟.
4.1.3. 14.3 delay
本节还提到了其他相关函数:
delay?和force.
delay 是一个接受一个 Clojure 形式作为参数的宏. delay 保证该形式只会被评估一次, 即第一次在其上调用 deref 时:
(def d (delay (println "evaluated"))) ; ❶ (deref d) ; ❷ ;; evaluated ;; nil @d ; ❸ ;; nil
❶ delay 返回一个 clojure.lang.Delay 类型的对象, 我们将其保存在一个名为 "d" 的变量中. 屏幕上不打印任何内容, 因为 delay 存储表达式而不对其进行评估.
❷ 一旦我们在 "d" 上调用 deref, 表达式就会被评估.
❸ 我们也可以使用读宏 "@" 而不是 deref. 评估表达式的结果被缓存在内部并返回. 我们可以看到第二次调用 deref 时没有打印输出.
用 delay 包装的评估具有以下属性:
- 它将一个定义与该定义的实际评估解耦. Clojure 中的大多数定义发生在编译时, 因此
delay可用于将评估推迟到运行时. - 在存在多个线程的情况下,
delay保证该形式只会被评估一次. - 评估结果被缓存并在后续调用
deref时返回.
延迟评估, 特别是对于像连接, 线程池或本地文件这样的有状态资源, 在应用程序被 AOT 编译时变得必要 (关于 AOT 编译的概述请参见
compile). 没有delay, 应用程序可能会在编译时尝试连接到数据库.
值得注意的是, 使用 atom 并不能替代对 delay 的需要. 在下面的例子中, 使用 atom 存储状态会导致多次初始化. 要看到例子的输出, 你需要在端口 "61817" 上有一个服务在监听. 你可以使用 "netcat" 命令行工具和 nc -l 61817 来实现这一点:
(import '[java.net InetAddress Socket]) (def connection (atom nil)) ; ❶ (defn connect [] ; ❷ (swap! connection (fn [conn] (or conn (let [socket (Socket. (InetAddress/getByName "localhost") 61817)] (print "Socket connected to 61817\n") socket))))) (defn handle-request [s] ; ❸ (let [conn (connect)] (print (format "Doing something with %s\n" s)))) (dotimes [i 3] ; ❹ (future (handle-request i))) (flush) ;; Socket connected to 61817 ;; Socket connected to 61817 ;; Doing something with 1 ;; Doing something with 0 ;; Socket connected to 61817 ;; Doing something with 2
❶ 该示例模拟了使用 java.net.Socket 连接到监听端口 "61817" 的服务的连接. 为了避免每次请求都创建连接的成本, 应用程序使用一个 atom 来存储一个打开的连接.
❷ connect 创建一个新的套接字连接. 它仅在当前没有可用的套接字对象时才用新的套接字对象 swap! atom.
❸ handle-request 执行主要计算. 它接受一个参数并请求连接以与外部服务通信.
❹ 当应用程序启动时, 它开始接收许多同时的请求. 传入请求的效果通过使用 future 来模拟. 输出显示了套接字似乎已连接的 3 行.
当应用程序开始接收请求时, 多个线程能够并发地执行 swap! 请求. atom 通过允许多次重试直到一个线程能够存储套接字连接来正确处理并发. 在这样做时, 其他连接已被创建但立即被放弃, 浪费了资源.
通过使用 delay 而不是 atom, 我们可以达到一次初始化连接的预期效果:
(def connection (delay ; ❶ (let [socket (Socket. (InetAddress/getByName "localhost") 61817)] (print "Socket connected to 61817\n") socket))) (defn handle-request [s] ; ❷ (let [conn @connection] (print (format "Doing something with %s\n" s)))) (dotimes [i 3] ; ❸ (future (handle-request i))) (flush) ;; Socket connected to 61817 ;; Doing something with 2 ;; Doing something with 1 ;; Doing something with 0
❶ 与定义 atom 不同, 连接现在被声明为 delay. 比较 atom 当前内容所需的逻辑已被移除.
❷ handle-request 现在使用 @ 来解引用 delay.
❸ 我们像之前一样启动相同数量的线程, 现在我们可以看到一个单一的打印输出, 确认套接字对象只被创建了一次. 随后, 我们可以看到由 handle-request 生成的 3 个输出.
delay?和force
delay?和force是帮助管理delay对象的工具函数.delay?询问给定的参数是否是delay:(def d (delay (println :evaluated))) (if (delay? d) ; ❶ :delay :normal) ;; :delay
❶
delay?是一个谓词函数, 当给定参数是delay对象时返回true. 注意delay?不会强制任何评估.force在处理可能是一个delay但我们不确定的对象时很有用. 如果参数是一个delay, 它会解引用其内容, 否则它会返回对象本身:(def coll [(delay (println :evaluated) :item0) :item1 :item2]) ; ❶ (map force coll) ; ❷ ;; :evaluated ;; (:item0 :item1 :item2)
❶ 集合 "coll" 包含延迟值和普通值的混合.
❷ 与对每个参数使用
delay?进行检查不同, 我们可以使用force来处理延迟值和普通值.请注意, 如果一个延迟的计算产生一个异常, 相同的异常对象会在每次
deref时被重新抛出:(def d (delay (throw (ex-info "error" {:cause (rand)})))) ; ❶ (try @d (catch Exception e (ex-data e))) ; ❷ ;; {:cause 0.14105452022720477} (try @d (catch Exception e (ex-data e))) ;; {:cause 0.14105452022720477}
❶ 这个
delay定义故意产生一个错误. 用ex-info创建的错误包含一个随机数, 以验证创建异常的主体是否被多次评估.❷ 正如我们通过在同一个
delay对象上两次调用deref/@所看到的, 异常是相同的.
4.1.4. 14.4 ref
本节还提到了其他相关函数, 如:
sync,dosync,alter,commute,ensure,ref-set,ref-history-count,ref-min-history,ref-max-history和io!.
ref, dosync 和本节中的其他函数是进入 Clojure 软件事务内存 (或简称 STM) 实现的主要入口点. STM 是一种并发控制机制, 类似于数据库事务, 旨在保护内存区域 (而不是磁盘) 213. 具体来说, ref 是与 atom, agent 和 var 一起的并发原语之一. ref 与其他并发原语的区别在于, 多个 ref 可以在同一个事务中协调. 事务中引用协调的典型例子是模拟从一个银行账户向另一个银行账户转移一笔款项:
(def account-1 (ref 1000)) ; ❶ (def account-2 (ref 500)) (defn transfer [amount] (dosync ; ❷ (when (pos? (- @account-1 amount)) (alter account-1 - amount) ; ❸ (alter account-2 + amount)) {:account-1 @account-1 :account-2 @account-2})) (transfer 300) ; ❹ ;; {:account-1 700, :account-2 800}
❶ ref 创建一个 clojure.lang.Ref 类型的对象. ref 接受任何类型的初始值 (包括 nil).
❷ dosync 初始化一个事务上下文, 监视表达式主体内对引用对象的访问.
❸ 像 alter 这样的操作会通知 STM 有意对引用进行更改. 这样的更改可能会立即发生, 在 dosync 块的末尾发生, 重复多次或根本不发生.
❹ 在这个简单的例子中, 我们可以验证从 "account-1" 中提取了一笔 "300" 的款项并转移到了 "account-2".
一个看似无害的账户转账操作 (如上所述), 在并发应用程序中会导致许多挑战: 在检查有足够的钱之后, 我们如何确保另一个线程在我们能够将钱转到第二个账户之前不会清空第一个账户? 这个问题的传统解决方案是使用显式锁定, 并将处理并发的责任委托给程序员. 然而, Clojure 采用了一种无锁的方法, 通过 STM 214 来进行线程协调.
dosync是一个不传递任何选项的sync的包装器.sync被设计为接受选项, 但到目前为止, 没有任何选项可用.
ref-history-count,ref-min-history,ref-max-history
ref实例包含一个类似队列的存储空间, 可以在事务期间使用. 默认情况下,ref不存储已提交的值, 因为ref-min-history为 0, 这意味着没有空间来存储值:(def r (ref "start value")) (ref-min-history r) ; ❶ ;; 0 (ref-max-history r) ; ❷ ;; 10
❶ 一个仅使用初始值创建的
ref的默认ref-min-history为 0.❷
ref-max-history的默认值是 10.这个默认值的影响可以在下面的例子中看到. 当一个较快的写入者 "T2" 能够在 "T1" 访问它之前提交
ref时, 一个较慢的读取者 "T1" 会产生一个读取故障:(let [r (ref 0) ; ❶ T1 (future ; ❷ (dosync (println "T1 starts") (Thread/sleep 1000) (println "T1 history-count" (ref-history-count r)) @r)) T2 (future (dosync (println "T2 starts") (alter r inc)))] ; ❸ [@T1 @T2 @r]) ;; T1 starts ;; T2 starts ;; T1 history-count 0 ; ❹ ;; T1 starts ; ❺ ;; T1 history-count 0 ;; [1 1 1]
❶ 一个
ref"r" 被初始化为 0.❷ 第一个事务 "T1" 在打印开始消息后休眠 1 秒, 然后打印
history-count. 当 "T1" 开始时, "r" 的事务内值为 0.❸ 第二个事务 "T2" 立即提交对 "r" 的更改, 将值设置为 1. "T1" 仍在休眠.
❹ 注意, 当我们询问当前的
ref-history-count时,ref返回 0.❺ 我们可以看到 "T1" 再次打印开始消息, 这意味着事务被重新启动.
即使这个例子表面上看起来很简单, STM 也必须解决相当多的挑战才能产生正确的结果. 在休眠 1 秒后, "T1" 请求对
ref的读访问, 但 "r" 已经被 "T2" 成功提交. 当 "T1" 访问 "r" 时, 它检索到一个过时的值 "0", STM 会重新启动事务. 我们可以在日志中看到 "T1 starts" 打印了两次. 最后, "T1" 正确地打印 "1" 作为读取 "r" 的结果, 因为到线程完成时, 那是可用的值.STM 的默认设置是最正确和最保守的假设: 一个线程不能访问一个过时的值, 并且事务会重新启动以获取更改. 然而, 如果
ref的新值不依赖于旧值, 就不需要重新启动事务, 并且可以容忍过时的读取. 在这种情况下, 每个事务可能会看到ref的不同值. 我们可以通过将min-history设置为一个正数来启用这种行为, 该正数表示ref在产生读取故障之前容忍多少个事务内值. 我们可以使用ref-min-history函数来做到这一点, 或者在创建ref时:(let [r (ref 0 :min-history 1) ; ❶ T1 (future (dosync (println "T1 starts") (Thread/sleep 1000) (println "T1 history-count" (ref-history-count r)) @r)) T2 (future (dosync (println "T2 starts") (alter r inc)))] ; ❷ [@T1 @T2 @r]) ;; T1 starts ;; T2 starts ;; T1 history count 1 ;; [0 1 1] ; ❸
❶ 引用 "r" 的新定义允许一个
ref的事务内值. 这意味着在并发访问的情况下, 至少有一个线程可以读取ref的过时值.❷ 计算的其余部分与前面的例子相同, 只是事务 "T1" 不会重新启动.
❸ 注意 "T1" 现在读取 0, 即使
ref已被另一个线程更改为 1.如果
:min-history允许更多的过时读取而不重新启动,:max-history则决定了引用在发生读取故障之前可以存储的最大值数. 这是因为 STM 可以自动检测事务重新启动次数过多的情况, 并相应地增加历史计数, 但最多到:max-history中的数字 (默认为 10). 一般来说, 初始事务越慢 (或并发线程数越高),:max-history需要越高才能防止因读取故障而重新启动 215.alter和ref-set
alter和ref-set在事务中改变一个引用. 它们的工作方式类似, 但alter接受一个从旧值到新值的函数:(def r (ref 0)) (dosync (alter r inc)) ; ❶ ;; 1 (dosync (ref-set r 2)) ; ❷ ;; 2
❶
alter接受引用和一个单参数函数. 该函数接收ref的旧值, 可用于计算新值.❷
ref-set忽略ref中的任何旧值, 只用新值替换它.对同一个
ref的并发修改会产生事务的重新启动以保证一致性. 下面的例子显示了一个perform函数, 它首先递增, 然后在一个短循环中将两个数字相加. 操作数和结果是可变和共享的, 所以它们被实现为ref对象.dosync事务边界标记了一个原子计算的区域, 该区域要么作为一个整体完成, 要么不完成:(def op1 (ref 0)) ; ❶ (def op2 (ref 1)) (def result (ref [])) (defn perform [] ; ❷ (dosync (dotimes [i 3] ; ❸ (println (format "###-%s-###\n" ; ❹ (hash (Thread/currentThread)))) (alter op1 inc) (alter op2 inc) (alter result conj (+ @op1 @op2)) (print (format "%s + %s = %s (i=%s)\n" @op1 @op2 (+ @op1 @op2) i)) (Thread/sleep 300)) @result)) (perform) ; ❺ ;; ###-2023564354-### ;; 1 + 2 = 3 (i=0) ;; ###-2023564354-### ;; 2 + 3 = 5 (i=1) ;; ###-2023564354-### ;; 3 + 4 = 7 (i=2) ;; [3 5 7] (perform) ;; ###-2023564354-### ;; 4 + 5 = 9 (i=0) ;; ###-2023564354-### ;; 5 + 6 = 11 (i=1) ;; ###-2023564354-### ;; 6 + 7 = 13 (i=2) ;; [3 5 7 9 11 13]
❶ 三个
ref对象分别被赋予初始值 0, 1 和空向量.❷
perform在一个dosync块内执行一些计算. 结果存储在ref中并返回.❸ 在每个
dotimes循环内,perform递增操作数并在屏幕上打印它们的和. 该循环在事务内执行, 强制执行一个约束, 即一旦调用perform, 所有更改要么作为一个整体发生, 要么不发生.❹ 在每个循环开始时, 我们还打印一条包含线程标识 (作为线程对象的哈希) 的消息. 这有助于理解线程是如何竞争以控制代码的执行的.
❺ 我们首先在没有并发的情况下调用
perform, 以显示预期的结果. 我们可以看到第一个结果是[3 5 7], 如果我们再次调用perform而不重置op1和op2, 则是[3 5 7 9 11 13].在前面的例子中,
perform在没有并发的情况下被调用了两次, 只是为了显示循环的行为. 如果我们在单独的线程中运行多个perform, STM 保证了在顺序情况下看到的相同结果, 代价是可能需要重新启动事务:(dosync ; ❶ (ref-set op1 0) (ref-set op2 1) (ref-set result [])) (let [p1 (future (perform)) ; ❷ p2 (future (perform))] [@p1 @p2] @result) ;; ###-1235449187-### ; ❸ ;; 1 + 2 = 3 (i=0) ;; ###-326623499-### ; ❹ ;; ###-326623499-### ;; ###-326623499-### ;; ###-1235449187-### ;; 2 + 3 = 5 (i=1) ;; ###-326623499-### ;; ###-326623499-### ;; ###-326623499-### ;; ###-1235449187-### ;; 3 + 4 = 7 (i=2) ;; ###-326623499-### ;; ###-326623499-### ;; ###-326623499-### ;; ###-326623499-### ; ❺ ;; 4 + 5 = 9 (i=0) ;; ###-326623499-### ;; 5 + 6 = 11 (i=1) ;; ###-326623499-### ;; 6 + 7 = 13 (i=2) ;; [3 5 7 9 11 13]
❶ 在开始每个实验之前, 将
ref对象重置到一些初始的已知状态是一个好习惯.❷
perform现在从两个独立的线程中调用, 然后我们通过在向量中解引用它们来等待结果返回. 结果通过在let块的末尾调用@ref来获得.❸ 其中一个线程, 无论是
p1还是p2, 首先进入事务.❹ 我们可以看到第二个线程 id "326623499" 的重复尝试访问. 我们看到的是 STM 重新启动
dosync指令主体的结果. 考虑到我们的休眠时间为 300 毫秒, 我们可以推断 STM 在事务重试之间应用了一个 100 毫秒的等待期 (这确实是情况, 并且是不可配置的).❺ 最终, 第二个线程能够进入循环. 这发生在第一个线程完成事务时.
要理解上面例子的输出如何交错, 我们需要考虑到一个线程总是首先进入事务. 一旦发生这种情况, 较晚的线程就会被迫重新启动几次. 一次重新启动不足以让第一个线程完成事务, 所以我们可以看到发生了几次重新启动. 在 STM 放弃并抛出异常之前, 有一个硬性的 10,000 次重试限制 (在我们的例子中, 我们离达到那个限制还很远).
commute
commute是alter的一种宽松形式, 它向 STM 发出信号, 表明使用此函数的写操作可以按任何顺序执行 (假设写操作是可交换的). 当使用commute代替alter时, 事务不需要重新启动来等待彼此的结果, 因为计算不依赖于读取顺序.对于非可交换操作,
commute是错误的选择, 例如前面例子中看到的增量和加法的混合. 然而, 在其他顺序更新不重要的场景中, 它是一个很好的候选者. 在下面的模拟中, 一个投票系统接收候选人的投票, 并打印第一个达到 100 票的候选人的名字. 我们不关心维护收到的偏好的有序列表, 所以commute似乎是一个自然的选择:(def votes (ref {})) ; ❶ (defn counter [poll votes] ; ❷ (future (dosync (doseq [pref poll] (commute votes update pref (fnil inc 0)))))) (defn generate-poll [& preference] ; ❸ (eduction (map-indexed #(repeat %2 (str "candidate-" %1))) cat preference)) (let [c1 (counter (generate-poll 40 64 19 82 11) votes) ; ❹ c2 (counter (generate-poll 10 89 23 75 22) votes)] [@c1 @c2] @votes) ;; {"candidate-0" 50 ; ❺ ;; "candidate-1" 153 ;; "candidate-2" 42 ;; "candidate-3" 157 ;; "candidate-4" 33}
❶
votes是一个由ref包装的 Clojure 映射. 投票由ref收集并在整个系统中共享.❷
counter是一个返回future的函数.future的主体接受传入的投票批次, 并在映射中增加对应于刚刚收到的投票的计数器. 如果我们使用alter, 它会强制重新启动以保持读取一致性, 但我们不关心哪个数字先被递增, 只关心它们的总和. STM 可以用commute来优化这种情况.❸
generate-poll模拟用户为候选人投票. 它接受任意数量的投票, 假设参数中每个数字的位置与从索引 0 开始的特定候选人相关, 然后是索引 1, 依此类推.❹ 传入的投票批次被分配给不同的计数器线程, 因此计数可以并行进行. 创建
future对象也启动了计算. 向量[@c1 @c2]确保在读取结果之前所有future都已完成.❺ 我们可以看到预期的结果计数.
即使在使用带有隔离事务的
ref时, 也只有通过使用适当的数据结构才能实现一致性. 通过使用一个既不是并发的也不是不可变的集合, 单独的 STM 将无法强制执行一致性.ensure
除了读取错误, 快照隔离也可能产生 "写偏斜". 例如, 当多个
ref共享约束时, 可能会发生写偏斜. 为了说明这个问题, 让我们给投票系统添加一个约束, 一旦有超过五个 "蜜罐" 投票就停止比赛. 网页上的 "蜜罐" 包括在表单上添加一个隐藏的输入字段. 人类看不到这个输入, 但机器人能看到 (并填写). 投票系统的新设计允许在检测到一定数量的可疑提交后立即停止比赛. 每个线程现在必须ensure(并非巧合地使用ensure) 共享的蜜罐计数值约束在当前事务之外不会改变:(def votes ; ❶ {"honeypot" (ref 0) "candidate-0" (ref 0) "candidate-1" (ref 0) "candidate-2" (ref 0) "candidate-3" (ref 0) "candidate-4" (ref 0)}) (defn batch [prefs] (future (dosync (ensure (votes "honeypot")) ; ❷ (doseq [color prefs :while (< @(votes "honeypot") 5)] (update votes color commute inc))))) (defn generate-poll [honeypot & preference] ; ❸ (concat (repeat honeypot "honeypot") (eduction (map-indexed #(repeat %2 (str "candidate-" %1))) cat preference))) (let [c1 (batch (generate-poll 3 10 30 20 30 20)) ; ❹ c2 (batch (generate-poll 5 20 10 10 30 20))] [@c1 @c2] {:total-votes (reduce + (map deref (vals votes))) :winner (ffirst (sort-by (comp deref second) > votes)) :fraud? (= @(votes "honeypot") 5)}) ;; {:total-votes 115, :winner "candidate-1", :fraud? true}
❶ 所有候选人现在都被建模为
votes映射中的引用对象. 这使得可以确保蜜罐键以及独立地交换投票.❷
dosync主体现在包含对包含蜜罐计数的引用的ensure调用.doseq也已更新, 以在继续之前检查蜜罐计数.❸
generate-poll接受要生成的蜜罐条目数量以及适当的候选人进行模拟.❹ 新投票系统的测试运行证实了可能存在欺诈. 仍然会计算出获胜者, 但额外的投票批次不会改变当前结果.
io!
使用 STM 时需要考虑的一个重要方面是, 确保事务中的表达式是无副作用的 (更确切地说, 表达式不依赖于副作用来成功). 由于事务可以调用任何其他函数, 因此需要一种方法让任意代码发出不适合事务的信号. 我们可以使用
io!来发出这个信号. 例如, 函数f1打开一个事务上下文, 其中涉及调用函数f2(可能在更深的多层之下).f2是有副作用的, 但为一般情况而设计. 我们可以使用io!来发出一个信号, 即如果f2曾经是事务的一部分, 事务应该抛出异常:(def counter (ref 0)) (defn f2 [value] ; ❶ (io! (println "Sorry, side effect on" value)) (inc value)) (defn f1 [] ; ❷ (dosync (f2 (commute counter f2)))) (f1) ; ❸ ;; IllegalStateException I/O in transaction user/f2
❶
f2是一个处理一个值并利用副作用的函数. 虽然f2是为一般情况设计的, 但在事务中使用它可能会产生问题. 知道这种可能性, 函数的作者将副作用包装在io!中.❷
f1在事务内部执行操作, 并显式使用f2(但f2的使用可能不那么容易看到).❸ 尝试运行
f1会揭示调用链中存在io!.最后, 值得一提的是, 你可以在构造期间使用
:meta选项向ref对象传递元数据:(def r (ref 0 :meta {:create-at :now})) ; ❶ (meta r) ; ❷ ;; {:create-at :now}
❶ 像
with-meta这样的函数不适用于引用类型. 但ref在构造期间提供了:meta选项来指定元数据.❷ 我们可以看到元数据被正确设置.
reduce-kv和reduced约定
关于
reduce-kv, 另一个需要提及的方面是, 像reduce一样, 它理解reduced信号系统. 这是一个有用的机制, 可以在所需结果已经可用时停止归约, 防止任何进一步的处理:(reduce-kv (fn [m k v] (if (> k 2) (reduced m) ; ❶ (assoc m k v))) {} [:a :b :c :d :e]) ;; {0 :a, 1 :b, 2 :c} ; ❷
❶ 我们选择一个基于某个键的任意条件. 当条件为真时, 我们返回一个 "reduced" 结果, 并跳过相关的
assoc操作, 标志着我们想要终止归约的事实.reduce知道如何解释这个信号, 不会再继续进行.❷ 正如预期的那样, 结果映射中缺少了大于 2 的键.
在实现
reduce-kv的扩展时 (类似于reduce), 我们应该始终记住遵守信号约定并处理reduced的情况. 如果我们不这样做, 那么我们可能会忽略信号并浪费额外的计算. 例如, 我们对java.util.Map的reduce-kv扩展的行为就不正确:(import 'java.util.LinkedHashMap) (reduce-kv (fn [m k v] (if (= k :abort) (reduced m) ; ❶ (assoc m k v))) {} (LinkedHashMap. {:a 1 :abort true :c 3})) ; ❷ ;; ClassCastException clojure.lang.Reduced cannot be cast to ;; clojure.lang.Associative
❶ 如果输入包含一个特殊的键 (这里称为 ":abort"), 我们希望归约过程停止. 使用
LinkedHashMap保证了条目按插入顺序检索, 所以我们期望在 ":abort" 之后没有其他键出现在结果中.❷ 我们可以看到, 使用
reduced并没有被我们之前的协议扩展处理. 我们不是在达到一个reduced项后停止, 而是将它传递给了失败的assoc.为了解决这个问题, 我们需要增强
java.util.Map类型的协议扩展, 以处理包装在reduced对象中的元素:(extend-protocol clojure.core.protocols/IKVReduce java.util.Map (kv-reduce [m f init] (let [iter (.. m entrySet iterator)] (loop [ret init] (if (.hasNext iter) (let [^java.util.Map$Entry kv (.next iter) ret (f ret (.getKey kv) (.getValue kv))] (if (reduced? ret) ; ❶ @ret (recur ret))) ret))))) (reduce-kv (fn [m k v] (if (= k :abort) (reduced m) (assoc m k v))) {} (LinkedHashMap. {:a 1 :abort true :c 3})) ;; {:a 1} ; ❷
❶ 我们重复之前的协议扩展, 但这一次, 我们检查是否传递了一个
reduced?元素, 如果是, 就停止递归. 我们还需要用 "@" (解引用) 读宏来解包reduced项.❷ 我们可以看到结果只包含到找到 ":abort" 请求为止的键.
另请参阅
reduce是reduce-kv的灵感来源模型. 对于所有其他非关联数据结构, 应考虑使用reduce.reduced是实现信号机制的函数, 这在reduce-kv中也讨论过.性能考虑和实现细节
=>
O(n)线性于 n 个条目reduce-kv的性能考虑与reduce非常相似:reduce-kv在条目数量 (映射中的键值对或向量中的项) 上呈线性执行. 在绝对值上, 归约的执行方式取决于输入集合的类型. 下图显示了reduce-kv在兼容类型和不同输入大小下的性能. 归约函数是(constantly nil), 因此除了纯迭代外, 不考虑其他时间.
Figure 43: Figure 11.4. reduce-kv 基准测试.
该图表显示, 记录慢一个数量级 (但它们也不太可能包含那么多键). 基准测试中最快的是
array-map, 但其他类型 (除了记录) 紧随其后.内存分配取决于归约函数: 从另一个映射生成一个保留所有键的映射, 在空间上是线性的.
reduce-kv(像reduce一样) 不是惰性的, 除非被reduced中断, 否则它会处理所有项, 不论下游消耗了多少.
4.1.5. 14.5 atom
本节还提到了其他相关函数, 如:
swap!,reset!和compare-and-set!
Clojure 的 atom 是一种用于控制同步且非协调的状态变更的并发感知结构. 让我们展开这个定义:
- 并发感知: 多个线程可以共享
atom的状态而无需显式锁定.atom的更改保证是作为更新开始时读取的旧值的函数. 如果另一个线程在当前线程能够应用其更改之前更改了atom的状态, 则操作会重复. - 同步: 更新操作在启动更新的同一线程上发生. 这与例如
agent不同, 但与ref类似. - 非协调: 没有机制来协调不同的
atom实例 (没有dosync结构来包围多个atom操作).
atom 被引入以实现保护单个引用免受并发访问的常见用例. atom 仍然存在 "事务" 的概念, 但它是隐式的, 并由更新函数本身界定:
(def a (atom 0)) ; ❶ (swap! a inc) ; ❷ ;; 1 @a ; ❸ ;; 1
❶ 一个 atom 是通过 atom 函数创建的, 传递一个初始值.
❷ swap! 接受一个 atom 实例和当前值的函数. 它返回新的更新后的值 (而不是 atom 实例). 在这种情况下, 函数是 inc, 但它可以是任何单参数函数.
❸ 我们可以随时使用与其他 Clojure 引用类型相同的模式从 atom 中读取值, 即使用 deref 或等效的读宏 @.
swap!
swap!是处理atom最灵活的选择. 它接受任意数量的额外参数以传递给更新函数, 使其成为更新集合的理想选择:(def m (atom {:a 1 :b {:c 2}})) ; ❶ (swap! m (fn [m] (update-in m [:b :c] (fn [x] (inc x))))) ; ❷ ;; {:a 1 :b {:c 3}} (swap! m update-in [:b :c] inc) ; ❸ ;; {:a 1 :b {:c 4}}
❶
atom"m" 包含一个深度嵌套的 Clojure 映射.❷ 这种形式使用显式函数来显示
update-in和inc的嵌套, 以将映射内的数字 2 更改为 3.❸ 像
swap!,update-in和inc这样的函数都遵循相同的语义: 它们接受一个从旧值到新值的函数, 并允许任意数量的额外参数. 前面的形式可以更简洁地写, 去掉匿名函数.如果传递给
swap!的更新函数包含副作用, 请注意swap!可能会执行该函数任意次数, 特别是在高并发场景中.reset!
如果对根据前一个值更改
atom不感兴趣, 我们可以使用reset!而不是swap!. 与swap!不同,reset!总是评估而无需重试. 如果许多线程试图执行reset!操作, 最后一个获得对atom访问权的线程获胜:(def configuration (atom {})) ; ❶ (defn initialize [] ; ❷ (reset! configuration (System/getenv))) (initialize) ; ❸ (take 3 (keys @configuration)) ;; ("JAVA_MAIN_CLASS_65503" "IRBRC" "PATH")
❶
configuration被设计为在初始化后包含环境变量的视图. 程序的其他部分可以随时更改配置, 但额外的初始化应该将atom重置为系统环境.❷
initialize可以移除配置atom的任何先前状态. 在这种情况下,reset!比swap!更合适, 因为reset!不会尝试和比较逻辑.❸ 调用
initialize后, 我们可以看到配置包含了系统环境的当前视图.一个
atom对象不一定是一个顶层变量.atom的一个典型用途是, 例如, "闭包" 状态在memoization中. 请参见memoize性能部分以查看atom在缓存重复计算中的作用.compare-and-set!
atom返回一个clojure.lang.Atom的实例, 它是java.util.concurrent.atomic.AtomicReference的一个包装对象. Java 的AtomicReference的主要目标是提供对现代硬件架构提供的低级 CAS (比较和交换) 实现的访问. 如果另一个线程在当前线程有机会做同样的事情之前更改了当前值, CAS 操作就会失败. 因此, 涉及 CAS 的典型使用模式是将更改逻辑放在一个无限循环中, 直到操作成功.swap!为我们执行这样的循环, 但如果我们想要对循环进行额外的控制 (例如, 在 3 次尝试后停止), 我们可以实现类似下面的swap-or-bail!:(defn swap-or-bail! [a f & [attempts]] ; ❶ (loop [i (or attempts 3)] (if (zero? i) (println "Could not update. Bailing out.") (let [old (deref a) success? (compare-and-set! a old (f old))] ; ❷ (when-not success? (println "Update failed. Retry" i) (recur (dec i))))))) (defn slow-inc [x] ; ❸ (Thread/sleep 5000) (inc x)) (def a (atom 0)) (def f (future (swap-or-bail! a slow-inc))) ; ❹ (reset! a 1) ; ❺ ;; "Update failed. Retry 3" (reset! a 2) ;; "Update failed. Retry 2" (reset! a 3) ;; "Update failed. Retry 1" ;; Could not update. Bailing out.
❶
swap-or-bail!的接口与swap!类似, 只是接受一个额外的 "attempts" 参数, 默认值为 3 (如果未给出).❷
(f old)在旧值上触发一个缓慢的更新函数. 如果在(f old)返回时,atom中的值发生了变化 (我们将在本例中创建这种情况), 那么compare-and-set!就会失败, 操作会重试.❸
slow-inc是一个故意缓慢的inc版本. 我们有 5 秒钟的时间来评估对atom的reset!调用, 以强制进行 CAS 重试.❹
swap-or-bail!在自己的线程中运行, 所以我们可以在它运行时自由地更改atom的内容. 为了在单独的线程中运行, 我们使用一个future.❺ 当每个
reset!操作在最后一次compare-and-set!尝试的 5 秒内发生时, 我们强制进行另一次尝试. 但在达到最大尝试次数后,swap-or-bail!会打印一条失败消息并退出.你应该避免用一个不是来自你试图更新的同一个
atom实例的值来调用compare-and-set!. 风险是会遇到由compare-and-set!使用的 Java 相等性语义决定的意外情况. 例如:(def a (atom 127)) (compare-and-set! a 127 128) ; ❶ ;; true (compare-and-set! a 127 128) ; ❷ ;; false (compare-and-set! a 128 129) ; ❸ ;; false
❶
compare-and-set!需要 3 个参数:atom实例, 一个比较值和期望的新值. 只有当比较值与atom的当前值相同时, 期望的值才会成为atom的新值.❷ 由于
atom被改变为包含 128, 第二个compare-and-set!操作失败, 因为比较值与当前值不匹配 (127 != 128).❸ 奇怪的是, 即使传递了正确的值 (128),
compare-and-set!仍然拒绝更新.compare-and-set!即使在旧值显然与提供的值相同时也拒绝更新atom的原因, 是因为 Java 的引用相等性 (Java 操作符==) 和 Clojure 的自动装箱. 从 -127 到 127 的Long值被缓存, 所以new Long(127) == new Long(127)是真的, 因为这两个数字实际上是同一个实例. 但new Long(128) == new Long(128)在 Java 中是假的, 因为这两个对象实际上是不同的实例 (因为没有隐式缓存). Clojure 将数值参数包装在一个新的java.lang.Long实例中, 导致了观察到的compare-and-set!行为.
4.1.6. 14.6 agent
本节还提到了其他相关函数, 如:
send,send-off,send-via,set-agent-send-executor!,set-agent-send-off-executor!,restart-agent,shutdown-agents,release-pending-sends,await,await-for,agent-error,set-error-handler!,error-handler,error-mode,set-error-mode!
agent 是一种并发感知结构, 它接受异步的, 非协调的和顺序的状态更改. 让我们展开这个密集的定义来了解更多:
- 异步:
agent在一个与调用者不同的线程中执行操作. 在这方面,agent类似于future(它们也共享同一个线程池). 与future不同,agent有一个内部状态. - 非协调: 像
atom一样,agent不能与另一个agent协调 (基于当前条件阻止另一个agent的状态更改), 但它们可以通过在提交前保持操作来参与 STM 事务. - 顺序: 发送给
agent的操作按接收顺序执行. 这使得agent成为处理有副作用操作的良好候选者.agent会处理排队的操作, 除非遇到错误条件. 待处理的工作可以在错误后恢复或被移除.agent也可以为自己或其他agent创建立即执行或在状态更改后执行的任务.
注意: agent 与 Erlang 的 actor 216 有一些相似之处. 然而, 有几个根本的区别: agent 不是分布式的, 它们接受任何函数 (不仅仅是预定义的消息集), 并且你可以在不向其发送消息的情况下随时访问 agent.
send
send向agent传递一个从当前值到新值的函数:(def a (agent 0)) ; ❶ (send a inc) ; ❷ (deref a) ; ❸ ;; 1 @(send a inc) ; ❹ ;; 1 (deref a) ; ❺ ;; 2
❶
agent创建一个带有初始值的新clojure.lang.Agent实例.❷
send向agent传递inc函数.❸ 我们可以用
deref或读宏@来检查agent的当前值.❹
send返回agent实例本身, 我们可能会立即尝试解引用它. 然而, 操作是异步运行的, 结果可能尚未更新.❺
inc是一个简单的操作, 所以我们可以在 REPL 中立即看到结果.await
如前例所示,
agent是异步的, 我们可能需要等待才能看到发送给它们的操作的结果. 如果我们想等待操作完成, 我们可以使用await:(def a (agent 10000)) ; ❶ (def b (agent 10000)) (defn slow-update [x] ; ❷ (Thread/sleep x) (inc x)) (send a slow-update) ; ❸ (send b slow-update) (time (await a b)) ; ❹ ;; "Elapsed time: 7664.066924 msecs" ;; nil
❶ 两个
agent包含一个等待的毫秒数.❷
slow-update在递增数字之前等待输入的毫秒数.❸
agent被发送了缓慢更新的操作. 正如预期的那样, 主线程不需要阻塞.❹ 然而, 如果我们想明确地等待所有发送给
agent的操作完成, 我们可以使用await. 请注意: 这里显示的耗时取决于在 REPL 中输入命令的速度. 评估越快, 耗时越接近 10 秒.await-for
await和await-for都接受任意数量的agent实例.await-for还接受一个超时, 以防agent返回时间过长:(send a slow-update) ; ❶ (time (await-for 2000 a)) ; ❷ ;; "Elapsed time: 2003.144351 msecs" ;; false
❶ 我们向其中一个
agent发送了另一个缓慢的更新操作.❷ 这一次,
await-for的调用在大约给定的超时毫秒数后返回, 而不是在 7/8 秒后返回. 注意, 如果由于超时而不是agent完成所有相关操作而返回,await-for也会返回 false.send-off
在前面的例子中, 一个
slow-update函数被发送给agent, 使一个线程可能长时间忙碌. 为了适应不同的工作负载,agent有两个默认选项可用:send在一个固定大小的线程池 (包含核心数 + 2 个线程) 上执行, 而send-off使用一个无界线程池. 使用哪一个取决于手头问题的具体情况. 较长的输入/输出操作通常会从send-off的无界池中受益, 而较短的 CPU 密集型操作更适合使用send. 然而, 如果不加以管理, 无界线程池可能会导致应用程序滞后或内存不足问题.- 控制线程池
send-via
如果预配置的线程池都不适合某个特定问题,
send-via允许使用自定义线程池. 对于较短的, CPU 密集型的任务, 一个不错的选择是 Java 8 217 引入的 ForkJoin 池:(import '[java.util.concurrent Executors]) (def fj-pool (Executors/newWorkStealingPool)) ; ❶ (defn send-fj [^clojure.lang.Agent a f & args] (apply send-via fj-pool a f args)) ; ❷ (def a (agent 1)) ; ❸ (send-fj a inc) (await a) @a
❶
java.util.concurrent.Executors类创建了一个新的WorkStealingPool, 我们可以保存下来以备后用.❷
send-fj提供了与send或send-off类似的接口, 用于向agent发送任务, 通过send-via使用新创建的池.❸
send-fj的用法与send或send-off相同.Clojure 还允许更改
send或send-off的线程池策略, 例如, 控制应用程序中的agent使用, 而无需更改所有调用点:(import '[java.util.concurrent Executors]) (def fj-pool (Executors/newWorkStealingPool 100)) ; ❶ (set-agent-send-executor! fj-pool) ; ❷ (set-agent-send-off-executor! fj-pool)
❶
fj-pool定义了一个WorkStealingPool, 它将尝试将并发工作线程的数量保持在 100 以下或等于 100 (这不一定反映在创建的线程数量上).❷ 从这一点开始,
send和send-off将使用新创建的线程池.*agent*动态变量
与
agent一起使用的一个有趣模式是内部递归的一种形式, 即agent向自身发送下一个操作. 这可以通过*agent*动态变量来实现, 该变量在更新函数的主体内部被设置为当前的agent实例:(def a (agent 10)) (send a #(do (println (identical? *agent* a)) (inc %))) ;; true ; ❶
❶ 我们可以看到, 在发送给
agent的更新函数内部,*agent*和 a 是同一个对象.使用
*agent*, 我们可以创建下面的 "ping"agent, 它执行一个对某个 URL 的请求, 只是为了验证它是否正确响应:(def a (agent {})) ; ❶ (defn ping [{:keys [enable url kill] :as m}] ; ❷ (when (and enable url) (try (slurp url) (println "alive!") (catch Exception e (println "dead!" (.getMessage e))))) (Thread/sleep 1000) (when-not kill (send-off *agent* ping)) ; ❸ m) (send-off a ping) ; ❹ (send-off a assoc :url "https://google.com") (send-off a assoc :enable true) ; ❺ ;; alive! ;; alive! ;; alive! (send-off a assoc :url "http://nowhere.nope") ; ❻ ;; dead! nowhere.nope ;; dead! nowhere.nope ;; dead! nowhere.nope (send-off a assoc :kill true) ; ❼
❶ 一个
agent用一个最初为空的状态映射初始化.❷
ping函数作为更新函数发送给atom. 它接受当前状态映射作为输入, 并在:url可用且:enable条件为真时, 打印关于目标可用性的消息. 除此之外,ping永远不会改变其内部状态, 并且总是返回agent的当前状态, 作为最后一行保持不变.❸ 注意,
ping函数在等待 1 秒后会send-off另一个请求来执行自己, 但只有当:kill键被设置为nil或 false 时. 一旦:kill键被设置为 true, 递归就停止了.❹ 第一个
send-off调用启动了内部agent递归, 但鉴于条件未满足,agent实际上并没有 ping 请求的网页.❺ 在所有条件都满足后, 我们终于可以看到来自内部循环的消息.
❻ 如果我们将目标页面更改为一个不存在的页面,
catch块会执行, 打印一条不同的消息.❼ 我们需要记住通过将
:kill键设置为 true 来关闭递归的agent.release-pending-sends
一个
agent操作可能导致以下任何一种 (或它们的组合):- 什么也没发生,
agent的状态保持不变. agent的状态改变.agent向自己分派另一个操作 (就像前面看到的ping函数).agent向其他agent分派一个或多个操作.
在更新函数内部有额外分派的情况下,
agent的默认行为是等待状态改变, 然后按顺序执行所有创建的操作. 但是, 如果这种等待是不可取的 (通常因为操作的执行顺序不重要), 我们可以用release-pending-sends强制所有待处理的操作立即开始. 在下面的例子中, 我们使用不同agent之间的协调来查找大型文本中的单词和字母频率. 当第一个agent忙于计算单词频率时, 我们可以为其他agent释放消息, 每个字母表中的字母一个:(require '[clojure.string :refer [split]]) (def alpha (mapv agent (repeat 26 0))) ; ❶ (def others (agent 0)) ; ❷ (def words (agent {})) ; ❸ (def war-and-peace "https://tinyurl.com/wandpeace") (def book (slurp war-and-peace)) (send-off words ; ❹ (fn [state] (doseq [letter book :let [l (Character/toLowerCase letter) idx (- (int l) (int \a))]] (send (get alpha idx others) inc)) (release-pending-sends) ; ❺ (merge-with + state (frequencies (split book #"\s+"))))) (apply await alpha) (map deref alpha) ; ❻ ;; (202719 34657 61621 118297 313572 ;; 54901 51327 167415 172257 2575 20432 ;; 96530 61648 184185 190083 45533 2331 ;; 148431 162897 226414 64400 27087 ;; 59209 4384 46236 2388)
❶
alpha是一个包含 26 个agent的向量, 字母表中的每个字母一个.❷ 我们还为任何不属于普通字母表的其他字母准备了
others.❸
"words"agent收集文本中所有单词的频率.❹ 处理从
send-off指令开始. 更新函数首先逐个字母处理书籍, 向每个相应的agent发送一个加一的请求. 第二部分用单词频率更新agent状态.❺ 创建频率是一个潜在的昂贵操作, 所以我们利用
release-pending-sends来开始处理字母频率, 即使当前agent的状态尚未更新.- 什么也没发生,
- 处理错误
当一个问题在不同的线程中发生时, 问题的根源通常会丢失, 除非采取特别的措施将问题提升到另一个控制线程的注意. 例如, 下面的
agent被赋予了将一个数除以零的不可能任务. 我们可以用agent-error来检查是否有问题:(def a (agent 2)) (send-off a #(/ % 0)) ; ❶ (agent-error a) ; ❷ ;; #error { ;; :cause "Divide by zero" ;; :via ;; [{:type java.lang.ArithmeticException ;; :message "Divide by zero" ;; :at [clojure.lang.Numbers divide "Numbers.java" 163]}] ;; ... ;; }
❶ 在故意生成一个
ArithmeticException之后,send-off调用不会报告问题, 因为它发生在不同的线程上.❷ 问题的根源被保存在
agent内部以供以后检查, 并在调用agent-error时可见. restart-agent
在
agent进入错误状态后, 它会停止处理更多的工作, 并且工作队列中的任何任务都会被暂停. 要重置agent的状态并恢复任何待处理的工作, 我们可以使用restart-agent(或者我们可以通过传递:clear-actions true来丢弃任何待处理的工作):(restart-agent a 2) ; ❶ (send-off a #(/ % 2)) ; ❷ @a (restart-agent a 2) ; ❸ ;; Execution error at user/eval339 (REPL:1). ;; Agent does not need a restart
❶
restart-agent移除任何错误条件, 并用作为参数传递的新状态替换当前状态.❷
agent现在准备好接受额外的工作.❸ 注意, 在一个没有错误条件的健康
agent上调用restart-agent会抛出异常.或者, 我们可以调用
set-error-handler!来指定一个接受两个参数的函数:agent实例和错误. 在发生错误的情况下,agent会调用错误处理器, 而不是进入错误状态:(def a (agent 2)) (defn handle-error [a e] (println "Error was" (.getMessage e)) (println "The agent has value" @a) (restart-agent a 2)) (set-error-handler! a handle-error) ; ❶ (send-off a #(/ % 0)) ;; Error was Divide by zero ; ❷ ;; The agent has value 2 @a ; ❸ ;; 2
❶
set-error-handler!允许在agent错误的情况下指定一个自定义的错误处理器.❷ 通过故意生成一个错误, 我们可以看到自定义消息出现.
❸ 自定义处理器也在错误后直接重置
agent状态, 所以处理可以立即恢复. 在现实世界中, 我们可以为可恢复的异常实现这样的行为, 对于更严重的错误, 让agent处于错误状态.如果所有错误条件都被认为是可恢复的, 并且我们总是可以接受在错误后恢复工作, 我们可以将
agent的:continue错误模式设置, 完全忽略问题 (并且不需要调用restart-agent):(def a (agent 2)) (set-error-mode! a :continue) ; ❶ (send-off a #(/ % 0)) ; ❷ @a ; ❸ ;; 2
❶
set-error-mode!更改agent处理错误的方式. 如果我们使用:continue(与默认的:fail模式相反),agent将简单地忽略任何错误.❷ 这个
send-off操作产生一个错误.agent不会进入失败状态, 也不会抛出错误.❸ 在产生错误的更新情况下, 状态不会改变.
最后, 如果运行中的
agent失控, 或者如果应用程序在执行后不能正常退出, 那么很可能一些agent线程仍然分配在线程池中 (浪费资源). 在那种情况下,shutdown-agents会对所有agent池执行一个优雅的关闭, 并从那时起阻止任何其他操作的执行.
4.1.7. 14.7 deref 和 realized?
deref 和 realized? 适用于本章中描述的许多引用类型. deref (及其相关的读宏 @) 在整本书中被广泛使用, 它也适用于不被视为引用的类型, 如 reduced. deref 还有一个支持超时的变体 (带有默认值), 用于那些可能导致阻塞调用的引用类型.
下表显示了所有支持 deref 的类型:
| 类型 | 示例 | 读宏 |
|---|---|---|
clojure.lang.Agent |
(deref (agent 0)) |
@(agent 0) |
clojure.lang.Atom |
(deref (atom 0)) |
@(atom 0) |
clojure.lang.Delay |
(deref (delay 0)) |
@(delay 0) |
clojure.lang.Reduced |
(deref (reduced 0)) |
@(reduced 0) |
clojure.lang.Ref |
(deref (ref 0)) |
@(ref 0) |
clojure.lang.Var |
(deref (def a 0)) |
@(def a 0) |
clojure.lang.Volatile |
(deref (volatile! 0)) |
@(volatile! 0) |
java.util.concurrent.Future |
(deref (future 0)) |
@(future 0) |
java.util.concurrent.Future |
(deref (promise)) (*) |
@(promise) |
deref 对表中的类型的工作方式类似, 但有一些区别:
- 当应用于
agent,var,volatile!或atom时, 它返回其当前状态. - 当应用于
delay时, 它也会强制其主体被评估, 除非它已经被评估: 在这种情况下, 它会立即返回缓存的值. - 当应用于事务中的
ref时, 它返回ref的事务内值. 在事务外时, 它返回最近提交的值. - 当应用于
future时, 调用可能会阻塞, 等待future完成其主体的评估. - 当应用于
promise时, 它会阻塞直到一个值被传递.
像
@(promise)这样的表达式会阻塞当前线程. 你应该始终将promise定义为一个独立的引用 (局部绑定或变量), 这样你就可以向它传递一个值, 例如:(let [p (promise)] (deliver p 0) @p). 或者, 使用支持超时的deref变体.
realized?
我们也可以使用
realized?来检查一个值是否可以从promise或future中获得. 与deref不同, 如果值不可用,realized?只会返回true或false而不会阻塞:(def p (promise)) ; ❶ (def f ; ❷ (future (loop [] (let [v (deref p 100 ::na)] (if (= ::na v) (recur) v))))) (realized? p) ; ❸ ;; false (realized? f) ;; false (deref f 100 ::not-delivered) ; ❹ ;; :user/not-delivered (deliver p ::finally) (deref f 100 ::not-delivered) ; ❺ ;; :user/finally (realized? p) ; ❻ ;; true (realized? f) ;; true
❶ 我们创建一个由变量 "p" 引用的
promise.❷ 我们还定义了一个包含一个 (潜在的无限) 循环的
future. 循环验证一个值是否已被传递到promise, 如果已传递, 它就返回该值. 我们不希望完全阻塞, 所以我们使用带有 100 毫秒超时的deref变体. 我们使用关键字::na("不可用") 作为后续条件的哨兵值.❸ 此时, "p" 和 "f" 都还没有实现.
❹
future仍在执行循环. 如果我们试图在没有超时的情况下对其调用deref, 主线程将会阻塞. 我们可以看到promise尚未被传递一个值.❺ 在向
promise传递一个值后, 我们重复对future的deref调用. 这次调用返回了传递的值.❻
realized?确认两个引用现在都已实现.realized?也适用于 Clojure 惰性序列, 以验证序列中的第一项是否已被评估 (并为以后使用而缓存):(def s1 (map inc (range 100))) ; ❶ (realized? s1) ; ❷ ;; false (first s1) ; ❸ ;; 1 (realized? s1) ; ❹ ;; true
❶
map(以及许多其他常见的顺序处理函数) 产生一个惰性序列.❷ 序列最初是未实现的, 正如在构造后立即对其调用
realized?所证明的那样.❸ 通过调用
first, 我们强制实现了序列中的第一个 (以及可能其他的) 元素.❹
realized?现在返回 true.
4.1.8. 14.8 set-validator! 和 get-validator
"Validation" 是为 var, atom, agent 和 ref 设计的一个特性, 用于防止不想要的状态更改. "validator" 是一个接受即将作为新引用状态持久化的新值的函数. 如果新状态不可接受, 验证器函数应返回 false 或抛出异常:
(def a (atom 1)) ; ❶ (set-validator! a pos?) ; ❷ (swap! a dec) ; ❸ ;; IllegalStateException Invalid reference state
❶ "a" 是一个初始化为值 1 的 atom.
❷ set-validator! 安装一个新的验证器, 验证新状态是一个正数.
❸ 请求更改状态以减少 atom 的当前值. 零不被验证器函数接受, 因为 (pos? 0) 返回 false.
如果我们想比泛泛的 IllegalStateException 更具体, 我们可以抛出一个更具描述性的错误:
(def a (atom 1)) (defn- should-be-positive [x] ; ❶ (if (pos? x) x (throw (ex-info (format "%s should be positive" x) {:valid? (pos? x) :value x :error "Should be a positive number" :action "State hasn't changed"})))) (set-validator! a should-be-positive) (swap! a dec) ; ❷ ;; ExceptionInfo 0 should be positive (try (swap! a dec) (catch Exception e (ex-data e))) ; ❸ ;; {:valid? false, ;; :value 0, ;; :error "Should be a positive number", ;; :action "State hasn't changed"}
❶ should-be-positive 是一个比单独的 pos? 更具描述性的验证器函数. 它不是只返回 false, 而是用 ex-info 抛出一个描述性的异常.
❷ 一个无效的操作现在解释了到底出了什么问题.
❸ 如果我们想了解更多细节, 我们可以捕获异常并用 ex-data 提取描述性的错误映射.
get-validator 检索验证器函数, 如果设置了的话:
(def a 1) (get-validator #'a) ; ❶ (set-validator! #'a pos?) (-> (get-validator #'a) ; ❷ class .getSimpleName clojure.repl/demunge symbol) ;; core/pos? (def a 0) ; ❸ ;; IllegalStateException Invalid reference state
❶ var 对象也接受验证函数. 我们需要记住使用 var 函数或等效的读宏 #' 来访问 var 对象.
❷ 在将 pos? 函数设置为验证器后, 我们可以从 get-validator 返回的函数对象中获取其名称. 除了使用 clojure.repl/demunge 将类名格式化回可读形式外, 没有其他方法可以从其编译的类中检索函数的名称.
❸ var "a" 现在是一个全局对象, 尝试重新定义它现在受到现有验证器的控制. 要移除一个验证器, 使用带 nil 的 set-validator!.
如果在安装新验证器函数时, 引用的当前状态已经违反了验证器约束,
set-validator!将会失败. 例如: 给定(def a (atom 0)), 那么(set-validator! a pos?)会抛出异常, 并且验证器不会被安装.
验证器函数也可以在引用创建时被接受 (除了 var). 我们可以使用验证器来防止在下面的银行转账模拟中账户透支:
(def account-1 (ref 1000 :validator pos?)) ; ❶ (def account-2 (ref 500 :validator pos?)) (defn transfer [amount a1 a2] ; ❷ (dosync (alter a1 - amount) (alter a2 + amount)) {:account-1 @a1 :account-2 @a2}) (transfer 1300 account-1 account-2) ; ❸ ;; IllegalStateException Invalid reference state
❶ 每个账户都由一个 ref 对象表示. 每个 ref 都安装了一个验证器, 防止账户余额变为 0 或以下.
❷ transfer 函数在一个 dosync 块内将钱从一个账户转移到另一个账户.
❸ 尝试转移比实际可用金额更多的钱会导致 IllegalStateException.
4.1.9. 14.9 add-watch 和 remove-watch
观察者, 类似于验证器, 在状态更改时被调用, 以发出引用状态即将改变的信号. 与验证器不同, 观察者不能阻止状态转换的发生, 但它们可以采取其他类型的操作. 可以用 add-watch 设置一个或多个观察者:
(def account-1 (ref 1000 :validator pos?)); ❶ (def account-2 (ref 500 :validator pos?)) (defn- to-monthly-statement [k r old new] ; ❷ (let [direction (if (< old new) "[OUT]" "[IN]")] (spit (str "/tmp/statement." k) (format "%s: %s$\n" direction (Math/abs (- old new))) :append true))) (add-watch account-1 "acc1" to-monthly-statement) ; ❸ (add-watch account-2 "acc2" to-monthly-statement) (transfer 300 account-1 account-2) ; ❹ (transfer 500 account-2 account-1) (println (slurp "/tmp/statement.acc1")) ; ❺ ;; [IN]: 300$ ;; [OUT]: 500$ (println (slurp "/tmp/statement.acc2")) ;; [OUT]: 300$ ;; [IN]: 500$
❶ account-1 和 account-2 是用一个防止它们透支的验证器函数创建的 ref.
❷ 此外, 我们希望账户在每次有资金进出时都向一个月度账单文件发送转账信息.
❸ 月度账单跟踪器被安装为每个引用对象的观察者.
❹ transfer 是与前面关于验证器的例子中使用的相同函数. 该函数从源账户中减去总和, 并在一个事务中将其移动到目标账户.
❺ 我们可以打印账单文件的内容来验证账户的提款和存款.
观察者同步执行, 并且只在新的引用状态被设置后执行, 将正确的状态处理与观察者调用中发生的任何问题隔离开来. 多个观察者以未指定的顺序被调用:
(def multi-watch (atom 0)) (dotimes [i 10] ; ❶ (add-watch multi-watch i (fn [k r o n] (print k ",")))) (swap! multi-watch inc) ; ❷ ;; 0 ,7 ,1 ,4 ,6 ,3 ,2 ,9 ,5 ,8 ,1
❶ 有 10 个键范围从 0 到 9 的观察者被添加到一个 atom 实例中.
❷ 调用 swap! 后, 每个观察者打印自己的键. 观察者被调用的顺序是未指定的 (就像 hash-map 的键以无特定顺序返回一样). 注意: 列表中的最后一个 "1" 是 swap! 调用的返回值.
如果一个观察者对于一个特定的场景不再有用, 可以用 remove-watch 来移除它:
(dotimes [i 10] ; ❶ (remove-watch multi-watch i)) (swap! multi-watch inc) ; ❷ ;; 2
❶ 参考前面的例子, 我们对所有 10 个键调用 remove-watch.
❷ 下一次调用 swap! 来改变状态时, 只会打印 atom 的新值.
4.1.10. 14.10 locking, monitor-enter 和 monitor-exit
locking 是 Clojure 中与 Java 的 synchronize 关键字等效的结构. locking 在一段代码的关键部分和一个 "锁" 对象 (任何对象都可以, 只要它只用于保护该关键部分) 之间建立一种关系. 在运行时, 一个线程在执行关键部分之前必须独占地 "获取" 锁. 如果锁已经被另一个线程获取, 当前线程需要等待直到它再次可用. 下面是一个基于可变的 volatile! 的银行转账例子的版本. 由于我们不使用并发感知的引用, 我们需要显式锁定来防止不可预测的结果:
(def lock (Object.)) ; ❶ (def acc1 (volatile! 1000)) ; ❷ (def acc2 (volatile! 300)) (defn transfer [sum orig dest] (locking lock ; ❸ (let [balance (- @orig sum)] (when (pos? balance) (vreset! orig balance) (vreset! dest (+ @dest sum))))) [@orig @dest]) (dotimes [_ 1500] ; ❹ (future (transfer 1 acc1 acc2))) [@acc1 @acc2] ; ❺ ;; [1 1299]
❶ "lock" Object 仅用于同步 transfer 函数中的关键部分. 我们可以使用任何新的对象引用, 但创建一个新的 java.lang.Object 是最自然的选择.
❷ volatile! 是一个可变对象, 它不实现任何防止并发访问的保护, 迫使我们使用某种形式的显式锁定.
❸ 通过 locking, 我们防止另一个线程在当前线程可以自由检查是否有足够的钱可以移动时更改账户的内容.
❹ 该示例故意创建了比实际可用金额多得多的并发转账请求.
❺ 我们的假设是, 在所有转账尝试结束时, 第一个账户中应该总是有 "1", 第二个账户中有 "1299".
如果你尝试从上面的例子中移除锁定保护, 你会看到第二个账户被记入了比预期多得多的钱, 好像它们是从无中生有的一样. 这就是为什么用锁定来保护代码的关键部分如此重要.
Clojure 的主要并发方法是通过引用类型 (如 atom 或 agent), 但在需要显式锁定时, 锁定被作为最后的手段. 显式锁定可能难以实现和调试, 所以不应该滥用锁定, 并且只应在与预先存在的 Java 对象的一些罕见的互操作性场景中出现.
"线程竞争" 通常指许多线程试图访问同一个受锁保护的代码部分的情况, 尽管竞争也可能发生在其他竞争资源上, 不仅仅是锁.
monitor-enter 和 monitor-exit 是更低级的原语, 它们更没有理由被显式使用. 它们是直接转换为相应的 Java 字节码的特殊形式, 标记了应受锁保护的关键部分:
(def v (volatile! 0)) (def lock (Object.)) (try (monitor-enter lock) ; ❶ (vswap! v inc) (finally (monitor-exit lock))) ; ❷ ;; 1
❶ monitor-enter 标记了应受并发访问保护的关键部分的开始.
❷ 如果我们未能释放锁 (例如, 因为在更新 volatile 时抛出了异常), 其他线程将不被允许执行该代码.
释放锁是至关重要的, 这也是优先选择 locking 的主要原因之一, 它确保关键部分总是后跟一个 finally 块, 该块会退出监视器. 按照它们目前的实现方式, monitor-enter 和 monitor-exit 没有强烈的理由被显式地用来替代 locking 宏. 一种场景可能是允许从不同的函数执行进入/退出操作, 但这目前是不可能的 218. 读者应该查阅 Java 文档中关于 ReentrantLock 的文档以获取替代选项.
4.1.11. 14.11 总结
Clojure 处理并发的方式自首次发布以来一直是其主要卖点之一. Clojure 的引用受到了 Standard ML 中引用模型的启发, 其中引用意味着访问一个值的某种语义 219. Clojure 通过添加并发语义将 ML 的引用提升到了一个新的水平. 有四种主要的并发原语: var, ref, atom 和 agent. 本章还阐述了处理 Java 线程和 future 的函数.
4.2. 15 类型, 类, 层次结构和多态
下一节探讨专门用于管理或生成新类型的函数.
第一组函数主要专用于与 Java 类型系统的互操作性. 这些函数允许与 Java 类型和接口进行紧密集成, 例如提供框架扩展, 类继承, 访问超类等.
第二组函数实现了 Clojure 对 "面向对象" 的观点. Clojure 对面向对象编程的立场与经典的 Java 至少在两个重要方面有所不同: 它不允许具体的继承, 并且它将继承与接口声明分开. 后者通常被称为 "点菜式多态" 220.
本章以一组专门用于检查, 转换或创建 Clojure 核心类型的函数开始. 然后转向更结构化和自定义的类型, 从更接近 Java 语义的函数开始, 逐步上升到表达 Clojure 多态方法的函数:
gen-class生成一个新的 Java 类, 其方法委托给由周围命名空间托管的函数实现. 它支持一组丰富的选项来指定应如何生成该类, 包括实现的接口和扩展的类.gen-interface使用与gen-class类似的机制生成一个新接口.deftype生成一个新类, 它还支持字段 (可变的或不可变的).definterface使用与deftype相同的语义生成一个接口, 但在gen-interface之上实现.proxy创建一个匿名类, 旨在通过其唯一的实例在程序生命周期内使用. 它可以扩展其他类并覆盖受保护的方法. 它支持闭包 (它捕获周围的局部绑定).reify与proxy类似, 但仅限于实现接口. 在大多数情况下, 它也比proxy快.defrecord是一个宏, 它创建一个基于deftype的新对象, 并通过类映射接口启用对字段的访问.defprotocol建立在gen-interface之上以创建一个新接口, 但与defrecord结合使用, 以独立于 Java 建立对函数的动态分派.
- 访问类型
每个 Clojure 对象都有一个相关的 Java 类型. 类型名称通常由一系列嵌套的命名空间 (基于 Java 包) 组成, 用点分隔, 然后是类型的名称. 我们可以使用函数
type或class来访问一个对象的类型:(class []) ; ❶ ;; clojure.lang.PersistentVector (class "") ; ❷ ;; java.lang.String (class #()) ; ❸ ;; user$eval25$fn__26 (class nil) ; ❹ ;; nil (type {:a 1}) ; ❺ ;; clojure.lang.PersistentArrayMap (type (with-meta {:a 1} {:type :custom})) ; ❻ ;; :custom
❶
[]是 Clojure 定义的一种类型. 该名称具有与 Java 中任何其他类相同的典型格式.❷ "" 字符串类型直接从 Java 借用, 与 Java 类型的类型完全相同.
❸
#()匿名类在每次评估时都会生成一个新的 Java 类. 打印的类名显示以下信息: 类名是 "user$eval25$fn\_26", 它被分配了评估 id "25", 并作为 id 为 "26" 的 "fn" 表达式生成. 增量数字和名称规则在类型的进一步显式使用中不被使用, 因此读者应将它们视为实现细节.❹
nil没有与之关联的类. 如果是这样, 那么就会有nil类型的实例. 但这会导致矛盾, 因为nil按定义是对象的缺失.❺ 我们也可以使用
type函数来检索一个类的类型.❻ 在这个例子中, 我们可以看到
type和class之间的区别: 如果对象的元数据中有可用的:type键,type将使用该键.
4.2.1. 15.1 symbol 和 keyword
本节还提到了其他相关函数, 如:
name和find-keyword.
Clojure 从 Java 借用了许多基本类型. 例如, 字符串, 数字, 字符和布尔值在两种语言中共享相同的实现. clojure.lang.Symbol 和 clojure.lang.Keyword 是 Clojure 特有的, 像 symbol 和 keyword 这样的函数创建了相应的新实例:
(symbol "s") ; ❶ ;; s (keyword "k") ; ❷ ;; :k
❶ 使用 symbol 函数创建一个新符号 "s".
❷ 使用 keyword 函数创建一个简单的关键字 ":k".
符号在打印时类似于没有双引号的字符串. 符号在以下方面也与字符串不同:
- 它可以进一步用命名空间限定. 符号的命名空间部分在其名称之前, 后面跟着 "/" . 例如:
a/b是命名空间 "a" 中的符号 "b". - 它支持元数据.
- 它可以作为函数来在映射中查找自己.
- 尽管符号允许空格或标点符号, 但它们通常不这样使用, 因为它们不代表通用文本.
使用
symbol或keyword函数可以绕过在使用它们各自的常量字面量时发生的一些验证检查. 有关有效符号和关键字的规则, 请参考 Clojure 参考指南 clojure.org/reference/reader.
符号在 Clojure 中被广泛用于别名 var 对象, 局部绑定或函数参数. 如果一个符号出现在表达式中, Clojure 会尝试在当前命名空间或周围作用域中查找该符号:
first ; ❶ ;; #object[clojure.core$first__4339] (let [a 1] (inc a)) ; ❷ ;; 2
❶ 符号 "first" 解析为 "user" 命名空间中的一个值. 这个值是对 clojure.core/first 函数的引用.
❷ 符号 "a" 的第一次出现被 let 用来定义一个局部绑定. 第二次出现时, Clojure 在局部上下文中查找它, 如果找不到, 则在当前命名空间中查找. 在这种情况下, "a" 在局部上下文中被找到.
符号在读取 Clojure 代码后也会出现, 这是它们存在的主要原因之一. 没有这种区分, 我们将无法区分属于程序的文本和代表数据的文本. 宏评估也出于类似原因产生符号: 宏是一个在读取 "文本" 之后但在实际评估之前执行的函数:
(def form (read-string "(a b)")) ; ❶ (map type form) ; ❷ ;; (clojure.lang.Symbol clojure.lang.Symbol) (defmacro reading-symbols [& symbols] ; ❸ `(map type '~symbols)) (reading-symbols a b) ; ❹ ;; (clojure.lang.Symbol clojure.lang.Symbol)
❶ read-string 接受一个 Clojure 文本的字符串, 并将其转换为代码.
❷ 在输入字符串中以文本形式出现的东西, 一旦文本被解释为代码, 就变成了符号.
❸ 宏是一个特殊的函数, 它在读取时评估, 就在读取器完成将字符串转换为 Clojure 数据结构之后.
❹ 未评估的形式对宏来说显示为一个符号列表.
符号或关键字名称中存在正斜杠 "/" 会将它们分配给一个特定的命名空间. 要访问限定的 221 符号的不同部分, 我们使用函数 name 和 namespace:
(def ax (symbol "a/x")) ; ❶ (def bx (symbol "b/x")) [(name ax) (name bx)] ; ❷ ;; ["x" "x"] (= ax bx) ; ❸ ;; false [(namespace ax) (namespace bx)] ; ❹ ;; ["a" "b"]
❶ 符号名称中存在 "/" 会在符号和命名空间对象之间创建一个链接.
❷ 命名空间限定在相等性中起作用: 这里名为 "x" 的符号在 2 个不同的命名空间中定义. 要查看符号的名称, 我们需要使用 name 函数.
❸ 即使 2 个符号有相同的名称, 它们也不相等.
❹ 它们不相等的原因是它们的命名空间组件不同.
将符号或关键字分配给命名空间的等效方法是使用它们的双参数构造函数:
(def ax (symbol "a" "x")) ; ❶ (def bx (keyword "b" "x")) [(namespace ax) (namespace bx)] ; ❷ ;; ["a" "b"]
❶ 这个例子产生与前一个等效的结果. 符号或关键字名称的命名空间部分也可以使用双参数构造函数的第一个参数来分配.
❷ 我们可以看到符号和关键字属于预期的命名空间.
从表面上看, 符号和关键字是相似的. 它们都帮助命名语言的元素, 而不是表示某种文本. 但关键字额外实现了一种称为 "驻留" 的缓存形式. 一旦创建了一个关键字, 对象实例就会被缓存和重用:
(identical? (symbol "a") (symbol "a")) ; ❶ ;; false (identical? (keyword "a") (keyword "a")) ; ❷ ;; true
❶ 两次使用相同字母 "a" 调用 symbol 会产生不同的对象.
❷ 驻留的效果在关键字上是可见的.
关键字的内部缓存在 Clojure 中特别有用, 因为它们通常用作映射中的键. 由于驻留, 如果一个应用程序主要处理映射, 使用关键字作为键会产生更小的内存占用. 如果关键字驻留对内存更好, 那么在速度方面它会稍慢一些:
(require '[criterium.core :refer [quick-bench]]) (quick-bench (symbol "a")) ; ❶ ;; Execution time mean : 3.663330 ns (quick-bench (keyword "a")) ; ❷ ;; Execution time mean : 11.791798 ns
❶ 我们比较创建符号和关键字的成本. symbol 在产生新对象方面更快, 但为同一个符号 "a" 分配了不同的对象.
❷ keyword 较慢, 但由于驻留, 它创建了关键字 :a 的单个实例.
速度差异与缓存机制的额外成本有关. 如果你需要检查一个关键字是否已经被缓存, 你可以使用 find-keyword:
(find-keyword "never-created") ; ❶ ;; nil (find-keyword "doc") ; ❷ ;; :doc
❶ 当 find-keyword 返回 nil 时, 该关键字从未被创建过.
❷ 关键字 :doc 在标准库中用于为函数添加文档.
4.2.2. 15.2 类型检查和强制转换
Clojure 包含一长串专门用于检查或转换类型的函数. 我们可以将这些函数分组如下:
- 获取或验证对象的类:
type,instance?,class - 类型强制转换:
cast,unchecked-byte,byte,unchecked-char,char,unchecked-double,double,unchecked-float,float,unchecked-int,int,unchecked-long,long,unchecked-short,short,boolean,bigint,biginteger,bigdec,rationalize,name,keyword和num - 类型检查:
byte?,char?,double?,float?,long?,short?,some?,nil?,string?,decimal?,integer?,number?,ratio?,rational?,class?,fn?,ifn?,map-entry?,map?,list?,set?,vector?,record?,seq?,coll?,sequential?,associative?,sorted?,counted?,var?,keyword?
type,instance?和class
我们可以使用
type或class来获取一个对象的类型. 与class不同,type首先检查对象的元数据中是否有:type标签:(let [add-meta (with-meta [1 2 3] {:type "MyVector"}) ; ❶ no-meta [1 2 3]] [(type add-meta) (class add-meta) (type no-meta)]) ; ❷ ;; ["MyVector" clojure.lang.PersistentVector clojure.lang.PersistentVector]
❶
add-meta是一个在元数据中有:type键的向量.no-meta是没有元数据的相同向量.❷ 我们可以看到
type首先验证:type键的存在, 并在没有键的情况下回退到类名.我们可以使用带有
:type元数据的映射来构建一种简单的多态形式. 例如, 一个 "contact" 可以是个人或企业, 我们希望以不同的方式打印它们:(defn make-type [obj t] ; ❶ (vary-meta obj assoc :type t)) (def person (make-type {:name "John" :title "Mr"} :person)) ; ❷ (def manning (make-type {:name "Manning" :owner "Marjan"} :business)) (defn print-contact [contact] ; ❸ (condp = (type contact) :person (println (:title contact) (:name contact)) :business (println (:name contact) (str "(" (:owner contact) ")")) String (println "Contact:" contact) (println "Unknown format."))) (print-contact person) ; ❹ ;; Mr John (print-contact manning) ;; Manning (Marjan) (print-contact "Mr. Renzo") ; ❺ ;; Contact: Mr. Renzo (print-contact nil) ;; Unknown format.
❶
make-type更改一个传入的对象, 向元数据映射中添加:type键. 如果我们想保持任何现有的元数据不变,vary-meta是完美的选择.❷ 我们可以看到一个个人和一个企业的定义. 这两个映射在键的数量和类型上有所不同. 它们的元数据包含一个值为
:person和:business的:type键.❸
print-contact接受一个联系人, 并根据类型以不同的方式打印它.condp("cond" 与 "p"-谓词) 在类型之上创建一个条件. 正如你所看到的, 我们不需要显式访问元数据.❹ 每个联系人都根据其类型以不同的方式打印.
❺ 当没有
:type元数据时,type也适用于类类型.前面的例子对于少量且固定的类型工作得很好. 如果类型频繁且大量地添加, Clojure 提供了一种基于多重方法的更好的解决方案. 通过多重方法, 类型可以增量地添加到应用程序中, 而无需触及现有代码. 我们将在相关部分详细研究多重方法的细节, 下面只是一个基本示例:
(defmulti print-contact type) ; ❶ (defmethod print-contact :person ; ❷ [contact] (println (:title contact) (:name contact))) (defmethod print-contact :business [contact] (println (:name contact) (str "(" (:owner contact) ")"))) (defmethod print-contact String [contact] (println "Contact:" contact)) (defmethod print-contact :default [contact] (println "Unknown format.")) (print-contact person) ; ❸ ;; Mr John (print-contact manning) ;; Manning (Marjan) (print-contact "Mr. Renzo") ;; Contact: Mr. Renzo (print-contact nil) ;; Unknown format.
❶
type是多重方法print-contact的分派函数.❷ 我们现在将先前在
condp中的每个条件提取到其自己的defmethod声明中. 我们可以在应用程序的生命周期中稍后添加更多的defmethod, 而无需触及现有代码: 分派机制会负责将调用路由到正确的defmethod.❸ 我们可以看到打印前面例子中定义的联系人会得到相同的输出.
- 类型命名规则
类型名称必须符合 Java 语言规范 222. Java 影响的最明显效果之一是, Clojure 习惯的破折号 "-" 需要被下划线 "_" 替换 (以及在规范中可以找到的与包名相关的其他限制). 例如:
(in-ns 'my-package) ; ❶ (clojure.core/refer-clojure) ; ❷ (type (fn q? [])) ; ❸ ;; my_package$eval1777$q_QMARK___1778
❶ 我们定义并设置 "my-package" 为当前命名空间名称.
❷ 在移动到新的命名空间时, Clojure 不会自动包含标准库中的所有函数. 为此, 我们可以
refer-clojure.❸ 我们创建一个新的命名函数 "q?". "?" 和 "-" 都不允许在包名中使用 (只留下少数其他可能的分隔符, 如 "$"). Clojure 将 "?" 转换为 "QMARK".
instance?返回真, 如果一个对象是特定类或接口的 "实例", 遵循 Java 继承规则:(instance? java.lang.Number (bigint 1)) ; ❶ ;; true (instance? java.lang.Comparable 1) ; ❷ ;; true
❶
bigint是 Clojure 中可用的表示无限精度整数的类型之一.java.lang.Number是所有数字 (在 Java 和 Clojure 中) 的基础抽象类.❷
java.lang.Comparable是一个接口. 像java.lang.Long这样的引用类型数字 (以及许多其他对象) 是可比较的.在生产使用中,
instance?应该谨慎出现. 当一些instance?调用累积在一个级联的 "if-then-else" 或一个cond表达式中时, 可能就该考虑一些更灵活的东西了, 比如协议. 多重方法也是一个选项, 但协议是专门为高效处理类型分派而设计的.
4.2.3. 15.3 gen-class 和 gen-interface
gen-class 和 gen-interface 是专门用于生成 Java 类或接口的宏. 特别是 gen-class, 是与 compile 223 一起用于 AOT (Ahead Of Time) 编译的基本工具. 生成的类可以以几种方式使用:
- 在文件系统上提供一个类的物理存在 (以便 Java 可以加载和使用它).
- 提供一个接口或类以便从 Java 扩展.
- 提供一个 "main" 方法以使用 Java 工具从命令行运行 Clojure 应用程序.
- 扩展, 访问或使用现有的 Java 类.
gen-interface 支持几个键值参数 (:name 用于指定接口名称, :extends 用于指定要实现的其他接口, :methods 用于指定方法签名), 并返回新生成的类:
(gen-interface :name "user.BookInterface" ; ❶ :extends [java.io.Serializable]) ; ❷ (ancestors user.BookInterface) ; ❸ ;; #{java.io.Serializable} (reify user.BookInterface ; ❹ Object (toString [_] "A marker interface for books.")) ;; #object[user$eval20 0x2e "A marker interface for books."]
❶ 我们请求在 "user" 包中生成一个名为 BookInterface 的接口.
❷ 该接口可以扩展另一个接口 (以及可选的更多接口).
❸ 我们可以用 ancestors 检查新创建的类.
❹ 该接口现在可以使用了, 例如, 用 reify 创建一个实现它的对象实例.
现在让我们看看 gen-class. 由 gen-class 生成的类不是设计为直接调用的, 而是与包含相关方法实现的 Clojure 命名空间协同工作. gen-class 的工作方式不像一个普通的函数或宏. 例如, 如果你直接调用 gen-class, 就没有输出或副作用:
(gen-class 'testgenclass) ; ❶ ;; nil
❶ 直接调用 gen-class 不会产生任何明显的效果, 无论是内存, 文件系统还是错误.
如果我们查看 gen-class 的实现, 我们可以看到 gen-class 在做任何工作之前会检查动态变量 *compile-files* 是否被设置为 true. 但如果我们再试一次, 即使绑定了该变量也不会产生任何可见的效果:
(binding [*compile-files* true] (gen-class 'testgenclass)) ; ❶
❶ 再次尝试生成类, 设置了 *compile-files*, 但没有产生任何明显的效果.
我们无法生成一个类的原因在于 gen-class 是一个在 Clojure 运行时引导时评估的宏. 例如, 如果我们从 REPL 启动 Clojure, *compile-files* 被设置为 false. `gen-class` 的评估会捕获 `*compile-files*` 的 false 值, 从那时起, 它将忽略任何调用. 只有当我们从不同于当前 REPL 的上下文中执行评估时, 我们才能看到 gen-class 的作用. 我们可以通过在一个包含 gen-class 声明的文件上调用 compile 来达到这个效果:
(spit (str *compile-path* "/bookgenclass.clj") ; ❶ "(ns bookgenclass) (gen-class :name book.GenClass :main true)") ; ❷ (compile 'bookgenclass) ; ❸ ;; bookgenclass
❶ 我们使用 spit 创建一个 Clojure 文件. 这个简单的文件包含一个命名空间声明和一个 gen-class 指令. 该文件创建在当前类路径的根目录下, 如 *compile-path* 所示. 注意, 文件名需要与命名空间的名称相对应 (并添加扩展名 ".clj").
❷ 通过使用 :name, 我们确保生成的类具有特定的包和名称. :main true 启用了一个 public static void main[] Java 方法的生成.
❸ compile 在运行的 JVM 的类路径内搜索文件. 如果一切按预期进行, 它应该会看到新创建的类的名称.
如果我们检查位于 *compile-path* 的文件夹 (例如, 这可能是 "target/classes" 或根据你的系统而定的不同文件夹), 我们可以看到一些由 Clojure 生成的以 "bookgenclass" 开头的类, 包括一个新的文件夹 "compile-path/book/GenClass.class". 我们现在可以在 GenClass 上调用生成的 main 方法:
(import 'book.GenClass) ; ❶ ;; book.GenClass (GenClass/main (make-array String 0)) ; ❷ ;; UnsupportedOperationException bookgenclass/-main not defined
❶ 我们导入了前一步中由 compile 生成的类.
❷ 注意, 异常指向 bookgenclass 命名空间中缺少一个 bookgenclass/-main 函数.
一旦我们尝试在新生成的 book.GenClass 类上调用定义的方法, 我们可以看到该类假定在 bookgenclass 命名空间 (之前写入磁盘的那个) 中存在函数 -main. 注意添加的前缀 "-", 这是一个默认值, 可以更改. 我们可以提供缺少的函数来证明生成的类和命名空间之间的联系:
(spit (str *compile-path* "/bookgenclass.clj") "(ns bookgenclass) (gen-class :name book.GenClass :main true) (defn -main [& args] ; ❶ (println \"Hello from Java!\"))") (compile 'bookgenclass) ; ❷ (GenClass/main (make-array String 0)) ; ❸ ;; Hello from Java!
❶ 与前面的例子相比, 我们添加了一个名为 "-main" 的新函数, 它接受可变数量的参数.
❷ 磁盘上的相关类需要再次生成. 前一个版本会自动被覆盖.
❸ 如果我们再次尝试调用静态的 GenClass/main 方法, 我们可以看到生成的类正确地在命名空间中查找 -main 函数.
如果命名空间的存在只是为了包含一个 gen-class 或 gen-interface 声明, 那么还有一个选项是将该指令直接嵌入到 ns 中. 请注意, 下面的命名空间需要写入磁盘并作为 Clojure 类路径的一部分加载, 以强制在文件系统上生成一个 book.GenClass2 类 (或者你可以像之前演示的那样使用 spit):
(ns bookgenclass2 (:gen-class :name book.GenClass2)) ; ❶ (defn -main [& args] ; ❷ (println "More greetings from Java!"))
❶ 嵌入的 :gen-class 键产生的效果与前面孤立的 gen-class 调用相同, 不同之处在于 main 函数现在是默认生成的 (不需要 :main true).
❷ 生成的类将调用这个特别设计的 -main 函数.
gen-class 接受一长串参数来影响类的生成, 涵盖了最复杂的互操作性场景 224. 丰富的功能集需要一些时间才能熟练使用. 此外, 还有更简单的替代方案, 如 proxy 或 reify, 涵盖了最常见的场景. 因此, gen-class 主要用作在其他选项失败时的低级工具. 一个例外是为 Clojure 应用程序生成主入口点, gen-class 在这方面被广泛使用.
4.2.4. 15.4 deftype 和 definterface
deftype 和 definterface 是用于生成 Java 类或接口的低级构造. 与 gen-class 相比, deftype 允许为生成的 Java 类声明属性. 另一个区别是 deftype 支持 (但不要求) AOT 编译. 例如, 以下是二维空间中的一个 Point 类型:
(deftype Point [x y]) ; ❶ (def p (new Point 1 2)) ; ❷ (def p (Point. 1 2)) (def p (->Point 1 2)) (.x p) ; ❸ ;; 1 (.-x p) ;; 1 (. p y) ;; 2
❶ deftype 需要一个属性向量. 在这种情况下, 生成的类包含两个属性 "x" 和 "y". 注意, 你可以轻松地重新定义 Point, 因为新的定义会替换旧的定义.
❷ 有几种方法可以创建新生成的类的实例. 我们在这里可以看到几个等效的选项. new 是一个特殊形式, 会导致调用相关的构造函数. 在类名后附加一个点是调用 new 操作符的更短形式. 最后一种使用箭头 "→" 的形式是由 deftype 生成的, 并立即传达了 Point 是由一个 deftype 调用生成的事实.
❸ 一旦创建了一个实例, 我们可以使用 Java 互操作性和 "." (点) 宏来访问属性. 同样, 有多种选项: 在同时存在 "x" 属性和 "x" 方法的情况下, 第二种形式 .-x 唯一地标识了属性调用. 最后一种形式 (其中 "." 与其余部分分离) 是最基本的形式, 它强调调用的接收者而不是发送者.
在属性声明之后, deftype 接受一个或多个接口声明, 后面跟着相关函数的实现. 例如, 我们可以根据点与二维平面原点的距离来比较点:
(defn- distance [x1 y1 x2 y2] ; ❶ (Math/sqrt (+ (Math/pow (- x1 x2) 2) (Math/pow (- y1 y2) 2)))) (deftype Point [x y] Comparable (compareTo [p1 p2] ; ❷ (compare (distance (.x p1) (.y p1) 0 0) (distance (.x p2) (.y p2) 0 0)))) (sort [(->Point 5 2) (->Point 2 4) (->Point 3 1)]) ; ❸ ;; (#object[user.Point 0x30fd77bf "user.Point@30fd77bf"] ;; #object[user.Point 0x1d81121b "user.Point@1d81121b"] ;; #object[user.Point 0x59dd184c "user.Point@59dd184c"])
❶ 两点之间的欧几里得距离是连接它们的直线的长度.
❷ 我们定义一个 Point, 其中包含一个 java.lang.Comparable 接口的声明. 这个接口需要一个 compareTo 方法, 它接受当前的 Point 实例和另一个点. 该函数计算当前 Point 与原点之间的距离, 然后是另一个 Point 与原点之间的距离.
❸ 当我们在一个点集合上调用 sort 时, 它们会按与原点距离的递增顺序返回. 然而, 该类型仍然缺少如何打印自身的指令.
读者可能已经能看到接下来我们应该做什么, 以便以一种能显示其坐标的方式打印一个点. 例如, 我们可以覆盖 Object 类的 toString:
(deftype Point [x y] Object (toString [this] ; ❶ (format "[%s,%s]" x y))) (Point. 1 2) ; ❷ ;; #object[user.Point 0x65f02188 "[1,2]"]
❶ 这个 deftype 声明展示了如何覆盖 Object 类的 toString. 你可以看到, 在实现的方法内部访问声明的字段时, 不需要互操作性 ("x" 和 "y" 在没有引用 "this" 的情况下使用).
❷ 我们可以看到 Point 的坐标作为对象签名的一部分被打印出来.
java.lang.Object是deftype接受的唯一不是接口的类.
如果我们用一个 toString 方法来完成我们的可比较 Point 定义, 我们可以证明 sort 正确地在平面上对点进行排序:
(deftype Point [x y] ; ❶ Object (toString [this] (format "[%s,%s]" x y)) Comparable (compareTo [p1 p2] (compare (distance (.x p1) (.y p1) 0 0) (distance (.x p2) (.y p2) 0 0)))) (sort [(->Point 5 2) (->Point 2 4) (->Point 3 1)]) ;; (#object[user.Point 0x15de9a05 "[3,1]"] ;; #object[user.Point 0x5ed68d62 "[2,4]"] ;; #object[user.Point 0x344c5f2a "[5,2]"])
❶ 一个完整的 Point 声明, 它既可比较又可打印, 显示 sort 从最接近原点 (0,0) 的点开始排序.
deftype 是在 Clojure 中创建真正可变对象的少数选项之一. deftype 的属性通常被声明为 public 和 final (一个 Java 关键字, 防止属性在赋值后被写入). 我们可以通过两种方式强制 deftype 移除 final 关键字:
- 通过使用
^:unsynchronized-mutable元数据, 属性被声明为非public和非final. 由于属性不再是public的, 它们需要通过 getter/setter 函数暴露出来. - 通过使用
^:volatile-mutable元数据, 我们将一个属性声明为非public, 非final和volatile225.
通过使
deftype属性可变, 程序员必须在并发访问该类型时处理显式同步, 就像在 Java 中发生的那样.
在下面的例子中, 我们创建了一个类似 bean 的 deftype 定义, 这是一个遵循 JavaBean 约定来访问和写入属性的 Java 类 226:
(definterface IPerson ; ❶ (getName []) (setName [s]) (getAge []) (setAge [n])) (deftype Person [^:unsynchronized-mutable name ; ❷ ^:unsynchronized-mutable age] IPerson (getName [this] name) (setName [this s] (set! name s)) ; ❸ (getAge [this] age) (setAge [this n] (set! age n))) (def p (->Person "Natasha" "823")) ; ❹ (.getAge p) ;; "823" (.setAge p 23) ;; 23
❶ deftype 要求函数声明出现在一个接口中. 我们可以用 definterface 创建一个接口. 注意, 接口声明的函数不需要一个显式的 "this" 参数. 还要注意, 在这个特殊情况下, 我们遵循 Java 的方法命名约定.
❷ Person 类型有两个可变属性 name 和 age.
❸ 要写入属性, 我们需要使用 set! 函数. 感叹号按惯例用于表示变异.
❹ 我们错误地将一个大数字作为字符串输入了年龄. 我们通过将数字 23 写入年龄字段来修复它.
deftype 生成的类在 AOT (Ahead Of Time) 编译期间特别有用, 因此它们可以被导出到文件系统上供 Java 应用程序使用. 在下面的例子中, 我们将 deftype 声明写入一个 Clojure 文件, 模拟编译发生的正常条件:
(spit (str *compile-path* "/bookdeftype.clj") ; ❶ "(ns bookdeftype) (defn bar [] \"bar\") (defprotocol P (foo [p])) (deftype Foo [] P (foo [this] (bar)))") (compile 'bookdeftype) ; ❷ ;; bookdeftype
❶ spit 指令在 *compile-path* 指示的文件夹中创建一个名为 bookdeftype.clj 的新文件. 该文件包含一个命名空间声明, 后面跟着一个 bar 函数声明, 一个 defprotocol 声明和一个 deftype 指令. 我们还展示了 deftype 支持 defprotocol 作为扩展机制的事实. 在类型 "Foo" 中声明的函数 foo 调用了 bar 函数.
❷ 一旦命名空间在磁盘上, 我们可以要求 Clojure 编译该文件以产生实际的 Java 类. compile 返回刚刚创建的类对象.
如果我们现在检查 *compile-path* 指示的文件系统位置, 我们可以看到 Clojure 编译器生成的几个文件. 如果我们现在退出当前的 REPL 会话并重新启动一个新的, 我们应该能够使用之前存储在磁盘上的生成的类, 但我们会遇到一个错误:
;; After restarting the REPL (import 'bookdeftype.Foo) ; ❶ ;; bookdeftype.Foo (def p (Foo.)) (.foo p) ; ❷ ;; IllegalStateException Attempting to call unbound fn: #'bookdeftype/bar
❶ 打开另一个 REPL 会话后, 我们导入新创建的类. bookdeftype.Foo 应该在类路径中, 正如前一步所生成的那样.
❷ 当我们尝试使用 Foo 类时, 出了点问题. 问题在于同一命名空间中但在 deftype 定义之外的函数可能不会自动加载.
在 deftype 定义中的 foo 函数使用的命名空间内的函数, 不一定仅仅通过导入生成的 Java 类就会被加载. deftype 包含一个选项, 可以在导入生成的 deftype 后加载宿主命名空间的内容:
(spit (str *compile-path* "/bookdeftype.clj") "(ns bookdeftype) (defn bar [] \"bar\") (defprotocol P (foo [p])) (deftype Foo [] :load-ns true P ; ❶ (foo [this] (bar)))") (compile 'bookdeftype) ;; bookdeftype
❶ 这与之前的命名空间定义相同, 但现在我们在 deftype 声明中使用了 :load-ns 选项.
如果我们再次尝试重新启动一个 REPL 会话并调用函数 foo, 这次我们应该不会看到任何错误:
(import 'bookdeftype.Foo) ;; After restarting the REPL ;; bookdeftype.Foo (def p (Foo.)) (.foo p) ; ❶ ;; "bar"
❶ 像之前一样加载了 Foo 类之后, 我们在一个新创建的实例上调用 .foo 方法. 这次它按预期打印了 "bar", 因为命名空间内函数 "bar" 的相应定义已被 Clojure 评估.
4.2.5. 15.5 proxy
proxy 生成一个 Java 类, 它可以扩展或实现其他类或接口. proxy 的主要目的 (追溯到它首次被引入时) 是为了支持复杂的互操作性场景. 例如, 有些 Java 框架明确要求客户端从特定的类扩展. 在那种情况下, 你可以选择使用 gen-class (但这需要一个特定的编译步骤) 或使用 proxy, 它会立即返回新创建的类的实例:
(def ^Runnable r ; ❶ (proxy [Runnable] [] ; ❷ (run [] (println (rand))))) ; ❸ (.run r) ; ❹ ;; 0.1678203879530764
❶ 考虑到 proxy 实例像任何其他 Java 对象一样被消费, 为它们添加类型提示通常是个好主意. 没有类型提示, Clojure 直到运行时才知道一个对象的类型, 那时进行任何优化都为时已晚.
❷ 我们正在创建一个实现 java.lang.Runnable 接口的新类.
❸ Runnable 接口要求实现一个名为 run 的单一方法. 如果我们不提供实现, Clojure 会生成一个默认的实现, 在调用时会抛出异常.
❹ 我们可以直接在新创建的 proxy 上调用 run.
proxy 捕获 proxy 定义形式周围的任何绑定, 我们可以将它们用作我们实现的一部分. 例如, 我们可以对 java.io.File 实现新功能, 而不触及现有接口:
(import '[java.io File]) (definterface Concatenable ; ❶ (^java.io.File concat [^java.io.File f])) ; ❷ (defn cfile [fname] (proxy [File Concatenable] [^String fname] ; ❸ (concat [^File f] ; ❹ (spit (.getPath f) (slurp this) :append true) f))) (def ^Concatenable etchosts (cfile "/etc/hosts")) ; ❺ (def ^Concatenable f2 (cfile "temp2.txt")) (spit f2 "# need to create this file\n") ; ❻ (.concat etchosts f2) ; ❼
❶ 我们希望 proxy 扩展现有的 java.io.File 类. 生成的 proxy 可以在任何会使用文件的地方使用. 在这种情况下, 我们希望添加一个新函数 (不改变现有函数的行为). 添加新行为的唯一方法是创建一个包含新方法的接口.
❷ 注意, 连接两个文件的接口只接受一个参数. 这是因为调用发生在第一个隐式参数 this 上. 接口上的类型提示被 proxy 正确地传播到相应的函数覆盖.
❸ cfile 创建一个新的 "concatenable-file", 它扩展了 java.io.File 并实现了 Concatenable. proxy 中的第二个向量列出了用于调用超类构造函数的参数. 在这种情况下, 我们用一个表示文件路径的字符串调用 java.io.File.
❹ 接下来是一系列函数实现. concat 将 this 的内容复制到第二个文件参数中.
❺ 我们使用 def 将文件存储在局部变量中. 注意, 只有第一次调用 cfile 会生成一个新类. 第二次调用创建 f2 会创建一个新实例, 但不是另一个类定义. 符合相同接口的生成类会被缓存和重用.
❻ 我们需要在将内容复制到 f2 之前对其使用 spit 来创建文件.
❼ concat 调用将 etchosts 追加到 f2 中. 如果我们打开 "temp2.txt", 我们可以看到一个初始的注释行 "need to create this file", 后面跟着 "/etc/hosts" 的内容.
具有相同签名的 proxy 类被缓存和重用, 以便快速实例化类似的 proxy. 尽管类被缓存, 但实际的 proxy 实例不是. proxy 使用实例属性来存储被覆盖的方法及其闭包的变量. 使用像 proxy-mappings 或 update-proxy 这样的函数, 我们可以在 proxy 创建后检查或更改实现的函数. 参考前面的例子, 我们现在可以向已经存在的 etchosts 实例添加一个在文件使用前自动创建文件的选项:
(update-proxy ; ❶ etchosts {"concat" #(let [^File f1 %1 ^File f2 %2] (.createNewFile ^File f2) ; ❷ (spit (.getPath f2) (slurp f1) :append true) f2)}) (-> etchosts ; ❸ (.concat (cfile "temp3.txt")) (.concat (cfile "hosts-copy.txt")))
❶ update-proxy 接受一个 proxy 实例和一个从方法名到函数的映射. 我们在之前创建的 etchosts proxy 上调用 update-proxy. 在映射内部, 每个键代表一个要被覆盖/实现的方法.
❷ 与相同函数的先前实现相比, 我们添加了一个对 .createNewFile 的调用, 当文件不存在时创建文件. 还要注意, 该函数接受 2 个显式参数: 第一个是 this, 第二个是目标文件. let 块的添加只是为了对参数进行类型提示.
❸ 我们不再需要在将 "temp3.txt" 或 "hosts-copy.txt" 添加到 concat 调用链之前创建它们.
proxy 函数将类生成, 对象创建和函数覆盖组合成一个单一的调用 (这通常非常方便). 然而, 你可以使用像 get-proxy-class, construct-proxy 和 init-proxy 这样的函数来分离生命周期阶段:
get-proxy-class给定一个 (可选的) 具体类来扩展和任意数量的接口, 生成proxy. 通过get-proxy-class, 我们可以例如在启动时预先生成所有proxy类, 并避免稍后生成它们的成本.construct-proxy选择一个构造函数来调用并实例化一个实际的对象. 当使用proxy时, 我们只有一个构造参数的选择, 但使用construct-proxy, 我们可以根据情况选择不同的参数.init-proxy接受一个方法覆盖映射, 类似于前面看到的update-proxy映射.
在下面的例子中, 我们创建了一小组异常类. 类的生成发生在定义时, 当 Clojure 解析包含 get-proxy-class 调用的命名空间时. 然后我们提供一个 bail 函数, 它根据参数数量创建实例. 你可以在 throw/catch 子句中使用生成的异常. 此外, 你可以解引用异常以访问描述错误的消*息*:
(import '[clojure.lang IDeref]) (def DocumentException (get-proxy-class Exception IDeref)) ; ❶ (def SyntaxException (get-proxy-class Exception IDeref)) (def FormattingException (get-proxy-class Exception IDeref)) (defn bail ; ❷ ([ex s] (throw (-> ex (construct-proxy s) (init-proxy {"deref" (fn [this] (str "Cause: " s))})))) ([ex s ^Exception e] (throw (-> ex (construct-proxy s e) (init-proxy {"deref" (fn [this] (str "Root: " (.getMessage e)))}))))) (defn verify-age [^String s] ; ❸ (try (Integer/valueOf s) (catch Exception e (bail SyntaxException "Age is not a number" e)))) (try ; ❹ (let [age "AA"] (verify-age age)) (catch Exception e @e)) ;; "Root: For input string: \"AA\""
❶ 我们创建了三个新的异常, 它们扩展了 java.lang.Exception 并实现了 clojure.lang.IDeref 接口. 新类的生成在这里发生在定义时.
❷ bail 函数展示了如果我们只有一个可用的消息, 或者消息加上根异常, 如何选择不同的构造函数. construct-proxy 在第一个类对象之后接受任意数量的参数.
❸ verify-age 是一个可能的输入验证的例子. 如果我们不能将输入转换为一个数字, 我们会捕获原始异常并调用 bail, 添加一条消息和原始异常.
❹ 在这个 try-catch 块中, 我们用一个故意错误的年龄 "AA" 来调用 verify-age. 正如预期的那样, 我们可以捕获 proxy 生成的异常实例并对其进行解引用 (使用方便的读宏 "@").
proxy 有几个限制:
- 如果
proxy扩展/实现的类或接口发生变化,proxy会继续使用缓存的类, 即使该类或接口被重新定义. 这在生产代码中是非常不可能发生的情况, 但在 REPL 中开发时更为常见. proxy不适合创建复杂的层次结构. 例如, 虽然你可以扩展和实现类或接口, 但你不能扩展另一个proxy.- 性能通常很好, 但
proxy上的每个方法都会执行一次查找, 以查看是否有可用的覆盖. - 控制反射调用 (例如使用
(set! *warn-on-reflection* true)) 并添加适当的类型提示也相当重要. - 这是 "封闭的多态": 要么方法在定义时就在接口中, 要么你以后就无法调用它们, 即使你用正确的覆盖
update-proxy.
从 proxy 中学到的教训是, 除非你被迫从 Java 框架中扩展一个类才能使用它, 否则你应该考虑使用 reify 而不是 proxy 来创建快速的一次性实例. 如果你的目标是在 Clojure 中实现多态, 那么协议和多重方法有更好的选择.
4.2.6. 15.6 reify
reify 是一个轻量级的 proxy. 它专注于本质: 生成一个实现一组接口的一次性对象实例. 当一个框架 (或计算模型) 需要创建一个具有特定接口的对象 (如 "events", "observables", "listeners" 等) 时, reify 可能很有用. 这些对象是短暂的, 为它们创建和维护一个显式的类没有太大的价值.
在下面的例子中, 一个 Java 框架提供了一些类, 当一些有趣的事情发生时 (例如按钮点击), 它们的属性会被 "触发". 该框架使用 java.beans 包中的 PropertyChangeSupport 工具来实现这个特性:
import java.beans.PropertyChangeSupport; import java.beans.PropertyChangeListener; public class ClassWithProperty { ❶ private final PropertyChangeSupport pcs = new PropertyChangeSupport(this); private String value; public String getValue() { return this.value; } public void addPropertyChangeListener(PropertyChangeListener listener) { this.pcs.addPropertyChangeListener(listener); } public void setValue(String newValue) { ❷ String oldValue = this.value; this.value = newValue; this.pcs.firePropertyChange("value", oldValue, newValue); } }
❶ ClassWithProperty 是一个示例类, 它具有可观察的属性, 这是它在 Java 框架中实现的方式.
❷ 当我们更改 value 字段的内容时, 该类会触发一个属性更改调用, 以通知所有潜在的监听器.
对这类事件感兴趣的监听器应该通过 PropertyChangeListener 接口注册自己. 我们将使用 reify 来做到这一点:
(import 'java.beans.PropertyChangeListener) (import 'ClassWithProperty) (let [observed (ClassWithProperty.) listener (reify PropertyChangeListener ; ❶ (propertyChange [this evt] (let [{:keys [oldValue newValue]} (bean evt)] (println "Button Clicked!" oldValue newValue))))] (.addPropertyChangeListener observed listener) ; ❷ (.setValue observed "I click")) ; ❸ ;; Button Clicked! nil I click
❶ 我们使用 reify 来实现 PropertyChangeListener 接口. 这个接口只有一个方法 propertyChange. 注意, 即使接口中没有声明, 我们也需要传递隐式的 this 参数. 我们使用 bean 方法来转换事件参数, 以便我们可以像从 Clojure 映射中访问键一样访问其属性.
❷ 具体化的实例已准备好使用, 我们现在可以注册它以接收事件.
❸ 一旦我们更改 Java 类上的值, propertyChange 就会被调用, 我们可以看到旧值和新值.
当 Clojure 需要提供扩展点时, 它通常使用 defprotocol. 协议还包括一个 Java 接口, reify 可以实现该接口. 我们在本书中已经看到了具体化的协议, 例如在讨论 reducer 以实现 clojure.core.reducers.CollFold 协议时. 我们可以使用类似的机制将 reduce-kv 扩展到 java.util.HashMap:
(import 'java.util.HashMap) (import 'clojure.core.protocols.IKVReduce) (def m (doto (HashMap.) ; ❶ (.put :a "a") (.put :b "b") (.put :c "c"))) (defn stringify-key [m k v] ; ❷ (assoc m (str k) v)) (reduce-kv stringify-key {} m) ; ❸ ;; IllegalArgumentException No implementation of method: :kv-reduce... (reduce-kv stringify-key {} (reify IKVReduce ; ❹ (kv-reduce [this f init] (reduce-kv f init (into {} m))))) ;; {":b" "b", ":c" "c", ":a" "a"}
❶ 我们使用 doto 创建一个 java.util.HashMap 实例, 并通过直接调用 .put 方法添加几个键值对.
❷ stringify-key 是一个简单的函数, 用于将一个键和值与作为参数传递的映射 "m" 关联.
❸ 如果我们试图直接在 java.util.HashMap 上使用 reduce-kv, 调用会产生异常. 原因是 Clojure 没有为 java.util.HashMap 提供 reduce-kv 的实现.
❹ 我们有几种方法来为 java.util.HashMap 提供 reduce-kv. 到目前为止最简单的是从 Java 映射创建一个 Clojure 映射, 并委托给那个版本的 reduce-kv. 一个性能更好的版本是就地改变 Java 映射, 假设我们的应用程序是单线程的, 并且没有并发问题.
reify 通常比 proxy 快. proxy 在实现具有许多方法的接口时有一些优势, 其中类缓存可以消除大型类的持续生成. 在所有你不需要任何 proxy 特性的情况下, reify 是更可取的.
4.2.7. 15.7 defrecord
defrecord 生成一个基于 deftype 的类, 该类额外地在声明的属性上实现了 Clojure 映射语义 227. 与 deftype 不同, 由 defrecord 产生的对象是不可变的:
(defrecord Point [x y]) ; ❶ (def p (Point. 1 2)) ; ❷ (.x p) ;; 1 (def p (map->Point {:x 1 :y 2})) ; ❸ (:x p) ;; 1
❶ 我们声明一个包含属性 "x" 和 "y" 的 Point 记录.
❷ 我们可以通过 Java 互操作性使用记录的 deftype 性质.
❸ defrecord 也理解映射语义, 所以我们可以像在映射中访问键一样访问属性, 或者从包含这些属性的映射中创建一个新的 Point.
除了像按关键字访问或 assoc-dissoc 这样的简单映射操作外, defrecord 完全与 Clojure 生态系统的其余部分集成: 你可以用 = 比较记录, 将它们用作哈希映射中的键, 或将它们与元数据一起使用.
defrecord在生成具有类映射语义的自定义类型方面取代了defstruct. 仍然有很少的合法情况会优先选择defstruct: 请查看defstruct以了解更多.
像 deftype 一样, defrecord 可以实现任意数量的接口. 一个记录默认也扩展了 java.lang.Object. 我们可以如下编写一个可比较的 Point 记录 (你可以在 deftype 部分看到类似的例子):
(defn- euclidean-distance [x1 y1 x2 y2] (Math/sqrt (+ (Math/pow (- x1 x2) 2) (Math/pow (- y1 y2) 2)))) (defrecord Point [x y] ; ❶ Comparable (compareTo [p1 p2] (compare (euclidean-distance (.x p1) (.y p1) 0 0) (euclidean-distance (.x p2) (.y p2) 0 0)))) (sort [(->Point 5 2) (->Point 2 4) (->Point 3 1)]) ; ❷ ;; (#user.Point{:x 3, :y 1} #user.Point{:x 2, :y 4} #user.Point{:x 5, :y 2})
❶ 与相同 Point 类的 deftype 版本相比, 唯一的区别是使用了 defrecord 而不是 deftype. 在 defrecord 关键字之后, 我们可以选择实现一个或多个接口. 方法按惯例在接口名称之后, 但它们可以按任何顺序出现.
❷ 我们可以通过对点进行排序来证明它们是可比较的. 在这种情况下, 它们按与坐标系原点 (0,0) 的欧几里得距离递增的顺序排序.
defrecord 打印比相应的 deftype 更有用的信息. 这是因为有一个针对记录的 print-method 覆盖, 它与 println 配合使用. 然而, 如果我们对一个记录调用 str, 我们会得到一个没有属性的原始字符串. 我们可以通过覆盖 toString() 来改变 defrecord 转换为字符串的方式:
(defrecord Point [x y]) (str (->Point 1 2)) ; ❶ ;; "user.Point@78de238e" (defrecord Point [x y] ; ❷ Object (toString [this] (format "[%s,%s]" x y))) (str (->Point 1 2)) ; ❸ ;; "[1,2]"
❶ 如果我们不提供特定的实现, 默认的 toString() 会用其类的名称后跟 "@" 符号和在其上调用 hashCode() 的结果来格式化一个对象 (这通常会导致一个大致映射到内存地址的十六进制字符串).
❷ 让我们扩展 Point 以包含对 toString() 的覆盖.
❸ 新的字符串渲染现在包含相关信息.
除了将它们用作类映射类的选项外, defrecord 在 Clojure 的多态产品中扮演着基础性的角色, 与协议协同工作. 我们将在接下来的部分探讨这方面的内容.
4.2.8. 15.8 defprotocol
defprotocol 宏初始化一个基于类型的函数的多态分派机制. 该宏协调以下内容的生成:
- 一个原生的 Java 接口 (很好地利用了
gen-interface). 该接口被赋予与协议相同的名称. - 一个包含有关方法及其签名的数据的变量.
- 将协议方法连接到其实现的分派函数.
我们可以在调用 defprotocol 并传入一个名称和方法列表后, 在当前命名空间中看到生成的构件:
(defprotocol MyProtocol ; ❶ (method1 [this]) (method2 [this])) (pprint (vec (.getDeclaredMethods user.MyProtocol))) ; ❷ ;; [#object[Method "public abstract java.lang.Object user.MyProtocol.method1()"] ;; #object[Method "public abstract java.lang.Object user.MyProtocol.method2()"]] (pprint MyProtocol) ; ❸ ;; {:on user.MyProtocol, ;; :on-interface user.MyProtocol, ;; :sigs ;; {:method1 {:name method1, :arglists ([this]), :doc nil}, ;; :method2 {:name method2, :arglists ([this]), :doc nil}}, ;; :var #'user/MyProtocol, ;; :method-map {:method1 :method1, :method2 :method2}, ;; :method-builders ;; {#'user/method2 #object["user$eval1675$fn__1676@6f9e2121"], ;; #'user/method1 #object["user$eval1675$fn__1687@78d76411"]}} (fn? method1) ; ❹ ;; true (fn? method2) ;; true
❶ defprotocol 定义接受一个名称 (这将是生成的类和局部变量的名称) 和一个方法签名列表. 这些方法是生成的接口的一部分.
❷ 类 user.MyProtocol 是由 defprotocol 生成的, 它包含两个预期的方法.
❸ 变量 MyProtocol 也是由 defprotocol 生成的. 它包含一个定义协议内容的映射, 包括方法签名和方法构建器. 每个方法构建器都为该特定函数的分派机制生成一个实例.
❹ defprotocol 还为每个方法创建一个函数. 每个函数的主体都由与函数同名的方法构建器生成.
defprotocol 在当前命名空间中为接口声明中找到的每个方法生成一个函数. 生成的函数包含分派机制, 用于根据第一个参数的类型查找和调用正确的函数:
(method1 "arg") ; ❶ ;; IllegalArgumentException: ;; No single method: foo of interface: user.Foo found for class: java.lang.String (extend java.lang.String ; ❷ MyProtocol {:method1 #(.toUpperCase %)}) (method1 "arg") ; ❸ ;; ARG
❶ 如果我们试图在定义协议后立即调用 method1, Clojure 会告诉我们没有可以调用的该方法的实现.
❷ 有几种方法可以添加一个有效的实现. 一种方法是使用 extend 并传递一个从协议上的方法名到要调用的函数的映射.
❸ 在为 String 类型添加了方法之后, method1 返回调用提供的函数的结果.
当我们 "扩展" 协议到一个类型时, 我们为该类型在分派表中提供了一个新条目. 然而, 我们不能为已经是协议声明一部分的类型扩展协议:
(deftype MyProtocolImpl [] ; ❶ MyProtocol (method1 [this] "MyProtocolImpl::method1")) (method1 (MyProtocolImpl.)) ; ❷ ;; "MyProtocolImpl::foo" (extend MyProtocolImpl ; ❸ MyProtocol {:method1 (constantly "extend::method1")}) ;; IllegalArgumentException class FooImpl already implements interface user.Foo
❶ MyProtocolImpl 是用 deftype 定义的一个类, 实现了之前由协议生成的 MyProtocol 接口.
❷ 协议方法 method1 对类 MyProtocolImpl 有一个可用的分派, 调用成功.
❸ 尝试将同一个类 MyProtocolImpl 扩展到协议 MyProtocol 失败, 因为该类已经直接实现了同一个接口.
- 基于实例的分派
Clojure 1.10 引入了一种新的基于元数据的分派方法:
(defprotocol Foo :extend-via-metadata true ; ❶ (foo [x])) ;; Foo (foo (with-meta [42] {`foo (fn [x] :boo)})) ; ❷ ;; :boo
❶ 新的分派机制不是默认启用的. 我们需要在协议创建期间将
:extend-via-metadata设置为 true.❷ 我们现在可以在向量 `[42]` 上定义一个基于实例的分派. 注意, 对符号 "foo" 使用了语法引用 (反引号), 以便将该符号完全限定到当前命名空间.
1.10 中的分派机制更新如下: 首先检查方法在实际类上的存在, 然后在元数据中 (如果启用), 最后在扩展表中.
从例子中我们可以看到, 提供协议方法的实现有两种选择:
- 直接实现协议接口 (这可以通过任何
defrecord,deftype,proxy或reify实现). - 将协议扩展到一个现有的类 (使用
extend和相关的变体extend-type或extend-record).
直接实现接口与稍后扩展协议一样快. 让我们看看下面的基准测试:
(require '[criterium.core :refer [bench]]) (defprotocol Bench (m [this])) ; ❶ (deftype DirectBench [] Bench (m [this])) ; ❷ (deftype LaterBench []) (extend-type LaterBench Bench (m [this])) ; ❸ (let [db (DirectBench.)] (bench (m db))) ; ❹ ;; Execution time mean : 3.052222 ns (let [lb (LaterBench.)] (bench (m lb))) ;; Execution time mean : 4.168180 ns
❶ 协议
Bench只有一个方法m.❷
DirectBench在定义时实现了协议. 该类包含方法m的定义.❸
LaterBench不实现协议接口, 因此不包含方法m的定义. 它稍后被扩展到协议.❹ 1 纳秒的差异完全可以忽略不计, 两种查找选项的性能大致相同.
考虑到我们目前所看到的, 使用
definterface而不是defprotocol几乎没有任何优势.defprotocol提供了一种更符合 Clojure 习惯的方式来调用接口方法, 包括大多数时候避免类型提示. 此外, 协议可以稍后扩展到现有类中, 允许灵活的多态性 (以及轻量级的继承). 我们将在下一节专门介绍extend时看到一些这方面的例子. - 直接实现协议接口 (这可以通过任何
4.2.9. 15.9 extend, extend-type 和 extend-protocol
本节还提到了其他相关函数, 如:
satisfies?,extends?和extenders.
extend (以及相关的辅助宏 extend-type 和 extend-protocol) 为协议添加了一个新的分派选项:
(require '[clojure.string :as s]) (defprotocol Reflect ; ❶ (declared-methods [this])) (extend java.lang.Object ; ❷ Reflect {:declared-methods (fn [this] (map (comp #(s/replace % #"clojure\.lang\." "cl.") #(s/replace % #"java\.lang\." "jl.")) (.getDeclaredMethods (class this))))}) (pprint (declared-methods (atom nil))) ; ❸ ;; ("public jl.Object cl.Atom.reset(jl.Object)" ;; "public jl.Object cl.Atom.swap(cl.IFn,jl.Object)" ;; "public jl.Object cl.Atom.swap(cl.IFn,jl.Object,jl.Object,cl.ISeq)" ;; "public jl.Object cl.Atom.swap(cl.IFn,jl.Object,jl.Object)" ;; "public jl.Object cl.Atom.swap(cl.IFn)" ;; "public boolean cl.Atom.compareAndSet(jl.Object,jl.Object)" ;; "public jl.Object cl.Atom.deref()")
❶ 我们创建一个 Reflect 协议, 其中包含一个 declared-methods 方法, 该方法检查一个类以检索其公共声明的方法.
❷ 通过 extend, 我们可以将这个新功能附加到任何类上. 由于 Java (和 Clojure) 中的所有类最终都扩展自 Object, declared-methods 现在可用于任何类型的参数.
❸ 作为测试, 我们在一个 atom 返回的对象上调用 declared-methods. 结果的方法列表为可读性而缩短.
extend 接受一个从函数名 (作为关键字) 到函数体的映射, 实现了在不同对象间简单地重用函数. 例如, 我们可以实现一个轻量级版本的 Java 抽象类 228 的相应特性:
(defprotocol IFace ; ❶ (m1 [this]) (m2 [this]) (m3 [this])) (def AFace ; ❷ {:m1 (fn [this] (str "AFace::m1")) :m2 (fn [this] (str "AFace::m2"))}) (defrecord MyFace []) ; ❸ (extend MyFace IFace (assoc AFace :m1 (fn [this] (str "MyFace::m1")))) ; ❹ (m1 (->MyFace)) ; ❺ ;; "MyFace::m1" (m2 (->MyFace)) ; ❻ ;; "AFace::m2" (m3 (->MyFace)) ; ❼ ;; No implementation of method: :m3 of protocol: #'user/IFace
❶ IFace 是一个包含 3 个方法 m1, m2 和 m3 的协议.
❷ 映射 AFace 包含 m1 和 m2 的默认实现, 但没有 m3, 因为 m3 没有一个适合所有类型的通用实现.
❸ 我们声明一个新的 defrecord MyFace. 正如你所见, 我们在声明时没有实现任何协议.
❹ 我们现在使用来自默认 AFace 映射的方法的 "混合" 以及任何覆盖来将协议 IFace 扩展到记录 MyFace. MyFace 将 "继承" m2 的默认行为, 并用不同的行为覆盖 m1. 我们仍然没有提供 m3 的实现.
❺ 函数 m1 已被一个自定义实现替换, 并打印与 AFace 映射中默认 m1 不同的消息.
❻ 函数 m2 被 "继承" 了, 并打印默认消息.
❼ 在 MyFace 上调用 m3 会产生一个错误, 告诉我们没有提供实现.
defrecord (或 deftype) 有两种实现协议的选项:
- 在声明时实现协议会将方法添加到生成类的接口中, 使它们从 Java 中可见, 但也无法扩展. 一旦在声明时附加了实现, 它就不能改变, 除非重新定义整个记录.
- 通过扩展实现协议允许记录的实例在稍后某个时间被扩展到协议, 包括在不重新定义记录的情况下更改实现的选项.
在下一个例子中, 我们看到一个先前创建的记录一旦我们扩展了协议定义的方法 m1, 其行为就会改变. 同样的情况也发生在应用程序中运行的相同记录类型的所有实例上:
(def my-face (->MyFace)) (m1 my-face) ; ❶ ;; "MyFace::m1" (extend MyFace IFace (assoc AFace :m1 (fn [this] (str "new")) ; ❷ :m3 (fn [this] (str "m3")))) (m1 my-face) ; ❸ ;; "new" (m3 my-face) ; ❹ ;; "m3"
❶ 参考前面的例子, 我们将 MyFace 记录的一个实例分配给变量 my-face, 显示它按预期打印了自定义的 m1 实现.
❷ 我们现在重复 extend 调用, 这次更改方法 m1 的实现.
❸ 先前创建的实例现在扩展了函数 m1 的新版本.
❹ 我们还借此机会提供了最后一个缺失的 m3 的实现, 现在它能正确打印.
我们可以将协议扩展到接口或其他协议. 在下一个例子中, 我们对树中节点之间的关系进行建模. 作为一个 "Node" 并且有一个 "value" 的事实被树中的分支和叶子都继承了:
(defprotocol INode (value [_])) ; ❶ (defprotocol IBranch (left [_]) (right [_])) (defprotocol ILeaf (compute [_])) (extend user.INode IBranch) ; ❷ (extend user.INode ILeaf) (defrecord Branch [id left right] ; ❸ INode (value [_] (str "Branch::" id)) IBranch (left [_] left) (right [_] right)) (defrecord Leaf [id] INode (value [_] (str "Leaf::" id)) ILeaf (compute [_] (str "computed:" id))) (def tree ; ❹ (->Branch 1 (->Branch :A (->Leaf 4) (->Leaf 5)) (->Branch :B (->Leaf 6) (->Leaf 7)))) (defn traverse ([tree] (traverse [] tree)) ([acc tree] (let [acc (conj acc (value tree))] ; ❺ (if (satisfies? IBranch tree) ; ❻ (into (traverse acc (left tree)) (traverse acc (right tree))) (conj acc (compute tree)))))) (traverse tree) ; ❼ ;; ["Branch::1" "Branch:::A" "Leaf::4" "computed:4" ;; "Branch::1" "Branch:::A" "Leaf::5" "computed:5" ;; "Branch::1" "Branch:::B" "Leaf::6" "computed:6" ;; "Branch::1" "Branch:::B" "Leaf::7" "computed:7"]
❶ INode, IBranch 和 ILeaf 是协议定义. INode 代表了树中节点所有共有的东西, 并被设计为与其他节点特化一起 "混合".
❷ 我们通过将 INode 协议扩展到 IBranch 和 ILeaf 协议来表达分支和叶子也是节点的事实. 这使得 INode 中的 value 方法可以在分支和叶子上被调用.
❸ Branch defrecord 接受一个 id 和左右两个分支. 它同时实现了 INode 和 IBranch 协议.
❹ 我们通过实例化并连接根, 分支和叶子来创建一个示例树.
❺ traverse 函数显示调用 (value tree) 始终有效, 不论节点的类型. traverse 在一个分支上递归调用, 并总是累积节点的值. traverse 还在最终结果中收集调用叶子上的 compute 的结果.
❻ 注意使用 satisfies? 来验证 IBranch 协议是否包含对 (type tree) (树对象的类) 的实现.
❼ 我们可以看到遍历的结果, 深度优先进入 "Leaf::4", 然后从左到右跟随树到最后一个可用的叶子.
extend-type 是 extend 的一种更短的形式, 它使用完全成形的函数体, 与 defrecord 声明时可用的非常相似:
(extend-type MyFace IFace (m2 [this] (str "MyFace::m2"))) ; ❶ (m2 my-face) ;; "MyFace::m2"
❶ extend-type 的语法与 MyFace 记录声明时找到的相同. 在这种情况下, 我们覆盖了 m2 的初始默认实现.
如果同一个协议需要扩展到许多类型, 那么为协议应扩展到的每个类型编写一个 extend-type 可能会很重复. extend-protocol 将所有类型聚合到一个调用中:
(defprotocol Money (as-currency [n])) (extend-protocol Money ; ❶ Integer (as-currency [n] (format "%s$" n)) clojure.lang.Ratio (as-currency [n] (format "%s$ and %sc" (numerator n) (denominator n)))) (extenders Money) ; ❷ ;; (java.lang.Integer clojure.lang.Ratio) (extends? Money Integer) ; ❸ ;; true
❶ 在这个例子中, Money 协议只扩展到 2 种类型, 但列表可能会更长. 我们可以用每个数字类型的一个 extend-type 来表达同样的事情, 但那样会更冗长.
❷ extenders 显示 Money 协议现在有两个扩展.
❸ 类似地, 我们可以用 extends? 来询问一个协议是否扩展到一个特定的类型.
在本节中, 我们已经看到了如何使用 defprotocol 来创建类型及其接口之间有趣的关系. extend 是分派函数调用的习惯用法, 但我们可以包含一个对象的其他方面, 不仅仅是类型. 这就是我们将在下一节专门介绍派生和多重方法时看到的.
4.2.10. 15.10 derive 和 make-hierarchy
本节还包括
underive,isa?,parents,ancestors和descendants的例子.
derive (以及 make-hierarchy, underive, isa?, parents, ancestors 和 descendants) 是一组专门用于在 Clojure 中创建和管理 "层次结构" 的函数. 例如, isa? 是多重方法分派的核心, 它提供了灵活的多态性.
本节中描述的函数为希望创建自己的分派机制的用户提供了同样的能力. Java 将继承与类型混为一谈, 而 Clojure 允许层次结构作为孤立的特性存在. 通过 Clojure 的层次结构, 我们可以:
- 使用提供的 "全局层次结构" 或独立使用任意数量的自定义层次结构.
- 用
derive创建父子关系, 或用underive移除现有关系. - 查询层次结构以获取现有关系 (用
isa?). - 获取所有可派生的实体 (用
descendants). - 获取我们可以从中派生一个对象的所有实体 (用
ancestors). - 获取一个对象的所有直接父对象 (用
parents).
层次结构支持符号, 关键字和类. Clojure 允许父子关系双向, 但仅限于符号和关键字. Java 类只允许作为子类:
(defn custom-hierarchy [& derivations] ; ❶ (reduce (fn [h [child parent]] (derive h child parent)) (make-hierarchy) derivations)) (def h (custom-hierarchy ; ❷ [:clerk :person] ['owner 'person] [String :person])) (isa? h 'owner 'person) ; ❸ ;; true (isa? h :clerk :person) ;; true (isa? h String :person) ;; true
❶ 我们现在将使用 custom-hierarchy 来重复地在父子派生对上应用 derive. 这使我们可以方便地创建许多这样的对.
❷ 要创建一个新的层次结构, 我们用任意数量的向量对调用 custom-hierarchy. 在这个例子中, 我们使用一个关键字, 一个符号和一个 Java 类 (但我们也可以使用任何其他实现了 clojure.lang.Named 接口的对象).
❸ 我们可以用 isa? 来检查我们刚刚创建的关系. 这三个例子都返回 true.
派生是可传递的:
(def h (custom-hierarchy [:unix :os] [:bsd :unix] [:mac :bsd])) (isa? h :mac :unix) ; ❶ ;; true
❶ :mac 是一个 :unix 的事实没有被明确声明, 但可以通过在多个级别上遍历层次结构来推断.
我们可以进一步查询层次结构以关注有趣的关系:
(def h (custom-hierarchy [:unix :os] [:windows :os] [:os2 :os] [:redhat :linux] [:debian :linux] [:linux :os] [:linux :unix] [:bsd :unix] [:mac :bsd])) (descendants h :unix) ; ❶ ;; #{:redhat :linux :debian :bsd :mac} (ancestors h :mac) ; ❷ ;; #{:unix :os :bsd}
❶ 我们可以使用 descendants 来发现 "什么是 Unix?"
❷ 或者, 我们可以使用 ancestors 来验证特定项的 "血统".
如果我们想改变层次结构, 我们可以随时使用 underive 移除关系:
(def h (custom-hierarchy ; ❶ [:unix :os] [:windows :unix] [:mac :unix])) (isa? h :windows :unix) ;; true (def h (underive h :windows :unix)) ; ❷ (isa? h :windows :unix) ;; false
❶ 我们想修改这个层次结构, 以移除 :windows 是一个 :unix 的关系.
❷ underive 接受层次结构 (可选) 和要移除的父子对.
isa? 在向量上通过测试它们各自的项来工作. 例如, 我们可以检查同一层次结构中的不同继承链:
(def h (custom-hierarchy ; ❶ [:clerk :person] [:owner :person] [:unix :os] [:bsd :unix] [:mac :bsd])) (isa? h [:mac :owner] [:unix :person]) ; ❷ ;; true
❶ 这个层次结构包含 "clerks" 和 "owners" 的特化, 以及 Unix 系统的各种风格.
❷ isa? 测试对 :mac 和 :unix, 接着是 :owner 和 :person. 然后只有当所有关系都为真时才返回真.
ancestors 对于检索一个类扩展或实现的类或接口的集合很有用. 当指向 Java 类时, 结果将总是至少包含 java.lang.Object:
(ancestors String) ; ❶ ;; #{java.lang.CharSequence ;; java.io.Serializable ;; java.lang.Comparable ;; java.lang.Object}
❶ 我们可以直接对 Java 类使用 ancestors, 并使用这些信息将对象强制转换为其超类或接口之一.
你可以将派生函数与多重方法一起使用, 以表达不基于类型的多态行为. 例如, isa? 被多重方法用来替代普通的相等性检查, 以在关键字或符号上启用派生. 我们将在下一节探讨它们的使用.
4.2.11. 15.11 defmulti 和 defmethod
本节还包括
remove-all-methods,remove-method,prefer-method,methods,get-method和prefers的例子.
本节中介绍的函数和宏组控制着 Clojure 中的 "多重方法". "多重方法" 是一个特殊的 Clojure 函数, 它有多个实现. 特定实现的选择是通过用户必须提供的一个分派函数来完成的. defmulti 是 Clojure 中最灵活的多态形式. 与协议相比, 多重方法可以分派任何东西, 不仅仅是类型. 此外, 多重方法不需要显式定义 Java 接口, 并且可以使用自定义的派生规则来设计复杂的分派层次结构.
例如, 以下是我们如何设计一个多重方法来评估表示为数据的数学运算. 我们可以创建一个 calculate 多重方法, 它分派已知的运算, 并使用一个 :default 情况来评估所有其他表达式:
(def total-payments ; ❶ {:op 'times :expr [[:loan 150000] {:op 'pow :expr [{:op 'plus :expr [[:incr 1] {:op 'divide :expr [[:rate 3.16] [:decimals 100] [:months 12]]}]}] {:op 'times :expr [[:months 12] [:years 10]]}]}]}) (def ops ; ❷ {'plus + 'times * 'divide / 'pow #(Math/pow %1 %2)}) (defmulti calculate ; ❸ (fn [form] (:op form))) (defmethod calculate 'plus ; ❹ [{:keys [op expr]}] (apply (ops op) (map calculate expr))) (defmethod calculate 'times [{:keys [op expr]}] (apply (ops op) (map calculate expr))) (defmethod calculate 'divide [{:keys [op expr]}] (apply (ops op) (map calculate expr))) (defmethod calculate 'pow [{[x y] :expr}] (Math/pow (calculate x) (calculate y))) (defmethod calculate nil ; ❺ [[descr number]] number) (defmethod calculate :default [form] ; ❻ (throw (RuntimeException. (str "Don't know how to calculate" form)))) (calculate total-payments) ; ❼ ;; 205659.10262863498
❶ total-payments 表示公式的数据结构: (* 150000 (Math/pow (+ 1 (/ 3.16 100 12)) (* 12 10))). 操作被编码为带有 :op 键和 :expr 向量的 Clojure 映射. 一个表达式可以是一个对 `[<:decription> <number>]` 或递归地是另一个操作.
❷ ops 是一个将操作从符号转换为要调用的实际函数的字典.
❸ 多重方法的定义以一个名为 calculate 的 defmulti 声明开始. 它接受一个单个参数 "form", 并使用 :op 键来选择一个特定的实现.
❹ 每个 defmethod 实现一个特定的操作. 我们可以解构参数中的形式, 只关注 "expr", 一个包含其他表达式的向量. 对于大多数支持的操作, 我们使用 apply 来接受任意数量的参数. 注意, 我们在表达式的内容上递归地调用 calculate.
❺ 在一个向量上调用关键字, 例如 `(:op [:int 20])`, 总是会返回 nil (关键字只能在映射中查找自己). 当我们到达数据结构中的一个 "叶子" 时, 我们停止递归并从向量对中返回数字.
❻ 特殊的分派值 ":default" 接收不匹配 defmethod 声明的调用. 我们可以用它来提示用户可能缺少一个分派值, 方法是停止评估并抛出异常.
❼ calculate 现在准备好评估 calculate-payments 数据. 我们在这里看到的是, 我们将如何偿还一笔 150,000 美元的贷款, 期限 10 年, 年利率为 3.16%.
我们可以使用一个自定义的层次结构来处理由类似的 defmethod 产生的潜在重复. 在前面的例子中, defmethod 的实现根据每个操作支持的参数数量而变化. 在下面的改进实现中, 我们为 calculate 提供了一个自定义的层次结构, 以按参数数量对操作进行分组. 自定义的层次结构建立在一个新的数据结构之上, 该结构替换了之前名为 ops 的字典:
(def ops {'plus [+ :varargs] ; ❶ 'times [* :varargs] 'divide [/ :varargs] 'pow [#(Math/pow %1 %2) :twoargs]})
❶ ops 是一个从操作符号 (例如 'plus) 到要调用的实际函数 (例如 +) 和操作类型 (例如, :onearg, :twoarg 或 :varargs) 的映射.
以下是我们如何在由新的 ops 映射表示的自定义层次结构之上建模 calculate:
(defn- add-ops [hierarchy ops] ; ❶ (reduce (fn [h [op [f kind]]] (derive h op kind)) hierarchy ops)) (def hierarchy ; ❷ (add-ops (make-hierarchy) ops)) (defn resolve-op [ops op] ; ❸ (first (ops op))) (do ; ❹ (def calculate nil) (defmulti calculate (fn [form] (:op form)) :hierarchy #'hierarchy)) (defmethod calculate :varargs ; ❺ [{:keys [op expr]}] (apply (resolve-op ops op) (map calculate expr))) (defmethod calculate :onearg [{op :op [x] :expr}] ((resolve-op ops op) (calculate x))) (defmethod calculate :twoargs [{op :op [x y] :expr}] ((resolve-op ops op) (calculate x) (calculate y))) (defmethod calculate nil [[_ number]] ; ❻ number) (defmethod calculate :default [form] (throw (RuntimeException. (str "Don't know how to calculate " form)))) (calculate total-payments) ; ❼ ;; 205659.10262863498
❶ add-ops 通过添加在 ops 参数中找到的子父关系来创建或修改一个现有的层次结构.
❷ hierarchy 将自定义的派生层次结构存储为一个 var 对象. 我们使用前面定义的 ops 数据映射来创建新的层次结构.
❸ resolve-op 知道如何检查操作符符号映射并找到要调用的函数.
❹ 前面的 defmulti 需要重新定义以接受新创建的自定义层次结构. 然而, Clojure 不会替换一个已存在的 defmulti 定义, 所以我们需要记住通过将 calculate 设置为 nil 来明确地销毁前一个.
❺ 先前定义的 defmethod 也需要用一个新的分派值替换: :varargs, :onearg, :twoargs, nil 或 :default. 之前定义的 total-payment 数据结构不需要改变. 例如, 操作符 :plus 由于自定义的层次结构而分派到 :varargs.
❻ 对 nil 和 :default 的分派需要重新定义, 因为即使它们没有改变, 它们也从未在新 defmulti 定义中注册过.
❼ 在重新评估了多重方法的组件之后, calculate 在之前的 total-payment 数据结构上按预期工作.
defmulti的定义是不可覆盖的. 尝试用与现有定义相同的名称和命名空间重新定义一个defmulti将会无声地失败.
多重方法的另一个有趣特性是, 我们可以在它们被声明后扩展它们. 与协议 (它们在运行时也是可扩展的) 不同, 我们不需要注册一个新的类型来添加行为. 下面的例子包含了一个带有新操作符的不同公式. 我们将使用一个特殊的形式 (它不是实际数据的一部分) 来指示 defmethod 关于新的操作符:
(defn sound-speed-by-temp [temp] ; ❶ {:op 'with-mapping :expr [{'inc [inc :onearg] 'sqrt [(fn [x] (Math/sqrt x)) :onearg]} {:op 'times :expr [[:mph 738.189] {:op 'sqrt :expr [{:op 'inc :expr [{:op 'divide :expr [[:celsius temp] [:zero 273.15]]}]}]}]}]}) (calculate (sound-speed-by-temp -60)) ; ❷ ;; RuntimeException Don't know how to calculate {:op with-mapping [...]}
❶ 函数 sound-speed-by-temp 接受一个温度并产生公式的数据等价物: (* 738.189 (Math/sqrt (inc (/ temp 273.15)))). 该公式计算给定温度下的声速, 并以英里每小时返回结果. 该公式被包装在 'with-mapping' 中, 这是一个由 :default 分派多重方法使用的特殊操作符.
❷ 如果我们尝试调用新的公式, 我们会得到一个错误, 因为它包含未知的符号: 'with-mapping', 'sqrt' 和 'inc'. :default 多重方法会通知我们问题所在.
计算声速与温度关系的公式引入了两个新的操作: 'sqrt' 和 'inc'. 下面的例子设计了一个新的 :default 分派方法来拦截 'with-mapping' 的存在. 在存在这个特殊操作符的情况下, 我们更改层次结构和操作符映射以引入新的操作:
(defmethod calculate :default [{op :op [ops forms] :expr :as form}] (if (= 'with-mapping op) (do (alter-var-root #'hierarchy add-ops ops) ; ❶ (alter-var-root #'ops into ops) ; ❷ (calculate forms)) ; ❸ (throw (RuntimeException. (str "Don't know how to calculate " form))))) (- (calculate (sound-speed-by-temp -60)) ; ❹ (calculate (sound-speed-by-temp 20))) ;; -112.64352508635466
❶ 我们使用 alter-var-root 来更改层次结构的内容并添加新的操作符. 注意这个操作是幂等的: 如果相同的关系已经存在, 层次结构不会改变.
❷ 映射定义 ops 也需要更新. 与之前在层次结构上的更新不同, 这个第二个 alter-var-root 会 "upsert" (更新或插入) 表中的给定操作符.
❸ calculate 现在可以继续处理数据结构的其余部分.
❹ 我们可以看到, -60 摄氏度 (大约 11000 英尺海拔处的典型温度) 下的声速比室温慢约 112 MPH.
现在让我们回顾一下多重方法的其他实用函数. 当 defmethod 为一个已存在的多重方法添加一个新的分派选项时, remove-method 执行相反的操作 (remove-all-methods 则移除所有分派选项):
(remove-method calculate :twoargs) ; ❶ (calculate {:op 'pow :expr [[:int 2] [:int 2]]}) ; ❷ ;; RuntimeException Don't know how to calculate {:op pow [...]}
❶ 参考前面涉及 calculate 多重方法的例子, 我们现在继续移除 :twoargs 键的分派方法.
❷ calculate 现在无法计算一个数的幂.
methods 提供了一种验证当前与多重方法注册的分派值的方式 (get-method 给定一个分派值检索单个分派函数):
(pprint (methods calculate)) ; ❶ ;; {nil ;; #object[user$eval2033$fn__2035 0x35addc75 "user$eval2033$fn__2035@35addc75"] ;; :onearg ;; #object[user$eval2045$fn__2047 0x5df37f84 "user$eval2045$fn__2047@5df37f84"] ;; :default ;; #object[user$eval2082$fn__2084 0x414b3262 "user$eval2082$fn__2084@414b3262"] ;; :varargs ;; #object[user$eval2013$fn__2015 0xcfa4eb3 "user$eval2013$fn__2015@cfa4eb3"]}
❶ methods 打印所有预期的多重方法, 确认 :twoargs 已从分派表中移除.
最后让我们看看 prefers 和 prefer-method. 我们能够表达偏好的原因是有时分派正确的 defmethod 存在歧义. 这在将多重方法扩展到接口类型时是典型情况, 因为 Java 允许从多个接口继承. 这里有一个使用 Clojure 数据结构的例子:
(defmulti edges ; ❶ "Retrieves first and last from a collection" type) (defmethod edges java.lang.Iterable [x] ; ❷ ((juxt first last) (seq x))) (defmethod edges clojure.lang.IPersistentList [x] ; ❸ ((juxt first last) (seq x))) (edges (list 1 2 3)) ; ❹ ;; IllegalArgumentException Multiple methods in multimethod 'edges' (prefer-method edges clojure.lang.IPersistentList java.lang.Iterable) (edges (list 1 2 3)) ; ❺ ;; [1 3]
❶ edges 是一个用于检索集合边缘项的多重方法. 它使用 type 函数进行分派.
❷ Clojure 中的许多集合都是可迭代的, 所以我们定义了一个版本的 edges 来处理它们.
❸ 我们还对 Clojure 列表的特定版本感兴趣.
❹ 如果我们尝试在一个列表上调用 edges, 我们会发现列表既是 IPersistentList 又是 Iterable.
❺ prefer-method 在分派有歧义时建立一个使用顺序.
我们可以使用 prefers 来检查偏好表中是否存在条目. 例如, 以下是 print-dup 定义的丰富偏好集:
(pprint (prefers print-dup)) ; ❶ ;; {clojure.lang.ISeq ;; #{clojure.lang.IPersistentCollection java.util.Collection} ;; clojure.lang.IRecord ;; #{java.util.Map clojure.lang.IPersistentCollection ;; clojure.lang.IPersistentMap} ;; java.util.Map ;; #{clojure.lang.Fn} ;; clojure.lang.IPersistentCollection ;; #{clojure.lang.Fn java.util.Map java.util.Collection} ;; java.util.Collection #{clojure.lang.Fn}}
❶ prefers 显示了 print-dup 的相当多的选择. Clojure 中几乎所有东西都是可打印的. 集合是一个典型的例子. print-dup 定义了一种适合将对象序列化到文件的格式, 并且必须处理互操作性所需的许多类似接口.
4.2.12. 15.12 总结
本章阐述了 Clojure 中用于生成类型和管理多态分派的设施. Clojure 提供了不同的方式来创建类型, 从更强大但更低级的 gen-class 到更专业的 proxy 或 reify. Clojure 也为多态分派提供了不同的选项. 多重方法在选择方法调用的接收者方面提供了极大的灵活性. 同时, 当速度很重要时, 使用协议进行基于类型的分派是一种更快的替代方案.
4.3. 16 Var 和命名空间
在介绍本节中的函数和宏之前, 有必要回顾一下关于 Clojure 命名空间, var 和局部绑定的几个定义.
- 命名空间
"命名空间" 是
clojure.lang.Namespace类的一个实例, 本质上是其他对象的容器. 它包含一个映射表和一个别名表.- "映射表" 是与每个命名空间关联的字典. 它包含 Clojure 符号和对象 (如 var 或类) 之间的映射. 像
intern或def这样的函数向表中添加项, 而ns-map显示其内容. - "别名表" 是与命名空间关联的另一种类型的字典. 它包含与其他命名空间的关系, 使用一个符号作为键, 一个命名空间名称作为值. 可以在命名空间创建期间使用
:as或使用alias函数向别名表添加项.ns-aliases显示其内容. - 一旦创建了一个命名空间, 一个引用就会被添加到 "全局命名空间仓库". 这是
clojure.lang.Namespace类内部的一个静态映射. 因此, 命名空间是 "全局的", 即运行的进程不需要持有显式的命名空间引用来保持它们存活 (从垃圾回收器的角度来看).
- "映射表" 是与每个命名空间关联的字典. 它包含 Clojure 符号和对象 (如 var 或类) 之间的映射. 像
- 库
"库" 是一个以其包含的命名空间声明命名的源文件. 库的概念与命名空间有很大的重叠, 但库规定了一些从文件中存储和重用 Clojure 代码的约定.
- 你可以使用
loaded-libs查看当前加载了哪些库. - 库的存在意味着相关命名空间的存在, 而反之则不总是成立 (例如,
create-ns只创建一个命名空间, 而不是一个库).require加载一个库和任何额外的传递性依赖.
- 你可以使用
- Var 和绑定
- "var" 对象是
clojure.lang.Var类的一个实例 (为了避免与其他语言混淆, 我们将使用更短的形式 "var" 而不是 "variable"). 一个 var 可以被认为是一个指向单个值的指针, 在涉及并发时可以选择持有多个值. - "根绑定" 是 var 可以关联的可选值. 它对所有线程都是可见的. 分配根绑定是 var 最典型的用法.
- "动态绑定" 是 var 与特定线程关联的值. 每个线程可以访问同一个 var 的不同值. 该特性不是默认启用的, 但可以通过在 var 定义期间传递
^:dynamic元数据来启用. - 一个允许动态绑定的 var 被称为 "动态的", 其名称按惯例用 "*" 包围 (口语上称为 "耳罩").
- 一个 var 可以是 "绑定的" (当它有根值时) 或 "线程绑定的" (当它至少有一个线程绑定的值时).
- 与根绑定相比, 线程绑定可以 "堆叠起来". 这是通过嵌套绑定形式来实现的. 在从每个嵌套的绑定作用域返回时, 先前的动态值被保留.
- 一个 var 总是至少与一个命名空间关联 (通过映射表). 因此, var (像命名空间一样) 也是全局的.
Var 的行为受到附加在其上的元数据的严重影响. 最重要的是:
:dynamic: 表示该 var 是启用线程局部的, 并且可以按线程基础堆叠值. 一个标记为动态的 var 可以与set!或var-get一起使用.:inline和:inline-arities启用 var "内联", 这是一种替代的实现, 在存在时优先于根绑定或线程绑定. 更多信息请参见definline.
Var 本身也是函数 (
ifn?在一个 var 上返回 true), 这是 Clojure 间接机制的组成部分 (这使得 Clojure 成为一种动态语言). 例如, 在用户命名空间中评估表达式(+ 1 1)会触发以下步骤:- 符号
+通过命名空间映射被解析. 假设存在一个键为+的条目 (对于用户命名空间总是如此), 则返回该条目的值. 命名空间映射中键+的值是名为clojure.core/+的 var 对象. - 如果来自映射的值是一个 var 对象, 它会被用给定的参数调用. 这相当于调用
(#'clojure.core/+ 1 1). 注意在这种情况下 var 对象被用作函数. - 当一个 var 对象作为函数被调用时, 它将调用委托给内联版本, 线程局部值或 var 的根绑定之间的第一个可用选项 (按此顺序). 具体来说,
+有一个针对两个参数的内联版本, 所以内联版本优先. 如果存在更多参数,+不会被内联, 所以会调用根绑定.
在这个详细的查找链的开始, 是符号
+的命名空间映射. 在链的末尾, 是编译期间生成的字节码. 为了理解当我们在 REPL 中调用(+ 1 1)时发生了什么, 我们可以单独重现每个步骤:(def user-ns-mapping (ns-map 'user)) ; ❶ (def lookup-var ('+ user-ns-mapping)) ; ❷ (lookup-var 1 1) ; ❸ ;; 2
❶ 首先, 我们保存一个对用户命名空间映射表内容的引用.
❷ 其次, 我们访问符号
+的值. 这是一个var类型的对象.❸ 最后, 我们用两个参数调用 var 对象. 这反过来
我们将从专门用于创建 var 的函数开始本章. 除了创建 var 对象本身, 这些函数还对命名空间数据结构产生副作用, 这使得 Clojure 能够动态工作.
- "var" 对象是
4.3.1. 16.1 def, declare, intern 和 defonce
def
def是一个特殊形式. 当用 "name" 和 "body" (最常见的调用方式) 调用时, 产生以下效果:- 创建并返回一个名为 "name" 的
clojure.lang.Var对象 (如果尚未存在). - 将 var 对象与评估的 "body" 关联.
- 在当前命名空间的映射中创建 (或替换) 相应的条目 (也称为将 var "驻留" 到命名空间中).
- 向 var 对象添加信息, 如源文件, 行号和列号.
我们可以通过以下步骤来验证以上所有内容:
(ns myns) ; ❶ (type (def mydef "thedef")) ; ❷ ;; clojure.lang.Var mydef ; ❸ ;; "thedef" (identical? (var mydef) ((ns-map 'myns) 'mydef)) ; ❹ ;; true (meta (var mydef)) ; ❺ ;; {:line 1, ;; :column 7, ;; :file "/private/var/form-init3920299731829243523.clj", ;; :name mydef, ;; :ns #object[clojure.lang.Namespace 0x68ff111c "myns"]}
❶
ns创建一个新命名空间 (除非已存在) 并将动态变量*ns*的值分配给相关的命名空间对象. 我们创建新命名空间的原因是, 我们希望确保能控制示例的所有方面, 而不受外部影响. 刚刚创建的命名空间处于 "原始" 状态: 映射表和别名表都没有更改.❷ 正如预期的那样,
def返回一个clojure.lang.Var类型的对象.❸ 在 REPL 中输入符号 "mydef" 默认会从命名空间映射中查找该 var. REPL 还会自动返回 var 的值, 而不是 var 对象本身. 换句话说, REPL 会自动在变量引用上调用
deref.❹ 我们可以用
ns-map从命名空间映射中获取 var 对象. 这里显示的两个表达式检索的是同一个对象. 最后一个是最明确的:ns-map返回与 'myns 对应的映射. 然后我们使用符号 'mydef 作为键来访问该映射.❺ 最后, 我们可以看到附加到 var 元数据上的其他信息. 评估该形式的 REPL 实例正在使用一个临时文件, 我们在这里可以看到它作为 ":file".
def也支持自定义元数据和一个文档字符串 (通常称为 "docstring"):(ns myns) (def ^{:created-at "date"} ; ❶ def-meta-doc "A def with metadata and docstring." 1) ; ❷ (clojure.repl/doc def-meta-doc) ; ❸ ;; ------------------------- ;; myns/def-meta-doc ;; A def with metadata and docstring. (:created-at (meta (var def-meta-doc))) ; ❹ ;; "date"
❶ 在
def和定义名称之间添加了一个元数据字面量映射. 它包含该定义的创建日期.❷ 文档字符串应该紧跟在
def名称之后, 在定义的主体之前.❸ 我们可以看到由
clojure.repl/doc提取的文档.❹ 元数据按预期附加到了 var 对象上.
- 创建并返回一个名为 "name" 的
declare
我们也可以在没有主体的情况下调用
def. 生成的 var 被称为 "未绑定的":(ns myns) (def unbound-var) ; ❶ ;; #'myns/unbound-var (type unbound-var) ; ❷ ;; clojure.lang.Var$Unbound
❶ 我们可以只用一个名称而没有主体来调用
def.❷ 评估
unbound-var会产生一个类型为Var$Unbound的占位符对象, 它代表了缺失的主体.在相互递归的定义中, 未绑定的 var 可能很有用. Clojure 甚至提供了一个
declare宏, 它创建一个命名的未绑定 var.declare有助于传达在没有主体的情况下创建 var 的语义含义. 在下面的例子中, 我们创建了一个状态机, 验证一个字符串中是否存在交替的 "0" 和 "1":(declare state-one) ; ❶ (def state-zero ; ❷ #(if (= \0 (first %)) (state-one (next %)) (if (nil? %) true false))) (def state-one ; ❸ #(if (= \1 (first %)) (state-zero (next %)) (if (nil? %) true false))) (state-zero "0100100001") ; ❹ ;; false (state-zero "0101010101") ; ❺ ;; true
❶
(declare state-one)等同于(def state-one), 但它立即阐明了缺少主体的原因:declare是关于后续定义中存在递归循环的警告.❷
state-zero定义了一个调用尚未定义的state-one的函数.declare允许state-one的定义, 不论是否存在主体.❸
state-one再次被定义, 这次带有适当的主体. 链接到state-one的 var 对象不会被再次创建, 而是被分配了一个用于评估的主体.❹ 状态机只匹配以 "0" 开始, 然后交替 "1" 和 "0" 的模式. 这个模式有一系列重复的零, 因此是无效的.
❺ 一个有效的模式会触发正确的答案.
intern
intern的工作方式与def类似, 但提供了在其他命名空间中创建定义的可能性:(ns myns) (create-ns 'ext) ; ❶ *ns* ; ❷ ;; #object[clojure.lang.Namespace 0x68ff111c "myns"] (intern 'ext 'ext-var 1) ; ❸ ;; #'ext/ext-var ((ns-map 'ext) 'ext-var) ; ❹ ;; #'ext/ext-var (intern 'yet-to-exist 'a 1) ; ❺ ;; Exception No namespace: yet-to-exist found
❶
create-ns创建一个新的命名空间 'ext'. 与其他与命名空间相关的宏相比,create-ns不会更改当前命名空间.❷ 我们可以检查动态变量
*ns*的内容, 以验证我们仍在同一个命名空间中.❸
intern执行了与def等效的操作, 目标是 'ext' 命名空间.❹ 'ext' 命名空间的映射包含了新生成的条目.
❺ 然而请注意,
intern不会自动创建不存在的命名空间, 如果命名空间不存在, 会抛出异常.intern对于所有程序的 var 定义都很有用. 例如, 我们可以创建一个新的命名空间和一系列 var, 而无需创建 Clojure 源文件:(def definitions ; ❶ {'ns1 [['a1 1] ['b1 2]] 'ns2 [['a2 2] ['b2 2]]}) (defn defns [definitions] ; ❷ (for [[ns defs] definitions [name body] defs] (do (create-ns ns) (intern ns name body)))) (defns definitions) ; ❸ ;; (#'ns1/a1 #'ns1/b1 #'ns2/a2 #'ns2/b2)
❶
definitions映射包含要创建的命名空间作为键, 以及作为向量的定义.❷
defns接受一个定义映射, 并使用for遍历命名空间和必需的定义. 我们需要记住在调用intern之前先create-ns, 以确保命名空间存在.❸
defns返回已创建并映射到相应命名空间的 var 列表.defonce
defonce是def的另一个变体.def通过 "upserting" 当前命名空间映射来允许重新定义: 如果一个条目已存在于定义中, 那么现有的 var 会被更新, 移除旧值 (var 评估为的值).defonce首先检查给定名称是否已存在一个已定义的 var, 并且仅在不存在时才创建新的定义:(def redefine "1") ; ❶ (defonce dont-redefine "1") (def redefine "2") (defonce dont-redefine "2") redefine ;; "2" dont-redefine ;; "1"
❶
def与defonce通过重复相同的定义并尝试将其值从 "1" 更改为 "2" 来进行比较.defonce不会改变其值.使用
defonce的一个好理由是保护重要数据免受意外重新定义.defonce的一个常见用法是与像 Stuart Sierra 的组件 229 这样的组件系统一起使用. "system" 作为def存在于某个命名空间中, 我们希望防止命名空间重载丢弃我们的系统, 而无法正确地关闭它. 对于这个特定的用例, 建议使用defonce.defonce不应与(def :^const)混淆. 在一个定义上存在元数据:const会产生类似于 "内联" 的效果: 所有对该定义的引用都会被该定义的值逐字替换. 评估后, 使用(def :^const)的 var 定义实际上停止存在, 不会创建命名空间映射或 var.
4.3.2. 16.2 var, find-var 和 resolve
本节还提到了其他相关函数, 如:
clojure.repl/dir-fn,clojure.repl/dir,bound?,thread-bound?,namespace
var
var是一个特殊形式, 它从当前或另一个命名空间中检索一个 var 定义 (与一个符号关联的clojure.lang.Var对象). 如果找不到 var, 它会抛出异常, 并且不会自动创建命名空间或符号:(var a) ; ❶ ;; CompilerException java.lang.RuntimeException: Unable to resolve var: a [...] (def a 1) (var a) ; ❷ ;; #'user/a (var test-var/a) ; ❸ ;; CompilerException java.lang.RuntimeException: Unable to resolve var: test-var/a [...] (create-ns 'test-var) (intern 'test-var 'a 1) (var test-var/a) ; ❹ ;; #'test-var/a (= (var a) (var test-var/a)) ; ❺ ;; false
❶ var "a" 在当前命名空间中不存在,
var抛出异常. 注意, 即使我们没有明确地将其限定为符号, "a" 也会被评估为符号. 在这方面,var的行为像一个宏.❷ 在定义 "a" 之后,
var正确地检索了 var 对象.❸
var接受命名空间限定的符号, 如test-var/a. 但命名空间尚不存在, 更不用说该命名空间中的 var "a" 了.❹ 在创建了命名空间和 "a" 的定义之后,
var返回与test-var/a关联的 var 对象.❺ 尽管定义在两种情况下都与符号 "a" 有关, 但 var 对象是不同的.
var和语法字面量#'
var还有一个等效的读宏#':(var clojure.core/+) ; ❶ ;; #'clojure.core/+ #'clojure.core/+ ; ❷ ;; #'clojure.core/+ (identical? (var clojure.core/+) #'clojure.core/+) ; ❸ ;; true
❶
var给定限定的符号clojure.core/+检索 var 对象. var 的打印方法被指示将 var 对象打印为读宏语法字面量.❷ Clojure 读宏将 "#" 解释为在读宏语法表中查找后面的 ' 单引号. 这在内部被转换为
(var clojure.core/+), 然后像往常一样编译, 导致评估完全相同的形式.find-var
find-var的工作方式与var类似, 但需要完全限定的符号作为输入 (一个符号名前面是一个命名空间, 并用正斜杠分隔, 例如:a/b). 在找不到 var 的情况下, 它不会抛出异常:(find-var 'user/test-find-var) ; ❶ ;; nil (find-var 'test-find-var) ; ❷ ;; IllegalArgumentException Symbol must be namespace-qualified
❶ 当搜索尚未创建的
test-find-var时,find-var返回nil. 注意, var 的名称是用user限定的, 这是一个在 REPL 中保证存在的命名空间.❷
find-var不接受非完全限定的符号.如果你不想使用
try-catch来处理不存在的 var, 优先使用find-var而不是var.resolve和ns-resolve
resolve和ns-resolve在查找 var 时在var和find-var的基础上增加了一些额外的选项.resolve总是使用当前命名空间进行搜索 (*ns*动态变量的内容), 而ns-resolve可以被给定一个特定的命名空间进行搜索.第一个增加的特性是搜索 Java 类以及 var 对象:
(resolve 'Exception) ; ❶ ;; java.lang.Exception (resolve (symbol "[I")) ; ❷ ;; [I
❶
resolve返回与符号'Exception关联的类. 这就是为什么在 REPL 中, 我们可以直接输入 "Exception" 而无需先导入该类. Clojure 会自动将大多数java.lang.*类导入到命名空间中.❷ 一个整数数组在 Java 中的类类型名称是用开方括号后跟字母 "I" 表示的. 我们可以通过从字符串创建符号来检索这种类型的类.
resolve提供的第二个特性是防止某些符号的解析. 我们可以使用该特性来有选择地允许覆盖某些 var 的值, 但不允许 "受保护的" var:(defn replace-var [name value] ; ❶ (let [protected #{'system}] (when (resolve protected name) (intern *ns* name value)))) (def mydef 1) ; ❷ (def system :dont-change-me) (replace-var 'x 2) ; ❸ ;; nil (replace-var 'mydef 2) ; ❹ mydef ;; 2 (replace-var 'system 2) ; ❺ system ;; :dont-change-me
❶
replace-var是一个用新值交换现有 var 值的函数. 它包含一组不能被覆盖的 "受保护的" var. 该集合被传递给resolve以避免解析一个现有的 var.❷ 我们定义了
mydef和system. 后者受replace-var保护.❸
resolve-var接受不存在的 var 并且不做任何事情.❹ 不受保护的现有 var 被替换为新的值/表达式.
❺ 然而, 我们无法替换受保护且对
resolve不可见的system.clojure.repl/dir-fn和clojure.repl/dir
dir-fn和dir是clojure.repl命名空间中的两个函数, 它们使用与 var 相关的函数来检索或打印命名空间中的公共定义. 例如:(require '[clojure.repl :refer [dir-fn dir]]) (require 'clojure.set) (dir-fn 'clojure.set) ; ❶ ;; (difference index intersection ;; join map-invert project rename ;; rename-keys select subset? ;; superset? union) (dir clojure.set) ; ❷ ;; difference ;; index ;; intersection ;; [..] ;; union ;; nil
❶
dir-fn返回命名空间中的公共定义列表. 在这种情况下, 我们可以看到clojure.set的公共定义. 该列表按字母顺序排序.❷
dir检索相同的列表并在屏幕上打印, 返回nil.bound?和thread-bound?
一个
clojure.lang.Var对象可以是 "绑定的" 或 "线程绑定的". 当一个表达式被分配为 var 的值时, 该 var 被称为 "绑定的". 在这种情况下, 所有线程共享相同的 var 视图. 但一个 var 也可以在特定线程的作用域内被赋值. 在后一种情况下, 每个线程都会看到自己的隔离值:(def ^:dynamic *dvar*) ; ❶ ((ns-map 'user) '*dvar*) ;; #'user/*dvar1* (bound? #'*dvar*) ;; false (thread-bound? #'*dvar*) ;; false (binding [*dvar* 1] ; ❷ [(bound? #'*dvar*) (thread-bound? #'*dvar*)]) ;; [true true] (def avar) ; ❸ (bound? #'avar) ;; false (thread-bound? #'avar) ;; false (intern *ns* 'avar 1) ; ❹ (bound? #'avar) ;; true (thread-bound? #'avar) ;; false
❶
*dvar*是一个用^:dynamic元数据标记的 var. 该 var 在定义时未绑定. 我们可以看到 var 对象已被创建并添加到命名空间映射中.bound?和thread-bound?都返回 false.❷ 通过
binding, 我们可以打开一个线程感知的上下文来设置动态 var. 在binding内部, 两个函数都返回 true.❸ 我们现在定义一个名为
avar的普通 var. 该 var 在定义时仍然是未绑定的, 两个函数都同意这一事实.❹ 如果我们用一个值来
intern该 var (这会查找映射中的 var 并更新其根), 我们可以看到该 var 现在是绑定的. 但从当前线程的角度来看, 该 var 仍然没有值,thread-bound?返回 false.两个函数都接受多个参数, 只有当所有 var 都被绑定时才返回 true:
(def a 1) (def b 2) (def c 3) (bound? #'a #'b #'c) ; ❶ ;; true
❶
bound?和thread-bound?都接受任意数量的 var. 在这种情况下, 它验证所有的 var 是否都已绑定.
4.3.3. 16.3 alter-var-root 和 with-redefs
alter-var-root
像
def或intern一样,alter-var-root更改一个 var 对象的根值. 与它们不同的是,alter-var-root不触及命名空间映射.alter-var-root接受一个从旧值到新值的函数作为参数:(def a-var {:a 1}) (alter-var-root #'a-var update-in [:a] inc) ; ❶ ;; {:a 2}
❶
alter-var-root更改了 vara-var的根绑定. 它接受一个从旧值到新值的函数 (在本例中是update-in), 以及任何额外的参数. 新值被返回.alter-var-root以原子方式执行更改: 在更改 var 时, 相应的 var 对象被锁定以进行读取或写入 ("synchronized" 在 Java 术语中):(def a-var 1) (future ; ❶ (alter-var-root #'a-var (fn [old] (Thread/sleep 10000) (inc old)))) ;; blocking call for 10 seconds a-var ; ❷ ;; 2
❶
alter-var-root从另一个线程执行, 有 10 秒的延迟.❷ 如果我们立即尝试访问
a-var来读取其值, 我们会被阻塞, 直到alter-var-root完成.alter-var-root和definline
即使
alter-var-root实际上交换了 var 的根绑定, 但如果 var 是内联的, 效果可能不会被看到. "内联" 意味着 var 在元数据中包含一个替代的实现, 该实现被调用而不是根绑定:(definline timespi [x] `(* ~x 3.14)) ; ❶ (alter-var-root #'timespi (fn [_] (constantly 1))) ; ❷ (timespi 100) ; ❸ ;; 314.0 (alter-meta! #'timespi dissoc :inline-arities :inline) ; ❹ (timespi 100) ; ❺ ;; 1
❶
timespi是一个将一个数字与 Pi 常量相乘的简单函数. 包含timespi的 var 是内联的: var 上的元数据包含一个预编译的函数评估.❷ 我们在 var 对象上调用
alter-var-root, 将根绑定更改为一个总是返回 1 的新函数.❸ 调用
timespi会调用函数的内联版本, 该版本并未更改.❹ 我们需要更改或移除 var 对象上的相关元数据, 以强制通过根绑定进行评估.
❺
timespi现在调用 var 对象的根绑定.with-redefs和with-redefs-fn
with-redefs和with-redefs-fn创建一个上下文, 在该上下文中, 一系列 var 临时采用不同的根绑定. 在从封闭形式返回后, 会重新建立先前的绑定:(defn fetch-title [url] ; ❶ (let [input (slurp url)] (last (re-find #"Title: (.*)\." input)))) (def sample-article "Some Title: Salary increases announced.") (with-redefs [slurp (constantly sample-article)] ; ❷ (= "Salary increases announced" (fetch-title "url"))) ;; true
❶
fetch-title被设计为请求给定网址的内容, 并用正则表达式搜索文本. 这个函数本身需要连接到网络来执行请求.❷ 我们不假设有可用的网络连接来测试函数, 而是使用
with-redefs来临时更改附加到slurpvar 的函数, 强制它返回一个示例字符串.with-redefs是一个包装with-redefs-fn的宏, 所以我们不需要使用显式的 var 对象和包装函数. 下面的例子与前一个等效, 但可读性稍差:(with-redefs-fn {#'slurp (constantly sample-article)} ; ❶ #(= "Salary increases announced" (fetch-title "url"))) ;; true
❶ 与
with-redefs相比,with-redefs-fn需要一些更多的语法糖, 但这两个函数是等效的.上面的例子与测试有关, 这并非巧合. 对于一个生产中的 Clojure 应用程序来说, 包含对
with-redefs或with-redefs-fn的调用是危险的, 因为它们不是线程安全的:(defn x [] 5) ; ❶ (defn y [] 9) (dotimes [i 10] ; ❷ (future (with-redefs [x #(rand)] (* (x) (y)))) (future (with-redefs [y #(rand)] (* (x) (y))))) [(x) (y)] ; ❸ ;; [0.6022778872500808 9]
❶
x和y是返回 5 和 9 的示例函数.❷ 我们创建了几个线程, 每个线程都在
with-redefs形式内更改x或y. 我们期望相应的 var 在经过线程后保持不变.❸
x或y(或两者) 可能已被with-redefs永久更改. 注意: 你可能会得到与本例中呈现的不同结果.上面例子中的问题是,
with-redefs在一个变量被其他线程更改的过程中可能会访问一个已更改的值. 然后它会替换回一个不是原始的根绑定. 为了解决这个问题, 我们应该使用动态的线程绑定 var:(defn ^:dynamic x [] 5) ; ❶ (defn ^:dynamic y [] 9) (dotimes [i 10] ; ❷ (future (binding [x #(rand)] (* (x) (y)))) (future (binding [y #(rand)] (* (x) (y))))) [(x) (y)] ; ❸ ;; [5 9]
❶ 现在
x和y都是动态 var.❷
with-redefs不会将值绑定到 var 的线程局部状态. 我们需要binding来访问线程局部状态.❸ 线程不再相互干扰, 因为每个绑定都是隔离的, 不会触及根绑定.
4.3.4. 16.4 binding
本节还提到了其他相关函数, 如:
with-binding,with-binding*,push-thread-bindings,pop-thread-bindings,bound-fn,bound-fn*.
binding 创建一个上下文, 在该上下文中, var 可以被分配一个线程局部值, 而不触及根绑定. 动态 var 可以用来在同一线程中的调用之间共享简单的状态, 而无需将相同的参数传递给所有函数. 下面的例子假设一个并发系统为每个请求分配一个线程 (Web 应用程序的常见情况). 如果系统被调用时带有 trace=enabled, 我们会收集关于该特定请求的更多信息:
(in-ns 'user) (def ^:dynamic *trace*) ; ❶ (defmacro trace! [msg & body] ; ❷ `(do (when (thread-bound? #'*trace*) (set! *trace* (conj *trace* ~msg))) ~@body)) (defn params [query] ; ❸ (let [pairs (clojure.string/split query #"&")] (trace! (format "Handling params %s" pairs) (->> pairs (map #(clojure.string/split % #"=")) (map #(apply hash-map %)) (apply merge))))) (defn handle-request [{:strs [op arg1 arg2]}] ; ❹ (let [op (resolve (symbol op)) x (Integer. arg1) y (Integer. arg2)] (trace! (format "Handling request %s %s %s" op x y) (op x y)))) (binding [*trace* []] ; ❺ (let [query "op=+&arg1=1&arg2=2" res (handle-request (params query))] (pprint *trace*) res)) ;; ["Handling params [\"op=+\" \"arg1=1\" \"arg2=2\"]" ;; "Handling request #'clojure.core/+ 1 2"] ;; 3
❶ *trace* var 是 ^:dynamic 并且未绑定的.
❷ trace! 是一个宏, 它在执行一个形式之前添加一个跟踪消息. 跟踪取决于 *trace* 中是否存在线程局部值, 这只在 *trace* 出现在绑定上下文中时发生. 如果绑定存在于任何上游, 跟踪就被启用.
❸ params 接受一个 URL 编码的参数字符串, 并将其转换为一个映射. 注意使用 trace! 宏在启用跟踪时产生一条消息.
❹ handle-request 执行参数的实际解释. 它遵循相同的模式来跟踪数据.
❺ 请求处理在一个初始化 *trace* 为空向量的绑定块内开始. 绑定的存在标志着需要跟踪该请求. 这方面可以附加到请求本身的参数中.
注意在上面的例子中, 包含消息的向量从未作为参数传递给其他函数. 消息通过 *trace* 动态 var 共享, 无需除封闭的 binding 形式之外的任何特殊同步.
bound-fn
本节中的其他函数,
with-binding,with-binding*,push-thread-bindings,pop-thread-bindings,bound-fn和bound-fn*, 要么是更低级的, 要么是更具体的 (并且很少使用). 以下是一个摘要:with-bindings和with-bindings*(宏和函数版本) 与binding类似, 但需要一个绑定映射和显式的 var 对象. 使用它们来定制获取 var 对象的方式, 或者如果你想分开存储绑定对 (var 对象和值).push-thread-bindings和pop-thread-bindings是用于设置线程局部绑定的更低级原语. 它们应该按以下顺序调用: 推送绑定, 评估主体, 在一个finally块中弹出绑定. 你不太可能需要以不同的方式处理绑定, 这就是binding已经为我们做的事情.bound-fn和bound-fn*(宏和函数版本) 是用于包装现有函数的辅助函数, 以便在函数从绑定形式内部创建新线程时传播线程局部变量.
bound-fn值得一些额外的解释. 动态 var 的值是线程局部的, 不与其他线程共享其状态. 然而, 在一个已存在的绑定上下文中创建一个新线程是合法的:(def ^:dynamic *debug*) (defn debug [msg] ; ❶ (when (and (thread-bound? #'*debug*) *debug*) (println "Debugging..." msg))) (binding [*debug* true] ; ❷ (.start (Thread. #(debug "from a thread.")))) ;; nil (binding [*debug* true] ; ❸ (.start (Thread. (bound-fn* #(debug "from a thread."))))) ;; Debugging... from a thread. ;; nil
❶
debug是一个检查*debug*动态 var 是否有线程绑定的函数.❷ 如果我们将函数调用包装在一个设置
*debug*为 true 的绑定形式中, 我们期望调试消息会打印在屏幕上. 但消息没有出现. 原因是内部形式正在创建一个独立的线程, 线程局部绑定按定义对新线程是不可见的.❸
bound-fn*将作为参数传递的函数包装在另一个函数中, 该函数在调用内部函数之前, 会将当前线程的绑定复制到下一个线程. 我们可以看到调试消息正确地出现了.bound-fn帮助正确地传播绑定. Clojure 本身在内部使用bound-fn与future和其他并发原语.
4.3.5. 16.5 with-local-vars, var-get 和 var-set
with-local-vars 创建一个线程局部作用域, 可以在其中创建和改变 var. 与 var-get 和 var-set 一起, with-local-vars 允许一种命令式的, 但线程安全的编程风格. 例如, 下面是一个 count-even 函数, 它每次一个数能被 2 整除时就递增一个计数器:
(defn ++ [v] ; ❶ (var-set v (inc (var-get v)))) (defn count-even [xs] ; ❷ (with-local-vars [a 0] (doseq [x xs] (when (zero? (rem x 2)) (++ a))) @a)) (count-even (range 10)) ; ❸ ;; 5
❶ ++ 用递增的方式在一个 var 对象上实现变异. 该函数希望模仿 Java 在循环中改变局部变量的方式, 不同之处在于 Clojure 提供了并发处理, 而无需任何显式锁定.
❷ with-local-vars 创建一个名为 "a" 的新 var 对象, 然后将其线程局部值赋为 0. var "a" 现在在该形式内部可供读取或写入.
❸ 正如预期的那样, 从 0 到 9 的范围内有 5 个偶数.
注意, 多个线程访问 count-even 会对计数器进行隔离的更改, 从而实现线程安全的变异. 还要注意 var "a" 从未在函数外显式定义 (例如用 def). 即使是这样 (例如, (def a 10) 出现在顶层某处), with-local-vars 内部 "a" 的定义也会覆盖任何外部引用.
使用 with-local-vars 的唯一原因是强制使用命令式风格的可变局部变量而不是习惯性的递归, 这是为了模仿其他具有此选项的 Lisp 语言而做出的让步. 然而, 在现实世界的 Clojure 代码中很少见到 with-local-vars.
4.3.6. 16.6 ns, in-ns, create-ns 和 remove-ns
ns 是 Clojure 中最基础的宏之一, 因为在声明任何其他东西之前, 必须先存在一个命名空间. 调用 (ns myns) 来创建命名空间 "myns", 会扩展为一个对 in-ns 的调用, 该调用执行以下初步操作:
- 在全局命名空间仓库中搜索一个已存在的命名空间 "myns". 如果没有找到, 它会创建一个新的, 并将其添加到全局命名空间仓库中.
- 在创建新命名空间时,
in-ns还会将 "默认导入" 注入到命名空间映射中, 例如,java.lang.*类的列表, 这些类可以直接在命名空间中声明的其他形式中使用. - 它将动态变量
*ns*设置为 "myns" (REPL 使用此信息来更改光标名称).
ns 宏在 in-ns 的基础上添加了以下操作:
- 为
clojure.core中的每个公共 var 在 "myns" 映射表中添加一个条目 (允许在不显式require的情况下访问标准库函数). - 将 "myns" (作为符号) 添加到存储在私有动态变量
*loaded-libs*中的已加载库列表中 (你可以使用函数loaded-libs访问*loaded-libs*的内容).
var 的定义隐式地使用 *ns* 作为其命名空间, 因此每个定义都自动与当前的命名空间声明 (或如果没有, 则为 user) 关联:
(def a 1) ; ❶ (ns-name (.ns #'a)) ;; user (ns ns1) (def b 1) ; ❷ (ns-name (.ns #'b)) ;; ns1
❶ Clojure REPL 在 user 命名空间中引导自己. 我们可以通过创建一个 var "a" 的定义并询问其命名空间的名称来验证这一点. 标准库中没有直接访问 var 对象的命名空间的函数, 所以我们使用 Java 互操作来调用 .ns 方法. ns-name 提取命名空间的名称.
❷ 在创建了一个新命名空间 "ns1" 之后, 我们重复该操作并创建另一个定义. 这次 var 的命名空间是 "ns1".
ns 支持大量选项, 以在创建命名空间时更改映射和别名. 大多数选项也作为顶层函数提供, 并且可以独立使用 (通过对当前 *ns* 命名空间的隐式引用). 由于函数的工作方式与 ns 中的相关选项类似, 请参考以下内容获取详细信息: refer-clojure, refer, require, use, import 和 gen-class. 以下是一个展示所有这些的例子:
(create-ns 'a) (ns my.ns (:refer a) ; ❶ (:refer-clojure :exclude [+ - * /]) ; ❷ (:import java.util.Date) ; ❸ (:require (clojure.set)) ; ❹ (:use (clojure.xml)) ; ❺ (:gen-class)) ; ❻
❶ :refer 从命名空间 "a" 的映射表中复制公共 var 到命名空间 "my.ns" 的映射表中. 注意我们之前创建了 "a".
❷ :refer-clojure 与 :refer 相同, 但仅适用于 clojure.core. 我们在这里看到一个支持的选项 :exclude, 它阻止了一些算术函数在 "my.ns" 中可用.
❸ :import 在 "my.ns" 的映射表中为一个或多个 Java 类创建一个新条目. Java 类仅使用名称作为键添加, 而不是整个包.
❹ :require 假定在当前类路径上存在一个文件. 约定是, 除了最后一个之外的所有点分隔的单词都构成从类路径根目录开始的文件夹路径 (例如 "clojure/"), 最后一个单词是文件名 (例如 "set.clj"). 如果文件存在, 则会创建相应的命名空间.
❺ :use 像 :require 一样加载相应的文件, 但额外地 :refer 到所有公共符号.
❻ :gen-class 在命名空间创建期间启用与 gen-class 相同的功能. 在这种情况下, 如果命名空间被编译, 它还将生成一个同名的类.
与 ns 和 in-ns 相比, create-ns 纯粹是关于创建命名空间. 使用 create-ns 只有两个副作用: 一个是在全局命名空间仓库中创建的条目, 另一个是从 java.lang.* 包中导入的类, 这些类立即在映射表中可用. 让我们验证 create-ns 的行为:
new-ns/var-def ; ❶ ;; CompilerException java.lang.RuntimeException: No such namespace: new-ns (contains? (set (map ns-name (all-ns))) 'new-ns) ; ❷ ;; false (create-ns 'new-ns) ; ❸ (intern 'new-ns 'var-def "now it's working") ; ❹ (contains? (ns-map 'new-ns) 'var-def) ; ❺ ;; true new-ns/var-def ; ❻ ;; "now it's working" (contains? (set (map ns-name (all-ns))) 'new-ns) ; ❼ ;; true ('Integer (ns-map 'new-ns)) ; ❽ ;; java.lang.Integer
❶ 命名空间 "new-ns" 不存在. 如果我们试图访问该命名空间中的任何东西, 就会得到一个错误.
❷ 全局命名空间仓库确认不存在这样的命名空间.
❸ create-ns 创建命名空间 (并且不改变当前的命名空间).
❹ intern 在 new-ns 中创建一个新 var "var-def".
❺ 我们还验证了 intern 在 "new-ns" 的映射表中添加了相关的条目.
❻ 简单的表达式现在可以正确解析, 在全局仓库中查找命名空间, 然后在映射表中查找符号.
❼ 对新创建的命名空间的存在进行最后一次检查.
❽ 属于 java.lang.* 命名空间的 Java 类 (除了少数例外) 立即在命名空间映射表中可用.
一个命名空间也可以用 remove-ns 删除. 让我们删除在前面例子中创建的命名空间 "new-ns":
(remove-ns 'new-ns) ; ❶ new-ns/var-def ; ❷ ;; CompilerException java.lang.RuntimeException: No such namespace: new-ns
❶ remove-ns 从全局仓库中移除给定的命名空间.
❷ 正如预期的那样, var 解析停止工作.
remove-ns 应谨慎使用, 因为它可能仍然在其他命名空间中被引用, 从而产生各种问题. 如果一个命名空间被另一个命名空间引用, 垃圾回收器将无法回收相应的对象引用. 更危险的是, 如果再次创建相同的命名空间, 可能会出现指向旧引用和新引用的命名空间的混合:
(create-ns 'disappear) ; ❶ (intern 'disappear 'my-var 0) (refer 'disappear :only ['my-var]) ;; nil my-var ;; 0 (remove-ns 'disappear) ;; #object[clojure.lang.Namespace 0x1f780201 "disappear"] (.ns #'my-var) ; ❷ ;; #object[clojure.lang.Namespace 0x1f780201 "disappear"] (create-ns 'disappear) ; ❸ (intern 'disappear 'my-var 1) my-var ; ❹ ;; 0 @#'disappear/my-var ; ❺ ;; 1
❶ 调用序列创建了一个新的命名空间 "disappear", 包括一个 var "my-var". 该 var 被导入到当前命名空间的映射中, 在那里它按预期评估为 0.
❷ 移除命名空间 "disappear" 后, 我们可以看到 "my-var" 仍然保持着命名空间的存活. 垃圾回收器不能移除命名空间对象, 直到没有更多对它的引用.
❸ 一个同名和 var 的命名空间再次被创建, 这次的值是 1.
❹ 然而, 本地的 "my-var" 条目仍然运行着 var 的旧副本.
❺ 我们可以看到新的 var 应该有不同的评估值, 但我们的命名空间中有一个过时的副本.
为了避免与移除命名空间相关的危险, 我们应该跟踪来自其他命名空间的所有对该命名空间的引用, 并相应地级联删除它们. 这很乏味且容易出错, 但幸运的是, 有像 "clojure/tools.namespace" 这样健壮的库来帮助我们 230.
4.3.7. 16.7 alias, ns-aliases 和 ns-unalias
函数组 alias, ns-aliases 和 ns-unalias 是控制命名空间别名映射的小型编程接口. 在创建命名空间之后, 别名表通常是空的:
(create-ns 'com.web.tired-of-typing-this.myns) (ns-aliases 'com.web.tired-of-typing-this.myns) ; ❶ ;; {}
❶ ns-aliases 显示命名空间 com.web.tired-of-typing-this.myns 的别名表内容. 这个名称故意设置得很长.
刚刚创建的命名空间有一个相当长的名字, 但这是一个很常见的情景. 如果创建的命名空间包含一个 var, 我们可以引用该 var 而无需 require 该命名空间:
(intern 'com.web.tired-of-typing-this.myns 'myvar 0) ; ❶ com.web.tired-of-typing-this.myns/myvar ; ❷ ;; 0
❶ intern 在命名空间中创建一个 var "myvar".
❷ 评估 com.web.tired-of-typing-this.myns/myvar 产生访问和解引用 "myvar" 的预期结果.
即使可以通过完全限定来访问 var, 但每次都输入包名是重复的, 而且不太可读. 我们可以给长命名空间分配一个别名, 并从那时起用它来引用原始命名空间:
(alias 'myns 'com.web.tired-of-typing-this.myns) ; ❶ (ns-aliases *ns*) ; ❷ ;; {myns #object[clojure.lang.Namespace 0x58d455df ;; "com.web.tired-of-typing-this.myns"]} myns/myvar ; ❸ ;; 0
❶ alias 在当前命名空间的别名表中添加一个条目.
❷ 如果我们检查别名表, 我们可以看到一个新的键 "myns" 和命名空间对象作为值.
❸ 使用别名代替原始命名空间具有与访问变量相同的效果.
ns 在使用 :as 选项时提供了一个类似的功能, 但前提是命名空间可以从文件中加载 (这是最常见的情况):
(ns anotherns (:require [clojure.set :as s])) ; ❶ (ns-aliases 'anotherns) ; ❷ ;; {s #object[clojure.lang.Namespace 0x5d1fa08b "clojure.set"]}
❶ ns (和 require) 提供了在使用 :as 选项时同时创建命名空间和别名的选项. 这只在命名空间在类路径的文件中定义时才有效. clojure.set 的情况就是这样, 它是标准库的一部分.
❷ 我们检查别名表以看到符号 "s" 现在指向 clojure.set 命名空间.
最后提及 ns-unalias, 毫不奇怪, 它从别名表中移除一个别名条目. 参考前面的例子, 我们可以决定移除别名:
(ns-aliases 'anotherns) ; ❶ ;; {s #object[clojure.lang.Namespace 0x5d1fa08b "clojure.set"]} (ns-unalias 'anotherns 's) ; ❷ (ns-aliases 'anotherns) ; ❸ ;; {}
❶ 之前创建的 clojure.set 的别名在别名表中仍然可见.
❷ ns-unalias 接受一个命名空间符号和要移除的条目键.
❸ 别名按预期被移除.
4.3.8. 16.8 ns-map 和 ns-unmap
每个命名空间都持有一个映射表的引用. 映射表是一个包含符号键到 var 对象引用的键值对的映射. 在评估符号时, 映射表是解析名称的主要设备. 如果命名空间是使用标准库的函数创建的 (而不是, 例如, Java 互操作), 映射表永远不会是空的:
(ns myns (:require [clojure.pprint :refer [pprint]])) (pprint (ns-map 'myns)) ; ❶ ;; {primitives-classnames #'clojure.core/primitives-classnames, ;; +' #'clojure.core/+', ;; Enum java.lang.Enum, ;; decimal? #'clojure.core/decimal?, ;; restart-agent #'clojure.core/restart-agent, ;; sort-by #'clojure.core/sort-by, ;; [...]} (distinct (map #(map type %) (ns-map 'myns))) ; ❷ ;; ((clojure.lang.Symbol clojure.lang.Var) ;; (clojure.lang.Symbol java.lang.Class))
❶ 一个新创建的命名空间中的映射列表相当大. 我们在这里只显示了初始部分.
❷ 存在的唯一两种键值对变体是符号到 var 或符号到类的映射.
我们可以使用 ns-unmap 从映射中移除一个条目 (例如, 移除一个已删除命名空间的内容). 在这里, 我们从 "myns" 中可用的函数中移除 +:
(ns-unmap 'myns '+) ; ❶ ;; nil (+ 1 1) ; ❷ ;; Unable to resolve symbol: +
❶ "+" 的条目已从命名空间中移除.
❷ 结果是, 我们无法对数字求和.
+ 函数并未从系统中消失, 只是在 "myns" 中不可用. 我们可以用 refer 将其放回:
(refer 'clojure.core :only ['+]) ; ❶ (+ 1 1) ;; 2
❶ refer 有权访问命名空间的映射表, 并将已移除的条目添加回去.
4.3.9. 16.9 ns-publics, ns-interns, ns-imports
ns-publics, ns-interns 和 ns-imports 是对 ns-map 返回结果的不同过滤器. ns-map 按原样检索命名空间映射表的内容, 其中包括公共 var, 私有 var 和类. 在继续示例之前, 让我们设置一个方便的空命名空间:
(ns user) (defn clean-ns [ns] ; ❶ (let [ks (keys (ns-map ns))] (doseq [k ks] (ns-unmap ns k)))) (ns myns) (#'user/clean-ns 'myns) (clojure.core/alias 'c 'clojure.core) ; ❷ (c/ns-map 'myns) ; ❸ ;; {}
❶ clean-ns 完全移除给定命名空间映射表中的所有映射.
❷ 清理命名空间后, 我们需要一个快速的方法来访问标准库中的函数, 而不创建任何映射. 我们可以使用 alias 来为 clojure.core 创建一个别名 "c".
❸ 我们可以看到命名空间确实是空的.
现在我们已经清除了命名空间, 我们可以添加一些定义来测试过滤器:
(def normal-var :public) ; ❶ (def ^:private private-var :private) (c/import 'java.lang.Number) (c/ns-map 'myns) ; ❷ ;; {private-var #'myns/private-var, ;; Number java.lang.Number, ;; normal-var #'myns/normal-var} (c/ns-publics 'myns) ; ❸ ;; {normal-var #'myns/normal-var} (c/ns-interns 'myns) ; ❹ ;; {private-var #'myns/private-var ;; normal-var #'myns/normal-var} (c/ns-imports 'myns) ; ❺ ;; {Number java.lang.Number}
❶ 注意, def 是一个特殊形式, 它在 clojure.core 或任何其他命名空间的映射表中没有条目, 所以我们不需要在调用前加上 c/def.
❷ 映射表的设置已完成, 我们可以看到其内容.
❸ ns-publics 仅检索值为公共 var 的条目.
❹ ns-interns 仅检索值为公共或私有 var 的条目.
❺ ns-imports 仅检索值为类的条目 (更准确地说, 是任何非 var 的东西).
4.3.10. 16.10 refer, refer-clojure, require, loaded-libs, use, import
我们在讨论 var 和命名空间时已经使用了本节中提到的大部分函数. 例如, ns 宏将其大部分选项委托给一个或多个 require, refer, use, import, refer-clojure. 我们将在这里看到更多细节.
refer
refer使用另一个命名空间作为源, 将条目添加到目标命名空间的映射表中. 我们将从一个完全干净的命名空间开始, 以展示其工作原理:(ns user) (defn clean-ns [ns] (ns 'user) (create-ns ns) (let [ks (keys (ns-map ns))] (doseq [k ks] (ns-unmap ns k))) (ns-map ns)) (clean-ns 'myns) ; ❶ ;; {} (binding [*ns* (the-ns 'myns)] ; ❷ (refer 'clojure.core :only ['+ '-] :rename {'+ 'plus '- 'minus})) (ns-map 'myns) ; ❸ ;; {minus #'clojure.core/- ;; plus #'clojure.core/+}
❶ "myns" 命名空间的映射表是完全空的.
❷
refer不接受目标命名空间, 但它使用*ns*的当前值作为源命名空间. 我们可以使用binding形式临时更改*ns*, 以使用 "myns" 作为源.refer支持一些选项, 例如:only来过滤要导入的符号, 以及:rename映射来更改它们的名称.❸ "myns" 中的映射列表确认我们导入了两个符号.
refer-clojure与refer非常相似, 但仅限于使用clojure.core作为导入源. 所以前面的例子可以写成:(binding [*ns* (the-ns 'myns)] ; ❶ (refer-clojure :only ['+ '-] :rename {'+ 'plus '- 'minus}))
❶ 用
refer-clojure重写前面的refer.require
require的工作单元是 "库", 这是类路径上遵循特定命名约定的文件. 作为加载库的副作用, 它还创建一个新的命名空间:(contains? (set (map ns-name (all-ns))) 'clojure.set) ; ❶ ;; false (require 'clojure.set) (contains? (set (map ns-name (all-ns))) 'clojure.set) ; ❷ ;; true
❶ 假设从 Clojure uberjar 中新启动一个 REPL 会话,
clojure.set命名空间不存在, 尽管类路径中包含一个名为clojure/set.clj的文件, 该文件包含创建该命名空间的配方. 但该文件从未被require.❷ 在命名空间上调用
require后, 一旦文件被加载, 它就会被创建. 该命名空间最终会出现在全局仓库中.我们可以使用
loaded-libs来验证到目前为止加载了哪些库. 这可能是显式调用require或use的结果, 或者是由于另一个库需要它们而传递性地遍历其他require语句的结果:(def libs (loaded-libs)) (pprint libs) ; ❶ ;; #{clojure.core.protocols clojure.core.server clojure.edn ;; clojure.instant clojure.java.browse clojure.java.io ;; clojure.java.javadoc clojure.java.shell clojure.main clojure.pprint ;; clojure.repl clojure.string clojure.uuid clojure.walk} (require '[clojure.data :refer [diff]]) (def nss (set (map ns-name (all-ns)))) (pprint (diff libs nss)) ; ❷ ;; [nil ; ❸ ;; #{user clojure.core clojure.set clojure.data} ; ❹ ;; #{clojure.core.protocols clojure.core.server clojure.edn ; ❺ ;; clojure.instant clojure.java.browse clojure.java.io ;; clojure.java.javadoc clojure.java.shell clojure.main clojure.pprint ;; clojure.repl clojure.string clojure.uuid clojure.walk}]
❶ 这是在一个新打开的 REPL 上运行
loaded-libs的典型结果. 我们可以看到 Clojure 标准库中的一些常见文件.❷ 一个需要验证的有趣方面是, 每个库肯定都有一个对应的命名空间, 但反之则不一定成立. 例如, 用
create-ns或in-ns创建的命名空间不被注册为库.❸ 我们将
clojure.data/diff的结果解释如下: 没有不是命名空间的库 (如预期的那样).❹ 有趣的是, 有一些命名空间没有库, 尽管像
clojure.set或clojure.data这样的命名空间在 Clojure 发行版中肯定有对应的文件. 这种行为的一个原因是, 像ns这样的宏作为特殊形式开始它们的存在, 并在引导过程中稍后被重新定义.ns的特殊形式缺少任何与更新全局命名空间仓库相关的功能. 一些命名空间是使用特殊形式ns创建的, 而另一些是使用宏重定义创建的.❺ 最后, 我们可以看到带有相应库文件的命名空间列表, 这是绝大多数.
注意,
require不会作用于没有文件支持的命名空间, 即使该命名空间已经存在:(create-ns 'test-require) ; ❶ (require 'test-require) ; ❷ ;; Could not locate test_require__init.class or test_require.clj on classpath.
❶
create-ns创建一个新命名空间.❷
require不会作用于不是作为加载相应库的副作用而创建的命名空间.require经常与:as或:refer选项一起使用. 这尤其在与ns宏结合时是正确的, 但它们也可以直接使用:(ns myns) (require '[clojure.set ; ❶ :as se ; ❷ :refer [union]] ; ❸ '[clojure.string ; ❹ :as st :refer :all]) ; ❺ ;; WARNING: reverse already refers to: #'clojure.core/reverse ;; WARNING: replace already refers to: #'clojure.core/replace
❶ 注意使用方括号. 它们是包含选项所必需的, 因为不同的库可能有不同的选项集.
❷
:as在当前命名空间中创建一个解析为库的别名.❸
:refer将指定的符号导入到命名空间映射中.❹ 你可以在一个
require调用中列出许多库.❺ 当指定
:refer :all时, 库中的所有公共 var 都会被导入到命名空间映射中.当命名空间映射表中的一个条目被一个具有相同键的不同条目替换时, Clojure 编译器会发出一个警告. 在上面的例子中, 我们可以看到
reverse和replace都已经存在于映射表中, 并且它们已经被来自clojure.string命名空间的新定义所替换. 这是应该谨慎使用:refer :all的原因之一, 以避免意外重新定义核心函数.关于从库中导入映射的一般智慧是, 将它们限制在可读性所需的最小范围内, 并在可能的情况下优先使用别名. 一旦一个库中的所有符号都被导入到当前命名空间的映射中, 就很难理解它们是在哪里定义的, 有随着时间推移污染命名空间不需要的映射的风险.
use
use混合了require的语义和refer的选项:(ns myns) (use '[clojure.java.io ; ❶ :only [reader file] ; ❷ :rename {reader r}] ; ❸ :verbose :reload-all) ; ❹ ;; (load "/clojure/java/io") ;; (in-ns 'myns) ;; (refer 'clojure.java.io :only '[reader file] :rename '{reader r})
❶ 在
ns宏之外使用时,use需要引用的符号. 我们可以引用向量以引用其中的所有符号.❷
:only将要导入到本地命名空间映射的符号数量限制. 也支持:exclude, 意图相反.❸
:rename通过提供以与原始命名空间不同的名称驻留符号的选项来工作.❹
use和require也支持:reload,:reload-all和:verbose. 重载强制重载文件以与文件系统上可能的变化重新同步.:reload-all也重载任何传递性依赖.:verbose打印关于命名空间加载的信息, 特别是关于依赖树的信息.use不支持用:as进行别名, 这可能导致非常长的:only符号列表. 可能由于这个原因, 它过去被滥用来一直导入所有符号, 吸引了大量的负面反馈. 如今, 用别名的require提供了比use更好的建立命名空间依赖的选项, 并且通常是首选. 但use仍然可以用于require不支持的重命名选项.import
import是refer对类的宏等价物, 而不是 var:(ns user) (clean-ns 'myns) ; ❶ ;; {} (binding [*ns* (the-ns 'myns)] ; ❷ (import '[java.util ArrayList HashMap])) ; ❸ (ns-imports 'myns) ; ❹ ;; {HashMap java.util.HashMap ;; ArrayList java.util.ArrayList}
❶ 请参见
refer中clean-ns函数的定义. 它会删除给定命名空间的所有映射.❷
import不接受源命名空间作为参数, 所以我们用binding临时交换当前命名空间.❸
import不支持选项, 但可以一次导入多个类. 向量显示了如何从同一个包中分组多个类名.❹ 我们可以看到请求的类已被添加到命名空间映射表中.
4.3.11. 16.11 find-ns 和 all-ns
find-ns 和 all-ns 是访问全局命名空间仓库的相对简单的函数:
(pprint (all-ns)) ; ❶ ;; (#object[clojure.lang.Namespace 0x20312893 "clojure.edn"] ;; #object[clojure.lang.Namespace 0x70eecdc2 "clojure.core.server"] (ns-name (first (all-ns))) ; ❷ ;; clojure.edn
❶ all-ns 返回一个命名空间对象的惰性序列.
❷ 我们可以使用 ns-name 来提取名称作为符号.
find-ns 给定一个符号作为其名称, 检索一个命名空间对象, 假设该命名空间存在:
(find-ns 'clojure.edn) ; ❶ ;; #object[clojure.lang.Namespace 0x20312893 "clojure.edn"] (find-ns 'no-ns) ; ❷ ;; nil
❶ find-ns 检索与给定符号对应的命名空间对象, 假设该命名空间在某个时刻被创建.
❷ 如果我们尝试一个尚未创建的命名空间, 我们会毫不意外地得到一个 nil.
4.3.12. 16.12 the-ns, ns-name 和 namespace
the-ns, ns-name 和 namespace 是帮助处理 var, 符号和命名空间的工具函数. the-ns 使用 find-ns 来检索一个命名空间或抛出异常:
(the-ns 'notavail) ; ❶ ;; Exception No namespace: notavail found (the-ns 'clojure.edn) ; ❷ ;; #object[clojure.lang.Namespace 0x20312893 "clojure.edn"] (the-ns *ns*) ; ❸ ;; #object[clojure.lang.Namespace 0xcc62a3b "user"]
❶ 如果命名空间不存在, the-ns 会抛出异常.
❷ 如果命名空间存在, the-ns 返回命名空间对象.
❸ the-ns 也直接与命名空间对象一起工作, 在这种情况下, 它们只是被返回.
ns-name 在 the-ns 之上工作, 以符号的形式访问命名空间的名称. 如果你有命名空间对象并希望将其转换为可以用作键的符号, 这很有用:
(ns com.package.myns) (ns-name *ns*) ; ❶ ;; com.package.myns
❶ ns-name 将一个命名空间对象 (本例中为当前命名空间) 转换为相应的名称作为符号.
namespace 检索命名空间感知对象 (如符号或关键字) 的命名空间部分:
(ns user) (namespace :notcreateyet/a) ; ❶ ;; "notcreateyet" (namespace ::a) ; ❷ ;; user (namespace 'alsosymbols/s) ; ❸ ;; "alsosymbols"
❶ 我们在一个完全限定的关键字上使用 namespace. 我们可以看到关键字的命名空间部分作为字符串返回.
❷ 通过使用双冒号表示法 ::a, 可以隐式地完全限定到当前命名空间.
❸ 最后, 我们可以看到 namespace 在一个符号上的作用.
4.3.13. 16.13 meta, with-meta, vary-meta, alter-meta! 和 reset-meta!
meta 和其他与元数据相关的函数是专门用于元数据管理的函数. 元数据 (字面上是 "关于数据的数据") 是一种不显眼的通信机制 (例如, 与函数参数相比). 非功能性需求通常是元数据的良好候选者: 调试信息, 类型, 文档等 231. 元数据按定义不会影响它们所附加的对象的相等性语义, 这意味着两个相等的对象在它们的元数据不同时仍然比较相等.
Clojure 内部出于多种目的使用元数据. 附加到 var 对象上的元数据可以极大地改变代码的评估或执行方式. 元数据也可以用来存储文档, 标记用于测试的函数, 给编译器提供类型提示等等. 我们在整本书中也以有趣的方式使用了元数据. 请检查以下例子:
- 我们在
defn中使用元数据来标记用于基准测试的函数. - 在
array-map中, 元数据被用来存储数据库映射. sorted-set有一个在元数据中存储时间戳的例子.
我们可以使用以下类别来对一个支持元数据的对象进行分类:
- 读取: 元数据存在于对象上, 我们可以用
meta读取它们. - 克隆: 对象支持创建一个与旧对象类型和值相同, 但元数据不同的新对象, 使用
with-meta或vary-meta. - 写入: 对象支持元数据的线程安全变异 (无需将它们克隆到一个新对象中), 使用
alter-meta!或reset-meta!.
标准库中的许多 Clojure 对象都是元数据感知的:
- 持久化数据结构通常支持读取和克隆: 列表, 向量, 集合或映射.
- 惰性序列也支持读取和克隆: 范围, cons, repeat, iterate 等.
- 引用类型支持可变的 (且线程安全的) 元数据: var, atom, ref, agent. 命名空间也支持可变的元数据, 但它们不是一种引用类型. 改变元数据的函数是
alter-meta!和reset-meta!. - 其他对象支持不同种类的元数据支持的混合: 符号, 函数, 子向量.
meta 显示附加到对象上的元数据, 否则返回 nil:
(pprint (meta #'+)) ; ❶ ;; {:added "1.2", ;; :ns #object[clojure.lang.Namespace 0x1edb61b1 "clojure.core"], ;; :name +, ;; :file "clojure/core.clj", ;; :inline-arities ;; #object[clojure.core$_GT_1_QMARK_ 0x7b22ec89 "GT_1_QMARK"], ;; :column 1, ;; :line 965, ;; :arglists ([] [x] [x y] [x y & more]), ;; :doc ;; "Returns the sum of nums." ;; :inline ;; #object[clojure.core$nary_inline 0x790132f7 "clojure.core$nary_inline"]} (meta 1) ; ❷ ;; nil
❶ meta 显示了标准库中函数 `""` 的相当丰富的元数据集. 元数据附加到 var 对象上, 而不是符号 `""`.
❷ 我们可以将 meta 指向不支持的对象, 而无需捕获异常.
with-meta 在持久性数据结构中很常见:
(def v (with-meta [1 2 3] {:initial-count 3})) ; ❶ (meta (conj v 3 4 5)) ; ❷ ;; {:initial-count 3} (meta (with-meta (with-meta [1 2 3] {:a 1}) {:a 2})) ; ❸ ;; {:a 2} (meta (into [] v)) ; ❹ ;; nil
❶ with-meta 存储了向量创建时的初始计数信息.
❷ 向向量中添加新元素并不会改变其元数据. 所以我们总是可以看到向量最初有多少项.
❸ 在这个例子中, 我们可以看到 with-meta 完全替换了现有的元数据集.
❹ 元数据在数据结构之间的迁移策略根据应用的函数而不同. into 使用另一个数据结构的内容创建一个新的数据结构, 但它不会迁移原始的元数据.
with-meta 会替换任何现有的元数据集. 如果你想保留现有的元数据, 或有选择地更新它们, 你可以使用 vary-meta:
(def v (with-meta [1 2 3] {:initial-count 3 :last-modified #inst "1985-04-12"})) ; ❶ (meta v) ;; {:initial-count 3 ;; :last-modified #inst "1985-04-12T00:00:00.000-00:00"} (def v (vary-meta (conj v 4) assoc :last-modified #inst "1985-04-13")) ; ❷ (meta v) ;; {:initial-count 3 ;; :last-modified #inst "1985-04-13T00:00:00.000-00:00"}
❶ 我们创建一个包含 3 个数字的向量, 并将 last-modified 时间戳作为元数据的一部分.
❷ vary-meta 接受一个旧元数据的函数以及任何额外的参数. 我们可以有选择地更新 last-modified 时间戳, 而保持任何其他元数据不变.
alter-meta! 的行为与 vary-meta 类似, 但变异是就地发生的:
(def counter ; ❶ (atom 0 :meta {:last-modified #inst "1985-04-12"})) (meta counter) ;; {:last-modified #inst "1985-04-12T00:00:00.000-00:00"} (alter-meta! ; ❷ (do (swap! counter inc) counter) assoc :last-modified #inst "1985-04-13") (meta counter) ; ❸ ;; {:last-modified #inst "1985-04-13T00:00:00.000-00:00"}
❶ 一个 atom 是一种支持可变元数据的引用类型. atom 构造函数在构造时接受一个 :metadata 键来初始化元数据.
❷ alter-meta! 接受一个旧元数据的函数以及任何额外的参数. 我们使用 assoc 来有选择地更改 :last-modified 键.
❸ 在 atom 上调用 meta 正确地报告了时间的更改.
最后, reset-meta! 提供了完全替换元数据映射的可能性, 以防我们不感兴趣保留旧的:
(reset-meta! *ns* {:doc "The default user namespace"}) ; ❶ (meta *ns*) ;; {:doc "The default user namespace"}
❶ 命名空间不是引用类型, 但它们支持可变的元数据. 我们使用 reset-meta! 来指定一些关于命名空间的文档.
4.3.14. 16.14 总结
我们到达了本章的结尾. 专门用于 var 处理和命名空间组织的函数集相当丰富, 反映了 Clojure 为产生模块化代码提供的功能范围. 一个需要记住的重要方面是, 由于 var 的间接性, Clojure 能够提供一个非常动态的编程环境.
4.4. 17 评估
本节中阐述的函数是读, 评估和打印循环 (简称 REPL) 的核心. 当你打开 Clojure REPL 时, 你会看到一个等待评估形式的提示符. 该提示符实际上是一个对 read 函数的阻塞调用, 使用标准输入作为参数. 在按下回车键后, eval 分析形式并发出相关的字节码, 该字节码立即执行. 结果被打印在屏幕上, 循环继续在下一个 read 调用上阻塞. Clojure 在 REPL 之外也广泛地使用相同的 read 和 eval 函数.
以下是本章中阐述的函数及其在评估周期中的作用的摘要:
read和read-string将一个有效的文本形式转换为 Clojure 数据结构. 该数据结构可以是纯数据或可执行代码. 与其他 Lisp 语言一样, Clojure 将数据视为代码, 将代码视为数据, 而read是这种转换的入口点.eval产生一个 Clojure 数据结构的内存中评估. 如果该数据结构表示一个函数调用,eval返回评估的结果.compile,load,load-file,load-reader和load-string操作的是库而不是数据结构. 库是存储在文件中的一组形式 232. 库通常评估为定义.compile也在磁盘上产生一个或多个类文件.test和assert执行一个表达式的评估, 以定义另一个表达式或函数的普遍有效性.<edn,clojure.edn/read>>和clojure.edn/read-string是针对 EDN (可扩展数据表示法) 的等效read和read-string操作. EDN 是 Clojure 语法的一个子集, 专门为传输数据和安全加载它们而设计.
4.4.1. 17.1 read 和 read-string
read
read接受一个输入流, 并根据 Clojure 语法的规则将其内容转换为 Clojure 数据结构. 输入流应该是java.io.PushbackReader或其子类的实例. 测试该函数最简单的方法是不带参数, 迫使其使用动态变量*in*作为输入:(instance? java.io.PushbackReader *in*) ; ❶ ;; true (def output (read)) ; ❷ ;; (+ 1 2) ; ❸ ;; #'user/output output ; ❹ ;; (+ 1 2) (type output) ; ❺ ;; clojure.lang.PersistentList
❶ 动态变量
*in*被初始化为clojure.lang.LineNumberingPushbackReader, 一个java.io.PushbackReader的实例.❷ 当不带参数调用时,
read使用*in*作为输入.❸ 终端在按回车之前输出我们输入的内容, 而提示符是阻塞的.
❹
read的结果不进行评估.❺ 输出的类型是一个列表.
read支持一些选项来控制读取过程. 例如, 读宏条件默认是关闭的 233.:read-cond可以设置为:allow或:preserve, 以分别允许读宏条件和保留所有分支:(def example ; ❶ "#?(:clj (System/currentTimeMillis) :cljs (js/Console :log) :cljr (|Dictionary<Int32,String>|.) :default <anything you want>)") (defn reader-from [s] ; ❷ (-> (java.io.StringReader. s) (clojure.lang.LineNumberingPushbackReader.))) (read (reader-from example)) ; ❸ ;; RuntimeException Conditional read not allowed (read {:read-cond :allow} (reader-from example)) ; ❹ ;; (System/currentTimeMillis) (read {:read-cond :preserve} (reader-from example)) ; ❺ ;; #?(:clj (System/currentTimeMillis) ;; :cljs (js/Console :log) ;; :cljr (|Dictionary<Int32 String>|.) ;; :default <anything you want>)
❶
#?前缀是读宏条件宏, 它根据可用的平台之一指定一个形式的版本.❷
reader-from接受一个字符串并创建一个适合与read一起使用的读宏.❸ 默认情况下,
read不允许条件宏并抛出异常.❹ 我们要求
read用:read-cond :allow启用读宏条件. 选择的形式是与 Clojure 运行时的宿主平台相对应的形式 (在这种情况下, "clj" 表示 JVM 上的 Clojure).❺ 如果我们使用
:preserve, 我们会阻止read做出任何选择, 并按原样返回形式. 这对于任何与平台相关的后处理都很有用.我们可以使用
:features选项添加一个新平台. 新平台将成为默认选项, 而不是由:default键指示的那个:(def example ; ❶ "#?(:cljs :cljs :my :my :default <missing>)") (read {:read-cond :allow} (reader-from example)) ; ❷ ;; <missing> (read {:read-cond :allow :features #{:my}} (reader-from example)) ; ❸ ;; :my
❶ 该示例包含一个先前未注册的主机
:my的关键字.❷ 假设当前平台键缺失 (在本例中是
:clj),read将选择:default.❸ 向选项中添加
:features #{:my}, 即使当前平台不同, 也允许read返回:my.使用
:eof选项, 我们可以控制read在读取一个形式之前到达文件末尾 (缩写为 "eof") 时的行为:(read (reader-from ";; a comment")) ; ❶ ;; RuntimeException EOF while reading (read {:eof nil} (reader-from ";; a comment")) ; ❷ ;; nil (read (reader-from ";; a comment") false nil) ; ❸ ;; nil
❶ 一个注释会跳到流的末尾而不读取一个形式. 在这种情况下,
read会抛出异常.❷ 如果我们更喜欢
nil, 我们可以使用:eof选项来指示.❸ 相同的选项也可以作为参数使用.
除了我们目前看到的选项外, 读宏还遵守
*read-eval*动态变量.*read-eval*控制读宏在解析读宏求值宏#=时的行为. 当出现在一个形式前面时, 读宏首先像往常一样解析该形式, 然后在其上调用eval:(read (reader-from "#=(+ 1 2)")) ; ❶ ;; 3
❶ 与预期的符号和两个数字的列表 (
'+ 1 2) 不同, 读宏还会评估该形式.读宏求值宏默认是启用的, 因为它是对语言动态性有贡献的基本特性. 但存在安全隐患, 例如, 如果某些代码试图执行恶意指令:
(read (reader-from "(java.lang.System/exit 0)")) ; ❶ ;; (java.lang.System/exit 0) ;; WARNING: the JVM will exit. (read (reader-from "#=(java.lang.System/exit 0)")) ; ❷
❶
System/exit调用会退出正在运行的 JVM. 但read只是将形式加载到一个列表中.❷ 形式前面的读宏求值宏强制评估该形式, 这会退出 JVM.
要防止评估, 请将
read包装在一个将*read-eval*设置为false的绑定上下文中:(binding [*read-eval* false] ; ❶ (read (reader-from "#=(java.lang.System/exit 0)"))) ;; RuntimeException EvalReader not allowed when *read-eval* is false
❶ 如果在形式中存在读宏求值宏并且
*read-eval*被设置为false,read会抛出异常.如果你想完全阻止读取 (例如, 防止大数据结构通过
read加载到内存中), 你可以使用:unknown而不是false:(binding [*read-eval* :unknown] ; ❶ (read (reader-from "(+ 1 2)"))) ;; RuntimeException Reading disallowed - *read-eval* bound to :unknown
❶ 将
*read-eval*设置为:unknown会完全阻止读取.还有另一个影响数据读取方式的特性: 标记字面量. 这是一种扩展可用读宏语法宏集的方法, 超出默认安装的那些. 请查看关于标记字面量的部分以了解更多信息.
read-string
到目前为止的例子都在一个字符串上创建了一个
clojure.lang.LineNumberingPushbackReader来模拟文件 (或其他输入流) 的内容. 但如果你直接处理一个字符串,read-string的工作方式与read相同:(read-string "(+ 1 2)") ; ❶ ;; (+ 1 2) (read-string {:eof "nothing to read"} "") ; ❷ ;; "nothing to read"
❶
read-string的工作方式与read完全相同, 使用一个字符串来创建一个读宏对象, 类似于我们为上面例子所做的.❷ 我们可以使用文件末尾选项来防止在读取空字符串时出现异常.
read-string支持与read相同的选项, 因此函数的描述也相同 (除了接受一个字符串作为输入).
4.4.2. 17.2 eval
eval 接受一个 Clojure 数据结构并返回其评估后的形式. 如果对象是一个原生序列 (仅仅是序列性的是不够的), eval 会将第一个元素视为一个函数, 并在序列的其余部分上调用该函数:
(eval '(+ 1 2)) ; ❶ ;; 3 (eval [+ 1 2]) ; ❷ ;; [#object[clojure.core$_PLUS "clojure.core$_PLUS"] 1 2]
❶ 列表是一个原生序列. eval 假设第一个元素是一个函数, 其余的是参数. 在这种情况下, eval 返回在参数上评估该函数的结果.
❷ 向量是序列性的 (在它上面调用 seq 时会产生一个序列), 但它本身不是一个序列. 向量评估为自身, 但符号 "+" 会在当前命名空间的映射表中被查找, 并被实际的函数对象替换.
要评估多个形式, 我们需要将它们包围在一个 do 块中:
(eval '(do (println "eval-ed") (+ 1 2))) ; ❶ ;; eval-ed ;; 3
❶ 在有多个形式包装在一个 do 块中的情况下, eval 会继续评估所有这些形式.
read 和 eval 之间的分离是元编程中的一个基本工具. 元编程是语言的一个方面, 它使一个程序能够操作另一个程序. 在正常执行期间, 像解析和评估这样的活动是由 Clojure 协调的, 但当显式使用 read 和 eval 时, 我们有机会以不同的方式解释一个程序. 这对于设计领域特定语言 (或 DSL) 特别有用. 例如, 下面是一个描述交通灯系统的简单 DSL. 这个系统中的规则不是有效的 Clojure 语法, 但我们可以使用 read-string 来实现一个中间的转换层:
(require '[clojure.string :refer [split-lines]]) (def rules ; ❶ "If the light is red, you should stop If the light is green, you can cross If the light is orange, it depends") (defmacro If [light & args] ; ❷ (let [[_ _ op v & action] args] `(when (= '~light '~v) '~action))) (defn parenthesize [s] ; ❸ (->> s split-lines (remove empty?) (map #(str "(" % ")")))) (defn traffic-light [color rules] ; ❹ (->> rules parenthesize (map read-string) (map #(list* (first %) color (rest %))) ; ❺ (some eval))) (traffic-light 'red rules) ; ❻ ;; (you should stop) (traffic-light 'green rules) ;; (you can cross) (traffic-light 'orange rules) ;; (it depends)
❶ rules 包含关于交通灯中不同颜色含义的简单事实. 我们的目标是评估这些事实以产生程序行为.
❷ 我们将大写的 If 转换为一个宏, 并将句子的其余部分转换为我们可以操作的参数. If 必须是一个宏, 这样句子的内容才不会被评估. 然后我们解构输入并使用 when 来验证 "light" 参数是否与句子描述的颜色相同.
❸ parenthesize 是对输入字符串的一个小转换, 以便每个句子都被包围在一组括号中. 句子应该对 eval 显示为列表, 这样它就会触发对 If 宏的调用.
❹ traffic-light 协调整个过程: 规则首先被包围在括号中, 然后使用 read-string 转换为列表.
❺ 现在规则被编码为列表, 我们注入缺失的 "light" 参数. 注意, 在这一点上, 我们是在操作列表, 而不是处理字符串. 列表已准备好供 eval 使用, 它会调用 If 宏并返回答案.
❻ 这里有几个不同颜色的例子来测试答案.
4.4.3. 17.3 load, load-file, load-reader 和 load-string
load, load-file, load-reader 和 load-string 专门用于从库中评估 Clojure 代码. 库是包含普通 Clojure 代码的文件, 但它们必须声明一个命名空间并遵守特定的约定:
- 文件应在当前进程的类路径中可用.
- 命名空间的名称应反映其声明所在文件的相对路径 (用点 "." 替换 "/").
load
load接受一个字符串文件路径作为参数. 如果路径以 "/" (正斜杠) 开头, 路径从类路径的根目录开始. 在所有其他情况下, 路径从当前命名空间的位置开始:(ns user) (clojure.zip/vector-zip []) ; ❶ ;; ClassNotFoundException clojure.zip (load "zip") ; ❷ ;; FileNotFoundException Could not locate zip__init.class [...] (ns clojure.set) ; ❸ (load "zip") ;; nil (clojure.zip/vector-zip []) ; ❹ ;; [[] nil]
❶ "clojure/zip.clj" 是每个 Clojure 发行版中都存在的一个库, 但我们在加载它之前不能使用它.
❷ 如果我们尝试加载库 "zip" 而不指定其在类路径上的绝对位置, Clojure 会尝试从 "user" 命名空间的相同位置加载它. 在这个位置没有 "zip" 库,
load会失败并报错.❸ 将当前命名空间设置为
clojure.set后, 我们就能够加载 "zip" 库了.❹ 我们现在可以使用
vector-zip.load支持一个有用的详细模式, 它在遍历依赖树时打印每个加载的文件. 使用*loading-verbosely*动态变量来激活这个特性:(ns user) (binding [clojure.core/*loading-verbosely* true] ; ❶ (load "clojure.reflect")) ;; (clojure.core/load "/clojure.reflect") ;; (clojure.core/in-ns 'clojure.reflect) ;; (clojure.core/alias 'set 'clojure.set) ;; (clojure.core/load "/clojure/reflect/java") ;; (clojure.core/in-ns 'clojure.reflect) ;; (clojure.core/alias 'set 'clojure.set) ;; (clojure.core/in-ns 'clojure.reflect) ;; (clojure.core/alias 'str 'clojure.string)
❶
load支持详细输出, 以打印遍历期间加载的所有依赖项, 包括关于创建的别名和引用的附加信息.在前面的跟踪中, 我们可以看到
clojure.reflect依赖于哪些额外的库. 我们还可以看到为每个库创建的别名定义.load-file
与
load相比,load-file评估不一定可从 Java 类路径中获得的文件.load-file(像load一样) 使用正斜杠 "/" 的存在来设置路径的初始位置. 我们可以使用load-file来运行一个简单的 Clojure 脚本 (一个从单个文件运行并终止的程序):(spit "source.clj" ; ❶ "(ns ns1) (def a 1) (def b 2) (println \"a + b =\" (+ a b))") (load-file "source.clj") ; ❷ ;; a + b = 3
❶
source.clj包含一个简单的 Clojure 程序, 它定义了两个变量 "a" 和 "b", 并将它们相加.❷ 不带正斜杠的
load-file使用从当前进程启动位置开始的相对位置 (Java 属性 "user.dir" 的内容).load-string
load-string实质上等同于read-string后跟eval:(= (eval (read-string "(+ 1 1)")) ; ❶ (load-string "(+ 1 1)")) ;; true
❶
load-string执行一个字符串的解析和评估. 我们可以看到它产生与read-string后跟eval相同的结果.然而, 有一些区别使得
load-string更适合加载文件的内容 (作为字符串):load-string不支持选项, 而read-string可以被指示关于读取过程的几个方面 (参见read-string以获取支持的选项列表).load-string不需要将多个形式包装在一个do块中. 而read-string只读取一个形式.load-string在 var 元数据中跟踪行号, 而read-string不跟踪.
让我们用一个例子来研究最后一个方面:
(ns user) ; ❶ (def code "(do (def a 1)\n(def b 2)\n(def c 3))") (ns code1) ; ❷ (load-string user/code) (map (comp :line meta) [#'a #'b #'c]) ;; (1 2 3) (ns code2) ; ❸ (eval (read-string user/code)) (map (comp :line meta) [#'a #'b #'c]) ;; (1 1 1)
❶
code是一个包含由换行符分隔的 var 定义的字符串, 形成一个等同于 3 行文件的文件.❷ 一个新的命名空间 "code1" 加载并评估
user/code的内容. var 定义上的元数据包含预期的行号.❸ 另一个命名空间 "code2" 使用
eval和read-string组合加载并评估user/code. 每个 var 定义现在都从同一行 1 加载.该示例显示,
read-string忽略换行符终止符, 并将所有表达式视为单个第一行的一部分. 另一方面,load-string在每个表达式上正确地识别行号.load-reader
load-reader的行为与load-string或load-file完全相同, 但它需要一个java.io.Reader输入类型. 当需要控制要使用的特定类型的读宏时,load-reader很有用.
4.4.4. 17.4 compile
compile 接受一个库路径作为符号, 并以类似于 load 的方式执行解析和评估 (我们在 load 和 var 章节的引言中讨论了 "库" 的定义). compile 额外地将生成的字节码转储到磁盘:
(spit (str *compile-path* "/source.clj") ; ❶ "(ns source) (defn plus [x y] (+ x y))") (compile 'source) ; ❷ ;; source
❶ spit 在磁盘上创建一个名为 "source" 的简单 Clojure 库. 文件保存到 *compile-path*, 根据你的环境, 它可能指向 "target/classes" 或类似的文件夹. *compile-path* 的重要方面是它是 Java 类路径的一部分.
❷ 我们在代表我们想要编译的命名空间的符号上调用 compile. compile 返回刚刚创建的类的符号, 在这种情况下是 "source".
compile 在磁盘上为 "source.clj" 生成了几个类文件: 你可以通过打开对应于 *compile-path* (默认为 "classes") 的文件夹来查看它们. 其中一些初始化了命名空间和相关的 var, 包括静态加载以在全局仓库中注册命名空间和在命名空间映射表中注册相关的 var. 另一个类文件实现了 "plus" 函数 (这个应该被命名为 "source$plus.class"). compile 将为源库中的每个函数 (包括匿名的) 生成额外的类文件. 在类路径上可用这些生成的类足以确保其中声明的命名空间和 var 在引导后可用.
用 compile 进行编译 (或者通过从命令行调用 clojure.lang.Compile 的 main 方法) 可以用来执行预先编译 (或简称 AOT), 它将 Clojure 编译的结果缓存到磁盘. AOT 编译有几个优点:
- 无需分发 Clojure 源代码. 一旦用
compile生成了类文件, 如果它们和源代码都存在, 类文件将优先. 类文件也适用于 "混淆", 即让类文件难以阅读或反编译的过程. - 减少应用程序的启动时间, 这对于大型应用程序特别有用.
- 使应用程序可用于 JVM 上的其他语言 (包括
gen-class类声明).
然而, AOT 不能在所有环境中默认启用. 原因在于 AOT 编译也移除了一些灵活性:
- 生成的类变得与某些特定的 Clojure-JVM 版本相关联. 这可能产生负面后果, 特别是对于被设计为作为其他应用程序一部分运行的 Clojure 库.
- AOT 为构建过程增加了复杂性. 好的 AOT 工具需要了解何时由于相关源代码的更改而需要编译类, 特别是对于较大的项目.
- AOT 也为测试过程增加了复杂性. 单元测试可能通过, 但应用程序仍然可能存在意想不到的错误. 这可能是单元测试不一定强制评估代码的某些部分的结果. AOT 通常被配置为编译所有文件, 即使是那些不受单元测试影响的文件. 一个好的测试方法也应该在 AOT 编译后对应用程序进行练习.
因此, 预先编译一个 Clojure 应用程序的选择是在 AOT 引入的额外复杂性和它在分发应用程序时带来的优势之间的权衡. 通常, Clojure 独立应用程序会连同其所有传递性依赖一起进行 AOT 编译 (这被称为 "Uberjar"), 这样应用程序就变得非常容易安装并且性能良好. 另一方面, Clojure 库通常不进行 AOT 编译, 以便让宿主应用程序自由决定最佳的编译策略.
4.4.5. 17.5 test 和 assert
test 和 assert 执行一个表达式的评估, 以验证其正确性. test 是 Clojure 中可用的最基本的测试形式, 并且相当有限, 特别是考虑到 Clojure 附带了 clojure.test 命名空间, 其中包含一个功能齐全的测试框架.
test 有一些简单的用例, 例如, 当我们想在我们正在编写的代码旁边表达期望时. 下面的函数计算一个数的平方根, 并且它被添加了一些测试来验证其行为:
(defn sqrt {:test ; ❶ #(when-not (== (sqrt 4) 2.) (throw (RuntimeException. "sqrt(4) should be 2")))} [x] (loop [guess 1.] (if (> (Math/abs (- (* guess guess) x)) 1e-8) (recur (/ (+ (/ x guess) guess) 2.)) guess))) (test #'sqrt) ; ❷ ;; RuntimeException sqrt(4) should be 2
❶ defn 在几个位置接受元数据. 我们需要提供一个 :test 键, 其值为一个无参数的函数. 在这种情况下, 最易读的位置是在参数之前 (也取决于测试函数的长度). 第二个选项是在函数体的末尾.
❷ 我们可以通过在包含该函数的 var 对象上调用 test 来证明该算法按预期工作. 在这种情况下, 我们遇到了一个意外, 因为我们的函数使用牛顿法猜测 4 的近似平方根为 2.0. 结果非常接近 2.0, 但不完全是 2.
正如你从例子中看到的, test 需要抛出一个异常来表示问题的存在. 为了减少创建和抛出异常所需的代码量, 我们可以使用 assert. assert 是一个宏, 它评估给定的表达式, 并在表达式为 false 或 nil 的情况下抛出异常:
(assert (= 1 (+ 3 3)) "It should be 6") ; ❶ ;; AssertionError Assert failed: It should be 6 ;; (= 1 (+ 3 3))
❶ 一个简单的例子来展示 assert 的工作方式.
以下是我们如何在前面的 sqrt 函数中使用 assert:
(defn sqrt {:test #(assert (== (sqrt 4) 2.) "sqrt(4) should be 2")} ; ❶ [x] (loop [guess 1.] (if (> (Math/abs (- (* guess guess) x)) 1e-8) (recur (/ (+ (/ x guess) guess) 2.)) guess))) (test #'sqrt) ;; AssertionError Assert failed: sqrt(4) should be 2 ;; (== (sqrt 4) 2.0)
❶ assert 消除了在出现错误条件时创建和抛出异常的需要.
我们可以使用函数上的 test 元数据来记录重要属性的存在. 如果一个函数期望表现出特定的行为, 并且该信息应该对函数的读者立即显而易见, 我们可以以 test 元数据的形式留下一个 "注释". 在任何更改后偶尔运行测试应该足以保证前提条件得到满足. 然而, 如果 test 元数据变得过于复杂, 你应该考虑将测试从函数中分离出来. 对于更具可扩展性的自动化测试方法, 请参见 clojure.test.
4.4.6. 17.6 clojure.edn/read 和 clojure.edn/read-string
EDN, 即可扩展数据表示法, 是 Clojure 语法的一个子集 (带有额外的更改), 专为与其他语言进行数据交换而设计 234. 将 EDN 限制为 Clojure 的一个子集的原因之一是, Clojure 包含专门的读宏, 在其他语言中使用可能没有直接意义. 一些例子是: () (匿名函数读宏), @ (var 解引用读宏), = (读求值宏), 语法引用 (反引号), ?# (读宏条件) 等.
clojure.edn/read 和 clojure.edn/read-string 的工作方式与其 clojure.core 中的等效物类似: clojure.edn/read 接受一个 java.io.PushbackReader 的实例作为输入, 而 clojure.edn/read-string 接受一个简单的字符串. 在本节的例子中, 我们将使用 clojure.edn/read-string, 因为 clojure.edn/read 在功能上是等效的. clojure.edn/read-string 通过抛出异常来限制一些读宏的使用:
(require '[clojure.edn :as edn]) ; ❶ (alias 'core 'clojure.core) (core/read-string "@#'+") ; ❷ ;; (clojure.core/deref (var +)) (edn/read-string "@#'+") ; ❸ ;; RuntimeException Invalid leading character: @
❶ clojure.edn 命名空间默认不可用, 需要显式 require. 仅为本例和后续例子, 我们将为 clojure.core 添加一个别名以求清晰.
❷ 表达式前面的 "@" 符号等同于调用 var 函数, 并被核心读宏正常解释.
❸ EDN 没有这样的宏 (以及其他几个), 并抛出异常.
EDN 读宏和 clojure.core 之间的另一个区别是支持的选项. EDN 忽略 :read-cond 或 :features (参见 read), 因为不支持读宏条件. 但 EDN 读取添加了以下新选项: :readers 和 :default.
:readers 选项声明额外的标记字面量, 作为一个从标签名到标签实现的映射. 如果一个给定标签的键已经存在, 那么新的标签会覆盖默认的:
(edn/read-string ; ❶ "#point [1 2]") ;; RuntimeException No reader function for tag point (edn/read-string ; ❷ {:readers {'point identity}} "#point [1 2]") ;; [1 2] (edn/read-string ; ❸ {:readers {'inst (constantly "override")}} "#inst \"2017-08-23T10:22:22.000-00:00\"") ;; "override"
❶ #point 是一个系统未知的标记字面量.
❷ 我们使用 :readers 选项来注册一个 point 键和 identity 来处理它 (当然它也可以实现更复杂的行为).
❸ "#inst" 是一个默认的标记字面量. 这个指令, 与其将 "#inst" 解析为一个 java.util.Date, 不如使用一个总是返回字符串 "override" 的实现.
如果在 default-data-readers 或 *data-readers* 中找不到一个标记字面量, :default 选项会创建一个默认的实现:
(edn/read-string ; ❶ {:default #(format "[Tag '%s', Value %s]" %1 %2)} "[\"There is no tag for \" #point [1 2] \"or\" #line [[1 2] [3 4]]]") ;; ["There is no tag for " ;; "[Tag 'point', Value [1 2]]" ;; "or" ;; "[Tag 'line', Value [[1 2] [3 4]]]"]
❶ 尝试读取 "#point" 或 "#line" 标签会导致异常. 我们可以用 :default 选项来处理所有缺失的标签. :default 接受一个接受两个参数的函数, 即标签名及其值.
下一节将更详细地描述标记字面量及其特性.
4.4.7. 17.7 tagged-literal 和 tagged-literal?
tagged-literal 是一个辅助函数, 它给定一个 "tag" 和一个 "form" 参数, 创建一个新的 clojure.lang.TaggedLiteral 对象:
(tagged-literal 'point [1 2]) ; ❶ ;; #point [1 2] (:tag (tagged-literal 'point [1 2])) ; ❷ ;; point (:form (tagged-literal 'point [1 2])) ;; [1 2]
❶ tagged-literal 创建一个新的 TaggedLiteral 对象. Clojure 知道如何漂亮地打印它们.
❷ 我们也可以访问 :tag 和 :form 键.
当读宏需要一个来解析自定义标签而不是自定义函数时, 可以使用 TaggedLiteral 对象, 从而节省一些输入. 目前有以下选项:
(require '[clojure.edn :as edn]) (edn/read-string {:default tagged-literal} ; ❶ "[\"There is no tag for \" #point [1 2] \"or\" #line [[1 2] [3 4]]]") ;; ["There is no tag for " #point [1 2] "or" #line [[1 2] [3 4]]] (binding [*default-data-reader-fn* tagged-literal] ; ❷ (read-string "[\"There is no tag for \" #point [1 2] \"or\" #line [[1 2] [3 4]]]")) ;; ["There is no tag for " #point [1 2] "or" #line [[1 2] [3 4]]]
❶ 我们在 edn/read-string 中见过这个例子, 其中我们使用了一个接受 2 个参数的匿名函数. tagged-literal 接收未注册的标签 point 和相关的形式作为参数.
❷ read 和 read-string 不支持 :default 选项. 然而, 动态变量 *default-data-reader-fn* 承担了相同的含义.
tagged-literal? 验证一个对象是否是 tagged literal 实例:
(tagged-literal? (tagged-literal 'tag :form)) ; ❶ ;; true
❶ 当给定对象是 clojure.lang.TaggedLiteral 的实例时, tagged-literal? 返回 true.
4.4.8. 17.8 default-data-readers
default-data-readers 检索与 Clojure 一起安装的默认数据读宏. 目前, Clojure 附带了以下数据读宏:
default-data-readers ; ❶ ;; {inst #'clojure.instant/read-instant-date, ;; uuid #'clojure.uuid/default-uuid-reader}
❶ default-data-readers 包含一个从标签名称作为符号到将接收由读宏读取的形式的单参数函数的映射.
数据读宏与 EDN 一起被引入, 以便在数据与字符串之间轻松地进行 "往返":
(def date (edn/read-string "#inst \"2017-08-23T10:22:22.000-00:00\"")) ; ❶ (= date (edn/read-string (pr-str date))) ; ❷ ;; true
❶ "#inst" 是一个默认的标记字面量, 被指示将后面的字符串解析为一个 java.util.Date 对象.
❷ 标记字面量被设计为可以写入和读取字符串, 从而在网络 (或文件) 上实现往返数据交换. 我们可以验证将一个日期转换为字符串并读回该字符串会产生相同的对象.
动态变量 *data-readers* 使用与 default-data-reader 相同的格式, 并且当被绑定时, 它允许添加或修改默认的读宏. 例如, 以下是我们如何教 Clojure 如何序列化和反序列化 java.net.URL 对象:
(import '[java.net URL] '[java.io File]) (defmethod print-method URL [url writer] ; ❶ (doto writer (.write "#url ") (.write "\"") (.write (.toString url)) (.write "\""))) (-> "/etc/hosts" File. .toURL pr-str) ; ❷ ;; "#url \"file:/etc/hosts\"" (binding [*data-readers* {'url #(URL. %)}] ; ❸ (-> "/etc/hosts" File. .toURL pr-str read-string))
❶ 我们扩展了 print-method 以便 pr-str 能够打印带有读宏可理解的标签的 URL 对象.
❷ 这显示了 URL 对象在转换为字符串后的样子.
❸ 全过程: 将 URL 对象打印成字符串, 并在绑定 *data-readers* 到一个适当的构造函数调用后将其读回成一个对象.
4.4.9. 17.9 reader-conditional 和 reader-conditional?
reader-conditional 是一个简单的辅助函数 (类似于 tagged-literal), 它创建一个新的 clojure.lang.ReaderConditional 对象:
(reader-conditional '(:clj :code) false) ; ❶ ;; #?(:clj :code) (reader-conditional '(:clj [1 2 3]) true) ; ❷ ;; #?@(:clj [1 2 3])
❶ reader-conditional 创建一个新的 ReaderConditional 对象. Clojure 有特定的打印行为来处理读宏条件.
❷ 第二个布尔参数决定这是否是一个 "拼接" 条件. 注意条件现在打印时带有一个额外的 "@" 符号.
reader-conditional 对于在不手动格式化相应字符串的情况下组装读宏条件选项很有用. 当读宏条件中的形式是一个集合时, 我们可以选择将其作为一个整体来解释 (不拼接), 或者依次取每个项, 移除包装的括号 (拼接). 这里有一个突出不同解释的例子:
(read-string {:read-cond :allow} "(list #?(:clj [1 2 3]))") ; ❶ ;; (list [1 2 3]) (read-string {:read-cond :allow} "(list #?@(:clj [1 2 3]))") ; ❷ ;; (list 1 2 3)
❶ 当读取一个不带拼接的读宏条件时, 读宏会字面地解释相应的形式, 在这种情况下是向量 `[1 2 3]`.
❷ 拼接会解开形式 (假设它在一个集合内) 并只检索元素.
reader-conditional? 执行一个检查以验证给定参数是否是一个读宏条件. 这在 :preserve 模式下分析读宏的输出时可能很有用:
(def parse (read-string {:read-cond :preserve} "#?(:clj [1 2 3])")) (reader-conditional? parse) ; ❶ ;; true
❶ 当给定参数是 clojure.lang.ReaderConditional 对象的一个实例时, reader-conditional? 返回 true.
在评估一个读宏条件实例后, 我们可以用以下方式访问其形式和拼接条件:
(def parse (read-string {:read-cond :preserve} "#?(:clj [1 2 3])")) (:form parse) ; ❶ ;; (:clj [1 2 3]) (:splicing? parse) ; ❷ ;; false
❶ 一个读宏条件对象提供一个 :form 键来访问匹配的形式, 包括平台.
❷ 另一个 :splicing? 键访问拼接状态, 在这种情况下是 false (没有 "@" 符号).
4.4.10. 17.10 总结
本章结束了关于 Clojure 读取和评估的章节. read-string 和 eval 分别是 Clojure API 中进入读宏和编译器的部分. 通过用 read-string 读取文本, 我们将 Clojure 程序的文本表示转换为一个数据结构. 通过用 eval 评估数据结构, 我们编译并可能运行一个 Clojure 程序. 本章中的其他函数与读取或编译 Clojure 有关, 提供了控制此过程的不同方式.
4.5. 18 格式化和打印
4.5.1. 18.1 format, printf 和 cl-format
format, printf 和 cl-format 是专门用于字符串格式化的函数. format 是 Java 的 String::format 方法的包装器, 该方法受到 C 语言中著名的 printf 函数的启发. 在 Clojure 中, printf 是一个包装了 println 和 format 的小函数.
而 cl-format 则是 Common Lisp 的 format 函数的移植, 以前是一个名为 XP 的外部包 235.
我们在整本书中已经多次看到 format 和 cl-format 的使用. 这里有几个例子供回顾:
- 在
memoize中, 我们使用format来打印缓存命中 (或未命中) 的信息. - 在
rand中, 我们使用format来打印一个基于文本的进度指示器. - 在
vec中, 我们使用format来渲染一个简单的 JSON 片段. - 在第 1 章, 描述如何改进十进制值的打印时, 我们在 XML 例子中使用了
cl-format.
format 有一套丰富的格式化指令. 邀请读者查看 java.util.Formatter API 参考以获取完整的细节 236, 但这里有一组有用的例子:
(format "%3d" 1) ;; " 1" ; ❶ (format "%03d" 1) ;; "001" ; ❷ (format "%.2f" 10.3456) ;; "10.35" ; ❸ (format "%10s", "Clojure") ;; " Clojure" ; ❹ (format "%-10s", "Clojure") ;; "Clojure " ; ❺ (format "%-11.11s" "truncatefixedsize") ;; "truncatefix" ; ❻ (format "%tT" (java.util.Calendar/getInstance)) ;; "22:15:11" ; ❼
❶ 用空格左填充一个数字, 总长度为 3.
❷ 用零左填充一个数字, 总长度为 3.
❸ 将一个小数四舍五入到 2 位.
❹ 用空格左填充一个字符串.
❺ 用空格右填充一个字符串.
❻ 如果字符串太长则截断, 如果太短则右填充.
❼ 格式化当前本地时间.
cl-format 更为复杂, 支持额外的特性, 但代价是增加了复杂性. 以下是一组基本示例 237:
(require '[clojure.pprint :refer [cl-format]]) ; ❶ (cl-format nil "~:d" 1000000) ;; "1,000,000" ; ❷ (cl-format nil "~b" 10) ;; "1010" ; ❸ (cl-format nil "Anno Domini ~@r" 25) ;; "Anno Domini XXV" ; ❹ (cl-format nil "~r" 158) ;; "one hundred fifty-eight" ; ❺ (cl-format nil "~:r and ~:r" 1 2) ;; "first and second" ; ❻ (cl-format nil "~r banana~:p" 1) ;; "one banana" (cl-format nil "~r banana~:p" 2) ;; "two bananas" ; ❼
❶ cl-format 在 clojure.pprint 命名空间中声明.
❷ 用逗号分隔符格式化大数.
❸ 以二进制格式打印. cl-format 也支持八进制和十六进制.
❹ 罗马数字转换.
❺ 将数字转换为单词.
❻ 将数字转换为序数词.
❼ 一个 "双重匹配" 输入的例子, 首先用于翻译成序数词, 然后用于触发复数形式.
cl-format 的一个有趣特性是条件格式化, 最终输出取决于输入的大小. 条件格式化和多重匹配为 cl-format 提供了一种生成语法正确的英语的方式:
(require '[clojure.pprint :refer [cl-format]]) (def num-sentence "~#[nope~;~a~;~a and ~a~:;~a, ~a~]~#[~; and ~a~:;, ~a, etc~].") ; ❶ (apply cl-format nil num-sentence [1 2]) ;; "1 and 2." (apply cl-format nil num-sentence [1 2 3]) ;; "1, 2 and 3." (apply cl-format nil num-sentence [1 2 3 4]) ;; "1, 2, 3, etc." (def pluralize "I see ~[no~:;~:*~r~] fish~:*~[es~;~:;es~].") ; ❷ (cl-format nil pluralize 0) ;; "I see no fishes." (cl-format nil pluralize 1) ;; "I see one fish." (cl-format nil pluralize 100) ;; "I see one hundred fishes."
❶ 我们将格式指令存储为一个局部变量 "num-sentence", 可以在多个例子中重用.
❷ "pluralize" 包含一个简单的格式指令, 用于将单词转换为复数, 包括一个对在单词末尾附加 "s" 的规则的例外, 这不适用于 "fish" (例如).
在下面的例子中, 我们看到 cl-format 在行动中, 将文本包装到特定的行大小 238:
(def paragraph ["This" "sentence" "is" "too" "long" "for" "a" "small" "screen" "and" "should" "appear" "in" "multiple" "lines" "no" "longer" "than" "20" "characters" "each" "."]) (println (cl-format nil "~{~<~%~1,20:;~A~> ~}" paragraph)) ; ❶ ;; This sentence is too ;; long for a small ;; screen and should ;; appear in multiple ;; lines no longer than ;; 20 characters each.
❶ 我们使用 cl-format 来安排句子中单词的排列, 使它们的长度永远不会超过 20 个字符. 这样的功能并非微不足道, 格式指令也需要一些学习曲线.
正如你所看到的, cl-format 非常强大, 但需要一些时间才能熟练使用: 有许多指令, 它们的语法可能难以阅读. 幸运的是, 大多数关于 Lisp 中 format 函数的文献都可以很容易地适应于 cl-format: 一个例子是 Peter Siebel 的 "Practical Common Lisp" 239 的第 18 章. 然而, 如果一个指令变得过于复杂, 用户应该考虑更长但更明确的替代方案, 比如使用顺序处理.
4.5.2. 18.2 pr, prn, pr-str, prn-str, print, println, print-str, println-str
Clojure 有一套丰富的打印函数, 本书的这一部分介绍了在 clojure.core 命名空间中声明的那些. 以完整前缀 "print" 开头的函数 (print, println, print-str 和 println-str) 产生为人类消费而优化的输出. 那些只以 "pr" 开头的 (pr, prn, pr-str, prn-str) 产生略有不同的输出, 旨在能被 read-string 读回, 从而实现基本的 Clojure 序列化 240.
下面的例子显示了 pr 和 print (以及同一组中的相关函数) 之间的典型区别:
(pr "a" 'a \a) ; ❶ ;; "a" a \a ;; nil (print "a" 'a \a) ; ❷ ;; a a a ;; nil
❶ 两个函数都以一个 nil 结尾, 这是 REPL 打印最后一个评估表达式结果的人为产物. pr 和 print 都是只产生副作用并返回 nil 的函数, nil 最后被打印. pr 通过用额外的双引号打印, 移除单引号和分别打印反斜杠 \ 来区分字符串, 符号和字符.
❷ println 以同样的方式打印相同的对象, 移除任何引用的装饰. 从 print 的结果来看, 我们无法区分它们的原始类型.
使 pr 的输出适合读回 Clojure 的是特定引用的存在, 这有助于读宏解释字符流. 当打印泛型对象, 如 Java 映射时, 这种差异更明显:
(import 'java.util.HashMap) (def java-map (HashMap. {:a "1" :b nil})) (prn java-map) ; ❶ ;; {:a "1", :b nil} (println java-map) ; ❷ ;; #object[java.util.HashMap 0x1ffddcad {:a=1, :b=null}]
❶ prn 在打印其参数后向标准输出附加一个新行. 形式的评估是 nil, REPL 在新行后打印它: 在这个例子中, 为了清晰起见, nil 被省略了.
❷ java-map 的人类可读输出包含 Java 对象的十六进制哈希, 类的名称和映射的内容. 正如你所看到的, nil 被打印为 null.
四个以 *-str 结尾的函数将其内容作为字符串返回, 而不是对 *out* 的当前值产生副作用 (这是一个默认指向标准输出的动态变量):
(def data {:a [1 2 3] :b '(:a :b :c) :c {"a" 1 "b" 2}}) (pr-str data) ; ❶ ;; "{:a [1 2 3], :b (:a :b :c), :c {\"a\" 1, \"b\" 2}}" (prn-str data) ; ❷ ;; "{:a [1 2 3], :b (:a :b :c), :c {\"a\" 1, \"b\" 2}}\n" (print-str data) ; ❸ ;; "{:a [1 2 3], :b (:a :b :c), :c {a 1, b 2}}" (println-str data) ; ❹ ;; "{:a [1 2 3], :b (:a :b :c), :c {a 1, b 2}}\n"
❶ pr-str 类似于 pr, 但结果是参数的打印输出作为字符串, 而不是打印到标准输出 (*out* 的默认值).
❷ prn-str 只是在 pr-str 的输出后添加一个新行.
❸ print-str 与 pr-str 相同, 但一些对象打印方式不同, 比如字符串 (参见两个例子中围绕它们的双引号).
❹ println-str 在字符串的末尾附加一个额外的新行, 这会显示为 `\n`.
在 pr, prn, print 和 println 的情况下, *out* 的值可以与 binding 一起绑定, 以输出到备用的 Java OutputStream 或 Writer (分别是专用于面向字节和面向字符输出的 Java 接口). 在下面的例子中, 我们将 print 的输出重定向到一个文件:
(require '[clojure.java.io :as io]) ; ❶ (with-open [w (io/writer "/tmp/range.txt")] ; ❷ (binding [*out* w] ; ❸ (print (range 100000)))) ; ❹
❶ clojure.java.io 是标准库的一部分的一个命名空间. 它包含包装 Java IO 框架的函数.
❷ io/writer 返回一个 BufferedWriter 对象 "w". with-open 确保在评估主体后缓冲区被正确关闭. 缓冲在写入磁盘前在内存中累积字符, 限制了对物理磁盘的传输次数 (一个昂贵的操作).
❸ binding 临时地将 *out* 的当前值与新创建的写入器交换.
❹ print 被指示输出一个长范围的数字. 注意 range 是惰性地创建 100,000 个数字.
使用 java.io.BufferedWriter (这是 clojure.java.io/writer 返回的默认对象类型) 打印到文件可以更有效地打印非常大的对象, 例如从惰性序列生成的对象. 惰性序列的输出永远不会一次性全部存在于内存中, 因为一旦新的元素被生成并打印, 它们就会立即被垃圾回收.
4.5.3. 18.3 pprint, pp, write 和 print-table
请同时参考 clojure.pprint 动态变量部分, 该部分专门描述了 clojure.pprint 中可用的许多配置选项.
本节中的函数专用于 "漂亮打印", 这是一项增强可读性的功能, 超越了基本的打印原语 (参见 pr 和 print). 漂亮打印在 REPL 中通过函数 pprint 或 pp 随时可用 (无需 require, 因为 REPL 会从 clojure.pprint 隐式导入它们):
(def data {:a ["red" "blue" "green"] :b '(:north :south :east :west) :c {"x-axis" 1 "y-axis" 2}}) data ; ❶ ;; {:a ["red" "blue" "green"], :b (:north :south :east :west), :c {"x-axis" 1, "y-axis" 2}} (pp) ; ❷ ;; {:a ["red" "blue" "green"], ;; :b (:north :south :east :west), ;; :c {"x-axis" 1, "y-axis" 2}} (pprint data) ; ❸ ;; {:a ["red" "blue" "green"], ;; :b (:north :south :east :west), ;; :c {"x-axis" 1, "y-axis" 2}}
❶ 在 REPL 中简单地输入 "data" 会触发相应 var 对象内容的基本打印输出. 如果 "data" 很大, 我们可能需要等待几秒钟, 屏幕上会滚动一大堆密集的文本.
❷ pp 在最后一个评估的表达式上调用 pprint. 我们可以看到 pprint 知道我们想要打印的对象类型, 并为我们很好地对齐了键和值, 使其可读. 同样, 如果对象很大, 我们需要等待几秒钟, 但结果仍然是可读的.
❸ 我们可以直接在任何可打印的对象上调用 pprint. 我们可以看到 pprint 在 "data" 上产生的输出与之前的 pp 完全相同.
- Clojure 中漂亮打印的贡献
pprint和cl-format是 Clojure 的众多独立开发的贡献之一, 后来被并入 (现已废弃的) "Clojure Contrib" 项目.Tom Faulhaber (github.com/tomfaulhaber/cl-format) 因其将
cl-format从 Lisp 移植以及在通用漂亮打印方面所做的工作而值得一提. 他在 2009 年底在 Clojure 邮件列表上宣布了他的库 241.pprint和pp是clojure.pprint中最突出的入口点, 但在同一个命名空间中还有其他可用的函数. 例如,clojure.pprint/write被pprint使用, 并提供了一组丰富的参数:(require '[clojure.pprint :as pretty]) (doc pretty/write) ; ❶ ;; ------------------------- ;; clojure.pprint/write ;; ([object & kw-args]) ;; Write an object subject to the current bindings of the printer control variables. ;; Use the kw-args argument to override individual variables for this call (and any ;; recursive calls). Returns the string result if :stream is nil or nil otherwise. ;; ;; The following keyword arguments can be passed with values: ;; Keyword Meaning Default value ;; :stream Writer for output or nil *out* ;; :base Base to use for writing rationals *print-base* ;; :length Maximum elements to show in sublists *print-length* ;; :level Maximum depth *print-level* ;; :miser-width Width to enter miser mode *print-miser-width* ; ❷ ;; :dispatch The pretty print dispatch function *print-pprint-dispatch* ;; :pretty If true, do pretty printing *print-pretty* ;; :radix If true, prepend a radix specifier *print-radix* ;; :right-margin The column for the right margin *print-right-margin* ;; :suppress-namespaces If true, no namespaces in symbols *print-suppress-namespaces*
❶
write函数本身的文档相当丰富, 值得一看.❷ 大多数设置都是自描述的, 但有些需要一些解释. "Miser-mode" 是一种超紧凑的打印风格, 当可用的打印宽度达到
*print-miser-width*指示的阈值时触发. 需要这个的原因是, 深度嵌套的数据结构通过缩进来消耗行宽. 更多信息请查看*print-miser-width*.下面的例子展示了如何使用
clojure.pprint/write中的一些可用参数:(require '[clojure.pprint :as pretty]) ; ❶ (require '[clojure.java.io :as io]) (with-open [w (io/writer "/tmp/prettyrange.txt")] ; ❷ (pretty/write (map range (range 12 0 -1)) :stream w ; ❸ :base 2 ; ❹ :length 6)) ; ❺
;; cat /tmp/prettyrange.txt ; ❻
((0 1 10 11 100 101 ...) (0 1 10 11 100 101 ...) (0 1 10 11 100 101 ...) (0 1 10 11 100 101 ...) (0 1 10 11 100 101 ...) (0 1 10 11 100 101 ...) ...)
❶ 其他函数如
clojure.pprint/write在requireclojure.pprint命名空间后可用. 在这个例子中, 我们还需要clojure.java.io.❷ 我们在 `/tmp` 文件夹中打开一个由文件支持的
BufferedWriter, 我们可以在其中写入. 在评估完形式后, 缓冲写入器会自动为我们关闭.❸ ":stream" 键将输出流设置为文件. 这通常是
*out*的值.❹ ":base" 键将数字的表示更改为不同的基数. 通常数字以 10 为基数打印, 但这里我们请求二进制表示.
❺ ":length" 键确定了在集合中要打印的最大项数.
write将只打印前 6 个元素, 用 "…" 截断其余部分.❻ 格式化的输出可以通过打开文件来查看. 在基于 Unix 的系统上, 你可以从命令行使用
cat.clojure.pprint/write支持一系列丰富的参数, 用于控制输出的格式化. 可用的参数被方便地分组到 "分派表" 中, 可用于打印不同的 Clojure 对象. 默认情况下, 使用clojure.pprint/simple-dispatch, 但也有其他可用的, 如clojure.pprint/code-dispatch, 用于处理代码片段而不是数据结构.在下一个例子中, 我们收到了一些作为文本的 Clojure 代码. 尽管在原始字符串中格式正确, 但我们无法用默认的
pprint设置正确打印:(def op-fn ; ❶ "(defn op [sel] (condp = sel \"plus\" + \"minus\" - \"mult\" * \"div\" / \"rem\" rem \"quot\" quot))") (pprint (read-string op-fn)) ; ❷ ;; (defn ; ❸ ;; op ;; [sel] ;; (condp ;; = ;; sel ;; "plus" ;; + ;; "minus" ;; - ;; "mult" ;; * ;; "div" ;; / ;; "rem" ;; rem ;; "quot" ;; quot))
❶ 我们被给定一个作为字符串的 Clojure 函数. 这可能是打开一个 Clojure 文件的结果, 或者它可能被存储在数据库中.
❷
read-string调用 Clojure Reader 来读取字符串的内容.read-string返回包含以符号 "defn" 开始的列表的列表. 该列表保持其未评估的形式.❸
pprint不区分包含代码的列表 (一个应该在某个时间点被评估的列表) 和一个简单的数据结构.包含 Clojure 代码的列表应该与包含通用数据的列表打印方式不同,
pprint通过允许不同的 "分派" 设置来解决这个问题. 我们可以使用with-pprint-dispatch并传递一个不同的分派函数来更改pprint的默认分派:(pretty/with-pprint-dispatch pretty/code-dispatch ; ❶ (pprint (read-string op-fn))) ;; (defn op [sel] ;; (condp = sel ;; "plus" + ;; "minus" - ;; "mult" * ;; "div" / ;; "rem" rem ;; "quot" quot))
❶
code-dispatch是一个多重方法, 定义了一组用于处理代码片段的打印指令. 当code-dispatch遇到一个 "defn" 符号时, 它会触发展示此类 Clojure 形式的正确行为 (对于 "condp" 或其他支持的形式也是如此).最后提及
print-table, 一个将 Clojure 映射渲染为二维表格的函数:(require '[clojure.pprint :as pretty]) (pretty/print-table (repeat 4 (zipmap (range 10) (range 100 110)))) ; ❶ ;; | 0 | 7 | 1 | 4 | 6 | 3 | 2 | 9 | 5 | 8 | ;; |-----+-----+-----+-----+-----+-----+-----+-----+-----+-----| ;; | 100 | 107 | 101 | 104 | 106 | 103 | 102 | 109 | 105 | 108 | ;; | 100 | 107 | 101 | 104 | 106 | 103 | 102 | 109 | 105 | 108 | ;; | 100 | 107 | 101 | 104 | 106 | 103 | 102 | 109 | 105 | 108 | ;; | 100 | 107 | 101 | 104 | 106 | 103 | 102 | 109 | 105 | 108 |
❶
print-table接受一个映射的集合, 并打印一个以键为列, 值为行的二维表格.print-table使用第一个映射的键来定义表格的标题. 我们可以使用第一个参数来覆盖列名的选择:(def headers [7 0 9 2]) (pretty/print-table headers ; ❶ (repeat 4 (zipmap (range 10) (range 100 110)))) ;; | 7 | 0 | 9 | 2 | ;; |-----+-----+-----+-----| ;; | 107 | 100 | 109 | 102 | ;; | 107 | 100 | 109 | 102 | ;; | 107 | 100 | 109 | 102 | ;; | 107 | 100 | 109 | 102 |
❶ 当传递特定的键时,
print-table只从映射的集合中选择那些键.
4.5.4. 18.4 print-method, print-dup 和 print-ctor
print-method, print-dup 和 print-ctor 是 Clojure 打印扩展机制的入口点 242.
在讨论 pr 和 print 时 (以及在整本书中), 我们已经看到 Clojure 为大多数 Clojure 数据结构产生了
一致的文本表示. 打印机制是基于一个多重方法的, 标准库为大多数 Clojure 类型提供了默认实现. 在不是这种情况时, 打印默认为类的名称和一些附加信息:
(deftype Point [x y]) ; ❶ ;; user.Point (pr (Point. 1 2)) ; ❷ ;; #object[user.Point 0x2e6b5958 "user.Point@2e6b5958"]
❶ deftype 在当前类路径中创建相应的 Java 类. Clojure 没有任何关于如何打印这个新对象的指令.
❷ 当我们打印一个新的自定义类型时, Clojure 使用默认的格式化: 它包括初始的 "#object" 声明, 后面跟着类名和对象的十六进制哈希 ("0x2e6b5958").
如果我们想以不同的方式打印自定义类型, 我们可以使用 print-method 告诉 Clojure:
(defmethod print-method user.Point [object writer] ; ❶ (let [class-name (.getName (class object)) args (str (.x object) " " (.y object))] (.append writer (format "(%s. %s)" class-name args)))) ; ❷ (def point (Point. 1 2)) (def point-as-str (pr-str point)) (def point-as-list (read-string point-as-str)) (def back-to-point (eval point-as-list)) [point-as-str :type (type point-as-str)] ; ❸ ;; ["(user.Point. 1 2)" :type java.lang.String] [point-as-list :type (type point-as-list)] ; ❹ ;; [(user.Point. 1 2) :type clojure.lang.PersistentList] [back-to-point :type (type back-to-point)] ; ❺ ;; [(user.Point. 1 2) :type user.Point]
❶ print-method 是一个多重方法. 我们用 defmethod 和对象的类型来扩展这个多重方法. print-method 用两个参数定义, 即接收打印 (或其他打印函数) 调用的对象和当前打开的 "writer" 实例.
❷ 我们现在可以向写入器 append 任何我们想要的东西: 在这个例子中, 我们选择与创建新 Point 实例相同的格式 (user.Point. x y), 用 "object" 的当前内容替换 "x" 和 "y".
❸ 让我们首先打印一个 Point 的字符串表示. 为清晰起见, 我们也打印类型.
❹ 我们现在可以获取字符串表示并要求 Clojure Reader 解析字符串的内容. 我们使用 read-string 来做到这一点. 结果是一个准备好进行评估的 PersistentList 实例.
❺ 在一个列表上调用 eval 会强制将第一个元素解释为函数 (或 Java 互操作调用, 像我们的情况一样), 并将列表的其余部分作为参数. eval 调用 Point 构造函数, 生成一个具有坐标 `[1 2]` 的初始 Point 的副本实例.
上面的例子达到了两个主要目标:
- 以有意义的方式打印自定义类型
Point. - 以一种可以从字符串中读回 Clojure 的方式打印自定义类型 (序列化).
这两个方面不需要一起处理, Clojure 通过 print-dup, print-ctor (和 #= 读宏) 提供了额外的基本序列化机制. print-dup 是一个类似于 print-method 的多重方法, Clojure 为大多数 Clojure 类型提供了 print-dup 的实现:
(binding [*print-dup* true] ; ❶ (pr-str {:a 1 :b 2})) ;; "#=(clojure.lang.PersistentArrayMap/create {:a 1, :b 2})"
❶ print-dup 不是一个直接调用的函数. 动态变量 *print-dup* 控制 print-dup 的序列化格式. 我们可以看到映射 {:a 1 :b 2} 被序列化为 PersistentArrayMap, 并且需要用 create 显式地创建.
print-dup 可以扩展到其他类型. 在下面的例子中, 我们重新定义了 Point 类的 print-method, 以便有一个紧凑且可读的表示, 以及一个适合序列化的 print-dup 格式:
(defmethod print-method user.Point [object writer] (.append writer (format "[x=%s, y=%s]" (.x object) (.y object)))) (pr-str (Point. 1 2)) ; ❶ ;; "[x=1, y=2]" (defmethod print-dup user.Point [object writer] ; ❷ (print-ctor object (fn print-args [object writer] (.append writer (str (.x object) " " (.y object)))) writer)) (binding [*print-dup* true] (pr-str (Point. 1 2))) ; ❸ ;; "#=(user.Point. 1 2)"
❶ 通过一个新的 print-method 定义, Point 实例产生了一个视觉上吸引人的表示. 然而, 请注意输出不是有效的 Clojure.
❷ 我们可以使用 print-dup 来创建一个 Clojure 感知的字符串表示. 我们定义一个新的多重方法实例来处理 Point 类. print-ctor 负责生成正确的构造函数调用.
❸ 为了触发备用的 print-dup 表示, 我们在使用任何打印函数 (在本例中是 pr-str) 之前将动态变量 *print-dup* 绑定为 true. 注意, print-ctor 在 "读求值宏" #=() 内部输出构造函数调用.
读求值宏 #= 的效果与在其后形式上调用 eval 相同. 因此, read-string 可以用于将字符串读回一个列表并同时对其进行评估:
(binding [*print-dup* true] (read-string (pr-str (Point. 1 2)))) ; ❶ ;; [x=1, y=2]
❶ 当与 print-dup 感知的对象一起使用时, read-string 产生读取和评估 Clojure 代码的组合效果.
用 print-dup 进行的 Clojure 序列化是有效的, 但容易受到代码注入的攻击. 这可能解释了为什么 print-dup 通常没有文档, 并且不鼓励使用 read-string (除非你完全控制序列化数据, 一个更好的选择是使用 Clojure EDN). 然而, 在某些情况下使用 print-dup 可能是有意义的, 例如临时将数据停放在磁盘上.
4.5.5. 18.5 slurp 和 spit
slurp 和 spit 是非常常见的函数, 在整本书中被广泛使用. 它们可能是分别读取和写入文件的最简单方式:
(spit "/tmp/test.txt" "Look, I can write a file!") ; ❶ (slurp "/tmp/test.txt") ; ❷ ;; "Look, I can write a file!"
❶ spit 接受两个参数, 一个目标路径和一个内容.
❷ slurp 接受一个参数 (以及这里不可见的其他选项).
此外, 如果第一个字符串参数可以被解释为一个 URL 243, slurp 可以从中读取并返回一个字符串 (spit, 另一方面, 只适用于以 file:// 开头的 URL):
(def book (slurp "https://tinyurl.com/wandpeace")) ; ❶ (reduce str (take 24 book)) ;; "\r\nThe Project Gutenberg"
❶ slurp 对于快速加载一个网站的内容很方便, 比如这个来自古登堡计划的书籍. 参数是一个字符串, 但格式与 java.net.URL 对象兼容.
两个函数也接受额外的键值对参数:
(slurp "/etc/hosts" :encoding "UTF-16") ; ❶ ;; "潳琠䑡瑡扡獥ਣਣ潣慬桯" (spit "/tmp/txt" "Something." :append true) ; ❷ (spit "/tmp/txt" "Something." :append true) (slurp "/tmp/txt") ;; "Something.Something."
❶ :encoding 键强制对正在读取 (如本例) 或写入 (使用 spit) 的字符串使用特定的编码. 这里我们看到将一个 UTF-8 文件解释为 UTF-16 的结果: 内容变得没有意义. 默认编码是 Java 属性 "file.encoding" 的值, 通常设置为 "UTF-8".
❷ 我们可以看到 :append true 对 spit 的影响: 后续对同一文件的写入调用会追加到当前内容之后, 而不是覆盖它 (默认行为).
slurp 和 spit 都会尽力自动处理其参数的类型. 下表显示了每种支持类型的示例. 要运行表中的代码片段, 你需要以下导入:
(import '[java.io FileReader FileWriter]) (import '[java.io ByteArrayInputStream ByteArrayOutputStream]) (import '[java.io File]) (import '[java.net URL Socket])
| I/O 类型 | slurp |
split |
|---|---|---|
| java.io Reader/Writer 子类 | (slurp (FileReader. "/etc/hosts")) |
(spit (FileWriter. "/tmp/xxx") "txt") |
| java.io InputStream/OutputStream\n子类 | ~(slurp (ByteArrayInputStream. `\n(byte-array [1 2 3])))` | ~(spit (ByteArrayOutputStream. ) `\n(byte-array [1 2 3]))` |
| java.io File | (slurp (File. "/etc/hosts")) |
(spit (File. "/tmp/xxx") "txt") |
| java.net URL (或 URI) | (slurp (URL. "http://google.com")) |
(spit (URL. "file:///tmp/xxx") "url") |
| java.net Socket | (slurp (Socket. "localhost" 3000)) |
(spit (Socket. "localhost" 3000) "msg") |
4.5.6. 18.6 总结
遵循 Lisp 的传统, Clojure 有一个优雅而完整的打印系统, 允许深度定制和扩展. 本章给出了一些例子, 但特别是在格式化和漂亮打印方面还有更多的参数可以探索. 格式化系统使用一个小的嵌入式语言来定义格式指令. 然而, 类似于正则表达式, 人们不应该滥用 cl-format 以避免代码过于晦涩难懂. 本章还探讨了如何对自定义对象进行序列化, 这是一种在分布式系统中有许多应用的技术.
4.6. 19 字符串和正则表达式
最常见的编程任务之一是处理字符串. Java 提供了一个不可变的 java.lang.String 类型, 它有一个丰富的 API, 经过多年的企业应用程序开发实践的考验. 除了 clojure.core 中的一些函数和一个专门的 clojure.string 命名空间外, Clojure 建立在这个坚实的基础之上:
(class "I'm a Clojure string") ; ❶ ;; java.lang.String
❶ Clojure 字符串是在 Java 字符串之上实现的.
在编程语言中发现的另一个常见特性是正则表达式的设施. "regex" 是一个定义其他字符串搜索模式的字符串. Clojure 使用相同的 Java 正则表达式抽象, 同时提供专门的函数, 包括一个模式匹配字面量语法:
(class #"I'm a pattern match string") ; ❶ ;; java.util.regex.Pattern
❶ Clojure 提供了一种快速创建模式匹配对象的方法 ("查询字符串", 定义了在另一个字符串中搜索的方式).
字符串支持和正则表达式函数是本章的主题.
4.6.1. 19.1 str
str 是最常用的 Clojure 函数之一. 它接受一个或多个对象, 并返回它们字符串表示的连接:
(str "This " 'is \space 1 " sentence") ; ❶ ;; "This is 1 sentence"
❶ str 将所有参数转换为它们的字符串表示后连接成一个单一的字符串.
在各种值上使用 str 是很常见的, 因为 Clojure 中的每种类型 (从 Java 继承了这种行为) 至少有一个默认的到字符串的转换. 默认的字符串转换只包含对象的类和一个十六进制 id. 有时这种行为是不可取的, 就像我们想在屏幕上打印这个惰性序列的情况:
(str :a 'b 1e8 (Object.) [1 2] {:a 1}) ; ❶ ;; ":ab1.0E8java.lang.Object@dd2856e[1 2]{:a 1}" (str (map inc (range 10))) ; ❷ ;; "clojure.lang.LazySeq@c5d38b66" (pr-str (map inc (range 10))) ; ❸ ;; "(1 2 3 4 5 6 7 8 9 10)"
❶ str 支持的一小部分值. 所有类型都有一个字符串表示, 因为 Object (Java 中所有类的父类) 有一个默认的 `.toString` 方法, 在没有其他选择时使用.
❷ 像 clojure.lang.LazySeq 这样的类型是可能尚未被评估的集合的容器. 它们在设计上没有专门的 toString 方法, 以防止对潜在无限序列的非请求评估.
❸ 有一种方法可以要求 Clojure 使用 pr-str 来打印惰性序列. pr-str 发现了序列序列化的更具体的 print-method 覆盖, 并将其打印为一个列表.
如果一个数据容器不提供字符串表示, 我们可以总是对每个项应用或归约 str:
(apply str (range 10)) ; ❶ ;; "0123456789" (reduce str (interpose "," (range 10))) ; ❷ ;; "0,1,2,3,4,5,6,7,8,9"
❶ 我们可以使用 apply 或 reduce (下面的例子) 来连接输入集合中所有项的字符串表示.
❷ 用逗号分隔是人类可读数据渲染的典型方式, 例如在 CSV (逗号分隔值) 文件中.
在通用性能方面, str 基于 java.lang.StringBuilder, 它在一个可变缓冲区中累积所有字符串片段 (在多个参数的情况下). 尽管 reduce 通常是更快的选项, 但这是 apply 表现更好的情况之一: reduce 会在每次迭代中简单地调用 str, 丢弃任何中间的 StringBuilder. 以下是一个显示差异的基准测试:
(require '[criterium.core :refer [quick-bench]]) (let [v (vec (range 1000))] (quick-bench (apply str v))) ; ❶ ;; Execution time mean : 36.978891 µs (let [v (vec (range 1000))] (quick-bench (reduce str v))) ; ❷ ;; Execution time mean : 609.917674 µs
❶ apply 调用 str 的可变参数元数, 它将每个转换后的字符串推入一个可变的 Java StringBuilder, 逐渐构建字符串. 这是连接字符串的最有效方式.
❷ reduce 产生相同的结果, 但慢得多: 每次迭代都会创建一个累积字符串加上新附加项的新 StringBuilder, 它会立即被连接成一个新字符串并被丢弃.
4.6.2. 19.2 join
join 函数是 clojure.string 命名空间的一部分. 基本形式接受一个对象的序列集合, 并将它们连接成一个字符串, 类似于 str:
(require '[clojure.string :refer [join]]) ; ❶ (join (list "Should " "this " "be " 1 \space 'sentence?)) ;; "Should this be 1 sentence?" ; ❷
❶ 我们需要从 clojure.string 命名空间中 require 该函数.
❷ 我们可以看到不同类型的对象被转换为它们的字符串等价物.
join 也接受一个可选的分隔符, 语义类似于 interpose, 但以字符串连接的形式返回结果:
(join "," (range 10)) ; ❶ ;; "0,1,2,3,4,5,6,7,8,9" (apply str (interpose "," (range 10))) ; ❷ ;; "0,1,2,3,4,5,6,7,8,9"
❶ join 也允许一个分隔符, 产生一个类似 interpose 调用的更短的版本.
❷ 与达到相同效果的等效 interpose 函数调用的快速比较.
join 的工作方式与 str 类似, 使用一个 StringBuilder 实例来累积字符串片段, 然后产生最终的字符串. 与上面的 interpose 版本相比, join 不会产生一个中间的惰性序列, 从而导致更快的处理 (特别是对于大型集合):
(require '[criterium.core :refer [quick-bench]]) (let [xs (interpose "," (range 10000))] (quick-bench (apply str xs))) ; ❶ ;; Execution time mean : 595.661421 µs (let [xs (range 10000)] (quick-bench (join "," xs))) ; ❷ ;; Execution time mean : 418.126884 µs
❶ "xs" 是对一个范围惰性应用 interpose 的结果. 考虑到我们想要从集合中得到一个单一的字符串, 我们付出了产生一个惰性序列的代价, 总是急切地消耗其内容.
❷ 在内部, join 在迭代输入集合时将分隔符添加到 StringBuilder 实例中, 而无需将分隔符 cons 到一个惰性序列中. 这导致了速度的提升.
4.6.3. 19.3 replace, replace-first, re-quote-replacement
clojure.string/replace (或简称 s/replace) 将字符串的段落替换为另一个字符串. 段落可以通过单个字符, 字符串或正则表达式来识别. 在下面的例子中, 我们想用空格替换所有的连字符 "-":
(require '[clojure.string :as s]) ; ❶ (def s "Chat-room messages are up-to-date") (s/replace s \- \space) ; ❷ ;; "Chat room messages are up to date"
❶ 我们需要 require clojure.string 命名空间来访问 replace.
❷ 用 s/replace 将连字符替换为空格.
核心命名空间中还有另一个
replace函数.clojure.core/replace在一个集合中执行项的替换, 而不是字符串中的片段.
我们可以用一个字符串而不是单个字符来替换整个单词, 但我们不能将字符替换与字符串目标混合使用 (反之亦然):
(s/replace "Closure is a Lisp" "Closure" "Clojure") ; ❶ ;; "Clojure is a Lisp" (s/replace "I'm unjure" "j" \s) ; ❷ ;; ClassCastException
❶ 我们可以使用 replace 来用字符串作为参数替换整个单词.
❷ 然而, 我们不能混合目标和替换的类型.
s/replace 也接受正则表达式: 当使用正则表达式作为第一个参数时, 我们还需要传递一个单参数的函数, 其中参数是匹配的表达式:
(def s "Why was 12 afraid of 14? Because 14 ate 18.") ; ❶ (s/replace s #"\d+" #(str (/ (Integer/valueOf %) 2))) ; ❷ ;; "Why was 6 afraid of 7? Because 7 ate 9."
❶ 这个笑话包含一个基本的错误: 看起来句子中的数字被加倍了.
❷ s/replace 的最后一个参数是一个接受一个参数并返回一个字符串的函数. 我们匹配句子中的所有数字并将它们除以 2.
此外, 在正则表达式目标的情况下, 我们可以使用分组捕获模式 "$1", "$2" 等 244:
(def s "Easter in 2038: 04/25/2038, Easter in 2285: 03/22/2285") ; ❶ (s/replace s #"(\d{2})/(\d{2})/(\d{4})" "$2/$1/$3") ; ❷ ;; "Easter in 2038: 25/04/2038, Easter in 2285: 22/03/2285"
❶ 一个字符串包含多个以月, 日, 年格式表示的日期. 我们可以创建一个使用圆括号围绕日期字符串的子部分来单独捕获它们的匹配模式.
❷ 特殊符号 "$" 后跟一个递增的数字代表不同的匹配组. 要交换月和日, 我们需要反转 "$1" 和 "$2" 的位置.
在最后一个例子中, 我们可以看到美元符号 "$" 在正则表达式中使用时有特殊的含义. 如果我们想将其视为字面量 (例如表示一种货币), 我们可以使用 re-quote-replacement:
(def s "May 2018, June 2019") (s/replace s #"May|June" "10$ in") ; ❶ ;; IllegalArgumentException (s/replace s #"May|June" (s/re-quote-replacement "10$ in")) ; ❷ ;; "10$ in 2018, 10$ in 2019"
❶ 我们想用 "10\(" 替换字符串中出现的每个月份. 我们的第一次尝试失败了, 因为 "\)" 对正则表达式有特殊的含义.
❷ re-quote-replacement 阻止了对美元符号的错误 (在这种情况下) 解释.
replace-first 的调用契约与 replace 相同, 但它只执行第一个替换, 如果有的话:
(def s "I could have a drink here and wine home.") (s/replace s #"a drink|beer|wine" "water") ; ❶ ;; "I could have water here and water home." (s/replace-first s #"a drink|beer|wine" "water") ; ❷ ;; "I could have water here and wine home."
❶ s/replace 对输入字符串中的每个匹配表达式执行一次替换.
❷ s/replace-first 在第一次替换时停止.
4.6.4. 19.4 subs, split 和 split-lines
函数 subs (在 core 中), clojure.string/split 和 clojure.string/split-lines 对于检索字符串的部分很有用:
(require '[clojure.string :as s]) ; ❶ (def s "The quick brown fox jumps over the lazy dog") (subs s 20 30) ; ❷ ;; "jumps over" (s/split s #"\s") ; ❸ ;; ["The" "quick" "brown" "fox" "jumps" "over" "the" "lazy" "dog"] (s/split-lines s) ; ❹ ;; ["The quick brown fox" "jumps over the lazy dog"]
❶ s/split 和 s/split-lines 在 clojure.string 命名空间中定义.
❷ subs 返回一个由 "start" (不含) 和 "end" (包含) 限定的子字符串. 如果省略第二个参数, 结束索引将成为字符串的长度.
❸ s/split 对给定正则表达式的每次匹配都创建输入字符串的一个分割. "\s" 表示 "任何空白字符", 其中也包括 "\n" 换行符. 结果向量包含所有的分割.
❹ s/split-lines 对每个 "\n" 换行符执行一个隐式的分割. 结果向量包含所有按换行符的分割.
当输入字符串具有固定结构且要提取的部分总是出现在相同位置时, subs 很有用:
(def errors ; ❶ ["String index out of range: 34" "String index out of range: 48" "String index out of range: 3"]) (map #(subs % 27) errors) ; ❷ ;; ("34" "48" "3")
❶ errors 包含来自日志文件的错误消息. 消息以相同的结构重复, 可变部分总是出现在索引 "27" 处 (索引是 0 基的).
❷ 如果我们知道数字总是出现在字符串的末尾, 我们就不需要指定结束位置.
如果我们需要提取的字符串部分不是固定的, 我们可以使用正则表达式和 s/split:
(def errors ; ❶ ["String is out of bound: 34" "48 is not a valid index." "Position 3 is out of bound."]) (map #(peek (s/split % #"\D+")) errors) ; ❷ ;; ("34" "48" "3")
❶ 新的错误消息包含关于错误索引的信息, 在字符串的不同位置.
❷ 通过在 `\D+` ("一个或多个非数字字符") 处分割, 我们从输入消息中移除了所有不是数字的东西. 这样做, 我们产生了一个向量作为输出, 其中数字是最后一个元素. peek 高效地访问向量的最后一个元素.
通过 s/split, 我们可以获得比 subs 更高的复杂性. 在下面的例子中, 我们访问了从 "/etc/cups/ppd" (Mac 操作系统的默认位置) 获得的打印机配置列表. 下面的 var 定义包含了在文件夹上执行 "ls" 命令的输出. 输出返回一个包含文件夹中所有文件的单个字符串. 我们可以先用 s/split-lines, 然后用 s/split 来隔离我们感兴趣的细节:
(require '[clojure.java.shell :refer [sh]]) ; ❶ (def ls (:out (sh "ls" "-al" "/etc/cups/ppd"))) ; ❷ (def printers (s/split-lines ls)) ; ❸ (last printers) ; ❹ ;; "-rw-r--r-- 1 root _lp 1111829 10 May 13:49 _192_168_176_12.ppd" (sequence (comp (map #(s/split % #"\s+")) ; ❺ (map last) (filter #(re-find #"\.ppd" %))) ; ❻ printers) ;; ("Brother_DCP_7055.ppd" ; ❼ ;; "Training_room.ppd" ;; "_192_168_176_12.ppd")
❶ sh 在操作系统提供的默认 shell 中执行一个命令. 它在 clojure.java.shell 命名空间中可用.
❷ sh 接受一个表示命令 (带有选项) 的字符串列表, 并返回一个包含输出字符串作为 :out 键的值的映射.
❸ 作为第一步, 我们将字符串分割成一行行的列表, 大致就像它们在终端执行命令后在屏幕上出现的那样.
❹ 我们可以看到 printers 内容的一个样本. 每一行都包含关于文件夹中文件的进一步信息, 包括权限, 所有权等等. 行的最后一部分包含打印机配置的名称, 扩展名为 ".pdd".
❺ 每一行的处理都以一个 s/split 指令开始, 该指令在每组空格或制表符处分割行, 将有趣的部分隔离成单个字符串.
❻ 打印机名称将作为每行的最后一个元素出现. 然而, 有些行不包含打印机名称, 比如 "." 或 ".." (特殊目录文件). 我们使用 filter 来移除它们.
❼ 我们可以看到一个预期的输出示例 (你可能需要调整 shell 命令和正则表达式才能在你的系统上执行这个示例).
正则表达式引擎, 例如 Clojure (通过 Java) 提供的引擎, 是一个复杂的工具, 会带来一些性能损失. 大多数时候, 正则表达式是无价的特性, 但如果你有一个固定结构的字符串要分析, 那么为了加速计算, 避免使用正则表达式是有意义的. 以下是一个比较 subs 和 s/split 的基准测试, 以让你了解性能影响:
(require '[criterium.core :refer [quick-bench]]) (let [s "String index out of range: 34"] (quick-bench (subs s 27))) ; ❶ ;; Execution time mean : 22.716615 ns (let [s "String index out of range: 34" re #"\D+"] (quick-bench (s/split s re))) ; ❷ ;; Execution time mean : 561.346569 ns
❶ subs 检索匹配的数字作为字符串, 而不是向量.
❷ s/split 总是返回一个向量. 我们应该使用 peek 来获得与 subs 相同的结果, 但我们可以暂时将它排除在基准测试之外.
正如你所看到的, 正则表达式比简单地从固定位置提取字符串的一部分要慢得多. 考虑到它们提供的功能, 这是预料之中的. 然而, 在对一个慢速应用程序进行性能分析时, 如果存在正则表达式, 它们几乎总是被涉及. 如果你不能没有它们, 有一些方法可以优化它们, 例如避免过于宽泛的模式或不必要的回溯 245.
4.6.5. 19.5 trim, triml, trimr, trim-newline
本节中的函数的目的是移除字符串周围的一个或多个 "空格". "空格" 的定义来自 Java, 包括相当多的变体, 如制表符, 回车符, 其他分隔符和相关的变体 (更多细节请参见下面的标注).
- Java 空白字符定义
Java "空白字符" 定义包括常见的 "空格", "制表符", "换行符" 字符以及来自扩展 Unicode 字符集的几个更多字符 246. 一些空白字符是可打印的, 其他则不是:
(map ; ❶ #(hash-map :int % :char (char %) :hex (format "%x" %)) (filter (comp #(Character/isWhitespace %) char) (range 65536))) ;; ({:int 9 :hex "9" :char \tab} ;; {:int 10 :hex "a" :char \newline} ;; {:int 11 :hex "b" :char \ } ; ❷ ;; {:int 12 :hex "c" :char \formfeed} ;; {:int 13 :hex "d" :char \return} ;; {:int 28 :hex "1c" :char \} ;; [...] (require '[clojure.string :as s]) ; ❸ (s/blank? "\t \n \u000b \f \r \u001c \u001d \u001e \u001f") ;; true (s/blank? "\u0020 \u1680 \u2000 \u2001 \u2002 \u2003") ;; true (s/blank? "\u2004 \u2005 \u2006 \u2008 \u2009") ;; true (s/blank? "\u200a \u2028 \u2029 \u205f \u3000") ;; true
❶ 如果我们遍历整数 (最多到 216, 或 65536), 我们可以列出 UTF-16 Unicode 字符集中的所有条目. 在任何情况下, `Character/isWhitespace` 最多只能工作到 65536.
❷ 这个列表中的一些条目是不可见的, 因为字符是不可打印的.
❸
clojure.string/blank?使用相同的 Java 方法来确定一个字符串是否只包含空白字符. 我们可以确认当使用上面列表中的任何字符时,blank?返回 true.请注意 Ogham 空格标记 `\u1680` 是一个具有可打印表示 (类似于 "-") 的空白字符, 但其他可打印的空白字符如 Ethiopic Wordspace `\u1361` 不被认为是空白字符. 相关的维基百科页面 en.wikipedia.org/wiki/Unicode 包含更多关于 Unicode 规范的信息.
所有四个函数都属于
clojure.string命名空间, 所以我们需要一个显式的require来使用它们.s/trim只移除出现在字符串边缘的一个或多个 Java 空白字符:(require '[clojure.string :as s]) (s/trim " *Look, no more spaces.* ") ; ❶ ;; "*Look, no more spaces.*" (s/trim "\t1\t2n\n") ; ❷
❶
s/trim从字符串的两端移除空白字符.❷ 正如讨论过的, 空白字符的定义也包括其他不可打印的字符, 如制表符.
s/trimr和s/triml与s/trim类似, 但它们分别只从字符串的右侧或左侧移除 Java 空白字符:(s/trimr " *Spaces on the left are not removed with trimr.* ") ; ❶ ;; " *Spaces on the left are not removed with trimr.*" (s/triml " *Spaces on the right are not removed with triml.* ") ; ❷ ;; "*Spaces on the right are not removed with triml.* "
❶
s/trimr只移除出现在字符串右边缘的 Java 空格.❷
s/triml只从字符串的左侧移除 Java 空格.最后,
s/trim-newline只从字符串的右侧移除换行符或回车符 (它们分别编码为 `\n` 和 `\r`):(s/trim-newline "\n Only return and\n newline at the end.\n\r") ; ❶ ;; "\n Only spaces and\n newline at the end."
❶
s/trim-newline只修剪字符串末尾的换行符 `\n` 和回车符 `\r`.
4.6.6. 19.6 escape, char-name-string, char-escape-string
escape 是 clojure.string 命名空间中的一个函数, 专用于字符串中字符的选择性替换. 该函数接受 2 个参数: 一个字符串 "s" 和一个从 char 到可打印对象 "cmap" 的函数 "f". escape 遍历 "s" 中的每个字符 "c", 如果 `(f c)` 不为 nil, 那么 `(f c)` 就会替换输出字符串中的 c. Clojure 映射是作为参数使用的非常方便的选择:
(require '[clojure.string :as s]) (def link ; ❶ "Patterson, John: 'Once Upon a Time in the West'") (def link-escape ; ❷ {\, "_comma_" \space "_space_" \. "_dot_" \' "_quote_" \: "_colon_" \newline "_newline_"}) (s/escape link link-escape) ; ❸ ;; "Patterson_comma__space_John_colon__space__quote_Once_space_Upon_ ;; space_a_space_Time_space_in_space_the_space_West_quote_"
❶ link 是一个用户希望用作网页章节标题的字符串. 该章节可以作为链接在互联网上分享. 正如读者所见, 章节标题包含许多在浏览器地址栏中不允许的字符.
❷ 使用映射的选项非常方便. link-escape 可以作为 escape 的函数使用.
❸ escape 将所有匹配的键替换为输出字符串中相应的值. 请注意, 输出中包含一个人为的换行符以限制行的长度.
char-name-string 和 char-escape-string 是 core 命名空间中的两个公共映射. 它们存在的原因主要是为了 Clojure 内部使用, 但了解它们的存在可能很有用. 类似于我们在例子中使用的 link-escape, char-name-string 和 char-escape-string 可以与 escape 一起使用或独立使用:
char-name-string ; ❶ ;; {\newline "newline" ;; \tab "tab" ;; \space "space" ;; \backspace "backspace" ;; \formfeed "formfeed" ;; \return "return"} (map #(char-name-string % %) "Hello all!\n") ; ❷ ;; (\H \e \l \l \o "space" \a \l \l \! "newline")
❶ 通过键入 char-name-string 而不带括号调用它, 我们可以看到有哪些可用的替换.
❷ char-name-string 无需使用 require 即可用. 我们将输入字符串视为一个序列, 并使用 char-name-string 执行每个转换. 注意, 我们可以传递两个参数 (百分号 % 出现两次): 第一个查找字符, 第二个用作默认值.
char-escape-string 执行类似的替换, 但不是用相应字符的名称替换输入, 而是使用其引用的转义序列:
char-escape-string ; ❶ ;; {\newline "\\n" ;; \tab "\\t" ;; \return "\\r" ;; \" "\\\"" ;; \\ "\\\\" ;; \formfeed "\\f" ;; \backspace "\\b"} (def s "Type backslash-t '\t' followed by backslash-n '\n'") ; ❷ (println s) ;; Type backslash-t ' ' followed by backslash-n ' ;; ' (println (s/escape s char-escape-string)) ; ❸ ;; Type backslash-t '\t' followed by backslash-n '\n'
❶ 像我们之前做的那样, 我们可以打印替换映射的内容以检查其内容.
❷ 我们希望按字符串中出现的方式打印这些指令, 但 println 正确地将像 `\n` 这样的特殊序列转换为屏幕上的一个新行.
❸ 带有 char-escape-string 的 s/escape 将特殊字符转换为它们的引用字符串, 以便它们按最初的意图打印.
4.6.7. 19.7 lower-case, upper-case, capitalize
lower-case, upper-case 和 capitalize 是 clojure.string 命名空间的一部分. lower-case 和 upper-case 分别将字符串中的所有字符转换为小写或大写. 我们可以使用 upper-case 来将 Clojure 渲染成类似于原始 Lisp 的形式:
(require '[clojure.repl :refer [source]]) (require '[clojure.string :as s]) (-> some? ; ❶ source ; ❷ with-out-str ; ❸ s/upper-case ; ❹ println) ;; (DEFN SOME? ; ❺ ;; "RETURNS TRUE IF X IS NOT NIL, FALSE OTHERWISE." ;; {:TAG BOOLEAN ;; :ADDED "1.6" ;; :STATIC TRUE} ;; [X] (NOT (NIL? X)))
❶ some? 是标准库中的一个简单函数, 我们想要查找它.
❷ 给定一个 var, `~clojur.repl/source~` 读取定义该 var 的文件并加载其源定义.
❸ with-out-str 为标准输出 (通常会打印源代码的地方) 创建一个到字符串的线程绑定, 这样我们以后就可以使用该字符串.
❹ s/upper-case 产生输入字符串的大写版本. 这个字符串包含像 "newlines" 这样的不可打印字符, 它们被 println 正确地解释.
❺ "全大写" 的 Clojure 现在包含无法识别的符号, 如果我们尝试使用它, 将无法编译.
以下是使用 lower-case 来实现字符串不区分大小写等价的示例:
(def primary-colors #{"red" "green" "blue"}); ❶ (def book (slurp "https://tinyurl.com/wandpeace")) ; ❷ (->> (s/split book #"\s+") ; ❸ (filter primary-colors) frequencies) ;; {"red" 87, "blue" 64, "green" 38} (->> (s/split book #"\s+") ; ❹ (map s/lower-case) (filter primary-colors) frequencies) ;; {"red" 89, "blue" 64, "green" 38}
❶ 我们有一个原色集合. 我们可以等价地将所有颜色拼写成大写, 假设我们对那部分代码因无特殊原因而突出显示感到满意.
❷ book 包含一个大型文本的字符串版本, 例如 "战争与和平".
❸ 我们使用 s/split 将书籍分割成单个单词. 我们用一个简单的正则表达式来做到这一点, 它涵盖了大多数情况. 我们可以通过使用 filter 和集合本身作为谓词来只过滤原色. 最后, 我们调用 frequencies 来查看数字. 这样做, 我们将我们所有小写颜色的列表与书籍的内容进行比较, 后者可能以不同的大小写出现.
❹ 在第二次尝试中, 单词在过滤前被转换为小写. 我们可以看到有两个额外的 "red" 出现, 可能是因为它们出现在句子的开头.
capitalize 将字符串的第一个字母转换为大写, 其他所有字母转换为小写. 这对于统一列表的格式, 或者正确拼写专有名词很有用. 我们可以对从不同来源收集的客户名称向量使用 capitalize, 以确保它们拼写正确:
(def names ["john abercrombie" "Brad mehldau" "Cassandra Wilson" "andrew cormack"]) (map (fn [name] (->> (s/split name #"\b") ; ❶ (map s/capitalize) ; ❷ s/join)) ; ❸ names) ;; ("John Abercrombie" ;; "Brad Mehldau" ;; "Cassandra Wilson" ;; "Andrew Cormack")
❶ 第一步是 s/split 包含全名的字符串. 我们需要在最后将字符串重新连接起来, 所以我们希望在分割期间保留空格. 正则表达式 `\b` 表示 "任何单词边界" (其中包括由空格或其他字符组成的单词). mapcat 将内部向量折叠成一个单一的单词集合.
❷ s/capitalize 将每个单词的首字母转换为大写.
❸ 现在名字的格式正确了, 我们需要准备用 s/join 将字符串重新连接起来.
注意 upper-case, lower-case 和 capitalize 可以用于任何可打印的对象 (实际上是所有 Clojure 和 Java 类型):
(map s/upper-case ['symbols :keywords 1e10 (Object.)]) ;; ("SYMBOLS" ":KEYWORDS" "1.0E10" "JAVA.LANG.OBJECT@4C7A1053")
4.6.8. 19.8 index-of, last-index-of
index-of 和 last-index-of 检索给定子字符串 (或单个字符) 在另一个字符串中的索引:
(require '[clojure.string :as s]) ; ❶ (s/index-of "Bonjure Clojure" \j) ; ❷ ;; 3 (s/last-index-of "Bonjure Clojure!" "ju") ; ❸ ;; 11
❶ index-of 和 last-index-of 都在 clojure.string 命名空间中声明.
❷ 第一个 `\j` 出现在索引 3 处 (大写 "B" 在索引 0).
❸ 字符串 "ju" 的最后一次出现从索引 11 开始.
两个函数都接受一个可选的整数索引作为搜索的起始位置. 如果给定了 "n", index-of 会跳过前 "n" 个字符, 而 last-index-of 会在开始向后搜索之前跳转到 "n":
(s/index-of "Bonjure Clojure" \j 4) ; ❶ ;; 11 (s/last-index-of "Bonjure Clojure!" "ju" 10) ; ❷ ;; 3
❶ index-of 在开始搜索之前跳过了输入字符串的前 "4" 个字符. 由于 "4" 超过了第一个 "j" 的位置, 下一个 "j" 在索引 11 处找到.
❷ last-index-of 在开始向后搜索之前跳转到索引 "10". 字符串中前一个 "ju" 在索引 "3" 处找到.
如果找不到目标字符或字符串, 或者起始索引超出了字符串的边界, 两个函数都返回 nil:
(s/index-of "Bonjure Clojure" "z") ;; nil ; ❶ (s/index-of "Bonjure Clojure" "j" 20) ;; nil (s/last-index-of "Bonjure Clojure" "z") ;; nil (s/last-index-of "Bonjure Clojure" "j" -1) ;; nil
❶ 一组例子, 展示了当我们搜索一个不存在的子字符串或传递超出字符串边界的起始索引 "n" 的值时会发生什么.
除了字符串和单个字符, 还接受其他类型的 java.lang.CharSequence, 例如 java.lang.StringBuffer:
(import 'java.lang.StringBuffer) (s/index-of ; ❶ (doto (StringBuffer.) (.append "Bonjure") (.append \space) (.append "Clojure")) \j) ;; 3
❶ java.lang.CharSequence 接口在 Java 标准库中有一些可用的实现, 例如 StringBuffer, StringBuilder 或非常常见的 String 类. index-of 和 last-index-of 适用于任何 CharSequence.
4.6.9. 19.9 blank?, ends-with?, starts-with?, includes?
这些属于 clojure.string 命名空间的函数是谓词, 用于识别另一个字符串 (或更一般地说, 一个 java.lang.CharSequence, 如 StringBuffer 或 StringBuilder) 中是否存在特定的字符或子字符串.
blank? 接受一个 java.lang.CharSequence, 如果它只包含 "空白字符", 则返回 true. Java 对 "空白字符" 的定义包括一组 Unicode 字符, 包括正常的空格, 制表符和其他类型的不可打印字符 (请参见 trim 部分中的这个摘要列表):
(require '[clojure.string :as s]) ; ❶ (s/blank? " \t \n \f \r ") ; ❷ ;; true (s/blank? "\u000B \u001C \u001D \u001E \u001F") ; ❸ ;; true
❶ 请记得 require clojure.string 命名空间.
❷ 这里是一些空白字符类型的第一个样本: 空格本身, 制表符, 换行符, 换页符, 回车符.
❸ 在这个例子中, 我们可以看到一些更不常见的 Unicode 字符, 它们也被认为是空白字符.
ends-with? 和 starts-with? 分别在给定的子字符串出现在另一个字符串的末尾或开头时返回 true:
(s/starts-with? "Bonjure Clojure" "Bon") ;; true (s/starts-with? "Bonjure Clojure" "Clo") ;; false (s/starts-with? "" "") ;; true (s/starts-with? "Anything starts with nothing." "") ;; true ; ❶ (s/ends-with? "Bonjure Clojure" "ure") ;; true (s/ends-with? "Bonjure Clojure" "Bon") ;; false (s/ends-with? "" "") ;; true (s/ends-with? "Anything ends with nothing." "") ;; true
❶ 注意, 对于 starts-with? 和 ends-with?, 空字符串总是开始或结束一个给定的字符串, 返回 true.
includes 在给定字符串的任何位置查找子字符串匹配:
(s/includes? "Bonjure Clojure" "e C") ; ❶ ;; true
❶ includes? 验证一个子字符串在另一个字符串内部的存在.
4.6.10. 19.10 re-pattern, re-matcher, re-groups, re-seq, re-matches, re-find
正则表达式是一种模式定义语言, 能够搜索, 验证或替换字符串. Clojure, 像其他编程语言一样, 包含一组专用于正则表达式的函数和设施. 在更详细的例子之前, 这里有一个简短的摘要:
re-pattern创建一个新的java.util.regex.Pattern对象实例. 这个对象执行正则表达式的解析和分析, 为后续应用于字符串做准备. 将模式的创建与其应用分开有很好的理由: 模式通常在许多字符串上重用, 我们不想多次承担解析的成本. Clojure 也包含一个正则表达式语法字面量#"", 它产生与re-pattern相同的结果.re-matcher是下一个逻辑步骤, 创建一个准备在特定字符串上工作的javax.util.regex.Matcher对象. 结果对象可以检索匹配的模式, 将搜索限制在字符串的特定区域, 或执行替换. 由re-matcher返回的对象是有状态的, 并记住最后请求匹配的位置. 尽管 Clojure 的其余函数理解Matcher对象的工作流程, 但这通常不是最常用的正则表达式入口点.re-groups检索正则表达式对字符串的所有匹配组. 组是与正则表达式中圆括号的存在相关的正则表达式特定概念. 每对圆括号都隔离出一部分字符串, 该部分被返回. 这对于匹配一个更大的表达式但只检索其特定部分很有用.re-seq从字符串上的正则表达式的匹配组中创建一个惰性序列. 这对于在长字符串上有数千个潜在匹配时只消耗部分匹配很有用.re-find返回给定正则表达式在字符串上的第一个匹配 (或下一个匹配, 如果有的话).
从摘要中我们可以看到, API 有一个无状态部分和一个基于与 Matcher 对象重复交互的有状态部分. 无状态部分无疑是使用最广泛的:
(filter #(re-find #"-seq" (str (key %))) ; ❶ (ns-publics 'clojure.core)) ; ❷ ;; ([tree-seq #'clojure.core/tree-seq] ; ❸ ;; [line-seq #'clojure.core/line-seq] ;; [iterator-seq #'clojure.core/iterator-seq] ;; [enumeration-seq #'clojure.core/enumeration-seq] ;; [resultset-seq #'clojure.core/resultset-seq] ;; [re-seq #'clojure.core/re-seq] ;; [lazy-seq #'clojure.core/lazy-seq] ;; [file-seq #'clojure.core/file-seq] ;; [chunked-seq? #'clojure.core/chunked-seq?] ;; [xml-seq #'clojure.core/xml-seq])
❶ 你可以使用 re-find 作为谓词来验证一个子字符串在另一个字符串内部的存在.
❷ 在这种情况下, 字符串列表来自核心命名空间中的所有公共函数名.
❸ 结果回答了这个问题: "标准库中有哪些函数的名称中包含 -seq?"
re-find 作为谓词是一个不错的选择, 因为即使有更多匹配, 它也会在第一个匹配处停止. 但如果我们想提取所有匹配的部分, 我们需要使用 re-seq. 例如, 这里我们想找到一个网页中所有的电子邮件:
(def so-contacts (slurp "https://stackoverflow.com/company/contact")) (set (map last (re-seq #">(\S+@\S+\.com)<" so-contacts))) ; ❶ ;; #{"legal@stackoverflow.com"}
❶ 这里展示的正则表达式是一个快速解决方案, 它依赖于电子邮件地址周围存在 HTML 标签. 在大多数网页抓取的情况下, 它的工作效果足够好. 它还假设电子邮件属于 ".com" 域, 这对于所有电子邮件地址来说肯定不是真的. re-seq 在同一个 Matcher 上执行多个 "find" 操作以累积结果.
我们现在可以简要比较几种验证一个字符串是否包含另一个字符串的选项. 我们已经看到了 index-of, re-find 和 includes?:
(require '[criterium.core :refer [quick-bench]]) ; ❶ (require '[clojure.string :as s]) (def contacts "Contact us: support@manning.com or 203-626-1510") ; ❷ (let [s contacts] (quick-bench (s/index-of s "support@manning.com"))) ;; Execution time mean : 16.570516 ns (let [s contacts re #"support@manning.com"] (quick-bench (re-find re s))) ;; Execution time mean : 345.104914 ns ; ❸ (let [s contacts] (quick-bench (s/includes? s "support@manning.com"))) ;; Execution time mean : 18.364512 ns
❶ 像本书其余部分一样, Criterium 库被用来对函数进行基准测试.
❷ 基准测试包括在一个短字符串中搜索 Manning 的支持电子邮件地址.
❸ 用 re-find 搜索大约慢 20 倍.
re-find 受到惩罚, 因为它在将其应用于输入字符串之前必须分析正则表达式. 同时, re-find 允许比检查子字符串存在更强大的功能.
4.6.11. 19.11 总结
在本章中, 我们已经看到了 Clojure 中可用于处理字符串的丰富函数集. 在不太可能的情况下, 如果 clojure.string 的内容不够用, Clojure 总是可以访问 java.lang.String 类上可用的更大方法集. 类似地, Clojure 依赖 Java 进行正则表达式. 在这两种情况下, 与 Java 相比, Clojure 都提供了一个更好, 更紧凑的接口.
4.7. 20 变异和副作用
Clojure 从其设计原则开始就实现并鼓励不变性. 然而, Clojure 是一种务实的语言, 在必要时允许可变性和副作用. Clojure 对可变性的处理仍然是优雅的, 并且大部分是函数式的. 在本章中, 我们将看到主要因其可变或副作用性质而存在的函数和数据结构. Clojure 的其他部分也适合可变性, 并在它们各自的章节中有所描述 (例如, 并发或 Java 互操作). 让我们从瞬态开始.
4.7.1. 20.1 transient, persistent!, conj!, pop!, assoc!, dissoc! 和 disj!
瞬态是一种可用于某些 Clojure 数据结构的可变状态, 也是一个同名的函数. 目前支持的集合是: 向量, 映射和集合.
瞬态的存在是为了解决一个优化问题. 当创建或转换大型持久数据结构时, 单个处理步骤会受到不变性的开销, 即使集合的客户端只对最终输出感兴趣. 瞬态提供了一种在集合仍在处理时关闭不变性的方法. 在瞬态状态期间, 集合:
- 停止支持像
assoc或conj这样的典型函数. - 支持类似但会变异的函数, 如
assoc!或conj!. - 可以通过调用
persistent!变回持久的.
瞬态集合被设计为防止标准库在瞬态状态之外意外使用它:
(class (transient [])) ; ❶ ;; clojure.lang.PersistentVector$TransientVector (conj (transient []) 1) ; ❷ ;; ClassCastException ;; clojure.lang.PersistentVector$TransientVector ;; cannot be cast to clojure.lang.IPersistentCollection
❶ 在一个向量上调用 transient, 返回 clojure.lang.PersistentVector$TransientVector 内部类的一个实例.
❷ 向集合中添加 1 的尝试失败, 因为瞬态不支持 IPersistentCollection 接口.
虽然像 get, nth 或 count 这样的只读函数子集仍然有效, 但有一整套新的函数可用于改变瞬态. 它们的名称与其他标准函数类似, 只是在末尾添加了常规的 "!" :
(def v (transient [])) (def s (transient #{})) (def m (transient {})) ((conj! v 0) 0) ; ❶ ;; 0 ((conj! s 0) 0) ; ❷ ;; 0 ((assoc! m :a 0) :a) ; ❸ ;; 0
❶ 一个瞬态向量 "v" 用 conj! 改变, 并用作函数来访问索引 "0" 处的项. 该项刚刚被添加到瞬态中, 是数字 "0".
❷ 类似地, 我们可以使用 conj! 向一个瞬态集合添加一个新元素. 我们可以使用瞬态集合作为函数来验证集合是否包含项 "0". 当元素不存在时, 返回 nil.
❸ 瞬态映射 "m" 用 assoc! 改变.
标准库在瞬态之上实现了许多基础函数: into, mapv, group-by, Set, frequencies (等等), 都是使用瞬态来加速内部处理的将一个集合转换为另一个集合的函数. 例如, 以下是瞬态对 frequencies 的影响:
(require '[criterium.core :refer [quick-bench]]) (defn frequencies* [coll] ; ❶ (reduce (fn [counts x] (assoc counts x (inc (get counts x 0)))) {} coll)) (let [coll (range 10000)] (quick-bench (frequencies* coll))) ;; Execution time mean : 2.335759 ms (let [coll (range 10000)] ; ❷ (quick-bench (frequencies coll))) ;; Execution time mean : 1.995676 ms
❶ frequency* 函数与标准库中的函数相同, 但它不使用瞬态.
❷ 我们可以看到原始的 frequencies 使用瞬态时快了大约 20%.
标准库中还有其他函数可以从瞬态中受益. 本书阐述了使用瞬态来提高 zipmap, merge, tree-seq, disj 和 select-keys 的性能. 我们还在以下地方使用了瞬态:
peek中创建reverse-mapv函数.dotimes包含一个使用瞬态的快速 "FizzBuzz" 实现.nth展示了如何在一个数组之上实现一个哈希表数据结构. 哈希表使用更快的瞬态操作来增长和缩小内部数组.
邀请读者访问上述例子以查看瞬态的实际应用. 在本节的剩余部分, 我们将关注一些重要的细节. 我们需要小心重用对瞬态的相同引用, 因为它可能会变得不一致. 这与像 java.util.HashMap 这样的其他可变数据结构形成对比. 下面的例子说明了这种行为:
(import 'java.util.HashMap) (def transient-map (transient {})) (def java-map (HashMap.)) (dotimes [i 20] ; ❶ (assoc! transient-map i i) (.put java-map i i)) (persistent! transient-map) ; ❷ ;; {0 0, 1 1, 2 2, 3 3, 4 4, 5 5, 6 6, 7 7} (into {} java-map) ; ❸ ;; {0 0, 7 7, 1 1, 4 4, 15 15, 13 13, 6 6, ;; 3 3, 12 12, 2 2, 19 19, 11 11, 9 9, 5 5, ;; 14 14, 16 16, 10 10, 18 18, 8 8, 17 17}
❶ dotimes 迭代表达式的主体 20 次. 每次迭代我们都向两个可变映射中添加键值对 [i i].
❷ persistent! 版本的瞬态映射似乎缺少了许多键.
❸ Java HashMap 正确地显示了 20 个键值对, 正如预期的那样.
Clojure 的瞬态不保证它会就地改变输入. 每个瞬态操作都应将输入视为 "过时的", 并使用变异函数返回的新版本. 使用瞬态的正确方法应该始终是使用前一个变异操作的输出:
(def transient-map (transient {})) (def m ; ❶ (reduce (fn [m k] (assoc! m k k)) transient-map (range 20))) (persistent! m) ; ❷ ;; {0 0, 7 7, 1 1, 4 4, 15 15, 13 13, 6 6, ;; 3 3, 12 12, 2 2, 19 19, 11 11, 9 9, 5 5, ;; 14 14, 16 16, 10 10, 18 18, 8 8, 17 17}
❶ 对一个瞬态应用多个变异的正确方法是始终使用最后变异的实例.
❷ transient-map 指向的同一个可变瞬态映射的状态与 reduce 调用的结果不同. 我们可以看到 persistent! 版本现在包含了预期的 20 个键.
读者还应记住, 瞬态是未同步的. 多个线程使用同一个瞬态实例可能导致不可预测的结果. 请参见 locking 以了解如何确保瞬态变异在同步上下文中发生.
4.7.2. 20.2 doseq, dorun, run!, doall, do
另请参见
dotimes和while, 这两个专为副作用设计的迭代函数, 在一个单独的章节中有单独的介绍.
本节中的所有函数都假定计算依赖于某些副作用才能正确评估. 标准库中的绝大多数函数, 由于惰性或一般的设计原则, 没有适当考虑副作用.
例如, doseq, dorun 和 run! 专为副作用而设计. 它们遍历一个惰性序列, 丢弃结果并返回 nil:
(defn unchunked [n] ; ❶ (map #(do (print ".") %) (subvec (vec (range n)) 0 n))) (doseq [x (unchunked 10) :while (< x 5)] x) ; ❷ ;; ......nil (dorun 5 (unchunked 10)) ; ❸ ;; ......nil (run! #(do (print "!") %) (unchunked 10)) ; ❹ ;; .!.!.!.!.!.!.!.!.!.!nil
❶ unchunked 创建一个大小为 "n" 的非分块惰性序列. 通过移除分块评估, 我们确保精确评估所请求的内容. 对于分块序列, 我们总是会看到前 32 个项的评估, 不论请求了多少个. subvec 是 seq 支持的少数非分块集合之一, 我们可以用它来创建一个新的非分块集合.
❷ doseq 配备了丰富的语义来迭代输入, 与 for 可用的相同. 这里显示的是 :while 关键字, 它在 "x" 变为等于 5 时停止迭代. 读者应该回顾 for 以查看所有其他可用选项. 我们可以看到每个通过 map 函数的输入元素都会打印一个点, 但表达式本身返回 nil.
❸ dorun 更简单, 提供的配置更少. 它接受一个可选的数字作为第一个参数, 代表要迭代的元素数量. 当没有数字时, dorun 迭代整个输入. 结果与 doseq 相同.
❹ run! 额外接受一个函数, 并将该函数应用于输入中的每个元素. run! 总是遍历整个输入.
正如我们从例子中看到的, doseq, dorun 和 run! 总是返回 nil, 不论输入如何, 所以如果在迭代期间发生任何有趣的事情, 它必须是一个副作用. 因此, doseq, dorun 和 run! 的内存分配都是 O(1), 因为它们不保留序列的头部 (或任何其他项).
doall 的行为与 dorun 类似, 但它返回输出, 在此过程中强制任何副作用. doall 经常被用来在离开一个序列正常工作所必需的状态之前完全实现一个惰性序列. 一个典型的例子是 with-open:
(require '[clojure.java.io :refer [reader]]) (defn get-lines [url] ; ❶ (with-open [r (reader url)] (line-seq r))) (def lines (get-lines "https://tinyurl.com/pi-digits")) ; ❷ (count lines) ; ❸ ;; IOException Stream closed
❶ get-lines 接受一个 url 并使用 clojure.java.io/reader 来产生该 url 内容的 line-seq. with-open 是一个宏, 确保在退出块后读宏被正确关闭.
❷ 从互联网上读取一些文本, 表面上没有问题.
❸ 但一旦我们试图在序列中向前移动, 例如检查有多少行, 我们就会得到一个 IOException.
在上面的例子中发生的是, 惰性序列应该从中读取的 java.io.Reader 实例在相关代码评估时已经被关闭. with-open, 正如预期的那样, 在函数内部处理了这方面的问题, 让惰性序列自由地逃离了连接仍然打开的上下文. 一个解决方案是完全实现序列:
(require '[clojure.java.io :refer [reader]]) (defn get-lines [url] ; ❶ (with-open [r (reader url)] (doall (line-seq r)))) (def lines (get-lines "https://tinyurl.com/pi-digits")) (count lines) ; ❷ ;; 29301
❶ 对 get-lines 的唯一更改是在离开 with-open 上下文之前, 对由 lazy-seq 产生的惰性序列添加 doall.
❷ 一旦序列被完全实现, 计算行数就不会产生任何问题.
用 doall 进行完全评估的代价是可能将大数据加载到内存中. 当这种方法不切实际时, 计算需要移动到副作用 (例如一个打开的连接) 仍然可能的上下文中. 例如, 如果我们想计算一个大的远程文件的行数, 我们需要将 count 移动到 with-open 内部:
(require '[clojure.java.io :refer [reader]]) (defn count-lines [url] ; ❶ (with-open [r (reader url)] (count (line-seq r)))) (count-lines "https://tinyurl.com/pi-digits") ;; 29301
❶ 与仅仅从远程 url 获取行不同, 我们现在同时用 count-lines 计算它们. 这个函数不那么通用, 但不需要将可能很大的文件加载到内存中以供以后使用.
本节的最后一个特殊形式是 do. do 评估所有表达式参数并返回最后一个的结果 (如果没有表达式, 则为 nil). 前面的表达式被假定为副作用, 因为它们的结果被完全忽略:
(do (println "hello") ; ❶ (+ 1 1)) ;; hello ;; 2 (if (some even? [1 2 3]) (do (println "found some even number") ; ❷ (apply + [1 2 3])) (println "there was no even number.")) ;; found some even number ;; 6
❶ 这种形式的 do 表达式经常被临时引入, 以在代码的关键部分打印调试消息. 其他跟踪技术, 如日志记录, 更有可能被留在 do 表达式内的代码中.
❷ do 的另一个典型用法是与 if 语句一起使用, 因为它们的 "then-else" 块只接受一个表达式.
专为副作用设计的函数, 如我们在本节中访问的那些, 不应在日常代码中频繁出现, 而应被限制在应用程序的特定部分. 它们的存在应该标志着执行计算所必需的副作用的需要. Clojure 对函数式编程的务实方法在实践中通过在标准库的设计中嵌入这种意识来实现. 其他语言更喜欢将有影响的编程包装在更受约束的抽象中 (例如 Monad 或 Applicative Functor 247), 它们提供了额外的控制, 但代价是复杂性急剧上升. 每种方法都有其优点, Clojure 倾向于简单和约定.
4.7.3. 20.3 volatile!, vreset!, vswap! 和 volatile?
volatile! 是从 1.7 版本开始对 Clojure 的一个相对较新的补充. 像 atom, agent, var 或 ref 一样, volatile! 是一个存储某种形式状态的并发相关结构. 与标准引用类型不同, volatile! 不是线程安全的. volatile! 在一些特定的场景中很有用, 在这些场景中, 状态更改应该立即对其他线程可见. 在这个意义上, volatile! 更关乎副作用而不是并发. 使用 volatile! 非常简单:
(def v (volatile! 0)) ; ❶ (volatile? v) ; ❷ ;; true (vswap! v inc) ; ❸ ;; 1 (vreset! v 0) ;; 0
❶ volatile! 被设计为像其他并发结构一样持有数据. 初始值必须是 volatile! 调用的 D 一部分.
❷ volatile! 返回一个 clojure.lang.Volatile, 它被保存在 var "v" 中. 然后我们可以询问 "v" 是否是 volatile?.
❸ 有两种方法可以改变 volatile!: 我们可以使用 vswap! 传递一个从旧值到新值的函数, 或者使用 vreset! 只是替换值.
- Java Volatile
volatile!不像其他并发原语那样保护其状态免受并发访问. 相反,volatile!的目标是确保并发线程迅速看到任何状态更改. 要理解为什么这可能是必要的, 我们需要谈谈 Java 中实例属性 (或简称变量) 的默认线程可见性.Java 虚拟机有多种加速代码执行的方法. 其中之一是变量访问重排序, 它改变变量被读取或写入的顺序以提高代码关键部分的性能. 除了重排序, JVM 可能决定在 CPU 寄存器中缓存变量值. 当代码顺序执行时, 重排序和局部缓存通常不是问题. 但当涉及多个线程时, 无法保证一个读操作会在预期的写操作之后执行.
这个问题可以通过锁定来解决, 但锁定成本高昂 248. 然而, 许多情况通过禁止重排序和寄存器缓存来解决会更好. 在 Java 中, 我们可以通过将变量声明为 "volatile" 来达到这样的目的. 当一个实例属性是
volatile时, 编译器会通知运行时, 对该变量的访问不应受重排序影响, 并且其值不应存储在缓存寄存器中.Clojure 的
volatile!定义了一个实现这种行为的引用类型. 在引入volatile!之前, 除了用:volatile-mutable指令创建一个完整的deftype外, 没有办法产生一个独立的 "volatile" 属性.在 Clojure 中引入
volatile!的主要原因是状态化的 transducer 及其在像core.async249 这样的并发环境中的使用.一些
core.async的结构, 如 "pipelines", 通过协调的多线程访问来实现并行. 在一个管道中, 多个线程负责一个 transducer 链的每个阶段, 但每个线程一次只访问一个阶段. 因此, 执行一个阶段的下一步的线程需要看到任何先前写入的状态.在
core.async管道的条件下, 一个状态化 transducer 内部的状态不一定需要是线程安全的. 更重要的是, 状态应该是立即可见的, 不被重排序, 也不被缓存在 CPU 寄存器中. 邀请读者查看transduce以看到一个使用volatile!的自定义状态化 transducer 的例子.除了状态化的 transducer,
volatile!也可以用来解决一些线程协调问题. 在下面的例子中, 一个 "生产者" 线程想通知一个消费者线程工作已完成, 结果已可用:(def ready (volatile! false)) (def result (volatile! nil)) (defn start-consumer [] (future (while (not @ready) ; ❶ (Thread/yield)) (println "Consumer getting result:" @result))) (defn start-producer [] ; ❷ (future (vreset! result :done) (vreset! ready :done))) (start-consumer) ; ❸ (start-producer) ; ❹ ;; Consumer getting result: :done
❶
start-consumer实现了一个 "自旋" 循环, 它持续检查结果是否准备好.Thread/yield传达了当前线程愿意将控制权交还给 CPU, 以便其他线程可以执行.❷
start-producer启动一个新的future线程, 该线程传递结果并将volatile!"ready" 从 false 更改为 true.❸ 自旋线程开始检查是否有结果.
❹ 一旦生产者翻转 "ready" 标志, 消费者就退出循环并打印一条消息.
在纯 Java 中, 忘记将 "ready" 或 "result" 声明为 "volatile", 我们可能会引入不一致的结果, 例如打印 "Consumer getting result: null", 而在 Clojure 中, 没有办法产生这种无效的结果.
在引入
volatile!之前, 我们可以使用普通的 var 或 atom 得到等效的有效结果. 然而,volatile!在没有内部锁定 (var) 或比较和交换语义 (atom) 的情况下实现了轻量级的线程同步. 因此,volatile!主要应被视为一种性能优化.
4.7.4. 20.4 set!
set! 是一个改变目标的变异宏. 它根据参数的类型以不同的方式工作. 例如, set! 可以写入 Java 类的静态或实例属性 (假设字段是 "public" 且不是 "final" 250):
(import 'java.awt.Point) ; ❶ (def p (Point.)) ; ❷ [(. p x) (. p y)] ;; [0 0] (set! (. p -x) 1) ; ❸ (set! (. p -y) 2) [(. p x) (. p y)] ;; [1 2]
❶ java.awt.Point 是 Java 标准库中抽象窗口工具包 (AWT) 的一个简单类. 它将 x,y 坐标暴露为公共实例字段.
❷ 不带参数的 Point 初始化器将点初始化在 x=0, y=0 坐标处. 我们可以使用点实例上可用的 getter 方法 "getX" 来查看坐标. Clojure 会自动将 `(. p x)` 转换为 `p.getX()`.
❸ 破折号 "-" 告诉 Clojure "-x" 是实例属性 "x" 而不是 getter 方法 `p.getX()`. set! 使用实例属性来设置新的坐标.
set! 也可以改变线程绑定的 var 对象 (永远不会是根值):
(def non-dynamic 1) ; ❶ (def ^:dynamic *dynamic* 1) (set! non-dynamic 2) ; ❷ ;; IllegalStateException (set! *dynamic* 2) ;; IllegalStateException (binding [*dynamic* 1] ; ❸ (set! *dynamic* 2)) ;; 2
❶ non-dynamic 和 *dynamic* 是 2 个 var. *dynamic* 被声明为动态的, 可以接受本地绑定的值.
❷ set! 在两种情况下都不能改变 var 的根绑定, 并抛出异常.
❸ 然而, 它可以改变动态 var 的本地绑定值.
set! 常见于设置本地绑定的变量, 如 *warn-on-reflection*, 这是一个由 Clojure 编译器隐式进行线程绑定的特殊动态 var. 由于它已经被线程绑定, *warn-on-reflection* 不需要被 binding 包围, 实际上看起来像一个全局 var:
(fn [x] (.toString x)) ; ❶ ;; #object["user$eval1935$fn__1936@146c987a"] (set! *warn-on-reflection* true) ; ❷ (fn [x] (.toString x)) ; ❸ ;; Reflection warning - reference to field toString can't be resolved
❶ 这个匿名函数使用 Java 互操作来在对象 "x" 上调用 toString 方法. 该调用产生一个 Java 对象, 该对象被打印在屏幕上.
❷ 对 *warn-on-reflection* 的访问被授予 set!, 因为 *warn-on-reflection* 隐式地绑定到当前运行的线程.
❸ 设置了 var 之后, 任何反射调用都会被及时报告.
set! 的另一个可能用途是在 deftype 定义中进行变异:
(deftype Counter [^:unsynchronized-mutable cnt] ; ❶ clojure.lang.IFn (invoke [this] (set! cnt (inc cnt)))) ; ❷ (def counter (->Counter 0)) ; ❸ (counter) ;; 1 (counter) ;; 2
❶ deftype 是 Clojure 中创建并发 "不安全" 对象的少数选项之一. Counter 定义了一个带私有字段 "cnt" 的类.
❷ 定义为类接口一部分的函数可以 set! 私有字段. 在这种情况下, 我们通过实现 clojure.lang.IFn 接口使计数器 "可调用".
❸ 创建了一个新的计数器实例后, 我们可以通过不带参数调用该对象来递增其内容.
在生产应用程序中看到 set! 是相当罕见的. set! 的存在可能表明存在不安全的可变对象, 对此 Clojure 有大量有效的替代方案.
4.7.5. 20.5 总结
Clojure 没有很多专用于副作用或变异的函数. 但当副作用是必需的时, 标准库会系统地规范它们的使用. 用户仍然可以自由地创建可变的混乱, 但 Clojure 稳步地推动应用程序走向函数式纯粹, 而不是规定性的.
4.8. 21 Java 互操作
本章中的函数和宏主要与 Java 互操作 (或简称 "interop") 相关, 这是标准库中最接近 Java 运行时的部分. 尽管处理的是一个面向状态的世界, Clojure 仍然提供了一种简洁易读的函数式语法. 以下是本章描述内容的摘要:
- "." (也称为 "dot", 但在代码中用作单个字符 ".") 是一个多功能的特殊形式, 用于访问 Java 方法和属性. 除了基本形式, dot 还有几个变体, 以帮助保持语法的可读性. ".." (double-dot) 对于组装链式调用很有用, 而 "doto" 则连接有副作用的调用.
new创建一个对象的新实例.try和catch(以及相关的特殊形式finally和throw) 是 Clojure 中异常处理的基本机制.ex-info和ex-data建立在 Java 异常机制之上, 通过隐藏一些低级语法并提供一种用异常传输数据的方式.bean是一个将 Java 对象包装在类映射接口中的宏.clojure.reflect命名空间中的函数对 Java 类的结构和内容进行内省.- Clojure 还有一套丰富的函数来处理 Java 数组.
make-array只是从 Clojure 创建数组的众多方式之一. 像aset,amap或areduce这样的宏对于用熟悉的函数式接口转换数组的内容很有用. 本节还包含了对数组宏变体以利用原始类型 (int, boolean, byte 等) 的简要解释.
4.8.1. 21.1 ".", ".." 和 doto
" . (dot)" 是一个用于访问 Java 对象的方法和属性的多功能特殊形式. 存在几种变体, 目标对象作为第一个参数出现 ("正向形式"), 或作为第二个 ("反向形式"), 或用斜杠 "/" 缩写 ("斜杠形式"). 表达式的含义也根据参数的类型而改变. 以下是所有可用变体的详尽列表:
; ❶ (. Thread sleep 1000) ;; Access static method of 1 arg. (. Math random) ;; Access static field first (if any) or static method of no args. (. Math (random)) ;; Access static method of no args (unambiguously). (. Math -PI) ;; Access static field access (unambiguously). (. Thread$State NEW) ;; Access inner class static method. ; ❷ (Thread/sleep 1000) ;; Access static method of 1 arg. (Math/random) ;; Access static field first (if any) or static method of no args. (Math/-PI) ;; Access static field (unambiguously). ; ❸ (def point (java.awt.Point. 1 2)) (. point x) ;; Access instance field first (if any) or method of no args. (.x point) ;; Same as above. (. point (getX)) ;; Access instance method (unambiguously). (.-x point) ;; Access instance field (unambiguously).
❶ 第一组点状形式展示了如何使用它们来访问 Java 类的静态成员. 一个 Java 类可以声明一个静态字段和一个同名的无参静态方法. 虽然在 Java 中这不会产生歧义, 但 Clojure 需要一种方式来区分这两个选项. 如果未指定, 它会首先尝试访问静态字段, 其次是无参静态方法. 要强制只访问静态字段, 我们可以在字段名前加上一个破折号 "-". 要强制只访问静态方法, 我们可以使用一对括号.
❷ "斜杠" 形式会扩展为相应的 "点状" 形式. 它更短且更易于阅读, 所以在可能的情况下是首选.
❸ 最后一组展示了如何使用 "." 来访问实例成员. 与静态成员类似, 一个破折号 "-" 前缀强制只访问实例字段, 即使存在一个同名的无参实例方法. 括号请求无歧义地访问实例方法.
" . (dot)" 在参数求值方面的行为类似于宏. 如果我们需要调用一个方法, 但方法名在编译时未知, 我们需要在 扩展时组装点状形式:
(defmacro getter [object field] ; ❶ (let [getName# (symbol (str "get" field))] ; ❷ `(. ~object ~getName#))) (defmacro setter [object field & values] ; ❸ (let [setName# (symbol (str "set" field))] `(. ~object ~setName# ~@values))) (getter (java.awt.Point. 2 2) "X") ; ❹ ;; 2.0 (doto ; ❺ (java.awt.Point. 2 2) (setter "Location" 4 5)) ;; #object[java.awt.Point 0x64d15330 "java.awt.Point[x=4,y=5]"]
❶ 在这个例子中, 我们想通过传递字段名 "x" 作为参数来组装名称 `getX()`.
❷ getter 方法的名称在 let 块中被组装成一个符号.
❸ 这是一个等效的 setter 方法, 用于在对象实例上设置属性.
❹ 我们可以看到如何使用 getter 来访问 "x" 坐标.
❺ Point 对象有一个接受 2 个参数 `setLocation(x, y)` 的方法, 即 "x" 和 "y" 坐标. 我们使用 doto (见下文) 来在设置新位置 (副作用) 后返回 Point 实例.
双点 ".." 使用前两个参数调用的结果作为下一对的输入, 依此类推, 直到没有更多参数. ".." 对于连接一连串改变状态的调用很有用, 这样它们总是作用于初始对象. 一个常见的例子是使用 Java 构建器模式来构建实例:
(import '[java.util Calendar Calendar$Builder]) (.. (Calendar$Builder.) ; ❶ (setCalendarType "iso8601") (setWeekDate 2019 4 (Calendar/SATURDAY)) (build)) ;; #inst "2019-01-26T00:00:00.000+00:00" (macroexpand ; ❷ '(.. (Calendar$Builder.) (setCalendarType "iso8601") (setWeekDate 2019 4 (Calendar/SATURDAY)) (build))) ;; (. (. (. (Calendar$Builder.) (setCalendarType "iso8601")) ;; (setWeekDate 2019 4 (Calendar/SATURDAY))) ;; (build))
❶ Java 标准库中的 Calendar API 支持通过构建器模式创建任意复杂的日历实例. 构建器作为第一个指令被创建, 每次调用的结果被传递给下一个指令, 直到最后的 build 调用返回组装好的日历. 返回的日历实例显示了 2019 年第四个星期六的日期.
❷ 相同形式的宏展开显示了执行相同指令所需的远不那么易读的点状形式.
本节的最后一个宏是 doto. doto 表面上类似于双点 ".." 宏, 但它不是传递前一个调用的结果, 而是目标对象在链的所有步骤中保持不变. 这对于对可变对象进行重复更改很有用, 例如 Java 集合:
(import 'java.util.ArrayList) (def l (ArrayList.)) (doto l ; ❶ (.add "fee") (.add "fi") (.add "fo") (.add "fum")) ;; ["fee" "fi" "fo" "fum"]
❶ ArrayList 被重复地添加元素, 而无需在所有形式中都插入 "l".
4.8.2. 21.2 new
new 是一个特殊形式 (在所有实际用途中, 都是一个宏), 它接受可变数量的参数: 第一个参数必须是一个解析为 Java 类的符号, 其余参数是可选的. 附加的参数 (如果有的话) 会直接传递给该类的构造函数:
(def sb (new StringBuffer "init")) ; ❶ (.append sb " item") (str sb) ; ❷ ;; "init item"
❶ 一个 java.lang.StringBuffer 是一个可变的字符串, 可以在一个空字符串或给定字符串的末尾追加新的片段.
❷ 一旦字符串被正确组装, 它可以很容易地转换回一个不可变的字符串.
一个类的构造函数定义可以来自类本身或任何超类 (子类中的构造函数被允许用附加的行为来扩展超类中相应的构造函数). 为了找到正确的构造函数, Clojure 会经历一个与参数数量及其类型进行模式匹配的过程. 由于参数上可能存在类型继承, 对于同一次调用可能会有多个匹配的构造函数. 一个微妙的例子是下面这个涉及 java.lang.BigDecimal 的例子:
(let [l (Long. 1)] (new BigDecimal l)) ❶ ;; java.lang.IllegalArgumentException: More than one matching method found
❶ BigDecimal 类的一个模糊的构造函数调用示例.
BigDecimal 没有一个接受 java.lang.Long 参数的构造函数, 但它确实包含一个接受原始类型 int 或 long 的构造函数. 从 Clojure 的角度来看, 问题在于两者都是可能的, 因为装箱类型 Long 可以向下转换为原始类型 int 或 long 而不损失精度. 传递一个原始类型 long 可以解决这个问题:
(let [l 1] (new BigDecimal l)) ❶ ;; 1M
❶ 在这个例子中, new 接收到一个用原始类型 long "l" 创建新 BigDecimal 的请求. BigDecimal 包含一个显式的 long 构造函数, 对于使用哪个构造函数没有歧义.
new 有一个通常被推荐的更短的形式. 它移除了使用 new 关键字的需要, 而是用类名后的一个 "." (点) 来替代:
(StringBuffer. "init") ; ❶ ;; #object[java.lang.StringBuffer 0x5fa1cc83 "init"] (macroexpand '(StringBuffer. "init")) ; ❷ ;; (new StringBuffer "init")
❶ new 有一个更短的形式, 它移除了使用关键字 new 本身的需要.
❷ 我们可以验证点状形式会扩展为调用 new.
4.8.3. 21.3 try, catch, finally 和 throw
try, catch, finally 和 throw 是任何非平凡的 Clojure 应用程序中都会出现的特殊形式. 它们用于处理称为 "异常" 的特殊情况, 在这些情况下, 程序会改变其正常的控制流.
让我们先谈谈 throw, 因为它有助于说明本节中的其他形式. throw 期望一个类型为 java.lang.Throwable 或其任何子类 (最值得注意的是, java.lang.Exception 和 java.lang.Error 都是 java.lang.Throwable 的子类) 的单个参数:
(throw (Throwable. "'there was a problem.'")) ; ❶ ;; Throwable 'there was a problem.' ; ❷ (clojure.repl/pst) ; ❸ ;; Throwable : there was a problem. ;; user/eval1927 (form-init5670973898278733609.clj:1) ;; user/eval1927 (form-init5670973898278733609.clj:1) ;; clojure.lang.Compiler.eval (Compiler.java:6927) ;; [....]
❶ 不需要导入 java.lang.Throwable, 因为 java.lang.* 中的许多类默认都是可用的.
❷ Throwable (以及所有其他异常类) 支持一个带字符串的构造函数, 该字符串通常用于描述异常的原因.
❸ 根据 REPL 和 JVM 的设置, 抛出异常时也会显示异常生成点的堆栈跟踪. 如果默认情况下不显示, 你可以使用 clojure.repl/pst (打印堆栈跟踪) 在屏幕上显示它.
try 接受一个主体表达式 (自动包装在一个 do 块中) 和任意数量的 catch 子句. catch 子句声明一个类型, 一个符号和一个表达式. 如果外部 try 中有异常, 并且有一个兼容的 catch 子句, 则相应的表达式会被评估:
(try (println "Program running as expected") ; ❶ (throw (RuntimeException. "Got a problem.")) ; ❷ (println "program never reaches this line") ; ❸ (catch Exception e ; ❹ (println "Could not run properly" e) ; ❺ "returning home")) ; ❻ ;; Program running as expected ;; Could not run properly. #error { ;; :cause Got a problem. ;; :via ;; [{:type java.lang.RuntimeException ;; :message Got a problem. ;; :at [user$eval1933 invokeStatic form-init5670973898278733609.clj 2]}] ;; :trace ;; [...]} ;; "returning home"
❶ try 支持任意数量的顶层表达式, 类似于 do 块.
❷ 我们故意抛出一个异常. 这会改变正常的程序流程, 例如跳过通常会被评估的行.
❸ 这一行永远不会打印, 因为它跟在一个 throw 指令后面.
❹ catch 指令声明 java.lang.Exception 作为它能够处理的异常类的类型. 该子句无法捕获更通用的错误, 如 java.lang.Throwable 或 java.lang.Error.
❺ catch 包含一个隐式的 do 块. 局部绑定 "e" 被绑定到被捕获的异常实例.
❻ 在打印一条消息后, catch 块返回最后一个表达式的评估结果.
评估的规则是基于继承的: 如果异常类型与声明的 catch 类型相同, 或者是其子类, 则子句匹配. 这允许从更具体的类型到最通用的类型进行 "级联" 风格的捕获:
(import '[java.net Socket InetAddress ConnectException SocketException]) (try (Socket. (InetAddress/getByName "localhost") 61817) ; ❶ (catch ConnectException ce ; ❷ (println "Could not connect. Retry." ce)) (catch SocketException se ; ❸ (println "Communication error" se)) (catch Exception e ; ❹ (println "Something weird happened." e) (throw e))) ;; nil
❶ 我们的应用程序需要连接到某个本地端口进行通信. 可能会出好几种问题, 例如对方可能还没准备好, 还在准备监听给定的端口, 或者我们可能能连接上但之后无法通信.
❷ 如果我们无法连接, 这意味着由于某种原因, 另一个应用程序没有在监听. 这可能是暂时的, 并且可能值得实现一个 "重试" 机制, 例如在宏章节中介绍的 with-backoff 宏. 注意, 我们将异常对象作为 println 指令的一部分放在打印输出中. 如果我们不这样做, 我们可能会丢弃异常中存储的重要信息 (这也被称为 "吞噬异常").
❸ 在成功连接到套接字后, 可能会有与通过通道发送的数据包相关的意外问题. 我们可以单独处理这种情况, 也许再次重试连接.
❹ 最后, 通用的 Exception 子句捕获任何其他情况. 注意, 我们不仅打印了一条消息, 还重新抛出了同一个异常. 重新抛出表示这个代码块无法处理该异常, 但允许上游的其他块来处理它.
finally 是一个特殊的 catch 子句, 即使在没有异常的情况下也总是被评估. try-finally 模式在处理必须总是被释放的资源方面非常流行, 即使在出现异常的情况下也是如此. with-open 是这种行为的一个很好的例子, 它使用 finally 来确保作为绑定一部分打开的任何资源都被正确关闭. 类似地, locking 使用 finally 来在执行关键区域后总是释放锁. 在下面的例子中, 我们构建了一个简化的 with-open 来只处理 java.io.Reader 对象:
(require '[clojure.java.io :as io]) (defmacro with-reader [r file & body] ; ❶ `(let [~r (io/reader ~file)] (try ~@body ; ❷ (finally ; ❸ (.close ~r))))) (with-reader r "/etc/hosts" (last (line-seq r))) ;; ::1
❶ 宏 with-reader 使用一个文件作为输入源, 将第一个参数绑定到一个打开的 java.io.Reader 实例.
❷ 当 "body" 被评估时, 参数 "r" 被绑定到一个打开的读宏.
❸ finally 保证读宏实例被正确关闭, 即使在评估主体时出现异常.
finally 可以单独使用, 也可以作为一组 catch 子句之后的最后一个语句. 整个表达式返回匹配的 catch 的评估结果, 但 finally 块总是为副作用而执行:
(try (/ 1 0) (catch Exception e "Returning from catch") ; ❶ (finally (println "Also executing finally"))) ; ❷ ;; Also executing finally ;; "Returning from catch"
❶ 整个表达式的结果是在处理由 1 除以 0 产生的异常的 catch 块中评估的字符串.
❷ finally 块不管 catch 块是否处理异常都会评估, 在输出中产生消息.
4.8.4. 21.4 ex-info 和 ex-data
ex-info 和 ex-data (本节也提到了 Throwable→map) 是标准库中相对较新的补充, 它们首次出现在 Clojure 1.4 中 (而 Throwable→map 更晚, 在 1.7 中).
ex-info 和 ex-data 的主要目的是用元数据来装饰 Java 异常, 丰富它们在异常情况下可以携带的信息量. 它们通过引入 clojure.lang.ExceptionInfo 来做到这一点, 这是一种在构造时也接受一个映射的新类型异常:
(def ex (ex-info "Temperature drop!" ; ❶ {:time "10:29pm" :reason "Front door open." :mitigation #(println "close the door")})) (type ex) ; ❷ ;; clojure.lang.ExceptionInfo ex ; ❸ ;; #error { ;; :cause "Temperature drop!" ;; :data {:time "10:29pm", :reason "Front door open.", ;; :mitigation #object[user$fn__1569 0x1ef43242]} ;; :via ;; [{:type clojure.lang.ExceptionInfo ;; :message "Temperature drop!" ;; :data {:time "10:29pm", :reason "Front door open.", ;; :mitigation #object[user$fn__1569 0x1ef43242]} ;; :at [clojure.core$ex_info invokeStatic "core.clj" 4617]}] ;; :trace ;; [[clojure.core$ex_info invokeStatic "core.clj" 4617] ;; [...] ;; [java.lang.Thread run "Thread.java" 748]]}
❶ ex-info 作为异常类型 clojure.lang.ExceptionInfo 的构造函数. 除了一个消息, 它还接受一个可以包含任何类型信息的映射.
❷ ex 的类型是 ExceptionInfo.
❸ 如果我们试图在 REPL 中打印异常对象, 它会像一个类记录的对象一样渲染自己.
ex-info 隐藏了创建异常对象所需的任何 Java 互操作性细节. 唯一需要的信息是一个消息和元数据映射. 它可选地接受第三个参数来捕获或重新抛出根本原因异常:
(try (/ 1 0) (catch Exception e ; ❶ (throw (ex-info "Don't do this." {:type "Math" :recoverable? false} e)))) ; ❷ ;; ArithmeticException Divide by zero
❶ catch 在评估一些代码后捕获一个异常.
❷ ex-info 包装了 "e" 并重新抛出一个用附加元数据装饰的新异常.
默认情况下, 元数据是隐藏的, 在打印用 ex-info 创建的 ExceptionInfo 实例时不会出现. 要查看和使用元数据, 我们可以使用 ex-data:
(defn randomly-recoverable-operation [] ; ❶ (throw (ex-info "Weak connection." {:type :connection :recoverable? (< 0.3 (rand))}))) (defn main-program-loop [] (try (println "Attempting operation...") (randomly-recoverable-operation) (catch Exception e (let [{:keys [type recoverable?]} (ex-data e)] ; ❷ (if (and (= :connection type) recoverable?) (main-program-loop) (ex-info "Not recoverable problem." {:type :connection} e)))))) (main-program-loop) ; ❸ ;; Attempting operation... ;; Attempting operation... ;; #error { ;; :cause "Weak connection." ;; :data {:type :connection, :recoverable? false} ;; :via ;; [{:type clojure.lang.ExceptionInfo ;; :message "Not recoverable problem." ;; :data {:type :connection} ;; :at [clojure.core$ex_info invokeStatic "core.clj" 4617]} ;; {:type clojure.lang.ExceptionInfo ;; :message "Problem." ;; :data {:type :connection, :recoverable? false} ;; :at [clojure.core$ex_info invokeStatic "core.clj" 4617]}]
❶ randomly-recoverable-operation 模拟一个经常失败但有时可以重复操作的函数. 该函数应用一个 "阈值" (用 rand 模拟) 来决定问题是否可恢复.
❷ main-program-loop 是使用随机可恢复函数的客户端. 在捕获一个潜在的异常后, 我们使用 ex-data 提取元数据信息. 在异常是可恢复的情况下, main-program-loop 再次评估.
❸ 几次尝试后, main-program-loop 退出, 因为错误是不可恢复的.
从上面的例子中我们可以看到, 当检查堆栈跟踪时, 嵌套的 ex-info 异常会很好地累加: 我们可以看到一个 "Not recoverable problem." 是由一个 "Weak connection." 引起的, 依此类推, 对于所有嵌套的异常.
本节的最后一个函数是 Throwable→map, 这是一个有用的函数, 用于将异常层次结构中分散的信息转换为一个漂亮的 Clojure 数据结构:
(def error-data ; ❶ (try (throw (ex-info "inner" {:recoverable? false})) (catch Throwable t (try (throw (ex-info "outer" {:recoverable? false} t)) (catch Throwable t (Throwable->map t)))))) (keys error-data) ; ❷ ;; (:cause :via :trace :data) (:cause error-data) ; ❸ ;; "inner" (:via error-data) ; ❹ ;; [{:type clojure.lang.ExceptionInfo, ;; :message "outer", ;; :at [clojure.core$ex_info invokeStatic "core.clj" 4617], ;; :data {:recoverable? false}} ;; {:type clojure.lang.ExceptionInfo, ;; :message "inner", ;; :at [clojure.core$ex_info invokeStatic "core.clj" 4617], ;; :data {:recoverable? false}}] (nth (:trace error-data) 3) ; ❺ ;; [user$fn__2151 invoke "form-init5670973898278733609.clj" 1] (:data error-data) ; ❻ ;; {:recoverable? false}
❶ error-data 为说明目的模拟了两个嵌套的异常. Throwable→map 将最后一个 java.lang.Throwable 实例转换为一个 Clojure 映射.
❷ error-data 有 4 个键, 包含描述错误的不同方面.
❸ :cause 键显示了根本原因的错误描述, 在这种情况下是 inner.
❹ :via 是一个映射的向量. 每个映射包含每个异常实例的基本数据. 如果异常是用 ex-info 创建的, 每个 :data 键都包含元数据.
❺ :trace 键是另一个向量, 包含异常堆栈跟踪中的每个条目的一个条目.
❻ 最后, :data 包含用于用 ex-info 创建异常的初始映射.
4.8.5. 21.5 bean
bean 是一个函数, 它创建对象中可用属性的类映射表示:
(import 'java.awt.Point) (def point (bean (Point. 2 4))) ; ❶ (keys point) ; ❷ [(:x point) (:y point)] ; ❸ ;; [2.0 4.0]
❶ java.awt.Point 是 AWT, 即原始 (且基本的) Java 抽象窗口工具包中的一个简单类. 它将 x,y 坐标暴露为公共属性, 包括用于访问它们的 getX() 和 getY() 方法.
❷ bean 创建一个实现 Clojure 类映射特性的代理实例, 包括公共属性的键.
❸ 我们现在可以使用类映射的键来访问原始类的属性.
bean 使用内省通过 JavaBean 编程接口来分析 Java 类的内容 (关于 JavaBean 的更多信息请参见下面的标注). 因此, 并非所有可用的属性都是可见的, 只有那些通过 JavaBean 标准暴露的属性. 例如, 比较以下内容:
(bean (Object.)) ; ❶ ;; {:class java.lang.Object} (import 'javax.swing.JButton) (pprint (bean (JButton.))) ; ❷ ;; {:y 0, ;; :selectedObjects nil, ;; :componentPopupMenu nil, ;; :focusable true, ;; :managingFocus false, ;; :validateRoot false, ;; :requestFocusEnabled true, ;; :containerListeners [], ;; :rolloverSelectedIcon nil, ;; :iconTextGap 4, ;; :mnemonic 0, ;; :debugGraphicsOptions 0, ;; [...]}
❶ bean 可以处理任何类型的对象, 但只有那些使用 JavaBean 约定的对象通常提供更多有用的信息. 在这里, 我们对一个基本的 Object 实例使用 bean, 它只包含默认的 :class 键.
❷ javax.swing.JButton 包含许多 getter 方法 (那些以 "get" 开头, 然后是属性名称的方法), bean 可以用它们来提取一个大的键-属性值映射.
- 什么是 JavaBean?
内省 (也称为反射) 是 Java 的一个特性, 可以在运行时访问类的结构, 例如列出方法, 构造函数或属性. 通过反射, Java 程序可以查询 Java 类的结构, 甚至调用构造函数来创建新对象. 在 1996 年引入 JavaBeans 后, Java 将内省提升到了一个新的水平, 这离 Java 诞生并不久.
JavaBean 标准指定了一组订阅 JavaBean 规范的类应遵守的约定 251:
- 所有属性都应该是私有的, 但可以通过 getter/setter 方法访问.
- 它应该提供一个公共的, 无参的构造函数.
- 它应该实现
java.io.Serializable接口.
有了这套约定, 工具就可以找到, 分析, 实例化和调用 JavaBean 上的方法. 工具也可以将 JavaBean 存储为字节或通过网络发送它们. JavaBean 在图形界面中很受欢迎, 在那里它们提供了自动发现的功能.
bean是一个需要记住的有用工具, 用于将类 bean 的 Java 对象快速转换为 Clojure 映射. 然而, 由于它大量使用反射, 你应该避免在速度很重要的代码关键部分使用bean. 例如, 以下是使用bean或使用自定义函数从一个点实例创建一个映射之间的差异:(require '[criterium.core :refer [quick-bench]]) (import 'java.awt.Point) (let [p (Point. 2 4)] (quick-bench {:class java.awt.Point :location (.getLocation p) :x (.getX p) :y (.getY p)})) ;; Execution time mean : 16.101893 ns (let [p (Point. 2 4)] (quick-bench (bean p))) ;; Execution time mean : 1.229609 µs
使用
bean或推出一个自定义映射之间的差异大约是三个数量级.
4.8.6. 21.6 reflect 和 type-reflect
clojure.reflect/reflect 对一个 Java 类型执行内省, 返回有用的信息, 如基类, 构造函数, 方法, 签名和返回类型. 虽然 reflect 对对象或类都有效, 但 type-reflect 只对类有效, 但提供了与 reflect 相同的功能 (实际上, reflect 是 type-reflect 的一个薄包装器). 在本节的其余部分, 我们对 reflect 所说的一切也适用于 type-reflect, 除非另有说明. 以下是如何使用 reflect 的一个简单示例:
(require '[clojure.reflect :as r]) ; ❶ (keys (r/reflect {})) ; ❷ (keys (r/reflect clojure.lang.APersistentMap)) ; ❸ ;; (:bases :flags :members) ; ❹
❶ 本节中的所有函数都属于 clojure.reflect 命名空间.
❷ reflect 接受一个对象作为参数. 它会在内部将该对象转换为相关的类.
❸ 在这个例子中, reflect 直接使用一个类.
❹ 两个对 reflect 的调用都返回一个包含 3 个键的 Clojure 映射.
由 reflect 返回的映射包含 3 个键:
:bases显示所有直接的超类或实现的接口.:flags显示类的修饰符 (如 public, final 等).:members是所有公共方法的列表.
reflect 也接受以下选项: 一个 :ancestors 键和一个 :reflector 键. 通过 :ancestors, reflect 检索所有级别的超类和超接口, 而不仅仅是目标类正上方的:
(pprint (:ancestors (r/reflect {} :ancestors true))) ; ❶ ;; #{java.lang.Object clojure.lang.Associative ;; java.util.concurrent.Callable java.util.Map clojure.lang.ILookup ;; java.lang.Runnable clojure.lang.IPersistentCollection ;; clojure.lang.IHashEq clojure.lang.IObj clojure.lang.IFn ;; clojure.lang.MapEquivalence clojure.lang.IKVReduce clojure.lang.IMeta ;; clojure.lang.Counted clojure.lang.IPersistentMap clojure.lang.Seqable ;; java.io.Serializable clojure.lang.AFn ;; clojure.lang.IEditableCollection clojure.lang.IMapIterable ;; clojure.lang.APersistentMap java.lang.Iterable} (count (:members (r/reflect {}))) ; ❷ ;; 37 (count (:members (r/reflect {} :ancestors true))) ;; 180
❶ 当存在 :ancestors true 时, reflect 检索超出第一层级的所有超类和超接口, 并将结果收集在附加的 :ancestors 键中.
❷ 当 :ancestors true 时, :members 键额外包含在任何祖先中声明的方法. 我们可以看到收集的成员 (方法或构造函数) 数量从 37 增加到 180.
:reflector 键允许指定一个不同的 "Reflector". 默认情况下, reflect 使用 Java 反射 (这需要将类加载到内存中进行检查). 其他提供与内置 Java 反射类似或更好功能的库可以通过 :reflector 键插入到 reflect 中. 例如, 以下是如何创建一个用于说明的虚拟反射器:
(deftype StubReflector [] ; ❶ r/Reflector (do-reflect [this typeref] {:bases #{} :flags #{} :members #{}})) (r/reflect java.lang.Integer :reflector (StubReflector.)) ; ❷ ;; {:bases #{}, :flags #{}, :members #{}}
❶ StubReflector 是一个实现 clojure.reflect/Reflector 协议的类. 该协议要求实现一个接受一个类型引用的 do-reflect 函数. 我们的实现只返回一个空值的映射.
❷ 要使用新创建的 StubReflector, 我们在调用 reflect 时将一个新实例传递给 :reflector 选项.
4.8.7. 21.7 Java 数组
Clojure 提供了一套丰富的专门用于 Java 数组的函数. 数组是一种特殊类型的对象, 初始化时包含固定数量的项. 数组不是特别复杂, 但它们非常高效. 寻求最大性能的 Clojure 应用程序经常使用数组: 快速数学运算, 图像处理, 字节流等等.
数组是 "索引的": 每个项都从索引 0 开始编号. 数组中的项必须是同一类型. 拥有不同类型项的唯一方法是将数组声明为 Object 类型. 下表总结了可用于创建数组的不同函数及其主要特性:
| 函数 | 输入值 | 大小参数 | 多维 | 自定义类型 | 输入集合 |
|---|---|---|---|---|---|
make-array |
否 | 是 | 是 | 是 | 否 |
object-array |
是 | 是 | 否 | 否 | 是 |
to-array |
是 | 否 | 否 | 否 | 是 |
into-array |
是 | 否 | 否 | 是 | 是 |
以下是对每一列含义的简要解释:
input values显示该函数是否接受数组的初始值集. 当没有初始值时, Java 会将数组初始化为默认值 (例如,int为 0,boolean为 false, 引用类型为 "null" 等).make-array是这组中唯一不允许用替代值进行自定义初始化的函数.size argument显示该函数是否接受一个整数来确定数组的大小. 像to-array或into-array这样的函数通过创建一个与输入集合大小相同的数组来隐式地提供该功能.multi-dimensional是一个数组, 其中一个项的类型是另一个数组. 最多可以有 255 个维度.make-array是唯一允许创建多维数组的函数.custom types显示该函数是否可以创建特定类型的数组 (不同于Object或其他原始类型). 例如: 使用make-array, 我们可以创建一个java.awt.Point类型的数组, 而使用to-array, 我们只能创建一个包含java.awt.Point的Object类型的数组.input collection显示该函数是否可以用另一个集合中的项来初始化数组.make-array是唯一不允许集合作为输入的函数.
在下面的部分中, 我们将更详细地看到如何从 Clojure 中创建和处理数组.
- 21.7.1 make-array
make-array创建一个请求类型和长度的 Java 数组:(def a (make-array Boolean/TYPE 3)) ; ❶ (vec a) ; ❷ ;; [false false false] (def b (make-array Boolean 3)) ; ❸ (vec b) ;; [nil nil nil]
❶
Boolean/TYPE是识别 Java 中原始布尔类型的便捷快捷方式.❷ 数组在不进行显式迭代的情况下不会打印其内容. 显示其内容的一个快速方法是使用
vec将其转换为向量.❸ 对于所有引用类型 (例如大写的
Boolean), 默认的初始化值为nil.最后一个参数之后的任何附加数字都会触发一个多维数组的创建:
(def a (make-array Integer/TYPE 4 2)) ; ❶ (mapv vec a) ; ❷ ;; [[0 0] [0 0] [0 0] [0 0]]
❶ 2 个整数的存在提示
make-array创建一个二维数组. 该结构包含四个每个包含两个整数的数组.❷ 这一次, 要转换回向量, 我们需要对初始数组的每个项调用
vec.make-array有一些 (合理的) 限制: 维度数量不能超过 255, 并且只接受零或正整数. 总的来说, 请求的数组应该能装入可用的内存.make-array是创建空数组 (空数组指用请求类型的默认值初始化的数组) 的最通用函数. 对原始类型数组的需求非常普遍, 以至于有一整套数组初始化器专门用于此任务. 我们将在下一节看到它们. - 21.7.2 object-array 和其他类型初始化器
本节还提到了其他相关函数, 如:
int-array,boolean-array,byte-array,short-array,char-array,long-array,float-array和double-array.object-array(以及其他专用于原始类型如int,boolean,byte等的数组初始化器) 创建一个指定类型和大小的空数组:(vec (object-array 3)) ; ❶ ;; [nil nil nil] (vec (char-array 3)) ; ❷ ;; [\ \ \] (vec (double-array 3)) ; ❸ ;; [0.0 0.0 0.0]
❶
object-array创建一个给定大小的数组. 在这里, 创建的 "Object" 类型数组包含 3 个nil元素.❷
char-array将数组初始化为与 ASCII 表索引 "0" 对应的不可打印字符.❸
double-array将数组初始化为双精度类型 "0.0".通过传递一个兼容类型的第二个参数, 我们可以用一个特定的值来初始化数组, 而不是 Java 提供的默认值:
(vec (float-array 3 1.0)) ; ❶ ;; [1.0 1.0 1.0]
❶ 当存在第二个参数并且它与创建的数组的类型兼容时, 该值用于初始化数组中的所有项.
当第一个参数是一个序列集合而不是一个数字时, 输入集合的内容被复制到新创建的数组中:
(vec (int-array [1 2 3])) ; ❶ ;; [1 2 3]
❶ 当
int-array的第一个参数是一个序列集合时, 会创建一个包含输入中项的int数组.输入集合中的项需要与数组的类型兼容. 如果它们不兼容 (即, 没有 "强制转换" 操作可以将输入转换为正确的类型), 编译器会抛出异常:
(vec (int-array [\a \b \c])) ; ❶ ;; ClassCastException java.lang.Character cannot be cast to java.lang.Number
❶ 输入集合中的项需要与数组声明的类型兼容.
一些兼容的情况是微妙的, 因为 Java 容忍某些类型的精度损失:
(vec (int-array [4294967296])) ; ❶ ;; [0]
❶ 输入集合包含一个大数 (本例中为 232, 超出
int容量). Java 会截断最高有效位以将大数装入可用的 32 位中. 截断的结果是数字 "0".最后, 我们可以同时传递一个大小和一个输入集合. 如果集合的内容不足以填充结果数组, 值会回退到默认值:
(vec (int-array 5 (range 10))) ; ❶ ;; [0 1 2 3 4] (vec (boolean-array 5 [true true])) ; ❷ ;; [true true false false false]
❶ 在这种情况下, 结果数组只能容纳输入集合中可用 10 项中的 5 项.
❷ 如果输入不足, 数组中剩余的项会用该原始类型的默认值初始化.
在下一节中, 我们将看到从一个现有的输入集合开始创建数组的其他方法.
- 21.7.3 to-array, into-array, to-array-2d
to-array与object-array非常相似, 但使用更快的实现来转换输入集合. 以下基准测试比较了to-array和object-array与一个输入向量. 输出是相同的, 但to-array快两倍:(require '[criterium.core :refer [bench]]) (let [v (vec (range 100))] (bench (to-array v))) ; ❶ ;; Execution time mean : 302.673403 ns (let [v (vec (range 100))] (bench (object-array v))) ; ❷ ;; Execution time mean : 609.085730 ns
❶ 当输入集合是向量时,
to-array的性能比object-array快两倍.❷
object-array较慢, 但它是创建对象数组而无需传递输入集合的有用选项.速度提升不是保证的, 而是取决于输入集合的类型. 在可能的情况下,
to-array将数组的创建委托给输入集合, 而object-array总是将输入转换为一个序列, 然后迭代其内容. 要从集合中创建一个对象数组, 优先使用to-array, 而object-array仍然提供了在没有任何输入的情况下创建对象数组的选项.into-array与to-array类似, 但它会尝试猜测或强制输出数组的特定类型:(type (to-array [1 2 3])) ; ❶ ;; [Ljava.lang.Object; (type (into-array [1 2 3])) ; ❷ ;; [Ljava.lang.Long;
❶
to-array总是创建一个新的Object数组, 不论输入集合中项的类型.❷
into-array会特化输出数组的类型, 选择java.lang.Long而不是更通用的java.lang.Object.into-array使用第一个元素的类型来猜测输出数组的适当类型. 一旦类型被固定, 所有后续元素都需要是相同的类型:(into-array [1 2 (short 3)]) ; ❶ ;; IllegalArgumentException array element type mismatch
❶
into-array不接受混合类型的数组. 即使对于像short到long这样的类型兼容的强制转换也是如此.或者,
into-array接受一个显式的类型参数. 在这种情况下,into-array只有在不会导致精度损失的情况下才会尝试强制转换输入:(def a (into-array Short/TYPE [1. 2 (short 3)])) ; ❶ (type a) ; ❷ ;; [S (map type a) ; ❸ ;; (java.lang.Short java.lang.Short java.lang.Short) (into-array Short/TYPE [Integer/MAX_VALUE]) ; ❹ ;; IllegalArgumentException Value out of range for short: 2147483647
❶ 输入集合包含混合的数字类型.
❷ 第一个参数要求一个
short类型的输出数组. 在这里我们可以看到 "short 数组" 类型的 Java 编码是什么.❸ 所有输入数字都已按预期被强制转换为
short.❹ 如果我们试图强制转换一个太大而无法容纳 16 位短类型的数字,
into-array会抛出异常.to-array-2d是创建二维对象数组的便捷快捷方式:(def a (to-array-2d [[1 2] [3 4]])) ; ❶ (map type a) ; ❷ ;; ([Ljava.lang.Object; [Ljava.lang.Object;) (mapv vec a) ; ❸ ;; [[1 2] [3 4]]
❶ "a" 是一个 "对象数组的数组" 类型的数组, 每个包含 2 个项.
❷ 我们可以通过使用
map和type来验证第一个数组的每个元素本身也是另一个数组.❸ 我们可以通过在数组上使用带
vec的映射来重建初始的输入向量. - 21.7.4 aget, aset, alength 和 aclone
aget和aset是按索引读取和写入数组项的基本操作:(def a (into-array [:a :b :c])) (aget a 0) ; ❶ ;; :a (aset a 0 :changed) ; ❷ ;; :changed (vec a) ; ❸ ;; [:changed :b :c]
❶ 我们可以使用
aget来访问数组 "a" 中索引 "0" 处的元素.aget返回该索引处数组的值.❷ 通过
aset, 我们可以写入数组的特定位置.aset返回刚刚写入的项.❸ 可变数组的操作方式与不可变的 Clojure 集合大不相同: 用
aset写入数组位置后, 数组已永久更改.如果数组是多维的,
aget和aset接受额外的索引来访问嵌套的数组:(def matrix (to-array-2d [[0 1 2] [3 4 5] [6 7 8]])) ; ❶ (aget matrix 1 1) ; ❷ ;; 4 (aset matrix 1 1 99) ; ❸ (mapv vec matrix) ;; [[0 1 2] [3 99 5] [6 7 8]]
❶ 我们使用
to-array-2d来创建一个 3x3 的long数组矩阵.❷
aget可以访问索引 "[1,1]" 处的元素, 这是矩阵的中心.❸ 与
aget类似,aset也允许额外的索引来访问嵌套的数组.在下面的例子中, 我们将看到
aget,aset和alength在生成方阵的转置中的作用. 矩阵的转置是一种常见的转换, 它将每个项翻转到其对角线上 252. 为了速度, 我们决定将矩阵实现为一个可变的双精度浮点数数组:(defn transpose! [matrix] ; ❶ (dotimes [i (alength matrix)] (doseq [j (range (inc i) (alength matrix))] (let [copy (aget matrix i j)] ; ❷ (aset matrix i j (aget matrix j i)) (aset matrix j i copy))))) (def matrix ; ❸ (into-array (map double-array [[1.0 2.0 3.0] [4.0 5.0 6.0] [7.0 8.0 9.0]]))) (transpose! matrix) (mapv vec matrix) ; ❹ ;; [[1.0 4.0 7.0] ;; [2.0 5.0 8.0] ;; [3.0 6.0 9.0]]
❶
transpose!就地交换项, 无需创建矩阵的副本. 这个版本的算法对于大型矩阵特别有效, 因为它们在任何给定点都不需要在内存中复制. 作为副作用, 输入矩阵被永久更改, 所以函数名以感叹号结尾来传达这一事实.❷ 我们总共需要 2 个
aget和 2 个aset操作. 注意, 我们可以对外部索引使用dotimes(跨越方阵的边长), 对内部循环使用doseq, 该循环需要从外部索引加一开始.❸ 我们不能使用
to-array-2d来创建一个二维的双精度浮点数数组. 我们需要对内部数组使用double-array, 对外部数组使用into-array(因为into-array在这一点上可以推断出类型).❹ 调用
transpose!后, 我们可以通过将数组转换为向量的向量来查看结果.在上面的
transpose!版本中, 我们决定就地改变数组. 该解决方案的优点是不需要复制整个矩阵, 代价是副作用. 我们可以重新设计这个例子, 将数组转置到一个新的副本中, 并用aclone避免任何副作用:(defn transpose [matrix] (let [size (alength matrix) output (into-array (map aclone matrix))] ; ❶ (dotimes [i size] ; ❷ (dotimes [j size] (aset output j i (aget matrix i j)))) output)) (def matrix (into-array (map double-array [[1.0 2.0 3.0] [4.0 5.0 6.0] [7.0 8.0 9.0]]))) (def transposed (transpose matrix)) ; ❸ (mapv vec transposed) ;; [[1.0 4.0 7.0] ;; [2.0 5.0 8.0] ;; [3.0 6.0 9.0]]
❶
transpose是对前面看到的函数transpose!的重构. 这个版本不需要改变输入数组. 我们使用aclone来克隆构成矩阵的每个内部数组. 现在所有更改都可以在一个全新的数组上进行.❷ 新方法简化了对坐标 "i" 和 "j" 的循环, 这只是将 "[i,j]" 处找到的值赋给输出上倒置的坐标 "[j,i]".
❸ 注意, 转置的矩阵现在是函数的输出. "matrix" 数组保持不变.
aclone不是解决矩阵转置问题的唯一方法. 我们可以创建一个空的多维数组来代替克隆输入. 然而请注意,aclone的优点是处理被复制数组的类型, 而无需transpose显式提及double-array(或其他类型化函数).计算转置矩阵 (如上例) 需要知道数组的长度. Clojure 为此提供了一个专门的函数
alength.count也可以工作, 但它会产生一个昂贵的反射调用, 因为count被设计为接收一个泛型对象, 没有其类型的编译时概念. 当数组的类型已知时,alength可以利用该信息. 请看下面的基准测试:(require '[criterium.core :refer [quick-bench]]) (let [a (int-array (range 1000))] (quick-bench (count a))) ; ❶ ;; Execution time mean : 109.572276 ns (let [a (int-array (range 1000))] (quick-bench (alength a))) ; ❷ ;; Execution time mean : 2.496323 ns
❶
count适用于数组, 但它不是计算长度最有效的方法, 正如基准测试所证明的那样.❷
alength知道数组的类型, 并相应地委托调用, 无需反射. - 21.7.5 amap 和 areduce
amap和areduce简化了处理 Java 数组的工作, 移除了对显式循环的需要, 同时强制执行了不变性.amap(以 "a" 表示数组, "map" 表示映射) 在数组的所有元素上执行给定的表达式:(def a1 (int-array (range 10))) (def a2 (amap a1 idx output 1)) ; ❶ (vec a2) ;; [1 1 1 1 1 1 1 1 1 1] (vec a1) ; ❷ ;; [0 1 2 3 4 5 6 7 8 9]
❶ 这个简单的转换用数字 1 替换每个元素. 注意我们没有使用 "idx" 或 "output". 关于这两个参数的含义, 请看下面的解释.
❷ 源数组在转换后保持不变.
amap接受数组, 一个索引符号 (通常是 "idx") 和一个结果符号 (通常是 "output") 以及一个表达式. 该表达式对输入中的每个元素评估一次, 索引符号绑定到当前索引, 结果符号绑定到正在构建的输出:(def a1 (int-array (range 4))) (defn debug [idx output] (println "idx:" idx "output:" output) 9) (def a2 (amap a1 idx output (debug idx (vec output)))) ; ❶ ;; idx: 0 output: [0 1 2 3] ;; idx: 1 output: [9 1 2 3] ;; idx: 2 output: [9 9 2 3] ;; idx: 3 output: [9 9 9 3]
❶ 借助
debug, 我们可以看到 "idx" 和 "output" 在每次迭代中如何变化. 显示的 "output" 值是在新值被分配到相应索引之前的值. 数字 9 被应用于每个映射操作.我们可以使用索引符号来访问输入数组, 并执行从旧项到新项的转换:
(defn ainc [a] (amap a idx _ (inc (aget a idx)))) ; ❶ (vec (ainc (int-array (range 10)))) ;; [1 2 3 4 5 6 7 8 9 10]
❶
ainc(或数组递增) 对一个数值数组中的每个元素加一. "idx" 被amap绑定到数组中的当前索引, 我们可以用它来转换该索引处的输入项.输出符号代表了迭代过程中每个阶段正在构建的输出数组. 我们可以使用这个信息来防止当更新项的总和超过某个限制时进行任何进一步的更改:
(defn asum-upto [a i] ; ❶ (loop [idx 0 sum 0] (if (= idx i) sum (recur (inc idx) (+ sum (aget a idx)))))) (defn amap-upto [a f limit] (amap a idx out (let [old (aget a idx) ; ❷ new (f old) sum (asum-upto out idx)] (if (> (+ new sum) limit) old new)))) (def a (int-array (range 10))) (vec (amap-upto a #(* % %) 60)) ; ❸ ;; [0 1 4 9 16 25 6 7 8 9]
❶
asum-upto是一个函数, 它对一个数值数组从索引 0 到索引 "i" 的数字求和.❷
amap表达式需要计算索引处的当前项, 转换后的新项的值, 以及到目前为止所有转换项的和. 只有当该和不超过限制时, 当前项才会被更新.❸ 我们可以看到, 在对几个数字进行平方后, 过程 "停止" 了 (它实际上没有停止, 它继续用自身的副本更新项).
- 数组和类型提示
使用数组的主要原因之一是速度, 特别是对于原始类型. 原始类型数组有两个优点: 原始类型在内存中占用更少的空间, 并且通常处理速度更快.
Clojure 提供了通常带有所有原始类型变体的数组函数:
int-array,aset-int等等. 但每次数组跨越函数边界时, 仍然有一个问题需要解决, 这涉及到将数组包装在一个泛型对象中:(set! *warn-on-reflection* true) (def a (int-array (range 10))) (alength a) ; ❶ ;; Reflection warning, call to static method alength on clojure.lang.RT can't be resolved. ;; 10
❶ 当在整数数组上使用
alength时, 我们会得到一个反射警告, 该警告与 Clojure 无法确定 "a" 的类型有关.数组 "a" 在当前命名空间中被定义为
clojure.lang.Var. 它必须通过一个自动的间接机制来检索: 符号 "a" 在当前命名空间的映射中找到, 这是访问相关 var 对象的键. Clojure 运行时会继续自动地在 var 对象上调用deref.deref返回一个java.lang.Object, 因为没有关于 var 指向什么的概念. 因此, Clojure 不知道要调用哪个alength类型, 并为泛型对象类型解析调用. 这个调用使用了反射. 为了避免反射警告, 我们需要一个类型提示:(def a (int-array (range 10))) (alength ^"[I" a) ; ❶ ;; 10 (alength ^ints a) ; ❷ ;; 10
❶ 如何使用 Java 数组类编码对原始整数数组进行类型提示.
❷ Clojure 为所有数组类型支持一个快捷版本, 所以我们不需要记住数组类的 Java 编码.
要加速性能, 另一个需要考虑的重要因素是避免自动装箱. 让我们回到示例中使用的函数
amap-upto, 看看反射和装箱警告:(set! *warn-on-reflection* true) (set! *unchecked-math* :warn-on-boxed) ; ❶ (defn amap-upto [a f limit] (amap a idx out (let [old (aget a idx) new (f old) sum (asum-upto out idx)] (if (> (+ new sum) limit) old new)))) ; ❷ ;; Reflection warning, method aclone on RT can't be resolved (argument types: unknown). ;; Reflection warning, alength on RT can't be resolved (argument types: unknown). ;; Boxed math warning, boolean Numbers.lt(long,Object). ;; Reflection warning, aget on RT can't be resolved (argument types: unknown, int). ;; Boxed math warning, Number Numbers.unchecked_add(Object,Object). ;; Boxed math warning, boolean Numbers.gt(Object,Object). ;; Reflection warning, aset on RT can't be resolved.
❶ 与
*warn-on-reflection*一样, 另一个有用的警告是*unchecked-math*, 带有:warn-on-boxed选项. 当 Clojure 有一个函数的原始类型变体但无法选择时,:warn-on-boxed会显示一条消息.❷ 我们可以看到一长串需要解决的反射和装箱数学问题.
像
amap-upto中那样的反射问题需要一些实践来解决. 首先, 你需要学习类型提示的语法 253, 其次, 你需要遵循编译器的消息来理解代码的哪一部分需要提示. 幸运的是, 编译器在指示信息缺失的位置方面相当精确, 有时一个类型提示就能解决许多警告. 以下是一个修复了所有警告的amap-upto版本:(defn amap-upto [^ints a f limit] ; ❶ (amap a idx out (let [old (aget a idx) ^int new (f old) ; ❷ ^int sum (asum-upto out idx)] (if (> (+ new sum) ^int limit) old new)))) ; ❸
❶ 第一个类型提示是关于输入数组的, 否则它会作为泛型对象进入函数.
❷ 编译器的另一个抱怨是关于 "
" 函数. 编译器无法理解要使用哪个 "" 重载. 我们需要明确地说 "new" 和 "sum" 都是原始整数.❸ 编译器的最后一个抱怨是关于 ">" (称为 "gt"). 我们也必须对 "limit" 进行类型提示.
从这个 "消除警告" 的练习中学到的教训是, 特别是在处理原生数组时, 你经常需要在函数边界添加类型提示. 此外, 当使用数组中的项时, 常常有不想要的原始类型装箱的风险.
我们将以对
areduce的一看结束本节. 正如你可能从名称中猜到的, 这是reduce的一个特殊数组版本. 它的工作方式与amap类似, 但有一个额外的 "init" 参数:(def a (int-array (range 10))) (areduce a idx acc 0 (+ acc (aget a idx))) ; ❶ ;; 45
❶
areduce在内部迭代期间绑定 "idx" 和 "acc", 以便表达式可以访问它们. 这与amap类似, 但 "acc" (累加器) 包含到目前为止的和, 而不是输出数组. 新的参数是计算的初始值.关于类型提示的相同建议在使用
areduce时也是有效的.
- 数组和类型提示
- 21.7.6 aset-int 和其他类型设置器
本节还提到了其他相关函数, 如:
aset-boolean,aset-byte,aset-short,aset-char,aset-long,aset-float,aset-double.本节中的函数组与
aset相关, 以及避免反射调用的需要. 观察下面的例子:(set! *warn-on-reflection* true) ; ❶ (def a (int-array [1 2 3])) ; ❷ (type a) ; ❸ ;; [I (aset a 0 9) ; ❹ ;; Reflection warning, call to static method aset on clojure.lang.RT ;; can't be resolved (argument types: unknown, int, long). ;; 9
❶
*warn-on-reflection*打开与反射调用相关的编译器警告. 如果编译器无法确定一个或多个操作数的类型, 它将发出一个反射警告. 该警告不会妨碍程序的正确性, 只是警告用户为了找到要分派的正确方法, 编译器必须使用反射.❷ 我们创建一个简单的原始整数数组.
❸ 数组的类型证实这确实是一个原始类型数组.
❹ 当我们在数组上使用
aset时, 编译器会发出一个警告, 表明它找不到要分派的正确的clojure.lang.RT/aset调用. 编译器还提供了详细信息, 例如搜索的参数类型. "Unknown" 是关于 "a", 原始的 "int" 是索引, 数字 "9" 是从读宏作为原始的 "long" 传递的. 注意数组仍然被修改, 刚刚写入的项被返回.上面的反射问题是由隐式的 var 间接引起的. 让我们重写这个例子, 使隐式的运行时步骤变得显式:
(def a-lookup (get (ns-map *ns*) 'a)) ; ❶ (type a-lookup) ; ❷ ;; clojure.lang.Var (type (deref a-lookup)) ;; [I (aset (deref a-lookup) 0 9) ; ❸ ;; Reflection warning, - call to static method aset on clojure.lang.RT ;; can't be resolved (argument types: unknown, int, long). ;; 9
❶
def除了创建一个java.lang.Var的实例外, 还会产生一个额外的副作用: 在本地命名空间映射中创建一个新条目 (*ns*是当前命名空间对象的快捷方式). 该条目是一个键值对, 键是符号 "a", 值是 var 对象. 我们可以使用ns-map从映射中检索该 var.❷
a-lookup具有预期的 "Var" 类型, 以及 var 的内容, 即预期的整数数组.❸ 这是
aset在编译时实际看到的内容.当 Clojure 编译上面的代码时, 它只能看到
deref返回一个对象 (因为一个 var 实际上可以指向任何东西), 即使存在针对不同原始类型的专门化的aset, 该信息现在也丢失了.有两种方法可以移除反射调用: 首先, 我们可以将
a-lookup类型提示为原始整数数组. 其次, 我们可以使用aset-int(或在其他原始类型的情况下使用任何其他类型的aset-*调用). 对数组进行类型提示的情况非常常见, 以至于 Clojure 提供了aset-int来简化事情:(aset ^ints a 0 9) ; ❶ ;; 9 (aset-int a 0 9) ; ❷ ;; 9
❶ 在第一种情况下, 我们对 "a" 进行类型提示, 以便它在编译时携带其类型信息, Clojure 可以发出对正确的
aset专有化 (在clojure.lang.RT中) 的调用.❷ 或者, 我们可以使用
aset-int并达到相同的结果, 而无需看到类型提示.本章中分组的
aset-int和其他类型的aset-*具有与aset相同的语义. 特别是, 它们支持多维数组的多个索引:(def matrix ; ❶ (into-array (map int-array [[1 2 3] [4 5 6]]))) (aset-int matrix 0 2 99) ; ❷ (mapv vec matrix) ;; [[1 2 99] [4 5 6]]
❶
matrix是一个原始整数的多维数组.❷
aset-int也接受在最后一个参数 (总是被认为是设置的值) 之前的附加索引.正如预期的那样, 数组的类型应与我们试图使用的特定
aset-*版本一致.aset-*函数遵循 Java 关于允许的类型转换的约定. 将需要较少精度的类型强制转换为需要更多精度的类型总是可能的, 但反之则不然:(def int-a (int-array 5)) (def double-a (double-array 5)) (aset-int double-a 0 99) ; ❶ ;; 99 (aset-double int-a 0 99.0) ; ❷ ;; IllegalArgumentException argument type mismatch
❶ 我们可以将
aset-int放入一个双精度数组中, 因为隐式的int到double的转换很好地适应了为数组中的项分配的字节数.❷ 然而, 反之则不然. 类型转换需要双精度数 "99.0" 的精度损失才能适应为原始
int类型分配的字节. - 21.7.7 ints 和其他类型数组转换
本节还提到了其他相关函数, 如:
booleans,bytes,shorts,chars,longs,floats和doubles.与
int-array(及相关的 *-array 函数) 和aset-int(及相关的aset-*函数) 类似, Clojure 也提供了一组专门的数组转换函数.Clojure 提供了这样一组专门的原始类型函数来帮助处理原始数组. 通过使用函数的专门版本, 我们可以提供必要的类型信息而无需类型提示, 这在通用可读性方面是一个很好的加分项. 例如, 以下是一个用于对数值数组求和的函数
asum:(defn asum [a1 a2] (let [a (aclone (if (> (alength a1) (alength a2)) a1 a2))] (amap a idx ret (aset a idx (+ (aget a1 idx) (aget a2 idx)))))) (vec (asum (int-array [1 2 3]) (int-array [4 5 6]))) ;; [5 7 9]
asum函数通用地适用于任何数组类型, 但由于许多反射调用和原始类型的装箱, 其性能较差:(set! *warn-on-reflection* true) ; ❶ (set! *unchecked-math* :warn-on-boxed) (defn asum [a1 a2] (let [a (aclone (if (> (alength a1) (alength a2)) a1 a2))] (amap a idx ret (aset a idx (+ (aget a1 idx) (aget a2 idx)))))) ;; Reflection warning, call to static method alength on RT can't be resolved (argument types: unknown). ;; Reflection warning, call to static method alength on RT can't be resolved (argument types: unknown). ;; Boxed math warning, call public static boolean Numbers.gt(Object,Object). ;; Reflection warning, call to static method aclone on RT can't be resolved (argument types: unknown). ;; Reflection warning, call to static method aclone on RT can't be resolved (argument types: unknown). ;; Reflection warning, call to static method alength on RT can't be resolved (argument types: unknown). ;; Boxed math warning, call public static boolean Numbers.lt(long,Object). ;; Reflection warning, call to static method aget on RT can't be resolved (argument types: unknown, int). ;; Reflection warning, call to static method aget on RT can't be resolved (argument types: unknown, int). ;; Boxed math warning, call public static Number Numbers.unchecked_add(Object,Object). ;; Reflection warning, call to static method aset on RT can't be resolved (argument types: unknown, int, Number). ;; Reflection warning, call to static method aset on RT can't be resolved (argument types: unknown, int, unknown).
❶ 如果在打开反射警告和装箱警告后我们重新评估相同的
asum函数, 我们会得到一个令人印象深刻的警告列表.如果我们能假设
asum总是对整数数组求和, 我们可以使用相关的专门转换:(defn asum-int [a1 a2] (let [a1 (ints a1) a2 (ints a2) ; ❶ a (aclone (if (> (alength a1) (alength a2)) a1 a2))] (amap a idx ret (aset a idx (+ (aget a1 idx) (aget a2 idx)))))) ;; #'user/asum-int ; ❷
❶
let绑定会保留并传播类型信息到下游的形式. 通过用ints对 "a1" 和 "a2" 进行转换, 我们为输入数组提供了编译器所需的所有信息.❷ 在输入上使用
ints后, 所有警告都消失了.其他类型数组转换函数的工作原理与上面例子中展示的
ints相同. 当相关的类型提示不可用或难以定位时, 原始数组转换很有用.
4.9. 22 工具箱
本书的最后一章收集了标准库中用于解决特定问题的各种函数. 本章中的一些函数或宏在本书中已经使用过, 这里我们将进行更详细的介绍. 本章中的函数按其来源命名空间分组. 以下是概述:
clojure.xml, 顾名思义, 包含用于读取或写入 XML 的函数.clojure.inspector包含用于可视化数据结构的工具.clojure.repl包含专用于改善 REPL 体验的函数.clojure.main是引导和执行 Clojure 应用程序的入口点. 它还包含实际的 REPL 实现和一组用于自定义 REPL 体验的函数.clojure.java.browse包含一个公共函数browse-url, 用于给定特定 URL 打开原生浏览器.clojure.java.shell: 这个命名空间中最重要的函数是sh, 一个用于向原生操作系统 "shell-out" 命令的函数.clojure.core.server包含一个套接字服务器的实现, 该服务向远程客户端提供 Clojure 评估 (类似于 REPL).clojure.java.io包含 Clojure 包装器, 用于管理 Java IO (输入/输出) 系统, 包括文件, 流, 类路径等.clojure.test是 Clojure 附带的测试框架.clojure.test是可配置和可扩展的.clojure.java.javadoc包含使用默认系统浏览器访问 Java 文档的工具.
4.9.1. 22.1 clojure.xml
clojure.xml最近被提议废弃 (参见相关的 Jira 问题), 在这里作为 Clojure 公共 API 的一部分进行文档记录. 它从未被重构或重新设计, 超出最初的实现, 尽管功能齐全 (虽然有一些限制), 读者应尽可能使用 Clojure Data XML.
clojure.xml 的主要目标是为 XML 输入源生成一个内存中的数据表示. 这样做, XML 内容被加载到内存中以供进一步处理. clojure.xml/parse 是从 XML 文档生成 Clojure 数据结构的主要入口点:
(require '[clojure.xml :as xml]) ; ❶ (def document (xml/parse "http://feeds.bbci.co.uk/news/rss.xml")) ; ❷ (keys document) ; ❸ ;; (:tag :attrs :content)
❶ 在使用 clojure.xml 之前, 我们需要 require 它.
❷ RSS 源通常被网站用来生成其内容的机器可读版本. RSS 建立在 XML 之上, 所以我们可以用 xml/parse 读取它.
❸ xml/parse 返回一个包含 3 个键的 struct-map.
xml/parse 构建一个由 struct-map 和向量组成的嵌套结构, 具有以下递归形状:
{:tag ... ; ❶ :attrs ... :content [{:tag ... :attrs ... :content [...]} ... {:tag ... :attrs ... :content [{:tag ... :attrs ... :content [...]} ... {:tag ... :attrs ... :content [...]}]}]}
❶ xml/parse 产生的 struct-map 的部分表示, 仅显示骨架数据结构.
每个结构体代表一个 XML 节点. :tag 键是节点的名称, :attrs 键包含一个节点属性的映射, 最后 :content 是一个子节点的向量.
在
clojure.xml中使用struct是标准库中为数不多的几个例子之一 (其他著名的例子是resultset-seq或cl-format).defrecord有效地替代了库其他部分以及日常 Clojure 编程中对struct的需求.
xml/parse 接受不同类型的输入: 一个 java.io.File, 一个表示 URL 的字符串或一个通用的 java.io.InputStream. 它还接受一个可选参数 "startparse", 可用于配置解析器的特殊功能. 例如, 我们可以使用此参数来禁用模式验证或阻止模式加载 254:
(require '[clojure.xml :as xml] '[clojure.java.io :as io]) (def conforming ; ❶ "<?xml version='1.0' encoding='utf-8'?> <!DOCTYPE html SYSTEM 'http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd'> <html xmlns='http://www.w3.org/1999/xhtml'> <article>Hello</article> </html>") (-> conforming .getBytes io/input-stream xml/parse) ; ❷ ;; hangs 60 seconds if missing or misconfigured network ; ❸ ;; {:tag :html, ;; :attrs {:xmlns "http://www.w3.org/1999/xhtml"}, ;; :content [{:tag :article, :attrs nil, :content ["Hello"]}]}
❶ 这个符合规范的 XHTML (XML 兼容的 HTML 方言) 片段需要一个外部 DTD 进行验证. DTD 文件包含 XHTML 中预期语法的规范.
❷ 对于这个实验, 我们直接将 XHTML 作为字符串加载. xml/parse 将字符串解释为 URL, 所以我们需要将字符串转换为输入流, 这是 clojure.java.io 中可用的一个函数.
❸ 如果我们有网络问题或 JDK 没有正确配置以允许出站连接, 我们很快就会发现解析可能需要长达 60 秒或更长时间 (取决于 JDK 的超时设置).
带验证的 XML 解析通常是明智的功能, 特别是在生产环境中. 然而, 对于测试或开发, 我们可能希望关闭它. 我们可以通过向 xml/parse 传递一个非验证的解析器函数来禁用 XML 验证:
(import '[javax.xml.parsers SAXParserFactory]) (defn non-validating [s ch] ; ❶ (.. (doto (SAXParserFactory/newInstance) ; ❷ (.setFeature "http://apache.org/xml/features/nonvalidating/load-external-dtd" false)) (newSAXParser) (parse s ch))) (-> conforming .getBytes io/input-stream (xml/parse non-validating)) ; ❸ ;; {:tag :html, ;; :attrs {:xmlns "http://www.w3.org/1999/xhtml"}, ;; :content [{:tag :article, :attrs nil, :content ["Hello"]}]}
❶ non-validating 是一个接受输入源和内容处理器 "ch" 的函数. 内容处理器是 clojure.xml 使用的默认处理器, 如果我们不需要改变 XML 的转换方式, 我们可以重用它.
❷ SAXParserFactory 对象接受使用 setFeature 方法的配置.
❸ 解析现在独立于网络调用, 但也是非验证的.
正如你可以用 xml/parse 解析 xml 一样, 你可以用 xml/emit 反转这个过程. xml/emit 接受 xml/parse 的输出, 并将其转换回一个字符串, 发送到标准输出:
(def xml ; ❶ {:tag :html, :attrs {:xmlns "http://www.w3.org/1999/xhtml"}, :content [{:tag :article, :attrs nil, :content ["Hello"]}]}) (xml/emit xml) ; ❷ ;; <?xml version='1.0' encoding='UTF-8'?> ;; <html xmlns='http://www.w3.org/1999/xhtml'> ;; <article> ;; Hello ;; </article> ;; </html> ;; nil
❶ xml 是前面解析例子的输出.
❷ xml/emit 将数据结构转换回 XML (除了 "DOCTYPE" 声明).
如果你想将 xml/emit 的输出捕获到一个字符串或文件中, 请查看 with-out-str 或 binding 以将输出重定向到不同的流.
4.9.2. 22.2 clojure.inspector
clojure.inspector 命名空间包含一个用于结构化数据的小型可视化工具. 检查器将数据包装在一个基本的 (Swing 255) 用户界面中, 该界面支持几种可视化模型: 表格, 序列和树状. 例如, 以下代码会生成下面显示的窗口:
(require '[clojure.inspector :refer [inspect-tree]]) ; ❶ (inspect-tree {:a 1 :b 2 :c [1 2 3 {:d 4 :e 5 :f [6 7 8]}]}) ; ❷
❶ inspect-tree 是 clojure.inspector 命名空间的一部分.
❷ inspect-tree 接受一个我们希望可视化的任意嵌套的数据结构.
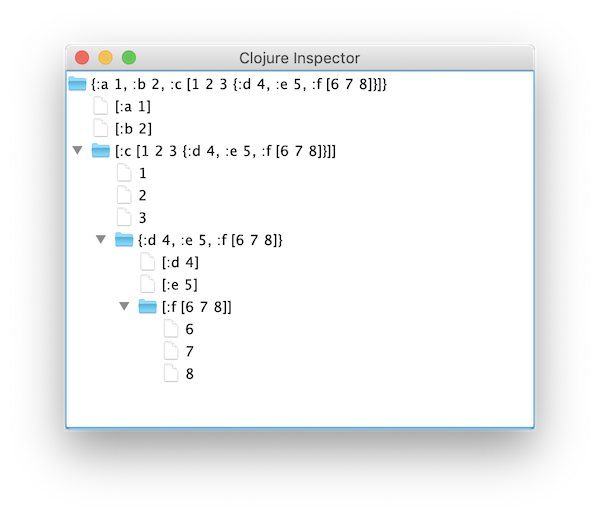
Figure 44: Figure 22.1. 嵌套数据结构的检查器可视化树.
或者, 我们可以检查一组相同类型的集合, 例如一个映射列表, 使用下面显示的表格模型. 检查器使用第一个记录 (或项列表) 来确定表格的大小. 这就是为什么数据类型应该相同 (相同的键或相同的大小) 才能正确显示:
(require '[clojure.inspector :refer [inspect-table]]) ; ❶ (def events [{:time "2017-05-04T13:08:57Z" :msg "msg1"} ; ❷ {:time "2017-05-04T13:09:52Z" :msg "msg2"} {:time "2017-05-04T13:11:03Z" :msg "msg3"} {:time "2017-05-04T23:13:10Z" :msg "msg4"} {:time "2017-05-04T23:13:23Z" :msg "msg5"}]) (inspect-table events) ;; See image below
❶ inspect-table 是 clojure.inspector 命名空间的一部分.
❷ 这个事件向量是那种用表格模型渲染得很好的数据结构. 第一个映射的键成为表格中的标题.
Figure 45: Figure 22.2. 一组统一数据的检查器可视化表格.
总的来说, clojure.inspector 对于快速可视化表格或树很有用. 然而, 它不提供任何特定的配置或可扩展性.
4.9.3. 22.3 clojure.repl
clojure.repl 包含帮助在 REPL (Read Eval Print Loop 控制台) 中工作的函数和宏. 它提供了两大类工具:
- 文档函数, 如
doc和with-out-str. - 与源代码和环境相关的函数, 如
source,apropos和dir. - 异常处理函数, 如:
root-cause或pst.
clojure.repl中的一些函数在 REPL 中可以直接使用, 无需require:source,apropos,dir,pst,doc和with-out-str.
doc
doc可能是最常用的文档宏. 它接受一个符号, 并从一个var或命名空间对象的元数据中返回 `:doc` 键的值. 在下面的例子中, 我们在向一个var添加文档前后展示doc:(def life 42) (doc life) ; ❶ ;; ------------------------- ;; user/life ;; nil ;; nil (alter-meta! #'life assoc :doc ; ❷ "Answer to the Ultimate Question of Life the Universe and Everything") (doc life) ; ❸ ;; ------------------------- ;; user/life ;; Answer to the Ultimate Question of Life the Universe and Everything ;; nil
❶ "life" 的定义没有文档字符串.
❷
alter-meta!永久地改变一个 var 的元数据, 在这种情况下, 通过向任何已存在的元数据映射中添加一个新的键.❸ 再次调用
doc后, 我们可以看到它正确地报告了文档字符串.doc对函数和命名空间的工作方式类似:(doc doc) ; ❶ ;; clojure.repl/doc ;; ([name]) ;; Macro ;; Prints documentation for a var or special form given its name (ns my-namespace "This namespace contains useful functions." (:require [clojure.repl :refer [doc]])) (doc my-namespace) ; ❷ ;; ------------------------- ;; my-namespace ;; This namespace contains useful functions. ;; nil
❶
doc可以为自身或标准库中的所有其他函数提供文档.❷
doc类似地从命名空间中提取文档字符串. 注意, 新的命名空间my-namespace默认没有可用的函数clojure.repl/doc, 所以在命名空间声明中添加了对doc的require-refer.find-doc
当你知道你到底在寻找什么时,
doc才有效. 如果你只碰巧知道名字的一部分, 或者你感兴趣的特定用例, 你可以用一个正则表达式 (作为字符串) 调用find-doc, 在所有可用的文档字符串中搜索匹配项. 下面的查询询问是否有以 "to-" 开头的函数或宏:(in-ns 'user) (find-doc "^to-") ; ❶ ;; ------------------------- ; ❷ ;; clojure.core/to-array ;; ([coll]) ;; Returns an array of Objects containing the contents of coll, which ;; can be any Collection. Maps to java.util.Collection.toArray(). ;; ------------------------- ;; clojure.core/to-array-2d ;; ([coll]) ;; Returns a (potentially-ragged) 2-dimensional array of Objects ;; containing the contents of coll, which can be any Collection of any ;; Collection.
❶
find-doc接受一个字符串, 该字符串被转换为一个正则表达式模式. 它在所有可用的文档字符串, var 或命名空间中搜索匹配项 (包括部分匹配).❷
find-doc(以及doc) 的输出被设计为直接打印到标准输出. 我们在这里可以看到所有以 "to-" 开头的函数.apropos
当使用过于通用的模式时,
find-doc可能会非常冗长. 例如, 如果你尝试搜索 "to-" 而不是像我们在上面的查询中那样搜索 "to-", 输出将会是几页长. 原因在于 "to-" 可以出现在函数名或文档字符串中. 如果你只想查看名称中包含 "to-" 的函数, 你可以使用apropos:(apropos "to-") ; ❶ ;; (clojure.core/into-array ;; clojure.core/to-array ;; clojure.core/to-array-2d)
❶ 与
find-doc相比,apropos只在定义的名称中搜索匹配项, 不包括命名空间或描述. 还要注意, 结果是一个列表, 不会打印到标准输出.dir
另一种搜索可用内容的有用方法是按命名空间.
dir宏打印一个命名空间内声明的所有公共定义的有序列表:(require 'clojure.reflect) (dir clojure.reflect) ; ❶ ;; ->AsmReflector ;; ->Constructor ;; ->Field ;; ->JavaReflector ;; ->Method ;; ClassResolver ;; Reflector ;; TypeReference ;; do-reflect ;; flag-descriptors ;; map->Constructor ;; map->Field ;; map->Method ;; reflect ;; resolve-class ;; type-reflect ;; typename
❶
dir显示clojure.reflect命名空间的内容. 该命名空间已按常规require, 以便可供检查.dir-fn
dir直接将结果打印到标准输出. 这是在 REPL 中访问该信息的最有用的方式, 但如果你需要将相同的结果作为序列来操作, 你可以使用dir-fn.dir-fn是一个函数, 所以与dir相比, 你需要引用命名空间:(require 'clojure.java.browse) (require '[clojure.repl :refer [dir-fn]]) ; ❶ (apply str (interpose "," (dir-fn 'clojure.java.browse))); ❷ ;; "*open-url-script*,browse-url"
❶ 与前面的例子不同,
dir-fn需要显式地refer.❷
dir-fn返回一个序列. 在这里, 我们用逗号分隔每个定义, 以产生一个单一的字符串.source
Clojure 是一种非常易读的语言. 阅读源代码 (特别是标准库的) 是一个有用的练习, 有时为了理解如何使用一个函数是必需的. 然而, 可能不立即清楚在哪里查找源代码.
source宏通过接受一个公共定义的名称并将其源代码打印到标准输出来解决这个问题:(source unchecked-inc-int) ; ❶ ;; (defn unchecked-inc-int ; ❷ ;; "Returns a number one greater than x, an int. ;; Note - uses a primitive operator subject to overflow." ;; {:inline (fn [x] `(. clojure.lang.Numbers (unchecked_int_inc ~x))) ;; :added "1.0"} ;; [x] (. clojure.lang.Numbers (unchecked_int_inc x)))
❶
source是一个宏, 无需引用作为参数传递的符号.❷
unchecked-int-inc的源定义以与原始定义相同的格式 (行和缩进) 打印在屏幕上.通过
source可以获得源代码, 但有一些限制:- 只有在加载了相应的命名空间后, 源代码才可用 (可能需要一个
require来加载命名空间). - 命名空间需要从当前的 Java 类路径中可见. 标准库和正常的应用程序依赖项就是这种情况, 但这排除了动态生成的函数.
- 特殊形式的定义不可用, 因为它们是用 Java 实现的. 类似地, 我们不能获取 Java 方法或类的源代码.
*read-eval*动态绑定不应被设置为:unknown.
关于
*read-eval*的最后一点需要解释.source内部使用 Clojure 读宏来从其位置加载源代码. Clojure 读宏支持*read-eval*宏, 以便立即评估以#=为前缀的形式 (关于这方面的更多信息, 请参考read).:unknown值是为测试与读宏求值宏的兼容性而设计的: 任何使用读宏加载源代码的代码, 如果*read-eval*变量的值是:unknown, 都应该抛出异常.- 只有在加载了相应的命名空间后, 源代码才可用 (可能需要一个
source-fn
source宏也有一个函数版本:source-fn接受一个符号并返回包含源代码的原始字符串, 而不将其打印到标准输出:(require '[clojure.repl :refer [source-fn]]) (source-fn 'not-empty) ; ❶ ;; "(defn not-empty\n \"If coll is empty, returns nil, else coll\"\n ; ❷ ;; {:added \"1.0\"\n :static true}\n [coll] (when (seq coll) coll))" (println *1) ; ❸ ;; (defn not-empty ;; "If coll is empty, returns nil, else coll" ;; {:added "1.0" ;; :static true} ;; [coll] (when (seq coll) coll))
❶
source-fn现在需要引用以将参数作为符号传递.❷ 函数
not-empty的源代码以原始格式 (换行符和空格) 出现.❸ 我们可以通过在其上调用
println来看到带有完整漂亮打印的函数. 注意:*1是一个动态变量, 它会自动与 REPL 中最后一个评估的表达式关联.pst
pst代表 "Print Stack Trace" (打印堆栈跟踪).pst是一个用于检索恰到好处的错误信息的有用函数. Java 可以产生巨大的堆栈跟踪, 在某些极端情况下, 需要滚动多页才能看到出现在顶部的根本原因. 为了避免屏幕混乱, REPL 默认只显示最重要的信息. 例如, REPL 只打印下面除以零错误的 hovedbesked:(/ 1 0) ; ❶ ;; ArithmeticException Divide by zero ;; clojure.lang.Numbers.divide (Numbers.java:158)
❶ REPL 默认只显示基本信息, 做得很好. 在这种情况下, 我们可以用一个简短的描述快速理解问题.
对于其他类型的错误, 我们可能需要查看完整的堆栈跟踪. 堆栈跟踪显示了异常如何从问题发生的地方传播到请求发出的地方. REPL 在
*e动态变量中存储了完整堆栈跟踪的副本:(/ 1 0) ;; ArithmeticException Divide by zero ;; clojure.lang.Numbers.divide (Numbers.java:158) *e ; ❶ ;; #error { ;; :cause "Divide by zero" ;; :via ;; [{:type java.lang.ArithmeticException ;; :message "Divide by zero" ;; :at [clojure.lang.Numbers divide "Numbers.java" 158]}] ;; :trace ;; [[clojure.lang.Numbers divide "Numbers.java" 158] ;; [clojure.lang.Numbers divide "Numbers.java" 3808] ; ❷ ;; ....
❶ 完整的错误消息存储在
*e动态变量中. 这里的错误被截断以在书中正确显示, 但它要长得多.❷ 从
:trace中的这个项开始, 我们可以看到关于异常如何向上传播到请求站点的新信息.默认情况下,
pst接受*e的内容, 并呈现堆栈跟踪中的前 12 个项:(/ 1 0) ;; ArithmeticException Divide by zero ;; clojure.lang.Numbers.divide (Numbers.java:158) (pst) ; ❶ ;; ArithmeticException Divide by zero ;; clojure.lang.Numbers.divide (Numbers.java:158) ;; clojure.lang.Numbers.divide (Numbers.java:3808) ;; user/eval2147 (form-init4179141376169992155.clj:1) ;; user/eval2147 (form-init4179141376169992155.clj:1) ;; clojure.lang.Compiler.eval (Compiler.java:6927) ;; clojure.lang.Compiler.eval (Compiler.java:6890) ;; clojure.core/eval (core.clj:3105) ;; clojure.core/eval (core.clj:3101) ;; clojure.main/repl/read-eval-print--7408/fn--7411 (main.clj:240) ;; clojure.main/repl/read-eval-print--7408 (main.clj:240) ;; clojure.main/repl/fn--7417 (main.clj:258) ;; clojure.main/repl (main.clj:258)
❶
pst默认查看*e的内容. 在调用pst之前你需要生成一个异常才能真正看到堆栈跟踪 (否则它会什么都不打印并返回nil).pst可选地接受一个异常参数, 如果我们对*e中可用的异常不感兴趣. 此外,pst接受从堆栈跟踪顶部检索多少个项 (默认为 12):(def ex (ex-info "Problem." {:status :surprise})) (pst ex) ; ❶ ;; ExceptionInfo Problem. {:status :surprise} ;; clojure.core/ex-info (core.clj:4617) ;; clojure.core/ex-info (core.clj:4617) ;; clojure.lang.Compiler$InvokeExpr.eval (Compiler.java:3652) ;; clojure.lang.Compiler$DefExpr.eval (Compiler.java:451) ;; clojure.lang.Compiler.eval (Compiler.java:6932) ;; clojure.lang.Compiler.eval (Compiler.java:6890) ;; clojure.core/eval (core.clj:3105) ;; clojure.core/eval (core.clj:3101) ;; clojure.main/repl/read-eval-print--7408/fn--7411 (main.clj:240) ;; clojure.main/repl/read-eval-print--7408 (main.clj:240) ;; clojure.main/repl/fn--7417 (main.clj:258) ;; clojure.main/repl (main.clj:258) (pst ex 4) ; ❷ ;; ExceptionInfo Problem. {:status :surprise} ;; clojure.core/ex-info (core.clj:4617) ;; clojure.core/ex-info (core.clj:4617) ;; clojure.lang.Compiler$InvokeExpr.eval (Compiler.java:3652) ;; clojure.lang.Compiler$DefExpr.eval (Compiler.java:451)
❶
pst接受一个java.lang.Throwable对象作为参数, 而不是查看*e(默认).❷ 我们也可以决定要看堆栈跟踪中的多少个项, 例如 4 个.
异常对象可以任意嵌套, 因此内部逻辑可以捕获异常, 对其进行处理, 并抛出一个包装了原始异常的新异常. 以这种方式形成的异常链会逐渐用更多信息来装饰原始异常, 但也变得更难阅读.
pst也会将任何嵌套的异常截断到所需的项数:(def ex ; ❶ (ex-info "Problem." {:status :surprise} (try (/ 1 0) (catch Exception e (ex-info "What happened?" {:status :unkown} e))))) (pst ex 3) ; ❷ ;; ExceptionInfo Problem. {:status :surprise} ;; clojure.core/ex-info (core.clj:4617) ;; clojure.core/ex-info (core.clj:4617) ;; clojure.lang.Compiler$InvokeExpr.eval (Compiler.java:3652) ;; Caused by: ;; ExceptionInfo What happened? {:status :unkown} ;; clojure.core/ex-info (core.clj:4617) ;; clojure.core/ex-info (core.clj:4617) ;; user/fn--2169 (form-init4179141376169992155.clj:5) ;; Caused by: ;; ArithmeticException Divide by zero ;; clojure.lang.Numbers.divide (Numbers.java:158) ;; clojure.lang.Numbers.divide (Numbers.java:3808)
❶ 这个代码片段生成多个嵌套的异常.
❷
pst对所有嵌套的异常应用相同的规则, 创建一个可读的堆栈跟踪.root-cause
在处理链式异常对象时, 直接访问根本原因可能很有用.
root-cause接受一个可能很长的异常链的初始引用, 并只检索根本原因:(require '[clojure.repl :refer [root-cause]]) ; ❶ (pst (root-cause ex) 3) ; ❷ ;; ArithmeticException Divide by zero ;; clojure.lang.Numbers.divide (Numbers.java:158) ;; clojure.lang.Numbers.divide (Numbers.java:3808) ;; user/fn--2169 (form-init4179141376169992155.clj:3)
❶
root-cause默认不可用, 我们需要从clojure.repl命名空间中require它.❷
ex是之前生成的链式异常对象. 它包含一个由 3 个异常组成的链.root-cause只保留最内层的.munge,demunge和stack-element-str
从到目前为止的堆栈跟踪中可能不立即清楚的一点是,
pst不仅控制了跟踪的总体长度, 而且还使用demunge对 Clojure 的 "名称" 进行了清理. 我们可以直接使用demunge, 或者通过stack-element-str, 后者专门用于改善堆栈跟踪元素的外观.虽然
munge和demunge相关, 但munge位于clojure.core命名空间, 而demunge位于clojure.repl. 这是因为demunge主要用于在 REPL 中美化跟踪项.munge/demunge存在的理由与 Clojure 和 Java 命名约定之间必要的转换有关. Java 包映射到文件系统文件夹, 限制了包名中可以使用的内容. Clojure 在函数名中可以使用的内容方面甚至更自由 (例如允许问号和其他符号), 所以存在一个隐式的转换层来在两种约定之间进行转换. 一个可见的后果是, 虽然命名空间名称中允许有破折号, 但相关的文件需要用下划线替换破折号. 为了帮助进行名称转换,munge将有效的 Clojure 函数/命名空间名称转换为有效的 Java 类/包名, 而demunge则反向操作:(ns my-namespace) ; ❶ (require '[clojure.repl :refer [demunge stack-element-str]]) ; ❷ (defn my-funct! [] (throw (ex-info "error" {}))) (str my-funct!) ; ❸ ;; "my_namespace$my_funct_BANG_@621ada4f" (demunge (str my-funct!)) ; ❹ ;; "my-namespace/my-funct!@4e212104" (def stack-trace (try (my-funct!) (catch Exception e (.getStackTrace e)))) ; ❺ (nth stack-trace 2) ; ❻ ;; [my_namespace$my_funct_BANG_ invokeStatic "form-init4179141376169992155.clj" 1] (stack-element-str (nth stack-trace 2)) ; ❼ ;; "my-namespace/my-funct! (form-init4179141376169992155.clj:1)"
❶ 注意
my-namespace包含一个破折号 "-" 符号. Java 中的类名不允许有破折号, 所以 Clojure 需要在命名空间成为类名和包组合的一部分之前对它们进行一些转换.❷
demunge和stack-element-str都需要显式require才能使用.❸ 当一个函数被定义时, 它的类就被生成了. 在生成之前, Clojure 的名称需要转换为 Java 的约定. 即使这里看不到对
munge的调用, 名称转换也是在幕后发生的. 包和类名已经遵循了 Java 的名称约定.❹
demunge接受一个表示 Java 名称的字符串, 并将其转换为一个符合 Clojure 习惯的名称. 例如, 我们可以看到像 "BANG" 这样的词被替换回了原始的 "!".❺ 当调用
my-funct!时, 它会产生一个异常. 我们可以通过在异常实例上调用 `.getStackTrace` 方法来检索一个堆栈跟踪元素的数组.❻ 如果我们访问数组中索引为 2 的元素, 我们可以看到它使用 Java 的约定来打印类, 即使它们是从 Clojure 函数生成的.
❼
stack-element-str使用更好看的 Clojure 约定来打印堆栈跟踪元素.REPL 提供了一些额外的配置来产生更好的开发体验. 我们将在讨论
clojure.main命名空间时看到其中的一些.
4.9.4. 22.4 clojure.main
clojure.main中的大多数函数都是公共的, 但其中一些应被视为 REPL 内部的实现细节. 本节简要地涉及其中一些, 主要关注那些可以在 REPL 之外重用的部分.
clojure.main 是所有 Clojure 应用程序的入口点. 该命名空间包含一个负责解析命令行参数和启动新 Clojure 程序的 main 函数. 其中一个程序是 REPL, 当没有指定其他程序时, 它是默认的. 该命名空间包含其他函数, 但只有少数足够通用, 可以用于其他目的. 因此, 我们只关注以下内容:
load-script编译和评估一个 Clojure 文件的内容.repl启动主 REPL 循环, 但它也可以用来创建一个自定义版本的 REPL.
load-script
load-script接受一个代表 Clojure 文件路径的字符串参数. 该文件可以是 Java 类路径的一部分, 也可以是文件系统的一部分.load-script通过命名约定来区分这两种情况: 如果文件以 "@" 或 "@/" 开头,load-script会从类路径加载和编译该文件:(require '[clojure.main :as main]) ; ❶ clojure.core.reducers/fold ; ❷ ;; CompilerException java.lang.ClassNotFoundException: clojure.core.reducers (main/load-script "@clojure/core/reducers.clj") ; ❸ clojure.core.reducers/fold ; ❹ ;; #object["clojure.core.reducers$fold@41414539"]
❶
clojure.main命名空间中的函数需要显式require.❷ 如果在启动新的 REPL 会话后, 我们输入一个从未加载过的 var 对象的完全限定名, 我们会得到一个错误.
❸ 我们使用
main/load-script来加载和编译clojure.core.reducers命名空间的内容. 这会产生创建一个新的命名空间对象并从文件中加载任何定义的副作用.❹ 调用
main/load-scriptfor the reducers 命名空间后, 我们可以看到函数fold现在可以正确解析.当我们使用 "@" 符号来加载一个 Clojure 文件时, 效果与使用
load函数非常相似, 只是路径的编码不同. 如果我们移除 "@" 符号, 我们会得到与load-file(核心命名空间中的另一个函数) 相同的效果:(require '[clojure.main :as main]) (spit "hello.exe" ; ❶ "(ns hello) (println \"Hello World!\")") (main/load-script "hello.exe") ; ❷ ;; "Hello World!" ;; nil
❶ 我们在文件系统上创建一个名为 "hello.exe" 的文件, 其中包含一个命名空间声明和一行打印 "Hello World!" 的代码. 该文件不一定需要有 "clj" 扩展名.
❷ 如果 "@" 符号不存在, 那么
load-script会尝试从 REPL 进程启动的文件夹开始加载 "hello.exe". 文件 "hello.exe" 被找到并评估.repl
clojure.main/repl函数启动一个新的读求值打印循环 (可能在一个已有的循环之上, 形成嵌套). 它接受一些配置选项, 这些选项有助于自定义 REPL 体验, 甚至可能创建一个完全不同的 REPL. 在下面的例子中, 我们假设我们已经在一个默认的 REPL 中, 然后启动一个新的 REPL:(require '[clojure.main :as main]) ; ❶ (main/repl :init #(println "Welcome to a new REPL! Press ctrl+D to exit.")) ; ❷ ;; Welcome to a new REPL! Press ctrl+D to exit. ; ❸ ;; my-namespace=>
❶
repl函数是clojure.main命名空间的一部分.❷
:init选项接受一个无参函数, 该函数在会话开始时执行一次. 在这个例子中, 它打印一条欢迎消息.❸ 注意, 你可以使用 "ctrl+d" (同时按下 "ctrl" 键和 "d" 键) 来退出嵌套的 REPL. 小心: 第二次这样做也会退出默认的 REPL!
:init选项对于初始化新的 REPL 很有用, 这样它就可以立即识别一些命令. 例如, 假设我们设计了一个实现 4 种基本运算 ("plus", "minus", "times" 和 "divide") 的小型计算器. 在启动新的计算器 REPL 时, 我们希望这些函数立即可用:(ns calculator) ; ❶ (defn plus [x y] (+ x y)) (defn minus [x y] (- x y)) (defn times [x y] (* x y)) (defn divide [x y] (/ x y)) (require '[clojure.main :as main]) (main/repl :init #(require '[calculator :refer :all])) ; ❷ (plus 1 2) ; ❸ ;; 3
❶ 计算器函数在
calculator命名空间中定义.❷
calculator命名空间的函数在初始化新 REPL 后立即被require.❸ 我们现在可以输入 4 种算术运算中的任何一种, 并相应地使用它们.
还有其他配置选项可以帮助改善设计自定义 REPL 环境的用户体验. 我们可以使用
:prompt来明确说明新 REPL 的目的:(require '[clojure.main :as main]) (def repl-options [:init #(require '[calculator :refer :all]) :prompt #(printf "enter expression :> ")]) (apply main/repl repl-options) ;; enter expression :> (+ 1 1) ; ❶ ;; 2
❶ 通过使用
:repl选项, 我们可以改变提示符的外观.我们可以更进一步, 完全脱离 Clojure REPL 通常评估表达式的方式. 在下面的例子中, 一个自定义的 REPL 计算小的中缀数学表达式. 为此, 我们需要使用相应的选项键来覆盖
:read函数和:eval函数:(require '[clojure.main :as main]) (def repl-options [:prompt #(printf "enter expression :> ") :read (fn [request-prompt request-exit] ; ❶ (or ({:line-start request-prompt :stream-end request-exit} ; ❷ (main/skip-whitespace *in*)) (re-find #"^(\d+)([\+\-\*\/])(\d+)$" (read-line)))) ; ❸ :eval (fn [[_ x op y]] ; ❹ (({"+" + "-" - "*" * "/" /} op) (Integer. x) (Integer. y)))]) (apply main/repl repl-options) ;; enter expression :> 2*3 ; ❺ ;; 6 ;; click ctrl+d to exit calculator
❶
:read选项接受一个接受 2 个参数的函数. 我们用它们来指示 REPL 何时应该请求一个新的提示符, 以及一个处理 "ctrl+D" (它会产生一个流结束信号) 的自定义方式.❷
main/skip-whitespace遍历标准输入, 跳过任何空白字符 (如果有), 并将标准输入 (一个有状态的对象) 定位在三个可能的位置之一::body,:line-start或:stream-end.:body是下一个可读的标记 (在我们的例子中是数学表达式), 所以or表达式跳转到包含read-line调用的下一个表达式.❸
read-line从标准输入读取一整行. 在我们的例子中, 它等待用户输入一个表达式并按回车. 此时, 该行被读取为字符串, 并发送到一个正则表达式, 该表达式将其分割成相关的匹配组.❹ 该行从
:read返回一个包含 4 项的列表. 第一项是整个表达式本身 (我们可以忽略). 接下来的 3 个参数是第一个操作数 "x", 操作符 "op" 和第二个操作数 "y".eval继续将操作数转换为数字, 将操作符转换为函数, 最终调用该函数.❺ 不同的提示符警告用户 REPL 的不同语义. 在新的表达式 REPL 中, 不需要括号, 操作符以中缀位置出现. 按 ctrl+D 退出内层循环并返回到正常的 REPL.
前面的例子显示,
clojure.main/repl在设计时考虑了可扩展性. 自定义的程度可以使 REPL 体验走得很远, 甚至允许与构建在 Clojure 之上的小语言进行交互.
4.9.5. 22.5 clojure.java.browse
clojure.java.browse 包含通过系统浏览器可视化 HTML 内容的函数. 主要且唯一的入口点是 browse-url, 一个接受 URL 作为字符串并与操作系统交互以使用可用方法之一打开 URL 的函数:
- HTML 浏览器: 这是默认方法. Clojure 运行的操作系统被假定有一个默认的系统浏览器来调用以打开给定的 URL.
- Swing 浏览器: 如果没有可用的默认 HTML 浏览器,
browse-url会尝试使用 Swing HTML 渲染工具. Swing 是 Java 运行时中可用的一个图形窗口工具包. - 自定义脚本: 用户也可以通过设置
clojure.java.broswe/*open-url-script*动态变量来自定义要使用的命令行可执行文件.
使用 browse-url 非常简单. 例如, 下面会打开一个浏览器, 显示本书的主页:
(require '[clojure.java.browse :refer [browse-url]]) (browse-url "https://www.manning.com/books/clojure-the-essential-reference") ; ❶
❶ browse-url 打开默认的系统浏览器, 指向给定的 URL.
在不太可能的情况下, 如果系统浏览器不可用, browse-url 会尝试使用 Swing 窗口工具包来打开页面. 为了模拟这个事件, 我们将绕过 browse-url 直接与负责渲染 Swing UI 的私有函数对话:
(require '[clojure.java.browse-ui :as bu]) ; ❶ (#'bu/open-url-in-swing "http://google.com") ; ❷ ;; #object[javax.swing.JFrame 0x268234e0...]
❶ clojure.java.browse-ui 的内容是私有的, 但我们将绕过这个限制来展示 Swing UI 的运行情况.
❷ 你应该会看到一个新的 Java 应用程序启动, 显示一个非常基本的 Google 主页渲染.
如果前两种方法都不可用, 或者我们需要一种特定的页面渲染方式, 我们可以使用动态变量 *open-url-script* 来提供一个命令行可执行文件:
(require '[clojure.java.browse :refer [browse-url *open-url-script*]]) (binding [*open-url-script* (atom "wget")] ; ❶ (browse-url "https://tinyurl.com/wandpeace")) ;; true
❶ *open-url-script* 已被绑定到 "wget", 一个流行的命令行浏览工具. 假设 "wget" 安装在本地系统上, 该代码片段会从古登堡项目网站下载<战争与和平>这本书.
clojure.java.browse 提供的基本功能在应用程序或 REPL 中使用起来不是很实用. 然而, 它们可以用来打开与函数或宏相关的文档. 这在 clojure.java.javadoc 命名空间中实现, 我们将在本章末尾看到.
4.9.6. 22.6 clojure.java.shell
clojure.java.shell 命名空间公开一个单一的入口点函数 sh, 它在宿主操作系统上作为一个独立的进程执行一个命令:
(require '[clojure.java.shell :refer [sh]]) ; ❶ (sh "ls" "/usr/share/dict") ; ❷ ;; {:exit 0, ; ❸ ;; :out "README\nconnectives\npropernames\nweb2\nweb2a\nwords\n", ;; :err ""}
❶ sh 是 clojure.java.shell 命名空间中主要且唯一的入口点. 我们可以直接引用该函数, 避免使用命名空间别名, 因为 sh 是一个简短且易于识别的名称.
❷ 如果命令行包含参数, 每个参数都必须指定为一个单独的字符串. 我们在这里可以看到如何在一个基于 Unix 的操作系统中列出一个文件夹的内容.
❸ 结果是一个带有 :exit, :out 和 :err 键的映射. 如果 :exit 数字大于零, 它表示该命令报告了一个错误条件. :out 包含命令定向到标准输出的输出, 而 :err 是标准错误流.
当命令在子进程 (正在运行的 Java 虚拟机的) 中执行时, sh 会阻塞直到退出码可用. 命令通常将结果打印到标准输出, 或将错误打印到标准错误. 两个输出都在结果映射中作为纯字符串报告.
sh 支持相当多的选项. 我们可以使用 :in 选项将内容传递给运行中进程的标准输入. :in 支持多种类型: 输入流, 输入读宏, 文件, 字节数组或字符串. 在下面的例子中, 我们调用 Unix 命令 "grep", 将一个字符串传递给它的标准输入:
(def result (sh "grep" "5" :in (apply str (interpose "\n" (range 50))))) ; ❶ (println (:out result)) ; ❷ ;; 5 ;; 15 ;; 25 ;; 35 ;; 45
❶ 这个 grep 命令接收一个用 :in 键传递的字符串.
❷ 我们可以通过使用 println 看到结果, 就像在 REPL 之外一样.
如果命令的输入是用另一种字符集编码的 (例如, 因为它不是在正在运行的 JVM 内部产生的), 那么我们可以使用 :in-enc 来指定输入是哪种编码. 类似地, :out-enc 可以用来用特定的编码来解释命令的输出. :out-enc 还支持一个特殊的值 :bytes, 当存在时, 不会将输出转换为字符串, 而是返回原始字节:
(def image-file "/usr/share/doc/cups/images/smiley.jpg") (def cmd (sh "cat" image-file :out-enc :bytes)) ; ❶ (count (:out cmd)) ; ❷ ;; 14120
❶ 这个命令假设你在指定的位置有一张图片. 我们可以用 sh 加载这张图片, 使用 "cat" 将图片发送到标准输出, 在那里它被收集为一个字节数组并返回. :out-enc :bytes 的存在阻止了任何到字符串的转换, 返回了原始字节.
❷ 我们可以看到图片的大小约为 14k.
知道如何传递输入, 我们可以构建一个辅助函数来将命令串联起来 256:
(defn pipe [cmd1 & cmds] ; ❶ (reduce (fn [{out :out} cmd] ; ❷ (apply sh (conj cmd :in out))) (apply sh cmd1) cmds)) (println (:out (pipe ; ❸ ["env"] ["grep" "-i" "java"]))) ;; JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home ;; JAVA_MAIN_CLASS_61966=clojure.main ;; _=/usr/bin/java ;; LEIN_JAVA_CMD=java ;; JAVA_MAIN_CLASS_62001=clojure.main
❶ pipe 函数至少接受一个参数, 可能更多. 它期望每个参数都是一个适合 sh 命令的字符串向量.
❷ pipe 总是通过执行第一个命令开始, 这成为 reduce 的初始值. 归约函数接受最后一个命令的输出和新命令. 然后它执行新命令, 使用前一个的输出作为下一个的输入.
❸ 我们可以尝试将 "env" 命令 (它返回当前设置的所有环境变量的列表) 和 "grep" 命令 (它搜索子字符串) 管道连接起来. 请注意: 你在这里看到的输出可能与在你的环境中执行的相同命令有很大的不同.
sh 在一个子进程中执行命令, 这意味着所有的父环境变量都被子进程继承. 我们可以改变这种行为, 并使用 :env 映射来传递一个完全不同的变量集:
(def env {"VAR1" "iTerm.app" "VAR2" "/bin/bash" "COMMAND_MODE" "Unix2003"}) (println (:out (sh "env" :env env))) ; ❶ ;; VAR1=iTerm.app ;; VAR2=/bin/bash ;; COMMAND_MODE=Unix2003
❶ 我们可以看到默认的环境变量已被 env 映射的内容完全替换.
sh 的另一个可覆盖的默认值是工作文件夹, 即命令执行的初始路径. 在下面的例子中, 我们首先打印当前的工作文件夹, 然后使用 :dir 键来更改它:
(println (:out (sh "pwd"))) ; ❶ ;; /Users/reborg/prj/my/book (println (:out (sh "pwd" :dir "/tmp"))) ; ❷ ;; /tmp
❶ 我们执行命令 "pwd" 来检索当前的工作文件夹.
❷ 我们再次执行相同的命令, 但这次我们使用 :dir 键来传递一个不同的工作文件夹.
我们可能需要使用相同的环境和工作文件夹设置来执行多个 sh 调用. 为了帮助避免在所有 sh 命令中重复 :dir 和 :env 键, clojure.java.sh 还包含两个方便的宏, 用于在线程局部绑定中设置这些:
(require '[clojure.java.shell :as shell :refer [sh]]) (shell/with-sh-dir "/usr/share" ; ❶ (shell/with-sh-env {:debug "true"} [(sh "env") (sh "pwd")])) ;; [{:exit 0, :out "debug=true\n", :err ""} ;; {:exit 0, :out "/usr/share\n", :err ""}]
❶ 我们使用 with-sh-dir 和 with-sh-env 来为形式中的所有 sh 命令设置工作文件夹和环境变量.
4.9.7. 22.7 clojure.core.server
clojure.core.server 包含一些函数, 用于通过套接字连接和跨网络边界来暴露 Clojure 环境. 典型的 REPL 从标准输入接受命令并向标准输出打印结果, 而基于套接字的 REPL 使用套接字来接收请求和发送响应. 在套接字的另一端, 一个进程 (或人) 像往常一样消费调用 Clojure 函数的结果. 默认情况下, clojure.core.server 使用与通过控制台提供的 REPL 略有修改的版本. 要启动服务器, 我们使用 start-server:
(require '[clojure.core.server :as server]) ; ❶ (server/start-server ; ❷ {:name "repl1" :port 8787 :accept clojure.core.server/repl}) ;; #object["ServerSocket[addr=localhost/127.0.0.1,localport=8787]"]
❶ 启动套接字服务器所需的函数在 clojure.core.server 命名空间中可用.
❷ start-server 接受一个强制性选项的映射 (其他是可选的).
套接字服务器是高度可配置的. 以下是可用选项及其含义的摘要:
:address是服务器应该使用的网络接口. 它默认为 127.0.0.1, 即默认的主机接口, 所以不是必需的.:port是服务器应该使用的端口. 没有默认值, 并且是强制性参数.:name是此服务器的标识符. 可能有许多套接字服务器在运行, 每个服务器都需要一个名称. 这是强制性参数.:accept是一个在类路径中可用的文件中声明的完全限定的函数. 不可能传递一个匿名函数.:args是accept函数的可选参数列表.:bind-err告诉服务器标准错误流是否应该绑定到输出套接字 (通常标准错误在 REPL 中绑定到*err*). 它默认为 true, 这意味着任何打印到标准错误的内容也会被发送到套接字的另一端 (与标准输出一起).:server-daemon确定运行的套接字服务器是否是守护线程. 默认情况下, 套接字服务器启动一个守护服务器, 这意味着即使它仍在服务请求, JVM 也可以退出.:client-daemon将客户端线程配置为守护线程. 当套接字服务器收到一个请求时, 它会将该请求作为一个独立的客户端线程来处理. 默认情况下, 服务传入请求的线程也是守护线程.
大多数可用选项都相当不言自明. 一个值得注意的选项是 :accept, 它决定了服务器处理传入请求的行为. 默认情况下, :accept 使用 clojure.core.server/repl, 它会启动一个新的 repl 循环. 下面的例子在一个现有的 REPL 之上运行, 使用标准输入/输出而不是套接字网络, 但效果类似:
(clojure.core.server/repl) ; ❶ ;; nil
:repl/quit ; ❷ ;; nil
❶ 调用 clojure.core.server/repl 的效果不是立即可见的. 在底层, 一个新的 "while true" REPL 循环已经开始处理传入的请求. 该循环通常会附加到一个套接字上, 但在这里我们可以从标准输入/输出与它交互.
❷ 与普通 REPL 的一个区别是, 套接字 REPL 需要一种处理退出请求的方式, 而不一定需要键入 "CTRL+D", 因为套接字的远程端可能没有键盘. 套接字服务器添加了一个 :repl/quit 命令, 该命令会退出 REPL 循环. 在这种情况下, 它会返回到外部 REPL.
如果我们想自定义套接字 REPL 的体验, 我们需要向 :accept 选项传递一个不同的函数. 下面的例子来自 Replicant 库, 这是一个由 Clojure 中套接字服务器功能的同一作者编写的小型概念验证 257:
(ns data-server (:require [clojure.main :as main] [clojure.core.server :as server]) (:import [java.net ServerSocket] [java.io BufferedWriter StringWriter])) ; ❶ (defn data-eval [form] ; ❷ (let [out-writer (StringWriter.) err-writer (StringWriter.) capture-streams (fn [] (.flush *out*) (.flush *err*) {:out (.toString out-writer) :err (.toString err-writer)})] (binding [*out* (BufferedWriter. out-writer) *err* (BufferedWriter. err-writer)] (try (let [result (eval form)] (merge (capture-streams) {:result result})) (catch Throwable t (merge (capture-streams) {:exception (Throwable->map t)})))))) (defn data-repl [& kw-opts] ; ❸ (println kw-opts) (apply main/repl (conj kw-opts :need-prompt (constantly false) :prompt (constantly nil) :eval data-eval))) (server/start-server {:name "repl2" :port 8788 :accept 'data-server/data-repl}) ; ❹
❶ 我们需要记住 accept 函数需要被完全限定. 为了确保示例在正确的命名空间中运行, 我们在定义函数之前创建一个.
❷ data-eval 是 REPL 循环在从套接字读取后将使用的评估函数. 我们不使用默认的 clojure.core/eval, 因为标准输出和标准错误在套接字的另一端是不可见的. data-eval 反而将标准输出和标准错误捕获到一个 StringWriter 实例上. 该写入器然后被用来通过将其转换为字符串来将输出推送到套接字.
❸ data-repl 是 clojure.main/repl 的一个薄层, 这样我们就可以传递我们的自定义评估函数.
❹ 我们现在可以使用自定义的 :accept 函数启动一个新的服务器.
如果你安装了 Telnet 258, 你可以像这样打开一个到正在运行的套接字服务器的会话:
> telnet 127.0.0.1 8788 ; ❶ Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. nil clojure.core=> (+ 1 1) ; ❷ 2
❶ 一个连接到套接字服务器以评估简单表达式的 Telnet 会话示例.
❷ 连接后, 我们会看到通常的提示符, 我们可以像往常一样评估表达式.
要停止一个正在运行的套接字服务器, 我们可以使用 stop-server, 或者用一个单一的调用 stop-servers 来关闭它们全部:
(server/stop-server "repl2") ; ❶ ;; true (server/stop-servers) ; ❷ ;; nil
❶ stop-server 需要一个服务器名称 (如果没有给出服务器名称, 它将尝试使用 server/session 动态变量). 在这个例子中, 我们停止了先前启动的服务器. stop-server 在成功时返回 true, 如果没有找到该名称的服务器, 则返回 nil.
❷ 或者, stop-servers 一次停止所有正在运行的实例, 无需传递它们的名称.
值得记住的是, 套接字服务器的主要目标之一是在一个已存在的应用程序之上启动一个分布式的 REPL, 而无需更改代码, 只需要配置. 我们可以通过向命令行传递必要的参数来从任何应用程序打开一个套接字服务器:
; ❶ export M2_REPO=~/.m2/repository export CLOJURE_18="$M2_REPO/org/clojure/clojure/1.8.0/clojure-1.8.0.jar" ; ❷ java -cp .:$CLOJURE_18 \ -Dclojure.server.repl="{:port 8881 :accept clojure.core.server/repl}" \ clojure.main ;; Clojure 1.8.0 ;; user=>
❶ 为了使这个例子正常工作, 有几个要求. 你需要一个 maven 仓库 (如果你使用 Leininghen, 这通常已经有了), 并将环境变量 M2_REPO 更改为指向该仓库的根目录. 默认情况下, Maven 仓库安装在主文件夹的 `.m2/repository` 中. 我们在这里使用的是一个 Clojure 1.8 的 jar 安装.
❷ 我们直接使用 clojure.main 类来启动 Clojure. 我们还设置了 clojure.server.repl Java 属性. 套接字服务器会检查这个属性的存在, 并根据配置启动一个或多个服务器. 正如你所看到的, 属性内容是一个 Clojure 映射.
你现在应该能够像以前一样打开一个到 127.0.0.1 8881 的 Telnet 连接. 要停止服务器和正在运行的 Clojure 实例, 只需在上面的 REPL 中键入 CTRL+C.
4.9.8. 22.8 clojure.java.io
clojure.java.io 包含一个函数集合, 用于简化与 Java 输入/输出系统 (或简称 IO) 的交互. 多年来, Java 将原始的 InputStream 和 OutputStream 抽象发展为 Reader 和 Writer, 最终还添加了异步 IO. 在这个转换过程中, Java 在保持向后兼容性方面付出了很多努力, 这一原则也与 Clojure 共享. 不幸的是, 现在共存的 IO API 对可用性产生了负面影响, 迫使 Java 开发者通过桥接和适配器在不同风格的 IO 之间移动.
clojure.java.io 不实现新的 IO 系统, 但它在将 Clojure 开发者从由碎片化的 Java 接口产生的多数不一致性中屏蔽出来方面做得很好. 这是通过一些可以进一步扩展的多态多重方法来实现的. 该命名空间还包含一些用于处理类路径, 文件和 URL 的工具函数.
- 流, 写入器和读取器
让我们从阐述以下函数开始:
clojure.java.io/reader和clojure.java.io/writer分别产生java.io.BufferedReader和java.io.BufferedWriter对象. 它们接受各种输入类型, 如读取器, 流, 文件, URL, 套接字, 数组和字符串. 读取器接受java.io.InputStream的事实, 例如, 移除了在 Java 中在这两种抽象之间移动所需的大部分样板代码.clojure.java.io/input-stream和clojure.java.io/output-stream分别产生java.io.InputStream和java.io.OutputStream对象. 它们接受与reader和writer相同的输入类型, 包括接受一个读取器作为输入 (在读取器/写入器和输入/输出流之间进行转换).
在下面的例子中, 我们可以看到如何从一个文件创建一个读取器. 读取器应该记住, 一般来说, IO 对象在宿主操作系统上分配资源, 并且它们需要被释放或关闭. 我们可以使用
with-open在使用后释放资源:(require '[clojure.java.io :as io]) ; ❶ (with-open [r (io/reader "/usr/share/dict/words")] ; ❷ (count (line-seq r))) ; ❸ ;; 235886
❶
clojure.java.io通常被别名为io.❷
reader将第一个字符串参数解释为文件路径或远程 URL.❸
line-seq通过从读取器对象中读取行项来创建一个惰性序列.有时从字符串创建一个读取器很有用 (特别是在测试时), 但
reader将字符串解释为位置. 我们可以通过先将字符串转换为字符数组来达到预期的效果:(require '[clojure.java.io :as io]) (def s "string->array->reader->bytes->string") ; ❶ (with-open [r (io/reader (char-array s))] ; ❷ (slurp r)) ; ❸ ;; "string->array->reader->bytes->string"
❶
io/reader通常用于加载外部资源. 有时, 特别是对于测试, 从字符串直接创建一个读取器很有用. 我们使用这个简单的字符串作为说明.❷
char-array将字符串转换为原始字符数组, 防止reader将字符串解释为位置.❸
slurp具有与reader类似的多态行为, 在这种情况下, 它通过读取其内容将读取器转换回字符串.本书包含其他使用
io/reader的有趣例子: 在line-seq中, 我们展示了如何从java.io.InputStream中读取. 而在disj中, 我们可以看到一个关于如何从java.net.Socket对象中读取的例子.不出所料,
writer创建一个新的写入器对象, 接受与reader相同的第一个参数类型:(with-open [w (io/writer "/tmp/output.txt")] ; ❶ (spit w "Hello\nClojure!!")) ; ❷ (println (slurp "/tmp/output.txt")) ; ❸ ;; Hello ;; Clojure!! ;; nil
❶ 使用写入器与使用读取器非常相似.
writer创建对象 "w", 由于with-open, 该对象将在表达式结束时自动关闭.❷
spit将字符串的内容发送到一个文件中. 如果文件已存在, 内容将被覆盖.❸ 要测试文件的内容, 我们可以使用
slurp而不是通过一个读取器.当数据处理包括从一个大文件中读取, 进行一些转换, 然后将结果写回磁盘时, 我们可以将一个读取器和一个写入器链接在一起, 并使用像
line-seq这样的惰性函数来处理数据. 通过这种方式操作, 我们避免了将整个输入加载到内存中:(require '[clojure.java.io :refer [reader writer]]) (require '[clojure.string :refer [upper-case]]) (with-open [r (reader "/usr/share/dict/words") ; ❶ w (writer "/tmp/words")] (doseq [line (line-seq r)] ; ❷ (.append w (str (upper-case line) "\n")))) ; ❸ ;; nil
❶
reader和writer都需要在用完后关闭. 在这个例子中, 我们使用大多数基于 Unix 的系统上都存在的词典文件. 该文件很大, 我们希望避免将其全部内容加载到内存中.❷ 使用
doseq, 我们确保副作用被惰性地评估, 并且不持有序列的头部. 净效果是, 在任何给定时间, 只有一小部分文件存在于内存中, 而垃圾回收器可以回收任何已经写入磁盘的已处理项.❸ 我们不能重复使用
spit, 因为第一次调用会关闭写入器.reader接受一个:encoding键, 而writer接受:encoding和:append两个键.:encoding键强制对读取或写入的数据使用特定的编码.:append键强制writer在输出流的末尾追加新数据. 下面的例子展示了如何强制使用 "UTF-16" 编码 (而不是默认的 "UTF-8"), 并移除了显式调用.append方法的需要 (与前面的例子相比):(with-open [r (reader "/usr/share/dict/words" :encoding "UTF-16") w (writer "/tmp/words" :append true :encoding "UTF-16")] ; ❶ (doseq [line (line-seq r)] (.write w (str (upper-case line) "\n")))) ; ❷
❶ 我们可以使用
:append来防止writer在写入新内容时移除文件中的任何先前内容.❷ 与使用
.append方法不同, 我们现在可以使用更通用的.write并使用配置选项来控制行为.请注意, 在上面的例子中强制使用 "UTF-16" 编码只有在输入文件是用该编码写入时才有意义. 在例子中它是为了说明目的而使用的.
- 资源和 URL
本书中的例子都显示了
reader或slurp使用字符串来指示其位置来加载资源.reader将给定的字符串解释为类似于 URL (统一资源定位符). URL 是一种格式化字符串以编码跨网络资源位置的约定. 令人困惑的是, 一个java.io.File对象有方法将其转换为 URI (统一资源标识符) 但不是 URL. URI 是比 URL 稍微更通用的对象 259.在 Java 编程中, URL 和 URI 需要一些复杂的转换才能与读取器和文件一起使用. Clojure 隐藏了这种复杂性, 允许我们从文件或字符串创建读取器, 而无需考虑这种转换. 更具体地说,
clojure.java.io中的以下函数可用于处理资源和位置:resource给定一个表示 Java 类路径上资源位置的字符串, 检索一个 URL 对象. 类路径上的资源与磁盘上的资源不同, 因为它们的位置与正在运行的 Java 可执行文件的位置无关.as-url: 给定一个表示其位置的字符串 (可以是类路径, 本地文件系统或其他协议, 如 "http"), 创建一个 URL 对象.
resource在 Clojure 编程中非常常见, 用于从 Java 类路径中检索资源. 类路径通常包含编译的 Java 类, Clojure 源代码 (除非它们被明确移除) 或其他构件. 例如, 我们可以用以下方式检索clojure.java.io命名空间的源代码:(require '[clojure.java.io :refer [resource reader]]) (def cjio (resource "clojure/java/io.clj")) ; ❶ (first (line-seq (reader cjio))) ; ❷ ;; "; Copyright (c) Rich Hickey. All rights reserved."
❶ Clojure 源代码作为 Clojure 可执行文件的一部分被打包. 我们可以使用文件在 Jar 存档中的相对路径来找到它们.
❷ 在使用
reader和line-seq后, 我们可以看到文件的第一行.as-url是一个创建 URL 对象的小工具函数 (无需导入java.net.URL来直接使用其构造函数).as-url为处理除字符串之外的输入类型添加了一定程度的多态性:(require '[clojure.java.io :refer [as-url file]]) (import 'java.nio.file.FileSystems) (def path ; ❶ (.. FileSystems getDefault (getPath "/tmp" (into-array String ["words"])) toUri)) (def u1 (as-url "file:///tmp/words")) ; ❷ (def u2 (as-url (file "/tmp/words"))) ; ❸ (def u3 (as-url path)) ; ❹ (= u1 u2 u3) ; ❺ ;; true
❶
path展示了如何将 Java NIO (New IO Api) 路径转换为 URI.❷
as-url接受字符串 (带有协议) 来识别磁盘上文件的位置.❸
as-url也接受相同位置作为java.io.File对象.❹ 最后,
as-url也接受一个作为通过java.nio.file.Path对象的结果的 URI.❺ 这 3 个 url 是不同的对象, 但它们代表了磁盘上文件 "/tmp/words" 的相同位置.
不幸的是,
clojure.java.io不直接处理java.nio.file.Path对象的强制转换或转换, 正如前面例子中我们必须在调用as-url之前显式调用toUri()所证明的那样. 但clojure.java.io可以被扩展以处理java.nio.file.path(以及类似的其他协议):(require '[clojure.java.io :as io]) (import '[java.nio.file Path FileSystems]) (extend-protocol io/Coercions ; ❶ Path (as-file [path] (io/file (.toUri path))) (as-url [path] (io/as-url (.toUri path)))) (def path ; ❷ (.. FileSystems getDefault (getPath "/usr" (into-array String ["share" "dict" "words"])))) (io/as-url path) ; ❸ ;; #object[java.net.URL 0x1255fa42 "file:"/usr/share/dict/words"] (io/file path) ; ❹ ;; #object[java.io.File 0x1c80a235 "/usr/share/dict/words"]
❶
clojure.java.io包含Coercions协议, 声明了两个函数,as-file和as-url. 虽然as-file有可用的file包装函数, 但as-url没有相应的url函数. 该实现包括将路径转换为 URI 并调用相应的 (已存在的) 实现.❷ Java NIO
Path对象大致等同于 URL.java.nio.file.Path只有一个可用的到 URI 的转换, 我们可以用它来创建一个 URL.getPath()方法接受一个路径初始部分的第一个 "root" 参数, 后面跟着任何其他段落作为可变参数类型. Clojure 需要创建一个字符串数组才能与类型签名兼容.❸ 扩展协议后, 我们可以使用
as-url来直接转换java.nio.file.Path.❹ 作为附带的好处,
file现在也可以直接从路径创建一个文件对象. - 处理文件
处理文件是任何编程语言中的另一个重要方面. Clojure 依赖
java.io.File进行文件操作, 而clojure.java.io包含一些用于处理文件的工具函数.我们在本节和整本书中已经多次看到
io/file的使用. 该函数接受一个或多个参数. 当只有一个参数时, 它可以是一个字符串, 另一个文件, 一个 URL 或 URI (或者, 不太有趣的是,nil):(require '[clojure.java.io :as io]) (keys (:impls io/Coercions)) ; ❶ ;; (nil java.lang.String java.io.File java.net.URL java.net.URI) (io/file "/a/valid/file/path") ;; #object[java.io.File 0x7936d006 "/a/valid/file/path"] (io/file (io/file "/a/valid/file/path")) ;; #object[java.io.File 0x3f46ce65 "/a/valid/file/path"] (io/file (io/as-url "file://a/valid/url")) ;; #object[java.io.File 0x7af35ada "/valid/url"] (io/file (.toUri (io/as-url "file://a/valid/uri"))) ;; #object[java.io.File 0x2de6a5c8 "/valid/uri"] (io/file nil) ;; nil
❶ 我们可以通过检查
Coercions协议的:impls键来查看io/file接受的单一参数类型. 后面是一系列所有可能的io/file调用及其各自的参数类型.io/file可以理解的默认类型列表在Coercion协议映射中可见, 正如示例中所证明的那样. 我们已经看到, 通过扩展这个协议, 我们可以将io/file应用于其他参数类型.io/file也接受第一个参数之后的其他参数, 具有相同的类型约束. 附加的参数必须是相对路径 (即, 它们不能以正斜杠 '/' 开头):(io/file "/root" (io/file "not/root") "filename.txt") ; ❶ ;; #object[java.io.File 0x6898f182 "/root/not/root/filename.txt"] (io/file "/root" (io/file "/not/relative") "filename.txt") ; ❷ ;; IllegalArgumentException /not/relative is not a relative path
❶
io/file的所有第一个参数之后的参数都必须是相对路径.❷ 这里第二个参数以 '/' 开头, 表示在第一个根路径之后的另一个根路径.
io/file实际上不创建物理资源, 只是一个 "指针", 其他函数如writer可以用它来写入内容. 创建内容的另一种方法是使用io/copy函数将一个文件复制到另一个文件:(require '[clojure.java.io :as io]) (io/copy "/usr/share/dict/words" (io/file "/tmp/words2")) ; ❶ ;; nil (.exists (io/file "/tmp/words2")) ; ❷ ;; true
❶ 我们可以使用
io/copy将现有的 `/usr/share/dict/words` 文件复制到 `/tmp` 文件夹中的一个新文件.❷ 要检查文件是否真的被创建, 我们可以使用
java.io.File对象上的exists().io/copy支持多种类型组合: 从读取器到写入器, 从字符串到文件, 从InputStream到OutputStream等等. 其中之一, 从文件到文件, 使用java.nio.channel.FileChannel进行了特别优化, 当文件被操作系统缓存时, 可以保证最佳性能. 然而,io/copy不支持字符串到字符串的传输 (使用文件到文件的复制实现). 我们可以使用相关的do-copy多重方法来扩展io/copy:(require '[clojure.java.io :as io]) (defmethod @#'io/do-copy [String String] [in out opts] ; ❶ (apply io/copy (io/file in) (io/file out) opts)) (io/copy "/tmp/words2" "/tmp/words3") ; ❷ ;; nil (.exists (io/file "/tmp/words3")) ; ❸ ;; true
❶
io/do-copy的defmethod定义在clojure.java.io中是私有的, 但我们仍然可以通过查找相关的 var 对象 (用读宏#') 然后解引用 var (用另一个读宏@) 来访问它. 该实现只是在每个参数上调用io/file.❷
io/copy现在接受一对字符串作为参数.❸ 我们可以验证文件是否被有效地创建.
io/do-copy的签名显示io/copy接受选项::buffer-size默认为 1024 字节, 当源参数是InputStream时可以使用.:encoding的用法与我们为reader和writer看到的相同选项类似, 强制使用特定的编码. 它默认为 "UTF-8".
当一个文件路径需要子文件夹, 但这些文件夹尚不存在时, 我们可以使用
make-parents来递归地创建所有文件夹.make-parents不会创建最后一个路径段, 将其视为文件名:(require '[clojure.java.io :as io]) (def segments ["/tmp" "a" "b" "file.txt"]) ; ❶ (apply io/make-parents segments) ; ❷ ;; true (io/copy (io/file "/tmp/words") (apply io/file segments)) ; ❸ ;; nil (count (line-seq (io/reader (io/file "/tmp/words")))) ; ❹ ;; 235886 (count (line-seq (io/reader (apply io/file segments)))) ;; 235886
❶ 我们不是用一个包含路径的单一字符串, 而是用片段来组装路径.
❷
make-parents创建任何不存在的文件夹, 但不会试图将 "file.txt" 解释为一个文件夹, 而是将其视为文件名.❸ 相同的文件名片段可以与
io/file一起使用, 将内容复制到新文件夹.❹ 我们可以通过比较源和目的地的行数来检查内容是否被正确复制.
我们可以使用
delete-file来删除文件. 支持的类型与io/file相同. 如果我们想防止delete-file在出错时抛出异常, 我们可以额外传递第二个参数:(require '[clojure.java.io :as io]) (io/delete-file "/does/not/exist") ; ❶ ;; IOException Couldn't delete /does/not/exist (io/delete-file "/does/not/exist" :ignore) ; ❷ ;; :ignore (io/delete-file "/tmp/a/b/file.txt" "This file should exist") ; ❸ ;; true
❶ 当我们试图删除一个不存在的文件时,
delete-file会抛出异常.❷ 我们可以通过传递第二个参数来防止在文件不存在的情况下抛出异常, 该参数会返回以表示操作未成功.
❸ 这个文件是之前创建的, 应该存在于文件系统上.
delete-file正确地返回 true.as-relative-path从资源对象 (如文件, URI, URL) 中检索路径. 这对于将文件对象转换为路径字符串以进行进一步处理特别有用:(require '[clojure.java.io :as io]) (def folders ["root/a/1" "root/a/2" "root/b/1" "root/c/1" "root/c/1/2"]) ; ❶ (map io/make-parents folders) ; ❷ ;; (true false true true true) (map io/as-relative-path (file-seq (io/file "root"))) ; ❸ ;; ("root" "root/a" "root/c" "root/c/1" "root/b")
❶ 我们有一个作为字符串向量的嵌套文件夹组.
❷ 我们可以使用
make-parents来创建所有必需的文件夹. 注意文件夹不以 "/" 开头 (在 Unix 系统上, 这意味着它们不是绝对路径).❸ 在用
file-seq创建了 "root" 内所有文件的序列之后, 我们可以用as-relative-path提取它们的路径字符串.
4.9.9. 22.9 clojure.test
clojure.test 是一个包含在标准 Clojure 发行版中的测试框架. 它的工作原理是将特定的元数据附加到 var 对象上, 以将它们标记为测试函数. 这个机制与 clojure.core/test 采用的相同, 但 clojure.test 提供了许多额外的功能, 例如:
- 多个测试上下文的嵌套和组合.
- 用
is和are提供的富有表现力和可扩展的断言语言. - 可扩展的输出格式.
- 用于设置和拆除测试上下文的 "Fixtures" 函数.
一个好的测试套件的设计, 包括如何结构化, 实现和构建测试, 超出了本书的范围. 然而, 本节将对可用的函数和扩展点提供一个很好的概述.
- 创建测试
clojure.test提供了几种创建测试的方法. 为了创建一些现实的测试例子, 我们将使用以下函数, 用牛顿法来求一个数的平方根:(defn sqrt [x] ; ❶ (when-not (neg? x) (loop [guess 1.] (if (> (Math/abs (- (* guess guess) x)) 1e-8) (recur (/ (+ (/ x guess) guess) 2.)) guess))))
❶
sqrt函数计算数 "x" 的平方根的近似值, 精确到第 8 位小数. 本节的其余部分使用这个函数作为一个简单的测试目标.clojure.test是少数几个习惯用法中:refer :all的一个.clojure.test提供了一个 "流式接口" 260, 使用限定的符号会破坏单元测试的可读性.定义测试最常见的方法是
deftest:(require '[clojure.test :refer [deftest]]) ; ❶ (deftest sqrt-test (assert (= 2 (sqrt 4)) "Expecting 2")) ; ❷ (:test (meta #'sqrt-test)) ; ❸ ;; #object[user$fn__1826 0xeb0db1f "user$fn__1826@eb0db1f"] (test #'sqrt-test) ; ❹ ;; AssertionError Assert failed: Expecting 2 ;; (= 2 (sqrt 4))
❶ 虽然习惯上是
:refer :all整个clojure.test命名空间, 但我们只限制在特定例子中需要的内容, 以避免任何可能的混淆.❷
deftest在当前命名空间中创建一个新函数sqrt-test.❸ 然后它将一个元键
:test添加到 var 对象sqrt-test中, 使用函数的主体作为值.❹ 我们可以使用
clojure.core/test来验证测试是否按预期运行.clojure.test提供了比assert更好的断言原语来设置期望. 我们稍后将在本节中看到它们.deftest是一个在当前命名空间中生成新函数的宏, 正如相关的宏展开所示:(macroexpand '(deftest sqrt-test)) ; ❶ ;; (def sqrt-test ;; (clojure.core/fn [] ;; (clojure.test/test-var (var sqrt-test))))
❶
deftest用def产生一个 var 定义, 其中包含一个函数.如果我们不希望这个函数是公共的, 我们可以使用
deftest-:(require '[clojure.test :refer [deftest-]]) (deftest- this-is-not-public) ; ❶ (keys (ns-publics *ns*)) ; ❷ ;; (clojuredocs help find-name sqrt sqrt-test ;; cdoc cjio apropos-better)
❶ 我们可以使用
deftest-来创建私有的测试函数. 这些在测试运行期间正常执行.❷ 命名空间中的公共 var 定义不包含该测试函数, 证实了它是私有的. 请注意: 本例中的结果列表在不同的 REPL 会话中运行时可能会有所不同.
deftest的一个轻微变体是with-test.with-test同时创建目标函数和测试定义, 不需要创建辅助函数来持有测试实现:(require '[clojure.test :refer [with-test]]) (with-test ; ❶ (defn sum [a b] (+ a b)) (println "test called")) (test #'sum) ; ❷ ;; test called ;; :ok ; ❸
❶
with-test是创建测试的最简单的宏, 除了手动设置元数据.❷ 我们对目标函数本身调用
clojure.core/test, 而不是像deftest那样在生成的测试函数上调用.❸ 这里打印的 ":ok" 是
test的返回值, 假设没有异常意味着测试是成功的. - 断言语言
clojure.test提供了比基本的assert更好的验证期望的方式. 例如,is验证给定的表达式是真值的, 并产生一个漂亮的测试结果摘要:(require '[clojure.test :refer [is deftest test-var]]) (deftest sqrt-test (is (= 2 (sqrt 4)) "Expecting 2")) ; ❶ (test-var #'sqrt-test) ; ❷ ;; FAIL in () (form-init796879.clj:1) ; ❸ ;; Expecting 2 ;; expected: (= 2 (sqrt 4)) ;; actual: (not (= 2 2.000000000000002))
❶ 与前面使用
deftest的例子相比, 我们用is替换了assert.❷ 我们开始使用
test-var而不是clojure.core/test. 没有太大的区别, 但test-var移除了clojure.core/test产生的令人困惑的:ok.❸
is与clojure.test的报告系统交互, 并在屏幕上产生更好看的结果.感谢
is打印的摘要, 我们终于可以看到测试失败的原因了. 到目前为止, 没有一个assert变体打印了失败的原因.is还接受一个可选的字符串, 以更好地描述测试的内容.为了使测试结果更具描述性, 我们可以使用
testing来丰富和分组测试:(require '[clojure.test :refer [is deftest testing test-var]]) (deftest sqrt-test (testing "The basics of squaring a number" ; ❶ (is (= 3 (sqrt 9)))) (testing "Known corner cases" (is (= 0 (sqrt 0))) (is (= Double/NaN (sqrt Double/NaN))))) (test-var #'sqrt-test) ; ❷ ;; FAIL in () (form-init796879.clj:3) ;; The basics of squaring a number ;; expected: (= 3 (sqrt 9)) ;; actual: (not (= 3 3.000000001396984)) ;; ;; FAIL in () (form-init796879.clj:5) ;; Known corner cases ;; expected: (= 0 (sqrt 0)) ;; actual: (not (= 0 6.103515625E-5)) ;; ;; FAIL in () (form-init796879.clj:6) ;; Known corner cases ;; expected: (= Double/NaN (sqrt Double/NaN)) ;; actual: (not (= NaN 1.0))
❶ 我们使用
testing来将相关的测试组组合在一起. 这具有视觉上分组测试的效果, 提高了可读性, 并且在测试的输出中也作为描述出现.❷ 看起来我们需要做相当多的工作来使
sqrt函数更健壮.在前面的例子中, 我们开始堆叠一组类似的测试, 所有测试都用不同的值重复相同的操作.
are建立在is的基础上, 提供了一种将许多类似的断言批量组合在一起的方法:(require '[clojure.test :refer [are deftest test-var]]) (deftest sqrt-test (are [x y] (= (sqrt x) y) ; ❶ 9 3 0 0 Double/NaN Double/NaN)) (test-var #'sqrt-test) ; ❷ ;; FAIL in () (form-init7968799.clj:2) ;; expected: (= (sqrt 9) 3) ;; actual: (not (= 3.000000001396984 3)) ;; ;; FAIL in () (form-init7968799.clj:2) ;; expected: (= (sqrt 0) 0) ;; actual: (not (= 6.103515625E-5 0)) ;; ;; FAIL in () (form-init7968799.clj:2) ;; expected: (= (sqrt Double/NaN) Double/NaN) ;; actual: (not (= 1.0 NaN))
❶
are需要 3 个声明: 第一个是将使用的变量 (在我们的例子中是 "x" 和 "y"). 第二部分是一个关联 "x" 和 "y" 的模板表达式. 在我们的例子中, 我们想看看第一个数的平方是否等于第二个. 最后, 是一个用于模板的 "x","y" 值列表.❷ 最终结果类似于多次执行
is, 每次对一对值执行一次.在
is和are中使用相等性作为谓词是很常见的, 但有些测试难以用相等性来表达, 例如一个函数是否应该在给定一些输入时抛出异常.clojure.test提供了一组扩展的谓词,thrown?,thrown-with-msg?和instance?, 用于不同于相等性的情况:(require '[clojure.test :refer [is deftest] :as t]) (deftest sqrt-test (is (thrown? IllegalArgumentException (sqrt -4))) ; ❶ (is (thrown-with-msg? IllegalArgumentException #"negative" (sqrt -4))) ; ❷ (is (instance? Double (sqrt nil)))) ; ❸ (binding [t/*stack-trace-depth* 3] ; ❹ (t/test-var #'sqrt-test)) ; ❺ ;; FAIL in () (form-init7968799.clj:2) ;; expected: (thrown? IllegalArgumentException (sqrt -4)) ;; actual: nil ;; ;; FAIL in () (form-init7968799.clj:3) ;; expected: (thrown-with-msg? IllegalArgumentException #"negative" (sqrt -4)) ;; actual: nil ;; ;; ERROR in () (Numbers.java:1013) ;; expected: (instance? Double (sqrt nil)) ;; actual: java.lang.NullPointerException: null ;; at clojure.lang.Numbers.ops (Numbers.java:1013) ;; clojure.lang.Numbers.isNeg (Numbers.java:100) ;; user$sqrt.invokeStatic (form-init7968.clj:2)
❶
thrown?验证目标函数是否抛出特定的异常.❷ 我们也可以使用
thrown-with-msg?来验证错误消息是否匹配特定的正则表达式.❸
instance?可以验证表达式是否返回特定的类型.❹
t/*stack-trace-depth*是clojure.test中可用的一个动态变量, 可用于配置在测试期间出现异常时显示多少项. 在这里, 我们只需要前 3 项.❺ 所有测试都失败了. 前两个测试失败是因为在传递负数时没有抛出异常. 最后一个测试迫使
sqrt在不应该抛出异常时抛出异常: 我们希望(sqrt 0)返回 0.0. - 创建自定义谓词
clojure.test提供了通过assert-exprdefmethod来扩展默认谓词集的方法. 例如, 我们可以添加一个roughly谓词, 它测试与某个容差的相等性 (默认为 2 位小数). 新的谓词还说明了通过do-report使用报告功能.do-report要求存在一组特定的键来表示成功, 期望值和实际值:(require '[clojure.test :refer [is deftest] :as t]) (defmethod t/assert-expr 'roughly [msg form] ; ❶ `(let [op1# ~(nth form 1) ; ❷ op2# ~(nth form 2) tolerance# (if (= 4 ~(count form)) ~(last form) 2) decimals# (/ 1. (Math/pow 10 tolerance#)) result# (< (Math/abs (- op1# op2#)) decimals#)] (t/do-report ; ❸ {:type (if result# :pass :fail) :message ~msg :expected (format "%s should be roughly %s with %s tolerance" op1# op2# decimals#) :actual result#}) result#)) (deftest sqrt-test ; ❹ (is (roughly 2 (sqrt 4) 14)) (is (roughly 2 (sqrt 4) 15))) (t/test-var #'sqrt-test) ;; FAIL in (sqrt-test) (form-init205.clj:3) ;; expected: "2 should be roughly 2.000000000000002 with 1.0E-15 tolerance" ;; actual: false
❶
roughly遵循clojure.test中其他内置谓词的实现.defmethod返回一个语法引用的表达式, 因为谓词的处理发生在宏展开时.❷ "form" 是传递给
is的第一个参数, 它包含符号roughly作为第一项, 2 个操作数和一个可选的容差值.❸ 在计算结果之后, 我们会产生一个副作用, 进入报告系统, 返回测试是否通过以及我们希望显示的任何附加信息.
❹ 我们可以立即开始使用新的谓词. 我们现在可以断言, 当输入为 4 时,
sqrt返回 "大约" 2, 这在最多 14 位小数的精度下通过了测试. 如果我们要求精确到第 15 位小数, 我们会得到一个错误, 因为结果不完全是 2. - 运行测试
现在我们已经看到了如何创建和增加我们测试的表现力, 是时候看看如何运行它们的选项了. 到目前为止我们使用的最基本的是
test-var.test-var接受一个 var 对象, 并执行在 var 元数据中的:test键中找到的函数, 如果有的话.test-vars(复数) 非常相似, 接受多个 var 对象进行测试. 但最常见的情况是在一个特定的命名空间中声明所有的测试函数 (和相关的 var 对象). 为了评估一个命名空间中的所有测试, 我们有几个选项, 例如test-all-vars:(ns my-tests) ; ❶ (require '[clojure.test :refer [is deftest] :as t]) (deftest a (is (= 1 (+ 2 2)))) (deftest b (is (= 2 (+ 2 2)))) (deftest c (is (= 4 (+ 2 2)))) (ns user) ; ❷ (require '[clojure.test :refer [test-all-vars]]) (test-all-vars 'my-tests) ;; FAIL in (a) (form-init205934.clj:1) ;; expected: (= 1 (+ 2 2)) ;; actual: (not (= 1 4)) ;; ;; FAIL in (b) (form-init20593408.clj:1) ;; expected: (= 2 (+ 2 2)) ;; actual: (not (= 2 4))
❶ 该示例在定义新测试之前切换当前命名空间到
my-tests.❷ 当我们回到
user命名空间时, 我们可以使用test-all-vars运行my-tests中的所有测试.test-ns与调用test-all-vars几乎相同, 只是它还遵守 "测试钩子" 并额外打印一个摘要.deftest调用可以随意嵌套, 或稍后通过将它们分组在一个特殊的函数test-ns-hook中来组合. 如果在目标命名空间中找到test-ns-hook,test-ns会执行该钩子, 而不是命名空间中的所有 var:(ns composable-tests) (require '[clojure.test :refer [is deftest]]) (deftest fail-a (is (= 1 (+ 2 2)))) ; ❶ (deftest fail-b (is (= 1 (+ 2 2)))) (deftest fail-c (is (= 1 (+ 2 2)))) (defn test-ns-hook [] (fail-a) (fail-c)) ; ❷ (ns user) (require '[clojure.test :refer [test-ns]]) (test-ns 'composable-tests) ; ❸ ;; FAIL in (fail-a) (form-init2059340.clj:1) ;; expected: (= 1 (+ 2 2)) ;; actual: (not (= 1 4)) ;; ;; FAIL in (fail-c) (form-init2059340.clj:1) ;; expected: (= 1 (+ 2 2)) ;; actual: (not (= 1 4)) ;; {:test 2, :pass 0, :fail 2, :error 0}
❶
composable-tests命名空间定义了 3 个失败的测试.❷ 我们还添加了一个
test-ns-hook函数, 它调用了一部分失败的测试, 跳过了 "fail-b".❸ 回到
user命名空间, 我们使用test-ns看到test-b没有执行, 这表明test-ns使用了test-ns-hook.继续看测试运行器, 与
test-ns相比,run-tests在运行结束时会添加一个摘要. 如果没有给出参数,run-tests也默认运行当前的命名空间:(ns running-tests) (require '[clojure.test :refer [is deftest run-tests]]) (deftest a (is (= 4 (+ 2 2)))) (deftest b (is (= 4 (+ 2 2)))) (deftest c (is (= 4 (+ 2 2)))) (run-tests) ;; Testing running-tests ;; ;; Ran 3 tests containing 3 assertions. ;; 0 failures, 0 errors. ;; {:test 3, :pass 3, :fail 0, :error 0, :type :summary}
到目前为止, 我们已经看到了如何在一个命名空间中运行测试, 但通过
run-all-tests, 我们可以在任何已加载的命名空间中运行所有测试. 它还接受一个正则表达式来过滤命名空间的子集:(ns a-new-test) ; ❶ (require '[clojure.test :refer [is deftest]]) (deftest a-1 (is (= 4 (+ 2 2)))) (deftest a-2 (is (= 4 (+ 2 2)))) (ns b-new-test) (require '[clojure.test :refer [is deftest]]) (deftest b-1 (is (= 4 (+ 2 2)))) (deftest b-2 (is (= 4 (+ 2 2)))) (ns user) (require '[clojure.test :refer [run-all-tests]]) (run-all-tests #".*new.*") ; ❷ ;; Testing b-new-test ;; ;; Testing a-new-test ;; ;; Ran 4 tests containing 4 assertions. ;; 0 failures, 0 errors. ;; {:test 4, :pass 4, :fail 0, :error 0, :type :summary}
❶ 创建了两个命名空间, 它们的名称中都包含 "new" 单词. 它们包含一些简单的说明性测试.
❷
run-all-tests运行所有已加载命名空间中的所有测试. 如果我们传递可选的正则表达式参数,run-all-tests只运行匹配的命名空间. - Fixtures
clojure.test也支持 fixtures. 编写有效单元测试的一个好的指导原则是, 它们应该是孤立的和可重复的. 不幸的是, 代码的某些部分不能完全没有副作用. Fixtures 可以帮助重新创建测试可靠运行所需的先决条件. 一个常见的情况是磁盘上特定文件的存在, 或数据库中的一个表, 执行测试需要向其写入结果. 一旦定义, fixture 可以在测试之前或之后应用.clojure.test还提供了在每个测试执行时运行 fixture 的选项, 或在测试命名空间中只运行一次.如果定义了
test-ns-hook, fixtures 永远不会运行. 参见下面关于test-ns-hook的用法.要在命名空间中注册 fixtures 以供执行, 我们可以使用
use-fixtures:(ns fixture-test-1 (:require [clojure.test :refer :all])) (defn setup [tests] ; ❶ (println "### before") (tests) (println "### after")) (use-fixtures :each setup) ; ❷ (deftest a-test (is (= 1 1))) (deftest b-test (is (= 1 1))) (run-tests) ; ❸ ;; Testing fixture-test-1 ;; ### before ;; ### after ;; ### before ;; ### after ;; ;; Ran 2 tests containing 2 assertions. ;; 0 failures, 0 errors. ;; {:test 2, :pass 2, :fail 0, :error 0, :type :summary}
❶ 一个 fixture 是一个接受一个参数的函数. 该参数是一个单一的测试或其组合. 调用该参数会执行测试 (或多个测试). 在测试执行之前, 我们可以设置一个数据库, 文件或其他资源. 类似地, 我们可以在运行测试后重新建立任何先前存在的条件.
❷
use-fixtures用:each或:once语义注册一个新的 fixture. 在这种情况下, 我们期望 fixture 为每个声明的测试运行一次, 所以我们使用:each.❸ 打印输出证实了 fixture 函数为每个测试运行了一次.
4.9.10. 22.10 clojure.java.javadoc
Clojure 程序员在 Java 文档中查找方法或类是很常见的. 文档的主要来源之一是 "Javadoc", 这是一种在 Java 源代码中创建文档的特定标记 261. javadoc 命令生成文档化类的 HTML 渲染, 结构化为文件夹和子文件夹. 它还生成一个 "index.html", 可以用浏览器打开以供离线或在线查看.
clojure.java.javadoc 为 Clojure 开发者提供了一种组织 Javadoc 离线和在线位置的方法. 它还与系统浏览器接口, 以直接从 REPL 打开 Javadoc. 例如, 要打开 String 类的文档, 我们可以使用 clojure.java.javadoc/javadoc:
(require '[clojure.java.javadoc :as browse]) ; ❶ (browse/javadoc "this is a string object") ; ❷ ;; true (browse/javadoc #("this fn class is not documented")) ; ❸
❶ 在使用 javadoc 之前, 需要先 require clojure.java.javadoc 命名空间.
❷ 我们可以在对象和类上调用 javadoc. 例如, 这个对 javadoc 的调用会在 Java 中打开系统浏览器, 显示 String 类的 Javadoc.
❸ 当给定的类没有生成的 Javadoc 时 (一个 Clojure lambda 函数动态生成一个相应的类, 该类不可能有相应的文档), javadoc 会打开一个通用的 Google 搜索.
下图显示了 String 类的 Javadoc 是什么样的:
Figure 46: Figure 22.3. Javadoc 打开 String 类的文档.
不幸的是, javadoc 默认打开的是现在非常旧的文档. javadoc 知道 Java 6 (如果当前使用) 或 7 (对于任何其他版本). 这意味着即使当前的 REPL 运行在 JDK 14 (或更高版本) 上, javadoc 也会无论如何都打开 JDK 7 的文档. 然而, javadoc 依赖于一些动态变量来传递不同的文档版本. 无需直接访问它们, 我们可以使用 add-remote-javadoc 来添加它们. 以下脚本检查当前的 Java 版本, 并有根据地猜测从 Oracle 网站搜索相应的 Javadoc:
(require '[clojure.java.javadoc :as browse]) (defn java-version [] ; ❶ (let [jsv (System/getProperty "java.specification.version")] (if-let [single-digit (last (re-find #"^\d\.(\d+).*" jsv))] single-digit jsv))) (def jdocs-template ; ❷ (format "https://docs.oracle.com/javase/%s/docs/api/" (java-version))) (def known-prefix ; ❸ ["java." "javax." "org.ietf.jgss." "org.omg." "org.w3c.dom." "org.xml.sax."]) (doseq [prefix known-prefix] ; ❹ (browse/add-remote-javadoc prefix jdocs-template)) (clojure.pprint/pprint @browse/*remote-javadocs*) ; ❺ ;; {"java." "https://docs.oracle.com/javase/8/docs/api/", ;; "javax." "https://docs.oracle.com/javase/8/docs/api/", ;; "org.apache.commons.codec." ;; "http://commons.apache.org/codec/api-release/", ;; "org.apache.commons.io." ;; "http://commons.apache.org/io/api-release/", ;; "org.apache.commons.lang." ;; "http://commons.apache.org/lang/api-release/", ;; "org.ietf.jgss." "https://docs.oracle.com/javase/8/docs/api/", ;; "org.omg." "https://docs.oracle.com/javase/8/docs/api/", ;; "org.w3c.dom." "https://docs.oracle.com/javase/8/docs/api/", ;; "org.xml.sax." "https://docs.oracle.com/javase/8/docs/api/"}
❶ 为了处理从双位数到单位数的更改, java-version 检查从 java.specification.version 属性报告的 Java 版本, 并在其以数字后跟点号开始的情况下提取版本作为单位数. 例如, 如果报告的 Java 版本是 "1.8", java-version 只返回 "8".
❷ Java Oracle 发布的 JDK 文档对所有版本都遵循相同的格式, 所以我们只需将 URL 调整到正确的版本.
❸ javadoc 使用目标类的包名来查找文档的 URL 列表. 我们将用新的 Javadoc URL 更新一些默认的前缀, 这些前缀在 known-prefix 定义中列出.
❹ 我们使用 doseq 和 add-remote-javadoc 重复更新前缀和 URL.
❺ 在打印 browse/remote-javadoc (负责在命名空间中存储它们的动态变量) 后, 当前的已知远程位置列表是可见的.
运行上面的例子后, javadoc 应该能够打开与当前 Java 版本相关的文档. 如果例子对你的 Java 版本不起作用, 可能是 Oracle 网站已经更改了 Javadoc 的位置. 要解决这个问题, 你需要更新 jdocs-template 以指向不同的 URL.
注意: clojure.java.javadoc 的一些设置也可用作动态变量. 更多信息请查看动态变量章节.
4.10. 23 标准库中的动态变量
本章描述了 Clojure 标准库中可用的动态变量. 其中一些已经在本书中出现过, 但其他的仍然值得更详细的解释, 这是本章的主题. 动态变量的主要用途之一是作为跨调用栈的通信渠道: 例如, 通过将一个函数调用包装在一个绑定形式中, 所有后续的调用都将能够读取和使用动态值. Clojure 本身广泛地使用动态变量来暴露不同功能的配置选项: 读取器, 编译器, 打印系统等等. 一些动态变量被分组到一个单独的部分, 当它们密切相关或是同一子系统的一部分时.
4.10.1. 23.1 *1, *2, *3 和 *e
动态变量的名称按惯例用一对星号 (俗称 "earmuffs") 包围, 但 *1, *2, *3 和 *e 是个例外. 一个可能的原因是, 它们旨在是只读的, 并且仅供 Clojure REPL 内部使用:
*1存储前一次评估的结果, 如果可用.*2存储*1之前的评估结果.*3存储*2之前的评估结果.*e如果前一次评估导致错误, 则存储异常对象.
例如, 让我们看看下面的 REPL 会话:
user=> (+ 1 1) 2 user=> (+ 2 2) 4 user=> (+ 3 3) 6 user=> [*1 *2 *3] ; ❶ [6 4 2]
❶ 前 3 次评估的结果会自动存储在相应的动态变量中.
*1, *2 和 *3 实际上代表一个大小为 3 的栈的索引, REPL 将所有评估都推入其中. 如果在评估一个任意复杂的形式期间出现错误, 我们可以随时使用 *e 访问异常的内容:
user=> (+ 1 (/ 1 0)) Execution error (ArithmeticException) at user/eval8 (REPL:1). Divide by zero user=> *e ; ❶ #error { :cause "Divide by zero" :via [{:type java.lang.ArithmeticException :message "Divide by zero" :at [clojure.lang.Numbers divide "Numbers.java" 188]}] :trace [...]
❶ 动态变量 *e 会自动绑定到最后一个未捕获的异常对象, 以供进一步检查.
4.10.2. 23.2 in, out 和 err
这些动态变量由 Clojure 自动绑定到代表 的对象. 这些对象也分别绑定到 System/in, System/out 和 System/err, 它们是标准流的等效 Java 引用. 例如, 在启动 REPL 会话后, *in* 被绑定到 clojure.lang.LineNumberingPushbackReader 的一个实例, 这是从控制台读取形式时默认使用的 Clojure 类:
user=> *in* ; ❶ #object["clojure.lang.LineNumberingPushbackReader@1549bba7"] user=> (read *in*) hello ; ❷ hello ; ❸ user=>
❶ 我们可以看到 *in* 被绑定到一个读取器实例.
❷ 我们在 REPL 中输入 "hello" 并按回车.
❸ Clojure 使用读取器实例来读取在控制台输入的内容, 直到 EOF (行尾, 通常是 `\n` "换行" 字符).
类似地, 我们可以写入标准输出 *out*, 它在 REPL 中被绑定到控制台:
user=> *out* ; ❶ #object["java.io.OutputStreamWriter@36dfbdaf"] user=> (.write *out* "hello\n") ; ❷ hello ; ❸ nil ; ❹ user=>
❶ 如果我们打印 *out* 的内容, 我们可以看到它被绑定到一个 java.io.OutputStreamWriter 的实例 (或 java.io.PrintWriter, 取决于 REPL 的实现).
❷ 我们可以在输出流上调用 .write, 将字符串 "hello" 和一个换行符发送出去.
❸ 控制台打印我们的消息.
❹ nil 是评估只产生副作用的形式的结果, 该形式写入到标准输出.
错误流传统上是与正在运行的进程的输出独立的流. 通过将它们分开, 我们可以将错误和诊断消息与主输出分开 262. 在 REPL 中, 我们可以通过将错误流重定向到输出流来看到错误流:
(.write *err* "error!\n") ; ❶ nil user=> user=> (binding [*err* *out*] (.write *err* "error!\n")) ; ❷ error! nil user=>
❶ 如果我们尝试写入 *err*, 我们不会立即在屏幕上看到任何东西. 消息实际上被发送到了独立的错误流, 该流没有连接到控制台的标准输出.
❷ 我们可以使用 binding 将 *err* 重定向到 *out*, 并看到错误消息.
我们在本书的许多例子中都使用了 binding 来设置输入/输出流. 更多信息, 邀请读者回顾以下内容:
- 在
defmacro backoff!函数中, 标准输出被重定向到标准错误, 其效果是形式中任何对println的使用都将打印到标准错误而不是标准输出. - 在
identical?中, 例子展示了如何创建一个执行线程, 确保标准输出被重定向到父线程, 这样就不会丢失任何消息. - 在
sortsave-chunk!函数中, 标准输出被绑定到一个文件写入器, 所以形式中任何对pr的使用都被重定向到一个文件.
out 的一个有趣用途是将标准输出捕获到一个字符串中以供以后检查 (当然, 同样的概念也适用于 err). with-out-str 是一个宏, 它将标准输出的绑定建立到一个 java.io.StringWriter 上, 这样它就可以被捕获为一个字符串:
(def captured-string (with-out-str ; ❶ (println "This is not going to standard output"))) captured-string ;; "This is not going to standard output\n"
❶ with-out-str 重定向了通常会打印到标准输出的函数和宏的输出. 捕获的字符串可以被使用或再次打印.
4.10.3. 23.3 agent
*agent* 动态变量会自动绑定到当前 agent 实例, 在发送给 agent 本身的函数闭包内部:
(println "Is there an *agent*?" *agent*) ;; Is there an *agent*? nil ; ❶ (send (agent 10) (fn [value] (Thread/sleep 1000) ; ❷ (println "Is there an *agent*?" (deref *agent*)))) ;; #object[clojure.lang.Agent 0x1ff5d0e {:status :ready, :val 10}] ;; Is there an *agent*? 10 ; ❸
❶ *agent* 动态变量始终可用, 但除非作为 agent 闭包的一部分使用, 否则不会被绑定.
❷ 这将暂停发送给 agent 的闭包函数 1 秒钟, 以便评估表达式的输出和打印的文本不会在控制台中混淆.
❸ 当我们在 agent 闭包内部访问 *agent* 时, 我们可以看到它自动绑定到 agent 实例本身.
*agent* 动态变量可以用来递归地调用 agent 实例, 正如在 agent 的相应例子中所演示的那样. 邀请读者访问该部分以了解更多信息.
4.10.4. 23.4 assert
*assert* 是一个控制 assert 宏行为的动态变量. 在标准的 Clojure 编译期间, *assert* 被设置为 true, 这会将 assert 宏配置为在给定表达式为 false 时抛出 java.lang.AssertionError:
(assert (= 1 (+ 3 3))) ; ❶ ;; AssertionError Assert failed: (= 1 (+ 3 3))
❶ assert 的标准行为是在表达式的评估产生一个假值结果时停止计算并引发一个错误.
*assert* 控制 assert 宏的编译时行为, 所以到 Clojure 运行时, assert 已经被宏展开并以 *assert* 绑定为 true 的方式编译. 下面的例子说明了这一事实:
(binding [*assert* false] (assert (= 1 2))) ;; AssertionError Assert failed: (= 1 2) ; ❶ (binding [*assert* false] (eval '(assert (= 1 2)))) ;; nil ; ❷
❶ 在 binding 将 *assert* 设置为 false 的时候, assert 宏已经被以 *assert* 设置为 true 的方式展开, 所以它抛出了 AssertionError.
❷ 如果我们对相同的形式调用 eval, 我们会强制在 binding 产生预期效果的上下文中评估 assert, 并且不会抛出错误.
Clojure 没有提供启动 Clojure 并将 *assert* 设置为 false 的命令行选项, 但你在 AOT 编译期间有一定的控制权, 可用于关闭断言检查. 在下面的例子中, 我们将在文件系统上创建一个小的命名空间, 其中包含一个使用 assert 的函数, 并使用 compile 来生成该命名空间的编译版本:
;; export CLOJURE_JAR=~/.m2/repository/org/clojure/clojure/1.8.0/clojure-1.8.0.jar ;; java -cp ${CLOJURE_JAR}:$(pwd)/classes clojure.main ; ❶
;; user=> (require '[clojure.java.io :as io]) (def source-file (str *compile-path* "/assertion.clj")) (io/make-parents source-file) ; ❷ (spit source-file "(ns assertion) (defn select [n] ; ❸ (case (rem n 3) 0 :ok 1 :possible 2 :reject (assert false \"Should never happen\")))") (compile 'assertion) ; ❹ ;; assertion (assertion/select 5) ;; :reject (assertion/select -5) ; ❺ ;; AssertionError Assert failed: Should never happen
❶ 要运行这个例子, 你需要控制类路径, 所以我们将使用 java 命令直接从 Clojure 发行版 jar 启动 REPL. 请注意, "clojure-x.y.z.jar" 的位置在你的本地机器上可能不同. 如果你不知道它在哪里, 你也可以从 下载一个新的 Clojure 安装. 还要注意, 其他 shell 环境或操作系统可能需要不同的语法来运行该命令. 例如, 如果你在 Windows 上运行该示例, 类路径分隔符将变为 ";" 而不是 ":".
❷ 我们需要确保 "classes" 文件夹 (或任何绑定到 *compile-path* 的其他文件夹) 在文件系统上存在, 所以如果不存在, 我们将用 io/make-parents 创建一个.
❸ "assertion" 命名空间包含一个 select 函数, 该函数根据一个数被 3 整除的余数来允许/禁止特定的数, 假设参数 "n" 将总是一个正数.
❹ 我们现在可以编译命名空间进行测试.
❺ 仍然有一些情况没有被 select 函数捕获, 例如如果我们传递一个负数或小数, 我们仍然可以看到断言错误.
select 函数中的 case 语句应该涵盖所有可能的情况, 以匹配一个整数除以 3 的余数. 然而, 我们想格外小心, 并添加了一个 assert 子句来传达我们的假设. 事实证明这个假设是不正确的, 在修复了所有可能的问题之后, 我们现在准备好自信地发布我们的代码了. 以下是最后一个测试, 以验证一切都正常工作:
(spit source-file "(ns assertion) (defn select [n] (if (integer? n) ; ❶ (case (mod n 3) ; ❷ 0 :ok 1 :possible 2 :reject (assert false \"Should never happen\")) :reject))") (compile 'assertion) ; ❸ ;; assertion (assertion/select -5) ; ❹ ;; :possible (assertion/select 5.2) ;; :reject
❶ select 现在只适用于整数, 所以它会拒绝任何其他类型的数字.
❷ 然而, 它可以通过使用 mod 而不是 rem 来接受负数, 所以一个负数除以整数的余数仍然是正数.
❸ 在再次使用之前, 需要重新编译 assertion 命名空间.
❹ 结果证实了 bug 已被修复.
我们的程序现在准备好发布了, 我们不希望有检查断言的性能损失. 与其移除它们, 我们可以简单地使用 *assert* 来关闭它们:
(spit source-file "(ns assertion) ; ❶ (defn select [n] (assert false \"Never triggers\"))") (binding [*assert* false] ; ❷ (compile 'assertion)) ;; assertion (assertion/select -5) ; ❸ ;; nil
❶ 为了证明断言永远不会触发, 我们用一个 (assert false) 语句替换了 select 函数的主体, 该语句将总是失败, 除非断言被禁用.
❷ 在编译时, 我们将 *assert* 动态变量绑定为 false, 防止断言触发.
❸ 调用 select 现在返回 nil, 表明 assert 从未被评估.
幸运的是, 我们不需要像上面演示的那样手动执行预先编译. Clojure 构建工具, 如 <github.com/technomancy/leiningen/blob/master/sample.project.clj#L289-L290,Leiningen> 或 Clojure <clojure.org/guides/depsandcli#aotcompilation,Deps>, 支持从命令行进行 AOT 编译, 包括设置 *assert* 变量的选项. Java 也有一个类似的断言工具, 它也包括传递一个 JVM 标志来打开或关闭断言的选项 (默认是关闭的) 263.
4.10.5. 23.5 clojure-version 和 command-line-args
这两个动态变量旨在是只读的, 用于传达 Clojure 启动时的版本和命令行参数. 下面的例子显示了如何读取它们以打印其结果:
;; export CLOJURE_JAR=~/.m2/repository/org/clojure/clojure/1.8.0/clojure-1.8.0.jar ;; java -jar $CLOJURE_JAR -r Hello Clojure ; ❶
*command-line-args* ; ❷ ;; ("Hello" "Clojure") *clojure-version* ; ❸ ;; {:major 1, :minor 8, :incremental 0, :qualifier nil}
❶ 为了显示一个收集命令行参数信息的例子, 我们从基本的 Java 命令和合适的 Clojure 发行版 jar 的位置开始启动 Clojure REPL. 在这种情况下, 环境变量 CLOJURE_JAR 指向这样一个位置. 你可以看到 Clojure 是用 2 个命令行参数启动的: "Hello" 和 "Clojure".
❷ *command-line-args* 报告了传递给 Clojure 主类的命令行参数列表.
❸ 我们还可以访问 Clojure 版本, 它已经为编程用途分割成典型的 : 主版本号, 次版本号, 增量版本号 (也称为补丁/修复) 和限定符 (这可能是一个增量构建号, 但不是语义化版本约定的一部分).
4.10.6. 23.6 compile-files
*compile-files* 是一个动态变量, 指示 Clojure 编译正在进行中. compile 是标准库中唯一建立绑定并将 *compile-files* 设置为 true 的函数. 动态变量可用于在预先编译 (AOT) 期间启用 (或禁用) 评估, 例如防止代码的某些部分用错误的环境初始化. 一个典型的例子是需要在启动时初始化系统的某些部分:
(require '[clojure.java.io :as io]) (require '[clojure.string :as string]) (defonce hosts ; ❶ (with-open [r (io/reader "/etc/hosts")] (println "Loaded hosts") (->> r line-seq (map #(string/split % #"\t")) ; ❷ (filter (comp #{"127.0.0.1"} first)) ; ❸ (remove (comp #{"localhost"} last)) ; ❹ (map last) doall))) (defn allow? [domain] ; ❺ (not (some (partial re-find domain) hosts))) (allow? #"reddit") ; ❻ ;; false
❶ hosts 是一个旨在只初始化一次的变量, 查看本地的 "/etc/hosts" 文件. 注意: 在 Linux 和 Mac 上, 文件名为 "/etc/hosts". 在 Windows 上, 你应该使用 "c:\Windows\System32\Drivers\etc\hosts".
❷ 我们感兴趣的行是 "<ip-address><tab-char><domain-name>" 的形式.
❸ 在所有行中, 我们想要那些路由到 IP 地址 "127.0.0.1" 且位于第一位置的行. 这是一种常规的方法, 通过将某些域名指向本地机器上不存在的 Web 服务器, 而不是允许正常的 DNS 解析, 来阻止它们正确解析.
❹ 然而, 将 "127.0.0.1" 映射到 "localhost" 的条目是合法的, 所以我们不希望它出现在最终的列表中.
❺ allow? 使用 hosts 来验证是否有任何条目匹配给定的域.
❻ 我们可以看到在这台计算机上不允许访问 "reddit".
上面的例子只要我们不进行预先编译, 就能按预期工作. 如果我们编译它, 主机列表会使用本地计算机的 "etc/hosts" 文件进行初始化, 但我们希望它根据应用程序部署到的计算机而不同地初始化. 我们有几种方法来解决这个问题. 我们已经看到了一个基于 delay 的解决方案, 邀请读者阅读专门介绍该函数的部分. 使用 delay 肯定是一个有效的解决方案, 但它需要显式地解引用持有初始化数据的变量. 或者, 我们可以使用 *compile-files* 来有条件地只在不编译时初始化 hosts 变量:
(defmacro defruntime [sym & body] ; ❶ `(defonce ~sym (when-not *compile-files* ~@body))) (defruntime hosts ; ❷ (with-open [r (io/reader "/etc/hosts")] (println "Loaded hosts") (->> r line-seq (map #(string/split % #"\t")) (filter (comp #{"127.0.0.1"} first)) (remove (comp #{"localhost"} last)) (map last) doall)))
❶ defruntime 宏定义了一种新的定义变量的方式, 它只有在没有编译发生时才继续评估主体参数.
❷ 我们需要做的唯一更改是使用 defruntime 宏而不是之前的 defonce.
该示例显示了如何根据编译的存在来保护特定表达式的评估, 这类似于其他语言 (如 "C" 或 "C++") 中存在的条件编译特性. Common Lisp 也有类似的 (但扩展的功能) 宏 <www.lispworks.com/documentation/HyperSpec/Body/sevalw.htm#eval-when,eval-when>.
4.10.7. 23.7 compile-path
*compile-path* 用于向编译器传达在哪里写入编译后的文件. 它默认为 "classes", 即当前工作文件夹的一个子文件夹. Clojure 总是将所有形式编译为 Java 类 (这些类被加载并动态评估), 但默认情况下不将它们存储到磁盘. Clojure 通过 compile 或通过从命令行调用 clojure.lang.Compile 类的 main 方法来显式地将编译后的类写入磁盘. 在这两种情况下, 我们都可以请求将类写入特定的文件夹 (在 clojure.lang.Compile 的情况下, 我们还可以使用 "-Dclojure.compile.path" Java 属性).
以下是一个涉及自定义 *compile-path* 的编译示例. 为了使 compile 能够与自定义路径正常工作, 我们假设 "mypath" 是当前工作文件夹内的一个磁盘上的文件夹, 并且我们可以在启动 REPL 时控制 Java 类路径:
;; mkdir mypath ;; export CLOJURE_JAR=~/.m2/repository/org/clojure/clojure/1.8.0/clojure-1.8.0.jar ;; java -cp $CLOJURE_JAR:mypath clojure.main ; ❶
(spit "mypath/example.clj" "(ns example) (println \"example loaded\")") (binding [*compile-path* "mypath"] ; ❷ (compile 'example)) ;; example loaded ;; example
❶ 注意, 我们正在使用一个特定的类路径来启动 REPL, 该类路径包括 Clojure 发行版和文件夹 "mypath".
❷ 如果在编译后打开 "mypath" 文件夹, 你会看到所有相关的 Clojure 编译文件, 用于 "example" 命名空间.
compile 的工作假设是编译单元是一个 Clojure 库, 这是一种遵循 Java 打包标准的组织 Clojure 代码的特定约定. 然而, 我们可以绕过标准的 compile 调用, 将任何形式写入磁盘, 而不仅仅是库. 我们可以通过以下方式使用 *compile-files* 和 eval 来实现这一点:
(binding [*compile-files* true *compile-path* "."] (eval '(+ 1 1))) ; ❶ ;; 2
❶ 这个 eval 调用在当前工作文件夹 "." 中产生编译的类, 但任何其他存在的文件夹也可以.
要理解为什么我们需要 eval 一个形式才能看到它的编译输出, 请考虑当 REPL 启动时, 所有引用 *compile-files* 的函数和宏都已经被以 *compile-files* 设置为 false 的方式编译了. 通过调用 eval, 我们将强制 Clojure 以 *compile-files* 设置为 true 的方式重新评估相关的形式和宏: 例如, 形式 `(+ 1 1)` 首先被编译成 Java 字节码, 然后其内容被保存到磁盘, 最后它被评估以产生 "2".
4.10.8. 23.8 compiler-options
*compiler-options* 动态变量可用于更改 Clojure 编译的某些方面. 它目前支持 3 个选项:
:disable-locals-clearing是一个布尔值, 它阻止编译器在一些局部属性使用后立即将其设置为 "null". 这对于调试目的可能很有用, 但在生产应用程序中通常设置为 true.:elide-meta是一个元数据关键字的向量, 编译时编译器不应将其存储在发出的 Java 类中. 这是一种优化, 可以减少通用可执行文件的大小及其启动时间.:direct-linking是一个布尔选项, 当为 true 时, 它告诉编译器启用 "直接链接", 这是一个移除由于需要解引用 var 而引入的间接层的特性.
*compiler-options* 映射中的所有键也可以作为命令行参数用 `-D` 选项传递: 分别是 "-Dclojure.compiler.disable-locals-clearing=true", "-Dclojure.compiler.elide-meta=[:doc :file :line :added]" 和 "-Dclojure.compiler.direct-linking=true". 我们将在下面的例子中探讨这些选项.
- disable-locals-clearing
本书首次提到 "locals" 是在描述
fn*时, 这是唯一一个提供对局部变量清除控制的函数定义形式. 要理解disable-locals-clearing的工作原理, 我们将使用一个 Java 反编译器, 例如 www.javadecompilers.com/ 上可用的几个之一 (现代 IDE 如 IntelliJ 或 Eclipse 也带有 Java 反编译器). 在下面的例子中, 我们将一个 Clojure 形式编译成相应的 Java 类, 以便我们可以检查它们:(binding [*compile-files* true *compile-path* "."] (eval '(let [s "potentially-huge"] (^:once fn* [] s)))) ; ❶
❶
eval编译一个let块和一个简单的 lambda 函数, 该函数不接受任何参数并返回局部绑定 "s" 的值.运行上面的例子后, 你应该会在 REPL 启动的同一文件夹中看到 2 个文件: 一个代表
let块的评估, 另一个是由fn*创建的 lambda 函数. 它们的名称类似于 `user$eval29.class` 和 `user$eval29$fn_30.class` (其中数字可能会有所不同). 我们现在可以继续反编译这两个类:import clojure.lang.AFunction; public final class user$eval29 extends AFunction { public static Object invokeStatic() { String s = "potentially-huge"; String var10002 = s; s = null; ❶ return new user$eval29$fn__30(var10002); } public Object invoke() { return invokeStatic(); } }
import clojure.lang.AFunction; public final class user$eval29$fn__30 extends AFunction { Object s; public user$eval29$fn__30(Object var1) { this.s = var1; } public Object invoke() { Object var10000 = this.s; this.s = null; ❷ return var10000; } }
❶ 创建了两个局部字符串实例. 字符串 "s" 是
let块声明的一部分, 而 "var10002" 是由 Clojure 编译器添加的, 用于在将 "s" 设置为 "null" 之前复制 "s" 的内容.❷ 第二个类实现了
fn*函数, 并包含一个类型为 "Object" 的属性 "s" 的声明, 对应于函数闭包. 和以前一样, 这个对象一旦其值被本地复制, 就会被设置为 "null".反编译的类显示了两个局部变量清除的例子. 第一个例子是用户通过在
fn*上使用元数据^{:once true}显式请求的, 第二个与let块的实现有关.disable-locals-clearing对两者都适用:(binding [*compile-files* true *compile-path* "." *compiler-options* {:disable-locals-clearing true}] ; ❶ (eval '(let [s "potentially-huge"] (^:once fn* [] s))))
❶ 与前面相同的表达式现在在设置
*compiler-options*映射时评估, 并将:disable-locals-clearing键设置为 true.在为相同的表达式生成新类后, 我们可以看到在将
:disable-locals-clearing设置为 true 后, 局部变量清除已被禁用:import clojure.lang.AFunction; public final class user$eval43 extends AFunction { public user$eval43() { } public static Object invokeStatic() { Object s = "local"; ❶ return new user$eval43$fn__44(s); } public Object invoke() { return invokeStatic(); } }
import clojure.lang.AFunction; public final class user$eval43$fn__44 extends AFunction { Object s; public user$eval43$fn__44(Object var1) { this.s = var1; ❷ } public Object invoke() { return this.s; } }
❶ 关闭局部变量清除后, 没有局部变量被设置为 "null".
❷
disable-locals-clearing也影响了带有^{:once true}元数据的fn*函数, 该元数据明确要求清除局部变量.当类实例在一个池中被重用时, 局部变量清除优化具有重要的效果, 允许垃圾回收器在请求之间释放内存 (更多信息请参见
future). 然而, 由于 Clojure 默认将局部变量置为 null, 当试图调试该类时, 这个信息会丢失. 这是使用disable-locals-clearing的主要原因之一. - elide-meta
elide-meta包含一个元数据关键字的向量, 编译时编译器应从编译的 Clojure 代码中移除这些元数据. 标准的元数据信息, 如函数描述或行/列号, 是编译的 Clojure 代码的一部分, 对于调试或文档很有用. 其他元数据可能是应用程序的一部分, 用于驱动自定义功能. 一般来说, 元数据对可执行文件大小或启动时间的影响是微不足道的. 然而, 在某些情况下, 编译代码中存在较大的元数据是不可取的.elide-meta选项告诉编译器从编译输出中移除给定的元数据关键字向量. 要看到elide-meta的效果, 请考虑以下标准编译过程:;; export CLOJURE_JAR=~/.m2/repository/org/clojure/clojure/1.8.0/clojure-1.8.0.jar ;; java -cp ${CLOJURE_JAR}:. clojure.main ; ❶
(spit "./example.clj" "(ns example) (def ^{:t1 \"secret metadata\" :doc \"here's some useful info\"} foo 1)") (binding [*compile-path* "."] ; ❷ (compile 'example))
❶ 我们在这里重复了我们在其他例子中做过的事情. 我们需要确保 Clojure REPL 启动时将当前文件夹 "." 添加到 Java 类路径中, 这样我们在当前文件夹中写入的所有东西都可以立即用于编译.
❷ 调用
compile后, 在当前文件夹中会出现一些类文件, 都以 "example" 为前缀.在上面的例子中调用
compile后, Clojure 在当前文件夹中创建了几个文件. 其中一个名为 "example_init.class". 这个文件初始化命名空间, 创建 "foo" 变量及其元数据, 如:t1和:doc键所示. 如果我们用 Java 反编译器反编译该文件, 我们可以看到元数据, 例如 www.javadecompilers.com 上可用的几个之一:public class example__init { public static void load() { [...] } public static void __init0() { [...] const__11 = (AFn) RT.map(new Object[] { RT.keyword((String) null, "t1"), "secret metadata", ❶ RT.keyword((String) null, "doc"), "here's some useful info", RT.keyword((String) null, "line"), 2, RT.keyword((String) null, "column"), 4, RT.keyword((String) null, "file"), "example.clj"}); } [...] }
❶ foo 变量的元数据初始化在这里表现为创建一个带有相关键的新映射对象.
反编译器的输出已被大量删减, 只显示相关部分. 像 "secret metadata" 或 "here' s some useful info" 这样的元数据是相关 Java 类静态初始化的一部分. Clojure 提供了一种控制存储为元数据的信息的方式, 从而减小可执行文件的大小并可能加速生成的应用程序. 我们现在要求从生成的应用程序中的任何元数据实例中省略
:doc和:t1键:(binding [*compile-path* "." *compiler-options* {:elide-meta [:doc :t1]}] ; ❶ (compile 'example))
❶ 要防止一组特定的元数据键成为最终可执行文件的一部分, 我们使用
*compiler-options*中的:elide-meta.新反编译的 "example_init.class" 现在不包括
:doc或:t1元数据值. 其他元数据, 如 "line" 或 "column" 的指示仍然可用, 但如果请求, 也可以省略. 上面例子中生成的 Clojure 程序在可执行文件大小或执行速度方面不太可能有什么改进. 但elide-meta选项对于从最终可执行文件中移除较大或敏感的元数据仍然很有用.请注意, 从元数据中移除
:doc值会导致doc无法正常工作. 同样, 你应该注意不要移除对应用程序正常工作至关重要的元数据. - direct-linking
直接链接是 Clojure 1.8 中引入的一个相对较新的特性, 适用于 Clojure AOT 编译. 当
*compiler-options*中的:direct-linking键被设置为 true 时, 编译器会移除clojure.lang.Var的间接层来访问 Clojure 变量, 包括调用函数. 这种间接性是 Clojure 允许在运行时重新定义系统行为, 在系统运行时更改函数实现的原因. 当这个选项被激活时, Clojure 不会通过 var 对象的间接来传递, 而是直接将每个调用点链接到相应的调用. 这样做的好处是移除了生成类中的 var 对象声明, 可能会减小可执行文件的大小和提高速度.与本章中的其他部分类似, 我们需要反编译生成的 Clojure 代码才能看到直接链接的效果. 让我们首先用特定的绑定来 AOT 编译一个小例子:
(binding [*compile-files* true *compile-path* "." *compiler-options* {:direct-linking false}] ; ❶ (eval '(do (defn plus [a b] (+ a b)) (plus 1 2))))
❶ 首先, 我们确保
direct-linking被设置为 false, 以观察 Clojure 标准的动态行为.上面的
eval指令在磁盘上产生两个文件, 一个名为 `user$plus.class`, 包含plus函数的定义. 另一个文件将被通用地命名为 `user$eval25.class`, 每次重新编译时数字都会增加. 我们继续使用 www.javadecompilers.com 和默认的 Procyon 选项来反编译 `user$eval25.class`:import clojure.lang.RT; import clojure.lang.IFn; import clojure.lang.Var; import clojure.lang.AFunction; public final class user$eval30 extends AFunction { public static final Var const__0; public static final Object const__1; public static final Object const__2; static { const__0 = RT.var("user", "plus"); ❶ const__1 = 1L; const__2 = 2L; } public static Object invokeStatic() { return ((IFn)user$eval30.const__0.getRawRoot()) ❷ .invoke(user$eval30.const__1, user$eval30.const__2); } public Object invoke() { return invokeStatic(); } }
❶ 该类定义了一个类型为
clojure.lang.Var的属性const__0, 该属性被赋予了从已初始化 var 池中查找 "plus" 函数的结果. 这意味着存在一个该 var 持有引用的类 "user$plus.class".❷ 要使用 var 对象, 我们需要用 `getRawRoot()` 获取它指向的对象的引用. 这是允许 Clojure 在程序运行时交换 var 引用的对象, 而不中断正在运行的程序的间接方式. 在检索到被引用的对象后, Clojure 继续用数字 1 和 2 (类型为 "long") 调用它.
正如我们从上面的反编译类中看到的, Clojure 利用一个
clojure.lang.Var对象来持有执行 "plus" 函数所需代码的引用. 要调用该函数, 我们需要先解引用该 var. 这是允许 Clojure 在程序运行时交换 "plus" 函数的实现的关键成分之一. 然而, 这种灵活性是有代价的, 在大多数情况下是可以容忍的. 如果这种成本成为问题, 我们可以将调用点 "直接链接" 到 "plus" 函数, 而无需任何 var 间接:(binding [*compile-files* true *compile-path* "." *compiler-options* {:direct-linking true}] ; ❶ (eval '(do (defn plus [a b] (+ a b)) (plus 1 2))))
❶ 我们现在已经打开了直接链接.
我们现在可以继续反编译新生成的类, 在我们打开
:directing-linking之后:import clojure.lang.AFunction; // // Decompiled by Procyon v0.5.36 // public final class user$eval35 extends AFunction { public static final Object const__1; public static final Object const__2; public static Object invokeStatic() { return user$plus ❶ .invokeStatic(user$eval35.const__1, user$eval35.const__2); } public Object invoke() { return invokeStatic(); } static { const__1 = 1L; const__2 = 2L; } }
❶ 现在的结果是通过直接访问
user$plus类来计算的, 没有任何 var 对象间接.新生成的类不包含
clojure.lang.Var对象声明, 它不从可用 var 池中查找 Var 对象, 也不访问 var 对象的根来获取 "plus" 函数类的实例. 这个例子太小, 无法在类大小或执行速度方面提供有价值的改进, 但在正常的应用程序中, var 对象的数量和所需的间接性可能相当可观. 考虑打开直接链接选项可能是值得的, 特别是考虑到在运行的生产应用程序中动态交换实现通常是不必要的 (或可能是危险的).direct-linking永远不会作用于动态变量, 因为它们可能需要线程局部的重新定义. 如果你仍然希望用直接链接来编译你的应用程序, 但允许一些 var 对象在运行时重新定义, 你可以使用:redef元数据. 在这个简短的定义中 `(def ^:redef doesnotdirectlink 1)`, var "doesnotdirectlink" 将不受直接链接的影响, 即使编译器被要求这样做.
4.10.9. 23.9 file 和 source-path
*file* 由编译器设置为当前正在编译的文件的完整路径. 类似地, *source-path* 被设置为文件名. 让我们假设类路径上有以下文件 "examples/compilefile.clj":
(ns examples.compile-file) (when *compile-files* (println "Compilation full path:" *file*) ; ❶ (println "Compilation file name:" *source-path*)) ; ❷
❶ 一个简单的命名空间, 其中包含一个使用 *file* 动态变量的 println 语句.
❷ 第二个语句打印 *source-path* 动态变量的内容.
如果我们从一个包含其位置作为类路径一部分 (例如当前文件夹 ".") 的 REPL 中编译 "examples/compilefile.clj", 我们可以看到以下输出:
(binding [*compile-path* "."] (compile 'examples.compile-file)) ; ❶ ;; Compilation full path: examples/compile_file.clj ;; Compilation file name: compile_file.clj ;; examples.compile-file
❶ 在 "examples.compile-file" 符号上调用 compile, 会产生一条消息, 显示 *file* 和 *source-path* 动态变量的内容.
我们使用 *compile-files* 来验证表达式是否作为 Clojure 编译过程的一部分被评估. 如果是, 我们打印 *file* 和 *source-path* 的内容. 正如预期的那样, 它们包含完整路径和文件名本身. 当 *file* 或 *source-path* 未被绑定时, 它们被赋予字符串 "NOSOURCEPATH". 这发生在任何不是通过 compile 调用启动的编译中:
(println "Compiling" *file*) ; ❶ ;; Compiling NO_SOURCE_PATH
❶ 当这个表达式被评估时, 没有实际的文件被编译.
*file* 和 *source-path* 动态变量在 Clojure 编译器中被广泛用于在出现错误时报告哪个文件单元导致了问题 (以及其他重要数据, 如列/行号).
4.10.10. 23.10 use-context-classloader
截至此提交,
*use-context-classloader*的值始终被绑定为 true, 不论用户的偏好如何. 因此,*use-context-classloader*应被视为已废弃, 不应使用. 该功能的初始设计在 Clojure 邮件列表中进行了讨论. 最近的讨论也可以在这个 Jira 问题中看到. 本节的其余部分将简要介绍 Clojure 如何使用不同的类加载器.
类加载器是在 Java 中实现类隔离的一种机制. 有几种内置的类加载器: 引导, 扩展和应用程序类加载器都是标准 Java 开发工具包 264 的一部分. 其他类加载器可以由用户应用程序创建. Clojure 运行时在应用程序类加载器内加载, 该类加载器由 JVM 创建以运行 Clojure 可执行文件:
(defn get-classloader [f] ; ❶ (.. f getClass getClassLoader)) (get-classloader #'+) ;; #object["jdk.internal.loader.ClassLoaders$AppClassLoader@277050dc"] (get-classloader #'fn) ;; #object["jdk.internal.loader.ClassLoaders$AppClassLoader@277050dc"] ; ❷
❶ 每个 Java 类都在一个类加载器中加载. 要检索类加载器实例, 我们可以对一个 java.lang.Class 实例调用 getClassLoader.
❷ 我们可以看到, 当 Clojure jar 归档被加载到内存中时, 标准库中的函数是使用应用程序类加载器加载的 (Clojure 库的类以预编译状态出现). 请注意, 根据 JDK 的版本, 类类型可能会有所不同 (例如, 在 Java 8 上是 sun.misc.Launcher$AppClassLoader).
要创建一个新的类加载器, 你总是需要指定一个父类加载器. 最简单和标准的选择是使用应用程序类加载器作为父类加载器. 然而, 在某些情况下, 外部库或框架 (一个著名的例子是 OSGi 框架 265) 可能希望在父类加载器方面施加不同的选择, 例如, 在同一个 JVM 中控制多个应用程序. 传达这种偏好的一种常规方法是使用线程局部类加载器, 该类加载器可从 java.lang.Thread 类中获得:
(.. Thread currentThread getContextClassLoader) ;; #object["clojure.lang.DynamicClassLoader@53142455"] ; ❶
❶ 你可以通过在当前线程实例上调用 `getContextClassLoader()` 来访问和查看当前分配的线程局部类加载器.
如果外部库或框架使用线程局部来传达类加载器的选择, 那么 Clojure 默认已经在查看线程局部了. 当 Clojure 评估一个表达式时, 它会创建并执行一个新的 Java 类, 该类需要与一个特定的类加载器实例关联. 为了能够动态地重新定义代码, Clojure 在一个隔离的类加载器中评估每个新表达式, 这样该表达式的定义就可以很容易地被丢弃并用另一个替换, 如果需要的话:
(get-classloader (fn [])) ;; #object["clojure.lang.DynamicClassLoader@1ac85b0c"] (get-classloader (fn [])) ;; #object["clojure.lang.DynamicClassLoader@2ad3a1bb"] ; ❶
❶ 注意, 每次我们检索新生成表达式的类加载器时, clojure.lang.DynamicClassLoader 实例的编号都不同. 这意味着为实现该表达式而生成的类被分配了一个新的类加载器.
每个表达式的评估都会生成一个新的类, 该类在一个独立的类加载器实例中加载, 类型为 clojure.lang.DynamicClassLoader, 这是负责管理 Clojure 特定类加载器的 Clojure 类. 让我们也看一下父类加载器:
(.getParent (get-classloader (fn []))) ;; #object["clojure.lang.DynamicClassLoader@53142455"] (.getParent (get-classloader (fn []))) ;; #object["clojure.lang.DynamicClassLoader@53142455"] ; ❶ (identical? ; ❷ (.. Thread currentThread getContextClassLoader) (.getParent (get-classloader (fn [])))) ;; true
❶ 所有生成类的父类加载器都是同一个 "53142455" DynamicClassLoader 实例.
❷ 父类加载器与线程局部类加载器相同.
正如我们在上面的例子中看到的, 新生成的表达式共享同一个名为 "53142455" 的父类加载器. 注意, 它也与线程局部类加载器相同. 如前所述, Clojure 遵循使用线程局部中可用的类加载器来加载新类的规则. 问题在于我们是否希望 Clojure 忽略线程局部类加载器 (并例如使用应用程序类加载器). 这里我们展示一个关于如何更改线程局部类加载器的例子, 包括显示 *use-context-classloader* 没有效果:
(import '[clojure.lang DynamicClassLoader]) (def application-classloader ; ❶ (.. #'+ getClass getClassLoader)) (def context-classloader ; ❷ (.. Thread currentThread getContextClassLoader)) (def custom-classloader (DynamicClassLoader.)) (.setContextClassLoader (Thread/currentThread) custom-classloader) ; ❸ (identical? (.. (get-classloader (fn [])) getParent) custom-classloader) ; ❹ ;; true (binding [*use-context-classloader* false] ; ❺ (identical? (.. (class (fn [])) getClassLoader getParent) custom-classloader)) ;; true (import '[clojure.lang DynamicClassLoader]) (def custom-classloader (DynamicClassLoader.)) (.setContextClassLoader (Thread/currentThread) custom-classloader) (identical? (.. (fn []) getClass getClassLoader getParent) custom-classloader) ;; true (binding [*use-context-classloader* false] (identical? (.. (fn []) getClass getClassLoader getParent) custom-classloader)) ;; true
❶ application-classloader 存储了应用程序类加载器实例, 即用于加载标准库中所有函数的同一个实例.
❷ context-classloader 保存了当前的线程局部类加载器实例, 这样如果需要, 我们可以将其改回原来的.
❸ 要更改线程局部类加载器, 我们可以对当前线程对象调用 setContextClassLoader. 现在线程局部实例是我们的自定义类加载器.
❹ 新生成类的父类加载器现在是我们的自定义类加载器.
❺ 我们可以看到, 尝试阻止 Clojure 使用线程局部类加载器失败了.
目前, 没有办法强制 Clojure 忽略线程局部类加载器的内容, 也没有办法告诉 Clojure 一个特定的替代方案. 因此, *use-context-classloader* 动态变量应被视为已废弃, 不应使用.
4.10.11. 23.11 allow-unresolved-vars
在 Clojure 编译过程中, 所有符号都会被分析并可能解析为一个 var 实例. 当符号无法解析时, Clojure 会抛出异常:
(+ 1 a) ; ❶ ;; CompilerException java.lang.RuntimeException: Unable to resolve symbol: a in this context
❶ 一个熟悉的 Clojure 错误: 使用了一个符号但未声明, 产生了一个错误.
这种行为是预期的, 因为 Clojure 除非所有符号都得到解析, 否则无法生成有效的字节码. 然而, Clojure 可以继续读取或分析表达式, 而不尝试加载生成的字节码. 虽然对 Clojure 读取器的访问是公共 API 的一部分 (通过像 read-string 这样的函数), 但对分析器的访问只能通过 Java:
(import '[clojure.lang Compiler Compiler$C]) (Compiler/analyze Compiler$C/EVAL (read-string "(+ 1 a)")) ; ❶ ;; CompilerException java.lang.RuntimeException: Unable to resolve symbol: a in this context
❶ 对 Clojure 分析器的访问只能通过 Java 互操作性来实现. 我们可以重现我们之前看到的相同错误.
Clojure 读取器不尝试解析符号 "a" (读取器可以很容易地验证 read-string 是否成功完成). 分析器负责确保出现在表达式中的每个符号都可以被解析, 无论是通过查找命名空间注册表还是局部绑定. 在上面的例子中, 分析失败, 出现了与我们之前看到的相同的错误. 但我们可以使用 *allow-unresolved-vars* 来请求分析器接受未解析的变量:
(binding [*allow-unresolved-vars* true] ; ❶ (Compiler/analyze Compiler$C/EVAL (read-string "(+ 1 a)"))) ;; #object["clojure.lang.Compiler$StaticMethodExpr@5e63cad"]
❶ 通过将 *allow-unresolved-vars* 设置为 true, 分析器完成了分析并返回一个我们可以使用的表达式对象.
分析器通常产生以 "Expr" 结尾的类 (表示特定类型的表达式). 表达式类不是为公共消费而设计的: 它们是包保护的, 而不是公共的, 需要一些技巧才能访问. 例子中产生的 clojure.lang.Compiler$StaticMethodExpr 对象代表了分析根表达式 (以及所有子表达式, 如果有的话) 产生的解析树. 表达式对象包含生成字节码并继续评估表达式所需的所有信息. 然而, 在这个特定的情况下, 它包含一个无法解析的符号 "a".
延迟符号解析的一个原因是, 以某种其他方式提供它们, 例如, 在非 JVM 的某个其他后端上执行 Clojure 代码. 在这种情况下, 缺失的变量可以作为不同环境的一部分提供. 例如, 我们可以重用标准的 Clojure 读取器和分析器来发出 JavaScript 而不是 Java 字节码. 实际上, *allow-unresolved-vars* 存在的原因就来自最初的 ClojureScript 实现 266. 标准的分析器有一个优势, 即始终与最新的 Clojure 更改保持同步. 另一方面, 这种方法是脆弱的, 因为分析器从未被完全设计为在运行时之间共享, 并且在其实现中保留了许多 "Java-isms". 在其他后端上的现代 Clojure 实现使用了更健壮的方法, 如 Clojure Tools Analyzer, 这是一个专门为此场景提供接口的库.
4.10.12. 23.12 read-eval 和 suppress-read
Clojure 读取器如果使用特殊的字面量语法 #=, 可以直接评估表达式, 例如:
(read-string "(+ 1 (+ 1 1))") ;; (+ 1 (+ 1 1)) ; ❶ (read-string "(+ 1 #=(+ 1 1))") ;; (+ 1 2) ; ❷
❶ 该字符串代表了有效的 Clojure 代码. 当我们 read-string 它时, 它会产生相应的 Clojure 数据结构, 符号和数字形式.
❷ 在包装了内部表达式 #=(+ 1 1) 之后, 读取器立即继续评估被包围的表达式.
我们可以使用 *read-eval* 来防止立即评估, 例如:
(binding [*read-eval* false] ; ❶ (read-string "(+ 1 #=(+ 1 1))")) ;; RuntimeException EvalReader not allowed when *read-eval* is false
❶ 如果输入字符串包含读宏求值宏 #=, 使用 *read-eval* 会产生异常.
我们在介绍 read 时已经遇到过 *read-eval*. 邀请读者查看这些例子以获得对 *read-eval* 的扩展解释.
*suppress-read* 实际上是一个实现细节, 与读宏条件在遇到未为当前平台定义的形式时的行为有关, 允许读取过程立即跳过其余的形式. 尽管 *suppress-read* 是公共的, 但它不打算供公共使用.
4.10.13. 23.13 data-readers 和 default-data-reader-fn
这些动态变量在整本书中已经得到了详细的解释. 邀请读者回顾 default-data-readers 中关于 *data-readers* 的例子和解释, 以及 tagged-literal 中关于 *default-data-reader-fn* 的例子和解释.
4.10.14. 23.14 load-tests 和 stack-trace-depth
这些动态变量属于 clojure.test 命名空间. 本书在阐述 clojure.test 时已经提供了 *stack-trace-depth* 的例子, 所以这部分主要将集中在 *load-tests* 上.
*load-tests* 控制 clojure.test 在加载一个命名空间时是否应该生成测试函数, 这是一个可能有性能影响的操作. 这种功能在现代几乎从不需要, 因为像 Leiningen 或 clojure.tools.deps 这样的构建工具强制将测试与生产代码分开, 完全防止它们出现在生产代码中. 要理解在什么情况下可能需要 *load-tests*, 我们需要考虑一种将单元测试与要测试的函数一起定义的编写风格, 例如:
(ns math ; ❶ (:require [clojure.test :as t])) (defn sum [a b] (+ a b)) (t/deftest sum-test ; ❷ (t/is (= 2 (sum 1 1)))) (test #'sum-test) ; ❸ ;; :ok
❶ math 是一个包含数学函数的命名空间.
❷ deftest 是 clojure.test 中的一个宏, 它为 sum 定义一个测试. 该测试与目标函数本身位于同一个命名空间中.
❸ 我们可以使用 test 来为 sum 运行测试.
这种编写单元测试的风格有几个问题. 其中之一是命名空间变得不那么可读, 特别是如果每个函数都有许多测试. 另一个是即使在将 math 命名空间部署到生产环境时也会生成测试函数, 而此时并没有运行测试的意图. 假设我们用这种风格开发了我们应用程序的测试, 我们可以使用 *load-tests* 在 AOT 编译命名空间时阻止生成单元测试. math 命名空间将被写入一个名为 "math.clj" 的文件, 该文件可从类路径中获得. 正如我们之前在讨论 *compile-path* 时所做的那样, 我们将文件存储在磁盘上并用 compile 进行 AOT 编译. 为了使 compile 正常工作, 我们需要运行 Clojure, 确保它在其类路径中包含当前文件夹:
;; export CLOJURE_JAR=~/.m2/repository/org/clojure/clojure/1.8.0/clojure-1.8.0.jar ; ❶ ;; java -cp $CLOJURE_JAR:. clojure.main
(spit "math.clj" ; ❷ "(ns math (:require [clojure.test :as t])) (defn sum [a b] (+ a b)) (t/deftest sum-test (t/is (= 2 (sum 1 1))))") (require '[clojure.test :as t]) (binding [*compile-path* "." t/*load-tests* false] ; ❸ (compile 'math)) ;; math
❶ 构建工具通常会自动将像 "src" 或 "target" 这样的文件夹添加到类路径中. 为了使例子通用, 我们需要运行 REPL, 确保当前文件夹 "." 是类路径的一部分. 有多种方法可以实现这一点, 但一种方法是在你的文件系统上找到 Clojure 库 (例如, 作为 Maven 仓库的一部分), 然后用一个自定义的类路径运行 clojure.main.
❷ 这与之前的 math 命名空间相同, 保存到一个名为 "math.clj" 的文件中, 在当前文件夹中.
❸ 我们可以在这里看到如何在我们编译 math 命名空间时使用 *load-tests*.
编译 math 命名空间后, 你应该会在本地文件夹中看到一些由编译过程创建的文件, 这些文件与 Clojure 作为包含应用程序的 Jar 归档文件的一部分会产生的文件相同. 我们现在可以用以下方式验证没有生成测试:
(require '[math :as m]) (test #'m/sum-test) ; ❶ ;; CompilerException java.lang.RuntimeException: Unable to resolve var: m/sum-test
❶ 用 *load-tests* 绑定为 false 编译 "math.clj" 后, 我们无法运行测试.
异常证实了 deftest 没有生成测试函数.
4.10.15. 23.15 feeling-lucky, local-javadocs 和 core-java-api
本节中的动态变量都声明在 clojure.java.javadoc 命名空间中 (邀请读者在该书的部分回顾该命名空间的一般用法和公共 API). 即使它们没有在标题中提到, 本节也展示了 *feeling-lucky-url* 和 *remote-javadocs* 的例子.
"手气不错" 是谷歌搜索引擎首次引入的一个功能: 主页上的一个按钮允许用户跳过搜索结果, 直接打开第一个命中. "手气不错" 这个标签表达了第一个结果可能 (或可能不) 是用户所搜索的内容的事实. 在 clojure.java.javadoc 命名空间的上下文中, *feeling-lucky* 变量决定了在没有为请求的类找到任何已知的 Javadoc 的情况下, javadoc 函数是否应该尝试访问 "手气不错" 的功能. 但如果我们尝试这个功能, 我们可以看到它不再工作:
(require '[clojure.java.javadoc :as jdoc]) (jdoc/javadoc []) ; ❶ (binding [jdoc/*feeling-lucky* false] ; ❷ (jdoc/javadoc [])) ;; Could not find Javadoc for clojure.lang.PersistentVector
❶ clojure.lang.PersistentVector 类不是 JVM 默认发行版的一部分, 所以对 jdoc/javadoc 的调用会打开一个相当通用的 Google 搜索.
❷ 我们可以通过将 *feeling-lucky* 设置为 false 来完全禁用该功能. 效果是现在 jdoc/javadoc 返回一个错误.
正如读者可以通过运行例子来验证的那样, "手气不错" 的功能并不像宣传的那样工作. 这是因为谷歌从未为编程访问设计该功能, 其工作方式的内部机制随时间而改变. 目前没有完全可行的解决方案来使用 "手气不错" 的功能. 然而, 我们可以使用 *feeling-lucky-url* 来设置一个不同的 URL:
(binding [jdoc/*feeling-lucky-url* "https://duckduckgo.com/?q=!ducky+"] ; ❶ (jdoc/javadoc []))
❶ 展示如何使用自定义的 "手气不错" URL.
新 URL 指向 DuckDuckGo, 另一个流行的搜索引擎. 这次该功能按预期工作, DuckDuckGo 打开了包含 clojure.lang.PersistentVector.java 源代码的 GitHub 页面. 其他搜索可能会返回不同类型的页面, 这取决于搜索引擎的设置 (毕竟它仍然是一个 "手气不错" 的请求).
*local-javadocs* 和 *remote-javadocs* 是两个包含从包名到本地或远程包位置的映射的引用. 这是 clojure.java.javadoc/javadoc 用来查找文档页面的 "数据库" (在尝试 "手气不错" 选项之前). 以下是它们的默认内容:
(pprint @jdoc/*local-javadocs*) ; ❶ ;; () (pprint (keys @jdoc/*remote-javadocs*)) ; ❷ ;; ("java." ;; "javax." ;; "org.apache.commons.codec." ;; "org.apache.commons.io." ;; "org.apache.commons.lang." ;; "org.ietf.jgss." ;; "org.omg." ;; "org.w3c.dom." ;; "org.xml.sax.")
❶ 没有默认的本地 URL 用于 Javadoc.
❷ 然而, 有一些对一些常见的 Java 包的选择.
要更改当前 JVM 会话的数据库内容, 我们可以使用 add-local-javadocs 或 add-remote-javadoc (我们已经在 clojure.java.javadoc 部分看到了如何添加远程 Javadoc). 对于任何本地更改, 你可以直接绑定变量:
(def clojure-javadoc "https://javadoc.io/doc/org.clojure/clojure/latest/") (binding [jdoc/*remote-javadocs* ; ❶ (ref {"clojure." clojure-javadoc})] (jdoc/javadoc [])) ; ❷
❶ 绑定临时更改了 jdoc/*remote-javadocs* 的内容.
❷ 我们可以再次调用 jdoc/javadoc 来检查添加 Clojure Javadoc 的效果. 你应该会看到默认的浏览器指向 javadoc.io/doc/org.clojure/clojure/latest/clojure/lang/PersistentVector.html
在下面的例子中, 我们想为 JDK 11 文档添加一个新的本地源 267. 在下载并解压包到用户主目录的 `~/javadocs/jdk11` (例如) 后, 我们可以用以下方式绑定 *local-javadocs*:
(def jdk11-javadoc ; ❶ (str (System/getProperty "user.home") "/javadocs/jdk11/api/java.base")) (binding [jdoc/*local-javadocs* (ref [jdk11-javadoc])] ; ❷ (jdoc/javadoc (Object.)))
❶ jdk11-javadoc 的定义指向用户主文件夹, 我们在那里解压了 Javadoc 归档文件的内容.
❷ 与 *remote-javadocs* 类似, 我们需要将 *local-javadoc* 包装在一个 ref 中.
最后一个公共动态变量, *core-java-api*, 在所有实际用途中都是只读的:
jdoc/*core-java-api* ; ❶ ;; "http://java.sun.com/javase/7/docs/api/"
❶ *core-java-api* 的默认值.
*core-java.api* 总是返回 Javadoc 的 JDK 7 版本 (除非你在 JDK 6 上运行 Clojure). 这是 clojure.java.javadoc 用于 Java核心 API 的文档版本.
4.10.16. 23.16 flush-on-newline
*flush-on-newline* 默认设置为 true. 这会在每次调用 prn, println 或 prn-str 时强制调用 flush. flush 反过来会调用 java.io.Writer::flush() 方法, 该方法保证任何仍在缓冲区中等待的字符都会被相应地处理.
将 *flush-on-newline* 设置为 false 的一个可见效果可以在以下情况中看到:
(binding [*flush-on-newline* false] (doseq [x (range 500)] (Thread/sleep 100) (println "Logging " x))) ; ❶ ;; "Logging 0" ;; "Logging 1" ;; [...] ;; "Logging 84" ;; "Logging 85" ;; [...] ;; Logging 499
❶ 一个简单的循环来强制副作用.
上面的 doseq 循环在每次迭代中打印 "Logging <x>". 然而, 字符被缓冲, 并且只以大约一百个的爆发形式出现, 这取决于缓冲区的大小. 很少有情况需要关闭此功能. 为了提高性能, 在使用非缓冲输出时, 我们可以关闭自动刷新.
4.10.17. 23.17 ns 和 loading-verbosely
Clojure 表达式总是在命名空间的上下文中评估, 这是一个与 Java 包的概念相关联的容器抽象, 并提供了一些用于搜索, 移除或重新加载其定义的原语. 与 Var 和命名空间相关的函数使用 *ns* 动态变量来定位特定的命名空间, 正如我们在 refer 中看到的. 邀请读者回顾该章中的其他例子, 以了解如何使用 *ns*.
*loading-verbosely* 不是公共的, 但它作为其他与命名空间相关的函数的一部分被间接使用, 例如 require 或 use:
(require '[clojure.reflect] :verbose) ; ❶ ;; (clojure.core/load "/clojure/reflect") ; ❷ ;; (clojure.core/load "/clojure/set") ;; (clojure.core/in-ns 'clojure.reflect) ;; (clojure.core/alias 'set 'clojure.set) ;; (clojure.core/load "/clojure/reflect/java") ;; (clojure.core/in-ns 'clojure.reflect) ;; (clojure.core/alias 'set 'clojure.set) ;; (clojure.core/in-ns 'clojure.reflect) ;; (clojure.core/alias 'str 'clojure.string)
❶ require 中的 :verbose 选项在内部将 *loading-verbosely* 绑定为 true. 这会在遍历加载所有必需依赖项所需的依赖图时, 打开与命名空间相关的函数的详细日志记录.
❷ 我们可以看到加载 clojure.reflect 所需的依赖遍历.
如果一个标准库函数不支持 :verbose 选项, 我们总是可以将其包装在一个 *loading-verbosely* 绑定中以达到类似的效果, 即使 *loading-verbosely* 是私有的:
(binding [clojure.core/*loading-verbosely* true] ; ❶ (compile 'clojure.test)) ;; (clojure.core/load "/clojure/test") ; ❷ ;; (clojure.core/load "/clojure/template") ;; (clojure.core/in-ns 'clojure.template) ;; (clojure.core/alias 'walk 'clojure.walk) ;; (clojure.core/in-ns 'clojure.test) ;; (clojure.core/alias 'temp 'clojure.template) ;; (clojure.core/load "/clojure/stacktrace") ;; (clojure.core/in-ns 'clojure.test) ;; (clojure.core/alias 'stack 'clojure.stacktrace) ;; (clojure.core/in-ns 'clojure.test) ;; (clojure.core/alias 'str 'clojure.string) ;; clojure.test
❶ *loading-verbosely* 是私有的, 但使用它相当安全, 所以我们做个例外, 通过在它前面加上 clojure.core 来绕过隐私控制以启用相关的绑定.
❷ 我们发现在编译期间, 命名空间的依赖树被遍历, 我们可以看到加载 clojure.test 所需的所有依赖项.
4.10.18. 23.18 math-context
java.math.BigDecimal 是 Java 中用于任意精度十进制数的实现. Clojure 为此类提供了一个构造函数, 使用 bigdec 函数和一个配置函数 with-precision, 该函数创建一个 java.math.MathContext 对象, 该对象被传递给所有 BigDecimal 操作. with-precision 提供了 MathContext 提供的所有功能, 具有更符合 Clojure 习惯的接口. 如果由于任何原因, 你无法使用 with-precision 宏, 你总是可以像这样直接使用 *math-context*:
(import '[java.math MathContext RoundingMode]) (binding [*math-context* (MathContext. 3 RoundingMode/UP)] ; ❶ (/ 22M 7)) ;; 3.15M
❶ 一个使用 *math-context* 来设置大十进制除法精度的例子.
4.10.19. 23.19 warn-on-reflection 和 unchecked-math
*warn-on-reflection* 和 *unchecked-math* 不一定是相关的动态变量, 可以独立使用. 然而, 当总体目标是性能优化时, 它们经常一起使用. 将 *warn-on-reflection* 设置为 true 的效果是打印关于编译器需要使用反射的详细信息, 这是一种昂贵的操作, Clojure 在可能的情况下会自动阻止:
(set! *warn-on-reflection* true) ; ❶ ;; true (defn exists? [file] ; ❷ (.exists file)) ;; Reflection warning - reference to field exists can't be resolved. (import '[java.io File]) (defn exists? [^File file] ; ❸ (.exists file))
❶ *warn-on-reflection* 可以在不使用 binding 的情况下被 set!, 以全局激活反射警告.
❷ 一个在 java.io.File 对象上使用操作的典型反射警告. 我们在整本书中看到了许多这样的反射警告例子, 展示了如何使用类型提示来避免它们.
❸ 我们可以使用一个类型提示来引导编译器使用一个特定的类来查找 `.exists` 方法.
*unchecked-math* 实现了一个特定的编译器优化, 适用于一组位操作, 算术和数组操作 268. *unchecked-math* 实际上执行了两个优化:
- 它将表达式直接编译成相应的 JVM 指令 (如果可用), 而不调用相关的
clojure.lang.Numbers操作. - 它移除了边界检查. 这类似于用
unchecked-add替换 `+`, 这是使用 JVM 指令的结果.
*unchecked-math* 要正常工作有一个警告, 即参数需要是原始 Java 类型. 让我们看看下面的 sum 函数:
(defn sum [a b] ; ❶ (+ a b)) (sum 1 2) ;; 3
❶ 一个简单的包装器, 用于将两个数字相加.
到 "a" 和 "b" 被传递给 `+` 的时候, 它们被视为 java.lang.Object (它们的运行时类型在 "2" 和 "3" 自动装箱后将是 java.lang.Long). `+` 是通过调用 clojure.lang.Numbers::add(Object a, Object b) 实现的, 这最终是接收调用的地方. 如果我们不关心检查整数溢出, 我们可以改用 unchecked-add:
(defn sum [a b] ; ❶ (unchecked-add a b)) (sum 1 2) ;; 3
❶ 使用 unchecked-add 的优点是移除了对 java.lang.Long 的边界检查, 以换取静默溢出的风险.
现在用 unchecked-add 编写的同一个 sum 函数产生一个对 clojure.lang.Numbers::unchecked_add(Object a, Object b) 的调用. 我们通过类型提示参数来进一步提升性能, 让 Clojure 避免参数自动装箱并选择一个更好的函数来执行求和:
(defn sum ^long [^long a ^long b] ; ❶ (unchecked-add a b)) (sum 1 2) ;; 3
❶ 添加类型提示移除了对两个数字 "1" 和 "2" 进行自动装箱的需要. 注意, 我们也为返回类型添加了一个类型提示, 该类型也受相同的自动装箱命运.
Clojure 编译器现在接收到关于参数 "a" 和 "b" 的信息, 这些参数被要求为 long 类型. 编译器可以使用这些信息将操作分派到 clojure.lang.Numbers::unchecked_add(long a, long b), 这是给定两个 long 数字时可用的最精确匹配.
*unchecked-math* 为我们执行了所有上述操作, 还有一个额外的优化:
(set! *unchecked-math* true) ; ❶ (defn sum ^long [^long a ^long b] ; ❷ (+ a b)) (sum 1 2) ;; 3
❶ 我们可以将 *unchecked-math* 设置为 true, 类似于我们对 *warn-on-reflection* 所做的.
❷ 注意我们不需要明确地忽略边界检查, 我们可以回到使用简单的 `+`.
在最后一个例子中, Clojure 编译器停止使用 clojure.lang.Numbers 来实现加法, 而是使用 JVM 指令 LADD. 这是最好的解决方案, 因为我们跳过了一个中间调用, 并且我们使用了一个 JIT 友好的 JVM 指令, HotSpot 可以积极地缓存它. 注意我们仍然需要类型提示才能让 *unchecked-math* 正常工作.
此外, 当 *unchecked-math* 被设置为 :warn-on-boxed 时, 上述所有操作仍然适用, 但如果原始类型仍然被装箱, 它还会打印一个警告:
(set! *unchecked-math* :warn-on-boxed) ; ❶ (defn sum [^long a b] ; ❷ (+ a b)) ;; Boxed math warning, - call: ; ❸ ;; public static Number clojure.lang.Numbers.unchecked_add(long,Object)
❶ *unchecked-math* 的值不严格是布尔值, 它也可以接受一个 :warn-on-boxed 关键字.
❷ 注意我们只留下了一个类型提示, 但我们忘记了对第二个参数进行类型提示.
❸ 正如预期的那样, 我们收到了一个装箱警告, 因为类型参数 "b" 是作为 java.lang.Object 传递的.
4.10.20. 23.20 漂亮打印变量
在谈到 cl-format (clojure.pprint API 的主要入口点之一) 时, 我们简要介绍了一些复杂的 Clojure 打印系统的功能. 也许并不奇怪, clojure.pprint 是高度可配置的, 并且大量使用动态变量. 一些变量是 clojure.core 的一部分, 而另一些则在 clojure.pprint 中声明. 下表是摘要和简要描述:
| 名称 | 命名空间 | 默认值 | 描述 |
|---|---|---|---|
*print-readably* |
clojure.core | true | 按字面量打印转义序列. |
*print-dup* |
clojure.core | false | 打印对象以便可以被读回内存. |
*print-length* |
clojure.core | nil | 在集合中打印的项数. |
*print-level* |
clojure.core | nil | 要打印的嵌套集合的层数. |
*print-meta* |
clojure.core | false | 元数据是否应作为对象的一部分打印. |
*print-pretty* |
clojure.pprint | true | 启用/禁用漂亮打印. |
*print-pprint-dispatch* |
clojure.pprint | fn | 设置漂亮打印机分派函数. |
*print-right-margin* |
clojure.pprint | 72 | 在换行前要使用的列数. |
*print-miser-width* |
clojure.pprint | 40 | 进入 miser 风格的列数. |
*print-suppress-namespaces* |
clojure.pprint | nil | 在符号中移除命名空间限定符. |
*print-radix* |
clojure.pprint | nil | 打印用于整数或比率的基数. |
*print-base* |
clojure.pprint | 10 | 更改打印整数或比率的基数. |
*print-readably*
*print-readably*控制像 "\n" (换行) 或 "\t" (制表符) 这样的不可打印字符在打印时应该如何出现. 它还控制用于装饰 Clojure 对象 (如双引号) 的字符.*print-readably*默认为 true, 并在像print或println这样的函数内部使用:(binding [*print-readably* false] ; ❶ (pr "a\nb\nc")) ;; a ;; b ;; cnil (print "a\nb\nc") ; ❷ ;; a ;; b ;; cnil
❶
pr是最基本的打印函数之一. 它默认遵守*print-readably*, 打印控制字符 (如换行符 `\n`) 的转义版本. 在这里, 我们通过强制pr不转义它们来避免这种行为.❷ 我们可以看到
pr和print之间的密切关系:print就像pr, 但它默认绑定*print-readably*.没有必要直接使用
*print-readably*, 鉴于可以在pr(及相关函数) 或print(及相关函数) 之间进行选择, 因为一组将*print-readably*设置为 true, 另一组则设置为 false. 然而, 如果你不能控制代码, 它可能会派上用场.*print-dup*
*print-dup*与print-dup相关, 这是一个我们在print-method中描述的同名多重方法.print-dup控制对象应如何序列化为字符串, 以便它们可以被读回 Clojure, 并且其值可以被重新安装. 我们可以使用*print-dup*来启用这种打印 (它默认为 true). 更多信息和示例, 请参考print-method和print-dup.*print-length*和*print-level*
*print-length*控制在集合中打印多少项. 这在打印大型和嵌套的集合时可能很有用, 以避免在屏幕上输出过多, 只显示每个集合的初始部分, 例如前 3 项:(require '[clojure.xml :as xml]) (def document (xml/parse "http://feeds.bbci.co.uk/news/rss.xml")) (binding [*print-length* 3] ; ❶ (pprint document)) ;; {:tag :rss, ;; :attrs ;; {:xmlns:media "http://search.yahoo.com/mrss/", ;; :version "2.0", ;; :xmlns:atom "http://www.w3.org/2005/Atom", ;; ...}, ;; :content ;; [{:tag :channel, ;; :attrs nil, ;; :content ;; [{:tag :title, :attrs nil, :content ["BBC News - Home"]} ;; {:tag :description, :attrs nil, :content ["BBC News - Home"]} ;; {:tag :link, :attrs nil, :content ["https://www.bbc.co.uk/news/"]} ;; ...]} ;; ...]}
❶ 只打印一个表示 XML 新闻源的大型深度嵌套集合的前 3 项.
正如你所看到的, 在将
*print-length*设置为 true 后, 集合被截断, 并且一个可见的 … 三个点替换了集合的其余部分. 即使无法看到全部数据, 只打印几项也有助于理解数据的总体形状.我们也可以用
*print-level*来控制打印多少层嵌套:(binding [*print-length* 3 *print-level* 4] ; ❶ (pprint document)) ;; {:tag :rss, ;; :attrs ;; {:xmlns:media "http://search.yahoo.com/mrss/", ;; :version "2.0", ;; :xmlns:atom "http://www.w3.org/2005/Atom", ;; ...}, ;; :content ;; [{#, #, #}]}
❶
*print-length*和*print-level*的组合效果.在上面的例子中, 我们可以看到集合中被截断的项被 … 替换, 被截断的嵌套分支被
#替换.*print-meta*
*print-meta*为面向序列化的打印函数启用元数据打印. Clojure 有两个主要的打印函数集: 那些只以pr开头的 (pr,prn,pr-str,prn-str) 打印对象, 以便它们可以用read-string读回.*print-meta*也启用元数据的额外打印 (以及它们反序列化回 Clojure):(def s ; ❶ (binding [*print-meta* true] (pr-str (with-meta [1 2 3] {:my :meta})))) (println s) ; ❷ ;; ^{:my :meta} [1 2 3] (def v (read-string s)) (println v) ; ❸ ;; [1 2 3] (meta v) ; ❹ ;; {:my :meta}
❶ 在绑定
*print-meta*之后, 我们产生一个带有元数据的向量的字符串版本.❷ 正如我们所看到的, 字符串也包含了元数据映射.
❸ 在将字符串读回 Clojure 数据结构后, 向量按预期打印.
❹ 元数据也按预期被保留.
*print-pretty*
*print-pretty*是主要的漂亮打印 "开/关" 开关. 它默认是 true, 但我们可以局部地 (使用binding) 或全局地 (使用alter-var-root) 将其关闭:(require '[clojure.pprint :as pprint]) (pprint/write (range 100)) ; ❶ ;; (0 ;; 1 ;; 2 ;; ... ;; 99)nil (binding [pprint/*print-pretty* false] ; ❷ (pprint/write (range 100))) ;; (0 1 2 ... 99)nil (alter-var-root #'pprint/*print-pretty* (constantly false)) ; ❸ (pprint/write (range 100)) ;; (0 1 2 ... 99)nil (alter-var-root #'pprint/*print-pretty* (constantly true)) ; ❹
❶
pprint/write的默认行为是将数字序列排列成单列.❷ 我们可以通过将
*print-pretty*设置为 false 来关闭任何漂亮打印行为.❸
alter-var-root更改*print-pretty*的默认值, 从那时起关闭漂亮打印.❹ 记得将漂亮打印重新打开.
*print-pprint-dispatch*
clojure.pprint通过定义基于要打印的对象类型的不同打印策略来工作. 默认情况下,clojure.pprint使用一个名为simple-dispatch的默认多重方法:(require '[clojure.pprint :as pprint]) (pprint/pprint (keys (methods pprint/simple-dispatch))) ; ❶ ;; (nil ; ;; clojure.lang.PersistentQueue ;; clojure.lang.ISeq ;; :default ;; clojure.lang.IPersistentVector ;; clojure.lang.IPersistentMap ;; clojure.lang.IDeref ;; clojure.lang.IPersistentSet ;; clojure.lang.Var)
❶
methods返回pprint/simple-dispatch多重方法的分派表.pprint/simple-dispatch多重方法的分派表显示了为最常见的 Clojure 类型安装的特定漂亮打印.pprint/simple-dispatch实现的主要目标是以人类可读的方式在屏幕上显示 Clojure 数据结构.clojure.pprint还包含一个专门用于 Clojure 源代码的不同格式化策略. Clojure 源代码仍然是数据结构, 但在格式化方面有不同的要求. 我们可以通过选择一个不同的多重方法分派来在不同的格式化策略之间切换:(require '[clojure.pprint :as pprint]) (def condp-statement '(condp = x 1 "one" 2 "two" 3 "three" 4 "four" 5 "five" 6 "six" :else :none)) (pprint/pprint condp-statement) ; ❶ ;; (condp ;; = ;; x ;; 1 ;; "one" ;; 2 ;; "two" ;; 3 ;; "three" ;; 4 ;; "four" ;; 5 ;; "five" ;; 6 ;; "six" ;; :else ;; :none) (binding [pprint/*print-pprint-dispatch* pprint/code-dispatch] ; ❷ (pprint/pprint condp-statement)) ;; (condp = x ;; 1 "one" ;; 2 "two" ;; 3 "three" ;; 4 "four" ;; 5 "five" ;; 6 "six" ;; :else :none)
❶ 第一次尝试漂亮打印
condp-statement不太可读,clojure.pprint使用了顺序列表的默认策略, 没有关于condp语句特定语义的任何知识.❷ 通过将
*print-pprint-dispatch*分配给pprint/code-dispatch(一个专门用于代码源的漂亮打印机), 我们可以看到一个好得多的渲染.clojure.pprint还提供了with-pprint-dispatch, 这是一个实现与将*print-pprint-dispatch*绑定到不同分派多重方法相同效果的宏.*print-right-margin*
*print-right-margin*设置一个理想的列数, 在截断当前行并使用新行之前使用:(require '[clojure.pprint :as pprint]) pprint/*print-right-margin* ; ❶ ;; 72 (defn words [n] (take n (repeat 'clojure))) ; ❷ (defn print-with-length [s] ; ❸ (pprint/pprint s) (count (with-out-str (pprint/pprint s)))) (print-with-length (words 8)) ; ❹ ;; (clojure clojure clojure clojure clojure clojure clojure clojure) ;; 66
❶
*print-right-margin*的默认值是 72.❷ 一个创建 "n" 个单词序列的函数.
❸
print-with-length漂亮地打印给定的输入, 并显示打印时需要多少列.❹ 我们可以看到一个由 8 个 "Clojure" 单词组成的序列需要 66 列来打印.
上面的例子计算了打印一个单词序列所需的列数.
clojure.pprint会继续添加空格, 括号和任何其他改善可视化的格式化构件. 让我们改变右边距, 强制漂亮打印分割成多行:(binding [pprint/*print-right-margin* 60] ; ❶ (print-with-length (words 8))) ;; (clojure ;; clojure ;; clojure ;; clojure ;; clojure ;; clojure ;; clojure ;; clojure)
❶ 将
*print-right-margin*设置为 60.在将右边距设置为 60 之后, 所有的单词都在一个新行上打印.
*print-miser-width*
"Miser mode" 是一种缩进风格, 在格式化源代码的情况下很有帮助, 当源代码被严重嵌套时, 它往往会向右边距累积. 为了看到 miser mode 的效果, 我们将通过设置一个小的右边距来强制这种情况:
(require '[clojure.pprint :as pprint]) pprint/*print-miser-width* ; ❶ ;; 40 (def nested-statement ; ❷ '(condp = x 1 "one" 2 "two" 3 "three" 4 "four" 5 "five" 6 "six" :else (condp = x 1 "one" 2 "two" 3 "three" 4 "four" 5 "five" 6 "six" :else :none))) (binding [pprint/*print-pprint-dispatch* pprint/code-dispatch ; ❸ pprint/*print-right-margin* 30] (pprint/pprint nested-statement)) ;; (condp ; ❹ ;; = ;; x ;; 1 "one" ;; 2 "two" ;; 3 "three" ;; 4 "four" ;; 5 "five" ;; 6 "six" ;; :else ;; (condp ;; = ;; x ;; 1 "one" ;; 2 "two" ;; 3 "three" ;; 4 "four" ;; 5 "five" ;; 6 "six" ;; :else :none))
❶ 默认的 miser 宽度是 40.
❷ 这个嵌套的
condp语句经过了轻微的格式化, 但实际上它可能出现在一行上.❸ 我们启用了
pprint/code-dispatch, 因为 miser mode 的效果很明显. 注意我们还设置了一个比默认右边距短的 30 列的右边距.❹ 结果看起来相当 fragmented.
condp语句似乎被我们强制设置的狭窄右边距正确地约束了, 产生了一种虽然可读但对换行符使用过多的格式. 如果我们现在假设这种格式出现在更深层嵌套的代码中, 左边会有很多空白, 因为缩进已经迫使这段代码向右累积.*print-miser-width*是漂亮打印进入 miser mode 之前要等待的列数. 在 miser mode 中, 漂亮打印机被允许更自由地使用换行符来弥补这种情况:(binding [pprint/*print-pprint-dispatch* pprint/code-dispatch pprint/*print-right-margin* 30 pprint/*print-miser-width* 20] ; ❶ (pprint/pprint nested-statement)) ;; (condp = x ; ❷ ;; 1 "one" ;; 2 "two" ;; 3 "three" ;; 4 "four" ;; 5 "five" ;; 6 "six" ;; :else (condp = x ;; 1 "one" ;; 2 "two" ;; 3 "three" ;; 4 "four" ;; 5 "five" ;; 6 "six" ;; :else :none))
❶ 我们将
*print-miser-width*设置为 20.❷ 代码现在看起来不那么受狭窄右边距的约束, 更好地利用了可用的空间.
*print-suppress-namespaces*
*print-suppress-namespaces*控制符号是否应在没有命名空间限定的情况下打印 (如果符号是完全限定的), 并且它默认为 false (命名空间应该出现):(require '[clojure.pprint :as pprint]) (pprint '{num/val 1 num/name "one"}) ; ❶ ;; {num/val 1, num/name "one"} (binding [pprint/*print-suppress-namespaces* true] ; ❷ (pprint '{num/val 1 num/name "one"})) ;; {val 1, name "one"} (binding [pprint/*print-suppress-namespaces* true] ; ❸ (pprint {:num/val 1 :num/name "one"})) ;; {:num/val 1, :num/name "one"}
❶ 当符号被命名空间限定时,
pprint默认显示命名空间.❷ 我们可以通过将
*print-suppress-namespaces*设置为 true 来抑制命名空间.❸
*print-suppress-namespaces*对关键字没有影响, 关键字是 Clojure 中另一个支持命名空间限定名称的类型.*print-suppress-namespaces*对于打印宏展开的形式特别有用. 符号通过语法引用自动被命名空间化, 这是卫生宏中的一个基本工具. 然而, 在打印时, 我们不一定希望看到自动的限定:(binding [pprint/*print-pprint-dispatch* pprint/code-dispatch] ; ❶ (pprint (macroexpand-1 '(definline myfn [])))) ;; (do ;; (clojure.core/defn myfn [] nil) ;; (clojure.core/alter-meta! ;; #'myfn ;; clojure.core/assoc ;; :inline ;; (clojure.core/fn myfn [] nil)) ;; #'myfn) (binding [pprint/*print-pprint-dispatch* pprint/code-dispatch ; ❷ pprint/*print-suppress-namespaces* true] (pprint (macroexpand-1 '(definline myfn [])))) ;; (do ;; (defn myfn [] nil) ;; (alter-meta! #'myfn assoc :inline (fn myfn [] nil)) ;; #'myfn)
❶
pprint/code-dispatch被激活以打印一个简单形式的宏展开.pprint打印完全限定的命名空间, 正如它们在宏展开后出现的那样.❷ 在将
*print-suppress-namespaces*设置为 true 后,clojure.core前缀被移除.*print-base*和*print-radix*
*print-base*允许以不同的基数打印数字 (默认情况下, 数字以 10 为基数打印):(require '[clojure.pprint :as pprint]) (binding [pprint/*print-base* 2] ; ❶ (pprint/pprint 500)) ;; 111110100 (binding [pprint/*print-base* 16] ; ❷ (pprint/pprint 3405691582)) ;; cafebabe
❶
*print-base*告诉漂亮打印机对数字使用基数 2.❷ "CAFEBABE" 是 Java 类文件结构中的魔数.
正如将 3405691582 转换为 16 进制所示, 当以不同的基数打印时, 一些数字很难与通用字符串区分开来. 我们可以使用
*print-radix*来引入一个基数说明符:(binding [pprint/*print-base* 16 pprint/*print-radix* true] ; ❶ (pprint/pprint 3405691582)) ;; #xcafebabe
❶ 当
*print-radix*设置为 true 时, 漂亮打印机在转换为不同基数的数字前添加一个基数限定符.*print-radix*只打印基数说明符#b,#o,#x, 分别用于基数 2 (二进制), 8 (八进制) 和 16 (十六进制).
4.10.21. 23.21 其他动态变量
本节收集了其他公共且可访问的动态变量, 但它们不打算供公共使用, 而应被视为相应命名空间的实现细节.
*current*,*sb*,*state*和*stack*. 这些动态变量都是clojure.xml命名空间的一部分.*depth*,*var-context*,*report-counters*,*initial-report-counters*,*testing-vars*,*testing-contexts*和*test-out*是clojure.test的一部分.*fn-loader*是 Clojure 编译器内部使用的一个机制, 用于传达应该使用哪个父类加载器来编译命名空间中的函数和表达式. 关于 Clojure 加载机制的概述, 请查阅*use-context-classloader*. 另请参阅这篇关于 Clojure 编译的文章, 其中提到了*fn-loader*在编译器实现中的使用.
4.10.22. 23.22 总结
动态变量既是一种并发机制 (它们可以按线程堆叠值), 也是一种使用线程局部内存的通信机制. 我们可以使用动态变量将信息从程序的一部分传递到另一部分. Clojure 广泛地使用动态变量来配置系统特定部分的行为, 本章的目标是描述对最终用户可用的内容. 动态变量也便于配置我们不拥有的程序, 通过用相关的绑定形式包围表达式. 动态变量与函数或宏类似, 属于标准库的公共接口.
5. 附录 A:
按字母顺序索引
- ".", ".." 和 doto: 21.1
- *1, *2, *3 和 *e: 23.1
- agent: 23.3
- allow-unresolved-vars: 23.11
- assert: 23.4
- clojure-version 和 command-line-args: 23.5
- compile-files: 23.6
- compile-path: 23.7
- compiler-options: 23.8
- data-readers 和 default-data-reader-fn: 23.13
- feeling-lucky, local-javadocs 和 core-java-api: 23.15
- file 和 source-path: 23.9
- flush-on-newline: 23.16
- in, out 和 err: 23.2
- load-tests 和 stack-trace-depth: 23.14
- math-context: 23.18
- ns 和 loading-verbosely: 23.17
- read-eval 和 suppress-read: 23.12
- use-context-classloader: 23.10
- warn-on-reflection 和 unchecked-math: 23.19
- +', -', *', inc' 和 dec': 5.8
- +, -, * 和 /: 5.1
- ->: 2.3.1
- ->>: 2.3.2
- < , > , <= , >=: 6.3
- = (equal) 和 not= (not equal): 6.1
- == (double equal): 6.2
- add-watch 和 remove-watch: 14.9
- agent: 14.6
- aget, aset, alength 和 aclone: 21.7.4
- alias, ns-aliases 和 ns-unalias: 16.7
- alter-var-root 和 with-redefs: 16.3
- amap 和 areduce: 21.7.5
- and, or: 3.2.2
- apply: 2.4.1
- apropos: apropos
- are: are
- array-map: 11.1.2
- as->: 2.3.5
- as-relative-path: as-relative-path
- as-url: as-url
- aset-int 和其他类型设置器: 21.7.6
- assoc, assoc-in 和 dissoc: 11.3.1
- atom: 14.5
- bean: 21.5
- binding: 16.4
- bit-and 和 bit-or: 3.2.3
- blank?, ends-with?, starts-with?, includes?: 19.9
- browse: browse
- case: 3.3.4
- cat: 7.2.4
- chunk-cons, chunk-first, chunk-rest, chunk-next, chunk-buffer, chunk-append 和 chunk: 10.12
- clojure.core.server: 22.7
- clojure.data/diff: 6.7
- clojure.edn/read 和 clojure.edn/read-string: 17.6
- clojure.inspector: 22.2
- clojure.java.browse: 22.5
- clojure.java.io: 22.8
- clojure.java.javadoc: 22.10
- clojure.java.shell: 22.6
- clojure.main: 22.4
- clojure.repl: 22.3
- clojure.set/map-invert: 11.4.3
- clojure.set/rename-keys: 11.4.2
- clojure.template/apply-template: 4.7
- clojure.template/do-template: 4.8
- clojure.test: 22.9
- clojure.walk/keywordize-keys 和 clojure.walk/stringify-keys: 11.4.1
- clojure.xml: 22.1
- clojure.zip: 8.4.4
- comp: 2.2.2
- compare: 6.4
- compile: 17.4
- complement: 2.2.3
- completing: 7.2.3
- concat 和 lazy-cat: 9.3.9
- cond: 3.3.2
- cond-> 和 cond->>: 2.3.3
- condp: 3.3.3
- conj: 8.2.1
- cons 和 list*: 9.4.2
- constantly: 2.2.4
- contains?: 8.2.3
- copy: copy
- count: 8.1.2
- create-struct, defstruct, struct-map, struct 和 accessor: 11.1.4
- def, declare, intern 和 defonce: 16.1
- default-data-readers: 17.8
- definline: 4.5
- defmacro: 4.1
- defmulti 和 defmethod: 15.11
- defn 和 defn-: 2.1.1
- defprotocol: 15.8
- defrecord: 15.7
- deftest: deftest
- deftype 和 definterface: 15.4
- delay: 14.3
- delete-file: delete-file
- demunge: demunge
- deref 和 realized?: 14.7
- derive 和 make-hierarchy: 15.10
- destructure: 4.6
- dir: dir
- dir-fn: dir-fn
- disj: 13.4
- distinct, dedupe 和 distinct?: 10.8
- doc: doc
- doseq, dorun, run!, doall, do: 20.2
- dotimes: 3.4.5
- drop, drop-while, drop-last, take, take-while, take-last, nthrest, nthnext: 10.2
- eduction: 7.2.2
- empty: 8.1.4
- empty? 和 not-empty: 8.1.6
- escape, char-name-string, char-escape-string: 19.6
- eval: 17.2
- every-pred 和 some-fn: 2.2.9
- every?, not-every?, some 和 not-any?: 8.1.5
- ex-info 和 ex-data: 21.4
- extend, extend-type 和 extend-protocol: 15.9
- file: file
- file-seq: 9.3.3
- filter 和 remove: 3.5.3
- filterv: 12.6
- find, key 和 val: 11.2.2
- find-doc: with-out-str
- find-ns 和 all-ns: 16.11
- first, second 和 last: 3.5.1
- flatten: 10.7
- fn: 2.1.2
- fn*: 2.1.3
- fnil: 2.2.1
- fold: 7.1.1
- foldcat, cat 和 append!: 7.1.4
- for: 3.4.3
- format, printf 和 cl-format: 18.1
- frequencies: 8.3.4
- future: 14.1
- gen-class 和 gen-interface: 15.3
- gensym: 4.4
- get: 8.2.2
- group-by: 8.3.6
- hash: 6.6
- hash-map: 11.1.1
- hash-set: 13.1
- identical?: 6.5
- identity: 2.2.5
- if, if-not, when 和 when-not: 3.3.1
- if-let, when-let, if-some 和 when-some: 3.1.2
- image-javadoc-string: image-javadoc-string
- inc 和 dec: 5.2
- index-of, last-index-of: 19.8
- inspector: inspector
- interpose 和 interleave: 10.5
- into: 8.1.1
- ints 和其他类型数组转换: 21.7.7
- is: is
- iterate: 9.2.2
- iterator-seq 和 enumeration-seq: 9.3.8
- javadoc: javadoc
- join: 19.2
- juxt: 2.2.6
- keep 和 keep-indexed: 10.3
- keys 和 vals: 11.2.1
- lazy-seq: 9.3.1
- let 和 let*: 3.1.1
- letfn 和 letfn*: 3.1.3
- line-seq: 9.3.6
- list: 9.4.1
- load, load-file, load-reader 和 load-string: 17.3
- load-script: load-script
- locking, monitor-enter 和 monitor-exit: 14.10
- loop, recur 和 loop*: 3.4.1
- lower-case, upper-case, capitalize: 19.7
- macroexpand, macroexpand-1 和 macroexpand-all: 4.2
- main: main
- make-array: 21.7.1
- make-parents: make-parents
- map 和 map-indexed: 3.5.2
- mapcat: 10.4
- mapv: 12.5
- max 和 min: 5.4
- max-key 和 min-key: 5.5
- memfn: 2.2.7
- memoize: 2.4.2
- merge 和 merge-with: 11.3.3
- meta, with-meta, vary-meta, alter-meta! 和 reset-meta!: 16.13
- monoid: 7.1.3
- munge: munge
- new: 21.2
- not: 3.2.1
- ns, in-ns, create-ns 和 remove-ns: 16.6
- ns-map 和 ns-unmap: 16.8
- ns-publics, ns-interns, ns-imports: 16.9
- nth: 8.1.3
- object-array 和其他类型初始化器: 21.7.2
- partial: 2.2.8
- partition, partition-all 和 partition-by: 10.6
- peek 和 pop: 12.3
- pmap, pcalls 和 pvalues: 9.1.5
- pprint, pp, write 和 print-table: 18.3
- pr, prn, pr-str, prn-str, print, println, print-str, println-str: 18.2
- prewalk 和 postwalk: 8.4.2
- prewalk-replace 和 postwalk-replace: 8.4.3
- print-method, print-dup 和 print-ctor: 18.4
- promise 和 deliver: 14.2
- proxy: 15.5
- pst: pst
- quot, rem 和 mod: 5.3
- quote: 4.3
- rand 和 rand-int: 5.6
- rand-nth: 8.3.1
- random-sample: 8.3.3
- range: 3.4.2
- re-pattern, re-matcher, re-groups, re-seq, re-matches, re-find: 19.10
- re-seq: 9.3.5
- read 和 read-string: 17.1
- reader: reader
- reader-conditional 和 reader-conditional?: 17.9
- reduce 和 reductions: 3.5.4
- reduce-kv: 11.3.4
- reduced, reduced?, ensure-reduced, unreduced: 7.3
- reducer 和 folder: 7.1.2
- ref: 14.4
- refer, refer-clojure, require, loaded-libs, use, import: 16.10
- reflect 和 type-reflect: 21.6
- reify: 15.6
- repeat 和 cycle: 9.2.3
- repeatedly: 9.2.1
- repl: repl
- repl: repl
- replace: 8.3.7
- replace, replace-first, re-quote-replacement: 19.3
- resource: resource
- rest, next, fnext, nnext, ffirst, nfirst 和 butlast: 10.1
- resultset-seq: 9.3.7
- reverse: 8.3.8
- root-cause: root-cause
- rseq: 9.1.2
- run-all-tests: run-all-tests
- run-tests: run-tests
- select, index, rename, join 和 project: 13.7
- select-keys 和 get-in: 11.2.3
- seq 和 sequence: 9.1.1
- seque: 9.1.4
- set!: 20.4
- set: 13.2
- set-validator! 和 get-validator: 14.8
- sh: sh
- shuffle: 8.3.2
- slurp 和 spit: 18.5
- socket-server: socket-server
- some-> 和 some->>: 2.3.4
- sort 和 sort-by: 8.3.5
- sorted-map 和 sorted-map-by: 11.1.3
- sorted-set 和 sorted-set-by: 13.3
- source: source
- source-fn: source-fn
- split-at 和 split-with: 10.10
- stack-element-str: stack-element-str
- stop-server: stop-server
- str: 19.1
- subs, split 和 split-lines: 19.4
- subseq 和 rsubseq: 9.1.3
- subset? 和 superset?: 13.6
- subvec: 12.7
- symbol 和 keyword: 15.1
- table-inspector: table-inspector
- tagged-literal 和 tagged-literal?: 17.7
- take-nth: 10.9
- test 和 assert: 17.5
- test-all-vars: test-all-vars
- test-ns: test-ns
- test-var: test-var
- testing: testing
- the-ns, ns-name 和 namespace: 16.12
- to-array, into-array, to-array-2d: 21.7.3
- trampoline: 2.4.3
- transduce: 7.2.1
- transient, persistent!, conj!, pop!, assoc!, dissoc! 和 disj!: 20.1
- tree-inspector: tree-inspector
- tree-seq: 9.3.2
- trim, triml, trimr, trim-newline: 19.5
- try, catch, finally 和 throw: 21.3
- unchecked-add 和其他 unchecked 运算符: 5.9
- unchecked-add-int 和其他 unckecked-int 运算符: 5.10
- union, difference 和 intersection: 13.5
- update 和 update-in: 11.3.2
- use-fixtures: use-fixtures
- var, find-var 和 resolve: 16.2
- vec: 12.2
- vector: 12.1
- vector-of: 12.4
- volatile!, vreset!, vswap! 和 volatile?: 20.3
- walk, prewalk-demo 和 postwalk-demo: 8.4.1
- when-first: 10.11
- while: 3.4.4
- with-local-vars, var-get 和 var-set: 16.5
- with-open: with-open
- with-precision: 5.7
- with-test: with-test
- writer: writer
- xml: xml
- xml-seq: 9.3.4
- zipmap: 11.1.5
6. 附录 B:
词汇表和常用术语
本节包含本书中使用的词汇和术语的词汇表. 其中许多是 Clojure 特有的 (随着时间的推移, 它们已被普遍接受为某些概念或语言部分的定义). 其他的则更通用, 在 Clojure 社区之外使用, 但在这里重复一下以便更好地理解.
6.1. B.1 函数语法规范
标准库中一些函数的契约相当复杂, 为了保持本书的实用性, 契约部分不使用严格的语法. 本书使用一种非正式的语法, 希望比相应的函数文档更具表现力, 但不旨在涵盖所有可能情况的全部范围. 读者应使用该语法来了解函数的一般作用, 但随后参考示例来涵盖其余情况. 以下是本书中使用的语法的词汇表:
"<term>": 尖括号中的术语是终端的, 不会进一步展开."[]": 方括号中的术语是函数定义中的实际向量."()": 圆括号中的术语是函数定义中的实际列表."OR": 表示在可能的选择中进行选择的选项.":=>": 显示一个可以进一步展开为其他术语的术语."..": 表示 "许多其他重复的" 围绕的表达式."?": 在一个术语之后表示该术语是可选的.
6.2. B.2 truthy, falsey 和逻辑布尔值
Clojure 将 true 和 false 的含义扩展到其他类型和常量字面量, 因此一个值总是可以被解释为布尔值, 即使其类型在技术上不是布尔值. "逻辑布尔值" 是一个伪类型, 以便:
false和nil被认为是false.- 其他任何东西都是
true.
由此得出:
(if [] :true :false) ; ❶ ;; :true (if "false" :true :false) ; ❷ ;; :true (if 0 :true :false) ; ❸ ;; :true
❶ 空集合是真值.
❷ 任何类似于布尔值但实际上不是布尔值的东西 (字符串 "true" 或关键字 :false) 都是真值.
❸ 数字总是真值.
6.3. B.3 谓词
在数理逻辑中, 谓词是一个接受一个参数并返回 true 或 false 的函数 269. 在编程中, 定义是相同的, 但可以选择允许函数返回任何类型 (不仅仅是布尔值), 前提是语言有一个约定来将所有可能的值分类为真或假.
Clojure 包含一个逻辑布尔值的定义, 它允许谓词返回任何类型. 谓词函数在整个标准库中被频繁使用, 例如与 filter 一起.
6.4. B.4 arity, arities, varargs
"arity" 是给函数的一个可能 "主体" 的名称. Clojure 函数允许多个独立的实现, 根据函数被调用的参数数量来执行. 一个称为 "vararg" (由 `&` 符号表示) 的特殊参数声明允许存在一个主体来捕获所有其他未声明的函数基数.
当一个函数包含多个主体时, 它支持 "multiple-arities". 当它只包含一个主体时, 该函数是 "single-arity". 例如, 以下是 vector (一个有八个元数的函数) 的文档字符串:
user=> (doc vector) ;; ------------------------- ;; clojure.core/vector ; ❶ ;; ([] [a] [a b] [a b c] [a b c d] [a b c d e] [a b c d e f] ;; [a b c d e f & args]) ;; Creates a new vector containing the args.
❶ 我们可以使用 doc 来查看附加到 var "vector" 的元数据中的文档字符串.
设计具有多个元数的函数主要有两个原因:
- 根据参数数量实现略有不同的行为.
- 通过为每个不同元数产生静态编译的入口点来提高性能.
上面 vector 的情况是出于性能考虑: 许多创建向量的调用只涉及少数几个项. 这些调用在编译时已经过优化, 没有运行时分派来选择正确的行为.
6.5. B.5 seqable
"Seqable" 是一个 Clojure 值, 其类型支持 clojure.lang.Seqable 接口, 使得 `(instance? clojure.lang.Seqable value)` 为真. 几乎所有的 Clojure 数据容器都是 "Seqable" 的, 只有少数例外 (瞬态, 数组和结构体).
6.6. B.6 绑定
"绑定" 是符号与其关联值之间的关系. 绑定可以是:
- "局部的", 当绑定包含一个单一的形式时.
let是创建局部绑定的典型方式.defn的参数也是参数名和函数被调用后的值之间的绑定. - "全局的", 当绑定在封闭形式之外保留其值时. 全局绑定通常用
def定义, 并且默认在当前命名空间中可见. 在require之后, 它也可以从其他命名空间中获得. 全局绑定可以随时用alter-var-root更改以指向另一个值. - "动态的", 当绑定值可以被更改 (像全局绑定一样), 但仅在调用线程的上下文中. 如果一个动态绑定发生变化, 它将只对在进行更改的同一线程的上下文中调用的函数可见. 执行相同函数的其他线程将无法看到这些更改. 它需要使用
binding宏.
6.7. B.7 基准测试
基准测试是比较与代码执行相关的指标的一般活动. 最常见的基准测试可能是比较产生大致相同结果的代码片段之间的速度, 以确定哪种解决方案最优. 其他类型的基准测试是关于内存消耗, 临时对象生成 (垃圾回收压力) 或其他与堆栈相关的 (使用了多少堆栈空间).
我们在整本书中都使用了 Criterium 库 (github.com/hugoduncan/criterium) 来在基准测试期间准备 Java 环境. 该库, 除了执行预热周期外, 还会多次重复被基准测试的代码, 收集统计数据, 然后在屏幕上打印出来.
一般来说, criterium.core/quick-bench 足以快速评估两个或多个形式的相对速度. 如果两个形式产生大致相当的结果, 值得使用 criterium.core/bench 来查看更准确的结果.
必要时, 在基准测试之间重新启动 JVM 也是有用的, 以确保测试之间没有依赖关系.
6.8. B.8 Java 互操作
术语 "interop" 是 "interoperability" (互操作性) 的缩写形式. 在 Clojure 中, 这个术语用来描述 Clojure 语法中允许直接调用 Java 方法和类的部分. 术语 "Java interop" 描述了 Clojure 代码调用 Java 方法或构造函数的情况, 这包括以下宏, 操作符和语法:
- "." 点宏启用了大多数 Java 调用. 根据位置 (在空格前, 紧挨着符号之前或之后, 带一个可选的 "-" 破折号), 它决定了调用的语义 (方法调用, 属性访问或构造函数调用).
- "/" 用在类名和方法名之间, 调用该类上的相关静态方法.
- "\^" 类型提示也是 Java 互操作能力的一部分.
6.9. B.9 装箱和自动装箱
"装箱", 在 Java 的上下文中, 指的是将原始类型包装到其对应的引用类型中的选项: 例如, int 包装为 java.lang.Integer, bool 包装为 java.lang.Boolean 等. Java 编译器可以在某些情况下自动执行此操作 (在这种情况下称为自动装箱).
当一个原始类型被分配给一个泛型容器时, 比如对象集合或接受泛型对象作为参数的函数 (绝大多数字节码生成的 Clojure 函数), 自动装箱可能是必需的. 装箱是有成本的, 在与性能相关的场景中应予以考虑. Clojure 允许程序员通过谨慎使用类型提示和其他方式来防止原始类型的装箱.
7. 附录 C:
参考书目
- [Stoyan] Herbert Stoyan, Early LISP history (1956 - 1959), LFP '84 Proceedings of the 1984 ACM Symposium on LISP and functional programming, Pages 299-310, available from the ACM Digital Library at dl.acm.org/citation.cfm?id=802047
- [clojure-style-guide] Bozhidar Batsov. The Clojure Style Guide. github.com/bbatsov/clojure-style-guide
- [oleg-polyvariadic] Oleg Kiselyov. Polyvariadic functions and keyword arguments: pattern-matching on the type of the context. okmij.org/ftp/Haskell/polyvariadic.html
- [compiler-macros] Arthur Lemmens. Compiler macros implementation from Lisp. www.pentaside.org/paper/compilermacro-lemmens/compiler-macros-for-publication.txt
- [random-fail-plane] George Marsaglia. Random Numbers Fall Mainly In The Planes. www.ics.uci.edu/~fowlkes/class/cs177/marsaglia.pdf
- [mccarthy-symbolic] John McCarthy. Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part I. www.brinckerhoff.org/clements/csc530-sp09/Readings/mccarthy-1960.pdf
- [mccarthy-lispmanual] John McCarthy, Lisp I Programmer' s Manual. Available at bitsavers.informatik.uni-stuttgart.de/pdf/mit/rlelisp/LISPIProgrammersManualMar60.pdf and many other links.
Footnotes:
Dvorak 用户经常声称与 QWERTY 用户相比有巨大的好处. 这里有一个比较, 包括其他类型的布局: lifehacker.com/should-i-use-an-alternative-keyboard-layout-like-dvorak-1447772004
manifesto.softwarecraftsmanship.org
参见最新的" Clojure 现状" 2020年调查: clojure.org/news/2020/02/20/state-of-clojure-2020. 文档在语言的主要问题列表中仍然排名靠前.
感兴趣的读者可以通过从 Github 上检出 Clojure 项目并使用以下 git 命令来了解这项工作的范围: git rev-list --reverse --format="- %B %cd" -n 1 HEAD-src/cli/runtime. C# 文件最终在 2007 年的某个时候通过提交 b6db84aea2db2ddebcef58918971258464cbf46f 从项目中移除.
David Miller 在 "Defn" 播客的这一集中谈论了 ClojureCLR 的历史: soundcloud.com/defn-771544745/48-david-miller-and-clojure-on-the-clr
ClojureScript 的努力可以追溯到 2008 年 5 月的 IRC 讨论 web.archive.org/web/http://clojure-log.n01se.net/date/2008-05-29.html#15:26
最初的 ClojureScript 发布公告被录制成视频, 可在 www.youtube.com/watch?v=tVooR-dFAg 观看
这是因为在引导过程中, Clojure 已经导入了几个对最终用户自动可用的命名空间. 非常流行的工具如 nRepl (github.com/nrepl/nrepl) 或 CIDER (github.com/clojure-emacs/cider) 在引导时也会加载库, 这些库随后在提示符下可用. 良好的实践是总是在命名空间中明确 require 有用的东西.
有关 STM 的良好介绍, 请参阅维基百科: en.wikipedia.org/wiki/Softwaretransactionalmemory
EDN 格式在此处描述: github.com/edn-format/edn
"Joy of Clojure" 可在 Manning 网站上获取: www.manning.com/books/the-joy-of-clojure-second-edition
2010 年的第一次调查可在此处获取: cemerick.com/2010/06/07/results-from-the-state-of-clojure-summer-2010-survey/. 最新的一次可在 Cognitect 博客上获取: clojure.org/news/2019/02/04/state-of-clojure-2019
这是与 Clojure.org 网站开源发布相关的求助请求: clojure.org/news/2016/01/14/clojure-org-live
blog.jayfields.com
github.com/functional-koans/clojure-koans
eval 和 apply 是 Lisp 著名的元循环解释器的核心. 整个 Lisp 历史本身就是另一篇引人入胜的读物. 请参阅 Herbert Stoyan 的任何相关论文.
有关有效 Clojure 符号的定义, 请参阅 Clojure Reader 主文档 clojure.org/reader.
有关如何使用 sha256 创建签名的更多信息, 可在此处找到: security.stackexchange.com/questions/20129/how-and-when-do-i-use-hmac
在 Clojure 源码中可以看到这 20 个 Java 方法组的地方, 例如: clojure.lang.IFn
Unix 纪元时间是一种测量相对时间的系统: en.wikipedia.org/wiki/Unixtime
流行的斐波那契数列常用于展示递归调用的实现. 更多信息请参阅维基百科: en.wikipedia.org/wiki/Fibonaccinumber
请参阅: en.wikipedia.org/wiki/Referentialtransparency
在关于这个主题的大量文献中, 我建议这篇对 Lambda 演算的温和介绍: www.cs.bham.ac.uk/~axj/pub/papers/lambda-calculus.pdf
这被称为创建一个 thunk: en.wikipedia.org/wiki/Thunk
Rich Hickey 在以下邮件列表帖子中相当广泛地描述了此功能: groups.google.com/forum/#!topic/clojure/FLrtjyYJdRU
另请参阅 Christophe Grand, 他在他的博客中描述了这种类型的内存泄漏: clj-me.cgrand.net/2013/09/11/macros-closures-and-unexpected-object-retention/
这是 fnil 的原始用例, 如 Clojure 邮件列表中的这个帖子所记录: <groups.google.com/d/msg/clojure/mcxKa5mWm4/CkSrutnPUfIJ, https://groups.google.com/d/msg/clojure/mcxKa_5mWm4/CkSrutnPUfIJ>
已经有一个改进版的 fnil 在这个补丁中提出, 准备添加到 Clojure 核心.
这种组合风格也称为无点风格
一篇介绍恒等函数概念的维基百科文章 en.wikipedia.org/wiki/Identityfunction
这句话归功于 Phil Karlton, 他曾是 Netscape 的架构师. 参见: skeptics.stackexchange.com/questions/19836/has-phil-karlton-ever-said-there-are-only-two-hard-things-in-computer-science
维基百科上关于组合逻辑的文章是对该主题的一个很好的介绍: en.wikipedia.org/wiki/Combinatorylogic
关于为什么 Clojure 线程运算符不能被认为是真正的 T-组合子, 请看 Michael Fogus 在他的博客上的非常好的解释 blog.fogus.me/2010/09/28/thrush-in-clojure-redux/
Clojure 风格指南 github.com/bbatsov/clojure-style-guide#literal-col-syntax
Enlive HTML 解析库可以在这里找到: github.com/cgrand/enlive
github.com/LonoCloud/synthread
github.com/pallet/thread-expr
维基百科文章包含对 Levenshtein 距离算法的良好介绍: en.wikipedia.org/wiki/Levenshteindistance
参阅维基百科上可用的度量标准列表: en.wikipedia.org/wiki/Stringmetric
在 Java 中使用 SoftReference 进行缓存的示例有很多. 这是一个很好的起点: www2.sys-con.com/itsg/virtualcd/java/archives/0507/shields/index.html
一个估算在 Java 中存储字符串所需内存量的足够好的公式是: www.javamex.com/tutorials/memory/stringmemoryusage.shtml
石头剪刀布是一个非常简单和流行的游戏: en.wikipedia.org/wiki/Rock-paper-scissors
这个 StackOverflow 问题总结了 Common Lisp 中两种不同 let 形式的辩论: stackoverflow.com/questions/554949/let-versus-let-in-common-lisp
"no.disassemble" 在 Github 上可用: github.com/gtrak/no.disassemble
core.async 是 Clojure 中一个流行的库, 用于建模并发或异步过程. 该项目的主页是: github.com/clojure/core.async
Clojure 中的 letrec 实现可以在这里找到: gist.github.com/michalmarczyk/3c6b34b8db36e64b85c0
Arc 编程语言: arclanguage.github.io/ref/
en.wikipedia.org/wiki/Truthtable
有关逻辑连接词的更多信息, 请参阅维基百科页面 en.wikipedia.org/wiki/Logicalconnective
请参阅维基百科页面 en.wikipedia.org/wiki/Bitwiseoperation 以获得深入的概述.
FizzBuzz, 在开发者面试中也很流行, 是一个教孩子们除法的游戏: en.wikipedia.org/wiki/Fizzbuzz
这里有一个关于扑克标准规则的很好的总结: en.wikipedia.org/wiki/Listofpokerhands
讨论 fcase 和 condp 被包含到标准库中的帖子: groups.google.com/forum/#!topic/clojure/3ukQvvYpYDU
为 condp 讨论增加 :>> 的帖子: groups.google.com/d/msg/clojure/DnULBF2HAfc/1nfJS7n3BQYJ. 它是由 Meikel Brandmeyer 提出的.
Scheme 中的 cond 文档可在此处获取: docs.racket-lang.org/guide/conditionals.html
要了解更多关于 "tableswitch" JVM 指令的信息, 请阅读这篇关于 Java 虚拟机中控制流的文章: www.artima.com/underthehood/flowP.html
Vim 是一款流行的文本编辑器, 由于其编辑上下文, 它的键组合非常短. 更多信息请参阅 en.wikipedia.org/wiki/Vim(texteditor).
在这张工单上可以看到一系列很好的 case 边界情况: clojure.atlassian.net/browse/CLJ-426
请参阅 www.owasp.org/index.php/Javagotchas #ImmutableObjects.2FWrapperClassCaching 了解 Java 内部对装箱值的缓存是如何工作的.
也许对递归计算和尾调用优化最好的解释之一是在 SICP, <计算机程序的结构和解释>中: mitpress.mit.edu/sites/default/files/sicp/full-text/book/book-Z-H-11.html#%sec1.2.1
斐波那契数列的特点是, 该系列中的每个数都是前一个数的和: en.wikipedia.org/wiki/Fibonaccinumber
自动装箱是将原始类型自动转换为相应的包装类 (例如 Java 中的 int 到 Integer). 装箱通常成本很小, 但在 Clojure 中, 当可以使用原始类型但却被函数调用转换为其包装对象时, 会产生很大的影响. 如果没有类型提示, Clojure 将需要将一个函数编译成能够处理任何类型参数的通用字节码 (例如, 使用一个通用的 java.lang.Object).
牛顿法可以推广到其他问题, 不仅仅是平方根计算. 更多细节可在 en.wikipedia.org/wiki/Newton%27smethod#Squarerootofanumber 上获取.
这里有一个关于如何选择初始猜测值的更详细的解释: math.stackexchange.com/questions/787019/what-initial-guess-is-used-for-finding-n-th-root-using-newton-raphson-method
Clojure 对自动尾递归的支持经常在邮件列表中被讨论. 一个解释了 Clojure 选择使用 loop-recur 而不是自动尾递归的理由的帖子可以在这里找到: groups.google.com/forum/#!msg/clojure/4bSdsbperNE/tXdcmbiv4g0J
维基百科对回文有很好的描述: en.wikipedia.org/wiki/Palindrome
请参阅 en.wikipedia.org/wiki/AKSprimalitytest
康威的生命游戏是细胞自动机的一个经典例子: en.wikipedia.org/wiki/Conway%27sGameofLife
en.wikipedia.org/wiki/Cellularautomaton
SHA-256 是一种非常著名的加密和哈希函数. 详情请见 en.wikipedia.org/wiki/SHA-2.
本着寻求最佳性能的精神, 这里介绍的 Fizz Buzz 版本还有其他重要因素需要考虑, 但本章不作讨论, 因为与讨论无关.
例如, 请看这个关于处理子序列时遇到的常见保留头部问题的优秀 StackOverflow 回答: stackoverflow.com/questions/15994316/clojure-head-retention
本书会在必要时尝试阐明集合和序列之间的区别, 但一个好的起点是 Alex Miller 关于序列的这篇文章: insideclojure.org/2015/01/02/sequences/
更多关于复利计算的例子请见 en.wikipedia.org/wiki/Compoundinterest
参见谷歌的论文, 该论文不久前普及了这个话题: research.google.com/archive/mapreduce.html
请阅读维基百科上关于移动平均线的文章 en.wikipedia.org/wiki/Movingaverage 以了解更多信息.
reduce 反而在 Java 中对大多数 Clojure 集合实现为一个 for 循环.
同像性是一种语言的属性, 其中它的语法用语言本身的数据结构来表示, 参见 en.wikipedia.org/wiki/Homoiconicity
core.async 库也许是最好的例子之一, 它实现了一个源到源的重写编译器, 作为一个单一的宏 github.com/clojure/core.async
宏中的卫生性与防止在宏外部定义的符号与宏内部发生的事情冲突有关. 有关该主题的初步概述, 请参阅 en.wikipedia.org/wiki/Hygienicmacro
关于意外符号捕获和卫生宏的问题, 更多信息请见: en.wikipedia.org/wiki/Hygienicmacro
一个使用 &env 的宏的实际真实世界例子是 core.async 的 go 宏, 这可能是迄今为止编写的最复杂的 Clojure 宏.
有关 LISP 中宏历史的更深入分析, 请参阅 Guy Steele 和 Richard Gabriel 的 "The Evolution of LISP" 第 3.3 章: www.csee.umbc.edu/courses/331/resources/papers/Evolution-of-Lisp.pdf
这在 Kent Pitman 1980 年代的论文 "Special Forms in LISP" 中有详细讨论: www.nhplace.com/kent/Papers/Special-Forms.html
www.newlisp.org/
picolisp.com/
Backus–Naur 范式, 一种用于描述语言语法的语言, 参见: en.wikipedia.org/wiki/Backus–NaurForm
参见 Clojure wiki 页面关于宏语法, 以了解当前正在进行的工作类型: archive.clojure.org/design-wiki/display/design/Home.html)
一阶逻辑是一种用于逻辑推理的形式系统. 与其他形式系统 (如命题逻辑) 相比, 一阶逻辑还允许对项目集合的逻辑表达式进行量化. 更多信息请参阅 en.wikipedia.org/wiki/First-orderlogic.
函数内联是编译器在编译时用函数体替换函数调用的内部过程. 更多信息可在维基百科上找到: en.wikipedia.org/wiki/Inlineexpansion
参见 clojure.atlassian.net/browse/CLJ-1227
参见 Clojure wiki 上的 archive.clojure.org/design-wiki/display/design/Inlined%2Bcode.html
一份使用内联的项目的部分列表可在 Clojure 邮件列表上找到: groups.google.com/d/msg/clojure-dev/UeLNJzp7UiI/WA6WALO6EPYJ
有关有效的 Clojure 符号的定义, 请参阅 Clojure Reader 主文档 clojure.org/reference/reader.
有关解构的更深入指南, 请参阅: clojure.org/guides/destructuring
grokbase.com/t/gg/clojure/124q5bb8y1/stackoverflowerror-caused-by-apply-template#20120423oadz7ag6ufqed27u2jsxsk5e64
github.com/clojure/core.unify
这篇简单的维基百科文章还说明了其他操作的单位元: en.wikipedia.org/wiki/Identityelement
要了解更多关于黎曼 zeta 函数的信息, 请参阅维基百科上的介绍性文章 en.wikipedia.org/wiki/Riemannzetafunction
随着 Java 8 的引入, 现在有一组新的算术运算, 在溢出/下溢的情况下会抛出异常, 正如 Clojure 一样. 例如, 请参阅: docs.oracle.com/javase/8/docs/api/java/lang/Math.html#addExact-long-long-
维基百科上这篇关于欧几里得除法的文章很好地解释了商和余数: en.wikipedia.org/wiki/Euclideandivision
维基百科上关于余数操作的文章也澄清了每种语言如何区分模和余数: en.wikipedia.org/wiki/Remainder
NaN (或非数字) 是一种特殊类型的数字, 在现代计算机体系结构中无法表示. 参见 en.wikipedia.org/wiki/NaN.
维基百科上有一篇关于最近邻问题的很好的介绍: en.wikipedia.org/wiki/Nearestneighborsearch
有关 Haversine 公式的示例和解释, 请参阅以下维基百科文章: en.wikipedia.org/wiki/Haversineformula
和往常一样, 维基百科有一篇关于 Java 中使用的随机算法类型的很好的介绍性文章, 称为线性同余生成器 en.wikipedia.org/wiki/Linearcongruentialgenerator
早期编程时代臭名昭著的 RANDU 生成器在 en.wikipedia.org/wiki/RANDU 中有描述.
这是关于 Diffie-Hellman 密钥交换算法的非常易于访问的维基百科条目: en.wikipedia.org/wiki/Diffie–Hellmankeyexchange
对于未检查的运算符在存在装箱数字时回退到已检查的数学的问题, 请参阅以下工单: clojure.atlassian.net/browse/CLJ-1832
原始的 Murmur3 算法是用 C++ 编写的, 可以在这里看到: github.com/aappleby/smhasher/blob/master/src/MurmurHash3.cpp
这篇文章中有一个很好的关于布雷森汉姆算法家族所用机制的插图 www.cs.helsinki.fi/group/goa/mallinnus/lines/bresenh.html
参见此问题的相关 Jira 工单 clojure.atlassian.net/browse/CLJ-1905
要了解更多信息, 请参阅以下 StackOverflow 回答 stackoverflow.com/questions/588004/is-floating-point-math-broken
Java 语言规范包含对可能转换和提升的广泛描述: www.cs.cornell.edu/andru/javaspec/5.doc.html
维基百科上的浮点数条目是对这个棘手主题所有相关内容的一个很好的总结: en.wikipedia.org/wiki/Floatingpoint
请参阅 docs.oracle.com/javase/7/docs/api/java/lang/Comparable.html 关于 Java 中的 Comparable
计算两个地理位置之间距离的公式可能会有所不同, 比如我们在邮局问题中看到的 Haversine 公式
请阅读维基百科关于哨兵的文章以获取更多背景信息: en.wikipedia.org/wiki/Sentinelvalue
关于这个影响 sorted-map 上 diff 的 bug, 请参见 clojure.atlassian.net/browse/CLJS-1709
Fork-Join 并行计算模型是一个复杂的主题, 无法在本书中详尽说明. 如果你想了解更多, 请阅读 Java 中 Fork-join 的作者 Doug Lea 的这篇论文: gee.cs.oswego.edu/dl/papers/fj.pdf
Iota 库的 README 解释了如何使用该库: github.com/thebusby/iota
有关该主题的介绍, 请参阅维基百科页面: en.wikipedia.org/wiki/Monoid
请参阅以下维基百科文章以了解更多关于埃及乘法的信息 en.wikipedia.org/wiki/AncientEgyptianmultiplication
块大小为 32 的原因是 eduction 返回一个 java.lang.Iterable, Clojure 中所有序列感知函数都以 32 项为一组的块来迭代它.
感谢 Max Penet (@mpenet on the Slack Clojurians group chat) 建议在书中加入这个比较
请阅读维基百科上关于移动平均线的文章 en.wikipedia.org/wiki/Movingaverage
一个抽象数据类型 (或 ADT) 描述了一个数据结构的行为, 而与其具体实现无关. 最常见的 ADT 的概述可在 en.wikipedia.org/wiki/Abstractdatatype 上找到.
块状序列是 Clojure 在幕后实现的性能优化的副产品.
哈希是将一个哈希函数应用于一个对象的操作. 哈希函数总是将对象转换为一个数字.
VisualVM 是一个免费的 JVM 分析器, 可以从 visualvm.github.io 下载
在关于用 seq 检查空集合的邮件列表上有几个帖子, 这是其中一个最清晰的: groups.google.com/forum/#!topic/clojure/yW1Xw1dllJ8
一些瞬态与集合操作不兼容的问题在此 Jira 工单中有描述: clojure.atlassian.net/browse/CLJ-700
Clojure 中使用红黑树来实现排序集合. 有关更多信息, 请参阅以下维基百科条目: en.wikipedia.org/wiki/Red–blacktree
这个来自邮件列表的长帖子总结了与 contains? 相关的许多担忧: groups.google.com/d/msg/clojure/bSrSb61u-8/3AmJbVYOrzwJ
HAMT (哈希数组映射树) 是 Phil Bagwell 首先提出的一种数据结构. 参见: lampwww.epfl.ch/papers/idealhashtrees.pdf
请注意, 记录不支持超过 255 个字段, 因此在整个测试中都使用了固定大小的记录.
水塘抽样是一系列专用于从任意大的输入中随机选择一个样本的算法. 算法 "R" 是这类算法中最常见的例子. 更多信息请参阅 en.wikipedia.org/wiki/Reservoirsampling.
维基百科上有一篇关于归并排序的非常详细的文章, 可在 en.wikipedia.org/wiki/Mergesort 获取
Timsort 最初是为 Python 语言实现的, 随后被 Java 采纳. 更多信息请参见 en.wikipedia.org/wiki/Timsort.
我们无法在书中添加太多关于 DNA 转录的细节. 然而, 其原理在这篇维基百科条目中有清晰的解释: en.wikipedia.org/wiki/Complementarity(molecularbiology) #DNAandRNAbasepaircomplementarity
Gerard Huet 在他 1993 年的论文中引入了 zipper 的形式化表示: gallium.inria.fr/%7ehuet/PUBLIC/zip.pdf
en.wikipedia.org/wiki/Palindromicsequence
关于高效 DNA 处理的主题, 请参见 www.ncbi.nlm.nih.gov/pmc/articles/PMC3602881/
请参阅维基百科上关于红黑树的这篇一般性介绍: en.wikipedia.org/wiki/Red–blacktree
"Purely Functional Data Structures" 是函数式编程中的一本重要书籍, 它描述了如何持久地实现最常见的数据结构, 即通过结构共享来保留旧版本.
参见 groups.google.com/forum/#!msg/clojure/CqV6smX3R0o/ZnnimboYjQJ
背压是事件驱动系统中的一个重要概念, 我们希望下游组件能够限制上游生产者. Zach Tellman 的这个演讲 www.youtube.com/watch?v=1bNOO3xxMc0 很好地介绍了关键概念.
ElasticSearch 是一个流行的文档存储. 对 ElasticSearch 的查询可以在 JSON 格式中检索可能大的文档列表.
莱布尼茨公式在专门的维基百科页面 en.wikipedia.org/wiki/Leibnizformulaforπ 上有很好的描述.
计数标记是具有单一符号的简单数字系统. 符号的数量是总数, 而它们的分组是帮助计算大数的视觉工具. 有关更多信息, 请参阅维基百科条目: en.wikipedia.org/wiki/Tallymarks
埃拉托斯特尼筛法可能是研究惰性效应最具有教学意义的算法之一. 这里介绍的朴素版本远非寻找素数的最佳算法, 但它相对容易理解. 这篇维基百科页面描述了基本形式的增强以及指向其他算法的链接: en.wikipedia.org/wiki/SieveofEratosthenes#Algorithmiccomplexity
高效生成素数的问题是广泛而迷人的: 如果你想了解更多, 这篇关于" 真正的埃拉托斯特尼筛法" 的论文值得一读: www.cs.hmc.edu/~oneill/papers/Sieve-JFP.pdf
超级计算机现在能够计算更多的数字, 参见 en.wikipedia.org/wiki/Pi#Modernquestformoredigits
JDBC, Java 数据库连接框架, 是著名的 Java 特性之一. 关于该框架的概述以及如何使用它, 请查阅 Java 教程 docs.oracle.com/javase/tutorial/jdbc/basics/index.html
Java 标准库中没有 ConcurrentHashSet, 但可以获得一个由 ConcurrentHashMap 支持的 KeySet, 它起到类似的作用. 更多信息请参阅 docs.oracle.com/javase/8/docs/api/java/util/concurrent/ConcurrentHashMap.html#newKeySet–
Stuart Sierra 写了一篇关于同样问题的文章 stuartsierra.com/2015/04/26/clojure-donts-concat
core.clj 是 Clojure 代码库中的主要标准库文件: github.com/clojure/clojure/blob/master/src/clj/clojure/core.clj
最近的较小值搜索是许多算法中使用的优化, 例如归并排序. 请参阅维基百科条目以获得概述: en.wikipedia.org/wiki/Allnearestsmallervalues
引入 lazy-seq 并移除 lazy-cons 的理由在 Clojure 官方网站的这个页面上有描述: clojure.org/reference/lazy. 该页面现在主要用于历史目的.
拓扑排序的典型应用是 Java classpath 的排序, 以便类只有在满足其所有依赖项时才被加载. 维基百科条目有更多例子: en.wikipedia.org/wiki/Topologicalsorting
参见 en.wikipedia.org/wiki/Datadeduplication
JVM 实现快速查找开关的方式有一些复杂性, 如果你想了解更多, 这是一个很好的起点 stackoverflow.com/questions/10287700/difference-between-jvms-lookupswitch-and-tableswitch
Clojure 1.1 的完整发布说明可以在这里看到 github.com/richhickey/clojure/blob/68aa96d832703f98f80b18cecc877e3b93bc5d26/changes.txt#L92, 这个链接指向分块序列函数
有关 HAMT 实现细节的更多信息, 请参阅向量章节.
有几个接口共同定义了映射的抽象: clojure.lang.ILookup 是最通用的, 定义了从键查找值的行为. clojure.lang.Associative 添加了为特定键添加值的行为. 最后, clojure.lang.IPersistentMap 进一步完善了抽象, 添加了 dissoc 键的选项 (在接口上称为 without).
优先队列是一种类似于队列的数据抽象类型, 其中每个项也被分配一个优先级. 优先级用于决定下一个出队的元素. 更多信息请参阅维基百科条目: en.wikipedia.org/wiki/Priorityqueue
en.wikipedia.org/wiki/A*searchalgorithm
红黑树是一种灵活的数据结构. 与普通二叉树相比, 红黑树提供了自我调整以避免不平衡的分支. 请查看维基百科文章以了解更多信息 en.wikipedia.org/wiki/Red–blacktree
VisualVM 可从 visualvm.github.io 免费获得
参见: clojure.atlassian.net/projects/CLJ/issues/CLJ-1005
clojure.atlassian.net/browse/CLJ-1789
比较和交换 (CAS) 是 Clojure 并发原语: atom, ref 和 agent 使用的语义. 它包括尝试一个非同步的变异操作, 然后检查原始值. 只有当原始值仍然完好无损时, 新值才会被提交到 atom 中.
参见: news.ycombinator.com/item?id=6446922
参见 hackage.haskell.org/package/persistent-vector-0.1.1/docs/Data-Vector-Persistent.html
P. Bagwell. Ideal Hash Trees. 技术报告, EPFL, 2001. lampwww.epfl.ch/papers/idealhashtrees.pdf
关于 Clojure 中向量工作原理的更详细但仍然易于理解的解释, 请参见 J. N. L' orange 的博客 hypirion.com/musings/understanding-persistent-vector-pt-1
以下是一些与 RBB-trees 相关的链接, 可能对进一步探索感兴趣: Bagwell 的 RRB-Trees 论文 infoscience.epfl.ch/record/169879/files/RMTrees.pdf, 一个 Clojure 实现 github.com/clojure/core.rrb-vector 和 提高 RRB-Tree 性能 hypirion.com/thesis.pdf
Clojure 风格指南 github.com/bbatsov/clojure-style-guide#literal-col-syntax
矩阵的转置是一个新矩阵, 其元素与输入相同, 但行和列的索引交换了. 另见: en.wikipedia.org/wiki/Transpose
github.com/jbellis/jamm
AJAX, "Asynchronous JavaScript and XML" 的缩写, 是一组技术, 允许网页内容更新而无需整个页面刷新. 更多信息请参阅 en.wikipedia.org/wiki/Ajax(programming).
github.com/clojure/core.cache
redis.io/
github.com/dakrone/cheshire
抽象数据类型是数据结构语义的规范, 没有具体细节. 最常见的抽象数据类型在此维基百科页面上有总结: en.wikipedia.org/wiki/Abstractdatatype
参见 Clojure Jira 工单系统 clojure.atlassian.net/browse/CLJ-1705
参见 en.wikipedia.org/wiki/Mandelbrotset
参见 en.wikipedia.org/wiki/Complexnumber
参见 github.com/rachbowyer/csl-10-vector-public
github.com/clojure/clojure/blob/master/src/clj/clojure/gvec.clj
为 vector-of 添加瞬态的开放工单 clojure.atlassian.net/browse/CLJ-1416
github.com/jbellis/jamm
en.wikipedia.org/wiki/Realcoordinatespace
en.wikipedia.org/wiki/Dotproduct#Algebraicdefinition
github.com/clojure/core.async
异步处理有许多可能的候选者. core.async 的独特优势是能够停放等待中的作业, 以便分配的线程可以被重用于活动动作, 从而实现更好的资源分配. 你总是可以用显式的回调实现相同的结果, 但这种方法会导致难以跟踪的副作用代码. 参见 core.async 的理由 clojure.org/news/2013/06/28/clojure-clore-async-channels
这个例子受到了以下 stack overflow 帖子的启发 stackoverflow.com/questions/31858846/waiting-for-n-channels-with-core-async
en.wikipedia.org/wiki/Leibnizformulaforπ
en.wikipedia.org/wiki/Listofrepresentationsofe#Asaninfiniteseries. 令人惊讶的是, 这个公式直到 2004 年才被发现!
"The Joy of Clojure by Michael Fogus and Chris Houser. Chapter 5.2.7"
en.wikipedia.org/wiki/Norm(mathematics)
en.wikipedia.org/wiki/Mergesort
HAMT, 或哈希数组映射树, 是一种树状数据结构, 适用于实现持久性集合. 我们在向量章节的开头介绍了它的一般属性.
在计算中, "蜜罐" 是一种与服务交互的合法机制, 允许区分欺诈性使用, 更多信息请参阅 en.wikipedia.org/wiki/Honeypot(computing)
Telnet 在许多 Linux 发行版, Mac OS 和 Windows 中默认安装 (尽管在 Windows 上可能需要配置才能启用).
关于集合论和其他可能的操作的更多信息, 请参阅维基百科页面: en.wikipedia.org/wiki/Settheory
关系代数定义了处理存储在关系数据库中的数据的操作的语义. 它大约在 1970 年在 IBM 发明. 更多信息请参阅 en.wikipedia.org/wiki/Relationalalgebra.
请参阅 en.wikipedia.org/wiki/Relationalalgebra.
关于并发问题中锁定的介绍, 请参见 en.wikipedia.org/wiki/Lock(computerscience)
香烟和吸烟者问题在此维基百科页面中有描述 en.wikipedia.org/wiki/Cigarettesmokersproblem
要了解更多关于 STM 的信息, 请查阅以下链接: en.wikipedia.org/wiki/Softwaretransactionalmemory
STM 内部确实使用了一定程度的锁定. STM 是 "无锁" 的说法是从用户的角度来看的, 而不是内部实现
STM 的行为相当复杂. 解释 STM 细节的最好的文档之一是 java.ociweb.com/mark/stm/article.html
像例子中的环境变量可以使用 Java 互操作调用 (System/getenv) 来检索. (System/getenv) 返回的类型是 java.util.Collections$UnmodifiableMap, 对于它没有默认的 reduce-kv 实现:
(reduce-kv (fn [m k v] (assoc m (transform k) v)) {} (System/getenv)) ; ❶ ;; IllegalArgumentException No implementation of method: :kv-reduce ;; of protocol: #'clojure.core.protocols/IKVReduce found for class: ;; java.util.Collections$UnmodifiableMap
❶ reduce-kv 没有为 (System/getenv) 返回的映射类型提供特定的实现. transform 在前面的例子中定义.
为了解决这个问题, 我们需要为 (System/getenv) 返回的映射类型提供一个合适的 reduce-kv 实现. 事实证明, java.util.Collections$UnmodifiableMap 扩展了 java.util.Map, 所以在解决环境变量问题的同时, 我们也解决了许多其他 Java 映射类型的问题:
(import 'java.util.HashMap) (extend-protocol clojure.core.protocols/IKVReduce ; ❶ java.util.Map ; ❷ (kv-reduce [m f init] (let [iter (.. m entrySet iterator)] ; ❸ (loop [ret init] (if (.hasNext iter) ; ❹ (let [^java.util.Map$Entry kv (.next iter)] (recur (f ret (.getKey kv) (.getValue kv)))) ret))))) (reduce-kv (fn [m k v] (assoc m (transform k) v)) {} (System/getenv)) ; ❺ ;; {:jenv-version "oracle64-1.8.0.121", ;; :tmux "/private/tmp/tmux-502/default,2685,2", ;; :term-program-version "3.1.5", ;; :github-username "reborg" ;; ...} (reduce-kv (fn [m k v] (assoc m (transform k) v)) {} (System/getProperties)) ; ❻ ;; {:java.vm.version "25.121-b13", ;; :java.specification.name "Java Platform API Specification", ;; :java.io.tmpdir "/var/folders/25/T/", ;; :java.runtime.name "Java(TM) SE Runtime Environment", ;; ...}
❶ 专门用于 reduce-kv 扩展的协议是 clojure.core.protocols/IKVReduce.
❷ 我们想使用专门的 extend-protocol 函数将协议扩展到 java.util.Map 类型.
❸ 迭代 Java Map 最快的方法是获取 entrySet (通常在内部缓存), 它提供了一个迭代器实例. 迭代器按顺序返回所有条目.
❹ 迭代的主要设计包括一个 loop-recur 指令, 直到迭代器 .hasNext 返回 true. 每次迭代, 我们读取条目的内容, 用到目前为止的结果, 键和值调用 "f". 调用 "f" 的结果按惯例是下一个结果的累积, 用于下一次迭代.
❺ 现在对 (System/getenv) 的 reduce-kv 调用会产生对相关协议扩展的多态调用, 产生预期的结果 (为简洁起见, 已截断).
❻ 类似地, 其他实现 java.util.Map 接口的 Java 类型现在也返回结果, 比如这个对 (System/getProperties) 的调用.
Erlang 是一种流行的函数式语言, 具有坚实的工业历史. 它推广了 "actor" 并发方法, 许多其他语言都从中获得了灵感. Clojure 的 agent 与 actor 有一些相似之处, 但在几个方面也有根本的不同.
ForkJoin 池也被 reducer 使用. 请参考相关章节以了解更多关于 fork-join 范式和工作窃取的信息.
跨函数调用锁定的需求很少见, 并且难以正确实现. 这篇文章阐述了一些需要这种实现的情况: www.ibm.com/developerworks/java/library/j-jtp10264/
参见 "The Definition of Standard ML" by Milner and others.
Rich Hickey 在这篇 Clojure 邮件列表的帖子中阐述了为什么 Clojure 中有这么多方法来生成类: groups.google.com/forum/#!msg/clojure/pZFl8gj1lMs/qVfIjQ4jDDMJ
在 Clojure 中, 符号或关键字的限定意味着它们被分配了一个命名空间引用. 命名空间关系的存在是可选的.
Java 语言规范的版本可从 docs.oracle.com/javase/specs/ 获得
AOT 编译在 Clojure 中用于在磁盘上生成物理类文件. 生成的类包含运行 Clojure 应用程序所需的字节码. 当类不保存到磁盘 (默认) 时, Clojure 只是在内存中生成它们. AOT 编译可用于避免分发 Clojure 源代码或加速 Clojure 启动时间.
gen-class 和 gen-interface 的文档很完善, 正如你在 REPL 中输入 (clojure.repl/doc gen-class) 时所看到的那样.
JavaBeans 规范可从 www.oracle.com/technetwork/java/javase/documentation/spec-136004.html 获得
当我们说一个数据结构提供 "Clojure 映射语义" 时, 我们的意思是通过名称访问属性的能力, 类似于在映射中通过键访问值.
Java 抽象类包含已实现的方法和抽象方法的混合. 在你将其子类化并提供缺失的实现部分之前, 你不能实例化一个抽象类.
github.com/stuartsierra/component
请参见 github.com/clojure/tools.namespace
应用程序的非功能性需求是所有不直接由业务需求驱动的方面: 日志记录, 跟踪, 性能, 稳定性, 健壮性等都对代码有影响, 但它们不是应用程序的主要目标.
请回顾 "Var 和命名空间" 的引言, 以获取关于库概念的解释.
读宏条件是一个相对较新的特性, 用于支持 Clojure 在其他平台上的实现, 特别是 ClojureScript 和 ClojureCLR. 更多信息请参见 clojure.org/guides/readerconditionals.
EDN 的理由和总体设计可在 github.com/edn-format/edn 获得
XP 漂亮打印库的描述在此有详细介绍 dspace.mit.edu/bitstream/handle/1721.1/6503/AIM-1102.pdf. 该论文还包含历史注释, 将我们的 Clojure cl-format 一直追溯到 1977 年 MacLisp 的原始打印系统.
docs.oracle.com/en/java/javase/14/docs/api/java.base/java/util/Formatter.html
clojure.pprint.cl-format 命名空间的源代码文档很完善, 值得一读: github.com/clojure/clojure/blob/master/src/clj/clojure/pprint/clformat.clj
这个例子改编自以下论文: cybertiggyr.com/fmt/fmt.pdf
www.gigamonkeys.com/book/a-few-format-recipes.html
序列化是一种将任意嵌套的数据结构或对象 (在 Java 的情况下) 持久化到磁盘或网络的机制. 这个名字来源于一个事实, 即通常在内存中显示为数据图的东西被扁平化为一排字节, 以便在网络上传输. 然后在字节被反序列化回其原始形状时恢复该图.
Tom Faulhaber 在这篇帖子 groups.google.com/d/msg/clojure/hkDA8zotzUc/x3b-QBbBfvYJ 中向 Clojure 邮件列表宣布了 cl-format 库.
关于历史观点, 请参见 groups.google.com/d/msg/clojure/5wRBTPNu8qo/1dJbtHX0G-IJ. 后缀 "dup" 指的是 "duplication", 因为打印的对象一旦从字符串中被评估回来, 实际上就被复制了.
统一资源定位符是描述互联网上资源位置的常规格式, 由以下 RFC 定义: tools.ietf.org/html/rfc1738
整本书和网站都专门介绍正则表达式. 一个有用的在线资源是这个网站.
这篇文章包含了一些加速正则表达式的技巧: www.loggly.com/blog/five-invaluable-techniques-to-improve-regex-performance/
Unicode 在空白字符的名下定义了大约 25 个字符: en.wikipedia.org/wiki/Whitespacecharacter#Unicode
参见 Conor McBride 的论文: www.staff.city.ac.uk/%7Eross/papers/Applicative.html
关于锁定的介绍, 请参见 en.wikipedia.org/wiki/Lock(computerscience).
core.async 是一个 Clojure 库, 实现了称为并发顺序进程 (CSP) 的一种并发形式.
下面的教程对 Java 字段可见性选项有一个很好的总结 docs.oracle.com/javase/tutorial/java/javaOO/accesscontrol.html.
JavaBean 规范可从 www.oracle.com/technetwork/java/javase/documentation/spec-136004.html 获得
(参见 en.wikipedia.org/wiki/Transpose).
一个好的起点是 clojure.org/reference/javainterop#typehints
XML 文档可以指定一个它们应该被强制遵守的模式. XML 解析器通常会遵循该指令并根据模式验证内容. 在某些文档损坏或缺乏网络连接的情况下, 我们可能需要关闭验证才能加载文档. 所有解析器功能的列表可在此处获得: xerces.apache.org/xerces2-j/features.html
Java Swing 框架是自 Java 1.2 起标准库的一部分的窗口工具包. 更多信息请参阅维基百科的介绍页面: en.wikipedia.org/wiki/Swing(Java).
在类 Unix 系统中, 管道 (或简称 "pipe") 是一种进程间通信机制.
Socket REPL 特性由 Alex Miller 与 Clojure 核心团队合作实现. 你可以在这里找到 Replicant 库: github.com/puredanger/replicant
古老的 Telnet 协议是一种通过网络使用终端的方式. Telnet 也是连接到远程套接字的客户端工具的名称, 不仅仅是协议.
描述 URI 的 RFC 可从 tools.ietf.org/rfc/rfc3986.txt 获得
流式接口是一种 API, 其中函数被设计为可以链式调用. 另请参见: en.wikipedia.org/wiki/Fluentinterface
关于 Javadoc 的概述, 请查看 en.wikipedia.org/wiki/Javadoc
在基于 Unix 的系统上, 我们可以使用以下 `2>&1` (在 Bash shell 中) 或 `>&` (在 C Shell 中) 将标准错误流重定向到标准输出.
Java 类加载器及其用法的主题对于本书来说太宽泛了. 关于类加载器的介绍, 请参阅以下文章: www.baeldung.com/java-classloaders
OSGi 是一个旨在提出和维护组件生命周期隔离标准的倡议. 该实现大量使用类路径机制来隔离加载整个组件 (或同一组件的多个版本). 更多信息, 请访问: en.wikipedia.org/wiki/OSGi.
好奇的读者可以看看下面的代码, 它显示了动态变量最初是如何使用的.
你可以从 www.oracle.com/java/technologies/javase-jdk11-doc-downloads.html 下载 Javadoc 归档文件.
支持的操作的全部范围在此 "Intrinsics" 表中可见: github.com/clojure/clojure/blob/master/src/jvm/clojure/lang/Intrinsics.java#L22
维基百科上关于数理逻辑中谓词的文章是 en.wikipedia.org/wiki/Predicate(mathematicallogic)