Git:从底层原理讲起
Table of Contents
2009年12月2日, 星期三 作者: John Wiegley
在我探寻和理解 Git 的过程中, 我发现从底层向上理解它,而不是仅仅通过其高层命令来学习,是很有帮助的。而且,从这个角度看,Git 是如此优美简洁,我想其他人或许有兴趣读读我的发现,并可能避免我摸索时所经历的痛苦。
本文档中所有示例均使用 Git 1.5.4.5 版本。
1. 许可协议
http://www.newartisans.com/2008/04/git-from-the-bottom-up.html ©2008,2009 John Wiegley
本文档在知识共享署名-相同方式共享 3.0 美国许可协议 (Creative Commons Attribution-Share Alike 3.0 United States License) 的条款下提供, 你可以在以下网址查看该协议: http://creativecommons.org/licenses/by-sa/3.0/us/
简而言之, 只要保留作者署名, 你可以将本文档内容用于任何个人、商业或其他目的。同样, 只要对文档的修改和衍生作品以与原始文档相同的条款向公众提供, 你就可以修改本文档, 并提供衍生作品和翻译版本。
2. 引言
http://www.newartisans.com/2008/04/git-from-the-bottom-up.html ©2008,2009 John Wiegley
欢迎来到 Git 的世界。我希望本文档能帮助你增进对这个强大的内容追踪系统的理解, 并揭示其背后的一些简洁之处——无论它那令人眼花缭乱的选项从外部看起来有多复杂。
在我们深入之前, 有几个术语需要先提一下, 因为它们会在全文中反复出现:
- 仓库 (repository) 仓库是 commit 的集合, 每个 commit 都是项目工作区在过去某个日期的存档, 无论是在你的机器上还是在别人的机器上。它还定义了 HEAD (见下文), 用于标识当前工作区源自哪个分支或 commit。最后, 它包含一组分支 (branches) 和标签 (tags), 用来通过名称标识特定的 commit。
- 索引 (the index) 与你可能使用过的其他类似工具不同, Git 不会直接将工作区中的更改提交到仓库中。相反, 更改首先被注册到一个叫做索引的地方。可以把它看作是在执行 commit (一次性记录所有你批准的更改) 之前, 逐个“确认”你的更改的一种方式。有些人觉得称之为“暂存区 (staging area)”比索引更有助于理解。
- 工作区 (working tree) 工作区是你文件系统上的任何目录, 它关联着一个仓库 (通常通过其中名为 .git. 的子目录来表示)。它包括该目录中的所有文件和子目录。
- commit commit 是你工作区在某个时间点的快照。你进行 commit 时 HEAD (见下文) 的状态成为该 commit 的父 commit。这就是“修订历史”概念的由来。
- 分支 (branch) 分支只是一个 commit 的名称 (稍后会详细介绍 commit), 也称为引用。commit 的父子关系定义了它的历史, 从而构成了通常所说的“开发分支”。
- 标签 (tag) 标签也是一个 commit 的名称, 类似于分支, 但它始终指向同一个 commit, 并且可以有自己的描述文本。
- master 大多数仓库中的主要开发线是在一个名为 “master” 的分支上完成的。尽管这是典型的默认设置, 但它并没有任何特殊之处。
- HEAD
HEAD 被你的仓库用来定义当前检出 (checked out) 的是什么:
- 如果你检出的是一个分支, HEAD 会符号化地引用该分支, 表明在下一次 commit 操作后, 该分支的名称应该被更新。
- 如果你检出的是一个特定的 commit, HEAD 只引用那个 commit。这被称为分离的 HEAD (detached HEAD), 例如, 当你检出一个标签名时就会发生这种情况。
通常的事件流程是这样的:创建仓库后, 你在工作区中进行工作。一旦你的工作达到一个重要的节点——比如完成一个 bug 修复, 一天工作结束, 或者一个所有代码都能编译的时刻——你便将你的更改逐个添加到索引中。一旦索引包含了你打算提交的所有内容, 你就将其内容记录到仓库中。这里有一个简单的图表演示了一个典型项目的生命周期:
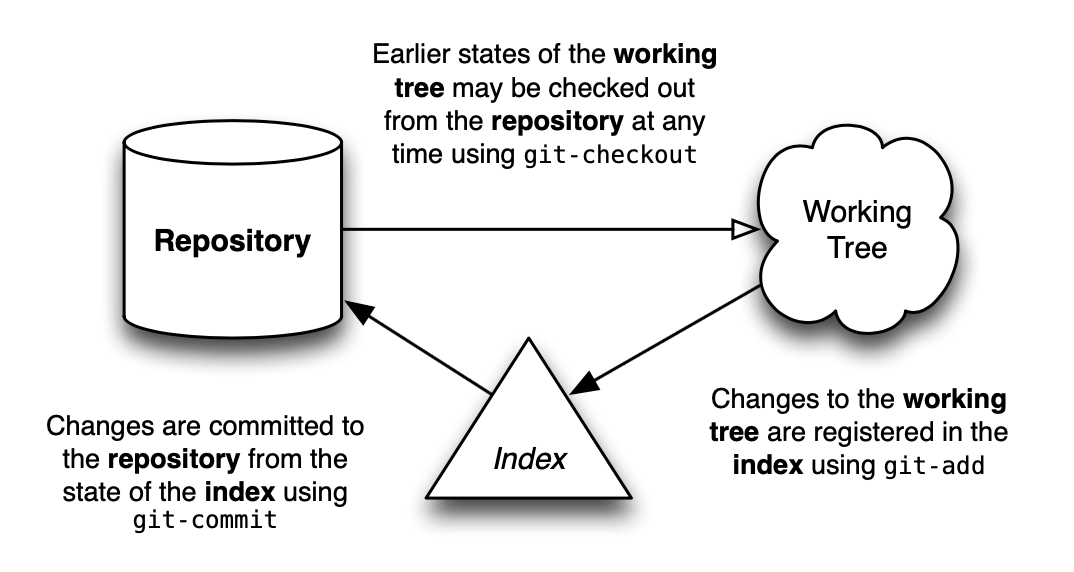 带着这个基本概念¹, 以下各节将尝试描述这些不同实体中的每一个对于 Git 的运作是何等重要。
带着这个基本概念¹, 以下各节将尝试描述这些不同实体中的每一个对于 Git 的运作是何等重要。
- 实际上, 一次 checkout 会导致内容从仓库复制到索引, 然后再写入工作区。但由于用户在 checkout 操作期间从未看到索引的这种用法, 我觉得在图表中不描绘它会更有意义。
3. 仓库:目录内容追踪
http://www.newartisans.com/2008/04/git-from-the-bottom-up.html ©2008,2009 John Wiegley
如上所述, Git 所做的事情相当初级:它维护一个目录内容的快照。其大部分内部设计都可以通过这个基本任务来理解。
Git 仓库的设计在很多方面都反映了 UNIX 文件系统的结构:文件系统以一个根目录开始, 通常包含其他目录, 其中大部分都有叶节点, 即包含数据的文件。关于这些文件内容的元数据存储在目录 (文件名) 和引用这些文件内容的 i-node (大小、类型、权限等) 中。每个 i-node 都有一个唯一的编号, 用于标识其相关文件的内容。虽然你可能有多个目录条目指向一个特定的 i-node (即硬链接), 但“拥有”文件系统上存储内容的是 i-node。
在内部, Git 有着惊人相似的结构, 尽管有一两个关键区别。首先, 它将你的文件内容表示为 blob, 这些 blob 也是一种非常接近目录的结构中的叶节点, 这种结构被称为 tree。正如 i-node 由系统分配的数字唯一标识一样, blob 通过计算其大小和内容的 SHA1 哈希 ID 来命名。出于所有意图和目的, 这只是一个像 i-node 一样的任意数字, 但它有两个额外的属性:首先, 它验证了 blob 的内容永远不会改变; 其次, 相同的内容将始终由相同的 blob 表示, 无论它出现在何处:跨 commit、跨仓库——甚至跨越整个互联网。如果多个 tree 引用同一个 blob, 这就像硬链接一样:只要至少有一个链接指向它, 该 blob 就不会从你的仓库中消失。
Git blob 和文件系统文件之间的区别在于, blob 不存储关于其内容的元数据。所有这些信息都保存在持有该 blob 的 tree 中。一个 tree 可能知道这些内容是一个名为 "foo" 的文件, 创建于 2004 年 8 月, 而另一个 tree 可能知道相同的内容是一个名为 "bar" 的文件, 创建于五年后。在普通文件系统中, 两个内容相同但元数据如此不同的文件总是表示为两个独立的文件。为什么会有这种差异?主要是因为文件系统旨在支持文件变化, 而 Git 则不是。Git 仓库中数据的不可变性是这一切能够运作的原因, 因此需要一种不同的设计。事实证明, 这种设计允许更紧凑的存储, 因为所有内容相同的对象都可以共享, 无论它们在哪里。
3.1. 引入 the blob
现在基本情况已经介绍完毕, 让我们来看一些实际的例子。我将从创建一个示例 Git 仓库开始, 并展示 Git 在该仓库中是如何自底向上工作的。你可以随意跟着阅读操作:
$ mkdir sample; cd sample $ echo 'Hello, world!' > greeting
这里我创建了一个名为 “sample” 的新文件系统目录, 其中包含一个内容平淡无奇的文件。我甚至还没有创建仓库, 但我已经可以开始使用一些 Git 命令来了解它将要做什么。首先, 我想知道 Git 将用哪个哈希 ID 来存储我的问候文本:
$ git hash-object greeting af5626b4a114abcb82d63db7c8082c3c4756e51b
如果你在你的系统上运行这个命令, 你会得到相同的哈希 ID。即使我们正在创建两个不同的仓库 (甚至可能相隔一个世界), 我们在这两个仓库中的 greeting blob 也会有相同的哈希 ID。我甚至可以从你的仓库拉取 commit 到我的仓库中, Git 会意识到我们正在跟踪相同的内容——因此只会存储一份副本!非常酷。
下一步是初始化一个新仓库并将文件提交进去。我现在会一步完成, 然后再分阶段重复一遍, 这样你就能看到底层发生了什么:
$ git init
$ git add greeting
$ git commit -m "Added my greeting"
此时, 我们的 blob 应该正如我们所预期的那样存在于系统中, 使用上面确定的哈希 ID。为了方便起见, Git 只需要哈希 ID 的足够多的数字来唯一地标识它在仓库中的位置。通常六七个数字就足够了:
$ git cat-file -t af5626b blob $ git cat-file blob af5626b Hello, world!
就是它了!我甚至没有查看它在哪个 commit 或哪个 tree 中, 但仅凭内容, 我就能假设它在那里, 而它确实在那里。无论仓库存在多久, 或者它内部的文件存储在哪里, 它都将始终具有这个相同的标识符。这些特定的内容现在被可验证地永久保存了。
通过这种方式, Git blob 代表了 Git 中的基本数据单元。实际上, 整个系统都是关于 blob 管理的。
3.2. Blobs are stored in trees
你的文件内容存储在 blob 中, 但这些 blob 本身几乎没有特征。它们没有名字, 没有结构——毕竟它们只是“blob”。
为了让 Git 表示你文件的结构和命名, 它将 blob 作为叶节点附加到一个 tree 中。现在, 我不能仅通过查看一个 blob 来发现它存在于哪个 tree 中, 因为它可能有许多许多的所有者。但我知道它必须存在于我刚刚创建的 commit 所持有的 tree 中的某个地方:
$ git ls-tree HEAD 100644 blob af5626b4a114abcb82d63db7c8082c3c4756e51b greeting
就是它了!这第一个 commit 将我的 greeting 文件添加到了仓库。这个 commit 包含一个 Git tree, 它有一个单独的叶节点:greeting 内容的 blob。
虽然我可以通过将 HEAD 传递给 ls-tree 来查看包含我的 blob 的 tree, 但我还没有看到该 commit 所引用的底层 tree 对象。这里有几个其他命令可以突出这种差异, 从而发现我的 tree:
$ git rev-parse HEAD 588483b99a46342501d99e3f10630cfc1219ea32 # different on your system $ git cat-file -t HEAD commit $ git cat-file commit HEAD tree 0563f77d884e4f79ce95117e2d686d7d6e282887 author John Wiegley <johnw@newartisans.com> 1209512110 -0400 committer John Wiegley <johnw@newartisans.com> 1209512110 -0400 Added my greeting
第一个命令将 HEAD 别名解码为其引用的 commit, 第二个命令验证其类型, 而第三个命令显示该 commit 所持有的 tree 的哈希 ID, 以及存储在 commit 对象中的其他信息。这个 commit 的哈希 ID 对我的仓库是唯一的——因为它包括我的名字和我创建 commit 的日期——但 tree 的哈希 ID 在你的示例和我的示例中应该是相同的, 因为它包含了相同名称下的相同 blob。
3.3. How trees are made
每个 commit 都持有一个单独的 tree, 但是 tree 是如何制作的呢?我们知道, blob 是通过将文件内容塞入 blob 中创建的——并且 tree 拥有 blob——但我们还没有看到持有 blob 的 tree 是如何制作的, 或者该 tree 是如何链接到其父 commit 的。
让我们再次从一个新的示例仓库开始, 但这次通过手动操作, 这样你就可以感受到引擎盖下到底发生了什么:
$ rm -fr greeting .git
$ echo 'Hello, world!' > greeting
$ git init
$ git add greeting
这一切都始于你第一次将文件添加到索引。现在, 我们只说索引是你用来从文件中初步创建 blob 的工具。当我添加 greeting 文件时, 我的仓库发生了一个变化。我还不能将这个变化看作一个 commit, 但有一种方法可以告诉我发生了什么:
$ git log # this will fail, there are no commits! fatal: bad default revision 'HEAD' $ git ls-files --stage # list blob referenced by the index 100644 af5626b4a114abcb82d63db7c8082c3c4756e51b 0 greeting
这是什么?我还没有向仓库提交任何东西, 但已经有一个对象诞生了。它的哈希 ID 和我开始这一切时得到的相同, 所以我知道它代表我的 greeting 文件的内容。我可以在此时对该哈希 ID 使用 cat-file -t, 我会看到它是一个 blob。事实上, 这与我第一次创建这个示例仓库时得到的 blob 是同一个。相同的文件总是会产生相同的 blob (以防我强调得还不够)。
这个 blob 还没有被任何 tree 引用, 也没有任何 commit。目前它只被一个名为 .git/index 的文件引用, 该文件引用了构成当前索引的 blob 和 tree。所以现在让我们在仓库中创建一个 tree, 让我们的 blob 有个归属:
$ git write-tree # record the contents of the index in a tree 0563f77d884e4f79ce95117e2d686d7d6e282887
这个数字也应该看起来很熟悉:一个包含相同 blob (和子 tree) 的 tree 将始终具有相同的哈希 ID。我还没有 commit 对象, 但现在仓库中有一个 tree 对象持有这个 blob。底层命令 write-tree 的目的就是获取索引的任何内容, 并将它们塞入一个新的 tree 中, 以便创建 commit。
我可以直接使用这个 tree 手动创建一个新的 commit 对象, 这正是 commit-tree 命令所做的:
$ echo "Initial commit" | git commit-tree 0563f77
5f1bc85745dcccce6121494fdd37658cb4ad441f
原始的 commit-tree 命令接受一个 tree 的哈希 ID, 并创建一个 commit 对象来持有它。如果我希望这个 commit 有一个父 commit, 我需要使用 -p 选项明确指定父 commit 的哈希 ID。另外, 请注意这里的哈希 ID 与你系统上出现的不同:这是因为我的 commit 对象引用了我的名字, 以及我创建 commit 的日期, 这两个细节总是与你的不同。
不过, 我们的工作还没有完成, 因为我还没有将这个 commit 注册为当前分支的新头部:
$ echo 5f1bc85745dcccce6121494fdd37658cb4ad441f > .git/refs/heads/master
这个命令告诉 Git, "master" 分支名现在应该引用我们最近的 commit。另一种更安全的方法是使用 update-ref 命令:
$ git update-ref refs/heads/master 5f1bc857
创建 master 后, 我们必须将我们的工作区与它关联起来。通常, 每当你检出一个分支时, 这都会自动发生:
$ git symbolic-ref HEAD refs/heads/master
这个命令将 HEAD 符号化地与 master 分支关联起来。这很重要, 因为将来从工作区进行的任何 commit 现在都会自动更新 refs/heads/master 的值。
很难相信它就这么简单, 但是, 是的, 我现在可以使用 log 来查看我新创建的 commit:
$ git log commit 5f1bc85745dcccce6121494fdd37658cb4ad441f Author: John Wiegley <johnw@newartisans.com> Date: Mon Apr 14 11:14:58 2008 -0400 Initial commit
一个旁注:如果我没有将 refs/heads/master 指向新的 commit, 它就会被认为是“不可达的”, 因为当前没有任何东西引用它, 它也不是任何可达 commit 的父 commit。在这种情况下, commit 对象会在某个时刻被仓库移除, 连同它的 tree 和所有的 blob。(这是由一个名为 gc 的命令自动完成的, 你很少需要手动使用它)。通过将 commit 链接到 refs/heads 内的一个名称, 正如我们上面所做的, 它变成了一个可达的 commit, 这确保了它从现在开始会被保留下来。
3.4. The beauty of commits
一些版本控制系统把“分支”变成了神奇的东西, 常常把它们与“主线”或“主干”区分开来, 而另一些系统则把这个概念讨论得好像它与 commit 截然不同。但在 Git 中, 没有作为独立实体的分支:只有 blob、tree 和 commit²。由于一个 commit 可以有一个或多个父 commit, 而那些 commit 又可以有父 commit, 这就使得单个 commit 可以被看作一个分支:因为它知道导致它的整个历史。
- 嗯, 还有 tag, 但它们只是对 commit 的花哨引用, 暂时可以忽略。
你可以随时使用 branch 命令检查所有顶级的、被引用的 commit:
$ git branch -v * master 5f1bc85 Initial commit
跟我一起说:分支只不过是对一个 commit 的命名引用。通过这种方式, 分支和标签是相同的, 唯一的例外是标签可以有自己的描述, 就像它们引用的 commit 一样。分支只是名字, 而标签是描述性的, 嗯, “标签”。
但事实是, 我们根本不需要使用别名。例如, 如果我愿意, 我可以仅使用 commit 的哈希 ID 来引用仓库中的所有东西。看我多疯狂, 我把我的工作区的 head 重置到一个特定的 commit:
$ git reset --hard 5f1bc85
--hard 选项表示清除我工作区中当前的所有更改, 无论它们是否已为签入注册 (稍后会详细介绍此命令)。做同样事情的一个更安全的方法是使用 checkout:
$ git checkout 5f1bc85
这里的区别在于我工作区中已更改的文件被保留了。如果我向 checkout 传递 -f 选项, 它在这种情况下会像 reset --hard 一样行事, 只不过 checkout 只会更改工作区, 而 reset --hard 会更改当前分支的 HEAD 以引用指定版本的 tree。
基于 commit 的系统的另一个乐趣是, 你可以用单一的词汇来重新表述即使是最复杂的版本控制术语。例如, 如果一个 commit 有多个父 commit, 它就是一个“merge commit”——因为它将多个 commit 合并成一个。或者, 如果一个 commit 有多个子 commit, 它代表一个“分支”的祖先, 等等。但实际上, 对于 Git 来说, 这些东西之间没有区别:对它来说, 世界只是一个 commit 对象的集合, 每个对象都持有一个引用其他 tree 和 blob 的 tree, 这些 tree 和 blob 存储你的数据。任何比这更复杂的东西都只是命名法上的把戏。
这是一个所有这些部分如何组合在一起的图片:
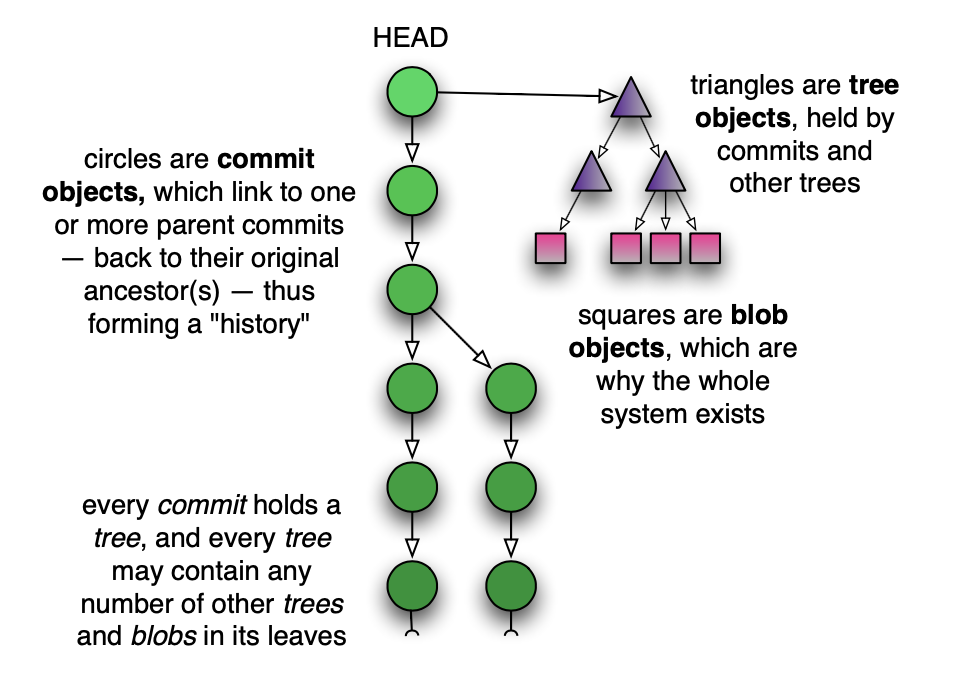
Figure 1: Git 对象关系图
- 圆形是 commit 对象, 它们链接到一个或多个父 commit——追溯到它们的原始祖先——从而形成一个“历史”。
- 每个 commit 都持有一个 tree, 每个 tree 可能在其叶子中包含任意数量的其他 tree 和 blob。
- 三角形是 tree 对象, 由 commit 和其他 tree 持有。
- 方形是 blob 对象, 这是整个系统存在的原因。
3.5. A commit by any other name…
理解 commit 是领悟 Git 的关键。当你脑海中只剩下 commit 的拓扑结构, 而抛开分支、标签、本地和远程仓库等的困惑时, 你就达到了分支智慧的禅定境界。希望这样的理解不需要你断臂³——尽管我能理解如果你现在已经考虑过这么做了。
如果 commit 是关键, 那么你如何命名 commit 就是通往精通的大门。有许多许多方法来命名 commit、commit 范围, 甚至 commit 所持有的一些对象, 大多数 Git 命令都接受这些方法。这里是一些更基本用法的总结:
- branchname 如前所述, 任何分支的名称都只是该“分支”上最新 commit 的别名。这与在该分支被检出时使用单词 HEAD 是一样的。
- 参见禅宗二祖慧可的例子。
- tagname 在命名 commit 方面, 标签名别名与分支别名相同。两者之间的主要区别在于, 标签别名从不改变, 而分支别名每次有新 commit 检入该分支时都会改变。
- HEAD 当前检出的 commit 总是被称为 HEAD。如果你检出的是一个特定的 commit——而不是一个分支名——那么 HEAD 只引用那个 commit, 而不引用任何分支。注意, 这种情况有些特殊, 被称为“使用分离的 HEAD” (I'm sure there's a joke to be told here…)。
- c82a22c39cbc32… 一个 commit 总是可以用其完整的 40 个字符的 SHA1 哈希 ID 来引用。通常这发生在复制粘贴时, 因为通常有其他更方便的方式来引用同一个 commit。
- c82a22c 你只需要使用足够多的哈希 ID 数字, 以便在仓库内唯一引用即可。大多数时候, 六七个数字就足够了。
- name^ 任何 commit 的父 commit 都用脱字符号引用。如果一个 commit 有多个父 commit, 则使用第一个。
- name^^ 脱字符号可以连续应用。这个别名指的是给定 commit 名称的“父 commit 的父 commit”。
- name2
如果一个 commit 有多个父 commit (例如一个 merge commit), 你可以使用
name^n来引用第 n 个父 commit。 - name~10
一个 commit 的第 n 个祖先可以用波浪号 (
) 后跟序数来引用。这种用法在 ~rebase -i中很常见, 例如, 意思是“给我看一堆最近的 commit”。这与name^^^^^^^^^^相同。 name:path 要引用一个 commit 内容树中的某个文件, 请在冒号后指定该文件名。这对于
show或者显示两个已提交文件版本之间的差异很有用:$ git diff HEAD^1:Makefile HEAD^2:Makefile
- nametree 你可以只引用一个 commit 所持有的 tree, 而不是 commit 本身。
- name1..name2
这和下面的别名表示 commit 范围, 这对于像
log这样的命令查看特定时间段内发生的事情非常有用。 左边的语法指的是从 name2 可达的所有 commit, 回溯到但不包括 name1。如果 name1 或 name2 被省略, 则使用 HEAD 代替。 - name1…name2
“三点”范围与上面的两点版本有很大不同。对于像
log这样的命令, 它指的是被 name1 或 name2 引用但不同时被两者引用的所有 commit。结果是两个分支中所有唯一 commit 的列表。 对于像diff这样的命令, 表达的范围是在 name2 和 name1 与 name2 的共同祖先之间。这与log的情况不同, 因为由 name1 引入的更改不会显示。 - master.. 这个用法等同于 “master..HEAD”。我把它加在这里, 即使上面已经暗示了, 因为我在审查当前分支所做的更改时经常使用这种别名。
- ..master 这个也特别有用, 在你做了一次 fetch 之后, 想看看自从你上次 rebase 或 merge 以来发生了什么变化。
- –since="2 weeks ago" 引用某个日期之后的所有 commit。
- –until="1 week ago" 引用某个日期之前的所有 commit。
- –grep=pattern 引用 commit 消息匹配正则表达式模式的所有 commit。
- –committer=pattern 引用 committer 匹配模式的所有 commit。
- –author=pattern 引用 author 匹配模式的所有 commit。commit 的 author 是创建其所代表更改的人。对于本地开发, 这总是与 committer 相同, 但是当补丁通过电子邮件发送时, author 和 committer 通常不同。
- –no-merges 引用范围内只有一个父 commit 的所有 commit——也就是说, 它忽略所有 merge commit。
大多数这些选项可以混合搭配。这里有一个例子, 显示了以下日志条目:在过去一个月内, 由我自己对当前分支(从 master 分支出来)所做的、包含文本 "foo" 的更改:
$ git log --grep='foo' --author='johnw' --since="1 month ago" master..
3.6. Branching and the power of rebase
Git 最强大的 commit 操作命令之一是那个名字朴实的 rebase 命令。基本上, 你工作的每个分支都有一个或多个“基础 commit”:即该分支诞生时的 commit。以以下典型场景为例。请注意, 箭头指向过去, 因为每个 commit 都引用其父 commit, 而不是其子 commit。因此, D 和 Z commit 代表它们各自自分支的头部:
A---B---C---D \ W---X---Y---Z
在这种情况下, 运行 branch 会显示两个“头部”:D 和 Z, 两个分支的共同父节点是 A。~show-branch~ 的输出向我们展示了这一信息:
$ git branch Z * D $ git show-branch ! [Z] Z * [D] D -- * [D] D * [D^] C * [D~2] B + [Z] Z + [Z^] Y + [Z~2] X + [Z~3] W +* [D~3] A
阅读这个输出需要一些适应, 但本质上它与上面的图表没有什么不同。它告诉我们:
- 我们所在的分支在 commit A (也称为 commit D~3, 如果你愿意, 甚至可以叫 Z~4) 处经历了第一次分叉。语法
commit^用于引用一个 commit 的父 commit, 而commit~3则引用其第三个父 commit, 或曾曾祖父 commit。 - 从下到上阅读, 第一列 (加号) 显示了一个名为 Z 的分叉分支, 有四个 commit:W, X, Y 和 Z。
- 第二列 (星号) 显示了在当前分支上发生的 commit, 即三个 commit:B, C 和 D。
- 输出的顶部, 由一条分割线与底部隔开, 标识了显示的分支, 它们的 commit 被哪个列标记, 以及用于标记的字符。
我们想要执行的操作是让工作分支 Z 跟上主分支 D 的进度。换句话说, 我们想把 B, C 和 D 的工作合并到 Z 中。
在其他版本控制系统中, 这种事情只能通过“分支合并”来完成。实际上, 在 Git 中仍然可以进行分支合并, 使用 merge, 并且在 Z 是一个已发布的分支且我们不想改变其 commit 历史的情况下仍然是必要的。以下是要运行的命令:
$ git checkout Z # switch to the Z branch $ git merge D # merge commits B, C and D into Z
这是合并后仓库的样子:
A---B---C---D \ \ W---X---Y---Z---Z' (Z+D)
如果我们现在检出 Z 分支, 它将包含前一个 Z (现在可以作为 Z^ 引用) 的内容, 并与 D 的内容合并。(但请注意:一个真正的合并操作需要解决 D 和 Z 状态之间的任何冲突)。
虽然新的 Z 现在包含了来自 D 的更改, 但它也包括了一个新的 commit 来代表 Z 与 D 的合并:现在显示为 Z' 的 commit。这个 commit 没有添加任何新东西, 而是代表了将 D 和 Z 结合在一起所做的工作。在某种意义上, 它是一个“元提交 (meta-commit)”, 因为它的内容与仅在仓库中完成的工作有关, 而不是与在工作区中完成的新工作有关。
然而, 有一种方法可以将 Z 分支直接移植到 D 上, 有效地将它在时间上向前移动:通过使用强大的 rebase 命令。这是我们想要达到的图表:
A---B---C---D
\
W'--X'--Y'--Z'
这种情况最直接地代表了我们想要做的事情:让我们的本地开发分支 Z 基于主分支 D 的最新工作。这就是为什么这个命令被称为“rebase”, 因为它改变了它运行所在分支的基础 commit。如果你重复运行它, 你可以无限期地携带一组补丁, 始终与主分支保持最新, 而无需向你的开发分支添加不必要的 merge commit⁴。以下是要运行的命令, 与上面执行的 merge 操作相比:
$ git checkout Z # switch to the Z branch $ git rebase D # change Z's base commit to point to D
为什么这只适用于本地分支?因为每次你 rebase, 你都可能改变分支中的每一个 commit。早些时候, 当 W 基于 A 时, 它只包含了将 A 转换为 W 所需的更改。然而, 在运行 rebase 之后, W 将被重写以包含将 D 转换为 W' 所需的更改。甚至从 W 到 X 的转换也改变了, 因为 A+W+X 现在是 D+W'+X'——等等。如果这是一个被其他人看到的分支, 并且你的任何下游消费者已经从 Z 创建了他们自己的本地分支, 他们的分支现在将指向旧的 Z, 而不是新的 Z'。
通常, 可以使用以下经验法则:如果你有一个没有其他分支从其分支出去的本地分支, 就使用 rebase, 在所有其他情况下使用 merge。当你准备好将本地分支的更改拉回主分支时, merge 也很有用。
3.6.1. Interactive rebasing
当上面运行 rebase 时, 它会自动重写从 W 到 Z 的所有 commit, 以便将 Z 分支 rebase 到 D commit (即 D 分支的头 commit) 上。然而, 你可以完全控制这个重写是如何完成的。如果你向 re- 提供 -i 选项
- 请注意, 有正当的理由不这样做, 而是使用 merge。选择取决于你的情况。rebase 的一个缺点是, 即使 rebase 后的工作区可以编译, 也不能保证中间的 commit 还能编译, 因为它们从未在新的 rebase 状态下被编译过。如果历史的有效性对你很重要, 请优先使用 merge。
base, 它会弹出一个编辑缓冲区, 你可以在其中选择对本地 Z 分支中的每个 commit 应该做什么:
- pick 这是如果你不使用交互模式时为分支中每个 commit 选择的默认行为。这意味着有问题的 commit 应该被应用到其 (现在已重写的) 父 commit 上。对于每个涉及冲突的 commit, rebase 命令会给你一个解决它们的机会。
- squash 一个被 squash 的 commit 将其内容“折叠”到前一个 commit 的内容中。这可以做任意多次。如果你拿上面的例子分支并 squash 了它所有的 commit (除了第一个, 它必须是 pick 才能 squash), 你最终会得到一个在 D 之上只有一个 commit 的新 Z 分支。这在你把更改分散在多个 commit 中, 但希望历史被重写为只显示一个 commit 时很有用。
- edit
如果你将一个 commit 标记为 edit, rebase 过程将在该 commit 处停止, 并让你在 shell 中, 当前工作区设置为反映该 commit 的状态。索引将拥有该 commit 的所有更改, 已注册以便在你运行 commit 时包含。因此, 你可以做任何你喜欢的更改:修正一个更改, 撤销一个更改等;在提交并运行
rebase --continue之后, 该 commit 将被重写, 就好像这些更改是最初做的一样。 - (drop) 如果你从交互式 rebase 文件中删除一个 commit, 或者你将其注释掉, 该 commit 将会消失, 就像它从未被签入过一样。请注意, 如果分支中后来的任何 commit 依赖于这些更改, 这可能会导致合并冲突。
这个命令的威力一开始很难体会, 但它让你对任何分支的形态拥有几乎无限的控制权。你可以用它来:
- 将多个 commit 合并成一个。
- 重新排序 commit。
- 移除你现在后悔的错误更改。
- 将你的分支的基点移动到仓库中的任何其他 commit 上。
- 修改单个 commit, 以便在事后很久修正一个更改。
我建议此时阅读 rebase 的 man page,因为它包含了一些很好的例子,说明了这头猛兽的真正威力是如何被释放的。为了让你最后体验一下这个工具有多强大, 考虑以下场景, 以及如果有一天你想将次要分支 L 迁移成为 Z 的新头部, 你会怎么做:
A---B---C---D
\ /
W---X---Y---Z
\
I---J---K---L
这张图的意思是:我们有我们的主开发线 D, 三个 commit 之前它分支出去开始了对 Z 的推测性开发。在这一切的中间, 当 C 和 X 分别是它们各自自分支的头部时, 我们决定开始另一个推测, 最终产生了 L。现在我们发现 L 的代码很好, 但还不足以合并回主线, 所以我们决定将这些更改移到开发分支 Z 上, 使它看起来好像我们一直是在一个分支上完成的。哦, 顺便说一句, 我们想快速编辑一下 J, 改变一下版权日期, 因为我们做那个更改时忘了那是 2008 年!这里是解开这个结所需的命令:
$ git checkout L $ git rebase -i Z
在解决了可能出现的任何冲突之后, 我现在有了这个仓库:
A---B---C---D \ W---X---Y---Z---(B+C+)I'---J'---K'---L'
正如你所看到的, 当涉及到本地开发时, rebase 让你对你的 commit 在仓库中的呈现方式拥有无限的控制权。
4. 索引:中间人
http://www.newartisans.com/2008/04/git-from-the-bottom-up.html ©2008,2009 John Wiegley
在你的数据文件 (存储在文件系统上) 和你的 Git blob (存储在仓库中) 之间, 站着一个有点奇怪的实体:Git 索引。这个家伙之所以难以理解, 部分原因是它的名字相当不幸。从某种意义上说, 它是一个索引, 因为它指向你通过运行 add 创建的一组新创建的 tree 和 blob。这些新对象很快就会被绑定到一个新的 tree 中, 以便提交到你的仓库——但在此之前, 它们只被索引引用。这意味着, 如果你用 reset 从索引中取消注册一个更改, 你最终会得到一个孤立的 blob, 它将在未来的某个时刻被删除。
索引实际上只是你下一次提交的暂存区, 它之所以存在有一个很好的理由:它支持一种对于 CVS 或 Subversion 用户可能陌生, 但对于 Darcs 用户却非常熟悉的开发模型:分阶段构建下一次提交的能力。
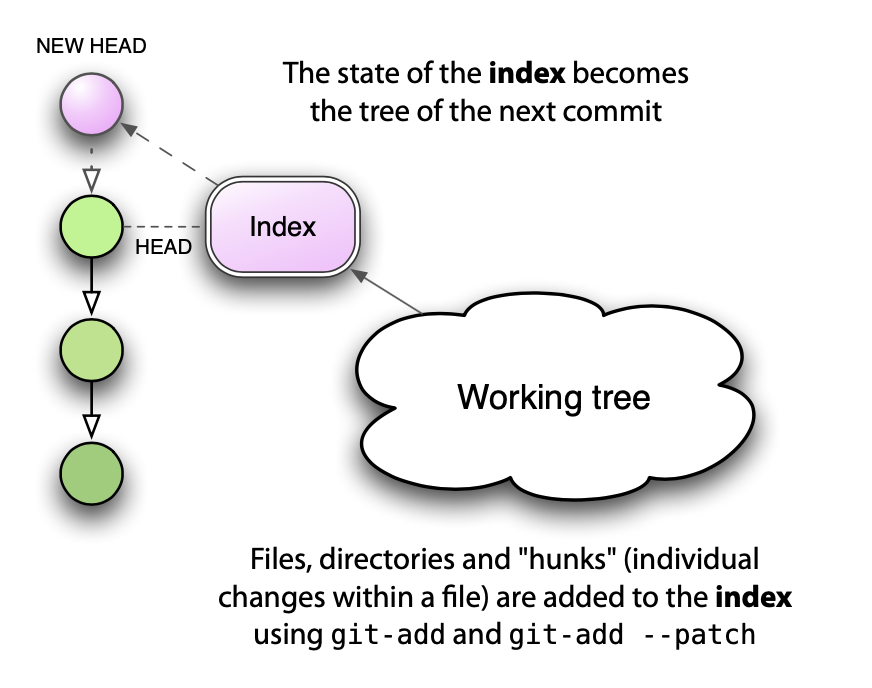
Figure 2: 索引在提交过程中的作用
- 新的 HEAD -> 索引的状态成为下一次提交的树 -> 工作区
- 文件、目录和 "hunks" (文件内的个别更改) 通过 git-add 和 git-add –patch 被添加到索引中
首先, 我要说有一种方法可以几乎完全忽略索引:通过向 commit 传递 -a 标志。例如, 看看 Subversion 的工作方式。当你输入 svn status 时, 你会看到一个将在下一次调用 svn commit 时应用于你的仓库的动作列表。在某种程度上, 这个“下一次动作列表”是一种非正式的索引, 通过将你的工作区状态与 HEAD 的状态进行比较来确定。如果文件 foo.c 已被更改, 你的下一次提交将保存这些更改。如果一个未知文件旁边有一个问号, 它将被忽略;但一个用 svn add 添加的新文件将被添加到仓库。
这与你使用 commit -a 时发生的情况没有什么不同:新的、未知的文件被忽略, 但用 add 添加的新文件以及对现有文件的任何更改都会被添加到仓库。这种交互方式与 Subversion 的做法几乎完全相同。
真正的区别在于, 在 Subversion 的情况下, 你的“下一次动作列表”总是通过查看当前工作区来确定的。而在 Git 中, “下一次动作列表”是索引的内容, 它代表了 HEAD 的下一个状态将会是什么, 并且你可以在执行 commit 之前直接操作它。这给了你一个额外的控制层, 允许你提前暂存那些更改。
如果这还不清楚, 考虑以下例子:你有一个可靠的源文件 foo.c, 并且你对它做了两组不相关的更改。你想做的是将这些更改分成两个不同的 commit, 每个都有自己的描述。在 Subversion 中, 你会这样做:
$ svn diff foo.c > foo.patch $ vi foo.patch <edit foo.patch, keeping the changes I want to commit later> $ patch -p1 -R < foo.patch # remove the second set of changes $ svn commit -m "First commit message" $ patch -p1 < foo.patch # re-apply the remaining changes $ svn commit -m "Second commit message"
听起来很有趣?现在对一个复杂、动态的更改集重复这个过程很多次。这是 Git 版本, 利用了索引:
$ git add --patch foo.c <select the hunks I want to commit first> $ git commit -m "First commit message" $ git add foo.c # add the remaining changes $ git commit -m "Second commit message"
而且, 它变得更容易了!如果你喜欢 Emacs, Christian Neukirchan 的超棒工具 gitsum.el⁵ 为这个可能乏味的过程提供了一个漂亮的界面。我最近用它从一组混杂的更改中分离出了 11 个独立的 commit。谢谢你, Christian!
4.1. Taking the index farther
让我们看看, 索引… 有了它, 你可以预先暂存一组更改, 从而在将其提交到仓库之前迭代地构建一个补丁。现在, 我在哪里听过这个概念…
如果你想到的是 "Quilt!"⁶, 那你完全正确。实际上, 索引与 Quilt 相差无几, 它只是增加了每次只能构建一个补丁的限制。
但是, 如果我在 foo.c 中不是有两组更改, 而是有四组呢?用纯 Git, 我必须一个个地分离出来, 提交, 然后再分离下一个。使用索引使这变得容易得多, 但是如果我想在签入之前在各种组合中测试这些更改呢?也就是说, 如果我将补丁标记为 A, B, C 和 D, 如果我想测试 A + B, 然后是 A + C, 然后是 A + D 等, 在决定任何更改是否真正完成之前怎么办?
Git 本身没有机制可以让你动态地混合和匹配并行的更改集。当然, 多个分支可以让你进行并行开发, 索引可以让你将多个更改分阶段地放入一系列 commit 中, 但你不能同时做这两件事:在分阶段处理一系列补丁的同时, 选择性地启用和禁用其中的一些, 以便在最终提交它们之前协同验证补丁的完整性。
要做这样的事情, 你需要一个允许比一次提交更深层次的索引。这正是 Stacked Git⁷ 提供的。
这是我如何使用纯 Git 将两个不同的补丁提交到我的工作区:
$ git add -i # select first set of changes $ git commit -m "First commit message" $ git add -i # select second set of changes $ git commit -m "Second commit message"
这很好用, 但我无法选择性地禁用第一个 commit 来单独测试第二个。为此, 我必须做以下操作:
$ git log # find the hash id of the first commit $ git checkout -b work <first commit's hash id>^ $ git cherry-pick <second commit's hash id> <... run tests ...> $ git checkout master $ git branch -D work # go back to the master "branch" # remove my temporary branch
肯定有更好的方法!有了 stg, 我可以把两个补丁都排队, 然后按我喜欢的任何顺序重新应用它们, 以便进行独立或组合测试等。这是我如何使用 stg 将前一个例子中的两个补丁排队:
$ stg new patch1 $ git add -i $ stg refresh --index $ stg new patch2 $ git add -i $ stg refresh --index # select first set of changes # select second set of changes
现在如果我想选择性地禁用第一个补丁只测试第二个, 这非常直接:
$ stg applied patch1 patch2 <... do tests using both patches ...> $ stg pop patch1 <... do tests using only patch2 ...> $ stg pop patch2 $ stg push patch1 <... do tests using only patch1 ...> $ stg push -a $ stg commit -a # commit all the patches
这绝对比创建临时分支并使用 cherry-pick 应用特定的 commit ID, 然后再删除临时分支要容易得多。
5. To reset, or not to reset
在 Git 中, reset 是比较难掌握的命令之一, 它似乎比其他命令更容易让人生畏。这是可以理解的, 因为它有潜力改变你的工作区和你当前的 HEAD 引用。所以我觉得对这个命令做一个快速的回顾会很有用。
基本上, reset 是一个引用编辑器, 一个索引编辑器, 和一个工作区编辑器。这部分是它如此令人困惑的原因, 因为它能够做这么多工作。让我们检查一下这三种模式之间的区别, 以及它们如何融入 Git 的 commit 模型。
5.1. Doing a mixed reset
如果你使用 --mixed 选项 (或者根本不带选项, 因为这是默认的), reset 会将你的索引的一部分连同你的 HEAD 引用一起恢复到与给定 commit 匹配的状态。与 --soft 的主要区别在于, --soft 只改变 HEAD 的含义, 而不触及索引。
$ git add foo.c $ git reset HEAD $ git add foo.c # add changes to the index as a new blob # delete any changes staged in the index # made a mistake, add it back
5.2. Doing a soft reset
如果你使用 --soft 选项来 reset, 这就等同于简单地将你的 HEAD 引用更改为另一个 commit。你的工作区更改保持不变。这意味着以下两个命令是等价的:
$ git reset --soft HEAD^ # backup HEAD to its parent, # effectively ignoring the last commit $ git update-ref HEAD HEAD^ # does the same thing, albeit manually
在这两种情况下, 你的工作区现在都位于一个较旧的 HEAD 之上, 所以如果你运行 status, 你应该会看到更多的更改。这并不是说你的文件被改变了, 只是它们现在正与一个较旧的版本进行比较。这可以给你一个机会来创建一个新的 commit 来代替旧的。事实上, 如果你想改变的 commit 是最近检入的那个, 你可以使用 commit --amend 来将你最新的更改添加到上一个 commit 中, 就好像你是一起完成的一样。
但请注意:如果你有下游消费者, 并且他们在你之前的 head (你丢弃的那个) 的基础上做了工作, 像这样改变 HEAD 将会迫使他们在下一次 pull 时发生合并。
5.3. Doing a hard reset
下面是经过一次 soft reset 和一次新 commit 后你的 tree 会是什么样子:
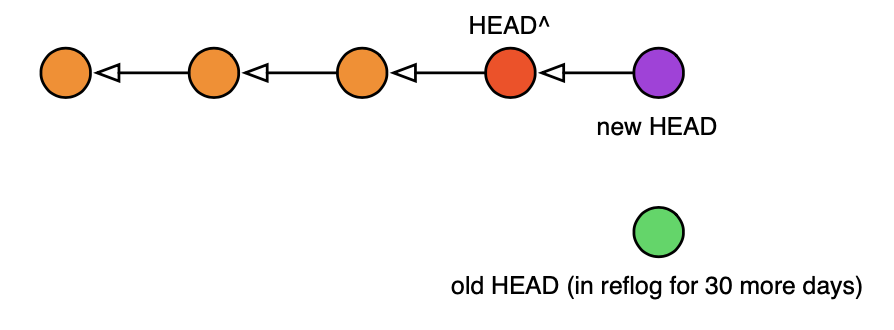
Figure 3: 一次 soft reset 和一次新提交之后你的树的样子
这里是你的消费者的 HEAD 在他们再次 pull 后会是什么样子, 用颜色显示各个 commit 如何匹配:
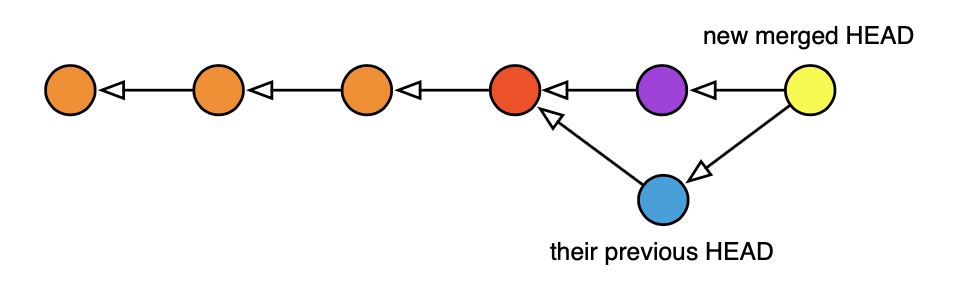
Figure 4: 下游用户 pull 之后其 HEAD 的样子
hard reset (--hard 选项) 有可能非常危险, 因为它能同时做两件不同的事情:首先, 如果你对当前的 HEAD 执行 hard reset, 它将擦除你工作区中的所有更改, 以使你当前的文件与 HEAD 的内容相匹配。
还有一个命令 checkout, 如果索引是空的, 它的作用就像 ~reset –hard~。否则, 它会强制你的工作区与索引匹配。
现在, 如果你对一个较早的 commit 执行 hard reset, 这就等同于先做一个 soft reset, 然后再用 reset --hard 来重置你的工作区。因此, 以下命令是等价的:
$ git reset --hard HEAD~3 # Go back in time, throwing away changes $ git reset --soft HEAD~3 # Set HEAD to point to an earlier commit $ git reset --hard # Wipe out differences in the working tree
如你所见, hard reset 可能非常具有破坏性。幸运的是, 有一种更安全的方法可以达到同样的效果, 使用 Git stash (见下一节):
$ git stash $ git checkout -b new-branch HEAD~3 # head back in time!
如果你不确定现在是否真的想修改当前分支, 这种方法有两个明显的优势:
- 它将你的工作保存在 stash 中, 你可以随时回来取。注意 stash 不是特定于分支的, 所以你可以在一个分支上 stash 你 tree 的状态, 稍后将这些差异应用到另一个分支上。
- 它将你的工作区恢复到一个过去的状态, 但是在一个新的分支上, 所以如果你决定针对过去的状态提交你的更改, 你不会改变你原始的分支。
如果你对 new-branch 做了更改, 然后决定让它成为你的新 master 分支, 运行以下命令:
$ git branch -D master # goodbye old master (still in reflog) $ git branch -m new-branch master # the new-branch is now my master
这个故事的寓意是:虽然你可以使用 reset --soft 和 reset --hard (它也改变工作区) 对你当前的分支进行大手术, 但你为什么要这么做呢?Git 使得处理分支如此简单和廉价, 几乎总是值得在一个分支上进行你的破坏性修改, 然后将那个分支移动过来取代你的旧 master。它有一种几乎像西斯武士般的吸引力…
那么如果你不小心运行了 reset --hard, 不仅丢失了当前的更改, 还从你的 master 分支中移除了 commit 呢?嗯, 除非你已经养成了使用 stash 来做快照的习惯 (见下一节), 否则你无法恢复你丢失的工作区。但是你可以通过再次使用 reset --hard 和 reflog 来将你的分支恢复到之前的状态 (这也会在下一节解释):
$ git reset --hard HEAD@{1} # restore from reflog before the change
为了安全起见, 永远不要在没有先运行 stash 的情况下使用 reset --hard~。它会在以后为你省去很多白发。如果你确实运行了 ~stash, 你现在可以用它来恢复你的工作区更改:
$ git stash # because it's always a good thing to do $ git reset --hard HEAD~3 # go back in time $ git reset --hard HEAD@{1} # oops, that was a mistake, undo it! $ git stash apply # and bring back my working tree changes
6. Last links in the chain: Stashing and the reflog
http://www.newartisans.com/2008/04/git-from-the-bottom-up.html ©2008,2009 John Wiegley
到目前为止, 我们已经描述了两种 blob 进入 Git 的方式:首先它们在你的索引中被创建, 既没有父 tree 也没有所属的 commit;然后它们被提交到仓库中, 作为该 commit 所持有的 tree 的叶子存在。但还有另外两种 blob 可以在你的仓库中存在的方式。
其中第一个是 Git reflog, 一种记录你对仓库所做的每一次更改的元仓库——以 commit 的形式。这意味着当你从你的索引创建一个 tree 并将其存储在一个 commit 下 (所有这些都由 commit 完成) 时, 你也在不经意间将该 commit 添加到了 reflog, 可以使用以下命令查看:
$ git reflog 5f1bc85... HEAD@{0}: commit (initial): Initial commit
reflog 的美妙之处在于它独立于你仓库中的其他更改而持久存在。这意味着我可以从我的仓库中取消链接上面的 commit (使用 reset), 但它仍然会被 reflog 引用 30 天, 保护它免受垃圾回收。这给了我一个月的时间来恢复这个 commit, 如果我发现我真的需要它的话。
blob 可以存在的另一个地方, 尽管是间接的, 是在你的工作区本身。我的意思是, 比如说你更改了一个文件 foo.c, 但你还没有将这些更改添加到索引中。Git 可能没有为你创建一个 blob, 但这些更改确实存在, 意味着内容存在——它只是存在于你的文件系统中而不是 Git 的仓库中。这个文件甚至有它自己的 SHA1 哈希 ID, 尽管没有真正的 blob 存在。你可以用这个命令查看它:
$ git hash-object foo.c <some hash id>
这对你有什么用?嗯, 如果你发现自己在你的工作区上忙碌了一整天, 在一天结束时, 一个好习惯是把你的更改 stash 起来:
$ git stash
这会把你目录的所有内容——包括你的工作区和索引的状态——都拿来, 在 git 仓库中为它们创建 blob, 一个持有这些 blob 的 tree, 以及一对 stash commit 来持有工作区和索引, 并记录你做 stash 的时间。
这是一个好习惯, 因为尽管第二天你只需用 stash apply 把你的更改从 stash 中拉回来, 你在每天结束时都会有一个你所有 stash 更改的 ~reflog~。
这是第二天早上回到工作岗位后你会做的事情 (WIP 在这里代表 "Work in progress"):
$ git stash list stash@{0}: WIP on master: 5f1bc85... Initial commit $ git reflog show stash # same output, plus the stash commit's hash id 2add13e... stash@{0}: WIP on master: 5f1bc85... Initial commit $ git stash apply
因为你 stash 的工作区是存储在一个 commit 下的, 你可以像处理任何其他分支一样处理它——随时都可以!这意味着你可以查看日志, 看看你是什么时候 stash 的, 并且可以从你 stash 的那一刻检出你过去的任何工作区:
$ git stash list stash@{0}: WIP on master: 73ab4c1... Initial commit ... stash@{32}: WIP on master: 5f1bc85... Initial commit $ git log stash@{32} # when did I do it? $ git show stash@{32} # show me what I was working on $ git checkout -b temp stash@{32} # let's see that old working tree!
最后一个命令特别强大:看, 我现在正在一个一个多月前未提交的工作区里玩耍。我甚至从未将那些文件添加到索引中;我只是每天在注销前简单地调用 stash (前提是你确实有更改需要 stash), 并在我重新登录时使用 ~stash apply~。
如果你想清理你的 stash 列表——比如说只保留最近 30 天的活动——不要使用 stash clear~;而是使用 ~reflog expire 命令:
$ git stash clear # DON'T! You'll lose all that history $ git reflog expire --expire=30.days refs/stash <outputs the stash bundles that've been kept>
stash 的美妙之处在于它让你对你的工作流程本身应用了非侵入式的版本控制:也就是你工作区日复一日的各个阶段。如果你愿意, 你甚至可以定期使用 stash, 比如用下面这样的快照脚本:
$ cat <<EOF > /usr/local/bin/git-snapshot #!/bin/sh git stash && git stash apply EOF $ chmod +x $_ $ git snapshot
没有理由你不能每小时从一个 cron 作业中运行这个脚本, 同时每周或每月运行 reflog expire 命令。
7. Conclusion
http://www.newartisans.com/2008/04/git-from-the-bottom-up.html ©2008,2009 John Wiegley
多年来, 我使用过许多版本控制系统和许多备份方案。它们都有检索文件过去内容的功能。它们中的大多数都有方法来显示文件随时间的变化。许多允许你回到过去, 开始一个分叉的推理路线, 然后稍后将这些新想法带回到现在。但更少的系统提供了对这个过程的细粒度控制, 让你以你觉得最能向公众展示你的想法的方式来收集你的思绪。Git 让你做所有这些事情, 并且相对容易——一旦你理解了它的基本原理。
它不是唯一拥有这种能力的系统, 也不是总能为其概念提供最好的界面。然而, 它所拥有的是一个坚实的工作基础。在未来, 我想会有许多新的方法被设计出来, 以利用 Git 所允许的灵活性。大多数其他系统都让我相信它们已经达到了概念上的平台期——从现在开始的一切都只是对我以前见过的东西的缓慢改进。然而, Git 给了我相反的印象。我觉得我们才刚刚开始看到它那看似简单的设计所承诺的潜力。
THE END
8. Further reading
http://www.newartisans.com/2008/04/git-from-the-bottom-up.html ©2008,2009 John Wiegley
如果你的学习 Git 的兴趣被激发了, 请查看以下文章:
- A tour of Git: the basics http://cworth.org/hgbook-git/tour/
- Manage source code using Git http://www.ibm.com/developerworks/linux/library/l-git/
- A tutorial introduction to git http://www.kernel.org/pub/software/scm/git/docs/tutorial.html
- GitFaq — GitWiki http://git.or.cz/gitwiki/GitFaq
- A git core tutorial for developers http://www.kernel.org/pub/software/scm/git/docs/gitcore-tutorial.html
- git for the confused http://www.gelato.unsw.edu.au/archives/git/0512/13748.html
- The Thing About Git http://tomayko.com/writings/the-thing-about-git