Fennel neovim开发配置
Table of Contents
- 1. Fennel 简史与开发环境
- 2. 序言: AI 加速编程后, 你应该学什么?
- 3. Fennel 语言速成—Lisp 语法
- 4. Fennel 语言速成—核心语法
- 5. Fennel 语言速成—Lua
- 6. Fennel 语言速成—nfnl 库
- 7. Lisp 深入—交互式开发
- 8. Lisp 深入—S-expression 编辑
- 9. Lisp 深入—宏
- 10. Lisp 深入—面向数据编程
- 11. 揭秘函数式编程 (FP)—高阶语义
- 12. 揭秘函数式编程 (FP)—定义的挑战
- 13. 揭秘函数式编程 (FP)—常用机制
- 14. 揭秘函数式编程 (FP)—高级主题
- 15. Fennel 语言速成—LuaRocks
- 16. Neovim 插件开发—Hello World
- 17. Neovim 插件开发—标准插件
- 18. Neovim 插件开发—如何调试?
- 19. 项目探讨—auto-conjure
- 20. 项目探讨—Conjure Piglet Client
- 21. Neovim 插件开发—入门
- 22. 项目探讨—WebSocket
- 23. 项目探讨—CBOR
- 24. 项目探讨—跳转定义背后的 Tree-sitter
- 25. 模式与原则—瓶颈与改进
- 26. 模式与原则—不确定性
- 27. 模式与原则—复杂性
- 28. 模式与原则—修改传播
- 29. 项目探讨—Fennel 的跳转到定义
- 30. fennel-fp-neovim
- 31. 模式与原则—隐性知识
1. Fennel 简史与开发环境
让我们来谈谈 Fennel 的历史, 这是一个关于创新的故事.
1.1. 从个人到社群:Fennel 的诞生
这里我们将谈到四位重要人物; 没有他们, 这一系列文章就不会存在:
- Thiago de Arruda
据说 Thiago 曾想为 Vim 添加异步和多线程支持, 但由于 Vim 复杂的项目架构, 很难进行大刀阔斧的修改. 他和其他几位开发者意识到, 彻底解决这个问题的唯一方法就是从零开始重写一个新的 Vim, 这就是 Neovim 的由来. 从 Neovim 诞生之初, 他就引入了 Lua 作为插件脚本.
- Calvin Rose
有一天, Calvin 觉得有一个能运行在 Lua 之上的 Lisp 会很有趣, 于是他随手刻出了一个 Fennel 的原型, 然后发布了它.
- Phil Hagelberg
Phil 在网上发现了 Fennel, 然后成为了 Fennel 的主要开发者, 先后发展了社区, 文档, 解答问题以及许多其他工作. 他目前维护着 Fennel 社区及其官方网站.
- Olical Caldwell
Olical 是一名 Clojure 程序员, 也是一名 Neovim 用户. 有一天, 他决定用 Clojure 语言开发自己的 交互式开发插件, 这就是 Conjure 的开端. 在 Conjure 开始之前, Vim 的其他交互式开发插件已经存在, 但这些插件通常是用 VimScript 编写的, 难以阅读和修改.
然后, 一个转折点出现了. 有一天, Olical 发现 Fennel 可以编译成 Lua, 于是他将原本用 Clojure 编写的 Conjure 移植到了 Fennel. 这次移植带来了很多好处, 因为一旦移植, 插件就不再需要依赖 JVM, 并且可以完全在 Neovim 内部运行, 这大大提高了速度. 因此, Conjure 从一个 Clojure 项目转变成了一个 Fennel 项目.
我是一名 Conjure 用户, 我也是因为使用了 Conjure 才发现了 Fennel.
1.1.1. “成功的创新” 是对机会的系统性回应
这些故事并非仅仅是巧合; 它们可以被看作是对特定机会的 系统性回应. 德鲁克在他的书《创新与企业家精神》中, 提出了七个准则来解释如何系统地选择创新机会.
- Thiago 抓住了 Vim 代码维护困难的 意外事件, 创造了 Neovim, 为“更好的插件开发工作流”这一 流程需求 提供了革命性的解决方案.
- Calvin 和 Phil 分别是“Lisp on Lua”这一 新知识 的创造者和推广者. Phil 通过建立社区, 成功利用了 Neovim 用户日益增多的 人口变化, 将 Fennel 从一个语言原型培育成了一个活跃的生态系统.
- Olical 敏锐地捕捉到 Fennel 可以编译成 Lua 的 新知识, 并将其应用于产品, 将 Conjure 移植到 Fennel, 解决了现有的性能瓶颈.
这些人之所以能引发一场革命, 部分是因为他们高超的技术能力, 但更重要的是, 他们能够 系统地识别和利用这些创新机会, 将看似偶然的机会转变为优秀的软件和蓬勃发展的社区.
1.2. 开发环境 - 安装
Fennel 开发环境主要由以下几个部分组成:
- Neovim: 既是编辑器也是运行时.
- 语法高亮插件.
- 彩虹括号插件.
- Conjure: 一个支持 交互式开发 的插件.
- S-expression 编辑插件.
- 代码格式化设置.
1.2.1. Neovim
如果你使用的是 Mac 电脑, 可以使用 brew 来安装.
- 安装 brew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- 安装 neovim
brew install neovim
如果你电脑上已经有 neovim, 别忘了先检查一下版本.
~$ nvim --version NVIM v0.11.3
如果版本不是 >= v0.11.3, 之后遇到插件不兼容问题时, 请考虑升级 Neovim.
1.2.2. Fnlfmt
Fnlfmt 也直接安装在操作系统上, 所以我们使用 brew 来安装:
brew install fnlfmt
1.2.3. Neovim 插件
- 首先, 安装一个插件管理器; 我使用 vim-plug.
vim-plug 安装:
sh -c 'curl -fLo "${XDG_DATA_HOME:-$HOME/.local/share}"/nvim/site/autoload/plug.vim --create-dirs \
https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim'
- 接下来, 通过 vim-plug 安装插件.
打开你的 Neovim 配置文件:
~$ nvim $HOME/.config/nvim/init.vim
在该文件中, 粘贴以下内容:
" Specify a directory for plugins.
call plug#begin(stdpath('data') . '/plugged')
" === Basic Setup ===
" color, look and feel
Plug 'tomasr/molokai'
" === Highlight ===
" Syntax highlight for fennel language
Plug 'bakpakin/fennel.vim'
" rainbow parentheses
Plug 'frazrepo/vim-rainbow'
" === Interactive Development ===
" Conjure
Plug 'Olical/conjure'
" === S-expression editing ===
Plug 'guns/vim-sexp'
Plug 'tpope/vim-sexp-mappings-for-regular-people'
Plug 'kylechui/nvim-surround'
Plug 'jiangmiao/auto-pairs', { 'tag': 'v2.0.0' }
call plug#end()
if !empty(glob(stdpath('data') . '/plugged/molokai'))
colorscheme molokai
endif
" Config the rainbow-parentheses
let g:rainbow_ctermfgs = [
\ 'red',
\ 'yellow',
\ 'green',
\ 'cyan',
\ 'magenta',
\ 'gray'
\ ]
" rainbow parentheses enabled for fennel
autocmd FileType fennel call rainbow#load()
let maplocalleader=","
let mapleader="\\"
" Make vim-sexp recognizes the fennel
let g:sexp_filetypes = 'fennel'
if !empty(glob(stdpath('data') . '/plugged/nvim-surround'))
lua require("nvim-surround").setup()
endif
function! Fnlfmt()
!fnlfmt --fix %
" :e is to force reload the file after it got formatted.
:e
endfunction
augroup FennelOnSave
" Format after save
autocmd!
autocmd BufWritePost *.fnl call Fnlfmt()
augroup END
接下来, 在 Neovim 的 Normal Mode 下, 执行以下命令:
:source % :PlugInstall
安装完成后, 打开一个 Fennel 文件, 应该会是这个样子:
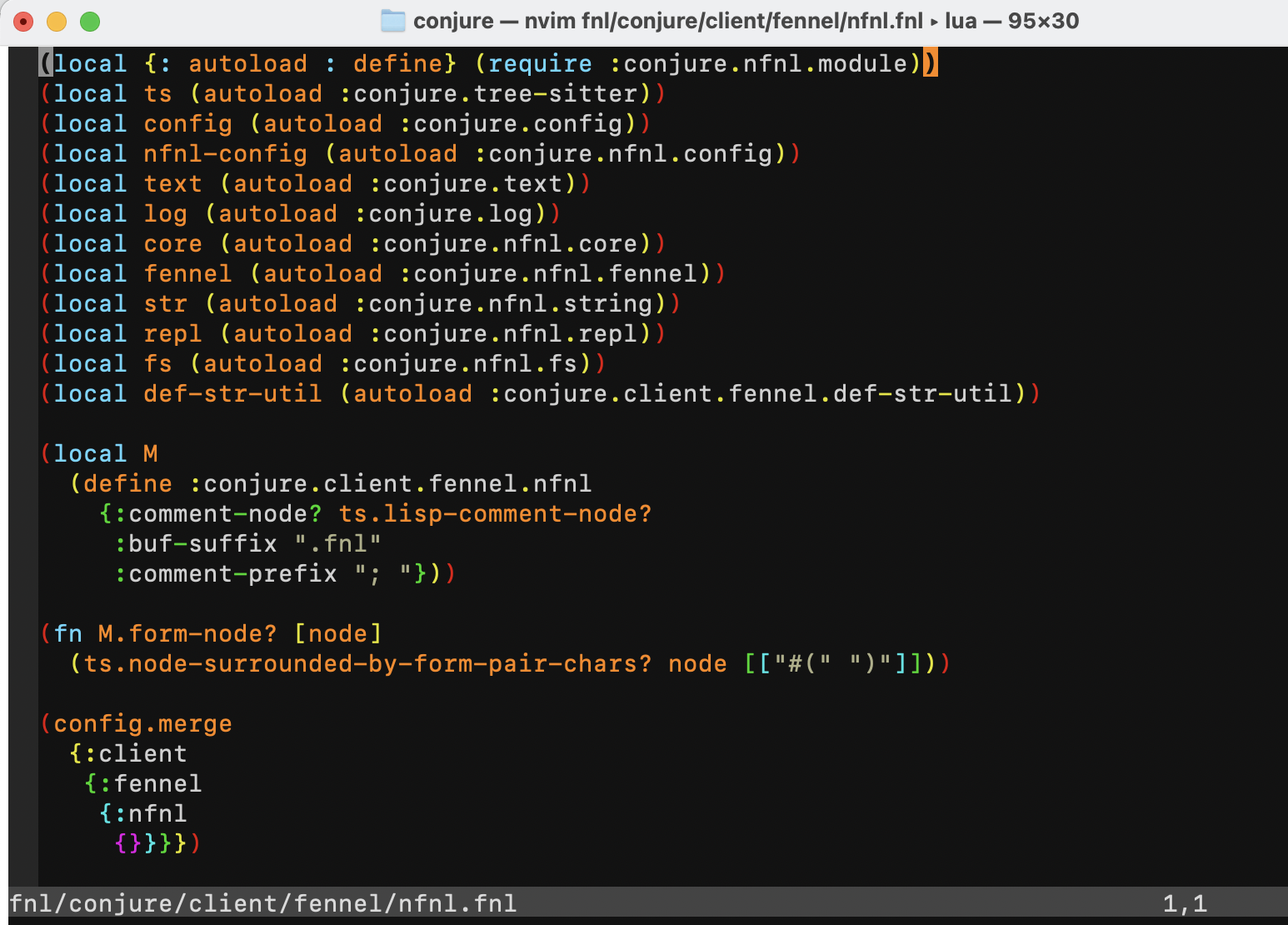
Figure 1: Neovim with Fennel file.
1.3. 开发环境 - 插件介绍
- vim-plug
vim-plug 是一个极简的插件管理器. 目前最流行的插件管理器是 LazyVim, 但因为我从未特别感觉到我的插件加载速度不够快, 所以我没有升级到它.
- tomasr/molokai
molokai 是一个配色方案. 这纯粹是我的个人喜好, 所以我把它包含了进来.
- 高亮相关
fennel.vim 提供了 Fennel 语言的 语法 高亮. vim-rainbow 让 括号 呈现彩虹渐变色.
- 交互式开发
Conjure 是一个交互式开发插件; 它在与 Clojure 语言配合使用时功能非常多, 以至于需要相当长的时间来掌握. 另一方面, 当与 Fennel 语言配合使用时, Conjure 也被简化了, 只保留了其最简约的核心功能.
交互式开发让你能轻松地提取代码的语法树的一部分, 将它们发送到解释器进行求值, 然后快速地在编辑器中显示结果.
- S-expression 编辑
S-expression 指的是一种将函数名放在括号内的函数编写方式.
;; S expression (fn your-fn-name [arg1 arg2] ... ) ;; M expression fn your-fn-name [arg1 arg2] ( ... )
S-expression 编辑, 和交互式开发一样, 是 95% 的程序员闻所未闻的概念. 它允许你通过命令直接在编程语言的语法树上进行编辑. 换句话说, 你编辑的最小单位不再是单个字符 (char), 单词 (word), 或行 (line), 而是语法树中的元素 (element).
1.4. 开发环境 - 自动格式化
以下 VimScript 代码片段可以让您编写的 Fennel 代码在保存后自动触发 fnlfmt 程序进行自动格式化.
function! Fnlfmt() !fnlfmt --fix % " :e is to force reload the file after it got formatted. :e endfunction augroup FennelOnSave " Format after save autocmd! autocmd BufWritePost *.fnl call Fnlfmt() augroup END
1.5. 交互式开发
- 下载一个练习用的 git 仓库并切换目录
git clone https://github.com/humorless/auto-conjure.git
cd auto-conjure
- 打开文件
nvim fnl/auto-conjure/hello.fnl
并粘贴以下内容:
(fn greet [name] (.. "Hello, " name "!")) (greet :world)
执行命令 :w 保存文件.
- 使用 Neovim 的 Ex 命令进行求值
:ConjureEval (+ 1 2 3)
你注意到了吗? 当你按下 Enter 键, (+ 1 2 3) 已经被传递给了一个 Fennel 解释器, 并且已经被求值了.
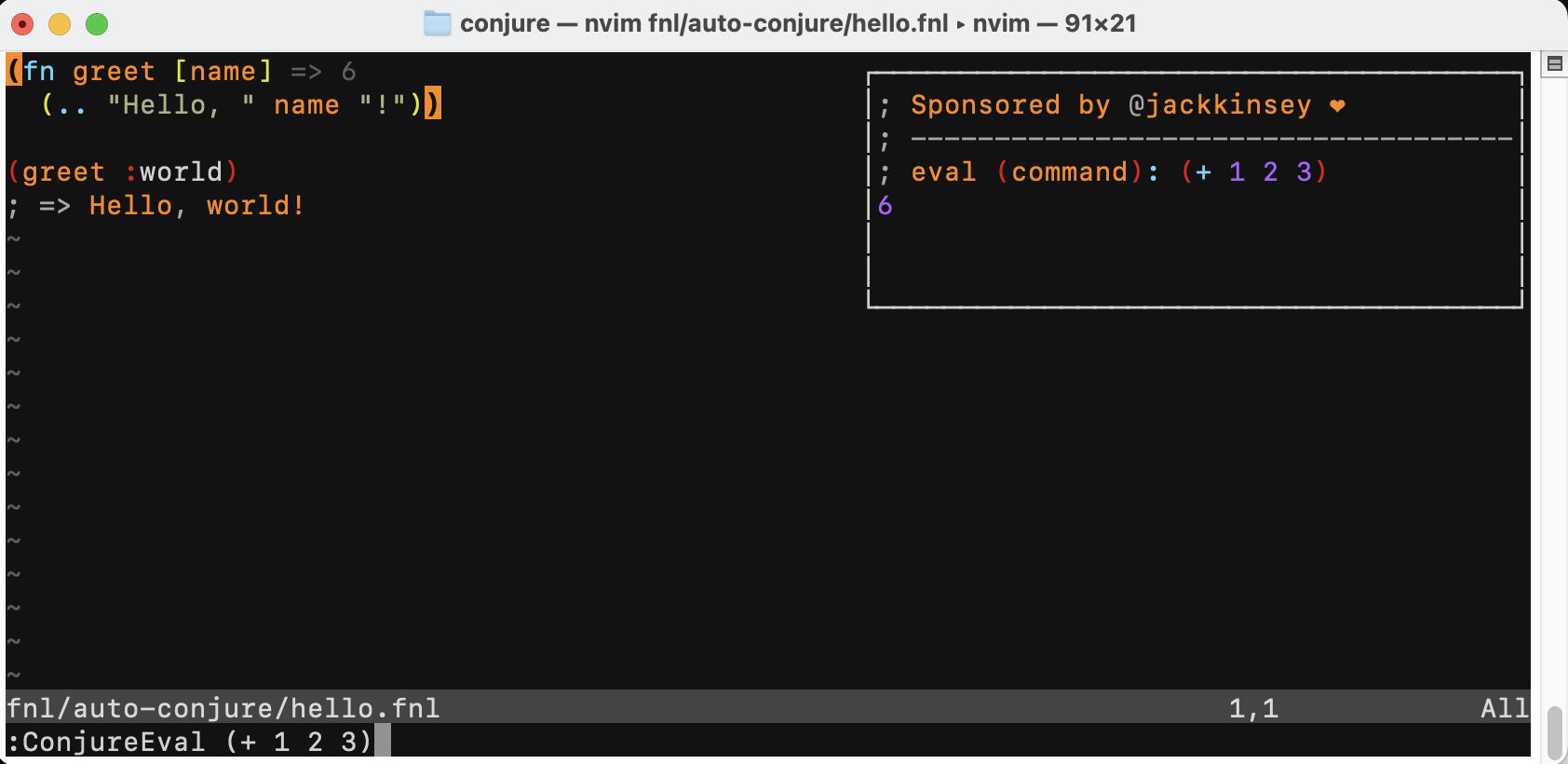
Figure 2: Ex command evaluation with Conjure.
- 使用 Neovim 的快捷键进行求值 (eval current-form)
- 将光标移动到第一行第一个字符
(, 然后按,ee - 将光标移动到第四行第一个字符
(, 然后按,ee
你注意到了吗? 当你按下 ,ee, 光标对应的 括号内的内容 已经被传递给了一个 Fennel 解释器并被求值了.
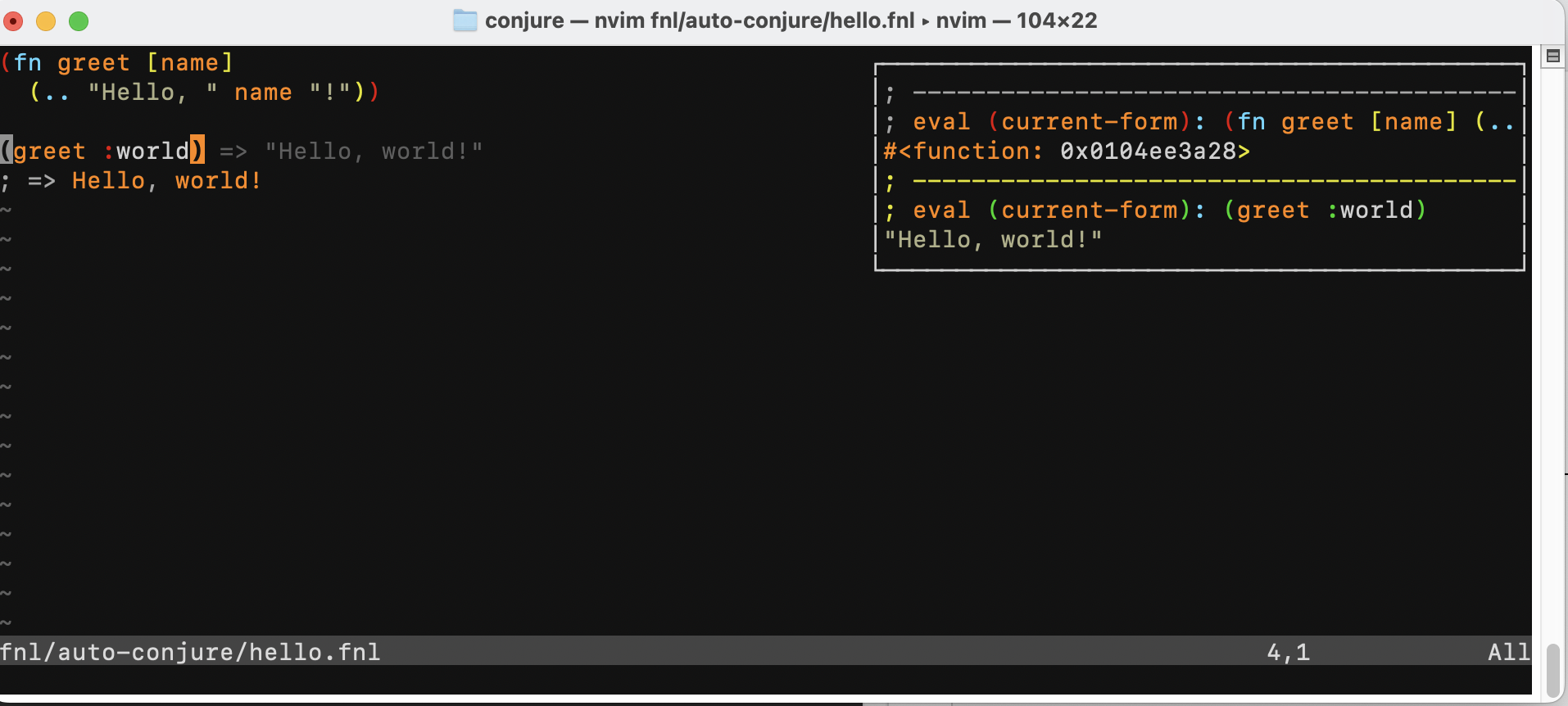
Figure 3: String evaluation with Conjure.
- 警告信息
如果你遇到以下红色文字, 你可以暂时忽略它; 你仍然可以正常操作. 这段红色文字通常在你按得太快时出现, 它还没来得及问你是否愿意信任某个配置文件. 一旦你按下允许, 警告就不会再出现.
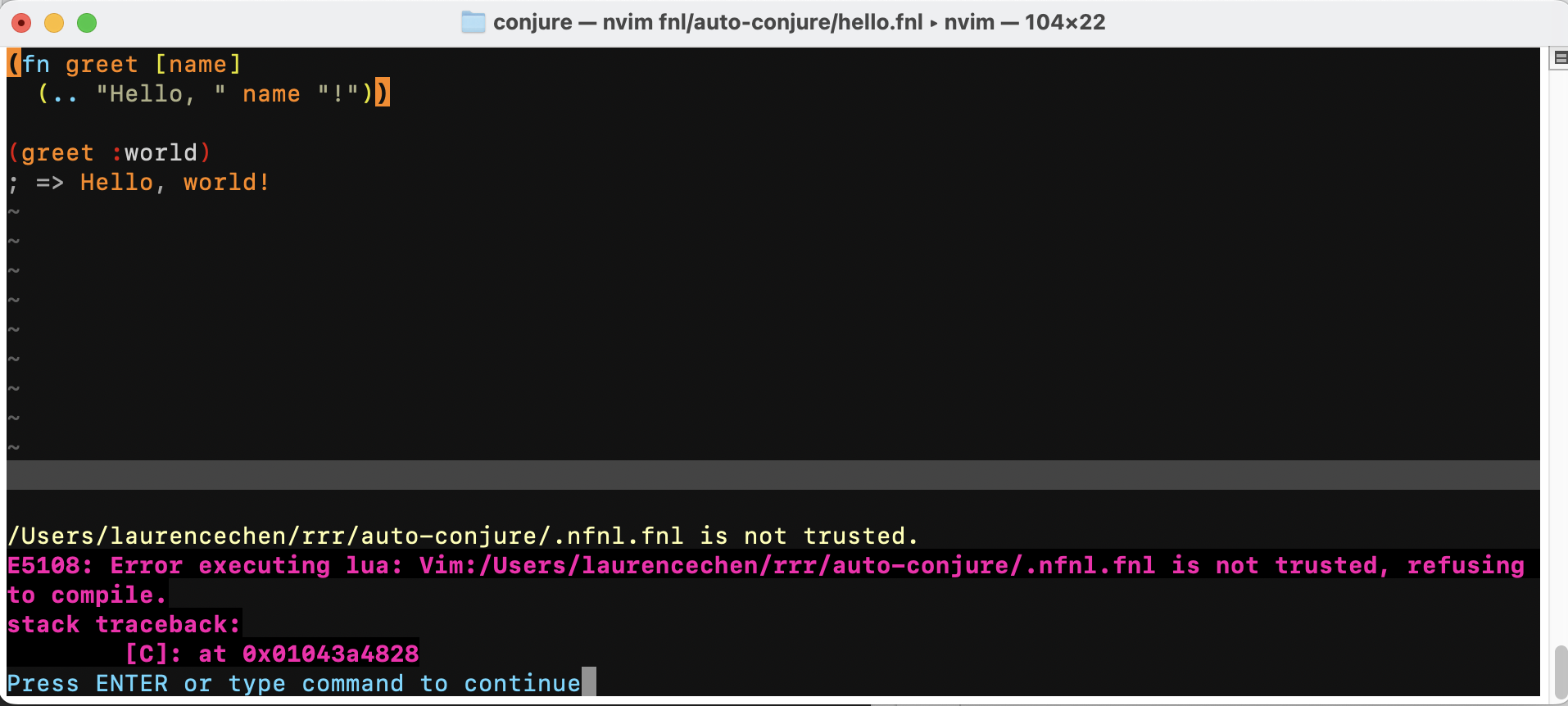
Figure 4: Warning message in Neovim.
1.6. S-expression 编辑
S-expression 编辑有很多技巧; 让我们先讨论两个最基本的.
- slurp (吞咽)
- barf (吐出)
1.6.1. Slurp
- 首先, 在
(greet ...)函数的右边加上一个字符串:great. 这里要特别注意: 在 Fennel 中, 连续的字符串可以用在前面加冒号来表示.
(greet :world) :great
- 将光标移动到行, 列 (4, 14) 并按下
>)
Figure 5: Code before slurp operation.
你注意到了吗? 当你按下 >), 光标对应的 括号 被向右移动了, 正好移到了 :great 的右边, 就像它“吞下”了 :great 一样.
Figure 6: Code after slurp operation.
1.6.2. Barf
- 将光标移动到行, 列 (4, 21) 并按下
<)
你注意到了吗? 当你按下 <), 光标对应的 括号 被向左移动了, 正好移到了 :great 的左边, 就像它“吐出”了 :great 一样.
1.6.3. 快速提示
安装和设置很容易卡住. 如果你卡住了, 不妨考虑写信给我? 或者在 Clojure 社区寻求帮助?
1.7. 总结
本章讨论了一些黑客故事和一些黑客技术: 交互式开发 和 S-expression 编辑.
在某种程度上, 这些人就像传说中的程序员: 手工打造编辑器, 手工打造编程语言, 手工锻造社区.
你愿意讲述别人的传奇? 还是活在传奇之中?
2. 序言: AI 加速编程后, 你应该学什么?
Emacs is a Lisp machine, disguised as a text editor.
(Emacs community proverb)
作为一名 Clojure 程序员, 我一直有一个遗憾: Clojure 社区最流行的编辑器是 Emacs (约占 40% 使用率), 但我一直学不会.
Emacs 的特别之处在于它的插件语言是 Elisp——一种 Lisp. 对于 Lisp 开发者来说, 这就像是生产力加成, 可以轻松地定制编辑器.
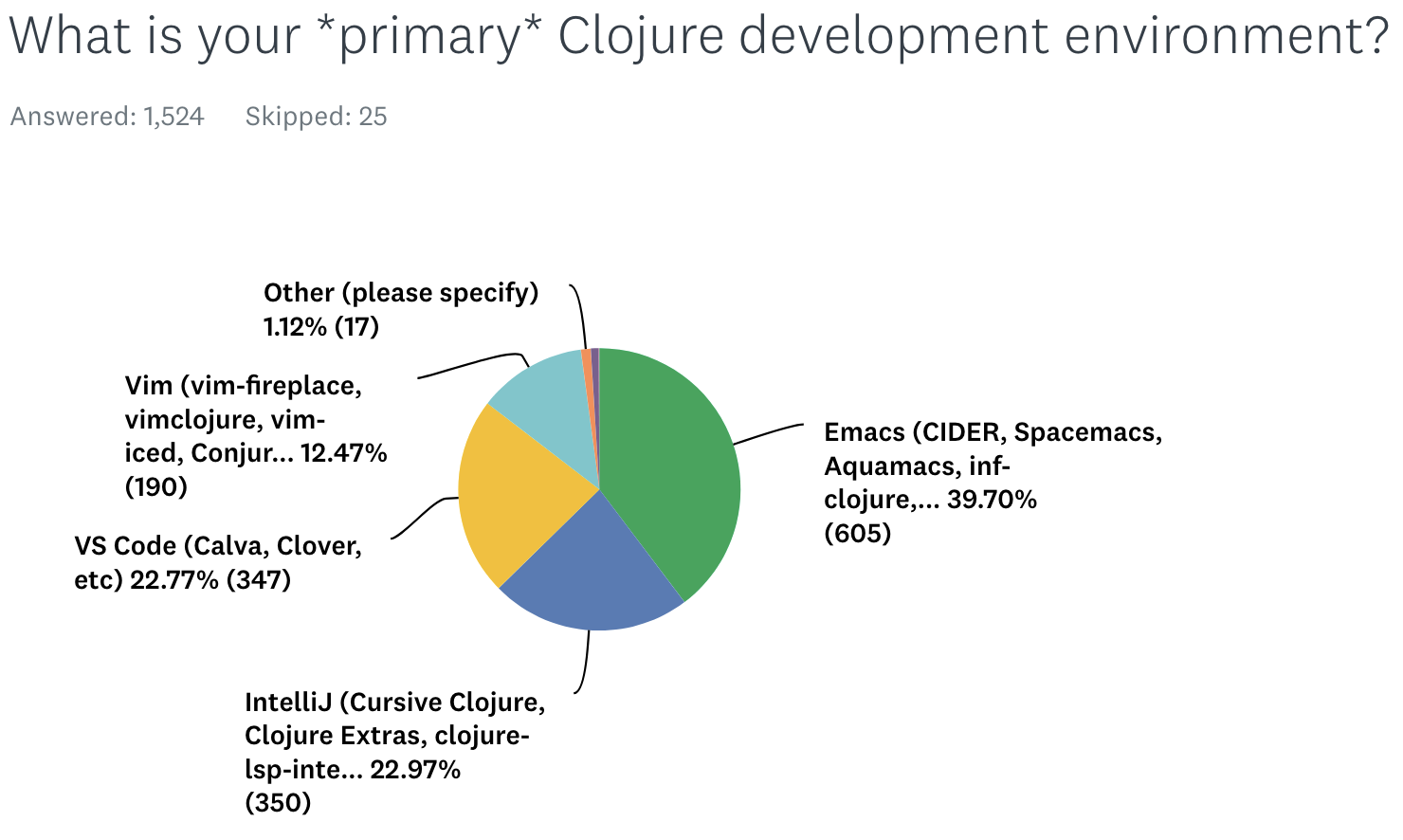
Figure 7: 2024 年编辑器使用情况调查
问题是: 我真的不习惯 Emacs, 而 Neovim 虽然支持 Lua 和 VimScript, 却没有 Lisp. 直到我发现了 Fennel——一种能编译成 Lua 的 Lisp——Neovim 才真正有了 Lisp 选项.
在用 Fennel 开发了几个插件后, 我发现它不仅解决了我的 Emacs 问题, 还让我重新思考: 在 AI 时代, 编程语言和开发范式的选择对生产力还有什么影响?
2.1. 软件开发在 AI 时代
到了 2025 年, 许多工程师可能会使用 AI 来辅助软件开发, 我也不例外. 在将 AI 应用于软件开发的过程中, 我发现我多年来使用的编程语言和范式不仅没有过时, 反而更加凸显了其价值. 它们原本就是改善 编程瓶颈 的优秀工具, 而在 AI 的加持下, 编程活动中现有的瓶颈变得比以前更加明显.
一般来说, 当工程师开发软件时, 时间大致花费在以下四个活动上:
- 编码前的研究, 包括研究代码和讨论需求
- 实际编码
- 测试和调试
- 调整和重构
这四个活动的时间分配可能因人和项目而异, 让我们假设一个分布为 20%: 30%: 30%: 20%. 应用 AI 后, 第二个活动“实际编码”所花费的时间通常会显著减少. 一些研究甚至指出, 使用 AI 后, 虽然第二个活动的时间大大减少, 但第三个活动的时间有时会增加, 因为 AI 写代码速度快但质量不稳定.
因为 Clojure 是一种 Lisp, 它支持 交互式开发, 让你可以在编写的同时进行测试. 95% 的程序员从未见过交互式开发; 你可以把它想象成一种不需要编写显式测试的测试驱动开发 (TDD). 换句话说, 仅交互式开发就能有效缩短 测试时间.
函数式编程 能有效减少 Bugs, 从而进一步缩短 调试时间, 这一点已经得到一些学术论文的支持.
假设一个工程师的开发时间分布, 分配给“测试和调试”的时间大约占总开发时间的 30%. 也就是说, 在没有 AI 的情况下, 交互式开发和函数式编程可以为你节省高达 30% 的测试和调试时间; 而当 AI 已经显著减少了“实际编码”的时间后, 交互式开发和函数式编程的效果就变得更加明显, 节省的时间可能接近总开发时间的 40%.
2.2. Fennel 降低了交互式开发 / 函数式编程的入门门槛
说实话, Clojure 真的不容易入门, 即使许多 Clojure 程序员固执地不愿承认. (编者注: 就承认你是在超越平均水平吧! 生产力比别人高三到五倍, 收入却只高了 barely 20%, 这没什么好羞愧的; 这只意味着你的薪水偏低.) 《独角兽项目》的作者 Gene Kim 也曾公开写过这一点.
Without doubt, Clojure was one of the most difficult things I’ve learned professionally, …
Clojure 的难点在于多个方面:
- Web 应用开发本来就不简单.
- Clojure 的核心库有 700 个函数和宏. 想象一下一个超丰富的标准库.
- Clojure 运行在 JVM 上, 所以你总会遇到需要使用 Java 库的情况.
- 一些 Clojure 程序员甚至放弃了基于 SQL 的 RDBMS, 转而使用 Datomic.
相比之下, 对于初学者来说, 如果你从 Fennel 开始, 上述每一点都显著简化了:
- 编辑器插件的变化有限.
- Fennel 的核心语法 + 核心库加起来不到 50 项.
- Fennel 运行在 Lua 的 VM 上, 所以你需要学习一些 Lua. Lua 也比 Java 简单得多.
- 编辑器插件通常不使用数据库; 即使使用, 通常也只是 SQLite.
让我们看一个 Fennel 的 "Hello World!" 例子:
(fn greet [name] (.. "Hello, " name "!")) (print (greet "world")) ; => Hello, world!
几年后, 我女儿的学校可能会开始教编程, 我已经在考虑用 Fennel 语言去申请做小学的代课计算机老师了.
2.3. 总结
如果这篇文章激发了你的兴趣, 让你想探索 Lisp 和函数式编程的魅力, 那么你无需再犹豫. Fennel 正是通往那个新世界的钥匙. 它的低入门门槛让你可以在熟悉的 Neovim 环境中无缝体验交互式开发的效率和函数式编程的优雅.
准备好了吗? 让我们一起踏上这场轻量级的 Lisp 冒险吧!
3. Fennel 语言速成—Lisp 语法
二十多年前, 计算机书籍通常喜欢以“24小时学会 C++”为题. 当然, 就像太阳饼里没有太阳, 老婆饼里没有老婆一样, “24小时学会 C++”很可能无法在24小时内完成.
由于 C++ 是最复杂的语言之一, 如果你想在24小时内学会一门编程语言并入门, 选择 C++ 是第一个错误. 另一方面, Lua 是生产环境中广泛使用的高级语言中最简单的. 换句话说, 如果你想快速掌握一门适合生产的编程语言, Lua 是首选.
下图提供了 Fennel 的概览: Lisp, Hosted on Lua VM, Minimalism. 其中, Minimalism 可以说是其精髓和特色. 例如, Clojure 也是一种运行在另一种语言运行时环境 (JVM) 上的 Lisp. 然而, Clojure 有自己的标准库和自己的语义. Fennel 则不同; 它只使用 Lisp 语法, 甚至其语义也大量借鉴了 Lua 的语义.

Figure 8: Fennel overview: Lisp on Lua VM with Minimalism.
由于 Fennel 借鉴了 Lua 的运行时, 库和大部分语义, 仅仅增加了 Lisp 的语法, 掌握 Fennel 的难度基本上与掌握 Lua 相差不远. 它真的可以是一门速成课!
3.1. 先谈谈语法
之前, 我们讨论了语法和语义这两个术语, 并明确指出了它们的区别. 这里有一个例子可以更清楚地解释它:
- Fennel 的 Hello World.
(print "hellow world")
- Lua 的 Hello World.
print("hellow world")
以上两段代码都是 Hello World. 在表现形式 (语法) 上, Fennel 使用 Lisp 语法, 所以括号的位置很特殊. 然而, 在操作行为 (语义) 上, 两者都调用了相同的 print 函数, 所以它们将是完全相同的.
让我们看一个更复杂的例子, 比如计算 1 + 2 * 3.
- Fennel
(+ 1 (* 2 3))
- Lua
1 + 2 * 3
与大多数通用编程语言使用的 中缀表示法 (操作符在中间) 相比, Lisp 语法采用 前缀表示法 (操作符在最前面), 并且增加了更多的括号.
你可能会想: “如果我已经会写 Lua, 写完 Lua 后, 我是不是只要改变 括号 和 操作符位置 就能写 Fennel 了?”
事情没那么简单. 有两个层面的区别. 第一个层面是: “Fennel 能做而 Lua 不能做的事情.”
- 操作符优先级: Fennel 开发者不需要记忆操作符优先级 (运算顺序完全由括号决定), 而 Lua 开发者仍然必须理解它.
- 开发风格: Fennel 支持交互式开发和 S-expression 编辑, 而 Lua 不支持.
- 元编程 (注): Fennel 可以编写 Lisp Macros, 而 Lua 不能.
第二个层面是: “Fennel 从 Clojure/Lisp 社区继承的开发风格.”
- 面向表达式.
- 函数式编程 (注).
3.1.1. 面向表达式
在命令式语言中, 行数通常被用作衡量代码量的单位, 我们通常认为自己是逐行编写代码. 每一行代码都是一个语句, 一个语句可以是一个函数调用, 变量赋值等等. 这种思维模型可以称为“面向语句”. 面向语句的思维模型在调试时尤其有效, 特别是使用 Debugger 时. 因为在调试时, 我们告诉 Debugger 逐步执行: “执行一行代码, 然后立即停止.”
然而, Lisp 程序员使用一种不同的 心智模型 进行编码: 他们认为自己是通过一系列 表达式 来编写代码. 表达式以树状方式连接, 形成一个 抽象语法树. 同时, 一个模块 (通常是一个源代码文件) 通常由多个语法树组成. 每个表达式在求值后都会有一个返回值. 即使是像 (print xxx) 这样只有副作用的函数调用表达式, 也会有一个 nil 返回值.
此外, 由于交互式开发的特性, Lisp 程序员几乎总是开着一个 Debugger. 交互式开发的运作原理是: 当用户发出像 Evaluate Code 这样的编辑器命令时, 编辑器会自动抓取一个表达式, 将其发送到一个正在运行的解释器进行求值, 然后将结果发送回编辑器. 换句话说, 在开发软件时, Lisp 程序员总是有一个正在运行的软件, 其内部状态会根据他们的意图不断改变. 这种效果几乎等同于非 Lisp 程序员在操作 Debugger 时所达到的效果: “有一个正在运行的程序, 工程师可以控制它执行到哪一行, 同时修改和监控其内部状态.”
2019年, 我去了一家公司 L Corp 开发软件. 那时, 作为一名承包商, L Corp 分配给我一台 Macbook Air 用于办公. 我用我通常的方式开发软件 (Clojure on JVM), 然后, 大约每个月一次, 在写了一些代码后, Macbook Air 会因为内存被交互式开发完全消耗而强制关机并重启.
想象一下, 如果你只能在一台 1975 年的 MITS Altair 8800 上编写代码, 你会选择 C 还是 Lisp? 你不需要选择, 因为高级的 Lisp 根本无法在上面运行.
3.1.2. 如何阅读 Fennel 代码
前面我们提到, Lisp 程序员不是逐行编写, 而是逐个表达式编写. 那么他们是如何阅读代码的呢?
在阅读代码时, 进行一些“非正式推理”是必不可少的. 如果代码的某些部分无法直观理解, 你必须先在脑海中运行它, 然后尝试推断其行为. 换句话说, 你成了一个活生生的解释器.
Fennel 代码的求值顺序只有三个规则:
- 从内到外 (Inside-Out)
- 从上到下 (Top-Down)
- 根据宏的实现 (According to Macro Implementation)
3.1.3. 从内到外
这个规则意味着当我们遇到一个嵌套表达式时, 我们必须首先对最里面的表达式求值, 然后递归地向外移动. 这就像一个俄罗斯套娃; 你必须一层一层地打开才能看到最里面的那个.
例如:
(+ 1 (* 2 3))
在阅读这段代码时, 我们不能直接计算 (+ 1 ...) , 因为我们不知道第二个参数是什么. 我们必须首先进入最里面的表达式 (* 2 3). 在我们的脑海中, 我们首先对 (* 2 3) 求值, 得到 6. 然后, 我们用这个值替换原来的表达式, 整个代码片段就变成了 (+ 1 6). 最后, 我们对这个外层表达式求值得到 7.
3.1.4. 从上到下
这个规则适用于任何包含多个互不嵌套的表达式的情况, 无论是在一个文件内还是在一个函数内. 当代码中有多个表达式时, 求值顺序从最顶层, 最左边的表达式开始, 依次向下进行.
3.1.5. 根据宏的实现
任何执行顺序无法用前两条规则解释的东西都是宏, 我们将在后面的章节中详细讨论宏. 对于初学者, 你只需要知道 let 和 if 是宏, 因为它们是最常用的.
if的执行顺序
首先, 对 A-expression 求值. 如果为真, 则对 B-expression 求值; 如果为假, 则对 C-expression 求值.
(if A-expression B-exression C-expression)
let的执行顺序
首先, 对 B-expression 求值, 然后将其结果临时绑定到 A-symbol. 接下来, 对 D-expression 求值, 然后将其结果临时绑定到 C-symbol. 最后, 对 E-expression 和 F-expression 求值.
(let [A-symbol B-expression C-symbol D-expression] E-expression F-expression)
3.1.6. 返回值
在我们刚刚看到了像 let 这样的赋值语法后, 一个问题出现了: “一个 let 表达式有返回值吗?”
是的, 它的返回值是它内部最后一个表达式的返回值, 也就是 F-expression 的返回值.
另一个与 let 非常相似的结构是 fn, 它是定义函数的语法. 下面, print-and-multiply 是一个函数. 当它被调用时, 它会执行函数定义内的表达式, 并使用最后一个表达式的返回值作为整个函数的返回值.
(fn print-and-multiply [a b] (print (+ a b)) (print (- a b)) (* a b))
以上面的代码为例, print-and-multiply 的返回值是 (* a b) 表达式的结果, 因为它也是整个函数定义内最后一个被求值的表达式.
这一点与大多数命令式语言中的函数返回值有显著不同. 在许多命令式语言中, 你必须显式使用 return 关键字来指定返回值; 否则, 函数可能没有返回值或返回 nil. 在 Fennel 中, 最后一个表达式的返回值被自动视为整个函数的返回值.
3.2. 总结
本文介绍了为什么 Fennel 可以成为一门速成课, 以及它的三个关键方面: Lisp, Hosted on Lua VM, Minimalism. 其中, Fennel 的 Lisp 语法部分也得到了详细讨论.
接下来, 我们将在未来的章节中继续讨论 Fennel 的语义.
— 注: “元编程”和“函数式编程”将在后续章节中详细讨论.
4. Fennel 语言速成—核心语法
那么我们到底如何使用 Fennel 来完成任务呢? 像所有高级语言一样, 我们至少需要:
- 函数
- 局部变量
- 数字和字符串
- 容器
- 循环
- 迭代
- 条件语句
4.1. 函数
(fn print-and-add [a b c] (print a) (+ b c))
fn 是定义函数的关键字. 方括号 [...] 包含函数的参数, 最后一个表达式将是函数的返回值.
(fn print-and-add [a b c] "purpose/context of fn here." (print a) (+ b c)) ; We use ~;~ as a comment
上面例子中的 "purpose/context of fn here." 是一个文档字符串, 它是可选的. 它的位置在方括号后面的那一行.
分号 ; 用于表示注释.
4.2. 局部变量
let用于创建在let块内有效的局部变量, 它们的值在创建后不能被修改.
(let [x (+ 89 5.2) f (fn [abc] (print (* 2 abc)))] (f x))
在上面的例子中, 在最后一个 ) 之后, 变量 x 和 f 就不再存在了.
(let [x 19] ;; (set x 88) <- not allowed! (let [x 88] (print (+ x 2))) ; -> 90 (print x)) ; -> 19
用 let 创建的变量不能用 set 修改. 但是, 你可以在内部嵌套第二个 let 块, 并在该第二个 let 块内创建一个同名变量来遮蔽原始变量.
local用于创建在单个文件内有效的局部变量, 它们的值在创建后不能被修改.
(local tau-approx 6.28318)
var用于创建在单个文件内有效的局部变量, 它们的值可以在以后使用set进行修改.
(var x 19) (set x (+ x 8)) (print x) ; -> 27
4.3. 数字与字符串
支持基本的算术运算: +, -, *, /. 当然, 操作符写在表达式的开头.
需要特别注意的是数字类型: 除了 Lua 5.3 及更高版本有整数类型外, 其他 Lua 版本中的数字都是 number 类型, 即双精度浮点数. Neovim 使用的 Lua 是 Luajit, 它与 Lua 5.1 兼容.
字符串是不可变类型. .. 用于字符串连接.
(.. "hello" " world") ; -> "hello world"
4.4. 容器
Python 有 list, dict 容器类型; Java 有 ArrayList, HashMap 容器类型; Golang 有 slice, map 容器类型. 然而, 在 Lua 和 Fennel 中, Table 是唯一的容器类型.
不过, 即使只有一种, 它也能满足字典和列表的用途.
4.4.1. 字典用途
当用作字典时, 使用 大括号 来声明. 在下面的例子中, "number" 是键; 531 是值.
{"key" value "number" 531 "f" (fn [x] (+ x 2))}
- 句点
.用于从Table中检索与“键”对应的“值”.
(let [tbl (function-which-returns-a-table) key "a certain key"] (. tbl key))
tset用于向Table写入新的“键/值”对或修改现有的.
(let [tbl {} key1 "a long string" key2 12] (tset tbl key1 "the first value") (tset tbl key2 "the second one") tbl) ; -> {"a long string" "the first value" 12 "the second one"}
4.4.2. 列表用途
当 Table 用于存储具有线性, 顺序语义的数据时, 我们需要将 Table 的所有 键 设置为从 1 开始递增的数值.
对于这种用例, Fennel 提供了一种新的声明语法, 使用 方括号 [. 在这种情况下, 你不需要写键值; 它们会自动从 1 开始生成.
["abc" "def" "xyz"] ; equivalent to {1 "abc" 2 "def" 3 "xyz"}
table.insert 有两种用法:
- 一种是插入一个没有索引的新值, 这种情况下
table.insert会将新值附加到列表的末尾. - 另一种是传递一个索引和一个新值, 这种情况下
table.insert会将新值插入到相应的索引处, 列表中所有其他元素的索引会自动调整.
table.remove 也有两种用法, 类似于 table.insert, 带或不带索引.
(local ltrs ["a" "b" "c" "d"]) (table.remove ltrs) ; Removes "d" (table.remove ltrs 1) ; Removes "a" (table.insert ltrs "d") ; Appends "d" (table.insert ltrs 1 "a") ; Prepends "a" (. ltrs 2) ; -> "b" ;; ltrs is back to its original value ["a" "b" "c" "d"]
在 Fennel 中, 我们通常将用于 字典目的 的 Table 称为 通用表 (General Tables), 将用于 列表目的 的 Table 称为 序列式表 (Sequential Tables).
4.4.3. 容器长度
length 可用于返回列表容器或字符串的长度.
(let [tbl ["abc" "def" "xyz"]] (+ (length tbl) (length (. tbl 1)))) ; -> 6
4.5. 循环
如果你不知道要执行多少次, 只知道要一直执行下去, 通常使用 while 循环语法.
(while (keep-looping?) (do-something))
还有 for 循环.
- 打印从 1 到 10
(for [i 1 10] (print i)) ;; 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
- 打印从 1 到 10, 步长为 2.
(for [i 1 10 2] (print i)) ;; 1, 3, 5, 7, 9
4.6. 迭代
然而, 大多数时候, 迭代能更清楚地表达我们的意图:
each结合pairs可以遍历一个通用表.each结合ipairs可以遍历一个序列式表.
(each [key value (pairs {"key1" 52 "key2" 99})] (print key value)) (each [index value (ipairs ["abc" "def" "xyz"])] (print index value))
要表达函数式编程中 map 或 filter 的语义, 可以使用 collect 和 icollect. (这两者的语义最接近 Python 的字典推导式和列表推导式.)
collect可以生成一个通用表.icollect可以生成一个序列式表.
(collect [_ s (ipairs [:greetings :my :darling])] s (length s)) ;; -> {:darling 7 :greetings 9 :my 2} (icollect [_ s (ipairs [:greetings :my :darling])] (if (not= :my s) (s:upper))) ;; -> ["GREETINGS" "DARLING"]
注意: 例子中的下划线 _ 用作变量的占位符. 因为 ipair 在左边会有两个变量, 但由于该变量后续不会被使用, 所以使用下划线符号.
此外, 要表达函数式编程中 reduce 的语义, 可以使用 accumulate. 参考.
4.7. 条件语句
Fennel 的 if 有两种用法:
- 第一种用法类似于 Lua 的
if.
(if (pass-the-exams?) (graduate) (repeat-the-grade))
- 第二种用法的语义更像 Lua 的
if elseif elseif … else, 但语法简单得多.
(let [x (math.random 64)] (if (= 0 (% x 2)) "even" (= 0 (% x 9)) "multiple of nine" "I dunno, something else"))
如果条件语句没有 else 分支, 通常使用 when. 注意 when 中包含的表达式通常也具有 副作用.(注)
(when (currently-raining?) (wear "boots") (deploy-umbrella))
4.8. 总结
我们探讨了 Fennel 的核心语法, 其中很多是直接从 Lua 沿用过来的.
本节大量借鉴了官方教程中的代码示例, 但官方教程涵盖了更多细节. 有兴趣的读者也可以参考一下.
— 注: 在软件和编程中, 副作用指的是函数, 方法或表达式在执行时, 除了返回值之外, 发生的对外部状态的改变. 这个概念与函数式编程密切相关, 后面会更详细地讨论.
5. Fennel 语言速成—Lua
昨天, 我们已经讨论了 Fennel 的核心语法, 这足以编写纯粹的数据转换. 另一方面, 现实世界软件开发的很大一部分涉及库, 所以我们现在将更多地讨论 Lua.
5.1. Lua 与极简主义
如前所述, Lua 是生产环境中广泛使用的最简单的高级语言. 为什么呢? 这是因为它通常用于嵌入: 在宿主应用程序中, Lua 通常作为库嵌入. 它之所以轻量, 是因为它缺乏内置的文件系统, 系统调用, 网络连接和其他功能. 这些底层操作通常由宿主应用程序 (通常是 C 或 C++) 处理. 这种设计理念使得 Lua 的核心非常精简, 更容易集成到各种应用环境中.
5.1.1. C 和 Lua 交互
Lua 的一大特色是它与 C/C++ 语言的无缝集成. 它提供了一个优雅的 C API, 允许宿主应用程序轻松注册 C 函数供 Lua 代码调用. 例如, 如果你的主程序需要读取一个配置文件, 你可以在 C 中编写一个 read_config_file 函数, 然后通过 Lua 库中的 C API 将其暴露给 Lua 环境.
当 Lua 代码调用 read_config_file 时, 控制权返回到宿主应用程序以执行 C 函数. 该函数完成后, 结果返回给 Lua. 这种机制使 Lua 不仅仅是一种脚本语言, 更像是一个高度可定制的“组件”, 可以与主程序进行深度交互, 用于逻辑处理, 配置, 甚至游戏插件等任务.
5.2. Lua 概览
5.2.1. 数据类型
Lua 提供 8 种数据类型:
nil: 表示“无值”. 如果在if条件中使用nil, 它被视为false.boolean: 只有true和false. 在 Lua 中, 只有nil和false被认为是假. 所有其他值, 包括数字0, 空字符串"", 或空 Table{}, 都被认为是真. 这与某些其他编程语言 (如 C++ 或 JavaScript) 的行为不同.number: 双精度浮点数.string: 字符串.table: 唯一的容器类型.thread: 虽然使用了“线程”这个词, 但它实际上指的是 协程.function: 函数.userdata: 如果某些类型是由 C 语言返回的, 则使用此类型.
在 Fennel 中, 你可以使用 (type $variable) 来检查 $variable 的类型.
5.2.2. 重要的全局函数
在 Lua 中, 标准库中的一些函数没有内置在全局环境中, 所以我们需要在使用它们之前 require 该库. 例如, 下面的 io.open:
local io = require("io") io.open("file.txt", "r")
另一方面, 有些函数直接内置在全局环境中; 这些是全局函数. 特别重要的包括:
tonumber: 将字符串转换为数字.tostring: 转换为字符串.print: 首先对其所有参数调用tostring, 然后打印它们, 后面跟着一个换行符. 打印时参数之间会插入空格.type: 返回类型.pcall: 在保护模式下调用函数. 因为是保护模式, 如果发生错误, 程序不会立即崩溃. 它返回两个值: 第一个是布尔值, 表示调用是否成功; 第二个是返回值或错误消息.error: 停止程序执行, 生成一个错误, 并跳转到最近的pcall.assert: 检查一个条件; 如果为假, 抛出一个错误.ipairs: 遍历序列式表.pairs: 遍历任何表.unpack: 将一个序列式表从单个表解包成多个独立的值.require: 加载并返回一个模块.
如果我们对上述函数做一个简单的分类:
- 辅助函数:
tonumber,tostring,print,type. - 错误和异常处理:
pcall,error,assert. - 容器相关:
ipairs,pair,unpack. - 模块加载:
require.
让我们看一个 Fennel 中 unpack 的用法示例:
(local t [:a :b :c]) (print (unpack t)) ;; a b c
如果你做过函数式编程, 是否会想到一个巧妙的函数 apply? 由于 Fennel 采用极简主义, 并且已经从 Lua 借鉴了 unpack, Fennel 不提供 apply 函数.
5.2.3. 标准库
如果你有任何前面介绍的函数无法处理的需求, 在引入第三方库之前, 首先查阅 Lua 5.1 手册. 你可能会在 Lua 的标准库中找到你需要的东西.
5.2.4. 在线编译, 反编译.
有时, GenAI 生成的代码根本无法运行, 甚至操作符位置都不正确. 这很常见, 因为 Fennel 是一种小众语言, 没有足够的训练数据供 AI 利用. 解决方法很简单: 你可以先让 GenAI 生成 Lua 代码, 然后使用编译器/反编译器将其转换为 Fennel 代码.
5.3. Lua Table 的其他用途
如前所述, Lua 的 Table 可以用作列表或字典. 然而, 这还不是全部. Lua 的 Table 还有其他用途:
- 模块 (
module) - 对象 (
object)
5.3.1. 模块
在 Lua 中, 一个 模块 本质上就是一个 Table. 这个 Table 包含了该模块打算向外部暴露的所有函数和变量. 当你使用 require 加载一个模块时, 它返回的就是这个 Table. 这种设计非常简洁, 因为你不需要额外的关键字或特殊语法来定义一个模块; 你只需创建一个 Table 并返回它.
例如, 假设你有一个名为 aa.lua 的文件, 内容如下:
local aa = {} function aa.ff() return "This is a public function." end aa.vv = 100 return aa
在这个例子中, aa 是一个 Table. 我们将 ff 和 vv 设置为这个 Table 中的键值对, 以便它们可以从外部访问.
5.3.2. 对象
Lua 的 Table 也可以用来实现面向对象编程 (OOP), 主要通过元表 (metatable) 功能.
一个 Lua Table 可以包含一个元表, 这个元表虽然也是一个 Table, 但带有特殊的语义. 当一个包含元表的 Table 被当作一个对象并进行方法调用时, 如果找不到该方法, 它会自动在元表中搜索, 从而实现面向对象编程的关键特性, 如继承和多态.
5.4. Fennel 针对 Table 的语法扩展
受 Clojure 的影响, Fennel 也从 Clojure 带来了一些优秀的设计, 导致了一些 Table 的特殊用法.
5.4.1. 冒号前缀表示法
如果容器的键是字符串类型且不包含空格或保留字符, 键可以用冒号前缀表示法书写, :shorthand.
{:key value :number 531}
这种冒号前缀表示法在 Table 键中尤其常见. 在 Clojure 语言中, 这种冒号前缀表示法直接对应于一个名为 关键字 的新数据类型, 专门用于容器键.
值得注意的是, 在 Fennel 中, 这种冒号前缀表示法在编译后会转换为 Lua 的字符串类型; 例如, :key 变成 "key". 这与 Clojure 的关键字不同, 后者是一个独立的数据类型, 但它提供了类似的便利性.
5.4.2. 读写
当 Table 的键使用冒号前缀表示法时, 可以使用 ${table}.${key} 来访问值, 这比 (. ${table} ${key}) 更简洁.
(let [tbl {:x 52 :y 91}] (+ tbl.x tbl.y)) ; -> 143
此外, ${table}.${key} 语法也可以与 set 函数一起使用.
(let [tbl {}] (set tbl.one 1) (set tbl.two 2) tbl) ; -> {:one 1 :two 2}
5.4.3. 解构 Table
- 对于序列式表, 可以进行 基于位置 的解构.
(let [data [1 2 3] [fst snd thrd] data] (print fst snd thrd)) ; -> 1 2 3
- 对于通用表, 可以进行 基于键 的解构.
(let [pos {:x 23 :y 42} {:x x-pos :y y-pos} pos] (print x-pos y-pos)) ; -> 23 42
对于基于键的解构, 如果接受解构值的变量名与键名完全相同, 可以使用更简化的语法: 键不再使用“冒号前缀表示法”, 而是直接写成“冒号”.
(let [pos {:x 23 :y 42} {: x : y} pos] (print x y)) ; -> 23 42
5.5. 总结
Fennel 官方网站也有一个 Lua Primer 文档, 它专门解释了 Fennel 作者认为重要的 Lua 部分, 内容比本章更多.
我推断 Fennel 作者的意图, 也许他认为开发者在阅读了他的 Fennel 教程和 Lua Primer 后, 就足以开始使用 Fennel 了?
6. Fennel 语言速成—nfnl 库
在 Fennel 的官方文档中, 有这样一段话:
There's also a Cljlib library, that implements a lot of functions from clojure.core namespace and has a set of macros to make writing code more familiar to Clojure programmers
对于那些想用 Clojure 风格编写代码的人来说, Cljlib 被认为是一个更完整的解决方案. 一个更方便的方法是使用 nfnl 库. 由于 Conjure 也捆绑了 nfnl, 如果你之前按照 day02 的步骤安装了 Conjure, 那么 nfnl 库已经可以使用了.
6.1. nfnl 示例
打开之前下载的 auto-conjure 项目.
cd auto-conjure
创建一个 fnl/auto-conjure/temp.fnl 文件.
nvim fnl/auto-conjure/temp.fnl
将以下内容粘贴到 temp.fnl 中, 并使用 ,ee 对每个顶层表达式求值.
(local core (require :conjure.nfnl.core)) (fn update-keys [t f] "for every key in t, apply ~(f key)~." (->> (core.seq t) (core.reduce (fn [acc v] (core.assoc acc (f (core.first v)) (core.second v))) {}))) (fn change-keyword [k] {:key k}) ;; (update-keys {:code "(+ 1 2)" :op :eval} change-keyword)
用 ,ee 求值时, 结果应该类似于:
; eval (current-form): (local core (require :conju... ; eval (current-form): (fn update-keys [t f] "for ... #<function: 0x01059a1a80> ; eval (current-form): (fn change-keyword [k] {:ke... #<function: 0x01057ac5d8>
简单解释:
- 第一行
(local ... )的返回值是nil, 所以什么都不显示. - 第三行和第十行
(fn ...)的返回值非nil, 所以我们可以在相邻的窗口中看到类似#<function: 0x01057ac5d8>的结果.
6.1.1. 注释可以作为测试
将光标移动到位置 (13, 4), 也就是 ;; (update-keys 中的 左括号, 按 ,ee 求值, 你仍然会得到一个结果.
这里有一个关键点: “即使是注释, 你仍然可以对它求值.” 方便吧? 注释就是测试.
6.1.2. 表的键也可以是表
这里解释一下代码的作用:
我定义了一个名为
update-keys的函数. 它可以使用作为其第二个参数提供的函数对 Table 的所有键应用一个操作.在第 13 行的注释中,
{:code "(+ 1 2)" :op :eval}经过操作后, 每个键都会从字符串变成一个 Table.
键可以使用字符串或数字以外的类型? 没错, Lua 的 Table 提供了这种语义.
6.2. Clojure 风格编程
前面例子中的这段代码:
(fn update-keys [t f] "for every key in t, apply ~(f key)~." (->> (core.seq t) (core.reduce (fn [acc v] (core.assoc acc (f (core.first v)) (core.second v))) {})))
如果弃用 nfnl 库, 它会变成:
- 命令式编程风格
(fn update-keys [t f] "for every key in t, apply ~(f key)~." (let [result {}] (each [k v (pairs t)] (tset result (f k) v)) result))
- 函数式编程风格
(fn update-keys [t f] "for every key in t, apply ~(f key)~." (collect [k v (pairs t)] (f k) v))
6.2.1. 表达力 vs. 性能
Clojure 库的一个特点是“几乎每个表达式都有一个返回值.” 写代码时, 不需要过多思考; 所有东西都 просто 有一个返回值. 此外, 借助交互式开发, 你不需要太费脑筋——只需写一点代码, 观察返回值如何变化, 然后不断调整直到达到目标.
因此, 当我使用 reduce 时, 在传递给它的匿名函数内部, 我调用了 assoc, 它也有一个返回值——它返回修改后的 Table. 在这个上下文中, tset 的语义与 assoc 类似, 都是修改一个 Table, 但 tset 的返回值是 nil, 所以如果用 tset 代替 assoc, 就会导致错误.
没办法, tset 毕竟是 Lua 的函数.
Fennel 毕竟也被设计成一种函数式编程语言, 所以它自然有函数式结构, 因此有了 collect. 然而, 其核心存在细微差别: Fennel 提供的语法是用宏实现的; 另一方面, :conjure.nfnl.core 主要由函数组成.
一方面, 宏不具备函数丰富的 表达力; 例如, 宏不能作为函数参数传递. 另一方面, 正因为它们是宏, 当这段代码被编译成 Lua 时, 几乎没有多余的变量复制, 这非常节省资源, 可以看作是一种 性能优化.
6.3. 总结
Fennel 在设计时, 考虑到嵌入式语言应用的环境, 性能往往是一个重要的考量. 因此, 牺牲了一些表达力以换取性能. 换句话说, 如果性能不是问题, 编写 Clojure 风格的 Fennel 也是一个可行的选择.
7. Lisp 深入—交互式开发
之前在 day02, 我们介绍了 Lisp, 交互式开发和 S-expression 编辑. 接下来, 我们将更深入地探讨 Lisp, 今天的主题是交互式开发.
7.1. 交互式开发的其他命令
之前, 我们介绍了 Conjure 的 Normal Mode 命令 ,ee. 这里需要澄清一下; 严格来说, Conjure 绑定的命令是: <localleader>ee.
打开 ~/.config/nvim/init.vim 文件, 你会看到一行将 <localleader> 定义为 ,.
let maplocalleader=","
这就是我们使用 ,ee 的原因. 读者可以根据自己的喜好将 <localleader> 设置为其他键.
除了之前提到的:
<localleader>ee: 对当前光标下的表达式求值. (evaluate expression).:ConjureEval [code]: 对当前的[code]求值.
其他常用的 Conjure 命令包括:
<localleader>lv: 打开日志缓冲区窗口. (log in vertical window)<localleader>lq: 关闭日志缓冲区窗口. (log quit)<localleader>lr: 清除日志缓冲区内的内容. (log reset)<localleader>eb: 对当前缓冲区的内容求值. (evaluate buffer)<localleader>ew: 对当前光标下的字符串求值. (evaluate word)<localleader>gd: 跳转到当前光标下字符串的定义. (go to definition)K: 查询当前光标下字符串的文档. (doc)
7.1.1. 记忆命令
记忆这些命令其实有英文线索. 例如, <localleader>lv 打开的窗口是垂直的, 所以你可以联想到 "log in vertical window". 一个稍微不那么明显的联想是, 文档的英文单词是 'documentation', 但通常缩写为 'doc', 对应 K.
Conjure 还有更多命令吗? 有的, 官方文档里有更多命令. 有必要研究更多吗? 我们这里讨论了总共 9 个 Conjure 命令, 这对于一个专业的 Lisp 程序员来说, 用五年应该也够了.
7.1.2. 命令分类
上述 9 个命令可以分为四大类, 下面逐一解释.
- 日志缓冲区
<localleader>lv, <localleader>lq, <localleader>lr 显然是用于日志缓冲区控制. 日志缓冲区是 Conjure 在众多 Vim 交互式开发插件中的一个突出设计. 日志缓冲区的一个主要优点是: 即使你求值的东西返回的数据过大, Neovim 通常也不会卡死. 数据只会存在日志缓冲区里.
- 表达式求值
这四个命令, <localleader>ee, :ConjureEval [code], <localleader>eb, <localleader>ew, 在 Conjure 的核心中, 与解释器通信时使用相同的结构. 例如, <localleader>ee 在 Conjure 中的实现是先读取一个表达式, 然后将其内容发送给解释器; 至于 <localleader>eb, 它是先读取整个缓冲区的内容, 然后将该内容发送给解释器. 上述两个命令的后半部分涉及相同的行为.
- 跳转到定义
它向解释器发送一个特殊命令来查询定义. 值得注意的是, Fennel 语言的跳转到定义功能在最新版本的 Conjure 中尚未实现. 另一方面, 我们仍然可以通过 LSP (language server protocol) 配合安装 fennel-ls 来实现跳转到定义的功能.
- 查询文档
它向解释器发送一个特殊命令来查询文档. 补充一下, K 是 Neovim 的一个内置命令, 用于查询光标下关键字的文档. Conjure 巧妙地集成了这个命令, 使得 K 可以自动向 Lisp 解释器发送查询请求, 这样我们就可以查找函数文档了.
7.2. 善用交互式开发
在 day03, 我们讨论过
因为交互式开发, Lisp 程序员几乎总是开着一个 Debugger.
交互式开发可以当做 Debugger 使用吗? 差不多.
Debugger 辅助调试通常分为三大类:
- 函数执行的返回值.
- 逐步执行.
- 函数内局部变量的运行时值.
1 和 2 显然可以被交互式开发替代. 对于 3, 你需要稍微绕个弯. 这里, 我们将介绍一个技巧: 行内检查 (Inline Inspection).
7.2.1. 行内检查
思考以下代码: 当我们想了解局部变量 z 的值时, 似乎 print 是唯一的选择. print 的烦人之处在于, 当打印太多时, 我们必须手动搜索想要的输出.
(fn wrong-add [x y] (let [z (+ x 2)] (+ z y)))
在 Fennel 中, 我们可以使用 tset (table set) 来“捕获”运行时局部变量的值, 并将它们写入一个全局 Table, 从而可以随时检查它们. 这个技巧的核心思想是: 通过修改一个全局可访问的状态来观察内部局部变量.
下面重写的关键点是: 在顶部添加 (local ddd {}), 并使用 (tset ddd :z z) 来捕获 z 的运行时值.
(local ddd {}) (fn wrong-add [x y] (let [z (+ x 2)] (tset ddd :z z) (+ z y))) (wrong-add 3 4)
用 <localleader>eb 对整个文件求值后, 将光标移到 ddd 上方, 执行命令 <localleader>eb, 你就会看到结果.
; evaluate (word): ddd {:z 5}
这个技巧在不同的 Lisp 方言中有不同的实现; 例如, 在 Clojure 中, 通常会使用 def 来达到类似的效果.
7.2.2. 调试库
想象一下, 在开发软件时, 你使用了一个库 A 的函数 pp. 你强烈怀疑 pp 有错误, 但如何测试来验证你的假设呢? 修改库? 这会不会有点费力, 特别是当 A 是一个已经安装的 jar 文件时?
在用 Clojure 开发时, 我做过这样的事:
- 对
pp执行跳转到定义, 跳转到库 A 的源代码中. - 修改
pp, 然后直接对缓冲区求值而不保存.
这样, pp 的定义就在解释器中被修改了, 你可以轻松地验证你的假设.
这里需要强调一点: 在 Neovim 中, 缓冲区不等于保存在硬盘上的文件. 缓冲区是你当前正在查看的文件的状态.
类似的技术在 Fennel 的情况下需要稍作调整.
对于第一步, Fennel 的跳转到定义通常无法处理库只有 Lua 源代码而没有 Fennel 源代码的情况. 在这种情况下, 你需要手动 grep 来找到正确的位置.
对于第二步, 如果找到的函数定义位置只是一个 Lua 文件, 你可以修改 Lua 文件, 并使用 Neovim 的 Ex 命令: :lua [content] 来对当前修改的内容求值.
7.3. 总结
本文介绍了九个常用的 Conjure 交互式开发命令和两个实用技巧.
有一个与奢侈品相关的谚语:
A luxury, once enjoyed, becomes a necessity.
交互式开发是一种奢侈品; 它让你的软件开发灵活性达到另一个层次. 你认为它是必需品吗?
8. Lisp 深入—S-expression 编辑
许多开发者在开始认真编写 Lisp 不久后, 就深深感受到编辑括号的不便. 第一个问题是: “这么多括号, 我该如何格式化?”
老实说, 多年前我刚开始写 Lisp 的时候, 我是像下面这样格式化代码的.
(fn factorial [x] (if (< x 2) 1 (* x (factorial (- x 1 ) ) ) ) )
上述格式化风格在编写代码时可以方便地在视觉上对齐括号. 另一方面, 在阅读代码时, 它大大增加了噪音并急剧增加了行数, 这当然不理想. Lisp 社区的标准格式化风格是下面这种.
(fn factorial [x] (if (< x 2) 1 (* x (factorial (- x 1)))))
第二种格式化风格更易于阅读, 但它带来了其他问题: “在手动编写代码时, 如何确保括号总是成对的?”
接下来, 我们将在介绍辅助插件功能的同时, 分解这些问题.
8.1. 括号配对问题
这个问题主要有两个层面:
- 阅读代码时, 如何即时看到括号之间的配对关系.
- 编写代码时, 如何确保括号总能成对出现.
8.1.1. 彩虹括号
在 day02, 这个插件是通过 vim-plug 安装的:
" rainbow parentheses Plug 'frazrepo/vim-rainbow'
参考下图; 有了这个插件, 括号的前后对应关系就变得非常清晰了.
Figure 9: Rainbow parentheses in Fennel code.
在 Lisp 社区, 对这个插件其实有不同的看法. 有些人认为写 Lisp 久了, 阅读代码时的重点不在括号上, 所以并不真的需要. 而彩虹括号插件则有分散注意力和造成过多视觉噪音的缺点.
另一方面, 考虑到初学者现有的思维模式, 我认为这还是相当有必要的.
8.1.2. 自动括号配对
对应的插件:
Plug 'jiangmiao/auto-pairs', { 'tag': 'v2.0.0' }
它能让你每次输入左括号时自动生成一个右括号. 并且这适用于你输入的任何东西: 圆括号, 方括号, 大括号, 或字符串引号符号. 换句话说, 一旦启用这个功能, 你的括号就会被强制成对.
8.2. 括号编辑问题
很多年前, 在我刚安装了“自动括号配对”插件后, 我其实觉得编码变得极其繁琐. 仅仅两个常见的编辑挫折就差点让我一度放弃“自动括号配对”.
- 当括号不成对时, 很难修正.
- 很难直接用括号包围一个已经打好的词.
8.2.1. 不成对的括号
因为编码过程中总有需要“复制粘贴”的时候, 会用到 Neovim 的 Normal Mode 命令. 然而, 自动括号配对插件只管理 Insert Mode 的命令. 也就是说, 如果我用“复制粘贴”时不小心, 就可能导致括号不成对. 但在这种情况下, 因为手动输入的括号总是成对的, 你就会卡住.
解决方法是使用 Normal Mode 命令 x 删除光标下的字符, 这样就可以直接移除不成对的括号.
8.2.2. 用括号包围
用括号包围的需求是什么? 例如, 如果我已经打了一个词, 'local', 打完才发现需要加括号, 就太晚了.
local
因为“自动括号配对”的缘故, 无论我在 'local' 前面还是后面插入括号, 它都会强制一次性输入一对括号.
()local
在学习 Lisp 的前半年, 我会用 slurp 命令对右括号 ) 进行操作, 让它“吃掉”右边的词. 半年来, 我完全依赖 slurp 和 barf 来权宜处理所有这类问题.
后来, 我发现其实有一个优雅的解决方案: 使用命令来用括号包围.
cseb: 用圆括号包围光标下的元素.cse[: 用方括号包围光标下的元素.cse{: 用大括号包围光标下的元素.dsf: 删除包围光标下元素的括号 (无论括号类型).
什么是元素? Element 是 vim-sexp-mappings-for-regular-people 插件定义的一个概念. 定义有点长, 但读者只需要记住定义中的三个规则:
- 复合形式 是由成对的
(),[], 或{}分隔的文本块. - 如果光标在字符串内, 元素就是当前字符串.
- 如果光标在成对的结构化括号上, 元素就是当前的 复合形式.
要使用上述命令, 需要的插件是:
Plug 'guns/vim-sexp' Plug 'tpope/vim-sexp-mappings-for-regular-people' Plug 'kylechui/nvim-surround'
眼尖的读者可能会注意到关键词: vim-sexp. 没错, 这三套是 S-expression 编辑的辅助插件. 另外, 我其实在前半年就已经在用 S-expression 编辑了, 但我只知道用 slurp 和 barf.
8.3. 在语法树中导航和编辑
这里还有三组常用的命令:
- 快速光标移动
- 移动元素
- 删除元素
8.3.1. 快速光标移动
在 Linux shell 中, 你可以这样移动光标:
CTRL + a: 移动到命令行的开头CTRL + e: 移动到命令行的末尾
在 Neovim 中编辑单行时, 你可以这样移动光标:
0: 移动到行首$: 移动到行尾
一旦你进入了 Lisp 的世界, 我们对代码的看法就变了; 基本单位不再只是一行代码或一个词. 最重要的基本单位之一是 S-expression, 一个接一个.
编辑 S-expression 时, 你可以这样移动光标:
(: 移动到 S-expression 的左括号.): 移动到 S-expression 的右括号.%: 从左括号跳转到其匹配的右括号, 或从右括号跳转到其匹配的左括号.
8.3.2. 移动元素
>e: 将光标下的元素向右移动.<e: 将光标下的元素向左移动.
这个功能在编写条件 if 语句时特别有用. 有时, 我们可能想交换 true 分支和 false 分支. 在分支的元素上执行一个 >e 命令就完成了交换.
8.3.3. 删除元素
我们也可以使用 vim-sexp-mappings-for-regular-people 插件定义的 元素 和 复合形式 概念作为删除的目标.
dae: 删除光标下的元素.daf: 删除光标下的复合形式.
删除后, 将光标移动到另一个位置并按下粘贴命令 p; 被删除的元素或复合形式将被粘贴到新位置.
8.3.4. 可用性的关键: 高级编辑命令
读者可能会问: “到底是什么让 S-expression 编辑这么好用? 有没有概念上的解释?”
当工程师开发软件时, 他们脑海中天生就有 语法树 的概念. 例如, 我们可能想交换一个条件语句的 true 分支和 false 分支, 每个分支都是一个子语法树. 然而, 不幸的是, 大多数时候, 编辑器无法像人类一样解析语法树. 因此, 在编写代码时, 即使我们脑子里想的是一个高度抽象的语义: “交换 true/false 分支,” 我们仍然必须将这个高级语义翻译成低级编辑器命令来完成编辑.
因为 Lisp 语法本身就反映了代码的语法树结构, 这种特殊的编程语言设计使得编辑器插件可以轻松解析 Lisp 的语法树, 从而使 高级编辑命令 (即 S-expression 编辑) 成为可能.
如果不是 Lisp, 编辑代码时, 我们在行, 词和字符之间移动 (注 1); 然而, 对于 Lisp, 编辑代码时, 我们可以在语法树内导航和编辑.
从设计的角度来看, 我们也可以说 Lisp 和 S-expression 编辑是 UNIX 哲学的一种体现:
Rule of Representation: Fold knowledge into data so program logic can be stupid and robust.
8.4. 总结
Lisp 开发者经常遇到的挑战主要围绕括号配对和括号编辑.
为了克服这些问题, 本文介绍了两大类实用的编辑器工具和技术:
- 自动括号管理: 通过彩虹括号和自动括号配对等编辑器插件, 括号关系一目了然, 并且它们的配对被自动确保, 解决了视觉和输入相关的困难.
- 高级 S-expression 编辑: 与传统的逐行或逐词编辑不同, Lisp 允许我们直接在语法树层面操作. 通过用括号包围, 快速光标移动, 移动元素和删除元素等命令, 编辑过程变得更加直观和高效.
如果说高级编程语言增强了代码的表达力, 那么 Lisp 则进一步增强了编辑器的表达力, 让开发者可以在语法树层面自由导航和操作.
—
注 1: 现代 IDE 在使用像 Tree-sitter 这样的高级库后, 也可以获取代码的语法树, 甚至实现类似导航语法树的效果. 然而, 在我写这篇文章的时候, Lisp 的 S-expression 编辑仍然超越了非 Lisp 语言.
9. Lisp 深入—宏
对于 Lisp, 我有一个从 Clojure 社区继承来的观点:
在开发应用软件时, 尽量少用 Lisp 宏.
如果是 Common Lisp 社区, 他们很可能会认为这个观点是无稽之谈, 因为在 Common Lisp 社区普遍认为: “宏是 Lisp 的精髓; 它们不仅仅是语法糖, 而是让工程师能够为特定问题定义新语言的优秀工具, 最终使代码更好地表达其意图.”
此外, 读者可能读过《黑客与画家》这本书, 也读过 Paul Graham 高度赞扬 Lisp 的文章: Beating The Averages. 确实, 那篇文章解释了因为 Lisp 有 Lisp 宏, 它可以使软件工程师的生产力 超越平庸. 而且, Paul Graham 还提供了证据: “在 Viaweb 的代码库中, 高达 20-25% 的代码是宏.”
这部分的争论可以暂时搁置; 让我们在学习了宏之后, 再来重新审视是否要积极使用它们.
9.1. Lisp 提供了什么宏?
在讨论宏之前, 让我们看两种代表性的语法类型:
{:key value}和[:a :b :c]: 这两种声明 Table 的语法被称为字面量语法 (Literal Syntax). 它们不是 S-expression. 这种类型的语法由 Lisp 编译器在读取阶段处理. 如果一个 Lisp 编译器提供 Reader Macros, 那么 Reader Macros 可以创建类似的字面量语法.->: 这是 Thread first 的语法. 这个语法是 S-expression 的形式, 所以它可以通过 Lisp 宏来实现.
下图显示了从源代码到可执行程序的流程, 可以分为两个工作阶段:
- 阶段一: 词法分析和生成语法树, Reader Macros 在此阶段操作. Reader Macro 是 Reader 的扩展机制, 因此它可以提供新的语法.
- 阶段二: 语义分析和编译, Lisp 宏在此阶段操作. Lisp 宏是编译器的扩展机制, 因此它可以提供新的语义.
大多数时候, 当我们不特别提及 Reader Macros 时, 我们所说的宏指的是在阶段二操作的 Lisp 宏.
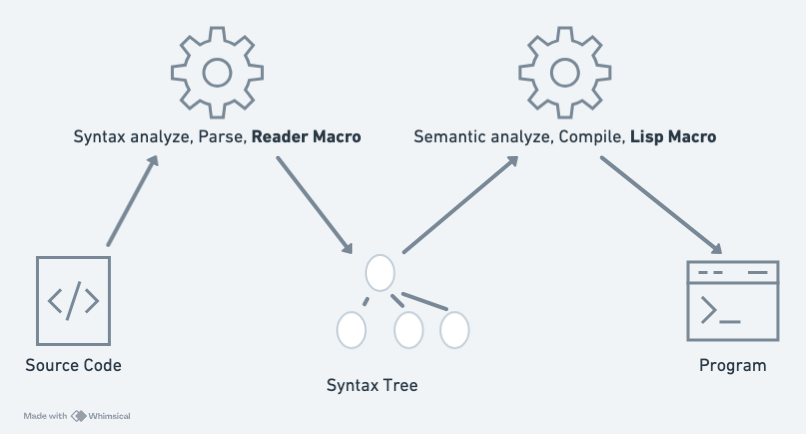
Figure 10: Macro processing pipeline.
9.1.1. 新语法 (表现形式)
在 Lua 中, 声明 Table 的语法是:
local fruits = {"apple", "banana", "orange"} local person = { name = "Alice", age = 30, city = "Taipei" }
对应的 Fennel 语法是:
(local fruits [:apple :banana :orange]) (local person {:age 30 :city :Taipei :name :Alice})
而 Reader Macros 的工作原理如下:
当 Reader 读取源代码时, 遇到 […] 字符, 它会触发对应的 [...] 的 Reader Macro, 从而将其解析为 (sequential-table ...) ; 类似地, 遇到 {…} 字符, 它会触发对应的 {...} 的 Reader Macro, 从而将其解析为 (general-table ...) . (这里, 假设上述 Fennel 语法是通过 Reader Macros 实现的, 但实际上, Fennel 是直接在 Reader 中实现的)
观察上面的例子, 可以看到 Reader Macros 只改变了代码的 表现形式; 换句话说, 它们只提供了新的语法.
9.1.2. 新语义 (行为)
与 Reader Macros 相反, Lisp 宏的核心能力在于定义新的语义, 这意味着‘改变代码的 行为, 而不仅仅是改变其 表现形式.’ 让我们用 Fennel 的 Thread First 宏 -> 作为例子来解释这个概念.
在 Fennel 中, 如果你想对一段数据执行一系列操作, 你会嵌套函数调用, 从内到外写. 例如, 如果你想先给一个数加一, 然后乘以十, 最后取绝对值:
(math.abs (* 10 (+ 1 5)))
这段代码的阅读顺序是从内层到外层: (+ 1 5) → (* 10 ...) → (math.abs ...). 这种由内向外的写法使得代码在处理复杂的顺序操作时难以阅读和理解.
Fennel 的 -> 宏解决了这个问题, 它允许你用一种更自然, 线性的方式来表达相同的逻辑:
(-> 5 (+ 1) (* 10) math.abs)
这是一个宏提供新语义的绝佳例子. 标准 Lisp 没有内置的“将前一个操作的结果作为下一个操作的参数”的语法. -> 是一个宏, 它的功能是在编译阶段将你写的线性代码:
(-> 5 (+ 1) (* 10) math.abs)
转换成一个嵌套的 S-expression:
(math.abs (* 10 (+ 1 5)))
这个重写过程就是宏赋予代码新行为的体现. 它不仅仅是替换一些字符, 而是创造了一个全新的操作流程和逻辑.
9.2. Fennel 的 Reader Macro
Fennel 的官方网站也含蓄地提到了 Reader Macros, 尽管方式很简约.
The parse-error and assert-compile hooks can be used to override how fennel behaves down to the parser and compiler levels. Possible use-cases include building atop fennel.view to serialize data with EDN-style tagging, or manipulating external s-expression-based syntax, such as tree-sitter queries.
我来翻译一下: parse-error 和 assert-compile 钩子可以在 Fennel 的解析器和编译器阶段添加新的行为.
9.3. 重新思考 Lisp 宏
事实上, 许多编程语言都有元编程这个高级主题. 换句话说, 这些具有元编程能力的语言也提供了等同于 Lisp 宏的功能: 即, 用程序编写程序.
然而, 能做等价的事情并不意味着等价的容易. Lisp 宏绝对是表达力最强, 最容易编写的.
Lisp 宏最大的特点是你所做的是定义一个函数, 这个函数将一组语法树转换成另一组语法树.
例如, 前面提到的 Thread 宏 ->, 它的参数是:
5 (+ 1) (* 10) math.abs
参数是一组语法树.
而它的输出是:
(math.abs (* 10 (+ 1 5)))
输出是另一组语法树.
9.3.1. 编写 Lisp 宏
由于在现实世界的软件开发场景中真正需要编写 Lisp 宏的概率并不高, 如何编写它们的部分留给读者自行研究.
另一方面, 有一种特殊的 Lisp 宏用法, Clojure 社区也鼓励经常使用, 可以称之为 With-Macros.
9.3.2. With-Macros
例如, Fennel 有一个 with-open 语法, 这是一种 With-Macro.
用法如下:
;; Basic usage (with-open [fout (io.open :output.txt :w) fin (io.open :input.txt)] (fout:write "Here is some text!\n") ((fin:lines))) ; => first line of input.txt
它的功能是帮助处理文件读取结束时关闭文件和释放资源. 换句话说, 虽然它也改变了‘行为’, 但它所做的行为改变通常只涉及开头和结尾的一些上下文管理.
这种 With-Macro 在处理与副作用相关的函数调用时特别有用.
在 Python 语言中, 没有 Lisp 宏, 但有一个与 With-Macros 等价的设计, 称为 Context Manager.
# Without using 'with' f = open('test.txt', 'r') try: content = f.read() # Even if an error occurs here, the f.close() in the finally block will still be executed. # This approach is more cumbersome and requires manual resource closing. print(content) finally: f.close() --- # Using 'with' with open('test.txt', 'r') as f: content = f.read() # If an error occurs in the code here, `with` ensures that the `f` object's # `__exit__` method is automatically called, thereby correctly closing the file. # This approach is more concise and safe. print(content)
9.4. 总结
本文解释了几个重要的概念: Reader Macros, Lisp 宏, 代码表现形式, 代码行为和 With-Macros. 它还解释了编程语言的读取和编译过程包含哪些内容.
下次你听到有人想设计或开发一种新的编程语言或 DSL 时, 你可以问他们: “你研究过 Lisp 吗?”
如果答案是肯定的, 那么这个人做了功课.
10. Lisp 深入—面向数据编程
关于 Clojure 有一个评论是这样的: “Clojure 是一种 Lisp, 但由于其独特的风味, 很难将其归类为传统的 Lisp.”
基本上, 任何使用 S-expression 作为其语法的编程语言, 我们都称之为 Lisp. 这个定义很有道理, 因为一旦使用了 S-expression, 就意味着三件事成为可能:
- 交互式开发
- S-expression 编辑
- Lisp 宏
那么 Clojure 的独特风味是什么样的呢? 让我们先看一些 Clojure 的独特语法:
[] -> Vector {} -> Dictionary #{} -> Set #() -> Anonymous Function
10.1. 树遍历的烦恼
在学习 Lisp 之前, 我已经编程超过十年了. 然而, 我从未用过设计模式书中提到的解释器模式 (Interpreter Pattern). 主要原因是我觉得树遍历非常麻烦.
许多编程语言都有处理树状结构的库, 但不仅不同编程语言的树遍历库不同, 即使在同一种编程语言中, 树遍历库也常常大相径庭. 无论是树的结构, 还是树遍历的 API, 都不一致.
因此, 我从来记不住任何一个树遍历库, 解释器模式也因此从未进入我的工具箱.
在 Lisp 社区, 树遍历是小菜一碟, 几乎每个人都会做, 因为代码本身就是 S-expression, Lisp 天生就非常适合处理树状结构.
如果使用 Lisp, 会用什么数据结构来表示下面的树呢?
祖父
/ \
父親 伯父
/ \
我 妹妹
当然是 S-expression.
(祖父 (父親 (我) (妹妹)) (伯父))
Lisp 的 S-expression 让工程师可以轻松地表达 数据结构 (这里的术语“数据结构”不是指算法中的数据结构, 而是指类似 JSON 或 XML 的表示). 正因为如此, Lisp 程序员可以说是最早发现 JSON 表示价值的人之一.
10.2. Clojure 的独特风味
在前面的例子中, 我相信读者已经感受到了“表示格式”的重要性. 如果数据能有一个简单, 可读且易于理解的表示, 将会极大地增强代码的可读性.
然而, Clojure 更进一步; 它试图实现两个目标:
- 让数据结构看起来像数据结构.
- 允许通过数据结构来表达逻辑.
10.2.1. 让数据结构看起来像数据结构
如果只用 S-expression 来构造向量和集合, 会写成这样:
(vector 1 2 3) (set 1 2 3)
然而, Clojure 提供了一种更简洁的语法, 让数据结构看起来更像数据:
[1 2 3] ;=> Represents a vector containing 1, 2, 3. #{1 2 3} ;=> Represents a set containing 1, 2, 3. Elements within a set must be unique.
经过符号的适当修改后, 语法是不是更简洁, 却仍然易于理解?
10.2.2. 允许通过数据结构来表达逻辑
传统的编程语言通常将数据和逻辑分开处理. 数据是数据, 函数是函数; 它们是相互独立的. 然而, 在 Clojure 中, 逻辑 通常可以通过某些数据结构来表达, 而且甚至更容易理解.
这是什么意思呢? 让我们看一个简单的例子.
在 Clojure 中, 你可以用一个向量来表示一个“路径”. 例如, 向量 [:a :b :c] 可以表示一个顺序的 逻辑操作: 先进入 :a, 然后进入 :b, 最后到达 :c.
当你把这个向量传递给 get-in 函数时, 这个向量就不再是简单的数据了; 它把自己转换成了“告诉函数如何执行”的逻辑.
(def data {:a {:b {:c 100}}}) (get-in data [:a :b :c]) ;; => 100
在这里, 向量 [:a :b :c] 清楚地表达了“从 data 字典中顺序检索 :a, :b, 和 :c 对应的值”的逻辑.
同样, 集合也可以用来表达逻辑. 想象你有一个数据序列 data-seq, 你想筛选出所有包含 :a 或 :b 的元素. 你不需要写一个冗长的匿名函数; 只需直接将集合 #{:a :b} 传递给 filter 函数.
(def data-seq [:a :c :b :d]) (filter #{:a :b} data-seq) ;; => (:a :b)
在这个例子中, filter 函数会依次将 data-seq 的每个元素 (:a, :c, :b, :d) 传递给作为函数的 #{:a :b}. 这个集合不仅仅是数据; 它还定义了筛选规则.
这是 Clojure 的核心思想之一: 通过简单, 可读的数据结构来表达逻辑, 这使得代码更简洁, 更易于理解. 也可以说, 在这些例子中, 数据结构是一种 DSL (领域特定语言), 因为它们被赋予了新的语义.
这种面向数据的思维模型让 Clojure 程序员一方面继承了 Lisp 程序员的传统: “为特定问题定义新语言 (DSL), 最终使代码成为表达其意图的优秀工具.” 另一方面, 它巧妙地避免了使用过多宏可能导致程序难以调试的缺点.
读者可能会问: “如果我想赋予数据结构非常复杂的语义, 我应该如何设计它们?”
这时候你就可以写一个树遍历解释器 (treewalk interpreter).
10.2.3. 代码即数据; 数据即代码
传统 Lisp 的一句经典名言, “代码即数据 (Code is Data),” 可以这样理解: 因为代码是 S-expression, 代码也是一个抽象语法树, 而抽象语法树是一种数据结构 (Data). 也就是说, 代码是一种数据结构. 而 Lisp 宏可以转换 S-expression, 从而增加新的语义. 换句话说, “代码即数据”说的是 Lisp 宏.
另一句经典名言是“数据即代码 (Data is Code),” 可以这样理解: 在 Lisp 代码中, 有一些 S-expression 不是函数, 不是宏, 而是数据结构 (Data). 而这些数据结构通常可以被赋予新的语义, 所以它们实际上是 DSL, 这是另一种形式的代码. 如果要赋予更复杂的语义, 就需要一个树遍历解释器. 换句话说, “数据即代码”说的是 作为 DSL 的数据结构.
与传统 Lisp 强调“代码即数据”哲学相比; Clojure 除了使用“代码即数据”哲学, 还积极使用“数据即代码”哲学.
10.3. 总结
本文介绍了传统 Lisp 和 Clojure 之间的关键区别: 面向数据编程 (Data-Oriented Programming).
总而言之, Lisp 可以带来四个强大的特性:
- 交互式开发
- S-expression 编辑
- Lisp 宏
- 面向数据编程
有趣的是, 尽管非 Lisp 语言很少同时具备这四个特性, 但这些特性却经常出现在现代数据栈 (Modern Data Stack) 和一些使用 JSON/YAML 作为脚本语言的 API 设计中.
Lisp 的哲学总是一代又一代的工程师重新发现, 不是吗?
11. 揭秘函数式编程 (FP)—高阶语义
一般来说, 在业界, 提倡使用 函数式编程 (FP) 的主要原因有两个:
- 开发速度快.
- Bug 少.
另一方面, 反对使用函数式编程的主要原因也有两个:
- 懂这个概念的工程师数量要少得多. 人难找, 难培养, 导致未来可维护性问题.
- 通常会以牺牲机器性能为代价.
从我的角度来看, 总结这两个原因: “开发速度快” 和 “人难找, 难培养, 可维护性问题”, 最终的结果与外部环境有关. 它涉及到外部环境和商业决策, 而不是纯粹的技术讨论.
例如, 一个人可能使用 FP, 导致开发速度快. 但是, 当把这个人与一个不使用 FP 的团队相比时, 即使这个人可能慢一点, 整个团队的速度可能更快. 或者, 如果我们把“个人开发速度快”看作是低开发人力成本. 那么如果我们把软件开发外包给第三世界国家, 而这些国家都使用命令式编程, 他们的成本仍然会更低.
总而言之, “FP 可以加速开发速度” 确实可能被“FP 从业者难找”的行业现实所抵消; 因此, 是否使用 FP 的主要考虑因素变成三个:
- 可能增加或减少人力开发成本 (?) ;; 取决于外部环境
- Bug 少
- 以牺牲机器性能为代价
我不知道读者是否觉得“Bug 少”和“以牺牲机器性能为代价”同时出现很熟悉? 没错, 这是一种典型的 高阶语义 解决方案常造成的现象.
11.1. 为什么 FP 被认为是高阶语义? 从会计说起
想象你需要记账, 但“**你只需要知道每天正确的总余额**”, 而不需要像一般公司那样出具财务报告.
| 日期 | 项目 | 收入 (+) | 支出 (-) | 备注 |
| :--- | :--- | :--- | :--- | :--- |
| 9/1 | 工资 | + $35,000 | 工资入账 | |
| 9/2 | 早餐 | - $65 | 买了三明治和咖啡 | |
| 9/3 | 付房租 | - $15,000 | 九月房租 | |
| 9/4 | 晚餐 | - $350 | 与朋友晚餐 | |
| 9/5 | 购买日用品 | - $850 | 洗衣粉, 牙膏等 |
在这种情况下, 你至少有两种方法可以达到目标:
11.1.1. 命令式编程
你会定义一个变量 balance, 然后通过一系列赋值操作来改变它的状态:
- ~balance = 0~ (initial value) - ~balance = balance + 35000~ (salary) - ~balance = balance - 65~ (breakfast) - ~balance = balance - 15000~ (rent)
用这种方法, 绝对是超级节省内存, 计算也简单. 它也能达到目标: 知道每天正确的总余额. 顺便说一句, 上述“顺序改变状态”的方法是命令式编程的一个特点; 在某种程度上, 这是一个特性, 因为它非常节省内存.
11.1.2. 函数式编程
那么, 用 函数式编程 (FP) 来记账会是什么样子呢?
FP 不是通过重复修改现有状态来实现计算, 而是将“计算余额”看作一个 函数. 你会将所有交易记录视为这个函数的 输入, 然后函数会给你一个 输出, 这就是最终的余额. 它最小化了“改变”状态, 而是重复地“计算”新结果.
例如, 你可以想象一个 sum 函数, 它的输入是一个包含所有交易的列表, 输出是最终的余额:
balance = sum([+35000, -65, -15000, -350, -850])
注意这里的计算方法: 一方面, 你需要记录每一笔交易, 一个都不能丢, 这显然消耗更多的内存. 另一方面, sum 函数的结果 (输出) 只与它的输入有关, 完全独立于任何外部状态.
11.1.3. 高阶语义解决了什么问题?
读到这里, 你可能会想: “两种方法都能得出最终余额, 那么 FP 的实际好处是什么?”
假设今天出了一个错误, 你发现最终结果算错了?
如果你的记账使用 命令式编程, 典型的调试方法是每次 balance 改变时检查新值是否正确. 换句话说, 你会不断地检查系统的内部状态.
但如果你的记账使用 函数式编程, 典型的调试方法是确保 sum 函数的数据转换是否正确, 以及提供给 sum 的输入是否正确. 你注意到了吗? 与 命令式编程 的调试方法相比, 函数式编程巧妙地将调试复杂度分成了两个领域: 数据转换 和 输入.
正是上面提到的这种“分而治之”的可能性, 使得调试可以大大简化.
11.2. 总结
函数式编程被认为是一种高阶语义, 正是因为它将 解决问题的复杂度从“如何一步步改变状态”提升到“如何定义纯函数来计算结果”.
这种抽象带来的好处是显而易见的: 你的代码更不容易出错, 因为它没有副作用, 也更容易测试和调试.
然而, 这种抽象并非没有代价. 为了避免中间状态的复杂性, 你必须存储更多的信息, 并在需要时重新计算, 这通常会消耗更多的 系统资源.
因此, FP 是一种典型的 高阶语义 解决方案, 它在更高层次的抽象上解决问题, 最终为你提供:
- Bug 更少, 因为代码更可预测且没有副作用.
- 但同时, 它可能会牺牲一些性能, 因为它通常需要更多的内存和计算.
12. 揭秘函数式编程 (FP)—定义的挑战
许多 FP 新手在接触 FP 不久后, 都会有两个主要问题:
- 我会用 map, filter, 和 reduce. 这算不算我懂 FP 了?
- FP 的定义到底是什么?
上面这两个问题其实是同一个问题的两面. 如果 FP 的定义就只是 map, filter, 和 reduce, 那可以说他们已经学会了. 如果没那么简单, 那…
12.1. 什么是函数式编程 (FP)? 它的定义是什么?
不幸的是, 这个定义没有一个简单的答案. 与 Lisp 语言的定义相比, 函数式编程的定义相对要模糊得多. 首先, 被称为函数式语言的编程语言至少分为两大语言体系:
- 以 Haskell 为代表的语言家族, 特点是强静态类型, 类型推断, Monad 等等.
- 以 Clojure 为代表的语言家族, 特点是动态类型, 同时也是 Lisp.
因此, 函数式编程的定义因人而异, 观点也各不相同. 有些人可能认为这两个语言体系的交集就是 FP. 其他人可能认为没有类型推断就不算.
换句话说, 函数式编程的定义就像 Lisp 是否应该积极使用宏一样具有争议性.
12.2. 区分概念与实现
关于定义问题, 我认为函数式编程 (FP) 应该被看作两部分: 概念和实现.
- 概念: 计算主要通过重复应用 无副作用的数据转换 来实现. 系统的 状态 因此可以最小化, 因为计算的输入和输出都是 不可变 的值.
- 实现: 这部分是多样的; 实现由各种可以帮助实现上述概念的机制组成. 它们包括高阶函数, 函数作为一等公民, Monad, 不可变集合等概念.
基于这种区分概念与实现的观点, 我会认为:
- 函数式编程的重点在于“*概念*”. 因为通过满足这个概念, 计算的语义变得更高级, 从而可以达到减少 bug 的效果, 并可能消耗更多的系统资源.
- 像高阶函数和函数作为一等公民这样的机制, 虽然这些确实像许多函数式编程语言的共同特征, 但它们本质上也是实现. 换句话说, 如果某个语言能够实现函数式编程的概念, 即使它不提供像高阶函数或函数作为一等公民这样的特性, 我仍然会认为它是函数式编程.
- 更进一步说: 我也相信某些编写 Linux Shell 管道的方式, 现代数据栈内的数据转换, 以及像 Datomic 这样的事件溯源设计都是函数式编程概念的体现.
12.3. 总结
本文探讨了函数式编程 (FP) 的定义, 指出由于不同语言体系的存在, FP 的定义存在争议, 但如果我们将概念与实现区分开来, 就可以获得一个新的视角.
FP 的核心概念在于使用无副作用的数据转换进行计算, 最小化系统状态, 并使用不可变值. 而高阶函数, Monads 等仅仅是帮助实现这一概念的实现机制. 因此, 在判断某事物是否属于 FP 时, 应关注其是否体现了无副作用和不可变的核心精神, 而不是拘泥于具体的实现工具.
13. 揭秘函数式编程 (FP)—常用机制
在上一篇文章中, 我们讨论了函数式编程的概念以及概念与实现之间的关注点分离. 那么, 在一般的编程中, 无论是 Neovim 插件开发, 前端开发, 后端开发等, 我们可以使用哪些 FP 机制呢?
让我们从一个非常常见的 FP 代码片段开始 (以 Fennel 为例).
;; Use Clojure inspired library nfnl (local core (require "conjure.nfnl.core")) ;; Define a function is-even? (fn is-even? [n] (= (% n 2) 0)) ;; map + filter (core.filter (fn [y] (is-even? y)) (core.map (fn [x] (+ 1 x)) [1 2 3 4 5])) ;; => [2 4 6]
解释:
core.map会将[1 2 3 4 5]转换为[2 3 4 5 6]core.filter会从[2 3 4 5 6]中提取偶数, 将其变为[2 4 6]
这里, 有一个 显式机制 支持 FP: 高阶函数; 还有一个 隐式机制: 值复制.
13.1. 高阶函数
最常用的高阶函数自然是 map, filter, reduce. 所以, 初学者常常会问还有哪些是必不可少的, 仿佛担心如果少用了几个高阶函数, 他们的代码就不够“FP”.
关于这个问题, 我曾思考过是否值得统计分析众多 GitHub 仓库中的函数使用频率, 以找出除了 map, filter, reduce 之外最常见的前十个高阶函数. 考虑到常用高阶函数自然会遵循 80/20 分布, 很可能掌握了前十个就意味着未来很少会遇到不熟悉的高阶函数了.
然而, 我后来意识到, 虽然上面提到的频率分析概念在理论上是可行的, 但实际上, 选择哪些 GitHub 仓库才足够有代表性是另一个挑战. 例如, 一些 GitHub 仓库提供了许多宏, 很有可能在这样的库中会使用 partition, 因为 partition 在编写宏时特别有用.
最后, 我做了一个粗略的概括: 除了最常用的 map, filter, reduce, 接下来 6 个最常见的高阶函数应该是:
- concat
- thread first (->)
- some (用于处理循环提前返回的场景)
- partition (用于宏)
- take
- unpack
13.2. 值复制
如果你仔细看最初的例子, 不使用 nfnl 库, 原始代码可以改写为:
;; Define a function is-even? (fn is-even? [n] (= (% n 2) 0)) (icollect [k v (ipairs [1 2 3 4 5])] (when (is-even? (+ 1 v)) (+ 1 v)))
这种方法相当于 直接迭代 原始数组 [1 2 3 4 5], 然后在循环内对每个元素执行 (+ 1 v) 并检查是否为偶数. 在这种情况下, 不会创建中间数组. 相比之下, 之前的 map + filter 方法先用 map 创建一个新数组 [2 3 4 5 6], 然后 filter 再根据这个新数组创建另一个新数组 [2 4 6].
这是 FP 处理集合时一个非常常见且重要的问题: 值复制. 因为 FP 强调不可变性, 当你对一个集合执行操作时, 比如 map 或 filter, 它不会就地修改原始集合; 相反, 它会创建一个新的集合来存储结果. 这保证了函数的纯粹性, 避免了许多副作用问题.
然而, 这种大量的复制可能会导致性能上的考量, 特别是对于大型数据集. 为了解决这个问题, FP 社区发展出了不同的策略:
- 使用宏来消除值复制
- 使用不可变集合
13.2.1. 使用宏来消除值复制
Fennel, 作为一种编译成 Lua 的 Lisp, 大量利用宏来解决这个问题. 宏是一种在编译时展开代码的工具. 你可以把它看作一个“代码生成器”.
例如, Fennel 的 icollect 实际上是一个宏. 当你写 (icollect ...) 时, 它在编译时会被展开成一个 Lua 的 for 循环. 这个循环直接对数据进行操作, 而不生成中间数组.
这样做的好处是, 在语法层面, 你仍然可以享受到 FP 语法提供的优雅和抽象, 但在底层, 它被转换成了性能更高的命令式代码, 大大减少了值复制.
13.2.2. 使用不可变集合
Clojure 是 FP 的另一个领导者, 它对大量复制问题的解决方案是不可变集合 (Immutable Collection). 什么叫不可变集合?
它是一种特殊的数据结构, 一旦创建就不能被修改. 如果你需要“修改”它, 你会得到一个新的不可变集合, 但这个新的集合和旧的集合会共享大部分底层结构.
以 Clojure 的向量为例, 它使用的是持久化向量 (Persistent Vector) 数据结构. 其原理是一个树形结构. 当你对一个向量执行 assoc (添加或修改元素) 操作时, 它不会复制整个向量, 而只复制从根节点到需要修改的叶子节点的路径. 这使得每次“修改”的成本非常小, 大约是 log32(n), 而不是 O(n).
这种设计的优点是:
- 性能优化: 显著减少了数据复制的开销, 特别是对于大型集合.
- 内存效率: 新旧集合共享大部分内存空间, 减少了内存消耗.
- 保持纯粹性: 仍然遵循 FP 的不可变性原则, 使代码更安全, 更易于推理.
总而言之, 在处理值复制问题时, FP 通过使用宏或特殊的不可变集合结构, 在保持不可变性核心概念的同时, 有效地解决了潜在的性能问题. 这是使 FP 在现代软件开发中得以实用的重要基础之一.
13.3. 总结
FP 有两个在实践中常用且重要的主要机制: 高阶函数 和 值复制.
像 map, filter, 和 reduce 这样的高阶函数帮助我们简洁地处理数据, 而其他像 thread first 也有其自身的用途.
同时, FP 的不可变性可能导致大量的值复制. 对于值复制问题, 我们讨论了两种常见的解决方案: Fennel 宏在编译时将 FP 语法转换为高效的底层代码; Clojure 则利用特殊的不可变数据结构来共享底层内存, 显著减少了复制开销.
14. 揭秘函数式编程 (FP)—高级主题
终于, 我们来到了关于 FP 的第四篇文章. 这是 FP 系列的最后一篇, 我们将讨论一些高级的 FP 主题:
- 函数式编程习语
- FP 与代码复用 (code reuse)
14.1. 函数式编程习语 (FP idioms)
函数式编程习语主要包括 mapcat 和 if 模式.
14.1.1. mapcat
在 Clojure 中, mapcat 是 map 和 concat 的组合. 它的目的是将一个函数应用于集合中的每个元素, 然后将所有返回的序列连接成一个单一的序列. 这在我们从集合中的每个元素生成一个新的集合, 然后需要将这些小集合合并成一个大集合时特别有用.
例如, 假设我们有一个包含多个子集合的集合, 我们想将它们扁平化成一个单一的序列.
(def data '((1 2) (3 4) (5 6))) ;; Using map and concat (apply concat (map identity data)) ;; => (1 2 3 4 5 6) ;; Using mapcat (mapcat identity data) ;; => (1 2 3 4 5 6)
另一个更常见的应用场景是, 当我们需要处理一个集合并从每个元素生成一个包含多个值的新序列时.
(def users '("Alice" "Bob" "Charlie")) ;; Suppose we have a function that can generate social media accounts related to a username (defn get-social-media-accounts [user] (condp = user "Alice" '("twitter/alice" "github/alice") "Bob" '("twitter/bob") "Charlie" '("twitter/charlie" "linkedin/charlie"))) ;; Use mapcat to get all social accounts for all users and merge them into a single sequence (mapcat get-social-media-accounts users) ;; => ("twitter/alice" "github/alice" "twitter/bob" "twitter/charlie" "linkedin/charlie")
14.1.2. if 模式
if 模式是一类变化多端的习语, 讨论起来相当冗长. 有兴趣的读者可以参考这篇文章.
14.2. FP 与代码复用 (code reuse)
由于面向对象编程 (OOP) 比 FP 流行得多, 当人们讨论 OOP 的优点时, 他们经常提到 OOP 可以支持软件复用 (代码复用), 因为 OOP 提供了像接口这样的松耦合机制 (多态).
那么 FP 呢? FP 也支持代码复用吗?
在讨论代码复用之前, 让我们先讨论松耦合机制.
最终的松耦合机制应该是一个 协议, 因为即使要接口的双方有不同的运行时, 只要它们通过网络通信并且可以相互传输数据, 遵循传输协议, 不同的系统就可以接口.
14.2.1. OOP 的松耦合机制
如果松耦合机制在面向对象的编程语言中, 包括 Java 和 Lua, 它们通常通过 Java 接口或 Lua 元表实现, 通常作为服务提供者接口 (Service Provider Interface). 未来, 如果我们需要替换一个通过这种机制耦合的旧模块, 我们只需要开发一个实现相同 Java 接口或注册相同 Lua 元表函数的新模块, 新模块就可以顺利替换旧模块.
因此, 我们可以说面向对象编程语言提供的松耦合机制是一种: “函数签名作为传输协议”.
14.2.2. FP 的松耦合机制
那么 FP 呢? 在典型的 FP 程序中, 我们不会创建很多对象, 因为没有必要. 对于数据建模, 大多数时候, 我们可以简单地使用像列表或字典这样的数据结构. 因此, 代码库将主要由大量的数据结构和函数组成.
那么有松耦合机制吗? 有的.
首先, 数据结构本身就是一种优秀的松耦合机制. 回想一下前面传输协议的例子, 传输协议仅仅规定通信双方相互传输正确形状的数据, 仅此而已. 换句话说, 我们可以说函数式编程语言提供的松耦合机制是一种: “数据结构作为传输协议”.
此外, 还有一个非常重要的概念: 许多动态语言实际上具有鸭子类型 (Duck Typing). 鸭子类型本身也可以被视为“函数签名作为传输协议”的一种实现.
14.3. 总结
本文讨论了函数式编程习语和代码复用.
关于习语, mapcat 非常常用; 对于 if 模式, 如果你用了而别人不理解, 不要太苛责他们.
关于代码复用, 我们从松耦合机制的角度进行了分析, 讨论了三种类型: “传输协议”, “函数签名作为传输协议”, 和“数据结构作为传输协议”. 显然, FP 使得实现代码复用非常容易.
15. Fennel 语言速成—LuaRocks
在 day05, 我们演示了如何使用 Lua 的标准库 io 和 require. 你可能会想, 第三方模块呢?
这就需要在你的电脑上先安装第三方模块, 然后同样通过 require 来引用它们. 有没有类似 Node.js 的 npm, 或者 Python 的 pip 这样的程序来帮助我们管理第三方模块呢? 有的, 它就是 LuaRocks.
一天下午, 我看到一位同事在 Emacs 中直接用一个命令就完成了一个 http get 请求, 我觉得这简直酷毙了.
于是, 我开始寻找 Neovim 插件, 结果发现我找到的所有 http 请求插件都需要用 LuaRocks 来安装.
“那就装 LuaRocks 吧?” 我心想.
brew install luarocksLuaRocks 成功安装在了我的 Macbook 笔记本上, 但那天下午, 无论我怎么努力, 就是无法到达终点.
问题出在哪里呢?
如果你曾经做过 Python 开发, 在一台电脑上不断切换 Python 3.10, 3.11, 3.22. 做过 Node.js 开发, 不断切换 node 20, node 21, node 22. 做过 Java 开发, 不断切换 JVM 8, 17, 21. 我遇到的正是这个问题.
15.1. 多解释器问题
Neovim 中的 Lua 是 LuaJIT, 它与 Lua 5.1 兼容. 这个解释器在安装 Neovim 时会自动包含进来. 它是一个嵌入式执行环境.
另一方面, 如果我用 Homebrew 安装 Lua, 在此时此刻, 它将是 Lua 5.4. 安装后, 我可以直接在 Macbook 的 shell 环境中运行 Lua.
brew install lua
同理, 我用 Homebrew 安装的 LuaRocks, 按理说, 自然会绑定到 Lua 5.4, 而不是 LuaJIT.
15.2. LuaRocks
安装 LuaRocks 有两种选择:
- 间接管理. 使用 Neovim 插件 luarocks.nvim 为你安装 LuaRocks, 然后让 Neovim 插件为你管理 LuaRocks. 这条路会更简单.
- 手动安装 LuaRocks. 这条路的优点是你会更熟悉 LuaRocks 命令, 如果你将来想把 Lua 应用到 Neovim 以外的平台, 你对 LuaRocks 的知识可以迁移过去.
15.2.1. 手动安装 LuaRocks
首先, 你需要安装 LuaJIT. 相比于找到 Neovim 的 LuaJIT, 直接用 Homebrew 安装一个新的会更简单.
brew install luajit
接下来, 开始下载 LuaRocks 的 tarball, 创建一个系统特定的 ~/.luarocks-luajit 目录, 设置参数, 编译并安装.
wget https://luarocks.org/releases/luarocks-3.12.0.tar.gz tar zxvf; cd luarocks-3.12.0 mkdir ~/.luarocks-luajit ./configure \ --with-lua=$(brew --prefix luajit) \ --with-lua-include=$(brew --prefix luajit)/include/luajit-2.1 \ --lua-suffix=jit \ --prefix=$HOME/.luarocks-luajit make && make install
最后, 我们需要告诉操作系统将来在哪里找到 luarocks 命令的可执行文件. 并使用 source 重新加载 shell 的配置文件.
echo 'export PATH=$HOME/.luarocks-luajit/bin:$PATH' >> ~/.zshrc source ~/.zshrc
特别注意: 上面提到的 LuaRocks 版本非常重要, 因为 LuaJIT 2.0 有 65536 个常量的限制. 如果不是特定的 LuaRocks 版本, 你会遇到这个错误: "Error: main function has more than 65536 constants"
15.2.2. 使用 LuaRocks
安装成功后, 当你发出命令:
luarocks install ${package}
新的 ${package} 将被安装在 $HOME/.luarocks-luajit/ 目录下.
15.2.3. 设置 Neovim 的路径
到目前为止, 尽管新的 Lua 模块已经安装到正确的位置, Neovim 内的 LuaJIT 仍然找不到它们, 所以我们必须明确设置路径.
首先, 找到 Neovim 的配置文件位置, 并在那里创建一个 lua 文件夹.
cd ~/.config/nvim/
mkdir lua
在该文件夹中, 创建一个 Lua 脚本: luarocks.lua. (文件名可以任意.)
nvim lua/luarocks.lua
将以下内容粘贴到 luarocks.lua 中, 然后保存.
local function add_luarocks_paths() local home_dir = os.getenv("HOME") local luarocks_path = string.format("%s/.luarocks-luajit/share/lua/5.1/?.lua;%s/.luarocks-luajit/share/lua/5.1/?/init.lua", home_dir, home_dir) local luarocks_cpath = string.format("%s/.luarocks-luajit/lib/lua/5.1/?.so", home_dir) package.path = package.path .. ";" .. luarocks_path package.cpath = package.cpath .. ";" .. luarocks_cpath end return {add_luarocks_paths = add_luarocks_paths}
最后一步是在 ~/.config/nvim/init.vim 中添加一行.
lua require("luarocks").add_luarocks_paths()
对更具体细节感兴趣的读者可以考虑使用 Ex 命令 :luafile % 在 Neovim 中加载当前打开的 Lua 模块, 以及 Ex 命令 :lua print(os.getenv("HOME")) 来快速验证这些 Lua 命令的效果.
15.3. 总结
在本章中, 我们讨论了 LuaRocks 的安装, 这比简单的 Homebrew 安装要复杂得多. 总而言之, 我们所做的是:
- 手动安装 LuaRocks, 下载 tarball, 重新编译并安装, 使其依赖于 LuaJIT.
- 配置 Neovim 的内部路径, 以便它可以读取 LuaRocks 安装第三方模块的路径.
16. Neovim 插件开发—Hello World
在 day16 的最后一部分, 我们讨论了可以在 ~/.config/nvim/fnl 文件夹中创建与 Neovim 配合使用的插件. 最关键的 Neovim Runtime 知识已经掌握, 那么让我们开始一个新的 Hello World!
16.1. Hello World 插件
16.1.1. 规格概述
我们将创建一个 Hello World 插件, 它将在 Neovim 启动时初始化, 并为 Neovim 注册一个 Ex 命令. 之后, 用户就可以使用 :HelloFennel Ex 命令.
16.1.2. 实现
- 先决条件, 准备 nfnl 配置文件.
echo "{}" > ~/.config/nvim/.nfnl.fnl
有了这个配置文件, nfnl 的自动编译功能就可以被启用. 详细说明请参考 nfnl 的 README.
- 创建插件文件夹
mkdir ~/.config/nvim/fnl
- 创建一个新文件 ~
/.config/nvim/fnl/hello.fnl, 内容如下:
(fn hello [] (print "Hello World Fennel!")) (fn setup [] (vim.api.nvim_create_user_command :HelloFennel hello {})) ;; Export the setup function so init.vim can call it {: setup}
- 修改
~/.config/nvim/init.vim文件, 添加以下行:
lua require("hello").setup()
- 测试:
当你保存 hello.fnl 文件时, nfnl 会自动将其编译成 ~/.config/nvim/lua/hello.lua.
重启 Neovim 后, 输入 Ex 命令 :HelloFennel, 你会看到底部打印出 Hello World Fennel! 的消息.
16.1.3. 解释
首先, 让我们看一下 hello.fnl 的内容. 在这个文件中, 我们定义了两个函数: hello 和 setup. hello 用于打印消息, 而 setup 用于注册一个 Ex 命令.
在 setup 内部, vim.api.nvim_create_user_command 是 Neovim 的 API. 这个 API 的第一个参数是 Ex 命令的名称; 第二个参数是 Ex 命令要执行的函数; 第三个参数是要传递给函数的参数 (Lua Table 数据类型).
在 hello.fnl 的末尾, 按照惯例, 写入一个包含此 hello 模块外部 API 的 Lua Table. 在这个例子中, 显然是 setup.
当 Neovim 启动时, 它首先读取 init.vim. 当它读到命令 lua require("hello").setup() 时, 它会在 ~/.config/nvim/lua/ 文件夹中查找并加载 hello.lua 文件. 然后, 该文件中的 setup 函数将执行并注册 :HelloFennel 命令.
16.2. 总结
在本文中, 我们成功完成了我们第一个 Fennel 插件的 "Hello World". 我们不仅亲自搭建了项目结构并编写了简单的 Fennel 代码, 而且通过实现, 验证了之前讨论过的概念:
- nfnl 插件如何自动将 Fennel 编译成 Neovim 能理解的 Lua.
- Neovim 如何使用
runtimepath变量来查找和加载编译后的 Lua 模块.
因此, 我们掌握了从零开始创建一个简单 Neovim 插件的最简化流程.
17. Neovim 插件开发—标准插件
在第 17 天, 我们演示了插件的 "Hello World". 显然, 一个稍微复杂一点的插件不会只包含一个文件. 此外, 我们希望插件是可安装的. 因此, 本文将演示如何创建一个标准插件.
17.1. 插件开发
17.1.1. 先决条件
- 首先, 确保 Neovim 中已安装 nfnl 插件.
- 创建一个项目文件夹并进入.
$ mkdir my-plugin $ cd my-plugin
- 在项目目录中准备 nfnl 配置文件.
echo "{}" > .nfnl.fnl
有了这个配置文件, nfnl 的自动编译功能就可以被启用. 详细说明请参考 nfnl 的 README.
- 创建子目录
mkdir -p lua/my-plugin fnl/my-plugin
17.1.2. 添加代码
- 创建文件
fnl/my-plugin/init.fnl, 内容如下:
(fn hi [] (print "Hi World Fennel!")) (fn setup [] (vim.api.nvim_create_user_command :HiFennel hi {})) ;; Export the setup function so that init.vim can call it {: setup}
- 保存文件后,
lua/my-plugin/init.lua将被自动生成. - 如果你运行
tree命令, 你应该会看到:
~$ tree -a
.
├── .nfnl.fnl
├── fnl
│ └── my-plugin
│ └── init.fnl
└── lua
└── my-plugin
└── init.lua
17.1.3. 发布插件
- 将以下文件包含在你的版本控制系统中:
.nfnl.fnl fnl/my-plugin/init.fnl lua/my-plugin/init.lua
- 将插件发布到你的 GitHub.
17.1.4. 安装
- 在你的 init.vim 文件中, 将你的插件添加到 Plug 块中:
call plug#begin(stdpath('data') . '/plugged')
Plug '$username/my-plugin'
call plug#end()
将 $username 替换为你的 GitHub 用户名.
- 在 Neovim 的 Normal Mode 下, 执行以下命令:
:source % :PlugInstall
- 在你的 init.vim 文件的 Plug 块下面, 再添加一行:
lua require("my-plugin").setup()
这一行用于初始化插件.
- 重启 Neovim 后, 你就可以在 Neovim 中使用定义的
:HiFennel命令了.
17.2. 模块导入
通常, 插件会分成几个模块. 这种情况下应该如何处理模块导入呢?
- 创建文件
fnl/my-plugin/util.fnl, 内容如下:
(fn inc [x] (+ 1 x)) {: inc}
这里, 创建了一个 util 模块, 它有一个名为 inc 的公共函数.
- 修改文件
fnl/my-plugin/init.fnl, 内容如下:
(local util (require :my-plugin.util)) (util.inc 15) (fn hi [] (print "Hi World Fennel!")) (fn setup [] (vim.api.nvim_create_user_command :HiFennel hi {})) ;; Export the setup function so that init.vim can call it {: setup}
前两行导入 util 模块并调用 util.inc.
- 测试导入
如果我们使用 <localleader>ee 对第一行 (local util (require :my-plugin.util)) 求值, 我们会得到类似以下的错误:
; eval (current-form): (local util (require :my-plugi...
; [Runtime] [string "local util = require("my-plugin.util")..."]:1: module 'my-plugin.util' not found:
; no field package.preload['my-plugin.util']
; no file './my-plugin/util.lua'
; no file '/opt/homebrew/share/luajit-2.1/my-plugin/util.lua'
; no file '/usr/local/share/lua/5.1/my-plugin/util.lua'
...
- 要修复路径问题, 执行以下 Ex 命令:
package.path = vim.fn.getcwd() .. "/lua/?.lua;" .. package.path
修复路径后, 用 <localleader>ee 重新对第一行求值就能正常工作了.
17.2.1. 错误原因
这个错误发生的原因是 Neovim 的 Lua 搜索路径 package.path 不包含你当前项目目录下的 lua 文件夹. 因此, 当 require 尝试加载 my-plugin.util 模块时, 它在默认路径中找不到对应的 lua/my-plugin/util.lua 文件, 从而抛出 'module 'my-plugin.util' not found' 错误.
执行命令 package.path = vim.fn.getcwd() .. "/lua/?.lua;" .. package.path 后, 这一行将当前工作目录下的 lua 文件夹添加到了 Lua 搜索路径中. 这样, require 就能正确找到并加载 my-plugin.util 模块了.
我们也可以使用目录本地 Neovim 配置 (Fennel)将这个对 Lua 搜索路径的修改直接整合到项目中, 这样将来就不需要用命令手动调整路径了. 此外, 一旦这个 Neovim 插件被安装, 这个路径问题将不复存在, 因为插件的目录会自动被包含在 Neovim 的 runtimepath 中.
17.3. 总结
本文介绍了标准的 Neovim 插件开发, 如何安装插件, 模块导入, 以及开发过程中常见的路径问题.
18. Neovim 插件开发—如何调试?
有两类 Runtime 知识对调试特别有用:
- 如何检查 Runtime 的内部状态?
- Runtime 的内部执行顺序是怎样的?
18.1. 检查内部状态
有几种方法可以帮助你检查 Neovim 的内部状态, 这对于调试至关重要.
18.1.1. :lua 命令
你可以直接在命令行中使用 :lua 执行 Lua 代码. 这是一个非常方便的 Ex 命令, 特别适合快速测试几行代码或检查变量值.
例如, 当你想确认一个 Lua 模块是否加载成功时, 你可以执行命令:
:lua print(require('module.name'))
如果模块加载成功, require 函数将返回该模块的 table, 然后 :lua print(...) 会打印这个 Table 的内存地址 (例如 table: 0x...). 如果模块不存在, require 会抛出一个错误. 这是一个简单但有效的验证方法.
18.1.2. 查看输出
当 Neovim 运行时, 所有由 print, vim.notify 等函数生成的输出都会被记录下来. 你可以使用以下 Ex 命令查看这些历史消息.
:messages
18.1.3. 处理 Lua Table 输出
当你直接使用 print 函数输出一个 Lua Table 时, 你通常只会看到一个类似 table: 0x... 的内存地址, 而不是具体内容. 这在调试时会造成很大的麻烦.
为了解决这个问题, 你可以使用 Neovim 内置的 vim.inspect 函数, 它可以将任何 Lua 值 (特别是 Table) 转换成人类可读的字符串格式. 这是一个非常实用的调试工具, 而且不需要安装任何额外的插件.
例如, 你可以在 Ex 命令或 Fennel 代码中使用它:
- 在 Ex 命令中
:lua print(vim.inspect({a = 5, b = "hello"}))
-- The output will be:
-- { a = 5, b = 'hello' }
- 在 Fennel 代码中
(vim.inspect {:a 5 :b "hello"})
18.2. 内部执行顺序
在 Neovim 插件开发中, 理解文件加载顺序对于调试和正确配置插件至关重要. 以下是几种常见的插件初始化方法及其区别.
18.2.1. plugin
plugin/ 目录下的文件在 Neovim 启动时立即加载, 无论你打开什么文件类型. 这些文件通常用于设置全局键绑定, 命令或自动命令 (autocmd), 并且这些配置应该始终处于活动状态.
18.2.2. ftplugin (Filetype Plugin)
ftplugin/ 目录下的文件仅在 Neovim 识别到特定文件类型 (filetype) 时才加载. 例如, ~/.config/nvim/ftplugin/lua.lua 仅在编辑 Lua 文件时才会执行. 这些文件适用于设置特定语言的键绑定, 缓冲区局部选项或自动命令.
18.2.3. after/plugin
after/plugin/ 目录下的文件仅在 plugin/ 目录下的文件加载完成后才会执行. 这是一个非常重要的概念; 它提供了一种覆盖或修改其他插件设置的机制.
例如, 如果你想修改一个在 plugin/ 目录下的插件设置的全局键绑定, 你可以在 after/plugin/ 目录下创建一个文件来重新定义它. 这确保了你的设置在插件的默认设置之后加载, 从而成功覆盖它们.
简单来说, plugin 用于全局设置, ftplugin 用于特定文件类型, 而 after/plugin 则在所有默认插件加载后提供了一个自定义或覆盖设置的机会. 理解这个执行顺序可以帮助你更有效地管理和调试你的 Neovim 配置.
18.3. 总结
有效的 Neovim 插件调试主要依赖于两个关键领域的知识: 检查内部状态 和 理解执行顺序.
当然, Neovim 用于检查内部状态的命令并不限于上面提到的那些; 还有许多其他命令. 同样, 内部执行顺序也有许多变化.
将上述概念融入你的开发工作流程, 并查阅官方文档, 肯定会使调试变得更容易.
19. 项目探讨—auto-conjure
auto-conjure 是我开发的第一个 Neovim 插件, 因此, 它非常简单.
在建立你的第一个 Neovim 插件项目时, 你可能想问自己, 我的主题是否比 auto-conjure 难得多? 如果是, 我是否应该先从更简单的开始?
19.1. 问题概述
在使用 Conjure 开发 ClojureScript 时, 我必须发出一个命令 :ConjureShadowSelect [build-id] 来启动 ClojureScript 的交互式开发模式, 但我经常忘记这个命令. 另外, 每次需要发出这个命令时, 我都得特地打开一个 shadow-cljs.edn 文件来找 [build-id], 这也相当烦人.
有一天, 我发现其他人似乎也有同样的问题, 于是他提出了一个基于 Neovim 自动命令的解决方案:
" define a function ~AutoConjureSelect~ to auto select
function! AutoConjureSelect()
let shadow_build=system("ps aux | grep 'shadow-cljs watch' | head -1 | sed -E 's/.*?shadow-cljs watch //' | tr -d '\n'")
let cmd='ConjureShadowSelect ' . shadow_build
execute cmd
endfunction
command! AutoConjureSelect call AutoConjureSelect()
" trigger the function ~AutoConjureSelect~ whenever you open a cljs file.
autocmd BufReadPost *.cljs :AutoConjureSelect
这个解决方案通过监控 shadow-cljs 进程的输出来获取 [build-id], 然后生成正确的命令.
不幸的是, 这个解决方案在我的电脑上效果不太好, 可能是由于操作系统的差异. 于是我自己修改了一个Babashka 脚本来替换上面解决方案中的 system(...).
#!/usr/bin/env bb (require '[clojure.edn :as edn]) (require '[clojure.java.io :as io]) (def shadow-config (edn/read-string (slurp (io/file "shadow-cljs.edn")))) (def build-ids (map name (keys (:builds shadow-config)))) ;; convert to string (print (first build-ids))
如果能把 Babashka 脚本改成 Fennel, 我的编辑器设置就可以完全依赖 Neovim 运行时, 而不必额外依赖 Babashka 运行时了.
19.2. 解决方案架构
最初, 我以为我会把 Babashka 脚本翻译成 Fennel. 毕竟, Babashka 也是一个受 Clojure 启发的 Lisp, 它的语法和 Fennel 大约有 70% 的相似度.
然后, 我遇到了一个问题: Fennel 没有解析 EDN 格式的库.
幸运的是, 不久之后, 我找到了一个由 Ray Stubbs 用 Lua 编写的用于解析 EDN 格式的库.
19.3. 总结
一个理想的入门项目应该足够小, 可以先用另一种语言实现一次, 然后通过翻译过程学习 Fennel 和 Neovim 插件开发.
一旦迈出了第一步, 剩下的就变得简单多了.
20. 项目探讨—Conjure Piglet Client
Conjure Piglet Client 是我的第二个 Neovim 插件项目, 它有点挑战性.
20.1. 问题概述
“Laurence, 你对 Piglet 感兴趣吗? 你想开发 Piglet 吗?”, Arne 问我. Piglet 是他最近发布的新语言, 当然, 它也是另一种 Lisp.
“当然, 我应该从哪里开始?”, 我回复他.
“你有两个选择:
- 学习 Emacs, 因为我已经为 piglet 开发了 Emacs 插件.
- 开发一个 Neovim 插件.”
我选择了 2., 于是这个项目开始了.
20.2. 解决方案架构
快速阅读了 Piglet 的文档和 Emacs 插件后, 我最初的计划如下:
- 首先, 开发 Fennel 代码来处理 Piglet 开发协议, 也就是说, 首先尝试让 Neovim 能够与 Piglet REPL 通信.
- 然后, 将第 1 步的代码打包成一个新的 Conjure 客户端, 这样 Conjure 就能支持 Piglet 的交互式开发.
Neovim 插件 Conjure 的设计允许它支持多种不同的编程语言; 而且它支持的方式非常巧妙, 因为 Conjure 本身也被设计成允许插件开发. 换句话说, 严格来说, Conjure Piglet Client 实际上是 一个 Neovim 插件的插件.
Piglet 开发协议 (PDP) 是 Piglet 的交互式开发协议, 工作流程是: 编辑器打开一个 WebSocket 服务器, Piglet REPL 作为客户端连接, 双方通过 CBOR (Concise Binary Object Representation, 一种二进制数据编码格式) 交换消息.
下图说明了 Piglet 开发协议: 编辑器和 REPL 通过 WebSocket 通信, 数据包使用 CBOR 编码.
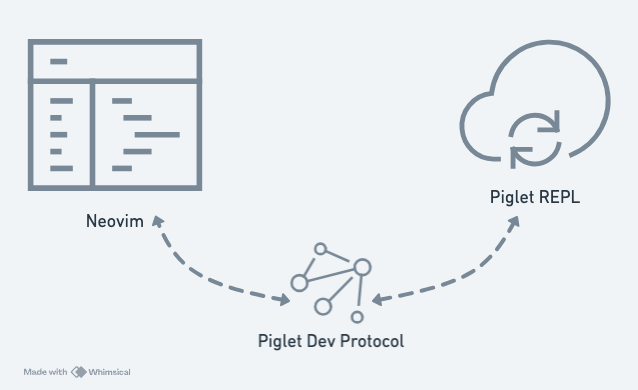
Figure 11: Piglet Dev Protocol diagram showing communication between editor and REPL via WebSocket with CBOR encoding.
基于以上, 至少有两个地方我需要集成第三方库:
- WebSocket
- CBOR
20.3. 总结
严格来说, 这个项目和之前的 auto-conjure 项目仍然有相似之处: 两者都是移植. 换句话说, 这类项目的内在难度更多地在于实现层面, 而不是设计层面.
21. Neovim 插件开发—入门
之前的文章探讨了 Fennel, Lisp 和函数式编程等概念. 从现在开始, 我们将开始将这些概念应用于 Neovim 插件开发. 首先, 让我们讨论一个失败的学习经历.
过去, 我最初以为开发 Vim 插件只有两个选择: VimScript 和 Lua. 发现 Fennel 后, 我兴奋地开始研究它.
起初, 我发现 Conjure 可以用于 Fennel 开发, 但关键的跳转到定义功能不工作. 然后, 我试图设定一个看似更简单的目标并尝试前进. 很快我意识到, 遇到问题时, 我常常不知道如何处理. 于是, 我把这件事搁置了.
21.1. 学习失败的原因
如果我们分析 Neovim 插件开发需要哪些知识, 除了 Neovim 编辑器操作的基础知识外, 至少还有以下四类知识:
- Conjure 相关的开发环境设置
- Fennel 和 Lua
- Neovim Runtime
- Neovim API
我之前的错误是: 作为一名 Clojure 程序员, 我已经具备了 Conjure 相关开发环境的知识. 我以为掌握了这一项, 就掌握了 50% 的知识, 于是直接开始挑战一个项目. 然而, 实际上, 我所具备的必要知识不到 25%.
自然, 在如此缺乏知识的情况下, 很难前进.
21.2. 相对合理的学习策略
一个更合理的学习策略应该是:
- 正确设置开发环境, 包括 Conjure, 语法高亮等等.
- 仔细通读大部分 Fennel 语言的介绍. 即使不能全部记住, 也先读一遍.
- 对 Neovim Runtime 进行一些初步研究.
- 在前面三种知识准备好后, 开始设定小问题, 边做边学.
读者可能这里会有一个问题: Neovim Runtime 和 API 有什么区别? 我这里讨论的 Runtime 知识主要涵盖以下几个方面:
- Lua 编译
- 路径
- 基本调试
这些是必不可少的知识. 而 Neovim API 则包罗万象. 例如, 有关于 Tree sitter API 的知识; 如果你根本不打算使用 Tree sitter, 你实际上可以暂时跳过它.
21.3. Neovim Runtime
当我们开发通用的 Web 应用程序 (Web Application) 时, 我们通常会先开发软件, 然后进行 单元测试, 接着是与数据库和 Http 服务器的 集成测试.
之前的交互式开发可以看作等同于单元测试, 因为我们可以快速验证单个 Fennel 函数的运行情况. 那么 集成测试 部分呢? 我们编写的 Fennel 程序如何与 Neovim 协同工作?
21.3.1. 两个挑战: 无法理解, 无法找到
为了让 Fennel 程序与 Neovim 协同工作, 我们主要需要克服两个挑战:
- Neovim 实际上不理解 Fennel, 因为它只有一个内置的 Lua Runtime. 因此, 我们必须将 Fennel 编译成 Lua.
- 在 Neovim 内部, 有一个名为
runtimepath的变量, 它根据该变量内的路径来查找要加载和执行的 Lua 文件. 更准确地说, 我们必须将我们的 Lua 代码放在runtimepath变量指向的文件夹下的/lua子目录中, Neovim 才能找到我们的代码.
21.3.2. 编译插件 nfnl
为了编译方便, 我们需要安装另一个插件: nfnl
安装方法:
- 打开文件
~/.config/nvim/init.vim - 在文件中找到由
plug#begin和plug#end包围的部分, 并添加 nfnl 安装命令.
call plug#begin(stdpath('data') . '/plugged')
...
" === Fennel (Config) Support ===
Plug 'Olical/nfnl'
...
call plug#end()
- 接下来, 在 Neovim 的 Normal Mode 下, 执行以下命令:
:source % :PlugInstall
- 此外, 因为自动编译插件的命令与
fnlfmt有些冲突, 我们必须修改~/.config/nvim/init.vim中的FennelOnSave设置. 将其更改如下:
augroup FennelOnSave " Format and compile after save autocmd! autocmd BufWritePost *.fnl call Fnlfmt() | NfnlCompileFile augroup END
安装并设置好这个 nfnl 插件后, 如果我们稍后编辑 $path/fnl/some_file.fnl 并保存文件, 该插件会自动生成一个对应的 $path/lua/some_file.lua 文件.
21.3.3. 让 Lua 文件可被发现
首先, 我们可以使用以下 Neovim Ex 命令来查看 runtimepath.
set runtimepath?
结果是:
runtimepath=~/.config/nvim, ...
因此, 我们可以知道放在 ~/.config/nvim/lua 文件夹中的 Lua 文件可以被 Neovim 读取.
回想一下, 之前在 day06, 当我们安装 LuaRocks 时, 我们也把我们手写的 luarocks.lua 放在了 ~/.config/nvim/lua 文件夹中.
让我们考虑另一个关键问题: “如果编译后的 Lua 文件应该放在 ~/.config/nvim/lua 文件夹中, 那么对应的 Fennel 文件呢?” 自然, 它们应该放在 ~/.config/nvim/fnl 文件夹中.
21.4. 总结
本文讨论了 Neovim 插件学习策略以及开发插件所必需的 Neovim Runtime 知识.
22. 项目探讨—WebSocket
在上一篇文章中, 开发 Conjure Piglet Client 时, 我提到了第三方库 WebSocket. 最初, 我天真地以为只要找一些 Neovim 插件或 Lua 库安装一下就能搞定. 然而, 一旦我开始动手, 我才发现这比我想象的要困难得多.
22.1. 问题概述
在尝试了几个选项后, 最接近我需求的是 lua-websockets 库, 而其他选项可能只实现了 WebSocket 客户端, 或者不是纯 Lua 实现. 由于我希望这个 conjure 客户端将来安装起来不会太困难, 我决定通过 Luarocks 安装的库是极限.
为了便于测试, 我还安装了 websocat, 这样我就可以先专注于测试 WebSocket, 而不需要同时测试 WebSocket 和 CBOR.
不久之后, 我成功地用 lua-websockets 创建了一个 WebSocket 回显服务器. 然后, 第一个挑战出现了: “虽然用 websocat 制作的客户端可以成功连接到在 Neovim 中运行的 WebSocket 服务器, 但在客户端断开连接后, Neovim 会完全卡死.”
22.2. 解决方案架构
发生了什么? 问题在于, 在 Neovim 中使用 lua-websockets 本身就不太合理. lua-websockets 库提供了两种异步机制: lua-ev 或 copas (协程), 然而, 这两种异步机制都没有使用 Neovim 的 vim.uv 作为其底层. 换句话说, 上述方法相当于使用了两个事件循环 (一个来自 Neovim, 另一个来自 lua-websockets), 这自然使得它非常容易出现上述的卡死现象.
在理解了卡死的原因后, 合理的解决方案就变得清晰了: 只应该有一个事件循环. 因此, 我决定修改 lua-websockets 的底层, 使其依赖于 Neovim 的 vim.uv. 简单来说, 我决定将 lua-websockets 移植到 vim.uv.
阅读了 lua-websockets 的源代码后, 我发现移植的重点应该在 src/websocket/server_ev.lua.
我使用了一个 LLM 来进行这部分的移植. 在尝试了两个提示后, 我最终完成了一个可用的 WebSocket 服务器.
22.2.1. 提示 1
重写 src/websocket/serverev.lua 以便它可以在 Neovim 中运行. 注意: 原始实现依赖于四个库:
ev,loop,websocket.ev_common,socket. 请移除对这些库的依赖, 转而使用vim.uv. …
提示 1 生成的代码大部分是可用的, 但其中一个函数 message_io 是一个严重的幻觉, 而这个幻觉相当合理, 因为我没有注意到 websocket.ev_common 实际上是 server_ev.lua 本身的一个主要部分, 而不是一个外部依赖.
因此, 我用了第二个提示来纠正这个问题.
22.2.2. 提示 2
考虑 src/websocket/evcommon.lua 中的
message_io, 它依赖于lua ev的loop. 请重构message_io, 并将message_io中的sock改为vim.uv中uv.new_tcp()的返回值, 意思是这个sock有像read_start,write这样的函数可以调用. …
经过两个提示后, 我进行了一些简单的手动调试, WebSocket 连接就建立起来了.
22.3. 总结
在某种程度上, 这次解决的问题仍然是一个移植问题, 就像之前的 day20 和 day21 一样. 在一个大的移植问题中, 有更小的移植问题.
因为我已经确定了这个问题移植的依赖关系, 所以 LLM 的提示可以顺利处理它. 另一方面, 如果没有手动澄清依赖关系, LLM 的成功几率会非常低.
23. 项目探讨—CBOR
当读者第一次听到 CBOR 时, 可能会觉得它陌生且难以理解. 这里简单解释一下: 读者可以把它想象成一个类似于 JSON encode 的库, 但它的编码方式是二进制的, 不能直接被人眼解读, 但性能更好.
23.1. 问题概述
如果读者仔细研究原始Emacs 插件中与 CBOR 相关的部分, 他们会发现: 在原始的 Emacs 插件中, CBOR 部分的做法是复制粘贴一个 CBOR 库的实现, 然后进行定制.
当我在移植这部分时, 我倾向于说: “如果可能的话, Conjure Piglet Client 应该直接依赖一个 Lua CBOR 库.” 像 Emacs 插件那样复制和修改源代码的做法, 暗中给应用开发者带来了巨大的认知压力.
出乎意料的是, 我设想的这种 模块化移植方法 比我想象的要困难得多.
建立 websocket 连接后, 我用 CBOR 对消息进行编码并发送给 Piglet 解释器进行求值. 令我惊讶的是, 它立刻就失败了. 我在 Piglet 端使用 cbor.me 网站检查了 CBOR 编码的结果, 以了解失败的原因.
问题是: Piglet 期望在 CBOR 编码中的关键字前添加一个标签 39.
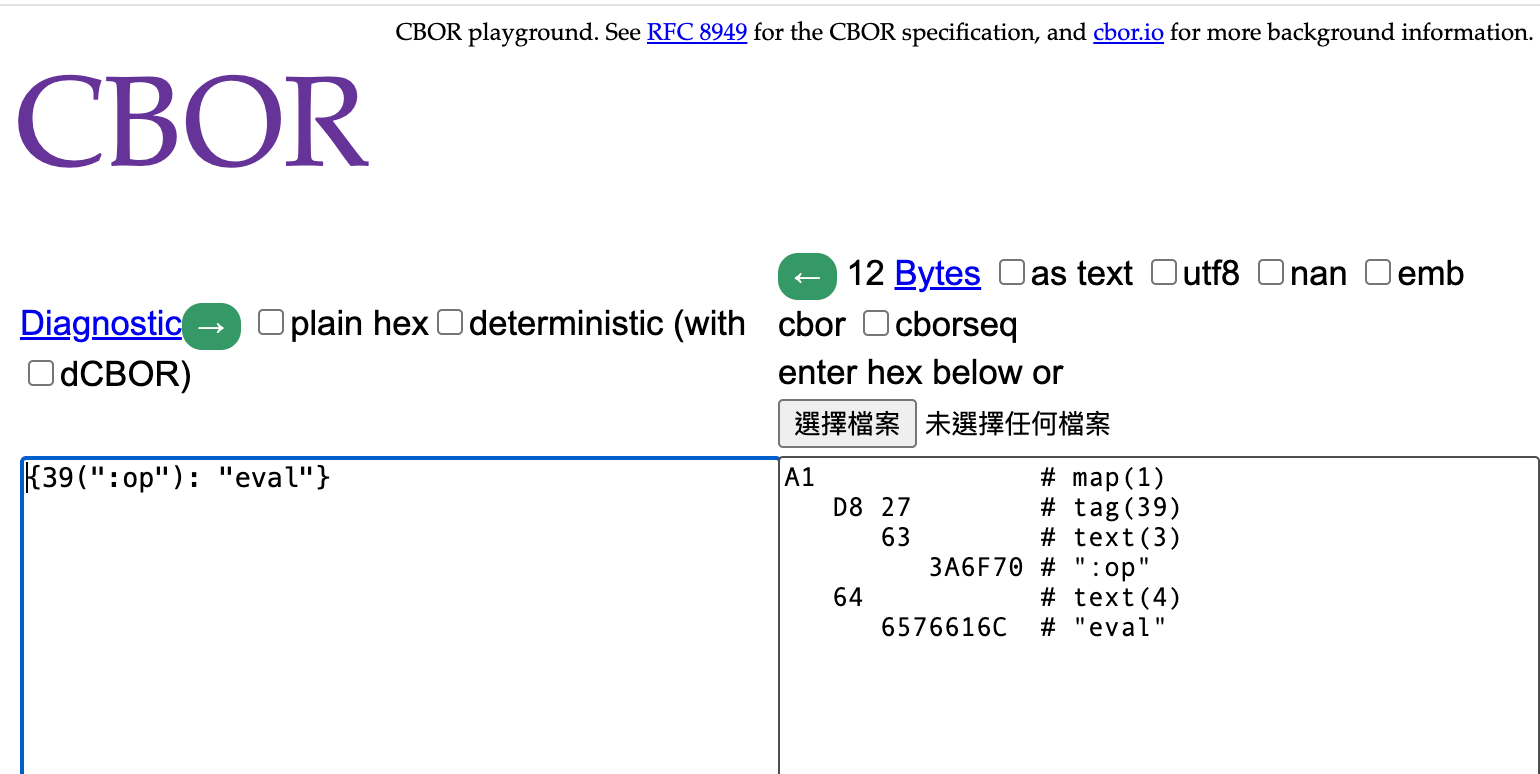
Figure 12: CBOR encoding showing tag 39 for keywords.
23.2. 解决方案架构
由于 spc476/CBOR 的 README 相对简洁, 而我对 Lua 非常不熟悉——不熟悉到我几乎不理解 setmetatable. 因此, 我卡住了: “我该如何调用 Lua cbor 库来成功插入标签 39, 并让标签 39 修改消息中的关键字?”
在开发过程中, 我问了 LLM 几次, LLM 提供了几种不同的调用方法, 全都是错误的.
我的提示是这样的:
考虑到使用以下 Lua 库 https://github.com/spc476/CBOR, 希望
lua.encode({op = "eval"})的十六进制结果是 "a1 d8 27 63 3a 6f 70 64 65 76 61 6c", 即希望插入一个标签 39 来修改op关键字.lua.encode应该如何调用?
最后, 我放弃了 LLM, 回去慢慢阅读 README 和 Lua 的 API, 最终找到了解决方案.
(local cbor (require :org.conman.cbor)) ;; Define a keyword function, which can be used to register the __tocbor function (fn keyword [s] ;; keyword changes the string $s => ~:$s~ ;; and return a table with the content is ~{:v $changed_string}~ ;; and the returned table has a ~__tocbor~ function in its metatable." (let [t {:v (.. ":" s)} mt {:__tocbor (fn [self] (cbor.TAG._id self.v))}] (setmetatable t mt))) ;; Declare a msg, where its keys must be modified by the above function. (local msg {(keyword "op") :eval (keyword "code") "(+ 1 1)"}) ;; Encode the entire msg with cbor, cbor.encode will call the __tocbor function. (cbor.encode msg)
23.2.1. 结构化思维提示
克服了这个障碍后, 我重新设计了我的提示, 在原始提示后添加了一段来引导 LLM 的思考:
在尝试解决这个问题时, 请按以下顺序思考:
- 所需功能是否是 spc476 库的设计者最初可能没有涵盖的场景?
- 库的设计者是否已经为这种情况应用了松耦合机制, 允许用户稍后进行修改?
- Lua 的松耦合机制有哪些?
- 考虑了 1, 2 和 3 之后, lua.encode 应该如何调用?
当我用这个新的提示来要求 LLM 演示库调用时, LLM 的输出质量显著提高. 一些 LLM 甚至成功了; 即使是失败的, 也只差一步之遥.
23.3. 总结
本文提出了一种使用“结构化思维提示”的 AI 应用方法, 这可以说是源于 CBOR 编码与 Piglet 期望格式不匹配的挑战.
在某种程度上, 这次解决的问题仍然是一个移植问题, 类似于 day20, day21, day22. 然而, 这是“模块化移植”, 我在移植的同时也提高了系统的模块化程度.
如果速度是唯一考量, 或许直接让 LLM 以暴力方式直接从 Emacs 插件移植 CBOR 可能会更快, 因为这可能完全由 AI 完成, 人工干预相对较少.
这就引出了一个矛盾的问题: “AI 擅长简单, 暴力的方法, 并且做得很快. 然而, 作为软件开发者, 人类能否一直与不优雅的代码共存?”
24. 项目探讨—跳转定义背后的 Tree-sitter
考虑以下需求: 你有一个用中文写的纯文本文件, 里面是一篇中文文章. 出于某种原因, 你需要将文章中的‘如果’ (rúguǒ - if) 替换成英文单词 'if'. 很多人可能会想, 这很简单, 只要做个字符串替换就行了.
然而, 如果那篇中文文章里有一个有问题的句子:
牛奶不如果汁好喝。
前面提到的简单字符串替换就会失败.
如何开发一个程序来防止它受到这种有问题的句子的影响?
- 首先, 使用形式语言学对纯文本文件中的数据进行自然语言语法树解析, 例如:
;; If it rains, I won't go.
S (Sentence)
├── CP (Conditional Clause)
│ ├── C (Conjunction): 如果
│ └── S (Sentence)
│ └── VP (Verb Phrase)
│ └── V (Verb): 下雨
└── S (Main Clause)
├── NP (Noun Phrase): 我
├── Adv (Adverb): 就
├── Neg (Negative): 不
├── VP (Verb Phrase)
│ └── V (Verb): 去
└── Part (Modal Particle): 了
- 查询这些生成的语法树. 首先, 找到所有连词 (C), 然后在这些连词中比较‘如果’. 这样, 它就不会受到 问题句子 的影响.
编程语言也可以进行语法树解析. 事实上, 现代编辑器的高级功能: 语法高亮, 自动格式化, 和 跳转到定义. 这些能力背后的基石也是编程语言的语法树解析.
24.1. 问题概述
在 day24, 我们提到了使用 Tree-sitter 来解析代码, 这带来了两个主要挑战:
- Tree-sitter 如何生成 Fennel 的语法树?
- 一旦获得了语法树, 我们如何查询它?
24.2. 解决方案架构
第一个问题, 生成语法树, 实际上是最难的, 因为我们必须为 Tree-sitter 提供一个 grammar.js 文件, 在其中必须很好地定义 Fennel 语言的语法规则 (Grammar Rules). 幸运的是, 在 Tree-sitter 的官方网站上, 许多不太常见的编程语言的语法规则已经存在了!
因此, 可以得到下图, 图的左边是 Tree-sitter 的输出.
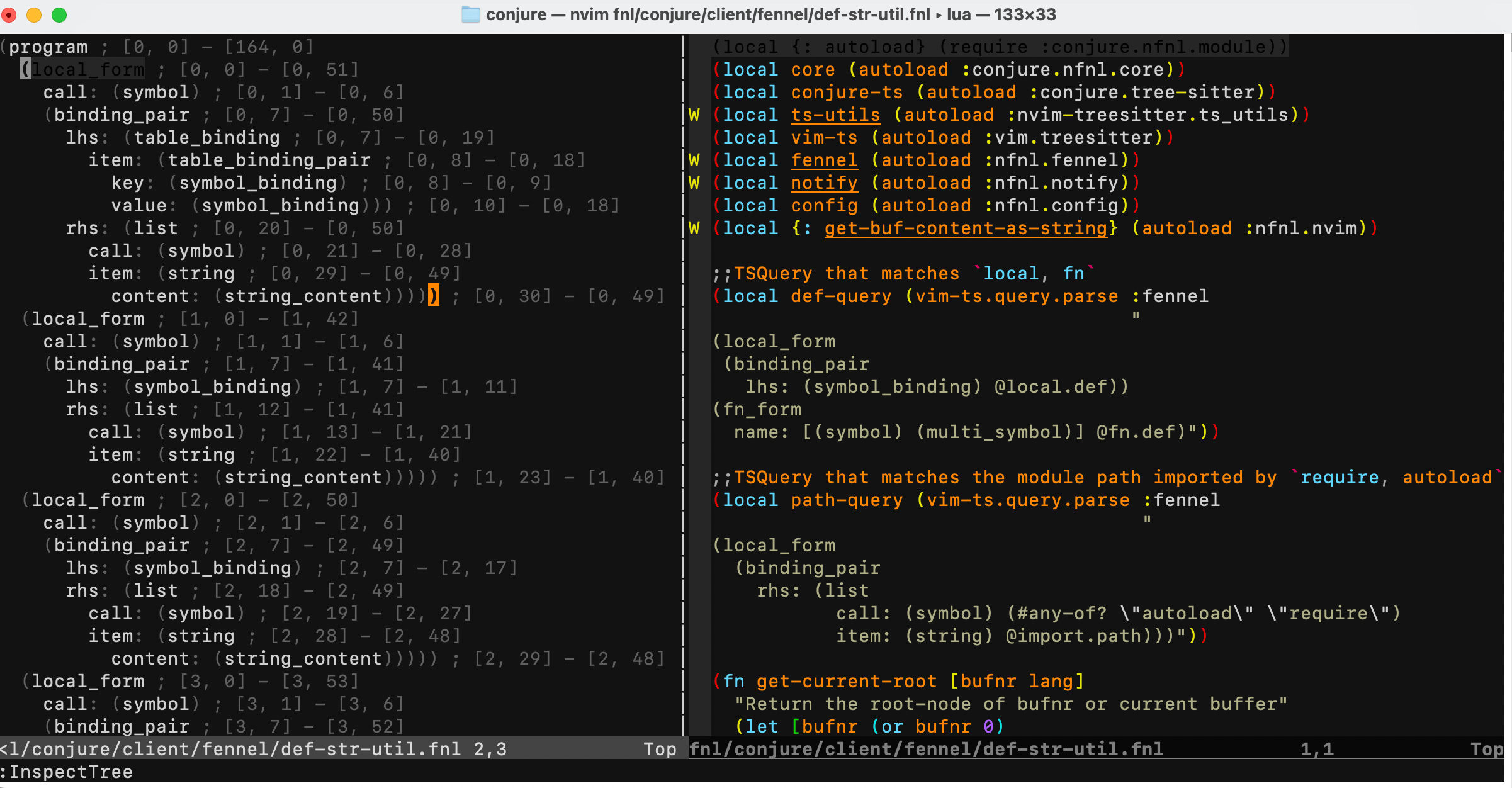
Figure 13: Tree-sitter output for Fennel code.
对于查询问题, 我们可以很好地利用 Neovim 的两个 Ex 命令:
- InspectTree
- EditQuery
在 EditQuery 窗口中, 输入 Tree-sitter 查询后, 成功匹配的源代码和语法树片段会自动高亮, 帮助你直观地确认你的意图是否与查询结果匹配. 我至今还没有学会 Tree-sitter 的查询语法; 我只是让 LLM 为我生成它.
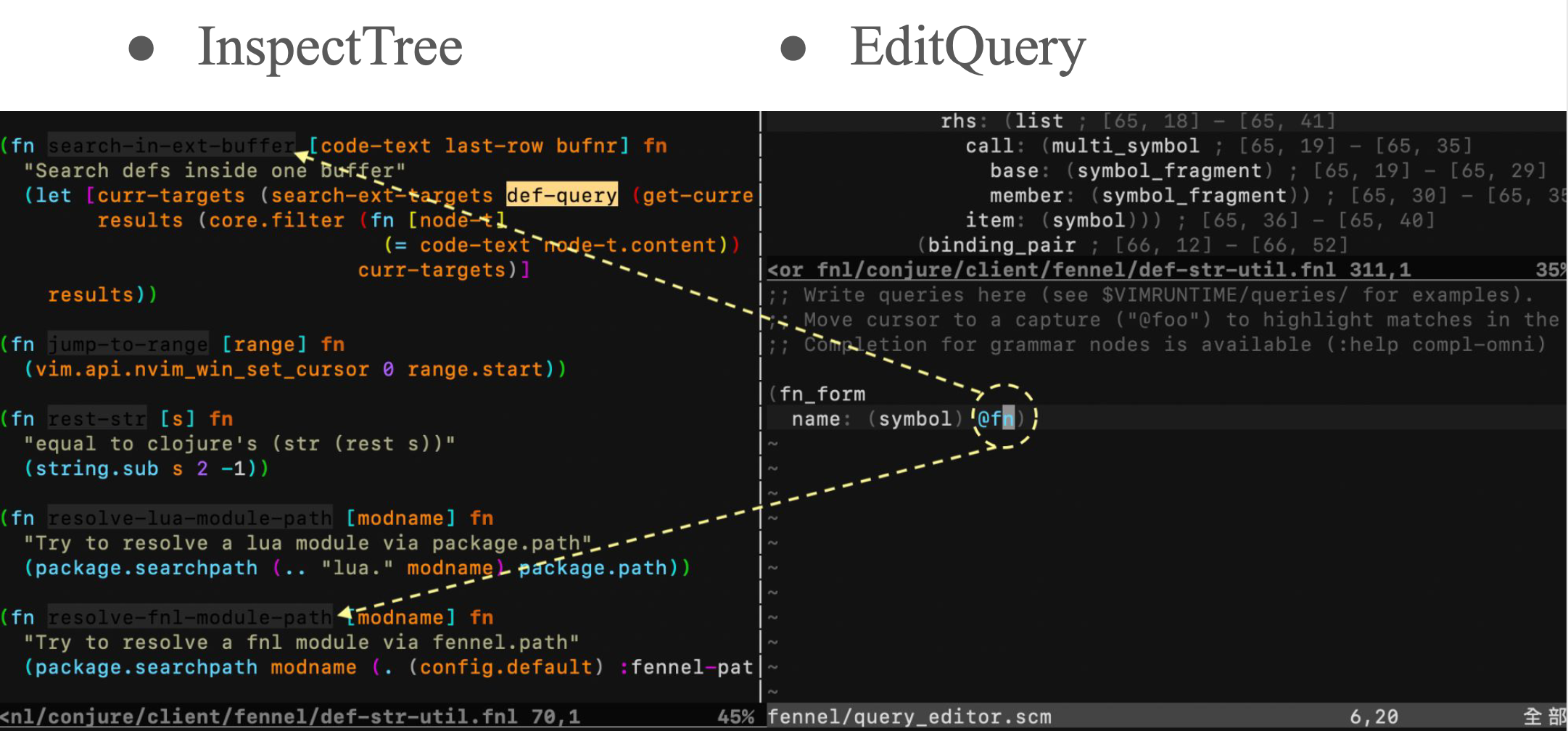
Figure 14: Tree-sitter query editing and highlighting.
24.3. 总结
自然语言和代码本身是具有隐式结构的数据. 通过使用解析生成的语法树, 我们可以像应用数据库一样, 以精确的方式理解, 查询和操作它们的数据.
25. 模式与原则—瓶颈与改进
在 day01, 我们讨论了 AI 时代的软件开发, 并提到了 Lisp 和 FP 如何通过减少测试和调试时间来提高软件开发效率. 它们之所以重要, 是因为虽然 AI 加速了编码, 但它使得“测试和调试”成为一个更显著的瓶颈.
然而, AI 的影响远不止于此. 当一个瓶颈被解决后, 新的瓶颈就会出现. 那么, 我们如何能从一个更高层次的视角, 来识别在 AI 时代哪些知识仍然重要, 甚至获得了更多价值? 我相信, 约束理论的简单框架足以提供许多启发.
25.1. 约束理论
约束理论 (ToC) 是由以色列物理学家 Eliyahu M. Goldratt 提出的管理哲学. 其核心思想很简单: 任何系统的性能都由其最薄弱的环节决定.
想象一条由三台不同机器串联组成的生产线. 如果一台机器每小时只能生产 100 个零件, 而其他机器每小时可以生产 200 个零件, 那么整条生产线每小时最多只能生产 100 个零件. 这台每小时生产 100 个零件的机器就是系统的“约束”.
ToC 认为, 如果想要提高整个系统的效率和产出, 所有的资源和努力都必须集中在识别和解决最关键的约束上.
25.2. AI 时代的最大约束
让我们回顾一下之前使用 AI 的例子:
- 在 WebSocket 章节, AI 被用于 移植, 尽管首先用人工干预来明确依赖关系.
- 在 CBOR 章节, AI 被用于 推断 库的用法, 尽管需要结构化思维提示才能成功.
- 在跳转到定义章节, AI 被用于 架构设计, 尽管后来被人工大幅简化.
- 在 Tree-sitter 章节, AI 被用于 生成查询.
AI 与其说是一种工具本身, 不如说是工具的原材料. 根据用户的提示, 它可以转变成各种不同的工具.
如果我们将软件开发看作一个系统, 其最终产出是一个功能齐全的应用程序. 在 AI 时代, 许多传统的瓶颈, 如代码编写, 单元测试生成, 甚至初步调试, 都因 AI 的辅助而得到了显著改善.
然而, 根据约束理论, 当一个瓶颈被解决后, 新的瓶颈就会出现. 这正是 AI 时代软件开发的核心挑战.
我相信, 对开发者而言, 软件开发最大的约束不再仅仅是“开发速度”或“技术实现能力”, 而是“*持续识别和适应生产力瓶颈的能力*”.
一个能够准确识别“当前最重要瓶颈”的开发者或团队, 更有可能将 AI 这个多功能工具聚焦在最关键的环节上, 从而产生最大的效益. 这也解释了为什么像 Lisp 和 FP 这样更偏向抽象思维和架构设计的知识领域, 在 AI 时代的重要性有所增加, 因为它们训练的是我们识别系统性瓶颈的能力, 而不仅仅是代码编写技巧.
25.3. 总结
在 AI 时代, 软件开发的生产力瓶颈变化比以前更快, 因此培养持续识别和适应这些瓶颈的能力变得更加必要.
在接下来的章节中, 我们将讨论一些常见的挑战, 因为这些挑战如果处理不当, 很容易成为生产力瓶颈. 此外, 由于后续章节将探讨普遍性挑战, 它们将不再局限于特定的编程语言或应用平台.
26. 模式与原则—不确定性
软件开发是一项充满不确定性的工作, 通常来自两个主要方面:
- 用户需求的澄清
- 组件的应用挑战
上述不确定性通常在 新开发项目 中尤其明显.
新开发项目有时不涉及真实用户, 因为真实用户只有在项目上线后才能获得. 换句话说, 无论最初的规格写得多详细, 都是基于对用户的想象, 真实的用户反馈仍然充满不确定性.
新开发项目有时也会通过改变一些现有项目的实践来适应: 更换语言, 架构, 数据库等等. 或者可能需要开发前所未有的新功能, 集成新的库, 或部署到新的平台. 上述情况都涉及应用新组件, 很可能这些新组件的文档模糊, 缺乏示例; 组件可能有 bug, 或者依赖某个与系统其他部分冲突的库.
26.1. 应对之道
仔细思考不确定性的本质, 它本质上是缺乏关键信息, 而这种信息通常是 基于反馈的信息. 换句话说, 如果我们能调整开发顺序或方法, 以更快地获取重要信息, 这就能迅速减少不确定性.
26.1.1. 行走骨架 (Walking Skeleton) (骨架先行)
在开发一个新项目时, 行走骨架是一种能快速减少不确定性的方法. 它的概念是: “先集成所有有副作用 (IO) 的组件, 然后再开发核心逻辑.” 一个更高级的行走骨架还包括从一开始就完成一键部署.
通过采用这种开发顺序, 一方面, 高度不确定的组件的集成被提前了, 所以系统中的整体不确定性在项目初期就迅速下降. 更重要的是, 一旦系统有了 UI, 非开发者协作者就可以加入项目提供反馈; 如果部署也到位了, 甚至可以及早收集到真实软件用户或客户的反馈.
虽然行走骨架是一种极其简单的方法, 但它能迅速减少不确定性, 并显著降低项目风险.
26.1.2. 移植 (Porting) (移植)
在规划许多系统时, 常常发现某些需要的模块不存在, 但它们在其他平台上存在. 在这种情况下, 我们可以采用移植作为减少不确定性的一种方式.
从其他平台移植模块可以说能迅速减少‘需求方向’的不确定性. 一般来说, 当我们谈论需求时, 这个词通常有两个含义: 一个是直接来自真实用户的需求. 另一个含义是由于外部用户需求而需要的 合理的模块接口. 设计合理的模块接口其实非常困难; 许多写在书中的经典接口设计都是无数前人尝试, 失败和改进的结果.
采用移植的方法可以将不确定性集中在软件实现和依赖上, 显著减少整体不确定性.
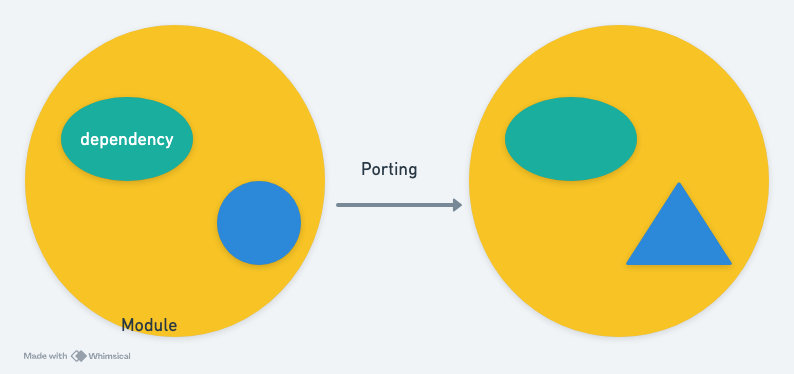
Figure 15: Porting concept diagram.
26.1.3. 剥离与包装 (Peel and Wrap) (剥皮嫁接)
当发现某些需要的模块不存在时, 除了自己重新开发, 也可以考虑移植.
另一方面, 在软件开发过程中, 很多时候我们也有第三方库可以使用; 然而, 虽然第三方模块可以用, 但它们通常很难用.
什么时候会发生这种情况? 例如, 当使用像 Clojure 这样主要支持函数式编程的语言时, 如果我们需要使用不太常见的用例, 我们可能会求助于第三方库, 特别是纯 Java 库. 然而, Java 库的一个特点是它们带有大量的类型. 如果直接引用, 会让 Clojure 代码中充满 Java 类型.
在这种情况下, 一个更好的方法是剥离与包装: 在引用 Java 库之前, 逐层剥离, 直到找到一个还没有将数据转换成无数类型的层. 直接剥掉该模块的上层, 用 Clojure 语言重写它们.
这种方法允许利用第三方库 (减少不确定性), 同时确保它们不会污染整个系统.
剥离与包装的方法来自 Arne Brasseur 的一条推文:
Much of Clojure development is peeling back layers and layers of Java libraries to get to the bit that actually matters, then wrapping that in a tiny API layer over plain data.
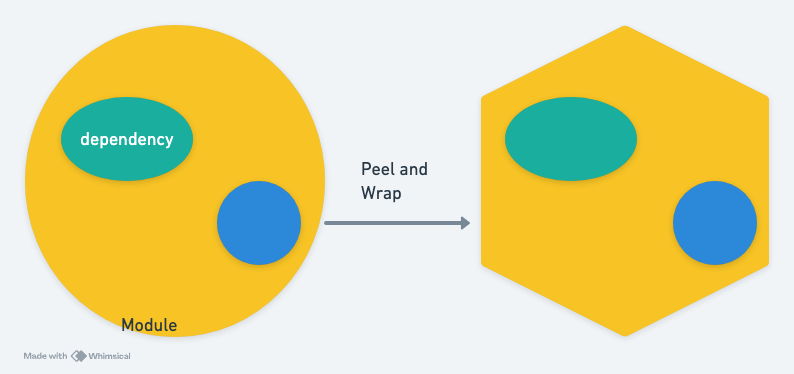
Figure 16: Peel and Wrap concept diagram.
26.2. 相关理论
这些应对不确定性的模式实际上呼应了复杂性科学家 Stuart A. Kauffman 提出的 邻近可能性 (Adjacent Possible) 的概念.
Kauffman 认为, 生物系统 (以及人类经济, 文化和技术系统) 的演化不是一个随机的跳跃, 而是从当前状态向其 邻近可能性 空间的逐步探索和扩展. 这个‘邻近可能性’是系统基于其当前拥有的所有组件和配置, 可以达到的所有可能的下一个状态的集合.
例如, 在生物进化中, 新的基因突变或性状通常是基于现有的基因和环境出现的, 而不是凭空出现的. 同样, 在软件开发中, 我们可以将我们当前的技术栈, 团队知识和用户反馈视为我们的‘当前状态’.
26.2.1. 邻近可能性: 约束与机会的二元性
邻近可能性 的一个关键特征在于其二元性: 它 既是约束也是机会.
- 作为约束: 系统的当前状态决定了你能去哪里. 你不能直接从一个 Java 项目跳到一个成熟复杂的 Rust 项目, 除非你先获得 Rust 知识, 找到相关库, 并完成架构验证. 现有的技术债, 团队技能和架构复杂性都限制了我们能有效探索的范围. 如果我们盲目地‘跃进’, 失败的概率会极高.
- 作为机会: 同时, 当前状态也是所有新可能性的来源. 你已经拥有的所有类, 函数, 接口和数据结构都是潜在的‘乐高积木’. 当你组合这些积木时, 一个新的, 可行的状态就会出现在你的 邻近可能性 中. 有效的开发策略是巧妙地使用现有的积木, 或引入最少量的外部积木, 来扩展这个空间.
从这个角度来看, 上述开发模式都可以被理解为系统地管理这些‘约束’和‘机会’:
- 行走骨架: 是一种通过尽早建立一个可工作的基础来 快速探索邻近可能性 的方法. 它首先稳定了最不确定的方面 (I/O, 部署), 将这些高风险的约束转变为稳定的基石. 这种新状态使得团队可以更安全地探索后续功能, 并从早期反馈中找到新的‘邻近可能性’方向.
- 移植: 是利用外部资源来战略性地扩展 邻近可能性 的边界. 它将其他领域经过验证的解决方案引入到我们的 邻近可能性 空间中, 直接绕过了需求方向的不确定性约束, 从而跳过了冗长的设计和试错过程.
- 剥离与包装: 也是一种利用外部资源 (机会) 的方法, 同时小心地 管理外部依赖带来的约束. 通过创建一个薄的 API 层, 它将外部组件转变为符合系统自身风格的新工具, 防止 邻近可能性 空间被混乱的外部依赖所污染, 并确保系统的内部一致性.
总而言之, 这些策略不仅仅是技术实践, 而是系统地管理不确定性并在 邻近可能性 空间内加速有效探索的方法. 它们的核心思想是: 首先建立一个稳定的基石, 将约束转化为机会, 然后有组织, 有目标地逐步扩展到下一个可行的状态, 而不是盲目地闯入未知.
26.3. 总结
软件开发充满了不确定性, 主要源于用户需求和技术挑战. 本文介绍了应对这种不确定性的三种模式:
- 骨架先行
- 移植
- 剥皮嫁接
这些模式不仅仅是技术技巧, 而是对不确定性的系统管理, 其核心哲学与复杂性科学家 Stuart A. Kauffman 提出的 邻近可能性 的概念相一致. 这些策略都涉及建立一个稳定的基石, 然后有组织, 有目标地逐步探索和扩展, 最终在可行范围内加速解决方案的发现.
27. 模式与原则—复杂性
软件开发的复杂性可以说是其众多特性中, 最不需要特别证明的一个. 即使是一个简单的 5-10 行的函数, 如果写得不好, 工程师也很难理解.
那么, 工程师有什么方法来理解代码呢?
主要只有两种方式: 通过“阅读源代码”来理解, 或“作为黑盒观察输入/输出行为”, 这分别对应于文章 Out of the Tar Pit 中的“非正式推理”和“测试”.
由于 Lisp 语言提供了交互式开发, 这有效地让工程师可以任意测试代码的任何部分, 自然为工程师理解复杂代码提供了巨大的帮助.
另一方面, 如果将“阅读源代码”视为一种理解方法, 那么代码的数量, 可变状态, 不直观的逻辑, 不恰当的命名等, 都会有效地增加复杂性, 导致工程师的痛苦.
27.1. 应对之道
在阅读某段代码时, 工程师在寻找什么答案? 十有八九, 他们是想了解:
- 这是什么? (what)
- 它是如何实现的? (how)
基于这个观察, 我们可以推断, 如果代码的编写方式能有效地将“它是什么”放在更高层次, 而“它是如何实现的”放在更低层次, 那么工程师理解代码的负担就可以被有效地减轻.
因为当工程师想了解“它是什么”时, 他们只需阅读更高层次的代码, 这里的代码量会小得多. 当工程师想了解“它是如何实现的”时, 他们可以先从更高层次的代码中选择他们最感兴趣的部分, 然后再寻找相应的实现. 换句话说, 分离 what/how 是一种通过“分而治之”来理解的有效策略, 而这种策略在软件开发中有许多体现.
在日常实践中, 有一个经验法则可以帮助我们入门: “*如果同样的东西出现三次, 就把它提取成一个函数.*” 这个经验法则简单易行, 重复也可能暗示该代码段符合“如何实现”的概念, 应该被封装. 然而, 要真正实现 what/how 的分离, 仅仅依靠这种机械的“三次”法则是不够的; 仍然需要有意识地思考“它是什么?”和“它是如何实现的?”之间的区别, 并积极设计抽象层.
27.1.1. 容器/展示者模式 (Container/Presenter Pattern)
容器/展示者模式是 React 前端开发中常见的设计方法. 其核心思想是分离“做什么”和“怎么做”, 使代码结构更清晰, 更易于维护.
- 容器 (Container) 负责“显示什么”和“交互发生后做什么”. 它管理状态, 处理逻辑, 并决定需要触发哪些事件. 换句话说, 容器回答的是 What to display 的问题.
- 展示者 (Presenter) 专注于“屏幕应该如何显示”. 它完全根据 props 来渲染 UI, 并将事件传递给注入的处理程序; 至于数据来源和事件语义, 它完全不关心. 展示者回答的是 How to display 的问题.
当一个复杂的 UI 被拆分成这两个角色时, what/how 分离的好处变得非常直观:
- 了解“屏幕需要什么数据, 点击后会发生什么” — 看容器.
- 了解“这些数据是如何呈现的, 按钮长什么样” — 看展示者.
这种分离简化了每个组件的职责, 从而大大降低了理解代码的难度.
27.1.2. DSL + 解释器模式 (Interpreter Pattern)
领域特定语言 (DSL) 和解释器模式的结合是 what/how 分离的另一个经典体现. 这就像设计一种专门的语言 (DSL) 来描述一个问题, 然后用一个解释器来执行它.
Tree-sitter 是一个用于解析代码语法的库, 它完美地体现了这一概念.
- what (查询语言): Tree-sitter 提供了一种强大的查询语言, 允许你使用类似 CSS 选择器的语法来描述你想在抽象语法树 (AST) 中找到什么. 例如, 你可能会写
(function_declaration name: (identifier) @name)来描述“我想找到所有函数声明并捕获它们的名称.” 这个查询本身就是一个 DSL; 它清楚地定义了你想要什么, 而不需要关心底层的搜索算法. - how (执行引擎): Tree-sitter 的核心引擎负责解释和执行你的查询. 它知道如何遍历语法树, 如何匹配节点类型, 如何处理命名捕获 (
@name) 等等. 对用户来说, 当查询语言始终正常工作时, 他们可以完全忽略执行引擎的实现.
换句话说, 当你使用 Tree-sitter 时, 你只专注于描述你的需求 (what), 即你想从代码中提取什么信息. 至于这个需求是如何实现的 (how), 则完全由底层引擎处理. 这种模式让你只需几行查询就能轻松完成复杂的代码分析任务, 而无需深入研究底层算法的细节.
27.2. 相关理论
这种将复杂系统分解为更小, 更易于管理, 按层次组织的子系统的模式, 与 Herbert Alexander Simon 在其著作《复杂性的架构》(The Architecture of Complexity) 中提出的层级复杂性 (hierarchical complexity) 概念不谋而合.
Simon 通过一个关于两个钟表匠 Hora 和 Tempus 的著名故事来说明这个概念. Hora 的制表方法是先组装所有零件, 然后再将它们全部固定在一起, 但他常常在完成前被打断, 导致所有工作都要从头开始. 而 Tempus 则采用了不同的方法: 他先将零件组装成小的子单元, 然后将这些子单元组合成更大的子单元, 最后将它们组装成一个完整的时钟. 当他被打断时, 他只需要重新组装最后一个完成的子单元, 而不是从头再来.
在这个类比中, Tempus 的工作方法代表了一个“可分解的层级系统”. 这样的系统由独立或近乎独立的子系统组成, 每个子系统又由更小的子系统组成, 如此层层递进. 这种结构确保了单个子系统内的变化不太可能影响其他子系统.
将这个概念应用于软件开发, 我们可以看到 what/how 分离是构建层级系统的有效方法. 在代码中, “what” (是什么) 处于更高的抽象层次, 描述了功能的目标, 而“how” (如何实现) 则处于较低层次, 包含具体的实现细节.
这让我们能像 Tempus 一样, 在单一层次上进行修改和理解, 而不必理解整个系统的庞大细节. 当我们想了解一个功能时, 我们可以从“what”的层次开始, 就像检查时钟的一个“子单元”; 如果需要更深入地了解其工作原理, 我们再深入到“how”的层次. 这种层级组织不仅使代码更容易理解, 也使维护和修改更有效率, 因为变化的范围被限制在特定的子系统中.
27.3. 总结
复杂性是软件开发中最广为人知的挑战, 但应对它的方法却相对鲜为人知. 本文介绍了“what/how 分离”的核心通用模式, 并提供了两个子模式:
- 容器/展示者模式
- DSL + 解释器模式
这些模式也与 Herbert Alexander Simon 提出的层级复杂性理论相符. 虽然在实践中我们可以通过遵循“如果同样的东西出现三次, 就把它提取出来”这个简单的规则来迈出第一步, 但要实现真正的 what/how 分离, 仍然需要设计者有意识地应用抽象. 这些模式的结果是, 当需要修改或理解时, 只需关注特定层次, 而无需从头开始.
28. 模式与原则—修改传播
时间可以说是软件的头号敌人.
即使经过很短的时间, 无数外部力量也会迫使软件系统进行修改. 用户需求可能会改变, 应用程序包中可能会发现安全风险需要替换, 依赖的第三方服务可能会下线, 或者数据库可能需要更换以满足新的性能要求等等.
从普通人的角度来看, 修改软件只需在电脑上打字即可, 理论上应该比更换马桶简单得多——至少不需要连接水, 电, 排污管, 或涂抹水泥. 然而, 因为修改常常会传播, 有时对一个函数的更改可能导致多米诺骨牌效应, 整个系统中依赖该函数的多个部分也必须修改. 这使得修改软件远比许多物理工程任务困难得多.
28.1. 应对之道
我们无法让迫使软件修改的外部力量消失; 然而, 我们可以尝试让修改不那么容易传播. 如果我们仔细思考修改传播的概念, 我们会发现传播意味着: “一个修改通过跨越模块边界感染了其他模块.”
正因为如此, 在设计模块边界时, 我们应该设计它们来防止修改传播. 防止修改传播的边界通常有两种形式:
- 对于消费者, 边界允许替换生产者.
- 对于生产者, 边界允许注入新的实现.
无论上述哪一种, 都可以称为 松耦合 机制. 为了防止修改传播, 增加软件的稳定性, 并减少重新学习的成本, 我们必须善用松耦合机制.
下面, 我们探讨一些常见的松耦合机制.
28.1.1. 传输协议作为接口
当我们使用传输协议 (例如, HTTP, gRPC) 作为不同服务或模块之间的接口时, 它提供了一个天然的隔离层. 服务 A 只需要知道如何根据商定的传输协议与服务 B 通信; 它不需要关心服务 B 内部是如何实现的.
如果今天服务 B 由于性能问题需要从 Node.js 重写为 Go 语言, 只要它提供给服务 A 的传输协议保持不变, 服务 A 就完全不需要任何修改. 这是“*对于消费者, 边界允许替换生产者*”的最佳例子. 服务 B 的内部实现改变了, 但对于服务 A, 边界 (传输协议) 是稳定的, 修改没有传播. 这种机制在微服务架构中尤其常见, 允许每个服务独立开发, 部署和扩展.
这个概念不仅限于服务之间的通信. 在单体应用中, 接口 可以扮演同样的角色. 当一个模块 (消费者) 依赖于一个接口而不是一个具体的类实现 (生产者) 时, 你可以自由地替换底层的实现而不影响消费者. 这正是依赖注入的结构基础.
28.1.2. 可扩展数据格式与策略模式
EDN (Extensible Data Notation) 是 Clojure 生态系统中常用的可扩展数据格式. 它类似于 JSON 或 XML, 但其最关键的优点是允许你使用标签来扩展数据类型.
例如, 你可以在 EDN 格式中自定义一个 #date 标签来表示日期, 当数据传输时, 它会以类似 #date "2025-09-24" 的格式出现. 接收端看到这个标签后, 就知道这是一个日期, 并可以将其恢复为相应的数据类型.
这种机制完美地体现了“*对于生产者, 边界允许注入新的实现*”的概念.
假设你的系统今天需要处理一种新的数据类型; 你不需要修改现有的架构或数据格式. 你只需要在 EDN 格式中定义一个新的标签, 并在接收端添加处理这个标签的代码. 这样, 新的数据类型可以通过微小的改动添加进来, 而无需大幅改动系统架构, 让你可以在不大动干戈地修改旧系统的情况下逐步扩展功能, 有效地防止了修改传播.
类似的概念也出现在 策略模式 中. 在这个模式中, 系统的核心部分 (例如, 一个支付处理模块) 定义一个接口, 但具体的支付方式 (如信用卡, PayPal, Apple Pay) 则作为不同的类实现. 当需要添加新的支付方式时, 你只需要添加一个新的实现类, 而无需修改核心处理模块的代码.
28.2. 相关理论
塔勒布在他的著作《反脆弱》中提出, 当系统面临冲击时, 它们可以是脆弱的, 稳健的, 或反脆弱的. 特别是反脆弱的系统, 不仅能承受冲击, 而且能通过小规模的扰动逐步增强.
如果将软件视为一个长期演化的系统, 那么“修改”就是它必须承受的不可避免的冲击. 如果设计不当, 修改会迅速传播, 使系统变得脆弱; 如果边界设计得好, 修改可以被局部吸收, 甚至成为进一步加强系统的机会.
这种加强机制的核心在于“*错误即信息*”的思想. 这些错误, 如测试失败, 小 bug, 或重构挑战, 提供了关于系统哪里脆弱以及哪些设计行不通的宝贵知识. 因此, 反脆弱性鼓励积极拥抱这些信息, 从小错误中学习并进行优化.
反脆弱性的观点提醒我们, 盲目避免小的修改很容易导致大规模的崩溃. 软件史上常见的“系统完全重写”往往是由于缺乏容纳局部修改的能力和长期压抑累积问题所致. 相反, 许多抵制修改传播的设计并非一开始就完全具备, 而是通过反复从错误中获取信息并进行重构而逐步演化出来的.
这也呼应了塔勒布的说法: “时间是脆弱性的过滤器.” 能够经受长期使用和演化考验的协议或数据格式, 往往比具体的实现更有韧性. 软件工程师在技术选型上的一大智慧, 就是在“新技术发展”和“经时间考验的解决方案”之间取得平衡:
- 新技术可能带来更高的效率或表达力, 但也伴随着更多未知的风险.
- 虽然旧技术可能不是最前沿的, 但其长寿证明了相对的安全性和可靠性.
因此, 从反脆弱性的角度来看, 修改不应仅仅被视为风险, 而应被视为系统成长的养分. 小规模, 可控的修改传播让系统能够通过持续演化逐渐积累适应性; 而技术选型的选择也是这个不断测试, 过滤, 最终保留能够经受时间考验的结构的过程的一部分.
28.3. 总结
许多软件项目最终崩溃, 正是因为缺乏对“*修改传播*”的有效管理. 本文阐述的 松耦合机制 提供了限制变更范围的两个关键路径:
- 对于消费者, 边界允许替换生产者.
- 对于生产者, 边界允许注入新的实现.
从 反脆弱性 的角度来看, 这些机制的作用是让系统能够吸收每次修改的冲击, 并将其转化为局部优化, 从而避免累积成最终的大规模崩溃. 一个能够长期演化的软件系统, 主要不取决于零修改, 而在于其处理小规模变化和持续演化的能力.
因此, 在设计模块边界时, 我们必须有意识地赋予它们松耦合的特性. 只有精心的设计才能确保系统从不断的变化中受益, 而不是受其伤害.
29. 项目探讨—Fennel 的跳转到定义
在开发 auto-conjure 和 Conjure Piglet Client 项目期间, 我最痛苦的事情是缺少跳转到定义的功能. 因此, 对于第三个项目, 我决定实现这个功能. 此外, 我考虑直接在 Conjure Fennel Client 中实现它, 然后向 Conjure 提交一个 Pull Request.
29.1. 问题概述
为了弄清楚如何实现这个功能, 我让一个 LLM 解释“编辑器中的跳转到定义”通常是如何实现的. LLM 回答说:
语言服务器如何实现“跳转到定义”? 它执行以下步骤:
- 代码解析: 语言服务器读取你的 Fennel 代码并将其解析成一个抽象语法树 (AST). 这种树状结构准确地表示了你代码的结构和语义.
- 符号分析: 在解析过程中, 服务器识别所有重要的符号, 例如: 变量, 函数, 宏, 键值对.
- 定义-引用链接: 服务器创建一个映射表, 将每个符号的使用位置链接到其定义位置. 例如, 当你在代码中调用 (my-function x) 时, 服务器找到带有 (defn my-function …) 的那一行并将它们链接起来.
- 提供给编辑器: 当你在编辑器中按下“跳转到定义”快捷键时, 编辑器向语言服务器发送一个请求, 告诉它: “用户当前在文件 A 的第 10 行, 第 5 列. 请告诉我这里的符号定义在哪里.”
- 返回结果: 语言服务器根据其内部映射表, 返回定义的位置 (文件, 行号, 列号), 然后编辑器自动跳转到该位置.
29.2. 解决方案架构
考虑到我是这个功能的用户, 我可以自己决定软件规格. 我决定尽可能地简化这个功能, 以便软件能尽快上线.
我做了三个简化:
- 我选择使用 Tree-sitter 进行代码解析, 而不是 Fennel 自己的解析器. 这样, 我的跳转到定义将无法处理宏. 然而, 跳转到宏的概率远低于跳转到函数, 而且 Tree-sitter 要简单得多.
- 我放弃了使用语言服务器协议, 而是直接在 Conjure 中实现. 这也使得它简单得多, 但我的这个功能将无法跨编辑器使用.
- 我放弃了‘预先代码解析’而采用‘实时代码解析’, 这进一步简化了问题.
它的工作方式如下:
- 收到“跳转到定义”命令后, Conjure Fennel Client 触发
def-str-util.search-and-jump函数. - 在
search-and-jump内部, 它使用 Tree-sitter 解析代码, 进一步解析模块的文件位置, 并最终找到要跳转的位置. - 跳转.
29.3. 总结
在开发过程中, 对于许多问题, 我会参考 LLM 的说法; 而且我喜欢分别询问策略/执行.
然而, 在策略层面, LLM 经常提供标准的解决方案, 这并不一定意味着标准解决方案最适合你的特定用例. 因此, 过度依赖 LLM 有时可能会导致走弯路.
30. fennel-fp-neovim
一系列 Neovim 插件开发入门文章, 使用 Fennel 作为编程语言来解释 Lisp, FP 和高级编程思想.
30.1. 在 Neovim 中探索 Fennel 和函数式编程
在 AI 时代, 开发者需要思考新的开发范式: “AI 帮助我们快速生成代码, 但调试和验证仍需开发者积极介入.” 本系列文章将从 Neovim + Fennel 出发, 引导读者进入 “交互式开发” 和 “函数式编程” 的新世界.
内容包括:
- Fennel 语言: 语法, 常用库.
- Lisp 思维: S-expression 编辑, 交互式开发.
- 函数式编程: 纯函数, map/filter/reduce 等实用技巧.
- Neovim 插件开发: 从简单脚本到完整插件.
- 模式与原则: 指引我们走向成功的法则.
让我们一起在 AI 时代探索更智能, 更优雅的程序开发之道.
30.2. 致谢
本系列文章的完成, 很大程度上受到我在 Gaiwan 和 LambdaIsland 工作的启发.
本系列最初在台湾发表, 之后我使用 markdown-translator 将原始的繁体中文版本翻译成英文.
如果您在阅读本系列后有任何想法, 欢迎随时与我联系.
30.3. 目录
- 序言: AI 加速编程后, 你应该学什么?
- 软件开发在 AI 时代
- Fennel 降低了交互式开发 / 函数式编程的入门门槛
- 总结
- Fennel 简史与开发环境
- 从个人到社区: Fennel 的诞生
- 开发环境 - 安装
- 开发环境 - 插件介绍
- 开发环境 - 自动格式化
- 交互式开发
- S-expression 编辑
- 总结
- Fennel 语言速成—Lisp 语法
- 先谈谈语法
- 总结
- Fennel 语言速成—核心语法
- 函数
- 局部变量
- 数字与字符串
- 容器
- 循环
- 迭代
- 条件语句
- 总结
- Fennel 语言速成—Lua
- Lua 与极简主义
- Lua 概览
- Lua Table 的其他用途
- Fennel 针对 Table 的语法扩展
- 总结
- Fennel 语言速成—LuaRocks
- 多解释器问题
- LuaRocks
- 总结
- Fennel 语言速成—nfnl 库
- nfnl 示例
- Clojure 风格编程
- 总结
- Lisp 深入—交互式开发
- 交互式开发的其他命令
- 善用交互式开发
- 总结
- Lisp 深入—S-expression 编辑
- 括号配对问题
- 括号编辑问题
- 在语法树中导航和编辑
- 总结
- Lisp 深入—宏
- Lisp 提供了什么宏?
- Fennel 的 Reader Macro
- 重新思考 Lisp 宏
- 总结
- Lisp 深入—面向数据编程
- 树遍历的烦恼
- Clojure 的独特风味
- 总结
- 揭秘函数式编程 (FP)—高阶语义
- 为什么 FP 被认为是高阶语义? 从会计说起
- 总结
- 揭秘函数式编程 (FP)—定义的挑战
- 什么是函数式编程 (FP)? 它的定义是什么?
- 区分概念与实现
- 总结
- 揭秘函数式编程 (FP)—常用机制
- 高阶函数
- 值复制
- 总结
- 揭秘函数式编程 (FP)—高级主题
- 函数式编程习语 (FP idioms)
- FP 与代码复用 (code reuse)
- 总结
- Neovim 插件开发—入门
- 学习失败的原因
- 相对合理的学习策略
- Neovim Runtime
- 总结
- Neovim 插件开发—Hello World
- Hello World 插件
- 总结
- Neovim 插件开发—标准插件
- 插件开发
- 模块导入
- 总结
- Neovim 插件开发—如何调试?
- 检查内部状态
- 内部执行顺序
- 总结
- 项目探讨—auto-conjure
- 问题概述
- 解决方案架构
- 总结
- 项目探讨—Conjure Piglet Client
- 问题概述
- 解决方案架构
- 总结
- 项目探讨—WebSocket
- 问题概述
- 解决方案架构
- 总结
- 项目探讨—CBOR
- 问题概述
- 解决方案架构
- 总结
- 项目探讨—Fennel 的跳转到定义
- 问题概述
- 解决方案架构
- 总结
- 项目探讨—跳转定义背后的 Tree-sitter
- 问题概述
- 解决方案架构
- 总结
- 模式与原则—瓶颈与改进
- 约束理论
- AI 时代的最大约束
- 总结
- 模式与原则—不确定性
- 应对之道
- 相关理论
- 总结
- 模式与原则—复杂性
- 应对之道
- 相关理论
- 总结
- 模式与原则—修改传播
- 应对之道
- 相关理论
- 总结
- 模式与原则—隐性知识
- 应对之道
- 相关理论
- 总结
30.4. 许可证
Copyright @ Laurence Chen
根据 知识共享署名 4.0 国际许可协议 的条款进行许可.
31. 模式与原则—隐性知识
在许多组织中, 沟通与协作是生产力的瓶颈之一, 而在软件开发领域, 沟通与协作的独特挑战在于“隐性知识”.
有一次, 我和一位工程师 A 结对编程. 我们首先要做的是在我的电脑上安装一个命令行程序. 不幸的是, A 的操作系统是 Linux, 所以他告诉我的配置文件位置在我的电脑上不起作用, 因为我的电脑是 macOS.
在我挣扎着寻找文档时, A 冷静而耐心地指导我使用 Dtrace 命令, 通过 Dtrace 监控那个命令行程序, 观察它启动时发出的系统调用, 然后 grep 一个特定的模式, 从而在 macOS 上找到了相应的配置文件.
像上面这个例子, 不查文档, 而是依靠对系统的透彻理解走捷径解决问题, 就是典型的隐性知识.
隐性知识转移的困难可以说是软件行业长期存在的挑战之一. 这个挑战不仅发生在组织内部; 可以说整个行业都受到这个困难的影响. 软件行业周期性地经历大规模的“*重复造轮子*”现象, 这通常是技术环境发生根本性变化 (例如, 从本地部署转向云原生, 或新编程范式的出现) 所驱动的必要转型. 然而, 这种转型之所以成本高昂且风险难以控制, 就在于前人隐性知识的继承困难. 当一个新项目启动时, 它很少能获得上一代系统的全部隐性知识, 导致团队只有在遇到重大困难或系统故障时, 才匆忙研究旧系统的痕迹. 隐性知识的断层, 将本已复杂的技术迁移变成了一项从零开始的艰巨挑战.
31.1. 应对之道
隐性知识转移的困难可以大致从两个方面来解决:
- 设计组织流程和沟通方法, 使隐性知识在组织的日常运作中逐渐显性化.
- 设计组织结构, 让不同的团队专注于不同的任务, 从而减少隐性知识转移的需求.
31.1.1. 流程
以软件项目交接为例, 这极大地需要流程的辅助. 一个好的流程可以有效地帮助接手工作的人快速避开所有坑, 确保隐性知识能够被转移.
一个简单的项目交接流程可以是:
- 确保新人可以在本地建立项目.
- 确保新人在本地进行基本测试.
- 确保新人知道如何部署项目.
- 确保新人知道如何在生产环境中调试.
如果标准流程要求将上述所有内容逐一执行并记录下来, 交接过程就可以避免许多旧的陷阱或及早发现新的陷阱, 从而减少未来的风险.
在软件中, 经常发生软件和文档都没有改变, 但构建失败, 部署失败的情况. 这是因为一些依赖版本已经更新, 或者一些用于部署的操作系统已经寿终正寝. 遇到这些陷阱时, 原项目开发者的隐性知识立刻就发挥了作用.
31.1.2. 文档 (沟通方法)
除了流程, 将隐性知识显性化最直接的方式就是写文档. 然而, 文档常常模糊不清, 原因是缺乏对文档旨在传达的知识是为了满足不同情况需求的意识.
Diátaxis 是一种系统化的文档方法, 它根据读者的需求将文档类型分为四类:
- 教程 (Tutorials): 这些文档旨在引导读者从零开始, 一步步地完成一个具体的, 有意义的项目或任务. 它们回答的是“我该如何开始?”的问题.
- 操作指南 (How-to guides): 当读者已经知道他们想要实现什么目标, 但不知道具体步骤时, 这些文档就派上用场了. 它们回答的是“我该如何解决一个特定问题?”的问题.
- 技术参考 (Technical reference): 这些文档就像一本字典或百科全书, 详细说明了所有函数, 类, 接口, 命令或配置选项. 它们回答的是“这是什么?”的问题.
- 解释 (Explanation): 这些文档旨在提供宏观的背景知识和理解, 回答的是“为什么?”的问题.
通过区分这四种文档类型, 我们可以确保每份文档都为特定的读者和情况提供最有效的信息. 这样, 文档将不再是孤立的知识碎片, 而是成为帮助团队持续成长的系统化知识库.
31.1.3. 基于 RAG 的知识库
除了手动编写文档, 现代 AI 工具的兴起为将隐性知识显性化提供了强大的技术途径. 传统上, 非正式文档容易散乱且易于过时, 但 RAG (Retrieval-Augmented Generation) 知识库工具改变了这一状况.
这些工具 (例如 Google NotebookLM) 的价值在于, 它们允许开发团队导入所有非结构化的知识碎片——包括会议记录, 旧代码, 设计文档, 甚至 Slack 聊天记录——来创建一个项目特定的知识索引.
这将隐性知识的转移从“人工搜索和综合”转变为“AI 驱动的快速检索和提炼”:
- 跨文档问答: 新工程师不再需要像大海捞针一样查找文档; 他们可以直接问 AI: “项目中
UserAuth模块最初的设计意图是什么?” AI 会准确地引用所有来源的代码注释, 设计文档或历史讨论来回答这个“为什么”的问题. - 代码与知识验证: RAG 工具不仅可以整理非正式讨论, 还可以将这些非正式知识 (例如, 某个设计决策) 与最新的代码状态进行比较, 指出潜在的语义矛盾或过时的描述, 以确保口头理论与实际操作的一致性.
通过基于 RAG 的知识库, 团队可以在不中断日常开发的情况下, 有效地将原本散落在开发者脑中且从未写下的“理论”转化为可查询, 可验证的显性知识, 从而大大降低隐性知识转移的成本和风险.
31.1.4. 组织结构
考虑到“不确定性”的挑战, Basecamp 提出了一种产品开发方法论 ShapeUp: 一个小组负责“塑造未来项目”; 而另一个小组则在六周的周期内负责“构建项目”. 我们也可以将其看作: 擅长处理不确定性挑战的团队是 塑造团队 (Shaping Team); 而在六周周期内工作的团队是 周期团队 (Cycle Team).
考虑到“复杂性”的挑战, 团队拓扑 (Team Topology) 提倡将团队分为流对齐团队 (Stream-aligned Teams) 和平台团队 (Platform Teams). 流对齐团队专注于单一的, 有价值的业务流程或产品; 他们是离客户最近的团队, 负责端到端地交付价值. 平台团队负责以“即服务 (as-a-Service)”的方式提供内部平台服务 (例如, 基础设施, 部署工具, 监控系统等), 允许流对齐团队自助使用. 这种分工的核心目的是减轻流对齐团队的认知负荷. 通过将复杂的底层技术细节委托给专业的平台团队, 流对齐团队可以更专注于业务逻辑和快速交付客户价值, 从而应对日益复杂的软件系统带来的挑战.
考虑到“变更传播”的挑战, 许多团队设有架构师角色, 他们在项目早期负责各种规划或技术选型, 以便即使后期发生变更传播, 仍然容易纠正或缓解.
通过专业化分工, 可以有效减少隐性知识转移的需求, 从而实现管理理论中所说的“让平凡的人做不平凡的事”.
31.2. 相关理论
Peter Naur 1985 年的著名文章 编程即理论构建 (Programming as Theory Building). 其核心论点是: 一个成功的软件系统的主要资产不是像代码或文档这样的物理产物, 而是存在于开发团队头脑中的一个“理论”.
31.2.1. 理论的本质: 软件开发中的隐性知识
Naur 所指的“理论”不是科学定律, 而是开发团队对以下两个方面的完整心智掌握 (Mental Grasp):
- 代码如何工作的原理: 程序的各个部分是如何设计的, 它们如何相互作用, 以及在执行过程中它如何与机器互动.
- 程序与其环境的关系: 代码如何反映现实世界的需求和约束, 以及环境中的哪些变化可能需要代码调整.
这个“理论”就是 Naur 所指的软件开发中的隐性知识. 它无法完全写进文档或代码注释, 只能通过经验, 对话和亲手实践来获得和维持.
因此, Naur 的论点为本文提到的“流程”和“文档”策略提供了哲学基础: 这些措施的真正目的是最大化地将团队共享的理论显性化和结构化, 并确保它能够在团队成员之间持续地被重构, 审查和转移.
31.3. 总结
尽管软件工程师拥有高于平均水平的语言和认知能力, 沟通与协作的困难依然存在. 这是因为一个软件系统的真正核心资产, 正如 Peter Naur 所说, 不是代码或文档本身, 而是存在于开发者头脑中的 *理论*——也就是那不可言说的隐性知识.
隐性知识的传递远比单纯的文件交换复杂. 正因为它难以被显性化, 它已成为影响软件开发生产力的主要瓶颈和风险来源. 因此, 我们必须从多个维度入手: 通过 流程 来规范知识路径, 通过 系统化的文档 或 RAG 工具 来集体构建知识, 并利用 组织结构 来减少认知负荷和隐性知识转移的需求, 才能有效管理这一无形的挑战.负荷和隐性知识转移的需求, 才能有效管理这一无形的挑战.