混凝土结构安全评估与寿命预测平台(概要设计+蓝图)
Table of Contents
\newpage
| V0.0.6 | 2025-03-10 | 详细设计.有限元分析.1, 2.1 | A | 明确FEM模块目标, 细化API接口定义 | 李照宇 | 李照宇 |
| V0.0.7 | 2025-03-15 | 详细设计.有限元分析.2.2, 2.3 | A | 设计任务处理层和MOOSE执行层组件 | 李照宇 | 李照宇 |
| V0.0.8 | 2025-03-20 | 详细设计.有限元分析.2.4, 3 | A | 设计结果处理层组件和数据库模型 | 李照宇 | 李照宇 |
| V0.0.9 | 2025-03-25 | 详细设计.有限元分析.4, 5 | A | 绘制FEM处理流程图, 补充部署配置说明 | 李照宇 | 李照宇 |
| V0.1.0 | 2025-03-28 | 详细设计.评估与预测模型.1, 2 | A | 细化评估与预测模型分层架构和核心算法 | 李照宇 | 李照宇 |
\newpage
1. 混凝土结构安全评估与寿命预测平台
1.1. 软件系统蓝图
1.1.1. 引言
本蓝图描绘了"混凝土结构安全评估与寿命预测平台"的软件架构. 平台旨在集成多源数据, 强大的有限元仿真能力, 先进的安全评估与寿命预测模型以及直观的可视化界面, 为水工混凝土结构等提供全生命周期的安全监控, 评估与预测服务. 本设计特别考虑了独立部署, 并采纳自主可控的技术栈.
1.1.2. 设计原则
- 分层清晰 (Clear Layers): 从高层抽象到细节实现, 逐层细化.
- 高内聚, 低耦合 (High Cohesion, Low Coupling): 每个容器或组件专注于单一职责, 通过定义良好的接口进行通信.
- 技术自主可控 (Polyglot Architecture): 允许根据任务特性选择最适合的技术, 例如使用 C++ 进行高性能计算封装, 使用 Clojure 进行数据处理或构建健壮的API服务, 使用 Python 进行快速开发和 AI/ML 集成.
- 可伸缩性与可靠性 (Scalability & Reliability): 架构设计需支持服务的水平扩展, 并考虑容错和高可用性.
- 独立部署 (Private Deployment Oriented): 所有技术选型和架构决策优先考虑在客户自有数据中心或私有云环境部署.
1.1.3. 分层模型设计
- 系统上下文图
系统边界, 展示了主要用户角色以及与平台交互的外部系统.
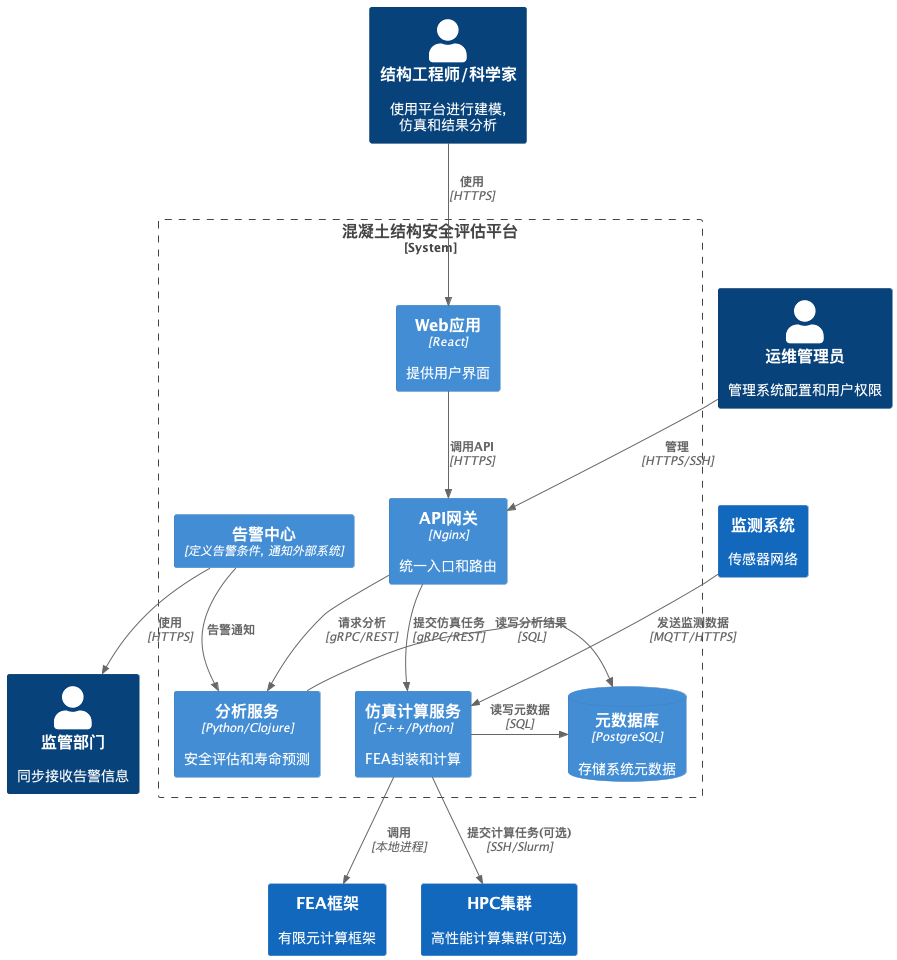
- 核心平台: 我们的系统, 提供所有核心功能.
- 用户: 结构工程师/结构科学家是主要用户, 运维管理员负责系统维护.
- 数据源: 监测系统和传感器是主要的数据输入来源. CAD/BIM系统提供几何模型.
- 依赖/集成: 可选地与HPC集群集成以加速计算, 与外部预警系统集成以发送通知.
- 容器图
此图将平台分解为一组高层级的, 可独立部署的技术容器(应用, 服务, 数据存储).

- 前端 (SPA): 用户的主要交互界面.
- API 网关: 所有外部请求的入口.
- 核心服务: 每个服务负责一部分业务逻辑, 可使用不同技术栈.
- 仿真计算服务 (FEM Service): 使用 C++ 编写MOOSE封装层以获得最佳性能, 或结合Python进行任务管理.
- 安全评估/寿命预测服务: 可使用 Python (AI/ML库) 或 Clojure (数据处理, 函数式编程优势).
- 数据接入服务: 可用 Clojure (并发处理能力) 或 Python/Java.
- 数据存储:
- PostgreSQL: 核心元数据.
- TimescaleDB/InfluxDB: 时间序列数据.
- MinIO: 私有化部署的对象存储, 用于存储网格, 点云, 仿真结果等大文件.
- Redis: 缓存.
- Kafka/RabbitMQ: 异步消息传递.
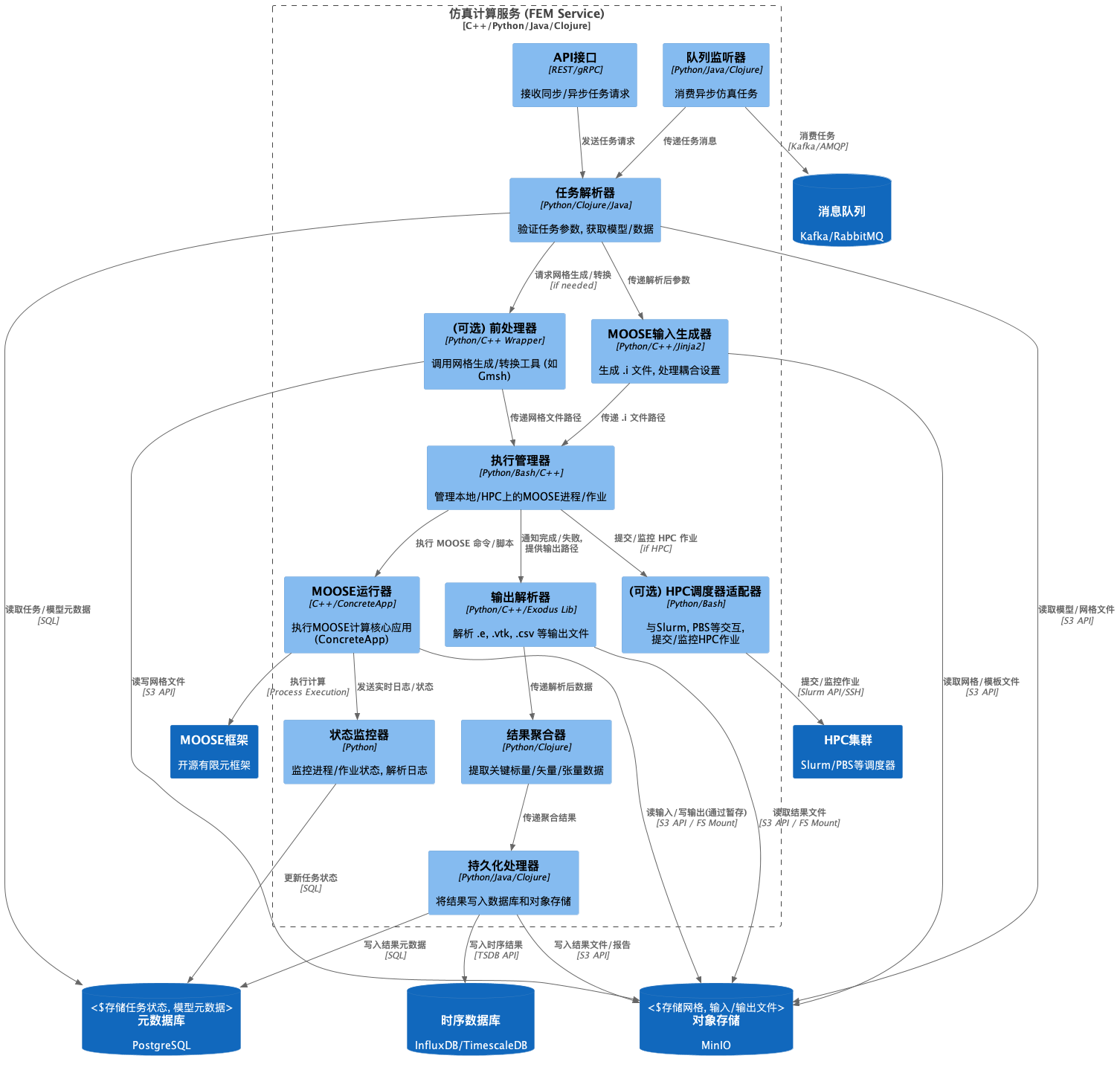
- 组件图 (Component Diagram) - 仿真计算服务 (FEM Service)
此图展示了"仿真计算服务" 内部的关键组件及其交互.
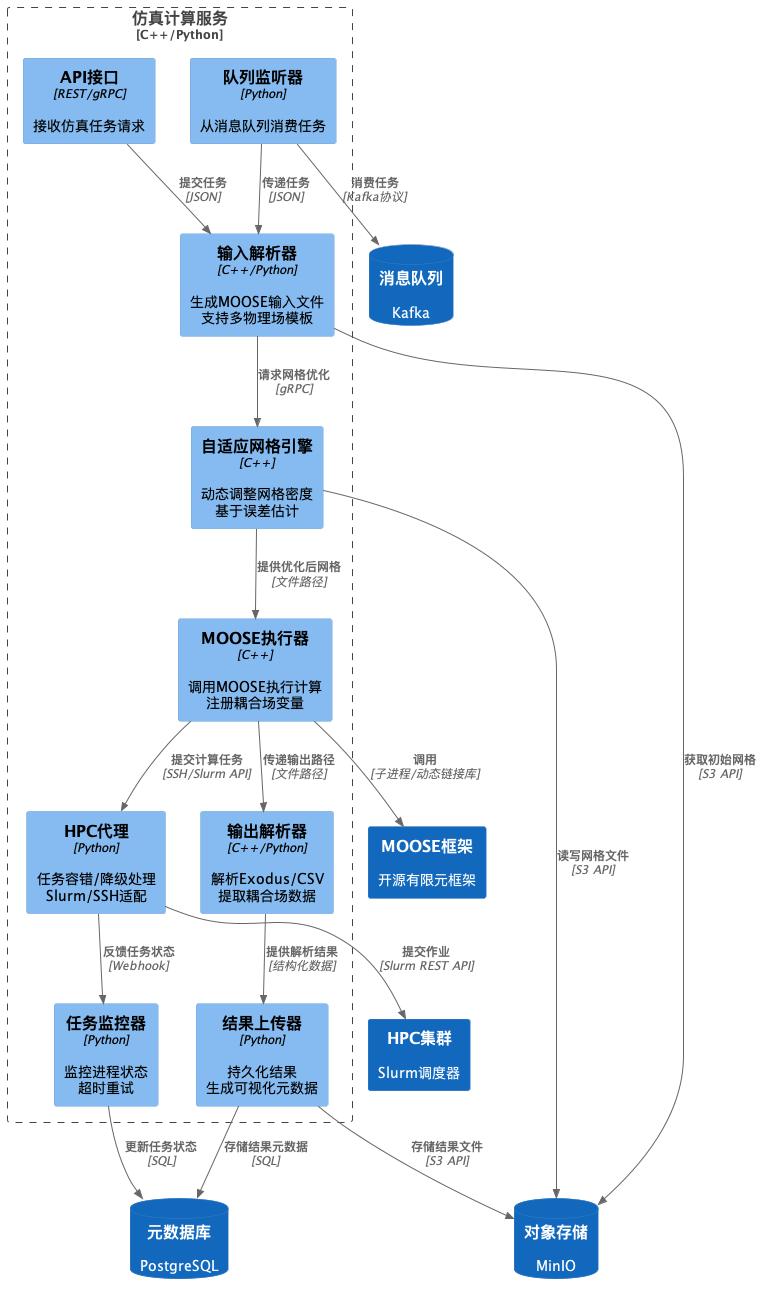
- API接口/队列监听器: 任务入口.
- 输入解析器: 核心转换逻辑, 将平台定义的任务参数转换为MOOSE
.i文件. 可能需要模板引擎. - MOOSE执行器: 直接与MOOSE可执行文件交互, 管理子进程. *这部分是使用 C++ 的理想位置, 以高效地处理文件I/O和进程管理, 或者直接链接MOOSE库(如果需要更深度的集成). *
- 任务监控器: 负责跟踪长时间运行的仿真任务.
- 输出解析器: 从MOOSE输出文件中提取数据.
- 结果上传器: 将处理后的结果持久化.
1.1.4. 核心模块
- 数据接入 (Data Ingestion Service):
- 使用 Clojure 或 Python. 提供多种协议适配器(MQTT, HTTP, 文件).
- 内置数据清洗和初步验证规则.
- 使用 Kafka/RabbitMQ 将数据推送到下游处理服务或直接写入数据库.
- 仿真计算 (FEM Service - MOOSE Wrapper):
- 核心采用 C++ 封装 MOOSE 调用, 确保性能和稳定性, 处理输入文件生成和输出文件解析.
- 外层可使用 Python (如 Celery Worker) 或 Java/Clojure 来处理任务队列, 状态管理和与其它服务的交互.
- 支持从 MinIO 读取网格/配置文件, 并将结果文件写回 MinIO.
- 与任务调度服务通过消息队列解耦.
- 安全评估/寿命预测 (Analysis Service):
- AHP-Fuzzy 模型: 使用 Python (NumPy, scikit-fuzzy) 实现. 封装为独立的 REST API 或 gRPC 服务.
- LSTM 模型: 使用 Python (TensorFlow/PyTorch) 实现. 包括模型训练(可能离线进行或由单独服务负责), 模型部署(如使用 TensorFlow Serving, TorchServe, 或直接在服务内加载)和推理.
- Clojure 应用: 可考虑使用 Clojure 开发此服务, 利用其在数据转换和处理方面的优势, 调用 Python 实现的 ML/AI 模型(例如通过 ZeroMQ, gRPC 或简单的进程调用).
- 服务从 PostgreSQL, TimescaleDB/InfluxDB, MinIO 获取所需数据.
- 数据存储:
- PostgreSQL: 存储配置数据, 用户权限, 模型元数据, 任务状态, 评估结果摘要等.
- TimescaleDB/InfluxDB: 高效存储和查询海量时间序列监测数据.
- MinIO: 作为私有化部署的核心对象存储, 存储所有非结构化和大型数据, 如三维点云, CAD模型文件, MOOSE网格文件 (如 Exodus), MOOSE结果文件 (Exodus, VTK), 报告文档, 模型文件等. 提供 S3兼容接口, 便于服务集成.
1.1.5. 横切关注点
- 安全: 身份认证 (如 Keycloak, LDAP集成), API 访问控制, 数据加密 (传输层 TLS, 存储层可选加密), 依赖项扫描.
- 可观测性: 日志 (Fluentd/Loki), 监控 (Prometheus/Grafana), 追踪 (Jaeger/Tempo).
- 配置管理: 使用配置中心 (如 Consul, Etcd) 或环境变量/配置文件进行管理.
- 部署与运维: 提供 Ansible/Terraform 脚本或 Helm Charts 以简化在私有环境(物理机或虚拟机, 私有 Kubernetes)的部署. 详尽的运维文档.
1.1.6. 部署策略
- 容器化: 所有服务(除了数据库等有状态服务可能直接部署或使用 Operator)使用 Docker 容器化.
- 编排: 推荐使用 Kubernetes (K8s) 进行部署, 管理和扩展. 若客户环境无 K8s, 可提供基于 Docker Compose 的简化部署方案, 或传统的虚拟机/物理机部署脚本.
- 数据存储部署: PostgreSQL, 时序数据库, MinIO, Redis, Kafka/RabbitMQ 需根据性能和高可用需求在私有环境中独立部署和配置. 可能需要主从, 集群配置.
- 网络: 确保内部服务网络互通, API 网关暴露给用户或上层系统. 配置防火墙规则.
1.2. 概要设计
1.2.1. 混凝土结构安全评估与寿命预测平台技术架构
设计目标
旨在明确"混凝土结构安全评估与寿命预测平台"的技术架构, 核心组件, 数据流, 接口规范及关键技术选型. 平台的目标是构建一个集成化, 智能化, 可视化的系统, 支撑从多源异构数据(监测, 检测, 环境, 模型)的接入, 处理, 存储管理, 到基于机理(FEM)和数据驱动(AI/模糊评价)模型的复杂仿真, 安全评估与寿命预测, 直至结果分析, 风险预警和辅助决策的全生命周期管理流程.
技术设计覆盖平台所需的所有软件技术层面, 并特别考虑在私有化环境下的部署与运维.
- 1.2. 核心技术理念:
- 微服务架构: 采用松耦合, 高内聚的服务设计, 将复杂系统分解为独立可部署, 可扩展, 技术异构的单元, 提高开发效率, 灵活性和系统弹性.
- 数据驱动与模型融合: 以全面, 高质量的数据为基础, 融合有限元仿真, 材料退化机理模型与人工智能, 模糊数学等数据驱动模型的优势, 实现相互验证与补充, 提升评估与预测的准确性和可靠性.
- 云原生适配: 拥抱容器化 (Docker) 和容器编排 (Kubernetes) 技术, 实现基础设施无关的应用部署与管理, 简化在客户私有云或数据中心的落地.
- 开放性与可扩展性: 通过标准化的 API 接口设计, 方便与第三方系统(如BIM, GIS, 运维系统)集成, 并支持未来新算法, 新模型和新功能的平滑扩展.
- 高性能计算支撑: 架构设计需支持对接和利用高性能计算 (HPC) 资源, 加速大规模, 高精度的有限元仿真计算.
- 1.3. 关键非功能性需求:
- 性能: 满足近实时数据处理, 大规模仿真任务的高效执行(分钟级响应), 复杂模型快速推理(秒级响应), 高并发用户访问的需求.
- 可靠性: 核心服务具备高可用性 (如 99.9%), 关键数据持久化且可恢复, 系统具备容错能力.
- 安全性: 遵循严格的用户认证, 权限控制, 数据传输与存储加密, 网络隔离等安全规范.
- 可扩展性: 支持计算, 存储, 服务实例的按需水平扩展, 以应对数据量和计算需求的增长.
- 可维护性: 模块化设计, 清晰的代码与文档, 完善的监控, 日志和告警机制.
- 易用性: (通过用户界面层体现) 提供直观, 符合工程师习惯的操作界面.
- 1.2. 核心技术理念:
平台总体技术架构
- 2.1. 技术栈选型:
- 前端: React, Three.js(用于三维模型渲染, 点云及仿真结果可视化), vtk.js (3D科学可视化核心库) , ECharts/Plotly.js (用于二维图表展示).
- 后端服务:
- 主要语言/框架: Java Java/clojure 提供稳定性和丰富的企业级生态; Python 在数据科学, AI/ML 和快速开发方面有优势.
- 特定场景语言: C++ (用于开发高性能 MOOSE Wrapper 核心, 结果解析库等性能敏感部分), Clojure (可选, 用于数据密集型处理或构建函数式风格的服务).
- 数据处理: Python (Pandas, Dask, NumPy, SciPy) 为主; 大规模流式/批处理可选 Apache Spark/Flink.
- 数据库: PostgreSQL (存储关系型元数据, 配置, 用户, 评估结果摘要), InfluxDB 或 TimescaleDB (存储传感器时序数据), MinIO (作为私有化部署的对象存储, 存储点云, 网格, 仿真结果, 模型文件等).
- 缓存: Redis.
- 消息队列: Kafka 或 RabbitMQ (根据对吞吐量, 持久化, 路由复杂性的需求选择).
- 仿真引擎: MOOSE Framework (核心有限元引擎), OpenFOAM (可选, 用于 CFD 耦合, 通过 Wrapper 集成).
- AI 框架: TensorFlow/PyTorch, scikit-learn.
- API 网关: Nginx
- 部署与编排: Docker, Kubernetes (K8s).
- 基础设施即代码 (IaC): Ansible 或 Terraform.
- CI/CD: Jenkins 和 TeamCity
- 监控与日志: Prometheus + Grafana, ELK Stack 或 Loki + Promtail + Grafana.
- 2.2. 架构分层与核心组件:
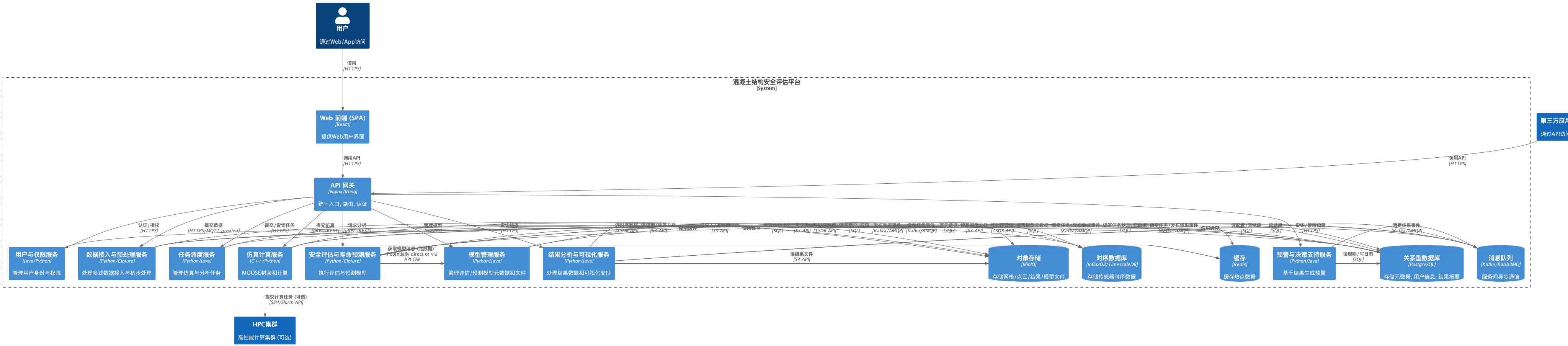
- 用户层: 提供人机交互界面或程序化访问入口.
- API网关层: 系统统一入口, 处理认证, 路由, 限流, 熔断, 日志聚合等.
- 核心服务层: 实现主要业务逻辑的微服务集合.
- 中间件与服务支撑层: 提供服务间通信, 缓存, 配置, 认证等基础能力.
- 数据与存储层: 持久化存储平台所需各类数据.
- 基础设施层: 提供运行平台所需的计算, 网络, 存储资源.
- 2.3. 微服务划分原则:
- 按业务能力: 每个服务聚焦于一个明确的业务领域(如数据接入, 仿真, 评估).
- 高内聚低耦合: 服务内部功能紧密相关, 服务间通过定义良好的接口(API, 消息)交互.
- 独立部署与扩展: 每个服务可以独立开发, 测试, 部署和扩展.
- 技术异构: 允许不同服务根据自身特点选择最适合的技术栈.
- 2.1. 技术栈选型:
- 核心模块技术设计概要
- 3.1. 数据接入与预处理服务:
- 功能: 负责从传感器, 文件, API 等多源采集数据; 执行清洗, 转换, 校验, 特征提取, LOD 生成等预处理; 将数据分发至下游或存入数据库.
- 技术: Python/Java/Clojure. 利用 Kafka/RabbitMQ 进行数据缓冲和解耦. 使用 Pandas/Dask/Spark 进行数据处理. 提供 MQTT/HTTP/WebSocket/文件上传接口.
- 3.2. 仿真计算服务 (FEM - MOOSE Wrapper):
- 功能: 封装 MOOSE 计算核心. 接收任务, 动态生成
.i输入文件(包括MultiApps和Transfers配置), 管理 MOOSE 进程(本地或通过 HPC 调度器), 解析结果, 持久化输出. - 技术:
- 接口: gRPC/REST API.
- 核心交互: C++ Runner/Wrapper 直接调用 MOOSE 应用二进制文件或链接库, 处理文件 I/O 和进程管理. Python/Java/Clojure 可用于外层任务管理, 队列交互和 API 封装.
- 输入生成: Python + Jinja2.
- MOOSE 应用 (
ConcreteApp): 定制的 MOOSE C++ 应用, 包含:- 材料模型:
GB50010ConcreteStress,ConcreteDamagedPlasticityStress,ConcreteCreepMaterial,ConcreteFatigueDamageModifier等 C++ 类. - 约束:
EmbeddedRebarConstraintC++ 类. - 后处理器:
CrackWidthPostprocessor,SectionForceCalculator等 C++ 类.
- 材料模型:
- HPC 集成: Python/Bash 脚本适配器, 与 Slurm/PBS 等交互 (提交
sbatch脚本, 查询squeue). - 结果解析: Python/C++ 使用
h5py/Exodus库, VTK库 解析.e,.vtk,.csv.
- 功能: 封装 MOOSE 计算核心. 接收任务, 动态生成
- 3.3. 安全评估服务:
- 功能: 执行安全评估算法, 如模糊综合评价, 深度学习模型等.
- 技术: Python 为主. 提供模型执行引擎, 支持加载和运行不同类型的模型.
- 模糊评价/AHP: NumPy, scikit-fuzzy.
- 深度学习: TensorFlow Serving/TorchServe 或直接在服务内使用
Keras/PyTorch 推理. 模型文件 (存 MinIO) 和版本通过
Model_Mgmt_Service管理. - 规则引擎: 可选集成 Drools 等.
- 3.4. 寿命预测服务:
- 功能: 执行寿命预测算法, 如材料退化模型, 疲劳累积损伤, 可靠性分析.
- 技术: Python/C++. 实现碳化, 氯离子扩散 (解偏微分方程或用经验公式), 疲劳累积 (Miner 法则) 等模型. 可靠性分析使用 SciPy/OpenTURNS 进行蒙特卡洛模拟.
- 3.5. 预警与决策支持服务:
- 功能: 基于评估和预测结果, 根据预设规则和动态阈值触发告警; 提供维修策略建议(可选).
- 技术: Python/Java. 从 DB 读取规则/阈值. 通过 Kafka/RabbitMQ 消费结果消息或定时轮询. 调用通知服务或网关发送告警.
- 3.6. 任务调度服务:
- 功能: 管理异步任务(仿真, 评估, 预测), 处理任务依赖, 记录任务状态.
- 技术: Python + Celery (配合 RabbitMQ/Redis), 或引入 Airflow/Argo Workflows 处理复杂 DAG 依赖.
- 3.7. 用户与权限管理服务:
- 功能: 管理用户信息, 角色, 权限, 与统一认证服务集成.
- 技术: Java (Spring Security)/Python. 存储用户, 角色, 权限映射关系于 PostgreSQL.
- 3.8. 模型管理服务:
- 功能: 存储, 版本化, 部署(可选)评估和预测模型(特别是 AI 模型).
- 技术: Python/Java. 使用 MLflow (可选) 或自定义方案, 模型文件存 MinIO, 元数据存 PostgreSQL.
- 3.9. 结果分析与可视化服务:
- 功能: 提供 API 接口, 供前端查询, 聚合, 处理分析结果和监测数据, 以支持可视化展示.
- 技术: Python/Java. 从各数据库和 MinIO 读取数据, 进行必要的处理后返回给前端.
- 3.1. 数据接入与预处理服务:
- 数据平台技术方案
- 4.1 数据存储:
- PostgreSQL: 用于元数据, 配置, 用户, 任务状态, 评估/预测摘要. 考虑主从复制 (Streaming Replication) 或 Patroni 实现高可用.
- TimescaleDB/InfluxDB: 用于存储和高效查询大量监测时序数据. 考虑集群部署以支持高并发写入和查询.
- MinIO: 作为核心对象存储, 分布式部署, 启用纠删码 (Erasure Coding) 或多副本保证数据可靠性和可用性. 存储原始数据文件, 模型文件, 网格, 仿真结果大文件等.
- Redis: 用于缓存热点数据, 用户会话, 分布式锁等. 考虑 Sentinel 或 Cluster 模式实现高可用.
- 4.2 数据通信/集成:
- Kafka/RabbitMQ: 用于服务间异步解耦, 事件通知, 任务分发. 选择 Kafka 应对高吞吐, 持久化日志场景; RabbitMQ 提供更灵活的路由. 考虑集群部署.
- API 网关 (Kong/Nginx): 统一管理南北向流量, 实现安全, 流控, 监控.
- gRPC: 用于内部服务间低延迟, 高性能的同步调用.
- RESTful API: 用于与前端和外部系统交互, 遵循 OpenAPI 规范.
- 4.1 数据存储:
5. 关键接口设计
- 5.1. 内部服务接口 (示例):
SimulationService.submitJob(JobRequest): gRPC.DataService.writeTimeSeries(TimeSeriesData): gRPC/Kafka message.EvaluationService.getLatestResult(StructureID): gRPC/REST.- 事件消息 (Kafka/RabbitMQ):
NewDataAvailable,SimulationCompleted,EvaluationFinished,AlertTriggered等.
- 5.2. 外部系统接口 (示例):
/api/v1/data/upload: REST POST (文件上传, 监测数据 JSON 推送)./api/v1/results/{structure_id}: REST GET (查询评估/预测结果)./api/v1/alerts/subscribe: WebSocket (订阅实时告警).mqtt://<broker>/sensors/{device_id}/data: MQTT Topic (传感器数据发布).
数据流设计 (典型场景: 监测数据触发评估与预警)
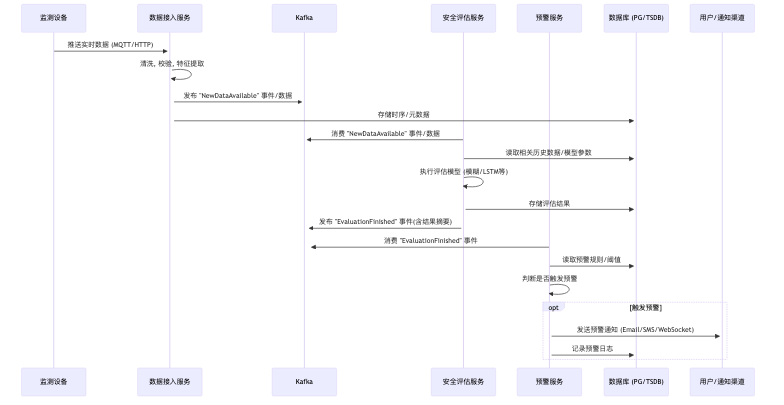

- 部署与运维技术方案
- 7.1. 基础设施: 面向客户提供的私有云或物理服务器环境.
- 7.2. 容器化与编排:
- 所有服务(除特殊情况)打包为 Docker 镜像.
- 优先使用 Kubernetes (K8s) 进行部署, 服务管理, 弹性伸缩. 提供 Helm Charts.
- 为无 K8s 环境提供基于 Docker Compose 的简化部署脚本(功能受限).
- 数据库, MinIO, Kafka 等有状态服务使用 K8s Operator 或 StatefulSet 进行部署和管理, 或在 K8s 外部独立部署集群.
- 7.3. CI/CD & IaC:
- 使用 Jenkins 或 TeamCity 搭建 CI/CD 流水线, 自动化构建, 测试, 打包, 部署流程.
- 使用 Ansible 或 Terraform 编写基础设施配置和应用部署脚本, 实现自动化和一致性.
- 7.4. 监控/日志/告警:
- 部署 Prometheus + Grafana 监控集群和应用指标.
- 部署 ELK Stack 或 Loki + Promtail + Grafana 收集, 存储, 查询服务日志.
- 配置 Alertmanager 实现基于监控指标和日志事件的告警.
- 安全技术方案
- 8.1. 认证/授权:
- 集成 Keycloak 或客户现有 IdP (如 LDAP/AD) 实现 SSO.
- API 网关进行 Token 校验 (JWT/OAuth2).
- 后端服务基于 RBAC (Role-Based Access Control) 和/或 ABAC (Attribute-Based Access Control) 进行细粒度权限控制.
- 服务间可选启用 mTLS 进行双向认证.
- 8.2. 网络安全: K8s NetworkPolicy 或防火墙规则限制服务间访问. API 网关配置 WAF 规则. 全链路启用 TLS 加密.
- 8.3. 数据安全: 数据库敏感字段加密. MinIO 启用服务端加密 (SSE-S3/SSE-KMS). 定期安全审计.
- 8.4. 应用安全: 依赖库漏洞扫描 (Snyk/Dependabot), 代码静态分析 (SAST), 安全编码培训, 定期渗透测试.
- 8.1. 认证/授权:
- 非功能性需求实现策略总结
- 性能: MPI并行(MOOSE/HPC), GPU(AI), 异步(MQ), 缓存(Redis), DB优化, 并行数据处理.
- 可靠性: K8s副本/自愈, DB/MQ/MinIO/Redis集群/主从, 备份恢复, 服务降级/熔断.
- 安全: 统一认证, RBAC/ABAC, TLS, 数据加密, 网络策略, WAF, 安全扫描.
- 扩展性: 微服务水平扩展(K8s HPA), DB/MQ/MinIO集群扩展.
- 可维护性: 模块化, 标准化接口, CI/CD, 集中监控日志.
关键风险与挑战:
- MOOSE 针对混凝土高级特性(复杂材料模型, 嵌入式钢筋)的定制开发工作量与技术难度.
- 多物理场耦合仿真的稳定性和效率调优.
- 多模型融合算法的有效性和鲁棒性.
- 大规模实时数据处理的性能保障.
后续步骤:
- 技术选型细化: 对每个模块的具体库, 框架版本进行最终确认.
- 接口详细设计: 定义所有服务间 API (gRPC/REST) 和消息队列 (Topic/Queue/Message Format) 的详细规范.
- 数据库模式设计: 设计 PostgreSQL, TimescaleDB/InfluxDB 的详细表结构和关系.
- 核心算法详细设计: 对模糊评价, LSTM, 材料退化模型, FEM Wrapper 内部逻辑进行更深入的设计.
- 部署架构详细设计: 针对目标私有化环境, 制定详细的 K8s 资源规划, 网络配置, 存储方案, 高可用和备份策略.
- 原型验证 (PoC): 对关键技术难点(如 MOOSE 定制, 模型融合, HPC 集成)进行原型开发和验证.
1.2.2. 有限元分析模块
模块定位与职责
该模块是平台的核心计算引擎, 负责接收来自上层应用(通过 API 网关或任务队列)的仿真任务请求, 调用 MOOSE 框架执行有限元分析, 并将结果返回或存储. 其核心职责包括:
- 解析用户定义的仿真任务(几何, 网格, 材料, 边界条件, 荷载, 分析类型).
- 生成符合 MOOSE 语法的输入文件 (
.i). - 管理和执行 MOOSE 计算进程.
- 监控仿真任务状态和进度.
- 解析 MOOSE 输出文件, 提取关键结果.
- 将结果持久化到数据库和对象存储.
- 支持单物理场及多物理场耦合仿真.
- 支持高性能计算 (HPC) 环境下的任务调度与执行.
技术架构
核心应用设计 (
moose_runner内部)框架层扩展的实现载体, 是一个定制化的应用 (例如命名为
ConcreteApp).- 应用程序结构 (基于 MOOSE 标准):
ConcreteApp.h,ConcreteApp.C: 应用程序主类.Makefile: 定义编译规则和依赖.src/,include/: 存放自定义的 C++ 源代码和头文件.materials/: 存放自定义混凝土材料模型 (GB50010, CDP, Creep, Fatigue 等).constraints/: 存放自定义约束 (如 Embedded Rebar Constraint).kernels/,bcs/,auxkernels/: 存放特定物理场或特殊边界条件所需的内核.postprocessors/: 存放自定义后处理器 (如 Crack Width, Section Force).actions/: (可选) 自定义 Action 来简化输入文件设置.
tests/: 存放单元测试和回归测试.
- 关键 C++ 类实现
- 材料 (
Material子类):GB50010ConcreteStress,ConcreteDamagedPlasticityStress,ConcreteCreepMaterial(可能需要包装其他材料),ConcreteFatigueDamageModifier(可能作用于 AuxVariable 或 Material property). - 约束 (
Constraint子类):EmbeddedRebarConstraint. - 后处理器 (
Postprocessor/VectorPostprocessor子类):CrackWidthPostprocessor,ReactionForceCalculator,SectionForceCalculator.
- 材料 (
- 编译与链接:
将所有自定义类正确添加到
Makefile中, 确保它们被编译并链接到最终的ConcreteApp-opt(优化版) 或ConcreteApp-dbg(调试版) 可执行文件中.
- 应用程序结构 (基于 MOOSE 标准):
多物理场耦合实现 (
MultiApps系统)MultiApps系统是实现多物理场耦合的标准方式, 通过松散或紧密耦合方式运行多个子应用(可以是同一个应用的不同实例或不同的应用).- 输入文件配置 (
.i文件):- 主应用 (Master App): 定义全局参数, 时间步长, 主求解器设置.
- [MultiApps] 块:
- 定义每个子应用 (Sub-App), 指定其类型(通常是
ConcreteApp), 输入文件. execute_on: 控制子应用执行的时机 (如timestep_begin,timestep_end,nonlinear_iteration_end).positions: 定义子应用的空间位置(对于几何重叠或子域问题).
- 定义每个子应用 (Sub-App), 指定其类型(通常是
- [Transfers] 块: 定义主应用和子应用之间, 或子应用之间的数据传递.
- 类型:
SolutionTransfer(传递场变量解),PostprocessorTransfer(传递标量/矢量值),FunctionValueTransfer,PointSamplerTransfer等. - 配置: 指定源应用, 目标应用, 源变量/后处理器, 目标变量/函数, 耦合方式 (最近点, 插值等).
- 类型:
- 仿真计算服务 (
input_generator) 的职责:- 根据用户在 GUI 或 API 请求中指定的耦合类型(如 热-力, 流-固,
损伤-力学), 自动生成包含
[MultiApps]和[Transfers]块的主应用输入文件, 以及各个子应用的输入文件. - 需要预定义好常见的耦合模板和传递规则. 例如:
- 热-力耦合: 热分析应用计算温度场, 通过
SolutionTransfer将温度传递给力学分析应用, 力学应用的材料属性依赖于传递过来的温度(通过FunctionMaterial或直接在材料类中接收). 力学分析产生的变形(可选)或热生成(可选)也可传递回热分析. - 流-固耦合 (FSI - 较复杂): 可能涉及 CFD 应用 (如 OpenFOAM, 可通过
MOOSE Wrapper 集成) 和固体力学应用 (
ConcreteApp). 通过SolutionTransfer或MultiAppGeometricInterpolationTransfer传递压力, 位移, 网格变形等.
- 热-力耦合: 热分析应用计算温度场, 通过
- 根据用户在 GUI 或 API 请求中指定的耦合类型(如 热-力, 流-固,
损伤-力学), 自动生成包含
- 执行管理 (
execution_manager): 启动主应用的 MOOSE 进程即可, MOOSE 内部会管理子应用的启动和数据交换.
- 输入文件配置 (
高性能计算 (HPC) 扩展策略
MOOSE 天生支持基于 MPI 的并行计算. 平台需要有效利用这一点.
- 并行执行 (
execution_manager,hpc_scheduler_adapter):- MPI: MOOSE 可执行文件 (
ConcreteApp-opt) 应使用 MPI 编译. 执行时使用mpiexec或srun(Slurm) 等命令启动并行任务.mpiexec -n <num_procs> ./ConcreteApp-opt -i <input.i>
- HPC 作业提交:
hpc_scheduler_adapter负责生成提交脚本 (如 Slurm batch script), 脚本中包含加载 MOOSE 环境, 设置 MPI 参数, 执行srun命令等. - 资源请求: 脚本需指定所需节点数 (
--nodes), 每节点核心数 (--ntasks-per-node), 内存, 运行时间等.
- MPI: MOOSE 可执行文件 (
- 并行 I/O:
- Exodus 输出: MOOSE 默认使用并行 Exodus (
Nemesis) 进行场数据输出, 将数据分散到多个文件. - 后处理: 平台的
output_parser需要能够处理这种并行格式(可能需要epu工具或其他能读取 Nemesis 格式的库). - 共享文件系统: HPC 环境通常有高性能并行文件系统 (如 Lustre, GPFS). 确保 MOOSE 的读写操作指向这些文件系统以获得最佳性能. MinIO 在此场景下主要用于任务输入文件的分发和最终结果的归档, 计算过程中的临时/并行文件通常落在共享文件系统上.
- Exodus 输出: MOOSE 默认使用并行 Exodus (
- 负载均衡与分区:
- MOOSE 内部进行网格分区 (通常使用
METIS=/=ParMETIS), 将计算负载分配到不同 MPI 进程. - 对于极大规模问题, 可能需要优化分区策略或调整 MOOSE/PETSc 设置以改善负载均衡.
- MOOSE 内部进行网格分区 (通常使用
- 平台与 HPC 的集成:
- 任务调度: 平台通过
hpc_scheduler_adapter向 HPC 提交作业, 并通过轮询 (squeue) 或回调机制监控作业状态. - 数据传输: 输入文件(
.i, 网格)需要传输到 HPC 的文件系统. 仿真完成后, 输出文件(.e,.csv)需要从 HPC 文件系统传回平台进行处理和存储(或直接在 HPC 上运行部分后处理). 可使用scp,rsync, Globus Online 或直接挂载文件系统/对象存储(如果网络允许). - 环境管理: 确保 HPC 节点上有正确配置的 MOOSE 运行环境(编译器, MPI, 依赖库如 PETSc, libMesh). 可使用 Spack, Conda 或容器技术 (Singularity/Apptainer) 在 HPC 上部署 MOOSE.
- 任务调度: 平台通过
- 并行执行 (
- 风险
- 复杂材料模型的收敛性: CDP 等高级模型在引入损伤和软化后,
非线性求解可能变得非常困难. 需要细致的参数调整,
网格敏感性分析以及可能的稳定化技术(如粘性正则化, 可能需自定义
Kernel). - 多物理场耦合的稳定性与效率: 显式或隐式耦合的选择, 数据传递的准确性和频率, 时间步长的协调都会影响耦合仿真的稳定性和计算成本. 特别是对于紧耦合或涉及大变形/接触的 FSI 问题.
- HPC 环境的适配: 不同 HPC 集群的环境, 调度器, 文件系统各异,
hpc_scheduler_adapter和数据传输策略需要适配具体环境. Singularity/Apptainer 容器可以极大简化环境一致性问题. - 大规模并行的 I/O 瓶颈: 对于超大规模仿真, 并行文件系统的 I/O 性能可能成为瓶颈. 需要关注 MOOSE 的输出频率和数据量, 并可能需要优化.
- 嵌入式钢筋与混凝土的相互作用: 精确模拟钢筋拔出,
粘结滑移等复杂行为对
EmbeddedRebarConstraint的实现提出了很高要求.
- 复杂材料模型的收敛性: CDP 等高级模型在引入损伤和软化后,
非线性求解可能变得非常困难. 需要细致的参数调整,
网格敏感性分析以及可能的稳定化技术(如粘性正则化, 可能需自定义
1.2.3. 混凝土结构安全评估与寿命预测模型
总体设计思路
本模型旨在综合运用多源数据, 机理模型(有限元, 材料退化)和数据驱动模型(模糊评价, 深度学习), 构建一个多层次, 多尺度, 动态更新的混凝土结构健康状态评估与寿命预测系统. 核心思路是:
- 数据融合: 有效整合实时监测数据, 定期检测数据, 仿真模拟数据和环境数据.
- 多模型协同: 发挥不同类型模型的优势, 相互补充, 相互验证.
- 动态校准: 利用实测数据反馈, 持续优化模型参数和权重.
- 风险驱动: 以识别和预测结构失效风险为导向, 提供决策支持.
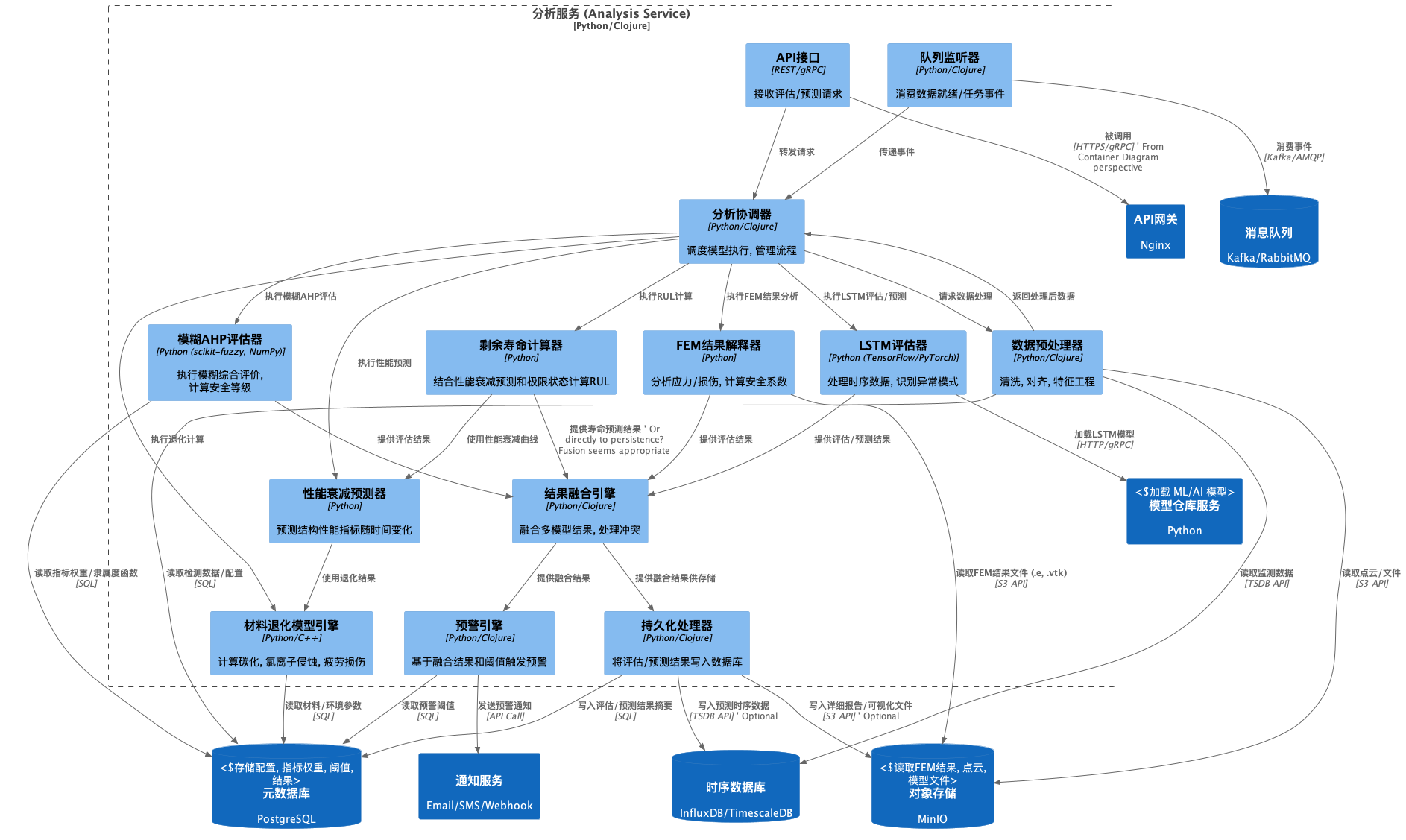
- 模型分层架构细化
- 数据层 (Data Layer):
- 数据源:
- 监测数据 (高频/实时): 振动, 应变, 位移, 温湿度等 (存储于时序数据库, 如 TimescaleDB).
- 检测数据 (低频/定期): 裂缝宽度/长度/深度, 碳化深度, 氯离子浓度, 保护层厚度, 回弹强度, 超声波数据等 (存储于关系型数据库 PostgreSQL, 关联结构部位).
- 环境数据: 温度, 湿度, CO₂浓度, 降雨量, 水位, 腐蚀性离子浓度等 (时序数据库或关系型数据库).
- 三维模型数据: 点云, BIM/CAD 模型, 有限元网格 (对象存储 MinIO).
- 材料属性: 设计值, 试验值, 规范参数 (关系型数据库 PostgreSQL).
- 仿真结果: 应力, 应变, 损伤场, 温度场, 裂缝扩展路径等 (对象存储 MinIO, 关键指标存入 PostgreSQL).
- 数据预处理: 清洗(去噪, 异常值处理), 对齐(时间/空间), 插值, 归一化, 特征工程(提取时域/频域特征, 损伤指数等).
- 数据源:
- 核心算法层 (Core Algorithm Layer):
- 安全评估模型 (Safety Evaluation Models):
- 模糊综合评价 (Fuzzy Comprehensive Evaluation):
- 指标体系: 建立多层次评价指标体系(如: 材料性能, 结构变形, 环境影响).
- AHP (Analytic Hierarchy Process): 结合专家经验确定各层级指标的相对权重. 平台提供权重配置界面.
- 隶属度函数库: 针对不同指标(裂缝宽度, 碳化深度等), 预定义或允许用户配置多种隶属度函数(梯形, 高斯, 三角等), 将具体检测值映射到各安全等级(如 优, 良, 中, 差, 劣)的隶属度.
- 模糊运算: 采用加权平均或其他模糊算子进行多级综合评判, 得到最终的安全等级隶属度向量.
- 聚类中心: (可选) 结合模糊 C 均值 (FCM) 等聚类算法, 动态更新各安全等级的特征中心, 辅助判断.
- 深度学习评估 (Deep Learning Evaluation):
- LSTM (Long Short-Term Memory): 重点处理时序监测数据(振动, 位移等), 预测短期趋势, 识别动态异常模式. 输入为时间序列特征, 输出为下一时间步的预测值或异常概率.
- (可选) CNN (Convolutional Neural Networks): 用于处理图像数据(裂缝识别)或将多传感器时序数据转换为图像进行模式识别.
- Adaboost/Ensemble Methods: 集成多个 LSTM 或其他模型(如基于不同特征子集的模型), 提高评估的鲁棒性和准确性. 通过加权投票或 stacking 方式融合预测结果.
- 有限元辅助评估 (FEM-Aided Evaluation):
- 应力/应变分析: 基于当前荷载工况和结构状态(考虑损伤)进行有限元计算 (调用 FEM 模块), 获取应力/应变分布.
- 损伤映射: 将计算得到的应力/应变状态通过材料本构(如 CDP 模型)映射为损伤因子分布图.
- 安全系数计算: 根据应力/强度比或能量准则, 评估关键部位的安全储备.
- 裂缝扩展模拟 (可选): 使用相场法 (Phase Field) 或内聚力模型 (CZM) 模拟现有裂缝在特定荷载下的扩展趋势.
- 模糊综合评价 (Fuzzy Comprehensive Evaluation):
- 寿命预测模型 (Lifespan Prediction Models):
- 材料退化模型 (Material Degradation Models):
- 碳化模型: 基于 Fick 定律或经验公式 (如
d_c = k*sqrt(t)), 结合环境参数 (CO₂, 温湿度) 和混凝土自身特性 (水灰比, 掺合料), 预测碳化深度随时间的发展. - 氯离子侵蚀模型: 基于 Fick 第二定律, 考虑对流, 扩散, 吸附效应, 预测混凝土内部氯离子浓度分布, 进而判断钢筋锈蚀起始时间. 需要考虑环境氯离子浓度, 保护层厚度, 裂缝影响等.
- 疲劳累积损伤模型: 基于 S-N 曲线和 Miner 法则(或更高级的非线性累积损伤模型), 结合 FEM 计算得到的循环应力幅值和监测到的荷载谱, 预测疲劳寿命.
- *(可选) 冻融循环模型, 碱骨料反应模型等. *
- 碳化模型: 基于 Fick 定律或经验公式 (如
- 性能衰减预测:
- 基于退化模型的预测: 将材料退化程度(碳化深度, 锈蚀率, 疲劳损伤度)与结构性能指标(承载力, 刚度)建立联系(可通过试验数据或细观力学模型), 预测宏观性能随时间衰减的曲线.
- 基于数据驱动的预测: 使用 LSTM 等模型, 基于长期的监测数据(变形, 频率变化)和历史性能评估结果, 直接预测未来性能指标的变化趋势.
- 剩余寿命评估:
- 定义性能极限状态(如承载力低于设计值, 变形超限, 钢筋锈蚀达到临界值).
- 结合性能衰减预测曲线, 确定结构达到极限状态的时间点, 计算剩余使用寿命 (RUL).
- 考虑不确定性, 输出寿命的概率分布或置信区间.
- 维修策略优化 (可选):
- 模拟不同维修措施(裂缝修补, 表面涂层, 置换混凝土等)对延缓材料退化和恢复结构性能的效果.
- 结合成本效益分析, 推荐最优的维修时机和方案.
- 材料退化模型 (Material Degradation Models):
- 安全评估模型 (Safety Evaluation Models):
- 应用服务层 (Application Service Layer):
- 模型调度服务: 接收用户请求或定时触发, 根据任务类型选择并调用核心算法层的相应模型. 管理模型版本和依赖.
- 结果融合引擎:
- 融合规则: 定义不同模型结果的融合逻辑(如基于置信度的加权平均, 投票, 证据理论等).
- 冲突处理: 实现您框架中定义的冲突解决策略(加权投票, 残差分析触发校准, 短期优先等).
- 不确定性传递: 考虑各模型输入和自身的不确定性, 输出融合结果的不确定性度量.
- 预警引擎:
- 阈值管理: 允许用户配置不同安全等级, 风险概率, 性能指标, 变形速率等的预警阈值.
- 触发逻辑: 实时/定期检查融合后的评估结果和预测趋势, 与阈值比较, 触发相应级别的预警.
- 预警通知: 调用通知服务(Email, SMS, 平台消息, Webhook)发送预警信息.
- 用户交互层 (User Interaction Layer):
- 可视化:
- 仪表盘: 展示结构整体安全状态, 关键指标, 预警信息.
- 二维图表: 监测数据时程曲线, 指标变化趋势, 寿命预测曲线, 概率分布图.
- 三维可视化: 在三维模型上叠加显示应力云图, 损伤分布, 裂缝扩展, 风险区域高亮等.
- 报告生成: 自动生成包含评估结果, 预测曲线, 可视化图表, 预警记录的评估报告.
- 参数配置: 提供界面供用户配置模型参数, AHP 权重, 隶属度函数, 预警阈值等.
- API 接口: 提供标准化的 API 供其他系统调用评估和预测功能.
- 可视化:
- 数据层 (Data Layer):
- 数据流设计细化
- 数据流向: 原始数据经过预处理后, 根据任务类型流向不同的核心算法模型. 有限元模型可能需要几何/网格数据, 并接收材料, 荷载参数. 评估/预测模型的输出汇聚到结果融合引擎, 最终结果驱动预警引擎和用户交互层.
- 模型校准回路: 监测数据与模型预测(包括 FEM
和寿命预测)的偏差定期进行分析. 当偏差超过阈值时, 触发模型校准流程:
- FEM 校准: 可能涉及材料参数反演, 边界条件修正.
- 寿命模型校准: 调整退化模型参数(如
k值, 扩散系数), 更新疲劳损伤累积. - 深度学习模型重训练: 使用最新的监测数据增量训练或重新训练 LSTM 等模型.
- 技术实现选型
- 核心算法实现:
- 模糊评价, AHP: Python (NumPy, SciPy, scikit-fuzzy) 或 Clojure.
- LSTM, Adaboost: Python (TensorFlow/Keras, PyTorch, scikit-learn).
- FEM: 调用基于 MOOSE 的 C++ 核心应用.
- 材料退化模型: Python 或 C++ (若需高性能或与 FEM 紧密集成).
- 服务框架: Python (Flask/FastAPI), Java (Spring Boot), Clojure (Ring/Compojure).
- 数据库: PostgreSQL, TimescaleDB, MinIO, Redis.
- 消息队列: Kafka/RabbitMQ.
- 可视化: ECharts, Plotly.js, VTK.js/Three.js.
- 核心算法实现:
- 验证与优化细化
- 验证数据集: 准备涵盖不同工况, 不同结构类型, 不同退化程度的验证数据集(包含历史数据和基准算例).
- 指标: 评估模型准确率(分类), 均方根误差(预测), 预警的召回率和精确率.
- 在线学习/模型更新: 设计策略以定期或事件触发方式更新模型. 例如, 当新的检测数据可用时, 更新模糊评价的隶属度函数或 LSTM 模型. 当监测数据与 FEM 预测偏差大时, 触发参数反演.
- 计算优化:
- 并行化: 利用多核 CPU 或 GPU 加速数据预处理, 深度学习训练/推理, 部分退化模型计算.
- FEM 优化: 利用 MOOSE 的 MPI 并行能力, 结合 HPC 资源. 研究模型降阶技术(ROM)以加速特定场景下的重复仿真.
1.3. 详细设计(进行中)
1.3.1. 有限元分析
- 概述
- 1.1. 模块目标: 本概要设计旨在明确" 混凝土结构安全评估与寿命预测平台" 中有限元分析模块的技术架构, 核心组件, 数据流, 接口规范及关键技术选型. 该模块的目标是提供一个健壮, 高效, 可扩展的有限元仿真能力, 作为平台安全评估与寿命预测的核心支撑. 重点在于封装强大的 MOOSE 框架, 通过标准化的服务接口简化用户交互, 支持混凝土结构特定的复杂分析需求(包括非线性材料行为, 损伤演化, 疲劳效应, 以及热-力-流等多物理场耦合), 并能有效利用本地计算资源及高性能计算 (HPC) 集群.
- 1.2. 核心功能:
- 通过 API 或消息队列接收结构化的仿真任务请求, 明确分析类型(单场或耦合场).
- 管理与仿真相关的模型文件(几何定义, 网格数据, 材料库参数).
- 基于任务参数和预定义模板, 动态生成 MOOSE 输入文件
(
.i), 特别注意正确配置多物理场耦合所需的[MultiApps]和[Transfers]部分. - 根据计算资源配置(本地并行或 HPC), 调度并执行 MOOSE 计算任务(对于耦合任务, 启动主应用进程).
- 实时监控 MOOSE 进程或 HPC 作业的状态, 进度和关键日志信息.
- 在仿真完成后, 自动解析 MOOSE 输出文件(可能来自主应用和多个子应用), 提取关键结果数据.
- 将结果摘要和原始输出文件持久化到平台的数据存储(数据库, 对象存储).
- 提供标准化的内部服务接口, 供平台的评估, 预测, 可视化等其他模块调用.
- 1.3. 设计原则:
- 模块化: 各组件职责单一, 易于开发, 测试和维护.
- 接口清晰: 组件间通过定义良好的 API 或消息进行交互.
- 配置驱动: 大部分仿真逻辑(材料, 边界条件, 耦合方式)通过输入配置而非硬编码实现.
- 状态管理: 精确跟踪每个仿真任务从提交到完成的完整生命周期状态.
- 错误处理: 对各种潜在错误(输入错误, 计算失败, 资源问题)有明确的处理和报告机制.
- 可观测性: 提供足够的日志, 监控指标和追踪能力, 便于问题排查和性能优化.
- 模块架构与组件设计 (详细组件)
- 2.1. 服务接口层 (API Interface / Queue Listener)
- 2.1.1 API 定义 (RESTful - 基于 FastAPI/Flask):
POST /api/fem/jobs: 提交新的仿真任务.- 请求体 (Request Body):
SimulationJobRequest(JSON 格式). 关键字段包括:job_name,description,user_id,project_id(元数据)priority(可选, 用于调度)compute_config: 指定运行环境 (local=/=hpc), HPC 配置 (hpc_profile,num_nodes,procs_per_node,wall_time).model_config: 引用网格文件 (mesh_ref- MinIO 路径, Exodus 格式), 材料分配 (material_assignments- 将网格块ID映射到材料名称), 可选的钢筋配置 (rebar_config).analysis_config:type: 分析类型枚举 (如"Static","Transient", ="CoupledThermalStress"=等).steps: 分析步列表, 每步包含荷载 (loads- 类型如 Gravity, Pressure, PointLoad; 值或函数; 作用位置 Nodeset/Sideset ID), 边界条件 (bcs- 类型如 FixedDisplacement, Symmetry; 作用位置; 约束分量), 求解器设置 (settings- 如 PETSc 选项), 输出请求 (output_requests- 需要输出的变量名或后处理器名).
postprocessing_config: 明确请求的 MOOSE 后处理器及其参数.
- 响应体 (异步):
{"job_id": "uuid-...", "status": "PENDING"}(HTTP 202 Accepted).
- 请求体 (Request Body):
GET /api/fem/jobs/{job_id}: 查询指定任务的状态.- 响应体:
SimulationJobStatus(JSON 格式, 包含任务ID, 名称, 当前状态, 进度估计, 时间戳, 最新消息, 计算节点/HPC作业ID, 结果链接等).
- 响应体:
GET /api/fem/jobs: 查询任务列表(支持过滤, 分页), 返回SimulationJobStatus列表.DELETE /api/fem/jobs/{job_id}: 请求取消任务.- 响应体:
{"job_id": "uuid-...", "status": "CANCEL_REQUESTED"}(HTTP 202 Accepted).
- 响应体:
- 2.1.2 队列监听器 (Celery Task / Kafka Consumer - 基于
Python/Java/Clojure):
- 输入: 消费来自指定消息队列主题 (如
fem.jobs.request) 的SimulationJobRequest消息. - 动作: 反序列化消息, 进行初步格式校验, 然后将任务请求传递给任务解析器进行后续处理.
- 错误处理: 记录格式错误或无法处理的消息, 并将其移入死信队列以供后续分析.
- 输入: 消费来自指定消息队列主题 (如
- 2.1.1 API 定义 (RESTful - 基于 FastAPI/Flask):
- 2.2. 任务处理与准备层 (Task Processing & Preparation)
- 2.2.1 任务解析器 (Task Parser - 基于 Python):
- 输入:
SimulationJobRequest对象. - 逻辑:
- 生成全局唯一的
job_id(UUID). - 在 PostgreSQL 中创建任务记录, 初始状态设为
PENDING. - 进行详细的语义校验: 检查引用的网格文件是否存在, 材料名称是否在库中, 荷载/边界条件类型是否支持, 节点集/边集 ID 是否有效, 耦合类型与参数是否匹配等.
- 从 PostgreSQL 加载完整的材料属性数据, HPC 配置详情.
- 识别任务类型(单场/耦合), 加载相应的处理流程或配置模板引用.
- 确定所需的全部输入文件(网格, 可能的辅助数据文件).
- (如果需要网格生成或转换) 调用前处理器组件.
- 将经过校验和补充的完整任务信息传递给输入生成器.
- 更新数据库任务状态为
PREPARING.
- 生成全局唯一的
- 输出: 一个包含执行仿真所需全部信息的内部数据结构.
- 输入:
- 2.2.2 输入生成器 (Input Generator - 基于 Python + Jinja2):
- 输入: 任务解析器输出的内部数据结构.
- 逻辑:
- 选择模板: 根据分析类型(包括耦合类型)选择合适的 Jinja2
.i文件模板(主模板及可能的子应用模板). 维护一个模板库. - 构造上下文: 创建一个包含所有 MOOSE 输入参数的 Python
字典, 作为 Jinja2
模板的渲染上下文. 这需要将平台定义的抽象概念(如荷载类型
"Gravity")映射到具体的 MOOSE 对象和参数(如
[Kernels/gravity]或[BCs/gravity_body_force]). - 渲染模板: 调用 Jinja2 引擎渲染模板, 生成最终的
.i文件. - 关键映射与生成细节:
- [Mesh]: 填充
file = <mesh_file_path>. - [Variables]/[AuxVariables]: 根据分析类型和输出请求定义所需的场变量和辅助变量.
- [Kernels]/[AuxKernels]: 根据物理场(力学, 热学等)和控制方程生成相应的计算内核.
- [Materials]: 使用加载的材料属性填充材料块. 对于自定义 C++
材料 (
GB50010ConcreteStress,CDP等), 确保参数名与 C++ 类中declareParameters()定义的一致. [MOOSE 集成验证点 #1: 自定义材料实例化与参数传递] - [Constraints]: 如有钢筋, 生成
EmbeddedRebarConstraint块. [MOOSE 集成验证点 #2: 钢筋约束配置与应用] - [BCs]: 将平台 BC 定义转换为 MOOSE BC 对象. [MOOSE 集成验证点 #3: 边界条件类型, 变量, 位置, 值的正确映射]
- [Functions]: 生成用于定义非均匀或时变荷载/BC/材料属性的函数.
- [Executioner]: 配置求解策略, 步长控制, 收敛判据.
- [Outputs]: 配置 Exodus/VTK 输出, 指定变量和频率.
- [Postprocessors]: 生成用户请求的后处理器定义. [MOOSE 集成验证点 #4: 自定义后处理器注册与依赖]
- [MultiApps]/[Transfers] (耦合场景):
- 基于内部" 耦合配方" 生成此部分. 配方定义了子应用名称, 类型, 输入文件, 执行时机
(
execute_on) 以及数据传递 (Transfers) 的详细规则(源/目标应用, 变量, 方式). - 为每个子应用生成对应的
.i文件. - [MOOSE 集成验证点 #5: MultiApps/Transfers 配置语法与逻辑正确性]
- 基于内部" 耦合配方" 生成此部分. 配方定义了子应用名称, 类型, 输入文件, 执行时机
(
- [Mesh]: 填充
- 将所有生成的
.i文件保存到为该任务分配的工作目录中.
- 选择模板: 根据分析类型(包括耦合类型)选择合适的 Jinja2
- 输出: 主
.i文件的路径(供执行管理器使用).
- 2.2.3 (可选) 前处理器 (Pre-processor - 基于 Python 调用 Gmsh 等):
- 输入: 几何文件引用 (MinIO 路径), 网格划分参数.
- 逻辑: 下载几何文件, 调用 Gmsh 命令行或 API 生成网格, 使用
meshio等库将网格转换为 Exodus (.e) 格式, 上传.e文件到 MinIO. - 输出: 生成的 Exodus 网格文件的 MinIO 路径.
- 2.2.1 任务解析器 (Task Parser - 基于 Python):
- 2.3. MOOSE 执行与监控层 (MOOSE Execution & Monitoring)
- 2.3.1 执行管理器 (Execution Manager - 基于 Python/Celery Worker):
- 输入: Job ID, 主
.i文件路径, 计算配置, 工作目录路径. - 逻辑:
- 更新 DB 任务状态为
QUEUED或RUNNING. - 准备工作目录: 在执行目标(本地节点或 HPC 共享文件系统)创建隔离的工作目录.
- 文件传输: 从 MinIO 下载网格文件到工作目录; 复制所有生成的
.i文件到工作目录. - 启动执行:
- 本地: 构造
mpiexec -n <procs> /path/to/ConcreteApp-opt -i <main_app.i>命令, 使用subprocess.Popen异步启动, 记录 PID. - HPC: 调用 HPC 调度器适配器的
submit方法, 传入生成的作业脚本和资源需求, 记录返回的 HPC Job ID.
- 本地: 构造
- 将 PID 或 HPC Job ID 关联到任务记录, 并通知状态监控器开始监控.
- 更新 DB 任务状态为
- 输出: 进程 ID 或 HPC 作业 ID.
- 输入: Job ID, 主
- *2.3.2 (可选) HPC 调度器适配器 (HPC Scheduler Adapter - 基于 Python
- Paramiko):*
- 接口: 提供
submit(script, resources),query_status(hpc_job_id),cancel(hpc_job_id)的统一接口. - 实现: 内部根据
hpc_profile配置, 通过 SSH 连接到 HPC 登录节点, 执行相应的调度器命令(sbatch,qsub,squeue,qstat,scancel,qdel等), 并解析返回结果.
- 2.3.3 MOOSE 运行器 (
ConcreteApp- C++ 二进制文件):- 核心: 已编译的, 包含所有自定义扩展(材料, 约束, 后处理器)的 MOOSE 应用程序.
- 执行: 读取主
.i文件, 自动处理 =[MultiApps]=(如果存在)启动子应用, 通过 MPI 进行并行计算, 输出结果和日志到工作目录. - [MOOSE 集成验证点 #6: 启动, 并行与输入解析]
- [MOOSE 集成验证点 #7: 基本物理场求解正确性]
- [MOOSE 集成验证点 #8: 非线性材料模型收敛性与鲁棒性]
- [MOOSE 集成验证点 #9: 耦合迭代执行与数据传递正确性]
- [MOOSE 集成验证点 #10: 输出文件生成与内容完整性]
- 2.3.4 状态监控器 (Status Monitor - 基于 Python 线程/任务):
- 输入: Job ID, PID 或 HPC Job ID.
- 逻辑:
- 轮询检查: 定期(如每 10-30 秒)检查进程是否存在或查询 HPC 作业状态.
- 日志解析: 读取 MOOSE 进程的标准输出/错误流(或重定向的日志文件). 使用正则表达式或特定标记解析关键信息, 如: 时间步完成, 非线性迭代次数, 残差范数, 警告, 错误信息. 对于耦合任务, 注意区分主/子应用日志或耦合迭代信息.
- 状态更新: 将解析到的状态, 进度(可基于时间步或模拟时间估计), 日志片段更新到 PostgreSQL 中的任务记录.
- 完成/失败判断: 检测到进程正常退出 (exit code 0) 或 HPC 作业状态为 COMPLETED, 触发结果处理流程. 检测到进程异常退出 (non-zero exit code), HPC 作业 FAILED/TIMEOUT, 或解析到明确的 MOOSE 错误信息, 标记任务为 FAILED, 记录错误详情.
- 超时处理: 如果任务运行时间超过
wall_time或长时间无进度更新, 标记为 FAILED/TIMEOUT. - 取消处理: 收到取消请求后, 调用
os.kill(本地) 或SchedulerAdapter.cancel(HPC), 并更新状态为 CANCELLED.
- [MOOSE 集成验证点 #11: MOOSE 日志可解析性与关键信息捕获]
- 2.3.1 执行管理器 (Execution Manager - 基于 Python/Celery Worker):
- 2.4. 结果处理与持久化层 (Result Processing & Persistence)
- 2.4.1 输出解析器 (Output Parser - 基于 Python + h5py/vtk/pandas):
- 输入: Job ID, 输出文件所在的工作目录路径.
- 逻辑:
- 更新 DB 状态为
POSTPROCESSING. - 识别任务类型, 确定需要解析的文件(主应用及可能的子应用输出). 文件名约定可能包含应用名和/或时间步信息.
- (若 MOOSE 输出并行 Exodus) 可选调用
epu合并, 或使用支持并行读取的库. - 读取数据: 使用
h5py或exodus.py读取.e文件中的网格, 节点/单元变量场, 全局/节点/单元变量, 后处理结果. 使用vtk或meshio读取.vtk文件. 使用pandas读取.csv文件.
- 更新 DB 状态为
- 输出: 包含所需数据的 Python 数据结构(如字典, NumPy 数组, Pandas DataFrame).
- [MOOSE 集成验证点 #12: 输出文件格式兼容性与数据读取完整性]
- 2.4.2 结果聚合器 (Result Aggregator - 基于 Python):
- 输入: 解析后的原始结果数据.
- 逻辑: 根据任务请求或默认配置, 计算结果摘要(如最大位移, 最大主应力, 平均损伤值), 提取特定点/线/面的时间历程数据, 生成用于快速预览的数据子集(如下采样后的场数据). 对于耦合结果, 将不同物理场的关键数据整合.
- 输出: 结构化的聚合结果.
- 2.4.3 持久化处理器 (Persistence Handler - 基于 Python):
- Input: Job ID, 聚合结果, 原始文件路径列表.
- Logic:
- 归档原始文件: 将工作目录中所有重要的输出文件 (
.e,.vtk,.csv,.log等) 上传到 MinIO, 路径结构通常为/{project_id}/{job_id}/outputs/. - 写入数据库: 将聚合结果摘要 (JSONB), 关键标量时间序列
(TimescaleDB/InfluxDB 或 PostgreSQL JSONB/Array), 指向 MinIO
的文件引用等, 更新到 PostgreSQL 的
fem_jobs表或其他关联结果表中. - 更新最终状态: 将
fem_jobs表的状态更新为COMPLETED. - 发布事件: 向 Kafka/RabbitMQ 发送
SimulationCompleted事件, 包含job_id和结果摘要信息或引用, 供下游服务(如评估, 可视化)消费.
- 归档原始文件: 将工作目录中所有重要的输出文件 (
- 错误处理: 若上传或写入 DB 失败, 将状态标记为
POSTPROCESSING_FAILED, 并记录详细错误. 考虑失败重试机制.
- 2.4.1 输出解析器 (Output Parser - 基于 Python + h5py/vtk/pandas):
- 2.1. 服务接口层 (API Interface / Queue Listener)
- 数据模型 (PostgreSQL 核心表)
- femjobs: (主键
job_idUUID) 存储任务的所有信息, 包括请求详情(request_detailsJSONB), 计算配置(compute_configJSONB), 状态(statusVARCHAR), 进度(progressFLOAT), 时间戳, HPC作业ID(hpc_job_idVARCHAR), 结果摘要(result_summaryJSONB), 输出文件位置(output_files_locationVARCHAR - MinIO 路径). - femmaterials: (主键
material_nameVARCHAR) 材料库, 存储材料类型 (material_typeVARCHAR) 和属性 (propertiesJSONB). - hpcprofiles: (主键
profile_nameVARCHAR) HPC 集群连接和提交参数 (connection_detailsJSONB,submit_optionsJSONB).
- femjobs: (主键
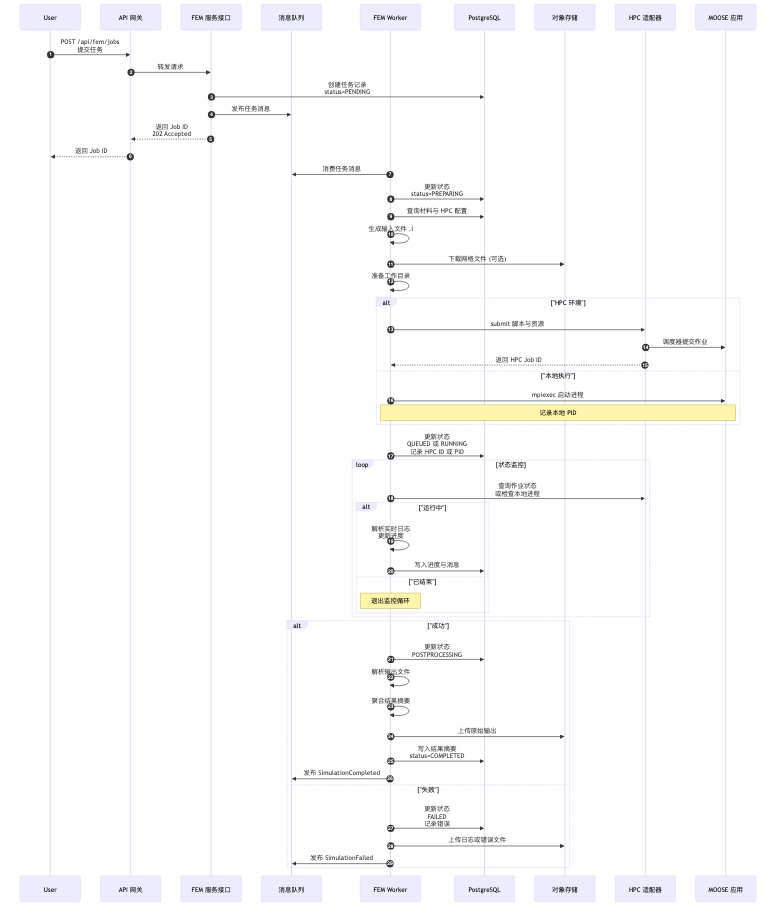
4. UML 流程图 (典型异步任务处理)
5. 部署与配置
- 容器化: FEM 服务打包为 Docker 镜像.
ConcreteApp打包为包含所有运行时依赖(MPI, PETSc, libMesh 等)的 Docker 镜像. - 编排: 使用 K8s 部署 FEM 服务(API 接口, Celery Worker 等). 数据库, MinIO, 消息队列等有状态服务建议使用 K8s Operator 或独立部署集群.
- 配置: 通过 K8s ConfigMap/Secret 或环境变量管理数据库连接, MinIO 访问密钥, 消息队列地址, HPC 登录信息, MOOSE 应用镜像标签等.
- 存储: K8s PV/PVC 对接 NFS/Ceph 等共享存储, 用于任务临时工作目录(如果 HPC 文件系统不能直接挂载).
6. 性能, 安全, 可靠性, 可观测性
遵循第 1.3 节的非功能性需求和之前设计中的相关策略(如 MPI 并行, 异步处理, 高可用部署, 安全措施, 日志监控等).