Windows 10 系统编程
Table of Contents
- 1. Windows 10 系统编程, 第 1 部分
- 2. Windows 10 系统编程, 第 2 部分
1. Windows 10 系统编程, 第 1 部分
Pavel Yosifovich
本书销售网址: http://leanpub.com/windows10systemprogramming
此版本发布于 2020-08-09
这是一本 Leanpub 书籍. Leanpub 通过精益出版 (Lean Publishing) 流程为作者和出版商赋能. 精益出版是一种使用轻量级工具和多次迭代来发布正在创作中的电子书的行为, 旨在获取读者反馈, 进行调整, 直到你写出正确的书, 并在此过程中建立吸引力.
© 2019 - 2020 Pavel Yosifovich
1.1. 介绍
术语“系统编程”指的是接近操作系统级别的编程. Windows 10 系统编程 为目标为现代 Windows 系统 (从 Windows 7 到最新的 Windows 10 版本) 的系统程序员提供指导.
本书使用已文档化的 Windows 应用程序编程接口 (API) 来利用系统级功能, 包括进程, 线程, 同步原语, 虚拟内存和 I/O. 由于 Windows API 的庞大规模和 Windows 系统功能的广泛性, 本书分为两部分. 你手中 (或你选择的屏幕上) 的是第 1 部分.
1.1.1. 谁应该阅读本书
本书面向那些以 Windows 平台为目标, 并且需要通过高级框架和库无法达到的控制水平的软件开发人员. 本书使用 C 和 C++ 作为代码示例, 因为 Windows API 主要基于 C. 在有意义的地方使用 C++, 例如在维护性, 清晰度, 资源管理以及以上任意组合方面其优势明显时. 本书不使用非平凡的 C++ 构造, 例如模板元编程. 本书不是关于 C++ 的, 而是关于 Windows 的.
也就是说, 其他语言可以通过其专门的互操作性机制来调用 Windows API. 例如, .NET 语言 (C#, VB, F# 等) 可以使用平台调用 (P/Invoke) 来调用 Windows API. 其他语言, 如 Python, Rust, Java 等许多语言都有其等效的功能.
1.1.2. 使用本书需要了解什么
读者应非常熟悉 C 编程语言, 尤其是指针, 结构体及其标准库, 因为这些在 Windows API 中非常常见. 强烈建议具备基本的 C++ 知识, 尽管仅凭 C 语言的熟练程度也可以通读本书.
1.1.3. 示例代码
书中的所有示例代码都可以在本书的 Github 仓库中免费获取: https://github.com/zodiacon/Win10SysProgBookSamples. 代码示例的更新将被推送到此仓库. 建议读者将仓库克隆到本地机器, 以便直接试验代码.
所有代码示例都已使用 Visual Studio 2019 编译. 如果需要, 大多数代码示例也可以使用早期版本的 Visual Studio 进行编译. 最新 C++ 标准的某些功能可能在早期版本中不受支持, 但这些问题应该很容易修复.
祝你阅读愉快! Pavel Yosifovich 2019 年 6 月
1.2. 第 1 章: 基础
Windows NT 系列操作系统历史悠久, 始于 1993 年推出的 3.1 版本. 今天的 Windows 10 是最初 NT 3.1 的最新继承者. 当前 Windows 系统的基本概念与 1993 年时基本相同. 这显示了最初操作系统设计的强大之处. 也就是说, 自诞生以来, Windows 显著增长, 增加了许多新功能并对现有功能进行了增强.
本书关于系统编程, 通常被认为是操作系统核心服务的低级编程, 没有这些服务, 就无法完成任何重要的工作. 系统编程使用低级 API 来使用和操作 Windows 中的核心对象和机制, 例如进程, 线程和内存.
在本章中, 我们将从核心概念和 API 开始, 探讨 Windows 系统编程的基础.
本章内容:
- Windows 架构概述
- Windows 应用程序开发
- 使用字符串
- 32位 vs. 64位开发
- 编码约定
- 处理 API 错误
- Windows 版本
1.2.1. Windows 架构概述
我们将首先简要描述 Windows 中的一些核心概念和组件. 这些内容将在接下来的相关章节中详细阐述.
- 进程
进程是一个包含和管理对象, 代表程序的运行实例. “进程运行”这个术语经常被使用, 但并不准确. 进程不运行——进程进行管理. 线程才是执行代码并技术上运行的单位. 从高层次的角度来看, 一个进程拥有以下内容:
- 一个可执行程序, 其中包含用于在进程内执行代码的初始代码和数据.
- 一个私有的虚拟地址空间, 用于为进程内代码所需的任何目的分配内存.
- 一个访问令牌 (有时称为*主令牌*), 这是一个存储进程默认安全上下文的对象, 由在进程内执行代码的线程使用 (除非线程通过模拟使用不同的令牌).
- 一个到 Executive (内核) 对象的私有句柄表, 例如事件, 信号量和文件.
- 一个或多个执行线程. 一个正常的 user-mode 进程创建时带有一个线程 (执行进程的主要入口点). 没有线程的 user-mode 进程基本上是无用的, 在正常情况下会被内核销毁.
一个进程的这些元素如图 1-1 所示.
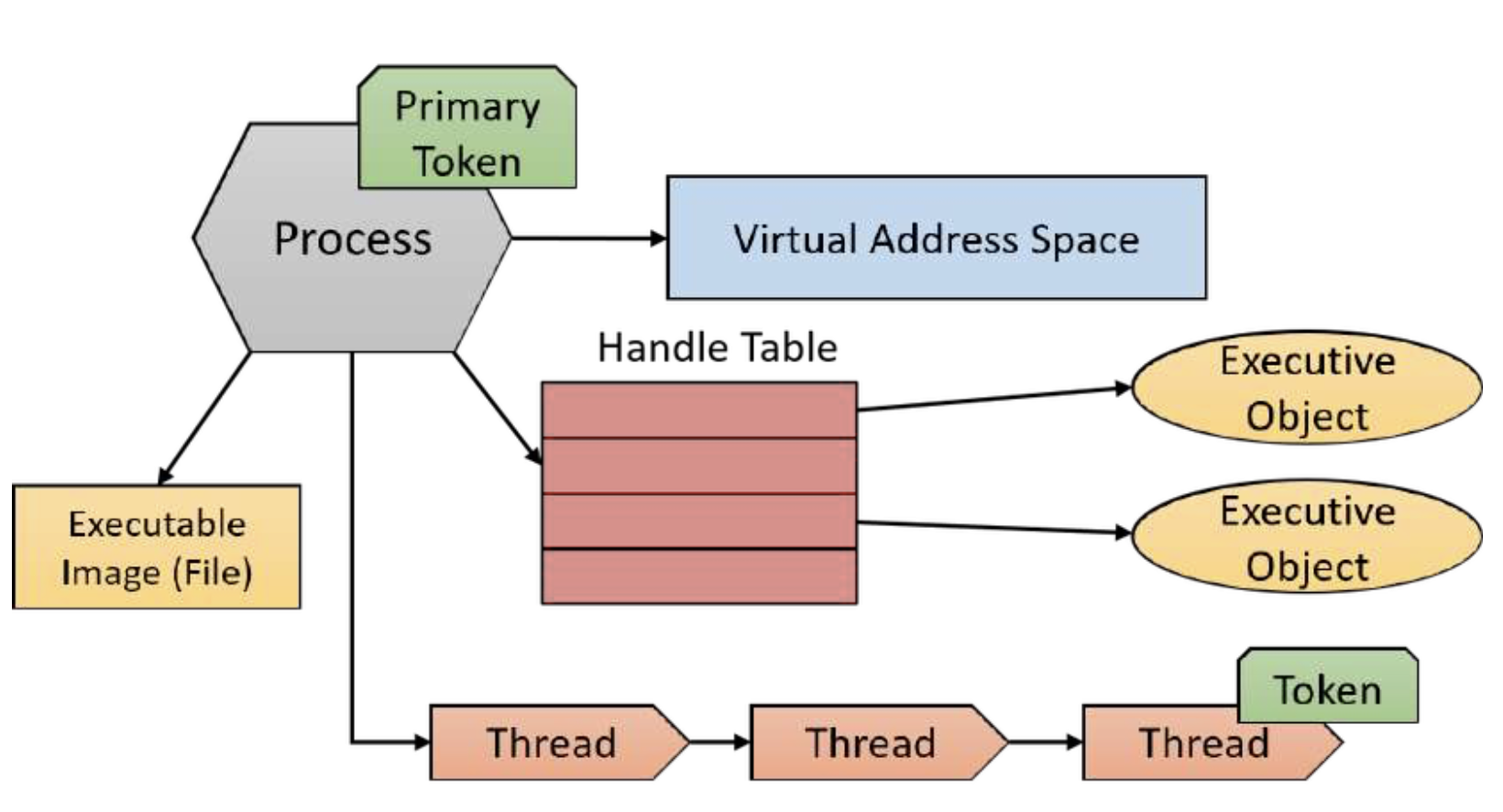
Figure 1: 进程的重要组成部分
一个进程由其进程 ID (Process ID) 唯一标识, 只要该内核进程对象存在, 该 ID 就保持唯一. 一旦它被销毁, 相同的 ID 可能会被新进程重用. 重要的是要认识到, 可执行文件本身并不是进程的唯一标识符. 例如, 可能同时有五个 `notepad.exe` 的实例在运行. 每个进程都有自己的地址空间, 自己的线程, 自己的句柄表, 自己唯一的进程 ID 等. 所有这五个进程都使用相同的镜像文件 (`notepad.exe`)作为它们的初始代码和数据. 图 1-2 显示了任务管理器“详细信息”选项卡的屏幕截图, 其中显示了五个 `Notepad.exe` 的实例, 每个都有自己的属性.
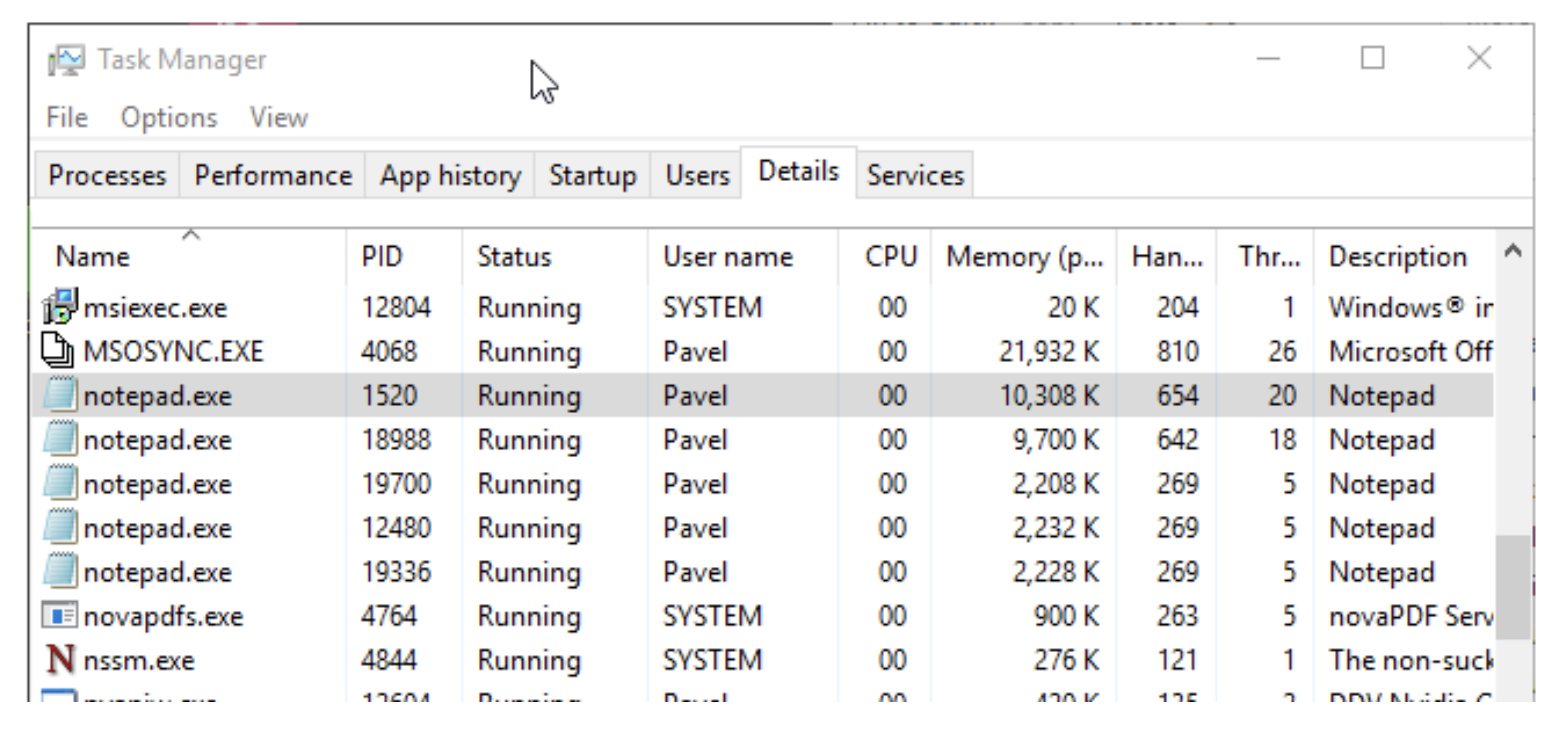
Figure 2: notepad 的五个实例
- 动态链接库
动态链接库 (Dynamic Link Libraries, DLLs) 是可执行文件, 可以包含代码, 数据和资源 (至少其中之一). DLLs 在进程初始化时 (称为*静态链接*) 或之后显式请求时 (称为*动态链接*) 动态加载到进程中. 我们将在第 15 章更详细地探讨 DLLs. DLLs 不像可执行文件那样包含标准的 `main` 函数, 因此不能直接运行. DLLs 允许在多个使用相同 DLL 的进程之间共享其物理内存中的代码, 这对于存储在 `System32` 目录中的所有标准 Windows DLLs 都是如此. 其中一些 DLLs, 称为*子系统 DLLs*, 实现了已文档化的 Windows API, 这是本书的重点.
图 1-3 显示了两个使用共享 DLL 的进程, 这些 DLL 映射到相同的物理 (和虚拟) 地址.
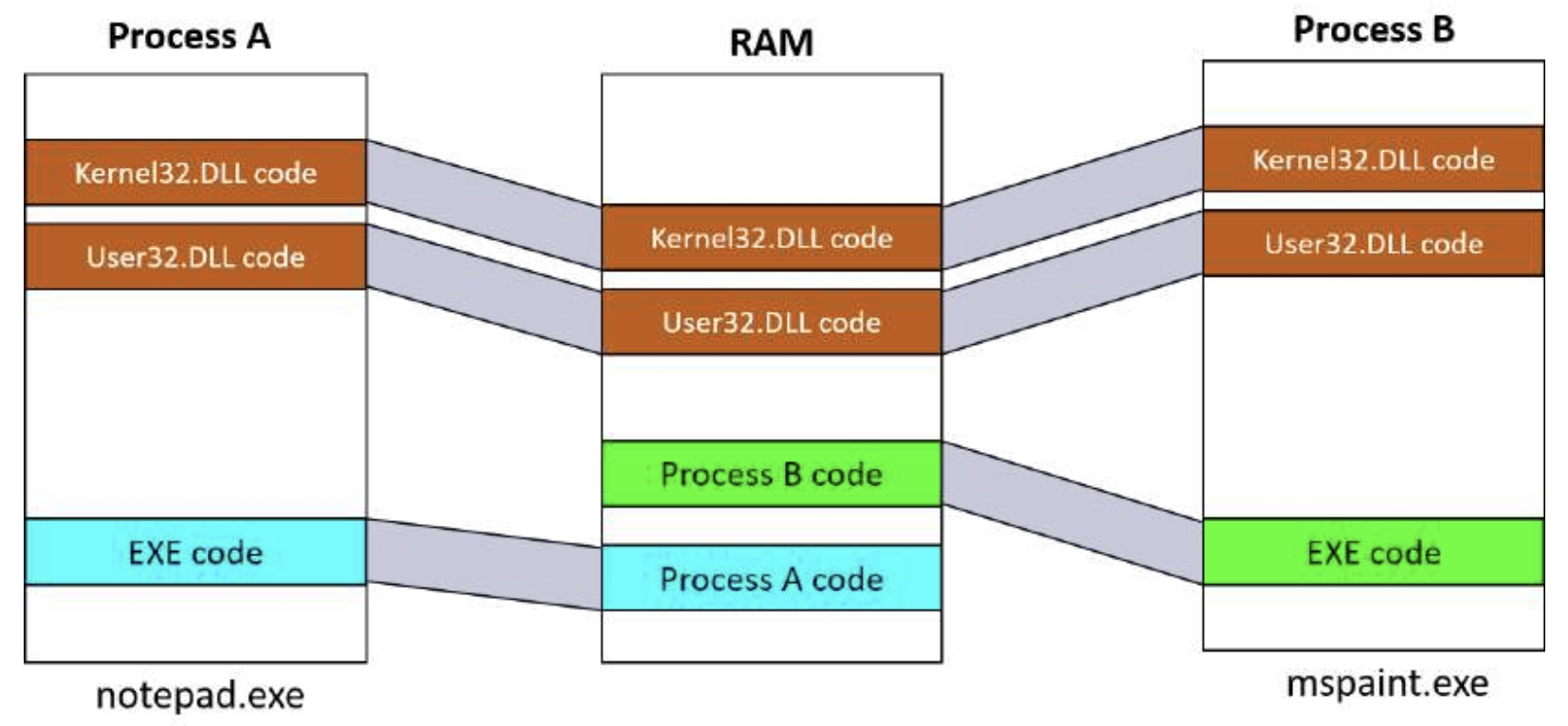
Figure 3: 共享 DLLs 代码
- 虚拟内存
每个进程都有其自己的虚拟, 私有, 线性地址空间. 这个地址空间开始时是空的 (或接近空的, 因为可执行镜像和
NtDll.Dll通常是首先被映射的). 一旦主 (第一个) 线程开始执行, 内存很可能会被分配, 更多的 DLLs 会被加载等等. 这个地址空间是私有的, 这意味着其他进程不能直接访问它. 地址空间范围从零开始 (尽管技术上地址的前 64KB 不能被分配), 一直到一个最大值, 这个最大值取决于进程的“位数” (32位或64位), 操作系统的“位数”和一个链接器标志, 如下所示:- 对于 32 位 Windows 系统上的 32 位进程, 进程地址空间大小默认为 2 GB.
- 对于使用增加用户地址空间设置的 32 位 Windows 系统上的 32 位进程, 该进程地址空间大小可以大到 3 GB (取决于确切的设置). 要获得扩展的地址空间范围, 创建该进程的可执行文件必须在其头部用
LARGEADDRESSAWARE链接器标志标记. 如果没有, 它仍然会被限制为 2 GB. - 对于 64 位进程 (自然是在 64 位 Windows 系统上), 地址空间大小为 8 TB (Windows 8及更早版本) 或 128 TB (Windows 8.1及更高版本).
- 对于 64 位 Windows 系统上的 32 位进程, 如果可执行镜像链接了
LARGEADDRESSAWARE标志, 则地址空间大小为 4 GB. 否则, 大小仍为 2 GB.
LARGEADDRESSAWARE标志的要求源于一个 2 GB 地址范围只需要 31 位, 留下了最高有效位 (MSB) 供应用程序使用. 指定此标志表示程序没有将第 31 位用于任何用途, 因此将该位设置为 1 (这会发生在地址大于 2 GB 的情况下) 不是问题.内存本身被称为 虚拟 内存, 这意味着地址范围与它在物理内存 (RAM) 中的确切位置之间存在间接关系. 进程中的缓冲区可能映射到物理内存, 或者可能暂时驻留在文件 (如页面文件) 中. “虚拟”一词指的是从执行的角度来看, 无需知道要访问的内存是否在 RAM 中; 如果内存确实映射到 RAM, CPU 将直接访问数据. 如果没有, CPU 将引发一个*页面错误*异常, 这将导致内存管理器的页面错误处理程序从相应的文件中获取数据, 将其复制到 RAM, 对映射缓冲区的页表条目进行必要的更改, 并指示 CPU 重试.
- 线程
实际执行代码的实体是线程. 线程包含在进程内, 使用进程暴露的资源来完成工作 (例如虚拟内存和内核对象的句柄). 线程拥有的最重要的属性如下:
- 当前访问模式, 用户模式或内核模式.
- 执行上下文, 包括处理器寄存器.
- 一个栈, 用于局部变量分配和调用管理.
- 线程局部存储 (TLS) 数组, 它提供了一种以统一访问语义存储线程私有数据的方法.
- 基础优先级和当前 (动态) 优先级.
- 处理器亲和性, 指示线程允许在哪些处理器上运行.
线程最常见的状态有:
- 运行中 - 当前正在 (逻辑) 处理器上执行代码.
- 就绪 - 等待被调度执行, 因为所有相关处理器都繁忙或不可用.
- 等待 - 等待某个事件发生才能继续. 一旦事件发生, 线程将移至*就绪*状态.
1.2.2. 通用系统架构
图 1-4 展示了 Windows 的通用架构, 包括用户模式和内核模式组件.
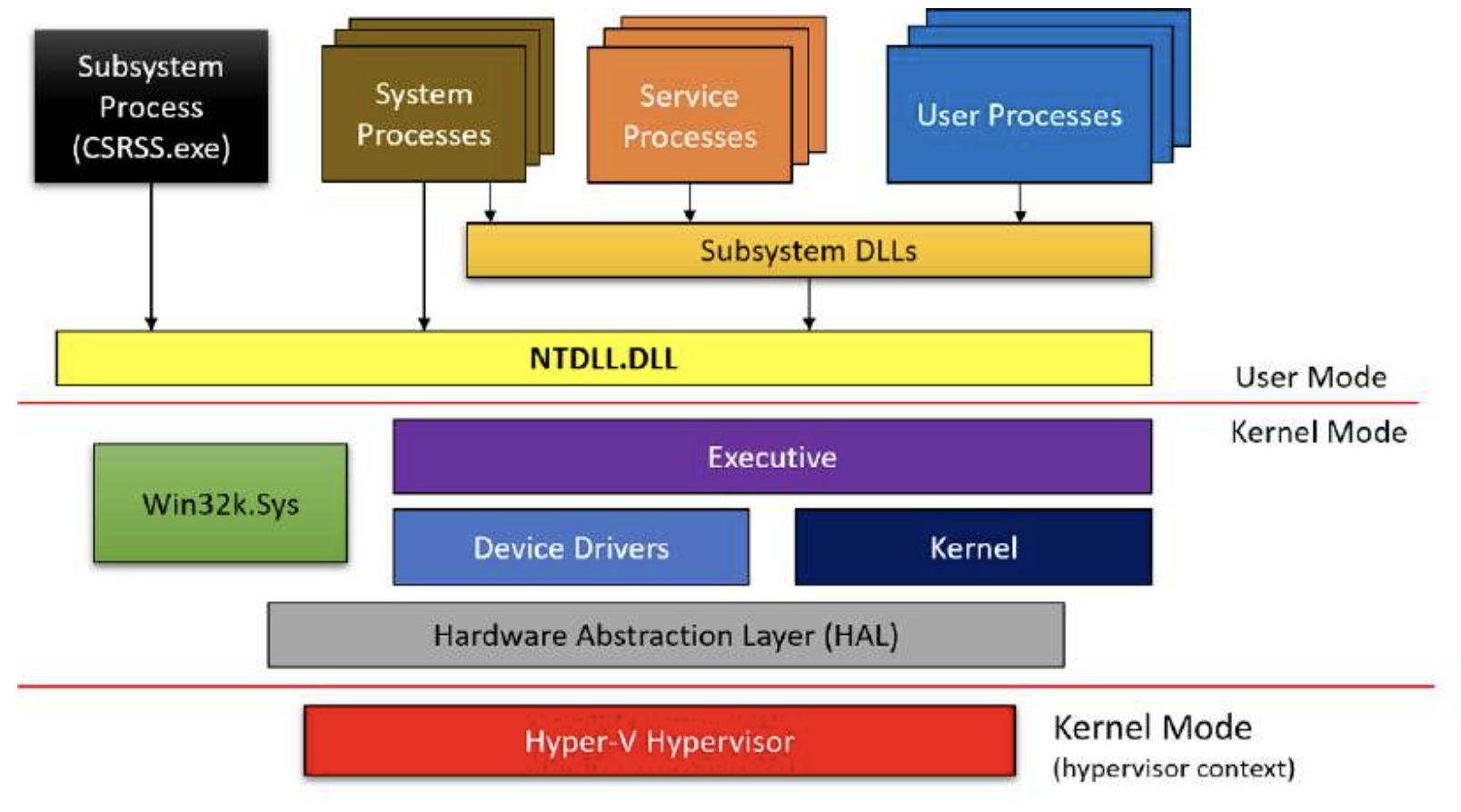
Figure 4: Windows 系统架构
以下是图 1-4 中出现的命名框的简要说明:
- 用户进程 这些是基于镜像文件的普通进程, 在系统上执行, 例如 `Notepad.exe`, `cmd.exe`, `explorer.exe` 的实例等等.
- 子系统 DLLs 子系统 DLLs 是实现子系统 API 的动态链接库 (DLLs). 子系统是内核暴露功能的某种视图. 从技术上讲, 从 Windows 8.1 开始, 只有一个子系统——Windows 子系统. 子系统 DLLs 包括众所周知的文件, 如 `kernel32.dll`, `user32.dll`, `gdi32.dll`, `advapi32.dll`, `combase.dll` 等等. 这些主要包含了 Windows 官方文档化的 API. 本书的重点是使用这些 DLLs 暴露的 API.
- NTDLL.DLL 一个系统范围的 DLL, 实现了 Windows native API. 这是仍然在用户模式下的最低层代码. 其最重要的作用是为系统调用进行到内核模式的转换. NTDLL 还实现了堆管理器, 镜像加载器和部分用户模式线程池. 尽管 native API 大部分是未文档化的, 我们在本书中会在标准文档化的 Windows API 无法实现某些目标时使用它的一部分.
- 服务进程 服务进程是与服务控制管理器 (SCM, 在 `services.exe` 中实现) 通信的普通 Windows 进程, 并允许对其生命周期进行一些控制. SCM 可以启动, 停止, 暂停, 恢复和向服务发送其他消息. 第 19 章将更详细地处理服务.
- Executive Executive 是 `NtOskrnl.exe` (即“内核”) 的上层. 它包含了内核模式下的大部分代码. 它主要包括各种“管理器”: 对象管理器, 内存管理器, I/O 管理器, 即插即用管理器, 电源管理器, 配置管理器等. 它远比下层的内核层要大.
- Kernel 内核层实现了内核模式操作系统代码中最基本和时间敏感的部分. 这包括线程调度, 中断和异常分派, 以及各种内核原语 (如互斥体和信号量) 的实现. 部分内核代码使用特定于 CPU 的机器语言编写, 以提高效率并直接访问特定于 CPU 的细节.
- 设备驱动程序 设备驱动程序是可加载的内核模块. 它们的代码在内核模式下执行, 因此拥有内核的全部能力. 经典的设备驱动程序提供了硬件设备与操作系统其余部分之间的粘合剂. 其他类型的驱动程序提供过滤功能. 有关设备驱动程序的更多信息, 请参阅我的书 “Windows Kernel Programming”.
- Win32k.sys Windows 子系统的内核模式组件. 本质上, 这是一个处理 Windows 用户界面部分和经典图形设备接口 (GDI) API 的内核模块 (驱动程序). 这意味着所有窗口操作都由该组件处理. 系统的其余部分对 UI 知之甚少.
- 硬件抽象层 (HAL) HAL 是最接近 CPU 的硬件之上的一个抽象层. 它允许设备驱动程序使用不需要详细和特定知识的 API, 例如中断控制器或 DMA 控制器. 自然地, 这一层主要对为处理硬件设备而编写的设备驱动程序有用.
- 系统进程 系统进程是一个总括性术语, 用于描述那些通常“就在那里”的进程, 它们做着自己的事情, 通常不与它们直接通信. 然而它们很重要, 有些实际上对系统的健康至关重要. 终止其中一些是致命的, 会导致系统崩溃. 一些系统进程是*原生进程*, 意味着它们只使用 native API (由 NTDLL 实现的 API). 系统进程的例子包括 `Smss.exe`, `Lsass.exe`, `Winlogon.exe`, `Services.exe` 等.
- 子系统进程 Windows 子系统进程, 运行着 `Csrss.exe` 镜像, 可以被看作是内核管理在 Windows 系统下运行的进程的助手. 这是一个关键进程, 意味着如果被杀死, 系统将会崩溃. 每个会话通常有一个 `Csrss.exe` 实例, 所以在标准系统上会存在两个实例——一个用于会话 0, 一个用于登录用户的会话 (通常是 1). 尽管 `Csrss.exe` 是 Windows 子系统 (如今唯一剩下的) 的“管理器”, 它的重要性远不止这个角色.
- Hyper-V Hypervisor Hyper-V hypervisor 存在于支持基于虚拟化的安全 (VBS) 的 Windows 10 和 Server 2016 (及更高版本) 系统上. VBS 提供了一个额外的安全层, 其中实际的机器实际上是由 Hyper-V 控制的虚拟机. VBS 超出了本书的范围. 更多信息, 请查阅 Windows Internals 书籍.
1.2.3. Windows 应用程序开发
Windows 提供了一个应用程序编程接口 (API), 供开发人员访问 Windows 的系统功能. 经典的 API 被称为 Windows API, 主要由一长串 C 函数组成, 提供从处理进程, 线程和其他低级对象的基本服务, 到用户界面, 图形, 网络和介于两者之间的一切功能. 本书主要侧重于使用此 API 来编程 Windows.
从 Windows 8 开始, Windows 支持两种稍有不同的应用程序类型: 经典的桌面应用程序, 这是 Windows 8 之前唯一的应用程序类型, 以及可以上传到 Windows 应用商店的通用 Windows 应用程序. 从内部角度看, 这两种类型的应用程序是相同的. 两种类型都使用线程, 虚拟内存, DLL, 句柄等. 应用商店应用程序主要使用 Windows 运行时 API (本节稍后描述), 但可以使用经典 Windows API 的一个子集. 相反, 桌面应用程序使用经典的 Windows API, 但也可以利用 Windows 运行时 API 的一个子集. 本书侧重于桌面应用程序, 因为整个 Windows API 都可供它们使用, 而此 API 包含了对系统编程有用的大部分功能.
Windows 提供的其他 API 风格, 特别是从 Windows Vista 开始, 都基于组件对象模型 (COM) 技术——一种于 1993 年发布的面向组件的编程范式, 至今仍在 Windows 的许多组件和服务中使用. 例子包括 DirectX, Windows Imaging Component (WIC), DirectShow, Media Foundation, Background Intelligent Transfer Service (BITS), Windows Management Instrumentation (WMI) 等等. COM 中最基本的概念是*接口*——一个由单个容器下的一组函数组成的契约. 我们将在第 18 章中探讨 COM 的基础知识.
自然地, 多年来, 针对这两种基本 API 风格开发了各种包装器, 有些由 Microsoft 开发, 有些由其他人开发. 以下是 Microsoft 开发的一些常见包装器:
- Microsoft Foundation Classes (MFC) - C++ 包装器, 主要用于 Windows 暴露的用户界面 (UI) 功能——处理窗口, 控件, 菜单, GDI, 对话框等.
- Active Template Library (ATL) - 一个基于 C++ 模板的库, 旨在构建 COM 服务器和客户端. 我们将在第 18 章中使用 ATL 来简化编写与 COM 相关的代码.
- Windows Template Library (WTL) - ATL 的一个扩展, 提供了基于模板的 Windows 用户界面功能包装器. 在功能方面, 它与 MFC 相当, 但更轻量级, 并且不附带 (大型) DLL (像 MFC 那样). 我们将在本书中使用 WTL 来简化与 UI 相关的代码, 因为 UI 不是本书的重点.
- .NET - 一个框架和运行时 (Common Language Runtime - CLR), 提供一系列服务, 例如将中间语言 (IL) 即时 (JIT) 编译为本地代码和垃圾回收. .NET 可以通过利用新语言 (C# 是最著名的) 来使用, 这些语言提供了许多功能, 其中许多功能抽象了 Windows 的功能并提高了生产力. .NET 框架使用标准的 Windows API 来完成其更高级别的功能. .NET 超出了本书的范围——有关 .NET 内部工作和功能的出色介绍, 请参阅 Jeffrey Richter 的 “CLR Via C#”.
- Windows Runtime (WinRT) - 这是在 Windows 8 及更高版本中添加的最新 API 层. 其主要目标是开发基于通用 Windows 平台 (UWP) 的应用程序. 这些应用程序可以打包并上传到 Windows 应用商店, 并由任何人下载. Windows Runtime 是围绕 COM 的增强版本构建的, 因此它也由接口作为其主要 (但不是唯一) 的构建块组成. 尽管这个平台是原生的 (而不是基于 .NET), 但它可以被 C++, C# (和其他 .NET 语言) 甚至 JavaScript 使用——Microsoft 提供了*语言投影*来简化对 Windows Runtime API 的访问. Windows Runtime API 的一个子集可用于 (经典) 桌面应用程序. 我们将在第 19 章中探讨 Windows Runtime 的基础知识.
大多数标准的 Windows API 函数定义都在 `windows.h` 头文件中可用. 在某些情况下, 需要额外的头文件以及额外的导入库. 本文将指出任何此类头文件和/或库.
- 你的第一个应用程序
本节描述了使用 Visual Studio 编写一个简单应用程序, 编译并成功运行它的基本知识. 如果你已经知道这些, 可以跳过本节.
首先, 你需要安装适当的 Windows 开发工具. 以下是按顺序排列的软件简短列表:
- Visual Studio 2017 或 2019, 任何版本, 包括免费的社区版 (可从 https://visualstudio.microsoft.com/downloads/ 获取). 早期版本的 Visual Studio 也可以正常工作, 但通常最好使用最新版本, 因为这些版本包括编译器改进以及可用性增强. 在安装程序的主窗口中, 确保至少选择了*使用 C++ 的桌面开发*工作负载, 如图 1-5 所示.
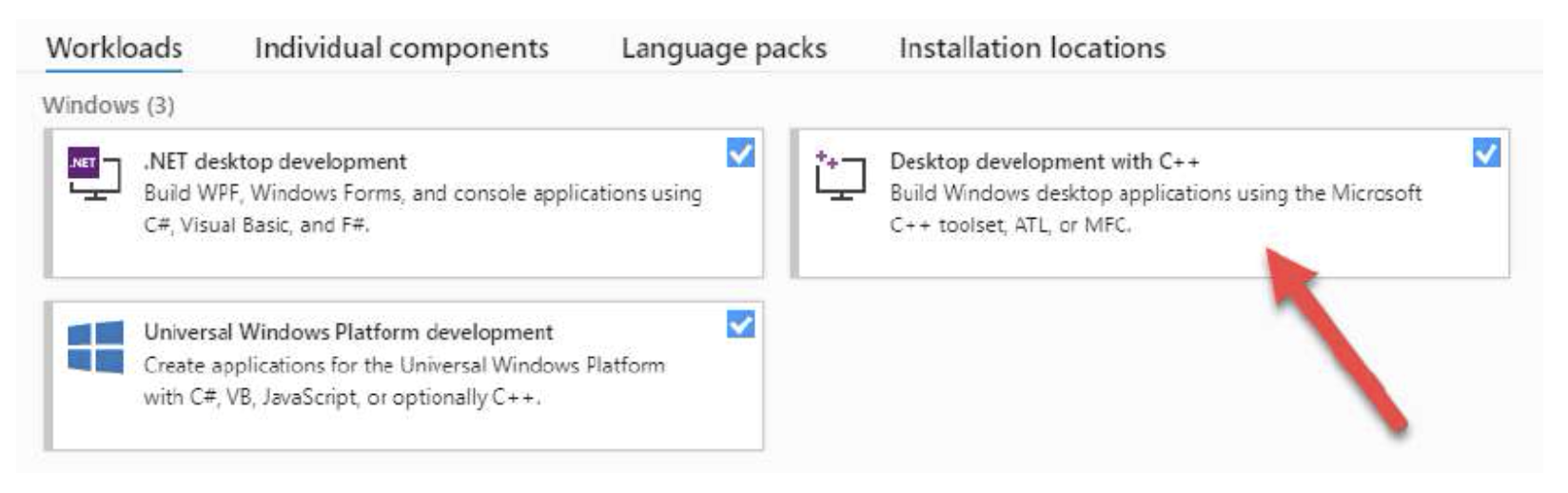
Figure 5: Visual Studio 安装程序主窗口
- Windows Software Development Kit (SDK) 是一个可选的安装项, 它提供 (可能) 更新的头文件和库, 以及各种工具.
一旦安装了 Visual Studio 2017/2019, 运行它并选择创建一个新项目.
- 在 Visual Studio 2017 中, 从菜单中选择 文件 / 新建项目…, 找到 C++ / 桌面 节点, 然后选择 Windows 控制台应用程序 项目模板, 如图 1-6 所示.
- 在 Visual Studio 2019 中, 从启动窗口选择*创建新项目*, 分别在项目类型和语言中用 `console` 和 `C++` 进行筛选, 然后选择*控制台应用* (确保列出的语言是 C++). 这如图 1-7 所示.
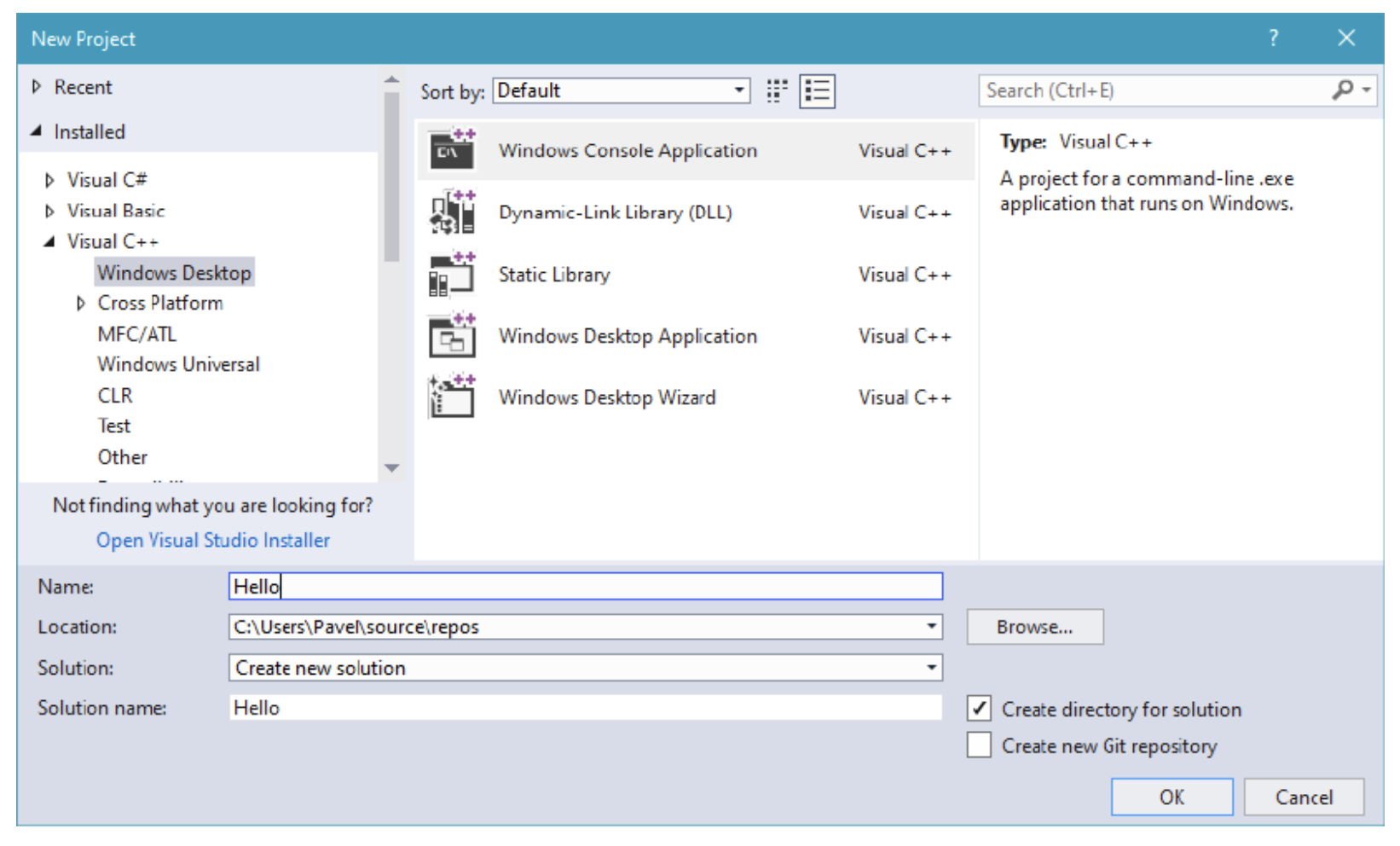
Figure 6: Visual Studio 2017 中的新项目对话框
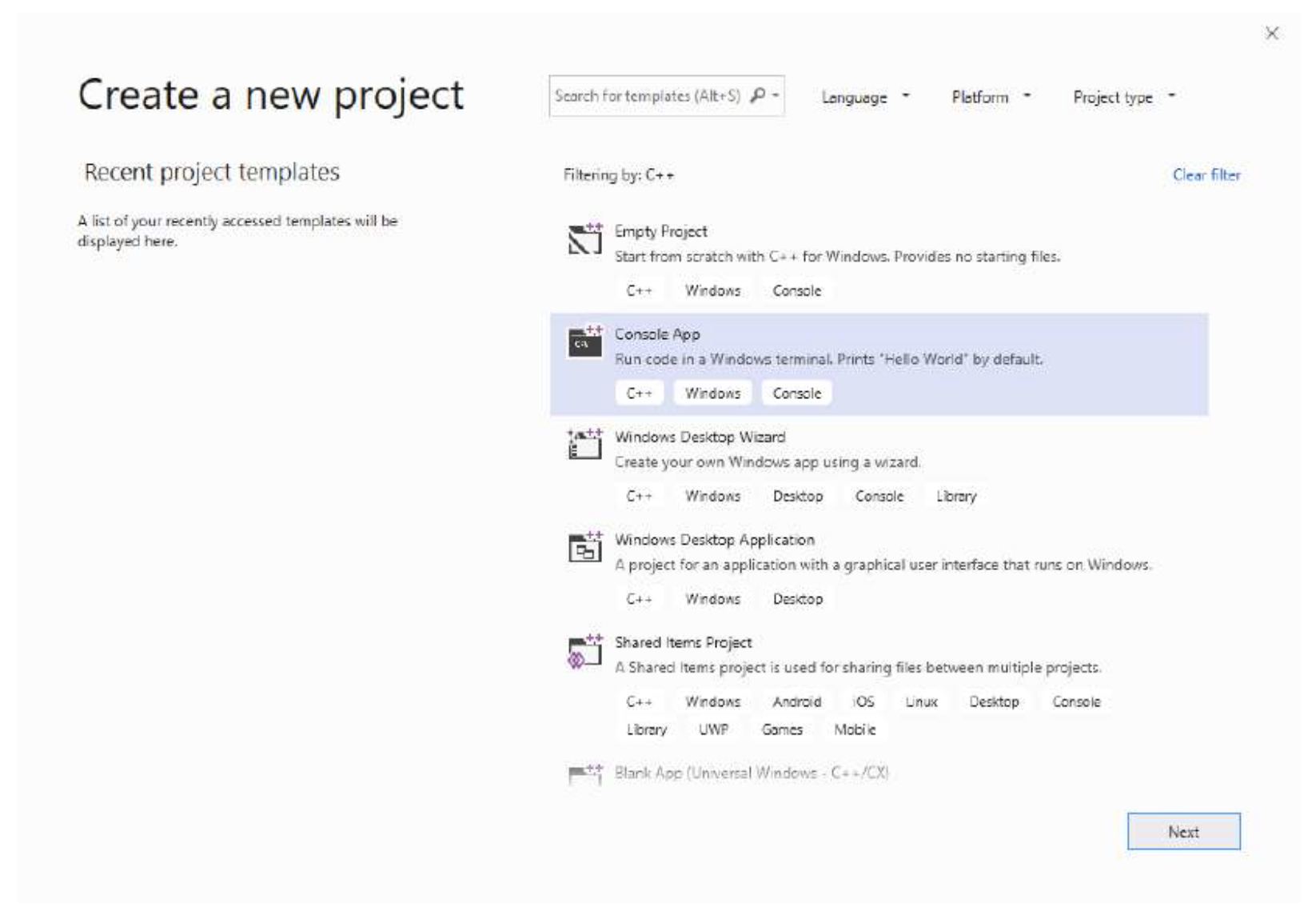
Figure 7: Visual Studio 2019 中的新项目对话框
将项目命名为 `HelloWin`, 如果需要可以更改目标文件夹, 然后单击确定. 项目应该被创建, 并在编辑器中打开一个 `HelloWin.cpp` 文件, 其中包含一个最小的 `main` 函数.
在文件顶部添加一个 `#include` 用于 `windows.h`:
#include <windows.h>
如果你的项目有预编译头 (每个 C/C++ 源文件的顶部都有一个 `#include "pch.h"`), 请将 `windows.h` 的 `#include` 添加到此文件中, 以便在第一次编译后, 后续的编译会更快.
你也可以根据喜好将其包含在 C/C++ 文件中, 但该包含必须在 `pch.h` 包含之后.
再添加一个 `#include` 用于 `stdio.h` 以便访问 `printf` 函数:
#include <stdio.h>
在第一个应用程序中, 我们将通过调用 `GetNativeSystemInfo` 函数来获取一些系统信息. 这是 `main` 函数的代码:
int main() { SYSTEM_INFO si; ::GetNativeSystemInfo(&si); printf("Number of Logical Processors: %d\n", si.dwNumberOfProcessors); printf("Page size: %d Bytes\n", si.dwPageSize); printf("Processor Mask: 0x%p\n", (PVOID)si.dwActiveProcessorMask); printf("Minimum process address: 0x%p\n", si.lpMinimumApplicationAddress); printf("Maximum process address: 0x%p\n", si.lpMaximumApplicationAddress); return 0; }
从*生成*菜单中, 选择*生成解决方案*来编译和链接项目 (技术上是解决方案中的所有项目). 一切都应该无错误地编译和链接. 按 `Ctrl+F5` 在不附加调试器的情况下启动可执行文件. (或者使用*调试*菜单并选择*开始执行(不调试)*). 应该会打开一个控制台窗口, 显示类似以下的输出:
Number of Logical Processors: 12 Page size: 4096 Bytes Processor Mask: 0x00000FFF Minimum process address: 0x00010000 Maximum process address: 0x7FFEFFFF
如果你通过按 F5 (调试菜单, 开始调试) 运行应用程序, 控制台窗口将出现并在应用程序退出时迅速消失. 使用 `Ctrl+F5` 会添加一个方便的“按任意键继续”提示, 让你在关闭窗口前查看控制台输出.
Visual Studio 通常会创建两个解决方案平台 (x86 和 x64), 可以通过位于主工具栏中的解决方案平台组合框轻松切换. 默认情况下, x86 被选中, 这会产生上面的输出. 如果你将平台切换到 x64 并重新生成 (假设你正在运行 Intel/AMD 64 位版本的 Windows), 你会得到稍微不同的输出:
Number of Logical Processors: 12 Page size: 4096 Bytes Processor Mask: 0x0000000000000FFF Minimum process address: 0x0000000000010000 Maximum process address: 0x00007FFFFFFEFFFF
这些差异源于 64 位进程使用 8 字节大小的指针, 而 32 位进程使用 4 字节的指针. 来自 `SYSTEMINFO` 结构的地址空间地址信息被类型化为指针, 因此它们的大小因进程的“位数”而异. 我们将在本章后面的“32位 vs. 64位开发”部分更详细地讨论 32 位和 64 位开发.
不用担心这个小应用程序呈现的信息的含义 (尽管其中一些是自解释的). 我们将在后面的章节中探讨这些术语.
在上述代码中, 函数名前使用双冒号 `::GetNativeSystemInfo` 是为了强调该函数是 Windows API 的一部分, 而不是当前 C++ 类的某个成员函数. 在这个例子中, 这是显而易见的, 因为周围没有 C++ 类, 但这个约定将在全书中使用 (它还稍微加快了编译器的函数查找). 更多编码约定将在本章后面的“编码约定”部分描述.
1.2.4. 使用字符串
在经典的 C 语言中, 字符串不是真正的类型, 而只是指向以零结尾的字符的指针. Windows API 在许多情况下以这种方式使用字符串, 但并非所有情况都是如此. 在处理字符串时, 编码问题就会出现. 在本节中, 我们将大致了解字符串以及它们在 Windows API 中的使用方式.
在经典的 C 语言中, 只有一个代表字符的类型 - `char`. 由 `char` 代表的字符最多为 8 位大小, 其中前 7 位值利用 ASCII 编码. 今天的系统必须支持来自多种语言的多个字符集, 而这些不能用 8 位来容纳. 因此, 在 Unicode 这个总称下创建了新的编码, 官方可在 http://www.unicode.org 在线获取.
Unicode 联盟定义了几种其他的字符编码. 以下是常见的几种:
- UTF-8 - 网页上普遍使用的编码. 这种编码对属于 ASCII 集的拉丁字符使用一个字节, 对其他语言 (如中文, 希伯来语, 阿拉伯语等) 的字符使用更多字节. 这种编码之所以流行, 是因为如果文本主要是英文, 它的大小就很紧凑. 通常, UTF-8 为每个字符使用一到四个字节.
- UTF-16 - 在大多数情况下为每个字符使用两个字节, 并且仅用两个字节就包含了所有语言. 一些来自中文和日文的更深奥的字符可能需要四个字节, 但这些很少见.
- UTF-32 - 每个字符使用四个字节. 这是最容易使用的, 但也可能是最浪费的.
UTF 代表 Unicode 转换格式 (Unicode Transformation Format).
当大小很重要时, UTF-8 可能是最好的, 但从编程的角度来看, 它是有问题的, 因为不能使用随机访问. 例如, 要获取 UTF-8 字符串中的第 100 个字符, 代码需要从字符串的开头扫描并按顺序工作, 因为无法知道第 100 个字符可能在哪里. 另一方面, UTF-16 在编程上要方便得多 (如果我们忽略深奥的情况), 因为访问第 100 个字符意味着在字符串的起始地址上增加 200 个字节. UTF-32 太浪费了, 很少使用.
幸运的是, Windows 在其内核内部使用 UTF-16, 其中每个字符正好是 2 个字节. Windows API 也效仿, 使用 UTF-16 编码, 这很好, 因为当 API 调用最终到达内核时, 字符串不需要转换. 然而, Windows API 有一点小复杂.
Windows API 的部分内容是从 16 位 Windows 和消费者 Windows (Windows 95/98) 迁移过来的. 这些系统使用 ASCII 作为它们的主要工作方式, 这意味着 Windows API 使用 ASCII 字符串而不是 UTF-16. 当引入双字节编码时, 出现了进一步的复杂性, 其中每个字符的大小为一或两个字节, 失去了随机访问的优势.
所有这些的最终结果是, 出于兼容性原因, Windows API 包含 UTF-16 和 ASCII 函数. 由于今天上述系统已不存在, 最好放弃单字节每字符的字符串, 只使用 UTF-16 函数. 使用 ASCII 函数将导致字符串被转换为 UTF-16, 然后再与 UTF-16 函数一起使用.
在与 .NET Framework 互操作时, UTF-16 也很有利, 因为 .NET 的字符串类型只存储 UTF-16 字符. 这意味着将 UTF-16 字符串传递给 .NET 不需要任何转换或复制.
这里有一个函数 `CreateMutex` 的例子, 如果在网上搜索, 会找到两个函数之一: `CreateMutexA` 和 `CreateMutexW`. 离线文档给出了这个原型:
HANDLE CreateMutex( _In_opt_ LPSECURITY_ATTRIBUTES lpMutexAttributes, _In_ BOOL bInitialOwner, _In_opt_ LPCTSTR lpName);
`Inopt_` 和其他类似的注解被称为语法注解语言 (Syntax Annotation Language, SAL), 用于向函数和结构定义传达元数据信息. 这对人类和静态分析工具都可能有用. C++ 编译器目前忽略这些注解, 但 Visual Studio Enterprise 版本中可用的静态分析器使用它来在实际运行程序之前检测潜在错误.
现在让我们专注于最后一个参数, 这是一个类型为 `LPCTSTR` 的字符串指针. 让我们来分解一下: L=Long P=Pointer C=Constant STR=String. 唯一的谜团是中间的 T. `LPCTSTR` 实际上是一个 `typedef`, 具有以下定义之一:
typedef LPCSTR LPCTSTR; // const char* (UNICODE not defined) typedef LPCWSTR LPCTSTR; // const wchar_t* (UNICODE defined)
“long pointer”这个术语今天已经没有什么意义了. 在特定进程中, 所有指针的大小都相同 (32 位进程中为 4 字节, 64 位进程中为 8 字节). “long”和“short” (或“near”) 这些术语是 16 位 Windows 的遗留物, 当时这些术语确实有不同的含义. 另外, `LPCTSTR` 及类似类型还有另一个等效项——没有 L 的——`PCTSTR`, `PCWSTR` 等. 这些在源代码中通常更受青睐.
`UNICODE` 编译常量的定义使 `LPCTSTR` 扩展为 UTF-16 字符串, 而其缺失则扩展为 ASCII 字符串. 这也意味着 `CreateMutex` 不能是一个函数, 因为 C 语言不允许函数重载, 即单个函数名可以有多个原型. `CreateMutex` 是一个宏, 根据 `UNICODE` 是否定义, 扩展为 `CreateMutexW` (已定义) 或 `CreateMutexA` (未定义). Visual Studio 在所有新项目中默认定义 `UNICODE` 常量, 这是件好事. 我们总是希望使用 UTF-16 函数来防止从 ANSI 到 UTF-16 的转换 (当然, 对于包含非 ASCII 字符的字符串, 这种转换肯定会丢失信息).
`CreateMutexW` 中的 W 代表 Wide, `CreateMutexA` 中的 A 代表 ANSI 或 ASCII.
如果代码需要使用一个常量 UTF-16 字符串, 就在字符串前加上 `L` 前缀, 以指示编译器将字符串转换为 UTF-16. 这里有两个版本的字符串, 一个是 ASCII, 另一个是 UTF-16:
const char name1[] = "Hello"; // 6 bytes (including NULL terminator) const wchar_t name2[] = L"Hello"; // 12 bytes (including UTF-16 NULL terminator)
从现在开始, 我们将使用术语“Unicode”来指代 UTF-16, 除非另有明确说明.
使用宏引出了一个问题, 即我们如何编译使用常量字符串的代码, 而不明确选择 ASCII 与 Unicode? 答案在于另一个宏, `TEXT`. 以下是 `CreateMutex` 的一个例子:
HANDLE hMutex = ::CreateMutex(nullptr, FALSE, TEXT("MyMutex"));
`TEXT` 宏根据是否定义了 `UNICODE` 宏, 扩展为带或不带“L”前缀的常量字符串. 由于 ASCII 函数的开销更大, 因为它们在调用宽函数之前会转换其值, 我们应该永远不要使用 ASCII 函数. 这意味着我们可以简单地使用“L”前缀而不用 `TEXT` 宏. 我们将在全书中采用这种约定.
`TEXT` 宏有一个更短的版本, 叫做 `T`, 定义在 `<tchar.h>` 中. 它们是等效的. 使用这些宏仍然是一种相当普遍的做法, 这本身并不坏. 然而, 我倾向于不使用它.
与 `LPCTSTR` 类似, 还有其他的 `typedef` 允许根据 `UNICODE` 编译常量使用 ASCII 或 Unicode. 表 1-1 显示了其中一些 `typedef`.
| 通用类型 | ASCII 类型 | Unicode 类型 |
| TCHAR | char, CHAR | wchart, WCHAR |
| LPTSTR, PTSTR | char*, CHAR*, PSTR | wchart*, WCHAR*, PWSTR |
| LPCTSTR, PCTSTR | const char*, PCSTR | const wchart*, PCWSTR |
- C/C++ 运行时中的字符串
C/C++ 运行时有两套用于操作字符串的函数. 经典的 (ASCII) 函数以“str”开头, 例如 `strlen`, `strcpy`, `strcat` 等, 但也有 Unicode 版本以“wcs”开头, 例如 `wcslen`, `wcscpy`, `wcscat` 等.
与 Windows API 一样, 也有一套宏, 根据另一个编译常量 `UNICODE` (注意下划线) 扩展为 ASCII 或 Unicode 版本. 这些函数的前缀是“tcs”. 所以我们有 `tcslen`, `tcscpy`, `tcscat` 等函数, 它们都使用 `TCHAR` 类型.
Visual Studio 默认定义 `UNICODE` 常量, 所以如果我们使用“tcs”函数, 我们会得到 Unicode 函数. 如果只定义了“UNICODE”常量中的一个, 那将非常奇怪, 所以要避免这种情况.
- 字符串输出参数
像 `CreateMutex` 那样将字符串作为输入传递给函数是非常常见的. 另一个常见的需求是以字符串的形式接收结果. Windows API 使用几种方式来传回字符串结果.
第一种 (也是更常见的) 情况是客户端代码分配一个缓冲区来保存结果字符串, 并向 API 提供缓冲区的大小 (字符串可以容纳的最大大小), API 则将字符串写入到指定大小的缓冲区中. 一些 API 还会返回实际写入的字符数和/或如果缓冲区太小所需的字符数.
考虑 `GetSystemDirectory` 函数, 定义如下:
UINT GetSystemDirectory( _Out_ LPTSTR lpBuffer, _In_ UINT uSize);
该函数接受一个字符串缓冲区及其大小, 并返回写入的字符数. 请注意, 所有大小都是以*字符*为单位, 而不是字节, 这很方便. 函数在失败时返回零. 以下是一个示例用法 (暂时省略错误处理):
WCHAR path[MAX_PATH]; ::GetSystemDirectory(path, MAX_PATH); printf("System directory: %ws\n", path);
不要被指针类型迷惑——`GetSystemDirectory` 的声明并不意味着你只提供一个指针. 相反, 你必须分配一个缓冲区并传递指向此缓冲区的指针.
`MAXPATH` 在 Windows 头文件中定义为 260, 这是 Windows 中标准的最大路径长度 (从 Windows 10 开始, 这个限制可以扩展, 我们将在第 11 章中看到). 注意 `printf` 使用 `%ws` 作为字符串格式来指示它是一个 Unicode 字符串, 因为 `UNICODE` 默认是定义的, 所以所有字符串都是 Unicode.
第二种常见情况是客户端代码只提供一个字符串指针 (通过其地址), API 本身分配内存并将结果指针放入提供的变量中. 这意味着客户端代码有责任在不再需要结果字符串时释放内存. 关键在于使用正确的函数来释放内存. API 的文档会指明使用哪个函数. 以下是使用 `FormatMessage` 函数的一个例子, 其 Unicode 变体定义如下:
DWORD FormatMessageW( _In_ DWORD dwFlags, _In_opt_ LPCVOID lpSource, _In_ DWORD dwMessageId, _In_ DWORD dwLanguageId, _When_((dwFlags & FORMAT_MESSAGE_ALLOCATE_BUFFER) != 0, _At_((LPWSTR*)lpBuffer, _Outptr_result_z_)) _When_((dwFlags & FORMAT_MESSAGE_ALLOCATE_BUFFER) == 0, _Out_writes_z_(nSize)) LPWSTR lpBuffer, _In_ DWORD nSize, _In_opt_ va_list *Arguments);
看起来很吓人, 对吧? 我特意包含了这个函数的完整 SAL 注解, 因为 `lpBuffer` 参数很棘手. `FormatMessage` 返回一个错误号的字符串表示 (我们将在本章后面的“API 错误”部分更详细地讨论错误). 该函数很灵活, 因为它可以自己分配字符串, 或者让客户端提供一个缓冲区来保存结果字符串. 实际行为取决于第一个 `dwFlags` 参数: 如果它包含 `FORMATMESSAGEALLOCATEBUFFER` 标志, 函数将分配正确大小的缓冲区. 如果没有该标志, 则由调用者提供存储返回字符串的空间.
所有这些使得函数有点棘手, 至少因为如果选择了前一个选项, 指针类型应该是 `LPWSTR*`——也就是说, 一个指向指针的指针, 由函数填充. 这需要一个难看的转换来让编译器满意.
以下是一个简单的 `main` 函数, 它接受命令行参数中的错误号, 并显示其字符串表示 (如果有的话). 它使用了让函数自己分配的选项.
int main(int argc, const char* argv[]) { if (argc < 2) { printf("Usage: ShowError <number>\n"); return 0; } int message = atoi(argv); LPWSTR text; DWORD chars = ::FormatMessage( FORMAT_MESSAGE_ALLOCATE_BUFFER | // function allocates FORMAT_MESSAGE_FROM_SYSTEM | FORMAT_MESSAGE_IGNORE_INSERTS, nullptr, message, 0, (LPWSTR)&text, // ugly cast 0, nullptr); if (chars > 0) { printf("Message %d: %ws\n", message, text); ::LocalFree(text); } else { printf("No such error exists\n"); } return 0; }
完整的项目名为 `ShowError`, 位于本书的 Github 仓库中.
请注意, 如果调用成功, 会调用 `LocalFree` 函数来释放字符串. `FormatMessage` 的文档说明这是释放缓冲区的函数.
这是一个示例运行:
C:\Dev\Win10SysProg\x64\Debug>ShowError.exe 2 Message 2: The system cannot find the file specified. C:\Dev\Win10SysProg\x64\Debug>ShowError.exe 5 Message 5: Access is denied. C:\Dev\Win10SysProg\x64\Debug>ShowError.exe 129 Message 129: The %1 application cannot be run in Win32 mode. C:\Dev\Win10SysProg\x64\Debug>ShowError.exe 1999 No such error exists
- 安全字符串函数
一些经典的 C/C++ 运行时字符串函数 (以及 Windows API 中的一些类似函数) 从安全性和可靠性的角度来看被认为不“安全”. 例如, `strcpy` 函数是有问题的, 因为它会复制源字符串到目标指针, 直到遇到 NULL 终止符. 这可能会溢出目标缓冲区, 在好的情况下导致崩溃 (例如, 缓冲区可能在栈上, 并破坏存储在那里的返回地址), 并被用作缓冲区溢出攻击, 其中一个备用返回地址被存储在栈上, 跳转到一个准备好的 shellcode.
为了减轻这些潜在的漏洞, Microsoft 向 C/C++ 运行时库添加了一组“安全”的字符串函数, 其中使用一个额外的参数来指定目标缓冲区的最大大小, 因此它永远不会溢出. 这些函数有“s”后缀, 例如 `strcpys`, `wcscats` 等.
以下是使用这些函数的一些例子:
void wmain(int argc, const wchar_t* argv[]) { // assume arc >= 2 for this demo WCHAR buffer; wcscpy_s(buffer, argv); // C++ version aware of static buffers WCHAR* buffer2 = (WCHAR*)malloc(32 * sizeof(WCHAR)); //wcscpy_s(buffer2, argv); // does not compile wcscpy_s(buffer2, 32, argv); // size in characters (not bytes) }
最大大小总是以字符而不是字节指定. 另请注意, 如果目标缓冲区是静态分配的, 这些函数能够自动计算最大大小, 这很方便.
另一组安全字符串函数也被添加到了 Windows API 中, 至少为了减少对 C/C++ 运行时的依赖. 这些函数在头文件 `<strsafe.h>` 中声明 (并实现). 它们是根据 Windows API 约定构建的, 其中函数实际上是扩展为带有“A”或“W”后缀的函数的宏. 以下是一些简单的用法示例 (使用与上面相同的声明):
StringCchCopy(buffer, _countof(buffer), argv); StringCchCat(buffer, _countof(buffer), L"cat"); StringCchCopy(buffer2, 32, argv); StringCchCat(buffer2, 32, L"cat");
“Cch” 代表字符计数 (Count of Characters).
注意这些函数没有能够处理静态分配缓冲区的 C++ 变体. 解决方案是使用 `countof` 宏, 该宏返回数组中的元素数量. 它的定义类似于 `sizeof(a)/sizeof(a[0])`, 给定一个数组 `a`.
你应该使用哪一套函数? 这主要取决于个人喜好. 重要的是避免使用经典的, 不安全的函数. 如果你确实尝试使用它们, 你会得到一个类似这样的编译器错误:
error C4996: 'wcscpy': This function or variable may be unsafe. Consider using wcscpy_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
显然, 这个错误可以通过在包含 C/C++ 头文件之前定义 `CRTSECURENOWARNINGS` 来禁用, 但这是一个坏主意. 这个宏的存在是为了帮助维护与旧源代码的兼容性, 这些代码在用新编译器编译时不应被触动.
从 Windows Vista 开始, Windows 有官方的 32 位和 64 位版本 (也有一个非商业版的 Windows XP 64 位版本). 从 Windows Server 2008 R2 开始, 所有服务器版本都只有 64 位. Microsoft 移除了 32 位服务器版本, 因为服务器通常需要大量的 RAM 和大的进程地址空间, 这使得 32 位系统对于服务器工作来说太有限了.
从 API 的角度来看, 32 位和 64 位的编程模型是相同的. 你应该能够通过在 Visual Studio 中选择所需的配置并点击生成来编译成 32 位或 64 位. 然而, 如果代码要为 32 位和 64 位目标都成功构建, 编码必须小心地正确使用类型. 在 64 位中, 指针大小为 8 字节, 而在 32 位中它们只有 4 字节. 如果假设指针的大小是某个特定值, 这种变化可能会导致错误. 例如, 考虑这个转换操作:
void* p = ...; int value = (int)p; // do something with value
这段代码是有问题的, 因为在 64 位中, 指针值被截断为 4 字节以适应 `int` (在 64 位编译中 `int` 仍然是 4 字节). 如果确实需要这样的转换, 应该使用一个替代类型 - `INTPTR`:
void* p = ...; INT_PTR value = (INT_PTR)p; // do something with value
`INTPTR` 的意思是: “一个指针大小的 int”. Windows 头文件为此精确原因定义了几种这样的类型. 其他类型无论编译的“位数”如何都保持其大小. 表 1-2 显示了一些常见类型及其大小的示例.
| type name | size (32 bit) | size (64 bit) | Description |
| ULONGPTR | 4 bytes | 8 bytes | unsigned integer the size of a pointer |
| PVOID, void* | 4 bytes | 8 bytes | void pointer |
| any pointer | 4 bytes | 8 bytes | |
| BYTE, uint8t | 1 bytes | 1 bytes | unsigned 8 bit integer |
| WORD, uint16t | 2 bytes | 2 bytes | unsigned 16 bit integer |
| DWORD, ULONG, uint32t | 4 bytes | 4 bytes | unsigned 32 bit integer |
| LONGLONG, _int64, int64t | 8 bytes | 8 bytes | signed 64 bit integer |
| SIZET, sizet | 4 bytes | 8 bytes | unsigned integer sized as native integer |
32 位和 64 位之间的差异超出了类型大小. 64 位进程的地址空间是 128 TB (Windows 8.1 及更高版本), 而 32 位进程只有 2 GB. 在 x64 系统 (Intel/AMD) 上, 32 位进程可以很好地执行, 这要归功于一个名为 WOW64 (Windows on Windows 64) 的转换层. 我们将在第 12 章中更深入地探讨这一层. 这也有一些影响, 这将在该章中讨论.
本书中的所有示例应用程序都应该在 x86 和 x64 上同样成功地构建和运行, 除非另有明确说明. 在开发过程中最好同时为 x86 和 x64 构建, 并修复可能出现的任何问题.
在本书中, 我们不会明确地涵盖 ARM 和 ARM64. 所有程序都应该可以在这样的系统上正常构建和运行 (32 位在 ARM 上, 64 位在 ARM64 上), 但我没有权限访问这样的系统, 所以无法亲自验证.
最后, 如果代码应该只在 64 位 (或只在 32 位) 中编译, 宏 `WIN64` 是为 64 位编译定义的. 例如, 我们可以将 `HelloWin` 中的以下行:
printf("Processor Mask: 0x%p\n", (PVOID)si.dwActiveProcessorMask);
替换为
#ifdef _WIN64 printf("Processor Mask: 0x%016llX\n", si.dwActiveProcessorMask); #else printf("Processor Mask: 0x%08X\n", si.dwActiveProcessorMask); #endif
这比使用 `%p` 格式字符串要清晰一些, `%p` 格式字符串在 32 位进程中自动期望 4 字节, 在 64 位进程中期望 8 字节. 这强制转换为 `PVOID`, 因为 `dwActiveProcessorMask` 是 `DWORDPTR` 类型, 与 `%p` 一起使用时会产生警告.
一个更好的选择是指定 `%zu` 或 `%zX`, 用于格式化 `sizet` 值, 相当于 `DWORDPTR`.
拥有任何编码约定对于一致性和清晰度都是好的, 但实际的约定当然是多种多样的. 本书中使用了以下编码约定.
- Windows API 函数使用双冒号前缀. 示例: `::CreateFile`.
- 类型名称使用 Pascal 命名法 (首字母大写, 每个单词的首字母也大写. 示例: Book, SolidBrush). 例外是与 UI 相关的类, 它们以大写 ‘C’ 开头; 这是为了与 WTL 保持一致.
- C++ 类中的私有成员变量以下划线开头, 并使用驼峰命名法 (首字母小写, 后续单词首字母大写). 示例: `size`, `isRunning`. 例外是 WTL 类, 其中私有成员变量名以 `m_` 开头. 这是为了与 ATL/WTL 风格保持一致.
- 变量名不使用旧的匈牙利表示法. 然而, 可能有一些偶尔的例外, 比如句柄的 `h` 前缀和指针的 `p` 前缀.
- 函数名遵循 Windows API 的约定, 使用 Pascal 命名法.
- 当需要像向量这样的通用数据类型时, 使用 C++ 标准库, 除非有充分的理由使用其他东西.
- 我们将使用 Microsoft 的 Windows Implementation Library (WIL), 它以 Nuget 包的形式发布. 这个库包含有用的类型, 以便更容易地使用 Windows API. 下一章将简要介绍 WIL.
- 一些示例有用户界面. 本书使用 Windows Template Library (WTL) 来简化与 UI 相关的代码. 你当然可以使用其他 UI 库, 如 MFC, Qt, 直接的 Windows API, 甚至 .NET 库, 如 WinForms 或 WPF (假设你知道如何从 .NET 调用本地函数). UI 不是本书的重点. 如果你需要更多关于本地 Windows UI 开发的细节, 请查阅 Charles Petzold 的经典著作“Programming Windows”, 第 6 版.
匈牙利表示法使用前缀来提示变量的类型. 示例: `szName`, `dwValue`. 这个约定现在被认为是过时的, 尽管 Windows API 中的参数名和结构成员大量使用它.
本书后面还会用到一些其他的编码约定, 当它们变得相关时将会被描述.
本书中的代码示例使用了一些 C++. 我们不会使用任何“复杂”的 C++ 特性, 主要是那些能够提高生产力, 帮助避免错误的特性. 以下是我们将使用的主要 C++ 特性:
- `nullptr` 关键字, 代表一个真正的 NULL 指针.
- `auto` 关键字, 允许在声明和初始化变量时进行类型推断. 这有助于减少混乱, 节省一些输入, 并专注于代码的重要部分.
- `new` 和 `delete` 操作符.
- 作用域枚举 (`enum class`).
- 带有成员变量和函数的类.
- 模板, 在它们有意义的地方.
- 构造函数和析构函数, 特别是用于构建 RAII (Resource Acquisition Is Initialization) 类型. RAII 将在下一章中更详细地讨论.
Windows API 函数可能会因各种原因失败. 不幸的是, 函数指示成功或失败的方式在所有函数中并不一致. 也就是说, 情况很少, 简要描述在表 1-3 中.
| function return type | Success is … | Failure is … | How to get the error number |
|---|---|---|---|
| `BOOL` | not `FALSE` (0) | `FALSE` (0) | call `GetLastError` |
| `HANDLE` | not `NULL` (0) and not `INVALIDHANDLEVALUE` (-1) | 0 or -1 | call `GetLastError` |
| `void` | cannot fail (usually) | None | Not needed, but in rare cases throws an SEH exception |
| `LSTATUS` or `LONG` | `ERRORSUCCESS` (0) | greater than zero | return value is the error itself |
| `HRESULT` | greater or equal to zero, usually `SOK` (0) | negative number | return value is the error itself |
| other | depends | depends | look up function documentation |
最常见的情况是返回一个 `BOOL` 类型. `BOOL` 类型与 C++ 的 `bool` 类型不同; `BOOL` 实际上是一个 32 位的有符号整数. 一个非零的返回值表示成功, 而返回的零 (`FALSE`) 表示函数失败. 重要的是不要显式地与 `TRUE` (1) 值进行测试, 因为成功有时可能会返回一个不同于 1 的值. 如果函数失败, 实际的错误代码可以通过调用 `GetLastError` 来获取, 该函数负责存储当前线程上发生的 API 函数的最后一个错误. 换句话说, 每个线程都有其自己的最后错误值, 这在像 Windows 这样的多线程环境中是有意义的——多个线程可能同时调用 API 函数.
以下是处理此类错误的示例:
BOOL success = ::CallSomeAPIThatReturnsBOOL(); if(!success) { // error - handle it (just print it in this example) printf("Error: %d\n", ::GetLastError()); }
表 1-3 中的第二项是用于返回 `void` 的函数. 实际上这样的函数很少, 而且大多数不会失败. 不幸的是, 有极少数这样的函数在极端情况下 (通常是内存资源非常低) 确实会失败, 并抛出结构化异常处理 (SEH) 异常. 我们将在第 20 章讨论 SEH. 你可能不需要太担心这样的函数, 因为如果其中一个失败, 这意味着整个进程甚至系统都处于大麻烦中.
接下来, 有返回 `LSTATUS` 或 `LONG` 的函数, 它们都只是有符号的 32 位整数. 使用这种方案的最常见的 API 是我们将在第 17 章中遇到的注册表函数. 这些函数如果成功则返回 `ERRORSUCCESS` (0). 否则, 返回值本身就是错误 (不需要调用 `GetLastError`).
表 1-3 列表中的下一个是 `HRESULT` 类型, 这又是一个有符号的 32 位整数. 这种返回类型对于组件对象模型 (COM) 函数是常见的 (COM 在第 18 章中讨论). 零或正值表示成功, 而负值表示错误, 由返回值标识. 在大多数情况下, 检查成功或失败是使用 `SUCCEEDED` 或 `FAILED` 宏完成的, 分别返回 `true` 或 `false`. 在极少数情况下, 代码需要查看实际值.
Windows 头文件包含一个宏, 用于将 Win32 错误 (`GetLastError`) 转换为适当的 `HRESULT`: `HRESULTFROMWIN32`, 如果 COM 方法需要基于失败的返回 `BOOL` 的 API 返回错误, 这很有用.
以下是处理基于 `HRESULT` 的错误的示例:
IGlobalInterfaceTable* pGit; HRESULT hr = ::CoCreateInstance(CLSID_StdGlobalInterfaceTable, nullptr, CLSCTX_ALL, IID_IGlobalInterfaceTable, (void**)&pGit); if(FAILED(hr)) { printf("Error: %08X\n", hr); } else { // do work pGit->Release(); // release interface pointer }
不用担心上述代码的细节. 第 21 章专门用于 COM.
表 1-3 中的最后一项是用于“其他”函数. 例如, 我们在几个部分前遇到的 `FormatMessage` 函数返回一个 `DWORD`, 指示复制到提供的缓冲区的字符数, 如果函数失败则为零. 对于这类函数, 没有硬性规定——文档是最好的指南. 幸运的是, 这样的函数并不多.
- 定义自定义错误代码
由 `GetLastError` 暴露的错误代码机制也可以被应用程序使用, 以类似的方式设置错误代码. 这是通过调用 `SetLastError` 并将错误设置在当前线程上来完成的. 一个函数可以使用许多预定义的错误代码之一, 或者它可以定义自己的错误代码. 为了防止与系统定义的代码发生任何冲突, 应用程序应在定义的错误代码中设置第 29 位.
以下是使用此技术的函数示例:
#define MY_ERROR_1 ((1 << 29) | 1) #define MY_ERROR_2 ((1 << 29) | 2) BOOL SomeApi1(int32_t, int32_t*); BOOL SomeApi2(int32_t, int32_t*); bool DoWork(int32_t value, int32_t* result) { int32_t result1; BOOL ok = ::SomeApi1(value, &result1); if (!ok) { ::SetLastError(MY_ERROR_1); return false; } int32_t result2; ok = ::SomeApi2(value, &result2); if (!ok) { ::SetLastError(MY_ERROR_2); return false; } *result = result1 + result2; return true; }
请注意, 在我的函数中, 我可以自由使用 C++ 的 `bool` 类型, 它可以是 `true` 或 `false`, 而不是一个 32 位的整数 (`BOOL`). 自定义的错误代码设置了第 29 位, 确保它们不会与系统定义的错误代码冲突.
在某些情况下, 查询当前应用程序正在其上执行的 Windows 操作系统版本是可取的. Windows 版本的官方版本号如表 1-4 所示.
| Windows 版本名称 | 官方版本号 |
|---|---|
| Windows NT 3.1 | 3.1 |
| Windows NT 3.5 | 3.5 |
| Windows NT 4.0 | 4 |
| Windows 2000 | 5.0 |
| Windows XP | 5.1 |
| Windows Server 2003 | 5.2 |
| Windows Vista / Server 2008 | 6.0 |
| Windows 7 / Server 2008 R2 | 6.1 |
| Windows 8 / Server 2012 | 6.2 |
| Windows 8.1 / Server 2012 R2 | 6.3 |
| Windows 10 / Server 2016 | 10.0 |
你可能想知道为什么版本号有这些值——我们稍后会谈到. 获取此信息的经典函数是 `GetVersionEx`, 声明如下:
typedef struct _OSVERSIONINFO { DWORD dwOSVersionInfoSize; DWORD dwMajorVersion; DWORD dwMinorVersion; DWORD dwBuildNumber; DWORD dwPlatformId; TCHAR szCSDVersion[ 128 ]; // Maintenance string for PSS usage } OSVERSIONINFO, *POSVERSIONINFO, *LPOSVERSIONINFO; BOOL GetVersionEx( _Inout_ POSVERSIONINFO pVersionInformation);
使用它相当直接:
OSVERSIONINFO vi = { sizeof(vi) }; ::GetVersionEx(&vi); printf("Version: %d.%d.%d\n", vi.dwMajorVersion, vi.dwMinorVersion, vi.dwBuildNumber);
然而, 使用最近的 SDK 编译它会导致编译错误: “error C4996: ‘GetVersionExW’: was declared deprecated”. 原因很快就会明了. 通过在包含 `<windows.h>` 之前添加以下定义, 可以移除此弃用警告:
#define BUILD_WINDOWS #include <Windows.h>
在 Windows 8 (含) 以下的 Windows 上运行上述代码片段会返回正确的 Windows 版本. 然而, 在 Windows 8.1 或 10 (及其服务器等效版本) 上运行, 将始终显示以下输出:
Version: 6.2.9200
这是 Windows 8 的 Windows 版本. 为什么? 这是微软在 Windows Vista 上遇到一些应用程序问题后设计的一种防御机制. 由于 Vista 在 2006 年 1 月发布, 几乎在 Windows XP 五年后, 许多应用程序是在 XP 时代构建的, 其中一些费力地检查最低 Windows 版本为 XP, 使用以下代码:
OSVERSIONINFO vi = { sizeof(vi) }; ::GetVersionEx(&vi); if(vi.dwMajorVersion >= 5 && vi.dwMinorVersion >= 1) { // XP or later: good to go? }
这段代码是有问题的, 因为它没有预见到主版本号为 6 或更高且次版本号为零的可能性. 所以, 对于 Vista, 上述条件失败, 并会通知用户“请使用 XP 或更高版本”. 正确的检查应该是这样的:
if(vi.dwMajorVersion > 5 || (vi.dwMajorVersion == 5 && vi.dwMinorVersion >= 1) { // XP or later: good to go! }
不幸的是, 太多应用程序有那个 bug, 所以微软为 Windows 7 决定不增加主版本号, 只将次版本号增加到 1; 这解决了这个 bug. Windows 8 的理由类似 (6.2). Windows 8.1 也是如此 (6.3). 但 Windows 10 呢? 版本应该是 6.4 吗? 这似乎是一个彻底的失败——微软能把主版本号一直留在 6 上多久? 嗯, Windows 10 的版本号是 10.0. 这是否意味着一切都好了? 不完全是. 正如我们所见, 即使在 Windows 10 上, 调用 `GetVersionEx` 也会返回 Windows 8 的数字. 这是怎么回事?
引入了一项新功能 (称为 Switchback), 它返回的 Windows 版本不高于 8 (6.2), 以防止兼容性问题, *除非*有问题的应用程序已声明其知道更高版本的 Windows 存在. 这是通过一个清单文件——一个带有配置信息的可选 XML 文件——来完成的, 该文件可用于指示对从 Vista 到 10 的特定 Windows 版本的感知.
这不仅仅是为了操纵返回的版本号, 也是为了一些 API 的行为变化以实现兼容性. 这是通过*Shims*完成的, 它根据所选的操作系统版本更改 API 的行为.
在 Visual Studio 中, 可以通过以下步骤添加一个清单文件:
- 向项目中添加一个名为 `manifest.xml` 之类的 XML 文件. 这将保存清单文件的内容.
- 填充清单 (在此列表后显示).
- 打开*项目/属性*并导航到*清单工具*节点, 输入和输出. 在*附加清单文件*中, 输入清单文件的名称 (图 1-8).
- 正常构建项目.

Figure 8: 设置清单文件
注意图 1-8 中的设置*嵌入清单 = 是*. 这会将清单作为资源嵌入到可执行文件中, 而不是将其作为与可执行文件同目录且始终命名为 `{exename}.exe.manifest` 的松散文件.
清单可以有几个元素, 但我们本章只关注一个 (我们将在适当的时候检查其他元素). 以下是清单内容:
<?xml version="1.0" encoding="utf-8"?> <assembly manifestVersion="1.0" xmlns="urn:schemas-microsoft-com:asm.v1"> <compatibility xmlns="urn:schemas-microsoft-com:compatibility.v1"> <application> <!-- Windows Vista --> <!--<supportedOS Id="{e2011457-1546-43c5-a5fe-008deee3d3f0}" />--> <!-- Windows 7 --> <!--<supportedOS Id="{35138b9a-5d96-4fbd-8e2d-a2440225f93a}" />--> <!-- Windows 8 --> <!--<supportedOS Id="{4a2f28e3-53b9-4441-ba9c-d69d4a4a6e38}" />--> <!-- Windows 8.1 --> <!--<supportedOS Id="{1f676c76-80e1-4239-95bb-83d0f6d0da78}" />--> <!-- Windows 10 --> <!--<supportedOS Id="{8e0f7a12-bfb3-4fe8-b9a5-48fd50a15a9a}" />--> </application> </compatibility> </assembly>
获取一个不错的清单文件进行调整的最简单方法是 (或许具有讽刺意味地) 创建一个简单的控制台 C# 应用程序, 然后向项目中添加一个*应用程序清单文件*项, 这将生成上述 XML 以及其他元素.
各种操作系统版本的 GUID 是在这些版本发布时创建的. 这意味着在 Windows 7 时代开发的应用程序无法获得 Windows 10 的版本, 例如.
如果你取消注释 Windows 8.1 版本并重新运行应用程序, 输出将是:
Version: 6.3.9600
如果你取消注释 Windows 10 GUID (无论 Windows 8.1 GUID 是否被注释掉都不重要), 你将获得真正的 Windows 10 版本 (当然, 如果在 Windows 10 机器上运行):
Version: 10.0.18362
- 获取 Windows 版本
鉴于 `GetVersionEx` 已被弃用 (至少出于上一节讨论的原因), 获取 Windows 版本的正确方法是什么? 有一套新的 API 可用, 它们可以返回结果, 但不是简单的数字形式, 而是通过对 Windows 版本问题返回 `true/false`. 这些 API 在 `<versionhelpers.h>` 头文件中可用.
这里是一些包含的函数: `IsWindowsXPOrGreater`, `IsWindowsXPSP3OrGreater`, `IsWindows7OrGreater`, `IsWindows8Point1OrGreater`, `IsWindows10OrGreater`, `IsWindowsServer`. 它们的使用很简单——它们不接受任何参数, 返回 `TRUE` 或 `FALSE`. 它们的实现使用了另一个与版本相关的函数, `VerifyVersionInfo`:
BOOL VerifyVersionInfo( _Inout_ POSVERSIONINFOEX pVersionInformation, _In_ DWORD dwTypeMask, _In_ DWORDLONG dwlConditionMask);
这个函数知道如何根据指定的标准 (dwConditionMask) 比较版本号, 例如主版本号或次版本号. 你可以在 `versionhelper.h` 内部找到所有布尔函数的实现.
有一种未文档化 (但可靠) 的方法可以获取版本号, 而不考虑清单文件, 也不调用 `GetVersionEx`. 它基于一个名为 `KUSERSHAREDDATA` 的数据结构, 该结构被映射到每个进程的相同虚拟地址 (`0x7FFE0000`). 其声明在此 Microsoft 链接中列出: https://docs.microsoft.com/en-us/windows-hardware/drivers/ddi/content/ntddk/ns-ntddk-kuser_shared_data. Windows 版本号是此共享结构的一部分, 在相同的偏移量处. 以下是显示 Windows 版本号的另一种方法:
auto sharedUserData = (BYTE*)0x7FFE0000; printf("Version: %d.%d.%d\n", *(ULONG*)(sharedUserData + 0x26c), // major version offset *(ULONG*)(sharedUserData + 0x270), // minor version offset *(ULONG*)(sharedUserData + 0x260)); // build number offset (Windows 10)
当然, 建议使用官方 API 而不是 `KUSERSHAREDDATA`.
- 编写一个控制台应用程序, 通过调用以下 API 打印比 `HelloWin` 应用程序更早显示的系统信息: `GetNativeSystemInfo`, `GetComputerName`, `GetWindowsDirectory`, `QueryPerformanceCounter`, `GetProductInfo`, `GetComputerObjectName`. 如果发生错误, 请处理它们.
在本章中, 我们从架构和编程两个方面探讨了 Windows 的基础知识. 在下一章中, 我们将深入研究内核对象和句柄, 因为它们构成了使用 Windows 的许多方面的基础.
1.3. 第 2 章: 对象和句柄
Windows 是一个基于对象的操作系统, 暴露了各种类型的对象 (通常称为*内核对象*), 它们提供了 Windows 的大部分功能. 对象类型的例子有进程, 线程和文件. 在本章中, 我们将讨论与内核对象相关的一般理论, 而不涉及任何特定对象类型的太多细节. 后续章节将详细介绍许多这些类型.
本章内容:
- 内核对象
- 句柄
- 创建对象
- 对象名称
- 共享内核对象
- 私有对象命名空间
1.3.1. 内核对象
Windows 内核为用户模式进程, 内核本身和内核模式驱动程序暴露了各种类型的对象. 这些类型的实例是系统 (内核) 空间中的数据结构, 由对象管理器 (Executive 的一部分) 在用户或内核模式代码请求时创建和管理. 内核对象是引用计数的, 因此只有当对象的最后一个引用被释放时, 对象才会被销毁并从内存中释放.
Windows 内核支持相当多的对象类型. 要一窥究竟, 请运行 Sysinternals 的 WinObj 工具 (提升权限) 并找到 `ObjectTypes` 目录. 图 2-1 展示了它的样子. 这些类型可以根据它们的可见性和用途进行分类:
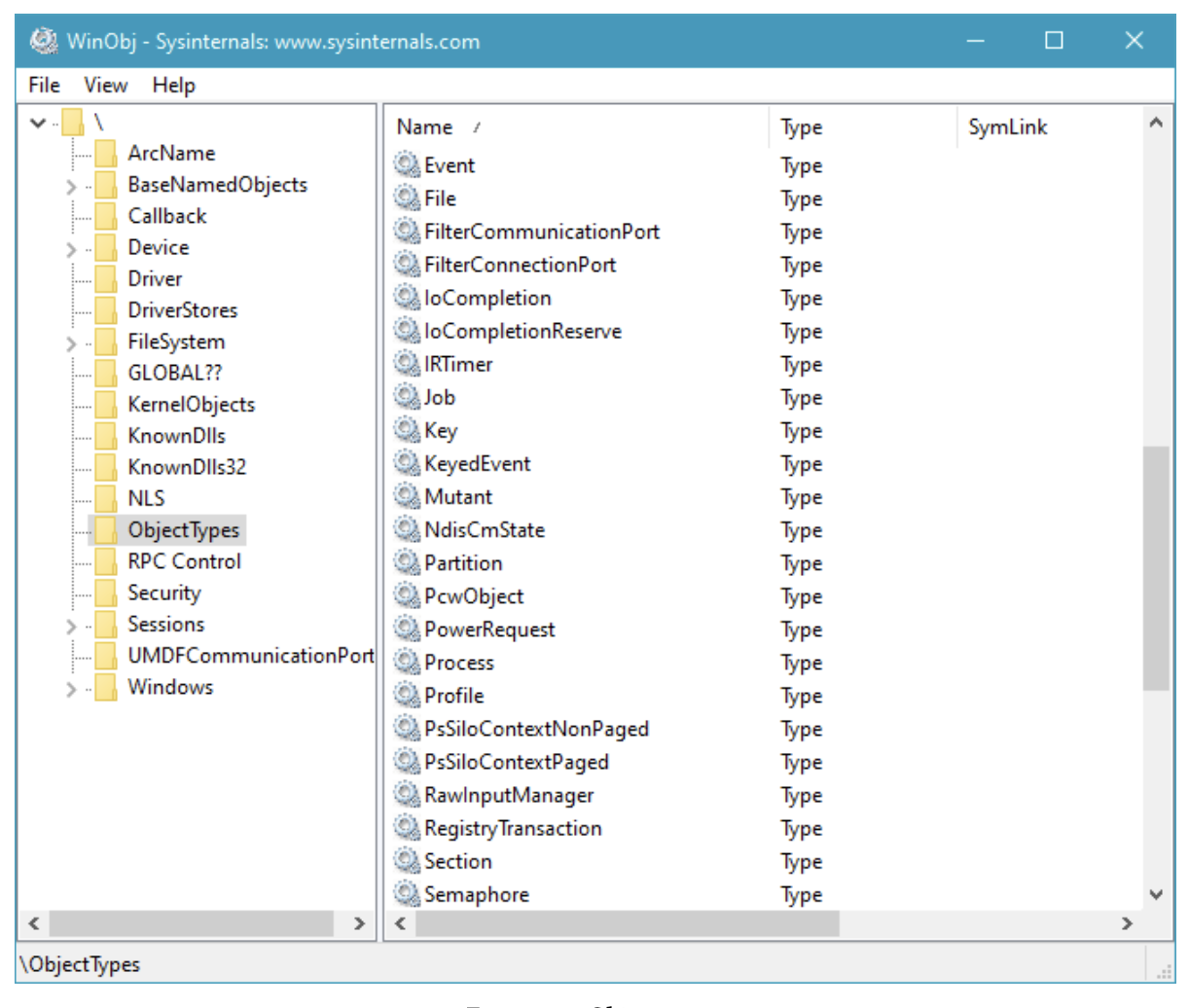
Figure 9: 对象类型
- 通过 Windows API 导出到用户模式的类型. 示例: mutex, semaphore, file, process, thread, timer. 本书讨论了许多这些对象类型.
- 未导出到用户模式, 但在 Windows 驱动程序工具包 (WDK) 中为设备驱动程序编写者记录的类型. 示例: device, driver, callback.
- 即使在 WDK 中也未记录的类型 (至少在撰写本文时). 这些对象类型仅供内核本身使用. 示例: partition, keyed event, core messaging.
内核对象的主要属性如图 2-2 所示.
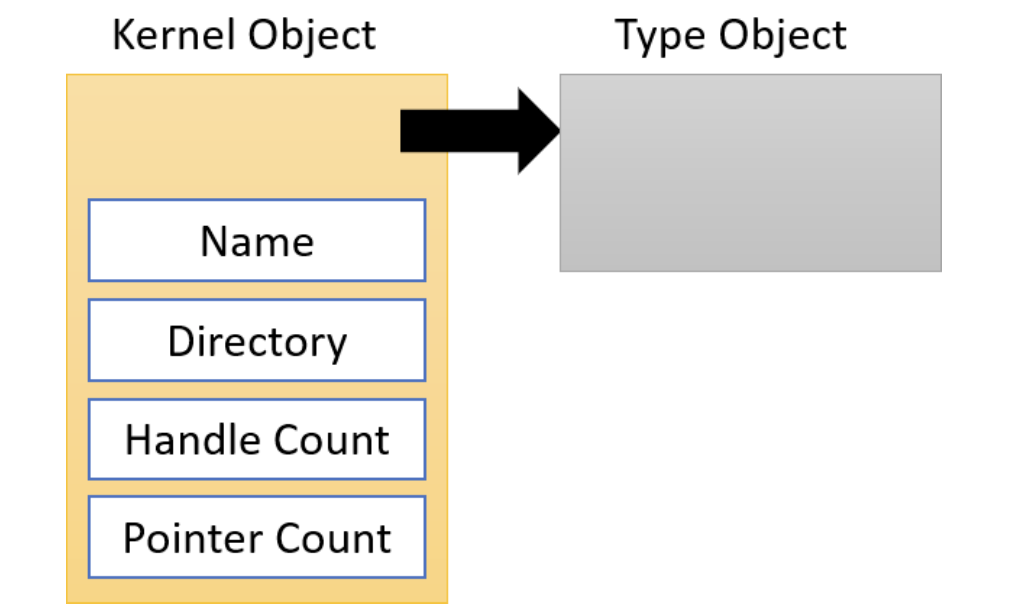
Figure 10: 内核对象属性
由于内核对象驻留在系统空间中, 因此无法从用户模式直接访问它们. 应用程序必须使用一种称为*句柄*的间接机制来访问内核对象. 句柄至少提供以下好处:
- 未来 Windows 版本中对象类型数据结构的任何更改都不会影响任何客户端.
- 可以通过安全访问检查来控制对对象的访问.
- 句柄对进程是私有的, 因此一个进程中特定对象的句柄在另一个进程上下文中没有任何意义.
内核对象是引用计数的. 对象管理器维护一个句柄计数和一个指针计数, 两者之和是对象的总引用计数 (直接指针可以从内核模式获得). 一旦用户模式客户端不再需要一个对象, 客户端代码应该通过调用 `CloseHandle` 来关闭用于访问该对象的句柄. 从那时起, 代码应将该句柄视为无效. 尝试通过关闭的句柄访问对象将失败, `GetLastError` 将返回 `ERRORINVALIDHANDLE` (6). 在一般情况下, 客户端不知道对象是否已被销毁. 如果对象的引用计数降至零, 对象管理器将删除该对象.
句柄值是 4 的倍数, 第一个有效句柄值为 4; 零永远不是有效的句柄值. 这个方案在 64 位系统上没有改变.
- 运行单个实例进程
`ERRORALREADYEXIST` 情况的一个相当众所周知的用法是限制一个可执行文件只有一个进程实例. 通常, 如果你在资源管理器中双击一个可执行文件, 就会基于该可执行文件生成一个新进程. 如果你重复此操作, 则会基于相同的可执行文件创建另一个进程. 如果你想阻止第二个进程启动, 或者至少让它在检测到同一可执行文件的另一个进程实例已在运行时关闭, 该怎么办.
诀窍是使用一些命名的内核对象 (通常使用互斥体, 尽管任何命名的对象类型都可以代替使用), 其中创建了一个具有特定名称的对象. 如果该对象已存在, 则必须有另一个实例已在运行, 因此该进程可以关闭 (可能会通知其同胞这一事实).
`SingleInstance` 演示应用程序演示了如何实现这一点. 这是一个基于 WTL 构建的对话框应用程序. 图 2-3 显示了此应用程序运行时的样子. 如果你尝试启动此应用程序的更多实例, 你会发现第一个窗口记录了来自新进程实例的消息, 然后该实例退出.
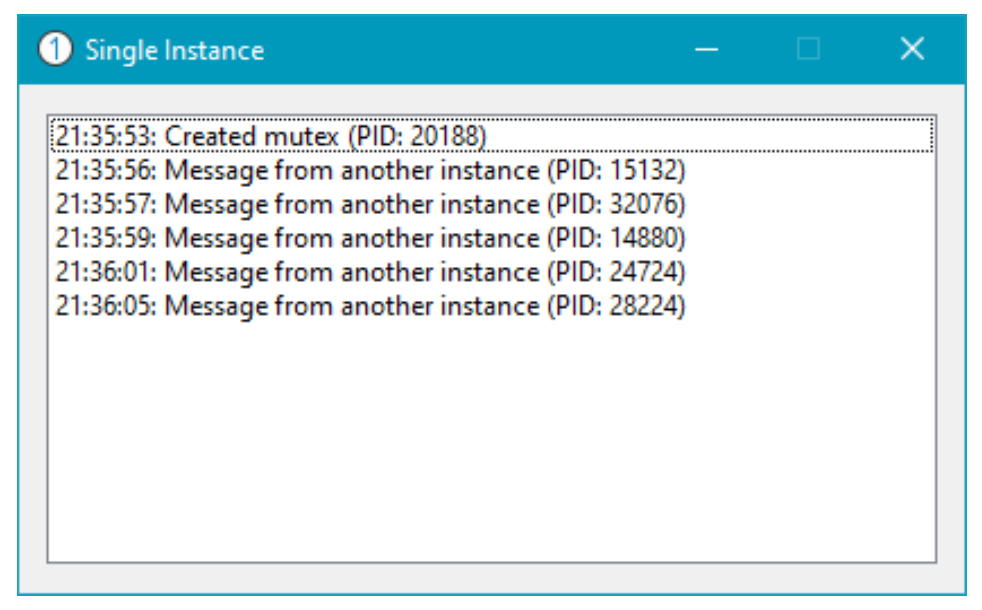 在 `WinMain` 函数中, 我们首先创建互斥体. 如果失败, 那么说明出了很严重的问题, 我们就退出.
在 `WinMain` 函数中, 我们首先创建互斥体. 如果失败, 那么说明出了很严重的问题, 我们就退出.
HANDLE hMutex = ::CreateMutex(nullptr, FALSE, L"SingleInstanceMutex"); if (!hMutex) { CString text; text.Format(L"Failed to create mutex (Error: %d)", ::GetLastError()); ::MessageBox(nullptr, text, L"Single Instance", MB_OK); return 0; }
创建互斥体失败应该极其罕见. 最可能的失败情况是另一个同名的内核对象 (不是互斥体) 已经存在.
现在我们得到了一个正确的互斥体句柄, 唯一的问题是互斥体是实际创建的, 还是我们收到了一个到现有互斥体的另一个句柄 (大概是由这个可执行文件的先前实例创建的):
if (::GetLastError() == ERROR_ALREADY_EXISTS) { NotifyOtherInstance(); return 0; }
如果在 `CreateMutex` 调用之前对象已存在, 那么我们调用一个辅助函数, 该函数向现有实例发送一些消息并退出. 这是 `NotifyOtherInstance`:
#define WM_NOTIFY_INSTANCE (WM_USER + 100) void NotifyOtherInstance() { auto hWnd = ::FindWindow(nullptr, L"Single Instance"); if (!hWnd) { ::MessageBox(nullptr, L"Failed to locate other instance window", L"Single Instance", MB_OK); return; } ::PostMessage(hWnd, WM_NOTIFY_INSTANCE, ::GetCurrentProcessId(), 0); ::ShowWindow(hWnd, SW_NORMAL); ::SetForegroundWindow(hWnd); }
该函数使用 `FindWindow` 函数搜索现有窗口, 并使用窗口标题作为搜索条件. 这在一般情况下并不理想, 但对于此示例来说已经足够好.
一旦找到窗口, 我们就向该窗口发送一个自定义消息, 并将当前进程 ID 作为参数. 这会显示在对话框的列表框中.
谜题的最后一部分是由对话框处理 `WMNOTIFYINSTANCE` 消息. 在 WTL 中, 窗口消息使用宏映射到函数. `MainDlg.h` 中对话框类 (`CMainDlg`) 的消息映射重复如下:
BEGIN_MSG_MAP(CMainDlg) MESSAGE_HANDLER(WM_NOTIFY_INSTANCE, OnNotifyInstance) MESSAGE_HANDLER(WM_INITDIALOG, OnInitDialog) COMMAND_ID_HANDLER(IDCANCEL, OnCancel) END_MSG_MAP()
自定义消息映射到 `OnNotifyInstance` 成员函数, 实现如下:
LRESULT CMainDlg::OnNotifyInstance(UINT, WPARAM wParam, LPARAM, BOOL &) { CString text; text.Format(L"Message from another instance (PID: %d)", wParam); AddText(text); return 0; }
进程 ID 从 `wParam` 参数中提取出来, 并将一些文本添加到列表框中, 使用 `AddText` 辅助函数:
void CMainDlg::AddText(PCWSTR text) { CTime dt = CTime::GetCurrentTime(); m_List.AddString(dt.Format(L"%T") + L": " + text); }
`mList` 是 `CListBox` 类型, 一个用于 Windows 列表框控件的 WTL 包装器.
- 句柄
如前一节所述, 句柄间接指向内核空间中的一个小数据结构, 该结构保存了该句柄的一些信息. 图 2-4 描绘了 32 位和 64 位系统上此数据结构的形态.

Figure 11: 句柄条目
在 32 位系统上, 此句柄条目大小为 8 字节, 在 64 位系统上为 16 字节 (技术上 12 字节就足够了, 但为了对齐目的扩展到 16 字节). 每个条目都包含以下成分:
- 指向实际对象的指针. 由于低位用于标志和提高 CPU 访问时间的地址对齐, 对象的地址在 32 位系统上是 8 的倍数, 在 64 位系统上是 16 的倍数.
- 访问掩码, 指示可以用此句柄做什么. 换句话说, 访问掩码是句柄的能力.
- 三个标志: 继承 (Inheritance), 防止关闭 (Protect from close) 和关闭时审核 (Audit on close) (稍后讨论).
访问掩码是一个位掩码, 其中每个“1”位指示可以使用该句柄执行的某个操作. 访问掩码在创建对象或打开现有对象时设置. 如果对象是创建的, 则调用者通常对对象拥有完全访问权限. 但如果对象是打开的, 调用者需要指定所需的访问掩码, 这可能会也可能不会得到.
例如, 如果一个应用程序想要终止某个进程, 它必须首先调用 `OpenProcess` 函数, 以获取具有至少 `PROCESSTERMINATE` 访问掩码的所需进程的句柄, 否则无法用该句柄终止进程. 如果调用成功, 那么对 `TerminateProcess` 的调用就必定成功.
以下是给定进程 ID 终止进程的示例:
bool KillProcess(DWORD pid) { // open a powerful-enough handle to the process HANDLE hProcess = ::OpenProcess(PROCESS_TERMINATE, FALSE, pid); if (!hProcess) return false; // now kill it with some arbitrary exit code BOOL success = ::TerminateProcess(hProcess, 1); // close the handle ::CloseHandle(hProcess); return success != FALSE; }
`OpenProcess` 函数具有以下原型:
HANDLE OpenProcess( _In_ DWORD dwDesiredAccess, // the access mask _In_ BOOL bInheritHandle, // inheritance flag _In_ DWORD dwProcessId); // process ID
由于这是一个 `Open` 操作, 所讨论的对象已经存在, 客户端需要指定它需要什么访问掩码来访问对象. 访问掩码有两种类型的访问位: 通用位和特定位. 我们将在第 16 章 (“安全性”) 中详细讨论这些细节. 进程的一个特定访问位是上面示例中使用的 `PROCESSTERMINATE`. 其他位包括 `PROCESSQUERYINFORMATION`, `PROCESSVMOPERATION` 等. 请参考 `OpenProcess` 的文档以找到完整的列表.
客户端代码应该使用什么访问掩码? 通常, 它应该反映客户端代码打算对对象执行的操作. 请求超过需要的可能会失败, 而请求不足显然是不够的.
与每个句柄关联的标志如下:
- 继承 - 此标志用于句柄继承——一种允许在协作进程之间共享对象的机制. 我们将在第 3 章中讨论句柄继承.
- 关闭时审核 - 此标志指示当该句柄关闭时, 是否应在安全日志中写入审计条目. 此标志很少使用, 默认是关闭的.
- 防止关闭 - 设置此标志可防止句柄被关闭. 调用 `CloseHandle` 将返回 `FALSE`, `GetLastError` 返回 `ERRORINVALIDHANLDLE` (6). 如果进程在调试器下运行, 则会引发一个异常, 并显示以下消息: “0xC0000235: NtClose was called on a handle that was protected from close via NtSetInformationObject”. 此标志很少使用.
可以使用 `SetHandleInformation` 函数更改继承和保护标志, 其定义如下:
#define HANDLE_FLAG_INHERIT 0x00000001 #define HANDLE_FLAG_PROTECT_FROM_CLOSE 0x00000002 BOOL SetHandleInformation( _In_ HANDLE hObject, _In_ DWORD dwMask, _In_ DWORD dwFlags);
第一个参数是句柄本身. 第二个参数是一个位掩码, 指示要操作的标志. 最后一个参数是这些标志的实际值. 例如, 要在某个句柄上设置“防止关闭”位, 可以使用以下代码:
::SetHandleInformation(h, HANDLE_FLAG_PROTECT_FROM_CLOSE, HANDLE_FLAG_PROTECT_FROM_CLOSE);
相反, 以下代码片段移除了这个位:
::SetHandleInformation(h, HANDLE_FLAG_PROTECT_FROM_CLOSE, 0);
也存在一个用于读回这些标志的相反函数:
BOOL GetHandleInformation( _In_ HANDLE hObject, _Out_ LPDWORD lpdwFlags);
可以使用 Sysinternals 的 Process Explorer 工具查看从特定进程打开的句柄. 导航到你感兴趣的进程, 并确保下方面板可见 (视图菜单, 显示下方面板). 下方面板显示两种视图之一——切换到句柄视图 (视图菜单, 下方面板视图, 句柄). 图 2-5 是该工具显示在 Explorer 进程中打开的句柄的屏幕截图. 默认显示的列只有类型和名称. 我通过右键单击标题区域并单击选择列添加了以下列: 句柄, 对象地址, 访问权限和解码的访问权限.

Figure 12: Process Explorer 中的句柄视图
以下是对这些列的简要描述:
- 句柄 - 这是句柄值本身, 仅与此进程相关. 相同的句柄值在另一个进程中可能有不同的含义, 即——指向不同的对象, 或者可能是一个空索引.
- 类型 - 对象类型名称. 这对应于图 2-1 中 WinObj 中显示的对象类型目录.
- 对象地址 - 这是实际对象结构所在的内核地址. 请注意, 这些地址在 64 位系统上以零十六进制数字结尾 (在 32 位系统上, 地址以“8”或“0”结尾). 用户模式代码对此信息无能为力, 但它可以用于调试目的: 如果你有两个对象的句柄, 并且你想知道它们是否指向同一个对象, 你可以比较对象地址; 如果它们相同, 那么它们是同一个对象.
- 访问权限 - 这是上面讨论的访问掩码. 要解释存储在此十六进制值中的位, 你需要在文档中找到访问掩码位. 为了减轻这种情况, 请使用*解码的访问权限*列.
- 解码的访问权限 - 为常见的对象类型提供访问掩码位的字符串表示. 这使得在不深入文档的情况下更容易解释访问掩码位.
我个人为 Process Explorer 实现了这一列.
Process Explorer 的句柄视图默认只显示命名对象的句柄. 要查看所有句柄, 请从视图菜单中启用*显示未命名句柄和映射*选项. 图 2-6 显示了选中此选项时视图的变化情况.

Figure 13: Process Explorer 中的句柄视图 (包括未命名对象)
“名称”这个术语比看起来要棘手. Process Explorer 认为的命名对象不一定是实际名称, 在某些情况下是方便的代号. 例如, 进程和线程句柄如图 2-5 所示, 即使进程和线程不能有基于字符串的名称. 还有其他对象类型带有“名称”, 但那不是它们的名称; 最令人困惑的是*文件*和*键*. 我们将在本章后面的“对象名称”部分讨论这种“怪异”.
进程句柄表中的句柄总数可作为 Process Explorer 和任务管理器中的一列. 图 2-7 显示了添加到任务管理器中的这一列.

Figure 14: 任务管理器中的句柄计数列
请注意, 显示的数字是句柄计数, 而不是对象计数. 这是因为可能存在多个引用同一对象的句柄.
在 Process Explorer 中双击句柄条目会打开一个对话框, 显示该对象 (而不是句柄) 的一些属性. 图 2-8 是这样一个对话框的屏幕截图.

Figure 15: Process Explorer 中的内核对象属性
基本对象信息从句柄条目中重复 (名称, 类型和地址). 这个特定的对象 (一个互斥体) 有 3 个打开的句柄. 引用数是误导性的, 并不反映实际的对象引用计数. 对于某些类型的对象 (例如互斥体), 会显示额外的信息. 在这种特殊情况下, 是互斥体当前是否被持有以及是否被放弃. (我们将在第 8 章中详细讨论互斥体).
要了解在给定时刻系统中对象和句柄的数量, 你可以运行我 Github 仓库中的 KernelObjectView 工具, 网址为 https://github.com/zodiacon/AllTools. 图 2-9 显示了该工具的屏幕截图. 显示了对象的总数 (按对象类型) 以及句柄的总数. 你可以按任何列排序; 哪个对象类型有最多的对象? 最多的句柄?

Figure 16: 内核对象查看器
- 伪句柄
一些句柄具有特殊值并且不可关闭. 这些被称为*伪句柄*, 尽管在需要时它们的使用方式与任何其他句柄一样. 在伪句柄上调用 `CloseHandle` 总是失败. 以下是返回伪句柄的函数:
- `GetCurrentProcess` (-1) - 返回到调用进程的伪句柄
- `GetCurrentThread` (-2) - 返回到调用线程的伪句柄
- `GetCurrentProcessToken` (-4) - 返回到调用进程的令牌的伪句柄
- `GetCurrentThreadToken` (-5) - 返回到调用线程的令牌的伪句柄
- `GetCurrentThreadEffectiveToken` (-6) - 返回到调用线程的有效令牌的伪句柄 (如果线程有自己的令牌——则使用它, 否则——使用其进程令牌)
最后三个伪句柄 (令牌句柄) 仅在 Windows 8 及更高版本上受支持, 其访问掩码仅为 `TOKENQUERY` 和 `TOKENQUERYSOURCE`.
进程, 线程和令牌将在本书后面讨论.
- RAII for Handles
一旦不再需要句柄, 关闭它很重要. 未能正确执行此操作的应用程序可能会出现“句柄泄漏”, 即句柄数量失控增长, 如果应用程序打开句柄但“忘记”关闭它们. 显然, 这是不好的.
一种帮助代码管理句柄而不会忘记关闭它们的方法是使用 C++ 实现一个众所周知的习语, 称为*资源获取即初始化* (RAII). 这个名字不太好, 但这个习语很好. 其思想是为包装在类型中的句柄使用析构函数, 以确保在销毁包装器对象时关闭句柄.
以下是一个句柄的简单 RAII 包装器 (为方便起见, 内联实现):
struct Handle { explicit Handle(HANDLE h = nullptr) : _h(h) {} ~Handle() { Close(); } // delete copy-ctor and copy-assignment Handle(const Handle&) = delete; Handle& operator=(const Handle&) = delete; // allow move (transfer ownership) Handle(Handle&& other) : _h(other._h) { other._h = nullptr; } Handle& operator=(Handle&& other) { if (this != &other) { Close(); _h = other._h; other._h = nullptr; } return *this; } operator bool() const { return _h != nullptr && _h != INVALID_HANDLE_VALUE; } HANDLE Get() const { return _h; } void Close() { if (_h) { ::CloseHandle(_h); _h = nullptr; } } private: HANDLE _h; };
`Handle` 类型提供了 RAII HANDLE 包装器所期望的基本操作. 复制构造函数和复制赋值运算符被移除, 因为复制可能拥有多个所有者的句柄没有意义 (导致 `CloseHandle` 对同一个句柄被调用两次). 可以通过复制句柄来实现这些复制操作 (参见本章后面的“共享内核对象”), 但这是一个不平凡的操作, 最好在隐式复制场景中避免. `bool` 运算符在当前持有的句柄有效时返回 true; 它将零和 `INVALIDHANDLEVALUE` (-1) 视为无效句柄. `Close` 函数关闭句柄, 通常由析构函数调用. 最后, `Get` 函数返回底层的句柄.
可以为 `HANDLE` 添加一个隐式转换运算符, 从而无需调用 `Get`.
以下是使用上述包装器的一些示例代码:
Handle hMyEvent(::CreateEvent(nullptr, TRUE, FALSE, nullptr)); if (!hMyEvent) { // handle failure return; } ::SetEvent(hMyEvent.Get()); // move ownership Handle hOtherEvent(std::move(hMyEvent)); ::ResetEvent(hOtherEvent.Get());
尽管编写这样一个 RAII 包装器是可能的, 但通常最好使用提供此 (及其他类似) 功能的现有库. 例如, 尽管 `CloseHandle` 是最常见的关闭句柄函数, 但还有其他类型的句柄需要不同的关闭函数. Microsoft 在 Windows 代码中使用的一个这样的库是 Windows Implementation Library (WIL). 这个库已在 Github 上发布, 并作为 Nuget 包提供.
- 使用 WIL
将 WIL 添加到项目就像添加任何其他 Nuget 包一样. 右键单击 Visual Studio 项目中的*引用*节点, 然后选择*管理 Nuget 包…*. 在*浏览*选项卡的搜索文本框中, 键入“wil”以快速搜索 WIL. 包的全名是“Microsoft.Windows.ImplementationLibrary”, 如图 2-10 所示.

Figure 17: 通过 Nuget 添加 WIL
RAII 句柄包装器位于 `<wil\resource.h>` 头文件中. 以下是使用 WIL 的相同代码:
#include <wil\resource.h> void DoWork() { wil::unique_handle hMyEvent(::CreateEvent(nullptr, TRUE, FALSE, nullptr)); if (!hMyEvent) { // handle failure return; } ::SetEvent(hMyEvent.get()); // move ownership auto hOtherEvent(std::move(hMyEvent)); ::ResetEvent(hOtherEvent.get()); }
`wil::uniquehandle` 是一个 `HANDLE` 包装器, 在销毁时调用 `CloseHandle`. 它主要模仿 C++ `std::uniqueptr<>` 类型. 请注意, 获取内部 `HANDLE` 是通过调用 `get()` 完成的. 要替换 `uniquehandle` 内部的值 (并关闭旧值), 请使用 `reset` 函数; 不带参数调用 `reset` 只会关闭底层句柄, 使包装器对象成为一个空壳.
通过添加 `using namespace wil;` 可以稍微简化代码, 这样就不需要在 WIL 中的每个类型前加上 `wil::`. 另外, 请注意可以使用 `auto` 来简化某些情况下的代码.
本书中的代码示例在某些情况下使用 WIL, 但并非全部. 从学习的角度来看, 有时使用原始类型来使事情更简单易懂会更好.
- 创建对象
所有创建新对象的函数都有一些共同的参数. 以下是 `CreateMutex` 和 `CreateEvent` 函数以作演示:
HANDLE CreateMutex( _In_opt_ LPSECURITY_ATTRIBUTES lpMutexAttributes, _In_ BOOL bInitialOwner, _In_opt_ LPCTSTR lpName); HANDLE CreateEvent( _In_opt_ LPSECURITY_ATTRIBUTES lpEventAttributes, _In_ BOOL bManualReset, _In_ BOOL bInitialState, _In_opt_ LPCTSTR lpName);
请注意, 两个函数都接受一个类型为 `SECURITYATTRIBUTES` 的参数. 这个结构在几乎所有的 `Create` 函数中都很常见, 定义如下:
typedef struct _SECURITY_ATTRIBUTES { DWORD nLength; LPVOID lpSecurityDescriptor; BOOL bInheritHandle; } SECURITY_ATTRIBUTES, *PSECURITY_ATTRIBUTES;
`nLength` 成员应设置为结构的大小. 这是 Windows 用于版本化结构的常用技术. 如果结构在未来的 Windows 版本中会有新成员, 旧代码仍然可以正常工作, 因为它会将长度设置为旧大小, 所以新的 Windows API 知道不要查看新成员, 因为旧代码不知道它们的存在. 也就是说, `SECURITYATTRIBUTES` 结构自第一个 Windows NT 版本以来尚未更改.
顾名思义, 该结构与新创建对象的安全设置有关. 主要与安全相关的成员是 `lpSecurityDescriptor`, 它可以指向一个安全描述符对象, 该对象基本上指定了谁可以对该对象做什么. 我们将在第 16 章中讨论安全描述符.
最后一个成员, `bInheritHandle` 具有安全含义, 这就是为什么它也托管在此结构中的原因. 这是前面提到的继承位. 这意味着可以通过使用此结构来设置继承位, 而无需在创建新对象时调用 `SetHandleInformation`. 以下是创建一个事件对象并使其返回的句柄设置了继承位的示例:
SECURITY_ATTRIBUTES sa = { sizeof(sa) }; // set nLength and zero the rest sa.bInheritHandle = TRUE; HANDLE hEvent = ::CreateEvent(&sa, TRUE, FALSE, nullptr); DWORD flags; ::GetHandleInformation(hEvent, &flags); // sets flags=1
句柄继承在第 3 章中讨论.
为 `SECURITYATTRIBUTES` 传递 `NULL` 会使继承位保持清除状态. 在安全性方面, 这意味着“默认安全性”, 它基于存储在进程访问令牌中的安全描述符. 我们将在第 16 章中讨论细节. 在任何情况下, 在大多数情况下, 为安全描述符使用 `NULL` (无论是显式地还是通过为 `SECURITYATTRIBUTES` 指针传递 `NULL`) 都是正确的做法.
- 对象名称
某些类型的对象可以有基于字符串的名称. 这些名称可以用于通过合适的 `Open` 函数按名称打开对象. 请注意, 并非所有对象都有名称; 例如, 进程和线程没有名称——它们有 ID. 这就是为什么 `OpenProcess` 和 `OpenThread` 函数需要一个进程/线程标识符 (一个数字) 而不是一个字符串基础名称的原因. 命名的对象可以用 Sysinternals 的 WinObj 工具查看.
从用户模式代码, 调用带有名称的 `Create` 函数会在该名称的对象不存在时创建该对象, 但如果它存在, 则只会打开现有对象. 在后一种情况下, 调用 `GetLastError` 会返回 `ERRORALREADYEXISTS`, 表明这不是一个新对象, 返回的句柄是现有对象的另一个句柄. 在这种情况下, 影响对象创建的参数 (如 `SECURITYATTRIBUTES` 结构) 不会被使用, 因为创建者已经设置好了.
提供给 `Create` 函数的名称不是对象的最终名称. 在经典 (桌面) 进程中, 它会前缀上 `\Sessions\x\BaseNamedObjects\`, 其中 `x` 是调用者的会话 ID. 如果会话为零, 名称仅前缀为 `\BaseNamedObjects\`. 如果调用者恰好在 AppContainer 中运行 (通常是通用 Windows 平台进程), 那么前缀字符串更复杂, 由唯一的 AppContainer SID 组成: `\Sessions\x\AppContainerNamedObjects\`.
图 2-11 显示了在 WinObj 中会话 1 的命名对象.

Figure 18: 会话 1 中的命名对象
图 2-12 显示了会话 0 中的命名对象.

Figure 19: 会话 0 中的命名对象
以上所有内容意味着对象名称是会话相关的 (在 AppContainer 的情况下是包相关的). 如果一个对象必须跨会话共享, 它可以在会话 0 中创建, 通过在对象名称前加上 `Global\` 前缀; 例如, 使用 `CreateMutex` 函数创建一个名为 `Global\MyMutex` 的互斥体, 将在 `\BaseNamedObjects` 下创建它. 请注意, AppContainers 无权使用会话 0 对象命名空间.
整个对象管理器命名空间层次结构可以用 WinObj 查看. 整个结构都保存在内存中, 并根据需要由对象管理器操作. 请注意, 未命名的对象不属于此结构的一部分, 这意味着在 WinObj 中看到的对象不包括所有现有对象, 而是所有用名称创建的对象.
WinObj 中显示的“目录”实际上是目录对象, 它们只是一种作为逻辑容器的内核对象.
回到 Process Explorer 的句柄视图——它默认显示“命名”对象. 这里的“命名”不仅意味着可以命名的对象, 还包括其他对象. 可以命名的对象是互斥体 (Mutants), 信号量, 事件, 节, ALPC 端口, 作业, 计时器以及其他一些不常用的对象类型. 还有一些显示带有名称的对象, 其含义与真正的命名对象不同:
- 进程和线程对象 - 名称显示为其唯一的 ID.
- 对于文件对象, 它显示文件对象指向的文件名 (或设备名). 这与对象的名称不同, 因为没有办法根据文件名获取文件对象的句柄——只能创建一个新的文件对象来访问相同的底层文件或设备 (假设原始文件对象的共享设置允许).
- *(注册表) 键对象*名称显示为注册表项的路径. 这不是一个名称, 原因与文件对象相同.
- *目录对象*显示其逻辑路径, 而不是真正的对象名称. 目录不是文件系统对象, 而是对象管理器目录.
- *令牌对象*名称显示为存储在令牌中的用户名.
要验证上述陈述, 请浏览 WinObj 并查找文件或键对象. 你不会找到任何, 这表明这些对象不能被命名.
- 共享内核对象
正如我们所见, 内核对象的句柄对进程是私有的. 在某些情况下, 一个进程可能希望与另一个进程共享一个内核对象. 这样的进程不能简单地以某种方式将句柄的值传递给另一个进程, 因为在另一个进程的句柄表中, 该句柄值可能指向一个不同的对象或者是空的.
显然, 必须有一些机制来允许这种共享. 实际上, 有三种:
- 按名称共享
- 按句柄继承共享
- 按句柄复制共享
我们将在这里探讨第一种和第三种选项, 并在下一章讨论句柄继承.
- 按名称共享
这是最简单的选项, 如果可用的话. “可用”意味着所讨论的对象可以有名称, 并且确实有名称. 典型的场景是协作进程 (2个或更多) 会用相同的对象名称调用适当的 `Create` 函数. 第一个进行调用的进程会创建对象, 而其他进程的后续调用会打开到同一对象的附加句柄.
`BasicSharing` 示例展示了使用内存映射文件对象按名称共享的例子. 此对象可用于在进程之间共享内存 (通常, 每个进程只能看到自己的地址空间). 运行应用程序的两个 (或更多) 实例 (如图 2-13 所示) 允许在这些进程之间共享文本数据.
内存映射文件的全部细节在第 14 章中讨论.

Figure 20: Basic Sharing 应用程序
要测试它, 请在编辑框中输入一些内容, 然后单击*写入*. 然后切换到另一个实例, 只需单击*读取*. 你输入的文本应该会出现在另一个应用程序的编辑框中. 当然, 你可以交换角色. 如果你启动另一个实例, 你可以单击*读取*并且最后输入的文本也会出现. 这是因为所有这些进程都在读写同一个 (共享) 内存.
顺便说一句, 这些不必是基于同一可执行文件的进程——这里只是为了方便. 决定因素是对象的名称.
在我们看代码之前, 让我们看看这在 Process Explorer 中是什么样子. 运行两个可执行文件的实例, 打开 Process Explorer 并找到这两个进程. 确保下方面板显示句柄 (而不是 DLL). 要查找的对象类型是*Section* (内存映射文件的内核名称). 找到一个名为“MySharedMemory”的节 (当然带有基于会话的前缀), 如图 2-14 所示.

Figure 21: 共享的 section 对象
如果你双击句柄, 你应该会看到如图 2-15 所示的节对象的属性.

Figure 22: Section 对象属性
请注意, 有两个打开的句柄指向该对象. 据推测, 它们来自持有该对象句柄的两个进程. 注意共享内存的大小: 4 KB——我们将在代码中看到这一点.
如果你使用此对象找到第二个进程 (参见图 2-16), 你应该在双击句柄时发现呈现了相同的信息. 你怎么能确定这些是指向同一个对象呢? 查看*对象地址*列. 如果地址相同, 那么它们是同一个对象 (反之亦然). 还要注意句柄值不相同 (正常情况). 在图 2-14 中, 句柄值为 `0x14c` (PID 22384), 在图 2-16 中为 `0x16c` (PID 27864). 尽管如此, 它们引用的是完全相同的对象.

Figure 23: 另一个进程中的共享节
如果你关闭其中一个实例, 会发生什么? 一个句柄会关闭, 但对象仍然存在. 这意味着启动一个全新的实例并单击*读取*将显示最近的文本. 如果我们关闭所有协作应用程序然后启动一个实例会发生什么. 如果我们单击*读取*会看到什么? 试着自己解释一下为什么会这样.
现在让我们把注意力转向代码. `BasicApplication` 是一个基于 WTL 的对话框项目. 对话框类 (`CMainDlg`) 包含一个我们感兴趣的成员, 即内存映射文件的句柄:
private: HANDLE m_hSharedMem;
当创建对话框时, 在 `WMINITDIALOG` 消息处理程序中, 我们创建文件映射对象并给它一个名称:
m_hSharedMem = ::CreateFileMapping(INVALID_HANDLE_VALUE, nullptr, PAGE_READWRITE, 0, 1 << 12, L"MySharedMemory"); if (!m_hSharedMem) { AtlMessageBox(m_hWnd, L"Failed to create/open shared memory", IDR_MAINFRAME); EndDialog(IDCANCEL); }
`CreateFileMapping` 用于创建 (或打开) 一个文件映射对象. 参数的详细信息在第 14 章 (第二部分) 中讨论. 这里我们关心一个特定的参数 (最后一个)——对象的名称. 这是我们在 Process Explorer 中看到过的名称 (带有标准的会话相关前缀). 如果这是第一个尝试创建该对象的进程——它就被创建了. 后续的调用会导致为同一个对象创建额外的句柄 (调用 `GetLastError` 会返回 `ERRORALREADYEXISTS`). 在这种情况下, 我们不关心这个调用是第一次还是不是——我们只想得到同一个内核对象的句柄, 以便它的“功能”可以从多个进程中获得.
倒数第二对参数 (`0` 和 `1 << 12`) 决定了共享内存的大小, 以 64 位值的形式. 在这种情况下, 它被设置为 4 KB (`1 << 12`). 如果调用因任何原因失败, 我们只打印一个简单的消息并关闭对话框, 导致进程本身退出.
当对话框关闭时, 关闭句柄是个好主意. 严格来说, 在这个特定的情况下没有必要这样做, 因为一旦对话框关闭, 进程就会退出, 而内核确保从终止的进程中所有句柄都被正确关闭. 尽管如此, 养成这个好习惯是好的 (除非某个 RAII 包装器为你做这件事). 为完整起见, 以下是在处理 `WMDESTROY` 消息时关闭句柄的调用:
if (m_hSharedMem) ::CloseHandle(m_hSharedMem);
现在是写入和读取部分. 访问共享内存是通过调用 `MapViewOfFile` 完成的, 结果是一个指向共享内存的指针 (同样, 详细信息在第 12 章中). 然后就是将文本复制到该映射内存的问题:
void* buffer = ::MapViewOfFile(m_hSharedMem, FILE_MAP_WRITE, 0, 0, 0); if (!buffer) { AtlMessageBox(m_hWnd, L"Failed to map memory", IDR_MAINFRAME); return 0; } CString text; GetDlgItemText(IDC_TEXT, text); ::wcscpy_s((PWSTR)buffer, text.GetLength() + 1, text); ::UnmapViewOfFile(buffer);
复制是通过 `wcscpys` 到映射内存完成的. 然后用 `UnmapViewOfFile` 取消内存映射. 读取数据非常相似. 访问掩码更改为 `FILEMAPREAD` 而不是 `FILEMAPWRITE`, 内存被复制到另一个方向, 直接到编辑框中:
void* buffer = ::MapViewOfFile(m_hSharedMem, FILE_MAP_READ, 0, 0, 0); if (!buffer) { AtlMessageBox(m_hWnd, L"Failed to map memory", IDR_MAINFRAME); return 0; } SetDlgItemText(IDC_TEXT, (PCWSTR)buffer); ::UnmapViewOfFile(buffer);
- 按句柄复制共享
按名称共享内核对象当然很简单. 那么那些没有 (或不能有) 名称的对象呢? 句柄复制可能是答案. 句柄复制没有固有的限制 (除了安全性)——它可以用于几乎任何内核对象, 无论命名与否, 并且它在任何时间点都有效 (在第 3 章中我们将看到句柄继承只在进程创建子进程时可用). 然而, 有一个问题; 这是实践中最困难的共享方式, 我们很快就会看到.
复制的 I/O 完成端口句柄在目标进程中不起作用.
复制句柄就像调用 `DuplicateHandle` 函数一样简单:
BOOL DuplicateHandle( _In_ HANDLE hSourceProcessHandle, _In_ HANDLE hSourceHandle, _In_ HANDLE hTargetProcessHandle, _Outptr_ LPHANDLE lpTargetHandle, _In_ DWORD dwDesiredAccess, _In_ BOOL bInheritHandle, _In_ DWORD dwOptions);
复制句柄需要一个源进程, 源句柄和目标进程. 如果成功, 一个新的句柄条目会写入目标进程的句柄表中, 指向与源句柄相同的对象. 复制前后的情况分别如图 2-17 和 2-18 所示.

Figure 24: 句柄复制前

Figure 25: 句柄复制后
技术上, `DuplicateHandle` 可以在任何可以获得正确句柄的两个进程上工作, 但典型的场景是将调用者的一个句柄复制到另一个进程的句柄表中. 另外, 源进程和目标进程可以是同一个. 让我们详细看一下 `DuplicateHandle` 的参数:
- `hSourceProcessHandle` - 这是到源进程的句柄. 此句柄必须有 `PROCESSDUPHANDLE` 访问掩码. 如果源是调用者的进程, 那么传递 `GetCurrentProcess` 就可以了 (它总是有完全访问权限).
- `hSourceHandle` - 要复制的源句柄. 此句柄在源进程的上下文中必须有效.
- `hTargetProcessHandle` - 目标进程的句柄. 通常必须使用一些对 `OpenProcess` 的调用来获得这样的句柄. 与源进程一样, `PROCESSDUPHANDLE` 访问掩码是必需的.
- `lpTargetHandle` - 这是结果句柄, 从目标进程的角度来看是有效的. 在图 2-18 中, 返回给调用者的句柄是 72. 这个值是相对于进程 B 的 (调用者假定为进程 A).
- `dwDesiredAccess` - 复制句柄所需的访问掩码. 如果 `dwOptions` 参数有 `DUPLICATESAMEACCESS` 标志, 则忽略此访问掩码. 否则, 这是为新句柄请求的访问掩码.
- `bInheritHandle` - 指定新句柄是否可继承 (更多关于句柄继承的内容见第 3 章).
- `dwOptions` - 一组标志. 一个是上面讨论的 `DUPLICATESAMEACCESS`. 第二个支持的是 `DUPLICATECLOSESOURCE`; 如果指定, 则在成功复制后关闭源句柄 (这意味着对象的句柄计数不会增加).
以下是一个简单的例子, 创建一个作业对象并在同一进程中复制一个它的句柄, 同时减少访问掩码 (省略了错误处理):
HANDLE hJob = ::CreateJobObject(nullptr, nullptr); HANDLE hJob2; ::DuplicateHandle(::GetCurrentProcess(), hJob, ::GetCurrentProcess(), &hJob2, JOB_OBJECT_ASSIGN_PROCESS | JOB_OBJECT_TERMINATE, FALSE, 0);
源进程和目标进程是当前进程. 运行这段代码并在 Process Explorer 中查看句柄, 会显示出差异 (图 2-19).

Figure 26: 简单的句柄复制
一个句柄 (`0xac`) 对作业对象拥有完全访问权限, 而另一个 (复制的) 句柄 (`0xb0`) 只有指定的所需访问掩码.
在更常见的情况下, 当前进程的句柄被复制到一个目标协作进程. 以下函数将从当前进程复制一个源句柄到目标进程:
HANDLE DuplicateToProcess(HANDLE hSource, DWORD pid) { // open a strong-enough handle to the target process HANDLE hProcess = ::OpenProcess(PROCESS_DUP_HANDLE, FALSE, pid); if (!hProcess) return nullptr; HANDLE hTarget = nullptr; // duplicate ::DuplicateHandle(::GetCurrentProcess(), hSource, hProcess, &hTarget, 0, FALSE, DUPLICATE_SAME_ACCESS); // cleanup ::CloseHandle(hProcess); return hTarget; }
这就是句柄复制变得不那么简单的情况. 问题不在于复制本身——那相当简单——一个函数调用. 问题在于如何将信息传达给目标进程. 必须向目标进程传达两部分信息:
- 当句柄被复制时.
- 复制的句柄值是多少?
记住, 调用者知道创建的句柄值, 但目标进程不知道. 必须有某种其他形式的进程间通信, 允许调用者进程将所需信息传递给目标进程 (因为它们是同一系统的一部分, 需要通过共享内核对象进行协作).
我们将在本书中探讨各种进程间通信机制.
- 私有对象命名空间
我们已经看到某些类型的内核对象可以有基于字符串的名称. 我们也看到这是在进程之间共享这些对象的一种 (方便的) 方法. 然而, 拥有命名对象有一些缺点:
- 其他一些不相关的进程, 可能会创建一个同名的对象, 这在以后创建对象时可能导致失败 (如果对象类型不同), 或者更糟, 创建“成功”, 因为它是相同的对象类型, 代码得到了一个到现有对象的句柄. 结果是一团糟, 进程使用了它们不期望的同一个对象.
- 这是上述要点的特例, 为了强调. 由于名称是可见的 (在工具中, 但也可以通过编程方式获得), 另一个进程可以“劫持”该对象或以其他方式干扰对象的使用. 从安全的角度来看
, 所讨论的对象过于可见. 未命名对象则要隐蔽得多, 因为没有好方法可以猜测特定对象的用途.
有没有一种方法可以让进程共享命名对象 (因为它很容易) 但又对其他进程不可见呢? 从 Windows Vista 开始, 有一种方法可以创建一个只有协作进程知道的私有对象命名空间. 使用工具或 API 不会揭示其全名.
`PrivateSharing` 示例应用程序是 `BasicSharing` 的增强版本, 其中内存映射文件对象的名称现在位于私有对象命名空间下, 并且不是对所有人都可见. 使用 Process Explorer 查看此对象仅显示部分名称 (图 2-20).

Figure 27: 带有私有命名空间的命名对象
如果一些随机代码尝试定位一个名为“MySharedMem”的对象, 它会失败, 因为这不是该对象的真实名称.
创建私有命名空间是一个两步过程. 首先, 必须创建一个名为*边界描述符* (Boundary Descriptor) 的辅助对象. 此描述符允许添加某些安全 ID (SID), 这些 SID 将能够使用基于该边界描述符创建的私有命名空间. 这有助于加强私有命名空间上的安全性. 要创建边界描述符, 请使用 `CreateBoundaryDescriptor`:
HANDLE CreateBoundaryDescriptor( _In_ LPCTSTR Name, _In_ ULONG Flags); // currently unused
一旦边界描述符存在, 可以使用两个函数来限制对通过该描述符创建的任何私有命名空间的访问: `AddSIDToBoundaryDescriptor` 和 `AddIntegrityLabelToBoundaryDescriptor` (后者从 Windows 7 开始可用):
BOOL AddSIDToBoundaryDescriptor( _Inout_ HANDLE* BoundaryDescriptor, _In_ PSID RequiredSid); BOOL AddIntegrityLabelToBoundaryDescriptor( _Inout_ HANDLE * BoundaryDescriptor, _In_ PSID IntegrityLabel);
两者都接受边界描述符句柄的地址和一个 SID. 使用 `AddSIDToBoundaryDescriptor`, SID 通常是一个组的 SID, 允许该组中的所有用户访问私有命名空间. `AddIntegrityLabelToBoundaryDescriptor` 允许为希望在此边界描述符管理的私有命名空间中打开对象的进程设置最低完整性级别.
SIDs 和完整性级别将在第 16 章中讨论.
一旦设置了边界描述符, 下一步就是用 `CreatePrivateNamespace` 创建实际的私有命名空间:
HANDLE CreatePrivateNamespace( _In_opt_ LPSECURITY_ATTRIBUTES lpPrivateNamespaceAttributes, _In_ LPVOID lpBoundaryDescriptor, // the boundary descriptor _In_ LPCWSTR lpAliasPrefix); // namespace name
令人困惑的是, 边界描述符类型是 `void*` 而不是 `HANDLE`. 这是 API 中的一个疏忽, 但由于 `HANDLE` 被定义为 `void*`, 所以这可以正常工作. 这个失误也暗示了边界描述符不是一个内核对象, 即使它返回一个 `HANDLE`; 它有自己的关闭函数 - `DeleteBoundaryDescriptor`.
对象命名空间也不是一个真正的内核对象. 如果命名空间已经存在, 该函数会失败, 必须改用 `OpenPrivateNamespace`. 它也有自己的关闭函数 (`ClosePrivateNamespace`):
HANDLE OpenPrivateNamespaceW( _In_ LPVOID lpBoundaryDescriptor, _In_ LPCWSTR lpAliasPrefix); // namespace name BOOLEAN ClosePrivateNamespace( _In_ HANDLE Handle, _In_ ULONG Flags); // 0 or PRIVATE_NAMESPACE_FLAG_DESTROY
另一个疏忽是函数 `ClosePrivateNamespace` 返回 `BOOLEAN` (typedef 为 `BYTE`) 而不是标准的 `BOOL`.
一旦命名空间被创建或打开, 命名对象就可以正常创建, 名称格式为 `alias\name`, 其中“alias”是创建或打开命名空间时的 `lpAliasPrefix` 参数.
让我们看看 `PrivateSharing` 应用程序中的具体代码. 对话框类现在有三个成员:
private: wil::unique_handle m_hSharedMem; HANDLE m_hBD{ nullptr }, m_hNamespace{ nullptr };
代码使用 WIL `uniquehandle` RAII 包装器来处理内存映射文件的句柄, 但边界描述符和命名空间作为原始句柄进行管理.
当对话框创建时, 内存映射文件的创建方式与 `BasicSharing` 中相同, 但这次是在一个私有命名空间下 (为清晰起见, 省略了错误处理):
// create the boundary descriptor m_hBD = ::CreateBoundaryDescriptor(L"MyDescriptor", 0); BYTE sid[SECURITY_MAX_SID_SIZE]; auto psid = reinterpret_cast<PSID>(sid); DWORD sidLen; ::CreateWellKnownSid(WinBuiltinUsersSid, nullptr, psid, &sidLen); ::AddSIDToBoundaryDescriptor(&m_hBD, psid); // create the private namespace m_hNamespace = ::CreatePrivateNamespace(nullptr, m_hBD, L"MyNamespace"); if (!m_hNamespace) { // maybe created already? m_hNamespace = ::OpenPrivateNamespace(m_hBD, L"MyNamespace"); } m_hSharedMem.reset(::CreateFileMapping(INVALID_HANDLE_VALUE, nullptr, PAGE_READWRITE, 0, 1 << 12, L"MyNamespace\\MySharedMem"));
在此示例中, 一个 SID 被添加到了边界描述符中. 这个 SID 是所有标准用户的. 也可以添加更严格的内容, 例如 Administrators 组, 这样在标准用户权限下运行的进程就无法访问此边界描述符. SID 是通过调用 `CreateWellKnownSid` 基于用户组的众所周知的 SID 创建的. 然后调用 `AddSIDToBoundaryDescriptor` 将 SID 附加到边界描述符.
不用担心这些 SID 和其他安全术语. 它们在第 16 章中有详细描述.
一旦边界描述符设置好, 就会调用 `CreatePrivateNamespace` 或 `OpenPrivateNamespace`, 别名为 “MyNamespace”. 这被用作使用 `CreateFileMapping` 创建的内存映射文件对象的前缀.
最后, 对话框的 `WMDESTROY` 消息处理程序会删除命名空间和边界描述符:
if (m_hNamespace) ::ClosePrivateNamespace(m_hNamespace, 0); if (m_hBD) ::DeleteBoundaryDescriptor(m_hBD);
- 附加内容: 用于私有命名空间的 WIL 包装器
WIL 库有许多用于各种句柄和指针的包装器. 不幸的是, 它没有边界描述符和私有命名空间的包装器. 幸运的是, 创建它们并不太难. 以下是一种方法:
namespace wil { static void close_private_ns(HANDLE h) { ::ClosePrivateNamespace(h, 0); }; using unique_private_ns = unique_any_handle_null_only<decltype( &close_private_ns), close_private_ns>; using unique_bound_desc = unique_any_handle_null_only<decltype( &::DeleteBoundaryDescriptor), ::DeleteBoundaryDescriptor>; }
我不会详细介绍上述声明的细节, 因为它们确实需要对 C++11 的 `decltype`, `using` 和模板有很好的了解.
`PrivateSharing2` 项目与 `PrivateSharing` 相同, 但使用 WIL 包装器 (以及上述添加) 来管理所有句柄, 甚至是 `MapViewOfFile` 返回的指针. 例如, 以下是 `Read` 函数:
wil::unique_mapview_ptr<void> buffer(::MapViewOfFile( m_hSharedMem.get(), FILE_MAP_READ, 0, 0, 0)); if (!buffer) { AtlMessageBox(m_hWnd, L"Failed to map memory", IDR_MAINFRAME); return 0; } SetDlgItemText(IDC_TEXT, (PCWSTR)buffer.get());
- 其他对象和句柄
内核对象在系统编程的上下文中很有趣, 并且是本书的重点. Windows 中还使用了其他常见的对象, 即用户对象和 GDI 对象. 以下是对这些对象及其句柄的简要描述.
任务管理器可以通过添加*用户对象*和 *GDI 对象*列来显示每个进程的此类对象的数量, 如图 2-21 所示.

Figure 28: 用户和 GDI 对象计数
- 用户对象
用户对象是窗口 (`HWND`), 菜单 (`HMENU`) 和钩子 (`HHOOK`). 这些对象的句柄具有以下属性:
- 无引用计数. 第一个销毁用户对象的调用者——它就消失了.
- 句柄值的作用域在一个窗口站下. 一个窗口站包含一个剪贴板, 桌面和原子表. 这意味着这些对象的句柄可以在共享桌面的所有应用程序之间自由传递, 例如.
窗口站和桌面这两个术语将在本书后面讨论. 原子表则不会, 因为它们与 Windows 中的 UI 子系统相关, 这不是本书的重点.
- GDI 对象
图形设备接口 (GDI) 是 Windows 中最初的图形 API, 至今仍在使用, 尽管有更丰富和更好的 API (例如 Direct2D). GDI 对象的示例: 设备上下文 (`HDC`), 画笔 (`HPEN`), 笔刷 (`HBRUSH`), 位图 (`HBITMAP`) 等. 以下是它们的属性:
- 无引用计数.
- 句柄仅在创建它们的进程中有效.
- 不能在进程之间共享.
- 用户对象
- 总结
在本章中, 我们探讨了内核对象以及如何通过使用句柄来访问和共享它们. 我们没有太深入地研究任何特定的对象类型, 因为这些将在其他章节中更详细地讨论. 在下一章中, 我们将深入探讨所有内核对象中最著名的——进程.
1.4. 第 3 章: 进程
进程是 Windows 中最基本的管理和包含对象. 任何执行都必须在某个进程上下文中进行, 不存在在进程之外运行的情况. 本章从多个角度审视进程——从创建到管理, 到销毁以及几乎所有介于两者之间的事情.
本章内容:
- 进程基础
- 进程创建
- 创建进程
- 进程终止
- 枚举进程
1.4.1. 进程基础
尽管自 Windows NT 的第一个版本以来, 进程的基本结构和属性没有改变, 但系统中引入了具有特殊行为或结构的新进程类型. 以下是当前支持的所有进程类型的简要概述, 而本章的后续部分将更详细地讨论每种进程类型.
- 受保护进程 - 这些进程是在 Windows Vista 中引入的. 它们是为了支持数字版权管理 (DRM) 保护而创建的, 防止对渲染受 DRM 保护内容的过程进行侵入性访问. 例如, 任何其他进程 (即使以管理员权限运行) 也无法读取受保护进程地址空间内的内存, 因此 DRM 保护的数据无法被直接窃取.
- UWP 进程 - 从 Windows 8 开始可用的这些进程, 承载 Windows 运行时, 并且通常发布到 Microsoft 应用商店. UWP 进程在一个名为 AppContainer 的沙箱内执行, 该沙箱限制了此进程可以执行的操作.
- 受保护进程轻量级 (PPL) - 这些进程 (从 Windows 8.1 开始可用) 通过添加多个保护级别扩展了 Vista 的保护机制, 甚至允许第三方服务作为 PPL 运行, 保护它们免受侵入性访问, 甚至免受管理员级进程的终止.
- Minimal 进程 - 从 Windows 10 版本 1607 开始可用的这些进程, 是一种真正新形式的进程. minimal 进程的地址空间不包含正常进程所具有的通常的映像和数据结构. 例如, 没有可执行文件映射到进程地址空间, 也没有 DLL. 进程地址空间是真正空的.
- Pico 进程 - 这些进程是 minimal 进程, 但增加了一个 Pico 提供程序, 这是一个内核驱动程序, 负责拦截 Linux 系统调用并将其转换为等效的 Windows 系统调用. 这些进程与适用于 Linux 的 Windows 子系统 (WSL) 一起使用, 从 Windows 10 版本 1607 开始可用.
进程的基本信息可以很容易地在任务管理器和 Process Explorer 等工具中看到. 图 3-1 显示了任务管理器“详细信息”选项卡, 其中添加了一些超出默认值的列.

Figure 29: 任务管理器的“详细信息”选项卡
让我们简要地看一下图 3-1 中出现的列:
- 名称
这通常是进程所基于的可执行文件的名称. 请记住, 这个名称不是进程的唯一标识符. 有些进程似乎根本没有可执行文件名. 例子包括 `System`, `Secure System`, `Registry`, `Memory Compression`, `System Idle Process` 和 `System Interrupts`.
- System Interrupts 实际上不是一个进程, 它只是用来衡量内核在服务硬件中断和延迟过程调用上花费的时间. 两者都超出了本书的范围. 你可以在 Windows Internals 和 Windows Kernel Programming 书籍中找到更多信息.
- System Idle Process 也不是一个真正的进程. 它总是有进程 ID (PID) 为零. 它核算 Windows 的空闲时间. 这是当无事可做时 CPU 的去处.
- System 进程是一个真正的进程, 技术上也是一个 minimal 进程. 它总是有 PID 为 4. 它代表了内核空间中发生的一切——内核和内核驱动程序使用的内存, 打开的句柄, 线程等等.
- Secure System 进程仅在启用了基于虚拟化的安全的 Windows 10 和 Server 2016 (及更高版本) 系统上可用. 它代表了安全内核中发生的一切. 请参考 Windows Internals 书籍以获取更多信息.
- Registry 进程是一个从 Windows 10 版本 1803 (RS4) 开始可用的 minimal 进程, 用作管理注册表的“工作区”, 而不是像以前版本那样使用分页池. 就本书而言, 这是一个不影响注册表以编程方式访问方式的实现细节.
- Memory Compression 进程是一个从 Windows 10 版本 1607 (但不在服务器上) 开始可用的 minimal 进程, 并在其地址空间中保存压缩内存. 内存压缩是 Windows 10 中增加的一项功能, 用于节省物理内存 (RAM), 特别适用于资源有限的设备, 如手机和物联网 (Internet of Things) 设备. 令人困惑的是, 任务管理器不显示此进程, 但 Process Explorer 正确显示它.
内存压缩 (Memory Compression) 不在任务管理器中显示的原因有些好笑. 在 Windows 10 版本 1607 之前支持内存压缩, 但压缩的内存存储在 System 进程的用户模式地址空间中, 这使得 System 进程看起来好像消耗了 (可能) 大量的内存. 那是压缩内存, 所以它实际上是*节省*内存, 但外观有时更重要, 所以压缩内存被移到了它自己的 (minimal) 进程中, 并且该进程被有意地从任务管理器的列表中隐藏了.
本章的其余部分, 直到“Minimal 和 Pico 进程”部分, 都涉及基于可执行文件的“正常”进程. 无论如何, minimal 和 Pico 进程只能由内核创建.
- PID
进程的唯一 ID. PID 是 4 的倍数, 最低的有效 PID 值为 4 (属于 System 进程). 进程 ID 在进程终止后会重用, 因此可能会看到一个新进程的 PID 曾经被一个 (现在已消失的) 进程使用. 如果需要一个进程的唯一标识符, 那么 PID 和进程启动时间的组合在某个系统上是真正唯一的.
你可能还记得第 2 章中, 句柄也是从 4 开始并且是 4 的倍数, 就像 PID 一样. 这不是巧合. 实际上, PID (和线程 ID) 是一个专门为此目的使用的特殊句柄表中的句柄值.
- 状态
状态 列是一个有趣的列. 它可以有三个值之一: 正在运行 (Running), 已挂起 (Suspended) 和 无响应 (Not Responding). 让我们逐一看看. 表 3-1 总结了这些状态基于进程类型的含义.
进程类型 正在运行时… 已挂起时… 无响应时… GUI 进程 (非 UWP) GUI 线程有响应 进程中的所有线程都已挂起 GUI 线程至少 5 秒内未检查消息队列 CUI 进程 (非 UWP) 至少一个线程未被挂起 进程中的所有线程都已挂起 从不 UWP 进程 在前台未被挂起 在后台 GUI 线程至少 5 秒内未检查消息队列 带有 GUI 的进程必须有一个处理其用户界面的线程. 此线程有一个消息队列, 一旦它调用任何 UI 或 GDI 函数就会为它创建. 因此, 此线程必须泵送消息——也就是说, 监听其消息队列并处理到达的消息. 典型的监听函数是
GetMessage或PeekMessage. 如果至少 5 秒内没有调用任何一个, 任务管理器 会将状态更改为*无响应*, 该线程拥有的窗口会变暗, 并在窗口标题中添加“(无响应)”. 有问题的线程没有检查其消息队列, 原因有三:- 它因任何原因被挂起.
- 它正在等待某个 I/O 操作完成, 并且耗时超过 5 秒.
- 它正在做一些 CPU 密集型工作, 耗时超过 5 秒.
我们将在第 5 章 (“线程基础”) 中探讨这些问题.
UWP 进程是特殊的, 因为当它们移动到后台时, 例如当应用程序窗口最小化时, 它们会非自愿地被挂起. 一个简单的实验可以验证这种情况: 在 Windows 10 上打开现代计算器, 并在 任务管理器 中找到它. 你应该看到它的状态为 正在运行, 这意味着它可以响应用户输入并通常地做它的事情. 现在最小化计算器, 你会看到几秒钟后状态变为 已挂起. 这种行为只存在于 UWP 进程中.
没有 GUI 的非 UWP 进程总是显示为 正在运行 状态, 因为 Windows 不知道这些进程实际上在做什么 (或不做什么). 唯一的例外是, 如果此类进程中的所有线程都被挂起, 那么其状态将变为 已挂起.
Windows API 没有挂起进程的函数, 只有挂起线程的函数. 技术上可以遍历某个进程中的所有线程并挂起每一个 (假设可以获得足够强大的句柄). native API (在 NtDll.Dll 中实现) 确实有一个用于此目的的函数,
NtSuspendProcess. 这是 Process Explorer 如果你右键单击一个进程并选择*挂起*时调用的函数. 当然, 相反的函数也存在 -NtResumeProcess. - 用户名
用户名指示进程在哪个用户下运行. 一个令牌对象附加到进程 (称为*主令牌*), 它基于用户持有进程的安全上下文. 该安全上下文包含诸如用户所属的组, 它拥有的特权等信息. 我们将在第 16 章中更深入地探讨令牌. 进程可以在特殊的内置用户下运行, 例如本地系统 (在任务管理器中显示为 `System`), 网络服务和本地服务. 这些用户帐户通常用于运行服务, 我们将在第 16 章中探讨.
- 会话 ID
进程执行的会话号. 会话 0 用于系统进程和服务, 会话 1 及更高版本用于交互式登录. 我们将在第 16 章中更详细地探讨会话.
- CPU
此列显示该进程的 CPU 百分比消耗. 请注意, 它只显示整数. 要获得更高的精度, 请使用 Process Explorer.
- 内存
与内存相关的列有些棘手. 任务管理器显示的默认列是 内存(活动私有工作集) (Windows 10 版本 1903) 或 内存(私有工作集) (早期版本). 工作集 这个术语指的是 RAM (物理内存). 私有工作集 是进程使用且不与其他进程共享的 RAM. 共享内存最常见的例子是 DLL 代码. *活动私有工作集*与*私有工作集*相同, 但对于当前挂起的 UWP 进程设置为零.
上述两个计数器是否能很好地指示进程使用的内存量? 不幸的是, 不能. 这些指示了使用的私有 RAM, 但当前分页出去的内存呢? 还有另一个列可以解决这个问题—— 提交大小 (Commit Size). 这是用于了解进程内存使用情况的最佳列. “不幸的”部分是任务管理器默认不显示此列.
Process Explorer 有一个与 Commit Size 等效的列, 但它被称为 Private Bytes, 这与性能计数器的名称一致.
这些内存术语将在第 12 章中进一步讨论.
- 基本优先级
基本优先级 列, 官方称为 优先级类, 显示六个值之一, 这些值为在该进程中执行的线程提供基本调度优先级. 可能的值及其关联的优先级级别如下:
- 空闲 (在任务管理器中称为*低*) = 4
- 低于正常 = 6
- 正常 = 8
- 高于正常 = 10
- 高 = 13
- 实时 = 24
最常见 (也是默认) 的优先级类是 正常 (8). 我们将在第 6 章中讨论优先级和调度.
- 句柄
句柄 列显示在特定进程中打开的内核对象句柄的数量. 这在第 2 章中已详细讨论.
- 线程
线程 列显示每个进程中的线程数. 通常, 这至少应该是一个, 因为没有线程的进程是无用的. 然而, 有些进程显示没有线程 (使用破折号). 具体来说, Secure System 显示没有线程, 因为安全内核实际上使用普通内核进行调度. System Interrupts 伪进程根本不是一个进程, 所以不能有任何线程. 最后, System Idle Process 也不拥有线程. 为此进程显示的线程数是系统上的逻辑处理器数.
任务管理器中还有其他感兴趣的列, 将在适当的时候进行检查.
1.4.2. Process Explorer 中的进程
Process Explorer 可以被认为是“打了类固醇的任务管理器”. 它具有任务管理器的大部分功能, 并且功能更多. 我们已经看到了它显示进程中打开句柄的能力. 在本节中, 我们将检查它的一些与进程相关的功能.
首先, Process Explorer 可以像任务管理器一样显示带有各种列的进程. 然而, 它的列比任务管理器中可用的要多. 立即显而易见的是进程显示的颜色. 每种颜色表示进程的某个有趣方面. 当然, 一个进程可以有多个这样的“方面”, 值得一种颜色, 在这种情况下, 一种颜色“获胜”, 而“失败”的颜色则不显示. 所有可用的颜色都可以通过选择*选项, 配置颜色…*从菜单中更改和启用或禁用, 如图 3-2 所示.

Figure 30: Process Explorer 中的颜色配置
表 3-2 总结了它们的背景颜色和含义.
| 名称 (默认颜色) | 含义 |
|---|---|
| 新建对象 (绿色) | 新建的对象 |
| 已删除对象 (红色) | 已被销毁的对象 |
| 自己的进程 (蓝色) | 在登录用户帐户下运行的进程 |
| 服务 (粉色) | 托管 Windows 服务的进程 (见第 19 章) |
| 已挂起进程 (灰色) | 已挂起的进程 |
| 打包的映像 (紫色) | 使用打包技术减小大小的可执行文件或 DLL. 在某些情况下, 恶意软件可能会使用此类技术 |
| 重定位的 DLL (黄色) | 显示在模块视图中 (而不是主进程视图). 在第 15 章中讨论 |
| 作业 (棕色) | 作为作业一部分的进程 (见第 4 章) |
| .NET 进程 (黄色) | 运行一些 .NET 代码的进程. 更准确地说, 是托管 .NET CLR 的进程 |
| Immersive 进程 (青色) | 通常是 UWP 进程 (未挂起). 更准确地说, 是托管 Windows 运行时的进程. 用于确定这一点的函数是 `IsImmersiveProcess` |
| 受保护进程 (紫红色) | 受保护进程和 PPL 进程 (见本章后面) |
| (所有其他) (白色) | 没有任何启用方面的进程. 如果所有颜色都启用, 剩下的主要是系统进程 |
我个人添加了受保护进程颜色, 并选择默认为紫红色 (与 Google 的新操作系统无关).
新建和销毁的对象颜色默认显示一秒钟. 你可以通过打开 选项 菜单, 差异高亮持续时间… 来使其更长.
Process Explorer 的另一个有趣功能是能够以树形结构“排序”进程 (更准确地说是进程树). 如果你单击 进程 列, 其中是映像名称, 你可以正常排序, 但第三次单击会将*进程*列变为进程树. 这些树的一部分如图 3-3 所示.

Figure 31: Process Explorer 中的进程树
树中的每个子节点都是其父节点的子进程. 有些进程似乎是左对齐的 (参见图 3-3 中的 Explorer.exe). 这些进程没有父进程, 或者更准确地说——曾经有一个父进程, 但它已经退出了. 双击这样的进程并切换到 映像 选项卡会显示该进程的基本信息, 包括其父进程. 图 3-4 显示了 Explorer.exe 实例的此信息.

Figure 32: Explorer.exe 属性
请注意, 父进程是未知的, 但其 PID 是已知的 (图 3-4 中为 4160). 这意味着父 PID 与子进程一起存储, 但如果父进程不再存在, 就没有其他关于它的信息了.
你可能想知道, 如果创建一个 PID 为 4160 的新进程会发生什么, 因为 PID 会被重用. 幸运的是, Process Explorer 不会混淆, 因为它会检查父进程的启动时间. 如果它晚于子进程, 那么显然该进程不可能是父进程.
为什么
Explorer.exe没有父进程? 这实际上是正常情况, 因为 Explorer 是由一个更早运行的进程UserInit.exe创建的, 它的工作 (除其他外) 是启动默认的 shell (在注册表中默认配置为Explorer.exe). 一旦它的工作完成,UserInit进程就会简单地退出.
关于这种父子进程关系要记住的重要一点是: 如果进程 A 创建了进程 B, 并且进程 A 死掉了, 进程 B 不受影响. 换句话说, Windows 中的进程更像兄弟姐妹——它们在创建后不会相互影响.
1.4.3. 进程创建
进程创建中涉及的主要部分如图 3-5 所示.

Figure 33: 进程创建流程
首先, 内核打开映像 (可执行) 文件并验证它是否是正确的格式, 即所谓的 可移植可执行 (PE). 文件扩展名无关紧要——只有实际内容才重要. 假设各种头文件有效, 内核然后创建一个新的进程内核对象和一个线程内核对象, 因为一个正常的进程创建时带有一个线程, 该线程最终应该执行主入口点.
此时, 内核将映像映射到新进程的地址空间, 以及 NtDll.Dll. NtDll 映射到每个进程 (除了 Minimal 和 Pico 进程), 因为它在进程创建的最后阶段有非常重要的职责 (如下所述), 同时也是系统调用的跳板. 仍然由创建者进程执行的最后一个主要步骤是通知 Windows 子系统进程 (Csrss.exe) 新的进程和线程已创建. (Csrss 可以被认为是内核管理 Windows 子系统进程某些方面的助手).
此时, 从内核的角度来看, 进程已成功创建, 因此调用者调用的进程创建函数 (通常是 CreateProcess, 在下一节中讨论) 返回成功. 然而, 新进程尚未准备好执行其初始代码. 进程初始化的第二部分必须在新进程的上下文中, 由新创建的线程执行.
一些开发人员认为, 在新进程中首先运行的是可执行文件的 main 函数. 然而, 这远非事实. 在实际的 main 函数开始运行之前, 有很多事情在发生. 这部分的明星是 NtDll, 因为此时进程中没有其他操作系统级别的代码. NtDll 在此时有几个职责.
首先, 它为进程创建用户模式管理对象, 称为 进程环境块 (PEB), 以及为第一个线程创建用户模式管理对象, 称为*线程环境块* (TEB). 这些结构是部分文档化的 (在 <winternl.h> 中), 并且官方不应由开发人员直接使用. 也就是说, 有些情况下这些结构很有用, 特别是当试图实现难以用其他方式做到的事情时.
可以通过
NtCurrentTeb()访问当前线程的 TEB, 而当前进程的 PEB 可通过NtCurrentTeb()->ProcessEnvironmentBlock访问.
然后进行其他一些初始化, 包括创建默认的进程堆 (见第 13 章), 创建和初始化默认的进程线程池 (见第 9 章) 等等. 完整的细节, 请查阅 Windows Internals 书籍.
在入口点可以开始执行之前的最后一个主要部分是加载所需的 DLL. NtDll 的这部分通常被称为 加载器. 加载器查看可执行文件的导入部分, 其中包括可执行文件所依赖的所有库. 这些通常包括 Windows 子系统 DLL, 如 kernel32.dll, user32.dll, gdi32.dll 和 advapi32.dll.
要了解这些导入库, 我们可以使用作为 Windows SDK 和 Visual Studio 安装一部分的 DumpBin.exe 工具. 打开开发人员命令提示符以方便访问各种工具, 并键入以下内容以查看 Notepad.exe 的导入:
c:\>dumpbin /imports c:\Windows\System32\notepad.exe
结果是所有导入库的转储以及从这些库中导入 (使用) 的符号. 以下是缩减后的输出 (Windows 10 版本 1903):
Dump of file c:\Windows\System32\notepad.exe
File Type: EXECUTABLE IMAGE
Section contains the following imports:
GDI32.dll
140022788 Import Address Table
1400289E8 Import Name Table
0 time date stamp
0 Index of first forwarder reference
35C SelectObject
2D0 GetTextFaceW
1C2 EnumFontsW
...
USER32.dll
140022840 Import Address Table
140028AA0 Import Name Table
0 time date stamp
0 Index of first forwarder reference
364 SetThreadDpiAwarenessContext
2AD PostMessageW
BA DialogBoxParamW
...
msvcrt.dll
140022FD8 Import Address Table
140029238 Import Name Table
0 time date stamp
0 Index of first forwarder reference
2F ?terminate@@YAXXZ
496 memset
...
api-ms-win-core-libraryloader-l1-2-0.dll
140022C60 Import Address Table
140028EC0 Import Name Table
0 time date stamp
0 Index of first forwarder reference
F GetModuleFileNameA
18 LoadLibraryExW
13 GetModuleHandleExW
...
urlmon.dll
00000001 Characteristics
000000014002C0D0 Address of HMODULE
000000014002F0E0 Import Address Table
0000000140028368 Import Name Table
0000000140028638 Bound Import Name Table
0000000000000000 Unload Import Name Table
0 time date stamp
0000000140020F31 3B FindMimeFromData
...
对于每个必需的 DLL, dumpbin 会显示从该 DLL 导入的函数, 即——可执行文件实际使用的函数. 有些 DLL 名称可能看起来很奇怪, 事实上你找不到它们作为实际文件. 上述输出中的示例是 api-ms-win-core-libraryloader-l1-2-0.dll. 这被称为 API Set, 它是从一个契约 (API Set) 到一个实际实现 DLL (有时称为 主机) 的间接映射.
API Sets 从 Windows 7 开始存在.
另一种查看这些依赖关系的方式是使用图形界面. 图 3-6 显示了这样一个工具, PE Explorer, 可从 http://github.com/zodiacon/AllTools 下载, 并显示了 Notepad.exe 的依赖关系. 对于每个 API Set 或 DLL, 它都会显示导入的函数.

Figure 34: PE Explorer 中的 Notepad.exe
API Sets 允许 Microsoft 将函数“声明”与实际实现分离开来. 这意味着实现 DLL 可以在以后的 Windows 版本中更改, 甚至在不同的设备形态 (IoT 设备, HoloLens, Xbox 等) 上也可以不同. API 集和实现之间的实际映射存储在每个进程的 PEB 中. 你可以使用 ApiSetMap.exe 工具查看这些映射, 该工具可从 https://github.com/zodiacon/WindowsInternals/releases 下载. 以下是输出的前几行:
C:\>APISetMap.exe
ApiSetMap - list API Set mappings - version 1.0
(c) Alex Ionescu, Pavel Yosifovich, and Contributors
http://www.alex-ionescu.com
api-ms-onecoreuap-print-render-l1-1-0.dll -> s{printrenderapihost.dll}
api-ms-win-appmodel-identity-l1-2-0.dll -> s{kernel.appcore.dll}
api-ms-win-appmodel-runtime-internal-l1-1-6.dll -> s{kernel.appcore.dll}
api-ms-win-appmodel-runtime-l1-1-3.dll -> s{kernel.appcore.dll}
api-ms-win-appmodel-state-l1-1-2.dll -> s{kernel.appcore.dll}
api-ms-win-appmodel-state-l1-2-0.dll -> s{kernel.appcore.dll}
api-ms-win-appmodel-unlock-l1-1-0.dll -> s{kernel.appcore.dll}
api-ms-win-base-bootconfig-l1-1-0.dll -> s{advapi32.dll}
api-ms-win-base-util-l1-1-0.dll -> s{advapi32.dll}
api-ms-win-composition-redirection-l1-1-0.dll -> s{dwmredir.dll}
api-ms-win-composition-windowmanager-l1-1-0.dll -> s{udwm.dll}
api-ms-win-containers-cmclient-l1-1-1.dll -> s{cmclient.dll}
api-ms-win-core-apiquery-l1-1-1.dll -> s{ntdll.dll}
api-ms-win-core-apiquery-l2-1-0.dll -> s{kernelbase.dll}
DLL 或 API Set 名称没有与之关联的完整路径. 加载器按以下顺序在以下目录中搜索, 直到找到 DLL:
- 如果 DLL 名称是 KnownDLLs 之一 (在注册表中指定), 则首先搜索系统目录 (见第 4 项) (Known DLLs 在第 15 章第 2 部分中描述). 这是 Windows 子系统 DLL 所在的位置 (
kernel32.dll,user32.dll,advapi32.dll等). - 可执行文件的目录.
- 进程的当前目录 (由父进程确定). (这将在下一节中讨论).
- 由
GetSystemDirectory返回的系统目录 (例如c:\windows\system32). - 由
GetWindowsDirectory返回的 Windows 目录 (例如c:\Windows). PATH环境变量中列出的目录.
在 Known DLLs 注册表项 (`HKEYLOCALMACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\KnownDLLs`) 中列出的 DLL 总是从系统目录加载, 以防止 DLL 劫持, 即在可执行文件的目录中放置一个同名的备用 DLL.
一旦找到 DLL, 它就会被加载, 并且它的 DllMain 函数 (如果存在) 会以 DLL_PROCESS_ATTACH 原因被调用, 表明 DLL 现在已加载到进程中. (关于 DLL 加载的完整讨论将在第 15 章中进行).
这个过程会递归地继续, 因为一个 DLL 可能依赖于另一个 DLL, 依此类推. 如果任何一个 DLL 没有找到, 加载器会显示一个类似图 3-7 的消息框. 然后加载器终止进程.

Figure 35: 未能定位到所需的 DLL
如果任何一个 DLL 的 `DllMain` 函数返回 `FALSE`, 这表明 DLL 无法成功初始化. 然后加载器停止进一步的进程, 并显示图 3-8 中的消息框, 之后进程关闭.

Figure 36: 未能初始化所需的 DLL
一旦所有必需的 DLL 都被加载并成功初始化, 控制权就转移到可执行文件的主要入口点. 所讨论的入口点不是开发人员提供的实际 `main` 函数. 相反, 它是 C/C++ 运行时提供的一个函数, 由链接器适当地设置. 为什么需要这样做? 从 C/C++ 运行时调用诸如 `malloc`, `operator new`, `fopen` 等函数需要一些设置. 此外, 甚至在你的 `main` 函数执行之前, 必须调用全局 C++ 对象的构造函数. 所有这些都是由 C/C++ 运行时启动函数完成的.
- 主要函数
开发人员实际上可以编写四种主要的函数, 每种都有一个对应的 C/C++ 运行时函数. 表 3-4 总结了这些名称以及它们的使用时机.
开发人员的 main C/C++ 运行时启动 场景 main mainCRTStartup 使用 ASCII 字符的控制台应用程序 wmain wmainCRTStartup 使用 Unicode 字符的控制台应用程序 WinMain WinMainCRTStartup 使用 ASCII 字符的 GUI 应用程序 wWinMain wWinMainCRTStartup 使用 Unicode 字符的 GUI 应用程序 正确的函数由链接器的 `/SUBSYSTEM` 开关设置, 该开关也通过 Visual Studio 在项目属性对话框中暴露, 如图 3-9 所示.

Figure 37: Visual Studio 中的系统链接器设置
基于控制台的进程与基于 GUI 的进程有什么不同吗? 不完全是. 这两种类型都是 Windows 子系统的成员. 控制台应用程序可以显示 GUI, GUI 应用程序也可以使用控制台. 区别在于各种默认值, 例如主函数原型以及是否默认创建控制台窗口.
GUI 应用程序可以使用 `AllocConsole` 创建一个控制台.
基于表 3-4 中的行, 开发人员可以编写四种 `main` 函数的变体:
int main(int argc, const char* argv[]); // const is optional int wmain(int argc, const wchar_t* argv[]); // const is optional int WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR commandLine, int showCmd); int wWinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPWSTR commandLine, int showCmd);
有时你会看到 `main` 函数写成 `tmain` 或 `tWinMain`. 正如你可能猜到的, 这允许根据编译常量 `UNICODE` 和 `UNICODE` 编译为 Unicode 或 ASCII.
使用经典的 `main/wmain` 函数, 命令行参数在调用 `(w)main` 之前由 C/C++ 运行时分解. `argc` 表示命令行参数的数量, 并且至少为 1, 因为第一个“参数”是可执行文件的完整路径. `argv` 是一个指向解析的 (基于空格分割) 参数的指针数组. 这意味着 `argv[0]` 指向完整的可执行文件路径.
使用 `w(WinMain)` 函数, 参数如下:
- `hInstance` 代表进程地址空间内的可执行模块本身. 技术上, 这是可执行文件映射到的地址. 由链接器指定此值. 默认情况下, Visual Studio 使用链接器选项 `/DYNAMICBASE`, 该选项在每次项目构建时生成一个伪随机基地址. 在任何情况下, 数字本身并不重要, 但在各种函数中需要它, 例如用于加载资源 (`LoadIcon`, `LoadString` 等).
`HINSTANCE` 类型只是一个 `void` 指针. 顺便说一句, `HMODULE` 类型有时与 `HINSTANCE` 互换使用, 实际上是同一回事. 存在两种类型而不是一种的原因与 16 位 Windows 有关, 当时它们的含义不同.
- `hPrevInstance` 应该代表同一可执行文件的先前实例的 `HINSTANCE`. 然而, 这个值总是 `NULL`, 并且没有真正使用. 在 16 位 Windows 时代, 它是非 `NULL` 的. 这意味着没有直接的方法知道是否有另一个运行相同可执行文件的进程已经存在. 我们在第 2 章的 `Singleton` 演示应用程序中看到了如果需要如何处理这个问题. `WinMain` 签名是从 16 位 Windows 保留下来的, 以便更容易地移植到 32 位 Windows (当时). 最终结果是这个参数通常在没有变量名的情况下编写, 因为它完全没用.
一种静默编译器警告 (尤其是在纯 C 中) 的替代技术是使用 `UNREFERENCEDPARAMETER` 宏, 变量名如: `UNREFERENCEDPARAMETER(hPrevInstance);`. 具有讽刺意味的是, 这个宏实际上通过简单地用分号结束来引用它的参数; 这足以让编译器满意.
- `commandLine` 是不包括可执行文件路径的命令行字符串——它是命令行的其余部分 (如果有的话). 它没有被“解析”成单独的标记——它只是一个单一的字符串. 如果解析是有益的, 可以使用以下函数:
#include <ShellApi.h> LPWSTR* CommandLineToArgvW(_In_ LPCWSTR lpCmdLine, _Out_ int* pNumArgs);
该函数接受命令行并将其分割成标记, 返回一个指向字符串指针数组的指针. 字符串的数量通过 `*pNumArgs` 返回. 该函数分配一个内存块来保存解析的命令行参数, 并且必须最终通过调用 `LocalFree` 来释放它. 以下代码片段显示了如何在 `wWinMain` 函数中正确解析命令行:
int wWinMain(HINSTANCE hInstance, HINSTANCE, LPWSTR lpCmdLine, int nCmdShow) { int count; PWSTR* args = CommandLineToArgvW(lpCmdLine, &count); WCHAR text = { 0 }; for (int i = 0; i < count; i++) { ::wcscat_s(text, 1024, args[i]); ::wcscat_s(text, 1024, L"\n"); } ::LocalFree(args); ::MessageBox(nullptr, text, L"Command Line Arguments", MB_OK); }
如果传递给 `CommandLineToArgvW` 的字符串是空字符串, 那么它的返回值是一个包含完整可执行文件路径的单个字符串. 另一方面, 如果传入的字符串包含非空参数, 它会返回一个只包含解析的参数的字符串指针数组, 而不将完整可执行文件路径作为第一个解析的字符串.
进程可以随时通过调用 `GetCommandLine` 获取其命令行, 并且它是 `CommandLineToArgvW` 的一个合适参数. 如果需要在 `wWinMain` 之外进行解析, 这可能很有用.
- `showCmd` 是最后一个参数, 它建议如何显示应用程序的主窗口. 它由进程创建者确定, 默认值为 `SWSHOWDEFAULT` (10). 应用程序当然可以自由地忽略此值, 并以任何它认为合适的方式显示其主窗口.
- 进程环境变量
环境变量是一组名称/值对, 可以在系统或用户级别上使用图 3-10 中显示的对话框 (可从系统属性对话框或简单搜索访问) 设置. 名称和值存储在注册表中 (像 Windows 中的大多数系统数据一样).

Figure 38: 环境变量编辑器
用户环境变量存储在 `HKEYCURRENTUSER\Environment` 中. 系统环境变量 (适用于所有用户) 存储在 `HKEYLOCALMACHINE\System\Current Control Set\Control\Session Manager\Environment` 中.
进程从其父进程接收环境变量, 这些变量是系统变量 (适用于所有用户) 和用户特定变量的组合. 在大多数情况下, 进程接收的环境变量是其父进程的副本 (见下一节).
控制台应用程序可以使用 `main` 或 `wmain` 的第三个参数来获取进程环境变量:
int main(int argc, char* argv[], const char* env[]); // const is optional int wmain(int argc, wchar_t* argv[], const wchar_t* env[]); // const is optional
`env` 是一个字符串指针数组, 其中最后一个指针是 `NULL`, 表示数组的结束. 每个字符串都以下列格式构建:
name=value
等号字符分隔了名称和值. 以下示例 `main` 函数打印出每个环境变量的名称和值:
int main(int argc, const char* argv[], char* env[]) { for (int i = 0; ; i++) { if (env[i] == nullptr) break; auto equals = strchr(env[i], '='); // change the equals to NULL *equals = '\0'; printf("%s: %s\n", env[i], equals + 1); // for consistency, revert the equals sign *equals = '='; } return 0; }
GUI 应用程序可以调用 `GetEnvironmentStrings` 来获取一个指向环境变量内存块的指针, 格式如下:
name1=value1\0 name2=value2\0 ... \0
以下代码片段使用 `GetEnvironmentStrings` 在一个巨大的消息框中显示所有环境变量:
PWSTR env = ::GetEnvironmentStrings(); WCHAR text = { 0 }; auto p = env; while (*p) { auto equals = wcschr(p, L'='); if (equals != p) { // eliminate empty names/values wcsncat_s(text, p, equals - p); wcscat_s(text, L": "); wcscat_s(text, equals + 1); wcscat_s(text, L"\n"); } p += wcslen(p) + 1; } ::FreeEnvironmentStrings(env);
可以使用 `SetEnvironmentStrings` 一次性替换环境块, 使用与 `GetEnvironmentStrings` 返回的相同格式.
环境块必须用 `FreeEnvironmentStrings` 释放. 通常, 应用程序不需要枚举环境变量, 而是更改或读取特定值. 以下函数用于此目的:
BOOL SetEnvironmentVariable( _In_ LPCTSTR lpName, _In_opt_ LPCTSTR lpValue); DWORD GetEnvironmentVariable( _In_opt_ LPCTSTR lpName, _Out_ LPTSTR lpBuffer, _In_ DWORD nSize);
`GetEnvironmentVariable` 如果缓冲区足够大, 则返回复制到缓冲区的字符数, 否则返回环境变量的长度. 如果失败 (如果指定的变量不存在), 则返回零. 通常的做法是调用该函数两次: 第一次不带缓冲区以获取长度, 然后在分配了适当大小的缓冲区后第二次调用以接收结果. 以下函数可用于通过返回 C++ `std::wstring` 来获取变量的值:
std::wstring ReadEnvironmentVariable(PCWSTR name) { DWORD count = ::GetEnvironmentVariable(name, nullptr, 0); if (count > 0) { std::wstring value; value.resize(count); ::GetEnvironmentVariable(name, const_cast<PWSTR>(value.data()), count); return value; } return L""; }
上面的 `constcast` 运算符移除了 `value.data()` 的“常量性”, 因为它返回 `const wchart*`. 一个粗暴的 C 风格转换也可以同样工作: `(PWSTR)value.data()`.
环境变量在许多情况下用于指定基于其当前值的信息. 例如, 文件路径可以指定为 “%windir%\\explorer.exe”. 百分号之间的名称是一个环境变量, 应扩展为其真实值. 普通的 API 函数对这些意图没有任何特殊的理解. 相反, 应用程序必须调用 `ExpandEnvironmentStrings` 将任何用百分号括起来的环境变量转换为其值:
DWORD ExpandEnvironmentStrings( _In_ LPCTSTR lpSrc, _Out_opt_ LPTSTR lpDst, _In_ DWORD nSize);
就像 `GetEnviromentVariable` 一样, `ExpandEnvironmentStrings` 返回复制到目标缓冲区的字符数, 或者如果缓冲区太小则返回所需的字符数 (加上 NULL 终止符). 以下是一个示例用法:
WCHAR path[MAX_PATH]; ::ExpandEnvironmentStrings(L"%windir%\\explorer.exe", path, MAX_PATH); printf("%ws\n", path); // c:\windows\explorer.exe
进程是在同一用户帐户下使用 `CreateProcess` 创建的. 存在扩展函数, 如 `CreateProcessAsUser`, 将在第 16 章中讨论. `CreateProcess` 需要一个实际的可执行文件. 它不能基于文档文件的路径创建进程. 例如, 传递类似 `c:\MyData\data.txt` 的东西, 假设 `data.txt` 是某个文本文件——将导致进程创建失败. `CreateProcess` 不会搜索与 TXT 文件关联的可执行文件来启动. 当在资源管理器中双击一个文件时, 例如, 会调用 Shell API 中的一个更高级别的函数——`ShellExecuteEx`. 这个函数接受任何文件, 如果它不是以“EXE”结尾, 将根据文件扩展名搜索注册表以找到要执行的关联程序. 然后 (如果找到), 它最终会调用 `CreateProcess`.
资源管理器在哪里查找这些文件关联? 我们将在第 17 章 (“注册表”) 中探讨这个问题.
`CreateProcess` 接受 9 个参数, 如下:
BOOL CreateProcess( _In_opt_ PCTSTR pApplicationName, _Inout_opt_ PTSTR pCommandLine, _In_opt_ PSECURITY_ATTRIBUTES pProcessAttributes, _In_opt_ PSECURITY_ATTRIBUTES pThreadAttributes, _In_ BOOL bInheritHandles, _In_ DWORD dwCreationFlags, _In_opt_ PVOID pEnvironment, _In_opt_ PCTSTR pCurrentDirectory, _In_ PSTARTUPINFO pStartupInfo, _Out_ PPROCESS_INFORMATION lpProcessInformation);
函数成功时返回 `TRUE`, 这意味着从内核的角度来看, 进程和初始线程已成功创建. 仍然有可能在新进程的上下文中完成的初始化 (如前一节所述) 会失败.
如果成功, 真正的返回信息可通过类型为 `PROCESSINFORMATION` 的最后一个参数获得:
typedef struct _PROCESS_INFORMATION { HANDLE hProcess; HANDLE hThread; DWORD dwProcessId; DWORD dwThreadId; } PROCESS_INFORMATION, *PPROCESS_INFORMATION;
提供了四部分信息: 唯一的进程和线程 ID, 以及两个到新创建的进程和线程的打开句柄 (具有所有可能的权限, 除非新进程受保护). 使用这些句柄, 创建 (父) 进程可以对新进程和线程做任何它想做的事情 (同样, 除非进程受保护, 见本章后面). 像往常一样, 一旦不再需要这些句柄, 关闭它们是个好主意.
现在让我们把注意力转向函数的其余输入参数.
- pApplicationName 和 pCommandLine
这些参数应提供作为新进程运行的可执行文件路径以及任何需要的命令行参数. 然而, 这些参数是不可互换的.
在大多数情况下, 你将使用第二个参数来表示可执行文件名和需要传递给可执行文件的任何命令行参数, 并将第一个参数设置为 `NULL`. 以下是第二个参数与第一个参数相比的一些好处:
- 如果文件名没有扩展名, 则会隐式添加 EXE 扩展名, 然后再搜索匹配项.
- 如果只提供了文件名 (而不是完整路径) 作为可执行文件, 系统会在加载器查找所需 DLL 的上一节中列出的目录中搜索, 这里为方便起见重复一遍:
- 调用者的可执行文件目录
- 进程的当前目录 (本节后面讨论)
- 由 `GetSystemDirectory` 返回的系统目录
- 由 `GetWindowsDirectory` 返回的 Windows 目录
- `PATH` 环境变量中列出的目录
如果 `pApplicationName` 不是 `NULL`, 那么它必须设置为可执行文件的完整路径. 在这种情况下, `pCommandLine` 仍然被视作命令行参数.
`pCommandLine` 参数有一个问题, 就是它的类型是 `PTSTR`, 意思是它是一个指向字符串的非 `const` 指针. 这意味着 `CreateProcess` 实际上会写入 (不仅仅是读取) 这个缓冲区, 如果用一个常量字符串调用, 会导致访问冲突, 像这样:
CreateProcess(nullptr, L"Notepad", ...);
编译时静态缓冲区默认放在可执行文件的只读部分, 并以只读保护映射, 导致任何写入都会引发异常. 最简单的解决方案是通过动态构建或将其放在栈上 (总是读/写) 来将字符串放在读/写内存中:
WCHAR name[] = L"Notepad"; CreateProcess(nullptr, name, ...);
缓冲区的最终内容与最初提供的内容相同. 你可能会想知道为什么 `CreateProcess` 会写入缓冲区. 不幸的是, 我知道的没有好的理由, 微软应该修复它. 但他们多年来一直没有, 所以我不会屏住呼吸.
这个问题不会发生在 `CreateProcessA` (ASCII 版本的 `CreateProcess`) 上. 原因可能很明显: `CreateProcessA` 必须将其参数转换为 Unicode, 为此它会动态分配一个缓冲区 (即可读/写), 转换字符串, 然后用该分配的缓冲区调用 `CreateProcessW`. 这并不意味着你应该使用 `CreateProcessA`!
- pProcessAttributes 和 pThreadAttributes
这两个参数是 `SECURITYATTRIBUTES` 指针 (用于新创建的进程和线程), 在第 2 章中讨论过. 在大多数情况下, 应传入 `NULL`, 除非返回的句柄应为可继承的, 在这种情况下, 可以传入一个 `bInheritHandle = TRUE` 的实例.
- bInheritHandles
此参数是一个全局开关, 允许或禁止句柄继承 (在下一小节中描述). 如果为 `FALSE`, 则父进程的句柄不会被 (新创建的) 子进程继承. 如果为 `TRUE`, 所有标记为可继承的句柄都将被子进程继承.
- dwCreationFlags
此参数可以是各种标志的组合, 更有用的标志在表 3-5 中描述. 在许多情况下, 零是一个合理的默认值.
标志 描述 CREATEBREAKAWAYFROMJOB 如果父进程是作业的一部分, 则子进程不是, 除非作业不允许从中脱离, 在这种情况下, 子进程仍然在同一作业下创建 (有关作业的更多信息, 请参见下一章) CREATESUSPENDED 进程和线程被创建, 但线程被挂起. 父进程最终应在返回的线程句柄上调用 `ResumeThread` 以开始执行 DEBUGPROCESS 父进程成为调试器, 创建的进程成为被调试者. 调试器将开始接收与子进程相关的调试事件. 从子进程创建的任何进程也成为父进程控制下的被调试者 DEBUGONLYTHISPROCESS 类似于 `DEBUGPROCESS`, 但只有子进程成为被调试者, 而不是由子进程创建的所有子进程 CREATENEWCONSOLE 新进程获得自己的控制台 (如果是 CUI 应用程序), 而不是继承其父控制台 CREATENOWINDOW 如果子进程是 CUI 应用程序, 则创建时没有控制台 DETACHEDPROCESS 有点像 `CREATENEWCONSOLE` 的反面. 子进程没有任何控制台. 如果需要, 它可以调用 `AllocConsole` 来创建一个 CREATEPROTECTEDPROCESS 新进程必须以受保护的方式运行 (见本章后面) CREATEDPROTECTEDPROCESS 以受保护的方式创建新进程. 这仅适用于由 Microsoft 专门签名的可执行文件 CREATEUNICODEENVIRONEMT 为新进程创建 Unicode 环境块, 而不是默认的 (具有讽刺意味的是 ASCII) INHERITPARENTAFFINITY (Windows 7+) 子进程继承其父组亲和性 (有关亲和性的更多信息, 请参见第 6 章) EXTENDEDSTARTUPINFOPRESENT 进程是使用包含进程属性的扩展 `STARTUPINFOEX` 结构创建的 (见本章后面的“进程 (和线程) 属性”部分) CREATEDEFAULTERRORMODE 使用系统默认错误模式创建进程, 而不是从父进程继承. 见第 20 章中关于错误模式的部分 除了表 3-5 中的标志外, 创建者还可以根据表 3-6 设置进程优先级类.
优先级类标志 基础优先级值 IDLEPRIORITYCLASS 4 BELOWNORMALPRIORITYCLASS 6 NORMALPRIORITYCLASS 8 ABOVENORMALPRIORITYCLASS 10 HIGHPRIORITYCLASS 13 REALTIMENORMALPRIORITYCLASS 24 如果没有指定优先级类标志, 默认是 `Normal`, 除非创建者的优先级类是 `Below Normal` 或 `Idle`, 在这种情况下, 新进程继承其父进程的优先级类. 如果指定了 `Real-time` 优先级类, 子进程必须以管理员权限执行; 否则, 它会得到一个 `High` 优先级类.
优先级类对进程本身意义不大. 相反, 它为新进程中的线程设置默认优先级. 我们将在第 6 章中探讨优先级的影响.
- pEnvironment
这是一个可选的指针, 指向一个要由子进程使用的环境变量块. 其格式与本章前面讨论的 `GetEnvironmentStrings` 返回的格式相同. 在大多数情况下, 传入 `NULL`, 这会导致父进程的环境块被复制到新进程的环境块中.
- pCurrentDirectory
这为新进程设置了当前目录. 当前目录用作搜索文件的一部分, 以防只使用文件名而不是完整路径. 例如, 调用 `CreateFile` 函数并使用文件名 “mydata.txt”, 将在进程的当前目录中搜索该文件. `pCurrentDirectory` 参数允许父进程设置已创建进程的当前目录, 这会影响为所需 DLL 执行 DLL 搜索的位置. 在大多数情况下, 传入 `NULL`, 这会将新进程的当前目录设置为父进程的当前目录.
通常, 进程可以使用 `SetCurrentDirectory` 更改其当前目录. 请注意, 这是一个进程范围的设置, 而不是线程范围的设置:
BOOL SetCurrentDirectory( _In_ PCTSTR pPathName);
当前目录由一个驱动器号和路径组成, 或者是一个通用命名约定 (UNC) 中的共享名, 例如 `\\MyServer\MyShare`.
当然, 当前目录可以用 `GetCurrentDirectory` 查询回来:
DWORD GetCurrentDirectory( _In_ DWORD nBufferLength, _Out_ LPTSTR lpBuffer);
返回值是零表示失败, 或者是复制到缓冲区的字符数 (包括 NULL 终止符). 如果缓冲区太小, 返回值是所需的字符长度 (包括 NULL 终止符).
- pStartupInfo
此参数指向两种结构之一, `STARTUPINFO` 或 `STARTUPINFOEX`, 定义如下:
typedef struct _STARTUPINFO { DWORD cb; PTSTR lpReserved; PTSTR lpDesktop; PTSTR lpTitle; DWORD dwX; DWORD dwY; DWORD dwXSize; DWORD dwYSize; DWORD dwXCountChars; DWORD dwYCountChars; DWORD dwFillAttribute; DWORD dwFlags; WORD wShowWindow; WORD cbReserved2; PBYTE lpReserved2; HANDLE hStdInput; HANDLE hStdOutput; HANDLE hStdError; } STARTUPINFO, *PSTARTUPINFO; typedef struct _STARTUPINFOEX { STARTUPINFO StartupInfo; PPROC_THREAD_ATTRIBUTE_LIST pAttributeList; } STARTUPINFOEXW, *LPSTARTUPINFOEXW;
此参数的最低用法是创建一个 `STARTUPINFO` 结构, 初始化其大小 (`cb` 成员) 并将其余部分清零. 将结构清零很重要, 否则它会包含垃圾值, 这很可能会导致 `CreateProcess` 失败. 以下是最小的代码:
STARTUPINFO si = { sizeof(si) }; CreateProcess(..., &si, ...);
`STARTUPINFOEX` 在本章后面的“进程 (和线程) 属性”部分讨论.
`STARTUPINFO` 和 `STARTUPINFOEX` 结构为进程创建提供了更多的自定义选项. 它们的一些成员只有在 `dwFlags` 成员中设置了某些值 (除了其他标志) 时才使用. 表 3-7 详细说明了 `dwFlags` 可能的值及其含义.
标志 含义 `STARTFUSESHOWWINDOW` `wShowWindow` 成员有效 `STARTFUSESIZE` `dwXSize` 和 `dwYSize` 成员有效 `STARTFUSEPOSITION` `dwX` 和 `dwY` 成员有效 `STARTFUSECOUNTCHARS` `dwXCountChars` 和 `dwYCountChars` 成员有效 `STARTFUSEFILLATTRIBUTE` `dwFillAttribute` 成员有效 `STARTFRUNFULLSCREEN` 对于控制台应用, 全屏运行 (仅限 x86) `STARTFFORCEONFEEDBACK` 指示 Windows 显示“后台工作”光标, 其形状可以在图 3-11 所示的鼠标属性对话框中找到. 如果在接下来的 2 秒内, 进程进行 GUI 调用, 它会给进程额外 5 秒的时间显示此光标. 如果在任何时候, 进程调用 `GetMessage`, 表明它已准备好处理消息, 光标会立即恢复正常. `STARTFFORCEOFFFEEDBACK` 不显示“后台工作”光标 `STARTFUSESTDHANDLES` `hStdInput`, `hStdOutput` 和 `hStdError` 成员有效 `STARTFUSEHOTKEY` `hStdInput` 成员有效, 并且是作为 `WMHOTKEY` 消息的 `wParam` 发送的值. 有关更多信息, 请参阅文档 `STARTFTITLEISLINKNAME` `lpTitle` 成员是用于启动进程的快捷方式文件 (.lnk) 的路径. Shell (Explorer) 会适当地设置此项 `STARTFTITLEISAPPID` `lpTitle` 成员是 `AppUserModelId`. 请参阅本表后的讨论 `STARTFPREVENTPINNING` 防止进程创建的任何窗口被固定到任务栏. 仅当也指定了 `STARTFTITLEISAPPID` 时才有效 `STARTFUNTRUSTEDSOURCE` 指示传递给进程的命令行来自不受信任的源. 这是给进程的一个提示, 让它仔细检查其命令行 
Figure 39: “后台工作”鼠标光标
现在让我们检查 `STARTUPINFO` 的其他成员.
有三个保留成员, `lpRserved`, `lpReserved2` 和 `cbReserved2`——这些应分别设置为 `NULL`, `NULL` 和零.
`lpDesktop` 成员为新进程指定一个备用窗口站, 为新线程指定一个备用桌面. 如果此成员为 `NULL` (或空字符串), 则使用父进程的窗口站和桌面. 或者, 可以指定一个完整的桌面名称, 格式为 `windowstation\desktop`. 例如, 可以使用 “winsta0\mydesktop”. 请参阅侧边栏*窗口站和桌面*以获取更多信息.
窗口站和桌面 一个窗口站是一个内核对象, 它是会话的一部分. 它包含与用户相关的对象: 一个剪贴板, 一个原子表和桌面. 一个桌面包含窗口, 菜单和钩子. 一个进程与一个窗口站关联. 交互式窗口站总是名为 “WinSta0”, 并且是会话中唯一可以“交互”的窗口站, 意味着与输入设备一起使用.
默认情况下, 交互式登录会话有一个名为 “winsta0” 的窗口站, 其中存在两个桌面: “default” 桌面, 用户通常在这里工作——在这里你看到资源管理器, 任务栏以及你通常运行的任何其他东西. 另一个桌面 (由 `Winlogon.exe` 进程创建) 被称为 “Winlogon”, 是在按下著名的 Ctrl+Alt+Del 组合键时使用的那个. Windows 调用 `SwitchDesktop` 函数将输入桌面切换到 “Winlogon” 桌面. 可以分别使用 `CreateDesktop` 和 `OpenDesktop` 创建或打开桌面.
你可以在我的博客文章中找到更多细节: https://scorpiosoftware.net/2019/02/17/windows-10-desktops-vs-sysinternals-desktops/.
`lpTitle` 成员可以保存控制台应用程序的标题. 如果为 `NULL`, 则使用可执行文件名作为标题. 如果 `dwFlags` 有 `STARTFTITLEISAPPID` 标志 (Windows 7 及更高版本), 那么 `lpTitle` 是一个 `AppUserModelId`, 这是一个 shell 用于任务栏项目分组和跳转列表的字符串标识符. 进程可以通过调用 `SetCurrentProcessExplicitAppUserModelID` 来显式设置其 `AppUserModelId`, 而不是让其父进程指定. 使用跳转列表和其他任务栏功能超出了本书的范围.
`dwX` 和 `dwY` 可以设置为进程创建的窗口的默认位置. 它们仅在 `dwFlags` 包含 `STARTFUSEPOSITION` 时使用. 如果新进程的调用 `CreateWindow` 或 `CreateWindowEx` 使用 `CWUSEDEFAULT` 作为窗口的位置, 则可以使用这些值. (有关更多详细信息, 请参见 `CreateWindow` 函数文档.) `dwXSize` 和 `dwYSize` 类似, 指定由子进程创建的新窗口的默认宽度和高度, 如果它在调用 `CreateWindow/CreateWindowEx` 时使用 `CWUSEDEFAULT` 作为宽度和高度. (当然, `STARTFUSESIZE` 必须在 `dwFlags` 中设置, 以便这些值传播).
`dwXCountChars` 和 `dwYCountChars` 设置由子进程创建的控制台窗口 (如果有的话) 的初始宽度和高度 (以字符为单位). 与前面的成员一样, `dwFlags` 必须有 `STARTFUSECOUNTCHARS` 才能使这些值生效.
`dwFillAttribute` 指定如果进程创建了新的控制台窗口, 则其初始文本和背景颜色. 像往常一样, 如果 `dwFlags` 包含 `STARTFUSEFILLATTRIBUTE`, 此成员才会生效. 可能的颜色组合各有 4 位, 导致 16 种文本和背景组合. 可能的值如表 3-8 所示.
颜色常量 值 文本/背景 FOREGROUNDBLUE 0x01 Text FOREGROUNDGREEN 0x02 Text FOREGROUNDRED 0x04 Text FOREGROUNDINTENSITY 0x08 Text BACKGROUNDBLUE 0x10 Background BACKGROUNDGREEN 0x20 Background BACKGROUNDRED 0x40 Background BACKGROUNDINTENSITY 0x80 Background `wShowWindow` (如果 `dwFlags` 包含 `STARTFUSESHOWWINDOW` 则有效) 指示进程的主窗口应如何显示 (假设它有 GUI). 这些值通常传递给 `ShowWindow` 函数, 带有 `SW_` 前缀. `wShowWindow` 是独特的, 因为它直接在 `WinMain` 函数中作为最后一个参数提供. 当然, 创建的进程可以完全忽略提供的值, 并以它认为合适的方式显示其窗口. 但尊重这个值是一个好习惯. 如果创建者不提供此成员, 则使用 `SWSHOWDEFAULT`, 表明应用程序可以使用任何逻辑来显示其主窗口. 例如, 它可能已保存上次窗口位置和状态 (最大化, 最小化等), 因此它将窗口恢复到保存的位置/状态.
一个可以控制此值的场景是使用 shell 创建的快捷方式. 图 3-12 显示了一个为运行 Notepad 创建的快捷方式. 在快捷方式属性中, 可以选择初始窗口的显示方式: 正常, 最小化或最大化. 资源管理器在创建进程时将此值传播到 `wShowWindow` 成员中 (`SWSHOWNORMAL`, `SWSHOWMINNOACTIVE`, `SWSHOWMAXIMIZED`).

Figure 40: 快捷方式中的显示窗口
`STARTUPINFO` 中的最后三个成员是标准输入 (`hStdInput`), 输出 (`hStdOutput`) 和错误 (`hStdError`) 的句柄. 如果 `dwFlags` 包含 `STARTFUSEHANDLES`, 这些句柄将按原样在新进程中使用. 否则, 新进程将使用默认值: 从键盘输入, 输出和错误到控制台缓冲区.
如果进程是从任务栏或跳转列表 (Windows 7+) 启动的, `hStdOutput` 句柄实际上是进程启动的监视器 (`HMONITOR`) 的句柄.
鉴于进程创建的所有这些各种选项 (以及本章后面“进程 (和线程) 属性”部分讨论的更多选项), 创建一个进程可能看起来令人生畏, 但在大多数情况下, 如果默认值可接受, 它相当直接. 以下代码片段创建了 Notepad 的一个实例:
WCHAR name[] = L"notepad"; STARTUPINFO si = { sizeof(si) }; PROCESS_INFORMATION pi; BOOL success = ::CreateProcess(nullptr, name, nullptr, nullptr, FALSE, 0, nullptr, nullptr, &si, &pi); if (!success) { printf("Error creating process: %d\n", ::GetLastError()); } else { printf("Process created. PID=%d\n", pi.dwProcessId); ::CloseHandle(pi.hProcess); ::CloseHandle(pi.hThread); }
从 `CreateProcess` 返回的句柄可以做什么? 一件事是当进程终止时 (无论何种原因) 得到通知. 这是通过 `WaitForSingleObject` 函数完成的. 这个函数不特定于进程, 但可以等待各种内核对象直到它们变为*已发出信号*状态. *已发出信号*的含义取决于对象类型; 对于进程, 它意味着已终止. 关于“等待”函数的详细讨论将在第 8 章中进行. 在这里, 我们将看几个例子. 首先, 我们可以无限期地等待直到进程退出:
// process creation succeeded printf("Process created. PID=%d\n", pi.dwProcessId); ::WaitForSingleObject(pi.hProcess, INFINITE); printf("Notepad terminated.\n"); ::CloseHandle(pi.hProcess); ::CloseHandle(pi.hThread);
`WaitForSingleObject` 将调用线程置于等待状态, 直到所讨论的对象变为已发出信号状态或超时到期. 在 `INFINITE` (-1) 的情况下, 它永远不会到期. 以下是非 `INFINITE` 超时的示例:
DWORD rv = ::WaitForSingleObject(pi.hProcess, 10000); // 10 seconds if (rv == WAIT_TIMEOUT) printf("Notepad still running...\n"); else if (rv == WAIT_OBJECT_0) printf("Notepad terminated.\n"); else // WAIT_ERROR (unlikely in this case) printf("Error! %d\n", ::GetLastError());
调用线程最多阻塞 10000 毫秒, 之后返回值指示进程的状态.
一个进程总是可以通过调用 `GetStartupInfo` 来获取它创建时所使用的 `STARTUPINFO`.
- 句柄继承
在第 2 章中, 我们探讨了在进程之间共享内核对象的方法. 一种是按名称共享, 另一种是复制句柄. 第三种选择是使用句柄继承. 此选项仅在进程创建子进程时可用. 在创建时, 父进程可以将选定的一组句柄复制到目标进程. 一旦以第五个参数设置为 `TRUE` 调用 `CreateProcess`, 父进程中所有设置了继承位的句柄都将被复制到子进程中, 句柄值与父进程中的相同.
最后一句话很重要. 子进程与父进程合作 (大概它们是同一软件系统的一部分), 它知道它将从其父进程那里获得一些句柄. 它*不*知道的是这些句柄的值. 一种提供这些值的简单方法是使用发送给被创建进程的命令行参数.
将句柄设置为可继承有几种方法:
- 如果所讨论的对象是由父进程创建的, 那么它的 `SECURITYATTRIBUTES` 可以用句柄继承标志初始化, 并传递给 `Create` 函数, 像这样:
SECURITY_ATTRIBUTES sa = { sizeof(sa) }; sa.bInheritHandles = TRUE; HANDLE h = ::CreateEvent(&sa, FALSE, FALSE, nullptr); // handle h will be inherited by child processes
- 对于现有句柄, 调用 `SetHandleInformation`:
::SetHandleInformation(h, HANDLE_FLAG_INHERIT , HANDLE_FLAG_INHERIT);
- 最后, 大多数 `Open` 函数允许在成功返回的句柄上设置继承标志. 以下是一个命名事件对象的示例:
HANDLE h = ::OpenEvent(EVENT_ALL_ACCESS, TRUE, // inheritable L"MyEvent");
`InheritSharing` 应用程序是第 2 章中内存共享应用程序的又一个变体. 这次, 共享是通过继承内存映射句柄到从第一个进程创建的子进程来实现的. 对话框现在有一个额外的*创建*按钮, 用于生成带有继承的共享内存句柄的新进程 (图 3-13).

Figure 41: 通过继承应用程序共享
当单击*创建*按钮时, `InheirtSharing` 进程会创建自己的另一个实例. 新实例必须获得共享内存对象的句柄, 这是通过继承完成的: 现有的共享内存句柄 (保存在 `wil::uniquehandle` 对象中) 需要设置为可继承, 以便它可以被复制到新进程. *创建*按钮单击处理程序首先设置继承位:
::SetHandleInformation(m_hSharedMem.get(), HANDLE_FLAG_INHERIT, HANDLE_FLAG_INHERIT);
现在可以用第五个参数设置为 `TRUE` 来创建新进程, 表明所有可继承的句柄都将被复制到新进程. 此外, 新进程需要知道其复制的句柄的值, 这是通过命令行传递的:
STARTUPINFO si = { sizeof(si) }; PROCESS_INFORMATION pi; // build command line WCHAR path[MAX_PATH]; ::GetModuleFileName(nullptr, path, MAX_PATH); WCHAR handle; ::_itow_s((int)(ULONG_PTR)m_hSharedMem.get(), handle, 10); ::wcscat_s(path, L" "); ::wcscat_s(path, handle); // now create the process if (::CreateProcess(nullptr, path, nullptr, nullptr, TRUE, 0, nullptr, nullptr, &si, &pi)) { // close unneeded handles ::CloseHandle(pi.hProcess); ::CloseHandle(pi.hThread); } else { MessageBox(L"Failed to create new process", L"Inherit Sharing"); }
命令行是通过首先调用 `GetModuleFileName` 构建的, 该函数通常允许获取进程中加载的任何 DLL 的完整路径. 当第一个参数设置为 `NULL` 时, 返回可执行文件的完整路径. 这种方法是健壮的, 这样就不会对可执行文件在文件系统中的实际位置产生依赖.
一旦返回此路径, 句柄值就作为命令行参数附加. 请记住, 继承的句柄的值总是与原始进程中的相同. 这是可能的, 因为新进程的句柄表最初是空的, 所以该条目肯定是未使用的.
谜题的最后一部分是当进程启动时. 它需要知道它是第一个实例, 还是一个获得现有继承句柄的实例. 在 `WMINITDIALOG` 消息处理程序中, 需要检查命令行. 如果命令行中没有句柄值, 那么进程需要创建共享内存对象. 否则, 它需要抓取句柄并直接使用它.
int count; PWSTR* args = ::CommandLineToArgvW(::GetCommandLine(), &count); if (count == 1) { // "master" instance m_hSharedMem.reset(::CreateFileMapping(INVALID_HANDLE_VALUE, nullptr, PAGE_READWRITE, 0, 1 << 16, nullptr)); } else { // first "real" argument is inherited handle value m_hSharedMem.reset((HANDLE)(ULONG_PTR)::_wtoi(args)); } ::LocalFree(args);
由于这不是 `WinMain`, 命令行参数不容易获得. `GetCommandLine` 总是可以用来在任何时候获取命令行. 然后使用 `CommandLineToArgvW` 来解析参数 (本章前面讨论过). 如果没有句柄值传入, `CreateFileMapping` 用于创建共享内存. 否则, 该值被解释为句柄并附加到 `wil::uniquehandle` 对象以进行安全保管.
你可以尝试从子进程创建一个新实例——它的工作方式与使用“原始”句柄传播到子进程完全相同.
使用 Visual Studio 调试子进程 在 `InheritSharing` 应用程序中, 不仅希望调试主实例, 还希望调试子进程, 因为它是用不同的命令行启动的. Visual Studio 默认不调试子进程 (由被调试的进程创建的进程).
然而, 有一个 Visual Studio 的扩展可以实现这一点. 打开扩展对话框 (在 VS 2017 中是*工具/扩展和更新*, 在 VS 2019 中是*扩展/管理扩展*), 转到*在线*节点并搜索 Microsoft Child Process Debugging Power Tool 并安装它 (图 3-14).

Figure 42: 扩展中的子进程调试 Power Tool
安装后, 转到*调试/其他调试目标/子进程调试器设置…*, 选中*启用子进程调试*并单击*保存*. 现在在 `CMainDlg::OnInitDialog` 处设置一个断点并正常开始调试 (F5).
第一次你命中该断点是在一个新进程的对话框出现时, 它创建了自己的共享内存对象. `count` 变量应为 1 (图 3-15).

Figure 43: 第一个进程中的断点
继续调试并单击*创建*. 一个新进程应该在调试器的控制下出现, 并且应该再次命中相同的断点 (图 3-16). 注意 `count` 现在是 2. 还要注意它是一个不同的进程——*进程*工具栏组合框应该显示两个进程 (图 3-17).

Figure 44: 第二个进程中的断点

Figure 45: 调试多个进程
- 进程驱动器目录
每个进程都有其当前目录, 用 `SetCurrentDirectory` 设置, 用 `GetCurrentDirectory` 检索. 当访问不带任何路径前缀的文件 (例如“mydata.txt”) 时, 使用此目录. 那么当访问带有驱动器前缀的文件 (例如“c:mydata.txt”) 时, 默认目录是什么 (注意缺少反斜杠).
事实证明, 系统使用进程环境变量来跟踪每个驱动器的当前目录. 如果你调用 `GetEnvironmentStrings`, 你会在块的开头发现类似以下的内容:
=C:=C:\Dev\Win10SysProg =D:=D:\Temp
要获取一个驱动器的当前目录, 请调用 `GetFullPathName`:
DWORD GetFullPathNameW( _In_ LPCWSTR lpFileName, _In_ DWORD nBufferLength, _Out_ LPWSTR lpBuffer, _Outptr_opt_ LPWSTR* lpFilePart);
通常来说, 这个函数返回一个给定文件名的完整路径. 具体来说, 对于一个驱动器号, 它返回其当前目录. 以下是一个例子:
WCHAR path[MAX_PATH]; ::GetFullPathName(L"c:", MAX_PATH, path, nullptr);
不要在冒号后附加反斜杠! 如果这样做, 你只会得到相同的字符串.
用一个驱动器号和一个文件名调用该函数, 会返回驱动器的当前目录和文件名的完整路径:
WCHAR path[MAX_PATH]; ::GetFullPathName(L"c:mydata.txt", MAX_PATH, path, nullptr); // no backslash
上面的代码可能会返回类似“c:Win10SysProg\mydata.txt”的东西.
`GetFullPathName` 不检查提供的文件是否存在.
- 进程 (和线程) 属性
我们在 `CreateProcess` 中遇到的 `STARTUPINFO` 结构有相当多的字段. 有理由认为, Windows 的未来版本可能需要更多的方式来定制进程创建. 一种可能的方式是扩展 `STARTUPINFO` 结构并添加更多的标志以使某些成员有效. 微软决定从 Windows Vista 开始以不同的方式扩展 `STARTUPINFO`.
定义了一个扩展结构, `STARTUPINFOEX`, 它扩展了 `STARTUPINFO`, 这里再次为方便起见显示:
typedef struct _STARTUPINFOEX { STARTUPINFO StartupInfo; PPROC_THREAD_ATTRIBUTE_LIST pAttributeList; } STARTUPINFOEXW, *LPSTARTUPINFOEXW;
`STARRTUPINFOEX` 的内存布局以 `STARTUPINFO` 开始, 只增加了一个成员: 一个不透明的属性列表. 这个属性列表是 `CreateProcess` (以及在第 5 章中讨论的 `CreateRemoteThreadEx`) 的主要扩展机制. 由于这个属性列表可以指向任意数量的属性, 因此无需进一步扩展 `STARTUPINFOEX`.
创建和填充一个属性列表需要以下步骤:
- 用 `InitializeProcThreadAttributeList` 分配和初始化一个属性列表.
- 通过为每个属性调用一次 `UpdateProcThreadAttribute` 来添加所需的属性.
- 将 `STARTUPINFOEX` 的 `pAttribute` 成员设置为指向属性列表.
- 用扩展结构调用 `CreateProcess`, 不要忘记在创建标志 (传递给 `CreateProcess` 的第六个参数) 中添加 `EXTENDEDSTARTUPINFOPRESENT` 标志.
- 用 `DeleteProcThreadAttributeList` 删除属性列表.
让我们依次来看这些步骤. 以下是 `InitializeProcThreadAttributeList` 的简化声明:
BOOL InitializeProcThreadAttributeList( _Out_ PPROC_THREAD_ATTRIBUTE_LIST pAttributeList, _In_ DWORD dwAttributeCount, _Reserved_ DWORD dwFlags, // must be zero PSIZE_T pSize);
第一步是分配一个足够大的缓冲区来容纳所需的属性数量. 这是通过调用 `InitializeProcThreadAttributeList` 两次来完成的: 第一次获取所需的大小, 分配一个缓冲区, 然后第二次调用来初始化缓冲区以容纳一个属性列表.
以下示例执行这些步骤 (省略了错误处理):
SIZE_T size; // get required size ::InitializeProcThreadAttributeList(nullptr, 1, 0, &size); // allocate the required size auto attlist = (PPROC_THREAD_ATTRIBUTE_LIST)malloc(size); // initialize ::InitializeProcThreadAttributeList(attlist, 1, 0, &size); // just one attribute
第一次调用 `InitializeProcThreadAttributeList` 返回 `FALSE`, `GetLastError` 返回 122 (“传递给系统调用的数据区域太小.”). 这是预期的, 因为真正的返回值是所需的大小. 属性列表本身必须由调用者分配 (`malloc` 在上面的片段中使用), 这也意味着它必须在调用 `CreateProcess` 后被释放.
接下来, 根据属性的数量多次调用 `UpdateProcThreadAttribute`. 可能的属性列表几乎在每个 Windows 版本中都在增长, 并且很可能会继续增长. 表 3-9 显示了进程和线程的文档化属性 (在撰写本文时), 并附有简要描述.
属性常量 (PROCTHREADATTRIBUTE_) 适用对象 最低版本 描述 PARENTPROCESS 进程 Windows Vista 设置一个不同的父进程, 从中继承各种属性 HANDLELIST 进程 Windows Vista 指定要由子进程继承的句柄列表 GROUPAFFINITY 线程 Windows 7 为新线程设置默认 CPU 亲和性组 (见第 6 章) PREFERREDNODE 进程 Windows 7 为新进程设置首选 NUMA 节点 IDEALPROCESSOR 线程 Windows 7 为新线程设置理想 CPU (见第 6 章) UMSTHREAD 线程 Windows 7 为新线程设置用户模式调度 (UMS) 上下文 (见第 10 章) MITIGATIONPOLICY 进程 Windows 7 为新进程设置安全缓解策略 (见第 16 章) SECURITYCAPABILITIES 进程 Windows 8 设置 AppContainer 的安全能力 (见第 16 章) PROTECTIONLEVEL 进程 Windows 8 以与创建者相同的保护级别启动新进程 CHILDPROCESSPOLICY 进程 Windows 10 指定新进程是否可以创建子进程 DESKTOPAPPPOLICY 进程 Windows 10 (1703) 适用于使用桌面桥转换到 UWP 的应用程序. 指定新进程的子进程是否将在桌面应用环境之外创建 桌面桥在第 18 章中讨论.
`UpdateProcThreadAttribute` 定义如下:
BOOL UpdateProcThreadAttribute( _Inout_ PPROC_THREAD_ATTRIBUTE_LIST pAttributeList, _In_ DWORD dwFlags, // must be zero _In_ DWORD_PTR Attribute, _In_ PVOID pValue, _In_ SIZE_T cbSize, _Out_ PVOID pPreviousValue, // must be NULL _In_opt_ PSIZE_T pReturnSize); // must be NULL
以下示例使用 `PROCTHREADATTRIBUTEPARENTPROCESS` 属性通过指定另一个进程的句柄来设置不同的父进程:
HANDLE hParent = ...; ::UpdateProcThreadAttribute(attlist, 0, PROC_THREAD_ATTRIBUTE_PARENT_PROCESS, &hParent, sizeof(hParent), nullptr, nullptr);
使用 `PROCTHREADATTRIBUTEPARENTPROCESS`, 属性值是到相关进程的一个打开的句柄. 请参阅文档以获取其他属性值的详细信息.
一旦属性列表完全更新, 就可以开始调用 `CreateProcess`, 注意使用正确的结构和标志以使属性生效:
STARTUPINFOEX si = { sizeof(si) }; si.lpAttributeList = attlist; PROCESS_INFORMATION pi; WCHAR name[] = L"Notepad"; ::CreateProcess(nullptr, name, nullptr, nullptr, FALSE, EXTENDED_STARTUPINFO_PRESENT, nullptr, nullptr, (STARTUPINFO*)&si, &pi);
必须设置两件事来指示一个属性列表: `STARTUPINFOEX` 结构和 `EXTENDEDSTARTUPINFOPRESENT` 标志. 没有后者, 属性将不会被应用.
最后一步是清理属性列表及其分配的内存:
::DeleteProcThreadAttributeList(attList); ::free(attList);
鉴于上述步骤, 以下函数基于其 ID 创建一个给定进程, 并将其父进程设置为另一个进程:
DWORD CreateProcessWithParent(PWSTR name, DWORD parentPid) { HANDLE hParent = ::OpenProcess(PROCESS_CREATE_PROCESS, FALSE, parentPid); if (!hParent) return 0; PROCESS_INFORMATION pi = { 0 }; PPROC_THREAD_ATTRIBUTE_LIST attList = nullptr; do { SIZE_T size = 0; ::InitializeProcThreadAttributeList(nullptr, 1, 0, &size); if (size == 0) break; attList = (PPROC_THREAD_ATTRIBUTE_LIST)malloc(size); if (!attList) break; if (!::InitializeProcThreadAttributeList(attList, 1, 0, &size)) break; if (!::UpdateProcThreadAttribute(attList, 0, PROC_THREAD_ATTRIBUTE_PARENT_PROCESS, &hParent, sizeof(hParent), nullptr, nullptr)) break; STARTUPINFOEX si = { sizeof(si) }; si.lpAttributeList = attList; if (!::CreateProcess(nullptr, name, nullptr, nullptr, FALSE, EXTENDED_STARTUPINFO_PRESENT, nullptr, nullptr, (STARTUPINFO*)&si, &pi)) break; ::CloseHandle(pi.hProcess); ::CloseHandle(pi.hThread); } while (false); ::CloseHandle(hParent); if (attList) { ::DeleteProcThreadAttributeList(attList); ::free(attList); } return pi.dwProcessId; }
大部分代码与处理属性的步骤相同, 增加了错误处理和适当的清理. 请注意, 进程句柄是以 `PROCESSCREATEPROCESS` 访问掩码打开的. 在使用 `PROCTHREADATTRIBUTEPARENTPROCESS` 属性时, 这是必需的. 这意味着并非所有进程都可以随意作为父进程.
从 Notepad 和 Explorer 进程的 PID 运行此函数, 会按预期创建 Notepad. 在 Process Explorer 中打开其属性会显示 Explorer 是其父进程 (图 3-18).

Figure 46: 更改父进程
另一个例子, 考虑以下应用了进程安全缓解策略的函数:
DWORD CreateProcessWithMitigations(PWSTR name, DWORD64 mitigation) { PROCESS_INFORMATION pi = { 0 }; PPROC_THREAD_ATTRIBUTE_LIST attList = nullptr; do { SIZE_T size = 0; ::InitializeProcThreadAttributeList(nullptr, 1, 0, &size); if (size == 0) break; attList = (PPROC_THREAD_ATTRIBUTE_LIST)malloc(size); if (!attList) break; if (!::InitializeProcThreadAttributeList(attList, 1, 0, &size)) break; if (!::UpdateProcThreadAttribute(attList, 0, PROC_THREAD_ATTRIBUTE_MITIGATION_POLICY, &mitigation, sizeof(mitigation), nullptr, nullptr)) break; STARTUPINFOEX si = { sizeof(si) }; si.lpAttributeList = attList; if (!::CreateProcess(nullptr, name, nullptr, nullptr, FALSE, EXTENDED_STARTUPINFO_PRESENT, nullptr, nullptr, (STARTUPINFO*)&si, &pi)) break; ::CloseHandle(pi.hProcess); ::CloseHandle(pi.hThread); } while (false); if (attList) { ::DeleteProcThreadAttributeList(attList); ::free(attList); } return pi.dwProcessId; }
代码几乎相同, 只是属性不同. 与 `PROCTHREADATTRIBUTEMITIGATIONPOLICY` 关联的值是一个 `DWORD` 或 `DWORD64`, 指示要应用于新进程的缓解措施.
进程缓解的完整讨论在第 16 章中.
例如, 用以下参数调用此函数
WCHAR name[] = L"notepad"; auto pid = CreateProcessWithMitigations(name, PROCESS_CREATION_MITIGATION_POLICY_WIN32K_SYSTEM_CALL_DISABLE_ALWAYS_ON);
导致 Notepad 初始化失败并终止, 在此之前会显示图 3-19 中的消息框. 原因是特定的缓解措施阻止了对 `Win32k.sys` (窗口管理器) 的调用, 这基本上意味着 `User32.dll` 无法正确初始化. 没有此功能, Notepad 是无用的, 无法正常执行. 这种缓解措施对于没有 UI 的进程很有用, 并且希望确保 `Win32k.sys` 的安全漏洞不能在此类进程中使用.

Figure 47: Notepad 初始化失败
- 受保护进程和 PPL 进程
受保护进程是在 Windows Vista 中引入的, 作为一种对抗数字版权管理 (DRM) 侵权的方式. 这些进程即使由管理员级用户也可以被授予某些访问权限. 允许对受保护进程的唯一访问掩码是: `PROCESSQUERYLIMITEDINFORMATION`, `PROCESSSETLIMITEDINFORMATION`, `PROCESSSUSPENDRESUME` 和 `PROCESSTERMINATE`.
只有具有特定扩展密钥用法 (EKU) 的 Microsoft 签名的可执行文件才允许执行受保护的进程.
Windows 8.1 引入了受保护进程轻量级 (PPL), 它扩展了保护模型以包括多个保护级别, 其中更高级别的受保护进程对较低级别的进程具有完全访问权限, 但反之则不行. 使用扩展模型, 现在可以通过与 Microsoft 协商并获得适当的签名来运行第三方反恶意软件服务. 此外, 某些 PPL 级别 (例如用于反恶意软件的) 拒绝 `PROCESSTERMINATE` 访问, 以便恶意软件, 即使具有提升的权限, 也无法停止或杀死这些服务. 表 3-10 列出了 PPL 签名者级别及其简要描述.
PPL 签名者 级别 描述 WinSystem 7 系统和最小进程 WinTcb 6 关键的 Windows 组件. `PROCESSTERMINATE` 被拒绝 Windows 5 处理敏感数据的重要 Windows 组件 Lsa 4 Lsass.exe (如果配置为受保护运行) Antimalware 3 反恶意软件服务进程, 包括第三方. `PROCESSTERMINATE` 被拒绝 CodeGen 2 .NET native code generation Authenticode 1 托管 DRM 内容 None 0 无效 (无保护) 级别 (以及进程是“普通”受保护还是 PPL) 显示在表 3-10 中, 存储在内核进程对象内部.
为受保护/PPL 进程允许的“有限”访问掩码迎合了设置/查询关于进程的表面信息, 例如查询其启动时间, 其优先级类或其可执行路径. 无法获取受保护进程内部的已加载模块列表, 因为这需要 `PROCESSQUERYINFORMATION` 的访问掩码, 这是不允许的. 图 3-20 显示了在 Process Explorer 中选择的 `Csrss.exe`. 请注意, 底部窗格中的模块列表是空的. 另外, 显示了*保护*列, 其中包含表 3-10 中的签名者值.

Figure 48: 受保护的进程
图 3-20 还显示了 Microsoft 自己的反恶意软件可执行文件 (`MsMpEng.exe` 和 `NisSrv.exe`, 称为“Windows Defender”) 作为反恶意软件 PPL 运行, 就像其他第三方反恶意软件服务一样.
受保护和 PPL 进程不能加载任意的 DLL, 以免受保护的进程被诱骗加载一个不受信任的 DLL, 该 DLL 将在进程的保护下运行. 所有由受保护/PPL 进程加载的 DLL 都必须正确签名.
创建受保护的进程需要在 `CreateProcess` 中使用 `CREATEPROTECTEDPROCESS` 标志. 当然, 这只能在正确签名的可执行文件上工作. 保护机制过于专门, 不适用于普通应用程序, 因此本书不会进一步讨论.
你可以在“Windows Internals 7th edition Part 1”一书的第 3 章中找到有关受保护/PPL 进程的更多信息.
- UWP 进程
通用 Windows 平台 (UWP) 进程与任何其他标准进程类似. 它使用 Windows 运行时平台/API 来完成大部分工作——无论是 UI, 图形, 网络, 后台处理等等. 它的一些独特属性包括:
- UWP 进程总是在一个名为 AppContainer 的应用程序沙箱下运行, 该沙箱限制了它能做什么和能访问什么 (在第 16 章“安全性”中有更详细的讨论).
- UWP 进程的状态由进程生命周期管理器 (PLM) 管理, 该管理器在 `Explorer.exe` 进程下运行, 可以根据其前台/后台活动和内存使用情况启动进程挂起, 恢复和终止 (在第 18 章中有更详细的讨论).
- UWP 包包含一组功能——声明——关于应用程序想要访问的内容 (例如相机, 位置, 图片文件夹), 并且这些功能在 Microsoft 应用商店中列出, 以便用户可以决定是否要下载这样的应用程序.
- UWP 进程默认是单实例的 (从 Windows 10 版本 1803 开始支持多个实例).
从进程创建的角度来看, 标准的 `CreateProcess` 调用无法创建 UWP 进程. 这是因为 UWP 应用程序具有*身份*, 这是标准可执行文件所没有的. 这样的应用程序被构建成一个包, 其中包含可执行文件, 库, 资源文件以及应用程序正常执行所需的任何其他内容. 这个包有一个全局唯一的名称, 这个名称是创建 UWP 进程所必需的.
你可以在任务管理器或 Process Explorer 中通过添加*包名*列来查看此名称.
作为对此要求的简单示例, 在 Windows 10 上运行计算器, 并用 Process Explorer 查看其属性 (图 3-21). 注意命令行; 忽略其长度和丑陋, 只需复制它, 然后使用*开始/运行*并粘贴命令行来启动另一个计算器. 你会得到一个类似于图 3-22 的错误消息框.

Figure 49: Process Explorer 中的计算器属性

Figure 50: 手动创建计算器时的错误消息框
图 3-22 中的错误消息似乎与任何事情都无关. 缺少的信息是包的全名, 需要指定为进程属性. 不幸的是, 这个特定的属性是未文档化的, 因此无法在 Windows 头文件的帮助下指定. 有一种方法可以使用为此目的设计的另一个创建机制来指定此参数, 并通过 COM 接口 (和类) 暴露.
`MetroManager` 应用程序, 如图 3-23 所示, 列出了机器上可用的 UWP 包, 并允许用户启动任何选定的包. 该应用程序演示了一些有趣的能力:
- 从非 UWP 应用程序中使用 Windows 运行时 API.
- 枚举包
- 以文档化的方式启动 UWP 进程.

Figure 51: Metro Manager 应用程序
Windows 运行时 (WinRT) 是建立在 COM 之上的, 这意味着它利用了 COM 世界的接口, 类, 类工厂, GUID 和其他概念 (尽管赋予了一些新名称). Windows 运行时支持通常在高级语言中找到的实体, 包括静态方法和泛型. 我们将在第 18 章中探讨这是如何工作的. 在这里, 我想主要集中在使用 Windows 运行时的机制上.
C++ 客户端可以通过几种方式使用 Windows 运行时 API:
- 直接地, 通过实例化适当的类并使用低级对象工厂, 直到创建一个实例, 然后使用正常的 COM 调用.
- 使用 Windows 运行时库 (WRL) C++ 包装器和帮助器.
- 使用 C++/CX 语言扩展, 它们通过非标准方式扩展 C++ 来提供对 WinRT 的轻松访问.
- 使用 CppWinRT 库, 它只使用标准的 C++ 提供了对 WinRT API 的相对轻松的访问.
上述四种方式都是官方支持的. 第一种选择是最繁琐的, 仅建议用于学习目的, 因为它对开发人员隐藏的东西很少, 因此非常冗长. 选项 2 更容易使用, 但今天已不被推荐, 甚至不被 Microsoft 推荐. 选项 3 是最简单的, 在 WinRT 的早期是最常见的, 但今天被鄙视, 因为它迫使开发人员使用非标准的 C++ 扩展. 这就留下了选项 4, 这是在 C++ 中使用 WinRT 的推荐方式, 因为它足够容易使用, 但仍然使用标准的 C++ 构造.
CppWinRT 超出了本书的范围, 但我们将介绍可以让你走得很远的基础知识. 首先, 我们需要为库添加 Nuget 包 (图 3-24). 接下来, 我们需要为我们希望从 WinRT 中使用的命名空间添加包含. 以下内容被添加到了预编译头 (项目源代码中的 `pch.h`) 中:

Figure 52: CppWinRT Nuget 包
更多 CppWinRT 信息可在在线 Microsoft 文档中找到.
#include <winrt/Windows.Foundation.h> #include <winrt/Windows.Foundation.Collections.h> #include <winrt/Windows.ApplicationModel.h> #include <winrt/Windows.Management.Deployment.h> #include <winrt/Windows.Storage.h>
这是 CppWinRT 头文件的通用格式: `winrt` 前缀, 然后是命名空间 (在 WinRT 文档中找到).
没有 `winrt` 前缀的头文件是“真正的” WinRT 头文件, 它们是内部包含的. 你在使用 CppWinRT 时通常不希望使用这些头文件.
由于所有 WinRT API 都在命名空间和嵌套命名空间中, 类型名称变得很长. 在源文件中添加 `using namespace` 语句, 或者在某些情况下, 在函数中添加以方便访问各种类型要容易得多:
using namespace winrt; using namespace winrt::Windows::Management::Deployment; using namespace winrt::Windows::ApplicationModel;
`winrt` 命名空间本身有一些通用的 CppWinRT 帮助器, 所以它是强制性的. 其他的则取决于我们使用的类型. UWP 包的枚举是通过 `winrt::Windows::Management::Deployment` 命名空间中的 `PackageManager` 类完成的:
auto packages = PackageManager().FindPackagesForUser(L"");
用户的空字符串会查看当前用户 (系统上的其他用户可能安装了不同的包).
`auto` 关键字在这里是真正的帮助手, 因为实际返回的类型是 `IIterable<Package>` (并且我假设我们有 `using namespace` , 缩短了两种类型). 重点是这个方法返回一个集合 (`IIterable<>`), 在 WinRT 的说法中. 由于 CppWinRT 中添加的便利性, 任何这样的集合都可以用 C++ 增强的基于范围的 for 语句进行迭代:
for (auto package : packages) { auto item = std::make_shared<AppItem>(); item->InstalledLocation = package.InstalledLocation().Path().c_str(); item->FullName = package.Id().FullName().c_str(); item->InstalledDate = package.InstalledDate(); item->IsFramework = package.IsFramework(); item->Name = package.Id().Name().c_str(); item->Publisher = package.Id().Publisher().c_str(); item->Version = package.Id().Version(); m_AllPackages.push_back(item); }
`AppItem` 是应用程序定义的一个普通 C++ 类, 用于在普通的 C++ 类型中存储信息, 而不是 WinRT 类型, 这在有意义的地方, 特别是对于字符串:
struct AppItem { CString Name, Publisher, InstalledLocation, FullName; winrt::Windows::ApplicationModel::PackageVersion Version; winrt::Windows::Foundation::DateTime InstalledDate; bool IsFramework; };
标准的 Windows 运行时字符串类型为 `HSTRING`, 这是一个包含其长度的不可变 UTF-16 字符数组.
这个 `AppItem` 存储的数据用于在应用程序的列表视图中显示信息.
运行 UWP 包是通过以下 COM (不是 WinRT) 接口完成的, 用 C++ 显示:
struct IApplicationActivationManager : public IUnknown { virtual HRESULT __stdcall ActivateApplication( /* [in] */ LPCWSTR appUserModelId, /* [unique][in] */ LPCWSTR arguments, /* [in] */ ACTIVATEOPTIONS options, /* [out] */ DWORD *processId) = 0; virtual HRESULT __stdcall ActivateForFile( /* [in] */ LPCWSTR appUserModelId, /* [in] */ IShellItemArray *itemArray, /* [unique][in] */ LPCWSTR verb, /* [out] */ DWORD *processId) = 0; virtual HRESULT __stdcall ActivateForProtocol( /* [in] */ LPCWSTR appUserModelId, /* [in] */ IShellItemArray *itemArray, /* [out] */ DWORD *processId) = 0; };
有几种方法可以“激活” UWP 应用程序, 使用所谓的*契约*, 其中一个契约叫做*启动*, 它自然地启动应用程序. `ActivateApplication` 使用启动契约, 而其他的则使用不同的契约. 我们在本应用程序中只使用启动契约.
启动应用程序的完整代码在 `CView::RunApp` 成员函数中. 首先, 我们需要使用其唯一的包全名 (存储在前面显示的 `AppItem` 结构中) 来定位关于包的一些信息. 这是第一个调用:
bool CView::RunApp(PCWSTR fullPackageName) { PACKAGE_INFO_REFERENCE pir; int error = ::OpenPackageInfoByFullName(fullPackageName, 0, &pir); if (error != ERROR_SUCCESS) return false;
`OpenPackageInfoByFullName` 返回一个指向保存所请求包信息的内部数据结构的不透明指针. 不幸的是, 包全名是不够的, 因为理论上一个包可以包含多个应用程序 (这还不支持), 所以需要从包中提取另一个应用程序 ID:
UINT32 len = 0; error = ::GetPackageApplicationIds(pir, &len, nullptr, nullptr); if (error != ERROR_INSUFFICIENT_BUFFER) break; auto buffer = std::make_unique<BYTE[]>(len); UINT32 count; error = ::GetPackageApplicationIds(pir, &len, buffer.get(), &count); if (error != ERROR_SUCCESS) break;
这是分两步完成的: 首先用 `NULL` 指针调用 `GetPackageApplicationIds` 获取应用程序 ID 和零长度. 这导致函数填充所需的长度. 然后, 用 `makeunique` 构建一个缓冲区 (确保当变量超出作用域时它会自动销毁), 并进行第二次调用.
返回的应用程序 ID 以 4 字节长度存储, 然后是数据本身. 由于只期望一个应用程序, 我们可以跳过前 4 个字节, 并将余下部分用作应用程序 ID. 最后一步是创建实现 `IApplicationActivationManager` 的实例, 并用应用程序 ID 调用 `ActivateApplication`:
CComPtr<IApplicationActivationManager> mgr; auto hr = mgr.CoCreateInstance(CLSID_ApplicationActivationManager); if (FAILED(hr)) break; DWORD pid; hr = mgr->ActivateApplication((PCWSTR)(buffer.get() + sizeof(ULONG_PTR)), nullptr, AO_NOERRORUI, &pid);
`ActivateApplication` 甚至还很友好地返回了创建进程的进程 ID. 最后, 需要释放包信息数据:
::ClosePackageInfo(pir);
如果你查看任何 UWP 进程的父进程, 你会发现它是一个 `Svchost.exe` 进程, 而不是直接的创建者 (参见图 3-22). 这是因为 UWP 进程实际上是由 DCOM Launch 服务启动的, 该服务托管在一个服务主机中 (图 3-25).

Figure 53: DCOM Launch 服务
- Minimal 和 Pico 进程
Minimal 进程仅包含一个用户模式地址空间. Memory Compression 和 Registry 是 minimal 进程的典型例子. Minimal 进程只能由内核创建, 因此本书不会进一步讨论.
Pico 进程是 minimal 进程, 但增加了一个转折: 一个 pico 提供程序, 它是一个内核驱动程序, 负责将 Linux 系统调用转换为等效的 Windows 系统调用.
大多数进程都会在系统关闭前的某个时候终止. 进程退出或终止的方式有几种. 要记住的一件事是, 无论进程如何终止, 内核都会确保进程的任何私有内容都不会保留: 所有私有 (非共享) 内存都会被释放, 进程句柄表中的所有句柄都会被关闭.
如果满足以下任一条件, 进程就会终止:
- 进程中的所有线程都退出或终止.
- 进程中的任何线程调用 `ExitProcess`.
- 进程被 (通常是外部, 但也可能是因为未处理的异常) 用 `TerminateProcess` 终止.
任何编写 Windows 应用程序的人通常都会在某个时候发现, 执行 `main` 函数的线程是“特殊的”, 通常被称为*主线程*. 可以观察到, 只要 `main` 函数返回, 进程就会退出. 这似乎是上面列出的进程退出原因中未列出的情况. 然而, 它确实是, 而且是情况 2. C/C++ 运行时库调用 `main/WinMain` (在本章前面的“进程创建”部分中讨论), 然后进行所需的清理, 例如调用全局 C++ 析构函数, C 运行时清理等, 然后作为其最终行为最终调用 `ExitProcess`, 导致进程退出.
从内核的角度来看, 进程中的所有线程都是平等的, 没有*主线程*. 当其中的所有线程都退出/终止时, 内核会销毁一个进程, 因为没有线程的进程基本上是无用的. 在实践中, 这种情况只能在原生进程 (只依赖于 `NtDll.dll` 并且没有 C/C++ 运行时的可执行文件) 中实现. 换句话说, 这在正常的 Windows 编程中不太可能发生.
`ExitProcess` 函数定义如下:
void ExitProcess(_In_ UINT exitCode);
调用进程是唯一能够调用 `ExitProcess` 的进程, 自然地, 这个函数永远不会返回. 外部进程可以尝试用 `TerminateProcess` (后面讨论) 终止一个进程. 退出代码成为进程的退出代码, 任何持有该进程句柄的人都可以用 `GetExitCodeProcess` 读取, 定义如下:
BOOL GetExitCodeProcess( _In_ HANDLE hProcess, _Out_ LPDWORD lpExitCode);
在进程退出后退出代码仍然可用可能看起来很奇怪, 但由于进程的句柄仍然打开, 内核进程结构仍然存在, 退出代码就存储在那里. 如果对一个活动进程调用 `GetExitCodeProcess` 会发生什么. 你可能会期望函数失败, 但令人困惑的是, 它成功了, 并返回一个名为 `STILLACTIVE` (0x103) 的退出代码.
在内核中, `STILLACTIVE` 被称为 `STATUSPENDING`, 在这种情况下表示进程仍然存在.
最后一句话意味着查看退出代码并不是 100% 确定的检查进程是否仍然存在的方法. 正确的方法是调用 `WaitForSingleObject(hProcess, 0)` 并检查返回值是否等于 `WAITOBJECT0`; 如果相等, 进程已死; 只有内核管理对象仍然存在, 因为至少有一个打开的句柄指向该进程.
`ExitProcess` 以有序的方式关闭进程, 执行以下重要操作:
- 进程中的所有其他线程终止.
- 进程中的所有 DLL 的 `DllMain` 函数都以 `PROCESSDLLDETACH` 的原因值被调用, 表明 DLL 即将被卸载, 应进行清理.
- 终止进程和调用线程 (`ExitProcess` 从不返回).
进程可能终止的第三种方式是因为调用了 `TerminateProcess`, 定义如下:
BOOL TerminateProcess( _In_ HANDLE hProcess, _In_ UINT uExitCode);
`TerminateProcess` 可以从进程外部调用, 假设可以获得具有 `PROCESSTERMINATE` 访问掩码的句柄. 该函数立即终止进程, 并指定其退出值. 所讨论的进程对此无能为力.
`TerminateProcess` 与 `ExitProcess` 在一个重要方面不同: 目标进程中所有 DLL 的 `DllMain` 函数都不会被调用, 因此无法执行任何清理操作. 这可能导致功能或数据丢失. 例如, 如果一个 DLL 在卸载时向日志文件写入一些信息, 它将没有机会这样做. 显然, `TerminateProcess` 应该作为最后的手段使用.
任务管理器的“详细信息”选项卡中的*结束任务*按钮如果能打开具有 `PROCESSTERMINATE` 访问掩码的进程句柄, 则会调用 `TerminateProcess`. *进程*选项卡中的*结束任务*按钮则更棘手, 因为对于 GUI 进程, 它首先尝试通过向其主窗口发送关闭消息 (使用 `SendMessage` 或 `PostMessage` 函数, 消息类型为 `WMCLOSE`) 来友好地请求进程退出.
在某些情况下, 枚举现有进程是有益的. 一个可能的原因是寻找某个感兴趣的特定进程. 另一个原因可能是创建一个提供有关现有进程信息的某种工具. 众所周知的工具, 如任务管理器和 Process Explorer, 都使用进程枚举.
Windows API 提供了三种文档化的方法来枚举进程. 我们将检查所有这些方法, 然后简要讨论第四种半文档化的选项.
- 使用 EnumProcesses
最简单的函数是 `EnumProcesses`, 它是所谓的进程状态 API (PSAPI) 的一部分, 包含在 `<psapi.h>` 中:
BOOL EnumProcesses( _Out_ DWORD *pProcessIds, _In_ DWORD cb, _Out_ DWORD *pBytesReturned);
这个函数提供了最少的信息——所有进程的 ID. 调用者必须分配一个足够大的缓冲区来存储所有的 PID. 返回时, 该函数指示实际存储在提供的缓冲区中的字节数. 如果它小于缓冲区大小, 这意味着缓冲区足够大, 可以包含所有 PID. 如果它等于缓冲区大小, 那么缓冲区可能太小了, 调用者应该用一个更大的缓冲区进行第二次调用, 直到第一个条件满足.
最简单的方法是用一个 (希望) 足够大的缓冲区调用该函数:
const int MaxCount = 1024; DWORD pids[MaxCount]; DWORD actualSize; if(::EnumProcesses(pids, sizeof(pids), &actualSize)) { // assume actualSize < sizeof(pids) int count = actualSize / sizeof(DWORD); for(int i = 0; i < count; i++) { // do something with pids[i] } }
更保守的方法需要动态分配 PID 数组, 以便在需要时可以调整其大小. 一种相对简单的方法是利用 C++ `std::uniqueptr<>` 模板类. 以下是修改后的示例:
int maxCount = 256; std::unique_ptr<DWORD[]> pids; int count = 0; for (;;) { pids = std::make_unique<DWORD[]>(maxCount); DWORD actualSize; if (!::EnumProcesses(pids.get(), maxCount * sizeof(DWORD), &actualSize)) break; count = actualSize / sizeof(DWORD); if (count < maxCount) break; // need to resize maxCount *= 2; } for (int i = 0; i < count; i++) { // do something with pids[i] }
记得为上面的编译添加 `#include <psapi.h>`.
你需要 `#include <memory>` 才能使用 `uniqueptr<>`.
如果你更喜欢使用经典的 C++ 甚至 C, 你当然可以通过利用 `new` 和 `delete` 操作符或 `malloc` 和 `free` 函数来做到这一点. 我建议使用现代 C++ 方法, 因为它不容易出错, 因为分配的内存在相关对象被销毁时会自动释放.
`EnumProcesses` 的缺点是其信息最少——只有每个进程的 PID. 如果需要关于进程的任何其他信息 (通常情况下), 则需要另一次调用 `OpenProcess` 来获取每个感兴趣的进程的句柄, 然后进行适当的调用来检索信息或执行所需的操作. 当然, `OpenProcess` 可能会失败, 因为并非每个访问掩码都一定能为一个进程获得.
以下代码片段显示了在成功调用 `EnumProcesses` 后如何获取进程映像名称及其启动时间:
// count is the number of processes for (int i = 0; i < count; i++) { DWORD pid = pids[i]; HANDLE hProcess = ::OpenProcess(PROCESS_QUERY_LIMITED_INFORMATION, FALSE, pid); if (!hProcess) { printf("Failed to open a handle to process %d (error=%d)\n", pid, ::GetLastError()); continue; } FILETIME start = { 0 }, dummy; ::GetProcessTimes(hProcess, &start, &dummy, &dummy, &dummy); SYSTEMTIME st; ::FileTimeToLocalFileTime(&start, &start); ::FileTimeToSystemTime(&start, &st); WCHAR exeName[MAX_PATH]; DWORD size = MAX_PATH; DWORD count = ::QueryFullProcessImageName(hProcess, 0, exeName, &size); printf("PID: %5d, Start: %d/%d/%d %02d:%02d:%02d Image: %ws\n", pid, st.wDay, st.wMonth, st.wYear, st.wHour, st.wMinute, st.wSecond, count > 0 ? exeName : L"Unknown"); }
`OpenProcess` 用于获取具有 `PROCESSQUERYLIMITEDINFORMATION` 访问掩码的进程句柄, 这是你能请求的最低权限. 这足以获取关于进程的浅层信息, 例如其启动时间 (`GetProcessTimes`) 或映像文件名 (`QueryFullProcessImageName`).
以下是 `GetProcessTimes` 的原型:
BOOL GetProcessTimes( _In_ HANDLE hProcess, _Out_ LPFILETIME lpCreationTime, _Out_ LPFILETIME lpExitTime, _Out_ LPFILETIME lpKernelTime, _Out_ LPFILETIME lpUserTime);
`FILETIME` 是一个 64 位值, 分为两个 32 位值. 创建和退出时间以从 1601 年 1 月 1 日午夜 UTC 开始测量的 100 纳秒为单位给出. 创建时间被转换为更易于管理的形式, 使用 `FileTimeToSystemTime`, 它将 64 位值分割成人类可读的部分 (日, 月, 年等).
内核和用户时间是相对的, 以相同的 100 纳秒为单位给出. 它们在上面的代码中未使用, 将其结果放入一个虚拟变量中. 请注意, 为任何参数提供 `NULL` 将导致函数抛出访问冲突异常.
`QueryFullProcessImageName` 允许获取给定进程的完整可执行文件路径:
BOOL QueryFullProcessImageName( _In_ HANDLE hProcess, _In_ DWORD dwFlags, _Out_ LPTSTR lpExeName, _Inout_ PDWORD lpdwSize );
`dwFlags` 参数通常为零, 但可以是 `PROCESSNAMENATIVE` (1), 它以设备形式返回路径, 这是 Windows 表示路径的本地方式 (例如 `\Device\HarddiskVolume3\MyDir\MyApp.exe`). 我们将在第 11 章中更详细地探讨这种形式. `lpExeName` 参数是调用者分配的缓冲区, 最后一个参数是指向缓冲区大小 (以字符为单位) 的指针. 这是一个输入/输出参数, 因此必须初始化为分配的缓冲区大小, 函数会将其更改为写入缓冲区的实际字符数.
用标准用户权限运行此代码会产生类似以下的输出:
Failed to get a handle to process 0 (error=87) Failed to get a handle to process 4 (error=5) Failed to get a handle to process 88 (error=5) Failed to get a handle to process 152 (error=5) Failed to get a handle to process 900 (error=5) Failed to get a handle to process 956 (error=5) Failed to get a handle to process 1212 (error=5) ... PID: 9796, Start: 26/7/2019 14:13:40 Image: C:\Windows\System32\sihost.exe PID: 9840, Start: 26/7/2019 14:13:40 Image: C:\Windows\System32\svchost.exe Failed to get a handle to process 9864 (error=5) PID: 9904, Start: 26/7/2019 14:13:40 Image: C:\Windows\System32\svchost.exe PID: 9936, Start: 26/7/2019 14:13:40 Image: C:\Windows\System32\svchost.exe PID: 10004, Start: 26/7/2019 14:13:40 Image: C:\Windows\System32\taskhostw.exe Failed to get a handle to process 10032 (error=5) PID: 9556, Start: 26/7/2019 14:13:40 Image: C:\Windows\explorer.exe ...
获取 PID 0 (System Idle Process in Task Manager) 的句柄失败, 因为 PID 0 无效. 这就是为什么错误号是 87 (`ERRORINVALIDPARAMETER`). 低 PID 范围内的其他进程也打开失败, 错误为 5 (`ERRORACCESSDENIED`).
以管理员权限运行相同的代码, 通过打开一个提升的命令窗口, 导航到输出目录并运行可执行文件, 会产生以下输出:
Failed to get a handle to process 0 (error=87) PID: 4, Start: 26/7/2019 14:13:20 Image: Unknown PID: 88, Start: 26/7/2019 14:13:01 Image: Unknown PID: 152, Start: 26/7/2019 14:13:01 Image: Unknown PID: 900, Start: 26/7/2019 14:13:20 Image: C:\Windows\System32\smss.exe Failed to get a handle to process 956 (error=5) PID: 1212, Start: 26/7/2019 14:13:33 Image: C:\Windows\System32\wininit.exe Failed to get a handle to process 1220 (error=5) PID: 1288, Start: 26/7/2019 14:13:33 Image: C:\Windows\System32\services.exe PID: 1300, Start: 26/7/2019 14:13:33 Image: C:\Windows\System32\LsaIso.exe PID: 1316, Start: 26/7/2019 14:13:33 Image: C:\Windows\System32\lsass.exe ...
这里有两件事要注意. 首先, 我们确实比标准用户权限成功打开了更多的进程. 其次, 对于某些进程, 我们无法检索到映像名称. 这是因为它们没有正常的的可执行文件名. 这些是“特殊的”进程: 4 (System), 88 (Secure System), 152 (Registry) 以及后面 (未显示) 的 Memory Compression. 显然, `QueryFullProcessImageName` 无法为这些进程提供名称.
即使有管理员权限, 我们似乎也无法打开所有可能的进程. 这种情况可以通过启用*Debug*权限来改善 (默认存在于管理员令牌中, 但未启用). 奇怪的是, 如果你直接从 Visual Studio (以提升权限运行) 运行代码, 你会得到与启用*Debug*权限相同的效果, 因为 Visual Studio 已经启用了其*Debug*权限, 并且因为它是启动进程的一方, 其访问令牌被复制到新进程, 所以*Debug*权限已经启用.
为了确保无论可执行文件从哪里启动, *Debug*权限都已启用, 我们可以使用以下函数:
bool EnableDebugPrivilege() { wil::unique_handle hToken; if (!::OpenProcessToken(::GetCurrentProcess(), TOKEN_ADJUST_PRIVILEGES, hToken.addressof())) return false; TOKEN_PRIVILEGES tp; tp.PrivilegeCount = 1; tp.Privileges.Attributes = SE_PRIVILEGE_ENABLED; if (!::LookupPrivilegeValue(nullptr, SE_DEBUG_NAME, &tp.Privileges.Luid)) return false; if (!::AdjustTokenPrivileges(hToken.get(), FALSE, &tp, sizeof(tp), nullptr, nullptr)) return false; return ::GetLastError() == ERROR_SUCCESS; }
完整的项目名为 `ProcEnum`, 位于示例库中.
这个函数的详细解释将在第 16 章 (“安全性”) 中进行. 现在, 我们可以简单地使用它并获得更好的结果:
Failed to get a handle to process 0 (error=87) PID: 4, Start: 26/7/2019 14:13:20 Image: Unknown PID: 88, Start: 26/7/2019 14:13:01 Image: Unknown PID: 152, Start: 26/7/2019 14:13:01 Image: Unknown PID: 900, Start: 26/7/2019 14:13:20 Image: C:\Windows\System32\smss.exe PID: 956, Start: 26/7/2019 14:13:30 Image: C:\Windows\System32\csrss.exe PID: 1212, Start: 26/7/2019 14:13:33 Image: C:\Windows\System32\wininit.exe PID: 1220, Start: 26/7/2019 14:13:33 Image: C:\Windows\System32\csrss.exe PID: 1288, Start: 26/7/2019 14:13:33 Image: C:\Windows\System32\services.exe PID: 1300, Start: 26/7/2019 14:13:33 Image: C:\Windows\System32\LsaIso.exe PID: 1316, Start: 26/7/2019 14:13:33 Image: C:\Windows\System32\lsass.exe PID: 1436, Start: 26/7/2019 14:13:33 Image: C:\Windows\System32\svchost.exe ...
现在我们可以为每个进程打开一个句柄 (当然, 除了 PID 0, 它不是一个真正的进程). 我们仍然无法获取特殊进程的名称. 下一种进程枚举技术解决了这个问题.
- 使用 Toolhelp 函数
所谓的“Toolhelp”函数提供了一种更方便的方式来获取有关进程的基本信息, 包括那些不基于可执行映像的特殊进程的进程“名称”. 所有这些都可以从一个标准用户权限的进程中获得——不需要提升的权限.
要访问这些函数, 请包含 `<tlhelp32.h>`. 最初要调用的函数是 `CreateToolhelp32Snapshot`, 它创建一个快照, 其中包含进程和线程的可选组合, 以及特定进程的堆和模块. 以下是创建快照以获取进程信息的调用:
HANDLE hSnapshot = ::CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0); if (hSnapshot == INVALID_HANDLE_VALUE) { // handle error }
`CreateToolhelp32Snapshot` 的第二个参数指示在请求模块或堆的情况下快照的目标进程. 对于进程和线程, 此参数必须为零, 并且快照中包含所有进程/线程.
现在进程枚举从 `Process32First` 开始, 后续进程可通过调用 `Process32Next` 获得, 直到后者返回 `FALSE`, 表示没有更多进程. 两个函数都接受一个 `PROCESSENTRY32` 结构指针, 其中返回每个进程的信息:
typedef struct tagPROCESSENTRY32 { DWORD dwSize; // size of structure DWORD cntUsage; // unused DWORD th32ProcessID; // PID ULONG_PTR th32DefaultHeapID; // unused DWORD th32ModuleID; // unused DWORD cntThreads; // # threads DWORD th32ParentProcessID; // parent PID LONG pcPriClassBase; // Base priority DWORD dwFlags; // unused TCHAR szExeFile[MAX_PATH]; // Path } PROCESSENTRY32;
第一个成员 (`dwSize`) 必须在调用前设置为结构的大小. 从注释中可以看出, 实际上只使用了一些成员. 以下代码演示了如何获取由进程快照提供的所有可能信息:
PROCESSENTRY32 pe; pe.dwSize = sizeof(pe); if (!::Process32First(hSnapshot, &pe)) { // unlikely - handle error } do { printf("PID:%6d (PPID:%6d): %ws (Threads=%d) (Priority=%d)\n", pe.th32ProcessID, pe.th32ParentProcessID, pe.szExeFile, pe.cntThreads, pe.pcPriClassBase); } while (::Process32Next(hSnapshot, &pe)); ::CloseHandle(hSnapshot);
本章示例中的 `ProcList` 项目有完整的代码. 以下是输出的前几行:
PID: 0 (PPID: 0): [System Process] (Threads=12) (Priority=0) PID: 4 (PPID: 0): System (Threads=359) (Priority=8) PID: 88 (PPID: 4): Secure System (Threads=0) (Priority=8) PID: 152 (PPID: 4): Registry (Threads=4) (Priority=8) PID: 900 (PPID: 4): smss.exe (Threads=2) (Priority=11) PID: 956 (PPID: 932): csrss.exe (Threads=13) (Priority=13) PID: 1212 (PPID: 932): wininit.exe (Threads=2) (Priority=13) PID: 1220 (PPID: 1204): csrss.exe (Threads=27) (Priority=13)
- 使用 WTS 函数
Windows 终端服务 (WTS) 函数用于在终端服务 (也称为远程桌面服务) 环境中工作, 其中服务器可能同时托管多个远程 (和本地) 会话. 也就是说, WTS API 可以在单会话机器上使用, 就像在多会话机器上一样. 这个 API 中有几个有趣的函数, 但就本节而言, 我们将使用其进程枚举函数: `WTSEnumerateProcesses` 和 `WTSEnumerateProcessesEx`. WTS API 在其自己的头文件 (`<wtsapi32.h>`, 默认不与 `<windows.h>` 一起包含) 中定义. 它还需要添加一个导入库——`wtsapi32.lib`——才能成功链接.
`WTSEnumerateProcesses` 定义如下:
typedef struct _WTS_PROCESS_INFO { DWORD SessionId; DWORD ProcessId; LPTSTR pProcessName; PSID pUserSid; } WTS_PROCESS_INFO, *PWTS_PROCESS_INFO; BOOL WTSEnumerateProcesses( _In_ HANDLE hServer, _In_ DWORD Reserved, _In_ DWORD Version, _Out_ PWTS_PROCESS_INFO *ppProcessInfo, _Out_ DWORD *pCount);
该函数可以通过第一个句柄枚举其他机器上的进程, 该句柄可以通过调用 `WTSOpenServer` 获得. 要使用本地机器, 可以改用常量 `WTSCURRENTSERVERHANDLE`. `Version` 参数必须设置为 1, 实际结果由函数本身分配和填充, 返回一个指向每个发现的进程的 `WTSPROCESSINFO` 类型结构数组的指针. 最后一个参数返回返回数组中的进程数. 由于函数分配了内存, 客户端应用程序必须最终用 `WTSFreeMemory` 释放它.
以下函数是 `ProcList2` 项目的一部分, 使用 `WTSEnumerateProcesses` 显示系统中所有进程的信息:
bool EnumerateProcesses1() { PWTS_PROCESS_INFO info; DWORD count; if (!::WTSEnumerateProcesses(WTS_CURRENT_SERVER_HANDLE, 0, 1, &info, &count)) return false; for (DWORD i = 0; i < count; i++) { auto pi = info + i; printf("\nPID: %5d (S: %d) (User: %ws) %ws", pi->ProcessId, pi->SessionId, (PCWSTR)GetUserNameFromSid(pi->pUserSid), pi->pProcessName); } ::WTSFreeMemory(info); return true; }
每个进程返回的信息相当少——进程 ID, 会话 ID, 进程名称 (可执行文件名或特殊进程名称, 如 `System`) 和运行进程的用户的安全标识符 (SID). 上面的函数显示了所有可用的信息, 并使用一个辅助函数将 SID (这是一个二进制大对象, 在第 16 章中讨论) 转换为人类可读的名称:
CString GetUserNameFromSid(PSID sid) { if (sid == nullptr) return L""; WCHAR name, domain; DWORD len = _countof(name); DWORD domainLen = _countof(domain); SID_NAME_USE use; if (!::LookupAccountSid(nullptr, sid, name, &len, domain, &domainLen, &use)) return L""; return CString(domain) + L"\\" + name; }
要正确链接, 必须将 `wtsapi32.lib` 添加到链接器的附加依赖项中 (在*项目/属性*中), 或者在源代码中用适当的 `#pragma` 添加:
#pragma comment(lib, "wtsapi32")
以标准用户权限运行调用 `EnumerateProcesses1` 的应用程序会显示类似以下的内容:
PID: 0 (S: 0) (User: ) PID: 4 (S: 0) (User: ) System PID: 88 (S: 0) (User: ) Secure System PID: 152 (S: 0) (User: ) Registry PID: 812 (S: 0) (User: ) smss.exe PID: 1004 (S: 0) (User: ) csrss.exe ... PID: 8904 (S: 1) (User: VOYAGER\Pavel) nvcontainer.exe PID: 8912 (S: 1) (User: VOYAGER\Pavel) nvcontainer.exe PID: 8992 (S: 1) (User: VOYAGER\Pavel) sihost.exe PID: 9040 (S: 1) (User: VOYAGER\Pavel) svchost.exe PID: 9104 (S: 0) (User: ) PresentationFontCache.exe ...
PID 0 (空闲进程) 就 WTS API 而言没有名称. 如前所述, 这不是一个真正的进程, 所以任何名称都是合成的. API 提供的 SID 在所有非运行用户的进程中都是 `NULL`. 要充分利用此函数, 包括 SID, 我们可以在一个提升的命令窗口中运行它 (或启动提升的 Visual Studio 并从 IDE 执行). 结果更好:
PID: 0 (S: 0) (User: ) PID: 4 (S: 0) (User: ) System PID: 88 (S: 0) (User: NT AUTHORITY\SYSTEM) Secure System PID: 152 (S: 0) (User: NT AUTHORITY\SYSTEM) Registry PID: 812 (S: 0) (User: NT AUTHORITY\SYSTEM) smss.exe PID: 1004 (S: 0) (User: NT AUTHORITY\SYSTEM) csrss.exe ... PID: 1360 (S: 0) (User: Font Driver Host\UMFD-0) fontdrvhost.exe PID: 1388 (S: 0) (User: NT AUTHORITY\LOCAL SERVICE) WUDFHost.exe PID: 1492 (S: 0) (User: NT AUTHORITY\NETWORK SERVICE) svchost.exe PID: 1540 (S: 0) (User: NT AUTHORITY\SYSTEM) svchost.exe PID: 1608 (S: 0) (User: NT AUTHORITY\LOCAL SERVICE) WUDFHost.exe PID: 1684 (S: 1) (User: NT AUTHORITY\SYSTEM) winlogon.exe PID: 1760 (S: 1) (User: Font Driver Host\UMFD-1) fontdrvhost.exe ... PID: 8396 (S: 0) (User: NT AUTHORITY\NETWORK SERVICE) svchost.exe PID: 8904 (S: 1) (User: VOYAGER\Pavel) nvcontainer.exe PID: 8912 (S: 1) (User: VOYAGER\Pavel) nvcontainer.exe PID: 8992 (S: 1) (User: VOYAGER\Pavel) sihost.exe PID: 9040 (S: 1) (User: VOYAGER\Pavel) svchost.exe ...
`WTSEnumerateProcessesEx` API (从 Windows 7 开始可用) 是 `WTSEnumerateProcesses` 的扩展版本, 提供每个进程的更多信息:
BOOL WTSEnumerateProcessesEx( _In_ HANDLE hServer, _Inout_ DWORD *pLevel, _In_ DWORD SessionID, _Out_ PTSTR *pProcessInfo, _Out_ DWORD *pCount);
`pLevel` 参数可以设置为 0 或 1. 设置为 1 时, 会返回一个包含每个进程更多信息的扩展结构数组:
typedef struct _WTS_PROCESS_INFO_EX { DWORD SessionId; DWORD ProcessId; LPTSTR pProcessName; PSID pUserSid; DWORD NumberOfThreads; DWORD HandleCount; DWORD PagefileUsage; DWORD PeakPagefileUsage; DWORD WorkingSetSize; DWORD PeakWorkingSetSize; LARGE_INTEGER UserTime; LARGE_INTEGER KernelTime; } WTS_PROCESS_INFO_EX, *PWTS_PROCESS_INFO_EX;
`SessionID` 参数允许枚举特定感兴趣会话中的进程, 但可以提供 `WTSANYSESSION` 来指示所有感兴趣的会话. `ppProcessInfo` 被类型化为指向字符串的指针, 这毫无意义. 它必须是基于级别值的指向 `PWTSPROCESSINFO` 或 `PWTSPROCESSINFOEX` 的指针. 以下是使用扩展结构的修订枚举函数:
bool EnumerateProcesses2() { PWTS_PROCESS_INFO_EX info; DWORD count; DWORD level = 1; // extended info if (!::WTSEnumerateProcessesEx(WTS_CURRENT_SERVER_HANDLE, &level, WTS_ANY_SESSION, (PWSTR*)&info, &count)) return false; for (DWORD i = 0; i < count; i++) { auto pi = info + i; printf("\nPID: %5d (S: %d) (T: %3d) (H: %4d) (CPU: %ws) (U: %ws) %ws", pi->ProcessId, pi->SessionId, pi->NumberOfThreads, pi->HandleCount, (PCWSTR)GetCpuTime(pi), (PCWSTR)GetUserNameFromSid(pi->pUserSid), pi->pProcessName); } ::WTSFreeMemoryEx(WTSTypeProcessInfoLevel1, info, count); return true; }
`WTSPROCESSINFOEX` 中与内存相关的字段 (`PagefileUsage`, `PeakPagefileUsage`, `WorkingSetSize` 和 `PeakWorkingSetSize`) 实际上是有问题的, 因为即使在 64 位进程中它们也是 32 位大小 (结构应该被修改, 以便 `DWORD` 至少更改为 `DWORDPTR`), 所以如果这些计数器中的一个超过 4 GB, 它们将显示错误的数字.
释放分配的内存块必须用一个专门的函数 (`WTSFreeMemoryEx`), 并带有适当的与级别相关的枚举来完成. 代码显示了与 `EnumerateProcesses1` 相比的一些额外数据——进程中的线程数, 句柄数和总 CPU 时间. `GetCpuTime` 辅助函数返回 CPU 时间的字符串表示:
CString GetCpuTime(PWTS_PROCESS_INFO_EX pi) { auto totalTime = pi->KernelTime.QuadPart + pi->UserTime.QuadPart; return CTimeSpan(totalTime / 10000000LL).Format(L"%D:%H:%M:%S"); }
`WTSPROCESSINFOEX` 的 `KernelTime` 和 `UserTime` 成员分别是进程的线程在内核模式和用户模式下花费的时间. 这个时间以 100 纳秒为单位 (100 乘以 10 的 -9 次方) 提供, 这在 Windows API 中非常常见. 这意味着转换为秒需要除以 1000 万. 上面的代码使用了 `CTimeSpan` ATL 辅助类, 它接受秒数并可以提供简单的字符串格式化值.
以下是使用管理员权限运行 `EnumerateProcesses2` 的一些示例输出:
PID: 0 (S: 0) (T: 12) (H: 0) (CPU: 7:16:22:09) (User: ) PID: 4 (S: 0) (T: 365) (H: 27610) (CPU: 0:00:14:39) (User: ) System PID: 88 (S: 0) (T: 0) (H: 0) (CPU: 0:00:00:00) (User: NT AUTHORITY\SYSTEM) Secure System PID: 152 (S: 0) (T: 4) (H: 0) (CPU: 0:00:00:01) (User: NT AUTHORITY\SYSTEM) Registry PID: 812 (S: 0) (T: 2) (H: 53) (CPU: 0:00:00:00) (User: NT AUTHORITY\SYSTEM) smss.exe PID: 1004 (S: 0) (T: 14) (H: 951) (CPU: 0:00:00:05) (User: NT AUTHORITY\SYSTEM) csrss.exe ...
- 使用 Native API
最后一个可用于进程 (和线程) 枚举的选项是使用 `NtDll.dll` 暴露的 native API. 这个 API 大部分是未文档化的, 在某些情况下是部分文档化的. 一些文档是 Windows 驱动程序工具包 (WDK) 的一部分, 因为一些内核 API 是 native 函数的目标, 因此共享一个原型. 在用户模式下, Microsoft 为 native API 提供了非常部分 的定义, 在文件 `<winternl.h>` 中.
其中一个函数是 `NtQuerySystemInformation`. 这个巨型函数可以根据指定所需信息类型的 `SYSTEMINFORMATIONCLASS` 返回各种信息. 以下是 `<winternl.h>` 中的定义:
typedef enum _SYSTEM_INFORMATION_CLASS { SystemBasicInformation = 0, SystemPerformanceInformation = 2, SystemTimeOfDayInformation = 3, SystemProcessInformation = 5, SystemProcessorPerformanceInformation = 8, SystemInterruptInformation = 23, SystemExceptionInformation = 33, SystemRegistryQuotaInformation = 37, SystemLookasideInformation = 45, SystemCodeIntegrityInformation = 103, SystemPolicyInformation = 134, } SYSTEM_INFORMATION_CLASS;
从枚举中可以看出, 有许多未文档化的信息类的空白. `SystemProcessInformation` 是一个检索系统中所有进程数据的值, 其字段比 `WTSPROCESSINFOEX` 提供的要多. 它甚至包括每个进程的所有线程. 事实上, 任务管理器和 Process Explorer 使用它来获取进程信息.
使用上述枚举返回 `SYSTEMPROCESSINFORMATION` 类型的对象, 该对象在 `<winternl.h>` 中声明如下:
typedef struct _SYSTEM_PROCESS_INFORMATION { ULONG NextEntryOffset; ULONG NumberOfThreads; BYTE Reserved1; UNICODE_STRING ImageName; KPRIORITY BasePriority; HANDLE UniqueProcessId; PVOID Reserved2; ULONG HandleCount; ULONG SessionId; PVOID Reserved3; SIZE_T PeakVirtualSize; SIZE_T VirtualSize; ULONG Reserved4; SIZE_T PeakWorkingSetSize; SIZE_T WorkingSetSize; PVOID Reserved5; SIZE_T QuotaPagedPoolUsage; PVOID Reserved6; SIZE_T QuotaNonPagedPoolUsage; SIZE_T PagefileUsage; SIZE_T PeakPagefileUsage; SIZE_T PrivatePageCount; LARGE_INTEGER Reserved7; } SYSTEM_PROCESS_INFORMATION, *PSYSTEM_PROCESS_INFORMATION;
尽管它提供了相当多的信息, 但有许多成员名为“reserved”——实际上是未文档化的字段, 而不是真正的保留字段. 我们能获取这些“保留”字段的详细信息吗?
尽管这些结构和枚举是未文档化的, 但有些已经从一些泄露的 Windows 源代码中找到, 逆向工程或在 Microsoft 提供的公共符号中可用. 一个使用许多这些官方未文档化函数和类型的应用程序是 Process Hacker, 一个开源的 Process Explorer 克隆, 可在 Github 上获得. 它的一个兄弟项目是 phnt, 它包含了我所知道的最大的 native API, 结构, 枚举和定义的定义 (https://github.com/processhacker/phnt).
作为一个快速示例, 完整的 `SYSTEMPROCESSINFORMATION` 看起来像这样:
typedef struct _SYSTEM_PROCESS_INFORMATION { ULONG NextEntryOffset; ULONG NumberOfThreads; LARGE_INTEGER WorkingSetPrivateSize; ULONG HardFaultCount; ULONG NumberOfThreadsHighWatermark; ULONGLONG CycleTime; // since WIN7 LARGE_INTEGER CreateTime; LARGE_INTEGER UserTime; LARGE_INTEGER KernelTime; UNICODE_STRING ImageName; KPRIORITY BasePriority; HANDLE UniqueProcessId; HANDLE InheritedFromUniqueProcessId; ULONG HandleCount; ULONG SessionId; ULONG_PTR UniqueProcessKey; SIZE_T PeakVirtualSize; SIZE_T VirtualSize; ULONG PageFaultCount; SIZE_T PeakWorkingSetSize; SIZE_T WorkingSetSize; SIZE_T QuotaPeakPagedPoolUsage; SIZE_T QuotaPagedPoolUsage; SIZE_T QuotaPeakNonPagedPoolUsage; SIZE_T QuotaNonPagedPoolUsage; SIZE_T PagefileUsage; SIZE_T PeakPagefileUsage; SIZE_T PrivatePageCount; LARGE_INTEGER ReadOperationCount; LARGE_INTEGER WriteOperationCount; LARGE_INTEGER OtherOperationCount; LARGE_INTEGER ReadTransferCount; LARGE_INTEGER WriteTransferCount; LARGE_INTEGER OtherTransferCount; SYSTEM_THREAD_INFORMATION Threads; } SYSTEM_PROCESS_INFORMATION, *PSYSTEM_PROCESS_INFORMATION;
大多数在文档化结构中不存在的字段仍然可以通过其他 API 函数获得. 例如, 进程创建时间可以用 `GetProcessTimes` 检索, 但这确实需要打开一个到进程的句柄 (在这种情况下, 访问掩码为 `PROCESSQUERYLIMITEDINFORMATION`). 显然, 一次性获取大量信息是一种胜利, 这就是为什么进程信息工具通常使用 native API 的原因.
在本书中, 我们不会使用 native API, 除非有非常好的理由这样做. 你可以探索 Process Hacker 的代码来了解如何使用这些 API. 在任何情况下, 如果存在官方 API, 使用它总是比依赖于未文档化的 native API 更安全.
- 编写一个名为 MiniProcExp 的 GUI 或控制台应用程序——一个迷你 Process Explorer, 它使用 Toolhelp API, WTS API 或 native API 来显示有关进程的信息. 通过打开一个合适的句柄并使用正确的函数来获取任何不易获得的信息. (在 `MinProcExp` 项目中提供了一个基本的应用程序).
- 通过在进程上添加操作来扩展前一个应用程序, 例如终止和更改优先级类.
- 继续以任何你认为合适的方式扩展应用程序!
进程是 Windows 中最基本的构建块. 它持有一组资源, 例如一个地址空间, 允许线程使用这些资源执行代码. 在下一章中, 我们将探讨如何使用*作业*将进程作为一个单元进行管理.
1.5. 第 4 章: 作业
自 Windows 2000 以来, 作业对象就已经存在, 能够管理一个或多个进程. 它们的大部分功能都围绕着以某种方式限制被管理的进程. 自 Windows 8 以来, 它们的用处显著增加. 在 Windows 7 及更早版本中, 一个进程只能是一个作业的成员, 而在 Windows 8 及更高版本中, 一个进程可以与多个作业关联.
本章内容:
- 作业简介
- 创建作业
- 嵌套作业
- 查询作业信息
- 设置作业限制
- 作业通知
- Silos
1.5.1. 作业简介
如果一个进程在一个作业下, 作业对象在 Process Explorer 中是间接可见的. 在这种情况下, 进程的属性中会出现一个*作业*选项卡 (如果进程不在任何作业下, 则此选项卡不存在). 另一种了解作业存在的方式是启用*作业*颜色 (默认为棕色), 在*选项 / 配置颜色…*中. 图 4-1 显示了移除了所有其他颜色后, Process Explorer 中显示*作业*颜色的情况.

Figure 54: 棕色进程在作业中
如果一个进程是作业的一部分, 其属性会显示一个*作业*选项卡, 其中包含作业名称 (如果有的话), 作为作业一部分的进程, 以及作业施加的限制 (如果有的话) 的详细信息. 图 4-2 显示了一个作为命名作业一部分的 WMI 工作进程 (`wmiprvse.exe`). 注意作业的限制.

Figure 55: Process Explorer 中的作业属性
一旦一个进程与一个作业关联, 它就无法脱离. 这是有道理的, 因为如果一个进程可以从作业中移除, 那将使作业变得太弱而无法在许多情况下发挥作用.
1.5.2. 创建作业
创建或打开一个作业与其他内核对象类型的其他创建/打开函数类似. 以下是 `CreateJobObject` 函数:
HANDLE CreateJobObject( _In_opt_ LPSECURITY_ATTRIBUTES pJobAttributes, _In_opt_ LPCTSTR pName);
第一个参数是熟悉的 `SECURITYATTRIBUTES` 指针, 通常设置为 `NULL`. 第二个参数是为新作业对象设置的可选名称. 与其他 `create` 函数一样, 如果提供了名称, 并且存在一个同名作业, 那么 (除非有安全限制) 将返回到现有作业的另一个句柄. 像往常一样, 调用 `GetLastError` 可以通过返回 `ERRORALREADYEXISTS` 来揭示作业是否是现有的.
可以通过 `OpenJobObject` 按名称打开一个现有的作业对象, 定义如下:
HANDLE OpenJobObject( _In_ DWORD dwDesiredAccess, _In_ BOOL bInheritHandle, _In_ PCTSTR pName);
大多数参数现在应该是不言自明的. 第一个参数指定了对命名作业对象所需的访问掩码. 此访问掩码会与作业对象的安全描述符进行检查, 只有当安全描述符包含允许所请求权限的条目时, 才会成功返回. 表 4-1 显示了有效的作业访问掩码及其简要描述.
| 访问掩码 | 描述 |
|---|---|
| JOBOBJECTQUERY (4) | 对作业进行查询操作, 例如 `QueryInformationJobObject` |
| JOBOBJECTASSIGNPROCESS (1) | 允许向作业添加进程 |
| JOBOBJECTSETATTRIBUTES (0x10) | 调用 `SetInformationJobObject` 所需 |
| JOBOBJECTTERMINATE (8) | 调用 `TerminateJobObject` 所需 |
| JOBOBJECTALLACCESS | 所有可能的作业访问权限 |
手头有一个作业句柄, 可以通过调用 `AssignProcessToJobObject` 将进程与作业关联:
BOOL AssignProcessToJobObject( _In_ HANDLE hJob, _In_ HANDLE hProcess);
作业句柄必须具有 `JOBOBJECTASSIGNPROCESS` 访问掩码, 这在创建新作业时总是如此, 因为调用者对作业拥有完全控制权. 要分配给作业的进程句柄必须具有 `PROCESSSETQUOTA` 和 `PROCESSTERMINATE` 访问掩码位. 这意味着某些进程永远不能成为作业的一部分, 例如受保护的进程, 因为无法为这些进程获取此访问掩码.
以下示例打开一个给定其 ID 的进程, 并将其添加到提供的作业中:
bool AddProcessToJob(HANDLE hJob, DWORD pid) { HANDLE hProcess = ::OpenProcess(PROCESS_SET_QUOTA | PROCESS_TERMINATE, FALSE, pid); if(!hProcess) return false; BOOL success = ::AssignProcessToJobObject(hJob, hProcess); ::CloseHandle(hProcess); return success ? true : false; }
一旦一个进程与一个作业关联, 它就无法脱离. 如果该进程创建了一个子进程, 默认情况下该子进程将作为父进程作业的一部分创建. 在两种情况下, 子进程可以在作业之外创建:
- `CreateProcess` 调用包含 `CREATEBREAKAWAYFROMJOB` 标志, 并且作业允许脱离 (通过设置限制标志 `JOBOBJECTLIMITBREAKAWAYOK` (参见本章后面的“设置作业限制”部分)).
- 作业具有 `JOBOBJECTLIMITSILENTBREAKAWAYOK` 限制标志. 在这种情况下, 任何子进程都在作业之外创建, 无需任何特殊标志.
1.5.3. 嵌套作业
Windows 8 引入了将一个进程与多个作业关联的能力. 这使得作业比以前更有用, 因为如果你希望用一个作业来控制一个进程, 但它已经是另一个作业的一部分——以前是没有办法将它与另一个作业关联的. 一个被分配第二个作业的进程, 会导致创建一个作业层次结构 (如果可能的话). 第二个作业成为第一个作业的子作业. 基本规则如下:
- 父作业施加的限制会影响该作业和所有子作业 (因此也影响这些作业中的所有进程).
- 父作业施加的任何限制都不能被子作业移除, 但可以更严格. 例如, 如果一个父作业设置了一个 200 MB 的作业范围内存限制, 一个子作业可以 (为其进程) 设置一个 150 MB 的限制, 但不能是 250 MB.
图 4-3 显示了通过按顺序调用以下操作创建的作业层次结构:

Figure 56: 作业层次结构
- 将进程 P1 分配给 J1.
- 将进程 P1 分配给 J2. 一个层次结构形成了.
- 将进程 P2 分配给 J2. 进程 P2 现在受到作业 J1 和 J2 的影响.
- 将进程 P3 分配给 J1.
由此产生的进程/作业关系如图 4-3 所示.
查看作业层次结构并不容易. 例如, Process Explorer 显示作业的详细信息, 包括所显示作业和所有子作业 (如果有的话) 的信息. 例如, 查看图 4-3 中 J1 作业的信息, 会列出三个进程: P1, P2 和 P3. 另外, 由于作业访问是间接的——如果一个进程在一个作业下, 则会有一个*作业*选项卡可用——显示的作业是该进程所属的直接作业. 任何父作业都不会显示.
以下代码创建了图 4-3 中描绘的层次结构.
#include <windows.h> #include <stdio.h> #include <assert.h> #include <string> HANDLE CreateSimpleProcess(PCWSTR name) { std::wstring sname(name); PROCESS_INFORMATION pi; STARTUPINFO si = { sizeof(si) }; if (!::CreateProcess(nullptr, const_cast<PWSTR>(sname.data()), nullptr, nullptr, FALSE, CREATE_BREAKAWAY_FROM_JOB | CREATE_NEW_CONSOLE, nullptr, nullptr, &si, &pi)) return nullptr; ::CloseHandle(pi.hThread); return pi.hProcess; } HANDLE CreateJobHierarchy() { auto hJob1 = ::CreateJobObject(nullptr, L"Job1"); assert(hJob1); auto hProcess1 = CreateSimpleProcess(L"mspaint"); auto success = ::AssignProcessToJobObject(hJob1, hProcess1); assert(success); auto hJob2 = ::CreateJobObject(nullptr, L"Job2"); assert(hJob2); success = ::AssignProcessToJobObject(hJob2, hProcess1); assert(success); auto hProcess2 = CreateSimpleProcess(L"mstsc"); success = ::AssignProcessToJobObject(hJob2, hProcess2); assert(success); auto hProcess3 = CreateSimpleProcess(L"cmd"); success = ::AssignProcessToJobObject(hJob1, hProcess3); assert(success); // not bothering to close process and job 2 handles return hJob1; } int main() { auto hJob = CreateJobHierarchy(); printf("Press any key to terminate parent job...\n"); ::getchar(); ::TerminateJobObject(hJob, 0); return 0; }
该代码可在本章源代码的 `JobTree` 项目中找到.
进程映像名称被有意地设置为不同, 以便更容易识别 (P1=mspaint, P2=mstsc, P3=cmd). 作业被命名, 也是为了更容易识别.
每个进程最初都是在任何作业之外创建的, 通过在 `CreateProcess` 调用中指定 `CREATEBREAKAWAYFROMJOB`. 否则, 从一个已经是作业一部分的进程 (例如 Visual Studio) 运行此应用程序会使作业层次结构复杂化.
图 4-4 显示了 `mspaint` 正在运行的作业. 注意是 `Job2`, 尽管 `mspaint` 也在 `Job1` 下. 图 4-5 显示了 `cmd` 正在运行的作业, 显示了三个进程. 这是因为 `cmd` 是 `Job1` 的一部分, 而 `Job1` 显示了所有进程, 包括那些在子作业中的.

Figure 57: Process Explorer 中的 Job2 属性

Figure 58: Process Explorer 中的 Job1 属性
查看作业层次结构并不容易, 因为没有文档化的 (或未文档化的) API 来枚举作业, 更不用说作业层次结构了. 我创建的一个名为 Job Explorer 的工具试图填补这个空白. 你可以在我的 Github 仓库中找到它: https://github.com/zodiacon/jobexplorer.
在 `JobTree` 应用程序等待按键时运行 Job Explorer, 当选择“所有作业”树节点并按名称对作业进行排序时, 会显示图 4-6 的屏幕截图.

Figure 59: Job Explorer 所有作业节点
双击 `Job1` 会在左侧展开作业层次结构, 并在右侧显示作业详细信息, 如图 4-7 所示.

Figure 60: Job Explorer 作业层次结构视图
作业层次结构在树视图中清晰可见. 请注意, `conhost.exe` 进程 (在启动 `cmd.exe` 时总是创建) 也是同一作业的一部分.
你可能想知道 Job Explorer 是如何工作的. 我计划写一篇博客文章来介绍.
1.5.4. 查询作业信息
一个作业对象即使没有任何特殊设置, 也会跟踪一些基本的作业统计信息. 查询作业对象信息的主要 API 被恰当地命名为 `QueryInformationJobObject`:
BOOL QueryInformationJobObject( _In_opt_ HANDLE hJob, _In_ JOBOBJECTINFOCLASS JobObjectInfoClass, _Out_ LPVOID pJobObjectInfo, _In_ DWORD cbJobObjectInfoLength, _Out_opt_ LPDWORD pReturnLength);
`hJob` 参数是作业的句柄——它必须具有 `JOBQUERY` 访问掩码; 然而, 正如 SAL 注解所提示的, `NULL` 值是有效的, 指向调用进程所在的作业 (如果有的话). 通过这种方式, 一个进程可以查询可能与其执行相关的信息, 例如作业施加的任何内存限制. 如果作业是嵌套的, 那么查询的是直接的作业. `JOBOBJECTINFOCLASS` 是可以查询的各种信息的枚举. 对于每种请求的信息类型, 必须在 `pJobObjectInfo` 参数中提供一个适当大小的缓冲区以供函数填充. 最后一个参数是一个可选值, 包含在提供的缓冲区中返回的数据大小, 这对于返回可变大小数据的查询类型很有用. 最后, 就像大多数 API 一样, 函数在成功时返回一个非 `FALSE` 的值.
表 4-2 总结了在查询操作中可用的 (文档化的) 信息类.
| 信息类 (JobObject*) | 信息结构类型 | 描述 |
|---|---|---|
| BasicAccountingInformation (1) | `JOBOBJECTBASICACCOUNTINGINFORMATION` | 基本统计 |
| BasicLimitInformation (2) | `JOBOBJECTBASICLIMITINFORMATION` | 基本限制 |
| BasicProcessIdList (3) | `JOBOBJECTBASICPROCESSIDLIST` | 作业中的进程 ID 列表 |
| BasicUIRestrictions (4) | `JOBOBJECTBASICUIRESTRICTIONS` | 用户界面限制 |
| EndOfJobTimeInformation (6) | `JOBOBJECTENDOFJOBTIMEINFORMATION` | 作业时间限制结束时发生什么 |
| BasicAndIoAccountingInformation (8) | `JOBOBJECTBASICANDIOACCOUNTINGINFORMATION` | 基本和 I/O 统计 |
| ExtendedLimitInformation (9) | `JOBOBJECTEXTENDEDLIMITINFORMATION` | 扩展限制 |
| GroupInformation (11) | `USHORT` 数组 | (Windows 7+) 作业的处理器组 (见第 6 章) |
| NotificationLimitInformation (12) | `JOBOBJECTNOTIFICATIONLIMITINFORMATION` | (Windows 8+) 通知限制 |
| LimitViolationInformation (13) | `JOBOBJECTLIMITVIOLATIONINFORMATION` | (Windows 8+) 关于限制违规的信息 |
| GroupInformationEx (14) | `GROUPAFFINITY` 数组 | (Windows 8+) 处理器组亲和性 |
| CpuRateControlInformation (15) | `JOBOBJECTCPURATECONTROLINFORMATION` | (Windows 8+) CPU 速率限制信息 |
| NetRateControlInformation (32) | `JOBOBJECTNETRATECONTROLINFORMATION` | (Windows 10+) 网络速率限制信息 |
| NotificationLimitInformation2 (33) | `JOBOBJECTNOTIFICATIONLIMITINFORMATION2` | (Windows 10+) 扩展限制信息 |
| LimitViolationInformation2 (34) | `JOBOBJECTLIMITVIOLATIONINFORMATION2` | (Windows 10+) 扩展限制违规信息 |
- 作业统计信息
如前所述, 作业会跟踪一些信息, 无论是否对它施加了任何限制. 基本的统计信息可通过 `JobObjectBasicAccountingInformation` 枚举和 `JOBOBJECTBASICACCOUNTINGINFORMATION` 结构获得, 定义如下:
typedef struct _JOBOBJECT_BASIC_ACCOUNTING_INFORMATION { LARGE_INTEGER TotalUserTime; // total user mode CPU time LARGE_INTEGER TotalKernelTime; // total kernel mode CPU time LARGE_INTEGER ThisPeriodTotalUserTime; // same counters as above LARGE_INTEGER ThisPeriodTotalKernelTime;// for a "period" DWORD TotalPageFaultCount; // page fault count DWORD TotalProcesses; // total processes ever existed in the job DWORD ActiveProcesses; // live processes in the job DWORD TotalTerminatedProcesses; // processes terminated because of limit violation } JOBOBJECT_BASIC_ACCOUNTING_INFORMATION, *PJOBOBJECT_BASIC_ACCOUNTING_INFORMATION;
各种时间以 `LARGEINTEGER` 结构提供, 每个结构都持有一个 64 位的值, 以 100 纳秒为单位. “this period”前缀报告自最近设置的每作业用户/内核时间限制 (如果有的话) 以来的时间. 这些值在作业创建时以及设置新的每作业时间限制时归零.
以下代码片段显示了如何对作业对象进行基本统计信息的查询调用:
// assume hJob is a job handle JOBOBJECT_BASIC_ACCOUNTING_INFORMATION info; BOOL success = QueryInformationJobObject(hJob, JobObjectBasicAccountingInformation, &info, sizeof(info), nullptr);
类似地, 使用 `JobObjectBasicAndIoAccountingInformation` 和 `JOBOBJECTBASICANDIOACCOUNTINGINFORMATION` 提供了作业的扩展统计信息, 包括 I/O 操作计数和大小. 这个扩展结构包括两个结构, 其中一个是 `JOBOBJECTBASICACCOUNTINGINFORMATION`:
typedef struct _IO_COUNTERS { ULONGLONG ReadOperationCount; ULONGLONG WriteOperationCount; ULONGLONG OtherOperationCount; ULONGLONG ReadTransferCount; ULONGLONG WriteTransferCount; ULONGLONG OtherTransferCount; } IO_COUNTERS, *PIO_COUNTERS; typedef struct JOBOBJECT_BASIC_AND_IO_ACCOUNTING_INFORMATION { JOBOBJECT_BASIC_ACCOUNTING_INFORMATION BasicInfo; IO_COUNTERS IoInfo; } JOBOBJECT_BASIC_AND_IO_ACCOUNTING_INFORMATION, *PJOBOBJECT_BASIC_AND_IO_ACCOUNTING_INFORMATION;
读写操作指的是 `ReadFile` 和 `WriteFile` (及类似) API, 我们将在本书后面看到. “其他”操作指的是 `DeviceIoControl` API 的使用, 它用于非读/写操作, 通常针对设备而不是文件系统文件.
`JobMon` 项目是本章源代码的一部分, 包括了我们讨论的许多作业特性. 运行它会显示图 4-8 中的窗口.

Figure 61: Job Monitor 初始窗口
单击*创建作业*按钮创建一个空作业. 你可以在创建作业之前为其设置一个名称. 作业创建时没有进程, 并显示基本和 I/O 信息 (图 4-9).

Figure 62: Job Monitor 和一个新创建的作业
要看到作业统计的实际效果, 请从 https://github.com/zodiacon/AllTools 下载 `CPUStres.exe` 工具. 单击三个点按钮浏览 `CpuStres.exe`. 然后多次单击*创建并添加进程*按钮, 将 `CPUStres` 的实例添加到作业中 (图 4-10). 注意统计信息不再是零.

Figure 63: Job Monitor 和几个 CPUStres 进程
`CPUStres` 是一个耗费 CPU 的实用程序, 在下一章中会更多地使用. 显示大约每 1.5 秒更新一次. 你可以向作业添加更多进程 (无论是 `CPUStres` 还是其他映像), 并关闭进程. 图 4-11 显示了在添加更多 `CPUStres` 并关闭一些后, Job Monitor 的情况.

Figure 64: Job Monitor 和更多进程
你可以单击*终止作业*来一次性终止作业中的所有进程. 这是通过调用 `TerminateJobObject` 实现的:
BOOL TerminateJobObject( _In_ HANDLE hJob, _In_ UINT uExitCode);
`TerminateJobObject` 的行为就像作业中每个活动进程都用 `TerminateProcess` 终止一样, 其中 `uExitCode` 是作业中所有进程的退出代码. 此时, 可以向作业添加新进程, 统计信息会正常更新.
- 查询作业进程列表
可以通过调用 `QueryInformationJobObject` 并使用 `JobObjectBasicProcessIdList` 信息类来检索作业中的活动 (实时) 进程列表, 在 `JOBOBJECTBASICPROCESSIDLIST` 结构中返回一个进程 ID 数组:
typedef struct _JOBOBJECT_BASIC_PROCESS_ID_LIST { DWORD NumberOfAssignedProcesses; DWORD NumberOfProcessIdsInList; ULONG_PTR ProcessIdList; } JOBOBJECT_BASIC_PROCESS_ID_LIST, *PJOBOBJECT_BASIC_PROCESS_ID_LIST;
该结构由于进程 ID 数组而具有可变大小. 这意味着一个固定大小的数组应该足够大以包含所有进程 ID, 并希望如此. 或者, 可以使用动态分配的缓冲区, 如果不够大, 则调整其大小. 以下示例显示了如何检索活动进程列表, 同时根据需要分配足够大的缓冲区.
#include <vector> #include <memory> std::vector<DWORD> GetJobProcessList(HANDLE hJob) { auto size = 256; std::vector<DWORD> pids; while (true) { auto buffer = std::make_unique<BYTE[]>(size); auto ok = ::QueryInformationJobObject(hJob, JobObjectBasicProcessIdList, buffer.get(), size, nullptr); if (!ok && ::GetLastError() == ERROR_MORE_DATA) { // buffer too small - resize and try again size *= 2; continue; } if (!ok) break; auto info = reinterpret_cast<JOBOBJECT_BASIC_PROCESS_ID_LIST*>(buffer.get()); pids.reserve(info->NumberOfAssignedProcesses); for (DWORD i = 0; i < info->NumberOfAssignedProcesses; i++) pids.push_back((DWORD)info->ProcessIdList[i]); break; } return pids; }
代码使用了一些 C++ 构造来简化内存管理. 函数本身返回一个 `std::vector<DWORD>`, 其中包含作业中的进程 ID. 在最一般的情况下, 预先不知道进程的数量, 因此函数用 `std::makeunique<BYTE[]>` 分配一个缓冲区, 该缓冲区分配一个给定元素数量 (大小) 的字节数组. `uniqueptr` 的析构函数在它超出作用域时释放缓冲区.
接下来, 用分配的字节缓冲区调用 `QueryInformationJobObject`. 如果它返回 `FALSE` 并且 `GetLastError` 返回 `ERRORMOREDATA`, 这意味着分配的缓冲区太小, 所以函数将大小加倍并重试.
一旦缓冲区足够大, 指针就被转换为 `JOBOBJECTBASICPROCESSIDLIST*`, 并且可以检索进程 ID 并将其放入 `std::vector` 中. 奇怪的是, 此结构中返回的进程 ID 类型为 `ULONGPTR`, 这意味着在 64 位进程中每个 ID 都是 64 位. 这是不寻常的, 因为进程 ID 通常是 32 位值 (`DWORD`). 这就是为什么我们不能简单地将整个数组一次性复制到向量中 (除非将向量更改为持有 `ULONGPTR`).
你可能会好奇为什么进程 ID 的类型是 `ULONGPTR`. 这是 Windows API 中很少发生的情况之一. 在内核内部, 进程 (和线程) ID 是使用一个专门为此目的的私有句柄表生成的. 而且由于 64 位系统上的句柄是 64 位值, 所以按原样使用它们可能“自然地”容易. 尽管如此, 由于句柄表限制在大约 1600 万个句柄, 目前不需要 64 位值 (并且不在内核外部用于进程 ID).
1.5.5. 设置作业限制
作业的主要目的是对其进程施加限制. 要使用的函数是 `QueryInformationJobObject` 的反面 - `SetInformationJobObject`, 定义如下:
BOOL SetInformationJobObject( _In_ HANDLE hJob, _In_ JOBOBJECTINFOCLASS JobObjectInfoClass, _In_ PVOID pJobObjectInfo, _In_ DWORD cbJobObjectInfoLength);
参数此时应该是不言自明的. 作业句柄必须具有 `JOBOBJECTSETATTRIBUTES` 访问掩码, 并且不能为 `NULL`. 表 4-3 总结了可以与 `SetInformationJobObject` 一起使用的 (文档化的) 信息类.
| 信息类 (JobObject-) | 信息结构 | 描述 |
|---|---|---|
| BasicLimitInformation (2) | `JOBOBJECTBASICLIMITINFORMATION` | 基本限制 |
| BasicUIRestrictions (4) | `JOBOBJECTBASICUIRESTRICTIONS` | 用户界面限制 |
| EndOfJobTimeInformation (6) | `JOBOBJECTENDOFJOBTIMEINFORMATION` | 作业时间限制结束时发生什么 |
| AssociateCompletionPortInformation (7) | `JOBOBJECTASSOCIATECOMPLETIONPORT` | 将完成端口与作业关联 |
| ExtendedLimitInformation (9) | `JOBOBJECTEXTENDEDLIMITINFORMATION` | 扩展限制 |
| GroupInformation (11) | `USHORT` 数组 | (Windows 7+) 作业的处理器组 (见第 6 章) |
| GroupInformationEx (14) | `GROUPAFFINITY` 数组 | (Windows 8+) 作业的处理器组和亲和性 (见第 6 章) |
| NotificationLimitInformation (12) | `JOBOBJECTNOTIFICATIONLIMITINFORMATION` | (Windows 8+) 通知限制 |
| LimitViolationInformation (13) | `JOBOBJECTLIMITVIOLATIONINFORMATION` | (Windows 8+) 关于限制违规的信息 |
| CpuRateControlInformation (15) | `JOBOBJECTCPURATECONTROLINFORMATION` | (Windows 8+) CPU 速率限制信息 |
| NetRateControlInformation (32) | `JOBOBJECTNETRATECONTROLINFORMATION` | (Windows 10+) 网络速率限制信息 |
| NotificationLimitInformation2 (33) | `JOBOBJECTNOTIFICATIONLIMITINFORMATION2` | (Windows 10+) 扩展限制信息 |
| LimitViolationInformation2 (34) | `JOBOBJECTLIMITVIOLATIONINFORMATION2` | (Windows 10+) 扩展限制违规信息 |
最“基本”的限制是用 `JobObjectBasicLimitInformation` 和 `JOBOBJECTBASICLIMITINFORMATION` 指定的, 而扩展限制是用 `JobObjectExtendedLimitInformation` 和 `JOBOBJECTEXTENDEDLIMITINFORMATION` 设置的. 这些结构定义如下:
typedef struct _JOBOBJECT_BASIC_LIMIT_INFORMATION { LARGE_INTEGER PerProcessUserTimeLimit; LARGE_INTEGER PerJobUserTimeLimit; DWORD LimitFlags; SIZE_T MinimumWorkingSetSize; SIZE_T MaximumWorkingSetSize; DWORD ActiveProcessLimit; ULONG_PTR Affinity; DWORD PriorityClass; DWORD SchedulingClass; } JOBOBJECT_BASIC_LIMIT_INFORMATION, *PJOBOBJECT_BASIC_LIMIT_INFORMATION; typedef struct _JOBOBJECT_EXTENDED_LIMIT_INFORMATION { JOBOBJECT_BASIC_LIMIT_INFORMATION BasicLimitInformation; IO_COUNTERS IoInfo; SIZE_T ProcessMemoryLimit; SIZE_T JobMemoryLimit; SIZE_T PeakProcessMemoryUsed; SIZE_T PeakJobMemoryUsed; } JOBOBJECT_EXTENDED_LIMIT_INFORMATION, *PJOBOBJECT_EXTENDED_LIMIT_INFORMATION;
可以设置的各种限制取决于 `JOBOBJECTBASICLIMITINFORMATION` 中的 `LimitFlags` 成员 (无论是独立的还是 `JOBOBJECTEXTENDEDLIMITINFORMATION` 的一部分). 有些标志没有关联的成员, 因为这些标志本身就足够了. 其他的则使相应的成员的值被 `SetInformationJobObject` 使用. 表 4-4 总结了没有相应成员的标志. 表 4-5 总结了有相应成员的标志.
| Limit flag (JOBOBJECTLIMIT*) | Description |
|---|---|
| DIEONUNHANDLEDEXCEPTION (0x400) | 防止作业中的进程在发生未处理异常时显示对话框 |
| PRESERVEJOBTIME (0x40) | 此标志保留任何先前设置的作业限制, 以便调用者可以进行进一步的更改. 此标志不能与 `JOBOBJECTLIMITJOBTIME` 一起使用 (反之亦然) |
| BREAKAWAYOK (0x800) | 允许从作业中的进程创建的进程在 `CreateProcess` 调用中指定 `CREATEBREAKAWAYFROMJOB` 标志时在作业之外创建. 如果进程是作业层次结构的一部分, 新进程将从此作业和所有具有此标志设置的父作业中脱离 |
| SILENTBREAKAWAYOK (0x1000) | 允许从作业中的进程创建的进程在作业之外创建, 无需对 `CreateProcess` 使用任何特殊标志 |
| KILLONJOBCLOSE (0x2000) | 当最后一个作业句柄关闭时, 终止作业中的所有进程 |
| Limit flag (JOBOBJECTLIMIT*) | Associated member (B/E) | Description |
|---|---|---|
| WORKINGSET (1) | `MinimumWorkingSetSize`, `MaximumWorkingSetSize` (B) | 限制每个进程的工作集 (RAM). 如果进程需要使用更多 RAM, 它将分页到自身 |
| PROCESSTIME (2) | `PerProcessUserTimeLimit` (B) | 限制作业中每个进程的用户模式执行时间 (以 100 纳秒为单位) |
| JOBTIME (4) | `PerJobUserTimeLimit` (B) | 限制作业范围的用户模式 CPU 时间. 如果进程使用更多 CPU 时间, 它将被终止 |
| ACTIVEPROCESS (8) | `ActiveProcessLimit` (B) | 限制作业中的活动 (实时) 进程. 违反此限制的新创建的进程会自动终止 |
| AFFINITY (0x10) | `Affinity` (B) | 为作业中的所有进程设置 CPU 亲和性 (有关亲和性的更多信息, 请参见第 6 章) |
| PRIORITYCLASS (0x20) | `PriorityClass` (B) | 限制作业中的进程使用相同的优先级类 (见第 6 章) |
| SCHEDULINGCLASS (0x80) | `SchedulingClass` (B) | 限制作业中所有进程的调度类. 值为 0 到 9, 其中 9 是最高的. 默认值为 5 (有关更多信息, 请参见第 6 章) |
| PROCESSMEMORY (0x100) | `Job _MEMORY` (E) | 限制每个进程的已提交内存 |
| JOBMEMORY (0x200) | `JobMemoryLimit` (E) | 限制作业范围的已提交内存 |
| SUBSETAFFINITY (0x4000) | `Affinity` (B) | (Windows 7+) 允许进程使用指定的亲和性的子集. `JOBOBJECTLIMITAFFINITY` 标志也是必需的 |
表 4-4 中的所有标志都必须与扩展限制结构 (`JOBOBJECTEXTENDEDLIMITINFORMATION`) 一起使用, 其中标志本身在嵌套的 `JOBOBJECTBASICLIMITINFORMATION` 结构的 `LimitFlags` 成员中指定. 在表 4-5 中, B/E 指示此限制是在基本 (B) 还是扩展 (E) 结构中指定的.
以下代码为给定作业设置了*低于正常*的优先级类:
bool SetJobPriorityClass(HANDLE hJob) { JOBOBJECT_BASIC_LIMIT_INFORMATION info; info.LimitFlags = JOB_OBJECT_LIMIT_PRIORITY_CLASS; info.PriorityClass = BELOW_NORMAL_PRIORITY_CLASS; return ::SetInformationJobObject(hJob, JobObjectBasicLimitInformation, &info, sizeof(info)); }
我们可以用 Job Monitor 应用程序来测试这类功能. 打开 Job Monitor, 创建一个新作业, 并向作业中添加一个进程 (图 4-12 中的 Notepad).

Figure 65: Job Monitor 和添加的 Notepad
如果你在任务管理器中检查此 Notepad 进程的*基本优先级*列, 你应该会看到*正常*值 (图 4-13).

Figure 66: 任务管理器中 Notepad 的基本优先级
基本优先级 (Priority Class) 的确切含义和效果在第 6 章中讨论.
现在回到 Job Monitor, 选择*优先级类*限制并将其值设置为*低于正常*, 然后单击*设置* (图 4-14).

Figure 67: 在 Job Monitor 中设置优先级类限制
现在切换到任务管理器. Notepad 的基本优先级现在应该显示*低于正常* (图 4-15).

Figure 68: Notepad 的受限基本优先级
尝试用任务管理器通过右键单击 Notepad 并选择*设置优先级*来更改基本优先级, 任何级别 (除了*低于正常*) 都不会有效果, 因为作业限制.
回到 Job Monitor 并单击优先级类限制上的*移除*将重新允许基本优先级的修改.
你可以在 `JobMon` 项目的 `MainDlg.cpp` 文件中找到设置/移除大多数可用作业限制的代码.
- CPU 速率限制
Windows 8 为可用的作业限制添加了 CPU 速率限制, 这不是由基本或扩展限制设置的, 而是使用其自己的作业限制枚举: `JobObjectCpuRateControlInformation`. 相关的结构是 `JOBOBJECTCPURATECONTROLINFORMATION`, 定义如下:
typedef struct _JOBOBJECT_CPU_RATE_CONTROL_INFORMATION { DWORD ControlFlags; union { DWORD CpuRate; DWORD Weight; struct { WORD MinRate; WORD MaxRate; }; }; } JOBOBJECT_CPU_RATE_CONTROL_INFORMATION, *PJOBOBJECT_CPU_RATE_CONTROL_INFORMATION;
有三种不同的方式来设置 CPU 速率限制, 由 `ControlFlags` 字段控制. 其可能的值在表 4-5 中总结.
标志 (JOBOBJECTCPURATE*) 描述 ENABLE (1) 启用 CPU 速率控制 WEIGHTBASED (2) CPU 速率基于相对权重 (`Weight` 成员) HARDCAP (4) 为 CPU 消耗设置硬上限 NOTIFY (8) 通知与作业关联的 I/O 完成端口 (如果有的话) 速率违规 MINMAXRATE (0x10) 在最小值和最大值之间设置 CPU 速率 (`MinRate` 和 `MaxRate` 成员) 如果启用了 CPU 速率控制, 并且未指定 `JOBOBJECTCPURATECONTROLWEIGHTBASED` 或 `JOBOBJECTCPURATECONTROLMINMAXRATE`, 那么 `CpuRate` 成员指定相对于 10000 的 CPU 限制百分比. 例如, 如果需要 15% 的 CPU, 该值应设置为 1500. 这允许指定小数 CPU 速率.
如果还指定了 `JOBOBJECTCPURATECONTROLHARDCAP` 标志, 则限制是硬性的——即使有可用的 CPU, 作业也不会获得更多的 CPU. 没有此标志, 如果有可用的处理器, 作业可能会获得更多的 CPU 时间.
在幕后, 内核通过测量作业在 300 毫秒时间间隔内的 CPU 消耗来应用这些限制, 允许/阻止它在下一个间隔内执行.
`CpuLimit` 项目演示了如何使用 `CpuRate` 成员和硬上限来控制 CPU 速率. `main` 函数接受一个要放入作业的进程 ID 数组, 以及一个用作硬 CPU 速率限制的百分比.
以下是 `main` 的开头:
int main(int argc, const char* argv[]) { if (!::IsWindows8OrGreater()) { printf("CPU Rate control is only available on Windows 8 and later\n"); return 1; } if (argc < 3) { printf("Usage: CpuLimit <pid> [<pid> ...] <precentage>\n"); return 0; } // create the job object HANDLE hJob = ::CreateJobObject(nullptr, L"CpuRateJob"); if (!hJob) return Error("Failed to create object"); for (int i = 1; i < argc - 1; i++) { int pid = atoi(argv[i]); HANDLE hProcess = ::OpenProcess(PROCESS_SET_QUOTA | PROCESS_TERMINATE, FALSE, pid); if (!hProcess) { printf("Failed to open handle to process %d (error=%d)\n", pid, ::GetLastError()); continue; } if (!::AssignProcessToJobObject(hJob, hProcess)) { printf("Failed to assign process %d to job (error=%d)\n", pid, ::GetLastError()); } else { printf("Added process %d to job\n", pid); } ::CloseHandle(hProcess); } }
`main` 首先检查应用程序是否至少在 Windows 8 上执行, 因为 CPU 速率控制在早期版本中不可用. 然后, 程序通过检查至少 3 个参数 (程序本身, PID, 速率) 来验证至少有一个进程 ID 和一个 CPU 百分比.
然后创建一个作业对象, 并带有名称, 以便更容易用工具识别. 每个进程都被打开并分配给作业, 如果可能的话.
现在程序准备好应用 CPU 速率控制:
JOBOBJECT_CPU_RATE_CONTROL_INFORMATION info; info.CpuRate = atoi(argv[argc - 1]) * 100; info.ControlFlags = JOB_OBJECT_CPU_RATE_CONTROL_ENABLE | JOB_OBJECT_CPU_RATE_CONTROL_HARD_CAP; if (!::SetInformationJobObject(hJob, JobObjectCpuRateControlInformation, &info, sizeof(info))) return Error("Failed to set job limits"); printf("CPU limit set successfully.\n"); printf("Press ENTER to quit.\n"); char dummy[10]; gets_s(dummy); ::CloseHandle(hJob); return 0; }
CPU 速率限制是通过从命令行获取参数并乘以 100 来计算的. 最后, 调用 `SetInformationJobObject` 来设置限制.
在程序退出之前, 它会等待用户按 ENTER. 这使得作业对象的句柄保持打开状态, 因此更容易用工具发现. 否则, 句柄将被关闭, 标记作业为删除. 然而, 只要有活动的进程, 限制仍然适用.
让我们通过启动两个 `CpuStress` 应用程序的实例来测试这个 (图 4-16). 这里使用的系统有 16 个逻辑处理器, 所以我们将在它们两个中都激活 4 个具有最大活动的线程. 这应该消耗系统上所有 CPU 时间的大约 50% (图 4-17). 任务管理器显示情况确实如此 (图 4-18).

Figure 69: 启动时的 2 个 CPU Stress 实例

Figure 70: 2 个具有 4 个最大活动线程的 CPU Stress

Figure 71: 任务管理器显示 50% 的 CPU 使用率
现在我们用进程 ID 和所需的 CPU 速率限制 (本例中为 20%) 执行 `CpuLimit`:
cpulimit 38984 28760 20
你应该会看到一组成功消息, 像这样:
CpuLimit.exe 20132 17480 20 Added process 20132 to job Added process 17480 to job CPU limit set successfully. Press ENTER to quit.
此时, 你应该能看到两个 `CPUStress` 实例的 CPU 消耗下降 (图 4-19). 两者消耗的总 CPU 应该在 20% 左右, 可以在任务管理器中看到.
打开 Job Explorer 并查看 `CpuRateJob` 作业 (这是代码中为方便识别而给定的名称) 应该会显示 CPU 速率限制 (图 4-20).
不幸的是, 在撰写本文时, Process Explorer 不显示作业的 CPU 速率控制信息.

Figure 72: CPU Stress 实例受 CPU 速率控制影响

Figure 73: Job Explorer 显示 CPU 速率控制
如果 `CpuLimit` 添加进程时失败并出现错误 5 (访问被拒绝), 请从命令窗口运行 `CpuStress` 而不是通过资源管理器. 如果你好奇, 请调查为什么会这样.
- 用户界面限制
另一组作业限制可通过 `JobObjectBasicUIRestrictions` 信息类获得, 用于与用户界面相关的限制. 这些由一个简单的结构中存储的单个 32 位值表示:
typedef struct _JOBOBJECT_BASIC_UI_RESTRICTIONS { DWORD UIRestrictionsClass; } JOBOBJECT_BASIC_UI_RESTRICTIONS, *PJOBOBJECT_BASIC_UI_RESTRICTIONS;
可用的限制是表 4-6 中列出的位标志.
使用 UI 限制的作业不能是作业层次结构的一部分.
UI 标志 (JOBOBJECTUILIMIT*) 描述 NONE (0) 无限制 HANDLES (1) 作业中的进程不能访问不属于作业的进程拥有的 USER 句柄 (例如窗口) READCLIPBOARD (2) 作业中的进程不能从剪贴板读取数据 WRITECLIPBOARD (4) 作业中的进程不能向剪贴板写入数据 SYSTEMPARAMETERS (8) 作业中的进程不能通过调用 `SystemParametersInfo` 更改系统参数 DISPLAYSETTINGS (0x10) 作业中的进程不能调用 `ChangeDisplaySettings` GLOBALATOMS (0x20) 作业中的进程不能访问全局原子. 作业有自己的原子表 (见下一个侧边栏) DESKTOP (0x40) 作业中的进程不能创建或切换桌面 (`CreateDesktop`, `SwitchDesktop`) EXITWINDOWS (0x80) 作业中的进程不能调用 `ExitWindows` 或 `ExitWindowsEx` 原子表是一个系统管理的表, 它将字符串 (或某个范围内的整数) 映射到整数. 表中的每个条目都是一个原子. 这些原子与用户界面 API 一起使用, 例如在注册窗口类 (`RegisterClass` / `RegisterClassEx`) 时, 或通过手动操作原子表 (`AddAtom`, `FindAtom`, `GlobalAddAtom` 等). 全局原子表对所有应用程序都可用——这就是在作业中用 `JOBOBJECTUILIMITGLOBALATOMS` 限制的那个.
这里有一个快速实验来展示 UI 限制的一个效果. 打开 Job Monitor, 创建一个新作业并在其中插入一个 Notepad 实例. 然后设置一个*写入剪贴板*的 UI 限制 (图 4-21).

Figure 74: Job Monitor 和一个 Notepad 及 UI 限制
现在在作业外部打开另一个 Notepad 实例 (或使用任何其他文本编辑应用程序). 从该应用程序复制一些文本, 然后尝试将其粘贴到作业中的 Notepad 实例中. 该操作应该会失败, 即使*编辑*菜单显示*粘贴*选项已启用.
`JOBOBJECTUILIMITHANDLES` 标志阻止作业中的进程访问作业外部的其他用户界面对象 (例如窗口). 这意味着调用诸如 `PostMessage` 或 `SendMessage` 到作业外部的窗口会失败. 在某些情况下, 需要从作业内部与作业外部的特定窗口通信. 作业外部的进程可以通过调用 `UserHandleGrantAccess` 来授予 (或移除) 对窗口 (或其他 USER 对象, 如菜单或钩子) 的访问权限:
BOOL UserHandleGrantAccess( _In_ HANDLE hUserHandle, // user object handle _In_ HANDLE hJob, // job handle _In_ BOOL bGrant); // TRUE to grant access, FALSE to remove it
上一段中提到的“钩子”是那些可以用 `SetWindowsHookEx` 安装的钩子之一 (在后面的章节中讨论). 在此限制下, 作业中的进程无法钩住作业外部进程中运行的线程.
当作业限制被违反, 或当某些事件发生时, 作业可以通过一个 I/O 完成端口通知感兴趣的一方, 该端口可以与作业关联. I/O 完成端口通常用于处理异步 I/O 操作的完成 (我们将在后面的章节中处理), 但在这种特殊情况下, 它们被用作通知某些作业事件发生时的机制.
作业是一个调度程序 (可等待) 对象, 当 CPU 时间违规发生时, 它会变为有信号状态. 对于这种简单的情况, 线程可以用 `WaitForSingleObject` (作为一个常见的例子) 等待, 然后处理 CPU 时间违规. 设置新的 CPU 时间限制会将作业重置为非有信号状态.
获取通知的第一步是将 I/O 完成端口与作业关联. 以下是 `JobMon` ( `MainDlg.cpp` 中的 `OnBindIoCompletion` 函数) 的相关代码片段 (为清晰起见, 省略了错误处理):
wil::unique_handle hCompletionPort(::CreateIoCompletionPort( INVALID_HANDLE_VALUE, nullptr, 0, 0)); JOBOBJECT_ASSOCIATE_COMPLETION_PORT info; info.CompletionKey = 0; // application defined info.CompletionPort = hCompletionPort.get(); ::SetInformationJobObject(m_hJob.get(), JobObjectAssociateCompletionPortInformation, &info, sizeof(info)); // transfer ownership and store in a member m_hCompletionPort = std::move(hCompletionPort);
通常, `CreateIoCompletionPort` 的第一个参数是文件句柄, 但在这种情况下是 `INVALIDHANDLEVALUE`, 表示没有文件与 I/O 完成端口关联.
下一步是等待完成端口触发, 通过调用 `GetQueuedCompletionStatus`, 定义如下:
BOOL GetQueuedCompletionStatus( _In_ HANDLE CompletionPort, _Out_ PDWORD pNumberOfBytesTransferred, _Out_ PULONG_PTR lpCompletionKey, _Out_ LPOVERLAPPED *pOverlapped, _In_ DWORD dwMilliseconds);
`JobMon` 创建一个线程并调用此函数, 无限期地等待直到通知到达. 在这种情况下需要一个新线程, 以便 `JobMon` 的 UI 线程不会阻塞, 导致 UI 变得无响应. 以下是 `JobMon` 中创建完成端口后的相关代码:
// create a thread to monitor notifications wil::unique_handle hThread(::CreateThread(nullptr, 0, [](auto p) { return static_cast<CMainDlg*>(p)->DoMonitorJob(); }, this, 0, nullptr));
线程创建将在下一章中详细解释.
线程被传递 `this` 指针, 以便它可以方便地调用成员函数 (`DoMonitorJob`). `DoMonitorJob` 调用 `GetQueuedCompletionStatus` 并在等待结束时响应:
DWORD CMainDlg::DoMonitorJob() { for (;;) { DWORD message; ULONG_PTR key; LPOVERLAPPED data; if (::GetQueuedCompletionStatus(m_hCompletionPort.get(), &message, &key, &data, INFINITE)) { // handle notification } } }
当与作业通知一起使用时 (而不是文件), `GetQueuedCompletionStatus` 的参数含义是特殊的. `pNumberOfBytesTransferred` 是通知类型, 总结在表 4-7 中. `CompletionKey` 参数与 `CreateIoCompletionPort` 中指定的相同, 并且是应用程序定义的. 最后, `pOverlapped` 是额外的信息, 其格式取决于通知的类型 (表 4-7).
| 通知 (JOBOBJECTMSG*) | 关联数据 (pOverlapped) | 描述 |
|---|---|---|
| ENDOFJOBTIME (1) | NULL | 作业时间限制已用尽. 时间限制现已取消, 作业中的进程继续运行 |
| ENDOFPROCESSTIME (2) | 进程的 PID | 一个进程超出了其每进程 CPU 时间 (该进程正在被终止) |
| ACTIVEPROCESSLIMIT (3) | NULL | 已超出活动进程限制 |
| ACTIVEPROCESSZERO (4) | NULL | 活动进程数变为零 (所有进程因任何原因退出) |
| NEWPROCESS (6) | 新进程的 PID | 一个新进程被添加到作业中 (无论是直接还是因为作业中的另一个进程创建了它). 当完成端口最初关联时, 所有活动进程都被报告 |
| EXITPROCESS (7) | 退出进程的 PID | 作业中的一个进程已退出 |
| ABNORMALEXITPROCESS (8) | 退出进程的 PID | 作业中的一个进程异常退出, 这意味着它因未处理的异常而终止, 来自给定异常列表 (请查看文档以获取完整列表) |
| PROCESSMEMORYLIMIT (9) | 进程的 PID | 作业中的一个进程超出了其内存消耗限制 |
| JOBMEMORYLIMIT (10) | 进程的 PID | 作业中的一个进程导致作业超出其作业范围的内存限制 |
| NOTIFICATIONLIMIT (11) | 进程的 PID | (Windows 8+) 作业中注册以接收通知限制的进程已超出限制 |
在通知限制的情况下, 调用 `QueryInformationJobObject` 并使用 `JobObjectNotificationLimitInformation` 和/或 `JobObjectNotificationLimitInformation2` (Windows 10) 来查询被违反的限制.
以下来自 `JobMon` 的代码片段显示了如何处理其中一些通知代码:
switch (message) { case JOB_OBJECT_MSG_ACTIVE_PROCESS_LIMIT: AddLog(L"Job Notification: Active process limit exceeded"); break; case JOB_OBJECT_MSG_ACTIVE_PROCESS_ZERO: AddLog(L"Job Notification: Active processes is zero"); break; case JOB_OBJECT_MSG_NEW_PROCESS: AddLog(L"Job Notification: New process created (PID: " + std::to_wstring(PtrToUlong(data)) + L")"); break; case JOB_OBJECT_MSG_EXIT_PROCESS: AddLog(L"Job Notification: process exited (PID: " + std::to_wstring(PtrToUlong(data)) + L")"); break; case JOB_OBJECT_MSG_ABNORMAL_EXIT_PROCESS: AddLog(L"Job Notification: Process " + std::to_wstring( PtrToUlong(data)) + L" exited abnormally"); break; case JOB_OBJECT_MSG_JOB_MEMORY_LIMIT: AddLog(L"Job Notification: Job memory limit exceed attempt by process " + std::to_wstring(PtrToUlong(data))); break; case JOB_OBJECT_MSG_PROCESS_MEMORY_LIMIT: AddLog(L"Job Notification: Process " + std::to_wstring( PtrToUlong(data)) + L" exceeded its memory limit"); break; case JOB_OBJECT_MSG_END_OF_JOB_TIME: AddLog(L"Job time limit exceeded"); break; case JOB_OBJECT_MSG_END_OF_PROCESS_TIME: AddLog(L"Process " + std::to_wstring(PtrToUlong(data)) + L" has exceeded its time limit"); break; }
`AddLog` 是一个私有函数, 将相应的消息添加到下方的列表视图中. 对于作业时间限制结束的违规, 默认采取的操作是终止作业中的所有进程. 每个进程的退出代码都设置为 `ERRORNOTENOUGHQUOTA` (1816), 并且不发送通知. 要更改这一点, 必须事先调用 `SetInformationJobObject`, 以便用 `JobObjectEndOfJobTimeInformation` 信息类设置不同的作业结束操作, 传递以下结构:
typedef struct _JOBOBJECT_END_OF_JOB_TIME_INFORMATION { DWORD EndOfJobTimeAction; } JOBOBJECT_END_OF_JOB_TIME_INFORMATION, *PJOBOBJECT_END_OF_JOB_TIME_INFORMATION; #define JOB_OBJECT_TERMINATE_AT_END_OF_JOB 0 #define JOB_OBJECT_POST_AT_END_OF_JOB 1
`JOBOBJECTTERMINATEATENDOFJOB` 是默认值, 而 `JOBOBJECTPOSTATENDOFJOB` 会在不终止进程的情况下发布通知消息. 如果没有与作业关联的完成端口, 此值无效, 并且使用终止协议.
1.5.6. Silos
Windows 10 版本 1607 和 Windows Server 2016 引入了作业的一个增强版本, 称为*Silo*. silo 总是作为作业开始, 但可以通过使用一个未文档化的信息类 `JobObjectCreateSilo` (35) 调用 `SetInformationJobObject` 来升级为 silo, 该信息类出现在 Windows SDK 头文件中, 但未被文档化. 一些 Silo API 在 Windows 驱动程序工具包 (WDK) 中为设备驱动程序编写者记录. 由于 silos 主要可从内核模式控制, 它们的编程用法超出了本书的范围.
silos 有两种变体: 应用程序 Silos 和服务器 Silos. 服务器 silos 仅在 Windows 服务器机器上受支持, 从 Server 2016 开始. 它们今天用于实现 Windows 容器, 即沙箱化进程的能力, 创建一个虚拟环境, 使进程认为它们在自己的机器上. 这需要重定向文件系统, 注册表和对象命名空间, 以成为特定 silo 的一部分, 因此内核内部必须进行重大更改以实现 silo 感知.
应用程序 silos 用于通过桌面桥技术转换为 UWP 的应用程序. 它们远不如服务器 silos 强大 (也不需要如此). Job Explorer 有一个*Silo 类型*列, 指示一个作业实际上是否是一个 silo, 通过列出其类型. 图 4-22 显示了机器上的三个应用程序 silos.

Figure 75: Job Explorer 显示 Silos
请注意, silos 有一个 silo ID, 这是一个唯一的作业 ID, 内部用于识别 silos.
有关 silos 的更多详细信息, 可在“Windows Internals, 7th edition, Part 1”的第 3 章中找到.
1.5.7. 练习
- 编写一个名为 `MemLimit` 的工具, 接受一个进程 ID 和一个代表该进程最大已提交内存的数字, 并使用作业设置该限制.
- 扩展 `JobMon` 以涵盖所有当前未实现的剩余限制, 例如 I/O 和网络限制.
1.5.8. 总结
作业提供了控制和限制进程的许多机会, 所有这些都由内核本身实现. Windows 8 中引入的嵌套作业使作业更有用, 限制更少.
在下一章中, 我们将开始研究线程. 进程和作业是管理对象, 但线程是实际分配给处理器来完成工作的对象, 因此没有线程就没有操作系统生命.
1.6. 第 5 章: 线程基础
进程是管理对象, 不直接执行代码. 要在 Windows 上做任何事, 都必须创建线程. 正如我们已经看到的, 用户模式进程创建时带有一个线程, 该线程最终执行可执行文件的主入口点. 在许多情况下, 这已经足够了, 应用程序可能不需要更多的线程.
然而, 一些应用程序可能会从使用在进程内执行的多个线程中受益. 每个线程都是一个独立的执行路径, 因此可以使用不同的处理器, 从而实现真正的并发. 在本章中, 我们将探讨创建和管理线程的基础知识. 在后续章节中, 我们将深入探讨线程的其他方面, 例如调度和同步.
本章内容:
- 介绍
- 创建和管理线程
- 终止线程
- 线程的栈
- 线程的名称
- C++ 标准库呢
1.6.1. 介绍
我们应该考虑的第一个问题是, 为什么要使用线程? 基本上有两个可能的原因:
- 通过利用多个核心并发执行来提高性能.
- 改进应用程序设计.
尽管你可能会想出其他使用线程的原因, 但这些原因在某种程度上都属于第二类. 总是有可能用单线程来设计 (例如, 通过使用计时器), 而无需创建更多线程. 尽管如此, 第二个原因仍然是有效的, 事实上也是主要的原因. 快速查看任务管理器中的*性能/CPU*选项卡会发现许多 (数千个) 线程, 远远超过处理器的数量, 但任何时候消耗的 CPU 百分比都很低, 这意味着原因 1 并不是主要原因 (图 5-1).

Figure 76: 任务管理器中的性能/CPU
线程抽象了一个独立的执行路径, (从执行的角度来看) 与可能同时活动的其他线程无关. 一旦线程开始执行, 它可能会执行以下任何操作, 直到退出:
- CPU 密集型操作 - 依赖 CPU 操作来取得进展的计算或函数调用.
- I/O 密集型操作 - 对 I/O 设备 (如磁盘或网络) 执行的操作. 在等待 I/O 操作完成时, 线程处于等待状态, 不消耗 CPU 周期.
- 可能导致线程进入等待状态的其他操作, 例如等待同步原语 (例如互斥体).
线程同步将在第 7 章中详细讨论.
图 5-1 中 CPU 使用率不是 100% 的事实意味着大多数线程处于等待状态 (不想执行). 事实上, 如果 16 个线程同时在机器上执行代码 (图 5-1), CPU 使用率将是 100%. 它只有大约 13%, 这意味着大约有 2 个处理器在同一时间是活动的.
- Sockets, Cores 和逻辑处理器
在我们进一步讨论线程之前, 我们必须认识到线程是处理器的抽象. 但处理器的确切定义是什么? 在多核构成典型 CPU 的今天, 这些术语可能会变得混乱. 图 5-2 显示了典型 CPU 的逻辑组成.

Figure 77: CPU 的逻辑组成
在图 5-2 中, 有一个*socket*, 它是插在计算机主板上的物理芯片. 笔记本电脑和家用电脑通常只有一个. 大型服务器机器可能包含多个 socket. 每个 socket 都有多个*cores*, 它们是独立的处理器 (图 5-2 中有 4 个).
在 Intel 处理器上, 每个核心可以分为两个*逻辑处理器*, 也称为*硬件线程*, 这是一种称为*超线程*的技术. 从 Windows 的角度来看, 处理器的数量是逻辑处理器的数量 (图 5-1 中为 16). 这意味着在任何给定时刻, 最多可以有 16 个线程在运行. sockets, cores 和逻辑处理器的数量也由任务管理器显示 (图 5-1).
AMD 有一种类似的技术, 称为同时多线程 (Simultaneous Multi Threading, SMT).
超线程可以在 BIOS 设置中禁用. 超线程的潜在缺点是, 每个共享一个核心的两个逻辑处理器也共享二级缓存, 因此可能会相互“干扰”. 第 6 章将更多地讨论缓存.
1.6.2. 创建和管理线程
创建线程的基本函数是 `CreateThread`:
HANDLE WINAPI CreateThread( _In_opt_ LPSECURITY_ATTRIBUTES lpThreadAttributes, _In_ SIZE_T dwStackSize, _In_ LPTHREAD_START_ROUTINE lpStartAddress, _In_opt_ LPVOID lpParameter, _In_ DWORD dwCreationFlags, _Out_opt_ LPDWORD lpThreadId);
`CreateThread` 的第一个参数现在应该很熟悉了, 通常设置为 `NULL`. `dwStackSize` 参数设置线程的栈大小, 在本章后面的“线程的栈”部分详细讨论. 通常设置为零, 这会设置一个默认大小, 基于 PE 头. 我说“大小”是因为栈有一个初始大小和一个最大大小 (稍后也会讨论).
`lpStartAddress` 参数是最重要的一个, 它指定了要从新线程调用的用户函数. 这个函数可以命名为任何东西, 但必须遵守以下原型:
DWORD WINAPI ThreadProc(_In_ PVOID pParameter);
线程函数必须返回一个 32 位数字, 这被认为是线程的退出代码, 稍后可以用 `GetExitCodeThread` 检索. `WINAPI` 宏扩展为 `_stdcall` 关键字, 表示大多数 Windows API 通用的标准调用约定. 最后, 传递给函数的参数是一个用户定义的值, 作为 `CreateThread` 的第四个参数传递, 并简单地按原样传递给线程函数. 这个值通常指向一些包含允许线程完成其工作的信息的数据结构.
回到 `CreateThread`——`lpParameter` 参数刚刚讨论过. 在最简单的情况下, 可以传递 `NULL`. `dwCreationFlags` 参数可以有三个可能的值 (可以组合). 指定 `CREATESUSPENDED` 标志会在挂起状态下创建线程. 线程已准备好运行, 但必须调用 `ResumeThread` 才能让它启动. 另一个可能的值是 `STACKSIZEPARAMISARESERVATION`, 它给栈大小参数赋予了另一种含义 (也在“线程的栈”部分讨论). 最后, 不指定这些标志中的任何一个 (最常见), 指示线程立即开始执行. `CreateThread` 的最后一个可选参数是新线程的唯一线程 ID. 如果调用者对此信息不感兴趣, 可以简单地为此参数指定 `NULL`.
`CreateThread` 的返回值是到新创建线程的句柄. 如果出了问题, 返回值为 `NULL`, 可以调用 `GetLastError` 来提取错误代码. 一旦不再需要该句柄, 就应该像任何其他内核对象句柄一样用 `CloseHandle` 关闭它.
以下代码片段从 `main` 函数创建一个线程, 等待它退出, 并打印其退出代码:
DWORD WINAPI DoWork(PVOID) { printf("Thread ID running DoWork: %u\n", ::GetCurrentThreadId()); // simulate some heavy work... ::Sleep(3000); // return a result return 42; } int main() { HANDLE hThread = ::CreateThread(nullptr, 0, DoWork, nullptr, 0, nullptr); if(!hThread) { printf("Failed to create thread (error=%d)\n", ::GetLastError()); return 1; } // print ID of main thread printf("Main thread ID: %u\n", ::GetCurrentThreadId()); // wait for the thread to finish ::WaitForSingleObject(hThread, INFINITE); DWORD result; ::GetExitCodeThread(hThread, &result); printf("Thread done. Result: %u\n", result); ::CloseHandle(hThread); return 0; }
这是一个示例输出:
Main thread ID: 19108 Thread ID running DoWork: 23700 Thread done. Result: 42
`GetExitCodeThread` 允许从线程函数中检索返回值:
BOOL GetExitCodeThread( _In_ HANDLE hThread, _Out_ LPDWORD lpExitCode);
你可能想知道如果用一个尚未退出的线程调用该函数会发生什么. 该函数不会失败, 而是返回 `STILLACTIVE` (0x103=259).
- 素数计数器应用程序
以下示例说明了多线程更复杂的用法. `PrimesCounter` 应用程序 (可在本章的示例中找到), 使用指定数量的线程计算一定范围内的素数数量. 其思想是将工作分配给几个线程, 每个线程在其数字范围内计算素数. 然后主线程等待所有工作线程退出, 从而可以简单地将所有线程的计数相加. 这在图 5-3 中有所描述.

Figure 78: 素数计数器设计
这种创建多个线程来做一些工作, 并在聚合结果之前等待它们退出的想法有时被称为*分叉-连接 (Fork-Join)*, 因为线程从某个初始线程“分叉”出来, 然后在完成后“连接”回初始线程.
这种模式的另一个名称是*结构化并行 (Structured Parallelism)*.
此应用程序中使用的线程数是算法的参数之一——有趣的问题是, 哪个线程数是完成计算最快的最佳选择? 这将在后面讨论; 但首先是代码.
`main` 函数接受命令行上的数字范围和线程数:
int main(int argc, const char* argv[]) { if (argc < 4) { printf("Usage: PrimesCounter <from> <to> <threads>\n"); return 0; } int from = atoi(argv); int to = atoi(argv); int threads = atoi(argv); if (from < 1 || to < 1 || threads < 1 || threads > 64) { printf("Invalid input.\n"); return 1; } }
线程数限制为 64. 为什么是这个数字? 这是 `WaitForMultipleObjects` 可以同时等待的最大句柄数, 稍后用于等待所有线程退出.
`main` 中的下一个调用是启动工作并返回结果的函数:
DWORD elapsed; int count = CalcAllPrimes(from, to, threads, elapsed); printf("Total primes: %d. Elapsed: %d msec\n", count, elapsed);
`CalcPrimes` 接受从命令行提取的参数, 并返回计数的素数总数, 并且还使用最后一个 `elapsed` 参数 (通过引用传递) 返回经过的时间 (以毫秒为单位). 最后, 结果被回显到控制台.
每个线程都需要它的“from”和“to”数字以及一个地方来放置结果. 由于线程函数可以返回一个 32 位无符号整数, 这里可以使用它. 但在一般情况下, 返回值可能不够灵活. 典型的解决方案是定义一个结构, 其中包含线程所需的所有信息, 包括输入和输出值. 对于我们的应用程序, 定义了以下结构:
struct PrimesData { int From, To; int Count; };
`CalcAllPrimes` 必须为每个线程分配一个 `PrimesData` 实例, 并初始化 `From` 和 `To` 数据成员:
int CalcAllPrimes(int from, int to, int threads, DWORD& elapsed) { auto start = ::GetTickCount64(); // allocate data for each thread auto data = std::make_unique<PrimesData[]>(threads); // allocate an array of handles auto handles = std::make_unique<HANDLE[]>(threads); }
在进行任何工作之前, 用 `GetTickCount64` 捕获当前时间. 此 API 返回自 Windows 启动以来经过的毫秒数. 尽管它不是最精确的 API (`QueryPerformanceCounter` 更精确), 但对于此应用程序的目的来说已经足够了.
`GetTickCount64` 取代了旧的 `GetTickCount`, 通过返回一个 64 位数字而不是 `GetTickCount` 返回的 32 位数字. 一个 32 位的毫秒数将在大约 49.7 天后溢出并回滚到零.
代码使用 `std::uniqueptr<[]>` 来管理一个数组, 当变量超出作用域时会自动清理. 这用于 `PrimesData` 数组以及线程句柄.
接下来, 函数计算每个线程的块大小, 然后循环以适当地创建线程:
int chunk = (to - from + 1) / threads; for (int i = 0; i < threads; i++) { auto& d = data[i]; d.From = i * chunk; d.To = i == threads - 1 ? to : (i + 1) * chunk - 1; DWORD tid; handles[i] = ::CreateThread(nullptr, 0, CalcPrimes, &d, 0, &tid); assert(handles[i]); printf("Thread %d created. TID=%u\n", i + 1, tid); }
每个线程的 `PrimesData` 实例都根据块大小用正确的 `From` 和 `To` 进行初始化. 唯一的麻烦是范围可能无法被线程数整除. 因此, 最后一个线程负责处理数字的“尾部” (如果有的话). 调用 `CreateThread` 来创建每个线程, 将每个线程指向 `CalcPrimes` 函数 (稍后讨论), 并将个人的 `PrimesData` 指针传递给它. 最后, 显示线程索引和 ID.
`CalcPrimes` 是负责在提供给该线程的范围内计算素数的线程函数:
DWORD WINAPI CalcPrimes(PVOID param) { auto data = static_cast<PrimesData*>(param); int from = data->From, to = data->To; int count = 0; for (int i = from; i <= to; i++) if (IsPrime(i)) count++; data->Count = count; return count; }
传递给线程的参数被转换为 `PrimesData` 指针. 然后一个简单的 for 循环检查数字是否为素数, 如果是, 则递增一个计数器, 该计数器最终存储在 `PrimesData` 的 `Count` 成员中. `IsPrime` 是一个简单的函数, 对于素数返回 true, 否则返回 false:
bool IsPrime(int n) { if (n < 2) return false; if(n == 2) return true; int limit = (int)::sqrt(n); for (int i = 2; i <= limit; i++) if (n % i == 0) return false; return true; }
`IsPrime` 中使用的算法肯定不是最优的, 但这不是重点.
回到 `CalcAllPrimes`, 所有线程都是在没有 `CREATESUSPENDED` 标志的情况下创建的, 所以它们立即开始. 剩下要做的就是等待所有线程退出:
::WaitForMultipleObjects(threads, handles.get(), TRUE, INFINITE);
关于等待函数的完整讨论将在第 7 章中进行. 上面的 `WaitForMultipleObjects` 按顺序接受以下参数:
- 数组中句柄的数量
- 要等待的句柄数组
- 一个布尔标志, 指示是等待所有句柄都变为有信号状态 (TRUE) 还是只有一个 (FALSE). 对于线程, “有信号”的含义是“已退出”.
- 超时 (以毫秒为单位), 在这种情况下, `INFINITE` 意味着等待多久都行.
一旦所有线程退出, 等待就结束了. 剩下要做的就是收集结果:
elapsed = static_cast<DWORD>(::GetTickCount64() - start); FILETIME dummy, kernel, user; int total = 0; for (int i = 0; i < threads; i++) { ::GetThreadTimes(handles[i], &dummy, &dummy, &kernel, &user); int count = data[i].Count; printf("Thread %2d Count: %7d. Execution time: %4u msec\n", i + 1, count, (user.dwLowDateTime + kernel.dwLowDateTime) / 10000); total += count; ::CloseHandle(handles[i]); } return total;
上面的代码使用 `GetThreadTimes` API 来检索线程的计时信息:
BOOL GetThreadTimes( _In_ HANDLE hThread, _Out_ LPFILETIME lpCreationTime, _Out_ LPFILETIME lpExitTime, _Out_ LPFILETIME lpKernelTime, _Out_ LPFILETIME lpUserTime);
该函数返回线程的创建时间, 退出时间, 在内核模式下执行所花费的时间以及在用户模式下执行所花费的时间. 对于此应用程序, 我想显示执行时间, 这意味着将内核时间和用户时间相加, 同时忽略创建和退出时间.
内核和用户时间在 `FILETIME` 结构中报告, 这是一个存储在两个 32 位值中的 64 位值:
typedef struct _FILETIME { DWORD dwLowDateTime; DWORD dwHighDateTime; } FILETIME, *PFILETIME, *LPFILETIME;
该值以 100 纳秒 (10 的 -7 次方) 为单位, 这意味着可以通过除以 10000 来获得以毫秒为单位的值. 该代码假定经过的时间不高于 32 位值的 100 纳秒单位, 这在一般情况下可能不正确.
- 运行素数计数器
以下是针对相同值范围的几次运行, 从一个线程的基线开始:
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 1 Thread 1 created (3 to 20000000). TID=29760 Thread 1 Count: 1270606. Execution time: 9218 msec Total primes: 1270606. Elapsed: 9218 msec C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 2 Thread 1 created (3 to 10000001). TID=22824 Thread 2 created (10000002 to 20000000). TID=41816 Thread 1 Count: 664578. Execution time: 3625 msec Thread 2 Count: 606028. Execution time: 5968 msec Total primes: 1270606. Elapsed: 5984 msec C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 4 Thread 1 created (3 to 5000001). TID=52384 Thread 2 created (5000002 to 10000000). TID=47756 Thread 3 created (10000001 to 14999999). TID=42296 Thread 4 created (15000000 to 20000000). TID=34972 Thread 1 Count: 348512. Execution time: 1312 msec Thread 2 Count: 316066. Execution time: 2218 msec Thread 3 Count: 306125. Execution time: 2734 msec Thread 4 Count: 299903. Execution time: 3140 msec Total primes: 1270606. Elapsed: 3141 msec C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 8 Thread 1 created (3 to 2500001). TID=25200 Thread 2 created (2500002 to 5000000). TID=48588 Thread 3 created (5000001 to 7499999). TID=52904 Thread 4 created (7500000 to 9999998). TID=18040 Thread 5 created (9999999 to 12499997). TID=50340 Thread 6 created (12499998 to 14999996). TID=43408 Thread 7 created (14999997 to 17499995). TID=53376 Thread 8 created (17499996 to 20000000). TID=33848 Thread 1 Count: 183071. Execution time: 578 msec Thread 2 Count: 165441. Execution time: 921 msec Thread 3 Count: 159748. Execution time: 1171 msec Thread 4 Count: 156318. Execution time: 1343 msec Thread 5 Count: 154123. Execution time: 1531 msec Thread 6 Count: 152002. Execution time: 1531 msec Thread 7 Count: 150684. Execution time: 1718 msec Thread 8 Count: 149219. Execution time: 1765 msec Total primes: 1270606. Elapsed: 1766 msec C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 16 Thread 1 created (3 to 1250001). TID=50844 Thread 2 created (1250002 to 2500000). TID=9792 Thread 3 created (2500001 to 3749999). TID=12600 Thread 4 created (3750000 to 4999998). TID=52804 Thread 5 created (4999999 to 6249997). TID=5408 Thread 6 created (6249998 to 7499996). TID=42488 Thread 7 created (7499997 to 8749995). TID=49336 Thread 8 created (8749996 to 9999994). TID=13384 Thread 9 created (9999995 to 11249993). TID=41508 Thread 10 created (11249994 to 12499992). TID=12900 Thread 11 created (12499993 to 13749991). TID=39512 Thread 12 created (13749992 to 14999990). TID=3084 Thread 13 created (14999991 to 16249989). TID=52760 Thread 14 created (16249990 to 17499988). TID=17496 Thread 15 created (17499989 to 18749987). TID=39956 Thread 16 created (18749988 to 20000000). TID=31672 Thread 1 Count: 96468. Execution time: 281 msec Thread 2 Count: 86603. Execution time: 484 msec Thread 3 Count: 83645. Execution time: 562 msec Thread 4 Count: 81795. Execution time: 671 msec Thread 5 Count: 80304. Execution time: 781 msec Thread 6 Count: 79445. Execution time: 812 msec Thread 7 Count: 78589. Execution time: 859 msec Thread 8 Count: 77729. Execution time: 828 msec Thread 9 Count: 77362. Execution time: 906 msec Thread 10 Count: 76761. Execution time: 1000 msec Thread 11 Count: 76174. Execution time: 984 msec Thread 12 Count: 75828. Execution time: 1046 msec Thread 13 Count: 75448. Execution time: 1078 msec Thread 14 Count: 75235. Execution time: 1062 msec Thread 15 Count: 74745. Execution time: 1062 msec Thread 16 Count: 74475. Execution time: 1109 msec Total primes: 1270606. Elapsed: 1188 msec C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 20 Thread 1 created (3 to 1000001). TID=30496 Thread 2 created (1000002 to 2000000). TID=7300 Thread 3 created (2000001 to 2999999). TID=50580 Thread 4 created (3000000 to 3999998). TID=21536 Thread 5 created (3999999 to 4999997). TID=24664 Thread 6 created (4999998 to 5999996). TID=34464 Thread 7 created (5999997 to 6999995). TID=51124 Thread 8 created (6999996 to 7999994). TID=29972 Thread 9 created (7999995 to 8999993). TID=50092 Thread 10 created (8999994 to 9999992). TID=49396 Thread 11 created (9999993 to 10999991). TID=18264 Thread 12 created (10999992 to 11999990). TID=33496 Thread 13 created (11999991 to 12999989). TID=16924 Thread 14 created (12999990 to 13999988). TID=44692 Thread 15 created (13999989 to 14999987). TID=53132 Thread 16 created (14999988 to 15999986). TID=53692 Thread 17 created (15999987 to 16999985). TID=5848 Thread 18 created (16999986 to 17999984). TID=12760 Thread 19 created (17999985 to 18999983). TID=13180 Thread 20 created (18999984 to 20000000). TID=49980 Thread 1 Count: 78497. Execution time: 218 msec Thread 2 Count: 70435. Execution time: 343 msec Thread 3 Count: 67883. Execution time: 421 msec Thread 4 Count: 66330. Execution time: 484 msec Thread 5 Count: 65366. Execution time: 578 msec Thread 6 Count: 64337. Execution time: 640 msec Thread 7 Count: 63798. Execution time: 640 msec Thread 8 Count: 63130. Execution time: 703 msec Thread 9 Count: 62712. Execution time: 718 msec Thread 10 Count: 62090. Execution time: 703 msec Thread 11 Count: 61937. Execution time: 781 msec Thread 12 Count: 61544. Execution time: 812 msec Thread 13 Count: 61191. Execution time: 796 msec Thread 14 Count: 60826. Execution time: 843 msec Thread 15 Count: 60627. Execution time: 875 msec Thread 16 Count: 60425. Execution time: 875 msec Thread 17 Count: 60184. Execution time: 875 msec Thread 18 Count: 60053. Execution time: 890 msec Thread 19 Count: 59681. Execution time: 875 msec Thread 20 Count: 59560. Execution time: 906 msec Total primes: 1270606. Elapsed: 1109 msec
这些运行所执行的系统有 16 个逻辑处理器. 以下是从上述输出中得出的几个有趣的观察:
- 随着线程数量的增加, 执行时间的改善不是线性的 (甚至相差甚远).
- 使用比逻辑处理器数量更多的线程会缩短执行时间.
我们为什么会得到这些结果? 在分叉-连接风格的算法中, 最佳线程数是多少? 看起来答案应该是“逻辑处理器的数量”, 因为更多的线程会导致上下文切换, 因为不是所有线程都能同时执行, 而使用更少的线程肯定会使一些处理器未被利用.
然而, 现实并不那么简单. 我们得到这两个观察的唯一原因是: 工作没有在线程之间平均分配 (就执行时间而言). 这仅仅是因为使用的算法: 数字越大, `sqrt` 函数需要做的工作就越多, 它的输出与它的输入成正比. 这通常是分叉-连接算法中的挑战: 公平地分配工作. 图 5-4 演示了在一个有四个线程的示例案例中会发生什么.

Figure 79: 有 4 个线程的素数计数器
请注意上面的输出中, 后面的线程运行时间更长, 仅仅因为它们有更多的工作要做. 现在, 即使系统只有 16 个逻辑处理器, 我们用 20 个线程也能获得更好的运行时间, 这就显而易见了. 提前完成的线程会释放处理器, 允许那些“额外的”线程 (16 个之后) 获得处理器, 从而推动工作向前进行. 有限制吗? 当然, 在某个时候, 上下文切换的开销, 加上由于为线程栈分配更多内存而可能发生的页面错误, 会开始使情况变得更糟. 显然, 问这个程序的最佳处理器数量是多少不是一个简单的问题. 而且情况可能会变得更糟: 这个程序只做 CPU 密集型操作; 没有 I/O. 如果线程需要不时地进行 I/O, 这个问题变得更加困难.
1.6.3. 终止线程
每个好 (或坏) 的线程都必须在某个时候结束. 线程终止有三种方式:
- 线程函数返回 (最佳选择)
- 线程调用 `ExitThread` (最好避免)
- 线程被 `TerminateThread` 终止 (通常是个坏主意)
最好的选择是简单地从线程函数返回. 当一个线程开始执行时, 线程函数实际上不是线程执行的第一个或唯一的函数. 线程实际上是在一个名为 `RtlUserThreadStart` 的 `NTDLL.dll` 函数内部开始执行的, 该函数在概念上调用提供给 `CreateThread` 的线程实际函数. 一旦线程的函数返回, `RtlUserThreadStart` 会做一些清理工作并调用 `ExitThread`. 请注意, `ExitThread` 只能由一个线程调用以终止自身, 正如其原型所示:
void ExitThread(_In_ DWORD exitCode);
来自 `Kernel32.dll` 的 `ExitThread` 实际上是到 `NtDll.Dll` 中 `RtlExitUserThread` 的一个转发器.
从线程的函数中显式调用 `ExitThread` 的问题至少在于 C++ 析构函数不会被调用, 因为 `ExitThread` 永远不会返回. 因此, 最好简单地从线程的函数返回, 以便它能够正确地清理局部 C++ 对象.
在任何情况下, `ExitThread` 还会为进程中的所有 DLL 调用 `DllMain` 函数, 并带有 `DLLTHREADDETACH` 原因参数. 这允许 DLL 执行每个线程的操作. 例如, DLL 可以分配一些内存块来管理每个线程的一些东西. 在许多情况下, 这与线程局部存储 (TLS) 相结合, 在第 10 章中讨论.
终止线程的第三种选择是调用 `TerminateThread`, 它可以从另一个线程 (甚至属于另一个进程) 发出. 唯一的条件是调用者能够获得一个具有 `THREADTERMINATE` 访问掩码的线程句柄. 以下是 `TerminateThread` 的定义:
BOOL WINAPI TerminateThread( _Inout_ HANDLE hThread, _In_ DWORD dwExitCode);
用这个调用终止一个线程几乎总是一个坏主意. 问题在于线程已经做了什么, 以及由于终止而尚未做什么. 如果线程在做实际工作时被终止, 无法判断它执行了哪些指令, 以及由于终止而无法执行哪些其他代码. 应用程序状态可能会处于不一致的状态. 作为一个极端 (但并非不可能) 的例子, 线程可能已经获取了一个临界区 (见第 7 章), 并且没有机会释放它, 导致死锁, 因为等待临界区的其他线程将永远等待.
`TerminateThread` 的另一个问题是它不会用 `DLLTHREADDETACH` 调用 DLL 的 `DllMain` 函数. 这意味着 DLL 无法运行一些可能释放内存或执行其他操作来逆转线程创建时所做的事情的代码.
`TerminateThread` 的这些问题意味着安全地调用此函数是一种罕见的情况, 应该有更好的方法来处理任何似乎需要它的情况. 尽管如此, 如果这是可取的, 调用者必须获得一个具有 `THREADTERMINATE` 访问权限的足够强大的句柄. 从 `CreateThread` 和 `CreateProcess` 返回的线程句柄总是有完全权限. 对于其他情况, 可以尝试用 `OpenThread` 获取任意线程的句柄:
HANDLE OpenThread( _In_ DWORD dwDesiredAccess, _In_ BOOL bInheritHandle, _In_ DWORD dwThreadId);
该函数看起来与第 3 章中讨论的 `OpenProcess` 类似. 如果可以获得请求的访问掩码, 则向调用者返回一个非 `NULL` 的句柄. 如果请求并接收到 `THREADTERMINATE`, 那么对 `TerminateThread` 的调用就必定成功.
1.6.4. 线程的栈
局部变量和函数返回地址驻留在线程的栈上. 线程的栈大小可以用 `CreateThread` 的第二个参数指定, 但实际上有两个值影响线程的栈: 一个作为栈最大大小的*保留*内存大小, 以及一个初始的*已提交*内存大小, 可供使用. *保留*和*已提交*这两个术语将在第 12 章中深入讨论, 但这里的要点是: 保留内存只是标记了一个连续的地址空间范围, 以便进程地址空间中的新分配不会使用该范围. 对于栈来说, 这是必不可少的, 因为栈总是连续的. 已提交内存意味着内存实际上已分配, 因此可以使用.
立即分配最大栈大小, 提前提交整个栈是可能的, 但这会很浪费, 因为一个线程可能不需要整个范围来进行与栈相关的工作. 内存管理器有一个优化技巧: 提交一个较小量的内存, 如果栈增长超过该量, 就触发栈的扩展, 直到达到保留的限制. 触发是由一个带有特殊标志 `PAGEGUARD` 的页面完成的, 如果触摸到该页面就会导致异常. 这个异常被内存管理器捕获, 然后内存管理器提交一个额外的页面, 将 `PAGEGUARD` 页面向下移动一个页面 (记住栈向低地址增长). 图 5-5 显示了这种安排.

Figure 80: 一个线程的栈
保护页的实际最小值为 12 KB, 即 3 页. 这保证了栈扩展将允许至少 12 KB 的已提交内存可用于栈.
通常, 传递给 `CreateThread` 的栈 (第二个) 参数为零. 在这种情况下, 会从可移植可执行 (PE) 头中存储的值中检索已提交和保留大小的默认值. 第一个线程, 由内核创建, 因此我们无法控制, 总是使用这些值. 你可以使用 Windows SDK 中可用的 `dumpbin` 实用程序来转储这些值. 以下是 Notepad 的一个例子:
C:\>dumpbin /headers c:\windows\system32\notepad.exe
Microsoft (R) COFF/PE Dumper Version 14.24.28314.0
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file c:\windows\system32\notepad.exe
PE signature found
File Type: EXECUTABLE IMAGE
FILE HEADER VALUES
8664 machine (x64)
7 number of sections
9E7797DD time date stamp
0 file pointer to symbol table
0 number of symbols
F0 size of optional header
22 characteristics
Executable
Application can handle large (>2GB) addresses
OPTIONAL HEADER VALUES
...
80000 size of stack reserve
11000 size of stack commit
100000 size of heap reserve
1000 size of heap commit
...
Notepad 中线程栈的默认提交大小是 0x11000 (68 KB), 保留大小是 0x80000 (512 KB). 这些值肯定用于 Notepad 的第一个线程. 用 `CreateThread` 显式创建的其他线程, 如果传递给 `CreateThread` 的栈参数为零, 将具有这些值.
你也可以在几个免费的图形工具中查看这些信息, 比如我自己的 PE Explorer v2.
你可以用 Sysinternals 的 VMMap 工具查看这些信息. 运行 Notepad, 然后运行 VMMap. 从对话框中选择 Notepad 进程 (图 5-6). 然后单击确定.

Figure 81: VMMap 中的进程选择器
VMMap 的主窗口打开. 在中间列表中选择*栈*项. 这会将下方的列表聚焦到仅线程栈 (图 5-7).

Figure 82: 在 VMMap 中选择栈
现在在下方面板中打开一个栈项. 你应该会看到一个提交大小为 0x11000 字节 (68 KB), 保护为读/写. 然后是一个 12 KB 的保护页范围, 其余内存为保留 (图 5-8).

Figure 83: VMMap 中的一个线程栈
VMMap 将在第 12 章中更详细地讨论.
`CreateThread` 函数只有一个栈大小参数, 因此它允许设置初始提交内存或最大保留内存, 但不能同时设置两者. 这基于标志参数. 如果它包含 `STACKSIZEPARAMISARESERVATION`, 那么该值是保留大小; 否则, 它是预先提交的大小.
`CreateThread` 只允许设置其中一个值似乎是一个疏忽. 本地函数 (来自 `NtDll`) `NtCreateThreadEx` 允许设置两个值.
Visual Studio 允许使用项目的属性, 在*链接器/系统*节点下更改默认的栈大小 (图 5-9). 这只是在 PE 头中设置请求的值.

Figure 84: Visual Studio 中的栈大小
最后, 线程可以调用 `SetThreadStackGuarantee` 来尝试保证某个栈大小可用:
BOOL SetThreadStackGuarantee(_Inout_ PULONG StackSizeInBytes);
如果函数成功, 栈大小的增加是通过分配更多的保护页 (也被标记为已提交) 来完成的, 这意味着如果需要栈扩展, 它们保证是可用的.
1.6.5. 线程的名称
从 Windows 10 和 Server 2016 开始, 线程可以有一个基于字符串的名称或描述, 用 `SetThreadDescription` 设置:
HRESULT SetThreadDescription( _In_ HANDLE hThread, _In_ PCWSTR lpThreadDescription);
线程句柄必须具有 `THREADSETLIMITEDINFORMATION` 访问掩码, 这对于几乎任何线程都很容易获得. 名称/描述可以是任何东西. 请注意, 此函数返回一个 `HRESULT`, 其中 `SOK` (0) 表示成功. 重要的是要认识到这与命名其他内核对象不同; 没有办法通过其名称/描述来查找线程. 名称只是存储在线程的内核对象中, 可以用作调试辅助. 以下是设置当前线程名称的简单示例:
::SetThreadDescription(::GetCurrentThread(), L"My Super Thread");
Visual Studio 2019 及更高版本在调试器的*线程*窗口中显示线程的名称 (如果有的话) (图 5-10).

Figure 85: Visual Studio 调试器中的线程名称
自然地, 相反的函数也存在:
HRESULT GetThreadDescription( _In_ HANDLE hThread, _Out_ PWSTR* ppszThreadDescription);
`GetThreadDescription` 在调用者分配的指针中返回结果. 该函数需要调用 `LocalFree` 来释放它分配的内存. 以下是一个示例:
PWSTR name; if (SUCCEEDED(::GetThreadDescription(::GetCurrentThread(), &name))) { printf("Name: %ws\n", name); ::LocalFree(name); }
1.6.6. C++ 标准库呢?
这本书是关于 Windows 编程的, 所以直接讨论 C++ 可能不合时宜. 尽管如此, 从 C++ 11 标准开始, C++ 标准库提供了线程机制 (事实上, 在早期的 C++ 标准中, 甚至没有提到 `thread` 这个词). 基本类型是 `std::thread`, 它允许创建一个线程. 其他类处理线程同步 (见第 7 章); 还有更多.
使用 C++ 标准库的最大好处在于它是标准的, 这意味着它是跨平台的. 如果这比其他考虑更重要, 那么就尽管去使用它. 与使用 Windows API 相比, C++ 标准库的缺点是可用的自定义项非常少. C++ 标准库不支持线程优先级, 亲和性, CPU 集 (所有这些都在第 6 章中讨论), 栈大小控制等等. 这种级别的控制只能通过使用 Windows 特定的 API 来实现.
1.6.7. 练习
- 创建一个基于 WTL 对话框的应用程序, 允许在一定范围内计算素数 (为数字输入添加编辑框). 在一个单独的线程上执行计算, 以免 UI 线程被阻塞.
- 在对话框中添加一个*取消*按钮, 允许在计算过程中取消素数计数.
- 创建一个控制台应用程序, 并发地用多个线程计算 Mandelbrot 集, 以便计算更快. (你可以在 wikipedia 上找到更多关于 Mandelbrot 集的信息.) 线程数应该是应用程序的一个输入, 以及输出位图的尺寸. 将总行数除以线程数, 并将每个线程分配到一定范围的行. 每个像素应该是 0 (属于集合) 或 1 (不属于集合). 将结果存储在一个二维数组中.
- 扩展应用程序以将输出写入 BMP 或 PPM 格式 (两者都相对简单), 以便可以在类似画图的应用程序中查看结果.
- 创建一个 WTL 应用程序, 并在不冻结 UI 的情况下用多个线程计算 Mandelbrot 集. 添加平移/缩放并根据需要重新计算的功能.
1.6.8. 总结
在本章中, 我们探讨了线程创建和管理的基础知识. 在下一章中, 我们将讨论线程调度及其相关属性, 例如优先级和亲和性.
1.7. 第 6 章: 线程调度
线程被创建来执行代码, 或者至少这应该是它们的意图. 这意味着在某个时候, 一个逻辑处理器需要运行线程的函数. 通常, 一个典型的系统上有很多线程, 但只有其中的一小部分实际上想要在同一时间执行代码. 大多数线程都在等待某事, 因此不是当时被调度到处理器上的候选者. 如果想要运行的线程数 (处于*就绪*状态) 小于或等于系统上的逻辑处理器数 (并且没有亲和性限制, 本章后面讨论), 那么所有就绪的线程就简单地执行.
然而, 可能会出现一些问题. 线程会获得多长时间的 CPU 时间? 如果一个新线程醒来会发生什么? 如果准备运行的线程比可用的处理器多, 情况又如何? 我们将尝试在本章中回答所有这些 (以及一些其他) 问题.
本章内容:
- 优先级
- 调度基础
- 多处理器调度
- 后台模式
- 处理器组
- 挂起和恢复
1.7.1. 优先级
每个线程都有一个关联的优先级, 这在想要执行的线程比可用处理器多的情况下很重要. 在本节中, 我们将探讨可用的优先级以及如何操作它们, 下一节我们将看到它们在调度中的应用.
线程优先级从 0 到 31, 其中 31 是最高的. 技术上, 线程 0 保留给一个名为*零页线程*的特殊线程, 它是内核中内存管理器的一部分. 它是唯一允许优先级为零的线程. 所以技术上, 可用的优先级是从 1 到 31. 在用户模式下 (我们在本书中编写代码的地方), 优先级不能设置为任意值. 相反, 线程的优先级是进程的*优先级类* (在任务管理器中称为*基本优先级*) 和该基本优先级周围的偏移量的组合. 图 6-1 显示了任务管理器, 其中高亮显示了*基本优先级*列.

Figure 86: 任务管理器中的基本优先级
每个优先级类都与一个优先级值相关联, 如表 6-1 所示.
| 优先级类 | 优先级值 | API 常量 |
|---|---|---|
| 空闲 (低) | 4 | IDLEPRIORITYCLASS |
| 低于正常 | 6 | BELOWNORMALPRIORITYCLASS |
| 正常 | 8 | NORMALPRIORITYCLASS |
| 高于正常 | 10 | ABOVENORMALPRIORITYCLASS |
| 高 | 13 | HIGHPRIORITYCLASS |
| 实时 | 24 | REALTIMEPRIORITYCLASS |
表 6-1 中的“实时”名称并不意味着 Windows 是一个实时操作系统; 它不是. Windows 无法提供实时操作系统所能提供的延迟和时序保证. 这是因为 Windows 适用于各种各样的硬件, 因此在硬件范围不受限制的情况下, 根本不可能有任何这样的保证. 表 6-1 中的“实时”仅表示“高于其他所有”.
进程的优先级类可以在用 `CreateProcess` 创建该进程时设置. 第六个参数 (标志) 可以与表 6-1 中的常量之一结合. 如果没有指定显式的优先级类, 优先级类默认为*正常*, 除非创建者的优先级类是*空闲*或*低于正常*, 在这种情况下, 使用创建者的优先级类.
如果一个进程已经存在, 可以用 `SetPriorityClass` 更改优先级类:
BOOL SetPriorityClass( _In_ HANDLE hProcess, _In_ DWORD dwPriorityClass);
任务管理器和 Process Explorer 都提供了一个上下文菜单来更改进程的优先级类.
所讨论的进程句柄必须具有 `PROCESSSETINFROMATION` 访问掩码才能使调用成功. 另外, 如果目标优先级类是*实时*, 调用者必须具有 `SeIncreaseBasePriority` 特权. 如果没有, 函数不会失败, 但最终的优先级类会设置为*高*而不是*实时*.
当然, 相反的函数也存在, 用于检索进程的优先级类:
DWORD GetPriorityClass(_In_ HANDLE hProcess);
句柄访问掩码只需要 `PROCESSQUERYLIMITEDINFORMATION`, 这对于几乎所有进程都可以获得.
进程优先级类对进程本身没有直接影响, 因为进程不运行——线程运行. 在进程中创建的所有线程的默认优先级都设置为优先级类级别. 例如, 在一个*正常*优先级类的进程中, 所有线程的默认优先级都是 8. 要更改线程的优先级, 可以使用 `SetThreadPriority` 函数:
BOOL SetThreadPriority( _In_ HANDLE hThread, _In_ int nPriority);
`nPriority` 参数不是一个绝对的优先级值. 相反, 它是七个可能值之一 (除了*实时*优先级类, 见下一个侧边栏), 如图 6-2 所示.
| 优先级值 | 效果 |
|---|---|
| THREADPRIORITYIDLE (-15) | 优先级降至 1, 实时优先级类除外, 线程优先级降至 16 |
| THREADPRIORITYLOWSET (-2) | 优先级相对于优先级类降低 2 |
| THREADPRIORITYBELOWNORMAL (-1) | 优先级相对于优先级类降低 1 |
| THREADPRIORITYNORMAL (0) | 优先级设置为进程优先级类值 |
| THREADPRIORITYABOVENORMAL (1) | 优先级相对于优先级类增加 1 |
| THREADPRIORITYHIGHEST (2) | 优先级相对于优先级类增加 2 |
| THREADPRIORITYTIMECRITICAL (15) | 优先级增加到 15, 实时优先级类除外, 线程优先级增加到 31 |
实时优先级类与表 6-2 有特殊关系. 该优先级类中的线程可以被分配任何从 16 到 31 的值. `SetThreadPriority` 接受从 -7 到 -3 和从 3 到 7 的值, 对应于优先级 17 到 21 和 27 到 30.
*高*优先级类只有六个级别. 这是因为优先级类不是实时的进程中的线程的优先级不能高于 15.
空闲*和*时间关键*值被称为*饱和值.
表 6-1 和表 6-2 的净效应可以总结在表 6-3 和图 6-2 中. 在图 6-2 中, 每个矩形表示基于 `SetPriorityClass`/`SetThreadPriority` 的可能线程优先级值. 表 6-3 是表 6-1 和 6-2 的汇总表示.

Figure 87: 线程优先级
| 优先级类 (右) 相对优先级 (下) | 实时 | 高 | 高于正常 | 正常 | 低于正常 | 空闲 |
|---|---|---|---|---|---|---|
| 时间关键 (+15) | 31 | 15 | 15 | 15 | 15 | 15 |
| 最高 (+2) | 26 | 15 | 12 | 10 | 8 | 6 |
| 高于正常 (+1) | 25 | 14 | 11 | 9 | 7 | 5 |
| 正常 (0) | 24 | 13 | 10 | 8 | 6 | 4 |
| 低于正常 (-1) | 23 | 12 | 9 | 7 | 5 | 3 |
| 最低 (-2) | 22 | 11 | 8 | 6 | 4 | 2 |
| 空闲 (-15) | 16 | 1 | 1 | 1 | 1 | 1 |
进程优先级类和相对线程优先级的组合结果是线程的最终优先级. 从内核调度器的角度来看, 只有最终的数字是重要的. 它不关心这个数字是如何得来的. 例如, 优先级 8 可以通过三种方式达到: 正常*优先级类和*正常 (0) 相对线程优先级; 低于正常*优先级类和*最高 (+2) 相对线程优先级; 高于正常*优先级类和*最低 (-2) 相对线程优先级. 从调度器的角度来看, 它们都是一样的; 它不关心进程, 只关心线程.
实时优先级范围 (16-31) 被许多为整个系统做基本工作的内核线程使用, 因此对于在该范围内运行的进程的线程来说, 不要消耗太多 CPU 时间是很重要的. 当然, 一个进程必须有非常好的理由才能进入该范围.
如果我们在像 Process Explorer 这样的工具中查看线程优先级, 我们会发现有两个优先级值: 基本优先级*和*动态优先级 (图 6-3).

Figure 88: Process Explorer 中的线程属性
基本优先级是开发者设置的 (或默认值), 而动态优先级是该线程的实际当前优先级. 在某些情况下, 优先级会暂时增加 (提升). 我们将在本章后面探讨这种提升的一些原因.
从调度器的角度来看, 动态优先级是决定性优先级值.
实时范围内的线程的优先级永远不会被提升.
1.7.2. 调度基础
调度通常相当复杂, 考虑到几个因素, 其中一些相互冲突: 多个处理器, 电源管理 (一方面希望节省电力, 另一方面希望利用所有处理器), NUMA (非统一内存架构), 超线程, 缓存等等. 确切的调度算法是未文档化的, 原因在于: 微软可以在后续的 Windows 版本和更新中进行修改和调整, 而无需开发者依赖于确切的算法. 话虽如此, 通过实验可以体验到许多调度算法.
我们将从最简单的调度可能开始——当系统上只有一个处理器时, 因为这对调度的工作方式至关重要. 稍后, 我们将看看这些算法在多处理系统上是如何改变的.
- 单 CPU 调度
调度器维护一个*就绪队列*, 其中管理着想要执行的线程 (处于*就绪*状态). 所有其他此时不想执行的线程 (处于*等待*状态) 都不会被考虑, 因为它们不想执行. 图 6-4 显示了一个示例系统, 其中有七个线程处于就绪状态. 它们根据其优先级被安排在多个队列中.

Figure 89: 处于就绪状态的线程
一个系统上可能有数千个线程, 但大多数都处于等待状态, 因此不被调度器考虑.
单个 CPU 的算法如下:
- 最高优先级的线程首先运行. 在图 6-4 中, 线程 1 和 2 具有最高 (且相同) 的优先级 (31), 因此优先级 31 的队列中的第一个线程运行; 让我们假设是线程 1 (图 6-5).

Figure 90: 最高优先级的线程运行
线程 1 运行一定的时间, 称为*量子*. 量子的长度在下一节讨论. 假设线程 1 有很多工作要做, 当它的量子到期时, 调度器会抢占线程 1, 将其状态保存在其内核栈中, 然后它回到*就绪*状态 (因为它仍然有事情要做). 线程 2 现在成为正在运行的线程, 因为它具有相同的优先级 (图 6-6).

Figure 91: 线程 2 正在运行, 线程 1 回到就绪状态
所以, 优先级是决定性因素. 只要线程 1 和 2 需要执行, 它们就会在 CPU 上轮流运行, 每个运行一个量子. 幸运的是, 线程通常不会永远运行. 相反, 它们在某个时候会进入等待状态. 以下是一些导致线程进入等待状态的例子:
- 执行同步 I/O 操作
- 等待一个当前未发出信号的内核对象
- 在没有 UI 消息时等待 UI 消息
- 进入自愿休眠
一旦一个线程进入等待状态, 它就会从调度器的就绪队列中移除. 让我们假设线程 1 和 2 进入了等待状态. 现在最高优先级的线程是线程 3, 它成为正在运行的线程 (图 6-7).

Figure 92: 线程 3 正在运行
线程 3 运行一个量子. 如果它仍然有工作要做, 它会得到另一个量子, 因为它是其优先级级别中唯一的一个. 然而, 如果线程 1 接收到它正在等待的任何东西, 它会进入就绪状态并抢占线程 3 (因为线程 1 有更高的优先级) 并成为正在运行的线程. 线程 3 回到就绪状态 (图 6-8). 这个切换不是在线程 3 的量子结束时, 而是在变化发生时 (线程 1 完成等待). 如果线程 3 的优先级高于 15 (在本例中是这样), 它的量子会被补充.
如果被抢占的线程的优先级是 16 或更高, 当它回到就绪状态时, 它的量子会被恢复.

Figure 93: 线程 1 正在运行, 线程 3 回到就绪状态
记住这个算法, 如果没有更高优先级的线程处于就绪状态, 线程 4, 5 和 6 将各自拥有自己的量子运行.
这是调度的基础. 事实上, 在真正的单 CPU 场景中, 这正是使用的算法. 然而, 即使在这种情况下, Windows 也会在某种程度上尝试做到“公平”. 例如, 图 6-4 到 6-8 中的线程 7 (优先级为 4) 如果有更高优先级的线程处于就绪状态, 可能不会运行, 因此它会遭受 CPU 饥饿. 那个线程在这种系统中注定要失败吗? 不完全是; 系统大约每 4 秒就会将该线程的优先级提升到 15, 给它一个更好的机会取得进展. 这种提升持续一个实际执行的量子, 然后优先级降回其初始值. 这只是一个临时优先级提升的例子. 你将在本章后面的“优先级提升”部分看到其他例子.
- 量子
量子在前一节中被提及了几次——但一个量子有多长? 调度器以两种正交的方式工作: 第一种是使用一个计时器, 默认情况下每 15.625 毫秒触发一次, 可以通过调用 `GetSystemTimeAdjustment` 并查看第二个参数来获得. 另一种方法是使用 SysInternals 的 `clockres` 工具:
C:\Users\pavel>clockres Clockres v2.1 - Clock resolution display utility Copyright (C) 2016 Mark Russinovich Sysinternals Maximum timer interval: 15.625 ms Minimum timer interval: 0.500 ms Current timer interval: 1.000 ms
与量子相关的值是*最大时间间隔*值.
来自 `clockres` 的*当前时间间隔*显示了当前的计时器触发间隔. 这通常低于最大间隔, 因为可能已请求了多媒体计时器. 这允许获得高达 1 毫秒分辨率的计时器通知. 无论如何, 量子本身不受*当前时间间隔*的影响.
客户端机器 (Home, Pro, Enterprise, XBOX 等) 的默认量子是 2 个时钟周期, 服务器机器是 12 个时钟周期. 换句话说, 客户端的量子是 31.25 毫秒, 服务器是 187.5 毫秒.
服务器版本获得更长量子的原因是为了增加客户端请求在单个量子内完全处理的机会. 这在客户端机器上不太重要, 因为它可能有许多进程各自做相对较少的工作, 其中一些带有用户界面, 应该响应迅速, 所以短量子更适合. 在量子方面, 从客户端切换到服务器 (或反之) 可以通过以下对话框实现, 我喜欢称之为“Windows 中最令人费解的对话框” (图 6-9).

Figure 94: 性能选项对话框
以下是如何进入此对话框: 转到系统属性 (从控制面板或右键单击此电脑在资源管理器中并选择属性). 然后单击高级系统设置. 一个对话框打开——单击性能设置按钮. 性能选项对话框出现. 单击高级选项卡, 你就到了.
这个对话框有两个完全不相关的部分. 下半部分控制页面文件的大小 (如果有的话), 本书后面会讨论. 上半部分是“令人费解的”部分. *程序*选项意味着短量子, 而*后台服务*选项意味着长量子. 如果你选中另一个单选按钮, 更改会立即生效.
这两个选项之间还有另一个区别. *程序*还意味着在前台进程 (托管前台窗口的进程) 中, 所有线程默认获得三倍量子. 这种量子拉伸效果在*后台服务*中不存在, 因为真正的服务器不太可能有一个坐在控制台前的交互式用户. 此外, 我们将在本章后面看到的一些优先级提升在选择*后台服务*时不适用.
还有其他方法可以改变量子. 对于细粒度控制, 注册表值 `HKLM\SYSTEM\CurrentControlSet\Control\PriorityControl\Win32PrioritySeparation` 不仅控制量子的长度, 还控制前台进程的量子拉伸. 有关详细信息, 请参见“Windows Internals”一书 (第 4 章). 最好将此值保留为默认值, 其中先前描述的规则适用.
控制量子的另一种方法是使用作业对象 (在第 4 章中详细描述), 并使用 `JOBOBJECTBASICLIMITINFORMATION` 中的 `SchedulingClass` 字段. 这仅适用于长固定量子系统 (服务器系统的默认值). 调度类值 (在 0 和 9 之间) 以下列方式为作业中的进程的线程设置量子:
Quantum = 2 * (timer interval) * (Scheduling class + 1);
默认的调度类是 5, 有效地给出了 12 * 计时器间隔的量子, 正如我们前面看到的, 这是服务器系统上的默认值. 最高值 (9) 导致线程是非抢占式的, 意味着它们有无限的量子 (理论上可以无限期地继续运行, 直到它们自愿进入等待状态). 大于 5 的值需要调用者具有 `SeIncreaseBasePriority` 特权, 默认情况下, Administrators 组中的用户可用, 但标准用户不可用.
调度类值仅适用于优先级类高于*空闲*的进程.
1.7.3. 处理器组
最初的 Windows NT 设计最多支持 32 个处理器, 使用一个机器字 (32 位) 来指示系统上的实际处理器, 每个位代表一个处理器. 当 64 位 Windows 出现时, 处理器的最大数量自然地扩展到 64.
从 Windows 7 (仅限 64 位系统) 开始, 微软希望支持超过 64 个处理器, 因此另一个参数进入了场景: 一个*处理器组*. 例如, Windows 7 和 Server 2008 R2 支持多达 256 个处理器, 这意味着一个有 256 个处理器的系统上有 4 个处理器组.
Windows 8 和 Server 2012 支持 640 个处理器 (10 组), Windows 10 支持更多. 基本规则仍然是——每组最多 64 个处理器——根据需要增加组的数量.
一个线程可以是一个处理器组的成员, 这意味着一个线程可以被调度到其当前组的一部分的 (最多) 64 个处理器中的一个上. 当一个进程被创建时, 它会以轮询的方式被分配一个处理器组, 以便进程在组之间“负载均衡”. 进程中的线程被分配到进程组. 父进程可以通过以下方式之一影响子进程的初始处理器组:
- 父进程可以在 `CreateProcess` 的标志中使用 `INHERITPARENTAFFINITY` 标志, 以指示子进程应继承其父处理器组, 而不是根据系统管理的轮询来获取它. 如果父进程的线程使用多个亲和性组, 则会任意选择一个组作为子进程组.
- 父进程可以使用 `PROCTHREADATTRIBUTEGROUPAFFINITY` 进程属性来指定所需的默认处理器组.
进程组亲和性可以用 `GetProcessGroupAffinity` 检索:
BOOL GetProcessGroupAffinity( _In_ HANDLE hProcess, _Inout_ PUSHORT GroupCount, _Out_ PUSHORT GroupArray);
可以使用 `SetThreadGroupAffinity` 函数控制特定线程的处理器组. 这将在本章后面的“硬亲和性”部分讨论.
1.7.4. 多处理器调度
多处理器调度给调度算法增加了复杂性. Windows 唯一保证的是, 想要执行的最高优先级线程 (如果超过一个, 至少有一个) 当前正在运行. 在本节中, 我们将看看影响调度的一些参数.
- 亲和性
通常, 一个线程可以被调度到任何处理器上. 然而, 线程的*亲和性*, 即它允许运行的处理器, 可以通过几种方式进行控制, 在以下部分中描述.
- 理想处理器
*理想处理器*是线程的一个属性, 有时也称为“软亲和性”. 理想处理器作为对调度器的提示——在所有其他条件相同的情况下——该线程执行代码的首选处理器. 默认的理想处理器是以轮询方式选择的, 从进程创建时生成的随机数开始. 在超线程系统上, 下一个理想处理器是从下一个核心中选择的, 而不是从下一个逻辑处理器中选择的.
理想处理器可以用 Process Explorer 工具查看, 作为*线程*选项卡中显示的属性之一 (图 6-10).

Figure 95: Process Explorer 中的线程理想处理器
一个线程的理想处理器可以用 `SetThreadIdealProcessor` 更改:
DWORD WINAPI SetThreadIdealProcessor( _In_ HANDLE hThread, _In_ DWORD dwIdealProcessor);
此函数更改的理想处理器在 0 和最大处理器数减 1 之间, 其中 63 是最大值, 因为这是任何组中最高的处理器号. 如果系统支持多个组, 则使用当前线程的组. 该函数返回先前的理想处理器号, 如果出错则返回 -1 (`0xffffffff`). 为理想处理器传递特殊值 `MAXIMUMPROCESSORS` (在 32 位系统上等于 32, 在 64 位系统上等于 64) 只会返回当前的理想处理器.
`SetThreadIdealProcessor` 更改线程所属的当前处理器组的理想处理器. 要更改不同组的, 可以使用扩展的 `SetThreadIdealProcessorEx` 函数:
typedef struct _PROCESSOR_NUMBER { WORD Group; BYTE Number; BYTE Reserved; } PROCESSOR_NUMBER, *PPROCESSOR_NUMBER; BOOL SetThreadIdealProcessorEx( _In_ HANDLE hThread, _In_ PPROCESSOR_NUMBER lpIdealProcessor, _Out_opt_ PPROCESSOR_NUMBER lpPreviousIdealProcessor);
`PROCESSORNUMBER` 结构的 `Group` 成员是要设置理想处理器的组, `Number` 成员是 CPU 索引 (0 到 63). 与非 Ex 函数一样, 可以使用最后一个可选参数检索先前的理想处理器.
- 硬亲和性
虽然理想处理器作为线程应在哪个处理器上执行的提示和建议, 但*硬亲和性* (有时简称为亲和性) 允许为特定线程或进程指定允许执行的处理器. 硬亲和性在两个级别上工作: 进程和线程, 基本规则是线程不能“逃脱”其进程设置的亲和性.
一般来说, 设置硬亲和性约束通常不是一个好主意. 它限制了调度器在分配处理器方面的自由, 并可能导致线程获得的 CPU 时间比没有硬亲和性约束时要少. 尽管如此, 在某些罕见的情况下, 这可能是有用的, 因为在同一组处理器上运行的线程更有可能获得更好的 CPU 缓存利用率. 这对于运行特定已知进程的系统可能有用, 而不是可能运行任何东西的随机机器. 硬亲和性的另一个用途是在压力测试中, 例如使用较少的处理器进行某些执行, 以查看具有该受限数量处理器的系统在运行相同进程时的行为.
设置进程范围的硬亲和性是通过 `SetProcessAffinityMask` 实现的:
BOOL WINAPI SetProcessAffinityMask( _In_ HANDLE hProcess, _In_ DWORD_PTR dwProcessAffinityMask);
进程句柄必须具有 `PROCESSSETINFORMATION` 访问掩码. 亲和性掩码本身是一个位掩码, 其中设置为 1 的位表示允许的处理器, 设置为 0 的位表示禁止的处理器. 例如, 亲和性掩码 `0x1a` (二进制为 11010) 表示只允许处理器 1, 3 和 4. 该函数更改当前进程处理器组的亲和性掩码.
任务管理器和 Process Explorer 允许更改进程的亲和性掩码. 对于任务管理器, 在*详细信息*选项卡中右键单击一个进程并选择*设置亲和性*会显示一个对话框, 其中包含当前进程处理器组的可用处理器 (系统亲和性掩码) (图 6-11). 单击确定会调用 `SetProcessAffinityMask` 来设置新的亲和性掩码. Process Explorer 有类似的功能.

Figure 96: 在任务管理器中设置硬亲和性
自然地, 反函数也可用, 它还提供了系统亲和性掩码:
BOOL WINAPI GetProcessAffinityMask( _In_ HANDLE hProcess, _Out_ PDWORD_PTR lpProcessAffinityMask, _Out_ PDWORD_PTR lpSystemAffinityMask);
以下是获取当前进程亲和性掩码的示例, 或许只是为了检索系统亲和性掩码:
DWORD_PTR processAffinity, systemAffinity; ::GetProcessAffinityMask(::GetCurrentProcess(), &processAffinity, &systemAffinity);
例如, 在一个有 16 个逻辑处理器的系统上, 返回的系统亲和性掩码是 `0xffff`.
设置进程亲和性掩码会约束进程中的所有线程使用该掩码. 单个线程可以通过调用 `SetThreadAffinityMask` 进一步限制其亲和性掩码:
DWORD_PTR WINAPI SetThreadAffinityMask( _In_ HANDLE hThread, _In_ DWORD_PTR dwThreadAffinityMask);
该函数如果可能, 则设置线程的亲和性掩码. 记住基本规则: 线程的亲和性掩码不能包含其进程亲和性掩码中未指定的处理器. 返回值是线程的先前亲和性掩码, 如果出错则为零.
在一个超过 64 个处理器的系统上, 线程可以通过 `SetThreadGroupAffinity` 在指定亲和性掩码的同时更改其处理器组:
typedef struct _GROUP_AFFINITY { KAFFINITY Mask; // affinity bit mask WORD Group; // group number WORD Reserved; } GROUP_AFFINITY, *PGROUP_AFFINITY; BOOL SetThreadGroupAffinity( HANDLE hThread, const GROUP_AFFINITY *GroupAffinity, PGROUP_AFFINITY PreviousGroupAffinity);
该函数可以做两件事: 更改指定线程的处理器组和/或更改该组中的硬亲和性掩码. 如果组被更改, 它将成为该线程进程的默认处理器组. 这会使事情复杂化, 所以通常最好确保一个进程中的所有线程都是同一组的一部分. 尽管如此, 如果一个进程中可能同时运行超过 64 个线程 (并且系统上有超过 64 个处理器), 那么更改某些线程的处理器组可能是有益的, 因为它们可以利用另一个组的处理器.
`KAFFINITY` 是 `ULONGPTR` 的 `typedef`.
如你所料, 反函数也可用:
BOOL GetThreadGroupAffinity( HANDLE hThread, PGROUP_AFFINITY GroupAffinity);
- CPU Sets
正如我们在前一节中看到的, 线程的亲和性不能“逃脱”其进程的亲和性. 然而, 在某些情况下, 让一个 (或多个) 线程使用进程中其他线程禁止使用的处理器是有益的. Windows 10 和 Server 2016 添加了此功能, 称为 CPU Sets.
术语“CPU Set”表示处理器的抽象视图, 其中每个 CPU set 可能映射到一个或多个逻辑处理器. 然而, 目前每个 CPU set 都精确地映射到一个逻辑处理器. 系统有自己的 CPU sets, 默认情况下包括系统上的所有处理器. 此信息可通过 `GetSystemCpuSetInformation` 获得:
BOOL WINAPI GetSystemCpuSetInformation( _Out_opt_ PSYSTEM_CPU_SET_INFORMATION Information, _In_ ULONG BufferLength, _Out_ PULONG ReturnedLength, _In_opt_ HANDLE Process, _Reserved_ ULONG Flags);
该函数返回一个 `SYSTEMCPUSETINFORMATION` 类型的结构数组, 定义如下:
typedef struct _SYSTEM_CPU_SET_INFORMATION { DWORD Size; CPU_SET_INFORMATION_TYPE Type; // currently union { struct { DWORD Id; WORD Group; BYTE LogicalProcessorIndex; BYTE CoreIndex; BYTE LastLevelCacheIndex; BYTE NumaNodeIndex; BYTE EfficiencyClass; union { BYTE AllFlags; struct { BYTE Parked : 1; BYTE Allocated : 1; BYTE AllocatedToTargetProcess : 1; BYTE RealTime : 1; BYTE ReservedFlags : 4; }; }; union { DWORD Reserved; BYTE SchedulingClass; }; DWORD64 AllocationTag; } CpuSet; }; } SYSTEM_CPU_SET_INFORMATION, *PSYSTEM_CPU_SET_INFORMATION;
要了解其中一些值的含义, 请运行 `CPUStress` 并选择*系统 / CPU Sets…*菜单项. 应该会显示系统 CPU set. 图 6-12 显示了一个具有 1 个 socket, 8 个核心和 16 个逻辑处理器的系统的输出.

Figure 97: CPUStress 中的系统 CPU Sets
目前, 任务管理器和 Process Explorer 不提供有关 CPU sets 的信息.
图 6-12 中的 `ID` 对应于 `SYSTEMCPUSETINFORMATION` 中的 `CpuSet.Id` 成员. 这是 CPU set 本身 ID 的一个抽象值. 第一个 CPU set 当前从 256 (`0x100`) 开始, 每个额外的 CPU set 递增一. 256 这个值是任意选择的, 本身没有任何意义. 然而, 这些 ID 是需要的, 以更改进程和线程的 CPU sets, 在以下段落中描述.
图 6-12 中的 `Group` 列对应于一个进程组 (`CpuSet.Group` 在结构中). `Core` 列指示该 CPU set 的核心 (`CpuSet.CoreIndex`). 通常这是真正的核心号 (此成员的确切定义更复杂和理论化——如果感兴趣请查看文档). `LP` 列显示该 CPU set 的逻辑处理器号 (`CpuSet.LogicalProcessorIndex`). `Node` 列显示该 CPU set 的 NUMA 节点 (`CpuSet.NumaNodeIndex`).
有关 `SYSTEMCPUSETINFORMATION` 其他成员的更多详细信息, 请查阅文档.
一个进程可以用 `SetProcessDefaultCpuSets` 为其线程设置默认的 CPU sets:
BOOL WINAPI SetProcessDefaultCpuSets( _In_ HANDLE Process, _In_opt_ const ULONG* CpuSetIds, _In_ ULONG CpuSetIdCound);
`CPUSetIds` 数组应包含 CPU set 的 ID, 可在 `SYSTEMCPUSETINFORMATION` 的 `CpuSet.Id` 成员中找到. `NULL` 值会移除当前的 CPU set 分配, 这意味着从没有特定选定 CPU sets 的进程中的线程中移除 CPU set 约束. 线程可以选择特定的 CPU sets, 这些 sets 可能与其进程分配不同, 使用 `SetThreadSelectedCpuSets`:
BOOL WINAPI SetThreadSelectedCpuSets( _In_ HANDLE Thread, _In_opt_ const ULONG* CpuSetIds, _In_ ULONG CpuSetIdCount);
以下是使用这些函数的示例:
ULONG sets[] = { 0x100, 0x101, 0x102, 0x103 }; ::SetProcessDefaultCpuSets(::GetCurrentProcess(), sets, _countof(sets)); ULONG tset[] = { 0x104 }; ::SetThreadSelectedCpuSets(::GetCurrentThread(), tset, _countof(tset));
前面的示例导致进程中的所有线程默认使用 CPU sets 0x100 到 0x103, 除了当前线程, 它使用 CPU set 0x104, 基本上“逃脱”了其父进程的 CPU sets. 这在线程应有自己的 CPU, 而进程中的其他线程不能使用的情况下可能很有用.
- CPU Sets vs. Hard Affinity
CPU sets 和硬亲和性可能会相互冲突. 在这种情况下, 硬亲和性总是获胜. 如果 CPU sets 与硬亲和性矛盾, CPU sets 将被忽略.
1.7.5. 系统 CPU Sets
系统有自己的 CPU set, 可以用 `GetSystemCpuSetInformation` 确定, 该函数通常返回系统上可用的 CPU sets. Windows API 没有提供文档化的更改方法, 但可以用 native `NtSetSystemInformation` 调用来完成. 这允许告诉“系统”避免某些处理器, 以免干扰用户进程. 此功能用于游戏模式, 在 Windows 10 版本 1703 及更高版本中可用.
游戏模式的详细讨论超出了本书的范围.
1.7.6. 修订后的调度算法
多处理器 (MP) 调度是复杂的: 硬亲和性, 理想处理器, CPU sets, 电源考虑, 游戏模式以及其他方面都使 MP 上的调度决策变得复杂. 在“调度基础”部分描述的就绪队列 (实际上是一个由 32 个队列组成的数组, 每个优先级一个) 在 MP 系统上得到了扩展: 每个处理器都有自己的就绪队列. 此外, 在 Windows 8 及更高版本中, 还有用于处理器组的共享就绪队列 (目前每组最多 4 个). 这允许调度器在需要为附加到共享就绪队列的就绪线程定位处理器时有更多选择 (每个 CPU 的就绪队列仍用于具有硬亲和性约束的线程).
上述细节可能会被微软在未来的 Windows 版本中更改. 文本旨在给出调度复杂性的一些想法.
图 6-13 中呈现了一个修订的, 简化的 MP 调度算法. 它假设没有亲和性或 CPU set 约束, 没有电源或其他特殊考虑.

Figure 98: MP 简化调度
从图 6-13 中可以看出, 理想处理器是首选使用的处理器, 其次是它上次运行的处理器 (处理器的缓存可能仍包含该线程使用的数据). 如果所有处理器都忙, 调度器不会抢占运行低优先级线程的第一个处理器; 那将是低效的, 因为可能需要搜索许多处理器. 相反, 该线程被放入其理想处理器的 (共享) 就绪队列中.
下一个 Windows 版本, 2004 (2020 年 4 月) 可能会更改理想处理器和先前处理器之间的检查顺序. 无论如何, 从开发人员的角度来看, 这几乎没有关系.
1.7.7. 观察调度
调度变化相当频繁, 但可以用工具观察到. 在以下部分中, 我将描述一些你可以用来调查和体验调度的实验. 本节是可选的, 可以安全地跳过.
- 通用调度
要对调度有一个大概的了解, 我们可以使用性能监视器. 运行 `CPUStress` 并终止两个线程, 以便只剩下两个. 激活两个线程 (图 6-14).

Figure 99: 带有两个活动线程的 CPUStress
现在打开性能监视器 (在运行提示符下键入 `perfmon` 或直接搜索). 性能控制台出现. 单击性能监视器项 (图 6-15).

Figure 100: 性能监视器
性能监视器是一个内置工具, 可以显示性能计数器, 这些计数器只是由各种系统组件暴露的数字. 技术上, 任何应用程序都可以注册和暴露性能计数器. 在以下示例中, 我们使用一些与调度相关的内置计数器.
删除默认计数器, 然后单击*添加* (绿色加号按钮) 以添加新计数器. 搜索*线程*类别并打开它 (图 6-16).

Figure 101: 线程性能计数器类别
现在选择以下计数器: 当前优先级*和*线程状态 (使用 Control 键多选) (图 6-17).

Figure 102: 从线程类别中选择的计数器
在下方的搜索框中, 键入 `CPustress` 并按 ENTER. 应该会显示一个线程列表. 选择线程 1 和 2 (这些应该是 `CPUStress` 左侧显示的数字). 单击*添加* (图 6-18) 然后单击确定.

Figure 103: 在线程类别中选择的两个线程
现在显示了 4 个图形, 分别是 `CPUStress` 的两个工作线程的当前优先级和状态. 右键单击一个空的图形区域并选择*属性*. 切换到*图形*选项卡并将垂直刻度更改为 0 到 16 之间 (图 6-19). 单击确定.

Figure 104: 更改图形刻度
现在优先级和状态应该更容易识别了 (图 6-20).

Figure 105: 正在工作的计数器
请注意, 线程的优先级是 8 (图 6-20 中的红线和绿线, 绿色被红色遮挡). 线程状态在 2 和 5 之间交替. 以下是主要的状态编号: 运行=2, 就绪=1, 等待=5. 现在切换到 `CPUStress` 应用程序. 注意线程优先级跃升到 10. 如果你切换到另一个应用程序, 它们会降回. 你可以将一个线程的活动级别更改为*高*并看到效果. (图 6-21). 你也可以玩转优先级.

Figure 106: 线程中的状态变化
- 硬亲和性
你可以通过从上一个实验继续来测试硬亲和性. `CPUStress` 允许限制亲和性 (你也可以使用任务管理器). 从菜单中选择*进程/亲和性*并选择一个 CPU 作为硬亲和性 (哪个都行) (图 6-22).

Figure 107: CPUStress 中的进程亲和性
你应该会看到线程不时地进入就绪状态, 因为两个线程都在争夺单个 CPU. 将它们的活动增加到*最大*并观察线程在状态 2 (运行) 和 1 (就绪) 之间交替 (图 6-23).

Figure 108: 单个处理器亲和性的最大活动
性能监视器每 1 秒才更新一次, 这意味着在这段时间内会经过几个量子. 这意味着你看到的并不完全准确, 但它给出了大致的想法.
- CPU Sets
观察 CPU sets 需要一个不同的工具, 一个可以显示线程使用的 CPU 编号的工具. 我们将使用 Windows SDK 的 Windows Performance Toolkit 中的 Windows Performance Recorder (WPR).
搜索 Windows Performance Recorder (`wprui.exe`). 如果找不到, 很可能它没有安装. 再次运行 Windows 10 SDK 安装程序并添加 Windows Performance Toolkit.
在 WPR 主 UI 中, 仅选择*第一级分类*. 这会捕获 CPU, 内存, I/O 和其他事件, 我们将从中查看与 CPU 相关的事件 (图 6-24).
WPR 使用 Windows 事件跟踪 (ETW) 来捕获包括调度器在内的各种系统组件发出的各种事件.

Figure 109: WPR 主用户界面
转到 `CPUStress` 并将亲和性重置为所有处理器. 另外, 使用*进程/CPU Sets*菜单项将进程 CPU sets 设置为前 4 个处理器 (图 6-25).

Figure 110: CPUStress 中受限的 CPU sets
接下来, 使用*线程/选定的 CPU Sets…*菜单项将其中一个工作线程设置为使用其他一些 CPU (图 6-26), 其中选择了 CPU 10.

Figure 111: CPUStress 中为线程选择的 CPU sets
确保 `CPUStress` 中的两个线程都处于活动状态. 现在回到 WPR 并单击*开始*按钮. 等待 2 或 3 秒然后单击*停止*. 等待处理完成, 完成后, 用*在 WPA 中打开*按钮在 Windows Performance Analyzer (WPA) 中打开跟踪.
Windows Performance Analyzer (WPA) 是用于 ETW 捕获的分析工具. 它相当复杂和多功能, 以下信息仅触及这个强大工具的表面. WPA 超出了本书的范围.
当跟踪打开时, 在左侧窗格中导航到*计算 / CPU 使用率 (精确) / 按进程, 线程, 活动的 CPU 利用率*. 你应该会看到类似图 6-27 的东西.

Figure 112: WPA 的典型 UI
ETW 跟踪总是系统范围的, 所以我们首先需要过滤到我们感兴趣的进程——`CPUStress`. 展开左上角的未命名*系列*树节点并找到 `CPUStress`. 右键单击它并选择*过滤到选择*. 视图应该会清除, 只留下 `CPUStress` 信息. 展开进程节点, 显示线程节点 (图 6-28).

Figure 113: WPA 过滤到 CPUStress 进程
如果你展开一个没有更改其选定 CPU sets 的线程, 你应该会看到 CPU 编号 0 到 3 (为进程 CPU set 设置的前四个处理器) (图 6-29). 另一方面, 展开具有自己选定 CPU set 的线程应该只显示该 CPU 被利用 (图 6-30).

Figure 114: 没有分配 CPU sets 的线程

Figure 115: 分配了 CPU set 到 CPU 10 的线程
有些进程自然比其他进程更重要. 例如, 如果一个用户使用 Microsoft Word, 她可能希望她与 Word 的交互和使用体验非常好. 另一方面, 像备份应用程序, 反病毒扫描程序, 搜索索引器等进程则不那么重要, 不应干扰用户的主要应用程序.
这些后台应用程序限制其影响的一种方法是降低其 CPU 优先级. 这是可行的, 但 CPU 只是进程使用的资源类型之一. 其他资源包括内存和 I/O. 这意味着降低线程的 CPU 优先级或进程的优先级类可能不足以减少此类进程的影响.
Windows 提供了*后台模式*的概念, 其中线程的 CPU 优先级降至 4, 内存优先级和 I/O 优先级也下降. 例如, 在 Process Explorer 的*线程*视图中查看 Windows 资源管理器, 会显示内存和 I/O 优先级以及 CPU 优先级 (图 6-31). I/O 优先级的默认值为“正常”, 内存优先级的默认值为 5 (可能的值为 0 到 7).

Figure 116: Process Explorer 中的内存和 I/O 优先级
内存优先级和 I/O 优先级的确切定义对于本次讨论并不重要. 我们将在后面的章节中讨论内存优先级. 对于 I/O 优先级——直观地——更高级别在访问 I/O 时优先于较低级别.
作为一个相反的例子, 检查图 6-32, 显示 `SerachFilterHost.exe` 进程的线程. 注意其内存和 I/O 优先级.

Figure 117: Process Explorer 中的低内存和 I/O 优先级
这个 `SearchProtocolHost.exe` 进程通过一次调用 `SetPriorityClass` 并使用特殊的 `PROCESSMODEBACKGROUNDBEGIN` 值来降低其 I/O 和内存优先级以及其 CPU 优先级, 像这样:
::SetPriorityClass(::GetCurrentProcess(), PROCESS_MODE_BACKGROUND_BEGIN);
到进程的句柄必须指向当前进程, 否则调用会失败. 后台模式对进程中的所有线程开始, 直到用 `PROCESSMODEBACKGROUNDEND` 进行补充调用:
::SetPriorityClass(::GetCurrentProcess(), PROCESS_MODE_BACKGROUND_END);
类似地, 可以在线程基础上用标准的 `SetThreadPriority` 和特殊值 `THREADMODEBACKGROUNDBEGIN` 和 `THREADMODEBACKGROUNDEND` 来进行调用. 这里, 线程句柄也必须引用当前线程才能使调用成功.
上述调用需要当前进程/线程的事实意味着一个线程或进程不能被“强制”进入后台模式; 相反, 线程或进程本身应该是一个“好公民”并自愿进入后台模式.
Process Explorer 确实允许强制一个进程进入后台模式. 右键单击一个进程并选择*设置优先级/后台*.
正如我们在“调度基础”部分看到的, 优先级是调度方面的决定性因素. 然而, Windows 采用了几种对优先级的调整, 称为*优先级提升*. 这些优先级的临时增加旨在使调度在某种意义上更“公平”, 或为用户提供更好的体验. 在本节中, 我将讨论一些常见的优先级提升原因. 无论如何, 不要依赖这些提升, 因为它们可能会在未来的 Windows 版本中被移除, 并且可能会出现新的提升.
记住, 实时范围 (优先级 16 到 31) 内的线程的优先级永远不会被提升.
- 完成 I/O 操作
当一个线程发出一个同步 I/O 操作时, 它会进入一个等待状态, 直到操作完成. 一旦完成, 负责 I/O 操作的设备驱动程序有机会提升请求线程的优先级, 以增加它在操作最终完成后更快运行的机会. 优先级提升 (如果应用) 会根据驱动程序的判断增加线程的优先级, 并且优先级在线程设法运行的每个量子后降低一级, 直到优先级降回其基本级别. 图 6-33 显示了此过程的概念视图.

Figure 118: 线程优先级提升和衰减
- 前台进程
系统上总有一个活动窗口——通常是标题颜色不同的那个. 这个窗口是由一个线程创建的, 该线程是进程的一部分. 这个进程有时被称为*前台进程*. 在一个配置为短量子 (Windows 客户端版本的默认设置) 的系统上的前台进程中: 当一个线程完成对内核对象的等待时, 它的优先级会得到 +2 的提升. 这个优先级在一个量子后衰减到其基本级别.
- GUI 线程唤醒
当一个具有用户界面的线程收到一个窗口消息时 (通常是其对 `GetMessage` 的调用返回), 它会得到一个 +2 的提升, 以提高其更快运行的机会. 这个优先级在一个量子后衰减到其基本级别.
- 饥饿避免
处于就绪状态至少 4 秒的线程, 会获得一个大的优先级提升到 15, 以进行单个量子的执行, 之后优先级降回其原始级别. 这允许低优先级的线程即使在相对繁忙的系统上也能取得一些进展.
1.7.8. 调度的其他方面
本节介绍尚未讨论的调度的其他方面.
- 挂起和恢复
一个线程可以在挂起状态下创建, 通过在 `CreateThread` 中指定 `CREATESUSPENDED` 标志. 这允许调用者在实际执行有用的代码之前准备线程以供执行, 例如操作其优先级或亲和性. 使用此标志创建的线程的挂起计数为 1. 更一般地, 一个线程可以被 `SuspendThread` 调用挂起:
DWORD WINAPI SuspendThread(_In_ HANDLE hThread);
线程句柄必须具有 `THREADSUSPENDRESUME` 访问掩码才能使调用成功. 该函数递增线程的挂起计数, 并挂起其执行. 该函数返回线程先前的挂起计数, 如果失败则返回 `(DWORD)-1`. 线程可以拥有的最大挂起计数定义为 `MAXIMUMSUSPENDCOUNT` (定义为 127). 一个线程可以挂起自己, 但不能恢复自己.
一旦挂起, 线程可以用 `ResumeThread` 恢复:
DWORD WINAPI ResumeThread(_In_ HANDLE hThread);
`ResumeThread` 递减线程的挂起计数, 如果为零, 它就变得有资格执行. 如果一个线程是用 `CREATESUSPENDED` 创建的, 则需要此函数.
通常, 挂起一个线程是个坏主意, 因为无法知道挂起发生的确切位置. 例如, 线程可能已经获取了一个其他线程正在等待的锁. 在它释放锁之前挂起这样的线程会导致死锁, 因为争夺该锁的其他线程将无限期地等待.
线程同步和锁将在下一章中讨论.
- 挂起和恢复进程
进程不被调度, 线程才被调度. 然而, 有时可能希望一次性挂起一个进程中的所有线程. 例如, UWP 进程在应用程序进入后台时, 其所有线程都会被挂起, 就使用了这种功能. Windows API 没有提供这个功能. 技术上可以遍历一个进程中的所有线程并调用 `SuspendThread`, 但这充其量是冒险的. 在迭代过程中可能会启动一个新线程, 这很可能会错过那个线程.
UWP 进程挂起建立在一个未文档化的作业对象特性上, 称为*深度冻结 (Deep Freeze)*.
然而, native API 确实提供了 (未文档化的) `NtSuspendProcess` 函数, 定义如下:
NTSTATUS NtSuspendProcess(_In_ HANDLE hProcess);
尽管未文档化, 但它已经存在很长时间了, 所以使用起来相当安全. 如果你使用它, 不要忘记在函数定义中添加 `extern "C"`, 以便链接器知道它是一个 C 函数. 另外, 将 `NtDll` 导入库添加到项目的链接器输入库中, 或者在源代码中像这样:
#pragma comment(lib, "ntdll")
反函数也存在, 恰当地命名为 `NtResumeProcess`:
NTSTATUS NtResumeProcess(_In_ HANDLE hProcess);
Process Explorer 提供了一个右键单击操作来挂起/恢复一个进程. 它在内部使用上述函数.
- 休眠和让步
一个线程可以通过进入休眠来自愿放弃其量子的剩余部分:
void Sleep(_In_ DWORD dwMilliseconds);
线程进入等待状态, 大约持续请求的毫秒数. 零值是有效的, 导致调度器执行队列中具有相同优先级的下一个线程. 如果没有, 线程继续执行. 另一个合法的值是 `INFINITE`, 这会导致线程永远休眠; 这几乎没用.
休眠间隔的准确性实际上取决于内部计时器分辨率是否已更改. 通常它应该与用于调度的时钟周期相同, 但通常会小得多, 因为其他一些线程请求了它. `clockres.exe` Sysinternals 实用程序的输出显示了当前的计时器间隔, 这会影响 (除其他外) 休眠时间的准确性.
作为调用 `Sleep(0)` 的替代方案, 线程可以调用 `SwitchToThread`:
BOOL SwitchToThread(void);
`SwitchToThread` 告诉调度器调度下一个就绪的线程, 即使其优先级低于当前线程. 如果调度器能够遵守, 函数返回 `TRUE`; 否则, 线程继续执行, 函数返回 `FALSE`.
1.7.9. 总结
在本章中, 我们探讨了调度的各个方面. 从优先级以及如何设置它们, 到简单的单 CPU 调度, 再到多处理器考虑, 以及亲和性和 CPU sets. 在下一章中, 我们将探讨线程同步, 其中线程必须协调它们的努力以及它们可以做的各种方式.
1.8. 第 7 章: 线程同步 (进程内)
在理想的线程世界中, 线程会各司其职, 互不干扰. 但在现实中, 线程有时必须相互同步. 典型的例子是访问共享数据结构, 比如动态数组. 如果一个线程试图向数组中插入一个项目, 任何其他线程都不应该操作同一个数组, 甚至不应该读取它. 可能是线程在不同的时间这样做, 但由于这一切都与时序有关, 它们可能会在同一时间这样做. 这将导致数据损坏或某些异常. 为了缓解这种情况, 线程有时需要同步它们的工作.
Windows 提供了一套丰富的原语来帮助实现这种 (以及其他) 同步. 在本章中, 我们将研究通过 Windows API 提供给用户模式开发人员的同步机制, 用于在单个进程内同步线程. 在下一章中, 我们将探讨更多可用于同步在不同进程中运行的线程的同步原语.
本章内容:
- 同步基础
- 原子操作
- 临界区
- 锁和 RAII
- 死锁
- MD5 计算器应用程序
- 读写锁
- 条件变量
- 等待地址
- 同步屏障
- C++ 标准库呢?
1.8.1. 同步基础
经典的同步是关于避免*数据竞争 (data race)*. 当两个或多个线程访问相同的内存位置, 并且至少其中一个线程正在写入该位置时, 就会发生数据竞争. 从同一位置并发读取从来不是问题. 但一旦写入介入, 一切都变得不确定. 数据可能会损坏, 读取可能会被撕裂 (一些数据在更改前被读取, 一些在更改后被读取). 这就是需要同步的地方.
在第 5 章中, 我们看到了一个并行化素数计算的示例应用程序. 那个特定的算法 (分叉/连接) 不需要任何同步, 除了等待所有线程完成. 这是理想的, 因为可以通过向问题投入更多的 CPU 来提高性能 (至少在一定程度上). 需要同步并不好玩, 因为它根据定义会降低性能, 因为一些操作必须顺序执行而不是并发执行. 事实上, 通过向问题添加更多线程/CPU 可以获得的加速取决于可以并行化的代码的百分比. 这被 Amdahl 定律很好地描述了:
\[ \text{Speedup Limit} = \frac{1}{1-p} \]
关于 Amdahl 定律的更详尽的讨论可以在维基百科上找到: https://en.wikipedia.org/wiki/Amdahl%27s_law
其中 p 是可以并行化的代码的百分比. 例如, 如果 80% 的代码可以并行化, 那么可能的最大加速是 5, 无论投入多少处理器.
大多数与同步相关的操作都需要线程等待某个条件, 直到可以安全地继续, 从而防止数据竞争. 在以下部分中, 我们将探讨 Windows API 提供的各种同步选项, 从最简单的到更复杂的.
1.8.2. 原子操作
一些看起来如此简单和快速的操作实际上并不是线程安全的. 即使是一个简单的 C 变量增量 (`x++`) 也不是线程或多处理器安全的. 例如, 考虑两个在两个处理器上并发运行的线程, 它们对同一个内存位置执行增量操作 (图 7-1).

Figure 119: 多个线程的简单增量
即使是一个简单的增量也涉及读取和写入. 在图 7-1 中, 每个线程都可能将初始值 (0) 读入 CPU 寄存器. 每个线程递增其处理器的寄存器, 然后写回结果. 最终写入 X 的结果是 1 而不是 2. 这个图是一个粗略的简化, 因为还有其他因素在起作用, 比如 CPU 缓存. 但即使忽略这一点, 这也显然是一个数据竞争. 事实上, 其中一个线程 (比如 T2) 可能会被抢占 (例如在 R 递增之后), 而当 T1 继续递增 X 时, 一旦 T2 获得 CPU 时间, 它就会将 1 写回 X, 从而有效地扼杀了线程 T1 所做的所有增量.
- 简单增量应用程序
图 7-2 所示的*简单增量*应用程序使用多个线程来做一件事: 递增单个内存位置. 该程序允许选择要并发运行的线程数以及每个线程应执行的增量数. 一旦单击*运行*按钮, 操作就开始了. 完成后, 会显示实际结果和预期结果, 以及执行所需的时间.

Figure 120: 简单增量应用程序
*同步*组合框允许选择如何同步增量. 第一个 (也是默认的) 选项 (“None”) 只是在共享内存位置上使用 `++` 操作符——完全没有同步. 单击*运行*并使用默认选项会显示类似图 7-3 的内容.

Figure 121: 无同步的简单增量应用程序
请注意, 最终结果与预期结果相差甚远. 这是因为缺乏同步, 导致增量“丢失”. 你可以再次单击*运行*, 会得到一个不同的结果. 这就是同步问题的本质. 以下是负责使用简单的 `++` 操作进行多线程增量的代码片段 (在 `MainDlg.cpp` 中):
void CMainDlg::DoSimpleCount() { auto handles = std::make_unique<HANDLE[]>(m_Threads); for (int i = 0; i < m_Threads; i++) { handles[i] = ::CreateThread(nullptr, 0, [](auto param) { return ((CMainDlg*)param)->IncSimpleThread(); }, this, 0, nullptr); } ::WaitForMultipleObjects(m_Threads, handles.get(), TRUE, INFINITE); for (int i = 0; i < m_Threads; i++) ::CloseHandle(handles[i]); } DWORD CMainDlg::IncSimpleThread() { for (int i = 0; i < m_Loops; i++) m_Count++; return 0; }
正如我们在第 5 章中看到的, 将信息传递给线程是通过 `CreateThread` 的 `PVOID` 参数完成的. 然而, 在许多情况下, 让线程函数成为实例函数而不是静态或全局函数更方便. 一个有用的技巧是将 `this` 作为参数传递, 并用它来调用实例函数, 在那里整个对象状态都是可用的. 这允许 `IncSimpleThread` 函数成为一个实例函数, 而不是静态函数.
你可能想知道为什么不直接捕获 `this` 指针并直接使用数据成员? 不幸的是, API 函数只能使用非捕获的 lambda 函数. 这就是为什么这个技巧是必要的.
在上面的代码中, `mThreads` 是线程数, `mLoops` 是要做的迭代次数, `mCount` 是被递增的共享内存位置.
这显然是一个人为的例子, 其中在同一个内存位置上执行了数百万次增量, 从而轻易地暴露了 bug. 在实际的应用程序中, 这些增量要少得多, 这意味着任何同步 bug 都更不可能发生, 事实上可能会被开发人员和 QA 错过, 只在客户的机器上被发现.
- Interlocked 系列函数
上述同步问题的解决方案是以*原子操作*的方式执行增量, 以便任何增量都与其他增量以及使用其他 `Interlocked` 函数对同一内存位置的任何其他访问隔离. 这个原子操作和其他类似的操作在 Windows API 中通过一组带有 `Interlocked` 前缀的函数暴露出来. 在简单的增量情况下, 那就是 `InterlockedIncrement`:
unsigned InterlockedIncrement(unsigned volatile *Addend);
这会执行一个原子增量, 并作为一个好处, 除了实际更改内存位置外, 还返回新值. 在幕后, 这不是一个真正的函数, 而是一个编译器内在函数, 它向 CPU 发出一条特殊指令来原子地执行此操作. 这很好, 因为利用硬件总是比软件更快. 另外, 由于没有使用显式的“锁”对象, 因此不可能发生死锁.
回到*简单增量*应用程序, 组合框中的第二个同步方法将增量方法设置为 `InterlockedIncrement`, 在 `InterlockedThread` 函数中使用:
DWORD CMainDlg::IncInterlockedThread() { for (int i = 0; i < m_Loops; i++) ::InterlockedIncrement((unsigned*)&m_Count); return 0; }
图 7-4 显示了在同步组合框中选择 `Interlocked` 选项的示例运行.

Figure 122: 使用 Interlocked 同步的简单增量应用程序
同类的其他简单函数包括 `InterlockedDecrement`, `InterlockedAdd`, `InterlockedExchange`, `InterlockedAnd`, `InterlockedOr`, `InterlckedXor`, `InterlockedExchangePointer`, `InterlockedCompareExchange` 等等. 它们也存在于 64 位和 16 位值, 分别在函数名后加上后缀 64 和 16 (例如 `InterlockedInrement64`).
还有扩展函数, 例如 `InterlockedAndAcquire`, `InterlockedAndRelease` 和 `InterlockedAndNoFence` (以及其他操作的类似函数). 这些专门的版本还指定了内存位置上的 acquire/release 语义. 讨论这些变体超出了本书的范围, 你应该使用“标准”函数, 这是最安全的, 除非你知道你在做什么. 有关 fences 和 acquire/release 语义的更多信息可以在网上找到. 最好的之一是 Herb Sutter 的演讲“Atomic<> Weapons”¹ . 你也可以 (或者) 观看我 (有所删节) 的会议“Concurrency and the C++ Memory Model”².
`InterlockedCompareExchange` 函数主要用于无锁编程, 这是一种使用 CPU 内在函数来避免在软件中使用任何锁的范式. 这个主题超出了本书的范围, 因为它不是特定于 Windows 的. 然而, Windows API 提供了一个无锁的单向链表实现. 这些函数使用 `SLISTHEADER` 联合作为链表头, `SLISTENTRY` 结构作为可以原子地添加/删除到列表中的条目.
两种类型都在 SDK 头文件中完全定义, 但只有 `SLISTENTRY` 应该对我们有些许兴趣:
typedef struct DECLSPEC_ALIGN(16) _SLIST_ENTRY { struct _SLIST_ENTRY *Next; } SLIST_ENTRY, *PSLIST_ENTRY;
`SLISTENTRY` 和 `SLISTHEADER` 必须在 16 字节边界上对齐, 这是通过用 `_declspec(align(16))` VC++ 编译器属性修饰类型来指示的. 这些类型的基于栈或静态的分配将正常工作, 但通常你需要动态分配 `SLISTENTRY`. C 运行时提供了 `alignedmalloc` 函数, 它保证了内存分配的指定对齐.
显然, 这是一个经典的单链表条目. 但实际数据在哪里? 期望是你的数据项本身包含 `SLISTENTRY` 作为第一个条目. 这确保了 `SLISTENTRY` 的对齐要求得到满足. 以下示例显示了适合存储在所述链表中的数据项类型:
struct MyDataItem { SLIST_ENTRY Entry; int MyValue; //... };
由于列表上的操作必须是无锁的, 并且列表是单向链接的, 它实际上实现了一个栈. 没有线程安全的方法可以在列表的尾部添加项目. 这就是为什么列表上的主要操作使用“Push”和“Pop”这两个名称的原因——这些术语用在基于栈的数据结构中.
表 7-1 列出了可用于无锁单向链表操作的函数.
函数 描述 `InitializeSListHead` 将列表的头初始化为空列表. `InterlockedPushEntrySList` 在列表的前面插入一个项目. `InterlockedPopEntrySList` 从列表的前面移除项目. `InterlockedPushListSListEx` 在列表的前面插入多个项目. `InterlockedFlushSList` 从列表中移除所有项目, 返回前面的项目 (如果有的话). `QueryDepthSList` 返回列表中的项目数. 此函数不是线程安全的, 最好避免使用. 最好自己跟踪项目数 (使用 `InterlockedIncrement` / `InterlockedDecrement`). - 临界区
`Interlocked` 系列函数对于像整数增量这样的简单情况非常有用. 然而, 对于其他操作, 需要一个更通用的机制. *临界区*是一种经典的同步机制, 基于最多一个线程获取一个锁. 一旦一个线程获取了一个特定的锁, 任何其他线程都不能获取同一个锁, 直到最初获取它的线程释放它. 只有那时, 等待的线程中的一个 (且只有一个) 才能获取锁. 这意味着在任何给定的时刻, 最多只有一个线程获取了锁. 这个想法如图 7-5 所示.

Figure 123: 使用临界区进行同步
获取了锁的线程也是它的*所有者*, 这意味着两件事:
- 所有者线程是唯一可以释放临界区的线程.
- 如果所有者线程试图第二次 (递归地) 获取临界区, 它会自动成功, 并增加一个内部计数器. 这意味着所有者线程现在必须释放临界区相同次数才能真正释放它.
获取和释放锁之间的代码被称为*临界区 (critical region)*.
临界区本身由 `CRITICALSECTION` 结构表示, 它本身是另一个结构 `RTLCRITICALSECTION` 的 `typedef`. 尽管该结构是完全定义的, 你应该将其视为不透明的. 初始化临界区必须使用以下函数之一:
void InitializeCriticalSection(LPCRITICAL_SECTION lpCriticalSection); BOOL InitializeCriticalSectionAndSpinCount( LPCRITICAL_SECTION lpCriticalSection, DWORD dwSpinCount); BOOL InitializeCriticalSectionEx( LPCRITICAL_SECTION lpCriticalSection, DWORD dwSpinCount, DWORD Flags);
临界区的初始化涉及将其成员设置为一些初始值. 这就是为什么第一个函数返回 `void`.
第二个和第三个变体为临界区设置一个*自旋计数*. 其思想是, 如果一个线程无法获取一个临界区, 它应该进入一个等待状态, 因为有另一个线程持有该临界区. 然而, 进入等待状态需要线程转换到内核模式, 这并不便宜. 一个折衷方案是自旋一小段时间, 因为当前临界区的所有者很可能会很快释放它, 从而可以避免转换到内核. 自旋计数的最大值是 `0x00ffffff` (剩余的十六进制数字在内部用作标志).
自旋计数应该是多少? 很难断然回答, 因为它取决于实际的处理器类型和其他硬件因素. 默认的自旋计数是 2000 (由 `InitializeCriticalSection` 使用).
如果系统只有一个处理器 (或者进程映像文件在其 PE 头中有“单 CPU”标志), 自旋计数总是设置为零. 这是有道理的, 因为另一个线程永远无法在这个线程自旋时释放临界区, 因为没有更多的处理器了.
最后一个初始化函数添加了一个 `flags` 参数. 头文件中定义了几个, 但只有一个被文档化 - `CRITICALSECTIONNODEBUGINFO` (`0x01000000`), 它指定临界区结构不应分配一个额外的调试结构, 该结构可以帮助诊断临界区问题.
当不再需要临界区时, 调用 `DeleteCriticalSection`:
void DeleteCriticalSection(LPCRITICAL_SECTION lpCriticalSection);
一旦临界区被初始化, 线程就可以使用以下函数获取和释放它:
void EnterCriticalSection(LPCRITICAL_SECTION lpCriticalSection); void LeaveCriticalSection(LPCRITICAL_SECTION lpCriticalSection);
`EnterCriticalSection` 尝试获取临界区, 并且只有在成功时才返回. 如果调用线程已经是临界区的所有者, 它会立即继续. 相反, `LeaveCriticalSection` 释放一个已经获取的临界区.
奇怪的是, 任何线程都可以调用 `LeaveCriticalSection` (不仅仅是当前的所有者线程) 并成功. 我会期望函数抛出异常 (因为它返回 `void`). 但它只是释放了临界区, 将所有者线程 ID 重置为零.
一个简单的例子显示在*简单增量*应用程序中. 如果你将同步机制选择为“临界区”并单击*运行*, 增量现在将由一个临界区保护 (图 7-6).

Figure 124: 带有临界区同步的简单增量应用程序
在*简单增量*中完成此同步的代码如下:
// m_CritSection is CRITICAL_SECTION void CMainDlg::DoCriticalSectionCount() { auto handles = std::make_unique<HANDLE[]>(m_Threads); ::InitializeCriticalSection(&m_CritSection); for (int i = 0; i < m_Threads; i++) { handles[i] = ::CreateThread(nullptr, 0, [](auto param) { return ((CMainDlg*)param)->IncCriticalSectionThread(); }, this, 0, nullptr); } ::WaitForMultipleObjects(m_Threads, handles.get(), TRUE, INFINITE); for (int i = 0; i < m_Threads; i++) ::CloseHandle(handles[i]); ::DeleteCriticalSection(&m_CritSection); } DWORD CMainDlg::IncCriticalSectionThread() { for (int i = 0; i < m_Loops; i++) { ::EnterCriticalSection(&m_CritSection); m_Count++; ::LeaveCriticalSection(&m_CritSection); } return 0; }
每次调用 `EnterCriticalSection` 都必须在同一个函数中与 `LeaveCriticalSection` 配对. 在调用 `LeaveCriticalSection` 之前从函数返回, 例如, 太危险了. 这个错误很容易犯, 即使没有这样的 bug, 它也迫使开发人员考虑它, 并确保对该函数的任何未来修改都不会破坏这对调用.
`EnterCriticalSection` 会等待临界区可用, 无论需要多长时间. 没有办法指定超时, 但有一种方法可以检查临界区, 如果它是空闲的——就获取它; 否则, 继续执行. 这正是 `TryEnterCriticalSection` 所做的:
BOOL TryEnterCriticalSection(LPCRITICAL_SECTION lpCriticalSection);
- 锁和 RAII
正如我们在前一节中看到的, `EnterCriticalSection` 和 `LeaveCriticalSection` 是天生的一对. 如果在调用 `LeaveCriticalSection` 之前从函数返回, 例如, 那将是不幸的. 这个错误很容易犯, 即使没有这样的 bug, 它也迫使开发人员考虑它, 并确保对该函数的任何未来修改都不会破坏这对调用.
如果能有代码无论如何都会自动调用 `LeaveCriticalSection`, 而代码不必担心它, 那会好得多. 有两种方法可以获得这种行为: 终止处理程序和 C++ 的*资源获取即初始化* (RAII).
终止处理程序将在后面的章节中更详细地讨论, 但以下是其要点:
CRITICAL_SECTION cs; void DoWork() { ::EnterCriticalSection(&cs); __try { // manipulate shared resource } __finally { ::LeaveCriticalSection(&cs); } }
`_try` 和 `_finally` 是两个 Microsoft 特定的关键字, 扩展了 C 语言, 目的是在离开 `_try` 块时运行 `_finally` 块中的代码, 无论如何. 即使在 `_try` 块内的 `return` 语句也会首先调用 `_finally` 块, 然后才实际从函数返回.
如果你正在使用 C (而不是 C++), 那么终止处理程序是你的最佳选择. 在使用 C++ 时, 利用构造函数和析构函数更好 (也更方便), 它们可以在对象构造和销毁时自动执行代码. (这在 C++ 中被称为 RAII 习语)
对于临界区, 一个 RAII 类可能看起来像这样:
// AutoCriticalSection.h struct AutoCriticalSection { AutoCriticalSection(CRITICAL_SECTION& cs); ~AutoCriticalSection(); // delete copy ctor, move ctor, assignment operators AutoCriticalSection(const AutoCriticalSection&) = delete; AutoCriticalSection& operator=(const AutoCriticalSection&) = delete; AutoCriticalSection(AutoCriticalSection&&) = delete; AutoCriticalSection& operator=(AutoCriticalSection&&) = delete; private: CRITICAL_SECTION& _cs; }; // AutoCriticalSection.cpp AutoCriticalSection::AutoCriticalSection(CRITICAL_SECTION& cs) : _cs(cs) { ::EnterCriticalSection(&_cs); } AutoCriticalSection::~AutoCriticalSection() { ::LeaveCriticalSection(&_cs); }
该代码是本章代码示例中 `ThreadingHelpers` 项目的一部分.
构造函数获取临界区, 析构函数释放它. 在*简单增量*应用程序中使用它可以像这样完成:
DWORD CMainDlg::IncCriticalSectionThread() { for (int i = 0; i < m_Loops; i++) { AutoCriticalSection locker(m_CritSection); m_Count++; } return 0; }
既然我们谈到了 RAII, 把临界区本身也包装在一个 RAII 类中可能是个好主意, 这样临界区的初始化和删除也是自动的. 以下是一个可能的实现:
// CriticalSection.h class CriticalSection : public CRITICAL_SECTION { public: CriticalSection(DWORD spinCount = 0, DWORD flags = 0); ~CriticalSection(); void Lock(); void Unlock(); bool TryLock(); }; // CriticalSection.cpp CriticalSection::CriticalSection(DWORD spinCount, DWORD flags) { ::InitializeCriticalSectionEx(this, (DWORD)spinCount, flags); } CriticalSection::~CriticalSection() { ::DeleteCriticalSection(this); } void CriticalSection::Lock() { ::EnterCriticalSection(this); } void CriticalSection::Unlock() { ::LeaveCriticalSection(this); } bool CriticalSection::TryLock() { return ::TryEnterCriticalSection(this); }
`Lock`, `Unlock` 和 `TryLock` 不是必需的, 但在某些情况下可能有用. 从 `CRITICALSECTION` 派生允许在需要 `CRITICALSECTION` 时传递 `CriticalSection`. 或者, 可以在结构内部嵌入一个 `CRITICALSECTION` 成员, 并带有一个可以隐式地将 `CriticalSection` 转换为 `CRITICALSECTION` 的运算符. 我将这个实现留给读者作为练习.
- 死锁
使用临界区似乎很简单. 即使我们使用各种 RAII 包装器, 仍然存在死锁的危险. 一个经典的死锁发生在线程 A 拥有锁 1 (例如一个临界区) 并等待线程 B 拥有的锁 2, 而线程 B 正在等待锁 1.
理论上避免死锁的方法很简单: 总是以相同的顺序获取锁. 这意味着每个需要多个锁的线程都应该总是以相同的顺序获取锁. 这保证了死锁不会发生 (至少不是因为这些锁). 实际问题是如何强制执行顺序; 如果不编写任何代码, 这是一个记录顺序的问题, 以便未来的代码继续遵守规则. 另一种选择是编写一个“多锁”包装器, 它总是以相同的顺序获取锁. 一个简单的方法是按锁在内存中的地址顺序获取.
编写一个这样的临界区多锁包装器.
- MD5 计算器应用程序
`MD5Calculator` 应用程序演示了临界区的使用, 比*简单增量*更有趣 (也更复杂) (我们稍后也会修改它).
该应用程序计算进程加载的映像文件 (EXE 和 DLL) 的 MD5 哈希. 由于进程通常使用许多常见的 DLL, 缓存已经计算过的哈希的结果更好. 该应用程序有几个挑战:
- 在后台进行计算时显示一个响应迅速的用户界面.
- 获取系统上任何进程加载的新映像 (DLL/EXE) 的通知.
- 管理一个包含文件及其 MD5 哈希的缓存.
图 7-7 显示了应用程序在任何活动之前的主屏幕.

Figure 125: MD5 计算器应用程序
默认情况下, 不对 MD5 哈希进行缓存. 单击绿色的*Go*按钮 (或*计算 / Go*菜单项), 开始捕获映像加载并为每个映像文件从头计算哈希, 即使加载了重复的映像 (图 7-8).

Figure 126: MD5 计算器应用程序在无缓存情况下运行
你可以启动一个新进程, 例如 Notepad, 并观察其模块加载并反映在列表视图显示的底部. 单击*停止*按钮以停止捕获映像加载. 你可以使用*编辑 / 清除*菜单项来清除显示.
现在你可以使用*计算 / 使用缓存*菜单项来切换缓存使用. 现在再次单击*Go*. 请注意, 在一些计算之后, 缓存开始变得有用, 当哈希值可以由缓存满足时, “已缓存?”列会显示更多的“是”项 (图 7-9).

Figure 127: MD5 计算器应用程序在有缓存情况下运行
让我们逐步了解应用程序最重要的部分.
- 计算 MD5 哈希
任何缓冲区的 MD5 哈希计算都可以使用 Windows 加密 API 完成. 一个名为 `MD5Calculator` 的简单类用于进行计算 (作为其自己的静态库项目 `HashCalc` 的一部分):
// MD5Calculator.h class MD5Calculator { public: static std::vector<uint8_t> Calculate(PCWSTR path); }; // MD5Calculator.cpp #include <wincrypt.h> #include "MD5Calculator.h" #include <wil\resource.h> std::vector<uint8_t> MD5Calculator::Calculate(PCWSTR path) { std::vector<uint8_t> md5; wil::unique_hfile hFile(::CreateFile(path, GENERIC_READ, FILE_SHARE_READ, nullptr, OPEN_EXISTING, FILE_FLAG_SEQUENTIAL_SCAN, nullptr)); if (!hFile) return md5; wil::unique_handle hMemMap(::CreateFileMapping(hFile.get(), nullptr, PAGE_READONLY, 0, 0, nullptr)); if (!hMemMap) return md5; wil::unique_hcryptprov hProvider; if (!::CryptAcquireContext(hProvider.addressof(), nullptr, nullptr, PROV_RSA_FULL, CRYPT_VERIFYCONTEXT)) return md5; wil::unique_hcrypthash hHash; if(!::CryptCreateHash(hProvider.get(), CALG_MD5, 0, 0, hHash.addressof())) return md5; wil::unique_mapview_ptr<BYTE> buffer((BYTE*)::MapViewOfFile(hMemMap.get(), FILE_MAP_READ, 0, 0, 0)); if (!buffer) return md5; auto size = ::GetFileSize(hFile.get(), nullptr); if (!::CryptHashData(hHash.get(), buffer.get(), size, 0)) return md5; DWORD hashSize; DWORD len = sizeof(DWORD); if (!::CryptGetHashParam(hHash.get(), HP_HASHSIZE, (BYTE*)&hashSize, &len, 0)) return md5; md5.resize(len = hashSize); ::CryptGetHashParam(hHash.get(), HP_HASHVAL, md5.data(), &len, 0); return md5; }
加密 API 的详细描述超出了本书的范围. 然而, 计算哈希的过程相当直接. 在调用实际的哈希函数 `CryptHashData` 之前, 有一些准备步骤. 这个函数接受一个表示哈希算法的句柄, 要哈希的缓冲区和要哈希的缓冲区的大小.
以下是 `MD5Calculator::Calculate` 按顺序执行的步骤:
- 用 `CreateFile` 打开所讨论的文件 (在第 11 章中详细讨论). 文件以读访问权限打开, 并带有可选的 `FILEFLAGSEQUENTIALSCAN` 标志, 这是对文件系统的一个提示, 表明读取将是顺序的.
- 文件的内容必须放在一个内存缓冲区中才能被哈希函数使用. 一种方法是分配一个与文件大小相同的缓冲区, 并使用 `ReadFile` 将其内容读入缓冲区. 一种更好的方法是使用内存映射文件 (在第 14 章中讨论), 它可以将文件的内容映射到内存 (见下文第 5 项), 而无需分配或读取任何东西. `CreateFileMapping` 函数用于基于文件句柄 (第一个参数) 创建文件映射对象.
- 调用 `CryptAcquireContext` 以获取基于提供者 (`PROVRSAFULL` 在我们的例子中) 的加密提供程序句柄.
- 对 `CryptCreateHash` 的调用返回一个到特定哈希算法 (`CALGMD5` for MD5) 的句柄.
- 调用 `MapViewOfFile` 将文件内容映射到内存, 返回一个指针. 这被 `WIL uniquemapviewptr<>` 包装, 当变量超出作用域时会调用 `UnmapViewOfFile`.
- 现在一切准备就绪, 可以调用 `CryptHashData` 来计算哈希了.
- 剩下要做的就是检索哈希大小和哈希数据本身. 两者都是通过调用 `CryptGetHashParam` 完成的: 第一个用 `HPHASHSIZE` 获取哈希大小 (对于 MD5 总是 16 字节, 但代码保持通用).
- 结果的缓冲区是通过在字节向量上调用 `resize` 来分配的. 然后第二次调用 `CryptGetHashParam`, 并使用 `HPHASHVAL` 来获取实际的哈希.
- 哈希缓存
缓存本身封装在 `HashCache` 类中, 定义如下:
using Hash = std::vector<uint8_t>; class HashCache { public: HashCache(); bool Add(PCWSTR path, const Hash& hash); const Hash Get(PCWSTR path) const; bool Remove(PCWSTR path); void Clear(); private: mutable CriticalSection _lock; std::unordered_map<std::wstring, Hash> _cache; };
缓存是用 C++ 标准库中的 `unorderedmap<>` 对象管理的, 它将文件路径映射到其哈希. 哈希本身存储为字节向量, 尽管对于 MD5 我本可以使用一个 16 字节的数组. 由于缓存可能会被多个线程访问, `unorderedmap<>` 必须受保护以防止并发访问. 在这里我使用了一个临界区. 实现相当直接, 用临界区保护每个操作:
HashCache::HashCache() { _cache.reserve(512); } bool HashCache::Add(PCWSTR path, const Hash& hash) { AutoCriticalSection locker(_lock); auto it = _cache.find(path); if (it == _cache.end()) { _cache.insert({ path, hash }); return true; } return false; } const Hash HashCache::Get(PCWSTR path) const { AutoCriticalSection locker(_lock); auto it = _cache.find(path); return it == _cache.end() ? Hash() : it->second; } bool HashCache::Remove(PCWSTR path) { AutoCriticalSection locker(_lock); auto it = _cache.find(path); if (it != _cache.end()) { _cache.erase(it); return true; } return false; } void HashCache::Clear() { AutoCriticalSection locker(_lock); _cache.clear(); }
代码使用前面定义的 RAII `AutoCriticalSection` 类来获取和释放, 无需终止处理程序 (`_try` / `_finally`).
主视图类 (`CView`) 持有一个名为 `mCache` 的 `HashCache` 实例, 如果启用了缓存使用 (`mUseCache` 成员), 则使用它.
- 镜像加载通知
谜题的下一个相对独立的部分是获取有关映像加载的通知. 从用户模式获取这些通知的一种强大方法是利用*Windows 事件跟踪 (ETW)*. ETW 是自 Windows 2000 以来就存在的一种机制, 它允许系统组件和其他应用程序生成丰富的事件, 这些事件可以实时使用或记录到文件中并稍后分析. 一个基本的 ETW 架构如图 7-10 所示.

Figure 128: ETW 架构
ETW 的主要部分如下:
- *提供程序*生成事件.
- *会话*封装一个或多个提供程序以及一些配置. 当会话开始时捕获事件, 直到停止.
- *控制器*启用或禁用提供程序, 并启动和停止会话.
- *消费者*实时或向文件 (ETL - 事件跟踪日志) 消费事件. 在典型情况下, 控制器也是消费者.
ETW 的完整处理超出了本书的范围.
在我们的例子中, 我们需要使用可以发送一堆事件的内核提供程序, 其中之一是映像加载. `TraceManager` 类封装了与 ETW 基础设施的工作. 它的定义如下:
class TraceManager final { public: ~TraceManager(); bool Start(std::function<void(PEVENT_RECORD)> callback); bool Stop(); private: void OnEventRecord(PEVENT_RECORD rec); DWORD Run(); private: TRACEHANDLE _handle{ 0 }; TRACEHANDLE _hTrace{ 0 }; EVENT_TRACE_PROPERTIES* _properties; std::unique_ptr<BYTE[]> _propertiesBuffer; EVENT_TRACE_LOGFILE _traceLog = { 0 }; wil::unique_handle _hProcessThread; std::function<void(PEVENT_RECORD)> _callback; };
由 `TraceManager` 暴露的接口相当简单. 一旦构造, 通过调用 `Start` 启动会话, 并通过调用 `Stop` 停止. 私有 `Run` 方法是启动会话在其自己的线程中运行的方法 (稍后会详细介绍). `OnEventRecord` 函数是为每个生成的事件调用的回调. 各种私有数据成员主要与构建和管理 ETW 会话有关. 让我们看一下实现.
析构函数只调用 `Stop`:
TraceManager::~TraceManager() { Stop(); }
`Start` 是一个庞大的函数, 它适当地设置 ETW 会话, 然后启动处理. 它接受来自感兴趣的消费者的回调, 以便为每个事件调用. 它的第一个主要任务是调用 `StartTrace`, 它配置并启动一个会话:
bool TraceManager::Start(std::function<void(PEVENT_RECORD)> cb) { _callback = cb; if (_handle || _hTrace) return true; auto size = sizeof(EVENT_TRACE_PROPERTIES) + sizeof(KERNEL_LOGGER_NAME); _propertiesBuffer = std::make_unique<BYTE[]>(size); ::memset(_propertiesBuffer.get(), 0, size); _properties = reinterpret_cast<EVENT_TRACE_PROPERTIES*>(_propertiesBuffer.get()); _properties->EnableFlags = EVENT_TRACE_FLAG_IMAGE_LOAD; _properties->Wnode.BufferSize = (ULONG)size; _properties->Wnode.Guid = SystemTraceControlGuid; _properties->Wnode.Flags = WNODE_FLAG_TRACED_GUID; _properties->Wnode.ClientContext = 1; _properties->LogFileMode = EVENT_TRACE_REAL_TIME_MODE; _properties->LoggerNameOffset = sizeof(EVENT_TRACE_PROPERTIES); auto error = ::StartTrace(&_handle, KERNEL_LOGGER_NAME, _properties); if (error != ERROR_SUCCESS && error != ERROR_ALREADY_EXISTS) return false; }
首先, 它检查一个会话是否已在进行中, 如果是, 它就简单地返回. 否则, 它会保存回调在一个数据成员中, 并继续准备 `EVENTTRACEPROPERTIES` 结构. 重要的部分是设置 `EnableFlags` 为 `EVENTTRACEFLAGIMAGELOAD`, 这指定了与映像相关的事件是感兴趣的, 以及 `LogFileMode` 为 `EVENTTRACEREALTIMEMODE` 来指示请求一个实时会话.
查看 `StartTrace` 的文档以获取全部细节.
ETW 会话的独特之处在于它们可以比进程存活得更久. 这意味着 `StartTrace` 可能会失败, 但如果最后一个错误是 `ERRORALREADYEXISTS`, 那么会话已经在运行, 我们可以作为消费者接入它.
接下来, 我们需要设置消费者, 通过调用 `OpenTrace`:
_traceLog.Context = this; _traceLog.LoggerName = KERNEL_LOGGER_NAME; _traceLog.ProcessTraceMode = PROCESS_TRACE_MODE_EVENT_RECORD | PROCESS_TRACE_MODE_REAL_TIME; _traceLog.EventRecordCallback = [](PEVENT_RECORD record) { ((TraceManager*)record->UserContext)->OnEventRecord(record); }; _hTrace = ::OpenTrace(&_traceLog); if (!_hTrace) return false;
每个事件的回调都在 `EVENTTRACELOGFILE` 结构 (`traceLog`) 的 `EventRecordCallback` 成员中设置. 它使用 `UserContext` 成员作为 `this` 指针 (在 `Context` 成员中更早设置) 来调用类的实例函数. 这个函数 (`OnEventRecord`) 将调用早些时候在 `Start` 中传递的回调.
消费者现在就位了, 所以需要做的最后一个操作是开始处理事件. 为此, 创建了一个单独的线程, 因为 `ProcessTrace` 函数是一个阻塞函数, 我们不希望在调用 `Start` 时阻塞调用者:
_hProcessThread.reset(::CreateThread(nullptr, 0, [](auto param) { return ((TraceManager*)param)->Run(); }, this, 0, nullptr)); return true; }
`Run` 成员函数只调用 `ProcessTrace`:
DWORD TraceManager::Run() { auto error = ::ProcessTrace(&_hTrace, 1, nullptr, nullptr); return error; }
如前所述, `OnEventRecord` 函数调用客户端的回调:
void TraceManager::OnEventRecord(PEVENT_RECORD rec) { if (_callback) _callback(rec); }
最后, `Stop` 函数关闭并停止跟踪:
bool TraceManager::Stop() { if (_hTrace) { ::CloseTrace(_hTrace); _hTrace = 0; } if (_handle) { ::StopTrace(_handle, KERNEL_LOGGER_NAME, _properties); _handle = 0; } return true; }
主框架类 (`CMainFrm`) 持有一个 `TraceManager` 实例. 当选择适当的菜单/工具栏项时, 它会调用 `Start` 和 `Stop`:
LRESULT CMainFrame::OnStartTrace(WORD, WORD, HWND, BOOL&) { m_TraceManager.Start([this](auto record) { m_view.OnEvent(record); // call the view }); // UI updates omitted... return 0; } LRESULT CMainFrame::OnStopTrace(WORD, WORD, HWND, BOOL&) { m_TraceManager.Stop(); // UI updates omitted return 0; }
- 事件解析
ETW 事件通过 `EVENTRECORD` 结构提供给事件回调, 该结构包含有关特定事件的所有内容. 以下是其定义:
typedef struct _EVENT_RECORD { EVENT_HEADER EventHeader; // Event header ETW_BUFFER_CONTEXT BufferContext; // Buffer context USHORT ExtendedDataCount;// Number of extended data items USHORT UserDataLength; // User data length PEVENT_HEADER_EXTENDED_DATA_ITEM ExtendedData; // Pointer to an array of extended data items PVOID UserData; // Pointer to user data PVOID UserContext; // Context from OpenTrace } EVENT_RECORD, *PEVENT_RECORD;
ETW 事件属性可以包括字符串 (ANSI 和 Unicode), 数字, 自定义结构以及一些其他特殊类型. 所有内容都作为 `EVENTRECORD` 的一部分存储在一个二进制大对象中, 从 `UserData` 地址开始. 要获取各种属性和值, 需要进行一些解析. `EventParser` 类是用于解析属性的帮助类. 它将每个解析的属性存储在一个 `EventProperty` 结构中, 定义如下:
struct EventProperty { EventProperty(EVENT_PROPERTY_INFO& info); std::wstring Name; BYTE* Data; ULONG Length; EVENT_PROPERTY_INFO& Info; template<typename T> T GetValue() const { static_assert(std::is_pod<T>() && !std::is_pointer<T>()); return *(T*)Data; } PCWSTR GetUnicodeString() const; PCSTR GetAnsiString() const; };
每个属性都有一个名称 (`Name` 成员), 一个指向实际数据的指针 (`Data`), 一个长度 (`Length`) 和一个对描述该属性的原始结构的引用 (`Info`). `GetValue<>` 模板函数检索简单 POD (“普通旧数据”) 类型的属性值, 例如数字类型. `staticassert` 语句指示编译器拒绝复杂类型, 因为它们会产生错误的值.
`staticassert` 是在 C++ 11 中引入的, 并在 C++ 14 中得到了增强.
`GetUnicodeString` 和 `GetAnsiString` 以其相应的字符串类型返回数据. `EventParser` 类声明如下:
class EventParser { public: EventParser(PEVENT_RECORD record); PTRACE_EVENT_INFO GetEventInfo() const; PEVENT_RECORD GetEventRecord() const; const EVENT_HEADER& GetEventHeader() const; const std::vector<EventProperty>& GetProperties() const; const EventProperty* GetProperty(PCWSTR name) const; // lookup by name DWORD GetProcessId() const; static std::wstring GetDosNameFromNtName(PCWSTR name); private: std::unique_ptr<BYTE[]> _buffer; PTRACE_EVENT_INFO _info{ nullptr }; PEVENT_RECORD _record; mutable std::vector<EventProperty> _properties; };
`EventParser` 实例接受一个 `EVENTRECORD` 作为其输入. 关于事件的所有内容都存储在那里. `EventParser` 的任务是提取所需的信息. 以下是实现, 除了 `GetDosNameFromNtName`, 我们将单独处理:
EventProperty::EventProperty(EVENT_PROPERTY_INFO& info) : Info(info) { } EventParser::EventParser(PEVENT_RECORD record) : _record(record) { ULONG size = 0; auto error = ::TdhGetEventInformation(record, 0, nullptr, _info, &size); if (error == ERROR_INSUFFICIENT_BUFFER) { _buffer = std::make_unique<BYTE[]>(size); _info = reinterpret_cast<PTRACE_EVENT_INFO>(_buffer.get()); error = ::TdhGetEventInformation(record, 0, nullptr, _info, &size); } ::SetLastError(error); } PTRACE_EVENT_INFO EventParser::GetEventInfo() const { return _info; } PEVENT_RECORD EventParser::GetEventRecord() const { return _record; } const EVENT_HEADER& EventParser::GetEventHeader() const { return _record->EventHeader; } const std::vector<EventProperty>& EventParser::GetProperties() const { if (!_properties.empty()) return _properties; _properties.reserve(_info->TopLevelPropertyCount); auto userDataLength = _record->UserDataLength; BYTE* data = (BYTE*)_record->UserData; for (ULONG i = 0; i < _info->TopLevelPropertyCount; i++) { auto& prop = _info->EventPropertyInfoArray[i]; EventProperty property(prop); property.Name.assign((WCHAR*)((BYTE*)_info + prop.NameOffset)); auto len = prop.length; property.Length = len; property.Data = data; data += len; userDataLength -= len; _properties.push_back(std::move(property)); } return _properties; } const EventProperty* EventParser::GetProperty(PCWSTR name) const { for (auto& prop : GetProperties()) if (prop.Name == name) return ∝ return nullptr; } DWORD EventParser::GetProcessId() const { return _record->EventHeader.ProcessId; } PCWSTR EventProperty::GetUnicodeString() const { return (PCWSTR)Data; } PCSTR EventProperty::GetAnsiString() const { return (PCSTR)Data; }
构造函数调用 `TdhGetEventInformation` 来获取基本的事件详细信息和一组属性, 所有这些都来自 `EVENTRECORD`. 该调用被调用两次: 第一次长度为零以获取所需的长度, 然后, 在分配所需的缓冲区后, 进行第二次调用以检索实际数据.
Tdh 函数需要头文件 `<tdh.h>` 并链接 `tdh.lib`. 如前所述, 对这些函数的详细讨论超出了本书的范围.
`GetProperties` 做了遍历事件中每个属性的艰苦工作, 提取重要信息并将其封装在一个 `EventProperty` 实例中. `GetProperty` 辅助函数返回一个给定其名称的属性 (如果有的话).
- 整合所有部分
现在我们有了所有的单个部分, 我们可以开始将它们集成到一个实际的应用程序中. 主视图类 (`CView`) 保存了实际显示的数据项. 这些以 `EventData` 结构的形式出现, 定义如下 (在 `view.h` 中):
struct EventData { CString FileName; ULONGLONG Time; DWORD ProcessId; Hash MD5Hash; DWORD CalculatingThreadId; DWORD CalculationTime; bool Cached : 1; bool CalcDone : 1; };
视图存储了这些项目的一个向量, 一个用于保护向量访问的临界区, 缓存本身, 以及是否应该使用它:
class CView... { //... private: std::vector<EventData> m_Events; HashCache m_Cache; CriticalSection m_EventsLock; bool m_UseCache{ false }; };
当一个事件进来时, 会调用回调 `OnEvent`. 回调需要获取事件的详细信息, 将它们存储在一个新的 `EventData` 对象中, 然后继续计算 MD5 哈希 (或使用缓存的结果). 首先, 它过滤掉不想要的事件:
void CView::OnEvent(PEVENT_RECORD record) { EventParser parser(record); // ID 10 is a load image event if (parser.GetEventHeader().EventDescriptor.Opcode != 10) return; }
请记住, ETW 跟踪只启用映像加载类型的事件. 事实证明, 实际上可能会发送四种事件. 只有其中一个 (操作码为 10) 是映像加载. 有关完整详细信息, 请参阅此参考资料³. 以下是映像加载事件集的结构:
[EventType(10, 2, 3, 4), EventTypeName("Load", "Unload", "DCStart", "DCEnd")] class Image_Load : Image { uint32 ImageBase; uint32 ImageSize; uint32 ProcessId; uint32 ImageCheckSum; uint32 TimeDateStamp; uint32 Reserved0; uint32 DefaultBase; uint32 Reserved1; uint32 Reserved2; uint32 Reserved3; uint32 Reserved4; string FileName; };上述格式被称为简化的 MOF (Managed Object Format). 它与 ETW 和 Windows Management Instrumentation (WMI) 一起使用.
³https://docs.microsoft.com/en-us/windows/win32/etw/image-load
一旦接收到正确的事件 (`Opcode=10`), 就会检索有趣的属性 (`FileName`) 并用于填充一个新的 `EventData` 实例, 在通过向视图发布自定义消息来启动 MD5 哈希的计算之前:
auto fileName = parser.GetProperty(L"FileName"); if (fileName) { EventData data; data.FileName = parser.GetDosNameFromNtName( fileName->GetUnicodeString()).c_str(); data.ProcessId = parser.GetProcessId(); data.Time = parser.GetEventHeader().TimeStamp.QuadPart; data.CalcDone = false; size_t size; { AutoCriticalSection locker(m_EventsLock); m_Events.push_back(std::move(data)); size = m_Events.size(); } int index = static_cast<int>(size - 1); // initiate work from the UI thread PostMessage(WM_START_CALC, index, size); } }
有几点值得注意:
- 保护视图数据的临界区被持有的时间尽可能短. 这是通过使用一个人工块来实现的, 以便一旦块退出, 临界区就可以被释放.
- 计算的启动不是在此函数中完成的, 因为它是由 `TraceManager` 的线程调用的, 该线程应尽快被释放以处理下一个事件. 相反, 调用 `PostMessage` 会导致一个消息被异步发送到窗口, 由 UI 线程处理, 从而允许当前函数返回.
上述代码的最后一个有趣的细节是使用 `GetDosNameFromNtName`. ETW 事件提供的文件名是“设备格式”的, 这是 NT 的本地格式, 看起来像这样: “`Device\HarddiskVolume3\SomeDirectory\SomeFile.dll`”. 内部设备名称具有此格式的原因将在第 11 章中讨论. 现在, 这种路径应该被翻译成像“`c:\SomeDirectory\SomeFile.dll`”这样的东西, 以便哈希计算中使用的 `CreateFile` API 可以使用. 静态 `EventParser::GetDosNameFromNtName` 用于翻译回 Win32 设备名称:
std::wstring EventParser::GetDosNameFromNtName(PCWSTR name) { static std::vector<std::pair<std::wstring, std::wstring>> deviceNames; static bool first = true; if (first) { auto drives = ::GetLogicalDrives(); int drive = 0; while (drives) { if (drives & 1) { // drive exists WCHAR driveName[] = L"X:"; driveName = (WCHAR)(drive + 'A'); WCHAR path[MAX_PATH]; if (::QueryDosDevice(driveName, path, MAX_PATH)) { deviceNames.push_back({ path, driveName }); } } drive++; drives >>= 1; } first = false; } for (auto& [ntName, dosName] : deviceNames) { if (::_wcsnicmp(name, ntName.c_str(), ntName.size()) == 0) return dosName + (name + ntName.size()); } return L""; }
该函数使用一个静态的字符串对向量, 每个都将 NT 设备名称映射到一个驱动器号. 第一次调用该函数时, 它会获取所有的驱动器号 (`GetLogicalDrives`) 作为位掩码, 其中位 0 对应于驱动器 A, 位 1 对应于驱动器 B, 位 2 对应于驱动器 C, 依此类推, 并为每个驱动器查询其 NT 设备名称, 使用 `QueryDosDevice` (有关 `QueryDosDevice` 的更多信息, 请参见第 11 章).
手头有传入的路径, 在向量中搜索设备名称并提取其对应的驱动器号. 最后, 路径的其余部分附加到提取的驱动器号并返回.
1.8.3. 读写锁
使用临界区来保护共享数据免受并发访问是有效的, 但它是一种悲观的机制——它最多只允许一个线程访问共享数据. 在某些情况下, 一些线程读取数据, 而其他线程写入数据, 可以进行优化: 如果一个线程读取数据, 没有理由阻止其他只读取数据的线程并发地这样做. 这正是“单写多读”机制的作用.
Windows API 提供了 `SRWLOCK` 结构, 代表了这样一种锁 (S 代表“Slim”). 其定义如下:
typedef RTL_SRWLOCK SRWLOCK, *PSRWLOCK;
那个 `RTLSRWLOCK` 呢? 它长这样:
typedef struct _RTL_SRWLOCK { PVOID Ptr; } RTL_SRWLOCK, *PRTL_SRWLOCK;
显然, 这只是一个应该被视为不透明的数据. 初始化 `SRWLOCK` 是通过 `InitializeSRWLock` 完成的:
void InitializeSRWLock(_Out_ PSRWLOCK SRWLock);
或者, 可以通过将其分配给 `SRWLOCKINIT` 宏来静态地初始化该结构, 该宏只是将结构清零. 奇怪的是, `SRWLOCK` 没有“delete”; 这是因为其所有内部信息都打包在该指针大小的单元格中.
使用初始化的 `SRWLOCK`, 线程可以尝试使用以下函数获取共享或独占锁:
void AcquireSRWLockShared (_InOut_ PSRWLOCK SRWLock); void AcquireSRWLockExclusive (_InOut_ PSRWLOCK SRWLock);
如果无法获取相关的锁, 线程会进入等待状态. 一旦获取, 线程可以向前推进并访问指定的共享资源, 这意味着由线程来决定不进行“错误”的访问. 例如, 如果一个线程获取了共享锁, 它就不能修改共享数据.
工作完成后, 线程使用相关的释放函数:
void ReleaseSRWLockShared (_Inout_ PSRWLOCK SRWLock); void ReleaseSRWLockExclusive (_Inout_ PSRWLOCK SRWLock);
SRW 锁存储的状态非常少, 因此它们的灵活性有限:
- 共享锁所有者不能直接将其锁升级为独占锁. 它必须首先释放其共享锁, 然后争夺独占锁.
- 独占所有者不能递归地获取锁; 这会导致死锁.
- 无法保证第一个获取锁的线程是第一个接收到它的线程. 正如文档所述: “SRW 锁既不是公平的也不是 FIFO 的”.
假设这些限制是可接受的, 如果大多数对数据的操作是读取而不是写入, 性能可能会得到提升.
- RAII 包装器
与临界区一样, 为 `SRWLOCK` 拥有 RAII 包装器很方便. 这里有三个类, 一个用于包装 `SRWLOCK`, 另外两个用于获取/释放:
class ReaderWriterLock : public SRWLOCK { public: ReaderWriterLock(); ReaderWriterLock(const ReaderWriterLock&) = delete; ReaderWriterLock& operator=(const ReaderWriterLock&) = delete; void LockShared(); void UnlockShared(); void LockExclusive(); void UnlockExclusive(); }; struct AutoReaderWriterLockExclusive { AutoReaderWriterLockExclusive(SRWLOCK& lock); ~AutoReaderWriterLockExclusive(); private: SRWLOCK& _lock; }; struct AutoReaderWriterLockShared { AutoReaderWriterLockShared(SRWLOCK& lock); ~AutoReaderWriterLockShared(); private: SRWLOCK& _lock; };
实现相当直接:
ReaderWriterLock::ReaderWriterLock() { ::InitializeSRWLock(this); } void ReaderWriterLock::LockShared() { ::AcquireSRWLockShared(this); } void ReaderWriterLock::UnlockShared() { ::ReleaseSRWLockShared(this); } void ReaderWriterLock::LockExclusive() { ::AcquireSRWLockExclusive(this); } void ReaderWriterLock::UnlockExclusive() { ::ReleaseSRWLockExclusive(this); } AutoReaderWriterLockExclusive::AutoReaderWriterLockExclusive(SRWLOCK& lock) : _lock(lock) { ::AcquireSRWLockExclusive(&_lock); } AutoReaderWriterLockExclusive::~AutoReaderWriterLockExclusive() { ::ReleaseSRWLockExclusive(&_lock); } AutoReaderWriterLockShared::AutoReaderWriterLockShared(SRWLOCK& lock) : _lock(lock) { ::AcquireSRWLockShared(&_lock); } AutoReaderWriterLockShared::~AutoReaderWriterLockShared() { ::ReleaseSRWLockShared(&_lock); }
这些包装器是 `Threadinghelpers` 项目的一部分.
- MD5 计算器 2
对于 MD5 计算器, 我们可以用 SRW 锁替换一些临界区, 以潜在地提高并发性, 因为多个读操作可能同时发生. 例如, 哈希缓存对临界区的使用可以替换为 SRWLOCK:
class HashCache { public: HashCache(); bool Add(PCWSTR path, const Hash& hash); const Hash Get(PCWSTR path) const; bool Remove(PCWSTR path); void Clear(); private: mutable ReaderWriterLock _lock; std::unordered_map<std::wstring, Hash> _cache; };
以及实现:
bool HashCache::Add(PCWSTR path, const Hash& hash) { AutoReaderWriterLockExclusive locker(_lock); auto it = _cache.find(path); if (it == _cache.end()) { _cache.insert({ path, hash }); return true; } return false; } const Hash HashCache::Get(PCWSTR path) const { AutoReaderWriterLockShared locker(_lock); auto it = _cache.find(path); return it == _cache.end() ? Hash() : it->second; } bool HashCache::Remove(PCWSTR path) { AutoReaderWriterLockExclusive locker(_lock); auto it = _cache.find(path); if (it != _cache.end()) { _cache.erase(it); return true; } return false; } void HashCache::Clear() { AutoReaderWriterLockExclusive locker(_lock); _cache.clear(); }
可以对 `CView` 类进行类似的修改.
上述更改可以在 `MD5Calculator2` 项目中找到.
最后, SRW 锁支持 `Try` 变体来获取锁:
BOOLEAN TryAcquireSRWLockExclusive (_Inout_ PSRWLOCK SRWLock); BOOLEAN TryAcquireSRWLockShared (_Inout_ PSRWLOCK SRWLock);
如果指定的锁被获取, 这些函数返回 `TRUE`, 否则返回 `FALSE`. 如果获取成功, 必须最终调用相应的 `Release` 函数.
1.8.4. 条件变量
条件变量是另一种同步机制, 提供了在临界区或 SRW 锁上等待直到某个条件发生的能力. 使用条件变量的一个经典例子是生产者/消费者场景. 假设一些线程生产数据项并将它们放入一个队列中. 每个线程都做任何需要的工作来生产这些项目. 与此同时, 其他线程作为消费者——每个都从队列中移除一个项目并以某种方式处理它 (图 7-11).

Figure 129: 生产者/消费者
如果项目生产的速度快于消费者处理的速度, 那么队列是非空的, 消费者继续工作. 另一方面, 如果消费者线程处理了所有项目, 它们应该进入等待状态, 直到新项目被生产出来, 在这种情况下它们应该被唤醒. 这正是条件变量提供的行为. 无事可做 (队列为空) 的消费者线程不应该自旋, 定期检查队列是否变为非空, 因为这会无谓地消耗 CPU 周期. 条件变量允许高效的等待 (不消耗 CPU), 直到线程被唤醒 (通常由生产者线程).
一个条件变量由一个 `CONDITIONVARIABLE` 不透明结构表示, 与 `SRWLOCK` 非常相似. 它必须通过调用 `InitializeConditionVariable` 来初始化:
void InitializeConditionVariable(_Out_ PCONDITION_VARIABLE ConditionVariable);
与 `SRWLOCK` 一样, 通过将 `CONDITIONVARIABLE` 设置为 `CONDITIONVARIABLEINIT` 可以进行静态初始化.
一个条件变量总是与一个临界区或 SRW 锁关联.
当一个线程需要等待直到一个条件变量被信号, 它必须首先获取临界区/SRW 锁, 然后调用相关的休眠函数:
BOOL SleepConditionVariableCS( _Inout_ PCONDITION_VARIABLE ConditionVariable, _Inout_ PCRITICAL_SECTION CriticalSection, _In_ DWORD dwMilliseconds); BOOL SleepConditionVariableSRW( _Inout_ PCONDITION_VARIABLE ConditionVariable, _Inout_ PSRWLOCK SRWLock, _In_ DWORD dwMilliseconds, _In_ ULONG Flags);
调用上述 `Sleep*` 函数之一的线程必须首先正好获取一次相关的同步对象. 该函数原子地释放同步对象并在条件变量上等待. 在等待时, 线程可能会被调用条件变量上的唤醒函数之一唤醒:
VOID WakeConditionVariable (_Inout_ PCONDITION_VARIABLE ConditionVariable); VOID WakeAllConditionVariable (_Inout_ PCONDITION_VARIABLE ConditionVariable);
`WakeConditionVariable` 唤醒一个线程 (如果多个线程在条件变量上休眠, 则不保证是哪个线程), 而 `WakeAllConditionVariable` 唤醒所有等待在条件变量上的线程.
一旦被唤醒, 线程重新获取同步对象并继续执行. 此时, 线程应该重新检查它正在等待的条件, 如果不满足, 再次调用 `Sleep*` 函数. 这可能会发生, 因为另一个线程可能在此之前醒来并做了一些工作, 使得条件再次为假. 这样一个线程的操作如图 7-12 所示 (使用临界区).

Figure 130: 消费者线程操作与条件变量
图 7-12 中涉及的步骤如下:
- 消费者线程获取临界区.
- 线程检查是否可以继续. 例如, 它可能会检查它应该处理的队列是否不为空.
- 如果队列为空, 线程调用 `SleepConditionVariableCS`, 这会释放临界区 (以便另一个线程可以获取它) 并进入休眠 (等待状态).
- 在某个时候, 一个生产者线程会通过调用 `WakeConditionVariable` 来唤醒消费者线程, 因为, 例如, 它向队列中添加了一个新项目.
- `SleepConditionVariableCS` 返回, 获取临界区, 并返回检查是否可以继续. 如果不能, 它会继续等待.
- 现在可以继续了, 线程可以做它的工作 (例如从队列中移除一个项目). 临界区仍然被持有.
- 最后, 工作完成, 必须释放临界区.
回到 `Sleep*` 函数: 如果成功, 这些函数返回 `TRUE`, 意味着线程已在同步原语被获取的情况下被唤醒. 如果它们返回 `FALSE`, 意味着可能发生了错误. 如果 `dwMillisecond` 参数不是 `INFINITE`, 它表示一个错误. 如果时间间隔是有限的, `FALSE` 可能表示线程在该间隔内没有被唤醒. 在这种情况下, `GetLastError` 返回 `ERRORTIMEOUT`.
对于 SRW 锁, `Flags` 参数指示这应该是独占获取还是非独占获取. 传递零意味着独占访问, 而传递 `CONDITIONVARIABLELOCKMODESHARED` 意味着共享访问.
- 队列演示应用程序
*队列演示*应用程序演示了使用条件变量来唤醒访问与生产者线程共享队列的消费者线程. 一旦启动, 它允许选择生产者和消费者线程的数量 (图 7-13).

Figure 131: 队列演示应用程序
单击*运行*按钮开始操作. 生产者线程生产项目 (即数字) 并将它们推入队列. 消费者线程从队列中弹出项目并检查数字是否为素数. 如果队列为空, 消费者线程会在一个条件变量上休眠, 直到被生产者线程唤醒. 当前队列大小显示在底部并定期更新.
如果生产者线程生产项目的速度快于消费者线程处理的速度, 队列大小会增加, 因为消费者试图赶上. 单击*停止*会停止生产者, 允许消费者赶上并清空队列. 另一方面, 如果消费者“更快” (也许因为它们很多), 队列大小将大多为零, 因为消费者足够快地拾取任何新项目并在新项目出现之前处理它.
在工作时, 会为消费者线程显示一些统计信息 (图 7-14). 你需要“玩转”线程计数以获得有趣的行为.

Figure 132: 正在工作的队列演示应用程序
`CMainDlg` 类定义了以下嵌套类型:
struct ConsumerThreadData { unsigned ItemsProcessed{ 0 }; unsigned Primes{ 0 }; wil::unique_handle hThread; }; struct WorkItem { unsigned Data; bool IsPrime; };
`ConsumerThreadData` 是由消费者线程操作的数据结构. 每个消费者线程都有一个这样的对象. 它存储一个到线程的句柄, 以及处理的项目数和找到的素数. 队列中存储的每个工作项由一个要确定是否为素数的数字和一个结果 (在应用程序中没有直接使用) 组成.
基于这些结构和应用程序的要求, 存储了以下数据成员:
std::queue<WorkItem> m_Queue; // the queue CriticalSection m_QueueLock; // the critical section protecting the queue CONDITION_VARIABLE m_QueueCondVar; std::vector<wil::unique_handle> m_ProducerThreads; std::vector<ConsumerThreadData> m_ConsumerThreads; wil::unique_handle m_hAbortEvent; static CMainDlg* m_pThis; // simplifies access to this
生产者线程只存储它们的句柄, 但它们可能会存储更多的状态, 类似于消费者线程. `CriticalSection` 类是来自 `ThreadingHelpers` 项目的包装器, 用于简化工作. `mhAbortEvent` 是一个事件内核对象句柄, 用于向生产者和消费者线程发出停止运行的信号. 事件内核对象将在下一章中详细讨论. 作为此应用程序的替代方案, 本可以使用一个 `volatile`布尔变量. 最后, `mpThis` 静态成员用于引用唯一的对话框实例, 以简化对线程函数的实例方法的访问.
`CMainDlg::OnInitDialog` 函数在控件方面对对话框进行一次性初始化, 但也初始化 `mpThis` 和中止事件:
LRESULT CMainDlg::OnInitDialog(UINT, WPARAM, LPARAM, BOOL&) { m_pThis = this; m_hAbortEvent.reset(::CreateEvent(nullptr, TRUE, FALSE, nullptr)); //... }
单击*运行*按钮会导致调用 `OnRun`, 该函数只调用 `Run` 来完成实际工作. 该函数首先获取消费者和生产者线程的数量, 并进行一些健全性检查:
void CMainDlg::Run() { int consumers = GetDlgItemInt(IDC_CONSUMERS); if (consumers < 1 || consumers > 64) { DisplayError(L"Consumer threads must be between 1 and 64"); return; } int producers = GetDlgItemInt(IDC_PRODUCERS); if (producers < 1 || producers > 64) { DisplayError(L"Producer threads must be between 1 and 64"); return; } }
上述代码中的数字 64 没有什么特别之处. 如果需要, 可以轻松选择更大的数字.
接下来, 应该为此运行进行一些初始化:
bool abort = false; ::ResetEvent(m_hAbortEvent.get()); ::InitializeConditionVariable(&m_QueueCondVar); m_ThreadList.DeleteAllItems();
中止事件被重置, 条件变量被初始化. 显示消费者线程的列表视图被清除任何现有项目. 现在是时候创建消费者线程了:
m_ConsumerThreads.clear(); m_ConsumerThreads.reserve(consumers); for (int i = 0; i < consumers; i++) { ConsumerThreadData data; data.hThread.reset(::CreateThread(nullptr, 0, [](auto p) { return m_pThis->ConsumerThread(PtrToLong(p)); }, LongToPtr(i), 0, nullptr)); if (!data.hThread) { abort = true; break; } m_ConsumerThreads.push_back(std::move(data)); } if (abort) { ::SetEvent(m_hAbortEvent.get()); return; }
每个消费者线程都是用一个普通的 `CreateThread` 创建的, 将线程函数指向实例函数 `ConsumerThread`, 并带有一个值, 指示消费者线程在消费者线程数组中的索引.
你可能认为将线程函数直接传递一个指向 `ConsumerThreadData` 实例的指针会更容易 (上面代码中的 `data`). 这会导致崩溃或损坏, 因为数据在栈上, 然后会被复制到向量中 (因此移动到堆中), 使得指针成为一个垃圾. 在这种情况下, 我决定传入索引, 因为它不会改变.
如果由于某种原因, 线程创建失败, 循环会中止, 事件被设置, 以导致所有先前创建的生产者线程中止.
接下来, 以类似的方式创建生产者线程:
m_ProducerThreads.clear(); m_ProducerThreads.reserve(producers); for (int i = 0; i < producers; i++) { wil::unique_handle hThread(::CreateThread(nullptr, 0, [](auto p) { return m_pThis->ProducerThread(); }, this, 0, nullptr)); if (!hThread) { DisplayError(L"Failed to create producer thread. Aborting"); abort = true; break; } } if (abort) { ::SetEvent(m_hAbortEvent.get()); return; }
生产者线程调用 `ProducerThread` 实例函数. 与消费者线程相反, 这些不需要任何特殊的上下文, 因为它们只是生成伪随机数. `Run` 函数的最后一部分是将消费者线程的基本信息添加到列表视图中, 并启动一个简单的计时器, 用于定期更新队列大小:
CString text; for (int i = 0; i < (int)m_ConsumerThreads.size(); i++) { const auto& t = m_ConsumerThreads[i]; text.Format(L"%2d", i); int n = m_ThreadList.InsertItem(i, text); m_ThreadList.SetItemText(n, 1, std::to_wstring(::GetThreadId(t.hThread.get())).c_str()); } GetDlgItem(IDC_RUN).EnableWindow(FALSE); GetDlgItem(IDC_STOP).EnableWindow(TRUE); SetTimer(1, 500, nullptr);
这是一个生产者线程的代码:
DWORD CMainDlg::ProducerThread() { for (;;) { if (::WaitForSingleObject(m_hAbortEvent.get(), 0) == WAIT_OBJECT_0) break; WorkItem item; item.IsPrime = false; LARGE_INTEGER li; ::QueryPerformanceCounter(&li); item.Data = li.LowPart; { AutoCriticalSection locker(m_QueueLock); m_Queue.push(item); } ::WakeConditionVariable(&m_QueueCondVar); // sleep a little bit from time to time if ((item.Data & 0x7f) == 0) ::Sleep(1); } return 0; }
该代码使用一个无限循环, 只有在中止事件被信号时才会中断. 然后准备一个 `WorkItem` 实例, 生成的数字使用 `QueryPerformanceCounter` 返回的低 32 位. 这个选择在这个例子中是完全任意的. 接下来, 线程获取临界区, 以防止工作项队列上的同步问题, 因为它被生产者和消费者 (甚至 UI 线程可能需要访问) 并发访问. 队列本身是标准的 C++ `std::queue<>` 类, 但任何其他队列实现都可以.
一旦一个新项目被添加到队列中, 线程通过调用 `WakeConditionVariable` 来向条件变量发信号, 以唤醒正在等待它的线程. 在循环以推送下一个项目之前, 最后一个代码位是可能的休眠, 以延迟线程一点.
消费者线程的代码如下所示:
DWORD CMainDlg::ConsumerThread(int index) { auto& data = m_ConsumerThreads[index]; auto tick = ::GetTickCount64(); for (;;) { WorkItem value; { bool abort = false; AutoCriticalSection locker(m_QueueLock); while (m_Queue.empty()) { if (::WaitForSingleObject(m_hAbortEvent.get(), 0) == WAIT_OBJECT_0) { abort = true; break; } ::SleepConditionVariableCS(&m_QueueCondVar, &m_QueueLock, INFINITE); } if (abort) break; ATLASSERT(!m_Queue.empty()); value = m_Queue.front(); m_Queue.pop(); } { // do the actual work bool isPrime = IsPrime(value.Data); if (isPrime) { value.IsPrime = true; ::InterlockedIncrement(&data.Primes); } ::InterlockedIncrement(&data.ItemsProcessed); } auto current = ::GetTickCount64(); if (current - tick > 600) { PostMessage(WM_UPDATE_THREAD, index); tick = current; } } PostMessage(WM_UPDATE_THREAD, index); return 0; }
该函数首先获取此消费者线程的数据结构的引用. 然后构造一个无限循环. 为队列获取临界区, 然后如果队列为空, 则进入一个内部 `while` 循环. 如果它为空, 线程无事可做, 因此它调用 `SleepConditionVariableCS` 进入等待状态, 直到被另一个线程唤醒, 使用条件变量. 在等待之前, 它会释放临界区. 当它醒来时 (因为一个生产者调用了 `WakeConditionVariable`), 它会自动再次获取临界区 (参见图 7-12), 并且必须重新检查条件 (队列为空), 因为另一个消费者线程可能早一点醒来并弹出了队列中的最后一项. 另外, 条件变量可能容易出现虚假唤醒, 这是重新检查条件的另一个原因.
如果队列不为空, 消费者可以继续并移除队列中的第一项 (此时临界区仍然被持有), 通过调用 `mQueue.front()` 获取项目, 并调用 `mQueue.pop()` 将其从队列中删除.
然后释放临界区 (作用域以 `AutoCriticalSection` 结束), 然后通过调用辅助函数 `IsPrime` 对项目进行实际工作. 如果需要, 会递增此线程维护的相关计数器. 增量是用 `InterlockedIncrement` 执行的, 因为 UI 线程可能会并发访问这些值. 最后, 每 600 毫秒左右向窗口发布一条消息, 以更新此线程的统计信息.
`WMUPDATETHREAD` 应用程序定义的消息接收消费者线程索引, 并更新处理的项目数和计算的素数:
LRESULT CMainDlg::OnUpdateThread(UINT, WPARAM index, LPARAM, BOOL&) { auto& data = m_ConsumerThreads[index]; int n = (int)index; CString text; text.Format(L"%u", ::InterlockedAdd((LONG*)&data.ItemsProcessed, 0)); m_ThreadList.SetItemText(n, 2, text); text.Format(L"%u", ::InterlockedAdd((LONG*)&data.Primes, 0)); m_ThreadList.SetItemText(n, 3, text); return 0; }
访问计数器可能会与消费者线程并发进行, 因此为了防止可能的撕裂读, 使用 `InterlockedAdd` 并加零来缓解. 直接读取计数器可能也可以, 但这可能取决于值在内存中的对齐以及目标处理器, 所以安全总比后悔好.
另一个 UI 更新是使用计时器定期更新队列大小:
LRESULT CMainDlg::OnTimer(UINT, WPARAM id, LPARAM, BOOL&) { if (id == 1) { size_t size; { AutoCriticalSection locker(m_QueueLock); size = m_Queue.size(); } SetDlgItemInt(IDC_QUEUE_SIZE, (unsigned)size, FALSE); } return 0; }
使用的计时器 ID 是 1, 由 `if` 语句检查. 对队列的任何访问都应在临界区的保护下进行, 然后在更新 UI 之前读取队列大小.
最后, 单击*停止*按钮会调用 `OnStop` 函数, 该函数只调用 `Stop`:
void CMainDlg::Stop() { // signal threads to abort ::SetEvent(m_hAbortEvent.get()); ::WakeAllConditionVariable(&m_QueueCondVar); // update UI GetDlgItem(IDC_RUN).EnableWindow(TRUE); GetDlgItem(IDC_STOP).EnableWindow(FALSE); }
该函数设置中止事件以导致所有生产者退出其无限循环. 条件变量用于唤醒所有消费者线程, 以便它们可以清空队列中剩余的任何项目.
为条件变量编写一个 RAII 包装器. 将*队列演示*应用程序更改为使用 SRW 锁而不是临界区.
1.8.5. 等待地址
Windows 8 和 Server 2012 添加了另一个同步机制, 允许线程高效地等待直到某个地址的值变为所需值. 然后它可以醒来并继续其工作. 使用其他同步机制 (例如使用条件变量) 来实现类似的效果当然是可能的, 但等待地址更高效, 并且不容易出现死锁, 因为没有直接使用临界区 (或其他软件同步原语).
线程可以进入等待状态, 直到某个“监视”的数据上出现某个值, 通过调用 `WaitOnAddress`:
BOOL WaitOnAddress( _In_ volatile VOID* Address, _In_ PVOID CompareAddress, _In_ SIZE_T AddressSize, _In_opt_ DWORD dwMilliseconds);
本节中的函数需要链接 `synchronization.lib` 导入库.
该函数检查 `*Address` 处的值是否与 `*CompreAddress` 中的相同. 如果它们不同, 调用会立即以 `TRUE` 的值返回. 否则, 线程进入等待状态. 要比较的值的大小在 `AddressSize` 参数中指定, 并且必须是 1, 2, 4 或 8. 最后一个参数指示要等待的时间, 可以是 `INFINITE`, 表示无论需要多长时间都等待.
在内部, 内核将等待的地址保存在一个哈希表中, 以地址为键.
其他一些线程可能会更改 `*Address` 中的值. 不幸的是, 这不会自动导致等待的线程醒来. 相反, 做出更改的线程必须调用“唤醒”函数之一:
VOID WakeByAddressSingle (_In_ PVOID Address); VOID WakeByAddressAll (_In_ PVOID Address);
使用前一个函数, 任何等待在指定地址上的线程都会被唤醒, 而后者只唤醒一个线程. 此机制也可能出现虚假唤醒, 因此被唤醒的线程应重新检查值是否确实是预期的值. 如果不是, 线程应该通过再次调用 `WaitOnAddress` (通常在循环中完成) 回到等待状态.
一个典型的代码可能看起来像这样:
DWORD undesiredValue = 0; DWORD actualValue = 0; void Thread1() { // set undesiredValue as appropriate while(actualValue == undesiredValue) { ::WaitOnAddress(&actualValue, &undesiredValue, sizeof(DWORD), INFINITE); } // actualValue != undesiredValue } void Thread2() { //... actualValue++; ::WakeByAddressSingle(&actualValue); }
1.8.6. 同步屏障
Windows 8 中引入的另一个同步原语是*同步屏障*. 此对象允许同步需要到达其工作中的某个点才能全部继续的线程. 例如, 假设一个系统的多个部分, 每个部分都需要在主应用程序代码可以继续之前分两个阶段进行初始化. 一种简单的方法是按顺序调用每个初始化函数:
void RunApp() { // phase 1 InitSubsystem1(); InitSubsystem2(); InitSubsystem3(); InitSubsystem4(); // phase 2 InitSubsystem1Phase2(); InitSubsystem2Phase2(); InitSubsystem3Phase2(); InitSubsystem4Phase2(); // go ahead and run main application code... }
这是可行的, 但如果每个初始化都可以并发完成, 以便每个初始化都由不同的线程执行. 每个线程都不能继续进行第 2 阶段的初始化, 直到所有其他线程都完成了第 1 阶段. 当然, 可以通过使用其他同步原语的组合来实现这样的方案, 但同步屏障已经为此目的而存在.
同步屏障由 `SYNCHRONIZATIONBARRIER` 不透明结构表示, 该结构必须用 `InitializeSynchronizationBarrier` 初始化:
BOOL InitializeSynchronizationBarrier( _Out_ LPSYNCHRONIZATION_BARRIER lpBarrier, _In_ LONG lTotalThreads, _In_ LONG lSpinCount);
`lTotalThreads` 是需要到达屏障才能全部继续的总线程数. `lSpinCount` 参数允许为到达屏障的线程在进入等待状态 (如果屏障尚未释放) 之前设置一个自旋计数. 值 -1 会设置一个默认的自旋.
文档指出默认的自旋是 2000. 然而, 据我所知, 自旋计数目前未使用.
一旦初始化, 需要在屏障处等待的线程调用 `EnterSynchronizationBarrier`:
BOOL EnterSynchronizationBarrier( _Inout_ LPSYNCHRONIZATION_BARRIER lpBarrier, _In_ DWORD dwFlags);
指定 `SYNCHRONIZATIONBARRIERFLAGSSPINONLY` 标志会导致线程自旋直到屏障被释放. 这只应在预期的屏障释放时间很短时使用. 相反的标志, `SYNCHRONIZATIONBARRIERFLAGSBLOCKONLY`, 指定如果屏障尚未释放, 则不应进行自旋, 线程应进入等待状态. 最后一个标志, `SYNCHRONIZATIONBARRIERFLAGSNODELETE` 是一个可能的优化, 它告诉 API 在删除屏障时跳过一些所需的同步. 如果指定, 所有进入屏障的线程都必须指定此标志.
该函数仅为单个线程返回 `TRUE`, 一旦屏障被释放, 对所有其他线程返回 `FALSE`. 在前面描述的场景中, 以下是在单独线程中运行的初始化函数之一:
DWORD WINAPI InitSubSystem1(PVOID p) { auto barrier = (PSYNCHRONIZATION_BARRIER)p; // phase 1 printf("Subsystem 1: Starting phase 1 initialization (TID: %u)...\n", ::GetCurrentThreadId()); // do work... printf("Subsystem 1: Ended phase 1 initialization...\n"); ::EnterSynchronizationBarrier(barrier, 0); printf("Subsystem 1: Starting phase 2 initialization...\n"); // do work printf("Subsystem 1: Ended phase 2 initialization...\n"); return 0; }
第 1 阶段初始化完成后, 调用 `EnterSynchronizationBarrier` 以等待所有其他线程完成其第 1 阶段的初始化. 主函数可以写成这样:
SYNCHRONIZATION_BARRIER sb; InitializeSynchronizationBarrier(&sb, 4, -1); LPTHREAD_START_ROUTINE functions[] = { InitSubSystem1, InitSubSystem2, InitSubSystem3, InitSubSystem4 }; printf("System initialization started\n"); HANDLE hThread; int i = 0; for (auto f : functions) { hThread[i++] = ::CreateThread(nullptr, 0, f, &sb, 0, nullptr); } ::WaitForMultipleObjects(_countof(hThread), hThread, TRUE, INFINITE); printf("System initialization complete\n"); // close thread handles...
运行这段代码会产生类似以下的输出:
System initialization started Subsystem 1: Starting phase 1 initialization (TID: 79480)... Subsystem 2: Starting phase 1 initialization (TID: 104836)... Subsystem 3: Starting phase 1 initialization (TID: 32556)... Subsystem 4: Starting phase 1 initialization (TID: 86268)... Subsystem 2: Ended phase 1 initialization... Subsystem 3: Ended phase 1 initialization... Subsystem 1: Ended phase 1 initialization... Subsystem 4: Ended phase 1 initialization... Subsystem 4: Starting phase 2 initialization... Subsystem 3: Starting phase 2 initialization... Subsystem 1: Starting phase 2 initialization... Subsystem 2: Starting phase 2 initialization... Subsystem 3: Ended phase 2 initialization... Subsystem 1: Ended phase 2 initialization... Subsystem 4: Ended phase 2 initialization... Subsystem 2: Ended phase 2 initialization... System initialization complete
最后, 一个同步屏障应该用 `DeleteSynchronizationBarrier` 删除:
BOOL DeleteSynchronizationBarrier(_Inout_ LPSYNCHRONIZATION_BARRIER lpBarrier);
在调用 `EnterSynchronizationBarrier` 后立即调用 `DeleteSynchronizationBarrier` 是可以的, 因为该函数会等待所有线程到达屏障才被删除, 除非所有线程都使用 `SYNCHRONIZATIONBARRIERFLAGSNODELETE` 标志, 这样删除函数就不能保证这一点. 如果屏障永远不会被删除, 这可能很有用.
1.8.7. C++ 标准库呢?
与第 5 章中同名部分类似, C++ 标准库提供了可以作为 Windows API 替代方案的同步原语, 特别是对于跨平台代码. 像往常一样, 对这些对象的自定义非常有限 (如果有的话). 示例包括:
- `std::mutex`, 它的作用类似于临界区, 但不支持递归获取.
- `std::recusrsivemutex`, 它的作用就像一个临界区 (支持递归获取).
- `std::sharedmutex`, 类似于 SRW 锁.
- `std::conditionvariable` 是一个条件变量的等价物.
- 其他
显然, C++ 中可能缺少一些东西, 例如等待地址和同步屏障. 然而, 这些可能会在未来的标准中添加. 在任何情况下, 所有 C++ 标准库类型都只在同一进程内工作. 没有办法跨进程使用它们.
1.8.8. 练习
- 创建一个可以并发运行多个工作项的系统, 但其中一些可能对其他工作项有依赖. 作为一个具体的例子, 考虑在 Visual Studio 中编译项目. 一些项目依赖于其他项目, 所以它们必须按顺序处理. 以下是一个项目层次结构的例子 (读作: 项目 4 依赖于 1, 项目 5 依赖于项目 2 和 3, 依此类推). 目标是在遵守依赖关系的同时尽快编译所有项目. 使用事件对象进行流同步.

Figure 133: 示例项目依赖关系
1.8.9. 总结
在本章中, 我们探讨了常用于线程同步的调度程序对象. 在下一章中, 我们将研究线程池, 它是显式创建线程的常见替代方案.
1.9. 第 8 章: 线程同步 (跨进程)
上一章描述了具有一个共同因素的各种同步机制: 它们可以用于在同一进程中运行的线程之间进行同步. 本章用基于内核对象的其他机制来补充这些机制, 由于其本质是系统空间的一部分, 因此可以自然地在进程之间共享, 从而被 (可能) 不同进程中运行的线程使用. 这并不意味着这些机制在同一进程场景中是无用的——远非如此. 但它们确实具有第 7 章中描述的机制所没有的特殊能力.
本章内容:
- Dispatcher 对象
- 互斥体
- 信号量
- 事件
- 可等待计时器
- 其他等待函数
1.9.1. Dispatcher 对象
第 2 章广泛地处理了内核对象和句柄. 以下列出了与内核对象相关的最重要点. 有关更多详细信息, 请参阅第 2 章.
- 内核对象驻留在系统 (内核) 空间中, 理论上可以从任何进程访问, 前提是该进程可以获得对所请求对象的句柄.
- 句柄是进程相关的.
- 有三种方法可以跨进程共享对象: 句柄继承, 名称和句柄复制.
一些内核对象更专业, 称为*调度程序对象*或*可等待对象*. 此类对象可以处于两种状态之一: 已发出信号*或*未发出信号. 已发出信号和未发出信号的含义取决于对象的类型. 表 8-1 总结了常见调度程序对象的这些状态的含义.
| 对象类型 | 已发出信号 | 未发出信号 |
|---|---|---|
| 进程 | 已退出/已终止 | 正在运行 |
| 线程 | 已退出/已终止 | 正在运行 |
| 作业 | 作业时间限制已到 | 限制未到或未设置 |
| 互斥体 | 空闲 (未拥有) | 已拥有 |
| 信号量 | 计数大于零 | 计数为零 |
| 事件 | 事件已设置 | 事件未设置 |
| 文件 | I/O 操作已完成 | I/O 操作正在进行或未开始 |
| 可等待计时器 | 计时器计数已到期 | 计时器计数未到期 |
| I/O 完成 | 异步 I/O 操作已完成 | I/O 操作未完成 |
文件和 I/O 完成端口在第 11 章中讨论. 可等待计时器, 互斥体, 信号量和事件对象将在本章后面讨论.
等待一个对象变为已发出信号状态通常由以下两个函数之一完成 (除了有其自己的等待函数的 I/O 完成端口, 在第 11 章中讨论):
DWORD WaitForSingleObject( _In_ HANDLE hHandle, _In_ DWORD dwMilliseconds); DWORD WaitForMultipleObjects( _In_ DWORD nCount, _In_ const HANDLE* lpHandles, _In_ BOOL bWaitAll, _In_ DWORD dwMilliseconds);
`WaitForSingleObject` 接受一个到调度程序对象的句柄, 该句柄必须具有 `SYNCHRONIZE` 访问权限. 超时参数指示最多等待对象变为已发出信号状态多长时间. 该值可以为零, 这意味着无论如何都不应发生等待. 相反, 该值可以设置为 `INFINITE`, 这意味着线程愿意等待直到对象变为已发出信号状态, 无论需要多长时间. `WaitForSingleObject` 有四种可能的返回值:
- `WAITOBJECT0` - 等待结束, 因为对象在超时到期前变为已发出信号状态.
- `WAITTIMEOUT` - 在线程等待的时间内对象没有变为已发出信号状态. 如果超时是 `INFINITE`, 则永远不会返回此值.
- `WAITFAILED` - 函数因某种原因失败. 调用通常的 `GetLastError` 查看原因.
- `WAITABANDONED` - 等待的是一个互斥体对象, 并且该互斥体已变为被放弃. 被放弃的互斥体的含义将在本章后面的“互斥体”部分讨论.
扩展的 `WaitForMultipleObjects` 函数允许等待一个或多个句柄. 该函数期望第二个参数是句柄数组, 第一个参数指示句柄的数量. 此句柄数量限制为 `MAXIMUMWAITOBJECTS` (64). 第三个参数指定线程是应该等待所有对象都变为已发出信号状态 (TRUE) 还是只有一个 (任何一个) 变为已发出信号状态 (FALSE).
该函数的返回值包括 `WAITTIMEOUT` 和 `WAITFAILED`, 就像 `WaitForSingleObject` 一样, 含义相同. 如果 `bWaitAll` 为 `TRUE` (等待所有对象), 返回值在 `WAITOBJECT0` 和 `WAITOBJECT0+count-1` 之间, 其中 `count` 是句柄的数量. 如果返回值在 `WAITABANDONED0` 和 `WAITABANDONED0+count-1` 之间, 这意味着所有对象都已发出信号, 并且至少有一个互斥体被放弃.
如果 `bWaitAll` 为 `FALSE`, 返回值 (如果不是超时或错误) 指示哪个对象 (数组中的索引) 处于已发出信号状态, 偏移量为 `WAITOBJECT0` 或 `WAITABANDONED0`. 例如, 返回 `WAITOBJECT0 + 3` 意味着第四个对象已发出信号, 等待因此结束. 如果有多个对象已发出信号, 则返回最小的索引.
- 等待成功
如果一个等待函数因为对象或对象变为已发出信号状态而成功, 线程被唤醒并可以恢复执行. 刚刚发出信号的对象是否保持在已发出信号状态? 这取决于对象的类型. 一些对象保持在已发出信号状态, 例如进程和线程. 一旦一个进程退出或终止, 它就变为已发出信号状态, 并在其生命周期 (只要有打开的句柄) 的其余部分保持如此.
某些类型的对象在成功等待后可能会改变其已发出信号状态. 例如, 对互斥体的成功等待会将其状态转回未发出信号状态 (原因将在下一节讨论互斥体时变得明了). 另一个在发出信号时表现出特殊行为的对象是自动重置事件. 当发出信号时, 它会释放一个线程 (且只有一个), 当这种情况发生时, 其状态会自动翻转为未发出信号.
如果多个线程等待同一个互斥体, 并且它变为已发出信号状态会发生什么? 只有一个线程可以在它翻转回未发出信号状态之前获取互斥体. 在幕后, 等待一个对象的线程存储在一个先进先出 (FIFO) 队列中, 因此队列中的第一个线程是被唤醒的那个 (无论其优先级如何). 然而, 不应依赖此行为. 一些内部机制可能会从等待中移除一个线程 (例如, 如果它被挂起, 比如用调试器), 然后当线程恢复时, 它将被推到队列的后面. 所以这里的简单规则是, 无法确定哪个线程会首先醒来. 在任何情况下, 此算法在未来的 Windows 版本中随时都可能更改.
我们将检查的第一个内核对象类型是互斥体. 互斥体 (是“mutual exclusion”的缩写) 提供了与第 7 章中讨论的临界区类似的功能. 其目的相同: 保护共享数据免受并发访问. 一次只有一个线程可以成功获取互斥体, 并继续访问共享数据. 所有其他等待互斥体的线程必须继续等待, 直到获取线程释放它.
创建互斥体对象需要调用 `CreateMutex` 或 `CreateMutexEx` 函数:
HANDLE CreateMutex( _In_opt_ LPSECURITY_ATTRIBUTES lpMutexAttributes, _In_ BOOL bInitialOwner, _In_opt_ LPCTSTR lpName); HANDLE CreateMutexEx( _In_opt_ LPSECURITY_ATTRIBUTES lpMutexAttributes, _In_opt_ LPCTSTR lpName, _In_ DWORD dwFlags, _In_ DWORD dwDesiredAccess);
两个函数的第一个参数都是通常的 `SECURITYATTRIBUTES` 指针, 通常设置为 `NULL`. 如果 `bInitialOwner` 设置为 `TRUE`, `CreateMutex` 将在返回之前尝试通过调用 `WaitForSingleObject` 获取互斥体, 直到可以获取. 通过在 `dwFlags` 参数中指定 `CREATEMUTEXINITIALOWNER` 标志, 可以用 `CreateMutexEx` 实现相同的效果. 如果创建了一个新对象, 那么这个获取会立即成功.
`lpName` 参数允许为互斥体设置一个名称. 如果存在同名的互斥体对象 (并且没有安全限制), 函数会打开一个到现有互斥体的句柄. 如果名称存在, 但对象不是互斥体, 函数会失败.
最后, 扩展函数允许为互斥体指定所需的访问掩码. 这在打开现有互斥体时最有用, 可能会请求比 `MUTEXALLACCESS` (这是 `CreateMutex` 默认请求的) 更弱的访问掩码.
一个现有的互斥体可以按名称用 `OpenMutex` 打开:
HANDLE OpenMutexW( _In_ DWORD dwDesiredAccess, _In_ BOOL bInheritHandle, _In_ LPCWSTR lpName);
如果指定的互斥体不存在, 函数会失败并返回 `NULL`. 如果两个 (或更多) 线程想要使用同名互斥体进行同步, 调用 `CreateMutex` 或 `CreateMutexEx` 更简单 (并避免了竞争条件): 第一个线程 (无论是哪个) 创建对象, 后续的调用者会获得到现有对象的新句柄.
像往常一样, 对于内核对象, 任何打开的句柄都应该最终用 `CloseHandle` 关闭. 在互斥体上调用 `WaitForSingleObject` 会导致线程等待直到它变为已发出信号状态, 这意味着空闲, 或不被任何其他线程拥有. 一旦获取, 互斥体原子地转换到未发出信号状态, 防止任何其他线程获取它. 一旦互斥体的所有者完成了对共享数据的工作, 它会调用 `ReleaseMutex` 来从其所有权中释放它, 使其再次变为已发出信号状态:
BOOL ReleaseMutex(_In_ HANDLE hMutex);
第 7 章的*简单增量*应用程序可以配置为使用互斥体作为同步原语 (图 8-1). 请注意, 正确地执行计数需要相当长的时间. 这是因为使用互斥体 (像所有内核对象一样) 进行同步需要从用户模式到内核模式的转换, 这不是免费的. 当然, 这个例子是刻意设计的, 所以与临界区相比, 差异看起来很大. 在实践中, 情况并没有那么糟.
Figure 134: 带有互斥体的简单增量
用于此循环增量的互斥体的代码如下:
void CMainDlg::DoMutexCount() { auto handles = std::make_unique<HANDLE[]>(m_Threads); m_hMutex = ::CreateMutex(nullptr, FALSE, nullptr); for (int i = 0; i < m_Threads; i++) { handles[i] = ::CreateThread(nullptr, 0, [](auto param) { return ((CMainDlg*)param)->IncMutexThread(); }, this, 0, nullptr); } ::WaitForMultipleObjects(m_Threads, handles.get(), TRUE, INFINITE); for (int i = 0; i < m_Threads; i++) ::CloseHandle(handles[i]); ::CloseHandle(m_hMutex); } DWORD CMainDlg::IncMutexThread() { for (int i = 0; i < m_Loops; i++) { ::WaitForSingleObject(m_hMutex, INFINITE); m_Count++; ::ReleaseMutex(m_hMutex); } return 0; }
互斥体可以递归地获取 (由同一个线程), 导致一个内部计数器被递增. 这意味着需要相同次数的 `ReleaseMutex` 调用才能真正释放互斥体. 由一个不拥有互斥体的线程调用 `ReleaseMutex` 会失败.
- 互斥体演示应用程序
`MutexDemo` 应用程序展示了在不同进程中运行的线程如何同步对共享文件的访问, 以便一次只有一个线程可以访问该文件. 由于涉及多个进程, 不能使用临界区.
要进行测试, 请打开两个命令窗口并导航到 `MutexDemo.exe` 所在的目录. 或者, 你可以从 Visual Studio 运行, 但你需要在项目的属性中设置一个命令行参数 (图 8-2). 该参数应该是一些不存在的文件路径.

Figure 135: 设置命令行参数
从两个命令窗口运行该应用程序, 指向同一个文件. 你应该在每个命令窗口中看到类似以下的输出:
Process 25092. Mutex handle: 0x9C Press any key to begin...
进程 ID 会不同, 句柄值很可能也不同. 这些是到同一个互斥体对象的句柄. 要验证这一点, 请打开 Process Explorer 并找到这两个进程实例. 在每个实例中找到互斥体 (其名称为“ExampleMutex”). 注意句柄值与打印的值相对应 (图 8-3).

Figure 136: Process Explorer 中的一个互斥体句柄
现在双击句柄并验证互斥体的句柄计数为 2 (图 8-4). 另外, 请注意它是未发出信号的 (持有: FALSE).

Figure 137: Process Explorer 中的互斥体属性
现在在两个控制台窗口中快速按任意键. 这些进程中的线程现在将使用互斥体来同步对文件的访问. 每个线程都会向文件中追加一行, 其中包含一个持有进程 ID 的字符串.
一旦进程完成执行, 你可以在文本编辑器中打开该文件. 你应该会看到类似以下的内容:
This is text from process 25092 This is text from process 25092 This is text from process 25092 This is text from process 25092 This is text from process 25092 This is text from process 36460 This is text from process 25092 This is text from process 36460 This is text from process 25092 This is text from process 36460 This is text from process 36460 This is text from process 25092 This is text from process 36460 This is text from process 25092 This is text from process 36460 ...
总行数应该是 200. 每个进程应该都用自己的进程 ID 写了正好 100 行.
`main` 函数创建/打开命名的互斥体, 打印进程 ID 和互斥体句柄, 然后等待用户按键:
int wmain(int argc, const wchar_t* argv[]) { if (argc < 2) { printf("Usage: MutexDemo <file>\n"); return 0; } HANDLE hMutex = ::CreateMutex(nullptr, FALSE, L"ExampleMutex"); if (!hMutex) return Error("Failed to create/open mutex"); printf("Process %d. Mutex handle: 0x%X\n", ::GetCurrentProcessId(), HandleToULong(hMutex)); printf("Press any key to begin...\n"); _getch(); }
`Error` 函数提供了一个我们之前遇到过的简单的错误显示:
int Error(const char* text) { printf("%s (%d)\n", text, ::GetLastError()); return 1; }
一旦按下键, 就会执行一个循环 100 次, 获取互斥体, 访问文件, 然后在同一次迭代中释放互斥体:
printf("Working...\n"); for (int i = 0; i < 100; i++) { // insert some randomness ::Sleep(::GetTickCount() & 0xff); // acquire the mutex ::WaitForSingleObject(hMutex, INFINITE); // write to the file if (!WriteToFile(argv)) return Error("Failed to write to file"); ::ReleaseMutex(hMutex); } ::CloseHandle(hMutex); printf("Done.\n"); return 0; }
`WriteToFile` 函数打开文件, 将文件指针设置到文件末尾, 将文本写入文件并关闭文件:
bool WriteToFile(PCWSTR path) { HANDLE hFile = ::CreateFile(path, GENERIC_WRITE, FILE_SHARE_READ, nullptr, OPEN_ALWAYS, 0, nullptr); if (hFile == INVALID_HANDLE_VALUE) return false; ::SetFilePointer(hFile, 0, nullptr, FILE_END); char text; sprintf_s(text, "This is text from process %d\n", ::GetCurrentProcessId()); DWORD bytes; BOOL ok = ::WriteFile(hFile, text, (DWORD)strlen(text), &bytes, nullptr); ::CloseHandle(hFile); return ok; }
文件 API 在第 11 章中详细讨论.
你可以并发运行任意数量的 `QueueDemo` 进程——共享文件不会被损坏. 这个演示使用相同的可执行文件的事实是无关紧要的——如果从不同的可执行文件使用, 它的工作方式相同. 重要的部分是共享互斥体.
将互斥体名称更改为 `NULL` 并重复实验. 你理解结果吗?
- 废弃的互斥体
如果一个拥有互斥体的线程退出或终止 (无论出于何种原因) 会发生什么? 由于互斥体的所有者是唯一可以释放互斥体的, 这可能会导致死锁, 其他等待互斥体的线程将永远无法获取它. 这种互斥体被称为*被放弃的互斥体*, 字面意思是其所有者线程放弃了它.
幸运的是, 内核知道互斥体的所有权, 因此如果它看到一个线程在持有互斥体时终止 (如果那是情况的话, 可能会是多个), 它会显式地释放被放弃的互斥体. 这导致下一个成功获取互斥体的线程从其 `WaitForSingleObject` 调用中得到 `WAITABANDONED` 而不是 `WAITOBJECT0`. 这意味着线程正常地获取了互斥体, 但特殊的返回值被用作一个提示, 表明前一个所有者在终止前没有释放互斥体. 这通常表示一个应该被调查的 bug.
为互斥体编写 RAII 包装器.
1.9.2. 信号量
信号量是我们检查的第一个同步内核对象, 它在第 7 章中检查的进程内原语中没有直接的对应物. 信号量的目的是以线程安全的方式限制某样东西.
一个信号量用一个当前计数和一个最大计数进行初始化. 只要其当前计数大于零, 它就处于已发出信号状态. 每当一个线程在信号量上调用 `WaitForSingleObject` 并且它处于已发出信号状态时, 信号量的计数就会递减, 并且该线程被允许继续. 一旦信号量计数达到零, 它就变为未发出信号, 任何试图等待它的线程都将被阻塞.
相反, 一个想要“释放”一个 (或更多) 信号量计数的线程, 会调用 `ReleaseSemaphore`, 导致信号量的计数增加并将其设置为已发出信号状态.
让我们回顾一下, 看看如何用以下函数之一创建信号量:
HANDLE CreateSemaphore( _In_opt_ LPSECURITY_ATTRIBUTES lpSemaphoreAttributes, _In_ LONG lInitialCount, _In_ LONG lMaximumCount, _In_opt_ LPCTSTR lpName); HANDLE CreateSemaphoreEx( _In_opt_ LPSECURITY_ATTRIBUTES lpSemaphoreAttributes, _In_ LONG lInitialCount, _In_ LONG lMaximumCount, _In_opt_ LPCTSTR lpName, _Reserved_ DWORD dwFlags, _In_ DWORD dwDesiredAccess);
一个信号量可以有一个名称, 就像一个互斥体一样. 这允许在不同进程中运行的线程之间轻松共享. 上述创建函数中的独特参数是信号量的初始计数和最大计数. 这些通常设置为相同的值, 表示由信号量限制的任何东西 (例如一个队列) 现在有零个元素. 扩展函数允许指定所需的访问掩码 (在调用 `CreateSemaphore` 时默认为 `SEMAPHOREALLACCESS`). `dwFlags` 参数当前未使用, 必须设置为零.
获取信号量的计数是用通常的等待函数完成的. 释放信号量计数是通过 `ReleaseSemaphore` 完成的:
BOOL ReleaseSemaphore( _In_ HANDLE hSemaphore, _In_ LONG lReleaseCount, _Out_opt_ LPLONG lpPreviousCount);
该函数允许指定要释放的计数 (即要添加到当前信号量计数的数量). 这个值通常是 1, 但可以更高. 最后一个参数允许检索新的信号量计数. 也可以为释放计数指定零, 只获取当前的信号量计数. 当然, 任何这样的检索都是一个潜在的竞争条件, 因为在检索和根据结果采取行动之间, 信号量的计数可能已被另一个线程更改.
一个最大计数为一的信号量是否等同于一个互斥体? 思考一下. 答案是绝对不是. 原因是信号量没有任何所有权的概念. 任何线程都可以获取它的一个计数, 任何线程都可以调用 `ReleaseSemaphore`. 信号量的目的与互斥体非常不同. 这种“自由风格”的行为如果不小心可能会导致死锁, 但在大多数情况下, 这是一件好事, 正如我们将在下一个代码示例中看到的.
与其他命名对象一样, 可以通过名称用 `OpenSemaphore` 获取现有信号量的句柄:
HANDLE OpenSemaphore( _In_ DWORD dwDesiredAccess, _In_ BOOL bInheritHandle, _In_ LPCTSTR lpName);
- 队列演示应用程序
图 8-5 中显示的*队列演示*应用程序是基于第 7 章中同名应用程序的. 这次, 添加了一个信号量, 以便工作项队列被限制在指定的数量内. 在第 7 章的版本中, 如果生产者线程生成数据的速度远快于消费者线程处理的速度, 队列可能会无限增长. 这是有问题的, 因为队列的内存消耗可能会过高, 甚至在极端情况下导致内存不足 (特别是在 32 位进程中).

Figure 138: 增强的队列演示应用程序
这就是信号量发挥作用的地方. 在原始应用程序中, 拥有新数据的生产者线程只会将其推入队列, 如果需要, 用条件变量唤醒消费者线程. 这一次, 生产者线程首先在信号量上调用 `WaitForSingleObject`. 如果信号量的计数大于零, 即已发出信号, 这意味着队列未满, 它可以继续推送一个项目. 在消费者端, 消费者线程从队列中弹出一个项目, 然后调用 `ReleaseSemaphore` 来指示队列现在少了一个项目.
首先, 信号量在 `CMainDlg::Run` 中根据对话框中指定的值创建:
//... int queueSize = GetDlgItemInt(IDC_MAX_QUEUE_SIZE); if (queueSize < 10 || queueSize > 100000) { DisplayError(L"Maximum queue size must be between 10 and 100000"); return; } // create semaphore m_hQueueSem.reset(::CreateSemaphore(nullptr, queueSize, queueSize, nullptr));
`mhQueueSem` 是一个持有信号量智能句柄的新数据成员 (`wil::uniquehandle`), 确保当信号量超出作用域或再次重置时调用 `CloseHandle`.
以下是修改后的生产者代码:
DWORD CMainDlg::ProducerThread() { for (;;) { if (::WaitForSingleObject(m_hAbortEvent.get(), 0) == WAIT_OBJECT_0) break; // wait if needed to make sure queue is not full ::WaitForSingleObject(m_hQueueSem.get(), INFINITE); WorkItem item; item.IsPrime = false; LARGE_INTEGER li; ::QueryPerformanceCounter(&li); item.Data = li.LowPart; { AutoCriticalSection locker(m_QueueLock); m_Queue.push(item); } ::WakeConditionVariable(&m_QueueCondVar); // sleep a little bit from time to time if ((item.Data & 0x7f) == 0) ::Sleep(1); } return 0; }
唯一的增加是对信号量调用 `WaitForSingleObject`. 消费者线程的代码也通过在从队列中移除一个项目后释放一个信号量来更改:
DWORD CMainDlg::ConsumerThread(int index) { auto& data = m_ConsumerThreads[index]; auto tick = ::GetTickCount64(); for (;;) { WorkItem value; { bool abort = false; AutoCriticalSection locker(m_QueueLock); while (m_Queue.empty()) { if (::WaitForSingleObject(m_hAbortEvent.get(), 0) == WAIT_OBJECT_0) { abort = true; break; } ::SleepConditionVariableCS(&m_QueueCondVar, &m_QueueLock, INFINITE); } if (abort) break; ATLASSERT(!m_Queue.empty()); value = m_Queue.front(); m_Queue.pop(); ::ReleaseSemaphore(m_hQueueSem.get(), 1, nullptr); } // rest of code omitted... } return 0; }
你可以使用 Process Explorer 的句柄视图查看信号量的基本属性. 图 8-6 显示了*队列演示*应用程序运行时来自该应用程序的信号量 (尽管 Process Explorer 不会自动更新对象的状态).

Figure 139: Process Explorer 中的信号量属性
信号量的灵活性是显而易见的: 生产者线程等待从信号量中获取一个计数, 而消费者线程释放计数——不是同一个线程.
为信号量编写 RAII 包装器.
1.9.3. 事件
事件在某种意义上是同步原语中最简单的——它只是一个可以被设置 (已发出信号状态) 或重置 (未发出信号状态) 的标志. 作为一个 (可能命名的) 内核对象, 它具有在单个进程内或跨进程工作的灵活性. 我们已经在*队列演示*应用程序中使用了一个事件. 现在我们将详细讨论它.
与事件相关的一个复杂性是存在两种类型的事件: 手动重置和自动重置. 表 8-2 总结了它们的属性, 接下来将详细阐述.
| 事件类型 | 内核名称 | `SetEvent` 的效果 |
|---|---|---|
| 手动重置 | Notification | 将事件置于已发出信号状态, 并释放所有等待它的线程 (如果有的话). 事件保持在已发出信号状态 |
| 自动重置 | Synchronization | 从等待中释放单个线程, 然后事件自动返回到未发出信号状态 |
表 8-2 中的内核类型名称对于像 Process Explorer 这样的工具很有用, 这些工具使用内核术语提供事件的类型名称.
创建事件对象与其他对象类型没有区别, 通过以下函数之一完成:
HANDLE CreateEvent( _In_opt_ LPSECURITY_ATTRIBUTES lpEventAttributes, _In_ BOOL bManualReset, _In_ BOOL bInitialState, _In_opt_ LPCTSTR lpName); HANDLE CreateEventEx( _In_opt_ LPSECURITY_ATTRIBUTES lpEventAttributes, _In_opt_ LPCTSTR lpName, _In_ DWORD dwFlags, _In_ DWORD dwDesiredAccess);
这些函数指定了要创建的事件类型. 一旦做出决定, 就无法更改. `CreateEvent` 使用 `bManualReset` 参数来指示手动重置事件 (`TRUE`) 或自动重置事件 (`FALSE`). 使用 `CreateEventEx`, 事件的类型是在 `dwFlags` 参数中指定的, 将其设置为 `CREATEEVENTMANUALRESET` 表示手动重置事件.
要做的第二个决定是事件的初始状态 (已发出信号或未发出信号). `CreateEvent` 允许在 `bInitialState` 参数中指定初始状态. 使用 `CreateEventEx`, 使用另一个标志来指示已发出信号的初始状态——`CREATEEVENTINITIALSET`.
与互斥体和信号量的扩展创建函数一样, `CreateEventEx` 允许为新事件句柄指定访问掩码 (默认为 `EVENTALLACCESS`, 与 `CreateEvent` 一样). 与前面的对象类似, 如果指定了名称并且存在同名事件, (并且没有安全限制), 则会打开到该事件的另一个句柄, 并且事件类型和初始状态将被忽略.
记住, 区分新对象和现有对象的方法是调用 `GetLastError` 并检查 `ERRORALREADYEXISTS`.
与其它对象类似, 可以通过 `OpenEvent` 按名称打开事件:
HANDLE OpenEvent( _In_ DWORD dwDesiredAccess, _In_ BOOL bInheritHandle, _In_ LPCTSTR lpName);
- 使用事件
事件的状态可以用 `SetEvent` 和 `ResetEvent` 函数显式地更改:
BOOL SetEvent(_In_ HANDLE hEvent); // signaled BOOL ResetEvent(_In_ HANDLE hEvent); // non-signaled
让我们看一个示例场景. 假设有几个作为同一系统一部分的进程正在运行. 再假设其中一个进程, 我们称之为*控制器*, 需要向该应用程序的所有其他进程发出信号, 以便优雅地关闭. 这如何实现?
事件提供了完美的候选者. 进程是隔离的, 因此没有直接的通信是可能的. 在大多数情况下, 这种隔离是件好事. 在某些情况下, 必须在进程之间发送一些信息. 在这种情况下, 要发送的信息很简单: 一个比特就足以指示需要关闭操作.
这个流同步可以用一个手动重置事件来完成. 所有进程都用一个预定义的名称创建一个命名事件, 例如“ShudownEvent”:
// notice a manual-reset event HANDLE hShutdown = ::CreateEvent(nullptr, TRUE, FALSE, L"ShutdownEvent");
由于对象是命名的, 只有第一个进程实际创建它, 其余的进程会得到到现有对象的句柄. 调用 `CreateEvent` 很方便, 不需要为“谁先创建事件”进行任何同步——这根本不重要.
接下来, 除了控制器之外的每个进程都需要在某个地方等待事件. 当事件变为已发出信号状态时, 每个进程都会启动自己的关闭过程:
::WaitForSingleObject(hShutdown, INFINITE); // object is signaled, initiate shutdown...
控制器进程只需要在需要关闭时设置事件:
::SetEvent(hShutdown); // initiate own shutdown...
这里需要一个手动重置事件, 因为设置事件应该唤醒所有等待它的线程, 这正是此场景所需要的.
一个可能出现的问题是, 参与的进程究竟在哪里等待事件? 最简单的解决方案是创建一个线程, 其唯一目的是进行等待. 这并不理想, 因为线程不应该被创建来只是等待. 一个更好的替代方案是使用线程池, 我们将在下一章中探讨.
自动重置事件的行为是不同的. 调用 `SetEvent` 会将其更改为已发出信号状态. 如果没有线程在等待它, 它会保持在已发出信号状态, 直到至少一个线程等待它. 然后, 一个线程被释放, 事件自动返回到未发出信号状态. 要唤醒另一个等待的线程, 需要再次调用 `SetEvent`.
*队列演示*应用程序显示了一个使用事件向生产者和消费者线程指示是时候中止的常见示例. 事件首先在 `CMainDlg::OnInitDialog` 中创建为一个手动重置事件, 因为多个线程需要通过一次调用被通知是时候退出了:
m_hAbortEvent.reset(::CreateEvent(nullptr, TRUE, FALSE, nullptr));
生产者代码检查事件是否已发出信号而不等待:
DWORD CMainDlg::ProducerThread() { for (;;) { if (::WaitForSingleObject(m_hAbortEvent.get(), 0) == WAIT_OBJECT_0) break; //... } }
如果事件已发出信号, 它会立即通过跳出无限循环来中止. 这个调用在每次迭代中都会进行, 以便生产者可以尽快退出. 消费者线程以类似的方式工作.
你可能想知道为什么不只使用一个布尔变量, 检查它是否为真, 如果为真就退出. 主要问题是编译器 (也可能是 CPU) 会将变量优化为具有一个不变的值, 因为编译器不知道它可能会从另一个线程更改. 一种可能的解决方案是将变量标记为 `volatile` 以防止任何优化, 并强制 CPU 访问实际值. 即使这样也不够可靠. 通常, 最好避免这些选项, 因为这种情况是数据竞争——多个线程访问同一个内存, 其中至少有一个在写入. 在任何情况下, 没有办法用简单变量模拟自动重置事件的行为, 更不用说在不同进程的线程之间进行协调了.
使用事件的最后一个函数是 `PulseEvent`:
BOOL PulseEvent(_In_ HANDLE hEvent);
`PulseEvent` 的目的是瞬间设置事件, 如果当前没有线程在等待, 就重置事件. 文档指出: “此函数不可靠, 不应使用. 它主要为了向后兼容而存在.”, 并接着给出了一个为什么使用此函数不是一个好主意的例子.
避免使用 `PulseEvent`.
Windows API 提供了对几种具有不同语义和编程模型的计时器的访问. 以下是主要的几种:
- 对于窗口化场景, `SetTimer` API 提供了一个通过向调用线程的消息队列发布 `WMTIMER` 消息来工作的计时器. 这个计时器适用于 GUI 应用程序, 因为计时器消息可以在 UI 线程上处理.
- Windows 多媒体 API 提供了一个用 `timeSetEvent` 创建的多媒体计时器, 它在一个优先级为 15 的单独线程上调用回调函数. 计时器可以是一次性的或周期性的, 并且可以非常精确 (其分辨率可以由函数设置). 零的分辨率值请求系统可以提供的最高分辨率. 以下是使用多媒体计时器的简单示例:
#include <mmsystem.h> #pragma comment(lib, "winmm") void main() { auto id = ::timeSetEvent( 1000, // interval (msec) 10, // resolution (msec) OnTimer, // callback 0, // user data TIME_PERIODIC); // periodic or one shot ::Sleep(10000); ::timeKillEvent(id); } void CALLBACK OnTimer(UINT id, UINT, DWORD_PTR userData, DWORD_PTR, DWORD_PTR) { printf("Timer struck at %u\n", ::GetTickCount()); }
我们本节将关注的计时器是*可等待计时器*, 它是一个内核对象, 因此值得在本章中出现. 可等待计时器在其到期时间到达时变为已发出信号状态.
创建一个可等待计时器是由两个函数之一完成的, 与之前遇到的函数有些类似:
HANDLE CreateWaitableTimer( _In_opt_ LPSECURITY_ATTRIBUTES lpTimerAttributes, _In_ BOOL bManualReset, _In_opt_ LPCTSTR lpTimerName); HANDLE CreateWaitableTimerEx( _In_opt_ LPSECURITY_ATTRIBUTES lpTimerAttributes, _In_opt_ LPCTSTR lpTimerName, _In_ DWORD dwFlags, _In_ DWORD dwDesiredAccess);
一个可等待计时器可以有一个名称, 就像互斥体, 信号量和事件一样. 可等待计时器有两种变体, 与事件类似: 手动重置计时器 (`bManualReset` 为 `TRUE` 或 `dwFlags` 为 `CREATEWAITABLETIMERMANUALRESET`) 或自动重置, 也称为同步计时器 (`bManualReset` 为 `FALSE` 或 `dwFlags` 为零). 最后, `CreateWaitableTimerEx` 可以为返回的句柄指定一个显式的访问掩码 (`TIMERALLACCESS`, 与 `CreateWaitableTimer` 默认的一样).
由于可等待计时器可以被命名, 现有的计时器可以按名称用 `OpenWaitableTimer` 打开:
HANDLE OpenWaitableTimer( _In_ DWORD dwDesiredAccess, _In_ BOOL bInheritHandle, _In_ LPCTSTR lpTimerName);
创建计时器是使用它的第一步, 还有至关重要的 `SetWaitableTimer(Ex)` 函数:
typedef VOID (CALLBACK *PTIMERAPCROUTINE)( _In_opt_ LPVOID lpArgToCompletionRoutine, _In_ DWORD dwTimerLowValue, _In_ DWORD dwTimerHighValue); BOOL SetWaitableTimer( _In_ HANDLE hTimer, _In_ const LARGE_INTEGER *lpDueTime, _In_ LONG lPeriod, _In_opt_ PTIMERAPCROUTINE pfnCompletionRoutine, _In_opt_ LPVOID lpArgToCompletionRoutine, _In_ BOOL fResume); BOOL SetWaitableTimerEx( _In_ HANDLE hTimer, _In_ const LARGE_INTEGER *lpDueTime, _In_ LONG lPeriod, _In_opt_ PTIMERAPCROUTINE pfnCompletionRoutine, _In_opt_ LPVOID lpArgToCompletionRoutine, _In_opt_ PREASON_CONTEXT WakeContext, _In_ ULONG TolerableDelay);
两个函数的前五个参数是相同的, 所以我们先处理它们. `lpDueTime` 参数表示时间应该何时到期. 它以 `LARGEINTEGER` 结构给出, 这不过是一个美化的 64 位数字, 如果需要, 可以方便地访问其两个 32 位部分. 存储的数字是有符号的, 对正数与负数有不同的含义:
- 正数表示从 1601 年 1 月 1 日午夜 UTC (通用协调时间, 也称为 GMT) 测量的 100 纳秒单位的绝对时间.
- 负数表示 100 纳秒单位的相对时间.
计时器的实际分辨率取决于硬件, 并且不在 100 纳秒的范围内.
让我们从最常见的情况开始, 一个相对间隔. 毫秒的间隔是相当常见的, 并且在 100 纳秒 (10 的 -7 次方) 到毫秒 (10 的 -3 次方) 之间转换, 意味着乘以 10000. 一个 10 毫秒的间隔可以通过初始化一个 `LARGEINTEGER` 来设置, 像这样:
LARGE_INTEGER interval; interval.QuadPart = -10000 * 10;
绝对时间更棘手, 因为零时间在一个看似奇怪的遥远过去. 最好的方法是使用 Windows API 提供的帮助函数来获得所需的值. 例如, 假设计时器应在 2020 年 3 月 10 日 17:30:00 (UTC) (我写这些行的日期) 到期, 以下代码片段有助于计算正确的值:
SYSTEMTIME st = { 0 }; st.wYear = 2020; st.wMonth = 3; st.wDay = 10; st.wHour = 17; st.wMinute = 30; FILETIME ft; ::SystemTimeToFileTime(&st, &ft); LARGE_INTEGER dueTime; dueTime.QuadPart = *(LONGLONG*)&ft;
`FILETIME` 结构与 `LARGEINTEGER` 相同, 但奇怪的是没有单个的 64 位数据成员, 只有两个 32 位值; 这就是为什么最后一行强制读取它为 64 位值的原因. 另外, 文件系统中常用的术语“文件时间”使用相同的时间测量.
如果需要本地时间作为基础, 而不是 UTC, 在调用 `SystemTimeToFileTime` 之前使用 `TzSpecificLocalTimeToSystemTime`, 像这样:
FILETIME ft; ::TzSpecificLocalTimeToSystemTime(nullptr, &st, &st); ::SystemTimeToFileTime(&st, &ft);
`TzSpecificLocalTimeToSystemTime` 默认使用当前时区 (第一个 `NULL` 值), 如果活动, 则考虑夏令时 (DST).
如果到期时间是绝对的, 并且指定了一个过去的值, 计时器会立即发出信号.
`SetWaitableTimer(Ex)` 的第三个参数指示计时器是一次性的还是周期性的. 指定零使其成为一次性的; 否则, 它是以毫秒为单位的周期. 请注意, 这在绝对和相对到期时间中都有效.
第四个参数是一个可选的函数指针, 当计时器发出信号 (到期) 时应该被调用. 参数可以是 `NULL`, 在这种情况下, 可以使用正常的等待函数来获取计时器何时到期的指示. 如果该值非 `NULL`, 则当计时器到期时, 该函数不会立即被调用; 相反, 该函数被包装在一个*异步过程调用* (APC) 中, 并附加到调用 `SetWaitableTimer(Ex)` 的线程.
APC 是一个注定要由特定线程执行的回调, 因此必须仅由该线程执行. 在可等待计时器的情况下, APC 被添加到调用 `SetWaitableTimer(Ex)` 的线程的 APC 队列中. 棘手的部分是这个 APC 不会立即执行. 那太危险了, 因为线程可能在计时器到期时正在做某事, 强制将其转移到 APC 的回调可能会产生意想不到的后果. 如果线程在调用时已获取了一个临界区怎么办? 通常, APC 对线程在其执行中的位置一无所知.
所有这些意味着 APC 被推到特定线程队列的末尾, 但为了运行它们, 线程必须进入一个*可警报状态*. 在此状态下, 线程首先检查其 APC 队列中是否累积了任何 APC, 如果有, 则按顺序运行所有这些 APC, 然后恢复其进入可警报状态后的代码执行.
一个线程如何进入可警报状态? 有几个函数可以完成这个任务, 最简单的是 `SleepEx`:
DWORD SleepEx( _In_ DWORD dwMilliseconds, _In_ BOOL bAlertable);
`SleepEx` 是熟悉的 `Sleep` 函数的超集. 事实上, `Sleep` 函数是通过调用 `SleepEx` 并将 `bAlertable` 参数设置为 `FALSE` 来实现的. 调用 `SleepEx` 并将 `bAletrable` 设置为 `TRUE` 会使线程在睡眠期间进入可警报状态. 如果在睡眠期间, APC 出现在线程的队列中, 它们会立即被执行, 并且睡眠结束. 如果在调用 `SleepEx` 时已经存在任何 APC, 则不会发生睡眠.
以下示例显示了如何设置一个每秒调用一次回调的可等待计时器, 通过将线程置于无限的可警报睡眠中 (本章代码示例中的 `SimpleTimer` 项目):
void CALLBACK OnTimer(void* param, DWORD low, DWORD high) { printf("TID: %u Ticks: %u\n", ::GetCurrentThreadId(), ::GetTickCount()); } int main() { auto hTimer = ::CreateWaitableTimer(nullptr, TRUE, nullptr); LARGE_INTEGER interval; interval.QuadPart = -10000 * 1000LL; ::SetWaitableTimer(hTimer, &interval, 1000, OnTimer, nullptr, FALSE); printf("Main thread ID: %u\n", ::GetCurrentThreadId()); while (true) ::SleepEx(INFINITE, TRUE); // we'll never get here return 0; }
运行这会产生类似以下的结果:
Main thread ID: 32024 TID: 32024 Ticks: 19648406 TID: 32024 Ticks: 19649406 TID: 32024 Ticks: 19650421 TID: 32024 Ticks: 19651421 TID: 32024 Ticks: 19652437 TID: 32024 Ticks: 19653437 TID: 32024 Ticks: 19654453 ...
请注意, 调用 `SetWaitableTimer` 的线程与执行回调的线程相同. 该代码使用带有无限超时的 `SleepEx`, 因为线程除了运行计时器回调外无事可做. 无限 `while` 循环是必要的, 否则在第一次回调运行后, 睡眠结束, 程序将退出. 该循环使线程保持活动状态, 只是等待 APC 的出现.
`SleepEx` 的另一个有用选项是使用零超时. 这可以被认为是一种简单的“垃圾回收”, 其中一个线程不时地调用 `SleepEx(0, TRUE)` 来运行任何可能已累积的 APC, 但线程不希望等待.
`SleepEx` 足够简单, 但其他场景需要更多的灵活性. 允许线程在可警报状态下等待的其他函数包括经典函数的扩展版本, 在下一节中讨论.
使用 APC 的其他形式在第 11 章中介绍.
Windows 支持三种类型的 APC: 用户模式 APC, 内核模式 APC 和特殊内核模式 APC. 前者是本书讨论的. 内核变体 (显然) 只对内核模式调用者可用 (事实上在 WDK 中没有文档化), 在任何情况下都不在本书的范围内. 请参阅我的书“Windows Kernel Programming”, 以及各种在线资源, 以获取有关内核模式 APC 的详细描述.
`SetWaitableTimer(Ex)` 的第五个参数是一个用户定义的值, 如果提供, 则按原样传递给回调函数. 回调本身接收此值作为其第一个参数, 以及两个 32 位值, 它们构成了前面描述的绝对格式的 64 位值, 指示计时器被触发的时间.
`SetWaitableTimer` 的第六个 (也是最后一个) 参数指定如果系统处于节能状态 (例如连接待机), 计时器到期是否应触发系统唤醒.
这结束了 `SetWaitableTimer`. 扩展函数 (从 Windows 7 和 Server 2008 R2 开始可用) 还有两个参数. 第一个 (第六个) 是一个可选的指向 `REASONCONTEXT` 结构的指针, 定义如下:
typedef struct _REASON_CONTEXT { ULONG Version; DWORD Flags; union { struct { HMODULE LocalizedReasonModule; ULONG LocalizedReasonId; ULONG ReasonStringCount; LPWSTR *ReasonStrings; } Detailed; LPWSTR SimpleReasonString; } Reason; } REASON_CONTEXT, *PREASON_CONTEXT;
该结构可以为计时器请求提供额外的上下文. 它也用于电源请求. 这有助于在计时器导致系统从低功耗状态唤醒时进行日志记录. 传递 `NULL` 表示没有特定的上下文. 有关 `REASONCONTEXT` 的确切详细信息, 请参阅文档.
`SetWaitableTimerEx` 的最后一个参数是计时器到期的容差值 (以毫秒为单位). 这与 Windows 7 中引入的一个名为*合并计时器*的功能有关. 假设你有两个计时器, 一个在 100 毫秒后到期, 另一个在 105 毫秒后到期. 通常, CPU 必须在 100 毫秒后醒来并发出第一个计时器的信号, 进入睡眠, 然后在 5 毫秒后醒来以发出第二个计时器的信号. 然而, 如果第二个 (或第一个) 计时器请求了 (比如说) 10 毫秒的容差, 系统将只唤醒 CPU 一次, 并一次性发出两个计时器的信号, 因为应用程序表示在与确切时间有一些容差间隔的情况下发出计时器信号是可以的. 指定零 (这是 `SetWaitableTimer` 内部做的) 意味着没有容差, 并且应用程序希望在可能消耗更多功率的情况下获得最佳精度. 否则, 会相对于系统上的其他计时器考虑容差.
我们还没有完成计时器——计时器也可以通过利用线程池更方便地处理, 我们将在下一章中探讨.
最后, 在成功调用 `SetWaitableTimer(Ex)` (但在计时器到期之前) 之后, 可以用 `CancelWaitableTimer` 取消计时器:
BOOL CancelWaitableTimer(_In_ HANDLE hTimer);
经典的等待函数 `WaitForSingleObject` 和 `WaitForMultipleObjects` 是最常用的. 然而, 还有其他变体, 我们将在本节中探讨.
- 在可警报状态下等待
存在通用函数的扩展版本, 它们接受一个额外的参数来指示是否在可警报状态下等待:
DWORD WaitForSingleObjectEx( _In_ HANDLE hHandle, _In_ DWORD dwMilliseconds, _In_ BOOL bAlertable); DWORD WaitForMultipleObjectsEx( _In_ DWORD nCount, _In_reads_(nCount) CONST HANDLE* lpHandles, _In_ BOOL bWaitAll, _In_ DWORD dwMilliseconds, _In_ BOOL bAlertable);
为 `bAlertable` 传递 `FALSE` 与调用原始函数相同. 将 `bAlertable` 设置为 `TRUE`, 附加到调用线程的任何 APC 都会按顺序执行, 然后等待结束. 在这种情况下, 返回值是 `WAITIOCOMPLETION`. 如果返回了这个值, 并且线程仍然想等待对象, 它可以再次调用等待函数.
其他函数也存在相同的模式, 提供了一个在可警报状态下等待的选项, 在下一节中描述.
- 在 GUI 线程上等待
GUI 线程通常不应使用 `WaitForSingleObject` 或 `WaitForMultipleObjects` (或其扩展变体) 并带有 `INFINITE` 超时, 如果等待时间可能很长. 问题在于, 如果所讨论的对象在很长一段时间内没有变为已发出信号状态, 该线程管理的所有 UI 活动都会冻结, 产生在任务管理器中令人畏惧的“无响应”状态, 该线程创建的窗口会变暗, 标题栏上会添加“无响应”. 这是一种非常糟糕的用户体验, 应不惜一切代价避免.
在许多情况下, GUI 线程不需要等待内核对象, 但在某些情况下这是不可避免的. 幸运的是, 有一个解决方案: `MsgWaitForMultipleObject(Ex)` 函数:
DWORD WINAPI MsgWaitForMultipleObjects( _In_ DWORD nCount, _In_ CONST HANDLE *pHandles, _In_ BOOL fWaitAll, _In_ DWORD dwMilliseconds, _In_ DWORD dwWakeMask); WINUSERAPI DWORD WINAPI MsgWaitForMultipleObjectsEx( _In_ DWORD nCount, _In_ CONST HANDLE *pHandles, _In_ DWORD dwMilliseconds, _In_ DWORD dwWakeMask, _In_ DWORD dwFlags);
这些函数通常在一个或多个对象上等待, 但也等待发往调用线程的 UI 消息, 其类型由 `dwWakeMask` 参数指定. 最简单的是 `QSALLEVENTS`, 它导致函数在线程的消息队列中出现任何消息时返回 `WAITOBJECT0+nCount` 的值. 在这种情况下, 线程应该泵送消息并恢复等待. 以下是在事件对象上等待并在其间泵送消息的示例:
void WaitWithMessages(HANDLE hEvent) { while (::MsgWaitForMultipleObjects(1, &hEvent, FALSE, INFINITE, QS_ALLEVENTS) == WAIT_OBJECT_0 + 1) { MSG msg; while (::PeekMessage(&msg, nullptr, 0, 0, PM_REMOVE)) { ::TranslateMessage(&msg); ::DispatchMessage(&msg); } } }
查看文档中的其他状态掩码 (`QS_`) 值.
扩展函数从原始函数中删除了 `fWaitAll` 参数, 而是提供了一个额外的 `dwFlags` 参数, 它可以为零或包含以下一个或多个标志:
- `MWMOALERTABLE` - 函数在可警报状态下等待, 如前一节所述.
- `MWMOINPUTAVAILABLE` - 如果消息队列中存在输入, 函数返回, 即使该输入已用 `PeekMessage` 或 `GetMessage` 查看过. 没有此标志, 只有新输入才会导致函数返回.
- `MWMOWAITALL` - 如果所有对象都已发出信号并且输入可用, 函数返回, 所有这些都在同一时间.
- 等待空闲的 GUI 线程
`WaitForInputIdle` 函数可用于等待指定进程中的 GUI 线程准备好处理消息:
DWORD WINAPI WaitForInputIdle( _In_ HANDLE hProcess, _In_ DWORD dwMilliseconds);
该函数对于创建一个子进程并希望与其 UI 线程 (通常是第一个线程) 交互的父进程最有用. 由于子进程的进程创建是异步的, 父进程无法知道线程何时准备好接收消息. 过早地向线程发布消息 (在线程的消息队列准备好之前) 会导致消息丢失.
以下是完成此任务的典型代码:
PROCESS_INFORMATION pi; //... ::CreateProcess(..., &pi); // error handling omitted ::WaitForInputIdle(pi.hProcess, INFINITE); // UI thread is ready, post some message to the main thread ::PostThreadMessage(pi.dwThreadId, WM_USER, 0, 0); //...
- 原子地发信号和等待
我们本章将看的最后一个等待函数是 `SignalObjectAndWait`:
DWORD SignalObjectAndWait( _In_ HANDLE hObjectToSignal, _In_ HANDLE hObjectToWaitOn, _In_ DWORD dwMilliseconds, _In_ BOOL bAlertable);
`hObjectToSignal` 可以是事件, 信号量或互斥体, 每个都用自己的函数发出信号: `SetEvent`, `ReleaseSemaphore` (计数为 1), 和 `ReleaseMutex` 分别. `hObjectToWaitOn` 可以指向任何可等待对象. 该函数将一个对象发出信号和原子地等待另一个对象结合起来.
这个函数的第一个好处是它的效率. 而不是像下面这样:
::SetEvent(hEvenet1); ::WaitForSingleObject(hEvent2, INFINITE);
`SignalObjectAndWait` 将这两个函数结合起来, 只需要一次到内核模式的转换:
::SignalObjectAndWait(hEvent1, hEvent2, INFINITE, FALSE);
第二个好处是这两个操作是原子的, 这意味着没有其他线程可以在线程进入等待状态之前观察到被信号对象的状态. 在一些涉及 `PulseEvent` 函数的边缘情况下, `SignalObjectAndWait` 提供了一个可靠的解决方案.
前面的警告适用——不要使用 `PulseEvent`.
1.9.4. 练习
- 创建一个可以并发运行多个工作项的系统, 但其中一些可能对其他工作项有依赖. 作为一个具体的例子, 考虑在 Visual Studio 中编译项目. 一些项目依赖于其他项目, 所以它们必须按顺序处理. 以下是一个项目层次结构的例子 (读作: 项目 4 依赖于 1, 项目 5 依赖于项目 2 和 3, 依此类推). 目标是在遵守依赖关系的同时尽快编译所有项目. 使用事件对象进行流同步.
Figure 140: 示例项目依赖关系
1.9.5. 总结
在本章中, 我们探讨了常用于线程同步的调度程序对象. 在下一章中, 我们将研究线程池, 它是显式创建线程的常见替代方案.
1.10. 第 9 章: 线程池
在最后几章中, 我们看到了如何创建和管理线程. 虽然这行得通, 但在某些情况下有些小题大做. 有时我们需要在不同的线程上执行一些有界操作, 但总是创建一个新线程会有其开销. 线程不是免费的: 内核有其管理线程信息的结构, 一个线程有用户模式和内核模式的栈, 并且创建线程本身也需要时间. 如果线程预计是相对短寿的, 额外的开销就会变得很显著.
本章讨论的线程池与 .NET 或 .NET Core 线程池没有关系, 后者在托管进程中可用. CLR / CoreCLR 有其自己的线程池实现.
本章内容:
- 为什么使用线程池?
- 线程池工作回调
- 线程池等待回调
- 线程池计时器回调
- 线程池 I/O 回调
- 线程池实例操作
- 回调环境
- 私有线程池
- 清理组
1.10.1. 为什么使用线程池?
Windows 提供了线程池, 这是一种允许将操作发送到线程池中的某个线程来执行的机制. 与手动创建和管理线程相比, 使用线程池的优势如下:
- 客户端代码不进行显式的线程创建或终止——线程池管理器处理这些.
- 完成的操作不会销毁工作线程——它会返回到池中以服务另一个请求.
- 池中的线程数可以根据工作项负载动态增长和收缩.
Windows 2000 是第一个提供线程池支持的 Windows 版本. 它为每个进程提供一个线程池. 从 Windows Vista 开始, 线程池 API 得到了显著增强, 包括增加了私有线程池, 这意味着一个进程中可以存在多个线程池.
我们将只描述较新的 API, 因为除非你的目标是 Vista 之前的 Windows 版本, 否则没有充分的理由使用旧的 API.
线程池的服务被一些 Windows 函数和第三方库内部使用, 所以你可能会发现即使你没有显式地使用任何与线程池相关的 API, 线程池线程也存在. 如果你运行一个简单的应用程序, 例如 Notepad, 它不需要超过一个线程, 你可能会发现, 在 Process Explorer 中查看该进程时, 它有几个线程, 其中一些以函数 `ntdll!TppWorkerThread` 开始 (图 9-1). 这是线程池线程的启动函数. 如果你让 Notepad 进程闲置一段时间, 你可能会发现线程池线程消失了 (图 9-2).
“Tpp” 是 Thread Pool Private 的缩写, 即一个私有的 (未导出的) 与线程池相关的函数. 负责管理线程池的内核对象称为 `TpWorkerFactory`.

Figure 141: Notepad 中的线程池线程

Figure 142: Notepad 中没有线程池线程
你可以通过运行我的 Object Explorer 工具来了解系统中线程池的数量, 该工具可从 https://github.com/zodiacon/AllTools 或 https://github.com/zodiacon/ObjectExplorer/Releases 下载. 打开后, 会显示对象类型. 按名称排序并查找 `TpWorkerFactory` (图 9-3). 注意系统中的此类对象的数量.

Figure 143: Object Explorer 中显示的 TpWorkerFactory 对象数量
你可以通过右键单击 `TpWorkerFactory` 对象并选择*所有对象*来查看更多详细信息, 以查看此类型的所有对象及其一些详细信息 (图 9-4). 你可以了解进程中有多少线程池.

Figure 144: 系统中的 TpWorkerFactory 对象
1.10.2. 线程池工作回调
向线程池提交工作项最简单的 API 是 `TrySubmitThreadpoolCallback`:
typedef VOID (NTAPI *PTP_SIMPLE_CALLBACK)( _Inout_ PTP_CALLBACK_INSTANCE Instance, _Inout_opt_ PVOID Context); BOOL TrySubmitThreadpoolCallback( _In_ PTP_SIMPLE_CALLBACK pfns, _Inout_opt_ PVOID pv, _In_opt_ PTP_CALLBACK_ENVIRON pcbe);
`TrySubmitThreadpoolCallback` 设置一个作为第一个参数提供的回调, 由线程池调用. 第二个参数允许指定一个上下文值, 该值按原样传递给回调函数. 最后一个可选参数, 与回调环境有关, 可以设置为 `NULL`. 我们将在本章后面探讨回调环境.
回调函数本身用两个参数调用, 其中第二个是提供给 `TrySubmitThreadpoolCallback` 的上下文. 类型为 `PTPCALLBACKINSTANCE` 的第一个参数是一个不透明的指针, 代表此回调实例. 我们也将在本章后面讨论此参数.
该函数在成功时返回 `TRUE`, 这在大多数情况下都应该如此, 除非 Windows 处于极端内存压力下. 一旦提交, 回调会尽快由线程池线程执行. 一旦提交, 没有内置的方法可以取消请求. 也没有直接的方法知道回调何时完成执行. 当然, 可以添加我们自己的机制, 例如从回调中发出事件对象的信号, 并在不同的线程上等待它.
- 简单工作应用程序
图 9-5 中显示的*简单工作*示例应用程序, 在其执行时允许使用 `TrySubmitThreadpoolCallback` 向线程池提交工作项, 同时观察每个回调在哪个线程下执行. 同时, 应用程序显示进程中的线程数.

Figure 145: 简单工作应用程序
当应用程序启动时, 线程数应该很低, 通常是 1 或 4. 单击*提交工作项*按钮以提交单个工作项. 如果线程数大于一, 它很可能会保持相同的数量, 因为至少有一个线程池线程已经存活并且可以接收请求 (图 9-6). 再多按几次相同的按钮将启动更多的工作项, 并且随着线程池“感知”到更高的负载, 线程数应该会增加.

Figure 146: 提交到线程池的单个工作项
现在多次单击*提交 10 个工作项*按钮, 并观察线程数大幅增加 (图 9-7).

Figure 147: 提交到线程池的多个工作项
如果你不提交很多项, 只需等待一段时间, 线程数就会开始下降. 如果给予足够的时间, 线程数将降至 1, 只留下主 UI 线程存活 (图 9-8). 这个应用程序展示了线程池的动态特性.

Figure 148: 简单工作在一段时间不活动后
“提交”按钮只是调用 `TrySubmitThreadpoolCallback`:
LRESULT CMainDlg::OnSubmitWorkItem(WORD, WORD wID, HWND, BOOL&) { if(!::TrySubmitThreadpoolCallback(OnCallback, this, nullptr)) AtlMessageBox(*this, L"Failed to submit work item callback", IDR_MAINFRAME, MB_ICONERROR); return 0; } LRESULT CMainDlg::OnSubmit10WorkItems(WORD, WORD, HWND, BOOL&) { for (int i = 0; i < 10; i++) { if (!::TrySubmitThreadpoolCallback(OnCallback, this, nullptr)) { AtlMessageBox(*this, L"Failed to submit work item callback", IDR_MAINFRAME, MB_ICONERROR); break; } } return 0; }
上下文参数设置为 `this`, 以便静态回调函数 (`OnCallback`) 可以访问对话框对象. 回调通过休眠一点来模拟工作, 通过 `PostMessage` 向对话框发布消息来指示它在哪个线程上被调用:
void CMainDlg::OnCallback(PTP_CALLBACK_INSTANCE instance, PVOID context) { auto dlg = (CMainDlg*)context; // post message indicating start dlg->PostMessage(WM_APP + 1, ::GetCurrentThreadId()); // simulate work... ::Sleep(10 * (::GetTickCount() & 0xff)); // post message indicating end dlg->PostMessage(WM_APP + 2, ::GetCurrentThreadId()); }
这些消息由普通的 WTL 消息映射映射到由 UI (主) 线程调用的函数. 这是因为任何发布 (或发送) 到窗口的消息总是放在窗口创建者线程的消息队列中, 并且只有该线程被允许从队列中检索消息并处理它们. 以下是自定义 `WMAPP + 1` 消息的处理程序:
LRESULT CMainDlg::OnCallbackStart(UINT, WPARAM wParam, LPARAM, BOOL&) { CString text; text.Format(L"Started on thread %d", wParam); m_List.AddString(text); return 0; }
第二条消息除了文本本身外是相同的. 获取当前进程中的线程数出奇地棘手, 因为没有文档化的 (或未文档化的, 就此而言) API 可以直接获取该值. 这里使用第 3 章中讨论的 Tool help API 来定位当前进程, 其中线程数作为 `PROCESSENTRY32` 结构的一部分提供. 该代码是一个 `WMTIMER` 消息处理程序的一部分, 每 2 秒调用一次以更新当前线程计数:
auto hSnapshot = ::CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0); if (hSnapshot == INVALID_HANDLE_VALUE) return 0; PROCESSENTRY32 pe; pe.dwSize = sizeof(pe); ::Process32First(hSnapshot, &pe); // skip idle process auto pid = ::GetCurrentProcessId(); ULONG threads = 0; while (::Process32Next(hSnapshot, &pe)) { if (pe.th32ProcessID == pid) { threads = pe.cntThreads; break; } } ::CloseHandle(hSnapshot); CString text; text.Format(L"Threads: %u\n", threads); SetDlgItemText(IDC_THREADS, text);
- 控制工作项
使用 `TrySubmitThreadpoolCallback` 相当直接, 但有时你需要更多的控制. 例如, 你可能想知道回调何时完成, 或者如果满足某些条件, 你可能想取消工作项. 对于这些情况, 你可以显式地创建一个线程池工作项. 实现这一点的 API 是 `CreateThreadPoolWork`:
PTP_WORK CreateThreadpoolWork( _In_ PTP_WORK_CALLBACK pfnwk, _Inout_opt_ PVOID pv, _In_opt_ PTP_CALLBACK_ENVIRON pcbe);
该函数看起来与 `TrySubmitThreadpoolCallback` 类似, 有两个区别. 第一个是返回值, 这是一个表示工作项的不透明 `PTPWORK` 指针, 如果失败则为 `NULL`. 第二个区别是回调原型, 看起来像这样:
typedef VOID (CALLBACK *PTP_WORK_CALLBACK)( _Inout_ PTP_CALLBACK_INSTANCE Instance, _Inout_opt_ PVOID Context, _Inout_ PTP_WORK Work);
回调有第三个参数, 即最初从 `CreateThreadpoolWork` 返回的工作项对象. 一旦创建了工作项对象, 就可以通过调用 `SubmitThreadpoolWork` 来提交它 (可能多次):
VOID SubmitThreadpoolWork( _Inout_ PTP_WORK Work );
请注意, 该函数返回 `void`, 暗示它不会失败. 这是因为如果 `CreateThreadpoolWork` 成功, `SubmitThreadpoolWork` 就不可能失败. 另一方面, 每次调用 `TrySubmitThreadpoolCallback` 都可能失败.
允许使用同一个工作对象多次调用 `SubmitThreadpoolWork`. 潜在的缺点是所有这些提交都使用相同的回调和相同的上下文, 因为这些只能在工作对象创建时提供. 一旦提交, 可以通过 `WaitForThreadpoolWorkCallbacks` 对提交的回调进行一些控制:
void WaitForThreadpoolWorkCallbacks( _Inout_ PTP_WORK pwk, _In_ BOOL fCancelPendingCallbacks);
第一个参数是从 `CreateThreadpoolWork` 返回的工作对象. 如果 `fCancelPendingCallbacks` 是 `FALSE`, 调用线程会进入一个等待状态, 直到通过该工作项提交的所有回调都已完成. 如果尚未提交任何回调, 该函数会立即返回.
如果 `fCancelPendingCallbacks` 是 `TRUE`, 该函数会取消任何尚未开始执行的已提交回调. 该函数永远不会取消正在进行的回调——那没有意义, 因为这样做的唯一方法是强行终止线程池线程, 这是一个坏主意. 调用线程会等待所有当前正在执行的回调完成, 然后其等待才会结束.
最后, 线程池工作对象必须最终用 `CloseThreadpoolWork` 释放:
void CloseThreadpoolWork(_Inout_ PTP_WORK pwk);
修改*简单工作*应用程序以使用本节中描述的 `CreateThreadpoolWork` 及相关函数. (解决方案是本章其他示例中的 `SimpleWork2` 项目.)
Windows Implementation Library (WIL) 有用于线程池工作对象的句柄: `wil::uniquethreadpoolwork`, `uniquethreadpoolworknocancel`, 和 `uniquethreadpoolworknowait`. “nowait” 变体只在工作对象超出作用域时关闭它. 前两个变体调用 `WaitForThreadpoolWorkCallbacks` 以等待所有待处理的回调完成, 前者将取消参数设置为 `TRUE`, 后者设置为 `FALSE`.
- MD5 计算器应用程序
第 7 章的 MD5 计算器应用程序为每个需要的计算创建一个新线程. 这是低效的, 线程池在这里可以作为替代方案. 要替换的代码在 `CView::OnStartCalc` 中, 目前为每个需要的计算创建一个线程:
// spawn a thread to do the actual calculation auto data = new CalcThreadData; data->View = this; data->Index = (int)index; auto hThread = ::CreateThread(nullptr, 0, [](auto param) { auto data = (CalcThreadData*)param; auto view = data->View; auto index = data->Index; delete data; return view->DoCalc(index); }, data, 0, nullptr); if (!hThread) { AtlMessageBox(nullptr, L"Failed to create worker thread!", IDR_MAINFRAME, MB_ICONERROR); return 0; } ::CloseHandle(hThread);
替换此代码的最简单方法是使用 `TrySubmitThreadpoolCallback`, 像这样:
auto data = new CalcThreadData; data->View = this; data->Index = (int)index; if (!::TrySubmitThreadpoolCallback([](auto instance, auto param) { auto data = (CalcThreadData*)param; auto view = data->View; auto index = data->Index; delete data; view->DoCalc(index); }, data, nullptr)) { AtlMessageBox(nullptr, L"Failed to submit thread pool work!", IDR_MAINFRAME, MB_ICONERROR); return 0; }
尽管 `CreateThread` 和 `TrySubmitThreadpoolCallback` 都可能失败, 但使用 `TrySubmitThreadpoolCallback` 发生的可能性较小, 因为它需要的资源比生成一个新线程要少.
另一个选择是使用一个完整的工作对象, 使用 `CreateThreadpoolWork`. 然而, 在这种情况下, 它的好处较少, 因为我们为每个工作项提交都需要一个不同的上下文, 所以它的主要优点是能够等待和可能取消待处理的操作. 尽管如此, 让我们在 WIL 包装器的帮助下这样做:
auto data = new CalcThreadData; data->View = this; data->Index = (int)index; wil::unique_threadpool_work_nowait work(::CreateThreadpoolWork( [](auto instance, auto param, auto work) { auto data = (CalcThreadData*)param; auto view = data->View; auto index = data->Index; delete data; view->DoCalc(index); }, data, nullptr)); if(!work) { AtlMessageBox(nullptr, L"Failed to submit thread pool work!", IDR_MAINFRAME, MB_ICONERROR); return 0; } ::SubmitThreadpoolWork(work.get());
我们选择 `uniquethreadpoolworknowait` 变体, 因为我们不希望在工作对象超出作用域时 (这发生在函数末尾) 等待待处理的操作. 在这个例子中, 使用手动创建的工作项没有真正的好处, 但其他情况可能会从这种方法中受益.
- 控制工作项
1.10.3. 线程池等待回调
在第 8 章的“使用事件”部分, 我们看了一个例子, 其中几个进程需要等待一个共同的事件 (“shutdown”), 为此, 每个进程都创建一个线程来进行等待. 正如该部分所提到的, 这是低效的——线程应该做实际的工作而不是等待. 一个更好的方法是让线程池等待事件. 乍一看, 这似乎是同一回事: 线程池线程不也是在等待吗? 如果是这样, 与应用程序创建的线程有什么区别?
区别在于同一个线程池线程可以等待多个对象, 由应用程序和可能的其他 Windows API 和库提交. 每个这样的线程可以使用熟悉的 `WaitForMultipleObjects` 同时等待多达 64 个对象.
如果需要超过 64 个等待, 可以从池中启动另一个线程来处理.
要创建一个线程池等待对象, 请调用 `CreateThreadpoolWait`:
typedef VOID (NTAPI *PTP_WAIT_CALLBACK)( _Inout_ PTP_CALLBACK_INSTANCE Instance, _Inout_opt_ PVOID Context, _Inout_ PTP_WAIT Wait, _In_ TP_WAIT_RESULT WaitResult); // just a DWORD PTP_WAIT CreateThreadpoolWait( _In_ PTP_WAIT_CALLBACK pfnwa, _Inout_opt_ PVOID pv, _In_opt_ PTP_CALLBACK_ENVIRON pcbe);
此时模式应该很明显了, 因为函数和回调与 `CreateThreadpoolWork` 非常相似. `CreateThreadpoolWait` 的参数与一个小的转折相同: 回调函数. 它提供了一个额外的参数, 指定了回调被调用的原因; 也就是说, 当一个对象的等待操作结束时, 回调被调用, 所以 `WaitResult` 指定了它结束的原因. 可能的值包括 `WAITOBJECT0` 来指示对象被信号, 以及 `WAITTIMEOUT` 指示超时在对象被信号之前到期.
`CreateThreadpoolWait` 返回一个表示等待对象的不透明 `PTPWAIT` 指针. 现在可以用 `SetThreadpoolWait` 提交实际的等待请求:
VOID SetThreadpoolWait( _Inout_ PTP_WAIT pwa, _In_opt_ HANDLE h, _In_opt_ PFILETIME pftTimeout);
除了等待对象, 该函数还接受要等待的句柄, 以及超时参数, 该参数指定了要等待多长时间. 此值的格式与第 8 章中关于可等待计时器的讨论相同: 负数表示 100 纳秒单位的相对时间, 正数表示从 1601 年 1 月 1 日午夜 UTC 开始计数的绝对时间, 以 100 纳秒为单位. 有关如何指定此值的完整讨论, 请参阅第 8 章. `NULL` 指针表示无限等待.
与线程池工作对象相反, 用同一个等待对象 (`PTPWAIT`) 调用 `SetThreadpoolWait` 会导致取消当前的等待 (如果尚未执行) 并用 (可能) 新的句柄和超时替换等待. 将句柄设置为 `NULL` 会停止排队新的回调.
对于我们的关闭事件示例, 等待可以通过如下代码完成:
void ConfigureWait() { HANDLE hShutdown = ::CreateEvent(nullptr, TRUE, FALSE, L"ShutdownEvent"); auto wait = ::CreateThreadpoolWait(OnWaitSatisfied, nullptr, nullptr); ::SetThreadpoolWait(wait, hShutdown, nullptr); // continue running normally... } void OnWaitSatisfied(PTP_CALLBACK_INSTANCE instance, PVOID context, PTP_WAIT wait, TP_WAIT_RESULT) { // Since the wait request specified infinite time, the fact that we're here // means the event was signaled DoShutdown(); // initiate shutdown }
还有一个扩展的 set 函数可用:
BOOL SetThreadpoolWaitEx( _Inout_ PTP_WAIT pwa, _In_opt_ HANDLE h, _In_opt_ PFILETIME pftTimeout, _Reserved_ PVOID Reserved);
该函数与 `SetThreadpoolWait` 基本相同, 除了返回值. 而不是 `void`, 它返回 `TRUE` 意味着一个等待是活动的并且现在已被替换. 如果返回 `FALSE`, 这意味着一个回调是为先前注册的句柄执行的或即将执行.
与线程池工作项类似, 可以通过 `WaitForThreadpoolWaitCallbacks` 进行一些控制:
VOID WaitForThreadpoolWaitCallbacks( _Inout_ PTP_WAIT pwa, _In_ BOOL fCancelPendingCallbacks);
`WaitForThreadpoolWaitCallbacks` 的语义和行为与 `WaitForThreadpoolWorkCallbacks` 基本相同.
最后, 等待项需要用 `CloseThreadpoolWait` 释放:
VOID CloseThreadpoolWait(_Inout_ PTP_WAIT pwa);
1.10.4. 线程池计时器回调
在第 8 章中, 我们看了一个可等待的计时器内核对象, 它可以在到期时启动操作, 可选地是周期性的. 然而, 启动操作并不方便. 它需要一些等待操作 (我们现在知道可以用线程池完成), 或者在调用 `SetWaitableTimer` 的线程上作为 APC 运行一个回调. 线程池提供了另一项服务, 它在指定的时间段过去后直接 (从池中) 调用一个回调, 可选地是周期性的.
相关函数的语义与我们已经看到的非常相似. 以下是线程池计时器对象的创建函数:
typedef VOID (CALLBACK *PTP_TIMER_CALLBACK)( _Inout_ PTP_CALLBACK_INSTANCE Instance, _Inout_opt_ PVOID Context, _Inout_ PTP_TIMER Timer); PTP_TIMER CreateThreadpoolTimer( _In_ PTP_TIMER_CALLBACK pfnti, _Inout_opt_ PVOID pv, _In_opt_ PTP_CALLBACK_ENVIRON pcbe);
函数参数此时应该是不言自明的. `CreateThreadpoolTimer` 返回一个表示计时器对象的不透明指针. 要启动一个实际的计时器, 请调用 `SetThreadpoolTimer`:
VOID SetThreadpoolTimer( _Inout_ PTP_TIMER pti, _In_opt_ PFILETIME pftDueTime, _In_ DWORD msPeriod, _In_opt_ DWORD msWindowLength);
`pftDueTime` 参数指定了到期的时间, 格式与 `SetWaitableTimer` 和 `SetThreadpoolWait` 使用的格式相同, 即使它的类型是 `FILETIME`. 如果此参数为 `NULL`, 它会导致计时器对象停止排队新的到期请求 (但已经排队的请求将在到期时被调用). `msPeriod` 是请求的周期, 以毫秒为单位. 如果指定为零, 计时器是一次性的. 最后一个参数的使用方式与 `SetWaitableTimerEx` 的最后一个参数类似——一个可接受的容差 (以毫秒为单位), 以便可以发生计时器合并以节省电力.
第二次用同一个计时器对象调用该函数会取消回调并用新信息替换计时器.
存在一个扩展函数, 类似于等待对象变体:
BOOL SetThreadpoolWaitEx( _Inout_ PTP_WAIT pwa, _In_opt_ HANDLE h, _In_opt_ PFILETIME pftTimeout, _Reserved_ PVOID Reserved);
与等待对象一样, 与非 Ex 函数唯一的区别是返回值. 该函数如果先前的计时器有效并且现在已被替换, 则返回 `TRUE`. 否则返回 `FALSE`.
要确定计时器对象上是否设置了计时器, 请调用 `IsThreadpoolTimerSet`:
BOOL WINAPI IsThreadpoolTimerSet(_Inout_ PTP_TIMER pti);
如你所料, 等待和可能取消计时器是可能的, 使用 `WaitForThreadpoolTimerCallbacks`:
VOID WaitForThreadpoolTimerCallbacks( _Inout_ PTP_TIMER pti, _In_ BOOL fCancelPendingCallbacks);
最后, 计时器池对象应该被关闭:
VOID CloseThreadpoolTimer(_Inout_ PTP_TIMER pti);
- 简单计时器示例
第 8 章的*简单计时器*示例可以重写为使用线程池计时器对象而不是可等待计时器. 以下是完整的代码:
void CALLBACK OnTimer(PTP_CALLBACK_INSTANCE inst, PVOID context, PTP_TIMER timer) { printf("TID: %u Ticks: %u\n", ::GetCurrentThreadId(), ::GetTickCount()); } int main() { auto timer = ::CreateThreadpoolTimer(OnTimer, nullptr, nullptr); if (!timer) { printf("Failed to create a thread pool timer (%u)", ::GetLastError()); return 1; } static_assert(sizeof(LONG64) == sizeof(FILETIME), "something weird!"); LONG64 interval; interval = -10000 * 1000LL; ::SetThreadpoolTimer(timer, (FILETIME*)&interval, 1000, 0); printf("Main thread ID: %u\n", ::GetCurrentThreadId()); ::Sleep(10000); ::WaitForThreadpoolTimerCallbacks(timer, TRUE); ::CloseThreadpoolTimer(timer); return 0; }
`staticassert` 关键字进行健全性检查, 以便一个 64 位整数可以被视为一个 `FILETIME` 结构. 计时器设置为一秒间隔, 周期为一秒. 对 `Sleep` 的调用只是让主线程等待, 而计时器回调则按指定的方式被调用.
1.10.5. 线程池 I/O 回调
由线程池处理的 I/O 回调用于服务异步 I/O 操作. 这在第 11 章“文件和设备 I/O”中讨论.
1.10.6. 线程池实例操作
我们还没有描述两个参数——回调环境和提供给回调的实例参数. 在本节中, 我们将看一下实例参数, 在下一节中我们将检查回调环境.
不透明的实例参数 (类型为 `PTPCALLBACKINSTANCE`) 与可从回调本身调用的几个函数一起使用. 我们将从 `CallbackMayRunLong` 开始:
BOOL CallbackMayRunLong(_Inout_ PTP_CALLBACK_INSTANCE pci);
调用此函数向线程池提供一个提示, 即此回调可能会长时间运行, 因此线程池应考虑此线程不属于线程池线程限制的一部分, 并生成一个新线程来服务下一个请求, 因为这个线程不太可能很快结束. 该函数返回 `TRUE` 以指示线程池能够为下一个请求生成一个新线程. 如果此时无法这样做, 它返回 `FALSE`. 长时间运行的标志仍然应用于该实例.
下一组函数请求线程池在回调真正结束并且线程可以返回池中之前执行某个操作:
VOID SetEventWhenCallbackReturns( _Inout_ PTP_CALLBACK_INSTANCE pci, _In_ HANDLE evt); VOID ReleaseSemaphoreWhenCallbackReturns( _Inout_ PTP_CALLBACK_INSTANCE pci, _In_ HANDLE sem, _In_ DWORD crel); VOID ReleaseMutexWhenCallbackReturns( _Inout_ PTP_CALLBACK_INSTANCE pci, _In_ HANDLE mut); VOID LeaveCriticalSectionWhenCallbackReturns( _Inout_ PTP_CALLBACK_INSTANCE pci, _Inout_ PCRITICAL_SECTION pcs); VOID FreeLibraryWhenCallbackReturns( _Inout_ PTP_CALLBACK_INSTANCE pci, _In_ HMODULE mod);
前四个函数相当直接, 在回调返回之前调用以下函数: `SetEvent`, `ReleaseSemaphore` (带有 `crel` 参数的计数), `ReleaseMutex`, `LeaveCriticalSection` 分别. 这看起来可能没什么大不了——客户端提供的回调函数不就可以调用适当的函数吗? 它可以, 但那将需要通过原始函数中的上下文参数传递相关的对象/句柄, 这可能不方便, 甚至有问题, 因为上下文只能在相关的线程池创建时设置一次.
列表中的最后一个函数, `FreeLibraryWhenCallbackReturns` 调用 `FreeLibrary` 来卸载一个动态链接库 (DLL). 它有一个额外的好处, 就是能够卸载回调本身起源的 DLL. 由回调本身调用 `FreeLibrary` 是致命的, 因为该函数将卸载自己的代码, 导致 `FreeLibrary` 返回后发生内存访问冲突. 让线程池调用 `FreeLibray` 解决了这个问题, 因为调用者不是 DLL 的一部分.
在实例参数上工作的最后一个函数是 `DisassociateCurrentThreadFromCallback`:
void DisassociateCurrentThreadFromCallback(_Inout_ PTP_CALLBACK_INSTANCE pci);
调用此函数告诉线程池此回调已完成其重要工作, 因此可能在 `WaitForThreadpoolWorkCallbacks` 等函数上等待的其他线程可以满足其等待, 即使回调在技术上仍在执行. 如果回调是清理组的一部分 (在下一节中描述), 此函数不会更改该关联.
1.10.7. 回调环境
每个线程池对象创建函数都有一个类型为 `PTPCALLBACKENVIRON` 的最后一个参数, 称为回调环境. 其目的是在使用线程池函数时允许进一步的自定义. 该结构本身在 `<winnt.h>` 头文件中定义, 但你应该将该结构视为不透明的, 并且只通过本节中描述的函数来操作它.
要将回调环境初始化为干净状态, 请调用 `InitializeThreadpoolEnvironment`:
VOID InitializeThreadpoolEnvironment(_Out_ PTP_CALLBACK_ENVIRON pcbe);
回调环境 API 函数是通过调用 `ntdll.dll` 中的其他函数内联实现的. 例如, `InitializeThreadpoolEnvironment` 调用 `TpInitializeCallbackEnviron`, 也在同一个头文件中实现. 回调环境的实际效果只有在传递给线程池函数时才明显.
回到 `InitializeThreadpoolEnvironment`——该函数当前将所有成员都清零, 除了 `Version` 字段, 该字段设置为 3 (Windows 7 及更高版本) 或 1 (Vista). 最终, 环境应该用 `DestroyThreadpoolEnvironment` 销毁:
VOID DestroyThreadpoolEnvironment(_Inout_ PTP_CALLBACK_ENVIRON);
目前, 这个函数什么也不做, 但这在未来的 Windows 版本中可能会改变, 所以一旦不再需要环境对象, 调用它是一个好习惯.
一旦回调环境被初始化, 就可以调用一组函数来自定义环境结构的各种成员. 表 9-1 总结了这些函数及其含义.
| 函数 | 描述 (对与回调环境关联的回调有效) |
|---|---|
| `SetThreadpoolCallbackPool` | 设置要用于回调的线程池对象 |
| `SetThreadpoolCallbackPriority` | 设置回调的优先级 |
| `SetThreadpoolCallbackRunsLong` | 设置一个提示, 表明回调是长时间运行的 |
| `SetThreadpoolCallbackLibrary` | 指示回调是 DLL 的一部分, 同步 DLL 处理的某些部分 |
| `SetThreadpoolCallbackCleanupGroup` | 将回调与一个清理组关联 (本章后面描述) |
回调环境, 线程池和各种线程池项之间的关系如图 9-9 所示.

Figure 149: 各种线程池实体之间的关系
一些函数需要更详细的讨论. `SetThreadpoolCallbackPool` 设置一个不同于进程默认的线程池. 下一节将介绍如何创建线程池.
`SetThreadpoolCallbackPriority` 提供了为回调设置相对于在同一线程池上运行的其他回调的优先级的机会:
VOID SetThreadpoolCallbackPriority( _Inout_ PTP_CALLBACK_ENVIRON pcbe, _In_ TP_CALLBACK_PRIORITY Priority);
`priority` 参数可以是 `TPCALLBACKPRIORITY` 枚举中的值之一:
typedef enum _TP_CALLBACK_PRIORITY { TP_CALLBACK_PRIORITY_HIGH, TP_CALLBACK_PRIORITY_NORMAL, TP_CALLBACK_PRIORITY_LOW, } TP_CALLBACK_PRIORITY;
保证高优先级回调在低优先级回调之前开始. 这在同一个线程池内提供了一定程度的灵活性.
此函数是在 Windows 7 和 Server 2008 R2 中添加的.
调用 `SetThreadpoolCallbackLibrary` 是为了让线程池知道回调是 DLL 的一部分, 因此只要该环境有回调, 它就应该保持 DLL 在进程中加载. 它还有助于防止如果其他线程试图获取加载器锁 (加载器锁在“动态链接库”一章中讨论) 时发生死锁.
1.10.8. 私有线程池
默认情况下, 进程有一个线程池, 不能被销毁. 当回调没有自定义回调环境时, 目标就是这个池. 使用回调环境, 可以通过调用 `SetThreadpoolCallbackPool` 将回调定向到不同的线程池:
VOID SetThreadpoolCallbackPool( _Inout_ PTP_CALLBACK_ENVIRON pcbe, _In_ PTP_POOL ptpp);
线程池本身由不透明的 `PTPPOOL` 指针表示. 私有线程池是用 `CreateThreadpool` 函数创建的:
PTP_POOL CreateThreadpool(_Reserved_ PVOID reserved);
如指示, 唯一的参数是保留的, 应设置为 `NULL`. 如果函数成功, 它会返回一个在后续调用中使用的不透明指针. 在极端低资源条件下可能会失败, 返回 `NULL`.
手头有一个线程池, 有一些函数可以在一定程度上对其进行自定义. 最重要的函数与池中的最小和最大线程数有关:
VOID SetThreadpoolThreadMaximum( _Inout_ PTP_POOL ptpp, _In_ DWORD cthrdMost); BOOL SetThreadpoolThreadMinimum( _Inout_ PTP_POOL ptpp, _In_ DWORD cthrdMic);
这些函数相当不言自明. 默认的最大线程数是 512, 最小是 0. 然而, 不应依赖这些数字, 所以最好调用上述函数来设置适当的值——毕竟这是创建私有线程池的主要原因之一. 如果最小线程数大于零, 这个数量的线程会预先创建, 准备处理回调.
奇怪的是, 没有文档化的相应函数来获取当前的最小和最大线程数.
这可以通过调用 native API 函数 `NtQueryInformationWorkerFactory` 来实现 (有关如何做的示例, 请参阅我的 Object Explorer 工具的源代码).
私有线程池支持的另一个自定义是该池中线程使用的栈大小:
typedef struct _TP_POOL_STACK_INFORMATION { SIZE_T StackReserve; SIZE_T StackCommit; }TP_POOL_STACK_INFORMATION, *PTP_POOL_STACK_INFORMATION; BOOL SetThreadpoolStackInformation( _Inout_ PTP_POOL ptpp, _In_ PTP_POOL_STACK_INFORMATION ptpsi);
默认大小来自 PE 头, 如第 5 章所述. 也就是说, 默认的默认值是 4KB 已提交内存和 1MB 保留内存. 这可能太多或太少, 因此调用 `SetThreadpoolStackInformation` 允许更好地利用线程池线程的内存.
奇怪的是, 栈大小确实有一个查询函数:
BOOL QueryThreadpoolStackInformation( _In_ PTP_POOL ptpp, _Out_ PTP_POOL_STACK_INFORMATION ptpsi);
还有更多的方法可以自定义线程池对象, 但这些目前没有被 Windows API 暴露, 所以这里不会描述.
最后, 线程池需要通过调用 `CloseThreadpool` 来正确销毁:
VOID CloseThreadpool(_Inout_ PTP_POOL ptpp);
更新*简单工作*应用程序以使用私有线程池并更改最大和最小线程数以及栈大小. (解决方案在 `SimpleWork3` 项目中).
1.10.9. 清理组
在一个大量使用线程池的应用程序中, 可能很难知道何时关闭各种线程池, 工作项, 等待项等. *清理组*跟踪与其关联的所有回调, 以便可以通过一次操作关闭它们, 而无需应用程序手动跟踪所有回调. 请注意, 这仅适用于私有线程池, 因为默认线程池不能被销毁.
一个清理组与上一节中讨论的回调环境相关联. 第一步是用 `CreateThreadpoolCleanupGroup` 创建一个新的清理组:
PTP_CLEANUP_GROUP CreateThreadpoolCleanupGroup();
如预期的那样, 该函数返回一个表示清理组的不透明指针. 要使其生效, 清理组必须与一个回调环境关联, 使用 `SetThreadpoolCallbackCleanupGroup`:
VOID SetThreadpoolCallbackCleanupGroup( _Inout_ PTP_CALLBACK_ENVIRON pcbe, _In_ PTP_CLEANUP_GROUP ptpcg, _In_opt_ PTP_CLEANUP_GROUP_CANCEL_CALLBACK pfng);
该函数接受一个已经初始化的回调环境, 要与环境关联的清理组, 以及一个可选的以下形式的回调:
typedef VOID (CALLBACK *PTP_CLEANUP_GROUP_CANCEL_CALLBACK)( _Inout_opt_ PVOID ObjectContext, _Inout_opt_ PVOID CleanupContext);
如果清理组被取消 (稍后讨论), 则会调用可选的回调. 每当调用诸如 `CreateThreadpoolWork`, `CreateThreadpoolWait` 等函数时, 它们都会被关联的清理组跟踪. 当你想清理所有东西时, 调用 `CloseThreadpoolCleanupGroupMembers`:
VOID CloseThreadpoolCleanupGroupMembers( _Inout_ PTP_CLEANUP_GROUP ptpcg, _In_ BOOL fCancelPendingCallbacks, _Inout_opt_ PVOID pvCleanupContext);
该函数等待所有未完成的回调完成. 这使你免于为为此池创建的项目调用各种关闭函数. 如果 `fCancelPendingCallbacks` 是 `TRUE`, 所有尚未开始执行的回调都会被取消, 并且为 `SetThreadpoolCallbackCleanupGroup` 提供的回调 (如果不是 `NULL`) 会为每个取消的项目调用.
回调被调用时, 带有在 `CreateThreadPool*` (工作, 等待, 计时器, I/O) 中设置的原始上下文参数, 以及在最后一个参数中 `SetThreadpoolCallbackCleanupGroup` 中提供的清理上下文.
一旦等待和可选的取消完成, 线程池和清理组可以优雅地用 `CloseThreadpool` 和 `CloseThreadpoolCleanupGroup` 关闭:
VOID CloseThreadpoolCleanupGroup(_Inout_ PTP_CLEANUP_GROUP ptpcg);
1.10.10. 练习
- 使用线程池来实现第 5 章中的 Mandelbrot 练习.
- 使用线程池来实现第 8 章中的练习.
1.10.11. 总结
线程池是提高重度多线程进程性能和可伸缩性的绝佳机制. 在下一章中, 我们将总结一些与线程相关的高级 (以及一些不那么高级) 特性, 这些特性在前面的章节中不太适合.
1.11. 第 10 章: 高级线程
本章总结了前面章节中不太适合的与线程相关的主题.
本章内容:
- 线程局部存储
- 远程线程
- 线程枚举
- 缓存和缓存行
- 等待链遍历
- 用户模式调度
- Init Once 初始化
- 调试多线程应用程序
1.11.1. 线程局部存储
一个线程自然可以访问其栈数据和进程范围的全局变量. 然而, 有时在每个线程的基础上拥有一些存储, 但以统一的方式访问, 是很方便的. 一个经典的例子是我们熟悉的 `GetLastError` 函数. 尽管任何线程都可以调用 `GetLastError`, 但每个线程的结果是不同的, 使得访问是独立的. 一种处理方法是存储一些以线程 ID 为键的哈希表, 然后根据该键查找值. 这行得通, 但有一些缺点. 一是哈希表需要同步, 因为多个线程可能会并发访问它. 第二, 搜索正确的线程可能不像人们希望的那么快.
线程局部存储 (TLS) 是一种用户模式机制, 允许在每个线程的基础上存储数据, 每个进程中的每个线程都可以访问, 但只能访问自己的数据; 然而, 访问方法是统一的.
为 `GetLastError` 存储的值不存储在 TLS 中; 它作为每个线程维护的*线程环境块* (TEB) 结构的一部分存储, 但想法是相同的.
TLS 用法的另一个经典例子是在 C/C++ 标准库中. 在 20 世纪 70 年代早期构思 C 标准库时, 还没有多线程的概念. 所以 C 运行时维护一组全局变量作为某些操作的状态. 例如, 以下经典的 C 代码尝试打开一个文件并处理可能的错误:
FILE* fp = fopen("somefile.txt", "r"); if(fp == NULL) { // something went wrong switch(errno) { case ENOENT: // no such file // break; case EFBIG: // break; // } }
任何 I/O 错误都反映在全局 `errno` 变量中. 但在多线程应用程序中, 这是一个问题. 想象一下线程 1 进行了一个 I/O 函数调用, 导致 `errno` 改变. 在它检查其值之前, 线程 2 也进行了一个 I/O 调用, 再次改变了 `errno`. 这导致线程 1 检查了由于线程 2 的活动而产生的值.
最终的结果是 `errno` 不能是一个全局变量. 所以今天, `errno` 不是一个变量, 而是一个宏, 它调用一个函数 `errno()`, 该函数使用线程局部存储来检索当前线程的值. 类似地, 像 `fopen` 这样的 I/O 函数的实现使用 TLS 将错误结果存储到当前线程.
同样的想法也适用于 C/C++ 运行时维护的其他全局变量.
- 动态 TLS
Windows API 提供了 4 个用于 TLS 使用的函数. 第一个函数为进程中的每个线程 (以及未来的线程) 分配一个槽:
DWORD TlsAlloc();
该函数返回一个可用的槽索引, 并将所有现有线程的相应单元格清零. 如果该函数返回 `TLSOUTOFINDEXES` (定义为 `0xffffffff`), 这意味着该函数失败, 并且所有可用的槽都已分配. 保证可用的槽数定义为 `TLSMINIMUMAVAILABLE` (目前为 64). 这可能看起来很多, 但不一定如此. TLS 对于 DLL 相当有用, 其中 DLL 可能希望在每个线程的基础上存储一些信息, 因此它在加载时会分配一个槽, 并在需要时使用它. 如果你看一个典型的进程, DLL 的数量可以轻松超过 100. 在实践中, 可用槽的数量高于 64. 如果你尝试分配槽直到失败, 你可以了解有多少槽可用:
int slots = 0; while (true) { DWORD slot = ::TlsAlloc(); if (slot == TLS_OUT_OF_INDEXES) { printf("Out of TLS indices!\n"); break; } slots++; } printf("Allocated: %d\n", slots);
在我的 Windows 10 版本 2004 的基本控制台应用程序上运行此程序会产生 1084 个槽. 如果你检查实际的槽值, 会发现有些已经分配了.
在内部, 64 个槽是预先分配的, 因此总是可用的. 如果请求更多, 如果可能的话, 会再分配 1024 个 (记住每个线程都需要自己的 TLS 数组). 然而, 你不应依赖此数字或行为.
TLS 中的每个单元格都是一个指针大小的值, 因此这里的最佳实践是使用单个槽, 并动态分配所需的任何结构来保存你需要存储在 TLS 中的所有信息, 只将指向数据的指针存储在槽中.
一旦索引可用, 就使用两个函数来存储或检索槽中的值:
BOOL TlsSetValue( _In_ DWORD dwTlsIndex, _In_opt_ PVOID pTlsValue); PVOID TlsGetValue(_In_ DWORD dwTlsIndex);
这些函数使用起来相当直接. 调用这些函数的线程只能访问其在特定槽索引中的自己的值. 没有直接的方法可以访问另一个线程的 TLS 槽——那会违背其目的. 这也意味着在访问 TLS 时永远不需要同步, 因为只有一个线程可以访问内存中的相同地址. TLS 数组如图 10-1 所示.

Figure 150: 线程局部存储
最终, 由 `TlsAlloc` 分配的 TLS 索引需要用 `TlsFree` 释放:
BOOL TlsFree(_In_ DWORD dwTlsIndex);
TLS 的一个非标准用途是在不实际传递参数的情况下向函数传递参数. 例如, 假设有一个已经存在的函数, 其原型不能更改. 如果该函数在调用时需要一个额外的上下文, 你如何传递一个额外的参数? TLS 是解决这个问题的一个很好的方案. 唯一需要共享的是为此目的分配的 TLS 索引.
这里有一个更具体的例子. 假设我们有一个名为 `Transaction` 的类, 它管理某种事务. 操作可能是事务的一部分, 但它们也可能在没有事务的情况下被调用. 我们如何模拟这种约束? 也许最明显的答案是向系统中的每个函数添加一个 `Transaction*` 参数, 以便每个函数都可以根据它是否是事务的一部分来做出决定.
然而, 如果函数已经存在, 这可能会有问题. 添加另一个参数并非易事, 可能会产生连锁反应. 在某些情况下, 如果涉及虚函数, 那么在不破坏大多数代码的情况下是不可能做到的, 因为对其签名的任何更改都可能产生级联效应, 从而失控.
当然, 存在一种替代方案, 即 (再次) 管理一些由线程 ID 键控的事务对象的哈希表, 但这是低效的 (管理哈希表并需要锁定)——事务是单线程的, 它在逐个线程的基础上传播. TLS 提供了一个优雅的解决方案. 以下是一个示例 `Transaction` 类的声明:
class Transaction { public: Transaction(); ~Transaction(); static Transaction* GetCurrent(); void AddLog(PCWSTR text); void AddError(PCWSTR text); private: int _errors = 0; // requires C++ 17 compiler inline static DWORD _tlsIndex = TLS_OUT_OF_INDEXES; }; // pre C++ 17 compiler DWORD Transaction::_tlsIndex = TLS_OUT_OF_INDEXES;
每当一个事务处于作用域时, 函数可以通过调用 `Transaction::GetCurrent()` 间接地从 TLS 获取它. 如果返回值为 `NULL`, 则没有事务. 否则, 就有一个事务, 代码可以使用它. 以下是 `Transaction` 类的概念性实现:
Transaction::Transaction() { if (_tlsIndex == TLS_OUT_OF_INDEXES) _tlsIndex = ::TlsAlloc(); ::TlsSetValue(_tlsIndex, this); } Transaction::~Transaction() { if (_errors == 0) { // commit transaction } else { // abort/rollback transaction } ::TlsSetValue(_tlsIndex, nullptr); } Transaction* Transaction::GetCurrent() { if (_tlsIndex == TLS_OUT_OF_INDEXES) return nullptr; return static_cast<Transaction*>(::TlsGetValue(_tlsIndex)); } void Transaction::AddError(PCWSTR) { _errors++; // more code } void Transaction::AddLog(PCWSTR) { // more code }
构造函数分配一个 TLS 索引 (仅一次). 然后它将自己的地址设置为 TLS 槽中的值. 析构函数决定是提交还是中止事务, 然后将 TLS 值设置为 `NULL`, 表示没有事务.
`GetCurrent` 只是检索 TLS 槽中的值并将其转换为 `Transaction*`. 以下是使用此类的示例代码:
bool DoWork() { // more code } void f1() { auto tn = Transaction::GetCurrent(); if (tn) tn->AddLog(L"f1 working"); if (!DoWork()) { if (tn) tn->AddError(L"Failed in DoWork"); else printf("Failed in DoWork"); } } void do_something() { Transaction t; f1(); }
这个想法, 有时被称为*环境事务*, 在 .NET Framework 中与 `TransactionScope` 类一起使用.
- 静态 TLS
线程局部存储也以一种更简单的形式可用, 通过在全局或静态变量上使用 Microsoft 扩展关键字或使用 C++ 11 或更高版本的编译器. 让我们研究一下这两种选项.
Microsoft 特定的说明符 `_declspec(thread)` 可用于指定一个线程局部变量, 如下所示:
__declspec(thread) int counter;
变量 `counter` 现在是线程局部的. 每个线程都有自己的值. 类似地, 使用 C++ 11 或更高版本, 这可以用跨平台的方式通过 `threadlocal` 关键字完成, 如下所示:
thread_local int counter;
结果是相同的. 这个 TLS 是“静态”的, 因为它不需要任何分配, 也不能被销毁. 在内部, 编译器将所有线程局部变量捆绑成一个块, 并将信息存储在 PE 中一个名为 `.tls` 的节中. 加载器 (NTDLL) 在进程启动时读取此信息, 调用 `TlsAlloc` 来分配一个槽, 并为每个启动的线程动态分配一个内存块, 该内存块包含所有线程局部变量. 这是可能的, 因为每个用户模式线程在调用传递给 `CreateThread` 的“真实”函数之前, 都会在一个 NTDLL 提供的函数中启动.
图 10-2 显示了编译了以下行的 PE 文件中的 TLS 数据:
thread_local int counter =5;
值“5”可以在 TLS 节的二进制数据中清楚地看到. 此外, 似乎还有更多的 TLS 数据被用作某些 Windows DLL 的一部分, 而这些 DLL 不是由应用程序直接创建的.

Figure 151: PE 文件中的 TLS
1.11.2. 远程线程
我们多次使用的 `CreateThread` 函数在当前进程中创建一个线程. 然而, 在某些情况下, 一个进程可能希望在另一个进程中创建一个线程. 这种情况的典型例子是调试器. 当需要强制断点时, 例如当用户按下“中断”按钮时, 调试器会在目标进程中创建一个线程, 并将其指向 `DebugBreak` 函数 (或一个发出中断指令的 CPU 内在函数), 导致进程中断并通知调试器.
允许这样做的函数是 `CreateRemoteThread` 和 `CreateRemoteThreadEx`:
HANDLE WINAPI CreateRemoteThread( _In_ HANDLE hProcess, _In_ LPSECURITY_ATTRIBUTES lpThreadAttributes, _In_ SIZE_T dwStackSize, _In_ LPTHREAD_START_ROUTINE lpStartAddress, _In_ LPVOID lpParameter, _In_ DWORD dwCreationFlags, _Out_opt_ LPDWORD lpThreadId); HANDLE CreateRemoteThreadEx( _In_ HANDLE hProcess, _In_opt_ LPSECURITY_ATTRIBUTES lpThreadAttributes, _In_ SIZE_T dwStackSize, _In_ LPTHREAD_START_ROUTINE lpStartAddress, _In_opt_ LPVOID lpParameter, _In_ DWORD dwCreationFlags, _In_opt_ LPPROC_THREAD_ATTRIBUTE_LIST lpAttributeList, _Out_opt_ LPDWORD lpThreadId);
`CreateRemoteThread` 与 `CreateThread` 相比只增加了一个参数——第一个——到目标进程的句柄. 这个句柄必须有一个相当大的访问掩码——`PROCESSCREATETHREAD`, `PROCESSQUERYINFORMATION`, `PROCESSVMOPERATION`, `PROCESSVMWRITE`, 和 `PROCESSVMREAD`. 这是有道理的, 因为在另一个进程中创建线程是一个非常侵入性的操作.
句柄也可以是 `GetCurrentProcess()`, 这使得该函数与 `CreateThread` 相同.
最有趣的参数是函数指针本身 (`lpStartAddress`). 函数的地址是相对于目标进程的, 这意味着线程需要执行的代码应该以某种方式已经存在. 一个想法是使用一个保证在目标进程中并且在已知地址的函数. Windows API 函数通常属于这种类型. 由于 Windows 子系统 DLL (`kernel32.dll`, `kernelbase.dll`, `user32.dll` 等, 当然还有 `ntdll.dll`) 都映射到所有进程的相同地址, 从调用进程获得的地址也可以在目标进程中使用.
`CreateRemoteThreadEx` 与 `CreateRemoteThread` 相比增加了一个参数: 一个属性列表. 这与第 3 章中讨论的属性列表相同. 一些属性与进程有关 (第 3 章), 但有些属性与线程有关, 这就是指定它们的方式. 请注意, 这对于本地线程和远程线程同样重要. 请参考表 3-9 以获取属性列表, 其中一些是针对线程的.
- Breakin 应用程序
`breakin` 示例应用程序使用远程线程调用 `DebugBreak` 函数, 对一个进程进行远程中断, 类似于调试器会做的方式.
技术上, 已经存在一个执行此操作的函数 - `DebugBreakProcess`.
第一步是从命令行获取一个进程 ID 并打开一个足够强大的句柄:
int main(int argc, const char* argv[]) { if (argc < 2) { printf("Usage: breakin <pid>\n"); return 0; } int pid = atoi(argv); auto hProcess = ::OpenProcess(PROCESS_CREATE_THREAD | PROCESS_QUERY_INFORMATION | PROCESS_VM_OPERATION | PROCESS_VM_READ | PROCESS_VM_WRITE, FALSE, pid); if (!hProcess) return Error("Failed to open process"); }
上面的代码中没有什么新东西. 重要的部分是请求 `CreateRemoteThread` 成功的最小访问掩码.
接下来是对 `CreateRemoteThread` 的调用. 我们利用了 `kernel32.dll` 映射到每个进程的相同地址的事实, 因此 `DebugBreak` 函数的地址在每个进程中都是相同的. 这意味着我们可以在此进程中定位此函数, 并指示远程线程使用相同的函数地址:
auto hThread = ::CreateRemoteThread(hProcess, nullptr, 0, (LPTHREAD_START_ROUTINE)::GetProcAddress( ::GetModuleHandle(L"kernel32"), "DebugBreak"), nullptr, 0, nullptr); if (!hThread) return Error("Failed to create remote thread"); printf("Remote thread created successfully!\n"); ::CloseHandle(hThread); ::CloseHandle(hProcess); return 0; }
`GetModuleHandle` 返回此进程中已加载模块 (`kernel32.dll`) 的地址, `GetProcAddress` 检索函数的地址. 这些函数和其他与 DLL 相关的函数将在第 15 章中详细讨论.
这段代码中还有一个隐藏的假设, 即关于线程函数的参数. 一个标准线程的函数看起来像这样:
DWORD WINAPI ThreadFunction(PVOID param);
这意味着我们要求远程线程 (或任何线程, 就此而言) 运行的任何函数都必须具有此原型或“足够接近”的东西. 在这种情况下, “足够接近”是可行的, 因为 `DebugBreak` 不接受任何东西, 所以我们可以传递一个 `NULL` 作为 `param` 值, 并且返回值也不会被使用, 所以这也无所谓. 如果该函数需要多个参数, 那将是有问题的, 因为没有简单的方法可以传递这些参数.
我们可以通过运行某个进程 (例如 `notepad`), 附加某个调试器, 并让进程自由运行来测试 `breakin` 应用程序. 然后, 我们可以使用 `breakin` 来强制断点. 结果应该是进程中的一个断点, 调试器重新获得控制权.
如果我们对一个没有被调试的进程这样做会发生什么? 试一试, 找出来!
`CreateRemoteThread(Ex)` 的一个更有用的用途是将 DLL 注入到目标进程中. 由于这涉及处理虚拟内存和 DLL, 我们将把这个示例用法推迟到第 15 章.
1.11.3. 线程枚举
我们在第 3 章中看到了几种枚举系统上运行的进程的方法. 那么线程呢? tool help 函数 `CreateToolhelp32Snapshot` 提供了一个标志, `TH32CSSNAPTHREAD`, 用于枚举系统中的所有线程.
HANDLE CreateToolhelp32Snapshot( DWORD dwFlags, DWORD th32ProcessID);
快照包含所有进程中的所有线程——没有办法指定一个特定的进程 ID. `CreateToolhelp32Snapshot` 的第二个参数确实包含一个进程 ID, 但这只在枚举模块或堆时有效.
一旦创建了快照, 你就可以通过调用一次 `Thread32First`, 然后通过调用 `Thread32Next` 进行迭代, 直到它返回 `false`, 来遍历快照中的线程:
BOOL Thread32First( HANDLE hSnapshot, LPTHREADENTRY32 lpte); BOOL Thread32Next( HANDLE hSnapshot, LPTHREADENTRY32 lpte);
两个函数都在一个 `THREADENTRY32` 结构中返回信息, 定义如下:
typedef struct tagTHREADENTRY32 { DWORD dwSize; // must be set before calls DWORD cntUsage; DWORD th32ThreadID; // this thread DWORD th32OwnerProcessID; // Process this thread is associated with LONG tpBasePri; // base priority LONG tpDeltaPri; // not used DWORD dwFlags; // not used } THREADENTRY32;
- thlist 应用程序
`thlist` 应用程序列出特定进程中的所有线程或系统中的所有线程, 具体取决于命令行上是否提供了进程 ID. 该函数还列出了每个线程所属的进程的映像名称.
应用程序的核心是一个辅助函数, `EnumThreads`, 它返回一个 `ThreadInfo` 结构的向量, 定义如下:
struct ThreadInfo { DWORD Id; // thread ID DWORD Pid; // process ID int Priority; // thread priority FILETIME CreateTime; // thread create time DWORD CPUTime; // thread CPU time (msec) std::wstring ProcessName; // process image name };
`THREADENTRY32` 结构不提供线程创建时间和 CPU 时间. 这些需要打开一个到线程的句柄, 如果成功, 则获取信息. 一个线程可以像一个进程一样, 通过提供其 ID 和一个请求的访问掩码来用 `OpenThread` 打开:
HANDLE OpenThread( _In_ DWORD dwDesiredAccess, _In_ BOOL bInheritHandle, _In_ DWORD dwThreadId);
`EnumThreads` 函数首先为进程和线程创建一个快照:
std::vector<ThreadInfo> EnumThreads(int pid) { std::vector<ThreadInfo> threads; HANDLE hSnapshot = ::CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS | TH32CS_SNAPTHREAD, 0); if (hSnapshot == INVALID_HANDLE_VALUE) return threads; }
快照包含进程和线程. 首先, 我们枚举进程, 这样我们就可以创建一个进程 ID 与其相关信息的映射. 然后在迭代线程时定位一个进程会很容易:
PROCESSENTRY32 pe; pe.dwSize = sizeof(pe); std::unordered_map<DWORD, PROCESSENTRY32> processes; processes.reserve(512); ::Process32First(hSnapshot, &pe); // skip idle process while (::Process32Next(hSnapshot, &pe)) { processes.insert({ pe.th32ProcessID, pe }); }
对于每个发现的进程, 一个条目被插入到 `unorderedmap<>` 中, 以便进程可以在第二阶段更快地查找. 进程 ID 0 (空闲进程) 被跳过, 因为它不是一个真正的进程, 也没有特别的兴趣 (`Process32First` 被调用, 但结果未被处理).
现在是线程枚举本身. `THREADENTRY32` 结构用适当的大小初始化:
threads.reserve(4096); THREADENTRY32 te; te.dwSize = sizeof(te);
接下来, 进行线程迭代. 对于每个线程, 在 `unorderedmap<>` 中查找相应的进程以定位进程映像名称:
::Thread32First(hSnapshot, &te); do { if (te.th32OwnerProcessID > 0 && (pid == 0 || te.th32OwnerProcessID == pid)) { ThreadInfo ti; ti.Id = te.th32ThreadID; ti.Pid = te.th32OwnerProcessID; ti.Priority = te.tpBasePri; ti.ProcessName = processes[ti.Pid].szExeFile; } }
`if` 语句检查是否指定了进程 ID (非零), 如果是, 则只处理该进程中的线程; 否则, 处理所有线程.
接下来, 我们需要获取一些不属于枚举的更多线程信息:
auto hThread = ::OpenThread(THREAD_QUERY_LIMITED_INFORMATION, FALSE, ti.Id); if (hThread) { FILETIME user, kernel, exit; ::GetThreadTimes(hThread, &ti.CreateTime, &exit, &kernel, &user); ti.CPUTime = DWORD((*(ULONGLONG*)&kernel + *(ULONGLONG*)&user) / 10000000); ::CloseHandle(hThread); } else { ti.CPUTime = 0; ti.CreateTime.dwHighDateTime = ti.CreateTime.dwLowDateTime = 0; }
`THREADQUERYLIMITEDINFORMATION` 是获取关于线程的表面信息所需的访问掩码, 例如其创建和执行时间, 使用 `GetThreadTimes`:
BOOL GetThreadTimes( _In_ HANDLE hThread, _Out_ LPFILETIME lpCreationTime, _Out_ LPFILETIME lpExitTime, _Out_ LPFILETIME lpKernelTime, _Out_ LPFILETIME lpUserTime);
该函数与我们之前使用过的 `GetProcessTimes` 类似, 但在线程基础上工作. 创建时间和退出时间以从 1601 年 1 月 1 日午夜 UTC 开始的通常的 100 纳秒为单位, 内核和用户执行时间以 100 纳秒为单位测量. 上面的代码将内核和用户时间的总和除以 1000 万, 以将数字减少到秒单位.
剩下的就是将 `ThreadInfo` 对象添加到向量中并继续迭代:
threads.push_back(std::move(ti)); } } while (::Thread32Next(hSnapshot, &te)); ::CloseHandle(hSnapshot); return threads; }
`main` 函数调用 `EnumThreads` 并用各种格式操作呈现信息:
int main(int argc, const char* argv[]) { DWORD pid = 0; if (argc > 1) pid = atoi(argv); auto threads = EnumThreads(pid); printf("%6s %6s %5s %18s %11s %s\n", "TID", "PID", "Pri", "Started", "CPU Time", "Process Name"); printf("%s\n", std::string(60, '-').c_str()); for (auto& t : threads) { printf("%6d %6d %5d %18ws %11ws %ws\n", t.Id, t.Pid, t.Priority, t.CreateTime.dwLowDateTime + t.CreateTime.dwHighDateTime == 0 ? L"(Unknown)" : (PCWSTR)CTime(t.CreateTime).Format(L"%x %X"), (PCWSTR)CTimeSpan(t.CPUTime).Format(L"%D:%H:%M:%S"), t.ProcessName.c_str()); } return 0; }
不带任何参数运行该应用程序会转储系统中的所有线程. 用一个进程 ID 运行它会将其输出限制在该进程:
C:\>thlist.exe 11740 TID PID Pri Started CPU Time Process Name ------------------------------------------------------------ 11744 11740 8 03/22/20 12:12:08 0:00:02:06 explorer.exe 11904 11740 8 03/22/20 12:12:08 0:00:00:27 explorer.exe 13280 11740 9 03/22/20 12:12:10 0:00:17:14 explorer.exe 11936 11740 8 03/22/20 12:12:11 0:00:00:27 explorer.exe 11716 11740 8 03/22/20 12:12:11 0:00:00:32 explorer.exe ... 5080 11740 8 03/25/20 11:14:36 0:00:00:00 explorer.exe 17064 11740 8 03/25/20 11:14:36 0:00:00:00 explorer.exe 41084 11740 8 03/25/20 11:14:37 0:00:00:00 explorer.exe 48916 11740 8 03/25/20 11:14:44 0:00:00:00 explorer.exe
第 3 章中描述的用于进程枚举的 native API 也提供了枚举每个进程中线程的能力.
1.11.4. 缓存和缓存行
在微处理器的早期, CPU 的速度和内存 (RAM) 的速度是相当的. 后来 CPU 速度上升, 内存速度落后. 这导致 CPU 经常停顿, 等待内存读写一个值. 为了补偿, 在 CPU 和内存之间引入了一个缓存, 如图 10-3 所示.

Figure 152: CPU 和内存之间的缓存
缓存是相对于主内存的快速内存, 它允许 CPU 减少停顿. 自然地, 缓存远没有主内存那么大, 但它的存在在今天的系统中至关重要. 缓存的重要性不可高估.
`SumMatrix` 项目比较了两种求和矩阵的方法, 如下所示:
long long SumMatrix1(const Matrix<int>& m) { long long sum = 0; for (int r = 0; r < m.Rows(); ++r) for (int c = 0; c < m.Columns(); ++c) sum += m[r][c]; return sum; } long long SumMatrix2(const Matrix<int>& m) { long long sum = 0; for (int c = 0; c < m.Columns(); ++c) for (int r = 0; r < m.Rows(); ++r) sum += m[r][c]; return sum; }
`Matrix<>` 类是一个一维数组的简单包装器. 从算法的角度来看, 两个函数求和矩阵元素所需的时间应该是相同的. 毕竟——代码只遍历了一次矩阵的所有元素. 但实际结果可能会令人惊讶. 以下是在我的机器上用各种矩阵大小和求和元素所需时间的运行结果 (一切都是单线程的):
Type Size Sum Time (nsec) ----------------------------------------------------------------- Row major 256 X 256 2147516416 34 usec Col Major 256 X 256 2147516416 81 usec Row major 512 X 512 34359869440 130 usec Col Major 512 X 512 34359869440 796 usec Row major 1024 X 1024 549756338176 624 usec Col Major 1024 X 1024 549756338176 3080 usec Row major 2048 X 2048 8796095119360 2369 usec Col Major 2048 X 2048 8796095119360 43230 usec Row major 4096 X 4096 140737496743936 8953 usec Col Major 4096 X 4096 140737496743936 190985 usec Row major 8192 X 8192 2251799847239680 35258 usec Col Major 8192 X 8192 2251799847239680 1035334 usec Row major 16384 X 16384 36028797153181696 142603 usec Col Major 16384 X 16384 36028797153181696 4562040 usec
差异是极端的, 这是由于缓存. 当 CPU 读取数据时, 它不会读取单个整数或任何它被指示读取的东西, 而是读取整个*缓存行* (通常是 64 字节) 并将其放入其内部缓存中. 然后当读取内存中的下一个整数时, 不需要内存访问, 因为该整数已经存在于缓存中. 这是最优的, 也是 `SumMatrix1` 的工作方式——它线性地遍历内存.
另一方面, `SumMatrix2` 读取一个整数 (连同其余的缓存行), 下一个整数在更远的地方, 在一个不同的缓存行上 (对于除了最小的矩阵之外的所有矩阵), 这需要读取另一个缓存行, 可能会丢弃可能很快需要的数据, 使事情变得更糟.
技术上, 大多数 CPU 中实现了 3 个缓存级别. 缓存离处理器越近, 它就越快, 也越小. 图 10-4 显示了 4 核 CPU (带超线程技术) 的典型缓存配置.

Figure 153: CPU 中的缓存级别
1 级缓存由数据缓存 (D-cache) 和指令缓存 (I-cache) 组成, 并且是每个逻辑处理器的. 然后是 2 级缓存, 由属于同一核心的逻辑处理器共享. 最后, 3 级缓存是系统范围的. 这些缓存的大小相当小, 大约比主内存小 3 个数量级. 系统上的缓存大小可以在任务管理器的*性能 / CPU*选项卡中轻松看到, 如图 10-5 所示.

Figure 154: 任务管理器中的缓存大小
在图 10-5 中, 3 级缓存大小为 16 MB (系统范围). 2 级缓存大小为 2 MB, 但这包括所有核心. 由于此系统有 8 个核心, 每个 2 级缓存实际上是 2MB/8=256KB. 类似地, 1 级缓存大小为 512 KB, 分布在 16 个逻辑处理器上, 使每个缓存为 512KB/16=32KB. 底线是缓存大小与主内存大小 (以千兆字节为单位) 相比很小.
任务管理器还未显示另一个重要的缓存, 称为*转换后备缓冲区* (TLB). 这是一个专用于快速将虚拟地址转换为物理地址的 CPU 缓存. 我们将在第 12 章中进一步讨论这个缓存.
让我们看另一个例子, 其中缓存和缓存行起着重要 (甚至是关键) 的作用. `FalseSharing` 项目演示了遍历一个大数组, 计算数组中偶数的数量. 这是用多个线程完成的——每个线程被分配一个数组的连续部分. 计数本身被放置在另一个数组中, 每个单元格由相应的线程修改. 图 10-6 显示了 4 个线程的这种安排.

Figure 155: False Sharing 应用程序
以下是计数偶数的第一个版本:
using namespace std; struct ThreadData { long long start, end; const int* data; long long* counters; }; long long CountEvenNumbers1(const int* data, long long size, int nthreads) { auto counters_buffer = make_unique<long long[]>(nthreads); auto counters = counters_buffer.get(); auto tdata = make_unique<ThreadData[]>(nthreads); long long chunk = size / nthreads; vector<wil::unique_handle> threads; vector<HANDLE> handles; for (int i = 0; i < nthreads; i++) { long long start = i * chunk; long long end = i == nthreads - 1 ? size : ((long long)i + 1) * chunk; auto& d = tdata[i]; d.start = start; d.end = end; d.counters = counters + i; d.data = data; wil::unique_handle hThread(::CreateThread(nullptr, 0, [](auto param) -> DWORD { auto d = (ThreadData*)param; auto start = d->start, end = d->end; auto counters = d->counters; auto data = d->data; for (; start < end; ++start) if (data[start] % 2 == 0) ++(*counters); return 0; }, tdata.get() + i, 0, nullptr)); handles.push_back(hThread.get()); threads.push_back(move(hThread)); } ::WaitForMultipleObjects(nthreads, handles.data(), TRUE, INFINITE); long long sum = 0; for (int i = 0; i < nthreads; i++) sum += counters[i]; return sum; }
`CountEvenNumbers1` 接受一个指向数据的指针, 其大小以及用于分区数据数组的线程数. 然后它分配 `countersbuffer`, 这是每个线程应该递增其指定单元格的缓冲区. 然后分配一个 `ThreadData` 数组 (`tdata`), 以便每个线程可以接收其自己的迭代参数. 接下来, 创建两个向量对象来保存线程句柄. 一个将它们作为 `wil::uniquehandle` 保存, 以便在对象超出作用域时自动关闭它们. 第二个向量 (`handles`) 将句柄作为普通的 `HANDLE` 实例保存, 以便可以直接传递给 `WaitForMultipleObjects`.
块大小也被计算.
现在开始循环, 为每个线程准备数据并调用 `CreateThread` 来启动线程. 分块的完成方式与第 5 章中素数计算应用程序中演示的几乎相同. 让我们仔细看看线程的循环:
for (; start < end; ++start) if (data[start] % 2 == 0) ++(*counters);
对于每个偶数, `counters` 指针的内容都会递增一. 请注意, 这里没有数据竞争——每个线程都有自己的单元格, 所以最终结果应该是正确的. 这个代码的问题在于, 当某个线程写入单个计数时, 会写入整个缓存行, 这会使其他处理器上查看此内存的任何缓存失效, 迫使它们通过从主内存再次读取来刷新其缓存, 这我们已经知道是慢的. 这种情况被称为*伪共享*.
另一种方法是不要写入与其他线程共享缓存行的单元格, 至少不要经常写入. 以下是 `CountEvenNumbers2` 函数中线程块内的代码, 在所有其他方面都是相同的:
auto d = (ThreadData*)param; auto start = d->start, end = d->end; auto data = d->data; size_t count = 0; for (; start < end; ++start) if (data[start] % 2 == 0) count++; *(d->counters) = count; return 0; }, tdata.get() + i, 0, nullptr));
主要的区别是将计数保存在一个局部变量 (`count`) 中, 只有在循环完成后才一次性写入结果数组中的单元格. 由于 `count` 在线程的栈上, 并且栈至少有 4 KB 大, 它们不可能与其他线程中的其他 `count` 变量在同一个缓存行上. 这大大提高了性能. 当然, 通常使用局部变量可能比间接访问内存更快, 因为编译器更容易将此变量缓存到寄存器中. 但真正的影响是避免了在线程之间共享缓存行.
`main` 函数用各种线程数测试两种实现, 像这样:
const long long size = (1LL << 32) - 1; // just a large number cout << "Initializing data..." << endl; auto data = make_unique<int[]>(size); for (long long i = 0; i < size; i++) data[i] = (unsigned)i + 1; auto processors = min(8, ::GetActiveProcessorCount(ALL_PROCESSOR_GROUPS)); cout << "Option 1" << endl; for (WORD i = 1; i <= processors; ++i) { auto start = ::GetTickCount64(); auto count = CountEvenNumbers1(data.get(), size, i); auto end = ::GetTickCount64(); auto duration = end - start; cout << setw(2) << i << " threads " << "count: " << count << " time: " << duration << " msec" << endl; } cout << endl << "Option 2" << endl; for (WORD i = 1; i <= processors; ++i) { auto start = ::GetTickCount64(); auto count = CountEvenNumbers2(data.get(), size, i); auto end = ::GetTickCount64(); auto duration = end - start; cout << setw(2) << i << " threads " << "count: " << count << " time: " << duration << " msec" << endl; }
你必须以 64 位进程运行此程序, 因为它分配了大约 16 GB 的内存.
该函数最多使用 8 个线程 (只是为了限制运行时间). 在一个行为良好的程序中, 我们期望几乎是线性的改进, 因为没有使用或需要同步.
但是, 在伪共享变体 (第一个) 中, 添加线程的改进不太明显, 并且在某些线程值下会使情况变得更糟:
Initializing data... Option 1 1 threads count: 2147483647 time: 4843 msec 2 threads count: 2147483647 time: 3391 msec 3 threads count: 2147483647 time: 2468 msec 4 threads count: 2147483647 time: 2125 msec 5 threads count: 2147483647 time: 2453 msec 6 threads count: 2147483647 time: 1906 msec 7 threads count: 2147483647 time: 2109 msec 8 threads count: 2147483647 time: 2532 msec Option 2 1 threads count: 2147483647 time: 4046 msec 2 threads count: 2147483647 time: 2313 msec 3 threads count: 2147483647 time: 1625 msec 4 threads count: 2147483647 time: 1328 msec 5 threads count: 2147483647 time: 1062 msec 6 threads count: 2147483647 time: 953 msec 7 threads count: 2147483647 time: 859 msec 8 threads count: 2147483647 time: 855 msec
请注意, 在伪共享选项 (1) 中, 在某些情况下, 更多的线程会降低性能. 在最佳情况下 (2), 有持续的改进.
1.11.5. 等待链遍历
在第 7 章和第 8 章中, 我们探讨了用于同步线程活动的各种同步原语. 同步的一个警告是可能发生死锁. 如果一个死锁发生在一个不平凡的应用程序中, 发现死锁在哪里并不容易. 有一些与调试器一起使用的技术可以帮助定位此类死锁. 在本节中, 我们将探讨一种可以识别各种死锁的编程技术, 称为*等待链遍历* (WCT).
WCT API 提供了从感兴趣的线程开始遍历等待链的能力. 一个等待链包含一个交替的线程和对象序列. 链中的每个线程都等待它后面的对象, 该对象由链中的下一个线程拥有, 依此类推. 例如, 一个线程可能是一个临界区的所有者, 并等待一个由另一个线程拥有的互斥体——这是一个等待链的例子.
等待链分析能够跟踪涉及以下对象的链:
- 临界区
- 互斥体 (包括跨进程)
- 异步本地过程调用 (ALPC) - Windows 组件使用的内部进程间通信机制
- `SendMessage` - `SendMessage` API 是同步的, 如果从一个不是窗口所有者的线程调用, 会导致线程阻塞
- 线程和进程上的等待操作
- 组件对象模型 (COM) 跨单元调用 (有关 COM 的更多信息, 请参见第 18 章)
- 套接字和简单消息块 (SMB) 操作
要开始等待链分析, 必须用 `OpenThreadWaitChainSession` 打开一个到 WCT 会话的句柄:
HWCT OpenThreadWaitChainSession ( _In_ DWORD Flags, _In_opt_ PWAITCHAINCALLBACK callback);
该函数为 WCT 打开一个会话, 并指定会话应该是同步的还是异步的. 为 `Flags` 指定零会设置一个同步会话. 这意味着执行分析的线程会被阻塞, 直到分析完成. 指定 `WCTASYNCOPENFLAG` (1) 表示一个异步会话, 在这种情况下, `callback` 参数应指向一个在分析完成时被调用的函数. 如果成功, `OpenThreadWaitChainSession` 会返回一个到 WCT 会话的不透明句柄. 否则, 返回 `NULL`.
我们将使用更简单的同步会话, 并描述异步会话的区别. 一旦 WCT 句柄就位, 就为特定线程调用一个等待链分析, 使用 `GetThreadWaitChain`:
BOOL GetThreadWaitChain ( _In_ HWCT WctHandle, _In_opt_ DWORD_PTR Context, _In_ DWORD Flags, _In_ DWORD ThreadId, _Inout_ LPDWORD NodeCount, _Out_writes_(*NodeCount) PWAITCHAIN_NODE_INFO NodeInfoArray, _Out_ LPBOOL IsCycle);
`WctHandle` 是从 `OpenThreadWaitChainSession` 接收的句柄. `Context` 是一个可选值, 在异步会话的情况下, 按原样传递给提供给 `OpenThreadWaitChainSession` 的回调. `Flags` 指示应考虑哪些进程外的情况, 如表 10-1 所述.
| 标志 | 描述 |
|---|---|
| WCTOUTOFPROCFLAG (1) | 没有此标志, 不会尝试进行进程外分析 |
| WCTOUTOFPROCCOMFLAG (2) | COM 分析所需 |
| WCTOUTOFPROCCSFLAG (4) | 临界区分析所需 |
| WCTNETWORKIOFLAG (8) | 套接字/SMB 分析所需 |
| WCTPGETINFOALLFLAGS | 结合所有前面的标志 |
`ThreadId` 是开始等待链分析的线程. 如果该线程是具有更高完整性级别的进程的成员 (有关更多信息, 请参见第 16 章), 分析可能会失败. 以管理员权限运行并启用 Debug 特权可以帮助访问此类进程.
`NodeCount` 指向函数愿意接受的分析节点数. 返回时, 它指定了实际写入了多少个节点. 最大分析深度, 即可以返回的最大节点数, 由 `WCTMAXNODECOUNT` 定义 (目前定义为 16). `NodeInfoArray` 是节点对象的输出数组. 最后, 最后一个输出参数, `IsCycle`, 指示分析中是否存在循环, 如果是死锁则返回 `TRUE`.
每个分析节点都是 `WAITCHAINNODEINFO` 类型, 定义如下:
typedef struct _WAITCHAIN_NODE_INFO { WCT_OBJECT_TYPE ObjectType; WCT_OBJECT_STATUS ObjectStatus; union { struct { WCHAR ObjectName[WCT_OBJNAME_LENGTH]; LARGE_INTEGER Timeout; // Not implemented BOOL Alertable; // Not implemented } LockObject; struct { DWORD ProcessId; DWORD ThreadId; DWORD WaitTime; DWORD ContextSwitches; } ThreadObject; }; } WAITCHAIN_NODE_INFO, *PWAITCHAIN_NODE_INFO;
每个节点代表链中的一个对象. 链总是以一个线程对象开始, 然后是 (如果线程正在等待某物) 一个对象, 然后是一个线程 (如果该线程拥有该对象), 依此类推.
`ObjectType` 和 `ObjectStatus` 总是有效的. 以下是它们的定义:
typedef enum _WCT_OBJECT_TYPE { WctCriticalSectionType = 1, WctSendMessageType, WctMutexType, WctAlpcType, WctComType, WctThreadWaitType, WctProcessWaitType, WctThreadType, WctComActivationType, WctUnknownType, WctSocketIoType, WctSmbIoType, WctMaxType } WCT_OBJECT_TYPE; typedef enum _WCT_OBJECT_STATUS { WctStatusNoAccess = 1, // ACCESS_DENIED for this object WctStatusRunning, // Thread status WctStatusBlocked, // Thread status WctStatusPidOnly, // Thread status WctStatusPidOnlyRpcss, // Thread status WctStatusOwned, // Dispatcher object status WctStatusNotOwned, // Dispatcher object status WctStatusAbandoned, // Dispatcher object status WctStatusUnknown, // All objects WctStatusError, // All objects WctStatusMax } WCT_OBJECT_STATUS;
`ObjectType` 指示当前节点代表什么对象. 如果是线程 (`WctThreadType`), 那么匿名联合的 `ThreadObject` 部分提供了更多信息: 线程 ID, 此线程的进程 ID, 等待的时间以及它 incurred 的上下文切换次数.
如果对象类型不是线程, 它可以是一个锁对象 (例如临界区或互斥体), 或者其他东西 (例如 `SendMessage` 调用或 COM). 在锁对象的情况下, 联合的 `LockObject` 部分是有效的, 并提供对象的名称 (如果有的话).
`ObjectStatus` 指示由节点描述的对象的状态, 如上面的 `WCTOBJECTSTATUS` 枚举定义所示.
此时剩下要做的就是遍历返回的节点数组, 对信息进行某种形式的分析.
最后, 当不再需要 WCT 时, 必须用 `CloseThreadWaitChainSession` 关闭会话:
VOID CloseThreadWaitChainSession(_In_ HWCT WctHandle);
- 死锁检测器应用程序
手头有 WCT 信息, 构建一个可以识别死锁的工具并不太难. `DeadlockDetector` 项目就是这样做的. 图 10-7 显示了启动时应用程序的窗口.

Figure 156: Deadlock Detector 启动时
*进程*组合框允许选择一个进程进行分析. 单击*检测死锁*会枚举所选进程中的所有线程, 然后对该进程中的每个线程执行等待链分析, 在树视图中显示结果, 其中每个根节点都是一个线程. 图 10-8 显示了应用程序检测到其中一个示例应用程序 `SimpleDeadlock1` 的死锁.

Figure 157: Deadlock Detector 检测到互斥体死锁
应用程序首先用 `Toolhelp` 函数枚举进程, 正如我们已经做过很多次, 所以我不会在这里重复代码. 然后用结果填充组合框.
一旦用户单击*检测死锁*, 消息处理程序首先为同步分析打开一个 WCT 会话:
LRESULT CMainDlg::OnDetect(WORD, WORD wID, HWND, BOOL&) { auto hWct = ::OpenThreadWaitChainSession(0, nullptr); if (hWct == nullptr) { AtlMessageBox(*this, L"Failed to open WCT session", IDR_MAINFRAME, MB_ICONERROR); return 0; } }
然后, 从组合框中选定的项目中提取所选的进程 ID, 并调用一个函数来枚举该进程中的线程:
auto pid = (DWORD)m_ProcCombo.GetItemData(m_ProcCombo.GetCurSel()); auto threads = EnumThreads(pid);
线程枚举函数返回一个 `vector<DWORD>`, 即进程中所有线程 ID 的一个向量. 用于线程枚举的代码与本章前面“线程枚举”部分中使用的代码非常相似.
此时, 我们需要开始一个循环遍历所有线程 ID, 并为每个线程执行分析:
m_Tree.DeleteAllItems(); int failures = 0; for (auto& tid : threads) { if (!DoWaitChain(hWct, tid)) failures++; } if (failures == threads.size()) { AtlMessageBox(*this, L"Failed to analyze wait chain. (try running elevated)", IDR_MAINFRAME, MB_ICONEXCLAMATION); } ::CloseThreadWaitChainSession(hWct); return 0; }
如果所有线程分析都失败, 这意味着目标进程不可访问, 并显示一条错误消息. `DoWaitChain` 函数为特定的线程 ID 启动分析:
bool CMainDlg::DoWaitChain(HWCT hWct, DWORD tid) { WAITCHAIN_NODE_INFO nodes[WCT_MAX_NODE_COUNT]; DWORD nodeCount = WCT_MAX_NODE_COUNT; BOOL cycle; auto success = ::GetThreadWaitChain(hWct, 0, WCTP_GETINFO_ALL_FLAGS, tid, &nodeCount, nodes, &cycle); if(success) { ParseThreadNodes(nodes, nodeCount, cycle); } return success; }
该函数在栈上分配最大大小的节点数组, 然后将 `nodeCount` 初始化为该最大值. 接下来, 调用 `GetThreadWaitChain` 来进行实际的分析. 如果成功, 返回的节点链由 `ParseThreadNodes` 处理. 为什么 `GetThreadWaitChain` 可能会失败? 除了已经提到的原因 (访问被拒绝), 也有可能所讨论的线程已经退出, 因为线程枚举是基于当前执行线程的快照, 并且可能有一些线程在此期间终止. 当然, 相反的情况也可能发生——进程中可能创建了新线程, 这些线程目前没有被分析. 这通常不是什么大问题, 因为新线程不太可能导致问题. 在任何情况下, 分析都可以重复, 并重新枚举线程.
`ParseThreadNodes` 首先为对象类型和状态类型定义文本表示:
void CMainDlg::ParseThreadNodes(const WAITCHAIN_NODE_INFO* nodes, DWORD count, bool cycle) { static PCWSTR objectTypes[] = { L"Critical Section", L"Send Message", L"Mutex", L"ALPC", L"COM", L"Thread Wait", L"Process Wait", L"Thread", L"COM Activation", L"Unknown", L"Socket", L"SMB", }; static PCWSTR statusTypes[] = { L"No Access", L"Running", L"Blocked", L"PID only", L"PID only RPCSS", L"Owned", L"Not Owned", L"Abandoned", L"Unknown", L"Error" }; }
然后, 一个遍历实际返回的节点的循环开始, 处理每个对象, 并将其信息作为子节点添加到树中. 一个 `switch` 语句用于区分三种对象类型: 线程, 锁对象, 和所有其余的. 对于每一种, 都会提取可用的信息并放入树中:
HTREEITEM hCurrentNode = TVI_ROOT; CString text; for (DWORD i = 0; i < count; i++) { auto& node = nodes[i]; auto type = node.ObjectType; auto status = node.ObjectStatus; switch (type) { case WctThreadType: text.Format(L"Thread %u (PID: %u) Wait: %u (%s)", node.ThreadObject.ThreadId, node.ThreadObject.ProcessId, node.ThreadObject.WaitTime, statusTypes[status - 1]); break; case WctCriticalSectionType: case WctMutexType: case WctThreadWaitType: case WctProcessWaitType: // waitable objects text.Format(L"%s (%s) Name: %s", objectTypes[type - 1], statusTypes[status - 1], node.LockObject.ObjectName); break; default: // other objects text.Format(L"%s (%s)", objectTypes[type - 1], statusTypes[node.ObjectStatus - 1]); break; } auto hOld = hCurrentNode; hCurrentNode = m_Tree.InsertItem(text, hCurrentNode, TVI_LAST); m_Tree.Expand(hOld, TVE_EXPAND); }
最后, 如果存在一个循环 (即死锁), 就会添加另一个带有文本“Deadlock!”的叶节点:
if (cycle) { m_Tree.InsertItem(L"Deadlock!", hCurrentNode, TVI_LAST); m_Tree.Expand(hCurrentNode, TVE_EXPAND); }
还有一个最后的细节值得一提. 对于 COM 分析, 需要一个特殊的注册, 以便 COM 基础设施与 WCT 连接. 以下代码片段在 `OnInitDialog` 中用于执行该连接:
auto comLib = ::GetModuleHandle(L"ole32"); if (comLib) { ::RegisterWaitChainCOMCallback( (PCOGETCALLSTATE)::GetProcAddress(comLib, "CoGetCallState"), (PCOGETACTIVATIONSTATE)::GetProcAddress(comLib, "CoGetActivationState") ); }
- 异步 WCT 会话
如果会话配置为异步, 提供给 `OpenThreadWaitChainSession` 的回调函数必须具有以下原型:
typedef VOID (CALLBACK *PWAITCHAINCALLBACK) ( HWCT WctHandle, DWORD_PTR Context, DWORD CallbackStatus, LPDWORD NodeCount, PWAITCHAIN_NODE_INFO NodeInfoArray, LPBOOL IsCycle);
对 `OpenThreadWaitChainSession` 的调用总是返回 `FALSE`, 但如果 `GetLastError` 返回 `ERRORIOPENDING`, 这意味着在 WCT 管理的线程上启动分析的调用是成功的. 一旦分析完成, 就会用结果调用回调. 大多数参数与 `OpenThreadWaitChainSession` 的参数类似, 除了 `CallbackStatus`, 它指示分析是否成功或失败的原因. `ERRORSUCCESS` (0) 表示成功, 失败的原因有几个. 最常见的失败是 `ERRORACCESSDENIED`, 正如前面提到的, 可以通过以管理员权限运行并启用 Debug 特权来避免.
`DeadlockDetector` 项目包含一个在 `DeadlockDetector.cpp` 中启用 Debug 特权的函数 (这样一个函数也在第 3 章中使用过).
第 6 章详细讨论了调度. 内核调度器负责确定哪个线程应该在哪个处理器上运行, 并在需要时进行上下文切换. 在某些极端情况下, 这并不像它可能的那样高效. 在某些情况下, 能够从用户模式而不是内核模式控制调度将是有利的. 这些决定不应该需要从用户模式切换到内核模式, 因为这些切换并不便宜.
在过去 (并且仍然支持), Windows 提供了*纤程 (fibers)*, 它们试图提供一个用户模式的调度机制. 然而, 纤程不被内核识别, 这导致了许多问题, 例如线程局部存储没有正确传播, 线程环境块结构与当前执行的纤程不对齐等等. 纤程今天不应该被使用, 因此本书没有描述它们.
从 Windows 7 和 Windows 2008 R2 开始, Windows 支持一种称为*用户模式调度* (UMS) 的替代机制, 其中一个用户模式线程成为一种调度器, 并且可以从用户模式调度线程, 而无需进行用户模式/内核模式转换. 该机制为内核所知, 因此纤程的缺点在 UMS 中不存在, 因为使用的是真正的线程而不是共享一个线程的纤程.
不幸的是, 构建一个使用 UMS 的真实系统并非易事, 因此本书不尝试对 UMS 进行深入描述. 相反, 微软 (自 2010 年起) 提供了一个名为 Concurrency Runtime 的库, 缩写为 Concrt, 发音为“concert”, 它在幕后使用 UMS, 以在需要并发执行时提供对线程的高效使用.
第 3 章的*素数计数器*应用程序被用作一个例子. 在该应用程序中, 我们创建了多个线程 (这是应用程序的一个参数), 并在线程之间分配计算素数的工作, 允许每个线程在其块中计数线程数, 然后最后对所有线程的结果求和.
我们面临的一个问题是, 很难公平地划分工作, 以便每个线程的工作量大致相同. 否则, 提前完成的线程会导致 CPU 空闲. 我们尝试通过拥有更多的线程来补偿, 但这在内存和上下文切换方面也有其成本.
在某些情况下, 并发运行时提供了非常简单的代码的良好解决方案, 与分区, 线程创建和管理的困难相比.
第 3 章的应用程序在本章的项目中也可用, 增加了在一定范围内计数素数的相同工作, 但这次使用 `concrt`.
首先需要的是一个 `#include`:
#include <ppl.h>
`ppl.h` 提供了便利的函数, 我们稍后会用到其中一个. 它包含了 `concrt` 的“真正”主力, `concrt.h`.
在 `main` 函数中, 在现有的计算代码完成后, 我们像这样使用 `concrt`:
count = 0; concurrency::parallel_for(from, to + 1, [&count](int n) { if (IsPrime(n)) ::InterlockedIncrement((unsigned*)&count); }); auto end = ::GetTickCount64(); printf("Using concrt: Primes: %d, Elapsed: %u msec\n", count, (ULONG)(end - start));
`parallelfor` 函数正如其名: 一个 `for` 循环, 自动并行化. 你只需指定初始值和最终值加一, 以及一个为每次迭代运行的函数 (这里以 lambda 形式提供). 这段代码以某种方式并发运行. 请注意, 没有指示要创建多少线程或如何管理它们. 这里唯一的警告是对 `count` 共享变量所需的同步. 在原始的分区方案中, 这是不需要的, 因为每个线程都在递增自己的计数器.
以下是我系统上的一个示例运行:
C:\>PrimesCounter.exe 3 20000000 16 Thread 1 created (3 to 1250001). TID=42576 Thread 2 created (1250002 to 2500000). TID=30636 Thread 3 created (2500001 to 3749999). TID=16944 ... Thread 15 created (17499989 to 18749987). TID=32580 Thread 16 created (18749988 to 20000000). TID=55440 Thread 1 Count: 96468. Execution time: 515 msec Thread 2 Count: 86603. Execution time: 796 msec ... Thread 15 Count: 74745. Execution time: 1906 msec Thread 16 Count: 74475. Execution time: 1906 msec Total primes: 1270606. Elapsed: 1985 msec Using concrt: Primes: 1270606, Elapsed: 1640 msec
不管我向问题投入多少线程, `concrt` 版本总是优于手动分区. 而且它用很少的代码行就做到了, 并且效率更高——它从不在系统上创建比逻辑处理器数量更多的线程.
SQL Server 使用 UMS 来提高其性能, 因为它是一个高度多线程的服务器应用程序.
许多应用程序中的一个常见模式是拥有一个单例对象. 在某些观点中, 这是一种反模式, 但这个争论超出了本书的范围. 事实是, 单例是有用的, 有时是必要的. 对单例的一个常见要求是只初始化一次. 在多线程应用程序中, 多个线程可能同时初始访问单例, 但单例必须只初始化一次. 这如何实现?
有几个众所周知的算法, 如果正确实现, 可以完成这项工作. 这不是一本通用的算法书, 所以这里不描述这些. 然而, Windows API 提供了一种内置的方法来调用一个函数, 保证它只被调用一次.
在 C++ 11 及更高版本中, 函数中的静态变量保证只被初始化一次. 另外, C++ 11 有 `std::callonce` 函数, 它动态地做同样的事情.
一次性初始化 API 从 Windows 8 和 Server 2012 开始可用. 最简单的版本是同步初始化, 这里描述. 对于异步版本, 请查阅官方文档.
一个类型为 `INITONCE` 的变量用于控制一次性初始化. 它必须以静态方式初始化 (pun not intended)——全局或静态变量, 以便其初始化保证只进行一次. 最简单的初始化方法是将其值设置为 `INITONCESTATICINIT`, 像这样:
INIT_ONCE init = INIT_ONCE_STATIC_INIT;
`INITONCE` 只是一个不透明指针的包装器. 另一种方法是用 `InitOnceInitialize` 初始化它:
VOID InitOnceInitialize(_Out_ PINIT_ONCE InitOnce);
然后, 当需要初始化时, 调用 `InitOnceExecuteOnce`:
BOOL InitOnceExecuteOnce( _Inout_ PINIT_ONCE InitOnce, _In_ __callback PINIT_ONCE_FN InitFn, _Inout_opt_ PVOID Parameter, _Outptr_opt_result_maybenull_ LPVOID* Context);
`InitOnce` 参数是先前初始化的那个, 控制此初始化. `InitFn` 是保证只被调用一次的函数. `Parameter` 是一个可选的上下文值, 传递给初始化函数, `Context` 是一个来自初始化函数的可选结果. 函数本身必须具有以下原型:
BOOL (WINAPI *PINIT_ONCE_FN) ( _Inout_ PINIT_ONCE InitOnce, _Inout_opt_ PVOID Parameter, _Outptr_opt_result_maybenull_ PVOID *Context);
如果回调返回 `TRUE`, 初始化被认为是成功的. 否则, 它被认为是失败的, 并且 `FALSE` 返回给 `InitOnceExecuteOnce`. `Parameter` 是从 `InitOnceExecuteOnce` 传入的值. 上下文可以返回一些值, 但它必须将最右边的 `INITONCECTXRESERVEDBITS` (2) 位清零, 这意味着如果它是一个地址, 它必须是 4 字节对齐的.
编写正确高效的多线程应用程序是困难的. 一旦 bug 潜入——而且它们会的——调试变得重要, 并且比单线程应用程序困难得多. 涵盖调试的所有方面超出了本书的范围. 相反, 我想提一些 Visual Studio 中可用的提示和帮助, 这些可能很有用, 特别是对于多线程应用程序.
调试是一个大话题, Visual Studio 不是镇上唯一的调试器. 事实上, 在生产环境中, 使用其他低级和低占用空间的调试器, 例如 `WinDbg`. 本节仅关于 Visual Studio 调试, 通常在开发人员的工作站上执行.
- 断点
当在代码的多线程部分设置断点时, 任何线程都会触发它, 并且所有线程都会因此被挂起. 执行调试器单步操作会恢复所有线程, 而不仅仅是你可能感兴趣的要隔离的线程. 隔离一个线程的一种方法是使用*线程*窗口冻结所有其他线程, 如图 10-9 所示.

Figure 158: 线程调试器窗口的上下文菜单选项
图 10-9 中显示的*在源代码中显示线程*选项会在断点命中时, 在源代码中一个或多个线程所在的位置添加一个线程图标.
断点可以是条件的. 可能的条件之一是线程 ID 或线程名称, 允许你只在特定的感兴趣的线程 (或线程) 上中断 (图 10-10).

Figure 159: 断点线程筛选器
- 并行堆栈
*并行堆栈*窗口 (可从*调试 / 窗口 / 并行堆栈*菜单访问) 显示了一个线程如何从其他线程生成的图形视图, 提供了进程中所有正在运行的线程的良好视觉表示 (图 10-11).

Figure 160: 并行堆栈窗口
- 并行监视
*并行监视*窗口, 以与*并行堆栈*类似的方式访问, 显示了由运行相同代码的多个线程使用的选择的变量或表达式, 每个线程都有自己的变量副本 (图 10-12).

Figure 161: 并行监视窗口
- 线程名称
第 5 章描述了线程名称, 在 Windows 10 中通过 `SetThreadDescription` 函数可用. 在调试期间, 也可以在*线程*窗口中直接更改线程的名称, 从而更容易地跟踪特定的线程. 调试会话结束后, 名称会重置, 所以最好在代码中对众所周知的线程调用 `SetThreadDescription`, 以便在开始调试时它们的名称就准备好了.
1.11.6. 练习
- 创建一个用 `concrt` 计算 Mandelbrot 集的控制台应用程序. 将你的结果与第 5 章的相同练习进行比较.
1.11.7. 总结
在本章中, 介绍了各种与线程相关的主题. 在下一章中, 我们将把线程抛在脑后, 看看文件和设备 I/O 操作.
1.12. 第 11 章: 文件和设备 I/O
在前面的章节中, 我们以各种方式使用线程来执行 CPU 密集型工作. 然而, 并非所有操作都与 CPU 相关. 有些需要与文件或其他设备通信, 通常称为 I/O 操作. 这些操作在操作完成之前不需要 CPU 使用, 此时线程代码会继续处理 I/O 操作的结果.
在本章中, 我们将研究同步和异步 I/O 操作, 并探讨线程如何高效地获取 I/O 结果以继续处理.
本章内容:
- I/O 系统
- CreateFile 函数
- 同步 I/O
- 异步 I/O
- I/O 完成端口
- I/O 取消
- 设备
- 管道和邮槽
- 事务性 NTFS
- 文件搜索和枚举
- NTFS 流
1.12.1. I/O 系统
I/O 系统的主要目的是抽象对物理和逻辑设备的访问. 在任何文件系统中访问文件应该不同于访问串行端口, USB 摄像头或打印机. I/O 系统由多个组件组成, 一些在用户模式, 大多数在内核模式. 最重要的部分如图 11-1 所示.

Figure 162: I/O 系统的重要部分
用户模式进程使用各种 Windows API 调用 I/O 系统, 本章将对此进行探讨. 内核端的所有文件和设备操作都由 I/O 管理器启动. 一个请求, 例如读或写, 是通过创建一个名为*I/O 请求包* (IRP) 的内核结构来处理的, 填写请求的详细信息, 然后将其传递给适当的设备驱动程序. 对于真正的文件, 这会转到一个文件系统驱动程序, 例如 NTFS. 这个过程与正常的系统调用没有本质上的不同, 如图 11-2 所示.

Figure 163: 读 I/O 操作调用流
就内核而言, I/O 操作总是异步的. 这意味着驱动程序应该启动操作并尽快返回, 以便调用线程可以重新获得控制权. 然而, 原始的调用者可以选择进行同步调用. 在这种情况下, I/O 管理器代表调用者等待, 直到操作完成. 这种灵活性从客户端的角度来看非常方便.
1.12.2. CreateFile 函数
`CreateFile` 函数是进入 I/O 操作世界的入口点. 函数名本身有些误导. `CreateFile` 中使用的术语“File”是“File Object”的缩写, 这是内核用来表示与设备连接的抽象, 无论该设备是文件系统中的文件还是其他设备. 以下是 `CreateFile` 的原型:
HANDLE CreateFile( _In_ LPCTSTR lpFileName, _In_ DWORD dwDesiredAccess, _In_ DWORD dwShareMode, _In_opt_ LPSECURITY_ATTRIBUTES lpSecurityAttributes, _In_ DWORD dwCreationDisposition, _In_ DWORD dwFlagsAndAttributes, _In_opt_ HANDLE hTemplateFile);
Windows 8 和 Server 2012 添加了一个类似的函数, `CreateFile2`, 定义如下:
typedef struct _CREATEFILE2_EXTENDED_PARAMETERS { DWORD dwSize; DWORD dwFileAttributes; DWORD dwFileFlags; DWORD dwSecurityQosFlags; LPSECURITY_ATTRIBUTES lpSecurityAttributes; HANDLE hTemplateFile; } CREATEFILE2_EXTENDED_PARAMETERS, *PCREATEFILE2_EXTENDED_PARAMETERS; HANDLE CreateFile2( _In_ LPCWSTR lpFileName, _In_ DWORD dwDesiredAccess, _In_ DWORD dwShareMode, _In_ DWORD dwCreationDisposition, _In_opt_ PCREATEFILE2_EXTENDED_PARAMETERS pCreateExParams);
`CreateFile2` 与 `CreateFile` 非常相似, 但可从 UWP 应用程序以及桌面应用程序使用. 另一方面, `CreateFile` 不能从 UWP 应用程序调用. 请注意, `CreateFile2` 仅为 Unicode, 而 `CreateFile` 具有通常的 `CreateFileA` 和 `CreateFileW` 变体. `CreateFile2` 还支持一个 `CreateFile` 无法提供的新标志 (`FILEFLAGOPENREQUIRINGOPLOCK`).
机会锁 (Oplocks) 超出了本章的范围.
`lpFileName` 参数指示要创建或打开的文件或设备名称. 这不一定是一个“文件名”, 正如参数名称所指示的. 它是到执行官的对象管理器命名空间的符号链接, 并添加了一些解析规则. 表 11-1 显示了一些常见的文件名模式, 其中一些将在以下段落中进一步阐述.
| 文件名格式 | 示例 | 描述 |
|---|---|---|
| `x:\dir1\dir2\file` | `c:\mydir\myfile.txt` | 到文件系统中的文件/目录的完整路径 |
| `..\dir1\file` | `..\mydir\myfile.txt` | 到文件/目录系统的相对路径 (.. 表示父目录) |
| `dir1\dir2\file` | `mydir1\mydir2\myfile.txt` | 从当前目录到文件/目录的相对路径 |
| `file` | `myfile.txt` | 在当前目录的文件系统中的文件 |
| `\server\share\dir1\dir2\file` | `\myserver\myshare\mydir\myfile.txt` | 另一台机器共享中的文件/目录 |
| `\server\pipe\pipename` | `\myserver\pipe\mypipe` | 命名管道客户端 |
| `\server\mailslot\mailslotname` | `\myserver\mailslot\mymailslot` | Mailslot 客户端 |
| `\.*devicename*` | `\.\kobjexp` | 设备符号链接名称 |
| `builtin` | `com1` | 旧的 DOS 名称被视为符号链接而不是当前目录中的文件 |
“符号链接”是 `CreateFile` 中为文件名提供的基本值. 即使像“c:”这样看起来非常“基本”的东西, 实际上也是一个符号链接. 要查看这些符号链接, 我们可以查看我们在第 2 章中简要介绍的 Sysinternals 的 `WinObj` 工具, 或者我自己的 `Object Explorer` 工具. 图 11-3 显示了选择了 `Global??` 对象目录的 `WinObj`. 图 11-4 显示了 `Object Explorer` 中的相同目录 (选择*对象 / 对象管理器命名空间*以打开该视图). 所选的目录是符号链接目录.

Figure 164: WinObj 中的符号链接

Figure 165: Object Explorer 中的符号链接
列表中的每个名称都是一个符号链接, 它是 `CreateFile` 的一个候选者, 前缀为 `\\.\`. 一些符号链接不需要此前缀, 例如“C:”. 注意,“C:”确实是一个符号链接, 指向类似“`\Device\HarddiskVolume3`”的东西, 这可以在*设备*对象管理器目录下找到.
一些符号链接看起来很好, 比如“C:”, “PhysicalDrive0”, “PIPE”等等, 而其他的看起来像一堆带 GUID 的数字. 这些链接大多用于硬件设备. 本章后面的“与设备通信”小节提供了更多细节.
接下来, 我们将在讨论可使用该函数访问的一些常见“文件”之前, 检查 `CreateFile` 的其余参数.
`dwDesiredAccess` 参数用于指定访问文件对象所需的访问掩码. 在大多数情况下, 你将使用一个或多个通用访问权限: `GENERICREAD` (从文件/设备读取数据), `GENERICWRITE` (向文件/设备写入数据), 或两者 (`GENERICREAD | GENERICWRITE`). 如果只需要访问非常表面的信息, 例如文件的时间戳或大小, 你也可以指定零. 你还可以使用与被访问的文件或设备相关的更细粒度的访问掩码. 例如, `FILEREADDATA` 是用于请求读取其内容的文件的一个特定访问掩码. 然而, 读取文件的属性需要另一个访问掩码——`FILEREADATTRIBUTES`. `GENERICREAD` 是一个通用访问掩码, 被映射到特定的访问掩码, 对于文件, 包括 `FILEREADDATA` 和 `FILEREADATTRIBUTES`.
无论是否明确指定, `SYNCHRONIZE` 和 `FILEREADATTRIBUTES` 访问掩码总是被请求的.
有关访问掩码和通用映射的更多信息, 请参见第 16 章 (“安全性”).
`dwShareMode` 参数指定了文件/设备应以何种共享模式打开. 这主要与文件系统文件或目录一起使用. 如果文件/目录未打开, 调用者指定她允许如何与其他 `CreateFile` 调用共享该对象. 例如, 如果初始调用者允许以只读方式共享, 后续的调用者就不能用 `GENERICWRITE` 访问权限打开该对象. 如果在另一个 `CreateFile` 调用进来时文件/目录已经打开, 共享模式将被忽略. 表 11-2 列出了可能的共享模式.
| 共享模式 | 描述 |
|---|---|
| 0 | 对象以独占访问权限打开. 没有其他 `CreateFile` 调用可以成功. |
| FILESHAREREAD | 允许后续调用者以 `GENERICREAD` 访问权限打开对象. |
| FILESHAREWRITE | 允许后续调用者以 `GENERICWRITE` 访问权限打开对象. |
| FILESHAREDELETE | 允许后续调用者以 `DELETE` 访问权限打开对象. 当所有句柄都关闭时, 文件将被删除. |
| 以上的组合 | 结合了每个标志的含义 |
下一个参数, `lpSecurityAttributes` 是第 2 章中讨论的标准 `SECURITYATTRRIBUTES`.
`dwCreationDisposition` 参数指定如何创建或打开文件系统对象 (文件和目录). 对于其他设备, 该标志应始终设置为 `OPENEXISTING`. 可能的值及其含义在表 11-3 中描述.
| 值 | 文件存在 | 文件不存在 |
|---|---|---|
| CREATENEW (1) | `CreateFile` 失败 | 创建一个新文件 |
| CREATEALWAYS (2) | 覆盖现有文件 | 创建一个新文件 |
| OPENEXISTING (3) | 打开文件 | `CreateFile` 失败 |
| OPENALWAYS (4) | 打开文件 (不覆盖) | 创建文件 |
| TRUNCATEEXISTING (5) | 打开文件并将其截断为零大小 | `CreateFile` 失败 |
`dwFlagsAndAttributes` 参数允许设置三个独立的标志/值, 可以用普通的 OR 运算符组合:
- 影响一旦文件对象创建后要执行的操作的各种标志 (表 11-4)
- 如果在文件系统中创建新文件, 则该文件的文件属性 (表 11-5)
- 如果 `SECURITYSQOSPRESENT` 标志存在, 则为命名管道客户端的服务质量标志. 命名管道在第 18 章 (第 2 部分) 中讨论.
| 标志 (FILEFLAG*) | 描述 |
|---|---|
| WRITETHROUGH | 强制任何写操作将数据刷新到磁盘 (并写入缓存) |
| NOBUFFERING | 强制操作直接到磁盘 (不使用缓存) |
| SEQUENTAILSCAN | 对文件系统的一个提示, 表明顺序读取是文件上的典型操作, 可能会对性能产生积极影响 |
| RANDOMACCESS | 对文件系统的一个提示, 表明期望对文件进行随机访问 |
| DELETEONCLOSE | 指示当最后一个句柄关闭时应删除该文件 |
| OVERLAPPED | 以异步操作模式打开文件/设备 (见本章后面) |
| BACKUPSEMANTICS | 打开目录句柄而不是文件所需的标志. 该标志允许具有备份或还原特权的调用者打开任何文件, 而不考虑文件的安全设置 |
| POSIXSEMANTICS | 请求文件名查找是区分大小写的. 此标志在最近的 Windows 版本中似乎不受尊重 |
| OPENREPARSEPOINT | 忽略重解析点的正常处理 (如果有的话), 并以正常访问权限打开文件 (重解析点超出了本章的范围) |
| OPENNORECALL | 对文件系统的一个提示, 远程文件不一定会读到本地存储 |
| SESSIONAWARE | (Windows 8+) 设备以会话感知方式打开. 这允许会话 0 打开以访问会话感知的设备. 此标志还需要一个注册表项来启用此检查. `IoEnableSessionZeroAccessCheck` 值必须在 `HKLM\System\CurrentControlSet\SessionManager\I/O System` 中设置为 1 |
| 文件属性 (FILEATTRIBUTE_) | 描述 |
|---|---|
| NORMAL 或 none | 正常文件 (如果使用, 必须没有任何以下属性) |
| HIDDEN | 文件是隐藏的 |
| ARCHIVE | 文件应该被存档. 它没有实际效果, 但执行文件备份的应用程序将其用作标记 |
| ENCRYPTED | 文件的内容是加密的 |
| READONLY | 文件是只读的, 不能以写访问权限打开 |
| SYSTEM | 文件是系统文件, 由操作系统和系统组件使用 |
| OFFLINE | 文件的实际存储在别处. 此标志不应随意设置 |
| TEMPORARY | 对文件系统和缓存管理器的一个提示, 文件用于临时存储. 系统尝试避免将文件的数据写入存储, 因为文件预计很快就会被删除. 与 `FILEFLAGDELETEONCLOSE` 结合使用效果很好 |
| NOTCONTENTINDEXED | 文件不会被索引服务索引 |
定义的属性列表比表 11-5 中显示的要长, 但这些额外的属性不能用 `CreateFile` 设置, 必须用不同的 API 设置 (取决于所讨论的属性), 本章后面会描述.
仔细使用与缓存相关的标志 (`FILEFLAGWRITETHROUGH`, `FILEFLAGNOBUFFERING`, `FILEFLAGSEQUENTAILSCAN`, `FILEFLAGRANDOMACCESS`) 对文件可以有性能上的好处. 然而, 对于 `FILEFLAGNOBUFFERING`, 有一些要求才能使其工作:
- 读/写访问大小必须是卷扇区大小的倍数. 这个大小可以通过调用 `GetDiskFreeSpace` 来发现.
- 在读/写操作中使用的缓冲区必须在物理扇区大小边界上对齐. 对于这类缓冲区, 建议使用 `VirtualAlloc` 函数进行分配, 因为它总是页 (4 KB) 对齐的 (有关 `VirtualAlloc` 的更多信息, 请参见第 13 章) 或使用 C 运行时 `alignedmalloc` 函数. 物理扇区大小可能与 `GetDiskFreeSpace` 提供的逻辑扇区大小不同. 要获取物理扇区大小, 需要在卷上使用 `IOCTLSTORAGEQUERYPROPERTY` 控制代码进行 `DeviceIoControl` 调用 (有关 `DeviceIoControl` 的更多信息, 请参见本章后面).
如果使用缓存 (正常情况), 你可以调用 `FlushFileBuffers` 来强制将数据刷新到文件:
BOOL FlushFileBuffers(_In_ HANDLE hFile);
`CreateFile` 的最后一个参数, `hTemplateFile`, 是一个可选的文件句柄, 用于在创建新文件时从中复制属性. 如果指定, 该句柄必须具有 `GENERICREAD` 访问掩码. 如果打开现有文件, 此参数将被忽略.
`CreateFile` 返回一个到创建的文件对象的句柄, 如果失败则返回 `INVALIDHANDLEVALUE` (少数不返回 `NULL` 的 `Create` 函数之一). 像往常一样, `GetLastError` 提供了有关错误的更多信息.
在以下部分中, 我们将研究使用文件和设备的各个方面, 并详细说明本节中描述的一些标志.
- 使用符号链接
正如我们所见, `CreateFile` 在内部通过解析符号链接来工作. 这些链接可以用 `QueryDosDevice` 查询:
DWORD QueryDosDevice( _In_opt_ LPCTSTR lpDeviceName, _Out_ LPTSTR lpTargetPath, _In_ DWORD ucchMax);
该函数以两种模式工作: 如果 `lpDeviceName` 不是 `NULL`, 该函数查找符号链接并将其目标 (如果有的话) 返回到 `lpTargetPath` 中. 如果 `lpDeviceName` 是 `NULL`, 它会在 `lpTargetPath` 中返回所有符号链接, 用 `\0` 分隔, 以便如果需要可以迭代它们, 为每个符号链接调用 `QueryDosDevice`. 在这种情况下, 最后一个条目有一个额外的 `\0` 来表示列表的结束. 该函数返回写入目标缓冲区的字符数, 如果函数失败则为零. 如果函数因为目标缓冲区太小而失败, `GetLastError` 返回 `ERRORINSUFFICIENTBUFFER`.
`symlinks` 应用程序允许使用 `QueryDosDevice` 查询符号链接. 如果没有传递参数, 应用程序会转储所有符号链接及其目标. 如果提供了参数, 应用程序只转储名称中具有提供字符串的那些符号链接.
第一步是分配一个足够大的缓冲区来读取所有符号链接. 这是必要的, 因为应用程序要么需要转储所有符号链接, 要么需要搜索它们以查找匹配项. 无论哪种方式, 都需要读取所有符号链接:
#include <memory> #include <string> #include <set> using namespace std; int wmain(int argc, wchar_t* argv[]) { auto size = 1 << 14; unique_ptr<WCHAR[]> buffer; for (;;) { buffer = make_unique<WCHAR[]>(size); if (0 == ::QueryDosDevice(nullptr, buffer.get(), size)) { if (::GetLastError() == ERROR_INSUFFICIENT_BUFFER) { size *= 2; continue; } else { printf("Error: %d\n", ::GetLastError()); return 1; } } else break; } }
一个循环被构造出来, 用 `std::makeunique<>` 分配一个字符数组, 然后用 `NULL` `lpDeviceName` 调用 `QueryDosDevice` 以获取所有符号链接. 如果缓冲区太小, 大小会加倍, 并重试.
一旦成功, 返回的列表必须被迭代, 再次为每个匹配提供的命令行参数的符号链接调用 `QueryDosDevice`, 或者所有符号链接. 应用程序通过使用 `std::set` (它将其元素插入到按元素排序的二叉搜索树中) 并使用自定义比较器来处理结果的排序, 以便比较不区分大小写 (这不是 `std::wstring` 的默认设置):
if (argc > 1) { // convert argument to lowercase ::_wcslwr_s(argv, ::wcslen(argv) + 1); } auto filter = argc > 1 ? argv : nullptr; // simplify stored type using LinkPair = pair<wstring, wstring>; struct LessNoCase { bool operator()(const LinkPair& p1, const LinkPair& p2) const { return ::_wcsicmp(p1.first.c_str(), p2.first.c_str()) < 0; } }; // sorted by LessNoCase set<LinkPair, LessNoCase> links; WCHAR target; for (auto p = buffer.get(); *p; ) { wstring name(p); auto locase(name); ::_wcslwr_s((wchar_t*)locase.data(), locase.size() + 1); if (filter == nullptr || locase.find(filter) != wstring::npos) { ::QueryDosDevice(name.c_str(), target, _countof(target)); // add pair to results links.insert({ name, target }); } // move to next item p += name.size() + 1; } // print results for (auto& link : links) { printf("%ws = %ws\n", link.first.c_str(), link.second.c_str()); }
以下是一些常见符号链接的示例运行:
C:\>symlinks.exe c: C: = \Device\HarddiskVolume3 c:\> symlinks.exe pipe PIPE = \Device\NamedPipe c:\>symlinks.exe nul NUL = \Device\Null c:\>symlinks con CimfsControl = \Device\cimfs\control CON = \Device\ConDrv\Console CONIN$ = \Device\ConDrv\CurrentIn CONOUT$ = \Device\ConDrv\CurrentOut ... PartmgrControl = \Device\PartmgrControl PciControl = \Device\PciControl ... UVMLiteController = \Device\UVMLiteController0x1 VolMgrControl = \Device\VolMgrControl
`QueryDosDevice` 的反函数也存在, 它允许定义新的符号链接:
BOOL DefineDosDevice( _In_ DWORD dwFlags, _In_ LPCTSTR lpDeviceName, _In_opt_ LPCTSTR lpTargetPath);
`lpDeviceName` 是符号链接的名称, `lpTargetPath` 是链接的目标. 例如, 进行以下调用会设置一个新的逻辑驱动器以指向一个现有的目录:
::DefineDosDevice(0, L"s:", L"c:\\Windows\\System32");
这与内置的 Windows 工具 `subst.exe` 提供的效果相同:
c:>subst s: c:\windows\system32
在前面的一个调用之后, 你可以打开资源管理器, 看到新驱动器就像任何其他驱动器一样出现.
然而, 回到 `WinObj` 或 `Object Explorer`, 新的符号链接不会出现在 `Global??` 对象管理器目录中; 那将是一个过于强大的操作. 相反, 它是与调用进程的令牌关联的*登录会话*的一部分. 图 11-5 显示了此类符号链接的存储位置.
如果调用者在 `LocalSystem` 帐户下运行, 映射会影响全局命名空间.

Figure 166: 用 DefineDosDevice 创建的符号链接
图 11-5 中箭头指向的目录名称是登录会话 ID. 这将在第 16 章 (“安全性”) 中进一步讨论. `DefineDosDevice` 的 `dwFlags` 参数可以为零或表 11-6 中显示的值的组合.
标志 描述 DDDNOBROADCASTSYSTEM 阻止函数广播 `WMSETTINGSCHANGE` 消息. 此消息通常允许像资源管理器这样的应用程序更新其状态 DDDRAWTARGETPATH 目标路径被解释为本地路径 (例如 `\Device\Harddiskvolume3\MyDir`), 而不是 Win32 路径 (`c:\MyDir`) DDDREMOVEDEFINITION 移除符号链接映射. 通常 `lpTargetPath` 设置为 `NULL` 以删除 `lpDeviceName` 中提供的名称. 否则, 会查找目标名称以进行删除 DDDEXACTMATCHONREMOVE 仅对前一个标志有效. 在目标路径上执行精确匹配 (而不是部分匹配) - 路径长度
`CreateFile` 的文件名长度传统上限制为 `MAXPATH` 字符, 定义为 260. 使用 Unicode 版本的函数 (`CreateFileW`), 该路径可以通过在路径前加上 `\\?\` 来扩展到大约 32767 个字符 (例如 `\\?\c:\MyDir\MyFile.txt`). 路径中的每个部分都限制为 255 个字符.
请记住, 作为 C/C++ 字符串的一部分, 每个反斜杠都必须用另一个反斜杠进行转义. 所以“c:\temp”必须写成“c:\\temp”. C++ 11 的一个替代方案是使用字符串字面量特性. 这是通过在字符串前加上 R 并在引号前加上括号来完成的. 示例: `R"(c:\temp\file.txt)"` 或使用 Unicode: `LR"(c:\temp\file.txt)"`. 一个可选的分隔符序列可以出现在 `(` 之前, 并且必须在 `)` 之后相同, 但对于路径来说这很少需要.
用 `\\?\` 扩展路径也支持通用命名约定 (UNC) 路径. 前缀更改为 `\\?\UNC\`.
Windows 10 版本 1607 和 Windows Server 2016 添加了一个新功能, 允许突破这些路径长度限制. 这是一个需要两个设置的选择性加入功能:
- 一个名为 `LongPathsEnabled` 的全局注册表值, 在 `HKLM\System\CurrentControlSet\Control\FileSystem` 中必须设置为 1 (`DWORD` 值). 第一次为进程调用 I/O 函数时, 会读取此值并为该进程的生命周期缓存. 这意味着对此值的任何更改只对新进程有效. 如果此值被更改并且系统重新启动, 所有进程都保证会看到新值.
- 特定的可执行文件必须在其清单中包含 `longPathAware` 元素并将其设置为 `true`. 这是清单 XML 文件中的完整部分:
<application xmlns="urn:schemas-microsoft-com:asm.v3"> <windowsSettings xmlns:ws2="http://schemas.microsoft.com/SMI/2016/WindowsSettings"> <ws2:longPathAware>true</ws2:longPathAware> </windowsSettings> </application>
注册表是一个机器范围的设置, 因此需要管理员访问权限才能更改.
大多数处理路径的 Windows API 函数都可以应对可能非常长的路径.
使用长路径时要小心, 因为大多数内置应用程序的清单中没有此设置. 例如, Windows 资源管理器就没有. 使用长路径, 资源管理器将无法处理此类路径.
- 目录
如果 `dwFlagsAndAttribute` 参数中指定了 `FILEFLAGBACKUPSEMANTICS` 标志, `CreateFile` 函数可以打开一个到现有目录的句柄. 要创建一个目录, 需要一个单独的函数:
BOOL CreateDirectory( _In_ LPCTSTR lpPathName, _In_opt_ LPSECURITY_ATTRIBUTES lpSecurityAttributes); BOOL CreateDirectoryEx( _In_ LPCTSTR lpTemplateDirectory, _In_ LPCTSTR lpNewDirectory, _In_opt_ LPSECURITY_ATTRIBUTES lpSecurityAttributes);
`CreateDirectory` 的 `lpPathName` 参数和 `CreateDirectoryExW` 的 `lpNewDirectory` 参数指定了新目录的路径 (这可以是完整路径或相对路径, 但路径的所有组件除了新目录外都必须在调用前存在).
可以提供一个可选的 `SECURITYATTRIBUTES` 指针来为新目录设置安全描述符 (有关更多信息, 请参见第 16 章). 最后, `CreateDirectoryEx` 的 `lpTemplateDirectory` 参数允许指定一个现有目录, 从中复制新目录的某些属性, 例如压缩和加密设置.
- 文件
一旦文件句柄打开, 就可以查询关于该文件的一些基本信息. 可能最常见的是文件的大小:
DWORD GetFileSize( _In_ HANDLE hFile, _Out_opt_ LPDWORD lpFileSizeHigh); BOOL GetFileSizeEx( _In_ HANDLE hFile, _Out_ PLARGE_INTEGER lpFileSize);
文件大小是 64 位的, 这意味着 Windows 可以处理非常大的文件. 实践中的最大文件大小比理论上的 2 的 64 次方 (16 EB) 字节要有限得多, 并且取决于实际的磁盘大小, 文件系统和一些属性, 例如文件是否被压缩或稀疏 (本章后面讨论). 尽管如此, 大于 32 位大小 (4 GB) 的文件相当常见, 代码通常应该期望这样的大小, 除非有令人信服的理由假设否则.
`GetFileSize` 返回文件大小的低 32 位作为其返回值, 如果指定, 则在高 32 位参数 `lpFileSizeHigh` 中返回. 如果 `lpFileSizeHigh` 为 `NULL`, 则不返回高 32 位值. 该函数在出错时返回 `INVALIDFILESIZE`, 定义为 `0xffffffff`.
`GetFileSizeEx` 更简单, 因为它在 `LARGEINTEGER` 结构中返回文件大小, 我们之前遇到过. 此函数返回通常的布尔值以指示成功或失败.
上述两个函数返回的文件大小是逻辑文件大小, 可能与物理文件大小不同. 例如, 如果文件被压缩或稀疏, 其在磁盘上的实际大小可能会更小. 对于此类文件, 有一个专门的函数可以用来查询磁盘上的实际文件大小:
DWORD GetCompressedFileSize( _In_ LPCTSTR lpFileName, _Out_opt_ LPDWORD lpFileSizeHigh);
`GetCompressedFileSize` 接受文件名而不是句柄, 并以与 `GetFileSize` 相同的格式返回请求的大小.
关于文件的另一个基本信息与其创建, 修改和访问时间有关. `GetFileTime` 检索这些值:
BOOL GetFileTime( _In_ HANDLE hFile, _Out_opt_ LPFILETIME lpCreationTime, _Out_opt_ LPFILETIME lpLastAccessTime, _Out_opt_ LPFILETIME lpLastWriteTime );
返回的时间以从 1601 年 1 月 1 日开始的通常的 100 纳秒为单位. 可以为任何时间提供 `NULL` 指针, 以指示对特定结果不感兴趣.
文件属性可以用 `GetFileAttributes` 或 `GetFileAttributesEx` 检索:
DWORD GetFileAttributes(_In_ LPCTSTR lpFileName); BOOL GetFileAttributesEx( _In_ LPCTSTR lpFileName, _In_ GET_FILEEX_INFO_LEVELS fInfoLevelId, _Out_ LPVOID lpFileInformation);
`GetFileAttributes` 接受一个文件名并返回其属性. 这些属性包括表 11-5 中的那些, 并且可以包括在 `CreateFile` 调用中设置不合法的其他属性. 这些附加值在表 11-7 中列出.
文件属性 (FILEATTRIBUTE_) 描述 DIRECTORY 或 none 目录 (而不是文件) REPARSEPOINT 文件具有关联的重解析点 COMPRESSED 文件被压缩 SPARSEFILE 文件是稀疏文件 INTEGRITYSTREAM (Windows 8+) 目录或数据流配置了完整性 (仅限 ReFS)* NOSCRUBDATA (Windows 8+) 数据流不应被数据完整性扫描器读取 (仅限 ReFS 和存储空间)* \* 对属性 `FILEATTRIBUTEINTEGRITYSTREAM` 和 `FILEATTRIBUTENOSCRUBDATA` 的详细讨论超出了本书的范围.
`GetFileAttributesEx` 目前接受一个值为 `GetFileExInfoStandard` 的单个“级别”, 并返回一个 `WIN32FILEATTRIBUTEDATA` 结构, 定义如下:
typedef struct _WIN32_FILE_ATTRIBUTE_DATA { DWORD dwFileAttributes; FILETIME ftCreationTime; FILETIME ftLastAccessTime; FILETIME ftLastWriteTime; DWORD nFileSizeHigh; DWORD nFileSizeLow; } WIN32_FILE_ATTRIBUTE_DATA, *LPWIN32_FILE_ATTRIBUTE_DATA;
除了前面讨论的文件属性, 该函数还返回文件的创建时间, 最后访问时间, 最后写入时间和大小.
要获取有关文件的更多信息, 请调用 `GetFileInformationByHandle`:
BOOL GetFileInformationByHandle( _In_ HANDLE hFile, _Out_ LPBY_HANDLE_FILE_INFORMATION lpFileInformation);
该函数接受一个到文件的句柄, 而不是文件路径, 并返回一个名为 `BYHANDLEFILEINFORMATION` 的 `WIN32FILEATTRIBUTEDATA` 的超集:
typedef struct _BY_HANDLE_FILE_INFORMATION { DWORD dwFileAttributes; FILETIME ftCreationTime; FILETIME ftLastAccessTime; FILETIME ftLastWriteTime; DWORD dwVolumeSerialNumber; DWORD nFileSizeHigh; DWORD nFileSizeLow; DWORD nNumberOfLinks; DWORD nFileIndexHigh; DWORD nFileIndexLow; } BY_HANDLE_FILE_INFORMATION, *PBY_HANDLE_FILE_INFORMATION;
该函数返回几部分信息, 其中一些也是 `WIN32FILEATTRIBUTEDATA` 的一部分. 额外的信息包括卷序列号, 到文件的链接数 (如果在 NTFS 上有硬链接, 可以超过 1), 以及文件的索引 (64 位, 作为两个 32 位数字提供). 时间以从 1601 年 1 月 1 日开始的通常的 100 纳秒为单位. 文件索引在特定卷上对文件是唯一的. 这意味着将文件索引与卷号结合起来可以为特定机器上的文件提供一个标识. 这可以用于比较两个文件句柄, 指示它们是否指向同一个文件.
如果你只对文件的属性感兴趣, `GetFileInformationByHandle` 比 `GetFileAttributes` 或 `GetFileAttributesEx` 快, 因为它使用一个已经打开的句柄. 其他函数需要打开文件, 获取信息并关闭它. 总是优先使用句柄 (如果你有的话) 而不是文件路径.
要获取关于文件的更多信息, 请调用 `GetFileInformationByHandleEx`:
BOOL GetFileInformationByHandleEx( _In_ HANDLE hFile, _In_ FILE_INFO_BY_HANDLE_CLASS FileInformationClass, _Out_ LPVOID lpFileInformation, _In_ DWORD dwBufferSize );
该函数可以检索相当多的信息, 其中请求的信息由 `FILEINFOBYHANDLECLASS` 枚举提供:
typedef enum _FILE_INFO_BY_HANDLE_CLASS { FileBasicInfo, FileStandardInfo, FileNameInfo, FileRenameInfo, FileDispositionInfo, FileAllocationInfo, FileEndOfFileInfo, FileStreamInfo, FileCompressionInfo, FileAttributeTagInfo, FileIdBothDirectoryInfo, FileIdBothDirectoryRestartInfo, FileIoPriorityHintInfo, FileRemoteProtocolInfo, FileFullDirectoryInfo, FileFullDirectoryRestartInfo, #if (_WIN32_WINNT >= _WIN32_WINNT_WIN8) FileStorageInfo, FileAlignmentInfo, FileIdInfo, FileIdExtdDirectoryInfo, FileIdExtdDirectoryRestartInfo, #endif #if (_WIN32_WINNT >= _WIN32_WINNT_WIN10_RS1) FileDispositionInfoEx, FileRenameInfoEx, #endif #if (NTDDI_VERSION >= NTDDI_WIN10_19H1) FileCaseSensitiveInfo, FileNormalizedNameInfo, #endif MaximumFileInfoByHandleClass } FILE_INFO_BY_HANDLE_CLASS, *PFILE_INFO_BY_HANDLE_CLASS;
那可真是一长串. 条件编译显示了在 Windows 8 / Server 2012 及更高版本, Windows 10 版本 1607 和 Server 2016, 以及 Windows 10 版本 1903 中添加了哪些值.
对于每个枚举值, 文档都会描述与该值关联的结构.
- 设置文件信息
`GetFileAttributes` 有一个补充函数来设置文件属性:
BOOL SetFileAttributes( _In_ LPCTSTR lpFileName, _In_ DWORD dwFileAttributes);
可以用这些函数设置的属性有: `FILEATTRIBUTEARCHIVE`, `FILEATTRIBUTEHIDDEN`, `FILEATTRIBUTENORMAL`, `FILEATTRIBUTENOTCONTENTINDEXED`, `FILEATTRIBUTEOFFLINE`, `FILEATTRIBUTEREADONLY`, `FILEATTRIBUTESYSTEM`, 和 `FILEATTRIBUTETEMPORARY`.
其他可以用其他 API 更改的属性包括:
- `FILEATTRIBUTECOMPRESSED` - 调用 `DeviceIoControl` 并使用 `FSCTLSETCOMPRESSION` 控制代码 (见本章后面关于 `DeviceIoControl` 的更多内容).
- `FILEATTRIBUTEENCRYPTED` - 如果不是这样创建的, 调用 `EncryptFile` 来加密文件的当前内容, 并设置该属性.
- `FILEATTRIBUTEREPARSEPOINT` - 调用 `DeviceIoControl` 并使用 `FSCTLSETREPARSEPOINT` 控制代码将文件与重解析点关联.
- `FILEATTRIBUTESPARSEFILE` - 调用 `DeviceIoControl` 并使用 `FSCTLSETSPARSE` 控制代码将文件转换为稀疏文件. 稀疏文件预计主要包含零, 因此它可以使用更少的磁盘空间.
更改与文件关联的时间是通过调用 `SetFileTime` 完成的:
BOOL SetFileTime( _In_ HANDLE hFile, _In_opt_ CONST FILETIME* lpCreationTime, _In_opt_ CONST FILETIME* lpLastAccessTime, _In_opt_ CONST FILETIME* lpLastWriteTime);
句柄必须具有 `FILEWRITEATTRIBUTES` 才能允许这些更改. 调用者可以为其不希望更改的每个值指定 `NULL`.
要设置文件的其他信息片段, 可以使用 `GetFileInformationByHandleEx` 的补充:
BOOL SetFileInformationByHandle( _In_ HANDLE hFile, _In_ FILE_INFO_BY_HANDLE_CLASS FileInformationClass, _In_reads_bytes_(dwBufferSize) LPVOID lpFileInformation, _In_ DWORD dwBufferSize);
`FileInformationClass` 参数与提供给 `GetFileInformationByHandleEx` 的枚举相同. 然而, 只有一小部分信息类可用于设置数据: `FileBasicInfo`, `FileRenameInfo`, `FileDispositionInfo`, `FileAllocationInfo`, `FileEndOfFileInfo`, 和 `FileIoPriorityHintInfo`.
- 路径长度
1.12.3. 同步 I/O
当调用 `CreateFile` 并且不在 `dwFlagsAndAttributes` 参数中指定 `FILEFLAGOVERLAPPED` 时, 文件对象仅为同步 I/O 创建. 这是最简单的使用方式, 所以我们先来解决同步 I/O.
执行 I/O 的主要函数是 `ReadFile` 和 `WriteFile`, 它们适用于任何文件对象 (不一定指向文件系统文件):
BOOL ReadFile( _In_ HANDLE hFile, _Out_ LPVOID lpBuffer, _In_ DWORD nNumberOfBytesToRead, _Out_opt_ LPDWORD lpNumberOfBytesRead, _Inout_opt_ LPOVERLAPPED lpOverlapped); BOOL WriteFile( _In_ HANDLE hFile, _In_ LPCVOID lpBuffer, _In_ DWORD nNumberOfBytesToWrite, _Out_opt_ LPDWORD lpNumberOfBytesWritten, _Inout_opt_ LPOVERLAPPED lpOverlapped);
这些函数适用于同步和异步 I/O. `lpBuffer` 是要从中读取数据 (`WriteFile`) 或要写入数据 (`ReadFile`) 的缓冲区. 对于 `ReadFile`, `nNumberOfBytesToRead` 指示要读入缓冲区的字节数, 对于 `WriteFile`, `nNumberOfBytesToWrite` 指示要写入的字节数.
实际读/写的字节数在 `lpNumberOfBytesRead` (读) 或 `lpNumberOfBytesWritten` (写) 中返回. 它可以小于请求的字节数甚至为零. 请注意, 对于同步 I/O, 你不能为这些参数传递 `NULL`, 否则当函数尝试取消引用 `NULL` 指针时会得到访问冲突.
最后一个参数 `lpOverlapped` 是异步操作必需的非 `NULL` 参数, 但对于同步 I/O, 它应该是 `NULL`.
这些函数是同步的, 这意味着调用线程现在被阻塞 (进入等待状态), 直到操作完成并且数据已传输. 函数在失败时返回 `FALSE`, `GetLastError` 提供遇到的确切错误.
以下示例显示了如何创建一个新文件并向其中写入一些数据:
HANDLE hFile = ::CreateFile(LR"(c:\temp\mydata.txt)", GENERIC_WRITE, // access 0, // sharing (exclusive) nullptr, // SECURITY_ATTRIBUTES CREATE_NEW, // creation disposition 0, // flags and attributes nullptr); // template file if(hFile != INVALID_HANDLE_VALUE) { char text[] = "Hello from Windows!"; DWORD bytes; ::WriteFile(hFile, text, ::strlen(text), &bytes, nullptr); ::CloseHandle(hFile); }
下一个示例读取文件中的所有字节:
HANDLE hFile = ::CreateFile(LR"(c:\temp\mydata.txt)", GENERIC_READ, // access FILE_SHARE_READ, // sharing nullptr, // SECURITY_ATTRIBUTES OPEN_EXISTING, // creation disposition 0, // flags and attributes nullptr); // template file if(hFile != INVALID_HANDLE_VALUE) { // assume file size is less than 4GB DWORD size = ::GetFileSize(hFile, nullptr); auto buffer = std::make_unique<char[]>(size + 1); DWORD bytes; if(::ReadFile(hFile, buffer.get(), size, &bytes, nullptr)) { // assume data is expected to be ASCII text buffer[bytes] = '\0'; // add string terminator printf("%s\n", buffer.get()); } ::CloseHandle(hFile); }
为同步访问打开的每个文件对象都维护一个内部文件指针, 该指针会随着每个 I/O 操作自动前进. 例如, 如果一个文件被打开并执行了 10 字节的读取操作, 文件指针在操作完成后会前进 10 字节. 如果再发出一个 10 字节的读取, 它会读取 10 到 19 字节, 并且文件指针前进到位置 20.
对于顺序读写, 这很棒. 然而, 在某些情况下, 你可能想向前或向后跳转并从不同的位置读/写. 这可以用以下函数之一完成:
DWORD SetFilePointer( _In_ HANDLE hFile, _In_ LONG lDistanceToMove, _Inout_opt_ PLONG lpDistanceToMoveHigh, _In_ DWORD dwMoveMethod); BOOL SetFilePointerEx( _In_ HANDLE hFile, _In_ LARGE_INTEGER liDistanceToMove, _Out_opt_ PLARGE_INTEGER lpNewFilePointer, _In_ DWORD dwMoveMethod);
这些函数将内部文件指针移动到所需位置. `SetFilePointerEx` 更容易使用, 因为它允许在 `liDistanceToMove` 参数中提供一个完整的 64 位偏移量. `SetFilePointer` 在 `lDistanceToMove` 中接受偏移量的低 32 位, 可选地在 `lpDistanceToMoveHigh` 中接受高 32 位. 两个函数都尝试返回先前的文件指针: `SetFilePointerEx` 在 `lpNewFilePointer` 中, `SetFilePointer` 在返回值 (低 32 位) 和 `lpDistanceToMoveHigh` 中 (如果非 `NULL`——高 32 位).
然而, 移动的偏移量不一定是从文件开头的偏移量. 最后一个参数 `dwMoveMethod` 指示如何解释提供的偏移量:
- `FILEBEGIN` (0) - 从文件开头
- `FILECURRENT` (1) - 从当前文件位置
- `FILEEND` (2) - 从文件末尾
你可以通过指定一个零移动距离和 `FILECURRENT` 移动方法来查询当前文件指针而不移动. 你可以通过为偏移量指定零和 `FILEEND` 方法来移动到文件末尾.
在同一个文件上打开的多个文件对象是不同的, 并且在任何方面都没有同步, 包括它们的文件指针. 每个都有自己的, 它们不会相互影响.
用一个超出文件当前大小的偏移量调用 `SetFilePointer(Ex)`, 会将文件扩展到该大小. 相反, 在将文件指针设置到所需大小后, 可以通过调用 `SetEndOfFile` 来修剪文件:
BOOL SetEndOfFile(_In_ HANDLE hFile);
1.12.4. 异步 I/O
正如本章开头所述, Windows I/O 系统本质上是异步的. 一旦设备驱动程序向其受控硬件 (例如磁盘驱动器) 发出请求, 驱动程序就不需要等待操作完成. 相反, 它将请求标记为“待处理”并返回给其调用者. 线程现在可以在 I/O 正在进行时自由地执行其他操作.
一段时间后, I/O 操作由硬件设备完成. 设备发出一个硬件中断, 导致一个驱动程序提供的回调运行并完成挂起的请求.
使用同步 I/O 简单易行, 在许多情况下也足够好. 然而, 如果要服务大量请求, 为每个请求创建一个线程, 该线程将启动一个 I/O 操作并等待它完成, 是低效的; 这种方法扩展性不好. 异步 I/O 提供了一个解决方案, 其中一个线程启动一个请求, 然后返回服务下一个请求, 依此类推, 因为 I/O 操作在 CPU 执行其他代码时并发操作. 这个简单模型中唯一的麻烦是一个线程如何被通知一个 I/O 操作的完成. 正如我们将很快看到的, Windows 提供了几种技术来处理这个问题.
请求异步操作必须从原始的 `CreateFile` 调用开始 (顺便说一句, 它总是同步的). `FILEFLAGOVERLAPPED` 标志必须作为 `dwFlagsAndAttributes` 参数的一部分指定. 这会以异步模式打开文件/设备.
为异步访问打开的文件的后果之一是再也没有文件指针了. 这意味着每个操作都必须以某种方式提供一个从文件开头执行操作的偏移量 (大小不是问题, 因为它是读/写调用的一部分). 这是 `OVERLAPPED` 结构的任务之一, 该结构必须作为 `ReadFile` 和 `WriteFile` 的最后一个参数传递:
typedef struct _OVERLAPPED { ULONG_PTR Internal; ULONG_PTR InternalHigh; union { struct { DWORD Offset; DWORD OffsetHigh; }; PVOID Pointer; }; HANDLE hEvent; } OVERLAPPED, *LPOVERLAPPED;
这个结构包含三个不同的信息片段:
- `Internal` 和 `InternalHigh` 如其名, 由 I/O 管理器使用, 不应被写入, 尽管它们的用法在下面描述.
- `Offset` 和 `OffsetHigh` 是要设置的偏移量, 指示操作应在文件中的何处开始. 联合的 `Pointer` 成员是这些字段的一个替代方案, 如果需要 64 位偏移量, 使用起来会更容易一些.
- `hEvent` 是一个到内核事件对象的句柄, 如果非 `NULL`, 则在操作完成时由 I/O 管理器发出信号.
技术上, `Internal` 保存 I/O 操作的错误代码. 对于正在进行的异步操作, 它保存 `STATUSPENDING`, 这是 `STILLACTIVE` (0x103) 的内核等价物. 事实上, Windows 定义了一个宏, `HasOverlappedIoCompleted`, 利用了这个事实. 以下是其定义:
#define HasOverlappedIoCompleted(lpOverlapped) \ (((DWORD)(lpOverlapped)->Internal) != STATUS_PENDING)
`InternalHigh` 成员在操作完成后存储传输的字节数.
在一个异步操作中, `ReadFile` 或 `WriteFile` 调用通常返回 `FALSE`, 因为操作尚未完成, 它只是刚刚开始. 在某些情况下, 底层设备驱动程序可能会决定同步执行该操作, 在这种情况下, 函数返回 `TRUE`. 这在针对文件系统文件的 `ReadFile` 和 `WriteFile` 中应该很少发生.
如果函数返回 `FALSE`, 那么调用 `GetLastError` 会返回 `ERRORIOPENDING`, 这意味着一切都按计划进行——操作正在进行中, 线程可以继续做其他事情. 如果返回了不同的错误, 那么这是一个真正的错误——操作没有开始.
`ReadFile` 和 `WriteFile` 都有一个返回字节的参数, 在同步操作的情况下返回传输的字节数. 对于异步操作, 这没有意义, 因为操作尚未完成. 尽管你可以提供一个 `DWORD` 的地址并忽略结果, 但最好为此参数指定 `NULL` 以避免任何混淆.
鉴于上述信息, 以下代码示例打开一个文件进行异步访问, 执行一个读取操作, 在操作进行时进行一些其他处理, 然后等待操作完成:
HANDLE hFile = ::CreateFile(LR"(c:\temp\mydata.txt)", GENERIC_READ, FILE_SHARE_READ, nullptr, OPEN_EXISTING, FILE_FLAG_OVERLAPPED, nullptr); if (hFile != INVALID_HANDLE_VALUE) { // initialize OVERLAPPED OVERLAPPED ov = { 0 }; // offset is zero ov.hEvent = ::CreateEvent(nullptr, TRUE, FALSE, nullptr); BYTE buffer[1 << 12]; // 4KB BOOL ok = ::ReadFile(hFile, buffer, sizeof(buffer), nullptr, &ov); if(!ok) { if (::GetLastError() != ERROR_IO_PENDING) { // some real error occurred... return; } else { // do some other work... // wait for the operation to complete ::WaitForSingleObject(ov.hEvent, INFINITE); ::CloseHandle(ov.hEvent); } } // do something with the result... ::CloseHandle(hFile); }
关于上述代码有几点要注意:
- `OVERLAPPED` 实例必须在 I/O 操作进行期间一直存在. 在上面的代码中, 它是在栈上分配的, 并且调用线程等待操作完成, 因此保证了实例的存在. 在更复杂的情况下, 可能需要动态分配.
- 事件由原始调用者等待, 但这不是必需的; 任何线程都可以等待该事件, 包括线程池线程 (如第 9 章所示).
一旦操作完成, 你怎么知道传输了多少字节? 我们无法从原始的 `ReadFile`/`WriteFile` 调用中得到它. 我们可以从 `OVERLAPPED` 结构的 `InternalHigh` 成员中得到它, 但有一个专门的函数可以获取此信息:
BOOL GetOverlappedResult( _In_ HANDLE hFile, _In_ LPOVERLAPPED lpOverlapped, _Out_ LPDWORD lpNumberOfBytesTransferred, _In_ BOOL bWait);
`GetOverlappedResult` 接受文件句柄和你感兴趣的特定操作的 `OVERLAPPED` 结构 (你可以从同一个文件句柄启动多个操作, 每个都有不同的 `OVERLAPPED` 实例). `lpNumberOfBytesTransferred` 返回实际传输的字节数.
最后一个参数 `bWait`, 指定是否在报告结果之前等待操作完成 (`TRUE`). 如果操作已经完成, 那么这无关紧要. 如果操作仍在进行中并且 `bWait` 是 `TRUE`, 调用线程会等待直到操作完成并且函数返回 `TRUE`. 如果 `bWait` 是 `FALSE` 并且操作仍在进行中, 函数返回 `FALSE` 并且 `GetLastError` 返回 `ERROIOINCOMPLETE`.
一个扩展函数, `GetOverlappedResultEx`, 在等待操作完成时提供了更多的灵活性:
BOOL GetOverlappedResultEx( _In_ HANDLE hFile, _In_ LPOVERLAPPED lpOverlapped, _Out_ LPDWORD lpNumberOfBytesTransferred, _In_ DWORD dwMilliseconds, _In_ BOOL bAlertable);
该函数允许设置等待的超时限制 (`dwMilliseconds`), 以及在可警报状态下等待的能力 (`bAlertable`) (有关可警报状态的更多信息, 请参见第 7 章).
Windows 提供了几种处理异步 I/O 完成的方法. 我们刚刚看到了其中一种, 使用一个事件对象. 表 11-8 总结了可用的选项.
| 机制 | 备注 |
|---|---|
| 等待文件句柄 | 使用简单, 但仅限于单个操作 |
| 等待 `OVERLAPPED` 结构中的事件 | 使用简单. 任何线程都可以等待该事件 |
| 使用带回调的 `ReadFileEx` 和 `WriteFileEx` | 回调作为 APC 排队到调用者线程, 意味着它是唯一可以处理结果的线程 |
| I/O 完成端口 | 不像其他的那么容易, 但灵活且功能强大 |
表 11-8 中的第一个选项指示文件句柄是一个可等待对象, 并且在异步操作完成时变为已发出信号状态. 如果一次只有一个这样的请求在进行中, 这可以正常工作. 如果有多个请求在进行中, 文件句柄在第一个完成时发出信号, 但无法保证是哪个请求.
通常, I/O 操作可以乱序完成, 因为这是驱动程序安排实际请求的特权. 你永远不应依赖某种 I/O 操作完成的顺序.
由于等待文件句柄并不理想, 你可以告诉系统不要费心去给它发信号:
BOOL SetFileCompletionNotificationModes( _In_ HANDLE FileHandle, _In_ UCHAR Flags);
其中一个标志是 `FILESKIPSETEVENTONHANDLE`, 这是告诉 I/O 管理器跳过文件句柄信号所需的.
第二个选项, 使用一个塞在 `OVERLAPPED` 结构中的事件对象, 效果很好, 前提是每个操作都与自己的事件关联. 任何线程都可以等待该事件, 包括线程池线程.
- ReadFileEx 和 WriteFileEx
响应已完成 I/O 操作的第三个选项是使用 `ReadFile` 或 `WriteFile` 的扩展版本:
BOOL ReadFileEx( _In_ HANDLE hFile, _Out_ LPVOID lpBuffer, _In_ DWORD nNumberOfBytesToRead, _Inout_ LPOVERLAPPED lpOverlapped, _In_ LPOVERLAPPED_COMPLETION_ROUTINE lpCompletionRoutine); BOOL WriteFileEx( _In_ HANDLE hFile, _In_ LPCVOID lpBuffer, _In_ DWORD nNumberOfBytesToWrite, _Inout_ LPOVERLAPPED lpOverlapped, _In_ LPOVERLAPPED_COMPLETION_ROUTINE lpCompletionRoutine);
这些函数与它们的非 Ex 对应函数相同, 除了一个额外的参数, 它是一个必须具有以下原型的函数指针:
typedef VOID (WINAPI *LPOVERLAPPED_COMPLETION_ROUTINE)( _In_ DWORD dwErrorCode, _In_ DWORD dwNumberOfBytesTransfered, _Inout_ LPOVERLAPPED lpOverlapped);
- 手动排队的 APC
值得描述另一个与 APC 相关的一般函数. 它是将 APC 排队到目标线程的能力:
DWORD QueueUserAPC( _In_ PAPCFUNC pfnAPC, _In_ HANDLE hThread, _In_ ULONG_PTR dwData);
该函数将 APC 排队到由 `hThread` 参数表示的目标线程, 该参数必须具有 `THREADSETCONTEXT` 访问掩码. `pfnAPC` 是一个必须具有以下原型的函数指针:
typedef VOID (WINAPI *PAPCFUNC)(_In_ ULONG_PTR Parameter);
`dwData` 是在 `Parameter` 参数中发送给 APC 函数的值.
这仍然是一个 APC, 因此目标线程必须进入可警报状态, APC 回调才能被执行. 这意味着向任意线程排队 APC 是有问题的; 调用者应该事先知道目标线程很可能在不久的将来处于可警报状态. 否则, 这些 APC 会排队, 直到某个限制, 但永远不会执行.
`QueueUserAPC` 的一个简单用途是实现一个由特定线程服务的简单队列, 而无需创建和管理任何数据结构. 运行工作项的线程需要一直处于可警报状态, 除非被指示退出:
DWORD WorkThread(PVOID param) { // assume an event handle is passed in to signal thread exit HANDLE hEvent = (HANDLE)param; for(;;) { if(::WaitForSingleObjectEx(hEvent, INFINITE, TRUE) == WAIT_OBJECT_0) break; // if the wait is over and the event is not set, this means one or more APCs // executed. Just continue waiting again for more APCs or an exit signal } return 0; }
线程是用以下代码创建的:
HANDLE hEvent = ::CreateEvent(nullptr, TRUE, FALSE, nullptr); HANDLE hThread = ::CreateThread(nullptr, 0, WorkThread, (PVOID)hEvent, 0, nullptr);
此时, 可以使用 `QueueUserAPC` 排队一个工作项:
::QueueUserAPC(hThread, SomeFunction, SomeData);
最后, 当线程应该被拆除时, 只需设置事件, 并可选地等待线程退出, 可能会完成仍在队列中的 APC:
::SetEvent(hEvent); ::WaitForSingleObject(hEvent, INFINITE);
1.12.5. I/O 完成端口
I/O 完成端口值得拥有自己的主要部分, 因为它们不仅对处理异步 I/O 有用. 我们在第 4 章讨论作业时简要地遇到了它们——一个作业可以与一个 I/O 完成端口关联, 以接收与该作业相关的通知. 在本节中, 我们将关注 I/O 完成在处理 I/O 完成方面的用法.
一个 I/O 完成端口与一个文件对象 (可以超过一个) 关联. 它封装了一个请求队列, 以及一个可以在这些请求完成后为它们服务的线程列表. 每当一个异步操作完成时, 等待在完成端口上的一个线程应该被唤醒并处理完成, 可能会启动下一个请求.
第一步是创建一个 I/O 完成端口对象并将其与一个或多个文件句柄关联. 这是 `CreateIoCompletionPort` 的任务:
HANDLE CreateIoCompletionPort( _In_ HANDLE FileHandle, _In_opt_ HANDLE ExistingCompletionPort, _In_ ULONG_PTR CompletionKey, _In_ DWORD NumberOfConcurrentThreads);
该函数可以执行两种不同的操作, 可能会将两者结合起来. 它可以做以下任何一项:
- 创建一个未与任何文件对象关联的 I/O 完成端口.
- 将一个现有的完成端口与一个文件对象关联.
- 在单个调用中结合上述两种操作.
这个函数是 `Create` 内核对象函数中唯一不接受 `SECURITYATTRIBUTES` 结构的函数. 这是因为一个完成端口总是对创建它的进程是本地的. 技术上, 将这样的句柄复制到另一个进程会成功, 但新的句柄是不可用的.
创建一个新的完成端口而不将其与任何文件关联只需要最后一个参数, 像这样:
HANDLE hNewCP = ::CreateIoCompletionPort(INVALID_HANDLE_VALUE, nullptr, 0, NumberOfConcurrentThreads);
并发线程数指示了可以通过此 I/O 完成端口处理 I/O 完成的最大线程数. 指定零会将该数字设置为系统上的逻辑处理器数. 我们稍后会看到这个参数的效果.
一旦创建了 I/O 完成端口对象, 就可以将其与一个或多个文件对象 (句柄) 关联. 对于每个文件句柄, 都指定了一个完成键, 这是应用程序定义的. 文件对象必须已用 `FILEFLAGOVERLAPPED` 打开. 以下是将一个文件对象添加到完成端口的示例:
const int Key = 1; HANDLE hFile = ::CreateFile(..., FILE_FLAG_OVERLAPPED, ...); HANDLE hOldCP = ::CreateIoCompletionPort(hFile, hNewCP, Key, 0); assert(hOldCP == hNewCP);
在这种情况下, 确实没有必要捕获返回的句柄, 因为现有的完成端口句柄被指定为第二个参数. 上面的 `assert` 只是让它更清楚.
请记住,“文件”不一定是在文件系统中的文件. 它可以是管道, 套接字或设备, 例如.
上述代码可以与其他文件对象重复, 所有这些都与完成端口关联. 完成端口的一个有点简单的图表如图 11-6 所示. 我们稍后会看到绑定线程是什么以及这一切是如何工作的.

Figure 167: I/O 完成端口组件
I/O 完成端口的目的是允许由工作线程处理已完成的 I/O 操作, 这里的“工作”可以意味着任何绑定到完成端口的线程. 当一个线程调用 `GetQueuedCompletionStatus` 时, 它就绑定到了一个完成端口:
BOOL GetQueuedCompletionStatus( _In_ HANDLE CompletionPort, _Out_ LPDWORD lpNumberOfBytesTransferred, _Out_ PULONG_PTR lpCompletionKey, _Out_ LPOVERLAPPED *lpOverlapped, _In_ DWORD dwMilliseconds);
该调用将线程置于等待状态, 直到与完成端口关联的文件对象之一启动的异步 I/O 操作完成, 或超时到期. 通常 `dwMilliseconds` 设置为 `INFINITE`, 意味着线程在 I/O 操作完成之前无事可做. 如果唤醒线程的操作成功完成, `GetQueuedCompletionStatus` 返回 `TRUE`, 并且 `out` 参数用传输的字节数, 最初与文件句柄关联的完成键以及用于请求的 `OVERLAPPED` 结构指针填充.
如果发生某些错误, 返回值为 `FALSE`, `GetLastError` 返回错误代码. 如果超时不是无限的, 返回值仍然是 `FALSE`, 但 `GetLastError` 返回 `WAITTIMEOUT`, 并且 `OVERLAPPED` 指针设置为 `NULL`.
任意数量的线程都可以调用 `GetQueuedCompletionStatus` 来等待一个已完成的数据包到达. I/O 完成端口不会允许超过在端口创建时指定的最大线程数同时成功调用该函数. 然而, 如果一个 `GetQueuedCompletionStatus` 成功的线程, 在处理完成操作时因任何原因进入等待状态 (`SuspendThread`, `WaitForSingleObject` 等), 完成端口将允许另一个线程使其 `GetQueuedCompletionStatus` 调用结束其等待. 这意味着, 定期地, 处理完成数据包的线程数可能高于原始指定的最大值. 然而, 只有最大数量的线程是“可运行的”——也就是说, 不在等待状态.
一旦一个线程第一次调用 `GetQueuedCompletionStatus`, 它就绑定到了完成端口, 直到线程退出, 完成端口被关闭, 或者线程在不同的完成端口上调用 `GetQueuedCompletionStatus`.
如果多个线程等待完成数据包, 获取下一个的是最后一个执行的, 即——它是一个后进先出 (LIFO) 队列 (技术上是一个栈). 这在完成操作速率相对较低的情况下是有益的, 允许同一个线程或少数线程进行处理. 这可能会减少上下文切换, 并肯定能更好地利用 CPU 缓存.
一个线程也可以用一个扩展版本的 `GetQueuedCompletionStatus` 请求出队多个 I/O 完成:
BOOL GetQueuedCompletionStatusEx( _In_ HANDLE CompletionPort, _Out_ LPOVERLAPPED_ENTRY lpCompletionPortEntries, _In_ ULONG ulCount, _Out_ PULONG ulNumEntriesRemoved, _In_ DWORD dwMilliseconds, _In_ BOOL fAlertable);
该函数填充一个 `OVERLAPPEDENTRY` 结构数组, 不超过 `ulCount`. 每个这样的结构看起来像这样:
typedef struct _OVERLAPPED_ENTRY { ULONG_PTR lpCompletionKey; LPOVERLAPPED lpOverlapped; ULONG_PTR Internal; DWORD dwNumberOfBytesTransferred; } OVERLAPPED_ENTRY, *LPOVERLAPPED_ENTRY;
该结构包括由 `GetQueuedCompletionStatus` 为单个完成条目提供的三个输出参数. `Internal` 成员就是那个, 不应被触动. 回到 `GetQueuedCompletionStatusEx`——返回的实际条目数由 `ulNumEntriesRemoved` 参数提供. 此外, 该函数允许在可警报状态下等待, 如果需要的话.
可以通过调用 `PostQueuedCompletionStatus` 来手动向 I/O 完成端口发布一个完成数据包, 这使得这些对象更通用, 不仅仅是关于 I/O. 这正是作业对象的通知工作方式.
BOOL PostQueuedCompletionStatus( _In_ HANDLE CompletionPort, _In_ DWORD dwNumberOfBytesTransferred, _In_ ULONG_PTR dwCompletionKey, _In_opt_ LPOVERLAPPED lpOverlapped);
除了完成端口, 该函数还接受将由 `GetQueuedCompletionStatus(Ex)` 稍后提取的三个参数. 通常, 完成键用于区分通知的类型. 另外, 对于非 I/O 操作, `OVERLAPPED` 结构没有什么意义, 因此通常在这种情况下传递 `NULL`.
- Bulk Copy 应用程序
`BuldCopy` 应用程序, 其主窗口如图 11-7 所示, 是一个如何将所有部分组合在一起以创建一个异步复制多个文件的应用程序的示例, 其中每个文件都可以自定义为复制到选定的目标.

Figure 168: Bulk Copy 应用程序的初始窗口
可以用*添加文件…*按钮添加源文件 (允许多个文件). 然后用*设置目标目录…*按钮选择一个复制目标 (对于所有源文件或其中一些). 图 11-8 显示了三个源文件的示例.

Figure 169: Bulk Copy 中添加的文件
现在*Go!*按钮变为启用状态, 允许执行复制操作. 对话框底部的进度条指示, 嗯, 进度 (图 11-9).

Figure 170: Bulk Copy 中的复制操作正在进行
当所有复制完成时, 应用程序会显示一个“全部完成!”消息框.
*添加目录…*按钮允许添加一个目录, 但应用程序没有为目录中的文件实现复制操作. 这留给读者作为练习.
复制文件远比仅仅从一个文件读取并写入另一个文件要复杂得多. 实际上需要复制更多元素, 例如安全描述符和 NTFS 流 (见本章后面关于 NTFS 流的内容).
向列表视图添加文件不是特别有趣, 除了为每个文件检索文件大小. 以下是完整的消息处理程序:
LRESULT CMainDlg::OnAddFiles(WORD, WORD wID, HWND, BOOL&) { CMultiFileDialog dlg(nullptr, nullptr, OFN_FILEMUSTEXIST | OFN_ALLOWMULTISELECT, L"All Files (*.*)\0*.*\0", *this); dlg.ResizeFilenameBuffer(1 << 16); if (dlg.DoModal() == IDOK) { CString path; int errors = 0; dlg.GetFirstPathName(path); do { wil::unique_handle hFile(::CreateFile(path, 0, FILE_SHARE_READ, nullptr, OPEN_EXISTING, 0, nullptr)); if (!hFile) { errors++; continue; } LARGE_INTEGER size; ::GetFileSizeEx(hFile.get(), &size); int n = m_List.AddItem(m_List.GetItemCount(), 0, path, 0); m_List.SetItemText(n, 1, FormatSize(size.QuadPart)); m_List.SetItemData(n, (DWORD_PTR)Type::File); } while (dlg.GetNextPathName(path)); m_List.EnsureVisible(m_List.GetItemCount() - 1, FALSE); UpdateButtons(); if (errors > 0) AtlMessageBox(*this, L"Some files failed to open", IDR_MAINFRAME, MB_ICONEXCLAMATION); } return 0; }
首先, 创建并向用户呈现一个多文件打开对话框. 每个文件都被打开以获取其文件大小, 使用 `GetFileSizeEx`. 注意提供的访问掩码为零, 因为如前所述, `SYNCHRONIZE` 和 `FILEREADATTRIBUTES` 总是被请求的, 这些属性包括文件大小. 然后将文件连同其大小 (由一个小帮助函数 `FormatSize` 格式化) 添加到列表视图中.
从 Windows API 的角度来看, 设置目标路径并不有趣, 因为它都是与 UI 相关的. 一旦单击*Go!*按钮, 真正的工作就开始了.
每个源/目标对, 连同这些文件的句柄, 都存储在一个帮助器结构中, 定义如下:
struct FileData { CString Src; CString Dst; wil::unique_handle hDst, hSrc; };
为了在 I/O 正在处理时保持句柄的存活, 这些结构被保存在对话框类的一个成员中 (`MainDlg.h` 中):
std::vector<FileData> m_Data;
*Go*按钮处理程序做的第一件事是构建这个向量, 但尚未打开文件:
LRESULT CMainDlg::OnGo(WORD, WORD wID, HWND, BOOL&) { // transfer list data to vector m_Data.clear(); int count = m_List.GetItemCount(); m_Data.reserve(count); for (int i = 0; i < count; i++) { if (m_List.GetItemData(i) != (DWORD_PTR)Type::File) { // folders not yet implemented continue; } FileData data; m_List.GetItemText(i, 0, data.Src); m_List.GetItemText(i, 2, data.Dst); m_Data.push_back(std::move(data)); } }
代码从列表视图中提取文件名并填充 `FileData` 结构, 将它们添加到向量中. UI 线程不应绑定到任何 I/O 完成端口, 因为这会导致 UI 在线程等待完成数据包时无响应, 因此创建一个新线程来服务 I/O 完成端口. 以下是 `OnGo` 函数的其余部分:
// create a worker thread auto hThread = ::CreateThread(nullptr, 0, [](auto param) { return ((CMainDlg*)param)->WorkerThread(); }, this, 0, nullptr); // error handling ommitted ::CloseHandle(hThread); // update UI state m_Progress.SetPos(0); m_Running = true; UpdateButtons(); return 0; }
真正的工作是由 `WorkerThread` 函数执行的. 它的第一个任务是创建一个新的 I/O 完成端口, 此时不与任何文件句柄关联:
DWORD CMainDlg::WorkerThread() { wil::unique_handle hCP(::CreateIoCompletionPort( INVALID_HANDLE_VALUE, nullptr, 0, 0)); ATLASSERT(hCP); if (!hCP) { PostMessage(WM_ERROR, ::GetLastError()); return 0; } }
接下来的各种读写操作将以块的形式进行, 设置为 64 KB (你可以用其他块大小进行实验).
const int chunkSize = 1 << 16; // 64 KB
I/O 操作的架构如图 11-10 所示.

Figure 171: 处理 I/O 操作
首先, 我们遍历所有文件对, 并打开每个源和目标. 对于源, 查询其大小:
LONGLONG count = 0; for (auto& data : m_Data) { // open source file for async I/O wil::unique_handle hSrc(::CreateFile(data.Src, GENERIC_READ, FILE_SHARE_READ, nullptr, OPEN_EXISTING, FILE_FLAG_OVERLAPPED, nullptr)); if (!hSrc) { PostMessage(WM_ERROR, ::GetLastError()); continue; } // get file size LARGE_INTEGER size; ::GetFileSizeEx(hSrc.get(), &size); }
目标文件可能存在也可能不存在. 我们需要打开或创建它, 然后设置其最终大小:
// create the target file and set final size CString filename = data.Src.Mid(data.Src.ReverseFind(L'\\')); wil::unique_handle hDst(::CreateFile(data.Dst + filename, GENERIC_WRITE, 0, nullptr, OPEN_ALWAYS, FILE_FLAG_OVERLAPPED, nullptr)); if (!hDst) { PostMessage(WM_ERROR, ::GetLastError()); continue; } ::SetFilePointerEx(hDst.get(), size, nullptr, FILE_BEGIN); ::SetEndOfFile(hDst.get());
现在将文件扩展到其最终大小很重要, 因为文件扩展总是同步完成的, 所以最好一次性完成.
现在我们可以将两个文件都与完成端口关联, 并将句柄保存在 `FileData` 结构中:
ATLVERIFY(hCP.get() == ::CreateIoCompletionPort(hSrc.get(), hCP.get(), (ULONG_PTR)Key::Read, 0)); ATLVERIFY(hCP.get() == ::CreateIoCompletionPort(hDst.get(), hCP.get(), (ULONG_PTR)Key::Write, 0)); data.hSrc = std::move(hSrc); data.hDst = std::move(hDst);
使用一个简单的枚举来识别源文件的完成键 (`Key::Read`) 与目标文件的完成键 (`Key::Write`), 因为我们需要为每个操作知道它是读还是写, 这是传播该信息的一种简单方法, 因为每个文件都用于读或写.
`ATLVERIFY` 类似于 `assert`, 但在 Release 构建以及 Debug 中都进行编译. 使用 `assert` 或 `ATLASSERT` 会从编译后的二进制文件中移除整个指令. 这些 `asserts` 只是验证添加到现有完成端口会返回相同的句柄.
现在是时候启动对源文件的第一个读取请求了. 我们需要为每个操作提供一些上下文信息. 我们可以使用的一个技巧是派生一个类自 `OVERLAPPED` 并添加我们需要的任何上下文. 指针将在每次成功调用 `GetQueuedCompletionStatus` 后可用, 然后我们就可以将其转换为完整的类型. 以下是派生的数据结构 (在 `MainDlg.h` 中定义):
struct IOData : OVERLAPPED { HANDLE hSrc, hDst; std::unique_ptr<BYTE[]> Buffer; ULONGLONG Size; };
我们需要到源文件和目标文件的句柄, 用于读写的缓冲区, 以及文件的大小. 这将允许我们确定文件是否已完全读取.
手头有这个结构, 我们可以构建第一个读取操作:
auto io = new IOData; io->Size = size.QuadPart; io->Buffer = std::make_unique<BYTE[]>(chunkSize); io->hSrc = data.hSrc.get(); io->hDst = data.hDst.get(); ::ZeroMemory(io, sizeof(OVERLAPPED)); auto ok = ::ReadFile(io->hSrc, io->Buffer.get(), chunkSize, nullptr, io); ATLASSERT(!ok && ::GetLastError() == ERROR_IO_PENDING); count += (size.QuadPart + chunkSize - 1) / chunkSize; }
结构是动态分配的, 因为它必须在操作完成之前一直存在. 在这个特定的应用程序中, 我们可以静态地创建这些数据结构, 因为所有操作都在一个函数中完成, 但我选择使用动态分配来演示这种模式, 如果应用程序以不同的方式架构, 这是必要的. `OVERLAPPED` 部分中的偏移量被清零 (文件开头), 缓冲区被分配, 大小从文件大小中复制, 并且用 `ReadFile` 和结构指针进行操作.
最后, 局部 `count` 变量用读取 (和写入) 整个文件所需的块数更新. 这将有助于确定何时所有操作都已完成.
此时, 根据文件数, 有多个读取操作正在进行. 现在是时候等待 I/O 完成通知并相应地采取行动了:
PostMessage(WM_PROGRESS_START, count); // update UI while (count > 0) { DWORD transferred; ULONG_PTR key; OVERLAPPED* ov; BOOL ok = ::GetQueuedCompletionStatus(hCP.get(), &transferred, &key, &ov, INFINITE); if (!ok) { PostMessage(WM_ERROR, ::GetLastError()); count--; delete ov; continue; } }
一旦 `GetQueuedCompletionStatus` 成功返回, 我们需要检查完成的数据包:
// get actual data object auto io = static_cast<IOData*>(ov); if (key == (DWORD_PTR)Key::Read) { // check if need another read ULARGE_INTEGER offset = { io->Offset, io->OffsetHigh }; offset.QuadPart += chunkSize; if (offset.QuadPart < io->Size) { auto newio = new IOData; newio->Size = io->Size; newio->Buffer = std::make_unique<BYTE[]>(chunkSize); newio->hSrc = io->hSrc; newio->hDst = io->hDst; ::ZeroMemory(newio, sizeof(OVERLAPPED)); newio->Offset = offset.LowPart; newio->OffsetHigh = offset.HighPart; auto ok = ::ReadFile(newio->hSrc, newio->Buffer.get(), chunkSize, nullptr, newio); auto error = ::GetLastError(); ATLASSERT(!ok && error == ERROR_IO_PENDING); } // read done, initiate write to the same offset in the target file // offset is the same, just a different file io->Internal = io->InternalHigh = 0; ok = ::WriteFile(io->hDst, io->Buffer.get(), transferred, nullptr, ov); auto error = ::GetLastError(); ATLASSERT(!ok && error == ERROR_IO_PENDING); } else { // write operation complete count--; delete io; PostMessage(WM_PROGRESS); } }
如果一个读取完成, 我们检查是否需要另一个读取, 如果是, 就分配一个新的 `IOData` 对象, 并用文件中的下一个块适当地填充它. 因为一个读取已完成, 就为一个写入操作启动, 将返回的缓冲区写入目标文件.
如果是一个写入完成, 我们递减剩余的操作计数, 释放 `IOData` 对象, 并向 UI 发送一个更新消息. 这个循环会一直持续, 直到所有 I/O 操作都完成.
最后, UI 可以更新, 所有文件数据向量都可以清除 (关闭所有文件的句柄), 线程可以优雅地退出, 同时也要关闭 I/O 完成端口.
当前, 读取操作被构造了两次: 第一次读取和所有其余的. 使用 `PostQueuedCompletionStatus` 来发布一个自定义通知, 以便初始读取的构造方式与后续读取相同.
添加一个选项来限制正在进行的并发 I/O 操作的数量. 当前, 这个数量是基于文件数的, 这可能会非常大.
- 使用线程池进行 I/O 完成
在第 9 章中, 我们看到了线程池的用途和好处. 我们省略的一个函数集与 I/O 操作有关. 现在是时候填补这个空白了. 在*Bulk Copy*应用程序中, 我们创建了一个专门的线程来调用 `GetQueuedCompletionStatus`, 并处理 I/O 完成. 这个服务也由线程池提供, 因此不需要创建显式的线程, 并且可以利用线程池的扩展性来让多个线程处理完成. 要开始工作, 调用 `CreateThreadpoolIo` 来在幕后创建一个完成端口并将其与一个文件句柄关联:
PTP_IO CreateThreadpoolIo( _In_ HANDLE hFile, _In_ PTP_WIN32_IO_CALLBACK pfnio, _Inout_opt_ PVOID pv, _In_opt_ PTP_CALLBACK_ENVIRON pcbe);
`hFile` 是要与内部 I/O 完成端口关联的文件句柄 (已经为异步 I/O 打开). `pfnio` 是一个由线程池线程在内部调用 `GetQueuedCompletionStatus` 返回时调用的回调.
`pv` 参数是一个应用程序定义的值, 按原样传递给回调函数. 最后, `pcbe` 是一个可选的回调环境, 在第 9 章中描述. 该函数返回一个表示 I/O 线程池对象的不透明指针.
回调必须具有以下原型:
typedef VOID (WINAPI *PTP_WIN32_IO_CALLBACK)( _Inout_ PTP_CALLBACK_INSTANCE Instance, _Inout_opt_ PVOID Context, _Inout_opt_ PVOID Overlapped, _In_ ULONG IoResult, _In_ ULONG_PTR NumberOfBytesTransferred, _Inout_ PTP_IO Io);
该函数提供标准的实例值 (`Instance` 参数) 作为其他线程池回调, 以及提供给 `CreateThreadpoolIo` 的上下文. 接下来的三个参数与 I/O 操作有关: `OVERLAPPED` 指针, 结果代码 (`ERRORSUCCESS` 如果一切顺利) 和传输的字节数. 最后一个参数是从 `CreateThreadpoolIo` 返回的 I/O 线程池对象. 正如我们很快将看到的, 拥有它很方便.
要启动线程池完成基础设施, 必须在每次异步操作之前调用 `StartThreadpoolIo`:
VOID StartThreadpoolIo(_Inout_ PTP_IO pio);
如果 `ReadFile` 或 `WriteFile` 调用返回一个错误 (返回值是 `FALSE` 并且 `GetLastError` 不是 `ERRORIOPENDING`), 线程池 I/O 必须用 `CancelThreadpoolIo` 取消:
VOID CancelThreadpoolIo(_Inout_ PTP_IO pio);
与我们遇到的其他线程池 API 类似, 线程可以等待和/或取消待处理的 I/O 操作:
VOID WaitForThreadpoolIoCallbacks( _Inout_ PTP_IO pio, _In_ BOOL fCancelPendingCallbacks );
最后, 线程池 I/O 对象需要被关闭:
VOID CloseThreadpoolIo(_Inout_ PTP_IO pio);
- Bulk Copy 2 应用程序
`BulkCopy2` 项目在功能上与 `BulkCopy` 项目相同, 但它使用线程池来响应 I/O 完成. 在本节中, 我们将看看使其工作的代码更改.
首先, 由于我们使用线程池, 创建一个专门的线程是不必要的——这就是线程池的作用. 响应 Go 按钮单击的 `OnGO` 函数调用一个名为 `StartCopy` 的函数来启动复制操作. 它首先遍历所有文件对, 打开文件, 并在目标中设置最终大小:
void CMainDlg::StartCopy() { m_OperationCount = 0; for (auto& data : m_Data) { // open source file for async I/O wil::unique_handle hSrc(::CreateFile(data.Src, GENERIC_READ, FILE_SHARE_READ, nullptr, OPEN_EXISTING, FILE_FLAG_OVERLAPPED, nullptr)); if (!hSrc) { PostMessage(WM_ERROR, ::GetLastError()); continue; } // get file size LARGE_INTEGER size; ::GetFileSizeEx(hSrc.get(), &size); // create target file and set final size CString filename = data.Src.Mid(data.Src.ReverseFind(L'\\')); wil::unique_handle hDst(::CreateFile(data.Dst + filename, GENERIC_WRITE, 0, nullptr, OPEN_ALWAYS, FILE_FLAG_OVERLAPPED, nullptr)); if (!hDst) { PostMessage(WM_ERROR, ::GetLastError()); continue; } ::SetFilePointerEx(hDst.get(), size, nullptr, FILE_BEGIN); ::SetEndOfFile(hDst.get()); } }
我们没有显式地创建一个 I/O 完成端口. 相反, 我们使用线程池来创建两个线程池 I/O 对象, 并将它们与两个文件关联. `FileData` 结构已扩展以存储这些句柄:
struct FileData { CString Src; CString Dst; wil::unique_handle hDst, hSrc; wil::unique_threadpool_io tpSrc, tpDst; };
注意使用 `wil::uniquethreadpoolio`, 当对象超出作用域时会调用 `CloseThreadpoolIo`.
在 `StartCopy` 内部继续, 我们创建线程池 I/O 对象:
data.tpDst.reset(::CreateThreadpoolIo(hDst.get(), WriteCallback, this, nullptr)); data.tpSrc.reset(::CreateThreadpoolIo(hSrc.get(), ReadCallback, data.tpDst.get(), nullptr));
对于写操作, `this` 作为上下文参数传递. 对于读操作, 传递的是写 I/O 池对象. 我们将在实现读写回调时看到为什么需要这样做. 这个循环中的最后一件事是启动第一个读取操作, 与 `Bulk Copy` 应用程序非常相似, 增加了 `StartThreadpoolIo` 来启动线程池 I/O 机制:
data.hSrc = std::move(hSrc); data.hDst = std::move(hDst); // initiate first read operation auto io = new IOData; io->Size = size.QuadPart; io->Buffer = std::make_unique<BYTE[]>(chunkSize); io->hSrc = data.hSrc.get(); io->hDst = data.hDst.get(); ::ZeroMemory(io, sizeof(OVERLAPPED)); ::StartThreadpoolIo(data.tpSrc.get()); auto ok = ::ReadFile(io->hSrc, io->Buffer.get(), chunkSize, nullptr, io); ATLASSERT(!ok && ::GetLastError() == ERROR_IO_PENDING); ::InterlockedAdd64(&m_OperationCount, (size.QuadPart + chunkSize - 1) / chunkSize); } PostMessage(WM_PROGRESS_START, (WPARAM)m_OperationCount); }
`StartCopy` 快速运行, 为所有文件启动读取操作, 然后返回到泵送 UI 消息. 其余的工作由在 `CreateThreadpoolIo` 中注册的两个静态回调完成. 以下是读取回调:
void CMainDlg::ReadCallback(PTP_CALLBACK_INSTANCE Instance, PVOID Context, PVOID Overlapped, ULONG IoResult, ULONG_PTR Transferred, PTP_IO Io) { if (IoResult == ERROR_SUCCESS) { auto io = static_cast<IOData*>(Overlapped); ULARGE_INTEGER offset = { io->Offset, io->OffsetHigh }; offset.QuadPart += chunkSize; if (offset.QuadPart < io->Size) { auto newio = new IOData; newio->Size = io->Size; newio->Buffer = std::make_unique<BYTE[]>(chunkSize); newio->hSrc = io->hSrc; newio->hDst = io->hDst; ::ZeroMemory(newio, sizeof(OVERLAPPED)); newio->Offset = offset.LowPart; newio->OffsetHigh = offset.HighPart; ::StartThreadpoolIo(Io); auto ok = ::ReadFile(newio->hSrc, newio->Buffer.get(), chunkSize, nullptr, newio); auto error = ::GetLastError(); ATLASSERT(!ok && error == ERROR_IO_PENDING); } // read done, initiate write to the same offset in the target file io->Internal = io->InternalHigh = 0; auto writeIo = (PTP_IO)Context; ::StartThreadpoolIo(writeIo); auto ok = ::WriteFile(io->hDst, io->Buffer.get(), (ULONG)Transferred, nullptr, io); auto error = ::GetLastError(); ATLASSERT(!ok && error == ERROR_IO_PENDING); } }
代码与原始应用程序处理读取完成非常相似. 在启动新请求之前, 强制调用 `StartThreadpoolIo`, 这显示了为什么拥有最后一个参数 (`PTPIO`) 很方便. 由于结束一个读取操作需要启动一个写入操作, 传入的上下文是目标的 `PTPIO` 对象, 允许调用正确的 `StartThreadpoolIo` 进行写入. 作为替代方案, 线程池 I/O 对象可以很容易地塞入 `IOData` 结构中.
写入回调更简单, 因为它只需要更新操作计数 (以线程安全的方式), 并释放已完成的操作:
void CMainDlg::WriteCallback(PTP_CALLBACK_INSTANCE Instance, PVOID Context, PVOID Overlapped, ULONG IoResult, ULONG_PTR Transferred, PTP_IO Io) { if (IoResult == ERROR_SUCCESS) { auto pThis = static_cast<CMainDlg*>(Context); pThis->PostMessage(WM_PROGRESS); auto io = static_cast<IOData*>(Overlapped); delete io; if (0 == InterlockedDecrement64(&pThis->m_OperationCount)) { pThis->PostMessage(WM_DONE); } } }
1.12.6. I/O 取消
一旦 I/O 操作正在进行, 如何取消它? Windows API 在这方面提供了一些选项.
对 I/O 取消的明显需求与异步操作有关. 为此, 有两个函数:
BOOL CancelIo(_In_ HANDLE hFile); BOOL CancelIoEx( _In_ HANDLE hFile, _In_opt_ LPOVERLAPPED lpOverlapped);
`CancelIo` 尝试取消由调用线程通过提供的文件句柄发起的所有异步操作. 为了更细粒度的控制, `CancelIoEx` 可以与一个表示要取消的操作的特定 `OVERLAPPED` 结构一起使用.
在任何情况下, 取消 I/O 操作都不能保证成功. 取消操作本身由负责该操作的设备驱动程序实现. 一些驱动程序 (特别是对于设备) 根本不支持取消. 即使驱动程序支持取消, 它也可能无法对每个操作都这样做. 例如, 如果一个操作当前正在由硬件处理, 可能已经太晚而无法取消. 你应该将取消 API 视为请求取消, 不带任何保证.
在以下情况下, I/O 操作也会被取消:
- 当文件句柄关闭时, 所有待处理的 I/O 操作都会被取消 (除非文件句柄与完成端口关联).
- 当一个线程退出时, 该线程发出的所有待处理的 I/O 操作都会被取消, 除了对与 I/O 完成端口关联的文件句柄发出的请求.
如果 I/O 操作成功取消, `GetLastError` (或线程池回调提供的错误结果) 的返回值是 `ERROROPERATIONABORTED`.
那么同步操作呢? 显然, 发起请求的线程无法取消它, 因为它正在等待 I/O 完成. 然而, 另一个线程可以尝试用 `CancelSynchronousIo` 取消:
BOOL CancelSynchronousIo(_In_ HANDLE hThread);
线程句柄必须具有 `PROCESSTERMINATE` 访问掩码. 如前所述, 取消不能保证. 如果取消了, 原始线程的等待会完成, 操作返回 `FALSE`, `GetLastError` 返回 `ERROROPERATIONABORTED`.
1.12.7. 设备
使用设备 (即非文件系统文件) 与使用文件系统文件本质上没有区别. `ReadFile` 和 `WriteFile` 函数适用于任何设备, 包括异步, 尽管不是所有设备都支持读写操作. 对于设备, 还有一个用于执行 I/O 操作的函数——`DeviceIoControl`:
BOOL DeviceIoControl( _In_ HANDLE hDevice, _In_ DWORD dwIoControlCode, _In_ LPVOID lpInBuffer, _In_ DWORD nInBufferSize, _Out_ LPVOID lpOutBuffer, _In_ DWORD nOutBufferSize, _Out_opt_ LPDWORD lpBytesReturned, _Inout_opt_ LPOVERLAPPED lpOverlapped);
`DeviceIoControl` 是一个通用函数, 允许发送一个由控制代码 (`dwIoControlCode`) 定义的请求, 并带有两个可选的缓冲区, 一个指定为“输入”, 另一个为“输出”.
该函数返回写入输出缓冲区的字节数 (如果有的话) (在 `lpBytesReturned` 中), 如果请求要异步执行, 则接受一个可选的 `OVERLAPPED` 结构.
例如, 考虑一个稀疏文件的想法. 稀疏文件应主要包含零, 因此文件系统可以以比正常存储所有字节更少的空间存储它. 压缩可以提供类似的效果, 但这些格式不相同. 要将一个文件转换为稀疏文件, 需要用 `FSCTLSETSPARSE` I/O 控制代码进行 `DeviceIoControl` 调用. 该控制代码的文档指示输入和输出缓冲区应包含什么. 在 `FSCTLSETSPARSE` 的情况下, 输入缓冲区应指向以下结构:
typedef struct _FILE_SET_SPARSE_BUFFER { BOOLEAN SetSparse; } FILE_SET_SPARSE_BUFFER;
一个非常简单的结构, 指示是打开还是关闭稀疏文件功能. 此操作没有输出缓冲区. 使一个文件稀疏可以像这样完成:
FILE_SET_SPARSE_BUFFER buffer; buffer.SetSparse = TRUE; DWORD bytes; ::DeviceIoControl(hFile, FSCTL_SET_SPARSE, &buffer, sizeof(buffer), nullptr, 0, &bytes, nullptr);
一旦一个文件是稀疏的, 必须用另一个控制代码 `FSCTLSETZERODATA` 显式地写入零, 像这样:
FILE_ZERO_DATA_INFORMATION buffer; buffer.FileOffset.QuadPart = 100; buffer.BeyondFinalZero.QuadPart = 1 << 20; ::DeviceIoControl(hFile, FSCTL_SET_ZERO_DATA, &buffer, sizeof(buffer), nullptr, 0, &bytes, nullptr);
许多其他标准控制代码存在于各种类型的设备中, 请查阅文档以获取更多信息.
`CreateFile` 适用于任何符号链接, 如图 11-3 和 11-4 所示. 例如, 有名为“PhysicalDrive0”的符号链接, 可能还有其他的, 这是一种直接打开驱动器扇区的方法, 而不通过文件系统的镜头看它.
`DumpDrive` 应用程序显示来自磁盘的原始字节, 从所需的扇区开始. `main` 函数首先解析命令行参数:
int main(int argc, const char* argv[]) { if (argc < 4) { printf("Usage: DumpDrive <index> <offset in sectors> <size in sectors>\\n"); return 0; } WCHAR path[] = L"\\\\.\\PhysicalDriveX"; path[::wcslen(path) - 1] = argv; auto offset = atoll(argv) * 512; auto size = atol(argv) * 512; }
偏移量和大小必须是扇区大小的倍数. 否则, 后面的 `ReadFile` 调用会失败, 并带有 `ERRORINVALIDPARAMETER`. 上面的代码假定每个扇区 512 字节. 最好不要假设, 而是通过编程方式获取实际大小. 本节末尾的练习将引导你朝正确的方向.
接下来, 我们需要打开驱动器, 将文件指针移动到所需的偏移量并执行读取:
HANDLE hDevice = ::CreateFile(path, GENERIC_READ, FILE_SHARE_READ | FILE_SHARE_WRITE, nullptr, OPEN_EXISTING, 0, nullptr); if (hDevice == INVALID_HANDLE_VALUE) return Error("Failed to open Physical drive"); LARGE_INTEGER fp; fp.QuadPart = offset; if (!::SetFilePointerEx(hDevice, fp, nullptr, FILE_BEGIN)) return Error("Failed in SetFilePointerEx"); auto buffer = std::make_unique<BYTE[]>(size); DWORD bytes; if (!::ReadFile(hDevice, buffer.get(), size, &bytes, nullptr)) return Error("Failed to read data"); DisplayData(offset, buffer.get(), bytes); ::CloseHandle(hDevice); return 0; }
我们正在使用一个设备而不是一个文件系统文件的事实并没有改变我们编写代码的基本方式. `CreateFile` 的路径才是重要的. `DisplayData` 是一个将十六进制字节转储到控制台的简单函数:
void DisplayData(long long offset, const BYTE* buffer, DWORD bytes) { const int bytesPerLine = 16; for (DWORD i = 0; i < bytes; i += bytesPerLine) { printf("%16X: ", offset + i); for (int b = 0; b < bytesPerLine; b++) { printf("%02X ", buffer[i + b]); } printf("\n"); } }
以下是在我的物理驱动器 1 上运行的截断示例:
c:\>DumpDrive 1 0 2 0: 33 C0 8E D0 BC 00 7C FB 50 07 50 1F FC BE 1B 7C 10: BF 1B 06 50 57 B9 E5 01 F3 A4 CB BD BE 07 B1 04 20: 38 6E 00 7C 09 75 13 83 C5 10 E2 F4 CD 18 8B F5 30: 83 C6 10 49 74 19 38 2C 74 F6 A0 B5 07 B4 07 8B 40: F0 AC 3C 00 74 FC BB 07 00 B4 0E CD 10 EB F2 88 50: 4E 10 E8 46 00 73 2A FE 46 10 80 7E 04 0B 74 0B 60: 80 7E 04 0C 74 05 A0 B6 07 75 D2 80 46 02 06 83 70: 46 08 06 83 56 0A 00 E8 21 00 73 05 A0 B6 07 EB ... 120: 32 E4 8A 56 00 CD 13 EB D6 61 F9 C3 49 6E 76 61 130: 6C 69 64 20 70 61 72 74 69 74 69 6F 6E 20 74 61 140: 62 6C 65 00 45 72 72 6F 72 20 6C 6F 61 64 69 6E 150: 67 20 6F 70 65 72 61 74 69 6E 67 20 73 79 73 74 ... 3E0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 3F0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
添加代码以动态确定扇区的大小. 使用 `IOCTLDISKGETDRIVEGEOMETRY` 控制代码来查询磁盘的几何形状.
符号链接的其他用途是用于“软件驱动程序”, 那些不管理任何硬件, 但需要做一些在用户模式下无法完成的事情的驱动程序. 一个典型的例子是 Process Explorer 的驱动程序, 它必须暴露一个符号链接, 以便 Process Explorer 本身 (驱动程序的客户端) 可以打开一个到该设备的句柄, 并对其进行 `DeviceIoControl` 调用, 请求各种服务, 基于驱动程序建立并为 Process Explorer 所知的通信协议.
如果你至少以管理员权限运行过一次 Process Explorer, 你会发现使用像 WinObj 或 ObjectExplorer 这样的工具, 符号链接名为“ProcExp152”. 这意味着 Process Explorer 使用类似以下的代码打开一个到其设备的句柄:
HANDLE hDevice = ::CreateFile(L"\\\\.\\ProcExp152", GENERIC_READ | GENERIC_WRITE, 0, nullptr, OPEN_EXISTING, 0, nullptr);
然后在需要时调用 `DeviceIoControl`.
我自己的工具, `ObjectExplorer`, 也使用一个内核驱动程序, 符号链接名为“KObjExp”. 我使用一个类似的 `CreateFile` 调用来与我的设备驱动程序通信.
另一个有趣的符号链接集看起来像无意义的字符串, 人类不可能选择的; 事实上, 它们是由内核生成的, 以 (至少) 确保唯一性. 这些看起来很奇怪的符号链接用于硬件设备名称. 例如, 如果你想访问连接到你计算机的摄像头, 你会怎么做? 没有一个叫做“Camera1”或类似东西的符号链接, 因为这种字符串有一些限制:
- 如果有两台或更多台相机怎么办?
- 设备可以被拔出然后再插回——数字值会以某种方式持久化吗?
- 英语有什么特别之处吗——为什么是“Camera”这个词? 每个驱动程序都可以想出自己的名字.
- 如果名称可以是任何东西, 如何枚举相机设备?
- 有些设备可能有多种“个性”. 例如, 一个打印机设备也可能是一个扫描仪.
一些来自 DOS 时代的经典名称仍然为兼容性而维护, 例如 PRN, LPT, COM, NUL 等.
在幕后, 设备暴露了*设备接口*, 你可以将其视为类似于软件接口. 每个接口都代表某种功能. 例如, 一个打印机设备可以“实现”一个打印接口和一个扫描接口. 使用这些接口, 你可以搜索“打印机”或“扫描仪”.
设备接口由 GUID 表示, 许多是由 Microsoft 定义的, 可以在文档中找到. 这意味着我们需要使用一个 API 来定位一个设备, 并且 API 返回的信息的一部分是设备的符号链接, 我们可以按原样传递给 `CreateFile`.
`EnumDevices` 应用程序显示了一个基于设备接口枚举设备并定位设备符号链接的示例. 应用程序的核心是 `EnumDevices` 函数, 它接受所请求设备接口的 GUID, 并执行枚举. 每个设备信息都返回在以下结构中:
struct DeviceInfo { std::wstring SymbolicLink; std::wstring FriendlyName; };
设备枚举首先用 `SetupDiGetClassDevs` 构建一个设备信息集 (infoset):
std::vector<DeviceInfo> EnumDevices(const GUID& guid) { std::vector<DeviceInfo> devices; auto hInfoSet = ::SetupDiGetClassDevs(&guid, nullptr, nullptr, DIGCF_PRESENT | DIGCF_INTERFACEDEVICE); if (hInfoSet == INVALID_HANDLE_VALUE) return devices; }
对 `SetupDi*` API 的详细讨论超出了本书的范围.
“SetupDi” 是“Setup Device Interface”的缩写.
`SetupDiGetClassDevs` 的第一个参数是设备 GUID, 它要求最后一个标志参数包含 `DIGCFINTERFACEDEVICE`. 另一个指定的标志 (`DIGCFPRESENT`) 指示只应枚举连接的设备.
一旦创建了 infoset, 就可以用几个枚举函数来枚举它, 在这种情况下, 我们需要的是 `SetupDiEnumDeviceInterfaces`. 如果它返回 `FALSE`, 这意味着没有更多的设备 (或发生了一些其他错误):
devices.reserve(4); SP_INTERFACE_DEVICE_DATA data = { sizeof(data) }; SP_DEVINFO_DATA ddata = { sizeof(ddata) }; BYTE buffer[1 << 12]; for (DWORD i = 0; ; i++) { if (!::SetupDiEnumDeviceInterfaces(hInfoSet, nullptr, &guid, i, &data)) break; }
枚举返回一个 `SPINTERFACEDEVICEDATA` 结构, 可用于查询符号链接:
if (::SetupDiGetDeviceInterfaceDetail(hInfoSet, &data, details, sizeof(buffer), nullptr, &ddata)) { DeviceInfo info; info.SymbolicLink = details->DevicePath; }
最后, 我们可以为设备获取一个“友好名称”, 并将设备添加到向量中:
if(::SetupDiGetDeviceRegistryProperty(hInfoSet, &ddata, SPDRP_DEVICEDESC, nullptr, buffer, sizeof(buffer), nullptr)) info.FriendlyName = (WCHAR*)buffer; devices.push_back(std::move(info)); } } ::SetupDiDestroyDeviceInfoList(hInfoSet); return devices; }
`DisplayDevices` 函数接受一个 `DeviceInfo` 实例的集合, 显示信息, 并尝试用 `CreateFile` 打开一个句柄:
void DisplayDevices(const std::vector<DeviceInfo>& devices, const char* name) { printf("%s\n%s\n", name, std::string(::strlen(name), '-').c_str()); for (auto& di : devices) { printf("Symbolic link: %ws\n", di.SymbolicLink.c_str()); printf(" Name: %ws\n", di.FriendlyName.c_str()); auto hDevice = ::CreateFile(di.SymbolicLink.c_str(), GENERIC_READ, FILE_SHARE_READ | FILE_SHARE_WRITE, nullptr, OPEN_EXISTING, 0, nullptr); if (hDevice == INVALID_HANDLE_VALUE) printf(" Failed to open device (%d)\n", ::GetLastError()); else { printf(" Device opened successfully!\n"); ::CloseHandle(hDevice); } } printf("\n"); }
主函数使用来自各种头文件的一些 GUID 来枚举某些类型的设备:
#define INITGUID #include <Wiaintfc.h> #include <Ntddvdeo.h> #include <devpkey.h> #include <Ntddkbd.h> int main() { auto devices = EnumDevices(GUID_DEVINTERFACE_IMAGE); DisplayDevices(devices, "Image"); // now in one stroke DisplayDevices(EnumDevices(GUID_DEVINTERFACE_MONITOR), "Monitor"); DisplayDevices(EnumDevices(GUID_DEVINTERFACE_DISPLAY_ADAPTER), "Display Adapter"); DisplayDevices(EnumDevices(GUID_DEVINTERFACE_DISK), "Disk"); DisplayDevices(EnumDevices(GUID_DEVINTERFACE_KEYBOARD), "keyboard"); return 0; }
以下是在我的机器上运行的示例 (截断):
...
Monitor
-------
Symbolic link: \\?\display#deld06e#4&5dd6935&0&uid200195#{e6f07b5f-ee97-4a90-b0\
76-33f57bf4eaa7}
Name: Generic PnP Monitor
Device opened successfully!
Symbolic link: \\?\display#deld070#4&5dd6935&0&uid208387#{e6f07b5f-ee97-4a90-b0\
76-33f57bf4eaa7}
Name: Generic PnP Monitor
Device opened successfully!
Display Adapter
---------------
Symbolic link: \\?\pci#ven_8086&dev_3e9b&subsys_09261028&rev_02#3&11583659&0&10\
#{5b45201d-f2f2-4f3b-85bb-30ff1f953599}
Name: Intel(R) UHD Graphics 630
Failed to open device (5)
Symbolic link: \\?\pci#ven_10de&dev_1f36&subsys_09261028&rev_a1#4&13a74b11&0&00\
08#{5b45201d-f2f2-4f3b-85bb-30ff1f953599} Name: NVIDIA Quadro RTX 3000
Failed to open device (5)
Symbolic link: \\?\root#basicdisplay#0000#{5b45201d-f2f2-4f3b-85bb-30ff1f953599}
Name: Microsoft Basic Display Driver
Failed to open device (5)
Disk
----
Symbolic link: \\?\scsi#disk&ven_nvme&prod_pm981a_nvme_sams#4&9bd8d03&0&020000#\
{53f56307-b6bf-11d0-94f2-00a0c91efb8b}
Name: Disk drive
Device opened successfully!
Symbolic link: \\?\usbstor#disk&ven_wd&prod_elements_10b8&rev_1012#575836314134\
344e39393230&0#{53f56307-b6bf-11d0-94f2-00a0c91efb8b}
Name: Disk drive
Device opened successfully!
keyboard
--------
Symbolic link: \\?\hid#vid_1532&pid_021e&mi_01&col01#9&5ed78c5&0&0000#{884b96c3\
-56ef-11d1-bc8c-00a0c91405dd}
Name: Razer Ornata Chroma
Failed to open device (5)
Symbolic link: \\?\hid#vid_044e&pid_1212&col01&col02#7&1551398c&0&0001#{884b96c\
3-56ef-11d1-bc8c-00a0c91405dd}
Name: HID Keyboard Device
Failed to open device (5)
...
前缀 `\\?\` 与 `\\.\` 相同.
- 管道和邮槽
本节值得一提的两种设备是——管道和邮槽. 管道是单向或双向 (也称为半双工和全双工) 的通信机制, 可以在进程之间和网络上的机器之间工作. 邮槽是单向的通信机制, 可以在本地或网络上工作.
你可以用 Object Explorer 查看现有的管道和邮槽. 从*对象*菜单中选择*管道…*或*邮槽…*. 一个典型的系统上有很多打开的管道 (图 11-11).

Figure 172: 系统上的管道 (Object Explorer)
表 11-1 显示了一个与命名管道和邮槽相关的路径示例. `CreateFile` 函数由命名管道/邮槽客户端使用. 对于服务器端点, 需要使用其他函数.
- 管道
管道有两种变体——匿名和命名. 匿名管道是一种简单的单向通信机制, 仅限于本地机器. 一个匿名管道对是用 `CreatePipe` 创建的:
BOOL CreatePipe( _Out_ PHANDLE hReadPipe, _Out_ PHANDLE hWritePipe, _In_opt_ LPSECURITY_ATTRIBUTES lpPipeAttributes, _In_ DWORD nSize);
`CreatePipe` 为管道的两端创建句柄. 使用匿名管道的一个经典例子是将输入和/或输出重定向到另一个进程. 这允许一个进程向另一个进程提供数据, 而另一个进程毫不知情, 也不在乎, 它只是使用标准句柄进行输入/输出.
`SimpleRedirect` 应用程序显示了将输出句柄重定向到前一节的 `EnumDevices` 应用程序的示例. `EnumDevices` 的输出不会进入其控制台, 而是会进入 `SimpleRedirect` 进程.
应用程序窗口是一个带有大编辑框的简单对话框 (图 11-12). 单击*创建和重定向*会创建管道, `EnumDevices` 进程并执行重定向. 结果是该进程写入的文本 (图 11-13).

Figure 173: Simple Redirect 启动时

Figure 174: Simple Redirect 中的重定向文本
基本的想法是创建一个匿名管道并将其写端与 `EnumDevices` 进程共享. 这样, `EnumDevices` 进程写入的任何内容, 管道的读端都可以用来读取它. 要使其工作, 管道的写端必须附加到 `EnumDevices` 进程的标准输出, 以便任何标准输出调用 (例如 `printf`) 都可以通过管道获得. 这种安排如图 11-14 所示.

Figure 175: 带重定向的匿名管道
诀窍是将写句柄传递给新进程, 这是通过进程句柄继承完成的, 如第 3 章所述. `CMainDlg::OnRedirect` 函数完成了创建管道和使用它的工作. 首先它创建管道:
LRESULT CMainDlg::OnRedirect(WORD, WORD wID, HWND, BOOL&) { wil::unique_handle hRead, hWrite; if (!::CreatePipe(hRead.addressof(), hWrite.addressof(), nullptr, 0)) return Error(L"Failed to create pipe"); }
接下来, 写句柄需要与新进程共享 (尚未创建), 因此它必须是可继承的:
::SetHandleInformation(hWrite.get(), HANDLE_FLAG_INHERIT, HANDLE_FLAG_INHERIT);
现在可以创建 `EnumDevices` 进程, 通过调用 `CreateOtherProcess` 辅助函数 (稍后讨论). 然后本地写句柄不再需要, 所以可以关闭:
if (!CreateOtherProcess(hWrite.get())) return Error(L"Failed to create process"); // local write handle not needed anymore hWrite.reset();
剩下的就是从管道的读端读取数据并使用这些数据:
char buffer[1 << 12] = { 0 }; DWORD bytes; CEdit edit(GetDlgItem(IDC_TEXT)); ATLASSERT(edit); while (::ReadFile(hRead.get(), buffer, sizeof(buffer), &bytes, nullptr) && bytes > 0) { CString text; edit.GetWindowText(text); text += CString(buffer); edit.SetWindowText(text); ::memset(buffer, 0, sizeof(buffer)); }
这是一个普通的 `ReadFile` 调用, 只要有数据从另一端写入管道, 就会重复调用.
要使其正常工作, 新进程需要用句柄继承创建, 并使用适当的标志使继承的句柄被用作标准输出:
bool CMainDlg::CreateOtherProcess(HANDLE hOutput) { PROCESS_INFORMATION pi; STARTUPINFO si = { sizeof(si) }; si.hStdOutput = hOutput; si.dwFlags = STARTF_USESTDHANDLES; WCHAR path[MAX_PATH]; ::GetModuleFileName(nullptr, path, _countof(path)); *::wcsrchr(path, L'\\') = L'\0'; ::wcscat_s(path, L"\\EnumDevices.exe"); BOOL created = ::CreateProcess(nullptr, path, nullptr, nullptr, TRUE, CREATE_NO_WINDOW, nullptr, nullptr, &si, &pi); if (created) { ::CloseHandle(pi.hProcess); ::CloseHandle(pi.hThread); } return created; }
`STARTUPINFO` 结构通过设置 `hStdOutput` 成员为写句柄的值来初始化. 这是可行的, 因为继承的句柄在新进程中具有相同的值. `STARTFUSESTDHANDLES` 标志确保标准句柄被新进程自动拾取.
要定位 `EnumDevices` 可执行文件, 代码假设它与当前可执行文件在同一目录中. `GetModuleFileName` 的第一个参数为 `NULL` 会返回当前进程的完整可执行文件路径. 然后, 文件名部分被替换为“EnumDevices”.
最后, 用 `TRUE` 的句柄继承标志调用 `CreateProcess` (第五个参数). 返回的句柄被正确关闭, 因为它们不是真正需要的. 添加 `CREATENOWINDOW` 标志是一个很好的点缀, 可以防止新进程弹出控制台窗口.
命名管道和邮槽在它们自己的章节 (第 2 部分) 中讨论.
- 管道
1.12.8. 事务性 NTFS
Windows 执行体有一个名为*内核事务管理器* (KTM) 的组件, 它为文件 (和注册表) 操作提供事务支持. 对于文件, 它有时被称为*事务性 NTFS* (TxF). 事务是一组遵循所谓 ACID 属性的操作:
- 原子性 - 事务中的所有操作要么全部成功, 要么全部失败.
- 一致性 - 文件系统将始终处于一致的状态.
- 隔离性 - 正在进行的多个事务不会相互影响.
- 持久性 - 系统故障不应导致事务违反先前的属性.
微软的文档多年来一直警告开发人员不要依赖 KTM, 并寻找其他机制来获得类似的结果. 警告指出, 文件和注册表操作的事务支持可能会在未来的 Windows 版本中被移除. 为什么? 我猜没有多少开发人员使用这个强大的功能. 在任何情况下, 它还没有发生, 在我看来, 文档中列出的替代方案并不是 KTM 的真正替代品.
本节提供了对 TxF 的快速介绍. 要开始进行事务操作, 请调用 `CreateTransaction` 来创建一个新事务:
HANDLE CreateTransaction ( _In_opt_ LPSECURITY_ATTRIBUTES lpTransactionAttributes, _In_opt_ LPGUID UOW, // must be NULL _In_opt_ DWORD CreateOptions, _In_opt_ DWORD IsolationLevel, // must be 0 _In_opt_ DWORD IsolationFlags, // must be 0 _In_opt_ DWORD Timeout, _In_opt_ LPTSTR Description);
事务 API 有自己的 `#include` (`<ktmw32.h>`) 和导入库 (`ktmw32.lib`).
该函数有一些未使用的参数. `lpTransactionAttributes` 是标准的 `SECURITYATTRIBUTES` 结构. `CreateOptions` 可以为零或 `TRANSACTIONDONOTPROMOTE` 以防止将事务提升为分布式事务. 如果提供了 `Timeout` 且不为零或 `INFINITE`, 事务将在指定的毫秒数后中止. 否则, 事务没有超时. 最后一个参数是描述事务的可选人类可读字符串.
该函数返回一个到新事务的句柄, 如果失败则返回 `INVALIDHANDLEVALUE`. 手头有一个事务句柄, 一些与文件相关的函数接受一个事务句柄, 例如 `CreateFileTransacted`:
HANDLE CreateFileTransacted( _In_ LPCTSTR lpFileName, _In_ DWORD dwDesiredAccess, _In_ DWORD dwShareMode, _In_opt_ LPSECURITY_ATTRIBUTES lpSecurityAttributes, _In_ DWORD dwCreationDisposition, _In_ DWORD dwFlagsAndAttributes, _In_opt_ HANDLE hTemplateFile, _In_ HANDLE hTransaction, _In_opt_ PUSHORT pusMiniVersion, _Reserved_ PVOID lpExtendedParameter); // NULL
该函数是 `CreateFile` 的扩展版本. 文件名必须引用一个本地文件, 否则函数会失败, `GetLastError` 返回 `ERRORTRANSACTIONSUNSUPPORTEDREMOTE`. `hTransaction` 是从 `CreateTransaction` 获得的事务句柄.
如果文件仅以读访问权限打开, `pusMiniVersion` 参数应为 `NULL`. 如果以写访问权限打开, 它指示文件在事务期间应向客户端呈现哪种视图 (在 `txfw32.h` 中定义):
- `TXFSMINIVERSIONCOMMITTEDVIEW` - 基于上次提交的视图.
- `TXFSMINIVERSIONDIRTYVIEW` - 正在被事务修改的脏视图.
- `TXFSMINIVERSIONDEFAULTVIEW` - 对于不修改文件的事务是已提交的, 否则是脏的.
也可以使用 `FSCTLTXFSCREATEMINIVERSION` I/O 控制代码创建自定义的微型版本视图 (请查看文档).
由 `CreateFileTransacted` 返回的句柄可以传递给正常的 I/O 访问函数, 例如 `ReadFile` 和 `WriteFile`. 这意味着一旦创建了一个事务性的文件对象, 文件上的所有其他操作都完全相同.
与 `CreateFileTransacted` 类似, 还有其他可以作为事务一部分工作的函数: `CopyFileTransacted`, `CreateHardLinkTransacted`, `DeleteFileTransacted`, `CreateDirectoryTransacted` 等.
一旦所有操作都成功完成, 可以用 `CommitTransaction` 提交事务:
BOOL CommitTransaction(_In_ HANDLE TransactionHandle);
如果事务中的各种操作出了问题, 你可以请求回滚所有操作:
BOOL RollbackTransaction(_In_ HANDLE TransactionHandle);
事务句柄通常用 `CloseHandle` 关闭.
事务的内核对象类型是 `TmTx`.
每个事务都有一个可以用 `GetTransactionId` 检索的 ID:
BOOL GetTransactionId ( _In_ HANDLE TransactionHandle, _Out_ LPGUID TransactionId);
返回的 GUID 可用于用 `OpenTransaction` 打开一个到现有事务的句柄:
HANDLE OpenTransaction ( _In_ DWORD dwDesiredAccess, _In_ LPGUID TransactionId);
事务是在通用日志文件系统 (CLFS) 日志记录功能的幕后实现的.
1.12.9. 文件搜索和枚举
有时需要搜索或枚举文件和目录. 幸运的是, 文件管理 API 提供了几个函数来完成这样的任务. 要开始枚举/搜索, 请调用 `FindFirstFile` 或 `FindFirstFileEx`:
HANDLE FindFirstFileW( _In_ LPCTSTR lpFileName, _Out_ LPWIN32_FIND_DATA lpFindFileData); HANDLE FindFirstFileEx( _In_ LPCTSTR lpFileName, _In_ FINDEX_INFO_LEVELS fInfoLevelId, _Out_ LPVOID lpFindFileData, _In_ FINDEX_SEARCH_OPS fSearchOp, _Reserved_ LPVOID lpSearchFilter, _In_ DWORD dwAdditionalFlags);
两个函数都接受一个文件名来开始搜索. 这可以是任何路径规范, 并包括通配符. 示例包括 `c:\temp\*.png` 和 `c:\mydir\file??.txt`.
每个结果都用 `WIN32FINDDATA` 结构返回, 定义如下:
typedef struct _WIN32_FIND_DATA { DWORD dwFileAttributes; FILETIME ftCreationTime; FILETIME ftLastAccessTime; FILETIME ftLastWriteTime; DWORD nFileSizeHigh; DWORD nFileSizeLow; DWORD dwReserved0; DWORD dwReserved1; _Field_z_ TCHAR cFileName[ MAX_PATH ]; _Field_z_ TCHAR cAlternateFileName[ 14 ]; } WIN32_FIND_DATA, *PWIN32_FIND_DATA, *LPWIN32_FIND_DATA;
该结构给出了文件的基本属性. 扩展函数有一个 `fInfoLevelId` 参数来指示要返回什么信息. 使用 `FindExInfoStandard` 等同于非扩展函数. 另一个值, `FindExInfoBasic`, 不返回短文件名 (在 `cAlternateFileName` 中), 这加快了搜索操作, 并被推荐, 因为短文件名很少 (如果有的话) 需要.
`fSearchOp` 参数唯一有用的值是 `FindExSearchLimitToDirectories`, 它提示只定位目录. 并非所有文件系统都支持此提示, 所以不要依赖它.
最后一个参数 `dwAdditionalFlags` 为搜索提供了一些更多的自定义:
- `FINDFIRSTEXCASESENSITIVE` - 搜索是区分大小写的.
- `FINDFIRSTEXLARGEFETCH` - 使用更大的缓冲区进行搜索, 这可以以更多内存使用为代价提高性能.
- `FINDFIRSTEXONDISKENTRIESONLY` - 跳过非驻留的文件 (例如像 OneDrive 这样的服务中常见的虚拟化文件).
函数返回一个搜索句柄, 如果发生错误则为 `INVALIDHANDLEVALUE`. 使用有效的句柄, 第一个搜索匹配是可用的. 要进行下一个匹配, 请调用 `FindNextFile`:
BOOL FindNextFile( _In_ HANDLE hFindFile, _Out_ LPWIN32_FIND_DATA lpFindFileData);
该函数返回下一个匹配项, 如果没有更多匹配项则返回 `FALSE`. 搜索完成后, 调用 `FindClose` 来关闭搜索句柄:
BOOL FindClose(_Inout_ HANDLE hFindFile);
1.12.10. NTFS 流
NTFS 文件系统支持*文件流*, 这本质上是文件中的文件. 通常, 我们使用默认的数据流, 但可以创建和使用其他数据流. 这些基本上对正常视图是隐藏的, 不会出现在像 Windows 资源管理器这样的标准工具中.
一个熟悉的例子是当从 Web 下载某些类型的文件时, 当在资源管理器中选择*属性*时, 会显示类似图 11-15 的内容.

Figure 176: “被阻止”文件的属性
资源管理器如何“知道”这个文件来自不同的机器? 秘密在于文件内的 NTFS 流. Sysinternals 的 `streams` 命令行工具可以识别此类流. 以下是图 11-15 中文件的输出:
C:\>streams -nobanner file.chm C:\file.chm: :Zone.Identifier:$DATA 26
文件中有一个名为“Zone.Identifier”的隐藏 NTFS 流, 长度为 26 字节. `Streams` 不显示 NTFS 流的内容, 但我的工具 `NTFS Streams` 可以 (图 11-16).

Figure 177: NTFS Streams 中的流内容
你可以在我的 Gitub 仓库 https://github.com/zodiacon/AllTools 或 https://github.com/zodiacon/NtfsStreams 中找到 NTFS Streams.
HTML 帮助 (`hh.exe`) Windows 应用程序会查找此流, 如果找到, 则不解析 HTML. 图 11-15 中的*取消阻止*复选框会删除该流, 允许 HTML 帮助正常工作.
我们如何创建这样的隐藏流? 可以使用正常的 `CreateFile` 函数, 其中文件名后附加一个冒号和流的名称. 以下是一个示例:
HANDLE hFile = ::CreateFile(L"c:\\temp\\myfile.txt:mystream", GENERIC_WRITE, 0, nullptr, CREATE_NEW, 0, nullptr); char text[] = "Hello from a hidden stream!"; DWORD bytes; ::WriteFile(hFile, text, ::strlen(text), &bytes, nullptr); ::CloseHandle(hFile);
以下是与新文件的一些交互:
C:\temp>dir myfile.txt
Volume in drive C is OS
Volume Serial Number is 9010-6C18
Directory of C:\temp
06-Apr-20 12:11 0 myfile.txt
1 File(s) 0 bytes
0 Dir(s) 904,581,414,912 bytes free
C:\temp>streams -nobanner myfile.txt
C:\temp\myfile.txt:
:mystream:$DATA 27
文件显示为零大小! 显然, 情况并非如此, 因为内部有一个隐藏的流, 它可以是任意长的. `NTFS Streams` 将显示流的内容.
“$DATA”后缀是默认的流重解析点. 可以创建由文件系统筛选器驱动程序以特殊方式处理的自定义重解析点. 这超出了本书的范围.
你可能想知道 `Streams` 和 `NTFS Streams` 是如何工作的. 存在两个用于在文件内枚举流的函数, 与前一节的搜索函数非常相似:
HANDLE WINAPI FindFirstStream( _In_ LPCTSTR lpFileName, _In_ STREAM_INFO_LEVELS InfoLevel, _Out_ LPVOID lpFindStreamData, _Reserved_ DWORD dwFlags); BOOL FindNextStreamW( _In_ HANDLE hFindStream, _Out_ LPVOID lpFindStreamData);
这些函数允许枚举文件中的所有流. `lpFindStreamData` 参数中的每个返回值实际上是以下结构:
typedef struct _WIN32_FIND_STREAM_DATA { LARGE_INTEGER StreamSize; WCHAR cStreamName[MAX_PATH + 36]; } WIN32_FIND_STREAM_DATA, *PWIN32_FIND_STREAM_DATA;
它提供了流的大小及其名称.
编写一个与 `Streams` 等效的工具.
1.12.11. 总结
本章全部是关于 I/O 操作. 我们看到了如何同步和异步地处理文件和设备. 我们没有涵盖更多与文件相关的 API, 你可以在文档中找到更多信息. 本章未讨论的功能示例包括文件操作 (复制, 移动等), 文件链接 (软链接和硬链接), 文件锁定以及文件加密和解密.
在下一章中, 我们将进入一个任何应用程序或操作系统都离不开的新领域——内存管理.
1.13. 第 12 章: 内存管理基础
内存是任何计算机系统的基本组成部分. 在过去, 使用内存相对简单, 因为应用程序直接分配物理内存, 使用它, 释放它, 就这样. 现代操作系统管理*虚拟内存*, 这个术语带有一些不幸的内涵. 在本章中, 我们将介绍与内存相关的所有主要概念——包括虚拟和物理内存.
本章内容:
- 基本概念
- 进程地址空间
- 内存计数器
- 进程内存映射
- 页面保护
- 枚举地址空间区域
- 共享内存
- 页面文件
- WOW64
- 虚拟地址转换
1.13.1. 基本概念
今天的现代 Intel/AMD 处理器在内存方面起步非常 modest. 最初的 8086/8088 处理器只支持 1 MB 的内存 (物理内存, 因为当时没有别的). 每次访问内存都是段地址和偏移量的组合, 这是必需的, 因为这些处理器内部使用 16 位值, 但内存访问需要 20 位 (1 MB). 段寄存器的值 (16 位) 乘以 16 (0x10), 然后加上一个偏移量, 以达到 1 MB 范围内的地址. 这种工作模式现在被称为*实模式 (Real Mode)*, 至今仍是当今 Intel/AMD 处理器唤醒时的模式.
随着 80386 处理器的引入, 虚拟内存诞生了, 并且基本上沿用至今, 包括仅使用偏移量线性访问内存的能力 (段寄存器仅设置为零). 这使得内存访问更加方便. 虚拟内存意味着每次内存访问都需要被转换为物理地址所在的位置. 这种模式被称为*保护模式 (Protected Mode)*. 在保护模式下, 无法直接访问物理内存——只能通过从虚拟地址到物理地址的映射. 这个映射必须由操作系统的内存管理器预先准备好, 因为 CPU 期望这个映射是存在的.
在 64 位系统上, 保护模式被称为*长模式 (Long Mode)*, 但它基本上是相同的机制, 扩展到 64 位地址.
虚拟地址和物理地址之间的映射, 以及在操作系统级别上内存块的管理, 都是以称为*页 (pages)*的块为单位进行的. 这是必要的, 因为管理每一个字节是不可能的——管理结构会比那个字节大得多. 有两种支持的页面大小, Windows 10 和 Server 2016 在 x64 系统上还支持第三种大小. 表 12-1 列出了 Windows 支持的所有架构的页面大小.
| 架构 | 小 (正常) 页 | 大页 | 巨页 |
|---|---|---|---|
| x86 | 4 KB | 2 MB | N/A |
| x64 | 4 KB | 2 MB | 1 GB |
| ARM | 4 KB | 4 MB | N/A |
| ARM64 | 4 KB | 2 MB | N/A |
小 (正常) 页是默认的, 本章 (以及后续章节) 中使用的术语“页”指的是小页或正常页, 在所有架构上都是 4 KB. 如果提到不同的页面大小, 它将伴随着“大”或“巨”的明确前缀.
1.13.2. 进程地址空间
每个进程都有其自己的线性, 虚拟, 私有地址空间. 地址空间从地址零开始, 到某个最大值结束, 具体取决于操作系统位数 (32 或 64) 和进程位数, 我们很快就会看到. 这里重要的部分是“私有”. 例如, 说某个数据在地址 `0x100000` 需要回答另一个问题: 在哪个进程中? 每个进程都有一个地址 `0x100000`, 但该地址可能映射到不同的物理地址, 文件, 或者根本没有映射. 这个概念性的映射如图 12-1 所示, 其中两个进程正在将它们的一些页面映射到物理内存 (RAM), 一些页面映射到磁盘, 还有一些是未映射的.

Figure 178: 虚拟地址映射
一个进程可以直接访问其自己地址空间中的内存. 这意味着一个进程不能意外地或恶意地通过操纵指针来读写另一个进程的地址空间. 访问另一个进程的内存是可能的, 但这需要调用一个函数 (`ReadProcessMemory` 或 `WriteProcessMemory`, 本章后面讨论) 并带有一个足够强大的句柄到目标进程.
进程的地址空间被称为*虚拟*的. 这指的是地址空间就是这样: 一个用于潜在内存映射的空间. 每个进程开始时都非常节俭地使用其虚拟地址空间——可执行文件被映射, `NtDll.Dll` 也被映射. 然后加载器 (`NtDll` 的一部分) 在进程地址空间内分配一些基本结构, 例如默认的进程堆 (在下一章中讨论), 第一个线程的*进程环境块* (PEB), 线程环境块 (TEB). 大部分地址空间是空的.
- 页面状态
虚拟内存中的每个页面都可以处于三种状态之一: 空闲 (free), 已提交 (committed) 和已保留 (reserved). *空闲*页面是未映射的, 因此尝试访问该页面会导致访问冲突异常. 大部分进程的地址空间开始时都是空闲的.
*已提交*页面与空闲相反——这是一个已映射的页面, 到 RAM 或文件, 访问该页面应该会成功 (除非有任何冲突的页面保护, 本章后面讨论). 如果页面在 RAM 中, CPU 直接访问数据并继续. 如果页面不在 RAM 中 (至少就 CPU 查询的表而言是这样), CPU 会引发一个称为*缺页错误 (page fault)*的异常, 该异常由内存管理器捕获. 如果该页确实驻留在磁盘上, 内存管理器会将其带回 RAM, 修复转换表以指向 RAM 中的新地址, 并指示 CPU 重试. 最终结果是, 从调用线程的角度来看, 访问是成功的. 如果确实涉及 I/O, 访问会变慢, 但调用线程不需要知道这一点或为此做任何特别的事情——它是透明地工作的.
技术上, 访问一个空闲页面也会导致缺页错误. 在这种情况下, 内存管理器得出结论, 给定地址后面没有任何东西, 并引发访问冲突异常.
已提交内存通常被称为“已分配”内存. 调用 C/C++ 内存分配函数, 例如 `malloc`, `calloc`, `operator new` 等, 总是提交内存 (如果它们成功的话).
我们将在下一章深入讨论内存分配 API.
最后一个页面状态介于空闲和已提交之间, 称为*已保留*. 已保留页面类似于空闲, 因为访问该页面会导致访问冲突——那里什么都没有. 已保留的页面稍后可能会被提交. 一个保留的页面范围确保正常的内存分配不会使用该范围, 因为它被保留用于其他目的. 我们已经看到了这个想法在线程栈管理方式中的应用. 由于线程的栈可以增长, 并且必须在虚拟内存中是连续的, 因此会保留一个页面范围, 以便进程中发生的其他分配不会使用该保留的地址范围.
表 12-2 总结了页面状态.
页面状态 含义 如果访问 Free 未分配的页面 访问冲突异常 Committed 已分配的页面 成功 (假设没有页面保护限制) Reserved 未分配的页面, 为将来使用保留 访问冲突异常 - 地址空间布局
在本节中, 我们将研究 32 位和 64 位系统上进程的地址布局. 表 12-3 总结了地址空间大小.
操作系统类型 进程类型 LARGEADDRESSAWARE clear LARGEADDRESSAWARE set 32-bit booted w/o increase UVA 32-bit 2 GB 2 GB 32-bit booted w/ increase UVA 32-bit 2 GB 2 GB to 3 GB 64-bit (Windows 8.1+) 32-bit 2 GB 4 GB 64-bit (Windows 8.1+) 64-bit 2 GB 128 TB 64-bit (up to Windows 8) 32-bit 2 GB 4 GB 64-bit (up to Windows 8) 64-bit 2 GB 8 TB `LARGEADDRESSAWARE` 是一个链接器标志, 可以在构建可执行文件时指定, 并存储在 PE 头中. 以后也可以用 PE 编辑工具 (例如 Windows SDK 中提供的 `editbin.exe` 命令行工具) 在没有源代码的情况下设置它. 这个标志的目的是什么?
然而, 如果可执行文件是签名的, 更改此标志 (或任何其他标志) 将使签名无效.
最初 (在 Windows NT 4 之前), 32 位进程只能获得 2 GB 的地址空间. 2 GB 需要 31 位来表示一个地址, 所以最高有效位 (MSB) 总是零. 从 NT 4 开始, 32 位 Windows 可以以每个进程 3 GB 的地址空间启动. 然而, 一些开发人员可能会利用他们使用的任何地址的 MSB 都设置为零这一事实, 并将空闲位用于某些应用目的. 然后, 如果给这样一个进程超过 2 GB 的空间, 其中 MSB 可能是 1, 进程会以某种方式失败, 因为它会在访问内存之前屏蔽掉 MSB. 设置 `LARGEADDRESSAWARE` 位表示该可执行文件的开发人员没有乱用地址的 MSB, 因此该进程可以接受大于 2 GB (`0x80000000`) 的地址而没有任何问题.
此位仅影响可执行文件, 不影响 DLL. DLL 必须始终正确工作, 并且永远不要假设它们被赋予的地址值的任何信息.
你通常在 Visual Studio 的项目属性 / 链接器 / 系统 (图 12-2) 中设置此位. 对于 32 位配置, 默认为“否”, 对于 64 位配置, 默认为“是”. 对于 32 位可执行文件, 假设你对地址没有任何特殊假设, 将该标志设置为“是”几乎没有任何缺点.

Figure 179: Visual Studio 中的 LARGEADDRESSAWARE 标志
确实存在一个缺点: 如果你的进程泄漏内存, 它将有更多的地址空间可以泄漏, 这意味着系统会因为你的进程而消耗更多的内存.
你可以使用 `Dumpbin.exe` 命令行工具来查看有关 PE 的信息, 包括 `LARGEADDRESSAWARE` 位的状态. 以下是 `Explorer.exe` 的一个例子:
C:\>dumpbin /headers c:\windows\explorer.exe Microsoft (R) COFF/PE Dumper Version 14.26.28720.3 Copyright (C) Microsoft Corporation. All rights reserved. Dump of file c:\windows\explorer.exe PE signature found File Type: EXECUTABLE IMAGE FILE HEADER VALUES 8664 machine (x64) 8 number of sections 4D818882 time date stamp 0 file pointer to symbol table 0 number of symbols F0 size of optional header 22 characteristics Executable Application can handle large (>2GB) addresses ...正如第 5 章中提到的, 有几个图形工具可以显示此信息, 例如我自己的 PE Explorer V2 (图 12-3).

Figure 180: PE Explorer V2 显示 PE 属性
- 32位系统
在 32 位系统上, 存在两种变体, 列在表 12-3 中, 并以图形方式显示在图 12-4 中.

Figure 181: 32 位地址空间布局
32 位意味着 4 GB, 这可能让你想知道为什么进程只能得到 2 GB. 图 12-2 解开了这个谜: 上面的 2 GB 是*系统空间* (也称为*内核空间*). 这是操作系统内核本身所在的地方, 连同所有的内核设备驱动程序, 以及它们在代码和数据方面消耗的内存.
请注意, 系统空间是单例的——只有一个系统, 只有一个内核. 这意味着系统空间中的地址是绝对的, 而不是相对的; 它们在每个进程上下文中都意味着相同的东西.
如果系统以“增加用户虚拟地址”选项启动, 系统只能使用 1 GB 的地址范围, 而用户进程可以获得 2 GB 到 3 GB (任何超过 2 GB 的都需要在其 PE 头中设置 `LARGEADDRESSAWARE` 标志).
可以通过在提升的命令窗口中运行以下命令, 然后重新启动系统, 来以“增加 UVA”选项启动 32 位系统:
c:\>bcdedit /set increaseuserva 3072
该数字是用户地址空间的数量 (以 MB 为单位), 可以从 2048 (2 GB 默认值) 到 3072 (3 GB).
要移除此选项, 请使用 `bcdedit /deletevalue increaseuserva`.
- 64位系统
将用户地址增加到 3 GB 的 32 位选项很好, 但还远远不够. 这是在真正的 64 位操作系统可用之前的权宜之计. 今天, 大多数 (如果不是全部) 桌面 Windows 版本都是 64 位的, 不仅仅是服务器. 64 位系统提供了几个优势, 其中第一个是大大增加的地址空间.
64 位的理论极限是 2 的 64 次方, 即 16 EB (Giga, Tera, Peta, Exa). 这是一个字面上的天文数字的地址范围, 在今天的系统中似乎是遥不可及的. 要使用这样的地址空间, 你需要有 RAM 加上接近这个数字的分页文件, 这仍然远远超出今天的系统. 事实上, 大多数现代处理器只支持 48 位的虚拟和物理地址. 这意味着可以获得的最大地址范围是 2 的 48 次方, 即 256 TB. 这就是为什么在 64 位系统上, 每个进程可以有 128 TB 的地址空间范围, 而另外 128 TB 用于系统空间.
Sunny Cove Intel 微架构支持 57 位的虚拟地址空间和 52 位的物理地址空间. 这意味着具有此类处理器的地址空间将是每个进程 64 PB, 系统空间 64 PB!
向 64 位系统的过渡基本上是无痛的, 因为能够在 64 位 x64 系统上运行 32 位 x86 进程而无需对原始二进制文件进行任何更改. 这将在本章后面的“WOW64”部分进一步讨论. 具有 `LARGEADDRESSAWARE` 位的 32 位可执行文件在 64 位系统上获得 4 GB 的地址空间. 这是有道理的, 因为从 3 GB 到 4 GB 的过渡确实需要额外的位, 所以一个可以处理 3 GB 的进程肯定可以处理 4 GB.
利用此功能的一个典型例子是 Visual Studio (`devenv.exe`). Visual Studio 是一个 32 位进程, 由于开发人员使用 64 位系统, Visual Studio 获得了 4 GB 的地址空间. 有人声称这让 Visual Studio 可以泄漏更多的内存 :)
从 32 位到 64 位的过渡有些痛苦. 痛苦在于将设备驱动程序从 32 位转换为 64 位. 内核中没有“WOW64”层. 复杂的内核驱动程序, 例如显示驱动程序, 在早期的 64 位时代存在稳定性问题. 幸运的是, 这些都已成为过去.
图 12-5 显示了 64 位系统上 32 位和 64 位进程的地址空间布局.

Figure 182: 64 位系统上的地址布局
Windows 8 及更早版本的 64 位版本只支持 8 TB 的用户地址空间和 8 TB 的系统空间. 这是由于内核中的一个实现细节, 在 Windows 8.1 中得到了修复.
然而, 64 位系统并非全是玫瑰园. 64 位进程可以泄漏内存到使系统瘫痪的程度, 因为地址空间几乎是无限的——在 64 位进程的地址空间用完之前, RAM 加上页面文件会先满. 另外, 地址转换需要比 32 位系统多一个级别, 如果转换后备缓冲区 (TLB) 缓存没有被有效利用, 可能会更慢 (见本章后面).
- 32位系统
- 地址空间使用情况
我们已经大致了解了各种类型进程可用的虚拟内存空间量. 然而, 并非整个用户地址空间范围都可用. 要了解可用和不可用的内容, 我们可以调用 `GetSystemInfo` 函数及其姐妹函数 `GetNativeSystemInfo`:
VOID GetSystemInfo(_Out_ LPSYSTEM_INFO lpSystemInfo); VOID GetNativeSystemInfo(_Out_ LPSYSTEM_INFO lpSystemInfo);
两个函数都返回一个 `SYSTEMINFO` 结构, 定义如下:
typedef struct _SYSTEM_INFO { union { DWORD dwOemId; // Obsolete, do not use struct { WORD wProcessorArchitecture; WORD wReserved; }; }; DWORD dwPageSize; LPVOID lpMinimumApplicationAddress; LPVOID lpMaximumApplicationAddress; DWORD_PTR dwActiveProcessorMask; DWORD dwNumberOfProcessors; DWORD dwProcessorType; // obsolete DWORD dwAllocationGranularity; WORD wProcessorLevel; WORD wProcessorRevision; } SYSTEM_INFO, *LPSYSTEM_INFO;
该结构包含一些系统级信息, 包括用户模式进程的最小和最大可用地址. `GetSystemInfo` 函数考虑了调用进程的位数. 64 位系统上的 32 位进程只能“看到”32 位值. `GetNativeSystemInfo` 允许查看“真实”的值——在一定程度上. 对于 32 位系统上的 32 位进程和 64 位系统上的 64 位进程, 函数是相同的.
`sysinfo` 应用程序显示 `SYSTEMINFO` 结构中可用的一些信息. 它首先简单地调用 `GetSystemInfo`:
SYSTEM_INFO si; ::GetSystemInfo(&si); DisplaySystemInfo(&si, "System information");
从 `GetSystemInfo` 返回的任何内容都传递给辅助函数 `DisplaySystemInfo` 以显示结果. 如果当前进程是 64 位系统上的 32 位进程 (WOW64 进程), 则会进行第二次调用 `GetNativeSystemInfo` 以显示更准确的信息:
BOOL isWow = FALSE; if (sizeof(void*) == 4 && ::IsWow64Process(::GetCurrentProcess(), &isWow) && isWow) { ::GetNativeSystemInfo(&si); printf("\n"); DisplaySystemInfo(&si, "Native System information"); }
问题是如何检查一个进程是否是 WOW64 进程. `IsWow64Process` 和较新的 `IsWow64Process2` 函数可以提供帮助:
BOOL IsWow64Process( _In_ HANDLE hProcess, _Out_ PBOOL Wow64Process); // Windows 10+ only BOOL IsWow64Process2( _In_ HANDLE hProcess, _Out_ USHORT* pProcessMachine, _Out_opt_ USHORT* pNativeMachine);
如果它是一个 WOW64 进程, `IsWow64Process` 在 `Wow64Process` 中返回 `TRUE`. 重要的是要注意, 如果在 32 位系统上运行, 该函数会将 `Wow64Process` 设置为 `FALSE`.
较新的 `IsWow64Process2` 函数提供了有关为进程提供动力的处理器和机器上的本地处理器的更多信息. `pProcessMachine` 返回 `<winnt.h>` 中定义的 `IMAGEFILEMACHINE*` 常量之一. 如果值为 `IMAGEFILEMACHINEUNKNOWN`, 这意味着该进程不是 WOW. 如果 `pNativeMachine` 不是 `NULL`, 它会从同一列表中返回本地机器标识符.
`sysinfo` 中的代码检查当前进程是否是 32 位的 (`sizeof(void*) == 4`) 并且是一个 WOW64 进程. 如果两者都为真, 那么本地系统与当前进程不同, 因此调用 `GetNativeSystemInfo` 是有道理的.
任务管理器在*详细信息*选项卡中提供了一个名为*平台*的列, 显示每个进程的“位数”.
`DisplaySystemInfo` 大多是直接的, 显示 `SYSTEMINFO` 实例中的大部分信息:
const char* GetProcessorArchitecture(WORD arch) { switch (arch) { case PROCESSOR_ARCHITECTURE_AMD64: return "x64"; case PROCESSOR_ARCHITECTURE_INTEL: return "x86"; case PROCESSOR_ARCHITECTURE_ARM: return "ARM"; case PROCESSOR_ARCHITECTURE_ARM64: return "ARM64"; } return "Unknown"; } void DisplaySystemInfo(const SYSTEM_INFO* si, const char* title) { printf("%s\n%s\n", title, std::string(::strlen(title), '-').c_str()); printf("%-24s%s\n", "Processor Architecture:", GetProcessorArchitecture(si->wProcessorArchitecture)); printf("%-24s%u\n", "Number of Processors:", si->dwNumberOfProcessors); printf("%-24s0x%llX\n", "Active Processor Mask:", (DWORD64)si->dwActiveProcessorMask); printf("%-24s%u KB\n", "Page Size:", si->dwPageSize >> 10); printf("%-24s0x%p\n", "Min User Space Address:", si->lpMinimumApplicationAddress); printf("%-24s0x%p\n", "Max User Space Address:", si->lpMaximumApplicationAddress); printf("%-24s%u KB\n", "Allocation Granularity:", si->dwAllocationGranularity >> 10); }
以下是在 64 位系统上编译为 64 位的应用程序的示例输出:
System information ------------------ Processor Architecture: x64 Number of Processors: 16 Active Processor Mask: 0xFFFF Page Size: 4 KB Min User Space Address: 0x0000000000010000 Max User Space Address: 0x00007FFFFFFEFFFF Allocation Granularity: 64 KB
请注意, 最低可用地址是 `0x10000`, 这意味着虚拟地址空间的前 64 KB 是不可用的. 这些传统上用于捕获 `NULL` 指针. 类似地, 地址空间的上 64 KB, 就在系统空间开始之前, 也是不可用的. 简而言之, 这意味着可用的地址空间范围比预期的要少 128 KB. 对于 64 位进程, 这是完全不明显的.
在 64 位系统上将同一个应用程序作为 32 位可执行文件运行会产生以下结果:
System information ------------------ Processor Architecture: x86 Number of Processors: 16 Active Processor Mask: 0xFFFF Page Size: 4 KB Min User Space Address: 0x00010000 Max User Space Address: 0x7FFEFFFF Allocation Granularity: 64 KB Native System information ------------------------- Processor Architecture: x64 Number of Processors: 16 Active Processor Mask: 0xFFFF Page Size: 4 KB Min User Space Address: 0x00010000 Max User Space Address: 0xFFFEFFFF Allocation Granularity: 64 KB
我们可以看到, 底部和顶部的相同 64 KB 是不可用的. 本地系统信息在处理器架构方面是准确的 (x64), 而“本地”版本声称处理器是 x86. 在地址方面, 本地输出中的上限假定整个 4 GB 的 32 位地址空间都可用, 如果可执行文件设置了 `LARGEADDRESSAWARE` 链接器标志, 则确实如此.
在所有这些情况下, 报告的页面大小都是 4 KB (报告的是小页面大小). 另外值得注意的是所谓的*分配粒度*, 我们稍后会看到, 这是用 `VirtualAlloc` 系列函数进行分配的粒度. 在所有 Windows 架构和版本上, 目前都是 64 KB.
以下是在具有 4 个逻辑处理器的 32 位 Windows 8.1 上的另一个输出:
System information ------------------ Processor Architecture: x86 Number of Processors: 4 Active Processor Mask: 0xF Page Size: 4 KB Min User Space Address: 0x00010000 Max User Space Address: 0x7FFEFFFF Allocation Granularity: 64 KB
与内存相关的值与 WOW64 版本相同, 因为此系统未在“增加 UVA”模式下启动.
1.13.3. 内存计数器
开发人员通常想了解他们的进程在内存使用方面的表现如何. 进程是否消耗大量内存? 是否可能存在内存泄漏? 系统本身呢? Windows 提供了许多与内存相关的计数器, 理解它们非常重要, 因为有些名称有些神秘, 在某些情况下, 不同的工具会用不同的名称称呼相同的计数器.
开发人员通常用来了解系统情况的第一个工具是任务管理器. 其*性能*选项卡, 选择了*内存*子选项卡, 显示了与系统内存相关的信息. 图 12-6 显示了一个带注释的快照.

Figure 183: 任务管理器的性能/内存信息
表 12-4 总结了图 12-6 中显示的信息片段.
| 名称 | 描述 |
|---|---|
| 内存使用图 | 显示过去 60 秒的物理内存 (RAM) 消耗 |
| In Use | 当前使用的物理内存 |
| (Compressed) | 压缩内存的数量 (见侧边栏“内存压缩”) |
| Committed / Commit Limit | 总已提交内存 / 页面文件扩展前的已提交内存限制 |
| 内存构成 - 已修改 | 尚未写入磁盘的内存 |
| 内存构成 - 空闲 | 空闲页面 (其中大部分是零页面) |
| Cached | 如果需要可以重新利用的内存 (备用 + 已修改) |
| Available | 可用物理内存 (备用 + 空闲) |
| Paged pool / Non-paged pool | 内核池内存使用情况 |
内存压缩 内存压缩是在 Windows 10 中添加的, 作为一种通过压缩当前不需要的内存来节省内存的方法, 特别适用于 UWP 进程在进入后台时, 因为它们不消耗 CPU, 因此这些进程使用的任何私有物理内存都可以被释放. 相反, 内存被压缩, 为其他进程留下空闲页面. 当进程醒来时, 内存会迅速解压缩并准备好使用, 避免了对页面文件的 I/O.
在 Windows 10 的前两个版本中, 压缩的内存存储在系统进程的用户模式地址空间中. 这在工具中太显眼了, 所以从 Windows 10 版本 1607 开始, 一个特殊的进程, 内存压缩 (一个 minimal 进程), 是持有压缩内存的那个. 此外, 任务管理器明确不显示此进程. 其他工具, 例如 Process Explorer, 正常显示此进程.
图 12-6 中的*内存构成*条形图大致指示了物理页面在内部是如何管理的. “使用中”部分是当前被视为进程和系统工作集一部分的页面. *备用*页面是其备份存储在磁盘上的内存, 但与拥有进程的关系仍然保留. 如果进程现在触摸其中一个页面, 它们会立即返回其工作集 (变为“使用中”). 如果这些页面被立即扔到“空闲”页面堆中, 则需要进行 I/O 才能将页面带回 RAM.
*已修改*部分表示其内容尚未写入后备存储 (通常是页面文件) 的页面, 因此这些页面不能被丢弃. 如果修改的页面数量变得太大, 或者备用和空闲页面计数变得太小, 修改的页面将被写入其后备文件, 并且它们将移动到备用状态.
所有这些转换和管理的目的是减少 I/O. 在 Process Explorer 的*系统信息*视图的*内存*选项卡中, 可以看到这些物理页面列表管理的更精确视图, 如图 12-7 所示. (使用*视图 / 系统信息…*菜单打开它.)

Figure 184: Process Explorer 中的内存系统信息
图 12-7 中的*分页列表*部分详细说明了执行官的内存管理用于管理物理页面的各种列表. 已清零*页面是只包含零的页面, 它们是与包含垃圾的*空闲*页面相比的大多数. 一个特殊的执行官线程, 称为*零页线程, 在优先级 0 (唯一具有此优先级的线程) 运行, 负责清零空闲页面. 零页之所以重要, 是为了满足一个安全要求, 即分配的内存永远不能包含曾经属于另一个进程的数据, 即使该进程已不再存在. 图 12-6 中内存构成中的*空闲*部分包括空闲和零页面.
图 12-7 的另一个有趣的部分是, 没有单个的备用页面列表, 而是有八个, 基于优先级. 这被称为*内存优先级*, 可以在 Process Explorer 中逐个线程地看到, 尽管这也是一个进程属性, 默认情况下由每个线程继承.
当需要将备用列表中的页面移动到空闲页面时, 因为进程或系统需要物理内存, 就会使用内存优先级. 问题是, 哪些页面应该首先“放手” (并失去与原始进程的连接)? 一个简单的方法是使用 FIFO 队列, 其中从进程工作集中移除的第一个页面是第一个变为空闲的.
- 进程内存计数器
任务管理器中与进程相关的内存计数器有些令人困惑. 第一个问题是任务管理器在*详细信息*选项卡中显示的默认内存计数器: 内存(私有工作集)*或*内存(活动私有工作集) (后者出现在 Windows 10 版本 1903 中). 让我们剖析这些术语:
- 工作集 - 进程使用的物理内存
- 私有 - 进程私有的内存 (不共享)
- 活动 - 不包括在后台的 UWP 进程
这些计数器的问题在于*工作集*部分. 它们指示当前在 RAM 中的私有内存. 然而, 这是一个不稳定的计数器, 可能会根据进程的活动而上下波动. 如果你试图确定进程提交 (分配) 了多少内存, 或者一个进程是否泄漏内存, 这些不是要看的计数器.
这些计数器只显示私有内存通常是件好事, 因为共享内存 (例如由 DLL 代码使用) 是恒定的, 所以任何人能做的事情很少. 私有内存是进程控制的内存.
那么应该看哪个正确的计数器呢? 是*提交大小*. 更令人困惑的是, Process Explorer 和性能监视器将此计数器称为*私有字节*. 图 12-8 显示了任务管理器, 其中*提交大小*和*活动私有工作集*并排显示, 按提交大小排序.

Figure 185: 任务管理器
*提交大小*也是关于私有内存的, 所以它与*私有工作集*是平等的. 区别在于*不在*工作集中的内存. 如果两个计数器很接近, 这意味着要么进程相当活跃, 并且正在使用其大部分内存, 要么 Windows 没有空闲内存不足, 所以内存管理器不会很快地从工作集中移除页面.
在某些情况下, 两个计数器之间的差异可能很大. 在图 12-8 中, `Code` 进程 (PID 34316) 的大部分已提交内存都不在其工作集中. 这就是为什么查看*私有工作集*计数器可能会产生误导. 它看起来好像那个进程消耗了大约 97 MB, 但它实际上消耗了大约 368 MB 的内存. 当然, 目前在 RAM 中它只使用了 97 MB, 但已提交的内存确实消耗了页表 (用于映射已提交的内存), 并且该内存计入系统的提交限制 (如图 12-6 所示).
底线: 使用任务管理器中的*提交大小*列来确定进程的内存消耗. 它不包括共享内存, 但这在大多数情况下不重要.
使用 Process Explorer, 提交大小*的等效项是*私有字节. 任务管理器和 Process Explorer 都包含更多与内存相关的列 (Process Explorer 比任务管理器多). 特别是有一列没有接近的等效项, 那就是*虚拟大小*列, 如图 12-9 所示.

Figure 186: Process Explorer 中的虚拟大小列
*虚拟大小*列计算所有不处于空闲状态的页面——即, 已提交和已保留. 这基本上是进程消耗的地址空间量. 对于 64 位进程, 其潜在地址空间为 128 TB, 这关系不大. 对于 32 位进程, 这可能是一个问题. 即使已提交的内存不是太高, 拥有大的保留内存区域也会限制新分配的可用地址空间, 这可能会导致分配失败, 即使整个系统可能有大量的空闲内存.
前面描述的计数器不包括保留内存, 这是有充分理由的. 保留内存的成本非常低, 因为从 CPU 的角度来看, 它与空闲内存相同——不需要描述保留内存的页表. 事实上, 从 Windows 8.1 开始, 保留内存的成本甚至更低.
如果你再看一下 VMMap (图 12-12), 你会发现对于每个块, VMMap 都提供了诸如该块的工作集 (RAM) 大小 (私有, 共享, 可共享) 等信息. 这些额外的信息可以用另一个 PSAPI 函数 `QueryWorkingSetEx` 获得:
BOOL QueryWorkingSetEx( _In_ HANDLE hProcess, _Out_ PVOID pv, _In_ DWORD cb);
进程句柄必须具有 `PROCESSQUERYINFORMATION` 访问掩码. `pv` 必须指向一个或多个 `PSAPIWORKINGSETEXINFORMATION` 类型的结构:
typedef union _PSAPI_WORKING_SET_EX_BLOCK { ULONG_PTR Flags; union { struct { ULONG_PTR Valid : 1; ULONG_PTR ShareCount : 3; ULONG_PTR Win32Protection : 11; ULONG_PTR Shared : 1; ULONG_PTR Node : 6; ULONG_PTR Locked : 1; ULONG_PTR LargePage : 1; ULONG_PTR Reserved : 7; ULONG_PTR Bad : 1; #if defined(_WIN64) ULONG_PTR ReservedUlong : 32; #endif }; struct { ULONG_PTR Valid : 1; // Valid = 0 in this format. ULONG_PTR Reserved0 : 14; ULONG_PTR Shared : 1; ULONG_PTR Reserved1 : 15; ULONG_PTR Bad : 1; #if defined(_WIN64) ULONG_PTR ReservedUlong : 32; #endif } Invalid; }; } PSAPI_WORKING_SET_EX_BLOCK, *PPSAPI_WORKING_SET_EX_BLOCK; typedef struct _PSAPI_WORKING_SET_EX_INFORMATION { PVOID VirtualAddress; PSAPI_WORKING_SET_EX_BLOCK VirtualAttributes; } PSAPI_WORKING_SET_EX_INFORMATION, *PPSAPI_WORKING_SET_EX_INFORMATION;
这个结构可能看起来很复杂, 但它只不过是一个感兴趣的地址 (`VirtualAddress`) 和一组标志 (`VirtualAttributes`). 以下是标志的概述:
- `Valid` - 如果页面在进程的工作集中, 则设置. 如果清除, 应查询联合的 `Invalid` 部分——大多数其他标志是无意义的.
- `Shared` - 指示页面是否可共享. 如果清除, 页面是私有的.
- `ShareCount` - 如果 `Shared` 已设置, 指示共享计数. 如果大于 1, 页面正在被共享. 此成员的最大计数是 7, 因此不应将其视为准确的共享计数.
- `Win32Protection` - 基本保护标志, 也可通过 `VirtualQuery(Ex)` 获得.
- `Node` - 此页面所属的 NUMA 节点.
- `Locked` - 如果设置, 则锁定在物理内存中 (有关锁定页面的更多信息, 请参见下一章).
- `LargePage` - 如果设置, 这是一个大页面. (有关大页面的更多信息, 请参见下一章).
- `Bad` - 如果设置, 这是一个坏页面 (从硬件角度来看). 技术上, 也可以表示一个内存 enclave (Windows 10+) (有关 enclaves 的更多信息, 请参见下一章).
`SimpleVMMap2` 应用程序是 `SimpleVMMap` 的增强版, 它为每个已提交的块添加了其工作集属性 (如果驻留). `DisplayBlock` 函数有一个额外的调用来查询一个已提交的页面范围:
if (mbi.State == MEM_COMMIT) DisplayWorkingSetDetails(hProcess, mbi);
`DisplayWorkingSetDetails` 完成了所有艰苦的工作:
void DisplayWorkingSetDetails(HANDLE hProcess, MEMORY_BASIC_INFORMATION& mbi) { auto pages = mbi.RegionSize >> 12; PSAPI_WORKING_SET_EX_INFORMATION info; ULONG attributes = 0; void* address = nullptr; SIZE_T size = 0; for (decltype(pages) i = 0; i < pages; i++) { info.VirtualAddress = (BYTE*)mbi.BaseAddress + (i << 12); if (!::QueryWorkingSetEx(hProcess, &info, sizeof(PSAPI_WORKING_SET_EX_INFORMATION))) { printf(" <<<Unable to get working set information>>>\n"); break; } if (attributes == 0) { address = info.VirtualAddress; attributes = (ULONG)info.VirtualAttributes.Flags; size = 1 << 12; } else if(attributes == (ULONG)info.VirtualAttributes.Flags) { size += 1 << 12; } if(attributes != (ULONG)info.VirtualAttributes.Flags || i == pages - 1) { printf(" Address: %16p (%10llu KB) Attributes: %08X %s\n", address, size >> 10, attributes, AttributesToString( *(PSAPI_WORKING_SET_EX_BLOCK*)&attributes).c_str()); size = 1 << 12; attributes = (ULONG)info.VirtualAttributes.Flags; address = info.VirtualAddress; } } }
该函数首先计算块中的页面数. 然后它遍历每个页面, 并使用 `QueryWorkingSetEx` 来查询其工作集状态. 代码中唯一的挑战是不要显示每个页面的状态, 而是将所有共享相同属性的连续页面分组.
只要属性相同, 块大小就会增加一个页面, 循环继续. 如果属性改变, 现有的统计信息就会被显示, 变量会重置为下一个值. 最后一部分是 `AttributesToString` 辅助函数, 它返回属性的字符串表示:
std::string AttributesToString(PSAPI_WORKING_SET_EX_BLOCK attributes) { if (!attributes.Valid) return "(Not in working set)"; std::string text; if (attributes.Shared) text += "Shareable, "; else text += "Private, "; if(attributes.ShareCount > 1) text += "Shared, "; if (attributes.Locked) text += "Locked, "; if (attributes.LargePage) text += "Large Page, "; if (attributes.Bad) text += "Bad, "; // eliminate last command and space return text.substr(0, text.size() - 2); }
以下是一个示例运行 (截断):
c:\>SimpleVMMap2.exe 42504
emory map for process 42504 (0xA608)
Base Address Size State Protection Alloc. Protecti\
on Type Details
-------------------------------------------------------------------------------\
---------------------
*0x0000000000000000 2097024 KB Free
*0x000000007FFE0000 4 KB Committed Read Read \
Private
Address: 000000007FFE0000 ( 4 KB) Attributes: 4000802F Shareable, Sha\
red
0x000000007FFE1000 32 KB Free
*0x000000007FFE9000 4 KB Committed Read Read \
Private
Address: 000000007FFE9000 ( 4 KB) Attributes: 4000802F Shareable, Sha\
red
0x000000007FFEA000 920090968 KB Free
*0x000000DBDDE40000 4 KB Reserved Read/Write
0x000000DBDDE41000 12 KB Committed Read/Write/Guard Read/Write \
Private
Address: 000000DBDDE43000 ( 4 KB) Attributes: 00000000 (Not in workin\
g set)
...
*0x000001FB57C00000 116 KB Committed Read Read \
Mapped
Address: 000001FB57C00000 ( 56 KB) Attributes: 4000802F Shareable, Sha\
red
Address: 000001FB57C0E000 ( 16 KB) Attributes: 40008000 (Not in workin\
g set)
Address: 000001FB57C12000 ( 16 KB) Attributes: 4000802F Shareable, Sha\
red
Address: 000001FB57C16000 ( 4 KB) Attributes: 40008000 (Not in workin\
g set)
Address: 000001FB57C17000 ( 24 KB) Attributes: 4000802F Shareable, Sha\
red
...
0x00007FF7BC559000 56 KB Committed Read Execute/WriteCo\
py Image \Device\HarddiskVolume3\Windows\System32\cmd.exe
Address: 00007FF7BC559000 ( 12 KB) Attributes: 4000802F Shareable, Sha\
red
Address: 00007FF7BC55C000 ( 4 KB) Attributes: 00400000 (Not in workin\
g set)
Address: 00007FF7BC55D000 ( 4 KB) Attributes: 4000802F Shareable, Sha\
red
Address: 00007FF7BC55E000 ( 36 KB) Attributes: 40008000 (Not in workin\
g set)
...
通常, 进程有独立的地址空间, 不会混合. 然而, 有时在进程之间共享内存是有益的. 典型的例子是 DLL. 所有用户模式进程都需要 `NtDll.dll`, 大多数需要 `Kernel32.Dll`, `KernelBase.dll`, `AdvApi32.Dll` 等等. 如果每个进程在物理内存中都有自己的 DLL 副本, 它会很快用完. 事实上, 最初拥有 DLL 的主要动机之一是能够共享 (至少是它们的代码). 代码按约定是只读的, 所以可以安全地共享. 这同样适用于来自 EXE 文件的可执行代码. 如果多个进程基于同一个映像文件执行, 没有理由不共享 (至少是代码). 这个想法如图 12-14 所示, 其中 `Kernel32.dll` 在两个进程之间共享.

Figure 187: 共享代码页
图 12-14 中 DLL 的虚拟地址在所有共享它的进程中都是相同的. 这是必要的, 因为并非所有代码都是可重定位的. 这将在第 15 章中进一步讨论.
那么全局数据呢? 如果我们在全局作用域中声明一个变量, 像这样:
int x; void main() { x++; //... }
我们运行这个可执行文件的两个实例——第二个实例中 x 的值会是什么? 答案是 1. x 是对一个进程是全局的, 而不是对系统是全局的. 这与 DLL 的工作方式相同. 如果一个 DLL 声明了一个全局变量, 它只对加载该 DLL 的每个进程是全局的.
在大多数情况下, 这就是我们想要的. 这是通过利用一种称为*写时复制 (Copy on Write)* (`PAGEWRITECOPY`) 的页面保护来实现的. 其思想是所有使用相同变量 (在可执行文件或这些进程使用的 DLL 中声明) 的进程都将该变量所在的页面映射到同一个物理页面 (图 12-15). 如果一个进程更改了该变量的值 (图 12-16 中的进程 A), 就会引发一个异常, 导致内存管理器创建一个页面的副本并将其作为私有页面交给调用进程, 移除写时复制保护 (图 12-16 中的页面 3).

Figure 188: 写时复制 - 之前

Figure 189: 写时复制 - 之后
将任何全局数据复制到每个使用它的进程会更简单, 但那会浪费物理内存. 如果数据没有被更改, 就不需要复制.
在某些情况下, 需要在进程之间共享数据. 一种相对简单的机制是使用全局变量, 但指定页面应该由正常的 `PAGEREADWRITE` 而不是 `PAGEWRITECOPY` 保护.
这可以通过在可执行文件或 DLL 中构建一个新的数据段, 并指定其期望的属性来完成. 以下显示了如何完成此操作:
#pragma data_seg("shared") int x = 0; #pragma data_seg() #pragma comment(linker, "/section:shared,RWS")
`dataseg` pragma 在 PE 中创建一个新节. 它的名称可以是任何东西 (最多 8 个字符), 在上面的代码中为了清晰起见称为“shared”. 然后, 应该共享的所有变量都放在该节中, 并且它们必须被显式地初始化, 否则它们将不会被存储在该节中.
技术上, 如果你有几个变量, 只有第一个需要被显式地初始化. 尽管如此, 最好还是将它们全部初始化.
第二个 `#pragma` 是给链接器的一个指令, 用 RWS (读, 写, 共享) 属性创建该节. 那个小的“S”是关键. 当映像被映射时, 它不会有 `PAGEWRITECOPY` 保护, 因此在使用相同 PE 的所有进程之间都是共享的.
此类变量是共享的, 这意味着并发访问是可能的. 你可能需要用互斥体等来保护对这些变量的访问.
`SimpleShare` 应用程序演示了这种技术的使用. 图 12-17 显示了应用程序首次启动时的对话框.

Figure 190: SimpleShare 启动时
现在你可以启动更多的实例, 并单击*递增*按钮来将显示的值加 1. 你会注意到所有实例都跟进. 每个应用程序都有一个 1 秒的计时器, 只读取当前值并显示它. 图 12-18 显示了一些具有匹配值的实例.

Figure 191: SimpleShare 实例同步
应用程序如上所述声明了一个全局共享变量:
#pragma data_seg("shared") int SharedValue = 0; #pragma data_seg() #pragma comment(linker, "/section:shared,RWS")
每次单击*递增*按钮都会对该变量进行简单的增量:
LRESULT CMainDlg::OnIncrement(WORD, WORD wID, HWND, BOOL&) { SharedValue++; return 0; }
计时器处理程序只读取共享值并输出它:
LRESULT CMainDlg::OnTimer(UINT, WPARAM id, LPARAM, BOOL&) { if (id == 1) SetDlgItemInt(IDC_VALUE, SharedValue); return 0; }
在进程之间共享内存的更通用的技术是使用内存映射文件, 我们将在第 14 章中详细讨论.
处理器只能访问物理内存 (RAM) 中的代码和数据. 如果启动某个可执行文件, Windows 会将可执行文件的代码和数据 (以及 `NTdll.dll`) 映射到进程的地址空间中. 然后, 进程的第一个线程开始执行. 这导致它执行的代码 (首先在 `NtDll.dll` 中, 然后是可执行文件) 被映射到物理内存并从磁盘加载, 以便 CPU 可以执行它.
假设该进程的线程都处于等待状态, 也许该进程有一个用户界面, 用户最小化了应用程序的窗口, 并且有一段时间没有使用该应用程序. Windows 可以将可执行文件使用的 RAM 重新用于需要它的其他进程. 现在假设用户恢复了应用程序的窗口——Windows 现在必须将应用程序的代码带回 RAM. 代码将从哪里读取? 可执行文件本身.
这意味着可执行文件和 DLL 是它们自己的备份. 事实上, Windows 为可执行文件和 DLL 创建了一个内存映射文件 (这也解释了为什么这样的文件不能被删除, 因为至少有一个打开的句柄指向这些文件).
那么数据呢? 如果某些数据长时间没有被访问 (或者 Windows 内存不足), 内存管理器可以将数据写入磁盘——到一个*页面文件*. 页面文件用作私有, 已提交内存的备份. 使用页面文件不是必需的——Windows 没有它也能正常工作. 但这会减少一次可以提交的内存量.
此外, Windows 支持多达 16 个页面文件. 它们必须在不同的磁盘分区中, 并命名为 `pagefile.sys`, 位于根分区 (文件默认是隐藏的). 如果一个分区太满, 或者另一个分区是一个独立的物理磁盘, 拥有多个页面文件可能是有益的, 这可以增加 I/O 吞吐量.
Windows on ARM 设备仅支持 2 个页面文件.
Windows 8 及更高版本还有一个名为 `Swapfile.sys` 的特殊页面文件, 在某些 UWP 进程场景中使用.
任务管理器中显示的提交限制 (图 12-6) 基本上是 RAM 的数量加上所有页面文件的当前大小. 每个页面文件都可以有一个初始大小和一个最大大小. 如果系统达到其提交限制, 页面文件会增加到其配置的最大值, 因此提交限制现在增加了 (可能会因为更多的 I/O 而导致性能下降). 如果已提交的内存降到原始提交限制以下, 页面文件大小将减小回其初始大小.
配置页面文件大小可以通过进入系统属性, 然后选择*高级系统设置*, 然后在*性能*部分选择*设置*, 然后选择*高级*选项卡, 最后在*虚拟内存*部分选择*更改…*, 从而得到图 12-19 中的对话框. 在单击最后一个按钮之前, 请注意分页文件的当前大小显示在按钮附近.

Figure 192: 页面文件配置对话框
通常, 顶部的复选框是选中的, 告诉 Windows 自动管理页面文件大小. 从 Windows 10 开始, 这是我的推荐选择. 早期的 Windows 版本使用一种启发式方法, 其中初始页面文件大小是 1 x RAM 大小, 最大大小是 3 x RAM (Windows 8+ 将其上限设为 32 GB). 这些启发式方法的问题在于, 系统拥有的 RAM 量与用户实际完成的工作没有真正的关系.
例如, 假设某个用户的工作需要 40 GB 的已提交内存. 如果机器有 8 GB 的 RAM, 那么页面文件大小应设置为大约 32 GB. 另一方面, 如果机器有 32 GB 的 RAM, 只需要 8 GB 的页面文件大小. 如果该系统有 64 GB 的 RAM, 根本就不需要页面文件!
当然, 拥有更多的 RAM 是有益的, 因为它减少了页面文件使用的可能性, 但页面文件大小与系统上的 RAM 量无关.
Windows 10 在选择“自动管理”时, 使用一种更好的方案来确定所需的页面文件大小. 它会跟踪过去 14 天的已提交内存使用情况, 并相应地调整大小, 这当然与实际用户正在做什么有关, 而与系统 RAM 大小无关.
在任何情况下, “自动管理”复选框都可以不选中, 从而允许用自定义的初始和最大大小进行配置, 或者完全移除分页文件.
最大页面文件大小为 16 TB, ARM 上除外, 其限制为 4 GB.
页面文件配置存储在注册表中 (像 Windows 中的大多数东西一样), 位于 `HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management\PagingFiles`.
Windows on Windows 64 (WOW64) 是一个软件层, 允许 32 位 x86 可执行文件在 x64 64 位系统上运行而无需任何更改. 在本节中, 我们将看看这是如何工作的, 以及本章前面尚未讨论的影响.
在 64 位 Windows (x64) 上, 你会发现两套 DLL 和可执行文件. 本机 (64 位) 映像存储在 `System32` 目录中 (例如 `c:\Windows\System32`), 而 32 位映像集存储在 `SysWow64` 目录中 (例如 `c:\Windows\SysWow64`). 这是必需的, 因为 Windows 强制执行一个基本规则, 即 32 位进程不能加载 64 位 DLL, 反之亦然. 这是有道理的, 因为指针大小不同, 地址范围也不同——这根本无法正常工作.
此规则的例外是只包含资源 (字符串, 位图等) 而没有代码的 DLL, 可以由任何进程加载.
这些限制的最终结果是, 32 位可执行文件必须链接和加载 32 位 DLL. 这就是为什么有一个单独的目录 (`SysWow64`) 包含所有 Windows 提供的 32 位 DLL 的原因.
`SysWow64` 目录还包含标准应用程序的 32 位版本, 例如 `Notepad`, `mspaint`, `cmd` 等.
使用 32 位 DLL 的问题在于内核仍然是 64 位的, 这意味着任何系统调用都必须作为 64 位调用, 通常由 64 位 `NtDll` 提供. 此外, 32 位系统上的标准 32 位 `NtDll` 直接调用一个系统调用, 这无法工作. 这意味着 64 位系统有一个特殊的 32 位 `NtDll`, 它不调用系统调用. 相反, 它调用一些提供必要的系统调用转换 (更改指针大小和其他参数) 的辅助 DLL, 然后再调用真正的 64 位 `NtDll`. 这个架构如图 12-20 所示.

Figure 193: WOW64 架构
32 位和 64 位 DLL 加载到同一个进程中的事实可能会令人困惑. 从内核的角度来看, 根本没有真正的 32 位进程. 32 位代码不知道它能看到的 4 GB 最大地址空间之外还有更多. 这就像二维生物生活在一张桌子上, 不知道有第三个维度.
图 12-21 显示了 Process Explorer 的屏幕截图, 显示了同一个进程中 `NtDll` 的两个版本. 一个来自 `System32`, 加载在一个高地址, 远高于 4 GB, 另一个来自 `SysWow64`, 加载在 2 GB 以下 (`Base` 列指示了映像加载到的地址).

Figure 194: 两个 NtDll.Dll 映像加载到一个 32 位进程中
你也可以在进程地址空间中找到三个与转换相关的 DLL. 对于 32 位 WOW64 进程, 还有其他变化. 每个线程有两个栈, 以及每个线程有两个*线程环境块*结构. 一个是在线程处于 32 位模式时, 另一个是当线程移动到 64 位环境时, 当“转换层” DLL 被调用时. 尽管从架构的角度来看很有趣, 但这些变化不应影响代码的执行方式.
有些 API 在 WOW64 进程中不起作用. 地址窗口化扩展 (AWE) 以及函数 `ReadFileScatter` 和 `WriteFileGather`. 幸运的是, 这些相当罕见, 所以在实践中不太可能成为问题.
- WOW64 重定向
如果一个 32 位 WOW64 进程调用 `GetSystemDirectory`? 或者直接从像 `c:\Windows\System32\ws2.dll` 这样的路径加载一个 DLL? 如前所述, 一个 32 位进程不能加载一个 64 位 DLL. 但可执行文件不知道它在 64 位系统上运行——这就是 WOW64 的重点.
Windows 提供文件系统重定向, 以便任何尝试访问 `System32` 的都会自动和透明地重定向到 `Syswow64`. 这适用于显式路径以及像 `GetSystemDirectory` 这样的函数调用. 在访问*Program Files*目录时也会发生类似的重定向——它会被重定向到*Program Files (x86)*.
一个线程可以暂时退出此重定向, 通过调用 `Wow64DisableWow64FsRedirection`:
BOOL Wow64DisableWow64FsRedirection(_Out_ PVOID* OldValue);
`OldValue` 参数是一个不透明的值, 应传递给 `Wow64RevertWow64FsRedirection` 以重新启用重定向:
BOOL Wow64RevertWow64FsRedirection(_In_ PVOID OldValue);
禁用重定向对于一个了解 WOW64 并需要如实查看事物的 I/O 操作的应用程序可能很有用. 该应用程序可能为了方便而编写为 32 位, 允许它在 32 位和 64 位系统上不加更改地运行.
禁用重定向仅对当前线程有效. 进程中的其他线程不受影响, 除非它们也请求禁用文件系统重定向.
要不经重定向地访问真正的 `System32`, 请使用虚拟路径 `c:\Windows\Sysnative`.
WOW64 层自动采用的另一种重定向形式是针对某些注册表项. 这些将在第 17 章中讨论.
1.13.4. 虚拟地址转换
在本章的最后一节, 我们将看看虚拟地址如何被转换为物理地址的基础知识. 本节是严格可选的, 可以完全跳过. 对转换表的详细讨论超出了本书的范围; 有关更多信息, 请参阅“Windows Internals 7th edition, Part 1”一书的第 5 章.
转换本身是自动的, 所以当 CPU 看到像这样的指令时:
mov eax, [100000H]
它知道地址 `0x100000` 是虚拟的而不是物理的 (因为 CPU 被配置为在保护模式/长模式下运行). CPU 现在必须查看由内存管理器预先准备的表, 这些表描述了该页面在 RAM 中的位置, 如果有的话. 如果它不在 RAM 中 (由转换表中的一个*有效*位为零标记), 它会引发一个*缺页错误*异常, 由内存管理器适当地处理. 涉及地址转换的基本组件如图 12-22 所示.

Figure 195: 虚拟地址转换
CPU 以一个虚拟地址作为输入, 并应输出 (并使用) 一个物理地址. 由于所有东西都以页为单位工作, 地址的低 12 位 (页内的偏移量) 从不被转换, 并按原样传递到最终地址.
CPU 需要上下文来进行转换. 每个进程都有一个单一的初始结构, 该结构总是驻留在 RAM 中. 对于 32 位系统, 它被称为*页目录指针表*, 对于 64 位系统, 它是*页映射级别 4* (这些是 Intel 的术语). 从这个初始结构, 使用其他结构, 包括页目录和最终的页表 (转换“树”的叶子). 页表条目是指向物理页面地址的条目 (如果有效位已设置). 当一个页面被移动到页面文件时, 内存管理器会将相应的页表条目标记为无效, 以便下次 CPU 遇到该页面时, 它会引发一个缺页错误异常.
最后, 转换后备缓冲区 (TLB) 是最近转换的页面的一个缓存, 因此访问这些页面不需要经过多级结构进行转换. 这个缓存相对较小, 从实践的角度来看非常重要. 这强调了我们在第 10 章中看到的一些关于缓存和连续内存的东西: 在相近的时间使用相同范围的内存地址对于利用 TLB 缓存非常有用.
1.13.5. 总结
在本章中, 我们开始了我们进入虚拟和物理内存世界的旅程. 我们探讨了进程的地址空间, 页面状态等等. 在下一章 (和下一本书) 中, 我们将学习如何有效地在我们的应用程序中使用与内存相关的 API.
2. Windows 10 系统编程, 第 2 部分
Pavel Yosifovich
本书在 http://leanpub.com/windows10systemprogrammingpart2 出售
此版本发布于 2020-08-09
这是一本 Leanpub 书籍. Leanpub 通过精益出版 (Lean Publishing) 流程为作者和出版商赋能. 精益出版是使用轻量级工具和多次迭代来发布正在创作中的电子书, 以获得读者反馈, 进行调整, 直到你写出合适的书籍并在此基础上获得吸引力.
© 2020 Pavel Yosifovich
2.1. 第 13 章: 使用内存
在第 12 章中, 我们学习了虚拟内存和物理内存的基础知识. 在本章中, 我们将讨论开发人员可用于管理内存的各种 API. 一些 API 更适合用于大内存分配, 而另一些则更适合管理小内存分配. 完成本章后, 你应该对各种 API 及其功能有很好的理解, 从而能够在涉及内存的工作中选择正确的工具.
本章内容:
- 内存 API
- The VirtualAlloc* 函数
- 预留和提交内存
- 工作集
- 堆
- 其他虚拟函数
- 写入和读取其他进程
- 大页面
- 地址窗口化扩展
- NUMA
- The VirtualAlloc2 函数
2.1.1. 内存 API
Windows 提供了几套 API 来处理内存. 图 13-1 显示了可用的 API 集合及其依赖关系.
 我们将从最低层到最高层逐一介绍这些 API. 每个 API 集都有其优点和缺点.
我们将从最低层到最高层逐一介绍这些 API. 每个 API 集都有其优点和缺点.
2.1.2. The VirtualAlloc* 函数
最底层 - Virtual API 是最接近内存管理器的, 这有几个含义:
- 它是最强大的 API, 几乎提供了所有可以用虚拟内存完成的操作.
- 它总是以页面为单位并在页面边界上工作.
- 正如我们将在本章中看到的, 它被更高级别的 API 使用.
允许预留和/或提交内存的最基本函数是 VirtualAlloc:
LPVOID VirtualAlloc( _In_opt_ LPVOID lpAddress, _In_ SIZE_T dwSize, _In_ DWORD flAllocationType, _In_ DWORD flProtect);
一个扩展函数, VirtualAllocEx, 可以在一个可能不同的进程上工作:
LPVOID VirtualAllocEx( _In_ HANDLE hProcess, _In_opt_ LPVOID lpAddress, _In_ SIZE_T dwSize, _In_ DWORD flAllocationType, _In_ DWORD flProtect);
VirtualAllocEx 与 VirtualAlloc 相同, 除了进程句柄参数, 该参数必须具有 PROCESS_VM_OPERATION 访问掩码.
VirtualAlloc(Ex) 不能从 UWP 进程中调用. Windows 10 添加了一个可以从 UWP 进程中调用的 VirtualAlloc 变体:
PVOID VirtualAllocFromApp( _In_opt_ PVOID BaseAddress, _In_ SIZE_T Size, _In_ ULONG AllocationType, _In_ ULONG Protection);
为了让 UWP 进程的事情更简单, VirtualAlloc 被定义为内联函数并调用 VirtualAllocFromApp, 所以技术上你可以从 UWP 进程中调用 VirtualAlloc.
Windows 10 版本 1803 中引入了另一个名为 VirtualAlloc2 的 VirtualAlloc 变体. 它有自己的章节进行讨论. 还有另一个 VirtualAlloc 变体 (VirtualAllocExNuma), 专门用于非一致性内存访问架构 (Non-Uniform Memory Architecture, NUMA). 我们也将在其自己的章节中讨论 NUMA.
我们将从描述基本的 VirtualAlloc 函数开始, 所有其他函数都是在此基础上构建的. VirtualAlloc 的主要目的是预留和/或提交一块内存.
VirtualAlloc 的第一个参数是一个可选的指针, 指示预留/提交应该发生的位置. 如果是新的分配, 通常传入 NULL, 表示内存管理器应该找到一些空闲地址. 如果区域已经被预留, 并且需要在该区域内进行提交, 那么 lpAddress 指示提交应该从哪里开始. 在任何情况下, 地址都会向下舍入到最近的页面. 对于新的预留, 它会向下舍入到分配粒度.
在所有 Windows 架构和版本上, 分配粒度当前为 64 KB. 你总是可以通过调用
GetSystemInfo动态获取该值.
dwSize 是要预留/提交的块的大小. 如果 lpAddress 是 NULL, 大小会向上舍入到最近的页面边界. 例如, 1 KB 会被舍入到 4 KB, 50 KB 会被舍入到 52 KB. 如果 lpAddress 不是 NULL, 那么 lpAddress 到 lpAddress+dwSize 范围内的所有页面都将包含在内.
flAllocationType 指示要执行的操作类型. 最常见的标志是 MEM_RESERVE 和 MEM_COMMIT. 使用 MEM_RESERVE, 区域被预留, 但如果 lpAddress 指定了一个已经预留的区域, 函数会失败.
MEM_COMMIT 提交一个先前预留的区域 (或部分区域). 这意味着在这种情况下 lpAddress 不能是 NULL. 然而, 可以通过组合两个标志来同时预留和提交内存. 例如, 以下代码预留并提交 128 KB 的内存:
void* p = ::VirtualAlloc(nullptr, 128 << 10, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE); if(!p) { // some error occurred }
一个 VirtualAlloc 的 Bug
技术上, 你可以仅使用
MEM_COMMIT来同时提交和预留内存. 严格来说, 这是不正确的. 这个功能之所以能用, 是因为 API 中的一个 bug 允许这样做. 不幸的是, 许多开发者 (有意或无意地) 滥用了这个 bug, 所以微软决定不修复它, 以免破坏现有代码. 如果要同时预留和提交, 你应该总是使用两个标志.
任何已提交的页面都保证被填充为零. 这与一个安全要求有关, 即一个进程永远不能看到属于另一个进程的任何内存, 即使该进程已不再存在. 为了明确这一点, 内存总是被清零.
💡 这与
malloc等函数不同. 原因将在本章稍后部分明晰.
预留一个已经预留的内存区域是一个错误. 另一方面, 提交一个已经提交的内存会隐式成功.
VirtualAlloc 的最后一个参数是为预留/提交的内存设置的页面保护 (关于保护标志的更多信息请参见第 12 章, 第 1 部分). 对于已提交的内存, 它就是设置的页面保护. 对于预留的内存, 这会设置初始保护 (MEMORY_BASIC_INFORMATION 中的 AllocationProtect 成员), 尽管在稍后提交内存时可以更改它. 保护标志对预留内存没有影响, 因为预留内存是不可访问的. 尽管如此, 即使在这种情况下也必须提供一个有效的值.
VirtualAlloc 的返回值是操作成功时的基地址, 否则为 NULL. 如果 lpAddress 不为 NULL, 返回的值可能等于也可能不等于 lpAddress, 这取决于其页面或分配粒度的对齐方式 (如前所述).
除了 MEM_RESERVE 和 MEM_COMMIT, VirtualAlloc 还有其他可能的标志:
MEM_RESET是一个标志, 如果使用, 必须是唯一的标志. 它向内存管理器指示范围内的已提交内存不再需要, 因此内存管理器不必费心将其写入页面文件. 已提交的内存不能由映射文件支持, 只能由页面文件支持. 请注意, 这与取消提交内存不同; 内存仍然是已提交的, 并且可以在以后使用 (见下一个标志).MEM_RESET_UNDO是MEM_RESET的反向操作, 表明已提交的内存区域再次变得重要. 范围内的值不一定是零, 因为内存管理器可能已经或可能没有重用映射的物理页面.MEM_LARGE_PAGES表示操作应使用大页面而不是小页面. 我们将在本章后面的“大页面”部分讨论此选项.MEM_PHYSICAL是一个只能与MEM_RESERVE一起指定的标志, 用于地址窗口化扩展 (Address Windowing Extensions, AWE), 本章稍后将对此进行描述.MEM_TOP_DOWN是一个给内存管理器的建议性标志, 以优先选择高地址而不是低地址.MEM_WRITE_WATCH是一个必须与MEM_RESERVE一起指定的标志. 此标志指示系统应跟踪对该区域的内存写入 (当然, 是在提交之后). 这在“内存跟踪”部分有进一步描述.
- 取消提交 / 释放内存
VirtualAlloc必须有一个相反的函数, 可以取消提交 (de-commit) 和/或释放 (与预留相反) 一块内存. 这就是VirtualFree和VirtualFreeEx的作用:BOOL VirtualFree( _in_ LPVOID lpAddress, _In_ SIZE_T dwSize, _In_ DWORD dwFreeType);
BOOL VirtualFreeEx( _In_ HANDLE hProcess, _In_ LPVOID lpAddress, _In_ SIZE_T dwSize, _In_ DWORD dwFreeType);
VirtualFreeEx是VirtualFree的扩展版本, 在由hProcess指定的进程中执行请求的操作, 该进程必须具有PROCESS_VM_OPERATION访问掩码 (就像VirtualAllocEx一样).dwFreeType参数只支持两个标志 -MEM_DECOMMIT和MEM_RELEASE- 必须指定其中一个 (且只能指定一个).MEM_DECOMMIT取消提交从lpAddress到lpAddress+dwSize的页面, 将内存区域返回到预留状态.MEM_RELEASE表示该区域应被完全释放.lpAddress必须是最初预留区域的基地址,dwSize必须为零. 如果区域中有任何内存被提交, 它会先被取消提交, 然后整个区域被释放 (页面变为空闲).
2.1.3. 预留和提交内存
当需要大块分配时, 使用 VirtualAlloc 函数来预留和提交内存是一个好主意, 因为这个函数以页面粒度工作. 对于小块分配, 使用 VirtualAlloc 太浪费了, 因为每个新的分配都会在一个新的页面上. 对于小块分配, 最好使用堆函数 (本章稍后描述).
已提交内存和 RAM
提交内存并不意味着 RAM 会立即为该内存分配. 提交内存会增加系统总提交量, 这意味着它保证了在访问已提交内存时它是可用的. 一旦访问了某个页面, 系统就会在 RAM 中提供该页面, 并且访问可以继续进行. 在 RAM 中提供此页面可能是以 RAM 中另一个页面为代价的, 如果系统内存不足, 该页面将被推送到磁盘. 无论如何, 这个过程对应用程序是透明的.
假设你想创建一个类似于 Microsoft Excel 的应用程序, 其中有一个单元格网格可用于输入各种数据. 我们进一步假设, 你希望用户有一个大的网格可供使用, 比如 1024 x 1024 个单元格, 每个单元格可以包含 1 KB 的数据. 在这样的应用程序中, 你将如何管理这些单元格呢?
一种方法是使用某种链表或映射实现, 其中每个元素是 1 KB 的内存块. 当用户访问一个单元格时, 根据管理的数据结构检索元素并使用. 由于每个单元格大小相同, 另一种选择可能是分配一个足够大的内存块, 然后通过快速计算来访问特定的单元格. 下面是一个例子:
int cellSize = 1 << 10; // 1 KB int maxx = 1 << 10, maxy = 1 << 10; // 1024 x 1024 cells void* data = malloc(maxx * maxy * cellSize); // locate cell (x,y) address void* pCell = (BYTE*)data + (y * maxx + x) * cellSize; // perform access to pCell...
这样做是可行的, 并且定位单元格非常快. 问题在于预先提交了 1 GB 的内存. 这是浪费的, 因为用户不太可能使用所有可用的单元格. 而且, 如果我们以后决定允许使用更多的单元格, 那么已提交的内存就必须更大.
我们想要的是一种能够继续非常快速地定位单元格, 但又不在单元格数据被使用前分配它的方法. 这就是预留内存和分块提交能够解决这个问题的地方. 我们从预留一个 1 GB 的地址空间开始:
void* data = ::VirtualAlloc(nullptr, maxx * maxy * cellSize, MEM_RESERVE, PAGE_READWRITE);
预留操作非常廉价 - 系统的提交大小没有改变. 现在每当需要访问一个单元格时, 我们可以像以前一样计算它在块内的地址, 然后提交所需的单元格:
// commit page for cell (x, y) void* pCell = (BYTE*)data + (y * maxx + x) * cellSize; ::VirtualAlloc(pCell, cellSize, MEM_COMMIT, PAGE_READWRITE); // access cell...
代码像以前一样计算单元格的地址, 但是因为内存最初是预留的, 所以那里什么都没有. 以任何方式访问该内存都会导致访问冲突异常. 通过使用带有 MEM_COMMIT 的 VirtualAlloc, 单元格所在的页面被提交, 使其变为“真实”的. 现在访问这个内存必须成功.
VirtualAlloc总是以页面为单位工作, 所以上面的代码提交了 4 个单元格 (记住每个单元格是 1 KB 大小), 而不仅仅是一个. 使用 Virtual* 函数时没有办法绕过这一点.
每次需要使用一个单元格时, 都会运行相同的代码, 提交该单元格 (以及相邻的 3 个单元格), 以便它们可以被访问. 内存的消耗仅限于那些被使用的单元格 (以及即使未使用但相邻的单元格). 这个方案允许我们使用非常大量的潜在单元格而不会浪费更多的内存. 例如, 我们可以将最大网格大小增加到 2048 x 2048. 唯一的变化是预留内存的数量, 以保持地址空间的连续性.
💡 这种方法的主要缺点是占用了大量的地址空间. 在 64 位进程中 (地址空间为 128 TB), 这不是问题. 在 32 位进程中, 这可能会失败. 例如, 使用一个 2048 x 2048 的网格, 每个单元格 1 KB 内存, 需要 4 GB 的地址空间, 这超出了一个 32 位进程的能力 (即使在设置了
LARGEADDRESSAWARE的 WOW64 上, 因为地址空间还必须包含 DLL, 线程堆栈等). 地址范围也必须是连续的, 即使是较小的尺寸, 在 32 位进程中也可能成为一个问题.
提交一个已经提交的内存不是问题, 但它确实会产生一个系统调用, 如果所讨论的单元格内存已经提交, 这或许可以避免. 这该怎么做呢?
一种方法是使用第 12 章中描述的 VirtualQuery 函数来查询内存区域, 并决定是否提交内存. 但这本身就需要一次系统调用, 所以实际上比在任何访问前直接提交更糟糕. 另一种方法是“盲目地”访问内存 - 如果它已经提交了, 它就能正常工作; 如果没有, 就会引发一个异常, 这个异常可以被捕获并通过提交所需的内存来处理. 下面是代码的基本思想:
void DoWork(void* data, int x, int y) { // in some function void* pCell = (BYTE*)data + (y * maxx + x) * cellSize; __try { // access the cell memory ::strcpy((char*)pCell, "some text data"); // if we get here, all is well } __except(FixMemory(pCell, GetExceptionCode())) { // no code needed here } } int FixMemory(void* p, DWORD code) { if(code == EXCEPTION_ACCESS_VIOLATION) { // we can fix it by comitting the memory ::VirtualAlloc(p, cellSize, MEM_COMMIT, PAGE_READWRITE); // tell the CPU to try again return EXCEPTION_CONTINUE_EXECUTION; } // some other exception, look elsewhere for a handler return EXCEPTION_CONTINUE_SEARCH; }
如果在 strcpy 调用中引发了异常, __except 表达式会通过调用 FixMemory 函数来求值, 并传入有问题的地址和异常代码. 这个函数的目的是返回三个可能的值之一, 指示异常处理机制接下来该做什么. 如果异常代码是访问冲突, 那么我们可以处理它, 在返回 EXCEPTION_CONTINUE_EXECUTION 之前提交所需的内存, 这表示处理器应该再次尝试原始指令. 如果是其他异常, 我们不处理它, 并返回 EXCEPTION_CONTINUE_SEARCH 以继续在调用堆栈上寻找处理程序.
另一个可能的返回值是
EXCEPTION_EXECUTE_HANDLER. 异常处理在第 23 章中有详细介绍.
- The Micro Excel Application
The Micro Excel 应用程序演示了上述技术. 运行它会显示图 13-2 中的对话框.
Figure 196: 图 13-2: Micro Excel 应用程序
该应用程序预留了一个 1 GB 的内存范围, 起始地址显示在顶部. Cell X 和 Cell Y 编辑框允许在任一方向上选择一个单元格 (0-1023). 通过在大的编辑框中输入内容并点击 Write, 文本将被写入所请求的单元格. 如果内存未提交 (第一次必须是这种情况), 它将通过处理访问冲突异常来提交. 在向单元格 (0,0) 添加一个字符串后, 应用程序窗口如图 13-3 所示.
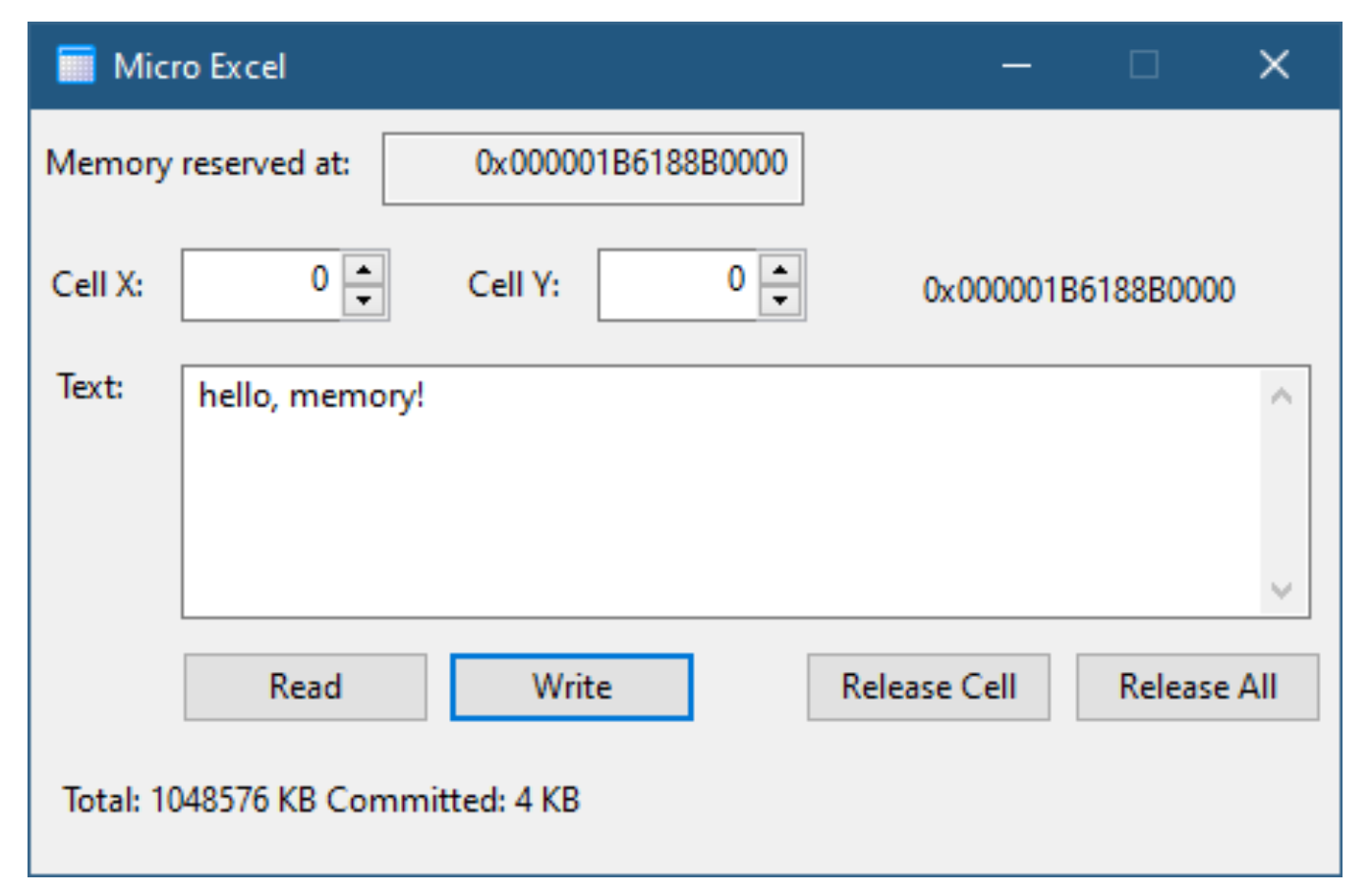
Figure 197: 图 13-3: Micro Excel 应用程序一次分配后的情况
底部的文本表示已提交了 4 KB, 这符合我们的预期, 因为 1 KB 的单元格需要一个单独的页面. 如果我们将单元格 X 设置为 1 并写入一些内容, 已提交的大小会是多少? 它将保持不变, 因为第一个提交的页面覆盖了 4 个单元格 (图 13-4).
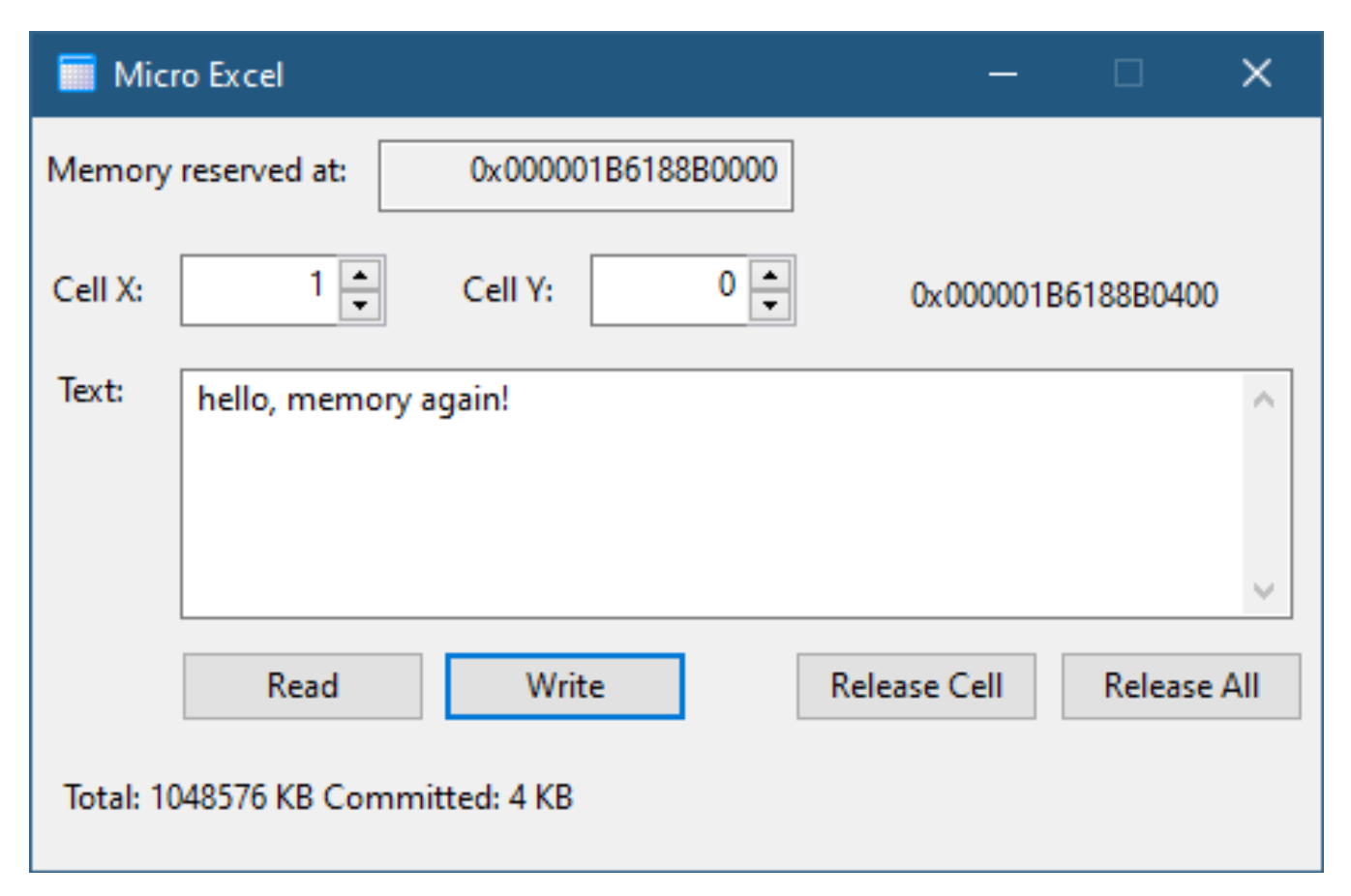
Figure 198: 图 13-4: 写入单元格 (1,0)
如果你向单元格 (0,1) 写入一些内容会发生什么? 试试看就知道! 你可以通过使用 Read 按钮从任何单元格读回数据. 如果单元格未提交, 将返回一个错误.
用 VMMap 查看分配的内存区域是很有趣的. 每当一个新页面被提交时, 它就会在大的预留区域中“打一个洞”. 图 13-5 显示了应用程序使用的内存区域, 其中有几个已提交内存的“打孔”.

Figure 199: 图 13-5: VMMap 显示大型预留区域内已提交的区域
该应用程序是作为一个标准的 WTL 基于对话框的应用程序构建的.
CMainDlg类包含几个与托管内存相关的数据成员:class CMainDlg : public CDialogImpl<CMainDlg> { //... const int CellSize = 1024, SizeX = 1024, SizeY = 1024; const size_t TotalSize = CellSize * SizeX * SizeY; void* m_Address{ nullptr }; };
各种大小被声明为常量, 但如果它们是动态设置的, 也不会有太大不同.
OnInitDialog调用AllocateRegion来预留初始内存区域:bool CMainDlg::AllocateRegion() { m_Address = ::VirtualAlloc(nullptr, TotalSize, MEM_RESERVE, PAGE_READWRITE); if (!m_Address) { AtlMessageBox(nullptr, L"Available address space is not large enough", IDR_MAINFRAME, MB_ICONERROR); EndDialog(IDCANCEL); return false; } // update the UI CString addr; addr.Format(L"0x%p", m_Address); SetDlgItemText(IDC_ADDRESS, addr); SetDlgItemText(IDC_CELLADDR, addr); return true; }
一旦用户点击任何按钮, 就需要检索单元格的地址. 这是通过
GetCell完成的:void* CMainDlg::GetCell(int& x, int& y, bool reportError /* = true */) const { // get indices from UI x = GetDlgItemInt(IDC_CELLX); y = GetDlgItemInt(IDC_CELLY); // check range validity if (x < 0 || x >= SizeX || y < 0 || y >= SizeY) { if(reportError) AtlMessageBox(*this, L"Indices out of range", IDR_MAINFRAME, MB_ICONEXCLAMATION); return nullptr; } return (BYTE*)m_Address + CellSize * ((size_t)x + SizeX * y); }
有趣的代码在 Write 按钮处理程序中. 首先, 检索单元格地址:
LRESULT CMainDlg::OnWrite(WORD, WORD, HWND, BOOL&) { int x, y; auto p = GetCell(x, y); if(!p) return 0;
接下来, 读取编辑框内容并写入内存块. 如果发生异常, 将调用辅助函数
FixMemory:WCHAR text; GetDlgItemText(IDC_TEXT, text, _countof(text)); __try { ::wcscpy_s((WCHAR*)p, CellSize / sizeof(WCHAR), text); } __except (FixMemory(p, GetExceptionCode())) { // nothing to do: this code is never reached }
如果确实是访问冲突,
FixMemory将尝试纠正错误:int CMainDlg::FixMemory(void* address, DWORD exceptionCode) { if (exceptionCode == EXCEPTION_ACCESS_VIOLATION) { // commit the cell ::VirtualAlloc(address, CellSize, MEM_COMMIT, PAGE_READWRITE); // tell the CPU to try again return EXCEPTION_CONTINUE_EXECUTION; } // some other error, continue to search a handler up the call stack return EXCEPTION_CONTINUE_SEARCH; }
技术上, 如果系统达到其最大提交限制,
FixMemory内部的VirtualAlloc调用可能会失败. 在那种情况下,VirtualAlloc返回NULL,FixMemory的返回值应该是EXCEPTION_CONTINUE_SEARCH.Read 按钮处理程序类似, 只是如果单元格未提交, 不会尝试提交, 而是显示一个错误:
LRESULT CMainDlg::OnRead(WORD, WORD, HWND, BOOL&) { int x, y; auto p = GetCell(x, y); if(!p) return 0; WCHAR text; __try { ::wcscpy_s(text, _countof(text), (PCWSTR)p); SetDlgItemText(IDC_TEXT, text); } __except (EXCEPTION_EXECUTE_HANDLER) { AtlMessageBox(nullptr, L"Cell memory is not committed", IDR_MAINFRAME, MB_ICONWARNING); } return 0; }
Release 和 Release All 按钮分别取消提交一个单元格和释放整个内存块:
LRESULT CMainDlg::OnRelease(WORD, WORD, HWND, BOOL&) { int x, y; auto p = GetCell(x, y); if (p) { ::VirtualFree(p, CellSize, MEM_DECOMMIT); } return 0; } LRESULT CMainDlg::OnReleaseAll(WORD, WORD wID, HWND, BOOL&) { ::VirtualFree(m_Address, 0, MEM_RELEASE); // allocate a new reserved region AllocateRegion(); return 0; }
最后, 使用定时器显示底部指示已提交内存量的输出, 该定时器使用第 12 章的
VirtualQueryAPI 遍历整个内存区域并计算已提交内存的大小:LRESULT CMainDlg::OnTimer(UINT, WPARAM id, LPARAM, BOOL&) { if (id == 1) { MEMORY_BASIC_INFORMATION mbi; auto p = (BYTE*)m_Address; size_t committed = 0; while (p < (BYTE*)m_Address + TotalSize) { ::VirtualQuery(p, &mbi, sizeof(mbi)); if (mbi.State == MEM_COMMIT) committed += mbi.RegionSize; p += mbi.RegionSize; } CString text; text.Format(L"Total: %llu KB Committed: %llu KB", TotalSize >> 10, committed >> 10); SetDlgItemText(IDC_STATS, text); } return 0; }
2.1.4. 工作集
术语 工作集 (Working Set) 表示无需发生页面错误即可访问的内存. 自然地, 一个进程希望其所有已提交的内存都在其工作集中. 内存管理器必须平衡一个进程的需求与所有其他进程的需求. 长时间未被访问的内存可能会从一个进程的工作集中移除. 这并不意味着它会自动被丢弃 - 内存管理器有精密的算法来将曾经是进程工作集一部分的物理页面在 RAM 中保留的时间可能比必要的更长, 以便如果所讨论的进程决定访问该内存, 它可以立即被错误地调入工作集 (这被称为 软页面错误 (soft page fault)).
内存管理器管理物理内存的方式的细节超出了本书的范围. 感兴趣的读者应查阅《Windows Internals, 7th ed. Part 1》一书的第 5 章.
一个进程的当前和峰值工作集可以通过调用 GetProcessMemoryInfo 来获取, 该函数在第 12 章 (第 1 部分) 中有描述, 这里为方便起见重复一下:
BOOL GetProcessMemoryInfo( HANDLE Process, PPROCESS_MEMORY_COUNTERS ppsmemCounters, DWORD cb);
PROCESS_MEMORY_COUNTERS 的 WorkingSetSize 和 PeakWorkingSetSize 成员给出了指定进程的当前和峰值工作集. 该 (及扩展) 结构的其他成员提供了其他有用的指标. 详情请参阅第 12 章.
一个进程有最小和最大工作集. 这些限制默认是软性的, 这样如果内存充足, 进程可以消耗比其最大工作集更多的 RAM, 如果内存稀缺, 可以使用比其最小工作集更少的 RAM. 你可以用 GetProcessWorkingSetSize 查询这些限制:
BOOL GetProcessWorkingSetSize( _In_ HANDLE hProcess, _Out_ PSIZE_T lpMinimumWorkingSetSize, // bytes _Out_ PSIZE_T lpMaximumWorkingSetSize); // bytes
进程句柄必须具有 PROCESS_QUERY_INFORMATION 或 PROCESS_QUERY_LIMITED_INFORMATION 访问掩码. 默认值是最小 50 页 (200 KB), 最大 345 页 (1380 KB), 但这些限制可以通过调用 SetProcessWorkingSetSize 来改变:
BOOL SetProcessWorkingSetSize( _In_ HANDLE hProcess, _In_ SIZE_T dwMinimumWorkingSetSize, // bytes _In_ SIZE_T dwMaximumWorkingSetSize); // bytes
进程句柄必须具有 PROCESS_SET_QUOTA 访问掩码, 这样操作才有机会成功. 如果最小或最大工作集值高于当前最大工作集, 调用者的令牌必须具有 SE_INC_WORKING_SET_NAME 特权. 这通常不是问题, 因为所有用户都拥有此特权.
最小工作集大小的最小值为 20 页 (80 KB), 最大工作集大小的最小值为 13 页 (52 KB). 最大工作集大小的最大值比可用内存少 512 页. 为任何值指定零都是一个错误.
一个特殊情况是为两个值都指定 (SIZE_T)-1. 这会导致系统从进程的工作集中移除尽可能多的页面. 这同样可以通过 EmptyWorkingSet 函数完成:
BOOL WINAPI EmptyWorkingSet(_In_ HANDLE hProcess);
进程句柄必须具有 PROCESS_SET_QUOTA 访问掩码以及 PROCESS_QUERY_INFORMATION 或 PROCESS_QUERY_LIMITED_INFORMATION 之一.
如前所述, 最小和最大工作集大小默认是软限制. 这可以通过 SetProcessWorkingSetSize 的扩展版本来改变:
BOOL SetProcessWorkingSetSizeEx( _In_ HANDLE hProcess, _In_ SIZE_T dwMinimumWorkingSetSize, _In_ SIZE_T dwMaximumWorkingSetSize, _In_ DWORD Flags);
额外的 Flags 参数可以是表 13-1 中列出的值的组合.
| Flag | Description |
|---|---|
QUOTA_LIMITS_HARDWS_MIN_ENABLE (1) |
最小工作集的硬限制 |
QUOTA_LIMITS_HARDWS_MIN_DISABLE (2) |
最小工作集的软限制 |
QUOTA_LIMITS_HARDWS_MAX_ENABLE (4) |
最大工作集的硬限制 |
QUOTA_LIMITS_HARDWS_MAX_DISABLE (8) |
最大工作集的软限制 |
如果一个进程被配置为使用最大工作集硬限制, 那么该进程可能希望拥有的任何额外已提交内存作为其工作集的一部分, 会导致其他页面被从其工作集中移除, 实质上是对自身产生页面错误. 为标志指定零不会改变限制标志, 实际上使调用等同于 SetProcessWorkingSetSize. 获取当前限制和标志的相反函数也存在:
BOOL GetProcessWorkingSetSizeEx( _In_ HANDLE hProcess, _Out_ PSIZE_T lpMinimumWorkingSetSize, _Out_ PSIZE_T lpMaximumWorkingSetSize, _Out_ PDWORD Flags);
- The Working Sets Application
Working Sets 应用程序显示所有进程的内存相关计数器, 例如工作集大小, 峰值工作集大小, 最小和最大值等. 它基于前一节讨论的 API. 了解各种进程如何使用内存是很有趣的 (有时也是必要的).
当应用程序首次启动时, 许多进程不显示任何内存计数器. 这是因为无法成功打开它们的句柄. 选择 View / Accessible Processes Only 仅在显示中留下可访问的进程. 或者, 选择 File / Run as Administrator (或以管理员权限启动应用程序) 会显示更多可访问的进程. 图 13-6 显示了这可能的样子.
Figure 200: 图 13-6: The Working Sets 应用程序
显示每秒自动刷新. 你可以尝试使用某个进程, 并观察其工作集和已提交内存使用情况的动态变化. 你可以按任何列排序. 图 13-7 显示了峰值工作集使用量最高的进程 (至少是从可以查询的进程中).

Figure 201: 图 13-7: 按峰值工作集排序的 Working Sets
Memory Compression 进程具有最高的峰值工作集, 这并不奇怪, 因为它持有压缩的内存, 从而节省了物理内存. 列表中的下一个是 Windows Defender, 它作为一个反恶意软件消耗了太多的内存. 接下来是 Visual Studio Code, 依此类推.
你可以选择 Process / Empty Working Set 菜单项来强制一个进程放弃其大部分物理内存使用 (至少是一段时间). 对于某些进程, 这会失败, 因为不可能为每个进程获取
PROCESS_SET_QUOTA.该应用程序是使用标准的 WTL 单文档界面 (SDI) 构建的, 视图基于列表视图控件. 最重要的函数是
CView::Refresh, 它在初始时和定时器到期时每秒调用一次. 每个进程信息都存储在以下结构中 (在 view.h 中定义为嵌套类型):struct ProcessInfo { DWORD Id; // process ID CString ImageName; SIZE_T MinWorkingSet, MaxWorkingSet; DWORD WorkingSetFlags; PROCESS_MEMORY_COUNTERS_EX Counters; bool CountersAvailable{ false }; }; std::vector<ProcessInfo> m_Items;
Refresh方法中的首要任务是开始进程枚举:void CView::Refresh() { wil::unique_handle hSnapshot(::CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0)); if (!hSnapshot) return; PROCESSENTRY32 pe; pe.dwSize = sizeof(pe); // skip the idle process ::Process32First(hSnapshot.get(), &pe); m_Items.clear(); m_Items.reserve(512);
使用了第 3 章中介绍的 Toolhelp 函数. 对于每个进程, 都会填充一个
ProcessInfo对象:while (::Process32Next(hSnapshot.get(), &pe)) { // attempt to open a handle to the process wil::unique_handle hProcess(::OpenProcess(PROCESS_QUERY_LIMITED_INFORMATION, FALSE, pe.th32ProcessID)); if (!hProcess && m_ShowOnlyAccessibleProcesses) continue; ProcessInfo pi; pi.Id = pe.th32ProcessID; pi.ImageName = pe.szExeFile;
如果无法获取句柄并且设置了 "show only accessible processes" 选项, 则跳过此进程. 否则, 填充所有进程都保证可用的两个值 - 进程 ID 和进程映像名称.
接下来, 如果可以打开一个合适的句柄, 则调用内存 API 来获取信息并将其存储在
ProcessInfo实例中:if (hProcess) { ::GetProcessMemoryInfo(hProcess.get(), (PROCESS_MEMORY_COUNTERS*)&pi.Counters, sizeof(pi.Counters)); ::GetProcessWorkingSetSizeEx(hProcess.get(), &pi.MinWorkingSet, &pi.MaxWorkingSet, &pi.WorkingSetFlags); pi.CountersAvailable = true; }
如果句柄可用,
CountersAvailable字段被设置为 true, 表示结构中的内存信息是有效的. 最后, 对象被添加到向量中, 循环继续处理所有进程:m_Items.push_back(pi); }
剩下的就是对项目进行排序 (如果需要) 并更新列表视图:
DoSort(GetSortInfo(*this)); SetItemCountEx(static_cast<int>(m_Items.size()), LVSICF_NOSCROLL | LVSICF_NOINVALIDATEALL); RedrawItems(GetTopIndex(), GetTopIndex() + GetCountPerPage()); }
我没有讨论
CView类中的其他函数, 因为它们不使用任何与内存相关的 API. 感兴趣的读者可以浏览完整的源代码.要清空工作集,
SetProcessWorkingSetSize被调用, 两个值都为 -1. 也可以调用EmptyWorkingSet函数:LRESULT CView::OnEmptyWorkingSet(WORD, WORD, HWND, BOOL&) { auto index = GetSelectedIndex(); ATLASSERT(index >= 0); const auto& item = m_Items[index]; wil::unique_handle hProcess(::OpenProcess(PROCESS_SET_QUOTA, FALSE, item.Id)); if (!hProcess) { AtlMessageBox(*this, L"Failed to open process", IDR_MAINFRAME, MB_ICONERROR); return 0; } if (!::SetProcessWorkingSetSize(hProcess.get(), (SIZE_T)-1, (SIZE_T)-1)) { AtlMessageBox(*this, L"Failed to empty working set", IDR_MAINFRAME, MB_ICONERROR); } return 0; }
💡 添加一个菜单选项来设置最小和/或最大工作集大小 (也许用一个对话框), 以及
SetProcessWorkingSetSizeEx可用的可选标志, 并做一些实验, 看看这些值如何影响正在运行的进程.
2.1.5. 堆
VirtualAlloc 系列函数非常强大, 因为它们非常接近内存管理器. 但它们有一个缺点. 这些函数只在页面块中工作: 如果你分配 10 字节, 你会得到一个页面. 如果你再分配 10 字节, 你会得到一个不同的页面. 这对于管理小型分配来说太浪费了, 而这在应用程序中非常普遍. 这正是堆 (heaps) 发挥作用的地方.
堆管理器 (Heap Manager) 是一个建立在虚拟 API 之上的组件, 它知道如何高效地管理小型分配. 在这种情况下, 一个 堆 是一个由堆管理器管理的内存块. 每个进程都以一个单一的堆开始, 称为 默认进程堆. 通过 GetProcessHeap 可以获得该堆的句柄:
HANDLE GetProcessHeap();
可以创建更多的堆, 在 其他堆 部分有描述. 有了堆的句柄, 分配 (提交) 内存是通过 HeapAlloc 完成的:
LPVOID HeapAlloc( _In_ HANDLE hHeap, _In_ DWORD dwFlags, _In_ SIZE_T dwBytes);
HeapAlloc 接受一个堆的句柄, 可选的标志和请求的内存字节数. 标志可以是零或者是以下值的组合:
HEAP_ZERO_MEMORY指定返回的内存块应由函数清零. 否则, 块中原有的内容将保留.HEAP_NO_SERIALIZE指示函数不应获取堆的锁. 这意味着开发者需要提供自己的同步或保证不会对堆进行并发访问. 这个值不应该为默认进程堆指定, 因为默认堆是在有同步的情况下创建的, 并且它被一些不期望非同步访问的 API 使用. 对于应用程序创建的堆, 可以在创建堆时指定此标志 (HeapCreate, 见后文), 这样就不需要为每次分配都指定此值.HEAP_GENERATE_EXCEPTIONS指示函数应该通过引发一个 SEH 异常 (STATUS_NO_MEMORY) 来报告失败, 而不是返回NULL. 如果希望所有堆操作都具有此行为, 可以在用HeapCreate创建堆时指定此标志.
下面是一个从默认进程堆分配一些数据的例子:
struct MyData { //... }; MyData* pData = (MyData*)::HeapAlloc(::GetProcessHeap(), 0, sizeof(MyData)); if(pData == nullptr) { // handle failure }
如果一个已分配的块需要增加或减少大小, 同时保留现有数据, 可以使用 HeapReAlloc:
LPVOID HeapReAlloc( _Inout_ HANDLE hHeap, _In_ DWORD dwFlags, _Frees_ptr_opt_ LPVOID lpMem, _In_ SIZE_T dwBytes);
lpMem 是现有地址, dwBytes 是新的请求大小. 函数返回新块的地址, 如果新大小比原始大小小, 或者有足够的空间在不移动的情况下调整块的大小, 这个地址可能与原始地址相同. 如果新大小更大但无法在现有堆块中容纳, 内存将被复制到一个新位置, 并返回新地址. 如果不希望进行此复制, HeapReAlloc 支持一个额外的标志 - HEAP_REALLOC_IN_PLACE_ONLY - 如果指定了该标志, 当新大小无法在现有块中容纳时, 重新分配会失败.
一旦不再需要分配, 调用 HeapFree 将其返回到堆中:
BOOL HeapFree( _Inout_ HANDLE hHeap, _In_ DWORD dwFlags, _In_ LPVOID lpMem);
HeapFree 唯一有效的标志是 HEAP_NO_SERIALIZE. 在成功调用 HeapFree 后, lpMem 地址应被视为无效. 在大多数情况下, 此地址在仍然指向已提交内存的意义上仍然有效, 但新的分配可能会重用此地址. 如果在没有适当分配的情况下访问该内存, 很可能不会抛出访问冲突异常. 这与 VirtualFree 不同, VirtualFree 会取消提交内存, 以便任何对同一页面的访问都会引发访问冲突异常.
- 私有堆
一个堆的生命周期始于一个预留的内存块, 其中一部分可能会被提交. 一个堆可以有固定的最大大小, 也可以是可增长的. 可增长的堆可以增长到进程地址空间允许的范围. 默认进程堆是可增长的 - 其初始预留和提交的大小可以通过链接器设置来指定. 图 13-8 显示了 Visual Studio 中用于设置这些值的项目属性对话框.
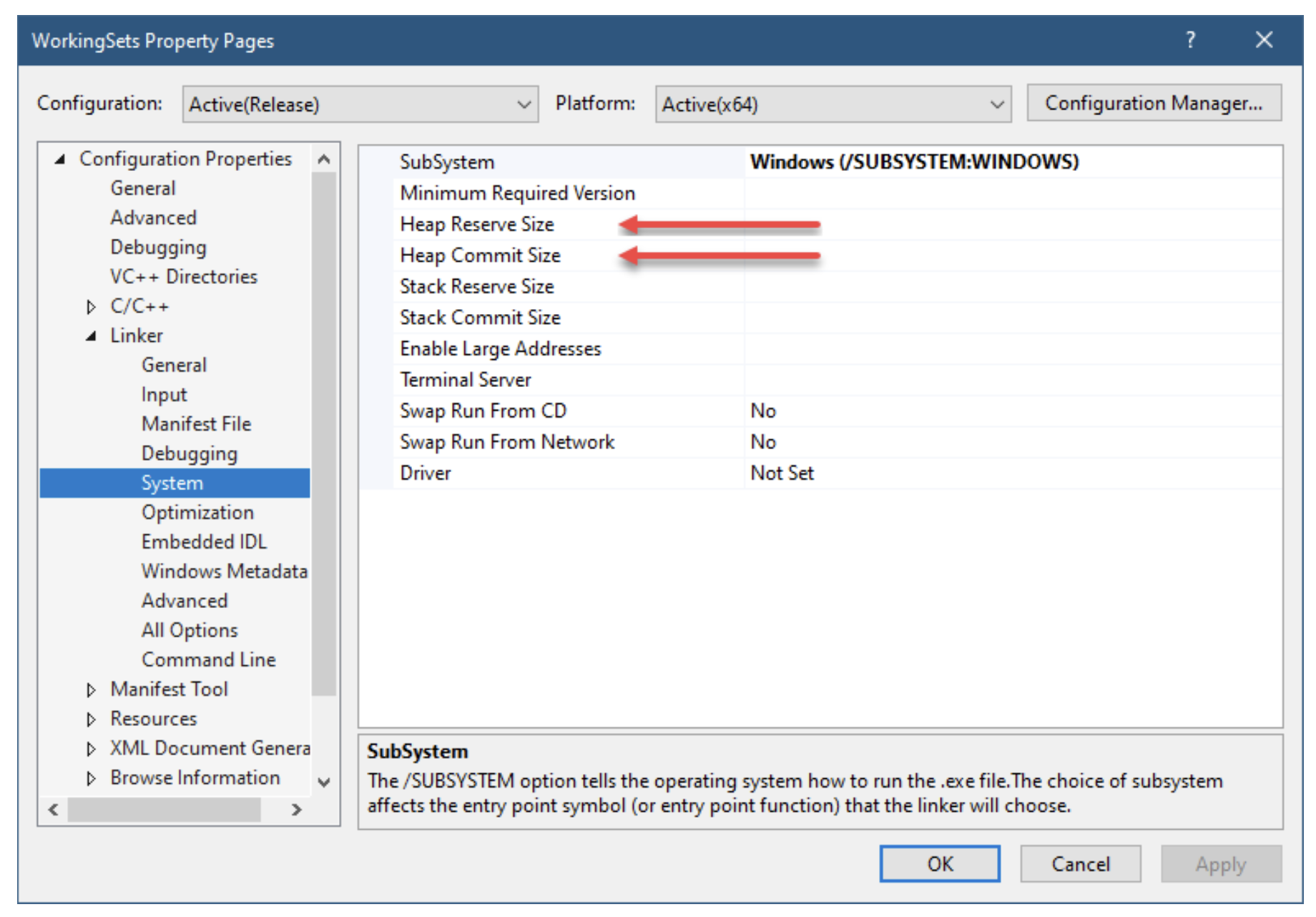
Figure 202: 图 13-8: 堆大小链接器设置
默认进程堆的默认大小可以使用任何 PE 查看器工具 (如 Dumpbin) 进行检查. 下面是 Notepad 的一个例子:
c:\>dumpbin /headers c:\Windows\System32\notepad.exe Microsoft (R) COFF/PE Dumper Version 14.26.28805.0 Copyright (C) Microsoft Corporation. All rights reserved. Dump of file c:\Windows\System32\notepad.exe PE signature found File Type: EXECUTABLE IMAGE ... OPTIONAL HEADER VALUES 20B magic # (PE32+) ... 100000 size of heap reserve 1000 size of heap commit ...
初始提交是单个页面, 初始预留大小为 1 MB. 这是默认值 (对于默认值), 如果在链接器设置中没有指定自定义值.
默认进程堆始终存在且不能被销毁. 既然它是可增长的, 为什么你还想创建额外的堆呢?
一个原因是避免碎片化. 当在同一个堆上使用不同大小的分配时, 或多或少都会不可避免地产生碎片化. 例如, 假设应用程序分配了几个 16 字节大小的结构. 现在假设其中一个结构被释放了, 需要分配一个 24 字节大小的新结构. 16 字节的空隙不够, 所以堆管理器在已使用的堆区域末尾分配块. 如果需要一个 12 字节的结构, 它可以放入那个 16 字节的空间, 但现在 4 字节的空间可能就再也用不上了. 这种碎片化导致使用的内存比实际需要的多. 如果进程运行数小时甚至更长时间, 有大量的分配和释放, 问题就会加剧.
💡 每次堆分配都会带来一些管理开销, 无论是在 CPU 还是内存方面. 因此, 使用
VirtualAlloc总是会快一些, 并且没有相同的内存开销.解决这个问题的一个 (部分) 方法是使用低碎片堆 (Low Fragmentation Heap, LFH), 在 堆类型 部分有描述. 另一个方法是创建一个单独的 (私有) 堆, 用于存放特定大小的块. 如果一个块被释放, 就会有足够的空间容纳一个相同大小的新块. 如果许多特定大小的对象 (通常是某个结构/类) 在进程的生命周期内被分配和释放, 这种方案很有用.
创建一个新堆是通过
HeapCreate完成的:HANDLE HeapCreate( _In_ DWORD flOptions, _In_ SIZE_T dwInitialSize, _In_ SIZE_T dwMaximumSize);
第一个选项参数可以是零或三个标志的组合, 其中两个我们已经在
HeapAlloc中见过:HEAP_GENERATE_EXCEPTIONS和HEAP_NO_SERIALIZE. 如果指定了HEAP_NO_SERIALIZE, 堆管理器在执行堆操作时不会持有任何锁. 这意味着对堆的任何并发访问都可能导致堆损坏. 这个选项使堆管理器稍快一些, 但如果需要, 开发者有责任提供对堆的同步访问. 设置此标志的一个潜在缺点是, 堆不能使用低碎片堆 (LFH) 层 (稍后描述).最后一个标志,
HEAP_CREATE_ENABLE_EXECUTE, 告诉堆管理器分配具有PAGE_EXECUTE_READWRITE访问权限的块, 而不仅仅是PAGE_READWRITE. 如果代码要被写入堆并执行, 例如在即时 (Just in time, JIT) 编译场景中, 这可能很有用.dwInitialSize参数指示应该预先提交的内存量. 该值向上舍入到最近的页面. 值为零等于单个页面.dwMaximumSize指定堆可以增长到的最大大小. 初始提交和最大大小之间的内存保持预留状态. 如果指定的最大值为零, 则堆是可增长的, 否则这就是堆的最大大小 (固定堆). 任何分配超过堆大小的尝试都会失败. 如果堆是固定的, 那么可以分配的最大块在 32 位系统中略小于 512 KB, 在 64 位系统中略小于 1 MB. 你不应该为这么大的尺寸使用堆 API, 而是应该使用VirtualAlloc函数.函数的返回值是新堆的句柄, 用于其他堆函数, 如
HeapAlloc和HeapFreee. 如果函数失败, 返回NULL.一个私有堆需要在某个时候被销毁, 这可以通过
HeapDestroy完成:BOOL HeapDestroy(_In_ HANDLE hHeap);
HeapDestroy一次性释放整个堆, 所以如果堆即将销毁, 就没有必要释放每个单独的分配. 这可能是创建私有堆的另一个动机.利用私有堆处理相同大小结构的一种方法是使用 C++ 的能力来重载
new和delete操作符, 这样结构的任何动态分配或释放都发生在私有堆上, 而开发者不必关心调用任何特定的 API. 下面是这种类型的示例头文件:class MyClass { public: void* operator new(size_t); void operator delete(void*); void DoWork(); private: static HANDLE s_hHeap; static unsigned s_Count; };
该类拥有两个静态成员 (所有
MyClass实例共用). 它们持有堆句柄和实例计数, 以便在最后一个实例被释放时可以销毁堆. 下面是实现:HANDLE MyClass::s_hHeap = nullptr; unsigned MyClass::s_Count = 0; void* MyClass::operator new(size_t size) { if (InterlockedIncrement(&s_Count) == 1) s_hHeap = ::HeapCreate(0, 64 << 10, 16 << 20); return ::HeapAlloc(s_hHeap, 0, size); } void MyClass::operator delete(void* p) { ::HeapFree(s_hHeap, 0, p); if (::InterlockedDecrement(&s_Count) == 0) ::HeapDestroy(s_hHeap); }
私有堆以 64 KB 的提交大小和最大 16 MB 的大小创建 (这些当然只是例子).
MyClass类型的任何客户端都可以使用普通的 C++ 操作:auto obj = new MyClass; obj->DoWork(); delete obj;
客户端不需要知道对象是在一个保证无碎片使用的私有堆上分配的.
- 堆类型
我们已经看到, 可以创建一个具有固定最大大小或可增长的堆. 为了帮助减轻堆碎片化, Windows 支持低碎片堆 (Low Fragmentation Heap, LFH), 用于那些不是在没有序列化的情况下创建的堆 (即没有
HEAP_NO_SERIALIZE标志). LFH 试图通过使用特定大小的块来最小化碎片化, 这些块有更好的机会满足分配请求. 例如, 一个 8 字节和一个 12 字节的分配请求将得到 16 字节. 当这样的分配被释放时, 如果其请求的大小不超过 16 字节, 就有更好的机会将新的分配放入同一个块中. 这意味着 LFH 通过可能为每次分配使用比需要更多的内存来最小化碎片化.LFH 是作为标准堆的一个可选的前端层构建的. 它在某些条件下自动激活, 一旦激活就无法关闭. 也不可能强制使用 LFH.
💡 Vista 之前的 Windows 版本确实允许打开和关闭 LFH. 开发者很难知道何时是进行此类操作的好时机, 所以现在堆管理器使用自己的调整逻辑.
你可以用
HeapQueryInformation查询堆的类型:BOOL HeapQueryInformation( _In_opt_ HANDLE HeapHandle, _In_ HEAP_INFORMATION_CLASS HeapInformationClass, _Out_ PVOID HeapInformation, _In_ SIZE_T HeapInformationLength, _Out_opt_ PSIZE_T ReturnLength);
该函数提供了一种通用的方式来查询一些堆参数, 基于
HEAP_INFORMATION_CLASS枚举, 其中只有一个值 (HeapCompatibilityInformation) 是官方文档化的. 输出缓冲区是一个 32 位数字, 可以是 0 (无 LFH) 或 2 (LFH). 以下示例查询默认进程堆的类型:ULONG type; ::HeapQueryInformation(::GetProcessHeap(), HeapCompatibilityInformation, &type, sizeof(type), nullptr);
Windows 8 引入了另一种称为 段堆 (Segment Heap) 的堆类型. 这种堆有更好的块管理和额外的安全措施, 以帮助防止进程中的恶意代码仅通过拥有一个指向堆上某处的指针来识别堆块. 段堆被所有 UWP 进程使用, 因为它有较小的内存占用, 这对于在手机或平板等小型设备上运行的 UWP 进程是有益的. 一些系统进程也使用段堆, 包括 smss.exe, csrss.exe 和 svchost.exe.
出于兼容性原因, 段堆不是默认堆. 可以通过在注册表项
HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image File Execution Options(这需要管理员访问权限) 中创建一个与可执行文件名 (带 EXE 扩展名但无路径) 相同的子项, 来为特定的可执行文件启用它. 在该子项中, 添加一个名为FrontEndHeapDebugOptions的 DWORD 值, 并将其值设置为 8. 图 13-9 显示了为 Notepad.exe 设置的此值. 下次启动此可执行文件时, 它将默认使用段堆.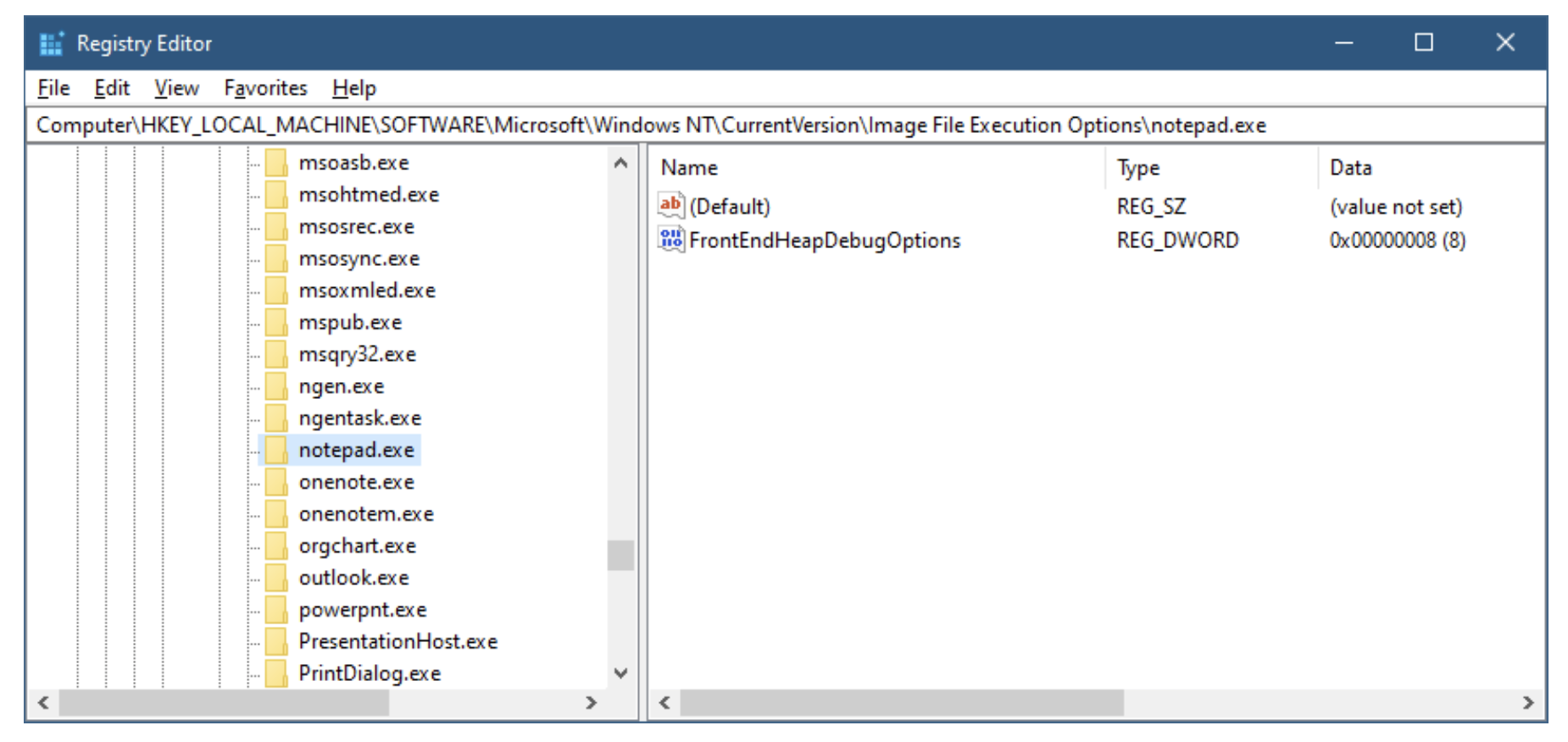
Figure 203: 图 13-9: 为可执行文件启用段堆
💡 有关段堆的更多信息, 请查阅《Windows Internals 7th edition Part 1》一书的第 5 章.
- 堆调试功能
在使用堆 API 时, 一个太常见的发生是堆损坏, 通常是由于访问悬空指针或写入超出分配大小的内存. 这些 bug 在除了最简单的应用程序之外的所有应用程序中都非常难以追踪. 使这类问题难以解决的主要问题是, 损坏本身通常在很久之后才被检测到, 当作恶的代码已经不在调用栈中了. 这些发生的其他原因有时是由于对堆的恶意代码注入尝试. 堆管理器在这方面提供了一些帮助.
你可以调用
HeapValidate函数来告诉堆管理器扫描给定堆中的所有分配并验证它们的完整性:BOOL HeapValidate( _In_ HANDLE hHeap, _In_ DWORD dwFlags, _In_opt_ LPCVOID lpMem);
该函数唯一有效的标志是
HEAP_NO_SERIALIZE, 前面已经讨论过. 如果lpMem为NULL, 则扫描整个堆, 否则只检查提供的内存块的完整性. 如果lpMem不为NULL, 指针必须指向一个分配的起始位置 (由先前调用HeapAlloc或HeapReAlloc返回).如果堆/块有效,
HeapValidate返回TRUE, 否则返回FALSE. 如果调试器连接到进程, 将触发一个异常, 默认情况下会中断到调试器. 验证整个堆可能非常耗时, 所以这个选项通常只应在调试时使用.💡 如果
lpMem为NULL,HeapValidate对于段堆总是返回TRUE.HeapValidate无法检测到一些错误. 如果一些代码写入一个恰好是空闲的块之外, 或者因为使用了 LFH 而有多余的内存,HeapValidate会错过这个溢出.另一种选择是请求堆管理器在检测到堆损坏时终止进程 (而不是继续运行), 这可以通过调用
HeapSetInformation来实现:BOOL HeapSetInformation( _In_opt_ HANDLE HeapHandle, _In_ HEAP_INFORMATION_CLASS HeapInformationClass, _In_ PVOID HeapInformation, _In_ SIZE_T HeapInformationLength);
这里涉及的
HEAP_INFORMATION_CLASS是HeapEnableTerminationOnCorruption. 这个选项是进程范围的, 所以堆句柄被忽略, 可以指定为NULL.HeapInformation和HeapInformationLength应分别设置为NULL和零. 一旦启用, 此功能在进程的生命周期内无法被禁用.还有一些其他的堆调试功能, 可以通过在前一节中使用的
Image File Execution Options注册表项中设置NtGlobalFlags值来启用. 通常, 这些值是用一个工具来设置的, 比如 GFlags (Windows SDK 的一部分, 通常与 Windows SDK 一起安装), 或者我自己的 GFlagsX 工具. 图 13-10 显示了用于 Notepad.exe 的 GFlags. 有几个与堆相关的选项, 在图 13-10 中标记. 请查阅 GFlags 工具文档以获取这些选项的描述.
Figure 204: 图 13-10: GFlags 堆相关选项
💡 使用任何调试选项 (除了 "Disable heap coalesce on free") 都会减慢所有堆操作, 所以最好只在调试或排查堆相关问题时使用这些选项.
- The C/C++ Runtime
C/C++ 内存管理函数的实现, 如
malloc,calloc,free, C++ 的new和delete操作符等等, 都依赖于编译器提供的库. 由于我们主要使用微软的编译器, 那么我们可以说一些关于 Visual C++ 运行时实现这些函数的事情.C/C++ 运行时使用堆函数来管理它们的分配. 当前的实现使用默认的进程堆. 由于 CRT 源代码与 Visual Studio 一起分发, 我们可以简单地查看实现. 以下是
malloc的实现, 为清晰起见, 移除了一些宏和指令 (在malloc.cpp中):extern "C" void* __cdecl malloc(size_t const size) { #ifdef _DEBUG return _malloc_dbg(size, _NORMAL_BLOCK, nullptr, 0); #else return _malloc_base(size); #endif }
malloc有两个实现 - 一个用于调试构建, 另一个用于发布构建. 以下是发布构建版本的摘录 (在文件malloc_base.cpp中):extern "C" __declspec(noinline) void* __cdecl _malloc_base(size_t const size) { // Ensure that the requested size is not too large: _VALIDATE_RETURN_NOEXC(_HEAP_MAXREQ >= size, ENOMEM, nullptr); // Ensure we request an allocation of at least one byte: size_t const actual_size = size == 0 ? 1 : size; for (;;) { void* const block = HeapAlloc(__acrt_heap, 0, actual_size); if (block) return block; //...code omitted... } }
全局的
__acrt_heap在这个函数中被初始化 (来自heap_handle.cpp):extern "C" bool __cdecl __acrt_initialize_heap() { __acrt_heap = GetProcessHeap(); if (__acrt_heap == nullptr) return false; return true; }
此实现使用默认的进程堆.
- The Local/Global APIs
带有
Local和Global前缀的 API 集合, 例如LocalAlloc,GlobalAlloc,LocalFree,LocalLock等, 最初是为了与 16 位 Windows 兼容而创建的. 它们的使用很笨拙, 因为分配返回一种句柄, 需要用LocalLock或GlobalLock函数转换成指针.有一些非常特殊的场景不幸地需要使用这些函数中的一些. 第一个与剪贴板操作有关. 将一些数据放到剪贴板上需要使用一个从
GlobalAlloc返回的HGLOBAL句柄. 另一个场景涉及一些 API (特别是安全 API), 其中一些会分配一些数据返回给调用者. 调用者通常必须在不再需要数据时用LocalFree函数释放数据.简而言之, 这些函数只应该在某些约束要求时使用. 对于所有其他情况, 使用堆, C/C++, 或虚拟 API.
- 其他堆函数
有一些在前几节中没有涉及到的堆函数. 本节简要描述这些函数及其用途.
通过
HeapSummary可以获取某个堆的摘要信息:typedef struct _HEAP_SUMMARY { DWORD cb; SIZE_T cbAllocated; SIZE_T cbCommitted; SIZE_T cbReserved; SIZE_T cbMaxReserve; } HEAP_SUMMARY, *PHEAP_SUMMARY; BOOL HeapSummary( _In_ HANDLE hHeap, _In_ DWORD dwFlags, _Out_ PHEAP_SUMMARY lpSummary);
在调用
HeapSummary之前, 将cb成员初始化为结构的大小.HEAP_SUMMARY的成员如下:cbAllocated是当前在堆上分配的 (活跃使用的) 字节数.cbCommitted是当前在堆上提交的字节数.cbReserved是堆可以增长到的预留内存大小.cbMaxReserve在当前实现中与cbReserved相同.
HeapSize函数允许查询一个已分配块的大小:SIZE_T HeapSize( _In_ HANDLE hHeap, _In_ DWORD dwFlags, _In_ LPCVOID lpMem);
唯一有效的标志是
HEAP_NO_SERIALIZE.lpMem指针必须是先前从HeapAlloc或HeapReAlloc返回的指针.没有
HEAP_NO_SERIALIZE创建的堆会维护一个临界区 (锁) 以防止并发访问时的堆损坏.HeapLock和HeapUnlock允许获取和释放堆的临界区:BOOL HeapLock(_In_ HANDLE hHeap); BOOL HeapUnlock(_In_ HANDLE hHeap);
这可以用来加速多个可以在不获取锁的情况下调用的操作. 一个可以用于调试目的的操作是使用
HeapWalk遍历堆块:BOOL HeapWalk( _In_ HANDLE hHeap, _Inout_ LPPROCESS_HEAP_ENTRY lpEntry);
堆枚举通过编写一个循环来工作, 该循环返回
PROCESS_HEAP_ENTRY类型的结构:typedef struct _PROCESS_HEAP_ENTRY { PVOID lpData; DWORD cbData; BYTE cbOverhead; BYTE iRegionIndex; WORD wFlags; union { struct { HANDLE hMem; DWORD dwReserved[ 3 ]; } Block; struct { DWORD dwCommittedSize; DWORD dwUnCommittedSize; LPVOID lpFirstBlock; LPVOID lpLastBlock; } Region; } DUMMYUNIONNAME; } PROCESS_HEAP_ENTRY, *LPPROCESS_HEAP_ENTRY, *PPROCESS_HEAP_ENTRY;
堆枚举始于分配一个
PROCESS_HEAP_ENTRY实例并将其lpData设置为NULL. 每次调用HeapWalk都会返回堆上下一个已分配块的数据. 当HeapWalk返回FALSE时, 枚举结束. 请查阅文档以获取各个字段的详细描述.💡 编写一个接受堆句柄并显示其各个块及其属性的堆枚举函数.
使用
HeapWalk的堆枚举仅适用于当前进程. 如果希望对其他进程进行此类堆遍历, ToolHelp 提供了一个用于CreateToolhelp32Snapshot的标志 (TH32CS_SNAPHEAPLIST), 它提供了一种在选定进程中枚举堆 (Heap32ListFirst,Heap32ListNext), 并进一步枚举每个堆中的块 (Heap32First,Heap32Next) 的方法.在处理堆时, 可能会有两个或多个连续的空闲内存块. 通常, 堆会自动合并这些相邻的空闲块. 图 13-10 中显示的全局标志之一允许禁用此功能 (称为 “Disable Heap Coalesce on Free”), 以节省一些处理时间. 在这种情况下, 你可以调用
HeapCompact来强制进行此合并:SIZE_T HeapCompact( _In_ HANDLE hHeap, _In_ DWORD dwFlags);
唯一有效的标志是
HEAP_NO_SERIALIZE. 如果此功能被禁用, 该函数会合并空闲块, 并返回堆上可分配的最大块.最后, 使用
GetProcessHeaps可以获取当前进程中所有堆的句柄:DWORD GetProcessHeaps( _In_ DWORD NumberOfHeaps, _Out_ PHANDLE ProcessHeaps);
该函数接受一个要返回的最大堆句柄数和一个句柄数组. 它返回进程中的总堆数. 如果该数字大于
NumberOfHeaps, 那么并非所有堆句柄都已返回. 获取当前进程中堆数的一种简单方法是使用以下代码片段:DWORD heapCount = ::GetProcessHeaps(0, nullptr);
2.1.6. 其他虚拟函数
在本节中, 我们将查看 Virtual 系列 API 中的其他函数, 但不包括在第 12 章中介绍的 VirtualQuery 函数.
- 内存保护
一旦内存区域被提交,
VirtualProtect*系列函数可用于更改属于同一初始预留区域的一系列页面的页面保护:BOOL VirtualProtect( _In_ LPVOID lpAddress, _In_ SIZE_T dwSize, _In_ DWORD flNewProtect, _Out_ PDWORD lpflOldProtect);
BOOL VirtualProtectEx( _In_ HANDLE hProcess, _In_ LPVOID lpAddress, _In_ SIZE_T dwSize, _In_ DWORD flNewProtect, _Out_ PDWORD lpflOldProtect);
BOOL VirtualProtectFromApp( _In_ PVOID Address, _In_ SIZE_T Size, _In_ ULONG NewProtection, _Out_ PULONG OldProtection);
与
VirtualAllocEx一样,VirtualProtectEx能够在不同的进程上下文中执行操作, 假设进程句柄具有PROCESS_VM_OPERATION访问掩码.VirtualProtectFromApp是允许从 UWP 进程调用的变体. 与VirtualAlloc一样, 如果定义了宏WINAPI_PARTITION_APP(表示 AppContainer 调用者),VirtualProtect会被内联实现为调用VirtualProtectFromApp.保护被更改的地址范围涵盖了
lpAddress和lpAddress+dwSize之间的所有页面, 将新的保护设置为flNewProtect(有关可能的保护属性列表, 请参阅第 12 章). 页面的先前保护通过lpflOldProtect参数返回 (不能为NULL). 如果页面范围有多个保护值, 则返回第一个. - 锁定内存
正如我们已经看到的, 属于进程工作集的已提交内存不保证会保留在工作集中, 而是可能会被分页出去. 在某些情况下, 进程可能希望告诉内存管理器某个内存缓冲区不应被分页出去, 即使它长时间未被访问.
VirtualLock函数可用于此目的, 而VirtualUnlock则是移除锁定的方式:BOOL VirtualLock( _In_ LPVOID lpAddress, _In_ SIZE_T dwSize);
BOOL VirtualUnlock( _In_ LPVOID lpAddress, _In_ SIZE_T dwSize);
两个函数的地址范围总是向上舍入到最近的页面边界, 就像任何虚拟 API 一样. 一个进程可以锁定的最大大小略小于其最小工作集大小. 如果要锁定更大的块, 应调用
SetProcessWorkingSetSize(Ex)来增加最小 (可能还有最大) 工作集大小. 当然, 进程应小心不要锁定太多内存, 因为这可能对其他进程和整个系统产生不利影响. - 内存提示函数
本节描述的函数绝不是绝对必要的, 但可以通过向内存管理器提供有关应用程序使用已提交内存的提示, 来在某些方面提高性能.
OfferVirtualMemory函数, 在 Windows 8.1 (和 Server 2012 R2) 中引入, 向内存管理器指示一个已提交内存范围不再需要, 因此系统可以丢弃该内存使用的物理页面. 系统不必费心将数据写入页面文件.typedef enum OFFER_PRIORITY { VmOfferPriorityVeryLow = 1, VmOfferPriorityLow, VmOfferPriorityBelowNormal, VmOfferPriorityNormal } OFFER_PRIORITY; DWORD OfferVirtualMemory( _Inout_ PVOID VirtualAddress, _In_ SIZE_T Size, _In_ OFFER_PRIORITY Priority);
虚拟地址必须是页面对齐的, 并且大小必须是页面大小的倍数.
乍一看, 简单地取消提交内存 (
VirtualFree) 似乎有同样的效果. 从释放 RAM 的角度来看, 这是相似的. 但使用VirtualFree, 应用程序放弃了地址范围和已提交的内存, 因此将来需要新的分配, 这可能会也可能不会成功; 它也比仅仅重用一个已经存在的已提交内存块要慢.priority参数指定了内存区域的重要性. 优先级越低, 物理内存被丢弃的可能性就越大, 速度也越快. 函数直接返回一个错误代码 (没有必要调用GetLastError), 其中ERROR_SUCCESS(0) 表示成功.一旦应用程序准备好再次使用提供的内存, 它可以用
ReclaimVirtualMemory将其回收:DWORD ReclaimVirtualMemory( _In_ void const* VirtualAddress, _In_ SIZE_T Size);
回收的内存可能包含也可能不包含其先前的内容. 应用程序应假设内存需要用有意义的数据重新填充.
另一个与
OfferVirtualMemory类似的变体是DiscardVirtualMemory:DWORD DiscardVirtualMemory( _Inout_ PVOID VirtualAddress, _In_ SIZE_T Size);
DiscardVirtualMemory等同于使用VmOfferPriorityVeryLow优先级调用OfferVirtualMemory.本节的最后一个函数是
PrefetchVirtualMemory(可用于 Windows 8 和 Server 2012):typedef struct _WIN32_MEMORY_RANGE_ENTRY { PVOID VirtualAddress; SIZE_T NumberOfBytes; } WIN32_MEMORY_RANGE_ENTRY, *PWIN32_MEMORY_RANGE_ENTRY; BOOL PrefetchVirtualMemory( _In_ HANDLE hProcess, _In_ ULONG_PTR NumberOfEntries, _In_ PWIN32_MEMORY_RANGE_ENTRY VirtualAddresses, _In_ ULONG Flags);
PrefetchVirtualMemory的目的是允许应用程序优化用于读取进程相当有信心将要使用的不连续内存块数据的 I/O 使用. 调用者提供已提交的内存块 (使用WIN32_MEMORY_RANGE_ENTRY结构数组), 内存管理器使用带有大缓冲区的并发 I/O 来比正常访问页面时更快地获取数据. 这个函数绝不是必需的, 它仅仅是一个优化.
2.1.7. 写入和读取其他进程
通常, 进程彼此之间是受保护的, 但在有足够强的句柄的情况下, 一个进程可以读写另一个进程的地址空间. 以下是可用的函数:
BOOL ReadProcessMemory( _In_ HANDLE hProcess, _In_ LPCVOID lpBaseAddress, _Out_ LPVOID lpBuffer, _In_ SIZE_T nSize, _Out_opt_ SIZE_T* lpNumberOfBytesRead);
BOOL WriteProcessMemory( _In_ HANDLE hProcess, _In_ LPVOID lpBaseAddress, _In_ LPCVOID lpBuffer, _In_ SIZE_T nSize, _Out_opt_ SIZE_T* lpNumberOfBytesWritten);
ReadProcessMemory 需要一个具有 PROCESS_VM_READ 访问掩码的句柄, 而 WriteProcessMemory 需要 PROCESS_VM_WRITE 访问掩码. lpBaseAddress 是目标进程中要读/写的地址. lpBuffer 是要读入或写出的本地缓冲区. nSize 是要读/写的缓冲区大小. 最后, 可选的最后一个参数返回实际读或写的字节数.
即使有进程访问掩码, 这些函数也可能因为不兼容的页面保护而失败. 例如, WriteProcessMemory 无法写入受 PAGE_READONLY 保护的页面. 当然, 调用者可以尝试用 VirtualProtectEx 来更改保护.
这些函数的主要用户是调试器. 调试器必须能够从被调试的进程中读取信息, 例如局部变量, 线程堆栈等. 类似地, 调试器允许其用户更改被调试进程中的数据. 然而, 这些函数还有其他用途. 我们将在第 15 章中使用 WriteProcessMemory 的一个例子来帮助将 DLL 注入到目标进程中.
2.1.8. 大页面
Windows 支持两种基本的页面大小, 小页面和大页面 (还有第三种巨大的页面大小, 在即将到来的附注中描述). 表 12-1 显示了页面的大小, 其中小页面在所有架构上都是 4 KB, 大页面在除 ARM 架构外的所有架构上都是 2 MB, ARM 架构上是 4 MB. VirtualAlloc 系列函数支持使用 MEM_LARGE_PAGE 标志进行大页面分配. 使用大页面有什么好处?
- 大页面在内部表现更好, 因为虚拟到物理地址的转换不需要页表 (只需要页目录, 见《Windows Internals》一书). 这也使得转换旁路缓冲 (Translation Lookaside Buffer, TLB) CPU 缓存更有效 - 单个条目映射 2 MB 而不是仅 4 KB.
- 大页面总是不可分页的 (永远不会被换出到磁盘).
然而, 大页面也有一些缺点:
- 大页面不能在进程之间共享.
- 大页面分配必须是大页面大小的精确倍数.
- 如果物理内存过于碎片化, 大页面分配可能会失败.
还有一个重要的注意事项 - 由于大页面总是不可分页的, 使用大页面需要 SeLockMemoryPrivilege 特权, 这个特权通常不授予任何用户, 包括管理员组. 图 13-11 显示了本地安全策略工具, 其中显示了特权列表, “锁定内存页面”特权显示没有分配用户或组.
Figure 205: 图 13-11: 本地安全策略特权窗口
有两种方法可以获得所需的特权:
- 管理员可以添加用户/组来拥有此特权. 下次这样的用户注销并重新登录后, 该特权将成为其访问令牌的一部分.
- 在本地系统帐户下运行的服务可以请求它想要的任何特权. (服务在第 19 章中有描述, 包括此功能).
系统上的大页面大小可以通过 GetLargePageMinimum 查询. 这很重要, 因为大页面分配必须以大页面大小的倍数进行:
SIZE_T GetLargePageMinimum();
巨大页面
现代处理器支持第三种页面大小, 巨大页面, 大小为 1 GB. 巨大页面的好处与大页面基本相同, 只是对 TLB 缓存的使用更好. 没有标志可以让
VirtualAlloc使用巨大页面. 相反, 当进行大页面分配时, 如果大小至少为 1 GB, 系统会首先尝试定位巨大页面, 然后使用大页面来处理剩余部分. 如果无法获得巨大页面 (因为这需要在物理内存中有连续的 1 GB 块), 将使用大页面.
拥有 SeLockMemoryPrivilege 特权是不够的 - 它还必须被启用. 这用一个与第 3 章中用于启用调试特权的函数非常相似的函数就足够了 (这段代码的详细讨论留到第 16 章):
bool EnableLockMemoryPrivilege() { HANDLE hToken; if (!::OpenProcessToken(::GetCurrentProcess(), TOKEN_ADJUST_PRIVILEGES, &hToken)) return false; bool result = false; TOKEN_PRIVILEGES tp; tp.PrivilegeCount = 1; tp.Privileges.Attributes = SE_PRIVILEGE_ENABLED; if (::LookupPrivilegeValue(nullptr, SE_LOCK_MEMORY_NAME, &tp.Privileges.Luid)) { if (::AdjustTokenPrivileges(hToken, FALSE, &tp, sizeof(tp), nullptr, nullptr)) result = ::GetLastError() == ERROR_SUCCESS; } ::CloseHandle(hToken); return result; }
现在使用大页面与使用普通页面没有什么不同, 只是多了 MEM_LARGE_PAGE 标志:
if (!EnableLockMemoryPrivilege()) { printf("Failed to enable privilege\n"); return 1; } auto largePage = ::GetLargePageMinimum(); // allocate 5 large pages auto p = ::VirtualAlloc(nullptr, 5 * largePage, MEM_RESERVE | MEM_COMMIT | MEM_LARGE_PAGES, PAGE_READWRITE); if (p) { // success - use memory } else { printf("Error: %u\n", ::GetLastError()); } // free memory ::VirtualFree(p, 0, MEM_RELEASE);
2.1.9. 地址窗口化扩展
在 Windows NT 的早期, 系统支持不超过 4 GB 的物理内存, 这是当时 Windows 运行的处理器所支持的最大值. 从 Intel Pentium Pro 开始, 32 位系统上支持超过 4 GB 的物理内存 (当时还没有 64 位). 想要利用超过 4 GB 的额外物理内存的应用程序必须使用一个特殊的 API, 称为地址窗口化扩展 (Address Windowing Extensions, AWE) - 任何超过 4 GB 的物理内存的使用都不是“自动”的.
AWE 允许进程直接分配物理页面, 然后将它们映射到其地址空间. 由于分配的物理内存量可能比 32 位地址空间能容纳的要大, 应用程序可以将一个“窗口”映射到这块内存中, 使用内存, 取消窗口映射, 然后在另一个偏移量处映射一个新窗口.
这个机制很笨拙, 在实践中用得很少. 唯一知名的在 32 位系统上使用 AWE 以获得大内存优势的应用程序是 SQL Server.
由于使用 AWE 意味着应用程序正在分配物理页面, 因此需要 SeLockMemoryPrivilege 特权, 就像大页面一样.
以下是使用 AWE 分配和使用物理页面的一个例子:
EnableLockMemoryPrivilege(); ULONG_PTR pages = 1000; // pages ULONG_PTR parray; // opaque array (PFNs) if (!::AllocateUserPhysicalPages(::GetCurrentProcess(), &pages, parray)) return ::GetLastError(); if (pages < 1000) printf("Only allocated %zu pages\n", pages); // access the first 200 pages at most auto usePages = min(pages, 200); // reserve memory region for mapping physical pages void* pWindow = ::VirtualAlloc(nullptr, usePages << 12, MEM_RESERVE | MEM_PHYSICAL, PAGE_READWRITE); // read/write is the only valid value if (!pWindow) return ::GetLastError(); // map pages to the process address space if (!::MapUserPhysicalPages(pWindow, usePages, parray)) return ::GetLastError(); // use the memory... ::memset(pWindow, 0xff, usePages << 12); // cleanup ::FreeUserPhysicalPages(::GetCurrentProcess(), &pages, parray); ::VirtualFree(pWindow, 0, MEM_RELEASE); return 0;
AWE 分配的页面是不可分页的, 并且必须用 PAGE_READWRITE 保护 - 不支持其他值.
💡 在 64 位 Windows 上运行的 32 位进程 (WOW64) 不能使用 AWE 函数.
AWE 今天很少使用, 因为在 64 位系统 (常规) 上, 任何数量的物理内存都可以在没有任何特殊 API 使用的情况下访问, 尽管正常的内存使用不保证它会一直驻留. AWE 的笨拙和它需要 SeLockMemoryPrivilege 特权的事实使它几乎无用.
2.1.10. NUMA
非一致性内存架构 (Non Uniform Memory Architecture, NUMA) 系统涉及一组节点, 每个节点拥有一组处理器和内存. 图 13-12 显示了这样一个系统的示例拓扑.
Figure 206: 图 13-12: 一个 NUMA 系统
图 13-12 显示了一个具有两个 NUMA 节点的系统示例. 每个节点都有一个插槽, 包含 4 个核心和 8 个逻辑处理器. NUMA 系统在任何 CPU 都可以运行任何代码并访问任何节点中的任何内存方面仍然是对称的. 然而, 从本地节点访问内存比从另一个节点访问内存要快得多.
Windows 了解 NUMA 系统的拓扑. 在第 6 章讨论的线程调度中, 调度程序很好地利用了这些信息, 并尝试在 CPU 上调度线程, 而这些 CPU 所在节点的物理内存中包含该线程的堆栈.
NUMA 系统在服务器机器上很常见, 那里通常存在多个插槽. 获取 NUMA 拓扑信息涉及多个 API 调用. 系统上的 NUMA 节点数可以通过 GetNumaHighestNodeNumber (有点间接地) 获得:
BOOL GetNumaHighestNodeNumber(_Out_ PULONG HighestNodeNumber);
该函数提供系统上最高的 NUMA 节点, 其中 0 表示它不是一个 NUMA 系统. 在一个双节点系统上, *HighestNodeNumber 在返回时被设置为 1.
对于每个节点, 进程亲和性掩码 (连接到节点的处理器) 可以通过 GetNumaNodeProcessorMaskEx 获得:
BOOL GetNumaNodeProcessorMaskEx( _In_ USHORT Node, _Out_ PGROUP_AFFINITY ProcessorMask);
连接到特定节点的处理器可以通过 GetNumaNodeProcessorMask 或 GetNumaNodeProcessorMaskEx 检索:
BOOL GetNumaNodeProcessorMask( _In_ UCHAR Node, _Out_ PULONGLONG ProcessorMask);
BOOL GetNumaNodeProcessorMaskEx( _In_ USHORT Node, _Out_ PGROUP_AFFINITY ProcessorMask );
GetNumaNodeProcessorMask 适用于少于 64 个处理器的系统 (它返回该节点所在组的进程掩码), 但 GetNumaNodeProcessorMaskEx 可以处理任意数量的处理器, 它返回一个 GROUP_AFFINITY 结构, 该结构结合了处理器组和处理器位掩码 (有关进程组的更多信息, 请参见第 6 章):
typedef struct _GROUP_AFFINITY { KAFFINITY Mask; WORD Group; WORD Reserved; } GROUP_AFFINITY, *PGROUP_AFFINITY;
节点中可用的物理内存量可以通过 GetNumaAvailableMemoryNodeEx 获得. 这可以在分配内存和针对特定节点时作为提示:
BOOL GetNumaAvailableMemoryNodeEx( _In_ USHORT Node, _Out_ PULONGLONG AvailableBytes);
以下函数使用上述函数显示 NUMA 节点信息:
void NumaInfo() { ULONG highestNode; ::GetNumaHighestNodeNumber(&highestNode); printf("NUMA nodes: %u\n", highestNode + 1); GROUP_AFFINITY group; for (USHORT node = 0; node <= (USHORT)highestNode; node++) { ::GetNumaNodeProcessorMaskEx(node, &group); printf("Node %d:\tProcessor Group: %2d, Affinity: 0x%08zX\n", (int)node, group.Group, group.Mask); ULONGLONG bytes; ::GetNumaAvailableMemoryNodeEx(node, &bytes); printf("\tAvailable memory: %llu KB\n", bytes >> 10); } }
以下是一个示例运行 (2 个节点, 总共 8 个处理器):
NUMA nodes: 2
Node 0: Processor Group: 0, Affinity: 0x0000000F
Available memory: 3567936 KB
Node 1: Processor Group: 0, Affinity: 0x000000F0
Available memory: 3283832 KB
VirtualAlloc 函数让系统决定已提交内存的物理内存应该来自哪里. 如果你想选择一个首选的 NUMA 节点, 调用 VirtualAllocExNuma:
LPVOID VirtualAllocExNuma( _In_ HANDLE hProcess, _In_opt_ LPVOID lpAddress, _In_ SIZE_T dwSize, _In_ DWORD flAllocationType, _In_ DWORD flProtect, _In_ DWORD nndPreferred);
该函数与 VirtualAllocEx 相同, 但在其最后一个参数中添加了一个首选的 NUMA 节点号. 提供的 NUMA 节点仅在初始内存块被预留或预留并提交时有效. 对同一内存区域的进一步操作会忽略 NUMA 节点参数, 继续使用 VirtualAlloc(Ex) 更容易.
下面是一个使用上述 NumaInfo 函数两次的例子, 在两次调用之间提交了一些内存 (并强制其进入 RAM):
NumaInfo(); auto p = ::VirtualAllocExNuma(::GetCurrentProcess(), nullptr, 1 << 30, // 1 GB MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE, 1); // node 1 // touch memory ::memset(p, 0xff, 1 << 30); NumaInfo(); ::VirtualFree(p, 0, MEM_RELEASE);
以下是一个示例输出:
NUMA nodes: 2
Node 0: Processor Group: 0, Affinity: 0x0000000F
Available memory: 3587332 KB
Node 1: Processor Group: 0, Affinity: 0x000000F0
Available memory: 3287952 KB
NUMA nodes: 2
Node 0: Processor Group: 0, Affinity: 0x0000000F
Available memory: 3584884 KB
Node 1: Processor Group: 0, Affinity: 0x000000F0
Available memory: 2243764 KB
注意节点 1 上物理内存的减少.
💡 在非 NUMA 系统上测试 NUMA 相关代码是有问题的, 因为只有一个节点. 解决这个问题的一种方法是使用虚拟化技术, 如 Hyper-V, 来模拟 NUMA 节点. 对于 Hyper-V, 可以在 CPU 节点中的虚拟机设置中配置 NUMA 节点 (请注意, 你必须禁用动态内存才能使其工作).
2.1.11. The VirtualAlloc2 Function
VirtualAlloc2 函数, 在 Windows 10 版本 1803 (RS4) 中引入, 作为各种其他 VirtualAlloc 变体的可能替代品. 它结合了所有这些变体的功能, 以便单个调用可以使用与当前进程不同的进程, 首选的 NUMA 节点, 特定的内存对齐, AWE 和选定的内存分区 (一个半文档化的实体, 超出本书的范围). 其原型如下:
PVOID VirtualAlloc2( _In_opt_ HANDLE Process, _In_opt_ PVOID BaseAddress, _In_ SIZE_T Size, _In_ ULONG AllocationType, _In_ ULONG PageProtection, _Inout_ MEM_EXTENDED_PARAMETER* ExtendedParameters, _In_ ULONG ParameterCount);
前 5 个参数与 VirtualAllocEx 相同. 最后两个参数是一个可选的 MEM_EXTENDED_PARAMETER 结构数组, 每个结构指定一些与调用相关的额外属性. 此类结构的数量由最后一个参数提供. 以下是 MEM_EXTENDED_PARAMETER 的样子:
typedef struct DECLSPEC_ALIGN(8) MEM_EXTENDED_PARAMETER { struct { DWORD64 Type : MEM_EXTENDED_PARAMETER_TYPE_BITS; DWORD64 Reserved : 64 - MEM_EXTENDED_PARAMETER_TYPE_BITS; } DUMMYSTRUCTNAME; union { DWORD64 ULong64; PVOID Pointer; SIZE_T Size; HANDLE Handle; DWORD ULong; } DUMMYUNIONNAME; } MEM_EXTENDED_PARAMETER, *PMEM_EXTENDED_PARAMETER;
这个结构实际上是一个联合体, 其中只有一个成员是有效的, 基于 Type 成员, 这是一个选择联合体中有效成员的枚举:
typedef enum MEM_EXTENDED_PARAMETER_TYPE { MemExtendedParameterInvalidType = 0, MemExtendedParameterAddressRequirements, MemExtendedParameterNumaNode, MemExtendedParameterPartitionHandle, MemExtendedParameterUserPhysicalHandle, MemExtendedParameterAttributeFlags, MemExtendedParameterMax } MEM_EXTENDED_PARAMETER_TYPE;
例如, 设置一个首选 NUMA 节点, 类似于 "NUMA" 部分给出的例子, 可以用 VirtualAlloc2 这样完成:
MEM_EXTENDED_PARAMETER param = { 0 }; param.Type = MemExtendedParameterNumaNode; param.ULong = 1; // NUMA node auto p = ::VirtualAlloc2(::GetCurrentProcess(), // NULL also works for current process nullptr, 1 << 30, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE, ¶m, 1);
请查阅文档以获取更多示例.
2.1.12. 总结
在本章中, 我们研究了 Windows 提供的用于分配和管理内存的各种 API. 内存是计算机系统中的基本资源之一, 几乎所有其他东西都以某种方式映射到内存使用上.
在下一章中, 我们将深入探讨内存映射文件及其将文件映射到内存和在进程之间共享内存的能力.
2.2. 第 14 章: 内存映射文件
内存映射文件 (Memory Mapped File), 在内核术语中称为 节(Section), 是一个提供无缝地将文件内容映射到内存的能力的对象. 此外, 它可以用来在进程之间高效地共享内存. 这些功能提供了几个好处, 本章将探讨这些好处.
在本章中:
- 简介
- 映射文件
- 共享内存
- Micro Excel 2 应用程序
- 其他内存映射函数
- 数据一致性
2.2.1. 简介
文件映射对象在 Windows 中无处不在. 当加载一个镜像文件 (EXE 或 DLL) 时, 它会使用内存映射文件映射到内存中. 通过这种映射, 对底层文件的访问是通过标准指针间接完成的. 当代码需要在镜像内执行时, 初始访问会导致页面错误异常, 内存管理器会通过从文件读取数据并将其放置在物理内存中来处理, 然后修复用于映射此内存的适当页表, 此时调用线程就可以访问代码/数据. 这一切对应用程序都是透明的.
在第 11 章中, 我们看了各种与 I/O 相关的 API 来读写数据, 例如 ReadFile 和 WriteFile. 想象一下, 一些代码需要在文件中搜索某些数据, 而这种搜索需要在文件中来回移动. 使用 I/O API, 这充其量是不方便的, 涉及到对 ReadFile (事先分配好缓冲区) 和 SetFilePointer(Ex) 的多次调用. 另一方面, 如果有一个指向文件的“指针”可用, 那么移动和执行文件操作就容易得多: 无需分配缓冲区, 无需调用 ReadFile, 任何文件指针的更改都只转换为指针算术. 所有其他常见的内存函数, 如 memcpy, memset 等, 与内存映射文件一起工作得也很好.
2.2.2. 映射文件
映射现有文件所需的步骤首先是使用普通的 CreateFile 调用打开它. 对 CreateFile 的访问掩码必须与对文件所需的访问权限相适应, 例如读和/或写. 一旦这样的文件被打开, 调用 CreateFileMapping 就会创建文件映射对象, 其中可以提供文件句柄:
HANDLE CreateFileMapping( _In_ HANDLE hFile, _In_opt_ LPSECURITY_ATTRIBUTES lpFileMappingAttributes, _In_ DWORD flProtect, _In_ DWORD dwMaximumSizeHigh, _In_ DWORD dwMaximumSizeLow, _In_opt_ LPCTSTR lpName);
CreateFileMapping 的第一个参数是文件句柄. 如果此 MMF 对象要映射一个文件, 那么应该提供一个有效的文件句柄. 如果文件映射对象将用于创建由页文件支持的共享内存, 那么应该指定 INVALID_HANDLE_VALUE, 表示使用页文件. 我们将在本章稍后部分研究不由特定文件支持的共享内存.
接下来, 可以设置标准的 SECURITY_ATTRIBUTES 指针, 通常设置为 NULL. flProtect 参数指示当物理存储 (稍后) 用于此文件映射对象时应使用什么页面保护. 这应该是稍后所需的最宽松的页面保护. 常见的例子是 PAGE_READWRITE 和 PAGE_READONLY. 表 14-1 总结了 flProtect 的有效值以及在使用文件映射对象时创建/打开文件时对应的有效值.
| MMF 保护标志 | 文件的最小访问标志 | 备注 |
|---|---|---|
PAGE_READONLY |
GENERIC_READ |
不允许写入内存/文件 |
PAGE_READWRITE |
GENERIC_READ 和 GENERIC_WRITE |
|
PAGE_WRITECOPY |
GENERIC_READ |
等同于 PAGE_READONLY |
PAGE_EXECUTE_READ |
GENERIC_READ 和 GENERIC_EXECUTE |
|
PAGE_EXECUTE_READWRITE |
GENERIC_READ, GENERIC_WRITE 和 GENERIC_EXECUTE |
|
PAGE_EXECUTE_WRITECOPY |
GENERIC_READ 和 GENERIC_EXECUTE |
等同于 PAGE_EXECUTE_READ |
表 14-1 中的一个值可以与一些标志组合, 如下所述 (还有更多标志, 但列表是官方文档化的那些):
SEC_COMMIT- 仅适用于页文件支持的 MMF (hFile是INVALID_HANDLE_VALUE), 指示所有映射的内存必须在视图映射到进程地址时提交. 此标志与SEC_RESERVE互斥, 如果两者都未指定, 则为默认值. 在任何情况下, 它对由特定文件支持的 MMF 都没有影响.SEC_RESERVE- 与SEC_COMMIT相反. 任何视图最初都是保留的, 因此实际的提交必须通过VirtualAlloc调用显式执行.SEC_IMAGE- 指定提供的文件是 PE 文件. 它应与PAGE_READONLY保护结合使用, 但映射是根据 PE 中的节进行的. 此标志不能与任何其他标志组合.SEC_IMAGE_NO_EXECUTE- 类似于SEC_IMAGE, 但 PE 不用于执行, 仅用于映射.SEC_LARGE_PAGES- 仅适用于页文件支持的 MMF. 指示映射时使用大页面. 这需要SeLockMemoryPrivilege, 如第 13 章所述. 它还要求任何到 MMF 的视图以及视图大小都必须是大页面大小的倍数. 此标志必须与SEC_COMMIT组合.SEC_NOCACHE和SEC_WRITECOMBINE- 很少使用的标志, 通常是因为设备驱动程序需要它才能正常操作.
CreateFileMapping 的接下来的两个参数使用两个 32 位值指定 MMF 大小, 这应该被视为一个 64 位值. 如果 MMF 是要映射一个具有只读访问权限的现有文件, 则将两个值都设置为零, 这有效地将 MMF 的大小设置为文件的大小.
如果所讨论的文件要被写入, 则将大小设置为文件的最大大小. 一旦设置, 文件就不能超出这个大小, 事实上, 它的大小会立即增长到指定的大小. 如果 MMF 由页文件支持, 那么大小指示内存块的大小, 系统中的页文件必须在 MMF 创建时能够容纳.
CreateFileMapping 的最后一个参数是对象的名称. 它可以是 NULL, 或者可以命名, 就像其他命名的对象类型 (例如事件, 信号量, 互斥体). 给定一个名称, 很容易与其他进程共享对象. 最后, 函数返回内存映射文件对象的句柄, 如果失败则返回 NULL.
以下示例基于数据文件创建一个内存映射文件对象, 仅用于读访问 (省略了错误处理):
HANDLE hFile = ::CreateFile(L"c:\\mydata.dat", GENERIC_READ, FILE_SHARE_READ, nullptr, OPEN_EXISTING, 0, nullptr); HANDLE hMemFile = ::CreateFileMapping(hFile, nullptr, PAGE_READONLY, 0, 0, nullptr); ::CloseHandle(hFile);
最后一行可能令人担忧. 关闭文件句柄可以吗? 这不会关闭文件, 使其无法被文件映射对象访问吗? 事实证明, MMF 不能依赖客户端保持文件句柄打开足够长的时间, 它会复制它以确保文件不被关闭. 这意味着关闭文件句柄是正确的做法.
一旦创建了内存映射文件对象, 进程就可以使用返回的句柄将文件的全部或部分数据映射到其地址空间, 通过调用 `MapViewOfFile`:
LPVOID MapViewOfFile( _In_ HANDLE hFileMappingObject, _In_ DWORD dwDesiredAccess, _In_ DWORD dwFileOffsetHigh, _In_ DWORD dwFileOffsetLow, _In_ SIZE_T dwNumberOfBytesToMap);
MapViewOfFile 接受 MMF 句柄并将文件 (或其一部分) 映射到进程地址空间. dwDesiredAccess 可以是表 14-2 中描述的一个或多个标志的组合.
| Desired access | Description |
|---|---|
FILE_MAP_READ |
映射以进行读访问 |
FILE_MAP_WRITE |
映射以进行写访问 |
FILE_MAP_EXECUTE |
映射以进行执行访问 |
FILE_MAP_ALL_ACCESS |
与 MapViewOfFile 一起使用时等同于 FILE_MAP_WRITE |
FILE_MAP_COPY |
写时复制访问. 任何写操作都会得到一个私有副本, 当视图取消映射时会被丢弃 |
FILE_MAP_LARGE_PAGES |
使用大页面进行映射 |
FILE_MAP_TARGETS_INVALID |
将视图中的所有位置设置为控制流保护 (CFG) 的无效目标. 默认情况下, 视图是 CFG 的有效目标 (有关 CFG 的更多信息, 请参见第 16 章) |
dwFileOffsetHigh 和 dwFileOffsetLow 构成了开始映射的 64 位偏移量. 偏移量必须是分配粒度 (在所有 Windows 版本和架构上为 64 KB) 的倍数. 最后一个参数 dwNumberOfBytesToMap 指定从偏移量开始要映射多少字节. 将其设置为零会映射到文件映射的末尾.
函数返回调用者地址空间中映射内存的虚拟地址. 调用者可以使用该指针进行所有标准的内存操作 (受映射约束). 一旦不再需要映射的视图, 应使用 `UnmapViewOfFile` 将其取消映射:
BOOL UnmapViewOfFile(_In_ LPCVOID lpBaseAddress);
lpBaseAddress 是从 MapViewOfFile 返回的相同值. 一旦取消映射, lpBaseAddress 指向的内存就不再有效, 任何访问都会导致访问冲突.
- The filehist Application
命令行应用程序
filehist(File Histogram) 统计文件中每个字节 (0 到 255) 的出现次数, 有效地构建了文件中字节值的直方图分布. 该应用程序是通过使用内存映射文件构建的, 以便将视图映射到进程地址空间, 然后用普通指针访问值. 该应用程序可以处理任何大小的文件, 但将有限的视图映射到进程地址空间, 处理数据, 取消映射, 然后映射文件的下一个块.不带参数运行应用程序会显示以下内容:
C:\>filehist.exe Usage: filehist [view size in MB] <file path> Default view size is 10 MB
视图大小是可配置的, 默认值为 10 MB (这个值没有特殊原因). 以下是一个大文件和默认视图大小的例子:
C:\>filehist.exe file1.dat File size: 938857496 bytes Using view size: 10 MB Mapping offset: 0x0, size: 0xA00000 bytes Mapping offset: 0xA00000, size: 0xA00000 bytes Mapping offset: 0x1400000, size: 0xA00000 bytes Mapping offset: 0x1E00000, size: 0xA00000 bytes ... Mapping offset: 0x36600000, size: 0xA00000 bytes Mapping offset: 0x37000000, size: 0xA00000 bytes Mapping offset: 0x37A00000, size: 0x55D418 bytes 0xB3: 445612 ( 0.05 %) 0x9E: 460881 ( 0.05 %) 0x9F: 469939 ( 0.05 %) 0x9B: 496322 ( 0.05 %) 0x96: 546899 ( 0.06 %) 0xB5: 555019 ( 0.06 %) ... 0x0F: 11226199 ( 1.20 %) 0x7F: 11755158 ( 1.25 %) 0x01: 14336606 ( 1.53 %) 0x8B: 14824094 ( 1.58 %) 0x48: 20481378 ( 2.18 %) 0xFF: 72242071 ( 7.69 %) 0x00: 342452879 (36.48 %)
值零显然是主导的. 如果我们将视图大小增加到 400 MB, 我们会得到这个:
C:\>filehist.exe 400 file1.dat File size: 938857496 bytes Using view size: 400 MB Mapping offset: 0x0, size: 0x19000000 bytes Mapping offset: 0x19000000, size: 0x19000000 bytes Mapping offset: 0x32000000, size: 0x5F5D418 bytes 0xB3: 445612 ( 0.05 %) 0x9E: 460881 ( 0.05 %) ... 0x48: 20481378 ( 2.18 %) 0xFF: 72242071 ( 7.69 %) 0x00: 342452879 (36.48 %)
在
main中做的第一件事是处理一些命令行参数:int wmain(int argc, const wchar_t* argv[]) { if (argc < 2) { printf("Usage:\tfilehist [view size in MB] <file path>\n"); printf("\tDefault view size is 10 MB\n"); return 0; } DWORD viewSize = argc == 2 ? (10 << 20) : (_wtoi(argv) << 20); if (viewSize == 0) viewSize = 10 << 20;
接下来, 我们需要一个数组来存储值和计数:
struct Data { BYTE Value; long long Count; }; Data count = { 0 }; for (int i = 0; i < 256; i++) count[i].Value = i;
现在我们可以打开文件, 获取其大小, 并创建一个指向该文件的文件映射对象:
HANDLE hFile = ::CreateFile(argv[argc - 1], GENERIC_READ, FILE_SHARE_READ, nullptr, OPEN_EXISTING, 0, nullptr); if (hFile == INVALID_HANDLE_VALUE) return Error("Failed to open file"); LARGE_INTEGER fileSize; if (!::GetFileSizeEx(hFile, &fileSize)) return Error("Failed to get file size"); HANDLE hMapFile = ::CreateFileMapping(hFile, nullptr, PAGE_READONLY, 0, 0, nullptr); if (!hMapFile) return Error("Failed to create MMF"); ::CloseHandle(hFile);
该文件以只读方式打开, 因为不打算更改文件中的任何内容. MMF 以
PAGE_READONLY访问方式打开, 与文件的GENERIC_READ访问兼容. 接下来, 我们需要循环多次, 具体取决于文件大小和选定的视图大小, 并处理数据:auto total = fileSize.QuadPart; printf("File size: %llu bytes\n", fileSize.QuadPart); printf("Using view size: %u MB\n", (unsigned)(viewSize >> 20)); LARGE_INTEGER offset = { 0 }; while (fileSize.QuadPart > 0) { auto mapSize = (unsigned)min(viewSize, fileSize.QuadPart); printf("Mapping offset: 0x%llX, size: 0x%X bytes\n", offset.QuadPart, mapSize); auto p = (const BYTE*)::MapViewOfFile(hMapFile, FILE_MAP_READ, offset.HighPart, offset.LowPart, mapSize); if (!p) return Error("Failed in MapViewOfFile"); // do the work for (DWORD i = 0; i < mapSize; i++) count[p[i]].Count++; ::UnmapViewOfFile(p); offset.QuadPart += mapSize; fileSize.QuadPart -= mapSize; }
::CloseHandle(hMapFile);
只要还有字节要处理, 就会调用
MapViewOfFile来从当前偏移量映射文件的部分, 映射的大小是视图大小和剩余要处理字节的最小值. 处理完数据后, 视图被取消映射, 偏移量增加, 剩余字节数减少, 循环重复.最后一件事是显示结果. 数据数组首先按计数排序, 然后按顺序显示所有内容:
// sort by ascending order std::sort(std::begin(count), std::end(count), [](const auto& c1, const auto& c2) { return c2.Count > c1.Count; }); // display results for (const auto& data : count) { printf("0x%02X: %10llu (%5.2f %%)\n", data.Value, data.Count, data.Count * 100.0 / total); }
💡 静态 C++ 数组可以像向量一样使用
std::sort进行排序. 全局的std::begin和std::end函数是必需的, 因为 C++ 数组中没有方法可以为数组提供迭代器.
2.2.3. 共享内存
进程彼此隔离, 因此每个进程都有自己的地址空间, 自己的句柄表等. 大多数时候, 这就是我们想要的. 然而, 有时数据需要以某种方式在进程之间共享. Windows 提供了许多进程间通信 (Interprocess Communication, IPC) 机制, 包括组件对象模型 (Component Object Model, COM), Windows 消息, 套接字, 管道, 邮件槽, 远程过程调用 (Remote Procedure Calls, RPC), 剪贴板, 动态数据交换 (Dynamic Data Exchange, DDE) 等. 每种机制都有其优缺点, 但上述所有机制的共同点是内存必须从一个进程复制到另一个进程.
内存映射文件是另一种 IPC 机制, 它是其中最快的, 因为没有复制操作 (事实上, 其他一些 IPC 机制在同一台机器上的进程之间通信时, 底层使用内存映射文件). 一个进程将数据写入共享内存, 所有其他拥有相同文件句柄的进程都可以立即看到内存 - 没有复制操作, 因为每个进程都将相同的内存映射到自己的地址空间.
共享内存基于多个进程访问同一个文件映射对象. 对象可以通过第 2 章中描述的三种方式中的任何一种共享. 最简单的是为文件映射对象使用一个名称. 共享内存本身可以由特定文件支持 (对 CreateFileMapping 的有效文件句柄), 在这种情况下, 即使文件映射对象被销毁, 数据也可用; 或者由页文件支持, 在这种情况下, 一旦文件映射对象被销毁, 数据就会被丢弃. 两种选项本质上工作方式相同.
我们将从第 2 章中的 Basic Sharing 应用程序开始. 在那里我们研究了基于对象名称的共享能力, 但现在我们可以深入了解共享本身的细节. 图 14-1 显示了运行的两个应用程序实例, 其中在一个进程中写入并在另一个进程中读取显示相同的数据, 因为它们使用相同的文件映射对象.

Figure 207: 图 14-1: Basic Sharing 的多个实例
在 CMainDlg::OnInitDialog 中, 文件映射对象被创建, 由页文件支持:
m_hSharedMem = ::CreateFileMapping(INVALID_HANDLE_VALUE, nullptr, PAGE_READWRITE, 0, 1 << 12, L"MySharedMemory");
MMF 是为读/写访问而创建的, 其大小为 4 KB. 它的名称 (“MySharedMemory”) 将是用于与其他进程共享对象的方法. 第一次使用该对象名称调用 CreateFileMapping 时, 对象被创建. 之后任何使用相同名称的调用都只是获取一个指向已存在的文件映射对象的句柄. 这意味着其他参数并未真正使用. 例如, 第二个调用者不能为内存指定不同的大小 - 初始创建者决定了大小.
或者, 一个进程可能希望打开一个指向现有文件映射对象的句柄, 如果它不存在则失败. 这就是 OpenFileMapping 的作用:
HANDLE OpenFileMapping( _In_ DWORD dwDesiredAccess, _In_ BOOL bInheritHandle, _In_ LPCTSTR lpName);
dwDesiredAccess 参数是表 14-2 中访问掩码的组合. bInheritHandle 指定返回的句柄是否可继承 (有关句柄继承的更多信息, 请参见第 2 章). lpName 是要定位的命名 MMF. 如果没有给定名称的文件映射对象, 函数会失败 (返回 NULL).
在大多数情况下, 使用 CreateFileMapping 更方便, 特别是如果共享是由基于相同可执行镜像的多个进程进行的 - 第一个进程创建对象, 所有后续进程只获取现有对象的句柄 - 无需同步创建与打开.
有了文件映射对象句柄, 写入内存是通过以下函数完成的:
LRESULT CMainDlg::OnWrite(WORD, WORD, HWND, BOOL &) { void* buffer = ::MapViewOfFile(m_hSharedMem, FILE_MAP_WRITE, 0, 0, 0); if (!buffer) { AtlMessageBox(m_hWnd, L"Failed to map memory", IDR_MAINFRAME); return 0; } CString text; GetDlgItemText(IDC_TEXT, text); ::wcscpy_s((PWSTR)buffer, text.GetLength() + 1, text); ::UnmapViewOfFile(buffer); return 0; }
对 MapViewOfFile 的调用与 filehist 应用程序的调用没有太大不同. FILE_MAP_WRITE 用于获取对映射内存的写访问权限. 偏移量为零, 映射大小也指定为零, 这意味着一直映射到末尾. 由于共享内存只有 4 KB, 这不是问题, 无论如何一切都会向上舍入到最近的页面边界. 数据写入后, 调用 UnmapViewOfFile 以从进程地址空间取消映射视图.
读取数据非常相似, 只是使用不同的标志进行访问:
LRESULT CMainDlg::OnRead(WORD, WORD, HWND, BOOL &) { void* buffer = ::MapViewOfFile(m_hSharedMem, FILE_MAP_READ, 0, 0, 0); if (!buffer) { AtlMessageBox(m_hWnd, L"Failed to map memory", IDR_MAINFRAME); return 0; } SetDlgItemText(IDC_TEXT, (PCWSTR)buffer); ::UnmapViewOfFile(buffer); return 0; }
我们可以创建一个新的应用程序, 它可以同样地使用共享内存. memview 应用程序监视共享内存中的数据变化, 并显示出现的任何新数据.
首先, 必须打开文件映射对象. 在这种情况下, 我决定使用 OpenFileMapping, 因为这是一个监视应用程序, 不应该能够确定共享内存大小或备份文件:
int main() { HANDLE hMemMap = ::OpenFileMapping(FILE_MAP_READ, FALSE, L"MySharedMemory"); if (!hMemMap) { printf("File mapping object is not available\n"); return 1; }
接下来, 我们需要将内存映射到进程地址空间:
WCHAR text = { 0 }; auto data = (const WCHAR*)::MapViewOfFile(hMemMap, FILE_MAP_READ, 0, 0, 0); if (!data) { printf("Failed to map shared memory\n"); return 1; }
“监视”是基于每隔一定时间 (以下代码中为 1 秒) 读取数据. text 局部变量存储共享内存中的当前文本. 它与新数据进行比较, 如果需要则更新:
for (;;) { if (::_wcsicmp(text, data) != 0) { // text changed, update and display ::wcscpy_s(text, data); printf("%ws\n", text); } ::Sleep(1000); }
在这个简单的例子中, 循环是无限的, 但很容易想出一个合适的退出条件. 你可以尝试一下, 观察每当运行的 Basic Sharing 实例向共享内存写入新字符串时, 文本都会更新.
如果你打开 Process Explorer 并查找文件映射对象的句柄之一, 你会发现 MMF 对象的总句柄数反映了使用共享内存的进程总数. 如果你有两个 Basic Sharing 实例和一个 memview 实例, 那么预计有三个句柄 (图 14-2).

Figure 208: 图 14-2: Process Explorer 中共享的对象
- Sharing Memory with File Backing
Basic Sharing+ 应用程序演示了使用可能由页文件以外的文件支持的共享内存. 该应用程序基于 Basic Sharing 应用程序. 图 14-3 显示了应用程序启动时的窗口.

Figure 209: 图 14-3: Basic Application+ 窗口
你可以指定一个要使用的文件, 或者将编辑框留空, 在这种情况下, 页文件将被用作备份 (等同于 Basic Sharing 应用程序). 点击 Create 按钮会创建文件映射对象. 如果指定了文件并且存在, 其大小决定了文件映射对象的大小. 如果文件不存在, 它会以
CreateFileMapping中指定的大小创建 (4 KB, 就像在 Basic Sharing 中一样). 文件大小本身立即变为 4 KB.一旦文件映射对象被创建, UI 焦点会更改为数据编辑框和读写按钮, 就像在 Basic Sharing 中一样. 如果你现在启动另一个 Basic Sharing+ 的实例, 它将自动进入编辑模式, 禁用 Create 按钮. 这是通过在进程启动时调用
OpenFileMapping来完成的. 如果文件映射对象存在, 就没有必要允许用户选择文件, 因为那没有效果.CMainDlg::OnInitDialog尝试打开文件映射对象, 如果它存在的话:m_hSharedMem = ::OpenFileMapping(FILE_MAP_READ | FILE_MAP_WRITE, FALSE, L"MySharedMemory"); if (m_hSharedMem) EnableUI();
如果成功,
EnableUI被调用以禁用文件名编辑框和 Create 按钮, 并启用数据编辑框和 Read 和 Write 按钮. 点击 Create 按钮 (如果启用), 会按请求创建文件映射对象:LRESULT CMainDlg::OnCreate(WORD, WORD, HWND, BOOL&) { CString filename; GetDlgItemText(IDC_FILENAME, filename); HANDLE hFile = INVALID_HANDLE_VALUE; if (!filename.IsEmpty()) { hFile = ::CreateFile(filename, GENERIC_READ | GENERIC_WRITE, 0, nullptr, OPEN_ALWAYS, 0, nullptr); if (hFile == INVALID_HANDLE_VALUE) { AtlMessageBox(*this, L"Failed to create/open file", IDR_MAINFRAME, MB_ICONERROR); return 0; } } m_hSharedMem = ::CreateFileMapping(hFile, nullptr, PAGE_READWRITE, 0, 1 << 12, L"MySharedMemory"); if (!m_hSharedMem) { AtlMessageBox(m_hWnd, L"Failed to create shared memory", IDR_MAINFRAME, MB_ICONERROR); EndDialog(IDCANCEL); } if (hFile != INVALID_HANDLE_VALUE) ::CloseHandle(hFile); EnableUI(); return 0; }
如果指定了文件名,
CreateFile会被调用来打开或创建文件. 它使用OPEN_ALWAYS标志, 意思是“如果文件不存在则创建, 否则打开”. 文件句柄被传递给CreateFileMapping以创建文件映射对象. 最后, 文件句柄被关闭 (如果之前已打开), 并调用EnableUI将应用程序置于数据编辑模式. - The Micro Excel 2 Application
第 13 章的 Micro Excel 应用程序演示了如何预留大片内存区域, 然后只提交那些被应用程序积极使用的页面. 我们可以将这种方法与内存映射文件相结合, 这样内存也可以在进程之间高效地共享. 图 14-4 显示了该应用程序的运行情况.

Figure 210: 图 14-4: The Micro Excel 2 应用程序
在不提交的情况下映射大片内存的秘诀是, 在调用
MapViewOfFile时, 使用CreateFileMapping的SEC_RESERVE标志. 这导致映射的区域只被预留, 意味着直接访问会导致访问冲突. 为了提交页面, 需要调用VirtualAlloc函数.让我们检查一下我们需要对 Micro Excel 进行的更改, 以支持文件映射的这种功能. 首先, 文件映射对象的创建:
bool CMainDlg::AllocateRegion() { m_hSharedMem = ::CreateFileMapping(INVALID_HANDLE_VALUE, nullptr, PAGE_READWRITE | SEC_RESERVE, TotalSize >> 32, (DWORD)TotalSize, L"MicroExcelMem"); if (!m_hSharedMem) { AtlMessageBox(nullptr, L"Failed to create shared memory", IDR_MAINFRAME, MB_ICONERROR); EndDialog(IDCANCEL); return false; } m_Address = ::MapViewOfFile(m_hSharedMem, FILE_MAP_READ | FILE_MAP_WRITE, 0, 0, TotalSize); CString addr; addr.Format(L"0x%p", m_Address); SetDlgItemText(IDC_ADDRESS, addr); SetDlgItemText(IDC_CELLADDR, addr); return true; }
AllocateRegion在对话框初始化时被调用. 对CreateFileMapping的调用使用页文件作为备份 (这是SEC_RESERVE支持的唯一场景), 并请求SEC_RESERVE标志以及PAGE_READWRITE. 文件映射对象被赋予一个名称, 以便与其他进程轻松共享.接下来, 调用
MapViewOfFile来映射整个共享内存 (TotalSize=1 GB). 当然, 也可以只映射这部分内存, 这对于 32 位进程来说实际上是个好主意, 因为地址空间范围有些受限. 由于SEC_RESERVE标志, 整个区域是预留的, 而不是提交的.从任何单元格读写数据的方式与原始的 Micro Excel 完全相同: 初始写入尝试会导致访问冲突异常, 该异常被捕获, 调用
VirtualAlloc显式提交特定单元格所在的页面, 然后返回EXCEPTION_CONTINUE_EXECUTION告诉处理器再次尝试访问. 为方便起见, 重复了用于写入和处理异常的代码:LRESULT CMainDlg::OnWrite(WORD, WORD, HWND, BOOL&) { int x, y; auto p = GetCell(x, y); if(!p) return 0; WCHAR text; GetDlgItemText(IDC_TEXT, text, _countof(text)); __try { ::wcscpy_s((WCHAR*)p, CellSize / sizeof(WCHAR), text); } __except (FixMemory(p, GetExceptionCode())) { // nothing to do: this code is never reached } return 0; } int CMainDlg::FixMemory(void* address, DWORD exceptionCode) { if (exceptionCode == EXCEPTION_ACCESS_VIOLATION) { ::VirtualAlloc(address, CellSize, MEM_COMMIT, PAGE_READWRITE); return EXCEPTION_CONTINUE_EXECUTION; } return EXCEPTION_CONTINUE_SEARCH; }
如果你运行第二个 Micro Excel 2 应用程序, 你会发现相同的信息在另一个进程中是可见的, 因为它是相同的映射内存. 然而, 请注意, 每个进程中 1 GB 区域映射到的地址可能不相同. 这完全没问题, 并且不会影响两个进程看到完全相同的内存这一事实 (图 14-5).

Figure 211: 图 14-5: 两个 Micro Excel 2 实例共享内存
如果你想在 VMMap 中查看此内存安排, 要查找的正确内存“类型”是 Shareable (图 14-6).

Figure 212: 图 14-6: VMMap 中由页文件支持的共享内存
2.2.4. 其他内存映射函数
MapViewOfFile 的一个扩展版本允许选择映射发生的地址:
LPVOID MapViewOfFileEx( _In_ HANDLE hFileMappingObject, _In_ DWORD dwDesiredAccess, _In_ DWORD dwFileOffsetHigh, _In_ DWORD dwFileOffsetLow, _In_ SIZE_T dwNumberOfBytesToMap, _In_opt_ LPVOID lpBaseAddress);
所有参数都与 MapViewOfFile 相同, 除了最后一个. 这是映射的请求地址. 地址必须是系统分配粒度 (64 KB) 的倍数. 如果指定的地址和请求的映射大小在进程地址空间中已经被占用, 函数可能会失败. 这就是为什么通过指定 NULL 作为值让系统定位一个空区域几乎总是更好的, 这使得该函数与 MapViewOfFile 相同.
你为什么要设置一个特定的地址? 一个常见的案例 (至少对于系统而言) 是当一个 PE 文件必须从多个进程映射时 (SEC_IMAGE 标志). 这用于 PE 镜像, 因为代码可以包含引用 PE 镜像范围中另一个位置的指针 (地址). 如果映射到不同的地址, 那么一些代码需要更改. 这通常发生在 DLL 需要重定位的情况下 (在下一章讨论).
对于数据, 也可以存储指向映射区域中其他位置的指针, 但这不是一个好主意, 因为 MapViewOfFileEx 可能会失败. 最好在数据中存储偏移量, 这样它们就是地址无关的.
MapViewOfFile 的另一个变体是关于为映射使用的物理内存选择一个首选的 NUMA 节点:
LPVOID MapViewOfFileExNuma( _In_ HANDLE hFileMappingObject, _In_ DWORD dwDesiredAccess, _In_ DWORD dwFileOffsetHigh, _In_ DWORD dwFileOffsetLow, _In_ SIZE_T dwNumberOfBytesToMap, _In_opt_ LPVOID lpBaseAddress, _In_ DWORD nndPreferred);
MapViewOfFileExNuma 用一个首选的 NUMA 节点扩展了 MapViewOfFileEx (有关 NUMA 的更多信息, 请参阅第 13 章).
Windows 10 版本 1703 (RS2) 引入了 `MapViewOfFile2`:
PVOID MapViewOfFile2( _In_ HANDLE FileMappingHandle, _In_ HANDLE ProcessHandle, _In_ ULONG64 Offset, _In_opt_ PVOID BaseAddress, _In_ SIZE_T ViewSize, _In_ ULONG AllocationType, _In_ ULONG PageProtection);
这个函数通过传递 NUMA_NO_PREFERRED_NODE (-1) 作为首选 NUMA 节点, 内联调用更扩展的函数 MapViewOfFileNuma2 来实现:
PVOID MapViewOfFileNuma2( _In_ HANDLE FileMappingHandle, _In_ HANDLE ProcessHandle, _In_ ULONG64 Offset, _In_opt_ PVOID BaseAddress, _In_ SIZE_T ViewSize, _In_ ULONG AllocationType, _In_ ULONG PageProtection, _In_ ULONG PreferredNode);
💡 这些函数以及本节中接下来的其他函数需要导入库
mincore.lib. 目前文档错误地指定了kernel32.lib.
这些函数添加了第二个参数 (hProcess) 来标识要映射视图的进程 (原始函数总是在当前进程上工作). 当然, 使用 GetCurrentProcess 是完全合法的. 如果所讨论的进程不同, 句柄必须具有 PROCESS_VM_OPERATION 访问掩码. 这些函数的一个好处是, 偏移量可以指定为单个 64 位数字, 而不是原始函数中的两个 32 位值.
AllocationType 参数可以是 0 (对于正常的已提交视图), 或 MEM_RESERVE 用于在不提交的情况下保留视图. 此外, 如果要使用大页面进行映射, 可以指定 MEM_LARGE_PAGES. 在这种情况下, 文件映射对象必须使用 SEC_LARGE_PAGES 标志创建, 并且调用者必须具有 SeLockMemoryPrivilege 特权.
其余参数与 MapViewOfFileExNuma 相同 (尽管顺序不同). 返回的地址仅在目标进程地址空间中有效. 当需要与另一个进程共享一些内存, 而该进程不知道需要打开的文件映射对象, 要映射的区域等信息时, 这些函数可能很有用. 这意味着文件映射对象可以在没有名称的情况下创建, 这使得它更难被干扰. 唯一需要传递给目标进程的信息是结果地址, 这甚至可以在 BaseAddress 不为 NULL 的情况下预定义. 将单个指针值传递给另一个进程比传递更复杂的信息要容易得多. 例如, 可以使用窗口消息, 甚至可以像第 12 章中演示的那样使用 DLL 的共享变量.
映射视图的取消映射可以从目标进程内部正常使用 UnmapViewOfFile 完成, 或者从映射进程使用 UnmapViewOfFile2:
BOOL UnmapViewOfFile2( _In_ HANDLE Process, _In_ PVOID BaseAddress, _In_ ULONG UnmapFlags );
UnmapFlags 通常为零, 但可以有两个以上的值. 请查阅文档以获取详细信息. 另一个变体是 UnmapViewOfFileEx, 它的工作方式与 UnmapViewOfFile2 类似, 但总是使用调用进程.
需要使用 MapViewOfFile2 的 UWP 进程有自己的版本, MapViewOfFile2FromApp. 与 Virtual 系列中的类似函数一样, 如果在 UWP 应用中编译, MapViewOfFile2 会被内联实现为调用 MapViewOfFile2FromApp. 请查阅文档以获取详细信息.
还有另一个 MapViewOfFile 变体, 在 Windows 10 版本 1803 (RS4) 中引入:
PVOID MapViewOfFile3( _In_ HANDLE FileMapping, _In_opt_ HANDLE Process, _In_opt_ PVOID BaseAddress, _In_ ULONG64 Offset, _In_ SIZE_T ViewSize, _In_ ULONG AllocationType, _In_ ULONG PageProtection, _Inout_ MEM_EXTENDED_PARAMETER* ExtendedParameters, _In_ ULONG ParameterCount);
这是一个“超级函数”, 结合了其他变体的能力, 其中属性作为 MEM_EXTENDED_PARAMETER 结构数组给出. 请参阅第 13 章中关于 VirtualAlloc2 的讨论, 因为这里使用了相同的结构.
正如可能预期的那样, 还有另一个适用于 UWP 进程的变体 - MapViewOfFile3FromApp, 其实现方式与前面描述的类似.
最后, Windows 10 版本 1809 (RS5) 添加了一个 CreateFileMapping 的变体:
HANDLE CreateFileMapping2( _In_ HANDLE File, _In_opt_ SECURITY_ATTRIBUTES* SecurityAttributes, _In_ ULONG DesiredAccess, _In_ ULONG PageProtection, _In_ ULONG AllocationAttributes, _In_ ULONG64 MaximumSize, _In_opt_ PCWSTR Name, _Inout_updates_opt_(ParameterCount) MEM_EXTENDED_PARAMETER* ExtendedParameters, _In_ ULONG ParameterCount);
这个函数目前似乎没有文档记录, 但它使用相同的 MEM_EXTENDED_PARAMETER 结构. 例如, 为此文件映射对象的所有映射指定一个首选的 NUMA 节点可以这样做:
HANDLE hFile = ...; MEM_EXTENDED_PARAMETER param = { 0 }; param.Type = MemExtendedParameterNumaNode; param.ULong = 1; // NUMA node 1 HANDLE hMemMap = ::CreateFileMapping2(hFile, nullptr, FILE_MAP_READ, PAGE_READONLY, 0, 0, nullptr, ¶m, 1);
2.2.5. 数据一致性
文件映射对象在数据一致性方面提供了几个保证.
- 同一数据/文件的多个视图, 即使来自多个进程, 也保证是同步的, 因为不同的视图都映射到相同的物理内存. 唯一的例外是在网络上映射远程文件时. 在这种情况下, 来自不同机器的视图可能根本不同步. 来自同一台机器的视图继续是同步的.
- 映射同一文件的多个文件映射对象不保证是同步的. 通常, 用两个或多个文件映射对象映射同一个文件是个坏主意. 最好是以独占访问的方式打开所讨论的文件, 这样就不会有其他对该文件的访问 (至少在打算写入时).
- 如果一个文件被一个文件映射对象映射, 同时又为正常的 I/O (
ReadFile,WriteFile等) 打开, 那么 I/O 操作的更改通常不会立即反映在映射到文件相同位置的视图中. 这种情况应该避免.
2.2.6. 总结
内存映射文件对象是灵活和快速的, 提供了共享内存的能力, 无论它们是映射一个特定的文件还是仅仅共享由页文件支持的内存. 它们非常高效, 我认为它们是 Windows 中我最喜欢的功能之一.
在下一章中, 我们将把注意力转向动态链接库 (DLL), 这是 Windows 的一个关键部分.
2.3. 第 15 章: 动态链接库
动态链接库 (DLLs) 自 Windows NT 诞生以来就是其基本组成部分. DLL 存在的主要动机是它们可以轻松地在进程之间共享, 这样 DLL 的单个副本就可以在 RAM 中, 所有需要它的进程都可以共享 DLL 的代码. 在那些早期, RAM 比今天小得多, 这使得内存节省非常重要. 即使在今天, 这些内存节省也是显著的, 因为一个典型的进程会使用数十个 DLL.
DLL 今天有很多用途, 我们将在本章中研究其中的许多.
本章内容:
- 简介
- 构建 DLL
- 显式和隐式链接
- DllMain 函数
- DLL 注入
- API 挂钩
- DLL 基地址
- 延迟加载 DLL
- LoadLibraryEx 函数
- 杂项函数
2.3.1. 简介
DLL 是可移植可执行 (PE) 文件, 可以包含以下一项或多项: 代码, 数据和资源. 每个用户模式进程都使用子系统 DLL, 例如 kernel32.dll, user32.dll, gdi32.dll, advapi32.dll, 实现文档化的 Windows API. 当然, Ntdll.Dll 在每个用户模式进程中都是强制性的, 包括本机应用程序.
DLL 是可以包含函数, 全局变量和资源 (如菜单, 位图, 图标) 的库. 一些函数 (和类型) 可以由 DLL 导出, 以便它们可以被加载 DLL 的另一个 DLL 或可执行文件直接使用. DLL 可以在进程启动时隐式加载, 或者在应用程序调用 LoadLibrary 或 LoadLibraryEx 函数时显式加载.
2.3.2. 构建一个 DLL
我们将从如何构建一个 DLL 和导出符号开始. 使用 Visual Studio, 可以通过选择适当的项目模板来创建一个新的 DLL 项目 (图 15-1).

Figure 213: 图 15-1: Visual Studio 中的新 DLL 项目
其中一个模板指示 DLL 导出符号, 但任何 DLL 模板都可以. 与 EXE 项目相比, DLL 项目唯一根本性的变化是项目属性中的配置类型 (图 15-2).

Figure 214: 图 15-2: Visual Studio 中的 DLL 项目属性
由 Visual Studio 创建的典型项目将具有以下文件:
pch.h和pch.cpp- 预编译头文件和实现.framework.h- 由pch.h包含, 应包含所有“标准”Windows 头文件, 例如Windows.h. 我通常会删除此文件, 并将所有 Windows 头文件放在pch.h中.dllmain.cpp- 包括DllMain函数 (本章稍后讨论).
此时我们可以成功构建项目. 然而, 这个 DLL 几乎没有用. 大多数 DLL 导出一些功能供其他模块 (其他 DLL 或 EXE) 调用. 让我们向 DLL 添加一个名为 IsPrime 的函数. 首先在一个可以被 DLL 用户包含的头文件中:
// Simple.h bool IsPrime(int n);
然后在另一个文件中实现, 因为这不应该对 DLL 的用户可见:
// Simple.cpp #include "pch.h" #include "Simple.h" #include <cmath> bool IsPrime(int n) { int limit = (int)::sqrt(n); for (int i = 2; i <= limit; i++) if (n % i == 0) return false; return true; }
实现对于本节的目的并不重要. 关键是, 我们在我们的 DLL 中有一些功能, 我们希望能够使用它. 让我们在 Visual Studio 的同一个解决方案中添加一个名为 SimplePrimes 的控制台应用程序项目.
为了访问 DLL 的功能, 我们在 main 函数之前添加一个对 Simple.h 的包含:
// SimplePrimes.cpp #include "..\SimpleDll\Simple.h" // other includes...
让我们通过调用 `IsPrime` 添加一个简单的测试:
int main() { bool test = IsPrime(17); printf("%d\n", (int)test); return 0; }
如果我们编译这个, 它编译得很好, 但链接时会失败, 出现可怕的“未解析的外部符号”错误: SimplePrimes.obj : error LNK2019: unresolved external symbol “bool __cdecl IsPrime(int)” (?IsPrime@@YA_NH@Z) referenced in function _main
编译器在 Simple.h 中找到了函数的声明, 所以它相对满意. 它也寻找一个实现, 但找不到. 它没有抱怨, 而是向链接器发信号, 表明 IsPrime 的实现缺失, 所以也许链接器可以解决它.
链接器如何做到这一点? 链接器对项目有一个“全局”视图, 并且知道可能作为已编译代码的二进制片段提供的库. 然而, 链接器在其知道的库列表中找不到任何东西, 最终以“未解析的外部符号”错误放弃.
这里缺少两样东西: 一个是某种引用, 指向在哪里找到实现. 我们将通过右键单击 SimplePrimes 项目中的 References 节点并从菜单中选择 Add Reference… 来添加它. Add Reference 对话框打开 (图 15-3).

Figure 215: 图 15-3: Add Reference 对话框
你必须勾选 Simple.Dll 的复选框并点击 OK. 一个名为 Simple.Dll 的节点出现在 References 节点下. 现在构建项目会产生相同的“未解析的外部符号”错误. 这就是第二个缺失的部分: IsPrime 函数必须被导出. 一种方法是在 Simple.h 中通过扩展 IsPrime 的声明来做到这一点:
__declspec(dllexport) bool IsPrime(int n);
通常, 有几种 __declspec 类型被微软的编译器支持, 因为没有标准的方法从模块中导出符号.
💡 C++20 标准中一个名为“模块 (Modules)”的 C++ 功能试图解决这个问题. 然而, 它不一定面向 DLL. 在撰写本文时, 它还没有被 Visual C++ 编译器完全实现.
现在我们可以构建项目, 并且应该可以成功构建. 我们可以运行 SimplePrimes 并得到预期的结果. 添加 dllexport 说明符将 IsPrime 函数添加到了导出符号列表中. 这仍然没有完全解释为什么链接器满意, 以及 DLL 是如何在运行时找到的. 我们将在下一节中详细介绍这些细节.
你现在可以打开任何 PE 查看器工具, 查看 Simple.Dll 和 SimplePrimes.exe. 对于 Simple.Dll, IsPrime 函数应该被列为导出的 (图 15-4 使用我自己的 PE Explorer V2). 你也可以用 Dumpbin.exe 命令行工具获取此信息, 像这样:
C:\>dumpbin /exports SimpleDll.dll Microsoft (R) COFF/PE Dumper Version 14.26.28805.0 Copyright (C) Microsoft Corporation. All rights reserved. Dump of file c:\dev\Win10SysProg\Chapter15\Debug\SimpleDll.dll File Type: DLL Section contains the following exports for SimpleDll.dll 00000000 characteristics FFFFFFFF time date stamp 0.00 version 1 ordinal base 1 number of functions 1 number of names ordinal hint RVA name 1 0 000111F9 ?IsPrime@@YA_NH@Z = @ILT+500(?IsPrime@@YA_NH@Z) Summary 1000 .00cfg 1000 .data 1000 .idata 1000 .msvcjmc 2000 .rdata 1000 .reloc 1000 .rsrc 7000 .text 10000 .textbss
注意这个 IsPrime 式的符号. 它有一些奇怪的修饰, 下一节会解释.

Figure 216: 图 15-4: Simple.dll 中的导出
图 15-5 显示了 SimplePrimes.exe 的导入. 其中一个来自 Simple.Dll - IsPrime 函数.

Figure 217: 图 15-5: SimplePrimes.exe 中的导入
2.3.3. 隐式和显式链接
有两种基本的方法可以链接到一个 DLL (以便其功能可以使用). 第一种也是最简单的是隐式链接 (有时称为到 DLL 的静态链接), 在上一节中使用. 第二种是显式链接, 这更复杂, 但对 DLL 的加载和卸载时间提供了更多的控制.
- 隐式链接
当生成 DLL 时, 默认情况下还会生成一个附带的文件, 称为 导入库. 该文件的扩展名为 LIB, 包含两部分信息:
- DLL 的文件名 (无路径)
- 导出符号列表 (函数和变量)
在 Visual Studio 中向 DLL 项目添加引用时, 正如上一节所做的那样, DLL 项目生成的导入库会作为依赖项添加到想要使用该 DLL 的 EXE 项目 (或其他 DLL 项目) 中. 与其使用 Visual Studio 添加引用 (这是 Visual Studio 早期版本中没有的选项), 不如使用项目的属性将 LIB 文件添加为依赖项 (图 15-6).

Figure 218: 图 15-6: 项目属性中的导入库
图 15-6 使用 Visual Studio 使用的 `$(TargetDir)` 变量来正确定位 LIB 文件, 但更一般地, LIB 文件可以复制到任何地方并被引用. 你可以看到应用程序链接的所有“标准”子系统 DLL 都使用 Visual Studio 安装提供的导入库.
另一种链接到导入库 (或静态库) 的方法是在代码中添加依赖项:
#ifdef _WIN64 #pragma comment(lib, "../x64/Debug/SimpleDll.lib") #else #pragma comment(lib, "../Debug/SimpleDll.lib") #endif
围绕定位 LIB 文件的操作并不优雅, 但可以通过更多的配置选项来改进, 将生成的 LIB 文件放置在一个更方便的目录中, 或者通过配置其他默认搜索目录 (所有这些都可以在项目的属性中完成).
💡 使用
#pragma选项在某种程度上更容易看到, 因为对 vcxproj 文件的依赖性减少了.有了导入库, 构建依赖项目 (使用 DLL 的那个) 需要以下步骤:
- 编译器看到一个对函数 (在
SimpleDll中的IsPrime) 的调用, 它在任何源文件中都找不到实现. - 编译器为链接器放置指令以定位这样的实现.
- 链接器尝试在静态库文件中定位一个实现 (通常也具有 LIB 扩展名), 但失败了.
- 链接器看到导入的 lib, 其中据说
IsPrime函数在SimpleDll.Dll中实现. 链接器将适当的数据添加到生成的 PE 中, 指示加载器在运行时定位该 DLL.
在运行时, 加载器 (在
NtDll.Dll中) 读取 PE 中的信息, 并意识到它需要定位SimpleDll.Dll文件. 加载器使用的搜索路径与第 3 章中描述的为新创建的进程定位所需 DLL 的搜索路径相同 - 这就是隐式链接的作用. 搜索列表 (按顺序) 在此重复以方便查阅:- 如果 DLL 名称是
KnownDLLs之一 (在注册表中指定), 则使用现有的映射文件而不进行搜索. - 可执行文件的目录.
- 进程的当前目录 (由父进程确定).
GetSystemDirectory返回的系统目录 (例如c:\windows\system32).GetWindowsDirectory返回的 Windows 目录 (例如c:\Windows).PATH环境变量中列出的目录.
如果在这些目录中都找不到 DLL, 进程会显示图 15-7 所示的错误消息框, 并且进程终止.

Figure 219: 图 15-7: 隐式链接时无法定位 DLL
KnownDLLs注册表项指定了应在系统目录中搜索的 DLL, 然后再尝试其他位置. 这用于防止劫持这些 DLL 之一. 例如, 一个恶意应用程序可能会在应用程序的目录中放置自己的 (比如说)kernel32.dll副本, 导致进程加载恶意版本. 然而, 这不会发生, 因为kernel32.dll在已知 DLL 列表中. 图 15-8 显示了HKLM\System\CurrentControlSet\Control\Session Manager\KnownDLLs中的KnownDLLs注册表项.
Figure 220: 图 15-8: 注册表中的 KnownDLLs
已知的 DLL 在系统初始化时被映射 (使用内存映射文件对象), 以便将这些 DLL 加载到进程中更快, 因为内存映射文件在进程需要 DLL 之前就已经准备好了. 这些文件映射 (节) 对象可以在 Sysinternals 的 WinObj (图 15-9) 或我自己的 Object Explorer 中看到.

Figure 221: 图 15-9: WinObj 中的 KnownDLLs 节
如果一个 DLL 对其他 DLL 有依赖关系 (再次是隐式链接), 这些 DLL 会以完全相同的方式递归搜索. 所有这些 DLL 都必须成功定位, 否则进程会以图 15-7 中的错误消息框终止.
一旦找到一个隐式加载的 DLL, 它的
DllMain函数 (如果提供) 会以DLL_PROCESS_ATTACH的原因参数执行, 向 DLL 指示它现在已被加载到一个进程中 (有关DllMain的更多信息, 请参见“DllMain 函数”一节). 如果DllMain返回FALSE, 它向加载器指示 DLL 未成功初始化, 进程会以与图 15-7 类似的消息框终止.所有隐式加载的 DLL 在进程启动时加载, 在进程退出/终止时卸载. 尝试使用
FreeLibrary函数 (稍后讨论) 卸载此类 DLL 似乎会成功, 但实际上什么也没做.从开发者的角度来看, 隐式链接到 DLL 很容易. 以下是想要隐式链接 DLL 的应用程序开发者所需的步骤摘要:
- 添加相关的
#include, 其中声明了导出的函数/变量. - 将 DLL 提供的导入库添加到其导入集中 (以之前描述的方式之一).
- 调用导出的函数或访问导出的变量.
“导出的函数”不一定是全局函数. 它们也可以是类中的 C++ 成员函数.
__declspec(dllexport)指令可以像这样应用于一个类:class __declspec(dllexport) PrimeCalculator { public: bool IsPrime(int n) const; std::vector<int> CalcRange(int from, int to); };
并且正常地使用这个类, 例如:
PrimeCalculator calc; printf("123 prime? %s\n", calc.IsPrime(123) ? "Yes" : "No");
- 显式链接
显式链接到一个 DLL 提供了对 DLL 何时加载和卸载的更多控制. 此外, 如果 DLL 加载失败, 进程不会崩溃, 因此应用程序可以处理错误并继续. 显式 DLL 链接的一个常见用途是加载与语言相关的资源. 例如, 一个应用程序可能会尝试加载一个具有当前系统区域设置资源的 DLL, 如果找不到, 可以加载一个作为应用程序安装一部分始终提供的默认资源 DLL.
使用显式链接时, 不使用导入库, 以便加载器不会尝试加载 DLL (因为它可能存在也可能不存在). 这也意味着你不能使用
#include来获取导出的符号声明, 因为链接器会因“未解析的外部符号”错误而失败. 我们如何使用这样的 DLL?第一步是在运行时加载它, 通常是在需要它的地方附近. 这是
LoadLibrary的工作:HMODULE LoadLibrary(_In_ LPCTSTR lpLibFileName);
LoadLibrary只接受文件名或完整路径. 如果只指定文件名, DLL 的搜索顺序与前一节描述的隐式加载的 DLL 相同. 如果指定了完整路径, 则只尝试加载该文件.在实际搜索开始之前, 加载器会检查是否已将同名模块加载到进程地址空间中. 如果是, 则不执行搜索, 并返回现有 DLL 的句柄. 例如, 如果已经加载了
SimpleDll.Dll(无论从什么路径), 并且调用LoadLibrary来加载名为SimpleDll.Dll的文件 (无论在什么路径或没有路径), 则不会加载额外的 DLL.如果 DLL 被成功定位, 它将被映射到进程地址空间,
LoadLibrary的返回值是它被映射到的进程中的虚拟地址. 类型本身是HMODULE, 有时是HINSTANCE, 它们是可以互换的; 它们在任何意义上都不是“句柄”. 这些类型名称是 16 位 Windows 的遗物. 无论如何, 这个返回值唯一地代表了进程地址空间中的 DLL, 并且是与其他访问 DLL 中信息的函数一起使用的参数, 我们马上就会看到.与所有 DLL 加载一样,
DllMain会在加载的 DLL 上被调用. 如果返回TRUE, 则认为 DLL 已成功加载, 控制权返回给调用者. 否则, DLL 会卸载, 函数失败.如果函数失败 (因为 DLL 定位失败或其
DllMain返回FALSE), 则返回NULL给调用者.现在 DLL 已加载, 我们如何访问 DLL 中的导出函数? 有问题的函数是
GetProcAddress:FARPROC GetProcAddress( _In_ HMODULE hModule, _In_ LPCSTR lpProcName);
该函数从 DLL 中返回一个导出符号的地址. 它的第一个参数是从
LoadLibrary返回的 DLL 句柄. 第二个参数是符号的名称. 注意名称必须是 ASCII - 没有 Unicode 变体. 返回值是一个通用的FARPROC, 这是旧的 16 位时代的另一个类型, 其中“far”和“near”意味着不同的东西.FARPROC的实际定义并不重要; 调用者将根据一些先验知识 (例如不能包含的头文件) 或老式文档将返回值转换为适当的类型. 如果符号不存在 (或未导出, 这是同一件事),GetProcAddress返回NULL.让我们回到从
SimpleDll.Dll导出的IsPrime函数, 像这样:__declspec(dllexport) bool IsPrime(int n);
它看起来很无辜. 以下是动态加载 `SimpleDll.Dll` 然后定位 `IsPrime` 的首次尝试:
auto hPrimesLib = ::LoadLibrary(L"SimpleDll.dll"); if (hPrimesLib) { // DLL found using PIsPrime = bool (*)(int); auto IsPrime = (PIsPrime)::GetProcAddress(hPrimesLib, "IsPrime"); if (IsPrime) { bool test = IsPrime(17); printf("%d\n", (int)test); } }
💡 上述代码中的
using语句是 C++ 11 及更高版本中创建类型定义的首选方式, 有效地取代了typedef. 如果你使用的是 C 或旧的编译器, 请将此行替换为typedef bool (*PIsPrime)(int);. 函数类型定义从来都不好看, 但使用它们可以使其可以忍受.代码看起来相对直接 - DLL 被加载 (它位于可执行文件的目录中, 当在 Visual Studio 中作为同一解决方案的一部分构建 DLL 和 EXE 时), 所以它被正确地找到了. 不幸的是, 对
GetProcAddress的调用失败了,GetLastError返回 127 (“找不到指定的过程”). 显然,GetProcAddress无法定位导出的函数, 尽管它被导出了. 为什么?原因与函数的名称有关. 如果我们回到
Dumpbin关于SimpleDll.Dll的信息, 我们会发现这个 (见本章前面):1 0 000111F9 ?IsPrime@@YA_NH@Z = @ILT+500(?IsPrime@@YA_NH@Z)
链接器将函数名称“mangled”成了
?IsPrime@@YA_NH@Z. 原因在于“IsPrime”这个名称在 C++ 中不够唯一. 一个IsPrime函数可以存在于类 A 和类 B 中, 也可以是全局的. 而且它可能是某个命名空间 C 的一部分. 如果这还不够, 由于 C++ 函数重载, 同一作用域中可以有多个名为IsPrime的函数. 所以链接器给函数一个看起来很奇怪的名称, 其中包含这些唯一的属性. 我们可以尝试在前面的代码示例中替换这个 mangled 名称, 像这样:auto IsPrime = (PIsPrime)::GetProcAddress(hPrimesLib, "?IsPrime@@YA_NH@Z");
这确实有效! 然而, 这不好玩, 我们必须用一个工具来查找 mangled 名称才能做对. 通常的做法是将所有导出的函数都变成 C 风格的函数. 因为 C 不支持函数重载或类, 链接器就不必做复杂的 mangling. 以下是一种将函数导出为 C 的方法:
extern "C" __declspec(dllexport) bool IsPrime(int n);
💡 如果你在编译 C 文件, 这将是默认的.
通过这个更改, 获取
IsPrime函数指针变得简单了:auto IsPrime = (PIsPrime)::GetProcAddress(hPrimesLib, "IsPrime");
这种将函数变成 C 风格的方案, 不能用于类中的成员函数. 这就是为什么使用
GetProcAddress访问 C++ 函数不切实际的原因. 这就是为什么大多数旨在与LoadLibrary/GetProcAddress一起使用的 DLL 只公开 C 风格函数的原因.一旦不再需要 DLL, 调用
FreeLibrary将其从进程中卸载:BOOL FreeLibrary(_In_ HMODULE hLibModule);
系统为每个加载的 DLL 维护一个每进程计数器. 如果对同一个 DLL 进行了多次
LoadLibrary调用, 那么需要相同数量的FreeLibrary调用才能真正地从进程地址空间卸载 DLL.如果需要一个已加载 DLL 的句柄, 可以使用
GetModuleHandle来检索它:HMODULE GetModuleHandle(_In_opt_ LPCTSTR lpModuleName);
模块名称不需要是完整路径, 只需要一个 DLL 名称. 如果没有提供扩展名, 默认会附加“.dll”. 该函数不会增加 DLL 的加载计数. 如果模块名称为
NULL, 则返回可执行文件的句柄. 可执行文件就像 DLL 一样被映射到进程地址空间 - 返回的“句柄”实际上是可执行文件镜像加载到的虚拟地址. - 调用约定
术语 调用约定 (Calling Convention) 指示 (除其他外) 函数参数是如何传递给函数的, 以及谁负责清理参数, 如果它们是在堆栈上传递的. 对于 x64, 只有一种调用约定. 对于 x86, 有几种. 最常见的是标准调用约定 (
stdcall) 和 C 调用约定 (cdecl).stdcall和cdecl都使用堆栈来传递参数, 从右到左推送. 它们之间的主要区别在于, 使用stdcall时, 被调用者 (函数体本身) 负责清理堆栈, 而使用cdecl时, 调用者负责.stdcall的优点是更小, 因为堆栈清理代码只出现一次 (作为函数体的一部分). 使用cdecl, 每次调用函数都必须跟一个指令来清理堆栈上的参数.cdecl函数的优点是它们可以接受可变数量的参数 (由 C/C++ 中的省略号...指定), 因为只有调用者知道传递了多少个参数.本节中关于调用约定的讨论远非详尽. 请查看在线资源以获取所有细节.
在 Visual C++ 的用户模式项目中使用的默认调用约定是
cdecl. 指定调用约定是通过在返回类型和函数名称之间放置适当的关键字来完成的. Microsoft 编译器为此目的识别__cdecl和__stdcall关键字. 使用的关键字也必须在实现中指定. 以下是将IsPrime转换为使用stdcall的示例:extern "C" __declspec(dllexport) bool __stdcall IsPrime(int n);
这也意味着在定义用于
GetProcAddress的函数指针时, 必须指定正确的调用约定, 否则我们会得到运行时错误或堆栈损坏:using PIsPrime = bool (__stdcall *)(int); // or typedef bool(__stdcall* PIsPrime)(int);
__stdcall是大多数 Windows API 使用的调用约定. 这通常通过使用以下宏之一来传达, 这些宏的意思完全相同 (WINAPI,APIENTRY,PASCAL,CALLBACK). 这就是为什么在 Windows 头文件中使用这些宏之一的原因. 以下是Sleep函数的精确声明:VOID WINAPI Sleep(_In_ DWORD dwMilliseconds);
在显示函数声明时, 我省略了这些宏, 以简化它们并专注于重要的东西.
stdcall函数还有一个额外的麻烦. 链接器对它们的 mangling 与cdecl不同, 它在它们的名字前加上一个下划线, 并在后面附加@符号和作为参数传递的字节数. 所以对于IsPrime, 实际导出的名字是_IsPrime@4. 这也意味着传递给GetProcAddress的名字对于 x86 应该是这个名字, 但对于 x64 只是IsPrime(x64 不 mangling 名字, 因为它只有一个调用约定).stdcall函数的解决方案是使用模块定义 (DEF) 文件. 这个文件可以添加到 DLL 项目中以指定各种选项. 它的主要用途是列出导出的符号, 这意味着不再需要使用__declspec(dllexport). 导出的函数可以按其简单的名称查找, 而不管调用约定如何.你可以通过使用 Visual Studio 的“Add New Item…”菜单添加一个 DEF 文件, 就像任何其他文件一样. 你可以搜索“def”或只显式指定文件的扩展名. DEF 文件名必须与项目名称相同, 这样它才能在没有任何额外配置的情况下被处理. 对于
SimpleDll, 文件名是SimpleDll.def. 以下是用于以一致方式导出IsPrime的 DEF 文件的内容:LIBRARY EXPORTS IsPrime如果需要更多导出, 可以在单独的行中添加每个. 有了这个文件,
IsPrime函数就可以用其简单的名称通过GetProcAddress查找. - DLL 搜索和重定向
当只用文件名调用
LoadLibrary时, 会使用一定的搜索路径. 可以用SetDllDirectory添加一个自定义路径来搜索 DLL:BOOL SetDllDirectory(_In_opt_ LPCTSTR lpPathName);
指定的路径在可执行文件的目录之后查找. 如果
lpPathName是NULL, 任何先前由SetDllDirectory设置的目录都会被移除, 恢复默认的搜索顺序. 如果lpPathName是一个空字符串, 那么进程的当前目录会从搜索列表中移除. 每次调用SetDllDirectory都会替换任何先前的调用.如果需要多个搜索目录, 调用
AddDllDirectory:DLL_DIRECTORY_COOKIE AddDllDirectory(_In_ PCTSTR NewDirectory);
该函数将指定的目录添加到搜索路径, 并返回一个表示此“注册”的不透明指针. 然而, 使用
AddDllDirectory添加的目录不会自动使用. 必须进行额外的调用SetDefaultDllDirectories以启用这些额外的目录:BOOL SetDefaultDllDirectories(_In_ DWORD DirectoryFlags);
标志可以是表 15-1 中列出的值的组合.
Value ( LOAD_LIBRARY_SEARCH_prefix)Description APPLICATION_DIR可执行文件目录包含在搜索中 USER_DIRS将使用 AddDllDirectory添加的目录添加到搜索中SYSTEM32将 System32 目录添加到搜索中 DEFAULT_DIRS结合所有先前的值 DLL_LOAD_DIR将加载的 DLL 的目录临时添加到搜索中以查找依赖的 DLL 要允许
AddDllDirectory目录对将来的LoadLibrary调用产生影响, 使用以下调用:::SetDefaultDllDirectories(LOAD_LIBRARY_SEARCH_USER_DIRS);
添加的目录应在某个时候用
RemoveDllDirectory移除:BOOL RemoveDllDirectory(_In_ DLL_DIRECTORY_COOKIE Cookie);
没有显式函数可以返回到默认的搜索路径. 处理这个问题的最佳方法是为每个
AddDllDirectory调用RemoveDllDirectory, 并用NULL调用SetDllDirectory. 或者,LoadLibraryEx函数可以用于“一次性”搜索路径更改 (见本章后面).
2.3.4. DllMain 函数
一个 DLL 可以有一个入口点, 传统上称为 DllMain, 它必须有以下原型:
BOOL WINAPI DllMain(HINSTANCE hInsdDll, DWROD reason, PVOID reserved);
hInstance 参数是 DLL 加载到进程中的虚拟地址. 如果 DLL 是显式加载的, 它与从 LoadLibrary 返回的值相同. reason 参数指示为什么调用 DllMain. 它可以具有表 15-2 中列出的值.
| Reason value | Description |
|---|---|
DLL_PROCESS_ATTACH |
当 DLL 附加到进程时调用 |
DLL_PROCESS_DETACH |
在 DLL 从进程卸载之前调用 |
DLL_THREAD_ATTACH |
当进程中创建新线程时调用 |
DLL_THREAD_DETACH |
在线程退出进程之前调用 |
当一个 DLL 被加载到一个进程中时, DllMain 会以 DLL_PROCESS_ATTACH 的原因被调用. 如果同一个 DLL 被多次加载到同一个进程中 (多次调用 LoadLibrary), DLL 的内部引用计数器会增加, 但 DllMain 不会再次被调用. 使用 DLL_PROCESS_ATTACH, DllMain 必须返回 TRUE 以指示 DLL 已正确初始化, 否则返回 FALSE. 如果返回 FALSE, DLL 会被卸载.
DLL_PROCESS_ATTACH 的反面是 DLL_PROCESS_DETACH, 在 DLL 卸载之前调用. 这可能是因为整个进程正在关闭, 或者因为调用了 FreeLibrary 来卸载这个 DLL. 请记住, 使用 TerminateProcess 强制终止进程不会调用 DllMain (更多细节见第 3 章).
剩下的两个值导致 DllMain 在创建新线程 (DLL_THREAD_ATTACH) 和线程退出 (DLL_THREAD_DETACH) 之前被调用. 许多 DLL 不关心其宿主进程中创建或销毁的线程. 在这种情况下, 一个有用的优化是调用 DisableThreadlibraryCalls:
BOOL DisableThreadLibraryCalls(_In_ HMODULE hLibModule);
使用 DLL 的模块句柄的这个调用告诉系统不要为线程相关的事件调用 DllMain. 这个调用通常在发送 DLL_PROCESS_ATTACH 原因时调用.
DLL_THREAD_ATTACH原因不会为进程中的第一个线程调用 - DLL 应该为此使用DLL_PROCESS_ATTACH.
如果 DLL 使用线程局部存储 (Thread Local Storage, TLS, 在第 10 章中讨论), 那么它可能希望为进程中的每个线程分配一些结构. DLL_THREAD_ATTACH 和 DLL_THREAD_DETACH 的原因对于这样的分配和释放是有用的.
💡 有第五个支持的原因值, 称为
DLL_PROCESS_VERIFIER(等于 4), 可以用来编写应用程序验证器 DLL, 尽管它没有被官方文档化. 我将在第 20 章中更多地讨论应用程序验证器.
DllMain 的最后一个参数被称为“reserved”, 但它指示 DLL 是隐式加载 (lpReserved 非 NULL) 还是显式加载 (lpReserved 为 NULL).
用 Visual Studio 创建一个 DLL 项目会提供一个仅返回 TRUE 的 DllMain 骨架, 用于所有通知. 以下是一个简单的 DllMain, 在 DLL 加载到进程中时调用 DisableThreadlibraryCalls:
BOOL APIENTRY DllMain(HMODULE hModule, DWORD reason, LPVOID lpReserved) { switch (reason) { case DLL_PROCESS_ATTACH: ::DisableThreadLibraryCalls(hModule); break; case DLL_THREAD_ATTACH: case DLL_THREAD_DETACH: case DLL_PROCESS_DETACH: break; } return TRUE; }
DllMain 函数是在持有加载器锁 (Loader Lock) 的情况下调用的. 你可以把加载器锁看作一个临界区. 这意味着从 DllMain 调用一些函数是不允许的或危险的, 因为它们可能导致死锁. 例如, 如果 DllMain 代码 (比如说在 DLL_THREAD_ATTACH 中) 等待获取一个由应用程序管理的互斥锁, 而另一个线程持有该互斥锁. 另一个线程在释放互斥锁之前, 调用了一些导致尝试获取加载器锁的函数, 比如调用 LoadLibrary 或 GetModuleHandle. 这就导致了死锁.
建议很简单: 在 DllMain 中尽可能少地做事情, 并将其他初始化推迟到一个可以在 DllMain 返回后立即调用的显式函数中. 创建/销毁进程和 DLL (CreateProcess, CreateThread 等) 的函数应该避免. 使用堆或虚拟 API, I/O 函数, TLS 和来自 kernel32.dll 的大多数其他函数是安全的.
2.3.5. DLL 注入
在某些情况下, 将一个 DLL 注入到另一个进程中是可取的. 我所说的“注入一个 DLL”是指以某种方式强制另一个进程加载一个特定的 DLL. 这允许该 DLL 在目标进程的上下文中执行代码. 这种能力有很多用途, 但它们基本上都归结为对目标进程内操作的某种形式的定制或拦截. 以下是一些具体的例子:
- 反恶意软件解决方案和其他应用程序可能希望挂钩目标进程中的 API 函数. 挂钩在下一个主要部分中描述.
- 通过子类化窗口或控件来自定义窗口的能力, 允许 UI 的行为改变.
- 作为目标进程的一部分, 可以无限制地访问该进程中的任何东西. 有些可以用于好的目的, 比如监视应用程序行为以定位错误的 DLL, 有些则用于坏的目的.
在本节中, 我们将看一些常见的 DLL 注入技术. 这些绝不是详尽无遗的, 因为网络安全社区总能想出巧妙的方法来向目标进程注入代码. 本节重点介绍更“传统”或“标准”的技术, 以便理解其基本原理.
- 使用远程线程注入
通过在目标进程中创建一个加载所需 DLL 的线程来注入 DLL, 可能是最著名和最直接的技术 (相对而言). 这个想法是在目标进程中创建一个线程, 该线程调用
LoadLibrary函数, 并传入要注入的 DLL 的路径. 问题是, 你如何让代码在目标进程中执行?Injector 项目演示了这种技术. 首先, 我们需要检查命令行参数:
int main(int argc, const char* argv[]) { if (argc < 3) { printf("Usage: injector <pid> <dllpath>\n"); return 0; }
注入器需要目标进程的 ID 和要注入的 DLL. 接下来我们打开目标进程的句柄:
HANDLE hProcess = ::OpenProcess( PROCESS_VM_WRITE | PROCESS_VM_OPERATION | PROCESS_CREATE_THREAD, FALSE, atoi(argv)); if (!hProcess) return Error("Failed to open process");
正如我们很快就会看到的, 我们需要相当多的访问掩码位来获得足够的权限来进行这种注入技术. 这意味着某些进程将无法访问.
这种注入方法的诀窍在于, 从二进制的角度来看,
LoadLibrary函数和线程的函数本质上是相同的:HMODULE WINAPI LoadLibrary(PCTSTR); DWORD WINAPI ThreadFunction(PVOID);
两个原型都接受一个指针, 这就是诀窍所在: 我们可以创建一个运行
LoadLibrary函数的线程! 这很好, 因为LoadLibrary的代码已经在目标进程中了 (因为它是kernel32.dll的一部分, 必须加载到 Windows 子系统的每个进程中).下一个任务是准备要加载的 DLL 路径. 路径字符串本身必须放在目标进程中, 因为
LoadLibrary将在那里执行. 我们可以为此目的使用VirtualAllocEx函数:void* buffer = ::VirtualAllocEx(hProcess, nullptr, 1 << 12, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE); if (!buffer) return Error("Failed to allocate buffer in target process");
使用
VirtualAllocEx需要PROCESS_VM_OPERATION访问掩码, 这是我们在OpenProcess时请求的. 我们分配一个 4 KB 的缓冲区, 这是过度的, 但即使我们指定得更少, 它也会被向上舍入到 4 KB. 注意返回的指针在调用者的进程中没有意义 - 它是目标进程中分配的地址.接下来我们需要用
WriteProcessMemory将 DLL 路径复制到分配的缓冲区中:if (!::WriteProcessMemory(hProcess, buffer, argv, ::strlen(argv) + 1, nullptr)) return Error("Failed to write to target process");
使用
WriteProcessMemory需要进程句柄具有PROCESS_VM_WRITE访问掩码, 它确实有. 代码使用 ASCII 写入从命令行检索到的 DLL 路径, 这可能看起来不寻常. 我们马上就会看到原因. 一切准备就绪 = 是时候创建远程线程了:DWORD tid; HANDLE hThread = ::CreateRemoteThread(hProcess, nullptr, 0, (LPTHREAD_START_ROUTINE)::GetProcAddress( ::GetModuleHandle(L"kernel32"), "LoadLibraryA"), buffer, 0, &tid); if (!hThread) return Error("Failed to create remote thread");
CreateRemoteThread接受目标进程句柄 (必须具有PROCESS_CREATE_THREAD访问掩码, 它有), 一个NULL安全描述符, 默认堆栈大小, 以及线程的启动例程. 这就是我们利用LoadLibrary和线程函数二进制等价性的地方.首先,
LoadLibrary根本不是一个函数 - 它是一个宏. 我们必须选择LoadLibraryA或LoadLibraryW- 我选择了LoadLibraryA, 只是因为它使用起来更方便一些. 这就是为什么上面复制的字符串是 ASCII 的原因. 我们可以使用LoadLibraryW并将一个 Unicode 字符串复制到目标进程, 基本上得到相同的结果.GetProcAddress调用用于动态定位LoadLibraryA的地址, 利用了它在当前进程中地址相同的事实. 这是这项技术的关键 - 无需将代码复制到目标进程. 线程的参数是buffer- 我们复制 DLL 路径的目标进程中的地址.就是这样. 一个重要的事情要注意的是, 注入的 DLL 必须与目标进程具有相同的“位数”, 因为 Windows 不允许一个 32 位进程加载一个 64 位 DLL, 反之亦然.
剩下的就是做一些清理工作:
printf("Thread %u created successfully!\n", tid); if (WAIT_OBJECT_0 == ::WaitForSingleObject(hThread, 5000)) printf("Thread exited.\n"); else printf("Thread still hanging around...\n"); // be nice ::VirtualFreeEx(hProcess, buffer, 0, MEM_RELEASE); ::CloseHandle(hThread); ::CloseHandle(hProcess);
等待线程终止不是强制性的, 但我们需要在调用
VirtualFreeEx之前给它一些时间来移除用VirtualAllocEx完成的分配. 这是礼貌的, 但不是严格必要的. 我们也可以将那 4 KB 的已提交内存留在目标进程中.本章的解决方案有一个名为 Injected 的 DLL 项目, 你可以用它来测试这项技术. 以下是用于测试的命令行示例:
C:\>Injector.exe 44532 C:\Dev\Win10SysProg\Chapter15\x64\Debug\Injected.dll💡 你可能会收到你的反病毒软件的通知, 如果你有的话, 因为上述 API 的组合通常被监控并被认为是恶意的. 我机器上的 Windows Defender 将 `Injector.exe` 标记为恶意软件, 威胁要删除它.
你必须指定 DLL 的完整路径, 因为加载规则是从目标进程的角度来看的, 而不是调用者的.
InjectedDLL 的DllMain显示一个简单的消息框:BOOL APIENTRY DllMain(HMODULE hModule, DWORD reason, PVOID lpReserved) { switch (reason) { case DLL_PROCESS_ATTACH: wchar_t text; ::StringCchPrintf(text, _countof(text), L"Injected into process %u", ::GetCurrentProcessId()); ::MessageBox(nullptr, text, L"Injected.Dll", MB_OK); break; } return TRUE; }
- Windows 钩子
本节中使用的术语 Windows 钩子 (Windows Hooks) 是指通过
SetWindowsHookExAPI 可用的一组与用户界面相关的钩子:HHOOK SetWindowsHookEx( _In_ int idHook, _In_ HOOKPROC lpfn, _In_opt_ HINSTANCE hmod, _In_ DWORD dwThreadId);
第一个参数是钩子类型. 有几种类型的钩子, 每种都有自己的语义. 你可以在官方文档中找到完整的列表和详细信息. 这些钩子可以为特定线程 (由
dwThreadId参数提供) 安装, 或者全局安装, 用于调用者桌面上的所有进程 (dwThreadId设置为零). 一些钩子类型只能全局安装 (WH_JOURNALRECORD,WH_JOURNALPLAYBACK,WH_MOUSE_LL,WH_KEYBOARD_LL,WH_SYSMSGFILTER), 而其他钩子可以全局安装或为特定线程安装.由
lpfn提供的钩子函数具有以下原型:typedef LRESULT (CALLBACK* HOOKPROC)(int code, WPARAM wParam, LPARAM lParam);
参数的含义为每种单独的钩子类型描述. 函数必须在被钩子进程的上下文中有效. 如果钩子是全局使用或在不同进程的线程上使用, 回调函数必须是 DLL 的一部分, 该 DLL 被注入到目标进程或进程中. 在那种情况下,
hmod参数是调用者提供的 DLL 的句柄. 如果被钩子的线程在调用进程内, 模块句柄可以是NULL, 钩子回调可以是调用者进程的一部分.对于全局钩子还有其他具体细节. 由于 32 位 DLL 不能被 64 位进程加载, 反之亦然, 你如何钩住 32 位和 64 位进程? 一种选择是有两个钩子应用程序, 32 位和 64 位, 每个都提供其自己的具有正确位数的 DLL. 另一种选择是只使用一个安装应用程序, 但这会导致其他位数的进程向必须泵送消息的钩子应用程序进行远程调用. 这可以工作, 但速度较慢, 并且回调不在目标进程的上下文中运行. 请查阅文档以获取更多详细信息.
SetWindowsHookEx的返回值是钩子的句柄, 如果函数失败则为NULL.SetWindowsHookEx的好处是 DLL (如果提供) 会在幕后由Win32k.sys自动注入. 这比使用像CreateRemoteThread这样的东西要隐蔽得多.SetWindowsHookEx并不完美. 以下是它的一些缺点:- 它只能用于加载
user32.dll的进程. 通常没有 GUI 的进程不加载user32.dll. - 全局钩子对于使用调用者桌面的所有线程都是“全局”的. 因此, 它无法钩住其他会话中的进程, 即使它们有 GUI.
- 它只能用于加载
- 使用 SetWindowsHookEx 进行 DLL 注入和挂钩
以下示例使用
SetWindowsHookEx和WH_GETMESSAGE钩子类型将 DLL 注入到找到的第一个 Notepad 进程中, 并监视所有键入的键. 这些键被发送到监视应用程序, 该应用程序有效地看到了用户在 Notepad 中进行的每一次按键.该系统涉及两个项目. 注入的可执行文件 (
HookInject) 和要通过SetWindowsHookEx间接注入的 DLL (HookDll). 让我们从注入应用程序开始.要测试这些, 首先运行 Notepad, 然后运行
HookInject. 现在开始在 Notepad 中键入. 你会看到相同的文本在HookInject的控制台窗口中回显 (图 15-10).
Figure 222: 图 15-10: 被钩住的 Notepad
你可以通过在 Process Explorer 中查找 Notepad 并检查加载的模块来确保 DLL 确实被注入 (图 15-11).

Figure 223: 图 15-11: Notepad 进程中注入的 DLL
首要任务是定位第一个 Notepad 实例的第一个线程, 因为我们需要获取由 Notepad 的 UI 处理的消息的信息, 这些消息由 Notepad 的第一个线程处理. 为此, 我们可以编写一个使用 Toolhelp API 的线程枚举函数并定位该线程:
DWORD FindMainNotepadThread() { auto hSnapshot = ::CreateToolhelp32Snapshot(TH32CS_SNAPTHREAD, 0); if (hSnapshot == INVALID_HANDLE_VALUE) return 0; DWORD tid = 0; THREADENTRY32 th32; th32.dwSize = sizeof(th32); ::Thread32First(hSnapshot, &th32); do { auto hProcess = ::OpenProcess(PROCESS_QUERY_LIMITED_INFORMATION, FALSE, th32.th32OwnerProcessID); if (hProcess) { WCHAR name[MAX_PATH]; if (::GetProcessImageFileName(hProcess, name, MAX_PATH) > 0) { auto bs = ::wcsrchr(name, L'\\'); if (bs && ::_wcsicmp(bs, L"\\notepad.exe") == 0) { tid = th32.th32ThreadID; } } ::CloseHandle(hProcess); } } while (tid == 0 && ::Thread32Next(hSnapshot, &th32)); ::CloseHandle(hSnapshot); return tid; }
CreateToolhelp32Snapshot与TH32CS_SNAPTHREAD一起使用以枚举系统中的所有线程 (API 不支持枚举特定进程中的线程). 对于每个线程, 打开其父进程的句柄. 如果成功, 使用GetProcessImageFileName查找可执行文件的镜像路径. 如果此路径以\Notepad.exe结尾, 则返回线程 ID, 因为它将是第一个线程.现在
main函数可以开始工作了. 它首先调用FindMainNotepadThread:int main() { DWORD tid = FindMainNotepadThread(); if (tid == 0) return Error("Failed to locate Notepad");
接下来, 加载要注入的 DLL, 并提取两个导出的函数:
auto hDll = ::LoadLibrary(L"HookDll"); if (!hDll) return Error("Failed to locate Dll\n"); using PSetNotify = void (WINAPI*)(DWORD, HHOOK); auto setNotify = (PSetNotify)::GetProcAddress(hDll, "SetNotificationThread"); if (!setNotify) return Error("Failed to locate SetNotificationThread function in DLL"); auto hookFunc = (HOOKPROC)::GetProcAddress(hDll, "HookFunction"); if (!hookFunc) return Error("Failed to locate HookFunction function in DLL");
SetNotificationThread是从 DLL 导出的一个函数, 稍后将用于将信息从 Notepad 进程传达给注入器/监视进程.HookFunction是钩子函数本身, 必须传递给SetWindowsHookEx.是时候安装钩子了:
auto hHook = ::SetWindowsHookEx(WH_GETMESSAGE, hookFunc, hDll, tid); if (!hHook) return Error("Failed to install hook");
钩子类型是
WH_GETMESSAGE, 它对于拦截发往由被钩子线程创建的窗口的消息很有用. 此钩子的一个额外好处是钩子函数能够根据需要在消息到达目的地之前更改消息.此时, 当下一条消息发送到 Notepad 的窗口时, 钩子 DLL 会自动注入到 Notepad 的进程中, 并且钩子函数将为每条消息被调用. 钩子函数能用消息信息做什么? 最简单的选择是简单地将其写入某个文件. 然而, 为了使其更有趣, 钩子函数通过使用线程消息通知注入进程所有的按键. 钩子函数 (在 Notepad 的进程内) 需要知道向哪个线程发送消息. 这就是
SetNotificationThread的作用, 现在被调用:setNotify(::GetCurrentThreadId(), hHook); ::PostThreadMessage(tid, WM_NULL, 0, 0);
SetNotificationThread被传递了两个信息: 调用者的线程 ID 以接收消息, 以及钩子句柄本身, 钩子函数将需要它, 我们很快就会看到. 如果你注意的话, 这个调用没有完全的意义, 因为它在本地进程中调用SetNotificationThread- DLL 被加载到这个进程中, 但这两个参数传达的信息应该在 Notepad 进程的上下文中可用. 这是怎么回事? 我们很快就会解开这个谜团.对
PostThreadMessage的调用是一个唤醒 Notepad 的技巧, 用一个虚拟消息 (WM_NULL) 强制它加载我们的钩子 DLL, 如果它还没有加载的话.PostThreadMessage是一个允许向线程发送窗口消息的函数. 正常的消息是针对一个窗口的 (使用窗口句柄). 使用PostThreadMessage, 窗口句柄实际上是NULL. 其余参数与其他窗口消息发送函数 (如SendMessage和PostMessage) 相同. 对于线程消息, 没有 “SendThreadMessage”, 这意味着PostThreadMessage本质上是异步的 - 它将消息放入目标线程的队列中并立即返回. 对于针对窗口句柄的消息, 有更多的灵活性 -SendMessage是同步的, 而PostMessage是异步的.现在剩下的就是等待来自被钩住的 Notepad 的传入消息并以某种方式处理它们:
MSG msg; while (::GetMessage(&msg, nullptr, 0, 0)) { if (msg.message == WM_APP) { printf("%c", (int)msg.wParam); if (msg.wParam == 13) printf("\n"); } } ::UnhookWindowsHookEx(hHook); ::FreeLibrary(hDll); return 0; }
GetMessage检查当前线程的消息队列, 只有在有消息时才返回. 由于当前线程没有窗口, 任何消息都是发往该线程的, 来自 Notepad 进程. 如果有除WM_QUIT以外的消息可用,GetMessage返回. 我们希望钩子函数在 Notepad 进程终止时发布WM_QUIT.预期的消息是
WM_APP(0x8000), 保证不被标准窗口消息常量使用, 它是从钩子函数发布的 (我们马上就会看到).MSG结构的wParam成员持有键 (同样, 由钩子函数提供), 应用程序只是将其回显到控制台.最后, 当收到
WM_QUIT消息时, 进程通过取消挂钩和卸载 DLL 来清理.现在让我们把注意力转向钩子 DLL. 我们之前遇到的难题是通过拥有一些作为 DLL 一部分的全局共享变量来解决的:
#pragma data_seg(".shared") DWORD g_ThreadId = 0; HHOOK g_hHook = nullptr; #pragma data_seg() #pragma comment(linker, "/section:.shared,RWS")
在 DLL (或 EXE) 中共享变量的这种技术在第 12 章中有描述. 注入应用程序在其自己的进程上下文中调用了
SetNotificationThread, 但该函数将信息写入共享变量, 因此它们对使用相同 DLL 的任何进程都可用:extern "C" void WINAPI SetNotificationThread(DWORD threadId, HHOOK hHook) { g_ThreadId = threadId; g_hHook = hHook; }
这种安排如图 15-12 所示.

Figure 224: 图 15-12: 注入和被注入的进程
DllMain函数的实现如下:BOOL APIENTRY DllMain(HMODULE hModule, DWORD reason, PVOID pReserved) { switch (reason) { case DLL_PROCESS_ATTACH: ::DisableThreadLibraryCalls(hModule); break; case DLL_PROCESS_DETACH: ::PostThreadMessage(g_ThreadId, WM_QUIT, 0, 0); break; } return TRUE; }
首先, 它在附加到进程时调用
DisableThreadLibraryCalls, 表示 DLL 不关心线程的创建/销毁. 当卸载时, 可能是因为 Notepad 正在退出, 一个WM_QUIT消息被发送到注入器的线程, 导致其GetMessage调用返回FALSE.有趣的工作是由钩子函数完成的:
extern "C" LRESULT CALLBACK HookFunction(int code, WPARAM wParam, LPARAM lParam) { if (code == HC_ACTION) { auto msg = (MSG*)lParam; if (msg->message == WM_CHAR) { ::PostThreadMessage(g_ThreadId, WM_APP, msg->wParam, msg->lParam); // prevent 'A' characters from getting to the app //if (msg->wParam == 'A' || msg->wParam == 'a') // msg->wParam = 0; } } return ::CallNextHookEx(g_hHook, code, wParam, lParam); }
每个与
SetWindowsHookEx一起使用的钩子函数都有相同的原型, 但规则不同. 你应该总是仔细阅读特定钩子回调的文档. 在我们的例子中 (WH_GETMESSAGE), 如果code是HC_ACTION, 钩子应该处理通知. 消息被打包到lParam值中. 如果消息是WM_CHAR, 表示一个“可打印”的字符, 回调会向注入器的线程发布一个带有消息信息的消息 (wParam持有键本身).注释掉的代码显示了更改消息是多么简单, 以至于键永远不会到达 Notepad 的线程. 最后, 建议调用
CallNextHookEx以允许钩子链中的其他钩子函数有机会完成它们的工作. 然而, 这不是强制性的.
2.3.6. API 挂钩
术语 API 挂钩 (API Hooking) 指的是拦截 Windows API (或更普遍地, 任何外部函数) 的行为, 以便可以检查其参数并可能更改其行为. 这是一种极其强大的技术, 首先被反恶意软件解决方案采用, 它们通常将自己的 DLL 注入到每个进程 (或大多数进程) 中, 并挂钩它们关心的某些函数, 例如 `VirtualAllocEx` 和 `CreateRemoteThread`, 将它们重定向到其 DLL 提供的备用实现. 在那个实现中, 它们可以检查参数并做任何它们需要做的事情, 然后返回一个失败代码给调用者或将调用转发给原始函数.
在本节中, 我们将看两种常见的函数挂钩技术.
- IAT 挂钩
导入地址表 (Import Address Table, IAT) 挂钩可能是最简单的函数挂钩方法. 它设置起来相对简单, 并且不需要任何平台特定的代码.
每个 PE 镜像都有一个导入表, 列出了它依赖的 DLL, 以及它从 DLL 中使用的函数. 你可以通过用 Dumpbin 或图形工具检查 PE 文件来查看这些导入. 以下是
Notepad.exe模块的摘录:dumpbin /imports c:\Windows\System32\notepad.exe Microsoft (R) COFF/PE Dumper Version 14.26.28805.0 Copyright (C) Microsoft Corporation. All rights reserved. Dump of file c:\Windows\System32\notepad.exe File Type: EXECUTABLE IMAGE Section contains the following imports: KERNEL32.dll 1400268B0 Import Address Table 14002D560 Import Name Table 0 time date stamp 0 Index of first forwarder reference 2B7 GetProcAddress DB CreateMutexExW 1 AcquireSRWLockShared 113 DeleteCriticalSection 220 GetCurrentProcessId 2BD GetProcessHeap ... GDI32.dll 1400267F8 Import Address Table 14002D4A8 Import Name Table 0 time date stamp 0 Index of first forwarder reference 34 CreateDCW 39F StartPage 39D StartDocW 366 SetAbortProc ... USER32.dll 140026B50 Import Address Table 14002D800 Import Name Table 0 time date stamp 0 Index of first forwarder reference 157 GetFocus 2AF PostMessageW 177 GetMenu 43 CheckMenuItem ...
上面的输出显示了 Notepad 从 Notepad 依赖的每个模块中使用的函数. 每个模块, 反过来, 都有自己的导入表. 以下是
User32.dll的例子:dumpbin /imports c:\Windows\System32\User32.dll Microsoft (R) COFF/PE Dumper Version 14.26.28805.0 Copyright (C) Microsoft Corporation. All rights reserved. Dump of file c:\Windows\System32\user32.dll File Type: DLL Section contains the following imports: win32u.dll 180092AD0 Import Address Table 1800AA0B0 Import Name Table 0 time date stamp 0 Index of first forwarder reference 297 NtMITSetInputDelegationMode 29B NtMITSetLastInputRecipient 363 NtUserEnableScrollBar 4FA NtUserTestForInteractiveUser 501 NtUserTransformRect 384 NtUserGetClassName ... ntdll.dll 180092700 Import Address Table 1800A9CE0 Import Name Table 0 time date stamp 0 Index of first forwarder reference 8C5 __chkstk 95F toupper 936 memcmp 96A wcscmp 937 memcpy 5A1 RtlSetLastWin32Error BB NlsAnsiCodePage ... GDI32.dll 180091C58 Import Address Table 1800A9238 Import Name Table 0 time date stamp 0 Index of first forwarder reference 309 PatBlt 36C SetBkMode 364 SelectObject 2E3 IntersectClipRect ...
这些导入函数被调用的方式是通过导入地址表, 该表包含了这些函数在加载器 (
NtDll.Dll) 在运行时映射它们之后的最终地址. 这些地址是事先不知道的, 因为 DLL 可能不会在它们的首选地址加载 (有关更多信息, 请参见本章后面的“DLL 基地址”部分).IAT 挂钩利用了所有调用都是间接的这一事实, 只是在运行时将表中的函数地址替换为指向备用函数的指针, 同时保存原始地址, 以便在需要时可以调用实现. 这种挂钩可以在当前进程上完成, 也可以与 DLL 注入结合在另一个进程的上下文中执行.
要挂钩的函数必须在所有进程模块中搜索, 因为每个模块都有自己的 IAT. 例如,
CreateFileW函数可以由Notepad.exe模块本身调用, 但也可以在调用打开文件对话框时由ComCtl32.dll调用. 如果只对 Notepad 的调用感兴趣, 那么只需要挂钩它的 IAT. 否则, 必须搜索所有加载的模块, 并替换它们的CreateFileWIAT 条目.为了演示这种技术, 我已将第 13 章的 Working Sets 应用程序复制到本章的 Visual Studio 解决方案中. 我们将挂钩
User32.Dll中的GetSysColorAPI 用于演示目的, 并在不触及应用程序 UI 代码的情况下更改应用程序中的几种颜色.在
WinMain函数中, 我们调用一个稍后介绍的辅助函数来执行挂钩. 首先, 我们需要一个变量来保存原始函数指针:decltype(::GetSysColor)* GetSysColorOrg;
`decltype` 关键字 (C++ 11+) 通过获取括号中表达式的正确类型来节省输入和错误, 在本例中是 `GetSysColor` 的类型. 现在我们可以开始获取原始函数:
void HookFunctions() { auto hUser32 = ::GetModuleHandle(L"user32"); // save original functions GetSysColorOrg = (decltype(GetSysColorOrg))::GetProcAddress( hUser32, "GetSysColor");
挂钩本身很简单, 因为有一些我们马上会看到的辅助函数:
auto count = IATHelper::HookAllModules("user32.dll", GetSysColorOrg, GetSysColorHooked); ATLTRACE(L"Hooked %d calls to GetSysColor\n", count); }
GetSysColorHooked是我们用于GetSysColor的钩子替换函数. 它必须具有与原始函数相同的原型. 以下是我们的自定义实现:COLORREF WINAPI GetSysColorHooked(int index) { switch (index) { case COLOR_BTNTEXT: return RGB(0, 128, 0); case COLOR_WINDOWTEXT: return RGB(0, 0, 255); } return GetSysColorOrg(index); }
被钩住的函数为几个索引返回不同的颜色, 并为所有其他输入调用原始函数.
秘密, 当然, 在于
IATHelper::HookAllModules. 这个函数和另一个辅助函数是名为IATHelper的静态库的一部分, 也是同一解决方案的一部分, 并链接到WorkingSets项目. 以下是类声明:// IATHelper.h struct IATHelper final abstract { static int HookFunction(PCWSTR callerModule, PCSTR moduleName, PVOID originalProc, PVOID hookProc); static int HookAllModules(PCSTR moduleName, PVOID originalProc, PVOID hookProc); };
HookFunction的任务是挂钩由单个模块调用的单个函数.HookAllModules遍历进程中所有当前加载的模块并调用HookFunction.HookAllModules接受要挂钩的函数导出的模块名称 (在我们的例子中是user32.dll). 注意它作为 ASCII 字符串而不是 Unicode 传递, 因为模块名称在导入表中是作为 ASCII 存储的. 接下来的参数是原始函数 (以便它可以在导入表中找到), 以及替换旧函数的新函数.int IATHelper::HookAllModules(PCSTR moduleName, PVOID originalProc, PVOID hookProc) { HMODULE hMod; // should be enough (famous last words) DWORD needed; if (!::EnumProcessModules(::GetCurrentProcess(), hMod, sizeof(hMod), &needed)) return 0; assert(needed <= sizeof(hMod)); WCHAR name; int count = 0; for (DWORD i = 0; i < needed / sizeof(HMODULE); i++) { if (::GetModuleBaseName(::GetCurrentProcess(), hMod[i], name, _countof(name) )) { count += HookFunction(name, moduleName, originalProc, hookProc); } } return count; }
该函数相当简单. 它用 PSAPI 函数
EnumProcessModules枚举当前进程中的模块, 其声明如下:BOOL EnumProcessModules( _In_ HANDLE hProcess, _Out_ HMODULE* lphModule, _In_ DWORD cb, _Out_ LPDWORD lpcbNeeded);
EnumProcessModules填充提供的lphModule数组, 直到达到cb设置的大小, 并在lpcbNeeded中返回所需的大小. 如果返回的大小大于cb, 那么一些模块没有被返回, 调用者应该重新分配并再次枚举. 在我的代码中, 我为简单起见假设不超过 1024 个模块, 但在生产级代码中这可能会错过模块. 进程句柄必须具有PROCESS_QUERY_INFORMATION访问掩码, 这对于当前进程来说从来不是问题.GetModuleBaseName是 PSAPI 的另一个函数, 它返回模块的基本名称 (不包括任何路径):DWORD GetModuleBaseName( _In_ HANDLE hProcess, _In_opt_ HMODULE hModule, _Out_ LPTSTR lpBaseName, _In_ DWORD nSize);
HookFunction完成了所有艰苦的工作. 它首先获取调用者的模块句柄, 作为访问其导入表的基础:int IATHelper::HookFunction(PCWSTR callerModule, PCSTR moduleName, PVOID originalProc, PVOID hookProc) { HMODULE hMod = ::GetModuleHandle(callerModule); if (!hMod) return 0;
现在是棘手的部分. 必须通过解析 PE 文件来定位导入表. 幸运的是,
dbghelp和imagehlp的一些 API 提供了这种解析逻辑的一部分. 在本例中, 使用一个dbghelp函数来快速到达导入表:ULONG size; auto desc = (PIMAGE_IMPORT_DESCRIPTOR)::ImageDirectoryEntryToData(hMod, TRUE, IMAGE_DIRECTORY_ENTRY_IMPORT, &size); if (!desc) // no import table return 0;
PE 文件格式的讨论超出了本章的范围. 更多信息可以在附录 A 中找到. 完整的规范文档在 https://docs.microsoft.com/en-us/windows/win32/debug/pe-format. 相当多的文章和博客很好地涵盖了该格式.
ImageDirectoryEntryToData返回所谓的 数据目录 之一, 它们是镜像 PE 的一部分. 以下是其声明:PVOID ImageDirectoryEntryToData ( _In_ PVOID Base, _In_ BOOLEAN MappedAsImage, _In_ USHORT DirectoryEntry, _Out_ PULONG Size);
Base是模块的基地址, 正如我们所知, 这就是模块的“句柄”.MappedAsImage应设置为TRUE, 因为镜像是作为真镜像映射到地址空间的, 而不是作为数据文件加载的.DirectoryEntry是要检索的数据目录的索引,Size返回数据目录的大小. 函数的返回值是数据目录所在的虚拟地址.特定模块的导入表可能包含此模块依赖的许多导入库. 我们只需要定位我们的函数所在的那一个. 在
WorkingSet示例中, 它是user32.dll.IMAGE_IMPORT_DESCRIPTOR是引导导入库的结构, 我们的搜索从这里开始:int count = 0; for (; desc->Name; desc++) { auto modName = (PSTR)hMod + desc->Name; if (::_stricmp(moduleName, modName) == 0) {
代码循环遍历所有模块, 并将其名称与有问题的模块进行比较. 模块名称存储为 ASCII, 这就是我们将其作为 ASCII 传递给
HookFunction的原因.IMAGE_IMPORT_DESCRIPTOR的Name成员是模块名称从模块开头存储的偏移量.现在模块找到了, 我们需要遍历所有导入的函数, 寻找我们的原始函数指针:
auto thunk = (PIMAGE_THUNK_DATA)((PBYTE)hMod + desc->FirstThunk); for (; thunk->u1.Function; thunk++) { auto addr = &thunk->u1.Function; if (*(PVOID*)addr == originalProc) { // found it
代码不是很漂亮, 它基于构成 PE 中信息的数据结构 - 在本例中是 `IMAGETHUNKDATA`. 这些“thunk”中的每一个都存储一个函数的地址, 所以我们将其与我们收到的原始函数进行比较. 如果它们相等, 我们就找到了我们的匹配项:
DWORD old; if (::VirtualProtect(addr, sizeof(void*), PAGE_WRITECOPY, &old)) { *(void**)addr = (void*)hookProc; count++; } } } break; } }
我们需要用新值替换现有值. 然而, 导入表的页面受
PAGE_READONLY保护, 所以我们必须用PAGE_WRITECOPY替换它, 以获取我们有权访问的页面的可写副本.结构和成员的布局基于 PE 文件格式文档.
💡 将 API 挂钩与前一节的 DLL 注入相结合, 在 Notepad 进程中挂钩
GetSysColor, 而不是当前进程. 尝试挂钩其他函数!基于 IAT 的挂钩有什么缺点? 首先, 如果稍后加载一个新模块, 它也必须被挂钩. 矛盾的是, 这可以通过挂钩
LoadLibraryW,LoadLibraryExW和LdrLoadDll(来自NtDll.dll的未文档化但可能使用的函数) 来完成.其次, 很容易通过避免 IAT 来规避它 - 通过直接用从
GetProcAddress返回的函数指针调用 API. 这意味着调用原始的GetSysColor函数可以用这段代码完成:return ((decltype(::GetSysColor)*)::GetProcAddress(GetModuleHandle(L"user32"), "GetSysColor"))(index);
如果挂钩是出于安全目的, 那么 IAT 挂钩可能是不可接受的, 因为它很容易被规避. 如果需要其他东西, 正常代码使用函数而不调用
GetProcAddress, IAT 挂钩是方便和可靠的. - “Detours” 风格挂钩
挂钩函数的另一种常见方法是遵循以下步骤:
- 定位原始函数的地址并保存它.
- 用一个 JMP 汇编指令替换代码的前几个字节, 保存旧代码.
- JMP 指令调用被钩住的函数.
- 如果要调用原始代码, 使用第一步中保存的地址.
- 取消挂钩时, 恢复修改的字节.
这个方案比 IAT 挂钩更强大, 因为真实的函数代码被修改了, 无论它是通过 IAT 调用还是不调用. 这种方法有两个缺点:
- 替换的代码是平台特定的. x86, x64, ARM 和 ARM64 的代码是不同的, 这使得正确实现更加困难.
- 上述步骤必须是原子的. 进程中可能有其他线程在汇编字节被替换时调用被钩住的函数. 这很可能导致崩溃.
实现这种挂钩是困难的, 需要对 CPU 指令和调用约定的深入了解, 更不用说上面提到的同步问题了.
有几个开源和免费的库提供了这个功能. 其中之一是微软的“Detours” (因此得名), 但还有其他的, 如
MinHook和EasyHook, 你可以在网上找到. 如果你需要这种挂钩, 考虑使用一个现有的库, 而不是自己动手.为了演示使用 Detours 库进行挂钩, 我们将使用第 14 章的 Basic Sharing 应用程序. 我们将挂钩两个函数:
GetWindowTextLengthW和GetWindowTextW. 使用被钩住的函数, 代码将只为编辑控件返回一个自定义字符串.第一步是添加对 Detours 的支持. 幸运的是, 通过 Nuget 这很容易 - 只需搜索“detours”, 你就会收到 (图 15-13).

Figure 225: 图 15-13: Nuget 包管理器中的 Detours 库
设置钩子相当直接. 以下是执行此操作的辅助函数:
#include <detours.h> bool HookFunctions() { DetourTransactionBegin(); DetourUpdateThread(GetCurrentThread()); DetourAttach((PVOID*)&GetWindowTextOrg, GetWindowTextHooked); DetourAttach((PVOID*)&GetWindowTextLengthOrg, GetWindowTextLengthHooked); auto error = DetourTransactionCommit(); return error == ERROR_SUCCESS; }
Detours 使用事务的概念 - 一组要原子执行的提交操作. 我们需要保存原始函数. 这可以在挂钩之前用
GetProcAddress完成, 或者直接用指针定义:decltype(::GetWindowTextW)* GetWindowTextOrg = ::GetWindowTextW; decltype(::GetWindowTextLengthW)* GetWindowTextLengthOrg = ::GetWindowTextLengthW;
被钩住的函数提供了一些实现. 以下是这个演示所做的:
static WCHAR extra[] = L" (Hooked!)"; bool IsEditControl(HWND hWnd) { WCHAR name; return ::GetClassName(hWnd, name, _countof(name)) && ::_wcsicmp(name, L"EDIT") == 0; } int WINAPI GetWindowTextHooked( _In_ HWND hWnd, _Out_ LPWSTR lpString, _In_ int nMaxCount) { auto count = GetWindowTextOrg(hWnd, lpString, nMaxCount); if (IsEditControl(hWnd)) { if (count + _countof(extra) <= nMaxCount) { ::StringCchCatW(lpString, nMaxCount, extra); count += _countof(extra); } } return count; } int WINAPI GetWindowTextLengthHooked(HWND hWnd) { auto len = GetWindowTextLengthOrg(hWnd); if(IsEditControl(hWnd)) len += (int)wcslen(extra); return len; }
被钩住的
GetWindowTextW仅向编辑控件添加额外的字符串. 如果你现在运行 Basic Sharing, 在编辑框中输入“hello”, 点击 Write, 然后点击 Read, 你会得到图 15-14 所示的内容.
Figure 226: 图 15-14: 一个被钩住的 Basic Sharing
Write 按钮点击处理程序调用
GetDlgItemText, 后者调用GetWindowText, 进而调用被钩住的函数.💡 使用 Detours 以类似于 Basic Sharing 的方式挂钩 Notepad.
2.3.7. DLL 基地址
每个 DLL 都有一个首选的加载 (基) 地址, 这是 PE 头的一部分. 它甚至可以在 Visual Studio 的项目属性中指定 (图 15-15).

Figure 227: 图 15-15: 在 Visual Studio 中设置 DLL 的基地址
默认情况下那里什么都没有, 这使得 Visual Studio 使用一些默认值. 对于 32 位 DLL 是 `0x10000000`, 对于 64 位 DLL 是 `0x180000000`. 你可以通过从 PE 中转储头信息来验证这些:
dumpbin /headers c:\dev\Win10SysProg\Chapter15\x64\Debug\HookDll.dll
...
OPTIONAL HEADER VALUES
20B magic # (PE32+)
...
112FD entry point (00000001800112FD) @ILT+760(_DllMainCRTStartup)
1000 base of code
180000000 image base (0000000180000000 to 0000000180025FFF)
...
dumpbin /headers c:\dev\Win10SysProg\Chapter15\Debug\HookDll.dll
...
OPTIONAL HEADER VALUES
10B magic # (PE32)
...
111B8 entry point (100111B8) @ILT+435(__DllMainCRTStartup@12)
1000 base of code
1000 base of data
10000000 image base (10000000 to 1001FFFF)
...
在旧时代 (Vista 之前), 当地址空间布局随机化 (ASLR) 不存在时, DLL 坚持加载到它们的首选地址. 如果该地址已经被某个其他 DLL 或数据占用, DLL 会经历 重定位. 加载器必须在进程地址空间中为 DLL 找到一个新位置. 此外, 它还必须执行代码修复 (由链接器存储在 PE 中), 因为一些代码必须更改. 例如, 一个期望在地址 x 的字符串现在移动到了某个其他地址 y, 加载器必须修复它. 这些修复需要时间, 以及额外的内存, 因为该页面中的代码不能再被共享.
在 Process Explorer 中, 重定位的 DLL 很容易发现. 首先, 有一个黄色的颜色, 你可以启用, 称为“Relocated DLLs”, 它出现在每个重定位 DLL 的模块 (DLL) 视图中. 其次, 识别重定位 DLL 的确定方法是 `Image Base` 列与 `Base` 不同 (图 15-16).

Figure 228: 图 15-16: Process Explorer 中的重定位 DLL
我选择了 Visual Studio 的进程 (`devenv.exe`) 在图 15-16 中, 它显示了许多重定位的 DLL. 然而, 这不像过去那样常见. 大多数进程只有很少的重定位 DLL.
解决重定位问题的方法是为不同的 DLL 选择不同的地址, 以最小化冲突的机会. 这有时是用 `rebase.exe` 工具完成的, 它是 Windows SDK 的一部分, 可以同时对多个 DLL 执行操作. 该工具不需要源代码, 因为它操作 PE. `rebase.exe` 工具的功能可以通过调试帮助 API 中的 `ReBaseImage64` 函数以编程方式获得.
大多数 DLL 都有动态基 (Dynamic Base) 特性标志, 表明 DLL 可以进行重定位. 使用 ASLR, 加载器会选择一个不与先前选择的 DLL 冲突的地址, 因此冲突的可能性非常低, 因为使用的地址从高地址开始, 并为每个加载的 DLL 向下移动. 一个 DLL 可以指定它需要一个固定的地址, 以便禁止重定位, 但如果其首选地址范围被占用, 这可能导致 DLL 加载失败. 一个 DLL 坚持一个固定的基地址应该有一个非常好的理由.
2.3.8. 延迟加载 DLL
我们已经研究了链接到 DLL 的两种主要方式: 要么用 LIB 文件进行隐式链接 (最简单方便), 要么动态链接 (显式加载 DLL 并定位要使用的函数). 事实证明, 还有第三种方式, 有点像是静态和动态链接之间的“中间地带” - 延迟加载 DLL.
使用延迟加载, 我们获得了两种选项的好处: 静态链接的便利性, 以及仅在需要时才动态加载 DLL.
要使用延迟加载 DLL, 需要对使用这些 DLL 的模块进行一些更改, 无论是可执行文件还是另一个 DLL. 应该延迟加载的 DLL 会被添加到链接器的选项中, 在 `Input` 选项卡中 (图 15-17).

Figure 229: 图 15-17: 在项目属性中指定延迟加载 DLL
如果你想支持动态卸载延迟加载的 DLL, 在 `Advanced` 链接器选项卡中添加该选项 (“Unload delay loaded DLL”).
剩下的就是链接 DLL 的导入库 (LIB) 文件, 并像使用隐式链接的 DLL 一样使用导出的功能.
以下是来自 `SimplePrimes2` 项目的示例, 该项目延迟加载链接了 `SimpleDll.Dll`:
#include "..\SimpleDll\Simple.h" #include <delayimp.h> bool IsLoaded() { auto hModule = ::GetModuleHandle(L"simpledll"); printf("SimpleDll loaded: %s\n", hModule ? "Yes" : "No"); return hModule != nullptr; } int main() { IsLoaded(); bool prime = IsPrime(17); IsLoaded(); printf("17 is prime? %s\n", prime ? "Yes" : "No"); __FUnloadDelayLoadedDLL2("SimpleDll.dll"); IsLoaded(); prime = IsPrime(1234567); IsLoaded(); return 0; }
看起来很奇怪的函数 `_FUnloadDelayLoadedDLL2` (来自 `delayimp.h`) 是用来卸载延迟加载的 DLL 的. 如果你调用 `FreeLibrary`, DLL 会卸载; 然而, 如果需要, 它不会仅仅通过调用一个导出的函数再次加载, 而是会抛出一个访问冲突异常.
运行上述程序会显示:
SimpleDll loaded: No SimpleDll loaded: Yes 17 is prime? Yes SimpleDll loaded: No SimpleDll loaded: Yes
当你从一个延迟加载的 DLL 调用一个导出的函数时, 实际上正在调用一个不同的函数 (由延迟加载基础设施提供), 它知道调用 `LoadLibrary` 和 `GetProcAddress`, 然后调用该函数, 修复导入表, 以便将来对同一函数的调用直接转到其实现. 这也解释了为什么卸载一个延迟加载的 DLL 必须用一个特殊的函数来完成, 以便可以将初始行为恢复.
2.3.9. The LoadLibraryEx Function
`LoadLibraryEx` 是一个扩展的 `LoadLibrary` 函数, 定义如下:
HMODULE LoadLibraryEx( _In_ LPCTSTR lpLibFileName, _Reserved_ HANDLE hFile, // must be NULL _In_ DWORD dwFlags);
`LoadLibraryEx` 的目的与 `LoadLibrary` 相同: 显式加载一个 DLL. 正如你所见, `LoadLibraryEx` 支持一组影响所讨论的 DLL 搜索和/或加载方式的标志. 一些可接受的标志来自表 15-1, 其中搜索路径和顺序可以在某种程度上修改. 以下是一些其他可能有用的标志 (请查阅文档以获取完整列表):
- `LOADLIBRARYASDATAFILE` - 这个标志表示 DLL 应该只被映射到进程地址空间, 但其 PE 镜像属性被忽略. `DllMain` 不被调用, 像 `GetModuleHandle` 或 `GetProcAddress` 这样的函数在返回的句柄上会失败.
- `LOADLIBRARYASDATAFILEEXCLUSIVE` - 类似于 `LOADLIBRARYASDATAFILE`, 但文件以独占访问方式打开, 以便其他进程在加载时无法修改它.
- `LOADLIBRARYASIMAGERESOURCE` - 将 DLL 作为镜像文件加载, 但不执行任何初始化, 例如调用 `DllMain`. 这个标志通常与 `LOADLIBRARYASDATAFILE` 一起用于提取资源.
- `LOADWITHALTEREDSEARCHPATH` - 如果指定的路径是绝对的, 那么该路径将作为搜索的基础.
当使用 `LOADLIBRARYASIMAGERESOURCE` 时, 返回的句柄可以用来提取资源, 使用的 API 包括 `LoadString`, `LoadBitmap`, `LoadIcon` 等. 自定义资源也受支持, 在这种情况下, 要使用的函数包括 `FindResource(Ex)`, `SizeOfResource`, `LoadResource` 和 `LockResource`.
2.3.10. 杂项函数
在本节中, 我们将简要介绍一些你可能会觉得有用的其他与 DLL 相关的函数. 我们将从 `GetModuleFileName` 和 `GetModuleFileNameEx` 开始:
DWORD GetModuleFileName( _In_opt_ HMODULE hModule, _Out_ LPTSTR lpFilename, _In_ DWORD nSize);
DWORD GetModuleFileNameEx( _In_opt_ HANDLE hProcess, _In_opt_ HMODULE hModule, _Out_ LPWSTR lpFilename, _In_ DWORD nSize);
两个函数都返回一个已加载模块的完整路径. `GetModuleFileNameEx` 可以在另一个进程中访问此类信息 (句柄必须具有 `PROCESSQUERYINFORMATION` 或 `PROCESSQUERYLIMITEDINFORMATION` 访问掩码). 如果 `hModule` 是 `NULL`, 则返回主模块路径 (可执行文件路径). 如果需要模块列表, 可以使用 `EnumProcessModules` (本章前面已显示).
`LoadPackagedLibrary` (Windows 8+) 是 `LoadLibrary` 的一个变体, UWP 进程可以用它来加载其包的一部分的 DLL:
HMODULE LoadPackagedLibrary ( _In_ LPCWSTR lpwLibFileName, _Reserved_ DWORD Reserved); // must be zero
如果一个线程需要卸载其代码正在运行的 DLL, 它不能使用 `FreeLibrary` 然后 `ExitThread` 的函数对, 因为一旦 `FreeLibrary` 返回, 线程的代码将不再是进程的一部分, 会发生崩溃. 为了解决这个问题, 使用 `FreeLibraryAndExitThread`:
VOID FreeLibraryAndExitThread( _In_ HMODULE hLibModule, _In_ DWORD dwExitCode);
该函数释放指定的模块, 然后调用 `ExitThread`, 这意味着该函数永远不会返回.
2.3.11. 总结
在本章中, 我们研究了 DLL - 如何构建它们以及如何使用它们. 我们还看到了将 DLL 注入到另一个进程中的能力, 这给了那个 DLL 在目标进程中很大的权力.
在下一章中, 我们将把注意力转向一个完全不同的话题: 安全.
2.4. 第 16 章: 安全
Windows NT 从其最初的设计就考虑到了安全性. 这与不支持安全性的 Windows 95/98 操作系统家族相反. Windows 遵循由美国国防部定义的 C2 级安全标准. C2 是通用操作系统可以达到的最高级别.
C2 的一些要求如下:
- 登录系统必须需要某种形式的身份验证.
- 死进程的内存绝不能泄露给另一个进程.
- 必须有一个能够对文件系统对象设置权限的文件系统.
在本章中, 我们将研究 Windows 安全性的基础, 并查看许多用于操纵它的 API.
本章内容:
- 简介
- SID
- 令牌
- 访问掩码
- 特权
- 安全描述符
- 用户访问控制
- 完整性级别
- 专用安全机制
2.4.1. 简介
Windows 中有几个与安全相关的组件. 图 16-1 显示了其中的大部分.

Figure 230: 图 16-1: 安全相关的组件
以下是图 16-1 中主要组件的快速概要:
- WinLogon
登录进程 (`Winlogon.exe`) 负责交互式登录. 它还负责响应安全注意序列 (SAS, 默认为 Ctrl+Alt+Del) 组合键, 通过切换到 Winlogon 桌面, 在那里显示熟悉的选项 (锁定, 切换用户, 注销等).
Winlogon 通过一个辅助进程 `LogonUI.exe` (见下一节) 从用户那里获取凭据, 并将它们发送到 `Lsass.exe` 进行身份验证. 如果身份验证成功, `Lsass` 会创建一个登录会话和一个访问令牌 (本章稍后讨论), 代表用户的安全上下文. 然后它创建启动进程 (默认为 `userinit.exe`, 从注册表中读取), 后者又创建 `Explorer.exe` (同样, 这只是注册表中的默认值). 访问令牌会为每个新创建的进程复制. 图 16-2 显示了由 Sysinternals 的 Process Monitor (`ProcMon.exe`) 工具生成的系统初始化过程树的一部分. 注意 `WinLogon`, `UserInit` 和 `Explorer` 之间的连接.

Figure 231: 图 16-2: 登录进程树
`Userinit` 还会运行启动脚本, 然后终止 (这就是为什么 `Explorer` 通常是无父进程的).
💡 上述设置的注册表项是 `HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Winlogon`.
- LogonUI
Windows 支持多种登录方式: 用户名/密码, 使用面部识别和指纹的“Windows Hello”等等. `LogonUI.exe` 进程由 `Winlogon` 启动, 以呈现所选身份验证方法的 UI. 在旧时代 (Vista 之前), `Winlogon` 负责此事 (`LogonUI` 不存在). 问题是, 如果 UI 组件崩溃, 它会连带 `Winlogon` 一起崩溃. 从 Vista 开始, 如果 UI 崩溃, `LogonUI` 会被终止, `Winlogon` 允许用户选择另一种身份验证方法.
`LogonUI` 显示由凭据提供程序 (Credential Provider) 提供的 UI - 这是一个 COM DLL, 为其关联的身份验证机制实现了一些用户界面. 凭据提供程序可以由任何需要自定义身份验证方法的人开发.
- LSASS
本地安全认证服务 (`lsass.exe`) 是身份验证管理的基石. 其最基本的作用是验证用户. 在常见的用户名/密码组合情况下, `Lsass` 会检查本地注册表 (在本地登录的情况下), 或与域控制器 (域登录) 通信, 以验证用户. 然后它将结果返回给 `Winlogon`. 如果身份验证成功, 它会为登录的用户创建并填充访问令牌.
- LsaIso
`LsaIso.exe` 进程存在于具有虚拟化基础安全 (VBS) 并开启了凭据保护 (Credential Guard) 功能的 Windows 10 (或更高版本) 系统中. `LsaIso` 被称为 trustlet, 这是一个在虚拟信任级别 (VTL) 1 中运行的用户模式进程, 安全内核和隔离用户模式 (IUM) 驻留在其中. 作为一个 IUM 进程, `LsaIso` 的访问受到 Hyper-V 虚拟机管理程序的保护, 因此即使从内核也无法访问. `LsaIso` 的目的是为 `Lsass` 保管秘密, 以便像“哈希传递”之类的某些类型的攻击得到缓解, 因为没有任何进程 (甚至不是管理员级别) 甚至内核可以窥探 `LsaIso` 的地址空间.
上段中有许多本书未解释的新术语, 因为它们与系统编程关系不大. 有关 VBS, Hyper-V, VTL 及相关概念的更多信息, 请查阅《Windows Internals 7th edition Part 1》一书和/或在线资源.
- 安全引用监视器
SRM 是执行体的一部分, 负责在发生某些操作时进行所需的访问检查. 例如, 尝试打开一个现有内核对象的句柄需要由 SRM 执行访问检查.
- 事件记录器
事件记录器服务是 Windows 提供的标准服务之一. 它不特定于安全, 但安全事件是使用此服务记录的. 查看日志中信息的常用方法是使用内置的事件查看器应用程序, 如图 16-3 所示 (选择了“安全”节点).

Figure 232: 图 16-3: 事件查看器应用程序
2.4.2. SIDs
术语 主体 (principal) 描述了一个可以在安全上下文中引用的实体. 例如, 可以向主体授予或拒绝权限. 主体可以代表用户, 组, 计算机等. 一个主体由一个安全 ID (Security ID, SID) 唯一标识, 这是一个可变大小的结构, 包含几个部分, 如图 16-4 所示.

Figure 233: 图 16-4: SID
当作为字符串显示时, SID 看起来像这样: `S-R-A-SA-SA-…-SA`
“S”是文字 S, 修订版 (R) 总是 1 (修订版从未改变), “A”是生成 SID 的 6 字节颁发机构, “SA”是 4 字节子颁发机构 (也称为相对 ID - RID) 的数组, 对生成它们的颁发机构是唯一的. 尽管 SID 的大小取决于子颁发机构的数量, 但子颁发机构的最大计数目前是 15, 这给 SID 的大小设了一个上限. 这在需要为 SID 分配缓冲区的情况下很有帮助, 你宁愿静态分配它而不是动态分配. 以下是来自 `winnt.h` 的定义:
#define SID_MAX_SUB_AUTHORITIES (15) #define SECURITY_MAX_SID_SIZE \ (sizeof(SID)-sizeof(DWORD)+(SID_MAX_SUB_AUTHORITIES*sizeof(DWORD))) // 68 bytes
SID 通常以其字符串形式显示 (通常也更容易将其作为字符串持久化). 在二进制和字符串形式之间转换可以通过以下函数完成 (在 `<sddl.h>` 中声明):
BOOL ConvertSidToStringSid( _In_ PSID Sid, _Outptr_ LPTSTR* StringSid);
BOOL ConvertStringSidToSid( _In_ LPCTSTR StringSid, _Outptr_ PSID* Sid);
两个函数都返回一个结果, 稍后必须由调用者用 `LocalFree` 释放.
组和别名
一个组, 由一个 SID 表示, 是一个主体的集合. 每个属于该组的主体都将在其安全上下文中拥有该组的 SID (参见本章后面的“令牌”一节). 这有助于在不事先指定单个主体的情况下建模组织结构.
一个别名 (也称为本地组) 是另一个容器主体, 它可以持有一组组和其他主体 (但不能是其他别名). 例如, 本地管理员组实际上是一个别名, 它可以包含单个 SID 和组 SID, 它们都是该别名的一部分. 别名总是本地于一台机器, 不能与其他机器共享.
组和别名之间的区别在实践中不那么重要, 但值得记住.
在表示不同主体时, SID 保证是统计上唯一的. 一些 SID 被称为“众所周知的 (Well-known)”, 它们在每台机器上都代表相同的主体. 例子包括“S-1-1-0” (Everyone 组) 和 S-1-5-32-544 (本地管理员别名). `winnt.h` 定义了一个枚举 `WELLKNOWNSIDTYPE`, 它持有众所周知的 SID 列表. 这些 SID 的存在是为了方便在任何机器上引用同一组主体. (想象一下如果每台机器都有自己的本地管理员 SID 会发生什么).
创建一个众所周知的 SID 是通过 `CreateWellKnownSid` 完成的:
BOOL CreateWellKnownSid( _In_ WELL_KNOWN_SID_TYPE WellKnownSidType, _In_opt_ PSID DomainSid, _Out_ PSID pSid, _Inout_ DWORD* cbSid);
对于某些类型的众所周知 SID, 需要 `DomainSid` 参数. 对于大多数, `NULL` 是一个可接受的值. 返回的 SID 被放置在调用者分配的缓冲区中. `cbSid` 应该包含调用者提供的缓冲区的大小, 返回时存储 SID 的实际大小.
我们可以结合 `CreateWellKnownSid` 和 `ConvertSidToStringSid` 来列出所有不需要域 SID 参数的众所周知 SID:
BYTE buffer[SECURITY_MAX_SID_SIZE]; PWSTR name; for (int i = 0; i < 120; i++) { DWORD size = sizeof(buffer); if (!::CreateWellKnownSid((WELL_KNOWN_SID_TYPE)i, nullptr, (PSID)buffer, &size)) continue; ::ConvertSidToStringSid((PSID)buffer, &name); printf("Well known sid %3d: %ws\n", i, name); ::LocalFree(name); }
SID 缓冲区是静态分配的, 具有最大的 SID 大小. 以下是简要输出:
Well known sid 0: S-1-0-0 Well known sid 1: S-1-1-0 Well known sid 2: S-1-2-0 Well known sid 3: S-1-3-0 ... Well known sid 20: S-1-5-14 Well known sid 22: S-1-5-18 Well known sid 23: S-1-5-19 ... Well known sid 36: S-1-5-32-555 Well known sid 37: S-1-5-32-556 Well known sid 51: S-1-5-64-10 Well known sid 52: S-1-5-64-21 Well known sid 53: S-1-5-64-14 ... Well known sid 118: S-1-18-3 Well known sid 119: S-1-5-32-583
💡 众所周知的 SID `WinLogonIdsSid` (21) 无法创建.
可以用 `IsWellKnownSid` 检查一个 SID 是否匹配一个特定的众所周知 SID:
BOOL IsWellKnownSid( _In_ PSID pSid, _In_ WELL_KNOWN_SID_TYPE WellKnownSidType);
我们也可以用 `LookupAccountSid` 获取众所周知的 SID 名称:
BOOL LookupAccountSid( _In_opt_ LPCTSTR lpSystemName, _In_ PSID Sid, _Out_ LPWSTR Name, _Inout_ LPDWORD cchName, _Out_ LPWSTR ReferencedDomainName, _Inout_ LPDWORD cchReferencedDomainName, _Out_ PSID_NAME_USE peUse);
`lpSystemName` 是 SID 查找的机器名, 其中 `NULL` 表示本地机器, `Sid` 是要查找的 SID. `Name` 是返回的账户名, `cchName` 指向名称接受的最大字符数. 返回时, 它存储实际复制的字符数. `ReferencedDomainName` 和 `cchReferencedDomainName` 对域名 (或更准确地说, 账户所在的颁发机构) 起同样的作用. 最后, `peUse` 返回所讨论的 SID 的类型, 基于 `SIDNAMEUSE` 枚举:
typedef enum _SID_NAME_USE { SidTypeUser = 1, SidTypeGroup, SidTypeDomain, SidTypeAlias, SidTypeWellKnownGroup, SidTypeDeletedAccount, SidTypeInvalid, SidTypeUnknown, SidTypeComputer, SidTypeLabel, SidTypeLogonSession } SID_NAME_USE, *PSID_NAME_USE;
向众所周知的 SID 迭代添加一个对 `LookupAccountSid` 的调用看起来像这样:
WCHAR accountName = { 0 }, domainName = { 0 }; SID_NAME_USE use; for (int i = 0; i < 120; i++) { DWORD size = sizeof(buffer); if (!::CreateWellKnownSid((WELL_KNOWN_SID_TYPE)i, nullptr, (PSID)buffer, &size)) continue; ::ConvertSidToStringSid((PSID)buffer, &name); DWORD accountNameSize = _countof(accountName); DWORD domainNameSize = _countof(domainName); ::LookupAccountSid(nullptr, (PSID)buffer, accountName, &accountNameSize, domainName, &domainNameSize, &use); printf("Well known sid %3d: %-20ws %ws\\%ws (%s)\n", i, name, domainName, accountName, SidNameUseToString(use)); ::LocalFree(name); }
循环遍历所有定义的众所周知 SID 索引 (当前 120 个值). C++ 中还没有静态反射, 所以使用数字和它一样好.
`SidNameUseToString` 函数只是将 `SIDNAMEUSE` 枚举转换为字符串. 运行这段代码会显示以下内容:
Well known sid 0: S-1-0-0 \NULL SID (Well Known Group) Well known sid 1: S-1-1-0 \Everyone (Well Known Group) Well known sid 2: S-1-2-0 \LOCAL (Well Known Group) Well known sid 3: S-1-3-0 \CREATOR OWNER (Well Known Group) Well known sid 4: S-1-3-1 \CREATOR GROUP (Well Known Group) ... Well known sid 22: S-1-5-18 NT AUTHORITY\SYSTEM (Well Known Group) Well known sid 23: S-1-5-19 NT AUTHORITY\LOCAL SERVICE (Well Known Group) Well known sid 24: S-1-5-20 NT AUTHORITY\NETWORK SERVICE (Well Known Group) Well known sid 25: S-1-5-32 BUILTIN\BUILTIN (Domain) Well known sid 26: S-1-5-32-544 BUILTIN\Administrators (Alias) Well known sid 27: S-1-5-32-545 BUILTIN\Users (Alias) Well known sid 28: S-1-5-32-546 BUILTIN\Guests (Alias) ... Well known sid 65: S-1-16-0 Mandatory Label\Untrusted Mandatory Level (Label) Well known sid 66: S-1-16-4096 Mandatory Label\Low Mandatory Level (Label) Well known sid 67: S-1-16-8192 Mandatory Label\Medium Mandatory Level (Label) ... Well known sid 84: S-1-15-2-1 APPLICATION PACKAGE AUTHORITY\ALL APPLICATION PAC\ KAGES (Well Known Group) Well known sid 85: S-1-15-3-1 APPLICATION PACKAGE AUTHORITY\Your Internet conne\ ction (Well Known Group) ... Well known sid 117: S-1-18-6 \Key property attestation (Well Known Group) Well known sid 118: S-1-18-3 \Fresh public key identity (Well Known Group) Well known sid 119: S-1-5-32-583 BUILTIN\Device Owners (Alias)
输出清楚地显示了哪些 SID 是别名 (而不是组).
`wellknownsids` 项目包含完整的代码. 它还有检索域 SID 的代码, 以便可以创建更多众所周知的 SID.
`LookupAccountSid` 有一个对应的函数, `LookupAccountName`:
BOOL LookupAccountName( _In_opt_ LPCTSTR lpSystemName, _In_ LPCTSTR lpAccountName, _Out_ PSID Sid, _Inout_ LPDWORD cbSid, _Out_ LPTSTR ReferencedDomainName, _Inout_ LPDWORD cchReferencedDomainName, _Out_ PSID_NAME_USE peUse);
`LookupAccountName` 是一个努力工作的函数, 试图定位一个名称并返回其 SID. 它首先检查众所周知的名称. `lpAccountName` 可以是一个简单的名称, 如“joe”, 或包含域名 (“mydomain\joe”, 从性能角度来看更好). 它还接受其他格式, 例如“joe@mydomain.com”. 它在 `Sid` 参数中返回 SID, 在 `ReferencedDomainName` 中返回域名, 以及一个 `SIDNAMEUSE`, 就像 `LookupAccountSid` 一样.
SID API 包括一些相当不言自明的函数, 如 `IsValidSid`, `CopySid`, `EqualSid`, `GetLengthSid`, `AllocatedAndInitializeSid`, `InitializeSid`, `FreeSid`, `GetSidIdentifierAuthority`, `GetSidSubAuthorityCount` 和 `GetSidSubAuthority`.
2.4.3. 令牌
当用户成功登录时, 无论是交互式还是非交互式, 都会在幕后创建一个 登录会话 对象, 持有与登录主体相关的信息. 通常, 登录会话隐藏在 访问令牌 (或简称 令牌) 后面, 这是一个维护几条信息并有一个指向登录会话的指针的对象.
令牌是开发者可以与之交互并在某种程度上操纵的对象. 一个进程总有一个与之关联的令牌, 称为 主令牌. 进程内的所有线程默认在执行需要安全上下文的操作时使用该主令牌. 一个线程可以通过承担一个不同的令牌, 称为 模拟令牌, 来执行 模拟. 一旦一个线程完成模拟, 它会恢复使用其进程 (主) 令牌. 登录会话, 令牌和进程之间的关系如图 16-6 所示.

Figure 234: 图 16-6: 一个登录会话, 令牌和进程
Windows 中总是存在三个登录会话, 由三个内置用户使用 - Local Service, Network Service 和 Local System (也称为 SYSTEM). 我们将在第 19 章 (“服务”) 中更详细地了解这些帐户, 这是它们的主要用途.
你可能会惊讶于在任何给定时间存在多少个登录会话. 从提升的命令窗口运行 Sysinternals 的 `pslogonsessions.exe` 工具. 它使用 `LsaEnumerateLogonSessions` API 返回一个登录会话 ID 数组. 对于每个 ID, 它调用 `LsaGetLogonSessionData` 来检索有关登录会话的详细信息. 以下是缩写的输出:
Logon session 00000000:000003e7:
User name: WORKGROUP\PAVEL7540$
Auth package: NTLM
Logon type: (none)
Session: 0
Sid: S-1-5-18
Logon time: 19-May-20 19:29:32
Logon server:
DNS Domain:
UPN:
...
Logon session 00000000:0001964a:
User name: Font Driver Host\UMFD-0
Auth package: Negotiate
Logon type: Interactive
Session: 0
Sid: S-1-5-96-0-0
Logon time: 19-May-20 19:29:32
...
Logon session 00000000:000003e5:
User name: NT AUTHORITY\LOCAL SERVICE
Auth package: Negotiate
Logon type: Service
Session: 0
Sid: S-1-5-19
Logon time: 19-May-20 19:29:32
...
Logon session 00000000:000003e4:
User name: WORKGROUP\PAVEL7540$
Auth package: Negotiate
Logon type: Service
Session: 0
Sid: S-1-5-20
Logon time: 19-May-20 19:29:32
...
Logon session 00000000:00023051:
User name: Window Manager\DWM-1
Auth package: Negotiate
Logon type: Interactive
Session: 1
Sid: S-1-5-90-0-1
Logon time: 19-May-20 19:29:32
...
Logon session 00000000:02edfae1:
User name: NT VIRTUAL MACHINE\47E3D5AD-77C2-4BCE-AC4F-252E2A6935DA
Auth package: Negotiate
Logon type: Service
Session: 0
Sid: S-1-5-83-1-1206113709-1271822274-774197164-3660933418
Logon time: 19-May-20 20:14:35
...
通常, 当用户成功登录时, `Lsass` 会创建一个令牌. `Winlogon` 将其附加到用户会话中创建的第一个进程, 并且该令牌会从该进程复制并传播到子进程, 依此类推.
一个令牌包含几条信息, 其中一些如下:
- 用户的 SID
- 主组
- 用户所属的组
- 用户拥有的特权 (稍后讨论)
- 新创建对象的默认安全描述符
- 令牌类型 (主令牌或模拟令牌)
主组是为与 POSIX 子系统一起使用而创建的, 因为这是 *NIX 安全权限的一部分, 因此基本上未使用.
Process Explorer 允许在其进程属性对话框的 Security 选项卡中查看进程主令牌的信息 (图 16-7).

Figure 235: 图 16-7: Process Explorer 中的 Security 选项卡
让我们通过查看如何获取令牌来开始我们对令牌的探索. 由于每个进程都必须有一个与之关联的令牌 (其主令牌), 因此可以用 `OpenProcessToken` 为一个进程打开一个令牌句柄:
BOOL OpenProcessToken( _In_ HANDLE ProcessHandle, _In_ DWORD DesiredAccess, _Outptr_ PHANDLE TokenHandle);
在尝试获取令牌句柄之前, 必须获取一个打开的进程句柄 (`OpenProcess`), 至少具有 `PROCESSQUERYINFORMATION` 访问掩码 (当然 `GetCurrentProcess` 总是有效的). `DesiredAccess` 是为令牌对象请求的访问掩码. 常见的值包括 `TOKENQUERY` (查询信息), `TOKENADJUSTPRIVILEGES` (启用/禁用特权), `TOKENADJUSTDEFAULT` (调整各种默认值), `TOKENDUPLICATE` (复制令牌), 以及 `TOKENIMPERSONATE` (模拟令牌). 还支持其他更强大的访问掩码, 但这些通常不能被授予, 因为它们需要一些强大的特权 (在“特权”一节中描述). 最后, 如果调用成功, `TokenHandle` 会返回实际的句柄.
如果需要一个线程的令牌 (很可能是该线程正在模拟一个不同于其进程的令牌), 可以调用 `OpenThreadToken`:
BOOL OpenThreadToken( _In_ HANDLE ThreadHandle, _In_ DWORD DesiredAccess, _In_ BOOL OpenAsSelf, _Outptr_ PHANDLE TokenHandle);
`ThreadHandle` 是所讨论线程的句柄, 必须具有 `THREADQUERYLIMITEDINFORMATION` 访问掩码. 这样的句柄可以用 `OpenThread` 打开 (`GetCurrentThread` 总是可以的). `DesiredAccess` 是返回的令牌句柄所需的访问权限. `OpenAsSelf` 指示应该在哪个令牌下进行令牌检索的访问检查. 如果 `OpenAsSelf` 是 `TRUE`, 访问检查是针对进程令牌进行的; 否则是针对当前线程的令牌. 当然, 这仅在当前线程当前正在模拟时才有意义.
手持一个具有 `TOKENQUERY` 访问掩码的令牌句柄, `GetTokenInformation` 提供了令牌内存储的大量数据:
BOOL GetTokenInformation( _In_ HANDLE TokenHandle, _In_ TOKEN_INFORMATION_CLASS TokenInformationClass, _Out_ LPVOID TokenInformation, _In_ DWORD TokenInformationLength, _Out_ PDWORD ReturnLength);
该函数非常通用, 使用 `TOKENINFORMATIONCLASS` 枚举来指示请求的信息类型. 对于枚举中的每个值, 都需要指定正确的缓冲区大小. 最后一个参数指示成功完成操作使用或需要多少字节. 枚举列表很长. 让我们看几个例子.
要获取与令牌关联的用户 SID, 使用 `TokenUser` 枚举值, 如下所示:
BYTE buffer[1 << 12]; // 4KB - should be large enough for anything if (::GetTokenInformation(hToken, TokenUser, buffer, sizeof(buffer), &len)) { auto data = (TOKEN_USER*)buffer; printf("User SID: %ws\n", SidToString(data->User.Sid).c_str()); }
`SidToString` 使用了已经讨论过的 `ConvertSidToStringSid` 函数:
std::wstring SidToString(const PSID sid) { PWSTR ssid; std::wstring result; if (::ConvertSidToStringSid(sid, &ssid)) { result = ssid; ::LocalFree(ssid); } return result; }
以下是另一个使用 `TokenStatistics` 令牌信息类的例子, 它检索一些关于令牌的有用统计信息:
TOKEN_STATISTICS stats; if (::GetTokenInformation(hToken, TokenStatistics, &stats, sizeof(stats), &len)) { printf("Token ID: 0x%08llX\n", LuidToNum(stats.TokenId)); printf("Logon Session ID: 0x%08llX\n", LuidToNum(stats.AuthenticationId)); printf("Token Type: %s\n", stats.TokenType == TokenPrimary ? "Primary" : "Impersonation"); if (stats.TokenType == TokenImpersonation) printf("Impersonation level: %s\n", ImpersonationLevelToString(stats.ImpersonationLevel)); printf("Dynamic charged (bytes): %lu\n", stats.DynamicCharged); printf("Dynamic available (bytes): %lu\n", stats.DynamicAvailable); printf("Group count: %lu\n", stats.GroupCount); printf("Privilege count: %lu\n", stats.PrivilegeCount); printf("Modified ID: %08llX\n\n", LuidToNum(stats.ModifiedId)); }
以下是上面使用的两个辅助函数:
ULONGLONG LuidToNum(const LUID& luid) { return *(const ULONGLONG*)&luid; } const char* ImpersonationLevelToString(SECURITY_IMPERSONATION_LEVEL level) { switch (level) { case SecurityAnonymous: return "Anonymous"; case SecurityIdentification: return "Identification"; case SecurityImpersonation: return "Impersonation"; case SecurityDelegation: return "Delegation"; } return "Unknown"; }
`TOKENSTATISTICS` 结构定义如下:
typedef struct _TOKEN_STATISTICS { LUID TokenId; LUID AuthenticationId; LARGE_INTEGER ExpirationTime; TOKEN_TYPE TokenType; SECURITY_IMPERSONATION_LEVEL ImpersonationLevel; DWORD DynamicCharged; DWORD DynamicAvailable; DWORD GroupCount; DWORD PrivilegeCount; LUID ModifiedId; } TOKEN_STATISTICS, *PTOKEN_STATISTICS;
它的一些成员需要解释. 首先, 有我们尚未遇到的 `LUID` 类型. 这是一个 64 位数字, 保证在特定系统运行时是唯一的. 以下是其定义:
typedef struct _LUID { DWORD LowPart; LONG HighPart; } LUID, *PLUID;
LUID 在 Windows 的几个地方使用, 不一定与安全相关. 这只是在每台机器的基础上获取唯一值的一种方式. 如果你需要生成一个, 调用 `AllocateLocallyUniqueId`.
`TokenId` 成员是此令牌实例 (对象, 而非句柄) 的唯一标识符, 因此比较令牌的一个简单方法是比较 `TokenId` 值. `AuthenticationId` 是登录会话 ID, 唯一标识登录会话本身.
💡 三个内置登录会话的登录会话 ID 有众所周知的 ID: 999 (`0x3e7`) 用于 `SYSTEM`, 997 (`0x3e5`) 用于 Local Service, 996 (`0x3e4`) 用于 Network Service.
`TOKENSTATISTICS` 中的 `TokenType` 要么是 `PrimaryToken` (进程令牌), 要么是 `ImpersonationToken` (线程令牌). 如果令牌是模拟令牌, 那么 `ImpersonationLevel` 成员有意义:
typedef enum _SECURITY_IMPERSONATION_LEVEL { SecurityAnonymous, // not really used SecurityIdentification, SecurityImpersonation, SecurityDelegation } SECURITY_IMPERSONATION_LEVEL;
模拟级别指示此模拟令牌具有什么样的“权力” - 从仅仅识别用户 (`SecurityIdentification`) 及其属性, 到仅在服务器进程的机器上模拟用户 (`SecurityImpersonation`), 再到在远程机器上模拟客户端 (相对于服务器进程的机器).
令牌中存储了更多的信息. 我们将在后续章节中研究更多细节. `token.exe` 应用程序演示了通过调用 `GetTokenInformation` 获得的更多令牌信息.
令牌内的某些信息也可以更改. 一种通用的方法是使用 `SetTokenInformation`, 它使用与 `GetTokenInformation` 相同的 `TOKENINFORMATIONCLASS` 枚举:
BOOL SetTokenInformation( _In_ HANDLE TokenHandle, _In_ TOKEN_INFORMATION_CLASS TokenInformationClass, _In_ LPVOID TokenInformation, _In_ DWORD TokenInformationLength);
不幸的是, 文档没有说明哪些信息类是有效的, 因为只有一个子集是有效的. 对令牌的一些更改可以通过不同的 API 实现. 表 16-1 描述了 `SetTokenInformation` 的有效信息类以及它们需要的特权和访问掩码 (如果有的话).
| TOKENINFORMATIONCLASS | Access mask required | Privilege required |
|---|---|---|
| `TokenOwner` | `TOKENADJUSTDEFAULT` | |
| `TokenPrimaryGroup` | `TOKENADJUSTDEFAULT` | |
| `TokenDefaultDacl` | `TOKENADJUSTDEFAULT` | |
| `TokenSessionId` | `TOKENADJUSTSESSIONID` | `SeTcbPrivilege` |
| `TokenVirtualizationAllowed` | `SeCreateTokenPrivilege` | |
| `TokenVirtualizationEnabled` | `TOKENADJUSTDEFAULT` | |
| `TokenOrigin` | `SeTcbPrivilege` | |
| `TokenMandatoryPolicy` | `SeCreateTokenPrivilege` |
举个例子, 以下是通过操纵其令牌来更改进程 UAC 虚拟化状态所需的代码. UAC 虚拟化将在本章后面的“用户访问控制”一节中讨论. 现在, 我们将专注于 `SetTokenInformation` 的机制. 对于每个信息类, 文档都说明了应该提供哪个关联的结构. 在本例中, 对于 `TokenVirtualizationEnabled`, 该值存储在一个简单的 `ULONG` 中, 其中 1 表示启用, 0 表示禁用. 以下是代码 (省略了错误处理):
// hProcess is an open process handle with PROCESS_QUERY_INFORMATION HANDLE hToken; ::OpenProcessToken(hProcess, TOKEN_ADJUST_DEFAULT, &hToken); ULONG enable = 1; // enable ::SetTokenInformation(hToken, TokenVirtualizationEnabled, &enable, sizeof(enable));
根据表 16-1, `TokenVirtualizationEnabled` 需要 `TOKENADJUSTDEFAULT` 访问掩码. `setvirt.exe` 是一个命令行应用程序 (来自本章的示例), 允许启用或禁用进程的 UAC 虚拟化 (当然, 这存储在其主令牌中). 以下是为进程 6912 启用 UAC 虚拟化的示例运行:
c:\>setvirt 6912 on
你可以使用任务管理器 (添加 UAC 虚拟化列, 图 16-8) 或在 Process Explorer 的安全选项卡 (图 16-9) 中查看 UAC 虚拟化状态.

Figure 236: 图 16-8: 任务管理器中的 UAC 虚拟化

Figure 237: 图 16-9: Process Explorer 中的 UAC 虚拟化
- The Secondary Logon Service
辅助登录服务 (`seclogon`) 是一个内置服务, 允许在与调用者不同的用户下启动进程. 它是与 `runas.exe` 内置命令行工具一起使用的服务. 调用该服务是通过调用 `CreateProcessWithLogonW` 完成的:
BOOL CreateProcessWithLogonW( _In_ LPCWSTR lpUsername, _In_opt_ LPCWSTR lpDomain, _In_ LPCWSTR lpPassword, _In_ DWORD dwLogonFlags, _In_opt_ LPCWSTR lpApplicationName, _Inout_opt_ LPWSTR lpCommandLine, _In_ DWORD dwCreationFlags, _In_opt_ LPVOID lpEnvironment, _In_opt_ LPCWSTR lpCurrentDirectory, _In_ LPSTARTUPINFOW lpStartupInfo, _Out_ LPPROCESS_INFORMATION lpProcessInformation);
💡 注意 `CreateProcessWithLogonW` 没有 ANSI 版本.
`CreateProcessWithLogonW` 的一些参数应该看起来很熟悉, 因为它们通常是提供给标准 `CreateProcess` 调用的. 实际上, `CreateProcessWithLogonW` 是两个单独的调用: `LogonUser` 和 `CreateProcessAsUser` 的组合. `LogonUser` 允许在给定适当凭据的情况下检索用户的令牌:
BOOL LogonUser( _In_ LPCTSTR lpszUsername, _In_opt_ LPCTSTR lpszDomain, _In_opt_ LPCTSTR lpszPassword, _In_ DWORD dwLogonType, _In_ DWORD dwLogonProvider, _Outptr_ PHANDLE phToken);
`lpszUsername` 是用户名, 可以是“普通”名称或用户主体名称 (UPN) - 类似于 “user@domanin.com”. 如果用户名是 UPN 名称, `lpszDomain` 必须是 `NULL`. 否则, `lpszDomain` 应该是一个域名, 其中“.”对于本地登录是有效的. `lpszPassword` 是用户的明文密码.
`dwLogonType` 是登录类型. 以下是常见的值 (请查阅文档以获取完整列表):
- `LOGON32LOGONINTERACTIVE` - 适用于将交互式使用机器的用户. 它会缓存登录信息以用于断开连接的操作, 这意味着它比其他登录类型有更高的开销.
- `LOGON32LOGONBATCH` - 适用于代表用户执行操作而无需其干预的情况. 此登录类型不缓存凭据.
- `LOGON32LOGONNETWORK` - 类似于批处理, 但返回的令牌是模拟令牌而不是主令牌. 这样的令牌不能与 `CreateProcessAsUser` 一起使用, 但可以用 `DuplicateTokenEx` (参见“模拟”一节) 转换为主令牌. 这是最快的登录类型.
要成功, 登录类型必须已授予要登录的帐户.
`dwLogonProvider` 选择登录提供程序, 要么是 `LOGON32PROVIDERWINNT50` (Kerberos, 也称为“negotiate”), 要么是 `LOGON32PROVIDERWINNT40` (NTLM - NT Lan manager). 指定 `LOGON32PROVIDERDEFAULT` 会选择 NTLM.
如果函数成功, `phToken` 会返回令牌句柄. 手持令牌, `CreateProcessAsUser` 只是一个函数调用:
BOOL CreateProcessAsUser( _In_opt_ HANDLE hToken, _In_opt_ LPCTSTR lpApplicationName, _Inout_opt_ LPTSTR lpCommandLine, _In_opt_ LPSECURITY_ATTRIBUTES lpProcessAttributes, _In_opt_ LPSECURITY_ATTRIBUTES lpThreadAttributes, _In_ BOOL bInheritHandles, _In_ DWORD dwCreationFlags, _In_opt_ LPVOID lpEnvironment, _In_opt_ LPCTSTR lpCurrentDirectory, _In_ LPSTARTUPINFO lpStartupInfo, _Out_ LPPROCESS_INFORMATION lpProcessInformation);
该函数看起来与 `CreateProcess` 相同, 除了额外的第一个参数: 一个主令牌, 新进程应该在其下执行. 虽然看起来很简单, 但至少有一个问题: 调用 `CreateProcessAsUser` 需要 `SeAssignPrimaryTokenPrivilege` 特权. 这个特权通常授予运行服务的帐户 (Local Service, Network Service 和 Local System), 但不授予标准用户甚至本地管理员别名. 这意味着从服务调用 `CreateProcessAsUser` 是可行的 (见第 18 章), 但在其他情况下是有问题的.
这就是辅助登录服务的作用. 由于它在本地系统帐户下运行, 它可以毫无问题地调用 `CreateProcessAsUser`. `CreateProcessWithLogonW` 是其驱动程序.
💡 实际上, 调用 `CreateProcessAsUser` 并不那么简单, 因为需要为进程成功启动配置一些安全设置.
`CreateProcessWithLogonW` 的 `dwLogonFlags` 参数可以是以下之一:
- `LOGONWITHPROFILE` - 导致 `CreateProcessWithLogonW` 加载用户的配置文件. 如果新进程需要访问 `HKEYCURRENTUSER` 注册表项, 这很重要.
- 零 (0) - 不加载用户的配置文件.
- `LOGONNETCREDENTIALSONLY` - 新进程将在调用者的用户下执行 (而不是指定的用户), 但会创建一个具有指定用户的新网络登录会话. 这意味着新进程的任何网络访问都将使用其他用户的令牌.
接下来的两个参数 `lpApplicationName` 和 `lpCommandLine` 的作用与它们在 `CreateProcess` 中的作用相同 (如果需要复习, 请参阅第 3 章). `dwCreationFlags` 是在内部传递给 `CreateProcessAsUser` 的标志的组合 - 在 `CreateProcess` 中有效的大多数标志在这里也有效. `lpEnvironment` 的含义与它在 `CreateProcess` 中的含义相同, 只是默认环境是其他用户的默认环境, 而不是调用者的.
最后, `lpStartupInfo` 和 `lpProcessInfo` 的含义与它们在 `CreateProcess` 中的含义相同.
你可能在想, 可以通过调用 `LogonUser`, 然后模拟新用户 (`ImpersonateLoggedOnUser`), 最后正常调用 `CreateProcess` 来在另一个用户下创建一个进程. 然而, 这会失败, 因为 `CreateProcess` 总是使用调用者的主 (进程) 令牌, 而不是活动的模拟令牌 (如果有的话).
还有一个调用辅助登录服务的函数 - `CreateProcessWithTokenW`:
BOOL CreateProcessWithTokenW( _In_ HANDLE hToken, _In_ DWORD dwLogonFlags, _In_opt_ LPCWSTR lpApplicationName, _Inout_opt_ LPWSTR lpCommandLine, _In_ DWORD dwCreationFlags, _In_opt_ LPVOID lpEnvironment, _In_opt_ LPCWSTR lpCurrentDirectory, _In_ LPSTARTUPINFOW lpStartupInfo, _Out_ LPPROCESS_INFORMATION lpProcessInformation);
此函数需要 `SeImpersonatePrivilege`, 通常授予本地管理员别名和服务帐户. 它使用一个现有的令牌 (例如, 来自一个成功的 `LogonUser` 调用), 但它确实需要一些额外的工作, 以便新进程不会初始化失败.
💡 使用 `CreateProcessWithLogonW` 是最简单的方法, 与 `CreateProcessWithLogonW` 和 `CreateProcessAsUser` 相比, 灵活性有所损失.
- 模拟
通常, 线程执行的任何操作都是使用进程的令牌完成的. 如果进程中的一个线程希望在执行某些操作之前对令牌进行临时更改怎么办? 对令牌的任何更改都将反映在进程级别, 影响进程中的所有线程. 线程可能希望有自己的私有令牌.
使用像 `DuplicateHandle` 这样的东西可能不会像预期的那样工作, 因为新句柄仍然引用同一个对象. 相反, 可以使用 `DuplicateTokenEx` 函数:
BOOL DuplicateTokenEx( _In_ HANDLE hExistingToken, _In_ DWORD dwDesiredAccess, _In_opt_ LPSECURITY_ATTRIBUTES lpTokenAttributes, _In_ SECURITY_IMPERSONATION_LEVEL ImpersonationLevel, _In_ TOKEN_TYPE TokenType, _Outptr_ PHANDLE phNewToken);
`DuplicateTokenEx` 在某种意义上是独一无二的, 因为它是唯一可以复制对象的函数. 没有用于互斥体或信号量的此类函数, 例如.
`hExistingToken` 是要复制的现有令牌. 它必须具有 `TOKENDUPLICATE` 访问掩码. `dwDesiredAccess` 是新令牌请求的访问掩码. 指定零会导致与原始令牌相同的访问掩码. 如果这个新令牌将用于模拟, 则需要 `TOKENIMPERSONATE`.
`lpTokenAttributes` 是标准的 `SECURITYATTRIBUTES` (在“安全描述符”一节中讨论), 通常设置为 `NULL`. `ImpersonationLevel` 指示新令牌中固有的模拟信息级别 (有关此内容的更多信息, 请参见本节后面的内容). `TokenType` 是 `TokenPrimary` (用于附加到进程) 或 `TokenImpersonation` (用于附加到线程). 最后, 如果调用成功, `phNewToken` 会接收新令牌句柄.
现在可以操纵新令牌 (启用/禁用特权, 更改 UAC 虚拟化状态等), 而不影响原始令牌. 为了让新令牌产生影响, 它需要附加到当前线程 (假设它被复制为模拟令牌), 这可以通过调用 `SetThreadToken` 来完成:
BOOL SetThreadToken( _In_opt_ PHANDLE Thread, _In_opt_ HANDLE Token);
`Thread` 是一个指向线程句柄的指针, 其中 `NULL` 表示当前线程.
💡 这是一种非常不寻常的指定线程句柄的方式; 通常使用直接句柄, 其中 `GetCurrentThread` 用于表示当前线程.
`Token` 是要使用的模拟令牌. `NULL` 是作为停止使用任何现有令牌的一种可接受的方式. 或者, 如果模拟是在当前线程上, 可以调用 `RevertToSelf` 函数:
BOOL RevertToSelf();
以下示例复制进程令牌以进行模拟, 并对模拟令牌进行“本地”更改 (省略了错误处理):
HANDLE hProcToken; ::OpenProcessToken(GetCurrentProcess(), TOKEN_DUPLICATE, &hProcToken); HANDLE hImpToken; ::DuplicateTokenEx(hProcToken, MAXIMUM_ALLOWED, nullptr, SecurityIdentification, TokenImpersonation, &hImpToken); ::CloseHandle(hProcToken); // enable UAC virtualization on the new token ULONG virt = 1; ::SetTokenInformation(hImpToken, TokenVirtualizationEnabled, &virt, sizeof(virt)); // impersonate ::SetThreadToken(nullptr, hImpToken); // do work... ::RevertToSelf(); ::CloseHandle(hImpToken);
获取当前进程令牌并将其复制为模拟令牌并附加到当前线程的整个过程可以用一次操作完成:
BOOL ImpersonateSelf(_In_ SECURITY_IMPERSONATION_LEVEL ImpersonationLevel);
`ImpersonateSelf` 复制进程令牌以创建一个模拟令牌, 然后调用 `SetThreadToken`.
当使用某个令牌 (不一定是进程令牌) 在当前线程上进行模拟时, 可以使用另一个简写函数:
BOOL ImpersonateLoggedOnUser(_In_ HANDLE hToken);
`ImpersonateLoggedOnUser` 接受一个主令牌或模拟令牌, 复制令牌 (如果需要), 并在当前线程上调用 `SetThreadToken`.
在以下示例中, `ImpersonateLoggedOnUser` 在 `LogonUser` 之后使用:
HANDLE hToken; ::LogonUser(L"alice", L".", L"alicesecretpassword", LOGON32_LOGON_BATCH, LOGON32_PROVIDER_DEFAULT, &hToken); // impersonate alice ::ImpersonateLoggedOnUser(hToken); // do work as alice... ::RevertToSelf(); ::CloseHandle(hToken);
- 客户端/服务器中的模拟
模拟的经典用法是在客户端/服务器场景中. 想象一个在用户 A 下运行的服务器进程. 多个客户端使用某种通信机制 (COM, 命名管道, RPC 等) 连接到服务器进程, 请求服务器进程代表它们执行某些操作 (图 16-10).

Figure 238: 图 16-10: 客户端/服务器
如果服务器进程使用其自己的身份 (A) 执行请求的操作, 那就不对了. 也许客户端 B 请求对一个 B 没有访问权限但 A 有的文件执行操作. 相反, 服务器在尝试执行操作之前应该模拟请求的客户端.
当复制令牌时, `SECURITYIMPERSONATIONLEVEL` 模拟级别指示当令牌发送到另一台机器上的服务器时, 生成的令牌中固有的“权力”:
typedef enum _SECURITY_IMPERSONATION_LEVEL { SecurityAnonymous, SecurityIdentification, SecurityImpersonation, SecurityDelegation } SECURITY_IMPERSONATION_LEVEL;
使用 `SecurityAnonymous`, 服务器不知道客户端是谁, 因此无法模拟它. 对于服务器被要求执行的某些类型的操作, 这可能没问题. `SecurityIdentification` 是下一个级别, 服务器可以查询客户端的属性, 但仍然无法模拟它 (除非服务器进程与客户端进程在同一台机器上). 使用 `SecurityImpersonation`, 服务器只能在服务器的机器上模拟客户端 (不能更远). 最后一个 (也是最宽松的) 模拟级别 `SecurityDelegation` 允许服务器在另一台机器上调用另一个服务器并传播令牌, 以便另一个服务器可以模拟原始客户端, 这可以持续任意多跳.
令牌传播机制取决于使用的通信机制. 表 16-2 显示了其中一些机制的模拟和恢复 API. 请查阅文档以获取模式详细信息 (命名管道在第 18 章中讨论, COM 在第 21 章中讨论).
Communication mechanism Impersonation Reverting Named pipes `ImpersonateNamedPipeClient` `RevertToSelf` RPC `RpcImpersonateClient` `RpcRevertToSelf` COM `CoImpersonateClient` `CoRevertToSelf`
2.4.4. 特权
特权是执行某些与特定对象无关的系统级操作的权利 (或被拒绝的权利). 示例特权包括: 加载设备驱动程序, 调试其他用户的进程, 获取对象的所有权等等. 完整的列表可以在本地安全策略管理单元中查看 (图 16-11). 对于每个特权 (“策略”列), 该工具列出了被授予该特权的帐户.

Figure 239: 图 16-11: 本地安全策略编辑器中的特权
技术上, 图 16-11 显示了特权和用户权限. 区别如下: 用户权限适用于帐户 - 即存储在用户数据库中的数据. 用户权限总是关于允许或拒绝某种形式的登录. 另一方面, 特权 (也作为静态数据存储在帐户数据库中), 但它们仅在用户登录后才适用. 特权存储在用户的访问令牌中, 而用户权限则不是, 因为它们仅在用户登录之前有意义.
用户权限的例子包括: “拒绝作为批处理作业登录”, “允许本地登录”和“允许通过远程桌面服务登录”.
一旦创建 (或复制) 了令牌, 就不能向令牌添加新的特权. 管理员可以向帐户 (数据库) 本身添加特权, 但这对现有令牌没有影响. 一旦用户注销并重新登录, 新的特权将在其令牌中可用.
大多数特权默认是禁用的. 这可以防止意外 (无意) 使用这些特权. 图 16-12 显示了 `Explorer.exe` 进程的特权列表 (在 Process Explorer 中显示). 唯一启用的特权 (这个默认启用) 是 `SeChangeNotifyPrivilege` - 其余的都被禁用了.

Figure 240: 图 16-12: Explorer 令牌中的特权
奇怪命名的 `SeChangeNotifyPrivilege` 特权默认授予所有用户并启用. 其描述性名称是“绕过遍历检查”. 它允许访问一个目录中的文件, 而该用户对该目录的某些父目录本身是不可访问的. 例如, 如果用户的安全描述符允许, 文件 `c:\A\B\c.txt` 是可访问的, 即使目录 A 不是. 遍历所有父目录的安全描述符是昂贵的, 这就是为什么默认启用此特权的原因.
获取令牌中的特权列表可以通过我们已经见过的 `GetTokenInformation` 来实现. 要启用, 禁用或移除一个特权, 需要调用 `AdjustTokenPrivileges`:
BOOL AdjustTokenPrivileges( _In_ HANDLE TokenHandle, _In_ BOOL DisableAllPrivileges, _In_opt_ PTOKEN_PRIVILEGES NewState, _In_ DWORD BufferLength, _Out_opt_ PTOKEN_PRIVILEGES PreviousState, _Out_opt_ PDWORD ReturnLength);
`TokenHandle` 必须具有 `TOKENADJUSTPRIVILEGES` 访问掩码, 以便调用有机会成功. 如果 `DisableAllPrivileges` 是 `TRUE`, 函数会禁用令牌中的所有特权, 并忽略接下来的两个参数. 要更改的特权由一个 `TOKENPRIVILEGES` 结构提供, 定义如下:
typedef struct _LUID_AND_ATTRIBUTES { LUID Luid; DWORD Attributes; } LUID_AND_ATTRIBUTES; typedef struct _TOKEN_PRIVILEGES { DWORD PrivilegeCount; LUID_AND_ATTRIBUTES Privileges[ANYSIZE_ARRAY]; } TOKEN_PRIVILEGES, *PTOKEN_PRIVILEGES;
特权在 Windows API 中表示为字符串. 例如, `SEDEBUGNAME` 定义为 `TEXT("SeDebugPrivilege")`. 然而, 每个特权在系统启动时也会被赋予一个 LUID, 每次系统重启时都不同. `AdjustTokenPrivileges` 希望以 LUID 而不是字符串的形式操作特权. 所以我们必须费点力气用 `LookupPrivilegeValue` 获取特权的 LUID:
BOOL LookupPrivilegeValue( _In_opt_ LPCTSTR lpSystemName, _In_ LPCTSTR lpName, _Out_ PLUID lpLuid);
该函数接受一个机器名 (`NULL` 对本地机器有效), 特权的名称, 并返回其 LUID.
回到 `AdjustTokenPrivileges` - `TOKENPRIVILEGES` 需要一个 `LUIDANDATTRIBUTES` 结构数组, 每个结构包含一个 LUID 和要使用的属性. 可能的值是 `SEPRIVILEGEENABLED` 用于启用特权, 零用于禁用它, `SEPRIVILEGEREMOVED` 用于移除它.
`NewState` 是一个指向 `TOKENPRIVILEGES` 的指针, `BufferLength` 是数据的大小, 因为可以同时修改多个特权. 最后, `PreviousState` 和 `ReturnedLength` 是可选参数, 可以返回修改的特权的先前状态. 大多数调用者对这两个参数都指定 `NULL`.
`AdjustTokenPrivileges` 的返回值有点棘手. 它在任何类型的成功时都返回 `TRUE`, 即使只有部分特权被成功更改. 正确的做法是 (如果调用返回 `TRUE`) 调用 `GetLastError`. 如果返回零, 一切顺利, 否则可能会返回 `ERRORNOTALLASSIGNED`, 这表示出了点问题. 如果只请求了一个特权, 这实际上表示失败.
我们已经在第 13 章和第 1 部分的几章中多次使用过 `AdjustTokenPrivileges`, 但没有完整的解释. 现在我们可以编写一个通用的函数, 通过利用 `AdjustTokenPrivileges` 和 `LookupPrivilegeValue` 来启用或禁用调用者令牌中的任何特权:
bool EnablePrivilege(PCWSTR privName, bool enable) { HANDLE hToken; if (!::OpenProcessToken(::GetCurrentProcess(), TOKEN_ADJUST_PRIVILEGES, &hToken)) return false; bool result = false; TOKEN_PRIVILEGES tp; tp.PrivilegeCount = 1; tp.Privileges.Attributes = enable ? SE_PRIVILEGE_ENABLED : 0; if (::LookupPrivilegeValue(nullptr, privName, &tp.Privileges.Luid)) { if (::AdjustTokenPrivileges(hToken, FALSE, &tp, sizeof(tp), nullptr, nullptr)) result = ::GetLastError() == ERROR_SUCCESS; } ::CloseHandle(hToken); return result; }
使用单个特权使得调用 `AdjustTokenPrivileges` 变得容易, 因为 `TOKENPRIVILEGES` 中正好有一个特权的空间, 无需额外的分配.
- 超级特权
对所有可用特权的详尽讨论超出了本书的范围. 然而, 一些特权确实值得特别提及. 有一组特权如此强大, 以至于拥有它们中的任何一个都允许几乎完全控制系统 (有些甚至允许完全控制). 它们有时被亲切地称为“超级特权”, 尽管这不是一个官方术语.
- Take Ownership
一个对象的所有者总是可以设置谁能对该对象做什么 (有关更多细节, 请参见“安全描述符”一节). `SeTakeOwnershipPrivilege` (`SETAKEOWNERSHIPNAME`) 允许其持有者将自己设置为任何内核对象 (文件, 互斥体, 进程等) 的所有者. 作为所有者, 用户现在可以给自己完全访问该对象的权限.
这个特权通常授予管理员, 这是有道理的, 因为管理员应该能够在需要时控制任何对象. 例如, 假设一个员工离开公司, 他/她拥有的一些文件/文件夹现在无法访问. 管理员可以行使获取所有权特权, 并将管理员设置为所有者, 从而允许设置对该对象的完全访问权限.
一种看到这个实际操作的方法是使用对象的安全描述符, 例如一个文件 (图 16-13). 点击 Advanced 按钮会显示图 16-14 中的对话框, 其中显示了所有者.

Figure 241: 图 16-13: 内核对象的安全设置

Figure 242: 图 16-14: 高级安全设置对话框
点击 Change 按钮会导致对话框处理程序启用获取所有权特权 (如果存在于调用者的令牌中, 在本例中是运行 Explorer 的用户) 并替换所有者.
- Backup
备份特权 (`SEBACKUPNAME`) 使其用户对任何对象都有读访问权限, 无论其安全描述符如何. 通常, 这应该给予执行某种形式备份的应用程序. 管理员和备份操作员组默认拥有此特权. 要将其用于文件, 在用 `CreateFile` 打开文件时指定 `FILEBACKUPSEMANTICS`.
- Restore
恢复特权 (`SERESTORENAME`) 是备份的反面, 并提供对任何内核对象的写访问权限.
- Debug
调试特权 (`SEDEBUGNAME`) 允许调试和内存操纵任何进程. 这包括调用 `CreateRemoteThread` 向任何进程注入线程. 这不包括受保护和 PPL 进程.
- TCB
TCB 特权 (可信计算基, `SETCBNAME`), 被描述为“作为操作系统的一部分”, 是最强大的特权之一. 一个证明是, 默认情况下它不授予任何用户或组. 拥有此特权允许用户模拟任何其他用户, 并通常拥有与内核相同的访问权限.
- Create Token
创建令牌特权 (`SECREATETOKENNAME`) 允许创建一个令牌, 从而用任何特权或组填充它. 这个特权默认不授予任何用户. 然而, `Lsass` 进程必须拥有它, 因为在成功登录后需要它. 如果你在 Process Explorer 中检查 `Lsass` 的安全属性, 你会发现它有这个特权. 如果没有用户被授予此特权, 这怎么可能呢? 我们将在第 19 章回答这个问题.
- Take Ownership
2.4.5. 访问掩码
我们之前已经多次遇到访问掩码. 起初, 它们可能看起来对各种访问位使用随机值, 但有一个逻辑的位分组, 如图 16-15 所示.

Figure 243: 图 16-15: 访问掩码的组成部分
“特定权限”部分 (低 16 位) 表示的正是这个: 对于每种对象类型都不同的特定权限. 例如, `PROCESSTERMINATE` 和 `PROCESSCREATETHREAD` 是进程对象的两个特定权限.
接下来, 有标准权限, 适用于多种对象类型. 例如, `SYNCHRONIZE`, `DELETE` 和 `WRITEDAC` 是标准权限的例子. 它们不一定对所有对象类型都有意义. 例如, `SYNCHRONIZE` 只对调度程序 (可等待) 对象有意义.
下一个位 (24) 是 `ACCESSSYSTEMSECURITY` 访问权限, 允许访问系统访问控制列表 (在下一节中讨论). `MAXIMUMALLOWED` (位 25) 是一个特殊的值, 如果使用, 提供客户端可以获得的最大访问掩码. 例如:
HANDLE hProcess = ::OpenProcess(MAXIMUM_ALLOWED, FALSE, pid);
如果可以获得一个句柄, 结果访问掩码是调用者可能得到的最高级别. 上述例子在实践中不那么有用, 因为调用者知道需要什么访问掩码来完成工作.
位 28-31 表示通用权限. 这些权限 (如果使用) 必须被翻译或映射到特定的访问权限. 例如, 指定 `GENERICWRITE` 必须映射到所讨论的对象类型中“写”的含义. 这是在内部用以下结构执行的:
typedef struct _GENERIC_MAPPING { ACCESS_MASK GenericRead; ACCESS_MASK GenericWrite; ACCESS_MASK GenericExecute; ACCESS_MASK GenericAll; } GENERIC_MAPPING;
默认的映射可以在 Object Explorer 工具中查看 (图 16-16), 但它们相当直观, 有些是在头文件中间接定义的. 例如, `FILEGENERICREAD` 是文件的 `GENERICREAD` 映射.

Figure 244: 图 16-16: Object Explorer 中的通用映射
2.4.6. 安全描述符
安全描述符是一个可变长度的结构, 包含有关谁能对附加到的对象做什么的信息. 一个安全描述符包含以下几部分信息:
- 所有者 SID - 对象的所有者.
- 主组 SID - 过去用于 POSIX 子系统应用程序中的组安全.
- 自由访问控制列表 (DACL) - 一个访问控制条目 (ACE) 的列表, 指定谁能对该对象做什么.
- 系统访问控制列表 (SACL) - 一个 ACE 的列表, 指示哪些操作应导致将审计条目写入安全日志.
对象的所有者总是拥有 `WRITEDAC` (和 `READCONTROL`) 标准访问权限, 这意味着它可以读取和更改对象的 DACL. 这很重要, 否则一个粗心的调用可能会使对象完全无法访问. 拥有 `WRITEDAC` 确保所有者无论如何都可以更改 DACL.
获取你拥有打开句柄的任何内核对象的安全描述符可以通过 `GetKernelObjectSecurity` 完成:
BOOL GetKernelObjectSecurity( _In_ HANDLE Handle, _In_ SECURITY_INFORMATION RequestedInformation, _Out_ PSECURITY_DESCRIPTOR pSecurityDescriptor, _In_ DWORD nLength, _Out_ LPDWORD lpnLengthNeeded);
句柄必须具有 `READCONTROL` 标准访问掩码. `SECURITYINFORMATION` 是一个枚举, 指定在生成的安全描述符中要返回哪种信息 (可以用 OR 操作符指定多个). 最常见的是 `OWNERSECURITYINFORMATION` 和 `DACLSECURITYINFORMATION`. 结果存储在 `PSECURITYDESCRIPTOR` 中. `SECURITYDESCRIPTOR` 结构是定义的, 但应被视为不透明的, 这就是为什么 `PSECURITYDESCRIPTOR` (指向该结构的指针) 被 `typedef` 为 `PVOID`. `GetKernelObjectSecurity` 要求调用者分配一个足够大的缓冲区, 在 `nLength` 参数中指定其长度, 并在 `lpnLengthNeeded` 中获取实际长度.
💡 使用 `SACLSECURITYINFORMATION` 请求 SACL 需要 `SeSecurityPrivilege`, 通常授予管理员.
手持 `PSECURITYDESCRIPTOR`, 有几个函数可以提取其中存储的数据:
DWORD GetSecurityDescriptorLength(_In_ PSECURITY_DESCRIPTOR pSecurityDescriptor); BOOL GetSecurityDescriptorControl( // control flags _In_ PSECURITY_DESCRIPTOR pSecurityDescriptor, _Out_ PSECURITY_DESCRIPTOR_CONTROL pControl, _Out_ LPDWORD lpdwRevision); BOOL GetSecurityDescriptorOwner( // owner _In_ PSECURITY_DESCRIPTOR pSecurityDescriptor, _Outptr_ PSID* pOwner, _Out_ LPBOOL lpbOwnerDefaulted); BOOL GetSecurityDescriptorGroup( // primary group (mostly useless) _In_ PSECURITY_DESCRIPTOR pSecurityDescriptor, _Outptr_ PSID* pGroup, _Out_ LPBOOL lpbGroupDefaulted);
BOOL GetSecurityDescriptorDacl( // DACL _In_ PSECURITY_DESCRIPTOR pSecurityDescriptor, _Out_ LPBOOL lpbDaclPresent, _Outptr_ PACL* pDacl, _Out_ LPBOOL lpbDaclDefaulted); BOOL GetSecurityDescriptorSacl( // SACL _In_ PSECURITY_DESCRIPTOR pSecurityDescriptor, _Out_ LPBOOL lpbSaclPresent, _Outptr_ PACL* pSacl, _Out_ LPBOOL lpbSaclDefaulted);
例如, 以下是一些显示给定 ID 的进程所有者的代码:
bool DisplayProcessOwner(DWORD pid) { HANDLE hProcess = ::OpenProcess(READ_CONTROL, FALSE, pid); if (!hProcess) return false; BYTE buffer[1 << 10]; auto sd = (PSECURITY_DESCRIPTOR)buffer; DWORD len; BOOL success = ::GetKernelObjectSecurity(hProcess, OWNER_SECURITY_INFORMATION, sd, sizeof(buffer), &len); ::CloseHandle(hProcess); if(!success) return false; PSID owner; BOOL isDefault; if (!::GetSecurityDescriptorOwner(sd, &owner, &isDefault)) return false; printf("Owner: %ws (%ws)\n", GetUserNameFromSid(owner).c_str(), SidToString(owner).c_str()); return true; }
另一个检索对象安全描述符的函数是 `GetNamedSecurityInfo` (`#include <AclAPI.h>`):
DWORD GetNamedSecurityInfo( _In_ LPCTSTR pObjectName, _In_ SE_OBJECT_TYPE ObjectType, _In_ SECURITY_INFORMATION SecurityInfo, _Out_opt_ PSID* ppsidOwner, _Out_opt_ PSID* ppsidGroup, _Out_opt_ PACL* ppDacl, _Out_opt_ PACL* ppSacl, _Out_ PSECURITY_DESCRIPTOR* ppSecurityDescriptor);
此函数只能用于命名对象 (互斥体, 事件, 信号量, 节) 和具有某种“路径”的对象 (文件和注册表项). 它不需要对象的打开句柄 - 只需要其名称和类型. 如果调用者无法获取 `READCONTROL` 访问掩码, 函数会失败.
`pObjectName` 是对象的名称, 其格式适合于 `SEOBJECTTYPE` 枚举给出的对象类型. 该函数可以返回整个安全描述符, 或只返回选定的部分. 函数的返回值是错误代码本身, 其中 `ERRORSUCCESS` (0) 表示一切顺利 (没有必要调用 `GetLastError`).
以下示例显示给定文件的所有者:
bool DisplayFileOwner(PCWSTR filename) { PSID owner; DWORD error = ::GetNamedSecurityInfo(filename, SE_FILE_OBJECT, OWNER_SECURITY_INFORMATION, &owner, nullptr, nullptr, nullptr, nullptr); if (error != ERROR_SUCCESS) return false; printf("Owner: %ws (%ws)\n", GetUserNameFromSid(owner).c_str(), SidToString(owner).c_str()); return true; }
注意你不要释放从 `GetNamedSecurityInfo` 返回的信息 - 这会导致异常.
💡 特别是对于文件, 还有另一个返回文件安全描述符的函数: `GetFileSecurity`. 然后需要用前面提到的函数之一 (如 `GetSecurityDescriptorOwner`) 检索各个部分. 此外, 对于桌面和窗口站对象, 存在另一个便利函数 - `GetUserObjectSecurity`.
安全描述符最重要的部分是 DACL. 这直接影响谁被允许以何种方式访问对象. DACL 最众所周知的视图是各种工具中可用的安全属性对话框, 例如在 Explorer 中用于文件和目录 (图 16-17).

Figure 245: 图 16-17: 安全属性对话框
图 16-17 中的对话框显示了 DACL. 对于每个用户或组, 它显示了允许或拒绝的操作. DACL 中的每个项目都是一个 访问控制条目 (Access Control Entry, ACE), 其中包含以下信息:
- 此 ACE 适用的 SID (例如一个用户或一个组).
- 此 ACE 控制的访问掩码 (例如一个进程对象的 `PROCESSTERMINATE`) (可以超过一位)
- ACE 类型, 最常见的是允许或拒绝.
当调用者试图获取对文件的特定访问权限时, 内核中的安全引用监视器必须检查请求的访问权限 (基于访问掩码) 是否被调用者允许. 它通过遍历 DACL 中的 ACE 来实现, 寻找一个明确的结果. 一旦找到, 遍历就终止了. 图 16-18 显示了某个文件对象上的 DACL 示例.

Figure 246: 图 16-18: 一个示例安全描述符
假设我们有两个用户, USER1 和 USER2, 它们是两个组 TEAM1 和 TEAM2 的一部分, 还有一个用户 USER3, 他只属于 TEAM2 组. 以下是我们能问的一些问题:
- 如果 USER1 想打开文件进行读访问, 会成功吗?
- 如果 USER1 想打开文件进行写访问, 会成功吗?
- 如果 USER2 想打开文件进行写访问, 会成功吗?
- 如果 USER2 想打开文件进行执行访问, 会成功吗?
- 如果 USER3 想打开文件进行读访问, 会成功吗?
ACE 按顺序遍历. 如果没有明确的答案, 则咨询下一个 ACE. 如果在咨询了所有 ACE 之后仍然没有明确的结果, 最终的裁决是拒绝访问.
如果安全描述符本身是 `NULL`, 这意味着对象没有保护, 所有访问都被允许. 如果安全描述符存在, 但 DACL 本身是 `NULL`, 这意味着同样的事情 - 没有保护. 另一方面, 如果 DACL 是空的 (即没有 ACE), 这意味着没有人可以访问该对象 (除了所有者).
让我们回答上面的问题:
- USER1 被拒绝读访问, 因为第二个 ACE. 第一个 ACE 没有说任何关于读访问的事情.
- USER1 被允许写访问 - ACE 的顺序很重要.
- USER2 被拒绝写访问.
- USER2 被允许执行访问, 因为它是 Everyone 组的一部分, 并且之前的 ACE 没有说任何关于执行的事情.
- USER3 被拒绝读访问, 因为没有 ACE 提供明确的答案, 所以最终的裁决是拒绝访问.
💡 还有其他因素会影响访问检查, 包括其他类型的 ACE, 例如继承 ACE. 请查阅文档以获取详细信息.
💡 如果你用 Explorer 显示的安全对话框编辑 DACL, 由安全对话框构建的 ACE 总是将拒绝 ACE 放在允许 ACE 之前. 图 16-18 中的例子永远不会被构建 (但可以按这个顺序编程构建), 因为 ACE 2 会被放在第一位, 因为它是一个拒绝 ACE.
💡 如果拒绝 ACE 被放在允许 ACE 之前, 上述问题的答案会如何改变?
💡 你可以用 `EditSecurity` API 编程方式显示安全属性对话框. 这不容易, 因为你需要提供 `ISecurityInformation` COM 接口的实现, 该接口为对话框的操作返回适当的信息. 你可以在我的 Object Explorer 工具的源代码和其他在线资源中找到一个示例实现.
一个 DACL (以及 SACL) 由 `ACL` 结构表示, 当用 `GetSecurityDescriptorDacl` 或 `GetNamedSecurityInfo` 检索 DACL 时, 会返回一个指向它的指针:
typedef struct _ACL { BYTE AclRevision; BYTE Sbz1; WORD AclSize; WORD AceCount; WORD Sbz2; } ACL; typedef ACL *PACL;
唯一有趣的成员是 `AceCount`. ACL 对象后面紧跟着一个 ACE 数组. 每个 ACE 的大小可能不同 (取决于 ACE 的类型), 但每个 ACE 总是以 `ACEHEADER` 开头:
typedef struct _ACE_HEADER { BYTE AceType; BYTE AceFlags; WORD AceSize; } ACE_HEADER; typedef ACE_HEADER *PACE_HEADER;
无需手动计算每个 ACE 的起始位置 - 只需调用 `GetAce`:
BOOL GetAce( _In_ PACL pAcl, _In_ DWORD dwAceIndex, _Outptr_ LPVOID* pAce);
`pAcl` 是 DACL 指针, `dwAceIndex` 是 ACE 索引 (从零开始), 返回的指针指向 ACE 本身, 它总是以 `ACEHEADER` 开头. 手持 ACE 的类型 (来自头), 从 `GetAce` 返回的指针可以强制转换为特定的 ACE 结构. 以下是两种最常见的 ACE 类型: 允许和拒绝:
typedef struct _ACCESS_ALLOWED_ACE { ACE_HEADER Header; ACCESS_MASK Mask; DWORD SidStart; } ACCESS_ALLOWED_ACE; typedef struct _ACCESS_DENIED_ACE { ACE_HEADER Header; ACCESS_MASK Mask; DWORD SidStart; } ACCESS_DENIED_ACE;
在这里你可以看到 ACE 的三个部分: 它的类型, 访问掩码, 和 SID. SID 紧跟在访问掩码之后, 所以 `SidStart` 实际上是一个虚拟值 - 只有它的地址重要. 以下是显示两种常见 ACE 类型信息的函数:
void DisplayAce(PACE_HEADER header, int index) { printf("ACE %2d: Size: %2d bytes, Flags: 0x%02X Type: %s\n", index, header->AceSize, header->AceFlags, AceTypeToString(header->AceType)); // simple enum to string switch (header->AceType) { case ACCESS_ALLOWED_ACE_TYPE: case ACCESS_DENIED_ACE_TYPE: // have the same binary layout { auto data = (ACCESS_ALLOWED_ACE*)header; printf("\tAccess: 0x%08X %ws (%ws)\n", data->Mask, GetUserNameFromSid((PSID)&data->SidStart).c_str(), SidToString((PSID)&data->SidStart).c_str()); } break; } }
`sd.exe` 应用程序允许查看线程, 进程, 文件, 注册表项和其他命名对象 (互斥体, 事件等) 的安全描述符. 上述代码是该应用程序的摘录. 以下是一些运行 `sd.exe` 的例子:
c:\>sd.exe Usage: sd [[-p <pid>] | [-t <tid>] | [-f <filename>] | [-k <regkey>] | [objectname]] If no arguments specified, shows the current process security descriptor SD Length: 116 bytes SD: O:BAD:(A;;0x1fffff;;;BA)(A;;0x1fffff;;;SY)(A;;0x121411;;;S-1-5-5-0-687579) Control: DACL Present, Self Relative Owner: BUILTIN\Administrators (S-1-5-32-544) DACL: ACE count: 3 ACE 0: Size: 24 bytes, Flags: 0x00 Type: ALLOW Access: 0x001FFFFF BUILTIN\Administrators (S-1-5-32-544) ACE 1: Size: 20 bytes, Flags: 0x00 Type: ALLOW Access: 0x001FFFFF NT AUTHORITY\SYSTEM (S-1-5-18) ACE 2: Size: 28 bytes, Flags: 0x00 Type: ALLOW Access: 0x00121411 NT AUTHORITY\LogonSessionId_0_687579 (S-1-5-5-0-687579) c:\>sd -p 4936 SD Length: 100 bytes SD: O:S-1-5-5-0-340923D:(A;;0x1fffff;;;S-1-5-5-0-340923)(A;;0x1400;;;BA) Control: DACL Present, Self Relative Owner: NT AUTHORITY\LogonSessionId_0_340923 (S-1-5-5-0-340923) DACL: ACE count: 2 ACE 0: Size: 28 bytes, Flags: 0x00 Type: ALLOW Access: 0x001FFFFF NT AUTHORITY\LogonSessionId_0_340923 (S-1-5-5-0-340923) ACE 1: Size: 24 bytes, Flags: 0x00 Type: ALLOW Access: 0x00001400 BUILTIN\Administrators (S-1-5-32-544) c:\>sd -f c:\temp\test.txt SD Length: 180 bytes SD: O:S-1-5-21-2575492975-396570422-1775383339-1001D:AI(D;;CCDCLCSWRPWPLOCRSDRC;;;S-\ 1-5-21-2575492975-396570422-1775383339-1009)(A;ID;FA;;;BA)(A;ID;FA;;;SY)(A;ID;0x1200\ a9;;;BU)(A;ID;0x1301bf;;;AU) Control: DACL Present, DACL Auto Inherited, Self Relative Owner: PAVEL7540\pavel (S-1-5-21-2575492975-396570422-1775383339-1001) DACL: ACE count: 5 ACE 0: Size: 36 bytes, Flags: 0x00 Type: DENY Access: 0x000301BF PAVEL7540\alice (S-1-5-21-2575492975-396570422-1775383339\ -1009) ACE 1: Size: 24 bytes, Flags: 0x10 Type: ALLOW Access: 0x001F01FF BUILTIN\Administrators (S-1-5-32-544) ACE 2: Size: 20 bytes, Flags: 0x10 Type: ALLOW Access: 0x001F01FF NT AUTHORITY\SYSTEM (S-1-5-18) ACE 3: Size: 24 bytes, Flags: 0x10 Type: ALLOW Access: 0x001200A9 BUILTIN\Users (S-1-5-32-545) ACE 4: Size: 20 bytes, Flags: 0x10 Type: ALLOW Access: 0x001301BF NT AUTHORITY\Authenticated Users (S-1-5-11)
以上一些输出需要一些解释. 安全描述符有一个基于安全描述符定义语言 (Security Descriptor Definition Language, SDDL) 的字符串表示. 有函数可以从二进制转换为字符串表示, 反之亦然: `ConvertSecurityDescriptorToStringSecurityDescriptor` 和 `ConvertStringSecurityDescriptorToSecurityDescriptor`.
安全描述符以两种格式存在: 自相对 (Self-relative) 和绝对 (Absolute). 使用自相对格式, 安全描述符的各个部分被打包成一个结构, 很容易移动. 绝对格式有指向安全描述符部分的内部指针, 因此在不修改内部指针的情况下无法移动. 在大多数情况下, 实际格式无关紧要, 并且可以用 `MakeAbsoluteSD` 和 `MakeSelfRelativeSD` 在两种格式之间转换.
- 默认安全描述符
几乎每个内核对象创建函数都有一个 `SECURITYATTRIBUTES` 结构作为参数. 提醒一下, 这是它的样子:
typedef struct _SECURITY_ATTRIBUTES { DWORD nLength; LPVOID lpSecurityDescriptor; BOOL bInheritHandle; } SECURITY_ATTRIBUTES;
我们使用 `bInheritHandle` 作为实现句柄继承的一种方式, 但 `lpSecurityDescriptor` 总是 `NULL`. 如果整个结构没有提供, 这意味着在 `lpSecurityDescriptor` 中为 `NULL`. 这是否意味着对象没有保护? 不一定.
我们可以在创建后通过使用 `GetKernelObjectSecurity` 检查附加到对象的安全描述符, 如下所示:
BYTE buffer[1 << 10]; DWORD len; HANDLE hEvent = ::CreateEvent(nullptr, FALSE, FALSE, nullptr); ::GetKernelObjectSecurity(hEvent, DACL_SECURITY_INFORMATION | OWNER_SECURITY_INFORMATION, (PSECURITY_DESCRIPTOR)buffer, sizeof(buffer), &len);
现在我们可以检查生成的安全描述符. 事实证明, 未命名的对象 (互斥体, 事件, 信号量, 文件映射对象) 会得到一个没有 DACL 的安全描述符. 然而, 命名对象 (包括文件和注册表项) 会得到一个带有默认 DACL 的安全描述符. 这个默认的 DACL 来自访问令牌, 所以我们可以查看它, 甚至更改它.
为什么未命名的对象没有保护? 原因可能是因为句柄是私有的, 它不能从进程外部访问. 只有注入的代码可以接触到这些句柄. 而且由于这样的句柄没有任何“识别标记”, 恶意代理不太可能知道它们的用途. 另一方面, 命名对象是可见的. 其他进程可以尝试按名称打开它们, 所以某种形式的保护是明智的.
查询默认 DACL 只是调用 `GetTokenInformation` 并使用正确的值:
HANDLE hToken; ::OpenProcessToken(GetCurrentProcess(), TOKEN_QUERY, &hToken); ::GetTokenInformation(hToken, TokenDefaultDacl, buffer, sizeof(buffer), &len); auto dacl = ((TOKEN_DEFAULT_DACL*)buffer)->DefaultDacl;
💡 你可以使用 Process Explorer 的句柄视图或我自己的 Object Explorer 的句柄和对象视图查看内核对象的 DACL.
2.4.7. 构建安全描述符
默认的安全描述符通常是没问题的, 但有时你可能想收紧安全或为某些用户或组提供额外的权限. 为此, 你需要构建一个新的安全描述符或更改一个现有的, 然后再将其应用到对象上.
以下示例为一个事件对象构建一个安全描述符, 其中所有者是管理员别名, 其 DACL 中有两个 ACE:
- 第一个允许对事件的所有可能访问, 针对管理员别名.
- 第二个只允许对事件的 `SYNCHRONIZE` 访问.
代码不漂亮, 但这里有一种方法 (省略了错误处理):
BYTE sdBuffer[SECURITY_DESCRIPTOR_MIN_LENGTH]; auto sd = (PSECURITY_DESCRIPTOR)sdBuffer; // initialize an empty security descriptor ::InitializeSecurityDescriptor(sd, SECURITY_DESCRIPTOR_REVISION); // build an owner SID BYTE ownerSid[SECURITY_MAX_SID_SIZE]; DWORD size; ::CreateWellKnownSid(WinBuiltinAdministratorsSid, nullptr, (PSID)ownerSid, &size); // set the owner ::SetSecurityDescriptorOwner(sd, (PSID)ownerSid, FALSE); // everyone SID BYTE everyoneSid[SECURITY_MAX_SID_SIZE]; b = ::CreateWellKnownSid(WinWorldSid, nullptr, (PSID)everyoneSid, &size); // build the DACL EXPLICIT_ACCESS ea; ea.grfAccessPermissions = EVENT_ALL_ACCESS; // all access ea.grfAccessMode = SET_ACCESS; ea.grfInheritance = NO_INHERITANCE; ea.Trustee.ptstrName = (PWSTR)ownerSid; ea.Trustee.TrusteeForm = TRUSTEE_IS_SID; ea.Trustee.TrusteeType = TRUSTEE_IS_ALIAS; ea.grfAccessPermissions = SYNCHRONIZE; // just SYNCHRONIZE ea.grfAccessMode = SET_ACCESS; ea.grfInheritance = NO_INHERITANCE; ea.Trustee.ptstrName = (PWSTR)everyoneSid; ea.Trustee.TrusteeForm = TRUSTEE_IS_SID; ea.Trustee.TrusteeType = TRUSTEE_IS_WELL_KNOWN_GROUP; PACL dacl; // create the DACL with 2 entries ::SetEntriesInAcl(_countof(ea), ea, nullptr, &dacl); // set the DACL in the security descriptor ::SetSecurityDescriptorDacl(sd, TRUE, dacl, FALSE); // finally, create the object with the created SD SECURITY_ATTRIBUTES sa = { sizeof(sa) }; sa.lpSecurityDescriptor = sd; HANDLE hEvent = ::CreateEvent(&sa, FALSE, FALSE, nullptr); // the DACL was allocated by SetEntriesInAcl ::LocalFree(dacl);
本例中使用的 API 并不是构建 DACL 和 SID 的唯一可用 API. 一种简单的方法 (如果你知道 SDDL) 是创建一个字符串形式的所需安全描述符, 并调用 `ConvertStringSecurityDescriptorToSecurityDescriptor` 将其转换为可以直接使用的“真实”安全描述符.
SDDL 在微软文档中有完整的记录.
上面的代码创建了一个在创建内核对象时使用的安全描述符. 如果一个对象已经存在, 有几个 API 可以用来更改现有的值 (请阅读文档以获取详细信息):
BOOL SetKernelObjectSecurity( // most generic _In_ HANDLE Handle, _In_ SECURITY_INFORMATION SecurityInformation, _In_ PSECURITY_DESCRIPTOR SecurityDescriptor);
DWORD SetSecurityInfo( // uses components of SD _In_ HANDLE handle, _In_ SE_OBJECT_TYPE ObjectType, _In_ SECURITY_INFORMATION SecurityInfo, _In_opt_ PSID psidOwner, _In_opt_ PSID psidGroup, _In_opt_ PACL pDacl, _In_opt_ PACL pSacl);
BOOL SetFileSecurity( // specific for files _In_ LPCTSTR lpFileName, _In_ SECURITY_INFORMATION SecurityInformation, _In_ PSECURITY_DESCRIPTOR pSecurityDescriptor);
DWORD SetNamedSecurityInfo( // named objects _In_ LPTSTR pObjectName, _In_ SE_OBJECT_TYPE ObjectType, _In_ SECURITY_INFORMATION SecurityInfo, _In_opt_ PSID psidOwner, _In_opt_ PSID psidGroup, _In_opt_ PACL pDacl, _In_opt_ PACL pSacl);
2.4.8. 用户访问控制
用户访问控制 (User Access Control, UAC) 是在 Windows Vista 中引入的一个功能, 给用户和开发者带来了不少麻烦. 在 Vista 之前的时代, 用户被创建为本地管理员, 这从安全角度来看是糟糕的. 任何执行的代码都拥有管理员权限, 这意味着任何恶意代码都可以控制系统.
以管理员权限运行是方便的, 因为大多数操作都能正常工作, 但可能会通过写入敏感文件或 `HKEYLOCALMACHINE` 注册表单元来造成损害.
Windows Vista 改变了这一点. 创建的用户不一定是管理员, 即使是第一个用户 (必须是本地管理员) 默认情况下也不以管理员权限操作. 事实上, `Lsass` (在成功登录后) 为本地管理员用户创建了两个访问令牌 - 一个是完整的管理员令牌, 另一个是具有标准用户权限的令牌. 默认情况下, 进程以标准用户权限令牌运行.
大多数进程不需要以管理员权限执行. 考虑像 Notepad, Word 或 Visual Studio 这样的应用程序. 在大多数情况下, 它们可以以标准用户权限完美运行. 然而, 可能有些情况下希望它们以管理员权限运行. 这可以通过提升 (稍后讨论) 来完成.
Windows Vista 通过放宽对某些操作的要求, 使以标准用户权限运行变得更容易:
- 更改时间特权被分为两个特权: 更改时间和更改时区. “更改时区”被授予所有用户, 而更改时间只授予管理员 (这是有道理的, 因为更改时区只是更改时间的视图, 而不是时间本身).
- 以前只允许管理员用户的一些配置, 现在也允许标准用户 (例如无线设置, 一些电源选项).
- 虚拟化 (稍后讨论).
如果一个进程需要以管理员权限运行, 它会请求提升. 这会显示两个对话框之一 - 要么是是/否批准 (如果用户是真正的管理员), 要么是要求输入用户名/密码的对话框 (如果用户没有管理员权限, 应该从 IT 部门或机器上的其他管理员用户那里调用一个管理员). 对话框的颜色指示允许应用程序提升以获得管理员权限的危险级别:
- 如果二进制文件由微软签名, 它会以浅蓝色显示 (蓝色被认为是放松的颜色).
- 如果二进制文件由微软以外的其他实体签名, 它会以浅灰色显示.
- 如果二进制文件未签名, 它会以明亮的橙色/黄色显示, 以引起用户的注意, 因为这可能是一个危险的可执行文件.
控制面板中的 UAC 对话框有 4 个级别, 用于指示在哪些情况下应该弹出提升对话框 (图 16-19).

Figure 247: 图 16-19: UAC 对话框
虽然看起来有 4 个选项, 但实际上只有 3 个与提升对话框有关:
- 总是通知 - 任何提升都会被相应的对话框提示.
- 从不通知 - 如果用户是真正的管理员, 就自动执行提升. 否则, 显示一个管理员用户名/密码输入的对话框 (也称为管理员批准模式 - AAM)
- 中间选项 - 如果用户是真正的管理员, 不要为 Windows 组件弹出同意对话框 (是/否).
💡 “Windows 组件”是什么意思? 这意味着由内核团队或非常接近它的团队创建的应用程序. 示例应用程序包括任务管理器, 任务计划程序, 设备管理器和性能监视器. 不包括的应用程序示例 (这些是由外部团队创建的微软组件) 是 `cmd.exe`, `notepad.exe` 和 `regedit.exe`. 如果选择了中级级别, 后者会得到一个同意对话框.
两个中间选项的区别在于, 上面的一个 (默认的) 在备用桌面上显示提升对话框 (背景设置为原始壁纸的褪色位图), 而下面的一个使用默认桌面.
在 Windows 8 之前的 Windows 版本上, “从不通知”导致系统使用 Vista 之前的模型, 其中只有一个管理员令牌 (如果用户是真正的管理员). 从 Windows 8 开始, UAC 不能完全关闭, 因为 UWP 进程总是以标准令牌运行.
- 提升
提升是以管理员权限运行可执行文件的行为. 提升的过程如图 16-20 所示.

Figure 248: 图 16-20: 提升
唯一文档化的提升启动进程的方法是使用 shell 函数 `ShellExecute` 或 `ShellExecuteEx` (包括 `<shellapi.h>`):
HINSTANCE ShellExecute( _In_opt_ HWND hwnd, _In_opt_ LPCTSTR lpOperation, _In_ LPCTSTR lpFile, _In_opt_ LPCTSTR lpParameters, _In_opt_ LPCTSTR lpDirectory, _In_ INT nShowCmd);
typedef struct _SHELLEXECUTEINFO { DWORD cbSize; ULONG fMask; HWND hwnd; LPCTSTR lpVerb; LPCTSTR lpFile; LPCTSTR lpParameters; LPCTSTR lpDirectory; int nShow; HINSTANCE hInstApp; void *lpIDList; LPCTSTR lpClass; HKEY hkeyClass; DWORD dwHotKey; union { HANDLE hIcon; HANDLE hMonitor; }; HANDLE hProcess; } SHELLEXECUTEINFO, *LPSHELLEXECUTEINFO; BOOL ShellExecuteExW(_Inout_ SHELLEXECUTEINFOW *pExecInfo);
这些函数由 shell (Explorer) 和其他应用程序使用, 以基于可执行文件路径以外的东西启动可执行文件 (`CreateProcess` 可以很好地做到这一点). 这些函数可以接受任何文件, 在注册表中查找其扩展名, 并启动相关的可执行文件. 例如, 使用 `txt` 文件扩展名调用 `ShellExecute(Ex)` 会启动 Notepad (如果用户没有更改该默认值), 通过在幕后用正确的值调用 `CreateProcess`.
用于提升目的的关键参数是 `lpVerb`, 必须设置为“runas”. 以下是提升启动 `notepad` 的一个例子:
::ShellExecute(nullptr, L"runas", L"notepad.exe", nullptr, nullptr, SW_SHOWDEFAULT);
提升的过程 (图 16-20) 导致一条消息被发送到 AppInfo 服务 (托管在标准的 `Svchost.exe` 中). 该服务调用一个辅助可执行文件 `consent.exe`, 显示相关的提升对话框. 如果一切顺利 (提升被批准), AppInfo 服务会调用 `CreateProcessAsUser` 以提升的令牌启动可执行文件, 然后新进程被“重新父化”, 以便它看起来像是原始进程创建的 (`Explorer` 在图 16-20 中, 但它可以是任何调用 `ShellExecute(Ex)` 的人).
这种“重新父化”是相当独特的. UWP 进程, 例如 (在第 3 章中讨论), 总是由 DCOM 启动服务 (也托管在标准的 `Svchost.exe` 实例中) 启动, 但没有尝试重新父化.
一些应用程序提供了一个“以管理员身份运行”选项 (以 Sysinternals 的 `WinObj` 为例). 尽管看起来进程突然变得提升了, 但情况并非如此. 当前进程退出, 并以提升的方式启动一个新进程. 没有办法就地提升令牌 (如果可以, UAC 就没用了).
- 要求以管理员身份运行
有些应用程序在以标准用户权限运行时根本无法正常工作. 此类可执行文件必须以某种方式通知系统它们无论如何都需要提升. 这是通过使用清单文件 (在第 1 章中讨论) 来完成的. 其中一部分涉及提升要求. 以下是相关部分:
<trustInfo xmlns="urn:schema-microsoft-com:asm.v3"> <security> <requestedPrivileges> <requestedExecutionLevel Level="requireAdministrator" /> </requestedPrivileges> </security> </trustInfo>
`Level` 值指示请求的提升类型. 这些是可能的值:
- `asInvoker` - 如果没有指定值, 则为默认值. 指示可执行文件应在其父进程以提升方式运行时以提升方式启动, 否则以标准用户权限运行.
- `requireAdministrator` - 指示需要管理员提升. 没有它, 进程将不会启动.
- `highestAvailable` - 中间值. 它指示如果启动用户是真正的管理员, 则尝试提升. 否则, 以标准用户权限运行.
`highestAvailable` 的一个例子是注册表编辑器 (`regedit.exe`). 如果用户是本地管理员, 它会请求提升. 否则, 它仍然运行. `regedit` 的某些部分将无法工作, 例如对 `HKEYLOCALMACHINE` 进行更改, 这对标准用户是不允许的; 但应用程序仍然可用.
在 Visual Studio 中, 很容易设置这些选项之一, 而无需手动创建 XML 文件并将其指定为清单 (图 16-21).

Figure 249: 图 16-21: Visual Studio 中的提升要求
- UAC 虚拟化
许多来自 Vista 之前时代的应用程序都假设 (有意或无意地) 用户是本地管理员. 其中一些应用程序执行的操作只有在管理员权限下才能成功, 例如写入系统目录或写入 `HKEYLOCALMACHINE\Software` 注册表项. 当这些应用程序在 Vista 或更高版本上运行时, 默认使用的令牌是标准用户令牌, 这会发生什么?
最简单的选择是向应用程序返回“访问被拒绝”错误, 但这会导致这些应用程序出现故障, 因为它们没有更新以考虑 UAC. 微软的解决方案是 UAC 虚拟化, 其中此类应用程序被重定向到用户文件下的文件系统/注册表的私有区域/`HKEYCURRENTUSER` hive, 因此调用不会失败.
然而, 这是一把双刃剑. 如果这样的应用程序对系统文件进行更改 (或认为它做了), 这些更改实际上并没有改变, 因此没有虚拟化的其他应用程序将不会看到这些更改. 应用程序将看到它自己的更改 - 系统首先查看私有存储, 如果找不到, 则查看真实位置.
💡 对于文件系统, 私有存储位于 `C:\Users\<username>\AppData\Local\VirtualStore`. 你可以通过搜索“UAC 虚拟化”在线找到更多详细信息.
UAC 虚拟化会自动应用于被视为“遗留”的可执行文件, 其中“遗留”意味着: 32 位可执行文件, 没有清单指示它是 Vista+ 应用程序. 无论如何, UAC 虚拟化可以通过在访问令牌中启用它来为其他进程打开. 你可以在任务管理器中查看 UAC 虚拟化列. 可能有三个值:
- 不允许 - 虚拟化被禁用且无法启用. 这是系统进程和服务的设置.
- 禁用 - 虚拟化未激活.
- 启用 - 虚拟化已激活.
你可以执行一个简单的实验来看 UAC 虚拟化的实际操作.
- 打开记事本, 写一些东西, 并将文件保存到 System32 目录. 这将失败, 因为该进程没有写入该目录的权限.
- 转到任务管理器, 右键单击记事本进程并启用 UAC 虚拟化.
- 现在尝试再次在记事本中保存文件. 这次会成功.
- 打开资源管理器并导航到 System32 目录. 注意你保存的文件不在那里. 它因为虚拟化而被保存在虚拟存储中.
- 为记事本禁用虚拟化并从 System32 打开文件. 它不会在那里.
2.4.9. 完整性级别
完整性级别是 Windows Vista 中引入的另一个功能 (官方称为强制完整性控制). 其存在的一个原因是将以标准权限令牌运行的进程与以提升令牌运行的进程分开, 在同一用户下. 显然, 以提升令牌运行的进程更强大, 是攻击者的首选目标. 区分它们的方法是使用完整性级别.
完整性级别由 SID 表示, 对于进程, 存储在进程的令牌中. 表 16-3 显示了定义的完整性级别.
| Integrity level | SID | Remarks |
|---|---|---|
| System | S-1-16-16384 | 最高, 由系统进程和服务使用 |
| High | S-1-16-12288 | 由以提升令牌运行的进程使用 |
| Medium Plus | S-1-16-8448 | |
| Medium | S-1-16-8192 | 由以标准用户权限运行的进程使用 |
| Low | S-1-16-4096 | 由 UWP 进程和大多数浏览器使用 |
Process Explorer 有一个完整性级别列, 显示进程的完整性级别 (图 16-22).

Figure 250: 图 16-22: Process Explorer 中的完整性级别
图 16-22 中显示的完整性级别的 AppContainer 值等于“Low”, 但术语 AppContainer 用于 UWP 进程所在的沙箱.
与完整性级别相关的一个术语是强制策略, 它指示完整性级别的差异实际上如何影响操作. 默认是禁止向上写, 这意味着当一个进程试图访问一个具有更高完整性级别的对象时, 不允许进行写类型的访问. 例如, 一个完整性级别为中等的进程 A 想要打开一个完整性级别为高的进程的句柄, 只能被授予以下访问掩码: `PROCESSQUERYLIMITEDINFORMATION`, `SYNCHRONIZE` 和 `PROCESSTERMINATE`.
不是进程的对象呢? 所有对象 (包括文件) 的完整性级别都是中等, 除非通过添加一个类型为“强制标签”且具有不同值的 ACE 来显式更改. 总是可以设置比调用者令牌更低的完整性级别, 但尝试设置更高的完整性级别只有在调用者拥有 `SeRelabelPrivilege` 时才可能, 通常不授予任何人.
另一个例子是, UWP 进程以低完整性运行意味着它们甚至不能访问像用户文档或图片这样的常见文件位置, 因为这些具有中等完整性级别. 今天大多数浏览器也以低完整性级别运行它们的进程. 这样, 如果通过这样的浏览器下载并执行了一个恶意文件, 它将以低完整性级别执行, 限制了其造成损害的能力.
💡 当一个可执行文件被启动时, 新进程的完整性级别是可执行文件完整性级别和调用者进程令牌的最小值.
你可以用 `GetTokenInformation` 和 `TokenIntegrityLevel` 枚举值读取进程的完整性级别, 并用 `SetTokenInformation` 设置.
完整性级别如何与 DACL 配合使用? 完整性级别优先. 如果调用者的完整性级别等于或高于目标对象, 则使用 DACL 进行正常的访问检查. 否则, “禁止向上写”策略优先.
有关完整性级别和相关术语的更多信息, 请查阅官方文档: https://docs.microsoft.com/en-us/windows/win32/secauthz/mandatory-integrity-control.
2.4.10. UIPI
用户界面特权隔离 (User Interface Privilege Isolation, UIPI) 是一个基于完整性级别的功能. 假设有一个具有高完整性级别的进程, 它有窗口 (GUI). 如果其他进程, 也许是较低完整性级别的进程, 向这些窗口发送消息会发生什么? 向窗口发送不受控制的消息可能导致创建窗口的线程执行通常不允许调用进程执行的操作.
UIPI 是一个存在的机制, 用于防止此类事件发生. 一个进程不能向由另一个具有更高完整性级别的进程拥有的窗口发送消息, 除了一些良性消息 (例如: `WMNULL`, `WMGETTEXT` 和 `WMGETICON`).
较高完整性级别的进程可以通过调用 `ChangeWindowMessageFilter` 或 `ChangeWindowMessageFilterEx` 来允许某些消息通过:
BOOL ChangeWindowMessageFilter( _In_ UINT message, _In_ DWORD dwFlag);
BOOL ChangeWindowMessageFilterEx( _In_ HWND hwnd, _In_ UINT message, _In_ DWORD action, _Inout_opt_ PCHANGEFILTERSTRUCT pChangeFilterStruct);
`ChangeWindowMessageFilter` 接受一个消息以允许通过或阻止, `dwFlag` 可以是 `MSGFLTADD` (允许) 或 `MSGFLTREMOVE` (阻止). 此调用影响进程中的所有窗口.
Windows 7 添加了 `ChangeWindowMessageFilterEx` 以允许对每个单独的窗口进行细粒度控制. `action` 可以是 `MSGFLTALLOW` (允许), `MSGFLTDISALLOW` (阻止, 除非被进程范围的过滤器允许), 或 `MSGFLTRESET` (重置为进程范围的设置). `pChangeFilterStruct` 是一个指向可选结构的指针, 该结构返回有关调用这两个函数效果的详细信息. 请查阅文档以获取更多信息.
2.4.11. 专用安全机制
自 Windows NT 的第一个版本以来, 基本的安全机制, 如安全描述符和特权, 就已经存在. 在此过程中, Windows 添加了更多的安全机制, 例如强制完整性控制. 今天, 恶意行为者的攻击比以往任何时候都更强大, Windows 试图通过包括新的防御机制来跟上. 其中许多超出了本书的范围 (例如虚拟化基础安全). 在本节中, 我们将看一些可以编程利用的机制.
- 控制流保护 (Control Flow Guard)
控制流保护 (Control Flow Guard, CFG) 在 Windows 10 和 Server 2016 中引入, 以减轻与间接调用相关的某种类型的攻击. 例如, C++ 虚函数调用是通过一个虚表指针完成的, 该指针指向一个虚表, 实际的目标函数存储在那里. 图 16-23 显示了一个示例 C++ 对象在有任何虚函数时在内存中的样子.

Figure 251: 图 16-23: 带有虚函数的 C++ 对象
每个对象都以一个虚表指针 (`vptr`) 开始, 该指针指向类 A 的虚表. 一个注入到进程中的恶意代理可以覆盖 `vptr` (因为它是读/写内存), 并将 `vptr` 重定向到其选择的备用 vtable (图 16-24).
💡 V-table 机制也用于 COM 类, 因此 CFG 也与此类对象相关.

Figure 252: 图 16-24: V-table 重定向
CFG 在任何间接调用之前提供了一个额外的检查. 如果间接调用的目标不在进程中的一个模块 (DLL 和 EXE) 中, 那么它必须被注入到进程中的一些 shellcode 重定向了, 在这种情况下, 进程会终止. 这个过程如图 16-25 所示.

Figure 253: 图 16-25: CFG 工作原理
获取 CFG 支持相当直接, 通过在 Visual Studio 的项目属性中选择 CFG 选项 (图 16-26). 请注意, CFG 与“编辑并继续的调试信息”冲突, 因此后者必须更改为“程序数据库”.

Figure 254: 图 16-26: Visual Studio 中的 CFG 选项
以下是一些 C++ 代码的例子 (在 `CfgDemo` 应用程序中可用):
class A { public: virtual ~A() = default; virtual void DoWork(int x) { printf("A::DoWork %d\n", x); } }; class B : public A { public: void DoWork(int x) override { printf("B::DoWork %d\n", x); } }; void main() { A a; a.DoWork(10); B b; b.DoWork(20); A* pA = new B; pA->DoWork(30); delete pA; }
类 A 定义了两个虚方法 - 析构函数和 `DoWork`, 所以它的 v-table 有两个函数指针, 按此顺序.
对 `a.DoWork` 和 `b.DoWork` 的调用不需要多态地发生. `pA->DoWork` 的调用必须多态地进行. 以下是应用 CFG 之前 `pA->DoWork` 的汇编输出 (x64, Debug):
; 29 : pA->DoWork(30); 000a5 mov rax, QWORD PTR pA$[rsp] 000aa mov rax, QWORD PTR [rax] 000ad mov edx, 30 000b2 mov rcx, QWORD PTR pA$[rsp] 000b7 call QWORD PTR [rax+8] ; normal call
你可以看到值 30 放在 EDX 中. RCX 是 `this` 指针 (x64 调用约定的一部分). RAX 指向 vtable, 调用本身是间接进行的, 进入 v-table 8 字节, 因为 `DoWork` 是第二个函数 (每个函数指针在 64 位进程中是 8 字节).
💡 如果你不懂汇编语言, 你可以安全地跳过这部分, 只知道 CFG 能工作就行了.
应用 CFG 后, 以下是 `pA->DoWork` 的结果代码:
; 29 : pA->DoWork(30); 000a5 mov rax, QWORD PTR pA$[rsp] 000aa mov rax, QWORD PTR [rax] 000ad mov rax, QWORD PTR [rax+8] 000b1 mov QWORD PTR tv70[rsp], rax ; tv70=128 000b9 mov edx, 30 000be mov rcx, QWORD PTR pA$[rsp] 000c3 mov rax, QWORD PTR tv70[rsp] 000cb call QWORD PTR __guard_dispatch_icall_fptr
最后一行是重要的. 它调用 `NtDll.dll` 中的一个函数, 检查调用目标是否有效. 如果是, 它进行调用. 否则, 它终止进程.
💡 验证 `delete pA` 调用 (它调用析构函数) 也是通过 CFG 调用的.
支持 CFG 的二进制文件在其 PE 中有额外的信息, 列出了二进制文件中的有效函数. 这不仅包括导出的函数, 还包括所有函数. 你可以用 `dumpbin.exe` 查看此信息:
C:\>dumpbin /loadconfig cfgdemo.exe Microsoft (R) COFF/PE Dumper Version 14.27.28826.0 Copyright (C) Microsoft Corporation. All rights reserved. Dump of file c:\dev\temp\ConsoleApplication6\x64\Debug\cfgdemo.exe File Type: EXECUTABLE IMAGE Section contains the following load config: ... 000000014000F008 Security Cookie 0000000140015000 Guard CF address of check-function pointer 0000000140015020 Guard CF address of dispatch-function pointer 0000000140015010 Guard XFG address of check-function pointer 0000000140015030 Guard XFG address of dispatch-function pointer 0000000140015040 Guard XFG address of dispatch-table-function pointer 0000000140013000 Guard CF function table 1C Guard CF function count 00014500 Guard Flags CF instrumented FID table present Export suppression info present Long jump target table present 0000 Code Integrity Flags 0000 Code Integrity Catalog 00000000 Code Integrity Catalog Offset 00000000 Code Integrity Reserved 0000000000000000 Guard CF address taken IAT entry table 0 Guard CF address taken IAT entry count 0000000000000000 Guard CF long jump target table 0 Guard CF long jump target count 0000000000000000 Guard EH continuation table 0 Guard EH continuation count 0000000000000000 Dynamic value relocation table 0000000000000000 Hybrid metadata pointer 0000000000000000 Guard RF address of failure-function 0000000000000000 Guard RF address of failure-function pointer 00000000 Dynamic value relocation table offset 0000 Dynamic value relocation table section 0000 Reserved2 0000000000000000 Guard RF address of stack pointer verification function pointer 00000000 Hot patching table offset 0000 Reserved3 0000000000000000 Enclave configuration pointer 0000000000000000 Volatile metadata pointer Guard CF Function Table Address -------- 0000000140001040 @ILT+48(??_EB@@UEAAPEAXI@Z) 0000000140001050 @ILT+64(mainCRTStartup) 0000000140001100 @ILT+240(??_Ebad_array_new_length@std@@UEAAPEAXI@Z) 0000000140001110 @ILT+256(?DoWork@A@@UEAAXH@Z) ... 00000001400013F0 @ILT+992(?DoWork@B@@UEAAXH@Z) ...
注意两个 `DoWork` 的 mangled 函数和各种 CFG 信息.
CFG 是如何工作的? 加载器创建一个大的预留位图, 其中每个有效函数都在这个大位图中“打”一个“1”位. 检查一个函数是否有效是一个 \(O(1)\) 操作, 其中函数指针被快速右移以到达表示它的位. 如果位是“1”, 函数是有效的. 如果位是“0”或者内存未提交, 地址是坏的, 进程终止.
💡 上述解释不完全准确, 但对于本书的目的来说已经足够了. 要了解确切的细节, 请查阅《Windows Internals, 7th edition, part 1》一书.
Process Explorer 有一个用于进程和模块的 CFG 列. 对于进程, 你可以看到 64 位进程的虚拟大小大约是 2 TB. 大部分内存是 CFG 位图, 其中大部分内存是预留的. 你可以通过在 VMMap Sysinternals 工具中打开进程来验证这一点. 图 16-27 显示了 Notepad 实例的 VMMap 及其 CFG 位图.

Figure 255: 图 16-27: VMMap 中的 CFG 位图
- 进程缓解措施
Windows 8 引入了进程缓解措施, 这是一种在进程上以单向方式设置各种与安全相关的属性的能力; 一旦设置了缓解措施, 就无法撤销. (如果可以, 恶意代码就可以关闭这些缓解措施). 缓解措施的列表几乎随着 Windows 的每个版本而增长.
有四种方法可以设置进程缓解措施:
- 使用组织中管理员控制的组策略设置.
- 使用仅基于可执行文件名称 (不是其完整路径) 的 Image File Execution Options 注册表项.
- 通过调用 `CreateProcess` 并使用进程属性在创建的进程上设置缓解措施.
- 通过从进程内部调用 `SetProcessMitigationPolicy`.
使用组策略对于本书的目的不感兴趣. 我们在第 13 章中遇到了 Image File Execution Options (IFEO) 注册表项. 完整的键路径是 `HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image File Execution Options`. 这是一个在进程启动时由加载器读取的键, 用于为进程设置各种属性. 其中之一与进程缓解措施有关. 体验许多这些缓解措施的一个方便方法是使用我的 GFlagsX 工具. 图 16-28 显示了打开了 Image 选项卡的 GFlagsX. 在这里你可以看到当前在其 IFEO 键中有一些设置的可执行文件列表. 你可以点击 New Image… 并为某个可执行文件创建一个键 (在示例中是 `Notepad.exe`) (扩展名是强制性的).

Figure 256: 图 16-28: GFlagsX
窗口的左侧与 NT 全局标志有关, 这不在本书的范围内. 其中一些将在第 20 章中讨论. 右侧显示了缓解选项列表. 对所有缓解类型的详细检查超出了本书的范围 (请查阅文档以获取完整细节). 以下是对其中一些的简要解释:
- 严格句柄检查 - 如果使用无效句柄, 终止进程而不是仅仅返回一个错误. 无效句柄可能是注入的恶意代码关闭句柄或滥用它的结果.
- 禁用 Win32K 调用 - 如果进行任何 `user32.dll` 或 `gdi32.dll` 调用, 则引发异常. `Win32k.sys` 是 Windows 子系统的内核组件, 它在过去 (以及可能现在和将来) 被用于各种攻击. 如果进程只是一个不需要 GUI 的工作者, 使用此缓解措施可以防止 `Win32k` 的利用.
- 控制流保护 - 要求加载的所有 DLL 都支持 CFG. 没有它, 非 CFG DLL 会正常加载, 它们的整个内存必须被设置为 CFG 的有效目标.
- 优先系统镜像 - 确保加载的任何存在于 System32 目录中的 DLL 都优先于任何其他位置 (这不包括总是从 System32 获取的已知 DLL).
作为一个简单的实验, 为 `Notepad.exe` 选择禁用 Win32K 调用并将其设置为 Always On, 然后点击应用设置. 现在尝试启动记事本. 它应该会失败, 因为记事本需要 `user32.dll` 和 `gdi32.dll`. 在这种情况下, GFlagsX 写入注册表的值如图 16-29 所示.

Figure 257: 图 16-29: IFEO 缓解选项值设置
💡 确保你为记事本移除了这个缓解措施 (或完全删除该键), 以便记事本可以正常执行.
父进程可以使用 `PROCTHREADATTRIBUTEMITIGATIONPOLICY` 进程属性为子进程设置进程缓解措施. (进程属性在第 3 章中讨论过). 以下是一个使用 `CreateProcess` 启动一个具有 CFG 缓解措施的可执行文件的例子:
HANDLE LaunchWithCfgMitigation(PWSTR exePath) { PROCESS_INFORMATION pi; STARTUPINFOEX si = { sizeof(si) }; SIZE_T size; // the mitigation DWORD64 mitigation = PROCESS_CREATION_MITIGATION_POLICY_CONTROL_FLOW_GUARD_ALWAYS_ON; // get required size for one attribute ::InitializeProcThreadAttributeList(nullptr, 1, 0, &size); // allocate si.lpAttributeList = (PPROC_THREAD_ATTRIBUTE_LIST)::malloc(size); // initialize with one attribute ::InitializeProcThreadAttributeList(si.lpAttributeList, 1, 0, &size); // add the attribute we want ::UpdateProcThreadAttribute(si.lpAttributeList, 0, PROC_THREAD_ATTRIBUTE_MITIGATION_POLICY, &mitigation, sizeof(mitigation), nullptr, nullptr); // create the process BOOL created = ::CreateProcess(nullptr, exePath, nullptr, nullptr, FALSE, EXTENDED_STARTUPINFO_PRESENT, nullptr, nullptr, (STARTUPINFO*)&si, &pi); // free resources ::DeleteProcThreadAttributeList(si.lpAttributeList); ::free(si.lpAttributeList); ::CloseHandle(pi.hThread); return created ? pi.hProcess : nullptr; }
子进程对应用的缓解措施没有“发言权” - 它必须能够应对.
设置缓解措施的最后一种方法是从进程本身调用 `SetProcessMitigationPolicy`. 然而, 并非所有缓解选项都可以这样设置 (请查阅文档以获取每个缓解措施的细节).
BOOL SetProcessMitigationPolicy( _In_ PROCESS_MITIGATION_POLICY MitigationPolicy, _In_ PVOID lpBuffer, _In_ SIZE_T dwLength);
`PROCESSMITIGATIONPOLICY` 是一个枚举, 包含支持的各种缓解措施. `lpBuffer` 是一个指向相关结构的指针, 具体取决于缓解措施的类型. 最后, `dwLength` 是缓冲区的大小.
以下示例显示了如何设置加载镜像策略缓解选项:
PROCESS_MITIGATION_IMAGE_LOAD_POLICY policy = { 0 }; policy.NoRemoteImages = true; policy.NoLowMandatoryLabelImages = true; ::SetProcessMitigationPolicy(ProcessImageLoadPolicy, &policy, sizeof(policy));
2.4.12. 总结
Windows 中的安全性是一个大话题, 可能需要一本书来专门讲解. 在本章中, 我们研究了 Windows 安全系统中的主要概念, 并检查了用于处理安全的各种 API. 更多信息可以在官方文档和各种在线资源中找到.
在下一章中, 我们将把注意力转向 Windows 中最著名的数据库 - 注册表.
2.5. 第 17 章: 注册表
Windows 注册表是 Windows NT 自诞生以来的一个基础部分. 它是一个层次化数据库, 存储与系统及其用户相关的信息. 部分数据是 易失性 的, 意味着它在系统运行时生成, 并在系统关闭时删除. 另一方面, 非易失性 数据则持久化在文件中.
Windows 有几个内置的工具用于检查和操作注册表. 主要的 GUI 工具是 `Regedit.exe`, 而经典的命令行工具是 `reg.exe`. 还有另一个选项用于批处理/命令行式操作, 使用 `PowerShell`.
💡 使用 `reg.exe` 和 `PowerShell` 超出了本章的范围.
过去, 软件开发者大量使用注册表来存储其应用程序的各种信息, 现在在某种程度上仍然如此. 建议不要使用注册表来存储应用程序或用户相关的数据. 相反, 应用程序应该将信息存储在文件系统中, 通常以某种方便的格式, 如 INI, XML, JSON 或 YAML (仅举几个常见的例子). 注册表应该只留给 Windows 使用. 也就是说, 如果信息很小, 有时将其存储在注册表中是很方便的. 一种常见的技术是在注册表值中存储一个文件路径, 以便大部分信息存储在该文件中, 仅由注册表指向.
在本章中, 我们将研究注册表最重要的部分以及如何对其进行编程.
本章内容:
- Hives
- 32 位特定的 Hives
- 使用键和值
- 注册表通知
- 事务性注册表
- 杂项注册表函数
2.5.1. Hives
注册表被划分为 hives, 每个都暴露某些信息. 尽管 `RegEdit.exe` 显示了 5 个 hives, 但实际上只有两个“真实”的, `HKEYUSERS` 和 `HKEYLOCALMACHINE`. 所有其他的都是由这两个“真实” hives 内的数据的某种组合构成的. 图 17-1 显示了 `Regedit.exe` 中的 hives.

Figure 258: 图 17-1: hives
以下各节简要描述了这些 hives.
- HKEYLOCALMACHINE
这个 hive 存储不特定于任何用户的机器范围的信息. 大部分数据对于正确的系统启动非常重要, 在进行任何更改时必须小心. 默认情况下, 只有管理员级别的用户才能对此 hive 进行更改. 以下是一些重要的子键:
- `SOFTWARE` - 这是已安装的应用程序通常存储其非用户特定信息的地方. 常见的子键模式是 `SOFTWARE\[CompanyName]\[ProductName]\[Version]` (“Version”部分不总是使用), 后面可能会有更多的子键. 例如, Microsoft Office 将其机器范围的信息存储在 `SOFTWARE\Microsoft\Office` 中, 并将一些信息存储在一个版本子键中.
- `SYSTEM` - 这是大多数系统参数存储和由各种系统组件在启动时读取的地方. 以下是一些对开发者有用的子键示例:
- `SYSTEM\CurrentControlSet\Services` - 存储有关系统上安装的服务和设备驱动程序的信息. 我们将在第 19 章 (“服务”) 中更深入地了解这个键.
- `SYSTEM\CurrentControlSet\Enum` - 这是硬件设备驱动程序的父键.
- `SYSTEM\CurrentControlSet\Control` - 这是许多各种系统组件 (如内核本身, 会话管理器 (`Smss.exe`), Win32 子系统进程 (`csrss.exe`), 服务控制管理器 (`Services.exe`) 等) 查看的许多旋钮的父键.
- `SYSTEM\BCD00000000` - 存储引导配置数据 (BCD) 信息.
- `SYSTEM\SECURITY` - 存储本地安全策略的信息 (默认情况下, 管理员无法访问此键, 但 SYSTEM 帐户可以访问).
- `SYSTEM\SAM` - 存储本地用户和组信息 (与上述键具有相同的访问限制).
💡 你可以通过使用 (例如) PsExec Sysinternals 工具以 SYSTEM 帐户运行 `Regedit.exe` 来查看 SAM 和 SECURITY 子键, 命令如下: `psexec -s -i -d regedit`. 另一种方法是行使获取所有权特权并更改这些键上的 DACL 以允许管理员访问 (见第 16 章), 但不推荐这样做.
子键 `SYSTEM\CurrentControlSet` 是指向 `SYSTEM\ControlSet001` 子键的链接. 这种间接性与 Windows NT 的一个旧功能“最后一次的正确配置”有关. 在某些情况下, 可能会有多个“控制集”. 子键 `SYSTEM\Select` 持有值来指示哪个是“当前”控制集.
最后一次的正确配置的一些细节在第 19 章中讨论.
此 hive 中的信息大多持久化在位于 `%SystemRoot%\System32\Config` 目录中的文件中. 表 17-1 列出了子键及其对应的存储文件 (这些文件的格式是未文档化的).
Subkey File name HKEYLOCALMACHINE\SAM SAM HKEYLOCALMACHINE\Security SECURITY HKEYLOCALMACHINE\Software SOFTWARE HKEYLOCALMACHINE\System SYSTEM 💡 hives 及其存储文件的完整列表可以在注册表本身的 `HKLM\System\CurrentControlSet\Control\hivelist` 键下找到.
- HKEYUSERS
`HKEYUSERS` hive 存储了曾经在本地系统上登录过的每个用户的每用户信息. 图 17-2 显示了这样一个 hive 的例子. 每个用户都由其 SID (作为字符串) 表示.

Figure 259: 图 17-2: HKEYUSERS hive
`.DEFAULT` 子键存储新创建用户获取的默认值. 接下来的三个短 SID 值应该从第 16 章看起来很熟悉 - 它们是 `SYSTEM`, `Local Service` 和 `Network Service` 帐户的. 然后, 那个长的随机样的 SID 代表一个“普通”用户. 上面那个带后缀“Classes”的第二个 SID 与 `HKEYCLASSESROOT` hive 有关, 在后续部分描述.
如果你打开其中一个 SID 子键, 你会发现与桌面, 控制台, 环境变量, 颜色, 键盘, 打印机等相关的各种每用户设置. 这些设置由各种组件 (如 Windows 资源管理器) 读取, 以根据用户的意愿调整环境.
- HKEYCURRENTUSER (HKCU)
`HKEYCURRENTUSER` hive 是一个指向运行 `RegiEdit.exe` 的当前用户的链接, 显示来自该用户的 `HKEYUSERS` 的相同信息. 此 hive 中的数据持久化在一个名为 `NtUser.dat` 的隐藏文件中, 该文件位于用户的目录中 (例如 `c:\users\username`).
- HKEYCLASSESROOT (HKCR)
这是一个相当奇特的 hive, 由现有的键构建而成, 结合了以下内容:
- `HKEYLOCALMACHINE\Software\Classes`
- `HKEYCURRENTUSER\Software\Classes` (`HKEYUSERS\{UserSid}Classes`)
在冲突的情况下, `HKEYCURRENTUSER` 的设置会覆盖 `HKEYLOCALMACHINE`, 因为用户的选择应该比机器默认值有更高的优先级. `HKEYCLASSESROOT` 包含两部分信息:
- Explorer Shell 数据: 文件类型和关联, 以及 shell 扩展信息.
- 组件对象模型 (COM) 相关信息.
Explorer shell 信息包括文件类型和关联的操作. 例如, 在 `HKEYCLASSESROOT` 中搜索 `.txt` 会找到一个键, 其默认值为 `txtfile`. 查找 `txtfile` 键会定位到子键 `shell\open\command`, 其默认值为 `%SystemRoot%\System32\NOTEPAD.EXE %1`, 清楚地表明 Notepad 是打开 txt 文件的默认应用程序.
其他与 shell 相关的键包括 Explorer shell 支持的各种 shell 扩展, 例如自定义图标, 自定义上下文菜单, 项目预览, 甚至完整的 shell 扩展. (Shell 自定义超出了本书的范围).
`HKEYCLASSESROOT` 中更基本重要的信息与 COM 注册有关. 细节很重要, 并在第 21 章中详细讨论.
- HKEYCURRENTCONFIG (HKCC)
这个 hive 只是一个指向 `HKEYLOCALMACHINE\SYSTEM\CurrentControlSet\Hardware Profiles\Current` 的链接. 在本书的上下文中, 它基本上没什么意思.
- HKEYPERFORMANCEDATA
这个 hive 在 `Regedit.exe` 中是不可见的, 这是有充分理由的. 这个 hive 作为一种遗留机制来消费性能计数器 (在第 20 章中讨论). 从 Windows 2000 开始, 有一个新的 API 用于处理性能计数器, 并且它比使用带有 `HKEYPERFORMANCEDATA` 的注册表 API 更受青睐.
2.5.2. 32-bit Specific Hives
在 64 位系统上, 注册表的某些部分应该有 32 位与 64 位不同的键. 例如, 应用程序安装信息通常存储在 `HKLM\Software\{CompanyName}\{AppName}` 中. 某些应用程序可以在同一系统上安装为 32 位和 64 位. 在这种情况下, 必须有一种方法来区分 32 位设置和 64 位设置.
打开上述键的 32 位进程会收到另一个以 `HKLM\Software\Wow6432Node` 开头的键. 这种重定向是透明的, 不需要应用程序做任何特殊的事情. 64 位进程看到的是注册表的原样, 没有这样的重定向.
这种重定向通常被称为注册表虚拟化.
`HKLM\Software` 不是唯一经过 32 位进程重定向的键. 一些 COM 相关信息也从 `HKCR` 重定向到 `HKCR\Wow3264Node`. 以下是一些被重定向的子键示例:
- `HKCR\CLSID` 对所有进程内 (DLL) COM 组件 (见第 21 章) 重定向到 `HKCR\Wow6432Node\CLSID`.
- `HKCR\AppID`, `HKCR\Interface`, 和 `HKCR\TypeLib` 也类似地重定向到 `Wow64` 子键.
32 位进程会自动获得这种重定向, 但这些进程可以通过在 `RegCreateKeyEx` 和 `RegOpenKeyEx` 函数 (见下一节) 中指定 `KEYWOW6464KEY` 访问标志来选择退出此重定向. 也存在相反的标志 (`KEYWOW6432KEY`) 以允许 64 位进程访问 32 位注册表部分, 而无需在键名中指定 `Wow6432Node`.
2.5.3. 使用键和值
打开一个现有的注册表项是通过 `RegOpenKeyEx` 完成的:
LSTATUS RegOpenKeyEx( _In_ HKEY hKey, _In_opt_ LPCTSTR lpSubKey, _In_opt_ DWORD ulOptions, _In_ REGSAM samDesired, _Out_ PHKEY phkResult);
与大多数其他 API 相比, 第一个可见的变化是返回值. 它是一个 32 位有符号整数, 返回操作的错误代码. 这与使用其他返回 `BOOL`, `HANDLE` 等 API 时使用的 `GetLastError` 返回的值相同. 这意味着成功是 `ERRORSUCCESS` (0); 此外, 没有必要调用 `GetLastError` - 事实上, 应该避免这样做, 因为它的值不会因为注册表 API 调用而改变.
现在让我们来看看实际的函数. `hKey` 是解释 `lpSubKey` 的基键. 这可以是预定义的键之一 (`HKEYLOCALMACHINE`, `HKEYCURRENTUSER` 等) 或来自先前注册表 API 调用的键句柄. 顺便说一下, 子键是不区分大小写的.
`ulOptions` 可以是零或 `REGOPTIONOPENLINK`, 在后一种情况下, 如果键是一个链接 (到另一个键), 那么链接键本身被打开, 而不是链接的目标. 指定零是常见的情况.
`samDesired` 是打开键所需的访问掩码. 如果无法授予访问权限, 调用会失败, 并返回“访问被拒绝”的错误代码 (5). 常见的访问掩码包括用于所有查询/枚举操作的 `KEYREAD` 和用于写/修改值和创建子键操作的 `KEYWRITE`. 这也是可以指定 32 位或 64 位注册表视图的地方, 如上一节所述. 你可以在文档中找到完整的注册表项访问掩码列表.
最后, 如果调用成功, `phkResult` 会返回键句柄. 注意注册表项有它们自己的类型 (`HKEY`), 这与其他 `HANDLE` 类型 (所有都是不透明的 `void*`) 没有什么不同, 但注册表项有它们自己的关闭函数:
LSTATUS RegCloseKey(_In_ HKEY hKey);
💡 你可能想知道为什么注册表项句柄是“特殊”的. 一个原因是注册表项可以被打开到另一台机器的注册表 (如果启用了远程注册表服务), 这意味着一些关闭操作可能涉及与远程系统的通信.
非 Ex 函数 (`RegOpenKey`) 仍然存在并受支持, 主要是为了与 16 位 Windows 兼容. 没有充分的理由使用这个 (以及其他类似的) 函数.
`RegOpenKeyEx` 打开一个现有的键, 如果键不存在则失败. 要创建一个新键, 调用 `RegCreateKeyEx`:
LSTATUS RegCreateKeyEx( _In_ HKEY hKey, _In_ LPCTSTR lpSubKey, _Reserved_ DWORD Reserved, _In_opt_ LPTSTR lpClass, _In_ DWORD dwOptions, _In_ REGSAM samDesired, _In_opt_ CONST LPSECURITY_ATTRIBUTES lpSecurityAttributes, _Out_ PHKEY phkResult, _Out_opt_ LPDWORD lpdwDisposition);
`hKey` 是开始的基键, 它可以是从先前调用 `RegCreateKeyEx/RegOpenKeyEx` 或标准预定义键之一获得的值. 调用者创建新子键的能力取决于键 `hKey` 的安全描述符, 而不是 `hKey` 打开时的访问掩码. `lpSubKey` 是要创建的子键. 它必须在 `hKey` 下 (直接或间接), 意味着子键可以有多个由反斜杠分隔的子键. 如果成功, 该函数会创建所有中间子键.
`Reserved` 应该为零, `lpClass` 应该为 `NULL`; 两者都无用. `dwOptions` 通常为零 (等同于 `REGOPTIONNONVOLATILE`). 这个值表示一个非易失性键, 在 hive 键持久化时被保存. 此外, 可以指定以下值的组合:
- `REGOPTIONVOLATILE` - 与 `REGOPTIONNONVOLATILE` 相反 - 键被创建为易失性, 意味着它存储在内存中, 但一旦 hive 键被卸载就会被丢弃.
- `REGOPTIONCREATELINK` - 创建一个符号链接键, 而不是一个“真实”的键. (参见本章后面的“创建注册表链接”一节)
- `REGOPTIONBACKUPRESTORE` - 该函数忽略 `samDesired` 参数, 而是如果调用者在其令牌中有 `SeBackupPrivilege`, 则用 `ACCESSSYSTEMSECURITY` 和 `KEYREAD` 创建/打开键. 如果调用者在其令牌中有 `SeRestorePrivilege`, 则授予 `ACCESSSYSTEMSECURITY`, `DELETE` 和 `KEYWRITE`. 如果两个特权都存在, 则结果是两者的并集, 有效地授予完全访问权限.
`samDesired` 是调用者请求的通常的访问掩码. `lpSecurityAttributes` 是我们熟悉的通常的 `SECURITYATTRIBUTES`. `phkResult` 是操作成功时的结果键. 最后, 最后一个 (可选) 参数 `lpdwDisposition` 返回键是实际创建的 (`REGCREATEDNEWKEY`) 还是打开了现有的键 (`REGOPENEDEXISTINGKEY`). 一个新创建的键没有值.
- 读取值
有一个打开的键 (无论是创建的还是打开的), 有几个操作是可能的. 最基本的是读写值. 读取一个值可以用 `RegQueryValueEx` 来实现:
LSTATUS RegQueryValueEx( _In_ HKEY hKey, _In_opt_ LPCTSTR lpValueName, _Reserved_ LPDWORD lpReserved, _Out_opt_ LPDWORD lpType, _Out_ LPBYTE lpData, _Inout_opt_ LPDWORD lpcbData);
`hKey` 是要读取的键, 可以是先前打开的键或预定义的键之一 (包括不太常见的, 如 `HKEYPERFORMANCEDATA`). `lpValueName` 是要查询的值名称. 如果是 `NULL` 或空字符串, 则检索键的默认值 (如果有的话).
`lpReserved` 就是这样, 应该设置为 `NULL`. `lpType` 是一个可选的指针, 返回返回数据的类型, 是表 17-2 中显示的值之一.
值 描述 `REGNONE` (0) 无值类型 `REGSZ` (1) 以 NULL 结尾的 Unicode 字符串 `REGEXPANDSZ` (2) 以 NULL 结尾的 Unicode 字符串 (可能包含 `%%` 中的未展开环境变量) `REGBINARY` (3) 二进制 (任何) 数据 `REGDWORD` (4) 32 位数字 (小端) `REGDWORDLITTLEENDIAN` (4) 同上 `REGDWORDBIGENDIAN` (5) 32 位数字 (大端) `REGLINK` (6) 符号链接 (Unicode) `REGMULTISZ` (7) 多个由 NULL 分隔的 Unicode 字符串, 第二个 NULL 结尾 `REGRESOURCELIST` (8) `CMRESOURCELIST` 结构 (仅在内核模式中有用) `REGFULLRESOURCEDESCRIPTOR` (9) `CMFULLRESOURCEDESCRIPTOR` 结构 (仅在内核模式中有用) `REGRESOURCEREQUIREMENTSLIST` (10) 仅在内核模式中有用 `REGQWORD` (11) 64 位数字 (小端) `REGQWORDLITTLEENDIAN` (11) 同上 如果调用者对此信息不感兴趣, `lpType` 可以指定为 `NULL`. 这通常是在调用者知道期望什么的情况下. `lpData` 是一个调用者分配的缓冲区, 用于数据本身. 对于某些值类型, 大小是恒定的 (例如 `REGDWORD` 为 4 字节), 但其他类型是动态的 (例如 `REGSZ`, `REGBINARY`), 这意味着调用者需要分配一个足够大的缓冲区, 否则只有部分数据被复制, 函数返回 `ERRORMOREDATA`. 调用者缓冲区的大小由最后一个参数指定. 在输入时, 它应该包含调用者的缓冲区大小. 在输出时, 它包含写入的字节数. 如果调用者需要数据大小, 它可以为 `lpData` 传递 `NULL`, 并在 `lpcbData` 中获取大小.
以下示例显示了如何读取 `HKCU\Console\FaceName` 的字符串值 (省略了错误处理):
HKEY hKey; ::RegOpenKeyEx(HKEY_CURRENT_USER, L"Console", 0, KEY_READ, &hKey); DWORD type; DWORD size; // first call to get size ::RegQueryValueEx(hKey, L"FaceName", nullptr, &type, nullptr, &size); assert(type == REG_SZ); // returned size includes the NULL terminator auto value = std::make_unique<BYTE[]>(size); ::RegQueryValueEx(hKey, L"FaceName", nullptr, &type, value.get(), &size); ::RegCloseKey(hKey); printf("Value: %ws\n", (PCWSTR)value.get());
另一个可用于检索值的函数是 `RegGetValue`:
LSTATUS RegGetValue( _In_ HKEY hkey, _In_opt_ LPCSTR lpSubKey, _In_opt_ LPCSTR lpValue, _In_ DWORD dwFlags, _Out_opt_ LPDWORD pdwType, _Out_ PVOID pvData, _Inout_opt_ LPDWORD pcbData);
该函数与 `RegQueryValueEx` 类似, 但增加了 (通过 `dwFlags` 参数) 限制可能返回的值类型的不错选项. 这允许调用者在它期望的值不是期望的类型时获得失败 (并节省了检索数据的时间). `dwFlags` 值可以是表 17-3 中显示的值的组合.
值 描述 `RRFRTREGNONE` (1) 允许 `REGNONE` 类型 `RRFRTREGSZ` (2) 允许 `REGSZ` 类型 `RRFRTREGEXPANDSZ` (4) 允许 `REGEXPANDSZ` 类型. 除非指定了 `RRFNOEXPAND` 标志, 否则展开环境变量 `RRFRTREGBINARY` (8) 允许 `REGBINARY` 类型 `RRFRTREGDWORD` (0x10) 允许 `REGDWORD` 类型 `RRFRTREGMULTISZ` (0x20) 允许 `REGMULTISZ` 类型 `RRFRTREGQWORD` (0x40) 允许 `REGQWORD` 类型 `RRFRTDWORD` `RRFRTREGBINARY \ RRFRTREGDWORD` `RRFRTQWORD` `RRFRTREGBINARY \ RRFRTREGQWORD` `RRFRTANY` (0x0000ffff) 无类型限制 `RRFSUBKEYWOW6464KEY` (0x10000) (Win 10+) 打开 64 位键 (如果 `subkey` 不为 NULL) `RRFSUBKEYWOW6432KEY` (0x20000) (Win 10+) 打开 32 位键 (如果 `subkey` 不为 NULL) `RRFNOEXPAND` (0x10000000) 不展开 `REGEXPANDSZ` 结果 `RRFZEROONFAILURE` (0x20000000) 失败时用零填充缓冲区 - 写入值
要向注册表项写入值, 调用 `RegSetValueEx`:
LSTATUS RegSetValueEx( _In_ HKEY hKey, _In_opt_ LPCTSTR lpValueName, _Reserved_ DWORD Reserved, _In_ DWORD dwType, _In_ CONST BYTE* lpData, _In_ DWORD cbData);
大多数参数此时应该是不言自明的. `hKey` 是要写入的键, 必须至少具有 `KEYSETVALUE` 访问掩码 (通常, 键是用包括 `KEYSETVALUE` 的 `KEYWRITE` 访问掩码打开的). `lpValueName` 是要设置的值名称, 不区分大小写. 如果此名称是 `NULL` 或空字符串, 它会设置默认值 (可以是任何类型). `Reserved` 参数必须为零.
数据类型由 `dwType` 参数指定, 并且必须是表 17-2 中的值之一 (对于 `REGLINK` 的特殊情况, 请参见“创建注册表链接”一节). 数据本身由一个通用指针 (`lpData`) 和大小组成. 数据必须适合指定的类型. 某些类型具有固定大小 (例如 `REGDWORD`), 而其他类型可以有任意长度 (例如 `REGSZ`, `REGBINARY`, `REGMULTISZ`). 请务必用 `NULL` 终止符结束字符串 (`REGSZ`), 并用两个 `NULL` 终止符结束 `MULTISZ`. 请注意, 指定的大小 (`cbData`) 总是以字节为单位, 无论值类型如何. 对于字符串, 此大小必须包括终止的 `NULL`.
如果指定的值已经存在, 它会被新值覆盖.
以下示例将 `HKEYCURRENTUSER\Console` 中的 `FaceName` 值更改为“Arial” (省略了错误处理):
HKEY hKey; ::RegOpenKeyEx(HKEY_CURRENT_USER, L"Console", 0, KEY_WRITE, &hKey); WCHAR value[] = L"Arial"; ::RegSetValueEx(hKey, L"FaceName", 0, REG_SZ, (const BYTE*)value, sizeof(value)); ::RegCloseKey(hKey);
有一个可用于相同目的的替代函数, `RegSetKeyValue`:
LSTATUS RegSetKeyValue( _In_ HKEY hKey, _In_opt_ LPCTSTR lpSubKey, _In_opt_ LPCTSTR lpValueName, _In_ DWORD dwType, _In_reads_bytes_opt_(cbData) LPCVOID lpData, _In_ DWORD cbData);
该函数几乎与 `RegSetValueEx` 相同. 它有时更方便使用, 因为它允许指定一个相对于 `hKey` 的子键 (`lpSubKey`), 这是设置值的最终键. 这避免了如果句柄不易获得时需要显式打开子键.
- 删除键和值
可以通过调用 `RegDeleteKey` 或 `RegDeleteKeyEx` 来删除注册表项:
LSTATUS RegDeleteKey ( _In_ HKEY hKey, _In_ LPCTSTR lpSubKey); LSTATUS RegDeleteKeyEx( _In_ HKEY hKey, _In_ LPCTSTR lpSubKey, _In_ REGSAM samDesired, _Reserved_ DWORD Reserved);
`RegDeleteKey` 是最简单的函数, 删除相对于打开的 `hKey` 的子键 (及其所有值). 用于打开键的访问掩码无关紧要 - 是键上的安全描述符指示调用者是否可以执行删除操作.
`RegDeleteKeyEx` 添加了通过为 `samDesired` 参数指定 `KEYWOW6432KEY` 或 `KEYWOW6464KEY` 来更改注册表视图的选项. 有关详细信息, 请参见本章前面的“32 位特定的 Hives”一节.
被删除的键被标记为删除, 只有在所有打开的键句柄都关闭后才会被删除. 上述删除函数只能删除没有子键的键. 如果键有子键, 函数会失败并返回 `ERRORACCESSDENIED` (5).
要删除一个键及其所有子键, 调用 `RegDeleteTree`:
LSTATUS RegDeleteTree( _In_ HKEY hKey, _In_opt_ LPCTSTR lpSubKey);
`hKey` 必须用以下权限打开: `DELETE`, `KEYENUMERATESUBKEYS`, `KEYQUERYVALUE` 和 (如果键有任何值) `KEYSETVALUE`. 如果 `lpSubKey` 是 `NULL`, 则会从 `hKey` 指定的键中删除所有键和值.
用 `RegDeleteKeyValue` 或 `RegDeleteValue` 删除值很简单:
LSTATUS RegDeleteValue( _In_ HKEY hKey, _In_opt_ LPCTSTR lpValueName); LSTATUS RegDeleteKeyValue( _In_ HKEY hKey, _In_opt_ LPCTSTR lpSubKey, _In_opt_ LPCTSTR lpValueName);
`hKey` 必须用 `KEYSETVALUE` 访问掩码打开. `RegDeleteValue` 删除 `hKey` 中的给定值, `RegDeleteKeyValue` 允许指定一个子键, 以从给定键到达要删除值的键.
💡 `RegDeleteValue` 在性能方面更好, 因为在内部, 每当提供一个子键时, API 都会打开子键, 执行操作并关闭子键. 这对于其他有可选子键的函数也是如此. 如果你有一个直接的键句柄, 使用它总是更快.
- 创建注册表链接
注册表支持链接 - 指向其他键的键. 我们已经见过几个这样的例子. 例如, 键 `HKEYLOCALMACHINE\System\CurrentControlSet` 是一个指向 `HKEYLOCALMACHINE\System\ControlSet001` 的符号链接 (在大多数情况下). 用 `RegEdit.exe` 查看这样的键, 符号链接看起来像普通键, 因为它们的行为与链接的目标相同. 图 17-3 显示了上述提到的键 - 它们看起来和行为完全相同.

Figure 260: 图 17-3: 一个键和指向该键的链接
我自己的注册表编辑器 `RegEditX.exe` 用不同的图标显示链接 (图 17-4). 它还揭示了链接目标的存储方式 - 使用值名称 `SymbolicLinkName`.

Figure 261: 图 17-4: RegEditX.exe 中的键和指向该键的链接
微软文档确实提供了有关如何创建注册表链接的完整信息. 第一步是创建键并指定它是一个链接而不是普通键. 以下示例假设我们的意图是在 `HKEYCURRENTUSER` 下创建一个名为 `DesktopColors` 的链接, 该链接指向 `HKEYCURRENTUSER\Control Panel\Desktop\Colors`. 以下代码片段通过在对 `RegCreateKeyEx` 的调用中指定 `REGOPTIONCREATELINK` 选项来创建所需的键作为链接 (省略了错误处理):
HKEY hKey; ::RegCreateKeyEx(HKEY_CURRENT_USER, L"DesktopColors", 0, nullptr, REG_OPTION_CREATE_LINK, KEY_WRITE, nullptr, &hKey, nullptr);
现在是第一个棘手的部分. 文档指出, 链接的目标应写入一个名为 `SymbolicLinkValue` 的值, 并且它必须是一个绝对的注册表路径. 这里的问题是所需的“绝对路径”不是像 `HKEYCURRENTUSER\Control Panel\Desktop\Colors` 这样的东西. 相反, 它必须是内核看待注册表的方式的绝对路径. 如果你打开名为“Registry”的树节点, 你可以在 `RegEditX.exe` 中看到这看起来像什么 (图 17-5).

Figure 262: 图 17-5: RegEditX.exe 中的“真实”注册表
这意味着 `HKEYCURRENTUSER` 必须被翻译成 `HKEYUSERS\<SID>`. 这可以用硬编码的 SID 字符串来完成, 但最好是动态获取它. 幸运的是, 基于第 16 章中详细介绍的信息, 我们可以像这样获取当前用户的 SID 作为字符串 (再次省略了错误处理):
HANDLE hToken; ::OpenProcessToken(::GetCurrentProcess(), TOKEN_QUERY, &hToken); // Win8+: HANDLE hToken = ::GetCurrentProcessToken(); BYTE buffer[sizeof(TOKEN_USER) + SECURITY_MAX_SID_SIZE]; DWORD len; ::GetTokenInformation(hToken, TokenUser, buffer, sizeof(buffer), &len); ::CloseHandle(hToken); auto user = (TOKEN_USER*)buffer; PWSTR stringSid; ::ConvertSidToStringSid(user->User.Sid, &stringSid); // use stringSid... ::LocalFree(stringSid);
现在我们可以像这样组合绝对路径:
// using std::wstring for convenience std::wstring path = L"\\REGISTRY\\USER\\"; path += stringSid; path += L"\\Control Panel\\Desktop\\Colors";
第二个棘手的部分是链接的路径必须在没有终止 `NULL` 字节的情况下写入注册表的 `SymbolicLinkValue` 值:
::RegSetValueEx(hKey, L"SymbolicLinkValue", 0, REG_LINK, (const BYTE*)path.c_str(), path.size() * sizeof(WCHAR)); // note - NULL terminator not counted in
这就可以了. 用前一节讨论的 `RegDeleteKey(Ex)` 无法完成注册表链接的删除. 如果你尝试它, 它会删除链接的目标, 而不是链接本身. 链接只能通过使用伪文档化的本机函数 `NtDeleteKey` (来自 `Ntdll.dll`) 来删除. 要使用它, 我们首先必须声明它并链接到 `ntdll` 导入库 (链接的另一个选项是动态调用 `GetProcAddress` 来发现 `NtDeleteKey` 的地址):
extern "C" int NTAPI NtDeleteKey(HKEY); #pragma comment(lib, "ntdll")
现在我们可以像这样删除符号链接键:
HKEY hKey; ::RegOpenKeyEx(HKEY_CURRENT_USER, L"DesktopColors", REG_OPTION_OPEN_LINK, DELETE, &hKey); ::NtDeleteKey(hKey); ::RegCloseKey(hKey);
最后, `RegCreateKeyEx` 不能打开一个现有的链接 - 它只能创建一个. 这与可以用 `RegCreateKeyEx` 打开或创建的“普通”键相反. 打开一个链接必须用 `RegOpenKeyEx` 和选项参数中的 `REGOPTIONOPENLINK` 标志来完成.
- 枚举键和值
像 `RegEdit.exe` 这样的工具需要枚举某个键下的子键或该键上设置的值. 枚举子键是用 `RegEnumKeyEx` 完成的:
LSTATUS RegEnumKeyEx( _In_ HKEY hKey, _In_ DWORD dwIndex, _Out_ LPTSTR lpName, _Inout_ LPDWORD lpcchName, _Reserved_ LPDWORD lpReserved, _Out_ LPTSTR lpClass, _Inout_opt_ LPDWORD lpcchClass, _Out_opt_ PFILETIME lpftLastWriteTime);
`hKey` 句柄必须用 `KEYENUMERATESUBKEYS` 访问掩码打开才能工作. 枚举的执行方式是为 `dwIndex` 指定一个零的索引, 并在一个循环中递增它, 直到调用返回 `ERRORNOMOREITEMS`, 表明没有更多的键. 返回的结果总是包括键的名称 (`lpName`), 它必须伴随着它的大小 (`lpcchName`, 在输入时设置为缓冲区可以存储的最大字符数, 包括 `NULL` 终止符, 并在输出时由函数更改为写入的实际字符数, 不包括终止的 `NULL`). 名称是键的简单名称, 而不是从 hive 根的绝对名称. 如果 `lpName` 缓冲区不够大, 无法容纳键名, 函数会失败, 并返回 `ERRORMOREDATA`, `lpName` 缓冲区中什么也没写.
💡 最大的键名长度是 255 个字符.
可以返回另外两个可选信息: 类名 (一个很少使用的可选用户定义值) 和键最后一次被修改的时间.
以下示例, 取自 `DumpKey.exe` 应用程序 (本章代码示例的一部分) 显示了如何枚举键:
#include <atltime.h> void DumpKey(HKEY hKey, bool dumpKeys, bool dumpValues, bool recurse) { FILETIME modified; //... if (dumpKeys) { printf("Keys:\n"); WCHAR name; for (DWORD i = 0; ; i++) { DWORD cname = _countof(name); auto error = ::RegEnumKeyEx(hKey, i, name, &cname, nullptr, nullptr, nullptr, &modified); if(error == ERROR_NO_MORE_ITEMS) // enumeration complete break; // cannot really happen, as the key name buffer is large enough if (error == ERROR_MORE_DATA) { printf(" (Key name too long)\n"); continue; } if (error == ERROR_SUCCESS) printf(" %-50ws Modified: %ws\n", name, (PCWSTR)CTime(modified).Format(L"%c")); if (recurse) { HKEY hSubKey; if (ERROR_SUCCESS == ::RegOpenKeyEx(hKey, name, 0, KEY_READ, &hSubKey)) { printf(" --------\n"); printf(" Subkey: %ws\n", name); DumpKey(hSubKey, dumpKeys, dumpValues, recurse); ::RegCloseKey(hSubKey); } } } } }
以类似的方式, 用 `RegEnumValue` 枚举一个给定键内的值:
LSTATUS RegEnumValue( _In_ HKEY hKey, _In_ DWORD dwIndex, _Out_ LPTSTR lpValueName, _Inout_ LPDWORD lpcchValueName, _Reserved_ LPDWORD lpReserved, _Out_opt_ LPDWORD lpType, _Out_opt_ LPBYTE lpData, _Inout_opt_ LPDWORD lpcbData);
该函数以与 `RegEnumKeyEx` 类似的方式工作, 其中 `dwIndex` 应从零开始, 并在一个循环中递增, 直到函数返回 `ERRORNOMOREITEMS`. `hKey` 必须具有 `KEYQUERYVALUE` 访问掩码 (也是 `KEYREAD` 的一部分), 否则函数返回 `ERRORACCESSDENIED`. 唯一强制性的返回结果是值的名称, 由 `lpValueName` 缓冲区及其大小 (`lpcchValueName`) 指定. 这里的规则与 `RegEnumKeyEx` 相同: 如果值名称缓冲区不够大, 名称中什么也不会返回. 这比 `RegEnumKeyEx` 的情况更棘手, 因为一个值的名称的最大长度是 16383 个字符. 解决这个问题的最简单方法是分配一个 16384 个字符大小的缓冲区 (加上 `NULL` 终止符), 但这可能被认为是低效的. 另一种处理方法是在枚举开始之前调用 `RegQueryInfoKey`, 它可以返回给定键内的最大值名称长度:
LSTATUS RegQueryInfoKey( _In_ HKEY hKey, _Out_opt_ LPWSTR lpClass, _Inout_opt_ LPDWORD lpcchClass, _Reserved_ LPDWORD lpReserved, _Out_opt_ LPDWORD lpcSubKeys, // # if subkeys _Out_opt_ LPDWORD lpcbMaxSubKeyLen, // max subkey length _Out_opt_ LPDWORD lpcbMaxClassLen, _Out_opt_ LPDWORD lpcValues, // # values _Out_opt_ LPDWORD lpcbMaxValueNameLen, // max value name length _Out_opt_ LPDWORD lpcbMaxValueLen, // max value size _Out_opt_ LPDWORD lpcbSecurityDescriptor, _Out_opt_ PFILETIME lpftLastWriteTime);
这个函数有太多的参数, 我觉得把所有这些值都放在一个结构中会更好. 尽管如此, 它还是相当容易使用的. 大多数参数都是可选的, 允许调用者只检索它关心的信息. 提供了最大值名称长度, 允许调用者为枚举中的任何值名称分配一个足够大的缓冲区, 这很可能比 16384 个字符小.
回到 `RegEnumValue` - 该函数可选地返回值的类型 (`lpType`) 和值本身 (`lpData`). 如果需要值 (`lpData` 不是 `NULL`), 值的缓冲区必须足够大以包含整个值, 否则函数会失败, 并返回 `ERRORMOREDATA`, 缓冲区中什么也没写.
以下示例 (取自 `DumpKey` 示例), 枚举值并显示值的名称和值 (对于最常见的类型):
void DumpKey(HKEY hKey, bool dumpKeys, bool dumpValues, bool recurse) { DWORD nsubkeys, nvalues; DWORD maxValueSize; DWORD maxValueNameLen; FILETIME modified; if (ERROR_SUCCESS != ::RegQueryInfoKey(hKey, nullptr, nullptr, nullptr, &nsubkeys, nullptr, nullptr, &nvalues, &maxValueNameLen, &maxValueSize, nullptr, &modified)) return; printf("Subkeys: %u Values: %u\n", nsubkeys, nvalues); if (dumpValues) { DWORD type; auto value = std::make_unique<BYTE[]>(maxValueSize); auto name = std::make_unique<WCHAR[]>(maxValueNameLen + 1); printf("values:\n"); for (DWORD i = 0; ; i++) { DWORD cname = maxValueNameLen + 1; DWORD size = maxValueSize; auto error = ::RegEnumValue(hKey, i, name.get(), &cname, nullptr, &type, value.get(), &size); if (error == ERROR_NO_MORE_ITEMS) break; auto display = GetValueAsString(value.get(), min(64, size), type); printf(" %-30ws %-12ws (%5u B) %ws\n", name.get(), (PCWSTR)display.first, size, (PCWSTR)display.second); } } //... }
`GetValueAsString` 辅助函数返回一个 `std::pair<CString, CString>`, 其中包含类型和值作为最常见类型的文本:
std::pair<CString, CString> GetValueAsString(const BYTE* data, DWORD size, DWORD type) { CString value, stype; switch (type) { case REG_DWORD: stype = L"REG_DWORD"; value.Format(L"%u (0x%X)", *(DWORD*)data, *(DWORD*)data); break; case REG_QWORD: stype = L"REG_QWORD"; value.Format(L"%llu (0x%llX)", *(DWORD64*)data, *(DWORD64*)data); break; case REG_SZ: stype = L"REG_SZ"; value = (PCWSTR)data; break; case REG_EXPAND_SZ: stype = L"REG_EXPAND_SZ"; value = (PCWSTR)data; break; case REG_BINARY: stype = L"REG_BINARY"; for (DWORD i = 0; i < size; i++) value.Format(L"%s%02X ", value, data[i]); break; default: stype.Format(L"%u", type); value = L"(Unsupported)"; break; } return { stype, value }; }
以下是调用 `DumpKey` 并将 `HKEYCURRENTUSER\Control Panel` 键的所有参数都设置为 true 的截断输出:
Subkeys: 15 Values: 1 values: SettingsExtensionAppSnapshot REG_BINARY ( 8 B) 00 00 00 00 00 00 00 00 Keys: Accessibility Modified: Tue Mar 10 12:47:14 2020 -------- Subkey: Accessibility Subkeys: 13 Values: 4 values: MessageDuration REG_DWORD ( 4 B) 5 (0x5) MinimumHitRadius REG_DWORD ( 4 B) 0 (0x0) Sound on Activation REG_DWORD ( 4 B) 1 (0x1) Warning Sounds REG_DWORD ( 4 B) 1 (0x1) Keys: AudioDescription Modified: Tue Mar 10 12:47:14 2020 -------- Subkey: AudioDescription Subkeys: 0 Values: 2 values: On REG_SZ ( 4 B) 0 Locale REG_SZ ( 4 B) 0 Keys: Blind Access Modified: Tue Mar 10 12:42:53 2020 -------- Subkey: Blind Access Subkeys: 0 Values: 1 values: On REG_SZ ( 4 B) 0 Keys: HighContrast Modified: Tue Mar 10 12:47:14 2020 -------- Subkey: HighContrast Subkeys: 0 Values: 3 values: Flags REG_SZ ( 8 B) 126 High Contrast Scheme REG_SZ ( 2 B) Previous High Contrast Scheme MUI Value REG_SZ ( 2 B) Keys: Keyboard Preference Modified: Tue Mar 10 12:42:53 2020 -------- Subkey: Keyboard Preference Subkeys: 0 Values: 1 values: On REG_SZ ( 4 B) 0 Keys: Keyboard Response Modified: Tue Mar 10 12:42:53 2020 -------- Subkey: Keyboard Response Subkeys: 0 Values: 9 values: AutoRepeatDelay REG_SZ ( 10 B) 1000 AutoRepeatRate REG_SZ ( 8 B) 500 BounceTime REG_SZ ( 4 B) 0 DelayBeforeAcceptance REG_SZ ( 10 B) 1000 Flags REG_SZ ( 8 B) 126 Last BounceKey Setting REG_DWORD ( 4 B) 0 (0x0) Last Valid Delay REG_DWORD ( 4 B) 0 (0x0) Last Valid Repeat REG_DWORD ( 4 B) 0 (0x0) Last Valid Wait REG_DWORD ( 4 B) 1000 (0x3E8) Keys: MouseKeys Modified: Tue Mar 10 12:42:53 2020
2.5.4. 注册表通知
一些应用程序需要知道注册表中发生某些更改时的情况, 并通过再次读取某些感兴趣的值来更新其行为. 注册表 API 为此目的提供了 `RegNotifyChangeKeyValue`.
LSTATUS RegNotifyChangeKeyValue( _In_ HKEY hKey, _In_ BOOL bWatchSubtree, _In_ DWORD dwNotifyFilter, _In_opt_ HANDLE hEvent, _In_ BOOL fAsynchronous);
`hKey` 是要监视的根键. 它可以通过正常的 `RegCreateKeyEx` 或 `RegOpenKeyEx` 调用获得, 方法是指定 `REGNOTIFY` 访问掩码, 或者可以使用 5 个主要预定义键之一. `bWatchSubtree` 指示是只监视指定的键 (‘FALSE’) 还是监视 `hKey` 下的整个键树以查找更改 (TRUE).
`dwNotifyFilter` 指示哪些操作应触发通知. 表 17-4 中显示的标志的任何组合都是有效的.
| Flag | Description |
|---|---|
| `REGNOTIFYCHANGENAME` (1) | 子键被添加或删除 |
| `REGNOTIFYCHANGEATTRIBUTES` (2) | 键的任何属性发生更改 |
| `REGNOTIFYCHANGELASTSET` (4) | 修改时间发生更改, 指示键值被添加, 更改或删除 |
| `REGNOTIFYCHANGESECURITY` (8) | 键的安全描述符发生更改 |
| `REGNOTIFYTHREADAGNOSTIC` (0x10000000) | (Win 8+) 通知注册与调用线程无关 (详见文本) |
`hEvent` 参数是一个可选的事件内核对象句柄, 当通知到达时它会变为有信号状态. 如果最后一个参数 (`fAsynchronous`) 设置为 `TRUE`, 则需要此参数. 如果 `fAsynchronous` 是 `FALSE`, 则调用直到检测到更改才返回. 如果 `fAsynchronous` 是 `TRUE`, 则调用立即返回, 并且必须等待事件以获取通知. `REGNOTIFYTHREADAGNOSTIC` 标志指示调用线程与注册无关, 以便任何线程都可以在事件句柄上等待. 如果未指定此标志并且调用线程终止, 则注册将被取消.
使用 `RegNotifyChangeKeyValue` 相当容易. 其主要缺点是它没有确切地指定发生了什么变化, 也没有提供有关发生变化的键和/或值的额外信息. 这使得它适用于简单的场景, 其中需要监视单个键 (非递归), 因此当检测到更改时, 检查键中的更改并不太昂贵.
`RegWatch` 示例应用程序显示了如何在同步模式下使用 `RegNotifyChangeKeyValue`. 有趣的部分如下所示:
// root is one of the standard hive keys // path is the subkey (can be NULL) HKEY hKey; auto error = ::RegOpenKeyEx(root, path, 0, KEY_NOTIFY, &hKey); if (error != ERROR_SUCCESS) { printf("Failed to open key (%u)\n", error); return 1; } // watch for adding/modifying keys/values DWORD notifyFlags = REG_NOTIFY_CHANGE_NAME | REG_NOTIFY_CHANGE_LAST_SET; printf("Watching...\n"); while (ERROR_SUCCESS == ::RegNotifyChangeKeyValue(hKey, recurse, notifyFlags, nullptr, FALSE)) { // no further info printf("Changed occurred.\n"); } ::RegCloseKey(hKey);
获取有关注册表更改的更多详细信息的替代方法是使用 Windows 事件跟踪 (Event Tracing For Windows, ETW). 这与第 7 章和第 9 章中用于检测 DLL 加载的机制相同. ETW 内核提供程序提供了一个可以处理的与注册表相关的通知列表.
`RegWatch2` 示例应用程序使用 ETW 来显示注册表活动. 没有内置的过滤器来获取某些键的通知, 这取决于消费者来过滤它不关心的通知. 所示的示例不进行任何过滤, 并显示与操作相关的键名 (如果有的话).
第 7 章和第 9 章中使用的 `TraceManager` 类已按原样复制. 唯一的更改是在 `Start` 方法 (`TraceManager.cpp`) 中, 它更改事件标志以指示注册表事件 (而不是原始代码中的镜像事件):
_properties->EnableFlags = EVENT_TRACE_FLAG_REGISTRY;
`EventParser` 类 (`EventParser.h/cpp`) 已按原样复制 (唯一的更改是添加了头文件, 因为 `RegWatch2` 不使用预编译头). 以下是主函数:
TraceManager* g_pMgr; HANDLE g_hEvent; int main() { TraceManager mgr; if (!mgr.Start(OnEvent)) { printf("Failed to start trace. Are you running elevated?\n"); return 1; } g_pMgr = &mgr; g_hEvent = ::CreateEvent(nullptr, FALSE, FALSE, nullptr); ::SetConsoleCtrlHandler([](auto type) { if (type == CTRL_C_EVENT) { g_pMgr->Stop(); ::SetEvent(g_hEvent); return TRUE; } return FALSE; }, TRUE); ::WaitForSingleObject(g_hEvent, INFINITE); ::CloseHandle(g_hEvent); return 0; }
主函数创建一个 `TraceManager` 对象并调用 `Start` (记住以这种方式使用 ETW 需要管理员权限). 停止会话是通过 Ctrl+C 组合键完成的. `SetConsoleCtrlHandler` 的调用用于在检测到此类组合键时得到通知. 不幸的是, `SetConsoleCtrlHandler` 的函数指针没有提供传递上下文参数的方法, 这就是为什么指向 `TraceManager` 的指针也存储在全局变量中的原因.
此外, 创建一个事件对象并保存在全局变量中, 以指示已调用 `Stop`, 以便满足等待并程序可以退出.
每个通知都发送到 `OnEvent` 函数, 该函数在对 `TraceManager::Start` 的调用中传递. 以下是 `OnEvent`:
void OnEvent(PEVENT_RECORD rec) { EventParser parser(rec); auto ts = parser.GetEventHeader().TimeStamp.QuadPart; printf("Time: %ws PID: %u: ", (PCWSTR)CTime(*(FILETIME*)&ts).Format(L"%c"), parser.GetProcessId()); switch (parser.GetEventHeader().EventDescriptor.Opcode) { case EVENT_TRACE_TYPE_REGCREATE: printf("Create key"); break; case EVENT_TRACE_TYPE_REGOPEN: printf("Open key"); break; case EVENT_TRACE_TYPE_REGDELETE: printf("Delete key"); break; case EVENT_TRACE_TYPE_REGQUERY: printf("Query key"); break; case EVENT_TRACE_TYPE_REGSETVALUE: printf("Set value"); break; case EVENT_TRACE_TYPE_REGDELETEVALUE: printf("Delete value"); break; case EVENT_TRACE_TYPE_REGQUERYVALUE: printf("Query value"); break; case EVENT_TRACE_TYPE_REGENUMERATEKEY: printf("Enum key"); break; case EVENT_TRACE_TYPE_REGENUMERATEVALUEKEY: printf("Enum values"); break; case EVENT_TRACE_TYPE_REGSETINFORMATION: printf("Set key info"); break; case EVENT_TRACE_TYPE_REGCLOSE: printf("Close key"); break; default: printf("(Other)"); break; } auto prop = parser.GetProperty(L"KeyName"); if (prop) { printf(" %ws", prop->GetUnicodeString()); } printf("\n"); }
只有一些可能的通知被特别捕获, 所有其他的都显示为“(other)”. 如果存在键名属性, 它也会被显示. 如果你运行该应用程序, 你会欣赏到在任何给定时间发生的注册表操作的纯粹数量.
每个事件都有其他信息. 调用 `EventParser::GetProperties()` 以获取事件记录的所有自定义属性.
我们看到的两种通知选项都不允许任何对更改的拦截. 这种强大的功能只有在使用内核 API 时才可用. 我的书《Windows 内核编程》展示了如何实现这一点.
2.5.5. 事务性注册表
在第 9 章 (第 1 部分) 中, 我们看到文件操作可以通过使用像 `CreateFileTransacted` 这样的函数成为事务的一部分, 将其与一个打开的事务关联起来. 这样的事务可以用 `CreateTransaction` 创建 (详见第 9 章). 注册表操作也可以是事务性的, 作为一组原子操作运行, 这也可以与文件事务操作相结合.
作为事务一部分的注册表操作必须通过使用由 `RegCreateKeyTransacted` 创建或由 `RegOpenKeyTransacted` 打开的键来完成:
LSTATUS RegCreateKeyTransacted ( _In_ HKEY hKey, _In_ LPCTSTR lpSubKey, _Reserved_ DWORD Reserved, _In_opt_ LPTSTR lpClass, _In_ DWORD dwOptions, _In_ REGSAM samDesired, _In_opt_ CONST LPSECURITY_ATTRIBUTES lpSecurityAttributes, _Out_ PHKEY phkResult, _Out_opt_ LPDWORD lpdwDisposition, _In_ HANDLE hTransaction, _Reserved_ PVOID pExtendedParemeter); LSTATUS RegOpenKeyTransacted ( _In_ HKEY hKey, _In_opt_ LPCTSTR lpSubKey, _In_opt_ DWORD ulOptions, _In_ REGSAM samDesired, _Out_ PHKEY phkResult, _In_ HANDLE hTransaction, _Reserved_ PVOID pExtendedParemeter);
这些扩展函数与非事务性版本具有相同的参数, 除了最后两个参数指示要处理的事务 (`hTransaction`). 使用返回的 `hKey` 的所有后续操作都是事务的一部分, 最终将全部成功, 或者全部失败, 作为一个原子单元.
有关事务的讨论, 请参见第 9 章.
2.5.6. 远程注册表
可以通过首先调用 `RegConnectRegistry` 连接到另一台机器上的注册表来在远程机器上打开或创建注册表项. 要使其工作, 远程计算机上必须运行远程注册表服务. 默认情况下, 此服务配置为手动启动, 因此它不太可能正在运行. 即使服务正在运行, 连接到远程注册表时还有其他安全限制. 请查阅文档以获取详细信息. 以下是 `RegConnectRegistry`:
LSTATUS RegConnectRegistry ( _In_opt_ LPCTSTR lpMachineName, _In_ HKEY hKey, _Out_ PHKEY phkResult);
`lpMachineName` 是要连接的机器, 必须具有 `\\computername` 格式. `hKey` 必须是以下预定义键之一: `HKEYUSERS`, `HKEYLOCALMACHINE` 或 `HKEYPERFORMANCEDATA`. 最后一个参数 (`phkResult`) 是要在本地使用的返回句柄.
有了新句柄, 可以执行正常的注册表操作, 包括读取值, 打开子键, 写入值等, 所有这些都受安全检查的约束. 完成后, 句柄应正常用 `RegCloseKey` 关闭.
`RegConnectRegistry` 的一个扩展版本也存在, `RegConnectRegistryEx`:
LSTATUS RegConnectRegistryEx ( _In_opt_ LPCTSTR lpMachineName, _In_ HKEY hKey, _In_ ULONG Flags, _Out_ PHKEY phkResult);
它与 `RegConnectRegistry` 相同, 但允许指定一些标志. 唯一当前支持的标志是 `REGSECURECONNECTION` (1), 它指示调用者想要建立到远程注册表的安全连接. 这导致发送到远程计算机的 RPC 调用被加密.
2.5.7. 杂项注册表函数
注册表 API 包括其他杂项函数, 其中一些在本节中简要描述.
`RegGetKeySecurity` 和 `RegSetKeySecurity` 函数允许检索和操纵给定键的安全描述符. 尽管更通用的 `GetSecurityInfo` 和 `SetSecurityInfo` 函数 (在第 16 章中描述) 可以与注册表项一起使用, 但特定的函数更容易使用.
LSTATUS RegGetKeySecurity( _In_ HKEY hKey, _In_ SECURITY_INFORMATION SecurityInformation, _Out_ PSECURITY_DESCRIPTOR pSecurityDescriptor, _Inout_ LPDWORD lpcbSecurityDescriptor); LSTATUS RegSetKeySecurity( _In_ HKEY hKey, _In_ SECURITY_INFORMATION SecurityInformation, _In_ PSECURITY_DESCRIPTOR pSecurityDescriptor);
一个注册表项 (及其所有值和子键) 可以通过调用 `RegSaveKey` 保存到一个文件:
LSTATUS RegSaveKey ( _In_ HKEY hKey, _In_ LPCTSTR lpFile, _In_opt_ CONST LPSECURITY_ATTRIBUTES lpSecurityAttributes);
这些函数将 `hKey` 及其后代的所有信息保存到由 `lpFile` 给出的文件中. `hKey` 可以是用标准函数打开的键或以下预定义键之一: `HKEYCLASSESROOT` 或 `HKEYCURRENTUSER`. `lpFile` 在调用之前必须不存在, 否则调用失败. 可选的提供的安全属性可以为新文件提供安全描述符; 如果是 `NULL`, 则使用默认的安全描述符, 通常从文件的父文件夹继承.
数据保存的格式称为“标准格式”, 自 Windows 2000 以来就受支持. 这种格式是专有的, 通常未文档化. 具体来说, 这不是在选择导出菜单项以备份注册表项时 `RegEdit.exe` 使用的 `.REG` 文件格式. `REG` 文件格式特定于 `RegEdit`, 并且通常不为注册表函数所知.
保存键的当前 (最新) 格式可以通过调用扩展函数 `RegSaveKeyEx` 获得:
LSTATUS RegSaveKeyEx( _In_ HKEY hKey, _In_ LPCTSTR lpFile, _In_opt_ CONST LPSECURITY_ATTRIBUTES lpSecurityAttributes, _In_ DWORD Flags);
该函数添加了一个 `Flags` 参数, 必须是以下值之一 (且只能是一个):
- `REGSTANDARDFORMAT` (1) - 原始格式, 与 `RegSaveKey` 使用的相同.
- `REGLATESTFORMAT` (2) - 最新 (更好) 的格式.
- `REGNOCOMPRESSION` (4) - 按原样保存未压缩的数据. 仅适用于真正的 hives (在 `RegEditX` 中用特殊图标标记). 完整的 hive 列表可以在注册表本身的 `HKLM\System\CurrentControlSet\Control\hivelist` 中查看.
`RegSaveKeyEx` 的一个缺点是, 不支持预定义的键 `HKEYCLASSESROOT`.
`RegSaveKey` 和 `RegSaveKeyEx` 都要求调用者在其令牌中拥有 `SeBackupPrivilege`. 这个特权通常授予管理员组的成员, 但不授予具有标准用户权限的用户.
手持一个保存的文件, 信息可以用 `RegRestoreKey` 恢复到注册表中:
LSTATUS RegRestoreKey( _In_ HKEY hKey, _In_ LPCTSTR lpFile, _In_ DWORD dwFlags);
`hKey` 指定要恢复信息的键. 它可以是任何打开的键或 5 个标准 hive 键之一. `lpFile` 是存储数据的文件. 恢复操作保留由 `hKey` 标识的根键的名称, 但替换该键的所有其他属性, 并替换所有子键/值, 如存储在文件中的那样.
`dwFlags` 提供了几个选项, 其中只有两个是官方文档化的:
- `REGFORCERESTORE` (8) - 即使有打开的键句柄指向将被覆盖的子键, 也强制执行恢复操作.
- `REGWHOLEHIVEVOLATILE` (1) - 仅在内存中创建一个新的 hive. 在这种情况下, `hKey` 必须是 `HKEYUSERS` 或 `HKEYLOCALMACHINE`. 该 hive 在下一次系统启动时被移除.
与 `RegSaveKey(Ex)` 类似, 调用者必须在其令牌中拥有 `SeRestorePrivilege`, 通常授予管理员.
用 `RegRestoreKey` 加载 hive 的一个替代方法是使用 `RegLoadAppKey`:
LSTATUS RegLoadAppKey( _In_ LPCTSTR lpFile, _Out_ PHKEY phkResult, _In_ REGSAM samDesired, _In_ DWORD dwOptions, _Reserved_ DWORD Reserved);
`RegLoadAppkey` 将由 `lpFile` 指定的 hive 加载到一个不可见的根中, 该根无法被枚举, 因此不属于标准注册表. 访问 hive 中任何东西的唯一方法是通过成功时返回的根 `phkResult` 键. 与 `RegRestoreKey` 相比的优势是调用者不需要 `SeRestorePrivilege`, 因此可以由非管理员调用者使用.
`dwOptions` 中唯一可用的标志 (`REGPROCESSAPPKEY`), 如果使用, 会阻止其他调用者在键句柄打开时加载相同的 hive 文件.
与 `REGWHOLEHIVEVOLATILE` 的 `RegRestoreKey` 类似的操作可以通过 `RegLoadKey` 实现, 其中可以从一个文件加载一个 hive 并将其存储在 `HKEYLOCALMACHINE` 或 `HKEYUSERS` 下的新 hive 中. 这在离线查看注册表文件时很有用, 例如从另一个系统带来的文件. `RegEdit` 通过在其菜单选项 `File / Load Hive…` 中调用 `RegLoadKey` 来提供此功能. 你会注意到此选项仅在树视图中选择的键是 `HKEYLOCALMACHINE` 或 `HKEYUSERS` 时才可用 (图 17-6).

Figure 263: 图 17-6: RegEdit 中的加载 Hive 选项
以下是 `RegLoadKey` 的定义:
LSTATUS RegLoadKey( _In_ HKEY hKey, _In_opt_ LPCTSTR lpSubKey, _In_ LPCTSTR lpFile);
`hKey` 可以是 `HKEYLOCALMACHINE` 或 `HKEYUSERS` (因为这些是真正的键, 而不是各种链接). `lpSubKey` 是子键的名称, hive 从 `lpFile` 指定的文件加载到其下. 对加载的键 (或其任何子键) 所做的任何更改最终都会持久化到文件中.
可以用 `RegUnloadKey` 卸载 hive:
LSTATUS RegUnLoadKey( _In_ HKEY hKey, _In_opt_ LPCTSTR lpSubKey);
参数反映了它们在 `RegLoadKey` 中的对应项.
2.5.8. 总结
注册表是 Windows 系统用于系统范围和用户特定设置的主要数据库. 注册表的某些部分在系统安全, 内核操作等方面尤其重要. 在本章中, 我们研究了注册表的概念和布局以及用于读取和操作它的最常见的 API 函数.